JP4867708B2 - 半導体集積回路の設計方法および設計装置 - Google Patents
半導体集積回路の設計方法および設計装置 Download PDFInfo
- Publication number
- JP4867708B2 JP4867708B2 JP2007045618A JP2007045618A JP4867708B2 JP 4867708 B2 JP4867708 B2 JP 4867708B2 JP 2007045618 A JP2007045618 A JP 2007045618A JP 2007045618 A JP2007045618 A JP 2007045618A JP 4867708 B2 JP4867708 B2 JP 4867708B2
- Authority
- JP
- Japan
- Prior art keywords
- logic
- wiring
- area
- design
- block
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images













Landscapes
- Design And Manufacture Of Integrated Circuits (AREA)
Description
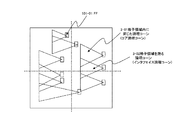
インタフェイス論理ブロックの設計については、実際のブロック間配線結果に基づく正確な遅延を考慮して、複数の論理ブロックにまたがるインタフェイス論理ブロック集合全体を一括して最適化できるため、従来の分割設計が持つ、分割損による、タイミング設計収束性悪化問題を解決することができる。
101-02 論理ゲート
101-03 信号線
101-04 論理パス
101-05 タイミング制約
101-06 フリップフロップ(FF)入力論理コーン
102-01 リピータ
102-02 信号配線
102-03 迂回配線
103-01 論理ブロックレイアウト領域
103-02 論理ブロック間配線領域
103-03 論理ブロック間信号配線
104-01 始点FF
104-02 終点FF
104-03 複数の論理ブロックを跨るパス
1 半導体集積回路の設計装置
1-01 チップ情報入力手段
1-02 仮ゲート配置手段
1-03 分割格子設定手段
1-04 FF入力論理コーンと分割格子を基準としたゲートグルーピング手段
1-05 コア論理ブロックとインタフェイス論理ブロック分割手段
1-06 コア論理ブロックとインタフェイス論理ブロックのレイアウト領域決定手段
1-07 コア論理ブロックレイアウト設計手段
1-08 ブロック間配線レイアウト設計手段
1-09 インタフェイス論理ブロックレイアウト設計手段
1-10 レイアウト設計統合手段
1-11 分割手段
1-12 設定手段
1-13 領域設定手段
2-01 仮ゲート配置結果
2-02 分割格子線
3-01 格子領域内に閉じた論理コーン(コア論理コーン)
3-02 格子領域を跨る論理コーン(インタフェイス論理コーン)
4-01 コア論理コーンサイズを増やすために移動する論理回路
4-02 論理コーンの移動による格子領域内に閉じた論理コーンサイズ増加
5-01 論理2重化対象回路
5-02 コア論理コーン
5-03 インタフェイス論理コーン
5-04 2重化対象ゲート
6-01 コア論理ブロックレイアウト領域
6-02 コア論理ブロック境界フリップフロップ
6-03 分割されたインタフェイス論理コーン
6-04 インタフェイス論理ブロックレイアウト領域
6-05 ブロック間信号
7-01 コア論理ブロックレイアウト設計
8-01 ブロック間配線レイアウト設計
8-02 ブラックボックス化された論理ブロック
9-01 ブラックボックス化されたコア論理ブロック
9-02 インタフェイス論理ブロックレイアウト設計
9-03 固定ブロック間配線レイアウト
9-04 同時最適化対象となるインタフェイス論理ブロック
10 統合されたレイアウト設計
Claims (10)
- 設計対象の半導体集積回路における、部品情報と、配線接続情報と、フリップフロップ間のタイミング制約と、に基づいて前記半導体集積回路を設計する設計装置が行う半導体集積回路の設計方法であって、
前記部品情報に基づいて複数の論理ゲートと複数のフリップフロップが配置されたチップ領域を、複数の領域に分割する分割ステップと、
入力部および出力部として異なる前記フリップフロップが用いられ前記入力部と前記出力部の間にはフリップフロップが接続されずに少なくとも前記論理ゲートのいずれかが接続される論理回路を、前記配線接続情報に基づいて、前記チップ領域から抽出し、1つの前記領域内に全体が含まれる前記論理回路をコア論理ブロックとし、2つ以上の前記領域にまたがる前記論理回路をインタフェイス論理ブロックとする設定ステップと、
前記配線接続情報と前記タイミング制約に基づいて、前記コア論理ブロックのレイアウト設計を行うコア論理ブロック設計ステップと、
前記配線接続情報に基づいて、前記領域間の配線のレイアウト設計を行う領域間配線設計ステップと、
前記配線接続情報と前記タイミング制約と前記配線のレイアウト設計の結果に基づいて、前記インタフェイス論理ブロックのレイアウト設計を行うインタフェイス論理ブロック設計ステップと、を含む半導体集積回路の設計方法。 - 請求項1記載の半導体集積回路の設計方法において、
前記チップ領域に、コア論理ブロックレイアウト領域と、インタフェイス論理ブロックレイアウト領域と、領域間の配線レイアウト領域と、を設定する領域設定ステップをさらに含み、
前記コア論理ブロック設計ステップでは、前記コア論理ブロックのレイアウト設計を、前記コア論理ブロックレイアウト領域で行い、
前記領域間配線設計ステップでは、前記領域間の配線のレイアウト設計を、前記領域間の配線レイアウト領域で行い、
前記インタフェイス論理ブロック設計ステップでは、前記インタフェイス論理ブロックの設計を、前記インタフェイス論理ブロックレイアウト領域で行う、半導体集積回路の設計方法。 - 請求項1記載の半導体集積回路の設計方法において、
前記分割ステップでは、前記部品情報に基づいて前記複数の論理ゲートおよび前記複数のフリップフロップをチップ配置領域に仮配置して前記チップ領域を生成し、前記チップ領域を格子状に分割することにより前記複数の領域を生成し、
前記設定ステップでは、前記領域において、当該領域に全体が含まれる前記論理回路の占める割合が大きくなるように、前記領域間で、前記論理回路を移動し、前記1つの領域内に全体が含まれる前記移動された論理回路を前記コア論理ブロックとし、前記2つ以上の領域にまたがる前記移動された論理回路を前記インタフェイス論理ブロックとする、半導体集積回路の設計方法。 - 請求項3記載の半導体集積回路の設計方法において、
前記設定ステップでは、前記1つの領域に全体が含まれる前記移動された論理回路と、前記2つ以上の領域にまたがる前記移動された論理回路と、の間に重複論理ゲートが存在する場合、当該重複論理ゲートを2重化して、前記1つの領域に全体が含まれる前記論理回路と、前記2つ以上の領域にまたがる前記論理回路と、を互いに排他的になるように分離し、前記1つの領域内に全体が含まれる前記排他的な論理回路を前記コア論理ブロックとし、前記2つ以上の領域にまたがる前記排他的な論理回路を前記インタフェイス論理ブロックとする、半導体集積回路の設計方法。 - 請求項1記載の半導体集積回路の設計方法において、
前記インタフェイス論理ブロック設計ステップでは、前記配線のレイアウト設計の結果から得られるブロック間配線遅延を考慮して、全てのインタフェイス論理ブロックのレイアウト設計を一括して行う、半導体集積回路の設計方法。 - 設計対象の半導体集積回路における、部品情報と、配線接続情報と、フリップフロップ間のタイミング制約と、に基づいて前記半導体集積回路を設計する、半導体集積回路の設計装置であって、
前記部品情報に基づいて複数の論理ゲートと複数のフリップフロップが配置されたチップ領域を、複数の領域に分割する分割手段と、
入力部および出力部として異なる前記フリップフロップが用いられ前記入力部と前記出力部の間にはフリップフロップが接続されずに少なくとも前記論理ゲートのいずれかが接続される論理回路を、前記配線接続情報に基づいて、前記チップ領域から抽出し、1つの前記領域内に全体が含まれる前記論理回路をコア論理ブロックとし、2つ以上の前記領域にまたがる前記論理回路をインタフェイス論理ブロックとする設定手段と、
前記配線接続情報と前記タイミング制約に基づいて、前記コア論理ブロックのレイアウト設計を行うコア論理ブロックレイアウト設計手段と、
前記配線接続情報に基づいて、前記領域間の配線のレイアウト設計を行う配線レイアウト設計手段と、
前記配線接続情報と前記タイミング制約と前記配線のレイアウト設計の結果に基づいて、前記インタフェイス論理ブロックのレイアウト設計を行うインタフェイス論理ブロックレイアウト設計手段と、を含む半導体集積回路の設計装置。 - 請求項6記載の半導体集積回路の設計装置において、
前記チップ領域に、コア論理ブロックレイアウト領域と、インタフェイス論理ブロックレイアウト領域と、領域間の配線レイアウト領域と、を設定する領域設定手段をさらに含み、
前記コア論理ブロックレイアウト設計手段は、前記コア論理ブロックのレイアウト設計を、前記コア論理ブロックレイアウト領域で行い、
前記配線レイアウト設計手段は、前記領域間の配線のレイアウト設計を、前記領域間の配線レイアウト領域で行い、
前記インタフェイス論理ブロックレイアウト設計手段は、前記インタフェイス論理ブロックの設計を、前記インタフェイス論理ブロックレイアウト領域で行う、半導体集積回路の設計装置。 - 請求項6記載の半導体集積回路の設計装置において、
前記分割手段は、
前記部品情報に基づいて、前記複数の論理ゲートおよび前記複数のフリップフロップをチップ配置領域に仮配置して前記チップ領域を生成する仮ゲート配置手段と、
前記チップ領域を格子状に分割することにより前記複数の領域を生成する分割格子設定手段と、を含み、
前記設定手段は、
前記配線接続情報に基づいて、前記論理回路を前記チップ領域から抽出し、前記領域において、当該領域に全体が含まれる前記論理回路の占める割合が大きくなるように、前記領域間で、前記論理回路を移動する移動手段と、
前記1つの領域内に全体が含まれる前記移動された論理回路を前記コア論理ブロックとし、前記2つ以上の領域にまたがる前記移動された論理回路を前記インタフェイス論理ブロックとする論理ブロック決定手段と、を含む、半導体集積回路の設計装置。 - 請求項8記載の半導体集積回路の設計装置において、
前記設定手段は、さらに、前記1つの領域に全体が含まれる前記移動された論理回路と、前記2つ以上の領域にまたがる前記移動された論理回路と、の重複論理ゲートが存在する場合、当該重複論理ゲートを2重化して、前記1つの領域に全体が含まれる前記論理回路と、前記2つ以上の領域にまたがる前記論理回路と、を互いに排他的になるように分離する論理ブロック分割手段を含み、
前記論理ブロック決定手段は、前記1つの領域内に全体が含まれる前記排他的な論理回路を前記コア論理ブロックとし、前記2つ以上の領域にまたがる前記排他的な論理回路を前記インタフェイス論理ブロックとする、半導体集積回路の設計装置。 - 請求項6記載の半導体集積回路の設計装置において、
前記インタフェイス論理ブロックレイアウト設計手段は、前記配線のレイアウト設計の結果から得られるブロック間配線遅延を考慮して、全てのインタフェイス論理ブロックのレイアウト設計を一括して行う、半導体集積回路の設計装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007045618A JP4867708B2 (ja) | 2007-02-26 | 2007-02-26 | 半導体集積回路の設計方法および設計装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007045618A JP4867708B2 (ja) | 2007-02-26 | 2007-02-26 | 半導体集積回路の設計方法および設計装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2008210109A JP2008210109A (ja) | 2008-09-11 |
| JP4867708B2 true JP4867708B2 (ja) | 2012-02-01 |
Family
ID=39786360
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007045618A Expired - Fee Related JP4867708B2 (ja) | 2007-02-26 | 2007-02-26 | 半導体集積回路の設計方法および設計装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4867708B2 (ja) |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004013248A (ja) * | 2002-06-04 | 2004-01-15 | Hitachi Ltd | 階層型論理合成方法及び装置 |
| JP4261172B2 (ja) * | 2002-12-10 | 2009-04-30 | 富士通マイクロエレクトロニクス株式会社 | 半導体集積回路のレイアウトプログラムおよび半導体集積回路のレイアウトシステム |
| JP2004302819A (ja) * | 2003-03-31 | 2004-10-28 | Kawasaki Microelectronics Kk | 半導体集積回路のレイアウト設計方法 |
| JP2006338090A (ja) * | 2005-05-31 | 2006-12-14 | Renesas Technology Corp | 半導体集積回路の設計方法および設計装置 |
-
2007
- 2007-02-26 JP JP2007045618A patent/JP4867708B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2008210109A (ja) | 2008-09-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8327301B2 (en) | Routing method for double patterning design | |
| US5774371A (en) | Semiconductor integrated circuit and layout designing method for the same | |
| TWI472938B (zh) | 在積體電路的電力網路中自動降低堆疊通孔的方法 | |
| US9236343B2 (en) | Architecture of spare wiring structures for improved engineering change orders | |
| KR102723633B1 (ko) | 회로 구성요소를 규정하는 표준 셀의 레이아웃을 수정하기 위한 컴퓨터 구현 시스템 및 방법 | |
| US6223329B1 (en) | Hybrid design method and apparatus for computer-aided circuit design | |
| US8782591B1 (en) | Physically aware logic synthesis of integrated circuit designs | |
| TWI868271B (zh) | 用於使用帶有金屬線的胞元進行電路設計的方法和設備及相應產生的佈局 | |
| CN102779201A (zh) | 用于将平面设计转换为FinFET设计的系统和方法 | |
| WO2005006004A1 (ja) | スキャンテスト設計方法、スキャンテスト回路、スキャンテスト回路挿入用cadプログラム、大規模集積回路及び携帯デジタル機器 | |
| US8370786B1 (en) | Methods and software for placement improvement based on global routing | |
| JP4761859B2 (ja) | 半導体集積回路のレイアウト設計方法 | |
| US20080301618A1 (en) | Method and System for Routing of Integrated Circuit Design | |
| JP4867708B2 (ja) | 半導体集積回路の設計方法および設計装置 | |
| US20170061063A1 (en) | Integrated circuit with reduced routing congestion | |
| JP2006301961A (ja) | 半導体集積回路の自動フロアプラン手法 | |
| JP4400428B2 (ja) | 半導体集積回路の設計方法と設計装置並びにプログラム | |
| JP3433025B2 (ja) | モジュール配置方法 | |
| JP4248925B2 (ja) | 自動フロアプラン決定方法 | |
| JP5076503B2 (ja) | 半導体集積回路の配線設計システム、半導体集積回路及び配線設計プログラム | |
| JP2005039001A (ja) | 半導体集積回路の圧縮方法 | |
| JPH08129576A (ja) | 半導体装置のマスクレイアウト設計方法 | |
| JP5696407B2 (ja) | 半導体集積回路の自動配置配線方法、レイアウト装置、自動配置配線プログラム、及び半導体集積回路 | |
| JP2010073728A (ja) | 半導体集積回路レイアウト設計方法及び半導体集積回路レイアウト設計装置 | |
| JP2009188093A (ja) | 半導体集積回路の設計装置、方法、及び、プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20100119 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20111012 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20111018 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20111031 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20141125 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |