KR20140107569A - Hpv에 대한 백신들 - Google Patents
Hpv에 대한 백신들 Download PDFInfo
- Publication number
- KR20140107569A KR20140107569A KR1020147020468A KR20147020468A KR20140107569A KR 20140107569 A KR20140107569 A KR 20140107569A KR 1020147020468 A KR1020147020468 A KR 1020147020468A KR 20147020468 A KR20147020468 A KR 20147020468A KR 20140107569 A KR20140107569 A KR 20140107569A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- leu
- ser
- thr
- amino acid
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images







Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39575—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from other living beings excluding bacteria and viruses, e.g. protozoa, fungi, plants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/12—Viral antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/20—Antivirals for DNA viruses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/04—Immunostimulants
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/005—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from viruses
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/521—Chemokines
- C07K14/523—Beta-chemokines, e.g. RANTES, I-309/TCA-3, MIP-1alpha, MIP-1beta/ACT-2/LD78/SCIF, MCP-1/MCAF, MCP-2, MCP-3, LDCF-1, LDCF-2
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/081—DNA viruses
- C07K16/084—Papillomaviridae (F); Polyomaviridae (F), e.g. SV40, BK virus or JC virus
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N7/00—Viruses; Bacteriophages; Compositions thereof; Preparation or purification thereof
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/53—DNA (RNA) vaccination
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/58—Medicinal preparations containing antigens or antibodies raising an immune response against a target which is not the antigen used for immunisation
- A61K2039/585—Medicinal preparations containing antigens or antibodies raising an immune response against a target which is not the antigen used for immunisation wherein the target is cancer
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/60—Medicinal preparations containing antigens or antibodies characteristics by the carrier linked to the antigen
- A61K2039/6031—Proteins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/60—Medicinal preparations containing antigens or antibodies characteristics by the carrier linked to the antigen
- A61K2039/6031—Proteins
- A61K2039/6056—Antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/64—Medicinal preparations containing antigens or antibodies characterised by the architecture of the carrier-antigen complex, e.g. repetition of carrier-antigen units
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/80—Vaccine for a specifically defined cancer
- A61K2039/892—Reproductive system [uterus, ovaries, cervix, testes]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/526—CH3 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/53—Hinge
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
- C07K2319/735—Fusion polypeptide containing domain for protein-protein interaction containing a domain for self-assembly, e.g. a viral coat protein (includes phage display)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2710/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA dsDNA viruses
- C12N2710/00011—Details
- C12N2710/20011—Papillomaviridae
- C12N2710/20022—New viral proteins or individual genes, new structural or functional aspects of known viral proteins or genes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2710/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA dsDNA viruses
- C12N2710/00011—Details
- C12N2710/20011—Papillomaviridae
- C12N2710/20034—Use of virus or viral component as vaccine, e.g. live-attenuated or inactivated virus, VLP, viral protein
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2710/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA dsDNA viruses
- C12N2710/00011—Details
- C12N2710/20011—Papillomaviridae
- C12N2710/20071—Demonstrated in vivo effect
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/22—Vectors comprising a coding region that has been codon optimised for expression in a respective host
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Immunology (AREA)
- Virology (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Genetics & Genomics (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Microbiology (AREA)
- Mycology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Epidemiology (AREA)
- Gastroenterology & Hepatology (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Oncology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Toxicology (AREA)
- Wood Science & Technology (AREA)
- Biotechnology (AREA)
- Communicable Diseases (AREA)
- Botany (AREA)
- General Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Tropical Medicine & Parasitology (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Peptides Or Proteins (AREA)
Abstract
Description

도 2: HPV-유도된 악성종양들에 대한 백시바디 DNA 백신의 제시된 활성 모드. 백시바디를 인코딩하는 네이키드 DNA 플라스미드가 피부내 주입된 후 전기천공된다. 상기 플라스미드는 국소 세포들로 유입되고 백시바디 단백질들이 생산되어 분비된다. 화학주성 타겟팅 모듈들이 CCR1 및 CCR5 발현 항원 제시 세포들(APC)을 유인하고 수지상세포들(DC)과 결합하고 흡수되는 것을 보장한다. 상기 DC는 CD4+ 및 CD8+ T 세포들에 항원성 펩타이드들을 제시할 것이고 CD8+ T 세포들이 자궁 경관 내 HPV-감염된 및 HPV-형질전환된 세포들을 죽일 것이다.
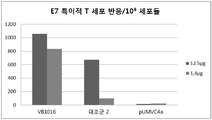
도 3: 투여된 다른 양의 백신의 작용(function)으로서 E7 및 E6 특이적 T 세포 반응들의 수를 보여주는 ELISPOT 결과들. C57BL/6 마우스들에 VB1009 및 VB1016을 인코딩하는 네이키드 DNA 플라스미드들 및 이들에 상응하는 대조군들을 피부내 주입한 후 0일 및 7일째에 전기천공(Cellectis, France)을 실시하였다. 비장세포들이 21일째에 수득되어 MHC 클래스 I-제한된 E7 또는 E6 펩타이드로 24시간 동안 자극되었다. IFNγ 분비성 비장세포들의 수가 ELISPOT에 의해 계산되었다. (A) 25 μg의 VB1009, 대조군 1(항원 단독) 및 pUMVC4a(공벡터)로 피부내 백신화시킨 후의 E7-특이적 반응들. (B) 12.5 및 1.4 μg의 VB1016, 대조군 2(항원 단독) 및 pUMVC4a(공벡터)로 피부내 백신화시킨 후의 E7-특이적 반응들. (C) 12.5 및 1.4 μg의 VB1016, 대조군 2(항원 단독) 및 pUMVC4a(공벡터)로 피부내 백신화시킨 후의 E6-특이적 반응들.
도 4. 측정된 종양 부피에 의해 보여지는 VB1016의 치료 효과. 5×105 TC-1 세포들이 0일째에 C57BL/6 마우스들에 피하 주입되었다. 3일 및 10일째에, 상기 마우스들에 12.5 μg의 VB1016을 인코딩하는 네이키드 DNA 플라스미드, 대조군 2 또는 공벡터를 피부내 주입하고 전기천공(Cellectis, France)을 실시하였다. 상기 종양 크기들이 캘리퍼스에 의해 한 주에 2 내지 3번씩 측정되고 종양 부피가 계산되었다.
도 5. 측정된 종양 부피에 의해 보여지는 VB1016의 치료 효과. 5×104 TC-1 세포들이 0일째에 C57BL/6 마우스들의 목 부위에 피하 주입되었다. 3일, 7일 및 10일째에, 상기 마우스들에 20 μg 또는 2 μg의 VB1016을 인코딩하는 네이키드 DNA 플라스미드, 대조군 2 또는 공벡터를 피부내 주입하고 전기천공(Cellectis, France)을 실시하였다. 상기 종양 크기들이 캘리퍼스에 의해 한 주에 2 내지 3번씩 측정되고 종양 부피가 계산되었다.
도 6. 측정된 종양 부피에 의해 보여지는 VB1020 및 VB1021의 치료 효과. 5×104 TC-1 세포들이 0일째에 C57BL/6 마우스들의 넓적다리 부위에 피하 주입되었다. 3일 및 10일째에, 상기 마우스들에 10 μg의 VB1016, VB1020 또는 VB1021을 인코딩하는 네이키드 DNA 플라스미드, 또는 공벡터를 피부내 주입하고 전기천공(Cellectis, France)을 실시하였다. 상기 종양 크기들이 캘리퍼스에 의해 한 주에 2 내지 3번씩 측정되고 종양 부피가 계산되었다.
Claims (56)
- 두 개의 동일한 아미노산 체인들의 호모다이머성 단백질로, 각 아미노산 체인은 (1) 시그널 펩타이드, (2) 타겟팅 단위(unit), (3) 다이머화 모티프 및 (4) 항원성 단위를 포함하고, 상기 타겟팅 단위는 서열번호 1의 아미노산 서열 24-93에 대해 최소 80% 서열 동일성을 가지는 아미노산 서열을 포함하고, 상기 항원성 단위는 인간 파필로마바이러스(HPV)의 아미노산 서열을 포함하는 항원성 단위, 예컨대 HPV16 및/또는 HPV18의 아미노산 서열을 포함하는 항원성 단위, 예컨대 HPV16 및/또는 HPV18의 초기 단백질 E6 및/또는 E7로부터 유래된 항원성 단위를 포함하는 것인 호모다이머성 단백질.
- 제1항에 있어서, 상기 아미노산 체인 내 상기 타겟팅 단위, 다이머화 모티프 및 항원성 단위는 N-말단부터 C-말단 순서로 타겟팅 단위, 다이머화 모티프 및 항원성 단위로 존재하는 것인 호모다이머성 단백질.
- 제1항 및 제2항 중 어느 하나의 항에 있어서, 상기 시그널 펩타이드는 서열번호 1의 아미노산 서열 1-23에 대해 최소 80% 서열 동일성을 가지는 아미노산 서열로 구성되는 것인 호모다이머성 단백질.
- 제3항에 있어서, 상기 시그널 펩타이드는 서열번호 1의 아미노산 서열 1-23에 대해 최소 85%, 예컨대 최소 86%, 예컨대 최소 87%, 예컨대 최소 88%, 예컨대 최소 89%, 예컨대 최소 90%, 예컨대 최소 91%, 예컨대 최소 92%, 예컨대 최소 93%, 예컨대 최소 94%, 예컨대 최소 95%, 예컨대 최소 96%, 예컨대 최소 97%, 예컨대 최소 98%, 예컨대 최소 99%, 예컨대 최소 100% 서열 동일성을 가지는 아미노산 서열로 구성되는 것인 호모다이머성 단백질.
- 제1항 내지 제4항 중 어느 하나의 항에 있어서, 상기 타겟팅 단위는 서열번호 1의 아미노산 서열 24-93에 대해 최소 85%, 예컨대 최소 86%, 예컨대 최소 87%, 예컨대 최소 88%, 예컨대 최소 89%, 예컨대 최소 90%, 예컨대 최소 91%, 예컨대 최소 92%, 예컨대 최소 93%, 예컨대 최소 94%, 예컨대 최소 95%, 예컨대 최소 96%, 예컨대 최소 97%, 예컨대 최소 98%, 예컨대 최소 99% 서열 동일성을 가지는 아미노산 서열로 구성되는 것인 호모다이머성 단백질.
- 제1항 내지 제5항 중 어느 하나의 항에 있어서, 상기 다이머화 모티프는 경첩부위(hinge region)를 포함하고 선택적으로 링커를 통해 연결되는 면역글로불린 도메인 같은 다이머화를 용이하게 하는 다른 도메인을 선택적으로 포함하는 것인 호모다이머성 단백질.
- 제6항에 있어서, 상기 경첩부위는 IgG3로부터 유래되는 경첩부위 같은 Ig 유래된 경첩부위인 호모다이머성 단백질.
- 제6항 및 제7항 중 어느 하나의 항에 있어서, 상기 경첩부위는 한 개, 두 개, 또는 여러 개의 공유결합들을 형성하는 능력을 가지는 것인 호모다이머성 단백질.
- 제8항에 있어서, 상기 공유결합은 이황화 브릿지(disulphide bridge)인 것인 호모다이머성 단백질.
- 제6항 내지 제9항 중 어느 하나의 항에 있어서, 상기 다이머화 모티프의 면역글로불린 도메인은 카르복시말단(carboxyterminal) C 도메인이거나, 또는 상기 C 도메인 또는 이의 변이체와 실질적으로 동일한 서열인 것인 호모다이머성 단백질.
- 제10항에 있어서, 상기 카르복시말단 C 도메인은 IgG로부터 유래되는 것인 호모다이머성 단백질.
- 제6항 내지 제11항 중 어느 하나의 항에 있어서, 상기 다이머화 모티프의 면역글로불린 도메인은 호모다이머화시키는 능력을 가지는 것인 호모다이머성 단백질.
- 제6항 내지 제12항 중 어느 하나의 항에 있어서, 상기 면역글로불린 도메인은 비공유결합성 상호작용들을 통해 호모다이머화시키는 능력을 가지는 것인 호모다이머성 단백질.
- 제13항에 있어서 상기 비공유결합성 상호작용들은 소수성 상호작용들인 것인 호모다이머성 단백질.
- 제1항 내지 제14항 중 어느 하나의 항에 있어서, 상기 다이머화 도메인은 CH2 도메인을 포함하지 않는 것인 호모다이머성 단백질.
- 제1항 내지 제15항 중 어느 하나의 항에 있어서, 상기 다이머화 모티프는 인간 IgG3의 CH3 도메인에 링커를 통해 연결되는 경첩 엑손들(hinge exons) h1 및 h4로 구성되는 것인 호모다이머성 단백질.
- 제1항 내지 제16항 중 어느 하나의 항에 있어서, 상기 다이머화 모티프는 서열번호 3의 아미노산 서열 94-237에 대해 최소 80% 서열 동일성을 가지는 아미노산 서열로 구성되는 것인 호모다이머성 단백질.
- 제2항 내지 제17항 중 어느 하나의 항에 있어서, 상기 링커는 G3S2G3SG 링커인 것인 호모다이머성 단백질.
- 제1항 내지 제18항 중 어느 하나의 항에 있어서, 상기 항원성 단위 및 다이머화 모티프는 링커, 예컨대 GLGGL 링커 또는 GLSGL 링커를 통해 연결되는 것인 호모다이머성 단백질.
- 제1항 내지 제19항 중 어느 하나의 항에 있어서, 상기 타겟팅 단위는 서열번호 1의 24-93의 아미노산들, 또는 이의 변이체로 구성되는 것인 호모다이머성 단백질.
- 제1항 내지 제20항 중 어느 하나의 항에 있어서, 호모다이머성 단백질은 서열번호 1의 24-93의 아미노산들, 또는 이의 변이체로 구성된 타겟팅 단위를 가지는 동일한 호모다이머성 단백질의 친화도와 비교 시 CCR1, CCR3 및 CCR5로부터 선택된 어느 하나의 케모카인 수용체에 대한 증가된 친화도를 가지는 것인 호모다이머성 단백질.
- 제1항 내지 제21항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 서열번호 3의 아미노산 서열 243-293에 대해 최소 80%, 예컨대 최소 81%, 예컨대 최소 82%, 예컨대 최소 83%, 예컨대 최소 84%, 예컨대 최소 85%, 예컨대 최소 86%, 예컨대 최소 87%, 예컨대 최소 88%, 예컨대 최소 89%, 예컨대 최소 90%, 예컨대 최소 91%, 예컨대 최소 92%, 예컨대 최소 93%, 예컨대 최소 94%, 예컨대 최소 95%, 예컨대 최소 96%, 예컨대 최소 97%, 예컨대 최소 98%, 예컨대 최소 99% 서열 동일성을 가지는 아미노산 서열을 포함하는 것인 호모다이머성 단백질.
- 제1항 내지 제22항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 서열번호 3의 아미노산 서열 243-293에 대해 최소 80%, 예컨대 최소 81%, 예컨대 최소 82%, 예컨대 최소 83%, 예컨대 최소 84%, 예컨대 최소 85%, 예컨대 최소 86%, 예컨대 최소 87%, 예컨대 최소 88%, 예컨대 최소 89%, 예컨대 최소 90%, 예컨대 최소 91%, 예컨대 최소 92%, 예컨대 최소 93%, 예컨대 최소 94%, 예컨대 최소 95%, 예컨대 최소 96%, 예컨대 최소 97%, 예컨대 최소 98%, 예컨대 최소 99% 서열 동일성을 가지는 아미노산 서열로 구성되는 것인 호모다이머성 단백질.
- 제22항 또는 제23항에 있어서, 상기 항원성 단위는 서열번호 22의 F47, L50, C63, C106 및 I128로 구성된 리스트로부터 선택된 위치에서 하나 이상의 아미노산 치환들, 또는 서열번호 22의 Y43-L50으로 구성된 리스트로부터 선택된 하나 이상의 아미노산을 포함하는 결실을 포함하는 것인 호모다이머성 단백질.
- 제1항 내지 제23항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 서열번호 3, 서열번호 5, 서열번호 7, 또는 서열번호 9의 아미노산 서열 243-293, 또는 이의 변이체 또는 항원성 단편을 포함하는 것인 호모다이머성 단백질.
- 제1항 내지 제23항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 서열번호 3, 서열번호 5, 서열번호 7, 또는 서열번호 9의 아미노산 서열 243-293, 또는 이의 변이체 또는 항원성 단편으로 구성되는 것인 호모다이머성 단백질.
- 제1항 내지 제21항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 서열번호 11의 아미노산 서열 243-340에 대해 최소 80%, 예컨대 최소 81%, 예컨대 최소 82%, 예컨대 최소 83%, 예컨대 최소 84%, 예컨대 최소 85%, 예컨대 최소 86%, 예컨대 최소 87%, 예컨대 최소 88%, 예컨대 최소 89%, 예컨대 최소 90%, 예컨대 최소 91%, 예컨대 최소 92%, 예컨대 최소 93%, 예컨대 최소 94%, 예컨대 최소 95%, 예컨대 최소 96%, 예컨대 최소 97%, 예컨대 최소 98%, 예컨대 최소 99% 서열 동일성을 가지는 아미노산 서열을 포함하는 것인 호모다이머성 단백질.
- 제1항 내지 제21항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 서열번호 11의 아미노산 서열 243-340에 대해 최소 80%, 예컨대 최소 81%, 예컨대 최소 82%, 예컨대 최소 83%, 예컨대 최소 84%, 예컨대 최소 85%, 예컨대 최소 86%, 예컨대 최소 87%, 예컨대 최소 88%, 예컨대 최소 89%, 예컨대 최소 90%, 예컨대 최소 91%, 예컨대 최소 92%, 예컨대 최소 93%, 예컨대 최소 94%, 예컨대 최소 95%, 예컨대 최소 96%, 예컨대 최소 97%, 예컨대 최소 98%, 예컨대 최소 99% 서열 동일성을 가지는 아미노산 서열로 구성되는 것인 호모다이머성 단백질.
- 제27항 또는 제28항에 있어서, 상기 항원성 단위는 서열번호 23의 C24, E26, C58, C61, C91, 및 C94로 구성된 리스트로부터 선택된 위치에서 하나 이상의 아미노산 치환들, 또는 서열번호 23의 L22-E26 및/또는 C58-C61 및/또는 C91-S95으로 구성된 리스트로부터 선택된 하나 이상의 아미노산을 포함하는 결실을 포함하는 것인 호모다이머성 단백질.
- 제1항 내지 제21항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 서열번호 11, 서열번호 13, 서열번호 15, 또는 서열번호 17의 아미노산 서열 243-340, 또는 이의 변이체 또는 항원성 단편을 포함하는 것인 호모다이머성 단백질.
- 제1항 내지 제21항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 서열번호 11, 서열번호 13, 서열번호 15, 또는 서열번호 17의 아미노산 서열 243-340, 또는 이의 변이체 또는 항원성 단편으로 구성되는 것인 호모다이머성 단백질.
- 제1항 내지 제21항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 서열번호 19, 서열번호 21, 서열번호 32, 또는 서열번호 34의 아미노산 서열 243-501에 대해 최소 80%, 예컨대 최소 81%, 예컨대 최소 82%, 예컨대 최소 83%, 예컨대 최소 84%, 예컨대 최소 85%, 예컨대 최소 86%, 예컨대 최소 87%, 예컨대 최소 88%, 예컨대 최소 89%, 예컨대 최소 90%, 예컨대 최소 91%, 예컨대 최소 92%, 예컨대 최소 93%, 예컨대 최소 94%, 예컨대 최소 95%, 예컨대 최소 96%, 예컨대 최소 97%, 예컨대 최소 98%, 예컨대 최소 99% 서열 동일성을 가지는 아미노산 서열을 포함하는 것인 호모다이머성 단백질.
- 제1항 내지 제21항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 서열번호 19, 서열번호 21, 서열번호 32, 또는 서열번호 34의 아미노산 서열 243-501에 대해 최소 80%, 예컨대 최소 81%, 예컨대 최소 82%, 예컨대 최소 83%, 예컨대 최소 84%, 예컨대 최소 85%, 예컨대 최소 86%, 예컨대 최소 87%, 예컨대 최소 88%, 예컨대 최소 89%, 예컨대 최소 90%, 예컨대 최소 91%, 예컨대 최소 92%, 예컨대 최소 93%, 예컨대 최소 94%, 예컨대 최소 95%, 예컨대 최소 96%, 예컨대 최소 97%, 예컨대 최소 98%, 예컨대 최소 99% 서열 동일성을 가지는 아미노산 서열로 구성되는 것인 호모다이머성 단백질.
- 제1항 내지 제22항, 제24항, 제25항, 제27항, 제29항, 제30항, 제32항 및 제33항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 초기 단백질 E6 및 E7 모두로부터 유래된 인간 파필로마바이러스 16(HPV16)의 아미노산 서열을 포함하는 것인 호모다이머성 단백질.
- 제32항 내지 제34항에 있어서, 상기 항원성 단위는 서열번호 22의 F47, L50, C63, C106 및 I128 그리고 서열번호 23의 C24, E26, C58, C61, C91, C94로 구성된 리스트로부터 선택된 위치에서 하나 이상의 아미노산 치환들을 포함하는 것인 호모다이머성 단백질.
- 제1항 내지 제21항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 서열번호 19, 서열번호 21, 서열번호 32, 또는 서열번호 34의 아미노산 서열 243-501, 또는 이의 변이체 또는 항원성 단편으로 구성되는 것인 호모다이머성 단백질.
- 제1항 내지 제21항 중 어느 하나의 항에 있어서, 상기 아미노산 체인은 서열번호 3, 서열번호 5, 서열번호 7, 서열번호 9, 서열번호 11, 서열번호 13, 서열번호 15, 서열번호 17, 서열번호 19, 서열번호 21, 서열번호 32, 또는 서열번호 34로 구성되는 리스트로부터 선택된 아미노산 서열, 또는 이의 변이체 또는 항원성 단편으로 구성되는 것인 호모다이머성 단백질.
- 제1항 내지 제21항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 서열번호 22, 서열번호 23, 서열번호 24, 및 서열번호 25로부터 선택된 어느 하나의 아미노산 서열에 대해 최소 80%, 예컨대 최소 81%, 예컨대 최소 82%, 예컨대 최소 83%, 예컨대 최소 84%, 예컨대 최소 85%, 예컨대 최소 86%, 예컨대 최소 87%, 예컨대 최소 88%, 예컨대 최소 89%, 예컨대 최소 90%, 예컨대 최소 91%, 예컨대 최소 92%, 예컨대 최소 93%, 예컨대 최소 94%, 예컨대 최소 95%, 예컨대 최소 96%, 예컨대 최소 97%, 예컨대 최소 98%, 예컨대 최소 99% 서열 동일성을 가지는 아미노산 서열을 포함하는 것인 호모다이머성 단백질.
- 제1항 내지 제21항 중 어느 하나의 항에 있어서, 상기 항원성 단위는 서열번호 22, 서열번호 23, 서열번호 24, 및 서열번호 25로부터 선택된 어느 하나의 아미노산 서열에 대해 최소 80%, 예컨대 최소 81%, 예컨대 최소 82%, 예컨대 최소 83%, 예컨대 최소 84%, 예컨대 최소 85%, 예컨대 최소 86%, 예컨대 최소 87%, 예컨대 최소 88%, 예컨대 최소 89%, 예컨대 최소 90%, 예컨대 최소 91%, 예컨대 최소 92%, 예컨대 최소 93%, 예컨대 최소 94%, 예컨대 최소 95%, 예컨대 최소 96%, 예컨대 최소 97%, 예컨대 최소 98%, 예컨대 최소 99% 서열 동일성을 가지는 아미노산 서열로 구성되는 것인 호모다이머성 단백질.
- 제1항 내지 제39항 중 어느 하나의 항에 있어서, 상기 호모다이머성 단백질은 어느 하나의 시그널 펩타이드 서열이 없는 성숙한 형태인 것인 호모다이머성 단백질.
- (1) 시그널 펩타이드, (2) 타겟팅 단위, (3) 다이머화 모티프 및 (4) 항원성 단위를 포함하는 아미노산 체인으로, 상기 타겟팅 단위는 서열번호 1의 아미노산 서열 24-93에 대해 최소 80% 서열 동일성을 가지는 아미노산 서열을 포함하고, 항원성 단위는 인간 파필로마바이러스(HPV)의 아미노산 서열을 포함하는 항원성 단위, 예컨대 HPV16 및/또는 HPV18의 아미노산 서열을 포함하는 항원성 단위, 예컨대 HPV16 및/또는 HPV18의 초기 단백질 E6 및/또는 E7로부터 유래된 항원성 단위를 포함하며, 상기 아미노산 체인은 제1항 내지 제40항 중 어느 하나의 항에 따른 호모다이머성 단백질을 형성할 수 있는 것인 아미노산 체인.
- 제41항에 따른 아미노산 체인을 인코딩하는 DNA 같은 핵산 분자.
- 제42항에 있어서, 핵산 분자는 인간 코돈 최적화된 것인 핵산 분자.
- 서열번호 2, 서열번호 4, 서열번호 6, 서열번호 8, 서열번호 10, 서열번호 12, 서열번호 14, 서열번호 16, 서열번호 18, 서열번호 20, 서열번호 31 및 서열번호 33으로 구성된 리스트로부터 선택된 뉴클레오타이드 서열들 중 어느 하나, 또는 이의 변이체를 포함하는 핵산 분자.
- 제42항 내지 제44항에 있어서, 상기 핵산은 벡터에 의해 포함되는 것인 핵산 분자.
- 제42항 내지 제45항 중 어느 하나의 항에 있어서, 상기 핵산 분자는 환자에서 호모다이머성 단백질의 생산을 유도하기 위해 상기 환자에게 투여하기 위해 제형화되는 것인 핵산 분자.
- 의약품(medicament)으로서 사용하기 위한 제1항 내지 제40항 중 어느 하나의 항에 따른 호모다이머성 단백질, 제41항에 따른 아미노산 체인, 또는 제42항 내지 제46항 중 어느 하나의 항에 따른 핵산 분자.
- 제1항 내지 제40항 중 어느 하나의 항에 따른 호모다이머성 단백질, 제41항에 따른 아미노산 체인, 또는 제42항 내지 제46항 중 어느 하나의 항에 따른 핵산 분자를 포함하는 약제학적 조성물.
- 제42항 내지 제46항 중 어느 하나의 항에 따른 핵산 분자를 포함하는 숙주세포.
- 제1항 내지 제40항 중 어느 하나의 항에 따른 호모다이머성 단백질, 또는 제41항의 아미노산 체인을 제조하는 방법으로, 상기 방법은
a) 제41항 내지 제45항 중 어느 하나의 항에 따른 핵산 분자를 세포 개체군(cell population) 내로 트랜스펙션시키는 단계;
b) 상기 세포 개체군을 배양하는 단계;
c) 상기 세포 개체군으로부터 발현된 상기 호모다이머성 단백질, 또는 아미노산 체인을 수득하고 정제시키는 단계를 포함하는 것인 방법. - 제42항 내지 제46항 중 어느 하나의 항에 따른 핵산 분자의 면역학적으로 효과적인 양을 포함하는 DNA 백신 같은 백신을 제조하는 방법으로, 상기 방법은
a) 제41항 내지 제45항 중 어느 하나의 항에 따른 핵산 분자를 제조하는 단계;
b) 약제학적으로 허용가능한 담체, 희석제 또는 완충액에 단계 a)에서 얻어진 상기 핵산 분자를 용해시키는 단계를 포함하는 것인 방법. - 제1항 내지 제40항 중 어느 하나의 항에 따른 호모다이머성 단백질, 또는 제41항에 따른 아미노산 체인, 또는 제42항 내지 제46항 중 어느 하나의 항에 따른 DNA 같은 핵산 분자의 면역학적으로 효과적인 양을 포함하는 HPV에 대한 백신으로, 상기 백신은 T-세포- 및 B-세포 면역반응 모두를 유발시킬 수 있는 것인 백신.
- 제52항에 있어서, 상기 백신은 약제학적으로 허용가능한 담체 및/또는 보조제(adjuvant)를 추가적으로 포함하는 것인 백신.
- 환자에서 HPV에 의해 야기되는 암 또는 감염성 질병 같은 HPV 유도된 질병 또는 상태를 치료 또는 예방하는 방법으로, 상기 방법은 제1항 내지 제40항 중 어느 하나의 항에 따른 호모다이머성 단백질, 또는 제41항에 따른 아미노산 체인, 또는 제42항 내지 제46항 중 어느 하나의 항에 따른 DNA 같은 핵산 분자를 이를 필요로 하는 상기 환자에게 투여하는 단계를 포함하는 것인 방법.
- 제54항에 있어서, 상기 방법은 다음의 전기천공 단계와 함께 제42항 내지 제46항 중 어느 하나의 항에 따른 DNA 같은 핵산 분자를 이를 필요로 하는 상기 환자에게 투여한 후 추가적인 전기천공을 실시하는 단계를 포함하는 것인 방법.
- 제54항 또는 제55항에 있어서, 상기 투여는 피부 내 또는 근육 내로 실시되는 것인 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201161578542P | 2011-12-21 | 2011-12-21 | |
| US61/578,542 | 2011-12-21 | ||
| PCT/EP2012/076404 WO2013092875A1 (en) | 2011-12-21 | 2012-12-20 | Vaccines against hpv |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20140107569A true KR20140107569A (ko) | 2014-09-04 |
| KR102057265B1 KR102057265B1 (ko) | 2019-12-18 |
Family
ID=47471832
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020147020468A Active KR102057265B1 (ko) | 2011-12-21 | 2012-12-20 | Hpv에 대한 백신들 |
Country Status (17)
| Country | Link |
|---|---|
| US (1) | US9901635B2 (ko) |
| EP (2) | EP2793937B1 (ko) |
| JP (1) | JP6258864B2 (ko) |
| KR (1) | KR102057265B1 (ko) |
| CN (1) | CN104039833B (ko) |
| AU (1) | AU2012356969B2 (ko) |
| BR (1) | BR112014015016B1 (ko) |
| CA (1) | CA2858963C (ko) |
| DK (1) | DK2793937T3 (ko) |
| ES (1) | ES2730718T3 (ko) |
| HU (1) | HUE043361T2 (ko) |
| IL (1) | IL233217B (ko) |
| PT (1) | PT2793937T (ko) |
| RU (1) | RU2644201C2 (ko) |
| TR (1) | TR201908199T4 (ko) |
| WO (1) | WO2013092875A1 (ko) |
| ZA (1) | ZA201404516B (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20180100659A (ko) * | 2016-01-08 | 2018-09-11 | 백시바디 에이에스 | 치료적 항암 네오에피토프 백신 |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2970466A1 (en) * | 2013-03-15 | 2016-01-20 | Vaccibody AS | Targeting vaccines for veterinary use |
| CN120939216A (zh) | 2014-01-13 | 2025-11-14 | 贝勒研究院 | 抗hpv和hpv相关的疾病的新疫苗 |
| CN107073070A (zh) * | 2014-08-15 | 2017-08-18 | 格纳西尼有限公司 | 治疗宫颈癌的方法 |
| JP6470872B2 (ja) * | 2015-08-20 | 2019-02-13 | ヤンセン ファッシンズ アンド プリベンション ベーフェーJanssen Vaccines & Prevention B.V. | 治療用hpv18ワクチン |
| EP3678699A1 (en) | 2017-09-07 | 2020-07-15 | University Of Oslo | Vaccine molecules |
| EP3678698A1 (en) * | 2017-09-07 | 2020-07-15 | University Of Oslo | Vaccine molecules |
| WO2021205027A1 (en) | 2020-04-09 | 2021-10-14 | Vaccibody As | Individualized therapeutic anticancer vaccine |
| JP7460094B2 (ja) | 2020-04-24 | 2024-04-02 | ジェネクシン・インコーポレイテッド | 子宮頸がんの治療方法 |
| KR20230005962A (ko) | 2020-05-01 | 2023-01-10 | 니코데 테라퓨틱스 에이에스에이 | 베타코로나바이러스 예방 및 치료요법 |
| KR20230164118A (ko) | 2021-03-26 | 2023-12-01 | 니코데 테라퓨틱스 에이에스에이 | 암 치료를 위한 치료 조합 |
| WO2022233851A1 (en) | 2021-05-03 | 2022-11-10 | Nykode Therapeutics ASA | Immunogenic constructs and vaccines for use in the prophylactic and therapeutic treatment of infectious diseases |
| WO2022238402A1 (en) | 2021-05-10 | 2022-11-17 | Nykode Therapeutics ASA | Tolerance-inducing constructs and composition and their use for the treatment of immune disorders |
| JP2024518463A (ja) | 2021-05-10 | 2024-05-01 | ナイコード セラピューティクス アルメン アクスイェ セルスカプ | 構築物及び免疫阻害化合物の共発現 |
| WO2022238381A2 (en) | 2021-05-10 | 2022-11-17 | Nykode Therapeutics ASA | Immunotherapy constructs for treatment of disease |
| WO2022238363A1 (en) | 2021-05-10 | 2022-11-17 | Nykode Therapeutics ASA | Immunogenic constructs and vaccines for use in the prophylactic and therapeutic treatment of infectious diseases |
| BR112023023260A2 (pt) | 2021-05-10 | 2024-01-30 | Nykode Therapeutics ASA | Vetor, métodos para produzir um vetor e para tratar um sujeito tendo uma doença ou uma doença infecciosa, célula hospedeira, e, composição farmacêutica |
| EP4337247A1 (en) | 2021-05-10 | 2024-03-20 | Nykode Therapeutics ASA | Tolerance-inducing constructs and compositions and their use for the treatment of immune disorders |
| WO2023079001A1 (en) | 2021-11-03 | 2023-05-11 | Nykode Therapeutics ASA | Immunogenic constructs and vaccines for use in the prophylactic and therapeutic treatment of diseases caused by sars-cov-2 |
| WO2024092025A1 (en) | 2022-10-25 | 2024-05-02 | Nykode Therapeutics ASA | Constructs and their use |
| WO2024100196A1 (en) | 2022-11-09 | 2024-05-16 | Nykode Therapeutics ASA | Co-expression of constructs and polypeptides |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB9105383D0 (en) * | 1991-03-14 | 1991-05-01 | Immunology Ltd | An immunotherapeutic for cervical cancer |
| AUPN015794A0 (en) | 1994-12-20 | 1995-01-19 | Csl Limited | Variants of human papilloma virus antigens |
| EP1553966B1 (en) * | 2002-10-03 | 2012-08-01 | Wyeth Holdings Corporation | Fusion peptides comprising the human papillomavirus e7 and e6 polypeptides and immunogenic compositions thereof |
| ES2531204T3 (es) * | 2003-02-25 | 2015-03-11 | Vaccibody As | Anticuerpo modificado |
| PL1576967T3 (pl) * | 2004-03-18 | 2008-03-31 | Pasteur Institut | Rekombinowane białko niosące epitopy ludzkiego wirusa brodawczaka wstawione w białko cyklazy adenylanowej lub jego fragment oraz jego zastosowania terapeutyczne |
| CA2595726A1 (en) | 2005-01-26 | 2006-08-03 | The Johns Hopkins University | Anti-cancer dna vaccine employing plasmids encoding mutant oncoprotein antigen and calreticulin |
| JP2013532971A (ja) * | 2010-06-25 | 2013-08-22 | バッシボディ アクスイェ セルスカプ | ホモ二量体タンパク質コンストラクト |
-
2012
- 2012-12-20 BR BR112014015016-8A patent/BR112014015016B1/pt active IP Right Grant
- 2012-12-20 CA CA2858963A patent/CA2858963C/en active Active
- 2012-12-20 AU AU2012356969A patent/AU2012356969B2/en active Active
- 2012-12-20 ES ES12809271T patent/ES2730718T3/es active Active
- 2012-12-20 CN CN201280064089.7A patent/CN104039833B/zh active Active
- 2012-12-20 JP JP2014548019A patent/JP6258864B2/ja active Active
- 2012-12-20 RU RU2014129788A patent/RU2644201C2/ru active
- 2012-12-20 US US14/365,536 patent/US9901635B2/en active Active
- 2012-12-20 PT PT12809271T patent/PT2793937T/pt unknown
- 2012-12-20 TR TR2019/08199T patent/TR201908199T4/tr unknown
- 2012-12-20 WO PCT/EP2012/076404 patent/WO2013092875A1/en not_active Ceased
- 2012-12-20 DK DK12809271.5T patent/DK2793937T3/da active
- 2012-12-20 EP EP12809271.5A patent/EP2793937B1/en active Active
- 2012-12-20 HU HUE12809271A patent/HUE043361T2/hu unknown
- 2012-12-20 EP EP19166523.1A patent/EP3533462A1/en not_active Withdrawn
- 2012-12-20 KR KR1020147020468A patent/KR102057265B1/ko active Active
-
2014
- 2014-06-18 IL IL233217A patent/IL233217B/en active IP Right Grant
- 2014-06-19 ZA ZA2014/04516A patent/ZA201404516B/en unknown
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20180100659A (ko) * | 2016-01-08 | 2018-09-11 | 백시바디 에이에스 | 치료적 항암 네오에피토프 백신 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2793937B1 (en) | 2019-04-10 |
| WO2013092875A1 (en) | 2013-06-27 |
| IL233217A0 (en) | 2014-08-31 |
| CA2858963C (en) | 2023-05-23 |
| DK2793937T3 (da) | 2019-07-01 |
| ES2730718T3 (es) | 2019-11-12 |
| JP2015508284A (ja) | 2015-03-19 |
| AU2012356969B2 (en) | 2017-05-04 |
| AU2012356969A1 (en) | 2014-07-03 |
| IL233217B (en) | 2019-05-30 |
| RU2014129788A (ru) | 2016-02-10 |
| BR112014015016A8 (pt) | 2023-05-09 |
| KR102057265B1 (ko) | 2019-12-18 |
| US20150056197A1 (en) | 2015-02-26 |
| HUE043361T2 (hu) | 2019-08-28 |
| EP2793937A1 (en) | 2014-10-29 |
| ZA201404516B (en) | 2017-04-26 |
| JP6258864B2 (ja) | 2018-01-10 |
| HK1202442A1 (en) | 2015-10-02 |
| CN104039833B (zh) | 2018-01-30 |
| EP3533462A1 (en) | 2019-09-04 |
| TR201908199T4 (tr) | 2019-06-21 |
| BR112014015016B1 (pt) | 2023-10-03 |
| CA2858963A1 (en) | 2013-06-27 |
| BR112014015016A2 (pt) | 2020-10-27 |
| US20150306217A9 (en) | 2015-10-29 |
| PT2793937T (pt) | 2019-06-05 |
| RU2644201C2 (ru) | 2018-02-08 |
| CN104039833A (zh) | 2014-09-10 |
| US9901635B2 (en) | 2018-02-27 |
| NZ626124A (en) | 2016-07-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102057265B1 (ko) | Hpv에 대한 백신들 | |
| AU2021232660B2 (en) | HPV vaccines | |
| US11479605B2 (en) | Homodimeric protein constructs | |
| CN101528255B (zh) | Hpv抗原融合蛋白疫苗组合物及其应用 | |
| Massa et al. | Antitumor activity of DNA vaccines based on the human papillomavirus-16 E7 protein genetically fused to a plant virus coat protein | |
| KR20140069222A (ko) | 교차 제시 수지상 세포를 표적으로 하는 백시바디 | |
| HK1202442B (en) | Vaccines against hpv | |
| NZ626124B2 (en) | Vaccines against hpv |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20140721 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| A201 | Request for examination | ||
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20171219 Comment text: Request for Examination of Application |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20190418 Patent event code: PE09021S01D |
|
| E90F | Notification of reason for final refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Final Notice of Reason for Refusal Patent event date: 20190722 Patent event code: PE09021S02D |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
Patent event code: PE07011S01D Comment text: Decision to Grant Registration Patent event date: 20191129 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
Comment text: Registration of Establishment Patent event date: 20191212 Patent event code: PR07011E01D |
|
| PR1002 | Payment of registration fee |
Payment date: 20191213 End annual number: 3 Start annual number: 1 |
|
| PG1601 | Publication of registration | ||
| PR1001 | Payment of annual fee |
Payment date: 20221129 Start annual number: 4 End annual number: 4 |
|
| PR1001 | Payment of annual fee |
Payment date: 20241127 Start annual number: 6 End annual number: 6 |