KR20090057072A - 척추동물 세포에 의한 비천연 아미노산의 부위 특이적 도입 - Google Patents
척추동물 세포에 의한 비천연 아미노산의 부위 특이적 도입 Download PDFInfo
- Publication number
- KR20090057072A KR20090057072A KR1020097006398A KR20097006398A KR20090057072A KR 20090057072 A KR20090057072 A KR 20090057072A KR 1020097006398 A KR1020097006398 A KR 1020097006398A KR 20097006398 A KR20097006398 A KR 20097006398A KR 20090057072 A KR20090057072 A KR 20090057072A
- Authority
- KR
- South Korea
- Prior art keywords
- cell
- protein
- trna
- amino acids
- cell line
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 150000001413 amino acids Chemical class 0.000 title claims abstract description 463
- 241000251539 Vertebrata <Metazoa> Species 0.000 title claims abstract description 150
- 238000010348 incorporation Methods 0.000 title description 12
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 284
- 102000004169 proteins and genes Human genes 0.000 claims abstract description 258
- 238000000034 method Methods 0.000 claims abstract description 131
- 108700028939 Amino Acyl-tRNA Synthetases Proteins 0.000 claims abstract description 64
- 102000052866 Amino Acyl-tRNA Synthetases Human genes 0.000 claims abstract description 63
- 229940024606 amino acid Drugs 0.000 claims description 475
- 210000004027 cell Anatomy 0.000 claims description 319
- 235000018102 proteins Nutrition 0.000 claims description 249
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 206
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 201
- 229920001184 polypeptide Polymers 0.000 claims description 197
- 108020004705 Codon Proteins 0.000 claims description 167
- 102000040430 polynucleotide Human genes 0.000 claims description 141
- 108091033319 polynucleotide Proteins 0.000 claims description 141
- 239000002157 polynucleotide Substances 0.000 claims description 139
- -1 T39765 Proteins 0.000 claims description 67
- 150000007523 nucleic acids Chemical class 0.000 claims description 55
- 102000039446 nucleic acids Human genes 0.000 claims description 50
- 108020004707 nucleic acids Proteins 0.000 claims description 50
- 238000001727 in vivo Methods 0.000 claims description 38
- 241000588724 Escherichia coli Species 0.000 claims description 24
- 108020005038 Terminator Codon Proteins 0.000 claims description 22
- 230000000295 complement effect Effects 0.000 claims description 20
- 239000003102 growth factor Substances 0.000 claims description 19
- 230000001225 therapeutic effect Effects 0.000 claims description 18
- OXCMYAYHXIHQOA-UHFFFAOYSA-N potassium;[2-butyl-5-chloro-3-[[4-[2-(1,2,4-triaza-3-azanidacyclopenta-1,4-dien-5-yl)phenyl]phenyl]methyl]imidazol-4-yl]methanol Chemical compound [K+].CCCCC1=NC(Cl)=C(CO)N1CC1=CC=C(C=2C(=CC=CC=2)C2=N[N-]N=N2)C=C1 OXCMYAYHXIHQOA-UHFFFAOYSA-N 0.000 claims description 17
- 108090000394 Erythropoietin Proteins 0.000 claims description 16
- 102000003951 Erythropoietin Human genes 0.000 claims description 16
- 108090000723 Insulin-Like Growth Factor I Proteins 0.000 claims description 16
- 229940105423 erythropoietin Drugs 0.000 claims description 16
- 102100020880 Kit ligand Human genes 0.000 claims description 14
- 210000001616 monocyte Anatomy 0.000 claims description 14
- 239000000546 pharmaceutical excipient Substances 0.000 claims description 13
- 239000003053 toxin Substances 0.000 claims description 13
- 231100000765 toxin Toxicity 0.000 claims description 13
- 108700012359 toxins Proteins 0.000 claims description 13
- 102000013275 Somatomedins Human genes 0.000 claims description 12
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 claims description 12
- 230000002757 inflammatory effect Effects 0.000 claims description 12
- 102000003298 tumor necrosis factor receptor Human genes 0.000 claims description 12
- 102000004127 Cytokines Human genes 0.000 claims description 11
- 108090000695 Cytokines Proteins 0.000 claims description 11
- 101000668058 Infectious salmon anemia virus (isolate Atlantic salmon/Norway/810/9/99) RNA-directed RNA polymerase catalytic subunit Proteins 0.000 claims description 11
- 241000124008 Mammalia Species 0.000 claims description 11
- 210000000440 neutrophil Anatomy 0.000 claims description 11
- 102000018233 Fibroblast Growth Factor Human genes 0.000 claims description 10
- 108050007372 Fibroblast Growth Factor Proteins 0.000 claims description 10
- 102100025390 Integrin beta-2 Human genes 0.000 claims description 10
- 108010064593 Intercellular Adhesion Molecule-1 Proteins 0.000 claims description 10
- 108010064548 Lymphocyte Function-Associated Antigen-1 Proteins 0.000 claims description 10
- 230000003213 activating effect Effects 0.000 claims description 10
- 229940126864 fibroblast growth factor Drugs 0.000 claims description 10
- 102000005962 receptors Human genes 0.000 claims description 10
- 108020003175 receptors Proteins 0.000 claims description 10
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 claims description 9
- 108010000521 Human Growth Hormone Proteins 0.000 claims description 9
- 239000000854 Human Growth Hormone Substances 0.000 claims description 9
- 102000002265 Human Growth Hormone Human genes 0.000 claims description 9
- 102000015696 Interleukins Human genes 0.000 claims description 9
- 108010063738 Interleukins Proteins 0.000 claims description 9
- 108010029697 CD40 Ligand Proteins 0.000 claims description 8
- 102100032937 CD40 ligand Human genes 0.000 claims description 8
- 241000193385 Geobacillus stearothermophilus Species 0.000 claims description 8
- 108090000100 Hepatocyte Growth Factor Proteins 0.000 claims description 8
- 102100021866 Hepatocyte growth factor Human genes 0.000 claims description 8
- 101710177504 Kit ligand Proteins 0.000 claims description 8
- 108700020796 Oncogene Proteins 0.000 claims description 8
- 102000043276 Oncogene Human genes 0.000 claims description 8
- 102000019197 Superoxide Dismutase Human genes 0.000 claims description 8
- 108010012715 Superoxide dismutase Proteins 0.000 claims description 8
- 108060008682 Tumor Necrosis Factor Proteins 0.000 claims description 8
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 claims description 8
- 102000006834 complement receptors Human genes 0.000 claims description 8
- 108010047295 complement receptors Proteins 0.000 claims description 8
- 230000002255 enzymatic effect Effects 0.000 claims description 8
- 230000001976 improved effect Effects 0.000 claims description 8
- 239000003262 industrial enzyme Substances 0.000 claims description 8
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 claims description 8
- 101150013553 CD40 gene Proteins 0.000 claims description 7
- 108010008212 Integrin alpha4beta1 Proteins 0.000 claims description 7
- 102100037877 Intercellular adhesion molecule 1 Human genes 0.000 claims description 7
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 claims description 7
- 108010000134 Vascular Cell Adhesion Molecule-1 Proteins 0.000 claims description 7
- 102100023543 Vascular cell adhesion protein 1 Human genes 0.000 claims description 7
- 230000001746 atrial effect Effects 0.000 claims description 7
- 239000000813 peptide hormone Substances 0.000 claims description 7
- 102000005969 steroid hormone receptors Human genes 0.000 claims description 7
- 108020003113 steroid hormone receptors Proteins 0.000 claims description 7
- CMUHFUGDYMFHEI-QMMMGPOBSA-N 4-amino-L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N)C=C1 CMUHFUGDYMFHEI-QMMMGPOBSA-N 0.000 claims description 6
- 102000005755 Intercellular Signaling Peptides and Proteins Human genes 0.000 claims description 6
- 108010070716 Intercellular Signaling Peptides and Proteins Proteins 0.000 claims description 6
- 108010050904 Interferons Proteins 0.000 claims description 6
- 102000014150 Interferons Human genes 0.000 claims description 6
- 108010039445 Stem Cell Factor Proteins 0.000 claims description 6
- 108010009583 Transforming Growth Factors Proteins 0.000 claims description 6
- 102000009618 Transforming Growth Factors Human genes 0.000 claims description 6
- 230000019491 signal transduction Effects 0.000 claims description 6
- 102000055006 Calcitonin Human genes 0.000 claims description 5
- 108060001064 Calcitonin Proteins 0.000 claims description 5
- 102000000589 Interleukin-1 Human genes 0.000 claims description 5
- 108010002352 Interleukin-1 Proteins 0.000 claims description 5
- 108010002350 Interleukin-2 Proteins 0.000 claims description 5
- 102000000588 Interleukin-2 Human genes 0.000 claims description 5
- 102000004890 Interleukin-8 Human genes 0.000 claims description 5
- 108090001007 Interleukin-8 Proteins 0.000 claims description 5
- 241000191940 Staphylococcus Species 0.000 claims description 5
- BBBFJLBPOGFECG-VJVYQDLKSA-N calcitonin Chemical compound N([C@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(N)=O)C(C)C)C(=O)[C@@H]1CSSC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1 BBBFJLBPOGFECG-VJVYQDLKSA-N 0.000 claims description 5
- 229960004015 calcitonin Drugs 0.000 claims description 5
- 230000010261 cell growth Effects 0.000 claims description 5
- 239000003112 inhibitor Substances 0.000 claims description 5
- 229940079322 interferon Drugs 0.000 claims description 5
- 210000001519 tissue Anatomy 0.000 claims description 5
- BNIFSVVAHBLNTN-XKKUQSFHSA-N (2s)-4-amino-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-1-[(2s)-4-amino-2-[[2-[[(2s)-2-[[(2s)-2-[[(2s)-1-[(2s)-6-amino-2-[[(2s)-2-[[(2s)-2-[[(2s,3r)-2-amino-3-hydroxybutanoyl]amino]-4-methylsulfanylbutanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]hexan Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(=O)N1[C@H](C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O)CCC1 BNIFSVVAHBLNTN-XKKUQSFHSA-N 0.000 claims description 4
- 102400000068 Angiostatin Human genes 0.000 claims description 4
- 108010079709 Angiostatins Proteins 0.000 claims description 4
- 102000007592 Apolipoproteins Human genes 0.000 claims description 4
- 108010071619 Apolipoproteins Proteins 0.000 claims description 4
- 108010083590 Apoproteins Proteins 0.000 claims description 4
- 102000006410 Apoproteins Human genes 0.000 claims description 4
- 101000716807 Arabidopsis thaliana Protein SCO1 homolog 1, mitochondrial Proteins 0.000 claims description 4
- 101800001288 Atrial natriuretic factor Proteins 0.000 claims description 4
- 102400001282 Atrial natriuretic peptide Human genes 0.000 claims description 4
- 101800001890 Atrial natriuretic peptide Proteins 0.000 claims description 4
- 102100021943 C-C motif chemokine 2 Human genes 0.000 claims description 4
- 101710155857 C-C motif chemokine 2 Proteins 0.000 claims description 4
- 102100032367 C-C motif chemokine 5 Human genes 0.000 claims description 4
- 102100025248 C-X-C motif chemokine 10 Human genes 0.000 claims description 4
- 101710098275 C-X-C motif chemokine 10 Proteins 0.000 claims description 4
- 102100039398 C-X-C motif chemokine 2 Human genes 0.000 claims description 4
- 102100036150 C-X-C motif chemokine 5 Human genes 0.000 claims description 4
- 102100036153 C-X-C motif chemokine 6 Human genes 0.000 claims description 4
- 101710085504 C-X-C motif chemokine 6 Proteins 0.000 claims description 4
- 102100036170 C-X-C motif chemokine 9 Human genes 0.000 claims description 4
- 101710085500 C-X-C motif chemokine 9 Proteins 0.000 claims description 4
- 102000001902 CC Chemokines Human genes 0.000 claims description 4
- 108010040471 CC Chemokines Proteins 0.000 claims description 4
- 108700012434 CCL3 Proteins 0.000 claims description 4
- 102100032912 CD44 antigen Human genes 0.000 claims description 4
- 108050006947 CXC Chemokine Proteins 0.000 claims description 4
- 102000019388 CXC chemokine Human genes 0.000 claims description 4
- 102000000013 Chemokine CCL3 Human genes 0.000 claims description 4
- 108010055166 Chemokine CCL5 Proteins 0.000 claims description 4
- 102100022641 Coagulation factor IX Human genes 0.000 claims description 4
- 102100023804 Coagulation factor VII Human genes 0.000 claims description 4
- 102000008186 Collagen Human genes 0.000 claims description 4
- 108010035532 Collagen Proteins 0.000 claims description 4
- 101710104662 Enterotoxin type C-3 Proteins 0.000 claims description 4
- 102100030844 Exocyst complex component 1 Human genes 0.000 claims description 4
- 101710082714 Exotoxin A Proteins 0.000 claims description 4
- 108010076282 Factor IX Proteins 0.000 claims description 4
- 108010023321 Factor VII Proteins 0.000 claims description 4
- 108010054218 Factor VIII Proteins 0.000 claims description 4
- 102000001690 Factor VIII Human genes 0.000 claims description 4
- 108010014173 Factor X Proteins 0.000 claims description 4
- 102000008946 Fibrinogen Human genes 0.000 claims description 4
- 108010049003 Fibrinogen Proteins 0.000 claims description 4
- 102100037362 Fibronectin Human genes 0.000 claims description 4
- 108010067306 Fibronectins Proteins 0.000 claims description 4
- 102100040837 Galactoside alpha-(1,2)-fucosyltransferase 2 Human genes 0.000 claims description 4
- 101710115997 Gamma-tubulin complex component 2 Proteins 0.000 claims description 4
- 108010017544 Glucosylceramidase Proteins 0.000 claims description 4
- 102000004547 Glucosylceramidase Human genes 0.000 claims description 4
- 102000006771 Gonadotropins Human genes 0.000 claims description 4
- 108010086677 Gonadotropins Proteins 0.000 claims description 4
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 claims description 4
- 102000018997 Growth Hormone Human genes 0.000 claims description 4
- 108010051696 Growth Hormone Proteins 0.000 claims description 4
- 102100034221 Growth-regulated alpha protein Human genes 0.000 claims description 4
- 108090000031 Hedgehog Proteins Proteins 0.000 claims description 4
- 102000003693 Hedgehog Proteins Human genes 0.000 claims description 4
- 102000001554 Hemoglobins Human genes 0.000 claims description 4
- 108010054147 Hemoglobins Proteins 0.000 claims description 4
- 102000007625 Hirudins Human genes 0.000 claims description 4
- 108010007267 Hirudins Proteins 0.000 claims description 4
- 101000889128 Homo sapiens C-X-C motif chemokine 2 Proteins 0.000 claims description 4
- 101000947186 Homo sapiens C-X-C motif chemokine 5 Proteins 0.000 claims description 4
- 101000868273 Homo sapiens CD44 antigen Proteins 0.000 claims description 4
- 101000893710 Homo sapiens Galactoside alpha-(1,2)-fucosyltransferase 2 Proteins 0.000 claims description 4
- 101001069921 Homo sapiens Growth-regulated alpha protein Proteins 0.000 claims description 4
- 101000973997 Homo sapiens Nucleosome assembly protein 1-like 4 Proteins 0.000 claims description 4
- 101000947178 Homo sapiens Platelet basic protein Proteins 0.000 claims description 4
- 101000582950 Homo sapiens Platelet factor 4 Proteins 0.000 claims description 4
- 101001076715 Homo sapiens RNA-binding protein 39 Proteins 0.000 claims description 4
- 101000652229 Homo sapiens Suppressor of cytokine signaling 7 Proteins 0.000 claims description 4
- 108091006905 Human Serum Albumin Proteins 0.000 claims description 4
- 102000008100 Human Serum Albumin Human genes 0.000 claims description 4
- 108090001061 Insulin Proteins 0.000 claims description 4
- 102000004877 Insulin Human genes 0.000 claims description 4
- 102000004218 Insulin-Like Growth Factor I Human genes 0.000 claims description 4
- 102000048143 Insulin-Like Growth Factor II Human genes 0.000 claims description 4
- 108090001117 Insulin-Like Growth Factor II Proteins 0.000 claims description 4
- 102100026720 Interferon beta Human genes 0.000 claims description 4
- 102100037850 Interferon gamma Human genes 0.000 claims description 4
- 108010047761 Interferon-alpha Proteins 0.000 claims description 4
- 102000006992 Interferon-alpha Human genes 0.000 claims description 4
- 108090000467 Interferon-beta Proteins 0.000 claims description 4
- 108010074328 Interferon-gamma Proteins 0.000 claims description 4
- 102000003814 Interleukin-10 Human genes 0.000 claims description 4
- 108090000174 Interleukin-10 Proteins 0.000 claims description 4
- 108090000177 Interleukin-11 Proteins 0.000 claims description 4
- 102000003815 Interleukin-11 Human genes 0.000 claims description 4
- 102000013462 Interleukin-12 Human genes 0.000 claims description 4
- 108010065805 Interleukin-12 Proteins 0.000 claims description 4
- 108010002386 Interleukin-3 Proteins 0.000 claims description 4
- 102000004388 Interleukin-4 Human genes 0.000 claims description 4
- 108090000978 Interleukin-4 Proteins 0.000 claims description 4
- 108010002616 Interleukin-5 Proteins 0.000 claims description 4
- 102100039897 Interleukin-5 Human genes 0.000 claims description 4
- 108010002586 Interleukin-7 Proteins 0.000 claims description 4
- 102100021592 Interleukin-7 Human genes 0.000 claims description 4
- 108010002335 Interleukin-9 Proteins 0.000 claims description 4
- 102000000585 Interleukin-9 Human genes 0.000 claims description 4
- 108010001831 LDL receptors Proteins 0.000 claims description 4
- 108010063045 Lactoferrin Proteins 0.000 claims description 4
- 102000010445 Lactoferrin Human genes 0.000 claims description 4
- 102000004058 Leukemia inhibitory factor Human genes 0.000 claims description 4
- 108090000581 Leukemia inhibitory factor Proteins 0.000 claims description 4
- 102100024640 Low-density lipoprotein receptor Human genes 0.000 claims description 4
- 102000004083 Lymphotoxin-alpha Human genes 0.000 claims description 4
- 108090000542 Lymphotoxin-alpha Proteins 0.000 claims description 4
- 102100036154 Platelet basic protein Human genes 0.000 claims description 4
- 102100030304 Platelet factor 4 Human genes 0.000 claims description 4
- 102000003743 Relaxin Human genes 0.000 claims description 4
- 108090000103 Relaxin Proteins 0.000 claims description 4
- 108090000783 Renin Proteins 0.000 claims description 4
- 102100028255 Renin Human genes 0.000 claims description 4
- 102100023361 SAP domain-containing ribonucleoprotein Human genes 0.000 claims description 4
- 101710194492 SET-binding protein Proteins 0.000 claims description 4
- 206010040070 Septic Shock Diseases 0.000 claims description 4
- 108010056088 Somatostatin Proteins 0.000 claims description 4
- 102000005157 Somatostatin Human genes 0.000 claims description 4
- 101000882406 Staphylococcus aureus Enterotoxin type C-1 Proteins 0.000 claims description 4
- 101000882403 Staphylococcus aureus Enterotoxin type C-2 Proteins 0.000 claims description 4
- 101001057112 Staphylococcus aureus Enterotoxin type D Proteins 0.000 claims description 4
- 108010023197 Streptokinase Proteins 0.000 claims description 4
- 102100021669 Stromal cell-derived factor 1 Human genes 0.000 claims description 4
- 101710088580 Stromal cell-derived factor 1 Proteins 0.000 claims description 4
- 102100030529 Suppressor of cytokine signaling 7 Human genes 0.000 claims description 4
- 108010078233 Thymalfasin Proteins 0.000 claims description 4
- 102400000800 Thymosin alpha-1 Human genes 0.000 claims description 4
- 206010044248 Toxic shock syndrome Diseases 0.000 claims description 4
- 231100000650 Toxic shock syndrome Toxicity 0.000 claims description 4
- 101710120037 Toxin CcdB Proteins 0.000 claims description 4
- 102000004887 Transforming Growth Factor beta Human genes 0.000 claims description 4
- 108090001012 Transforming Growth Factor beta Proteins 0.000 claims description 4
- 101800004564 Transforming growth factor alpha Proteins 0.000 claims description 4
- 102400001320 Transforming growth factor alpha Human genes 0.000 claims description 4
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 claims description 4
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 claims description 4
- 102100039037 Vascular endothelial growth factor A Human genes 0.000 claims description 4
- 102000015395 alpha 1-Antitrypsin Human genes 0.000 claims description 4
- 108010050122 alpha 1-Antitrypsin Proteins 0.000 claims description 4
- 229940024142 alpha 1-antitrypsin Drugs 0.000 claims description 4
- 230000002587 anti-hemolytic effect Effects 0.000 claims description 4
- FZCSTZYAHCUGEM-UHFFFAOYSA-N aspergillomarasmine B Natural products OC(=O)CNC(C(O)=O)CNC(C(O)=O)CC(O)=O FZCSTZYAHCUGEM-UHFFFAOYSA-N 0.000 claims description 4
- NSQLIUXCMFBZME-MPVJKSABSA-N carperitide Chemical compound C([C@H]1C(=O)NCC(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@H](C(NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CSSC[C@@H](C(=O)N1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)=O)[C@@H](C)CC)C1=CC=CC=C1 NSQLIUXCMFBZME-MPVJKSABSA-N 0.000 claims description 4
- 229920001436 collagen Polymers 0.000 claims description 4
- 239000004074 complement inhibitor Substances 0.000 claims description 4
- 239000002934 diuretic Substances 0.000 claims description 4
- 229960004222 factor ix Drugs 0.000 claims description 4
- 229940012413 factor vii Drugs 0.000 claims description 4
- 229960000301 factor viii Drugs 0.000 claims description 4
- 229940012426 factor x Drugs 0.000 claims description 4
- 229940012952 fibrinogen Drugs 0.000 claims description 4
- 239000002622 gonadotropin Substances 0.000 claims description 4
- WQPDUTSPKFMPDP-OUMQNGNKSA-N hirudin Chemical compound C([C@@H](C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC(OS(O)(=O)=O)=CC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCCCN)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@H]1NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]2CSSC[C@@H](C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(=O)N[C@H](C(NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N2)=O)CSSC1)C(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]1NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=2C=CC(O)=CC=2)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)C(C)C)[C@@H](C)O)CSSC1)C(C)C)[C@@H](C)O)[C@@H](C)O)C1=CC=CC=C1 WQPDUTSPKFMPDP-OUMQNGNKSA-N 0.000 claims description 4
- 229940006607 hirudin Drugs 0.000 claims description 4
- 229940125396 insulin Drugs 0.000 claims description 4
- 102000002467 interleukin receptors Human genes 0.000 claims description 4
- 108010093036 interleukin receptors Proteins 0.000 claims description 4
- CSSYQJWUGATIHM-IKGCZBKSSA-N l-phenylalanyl-l-lysyl-l-cysteinyl-l-arginyl-l-arginyl-l-tryptophyl-l-glutaminyl-l-tryptophyl-l-arginyl-l-methionyl-l-lysyl-l-lysyl-l-leucylglycyl-l-alanyl-l-prolyl-l-seryl-l-isoleucyl-l-threonyl-l-cysteinyl-l-valyl-l-arginyl-l-arginyl-l-alanyl-l-phenylal Chemical compound C([C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 CSSYQJWUGATIHM-IKGCZBKSSA-N 0.000 claims description 4
- 229940078795 lactoferrin Drugs 0.000 claims description 4
- 235000021242 lactoferrin Nutrition 0.000 claims description 4
- OHDXDNUPVVYWOV-UHFFFAOYSA-N n-methyl-1-(2-naphthalen-1-ylsulfanylphenyl)methanamine Chemical compound CNCC1=CC=CC=C1SC1=CC=CC2=CC=CC=C12 OHDXDNUPVVYWOV-UHFFFAOYSA-N 0.000 claims description 4
- 230000001452 natriuretic effect Effects 0.000 claims description 4
- 230000002188 osteogenic effect Effects 0.000 claims description 4
- 239000000199 parathyroid hormone Substances 0.000 claims description 4
- 108010012038 peptide 78 Proteins 0.000 claims description 4
- 229940125863 peptide 78 Drugs 0.000 claims description 4
- 230000001698 pyrogenic effect Effects 0.000 claims description 4
- NHXLMOGPVYXJNR-ATOGVRKGSA-N somatostatin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CSSC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(=O)N1)[C@@H](C)O)NC(=O)CNC(=O)[C@H](C)N)C(O)=O)=O)[C@H](O)C)C1=CC=CC=C1 NHXLMOGPVYXJNR-ATOGVRKGSA-N 0.000 claims description 4
- 229960000553 somatostatin Drugs 0.000 claims description 4
- 229960005202 streptokinase Drugs 0.000 claims description 4
- 231100000617 superantigen Toxicity 0.000 claims description 4
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 claims description 4
- NZVYCXVTEHPMHE-ZSUJOUNUSA-N thymalfasin Chemical compound CC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O NZVYCXVTEHPMHE-ZSUJOUNUSA-N 0.000 claims description 4
- 229960004231 thymalfasin Drugs 0.000 claims description 4
- 102100032366 C-C motif chemokine 7 Human genes 0.000 claims description 3
- 101150093802 CXCL1 gene Proteins 0.000 claims description 3
- 108010055124 Chemokine CCL7 Proteins 0.000 claims description 3
- 102000000012 Chemokine CCL8 Human genes 0.000 claims description 3
- 108010055204 Chemokine CCL8 Proteins 0.000 claims description 3
- 108010014419 Chemokine CXCL1 Proteins 0.000 claims description 3
- 102000016950 Chemokine CXCL1 Human genes 0.000 claims description 3
- 229940124073 Complement inhibitor Drugs 0.000 claims description 3
- 102100024746 Dihydrofolate reductase Human genes 0.000 claims description 3
- 101100449536 Drosophila melanogaster gro gene Proteins 0.000 claims description 3
- 101710146739 Enterotoxin Proteins 0.000 claims description 3
- 102000003746 Insulin Receptor Human genes 0.000 claims description 3
- 108010001127 Insulin Receptor Proteins 0.000 claims description 3
- 102000015271 Intercellular Adhesion Molecule-1 Human genes 0.000 claims description 3
- 102000004889 Interleukin-6 Human genes 0.000 claims description 3
- 108090001005 Interleukin-6 Proteins 0.000 claims description 3
- 108090000375 Mineralocorticoid Receptors Proteins 0.000 claims description 3
- 102000003979 Mineralocorticoid Receptors Human genes 0.000 claims description 3
- 101000686985 Mouse mammary tumor virus (strain C3H) Protein PR73 Proteins 0.000 claims description 3
- 102000004140 Oncostatin M Human genes 0.000 claims description 3
- 108090000630 Oncostatin M Proteins 0.000 claims description 3
- 102000003982 Parathyroid hormone Human genes 0.000 claims description 3
- 108090000445 Parathyroid hormone Proteins 0.000 claims description 3
- 102000016971 Proto-Oncogene Proteins c-kit Human genes 0.000 claims description 3
- 108010014608 Proto-Oncogene Proteins c-kit Proteins 0.000 claims description 3
- 239000012190 activator Substances 0.000 claims description 3
- 108010080146 androgen receptors Proteins 0.000 claims description 3
- 102000001307 androgen receptors Human genes 0.000 claims description 3
- 108020001096 dihydrofolate reductase Proteins 0.000 claims description 3
- 239000000147 enterotoxin Substances 0.000 claims description 3
- 231100000655 enterotoxin Toxicity 0.000 claims description 3
- 102000015694 estrogen receptors Human genes 0.000 claims description 3
- 108010038795 estrogen receptors Proteins 0.000 claims description 3
- 239000000463 material Substances 0.000 claims description 3
- 229960001319 parathyroid hormone Drugs 0.000 claims description 3
- 102000003998 progesterone receptors Human genes 0.000 claims description 3
- 108090000468 progesterone receptors Proteins 0.000 claims description 3
- 108090000373 Tissue Plasminogen Activator Proteins 0.000 claims description 2
- 102000003978 Tissue Plasminogen Activator Human genes 0.000 claims description 2
- 229940012957 plasmin Drugs 0.000 claims description 2
- 229960000187 tissue plasminogen activator Drugs 0.000 claims description 2
- 241000282326 Felis catus Species 0.000 claims 8
- OMFXVFTZEKFJBZ-UHFFFAOYSA-N Corticosterone Natural products O=C1CCC2(C)C3C(O)CC(C)(C(CC4)C(=O)CO)C4C3CCC2=C1 OMFXVFTZEKFJBZ-UHFFFAOYSA-N 0.000 claims 2
- 102000001617 Interferon Receptors Human genes 0.000 claims 2
- 108010054267 Interferon Receptors Proteins 0.000 claims 2
- 102100039064 Interleukin-3 Human genes 0.000 claims 2
- OMFXVFTZEKFJBZ-HJTSIMOOSA-N corticosterone Chemical compound O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@H](CC4)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 OMFXVFTZEKFJBZ-HJTSIMOOSA-N 0.000 claims 2
- 210000000981 epithelium Anatomy 0.000 claims 2
- 210000005260 human cell Anatomy 0.000 claims 2
- 210000002510 keratinocyte Anatomy 0.000 claims 2
- CBQJSKKFNMDLON-JTQLQIEISA-N N-acetyl-L-phenylalanine Chemical compound CC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 CBQJSKKFNMDLON-JTQLQIEISA-N 0.000 claims 1
- 108090000435 Urokinase-type plasminogen activator Proteins 0.000 claims 1
- 102000003990 Urokinase-type plasminogen activator Human genes 0.000 claims 1
- 229960005356 urokinase Drugs 0.000 claims 1
- 239000000203 mixture Substances 0.000 abstract description 72
- 238000013519 translation Methods 0.000 abstract description 51
- 102000003960 Ligases Human genes 0.000 abstract description 31
- 108090000364 Ligases Proteins 0.000 abstract description 31
- 235000001014 amino acid Nutrition 0.000 description 461
- 108020004566 Transfer RNA Proteins 0.000 description 129
- 230000014616 translation Effects 0.000 description 53
- 239000003550 marker Substances 0.000 description 48
- 125000003275 alpha amino acid group Chemical group 0.000 description 44
- 238000012216 screening Methods 0.000 description 44
- 241000894007 species Species 0.000 description 36
- 230000027455 binding Effects 0.000 description 33
- 230000002103 transcriptional effect Effects 0.000 description 32
- 102000034356 gene-regulatory proteins Human genes 0.000 description 30
- 108091006104 gene-regulatory proteins Proteins 0.000 description 30
- 230000002163 immunogen Effects 0.000 description 28
- 230000006870 function Effects 0.000 description 27
- 102000004190 Enzymes Human genes 0.000 description 26
- 108090000790 Enzymes Proteins 0.000 description 26
- 229940088598 enzyme Drugs 0.000 description 26
- 230000004481 post-translational protein modification Effects 0.000 description 23
- 239000000126 substance Substances 0.000 description 22
- 230000015572 biosynthetic process Effects 0.000 description 20
- 125000000304 alkynyl group Chemical group 0.000 description 19
- 238000009472 formulation Methods 0.000 description 19
- 238000013518 transcription Methods 0.000 description 19
- 230000035897 transcription Effects 0.000 description 19
- 150000001875 compounds Chemical class 0.000 description 18
- 238000000338 in vitro Methods 0.000 description 18
- 238000003786 synthesis reaction Methods 0.000 description 18
- 102100039556 Galectin-4 Human genes 0.000 description 17
- 101000608765 Homo sapiens Galectin-4 Proteins 0.000 description 17
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 17
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 17
- 239000004473 Threonine Chemical group 0.000 description 17
- 238000012360 testing method Methods 0.000 description 17
- 230000004048 modification Effects 0.000 description 16
- 238000012986 modification Methods 0.000 description 16
- 229960004441 tyrosine Drugs 0.000 description 16
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 16
- 125000000852 azido group Chemical group *N=[N+]=[N-] 0.000 description 15
- 230000002068 genetic effect Effects 0.000 description 15
- 238000004519 manufacturing process Methods 0.000 description 15
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical group NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 14
- 235000004279 alanine Nutrition 0.000 description 14
- 108020004414 DNA Proteins 0.000 description 13
- 241000196324 Embryophyta Species 0.000 description 13
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Chemical group OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 13
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Chemical group CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 13
- 238000006243 chemical reaction Methods 0.000 description 13
- 230000000694 effects Effects 0.000 description 13
- 231100000350 mutagenesis Toxicity 0.000 description 13
- 230000004044 response Effects 0.000 description 13
- 235000004400 serine Nutrition 0.000 description 13
- 235000008521 threonine Nutrition 0.000 description 13
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical group OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 12
- 241000238631 Hexapoda Species 0.000 description 12
- 108091060545 Nonsense suppressor Proteins 0.000 description 12
- 239000003795 chemical substances by application Substances 0.000 description 12
- 230000014509 gene expression Effects 0.000 description 12
- 238000002703 mutagenesis Methods 0.000 description 12
- 239000000047 product Substances 0.000 description 12
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Chemical group OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 12
- 235000002374 tyrosine Nutrition 0.000 description 12
- 239000003153 chemical reaction reagent Substances 0.000 description 11
- 230000008569 process Effects 0.000 description 11
- JSXMFBNJRFXRCX-NSHDSACASA-N (2s)-2-amino-3-(4-prop-2-ynoxyphenyl)propanoic acid Chemical compound OC(=O)[C@@H](N)CC1=CC=C(OCC#C)C=C1 JSXMFBNJRFXRCX-NSHDSACASA-N 0.000 description 10
- 241000894006 Bacteria Species 0.000 description 10
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical group CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 10
- 206010028980 Neoplasm Diseases 0.000 description 10
- 239000002202 Polyethylene glycol Substances 0.000 description 10
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 10
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 10
- 230000006229 amino acid addition Effects 0.000 description 10
- 230000003197 catalytic effect Effects 0.000 description 10
- 229920001223 polyethylene glycol Polymers 0.000 description 10
- 238000011282 treatment Methods 0.000 description 10
- 235000014393 valine Nutrition 0.000 description 10
- 239000004474 valine Substances 0.000 description 10
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 9
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical group C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 9
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 9
- 101150050575 URA3 gene Proteins 0.000 description 9
- 229960001230 asparagine Drugs 0.000 description 9
- 238000003018 immunoassay Methods 0.000 description 9
- 239000002609 medium Substances 0.000 description 9
- 238000000746 purification Methods 0.000 description 9
- 238000006467 substitution reaction Methods 0.000 description 9
- 241000233866 Fungi Species 0.000 description 8
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 8
- 239000002253 acid Substances 0.000 description 8
- 230000037361 pathway Effects 0.000 description 8
- 229960005190 phenylalanine Drugs 0.000 description 8
- 239000004471 Glycine Chemical group 0.000 description 7
- 238000006736 Huisgen cycloaddition reaction Methods 0.000 description 7
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical group CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 7
- 241001465754 Metazoa Species 0.000 description 7
- 101710146427 Probable tyrosine-tRNA ligase, cytoplasmic Proteins 0.000 description 7
- 102000018378 Tyrosine-tRNA ligase Human genes 0.000 description 7
- 101710107268 Tyrosine-tRNA ligase, mitochondrial Proteins 0.000 description 7
- 238000003556 assay Methods 0.000 description 7
- 230000006696 biosynthetic metabolic pathway Effects 0.000 description 7
- 239000000872 buffer Substances 0.000 description 7
- 150000001720 carbohydrates Chemical class 0.000 description 7
- 230000009260 cross reactivity Effects 0.000 description 7
- 239000003814 drug Substances 0.000 description 7
- 239000000975 dye Substances 0.000 description 7
- 210000003527 eukaryotic cell Anatomy 0.000 description 7
- 239000012634 fragment Substances 0.000 description 7
- 125000000468 ketone group Chemical group 0.000 description 7
- 101150066555 lacZ gene Proteins 0.000 description 7
- 108020004999 messenger RNA Proteins 0.000 description 7
- 229910052751 metal Inorganic materials 0.000 description 7
- 239000002184 metal Substances 0.000 description 7
- 229930182817 methionine Natural products 0.000 description 7
- 235000006109 methionine Nutrition 0.000 description 7
- 229920001542 oligosaccharide Polymers 0.000 description 7
- 150000002482 oligosaccharides Chemical class 0.000 description 7
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 7
- 235000008729 phenylalanine Nutrition 0.000 description 7
- 238000012545 processing Methods 0.000 description 7
- 210000001236 prokaryotic cell Anatomy 0.000 description 7
- 239000013598 vector Substances 0.000 description 7
- NEMHIKRLROONTL-QMMMGPOBSA-N (2s)-2-azaniumyl-3-(4-azidophenyl)propanoate Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N=[N+]=[N-])C=C1 NEMHIKRLROONTL-QMMMGPOBSA-N 0.000 description 6
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 6
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 6
- 239000004971 Cross linker Substances 0.000 description 6
- 230000004568 DNA-binding Effects 0.000 description 6
- OAKJQQAXSVQMHS-UHFFFAOYSA-N Hydrazine Chemical compound NN OAKJQQAXSVQMHS-UHFFFAOYSA-N 0.000 description 6
- 238000007792 addition Methods 0.000 description 6
- 235000009582 asparagine Nutrition 0.000 description 6
- 230000001851 biosynthetic effect Effects 0.000 description 6
- 150000001615 biotins Chemical class 0.000 description 6
- 230000001413 cellular effect Effects 0.000 description 6
- ZPUCINDJVBIVPJ-LJISPDSOSA-N cocaine Chemical compound O([C@H]1C[C@@H]2CC[C@@H](N2C)[C@H]1C(=O)OC)C(=O)C1=CC=CC=C1 ZPUCINDJVBIVPJ-LJISPDSOSA-N 0.000 description 6
- 231100000433 cytotoxic Toxicity 0.000 description 6
- 230000001472 cytotoxic effect Effects 0.000 description 6
- 210000004962 mammalian cell Anatomy 0.000 description 6
- 238000002360 preparation method Methods 0.000 description 6
- 238000001742 protein purification Methods 0.000 description 6
- 210000003705 ribosome Anatomy 0.000 description 6
- 210000002966 serum Anatomy 0.000 description 6
- 238000002741 site-directed mutagenesis Methods 0.000 description 6
- 108020005098 Anticodon Proteins 0.000 description 5
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 5
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 5
- 101150009006 HIS3 gene Proteins 0.000 description 5
- 241000205062 Halobacterium Species 0.000 description 5
- 101100246753 Halobacterium salinarum (strain ATCC 700922 / JCM 11081 / NRC-1) pyrF gene Proteins 0.000 description 5
- 108060003951 Immunoglobulin Proteins 0.000 description 5
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 5
- 108020004485 Nonsense Codon Proteins 0.000 description 5
- 108091028043 Nucleic acid sequence Proteins 0.000 description 5
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 5
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 5
- 108091027981 Response element Proteins 0.000 description 5
- 101710195626 Transcriptional activator protein Proteins 0.000 description 5
- 108091032917 Transfer-messenger RNA Proteins 0.000 description 5
- 241000700605 Viruses Species 0.000 description 5
- 235000008206 alpha-amino acids Nutrition 0.000 description 5
- 230000000689 aminoacylating effect Effects 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 125000004429 atom Chemical group 0.000 description 5
- 201000011510 cancer Diseases 0.000 description 5
- 235000014633 carbohydrates Nutrition 0.000 description 5
- 230000008859 change Effects 0.000 description 5
- 230000037433 frameshift Effects 0.000 description 5
- 239000005090 green fluorescent protein Substances 0.000 description 5
- 102000018358 immunoglobulin Human genes 0.000 description 5
- 230000035772 mutation Effects 0.000 description 5
- 125000003729 nucleotide group Chemical group 0.000 description 5
- 230000006798 recombination Effects 0.000 description 5
- 238000005215 recombination Methods 0.000 description 5
- 238000003860 storage Methods 0.000 description 5
- 235000000346 sugar Nutrition 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- RZVAJINKPMORJF-UHFFFAOYSA-N Acetaminophen Chemical compound CC(=O)NC1=CC=C(O)C=C1 RZVAJINKPMORJF-UHFFFAOYSA-N 0.000 description 4
- 239000004475 Arginine Substances 0.000 description 4
- 241000271566 Aves Species 0.000 description 4
- 108010035563 Chloramphenicol O-acetyltransferase Proteins 0.000 description 4
- 108010071942 Colony-Stimulating Factors Proteins 0.000 description 4
- 102000004594 DNA Polymerase I Human genes 0.000 description 4
- 108010017826 DNA Polymerase I Proteins 0.000 description 4
- 241000206602 Eukaryota Species 0.000 description 4
- 102000003972 Fibroblast growth factor 7 Human genes 0.000 description 4
- 108090000385 Fibroblast growth factor 7 Proteins 0.000 description 4
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 4
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 4
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 4
- 229930194542 Keto Natural products 0.000 description 4
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical group SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 4
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 4
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 4
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 4
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 4
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical group CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 4
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical group CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 4
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 4
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Chemical group CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 4
- 238000001042 affinity chromatography Methods 0.000 description 4
- 239000007801 affinity label Substances 0.000 description 4
- 150000001371 alpha-amino acids Chemical class 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 4
- 239000000427 antigen Substances 0.000 description 4
- 108091007433 antigens Proteins 0.000 description 4
- 102000036639 antigens Human genes 0.000 description 4
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 4
- 235000009697 arginine Nutrition 0.000 description 4
- 150000001540 azides Chemical class 0.000 description 4
- 239000002738 chelating agent Substances 0.000 description 4
- 238000010276 construction Methods 0.000 description 4
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Chemical group SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 4
- 235000018417 cysteine Nutrition 0.000 description 4
- 210000000805 cytoplasm Anatomy 0.000 description 4
- 235000014113 dietary fatty acids Nutrition 0.000 description 4
- 235000015872 dietary supplement Nutrition 0.000 description 4
- 239000003937 drug carrier Substances 0.000 description 4
- 238000007350 electrophilic reaction Methods 0.000 description 4
- 239000013604 expression vector Substances 0.000 description 4
- 229930195729 fatty acid Natural products 0.000 description 4
- 239000000194 fatty acid Substances 0.000 description 4
- 150000004665 fatty acids Chemical class 0.000 description 4
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 4
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 4
- 235000004554 glutamine Nutrition 0.000 description 4
- 150000002308 glutamine derivatives Chemical class 0.000 description 4
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 4
- 235000014304 histidine Nutrition 0.000 description 4
- 239000001257 hydrogen Substances 0.000 description 4
- 229910052739 hydrogen Inorganic materials 0.000 description 4
- 230000003993 interaction Effects 0.000 description 4
- 230000003834 intracellular effect Effects 0.000 description 4
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Chemical group CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 4
- 229960000310 isoleucine Drugs 0.000 description 4
- 235000014705 isoleucine Nutrition 0.000 description 4
- 235000005772 leucine Nutrition 0.000 description 4
- 150000002632 lipids Chemical class 0.000 description 4
- 230000007246 mechanism Effects 0.000 description 4
- 239000002773 nucleotide Substances 0.000 description 4
- 210000004940 nucleus Anatomy 0.000 description 4
- 238000002823 phage display Methods 0.000 description 4
- 150000002993 phenylalanine derivatives Chemical class 0.000 description 4
- BZQFBWGGLXLEPQ-REOHCLBHSA-N phosphoserine Chemical compound OC(=O)[C@@H](N)COP(O)(O)=O BZQFBWGGLXLEPQ-REOHCLBHSA-N 0.000 description 4
- 239000013612 plasmid Substances 0.000 description 4
- 229920000570 polyether Polymers 0.000 description 4
- 229920000642 polymer Polymers 0.000 description 4
- 239000000651 prodrug Substances 0.000 description 4
- 229940002612 prodrug Drugs 0.000 description 4
- 239000000376 reactant Substances 0.000 description 4
- 230000002829 reductive effect Effects 0.000 description 4
- 239000011347 resin Substances 0.000 description 4
- 229920005989 resin Polymers 0.000 description 4
- 230000002441 reversible effect Effects 0.000 description 4
- 239000000523 sample Substances 0.000 description 4
- 239000000758 substrate Substances 0.000 description 4
- 230000001629 suppression Effects 0.000 description 4
- 229940124597 therapeutic agent Drugs 0.000 description 4
- 231100000419 toxicity Toxicity 0.000 description 4
- 230000001988 toxicity Effects 0.000 description 4
- 238000010396 two-hybrid screening Methods 0.000 description 4
- 210000005253 yeast cell Anatomy 0.000 description 4
- KLSJWNVTNUYHDU-UHFFFAOYSA-N Amitrole Chemical compound NC1=NC=NN1 KLSJWNVTNUYHDU-UHFFFAOYSA-N 0.000 description 3
- 241000193830 Bacillus <bacterium> Species 0.000 description 3
- 108010009685 Cholinergic Receptors Proteins 0.000 description 3
- 241000557626 Corvus corax Species 0.000 description 3
- FDKWRPBBCBCIGA-UWTATZPHSA-N D-Selenocysteine Natural products [Se]C[C@@H](N)C(O)=O FDKWRPBBCBCIGA-UWTATZPHSA-N 0.000 description 3
- WHUUTDBJXJRKMK-GSVOUGTGSA-N D-glutamic acid Chemical compound OC(=O)[C@H](N)CCC(O)=O WHUUTDBJXJRKMK-GSVOUGTGSA-N 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- ZRALSGWEFCBTJO-UHFFFAOYSA-N Guanidine Chemical compound NC(N)=N ZRALSGWEFCBTJO-UHFFFAOYSA-N 0.000 description 3
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 3
- ZFOMKMMPBOQKMC-KXUCPTDWSA-N L-pyrrolysine Chemical compound C[C@@H]1CC=N[C@H]1C(=O)NCCCC[C@H]([NH3+])C([O-])=O ZFOMKMMPBOQKMC-KXUCPTDWSA-N 0.000 description 3
- ZKZBPNGNEQAJSX-REOHCLBHSA-N L-selenocysteine Chemical compound [SeH]C[C@H](N)C(O)=O ZKZBPNGNEQAJSX-REOHCLBHSA-N 0.000 description 3
- 108060001084 Luciferase Proteins 0.000 description 3
- 239000005089 Luciferase Substances 0.000 description 3
- 208000000112 Myalgia Diseases 0.000 description 3
- 108091007494 Nucleic acid- binding domains Proteins 0.000 description 3
- GEYBMYRBIABFTA-VIFPVBQESA-N O-methyl-L-tyrosine Chemical compound COC1=CC=C(C[C@H](N)C(O)=O)C=C1 GEYBMYRBIABFTA-VIFPVBQESA-N 0.000 description 3
- 102000035195 Peptidases Human genes 0.000 description 3
- 108091005804 Peptidases Proteins 0.000 description 3
- 206010037660 Pyrexia Diseases 0.000 description 3
- 241000205160 Pyrococcus Species 0.000 description 3
- 102000014450 RNA Polymerase III Human genes 0.000 description 3
- 108010078067 RNA Polymerase III Proteins 0.000 description 3
- 108700008625 Reporter Genes Proteins 0.000 description 3
- 101100394989 Rhodopseudomonas palustris (strain ATCC BAA-98 / CGA009) hisI gene Proteins 0.000 description 3
- 102000034337 acetylcholine receptors Human genes 0.000 description 3
- 230000004913 activation Effects 0.000 description 3
- 239000000556 agonist Substances 0.000 description 3
- 150000001299 aldehydes Chemical class 0.000 description 3
- 125000003118 aryl group Chemical group 0.000 description 3
- 229940009098 aspartate Drugs 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 108010005774 beta-Galactosidase Proteins 0.000 description 3
- 238000004587 chromatography analysis Methods 0.000 description 3
- 229960003920 cocaine Drugs 0.000 description 3
- 238000001514 detection method Methods 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 230000018109 developmental process Effects 0.000 description 3
- 239000000032 diagnostic agent Substances 0.000 description 3
- 229940039227 diagnostic agent Drugs 0.000 description 3
- 239000000539 dimer Substances 0.000 description 3
- 241001493065 dsRNA viruses Species 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 125000000524 functional group Chemical group 0.000 description 3
- 230000002538 fungal effect Effects 0.000 description 3
- BTCSSZJGUNDROE-UHFFFAOYSA-N gamma-aminobutyric acid Chemical compound NCCCC(O)=O BTCSSZJGUNDROE-UHFFFAOYSA-N 0.000 description 3
- 150000002334 glycols Chemical class 0.000 description 3
- IPCSVZSSVZVIGE-UHFFFAOYSA-M hexadecanoate Chemical compound CCCCCCCCCCCCCCCC([O-])=O IPCSVZSSVZVIGE-UHFFFAOYSA-M 0.000 description 3
- 238000001802 infusion Methods 0.000 description 3
- 230000002401 inhibitory effect Effects 0.000 description 3
- 238000001990 intravenous administration Methods 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- 230000000670 limiting effect Effects 0.000 description 3
- 101150109301 lys2 gene Proteins 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 3
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 3
- 210000000287 oocyte Anatomy 0.000 description 3
- 230000026792 palmitoylation Effects 0.000 description 3
- 230000026731 phosphorylation Effects 0.000 description 3
- 238000006366 phosphorylation reaction Methods 0.000 description 3
- 230000000704 physical effect Effects 0.000 description 3
- 230000003389 potentiating effect Effects 0.000 description 3
- 230000009145 protein modification Effects 0.000 description 3
- 230000004850 protein–protein interaction Effects 0.000 description 3
- 238000002708 random mutagenesis Methods 0.000 description 3
- 230000009257 reactivity Effects 0.000 description 3
- 238000012552 review Methods 0.000 description 3
- 230000003248 secreting effect Effects 0.000 description 3
- 235000016491 selenocysteine Nutrition 0.000 description 3
- ZKZBPNGNEQAJSX-UHFFFAOYSA-N selenocysteine Natural products [SeH]CC(N)C(O)=O ZKZBPNGNEQAJSX-UHFFFAOYSA-N 0.000 description 3
- 229940055619 selenocysteine Drugs 0.000 description 3
- 239000007787 solid Substances 0.000 description 3
- 238000010561 standard procedure Methods 0.000 description 3
- 125000001424 substituent group Chemical group 0.000 description 3
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 3
- 125000000341 threoninyl group Chemical group [H]OC([H])(C([H])([H])[H])C([H])(N([H])[H])C(*)=O 0.000 description 3
- 231100000167 toxic agent Toxicity 0.000 description 3
- 239000003440 toxic substance Substances 0.000 description 3
- VBEQCZHXXJYVRD-GACYYNSASA-N uroanthelone Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1 VBEQCZHXXJYVRD-GACYYNSASA-N 0.000 description 3
- 229960005486 vaccine Drugs 0.000 description 3
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 3
- 238000001262 western blot Methods 0.000 description 3
- ZXSBHXZKWRIEIA-JTQLQIEISA-N (2s)-3-(4-acetylphenyl)-2-azaniumylpropanoate Chemical compound CC(=O)C1=CC=C(C[C@H](N)C(O)=O)C=C1 ZXSBHXZKWRIEIA-JTQLQIEISA-N 0.000 description 2
- HVCOBJNICQPDBP-UHFFFAOYSA-N 3-[3-[3,5-dihydroxy-6-methyl-4-(3,4,5-trihydroxy-6-methyloxan-2-yl)oxyoxan-2-yl]oxydecanoyloxy]decanoic acid;hydrate Chemical compound O.OC1C(OC(CC(=O)OC(CCCCCCC)CC(O)=O)CCCCCCC)OC(C)C(O)C1OC1C(O)C(O)C(O)C(C)O1 HVCOBJNICQPDBP-UHFFFAOYSA-N 0.000 description 2
- JZRBSTONIYRNRI-VIFPVBQESA-N 3-methylphenylalanine Chemical compound CC1=CC=CC(C[C@H](N)C(O)=O)=C1 JZRBSTONIYRNRI-VIFPVBQESA-N 0.000 description 2
- IRZQDMYEJPNDEN-UHFFFAOYSA-N 3-phenyl-2-aminobutanoic acid Natural products OC(=O)C(N)C(C)C1=CC=CC=C1 IRZQDMYEJPNDEN-UHFFFAOYSA-N 0.000 description 2
- PZNQZSRPDOEBMS-QMMMGPOBSA-N 4-iodo-L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(I)C=C1 PZNQZSRPDOEBMS-QMMMGPOBSA-N 0.000 description 2
- OPIFSICVWOWJMJ-AEOCFKNESA-N 5-bromo-4-chloro-3-indolyl beta-D-galactoside Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1OC1=CNC2=CC=C(Br)C(Cl)=C12 OPIFSICVWOWJMJ-AEOCFKNESA-N 0.000 description 2
- 241000251468 Actinopterygii Species 0.000 description 2
- 108700023418 Amidases Proteins 0.000 description 2
- 241000203069 Archaea Species 0.000 description 2
- 241000238421 Arthropoda Species 0.000 description 2
- BSYNRYMUTXBXSQ-UHFFFAOYSA-N Aspirin Chemical compound CC(=O)OC1=CC=CC=C1C(O)=O BSYNRYMUTXBXSQ-UHFFFAOYSA-N 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- BTBUEUYNUDRHOZ-UHFFFAOYSA-N Borate Chemical compound [O-]B([O-])[O-] BTBUEUYNUDRHOZ-UHFFFAOYSA-N 0.000 description 2
- 206010006187 Breast cancer Diseases 0.000 description 2
- 208000026310 Breast neoplasm Diseases 0.000 description 2
- 102000014914 Carrier Proteins Human genes 0.000 description 2
- 108050001186 Chaperonin Cpn60 Proteins 0.000 description 2
- 102000052603 Chaperonins Human genes 0.000 description 2
- RTZKZFJDLAIYFH-UHFFFAOYSA-N Diethyl ether Chemical compound CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- 238000002965 ELISA Methods 0.000 description 2
- 241000224431 Entamoeba Species 0.000 description 2
- 241000305071 Enterobacterales Species 0.000 description 2
- 241000588722 Escherichia Species 0.000 description 2
- 101150077230 GAL4 gene Proteins 0.000 description 2
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 2
- 229930186217 Glycolipid Natural products 0.000 description 2
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 2
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 description 2
- 241000204991 Haloferax Species 0.000 description 2
- 241000204933 Haloferax volcanii Species 0.000 description 2
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 2
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 2
- 102000000646 Interleukin-3 Human genes 0.000 description 2
- WTDRDQBEARUVNC-LURJTMIESA-N L-DOPA Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C(O)=C1 WTDRDQBEARUVNC-LURJTMIESA-N 0.000 description 2
- WTDRDQBEARUVNC-UHFFFAOYSA-N L-Dopa Natural products OC(=O)C(N)CC1=CC=C(O)C(O)=C1 WTDRDQBEARUVNC-UHFFFAOYSA-N 0.000 description 2
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 2
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- 241000270322 Lepidosauria Species 0.000 description 2
- 102000003820 Lipoxygenases Human genes 0.000 description 2
- 108090000128 Lipoxygenases Proteins 0.000 description 2
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- 241000203407 Methanocaldococcus jannaschii Species 0.000 description 2
- 241000699666 Mus <mouse, genus> Species 0.000 description 2
- 241000699670 Mus sp. Species 0.000 description 2
- 108010021466 Mutant Proteins Proteins 0.000 description 2
- 102000008300 Mutant Proteins Human genes 0.000 description 2
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 2
- 102000007399 Nuclear hormone receptor Human genes 0.000 description 2
- 108020005497 Nuclear hormone receptor Proteins 0.000 description 2
- 108091005461 Nucleic proteins Proteins 0.000 description 2
- 108091034117 Oligonucleotide Proteins 0.000 description 2
- 239000004721 Polyphenylene oxide Substances 0.000 description 2
- RJKFOVLPORLFTN-LEKSSAKUSA-N Progesterone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H](C(=O)C)[C@@]1(C)CC2 RJKFOVLPORLFTN-LEKSSAKUSA-N 0.000 description 2
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 2
- ATUOYWHBWRKTHZ-UHFFFAOYSA-N Propane Chemical compound CCC ATUOYWHBWRKTHZ-UHFFFAOYSA-N 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 2
- MUMGGOZAMZWBJJ-DYKIIFRCSA-N Testostosterone Chemical compound O=C1CC[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 MUMGGOZAMZWBJJ-DYKIIFRCSA-N 0.000 description 2
- 241000224526 Trichomonas Species 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- 241000269370 Xenopus <genus> Species 0.000 description 2
- 238000010958 [3+2] cycloaddition reaction Methods 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- 125000002777 acetyl group Chemical group [H]C([H])([H])C(*)=O 0.000 description 2
- 230000021736 acetylation Effects 0.000 description 2
- 238000006640 acetylation reaction Methods 0.000 description 2
- 229960001138 acetylsalicylic acid Drugs 0.000 description 2
- 230000001154 acute effect Effects 0.000 description 2
- 125000002252 acyl group Chemical group 0.000 description 2
- 230000010933 acylation Effects 0.000 description 2
- 238000005917 acylation reaction Methods 0.000 description 2
- 101150067366 adh gene Proteins 0.000 description 2
- 239000002671 adjuvant Substances 0.000 description 2
- 239000000443 aerosol Substances 0.000 description 2
- 125000003342 alkenyl group Chemical group 0.000 description 2
- 125000000217 alkyl group Chemical group 0.000 description 2
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 2
- 102000005922 amidase Human genes 0.000 description 2
- 239000012491 analyte Substances 0.000 description 2
- 210000004102 animal cell Anatomy 0.000 description 2
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 2
- 125000003236 benzoyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C(*)=O 0.000 description 2
- 102000005936 beta-Galactosidase Human genes 0.000 description 2
- UCMIRNVEIXFBKS-UHFFFAOYSA-N beta-alanine Chemical class NCCC(O)=O UCMIRNVEIXFBKS-UHFFFAOYSA-N 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- ZADPBFCGQRWHPN-UHFFFAOYSA-N boronic acid Chemical compound OBO ZADPBFCGQRWHPN-UHFFFAOYSA-N 0.000 description 2
- 210000004899 c-terminal region Anatomy 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 2
- 150000001719 carbohydrate derivatives Chemical class 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 230000003915 cell function Effects 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- WHTVZRBIWZFKQO-UHFFFAOYSA-N chloroquine Chemical compound ClC1=CC=C2C(NC(C)CCCN(CC)CC)=CC=NC2=C1 WHTVZRBIWZFKQO-UHFFFAOYSA-N 0.000 description 2
- 238000012875 competitive assay Methods 0.000 description 2
- 230000009137 competitive binding Effects 0.000 description 2
- 238000012258 culturing Methods 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 229950006137 dexfosfoserine Drugs 0.000 description 2
- 238000010494 dissociation reaction Methods 0.000 description 2
- 230000005593 dissociations Effects 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 108010048367 enhanced green fluorescent protein Proteins 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 150000002148 esters Chemical class 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 239000004220 glutamic acid Substances 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- 229960004198 guanidine Drugs 0.000 description 2
- 125000005843 halogen group Chemical group 0.000 description 2
- 229940022353 herceptin Drugs 0.000 description 2
- 125000000623 heterocyclic group Chemical group 0.000 description 2
- 229930195733 hydrocarbon Natural products 0.000 description 2
- 150000002430 hydrocarbons Chemical class 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 150000002466 imines Chemical class 0.000 description 2
- 230000028993 immune response Effects 0.000 description 2
- 230000003053 immunization Effects 0.000 description 2
- 238000002649 immunization Methods 0.000 description 2
- 230000005847 immunogenicity Effects 0.000 description 2
- 239000003547 immunosorbent Substances 0.000 description 2
- 230000006698 induction Effects 0.000 description 2
- 208000015181 infectious disease Diseases 0.000 description 2
- 108091006086 inhibitor proteins Proteins 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 229940047122 interleukins Drugs 0.000 description 2
- 238000007918 intramuscular administration Methods 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 125000005647 linker group Chemical group 0.000 description 2
- 238000004020 luminiscence type Methods 0.000 description 2
- 235000018977 lysine Nutrition 0.000 description 2
- 239000000178 monomer Substances 0.000 description 2
- QCQYVCMYGCHVMR-AAZUGDAUSA-N n-[(2r,3r,4s,5r)-4,5,6-trihydroxy-1-oxo-3-[(2r,3r,4s,5r,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyhexan-2-yl]acetamide Chemical compound CC(=O)N[C@@H](C=O)[C@H]([C@@H](O)[C@H](O)CO)O[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O QCQYVCMYGCHVMR-AAZUGDAUSA-N 0.000 description 2
- 230000000269 nucleophilic effect Effects 0.000 description 2
- 238000010397 one-hybrid screening Methods 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 229940029358 orthoclone okt3 Drugs 0.000 description 2
- PSWJVKKJYCAPTI-UHFFFAOYSA-N oxido-oxo-phosphonophosphanylphosphanium Chemical compound OP(O)(=O)PP(=O)=O PSWJVKKJYCAPTI-UHFFFAOYSA-N 0.000 description 2
- TVIDEEHSOPHZBR-AWEZNQCLSA-N para-(benzoyl)-phenylalanine Chemical compound C1=CC(C[C@H](N)C(O)=O)=CC=C1C(=O)C1=CC=CC=C1 TVIDEEHSOPHZBR-AWEZNQCLSA-N 0.000 description 2
- 229960005489 paracetamol Drugs 0.000 description 2
- 238000007911 parenteral administration Methods 0.000 description 2
- 230000035699 permeability Effects 0.000 description 2
- 239000008194 pharmaceutical composition Substances 0.000 description 2
- DCWXELXMIBXGTH-QMMMGPOBSA-N phosphonotyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(OP(O)(O)=O)C=C1 DCWXELXMIBXGTH-QMMMGPOBSA-N 0.000 description 2
- 229920002704 polyhistidine Polymers 0.000 description 2
- 230000029279 positive regulation of transcription, DNA-dependent Effects 0.000 description 2
- 230000001124 posttranscriptional effect Effects 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 235000013930 proline Nutrition 0.000 description 2
- 125000001500 prolyl group Chemical class [H]N1C([H])(C(=O)[*])C([H])([H])C([H])([H])C1([H])[H] 0.000 description 2
- 235000019419 proteases Nutrition 0.000 description 2
- 238000003498 protein array Methods 0.000 description 2
- 230000012846 protein folding Effects 0.000 description 2
- 230000002285 radioactive effect Effects 0.000 description 2
- 230000003252 repetitive effect Effects 0.000 description 2
- 229960004641 rituximab Drugs 0.000 description 2
- 150000003839 salts Chemical class 0.000 description 2
- 239000006152 selective media Substances 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 125000000446 sulfanediyl group Chemical group *S* 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 238000009482 thermal adhesion granulation Methods 0.000 description 2
- 150000003573 thiols Chemical class 0.000 description 2
- 231100000331 toxic Toxicity 0.000 description 2
- 230000002588 toxic effect Effects 0.000 description 2
- 108091008023 transcriptional regulators Proteins 0.000 description 2
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 2
- 230000004614 tumor growth Effects 0.000 description 2
- JPZXHKDZASGCLU-LBPRGKRZSA-N β-(2-naphthyl)-alanine Chemical compound C1=CC=CC2=CC(C[C@H](N)C(O)=O)=CC=C21 JPZXHKDZASGCLU-LBPRGKRZSA-N 0.000 description 2
- OGNSCSPNOLGXSM-UHFFFAOYSA-N (+/-)-DABA Chemical class NCCC(N)C(O)=O OGNSCSPNOLGXSM-UHFFFAOYSA-N 0.000 description 1
- VKBLQCDGTHFOLS-NSHDSACASA-N (2s)-2-(4-benzoylanilino)propanoic acid Chemical compound C1=CC(N[C@@H](C)C(O)=O)=CC=C1C(=O)C1=CC=CC=C1 VKBLQCDGTHFOLS-NSHDSACASA-N 0.000 description 1
- ULBLZIPFWGIOJF-QMMMGPOBSA-N (2s)-2-(bromoamino)-3-phenylpropanoic acid Chemical compound OC(=O)[C@@H](NBr)CC1=CC=CC=C1 ULBLZIPFWGIOJF-QMMMGPOBSA-N 0.000 description 1
- YYTDJPUFAVPHQA-VKHMYHEASA-N (2s)-2-amino-3-(2,3,4,5,6-pentafluorophenyl)propanoic acid Chemical compound OC(=O)[C@@H](N)CC1=C(F)C(F)=C(F)C(F)=C1F YYTDJPUFAVPHQA-VKHMYHEASA-N 0.000 description 1
- PEMUHKUIQHFMTH-QMMMGPOBSA-N (2s)-2-amino-3-(4-bromophenyl)propanoic acid Chemical compound OC(=O)[C@@H](N)CC1=CC=C(Br)C=C1 PEMUHKUIQHFMTH-QMMMGPOBSA-N 0.000 description 1
- 108010052418 (N-(2-((4-((2-((4-(9-acridinylamino)phenyl)amino)-2-oxoethyl)amino)-4-oxobutyl)amino)-1-(1H-imidazol-4-ylmethyl)-1-oxoethyl)-6-(((-2-aminoethyl)amino)methyl)-2-pyridinecarboxamidato) iron(1+) Proteins 0.000 description 1
- WHTVZRBIWZFKQO-AWEZNQCLSA-N (S)-chloroquine Chemical compound ClC1=CC=C2C(N[C@@H](C)CCCN(CC)CC)=CC=NC2=C1 WHTVZRBIWZFKQO-AWEZNQCLSA-N 0.000 description 1
- POPPVIRYGJQIOF-UHFFFAOYSA-N 2-acetyloxyethyl(trimethyl)azanium;3-(1-methylpyrrolidin-2-yl)pyridine Chemical compound CC(=O)OCC[N+](C)(C)C.CN1CCCC1C1=CC=CN=C1 POPPVIRYGJQIOF-UHFFFAOYSA-N 0.000 description 1
- SPCKHVPPRJWQRZ-UHFFFAOYSA-N 2-benzhydryloxy-n,n-dimethylethanamine;2-hydroxypropane-1,2,3-tricarboxylic acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O.C=1C=CC=CC=1C(OCCN(C)C)C1=CC=CC=C1 SPCKHVPPRJWQRZ-UHFFFAOYSA-N 0.000 description 1
- 125000003903 2-propenyl group Chemical group [H]C([*])([H])C([H])=C([H])[H] 0.000 description 1
- 108020005065 3' Flanking Region Proteins 0.000 description 1
- JNRLEMMIVRBKJE-UHFFFAOYSA-N 4,4'-Methylenebis(N,N-dimethylaniline) Chemical compound C1=CC(N(C)C)=CC=C1CC1=CC=C(N(C)C)C=C1 JNRLEMMIVRBKJE-UHFFFAOYSA-N 0.000 description 1
- 108020005029 5' Flanking Region Proteins 0.000 description 1
- SEHFUALWMUWDKS-UHFFFAOYSA-N 5-fluoroorotic acid Chemical compound OC(=O)C=1NC(=O)NC(=O)C=1F SEHFUALWMUWDKS-UHFFFAOYSA-N 0.000 description 1
- HBAQYPYDRFILMT-UHFFFAOYSA-N 8-[3-(1-cyclopropylpyrazol-4-yl)-1H-pyrazolo[4,3-d]pyrimidin-5-yl]-3-methyl-3,8-diazabicyclo[3.2.1]octan-2-one Chemical class C1(CC1)N1N=CC(=C1)C1=NNC2=C1N=C(N=C2)N1C2C(N(CC1CC2)C)=O HBAQYPYDRFILMT-UHFFFAOYSA-N 0.000 description 1
- 208000030507 AIDS Diseases 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- 102000007698 Alcohol dehydrogenase Human genes 0.000 description 1
- 108010021809 Alcohol dehydrogenase Proteins 0.000 description 1
- PQSUYGKTWSAVDQ-UHFFFAOYSA-N Aldosterone Natural products C1CC2C3CCC(C(=O)CO)C3(C=O)CC(O)C2C2(C)C1=CC(=O)CC2 PQSUYGKTWSAVDQ-UHFFFAOYSA-N 0.000 description 1
- PQSUYGKTWSAVDQ-ZVIOFETBSA-N Aldosterone Chemical compound C([C@@]1([C@@H](C(=O)CO)CC[C@H]1[C@@H]1CC2)C=O)[C@H](O)[C@@H]1[C@]1(C)C2=CC(=O)CC1 PQSUYGKTWSAVDQ-ZVIOFETBSA-N 0.000 description 1
- 102000006534 Amino Acid Isomerases Human genes 0.000 description 1
- 108010008830 Amino Acid Isomerases Proteins 0.000 description 1
- OZDNDGXASTWERN-CTNGQTDRSA-N Apovincamine Chemical compound C1=CC=C2C(CCN3CCC4)=C5[C@@H]3[C@]4(CC)C=C(C(=O)OC)N5C2=C1 OZDNDGXASTWERN-CTNGQTDRSA-N 0.000 description 1
- 241000205042 Archaeoglobus fulgidus Species 0.000 description 1
- 241000712891 Arenavirus Species 0.000 description 1
- 241000228212 Aspergillus Species 0.000 description 1
- YOZSEGPJAXTSFZ-ZETCQYMHSA-N Azatyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=N1 YOZSEGPJAXTSFZ-ZETCQYMHSA-N 0.000 description 1
- 239000004135 Bone phosphate Substances 0.000 description 1
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical class [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 102000005367 Carboxypeptidases Human genes 0.000 description 1
- 108010006303 Carboxypeptidases Proteins 0.000 description 1
- 102000000496 Carboxypeptidases A Human genes 0.000 description 1
- 108010080937 Carboxypeptidases A Proteins 0.000 description 1
- 108010078791 Carrier Proteins Proteins 0.000 description 1
- 206010009944 Colon cancer Diseases 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- 241000711573 Coronaviridae Species 0.000 description 1
- 241000938605 Crocodylia Species 0.000 description 1
- 241000195493 Cryptophyta Species 0.000 description 1
- 102000005636 Cyclic AMP Response Element-Binding Protein Human genes 0.000 description 1
- 108010045171 Cyclic AMP Response Element-Binding Protein Proteins 0.000 description 1
- 102100027309 Cyclic AMP-responsive element-binding protein 5 Human genes 0.000 description 1
- QNAYBMKLOCPYGJ-UWTATZPHSA-N D-alanine Chemical compound C[C@@H](N)C(O)=O QNAYBMKLOCPYGJ-UWTATZPHSA-N 0.000 description 1
- QNAYBMKLOCPYGJ-UHFFFAOYSA-N D-alpha-Ala Natural products CC([NH3+])C([O-])=O QNAYBMKLOCPYGJ-UHFFFAOYSA-N 0.000 description 1
- JUQLUIFNNFIIKC-UHFFFAOYSA-N D-alpha-Aminopimelic acid Natural products OC(=O)C(N)CCCCC(O)=O JUQLUIFNNFIIKC-UHFFFAOYSA-N 0.000 description 1
- 229930195713 D-glutamate Natural products 0.000 description 1
- YAHZABJORDUQGO-NQXXGFSBSA-N D-ribulose 1,5-bisphosphate Chemical compound OP(=O)(O)OC[C@@H](O)[C@@H](O)C(=O)COP(O)(O)=O YAHZABJORDUQGO-NQXXGFSBSA-N 0.000 description 1
- 102000003844 DNA helicases Human genes 0.000 description 1
- 108090000133 DNA helicases Proteins 0.000 description 1
- 230000004543 DNA replication Effects 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 206010012335 Dependence Diseases 0.000 description 1
- 239000004338 Dichlorodifluoromethane Substances 0.000 description 1
- 206010061818 Disease progression Diseases 0.000 description 1
- 238000012286 ELISA Assay Methods 0.000 description 1
- 102400001368 Epidermal growth factor Human genes 0.000 description 1
- 101800003838 Epidermal growth factor Proteins 0.000 description 1
- 108020002908 Epoxide hydrolase Proteins 0.000 description 1
- 102000005486 Epoxide hydrolase Human genes 0.000 description 1
- 241001125671 Eretmochelys imbricata Species 0.000 description 1
- 241000402754 Erythranthe moschata Species 0.000 description 1
- 108090000371 Esterases Proteins 0.000 description 1
- 241000724791 Filamentous phage Species 0.000 description 1
- 108090000331 Firefly luciferases Proteins 0.000 description 1
- 241000710831 Flavivirus Species 0.000 description 1
- 101150103317 GAL80 gene Proteins 0.000 description 1
- 241000224466 Giardia Species 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 108010053070 Glutathione Disulfide Proteins 0.000 description 1
- 102000000587 Glycerolphosphate Dehydrogenase Human genes 0.000 description 1
- 108010041921 Glycerolphosphate Dehydrogenase Proteins 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 108010031186 Glycoside Hydrolases Proteins 0.000 description 1
- 102000005744 Glycoside Hydrolases Human genes 0.000 description 1
- 102000051366 Glycosyltransferases Human genes 0.000 description 1
- 108700023372 Glycosyltransferases Proteins 0.000 description 1
- 102100039619 Granulocyte colony-stimulating factor Human genes 0.000 description 1
- 241000204946 Halobacterium salinarum Species 0.000 description 1
- 108010068250 Herpes Simplex Virus Protein Vmw65 Proteins 0.000 description 1
- 108010003774 Histidinol-phosphatase Proteins 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000726193 Homo sapiens Cyclic AMP-responsive element-binding protein 5 Proteins 0.000 description 1
- 101000746367 Homo sapiens Granulocyte colony-stimulating factor Proteins 0.000 description 1
- 101000746373 Homo sapiens Granulocyte-macrophage colony-stimulating factor Proteins 0.000 description 1
- 101000959820 Homo sapiens Interferon alpha-1/13 Proteins 0.000 description 1
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 1
- 101000611183 Homo sapiens Tumor necrosis factor Proteins 0.000 description 1
- 206010062904 Hormone-refractory prostate cancer Diseases 0.000 description 1
- 241000598436 Human T-cell lymphotropic virus Species 0.000 description 1
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 1
- AVXURJPOCDRRFD-UHFFFAOYSA-N Hydroxylamine Chemical compound ON AVXURJPOCDRRFD-UHFFFAOYSA-N 0.000 description 1
- HEFNNWSXXWATRW-UHFFFAOYSA-N Ibuprofen Chemical compound CC(C)CC1=CC=C(C(C)C(O)=O)C=C1 HEFNNWSXXWATRW-UHFFFAOYSA-N 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 208000026350 Inborn Genetic disease Diseases 0.000 description 1
- 102100040019 Interferon alpha-1/13 Human genes 0.000 description 1
- 102000004310 Ion Channels Human genes 0.000 description 1
- 108090000769 Isomerases Proteins 0.000 description 1
- 102000004195 Isomerases Human genes 0.000 description 1
- 102000011782 Keratins Human genes 0.000 description 1
- 108010076876 Keratins Proteins 0.000 description 1
- JUQLUIFNNFIIKC-YFKPBYRVSA-N L-2-aminopimelic acid Chemical compound OC(=O)[C@@H](N)CCCCC(O)=O JUQLUIFNNFIIKC-YFKPBYRVSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-N L-arginine Chemical compound OC(=O)[C@@H](N)CCCN=C(N)N ODKSFYDXXFIFQN-BYPYZUCNSA-N 0.000 description 1
- 235000014852 L-arginine Nutrition 0.000 description 1
- 229930064664 L-arginine Natural products 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- 241000222722 Leishmania <genus> Species 0.000 description 1
- 108010054320 Lignin peroxidase Proteins 0.000 description 1
- 101710155614 Ligninase A Proteins 0.000 description 1
- 101710155621 Ligninase B Proteins 0.000 description 1
- 108090001060 Lipase Proteins 0.000 description 1
- 102000004882 Lipase Human genes 0.000 description 1
- 239000004367 Lipase Substances 0.000 description 1
- 206010026749 Mania Diseases 0.000 description 1
- 102100027754 Mast/stem cell growth factor receptor Kit Human genes 0.000 description 1
- 108010008364 Melanocortins Proteins 0.000 description 1
- XADCESSVHJOZHK-UHFFFAOYSA-N Meperidine Chemical compound C=1C=CC=CC=1C1(C(=O)OCC)CCN(C)CC1 XADCESSVHJOZHK-UHFFFAOYSA-N 0.000 description 1
- 241001302042 Methanothermobacter thermautotrophicus Species 0.000 description 1
- 102000008109 Mixed Function Oxygenases Human genes 0.000 description 1
- 108010074633 Mixed Function Oxygenases Proteins 0.000 description 1
- 231100000678 Mycotoxin Toxicity 0.000 description 1
- CHJJGSNFBQVOTG-UHFFFAOYSA-N N-methyl-guanidine Natural products CNC(N)=N CHJJGSNFBQVOTG-UHFFFAOYSA-N 0.000 description 1
- 238000005481 NMR spectroscopy Methods 0.000 description 1
- MVANFYUBACDPQK-UHFFFAOYSA-N NN.ON Chemical compound NN.ON MVANFYUBACDPQK-UHFFFAOYSA-N 0.000 description 1
- 108010024026 Nitrile hydratase Proteins 0.000 description 1
- 101710163270 Nuclease Proteins 0.000 description 1
- 108700026244 Open Reading Frames Proteins 0.000 description 1
- 102100037214 Orotidine 5'-phosphate decarboxylase Human genes 0.000 description 1
- 108010055012 Orotidine-5'-phosphate decarboxylase Proteins 0.000 description 1
- 108090000417 Oxygenases Proteins 0.000 description 1
- 102000004020 Oxygenases Human genes 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- 208000002193 Pain Diseases 0.000 description 1
- 102100036893 Parathyroid hormone Human genes 0.000 description 1
- 108090000284 Pepsin A Proteins 0.000 description 1
- 102000057297 Pepsin A Human genes 0.000 description 1
- 108700019535 Phosphoprotein Phosphatases Proteins 0.000 description 1
- 102000045595 Phosphoprotein Phosphatases Human genes 0.000 description 1
- 241000709664 Picornaviridae Species 0.000 description 1
- 108010064851 Plant Proteins Proteins 0.000 description 1
- 208000000474 Poliomyelitis Diseases 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- 108010069820 Pro-Opiomelanocortin Proteins 0.000 description 1
- 239000000683 Pro-Opiomelanocortin Substances 0.000 description 1
- 108010076181 Proinsulin Proteins 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 102000001253 Protein Kinase Human genes 0.000 description 1
- 241000205156 Pyrococcus furiosus Species 0.000 description 1
- 241000522615 Pyrococcus horikoshii Species 0.000 description 1
- ASNFTDCKZKHJSW-REOHCLBHSA-N Quisqualic acid Chemical class OC(=O)[C@@H](N)CN1OC(=O)NC1=O ASNFTDCKZKHJSW-REOHCLBHSA-N 0.000 description 1
- 102000004879 Racemases and epimerases Human genes 0.000 description 1
- 108090001066 Racemases and epimerases Proteins 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 1
- 102000002278 Ribosomal Proteins Human genes 0.000 description 1
- 108010000605 Ribosomal Proteins Proteins 0.000 description 1
- 108010003581 Ribulose-bisphosphate carboxylase Proteins 0.000 description 1
- 101001102892 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Adenylosuccinate synthetase Proteins 0.000 description 1
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 1
- 241000191967 Staphylococcus aureus Species 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 241000194017 Streptococcus Species 0.000 description 1
- 108090000787 Subtilisin Proteins 0.000 description 1
- 241000223892 Tetrahymena Species 0.000 description 1
- 241000248384 Tetrahymena thermophila Species 0.000 description 1
- 241000589499 Thermus thermophilus Species 0.000 description 1
- 102000003929 Transaminases Human genes 0.000 description 1
- 108090000340 Transaminases Proteins 0.000 description 1
- 102000040945 Transcription factor Human genes 0.000 description 1
- 108091023040 Transcription factor Proteins 0.000 description 1
- 206010052779 Transplant rejections Diseases 0.000 description 1
- 241000209140 Triticum Species 0.000 description 1
- 235000021307 Triticum Nutrition 0.000 description 1
- 241000223104 Trypanosoma Species 0.000 description 1
- 102100040247 Tumor necrosis factor Human genes 0.000 description 1
- 206010046865 Vaccinia virus infection Diseases 0.000 description 1
- 108700040099 Xylose isomerases Proteins 0.000 description 1
- HFYBTHCYPKEDQQ-UHFFFAOYSA-N [2,3-dihydroxy-3-(1h-imidazol-5-yl)propyl] dihydrogen phosphate Chemical compound OP(=O)(O)OCC(O)C(O)C1=CN=CN1 HFYBTHCYPKEDQQ-UHFFFAOYSA-N 0.000 description 1
- PKPNDTZHXWGVQO-QRPNPIFTSA-N [F].N[C@@H](Cc1ccccc1)C(O)=O Chemical compound [F].N[C@@H](Cc1ccccc1)C(O)=O PKPNDTZHXWGVQO-QRPNPIFTSA-N 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 230000009824 affinity maturation Effects 0.000 description 1
- 229960002478 aldosterone Drugs 0.000 description 1
- 125000006319 alkynyl amino group Chemical class 0.000 description 1
- 230000000735 allogeneic effect Effects 0.000 description 1
- 229940061720 alpha hydroxy acid Drugs 0.000 description 1
- 150000001280 alpha hydroxy acids Chemical class 0.000 description 1
- HSFWRNGVRCDJHI-UHFFFAOYSA-N alpha-acetylene Natural products C#C HSFWRNGVRCDJHI-UHFFFAOYSA-N 0.000 description 1
- 150000001370 alpha-amino acid derivatives Chemical class 0.000 description 1
- 125000000266 alpha-aminoacyl group Chemical group 0.000 description 1
- 150000001408 amides Chemical group 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 229940093740 amino acid and derivative Drugs 0.000 description 1
- 125000003277 amino group Chemical group 0.000 description 1
- 229940124277 aminobutyric acid Drugs 0.000 description 1
- 125000002344 aminooxy group Chemical group [H]N([H])O[*] 0.000 description 1
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical compound N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 1
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 1
- 238000012870 ammonium sulfate precipitation Methods 0.000 description 1
- 235000011130 ammonium sulphate Nutrition 0.000 description 1
- 238000005349 anion exchange Methods 0.000 description 1
- 150000001450 anions Chemical class 0.000 description 1
- 239000005557 antagonist Substances 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 230000001754 anti-pyretic effect Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 108010082685 antiarrhythmic peptide Proteins 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 238000003452 antibody preparation method Methods 0.000 description 1
- 229940125715 antihistaminic agent Drugs 0.000 description 1
- 239000000739 antihistaminic agent Substances 0.000 description 1
- 239000003430 antimalarial agent Substances 0.000 description 1
- 229940033495 antimalarials Drugs 0.000 description 1
- 239000002246 antineoplastic agent Substances 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 239000002221 antipyretic Substances 0.000 description 1
- 229940125716 antipyretic agent Drugs 0.000 description 1
- OZDNDGXASTWERN-UHFFFAOYSA-N apovincamine Natural products C1=CC=C2C(CCN3CCC4)=C5C3C4(CC)C=C(C(=O)OC)N5C2=C1 OZDNDGXASTWERN-UHFFFAOYSA-N 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 244000052616 bacterial pathogen Species 0.000 description 1
- 239000003899 bactericide agent Substances 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- RWCCWEUUXYIKHB-UHFFFAOYSA-N benzophenone Chemical compound C=1C=CC=CC=1C(=O)C1=CC=CC=C1 RWCCWEUUXYIKHB-UHFFFAOYSA-N 0.000 description 1
- 239000012965 benzophenone Substances 0.000 description 1
- WQZGKKKJIJFFOK-FPRJBGLDSA-N beta-D-galactose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-FPRJBGLDSA-N 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 229940000635 beta-alanine Drugs 0.000 description 1
- 150000001576 beta-amino acids Chemical class 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 125000001246 bromo group Chemical group Br* 0.000 description 1
- 239000007975 buffered saline Substances 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 125000004432 carbon atom Chemical group C* 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 238000012219 cassette mutagenesis Methods 0.000 description 1
- 238000006555 catalytic reaction Methods 0.000 description 1
- 238000005341 cation exchange Methods 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 230000009134 cell regulation Effects 0.000 description 1
- 210000004671 cell-free system Anatomy 0.000 description 1
- 230000003196 chaotropic effect Effects 0.000 description 1
- 210000000038 chest Anatomy 0.000 description 1
- 210000003763 chloroplast Anatomy 0.000 description 1
- 229960003677 chloroquine Drugs 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 230000003081 coactivator Effects 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 238000002967 competitive immunoassay Methods 0.000 description 1
- 238000002591 computed tomography Methods 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 238000011443 conventional therapy Methods 0.000 description 1
- 239000003246 corticosteroid Substances 0.000 description 1
- 229960001334 corticosteroids Drugs 0.000 description 1
- 108010082242 corticosterone receptor Proteins 0.000 description 1
- 125000004093 cyano group Chemical group *C#N 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 238000006352 cycloaddition reaction Methods 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 229940127089 cytotoxic agent Drugs 0.000 description 1
- 239000002254 cytotoxic agent Substances 0.000 description 1
- 231100000599 cytotoxic agent Toxicity 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 230000006324 decarbonylation Effects 0.000 description 1
- 238000006606 decarbonylation reaction Methods 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 206010012601 diabetes mellitus Diseases 0.000 description 1
- PXBRQCKWGAHEHS-UHFFFAOYSA-N dichlorodifluoromethane Chemical compound FC(F)(Cl)Cl PXBRQCKWGAHEHS-UHFFFAOYSA-N 0.000 description 1
- 235000019404 dichlorodifluoromethane Nutrition 0.000 description 1
- SWSQBOPZIKWTGO-UHFFFAOYSA-N dimethylaminoamidine Natural products CN(C)C(N)=N SWSQBOPZIKWTGO-UHFFFAOYSA-N 0.000 description 1
- 229960000520 diphenhydramine Drugs 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 230000005750 disease progression Effects 0.000 description 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 229960004679 doxorubicin Drugs 0.000 description 1
- 241001492478 dsDNA viruses, no RNA stage Species 0.000 description 1
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 1
- 230000009483 enzymatic pathway Effects 0.000 description 1
- 229940116977 epidermal growth factor Drugs 0.000 description 1
- 229940011871 estrogen Drugs 0.000 description 1
- 239000000262 estrogen Substances 0.000 description 1
- 238000012869 ethanol precipitation Methods 0.000 description 1
- 150000002170 ethers Chemical class 0.000 description 1
- 125000002534 ethynyl group Chemical group [H]C#C* 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 239000002095 exotoxin Substances 0.000 description 1
- 231100000776 exotoxin Toxicity 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 235000013861 fat-free Nutrition 0.000 description 1
- 238000009093 first-line therapy Methods 0.000 description 1
- ZHNUHDYFZUAESO-UHFFFAOYSA-N formamide Substances NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 229960003692 gamma aminobutyric acid Drugs 0.000 description 1
- 210000001035 gastrointestinal tract Anatomy 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 238000007429 general method Methods 0.000 description 1
- 208000016361 genetic disease Diseases 0.000 description 1
- 238000012248 genetic selection Methods 0.000 description 1
- 238000011331 genomic analysis Methods 0.000 description 1
- 229960002743 glutamine Drugs 0.000 description 1
- YPZRWBKMTBYPTK-BJDJZHNGSA-N glutathione disulfide Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@H](C(=O)NCC(O)=O)CSSC[C@@H](C(=O)NCC(O)=O)NC(=O)CC[C@H](N)C(O)=O YPZRWBKMTBYPTK-BJDJZHNGSA-N 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 210000002288 golgi apparatus Anatomy 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 208000006454 hepatitis Diseases 0.000 description 1
- 231100000283 hepatitis Toxicity 0.000 description 1
- 239000004009 herbicide Substances 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 238000002744 homologous recombination Methods 0.000 description 1
- 230000006801 homologous recombination Effects 0.000 description 1
- 210000004408 hybridoma Anatomy 0.000 description 1
- 150000002429 hydrazines Chemical class 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 238000004191 hydrophobic interaction chromatography Methods 0.000 description 1
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 1
- 150000002443 hydroxylamines Chemical class 0.000 description 1
- 238000012872 hydroxylapatite chromatography Methods 0.000 description 1
- 229960001680 ibuprofen Drugs 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 239000000367 immunologic factor Substances 0.000 description 1
- 230000008676 import Effects 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 210000003000 inclusion body Anatomy 0.000 description 1
- 230000002458 infectious effect Effects 0.000 description 1
- 206010022000 influenza Diseases 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 229940047124 interferons Drugs 0.000 description 1
- 239000000543 intermediate Substances 0.000 description 1
- 238000007852 inverse PCR Methods 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- JEIPFZHSYJVQDO-UHFFFAOYSA-N iron(III) oxide Inorganic materials O=[Fe]O[Fe]=O JEIPFZHSYJVQDO-UHFFFAOYSA-N 0.000 description 1
- YOBAEOGBNPPUQV-UHFFFAOYSA-N iron;trihydrate Chemical compound O.O.O.[Fe].[Fe] YOBAEOGBNPPUQV-UHFFFAOYSA-N 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 239000002523 lectin Substances 0.000 description 1
- 235000019421 lipase Nutrition 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 239000006194 liquid suspension Substances 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 210000003712 lysosome Anatomy 0.000 description 1
- 230000001868 lysosomic effect Effects 0.000 description 1
- 230000010534 mechanism of action Effects 0.000 description 1
- 239000002865 melanocortin Substances 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 230000037353 metabolic pathway Effects 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 235000013336 milk Nutrition 0.000 description 1
- 239000008267 milk Substances 0.000 description 1
- 210000004080 milk Anatomy 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 210000003470 mitochondria Anatomy 0.000 description 1
- 208000013465 muscle pain Diseases 0.000 description 1
- 239000002636 mycotoxin Substances 0.000 description 1
- 125000000449 nitro group Chemical group [O-][N+](*)=O 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 208000002154 non-small cell lung carcinoma Diseases 0.000 description 1
- 238000007344 nucleophilic reaction Methods 0.000 description 1
- 238000010534 nucleophilic substitution reaction Methods 0.000 description 1
- 239000002777 nucleoside Substances 0.000 description 1
- 125000003835 nucleoside group Chemical group 0.000 description 1
- 235000015097 nutrients Nutrition 0.000 description 1
- 235000016709 nutrition Nutrition 0.000 description 1
- 239000011022 opal Substances 0.000 description 1
- YPZRWBKMTBYPTK-UHFFFAOYSA-N oxidized gamma-L-glutamyl-L-cysteinylglycine Natural products OC(=O)C(N)CCC(=O)NC(C(=O)NCC(O)=O)CSSCC(C(=O)NCC(O)=O)NC(=O)CCC(N)C(O)=O YPZRWBKMTBYPTK-UHFFFAOYSA-N 0.000 description 1
- 229910052760 oxygen Inorganic materials 0.000 description 1
- 238000012856 packing Methods 0.000 description 1
- 229960001592 paclitaxel Drugs 0.000 description 1
- 244000045947 parasite Species 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 229940111202 pepsin Drugs 0.000 description 1
- 239000000816 peptidomimetic Substances 0.000 description 1
- 229960000482 pethidine Drugs 0.000 description 1
- 239000000825 pharmaceutical preparation Substances 0.000 description 1
- CTRLRINCMYICJO-UHFFFAOYSA-N phenyl azide Chemical compound [N-]=[N+]=NC1=CC=CC=C1 CTRLRINCMYICJO-UHFFFAOYSA-N 0.000 description 1
- 229940080469 phosphocellulose Drugs 0.000 description 1
- DTBNBXWJWCWCIK-UHFFFAOYSA-K phosphonatoenolpyruvate Chemical compound [O-]C(=O)C(=C)OP([O-])([O-])=O DTBNBXWJWCWCIK-UHFFFAOYSA-K 0.000 description 1
- 239000007856 photoaffinity label Substances 0.000 description 1
- 230000029553 photosynthesis Effects 0.000 description 1
- 238000010672 photosynthesis Methods 0.000 description 1
- 230000008635 plant growth Effects 0.000 description 1
- 230000036470 plasma concentration Effects 0.000 description 1
- 229920003023 plastic Polymers 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 238000011176 pooling Methods 0.000 description 1
- 108010066381 preproinsulin Proteins 0.000 description 1
- 108010091624 preproparathormone Proteins 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 108010075850 pro-calcitonin gene-related peptide Proteins 0.000 description 1
- 229960003387 progesterone Drugs 0.000 description 1
- 239000000186 progesterone Substances 0.000 description 1
- 239000001294 propane Substances 0.000 description 1
- 239000003380 propellant Substances 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- 235000019833 protease Nutrition 0.000 description 1
- 108060006633 protein kinase Proteins 0.000 description 1
- 238000001814 protein method Methods 0.000 description 1
- 238000003257 protein preparation method Methods 0.000 description 1
- 230000030788 protein refolding Effects 0.000 description 1
- 238000001243 protein synthesis Methods 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 239000011541 reaction mixture Substances 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 239000006176 redox buffer Substances 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000001172 regenerating effect Effects 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 230000003014 reinforcing effect Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 125000006853 reporter group Chemical group 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 125000000548 ribosyl group Chemical group C1([C@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 1
- 238000007363 ring formation reaction Methods 0.000 description 1
- 201000005404 rubella Diseases 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 229930195734 saturated hydrocarbon Natural products 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 101150091813 shfl gene Proteins 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000008279 sol Substances 0.000 description 1
- 239000007790 solid phase Substances 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 238000004611 spectroscopical analysis Methods 0.000 description 1
- 108010068698 spleen exonuclease Proteins 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 239000008107 starch Substances 0.000 description 1
- 239000007858 starting material Substances 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 125000003107 substituted aryl group Chemical group 0.000 description 1
- 125000002653 sulfanylmethyl group Chemical group [H]SC([H])([H])[*] 0.000 description 1
- 125000000472 sulfonyl group Chemical group *S(*)(=O)=O 0.000 description 1
- 229910052717 sulfur Inorganic materials 0.000 description 1
- 239000000375 suspending agent Substances 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 1
- 229960003604 testosterone Drugs 0.000 description 1
- 229940126622 therapeutic monoclonal antibody Drugs 0.000 description 1
- 230000004797 therapeutic response Effects 0.000 description 1
- 239000002562 thickening agent Substances 0.000 description 1
- 125000003396 thiol group Chemical group [H]S* 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 1
- 239000003734 thymidylate synthase inhibitor Substances 0.000 description 1
- 238000004448 titration Methods 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 238000006257 total synthesis reaction Methods 0.000 description 1
- 108091006106 transcriptional activators Proteins 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- GBXQPDCOMJJCMJ-UHFFFAOYSA-M trimethyl-[6-(trimethylazaniumyl)hexyl]azanium;bromide Chemical compound [Br-].C[N+](C)(C)CCCCCC[N+](C)(C)C GBXQPDCOMJJCMJ-UHFFFAOYSA-M 0.000 description 1
- 239000001226 triphosphate Substances 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- 125000002264 triphosphate group Chemical class [H]OP(=O)(O[H])OP(=O)(O[H])OP(=O)(O[H])O* 0.000 description 1
- 229960004799 tryptophan Drugs 0.000 description 1
- 210000004881 tumor cell Anatomy 0.000 description 1
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 229930195735 unsaturated hydrocarbon Natural products 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
- 208000007089 vaccinia Diseases 0.000 description 1
- 210000003934 vacuole Anatomy 0.000 description 1
- 238000005303 weighing Methods 0.000 description 1
- 238000001086 yeast two-hybrid system Methods 0.000 description 1
Images



Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/52—Genes encoding for enzymes or proenzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/93—Ligases (6)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/10—Cells modified by introduction of foreign genetic material
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P21/00—Preparation of peptides or proteins
- C12P21/02—Preparation of peptides or proteins having a known sequence of two or more amino acids, e.g. glutathione
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Genetics & Genomics (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Cell Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Medicinal Chemistry (AREA)
- Plant Pathology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Acyclic And Carbocyclic Compounds In Medicinal Compositions (AREA)
- Organic Low-Molecular-Weight Compounds And Preparation Thereof (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Peptides Or Proteins (AREA)
Abstract
본 발명은 척추동물 세포에서 유전적으로 코딩되는 아미노산의 수를 확장시키는 번역 성분을 제조하는 방법 및 조성물을 제공한다. 상기 번역 성분은 오르소고날 tRNA, 오르소고날 아미노아실-tRNA 합성효소, 오르소고날 tRNA/합성효소 쌍 및 비천연 아미노산을 포함한다. 척추동물 세포에서 비천연 아미노산을 포함하는 단백질 및 그 제조 방법이 또한 제공된다.
Description
본 발명은 척추동물 세포에서의 번역 생화학 분야에 관한 것이다. 본 발명은 척추동물 세포에서 오르소고날(orthogonal) tRNA, 오르소고날 합성효소 및 이들의 쌍을 제조하는 방법 및 조성물에 관한 것이다. 본 발명은 또한 비천연 아미노산의 조성물, 비천연 아미노산을 포함하는 단백질 및 척추동물 세포에서 비천연 아미노산을 포함하는 단백질을 제조하는 방법에 관한 것이다.
박테리아에서 인간에 이르기까지 알려진 모든 생물의 유전자 코드는 동일한 20종의 일반 아미노산을 코딩하다. 동일한 20종의 천연 아미노산의 상이한 조합이 광합성에서 신호 전달 및 면역반응에 이르는, 실질적으로 모든 복잡한 생명 현상을 수행하는 단백질을 형성한다. 단백질의 구조 및 기능을 연구하고 변형시키기 위하여, 과학자들은 단백질의 유전자 코드 및 아미노산 서열 모두를 조작하는 시도를 해 왔다. 그러나, 단백질을 20개의 유전적으로 코딩되는 표준 빌딩 블록으로 제한하는 유전자 코드에 의한 구속을 제거하는 것은, 셀레노시스테인(예를 들어, A. Bock et al., (1991), Molecular Microbiology 5:515-20) 및 피롤리신(예를 들어, G. Srinivasan, et al., (2002), Science 296:1459-62)의 드문 경우를 제외하고는 어려웠다.
이러한 구속을 제거하는 데 얼마간의 진전이 있었지만, 이러한 과정은 제한적이었으며, 단백질 구조 및 기능을 합리적으로 제어하는 능력은 아직 아주 초기 단계에 있다. 예를 들어, 화학자들은 작은 분자를 합성하고 그 구조를 조작하는 방법 및 전략을 개발하여 왔다(예를 들어, E. J. Corey, & X. M. Cheng, The Logic of Chemical Synthesis(Wiley-Interscience, New York, 1995)). 전합성(예를 들어, B. Merrifield, (1986), Science 232:341-7 (1986)), 및 반합성 방법(예를 들어, D. Y. Jackson et al., (1994) Science 266:243-7; and, P. E. Dawson, & S. B. Kent, (2000), Annual Review of Biochemistry 69:923-60)은 펩티드 및 작은 단백질을 합성하는 것을 가능하게 하였지만, 이런 방법들을 10 킬로 달톤(kDa)이 넘는 단백질에 사용하기에는 한계가 있다. 돌연변이 유발법도 강력하기는 하지만, 제한된 수의 구조적 변화로 한정된다. 많은 경우에, 일반 아미노산의 근사한 구조적 유사체를 경쟁적으로 도입하는 것이 가능하였다(예를 들어, R. Furter, (1998), Protein Science 7:419-26; K. Kirshenbaum, et al., (2002), ChemBioChem 3:235-7: and, V. Doring et al., (2001), Science 292:501-4).
단백질 구조 및 기능을 조작하는 능력을 확장시키려는 시도로서, 화학적으로 아실화된 오르소고날 tRNA를 사용하는 시험관내 방법이 개발되었으며, 이는 비천연 아미노산이 시험관내에서 넌센스 코돈에 응답하여 선택적으로 통합(도입)되는 것을 가능하게 하였다(예를 들어, J. A. Ellman, et al., (1992), Science 255:197-200). 신규한 구조 및 물리적 특성을 갖는 아미노산을 단백질 내로 선택적으로 도 입하여 단백질 폴딩 및 안정성, 생분자 인식 및 촉매 작용을 연구하였다(예를 들어, D. Mendel, et al., (1995), Annual Review of Biophysics and Biomolecular Structure 24:435-462; and, V. W. Cornish, et al., (Mar. 31, 1995), Angewandte Chemie-International Edition in English 34:621-633). 그러나, 이러한 과정의 화학량론적 특성으로 인해 제조될 수 있는 단백질의 양은 극히 제한되었다.
비천연 아미노산을 세포 내로 미세주사하였다. 예를 들어, 비천연 아미노산을 화학적으로 잘못 아실화된(misacylated) 테트라하이메나 써모필라(Tetrahymena thermophila) tRNA(예를 들어, M.E. Saks, et al., (1996), An engineered Tetrahymena tRNAGln for in vivo incorporation of unnatural amino acids into proteins by nonsense suppression, J. Biol. Chem. 271:23169-23175) 및 관련 mRNA를 미세주사하여 제노푸스(Xenopus) 난모 세포 중 니코틴 아세틸콜린 수용체 내로 도입하였다(예를 들어, M.W. Nowak, et al., (1998), In vivo incorporation of unnatural amino acids into ion channels in Xenopus oocyte expression system, Method Enzymol. 293:504-529). 이에 의해 독특한 물리적 또는 화학적 성질을 갖는 측쇄를 함유하는 아미노산을 도입함으로써 난모 세포 중 수용체의 상세한 생물물리학적 연구를 할 수 있었다(D. A. Dougherty (2000), Unnatural amino acids as probes of protein structure and function, Curr. Opin. Chem. Biol. 4:645-6520). 불행하게도, 이 방법도 미세주사될 수 있는 세포 중의 단백질에 한정적으로만 사용될 수 있는데, 관련 tRNA는 시험관내에서 화학적으로 아실화되어 재아실화될 수 없기 때문에 단백질의 수율은 매우 낮다.
이 한계를 극복하기 위하여, 원핵 세포 에스케리치아 콜라이(Escherichia coli)의 단백질 생합성 기구에 새로운 성분을 가하였으며(예를 들어, L. Wang, et al., (2001), Science 292:498-500), 이에 의해 생체내 비천연 아미노산을 유전적으로 코딩하는 것이 가능하게 되었다. 이 방법을 이용하여 신규 화학적, 물리적 또는 생물학적 특성을 갖는 다수의 새로운 아미노산, 비제한적인 예로서, 광친화도 표지, 및 광이성질체화 가능한 아미노산, 케토 아미노산 및 글리코실화 아미노산이 이 콜라이 중에서 앰버 코돈 TAG에 응답하여 단백질 내로 높은 신뢰도 및 효율로 도입되어 왔다(예를 들어, J. W. Chin et al., (2002), Journal of the American Chemical Society 124:9026-9027; J. W. Chin, & P. G. Schultz, (2002), ChemBioChem 11:1135-1137; J. W. Chin, et al., (2002), PNAS United States of America 99:11020-11024: and, L. Wang, & P. G. Schultz, (2002), Chem. Comm., 1-10). 그러나, 원핵 세포 및 진핵 세포의 번역 기구는 매우 보존적이지는 않다. 따라서, 이 콜라이에 가해진 생합성 기구의 성분은 종종 척추동물 세포 내에서 단백질 내로 비천연 아미노산을 도입하는 데 부위 특이적으로 사용되지 않을 수 있다. 예를 들어, 이 콜라이에서 사용되었던 메타노코커스 자니쉬( Methanococcus jannaschii ) 타이로실-tRNA 합성효소/tRNA 쌍은 척추동물 세포에서 오르소고날하지 않다. 또한, 원핵 세포가 아닌 진핵 세포에서의 tRNA 전사는 RNA 폴리머라제 III에 의해 수행되며, 이는 척추동물 세포에서 전사될 수 있는 tRNA 구조 유전자의 일차 서열에 제한을 두고 있다. 더구나, 원핵 세포와는 대조적으로, 척추동물 세포 중의 tRNA는 이들이 전사되는 장소인 핵으로부터 이출되어 세포질로 들어감으로써 번역 시에 기능을 할 수 있다. 마지막으로, 척추동물 80S 리보좀은 70S 원핵 세포 리보좀과는 차이가 있다. 따라서, 척추동물 유전자 코드를 확장하기 위해서 개선된 생합성 기구 성분을 개발할 필요가 있다. 본 발명은 하기 개시내용으로부터 명백해지는 바와 같이, 위와 같은 또한 다른 필요를 충족시키기 위한 것이다.
[발명의 개요]
본 발명은 척추동물 세포에서 성장하는 폴리펩티드 사슬에 비천연 아미노산을 통합시키기 위해 척추동물 단백질 생합성 기구에 사용되는 번역 성분, 예를 들어, 오르소고날 아미노아실-tRNA 합성효소(O-RS)와 오르소고날 tRNA(O-tRNA)의 쌍 및 이들의 개별 성분을 갖는 척추동물 세포를 제공한다.
본 발명의 조성물은 척추동물 세포에서 오르소고날 tRNA(O-tRNA)를 적어도 하나의 비천연 아미노산으로 우선적으로 아미노아실화하는 오르소고날 아미노아실-tRNA 합성효소(O-RS)(예를 들어, 에스케리치아 콜라이, 바실러스 스테아로써모필러스 등의 비척추동물 유기체로부터 유래된)를 포함하는 척추동물 세포(예를 들어, 포유류 세포, 조류 세포, 어류 세포, 파충류 세포, 양서류 세포, 비포유류 동물로부터 유래한 세포 등)를 포함한다. 경우에 따라, 2 이상의 O-tRNA가 주어진 척추동물 세포에서 아미노아실화될 수 있다. 일 측면에 있어서, O-RS는 O-tRNA를 비천연 아미노산으로, 예컨대, 서열 번호 86 또는 45에 개시된 아미노산 서열을 갖는 O-RS가 아미노아실화하는 것의, 예를 들어, 적어도 40%, 적어도 45%, 적어도 50%, 적어도 60%, 적어도 75%, 적어도 80%, 또는 심지어 90% 또는 그 이상의 효율로 아미노아실화한다. 일 실시태양에 있어서, 본 발명의 O-RS는 O-tRNA를 비천연 아미노산으로, O-RS가 O-tRNA를 천연 아미노산으로 아미노아실화하는 것보다, 예를 들어, 적어도 10배, 적어도 20배, 적어도 30배 더 큰 효율로 아미노아실화한다.
일 실시태양에 있어서, O-RS 또는 그 일부분은 서열 번호 3 내지 35 중 어느 하나에 개시된 폴리뉴클레오티드 서열 또는 이의 상보적 폴리뉴클레오티드 서열에 의해 코딩된다. 또 다른 실시태양에 있어서, O-RS는 서열 번호 36 내지 63 및/또는 86 중 어느 하나에 개시된 아미노산 서열 또는 이의 보존적 변이체를 포함한다. 또 다른 실시태양에 있어서, O-RS는 천연 타이로실 아미노아실-tRNA 합성효소(TyrRS)의 아미노산 서열과, 예를 들어, 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99%, 또는 적어도 99.5% 또는 그 이상 동일하며, 그룹 A 내지 E로부터의 2 이상의 아미노산 치환을 포함하는 아미노산 서열을 포함한다. 그룹 A는 이 콜라이 TyrRS의 Tyr37에 상응하는 위치에 발린, 이소루신, 루신, 글리신, 세린, 알라닌 또는 트레오닌을 포함하고; 그룹 B는 이 콜라이 TyrRS의 Asn126에 상응하는 위치에 아스파르테이트를 포함하며; 그룹 C는 이 콜라이 TyrRS의 Asp182에 상응하는 위치에 트레오닌, 세린, 아르기닌, 아스파라긴 또는 글리신을 포함하고; 그룹 D는 이 콜라이 TyrRS의 Phe183에 상응하는 위치에 메티오닌, 알라닌, 발린 또는 타이로신을 포함하고; 그룹 E는 이 콜라이 TyrRS의 Leu186에 상응하는 위치에 세린, 메티오닌, 발린, 시스테인, 트레오닌 또는 알라닌을 포함한다.
또 다른 실시태양에 있어서, O-RS는 천연 아미노산에 비교하여 비천연 아미노산에 대해 하나 이상의 개선된 또는 증진된 효소 특성을 나타낸다. 예를 들어, 천연 아미노산에 비하여 비천연 아미노산에 대한 개선된 또는 증진된 효소 특성은, 예를 들어, 보다 높은 Km, 보다 낮은 Km, 보다 높은 kcat, 보다 낮은 kcat, 보다 낮은 kcat/km, 보다 높은 kcat/km 등을 포함한다.
척추동물 세포는 또한 경우에 따라 비천연 아미노산을 포함한다. 척추동물 세포는 경우에 따라 오르소고날 tRNA(O-tRNA)(예를 들어, 에스케리치아 콜라이, 바실러스 스테아로써모필러스 등의 비척추동물 유기체로부터 유래된)를 포함하며, O-tRNA는 셀렉터 코돈을 인식하며, O-RS에 의해 비천연 아미노산으로 우선적으로 아미노아실화된다. 일 측면에 있어서, O-tRNA는 단백질 내로의 비천연 아미노산의 도입을, 예를 들어, 서열 번호 65에 개시된 폴리뉴클레오티드 서열을 포함하거나 세포에서 그로부터 프로세싱된 tRNA의 효율의 적어도 45%, 적어도 50%, 적어도 60%, 적어도 75%, 적어도 80%, 적어도 90%, 적어도 95%, 또는 99% 이상의 효율로 매개한다. 또 다른 측면에 있어서, O-tRNA는 서열 번호 65의 서열을 포함하며, O-RS는 서열 번호 36 내지 63 및/또는 86 중 어느 하나에 개시된 아미노산 서열 및/또는 이의 보존적 변이체로부터 선택된 폴리펩티드 서열을 포함한다.
또 다른 실시태양에 있어서, 척추동물 세포는 관심있는 폴리펩티드를 코딩하는 폴리뉴클레오티드를 포함하는 핵산을 포함하는데, 그 폴리뉴클레오티드는 O-tRNA에 의해 인식되는 셀렉터 코돈을 포함한다. 일 측면에 있어서, 비천연 아미노산을 포함하는 관심있는 폴리펩티드의 수율은, 셀렉터 코돈이 없는 폴리뉴클레오티드에 의해 세포로부터 얻어지는 관심있는 천연 폴리펩티드에 대해 얻어지는 수율의, 예를 들어, 적어도 2.5%, 적어도 5%, 적어도 10%, 적어도 25%, 적어도 30%, 적어도 40%, 50% 또는 그 이상이다. 또 다른 측면에 있어서, 세포는 비천연 아미노산의 부재하에 관심있는 폴리펩티드를, 비천연 아미노산 존재하의 폴리펩티드의 수율의, 예를 들어, 35% 미만, 30% 미만, 20% 미만, 15% 미만, 10% 미만, 5% 미만, 2.5% 미만의 수율로 제조한다.
본 발명은 또한 오르소고날 아미노아실-tRNA 합성효소(O-RS), 오르소고날 tRNA(O-tRNA), 비천연 아미노산, 및 관심있는 폴리펩티드를 코딩하는 폴리뉴클레오티드를 포함하는 핵산을 포함하는 척추동물 세포를 제공한다. 폴리뉴클레오티드는 O-tRNA에 의해 인식되는 셀렉터 코돈을 포함한다. 또한, O-RS는 척추동물 세포에서 오르소고날 tRNA(O-tRNA)를 비천연 아미노산으로 우선적으로 아미노아실화하며, 세포는 비천연 아미노산의 부재하에 관심있는 폴리펩티드를, 비천연 아미노산 존재하의 폴리펩티드의 수율의, 예를 들어, 35% 미만, 30% 미만, 20% 미만, 15% 미만, 10% 미만, 5% 미만, 2.5% 미만의 수율로 제조한다.
오르소고날 tRNA(O-tRNA)를 포함하는 척추동물 세포를 포함하는 조성물 또한 본 발명의 특징이다. 일반적으로, O-tRNA는 생체내에서 O-tRNA에 의해 인식되는 셀렉터 코돈을 포함하는 폴리뉴클레오티드에 의해 코딩되는 단백질 내로 비천연 아미노산의 도입을 매개한다. 일 실시태양에 있어서, O-tRNA는 단백질 내로의 비천연 아미노산의 도입을, 서열 번호 65에 개시된 폴리뉴클레오티드를 포함하거나 세포 내에서 그로부터 프로세싱된 tRNA 효율의, 예를 들어, 적어도 45%, 적어도 50%, 적어도 60%, 적어도 75%, 적어도 80%, 적어도 90%, 적어도 95%, 또는 심지어 99% 또는 그 이상의 효율로 매개한다. 또 다른 실시태양에 있어서, O-tRNA는 서열 번호 65에 개시된 폴리뉴클레오티드 서열 또는 이의 보존적 변이체를 포함하거나 세포에서 그로부터 프로세싱된다. 또 다른 실시태양에 있어서, O-tRNA는 재생 가능한 O-tRNA를 포함한다.
본 발명의 일 측면에 있어서, 상기 O-tRNA는 전사후 변형된다. 본 발명은 또한 척추동물 세포에서 O-tRNA를 코딩하는 핵산 또는 이의 상보적 폴리뉴클레오티드를 제공한다. 일 실시태양에 있어서, 상기 핵산은 A 박스 및 B 박스를 포함한다.
본 발명은 또한 번역 성분, 예컨대, O-RS 또는 O-tRNA/O-RS 쌍을 제조하는 방법(및 이들 방법에 의해 제조된 번역 성분)을 특징으로 한다. 예를 들어, 본 발명은 척추동물 세포에서 오르소고날 tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하는 오르소고날 아미노아실-tRNA 합성효소(O-RS)를 제조하는 방법을 제공한다. 이와 같은 방법은, 예를 들어, (a) 제1 종의 척추동물 세포 집단[척추동물 세포는 각각 i) 아미노아실-tRNA 합성효소(RS) 라이브러리의 구성원, ii) 오르소고날 tRNA(O-tRNA), iii) 양성 선택 마커를 코딩하는 폴리뉴클레오티드, 및 iv) 음성 선택 마커를 코딩하는 폴리뉴클레오티드를 포함함]을 비천연 아미노산 존재하에 양성 선택하는 단계(이때 양성 선택을 극복하는 세포는 비천연 아미노산 존재하에 오르소고날 tRNA(O-tRNA)를 아미노아실화하는 활성 RS를 포함함)를 포함한다. 이어서, (b) 양성 선택을 극복한 세포를 비천연 아미노산 부재하에 음성 선택하여 O-tRNA를 천연 아미노산으로 아미노아실화하는 활성 RS를 제거한다. 이러한 과정은 O-tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하는 O-RS를 제공한다.
일부 실시태양에 있어서, 양성 선택 마커를 코딩하는 폴리뉴클레오티드는 반응 요소에 작동 가능하게 연결되어 있고, 세포는 a) 반응 요소로부터의 전사를 조절하는 전사 조절인자 단백질(예를 들어, 척추동물 전사 조절인자 단백질 등)을 코딩하며, b) 적어도 하나의 셀렉터 코돈을 포함하는 폴리뉴클레오티드를 더 포함한다. 비천연 아미노산으로 아미노아실화된 O-tRNA에 의한 전사 조절인자 단백질 내로의 비천연 아미노산의 도입은 양성 선택 마커의 전사로 이어진다. 일 실시태양에 있어서, 전사 조절인자 단백질은 전사 활성화 인자 단백질(예를 들어, GAL4 등)이고, 셀렉터 코돈은 앰버 종결 코돈으로서, 앰버 종결 코돈이 전사 활성화 인자 단백질의 DNA 결합 도메인을 코딩하는 폴리뉴클레오티드의 부분 내에 또는 실질적으로 그에 근접하여 위치한다.
양성 선택 마커는 각종 분자 중 임의의 것일 수 있다. 일 실시태양에 있어서, 양성 선택 마커는 성장을 위한 영양 보충물을 포함하며, 선택은 그 영양 보충물이 결여된 배지에서 이루어진다. 또 다른 실시태양에 있어서, 양성 선택 마커를 코딩하는 폴리뉴클레오티드는, 예를 들어, ura3, leu2, lys2, lacZ 유전자, his3(예를 들어, his3 유전자가 이미다졸 글리세롤 포스페이트 탈수소효소를 코딩하는 경우, 3-아미노트리아졸(3-AT)을 제공함으로써 검출됨) 등이다. 또 다른 실시태양에 있어서, 양성 선택 마커를 코딩하는 폴리뉴클레오티드는 셀렉터 코돈을 포함한다.
양성 선택 마커에서와 같이, 음성 선택 마커도 다양한 분자 중 어느 것이나 가능하다. 일부 실시태양에 있어서, 음성 선택 마커를 코딩하는 폴리뉴클레오티드는 그로부터 전사 조절인자 단백질에 의해 전사가 매개되는 반응 요소에 작동 가능하게 연결되어 있다. 비천연 아미노산으로 아미노아실화된 O-tRNA에 의한 전사 조절인자 단백질 내로의 비천연 아미노산의 도입은 음성 선택 마커의 전사로 이어진다. 일 실시태양에 있어서, 음성 선택 마커를 코딩하는 폴리뉴클레오티드는, 예를 들어, ura3 유전자이며, 음성 선택은 5-플루오로오로트산(5-FOA)을 포함하는 배지 상에서 수행된다. 또 다른 실시태양에 있어서, 음성 선택에 사용되는 배지는 음성 선택 마커에 의해 검출 가능한 물질로 전환되는 선택제 또는 스크리닝제를 포함한다. 본 발명의 일 측면에 있어서, 검출 가능한 물질은 독성 물질이다. 일 실시태양에 있어서, 음성 선택 마커를 코딩하는 폴리뉴클레오티드는 셀렉터 코돈을 포함한다.
일부 실시태양에 있어서, 양성 선택 마커 및/또는 음성 선택 마커는 적절한 반응물의 존재하에 형광을 내거나 발광 반응을 촉진하는 폴리펩티드를 포함한다. 본 발명의 일 측면에 있어서, 양성 선택 마커 및/또는 음성 선택 마커는 형광 활성화된 세포 분류(FACS) 또는 발광에 의해 검출된다. 일부 실시태양에 있어서, 양성 선택 마커 및/또는 음성 선택 마커는 친화도에 기초한 스크리닝 마커, 또는 전사 조절인자 단백질을 포함한다. 일 실시태양에 있어서, 하나의 같은 폴리뉴클레오티드가 양성 선택 마커 및 음성 선택 마커를 둘 다 코딩한다.
일 실시태양에 있어서, 본 발명의 양성 선택 마커 및/또는 음성 선택 마커를 코딩하는 폴리뉴클레오티드는 적어도 2개의 셀렉터 코돈을 포함할 수 있으며, 셀렉터 코돈 각각 또는 둘 다가 적어도 2개의 상이한 셀렉터 코돈을 포함하거나 적어도 2개의 동일한 셀렉터 코돈을 포함할 수 있다.
추가 수준의 선택/스크리닝 엄격도가 또한 본 발명의 방법에 사용될 수 있다. 일 실시태양에 있어서, 그 방법은 단계 (a), (b) 또는 (a)와 (b) 두 단계 모두에 변화하는 양의 불활성 합성효소를 제공하는 것을 포함할 수 있으며, 여기서 변화하는 양의 불활성 합성효소가 추가 수준의 선택 또는 스크리닝 엄격도를 제공한다. 일 실시태양에 있어서, O-RS를 제조하는 방법의 단계 (a), (b) 또는 (a)와 (b) 두 단계 모두는, 예를 들어, 양성 및/또는 음성 선택 마커의 선택 또는 스크리닝 엄격도를 변화시키는 것을 포함한다. 방법은 경우에 따라 0-tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하는 O-RS에 추가의 선택 회차, 예를 들어, 추가의 양성 선택 회차, 추가의 음성 선택 회차, 또는 양성 및 음성 선택을 둘 다 조합한 회차를 수행하는 것을 포함한다.
일 실시태양에 있어서, 선택 또는 스크리닝 과정은 1회 이상의 양성 또는 음성 선택 또는 스크리닝을 포함할 수 있으며, 이는 예를 들어, 아미노산 투과성에 있어서의 변화, 번역 효율에 있어서의 변화, 번역 신뢰도에 있어서의 변화 등을 포함한다. 하나 이상의 변화는 단백질을 제조하는 데 사용되는 오르소고날 tRNA-tRNA 합성효소 쌍의 성분을 코딩하는 하나 이상의 폴리뉴클레오티드에 있어서의 돌연변이에 기초한다.
일반적으로, RS의 라이브러리(예를 들어, 돌연변이 RS의 라이브러리)는 적어도 하나의, 예컨대, 비척추동물 유기체로부터의 아미노아실-tRNA 합성효소(RS)로부터 유래된 RS를 포함한다. 일 실시태양에 있어서, RS 라이브러리는 불활성 RS로부터 유래하며, 예컨대, 활성 RS를 돌연변이 유발시켜 불활성 RS를 제조한 경우이다. 또 다른 실시태양에 있어서, 불활성 RS는 아미노산 결합 포켓을 포함하며, 아미노산 결합 포켓을 구성하는 하나 이상의 아미노산은 하나 이상의 다른 아미노산으로 치환되고, 예컨대, 치환된 아미노산은 알라닌으로 치환된 경우가 있다.
일부 실시태양에 있어서, O-RS를 제조하는 방법은 추가로 RS를 코딩하는 핵산 상에 무작위 돌연변이 유발, 부위 특이적 돌연변이 유발, 재조합, 키메라 제작 또는 이들의 조합 등을 수행함으로써, 돌연변이 RS 라이브러리를 제조하는 것을 포함한다. 일부 실시태양에 있어서, 방법은 추가로, 예를 들어, (c) O-RS를 코딩하는 핵산을 단리하는 단계; (d) 핵산으로부터 돌연변이된 O-RS를 코딩하는 한 세트의 폴리뉴클레오티드를 제조하는 단계(예를 들어, 무작위 돌연변이 유발, 부위 특이적 돌연변이 유발, 재조합, 키메라 제작 또는 이들의 임의의 조합에 의하여); 및 (e) O-tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하는 돌연변이된 O-RS가 얻어질 때까지 단계 (a) 및/또는 (b)를 반복하는 단계를 포함한다. 본 발명의 일 측면에 있어서, 단계 (c) 내지 (e)는 적어도 2회 수행된다.
O-tRNA/O-RS 쌍을 제조하는 방법 역시 본 발명의 특징이다. 일 실시태양에 있어서, O-RS는 상기한 바와 같이 얻어지며, O-tRNA는 제1 종의 척추동물 세포(척추동물 세포는 tRNA 라이브러리의 구성원을 포함함)의 집단을 음성 선택하여, 척추동물 세포에 내인성인 아미노아실-tRNA 합성효소(RS)에 의해 아미노아실화되는 tRNA 라이브러리의 구성원을 포함하는 세포를 제거하는 단계에 의해 얻어진다. 이는 제1 종의 척추동물 세포에 오르소고날한 tRNA의 풀(pool)을 제공한다. 본 발명의 일 측면에 있어서, tRNA의 라이브러리는 적어도 하나의, 예를 들어, 비척추동물 유기체로부터의 tRNA로부터 유래되는 tRNA를 포함한다. 본 발명의 또 다른 측면에 있어서, 아미노아실-tRNA 합성효소(RS)의 라이브러리는 적어도 하나의, 예컨대, 비척추동물 유기체로부터의 아미노아실-tRNA 합성효소(RS)로부터 유래되는 RS를 포함한다. 본 발명의 또 다른 측면에 있어서, tRNA의 라이브러리는 적어도 하나의, 제1의 비척추동물 유기체로부터의 tRNA로부터 유래되는 tRNA를 포함한다. 아미노아실-tRNA 합성효소(RS)의 라이브러리는 경우에 따라 적어도 하나의 제2의 비척추동물 유기체로부터의 아미노아실-tRNA 합성효소(RS)로부터 유래되는 RS를 포함한다. 일 실시태양에 있어서, 제1 및 제2 비척추동물 유기체는 동일하다. 다른 식으로, 제1 및 제2의 비척추동물 유기체는 다를 수 있다. 본 발명의 방법에 의해 제조된 특이적 O-tRNA/O-RS 쌍 역시 본 발명의 특징이다.
본 발명의 또 다른 특징은 하나의 종에서 번역 성분을 제조하고, 선택/스크리닝된 번역 성분을 제2의 종으로 도입하는 방법이다. 예를 들어, 제1의 종(예를 들어, 효모 등의 척추동물 종)에서 O-tRNA/O-RS 쌍을 제조하는 방법은 O-tRNA를 코딩하는 핵산 및 O-RS를 코딩하는 핵산을 제2의 종(예를 들어, 포유동물, 곤충, 진균류, 조류, 식물 등)의 척추동물 세포로 도입하는 단계를 추가로 포함한다. 제2의 종은 도입된 번역 성분을 사용하여 생체내에서, 예컨대, 번역시에 비천연 아미노산을 성장하는 폴리펩티드 사슬 내로 통합시킬 수 있다.
또 다른 실시태양에 있어서, 척추동물 세포에서 오르소고날 tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하는 오르소고날 아미노아실-tRNA 합성효소(O-RS)를 제조하는 방법은, (a) 제1 종(예를 들어, 효모 등과 같은 척추동물 종)의 척추동물 세포의 집단을, 비천연 아미노산의 존재하에 양성 선택하는 단계를 포함한다. 제1 종의 척추동물 세포는 각각 i) 아미노아실-tRNA 합성효소(RS) 라이브러리의 구성원, ii) 오르소고날 tRNA(O-tRNA), iii) 양성 선택 마커를 코딩하는 폴리뉴클레오티드, 및 iv) 음성 선택 마커를 코딩하는 폴리뉴클레오티드를 포함한다. 양성 선택을 극복하는 세포는 비천연 아미노산의 존재하에 오르소고날 tRNA(O-tRNA)를 아미노아실하는 활성 RS를 포함한다. 양성 선택을 극복한 세포를 비천연 아미노산의 부재하에 음성 선택하여 O-tRNA를 천연아미노산으로 아미노아실화하는 활성 RS를 제거함으로써, O-tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하는 O-RS를 제공한다. O-tRNA를 코딩하는 핵산 및 O-RS를 코딩하는 핵산을 제2의 종(예를 들어, 포유동물, 곤충, 진균, 조류, 식물 등)의 척추동물 세포 내로 도입한다. 이들 성분은 제2의 종 내에서 번역될 때 사용되어 제2의 종에서 비천연 아미노산을 관심있는 단백질 또는 폴리펩티드 내에 통합시킬 수 있다. 일 실시태양에 있어서, O-tRNA 및/또는 O-RS를 제2의 종의 척추동물 세포 내로 도입한다.
일부 실시태양에 있어서, O-tRNA는 제1의 종의 척추동물 세포(척추동물 세포는 tRNA 라이브러리의 구성원을 포함함)를 음성 선택하여, 척추동물 세포에 내인성인 아미노아실-tRNA 합성효소(RS)에 의해 아미노아실화되는 tRNA 라이브러리의 구성원을 포함하는 세포를 제거하는 단계를 포함한다. 이 과정은 제1 종 및 제2 종의 척추동물 세포에 오르소고날한 tRNA의 풀을 제공한다.
적어도 하나의 비천연 아미노산을 갖는 단백질(또는 관심있는 폴리펩티드)도 또한 본 발명의 특징이다. 본 발명의 일부 실시태양에 있어서, 적어도 하나의 비천연 아미노산을 갖는 단백질은 적어도 하나의 번역후 변형을 포함한다. 일 실시태양에 있어서, 적어도 하나의 번역후 변형은 제2의 반응성 기를 포함하는 분자(예를 들어, 염료, 폴리에틸렌 글리콜 유도체와 같은 중합체, 광가교결합제, 세포독성 화합물, 친화도 표지, 비오틴 유도체, 수지, 제2 단백질 또는 폴리펩티드, 금속 킬레이터, 보조 인자, 지방산, 탄수화물, 폴리뉴클레오티드(예를 들어, DNA, RNA 등) 등)를 [3+2] 고리화 첨가 반응에 의해 제1의 반응성 기를 포함하는 적어도 하나의 비천연 아미노산에 부착시키는 것을 포함한다. 예를 들어, 제1의 반응성 기는 알키닐 잔기(예를 들어, 비천연 아미노산 p-프로파길옥시페닐알라닌 중, 이 기는 또한 종종 아세틸렌 잔기라고도 불리움)이고, 제2의 반응성 기는 아지도 잔기이다. 또 다른 예에서, 제1의 반응성 기는 아지도 잔기(예를 들어, 비천연 아미노산 p-아지도-L-페닐알라닌 중)이고, 제2의 반응성 기는 알키닐 잔기이다. 일부 실시태양에 있어서, 본 발명의 단백질은 적어도 하나의 번역후 변형을 포함하는 적어도 하나의 비천연 아미노산(예를 들어, 케토 비천연 아미노산)을 포함하며, 여기서 적어도 하나의 번역후 변형은 당류 잔기를 포함한다. 일부 실시태양에 있어서, 번역후 변형은 척추동물 세포 생체내에서 만들어진다.
일부 실시태양에 있어서, 단백질은 척추동물 세포 생체내에서 만들어지는 적어도 하나의 번역후 변형을 포함하며, 그러한 번역후 변형은 원핵생물 세포에서는 일어나지 않는 것이다. 번역후 변형의 예는 아세틸화, 아실화, 지질 변형, 팔미토일화, 팔미테이트 부가, 포스포릴화, 당지질 결합 변형 등을 포함하나, 이에 한정되는 것은 아니다. 일 실시태양에 있어서, 번역후 변형은 올리고당을 아스파라긴에 GlcNAc-아스파라긴 결합[예를 들어, 올리고당이 (GlcNAc-Man)2-Man-GlcNAc-GlcNAc 등을 포함하는 경우 등]를 통해 부착시키는 것을 포함한다. 또 다른 실시태양에 있어서, 번역후 변형은 올리고당(예를 들어, Gal-GalNAc, Gal-GlcNAc 등)를 세린 또는 트레오닌에 GalNAc-세린, GalNAc-트레오닌, GlcNAc-세린 또는 GlcNAc-트레오닌 결합을 통해 부착시키는 것을 포함한다. 일부 실시태양에 있어서, 본 발명의 단백질 또는 폴리펩티드는 분비 또는 편재화 서열, 에피토프 태그, FLAG 태그, 폴리히스티딘 태그, GST 융합부 등을 포함할 수 있다.
일반적으로, 단백질은 임의의 이용 가능한 단백질(예를 들어, 치료용 단백질, 진단용 단백질, 산업용 효소 또는 이들의 일부분 등)과, 예를 들어, 적어도 60%, 적어도 70%, 적어도 75%, 적어도 80%, 적어도 90%, 적어도 95%, 또는 심지어 적어도 99% 또는 그 이상 동일하며, 하나 이상의 비천연 아미노산을 포함한다. 일 실시태양에 있어서, 본 발명의 조성물은 관심있는 단백질 또는 폴리펩티드와 부형제(예를 들어, 완충제, 제약상 허용 가능한 부형제 등)를 포함한다.
관심있는 단백질 또는 폴리펩티드는 적어도 1개, 적어도 2개, 적어도 3개, 적어도 4개, 적어도 5개, 적어도 6개, 적어도 7개, 적어도 8개, 적어도 9개, 또는 10개 또는 그 이상의 비천연 아미노산을 함유할 수 있다. 비천연 아미노산은 동일하거나 상이할 수 있으며, 단백질 내에 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개 또는 그 이상의 상이한 비천연 아미노산을 포함하는 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개 또는 그 이상의 상이한 위치가 있을 수 있다. 일부 실시태양에 있어서, 단백질의 천연 형태에 존재하는 적어도 하나, 그러나 전부보다는 작은 수의 아미노산이 비천연 아미노산으로 치환된다.
단백질(또는 관심있는 폴리펩티드)의 예로는 사이토카인, 성장 인자, 성장 인자 수용체, 인터페론, 인터루킨, 염증 분자, 암유전자 생성물, 펩티드 호르몬, 신호 전달 분자, 스테로이드 호르몬 수용체, 에리스로포이에틴(EPO), 인슐린, 인간 성장 호르몬, 알파-1 안티트립신, 안지오스타틴, 항용혈 인자, 항체, 아포지단백질, 아포단백질, 심방 나트륨 이뇨 인자, 심방 나트륨 이뇨 폴리펩티드, 심방 펩티드, C-X-C 케모카인, T39765, NAP-2, ENA-78, Gro-a, Gro-b, Gro-c, IP-10, GCP-2, NAP-4, SDF-1, PF4, MIG, 칼시토닌, c-kit 리간드, 사이토카인, CC 케모카인, 단핵구 화학유인 단백질-1, 단핵구 화학유인 단백질-2, 단핵구 화학유인 단백질-3, 단핵구 염증 단백질-1 알파, 단핵구 염증 단백질-1 베타, RANTES, I309, R83915, R91733, HCC1, T58847, D31065, T64262, CD40, CD40 리간드, c-kit 리간드, 콜라겐, 콜로니 자극 인자(CSF), 보체 인자 5a, 보체 억제제, 보체 수용체 1, 사이토카인, DHFR, 상피세포 호중구 활성화 펩티드-78, GROα/MGSA, GROβ, GROγ, MIP-1α, MIP-1δ, MCP-1, 상피세포 성장 인자(EGF), 상피세포 호중구 활성화 펩티드, 에리스로포이에틴(EPO), 박리 독소(exfoliating toxin), 인자 IX, 인자 VII, 인자 VIII, 인자 X, 섬유아세포 성장 인자(FGF), 피브리노겐, 피브로넥틴, G-CSF, GM-CSF, 글루코세레브로시다제, 고나도트로핀, 성장 인자, 성장 인자 수용체, 헤지호그(Hedgehog) 단백질, 헤모글로빈, 간세포 성장 인자(HGF), 히루딘, 인간 혈청 알부민, ICAM-1, ICAM-1 수용체, LFA-1, LFA-1 수용체, 인슐린, 인슐린 유사 성장 인자(IGF), IGF-I, IGF-II, 인터페론, IFN-α, IFN-β, IFN-γ, 인터루킨, IL-1, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8, IL-9, IL-10, IL-11, IL-12, 각질 세포 성장 인자(KGF), 락토페린, 백혈병 억제 인자, 루시퍼라제, 뉴투린, 호중구 억제 인자(NIF), 온코스타틴 M, 골원성 단백질, 암유전자 생성물, 부갑상선 호르몬, PD-ECSF, PDGF, 펩티드 호르몬, 인간 성장 호르몬, 플레이오트로핀, 단백질 A, 단백질 G, 발열성 외독소 A, B 또는 C, 릴렉신, 레닌, SCF, 가용성 보체 수용체 I, 가용성 I-CAM 1, 가용성 인터루킨 수용체, 가용성 TNF 수용체, 소마토메딘, 소마토스타틴, 소마토트로핀, 스트렙토키나제, 슈퍼항원, 스타필로코커스 장독소, SEA, SEB, SEC1, SEC2, SEC3, SED, SEE, 스테로이드 호르몬 수용체, 슈퍼옥시드 디스뮤타제(SOD), 독성 쇼크 증후군 독소, 티모신 알파 1, 조직 플라스미노겐 활성화 인자, 종양 성장 인자(TGF), TGF-α, TGF-β, 종양 괴사 인자, 종양 괴사 인자 알파, 종양 괴사 인자 베타, 종양 괴사 인자 수용체(TNFR), VLA-4 단백질, VCAM-1 단백질, 혈관 내피세포 성장 인자(VEGEF), 유로키나제, Mos, Ras, Raf, Met; p53, Tat, Fos, Myc, Jun, Myb, Rel, 에스트로겐 수용체, 프로게스테론 수용체, 테스토스테론 수용체, 알도스테론 수용체, LDL 수용체, SCF/c-Kit, CD40L/CD40, VLA-4/VCAM-1, ICAM-1/LFA-1, 히알루린/CD44 및 코르티코스테론, 진뱅크(Genbank) 또는 다른 데이터베이스에 존재하는 단백질 등, 또는 이들의 일부분을 포함하나, 이에 한정되는 것은 아니다. 일 실시태양에 있어서, 관심있는 폴리펩티드는 전사 조절인자 단백질(예를 들어, 전사 활성화 인자 단백질(GAL4 등), 또는 전사 억제제 단백질 등) 또는 그 일부분을 포함한다.
본 발명의 척추동물 세포는 비천연 아미노산을 포함하는 단백질을 많은 유용한 양으로 합성하는 능력을 제공한다. 예를 들어, 비천연 아미노산을 포함하는 단백질은 세포 추출물, 완충액, 제약상 허용 가능한 부형제 등에, 예컨대, 적어도 10 ㎍(단백질)/ℓ, 적어도 50 ㎍/ℓ, 적어도 75 ㎍/ℓ, 적어도 100 ㎍/ℓ, 적어도 200 ㎍/ℓ, 적어도 250 ㎍/ℓ, 또는 적어도 500 ㎍/ℓ 또는 그 이상의 농도로 제조될 수 있다. 일부 실시태양에 있어서, 본 발명의 조성물은 비천연 아미노산을 포함하는 단백질을, 예를 들어, 적어도 10 ㎍, 적어도 50 ㎍, 적어도 75 ㎍, 적어도 100 ㎍, 적어도 200 ㎍, 적어도 250 ㎍, 또는 적어도 500 ㎍ 또는 그 이상 포함한다.
일부 실시태양에 있어서, 관심있는 단백질 또는 폴리펩티드(또는 그 일부분)는 핵산에 의해 코딩된다. 일반적으로는, 핵산은 적어도 1개의 셀렉터 코돈, 적어도 2개의 셀렉터 코돈, 적어도 3개의 셀렉터 코돈, 적어도 4개의 셀렉터 코돈, 적어도 5개의 셀렉터 코돈, 적어도 6개의 셀렉터 코돈, 적어도 7개의 셀렉터 코돈, 적어도 8개의 셀렉터 코돈, 적어도 9개의 셀렉터 코돈, 또는 10개 또는 그 이상의 셀렉터 코돈을 포함한다.
본 발명은 또한 척추동물 세포에서 적어도 하나의 비천연 아미노산을 포함하는 적어도 하나의 단백질을 제조하는 방법(그러한 방법에 의해 제조된 단백질뿐만 아니라)을 제공한다. 그 방법은, 예를 들어, 적절한 배지 중에서 적어도 하나의 셀렉터 코돈을 포함하며, 단백질을 코딩하는 핵산을 포함하는 척추동물 세포를 배양하는 것을 포함한다. 척추동물 세포는 또한 세포 내에서 기능하고, 셀렉터 코돈을 인식하는 오르소고날 tRNA(O-tRNA), 및 O-tRNA를 비천연 아미노산으로 우선적으로 아미노아실하는 오르소고날 아미노아실 tRNA 합성효소(O-RS)를 포함하며, 배지는 비천연 아미노산을 포함한다. 일 실시태양에 있어서, O-RS는 O-tRNA를 비천연 아미노산으로, 예를 들어, 서열 번호 86 또는 45에 개시된 아미노산 서열을 갖는 O-RS가 아미노아실화하는 효율의, 예를 들어, 적어도 45%, 적어도 50%, 적어도 60%, 적어도 75%, 적어도 80%, 적어도 90%, 적어도 95%, 또는 심지어 99% 또는 그 이상의 효율로 아미노아실화한다. 또 다른 실시태양에 있어서, O-tRNA는 서열 번호 64 또는 65 또는 이의 상보적 폴리뉴클레오티드 서열을 포함하거나, 그로부터 프로세싱되거나 또는 그에 의해 코딩된다. 또 다른 실시태양에 있어서, O-RS는 서열 번호 36 내지 63 및/또는 86 중 어느 하나에 개시된 아미노산 서열을 포함한다.
일 실시태양에 있어서, 상기 방법은 단백질 내로 제1 반응성 기를 갖는 비천연 아미노산을 도입하는 단계, 및 그 단백질을 제2 반응성 기를 포함하는 분자(예를 들어, 염료, 폴리에틸렌 글리콜 유도체와 같은 중합체, 광가교결합제, 세포독성 화합물, 친화도 표지, 비오틴 유도체, 수지, 제2 단백질 또는 폴리펩티드, 금속 킬레이터, 보조 인자, 지방산, 탄수화물, 폴리뉴클레오티드(예를 들어, DNA, RNA 등) 등)와 접촉시키는 단계를 더 포함한다. 제1 반응성 기는 제2 반응성 기와 반응하여 분자를 비천연 아미노산에 [3+2] 고리화 첨가 반응을 통해 부착시킨다. 일 실시태양에 있어서, 제1 반응성 기는 알키닐 또는 아지도 잔기이고, 제2 반응성 기는 아지도 또는 알키닐 잔기이다. 예를 들어, 제1 반응성 기는 알키닐 잔기(예를 들어, 비천연 아미노산 p-프로파길옥시페닐알라닌 중)이고, 제2 반응성 기는 아지도 잔기이다. 또 다른 예에서, 제1 반응성 기는 아지도 잔기(예를 들어, 비천연 아미노산 p-아지도-L-페닐알라닌 중)이고, 제2 반응성 기는 알키닐 잔기이다.
일부 실시태양에 있어서, 코딩되는 단백질은 치료용 단백질, 진단용 단백질, 산업용 효소 또는 그 일부분을 포함한다. 일 실시태양에 있어서, 그와 같은 방법에 의해 제조된 단백질은 비천연 아미노산을 통해 변형된다. 비천연 아미노산은, 예를 들어, 친핵성-친전자성 반응, [3+2] 고리화 첨가 반응 등에 의해서 변형된다. 또 다른 실시태양에 있어서, 그와 같은 방법에 의해 제조된 단백질은 생체내에서 적어도 하나의 번역후 변형(예를 들어, N-글리코실화, O-글리코실화, 아세틸화, 아실화, 지질 변형, 팔미토일화, 팔미테이트 부가, 포스포릴화, 당지질 결합 변형 등)에 의해 변형된다.
스크리닝 또는 선택용 전사 조절인자 단백질을 제조하는 방법(이러한 방법에 의해서 제조되는 스크리닝 또는 선택용 전사 조절인자 단백질과 같이)이 또한 제공된다. 이 방법은, 예를 들어, 핵산 결합 도메인을 코딩하는 제1 폴리뉴클레오티드 서열을 선택하는 단계, 및 제1 폴리뉴클레오티드 서열이 적어도 하나의 셀렉터 코돈을 포함하도록 돌연변이시키는 단계를 포함한다. 이 과정은 스크리닝 또는 선택 폴리뉴클레오티드 서열을 제공한다. 방법은 또한, 예를 들어, 전사 활성화 도메인을 코딩하는 제2의 폴리뉴클레오티드 서열을 선택하는 단계; 제2의 폴리뉴클레오티드 서열에 작동 가능하게 연결된 스크리닝 또는 선택 폴리뉴클레오티드 서열을 포함하는 구성체를 제공하는 단계; 및 구성체, 비천연 아미노산, 오르소고날 tRNA 합성효소(O-RS) 및 오르소고날 tRNA(O-tRNA)를 세포 내로 도입하는 단계를 포함한다. 이들 성분으로, O-RS는 O-tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하고, O-tRNA는 셀렉터 코돈을 인식하여 스크리닝 또는 선택 폴리뉴클레오티드 서열 중 셀렉터 코돈에 응답하여 비천연 아미노산을 핵산 결합 도메인 내로 통합시킨다. 이 과정은 스크리닝 또는 선택 전사 조절인자 단백질을 제공한다.
일부 실시태양에 있어서, 본 발명의 조성물 및 방법은 척추동물 세포를 포함한다. 본 발명의 척추동물 세포는, 예를 들어, 포유동물 세포, 효모 세포, 진균 세포, 식물 세포, 곤충 세포 등 어느 것이라도 무방하다. 본 발명의 번역 성분은 여러 유기체, 예를 들어, 비척추동물 유기체로서 원핵 생물(예를 들어, 에스케리치아 콜라이, 바실러스 스테아로써모필러스 등) 또는 원시 박테리아류, 또는 척추동물로부터 유래할 수 있다.
본 발명의 셀렉터 코돈은 척추동물 단백질 생합성 기구의 유전자 코돈 프레임워크를 확장시킨다. 각종 셀렉터 코돈은 어느 것이나 사용할 수 있으며, 비제한적인 예로서, 종결 코돈(예를 들어, 앰버 코돈, 오커 코돈, 또는 오팔 종결 코돈), 넌센스 코돈, 희귀 코돈, 4(또는 그 이상의) 염기 코돈 등을 사용할 수 있다.
본 명세서에 기재된 조성물 및 방법에 사용될 수 있는 비천연 아미노산의 예는 p-아세틸-L-페닐알라닌, p-요오도-L-페닐알라닌, O-메틸-L-타이로신, p-프로파길옥시페닐알라닌, L-3-(2-나프틸)알라닌, 3-메틸-페닐알라닌, O-4-알릴-L-타이로신, 4-프로필-L-타이로신, 트리-O-아세틸-GlcNAcβ-세린, L-Dopa, 플루오르화 페닐알라닌, 이소프로필-L-페닐알라닌, p-아지도-L-페닐알라닌, p-아실-L-페닐알라닌, p-벤조일-L-페닐알라닌, L-포스포세린, 포스포노세린, 포스포노타이로신, p-브로모페닐알라닌, p-아미노-L-페닐알라닌, 이소프로필-L-페닐알라닌, 타이로신 아미노산의 비천연 유사체; 글루타민 아미노산의 비천연 유사체; 페닐알라닌 아미노산의 비천연 유사체; 세린 아미노산의 비천연 유사체; 트레오닌 아미노산의 비천연 유사체; 알킬, 아릴, 아실, 아지도, 시아노, 할로, 히드라진, 히드라지드, 히드록실, 알케닐, 알키닐, 에테르, 티올, 설포닐, 셀레노, 에스테르, 티오산, 보레이트, 보로네이트, 포스포, 포스포노, 포스핀, 헤테로시클릭, 엔온, 이민, 알데히드, 히드록실아민, 케토, 또는 아미노 치환된 아미노산, 또는 이들의 임의의 조합; 광활성화 가능한 가교결합제를 갖는 아미노산; 스핀 표지 아미노산; 형광 아미노산; 금속 결합 아미노산; 금속 함유 아미노산; 방사성 아미노산; 광케이징된(photocaged) 아미노산 및/또는 광이성질체화 가능한 아미노산; 비오틴 또는 비오틴 유사체 함유 아미노산; 케토 함유 아미노산; 폴리에틸렌 글리콜 또는 폴리에테르를 포함하는 아미노산; 중원자 치환된 아미노산; 화학적 절단 또는 광절단 가능한 아미노산; 연장된 측쇄를 갖는 아미노산; 독성 기를 함유하는 아미노산; 당 치환된 아미노산; 탄소 결합된 당 함유 아미노산; 산화환원 활성 아미노산; α-히드록시 함유 아미노산; 아미노 티오산; α,α-이치환 아미노산; β-아미노산; 프롤린 또는 히스티딘이 아닌 시클릭 아미노산, 및 페닐알라닌, 타이로신 또는 트립토판이 아닌 방향족 아미노산 등을 포함하나, 이에 한정되는 것은 아니다.
본 발명은 또한 폴리펩티드(O-RS) 및 폴리뉴클레오티드, 예를 들어, O-tRNA, O-RS 또는 그 일부분(예를 들어, 합성효소의 활성 부위)을 코딩하는 폴리뉴클레오티드, 아미노아실-tRNA 합성효소 변이체를 제작하는 데 사용되는 올리고뉴클레오티드, 하나 이상의 셀렉터 코돈을 포함하는 관심있는 단백질 또는 폴리펩티드를 코딩하는 폴리뉴클레오티드 등을 제공한다. 예를 들어, 본 발명의 폴리펩티드는 서열 번호 36 내지 63 및/또는 86 중 어느 하나에 개시된 아미노산 서열을 포함하는 폴리펩티드, 서열 번호 3 내지 35 중 어느 하나에 개시된 폴리뉴클레오티드 서열에 의해 코딩되는 아미노산 서열을 포함하는 폴리펩티드, 및 서열 번호 36 내지 63 및/또는 86 중 어느 하나에 개시된 아미노산 서열을 포함하는 폴리펩티드에 대해 특이적인 항체와 특이적 면역반응성을 나타내는 폴리펩티드, 또는 서열 번호 3 내지 35 중 어느 하나에 개시된 폴리뉴클레오티드 서열에 의해 코딩되는 아미노산 서열을 포함하는 폴리펩티드를 포함한다.
본 발명의 폴리펩티드에는 또한 천연 타이로실 아미노아실-tRNA 합성효소(TyrRS)(예를 들어, 서열 번호 2)의 서열과 적어도 90% 동일한 아미노산 서열을 포함하며, 그룹 A 내지 E(상기한 바와 같음)의 두 개 이상의 아미노산 치환을 포함하는 폴리펩티드가 포함된다. 마찬가지로, 본 발명의 폴리펩티드는 또한 경우에 따라 서열 번호 36 내지 63 및/또는 86 중 어느 하나의 적어도 20개의 연속적 아미노산과 상기한 그룹 A 내지 E의 2 개 이상의 아미노산 치환을 포함하는 폴리펩티드를 포함한다. 상기한 임의의 폴리펩티드의 보존적 변이를 포함하는 아미노산 서열이 또한 본 발명의 폴리펩티드로서 포함된다.
일 실시태양에 있어서, 조성물은 본 발명의 폴리펩티드 및 부형제(예를 들어, 완충제, 물, 제약상 허용 가능한 부형제 등)를 포함한다. 본 발명은 또한 본 발명의 폴리펩티드와 특이적 면역반응성을 나타내는 항체 또는 항혈청을 제공한다.
본 발명에 따르면 또한 폴리뉴클레오티드가 제공된다. 본 발명의 폴리뉴클레오티드는 하나 이상의 셀렉터 코돈을 갖는, 본 발명의 관심있는 단백질 또는 폴리펩티드를 코딩하는 것을 포함한다. 또한, 본 발명의 폴리뉴클레오티드는, 예를 들어, 서열 번호 3 내지 35, 64 내지 85 중 어느 하나에 개시된 뉴클레오티드 서열을 포함하는 폴리뉴클레오티드; 그에 상보적이거나 이의 폴리펩티드 서열을 코딩하는 폴리뉴클레오티드; 및/또는 서열 번호 36 내지 63 및/또는 86 중 어느 하나에 개시된 아미노산 서열을 포함하는 폴리펩티드 또는 이의 보존적 변이체를 코딩하는 폴리뉴클레오티드를 포함한다. 본 발명의 폴리뉴클레오티드는 또한 본 발명의 폴리펩티드를 코딩하는 폴리뉴클레오티드를 포함한다. 마찬가지로, 고도로 엄격한 조건하에 실질적으로 핵산의 전체 길이에 걸쳐 상기한 바와 같은 폴리뉴클레오티드에 하이브리드화하는 핵산도 또한 본 발명의 폴리뉴클레오티드이다.
본 발명의 폴리뉴클레오티드는 또한 천연 타이로실 아미노아실-tRNA 합성효소(TyrRS)(예를 들어, 서열 번호 2) 서열과 적어도 90% 동일한 아미노산 서열을 포함하며, 상기 그룹 A 내지 E(상기한 바와 같음)에서와 같은 2 이상의 돌연변이를 포함하는 폴리펩티드를 코딩하는 폴리뉴클레오티드를 포함한다. 상기 폴리뉴클레오티드와 적어도 70%, (또는 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 98%, 또는 적어도 99% 또는 그 이상) 동일한 폴리뉴클레오티드, 및/또는 상기한 임의의 폴리뉴클레오티드의 보존적 변이를 포함하는 폴리뉴클레오티드가 본 발명의 폴리뉴클레오티드에 포함된다.
일부 실시태양에 있어서, 벡터(예를 들어, 플라스미드, 코스미드, 파지, 바이러스 등)는 본 발명의 폴리뉴클레오티드를 포함한다. 일 실시태양에 있어서, 벡터는 발현 벡터이다. 또 다른 실시태양에 있어서, 발현 벡터는 본 발명의 하나 이상의 폴리뉴클레오티드에 작동 가능하게 연결 프로모터를 포함한다. 또 다른 실시태양에 있어서, 세포는 본 발명의 폴리뉴클레오티드를 포함하는 벡터를 포함한다.
또 다른 측면에 있어서, 본 발명은 화합물의 조성물 및 그러한 화합물을 제조하는 방법을 제공한다. 예를 들어, 화합물은 비천연 아미노산(예를 들어, p-(프로파길옥시)-페닐알라닌(예를 들어, 도 11의 1), 아지도 염료(예를 들어, 화학 구조 4 및 6에 나타낸 것과 같음), 알키닐 폴리에틸렌 글리콜(예를 들어, 화학 구조 7에 나타낸 것과 같음; n은, 예를 들어, 50 내지 10,000, 75 내지 5,000, 100 내지 2,000, 100 내지 1,000 사이의 정수임) 등을 포함한다. 본 발명의 실시태양에 있어서, 알키닐 폴리에틸렌 글리콜은 분자량이, 예를 들어, 약 5,000 내지 약 100,000 Da, 약 20,000 내지 약 50, 000 Da, 약 20,000 내지 약 10,000 Da(예를 들어, 20,000 Da)이다.
예를 들어, 단백질 및 세포와 함께 이들 화합물을 포함하는 각종 조성물이 제공된다. 일 측면에 있어서, p-(프로파길옥시)-페닐알라닌 비천연 아미노산을 포함하는 조성물은 오르소고날 tRNA를 추가로 포함한다. 비천연 아미노산은 오르소고날 tRNA에 결합될 수 있으며(예컨대, 공유적으로), 예를 들어, 오르소고날 tRNA에 아미노-아실 결합을 통하여 공유 결합되거나, 오르소고날 tRNA의 말단 리보스 당의 3 'OH 또는 2 'OH에 공유 결합된다.
키트도 또한 본 발명의 특징이다. 예를 들어, 세포 중에서 적어도 하나의 비천연 아미노산을 포함하는 단백질을 제조하기 위한 키트가 제공되는데, 이 키트는 O-tRNA를 코딩하는 폴리뉴클레오티드 서열 또는 O-tRNA, 및 O-RS를 코딩하는 폴리뉴클레오티드 서열 또는 O-RS를 함유하는 용기를 포함한다. 일 실시태양에 있어서, 상기 키트는 적어도 하나의 비천연 아미노산을 더 포함한다. 또 다른 실시태양에 있어서, 상기 키트는 단백질 제조에 관한 설명 자료를 더 포함한다.
[도면의 간단한 설명]
도 1은 hGH로의 파라-아세틸-페닐알라닌의 도입을 도시하고 있다.
도 2는 다양한 농도의 파라-아세틸-페닐알라닌의 hGH로의 도입을 도시하고 있다.
[상세한 설명]
본 발명을 상세하게 설명하기에 앞서, 본 발명은 특정 장치나 생물학적 계에 한정되는 것이 아니라 당연히 변화될 수 있는 것이라는 것을 이해하여야 한다. 또한, 본 명세서에서 사용된 용어들은 단지 특정 실시태양을 기술할 목적으로 사용되는 것으로서 제한할 의도로 사용되는 것이 아니라는 것도 이해하여야 한다. 본 명세서 및 첨부된 특허청구의 범위에서 "하나의" "그" 등의 단수 형태는 문맥상 명백히 단수를 의미하는 것이 아닌 한 복수 형태를 포함한다. 따라서, 예를 들어, "(하나의) 세포"라는 것은 2 이상의 세포의 조합을 의미하는 것을 포함하며, "박테리아"는 박테리아의 혼합물을 포함한다.
본 명세서 또는 하기에서 달리 정의되지 않는 한, 본 명세서에 사용된 모든 기술 및 과학 용어는 본 발명이 속하는 분야의 통상의 지식을 가진 자에게 통상적으로 이해되는 의미를 갖는다.
상동성: 단백질 및/또는 단백질 서열은 이 서열들이 천연적으로나 인공적으로 공통의 조상 단백질 또는 단백질 서열로부터 유래되었을 때 "상동성"이다. 마찬가지로, 핵산 및/또는 핵산 서열은 이들이 천연적으로나 인공적으로 공통의 조상 핵산 또는 핵산 서열로부터 유래되었을 때 "상동성"이다. 예를 들어, 천연 핵산은 임의의 돌연변이 유발법으로 변형되어 하나 이상의 셀렉터 코돈을 포함할 수 있다. 발현되었을 때, 이 돌연변이된 핵산은 하나 이상의 비천연 아미노산을 포함하는 폴리펩티드를 코딩한다. 돌연변이 과정은 추가로 하나 이상의 표준 코돈을 변화시킴으로써 돌연변이 단백질을 제조할 수 있다. 상동성은 일반적으로는 2 이상의 핵산 또는 단백질(또는 이들의 서열) 사이의 서열 유사성으로부터 추정된다. 상동성을 확립하는 데 유용한 서열들 사이의 정확한 유사성 퍼센트는 해당 핵산 및 단백질에 따라 달라질 것이나, 적게는 25% 서열 유사성도 통상적으로 상동성을 확립하는 데 사용된다. 보다 높은 서열 유사성, 예를 들어, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95%, 또는 99% 이상의 유사성 또한 상동성을 확립하는 데 사용될 수 있다. 서열 유사성 퍼센트를 측정하는 방법(예를 들어, 디폴트 파라미터를 사용하는 BLASTP 및 BLASTN)이 본 명세서에 기재되어 있으며, 일반적으로 이용 가능하다.
오르소고날: 본 명세서에서 "오르소고날"이란 세포 또는 번역계에 내인성인 상응하는 분자에 비하여 세포의 내인성 성분과 감소된 효율로 기능하거나 세포의 내인성 성분과 기능하지 못하는 분자(예를 들어, 오르소고날 tRNA(O-tRNA) 및/또는 오르소고날 아미노아실-tRNA 합성효소(O-RS))를 의미한다. tRNA 및 아미노아실-tRNA 합성효소에 있어서, 오르소고날이란 내인성 tRNA가 내인성 tRNA 합성효소와 기능하는 것에 비하여 오르소고날 tRNA가 내인성 tRNA 합성효소와 기능하는 것이, 또는 내인성 tRNA 합성효소가 내인성 tRNA와 기능하는 것에 비하여 오르소고날 아미노아실-tRNA 합성효소가 내인성 tRNA와 기능하는 것이 불능이거나 또는 감소된 효율, 예를 들어, 20% 미만, 10% 미만, 5% 미만, 또는 1% 미만으로 효율적이라는 것을 의미한다. 오르소고날 분자는 세포 내에 기능적 내인성 상보적 분자를 가지고 있지 않다. 예를 들어, 세포 내의 오르소고날 tRNA는 내인성 tRNA의 내인성 RS에 의한 아미노아실화와 비교할 때 세포의 임의의 내인성 RS에 의해 감소된 또는 심지어는 제로의 효율로 아미노아실화된다. 또 다른 예로서, 오르소고날 RS는 내인성 tRNA의 내인성 RS에 의한 아미노아실화와 비교할 때 세포 중의 관심있는 내인성 tRNA를 감소된 또는 심지어는 제로의 효율로 아미노아실화한다. 제1 오르소고날 분자와 함께 기능하는 제2 오르소고날 분자를 세포 내로 도입할 수 있다. 예를 들어, 오르소고날 tRNA/RS 쌍은 세포 내에서 함께 효율적으로(예를 들어, 상응하는 tRNA/RS 내인성 쌍 효율의 50% 효율, 60% 효율, 70% 효율, 75% 효율, 80% 효율, 90% 효율, 95% 효율, 또는 99% 또는 그 이상의 효율) 기능하는, 도입된 상보적 성분을 포함한다.
상보적: "상보적"이란 오르소고날 쌍, 예컨대, O-RS가 O-tRNA를 아미노아실화하는 경우와 같이 함께 기능하는 O-tRNA와 O-RS의 성분을 이르는 것이다.
우선적(으로) 아미노아실화: "우선적(으로) 아미노아실화"란 O-RS가 천연 tRNA 또는 O-tRNA를 제조하는 데 사용되는 출발 물질을 아미노아실화하는 것에 비해 O-RS가 O-tRNA를 비천연 아미노산으로 아미노아실화하는 효율이, 예를 들어, 70% 효율적, 75% 효율적, 85% 효율적, 90% 효율적, 95% 효율적, 또는 99% 이상 효율적인 것을 의미한다. 비천연 아미노산은 성장하는 폴리펩티드 사슬 내로 높은 신뢰도로, 예를 들어, 주어진 셀렉터 코돈에 대해 약 75%를 초과하는 효율, 주어진 셀렉터 코돈에 대해 약 80%를 초과하는 효율, 주어진 셀렉터 코돈에 대해 약 90%를 초과하는 효율, 주어진 셀렉터 코돈에 대해 약 95%를 초과하는 효율, 또는 주어진 셀렉터 코돈에 대해 약 95%를 초과하는 효율 또는 그 이상의 효율로 통합된다.
셀렉터 코돈: "셀렉터 코돈"이란 번역 과정 중 O-tRNA에 의해 인식되나 내인성 tRNA에 의해서는 인식되지 않는 코돈을 말한다. O-tRNA 안티코돈 루프는 mRNA 상의 셀렉터 코돈을 인식하고, 폴리펩티드 중 그 위치에 이의 아미노산, 예를 들어, 비천연 아미노산을 통합시킨다. 셀렉터 코돈은, 예를 들어, 넌센스 코돈, 예컨대, 앰버, 오커 및 오팔 코돈과 같은 종결 코돈; 4개 또는 그 이상의 염기 코돈; 희귀 코돈; 천연 또는 비천연 염기쌍으로부터 유도된 코돈 등을 포함한다.
서프레서 tRNA: 서프레서 tRNA는 주어진 번역계에서, 예컨대, 셀렉터 코돈에 반응하여 폴리펩티드 내로 아미노산을 도입하는(통합시키는) 메카니즘을 제공함으로써, 메신저 RNA(mRNA)의 판독을 변화시키는 tRNA를 의미한다. 예를 들어, 서프레서 tRNA는 종결 코돈, 4염기 코돈, 희귀 코돈 등을 읽고 지나갈 수 있다.
재생 가능한 tRNA: "재생 가능한 tRNA"란 번역 중 하나 이상의 폴리펩티드 사슬 내로 아미노산(예를 들어, 비천연 아미노산)을 도입하기 위해 아미노산(예를 들어, 비천연 아미노산)으로 아미노아실화되고 반복적으로 탈아미노아실화될 수 있는 tRNA를 의미한다.
번역계: "번역계"란 천연 아미노산을 성장하는 폴리펩티드 사슬(단백질) 내로 통합시키는 성분들의 전체 세트를 의미한다. 번역계의 성분들은, 예를 들어, 리보좀, tRNA, 합성효소, mRNA, 아미노산 등을 포함할 수 있다. 본 발명의 성분들(예를 들어, O-RS, O-tRNA, 비천연 아미노산 등)이 시험관내 또는 생체내 번역계, 예를 들어, 척추동물 세포, 예를 들어, 효모 세포, 포유류 세포, 식물 세포, 조류 세포, 진균 세포, 곤충 세포 등에 가해질 수 있다.
비천연 아미노산: 본 명세서에서 "비천연 아미노산"이란 20 가지의 천연 아미노산, 셀레노시스테인 또는 피롤리신 중 하나가 아닌 임의의 아미노산, 변형된 아미노산 및/또는 아미노산 유사체를 말한다.
유래된: 본 명세서에서 "(로부터) 유래된"이란 특정 분자 또는 유기체로부터 단리되거나 그로부터의 정보를 사용하여 만들어지 성분을 이르는 말이다.
불활성 RS: "불활성 RS"란 돌연변이되어 더 이상 이의 천연 동족(cognate) tRNA를 아미노산으로 아미노아실화할 수 없는 합성효소를 의미한다.
양성 선택 또는 스크리닝 마커: "양성 선택 또는 스크리닝 마커"란 발현이나 활성화 등에 의해 존재하는 경우, 양성 선택 마커가 없는 세포로부터 양성 선택 마커가 있는 세포를 구별하게 해주는 마커를 의미한다.
음성 선택 또는 스크리닝 마커: 본 명세서에서 "음성 선택 또는 스크리닝 마커"는 발현이나 활성화 등에 의해 존재하는 경우, 목적하는 특성을 갖지 않는 세포를 찾아내도록(예를 들어, 목적하는 특성을 갖는 세포와 비교하여) 하는 마커를 의미한다.
리포터: 본 명세서에서 "리포터"란 관심있는 계의 표적 성분을 선택하는 데 사용될 수 있는 성분이다. 예를 들어, 리포터는 형광 스크리닝 마커(예를 들어, 녹색 형광 단백질), 발광 마커(예를 들어, 반딧불이 루시퍼라제 단백질), 친화도에 기초한 스크리닝 마커, 또는 선택 마커 유전자, 예컨대, his3, ura33, leu2, lys2, lacZ, β-gal/lacZ(β-갈락토시다제), Adh(알콜 데하이드로게나제) 등을 포함할 수 있다.
척추동물: "척추동물"이란 발생계통상 진핵생물(Eucarya)에 속하는 생물, 예를 들어, 포유류, 파충류, 조류 등의 동물을 의미한다.
비진핵생물: 본 명세서에서 "비진핵생물"이란 비척추동물 유기체를 말한다. 예를 들어, 비척추동물 유기체는 발생계통상 진정세균(Eubacteria), 예를 들어, 에스케리치아 콜라이(Escherichia coli), 써머스 써모필러스(Thermus thermophilus), 바실러스 스테아로써모필러스(Bacillus stearothermophilus) 등; 또는 고세균(Archaea), 예를 들어, 메타노코커스 쟈나쉬(Methanococcus jannaschii), 메타노박테리움 써모오토트로피컴(Methanobacterium thermoautotrophicum), 할로박테리움(Halobacterium) 속으로서 할로페락스 볼카니(Haloferax volcanii) 및 할로박테리움 종 NRC-1, 아키오글로버스 풀지더스(Archaeoglobus fulgidus), 파이로코커스 퓨리오수스(Pyrococcus furiosus), 파이로코커스 호리코쉬(Pyrococcus horikoshii), 유로파이럼 페르닉스(Aeuropyrum pernix) 등에 속할 수 있다.
항체: 본 명세서에서, "항체"는 면역글로불린 유전자(들)에 의해 실질적으로 코딩되는 폴리펩티드 또는 이의 단편으로서, 분석 대상물(항원)에 특이적으로 결합하고 인식하는 것을 포함하나, 이에 한정되는 것은 아니다. 항체의 예는 폴리클로날, 모노클로날, 키메라, 및 단일쇄 항체 등을 포함한다. Fab 단편, 및 파지 디스플레이를 포함하는 발현 라이브러리에 의해 제조된 단편을 포함하는 면역글로불린 단편이 또한 본 명세서에서 사용되는 "항체"라는 용어에 포함된다. 항체의 구조 및 용어에 대해서는, 예를 들어, 문헌(Paul, Fundamental Immunology, 4th Ed., 1999, Raven Press, New York)을 참조할 수 있다.
보존적 변이체: "보존적 변이체"는 보존적 변이체 O-tRNA 또는 보존적 변이체 O-RS와 같은 번역 성분으로서, 이들이 기초한 성분, 즉, O-tRNA 또는 O-RS와 유사하게 기능을 수행하지만 서열 내에 변화를 갖는 성분을 의미한다. 예를 들어, O-RS는 상보적 O-tRNA 또는 보존적 변이체 O-tRNA를 비천연 아미노산으로 아미노아실화할 것이지만, O-tRNA와 보존적 변이체 O-tRNA는 동일한 서열을 갖지는 않는다. 보존적 변이체는 그것이 상응하는 O-tRNA 또는 O-RS에 상보적인 한, 서열 내에 예컨대, 1개의 변이, 2개의 변이, 3개의 변이, 4개의 변이, 또는 5개 또는 그 이상의 변이를 가질 수 있다.
선택제 또는 스크리닝제: 본 명세서에서 "선택제 또는 스크리닝제"는 이의 존재시에 집단으로부터 특정 성분의 선택/스크리닝을 가능하게 하는 물질을 의미한다. 선택제 또는 스크리닝제는, 예를 들어, 영양소, 항생제, 빛의 파장, 항체, 발현된 폴리펩티드(예를 들어, 전사 조절인자 단백질) 등을 포함하나, 이에 한정되는 것은 아니다. 선택제는 농도, 강도 등에 있어서 변화될 수 있다.
검출 가능한 물질: 본 명세서에서 "검출 가능한 물질"이란 활성화되거나, 변화되거나, 발현되거나 하였을 때, 집단으로부터 특정 성분을 선택/스크리닝하는 것을 가능하게 하는 물질을 말한다. 검출 가능한 물질은 화합물일 수 있으며, 예를 들어, 5-플루오로오로트산(5-FOA)이 있는데, 이는 예컨대, URA3 리포터의 발현이라는 조건하에 URA3 리포터를 발현하는 세포를 사멸시키는 독소 생성물로서 검출 가능하게 된다.
척추동물 세포에서 유전자 코드에 의해 부과된 화학적 구속을 넘어서서 단백질의 구조를 직접적으로 유전적으로 변형시키는 능력은 세포 프로세싱을 프로빙하고 조작하는 강력한 분자상 도구를 제공할 것이다. 본 발명은 척추동물 세포에서 유전적으로 코딩되는 아미노산의 수를 확장하는 번역 성분을 제공한다. 이 성분은 tRNA(예를 들어, 오르소고날 tRNA, O-tRNA), 아미노아실-tRNA 합성효소(예를 들어, 오르소고날 합성효소, O-RS), O-tRNA/O-RS 쌍, 및 비천연 아미노산을 포함한다.
일반적으로, 본 발명의 O-tRNA는 효율적으로 발현 및 프로세싱되며, 척추동물 세포에서 번역 중에 기능을 하지만, 숙주의 아미노아실-tRNA 합성효소에 의해 상당히 아미노아실화되지는 않는다. 본 발명의 O-tRNA는 통상의 20개 아미노산 중 어느 것도 코딩하지 않는 셀렉터 코돈에 응답하여 mRNA 번역시에 비천연 아미노산을 성장하는 폴리펩티드 사슬로 전달한다.
본 발명의 O-RS는 척추동물 세포에서 본 발명의 O-tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하지만, 숙주의 세포질 tRNA의 어느 것도 아미노아실화하지 않는다. 또한, 본 발명의 아미노아실-tRNA 합성효소의 특이성으로 인해 내인성 아미노산을 배척하면서 비천연 아미노산을 수용한다. 예시적 O-RS의 아미노산 서열 또는 그 일부분을 포함하는 폴리펩티드가 또한 본 발명의 특징이다. 본 발명의 특징은 또한 번역 성분인 O-tRNA, O-RS 및 그 일부분을 코딩하는 폴리뉴클레오티드이다.
본 발명은 또한 척추동물 세포에서 사용하기 위한, 비천연 아미노산을 이용하는 목적하는 번역 성분, 예를 들어, O-RS, 및 오르소고날 쌍(오르소고날 tRNA 및 오르소고날 아미노아실-tRNA 합성효소)을 제조하는 방법(및 그와 같은 방법에 의해 제조된 번역 성분)을 제공한다. 예를 들어, 이 콜라이로부터의 타이로실-tRNA 합성효소/tRNACUA 쌍이 본 발명의 0-tRNA/O-RS 쌍이다. 또한, 본 발명은 하나의 척추동물 세포에서 번역 성분을 선택 및/또는 스크리닝하고, 일단 선택 및/또는 스크리닝되면 그 성분을 다른 척추동물 세포(선택 및/또는 스크리닝에 사용되지 않은 척추동물 세포)에서 사용하는 방법을 특징으로 한다. 예를 들어, 척추동물 세포를 위한 번역 성분을 제조하기 위한 선택 및/또는 스크리닝 방법은 효모, 예를 들어, 사카로마이세스 세레비시아(Saccharomyces cerevisiae)에서 수행될 수 있으며, 그 다음 선택된 성분을 다른 척추동물 세포, 예를 들어, 다른 효모 세포, 포유류 세포, 곤충 세포, 식물 세포, 진균 세포 등에서 사용할 수 있다.
본 발명은 또한 척추동물 세포에서 비천연 아미노산을 포함하는 단백질을 제조하는 방법을 제공한다. 단백질은 본 발명의 번역 성분을 사용하여 제조된다. 본 발명은 비천연 아미노산을 포함하는 단백질(및 본 발명의 방법으로 제조된 단백질)을 제공한다. 관심있는 단백질 또는 폴리펩티드는 또한 원핵 세포에서는 일어나지 않는 번역후 변형, 예컨대, [3+2] 고리화 첨가 반응 또는 친핵성-친전자성 반응을 통해 가해지는 변형을 포함할 수 있다. 일부 실시태양에 있어서는, 비천연 아미노산을 포함하는 전사 조절인자 단백질을 제조하는 방법(및 그러한 방법에 의해 제조된 단백질)이 또한 본 발명에 포함된다. 비천연 아미노산을 포함하는 단백질을 포함하는 조성물도 또한 본 발명의 특징을 이룬다.
비천연 아미노산을 갖는 단백질 또는 폴리펩티드를 제조하기 위한 키트도 또한 본 발명의 특징이다.
오르소고날
아미노아실
-
tRNA
합성효소(
O-
RS
)
척추동물 세포에서 관심있는 단백질 또는 폴리펩티드에 비천연 아미노산을 특이적으로 포함시키기 위해, 20종의 일반 아미노산이 아닌 단지 목적하는 비천연 아미노산만이 tRNA에 충전되도록 합성효소의 기질 특이성을 변화시킨다. 오르소고날 합성효소가 아미노산을 구별하지 않는 경우, 표적 부위에 천연 및 비천연 아미노산의 혼합물을 포함하는 돌연변이 단백질이 생긴다. 본 발명은 기질 특이성을 특정 비천연 아미노산에 대하여 변화시킨 오르소고날 아미노아실-tRNA 합성효소를 제조하는 조성물 및 방법을 제공한다.
오르소고날 아미노아실-tRNA 합성효소(O-RS)를 포함하는 척추동물 세포 또한 본 발명의 특징이다. O-RS는 척추동물 세포에서 오르소고날 tRNA(O-tRNA)를 비천연 아미노산으로 우선적으로 아미노아실화한다. 일부 실시태양에 있어서, O-RS는 1개 이상, 예를 들어, 2개 이상, 3개 이상의 비천연 아미노산을 이용한다. 따라서, 본 발명의 O-RS는 O-tRNA를 상이한 비천연 아미노산으로 우선적으로 아미노아실화할 수 있는 능력을 가질 수 있다. 이러한 능력은 어떠한 비천연 아미노산 또는 비천연 아미노산의 조합이 세포에 의해 허용될 수 있는지를 선택하고(거나) 세포에 의해 삽입이 허용되는 비천연 아미노산의 상이한 양을 선택함으로써 추가 수준의 조절이 가능하다.
본 발명의 O-RS는 경우에 따라 천연 아미노산에 비하여 비천연 아미노산에 대해 하나 이상의 개선되거나 증진된 효소 특성을 갖는다. 이러한 특성은, 예를 들어, 천연 아미노산, 예를 들어, 20종의 공지된 일반 아미노산에 비하여, 비천연 아미노산에 대한 더 높은 Km, 더 낮은 Km, 더 높은 kcat, 더 낮은 kcat, 더 낮은 kcat/km, 더 높은 kcat/km 등을 포함한다.
경우에 따라, O-RS는 척추동물 세포에 O-RS 또는 그 일부분을 포함하는 폴리펩티드 및/또는 O-RS 또는 그 일부분을 코딩하는 폴리뉴클레오티드에 의하여 제공될 수 있다. 예를 들어, O-RS 또는 그 일부분은 서열 번호 3 내지 35 중 어느 하나에 개시된 폴리뉴클레오티드 서열 또는 이의 상보적 폴리뉴클레오티드 서열에 의해 코딩된다. 또 다른 실시태양에 있어서, O-RS는 서열 번호 36 내지 63 및/또는 86 중 어느 하나에 개시된 아미노산 서열 또는 이의 보존적 변이체를 포함한다. 예시적 O-RS 분자의 서열에 대해서는 표 5, 6 및 8, 및 실시예 6을 참조할 수 있다.
O-RS는 또한 천연 타이로실 아미노아실-tRNA 합성효소(TyrRS)의 아미노산 서열(예를 들어, 서열 번호 2에 개시된 서열)과, 예를 들어, 90% 이상, 95% 이상, 98% 이상, 99% 이상, 또는 심지어 99.5% 이상 동일하며, 그룹 A 내지 E의 2 이상의 아미노산을 포함하는 아미노산 서열을 포함한다. 그룹 A는 이 콜라이 TyrRS의 Tyr37에 상응하는 위치에 발린, 이소루신, 루신, 글리신, 세린, 알라닌 또는 트레오닌을 포함하고; 그룹 B는 이 콜라이 TyrRS의 Asn126에 상응하는 위치에 아스파르테이트를 포함하며; 그룹 C는 이 콜라이 TyrRS의 Asp182에 상응하는 위치에 트레오닌, 세린, 아르기닌, 아스파라긴 또는 글리신을 포함하고; 그룹 D는 이 콜라이 TyrRS의 Phe183에 상응하는 위치에 메티오닌, 알라닌, 발린 또는 타이로신을 포함하고; 그룹 E는 이 콜라이 TyrRS의 Leu186에 상응하는 위치에 세린, 메티오닌, 발린, 시스테인, 트레오닌 또는 알라닌을 포함한다. 또한, 본 명세서의 표 4, 표 6 및 표 8을 참조할 수 있다.
O-RS 이외에, 본 발명의 척추동물 세포는 추가의 성분, 예를 들어, 비천연 아미노산을 포함할 수 있다. 척추동물 세포는 또한 오르소고날 tRNA(O-tRNA)(예를 들어, 이 콜라이, 바실러스 스테아로써모필러스 등과 같은 비척추동물 유기체로부터 유래된 것)를 포함할 수 있으며, 여기서 O-tRNA는 셀렉터 코돈을 인식하여 O-RS에 의해 비천연 아미노산으로 우선적으로 아미노아실화된다. 관심있는 폴리펩티드를 코딩하는 폴리뉴클레오티드를 포함하는 핵산으로서, 폴리뉴클레오티드가 O-tRNA에 의해 인식되는 셀렉터 코돈을 포함하는 핵산 또는 이러한 하나 이상의 핵산의 조합이 또한 세포 내에 존재할 수 있다.
일 측면에 있어서, O-tRNA는 비천연 아미노산을 단백질 내로 통합시키는 것을, 서열 번호 65에 개시된 폴리뉴클레오티드 서열을 포함하거나 그로부터 프로세싱된 tRNA의 효율의 45% 이상, 50% 이상, 60% 이상, 75% 이상, 80% 이상, 90% 이상, 95% 또는 99% 이상의 효율로 매개한다. 또 다른 측면에 있어서, O-tRNA는 서열 번호 65를 포함하며, O-RS는 서열 번호 36 내지 63 및/또는 86 중 어느 하나에 개시된 폴리펩티드 서열 및/또는 이의 보존적 변이체를 포함한다. 예시적 O-RS 및 O-tRNA 분자의 서열에 대해서는 본 명세서의 표 5 및 실시예 6을 참조할 수 있다.
일례로서, 척추동물 세포는 오르소고날 아미노아실-tRNA 합성효소(O-RS), 오르소고날 tRNA(O-tRNA), 비천연 아미노산, 및 관심있는 폴리펩티드로서 0-tRNA에 의해 인식되는 셀렉터 코돈을 포함하는, 폴리펩티드를 코딩하는 폴리뉴클레오티드를 포함하는 핵산을 포함한다. O-RS는 척추동물 세포에서 오르소고날 tRNA(O-tRNA)를 비천연 아미노산으로 우선적으로 아미노아실화하고, 세포는 관심있는 폴리펩티드를 비천연 아미노산의 부재하에, 비천연 아미노산의 존재하에서의 수율보다, 예를 들어, 30% 미만, 20% 미만, 15% 미만, 10% 미만, 5% 미만, 2.5% 미만의 수율로 제조한다.
본 발명의 특징인 O-RS의 제조 방법은 경우에 따라 야생형 합성효소의 프레임워크로부터 돌연변이 합성효소의 풀을 생성하는 단계, 및 돌연변이된 RS를 20종의 일반 아미노산에 비하여 비천연 아미노산에 대한 특이성에 기초하여 선택하는 단계를 포함한다. 그러한 합성효소를 단리하기 위하여, 선택 방법은 (i) 민감한 것이고(초기 회차로부터의 목적하는 합성효소의 활성이 낮을 수 있고, 집단이 작기 때문에); (ii) "조정 가능"하고(다른 선택 회차에서 선택 엄격도를 달리하는 것이 바람직하기 때문에); (iii) 일반적인 것(그 방법이 다른 비천연 아미노산에도 사용될 수 있도록)이다.
척추동물 세포에서 오르소고날 tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하는 오르소고날 아미노아실-tRNA 합성효소(O-RS)를 제조하는 방법은 일반적으로는 양성 선택 후에 음성 선택을 하는 선택의 조합을 수행하는 것을 포함한다. 양성 선택에서, 양성 마커의 비필수 위치에 도입된 셀렉터 코돈을 억제하는 것이 척추동물 세포로 하여금 양성 선택 압력하에 살아남도록 한다. 비천연 아미노산의 존재하에, 생존 세포는 따라서 오르소고날 서프레서 tRNA를 비천연 아미노산으로 충전하는 활성 합성효소를 코딩한다. 음성 선택에서, 음성 마커의 비필수 위치에 도입된 셀렉터 코돈을 억제하는 것이 천연 아미노산 특이성을 갖는 합성효소를 제거한다. 양성 및 음성 선택의 생존 세포는 오르소고날 서프레서 tRNA를 비천연 아미노산만으로(또는 적어도 우선적으로) 아미노아실화(충전)하는 합성효소를 코딩한다.
예를 들어, 위와 같은 방법은 (a) 제1 종의 척추동물 세포 집단(척추동물 세포는 각각 i) 아미노아실-tRNA 합성효소(RS) 라이브러리의 구성원, ii) 오르소고날 tRNA(O-tRNA), iii) 양성 선택 마커를 코딩하는 폴리뉴클레오티드, 및 iv) 음성 선택 마커를 코딩하는 폴리뉴클레오티드를 포함함)을 비천연 아미노산 존재하에 양성 선택하는 단계(이때 양성 선택을 극복하는 세포는 비천연 아미노산 존재하에 오르소고날 tRNA(O-tRNA)를 아미노아실화하는 활성 RS를 포함함); 및 (b) 양성 선택을 극복한 세포를 비천연 아미노산 부재하에 음성 선택하여 O-tRNA를 천연 아미노산으로 아미노아실화하는 활성 RS를 제거함으로써, O-tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하는 O-RS를 제공하는 단계를 포함한다.
양성 선택 마커는 각종 분자 중 어느 것이나 무방하다. 일 실시태양에 있어서, 양성 선택 마커는 성장을 위한 영양 보충물을 제공하는 생성물이며, 선택은 영양 보충물이 결핍된 배지 상에서 수행된다. 양성 선택 마커를 코딩하는 폴리뉴클레오티드의 예는 세포의 아미노산 영양 요구성 보완에 기초한 리포터 유전자, his3 유전자(예를 들어, his3 유전자가 이미다졸 글리세롤 포스페이트 데하이드라타제를 코딩하는 경우, 3-아미노트리아졸(3-AT)을 제공함으로써 검출됨), ura3 유전자, leu2 유전자, lys2 유전자, lacZ 유전자, adh 유전자 등을 포함하나, 이에 한정되는 것은 아니다. 문헌(GM. Kishore, & D.M. Shah, (1988), Amino acid biosynthesis inhibitors as herbicides, Annual Review of Biochemistry 57:627-663)을 참조할 수 있다. 일 실시태양에 있어서, lacZ 제조는 오르소-니트로페닐-β-D-갈락토피라노사이드(ONPG) 가수분해에 의해 검출된다(예를 들어, LG. Serebriiskii, & E.A. Golemis, (2000), Uses of lacZ to study gene function: evaluation of beta-galactosidase assays employed in the yeast two-hybrid system, Analytical Biochemistry 285:1-15). 추가의 양성 선택 마커는, 예를 들어, 루시퍼라제, 녹색 형광 단백질(GFP), YFP, EGFP, RFP, 항생제 내성 유전자 생성물(예를 들어, 클로람페니콜 아세틸트랜스퍼라제(CAT)), 전사 조절인자 단백질(예를 들어, GAL4) 등을 포함한다. 경우에 따라, 양성 선택 마커를 코딩하는 폴리뉴클레오티드는 셀렉터 코돈을 포함한다.
양성 선택 마커를 코딩하는 폴리뉴클레오티드는 반응 요소에 작동 가능하게 연결될 수 있다. 반응 요소로부터의 전사를 조절하는 전사 조절인자 단백질을 코딩하며, 하나 이상의 셀렉터 코돈을 포함하는 또 다른 폴리뉴클레오티드가 또한 존재할 수 있다. 비천연 아미노산으로 아미노아실화된 O-tRNA에 의해 전사 조절인자 단백질 내에 비천연 아미노산을 도입하면 양성 선택 마커를 코딩하는 폴리뉴클레오티드(예를 들어, 리포터 유전자)의 전사가 일어난다. 경우에 따라, 셀렉터 코돈은 전사 조절인자 단백질의 DNA 결합 도메인을 코딩하는 폴리뉴클레오티드의 부분 내에 또는 실질적으로 그에 근접하게 위치된다.
음성 선택 마커를 코딩하는 폴리뉴클레오티드도 또한 그로부터 전사 조절인자 단백질에 의해 전사가 매개되는 반응 요소에 작동 가능하게 연결될 수 있다(예를 들어, AJ. DeMaggio. et al., (2000), The yeast split-hybrid system, Method Enzymol. 328:128-137; H.M. Shih, et al., (1996), A positive genetic selection for disrupting protein-protein interactions: identification of CREB mutations that prevent association with the coactivator CBP, Proc. Natl. Acad. Sci. U.S.A. 93:13896-13901; M. Vidal, et al., (1996), Genetic characterization of a mammalian protein-protein interaction domain by using a yeast reverse two-hybrid system, [comment], Proc. Natl. Acad. Sci. U.S.A. 93:10321-10326; and, M. Vidal, et al., (1996), Reverse two-hybrid and one-hybrid systems to detect dissociation of protein-protein and DNA-protein interactions. [comment], Proc. Natl. Acad. Sci. U.S.A. 93:10315-10320). 천연 아미노산으로 아미노아실화된 O-tRNA에 의해 전사 조절인자 단백질 내에 천연 아미노산을 도입하면 음성 선택 마커의 전사가 일어난다. 경우에 따라, 음성 선택 마커는 셀렉터 코돈을 포함한다. 일 실시태양에 있어서, 본 발명의 양성 선택 마커 및/또는 음성 선택 마커는 2 이상의 셀렉터 코돈을 포함할 수 있으며, 이들 둘 다 또는 각각은 2 이상의 상이한 셀렉터 코돈 또는 2 이상의 동일한 셀렉터 코돈을 포함할 수 있다.
전사 조절인자 단백질은 핵산 서열(예를 들어, 반응 요소)에 (직접적으로 또는 간접적으로) 결합하여, 반응 요소에 작동 가능하게 연결된 서열의 전사를 조절하는 분자이다. 전사 조절인자 단백질은 전사 활성화 인자 단백질(예를 들어, GAL4, 핵 호르몬 수용체, AP1, CREB5 LEF/tcf 패밀리 구성원, SMAD, VP16, SPl 등), 전사 억제제 단백질(예를 들어, 핵 호르몬 수용체, 그로우초(Groucho)/tle 패밀리, 인그레일드(Engrailed) 패밀리 등), 또는 환경에 따라 두 가지 활성을 모두 가질 수 있는 단백질(예를 들어, LEF/tcf, 호모박스 단백질 등)일 수 있다. 반응 요소는 일반적으로는 전사 조절인자 단백질에 의해 인식되는 핵산 서열 또는 전사 조절인자 단백질과 함께 협동하여 작용하는 또 다른 물질이다.
전사 조절인자 단백질의 또 다른 예는 전사 활성화 인자 단백질 GAL4이다(예를 들어, A. Laughon, et al., (1984), Identification of two proteins encoded by the Saccharomyces cerevisiae GAL4 gene, Molecular & Cellular Biology 4:268-275; A. Laughon, & R.F. Gesteland, (1984), Primary structure of the Saccharomyces cerevisiae GAL4 gene, Molecular & Cellular Biology 4:260-267; L. Keegan, et al., (1986), Separation of DNA binding from the transcription-activating function of a vertebrate regulatory protein, Science 231:699-704: and, M. Ptashne, (1988), How vertebrate transcriptional activators work, Nature 335:683-689). 이러한 881개 아미노산 단백질의 N-말단 147개 아미노산은 DNA 서열에 특이적으로 결합하는 DNA 결합 도메인(DBD)을 형성한다(M. Carey, et al., (1989), An amino-terminal fragment ofGAL4 binds DNA as a dimer, J. Mol. Biol. 209:423-432; and, E. Giniger, et al., (1985), Specific DNA binding of GAL4, a positive regulatory protein of yeast, Cell 40:767-774). DBD는 사이에 존재하는 단백질 서열에 의해 C-말단 113개 아미노산의 활성화 도메인(AD)에 연결되어 있으며, AD가 DNA에 결합될 때 전사를 활성화시킬 수 있다(J. Ma, & M. Ptashne, (1987), Deletion analysis of GAL4 defines two transcriptional activating segments, Cell 48:847-853: and, J. Ma, & M. Ptashne, (1987), The carboxy-terminal 30 amino acids of GAL4 are recognized by GAL80, Cell 50:137-142). 앰버 코돈을, 예컨대, GAL4의 N-말단 DBD 및 이의 C-말단 AD를 모두 함유하는 단일 폴리펩티드의 N-말단 DBD 쪽으로 배치시킴으로써 O-tRNA/O-RS 쌍에 의한 앰버 억제가 GAL4에 의한 전사 활성화에 연결될 수 있다. GAL4 활성화된 리포터 유전자는 이들 유전자로 양성 및 음성 선택을 하는 데 사용될 수 있다.
음성 선택을 하는 데 사용되는 배지는 음성 선택 마커에 의해 검출 가능한 물질로 전환되는 선택 또는 스크리닝제를 포함할 수 있다. 본 발명의 일 측면에 있어서, 검출 가능한 물질은 독성 물질이다. 음성 선택 마커를 코딩하는 폴리뉴클레오티드는, 예를 들어, ura3 유전자일 수 있다. 예를 들어, URA3 리포터를 GAL4 DNA 결합 부위를 포함하는 프로모터의 조절하에 둘 수 있다. 음성 선택 마커가, 예를 들어, 셀렉터 코돈을 갖는 GAL4를 코딩하는 폴리뉴클레오티드의 번역에 의해 제조되었을 때, GAL4는 URA3의 전사를 활성화시킨다. 음성 선택은 5-플루오로오로트산(5-FOA)을 포함하는 배지 상에서 수행되며, 5-플루오로오로트산은 ura3 유전자의 유전자 생성물에 의해 검출 가능한 물질(예를 들어, 세포를 죽이는 독성 물질)로 전환된다(J.D. Boeke, et al., (1984), A positive selection for mutants lacking orotidine-5'-phosphate decarboxylase activity in yeast: 5-fluoroorotic acid resistance, Molecular & General Genetics 197:345-346); M. Vidal, et al., (1996), Genetic characterization of a mammalian protein-protein interaction domain by using a yeast reverse two-hybrid system. [comment], Proc. Natl. Acad. Sci. U.S.A. 93:10321-10326; and, M. Vidal, et al., (1996), Reverse two-hybrid and one-hybrid systems to detect dissociation of protein-protein and DNA-protein interactions, [comment], Proc. Natl. Acad. Sci. U.S.A. 93:10315-10320).
양성 선택 마커와 마찬가지로, 음성 선택 마커 또한 각종 분자 중 어느 하나일 수 있다. 일 실시태양에 있어서, 양성 선택 마커 및/또는 음성 선택 마커는 적절한 반응물의 존재하에 형광을 내거나 발광 반응을 촉진하는 폴리펩티드이다. 예를 들어, 음성 선택 마커는 루시퍼라제, 녹색 형광 단백질(GFP), YFP, EGFP, RPP, 항생제 내성 유전자 생성물(예를 들어, 클로람페니콜 아세틸트랜스퍼라제(CAT)), lacZ 유전자 생성물, 전사 조절인자 단백질 등을 포함하나, 이에 한정되는 것은 아니다. 본 발명의 한 측면에 있어서, 양성 선택 마커 및/또는 음성 선택 마커는 형광 활성화 세포 분류(FACS) 또는 발광에 의해 검출된다. 다른 예에서, 양성 선택 마커 및/또는 음성 선택 마커는 친화도에 기초한 스크리닝 마커를 포함한다. 같은 폴리뉴클레오티드가 양성 선택 마커 및 음성 선택 마커를 둘 다 코딩할 수 있다.
추가 수준의 선택 및/또는 스크리닝 엄격도를 본 발명의 방법에 사용할 수 있다. 선택 또는 스크리닝 엄격도는 O-RS를 제조하는 방법의 하나 또는 두 단계 모두에서 다를 수 있다. 이는 예컨대, 양성 선택 마커 및/또는 음성 선택 마커를 코딩하는 폴리뉴클레오티드 중 반응 요소의 양을 변화시키는 것, 어느 한 단계 또는 두 단계 모두에 변화하는 양의 불활성 합성효소를 가하는 것, 사용되는 선택 및/또는 스크리닝제의 양을 변화시키는 것 등을 포함할 수 있다. 추가 회차의 양성 및/또는 음성 선택을 수행할 수 있다.
선택 또는 스크리닝 과정은 1회 이상의 양성 또는 음성 선택 또는 스크리닝을 포함할 수 있으며, 이는 예를 들어, 아미노산 투과성에 있어서의 변화, 번역 효율에 있어서의 변화, 번역 신뢰도에 있어서의 변화 등을 포함한다. 일반적으로, 하나 이상의 변화는 단백질을 제조하는 데 사용되는 오르소고날 tRNA-tRNA 합성효소 쌍의 성분을 포함하거나 이를 코딩하는 하나 이상의 폴리뉴클레오티드에 있어서의 변이에 기초한다.
모델 풍부화 연구를 과량의 불활성 합성효소로부터 활성 합성효소를 신속히 선택하는 데 사용할 수도 있다. 양성 및/또는 음성 모델 선택 연구가 수행될 수 있다. 예를 들어, 강력한 활성 아미노아실-tRNA 합성효소를 포함하는 척추동물 세포를 변화하는 배수의 과량의 불활성 아미노아실-tRNA 합성효소와 혼합한다. 비선택 배지에서 성장하고, 예를 들어, X-GAL 오버레이로 분석된 세포와, 선택 배지에서 성장하고 살아남을 수 있고(예를 들어, 히스티딘 및/또는 우라실 부재하에) 예를 들어, X-GAL 분석으로 평가한 세포 사이의 비율 비교를 수행한다. 음성 모델 선택에 있어서, 강력한 활성 아미노아실-tRNA 합성효소를 변화하는 배수의 과량의 불활성 아미노아실-tRNA 합성효소와 혼합하고, 선택을 음성 선택 물질, 예를 들어, 5-FOA로 수행한다.
일반적으로, RS의 라이브러리(예를 들어, 돌연변이 RS의 라이브러리)는 적어도 하나의 아미노아실-tRNA 합성효소(RS), 예를 들어, 비척추동물 유기체로부터 유래한 RS를 포함한다. 일 실시태양에 있어서, RS의 라이브러리는 불활성 RS로부터 유래하며, 예컨대, 불활성 RS는 활성 RS를, 예를 들어, 합성효소 내 활성 부위, 합성효소 편집 메카니즘 부위, 합성효소의 상이한 도메인의 조합에 의한 상이한 부위 등에서 돌연변이 유발시켜 제조된다. 예를 들어, RS의 활성 부위 내의 잔기를, 예를 들어, 알라닌 잔기로 돌연변이시킨다. 알라닌 돌연변이된 RS를 코딩하는 폴리뉴클레오티드는 알라닌 잔기를 모든 20종의 아미노산으로 돌연변이시키는 주형으로 사용된다. 돌연변이 RS 라이브러리를 선택 및/또는 스크리닝하여 O-RS를 제조한다. 또 다른 실시태양에 있어서, 불활성 RS는 하나 이상의 아미노산이 하나 이상의 상이한 아미노산으로 치환된 아미노산 결합 포켓을 포함한다. 일례에 있어서, 치환된 아미노산은 알라닌으로 치환된다. 경우에 따라, 알라닌 돌연변이된 RS를 코딩하는 폴리뉴클레오티드는 알라닌 잔기를 모든 20종의 아미노산으로 돌연변이시키는 주형으로 사용되고, 선택 및/또는 스크리닝된다.
O-RS를 제조하는 방법은 당업계에 알려진 각종 돌연변이 유발 기술을 사용하여 RS 라이브러리를 생성하는 단계를 추가로 포함한다. 예를 들어, 돌연변이 RS는 부위 특이적 돌연변이 유발, 무작위 점 돌연변이 유발, 상동 재조합, DNA 셔플링 또는 다른 반복적 돌연변이 유발법, 키메라 제작 또는 이들의 임의의 조합에 의해 생성될 수 있다. 예를 들어, 돌연변이 RS의 라이브러리는 2 이상의 다른, 예컨대, 보다 작고 덜 다양한 "서브-라이브러리"로부터 제조될 수 있다. 일단 합성효소에 양성 및 음성 선택/스크리닝 전략을 수행한 후에, 이들 합성효소를 추가로 돌연변이시킬 수 있다. 예를 들어, O-RS를 코딩하는 핵산을 단리하고; 이로부터(예를 들어, 무작위 돌연변이 유발, 부위 특이적 돌연변이 유발, 재조합 또는 이들의 조합에 의해) 돌연변이된 O-RS를 코딩하는 한 세트의 폴리뉴클레오티드를 제조할 수 있으며; 이들 개개의 단계 또는 단계들의 조합을 O-tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하는 돌연변이된 O-RS가 얻어질 때까지 반복할 수 있다. 본 발명의 일 측면에 있어서, 상기 단계들을 2회 이상 수행한다.
O-RS 제조에 관한 추가의 상세한 사항은 WO 2002/086075(발명의 명칭: "Methods and compositions for the production of orthogonal tRNA-aminoacyl tRNA synthetase pairs") 및 문헌(Hamano-Takaku et ah, (2000) A mutant Escherichia coli Tyrosyl-tRNA Synthetase Utilizes the Unnatural Amino Acid Azatyrosine More Efficiently than Tyrosine, Journal of Biological Chemistry. 275(51):40324-40328; Kiga et al., (2002), An engineered Escherichia coli tyrosyl-tRNA synthetase for site-specific incorporation of an unnatural amino acid into proteins in vertebrate translation and its application in a wheat germ cell-free system, PNAS 99(15): 9715-9723; and, Francklyn et al., (2002), Aminoacyl-tRNA synthetases: Versatile players in the changing theater of translation: RNA 8:1363-1372)을 참조할 수 있다.
오르소고날 tRNA
본 발명에 따르면 오르소고날 tRNA(O-tRNA)를 포함하는 진핵 세포가 제공된다. 오르소고날 tRNA는 생체내에서 O-tRNA에 의해 인식되는 셀렉터 코돈을 포함하는 폴리뉴클레오티드에 의해 코딩되는 단백질 내로 비천연 아미노산을 도입하는 것을 매개한다. 일부 실시태양에 있어서, 본 발명의 O-tRNA는 비천연 아미노산을 단백질 내로, 서열 번호 65에 개시된 폴리뉴클레오티드를 포함하거나 세포내에서 그로부터 프로세싱된 tRNA의 효율의, 예를 들어, 적어도 40%, 적어도 45%, 적어도 50%, 적어도 60%, 적어도 75%, 적어도 80%, 또는 심지어는 90% 이상의 효율로 통합시킨다(본 명세서의 표 5 참조).
본 발명의 O-tRNA의 예는 서열 번호 65이다(실시예 6 및 표 5 참조). 서열 번호 65는 프리 스플라이싱/프로세싱 전사체로서, 경우에 따라 세포 내에서 예컨대, 표준 내인성 세포내 스플라이싱 및 프로세싱 기구를 사용하여 프로세싱되며, 변형되어 활성 O-tRNA를 형성한다. 일반적으로, 그러한 프리 스플라이싱 전사체의 집단이 세포 내에서 활성 tRNA의 집단을 형성한다. 본 발명은 또한 O-tRNA의 보존적 변이체 및 이의 프로세싱된 세포 생성물을 포함한다. 예를 들어, O-tRNA의 보존적 변이체는 서열 번호 65의 O-tRNA와 같이 기능하고, 프로세싱된 형태에서 tRNA L형 구조를 유지하지만, 서열은 동일하지 않은(또한 야생형 tRNA 분자가 아닌) 분자를 포함한다. 일반적으로, 본 발명의 O-tRNA는 재생 가능한 O-tRNA로서, O-tRNA는 생체내에서 다시 아미노아실화되어 셀렉터 코돈에 반응하여 폴리뉴클레오티드에 의해 코딩되는 단백질 내로 비천연 아미노산의 도입을 매개한다.
원핵 세포가 아닌 진핵 세포에서의 tRNA의 전사는 RNA 폴리머라제 III에 의해 이루어지며, 이 효소는 척추동물 세포에서 전사될 수 있는 tRNA 구조 유전자의 일차 서열에 제한을 둔다. 또한, 척추동물 세포에서 tRNA는 이들이 전사된 곳인 핵으로부터 세포질로 나와서 번역시에 기능하게 된다. 본 발명의 O-tRNA를 코딩하는 핵산 및 이들의 상보적 폴리뉴클레오티드가 또한 본 발명의 특징이다. 본 발명의 일 측면에 있어서, 본 발명의 O-tRNA를 코딩하는 핵산은 내부 프로모터 서열, 예컨대, A 박스(예를 들어, TRGCNNAGY) 및 B 박스(예를 들어, GGTTCGANTCC, 서열 번호 87)를 포함한다. A 박스 및 B 박스 서열의 추가적인 예는 문헌 [Geiduschek, (1988), Transcription by RNA Polymerase III, Ann. Rev. Biochem. 57:873-917]에서 확인할 수 있다. 본 발명의 O-tRNA는 또한 전사후 변형될 수 있다. 예를 들어, 진핵 세포에서 tRNA 유전자의 전사후 변형은 각각 Rnase P 및 3'-엔도뉴클레아제에 의한 5'- 및 3'-측면 서열의 제거를 포함한다. 3'-CCA 서열의 부가 또한 진핵 세포에서 tRNA 유전자의 전사후 변형의 하나이다.
일 실시태양에 있어서, O-tRNA는 tRNA 라이브러리의 구성원을 포함하는 제1 종의 척추동물 세포의 집단을 음성 선택하여 얻어진다. 음성 선택은 척추동물 세포에 내인성인 아미노아실-tRNA 합성효소(RS)에 의해 아미노아실화되는 tRNA 라이브러리의 구성원을 포함하는 세포를 제거한다. 이 과정은 제1 종의 척추동물 세포에 오르소고날한 tRNA의 풀을 제공한다.
대안으로, 또는 폴리펩티드 내로 비천연 아미노산을 도입하는 상기 기재된 다른 방법과 함께, 트랜스-번역계를 사용할 수 있다. 이러한 계는 에스케리치아 콜라이에 존재하는, tmRNA라 불리는 분자를 포함한다. 이 RNA 분자는 구조적으로 알라닐 tRNA와 관련이 있으며, 알라닐 합성효소에 의해 아미노아실화된다. tmRNA와 tRNA의 차이는 안티코돈 루프가 특이한 큰 서열로 대체되어 있다는 것이다. 이 서열은 리보좀이 tmRNA 내에 코딩된 오픈 리딩 프레임을 주형으로 사용하여 머뭇거리고 있는 서열 상에서 번역을 재개할 수 있도록 한다. 본 발명에서, 오르소고날 합성효소에 의해 우선적으로 아미노아실화되고, 비천연 아미노산으로 충전되는 오르소고날 tmRNA가 제조될 수 있다. 그러한 계에 의하여 유전자를 전사함으로써, 리보좀이 특정 위치에서 지연되면, 비천연 아미노산이 그 위치에 도입되고, 오르소고날 tmRNA 내에 코딩된 서열을 사용하여 번역이 재개된다.
재조합 오르소고날 tRNA를 제조하는 또 다른 방법은, 예를 들어, 국제 특허 출원 WO 2002/086075(발명의 명칭: "Methods and compositions for the production of orthogonal tRNA-aminoacyl tRNA synthetase pairs")에서 찾아볼 수 있으며, 또한 문헌(Forster et al., (2003) Programming peptidomimetic synthetases by translating genetic codes designed de novo PNAS 100(11):6353-6357; and, Feng et al., (2003), Expanding tRNA recognition of a tRNA synthetase by a single amino acid change, PNAS 100(10): 5676-5681)을 참조할 수 있다.
오르소고날 tRNA 및 오르소고날 아미노아실-tRNA
합성효소 쌍
오르소고날 쌍은, 예를 들어, 서프레서 tRNA, 프레임쉬프트 tRNA 등의 O-tRNA와 O-RS로 이루어진다. O-tRNA는 내인성 합성효소에 의해서 아실화되지 않으며, 생체내에서 O-tRNA에 의해 인식되는 셀렉터 코돈을 포함하는 폴리뉴클레오티드에 의해 코딩되는 단백질 내로 비천연 아미노산을 도입하는 것을 매개할 수 있다. O-RS는 O-tRNA를 인식하며, 척추동물 세포에서 O-tRNA를 비천연 아미노산으로 우선적으로 아미노아실화한다. 오르소고날 쌍을 제조하는 방법, 그러한 방법에 의해 제조된 오르소고날 쌍, 및 척추동물 세포에 사용하기 위한 오르소고날 쌍의 조성물이 본 발명에 포함된다. 다수의 오르소고날 tRNA/합성효소 쌍의 개발은 척추동물 세포에서 상이한 코돈을 사용하여 다수의 비천연 아미노산을 동시에 도입하는 것을 가능하게 할 수 있다.
척추동물 세포에서 오르소고날 O-tRNA/O-RS 쌍은 비효율적인 종 교차 아미노아실화를 갖는 다른 유기체로부터 쌍, 예를 들어, 넌센스 서프레서 쌍을 이입함으로써 제조될 수 있다. O-tRNA 및 O-RS는 척추동물 세포에서 효율적으로 발현 및 프로세싱되고, O-tRNA는 핵으로부터 세포질로 효율적으로 이출된다. 예를 들어, 그와 같은 쌍 중 하나는 이 콜라이로부터의 타이로실-tRNA 합성효소/tRNACUA 쌍이다(예를 들어, H. M. Goodman, et al., (1968), Nature 217:1019-24; and, D. G. Barker, et al., (1982), FEBS Letters 150:419-23). 이 콜라이 타이로실-tRNA 합성효소는 그것과 이의 동족 이 콜라이 tRNACUA가 둘 다 에스 세레비시아의 세포질에 발현되었을 때, 동족 이 콜라이 tRNACUA를 효율적으로 아미노아실화하지만, 에스 세레비시아 tRNA는 아미노아실화하지 않는다(예를 들어, H. Edwards, & P. Schimmel, (1990), Molecular & Cellular Biology 10:1633-41; and, H. Edwards, et al., (1991), PNAS United States of America 88:1153-6). 또한, 이 콜라이 타이로실 tRNACUA는 에스 세레비시아 아미노아실-tRNA 합성효소에 대해서는 불량한 기질이지만(예를 들어, V. Trezeguet, et al., (1991), Molecular & Cellular Biology 11 :2744-51), 에스 세레비시아 중 단백질 번역시에는 효율적으로 기능한다. 이에 대해서는, 예를 들어, 문헌들(H. Edwards, & P. Schimmel, (1990) Molecular & Cellular Biology 10:1633-41 ; H. Edwards, et al., (1991). PNAS United States of America 88:1153-6; and, V. Trezeguet, et al., (1991), Molecular & Cellular Biology 11:2744-51)을 참조할 수 있다. 또한, 이 콜라이 TyrRS는 tRNA에 결합된 비천연 아미노산을 교정하는 편집 기구를 가지고 있지 않다.
O-tRNA 및 O-RS는 천연 발생이거나, 각종 생물로부터의 천연 tRNA 및/또는 RS의 돌연변이 유발에 의해 유도될 수 있으며, 이는 tRNA 라이브러리 및/또는 RS 라이브러리를 제조한다. 본 명세서의 "공급원 및 숙주"란을 참조할 수 있다. 각종 실시태양에 있어서, O-tRNA 및 O-RS는 하나 이상의 생물로부터 유래된다. 다른 실시태양에 있어서, O-tRNA는 제1 종으로부터의 천연 또는 돌연변이된 천연 tRNA로부터 유래하며, O-RS는 제2 종으로부터의 천연 또는 돌연변이된 천연 RS로부터 유래한다. 일 실시태양에 있어서, 제1 및 제2의 비척추동물 유기체는 동일하다. 이와는 달리, 제1 및 제2의 비척추동물 유기체는 상이할 수 있다.
O-RS 및 O-tRNA를 제조하는 방법에 관해서는 본 명세서의 "오르소고날 아미노아실-tRNA 합성효소" 및 "O-tRNA"란을 참조할 수 있다. 또한, 국제 특허 출원 WO 2002/086075(발명의 명칭: "Methods and compositions for the production of orthogonal tRNA-aminoacyltRNA synthetase pairs")을 참조할 수 있다.
신뢰도, 효율 및 수율
신뢰도란 비천연 아미노산 또는 아미노산과 같은 목적하는 분자가 성장하는 폴리펩티드 사슬 내로 목적하는 위치에서 삽입되는 정확도를 의미한다. 본 발명의 번역 성분은 셀렉터 코돈에 반응하여 비천연 아미노산을 단백질 내로 높은 신뢰도로 도입한다. 예를 들어, 본 발명의 성분을 사용하여, 목적하는 비천연 아미노산을(예를 들어, 셀렉터 코돈에 반응하여) 성장하는 폴리펩티드 사슬 내 목적하는 위치로 도입하는 효율은, 특정 천연 아미노산이 성장하는 폴리펩티드 사슬 내 목적하는 위치로 원하지 않게 도입되는 것의, 예컨대, 75% 초과, 85% 초과, 95% 초과, 또는 심지어는 99%를 초과하는 효율이다.
효율은 또한 관련 대조에 비하여 O-RS가 O-tRNA를 비천연 아미노산으로 아미노아실화하는 정도를 의미한다. 본 발명의 O-RS는 이의 효율로 정의될 수 있다. 본 발명의 일부 실시태양에 있어서, O-RS는 다른 O-RS와 비교된다. 예를 들어, 본 발명의 O-RS는 O-tRNA를 비천연 아미노산으로, 예를 들어, 서열 번호 86 또는 45에 개시된 아미노산 서열을 갖는 O-RS 또는 표 5에 나타낸 다른 RS가 O-tRNA를 아미노아실화하는 것에 비하여, 예컨대, 적어도 40%, 적어도 50%, 적어도 60%, 적어도 75%, 적어도 80%, 적어도 90%, 적어도 95%, 또는 심지어 적어도 99% 이상의 효율로 아미노아실화한다. 또 다른 실시태양에 있어서, 본 발명의 O-RS는 O-tRNA를 비천연 아미노산으로, O-RS가 O-tRNA를 천연 아미노산으로 아미노아실화하는 것보다 10배 이상, 20배 이상, 30배 이상 효율적으로 아미노아실화한다.
본 발명의 번역 성분을 사용할 때, 비천연 아미노산을 포함하는 관심있는 폴리펩티드의 수율은, 세포로부터 폴리뉴클레오티드에 셀렉터 코돈이 결여된 관심있는 천연 폴리펩티드에 대해 얻어지는 수율의, 예컨대, 적어도 5%, 적어도 10%, 적어도 20%, 적어도 30%, 적어도 40%, 50% 또는 그 이상이다. 또 다른 실시태양에 있어서, 세포는 비천연 아미노산의 부재하에 관심있는 폴리펩티드를, 비천연 아미노산 존재하의 폴리펩티드 수율의, 예컨대, 30% 미만, 20% 미만, 15% 미만, 10% 미만, 5% 미만, 2.5% 미만의 수율로 제조한다.
공급원 및 숙주 생물
본 발명의 오르소고날 번역 성분은 일반적으로는 척추동물 세포 또는 번역계에 사용하기 위하여 비척추동물 유기체로부터 유래한다. 예를 들어, 오르소고날 O-tRNA는 비척추동물 유기체로서, 에스케리치아 콜라이, 써머스 써모필러스, 바실러스 스테아로써모필러스 등과 같은 진정세균, 또는 메타노코커스 쟈나쉬, 메타노박테리움 써모오토트로피컴, 할로박테리움 속으로서 할로페락스 볼카니 및 할로박테리움 종 NRC-1, 아키오글로버스 풀지더스, 파이로코커스 퓨리오수스, 파이로코커스 호리코쉬, 유로파이럼 페르닉스 등의 고세균으로부터 유래될 수 있는 한편, 오르소고날 O-RS는 비척추동물 유기체로서, 에스케리치아 콜라이, 써머스 써모필러스, 바실러스 스테아로써모필러스 등의 진정세균, 또는 메타노코커스 쟈나쉬, 메타노박테리움 써모오토트로피컴, 할로박테리움 속으로서 할로페락스 볼카니 및 할로박테리움 종 NRC-1, 아키오글로버스 풀지더스, 파이로코커스 퓨리오수스, 파이로코커스 호리코쉬, 유로파이럼 페르닉스 등의 고세균으로부터 유래할 수 있다. 또한, 성분들이 관심있는 세포 또는 번역계에 오르소고날한 경우 또는 성분들이 변형되어(예를 들어, 돌연변이되어) 세포 또는 번역계에 오르소고날하게 된 경우, 척추동물 공급원, 예컨대, 식물, 조류, 원생생물, 진균, 효모, 동물(예를 들어, 포유동물, 곤충, 절지동물 등) 등이 또한 사용될 수 있다.
O-tRNA/O-RS 쌍의 개별 성분은 동일한 생물 또는 상이한 생물로부터 유래될 수 있다. 일 실시태양에 있어서, O-tRNA/O-RS 쌍은 동일한 생물로부터 유래한다. 예를 들어, O-tRNA/O-RS 쌍은 이 콜라이로부터의 타이로실-tRNA 합성효소/tRNACUA 쌍으로부터 유래할 수 있다. 또한, O-tRNA/O-RS 쌍의 O-tRNA 및 O-RS는 경우에 따라 다른 생물로부터 유래될 수 있다.
오르소고날 O-tRNA, O-RS 또는 O-tRNA/O-RS 쌍을 척추동물 세포에서 선택 또는 스크리닝 및/또는 사용하여 비천연 아미노산을 포함하는 폴리펩티드를 제조할 수 있다. 척추동물 세포는 각종 공급원, 예컨대, 임의의 척추동물(예를 들어, 포유동물, 양서류, 조류, 파충류, 어류 등)로부터 유래된 것일 수 있다. 본 발명의 번역 성분을 갖는 척추동물 세포의 조성물 또한 본 발명의 특징이다.
본 발명은 또한 하나의 종에서 경우에 따라 그 종에 사용하기 위하여 및/또는 제2의 종에 사용하기 위하여(경우에 따라 추가의 선택/스크리닝 없이) 효율적으로 스크리닝하는 방법을 제공한다. 예를 들어, O-tRNA/O-RS의 성분들을 하나의 종, 예컨대, 쉽게 조작할 수 있는 종(효모 세포와 같은)에서 선택 또는 스크리닝한 다음, 제2의 종에서 비천연 아미노산을 생체내 통합시키는 데 사용하기 위하여 제2의 척추동물 종, 예컨대, 식물(예를 들어, 단자엽 또는 쌍자엽 식물과 같은 고등식물), 조류, 원생생물, 진균, 효모, 동물(예를 들어, 포유동물, 곤충, 절지동물 등) 등에 도입한다.
예를 들어, 사카로마이세스 세레비시아를 척추동물 제1 종으로 선택할 수 있으며, 이는 이 종이 단세포이고, 세대 기간이 짧고, 유전자가 비교적 잘 규명되어 있기 때문이다(예를 들어, Burke, et al., (2000) Methods in Yeast Genetics Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY). 또한, 진핵 세포의 번역 기구는 고도로 보존되어 있기 때문에(예를 들어, (1996) Translational Control. Cold Spring Harbor Laboratory, Cold Spring Harbor, NY; Y. Kwok, & J.T. Wong, (1980), Evolutionary relationship between Halobacterium cutirubrum and eukaryotes determined by use of aminoacyl-tRNA synthetases as phylogenetic probes, Canadian Journal of Biochemistry 58:213-218; and, (2001) The Ribosome. Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY), 에스 세레비시아에서 발견된 비천연 아미노산의 도입을 위한 aaRS 유전자를 고등 척추동물로 도입하여 동족 tRNA와 협동하여 비천연 아미노산을 도입하는 데 사용될 수 있게 할 수 있다(예를 들어, K. Sakamoto, et al., (2002) Site-specific incorporation of an unnatural amino acid into proteins in mammalian cells, Nucleic Acids Res. 30:4692-4699; and, C. Kohrer, et al., (2001), Import of amber and ochre suppressor tRNA's into mammalian cells: a general approach to site-specific insertion of amino acid analogues into proteins, Proc. Natl. Acad. Sci. U.S.A. 98:14310-14315).
일례로서, 본 명세서에 기재된 바와 같이 제1 종에서 O-tRNA/O-RS를 제조하는 방법은 O-tRNA를 코딩하는 핵산과 O-RS를 코딩하는 핵산을 제2의 종(예를 들어, 포유동물, 곤충, 진균, 조류, 식물 등)의 척추동물 세포 내로 도입하는 것을 추가로 포함한다. 또 다른 예로서, 척추동물 세포에서 오르소고날 tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하는 오르소고날 아미노아실-tRNA 합성효소(O-RS)를 제조하는 방법은 (a) 제1 종(예를 들어, 효모 등)의 척추동물 세포의 집단을 비천연 아미노산의 존재하에 양성 선택하는 것을 포함한다. 척추동물 세포 각각은 i) 아미노아실-tRNA 합성효소(RS) 라이브러리의 구성원, ii) 오르소고날 tRNA(O-tRNA), iii) 양성 선택 마커를 코딩하는 폴리뉴클레오티드, 및 iv) 음성 선택 마커를 코딩하는 폴리뉴클레오티드를 포함한다. 양성 선택에서 살아남는 세포는 비천연 아미노산의 존재하에 오르소고날 tRNA(O-tRNA)를 아미노아실화하는 활성 RS를 포함한다. 양성 선택에서 살아남은 세포를 비천연 아미노산의 부재하에 음성 선택하여 O-tRNA를 천연 아미노산으로 아미노아실화하는 활성 RS를 제거한다. 이러한 과정은 O-tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하는 O-RS를 제공한다. O-tRNA를 코딩하는 핵산 및 O-RS를 코딩하는 핵산(또는 성분 O-tRNA 및/또는 O-RS)을 제2의 종, 예를 들어, 포유류, 곤충, 진균, 조류, 식물 등의 척추동물 세포 내로 도입한다. 일반적으로, O-tRNA는 tRNA 라이브러리의 구성원을 포함하는 제1 종의 척추동물 세포의 집단을 음성 선택하여 얻어진다. 음성 선택은 척추동물 세포에 내인성인 아미노아실-tRNA 합성효소(RS)에 의해 아미노아실화되는 tRNA 라이브러리의 구성원을 포함하는 세포를 제거하여, 제1 종 및 제2 종의 척추동물 세포에 오르소고날한 tRNA의 풀을 제공한다.
셀렉터 코돈
본 발명의 셀렉터 코돈은 단백질 생합성 기구의 유전자 코돈 프레임워크를 확장시킨다. 예를 들어, 셀렉터 코돈은 독특한 3염기 코돈, 앰버 코돈(UAG), 오팔 코돈(UGA)과 같은 종결 코돈 등의 넌센스 코돈, 비천연 코돈, 4염기 이상의 코돈, 희귀 코돈 등을 포함한다. 다수의, 예를 들어, 1개 이상, 2개 이상, 3개 이상의 셀렉터 코돈이 목적하는 유전자 내로 도입될 수 있다. 하나의 유전자는 주어진 셀렉터 코돈의 다수 개의 카피를 포함할 수 있거나, 다수의 상이한 셀렉터 코돈 또는 이들의 조합을 포함할 수 있다.
일 실시태양에 있어서, 척추동물 세포 내에서 비천연 아미노산을 생체내 통합하기 위한 방법은 종결 코돈인 셀렉터 코돈을 사용하는 것을 포함한다. 예를 들어, 종결 코돈, 예컨대, UAG를 인식하는 O-tRNA가 제조되어 O-RS에 의해 목적하는 비천연 아미노산으로 아미노아실화된다. 이와 같은 O-tRNA는 천연 숙주의 아미노아실-tRNA 합성효소에 의해서는 인식되지 않는다. 관심있는 폴리펩티드의 관심있는 위치에 종결 코돈, 예컨대, TAG를 도입하기 위하여 통상의 부위 특이적 돌연변이 유발법을 사용할 수 있다(예를 들어, Sayers, J.R., et al., (1988), 5',3'Exonuclease in phosphorothioate-based oligonucleotide-directed mutagenesis. Nucleic Acids Res, 791-802). O-RS, O-tRNA 및 관심있는 폴리펩티드를 코딩하는 핵산이 생체내에 조합되어 존재할 때, UAG 코돈에 응답하여 비천연 아미노산이 통합됨으로써 특정 위치에 비천연 아미노산을 포함하는 폴리펩티드가 제조된다.
생체내 비천연 아미노산의 도입은 척추동물 숙주세포를 상당히 교란시키지 않으면서 이루어질 수 있다. 예를 들어, UAG 코돈에 대한 억제 효율이 O-tRNA, 예컨대, 앰버 서프레서 tRNA와 척추동물 방출 인자(예를 들어, eRF가 있으며, 종결 코돈에 결합하여 성장하는 펩티드의 리보좀으로부터의 방출을 개시함) 사이의 경쟁에 따라 달라지므로, O-tRNA, 예를 들어, 서프레서 tRNA의 발현 수준을 증가시키는 등의 방법으로 억제 효율을 조절할 수 있다.
셀렉터 코돈은 또한 연장된 코돈, 예를 들어, 4염기, 5염기, 6염기 또는 그 이상의 염기의 코돈 등, 4염기 이상의 코돈을 포함한다. 4염기 코돈의 예는 AGGA, CUAG, UAGA, CCCU 등을 포함한다. 5염기 코돈의 예는 AGGAC, CCCCU, CCCUC, CUAGA. CUACU5 UAGGC 등을 포함한다. 본 발명의 특징은 프레임쉬프트 억제에 기초하여 연장된 코돈을 사용하는 것을 포함한다. 4염기 이상의 코돈은 같은 단백질 내에 하나 또는 다수의 비천연 아미노산을 삽입할 수 있다. 일례로서, 돌연변이된 O-tRNA, 예를 들어, 8 내지 10개 뉴클레오티드 이상의 안티코돈 루프를 갖는 특별한 프레임쉬프트 서프레서 tRNA의 존재하에, 4염기 이상의 코돈은 하나의 아미노산으로 판독된다. 다른 실시태양에 있어서, 안티코돈 루프는, 예를 들어, 4염기 이상의 코돈, 5염기 이상의 코돈 또는 6염기의 이상 코돈을 판독할 수 있다. 가능한 256개의 4염기 코돈이 존재할 수 있으므로, 같은 세포 내에서 4염기 이상의 코돈을 사용하여 다수의 비천연 아미노산을 코딩할 수 있다(Anderson et al., (2002) Exploring the Limits of Codon and Anticodon Size, Chemistry and Biology, 9:237-244; Magliery, (2001) Expanding the Genetic Code: Selection of Efficient Suppressors of Four-base Codons and Identification of "Shifty " Four-base Codons with a Library Approach in Escherichia coli, J. Moi. Biol. 307: 755-769).
예를 들어, 4염기 코돈은 시험관내 생합성법에서 단백질 내로 비천연 아미노산을 도입하는 데 사용되어 왔다(예를 들어, Ma et al., (1993) Biochemistry 32:7939; and Hohsaka et al., (1999) J. Am. Chem. Soc. 121:34). CGGG 및 AGGU를 사용하여 시험관내에서 두 가지 화학적으로 아실화된 프레임쉬프트 서프레서 tRNA로 스트렙타비딘에 각각 2-나프틸알라닌 및 리신의 NBD 유도체를 동시에 도입하였다(Hohsaka et al., (1999) J. Am. Chem. Soc. 121 :12194). 시험관내 연구에서 무어(Moore et al.) 등은 NCUA 안티코돈을 갖는 tRNALeu 유도체가 UAGN 코돈(N은 U, A, G 또는 C일 수 있음)을 억제하는 것을 조사하였으며, 4중 UAGA가 UCUA 안티코돈을 갖는 tRNALeu로 해독될 수 있고, 이때 효율은 13 내지 26%로서 0 또는 -1 프레임에서 해독은 거의 없다는 것을 발견하였다(Moore et al., (2000) J. Mol. Biol., 298:195). 일 실시태양에 있어서, 희귀 코돈 또는 넌센스 코돈에 기초한 연장된 코돈이 본 발명에 사용될 수 있으며, 이는 다른 원하지 않는 위치에서 미스센스 리드쓰루(readthrough) 및 프레임쉬프트 억제를 감소시킬 수 있을 것이다.
주어진 계에서, 내인성 계가 천연 염기 코돈을 사용하지 않거나 아주 드물게 사용하는 경우, 셀렉터 코돈은 그러한 천연 3염기 코돈 중 하나를 포함할 수 있다. 예를 들어, 이것은 천연 3염기 코돈을 인식하는 tRNA가 결여된 계 및/또는 3염기 코돈이 희귀 코돈인 계를 포함한다.
셀렉터 코돈은 경우에 따라 비천연 염기쌍을 포함한다. 이들 비천연 염기쌍은 또한 존재하는 유전자 알파벳을 확장시킨다. 하나의 추가의 염기쌍은 삼중 코돈의 수를 64에서 125로 증가시킨다. 세 번째 염기쌍의 특성은 안정하고 선택적인 염기쌍 형성, 폴리머라제에 의한 높은 신뢰도로 DNA 내로의 효율적인 효소적 도입, 및 초기 비천연 염기쌍 합성 후의 효율적인 계속된 프라이머 연장을 포함한다. 본 발명의 방법 및 조성물에 사용될 수 있는 비천연 염기쌍에 대한 설명이, 예를 들어, 문헌(Hirao, et al., (2002) An unnatural base pair for incorporating amino acid analogues into protein, Nature Biotechnology, 20:177-182)에 기재되어 있다. 다른 관련 간행물은 하기에 열거되어 있다.
생체내 사용을 위해서, 비천연 뉴클레오시드는 막 투과성이며, 포스포릴화되어 상응하는 트리포스페이트를 형성한다. 또한, 증가된 유전적 정보는 안정하고, 세포내 효소에 의해 파괴되지 않는다. 베너(Benner) 등의 이전의 연구는 캐논형 왓슨-크릭 쌍(canonical Watson-Crick pairs)의 것과는 다른 수소 결합 패턴을 이용하였으며, 가장 주목할 만한 예는 이소-C:이소-G 쌍이다(Switzer et al., (1989) J. Am. Chem. Soc. 111 :8322; and Piccirilli et al., (1990) Nature, 343:33; Kool, (2000) Curr. Opin. Chem. Biol.. 4:602). 이들 염기는 일반적으로 천연 염기와 어느 정도 잘못된 쌍을 형성하며, 효소적으로 복제될 수 없다. 쿨(Kool)과 이의 동료들은 염기들 사이의 소수성 팩킹 상호작용이 수소 결합을 대체하여 염기쌍 형성을 일으킬 수 있음을 입증하였다(Kool, (2000) Curr. Opin. Chem. Biol.. 4:602; and Guckian and Kool, (1998) Angew. Chem. Int. Ed. Engl.. 36, 2825). 상기한 모든 요건을 충족시키는 비천연 염기쌍 개발을 위한 노력으로서, 슐츠(Schultz), 로메스버그(Romesberg) 및 동료들은 일련의 비천연 소수성 염기들을 쳬계적으로 합성 및 연구하였다. PICS:PICS 자기 쌍(self-pair)은 천연 염기쌍보다 안정한 것으로 밝혀졌으며, 이 콜라이 DNA 폴리머라제 I의 클레나우(Klenow) 단편(KF)에 의해 DNA 내로 효율적으로 통합될 수 있다(예를 들어, McMinn et al., (1999) J. Am. Chem. Soc., 121:11586; and Ogawa et al., (2000) J. Am. Chem. Soc. 122:3274). 3MN:3MN 자기 쌍이 생물학적 기능을 하기에 충분한 효율 및 선택성으로 KF에 의해 합성될 수 있다(예를 들어, Ogawa et al., (2000) J. Am. Chem. Soc. 122:8803). 그러나, 두 염기들은 모두 더 이상의 복제에 대한 사슬 종결 인자로 작용할 수 있다. PICS 자기 쌍을 복제하는 데 사용될 수 있는 돌연변이 DNA 폴리머라제가 최근 개발되었다. 또한, 7AI 자기 쌍이 복제될 수 있다(예를 들어, Tae et al., (2001) J. Am. Chem. Soc. 123:7439). 신규 메탈로염기 쌍 Dipic:Py이 최근 개발되었는데, 이는 Cu(II)에 결합시 안정한 쌍을 형성한다(Meggers et al., (2000) J. Am. Chem. Soc. 122:10714). 연장된 코돈 및 비천연 코돈은 실질적으로 천연 코돈에 오르소고날하기 때문에, 본 발명의 방법은 이러한 특성을 이용하여 그들에 대한 오르소고날 tRNA를 제조할 수 있다.
번역 바이패싱(bypassing) 계를 또한 목적하는 폴리펩티드 내에 비천연 아미노산을 도입하는 데 사용할 수 있다. 번역 바이패싱 계에서, 큰 서열이 유전자 내로 삽입되지만, 단백질로 번역되지는 않는다. 그러한 서열은 리보좀이 그 서열을 건너뛰어 삽입물의 하류에서 번역을 다시 시작하도록 유도하는 단서로서 작용하는 구조를 포함한다.
비천연 아미노산
본 명세서에서, 비천연 아미노산이란 셀레노시스테인 및/또는 피롤리신 및 하기 유전적으로 코딩되는 20종의 알파-아미노산 이외의 임의의 아미노산, 변형 아미노산 또는 아미노산 유사체를 의미한다: 알라닌, 아르기닌, 아스파라긴, 아스파르트산, 시스테인, 글루타민, 글루탐산, 글리신, 히스티딘, 이소루신, 루신, 리신,메티오닌, 페닐알라닌, 프롤린, 세린, 트레오닌, 트립토판, 타이로신, 발린. 알파-아미노산의 일반적 구조가 화학식 I에 도시되어 있다:

비천연 아미노산은 일반적으로 화학식 I의 임의의 구성체로서, R 기는 20종의 천연 아미노산 내의 측쇄와 다른 임의의 치환기일 수 있다, 20종의 천연 아미노산 구조에 대해서는, 예를 들어, 문헌(Biochemistry by L. Stryer, 3rd ed. 1988, Freeman and Company, New York)을 참조할 수 있다. 본 발명의 비천연 아미노산이 상기 20종의 천연 알파-아미노산이 아닌 천연적으로 발생하는 화합물일 수 있음에 주목하여야 한다.
본 발명의 비천연 아미노산이 일반적으로는 측쇄에 있어서 천연 아미노산과 다르기 때문에, 비천연 아미노산은 천연 단백질에서 형성되는 것과 같은 방식으로 다른, 예컨대, 천연 또는 비천연 아미노산과 아미드 결합을 형성한다. 그러나, 비천연 아미노산은 천연 아미노산과는 확실히 구별되는 측쇄를 갖는다. 예를 들어, 화학식 I의 R은 경우에 따라 알킬-, 아릴-, 아실-, 케토-, 아지도-, 히드록실-, 히드라진, 시아노-, 할로-, 히드라지드, 알케닐, 알키닐, 에테르, 티올, 셀레노-, 설포닐-, 보레이트, 보로네이트, 포스포, 포스포노, 포스핀, 헤테로시클릭, 엔온, 이민, 알데히드, 에스테르, 티오산, 히드록실아민, 아민 등, 또는 이들의 조합을 포함한다. 관심있는 다른 비천연 아미노산은 광활성화 가능한 가교결합제를 포함하는 아미노산, 스핀 표지된 아미노산, 형광 아미노산, 금속 결합 아미노산, 금속 함유 아미노산, 방사성 아미노산, 신규 작용기를 갖는 아미노산, 다른 분자와 공유 또는 비공유 상호작용하는 아미노산, 광케이징된 아미노산 및/또는 광이성질체화 가능한 아미노산, 비오틴 또는 비오틴 유사체 함유 아미노산, 케토 함유 아미노산, 폴리에틸렌 글리콜 또는 폴리에테르를 포함하는 아미노산, 중원자 치환된 아미노산, 화학적 절단 또는 광절단 가능한 아미노산, 천연 아미노산에 비해 연장된 측쇄(예를 들어, 폴리에테르 또는 장쇄 탄화수소, 예를 들어, 탄소수가 약 5 또는 약 10을 넘는 것)를 갖는 아미노산, 탄소 결합된 당 함유 아미노산, 산화환원 활성 아미노산, 아미노 티오산 함유 아미노산, 및 하나 이상의 독소 잔기를 함유하는 아미노산을 포함하나, 이에 한정되는 것은 아니다. 일부 실시태양에 있어서, 비천연 아미노산은, 예를 들어, 단백질을 고상 지지체에 결합시키는 데 사용하기 위한 광활성화 가능한 가교결합제를 갖는다. 일 실시태양에 있어서, 비천연 아미노산은 아미노산 측쇄에 부착된 당류 잔기(예를 들어, 글리코실화 아미노산) 및/또는 다른 탄수화물 변형을 갖는다.
신규 측쇄를 함유하는 비천연 아미노산 이외에, 비천연 아미노산은 또한 경우에 따라 예를 들어, 화학식 II 및 III의 구조에 나타난 바와 같은 변형된 골격 구조를 포함한다:

상기 식에서, Z는 일반적으로 OH, NH2, SH, NH-R' 또는 S-R'를 포함하며; X 및 Y는 동일하거나 상이할 수 있으며, 일반적으로 S 또는 O를 포함하고, R 및 R'는 경우에 따라 동일하거나 상이할 수 있으며, 일반적으로 수소 또는 상기 화학식 I의 비천연 아미노산에 대해 기재된 바와 같은 R 기로부터 선택된다. 예를 들어, 본 발명의 비천연 아미노산은 경우에 따라 화학식 II 및 III에 나타낸 바와 같이 아미노 또는 카복실 기에 치환기를 갖는다. 이러한 유형의 비천연 아미노산은, 예를 들어, 통상의 20종의 천연 아미노산과 같은 측쇄 또는 비천연 측쇄를 갖는 α-히드록시 산, α-티오산, α-아미노티오카복실레이트를 포함하나, 이에 한정되는 것은 아니다. 또한, α-탄소에서의 치환은 경우에 따라 L, D, 또는 α,α-이치환 아미노산, 예컨대, D-글루타메이트, D-알라닌, D-메틸-O-타이로신, 아미노부티르산 등을 포함한다. 다른 구조적 대용 아미노산으로는 시클릭 아미노산, 예를 들어, 프롤린 유사체뿐만 아니라 3, 4, 6, 7, 8 및 9원 환 프롤린 유사체; β 및 γ 아미노산, 예를 들어, 치환된 β-알라닌 및 γ-아미노 부티르산이 있다. 예를 들어, 많은 비천연 아미노산이 타이로신, 글루타민, 페닐알라닌 등의 천연 아미노산에 기초한다. 타이로신 유사체는 파라 치환된 타이로신, 오르소 치환된 타이로신 및 메타 치환된 타이로신을 포함하며, 치환된 타이로신은 예를 들어, 케토기(예를 들어, 아세틸기), 벤조일기, 아미노기, 히드라진, 히드록시아민, 티올기, 카복시기, 이소프로필기, 메틸기, C6-C20 직쇄 또는 분지쇄 탄화수소, 포화 또는 불포화 탄화수소, O-메틸기, 폴리에테르기, 니트로기, 알키닐기 등을 포함한다. 또한, 다중 치환된 아릴 환도 또한 고려된다. 본 발명의 글루타민 유사체는 α-히드록시 유도체, γ-치환된 유도체, 사이클릭 유도체, 및 아미드 치환된 글루타민 유도체를 포함하나, 이에 한정되는 것은 아니다. 페닐알라닌 유사체의 예는 파라-치환된 페닐알라닌, 오르소 치환된 페닐알라닌 및 메타 치환된 페닐알라닌으로서, 치환기가, 예를 들어 히드록시기, 메톡시기, 메틸기, 알릴기, 알데히드, 아지도, 요오도, 브로모, 케토기(예를 들어, 아세틸기), 벤조일기, 알키닐기를 포함하나, 이에 한정되는 것은 아니다. 비천연 아미노산의 구체적인 예는 p-아세틸-L-페닐알라닌, p-프로파길옥시페닐알라닌, O-메틸-L-타이로신, L-3-(2-나프틸)알라닌, 3-메틸-페닐알라닌, O-4-알릴-L-타이로신, 4-프로필-L-타이로신, 트리-O-아세틸-GlcNAcβ-세린, L-Dopa, 플루오르화 페닐알라닌, 이소프로필-L-페닐알라닌, p-아지도-L-페닐알라닌, p-아실-L-페닐알라닌, p-벤조일-L-페닐알라닌, L-포스포세린, 포스포노세린, 포스포노타이로신, p-요오도-페닐알라닌, p-브로모페닐알라닌, p-아미노-L-페닐알라닌 및 이소프로필-L-페닐알라닌 등을 포함하나, 이에 한정되는 것은 아니다. 각종 비천연 아미노산의 구조가 예를 들어, WO 2002/085923(발명의 명칭: "In vivo incorporation of unnatural amino acids")의 도 16, 17, 18, 19, 26 및 29에 제공되어 있다. 또 다른 메티오닌 유사체에 대해서는, 문헌(Kiick et al., (2002) Incorporation of azides into recombinant proteins for chemoselective modification by the Staudinger ligation, PNAS 99:19-24)의 도 1의 구조 2 내지 5를 참조할 수 있다.
일 실시태양에 있어서, 비천연 아미노산(예를 들어, p-(프로파길옥시)-페닐알라닌)을 포함하는 조성물이 제공된다. p-(프로파길옥시)-페닐알라닌을 포함하는 각종 조성물 및 예를 들어, 단백질 및/또는 세포가 또한 제공된다. 일 측면에 있어서, p-(프로파길옥시)-페닐알라닌 비천연 아미노산을 포함하는 조성물은 추가로 오르소고날 tRNA를 포함한다. 비천연 아미노산은 오르소고날 tRNA에(예를 들어, 공유적으로) 결합될 수 있으며, 예컨대, 오르소고날 tRNA에 아미노-아실 결합을 통해 공유 결합되거나, 또는 오르소고날 tRNA의 말단 리보스 당의 3'OH 또는 2'OH에 공유 결합될 수 있다.
단백질 내로 통합될 수 있는 비천연 아미노산을 통한 화학적 잔기는 단백질에 각종 장점 및 조작을 가능하게 한다. 예를 들어, 케토 작용기의 독특한 반응성은 시험관내 및 생체내에서 단백질을 다수의 각종 히드라진- 및 히드록실아민 함유 반응제로 선택적으로 변형할 수 있게 한다. 중원자 비천연 아미노산은, 예를 들어, X-선 구조 데이터를 페이징하는 데 유용할 수 있다. 비천연 아미노산을 사용한 중원자의 부위 특이적 도입은 중원자 위치를 선택함에 있어서 선택성과 유연성을 제공한다. 광반응성 비천연 아미노산(예를 들어, 벤조페논 및 페닐아지드와 같은 아릴아지드 측쇄를 갖는 아미노산)은, 예를 들어, 시험관내 및 생체내 단백질을 광가교결합시키는 데 있어서 효율적이다. 광반응성 비천연 아미노산의 예는 p-아지도-페닐알라닌 및 p-벤조일-페닐알라닌을 포함하나, 이에 한정되는 것은 아니다. 광반응성 비천연 아미노산을 갖는 단백질은 광반응성 기 제공 일시적(및/또는 공간적) 콘트롤을 여기시켜 의도에 따라 가교결합될 수 있다. 일 실시태양에 있어서, 비천연 아미노산의 메틸기는, 예를 들어, 핵자기 공명 및 진동 분광분석을 이용하는 경우, 지엽적 구조 및 동력학의 프로브로서 동위원소로 표지된, 예컨대, 메틸기로 치환될 수 있다. 알키닐 또는 아지도 작용기는, 예를 들어, 단백질을 [3+2] 고리화 첨가 반응 반응을 통해 다른 분자로 선택적으로 변형시키는 것을 가능하게 한다.
비천연 아미노산의 화학적 합성
상기 제공된 많은 수의 비천연 아미노산이, 예를 들어, 시그마(Sigma, USA) 또는 알드리치(Aldrich; Milwaukee, WI, USA)로부터 시판되고 있다. 시판되고 있지 않은 것은 경우에 따라 본 명세서에 기재된 바에 따라, 각종 문헌에 기재된 방법에 따라 또는 당업계에 알려진 표준 방법으로 합성될 수 있다. 유기 합성 기술에 대해서는, 예를 들어, 문헌(Organic Chemistry by Fessendon and Fessendon, (1982, Second Edition, Willard Grant Press, Boston Mass.); Advanced Organic Chemistry by March(Third Edition, 1985, Wiley and Sons, New York); and Advanced Organic Chemistry by Carey and Sundberg(Third Edition, Parts A and B, 1990, Plenum Press, New York))을 참조할 수 있다. 비천연 아미노산의 합성을 기술하고 있는 다른 간행물은, 예를 들어, WO 2002/085923(발명의 명칭: "In vivo incorporation of Unnatural Amino Acids") 및 문헌(Matsoukas et al., (1995) J. Med. Chem.. 38, 4660-4669; King, F.E. & Kidd, D.A.A. (1949) A New Synthesis of Glutamine and of γ-Dipeptides of Glutamic Acid from Phthylated Intermediates. J. Chem. Soc. 3315-3319; Friedman, O.M. & Chatterrji, R. (1959) Synthesis of Derivatives of Glutamine as Model Substrates for Anti-Tumor Agents. J. Am. Chem. Soc. 81, 3750-3752; Craig, J.C. et al., (1988) Absolute Configuration of the Enantiomers of 7-Chloro-4 [[4-(diethylamino)-1-methylbutyl]amino]quinoline(Chloroquine). J. Org. Chem. 53, 1167-1170; Azoulay, M., Vilmont, M. & Frappier, F. (1991) Glutamine analogues as Potential Antimalarials,. Eur. J. Med. Chem. 26, 201-5; Koskinen, A.M.P. & Rapoport, H. (1989) Synthesis of 4-Substituted Prolines as Conformationally Constrained Amino Acid Analogues. J. Org. Chem. 54, 1859-1866; Christie, B.D. & Rapoport, H. (1985) Synthesis of Optically Pure Pipecolates from L-Asparagine. Application to the Total Synthesis of(+)-Apovincamine through Amino Acid Decarbonylation and lminium Ion Cyclization. J. Org. Chem. 1989:1859-1866; Barton et al., (1987) Synthesis of Novel α-Amino-Acids and Derivatives Using Radical Chemistry: Synthesis of L- and D-α-Amino-Adipic Acids, L-α-aminopimelic Acid and Appropriate Unsaturated Derivatives. Tetrahedron Lett. 43:4297-4308; and, Subasinghe et al., (1992) Quisqualic acid analogues: synthesis of beta-heterocyclic 2-aminopropanoic acid derivatives and their activity at a novel quisqualate-sensitized site, J. Med. Chem. 35:4602-7)을 포함한다.
비천연 아미노산의 세포 흡수
척추동물 세포에 의한 비천연 아미노산의 흡수는, 예컨대, 단백질 내로 도입하기 위해 비천연 아미노산을 설계하고 선택할 때 일반적으로 고려되는 한 가지 문제이다. 예를 들어, α-아미노산의 높은 전하 밀도는 이들 화합물이 세포 투과성이지 못할 것이라는 암시를 준다. 천연 아미노산은 척추동물 세포 내로 일련의 단백질 기초 운송계에 의해 흡수된다. 가능하다면 어떤 비천연 아미노산이 세포에 의해 흡수될 것인가를 평가하는 빠른 스크리닝을 수행할 수 있다. 독성 분석에 대해서는 출원(발명의 명칭: "Protein Arrays," 대리인 사건 번호 P1OOlUS00, 2002년 12월 22일 출원) 및 문헌(Liu, D.R. & Schultz, P.G. (1999) Progress toward the evolution of an organism with an expanded genetic code, PNAS United States 96:4780-4785)을 참조할 수 있다. 각종 분석법으로 흡수를 쉽게 분석할 수 있지만, 세포 흡수 경로에 이용될 수 있는 비천연 아미노산을 설계하는 것에 대한 다른 대안은 생체내 아미노산을 제조하는 생합성 경로를 제공하는 것이다.
비천연 아미노산의 생합성
세포 내에는 아미노산 및 다른 화합물을 제조하기 위한 많은 생합성 경로가 이미 존재한다. 특정 비천연 아미노산의 생합성 경로는 자연, 예를 들어, 척추동물 세포에는 존재하지 않을 수 있지만, 본 발명은 그러한 방법을 제공한다. 예를 들어, 비천연 아미노산의 생합성 경로는 경우에 따라 숙주 세포에 새로운 효소를 가하거나 존재하는 생합성 경로를 변화시켜 숙주 세포 내에 생성될 수 있다. 추가되는 새로운 효소는 경우에 따라 천연 효소이거나 인공적으로 개발된 효소이다. 예를 들어, p-아미노페닐알라닌의 생합성(예를 들어, WO 2002/085923, 발명의 명칭 "In vivo incorporation of unnatural amino acids"에 기재된 바와 같은)은 다른 생물로부터 공지된 효소의 조합을 가하는 것이다. 이들 효소에 대한 유전자는 척추동물 세포를 그러한 유전자를 포함하는 플라스미드로 형질전환시킴으로써 세포 내에 도입될 수 있다. 유전자는 세포 내에서 발현될 때 목적하는 화합물을 제조하는 효소적 경로를 제공한다. 임의로 가해지는 효소 유형의 예는 하기 실시예에 제공되어 있다. 추가되는 효소 서열은, 예를 들어, 진뱅크부터 얻을 수 있다. 인공적으로 개발된 효소 또한 경우에 따라 같은 방법으로 세포에 가해진다. 이와 같은 방식으로, 세포 내 기구 및 자원이 조작되어 아미노산을 제조하게 된다.
생합성 경로에 사용하거나 기존의 경로를 개발하는 데 사용하기 위한 신규 효소를 제조하는 데 각종 방법을 이용할 수 있다. 경우에 따라, 예를 들어, 맥시젠(Maxygen, Inc., www.maxygen.com)에 의해 개발된 바와 같은 반복적 재조합을 이용하여 신규 효소 및 경로를 개발할 수 있다(예를 들어, Stemmer(1994), Rapid evolution of a protein in vitro by DNA shuffling, Nature 370(4):389-391 ; and, Stemmer, (1994), DNA shuffling by random fragmentation and reassembly: In vitro recombination for molecular evolution, Proc . Natl . Acad . Sci . USA .. 91 : 10747-10751). 마찬가지로, 경우에 따라 제넨코(Genencor, www.genencor.com)에 의해 개발된 디자인패스(DesignPath™)를 사용하여 대사 경로 가공, 예를 들어, 세포에서 O-메틸-L-타이로신을 제조하는 경로를 가공할 수 있다. 이러한 기술은, 예컨대, 기능적 게놈 분석, 분자 개발 및 설계를 통해 확인되는 바와 같은, 새로운 유전자의 조합을 사용하여 숙주 생물내 기존의 경로를 사용하여 재구축할 수 있다. 다이버사 코포레이션(Diversa Corporation, www.diversa.com)은 또한 예를 들어, 새로운 경로를 생성하기 위해 유전자 및 유전자 경로의 라이브러리를 신속하게 스크리닝하는 기술을 제공한다.
일반적으로, 본 발명의 가공된 생합성 경로로 제조되는 비천연 아미노산은 단백질 생합성에 충분한 농도, 예를 들어, 천연 세포 내의 양이지만, 다른 아미노산의 농도에 영향을 미치거나 다른 세포 내 자원을 소진시키지 않는 정도로 제조된다. 이와 같은 방식으로 생체내 제조되는 전형적인 농도는 약 10 mM 내지 약 0.05 mM이다. 일단 세포가 특별한 경로에 바람직한 효소를 제조하는 데 사용되는 유전자를 포함하는 플라스미드로 형질전환되어 비천연 아미노산이 제조되면, 경우에 따라 리보좀 단백질 합성 및 세포 성장을 위한 비천연 아미노산의 제조를 더욱 최적화하기 위한 생체내 선택이 이용된다.
비천연 아미노산을 갖는 폴리펩티드
하나 이상의 비천연 아미노산을 갖는 단백질 또는 폴리펩티드는 본 발명의 특징이다. 본 발명은 또한 본 발명의 조성물 및 방법을 사용하여 제조된 적어도 하나의 비천연 아미노산을 갖는 단백질 또는 폴리펩티드를 포함한다. 부형제(예를 들어, 제약상 허용 가능한 부형제)가 또한 단백질과 함께 존재할 수 있다.
척추동물 세포 내에서 하나 이상의 비천연 아미노산을 갖는 관심있는 단백질 또는 폴리펩티드를 제조함으로써, 단백질이나 폴리펩티드는 일반적으로 척추동물 세포의 번역후 변형을 포함하게 될 것이다. 일부의 실시태양에 있어서, 단백질은 하나 이상의 비천연 아미노산과 척추동물 세포에서 생체내에서 만들어지는 적어도 하나의 번역후 변형을 포함하는데, 그와 같은 번역후 변형은 원핵 세포에서는 만들어지지 않는다. 예를 들어, 번역후 변형은 아세틸화, 아실화, 지질 변형, 팔미토일화, 팔미테이트 부가, 포스포릴화, 당-지질 결합 변형, 글리코실화 등을 포함한다. 일 측면에 있어서, 번역후 변형은 올리고당(예를 들어, (GlcNAc-Man)2-Man-GlcNAc-GlcNAc))를 아스파라긴에 GlcNAc-아스파라긴 결합을 통해 부착시키는 것을 포함한다. 표 7은 척추동물 단백질의 N-결합된 올리고당의 예를 보여주고 있는데(도시되지 않은 추가의 잔기가 있을 수 있음), 이를 참조할 수 있다. 또 다른 측면에 있어서, 번역후 변형은 올리고당(예를 들어, Gal-GalNAc, Gal-GlcNAc 등)를 세린 또는 트레오닌에 GalNAc-세린 또는 GalNAc-트레오닌 결합 또는 GlcNAc-세린 또는 GlcNAc-트레오닌 결합을 통해 부착시키는 것을 포함한다.
표 7: GlcNAc-결합을 통한 올리고당의 예
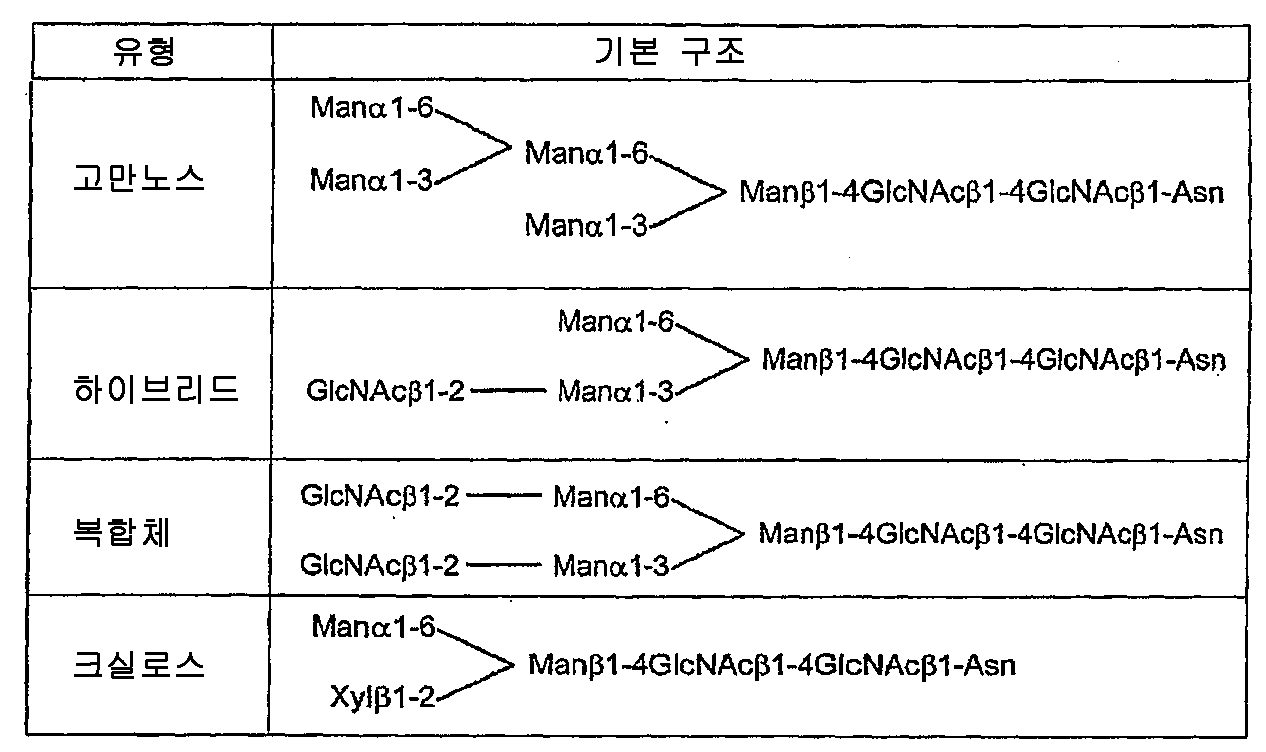
또 다른 측면에 있어서, 번역후 변형은 전구체(예를 들어, 칼시토닌 전구체, 칼시토닌 유전자 관련 펩티드 전구체, 프리프로부갑상선 호르몬, 프리프로인슐린, 프로인슐린, 프리프로-오피오멜라노코르틴, 프로-오피오멜라노코르틴 등)의 단백질 분해 프로세싱, 멀티서브유닛 단백질로의 어셈블리 또는 거대분자 어셈블리, 세포내 다른 위치로의 번역(예를 들어, 소포체, 골지체, 핵, 라이소좀, 퍼옥시좀, 미토콘드리아, 엽록체, 액포 등과 같은 소기관으로 또는 분비 경로를 통하여) 등을 포함한다. 일부 실시태양에 있어서, 단백질은 분비 또는 편재화 서열, 에피토프 태그, FLAG 태그, 폴리히스티딘 태그, GST 융합부 등을 포함한다.
비천연 아미노산의 하나의 장점은 다른 분자를 부착시킬 수 있는 추가의 화학적 잔기를 제공한다는 것이다. 이들 변형은 척추동물 세포에서 생체내 또는 시험관내에서 만들어질 수 있다. 따라서, 일부 실시태양에 있어서, 번역후 변형은 비천연 아미노산을 통해서 이루어진다. 예를 들어, 번역후 변형은 친핵성-친전자성 반응을 통해 일어날 수 있다. 단백질의 선택적 변형에 현재 사용되고 있는 대부분의 반응은 친핵성 및 친전자성 반응 파트너 사이의 공유 결합 형성, 예를 들어, α-할로케톤과 히스티딘 또는 시스테인 측쇄의 반응을 포함한다. 이 경우에 선택성은 단백질 중 친핵성 잔기의 수 및 접근성에 의해 결정된다. 본 발명의 단백질에서, 다른 보다 선택적인 반응, 예컨대, 시험관내 및 생체내에서 비천연 케토아미노산과 하이드라진 또는 아미노옥시 화합물과의 반응을 이용할 수 있다(예를 들어, Cornish, et al., (1996) Am. Chem. Soc. 118:8150-8151; Mahal, et al., (1997) Science, 276:1 125-1128; Wang, et al., (2001) Science 292:498-500; Chin, et al., (2002) Am. Chem. Soc. 124:9026-9027; Chin, et al., (2002) Proc. Natl. Acad. Sci. 99:11020-11024; Wang, et al., (2003) Proc. Natl. Acad. Sci., 100:56-61; Zhang, et al., (2003) Biochemistry, 42:6735-6746; and, Chin, et al., (2003) Science, in press). 이는 실질적으로 모든 단백질을 다수의 반응제, 예를 들어, 형광물질, 가교결합제, 당류 유도체 및 세포독성 분자로 선택적 표지하는 것을 가능하게 한다(미국 특허 출원 제10/686,944호, 발명의 명칭 "Glycoprotein synthesis," 2003년 10월 15일 출원). 번역후 변형, 예를 들어, 아지도 아미노산을 통한 변형은, 또한 스토딩거(Staudinger) 연결을 통해서(예를 들어, 트리아릴포스핀 반응제와 함께) 이루어질 수 있다(예를 들어, Kiick et al., (2002) Incorporation of azides into recombinant proteins for chemoselective modification by the Staudinger ligation, PNAS 99: 19-24).
본 발명은 단백질의 선택적 변형을 위한 또 다른 고도의 효율적 방법을 제공하는데, 이는 비천연 아미노산, 예를 들어, 아지드 또는 알키닐 잔기를 함유하는 비천연 아미노산을 셀렉터 코돈에 반응하여 단백질 내로 유전적으로 통합시키는 것을 포함한다. 이들 아미노산 사슬은 이어서, 예컨대, 각각 알키닐 또는 아지드 유도체와 함께 휘스젠(Huisgen) [3+2] 고리화 첨가 반응 반응(예를 들어, Padwa, A. in Comprehensive Organic Synthesis. Vol. 4, (1991) Ed. Trost, B. M., Pergamon, Oxford, p. 1069-1109; and, Huisgen, R. in 1,3-Dipolar Cycloaddition Chemistry. (1984) Ed. Padwa, A., Wiley, New York, p. 1-176)에 의해서 변형될 수 있다. 예를 들어, 도 16을 참조할 수 있다. 이 방법이 친핵성 치환이 아닌 고리화 첨가 반응을 포함하는 것이기 때문에, 단백질은 극도로 높은 선택성으로 변형될 수 있다. 이 반응은 실온에서 수성 조건하에 촉매량의 Cu(I) 염을 반응 혼합물에 가함으로써 탁월한 방향선택성(1,4 > 1,5)으로 수행될 수 있다(예를 들어, Tornoe, et al., (2002) Org. Chem. 67:3057-3064; and, Rostovtsev, et al., (2002) Angew. Chem. Int. Ed. 41:2596-2599). 사용될 수 있는 또 다른 방법은 이비소(biarsenic) 화합물 상에서 테트라시스테인 모티프로 리간드 교환하는 것이다(예를 들어, Griffin, et al., (1998) Science 281:269-272).
본 발명의 단백질에 비천연적으로 코딩된 아미노산의 작용기를 통해 부가될 수 있는 분자는 상보적인 작용기를 갖는 실질적으로 모든 분자이다. 그러한 분자는 염료, 형광 물질, 가교결합제, 당류 유도체, 중합체(예를 들어, 폴리에틸렌 글리콜의 유도체), 광가교결합제, 세포독성 화합물, 친화도 표지, 비오틴 유도체, 수지, 비드, 제2 단백질 또는 폴리펩티드(또는 그 이상의 단백질 또는 폴리펩티드 등), 폴리뉴클레오티드(예를 들어, DNA, RNA 등), 금속 킬레이터, 보조 인자, 지방산, 탄수화물 등을 포함하나, 이에 한정되는 것은 아니다. 또 다른 측면으로서, 본 발명은 그와 같은 분자를 포함하는 조성물 및 이러한 분자, 예컨대, n이 50 내지 10,000, 75 내지 5,000, 100 내지 2,000, 100 내지 1,000 사이의 정수인 폴리에틸렌 글리콜을 제조하는 방법을 제공한다. 본 발명의 실시태양에 있어서, 폴리에틸렌 글리콜은 분자량이, 예를 들어, 약 5,000 내지 약 100,000 Da, 약 20,000 내지 약 30,000, 약 40,000 또는 약 50,000 Da, 약 20,000 내지 약 10,000 Da이다.
단백질 또는 세포와 함께 이들 화합물을 포함하는 각종 조성물이 또한 제공된다. 본 발명의 일 측면에 있어서, 아지도 염료(예를 들어, 화학 구조 4 또는 화학 구조 6)를 포함하는 단백질은 하나 이상의 비천연 아미노산(예를 들어, 알키닐 아미노산)을 추가로 포함하며, 여기서 아지도 염료는 [3+2] 고리화 첨가 반응을 통해서 비천연 아미노산에 부착된다.
본 발명의 척추동물 세포는 비천연 아미노산을 유용한 다량으로 포함하는 단백질을 합성하는 능력을 제공한다. 일 측면에 있어서, 조성물은 경우에 따라 비천연 아미노산을 포함하는 단백질을 10 ㎍ 이상, 50 ㎍ 이상, 75 ㎍ 이상, 100 ㎍ 이상, 200 ㎍ 이상, 250 ㎍ 이상, 500 ㎍ 이상, 1 mg 이상, 10 mg 이상 포함하거나, 생체내 단백질 제조 방법(재조합 단백질 제조 및 정제에 관한 상세한 사항이 본 명세서에 기재되어 있음)에서 얻어질 수 있는 양만큼 포함한다. 또 다른 측면에 있어서, 단백질은 경우에 따라 조성물 중에, 예컨대, 세포 용해물, 완충액, 제약용 완충액 또는 다른 액상 현탁액(예를 들어, 약 1 nl 내지 약 100 L 중 어느 부피로나) 중에, 예컨대, 10 ㎍(단백질)/L 이상, 50 ㎍/L 이상, 75 ㎍/L 이상, 100 ㎍/L 이상, 200 ㎍/L 이상, 250 ㎍/L 이상, 500 ㎍/L 이상, 1 mg/L 이상, 또는 10 mg/L 또는 그 이상의 농도로 존재한다. 척추동물 세포에서 하나 이상의 비천연 아미노산을 포함하는 단백질을 다량(다른 방법, 예컨대, 시험관내 번역에서 일반적으로 얻어지는 것보다 많은 양) 제조하는 것 또한 본 발명의 특징이다.
비천연 아미노산의 도입은 단백질 구조 및/또는 기능에 있어서의 맞춤식 변화, 예를 들어, 크기, 산성도, 친전자도, 수소 결합, 소수성도, 프로테아제 표적 부위의 접근성, 잔기로의 표적 유도(예를 들어, 단백질 어레이를 위해) 등을 변화시키기 위해 수행될 수 있다. 비천연 아미노산을 포함하는 단백질은 증가되거나 심지어는 전혀 새로운 촉매적 또는 물리적 특성을 갖는다. 예를 들어, 다음 특성들이 경우에 따라 단백질 내로 비천연 아미노산을 포함시키는 것에 의해 변화된다: 독성, 생체내 분포, 구조적 특성, 분광 특성, 화학 및/또는 광화학 특성, 촉매 능력, 반감기(예를 들어, 혈청 반감기), 다른 분자와, 예를 들어, 공유적으로 또는 비공유적으로 반응하는 능력 등. 하나 이상의 비천연 아미노산을 포함하는 단백질을 포함하는 조성물은, 예를 들어, 신규 치료제, 진단제, 촉매 효소, 산업용 효소, 결합 단백질(예를 들어, 항체), 및 단백질 구조 및 기능의 연구에 유용하다(예를 들어, Dougherty, (2000) Unnatural Amino Acids as Probes of Protein Structure and Function, Current Opinion in Chemical Biology 4:645-652).
본 발명의 일 측면에 있어서, 조성물은 적어도 1개, 예를 들어, 적어도 2개, 적어도 3개, 적어도 4개, 적어도 5개, 적어도 6개, 적어도 7개, 적어도 8개, 적어도 9개, 또는 적어도 10개 또는 그 이상의 비천연 아미노산을 갖는 하나 이상의 단백질을 포함한다. 비천연 아미노산은 동일하거나 상이할 수 있으며, 단백질 내에는 1, 2, 3, 4, 5, 6, 7, 8, 9 또는 10개 또는 그 이상의 상이한 비천연 아미노산을 포함하는 1, 2, 3, 4, 5, 6, 7, 8, 9 또는 10개 또는 그 이상의 상이한 부위가 있을 수 있다. 또 다른 측면에 있어서, 조성물은 단백질 중 적어도 하나 이상의, 그러나 전부보다는 적은 수의 특정 아미노산이 비천연 아미노산으로 치환된 단백질을 포함한다. 2개 이상의 비천연 아미노산을 갖는 주어진 단백질에서, 비천연 아미노산은 동일하거나 상이할 수 있다(예컨대, 단백질은 2개 이상의 상이한 유형의 비천연 아미노산을 포함하거나, 같은 비천연 아미노산 2개를 포함할 수 있다). 3개 이상의 비천연 아미노산을 포함하는 주어진 단백질에서, 비천연 아미노산은 동일하거나 상이하거나, 또는 같은 종류의 다수의 아미노산과 하나 이상의 다른 비천연 아미노산의 조합일 수 있다.
실질적으로 비천연 아미노산을 포함하는 어떠한 단백질이나 그 일부분(및, 예를 들어, 하나 이상의 셀렉터 코돈을 포함하는 상응하는 코딩 핵산)을 본 명세서 기재된 조성물 및 방법을 사용하여 제조할 수 있다. 수백 수천의 공지된 단백질을 확인하기 위한 시도는 없었지만, 이들 중 어느 것이나 하나 이상의 비천연 아미노산을 포함하도록, 예를 들어, 관련 번역계에 하나 이상의 적절한 셀렉터 코돈을 포함하도록 이용 가능한 돌연변이 유발법을 맞춤 사용하여 변형시킬 수 있다. 공지된 단백질에 대한 공공 서열 저장 기관은 진뱅크, EMBL, DDBJ 및 NCBI를 포함한다. 인터넷을 검색하여 다른 저장 기관도 쉽게 찾을 수 있을 것이다.
일반적으로, 단백질은 임의의 이용 가능한 단백질(예를 들어, 치료용 단백질, 진단용 단백질, 산업용 효소, 또는 이들의 일부분)에, 예를 들어, 적어도 60%, 적어도 70%, 적어도 75%, 적어도 80%, 적어도 90%, 적어도 95%, 또는 적어도 99% 또는 그 이상 동일하며, 하나 이상의 비천연 아미노산을 포함한다. 치료제, 진단제, 및 하나 이상의 비천연 아미노산을 포함하도록 변형될 수 있는 다른 단백질의 예는 알파-1 안티트립신, 안지오스타틴, 항용혈 인자, 항체(항체에 대한 상세 설명은 이하 기재됨), 아포지단백질, 아포단백질, 심방 나트륨 이뇨 인자, 심방 나트륨 이뇨 폴리펩티드, 심방 펩티드, C-X-C 케모카인(예를 들어, T39765, NAP-2, ENA-78, Gro-a, Gro-b, Gro-c, IP-10, GCP-2, NAP-4, SDF-1, PF4, MIG), 칼시토닌, CC 케모카인(예를 들어, 단핵구 화학유인 단백질-1, 단핵구 화학유인 단백질-2, 단핵구 화학유인 단백질-3, 단핵구 염증 단백질-1 알파, 단핵구 염증 단백질-1 베타, RANTES, I309, R83915, R91733, HCC1, T58847, D31065, T64262), CD40 리간드, C-kit 리간드, 콜라겐, 콜로니 자극 인자(CSF), 보체 인자 5a, 보체 억제제, 보체 수용체 1, 사이토카인(예를 들어, 상피세포 호중구 활성화 펩티드-78, GROα/MGSA, GROβ, GROγ, MIP-1α, MIP-1δ, MCP-1), 상피세포 성장 인자(EGF), 에리스로포이에틴("EPO", 하나 이상의 비천연 아미노산 도입에 의한 변형의 바람직한 표적이 됨), 박리 독소 A 및 B, 인자 IX, 인자 VII, 인자 VIII, 인자 X, 섬유아세포 성장 인자(FGF), 피브리노겐, 피브로넥틴, G-CSF, GM-CSF, 글루코세레브로시다제, 고나도트로핀, 성장 인자, 헤지호그 단백질(예를 들어, 소닉(Sonic), 인디언(Indian), 데저트(Desert)), 헤모글로빈, 간세포 성장 인자(HGF), 히루딘, 인간 혈청 알부민, 인슐린, 인슐린 유사 성장 인자(IGF), 인터페론(예를 들어, IFN-α, IFN-β, IFN-γ), 인터루킨(예를 들어, IL-1, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8, IL-9, IL-10, IL-11, IL-12 등), 각질 세포 성장 인자(KGF), 락토페린, 백혈병 억제 인자, 루시퍼라제, 뉴투린, 호중구 억제 인자(NIF), 온코스타틴 M, 골원성 단백질, 부갑상선 호르몬, PD-ECSF, PDGF, 펩티드 호르몬(예를 들어, 인간 성장 호르몬), 플레이오트로핀, 단백질 A, 단백질 G, 발열성 외독소 A, B 및 C, 릴렉신, 레닌, SCF, 가용성 보체 수용체 I, 가용성 I-CAM 1, 가용성 인터루킨 수용체(IL-I, 2, 3, 4, 5, 6, 7, 9, 10, 11, 12, 13, 14, 15), 가용성 TNF 수용체, 소마토메딘, 소마토스타틴, 소마토트로핀, 스트렙토키나제, 슈퍼항원, 즉 스타필로코커스 외독소(SEA, SEB, SEC1, SEC2, SEC3, SED, SEE), 슈퍼옥시드 디스뮤타제(SOD), 독성 쇼크 증후군 독소(TSST-I), 티모신 알파 1, 조직 플라스미노겐 활성화 인자, 종양 괴사 인자 베타(TNFβ), 종양 괴사 인자 수용체(TNFR), 종양 괴사 인자-알파(TNFα), 혈관 내피세포 성장 인자(VEGEF), 유로키나제 및 기타 여러 가지를 포함하나, 이에 한정되는 것은 아니다.
본 명세서에 기재된 바와 같은 비천연 아미노산의 생체내 도입을 위한 조성물 및 방법을 사용하여 만들 수 있는 한 부류의 단백질은 전사 조절인자 또는 그 일부분을 포함한다. 전사 조절인자의 예는 세포 성장, 분화, 조절 등을 조절하는 유전자 및 전사 조절인자 단백질을 포함한다. 전사 조절인자는 원핵 생물, 바이러스, 및 진균, 식물, 효모, 곤충 및 포유류 등의 동물 등을 포함하는 진핵 생물에서 발견되어, 광범위한 치료 표적을 제공한다. 발현 및 전사 활성화 인자는 많은 메카니즘을 통해서, 예컨대, 수용체에의 결합, 신호 전달 캐스케이드 자극, 전사 인자의 발현 조절, 프로모터 및 인핸서에의 결합, 프로모터 및 인핸서에 결합하는 단백질에의 결합, DNA 풀기, 프리-mRNA 스플라이싱, RNA 폴리아데닐화 및 RNA 분해를 통해서 전사를 조절하는 것이 잘 알려져 있다. 예를 들어, 척추동물 세포 중 GAL4 단백질 또는 그 일부분의 조성물이 또한 본 발명의 특징이다. 일반적으로, GAL4 단백질 또는 그 일부분은 하나 이상의 비천연 아미노산을 포함한다. "오르소고날 아미노아실-tRNA 합성효소"란을 참조할 수 있다.
본 발명의 단백질의 한 부류(하나 이상의 비천연 아미노산을 포함하는 단백질)는 발현 활성화제, 예컨대, 사이토카인, 염증 분자, 성장 인자, 이들의 수용체, 및 암유전자 생성물, 예를 들어, 인터루킨(예를 들어, IL-1, IL-2, IL-8 등), 인터페론, FGF, IGF-I, IGF-II, FGF, PDGF, TNF, TGF-α, TGF-β, EGF, KGF, SCF/c-Kit, CD40L/CD40, VLA-4/VCAM-1, ICAM-l/LFA-1, 및 히알루린/CD44; 신호 전달 분자 및 상응하는 암유전자 생성물, 예를 들어, Mos, Ras, Raf 및 Met; 및 전사 활성화 인자 및 억제제, 예를 들어, p53, Tat, Fos, Myc, Jun, Myb, Re1 및 스테로이드 호르몬 수용체, 예컨대, 에스트로겐, 프로게스테론, 테스토스테론, 알도스테론, LDL 수용체 리간드 및 코르티코스테론 수용체를 포함한다.
하나 이상의 비천연 아미노산을 갖는 효소(예를 들어, 산업용 효소) 또는 그 일부분이 또한 본 발명에 의해 제공된다. 효소의 예는, 아미다제, 아미노산 라세마제, 아실라제, 데할로게나제, 디옥시게나제, 다아릴프로판 퍼옥시다제, 에피머라제, 에폭시드 하이드롤라제, 에스터라제, 이소머라제, 키나제, 글루코스 이소머라제, 글리코시다제, 글리코실 트랜스퍼라제, 할로퍼옥시다제, 모노옥시게나제(예를 들어, p450s), 리파제, 리그닌 퍼옥시다제, 니트릴 하이드라타제, 니트릴라제, 프로테아제, 포스파타제, 서브틸리신, 트랜스아미나제 및 뉴클레아제 등을 포함하나, 이에 한정되는 것은 아니다.
이들 단백질 중 다수가 상업적으로 이용 가능한 것이고(예를 들어, Sigma BioSciences 2002 카탈로그 및 가격표 참조), 상응하는 단백질 서열 및 유전자, 및 일반적으로는 이들의 변이체가 잘 알려져 있다(예를 들어, 진뱅크). 이들 중 어느 것이나 본 발명에 따른 하나 이상의 비천연 아미노산 삽입에 의해 변형되어, 예컨대, 관심있는 한 가지 이상의 치료, 진단 또는 효소 특성과 관련하여 단백질을 변화시킬 수 있다. 치료 관련 특성의 예는 혈청 반감기, 보관 반감기, 안정성, 면역원성, 치료 활성, 검출 가능성(예를 들어, 표지 또는 표지 결합 부위와 같은 리포터기를 비천연 아미노산 내에 포함시켜), LD50 또는 다른 부작용의 감소, 소화관을 통해 체내로 들어가는 능력(예를 들어, 경구 투여 가능성) 등을 포함한다. 진단제 관련 특성의 예는 보관 반감기, 안정성, 진단 활성, 검출 가능성 등을 포함한다. 효소 관련 특성의 예는 보관 반감기, 안정성, 효소 활성, 제조 성능 등을 포함한다.
각종 다른 단백질이 하나 이상의 비천연 아미노산을 갖도록 변형될 수 있다. 예를 들어, 본 발명은 하나 이상의 백신 단백질 내의 하나 이상의 천연 아미노산을 비천연 아미노산으로 치환하는 것을 포함하며, 백신 단백질은, 예컨대, 감염성 진균, 예를 들어, 아스퍼질러스(Aspergillus), 캔디다(Candida) 종; 박테리아, 특히 병원성 박테리아의 모델인 이 콜라이뿐만 아니라, 스타필로코커스(예를 들어, 스타필로코커스 오레우스(Staphylococcus aureus)) 또는 스트렙토코커스(예를 들어, 스트렙토코커스 뉴모니아(Streptococci pneumoniae))와 같은 의학적으로 중요한 박테리아; 포자충(예를 들어, 플라스모디아(Plasmodia)), 근족충(예를 들어, 엔트아메바(Entamoeba)) 및 편모충(트리파노소마(Trypanosoma), 레이쉬마니아(Leishmania), 트리코모나스(Trichomonas), 쟈르디아(Giardia) 등)과 같은 원생동물; (+)RNA 바이러스(예를 들어, 백시니아와 같은 폭스바이러스; 폴리오와 같은 피코르나바이러스; 루벨라와 같은 토가바이러스; HCV와 같은 플라비바이러스; 및 코로나바이러스), (-)RNA 바이러스(예를 들어, VSV와 같은 랍도바이러스; RSV와 같은 파라믹소바이러스; 인플루엔자와 같은 오르소믹소바이러스; 버냐바이러스; 및 아레나바이러스), dsDNA 바이러스(예를 들어, 레오바이러스), RNA로부터 DNA 복제 바이러스, 즉, 레트로바이러스, 예를 들어, HIV 및 HTLV, 및 DNA로부터 RNA 복제 바이러스, 예를 들어, 간염 바이러스 B로부터의 것이다.
농업 관련 단백질, 예컨대, 곤충 내성 단백질(예를 들어, Cry 단백질), 전분 및 지질 제조 효소, 식물 및 곤충 독소, 독소 내성 단백질, 마이코톡신 해독 단백질, 식물 생장 효소(예를 들어, 리뷸로스 1,5-비스포스페이트 카복실라제/옥시게나제, "RUBISCO"), 리폭시게나제(LOX), 및 포스포에놀피루베이트(PEP) 카복실라제가 또한 비천연 아미노산 변형의 적절한 표적이다.
본 발명은 또한 척추동물 세포에서 하나 이상의 비천연 아미노산을 포함하는하나 이상 단백질을 제조하는 방법(및 이와 같은 방법에 의해 제조된 단백질)을 제공한다. 예를 들어, 그 방법은 적어도 하나 이상의 셀렉터 코돈을 포함하며 단백질을 코딩하는 핵산을 포함하는 척추동물 세포를 적절한 배지 중에서 배양하는 단계를 포함한다. 척추동물 세포는 또한 그 세포 내에서 기능하고 셀렉터 코돈을 인식하는 오르소고날 tRNA(O-tRNA); 및 O-tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하는 오르소고날 아미노아실 tRNA 합성효소(O-RS)를 포함하고, 배지는 비천연 아미노산을 포함한다.
일 실시태양에 있어서, 본 발명의 방법은 단백질 내에 제1 반응성 기를 갖는 비천연 아미노산을 도입하는 단계; 및 단백질을 제2의 반응성 기를 갖는 분자(예를 들어, 염료, 폴리에틸렌 글리콜 유도체와 같은 중합체, 광가교결합제, 세포독성 화합물, 친화도 표지, 비오틴 유도체, 수지, 제2 단백질 또는 폴리펩티드, 금속 킬레이터, 보조 인자, 지방산, 탄수화물, 폴리뉴클레오티드(예를 들어, DNA, RNA 등) 등)와 접촉시키는 단계를 포함한다. 제1 반응성 기는 제2 반응성 기와 반응하여 분자를 [3+2] 고리화 첨가 반응을 통해 비천연 아미노산에 부착시킨다. 일 실시태양에 있어서, 제1 반응성 기는 알키닐 또는 아지도 잔기이고, 제2 반응성 기는 아지도 또는 알키닐 잔기이다. 예를 들어, 제1 반응성 기는 알키닐 잔기(예를 들어, 비천연 아미노산 p-프로파길옥시페닐알라닌 중)이고, 제2 반응성 기는 아지도 잔기이다. 또 다른 실시태양에 있어서, 제1 반응성 기는 아지도 잔기(예를 들어, 비천연 아미노산 p-아지도-L-페닐알라닌 중)이고, 제2 반응성 기는 알키닐 잔기이다.
일 실시태양에 있어서, O-RS는 O-tRNA를 비천연 아미노산으로, 예컨대, 서열 번호 86 또는 45에 개시된 아미노산 서열을 갖는 O-RS의 효율의 적어도 50%의 효율로 아미노아실화한다. 또 다른 실시태양에 있어서, O-tRNA는 서열 번호 65 또는 64, 또는 이의 상보적 폴리뉴클레오티드 서열을 포함하거나, 그로부터 프로세싱되거나, 그에 의해 코딩된다. 또 다른 실시태양에 있어서, O-RS는 서열 번호 36 내지 63 및/또는 86 중 어느 하나에 개시된 아미노산 서열을 포함한다.
코딩된 단백질은, 예를 들어, 치료용 단백질, 진단용 단백질, 산업용 효소 또는 이들의 일부분을 포함할 수 있다. 경우에 따라, 본 발명의 방법에 의해 제조된 단백질은 비천연 아미노산을 통해 더욱 변형된다. 예를 들어, 본 발명의 방법에 의해 제조된 단백질은 경우에 따라 적어도 하나의 생체내 번역후 변형에 의해 변형된다.
스크리닝 또는 선택용 전사 조절인자 단백질을 제조하는 방법(및 그러한 방법에 의해 제조된 스크리닝 또는 선택 전사 조절인자 단백질)이 또한 제공된다. 예를 들어, 방법은 핵산 결합 도메인을 코딩하는 제1 폴리뉴클레오티드 서열을 선택하는 단계; 및 제1 폴리뉴클레오티드 서열이 적어도 하나의 셀렉터 코돈을 포함하도록 돌연변이 유발시키는 단계를 포함한다. 이에 의해 스크리닝 또는 선택용 폴리뉴클레오티드 서열이 제공된다. 이 방법은 또한 전사 활성화 도메인을 코딩하는 제2의 폴리뉴클레오티드 서열을 선택하는 단계; 제2의 폴리뉴클레오티드 서열에 작동 가능하게 연결된 스크리닝 또는 선택용 폴리뉴클레오티드 서열을 포함하는 구성체를 제공하는 단계; 및 세포 내로 상기 구성체, 비천연 아미노산, 오르소고날 tRNA 합성효소(O-RS) 및 오르소고날 tRNA(O-tRNA)를 도입하는 단계를 포함한다. 이들 성분들 존재하에, O-RS는 O-tRNA를 비천연 아미노산으로 우선적으로 아미노아실화하고, O-tRNA는 셀렉터 코돈을 인식하여, 스크리닝 또는 선택용 폴리뉴클레오티드 서열 중 셀렉터 코돈에 반응하여 비천연 아미노산을 핵산 결합 도메인 내로 도입함으로써, 스크리닝 또는 선택용 전사 조절인자 단백질을 제공한다.
일부 실시태양에 있어서, 본 발명의 방법 및/또는 조성물 중의 관심있는 단백질 또는 폴리펩티드(또는 그 일부분)은 핵산에 의해 코딩된다. 일반적으로, 핵산은 적어도 하나의 셀렉터 코돈, 적어도 2개의 셀렉터 코돈, 적어도 3개의 셀렉터 코돈, 적어도 4개의 셀렉터 코돈, 적어도 5개의 셀렉터 코돈, 적어도 6개의 셀렉터 코돈, 적어도 7개의 셀렉터 코돈, 적어도 8개의 셀렉터 코돈, 적어도 9개의 셀렉터 코돈, 10개 또는 그 이상의 셀렉터 코돈을 포함한다.
관심있는 단백질 또는 폴리펩티드를 코딩하는 유전자는 당업자에게 잘 알려져 있고, 본 명세서의 "돌연변이 유발 및 다른 분자생물학적 기술"란에 기술된 방법을 사용하여, 비천연 아미노산의 도입을 위한 하나 이상의 셀렉터 코돈을 포함하도록 변이될 수 있다. 예를 들어, 관심있는 단백질에 대한 핵산을 돌연변이시켜 하나 이상의 셀렉터 코돈을 포함하게 하여, 하나 이상의 비천연 아미노산을 도입할 수 있다. 본 발명은 적어도 하나의 비천연 아미노산을 포함하는 임의의 그러한 변이체, 예를 들어, 단백질 변이체 또는 버전을 포함한다. 마찬가지로, 본 발명은 상응하는 핵산, 즉, 하나 이상의 비천연 아미노산을 코딩하는 하나 이상의 셀렉터 코돈을 갖는 임의의 핵산을 포함한다.
비천연 아미노산을 포함하는 재조합 단백질의 정제
본 발명의 단백질, 예컨대, 비천연 아미노산을 포함하는 단백질, 비천연 아미노산을 포함하는 단백질에 대한 항체 등은, 당업자에게 알려져 있고 사용되고 있는 표준 과정으로 부분적으로 또는 실질적으로 균질한 정도로 정제될 수 있다. 따라서, 본 발명의 폴리펩티드는 당업계에 잘 알려진 많은 방법 중 임의의 방법, 비제한적인 예로서, 황산암모늄 또는 에탄올 침전, 산 또는 염기 추출, 칼럼 크로마토그래피, 친화도 칼럼 크로마토그래피, 음이온 또는 양이온 교환 크로마토그래피, 포스포셀룰로스 크로마토그래피, 소수성 상호작용 크로마토그래피, 히드록실 아파타이트 크로마토그래피, 렉틴 크로마토그래피, 겔 전기 영동 등의 방법으로 회수 및 정제될 수 있다. 정확하게 폴딩된 성숙 단백질을 제조하는 데 바람직한 경우, 단백질 리폴딩 단계를 이용할 수 있다. 높은 순도가 요구되는 경우, 고성능 액체 크로마토그래피(HPLC), 친화도 크로마토그래피 또는 다른 적절한 방법을 최종 정제 단계에 사용할 수 있다. 일 실시태양에 있어서, 비천연 아미노산(또는 비천연 아미노산을 포함하는 단백질)에 대해서 만들어진 항체를 정제 시약으로, 예를 들어, 하나 이상의 비천연 아미노산을 포함하는 단백질의 친화도에 기초한 정제에 사용한다. 일단 필요에 따라 부분적으로 또는 균질한 정도로 정제되면, 폴리펩티드는 경우에 따라, 예컨대, 분석 성분, 치료 반응제, 또는 항체 제조의 면역원으로 사용된다.
본 명세서에 기재된 다른 참고 문헌 외에, 각종 정제/단백질 폴딩 방법이 당업계에 잘 알려져 있으며, 예를 들어, 문헌(R. Scopes, Protein Purification. Springer-Verlag, N.Y. (1982); Deutscher, Methods in Enzymology Vol. 182: Guide to Protein Purification. Academic Press, Inc. N.Y. (1990); Sandana(1997) Bioseparation of Proteins. Academic Press, Inc.; Bollag et al., (1996) Protein Methods, 2nd Edition Wiley-Liss, NY; Walker(1996) The Protein Protocols Handbook Humana Press, NJ, Harris and Angal(1990) Protein Purification Applications: A Practical Approach IRL Press at Oxford, Oxford, England; Harris and Angal Protein Purification Methods: A Practical Approach IRL Press at Oxford, Oxford, England; Scopes(1993) Protein Purification: Principles and Practice 3rd Edition Springer Verlag, NY; Janson and Ryden(1998) Protein Purification: Principles. High Resolution Methods and Applications. Second Edition Wiley-VCH, NY; and Walker(1998) Protein Protocols on CD-ROM Humana Press, NJ) 및 그 문헌에 인용된 참고 문헌에 기재되어 있다.
척추동물 세포에서 비천연 아미노산을 포함하는 관심있는 단백질 또는 폴리펩티드를 제조하는 것의 장점은, 일반적으로 그 단백질 또는 폴리펩티드가 천연의 구조로 폴딩된다는 것이다. 그러나, 본 발명의 일부 실시태양에 있어서, 당업자는 합성, 발현 및/또는 정제 후에 단백질이 관련 단백질의 바람직한 구조와는 다른 구조를 가질 수 있다는 것을 잘 인식하고 있을 것이다. 본 발명의 일 측면은, 발현된 단백질이 경우에 따라 변성된 다음 다시 재생되는 것이다. 이는, 예를 들어, 샤페로닌을 관심있는 단백질 또는 폴리펩티드에 가하고(거나) 단백질을 구아니딘 HCl과 같은 카오트로픽제에 용해시키는 것에 의해 수행된다.
일반적으로, 발현된 단백질을 변성 및 환원시킨 다음, 폴리펩티드가 원하는 구조로 폴딩되도록 하는 것이 때때로 바람직할 수 있다. 예를 들어, 구아니딘, 우레아, DTT, DTE 및/또는 샤페로닌을 관심있는 번역 생성물에 가할 수 있다. 단백질을 환원, 변성 및 재생시키는 방법은 당업자에게 잘 알려져 있다(상기 참고 문헌, 및 Debinski, et al., (1993) L. Biol. Chem.. 268: 14065-14070; Kreitman and Pastan(1993) Bioconjug. Chem., 4: 581-585; and Buchner, et al., (1992) Anal. Biochem. 205: 263-270). 데빈스키(Debinski) 등은, 예를 들어, 구아니딘-DTE 중에서 봉입체 단백질을 변성 및 환원시키는 것을 기재하고 있다. 단백질은, 예를 들어, 산화된 글루타티온 및 L-아르기닌을 함유하는 산화환원 완충액 중에서 리폴딩될 수 있다. 리폴딩 시약은 하나 이상의 폴리펩티드 또는 다른 발현 생성물과 접촉되도록 흘려 넣거나 다른 방식으로 전달될 수 있고, 역으로도 할 수 있다.
항체
일 실시태양에 있어서, 본 발명은 본 발명의 분자, 예컨대, 합성효소, tRNA, 및 비천연 아미노산을 포함하는 단백질에 대한 항체 분자를 제공한다. 본 발명의 분자에 대한 항체는 정제 시약으로서, 예를 들어, 본 발명의 분자를 정제하는 데 사용할 수 있다. 또한, 항체는 합성효소, tRNA, 또는 비천연 아미노산을 포함하는 단백질의 존재를 지시하는 지시제 시약으로서, 예컨대, 분자의 존재나 위치를 조사하는 데(예를 들어, 생체내 또는 원래 위치에서) 사용될 수 있다.
본 발명의 항체는 실질적으로 또는 부분적으로 면역글로불린 유전자 또는 면역글로불린 유전자의 단편에 의해 코딩되는 하나 이상의 폴리펩티드를 포함하는 단백질일 수 있다. 알려진 면역글로불린 유전자는 카파, 람다, 알파, 감마, 델타, 엡실론 및 뮤 불변 영역뿐만 아니라 무수히 많은 면역글로불린 가변 영역 유전자를 포함한다. 경쇄는 카파 또는 람다로 분류된다. 중쇄는 감마, 뮤, 알파, 델타 또는 엡실론으로 분류되며, 이는 다시 각각 면역글로불린 클래스 IgG, IgM, IgA, IgD 및 IgE에 해당한다. 전형적인 면역글로불린(예를 들어, 항체) 구조 단위는 테트라머를 포함한다. 각 테트라머는 2개의 동일한 쌍의 폴리펩티드로 이루어지는데, 각 쌍은 하나의 "경쇄"(약 25 kD) 및 하나의 "중쇄"(약 50 내지 70 kD)를 갖는다. 각 사슬의 N-말단은 주로 항원 인식을 담당하는 약 100 내지 110 또는 그 이상의 아미노산으로 된 가변 영역을 한정한다. 가변 경쇄(VL) 및 가변 중쇄(VH)는 각각 이들 경쇄 및 중쇄를 이르는 것이다.
항체는 온전한 면역글로불린으로 존재하거나, 각종 펩티다제 분해에 의해 제조된, 다수의 잘 특성화된 단편으로서 존재한다. 따라서, 예를 들어, 펩신은 항체를 힌지 영역 중 디설파이드 결합 아래에서 절단하여 F(ab')2를 제조하는데, 이는 Fab의 이량체로서 그 자체는 디설파이드 결합에 의해서 VH-CH1에 연결된 경쇄이다. F(ab')2는 온화한 조건하에 환원되어 힌지 영역에서 디설파이드 결합을 파괴함으로써 F(ab')2 이량체를 Fab' 단량체로 전환시킨다. Fab' 단량체는 실질적으로는 힌지 영역의 일부를 갖는 Fab이다(다른 항체 단편에 대한 상세한 사항에 대해서는, Fundamental Immunology, 4th addition, W.E. Paul, ed., Raven Press, N. Y. (1999)를 참조). 각종 항체 단편이 온전한 항체의 분해에 의해 정의되는 한편, 당업자는 그러한 Fab' 단편 등이 화학적으로 또는 재조합 DNA 기술을 이용하여 신규(de novo) 합성될 수 있다는 것을 알 것이다. 본 명세서에서 항체란 경우에 따라 전체 항체의 변형에 의해서나 재조합 DNA 기술을 이용한 신규 합성에 의한 항체 단편을 포함한다. 항체는 단일쇄 항체를 포함하며, 이의 비제한적인 예로서, 단일쇄 Fv(sFv 또는 scFv) 항체는 가변 중쇄 및 가변 경쇄가 함께 연결되어(직접 또는 펩티드 링커를 통하여) 연속 폴리펩티드를 형성하고 있다. 본 발명의 항체는, 예를 들어, 폴리클로날, 모노클로날, 키메라, 인간화, 단일쇄, Fab 단편, Fab 발현 라이브러리에 의해 제조된 단편 등을 포함한다.
일반적으로, 본 발명의 항체는 각종 분자 생물학 또는 약제학 과정에서 일반적인 시약 및 치료제로서 가치가 있다. 폴리클로날 및 모노클로날 항체의 제조 방법이 알려져 있으며, 본 발명의 항체를 만드는 데 적용될 수 있다. 다수의 기초적 서적이 표준 항체 제조 방법을 기재하고 있다[예를 들어, Borrebaeck(ed)(1995) Antibody Engineering. 2nd Edition Freeman and Company, NY(Borrebaeck); McCafferty et al., (1996) Antibody Engineering. A Practical Approach IRL at Oxford Press, Oxford, England(McCafferty), and Paul(1995) Antibody Engineering Protocols Humana Press, Towata, NJ(Paul); Paul(ed.), (1999) Fundamental Immunology. Fifth edition Raven Press, N. Y.; Coligan(1991) Current Protocols in Immunology Wiley/Greene, NY; Harlow and Lane(1989) Antibodies: A Laboratory Manual Cold Spring Harbor Press, NY; Stites et al., (eds.) Basic and Clinical Immunology(4th ed.) Lange Medical Publications, Los Altos, CA, and references cited therein; Goding(1986) Monoclonal Antibodies: Principles and Practice(2d ed.) Academic Press, New York, NY; and Kohler and Milstein(1975) Nature 256: 495-497].
예컨대, 항원을 동물 내로 주사하는 것과 같은 것이 아닌, 항체 제조를 위한 다양한 재조합 기술이 개발되어 왔으며, 본 발명에 사용될 수 있다. 예를 들어, 파지 또는 유사 벡터 중에 재조합 항체 라이브러리를 제조 및 선택하는 것이 가능할 수 있다(예를 들어, Winter et al., (1994) Making Antibodies by Phage Display Technology Annu. Rev. Immunol. 12:433-55 및 그에 인용된 문헌). 또한, 문헌(Griffiths and Duncan(1998) Strategies for selection of antibodies by phage display, Curr Opin Biotechnol. 9: 102-8; Hoogenboom et al., (1998) Antibody phage display technology and its applications, Immunotechnology 4: 1-20; Gram et al., (1992) in vitro selection and affinity maturation of antibodies from a naive combinatorial immunoglobulin library, PNAS 89:3576-3580; Huse et al., (1989) Science 246: 1275-1281; and Ward, et al., (1989) Nature 341 : 544-546)을 참조할 수 있다.
일 실시태양에 있어서, 항체 라이브러리는 필라멘트상 박테리오파지 표면 상에 관련 중쇄 및 경쇄 가변 도메인을 디스플레이하기 위해 클로닝된 V 유전자의 레퍼토리(예를 들어, 림프구 집단으로부터 수거되거나, 시험관내 조립된)를 포함할 수 있다. 파지는 항원에 결합함으로써 선택된다. 가용성 항체가 파지 감염된 박테리아로부터 발현되며, 항체는, 예를 들어, 돌연변이 유발을 통해 개선될 수 있다(예를 들어, Balint and Larrick(1993) Antibody Engineering by Parsimonious Mutagenesis, Gene 137:109-118; Stemmer et al., (1993) Selection of an Active Single Chain Fv Antibody From a Protein Linker Library Prepared by Enzymatic Inverse PCR Biotechniques 14(2):256-65; Crameri et al., (1996) Construction and evolution of antibody-phage libraries by DNA shuffling, Nature Medicine 2:100-103: and Crameri and Stemmer(1995) Combinatorial multiple cassette mutagenesis creates all the permutations of mutant and wildtype cassettes, BioTechniques 18:194-195).
재조합 항체 파지계를 클로닝 및 발현하기 위한 키트 역시 알려져 있으며 이용될 수 있다("재조합 파지 항체계, 마우스 ScFv 모듈," 제조원 Amersham-Pharmacia Biotechnology, Uppsala, Sweden). 사슬 셔플링에 의한 고친화도 인간 항체를 위한 박테리오파지 항체 라이브러리가 또한 제조되었다(예를 들어, Marks et al., (1992) By-Passing Immunization: Building High Affinity Human Antibodies by Chain Shuffling, Biotechniques 10:779-782). 항체가 다수의 상업용 기관(예를 들어, Bethyl Laboratories, Montgomery, TX; Anawa, Switzerland; Eurogentec, Belgium and Philadelphia, PA, US 등)에 의해 제조될 수 있음이 잘 알려져 있다.
일부 실시태양에 있어서, 예컨대, 항체가 치료용으로 투여되는 경우, 본 발명의 항체를 인간화하는 것이 유용하다. 인간화 항체를 사용함으로써 치료용 항체에 대한 원치않는 면역 반응이 감소될 수 있다(환자가 사람인 경우). 항체에 관한 상기 참조 문헌들은 인간화 전략도 기술하고 있다. 인간화 항체 외에 인간 항체가 또한 본 발명의 특징이다. 인간 항체는 특징적 인간 면역글로불린 서열로 이루어진다. 인간 항체는 아주 광범위하게 다양한 기술에 의해 제조될 수 있다(예를 들어, Larrick et al., 미국 특허 제5,001,065호). 트리오마 기술에 의해 인간 항체를 제조하는 일반적인 방법은 문헌에 기재되어 있다(예를 들어, Ostberg et al(1983), Hybridoma 2: 361-367, Ostberg, 미국 특허 제4,634,664호, 및 Engelman et al., 미국 특허 제4,634,666호).
단백질의 정제 및 검출에서 항체를 이용하는 다수의 방법이 알려져 있으며, 본 명세서에 기재된 바와 같은 비천연 아미노산을 포함하는 단백질을 검출 및 정제하는 데 사용될 수 있다. 일반적으로, 항체는 ELISA, 웨스턴 블롯팅, 면역화학, 친화도 크로마토그래피 방법, SPR 및 많은 다른 방법에 유용한 시약이다. 상기한 참고 문헌들은 ELISA 분석, 웨스턴 블롯, 표면 플라즈몬 공명(SPR) 등을 수행하는 방법을 상세하게 기재하고 있다.
본 발명의 일 측면에 있어서, 본 발명의 항체 그 자체가 비천연 아미노산을 포함하여, 관심있는 특성(예를 들어, 개선된 반감기, 안정성, 독성 등)을 갖는 항체를 제공한다. 이에 대해 본 명세서의 "비천연 아미노산을 포함하는 폴리펩티드"란을 참조할 수 있다. 항체는 현재 임상 연구 중인 모든 화합물의 거의 50%를 차지하며(Wittrup, (1999) Phage on display, Tibtech 17: 423-424), 항체는 진단 시약으로서 아주 널리 사용되고 있다. 따라서, 항체를 비천연 아미노산으로 변형하는 것은 이들 값진 시약을 변형하는 중요한 수단을 제공한다.
예를 들어, 진단 분야에는 많은 MAb 용도가 있다. 분석법은 단순한 스팟 테스트에서, 좀더 복잡한 방법, 예컨대, 종양 이미지화를 위한 방사성 표지 NR-LU-10 MAb(DuPont Merck Co.)에 이른다(Rusch et al., (1993) NR-LU-10 monoclonal antibody scanning. A helpful new adjunct to computed tomography in evaluating non-small-cell lung cancer. J. Thorac Cardiovasc Surg. 106: 200-4). 상기한 바와 같이, MAb는 ELISA, 웨스턴 블롯팅, 면역화학, 친화도 크로마토그래피 방법 등을 위한 중심적인 시약이다. 그러한 어느 항체나 변형되어 하나 이상의 비천연 아미노산을 포함함으로써, 예를 들어, 표적에 대한 항체의 특이성 또는 결합능을 변화시키거나, 비천연 아미노산 내에 검출 표지(예를 들어, 분광분석, 형광, 발광 등)를 포함시킴으로써 하나 이상의 검출 특성을 변화시킬 수 있다.
유용한 항체 시약의 한 부류는 치료용 항체이다. 예를 들어, 항체는 항체 의존적 세포 매개 세포독성(ADCC) 또는 보체 매개 용해(CML)에 의한 파괴를 위해 종양 세포를 표적으로 함으로써 종양 성장을 정지시키는 종양 특이적 모노클로날 항체일 수 있다(이들 항체의 유형을 때대로 "매직 불렛"이라고 함). 한 예는 리툭산(Rituxan)으로서, 이는 비호지킨(Non-Hodgkins) 림프종의 치료를 위한 항-CD20 MAb이다(Scott(1998) Rituximab: a new therapeutic monoclonal antibody for non-Hodgkin's lymphoma Cancer Pract 6: 195-7). 두 번째 예는 종양 성장의 중요 성분과 간섭하는 항체이다. 헤르셉틴(Herceptin)은 전이상 유방암의 치료를 위한 항-HER-2 모노클로날 항체이며, 그와 같은 작용 메카니즘을 갖는 항체의 예이다(Baselga et al., (1998) Recombinant humanized anti-HER2 antibody(Herceptin) enhances the antitumor activity of paclitaxel and doxorubicin against HER2/neu overexpressing human breast cancer xenografts [published erratum appears in Cancer Res(1999) 59(8):2020], Cancer Res 58: 2825-31). 세 번째 예는 세포독성 화합물(독소, 방사선 핵종 등)을 직접 종양 또는 다른 관심있는 부위로 전달하기 위한 항체이다. 예를 들어, 그러한 모노클로날 항체는 CYT-356로서, 이는 방사선을 직접 전립선 암세포로 유도하는 90Y-결합된 항체이다(Deb et al., (1996) Treatment of hormone-refractory prostate cancer with 90Y-CYT-356 monoclonal antibody Clin Cancer Res 2: 1289-97). 네 번째 용도는 항체 유도 효소 전구약물 치료법으로, 종양으로 유도된 효소가 종양 근처에서 전신적으로 투여된 전구약물을 활성화시킨다. 예를 들어, 카복시펩티다제 A에 연결된 항-Ep-CAM1 항체가 결직장암의 치료를 위해 개발되고 있다(Wolfe et al., (1999) Antibody-directed enzyme prodrug therapy with the T268G mutant of human carboxypeptidase Al: in vitro and in vivo studies with prodrugs of methotrexate and the thymidylate synthase inhibitors GW1031 and GW1843 Bioconjug Chem. 10:38-48). 다른 항체(예를 들어, 길항제)는 치료를 위해 정상 세포 기능을 특이적으로 억제하도록 설계된다. 그 일례는 오르소클론(Orthoclone) OKT3로서, 급성 조직 이식 거부를 감소시키기 위해 존슨 앤드 존슨(Johnson and Johnson)에 의해 개발된 항-CD3 MAb이다(Strate et al., (1990) Orthoclone OKT3 as first-line therapy in acute renal allograft rejection Transplant Proc. 22: 219-20). 다른 부류의 항체 생성물은 작용제(agonist)이다. 이들 모노클로날 항체는 치료를 위해 정상 세포 기능을 특이적으로 증진하도록 설계된 것이다. 예를 들어, 신경 치료를 위한 아세틸콜린 수용체의 모노클로날 항체 기반 작용제가 개발 중에 있다(Xie et al., (1997) Direct demonstration of MuSK involvement in acetylcholine receptor clustering through identification of agonist ScFv Nat. Biotechnol. 15: 768-71). 이들 항체 중 어느 것이나 하나 이상의 비천연 아미노산을 포함하도록 변형되어 하나 이상의 치료 특성(특이성, 결합능, 혈청 반감기 등)을 증진시킬 수 있다.
항체 생성물의 또 다른 부류는 새로운 기능을 제공한다. 이러한 군의 주된 항체는 촉매 항체로서, 예컨대, 효소의 촉매 능력을 모방하도록 가공된 Ig 서열이 있다(Wentworth and Janda(1998) Catalytic antibodies Curr Opin Chem Biol 2: 138-44). 예를 들어, 흥미를 끄는 용도는 촉매 항체 mAb-15A10을 중독증 치료를 위해 생체내 코카인을 가수분해하도록 사용하는 것을 포함한다(Mets et al., (1998) A catalytic antibody against cocaine prevents cocaine's reinforcing and toxic effects in rats Proc Natl Acad Sci USA 95: 10176-81). 촉매 항체는 또한 하나 이상의 비천연 아미노산을 포함하도록 변형되어 관심있는 특성 하나 이상을 개선시킨다.
면역반응성에 의한 폴리펩티드의 정의
본 발명의 폴리펩티드가 각종의 신규 폴리펩티드 서열(예를 들어, 본 발명의 번역계에서 합성된 단백질의 경우, 비천연 아미노산을 포함하는 서열, 또는 본 발명의 신규 합성효소의 경우에는 표준 아미노산의 새로운 서열)을 제공하기 때문에, 폴리펩티드는 또한 예를 들어, 면역 분석에서 인식될 수 있는 새로운 구조적 특징을 제공한다. 본 발명의 폴리펩티드에 특이적으로 결합하는 항체 또는 항혈청뿐만 아니라 그러한 항체 또는 항혈청에 의해 결합되는 폴리펩티드가 본 발명의 특징이다.
예를 들어, 본 발명은 서열 번호 36 내지 63 및/또는 86 중 하나 이상으로부터 선택된 아미노산 서열을 포함하는 면역원에 대하여 제조된 항체 또는 항혈청에 특이적으로 결합하거나 그와 특이적으로 면역반응하는 합성효소 단백질을 포함한다. 다른 동족체와의 교차 반응성을 제거하기 위하여, 항체 또는 항혈청을 이용 가능한 대조군 합성효소 동족체, 예를 들어, 야생형 이 콜라이 타이로실 합성효소(TyrRS)(예를 들어, 서열 번호 2)로 서브트랙션(subtraction)한다.
전형적인 포맷 중 하나에 있어서, 면역분석은 서열 번호 36 내지 63 및/또는 86 중 하나 이상에 상응하는 하나 이상의 서열 또는 이의 실질적 부분서열(subsequence)(즉, 제공된 전체 길이 서열의 적어도 약 30% 이상)을 포함하는 하나 이상의 폴리펩티드에 대해 유발시킨 폴리클로날 항체 또는 항혈청을 사용한다. 서열 번호 36 내지 63 및 86으로부터 유도된 유력한 폴리펩티드 면역원의 세트를 이하 총칭하여 "면역원성 폴리펩티드"라 한다. 생성된 항혈청은 경우에 따라 대조군 합성효소 동족체에 대하여 낮은 교차 반응성 갖는 것으로 선택되며, 면역 분석에서 폴리클로날 항혈청을 사용하기 전에 교차 반응성을, 예를 들어, 하나 이상의 대조군 합성효소 동족체를 사용하여 면역흡착에 의해 제거한다.
면역분석에 사용하기 위한 항혈청을 제조하기 위하여, 하나 이상의 면역원성 폴리펩티드를 본 명세서에 기재된 바와 같이 제조 및 정제한다. 예를 들어, 재조합 단백질은 재조합 세포에서 제조될 수 있다. 동종 번식 마우스(마우스의 실질적 유전적 일치성에 기인하여 보다 재현성 있는 결과가 얻어지므로 이 분석에 사용함)를 프로인트(Freund) 보조제와 같은 표준 보조제와 함께 면역원성 단백질로 표준 마우스 면역화 프로토콜로 면역화시킨다. 특이적 면역반응성을 결정하기 위해 사용될 수 있는 항체 제조 및 면역분석 포맷 및 조건에 관한 표준적 사항에 관해서는, 예를 들어, 문헌(Harlow and Lane(1988) Antibodies, A Laboratory Manual, Cold Spring Harbor Publications, New York)을 참조할 수 있다. 항체에 대한 추가의 참고 문헌 및 고찰은 본 명세서에 기재되어 있으며, 면역반응성에 의해 폴리펩티드를 정의/검출하는 항체를 만드는 데 응용될 수 있다. 또한, 본 명세서에 개시된 서열로부터 유도된 하나 이상의 합성 또는 재조합 폴리펩티드가 캐리어 단백질에 접합되어 면역원으로 사용될 수 있다.
폴리클로날 혈청을 풀링(pooling)하여, 면역분석, 예를 들어, 고체 지지체 상에 고정된 하나 이상의 면역원성 단백질을 사용하는 고상 면역분석으로 면역원성 폴리펩티드에 대한 역가를 측정(적정)한다. 역가가 106 이상인 폴리클로날 항혈청을 선택하여 풀링하고, 대조군 합성효소 폴리펩티드로 서브트랙션하여, 서브트랙션, 풀링 및 적정된 폴리클로날 항혈청을 얻는다.
서브트랙션, 풀링 및 적정된 폴리클로날 항혈청을 경쟁 면역분석으로 대조군 동족체에 대한 교차반응성에 대해 테스트한다. 이 경쟁 분석에서, 서브트랙션 및 적정된 폴리클로날 항혈청에 대해 적정된 폴리클로날 항혈청이 면역원성 합성효소에 결합하는 것이 대조군 합성효소 동족체에 결합하는 것에 비하여 적어도 약 5 내지 10배 높은 시그널 대 노이즈 비율을 가져오는 특이적 결합 조건을 결정한다. 즉, 결합/세척 반응의 엄격도를 알부민 또는 비지방 건조 우유와 같은 비특이적 경쟁자를 가하고(거나) 염 조건, 온도 등을 조정함으로써 조정한다. 이들 결합/세척 조건은 추후 분석에서 테스트 폴리펩티드(면역원성 폴리펩티드 및/또는 대조군 폴리펩티드와 비교되는 폴리펩티드)가 풀링 및 서브트랙션된 폴리클로날 항혈청에 의해 특이적으로 결합되는지 여부를 측정하는 데 사용된다. 특히, 특이적 결합 조건하에서 대조군 합성효소 동족체보다 적어도 2 내지 5배 높은 시그널 대 노이즈 비율, 및 면역원성 폴리펩티드에 비해 적어도 약 1/2의 시그널 대 노이즈 비율을 나타내는 테스트 폴리펩티드는 공지된 합성효소에 비하여 면역원성 폴리펩티드와 실질적 구조 유사성을 가지며, 따라서 본 발명의 폴리펩티드이다.
또 다른 예에서, 경쟁 결합 포맷의 면역분석을 테스트 폴리펩티드의 검출을 위해 사용한다. 예를 들어, 상기한 바와 같이, 교차 반응 항체를 대조군 폴리펩티드를 사용한 면역흡착에 의해 풀링된 항혈청 혼합물로부터 제거한다. 면역원성 폴리펩티드를 고체 지지체에 고정화시키고, 서브트랙션 및 풀링된 항혈청에 노출시킨다. 테스트 단백질을 분석에 가하여 풀링 및 서브트랙션된 항혈청에 결합하기 위해 경쟁하도록 한다: 테스트 단백질이 면역원성 단백질에 비하여 풀링 및 서브트랙션된 항혈청에 결합하기 위해 경쟁하는 능력을, 분석에 가해진 면역원성 단백질이 결합을 위해 경쟁하는 능력(면역원성 폴리펩티드는 풀링된 항혈청에 결합하기 위하여 고정화된 면역원성 폴리펩티드와 효율적으로 경쟁함)과 비교한다. 테스트 단백질에 대한 퍼센트 교차 반응성을 표준 계산법에 따라 계산한다.
평행 분석으로서, 대조군 단백질이 풀링 및 서브트랙션된 항혈청에 결합하기 위해 경쟁하는 능력을 경우에 따라 면역원성 단백질이 항혈청에 결합하기 위해 경쟁하는 능력과 비교하여 측정한다. 다시, 대조군 단백질에 대한 퍼센트 교차 반응성을 표준 계산법에 따라 계산한다. 퍼센트 교차 반응성이 대조군 폴리펩티드에 비해 테스트 폴리펩티드에 있어서 적어도 5 내지 10배 높은 경우, 및/또는 테스트 폴리펩티드의 결합이 대략 면역원성 폴리펩티드의 결합의 범위 내에 있는 경우, 테스트 폴리펩티드는 풀링 및 서브트랙션된 항혈청에 특이적으로 결합하는 것으로 본다.
일반적으로, 면역흡착 및 풀링된 항혈청은 본 명세서에 기재된 바와 같이, 임의의 테스트 폴리펩티드를 면역원성 및/또는 대조군 폴리펩티드에 비교하기 위해 경쟁적 결합 면역분석에 사용될 수 있다. 이와 같은 비교를 위하여, 면역원성, 테스트 및 대조군 폴리펩티드를 넓은 범위의 농도에서 각각 분석하고, 서브트랙션된 항혈청이, 예를 들어, 고정화된 대조, 테스트 또는 면역원성 단백질에 결합하는 것을 50% 억제하는 데 필요한 각 단백질의 양을 표준 기술을 이용하여 측정한다. 경쟁 분석에서 결합에 요구되는 테스트 폴리펩티드의 양이 요구되는 면역원성 폴리펩티드의 양의 두 배보다 작은 경우, 테스트 폴리펩티드는 면역원성 폴리펩티드에 대해 제조된 항체에 특이적으로 결합한다고 할 수 있으며, 단, 그 양은 대조군 폴리펩티드에 대한 것보다 약 5 내지 10배 높은 것이어야 한다.
특이성의 추가 측정으로서, 풀링된 항혈청을 경우에 따라 면역원성 폴리펩티드(대조군 폴리펩티드가 아님)로, 면역원성 단백질로 서브트랙션 및 풀링된 항혈청이 면역흡착에 사용된 면역원성 폴리펩티드에 결합하는 것이 거의 또는 전혀 검출되지 않을 때까지 완전히 면역흡착시킨다. 이와 같이 완전히 면역흡착된 항혈청을 테스트 폴리펩티드와의 반응성에 대해 테스트한다. 반응성이 거의 없거나 전혀 관찰되지 않는 경우(즉, 완전히 면역흡착된 항혈청이 면역원성 폴리펩티드에 결합하는 것에 대해 관찰된 시그널 대 노이즈 비율의 2배 이하인 경우), 테스트 폴리펩티드는 면역원성 단백질에 의해 유발된 항혈청에 의해 특이적으로 결합되는 것이다.
제약 조성물
본 발명의 폴리펩티드 또는 단백질(예를 들어, 합성효소, 하나 이상의 비천연 아미노산을 포함하는 단백질 등)은 경우에 따라 치료용으로, 예를 들어, 적절한 제약용 담체와 함께 사용된다. 그러한 조성물은, 예를 들어, 치료 유효량의 화합물 및 제약상 허용 가능한 담체 또는 부형제를 포함한다. 그러한 담체 또는 부형제는 생리 염수, 완충된 생리 염수, 덱스트로스, 물, 글리세롤, 에탄올 및/또는 이들의 조합을 포함하나, 이에 한정되는 것은 아니다. 제제는 투여 방식에 적절하게 제조된다. 일반적으로, 단백질을 투여하는 방법은 당업계에 잘 알려져 있으며, 본 발명의 폴리펩티드를 투여하는 데에도 적용될 수 있다.
하나 이상의 본 발명의 폴리펩티드를 포함하는 치료 조성물은 경우에 따라 효능, 조직 대사를 확인하기 위해서, 또한 투여량을 결정하기 위해서 당업계에 알려진 방법에 따라 하나 이상의 적절한 시험관내 및/또는 생체내 질병 동물 모델에서 테스트된다. 특히, 투여량은 초기에는 천연 아미노산 동족체에 비교한 본 발명의 비천연 아미노산 변형체의 활성, 안정성 및 다른 적절한 수단을 측정하여(예를 들어, 하나 이상의 비천연 아미노산을 포함하도록 변형된 EPO를 천연 아미노산 EPO와 비교) 관련 분석에서 결정된다.
투여는 분자를 궁극적으로는 혈액 또는 조직 세포와 접촉하도록 도입하는 데 일반적으로 사용되는 경로 중 어느 것에 의해서나 이루어진다. 본 발명의 비천연 아미노산 폴리펩티드는 임의의 적절한 방식으로, 경우에 따라 하나 이상의 제약상 허용 가능한 담체와 함께 투여된다. 본 발명에서 그러한 폴리펩티드를 환자에 투여하는 적절한 방법을 이용할 수 있지만, 2 이상의 경로가 특정 조성물의 투여에 이용될 수 있으며, 또한 어느 한 경로는 종종 다른 경로보다 즉각적이고 효율적인 작용 또는 반응을 제공한다.
제약상 허용 가능한 담체는 부분적으로는 투여되는 조성물뿐만 아니라 그 조성물을 투여하는 데 사용되는 방법에 의해 결정된다. 따라서 아주 광범위한 약학 제제로 본 발명의 제약 조성물을 제형화할 수 있다.
폴리펩티드 조성물은 각종 경로, 예를 들어, 경구, 정맥내, 복강내, 근육내, 경피, 피하, 국소, 설하, 또는 직장내 투여될 수 있으나, 투여 경로가 이에 한정되는 것은 아니다. 비천연 아미노산 폴리펩티드 조성물은 또한 리포좀을 통해 투여될 수 있다. 그러한 투여 경로 및 적절한 제형은 당업자에게 일반적으로 알려져 있다.
비천연 아미노산 폴리펩티드는 단독으로 또는 다른 적절한 성분과 함께 흡입 투여를 위해 에어로졸 제제(즉, "분무화"될 수 있음)로 만들어질 수 있다. 에어로졸 제제는 가압된 허용 가능한 추진제, 예컨대, 디클로로디플루오로메탄, 프로판, 질소 내로 제제화된다.
비경구 투여, 예를 들어, 관절내(관절강 내로), 정맥내, 근육내, 피내, 복강내 및 피하 경로에 적절한 제제는 수성 및 비수성, 등장성 멸균 주사 용액(이러한 제제는 항산화제, 완충제, 정균제, 제제를 의도하는 수약자의 혈액과 등장성으로 만드는 용질을 함유할 수 있음), 및 수성 및 비수성 멸균 현탁액(현탁화제, 용해제, 증점제, 안정화제 및 보존제를 함유할 수 있음)을 포함한다. 포장된 핵산의 제제는 앰풀이나 바이알 같은, 일회 투여 또는 복수회 투여 밀봉 용기에 존재할 수 있다.
비경구 및 정맥 투여가 바람직한 투여 방법이다. 특히, 천연 아미노산 동족체 체료제에 이미 사용되고 있는 경로(예를 들어, EPO, GCSF, GMCSF, IFN, 인터루킨, 항체 및/또는 임의의 다른 약제로서 전달되는 단백질에 일반적으로 사용되는 경로)는 현재 사용되고 있는 제제와 함께 본 발명의 비천연 아미노산을 포함하는 단백질(예를 들어, 현재의 치료용 단백질의 PEG화 변형체 등)에 바람직한 투여 경로 및 제제를 제공한다.
본 발명과 관련하여 환자에 투여되는 용량은 환자에 있어서 시간이 지남에 따라 유익한 치료 반응을 나타내거나, 또는, 예를 들어, 적용증에 따라 병원체에 의한 감염 또는 다른 적절한 활성을 억제하는 데 충분한 양이다. 투여량은 특정 조성물/제제의 효능, 사용된 비천연 아미노산을 포함하는 폴리펩티드의 활성, 안정성, 또는 혈청 반감기 및 환자의 상태뿐만 아니라 치료될 환자의 체중 또는 체표면적에 의해 결정된다. 투여량 크기는 또한 특정 환자에서 특정 조성물/제제의 투여에 수반되는 부작용의 존재, 성질 및 정도에 따라 결정된다.
질병(예를 들어, 암, 유전병, 당뇨병, AIDS 등)의 치료 또는 예방에서 투여될 조성물/제제의 유효량을 결정함에 있어서, 의사는 순환 혈장 수준, 제제 독성, 질병의 진행 및/또는 관련있는 경우, 항-비천연 아미노산 폴리펩티드 항체의 제조를 고려할 것이다.
예를 들어, 체중 70 kg의 환자에게 투여되는 용량은, 일반적으로는 현재 사용되고 있는 치료용 단백질의 투여량과 동등한 범위 내이며, 관련 조성물의 변화된 활성 또는 혈청 반감기에 따라 조정된다. 본 발명의 조성물/제제는 알려진 통상의 치료법, 비제한적인 예로서, 항체 투여, 백신 투여, 세포독성제, 비천연 아미노산 폴리펩티드, 핵산, 뉴클레오티드 유사체, 생물 반응 개질제의 투여 등에 의해 치료 조건을 증진시킬 수 있다.
투여에 있어서, 본 발명의 제제는 관련 제제의 LD50, 및/또는 환자의 전반적 건강 상태를 고려하여 각종 농도에서 비천연 아미노산의 부작용 여부 관찰에 의해 결정된 비율로 투여된다. 투여는 단일회로 또는 분할 투여로 이루어질 수 있다.
제제의 주입을 받는 환자가 발열, 오한 또는 근육 통증을 나타내는 경우, 그 환자는 적절한 양의 아스피린, 이부프로펜, 아세트아미노펜 또는 다른 통증/발열 조절 약물을 투여받는다. 주입에 대해 발열, 근육통 및 오한을 경험한 환자에게는 차후의 주입 30분 전에 아스피린, 아세트아미노펜, 예를 들어, 디펜히드라민을 미리 투약한다. 메페리딘은 해열제 및 항히스타민제에 신속히 반응하지 않는 보다 강한 오한 및 근육통에 사용된다. 치료는 반응의 심각도에 따라서 속도를 늦추거나 불연속적으로 실시된다.
핵산 및 폴리펩티드 서열 및 변이체
본 명세서에 기재된 바와 같이, 본 발명은 핵산 폴리뉴클레오티드 서열 및 폴리펩티드 아미노산 서열, 예를 들어, O-tRNA 및 O-RS, 및 예를 들어, 이들 서열을 포함하는 조성물 및 방법을 제공한다. 상기 서열의 예, 예를 들어, O-tRNA 및 O-RS의 예가 본 명세서에 개시되어 있다(표 5, 예컨대, 서열 번호 3 내지 65, 86, 서열 번호 1 및 2를 제외한 다른 서열). 그러나, 당업자는 본 발명이 본 명세서, 예를 들어, 실시예 및 표 5에 개시된 서열에만 한정되는 것이 아니라는 것을 잘 알 것이다. 당업자는 또한 본 발명이 본 명세서에 기재된 기능, 예를 들어, O-tRNA 또는 O-RS를 코딩하는 것과 관련된 많은 서열 및 심지어는 관련되지 않은 서열도 제공한다는 것을 알 것이다.
본 발명은 또한 폴리펩티드(O-RS) 및 폴리뉴클레오티드, 예를 들어, O-tRNA, O-RS 또는 그 일부분을 코딩하는 폴리뉴클레오티드(예를 들어, 합성효소의 활성 부위), 아미노아실-tRNA 합성효소 변이체를 제작하기 위한 올리고뉴클레오티드를 제공한다. 예를 들어, 본 발명의 폴리펩티드는 서열 번호 36 내지 63 및/또는 86 중 어느 하나에 개시된 아미노산 서열을 포함하는 폴리펩티드, 서열 번호 3 내지 35 중 어느 하나에 개시된 폴리뉴클레오티드 서열에 의해 코딩되는 아미노산 서열을 포함하는 폴리펩티드, 및 서열 번호 36 내지 63 및/또는 86 중 어느 하나에 개시된 아미노산 서열을 포함하는 폴리펩티드 또는 서열 번호 3 내지 35 중 어느 하나에 개시된 폴리뉴클레오티드 서열에 의해 코딩되는 아미노산 서열을 포함하는 폴리펩티드에 특이적인 항체와 특이적으로 면역반응하는 폴리펩티드를 포함한다.
본 발명의 폴리펩티드 중에는, 천연 타이로실 아미노아실-tRNA 합성효소(TyrRS)의 아미노산 서열(예를 들어, 서열 번호 2)과 적어도 90% 일치하는 아미노산 서열을 포함하며, 그룹 A 내지 E의 아미노산 2 이상을 포함하는 폴리펩티드가 포함된다. 예를 들어, 그룹 A는 이 콜라이 TyrRS의 Tyr37에 상응하는 위치에 발린, 이소루신, 루신, 글리신, 세린, 알라닌 또는 트레오닌을 포함하고; 그룹 B는 이 콜라이 TyrRS의 Asn126에 상응하는 위치에 아스파르테이트를 포함하며, 그룹 C는 이 콜라이 TyrRS의 Asp182에 상응하는 위치에 트레오닌, 세린, 아르기닌, 아스파라긴 또는 글리신을 포함하며, 그룹 D는 이 콜라이 TyrRS의 Phe183에 상응하는 위치에 메티오닌, 알라닌, 발린 또는 타이로신을 포함하며; 그룹 E는 이 콜라이 TyrRS의 Leu186에 상응하는 위치에 세린, 메티오닌, 발린, 시스테인, 트레오닌 또는 알라닌을 포함한다. 마찬가지로, 본 발명의 폴리펩티드는 또한 서열 번호 36 내지 63, 및/또는 86의 적어도 20개의 연속 아미노산을 포함하며, 그룹 A-E에서 상기한 바와 같은 2 이상의 아미노산 치환을 갖는 폴리펩티드를 포함한다. 또한, 표 4, 6 및/또는 표 8을 참조할 수 있다. 상기 폴리펩티드의 보존적 변이를 포함하는 아미노산 서열 또한 본 발명의 폴리펩티드에 포함된다.
일 실시태양에 있어서, 조성물은 본 발명의 폴리펩티드 및 부형제(예를 들어, 완충제, 물, 제약상 허용 가능한 부형제 등)를 포함한다. 본 발명은 또한 본 발명의 폴리펩티드와 특이적 면역반응성을 나타내는 항체 또는 항혈청을 제공한다.
본 발명에 의하면 폴리뉴클레오티드 역시 제공된다. 본 발명의 폴리뉴클레오티드는 본 발명의 관심있는 단백질 또는 폴리펩티드를 코딩하는 폴리뉴클레오티드, 또는 하나 이상의 셀렉터 코돈을 포함하는 폴리뉴클레오티드, 또는 둘 다를 포함하는 폴리뉴클레오티드를 포함한다. 예를 들어, 서열 번호 3 내지 35, 64 내지 85 중 어느 하나에 개시된 뉴클레오티드 서열을 포함하는 폴리뉴클레오티드; 그러한 서열에 상보적이거나 이의 폴리펩티드 서열을 코딩하는 폴리뉴클레오티드; 및/또는 서열 번호 36 내지 63 및/또는 86 중 어느 하나에 개시된 아미노산 서열을 포함하는 폴리펩티드를 코딩하는 폴리뉴클레오티드, 또는 이의 보존적 변이체를 포함한다. 본 발명의 폴리뉴클레오티드는 또한 본 발명의 폴리펩티드를 코딩하는 폴리뉴클레오티드를 포함한다. 마찬가지로, 상기한 폴리뉴클레오티드에 실질적으로 핵산의 전 길이에 걸쳐 고엄격 조건하에 하이브리드화하는 핵산도 또한 본 발명의 폴리뉴클레오티드이다.
본 발명의 폴리뉴클레오티드는 또한 천연 타이로실 아미노아실-tRNA 합성효소(TyrRS)의 서열(예를 들어, 서열 번호 2)과 적어도 90% 동일한 아미노산 서열을 포함하며, 상기한 바와 같은 그룹 A 내지 E에 속하는 2 이상의 치환을 포함하는 폴리펩티드를 코딩하는 폴리뉴클레오티드를 포함한다. 상기한 폴리뉴클레오티드와 적어도 70%, (또는 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 98%, 또는 적어도 99% 또는 그 이상) 동일한 폴리뉴클레오티드, 및/또는 상기한 폴리뉴클레오티드 중 어느 하나의 보존적 변이를 포함하는 폴리뉴클레오티드도 또한 본 발명의 폴리뉴클레오티드에 속한다.
일부 실시태양에 있어서, 벡터(예를 들어, 플라스미드, 코스미드, 파지, 바이러스 등)는 본 발명의 폴리뉴클레오티드를 포함한다. 일 실시태양에 있어서, 벡터는 발현 벡터이다. 또 다른 실시태양에 있어서, 발현 벡터는 하나 이상의 본 발명의 폴리뉴클레오티드에 작동 가능하게 연결된 프로모터를 포함한다. 또 다른 실시태양에 있어서, 세포는 본 발명의 폴리뉴클레오티드를 포함하는 벡터를 포함한다.
당업자는 개시된 서열의 많은 변이체가 본 발명에 포함된다는 것을 알 것이다. 예를 들어, 기능적으로 동일한 서열을 제조하는, 개시된 서열의 보존적 변이체가 본 발명에 포함된다. 핵산 폴리뉴클레오티드 변이체는, 그와 같은 변이체가 적어도 하나의 개시된 서열에 하이브리드화할 때, 본 발명에 포함되는 것으로 간주된다. 본 명세서에 개시된 서열의, 예를 들어, 표준 서열 비교 기법에 의해 결정된 바와 같은 독특한 부분서열이 또한 본 발명에 포함된다.
보존적 변이
유전자 코드의 축퇴성으로 인해, "침묵 치환"(즉, 코딩된 폴리펩티드에 변화를 가져오지 않는 핵산 서열 중의 치환)은 아미노산을 코딩하는 모든 핵산 서열의 내재된 특징이다. 마찬가지로, 아미노산 서열 중 하나 또는 여러 개의 아미노산이 매우 유사한 특성의 다른 아미노산으로 치환되는 것인 "보존적 아미노산 치환"도 또한 개시된 구성체에 매우 유사한 것으로 쉽게 밝혀진다. 개시된 각 서열의 보존적 변이체는 본 발명의 특징이다.
특정 핵산 서열의 보존적 변이체는 동일하거나 실질적으로 동일한 아미노산 서열을 코딩하는 핵산, 또는 핵산이 아미노산 서열을 코딩하고 있지 않은 경우, 실질적으로 동일한 서열을 이르는 말이다. 당업자는 코딩된 서열에서 단일 아미노산 또는 소수 퍼센트(일반적으로는 5% 미만, 보다 일반적으로는 4%, 2% 또는 1% 미만)의 아미노산을 변화, 부가, 결실시키는 개개의 치환, 결실 또는 부가는, 그러한 변화가 아미노산의 결실, 아미노산의 부가 또는 화학적으로 유사한 아미노산으로의 치환을 가져오는 경우, "보존적으로 변형된 변이체"라는 것을 잘 인식하고 있다. 본 발명의 목록에 개시된 폴리펩티드 서열의 "보존적 변이체"는 폴리펩티드 서열 중 소수 퍼센트, 일반적으로는 5% 미만, 보다 일반적으로는 2% 또는 1% 미만의 아미노산이 동일한 보존적 치환 군에 속하는 보존적으로 선택된 아미노산으로 치환되는 것을 포함한다. 마지막으로, 핵산 분자의 코딩된 활성을 변화시키지 않는 서열의 부가, 예를 들어, 비기능적 서열의 부가는 기초 핵산의 보존적 변이체 이다.
기능적으로 유사한 아미노산을 제공하는 보존적 치환의 표가 당업계에 잘 알려져 있다. 다음 표는 서로에 대해 "보존적 치환"을 포함하는 천연 아미노산을 포함하는 군의 예를 나타내고 있다.
| 보존적 치환 군 | |
| 1 | 알라닌(A) 세린(S) 트레오닌(T) |
| 2 | 아스파르트산(D) 글루탐산(E) |
| 3 | 아스파라긴(N) 글루타민(Q) |
| 4 | 아르기닌(R) 리신(K) |
| 5 | 이소루신(I) 루신(L) 메티오닌(M) 발린(V) |
| 6 | 페닐알라닌(F) 타이로신(Y) 트립토판(W) |
핵산 하이브리드화
비교 하이브리드화를 이용하여 이의 보존적 변이체를 포함하는 본 발명의 핵산을 찾아낼 수 있으며, 이 비교 하이브리드화 방법은 본 발명의 핵산을 구별하는 바람직한 방법이다. 또한, 고도, 초고도, 및 최고 초고도의 엄격한 조건하에 서열 번호 3 내지 35, 64 내지 85에 하이브리드화하는 표적 핵산이 본 발명의 특징이다. 그러한 핵산의 예는 주어진 서열에 비하여 하나 또는 여러 개의 침묵 또는 보존적 핵산 치환을 갖는 핵산을 포함한다.
테스트 핵산은 그것이 완전히 매칭된 상보적 표적에 하이브리드화하는 것의 적어도 1/2의 정도로 프로브에 하이브리드화할 때, 즉, 완전하게 매칭된 프로브가 완전하게 매칭된 상보적 표적에 임의의 비매칭된 표적 핵산에 하이브리드화하는 것에 대해 관찰되는 값의 적어도 약 5 내지 10배 높은 시그널 대 노이즈 비율로 하이브리드화하는 조건하에 프로브가 표적에 하이브리드화하는 것의 적어도 1/2만큼 높은 시그널 대 노이즈 비율로 프로브에 하이브리드화할 때, 프로브 핵산에 특이적으로 하이브리드화한다고 말해진다.
핵산은 이들이 일반적으로는 용액 중에서 회합될 때 "하이브리드화"한다. 핵산은 각종의 잘 특성화된 물리화학적 힘, 예를 들어, 수소 결합, 용매 배제, 염기 스택킹 등에 의해 하이브리드화한다. 핵산의 하이브리드화에 대한 광범위한 지침 사항이 문헌(Tijssen(1993) Laboratory Techniques in Biochemistry and Molecular Biology--Hybridization with Nucleic Acid Probes part I chapter 2, "Overview of principles of hybridization and the strategy of nucleic acid probe assays," (Elsevier, New York), and Ausubel, supra)에 기재되어 있다. 또한, 문헌(Hames and Higgins(1995) Gene Probes 1 IRL Press at Oxford University Press, Oxford, England, (Hames and Higgins 1) and Hames and Higgins(1995) Gene Probes 2 IRL Press at Oxford University Press, Oxford, England(Hames and Higgins 2))은 올리고뉴클레오티드를 포함하는 DNA 및 RNA의 합성, 표지, 검출 및 정량에 관해 상세하게 기재하고 있다.
서던 또는 노던 블롯 중 필터 상의 100개를 넘는 상보적 잔기를 갖는 상보적 핵산의 하이브리드화를 위한 엄격한 하이브리드화 조건의 예는, 42℃에서 1 mg의 헤파린과 함께 50% 포르말린을 사용하여 밤새 수행하는 것이다. 엄격한 세척 조건의 예는 65℃에서 15분간의 0.2 x SSC 세척이다(SSC 완충액에 관해서는 상기 Sambrook의 문헌 참조). 종종 고엄격도 세척을 하기 전에 저엄격도 세척을 선행하여 백그라운드 프로브 시그널을 제거한다. 저엄격도 세척의 예는 40℃에서 15분간의 2 x SSC 세척이다. 일반적으로, 특정 하이브리드화 분석에서 관련 없는 프로브에 대해 관찰된 값의 5배가 넘는(높은) 시그널 대 노이즈 비율은 특이적 하이브리드화의 검출을 나타낸다.
서던 및 노던 하이브리드화와 같은 핵산 하이브리드화 실험과 관련하여 "엄격한 하이브리드화 세척 조건"은 서열에 따라 달라지는 것이며, 다른 환경 파라미터 하에 달라진다. 핵산의 하이브리드화에 관한 광범위한 지침은 문헌(Tijssen(1993), supra, and in Hames and Higgins, 1 and 2)에 나타나 있다. 엄격한 하이브리드화 및 세척 조건은 어느 테스트 핵산에 대해서나 경험적으로 쉽게 결정될 수 있다. 예를 들어, 고도로 엄격한 하이브리드화 및 세척 조건을 결정함에 있어서, 선택된 세트의 기준이 충족될 때까지 하이브리드화 및 세척 조건을 점차적으로 증가시킨다(예를 들어, 온도를 증가시키거나, 염 농도를 감소시키거나, 세척제 농도를 증가시키고(거나) 하이브리드화 또는 세척 중에 포르말린과 같은 유기 용매의 농도를 증가시킨다). 예를 들어, 프로브가 완전하게 매칭된 상보적 표적에, 매칭되지 않는 표적에 하이브리드화하는 것에 대해 관찰된 값보다 적어도 5배 높은 시그널 대 노이즈 비율로 결합할 때까지 하이브리드화 및 세척 조건을 점차적으로 증가시킨다.
"매우 엄격한" 조건은 특정 프로브에 대한 열 융점(Tm)과 같아지도록 선택된다. Tm은 테스트 서열의 50%가 완전하게 매칭된 프로브에 하이브리드화하는 온도(소정의 이온 강도 및 pH 하의)이다. 본 발명에서, 일반적으로 "고도로 엄격한" 하이브리드화 및 세척 조건은 정의된 이온 강도 및 pH에서 특정 서열에 대한 Tm보다 약 5℃ 더 낮은 온도가 되도록 선택된다.
"초고도로 엄격한" 하이브리드화 및 세척 조건은 프로브가 완전하게 매칭된 상보적 표적에, 매칭되지 않은 표적 핵산에 하이브리드화하는 것에 대해 관찰된 값보다 적어도 10 배 높은 시그널 대 노이즈 비율로 결합할 때까지 하이브리드화 및 세척 조건을 점차적으로 증가시킨 하이브리드화 및 세척 조건이다. 그러한 조건하에 완전하게 매칭된 상보적 표적 핵산에 대한 값의 적어도 1/2의 시그널 대 노이즈 비율로 프로브에 하이브리드화하는 표적 핵산은 프로브에 초고도 엄격도 조건하에 결합하다고 말해진다.
마찬가지로, 보다 높은 수준의 엄격도는 관련 하이브리드화 분석의 하이브리드화 및 세척 조건을 점차적으로 증가시켜 결정될 수 있다. 예를 들어, 프로브가 완전하게 매칭된 상보적 표적에, 매칭되지 않은 표적에 하이브리드화하는 것에 대해 관찰된 값보다 적어도 10배, 20배, 50배, 100배 또는 500배 또는 그 이상의 배수로 높은 시그널 대 노이즈 비율로 결합할 때까지 점차적으로 증가시킨 하이브리드화 및 세척 조건을 예로 들 수 있다. 그러한 조건하에 완전하게 매칭된 상보적 표적 핵산에 대한 값의 적어도 1/2의 시그널 대 노이즈 비율로 프로브에 하이브리드화하는 표적 핵산은 프로브에 최고 초고도의 엄격도 조건하에 결합한다고 한다.
엄격한 조건하에 서로 하이브리드화하지 않는 핵산일지라도 이들이 코딩하는 폴리펩티드가 실질적으로 동일하면 실질적으로 동일하다. 이러한 경우는, 예를 들어, 핵산의 한 카피가 유전자 코드에 의해 허용되는 최대의 코돈 축퇴성을 이용하여 생성되는 경우에 일어난다.
독특한 부분서열
일 측면에 있어서, 본 발명은 명세서에 개시된 O-tRNA 및 O-RS의 서열로부터 선택된 핵산 중의 독특한 부분서열을 포함하는 핵산을 제공한다. 독특한 부분서열은 임의의 공지된 O-tRNA 또는 O-RS 핵산 서열에 상응하는 핵산과 비교하여 독특하다. 정렬은, 예를 들어, 디폴트 파라미터로 설정된 BLAST를 이용하여 수행할 수 있다. 어느 독특한 부분서열이나, 예를 들어, 본 발명의 핵산을 찾아내는 프로브로서 유용하다.
마찬가지로, 본 발명은 본 명세서 개시된 O-RS의 서열로부터 선택된 폴리펩티드 중의 독특한 부분서열을 포함하는 폴리펩티드를 포함한다. 여기서, 독특한 부분서열이란 임의의 공지된 폴리펩티드 서열에 상응하는 폴리펩티드와 비교하여 독특한 것을 의미한다.
본 발명은 또한 O-RS의 서열로부터 선택된 폴리펩티드 중의 독특한 부분서열을 코딩하는 독특한 코딩 올리고뉴클레오티드에 엄격한 조건하에 하이브리드화하는 표적 핵산을 제공하며, 여기서 독특한 부분서열은 임의의 대조군 폴리펩티드(예를 들어, 본 발명의 합성효소가 돌연변이에 의해 그로부터 유래된 패어런트 서열)에 상응하는 폴리펩티드에 비하여 독특한 것이다. 독특한 부분서열은 상기한 바와 같이 결정된다.
서열 비교, 동일성 및 상동성
2 이상의 핵산 또는 폴리펩티드 서열에 있어서, "동일한" 또는 퍼센트 "동일성"이란 2 이상의 서열 또는 부분서열이 최대 일치를 위해 비교 및 정렬되었을 때, 하기 서열 비교 알고리즘 중 하나(또는 당업자가 이용할 수 있는 다른 알고리즘)를 이용하여 또는 시각적 조사에 의해 측정된 바, 동일하거나 특정 퍼센트 동일한 아미노산 잔기 또는 뉴클레오티드를 갖는 것을 의미한다.
두 핵산 또는 폴리펩티드(예를 들어, O-tRNA 또는 O-RS를 코딩하는 DNA, 또는 O-RS의 아미노산 서열)와 관련하여 "실질적으로 동일한"이란 2 이상의 서열 또는 부분서열이 최대 일치를 위해 비교 및 정렬되었을 때, 서열 비교 알고리즘을 이용하여 또는 시각적 조사에 의해 측정된 바, 적어도 약 60%, 바람직하게는 80%, 가장 바람직하게는 90 내지 95%에 이르는 뉴클레오티드 또는 아미노산 잔기 동일성을 갖는 것을 의미한다. 그러한 "실질적으로 동일한" 서열은 실제적인 조상에 대한 언급이 없이, 일반적으로 "상동성"인 것으로 간주된다. 바람직하게는, "실질적 동일성"은 길이에 있어서 적어도 약 50개 잔기의 서열 영역에 걸쳐서, 보다 바람직하게는, 길이에 있어서 적어도 약 100개 잔기의 서열 영역에 걸쳐서 존재하며, 가장 바람직하게는 비교되는 두 서열의 적어도 약 150개 잔기에 걸쳐 또는 전체 길이에 걸쳐 실질적으로 동일하다.
서열 비교 및 상동성 결정에 있어서, 일반적으로 하나의 서열이 표준 서열로 작용하고, 이에 테스트 서열을 비교한다. 서열 비교 알고리즘을 사용할 때, 테스트 서열 및 표준 서열을 컴퓨터 내로 입력하고, 필요에 따라 부분서열 좌표를 지정하고, 서열 알고리즘 프로그램 파라미터를 지정한다. 서열 비교 알고리즘은 지정된 프로그램 파라미터에 기초하여 표준 서열에 대한 테스트 서열의 퍼센트 동일성을 계산한다.
비교를 위한 서열의 최적 정렬은, 예를 들어, 국부적 상동성 알고리즘에 의해(Smith & Waterman, Adv. Appl. Math. 2:482(1981)), 상동성 정렬 알고리즘에 의해(Needleman & Wunsch, J. Mol. Biol. 48:443(1970)), 유사성 방법을 검색하여(Pearson & Lipman, Proc. Nat'l. Acad. Sci. USA 85:2444(1988)), 이들 알고리즘의 컴퓨터화 실행에 의해(GAP, BESTFIT, FASTA, and TFASTA in the Wisconsin Genetics Software Package, Genetics Computer Group, 575 Science Dr., Madison, WI), 또는 시각적 조사에 의해(Ausubel et al., infra)에 의해 수행될 수 있다.
퍼센트 서열 동일성 또는 서열 유사성을 결정하는 데 적절한 알고리즘의 한 예는 BLAST 알고리즘으로서, 이는 문헌(Altschul et al., J. Mol. Biol. 215:403-410(1990))에 기재되어 있다. BLAST 분석을 수행하기 위한 소프트웨어는 국립생물공학 정보센터(the National Center for Biotechnology Information; www.ncbi.nlm.nih.gov/)를 통해 공개적으로 이용이 가능하다. 이 알고리즘은 대상 서열에서 길이 W의 짧은 워드(word)를 찾아내어 제일 먼저 하이 스코어링 서열 쌍(HSP)을 찾는 것을 포함하며, 이는 데이터베이스 서열 중 같은 길이의 워드와 정렬될 때 매칭되거나 어느 정도 양의 값의 한계치 스코어 T를 충족시킨다. T는 이웃 워드 스코어 한계치로 불리운다(Altschul et al., supra). 이들 초기의 이웃 워드 히트는 그들을 함유하는 더 긴 길이의 HSP를 찾기 위한 검색을 개시하는 시드(seed)로서 작용한다. 워드 히트는 이어서 누적 정렬 스코어가 증가될 수 있는 한 각 서열을 따라서 양 방향으로 연장된다. 누적 스코어는, 뉴클레오티드 서열에 대해서 파라미터 M(매칭된 잔기의 쌍에 대한 리워드 스코어; 항상 0보다 큼) 및 N(미스매칭된 잔기에 대한 패널티 스코어; 항상 0보다 작음)을 사용하여 계산된다. 아미노산 서열에 대해서는, 누적 스코어를 계산하기 위해 스코어링 매트릭스를 이용한다. 각 방향으로의 워드 히트의 연장은 누적 정렬 스코어가 얻어진 최대 값으로부터 수량 X만큼 떨어졌을 때, 누적 스코어가 하나 이상의 음의 값의 스코어링 잔기 정렬의 누적으로 인해 0 또는 그 이하로 내려갈 때, 또는 서열의 어느 한 쪽 말단에 달했을 때 정지된다. BLAST 알고리즘 파라미터 W, T, 및 X는 정렬의 감도 및 속도를 결정한다. BLASTN 프로그램(뉴클레오티드 서열용)은 디폴트로서 워드 길이(W) 11, 기대치(E) 10, 컷 오프 100, M=5, N=-4, 및 두 서열 모두 비교를 사용한다. 아미노산 서열에 대해, BLASTP 프로그램은 디폴트로서 워드 길이(W) 3, 기대치(E) 10, 및 BLOSUM62 스코어링 매트릭스(Henikoff & Henikoff(l989) Proc. Natl. Acad. Sci. USA 89: 109151)를 사용한다.
퍼센트 서열 동일성을 계산하는 것 이외에, BLAST 알고리즘은 또한 두 서열 사이의 통계적 유사성 분석을 수행한다(예를 들어, Karlin & Altschul, Proc. Nat'l. Acad. Sci. USA 90:5873-5787(1993)). BLAST 알고리즘에 의해 제공되는 하나의 유사도 척도는 최소 합계 확률(P(N))로서, 이는 두 뉴클레오티드 또는 아미노산 서열 간의 매치가 우연히 일어날 확률을 나타내는 것이다. 예를 들어, 핵산은 그를 표준 핵산과 비교하여 최소 합계 확률이 약 0.1 미만, 보다 바람직하게는 약 0.01 미만, 가장 바람직하게는 약 0.001 미만인 경우, 표준 서열에 유사한 것으로 간주된다.
돌연변이 유발 및 다른 분자생물학 기술
분자생물학적 기술을 기재하고 있는 일반 서적은 문헌(Berger and Kimmel, Guide to Molecular Cloning Techniques, Methods in Enzymology volume 152 Academic Press, Inc., San Diego, CA(Berger); Sambrook et al., Molecular Cloning - A Laboratory Manual(2nd Ed), Vol. 1-3. Cold Spring Harbor Laboratory, Cold Spring Harbor, New York, 1989("Sambrook") and Current Protocols in Molecular Biology. F.M. Ausubel et al., eds., Current Protocols, a joint venture between Greene Publishing Associates, Inc. and John Wiley & Sons, Inc., (supplemented through 1999)("Ausubel"))을 포함한다. 이들 서적은 돌연변이 유발, 벡터의 사용, 플라스미드 및 람다 파지를 위한 DNA 제조, 프로모터 및 예를 들어, 비천연 아미노산을 포함하는 단백질 제조를 위한 셀렉터 코돈을 포함하는 유전자, 오르소고날 tRNA, 오르소고날 합성효소 및 이들의 쌍의 제조과 관련된 많은 다른 관련 주제를 기재하고 있다.
각종 유형의 돌연변이 유발법을 본 발명에서 사용하여, 예를 들어, tRNA 라이브러리를 제조하거나, 합성효소 라이브러리를 제조하거나, 관심있는 단백질 또는 폴리펩티드 중 비천연 아미노산을 코딩하는 셀렉터 코돈을 삽입한다. 이들 방법은 부위 특이적, 무작위 점 돌연변이 유발, 상동 재조합, DNA 셔플링 또는 다른 반복적 돌연변이 유발법, 키메라 제작, 우라실 함유 주형을 사용한 돌연변이 유발, 올리고뉴클레오티드 유도 돌연변이 유발, 포스포로티오에이트 변형 DNA 돌연변이 유발, 갭이 있는 이중 가닥 DNA를 사용한 돌연변이 유발 또는 이들의 조합을 포함하나, 이에 한정되는 것은 아니다. 또 다른 적절한 방법은 포인트 미스매치 복구, 수복 결함 숙주를 이용한 돌연변이 유발, 제한 선택 및 제한 정제, 결실 돌연변이 유발, 전체 유전자 합성에 의한 돌연변이 유발, 이중 가닥 파괴 복구 등을 포함한다. 예를 들어, 키메라 구성체를 포함하는 돌연변이 유발도 본 발명에 포함된다. 일 실시태양에 있어서, 돌연변이 유발은 천연 분자, 또는 변경되거나 돌연변이된 천연 분자에 대한 공지된 정보, 예를 들어, 서열, 서열 비교, 물리적 특성, 결정 구조 등에 의해 가이딩될 수 있다.
상기 서적 및 본 명세서의 실시예는 이들 과정을 기재하고 있다. 추가 정보는 하기 간행물들 및 이들에 인용된 참고 문헌에 기재되어 있다:


상기한 방법들 중 많은 방법에 대한 상세한 사항을 문헌(Methods in Enzymology Volume 154)에서 찾아볼 수 있으며, 이 문헌은 또한 각종 돌연변이 유발법에 있어서의 문제 해결을 위한 유용한 수단을 기재하고 있다.
본 발명은 또한 비천연 아미노산을 오르소고날 tRNA/RS 쌍을 통해 생체내에 통합시키기 위한 척추동물 숙주 세포 및 생물에 관한 것이다. 숙주 세포는 본 발명의 폴리뉴클레오티드 또는 본 발명의 폴리뉴클레오티드를 포함하는 구성체, 예를 들어, 클로닝 벡터 또는 발현 벡터일 수 있는 본 발명의 벡터로 유전적으로 조작(예를 들어, 형질전환, 형질도입 또는 형질감염)된다. 벡터는, 예를 들어, 플라스미드, 박테리아, 바이러스, 네이키드 폴리뉴클레오티드, 또는 접합 폴리뉴클레오티드일 수 있다. 벡터를 전기천공(From et al., Proc. Natl. Acad. Sci. USA 82, 5824(1985)), 바이러스 벡터에 의한 감염, 작은 비드 또는 입자의 매트릭스 내에 또는 표면 상에 핵산을 갖는 소립자의 고속 탄도 침투(Klein et al., Nature 327, 70-73(1987)) 등을 포함하는 표준 방법으로 세포 및/또는 미생물 내로 도입한다.
조작된 숙주 세포는 스크리닝 단계, 프로모터 활성화 또는 형질전환체 선택 등의 단계에서 필요에 따라 적절히 보충된 통상의 영양 배지 중에서 배양된다. 이들 세포는 경우에 따라 트랜스제닉 유기체 내에서 배양될 수 있다. 예컨대, 세포 단리 및 배양(예를 들어, 후속되는 핵산 단리를 위한)에 대한 다른 유용한 참고 문헌으로는 문헌(Freshney(1994) Culture of Animal Cells, a Manual of Basic Technique, third edition, Wiley-Liss, New York and the references cited therein; Payne et al(1992) Plant Cell and Tissue Culture in Liquid Systems John Wiley & Sons, Inc. New York, NY; Gamborg and Phillips(eds)(1995) Plant Cell. Tissue and Organ Culture; Fundamental Methods Springer Lab Manual, Springer-Verlag(Berlin Heidelberg New York) and Atlas and Parks(eds) The Handbook of Microbiological Media(1993) CRC Press, Boca Raton, FL)이 있다.
본 발명은 또한 오르소고날 tRNA/RS 쌍을 통해 비천연 아미노산을 도입하는 능력을 갖는 척추동물 세포주에 관한 것이다. 이들 세포주는 본 발명의 폴리뉴클레오티드 또는 본 발명의 폴리뉴클레오티드를 포함하는 구성체로 형질전환, 형질도입 또는 형질감염된 숙주 세포에 관해 당업계에 알려져 있는 세포 배양 기술을 사용하여 수립될 수 있다. 이와 같은 기술은 덱스트란 매개 형질감염, 인산칼슘 침전, 염화칼슘 처리, 폴리브렌 매개 형질감염, 프로토플라스트 융합, 전기천공, 바이러스 또는 파지 감염, 폴리뉴클레오티드의 리포좀 내 캡슐화, 및 직접 미세주사를 포함하나, 이에 한정되는 것은 아니다.
세포는 DNA가 일시적으로 또는 안정적으로 도입될 수 있게 하는 방식으로 형질전환 또는 형질감염된다. 재조합 단백질의 장기간 고수율 제조를 위해서는 안정한 발현이 바람직하다. 예를 들어, 항체 분자를 안정하게 발현하는 세포주가 조작될 수 있다. 바이러스 복제 기점을 함유하는 발현 벡터를 사용하기 보다는 숙주 세포를 적절한 발현 조절 요소(예를 들어, 프로모터, 인핸서, 서열, 전사 터미네이터, 폴리아데닐화 위치 등)에 의해 조절되는 DNA 및 선택 마커에 의해 형질전환시킬 수 있다. 외래 DNA를 도입한 후에, 조작된 세포를 풍부한 배지에서 1 내지 2일 동안 배양한 후, 선택 배지로 옮긴다. 재조합 플라스미드 중 선택 마커는 선택에 대한 내성을 부여하며, 세포로 하여금 플라스미드를 염색체 내로 안정하게 통합하게 하며, 성장하여 다시 클로닝되어 세포주로 확장될 수 있는 중심을 형성하게 한다. 이 방법을 사용하여 항체 분자를 발현하는 세포주를 조작한다. 그러한 조작된 세포주는 항체 분자와 직접적으로 또는 간접적으로 상호작용하는 화합물을 스크리닝하고 평가하는 데 유용하다. 또한, 당업계에 잘 알려진 다른 기술, 예컨대, 바이러스 매개 벡터 형질감염 기술로 세포를 임시적으로 형질감염할 수 있다.
표적 핵산을 세포 내로 도입하는 몇몇 잘 알려진 방법을 이용할 수 있으며, 그 중 어느 것이나 본 발명에 사용할 수 있다. 이들 방법은, 수용 세포와 DNA를 함유하는 박테리아 프로토플라스트의 융합, 전기천공, 발사 충격 및 바이러스 벡터로 감염(하기 설명함) 등을 포함한다. 박테리아 세포는 본 발명의 DNA 구성체를 함유하는 플라스미드의 수를 증폭시키는 데 사용할 수 있다. 박테리아를 로그 단계로 성장시킨 다음, 박테리아 내의 플라스미드를 당업계에 알려진 각종 방법으로 단리할 수 있다(예를 들어, Sambrook의 상기 문헌). 또한, 많은 키트가 박테리아로부터 플라스미드를 정제하는 데 이용할 수 있다(예를 들어, EasyPrep™, FlexiPrep™, Pharmacia Biotech; StrataClean™, Stratagene; QIAprep™, Qiagen). 단리되고 정제된 플라스미드를 추가로 조작하여 다른 플라스미드를 제조하고, 세포를 형질감염시키거나 생물을 감염시키기 위한 관련 벡터 내로 통합시키는 데 사용할 수 있다. 전형적인 벡터는 전사 및 번역 터미네이터, 전사 및 번역 개시 서열, 및 특정 표적 핵산의 발현 조절에 유용한 프로모터를 포함한다. 벡터는 경우에 따라 적어도 하나의 독립적 터미네이터 서열, 진핵 세포, 원핵 세포 또는 둘 다(예를 들어, 셔틀 벡터)에서 카세트의 복제를 허용하는 서열, 및 원핵 세포 및 척추동물 세포계를 위한 선택 마커를 함유하는 총괄적 발현 카세트를 포함한다. 벡터는 원핵 세포, 진핵 세포, 또는 바람직하게는 양자 모두에서 복제 및 통합되기에 적절하다(Giliman & Smith, Gene 8:81(1979); Roberts, et al., Nature. 328:731(1987); Schneider, B., et al., Protein Expr. Purif. 6435:10(1995); Ausubel, Sambrook, Berger(all supra)). 클로닝에 유용한 박테리아 및 박테리오파지의 카탈로그가, 예를 들어, ATCC에 의해 제공된다(The ATCC Catalogue of Bacteria and Bacteriophage(1992) Gherna et al., (eds) published by the ATCC). 시퀀싱, 클로닝에 대한 추가의 기초적 과정 및 분자 생물학의 다른 측면 및 이의 기초가 되는 이론적 고려 사항 등이 또한 문헌에 기재되어 있다(Watson et al., (1992) Recombinant DNA Second Edition Scientific American Books, NY). 또한, 실질적으로 어느 핵산(표준, 비표준을 불문하고, 실질적으로 임의의 표지된 핵산)이라도 여러 상업적 공급원[The Midland Certified Reagent Company(Midland, TX, www.mcrc.com); The Great American Gene Company(Ramona, CA, www.genco.com), ExpressGen Inc. (Chicago, IL, www.expressgen.com), Operon Technologies Inc. (Alameda, CA) 등]으로부터 맞춤식 또는 표준 주문할 수 있다.
키트
키트 역시 본 발명의 특징이다. 예를 들어, 세포 내에서 적어도 하나의 비천연 아미노산을 포함하는 단백질을 제조하기 위한 키트가 제공되며, 이 키트는 O-tRNA를 코딩하는 폴리뉴클레오티드 서열, 및/또는 O-tRNA, 및/또는 O-RS를 코딩하는 폴리뉴클레오티드 서열, 및/또는 O-RS를 함유하는 용기를 포함한다. 일 실시태양에 있어서, 상기 키트는 추가로 적어도 하나의 비천연 아미노산을 포함한다. 또 다른 실시태양에 있어서, 상기 키트는 추가로 단백질 제조에 관한 설명 자료를 포함한다.
하기 실시예는 청구된 발명을 제한하려는 것이 아니라 상세히 설명하기 위해 제공되는 것이다. 당업자는 청구된 발명의 범주를 벗어남이 없이 변화시킬 수 있는 비결정적 변수들을 인지하고 있을 것이다.
실시예 1 : 척추동물 세포 내에서 비천연 아미노산을 도입하는 아미노아실-tRNA 합성효소의 제조 방법 및 조성물
새로운 물리적, 화학적 또는 생물학적 특성을 갖는 비천연 아미노산을 포함하도록 척추동물 세포 유전자 코드를 확장시키는 것은 이들 세포에서 단백질 기능을 분석하고 조절하는 데 있어 강력한 수단을 제공할 것이다. 이러한 목적을 향해, 사카로마이세스 세레비시아에서 앰버 코돈에 응답하여 비천연 아미노산을 단백질 내로 높은 신뢰도로 도입하는 아미노아실-tRNA 합성효소의 단리를 위한 일반적인 접근법이 기재되어 있다. 이 방법은 GAL4의 DNA 결합 도메인과 전사 활성화 도메인 사이의 앰버 코돈을 억제하여 GAL4 응답성 리포터 유전자인 HIS3, URA3 또는 LacZ를 활성화시키는 것에 기초한다. 활성 에스케리치아 콜라이 타이로실-tRNA 합성효소(EcTyrRS) 변이체의 양성 선택을 위한 GAL4 리포터의 최적화가 기재되어 있다. 불활성 EcTyrRS 변이체를 '독성 대립자'로서 배양 배지에 가해지는 작은 분자(5-플루오로오로트산(5-FOA))를 사용하여 URA3 리포터로 음성 선택하는 것이 또한 개발되었다. 중요한 점은, 양성 및 음성 선택 모두를 단일 세포 상에 일정 범위의 엄격도로 수행할 수 있다는 것이다. 이는 돌연변이 합성효소의 대형 라이브러리로부터 일정 범위의 아미노아실-tRNA 합성효소(aaRS) 활성을 단리하는 것을 촉진시킨다. 목적하는 aaRS 표현형을 단리하는 방법의 힘은 모델 선택에 의해 입증된다.
실시예 2
포유동물 세포에서 pAF의 부위 특이적 도입
플라즈미드 제작:
Sal I 및 EcoR V 제한효소 부위에서 N-말단 쳔연 분비 신호를 갖는 hGH를 코딩하는 DNA 삽입물과 pMl-MT 벡터(Roche)를 결찰시켜 야생형 인간 성장 호르몬(hGH) 및 hGH 앰버 돌연변이체 발현 벡터를 제작하였다.
5' 제한효소 부위 EcoR I 및 BgI II, 인간 tRNATyr의 5' 측접 서열(GGATTACGCATGCTCAGTGCAATCTTCGGTTGCCTGGACTAGCGCTCCGGTTTTTCTGTGCTGAACCTCAGGGGACGCCGACACACGTACACGTC(서열 번호 88)), 3'-CCA이 결실된 비. 스테아로써모필러스 tRNA 앰버 억제 돌연변이체, 인간 tRNATyr의 3' 측접 서열(GACAAGTGCGGTTΓTTTTCTCCAGCTCCCGATGACTTATGGC(서열 번호 89)) 및 3' 제한효소 부위 BamH I 및 Hind III를 포함하는 단일 카비 비. 스테아로써모필러스 tRNA 발현 삽입물을 하기의 프라이머를 이용한 중첩 PCR을 통해 제작하였다:
FTam 73: EcoR I 및 BgI II 부위를 갖는 포워드 프라이머
GTACGAATTCCCGAGATCTGGATTACGCATGCTCAGTGCAATCTTCGGTTGCCTGGACTAGCGCTCCGGTTTTTCTGTGC(서열 번호 90)
FTam 74: FTam73과 중첩되는 리버스 프라이머
AGTCCGCCGCGTTTAGCCACTTCGCTACCCCTCCGACGTGTACGTGTGTCGGCGTCCCCTGAGGTTCAGCACAGAAAAACCGGAGCGC(서열 번호 91)
FTam 75: FTam74 및 FTam 76과 중첩되는 포워드 프라이머
GAAGTGGCTAAACGCGGCGGACTCTAAATCCGCTCCCTTTGGGTTCGGCGGTTCGAATCCGTCCCCCTCCA GACAAGTG(서열 번호 92)
FTam 76: BamH I 및 Hind III 부위를 가지며, FTam 75와 중첩되는 리버스 프라이머
GATGCAAGCTTGATGGATCCGCCATAAGTCATCGGGAGCTGGAGAAAAAAACCGCACTTGTCTGGAGGGGGACGG(서열 번호 93)
단일 카피 tRNA 발현 벡터를 제작하기 위해, 상기 기술한 삽입물을 EcoR I/Hind III으로 효소분해하고 동일한 제한효소로 절단한 pUC 19 벡터에 결찰시켰다. 2 카피 tRNA 발현 벡터의 제작을 위해, 단일 카피 삽입물을 EcoR I 및 BamH I으로 효소분해하고 EcoR I 및 Bgl II로 절단한 단일 카피 발현 벡터에 결찰시켰다. 결찰된 생성물은 5' EcoR I 및 3' Bgl II 부위를 재생시켰다. 유사한 전략을 반복적인 방식으로 사용하여 직렬 카피의 tRNA 서열을 포함하는 발현 벡터를 제작할 수 있다.
FLAG 태그(DYKDDDDK)를 야생형 이.콜라이 Tyr tRNA 합성효소 및 비천연 아미노산을 충전시킨 이의 돌연변이체의 C-말단에 부가하였다. RS 유전자를 PCR을 통해 증폭하고 pcDNA3.1/Zeo(+)(Invitrogen)에 결찰시켰다.
세포 배양
형질감염 하루전에, 대략 3.5×105 CHO K1 세포를 10% 태아 소혈청(FBS) (Hyclone) 및 100 U/ml 페니실린 G 나트륨 및 100 ug/ml 스트렙토마이신 설페이트(Gibco)가 보충된 F-12 + Glutmax 배지(Gibco) 중의 6-웰 조직 배양 플레이트(BD bioscience)의 각 웰에 플레이팅하였다. 이 플레이트를 37℃, 5% CO2에서 항온배양하였다. 95% 합류점에서, 리포펙타민 2000(Invitrogen)에 대한 표준 형질감염 프로토콜에 따라서 형질감염을 수행하였다. 일시적인 억제를 관찰하기 위해, 각 플라즈미드(즉, tRNA, RS, GOI 플라즈미드) 1 ㎍을 각 웰에 부가하였다. 항온반응 4시간 후, 형질감염 용액을 2 ml의 성장 배지(10% FBS 혈청 및 100 U/ml 페니실린 G 나트륨 및 100 ug/ml 스트렙토마이신 설페이트가 보충된 F-12 + Glutmax 배지)로 교체하였다. 비천연 아미노산 tRNA/RS 쌍으로 형질감염된 이들 웰에 대해서, 보충물로서 상응하는 비천연 아미노산 1 mM을 부가하였다. 대부분의 경우, 실험은 3회 반복하여 수행하였다. hGH의 발현은 활성 인간 성장 호르몬 ELISA 키트( Diagnostic Systems Laboratories Inc.)를 이용하여 40 시간 이후에 분석하였다.
결과:
CHO-K1에서 비천연 아미노선에 의한 부위 특이적 앰버 억제(도 1).
앰버 억제의 비천연 아미노산 의존성은 hGH G131 앰버 돌연변이체를 이용하여 평가하였다. CHO Kl 세포는 앰버-억제 비. 스테아로써모필러스 tRNA 돌연변이체의 6 직렬 카피를 보유하는 플라즈미드; hGH-G131 앰버 돌연변이체를 코딩하는 목적 유전자 플라즈미드; 및 티로신(Tyr), 파라-아세틸페닐알라닌(pAF), 파라-아지도페닐알라닌(pAz) 및 파라-벤조일페닐알라닌(pBz)를 이용하여 이의 동족 tRNA를 아미노아실화시키는 이.콜라이 Tyr tRNA 합성효소 돌연변이체를 코딩하는 플라즈미드와 함께 공동형질감염시켰다. 형질감염 용액과 함께 4시간 항온반응시킨 후, 형질 감염 용액은 성장 배지 +/- 상응하는 1 mM 비천연 아미노산으로 교체하였다. hGH의 발현은 24시간 후에 분석하였다. pAF 및 pBz에 대해, 전장 hGH 발현은 상응하는 비천연 아미노산의 존재하에서만 관찰되었다. 비천연 아미노선이 없는 경우, 어떠한 전장 hGH 발현도 검출되지 않았다. pAZ를 이용한 앰버 억제의 경우, pAZ의 존재 및 부재하에서 어떠한 hGH 발현도 관찰되지 않았다. 이는 항-FLAG 웨스턴 블랏에 의해 관찰되었던, pAZ tRNA 합성효소의 발현 불능에 의한 것인 듯 하다.
Tyr 및 pAF의 앰버 억제에 대한 pAF 농도의 영향은 hGH E88 앰버 돌연변이체를 이용하여 평가하였다. hGH E88 앰버 돌연변이체, 6-카피(도 2) 비. 스테아로써모필러스 tRNA, 및 Tyr와 pAF가 충전된 상응하는 이.콜라이 tRNA 합성효소를 코딩하는 플라즈미드를 CHO K1 세포에 공동 형질감염시켰다. 형질감염 용액과 함께 4시간 항온반응시킨 후, 형질감염 용액을 1 M HCl(성장 배지 부피에 대해 1:1000)이 부가되거나 부가되지 않은 성장 배지로 교체하였다. 최종 배지는 다음으로 1 M HCl 중 1 M pAF 스톡 용액을 이용하여 1, 2, 4, 6, 8 및 10 mM pAF를 보충하였고, 동일 부피의 1 M NaOH로 중성화시켰다. hGH 발현은 42시간 후에 분석하였다. Tyr 역제의 경우, 억제 효율은 HCl/NaOH 처리에 따라 약간 감소하였다. pAF 억제의 경우, 어떠한 hGH 발현도 pAF 부재하에서 검출되지 않았다. Tyr 및 pAF-기반 억제 둘 모두에서, 효율은 1 및 2 mM pAF에서 최대였다. 억제 효율은 pAF 농도가 4 mM에서 10 mM로 증가함에 따라 감소하였다.
실시예 3
하이브리드 tRNA를 이용한 pAF를 갖는 현탁 세포에서의 인간 Fc의 앰버 억제
인간 Fc I21 앰버 돌연변이체, 인간 tRNA 및 pAF를 충전한 이.콜라이 tRNA 합성효소 돌연변이체를 포함하는 플라즈미드를 CHO-S FreeStyle 현택 세포에 공동 형질감염시켰다. 4 카피의 htRNA를 실험에서 사용하였다. 발현 배지는 1 mM pAF를 포함하였다. 인간 Fc의 발현은 형질감염 72 시간 후에 분석하였다. 형질감염된 pAF 특이적 합성효소(pAFRS)의 양이 감소함에 따라 보다 높은 인간 Fc의 억제가 검출되었다.
hIgGl-Fc2 DNA 서열:

5' IL2 신호 서열:
ATGTACAGGATGCAACTCCTGTCTTGCATTGCACTAAGTCT (서열 번호 95)
hIgGl-Fc2 단백질 서열

IL2 신호 서열:
MYRMQLLSCIALSLALVTNS (서열 번호 97)
일 측면에 있어서, 본 발명은 다른 치환 분자에 커플링된 비천연 아미노산을 포함하는 단백질의 제조 방법 및 관련 조성물을 제공한다.
본 명세서에 기재된 실시예 및 실시태양은 단지 예시의 목적으로 주어진 것으로서, 이들에 비추어 각종 수정 및 변경이 당업자에게 명백할 것이며, 이들 수정 또는 변경이 또한 본 발명의 요지 및 취지, 및 첨부된 청구의 범위에 포함되는 것임을 이해하여야 한다.
본 명세서에서 발명을 명확히 하고 이해를 쉽게 할 목적으로 어느 정도 상세하게 기재하고 있으나, 본 명세서에 개시된 사항을 읽음으로써 본 발명의 진정한 범주를 벗어나지 않고서도 형식적 및 상세한 사항에 있어 여러 가지 변화가 가능하다는 것이 당업자에게 명백할 것이다. 예를 들어, 본 명세서 기재된 모든 기술 및 장치는 여러 가지 조합으로 사용될 수 있을 것이다. 모든 문헌, 특허, 특허 출원 및/또는 본 출원에 인용된 다른 문헌들은, 이러한 개개의 문헌, 특허, 특허 출원 및/또는 다른 문헌들이 어떠한 의도로든 본 명세서에 포함되는 것으로 개별적으로 표시된 것과 같은 정도로, 모든 목적을 위해 그 전문이 본 명세서에 포함된다.
표 5
















a 이 클론은 또한 Asp165Gly 돌연변이체를 포함한다.
SEQUENCE LISTING
<110> Feng, Tian
Norman, Thea
Chu, Stephanie
<120> SITE SPECIFIC INCORPORATION OF NON-NATURAL AMINO ACIDS BY
VERTEBRATE CELLS
<130> AMBX-0123.00PCT
<150> 60/843,473
<151> 2006-09-08
<160> 97
<170> PatentIn version 3.4
<210> 1
<211> 1275
<212> DNA
<213> Escherichia coli
<400> 1
atggcaagca gtaacttgat taaacaattg caagagcggg ggctggtagc ccaggtgacg 60
gacgaggaag cgttagcaga gcgactggcg caaggcccga tcgcgctcta ttgcggcttc 120
gatcctaccg ctgacagctt gcatttgggg catcttgttc cattgttatg cctgaaacgc 180
ttccagcagg cgggccacaa gccggttgcg ctggtaggcg gcgcgacggg tctgattggc 240
gacccgagct tcaaagctgc cgagcgtaag ctgaacaccg aagaaactgt tcaggagtgg 300
gtggacaaaa tccgtaagca ggttgccccg ttcctcgatt tcgactgtgg agaaaactct 360
gctatcgcgg cgaacaacta tgactggttc ggcaatatga atgtgctgac cttcctgcgc 420
gatattggca aacacttctc cgttaaccag atgatcaaca aagaagcggt taagcagcgt 480
ctcaaccgtg aagatcaggg gatttcgttc actgagtttt cctacaacct gttgcagggt 540
tatgacttcg cctgtctgaa caaacagtac ggtgtggtgc tgcaaattgg tggttctgac 600
cagtggggta acatcacttc tggtatcgac ctgacccgtc gtctgcatca gaatcaggtg 660
tttggcctga ccgttccgct gatcactaaa gcagatggca ccaaatttgg taaaactgaa 720
ggcggcgcag tctggttgga tccgaagaaa accagcccgt acaaattcta ccagttctgg 780
atcaacactg cggatgccga cgtttaccgc ttcctgaagt tcttcacctt tatgagcatt 840
gaagagatca acgccctgga agaagaagat aaaaacagcg gtaaagcacc gcgcgcccag 900
tatgtactgg cggagcaggt gactcgtctg gttcacggtg aagaaggttt acaggcggca 960
aaacgtatta ccgaatgcct gttcagcggt tctttgagtg cgctgagtga agcggacttc 1020
gaacagctgg cgcaggacgg cgtaccgatg gttgagatgg aaaagggcgc agacctgatg 1080
caggcactgg tcgattctga actgcaacct tcccgtggtc aggcacgtaa aactatcgcc 1140
tccaatgcca tcaccattaa cggtgaaaaa cagtccgatc ctgaatactt ctttaaagaa 1200
gaagatcgtc tgtttggtcg ttttacctta ctgcgtcgcg gtaaaaagaa ttactgtctg 1260
atttgctgga aataa 1275
<210> 2
<211> 424
<212> PRT
<213> Escherichia coli
<400> 2
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Tyr Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Asp Phe Ala Cys Leu Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 3
<211> 1275
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 3
atggcaagca gtaacttgat taaacaattg caagagcggg ggctggtagc ccaggtgacg 60
gacgaggaag cgttagcaga gcgactggcg caaggcccga tcgcactcgt gtgtggcttc 120
gatcctaccg ctgacagctt gcatttgggg catcttgttc cattgttatg cctgaaacgc 180
ttccagcagg cgggccacaa gccggttgcg ctggtaggcg gcgcgacggg tctgattggc 240
gacccgagct tcaaagctgc cgagcgtaag ctgaacaccg aagaaactgt tcaggagtgg 300
gtggacaaaa tccgtaagca ggttgccccg ttcctcgatt tcgactgtgg agaaaactct 360
gctatcgcgg ccaataatta tgactggttc ggcaatatga atgtgctgac cttcctgcgc 420
gatattggca aacacttctc cgttaaccag atgatcaaca aagaagcggt taagcagcgt 480
ctcaaccgtg aagatcaggg gatttcgttc actgagtttt cctacaacct gctgcagggt 540
tatagtatgg cctgtttgaa caaacagtac ggtgtggtgc tgcaaattgg tggttctgac 600
cagtggggta acatcacttc tggtatcgac ctgacccgtc gtctgcatca gaatcaggtg 660
tttggcctga ccgttccgct gatcactaaa gcagatggca ccaaatttgg taaaactgaa 720
ggcggcgcag tctggttgga tccgaagaaa accagcccgt acaaattcta ccagttctgg 780
atcaacactg cggatgccga cgtttaccgc ttcctgaagt tcttcacctt tatgagcatt 840
gaagagatca acgccctgga agaagaagat aaaaacagcg gtaaagcacc gcgcgcccag 900
tatgtactgg cggagcaggt gactcgtctg gttcacggtg aagaaggttt acaggcggca 960
aaacgtatta ccgaatgcct gttcagcggt tctttgagtg cgctgagtga agcggacttc 1020
gaacagctgg cgcaggacgg cgtaccgatg gttgagatgg aaaagggcgc agacctgatg 1080
caggcactgg tcgattctga actgcaacct tcccgtggtc aggcacgtaa aactatcgcc 1140
tccaatgcca tcaccattaa cggtgaaaaa cagtccgatc ctgaatactt ctttaaagaa 1200
gaagatcgtc tgtttggtcg ttttacctta ctgcgtcgcg gtaaaaagaa ttactgtctg 1260
atttgctgga aataa 1275
<210> 4
<211> 1275
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 4
atggcaagca gtaacttgat taaacaattg caagagcggg ggctggtagc ccaggtgacg 60
gacgaggaag cgttagcaga gcgactggcg caaggcccga tcgcactcac ttgtggcttc 120
gatcctaccg ctgacagctt gcatttgggg catcttgttc cattgttatg cctgaaacgc 180
ttccagcagg cgggccacaa gccggttgcg ctggtaggcg gcgcgacggg tctgattggc 240
gacccgagct tcaaagctgc cgagcgtaag ctgaacaccg aagaaactgt tcaggagtgg 300
gtggacaaaa tccgtaagca ggttgccccg ttcctcgatt tcgactgtgg agaaaactct 360
gctatcgcgg ccaataatta tgactggttc agcaatatga atgtgctgac cttcctgcgc 420
gatattggca aacacttctc cgttaaccag atgatcaaca aagaagcggt taagcagcgt 480
ctcaaccgtg aagatcaggg gatttcgttc actgagtttt cctacaacct gctgcagggt 540
tatacgtatg cctgtctgaa caaacagtac ggtgtggtgc tgcaaattgg tggttctgac 600
cagtggggta acatcacttc tggtatcgac ctgacccgtc gtctgcatca gaatcaggtg 660
tttggcctga ccgttccgct gatcactaaa gcagatggca ccaaatttgg taaaactgaa 720
ggcggcgcag tctggttgga tccgaagaaa accagcccgt acaaattcta ccagttctgg 780
atcaacactg cggatgccga cgtttaccgc ttcctgaagt tcttcacctt tatgagcatt 840
gaagagatca acgccctgga agaagaagat aaaaacagcg gtaaagcacc gcgcgcccag 900
tatgtactgg cggagcaggt gactcgtctg gttcacggtg aagaaggttt acaggcggca 960
aaacgtatta ccgaatgcct gttcagcggt tctttgagtg cgctgagtga agcggacttc 1020
gaacagctgg cgcaggacgg cgtaccgatg gttgagatgg aaaagggcgc agacctgatg 1080
caggcactgg tcgattctga actgcaacct tcccgtggtc aggcacgtaa aactatcgcc 1140
tccaatgcca tcaccattaa cggtgaaaaa cagtccgatc ctgaatactt ctttaaagaa 1200
gaagatcgtc tgtttggtcg ttttacctta ctgcgtcgcg gtaaaaagaa ttactgtctg 1260
atttgctgga aataa 1275
<210> 5
<211> 1275
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 5
atggcaagca gtaacttgat taaacaattg caagagcggg ggctggtagc ccaggtgacg 60
gacgaggaag cgttagcaga gcgactggcg caaggcccga tcgcactcgt gtgtggcttc 120
gatcctaccg ctgacagctt gcatttgggg catcttgttc cattgttatg cctgaaacgc 180
ttccagcagg cgggccacaa gccggttgcg ctggtaggcg gcgcgacggg tctgattggc 240
gacccgagct tcaaagctgc cgagcgtaag ctgaacaccg aagaaactgt tcaggagtgg 300
gtggacaaaa tccgtaagca ggttgccccg ttcctcgatt tcgactgtgg agaaaactct 360
gctatcgcgg ccaataatta tgactggttc ggcaatatga atgtgctgac cttcctgcgc 420
gatattggca aacacttctc cgttaaccag atgatcaaca aagaagcggt taagcagcgt 480
ctcaaccgtg aagatcaggg gatttcgttc actgagtttt cctacaacct gctgcagggt 540
tatagtatgg cctgtttgaa caaacagtac ggtgtggtgc tgcaaattgg tggttctgac 600
cagtggggta acatcacttc tggtatcgac ctgacccgtc gtctgcatca gaatcaggtg 660
tttggcctga ccgttccgct gatcactaaa gcagatggca ccaaatttgg taaaactgaa 720
ggcggcgcag tctggttgga tccgaagaaa accagcccgt acaaattcta ccagttctgg 780
atcaacactg cggatgccga cgtttaccgc ttcctgaagt tcttcacctt tatgagcatt 840
gaagagatca acgccctgga agaagaagat aaaaacagcg gtaaagcacc gcgcgcccag 900
tatgtactgg cggagcaggt gactcgtctg gttcacggtg aagaaggttt acaggcggca 960
aaacgtatta ccgaatgcct gttcagcggt tctttgagtg cgctgagtga agcggacttc 1020
gaacagctgg cgcaggacgg cgtaccgatg gttgagatgg aaaagggcgc agacctgatg 1080
caggcactgg tcgattctga actgcaacct tcccgtggtc aggcacgtaa aactatcgcc 1140
tccaatgcca tcaccattaa cggtgaaaaa cagtccgatc ctgaatactt ctttaaagaa 1200
gaagatcgtc tgtttggtcg ttttacctta ctgcgtcgcg gtaaaaagaa ttactgtctg 1260
atttgctgga aataa 1275
<210> 6
<211> 1275
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 6
atggcaagca gtaacttgat taaacaattg caagagcggg ggctggtagc ccaggtgacg 60
gacgaggaag cgttagcaga gcgactggcg caaggcccga tcgcactcgt gtgtggcttc 120
gatcctaccg ctgacagctt gcatttgggg catcttgttc cattgttatg cctgaaacgc 180
ttccagcagg cgggccacaa gccggttgcg ctggtaggcg gcgcgacggg tctgattggc 240
gacccgagct tcaaagctgc cgagcgtaag ctgaacaccg aagaaactgt tcaggagtgg 300
gtggacaaaa tccgtaagca ggttgccccg ttcctcgatt tcgactgtgg agaaaactct 360
gctatcgcgg ccaataatta tgactggttc ggcaatatga atgtgctgac cttcctgcgc 420
gatattggca aacacttctc cgttaaccag atgatcaaca aagaagcggt taagcagcgt 480
ctcaaccgtg aagatcaggg gatttcgttc actgagtttt cctacaacct gctgcagggt 540
tatagtatgg cctgtttgaa caaacagtac ggtgtggtgc tgcaaattgg tggttctgac 600
cagtggggta acatcacttc tggtatcgac ctgacccgtc gtctgcatca gaatcaggtg 660
tttggcctga ccgttccgct gatcactaaa gcagatggca ccaaatttgg taaaactgaa 720
ggcggcgcag tctggttgga tccgaagaaa accagcccgt acaaattcta ccagttctgg 780
atcaacactg cggatgccga cgtttaccgc ttcctgaagt tcttcacctt tatgagcatt 840
gaagagatca acgccctgga agaagaagat aaaaacagcg gtaaagcacc gcgcgcccag 900
tatgtactgg cggagcaggt gactcgtctg gttcacggtg aagaaggttt acaggcggca 960
aaacgtatta ccgaatgcct gttcagcggt tctttgagtg cgctgagtga agcggacttc 1020
gaacagctgg cgcaggacgg cgtaccgatg gttgagatgg aaaagggcgc agacctgatg 1080
caggcactgg tcgattctga actgcaacct tcccgtggtc aggcacgtaa aactatcgcc 1140
tccaatgcca tcaccattaa cggtgaaaaa cagtccgatc ctgaatactt ctttaaagaa 1200
gaagatcgtc tgtttggtcg ttttacctta ctgcgtcgcg gtaaaaagaa ttactgtctg 1260
atttgctgga aataa 1275
<210> 7
<211> 1275
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 7
atggcaagca gtaacttgat taaacaattg caagagcggg ggctggtagc ccaggtgacg 60
gacgaggaag cgttagcaga gcgactggcg caaggcccga tcgcactcac gtgtggcttc 120
gatcctaccg ctgacagctt gcatttgggg catcttgttc cattgttatg cctgaaacgc 180
ttccagcagg cgggccacaa gccggttgcg ctggtaggcg gcgcgacggg tctgattggc 240
gacccgagct tcaaagctgc cgagcgtaag ctgaacaccg aagaaactgt tcaggagtgg 300
gtggacaaaa tccgtaagca ggttgccccg ttcctcgatt tcgactgtgg agaaaactct 360
gctatcgcgg ccaataatta tgactggttc ggcaatatga atgtgctgac cttcctgcgc 420
gatattggca aacacttctc cgttaaccag atgatcaaca aagaagcggt taagcagcgt 480
ctcaaccgtg aagatcaggg gatttcgttc actgagtttt cctacagcct gctgcagggt 540
tatacgatgg cctgtctgaa caaacagtac ggtgtggtgc tgcaaattgg tggttctgac 600
cagtggggta acatcacttc tggtatcgac ctgacccgtc gtctgcatca gaatcaggtg 660
tttggcctga ccgttccgct gatcactaaa gcagatggca ccaaatttgg taaaactgaa 720
ggcggcgcag tctggttgga tccgaagaaa accagcccgt acaaattcta ccagttctgg 780
atcaacactg cggatgccga cgtttaccgc ttcctgaagt tcttcacctt tatgagcatt 840
gaagagatca acgccctgga agaagaagat aaaaacagcg gtaaagcacc gcgcgcccag 900
tatgtactgg cggagcaggt gactcgtctg gttcacggtg aagaaggttt acaggcggca 960
aaacgtatta ccgaatgcct gttcagcggt tctttgagtg cgctgagtga agcggacttc 1020
gaacagctgg cgcaggacgg cgtaccgatg gttgagatgg aaaagggcgc agacctgatg 1080
caggcactgg tcgattctga actgcaacct tcccgtggtc aggcacgtaa aactatcgcc 1140
tccaatgcca tcaccattaa cggtgaaaaa cagtccgatc ctgaatactt ctttaaagaa 1200
gaagatcgtc tgtttggtcg ttttacctta ctgcgtcgcg gtaaaaagaa ttactgtctg 1260
atttgctgga aataa 1275
<210> 8
<211> 540
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 8
cgggggctgg tagcccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcacttgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcagcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttatacg tatgcctgtc tgaacaaaca gtacggtgtg 540
<210> 9
<211> 540
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 9
cgggggctgg taccccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcacttgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcagcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttatacg tatgcctgtc tgaacaaaca gtacggtgtg 540
<210> 10
<211> 540
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 10
cgggggctgg tagcccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcacttgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcagcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttatacg tatgcctgtc tgaacaaaca gtacggtgtg 540
<210> 11
<211> 540
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 11
cgggggctgg tagcccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcacttgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttattcg tatgcctgtg cgaacaaaca gtacggtgtg 540
<210> 12
<211> 540
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 12
cgggggctgg tagcccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcacttgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcagcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttatacg tatgcctgtc tgaacaaaca gtacggtgtg 540
<210> 13
<211> 540
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 13
cgggggctgg taccccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcctttgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttattct attgcctgtt cgaacaaaca gtacggtgtg 540
<210> 14
<211> 540
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 14
cgggggctgg tagcccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcgtgtgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttatagt attgcctgtt tgaacaaaca gtacggtgtg 540
<210> 15
<211> 540
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 15
cgggggctgg taccccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcgtgtgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttatagt attgcctgtt tgaacaaaca gtacggtgtg 540
<210> 16
<211> 540
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 16
cgggggctgg tagcccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tctggtgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaagg ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaatt gttatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttatatg cgtgcctgtg agaacaaaca gtacggtgtg 540
<210> 17
<211> 624
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 17
cgggggctgg tagcccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcatttgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaaggtc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttatggt atggcctgtg ctaacaaaca gtacggtgtg 540
gtgctgcaaa ttggtggttc tgaccaatgg ggtaacatca cttctggtat cgacctgacc 600
cgtcgtctgc atcagaatca ggtg 624
<210> 18
<211> 609
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 18
caggtgacgg acgaggaagc gttagcagag cgactggcgc aaggcccgat cgcactcggt 60
tgtggcttcg atcctaccgc tgacagcttg catttggggc atcttgttcc attgttatgc 120
ctgaaacgct tccagcaggc gggccacaag ccggttgcgc tggtaggcgg cgcgacgggt 180
ctgattggcg acccgagctt caaagctgcc gagcgtaagc tgaacaccga agaaactgtt 240
caggagtggg tggacaaaat ccgtaagcag gttgccccgt tcctcgattt cgactgtgga 300
gaaaactctg ctatcgcggc caataattat gactggttcg gcaatatgaa tgtgctgacc 360
ttcctgcgcg atattggcaa acacttctcc gttaaccaga tgatcaacaa agaagcggtt 420
aagcagcgtc tcaaccgtga agatcagggg atttcgttca ctgagttttc ctacaacctg 480
ctgcagggtt atggttttgc ctgtttgaac aaacagtacg gtgtggtgct gcaaattggt 540
ggttctgacc agtggggtaa catcacttct ggtatcgacc tgacccgtcg tctgcatcag 600
aatcaggtg 609
<210> 19
<211> 591
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 19
gcgttagcag agcgactggc gcaaggcccg atcgcactcg ggtgtggctt cgatcctacc 60
gctgacagct tgcatttggg gcatcttgtt ccattgttat gcctgaaacg cttccagcag 120
gcgggccaca agccggttgc gctggtaggc ggcgcgacgg gtctgattgg cgacccgagc 180
ttcaaagctg ccgagcgtaa gctgaacacc gaagaaactg ttcaggagtg ggtggacaaa 240
atccgtaagc aggttgcccc gttcctcgat ttcgactgtg gagaaaactc tgctatcgcg 300
gccaataatt atgactggtt cggcaatatg aatgtgctga ccttcctgcg cgatattggc 360
aaacacttct ccgttaacca gatgatcaac aaagaagcgg ttaagcagcg tctcaaccgt 420
gaagatcagg ggatttcgtt cactgagttt tcctacaacc tgctgcaggg ttatggttat 480
gcctgtatga acaaacagta cggtgtggtg ctgcaaattg gtggttctga ccagtggggt 540
aacatcactt ctggtatcga cctgacccgt cgtctgcatc agaatcaggt g 591
<210> 20
<211> 621
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<220>
<221> misc_feature
<222> (26)..(26)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (612)..(612)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (618)..(618)
<223> n is a, c, g, or t
<400> 20
gggctggtag cccaggtgac ggacgnagaa gcgttagcag agcgactggc gcaaggcccg 60
atcgcactcc tttgtggctt cgatcctacc gctgacagct tgcatttggg gcatcttgtt 120
ccattgttat gcctgaaacg cttccagcag gcgggccaca agccggttgc gctggtaggc 180
ggcgcgacgg gtctgattgg cgacccgagc ttcaaagctg ccgagcgtaa gctgaacacc 240
gaagaaactg ttcaggagtg ggtggacaaa atccgtaagc aggttgcccc gttcctcgat 300
ttcgactgtg gagaaaactc tgctatcgcg gccaataatt atgactggtt cggcaatatg 360
aatgtgctga ccttcctgcg cgatattggc aaacacttct ccgttaacca gatgatcaac 420
aaagaagcgg ttaagcagcg tctcaaccgt gaagatcagg ggatttcgtt cactgagttt 480
tcctacaacc tgctgcaggg ttattctatg gcctgtgcga acaaacagta cggtgtggtg 540
ctgcaaattg gtggttctga ccagtggggt aacatcactt ctggtatcga cctgacccgt 600
cgtctgcatc anaatcangt g 621
<210> 21
<211> 588
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 21
ttagcagagc gactggcgca aggcccgatc gcactcgttt gtggcttcga tcctaccgct 60
gacagcttgc atttggggca tcttgttcca ttgttatgcc tgaaacgctt ccagcaggcg 120
ggccacaagc cggttgcgct ggtaggcggc gcgacgggtc tgattggcga cccgagcttc 180
aaagctgccg agcgtaagct gaacaccgaa gaaactgttc aggagtgggt ggacaaaatc 240
cgtaagcagg ttgccccgtt cctcgatttc gactgtggag aaaactctgc tatcgcggcc 300
aataattatg actggttcgg caatatgaat gtgctgacct tcctgcgcga tattggcaaa 360
cacttctccg ttaaccagat gatcaacaaa gaagcggtta agcagcgtct caaccgtgaa 420
gatcagggga tttcgttcac tgagttttcc tacaacctgc tgcagggtta ttctgcggcc 480
tgtgcgaaca aacagtacgg tgtggtgctg caaattggtg gttctgacca gtggggtaac 540
atcacttctg gtatcgacct gacccgtcgt ctgcatcaga atcaggtg 588
<210> 22
<211> 600
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<220>
<221> misc_feature
<222> (403)..(403)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (513)..(513)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (515)..(515)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (518)..(518)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (531)..(531)
<223> n is a, c, g, or t
<400> 22
gacgaggaag cgttagcaga gcgactggcg caaggcccga tcgcactcct gtgtggcttc 60
gatcctaccg ctgacagctt gcatttgggg catcttgttc cattgttatg cctgaaacgc 120
ttccagcagg cgggccacaa gccggttgcg ctggtaggcg gcgcgacggg tctgattggc 180
gacccgagct tcaaagctgc cgagcgtaag ctgaacaccg aagaaactgt tcaggagtgg 240
gtggacaaaa tccgtaagca ggttgccccg ttcctcgatt tcgactgtgg agaaaactct 300
gctatcgcgg ccaataatta tgactggttc ggcaatatga atgtgctgac cttcctgcgc 360
gatattggca aacacttctc cgttaaccag atgatcaaca aanaagcggt taagcagcgt 420
ctcaaccgtg aagatcaggg gatttcgttc actgagtttt cctacaacct gctgcagggt 480
tattcggctg cctgtgcgaa caaacagtac ggngnggngc tgcaaattgg nggttctgac 540
caggggggta acatcacttc tggtatcgac ctgacccgtc gtctgcatca aaatcaggtg 600
<210> 23
<211> 591
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<220>
<221> misc_feature
<222> (588)..(588)
<223> n is a, c, g, or t
<400> 23
gcgttagcag agcgactggc gcaaggcccg atcgcactcg tttgtggctt cgatcctacc 60
gctgacagct tgcatttggg gcatcttgtt ccattgttgt gcctgaaacg cttccagcag 120
gcgggccaca agccggttgc gctggtaggc ggcgcgacgg gtctgattgg cgacccgagc 180
ttcaaagctg ccgagcgtaa gctgaacacc gaagaaactg ttcaggagtg ggtggacaaa 240
atccgtaagc aggttgcccc gttcctcgat ttcgactgtg gagaaaactc tgctatcgcg 300
gccaataatt atgactggtt cggcaatatg aatgtgctga ccttcctgcg cgatattggc 360
aaacacttct ccgttaacca gatgatcaac aaagaagcgg ttaagcagcg tctcaaccgt 420
gaagatcagg ggatttcgtt cactgagttt tcctacaacc tgctgcaggg ttatagtgcg 480
gcctgtgtta acaaacagta cggtgtggtg ctgcaaattg gtggttctga ccagtggggt 540
aacatcactt ctggtatcga cctgacccgt cgtctgcatc agaatcangt g 591
<210> 24
<211> 600
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 24
gacgaggaag cgttagcaga gcgactggcg caaggcccga tcgcactcat ttgtggcttc 60
gatcctaccg ctgacagctt gcatttgggg catcttgttc cattgttatg cctgaaacgc 120
ttccagcagg cgggccacaa gccggttgcg ctggtaggcg gcgcgacggg tctgattggc 180
gacccgagct tcaaagctgc cgagcgtaag ctgaacaccg aagaaactgt tcaggagtgg 240
gtggacaaaa tccgtaagca ggttgccccg ttcctcgatt tcgactgtgg agaaaactct 300
gctatcgcgg ccaatgatta tgactggttc ggcaatatga atgtgctgac cttcctgcgc 360
gatattggca aacacttctc cgttaaccag atgatcaaca aagaagcggt taagcagcgt 420
ctcaaccgtg aagatcaggg gatttcgttc actgagtttt cctacaacct gctgcagggt 480
tataattttg cctgtgtgaa caaacagtac ggtgtggtgc tgcaaattgg tggttctgac 540
cagtggggta acatcacttc tggtatcgac ctgacccgtc gtctgcatca gaatcaggtg 600
<210> 25
<211> 579
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 25
cgactggcgc aaggcccgat cgcactcacg tgtggcttcg atcctaccgc tgacagcttg 60
catttggggc atcttgttcc attgttatgc ctgaaacgct tccagcaggc gggccacaag 120
ccggttgcgc tggtaggcgg cgcgacgggt ctgattggcg acccgagctt caaagctgcc 180
gagcgtaagc tgaacaccga agaaactgtt caggagtggg tggacaaaat ccgtaagcag 240
gttgccccgt tcctcgattt cgactgtgga gaaaactctg ctatcgcggc caataattat 300
gactggttcg gcaatatgaa tgtgctgacc ttcctgcgcg atattggcaa acacttctcc 360
gttaaccaga tgatcaacaa agaagcggtt aagcagcgtc tcaaccgtga agatcagggg 420
atttcgttca ctgagttttc ctacaatctg ctgcagggtt attcggctgc ctgtcttaac 480
aaacagtacg gtgtggtgct gcaaattggt ggttctgacc agtggggtaa catcacttct 540
ggtatcgacc tgacccgtcg tctgcatcag aatcaggtg 579
<210> 26
<211> 624
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is a, c, g, or t
<220>
<221> misc_feature
<222> (599)..(599)
<223> n is a, c, g, or t
<400> 26
cgggggctgg tancccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcgggtgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttattct atggcctgtt tgaacaaaca gtacggtgtg 540
gtgctgcaaa ttggtggttc tgaccagtgg ggtaacatca cttctggtat cgacctganc 600
cgtcgtctgc atcagaatca ggtg 624
<210> 27
<211> 625
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<220>
<221> misc_feature
<222> (600)..(600)
<223> n is a, c, g, or t
<400> 27
cgggggctgg tagcccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcacgtgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca atctgctgca gggttattcg gctgcctgtc ttaacaaaca gtacggtgtg 540
gtgctgcaaa ttggtggttc tgaccagtgg ggtaacatca cttctggtat cgaacctgan 600
ccgtcgtctg catcaaaatc aagtg 625
<210> 28
<211> 624
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 28
cgggggctgg taccccaagt gacggacgag gaaacgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tctcttgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcaggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttatacg atggcctgtg tgaacaaaca gtacggtgtg 540
gtgctgcaaa ttggtggttc tgaccagtgg ggtaacatca cttctggtat cgacctgacc 600
cgtcgtctgc atcagaatca ggtg 624
<210> 29
<211> 624
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 29
cgggggctgg tagcccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcgcgtgcgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaagg ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttattct tatgcctgtc ttaacaaaca gtacggtgtg 540
gtgctgcaaa ttggtggttc tgaccagtgg ggtaacatca cttctggtat cgacctgacc 600
cgtcgtctgc atcagaatca ggtg 624
<210> 30
<211> 624
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 30
cgggggctgg tagcccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcgcgtgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttatacg atggcctgtt gtaacaaaca gtacggtgtg 540
gtgctgcaaa ttggtggttc tgaccagtgg ggtaacatca cttctggtat cgacctgacc 600
cgtcgtctgc atcagaatca ggtg 624
<210> 31
<211> 624
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 31
cgggggctgg taccccaagt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcacgtgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcgctgag 480
ttttcctaca acctgctgca gggttatacg tttgcctgta tgaacaaaca gtacggtgtg 540
gtgctgcaaa ttggtggttc tgaccagtgg ggtaacatca cttctggtat cgacctgacc 600
cgtcgtctgc atcagaatca ggtg 624
<210> 32
<211> 606
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 32
gtgacggacg aggaagcgtt agcagagcga ctggcgcaag gcccgatcgc actcacgtgt 60
ggcttcgatc ctaccgctga cagcttgcat ttggggcatc ttgttccatt gttatgcctg 120
aaacgcttcc agcaggcggg ccacaagccg gttgcgctgg taggcggcgc gacgggtctg 180
attggcgacc cgagcttcaa agctgccgag cgtaagctga acaccgaaga aactgttcag 240
gagtgggtgg acaaaatccg taagcaggtt gccccgttcc tcgatttcga ctgtggagaa 300
aactctgcta tcgcggccaa taattatgac tggttcggca atatgaatgt gctgaccttc 360
ctgcgcgata ttggcaaaca cttctccgtt aaccagatga tcaacaaaga agcggttaag 420
cagcgtctca accgtgaaga tcaggggatt tcgttcactg agttttccta caatctgctg 480
cagggttatt cggctgcctg tcttaacaaa cagtacggtg tggtgctgca aattggtggt 540
tctgaccagt ggggtaacat cacttctggt atcgacctga cccgtcgtct gcatcagaat 600
caggtg 606
<210> 33
<211> 624
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 33
cgggggctgg tagcccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcgtttgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttattcg atggcctgta cgaacaaaca gtacggtgtg 540
gtgctgcaaa ttggtggttc tgaccagtgg ggtaacatca cttctggtat cgacctgacc 600
cgtcgtctgc atcagaatca ggtg 624
<210> 34
<211> 624
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<220>
<221> misc_feature
<222> (13)..(13)
<223> n is a, c, g, or t
<400> 34
cgggggctgg tancccaagt gacggacggg gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcagttgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatctcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttatagt tttgcctgtc tgaacaaaca gtacggtgtg 540
gtgctgcaaa ttggtggttc tgaccagtgg ggtaacatca cttctggtat cgacctgacc 600
cgtcgtctgc atcagaatca ggtg 624
<210> 35
<211> 624
<212> DNA
<213> Artificial
<220>
<223> artificial synthetase
<400> 35
cgggggctgg tagcccaggt gacggacgag gaagcgttag cagagcgact ggcgcaaggc 60
ccgatcgcac tcacgtgtgg cttcgatcct accgctgaca gcttgcattt ggggcatctt 120
gttccattgt tatgcctgaa acgcttccag caggcgggcc acaagccggt tgcgctggta 180
ggcggcgcga cgggtctgat tggcgacccg agcttcaaag ctgccgagcg taagctgaac 240
accgaagaaa ctgttcagga gtgggtggac aaaatccgta agcaggttgc cccgttcctc 300
gatttcgact gtggagaaaa ctctgctatc gcggccaata attatgactg gttcggcaat 360
atgaatgtgc tgaccttcct gcgcgatatt ggcaaacact tctccgttaa ccagatgatc 420
aacaaagaag cggttaagca gcgtctcaac cgtgaagatc aggggatttc gttcactgag 480
ttttcctaca acctgctgca gggttatacg tttgcctgta ctaacaaaca gtacggtgtg 540
gtgctgcaaa ttggtggttc tgaccagtgg ggtaacatca cttctggtat cgacctgacc 600
cgtcgtctgc atcagaatca ggtg 624
<210> 36
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 36
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Val Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Tyr Ala Cys Leu Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 37
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 37
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Ile Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Met Ala Cys Leu Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 38
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 38
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Val Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Met Ala Cys Ala Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 39
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 39
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Val Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Met Ala Cys Leu Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 40
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 40
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Thr Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Thr Met Ala Cys Leu Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 41
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 41
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Thr Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Thr Tyr Ala Cys Leu Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 42
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 42
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Leu Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Met Ala Cys Ser Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 43
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 43
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Leu Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Met Ala Cys Ala Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 44
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 44
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Thr Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Arg Met Ala Cys Leu Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 45
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 45
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Ile Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Gly Met Ala Cys Ala Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 46
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 46
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Gly Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Gly Phe Ala Cys Ala Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 47
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 47
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Gly Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Gly Tyr Ala Cys Met Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 48
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 48
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Leu Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Met Ala Cys Ala Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 49
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 49
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Val Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Ala Ala Cys Ala Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 50
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 50
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Leu Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Ala Ala Cys Ala Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 51
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 51
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Val Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Ala Ala Cys Val Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 52
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 52
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Ile Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asp Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Asn Phe Ala Cys Val Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 53
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 53
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Thr Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Ala Ala Cys Leu Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 54
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 54
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Gly Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Met Ala Cys Leu Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 55
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 55
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Thr Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Ala Ala Cys Leu Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 56
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 56
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Ser Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Thr Met Ala Cys Val Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 57
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 57
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Ala Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Tyr Ala Cys Leu Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 58
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 58
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Ala Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Thr Met Ala Cys Cys Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 59
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 59
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Thr Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Thr Phe Ala Cys Met Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 60
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 60
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Thr Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Val Ala Cys Leu Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 61
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 61
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Val Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Met Ala Cys Thr Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 62
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 62
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Ser Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Ser Phe Ala Cys Leu Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 63
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 63
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Thr Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Asp Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Thr Phe Ala Cys Thr Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 64
<211> 129
<212> DNA
<213> Escherichia coli
<400> 64
agcttcccga taagggagca ggccagtaaa aagcattacc ccgtggtggg gttcccgagc 60
ggccaaaggg agcagactct aaatctgccg tcatcgacct cgaaggttcg aatccttccc 120
ccaccacca 129
<210> 65
<211> 129
<212> RNA
<213> Escherichia coli
<400> 65
agcuucccga uaagggagca ggccaguaaa aagcauuacc ccgugguggg guucccgagc 60
ggccaaaggg agcagacucu aaaucugccg ucaucgaccu cgaagguucg aauccuuccc 120
ccaccacca 129
<210> 66
<211> 34
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 66
atgaagtagc tgtcttctat cgaacaagca tgcg 34
<210> 67
<211> 34
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 67
cgaacaagca tgcgattagt gccgacttaa aaag 34
<210> 68
<211> 33
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 68
cgctactctc ccaaatagaa aaggtctccg ctg 33
<210> 69
<211> 32
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 69
ctggaacagc tatagctact gatttttcct cg 32
<210> 70
<211> 34
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 70
gccgtcacag attagttggc ttcagtggag actg 34
<210> 71
<211> 33
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 71
gattggcttc ataggagact gatatgctct aac 33
<210> 72
<211> 33
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 72
gcctctatag ttgagacagc atagaataat gcg 33
<210> 73
<211> 35
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 73
gagacagcat agatagagtg cgacatcatc atcgg 35
<210> 74
<211> 37
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 74
gaataagtgc gacatagtca tcggaagaga gtagtag 37
<210> 75
<211> 35
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 75
ggtcaaagac agttgtaggt atcgattgac tcggc 35
<210> 76
<211> 34
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 76
cgctactctc cccaaattta aaaggtctcc gctg 34
<210> 77
<211> 34
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 77
cgctactctc cccaaatata aaaggtctcc gctg 34
<210> 78
<211> 34
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 78
cgctactctc cccaaatgga aaaggtctcc gctg 34
<210> 79
<211> 34
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 79
cgctactctc cccaaagata aaaggtctcc gctg 34
<210> 80
<211> 34
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 80
cgctactctc cccaaaaaaa aaaggtctcc gctg 34
<210> 81
<211> 34
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 81
gccgtcacag attttttggc ttcagtggag actg 34
<210> 82
<211> 34
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 82
gccgtcacag attatttggc ttcagtggag actg 34
<210> 83
<211> 34
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 83
gccgtcacag attggttggc ttcagtggag actg 34
<210> 84
<211> 34
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 84
gccgtcacag atgatttggc ttcagtggag actg 34
<210> 85
<211> 34
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide primer
<400> 85
gccgtcacag ataaattggc ttcagtggag actg 34
<210> 86
<211> 424
<212> PRT
<213> Artificial
<220>
<223> artificial synthetase
<400> 86
Met Ala Ser Ser Asn Leu Ile Lys Gln Leu Gln Glu Arg Gly Leu Val
1 5 10 15
Ala Gln Val Thr Asp Glu Glu Ala Leu Ala Glu Arg Leu Ala Gln Gly
20 25 30
Pro Ile Ala Leu Ile Cys Gly Phe Asp Pro Thr Ala Asp Ser Leu His
35 40 45
Leu Gly His Leu Val Pro Leu Leu Cys Leu Lys Arg Phe Gln Gln Ala
50 55 60
Gly His Lys Pro Val Ala Leu Val Gly Gly Ala Thr Gly Leu Ile Gly
65 70 75 80
Asp Pro Ser Phe Lys Ala Ala Glu Arg Lys Leu Asn Thr Glu Glu Thr
85 90 95
Val Gln Glu Trp Val Asp Lys Ile Arg Lys Gln Val Ala Pro Phe Leu
100 105 110
Asp Phe Asp Cys Gly Glu Asn Ser Ala Ile Ala Ala Asn Asn Tyr Asp
115 120 125
Trp Phe Gly Asn Met Asn Val Leu Thr Phe Leu Arg Asp Ile Gly Lys
130 135 140
His Phe Ser Val Asn Gln Met Ile Asn Lys Glu Ala Val Lys Gln Arg
145 150 155 160
Leu Asn Arg Glu Gly Gln Gly Ile Ser Phe Thr Glu Phe Ser Tyr Asn
165 170 175
Leu Leu Gln Gly Tyr Gly Met Ala Cys Ala Asn Lys Gln Tyr Gly Val
180 185 190
Val Leu Gln Ile Gly Gly Ser Asp Gln Trp Gly Asn Ile Thr Ser Gly
195 200 205
Ile Asp Leu Thr Arg Arg Leu His Gln Asn Gln Val Phe Gly Leu Thr
210 215 220
Val Pro Leu Ile Thr Lys Ala Asp Gly Thr Lys Phe Gly Lys Thr Glu
225 230 235 240
Gly Gly Ala Val Trp Leu Asp Pro Lys Lys Thr Ser Pro Tyr Lys Phe
245 250 255
Tyr Gln Phe Trp Ile Asn Thr Ala Asp Ala Asp Val Tyr Arg Phe Leu
260 265 270
Lys Phe Phe Thr Phe Met Ser Ile Glu Glu Ile Asn Ala Leu Glu Glu
275 280 285
Glu Asp Lys Asn Ser Gly Lys Ala Pro Arg Ala Gln Tyr Val Leu Ala
290 295 300
Glu Gln Val Thr Arg Leu Val His Gly Glu Glu Gly Leu Gln Ala Ala
305 310 315 320
Lys Arg Ile Thr Glu Cys Leu Phe Ser Gly Ser Leu Ser Ala Leu Ser
325 330 335
Glu Ala Asp Phe Glu Gln Leu Ala Gln Asp Gly Val Pro Met Val Glu
340 345 350
Met Glu Lys Gly Ala Asp Leu Met Gln Ala Leu Val Asp Ser Glu Leu
355 360 365
Gln Pro Ser Arg Gly Gln Ala Arg Lys Thr Ile Ala Ser Asn Ala Ile
370 375 380
Thr Ile Asn Gly Glu Lys Gln Ser Asp Pro Glu Tyr Phe Phe Lys Glu
385 390 395 400
Glu Asp Arg Leu Phe Gly Arg Phe Thr Leu Leu Arg Arg Gly Lys Lys
405 410 415
Asn Tyr Cys Leu Ile Cys Trp Lys
420
<210> 87
<211> 11
<212> DNA
<213> Artificial
<220>
<223> B box sequence
<220>
<221> misc_feature
<222> (8)..(8)
<223> n is a, c, g, or t
<400> 87
ggttcgantc c 11
<210> 88
<211> 95
<212> DNA
<213> Artificial
<220>
<223> B. stearothermophilus tRNA expression insert
<400> 88
ggattacgca tgctcagtgc aatcttcggt tgcctggact agcgctccgg tttttctgtg 60
ctgaacctca ggggacgccg acacacgtac acgtc 95
<210> 89
<211> 42
<212> DNA
<213> Artificial
<220>
<223> B. stearothermophilus tRNA amber suppression mutant
<400> 89
gacaagtgcg gtttttttct ccagctcccg atgacttatg gc 42
<210> 90
<211> 80
<212> DNA
<213> Artificial
<220>
<223> FTam 73: forward primer
<400> 90
gtacgaattc ccgagatctg gattacgcat gctcagtgca atcttcggtt gcctggacta 60
gcgctccggt ttttctgtgc 80
<210> 91
<211> 88
<212> DNA
<213> Artificial
<220>
<223> FTam 74: Reverse primer
<400> 91
agtccgccgc gtttagccac ttcgctaccc ctccgacgtg tacgtgtgtc ggcgtcccct 60
gaggttcagc acagaaaaac cggagcgc 88
<210> 92
<211> 75
<212> DNA
<213> Artificial
<220>
<223> FTam 75: Forward primer
<400> 92
gatgcaagct tgatggatcc gccataagtc atcgggagct ggagaaaaaa accgcacttg 60
tctggagggg gacgg 75
<210> 93
<211> 75
<212> DNA
<213> Artificial
<220>
<223> FTam 76: Reverse primer
<400> 93
gatgcaagct tgatggatcc gccataagtc atcgggagct ggagaaaaaa accgcacttg 60
tctggagggg gacgg 75
<210> 94
<211> 790
<212> DNA
<213> Artificial
<220>
<223> hIgG1-Fc2 DNA
<400> 94
ctgagatcac cggcgaagga gggccaccat gtacaggatg caactcctgt cttgcattgc 60
actaagtctt gcacttgtca cgaattcgat atcggccatg gttagatctg acaaaactca 120
cacatgccca ccgtgcccag cacctgaact cctgggggga ccgtcagtct tcctcttccc 180
cccaaaaccc aaggacaccc tcatgatctc ccggacccct gaggtcacat gcgtggtggt 240
ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg tacgtggacg gcgtggaggt 300
gcataatgcc aagacaaagc cgcgggagga gcagtacaac agcacgtacc gtgtggtcag 360
cgtcctcacc gtcctgcacc aggactggct gaatggcaag gagtacaagt gcaaggtctc 420
caacaaagcc ctcccagccc ccatcgagaa aaccatctcc aaagccaaag ggcagccccg 480
agaaccacag gtgtacaccc tgcccccatc ccgggaggag atgaccaaga accaggtcag 540
cctgacctgc ctggtcaaag gcttctatcc cagcgacatc gccgtggagt gggagagcaa 600
tgggcagccg gagaacaact acaagaccac gcctcccgtg ctggactccg acggctcctt 660
cttcctctac agcaagctca ccgtggacaa gagcaggtgg cagcagggga acgtcttctc 720
atgctccgtg atgcatgagg gtctgcacaa ccactacacg cagaagagcc tctccctgtc 780
tccgggtaaa 790
<210> 95
<211> 41
<212> DNA
<213> Artificial
<220>
<223> 5' IL2 signal sequence
<400> 95
atgtacagga tgcaactcct gtcttgcatt gcactaagtc t 41
<210> 96
<211> 254
<212> PRT
<213> Artificial
<220>
<223> hIgG1-Fc2 protein sequence
<400> 96
Met Tyr Arg Met Gln Leu Leu Ser Cys Ile Ala Leu Ser Leu Ala Leu
1 5 10 15
Val Thr Asn Ser Ile Ser Ala Met Val Arg Ser Asp Lys Thr His Thr
20 25 30
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
35 40 45
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
50 55 60
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
65 70 75 80
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
85 90 95
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
100 105 110
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
115 120 125
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
130 135 140
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
145 150 155 160
Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
165 170 175
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
180 185 190
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
195 200 205
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
210 215 220
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Gly Leu His
225 230 235 240
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
245 250
<210> 97
<211> 20
<212> PRT
<213> Artificial
<220>
<223> IL2 signal sequence protein
<400> 97
Met Tyr Arg Met Gln Leu Leu Ser Cys Ile Ala Leu Ser Leu Ala Leu
1 5 10 15
Val Thr Asn Ser
20
Claims (51)
- 오르소고날 아미노아실-tRNA 합성효소(O-RS)를 포함하는 척추동물 세포 또는 세포주로서, 여기서 O-RS는 척추동물 세포에서 파라-아세틸-페닐알라닌(PAF)으로 오르소고날 tRNA(O-tRNA)를 우선적으로 아미노아실화시키는 것인 척추동물 세포 또는 세포주.
- 제1항에 있어서, O-RS는 O-RS가 천연 아미노산으로 O-tRNA를 아미노아실화시키는 것에 비하여 10배 이상 더욱 효과적으로 O-tRNA를 PAF로 아미노아실화시키는 것인 세포 또는 세포주.
- 제1항에 있어서, 0-RS는 비척추동물 유기체로부터 유래한 것인 세포 또는 세포주.
- 제3항에 있어서, 비척추동물 유기체는 에스케리치아 콜라이(Escherichia coli) 또는 바실러스 스테아로써모필러스(Bacillus stearothermophilus)인 세포 또는 세포주.
- 제1항에 있어서, 척추동물 세포 또는 세포주는 포유류의 것인 세포 또는 세포주.
- 제5항에 있어서, 척추동물 세포주는 인간 세포주인 세포주.
- 제1항에 있어서, O-RS는 천연 아미노산과 비교하여 하나 이상의 비천연 아미노산에 대해 하나 이상의 개선되거나 향상된 효소 특성을 가지며, 상기 특성은 보다 높은 Km, 보다 낮은 Km, 보다 높은 kcat, 보다 낮은 kcat, 보다 낮은 kcat/km 및 보다 높은 kcat/km으로 이루어진 군으로부터 선택된 것인 세포 또는 세포주.
- 제1항에 있어서, O-tRNA는 비척추동물 유기체로부터 유래한 것인 세포 또는 세포주.
- 제8항에 있어서, 비척추동물 유기체는 에스케리치아 콜라이 또는 바실러스 스테아로써모필러스인 세포 또는 세포주.
- 제1항에 있어서, 목적하는 폴리펩티드를 코딩하는 폴리뉴클레오티드를 포함하는 핵산을 더 포함하고, 여기서 상기 폴리뉴클레오티드는 O-tRNA에 의해 인식되는 셀렉터 코돈을 포함하는 세포 또는 세포주.
- 제10항에 있어서, 셀렉터 코돈은 앰버 코돈, 오커 코돈, 오팔 코돈 또는 4 또는 그 이상의 염기 코돈으로 이루어진 군으로부터 선택되는 세포 또는 세포주.
- 제10항에 있어서, 셀렉터 코돈은 앰버 코돈인 세포 또는 세포주.
- 제10항에 있어서, 셀렉터 코돈은 오커 코돈인 세포 또는 세포주.
- 제10항에 있어서, 셀렉터 코돈은 오팔 코돈인 세포 또는 세포주.
- 제10항에 있어서, 셀렉터 코돈은 4 또는 그 이상의 염기 코돈을 포함하는 세포 또는 세포주.
- 제10항에 있어서, 하나 이상의 비천연 아미노산을 포함하는 목적하는 폴리펩티드의 수율은 폴리뉴클레오티드에 상기 셀렉터 코돈이 결실된 세포로부터 유래하는 목적하는 천연 발생 폴리펩티드에 대해 얻어지는 것의 5% 이상인 세포 또는 세포주.
- 제1항에 있어서, 세포는 하나 이상의 비천연 아미노산의 존재하에 폴리펩티드 수율의 30%보다 낮은 수율로 하나 이상의 비천연 아미노산의 부재하에 목적하는 폴리펩티드를 생산하는 세포 또는 세포주.
- 제10항에 있어서, 목적하는 폴리펩티드는 치료용 단백질, 진단용 단백질, 산업용 효소 또는 이의 부분인 세포 또는 세포주.
- 제10항에 있어서, 목적하는 폴리펩티드가 사이토카인, 성장 인자, 성장 인자 수용체, 인터페론, 인터루킨, 염증 분자, 암유전자 생성물, 펩티드 호르몬, 신호 전달 분자, 스테로이드 호르몬 수용체, 에리스로포이에틴(EPO), 인슐린, 인간 성장 호르몬, 알파-1 안티트립신, 안지오스타틴, 항용혈 인자, 항체, 아포지단백질, 아포단백질, 심방 나트륨 이뇨 인자, 심방 나트륨 이뇨 폴리펩티드, 심방 펩티드, C-X-C 케모카인, T39765, NAP-2, ENA-78, Gro-a, Gro-b, Gro-c, IP-10, GCP-2, NAP-4, SDF-1, PF4, MIG, 칼시토닌, c-kit 리간드, 사이토카인, CC 케모카인, 단핵구 화학유인 단백질-1, 단핵구 화학유인 단백질-2, 단핵구 화학유인 단백질-3, 단핵구 염증 단백질-1 알파, 단핵구 염증 단백질-1 베타, RANTES, I309, R83915, R91733, HCC1, T58847, D31065, T64262, CD40, CD40 리간드, c-kit 리간드, 콜라겐, 콜로니 자극 인자(CSF), 보체 인자 5a, 보체 억제제, 보체 수용체 1, 사이토카인, DHFR, 상피세포 호중구 활성화 펩티드-78, GROα/MGSA, GROβ, GROγ, MIP-1α, MIP-1δ, MCP-1, 상피세포 성장 인자(EGF), 상피세포 호중구 활성화 펩티드, 에리스로포이에틴(EPO), 박리 독소(exfoliating toxin), 인자 IX, 인자 VII, 인자 VIII, 인자 X, 섬유아세포 성장 인자(FGF), 피브리노겐, 피브로넥틴, G-CSF, GM-CSF, 글루코세레브로시다제, 고나도트로핀, 성장 인자, 성장 인자 수용체, 헤지호그(Hedgehog) 단백질, 헤모글로빈, 간세포 성장 인자(HGF), 히루딘, 인간 혈청 알부민, ICAM-1, ICAM-1 수용체, LFA-1, LFA-1 수용체, 인슐린, 인슐린 유사 성장 인자(IGF), IGF-I, IGF-II, 인터페론, IFN-α, IFN-β, IFN-γ, 인터루킨, IL-1, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8, IL-9, IL-10, IL-11, IL-12, 각질 세포 성장 인자(KGF), 락토페린, 백혈병 억제 인자, 루시퍼라제, 뉴투린, 호중구 억제 인자(NIF), 온코스타틴 M, 골원성 단백질, 암유전자 생성물, 부갑상선 호르몬, PD-ECSF, PDGF, 펩티드 호르몬, 인간 성장 호르몬, 플레이오트로핀, 단백질 A, 단백질 G, 발열성 외독소 A, B 또는 C, 릴렉신, 레닌, SCF, 가용성 보체 수용체 I, 가용성 I-CAM 1, 가용성 인터루킨 수용체, 가용성 TNF 수용체, 소마토메딘, 소마토스타틴, 소마토트로핀, 스트렙토키나제, 슈퍼항원, 스타필로코커스 장독소, SEA, SEB, SEC1, SEC2, SEC3, SED, SEE, 스테로이드 호르몬 수용체, 슈퍼옥시드 디스뮤타제(SOD), 독성 쇼크 증후군 독소, 티모신 알파 1, 조직 플라스미노겐 활성화 인자, 종양 성장 인자(TGF), TGF-α, TGF-β, 종양 괴사 인자, 종양 괴사 인자 알파, 종양 괴사 인자 베타, 종양 괴사 인자 수용체(TNFR), VLA-4 단백질, VCAM-1 단백질, 혈관 내피세포 성장 인자(VEGEF), 유로키나제, Mos, Ras, Raf, Met; p53, Tat, Fos, Myc, Jun, Myb, Rel, 에스트로겐 수용체, 프로게스테론 수용체, 테스토스테론 수용체, 알도스테론 수용체, LDL 수용체, SCF/c-Kit, CD40L/CD40, VLA-4/VCAM-1, ICAM-1/LFA-1, 히알루린/CD44 및 코르티코스테론으로 구성된 군에서 선택되는 단백질 또는 단백질의 일부분을 포함하는 것인 세포 또는 세포주.
- 오르소고날 아미노아실-tRNA 합성효소(O-RS)를 포함하는 척추동물 세포 또는 세포주로서, 여기서 O-RS는 척추동물 세포에서 파라-아미노-페닐알라닌으로 오르소고날 tRNA(O-tRNA)를 우선적으로 아미노아실화시키는 것인 척추동물 세포 또는 세포주.
- 제1항에 있어서, O-RS는 O-RS가 천연 아미노산으로 O-tRNA를 아미노아실화시키는 것에 비해 10배 이상 더욱 효율적으로 O-tRNA를 파라-아미노-페닐알라닌으로 아미노아실화시키는 세포 또는 세포주.
- 제20항에 있어서, O-RS는 비척추동물 유기체로부터 유래된 것인 세포 또는 세포주.
- 제22항에 있어서, 비척추동물 유기체는 에스케리치아 콜라이 또는 바실러스 스테아로써모필러스인 세포 또는 세포주.
- 제20항에 있어서, 척추동물 세포 또는 세포주는 포유류의 것인 세포 또는 세포주.
- 제20항에 있어서, 척추동물 세포주는 인간 세포주인 세포주.
- 제20항에 있어서, O-RS는 천연 아미노산에 비하여 하나 이상의 비천연 아미 노산에 대해 하나 이상의 개선되거나 향상된 효소 특성을 가지며, 상기 특성은 보다 높은 Km, 보다 낮은 Km, 보다 높은 kcat, 보다 낮은 kcat, 보다 낮은 kcat/km 및 보다 높은 kcat/km으로 이루어진 군으로부터 선택된 것인 세포 또는 세포주.
- 제20항에 있어서, O-tRNA는 비척추동물 유기체로부터 유래한 것인 세포 또는 세포주.
- 제27항에 있어서, 비척추동물 유기체는 에스케리치아 콜라이 또는 바실러스 스테아로써모필러스인 세포 또는 세포주.
- 제20항에 있어서, 목적하는 폴리펩티드를 코딩하는 폴리뉴클레오티드를 포함하는 핵산을 더 포함하고, 여기서 상기 폴리뉴클레오티드는 O-tRNA에 의해 인식되는 셀렉터 코돈을 포함하는 세포 또는 세포주.
- 제29항에 있어서, 셀렉터 코돈은 앰버 코돈, 오커 코돈, 오팔 코돈 또는 4 또는 그 이상의 염기 코돈으로 이루어진 군으로부터 선택되는 세포 또는 세포주.
- 제29항에 있어서, 셀렉터 코돈은 앰버 코돈인 세포 또는 세포주.
- 제29항에 있어서, 셀렉터 코돈은 오커 코돈인 세포 또는 세포주.
- 제29항에 있어서, 셀렉터 코돈은 오팔 코돈인 세포 또는 세포주.
- 제29항에 있어서, 셀렉터 코돈은 4 또는 그 이상의 염기 코돈을 포함하는 세포 또는 세포주.
- 제29항에 있어서, 하나 이상의 비천연 아미노산을 포함하는 목적하는 폴리펩티드의 수율은 폴리뉴클레오티드에 상기 셀렉터 코돈이 결실된 세포로부터 유래하는 목적하는 천연 발생 폴리펩티드에 대해 얻어지는 것의 5% 이상인 세포 또는 세포주.
- 제20항에 있어서, 세포는 하나 이상의 비천연 아미노산의 존재하에 폴리펩티드 수율의 30%보다 낮은 수율로 하나 이상의 비천연 아미노산의 부재하에 목적하는 폴리펩티드를 생산하는 세포 또는 세포주.
- 제29항에 있어서, 목적하는 폴리펩티드는 치료용 단백질, 진단용 단백질, 산업용 효소 또는 이의 부분인 세포 또는 세포주.
- 제29항에 있어서, 목적하는 폴리펩티드가 사이토카인, 성장 인자, 성장 인자 수용체, 인터페론, 인터루킨, 염증 분자, 암유전자 생성물, 펩티드 호르몬, 신호 전달 분자, 스테로이드 호르몬 수용체, 에리스로포이에틴(EPO), 인슐린, 인간 성장 호르몬, 알파-1 안티트립신, 안지오스타틴, 항용혈 인자, 항체, 아포지단백질, 아포단백질, 심방 나트륨 이뇨 인자, 심방 나트륨 이뇨 폴리펩티드, 심방 펩티드, C-X-C 케모카인, T39765, NAP-2, ENA-78, Gro-a, Gro-b, Gro-c, IP-10, GCP-2, NAP-4, SDF-1, PF4, MIG, 칼시토닌, c-kit 리간드, 사이토카인, CC 케모카인, 단핵구 화학유인 단백질-1, 단핵구 화학유인 단백질-2, 단핵구 화학유인 단백질-3, 단핵구 염증 단백질-1 알파, 단핵구 염증 단백질-1 베타, RANTES, I309, R83915, R91733, HCC1, T58847, D31065, T64262, CD40, CD40 리간드, c-kit 리간드, 콜라겐, 콜로니 자극 인자(CSF), 보체 인자 5a, 보체 억제제, 보체 수용체 1, 사이토카인, DHFR, 상피세포 호중구 활성화 펩티드-78, GROα/MGSA, GROβ, GROγ, MIP-1α, MIP-1δ, MCP-1, 상피세포 성장 인자(EGF), 상피세포 호중구 활성화 펩티드, 에리스로포이에틴(EPO), 박리 독소(exfoliating toxin), 인자 IX, 인자 VII, 인자 VIII, 인자 X, 섬유아세포 성장 인자(FGF), 피브리노겐, 피브로넥틴, G-CSF, GM-CSF, 글루코세레브로시다제, 고나도트로핀, 성장 인자, 성장 인자 수용체, 헤지호그(Hedgehog) 단백질, 헤모글로빈, 간세포 성장 인자(HGF), 히루딘, 인간 혈청 알부민, ICAM-1, ICAM-1 수용체, LFA-1, LFA-1 수용체, 인슐린, 인슐린 유사 성장 인자(IGF), IGF-I, IGF-II, 인터페론, IFN-α, IFN-β, IFN-γ, 인터루킨, IL-1, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8, IL-9, IL-10, IL-11, IL-12, 각질 세포 성장 인자(KGF), 락토페린, 백혈병 억제 인자, 루시퍼라제, 뉴투린, 호중구 억제 인 자(NIF), 온코스타틴 M, 골원성 단백질, 암유전자 생성물, 부갑상선 호르몬, PD-ECSF, PDGF, 펩티드 호르몬, 인간 성장 호르몬, 플레이오트로핀, 단백질 A, 단백질 G, 발열성 외독소 A, B 또는 C, 릴렉신, 레닌, SCF, 가용성 보체 수용체 I, 가용성 I-CAM 1, 가용성 인터루킨 수용체, 가용성 TNF 수용체, 소마토메딘, 소마토스타틴, 소마토트로핀, 스트렙토키나제, 슈퍼항원, 스타필로코커스 장독소, SEA, SEB, SEC1, SEC2, SEC3, SED, SEE, 스테로이드 호르몬 수용체, 슈퍼옥시드 디스뮤타제(SOD), 독성 쇼크 증후군 독소, 티모신 알파 1, 조직 플라스미노겐 활성화 인자, 종양 성장 인자(TGF), TGF-α, TGF-β, 종양 괴사 인자, 종양 괴사 인자 알파, 종양 괴사 인자 베타, 종양 괴사 인자 수용체(TNFR), VLA-4 단백질, VCAM-1 단백질, 혈관 내피세포 성장 인자(VEGEF), 유로키나제, Mos, Ras, Raf, Met; p53, Tat, Fos, Myc, Jun, Myb, Rel, 에스트로겐 수용체, 프로게스테론 수용체, 테스토스테론 수용체, 알도스테론 수용체, LDL 수용체, SCF/c-Kit, CD40L/CD40, VLA-4/VCAM-1, ICAM-1/LFA-1, 히알루린/CD44 및 코르티코스테론으로 구성된 군에서 선택되는 단백질 또는 단백질의 일부분을 포함하는 것인 세포 또는 세포주.
- 제1항에 있어서, 세포주는 일시적으로 형질감염된 척추동물 세포주.
- 제1항에 있어서, 세포주는 안정하게 형질감염된 척추동물 세포주.
- 오르소고날 tRNA(O-tRNA)를 포함하는 척추동물 세포 또는 세포주로서, 여기 서 O-tRNA는 생체 내에서 O-tRNA에 의해 인식되는 셀렉터 코돈을 포함하는 폴리뉴클레오티드에 의해 코딩되는 단백질로 파라-아세틸-페닐알라닌이 도입되는 것을 매개하는 것인 척추동물 세포 또는 세포주.
- 제41항에 있어서, 단백질은 2 이상의 비천연 아미노산을 포함하는 세포 또는 세포주.
- 제41항에 있어서, 단백질은 2 이상의 상이한 비천연 아미노산을 포함하는 세포 또는 세포주.
- 제41항에 있어서, 단백질은 약학적으로 허용되는 부형제를 더 포함하는 세포 또는 세포주.
- 오르소고날 tRNA(O-tRNA)를 포함하는 세포 또는 세포주로서, 여기서 O-tRNA는 생체 내에서 O-tRNA에 의해 인식되는 셀렉터 코돈을 포함하는 폴리뉴클레오티드에 의해 코딩되는 단백질로 파라-아미노-페닐알라닌이 도입되는 것을 매개하는 것인 세포 또는 세포주.
- 제45항에 있어서, 단백질은 2 이상의 비천연 아미노산을 포함하는 세포 또는 세포주.
- 제45항에 있어서, 단백질은 2 이상의 상이한 비천연 아미노산을 포함하는 세포 또는 세포주.
- 제45항에 있어서, 단백질은 약학적으로 허용되는 부형제를 더 포함하는 세포 또는 세포주.
- 세포에서 하나 이상의 비천연 아미노산을 포함하는 단백질을 생산하기 위한 키트로서, O-tRNA를 코딩하는 폴리뉴클레오티드 서열, 및 O-RS를 코딩하는 폴리뉴클레오티드 서열 또는 O-RS를 함유하는 용기를 포함하는 키트.
- 제49항에 있어서, 하나 이상의 비천연 아미노산을 더 포함하는 키트.
- 제49항에 있어서, 단백질을 생산하기 위한 설명 자료를 더 포함하는 키트.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US84347306P | 2006-09-08 | 2006-09-08 | |
| US60/843,473 | 2006-09-08 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20090057072A true KR20090057072A (ko) | 2009-06-03 |
Family
ID=39157897
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020097006398A Withdrawn KR20090057072A (ko) | 2006-09-08 | 2007-09-07 | 척추동물 세포에 의한 비천연 아미노산의 부위 특이적 도입 |
Country Status (13)
| Country | Link |
|---|---|
| US (1) | US20100093082A1 (ko) |
| EP (1) | EP2064316B1 (ko) |
| JP (1) | JP2010502221A (ko) |
| KR (1) | KR20090057072A (ko) |
| CN (2) | CN101528914B (ko) |
| AT (1) | ATE542888T1 (ko) |
| AU (1) | AU2007292891B2 (ko) |
| CA (1) | CA2662752C (ko) |
| IL (2) | IL196893A (ko) |
| MX (1) | MX2009002524A (ko) |
| NZ (1) | NZ574673A (ko) |
| SG (1) | SG174780A1 (ko) |
| WO (1) | WO2008030612A2 (ko) |
Families Citing this family (75)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| BRPI0923155A2 (pt) * | 2008-12-05 | 2018-10-23 | Abraxis Bioscience Llc | scfcs de ligação a sparc |
| WO2010096394A2 (en) | 2009-02-17 | 2010-08-26 | Redwood Biosciences, Inc. | Aldehyde-tagged protein-based drug carriers and methods of use |
| EP2403864B1 (en) | 2009-02-27 | 2015-08-12 | Atyr Pharma, Inc. | Polypeptide structural motifs associated with cell signaling activity |
| AU2010247938B2 (en) | 2009-05-11 | 2016-02-18 | Pelican Technology Holdings, Inc. | Production of recombinant proteins utilizing non-antibiotic selection methods and the incorporation of non-natural amino acids therein |
| CA2797093C (en) | 2010-04-26 | 2019-10-29 | Atyr Pharma, Inc. | Innovative discovery of therapeutic, diagnostic, and antibody compositions related to protein fragments of cysteinyl-trna synthetase |
| EP2563381B1 (en) | 2010-04-27 | 2017-08-09 | aTyr Pharma, Inc. | Innovative discovery of therapeutic, diagnostic, and antibody compositions related to protein fragments of isoleucyl trna synthetases |
| AU2011248521B2 (en) | 2010-04-27 | 2017-03-16 | Pangu Biopharma Limited | Innovative discovery of therapeutic, diagnostic, and antibody compositions related to protein fragments of threonyl tRNA synthetases |
| CN103097524B (zh) | 2010-04-28 | 2016-08-03 | Atyr医药公司 | 与丙氨酰-tRNA合成酶的蛋白片段相关的治疗、诊断和抗体组合物的创新发现 |
| EP2563383B1 (en) | 2010-04-29 | 2017-03-01 | Atyr Pharma, Inc. | Innovative discovery of therapeutic, diagnostic, and antibody compositions related to protein fragments of valyl trna synthetases |
| CA2797374C (en) | 2010-04-29 | 2021-02-16 | Pangu Biopharma Limited | Innovative discovery of therapeutic, diagnostic, and antibody compositions related to protein fragments of asparaginyl trna synthetases |
| AU2011248227B2 (en) | 2010-05-03 | 2016-12-01 | Pangu Biopharma Limited | Innovative discovery of therapeutic, diagnostic, and antibody compositions related to protein fragments of phenylalanyl-alpha-tRNA synthetases |
| EP2566516B1 (en) | 2010-05-03 | 2019-07-03 | aTyr Pharma, Inc. | Innovative discovery of therapeutic, diagnostic, and antibody compositions related to protein fragments of seryl-trna synthetases |
| CN103096925A (zh) | 2010-05-03 | 2013-05-08 | Atyr医药公司 | 与精氨酰-tRNA合成酶的蛋白片段相关的治疗、诊断和抗体组合物的创新发现 |
| ES2668207T3 (es) | 2010-05-03 | 2018-05-17 | Atyr Pharma, Inc. | Descubrimiento innovador de composiciones terapéuticas, de diagnóstico y de anticuerpos relacionadas con fragmentos de proteínas de metionil-ARNt sintetasas |
| CN103096909A (zh) | 2010-05-04 | 2013-05-08 | Atyr医药公司 | 与谷氨酰-脯氨酰-tRNA合成酶的蛋白片段相关的治疗、诊断和抗体组合物的创新发现 |
| JP6008844B2 (ja) | 2010-05-04 | 2016-10-19 | エータイアー ファーマ, インコーポレイテッド | p38MULTI−tRNA合成酵素複合体のタンパク質フラグメントに関連した治療用、診断用および抗体組成物の革新的発見 |
| EP2568996B1 (en) | 2010-05-14 | 2017-10-04 | aTyr Pharma, Inc. | Therapeutic, diagnostic, and antibody compositions related to protein fragments of phenylalanyl-beta-trna synthetases |
| US9034598B2 (en) | 2010-05-17 | 2015-05-19 | Atyr Pharma, Inc. | Innovative discovery of therapeutic, diagnostic, and antibody compositions related to protein fragments of leucyl-tRNA synthetases |
| CN103096913B (zh) | 2010-05-27 | 2017-07-18 | Atyr 医药公司 | 与谷氨酰胺酰‑tRNA合成酶的蛋白片段相关的治疗、诊断和抗体组合物的创新发现 |
| CA2800281C (en) | 2010-06-01 | 2021-01-12 | Atyr Pharma, Inc. | Innovative discovery of therapeutic, diagnostic, and antibody compositions related to protein fragments of lysyl-trna synthetases |
| KR20180059575A (ko) * | 2010-07-12 | 2018-06-04 | 에이티와이알 파마, 인코포레이티드 | 아스파르틸trna 합성효소의 단백질 단편에 관련된 치료적, 진단적, 및 항체 조성물의 혁신적 발견 |
| AU2011289831C1 (en) | 2010-07-12 | 2017-06-15 | Pangu Biopharma Limited | Innovative discovery of therapeutic, diagnostic, and antibody compositions related to protein fragments of glycyl-tRNA synthetases |
| US8999321B2 (en) | 2010-07-12 | 2015-04-07 | Atyr Pharma, Inc. | Innovative discovery of therapeutic, diagnostic, and antibody compositions related to protein fragments of glycyl-tRNA synthetases |
| KR20130102534A (ko) | 2010-07-12 | 2013-09-17 | 에이티와이알 파마, 인코포레이티드 | 히스티딜trna 합성효소의 단백질 단편에 관련된 치료적, 진단적, 및 항체 조성물의 혁신적 발견 |
| US9567386B2 (en) | 2010-08-17 | 2017-02-14 | Ambrx, Inc. | Therapeutic uses of modified relaxin polypeptides |
| EA030886B1 (ru) | 2010-08-17 | 2018-10-31 | Амбркс, Инк. | Модифицированные полипептиды релаксина, содержащие некодируемую в природе аминокислоту, связанную с полимером, и их применение |
| CN103108650A (zh) | 2010-08-25 | 2013-05-15 | Atyr医药公司 | 与酪氨酰-tRNA合成酶的蛋白片段相关的治疗、诊断和抗体组合物的创新发现 |
| CN103118696B (zh) * | 2010-10-06 | 2020-02-14 | Atyr 医药公司 | 与色氨酰-tRNA合成酶的蛋白片段相关的治疗、诊断和抗体组合物 |
| DE102010056289A1 (de) | 2010-12-24 | 2012-06-28 | Geneart Ag | Verfahren zur Herstellung von Leseraster-korrekten Fragment-Bibliotheken |
| WO2012097333A2 (en) | 2011-01-14 | 2012-07-19 | Redwood Bioscience, Inc. | Aldehyde-tagged immunoglobulin polypeptides and method of use thereof |
| US8852599B2 (en) | 2011-05-26 | 2014-10-07 | Bristol-Myers Squibb Company | Immunoconjugates, compositions for making them, and methods of making and use |
| US9714419B2 (en) | 2011-08-09 | 2017-07-25 | Atyr Pharma, Inc. | PEGylated tyrosyl-tRNA synthetase polypeptides |
| WO2013086216A1 (en) | 2011-12-06 | 2013-06-13 | Atyr Pharma, Inc. | Improved aspartyl-trna synthetases |
| WO2013086228A1 (en) | 2011-12-06 | 2013-06-13 | Atyr Pharma, Inc. | Pegylated aspartyl-trna synthetase polypeptides |
| CA2858613A1 (en) | 2011-12-29 | 2013-08-08 | Atyr Pharma, Inc. | Aspartyl-trna synthetase-fc conjugates |
| WO2013109994A1 (en) | 2012-01-20 | 2013-07-25 | Sea Lane Biotechnologies, Llc | Surrobody cojugates |
| HUE033704T2 (en) | 2012-02-13 | 2017-12-28 | Bristol Myers Squibb Co | Enediyne compounds, conjugates thereof, and uses and methods therefor |
| CA2867444C (en) * | 2012-03-16 | 2021-04-13 | University Health Network | Compositions containing soluble toso protein and uses thereof |
| EP2859017B1 (en) | 2012-06-08 | 2019-02-20 | Sutro Biopharma, Inc. | Antibodies comprising site-specific non-natural amino acid residues, methods of their preparation and methods of their use |
| WO2014004639A1 (en) | 2012-06-26 | 2014-01-03 | Sutro Biopharma, Inc. | Modified fc proteins comprising site-specific non-natural amino acid residues, conjugates of the same, methods of their preparation and methods of their use |
| HK1211208A1 (zh) | 2012-08-22 | 2016-05-20 | Immunogen, Inc. | 細胞毒性苯並二氮呯衍生物 |
| EP2890402B1 (en) | 2012-08-31 | 2019-04-17 | Sutro Biopharma, Inc. | Modified amino acids comprising an azido group |
| LT2956173T (lt) | 2013-02-14 | 2017-06-26 | Bristol-Myers Squibb Company | Tubulizino junginiai, gavimo ir panaudojimo būdai |
| ES2708565T3 (es) | 2013-03-15 | 2019-04-10 | Atyr Pharma Inc | Conjugados de Fc-histidil-ARNt sintetasa |
| WO2015006555A2 (en) | 2013-07-10 | 2015-01-15 | Sutro Biopharma, Inc. | Antibodies comprising multiple site-specific non-natural amino acid residues, methods of their preparation and methods of their use |
| CN104293735A (zh) * | 2013-07-18 | 2015-01-21 | 北京大学第一医院 | 用于制备Col17-IgG1Fc融合蛋白的细胞系及其应用 |
| AU2014306592B2 (en) | 2013-08-14 | 2019-04-04 | Bristol-Myers Squibb Company | Derivatives of uncialamycin, methods of synthesis and their use as antitumor agents |
| EP3055298B1 (en) | 2013-10-11 | 2020-04-29 | Sutro Biopharma, Inc. | Modified amino acids comprising tetrazine functional groups, methods of preparation, and methods of their use |
| US10077287B2 (en) | 2014-11-10 | 2018-09-18 | Bristol-Myers Squibb Company | Tubulysin analogs and methods of making and use |
| BR112017014937A2 (pt) | 2015-01-14 | 2018-03-13 | Bristol-Myers Squibb Company | dímeros de benzodiazepina ligados em ponte a heteroarileno, conjugados dos mesmos, e métodos de preparação e uso |
| WO2017062334A1 (en) | 2015-10-05 | 2017-04-13 | Merck Sharp & Dohme Corp. | Antibody peptide conjugates that have agonist activity at both the glucagon and glucagon-like peptide 1 receptors |
| CA3008678A1 (en) | 2015-12-21 | 2017-06-29 | Bristol-Myers Squibb Company | Variant antibodies for site-specific conjugation |
| WO2017132615A1 (en) | 2016-01-27 | 2017-08-03 | Sutro Biopharma, Inc. | Anti-cd74 antibody conjugates, compositions comprising anti-cd74 antibody conjugates and methods of using anti-cd74 antibody conjugates |
| JP2019515677A (ja) | 2016-04-26 | 2019-06-13 | アール.ピー.シェーラー テクノロジーズ エルエルシー | 抗体複合体ならびにそれを作製および使用する方法 |
| CN109641911B (zh) | 2016-08-19 | 2023-02-21 | 百时美施贵宝公司 | seco-环丙吡咯并吲哚化合物和其抗体-药物缀合物以及制备和使用方法 |
| US10398783B2 (en) | 2016-10-20 | 2019-09-03 | Bristol-Myers Squibb Company | Antiproliferative compounds and conjugates made therefrom |
| PE20191716A1 (es) | 2017-02-08 | 2019-12-05 | Bristol Myers Squibb Co | Polipeptidos de relaxina modificada que comprenden un mejorador farmacocinetico y sus usos |
| CA3060514A1 (en) | 2017-04-20 | 2018-10-25 | Atyr Pharma, Inc. | Compositions and methods for treating lung inflammation |
| PL3630977T3 (pl) | 2017-06-02 | 2024-06-24 | Ambrx, Inc. | Sposoby i kompozycje promujące produkcję białek zawierających nienaturalne aminokwasy |
| US10494370B2 (en) | 2017-08-16 | 2019-12-03 | Bristol-Myers Squibb Company | Toll-like receptor 7 (TLR7) agonists having a pyridine or pyrazine moiety, conjugates thereof, and methods and uses therefor |
| US10487084B2 (en) | 2017-08-16 | 2019-11-26 | Bristol-Myers Squibb Company | Toll-like receptor 7 (TLR7) agonists having a heterobiaryl moiety, conjugates thereof, and methods and uses therefor |
| US10508115B2 (en) | 2017-08-16 | 2019-12-17 | Bristol-Myers Squibb Company | Toll-like receptor 7 (TLR7) agonists having heteroatom-linked aromatic moieties, conjugates thereof, and methods and uses therefor |
| US10472361B2 (en) | 2017-08-16 | 2019-11-12 | Bristol-Myers Squibb Company | Toll-like receptor 7 (TLR7) agonists having a benzotriazole moiety, conjugates thereof, and methods and uses therefor |
| US10457681B2 (en) | 2017-08-16 | 2019-10-29 | Bristol_Myers Squibb Company | Toll-like receptor 7 (TLR7) agonists having a tricyclic moiety, conjugates thereof, and methods and uses therefor |
| WO2019209811A1 (en) | 2018-04-24 | 2019-10-31 | Bristol-Myers Squibb Company | Macrocyclic toll-like receptor 7 (tlr7) agonists |
| MX2020012674A (es) | 2018-05-29 | 2021-02-09 | Bristol Myers Squibb Co | Porciones autoinmolantes modificadas para usarse en profarmacos y conjugados y metodos de uso y fabricacion. |
| US11554120B2 (en) | 2018-08-03 | 2023-01-17 | Bristol-Myers Squibb Company | 1H-pyrazolo[4,3-d]pyrimidine compounds as toll-like receptor 7 (TLR7) agonists and methods and uses therefor |
| AU2020295571B2 (en) * | 2019-06-21 | 2026-03-26 | Trustees Of Boston College | Enhanced platforms for unnatural amino acid incorporation in mammalian cells |
| US20230095053A1 (en) | 2020-03-03 | 2023-03-30 | Sutro Biopharma, Inc. | Antibodies comprising site-specific glutamine tags, methods of their preparation and methods of their use |
| WO2022245902A2 (en) * | 2021-05-19 | 2022-11-24 | Trustees Of Tufts College | Aminoacyl transfer rna synthetases |
| TW202342106A (zh) | 2022-02-09 | 2023-11-01 | 日商第一三共股份有限公司 | 環境應答性遮蔽抗體及其利用 |
| WO2025188694A1 (en) | 2024-03-05 | 2025-09-12 | Bristol-Myers Squibb Company | Tricyclic tlr7 agonists and uses thereof |
| WO2025188693A1 (en) | 2024-03-05 | 2025-09-12 | Bristol-Myers Squibb Company | Bicyclic tlr7 agonists and uses thereof |
| WO2026043823A2 (en) | 2024-08-19 | 2026-02-26 | Sutro Biopharma, Inc. | Antibodies comprising site-specific non-natural amino acid residues, methods of preparation and uses thereof |
| CN118956782A (zh) * | 2024-10-16 | 2024-11-15 | 北京溯本源和生物科技有限公司 | 表达pd-1人源抗体的重组流感病毒及其制备和应用 |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002085923A2 (en) * | 2001-04-19 | 2002-10-31 | The Scripps Research Institute | In vivo incorporation of unnatural amino acids |
| US7566555B2 (en) * | 2002-10-31 | 2009-07-28 | Riken | Method of expressing proteins comprising non-naturally-occurring amino acids |
| JP5642916B2 (ja) * | 2003-04-17 | 2014-12-17 | ザ スクリプス リサーチ インスティテュート | 真核遺伝コードの拡張 |
| EP2410331B1 (en) * | 2003-06-18 | 2015-09-23 | The Scripps Research Institute | Aminoacyl-tRNA synthetase for aminoacylation tRNA with unnatural amino acids |
| CN101160525A (zh) * | 2003-06-18 | 2008-04-09 | 斯克利普斯研究院 | 非天然活性氨基酸遗传密码增加 |
| EP1836298B1 (en) * | 2004-12-22 | 2012-01-18 | Ambrx, Inc. | COMPOSITIONS OF AMINOACYL-tRNA SYNTHETASE AND USES THEREOF |
-
2007
- 2007-09-07 JP JP2009527448A patent/JP2010502221A/ja active Pending
- 2007-09-07 EP EP07837970A patent/EP2064316B1/en active Active
- 2007-09-07 CA CA2662752A patent/CA2662752C/en active Active
- 2007-09-07 WO PCT/US2007/019654 patent/WO2008030612A2/en not_active Ceased
- 2007-09-07 CN CN200780033055.0A patent/CN101528914B/zh active Active
- 2007-09-07 US US12/440,012 patent/US20100093082A1/en not_active Abandoned
- 2007-09-07 MX MX2009002524A patent/MX2009002524A/es active IP Right Grant
- 2007-09-07 CN CN201410578532.3A patent/CN104328086A/zh active Pending
- 2007-09-07 SG SG2011064227A patent/SG174780A1/en unknown
- 2007-09-07 AU AU2007292891A patent/AU2007292891B2/en active Active
- 2007-09-07 NZ NZ574673A patent/NZ574673A/en unknown
- 2007-09-07 KR KR1020097006398A patent/KR20090057072A/ko not_active Withdrawn
- 2007-09-07 AT AT07837970T patent/ATE542888T1/de active
-
2009
- 2009-02-04 IL IL196893A patent/IL196893A/en active IP Right Grant
-
2013
- 2013-04-14 IL IL225738A patent/IL225738A/en active IP Right Grant
Also Published As
| Publication number | Publication date |
|---|---|
| HK1132760A1 (en) | 2010-03-05 |
| ATE542888T1 (de) | 2012-02-15 |
| CA2662752C (en) | 2016-04-12 |
| WO2008030612A3 (en) | 2008-11-27 |
| CN101528914A (zh) | 2009-09-09 |
| CA2662752A1 (en) | 2008-03-13 |
| AU2007292891B2 (en) | 2012-04-12 |
| IL225738A (en) | 2016-09-29 |
| IL225738A0 (en) | 2013-06-27 |
| NZ574673A (en) | 2012-02-24 |
| EP2064316A4 (en) | 2009-09-30 |
| EP2064316A2 (en) | 2009-06-03 |
| CN104328086A (zh) | 2015-02-04 |
| WO2008030612A2 (en) | 2008-03-13 |
| EP2064316B1 (en) | 2012-01-25 |
| US20100093082A1 (en) | 2010-04-15 |
| MX2009002524A (es) | 2009-06-22 |
| JP2010502221A (ja) | 2010-01-28 |
| IL196893A0 (en) | 2011-08-01 |
| CN101528914B (zh) | 2014-12-03 |
| AU2007292891A1 (en) | 2008-03-13 |
| IL196893A (en) | 2013-05-30 |
| SG174780A1 (en) | 2011-10-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN101528914B (zh) | 通过脊椎动物细胞位点特异性并入非天然氨基酸 | |
| KR101171397B1 (ko) | 진핵 유전자 코드의 확장 | |
| JP5932117B2 (ja) | 脊椎動物細胞内におけるサプレッサーtrnaの転写 | |
| EP2410331B1 (en) | Aminoacyl-tRNA synthetase for aminoacylation tRNA with unnatural amino acids | |
| US9868972B2 (en) | Hybrid suppressor tRNA for vertebrate cells | |
| AU2004253857B2 (en) | Unnatural reactive amino acid genetic code additions | |
| HK1167711A (en) | Aminoacyl-trna synthetase for aminoacylation trna with unnatural amino acids |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20090327 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| PC1203 | Withdrawal of no request for examination | ||
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |