KR20110000741A - 멀티코어 처리 시스템 - Google Patents
멀티코어 처리 시스템 Download PDFInfo
- Publication number
- KR20110000741A KR20110000741A KR1020107023111A KR20107023111A KR20110000741A KR 20110000741 A KR20110000741 A KR 20110000741A KR 1020107023111 A KR1020107023111 A KR 1020107023111A KR 20107023111 A KR20107023111 A KR 20107023111A KR 20110000741 A KR20110000741 A KR 20110000741A
- Authority
- KR
- South Korea
- Prior art keywords
- consistency group
- core
- processor
- information
- consistency
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/16—Combinations of two or more digital computers each having at least an arithmetic unit, a program unit and a register, e.g. for a simultaneous processing of several programs
Landscapes
- Engineering & Computer Science (AREA)
- Computer Hardware Design (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Memory System Of A Hierarchy Structure (AREA)
Abstract
Description
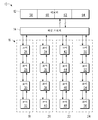
도 1은 일 실시예에 따른 시스템의 블록도.
도 2는 도 1의 시스템에 사용되는 코어의 블록도.
도 3은 대안 구성에서의 도 1의 시스템의 블록도.
도 4는 다른 실시예에 따른 시스템의 블록도.
도 5는 대안 구성에서의 도 4의 시스템의 블록도.
Claims (20)
- 집적 회로 내의 정보 시스템을 동작시키기 위한 방법으로서,
상기 집적 회로의 멀티 프로세서 코어 회로의 제1 프로세서 코어에 의해 정보의 제1 패킷을 생성하는 단계-상기 정보의 제1 패킷은 메모리로 지향됨-; 및
상기 정보의 제1 패킷을 상기 제1 프로세서 코어로부터 상기 메모리로 전송하는 단계
를 포함하며,
상기 전송 단계는 상기 제1 패킷을 상기 멀티 프로세서 코어 회로의 제2 프로세서 코어를 통해 전송하는 단계를 포함하고, 상기 제1 패킷을 제2 프로세서 코어를 통해 전송하는 단계는 상기 제2 프로세서 코어에 의해 상기 제1 패킷을 수신하고, 상기 제2 프로세서 코어에 의해 상기 제1 패킷을 전송하는 단계를 포함하는, 정보 시스템 동작 방법. - 제1항에 있어서, 상기 메모리로 전송하는 단계는 패킷 스위치 회로를 통해 상기 메모리로 전송하는 단계를 포함하고, 상기 제2 프로세서 코어는 상기 패킷을 상기 패킷 스위치 회로로 전송하는, 정보 시스템 동작 방법.
- 제1항에 있어서, 상기 멀티 프로세서 코어 회로는 제3 프로세서 코어를 포함하고, 상기 제3 프로세서 코어는 상기 제1 패킷의 기입 일관성 정보(write coherency information)를 수신하지 않는, 정보 시스템 동작 방법.
- 제3항에 있어서, 상기 제1 프로세서 코어에 의해 기입 일관성 정보를 상기 멀티 프로세서 코어 회로의 제4 프로세서 코어로 전송하는 단계를 더 포함하며,
상기 제4 프로세서 코어는 상기 제1 프로세서 코어로부터 상기 기입 일관성 정보를 수신하고, 상기 제4 프로세서 코어는 상기 기입 일관성 정보를 이용하여, 상기 제1 패킷이 상기 제4 프로세서 코어 내에 캐시된 위치에서 상기 메모리 내의 데이터를 변경하고 있는지를 결정하는, 정보 시스템 동작 방법. - 제4항에 있어서, 상기 제4 프로세서 코어에 의해 상기 기입 일관성 정보를 상기 멀티 프로세서 코어 회로의 제5 프로세서 코어로 전송하는 단계를 더 포함하며,
상기 제5 프로세서 코어는 상기 기입 일관성 정보를 이용하여, 상기 제1 패킷이 상기 제5 프로세서 코어 내에 캐시된 장소에서 상기 메모리 내의 데이터를 변경하고 있는지를 결정하는, 정보 시스템 동작 방법. - 제3항에 있어서,
상기 제3 프로세서 코어에 의해 정보의 제2 패킷을 생성하는 단계-상기 정보의 제2 패킷은 상기 메모리로 지향됨-; 및
상기 정보의 제2 패킷을 상기 메모리로 전송하는 단계
를 더 포함하며,
상기 전송 단계는 상기 제2 패킷을 상기 멀티 프로세서 코어 회로의 제4 프로세서 코어 및 패킷 스위치 회로를 통해 전송하는 단계를 포함하고, 상기 패킷을 제4 프로세서 코어를 통해 전송하는 단계는 상기 제4 프로세서 코어에 의해 상기 정보 패킷을 수신하고, 상기 제4 프로세서 코어에 의해 상기 패킷을 전송하는 단계를 포함하는, 정보 시스템 동작 방법. - 제6항에 있어서, 상기 제1 프로세서 코어 및 상기 제2 프로세서 코어가 상기 제2 패킷의 기입 일관성 정보를 수신하지 않고, 상기 제4 프로세서 코어가 상기 제1 패킷의 기입 일관성 정보를 수신하지 않는, 정보 시스템 동작 방법.
- 제6항에 있어서,
상기 정보의 제1 패킷을 상기 메모리로 전송하는 단계는 상기 제1 패킷을 상기 제3 프로세서 코어 및 상기 제4 프로세서 코어가 아니라 상기 제1 프로세서 코어 및 상기 제2 프로세서 코어에 의해 액세스될 수 있는 상기 메모리의 제1 파티션으로 전송하는 단계를 포함하고,
상기 정보의 제2 패킷을 상기 메모리로 전송하는 단계는 상기 제2 패킷을 상기 제1 프로세서 코어 및 상기 제2 프로세서 코어가 아니라 상기 제3 프로세서 코어 및 상기 제4 프로세서 코어에 의해 액세스될 수 있는 제2 파티션으로 전송하는 단계를 포함하는, 정보 시스템 동작 방법. - 제8항에 있어서, 상기 제1 파티션 및 상기 제2 파티션이 오버랩핑되지 않는 어드레스들을 갖는, 정보 시스템 동작 방법.
- 제1항에 있어서, 상기 전송 동안, 상기 멀티 프로세서 코어 회로가 제1 일관성 그룹을 포함하고, 상기 제1 일관성 그룹은 상기 제1 프로세서 코어 및 상기 제2 프로세서 코어를 포함하는 상기 멀티 프로세서 코어 회로의 제1 복수의 프로세서 코어를 포함하고, 상기 제1 일관성 그룹의 프로세서 코어들은 정보 패킷들을 전송하도록 직렬로 통신 결합되고, 상기 제1 일관성 그룹의 각각의 프로세서 코어는 상기 제1 일관성 그룹의 다른 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들로부터 캐시 일관성 정보를 수신하는, 정보 시스템 동작 방법.
- 제10항에 있어서, 상기 전송 동안, 상기 멀티 프로세서 코어 회로는 제2 일관성 그룹을 포함하고, 상기 제2 일관성 그룹은 상기 멀티 프로세서 코어 회로의 제2 복수의 프로세서 코어를 포함하고, 상기 제2 일관성 그룹의 프로세서 코어들은 정보 패킷들을 전송하도록 직렬로 통신 결합되고, 상기 제2 일관성 그룹의 각각의 프로세서 코어는 상기 제2 일관성 그룹의 다른 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들로부터 캐시 일관성 정보를 수신하고, 상기 제1 일관성 그룹의 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들의 캐시 일관성 정보를 수신하지 않는, 정보 시스템 동작 방법.
- 제11항에 있어서, 상기 전송 동안, 상기 멀티 프로세서 코어 회로는 제3 일관성 그룹을 포함하고, 상기 제3 일관성 그룹은 상기 멀티 프로세서 코어 회로의 제3 복수의 프로세서 코어를 포함하고, 상기 제3 일관성 그룹의 프로세서 코어들은 정보 패킷들을 전송하도록 직렬로 통신 결합되고, 상기 제3 일관성 그룹의 각각의 프로세서 코어는 상기 제3 일관성 그룹의 다른 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들로부터 캐시 일관성 정보를 수신하고, 상기 제1 일관성 그룹의 프로세서 코어들에 의해 그리고 상기 제2 일관성 그룹의 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들의 캐시 일관성 정보를 수신하지 않는, 정보 시스템 동작 방법.
- 제11항에 있어서,
다른 시간 동안, 상기 멀티 프로세서 코어 회로는 상기 멀티 프로세서 코어 회로의 프로세서 코어들의 제3 일관성 그룹 및 상기 멀티 프로세서 코어 회로의 프로세서 코어들의 제4 일관성 그룹을 포함하고, 상기 제3 일관성 그룹은 상기 제1 복수의 프로세서 코어 중 적어도 하나의 프로세서 코어 및 상기 제2 복수의 프로세서 코어 중 적어도 하나의 프로세서 코어를 포함하고, 상기 제3 일관성 그룹의 프로세서 코어들은 정보 패킷들을 전송하도록 직렬로 통신 결합되고, 상기 제3 일관성 그룹의 각각의 프로세서 코어는 상기 제3 일관성 그룹의 다른 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들로부터 캐시 일관성 정보를 수신하고, 상기 제4 일관성 그룹의 프로세서 코어들에 의해 생성되고, 상기 제3 일관성 그룹 내에 있지 않은 상기 제1 일관성 그룹의 프로세서 코어들에 의해 생성되고, 그리고 상기 제3 일관성 그룹 내에 있지 않은 상기 제2 일관성 그룹의 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들의 캐시 일관성 정보를 수신하지 않고,
상기 제4 일관성 그룹은 상기 제1 복수의 프로세서 코어 중 적어도 하나의 프로세서 코어를 포함하고, 상기 제4 일관성 그룹의 프로세서 코어들은 정보 패킷들을 전송하도록 직렬로 통신 결합되고, 상기 제4 일관성 그룹의 각각의 프로세서 코어는 상기 제4 일관성 그룹의 다른 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들로부터 캐시 일관성 정보를 수신하고, 상기 제3 일관성 그룹의 프로세서 코어들에 의해 생성되고, 상기 제4 일관성 그룹 내에 있지 않은 상기 제1 일관성 그룹의 프로세서 코어들에 의해 생성되고, 그리고 상기 제4 일관성 그룹 내에 있지 않은 상기 제2 일관성 그룹의 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들의 캐시 일관성 정보를 수신하지 않는, 정보 시스템 동작 방법. - 제1항에 있어서, 상기 패킷의 데이터를 상기 메모리 내의 위치에 기입하는 단계를 더 포함하며, 상기 위치의 어드레스는 상기 패킷 내에 지시되는, 정보 시스템 동작 방법.
- 제1항에 있어서, 상기 정보의 제1 패킷을 전송하는 단계는 흐름 제어 및 다수의 우선 순위화된 트랜잭션들을 지원하는 순서화된(ordered) 패킷들을 갖는 패킷 기반 프로토콜에 의해 상기 제1 패킷을 전송하는 단계를 포함하는, 정보 시스템 동작 방법.
- 멀티 프로세서 코어 회로를 포함하는 집적 회로
를 포함하며,
상기 멀티 프로세서 코어 회로는
제1 일관성 그룹-상기 제1 일관성 그룹은 상기 멀티 프로세서 코어 회로의 제1 복수의 프로세서 코어를 포함하고, 상기 제1 일관성 그룹의 프로세서 코어들은 정보 패킷들을 전송하도록 직렬로 통신 결합되고, 상기 제1 일관성 그룹의 각각의 프로세서 코어는 상기 제1 일관성 그룹의 다른 프로세서 코어들에 의해 생성되는 메모리로의 기입 패킷들로부터 캐시 일관성 정보를 수신함-;
제2 일관성 그룹-상기 제2 일관성 그룹은 상기 멀티 프로세서 코어 회로의 제2 복수의 프로세서 코어를 포함하고, 상기 제2 일관성 그룹의 프로세서 코어들은 정보 패킷들을 전송하도록 직렬로 통신 결합되고, 상기 제2 일관성 그룹의 각각의 프로세서 코어는 상기 제2 일관성 그룹의 다른 프로세서 코어들에 의해 생성되는 메모리로의 기입 패킷들로부터 캐시 일관성 정보를 수신하고, 상기 제1 일관성 그룹의 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들의 캐시 일관성 정보를 수신하지 않음-
을 포함하도록 동작 가능하고,
상기 제1 일관성 그룹의 각각의 프로세서 코어는 상기 제2 일관성 그룹의 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들의 캐시 일관성 정보를 수신하지 않는 장치. - 제16항에 있어서, 상기 집적 회로는 패킷 스위치 회로를 더 포함하며, 상기 멀티 프로세서 코어 회로는 상기 패킷 스위치 회로를 통해 상기 메모리에 통신 결합되는 장치.
- 제16항에 있어서, 상기 집적 회로는 상기 멀티 프로세서 코어 회로의 프로세서 코어들에 결합되는 제어기를 더 포함하며, 상기 제어기는 상기 멀티 프로세서 코어 회로의 프로세서 코어들을 일관성 그룹들로 그룹화하기 위한 일관성 제어 정보를 제공하는 장치.
- 제16항에 있어서,
상기 멀티 프로세서 코어 회로는 상기 멀티 프로세서 코어 회로의 프로세서 코어들의 제3 일관성 그룹 및 상기 멀티 프로세서 코어 회로의 프로세서 코어들의 제4 일관성 그룹을 포함하도록 동작 가능하고,
상기 제3 일관성 그룹은 상기 제1 복수의 프로세서 코어 중 적어도 하나의 프로세서 코어 및 상기 제2 복수의 프로세서 코어 중 적어도 하나의 프로세서 코어를 포함하고, 상기 제3 일관성 그룹의 프로세서 코어들은 정보 패킷들을 전송하도록 직렬로 통신 결합되고, 상기 제3 일관성 그룹의 각각의 프로세서 코어는 상기 제3 일관성 그룹의 다른 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들로부터 캐시 일관성 정보를 수신하고, 상기 제4 일관성 그룹의 프로세서 코어들에 의해 생성되고, 상기 제3 일관성 그룹 내에 있지 않은 상기 제1 일관성 그룹의 프로세서 코어들에 의해 생성되고, 그리고 상기 제3 일관성 그룹 내에 있지 않은 상기 제2 일관성 그룹의 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들의 캐시 일관성 정보를 수신하지 않으며,
상기 제4 일관성 그룹은 상기 제1 복수의 프로세서 코어 중 적어도 하나의 프로세서 코어를 포함하고, 상기 제4 일관성 그룹의 프로세서 코어들은 정보 패킷들을 전송하도록 직렬로 통신 결합되고, 상기 제4 일관성 그룹의 각각의 프로세서 코어는 상기 제4 일관성 그룹의 다른 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들로부터 캐시 일관성 정보를 수신하고, 상기 제3 일관성 그룹의 프로세서 코어들에 의해 생성되고, 상기 제4 일관성 그룹 내에 있지 않은 상기 제1 일관성 그룹의 프로세서 코어들에 의해 생성되고, 그리고 상기 제4 일관성 그룹 내에 있지 않은 상기 제2 일관성 그룹의 프로세서 코어들에 의해 생성되는 상기 메모리로의 기입 패킷들의 캐시 일관성 정보를 수신하지 않는 장치. - 제16항에 있어서, 상기 제1 일관성 그룹은 상기 제1 일관성 그룹의 프로세서 코어들 사이에 통신 링크들을 통해 직렬로 통신 결합되며, 상기 통신 링크들은 광 통신 링크들, 무선 라디오 주파수 통신 링크들 및 저전압 차동 시그널링 통신 링크들로 구성되는 그룹 중 적어도 하나를 포함하는 장치.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US12/103,250 | 2008-04-15 | ||
| US12/103,250 US7941637B2 (en) | 2008-04-15 | 2008-04-15 | Groups of serially coupled processor cores propagating memory write packet while maintaining coherency within each group towards a switch coupled to memory partitions |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20110000741A true KR20110000741A (ko) | 2011-01-05 |
Family
ID=41164943
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020107023111A Ceased KR20110000741A (ko) | 2008-04-15 | 2009-02-16 | 멀티코어 처리 시스템 |
Country Status (6)
| Country | Link |
|---|---|
| US (2) | US7941637B2 (ko) |
| JP (1) | JP5419107B2 (ko) |
| KR (1) | KR20110000741A (ko) |
| CN (1) | CN101999115B (ko) |
| TW (1) | TW200945048A (ko) |
| WO (1) | WO2009128981A1 (ko) |
Families Citing this family (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8547971B1 (en) | 2009-01-07 | 2013-10-01 | Marvell Israel (M.I.S.L) Ltd. | Multi-stage switching system |
| US8358651B1 (en) | 2009-09-21 | 2013-01-22 | Marvell International Ltd. | Switch device having a plurality of processing cores |
| US9460038B2 (en) * | 2010-12-22 | 2016-10-04 | Via Technologies, Inc. | Multi-core microprocessor internal bypass bus |
| US9172659B1 (en) | 2011-07-12 | 2015-10-27 | Marvell Israel (M.I.S.L.) Ltd. | Network traffic routing in a modular switching device |
| US9372724B2 (en) * | 2014-04-01 | 2016-06-21 | Freescale Semiconductor, Inc. | System and method for conditional task switching during ordering scope transitions |
| US9372723B2 (en) * | 2014-04-01 | 2016-06-21 | Freescale Semiconductor, Inc. | System and method for conditional task switching during ordering scope transitions |
| US9733981B2 (en) | 2014-06-10 | 2017-08-15 | Nxp Usa, Inc. | System and method for conditional task switching during ordering scope transitions |
| US9448741B2 (en) | 2014-09-24 | 2016-09-20 | Freescale Semiconductor, Inc. | Piggy-back snoops for non-coherent memory transactions within distributed processing systems |
| US11449452B2 (en) | 2015-05-21 | 2022-09-20 | Goldman Sachs & Co. LLC | General-purpose parallel computing architecture |
| ES2929626T3 (es) * | 2015-05-21 | 2022-11-30 | Goldman Sachs & Co Llc | Arquitectura de computación paralela de propósito general |
| US10904150B1 (en) | 2016-02-02 | 2021-01-26 | Marvell Israel (M.I.S.L) Ltd. | Distributed dynamic load balancing in network systems |
| US10866753B2 (en) * | 2018-04-03 | 2020-12-15 | Xilinx, Inc. | Data processing engine arrangement in a device |
| CN112948282A (zh) * | 2019-12-31 | 2021-06-11 | 北京忆芯科技有限公司 | 用于数据快速查找的计算加速系统 |
| WO2022047422A1 (en) * | 2020-08-31 | 2022-03-03 | Botimer Jacob | Inter-layer communication techniques for memory processing unit architectures |
| US12086066B1 (en) * | 2023-03-15 | 2024-09-10 | Cornami, Inc. | Cache architecture for a massively parallel processing array |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4710868A (en) * | 1984-06-29 | 1987-12-01 | International Business Machines Corporation | Interconnect scheme for shared memory local networks |
| JPH07104923B2 (ja) * | 1988-12-28 | 1995-11-13 | 工業技術院長 | 並列画像表示処理方法 |
| US7106742B1 (en) | 2000-01-13 | 2006-09-12 | Mercury Computer Systems, Inc. | Method and system for link fabric error detection and message flow control |
| US6754752B2 (en) | 2000-01-13 | 2004-06-22 | Freescale Semiconductor, Inc. | Multiple memory coherence groups in a single system and method therefor |
| US6862283B2 (en) | 2000-01-13 | 2005-03-01 | Freescale Semiconductor, Inc. | Method and apparatus for maintaining packet ordering with error recovery among multiple outstanding packets between two devices |
| US7031258B1 (en) | 2000-01-13 | 2006-04-18 | Mercury Computer Systems, Inc. | Digital data system with link level message flow control |
| US6678773B2 (en) | 2000-01-13 | 2004-01-13 | Motorola, Inc. | Bus protocol independent method and structure for managing transaction priority, ordering and deadlocks in a multi-processing system |
| US6996651B2 (en) | 2002-07-29 | 2006-02-07 | Freescale Semiconductor, Inc. | On chip network with memory device address decoding |
| CN1320464C (zh) * | 2003-10-23 | 2007-06-06 | 英特尔公司 | 用于维持共享高速缓存一致性的方法和设备 |
| JP2005135359A (ja) * | 2003-10-31 | 2005-05-26 | Hitachi Hybrid Network Co Ltd | データ処理装置 |
| US7243205B2 (en) | 2003-11-13 | 2007-07-10 | Intel Corporation | Buffered memory module with implicit to explicit memory command expansion |
| US7590797B2 (en) | 2004-04-08 | 2009-09-15 | Micron Technology, Inc. | System and method for optimizing interconnections of components in a multichip memory module |
| US7240160B1 (en) * | 2004-06-30 | 2007-07-03 | Sun Microsystems, Inc. | Multiple-core processor with flexible cache directory scheme |
| US20060143384A1 (en) * | 2004-12-27 | 2006-06-29 | Hughes Christopher J | System and method for non-uniform cache in a multi-core processor |
| US7412353B2 (en) * | 2005-09-28 | 2008-08-12 | Intel Corporation | Reliable computing with a many-core processor |
| US7624250B2 (en) * | 2005-12-05 | 2009-11-24 | Intel Corporation | Heterogeneous multi-core processor having dedicated connections between processor cores |
| US20070168620A1 (en) * | 2006-01-19 | 2007-07-19 | Sicortex, Inc. | System and method of multi-core cache coherency |
-
2008
- 2008-04-15 US US12/103,250 patent/US7941637B2/en active Active
-
2009
- 2009-02-16 CN CN200980112853.1A patent/CN101999115B/zh not_active Expired - Fee Related
- 2009-02-16 JP JP2011505052A patent/JP5419107B2/ja active Active
- 2009-02-16 KR KR1020107023111A patent/KR20110000741A/ko not_active Ceased
- 2009-02-16 WO PCT/US2009/034189 patent/WO2009128981A1/en not_active Ceased
- 2009-02-27 TW TW098106572A patent/TW200945048A/zh unknown
-
2010
- 2010-12-20 US US12/972,878 patent/US8090913B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US8090913B2 (en) | 2012-01-03 |
| CN101999115A (zh) | 2011-03-30 |
| TW200945048A (en) | 2009-11-01 |
| US20090259825A1 (en) | 2009-10-15 |
| WO2009128981A1 (en) | 2009-10-22 |
| JP2011517003A (ja) | 2011-05-26 |
| US20110093660A1 (en) | 2011-04-21 |
| JP5419107B2 (ja) | 2014-02-19 |
| CN101999115B (zh) | 2014-04-02 |
| US7941637B2 (en) | 2011-05-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20110000741A (ko) | 멀티코어 처리 시스템 | |
| KR100985926B1 (ko) | 메모리 시스템 컴포넌트들 사이에서 신호들을 리라우팅하는시스템 및 방법 | |
| CN101076790B (zh) | 动态多群集系统重新配置 | |
| US12457271B2 (en) | System, apparatus and method for handling multi-protocol traffic in data link layer circuitry | |
| US9009372B2 (en) | Processor and control method for processor | |
| KR101245096B1 (ko) | 상호연결 시스템에서의 스큐 관리 | |
| KR102546932B1 (ko) | 타일드 라스트 레벨 캐시들을 위한 비균일 버스 상호 연결 프로토콜 | |
| JPH08500687A (ja) | ウェハ規模の集積化のためのフォルトトレラントな高速度のバス装置及びバスインタフェース | |
| KR102092660B1 (ko) | Cpu 및 다중 cpu 시스템 관리 방법 | |
| WO2013081580A1 (en) | Raw memory transaction support | |
| US20150186277A1 (en) | Cache coherent noc with flexible number of cores, i/o devices, directory structure and coherency points | |
| US10268617B2 (en) | Frame format for a serial interface | |
| NO343359B1 (en) | Interconnect switch in multiprocessor systems | |
| US8782468B2 (en) | Methods and tools to debug complex multi-core, multi-socket QPI based system | |
| KR101183739B1 (ko) | 멀티포트 메모리 슈퍼셀 및 데이터 경로 스위칭 회로를 갖는 집적 회로 | |
| CN106951390A (zh) | 一种可降低跨节点访存延时的numa系统构建方法 | |
| US10628365B2 (en) | Packet tunneling for multi-node, multi-socket systems | |
| US10592465B2 (en) | Node controller direct socket group memory access | |
| US7596650B1 (en) | Increasing availability of input/output (I/O) interconnections in a system | |
| US10776309B2 (en) | Method and apparatus to build a monolithic mesh interconnect with structurally heterogenous tiles | |
| CN117420945A (zh) | 用于经由多个模式存取存储器装置的控制器和方法 | |
| JP5595796B2 (ja) | 動的サブネットワークを備えた相互接続ネットワーク | |
| US20250181491A1 (en) | System, method, and computer program product for improving memory systems |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20101015 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| A201 | Request for examination | ||
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20140217 Comment text: Request for Examination of Application |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20150803 Patent event code: PE09021S01D |
|
| E601 | Decision to refuse application | ||
| PE0601 | Decision on rejection of patent |
Patent event date: 20160329 Comment text: Decision to Refuse Application Patent event code: PE06012S01D Patent event date: 20150803 Comment text: Notification of reason for refusal Patent event code: PE06011S01I |