KR20200058525A - 스타필로코커스 표적 항원 및 보체 성분에 결합하는 이특이적 항원-결합 분자 및 이의 용도 - Google Patents
스타필로코커스 표적 항원 및 보체 성분에 결합하는 이특이적 항원-결합 분자 및 이의 용도 Download PDFInfo
- Publication number
- KR20200058525A KR20200058525A KR1020207012271A KR20207012271A KR20200058525A KR 20200058525 A KR20200058525 A KR 20200058525A KR 1020207012271 A KR1020207012271 A KR 1020207012271A KR 20207012271 A KR20207012271 A KR 20207012271A KR 20200058525 A KR20200058525 A KR 20200058525A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- amino acid
- less
- acid sequence
- antigen
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/12—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from bacteria
- C07K16/1267—Gram-positive bacteria
- C07K16/1271—Micrococcaceae (F); Staphylococcaceae (F), e.g. Staphylococcus (G)
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/40—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum bacterial
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/04—Antibacterial agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/57—Medicinal preparations containing antigens or antibodies characterised by the type of response, e.g. Th1, Th2
- A61K2039/572—Medicinal preparations containing antigens or antibodies characterised by the type of response, e.g. Th1, Th2 cytotoxic response
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/734—Complement-dependent cytotoxicity [CDC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Genetics & Genomics (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Medicinal Chemistry (AREA)
- Biomedical Technology (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Immunology (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Microbiology (AREA)
- Veterinary Medicine (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Public Health (AREA)
- Oncology (AREA)
- General Chemical & Material Sciences (AREA)
- Plant Pathology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Physics & Mathematics (AREA)
- Communicable Diseases (AREA)
- Mycology (AREA)
- Epidemiology (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Medicinal Preparation (AREA)
- Materials For Medical Uses (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
Abstract
특정 구현예에 따라, 본원의 개시내용은 스타필로코커스 종 표적 항원에 특이적으로 결합하는 제1 항원-결합 도메인 및 보체 성분에 결합하는 제2 항원 결합 도메인을 포함하는 이특이적 항원-결합 분자를 제공한다. 특정 구현예에서, 본원 개시내용의 이특이적 항원-결합 분자는 약 10nM 이하의 EC50으로 스타필로코커스 종 표적 항원에 결합할 수 있고/있거나 약 10nM의 EC50으로 스타필로코커스 종상에 보체 침적을 촉진시킬 수 있다. 본원 개시내용의 항체는 스타필로코커스 종의 성장의 억제 또는 감소가 요구되고/되거나 치료학적으로 이로운 질환을 치료하기 위해, 예를 들어, 피부 감염, 봉와직염, 폐렴, 뇌수막염, 요로 감염, 독성 쇼크 증후군, 심내막염, 골수염, 균혈증, 또는 패혈증을 포함하는 스타필로코커스 감염을 치료하기 위해, 또는 수술적 과정의 결과로서 일어나는 스타필로코커스 감염을 예방하거나 치료하기 위해 유용하다.
Description
[0001] 본 출원은 현재 2018년 9월 27일자로 PCT 국제 특허 출원으로 출원되어 있으며, 미국 가특허 출원인 2017년 9월 29일자로 출원된 제62/565,569호; 및 2018년 4월 9일로 출원된 제62/654,576호에 대한 우선권의 이익을 주장하고, 이들 각 개시내용은 전문이 본원에 참조로서 인용된다.
[0002] 본원의 개시내용은 스타필로코커스(Staphylococcus) 종 표적 항원 및 보체 성분에 결합하는 이특이적 항원 결합 분자 및 이의 용도에 관한 것이다.
[0003] 스타필로코커스 (S taphylococcus), 특히, 메티실린 내성 스타필로코커스 아우레우스(S taphylococcus aureus)에 의한 사람 감염은 유행성 상태가 되고 있다. 2005년에, 스타필로코커스 아우레우스를 사용한 감염은 미국에서 100,000명의 사람들 당 6.3명의 사망률을 가졌다. 결과로서, 백신 개발에 대한 상당한 연구가 있어왔다. 백신 전략은 캡슐 폴리사카라이드, 철 제거 단백질 lsdB, 클럼핑 인자 a, 및 리포테이코산을 표적화하였다. (문헌참조: Daum et al, Clin Inf. Dis. 54:560 (2012)). 그러나, 이들 백신은 임상 시험에 매우 효과적이지 않았고 이는 백신 전략이 다중 항원 및/또는 면역 반응의 자극의 조합을 필요로 할 수 있음을 시사한다.
[0004] 스타필로코커스는 숙주 면역 반응을 회피하는데 능숙하다. 스타필로코커스 감염에 대한 숙주의 면역 반응의 하나의 양상은 세포 표면을 옵소닌화하여 보체 매개된 용해 및/또는 식세포작용을 유도하는 항체를 생성하는 것이다. 스타필로코커스 종의 캡슐 폴리사카라이드는 식세포작용으로부터 보호한다. 세포 표면 단백질 A는 또한 항체의 Fc 부분에 결합함에 의해 항체를 격리시켜 식세포작용을 억제한다. 일부 종은 보체 기능 및 보체 매개된 용해를 억제하는 분자를 생성한다. 이들 성질은 특히 미생물이 항생제 내성인 경우 스타필로코커스 감염의 치료를 어렵게 한다. 따라서, 스타필로코커스 감염을 억제할 수 있는 보다 효과적인 치료학적 제제가 요구된다.
개시내용의 개요
[0005] 제1 양상에 따라, 본원의 개시내용은 스타필로코커스 종 표적 항원에 결합하는 제1 항원-결합 도메인 (D1) 및 보체 성분에 결합하는 제2 항원-결합 도메인 (D2)를 포함하는 이특이적 항원-결합 분자를 제공한다. 전형적인 보체 성분은 C1q, C1r, C1s, C2, C3, C4, C5, C6, C7, C8, C9, 또는 이의 임의의 단편(보체 캐스케이드에 의해 생성된 단백질용해 단편을 포함하는)을 포함한다. 구현예에서, 이특이적 항원-결합 분자는 약 10nM 이하의 EC50으로 스타필로코커스 종 표적 항원에 결합한다. 추가의 구현예에서, 이특이적 항원-결합 분자는 스타필로코커스 종 상에 보체 성분의 침적을 촉진시키고 EC50은 약 10nM 이하이다. 구현예에서, 보체 성분은 C1q이다. 여전히 다른 구현예에서, C1q는 사람 C1q이다. 구현예에서, 스타필로코커스 종은 스타필로코커스 아우레우스 (Staphylococcus aureus) 또는 스타필로코커스 에피더미디스(Staphylococcus epidermidis)이다. 구현예에서, 스타필로코커스 종 표적 항원은 캡슐 폴리사카라이드 5형, 캡슐 폴리사카라이드 8형, IsdB, IsdA, IsdH, 리포테이코산, 벽 테이코산, 리파제, V8 리파제, 지방산 변형 효소, 접착 매트릭스 분자를 인지하는 미생물 표면 성분(예를 들어, 어드헤신, 피브리노겐 결합 분자, 피브로넥틴 결합 단백질 A, 피브로넥틴 결합 단백질 B), 클럼핑 인자 A (clfA), 폴리-N-아세틸 글루코사민(PNAG), 또는 이의 조합을 포함한다. 구현예에서, 스타필로코커스 종 표적 항원은 철 조절된 표면 결정인자 B (IsdB)이다.
[0006] 특정 예시적인 구현예에 따라, 이특이적 항원-결합 분자는 스타필로코커스 종 표적 항원 철 조절된 표면 결정인자 B (IsdB) 및 사람 C1q에 결합하고; 상기 이특이적 항원-결합 분자는 또한 본원에서 "항-IsdB x 항-C1q 이특이적 분자"로서 언급된다. 항-IsdB x 항-C1q 이특이적 분자의 항-IsdB 항원 결합 도메인은 IsdB를 발현하는 미생물(예를 들어, 스타필로코커스 아우레우스)을 표적화하기 위해 유용하고 이특이적 분자의 항-C1q 항원 결합 도메인은 스타필로코커스 종상에 C1q의 침적을 촉진시키기 위해 유용하다. IsdB와 같은 표적 항원으로의 항원 결합 분자 및 사람 C1q로의 동시 결합은 표적화된 미생물의 지시된 사멸 (세포 용해)을 촉진시킨다. 개시내용의 항-IsdB x 항-C1q 이특이적 항원-결합 분자는 따라서 특히 미생물과 관련되거나 이에 의해 유발된 질환 및 장애 (예를 들어, 감염, 패혈증 등)를 치료하기 위해 유용하다.
[0007] 본원의 개시내용의 상기 양상에 따라 이특이적 항원-결합 분자는 IsdB에 특이적으로 결합하는 제1 항원-결합 도메인 (D1) 및 사람 C1q에 특이적으로 결합하는 제2 항원-결합 도메인 (D2)을 포함한다. 본원의 개시내용은 항-IsdB x 항-C1q 이특이적 분자(예를 들어, 이특이적 항체)를 포함하고, 여기서, 각각의 항원-결합 도메인은 경쇄 가변 영역 (LCVR)과 쌍을 형성한 중쇄 가변 영역(HCVR)을 포함한다. 개시내용의 특정 예시적 구현예에서, 항-C1q 항원-결합 도메인 (D2) 및 항-IsdB(D1) 항원-결합 도메인 각각은 동일하거나 상이한 LCVR과 쌍을 형성한 상이한 특유의 HCVR을 포함한다. 예를 들어, 본원의 실시예 3에서 설명된 바와 같이, 이특이적 항체가 작제되고, 항-IsdB 항체로부터 유래된 HCVR/LCVR 쌍을 포함하는 제1 항원-결합 도메인; 및 항-C1q 항체로부터 유래된 HCVR/LCVR 쌍을 포함하는 제2 항원-결합 도메인을 포함한다. 본원에 기재된 예시적 분자에서, 표 3에 본원에 기재된 서열을 갖는 LCVR과, 항-IsdB 항체 기원의 HCVR의 쌍형성은 IsdB에 특이적으로 결합하는 (그러나 C1q에 결합하지 않는) 항원-결합 도메인을 생성한다. 본원에 기재된 예시적 분자에서, 표 1에 본원에 기재된 서열을 갖는 LCVR과, 항-C1q 항체 기원의 HCVR의 쌍형성은 C1q에 특이적으로 결합하는 (그러나 IsdB에 결합하지 않는) 항원-결합 도메인을 생성한다.
[0008] 본원의 개시내용과 관련하여 사용된 바와 같은 항원-결합 분자는 표면 플라스몬 공명 검정에서 측정시, 약 25nM 미만, 약 20nM 미만, 약 15nM 미만, 약 10nM 미만, 약 5nM 미만, 약 1nM 미만, 약 500 pM 미만, 약 400 pM 미만, 약 300 pM 미만, 약 200 pM 미만, 약 100 pM 미만, 약 90 pM 미만, 약 80 pM 미만, 약 70 pM 미만, 약 60 pM 미만, 약 50 pM 미만, 약 40 pM 미만, 약 30 pM 미만, 약 20 pM 미만, 약 10 pM 미만, 약 5 pM 미만, 약 4 pM 미만, 약 2 pM 미만, 약 1 pM 미만, 약 0.5 pM 미만, 약 0.2 pM 미만, 약 0.1 pM 미만, 또는 약 0.05 pM 미만의 KD로 특정 항원 (예를 들어, 표적 분자 [T] 또는 이의 일부)에 결합하는 폴리펩타이드를 포함한다.
[0009] 항원-결합 도메인은 표면 플라스몬 공명 검정에서 측정시, 약 25nM 미만, 약 20nM 미만, 약 15nM 미만, 약 10nM 미만, 약 5nM 미만, 약 1nM 미만, 약 500 pM 미만, 약 400 pM 미만, 약 300 pM 미만, 약 200 pM 미만, 약 100 pM 미만, 약 90 pM 미만, 약 80 pM 미만, 약 70 pM 미만, 약 60 pM 미만, 약 50 pM 미만, 약 40 pM 미만, 약 30 pM 미만, 약 20 pM 미만, 약 10 pM 미만, 약 5 pM 미만, 약 4 pM 미만, 약 2 pM 미만, 약 1 pM 미만, 약 0.5 pM 미만, 약 0.2 pM 미만, 약 0.1 pM 미만, 또는 약 0.05 pM 미만의 KD로 IsdB와 같은 스타필로코커스 종 표적 항원(예를 들어, 표적 분자 [T] 또는 이의 일부)에 결합하는 폴리펩타이드를 포함한다.
[0010] 항원-결합 도메인은 표면 플라스몬 공명 검정에서 측정시, 약 25nM 미만, 약 20nM 미만, 약 15nM 미만, 약 10nM 미만, 약 5nM 미만, 약 1nM 미만, 약 500 pM 미만, 약 400 pM 미만, 약 300 pM 미만, 약 200 pM 미만, 약 100 pM 미만, 약 90 pM 미만, 약 80 pM 미만, 약 70 pM 미만, 약 60 pM 미만, 약 50 pM 미만, 약 40 pM 미만, 약 30 pM 미만, 약 20 pM 미만, 약 10 pM 미만, 약 5 pM 미만, 약 4 pM 미만, 약 2 pM 미만, 약 1 pM 미만, 약 0.5 pM 미만, 약 0.2 pM 미만, 약 0.1 pM 미만, 또는 약 0.05 pM 미만의 KD로 C1q와 같은 보체 성분에 결합하는 폴리펩타이드를 포함한다.
[0011] 본원의 개시내용은 항-IsdB x 항-C1q 이특이적 분자를 제공하고, 여기서, IsdB에 특이적으로 결합하는 상기 제1 항원-결합 도메인은 서열번호 169의 아미노산 3 내지 574의 아미노산 서열을 포함하는 IsdB에 결합한다. 스타필로코커스의 종은 IsdB의 상이한 아미노산 서열을 가질 수 있다. 상기 아미노산 서열은 용이하게 수득될 수 있다.
[0012] 구현예에 있어서, 제1 항원-결합 도메인 D1은 서열번호 138의 아미노산 서열 또는 서열번호 154의 아미노산 서열을 포함하는 HCVR 내에 함유된 중쇄 가변 영역 (HCVR) CDR과 서열번호 146의 아미노산 서열 또는 서열번호 162의 아미노산 서열을 포함하는 LCVR 영역 내 함유된 경쇄 가변 영역 (LCVR) CDR을 포함한다. 제1 항원-결합 도메인 D1은 표 3 또는 표 6에 제시된 바와 같은 임의의 HCVR 아미노산 서열을 포함한다. 제1 항원-결합 도메인 D1은 또한 표 3 또는 표 6에 제시된 바와 같은 임의의 LCVR 아미노산 서열을 포함할 수 있다. 특정 구현예에 따라, 제1 항원-결합 도메인 D1은 서열번호 138/146 또는 서열번호 154/162의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함한다. 본원의 개시내용은 또한 항-IsdB x 항-C1q 이특이적 분자를 제공하고, 여기서, 상기 제1 항원-결합 도메인 D1은 표 3 또는 표 6에 제시된 바와 같이 임의의 중쇄 CDR1-CDR2-CDR3 아미노산 서열 및/또는 표 3 또는 표 6에 제시된 바와 같은 임의의 경쇄 CDR1-CDR2-CDR3 아미노산 서열을 포함한다.
[0013] 특정 구현예에 따라, 본원의 개시내용은 항-IsdB x 항-C1q 이특이적 분자를 제공하고, 여기서, 상기 제1 항원-결합 도메인 D1은 서열번호 138, 서열번호 154의 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 가변 영역 (HCVR)을 포함한다.
[0014] 본원의 개시내용은 항-IsdB x 항-C1q 이특이적 분자를 제공하고, 여기서, 상기 제1 항원-결합 도메인 D1은 서열번호 146, 서열번호 162의 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 가변 영역 (LCVR)을 포함한다.
[0015] 본원의 개시내용은 또한 항-IsdB x 항-C1q 이특이적 분자를 제공하고, 여기서, 상기 제1 항원-결합 도메인 D1은 서열번호 144, 서열번호 160의 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR3 (HCDR3) 및 서열번호 152, 서열번호 168의 아미노산 서열 또는 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR3 (LCDR3)을 포함한다. 특정 구현예에서, 제1 항원-결합 도메인 D1은 서열번호 144/152, 144/168, 160/152 또는 160/168의 아미노산 서열을 포함하는 HCDR3/LCDR3 쌍을 포함한다.
[0016] 본원의 개시내용은 또한 항-IsdB x 항-C1q 이특이적 항원 결합 분자를 제공하고, 여기서, 상기 제1 항원-결합 도메인 D1은 서열번호 140, 서열번호 156의 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR3 (HCDR1), 서열번호 142, 서열번호 158의 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR2 (HCDR2) 및 서열번호 144, 서열번호 160의 아미노산 서열 또는 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR3 (HCDR3)을 포함한다. 구현예에서, 제1 항원-결합 도메인 D1은 서열번호 148, 서열번호 164의 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR1 (LCDR1), 서열번호 150, 서열번호 166의 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR2 (LCDR2) 및 서열번호 152, 서열번호 168의 아미노산 서열 또는 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR3 (LCDR3)을 포함한다.
[0017] 본원 개시내용의 특정 비제한 예시적인 항-IsdB x 항-C1q 이특이적 항원-결합 분자는 각각 HCDR1-HCDR2-HCDR3-LCDR1-LCDR2-LCDR3 CDR의 세트를 포함하는 제1 항원-결합 도메인 D1을 포함하고, 상기 HCDR1-HCDR2-HCDR3-LCDR1-LCDR2-LCDR3 CDR 세트는 서열번호 140, 142, 144, 148, 150, 152; 140, 142, 144, 164, 166, 168; 156, 158, 160, 148, 150, 152; 또는 156, 158, 160, 164, 166, 168의 아미노산 서열을 포함한다.
[0018] 본원의 개시내용은 또한 항-IsdB x 항-C1q 이특이적 항원 결합 분자를 제공하고, 여기서, C1q에 특이적으로 결합하는 상기 제2 항원-결합 도메인 D2는 서열번호 170, 서열번호 171 및 서열번호 172의 아미노산 서열을 포함하는 사람 C1q에 결합한다. 구현예에서, 이특이적 항원-결합 분자는 약 10nM 이하의 IC50으로 사람 C1q의 사람 IgG1-k로의 결합을 차단한다. 다른 구현예에서, 이특이적 항원-결합 분자는 약 50nM 이하의 IC50으로 사람 C1q의 사람 IgM으로의 결합을 차단한다. 구현예에서, 이특이적 항원-결합 분자는 약 10nM 이하의 EC50으로 사람 C1q의 침적을 제공한다.
[0019] 구현예에서, 제2 항원-결합 도메인 D2는 서열번호 2, 10, 18, 26, 34, 42, 50, 58, 66, 74, 82, 90, 98, 106, 114, 122, 130의 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 HCVR 내 함유된 HCVR CDR을 포함한다.
[0020] 본원의 개시내용은 또한 항-IsdB x 항-C1q 이특이적 분자를 제공하고, 여기서, 상기 제2 항원-결합 도메인 D2는 서열번호 146, 서열번호 162의 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 LCVR 내 함유된 LCVR CDR을 포함한다.
[0021] 본원의 개시내용은 또한 항-IsdB x 항-C1q 이특이적 분자를 제공하고, 여기서, 상기 제2 항원-결합 도메인 D2는 서열번호 2/146, 10/146, 90/146, 98/146, 106/146, 66/162, 74/162,82/162, 18/162, 26/162, 34/162, 42/162, 50/162, 58/162, 114/162, 122/162, 또는 130/162의 아미노산 서열을 포함하는 HCVR 및 LCVR (HCVR/LCVR) 쌍을 포함한다.
[0022] 본원의 개시내용은 또한 항-IsdB x 항-C1q 이특이적 분자를 제공하고, 여기서, 상기 제2 항원-결합 도메인 D2는 서열번호 8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, 104, 112, 120, 128, 136의 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR3 (HCDR3) 및 서열번호 152, 서열번호 168의 아미노산 서열 또는 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR3 (LCDR3)을 포함한다.
[0023] 특정 구현예에서, 제2 항원-결합 도메인 D2는 서열번호 8/152, 8/168, 16/152, 16/168, 24/152, 24/168, 32/152, 32/168, 40/152, 40/168, 48/152, 48/168, 56/152, 56/168, 64/152, 64/168, 72/152, 72/168, 80/152, 80/168, 88/152, 88/168, 96/152, 96/168, 104/152, 104/168, 112/152, 112/168, 120/152, 120/168, 128/152, 128/168, 136/152, 또는 136/168의 아미노산 서열을 포함하는 HCDR3/LCDR3 쌍을 포함한다.
[0024] 본원의 개시내용은 또한 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 제공하고, 여기서, 상기 제2 항원-결합 도메인 D2는 서열번호 4, 12, 20, 28, 36, 44, 52, 60, 68, 76, 84, 92, 100, 108, 116, 124, 132의 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR1 (HCDR1), 서열번호 6, 14, 22, 30, 38, 46, 54, 62, 70, 78, 86, 94, 102, 110, 118, 126, 또는 134의 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR2 (HCDR2) 및 서열번호 8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, 104, 112, 120, 128, 또는 136의 아미노산 서열을 포함하는 중쇄 CDR3 (HCDR3)을 포함한다. 구현예에서, 제2 항원-결합 도메인 D2는 서열번호 148, 서열번호 164의 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR1 (LCDR1), 서열번호 150, 서열번호 166의 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR2 (LCDR2) 및 서열번호 152, 서열번호 168의 아미노산 서열 또는 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR3 (LCDR3)을 포함한다.
[0025] 본원 개시내용의 특정 비-제한 예시적 항-IsdB x 항-C1q 이특이적 항원-결합 분자는 각각 HCDR1-HCDR2-HCDR3-LCDR1-LCDR2-LCDR3 CDR 세트를 포함하는 제2 항원-결합 도메인 D2를 포함하고, 상기 HCDR1-HCDR2-HCDR3-LCDR1-LCDR2-LCDR3 CDR 세트는 서열번호 4, 6, 8, 148, 150, 152; 12, 14, 16, 148, 150, 152; 92, 94, 96, 148, 150, 152; 100, 102, 104, 148, 150, 152; 108, 110, 112, 148, 150, 152; 20, 22,24, 148, 150, 152; 28,30, 32, 148, 150, 152; 36,38, 40, 148, 150, 152; 44, 46, 48, 148, 150, 152; 52, 54, 56, 148, 150, 152; 60, 62, 64, 148, 150, 152; 68, 70, 72, 148, 150, 152; 76, 78, 80, 148, 150, 152; 84, 86, 88, 148, 150, 152; 116, 118, 120, 148, 150, 152; 124, 126, 128, 148, 150, 152; 132, 134, 136, 148, 150, 152; 4, 6, 8, 164, 166, 168; 12, 14, 16, 164, 166, 168; 92, 94, 96, 164, 166, 168; 100, 102, 104, 164, 166, 168; 108, 110, 112, 164, 166, 168; 20, 22, 24, 164, 166, 168; 28,30, 32, 164,166, 168; 36,38, 40, 164, 166, 168; 44, 46, 48, 164, 166, 168; 52, 54, 56, 164, 166, 168; 60, 62, 64, 164, 166, 168; 68, 70, 72, 164, 166, 168; 76,78, 80, 164, 166, 168; 84, 86, 88, 164, 166, 168; 116, 118, 120, 164, 166, 168; 124, 126, 128, 164, 166, 168; 또는 132, 134, 136, 164, 166, 168의 아미노산 서열을 포함한다.
[0026] 관련 구현예에서, 본원의 개시내용은 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 포함하고, 여기서, 상기 제2 항원-결합 도메인 D2는 중쇄 및 경쇄 가변 영역 (HCVR/LCVR) 서열의 쌍 내 함유된 중쇄 및 경쇄 CDR을 포함하고, 상기 HCVR/LCVR 쌍은 서열번호 2/146, 10/146, 90/146, 98/146, 106/146, 66/162, 74/162, 82/162, 18/162, 26/162, 34/162, 42/162, 50/162, 58/162, 114/162, 122/162, 또는 130/162의 아미노산 서열을 포함한다.
[0027] 구현예에서, 단리된 이특이적 항원-결합 분자는 서열번호 140, 142, 144의 아미노산 서열을 포함하는 HCVR CDR, 및 서열번호 148,150,152의 아미노산 서열을 포함하는 LCVR CDR을 포함하는 제1 항원-결합 도메인 D1; 및 서열번호 4, 6, 8의 아미노산 서열을 포함하는 HCVR CDR, 및 서열번호 148, 150, 152의 아미노산 서열을 포함하는 LCVR CDR을 포함하는 제2 항원-결합 도메인 D2를 포함한다. 다른 구현예에서, 단리된 이특이적 항원-결합 분자는 서열번호 140, 142, 144의 아미노산 서열을 포함하는 HCVR CDR, 및 서열번호 148,150,152의 아미노산 서열을 포함하는 LCVR CDR을 포함하는 제1 항원-결합 도메인 D1; 및 서열번호 108, 110, 112의 아미노산 서열을 포함하는 HCVR CDR, 및 서열번호 148, 150, 152의 아미노산 서열을 포함하는 LCVR CDR을 포함하는 제2 항원-결합 도메인 D2를 포함한다. 추가의 구현예에서, 단리된 이특이적 항원-결합 분자는 서열번호 138/146 또는 서열번호 154/162의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하는 제1 항원-결합 도메인; 및 서열번호 2/146, 10/146, 90/146, 98/146, 106/146, 66/162, 74/162, 82/162, 18/162, 26/162, 34/162, 42/162, 50/162, 58/162, 114/162, 122/162, 또는 130/162의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하는 제2 항원-결합 도메인을 포함한다.
[0028] 또 다른 양상에서, 본원의 개시내용은 임의의 기능적 조합 또는 정렬로 본원의 표 2 및 4에 제시된 바와 같은 폴리뉴클레오타이드 서열을 포함하는 핵산 분자, 및 표 2 및 4에 제시된 바와 같은 2개 이상의 폴리뉴클레오타이드 서열을 포함하는 핵산 분자를 포함하는, 본원에 기재된 항-IsdB x 항-C1q 이특이적 항원-결합 분자의 임의의 HCVR, LCVR 또는 CDR 서열을 암호화하는 핵산 분자를 제공한다. 본원 개시내용의 핵산을 함유하는 재조합 발현 벡터, 및 상기 벡터가 도입된 숙주 세포, 및 항체의 생성을 허용하는 조건하에서 숙주 세포를 배양함에 의해 항체를 생성하고 생성된 항체를 회수하는 방법이 본원 개시내용에 의해 포괄된다.
[0029] 본원의 개시내용은 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 포함하고, 여기서, C1q에 특이적으로 결합하는 임의의 상기 언급된 항원-결합 도메인은 IsdB에 특이적으로 결합하는 임의의 상기 언급된 항원-결합 도메인과 조합되거나, 연결되거나 달리 연합되어 C1q 및 IsdB에 결합하는 이특이적 항원-결합 분자를 형성한다. 항원-결합 도메인은 본원에 기재된 바와 같이 단일쇄 Fv, 이중 친화성 재표적화 단백질, 탠덤 디아바디, 크놉 및 정공(hole) 쌍 형성, 전하 쌍 형성, 교차 Mab, 이중 가변 도메인 Ig, s-Fab, 및 Fv-Fc를 포함하는 다수의 상이한 방식으로 조합될 수 있다.
[0030] 본원의 개시내용은 변형된 당화 패턴을 갖는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 포함한다. 일부 응용에서, 바람직하지 않은 글리코실화 부위를 제거하기 위한 변형, 또는 예를 들어, 항체 의존성 세포성 세포독성(ADCC) 기능을 증가시키기 위해 올리고사카라이드 쇄 상에 존재하는 푸코스 잔기가 결핍된 항체가 유용할 수 있다(참조; Shield et al. (2002) JBC 277:26733). 다른 응용에서, 보체 의존성 세포독성(CDC)을 변형시키기 위해 갈락토실화의 변형이 이루어질 수 있다 (예를 들어, 말단 갈락토스 첨가는 ADCC를 증진시킨다).
[0031] 또 다른 양상에서, 본원의 개시내용은 본원에 기재된 바와 같은 항-IsdB x 항-C1q 이특이적 항원-결합 분자 및 약제학적으로 허용되는 담체를 포함하는 약제학적 조성물을 제공한다. 관련된 양상에서, 본원의 개시내용은 항-IsdB x 항-C1q 이특이적 항원-결합 분자 및 제2 치료학적 제제의 조합인 조성물을 특징으로 한다. 하나의 구현예에서, 제2 치료학적 제제는 항-IsdB x 항-C1q 이특이적 항원-결합 분자와 유리하게 조합된 임의의 제제이다. 항-IsdB x 항-C1q 이특이적 항원-결합 분자와 유리하게 조합될 수 있는 예시적 제제는 항생제, 스타필로코커스 항원에 결합하는 항체, 스타필로코커스 독소에 결합하는 항체, 사람 또는 시노몰구스 C1q에 결합하는 항체, 스타필로코커스 종에 특이적인 백신, 및 항체 약물 접합체 (예를 들어, 항생제와 조합된 이특이적 항체)를 포함한다.
[0032] 또 다른 양상에서, 본원의 개시내용은 대상체에서 스타필로코커스 종의 성장을 억제하기 위한 치료학적 방법을 제공하고, 상기 방법은 본원에 기재된 바와 같은 단리된 이특이적 항원-결합 분자 또는 이특이적 항원 결합 분자를 포함하는 약제학적 조성물을 상기 대상체에게 투여함을 포함한다. 구현예에서, 상기 방법은 대상체에서 스타필로코커스 종에 의한 감염을 치료하는 방법이다. 일부 구현예에서, 상기 방법은 스타필로코커스 종에 의해 유발된 질환 또는 장애를 갖는 대상체를 치료하기 위한 것이고, 여기서, 상기 질환 또는 장애는 피부 감염, 봉와직염, 폐렴, 뇌수막염, 요로 감염, 독성 쇼크 증후군, 심내막염, 심낭염, 골수염, 균혈증, 또는 패혈증이다. 일부 구현예에서, 상기 방법은 수술 과정을 진행하였거나 이를 계획하고 있거나 진행 중에 있는 대상체를 치료하기 위한 것이고, 여기서, 상기 대상체는 스타필로코커스로 감염될 위험에 처해 있다. 일부 구현예에서, 상기 수술적 과정은 팔 또는 다리 또는 고관절 대체물과 같은, 의지 (prosthetic limb)를 포함하는 보철의 이식을 포함한다. 일부 구현예에서, 보철은 안구 보철, 실리콘 손, 손가락, 발가락, 유방 또는 안면 이식을 포함하는 성형용 보철이다.
[0033] 구현예에서, 상기 방법은 본원의 개시내용의 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 사용하여 IsdB와 같은 표적 항원을 발현하는 스타필로코커스 세포를 표적화하고/사멸시키는 방법이고, 여기서, 상기 치료학적 방법은 본원 개시내용의 항-IsdB/항-C1q 이특이적 항원-결합 분자를 포함하는 치료학적 유효량의 약제학적 조성물을 이를 필요로 하는 대상체에게 투여함을 포함한다.
[0034] 본원의 개시내용은 또한 스타필로코커스와 관련되거나 이에 의해 유발된 질환 또는 장애의 치료를 위한 약제의 제조에 있어서 본원 개시내용의 항-IsdB x 항-C1q 이특이적 항원-결합 분자의 용도를 포함한다.
[0035] 다른 구현예는 계속되는 발명의 상세한 설명으로부터 자명해질 것이다.
[0036] 본 발명을 기재하기에 앞서 본원의 개시내용은 상기 방법 및 조건이 다양할 수 있으므로 기재된 특정 방법 및 실험 조건으로 제한되지 않는 것으로 이해되어야만 한다. 또한, 본원에 사용된 용어는 단지 특정 구현예를 기술할 목적인 것이고 본 발명의 범위는 첨부된 청구항에 의해서만 제한될 것이기 때문에 제한하는 것으로 의도지 않는 것으로 이해되어야만 한다.
[0037] 달리 정의되지 않는 경우, 본원에 사용된 모든 기술적 및 과학적 용어는 본 발명이 속하는 당업계의 기술자가 통상적으로 이해하는 바와 동일한 의미를 갖는다. 본원에 사용된 바와 같은 용어 “약”이 특정 인용된 수치 값을 언급하기 위해 사용되는 경우 상기 값은 언급된 값의 1% 이하까지 다양할 수 있음을 의미한다. 예를 들어, 본원에 사용된 바와 같이 표현 “약 100”은 99 및 101, 및 이들 사이의 모든 값 (예를 들어, 99.1, 99.2, 99.3, 99.4 등)을 포함한다.
[0038] 본원에 기재된 것과 유사하거나 균등한 임의의 방법과 물질들을 본원 개시내용의 실시 또는 시험에 사용할 수 있으나, 바람직한 방법과 물질들을 이제 기술할 것이다.
정의
[0039] 본원에 사용된 바와 같은 "보체 성분에 결합하는 항체” 또는 "항-보체 성분 항체"는 보체 성분을 특이적으로 인지하는 항체 및 이의 항원-결합 단편을 포함한다. 하나의 구현예에서, 본원 개시내용의 항원 결합 분자는 보체 성분 C1q에 결합한다. 예시적인 C1q 단백질은 서열번호 170, 서열번호 171, 및 서열번호 172의 아미노산 서열을 갖는다.
[0040] 본원에 사용된 바와 같은 표현 "보체 성분에 결합하는 항체”, “항-보체 성분 항체", 또는 "항-C1q 항체"는 단일 특이성을 갖는 1가 항체, 및 IsdB에 결합하는 제1 아암 및 C1q에 결합하는 제2 아암을 포함하는 이특이적 항체 둘다를 포함하고, 여기서, 상기 항-C1q 아암은 본원의 표 1 또는 표 6에 제시된 바와 같은 임의의 HCVR/LCVR 또는 CDR 서열을 포함한다. 항-C1q 이특이적 항체의 예는 본원의 다른 곳에 기재되어 있다.
[0041] 본원에 사용된 바와 같은 표현 "C1q"는 보체 캐스케이드의 구성원인 보체 성분 C1q를 언급한다. 사람 보체 C1q는 3개의 특유한 서브유닛을 포함하는 6량체이다: A(29 kDa); B(26kDa); 및 C(22 kDa). 서브유닛 A의 예시적 서열은 승인 번호 NP_057075의 아미노산 1-245에서 발견되고 서열번호 170으로 나타낸다. 서브유닛 B의 예시적 서열은 승인 번호 NP_000482의 아미노산 1-253에서 발견되고 서열번호 171로 나타낸다. 서브유닛 C의 예시적 서열은 승인 번호 NP_758957의 아미노산 1-245에서 발견되고 서열번호 172로 나타낸다. 구현예에서, C1q는 사람 C1q이다.
[0042] 본원에 사용된 바와 같은, "C1q에 결합하는 항체" 또는 "항-C1q 항체"는 단일 C1q 서브유닛 (예를 들어, 성분 A, B 또는 C)을 특이적으로 인지하는 항체 및 이의 항원-결합 단편, 및 3량체 또는 6량체와 같은 다량체를 특이적으로 인지하는 항체 및 이의 항원-결합 단편을 포함한다. C1q는 재조합 C1q 단백질 또는 이의 변이체 뿐만 아니라 천연 C1q 단백질을 포함한다.
[0043] 본원에 사용된 바와 같은 표현 "C1q에 결합하는 항체” 또는 “항-C1q 항체"는 단일 특이성을 갖는 1가 항체, 및 스타필로코커스 종 표적 항원에 결합하는 제1 아암 및 C1q에 결합하는 제2 아암을 포함하는 이특이적 항체 둘다를 포함하고, 여기서, 상기 항-C1q 아암은 본원의 표 1 또는 표 6에 제시된 바와 같은 임의의 HCVR/LCVR 또는 CDR 서열을 포함한다. 항-C1q 이특이적 항체의 예는 본원의 다른 곳에 기재되어 있다.
[0044] 본원에 사용된 바와 같은 표현 "항원-결합 분자"는 단독으로 또는 하나 이상의 추가의 CDR 및/또는 프레임워크 영역 (FR)과 조합되어 특정 항원에 특이적으로 결합하는 적어도 하나의 상보성 결정 영역 (CDR)을 포함하거나 이들로 이루어진 단백질, 폴리펩타이드 또는 분자 복합체를 의미한다. 구현예에서, 항원 결합 분자는 하나 이상의 항원 결합 도메인을 포함한다. 용어 "항원-결합 분자"는 예를 들어, 이특이적 항체를 포함하는, 항체 및 항체의 항원-결합 단편을 포함한다.
[0045] 본원에 사용된 바와 같은 표현 "스타필로코커스 종”은 미생물 스타필로코커스의 종을 언급한다. 구현예에서, 스타필로코커스 종은 스타필로코커스 에피더미디스(Staphylococcus epidermidis), 스타필로코커스 아우레우스 (Staphylococcus aureus), 스타필로코커스 루그두넨시스(Staphylococcus lugdunensis) 및/또는 스타필로코커스 사프로피티쿠스(Staphylococcus saprophiticus)를 포함하는, 사람에서 감염과 연관된 종이다.
[0046] 본원에 사용된 바와 같은 “표적 항원”은 스타필로코커스 종에서 또는 종 상에서 발견되는 항원을 언급한다. 표적 항원은 스타필로코커스 종의 세포 표면 상에서 발견되는 항원들을 포함한다. 예시적 표적 항원은 캡슐 폴리사카라이드 5형, 캡슐 폴리사카라이드 8형, IsdB, IsdA, IsdH, 리포테이코산, 벽 테이코산, 클럼핑 인자 A (clfA), 폴리-N-아세틸 글루코사민(PNAG), 리파제, V8 리파제, 지방산 변형 효소, 접착 매트릭스 분자를 인지하는 미생물 표면 성분(예를 들어, 어드헤신, 피브리노겐 결합 분자, 피브로넥틴 결합 단백질 A, 피브로넥틴 결합 단백질 B) 또는 이의 조합을 포함한다.
[0047] 본원에 사용된 바와 같은 “스타필로코커스 종 표적 항원에 결합하는 항체” 또는 "항-스타필로코커스 종 표적 항체"는 스타필로코커스 종의 세포 표면 상에서 또는 상기 종에서 표적 항원을 특이적으로 인지하는 항체 및 이의 항원-결합 단편을 포함한다. 하나의 구현예에서, 본원의 개시내용의 항원 결합 분자는 "철 조절된 표면 단백질 B", 또는 "IsdB"로서 언급되는 표적 항원에 결합한다. 예시적 IsdB 단백질은 서열번호 169의 아미노산 3 내지 574의 아미노산 서열을 갖는다.
[0048] 본원에 사용된 바와 같은 표현 "스타필로코커스 종 표적 항원에 결합하는 항체”, “항-스타필로코커스 종 표적 항체", 또는 "항-IsdB 항체"는 단일 특이성을 갖는 1가 항체, 및 IsdB에 결합하는 제1 아암 및 C1q에 결합하는 제2 아암을 포함하는 이특이적 항체 둘다를 포함하고, 여기서, 상기 항-IsdB 아암은 본원의 표 3 또는 표 6에 제시된 바와 같은 임의의 HCVR/LCVR 또는 CDR 서열을 포함한다. 항-IsdB 이특이적 항체의 예는 본원의 다른 곳에 기재되어 있다. 하나의 구현예에서, IsdB에 결합하는 하나의 아암 및 C1q에 결합하는 하나의 아암을 포함하는 이특이적 항체는 하기의 전장 아미노산 서열을 포함한다: 서열번호 173은 C1q에 결합하는 항체의 중쇄 (HC)의 전장 아미노산 서열을 포함하고; 서열번호 174는 IsdB에 결합하는 항체의 중쇄의 전장 아미노산 서열을 포함하고; 서열번호 175는 IsdB 및 C1q에 결합하는 이특이적 항체의 경쇄 (LC)의 전장 아미노산 서열을 포함한다. 하나의 구현예에서, 이들의 전장 서열을 갖는 항체는 H1H20631D로서 지정된다.
[0049] 본원에 사용된 바와 같은 용어 "항체"는 특정 항원 (예를 들어, C1q)에 특이적으로 결합하거나 이와 상호작용하는 적어도 하나의 상보성 결정 영역 (CDR)을 포함하는 임의의 항원-결합 분자 또는 분자 복합체를 의미한다. 용어 “항체”는 2개의 중(H)쇄 및 2개의 경(L)쇄가 디설파이드 결합에 의해 상호 연결된 4개의 폴리펩타이드 쇄 및 이의 다량체 (예를 들어, IgM)를 포함하는 면역글로불린 분자를 포함한다. 각각의 중쇄는 중쇄 가변 영역 (본원에서 HCVR 또는 VH로서 약칭됨) 및 중쇄 불변 영역을 포함한다. 중쇄 불변 영역은 3개의 도메인 CH1, CH2 및 CH3을 포함한다. 각각의 경쇄는 경쇄 가변 영역 (본원에서 LCVR 또는 VL로서 약칭됨) 및 경쇄 불변 영역을 포함한다. 경쇄 불변 영역은 하나의 도메인(CL1)을 포함한다. VH 및 VL 영역은 추가로 프레임워크 영역 (FR)으로 호칭되는 보다 보존된 영역과 함께 산재되어 있는 상보성 결정 영역 (CDR)으로 호칭되는 초가변 영역으로 세분될 수 있다. 각각의 VH 및 VL은 하기의 순서로 아미노 말단으로부터 카복시 말단으로 정렬된 3개의 CDR 및 4개의 FR로 구성된다: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4. 본원의 개시내용의 상이한 구현예에서, 항-C1q 항체 (또는 이의 항원 결합부)의 FR은 사람 생식계열 서열과 동일할 수 있거나 천연적으로 또는 인위적으로 변형될 수 있다. 본원 개시내용의 상이한 구현예에서, 항-IsdB 항체 (또는 이의 항원 결합부)의 FR은 사람 생식계열 서열과 동일할 수 있거나 천연적으로 또는 인위적으로 변형될 수 있다. 아미노산 컨센서스 서열(consensus sequence)은 2개 이상의 CDR의 병행 분석을 기반으로 정의될 수 있다.
[0050] 본원에 사용된 바와 같은 용어 “항체”는 또한 전체 항체 분자의 항원-결합 단편을 포함한다. 본원에 사용된 바와 같은 용어 항체의 “항원-결합부”, 항체의 “항원 결합 도메인”, 항체의 “항원-결합 단편” 등은 임의의 천연적으로 존재하거나, 효소적으로 수득될 수 있거나, 합성되거나 항원에 특이적으로 결합하여 복합체를 형성하는 유전학적으로 가공된 폴리펩타이드 또는 당단백질을 포함한다. 항체의 항원-결합 단편은 예를 들어, 항체 가변 및 임의로 불변 도메인을 암호화하는 DNA의 조작 및 발현을 포함하는 단백질용해 분해 또는 재조합 유전학적 가공과 같은 임의의 적합한 표준 기술을 사용하여 전체 항체 분자로부터 유래될 수 있다. 상기 DNA는 공지되어 있고/있거나 예를 들어, 상업적 공급원, DNA 라이브러리 (예를 들어, 파아지-항체 라이브러리를 포함하는)로부터 용이하게 가용하거나, 합성될 수 있다. DNA는 화학적으로 또는 분자 생물학 기술을 사용함에 의해 서열 분석되고 조작되어, 예를 들어, 하나 이상의 가변 및/또는 불변 도메인을 적합한 구성으로 정렬하거나 코돈을 도입하거나, 시스테인 잔기를 생성시키거나, 아미노산을 변형시키거나, 첨가하거나 결실시키는 것등을 할 수 있다.
[0051] 본원에 사용된 바와 같은 표현 "항원-결합 도메인"은 관심 대상의 특정 항원(예를 들어, 보체 성분 또는 스타필로코커스 종 표적 항원)에 특이적으로 결합할 수 있는 임의의 펩타이드, 폴리펩타이드, 핵산 분자, 스캐폴드형 분자, 펩타이드 디스플레이 분자 또는 폴리펩타이드-함유 작제물을 의미한다.
[0052] 본원에 사용된 바와 같은 용어 "특이적으로 결합하는” 등은 항원-결합 도메인이 25nM 이하의 해리 상수 (KD)를 특징으로 하는 특정 항원과 복합체를 형성함을 의미한다. 본원의 개시내용과 관련하여 사용될 수 있는 항원-결합 도메인의 예시적 카테고리는 항체, 항체의 항원-결합부, 특정 항원과 특이적으로 상호작용하는 펩타이드(예를 들어, 펩티바디), 특정 항원과 특이적으로 상호작용하는 수용체 분자, 특정 항원에 특이적으로 결합하는 수용체의 리간드-결합부를 포함하는 단백질, 항원-결합 스캐폴드(예를 들어, DARPins, HEAT 반복 단백질, ARM 반복 단백질, 테트라트리코펩타이드 반복 단백질, 및 천연에 존재하는 반복 단백질을 기준으로 하는 다른 스캐폴드 등[문헌참조: 예를 들어, Boersma and Pluckthun, 2011, Curr. Opin. Biotechnol. 22:849-857, and references cited therein]), 및 압타머 또는 이의 일부를 포함한다.
[0053] 두 분자가 특이적으로 결합하는지의 여부를 측정하기 위한 방법은 당업계에 널리 공지되어 있으며, 예를 들어, 평형 투석, 표면 플라스몬 공명 등을 포함한다. 예를 들어, 항원-결합 분자는 본원에서 사용된 바와 같이, 표면 플라스몬 공명 검정에서 측정시, 약 25nM 미만, 약 20nM 미만, 약 15nM 미만, 약 10nM 미만, 약 5nM 미만, 약 1nM 미만, 약 500 pM 미만, 약 400 pM 미만, 약 300 pM 미만, 약 200 pM 미만, 약 100 pM 미만, 약 90 pM 미만, 약 80 pM 미만, 약 70 pM 미만, 약 60 pM 미만, 약 50 pM 미만, 약 40 pM 미만, 약 30 pM 미만, 약 20 pM 미만, 약 10 pM 미만, 약 5 pM 미만, 약 4 pM 미만, 약 2 pM 미만, 약 1 pM 미만, 약 0.5 pM 미만, 약 0.2 pM 미만, 약 0.1 pM 미만, 또는 약 0.05 pM 미만의 KD로 특정 항원 (예를 들어, 표적 분자 [T] 또는 이의 일부)에 결합하는 폴리펩타이드를 포함한다.
[0054] 항원-결합 단편의 비제한적인 예는 다음을 포함한다: (i) Fab 단편; (ii) F(ab')2 단편; (iii) Fd 단편; (iv) Fv 단편; (v) 단일쇄 Fv (scFv) 분자; (vi) dAb 단편; 및 (vii) 항원 결합 도메인, 및 (viii) 항체의 초가변 영역을 모방하는 아미노산 잔기로 이루어진 최소 인지 유닛 (예를 들어, 단리된 상보성 결정 영역 (CDR), 예를 들어, CDR3 펩타이드), 또는 속박된 FR3-CDR3-FR4 펩타이드. 다른 가공된 분자, 예를 들어, 도메인-특이적 항체, 단일 도메인 항체, 도메인-결실된 항체, 키메라 항체, CDR-접목 항체, 디아바디, 트리아바디, 테트라바디, 미니바디, 나노바디 (예를 들어. 1가 나노바디, 2가 나노바디 등), 소형 모듈러 면역약제(SMIP), 및 샤크 가변 IgNAR 도메인은 또한 본원에 사용된 바와 같은 표현 “항원 결합 단편”에 포함된다.
[0055] 항체의 항원-결합 단편은 전형적으로 적어도 하나의 가변 도메인을 포함한다. 가변 도메인은 임의의 크기 또는 아미노산 조성을 가질 수 있고 일반적으로 하나 이상의 프레임워크 서열에 인접해 있거나 프레임내에 있는 적어도 하나의 CDR을 포함한다. VL 도메인과 연합된 VH 도메인을 갖는 항원 결합 단편에서, VH 및 VL 도메인은 서로 상대적으로 임의의 적합한 정렬로 위치할 수 있다. 예를 들어, 가변 영역은 이량체일 수 있고 VH-VH, VH-VL 또는 VL-VL 이량체를 함유한다. 대안적으로, 항체의 항원-결합 단편은 단량체성 VH 또는 VL 도메인을 함유할 수 있다.
[0056] 특정 구현예에서, 항체의 항원-결합 단편은 적어도 하나의 불변 도메인에 공유적으로 연결된 적어도 하나의 가변 도메인을 함유할 수 있다. 본원 개시내용의 항체의 항원 결합 단편 내에서 발견될 수 있는 가변 및 불변 도메인의 비제한적인 예시적 구성은 다음을 포함한다: (i) VH-CH1; (ii) VH-CH2; (iii) VH-CH3; (iv) VH-CH1-CH2; (v) VH-CH1-CH2-CH3; (vi) VH-CH2-CH3; (vii) VH-CL; (viii) VL-CH1; (ix) VL-CH2; (x) VL-CH3; (xi) VL-CH1-CH2; (xii) VL-CH1-CH2-CH3; (xiii) VL-CH2-CH3; 및 (xiv) VL-CL. 상기 열거된 예시적 임의의 구성을 포함하는 가변 및 불변 도메인의 임의의 구성에서, 가변 및 불변 도메인은 서로 직접적으로 연결될 수 있거나 완전한 또는 부분적 힌지 또는 링커 영역에 의해 연결될 수 있다. 힌지 영역은 적어도 2 (예를 들어, 5, 10, 15, 20, 40, 60 이상) 아미노산을 포함하거나 이들로 이루어질 수 있고 이는 단일 폴리펩타이드 분자에서 인접한 가변 및/또는 불변 도메인 간의 유연하거나 반-유연한 연결체를 생성한다. 더욱이, 본원 개시내용의 항체의 항원 결합 단편은 서로 간의 비-공유적 연합하에 및/또는 하나 이상의 단량체 VH 또는 VL 도메인과 함께 (예를 들어, 디설파이드 결합(들)에 의해) 상기 열거된 임의의 가변 및 불변 도메인 구성의 동종-이량체 또는 이종-이량체(또는 다른 다량체)를 포함할 수 있다.
[0057] 전체 항체 분자와 관련하여, 항원-결합 단편은 일특이적 또는 다중특이적 (예를 들어, 이특이적)일 수 있다. 항체의 다중특이적 항원-결합 단편은 전형적으로 적어도 2개의 상이한 가변 도메인을 포함하고, 여기서, 각각의 가변 도메인은 별도의 항원에 특이적으로 결합할 수 있거나 동일한 항원 상에 상이한 에피토프에 특이적으로 결합할 수 있다. 본원에서 개시된 예시적인 이특이적 항체 포맷을 포함하는 임의의 다중특이적 항체 포맷은 당업계에서 이용가능한 일상적인 기법을 사용하여 본원 개시내용의 항체의 항원-결합 단편과 관련된 사용을 위해 조정될 수 있다.
[0058] 본원 개시내용의 항체는 보체-의존성 세포독성 (CDC) 또는 항체-의존성 세포-매개된 세포독성(ADCC)을 통해 기능할 수 있다. "보체-의존성 세포독성" (CDC)은 보체의 존재하에 개시내용의 항체에 의한 항원-발현 세포의 용해를 언급한다. "항체-의존성 세포-매개된 세포독성" (ADCC)는 세포-매개된 반응을 언급하고, 여기서, Fc 수용체 (FcR)를 발현하는 비특이적 세포독성 세포 (예를 들어, 천연 킬러 (NK) 세포, 호중구 및 마크로파아지)는 표적 세포 상에 결합된 항체를 인지하고 이로써 표적 세포의 용해를 유도한다. CDC 및 ADCC는 당업계에 널리 공지되고 가용한 검정을 사용하여 측정될 수 있다. (문헌참조:, 예를 들어, 미국 특허 제5,500,362호 및 제5,821,337호, 및 Clynes et al. (1998) Proc. Natl. Acad. Sci. (USA) 95:652-656).
[0059] 본원 개시내용의 특정 구현예에서, 본원 개시내용의 항-C1q 및/또는 항-IsdB 항체 (일특이적 및 이특이적)는 사람 항체이다. 본원에 사용된 "사람 항체"라는 용어는 사람 생식계열의 면역글로불린 서열로부터 유래된 가변 및 불변 영역을 갖는 항체를 포함하는 것으로 의도된다. 본원 개시내용의 사람 항체는 예를 들어, CDR 및 특히 CDR3에서 사람 생식계열 면역글로불린 서열에 의해 암호화되어 있지 않은 아미노산 잔기(예를 들어, 시험관내 무작위 또는 부위-특이적 돌연변이유발에 의해 도입된 돌연변이 또는 생체내 체세포 돌연변이에 의해)를 포함할 수 있다. 그러나, 본원에 사용된 바와 같은 용어 “사람 항체”는 마우스와 같은 또 다른 포유동물 종의 생식계열로부터 유래된 CDR 서열이 사람 프레임워크 서열 상으로 접목된 항체를 포함하는 것으로 의도되지 않는다. 상기 용어는 비-사람 포유동물, 또는 비-사람 포유동물의 세포에서 재조합에 의해 제조된 항체를 포함한다. 상기 용어는 사람 대상체로부터 단리되거나 사람 대상체에서 생성된 항체를 포함하는 것으로 의도되지 않는다.
[0060] 본원 개시내용의 항체는 일부 구현예에서 재조합 사람 항체일 수 있다. 본원에 사용된 바와 같은 용어 “재조합 사람 항체”는 재조합 수단에 의해 제조되거나, 발현되거나, 생성되거나 단리된 모든 사람 항체, 예를 들어, 숙주 세포로 형질감염된 재조합 발현 벡터를 사용하여 발현된 항체(하기에 추가로 기재된), 재조합의 조합 사람 항체 라이브러리로부터 단리된 항체 (추가로 하기에 기재된), 사람 면역글로불린 유전자에 대해 유전자전이된 동물(예를 들어, 마우스)로부터 단리된 항체(문헌참조: 예를 들어, Taylor et al. (1992) Nucl. Acids Res. 20:6287-6295) 또는 사람 면역글로불린 유전자 서열의 다른 DNA 서열로의 스플라이싱을 포함하는 임의의 다른 수단에 의해 제조되거나, 발현되거나, 생성되거나 단리된 항체를 포함하는 것으로 의도된다. 상기 재조합 사람 항체는 사람 생식계열 면역글로불린 서열로부터 유래된 가변 및 불변 영역을 갖는다. 특정 구현예에서, 그러나, 상기 재조합 사람 항체는 시험관내 돌연변이유발 (또는 사람 Ig 서열에 대해 유전자전이된 동물이 사용되는 경우, 생체내 체세포 돌연변이유발)에 적용되고 따라서, 재조합 항체의 VH 및 VL 영역의 아미노산 서열은 사람 생식계열 VH 및 VL 서열로부터 유래되고 이와 관련되지만 천연적으로 생체내 사람 항체 생식계열 레퍼토리내에 존재하지 않을 수 있는 서열이다.
[0061] 사람 항체는 힌지 이종성과 연관된 2개의 형태로 존재할 수 있다. 하나의 형태에서, 면역글로불린 분자는 대략 150 내지 160 kDa의 안정한 4개의 쇄 작제물을 포함하고, 여기서, 상기 이량체는 쇄간 중쇄 디설파이드 결합에 의해 함께 유지되고 있다. 제2 형태에서, 상기 이량체는 쇄간 디설파이드 결합을 통해 결합되어 있지 않고 약 75-80 kDa의 분자는 공유 커플링된 경쇄 및 중쇄 (절반-항체)으로 구성되어 형성된다. 이들 형태들은 친화성 정제 후에도 분리하기가 극히 어려웠다.
[0062] 다양한 온전한 IgG 이소형 중에서 제2 형태의 출현 빈도는 항체의 힌지 영역 이소형과 관련된 구조적 차이로 인한 것이지만 이에 제한되지 않는다. 사람 IgG4 힌지의 힌지 영역에서 단일 아미노산 치환은 제2 형태(문헌참조: Angal et al. (1993) Molecular Immunology 30:105)의 출현을 전형적으로 사람 IgG1 힌지를 사용하여 관찰된 수준으로 상당히 감소시킬 수 있다. 본원의 개시내용은 목적하는 항체 형태의 수율을 개선시키기 위해, 예를 들어, 제조에서 요구될 수 있는 힌지, CH2 또는 CH3 영역 내 하나 이상의 돌연변이를 갖는 항체를 포함한다.
[0063] 본원 개시내용의 항체는 단리된 항체일 수 있다. 본원에 사용된 바와 같은 “단리된 항체”는 이의 천연 환경의 적어도 하나의 성분으로부터 동정되고 분리되고/되거나 회수된 항체를 의미한다. 예를 들어, 유기체의 적어도 하나의 성분으로부터 또는 항체가 천연적으로 존재하거나 천연적으로 생산되는 조직 또는 세포로부터 분리되거나 제거된 항체는 본원의 개시내용의 목적을 위해 “단리된 항체”이다. 단리된 항체는 또한 재조합 세포 내 동일계 항체를 포함한다. 단리된 항체는 적어도 하나의 정제 또는 단리 단계에 적용되는 항체이다. 특정 구현예에 따라, 단리된 항체는 다른 세포 물질 및/또는 화학물질이 실질적으로 없을 수 있다.
[0064] 본원의 개시내용은 또한 C1q 또는 IsdB에 결합하는 하나의 아암 항체를 포함한다. 본원에 사용된 바와 같은 "하나의 아암 항체"는 단일 항체 중쇄 및 단일 항체 경쇄를 포함하는 항원-결합 분자를 의미한다. 본원 개시내용의 하나의 아암 항체는 본원의 표 1 또는 표 3에 제시된 바와 같은 임의의 HCVR/LCVR 또는 CDR 아미노산을 포함할 수 있다.
[0065] 본원에 기재된 항-C1q, 항-IsdB, 또는 이특이적 항원 결합 분자는 항체가 이로부터 유래하는 상응하는 생식계열의 서열과 비교하여, 중쇄 및 경쇄 가변 도메인의 프레임워크 및/또는 CDR 영역 내에 하나 이상의 아미노산 치환, 삽입 및/또는 결실을 포함할 수 있다. 이러한 돌연변이는 본원에 개시된 아미노산 서열을 예를 들어, 공공 항체 서열 데이터베이스로부터 이용가능한 생식계열의 서열과 비교함으로써 쉽게 확인할 수 있다. 본원의 개시내용은 임의의 본원에 기재된 임의의 아미노산 서열로부터 유래되는 항원 결합 분자, 항체 및 이의 항원-결합 단편으로서, 하나 이상의 프레임워크 및/또는 CDR 영역 내의 하나 이상의 아미노산이 항체가 유래되는 생식계열의 서열 중의 상응하는 잔기(들)로 돌연변이되거나, 또는 또 다른 사람 생식계열의 서열 중의 상응하는 잔기(들)로 돌연변이되거나, 또는 상응하는 생식계열의 잔기(들)의 보존적 아미노산 치환으로 돌연변이되는 (이러한 서열 변화들은 본원에서 총괄적으로 "생식계열의 돌연변이"로 지칭함), 항원 결합 분자, 항체 및 이의 항원-결합 단편을 포함한다. 당업자라면 누구나, 본원에 기재된 중쇄 및 경쇄 가변 영역 서열로부터 출발하여, 하나 이상의 개별 생식계열의 돌연변이 또는 이들의 조합을 포함하는 다수의 항원 결합 분자, 항체 및 항원-결합 단편을 쉽게 제조할 수 있다. 특정 구현예에서, V H 및/또는 V L 도메인 내의 모든 프레임워크 및/또는 CDR 잔기들은 항체가 이로부터 유래되는 본래의 생식계열의 서열에서 발견되는 잔기들로 복귀 돌연변이된다. 다른 구현예에서, 오직 특정 잔기들만 본래의 생식계열의 서열로 복귀 돌연변이되는데, 예를 들어, FR1의 처음 8개의 아미노산 내 또는 FR4의 마지막 8개의 아미노산 내에서 발견되는 돌연변이된 잔기들만, 또는 CDR1, CDR2 또는 CDR3 내에서 발견되는 돌연변이된 잔기들만이 본래의 생식계열의 서열로 복귀 돌연변이된다. 다른 구현예에서, 하나 이상의 프레임워크 및/또는 CDR 잔기(들)은 상이한 생식계열의 서열 (즉, 항체가 본래 유래된 생식계열의 서열과는 다른 생식계열의 서열)의 상응하는 잔기(들)로 돌연변이된다. 추가로, 본원 개시내용의 항원 결합 분자, 항체 및 항원-결합 단편은 프레임워크 및/또는 CDR 영역 내에 2 이상의 생식계열의 돌연변이의 임의의 조합, 예를 들어, 특정 개별 잔기들은 특정 생식계열의 서열의 상응하는 잔기로 돌연변이되는 한편, 본래의 생식계열의 서열과는 다른 특정한 다른 잔기들은 유지되거나 상이한 생식세포 계열의 서열의 상응하는 잔기로 돌연변이되는 임의의 상기 조합을 포함할 수 있다. 하나 이상의 생식계열의 돌연변이를 포함하는, 항원 결합 분자, 항체 및 항원-결합 단편은, 일단 수득되면, 하나 이상의 목적하는 특성 예를 들어, 개선된 결합 특이성, 증가된 결합 친화성, 개선된 또는 증진된 길항제 또는 효능제 생물학적 성질 (경우에 따라), 감소된 면역원성 등에 대하여 용이하게 시험할 수 있다. 상기 일반적인 방식으로 수득된 항원 결합 분자, 항체 및 항원-결합 단편은 본 발명에 포함된다.
[0066] 또한, 본원의 개시내용은 하나 이상의 보존적 치환을 갖는 본원에 개시된 임의의 HCVR, LCVR, 및/또는 CDR 아미노산 서열의 변이체를 포함하는, 항-C1q, 항-IsdB 또는 이특이적 항원 결합 분자를 포함한다. 예를 들어, 본원의 개시내용은 본원에 표 1 또는 표 3에 제시된 임의의 HCVR, LCVR 및/또는 CDR 아미노산 서열과 비교하여, 예를 들어, 10개 이하, 8개 이하, 6개 이하, 4개 이하 등의 보존적 아미노산 치환을 갖는 HCVR, LCVR 및/또는 CDR 아미노산 서열을 갖는 항-C1q, 항-IsdB 또는 이특이적 항원 결합 분자를 포함한다. “보존적 아미노산 치환"은 아미노산 잔기가 유사한 화학적 성질 (예를 들어, 전하 또는 소수성)을 갖는 측쇄 (R 그룹)를 갖는 또 다른 아미노산 잔기에 의해 치환되는 것이다. 일반적으로, 보존적 아미노산 치환은 단백질의 기능적 성질을 실질적으로 변화시키지 않을 것이다. 유사한 화학적 특성을 갖는 측쇄를 갖는 아미노산 그룹의 예로는 1) 지방족 측쇄: 글리신, 알라닌, 발린, 류신 및 이소류신; 2) 지방족-하이드록실 측쇄: 세린 및 트레오닌; 3) 아미드-함유 측쇄: 아스파라긴 및 글루타민; 4) 방향족 측쇄: 페닐알라닌, 티로신 및 트립토판; 5) 염기성 측쇄: 리신, 아르기닌 및 히스티딘; 6) 산성 측쇄: 아스파르테이트 및 글루타메이트, 및 7) 황-함유 측쇄: 시스테인 및 메티오닌을 포함한다. 바람직한 보존적 아미노산 치환 기로는 발린-류신-이소류신, 페닐알라닌-티로신, 리신-아르기닌, 알라닌-발린, 글루타메이트-아스파르테이트 및 아스파라긴-글루타민이다. 대안적으로, 보존적 대체는 문헌 [참조: Gonnet et al. (1992) Science 256: 1443-1445]에 개시된 PAM250 로그-우도 매트릭스(log-likelihood matrix)에서 양의 값을 갖는 임의의 변화이다. “적당히 보존적인" 대체는 PAM250 로그-우도 매트릭스에서 음이 아닌 값을 갖는 임의의 변화이다.
[0067] “에피토프"라는 용어는 파라토프(paratope)로 알려져 있는 항체 분자의 가변 영역 내에서 특이적 항원 결합 부위와 상호작용하는 항원 결정기를 지칭한다. 단일 항원은 하나 초과의 에피토프를 가질 수 있다. 따라서, 상이한 항체들은 항원 상의 상이한 영역에 결합할 수도 있고 상이한 생물학적 효과를 가질 수도 있다. 에피토프는 형태적이거나 선형일 수 있다. 형태적 에피토프는 선형 폴리펩타이드 쇄의 상이한 분절 기원의 공간적으로 인접한 아미노산에 의해 생성된다. 선형 에피토프는 폴리펩타이드 쇄에서 인접한 아미노산 잔기에 의해 생성된 것이다. 특정 상황에서, 에피토프는 항원 상에 사카라이드, 포스포릴 그룹 또는 설포닐 그룹의 모이어티를 포함할 수 있다.
[0068] 핵산 또는 이의 단편을 언급하는 경우에 "실질적 동일성(substantial identity)" 또는 "실질적으로 동일한(substantially identical)"이라는 용어는, 적절한 뉴클레오타이드 삽입 또는 결실로 다른 핵산(또는 이의 상보성 가닥)과 최적으로 정렬할 때, 아래에 논의된 바와 같이 FASTA, BLAST 또는 GAP과 같은 널리 알려진 서열 동일성에 대한 임의의 알고리즘으로 측정시, 뉴클레오타이드 염기 중 적어도 약 95%, 및 보다 바람직하게는 적어도 약 96%, 97%, 98% 또는 99%에서 뉴클레오타이드 서열 동일성이 존재하는 것을 지적한다. 참조 핵산 분자에 대하여 실질적 동일성을 갖는 핵산 분자는, 특정 경우에는, 참조 핵산 분자에 의해 암호화된 폴리펩타이드와 동일하거나 또는 실질적으로 유사한 아미노산 서열을 갖는 폴리펩타이드를 암호화할 수 있다.
[0069] 폴리펩타이드에 적용되는 것과 같이, "실질적 유사성(substantial similarity)" 또는 "실질적으로 유사한(substantially similar)"이라는 용어는, 디폴트 갭 가중치(default gap weight)를 사용하는 프로그램 GAP 또는 BESTFIT에 의해서와 같이 두 펩타이드 서열을 최적으로 정렬하는 경우, 적어도 95%의 서열 동일성, 보다 더 바람직하게는 적어도 98% 또는 99%의 서열 동일성을 공유하는 것을 의미한다. 바람직하게는, 동일하지 않은 잔기 위치는 보존적 아미노산 치환에 의해 상이하다. 2개 이상의 아미노산 서열이 서로 보존적 치환에 의해 서로 상이한 경우, 유사성의 퍼센트 서열 동일성 또는 정도는 치환의 보존적 성질을 보정하기 위해 상향 조정될 수 있다. 상기 조정을 수행하는 방법은 당업자에게 널리 공지되어 있다. (문헌참조: 예를 들어, Pearson (1994) Methods Mol. Biol. 24: 307-331). 또한 서열 동일성으로서 언급되는, 폴리펩타이드에 대한 서열 유사성은 전형적으로 서열 분석 소프트웨어를 사용하여 측정된다. 단백질 분석 소프트웨어는 다양한 치환, 결실 및 보존적 아미노산 치환을 포함한 기타 변형에 지정된 유사성의 측정치를 사용하여 유사한 서열을 매칭시킨다. 예를 들어, GCG 소프트웨어는, 디폴트 파라미터를 사용하여 서로 다른 유기체 종의 상동성 폴리펩타이드와 같이 밀접하게 연관된 폴리펩타이드들 간의 서열 상동성 또는 서열 동일성, 또는 야생형 단백질과 이의 뮤테인 간의 서열 상동성 또는 서열 동일성을 결정하는데 사용될 수 있는, Gap 및 Bestfit와 같은 프로그램을 포함하고 있다. 문헌(예를 들어, GCG 버젼 6.1)을 참조한다. 폴리펩타이드 서열은 GCG 버전 6.1 내의 프로그램인 디폴트 또는 추천된 파라미터와 함께 FASTA를 사용하여 비교할 수도 있다. FASTA (예를 들어, FASTA2 및 FASTA3)은 질의 탐색 및 검색 서열 간의 최상의 중복 영역에 대한 정렬 및 % 서열 동일성을 제공한다(Pearson (2000) 상기 참조). 본원 개시내용의 서열을 상이한 유기체로부터의 다수의 서열들을 포함하고 있는 데이터베이스와 비교하는 경우에 있어서의 또 다른 바람직한 알고리즘은 디폴트 파라미터를 사용하는 컴퓨터 프로그램 BLAST, 특히 BLASTP 또는 TBLASTN이다. 예를 들어, 문헌(Altschul et al. (1990) J. Mol. Biol. 215:403-410 and Altschul et al. (1997) Nucleic Acids Res. 25:3389-402)을 참조한다.
항-보체 성분 항체 또는 이의 항원 결합 단편
[0070] 본원 개시내용의 하나의 양상에 따라, 항-보체 성분 항체가 제공된다. 보체 성분은 C1q, C1r, C1s, C2, C3, C4, C5, C6, C7, C8, C9, 또는 이의 임의의 단편(보체 캐스케이드에 의해 생성된 단백질용해 단편을 포함하는)을 포함한다. 구현예에서, C1q에 결합하는 항체 (예를 들어, 일특이적 항-C1q 항체)가 제공된다. 구현예에서, C1q는 사람 C1q이다. 사람 C1q는 서열번호 170, 서열번호 171, 및/또는 서열번호 172의 아미노산 서열을 포함한다. 본원 개시내용의 상기 양상에 따른 항체는 특히 C1q 표적화 및 특정 표적에 대한 보체 활성화를 위해 유용하다. 본원 개시내용의 항-C1q 항체 또는 이의 항원-결합부는 특정 표적 세포 유형, 예를 들어, 스타필로코커스 종에 대한 C1q-매개된 보체 활성화를 지시하는 이특이적 항원-결합 분자에 포함될 수 있다.
[0071] 구현예에서, 면역글로불린 분자로의 C1q 결합을 억제하고, 용혈을 억제하고/하거나 보체 의존성 세포독성을 억제하는 항-C1q 항체가 선택된다. 구현예에서, 이특이적 항원-결합 분자는 약 10nM 이하의 IC50으로 사람 C1q의 사람 IgG1-k로의 결합을 차단한다. 다른 구현예에서, 이특이적 항원 결합 분자는 약 50nM 이하의 IC50으로 사람 C1q의 사람 IgM으로의 결합을 차단한다. 구현예에서, 이특이적 항원 결합 분자는 약 100nM 이하의 IC50으로 보체 의존성 세포독성을 억제한다. 또 다른 구현예에서, 이특이적 항원 결합 분자는 약 10nM 이하의 EC50으로 사람 C1q의 침적을 제공한다. 특정 구현예에서, 본 발명의 항원 결합 분자는 하기 중 하나 이상을 나타내지 않을 수 있다: 본원에 기재된 바와 같이 IgG 결합 또는 용혈의 차단 또는 억제 또는 보체 의존성 세포독성은 그러나 여전히 스타필로코커스 감염을 예방하기 위해 또는 대상체에서 기존의 감염을 치료하기 위해 효과적일 수 있다.
[0072] 본원 개시내용의 예시적인 항-C1q 항체는 본원에 표 1 및 2에 열거되어 있다. 표 1은 예시적인 항-C1q 항체의 중쇄 상보성 결정 영역 (HCDR1, HCDR2 및 HCDR3) 및 경쇄 상보성 결정 영역 (LCDR1, LCDR2 및 LCDR3) 뿐만 아니라 중쇄 가변 영역 (HCVR) 및 경쇄 가변 영역(LCVR)의 아미노산 서열 식별자를 제시하고 있다. 표 2는 예시적인 항-C1q 항체의 HCVR, LCVR, HCDR1, HCDR2, HCDR3, LCDR1, LCDR2 및 LCDR3을 암호화하는 핵산 분자의 서열 식별자를 제시하고 있다.
[0073] 본원의 개시내용은 표 1에 열거된 임의의 HCVR 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 HCVR 내 함유된 중쇄 가변 영역 CDR을 포함하는, 사람 C1q에 결합하는 항체 또는 이의 항원 결합 단편을 제공한다.
[0074] 또한, 본원의 개시내용은 표 1에 열거된 임의의 LCVR 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 LCVR 내 함유된 경쇄 가변 영역 CDR을 포함하는, 항-C1q 항체 또는 이의 항원-결합 단편을 제공한다.
[0075] 또한, 본원의 개시내용은 표 1에 열거된 임의의 LCVR 아미노산 서열과 쌍을 이루는 표 1에 열거된 임의의 HCVR 아미노산 서열을 포함하는 HCVR 및 LCVR 쌍 (HCVR/LCVR)을 포함하는, 항-C1q 항체 또는 이의 항원 결합 단편을 제공한다. 특정 구현예에 따라, 본원의 개시내용은 표 1에 열거된 임의의 예시적인 항-C1q 항체 내에 함유된 HCVR/LCVR 쌍을 포함하는, 항체 또는 이의 항원 결합 단편을 제공한다. 특정 구현예에서, 항-C1q 항체는 HCVR/LCVR 쌍으로서, 서열번호 2/146(예를 들어, H1xH17736P2); 서열번호 10/146 (예를 들어, H1xH17738P2), 서열번호 18/162 (예를 들어, H1xH17751P2), 서열번호 34/162 (예를 들어, H1xH17758P2), 서열번호 66/162 (예를 들어, H1xH17773P2), 90/146 (예를 들어, H1xH18392P2); 98/146 (예를 들어, H1xH18394P2); 106/146 (예를 들어, H1xH18395P2); 74/162 (예를 들어, H1xH17779P2); 82/162 (예를 들어, H1xH17781P2); 26/162 (예를 들어, H1xH17756P2); 42/162 (예를 들어, H1xH17760P2); 50/162 (예를 들어, H1xH17763P2); 58/162 (예를 들어, H1xH17769P2); 114/162 (예를 들어, H1xH18400P2); 122/162 (예를 들어, H1xH18411P2); 또는 130/162 (예를 들어, H1xH18412P2)의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함한다.
[0076] 또한, 본원의 개시내용은 표 1에 열거된 임의의 HCDR1 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR1 (HCDR1)을 포함하는 사람 C1q에 결합하는 항체 또는 이의 항원 결합 단편을 제공한다.
[0077] 또한, 본원의 개시내용은 표 1에 열거된 임의의 HCDR2 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR2 (HCDR2)을 포함하는 사람 C1q에 결합하는 항체 또는 이의 항원 결합 단편을 제공한다.
[0078] 또한, 본원의 개시내용은 표 1에 열거된 임의의 HCDR3 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR3 (HCDR3)을 포함하는 사람 C1q에 결합하는 항체 또는 이의 항원 결합 단편을 제공한다.
[0079] 또한, 본원의 개시내용은 표 1에 열거된 임의의 LCDR1 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR1 (LCDR1)을 포함하는 사람 C1q에 결합하는 항체 또는 이의 항원 결합 단편을 제공한다.
[0080] 또한, 본원의 개시내용은 표 1에 열거된 임의의 LCDR2 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR2 (LCDR2)을 포함하는 사람 C1q에 결합하는 항체 또는 이의 항원 결합 단편을 제공한다.
[0081] 또한, 본원의 개시내용은 표 1에 열거된 임의의 LCDR3 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR3 (LCDR3)을 포함하는 사람 C1q에 결합하는 항체 또는 이의 항원 결합 단편을 제공한다.
[0082] 또한, 본원의 개시내용은 표 1에 열거된 임의의 LCDR3 아미노산 서열과 쌍을 이루는 표 1에 열거된 임의의 HCDR3 아미노산 서열을 포함하는 HCDR3 및 LCDR3 쌍 (HCDR3/LCDR3)을 포함하는 사람 C1q에 결합하는 항체 또는 이의 항원 결합 단편을 제공한다. 특정 구현예에 따라, 본원의 개시내용은 표 1에 열거된 임의의 예시적인 항-C1q 항체 내에 함유된 HCDR3/LCDR3 쌍을 포함하는, 항체 또는 이의 항원 결합 단편을 제공한다. 특정 구현예에서, HCDR3/LCDR3 쌍은 서열번호 16/152 (예를 들어, H1xH17738P2), 서열번호 24/168 (예를 들어, H1xH17751P2), 서열번호 40/168 (예를 들어, H1xH17758P2), 서열번호 72/168 (예를 들어, H1xH17773P2), 서열번호 8/152 (예를 들어, H1xH17736P2); 96/152 (예를 들어, H1xH18392P2); 104/152 (예를 들어, H1xH18394P2); 112/152 (예를 들어, H1xH18395P2); 80/168 (예를 들어, H1xH17779P2); 88/168 (예를 들어, H1xH17781P2); 32/168 (예를 들어, H1xH17756P2); 48/168 (예를 들어, H1xH17760P2); 56/168 (예를 들어, H1xH17763P2); 64/168 (예를 들어, H1xH17769P2); 120/168 (예를 들어, H1xH18400P2); 128/168 (예를 들어, H1xH18411P2); 또는 136/168 (예를 들어, H1xH18412P2)의 아미노산 서열을 포함한다.
[0083] 또한, 본원의 개시내용은 표 1에 열거된 임의의 예시적인 항-C1q 항체 중에 함유된 6개의 CDR의 세트 (즉, HCDR1-HCDR2-HCDR3-LCDR1-LCDR2-LCDR3)를 포함하는 사람 C1q에 결합하는 항체 또는 이의 항원 결합 단편을 제공한다. 특정 구현예에서, 상기 HCDR1-HCDR2-HCDR3-LCDR1-LCDR2-LCDR3 세트는 서열번호 4,6,8,148,150,152 (예를 들어, H1xH17736P2); 92, 94, 96, 148,150,152 (예를 들어, H1xH18392P2); 100, 102, 104, 148, 150, 152(예를 들어, H1xH18394P2); 108, 110, 112, 148, 150, 152 (예를 들어, H1xH18395P2); 76, 78, 80, 164, 166, 168 (예를 들어, H1xH17779P2); 84, 86, 88, 164, 166, 168 (예를 들어, H1xH17781P2); 28, 30, 32, 164, 166, 168 (예를 들어, H1xH17756P2); 44, 46, 48, 164, 166, 168(예를 들어, H1xH17760P2); 52, 54, 56, 164, 166, 168 (예를 들어, H1xH17763P2); 60, 62, 64, 164, 166, 168 (예를 들어, H1xH17769P2); 116, 118, 120, 164, 166, 168 (예를 들어, H1xH18400P2); 124, 126, 128, 164, 166, 168 (예를 들어, H1xH18411P2); ); 서열번호 12, 14, 16, 18, 150, 152 (예를 들어, H1xH17738P2), 서열번호 20, 22, 24, 164, 166, 168 (예를 들어, H1xH17751P2), 서열번호 36, 38, 40, 164, 166, 168 (예를 들어, H1xH17758P2), 서열번호 68, 70, 72, 164, 166, 168 (예를 들어, H1xH17773P2), 또는 132, 134, 136, 164, 166, 168 (예를 들어, H1xH18412P2)의 아미노산 서열을 포함한다.
[0084] 관련 구현예에서, 본원의 개시내용은 표 1에 열거된 임의의 예시적 항-C1q 항체에 의해 정의된 바와 같은 HCVR/LCVR 쌍 내 함유된 6개 CDR(즉, HCDR1-HCDR2-HCDR3-LCDR1-LCDR2-LCDR3) 세트를 포함하는, 사람 C1q에 결합하는 항체 또는 이의 항원-결합 단편을 제공한다. 예를 들어, 본원의 개시내용은 서열번호 2/146 (예를 들어, H1xH17736P2); ); 서열번호 10/146 (예를 들어, H1xH17738P2), 서열번호 18/162 (예를 들어, H1xH17751P2), 서열번호 34/162 (예를 들어, H1xH17758P2), 서열번호 66/162 (예를 들어, H1xH17773P2), 90/146 (예를 들어, H1H20633D; 98/146 (예를 들어, H1xH18392P2); 106/146 (예를 들어, H1xH18395P2); 74/162 (예를 들어, H1xH17779P2); 82/162 (예를 들어, H1xH17781P2); 26/162 (예를 들어, H1xH17756P2); 42/162 (예를 들어, H1xH17760P2); 50/162 (예를 들어, H1xH17763P2); 58/162 (예를 들어, H1xH17769P2); 114/162 (예를 들어, H1xH18400P2); 122/162 (예를 들어, H1xH18411P2); 또는 130/162 (예를 들어, H1xH18412P2)의 아미노산 서열을 포함하는 HCVR/LCVR 쌍 내 함유된 HCDR1-HCDR2-HCDR3-LCDR1-LCDR2-LCDR3 세트를 포함하는, 항체 또는 이의 항원-결합 단편을 포함한다. HCVR 및 LCVR 아미노산 서열 내의 CDR을 확인하기 위한 방법 및 기술은 당업계에 널리 공지되어 있으며 본원에 개시된 특정 HCVR 및/또는 LCVR 아미노산 서열 내의 CDR을 동정하는데 사용될 수 있다. CDR의 경계를 동정하는데 사용될 수 있는 예시적인 방법으로는, 예를 들어, 카바트(Kabat) 정의, 코티아(Chothia) 정의, 및 AbM 정의를 포함한다. 일반적으로, 카바트 정의는 서열 변동성을 기반으로 하고, 코티아 정의는 구조적 루프 영역의 위치를 기반으로 하며, AbM 정의는 카바트와 코티아 접근 방법을 절충한 것이다. 예를 들어, 문헌( Kabat, "Sequences of Proteins of Immunological Interest," National Institutes of Health, Bethesda, Md. (1991); Al-Lazikani et al., J. Mol. Biol. 273:927-948 (1997); and Martin et al., Proc. Natl. Acad. Sci. USA 86:9268-9272 (1989))을 참조한다. 공용 데이터베이스도 항체 내의 CDR 서열을 동정하는데 활용될 수 있다.
[0085] 본원의 개시내용은 또한 항-C1q 항체 또는 이의 일부를 암호화하는 핵산 분자를 제공한다. 예를 들어, 본원의 개시내용은 표 1에 열거된 임의의 HCVR 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 2에 열거된 임의의 HCVR 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[0086] 또한, 본원의 개시내용은 표 1에 열거된 임의의 LCVR 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 2에 열거된 임의의 LCVR 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[0087] 또한, 본원의 개시내용은 표 1에 열거된 임의의 HCDR1 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 2에 열거된 임의의 HCDR1 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[0088] 또한, 본원의 개시내용은 표 1에 열거된 임의의 HCDR2 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 2에 열거된 임의의 HCDR2 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[0089] 또한, 본원의 개시내용은 표 1에 열거된 임의의 HCDR3 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 2에 열거된 임의의 HCDR3 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[0090] 또한, 본원의 개시내용은 표 1에 열거된 임의의 LCDR1 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 2에 열거된 임의의 LCDR1 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[0091] 또한, 본원의 개시내용은 표 1에 열거된 임의의 LCDR2 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 2에 열거된 임의의 LCDR2 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[0092] 또한, 본원의 개시내용은 표 1에 열거된 임의의 LCDR3 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 2에 열거된 임의의 LCDR3 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[0093] 또한, 본원의 개시내용은 HCVR을 암호화하는 핵산 분자를 제공하는데, 여기서 상기 HCVR은 3개의 CDR의 세트 (즉, HCDR1-HCDR2-HCDR3)를 포함하고, 상기 HCDR1-HCDR2-HCDR3 세트는 표 1에 열거된 임의의 예시적인 항-C1q 항체에 의해 정의된 바와 같다.
[0094] 또한, 본원의 개시내용은 LCVR을 암호화하는 핵산 분자를 제공하는데, 여기서 상기 LCVR은 3개의 CDR의 세트 (즉, LCDR1-LCDR2-LCDR3)를 포함하고, 상기 LCDR1-LCDR2-LCDR3 세트는 표 1에 열거된 임의의 예시적인 항-C1q 항체에 의해 정의된 바와 같다.
[0095] 또한, 본원의 개시내용은 HCVR 및 LCVR 둘다를 암호화하는 핵산 분자를 제공하는데, 여기서 상기 HCVR은 표 1에 열거된 임의의 HCVR 아미노산 서열 중의 아미노산 서열을 포함하고, 상기 LCVR은 표 1에 열거된 임의의 LCVR 아미노산 서열 중의 아미노산 서열을 포함한다. 특정 구현예에서, 상기 핵산 분자는 표 2에 열거된 임의의 HCVR 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리펩타이드 서열, 및 표 2에 열거된 임의의 LCVR 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다. 본원 개시내용의 상기 양상에 따른 특정 구현예에서, 상기 핵산 분자는 HCVR 및 LCVR을 암호화하고, 여기서 HCVR 및 LCVR은 둘다 표 1에 열거된 동일한 항-C1q 항체로부터 유래한다.
[0096] 본원의 개시내용은 또한 항-C1q 항체의 중쇄 또는 경쇄 가변 영역을 포함하는 폴리펩타이드를 발현할 수 있는 재조합 발현 벡터를 제공한다. 예를 들어, 본원의 개시내용은 상기 언급한 임의의 핵산 분자, 즉, 표 1에 기재된 바와 같은 HCVR, LCVR 및/또는 CDR 서열 중 임의의 것을 암호화하는 핵산 분자를 포함하는 재조합 발현 벡터를 포함한다. 또한, 이러한 벡터가 도입된 숙주 세포 뿐만 아니라 항체 또는 항체 단편의 생산을 가능케 하는 조건 하에 상기 숙주 세포를 배양하고, 이렇게 하여 생산된 항체 및 항체 단편을 회수함으로써 항체 또는 이의 부분을 제조하는 방법도 본원의 개시내용의 범위 내에 포함된다.
[0097] 본원의 개시내용은 변형된 글리코실화 패턴을 갖는 항-C1q 항체를 포함한다. 일부 구현예에서, 바람직하지 않은 글리코실화 부위를 제거하기 위한 변형, 또는 예를 들어, 항체 의존성 세포성 세포독성(ADCC) 기능을 증가시키기 위해 올리고사카라이드 쇄 상에 존재하는 푸코스 잔기가 결핍된 항체가 유용할 수 있다(참조; Shield et al. (2002) JBC 277:26733). 또 다른 응용에서, 보체 의존성 세포독성(CDC)을 변형시키기 위해 갈락토실화의 변형이 이루어질 수 있다.
항-스타필로코커스 종 표적 항원 항체 또는 이의 항원 결합 단편
[0098] 또 다른 양상에서, 본원의 개시내용은 스타필로코커스 종 표적 항원에 결합하는 항체 및 이의 항원 결합 단편(예를 들어, 스타필로코커스 종 표적 항원에 대한 일특이적 항체)를 제공한다. 구현예에서, 스타필로코커스 종은 사람에서 감염을 유발하는 종이다. 구현예에서, 스타필로코커스 종은 스타필로코커스 에피더미디스(Staphylococcus epidermidis), 스타필로코커스 아우레우스(Staphylococcus aureus), 스타필로코커스 루그두넨시스(Staphylococcus lugdunensis) 및/또는 스타필로코커스 사프로피티쿠스(Staphylococcus saprophiticus)를 포함한다. 구현예에서, 스타필로코커스 종 표적 항원은 캡슐 폴리사카라이드 5형, 캡슐 폴리사카라이드 8형, IsdB, IsdA, IsdH, 리포테이코산, 벽 테이코산, 클럼핑 인자 A (clfA), 폴리-N-아세틸 글루코사민(PNAG), 리파제, V8 리파제, 지방산 변형 효소, 접착 매트릭스 분자를 인지하는 미생물 표면 성분(예를 들어, 어드헤신, 피브리노겐 결합 분자, 피브로넥틴 결합 단백질 A, 피브로넥틴 결합 단백질 B), 단백질 A 또는 이의 조합을 포함한다.
[0099] 하나의 구현예에서, 항체 또는 이의 항원 결합 단편은 특이적으로 IsdB에 결합한다. 하나의 구현예에서, IsdB에 특이적으로 결합하는 항체 또는 이의 항원 결합 단편은 서열번호 169의 아미노산 3 내지 574의 아미노산 서열을 포함하는 IsdB에 결합한다. 본원 개시내용의 항-IsdB 항체 또는 이의 항원-결합부는 감염성 제제와 같은 특정 표적 세포 유형에 결합하는 이특이적 항원-결합 분자에 포함될 수 있다. 구현예에서, 이특이적 항원-결합 분자는 약 10nM 이하의 IC50으로 스타필로코커스 종에 결합한다.
[00100] 본원 개시내용의 예시적인 항-IsdB 항체는 표 3 및 4에 열거되어 있다. 표 3은 예시적인 항-IsdB 항체의 중쇄 상보성 결정 영역 (HCDR1, HCDR2 및 HCDR3) 및 경쇄 상보성 결정 영역 (LCDR1, LCDR2 및 LCDR3) 뿐만 아니라 중쇄 가변 영역 (HCVR) 및 경쇄 가변 영역(LCVR)의 아미노산 서열 식별자를 제시한다. 표 4는 예시적인 항-IsdB 항체의 HCVR, LCVR, HCDR1, HCDR2, HCDR3, LCDR1, LCDR2 및 LCDR3을 암호화하는 핵산 분자의 서열 식별자를 제시하고 있다.
[00101] 본원의 개시내용은 서열번호 138의 아미노산 서열, 서열번호 154의 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 HCVR 내 함유된 중쇄 가변 영역 (HCVR) CDR 및 서열번호 146의 아미노산 서열, 서열번호 162의 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 LCVR 영역 내 함유된 경쇄 가변 영역 (LCVR) CDR을 포함하는, IsdB에 결합하는 항체 또는 이의 항원-결합 단편을 제공한다.
[00102] 또한, 본원의 개시내용은 표 3에 열거된 임의의 LCVR 아미노산 서열과 쌍을 이루는 표 3에 열거된 임의의 HCVR 아미노산 서열을 포함하는 HCVR 및 LCVR 쌍 (HCVR/LCVR)을 포함하는, 항체 또는 이의 항원 결합 단편을 제공한다. 특정 구현예에 따라, 본원의 개시내용은 표 3에 열거된 임의의 예시적인 항-IsdB 항체 내에 함유된 HCVR/LCVR 쌍을 포함하는, 항체 또는 이의 항원 결합 단편을 제공한다. 특정 구현예에서, HCVR/LCVR 쌍은 서열번호 138/146, 또는 서열번호 154/162의 아미노산 서열을 포함한다.
[00103] 또한, 본원의 개시내용은 표 3에 열거된 임의의 HCDR1 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR1 (HCDR1)을 포함하는, IsdB에 결합하는 항체 또는 이의 항원-결합 단편을 제공한다.
[00104] 또한, 본원의 개시내용은 표 3에 열거된 임의의 HCDR2 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR2 (HCDR2)을 포함하는, 사람 IsdB에 결합하는 항체 또는 이의 항원 결합 단편을 제공한다.
[00105] 또한, 본원의 개시내용은 표 3에 열거된 임의의 HCDR3 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR3 (HCDR3)을 포함하는, IsdB에 결합하는 항체 또는 이의 항원-결합 단편을 제공한다.
[00106] 또한, 본원의 개시내용은 표 3에 열거된 임의의 LCDR1 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR1 (LCDR1)을 포함하는, IsdB에 결합하는 항체 또는 이의 항원-결합 단편을 제공한다.
[00107] 또한, 본원의 개시내용은 표 3에 열거된 임의의 LCDR2 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR2 (LCDR2)을 포함하는, IsdB에 결합하는 항체 또는 이의 항원-결합 단편을 제공한다.
[00108] 또한, 본원의 개시내용은 표 3에 열거된 임의의 LCDR3 아미노산 서열로부터 선택된 아미노산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR3 (LCDR3)을 포함하는, IsdB에 결합하는 항체 또는 이의 항원-결합 단편을 제공한다.
[00109] 또한, 본원의 개시내용은 표 3에 열거된 임의의 LCDR3 아미노산 서열과 쌍을 이루는 표 3에 열거된 임의의 HCDR3 아미노산 서열을 포함하는 HCDR3 및 LCDR3 쌍 (HCDR3/LCDR3)을 포함하는 IsdB에 결합하는 항체 또는 이의 항원 결합 단편을 제공한다. 특정 구현예에 따라, 본원의 개시내용은 표 3에 열거된 임의의 예시적인 IsdB 항체 내에 함유된 HCDR/LCDR3 쌍을 포함하는, 항체 또는 이의 항원 결합 단편을 제공한다. 특정 구현예에서, IsdB에 특이적으로 결합하는 제1 항원-결합 도메인은 서열번호 144/152, 144/168, 160/152 또는 160/168의 아미노산 서열을 포함하는 HCDR3/LCDR3 쌍을 포함한다.
[00110] 본원의 개시내용은 또한 IsdB에 결합하는 항체 또는 이의 항원 결합 단편을 제공하고, 상기 항체 또는 단편은 서열번호 140, 서열번호 156의 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR1 (HCDR1), 서열번호 142, 서열번호 158의 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR2 (HCDR2) 및 서열번호 144, 서열번호 160의 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 중쇄 CDR3 (HCDR3)을 포함한다. 구현예에서, IsdB에 특이적으로 결합하는 제1 항원-결합 도메인은 서열번호 148, 서열번호 164의 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR1 (LCDR1), 서열번호 150, 서열번호 166의 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR2 (LCDR2) 및 서열번호 152, 서열번호 168의 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적으로 유사한 서열을 포함하는 경쇄 CDR3 (LCDR3)을 포함한다.
[00111] IsdB에 결합하는 특정 비제한적인 예시적 항체 또는 이의 항원 결합 단편은 각각 6개 CDR HCDR1-HCDR2-HCDR3-LCDR1-LCDR2-LCDR3 세트를 포함하고, 상기 세트는 서열번호 140, 142, 144, 148, 150, 152; 140, 142, 144, 164, 166, 168; 156, 158, 160, 148, 150, 152; 또는 156, 158, 160, 164, 166, 168의 아미노산 서열을 포함한다.
[00112] 또 다른 양상에서, 본원의 개시내용은 임의의 기능적 조합 또는 정렬로 표 2 및 4에 제시된 바와 같은 2개 이상의 폴리뉴클레오타이드 서열을 포함하는 핵산 분자 뿐만 아니라, 표 4에 제시된 바와 같은 폴리뉴클레오타이드 서열을 포함하는 핵산 분자를 포함하는, IsdB에 결합하는 항체 또는 이의 항원-결합 단편의 임의의 HCVR, LCVR 또는 CDR 서열을 암호화하는 핵산 분자를 제공한다. 본원 개시내용의 핵산을 함유하는 재조합 발현 벡터, 및 상기 벡터가 도입된 숙주 세포, 및 항체의 생성을 허용하는 조건하에서 숙주 세포를 배양함에 의해 항체를 생성하고 생성된 항체를 회수하는 방법이 본원 개시내용에 의해 포괄된다.
[00113] 본원의 개시내용은 또한 항-IsdB 항체 또는 이의 일부를 암호화하는 핵산 분자를 제공한다. 예를 들어, 본원의 개시내용은 표 3에 열거된 임의의 HCVR 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 4에 열거된 임의의 HCVR 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[00114] 또한, 본원의 개시내용은 표 3에 열거된 임의의 LCVR 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 4에 열거된 임의의 LCVR 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[00115] 또한, 본원의 개시내용은 표 3에 열거된 임의의 HCDR1 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 4에 열거된 임의의 HCDR1 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[00116] 또한, 본원의 개시내용은 표 3에 열거된 임의의 HCDR2 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 4에 열거된 임의의 HCDR2 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[00117] 또한, 본원의 개시내용은 표 3에 열거된 임의의 HCDR3 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 4에 열거된 임의의 HCDR3 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[00118] 또한, 본원의 개시내용은 표 3에 열거된 임의의 LCDR1 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 4에 열거된 임의의 LCDR1 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[00119] 또한, 본원의 개시내용은 표 3에 열거된 임의의 LCDR2 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 4에 열거된 임의의 LCDR2 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[00120] 또한, 본원의 개시내용은 표 3에 열거된 임의의 LCDR3 아미노산 서열을 암호화하는 핵산 분자를 제공하고; 특정 구현예에서, 상기 핵산 분자는 표 4에 열거된 임의의 LCDR3 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다.
[00121] 또한, 본원의 개시내용은 HCVR을 암호화하는 핵산 분자를 제공하는데, 여기서 상기 HCVR은 3개의 CDR의 세트 (즉, HCDR1-HCDR2-HCDR3)를 포함하고, 상기 HCDR1-HCDR2-HCDR3 세트는 표 3에 열거된 임의의 예시적인 항-IsdB 항체에 의해 정의된 바와 같다.
[00122] 또한, 본원의 개시내용은 LCVR을 암호화하는 핵산 분자를 제공하는데, 여기서 상기 LCVR은 3개의 CDR의 세트 (즉, LCDR1-LCDR2-LCDR3)를 포함하고, 상기 LCDR1-LCDR2-LCDR3 세트는 표 3에 열거된 임의의 예시적인 항-IsdB 항체에 의해 정의된 바와 같다.
[00123] 또한, 본원의 개시내용은 HCVR 및 LCVR 둘다를 암호화하는 핵산 분자를 제공하는데, 여기서 상기 HCVR은 표 3에 열거된 임의의 HCVR 아미노산 서열 중의 아미노산 서열을 포함하고, 상기 LCVR은 표 3에 열거된 임의의 LCVR 아미노산 서열 중의 아미노산 서열을 포함한다. 특정 구현예에서, 상기 핵산 분자는 표 4에 열거된 임의의 HCVR 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열, 및 표 4에 열거된 임의의 LCVR 핵산 서열, 또는 이에 대해 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99%의 서열 동일성을 갖는 이의 실질적으로 유사한 서열로부터 선택되는 폴리뉴클레오타이드 서열을 포함한다. 본원 개시내용의 상기 양상에 따른 특정 구현예에서, 상기 핵산 분자는 HCVR 및 LCVR을 암호화하고, 여기서 HCVR 및 LCVR은 둘다 표 3에 열거된 동일한 항-IsdB 항체로부터 유래한다.
[00124] 본원의 개시내용은 또한 항-IsdB 항체의 중쇄 또는 경쇄 가변 영역을 포함하는 폴리펩타이드를 발현할 수 있는 재조합 발현 벡터를 제공한다. 예를 들어, 본원의 개시내용은 상기 언급한 임의의 핵산 분자, 즉, 표 3에 기재된 바와 같은 HCVR, LCVR 및/또는 CDR 서열 중 임의의 것을 암호화하는 핵산 분자를 포함하는 재조합 발현 벡터를 포함한다. 또한, 이러한 벡터가 도입된 숙주 세포 뿐만 아니라 항체 또는 항체 단편의 생산을 가능케 하는 조건 하에 상기 숙주 세포를 배양하고, 이렇게 하여 생산된 항체 및 항체 단편을 회수함으로써 항체 또는 이의 부분을 제조하는 방법도 본원의 개시내용의 범위 내에 포함된다.
[00125] 본원의 개시내용은 변형된 글리코실화 패턴을 갖는 항-IsdB 항체를 포함한다. 일부 구현예에서, 바람직하지 않은 글리코실화 부위를 제거하기 위한 변형, 또는 예를 들어, 항체 의존성 세포성 세포독성(ADCC) 기능을 증가시키기 위해 올리고사카라이드 쇄 상에 존재하는 푸코스 모이어티가 결핍된 항체가 유용할 수 있다(참조; Shield et al. (2002) JBC 277:26733). 또 다른 응용에서, 보체 의존성 세포독성(CDC)을 변형시키기 위해 갈락토실화의 변형이 이루어질 수 있다.
이특이적 항원-결합 분자
[00126] 본원의 개시내용의 이특이적 항원-결합 분자는 2개의 분리된 항원-결합 도메인 (D1 및 D2)을 포함한다. 하나의 항원-결합 도메인 (D1)은 스타필로코커스 종 표적 항원, 예를 들어, IsdB에 특이적으로 결합하고 제2 항원-결합 도메인 (D2)는 보체 성분, 예를 들어, C1q에 결합한다.
[00127] 구현예에서, 제1 항원 결합 도메인은 스타필로코커스 종 표적 항원에 결합한다(예를 들어, 스타필로코커스 종 표적 항원에 대한 일특이적 항체). 구현예에서, 스타필로코커스 종은 사람에서 감염을 유발하는 종이다. 구현예에서, 스타필로코커스 종은 스타필로코커스 에피더미디스(Staphylococcus epidermidis), 스타필로코커스 아우레우스(Staphylococcus aureus), 스타필로코커스 루그두넨시스(Staphylococcus lugdunensis) 및/또는 스타필로코커스 사프로피티쿠스(Staphylococcus saprophiticus)를 포함한다. 구현예에서, 스타필로코커스 종 표적 항원은 캡슐 폴리사카라이드 5형, 캡슐 폴리사카라이드 8형, IsdB, IsdA, IsdH, 리포테이코산, 벽 테이코산, 클럼핑 인자 A (clfA), 폴리-N-아세틸 글루코사민(PNAG), 리파제, V8 리파제, 지방산 변형 효소, 접착 매트릭스 분자를 인지하는 미생물 표면 성분(예를 들어, 어드헤신, 피브리노겐 결합 분자, 피브로넥틴 결합 단백질 A, 피브로넥틴 결합 단백질 B), 단백질 A 또는 이의 조합을 포함한다. 특정 구현예에서, 스타필로코커스 종 표적 항원은 IsdB이다.
[00128] 구현예에서, 상기 제2 항원-결합 도메인 (D2)는 보체 성분 중 어느 하나에 결합한다. 보체 성분은 C1q, C1r, C1s, C2, C3, C4, C5, C6, C7, C8, C9, 또는 이의 임의의 단편(보체 캐스케이드에 의해 생성된 단백질용해 단편을 포함하는)을 포함한다. 특정 구현예에서, 보체 성분은 C1q이다. 보체는 3가지 주요 경로에 의해 활성화된 일련의 단백질용해 단계를 통해 활성화된다: 전형적으로 면역 복합체에 의해 활성화되는 전형적 경로(CP), 보호되지 않은 세포 표면에 의해 유도될 수 있는 대체 경로 (AP), 및 만노스 결합 렉틴 (MBL) 경로. 전형적 경로는 IgM 및 IgG의 Fc 영역으로의 C1q/r2/s2 결합 또는 병원체 표면에 직접적인 결합에 의해 개시되고, 이는 세린 프로테아제 C1s를 활성화시키는 세린 프로테아제 C1r의 자가활성화를 유도하고 이어서 이는 C2 및 C4를 절단하고/활성화시키고 이어서 C3 및 C5의 절단을 유도하고, C5b는 C6, C7, C8, 및 C9와 조합하여 막 공격 복합체 (MAC)를 형성하여 세포 용해를 유도한다.
[00129] 항원-결합 도메인은 표면 플라스몬 공명 검정에서 측정시, 약 25nM 미만, 약 20nM 미만, 약 15nM 미만, 약 10nM 미만, 약 5nM 미만, 약 1nM 미만, 약 500 pM 미만, 약 400 pM 미만, 약 300 pM 미만, 약 200 pM 미만, 약 100 pM 미만, 약 90 pM 미만, 약 80 pM 미만, 약 70 pM 미만, 약 60 pM 미만, 약 50 pM 미만, 약 40 pM 미만, 약 30 pM 미만, 약 20 pM 미만, 약 10 pM 미만, 약 5 pM 미만, 약 4 pM 미만, 약 2 pM 미만, 약 1 pM 미만, 약 0.5 pM 미만, 약 0.2 pM 미만, 약 0.1 pM 미만, 또는 약 0.05 pM 미만의 KD로 IsdB와 같은 스타필로코커스 종 표적 항원(예를 들어, 표적 분자 [T] 또는 이의 일부)에 결합하는 폴리펩타이드를 포함한다. 구현예에서, 항원-결합 도메인은 표면 플라스몬 공명 검정에서 측정시, 약 5nM 미만, 약 1nM 미만, 약 500 pM 미만, 약 400 pM 미만, 약 300 pM 미만, 약 200 pM 미만, 약 100 pM 미만, 약 90 pM 미만, 약 80 pM 미만, 약 70 pM 미만, 약 60 pM 미만, 약 50 pM 미만, 약 40 pM 미만, 약 30 pM 미만, 약 20 pM 미만, 약 10 pM 미만, 약 5 pM 미만, 약 4 pM 미만, 약 2 pM 미만, 약 1 pM 미만, 약 0.5 pM 미만, 약 0.2 pM 미만, 약 0.1 pM 미만, 또는 약 0.05 pM 미만의 KD로 IsdB에 결합하는 폴리펩타이드를 포함한다.
[00130] 항원-결합 도메인은 표면 플라스몬 공명 검정에서 측정시, 약 25nM 미만, 약 20nM 미만, 약 15nM 미만, 약 10nM 미만, 약 5nM 미만, 약 1nM 미만, 약 500 pM 미만, 약 400 pM 미만, 약 300 pM 미만, 약 200 pM 미만, 약 100 pM 미만, 약 90 pM 미만, 약 80 pM 미만, 약 70 pM 미만, 약 60 pM 미만, 약 50 pM 미만, 약 40 pM 미만, 약 30 pM 미만, 약 20 pM 미만, 약 10 pM 미만, 약 5 pM 미만, 약 4 pM 미만, 약 2 pM 미만, 약 1 pM 미만, 약 0.5 pM 미만, 약 0.2 pM 미만, 약 0.1 pM 미만, 또는 약 0.05 pM 미만의 KD로 C1q와 같은 보체 성분에 결합하는 폴리펩타이드를 포함한다. 구현예에서, 항원-결합 도메인은 표면 플라스몬 공명 검정에서 측정시, 약 1nM 미만, 약 500 pM 미만, 약 400 pM 미만, 약 300 pM 미만, 약 200 pM 미만, 약 100 pM 미만, 약 90 pM 미만, 약 80 pM 미만, 약 70 pM 미만, 약 60 pM 미만, 약 50 pM 미만, 약 40 pM 미만, 약 30 pM 미만, 약 20 pM 미만, 약 10 pM 미만, 약 5 pM 미만, 약 4 pM 미만, 약 2 pM 미만, 약 1 pM 미만, 약 0.5 pM 미만, 약 0.2 pM 미만, 약 0.1 pM 미만, 또는 약 0.05 pM 미만의 KD로 C1q에 결합하는 폴리펩타이드를 포함한다.
[00131] 본원에 사용된 바와 같은 "표면 플라스몬 공명"이라는 용어는, 예를 들어, BIAcore™ 시스템 [뉴저지주 피스카타웨이 소재의 GE 헬스케어의 바이오코어 라이프 사이언스부 (Biacore Life Sciences division of GE Healthcare, Piscataway, NJ]을 사용하여 바이오센서 매트릭스 내 단백질 농도 변화의 검출에 의해 실시간 상호작용의 분석을 가능하게 하는 광학적 현상을 지칭한다.
[00132] 본원에 사용된 바와 같은 용어 "KD "는 특정 단백질-단백질 상호작용 (예를 들어, 항체-항원 상호작용)의 평형 해리 상수를 의미한다. 달리 지적되지 않는 경우, 본원에 기재된 KD 값은 25℃에서 및/또는 37℃에서 표면 플라스몬 공명 검정에 의해 결정된 KD 값을 언급한다.
[00133] 본원의 개시내용은 면역글로불린의 하나의 아암이 스타필로코커스 종 표적 항원에 결합하고 (예를 들어, 제1 항원-결합 도메인 D1) 및 상기 면역글로불린의 다른 아암이 C1q와 같은 보체 성분에 특이적인 (예를 들어, 제2 항원-결합 도메인, D2) 이특이적 항원 결합 분자를 포함하지만, 표적 항원은 이에 대하여 표적화된 면역 반응이 요구되는 스타필로코커스 종 상에서 또는 종 내에서 발현되는 임의의 항원일 수 있다. 구현예에서 보체 성분은 C1q, C1r, C1s, C2, C3, C4, C5, C6, C7, C8, C9, 또는 이의 임의의 단편(보체 캐스케이드에 의해 생성된 단백질용해 단편을 포함하는)을 포함할 수 있다. 특정 구현예에서, 보체 성분은 C1q이다. 본원의 개시내용의 이특이적 항원-결합 분자의 D1 및/또는 D2 성분은 전체 항체 분자의 항원-결합 단편들을 포함하거나 이들로 이루어질 수 있다.
[00134] 항체의 하나의 아암이 C1q에 결합하고 다른 아암이 스파필로코커스 종 표적 항원에 결합하는 본원의 개시내용의 이특이적 항원 결합 분자와 관련하여, 표적 항원은 세포 표면 항원일 수 있다. 특이적 표적 항원의 비제한적인 예는 캡슐 폴리사카라이드 5형, 캡슐 폴리사카라이드 8형, IsdB, IsdA, IsdH, 리포테이코산, 벽 테이코산, 클럼핑 인자 A (clfA), 폴리-N-아세틸 글루코사민(PNAG), 리파제, V8 리파제, 지방산 변형 효소, 접착 매트릭스 분자를 인지하는 미생물 표면 성분(예를 들어, 어드헤신, 피브리노겐 결합 분자, 피브로넥틴 결합 단백질 A, 피브로넥틴 결합 단백질 B), 단백질 A 또는 이의 조합을 포함한다.
[00135] 항체의 하나의 아암이 C1q에 결합하고 다른 아암이 스파필로코커스 종 표적 항원에 결합하는, 본원의 개시내용의 이특이적 항원 결합 분자와 관련하여, 이특이적 항원 결합 분자는 약 10nM 이하의 EC50으로 스타필로코커스 종 표적 항원에 결합한다. 구현예에서, 스타필로코커스 종은 스타필로코커스 에피더미디스(Staphylococcus epidermidis), 스타필로코커스 아우레우스(Staphylococcus aureus), 스타필로코커스 루그두넨시스(Staphylococcus lugdunensis) 또는 스타필로코커스 사프로피티쿠스(Staphylococcus saprophiticus)를 포함한다. 항체의 하나의 아암이 C1q에 결합하고 다른 아암이 스파필로코커스 종 표적 항원에 결합하는 본원의 개시내용의 이특이적 항원 결합 분자와 관련하여, 이특이적 항원 결합 분자는 약 10nM 이하의 EC50으로 스타필로코커스 종상에 사람 C1q 침적을 촉진시킨다.
[00136] 특정 예시적인 구현예에 따라, 본원의 개시내용은 C1q 및 IsdB에 특이적으로 결합하는 이특이적 항원-결합 분자를 포함한다. 상기 분자는 본원에서, 예를 들어, "항-IsdB/항-IC1q" 또는 "항-IsdBxC1q" 또는 "항-IsdB x 항-C1q” 또는 “IsdBxC1q” 이특이적 분자 또는 다른 유사 용어로서 언급될 수 있다.
[00137] 본원에 사용된 바와 같은 표현 “이특이적 항원-결합 분자”는 적어도 제1 항원-결합 도메인 및 제2 항원-결합 도메인을 포함하는 단백질, 폴리펩타이드 또는 분자 복합체를 의미한다. 이특이적 항원-결합 분자 내 각각의 항원-결합 도메인은 단독으로 또는 하나 이상의 추가의 CDR 및/또는 FR과 조합되어 특정 항원에 특이적으로 결합하는 적어도 하나의 CDR을 포함한다. 본원의 개시내용과 관련하여, 제1 항원-결합 도메인은 제1 항원 (예를 들어, 스타필로코커스 종 표적 항원)에 특이적으로 결합하고, 제2 항원-결합 도메인은 제2의 별개의 항원 (예를 들어, C1q)에 특이적으로 결합한다.
[00138] 본원 개시내용의 특정 예시적 구현예에서, 상기 이특이적 항원-결합 분자는 이특이적 항체이다. 이특이적 항체의 각각의 항원 결합 도메인은 중쇄 가변 도메인(HCVR) 및 경쇄 가변 도메인(LCVR)을 포함한다.
[00139] 본원 개시내용의 특정 예시적 구현예에서, 이특이적 항원-결합 분자는 제1 항원-결합 도메인 (D1) 및 제2 항원-결합 도메인 (D2)를 포함한다. 제1 항원-결합 도메인 및 제2 항원-결합 도메인은 직간접적으로 서로 연결되어 본원 개시내용의 이특이적 항원-결합 분자를 형성할 수 있다. 대안적으로, 제1 항원-결합 도메인 및 제2 항원-결합 도메인은 각각 별도의 다량체화 도메인에 연결될 수 있다. 하나의 다량체화 도메인과 또 다른 다량체화 도메인의 연합은 2개의 항원-결합 도메인 간의 연합에 의해 이특이적 항원-결합 분자의 형성을 촉진시킨다. 본원에 사용된 바와 같은 "다량체화 도메인"은 임의의 거대분자, 단백질, 폴리펩타이드, 펩타이드, 또는 동일하거나 유사한 구조 또는 구성의 제2 다량체화 도메인과 연합하는 능력을 갖는 아미노산이다. 예를 들어, 다량체화 도메인은 면역글로불린 CH3 도메인을 포함하는 폴리펩타이드일 수 있다. 다량체화 성분의 비제한적인 예는 면역글로불린의 Fc 부분 (CH2-CH3 도메인을 포함하는), 예를 들어, 이소형 IgG1, IgG2, IgG3, 및 IgG4로부터 선택되는 IgG의 Fc 도메인, 및 각각의 이소형 그룹 내 임의의 동종이인자형이다.
[00140] 본원 개시내용의 이특이적 항원-결합 분자는 전형적으로 2개의 다량체화 도메인, 예를 들어, 각각 개별적으로 별도의 항체 중쇄의 일부인 2개의 Fc 도메인을 포함한다. 제1 및 제2 다량체화 도메인은 예를 들어, IgG1/IgG1, IgG2/IgG2, IgG4/IgG4와 같은 동일한 IgG 이소형일 수 있다. 대안적으로, 제1 및 제2 다량체화 도메인은 예를 들어, IgG1/IgG2, IgG1/IgG4, IgG2/IgG4 등과 같은 상이한 IgG 이소형일 수 있다.
[00141] 특정 구현예에서, 다량체화 도메인은 적어도 하나의 시스테인 잔기를 함유하는 길이가 1 내지 약 200개 아미노산의 Fc 단편 또는 아미노산 서열이다. 다른 구현예에서, 다량체화 도메인은 시스테인 잔기, 또는 짧은 시스테인-함유 펩타이드이다. 다른 다량체화 도메인은 류신 지퍼, 헬릭스-루프 모티프 (helix-loop motif) 또는 코일드-코일 모티프(coiled-coil motif)를 포함하거나 이들로 이루어진 펩타이드 또는 폴리펩타이드를 포함한다. 구현예에서, 다량체화 도메인은 크놉이 하나의 다량체화 도메인 상에 형성되도록 하는 CH3 영역 내 아미노산 변형 및 다량체화 도메인의 쌍 형성을 제공하는 또 다른 다량체화 도메인 상에 상응하는 정공을 유도하는 CH3 영역 내 아미노산 변형을 포함할 수 있다. 구현예에서, 아미노산 변형은 2개의 다량체화 도메인의 전하 쌍형성을 제공할 수 있다.
[00142] 임의의 이특이적 항원 결합 분자 포맷 및 기술을 사용하여 본원 개시내용의 이특이적 항원-결합 분자를 제조할 수 있다. 예를 들어, 제1 항원 결합 특이성을 갖는 항체 또는 이의 단편은 제2 항원-결합 특이성을 갖는 또 다른 항체 또는 항체 단편과 같은 하나 이상의 다른 분자 실체에 기능적으로 연결(예를 들어, 화학적 커플링, 유전학적 융합, 비공유 연합 또는 기타에 의해)되어 이특이적 항원 결합 분자를 생성할 수 있다. 본원의 개시내용과 관련하여 사용될 수 있는 특이적인 예시적 이특이적 포맷은 제한 없이, 예를 들어, scFv-기반 또는 디아바디 이특이적 포맷, IgG-scFv 융합체, 이원 가변 도메인 (DVD)-Ig, 3기능성 항체, 크놉-인투-홀, 공통의 경쇄 (예를 들어, 크놉-인투-홀을 갖는 공통의 경쇄 등), 크로스Mab, 크로스Fab, (씨드) 바디, 류신 지퍼, 두오바디, IgG1/IgG2, 이원 작용 Fab (DAF)-IgG, 및 Mab2 이특이적 포맷을 포함한다(문헌참조: 예를 들어, Klein et al. 2012, mAbs 4:6, 1-11, 및 이전의 포맷의 검토를 위한 본원에 인용된 문헌).
[00143] 본원의 개시내용의 이특이적 항원-결합 분자와 관련하여, 다량체화 도메인, 예를 들어, Fc 도메인은 야생형의 천연적으로 존재하는 버젼의 Fc 도메인과 비교하여 하나 이상의 아미노산 변화 (예를 들어, 삽입, 결실 또는 치환)를 포함할 수 있다. 예를 들어, 본원 개시내용은 Fc와 FcRn 사이에 변형된 결합 상호작용 (예를 들어, 증진되거나 감소된)을 갖는 변형된 Fc 도메인을 유도하는 Fc 도메인에서의 하나 이상의 변형을 포함하는 이특이적 항원-결합 분자를 포함한다. 또 다른 구현예에서, 본원의 개시내용은 단백질 A와 변형된 결합 상호작용(예를 들어, 감소된)을 갖는 변형된 Fc 도메인을 유도하는 Fc 도메인에서의 하나 이상의 변형을 포함하는 이특이적 항원 결합 분자를 포함한다.
[00144] 하나의 구현예에서, 이특이적 항원 결합 분자는 CH2 또는 CH3 영역에서 변형을 포함하고, 여기서, 상기 변형은 산성 환경 (예를 들어, pH가 약 5.5 내지 약 6.0의 범위에 있는 엔도좀 내)에서 FcRn에 대한 Fc 도메인의 친화성을 증가시킨다. 이러한 돌연변이는 동물에게 투여되는 경우 항체의 혈청 반감기의 증가를 유도할 수 있다. 이러한 Fc 변형의 비제한적인 예로는, 예를 들어, 위치 250 (예를 들어, E 또는 Q); 250 및 428 (예를 들어, L 또는 F); 252 (예를 들어, L/Y/F/W 또는 T), 254 (예를 들어, S 또는 T) 및 256 (예를 들어, S/R/Q/E/D 또는 T)에서의 변형; 또는 위치 428 및/또는 433 (예를 들어, H/L/R/S/P/Q 또는 K) 및/또는 434 (예를 들어, H/F 또는 Y)에서의 변형; 또는 위치 250 및/또는 428에서의 변형; 또는 위치 307 또는 308 (예를 들어, 308F, V308F) 및 434에서의 변형을 포함한다. 하나의 구현예에서, 상기 변형은 428L (예를 들어, M428L) 및 434S (예를 들어, N434S) 변형; 428L, 259I (예를 들어, V259I), 및 308F (예를 들어, V308F) 변형; 433K (예를 들어, H433K) 및 434 (예를 들어, 434Y) 변형; 252, 254, 및 256 (예를 들어, 252Y, 254T, 및 256E) 변형; 250Q 및 428L 변형 (예를 들어, T250Q 및 M428L); 및 307 및/또는 308 변형 (예를 들어, 308F 또는 308P)을 포함한다.
[00145] 예를 들어, 본원의 개시내용은 항-C1q 항체, 항-IsdB 항체, 및/또는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 포함하고, 이는 하기 그룹으로부터 선택되는 돌연변이의 하나 이상의 쌍 또는 그룹을 포함하는 Fc 도메인을 포함한다: 250Q 및 248L (예를 들어, T250Q 및 M248L); 252Y, 254T 및 256E (예를 들어, M252Y, S254T 및 T256E); 428L 및 434S (예를 들어, M428L 및 N434S); 및 433K 및 434F (예를 들어, H433K 및 N434F). 상기 Fc 도메인 돌연변이, 및 본원에 기재된 항체 가변 도메인 내의 다른 돌연변이의 가능한 모든 조합들이 본원 개시내용의 범위 내에서 고려된다.
[00146] 본원의 개시내용은 또한 제1 CH3 도메인 및 제2 Ig CH3 도메인을 포함하는 이특이적 항원-결합 분자를 포함하고, 여기서, 상기 제1 및 제2 Ig CH3 도메인은 적어도 하나의 아미노산에 의해 서로 상이하고 적어도 하나의 아미노산 차이는 아미노산 차이가 없는 이특이적 항원 결합 분자와 비교하여 단백질 A로의 이특이적 항원 결합 분자의 결합을 감소시킨다. 하나의 구현예에서, 제1 Ig CH3 도메인은 단백질 A에 결합하고 제2 Ig CH3 도메인은 H95R 변형(IMGT 엑손 넘버링에 의한; EU 넘버링에 따르면 H435R)과 같은 단백질 A 결합을 감소시키거나 폐지시키는 돌연변이를 함유한다. 제2 CH3은 Y96F 변형 (IMGT에 의한; EU에 따르면 Y436F)을 추가로 포함할 수 있다. 제2 CH3 내에서 발견될 수 있는 추가의 변형은 다음을 포함한다: IgG1 항체의 경우에 D16E, L18M, N44S, K52N, V57M, 및 V82I (IMGT에 의한; EU에 따르면 D356E, L358M, N384S, K392N, V397M, 및 V422I); IgG2 항체의 경우에 N44S, K52N, 및 V82I (IMGT; EU에 따르면 N384S, K392N, 및 V422I); 및 IgG4 항체의 경우에 Q15R, N44S, K52N, V57M, R69K, E79Q, 및 V82I (IMGT에 의한; EU에 따르면 Q355R, N384S, K392N, V397M, R409K, E419Q, 및 V422I).
[00147] 특정 구현예에서, Fc 도메인은 하나 이상의 면역글로불린 이소형으로부터 유래된 Fc 서열이 조합된 키메라일 수 있다. 예를 들어, 키메라 Fc 도메인은 사람 IgG1, 사람 IgG2 또는 사람 IgG4 CH2로부터 유래된 CH2 서열의 일부 또는 전부 및 사람 IgG1, 사람 IgG2 또는 사람 IgG4로부터 유래된 CH3 서열의 일부 또는 전부를 포함할 수 있다. 키메라 Fc 도메인은 또한 키메라 힌지 영역을 함유할 수 있다. 예를 들어, 키메라 힌지는 사람 IgG1, 사람 IgG2 또는 사람 IgG4 힌지 영역으로부터 유래된, “하부 힌지” 서열과 조합된, 사람 IgG1, 사람 IgG2 또는 사람 IgG4 힌지 영역으로부터 유래된 “상부 힌지” 서열을 포함할 수 있다. 본원에 제시된 임의의 항원-결합 분자에 포함될 수 있는 키메라 Fc 도메인의 특정 예는 N-말단에서 C-말단으로 다음을 포함한다: [IgG4 CH1] - [IgG4 상부 힌지] - [IgG2 하부 힌지] - [IgG4 CH2] - [IgG4 CH3]. 본원에 제시된 임의의 항원-결합 분자에 포함될 수 있는 키메라 Fc 도메인의 또 다른 예는 N-말단에서 C-말단으로 다음을 포함한다: [IgG1 CH1] - [IgG1 상부 힌지] - [IgG2 하부 힌지] - [IgG4 CH2] - [IgG1 CH3]. 본원의 개시내용의 임의의 항원-결합 분자에 포함될 수 있는 키메라 Fc 도메인의 상기 예 및 다른 예는 2014년 1월 31일자로 출원된 미국 특허 제9,359,437호에 기재되어 있다. 이들 일반 구조적 정렬을 갖는 키메라 Fc 도메인 및 이의 변이체는 변형된 Fc 수용체 결합을 가질 수 있고 이는 이어서 Fc 이펙터 기능에 영향을 미친다.
[00148] 본원의 개시내용의 항-IsdB x 항-C1q 이특이적 항원-결합 분자에 포함될 수 있는 예시적 항원-결합 도메인(D1 및 D2)은 본원에 기재된 임의의 항-IsdB (D1) 및 항-C1q (D2) 항체로부터 유래된 항원-결합 도메인을 포함한다. 예를 들어, 본원의 개시내용은 표 3에 열거된 임의의 HCVR 아미노산 서열로부터 선택된 아미노산 서열을 포함하는 HCVR을 포함하는 D1 항원-결합 도메인 및 표 1에 열거된 임의의 HCVR 아미노산 서열로부터 선택된 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 실질적으로 유사 서열을 포함하는 HCVR을 포함하는 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 포함한다.
[00149] 본원의 개시내용은 또한 표 3에 열거된 임의의 LCVR 아미노산 서열로부터 선택된 아미노산 서열을 포함하는 LCVR을 포함하는 D1 항원-결합 도메인 및 표 1에 열거된 임의의 LCVR 아미노산 서열로부터 선택된 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 실질적으로 유사 서열을 포함하는 LCVR을 포함하는 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 제공한다.
[00150] 또한, 본원의 개시내용은 표 3 또는 표 1에 열거된 임의의 LCVR 아미노산 서열과 쌍을 이루는 표 3 또는 표 1에 열거된 임의의 HCVR 아미노산 서열을 포함하는 HCVR 및 LCVR 쌍 (HCVR/LCVR)을 포함하는, D1 및 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 제공한다.
[00151] 특정 구현예에 따라, 본원의 개시내용은 HCVR/LCVR 쌍을 포함하는 D1 및 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 제공하고, 여기서, 이특이적 항원 결합 분자의 D1은 표 3에서 임의의 HCVR 서열로부터 선택되는 HCVR 아미노산 서열을 포함하고 이특이적 항원 결합 분자의 D2는 표 1에서 임의의 HCVR 서열로부터 선택되는 HCVR 아미노산 서열을 포함하고 이특이적 항원 결합 분자의 LCVR 아미노산 서열은 표 1 또는 3에 나타낸 임의의 LCVR 아미노산 서열을 포함한다.
[00152] 명료하게 할 목적으로, 본원 개시내용의 이특이적 항체는 표 6에 요약하고, 이는 제1 항원-결합 도메인 (D1, 항-IsdB)에 할당된 HCVR 및 HCDR에 대한 특정 아미노산 서열 식별자, 제2 항원-결합 도메인 (D2 항-C1q)에 할당된 HCVR 및 HCDR에 대한 아미노산 서열 식별자 및 LCVR 및 LCDR에 할당된 아미노산 서열 식별자를 보여준다. 각각의 항-IsdB x 항-C1q 이특이적 항체는 좌측 상에 제1 컬럼에 보여지는 새로운 항체 확인 번호 (PID)를 할당하였다.
[00153] 본원의 개시내용은 또한 표 3에 열거된 임의의 HCDR1 아미노산 서열로부터 선택된 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적인 유사 서열을 포함하는 중쇄 CDR1 (HCDR1)을 포함하는 D1 항원-결합 도메인 및 표 1에 열거된 임의의 HCDR1 아미노산 서열로부터 선택되는 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적인 유사 서열을 포함하는 중쇄 CDR1 (HCDR1)을 포함하는 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 제공한다.
[00154] 본원의 개시내용은 또한 표 3에 열거된 임의의 HCDR2 아미노산 서열로부터 선택된 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적인 유사 서열을 포함하는 중쇄 CDR2 (HCDR2)을 포함하는 D1 항원-결합 도메인 및 표 1에 열거된 임의의 HCDR2 아미노산 서열로부터 선택되는 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적인 유사 서열을 포함하는 중쇄 CDR2 (HCDR2)을 포함하는 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 제공한다.
[00155] 본원의 개시내용은 또한 표 3에 열거된 임의의 HCDR3 아미노산 서열로부터 선택된 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 실질적으로 유사 서열을 포함하는 중쇄 CDR3 (HCDR3)을 포함하는 D1 항원-결합 도메인 및 표 1에 열거된 임의의 중쇄 HCDR3 아미노산 서열로부터 선택된 아미노산 서열, 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적인 유사 서열을 포함하는 중쇄 CDR3 (HCDR3)을 포함하는 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 제공한다.
[00156] 본원의 개시내용은 또한 표 3에 열거된 임의의 LCDR1 아미노산 서열로부터 선택된 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적인 유사 서열을 포함하는 경쇄 CDR1 (LCDR1)을 포함하는 D1 항원-결합 도메인 및 표 1에 열거된 임의의 LCDR1 아미노산 서열로부터 선택되는 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적인 유사 서열을 포함하는 경쇄 CDR1 (LCDR1)을 포함하는 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 제공한다.
[00157] 본원의 개시내용은 또한 표 3에 열거된 임의의 LCDR2 아미노산 서열로부터 선택된 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적인 유사 서열을 포함하는 경쇄 CDR2 (LCDR2)을 포함하는 D1 항원-결합 도메인 및 표 1에 열거된 임의의 LCDR2 아미노산 서열로부터 선택되는 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적인 유사 서열을 포함하는 경쇄 CDR2 (LCDR2)을 포함하는 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 제공한다.
[00158] 본원의 개시내용은 또한 표 3에 열거된 임의의 LCDR3 아미노산 서열로부터 선택된 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적인 유사 서열을 포함하는 경쇄 CDR3 (LCDR3)을 포함하는 D1 항원-결합 도메인 및 표 1에 열거된 임의의 LCDR3 아미노산 서열로부터 선택되는 아미노산 서열 또는 상기 서열과 적어도 90%, 적어도 95%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 이의 실질적인 유사 서열을 포함하는 경쇄 CDR3 (LCDR3)을 포함하는 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 제공한다.
[00159] 또한, 본원의 개시내용은 표 1 또는 표 3에 열거된 임의의 LCDR3 아미노산 서열과 쌍을 이루는 표 1 또는 표 3에 열거된 임의의 HCDR3 아미노산 서열을 포함하는 HCDR3 및 LCDR3 쌍 (HCDR3/LCDR3)을 포함하는, D1 및/또는 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 제공한다.
[00160] 본원의 개시내용은 또한 표 1 또는 표 3에 열거된 임의의 예시적 항-IsdB 또는 항-C1q 항체 내 함유된 6개 CDR (즉, HCDR1-HCDR2-HCDR3-LCDR1-LCDR2-LCDR3) 세트를 포함하는 D1 및/또는 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 제공한다.
[00161] 관련 구현예에서, 본원의 개시내용은 표 1 또는 표 3에 열거된 임의의 예시적 항-IsdB 또는 항-C1q 항체에 의해 정의된 바와 같은 HCVR/LCVR 쌍 내 함유된 6개 CDR(즉, HCDR1-HCDR2-HCDR3-LCDR1-LCDR2-LCDR3) 세트를 포함하는, D1 및/또는 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 제공한다.
[00162] 본원 개시내용의 항-IsdB x 항-C1q 이특이적 항원-결합 분자는 표 3의 임의의 항-IsdB 항체로부터 유래된 D1 항원-결합 도메인 및 표 1의 임의의 항-C1q 항체로부터 유래된 D2 항원-결합 도메인을 포함할 수 있다. 본원의 개시내용의 항-IsdB x 항-C1q 이특이적 항체의 비제한적인 예는 표 6에 도시한다.
[00163] 비-제한 예시적 예로서, 본원의 개시내용은 D1 항원-결합 도메인 및 D2 항원-결합 도메인을 포함하는 항-IsdB x 항-C1q 이특이적 항원 결합 분자를 포함하고, 여기서, 상기 D1 항원 결합 도메인은 서열번호 138/146의 아미노산 서열을 포함하는 HCVR/LCVR 쌍 또는 중쇄 및 경쇄 CDR 세트 (HCDR1-HCDR2-HCDR3-LCDR1-LCDR2-LCDR3)를 포함하고, 상기 세트는 서열번호 140-142-144-148-150-152의 아미노산 서열을 포함하고, 여기서, 상기 D2 항원-결합 도메인은 서열번호 2/146의 아미노산 서열을 포함하는 HCVR/LCVR 쌍, 또는 중쇄 및 경쇄 CDR (HCDR1-HCDR2-HCDR3-LCDR1-LCDR2-LCDR3) 세트를 포함하고, 상기 세트는 서열번호 4-6-8-148-150-152의 아미노산 서열을 포함한다. 이들 서열 특징을 갖는 예시적 항-IsdB x 항-C1q 이특이적 항체는 H1H20631D로 지정된 이특이적 항체이고, 이는 H1H20295P2로부터 유래된 D1 및 H1 X H17736P2로부터 유래된 D2를 포함한다(본원에서 표 6을 참조한다).
서열 변이체
[00164] 본원 개시내용의 항체 및 이특이적 항원-결합 분자는 상기 개별 항원-결합 도메인이 이로부터 본원에 기재된 바와 같이 유래하는 상응하는 생식계열의 서열과 비교하여, 중쇄 및 경쇄 가변 도메인의 프레임워크 및/또는 CDR 영역 내에 하나 이상의 아미노산 치환, 삽입 및/또는 결실을 포함할 수 있다. 또한, 본원의 개시내용은 항원-결합 도메인 하나 또는 둘다가 하나 이상의 보존적 치환을 갖는 본원에 기재된 임의의 HCVR, LCVR, 및/또는 CDR 아미노산 서열의 변이체를 포함하는, 항원-결합 분자를 포함한다. 예를 들면, 본원의 개시내용은 본원에 기재된 임의의 HCVR, LCVR 및/또는 CDR 아미노산 서열 중 임의의 것과 비교하여 예를 들면 10개 이하, 8개 이하, 6개 이하, 4개 이하 등의 보존적 아미노산 치환을 갖는 HCVR, LCVR 및/또는 CDR 아미노산 서열을 갖는 항원-결합 도메인을 포함하는 항원-결합 분자를 기재한다. 보존적 아미노산 치환은 본원의 다른 곳에 기재되어 있다.
[00165] 본원의 개시내용은 또한 본원에 기재된 임의의 HCVR, LCVR, 및/또는 CDR 아미노산 서열과 실질적으로 동일한 HCVR, LCVR, 및/또는 CDR 아미노산 서열을 갖는 항원-결합 도메인을 포함하는 항원-결합 분자를 포함한다.
pH-의존성 결합
[00166] 본원의 개시내용은 pH-의존성 결합 특징을 갖는, 항-C1q 항체, 항-IsdB 항체, 및/또는 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 포함한다. 예를 들어, 본원의 개시내용의 이특이적 항원 결합 분자는 중성 pH와 비교하여 산성 pH에서 C1q 또는 IsdB로의 감소된 결합을 나타낼 수 있다. 대안적으로, 본원 개시내용의 이특이적 항원 결합 분자는 중성 pH와 비교하여 산성 pH에서 C1q 또는 IsdB로의 증진된 결합을 나타낼 수 있다. 표현 "산성 pH"는 약 6.2 미만, 예를 들어, 약 6.0, 5.95, 5,9, 5.85, 5.8, 5.75, 5.7, 5.65, 5.6, 5.55, 5.5, 5.45, 5.4, 5.35, 5.3, 5.25, 5.2, 5.15, 5.1, 5.05, 5.0 이하의 pH 값을 포함한다. 본원에 사용된 바와 같은 표현 "중성 pH"는 약 7.0 내지 약 7.4의 pH를 의미한다. 표현 "중성 pH"는 약 7.0, 7.05, 7.1, 7.15, 7.2, 7.25, 7.3, 7.35, 및 7.4의 pH 값을 포함한다.
[00167] 특정 경우에, "중성 pH와 비교하여 산성 pH에서...감소된 결합"은 중성 pH에서 이의 항원으로의 항체 결합의 KD 값에 대한 산성 pH에서 이의 항원로의 항체 결합의 KD 값의 비율로 나타낸다(또 그 역으로). 예를 들어, 항체 또는 이의 항원-결합 단편은 항체 또는 이의 항원 결합 단편이 약 3.0 이상의 산성/중성 KD 비율을 나타내는 경우, 본원 개시내용의 목적을 위해 “중성 pH와 비교하여 산성 pH에서 감소된 결합”을 나타내는 것으로서 간주될 수 있다. 특정 예시적 구현예에서, 본원 개시내용의 항체 또는 항원-결합 단편에 대한 산성/중성 KD 비율은 약 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0, 6.5, 7.0, 7.5, 8.0, 8.5, 9.0, 9.5, 10.0, 10.5, 11.0, 11.5, 12.0, 12.5, 13.0, 13.5, 14.0, 14.5, 15.0, 20.0. 25.0, 30.0, 40.0, 50.0, 60.0, 70.0, 100.0 이상일 수 있다.
[00168] pH-의존성 결합 특징을 갖는 항체는 예를 들어, 중성 pH와 비교하여 산성 pH에서 특정 항원으로의 감소된 (또는 증진된) 결합에 대해 항체 집단을 스크리닝함에 의해 수득될 수 있다. 추가로, 아미노산 수준에서 항원 결합 도메인의 변형은 pH-의존성 특징을 갖는 항체를 생성시킬 수 있다. 예를 들어, 항원 결합 도메인 (예를 들어, CDR 내)의 하나 이상의 아미노산을 히스티딘 잔기로 치환함에 의해, 중성 pH와 비교하여 산성 pH에서 감소된 항원 결합을 갖는 항체가 수득될 수 있다.
항체 및 이특이적 항원-결합 분자의 생물학적 특징
[00169] 본원의 개시내용은 보체 성분, 예를 들어, C1q에 결합하는 항체, 이의 항원-결합 단편 및 이특이적 항원 결합 분자를 포함한다. 구현예에서, 이특이적 항원 결합 분자는 면역글로불린 분자로의 C1q 결합을 억제하고, 용혈 및/또는 보체 의존성 세포독성을 억제한다. 구현예에서, 이특이적 항원-결합 분자는 약 10nM 이하의 IC50으로 사람 C1q의 사람 IgG1-k로의 결합을 차단한다. 다른 구현예에서, 이특이적 항원 결합 분자는 약 50nM 이하의 IC50으로 사람 C1q의 사람 IgM으로의 결합을 차단한다. 구현예에서, 이특이적 항원 결합 분자는 약 10nM 이하의 IC50으로 보체 의존성 세포독성을 억제한다. 추가의 구현예에서, 이특이적 항원-결합 분자는 약 10nM 이하의 EC50으로 사람 C1q의 침적을 제공한다.
[00170] 본원의 개시내용은 스타필로코커스 종 표적 항원에 결합하는 항체, 이의 항원-결합 단편 및 이특이적 항원 결합 분자를 포함한다. 구현예에서, 스타필로코커스 종은 스타필로코커스 에피더미디스(Staphylococcus epidermidis), 스타필로코커스 아우레우스(Staphylococcus aureus), 스타필로코커스 루그두넨시스(Staphylococcus lugdunensis) 및/또는 스타필로코커스 사프로피티쿠스(Staphylococcus saprophiticus)를 포함한다. 구현예에서, 스타필로코커스 종은 메티실린 내성 스타필로코커스 아우레우스와 같은 항생제 내성 종이다. 구현예에서, 스타필로코커스 종 표적 항원은 캡슐 폴리사카라이드 5형, 캡슐 폴리사카라이드 8형, IsdB, IsdA, IsdH, 리포테이코산, 벽 테이코산, 클럼핑 인자 A (clfA), 폴리-N-아세틸 글루코사민(PNAG), 리파제, V8 리파제, 지방산 변형 효소, 접착 매트릭스 분자를 인지하는 미생물 표면 성분(예를 들어, 어드헤신, 피브리노겐 결합 분자, 피브로넥틴 결합 단백질 A, 피브로넥틴 결합 단백질 B), 단백질 A 또는 이의 조합을 포함한다.
[00171] 구현예에서, 스타필로코커스 종 표적 항원에 결합하는 제1 항원-결합 도메인 (D1) 및 사람 C1q에 결합하는 제2 항원-결합 도메인 (D2)를 포함하는 단리된 이특이적 항원 결합 분자는 약 10nM 이하의 EC50으로 스타필로코커스 종 표적 항원에 결합한다. 구현예에서, 제1 항원-결합 도메인 D1 및 제2 항원-결합 도메인 D2를 포함하는 단리된 이특이적 항원 결합 분자는 약 10nM 이하의 EC50으로 스타필로코커스 종상에서 사람 C1q 침적을 촉진시킨다.
[00172] 본원의 개시내용은 고친화성, 예를 들어 1nM 이하로 사람 C1q에 결합하는 항체 및 항원-결합 단편을 포함한다. 본원의 개시내용은 또한 요구되는 치료 내용 및 요구되는 특정 치료 성질에 의존하여 중간 또는 낮은 친화성, 예를 들어, 약 2nM 이상으로 사람 C1q에 결합하는 항체 및 항원-결합 단편을 포함한다. 본원의 개시내용은 고친화성, 예를 들어 5nM 이하로 IsdB에 결합하는 항체 및 항원-결합 단편을 포함한다. 본원의 개시내용은 또한 요구되는 치료 내용 및 요구되는 특정 치료 성질에 의존하여 중간 또는 낮은 친화성, 예를 들어, 약 10nM 이상으로 IsdB에 결합하는 항체 및 이의 항원-결합 단편을 포함한다.
[00173] 본원의 개시내용은 대상체에서 스타필로코커스 종의 성장 또는 이에 의한 감염을 억제할수 있는, 항-IsdB x 항-C1q 이특이적 항원-결합 분자를 포함한다(예를 들어, 실시예 8, 실시예 9 참조). 예를 들어, 특정 구현예에 따라, 항-IsdB x 항-C1q 이특이적 항원-결합 분자가 제공되고, 여기서, 상기 이특이적 항원-결합 분자의 대상체로의 단일 투여(예를 들어, 약 0.1 mg/kg, 약 0.08 mg/kg, 약 0.06 mg/kg, 약 0.04 mg/kg, 약 0.04 mg/kg, 약 0.02 mg/kg, 약 0.01 mg/kg 이하의 용량으로)는 대상체에서 (예를 들어, 대상체로부터 채취된 혈액 샘플에서) 스타필로코커스 종의 콜로니 형성 유닛 (CFU)에서의 감소를 유발한다. 특정 구현예에서, 약 0.1 mg/kg의 용량으로 항-IsdB x 항-C1q 이특이적 항원-결합 분자의 단일 투여는 이특이적 항원-결합 분자의 대상체로의 투여 후 약 21일, 약 18일, 약 14일, 약 10일, 약 7일, 약 5일, 약 2일, 또는 약 1일까지 스타필로코커스 아우레우스로 감염된 동물의 생존을 증가시킨다.
에피토프 맵핑 및 관련 기술
[00174] 본원 개시내용의 이특이적 항원-결합 분자가 결합하는 C1q 또는 IsdB 상의 에피토프는 C1q 단백질 또는 IsdB 단백질의 3개 이상(예를 들어, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20개 이상)의 단일 연속 서열을 포함하거나 이들로 이루어질 수 있다. 대안적으로, 상기 에피토프는 C1q 또는 IsdB의 다수의 비-연속 아미노산 (또는 아미노산 서열)을 포함하거나 이들로 이루어질 수 있다. 본원 개시내용의 항체는 단일 C1q 쇄내에 함유된 아미노산 (예를 들어, 성분 a, b 또는 c)과 상호작용할 수 있거나, 2개 이상의 상이한 C1q 쇄의 아미노산과 상호작용할 수 있거나 3량체와 상호작용할 수 있거나 6량체와 상호작용할 수 있다. 당업자에게 공지된 다양한 기술들을 사용하여 항체의 항원-결합 도메인이 폴리펩타이드 또는 단백질 내에서 "하나 이상의 아미노산과 상호작용하는지”의 여부를 결정할 수 있다. 예시적 기술은 예를 들어, 문헌(참조: Antibodies, Harlow and Lane (Cold Spring Harbor Press, Cold Spring Harb., NY))에 기재된 것과 같은 통상의 교차-차단 검정, 알라닌 스캐닝 돌연변이 분석, 펩타이드 블롯 분석 (문헌참조: Reineke, 2004, Methods Mol Biol 248:443-463), 및 펩타이드 절단 분석을 포함한다. 또한, 에피토프 절제, 에피토프 추출 및 항원의 화학적 변형과 같은 방법도 사용될 수 있다(문헌참조: Tomer (2000) Prot. Sci. 9: 487-496). 항체의 항원-결합 도메인이 상호작용하는 폴리펩타이드 내 아미노산을 동정하기 위해 사용될 수 있는 또 다른 방법은 질량 분광측정기로 검출되는 수소/중수소 교환법이다. 일반적으로, 상기 수소/중수소 교환법은 관심대상 단백질을 중수소-표지화한 후, 항체를 중수소-표지된 단백질에 결합시키는 단계를 포함한다. 이어서, 단백질/항체 복합체는 물에 첨가하여 항체에 의해 보호된 잔기 (중수소-표지된 상태로 남아있는)를 제외한 모든 잔기에서 수소-중수소 교환이 일어날 수 있게 한다. 항체의 해리 후, 표적 단백질을 프로테아제 절단 및 질량 분광측정 분석에 적용함으로써, 상기 항체가 상호작용하는 특이적 아미노산에 상응하는 중수소-표지된 잔기를 밝혀낸다. 예를 들어, 문헌(Ehring (1999) Analytical Biochemistry 267(2):252-259; Engen and Smith (2001) Anal. Chem. 73:256A-265A)을 참조한다. 항원/항체 복합체의 X-선 결정학은 또한 에피토프 맵핑 목적을 위해 사용될 수 있다.
[00175] 본원의 개시내용은 또한 스타필로코커스 종 표적 항원에 특이적으로 결합하는 제1 항원-결합 도메인 (D1) 및 보체 성분에 특이적으로 결합하는 제2 항원 결합 도메인 (D2)를 포함하는 이특이적 항원-결합 분자를 포함하고, 여기서, 상기 제1 항원-결합 도메인은 본원에 기재된 임의의 특정 예시적 스타필로코커스 종 표적 항원-결합 도메인 상에 동일한 에피토프에 결합하고/하거나 상기 제2 항원-결합 도메인은 본원에 기재된 임의의 특정 예시적 C1q-특이적 항원-결합 도메인으로서 보체 성분 상에 동일한 에피토프상에 결합한다. 예시적 구현예는 서열번호 2/146 또는 서열번호 106/146의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하는 참조 항체와 사람 C1q 상에 동일한 에피토프에 결합하는 단리된 이특이적 항원 결합 분자를 포함한다. 예시적 구현예는 서열번호 138/146의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하는 참조 항체와 IsdB상에 동일한 에피토프에 결합하는 단리된 이특이적 항원 결합 분자를 포함한다.
[00176] 또한, 본원의 개시내용은 IsdB에 특이적으로 결합하는 제1 항원-결합 도메인 (D1), 및 사람 C1q에 특이적으로 결합하는 제2 항원 결합 도메인 (D2)를 포함하는 이특이적 항원-결합 분자를 포함하고, 상기 제1 항원-결합 도메인은 임의의 특정 예시적 IsdB-특이적 항원-결합 도메인, 예를 들어, 서열번호 138/146의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하는 참조 항체와 IsdB에 결합하는 것에 대해 경쟁하고/하거나 상기 제2 항원-결합 도메인은 본원에 기재된 특정 예시적 C1q-특이적 항원-결합 도메인, 예를 들어, 서열번호 2/146 또는 서열번호 106/146의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하는 참조 항체와 사람 C1q에 결합하는 것에 대해 경쟁한다.
[00177] 당업자는 특정 항원-결합 분자 (예를 들어, 항체) 또는 이의 항원-결합 도메인이 본원의 개시내용의 참조 항원-결합 분자와 동일한 에피토프에 결합하거나 이와 결합하는 것에 대해 경쟁하는지를 당업계에 공지된 통상의 방법을 사용함에 의해 용이하게 결정할 수 있다. 예를 들어, 시험 항체가 본원 개시내용의 참조 이특이적 항원-결합 분자와 C1q 상에 동일한 에피토프에 결합하는지를 결정하기 위해, 참조 이특이적 분자는 먼저 C1q 단백질 (또는 IsdB 단백질)에 결합하도록 한다. 다음으로, C1q (또는 IsdB) 분자에 결합하는 시험 항체의 능력을 평가한다. 시험 항체가 참조 이특이적 항원-결합 분자와 포화 결합한 후에 C1q (또는 IsdB)에 결합할 수 있는 경우, 상기 시험 항체는 참조 이특이적 항원-결합 분자와 C1q (또는 IsdB)의 상이한 에피토프 에 결합한다는 결론을 내릴 수 있다. 한편, 시험 항체가 표준 이특이적 항원-결합 분자와 포화 결합한 후에 C1q (또는 IsdB)에 결합할 수 없는 경우, 상기 시험 항체는 본원 개시내용의 참조 이특이적 항원-결합 분자에 의해 결합된 에피토프와 동일한, C1q (또는 IsdB)의 에피토프에 결합할 수 있다. 추가의 통상의 실험 (예를 들어, 펩타이드 돌연변이 및 결합 분석)을 수행하여 시험 항체에서 관찰된 결합부 부재가 실제로 참조 이특이적 항원-결합 분자와 동일한 에피토프로의 결합으로 인한 것인지 또는 입체 차단(또는 또 다른 현상)이 관찰된 결합 부재에 관여하는지를 확인할 수 있다. 이러한 종류의 실험은 ELISA, RIA, 바이아코어, 유동 세포 측정 또는 당업계에서 이용하는 임의의 기타 정량적 또는 정성적 항체 결합 검정을 사용하여 수행될 수 있다. 본원의 개시내용의 특정 구현예에 따라, 2개의 항원-결합 단백질은 예를 들어, 1-, 5-, 10-, 20- 또는 100-배 과량의 하나의 항원-결합 단백질이 경쟁 결합 검정에서 측정시 적어도 50% 그러나 바람직하게 75%, 90% 또는 심지어 99% 까지 다른 것의 결합을 억제하는 경우 동일한 (또는 중복) 에피토프에 결합한다(문헌참조: 예를 들어, Junghans et al., Cancer Res. 1990:50:1495-1502). 대안적으로, 2개의 항원-결합 단백질은 하나의 항원-결합 단백질의 결합을 감소시키거나 제거하는 항원에서의 필수적으로 모든 아미노산 돌연변이가 다른 것의 결합을 감소시키거나 제거하는 경우 동일한 에피토프에 결합하는 것으로 간주된다. 2개의 항원-결합 단백질은 하나의 항원-결합 단백질의 결합을 감소시키거나 제거하는 아미노산 돌연변이의 서브세트 만이 다른 것의 결합을 감소시키거나 제거하는 경우 “중복 에피토프”를 갖는 것으로 간주된다.
[00178] 항체 또는 이의 항원-결합 도메인이 참조 항원-결합 분자와 결합에 대하여 경쟁하는지의 여부를 결정하기 위해, 상기된 결합 방법은 두 가지 방식으로 수행된다: 첫 번째 방식에서, 상기 참조 항원-결합 분자는 포화 조건 하에 C1q 단백질 (또는 IsdB 단백질)에 결합하도록한 후, C1q (또는 IsdB) 분자에 대한 시험 항체의 결합에 대하여 평가한다. 두 번째 방식에서, 상기 시험 항체는 포화 조건 하에 C1q (또는 IsdB) 분자에 결합하도록한 후, C1q (또는 IsdB) 분자에 대한 참조 항원-결합 분자의 결합에 대하여 평가한다. 방식 둘다에서, 첫 번째 (포화) 항원-결합 분자만이 C1q (또는 IsdB) 분자에 결합할 수 있는 경우라면, 상기 시험 항체 및 참조 항원-결합 분자는 C1q(또는 IsdB)에 대한 결합에 대하여 경쟁하고 있는 것으로 결론을 내린다. 당업자라면 알 수 있듯이, 참조 항원-결합 분자와 결합에 대하여 경쟁하는 항체는 필수적으로 참조 항체와 동일한 에피토프에 결합하지 않을 수도 있지만, 중복되거나 인접하는 에피토프에 결합하여 참조 항체의 결합을 입체적으로 차단할 수 있다.
항원-결합 도메인의 제조 및 이특이적 분자의 작제
[00179] 특정 항원에 특이적인 항원-결합 도메인은 당업계에 공지된 임의의 항체 생성 기술에 의해 제조될 수 있다. 일단 수득되면, 2개의 상이한 항원 (예를 들어, C1q 및 IsdB)에 특이적인 2개의 상이한 항원-결합 도메인은 서로 상대적으로 적절히 정렬되어 통상의 방법을 사용하여 본원의 개시내용의 이특이적 항원-결합 분자를 생성할 수 있다. (본원 개시내용의 이특이적 항원-결합 분자를 작제하기 위해 사용될 수 있는 예시적 이특이적 항체의 논의는 본원의 다른 곳에서 제공된다). 특정 구현예에서, 본원 개시내용의 다중특이적 항원-결합 분자의 개별 성분들 (예를 들어, 중쇄 및 경쇄) 중 하나 이상은 키메라, 사람화된 또는 완전한 사람 항체로부터 유래된다.
[00180] 상기 항체를 제조하기 위한 방법은 당업계에 널리 공지되어 있다. 예를 들어, 본원 개시내용의 이특이적 항원-결합 분자의 중쇄 및/또는 경쇄 중 하나 이상은 VELOCIMMUNE® 기술을 사용하여 제조될 수 있다. VELOCIMMUNE® 기술 (또는 임의의 다른 사람 항체 생성 기술)을 사용하여, 처음에 사람 가변 영역 및 마우스 불변 영역을 갖는 특정 항원 (예를 들어, C1q 또는 IsdB)에 대한 고친화성 키메라 항체가 단리된다. 항체는 친화성, 선택성, 에피토프 등을 포함하는 요구될 수 있는 특징에 대해 특징 분석되고 선택된다. 마우스 불변 영역은 목적하는 사람 불변 영역으로 대체하여 본원 개시내용의 이특이적 항원-결합 분자로 혼입될 수 있는 완전한 사람 중쇄 및/또는 경쇄를 생성한다.
[00181] 유전학적으로 가공된 동물을 사용하여 사람 이특이적 항원-결합 분자를 생성할 수 있다. 예를 들어, 내인성 마우스 면역글로불린 경쇄 가변 서열을 재정렬하고 발현할 수 없는 유전학적으로 변형된 마우스를 사용할 수 있고, 여기서, 상기 마우스는 내인성 마우스 카파 유전자좌에서 마우스 카파 불변 유전자에 작동적으로 연결된 사람 면역글로불린 서열에 의해 암호화된 단지 하나 또는 2개의 사람 경쇄 가변 도메인을 발현한다. 상기 유전학적으로 변형된 마우스를 사용하여 2개의 상이한 사람 경쇄 가변 영역 유전자 분절 중 하나로부터 유래된 가변 도메인을 포함하는 동일한 경쇄와 연합된 2개의 상이한 중쇄를 포함하는 완전한 사람 이특이적 항원-결합 분자를 생성할 수 있다. (예를 들어, 상기 조작된 마우스 및 이특이적 항원-결합 분자를 생성하기 위한 이의 용도에 대한 상세한 논의는 US 2011/0195454를 참조한다).
생등가물
[00182] 본원의 개시내용은 본원에 기재된 예시적 분자의 것들과는 상이하지만 C1q 및/또는 IsdB에 결합하는 능력을 보유하는 아미노산 서열을 갖는 항원-결합 분자를 포괄한다. 이러한 변이체 분자는 모체 서열(parent sequence)과 비교했을 때 아미노산의 하나 이상의 부가, 결실 또는 치환을 포함하지만, 본원에 기재된 이특이적 항원-결합 분자와 본질적으로 동등한 생물학적 활성을 나타낼 수 있다.
[00183] 본원의 개시내용은 본원에 제시된 임의의 예시적 항원-결합 분자와 생등가성인 항원-결합 분자를 포함한다. 2개의 항원 결합 단백질 또는 항체는, 예를 들어, 이들을 유사한 실험 조건 하에 단일 용량으로든 다중 용량으로든 간에 동일한 몰 용량으로 투여했을 때, 흡수율 및 흡수 정도가 유의적인 차이를 보이지 않는 약제학적 등가물 또는 약제학적 대체물인 경우에 생등가성인 것으로 간주된다. 일부 항원-결합 단백질은, 이들이 흡수 정도에서는 등가성이지만 흡수율에서 등가성이 아니라면 등가물 또는 약제학적 대체물로 간주될 것이고, 그럼에도 등가성인 것으로 간주될 수 있는데, 그 이유는 흡수율에 있어서의 이러한 차이가 의도적인 것이고, 표지화에 반영되며, 예를 들어 만성 사용시 유효 체내 약물 농도의 달성에 필수적인 것이 아니고, 연구되는 특정 약물 제품에 대해 의학적으로 무의미한 것으로 간주되기 때문이다.
[00184] 하나의 구현예에서, 두 항원-결합 단백질은 이들의 안전성, 순도 및 효능에 있어서 임상적으로 의미있는 차이가 없는 경우에 생등가성이다.
[00185] 하나의 구현예에서, 두 항원-결합 단백질은 환자가 참조 제품과 생물학적 제품 간에 1회 이상 전환하는 경우라도 이러한 전환이 없는 연속 치료법에 비해 면역원성에 있어서의 임상적으로 유의적인 변화 또는 감소된 효능을 비롯한 부작용 위험의 증가가 예상되지 않는다면 생등가성이다.
[00186] 하나의 구현예에서, 두 항원-결합 단백질은 이들이 둘다 사용 조건 또는 조건들에 대한 공통의 작용 기전들에 의해 이러한 기전이 알려져 있는 정도로 작용하는 경우라면 생등가성이다.
[00187] 생등가성은 생체내 및 시험관내 방법으로 입증될 수 있다. 생등가성 측정은 예를 들어, (a) 항체 또는 이의 대사산물의 농도를 시간의 함수로서 혈액, 혈장, 혈청 또는 기타 생물학적 체액 내에서 측정하는, 사람 또는 기타 포유동물에서의 생체내 시험; (b) 사람 생체내 생체이용률 데이터와 상관성이 있고 이를 합리적으로 예측하는 시험관내 시험; (c) 항체 (또는 이의 표적)의 적절한 단시간의 약리학적 효과를 시간의 함수로서 측정하는 사람 또는 다른 포유동물에서의 생체내 시험; 및 (d) 항체의 안전성, 효능, 또는 생체이용률 또는 생등가성을 확립하는 잘 비교된 임상 시험을 포함한다.
[00188] 본원에 제시된 예시적 이특이적 항원-결합 분자의 생등가성 변이체는 예를 들어, 잔기 또는 서열의 다양한 치환을 수행하거나 생물학적 활성에 필요치 않은 말단 또는 내부 잔기 또는 서열을 결실시킴으로써 작제될 수 있다. 예를 들어, 생물학적 활성에 필수적이지 않은 시스테인 잔기는 복원시 불필요하거나 부정확한 분자내 디설파이드 브릿지의 형성을 방지하기 위해 결실시키거나 다른 아미노산으로 대체할 수 있다. 다른 문맥에서, 생등가성 항원-결합 단백질은 분자의 글리코실화 특징을 변형시키는 아미노산 변화를 포함하는 본원에 제시된 예시적 이특이적 항원-결합 분자의 변이체, 예를 들어, 글리코실화를 제거하거나 (eliminate) 제거하는 (remove) 돌연변이를 포함할 수 있다.
면역접합체
[00189] 본원의 개시내용은 세포독소, 화학치료학적 약물, 면역억제제 또는 방사능동위원소와 같은 치료학적 모이어티에 접합된 항원-결합 분자 (“면역접합체”)를 포괄한다. 세포독성 제제는 세포에 해로운 임의의 제제를 포함한다. 면역접합체를 형성하기에 적합한 세포독성 제제 및 화학치료학적 제제의 예는 당업계에 공지되어 있다(예를 들어, WO 05/103081을 참조한다).
치료학적 제형 및 투여
[00190] 본원의 개시내용은 본원 개시내용의 항원-결합 분자를 포함하는 약제학적 조성물을 제공한다. 본원 개시내용의 약제학적 조성물은 적합한 담체, 부형제, 및 적합한 이동, 전달, 관용성 등을 제공하는 다른 제제와 함께 제형화된다. 다수의 적당한 제형은 모든 약제학적 화학에 공지된 처방에서 발견될 수 있다: Remington's Pharmaceutical Sciences, Mack Publishing Company, Easton, PA. 이들 제형은 예를 들어, 산제, 페이스트, 연고, 젤리, 왁스, 오일, 지질, 지질(양이온성 또는 음이온성) 함유 소포(예를 들어 LIPOFECTIN™,Life Technologies, Carlsbad, CA), DNA 접합체, 무수 흡수 페이스트, 수중유 및 유중수 에멀젼, 에멀젼 카보왁스(다양한 분자량의 폴리에틸렌 글리콜 ), 반-고체 겔, 및 카보 왁스를 함유하는 반-고체 혼합물을 포함한다. 또한 문헌(Powell et al. "Compendium of excipients for parenteral formulations" PDA (1998) J Pharm Sci Technol 52:238-311)을 참조한다.
[00191] 환자에게 투여되는 항원-결합 분자의 용량은 환자의 연령 및 크기, 표적 질환, 병태, 투여 경로 등에 따라 다양할 수 있다. 바람직한 용량은 전형적으로 체중 또는 체표면적에 따라 계산된다. 본원의 개시내용의 이특이적 항원-결합 분자가 성인 환자에서의 치료 목적을 위해 사용되는 경우, 본원 개시내용의 이특이적 항원-결합 분자를 정상적으로 약 0.01 내지 약 20 mg/kg 체중, 보다 바람직하게 약 0.02 내지 약 7, 약 0.03 내지 약 5, 또는 약 0.05 내지 약 3 mg/kg 체중의 단일 용량으로 정맥내로 투여하는 것이 유리할 수 있다. 질환의 중증도에 따라, 치료의 빈도 및 지속시간을 조절할 수 있다. 이특이적 항원-결합 분자를 투여하기 위한 유효 용량 및 스케줄은 경험적으로 결정될 수 있고; 예를 들어, 환자 경과는 주기적 평가에 의해 모니터링될 수 있고 용량은 상응하게 조정된다. 더욱이, 용량의 종간 스케일링은 당업계에 널리 공지된 방법을 사용하여 수행될 수 있다(예를 들어, Mordenti et al., 1991, Pharmaceut. Res. 8:1351).
[00192] 다양한 전달 시스템이 공지되어 있고 이를 사용하여 본원 개시내용의 약제학적 조성물을 투여할 수 있고, 예를 들어, 리포좀 내 캡슐화, 미세입자, 미세캡슐, 돌연변이체 바이러스를 발현할 수 있는 재조합 세포, 수용체 매개된 세포내이입(문헌참조: 예를 들어, Wu et al., 1987, J. Biol. Chem. 262: 4429-4432). 도입 방법은 피내, 근육내, 복막내, 정맥내, 피하, 비강내, 경막외, 및 경구 경로를 포함하지만 이에 제한되지 않는다. 조성물은 임의의 간편한 경로에 의해, 예를 들어, 주입 또는 볼러스 주사에 의해, 상피 또는 점막피부 내벽(예를 들어, 경구 점막, 직장 및 장 점막 등)을 통한 흡수에 의해 투여될 수 있고 다른 생물학적 활성제와 함께 투여될 수 있다. 투여는 전신 또는 국소일 수 있다.
[00193] 본원 개시내용의 약제학적 조성물은 표준 니들 및 시린지로 피하 또는 정맥내 전달될 수 있다. 추가로, 피하 전달과 관련하여, 펜 전달 장치는 본원 개시내용의 약제학적 조성물을 전달하는데 용이하게 적용된다. 그러한 펜 전달 장치는 재사용가능하거나 1회용일 수 있다. 재사용가능한 펜 전달 장치는 일반적으로 약제학적 조성물을 함유하는 대체가능한 카트릿지를 사용한다. 일단 카트릿지 내 모든 약제학적 조성물이 투여되고 카트릿지가 속 빈 상태가 되면, 속 빈 카트릿지는 용이하게 처분될 수 있고 약제학적 조성물을 함유하는 새로운 카트릿지로 대체될 수 있다. 그렇게 한 후, 펜 전달 장치를 재사용할 수 있다. 1회용 펜 전달 장치에서는 대체가능한 카트릿지가 없다. 차라리, 1회용 펜 전달 장치는 장치내 저장소에 유지되는 약제학적 조성물로 미리 채워진다. 일단 저장소에 약제학적 조성물이 비워지면 전체 장치를 버린다.
[00194] 다양한 재사용 가능한 펜 및 자동주사 전달 장치는 본원 개시내용의 약학 조성물의 피하 전달에 적용된다. 이의 예로, 몇 가지만 들면, AUTOPEN™ [영국 우드스탁 소재의 오웬 멈포드 인코포레이티드(Owen Mumford, Inc.)사 제조], DISETRONIC™ 펜 [스위스 버그도프 소재의 디세트로닉 메디컬 시스템즈(Disetronic Medical Systems)사 제조], HUMALOG MIX 75/25™ 펜, HUMALOG™ 펜, HUMALIN 70/30™ 펜 [미국 인디애나주 인디애나폴리스 소재의 엘리 릴리 앤 컴퍼니(Eli Lilly and Co.)사 제조], NOVOPEN™ I, II 및 III [덴마트 코펜하겐 소재의 노보 노디스크(Novo Nordisk)사 제조], NOVOPEN JUNIOR™ (덴마트 코펜하겐 소재의 노보 노디스크사 제조), BD™ 펜 [미국 뉴저지주 플랭클린 레이크 소재의 벡톤 디킨슨(Becton Dickinson)사 제조], OPTIPEN™, OPTIPEN PRO™, OPTIPEN STARLET™ 및 OPTICLIK™ [독일 프랑크푸르트 소재의 사노피-아벤티스(sanofi-aventis)사 제조]를 포함하지만, 여기에 제한되는 것은 아니다. 본원 개시내용의 약제학적 조성물의 피하 전달에 응용되는 1회용 펜 전달 장치의 예는 단지 일부 거론하자면, SOLOSTAR™ 펜 (사노피-아벤티스), FLEXPEN™ (노보 노디스크) 및 KWIKPEN™ (엘리 릴리), SURECLICK ™ 자동주사기 [미국 캘리포니아주 싸우전드 오크스 소재의 암젠(Amgen)사 제조], PENLET ™ [독일 슈투트가르트 소재의 하셀마이어(Haselmeier)사 제조], EPIPEN [데이 엘.피.(Dey, L.P.)사 제조] 및 HUMIRA ™ 펜 [미국 일리노이주 애보트 파크 소재의 애보트 랩스(Abbott Labs)사 제조]를 포함하지만, 이에 제한되지 않는다.
[00195] 특정 상황에서, 약제학적 조성물은 조절 방출 시스템으로 전달될 수 있다. 하나의 구현예에서, 펌프가 사용될 수 있다(문헌참조: Langer, supra; Sefton, 1987, CRC Crit. Ref. Biomed. Eng. 14:201). 또 다른 구현예에서, 중합체 물질이 사용될 수 있고; 문헌(Medical Applications of Controlled Release, Langer and Wise (eds.), 1974, CRC Pres., Boca Raton, Florida)을 참조한다. 또 다른 구현예에서, 조절 방출 시스템은 조성물의 표적에 인접하게 위치할 수 있고 따라서 전신 용량의 분획만을 필요로 한다(문헌참조, 예를 들어, Goodson, 1984, in Medical Applications of Controlled Release, supra, vol. 2, pp. 115-138). 다른 조절 방출 시스템은 문헌 (Langer, 1990, Science 249:1527-1533)에 의한 검토에서 논의된다.
[00196] 주사가능한 제제는 정맥내, 피하, 피내 및 근육내 주사, 점적 주입 등을 위한 투여 형태를 포함할 수 있다. 이들 주사가능한 제제는 공지된 방법에 의해 제조될 수 있다. 예를 들어, 주사 가능한 제제는 예를 들어,, 주사를 위해 통상적으로 사용되는 멸균 수성 매질 또는 오일 매질 중에 상기된 바와 같은 항체 또는 이의 염을 용해시키거나, 현탁시키거나 유화시킴에 의해 제조될 수 있다. 주사를 위한 수성 매질로서 예를 들어, 생리학적 식염수, 글루코스를 함유하는 등장성 용액 및 다른 보조제 등이 있고, 이는 적당한 가용화제, 예를 들어, 알콜 (예를 들어, 에탄올), 폴리알콜 (예를 들어, 프로필렌 글리콜, 폴리에틸렌 글리콜), 비이온성 계면활성제[예를 들어, 폴리소르베이트 80, HCO-50 (수소화된 아주까리유의 폴리옥시에틸렌 (50 mol) 부가물)] 등과 조합하여 사용될 수 있다. 오일 매질로서, 예를 들어, 참깨유, 대두유 등이 사용되고, 이것은 벤질 벤조에이트, 벤질 알콜 등과 같은 가용화제와 조합하여 사용될 수 있다. 따라서 제조된 주사액은 바람직하게 적당한 앰푸울에 충전된다.
[00197] 유리하게, 상기된 경구 또는 비경구 사용을 위한 약제학적 조성물은 활성 성분의 용량에 맞도록 적합화된 유닛 용량 중 투여형으로 제조된다. 이러한 유닛 용량의 투여형으로는, 예를 들어, 정제, 환제, 캡슐, 주사제 (앰푸울), 좌제 등을 포함한다. 상기 함유된 상기 항체의 양은 일반적으로 유닛 용량의 투여형 당 약 5 내지 약 500 mg이고; 특히 주사제 형태에 있어서는, 상기 항체가 약 5 내지 약 100 mg으로, 다른 제형에 있어서는 약 10 내지 약 250 mg으로 함유되는 것이 바람직하다.
항원-결합 분자의 치료학적 용도
[00198] 본원의 개시내용은 대상체에서 스타필로코커스 종의 성장을 억제하는 방법을 포함하고, 상기 방법은 보체 성분(예를 들어,C1q) 및 스타필로코커스 종 표적 항원(예를 들어, IsdB)에 특이적으로 결합하는 이특이적 항원-결합 분자를 포함하는 치료학적 조성물을 이를 필요로 하는 대상체에게 투여함을 포함한다. 치료학적 조성물은 본원에 기재된 바와 같은 임의의 항체 또는 이의 단편 또는 이특이적 항원-결합 분자 및 약제학적으로 허용되는 담체 또는 희석제를 포함할 수 있다. 본원에 사용된 바와 같은 표현 "이를 필요로 하는 대상체"는 감염의 하나 이상의 증상 또는 징후를 나타내거나 스타필로코커스 종의 억제 또는 감소가 이득이 되는 사람 또는 비-사람 동물을 의미한다.
[00199] 본원 개시내용의 항체 및 이특이적 항원-결합 분자 (및 이들을 포함하는 치료학적 조성물)는 특히 스타필로코커스 종의 성장의 억제, 감소가 이득이 되는 임의의 질환 또는 장애를 치료하기 위해 유용하다. 특히, 본원 개시내용의 항-IsdB x 항-C1q 이특이적 항원-결합 분자는 스타필로코커스 종과 연관되거나 이에 의해 매개되는 임의의 질환 또는 장애의 치료, 예방 및/또는 개선을 위해 사용될 수 있다. 본원 개시내용의 치료학적 방법이 성취되는 작용 기전은 이펙터 세포의 존재하에, 예를 들어, CDC, 아폽토시스, ADCC, 식세포작용에 의해 또는 이들 기전의 2개 이상의 조합에 의해 IsdB를 발현하는 세포의 사멸을 포함한다. 본원의 개시내용의 이특이적 항원-결합 분자를 사용하여 억제되거나 사멸될 수 있는, IsdB 또는 다른 표적 항원을 발현하는 세포는 예를 들어, 스타필로코커스 에피더미디스, 스타필로코커스 아우레우스, 스타필로코커스 루그두넨시스, 및/또는 스타필로코커스 사프로피티쿠스를 포함한다. 구현예에서, 스타필로코커스 종은 메티실린 내성 스타필로코커스 아우레우스와 같은 항생제 내성 종이다.
[00200] 본원의 개시내용의 항원-결합 분자를 사용하여 스타필로코커스 종, 특히, 항생제 내성 종에 의한 감염과 연관된, 피부 감염, 봉와직염, 폐렴, 뇌수막염, 요로 감염, 독성 쇼크 증후군, 심내막염, 심막염, 골수염, 균혈증 또는 패혈증을 포함하는 질환 또는 장애를 치료할 수 있다. 본원 개시내용의 항원-결합 분자를 또한 사용하여 보철 이식을 포함하는 수술과 같은 수술 과정 동안에 또는 수술 과정 후 발생할 수 있는 스타필로코커스 종에 의한 감염을 예방할 수 있다. 특정 구현예에서, 보철은 팔 또는 다리와 같은 의지 (prosthetic limb)일 수 있다. 특정 구현예에서, 보철은 고관절 대체물일 수 있다. 특정 구현예에서, 보철은 이에 제한되지 않지만 눈 보철, 실리콘 손, 손가락, 유방, 발가락, 발톱 또는 안면 이식과 같은 성형용 보철일 수 있다.
조합 치료요법 및 제형
[00201] 본원의 개시내용은 하나 이상의 추가의 치료학적 제제와 조합된, 본원에 기재된 예시적 항체 및 이특이적 항원-결합 분자를 포함하는 약제학적 조성물을 투여함을 포함한다. 본원 개시내용의 항원-결합 분자와 조합될 수 있거나 조합하여 투여될 수 있는 예시적 추가의 치료학적 제제는 항생제, 스타필로코커스 항원에 결합하는 항체, 스타필로코커스 독소에 결합하는 항체, 사람 또는 시노몰구스 C1q에 결합하는 항체, 스타필로코커스 종에 특이적인 백신, 항체 약물 접합체 (예를 들어, 항생제에 접합된 이특이적 항체) 또는 이의 조합을 포함한다.
[00202] 추가의 치료학적 활성 성분(들)은 본원 개시내용의 항원-결합 분자의 투여 직전, 이와 동시에 또는 직후에 투여될 수 있다(본원 개시내용의 목적을 위해, 상기 투여 용법은 추가의 치료학적 활성 성분과 “조합된” 항원-결합 분자의 투여를 고려한다).
[00203] 본원의 개시내용은, 본원 개시내용의 항원-결합 분자가 본원의 다른 곳에 기재된 바와 같이 추가의 치료적 활성 성분(들) 중 하나 이상과 함께 제형화된 약제학적 조성물을 포함한다.
투여 용법
[00204] 본원 개시내용의 특정 구현예에 따라, 항원-결합 분자 (예를 들어, IsdB 및 C1q에 특이적으로 결합하는 이특이적 항원-결합 분자)는 한정된 시간 동안 대상체에게 투여될 수 있다. 본원 개시내용의 상기 양상에 따른 방법은 본원 개시내용의 항원-결합 분자의 다중 용량을 순차적으로 대상체에게 투여함을 포함한다. 본원에 사용된 바와 같은 "순차적으로 투여하는"이라는 용어는, 항원-결합 분자의 각 용량을 서로 다른 시점에, 예를 들면, 소정의 간격(예컨대, 수시간, 수일, 수주 또는 수개월)으로 서로 다른 날짜에 대상체에게 투여한다는 것을 의미한다. 본원의 개시내용은 항원-결합 분자의 단일 초기 용량에 이어서 항원-결합 분자의 하나 이상의 2차 용량 및 임의로 항원-결합 분자의 하나 이상의 3차 용량을 환자에게 순차적으로 투여함을 포함하는 방법을 포함한다.
[00205] “초기 용량", "2차 용량" 및 "3차 용량"이라는 용어는 본원 개시내용의 항원-결합 분자 투여의 시간 순서를 언급한다. 따라서, "초기 용량"은 치료 용법의 개시에 투여되는 용량(또한 “기준선 용량”으로서 언급됨)이고; "2차 용량"은 초기 용량 후 투여되는 용량이고; "3차 용량"은 2차 용량 후 투여되는 용량이다. 상기 초기, 2차 및 3차 용량은 모두 동일한 양의 항원-결합 분자를 함유할 수 있으나, 일반적으로 투여 빈도의 관점에서는 서로 상이할 수 있다. 그러나, 특정 구현예에서, 상기 초기, 2차 및/또는 3차 용량에 함유된 항원-결합 분자의 양은 치료 과정 동안 서로 상이하다 (예를 들면, 적절히 상향 또는 하향 조절됨). 특정 구현예에서, 2회 이상(예를 들면, 2회, 3회, 4회 또는 5회) 용량을 "부하 용량"으로서 치료 용법의 시작시 투여한 후, 후속 용량을 보다 적은 빈도로 투여한다(예를 들면, "유지 용량").
[00206] 본원 개시내용의 하나의 예시적인 구현예에서, 각각의 2차 및/또는 3차 용량은 직전 선행 용량 이후 1시간 내지 26시간 (예를 들어, 1, 1½, 2, 2½, 3, 3½, 4, 4½, 5, 5½, 6, 6½, 7, 7½, 8, 8½, 9, 9½, 10, 10½, 11, 11½, 12, 12½, 13, 13½, 14, 14½, 15, 15½, 16, 16½, 17, 17½, 18, 18½, 19, 19½, 20, 20½, 21, 21½, 22, 22½, 23, 23½, 24, 24½, 25, 25½, 26, 26½시간 또는 그 이상) 후에 투여한다. 본원에 사용된 바와 같은 "직전 선행 용량”이라는 용어는, 다중 용량 투여의 순서에 있어서, 개입된 용량(intervening dose)없이 순서상 바로 다음 용량의 투여 전에 환자에게 투여되는 항원-결합 분자의 용량을 의미한다.
[00207] 본원 개시내용의 상기 양상에 따른 방법은 항원-결합 분자 (예를 들어, IsdB 및 C1q에 특이적으로 결합하는 이특이적 항원-결합 분자)의 임의의 수의 2차 및/또는 3차 용량을 환자에게 투여함을 포함할 수 있다. 예를 들어, 특정 구현예에서, 단일 2차 용량만이 환자에게 투여된다. 다른 구현예에서, 2개 이상(예를 들어, 2, 3, 4, 5, 6, 7, 8 이상)의 2차 용량이 환자에게 투여된다. 또한, 특정 구현예에서, 단일 3차 용량만이 환자에게 투여된다. 다른 구현예에서, 2개 이상(예를 들어, 2, 3, 4, 5, 6, 7, 8 이상)의 3차 용량이 환자에게 투여된다.
[00208] 다중 2차 용량을 포함하는 구현예에서, 각각의 2차 용량은 다른 2차 용량과 동일한 빈도로 투여될 수 있다. 예를 들어, 각각의 2차 용량은 직전 선행 용량 후 1 내지 2주에 환자에게 투여될 수 있다. 유사하게, 다중 3차 용량을 포함하는 구현예에서, 각각의 3차 용량은 다른 3차 용량과 동일한 빈도로 투여될 수 있다. 예를 들어, 각각의 3차 용량은 직전 선행 용량 후 2 내지 4주에 환자에게 투여될 수 있다. 대안적으로, 2차 및/또는 3차 용량이 환자에게 투여되는 빈도는 치료 용법의 과정에 따라 다양할 수 있다. 투여 빈도는 또한 임상 조사 후 개별 환자의 요구에 의존하여 담당의에 의해 치료 과정 동안에 조정될 수 있다.
실시예
[00209] 하기의 실시예는 당업자에게 본원 개시내용의 방법 및 조성물을 제조하고 사용하는 법의 완전한 기재 및 기술을 제공하기 위해 제시된 것이고 발명자가 이들의 본원 개시내용으로서 간주하는 것의 범위를 제한하는 것으로 의도되지 않는다. 사용되는 숫자(예를 들어, 양, 온도 등)와 관련하여 확실히 정확하게 하기 위해 노력하였지만 일부 실험 오차 및 편차가 고려되어야만 한다. 달리 지정되지 않는 경우, 부는 중량부이고, 분자량은 평균 분자량이고, 온도는 섭씨 온도이고 압력은 대기압 또는 대기압 근처이다.
실시예 1. 항-C1q 항체의 제조
[00210] 항-C1q 항체는 사람 보체 성분 1q (C1q)로 VELOCIMMUNE® 마우스 (즉, 사람 면역글로불린 중쇄 및 카파 경쇄 가변 영역을 암호화하는 DNA를 포함하는 조작된 마우스; US6,596,541을 참조한다)를 면역화시킴에 의해 수득하였다. 사람 보체 C1q는 3개의 특유한 서브유닛을 포함하는 6량체이다: A(29 kDa); B(26 kDa); 및 C(22 kDa). 서브유닛 A의 예시적 서열은 승인 번호 NP_057075의 아미노산 1-245(서열번호 170)에서 발견된다. 서브유닛 B의 예시적 서열은 승인 번호 NP_000482의 아미노산 1-253(서열번호 171)에서 발견된다. 서브유닛 C의 예시적 서열은 승인 번호 NP_758957의 아미노산 1-245 (서열번호 172)에서 발견된다. 사람 C1q는 또한 제조원 (Quidel)과 같은 공급원으로부터 시판된다. 구현예에서, 제조원 (Quidel)로부터 시판되는 사람 C1q는 면역원으로서 사용되었다. 항체 면역 반응은 C1q-특이적 면역검정에 의해 모니터링하였다.
[00211] 수개의 완전한 사람 항-C1q 항체는 US7,582,298에 기재된 바와 같이, 골수종 세포와의 융합 없이 VELOCIMMUNE® 마우스 기원의 항원-양성 B 세포로부터 직접 단리하였다. 항체는 전형적으로 본원에서 하기의 명명법에 따라 지칭된다: Fc 접두사 (예를 들어, "H1H," "H1xH" 등)를 기재한 후, 수치 식별자 (예를 들어, 표 1에 나타낸 바와 같이 "2712", "2692", 등)를 기재한 후, "P," 또는 "D" 접미사를 기재함. 명칭 "H1 X H"은 Fc가 단백질 A로의 결합을 배제하기 위해 변형되고/돌연변이된 항체를 언급한다. 단백질 A에 결합하지 않는 항체를 제공하는 Fc 도메인의 예시적 변형은 본원의 다른 곳에 기재되어 있다. 본원에서 사용된 항체의 명칭에서 H1H 및 H1xH 접두사는 상기 항체의 특정 Fc 영역의 이소형을 지적한다. 예를 들어, "H1H" 항체는 사람 IgG1 Fc를 갖고 "H1xH" 항체는 돌연변이된 Fc를 갖는다(문헌참조: US8,586,713). 모든 가변 영역은 항체 명칭에서 처음 “H”에 의해 지칭되는 바와 같이 완전히 사람이다. 당업자라면 누구나 알 수 있는 바와 같이, 특정 Fc 이소형을 갖는 항체는 상이한 Fc 이소형을 가진 항체 (예를 들어, 마우스 IgG1 Fc를 갖는 항체는 사람 IgG4 등을 갖는 항체 등으로 전환될 수 있음)로 전환될 수 있지만, 어떠한 경우가 됐던, (CDR을 포함하는) 가변 도메인 - 표 1에서 나타낸 수치 식별자로 표시됨 - 은 동일하게 유지될 것이고, 결합 성질은 Fc 도메인의 성질에 관계없이 동일하거나 실질적으로 유사할 것으로 기대된다.
[00212] 항체가 일단 단리되면, 핵산 및 아미노산 서열을 수득하였다. 항-C1q 항체 중쇄 가변 영역(HCVR), 중쇄 상보성 결정 영역 1 (HCDR1), 중쇄 상보성 결정 영역 2 (HCDR2), 중쇄 상보성 결정 영역 3 (HCDR3), 경쇄 가변 영역 (LCVR), 경쇄 상보성 결정 영역 1 (LCDR1), 경쇄 상보성 결정 영역 2 (HCDR2), 경쇄 상보성 결정 영역 3 (HCDR3)의 아미노산 서열 식별기호는 하기 표 1에 나타낸다. 핵산 아미노산 식별기호는 표 2에 나타낸다.
[표 1]

[표 2]

실시예 2. 항 -IsdB 항체의 제조
[00213] 항-IsdB 항체는 스타필로코커스 아우레우스 기원의 헴 취득 단백질 IsdB로부터 유래된 항원(IsdB)으로 VELOCIMMUNE® 마우스 (즉, 사람 면역글로불린 중쇄 및 카파 경쇄 가변 영역을 암호화하는 DNA를 포함하는 조작된 마우스; US6,596,541을 참조한다)를 면역화시킴에 의해 수득하였다. 항원의 구현예는 승인 번호 WP__063557416의 아미노산 41 내지 613을 포함한다. IsdB 항원의 아미노산 서열의 하나의 예는 서열번호 169의 아미노산 3 내지 574이다. 항체 면역 반응은 IsdB-특이적 면역검정에 의해 모니터링하였다.
[00214] 수개의 완전한 사람 항-IsdB 항체는 US7,582,298에 기재된 바와 같이, 골수종 세포로의 융합 없이 항원-양성 B 세포 VELOCIMMUNE® 마우스로부터 직접 단리하였다. 항체가 일단 단리되면, 핵산 및 아미노산 서열을 수득하였다. 항-C1q 항체 중쇄 가변 영역(HCVR), 중쇄 상보성 결정 영역 1 (HCDR1), 중쇄 상보성 결정 영역 2 (HCDR2), 중쇄 상보성 결정 영역 3 (HCDR3), 경쇄 가변 영역 (LCVR), 경쇄 상보성 결정 영역 1 (LCDR1), 경쇄 상보성 결정 영역 2 (HCDR2), 경쇄 상보성 결정 영역 3 (HCDR3)의 아미노산 서열 식별기호는 하기 표 3에 나타낸다. 핵산 아미노산 서열 식별기호는 표 4에 나타낸다.
[표 3]

[표 4]

실시예 3. 이특이적 항-C1q 및 항-IsdB 이특이적 항체의 제조
[00215] 항-C1q-특이적 결합 도메인 및 항-IsdB 특이적 결합 도메인을 포함하는 이특이적 항체는 표준 방법을 사용하여 작제하였고, 여기서, 항-C1q 항체로부터의 중쇄, 및 경쇄는 항-IsdB 항체로부터의 중쇄, 및 경쇄와 조합된다. 본 실시예의 이특이적 항체를 작제하기 위해 사용되는 항-C1q 항체는 실시예 1에 기재된 바와 같이 VelocImmune® 마우스를 면역화시킴에 의해 수득하였다. 본 실시예의 이특이적 항체를 작제하기 위해 사용되는 항-IsdB 항체는 실시예 2에 기재된 바와 같이 수득하였다.
[00216] 본 실시예에 따라 생성된 이특이적 항체는 2개의 별개의 항원-결합 도메인 (즉, 결합 아암), D1 및 D2를 포함한다. 구현예에서, 제1 항원-결합 도메인 (D1)은 경쇄 가변 영역 (LCVR)과 쌍을 이루는 항-IsdB 항체로부터 유래된 중쇄 가변 영역 (HCVR)("IsdB-VH")을 포함하고, 스타필로코커스 아우레우스 IsdB 단백질을 특이적으로 인지하는 항원-결합 도메인을 생성한다. 구현예에서, 제2 항원-결합 도메인 (D2)은 경쇄 가변 영역 (LCVR)과 쌍을 이루는 항-C1q로부터 유래된 중쇄 가변 영역 (HCVR)("Clq-VH")을 포함하고, 사람 C1q을 특이적으로 인지하는 항원-결합 도메인을 생성한다. 당업자는 이특이적 항체가 단일쇄 Fv, 이중 친화성 재표적화 단백질, 탠덤 디아바디, 크놉 및 정공(hole) 쌍 형성, 전하 쌍 형성, 교차 Mab, 이중 가변 도메인 Ig, s-Fab, 및 Fv-Fc를 포함하는 많은 다른 포맷으로 작제될 수 있다. 아암 및 이특이적 항체 각각의 식별기호의 목록은 표 5에 제공된다. 이특이적 항체의 각각의 아암의 중쇄 가변 도메인 및 CDR의 아미노산 서열 식별기호는 표 6에 나타낸다.
[표 5]

[표 6]
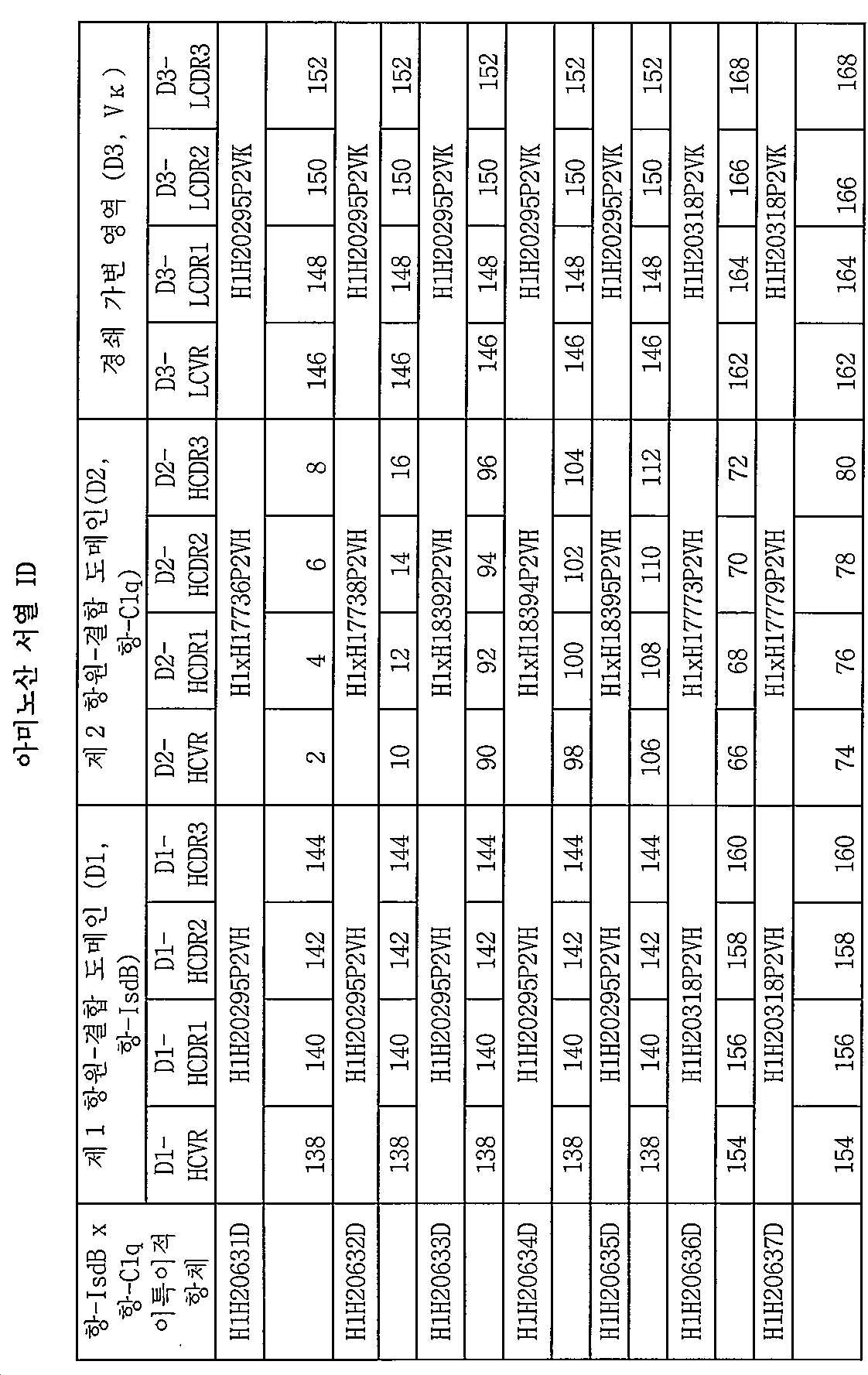
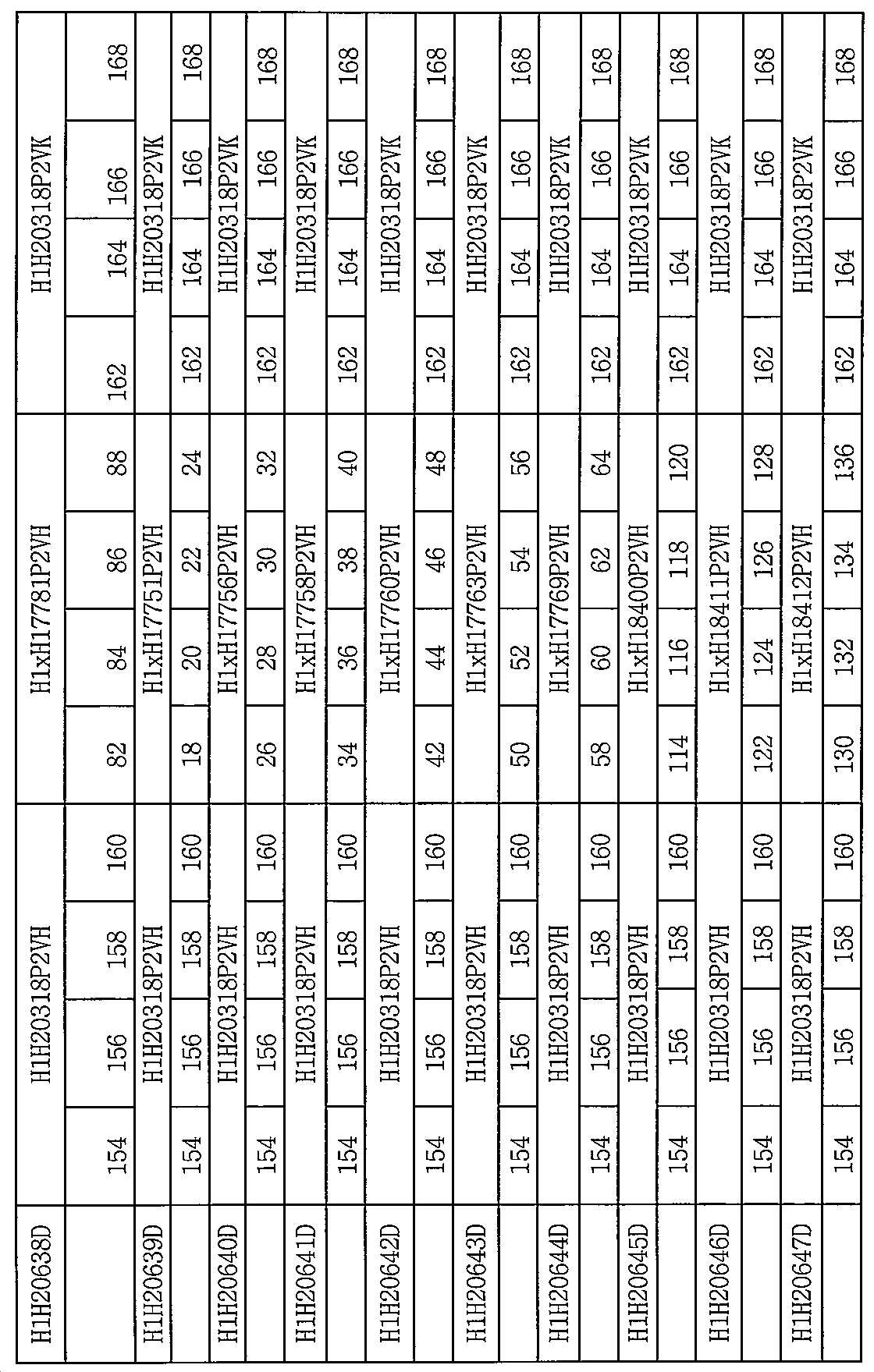
실시예 4 25℃ 및 37℃에서 항-IsdB x 항-C1q 이특이적 항체로의 사람 C1q 및 IsdB-6xHis 결합의 동력학
[00217] 정제된 항-IsdB x 항-C1q 이특이적 항체의 각각의 C1q 및 IsdB 아암으로의 사람 C1q (Quidel) 및 IsdB-6xHis (REGN2655; 또한 서열번호 169를 참조한다) 결합에 대한 평형 해리 상수 (KD 값)는 실시간 표면 플라스몬 공명 바이오센서 (Biacore 4000)를 사용하여 결정하였다. 상기 CM5 Biacore 센서 표면을 단일클론 마우스 항-사람 Fc 항체 [GE 헬스케어(Healthcare), # BR-1008-39]와의 아민 커플링으로 유도체화시켜 정제된 항-IsdB x 항-C1q 이특이적 항체를 포획하였다. 모든 Biacore 결합 연구를 0.01M HEPES pH 7.4, 0.15M NaCl, 3mM EDTA, 0.05% v/v 계면활성제 P20으로 구성된 완충액 (전개 완충액) 중에서 수행하였다. 사람 혈청으로부터 정제된 본래의 사람 보체 성분 C1q 단백질은 제조원 (Quidel)로부터 구입하였고 여기서 hC1q로 언급된 것에 대해 0.6nM 내지 20nM의 범위의 농도에서 시험하였다. IsdB-6xHis로서 여기서 언급된 것에 대해 헥사히스티딘 태그와 함께 발현된 재조합 세균 IsdB(IsdB-6xHis;REGN2655; 서열번호169; WP_063557416.1)은 0.37nM - 90nM 범위의 농도에서 시험하였고 30μL/분의 유속으로 항-IsdB x 항-C1q 이특이적 항체-포획된 표면 상에 주입하였다. 항체-시약 결합은 3분동안 모니터링하였고 해리는 5분동안 모니터링하였다. 모든 결합 동력학 실험은 25℃ 또는 37℃에서 수행하였다. 동력학 결합(ka) 및 해리(kd) 속도 상수는 Scrubber 2.0c 곡선 피팅 소프트웨어를 사용하여 실시간 센서그램을 1:1 결합 모델에 피팅함에 의해 결정하였다. 결합 해리 평형 상수 (KD) 및 해리 반감기 (t½)는 하기와 같이 동력학 속도 상수로부터 계산하였다:
K
D
(M) =
 , 및 t½ (min) =
, 및 t½ (min) =

NB는 실험 조건하에서 관찰된 어떠한 결합을 언급하지 않는다.
결과 및 결론
[00218] 25℃에서 표 7에 나타낸 바와 같이, 본원의 개시내용의 모든 17 항-IsdB x 항-C1q 항체는 11.4pM - 2.12nM 범위의 KD 값으로 hC1q에 결합한다. 25℃에서 표 8에 나타낸 바와 같이, 본원의 개시내용의 모든 17 항-IsdB x 항-C1q 항체는 1.70nM - 12.3nM 범위의 KD 값으로 IsdB-6xHis에 결합한다. 표 9에 나타낸 바와 같이, 37℃에서 본원의 개시내용의 모든 17 항-IsdB x 항-C1q 항체는 50.1pM - 5.01nM 범위의 KD 값으로 hC1q에 결합한다. 표 10에 나타낸 바와 같이, 37℃에서 본원의 개시내용의 모든 17 항-IsdB x 항-C1q 항체는 3.33nM - 21.5nM 범위의 KD 값으로 IsdB-6xHis에 결합한다. 이소형 (음성) 대조군 항체 (REGN1932)로의 hC1q 및 IsdB-6xHis의 결합은 상기된 실험 조건하에서 관찰되지 않았다.
[표 7]

[표 8]

[표 9]

[표 10]

실시예 5 차단 ELISA
[00219] 보체 성분 C1q는 항원과 복합체를 형성함에 따라서 보체 캐스케이드를 개시하는 면역글로불린을 인지하고 이에 결합하는 순환 6량체이다. 항-C1q 항체를 단리하고 후속적으로 사람 C1q, 및 헤모글로빈으로부터 철을 제거하는데 관여하는 스타필로코커스 아우레우스의 철-조절된 표면 결정인자 단백질 B인 IsdB로의 이중 결합을 갖는 이특이적 항체로서 조작하였다. 본래의 사람 보체 성분 C1q의 이의 천연 리간드, 사람 IgG1, 사람 IgG2, 사람 IgG3 및 사람 IgM으로의 결합을 차단시키는 항-IsdB x 항-C1q 이특이적 항체의 능력은 경쟁 샌드위치 ELISA 검정을 사용하여 측정하였다.
방법
[00220] 사람 혈청으로부터 정제된 본래의 사람 보체 C1q 단백질은 제조원 (Quidel) 으로부터 구입하였고 바이오틴-표지화(biot-hC1q)시켰다. 사람 IgG1 카파 (hIgG1-k, Sigma Aldrich), 사람 IgG2 카파 (hIgG2-k, EMD Millipore), 사람 IgG3 카파 (hIgG3-k, EMD Millipore) 및 사람 IgM 전체 분자 (Jackson ImmunoResearch)는 사람 혈장 또는 뇨로부터 정제하였다. 항-IsdB x 항-C1q 이특이적 항체에 대한 음성 이소형 대조군으로서, 항-Fel d 1 사람 IgG1 항체(REGN 1932)는 코팅된 면역글로불린으로의 기본(background) 결합을 위해 포함시켰다. 시험된 항체는 표 6에 나타낸다.
[00221] 실험은 하기의 과정을 사용하여 수행하였다. 사람 면역글로불린은 4℃에서 밤새 96웰 미세역가 플레이트 상에서 PBS 중에서 hIgG1-k, hIgG2-k, hIgG3-k에 대해 2 μg/mL의 농도 또는 hIgM에 대해 5 μg/mL의 농도로 별도로 코팅시켰다. 비특이적 결합 부위는 후속적으로 PBS 중에서 BSA의 0.5% (w/v)를 사용하여 차단시켰다. 또 다른 미세역가 플레이트 상에서, 일정 양의 biot-hC1q 단백질 (hIgG1-k, hIgG3-k 차단에 대해 30pM 또는 hIgG2-k, hIgM 차단에 대해 6nM)은 농도 범위 (hIgG1-k, hIgG3-k 차단에 대해 508 fM - 30 nM 또는 hIgG2-k, hIgM 차단에 대해 10 pM - 600 nM)에서 항-IsdB x 항-C1q 이특이적 항체 또는 이소형 대조군 항체와 혼합하였다. 항체 억제 검정을 위한 일정 농도의 biot-hC1q는 플레이트-코팅된 hIgG1-k, hIgG2-k, hIgG3-k, 또는 hIgM에 대한 biot-hC1q 개별 결합 곡선의 선형 부분 내 대략 중간 지점으로부터 선택하였다.
[00222] 어떠한 일정한 hC1q를 갖지 않은 샘플은 배경 신호를 결정하기 위해 포함시켰고 어떠한 항체를 갖지 않지만 30pM 또는 6nM biot-hC1q 단백질을 함유하는 용액을 또한 시험하여 일정한 결합 신호만을 측정하였다. 30pM의 일정 농도의 biot-hC1q 단백질을 갖는 항체-단백질 복합체는 ThIgG1-k 또는 hIgG3로 코팅된 미세역가 플레이트에 전달하였고, 6nM 일정 농도의 biot-hC1q를 갖는 항체-단백질 복합체는 hIgG2-k 또는 hIgM 코팅된 플레이트에 전달하였다. 실온에서 1시간 항온처리 후, 웰은 세척하고 플레이트-결합된 biot-hC1q는 서양고추냉이 퍼옥시다제 (Thermo Scientific)와 접합된 스트렙타비딘으로 검출하였다. 이어서 플레이트는 제조업자의 추천에 따라 TMB 기질 용액 (BD Biosciences)을 사용하여 전개하였고 450nm에서의 흡광도는 Victor X4 플레이트 판독기(PerkinElmer)상에서 측정하였다.
[00223] 데이터 분석은 Prism™ 소프트웨어 (GraphPad) 내에서 S자형 용량-반응 모델을 사용하여 수행하였다. C1q의 면역글로불린으로의 결합의 50%를 감소시키기 위해 요구되는 항체의 농도로서 정의되는 계산된 IC50 값은 차단 효능의 지표로서 사용하였다. 각각의 검정에서 시험된 항체의 최대 농도에서 퍼센트 차단을 계산하였다. 상기 계산에서, 항체의 존재 없이 30pM 또는 6nM의 biot-hC1q의 샘플의 결합 신호는 100% 결합 또는 0% 차단으로서 언급되었고; biot-hC1q 또는 항체 부재의 완충액 샘플의 배경 신호는 0% 결합 또는 100% 차단으로서 언급되었다.
결과 및 결론
[00224] 차단 결과는 표 11에 요약하고 항체는 개별 또는 다중 코팅 표면으로의 C1q 결합을 차단하는 이들의 능력을 기준으로 3개의 그룹으로 구성된다. % 차단은 모든 항체에 대해 보고하고 컬럼 표제에 지적된 바와 같이 각각의 검정에서 시험된 최고 농도에서 계산한다. 음성 최대 차단 %는 항체의 존재하에 검출된 biot-hC1q 결합의 증가를 지적한다. IC50 값은 hIgG1-k, hIgG2-k, IgG3-k 또는 IgM으로의 C1q 결합의 >50%를 차단하는 항체에 대해서만 나타내고 마이너스 기호는 최고 시험된 농도에서 < 50%를 차단하는 항체를 지정한다. IC50 값은 Prism™ 소프트웨어 4-파라미터 로지스틱 수학식을 피팅할 수 없는 억제 곡선을 갖는 항체에 대해 비결정적인 (INC)으로서 보고된다. 시험된 개시내용의 17개 항-IsdB x 항-C1q 이특이적 항체 중 9개는 hIgG1-k, hIgG2-k, hIgG3-k 및 hIgM 리간드로의 >50% biot-hC1q 단백질 결합을 차단하는 것으로서 동정되었다. 이들 항-IsdB x 항-C1q 이특이적 항체는 hIgG1-k 및 hIgG3-k로의 30pM biot-hC1q 결합 및 hIgG2-k 및 hIgM으로의 6nM biot-C1q 결합을 차단시키고 IC50 값은 110 pM 내지 83 nM 범위이고 % 차단은 53% 내지 99% 범위이다.
[표 11]
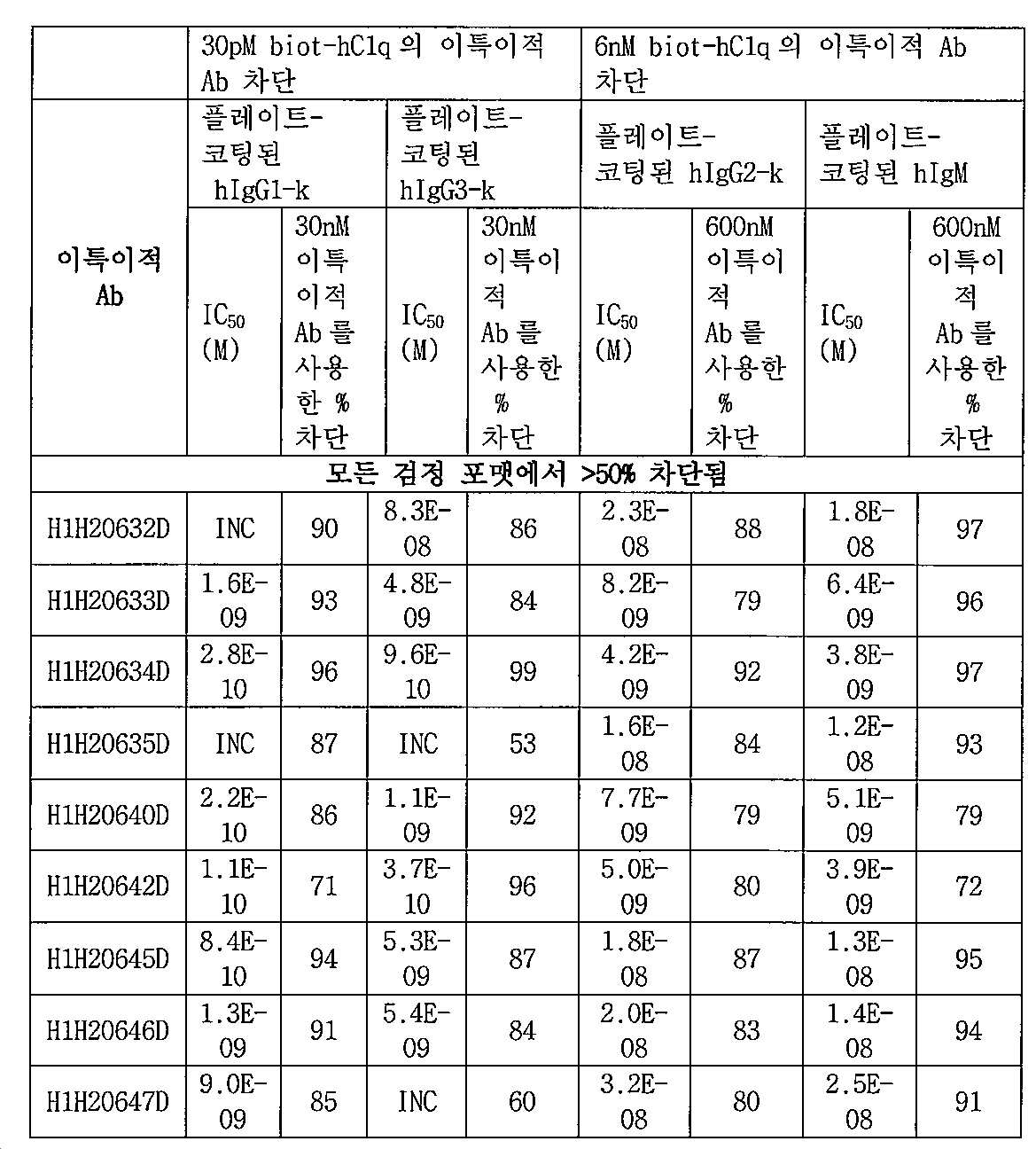

[00225] 시험된 항체의 최고의 농도에서, 17 항-IsdB x 항-C1q 이특이적 항체 중 5개는 시험된 hC1q 리간드 중 단지 일부로의 >50% biot-hC1q 결합을 차단시켰다. 이들 항체 중 하나 (H1H20631D)는 hIgG1-k 및 hIgG3-k로의 30pM biot-hC1Q 결합 및 hIgG2-k로의 6nM biot-hC1q 결합을 차단시켰고 IC50 값은 8.8 nM 내지 21 nM 범위이고 % 차단은 51% 내지 78%이다. 200nM의 농도에서 상기 항-IsdB x 항-C1q 이특이적 항체는 67%의 % 차단과 함께 hIgM으로의 6nM biot-hC1q 결합을 차단시켰지만, 600nM의 최고 시험된 농도에서, 이것은 38%의 차단과 함께 hIgM으로의 biot-hC1q 결합을 차단시켰다. 3개의 항체(H1H20639D, H1H20643D, 및 H1H20644D)는 hIgG1-k로의 30pM biot-C1q 결합 및 hIgG2-k 및 hIgM으로의 6 nM biot-hC1q 결합에 대해서만 >50%를 차단시켰고 IC50 값은 24 nM 내지 71 nM의 범위이고 % 차단은 64% 내지 95%이다. 또 다른 항체(H1H20637D)는 hIgG2-k 및 hIgM으로의 6 nM biot-hC1q 결합에 대해서만 >50%를 차단시켰고 IC50 값은 71 nM 내지 100 nM의 범위이고 % 차단은 70% 내지 88%이다.
[00226] 17개 항-IsdB x 항-C1q 이특이적 항체 중 3개 (H1H20636D, H1H20638D, H1H20641D) 및 관련없는 이소형 대조군 항체는 hIgG1-k, hIgG2-k, hIgG3-k 및 hIgM으로의 biot-hC1q 결합의 <50%을 차단시켰다.
[00227] 이특이적 항체에 의한 사람 C1q의 항체로의 결합 차단은 이특이적 항체의 대부분이 적어도 부분적으로 면역글로불린 분자 상의 부위로 C1q의 결합을 차단함을 지적한다.
실시예 6 전형적 경로 용혈 검정
[00228] 보체계는, 활성화시 표적 세포 용해를 유도하여 옵소닌작용을 통한 식세포작용을 촉진하는 일군의 단백질이다. 보체 성분 C1q는 1개의 스톡 및 6개 줄기/헤드를 함유하는 6량체를 형성하는 410 kDa 단백질이다. 각각의 줄기/헤드는 3개의 폴리펩타이드 (A, B, C)를 함유한다. C1q A, B, C 단백질은 각각 길이가 245, 253, 및 245이다. 각각의 쇄는 시스테인 잔기를 함유하는 N-말단 영역에 이어서 콜라겐 유사 영역 (CLR) 및 C-말단 (구형 헤드 영역)을 갖는다. C1q는 C1r의 2개의 분자 및 C1s의 2개의 분자와 복합체를 형성하고 C1 복합체로서 언급된다.
[00229] 보체는 3가지 주요 경로에 의해 활성화된 일련의 단백질용해 단계를 통해 활성화된다: 전형적으로 면역 복합체에 의해 활성화되는 전형적 경로(CP), 보호되지 않은 세포 표면에 의해 유도될 수 있는 대체 경로(AP), 및 만노스 결합 렉틴 (MBL) 경로. 전형적 경로는 IgM 및 IgG의 Fc 영역으로의 C1q/r2/s2 결합 또는 병원체 표면에 직접적인 결합에 의해 개시되고, 이는 세린 프로테아제 C1s를 활성화시키는 세린 프로테아제 C1r의 자가활성화를 유도하고 이어서 이는 C2 및 C4를 절단하고/활성화시키고 이어서 C3 및 C5의 절단을 유도하고, 이는 궁극적으로 막 공격 복합체 (MAC)를 생성하여 세포 용해를 유도한다.
[00230] 전형적 경로 (CP) 검정은 전형적 보체 경로의 활성화에 대한 스크리닝 검정이고, 이는 경로 중의 임의의 성분의 감소, 부재 및/또는 비활성에 대하여 민감하다. 상기 CP 검정은 토끼 항-양 적혈구 항체 (용혈소)로 미리 코팅된 양 적혈구 (SRBC)를 용해시키는 전형적 경로의 혈청 보체 성분의 기능적 능력을 시험한다. 항체-코팅된 SRBC를 시험 혈청으로 항온처리하는 경우, 보체의 전형적 경로는 활성화되어 용혈이 발생한다. 보체 성분 (예를 들어 C1q)이 부재인 경우, 퍼센트 용혈 활성은 0이 될 것이고; 전형적 경로의 하나 이상의 성분이 감소되는 경우, CP 활성은 감소될 것이다 (Giclas PC 1994). 본 검정은 항-IsdB x 항-C1q 항체의 특징 분석 및 스크리닝을 위해 사용된다.
방법
[00231] 목적하는 수의 양 SRBC는 GVB++ 완충액 (Ca 및 Mg를 갖는 젤라틴 베로날 완충액(Gelatin Veronal Buffer)(제조원: CompTech))에서 세척하고 1x109 세포/mL로 재현탁시켰다. SRBC를 감작화하기 위해, 총 1x109 개/mL의 SRBC 세포를 동일한 용적의 1:50 희석된 래빗 항-양 용혈소 (1.5 mg/mL)와 함께 37℃에서 20분간 혼합하였다 (SRBC의 최종 세포 농도; 5x108 세포/mL 및 0.75mg/mL에서 용혈소). 감작화된 SRBC는 용혈 검정에서 사용하기 전에 GVB++ 완충액 중에서 2x108 개의 세포/mL로 희석하였다. C1q 고갈된 사람 혈청은 GVB++ 완충액으로 100%에서 4%로 희석시켰다. 사람 C1q는 GVB++ 완충액 중에서 312pM로 희석시켰다. 시험 항체는 GVB++ 완충액 중에서 83.33 nM 내지 0.041 nM 범위로 제조하였다.
[00232] 총 75 uL 각각의 시험 항체를 80 uL의 총 용적을 위해 5 uL의 사람 C1q와 조합하였고, 여기서, 최종 항체 농도 범위는 78.13 nM 내지 0.038 nM가 되었고 C1q는 19.5 pM의 고정된 농도로 있다. 시험 항체는 이특이적 항체이다: H1H20631D, H1H20632D, H1H20633D, H1H20634D, H1H20635D, H1H20636D, H1H20637D, H1H20638D, H1H20639D, H1H20640D, H1H20641D, 및 H1H20642D. 상기 80 uL 혼합물로부터, 50 uL를 이어서 새로운 96-웰 플레이트에 전달하고 50 uL의 4% C1q 고갈된 사람 혈청과 혼합하였다. 100 uL의 총 용적에서, 최종 항체 농도는 39.1 nM 내지 0.019 nM 범위이고, C1q는 9.75 pM의 고정된 농도로 있고 C1q 고갈된 혈청은 2% 농도로 있다. 즉각적으로, 100 uL의 감작화된 SRBC (2x108 세포/mL에서)를 200uL의 총 용적에 대해 첨가하고 37℃에서 1시간 동안 항온처리하였다. 항온처리 시간 후, 세포는 4℃에서 1250 x g에서 원심분리하여 회전 하강시켰다. 총 100 uL의 상등액을 새로운 96-웰 평저 플레이트에 전달하고 Molecular Devices Spectramax M5 미세플레이트 판독기 및 SoftMax Pro 소프트웨어 상에서 412nm에서 판독한다.
[00233] 추가로, C1q 고갈된 사람 혈청 중에서 사람 C1q 용량 반응은 다음과 같이 결정하였다. C1q 고갈된 사람 혈청의 2x 스톡은 혈청을 GVB++ 완충액 중에서 100%에서 4%로 희석시킴에 의해 제조하였다. 사람 C1q 단백질의 2x 스톡을 GVB++ 완충액 중에서 6.1 x 10-8 M에서 7.2 x 10-15 M로 희석시켰다. 총 50 uL의 2x 스톡의 C1q 고갈된 혈청을 총 100uL에 대해 희석 범위에 걸쳐 제조된 50 uL의 2x 스톡의 C1q에 첨가하였고, 여기서, 최종 C1q 고갈된 사람 혈청 농도는 2%이고 최종 C1q 농도는 3.05 x 10-8 M 내지 3.6 x 10-15 M 범위이다. 즉각적으로, 100 uL의 감작화된 SRBC (2x108 세포/mL에서)를 200uL의 총 용적에 대해 첨가하고 37℃에서 1시간 동안 항온처리하였다. 항온처리 시간 후, 세포는 4℃에서 1250 x g에서 원심분리하여 회전 하강시키고 상등액은 상기된 바와 같이 412nm에서 판독하였다.
[00234] 용혈 활성은 다음과 같이 2%의 최종 혈청 농도에서 계산하였다: 처음에 단독의 GVB++ 희석물(SRBC 부재)의 OD412는 모든 데이터로부터 공제하였고 이어서 기본 세포 용해 (즉, 임의의 혈청이 부재인 GVB++ 완충액에서만 항온처리된 세포)의 OD412는 모든 데이터로부터 공제하였다. 이어서, 모든 실험 샘플의 OD412는 최대 세포 용해 (100uL 물로 처리된 세포)에서의 OD412로 나누고 이어서 100을 곱하였다.
[00235] 요약하면, 용혈 퍼센트는 하기의 수학식을 사용하여 계산하였다:

% 용혈로서 표현된 결과는 프리즘 6 소프트웨어 (GraphPad)와 함께 비선형 회귀 (4-파라미터 로지스틱)을 사용하여 분석하여 IC50 값을 수득하였다. 이특이적 항체 또는 이소형 대조군에 의한 용혈의 0-100% 억제는 최저 항체 농도와 C1q 용량 반응의 바닥 간의 % 용혈에서의 차이로 나누고 100을 곱한, 최저 및 최고 농도 사이의 % 용혈에서의 차이를 기준으로 한다. 나타낸 데이터는 단일 포인트이다(중복 수행하지 않음).
[00236] 본원 개시내용의 11 항-IsdB x 항-C1q 이특이적 항체는 전형적 경로 (CP) 용혈 검정에서 시험하였다. 7개 특이적 항체; H1H20631D, H1H20632D, H1H20633D, H1H20634D, H1H20635D, H1H20640D, H1H20642D는 CP 용혈 활성의 강한 차단제이다. 하나의 이특이적 항체 H1H20637D는 중간정도의 차단제(40nM의 최고 시험 농도에서)이고; 3개의 이특이적 항체 H1H20636D, H1H20638D 및 H1H20641D는 CP 용혈 활성의 비-차단제이다. (하기 표 12를 참조한다)
[00237] 결론을 내리기 위해, 본원 개시내용의 11개 항체 중 7개는 전형적 보체 경로 활성화를 차단한다.
[표 12]

실시예 7 보체 의존성 세포독성 검정
[00238] 전형적 보체 의존성 세포독성 (CDC) 검정은 사람 보체 성분 C1q(hC1q)에 의해 매개된 CDC를 차단시키는 본원 개시내용의 이특이적 항체의 능력을 평가하기 위해 개발하였다. 보체 성분의 공급원으로서 Daudi 세포, CD20을 발현하는 사람 B 세포주, 항-CD20 항체 및 정상 사람 혈청을 사용하였다. B-세포 특이적 세포-표면 항원 CD20에 대한 치료학적 항-CD20 항체는 B-세포의 CDC를 유도하는 것으로 나타났고(문헌참조: Glennie et al., Mechanisms of killing by anti-CD20 monoclonal antibodies, Molecular Immunology, Volume 44, Issue 16, September 2007, Pages 3823-3837) CD20을 발현하는 세포주를 사용한 CDC 검정은 이전에 기재되었다(문헌참조: Flieger et al., Mechanism of cytotoxicity induced by chimeric mouse human monoclonal antibody IDEC-C2B8 in CD20-expressing lymphoma cell lines, Cellular Immunology, Volume 204, Issue 1, August 25 2000, Pages 55-63).
방법
[00239] 생검정을 위해, Daudi 세포를 10% 열 불활성화된 FBS, 페니실린/스트렙토마이신, L-글루타민, 나트륨 피루베이트 및 비필수 아미노산을 함유하는 RPMI (RPMI 완전 배지)에서 웰당 10,000개의 세포로 96-웰 검정 플레이트 상에 씨딩하였다. CDC를 측정하기 위해, 상기 항-CD20 항체를 100 nM에서 2 pM로 1:3으로 희석하고 (항체를 함유하지 않는 대조군 샘플 포함), 세포와 함께 25℃에서 10분간 항온처리시킨 후, 1.67%의 보체 보존된 사람 혈청을 첨가하였다. CDC의 억제를 시험하기 위해, 항-IsdB x 항-hC1q 이특이적 항체, 항-IsdB 통상의 항체, 항-C1q 항체 또는 이소형 대조군 항체를 750nM에서 13pM로 또는 611nM에서 10pM로 1:3으로 희석 (항체를 함유하지 않는 대조군 샘플을 포함하는)하고 30분동안 1.67% 혈청으로 항온처리하였다. 세포에 혈청과 함께 항체를 첨가하기 10분 전에, 항-CD20 항체를 2 nM로 세포에 첨가하였다. 상기 항-CD20 항체와의 항온처리 종료시에, 상기 항체 + 혈청 혼합물을 세포에 첨가하였다. 37℃ 및 5% CO2에서 항온처리 3.5시간 후에 이어서 25℃에서 15분간의 항온처리 및 CytoTox-Glo™ 시약 [프로메가(Promega), # G9292]의 후속적 첨가로 세포독성을 측정하였다. CytoTox-Glo™은 세포 사멸을 측정하는 발광 기반 시약이고, 증가된 발광도가 증가된 세포독성과 함께 관찰되도록 한다(상대적 광 유닛인 RLU로 측정함). 대조군 웰 중의 미처리된 세포를 CytoTox-Glo™ 시약 첨가 직후에 166.7ug/mL의 디기토닌 처리로 용해시켜 세포에 대한 최대 사멸을 측정하였다. CytoTox-Glo™의 첨가 15분 후 Victor X 장비 [퍼킨 엘머(Perkin Elmer)]에 의해 플레이트를 발광도에 대해 판독하였다.
[00240] 하기의 수학식을 사용함에 의해 세포독성의 퍼센트를 RLU 값과 함께 계산하였다:

상기 수학식에서, “기본 세포 용해”는 어떠한 항-CD20 항체도 사용하지 않은 배지 및 혈청 단독으로 처리한 세포로부터의 발광도이고, “최대 세포 용해”는 166.7ug/mL의 디기토닌으로 처리한 세포로부터의 발광도이다. % 세포독성으로 나타낸 상기 결과들을 프리즘(Prism) 5 소프트웨어 (GraphPad)와 함께 비선형 회귀 (4-파라미터 로지스틱)를 사용하여 분석하여 EC50과 IC50 값을 수득하였다. 항체의 % 억제는 하기의 수학식을 사용하여 계산하였다:

상기 수학식에서 “세포독성기준선”은 단독의 2nM의 항-CD20 항체로 치리된 세포로부터의 % 세포독성이고, “세포독성억제”는 2nM 항-CD20 항체와 함께 특정 억제 항체의 용량 반응으로부터의 최소 % 세포독성 값이고, “세포독성기본”은 임의의 항체 없이 세포로부터의 % 세포독성이다. 상기 수학식에서, 모든 조건은 1.67% 혈청을 함유한다.
[00241] 본원 개시내용의 17 항-IsdB x 항-C1q 이특이적 항체는 1.67% 사람 혈청 및 2nM 항-CD20 항체와 함께 Daudi 세포를 사용한 CDC 검정에서 C1q를 억제하는 이들의 능력에 대해 시험하였다. 표 13에 나타낸 바와 같이, 17개 이특이적 항체 중 11개는 C1q 매개된 CDC의 적어도 94%의 억제를 보여주었고 IC50 값은 10nM 내지 100nM 초과의 범위이다. 나머지 이특이적 항체 중 5개는 100 nM 초과의 IC50 및 (750 nM의 항체에서) 33% 내지 88% 범위의 최대 억제를 갖는 차단제이다. 이특이적 항체의 항-IsdB 결합 영역을 함유한, 통상적인 항-IsdB 항체와 함께 이특이적 항체 중 하나(H1H20636D)는 hC1q 매개된 CDC의 억제를 보여주지 않았다. 사람 IgG1 이소형 대조군 항체, 대조군 mAb1은 또한 CDC의 임의의 유의적 억제를 입증하지 않았다. 시판되는 항-C1q 모노클로날 항체(Quidel, A201)는 CDC의 >99% 억제를 보여주었고 IC50 값은 3.0nM이었다. 항-CD20 항체는 1.67% 사람 혈청과 함께 Daudi 세포의 CDC를 보여주었고 EC50 값은 892pM이고 최대 % 세포독성은 100nM에서 62%이다.
[표 13]
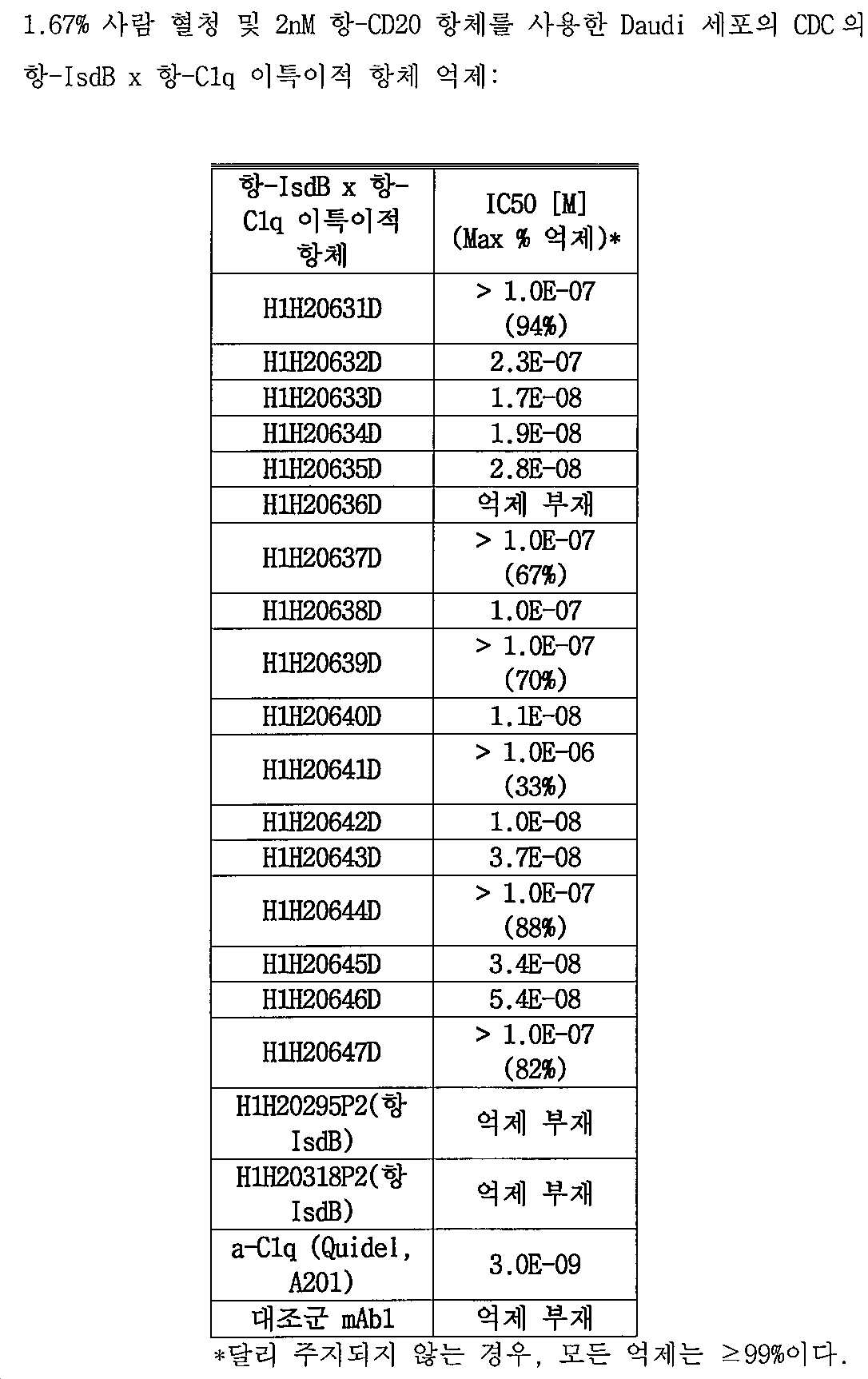
실시예 8 A: 항-IsdB x 항-C1q 이특이적 항체의 에스. 아우레우스 우드 46으로의 결합
[00242] 에스. 아우레우스의 표면 상에서 발현된 IsdB로의 항-IsdB x 항-C1q 이특이적 항체의 결합은 ELISA 기반 포맷으로 결정하였다. 에스. 아우레우스에 의해 발현되는 단백질 A에 대한 항체의 비-특이적 결합과 IsdB로의 결합을 구분하기 위해(문헌참조: Lindmark et. al, J Immunol Methods, 1983 Aug 12;62(1):1-13), 세균의 단백질 A 결핍 균주인, 에스. 아우레우스 우드 46은 상기 검정에 사용하였다.
방법
[00243] 본 발명의 항-IsdB x 항-C1q 이특이적 항체(H1H20631D, H1H20632D, H1H20633D, H1H20634D, H1H20635D, H1H20636D, H1H20637D, H1H20638D, H1H20639D, H1H20640D, H1H20641D, H1H20642D, H1H20643D, H1H20644D, H1H20645D, H1H20646D, H1H20647D)는 ELISA에 의해 에스. 아우레우스 우드 46으로의 결합에 대해 시험하였다. 간략하게, 에스. 아우레우스 우드 46은 RPMI에서 밤새 성장시키고, PBS 중에서 세척하고 0.25의 OD600으로 조정하였다. MaxiSorp 96 웰 미세역가 플레이트는 웰당 100 μl의 에스. 아우레우스 배양물로 밤새 코팅하였다. 플레이트는 세척하고 3% BSA로 차단시켰다. 항-IsdB x 항-C1q 이특이적 항체, 대조군 I, 대조군 II, 대조군 III 및 음성 이소형 대조군 항체의 1:3 희석과 함께 0.14nM-0.1μM 범위의 적정물을 에스. 아우레우스-함유 웰에 첨가하고 25℃에서 1시간 동안 항온처리하였다. 항-사람 HRP 접합된 제2 항체를 세척된 플레이트에 첨가하였다. 발광 시약(SuperSignal Pico)은 이어서 웰에 첨가하고 신호는 즉시 플레이트 판독기 (Victor X3 플레이트 판독기, Perkin Elmer)에서 검출하였다. 발광 값은 4-파라미터 로지스틱 수학식에 의해 7-포인트 반응 곡선 (GraphPad Prism) 상에서 분석하여 항체의 결합 EC50을 결정하였다.
[00244] 본 연구에 사용되는 대조군 항체 (실시예 8A 및 8B)는 하기를 포함한다: 대조군 I는 US2010/0166772에 기재된 항-IsdB hIgG1 항체이고 CS-D7로 지정하였다(또한 US2010/0166772에서 서열번호 1 및 서열번호 2를 참조한다). 대조군 II는 본원에 기재된 바와 같이 제조된 IsdB에 특이적인 2가 항체(실시예 2, 표 3)이다: 서열번호 138/146의 아미노산 서열을 갖는 항체 H1H20295P2 및 HCVR/LCVR 쌍. 대조군 III은 본원에 기재된 바와 같이 제조된 IsdB에 특이적인 2가 항체이다(실시예 2, 표 3): 서열번호 154/162의 아미노산 서열을 갖는 H1H20318P2 및 HCVR/LCVR 쌍. 대조군 II 및 대조군 III 항체는 C1q에 결합하는 항원-결합 도메인을 갖지 않는다. REGN1932은 IsdB 또는 C1q 이외의 다른 항원에 특이적인 음성 이소형 대조군 항체이다.
결과:
[00245] ELISA에 의해 에스. 아우레우스 우드 46에 결합하는 이들의 능력에 대해 검정되는 경우, 본 발명에 기재된 항체는 1.04 x 10-9 M 내지 1.8 x 10-8 M 범위의 결합 친화성을 나타냈고, 대조군 I-III는 9.13 x 10-11 M 내지 3.6 x 10-9 M 범위의 결합 친화성을 나타냈다. 음성 이소형 대조군 항체는 에스. 아우레우스 우드 46에 결합하지 않았다(표 14).
실시예 8B: 에스. 아우레우스 코완 I 상에 항-IsdB x 항-C1q 이특이적 항체 의존성 C1q 보체 침적
[00246] 에스. 아우레우스 코완 I 균주의 표면 상에 항-IsdB x 항-C1q 이특이적 항체에 의해 강화된 C1q 침적은 이특이적 항체에 의해 매개된 병원체 표면 상에 사람 혈청으로부터 침적된 C1q를 직접 측정함에 의해 ELISA 기반 포맷으로 측정하였다.
방법
[00247] 본 발명의 항-IsdB x 항-C1q 이특이적 항체(H1H20631D, H1H20632D, H1H20633D, H1H20634D, H1H20635D, H1H20636D, H1H20637D, H1H20638D, H1H20639D, H1H20640D, H1H20641D, H1H20642D, H1H20643D, H1H20644D, H1H20645D, H1H20646D, H1H20647D)는 ELISA 기반 검정 포맷으로 에스. 아우레우스 코완 I 상에 보체 침적에 대해 시험하였다. 간략하게, 에스. 아우레우스 코완 I는 RPMI에서 밤새 성장시키고, PBS 중에서 세척하고 0.25의 OD600으로 조정하였다. MaxiSorp 96 웰 미세역가 플레이트는 웰당 100 μl의 에스. 아우레우스 배양물로 밤새 코팅하였다. 플레이트는 2% 파라포름알데하이드로 고정시키고 25℃에서 1시간 동안 항-IsdB x 항-C1q 이특이적 항체, 대조군 I, 대조군 II, 대조군 III 및 이소형 대조군 항체의 1:3의 희석으로 0.14nM 내지 0.1uM 범위의 적정물 첨가 전 3% BSA로 차단시켰다. 세척 후, 60 μg/mL 정제된 사람 C1q가 보충된 5% 단백질 A/G 흡착된 C1q 고갈된 혈청은 37℃에서 1.5시간 동안 첨가하였다. 항-염소-C1q 항체는 C1q 침적물을 검출하기 위해 첨가하고 이어서 당나귀 항-염소 HRP 2차 항체를 첨가하였다. 플레이트는 각각의 단계 사이에서 플레이트 세척기에서 세척하였다. 발광 시약(SuperSignal Pico)은 이어서 웰에 첨가하고 신호는 즉시 플레이트 판독기 (Victor X3 플레이트 판독기, Perkin Elmer)에서 검출하였다. 발광 값은 4-파라미터 로지스틱 수학식에 의해 7-포인트 반응 곡선 (GraphPad Prism) 상에서 분석하여 항체의 결합 EC50을 계산하였다.
결과
[00248] 에스. 아우레우스 코완 I 상에 C1q 침적을 촉진시키는 이들의 능력에 대해 검정되는 경우, 본 발명의 모든 항체는 3.76 x 10-12 M 내지 8.54 x 10-9 M 범위의 EC50 값을 나타냈고 어떠한 C1q 침적은 대주군 I-III 및 음성 이소형 대조군으로 측정하였다(표 14).
[표 14]
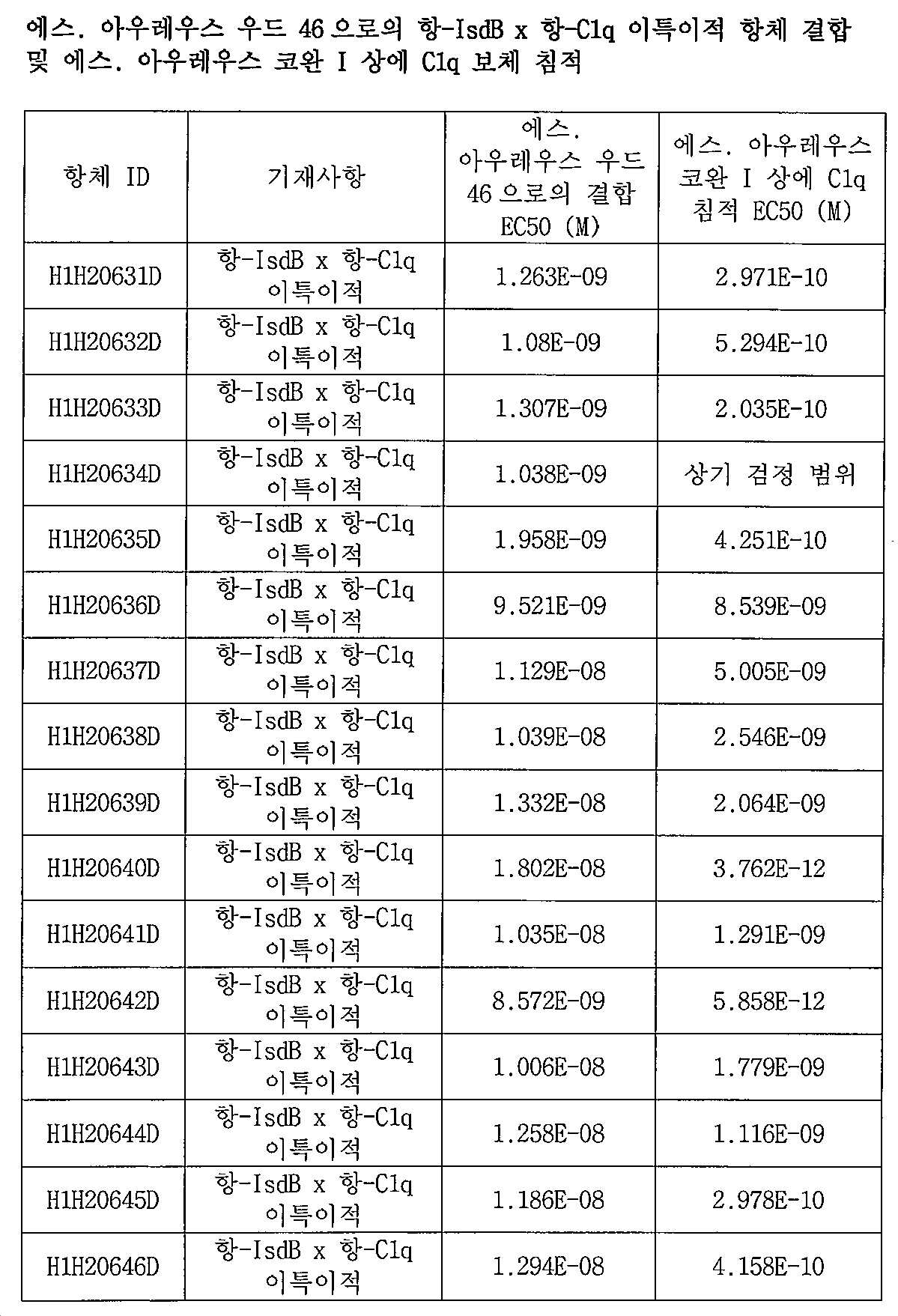

실시예 9A 기능적 검정: 전혈 세균 생존: 사람 전혈에서 에스. 아우레우스 생존 및 항-IsdB x 항-C1q의 효과
[00249] 사람 전혈에서 에스. 아우레우스 생존은 생체외 검정에서 평가하여 세균 성장을 조절하기 위한 보체 및 면역 이펙터 세포의 역할을 탐구하였다(문헌참조: J Exp Med. 2009 Oct26;206(11):2417-27). 에스. 아우레우스 생존을 조절하는데 있어서 항-IsdB x 항-C1q 이특이적 항체의 활성은 상기 검정에서 측정하고 여기서, 상기 이특이적 항체 또는 대조군 항체는 전혈에 첨가되고 생존은 24시간 후 평가한다.
방법
[00250] 본 발명의 항-IsdB x 항-C1q 이특이적 항체(H1H20631D, H1H20632D, H1H20633D, H1H20634D, H1H20635D, H1H20636D, H1H20637D, H1H20638D, H1H20639D, H1H20640D, H1H20641D, H1H20642D, H1H20643D, H1H20644D, H1H20645D, H1H20646D, H1H20647D)는 전혈 생존 검정에서 에스. 아우레우스 뉴만 (Newman)에 대한 살균 활성에 대해 평가하였다. 간략하게, 에스. 아우레우스 뉴만의 배양물은 밤새 RPMI에서 성장시키고, PBS에서 세척하고 PBS 중에 1 x 108 콜로니 형성 유닛 (CFU)/mL의 농도로 재현탁시켰다. 중복적으로, 10분동안 10ug/mL 시험 및 대조군 항체와 예비 혼합된 10uL의 에스. 아우레우스 현탁액을 100uL의 사람 전혈(응고 형성을 예방하기 위해 추가의 500nM 다비가트란과 함께 항-응고제로서 나트륨 시트레이트 중에)에 첨가하였다. 샘플은 24시간 동안 진탕 (100rpm)과 함께 37oC에서 96웰 플레이트에서 항온처리하였다. 항온 처리 후, 100ul의 응집 용해 완충액(PBS ml 당 200U 스트렙토키나제, 2ug/mL RNase, 10ug/mL DNase, 0.5% 사포닌, 100ug 트립신이 보충된 PBS)을 샘플에 첨가하고 펠렛이 사라질때까지 왕성하게 와동시켰다. 각각의 샘플로부터 총 50uL는 PBS 중에서 연속으로 희석하고 CFU의 계수를 위해 LB 한천 플레이트 상에 분주하였다.
[00251] 본 연구에 사용되는 대조군 항체 (실시예 9A 및 9B)는 하기를 포함한다: 대조군 I는 US2010/0166772에 기재된 항-IsdB hIgG1 항체이고 CS-D7로 지정하였다(또한 US2010/0166772에서 서열번호 1 및 서열번호 2를 참조한다). 대조군 II는 본원에 기재된 바와 같이 제조된 IsdB에 특이적인 2가 항체(실시예 2, 표 3)이다: 서열번호 138/146의 아미노산 서열을 갖는 항체 H1H20295P2 및 HCVR/LCVR 쌍. 대조군 III은 본원에 기재된 바와 같이 제조된 IsdB에 특이적인 2가 항체이다(실시예 2, 표 3): 서열번호 154/162의 아미노산 서열을 갖는 H1H20318P2 및 HCVR/LCVR 쌍. 대조군 II 및 대조군 III 항체는 C1q에 결합하는 항원-결합 도메인을 갖지 않는다. REGN1932은 IsdB 또는 C1q 이외의 다른 항원에 특이적인 음성 이소형 대조군 항체이다.
결과
[00252] 이특이적 또는 대조군 항체를 사용한 치료 후 에스. 아우레우스의 퍼센트 생존으로서 나타낸 2개의 독립적 실험으로부터의 결과는 본원에 기재되고 표 15에 요약한다. 시험 항체의 부재하에 사람 전혈에서 전체 성장은 100%로 규정화한다. 대조군 및 음성 이소형 대조군 항체에서 에스. 아우레우스의 생존은 영향받지 않았고 96-100% 범위이고, H1H20631D는 29-42% 생존을 유도하였고 H1H20635D는 35-42% 생존을 유도하였다. H1H20634D는 보다 온건한 효과를 가졌고 73-76% 생존을 유도하였다. 나머지 이특이적 항체는 에스. 아우레우스의 생존을 변화시키지 않았다.
[표 15]

실시예 9B
.
C5 차단 항체 및 시토칼라신 D의 존재하에 사람 전혈 중 에스. 아우레우스 생존
[00253] 항-IsdB x 항-C1q 이특이적 항체의 작용 기전을 결정하기 위해, 상기된 전혈 에스. 아우레우스 생존 검정을 사용하였다. C5 차단 항체를 사용하여 생존에서의 감소가 면역 이펙터 세포 또는 막 공격 복합체에 의해 증가된 흡수를 유도하는 C4 또는 C3 분해 생성물 (C5의 다운스트림)에 의한 옵소닌화의 결과인지를 결정하였다. 시토칼라신 D는 액틴 중합화를 차단함에 따라서 면역 이펙터 세포가 병원체를 포식하는 것을 예방한다.
방법
[00254] 실험은 하기의 첨가물과 함께 상기된 바와 같이 수행하였다. 혈액 부분을 에스. 아우레우스로의 첨가 전 실온에서 10분동안 40uM 시토칼라신 D 또는 5uM C5 차단 Fab 또는 5uM Fab 대조군으로 전처리하였다. 에스. 아우레우스가 PBS로 예비 항온처리된 대조군 (항체 치료 부재) 조건을 제외하고, 에스. 아우레우스는 비처리된, C5 차단 Fab 처리된, 대조군 Fab 처리된 또는 시토칼라신 D 처리된 사람 전혈의 첨가 전 10분동안 100 ug/mL의 H1H20631D와 예비 항온처리하였다. 상기와 같이, 샘플은 24시간 동안 진탕 (100rpm)과 함께 37oC에서 96웰 플레이트에서 항온처리하였다. 항온처리 후, 100ul의 응집 용해 완충액을 첨가하여 혈액 응고를 용해시키고 생존 세균은 LB 한천 플레이트 상에 분주하여 CFU를 결정하였다.
결과
[00255] 24시간 후, 세균의 7%만이 항체 부재 대조군과 비교하여 H1H20631D를 사용한 치료 후 생존하였다. 보체 성분 단백질 5; C5 차단 Fab의 첨가는 생존을 91%까지 증가시켰고; 대조군 Fab는 세균 생존을 감소시키는데 (5%) H1H20631D의 활성에 간섭하지 않았다. 그러나, 액틴 중합을 억제함에 의해 시토칼라신 D를 사용한 백혈구 세포의 식세포작용 활성의 차단은 에스. 아우레우스 생존(12%)을 인지할만하게 개선시키지 않는다. 이를 종합해 보면, 이들 데이터는 항-IsdB x 항-C1q 이특이적 항체의 활성이 주로 C5의 다운스트림, 주지할만하게 막 공격 복합체의 용해 활성임을 시사한다. 생존 데이터는 표 16에 요약한다.
[표 16]

실시예 10 에스. 아우레우스 균혈증의 마우스 모델에서 항-IsdB x 항-C1q 항체의 생물학적 활성의 결정
[00256] 에스. 아우레우스는 환자에서 균혈증의 주요 원인이고 이들 감염은 흔히 치명적이다. 균혈증의 마우스 모델은 다양한 연구-적응되고 임상적 에스. 아우레우스 단리물을 사용한 많은 연구소에 의해 그리고 다양한 마우스 배경에서 개발되어(문헌참조: O'Keeffe KM, et al, Infect Immun. 2015 Sep;83(9):3445-57. Manipulation of Autophagy in Phagocytes Facilitates Staphylococcus aureus Bloodstream Infection.; Rauch et al, Infect Immun. 2012 Oct;80(10):3721-32. Abscess formation and alpha-hemolysin induced toxicity in a mouse model of Staphylococcus aureus peritoneal infection.) 잠재적 치료제의 감염 역학 및 효과를 연구하였다. 균혈증 모델은 세균 부하를 감소시키고 생존을 개선시키는 것 둘다에서 에스. 아우레우스에 대한 항-IsdB x 항-C1q 이특이적 항체의 활성을 평가하기 위해 확립하였다.
방법
[00257] 사람화된 C1q (C1qHu/Hu) 마우스는 혼합된 마우스 종 배경에서 마우스 C1q 서열을 대체하는 중복 마우스 서열과 함께 C1QA, C1QB 및 C1QC의 C1q 구형 헤드 도메인에 대한 사람 서열을 사용하여 생성하였다(고-분리 발현 분석과 커플링된 마우스 게놈의 고속처리 조작. Nat. Biotech. 21(6): 652-659). 수득한 마우스는 사람 헤드, 마우스 줄기 및 마우스 스톡과의 키메라 C1q 단백질을 발현한다. C1qHu/Hu 마우스는 37℃에서 TSB 중에서 로그 단계, OD600 ≤ 1로 성장한 에스. 아우레우스 뉴만 종의 200ul 용적에서 마우스 당 1.7 x 108 콜로니 형성 유닛(CFU)으로 복막내 감염시키고, PBS에서 3회 세척하였다. 감염 직후, 마우스에 1000ul의 용적에서 100ug의 각각의 개별 항체, 대조군 II 또는 이소형-일치된 항체를 복막내로 투여하였다. 마우스는 3일 후 감염때까지 매일 무게를 측정하고 체중에서의 변화를 기록하였다. 마우스는 3일째에 안락사키고 신장을 수거하여 기관 부하를 결정하였다. 간략하게, 신장은 프로그램-E를 사용한 gentleMACS Octo 분해자 (Miltenyi Biotec)를 사용하여 5.0mL의 PBS에서 파쇄하였다. 조직 파쇄물은 PBS 중에 희석하고 다수의 10배 연속 희석물을 LB 한천 플레이트 상에 분주하고 37℃에서 밤새 항온처리하였다. 다음 날, 개별 콜로니를 계수하여 감염 후 시점에서 세균 부하를 결정하였고 결과는 CFU/그램 조직으로서 보고하였다.
[00258] 생존에 대한 항-IsdB x 항-C1q 이특이적 항체의 효과를 조사하기 위해, 마우스에 에스. 아우레우스 뉴만의 마우스 당 1.5 x 108 CFU로 감염시키고 상기된 바와 같이 항체로 처리하였다. 대조군은 이소형 (음성) 대조군 및 대조군 II이고; 본원에 기재된 바와 같이 제조된 IsdB에 특이적인 2가 항체(실시예 2, 표 3)는 서열번호 138/146의 아미노산 서열을 갖는 항체 H1H20295P2 및 HCVR/LCVR 쌍이다. 3일째에 마우스를 희생시키는 것 대신, 이들은 18일때까지 모니터링하였다. 이들의 처음 체중의 20%를 상실한 마우스를 희생시키고 죽은 것으로서 기록하였다. 생존 동물의 퍼센트는 연구 말기에 보고하였다.
결과 및 결론:
[00259] 이특이적 항-IsdB x 항-C1q 항체, H1H20631D, H1H20633D, H1H20635D 및 H1H20636D는 암컷 C1qHu/Hu 마우스에서 신장 부하를 감소시키는데 있어서의 효능을 위한 대조군 항체 및 이소형 대조군 항체와 함께 시험하였다(n=5). 감염 대조군 또는 단독의 이소형 대조군 항체로 처리된 마우스와 비교하여, 에스. 아우레우스 CFU의 9 로그가 3일째 신장으로부터 회수되는 경우, H1H20631D를 사용한 치료 후 전체 CFU에서의 4 로그 감소 및 H1H20635D를 사용한 치료 후 CFU에서 2 로그 감소가 관찰되었다. (표 17 참조) 2개의 이특이적 항체 H1H20633D 및 H1H20636D는 신장 세균 하중에 대해 어떠한 측정가능한 효과를 갖지 않았다.
[표 17]
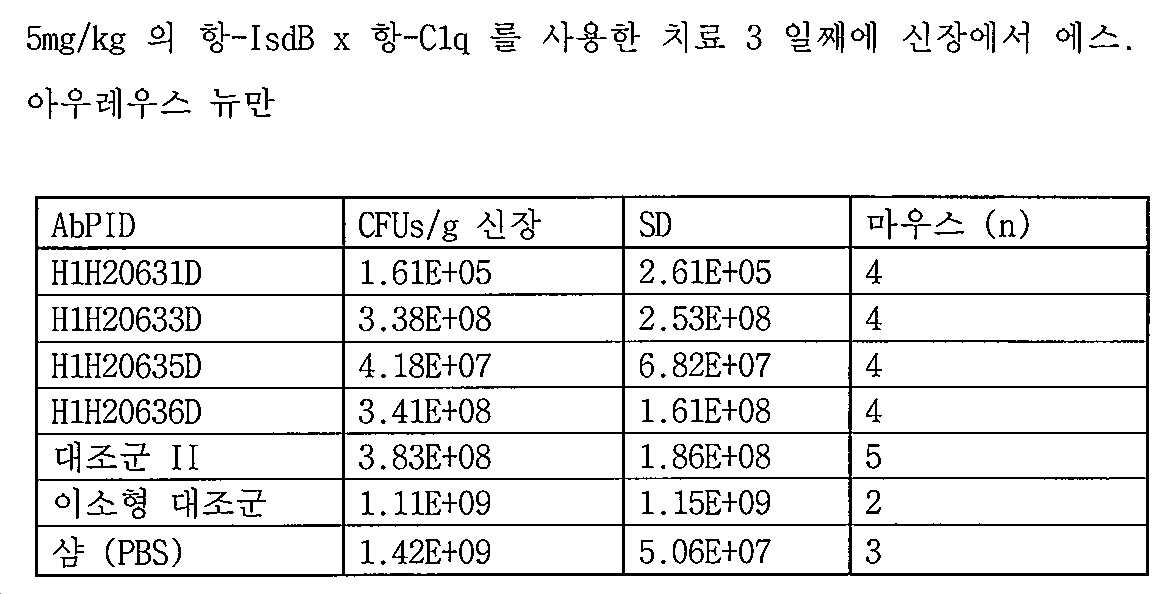
[00260] 표 18에 나타낸 바와 같이, 1일 내지 3일까지, H1H20631D로 처리된 마우스에서 8.5%의 체중 증가 및 H1H20635D로 처리된 마우스에서 7.9%의 체중 증가를 기록하였다. 모든 다른 시험 그룹에서 마우스는 이들의 체중 손실을 유지하거나 매우 온건한 증가를 가졌다(음성 이소형 대조군 및 H1H20633D 처리된).
[표 18]
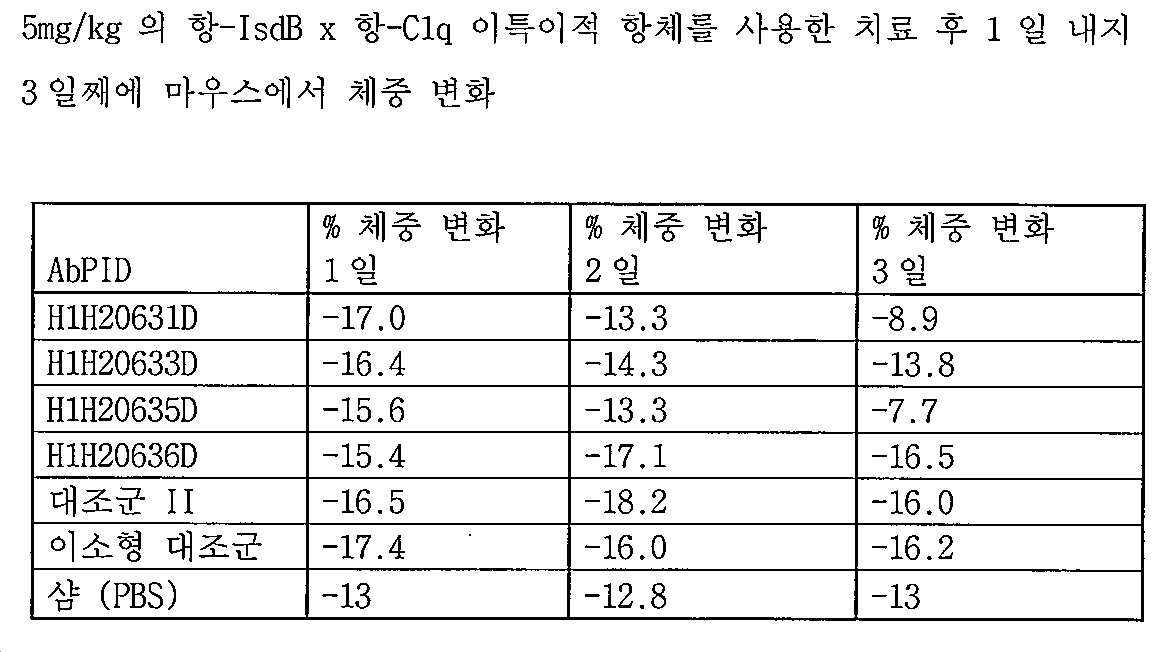
[00261] 이특이적 항-IsdB x 항-C1q 항체, H1H20631D는 C1qHu/Hu 암컷 마우스에서의 생존 연구에서 효능을 위한 대조군 항체 및 음성 이소형 대조군 항체와 함께 시험하였다(n=9). 표 19에 나타낸 바와 같이, 연구의 말기에, 감염 후 18일째에, H1H20631D으로 처리된 마우스의 100%가 생존한 반면 대조군 또는 샴 처리된 마우스는 56%이고 음성 이소형 대조군 처리된 마우스는 78%이다.
[00262] 이를 종합해 보면, 본원 개시내용의 항-IsdB x 항-C1q 항체는 에스. 아우레우스 균혈증의 모델에서 주요 세균 부하를 감소시키고 사람화된 C1q 마우스 균주에서의 생존을 개선시키는데 효과적이다.
[표 19]

실시예 11. 항-IsdB x 항-C1q 이특이적 mAb에 대한 C1q 교차-경쟁
[00263] 본원에 기재된 항-IsdB x 항-C1q 이특이적 항체는 Octet HTX 바이오센서 상에서 실시간. 무표지 바이오-층 간섭계법 (BLI) 검정을 사용하여 교차 경쟁에 대해 시험하였다. 교차 경쟁 검정은 사람 c1q로의 결합에 대해 서로 경쟁하는 이특이적 항체의 결정을 제공한다.
[00264] hC1q (Quidel)에 대한 항-IsdB x 항-C1q 이특이적 항체 간의 결합 경쟁은 Octet HTX 바이오센서 상에서 실시간, 무표지 바이오-층 간섭계법 (BLI)(ForteBio/Pall Life Sciences) 검정을 사용하여 결정하였다. 실험은 0.01 M HEPES pH 7.4, 0.15 M NaCl, 3mM EDTA, 0.05% v/v 계면활성제 P20, 1.0mg/mL BSA로 구성된 완충액 (Octet HBS-EP 완충액) 중에서 플레이트를 1000 rpm의 속도로 진탕시키면서 25℃에서 수행하였다. 2개의 항체가 사람 C1q 상에 이들의 각각의 에피토프에 결합하는 것에 대해 서로 경쟁할 수 있는지를 평가하기 위해, 항-IsdB x 항-C1q 이특이적 항체(mAb-1로 지칭됨)는 먼저 상기 바이오센서를 3분동안 항-IsdBxC1q 이특이적 항체의 10μg/mL 용액을 함유하는 웰에 침지시킴에 의해 항-hFc 항체 코팅된 Octet 바이오센서(Fortebio Inc, #18-5060) 상에 포획하였다. mAb-1 포획된 센서 팁 상에 여분의 유리된 항-hFc 부위는 4분동안 200ug/ml의 차단 항체 (차단 mAb로 지칭됨) 용액을 함유하는 웰에 침지시킴에 의해 H1H 이소형 대조군 항체로 포화시켰다. 상기 바이오센서 팁은 후속적으로 10분동안 사람 C1q (10ug/ml)의 동시 복합체화된 용액 및 대략 10배 몰 과량의 제2 항-IsdB x 항-C1q 이특이적 mAb (mAb-2로 지칭됨)를 함유하는 웰에 침지시켰다.
[00265] 모든 바이오센서 팁은 본 실험의 매 단계 사이마다 Octet HBS-ET 완충액 중에서 세척하였다. 실시간 결합 반응을 실험 과정을 진행하는 동안 모니터링하였고, 매 단계의 종료시마다 결합 반응을 기록하였다. 포획된 mAb-1으로의 mAb-2 결합으로 예비 복합체화된 C1q의 반응은 기본 결합에 대해 보정하고, 이를 비교하고 경쟁/비-경쟁 거동은 모두 17 항-IsdB x 항-C1q 이특이적 항체에 대해 결정하였다.
결과 및 결론
[00266] 표 20은 결합의 순서와는 독립적으로, 양 방향으로 경쟁하는 항체들의 관계를 보여준다. 4개의 항-IsdB x 항-C1q 이특이적 항체(H1H20633D, H1H20635D, H1H20636D, H1H20641D)는 본 연구에서 조사된 다른 임의의 항체와 교차 경쟁하지 않았다. 항체 H1H20631는 세균 부하를 감소시키고 생존을 증가시키기 위한 시험관내 및 생체내 검정에서 효과적인 이특이적 항체였다. 항체 H1H20631은 항체 H1H20638D와 교차 경쟁하였다.
[표 20]
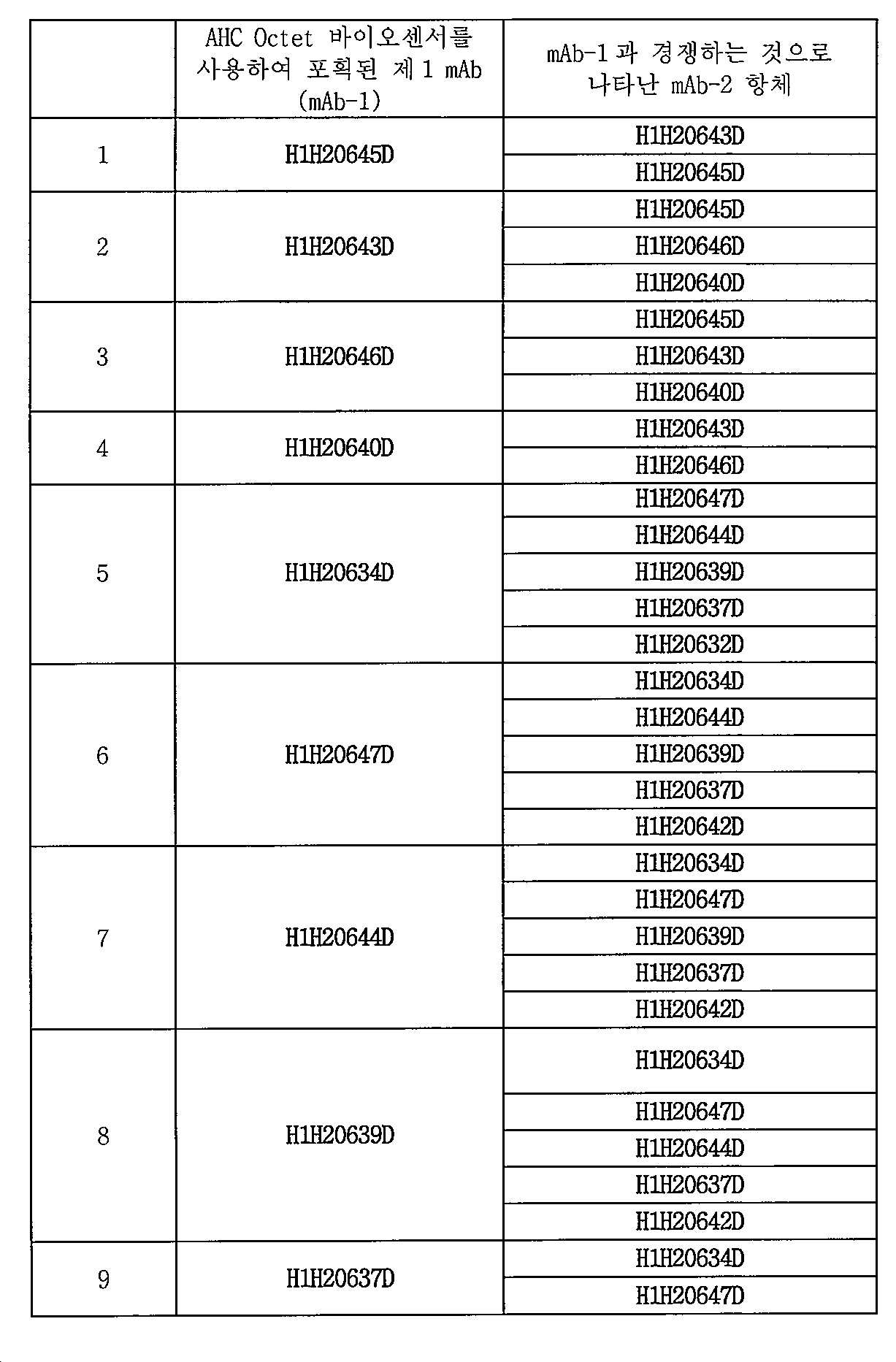

실시예 12. 에스. 아우레우스 MRSA 균혈증의 마우스 모델에서 항-IsdB x 항-C1q 항체의 생물학적 활성의 결정
[00267] 에스. 아우레우스 감염 동력학 및 잠재적 치료제의 효과를 연구하기 위해, 메티실린 내성 에스. 아우레우스 (MRSA) 균주를 사용한 균혈증 모델을 개발하였다. 2개의 상이한 MRSA 균주는 이들 실험에서 사용되었고, USA300 MRSA 균주, CA127 (NARSA, Cat. No. NRS643) 뿐만 아니라 USA400 MRSA 균주, MW2 (ATCC, Cat. No. BAA-1707, 로트 번호 58910673)이 사용되었다. 에스. 아우레우스 뉴만 균주(메티실린 민감성 임상적 단리물, (MSSA))가 또한 이들 연구에 사용되었다. 상기 모델을 사용하여 세균 부하를 감소시키는데 있어서의 항-IsdB x 항-C1q 이특이적 항체의 활성을 평가하였다.
실험 과정:
[00268] 사람화된 C1q (C1qHu/Hu) 마우스에 200ul의 용적으로 에스. 아우레우스 뉴만 종의 마우스 당 1.5 x 108 콜로니 형성 유닛(CFU), 200ul의 용적으로 MW2로 지정된 MRSA 균주의 마우스 당 1.4 x 108 CFU, 또는 200ul 용적으로 CA127 지정된 또 다른 MRSA 균주의 마우스 당 1.4 x 108 CFU로 복막내 감염시켰다. 모든 3개의 에스. 아우레우스 균주는 37℃에서 트립신분해 대두 브로쓰 (TSB)에서 로그 단계 OD600 ≤ 1까지 성장시키고 포스페이트 완충 식염수 (PBS) 중에서 3회 세척하고 감염을 위한 목적하는 밀도로 조정하였다. 감염 24시간 후 (1일), 마우스에 H1H20631D로 지정된 항-IsdB x 항-C1q 이특이적 항체 100ug (아미노산 서열 식별기호에 대해 표 6을 참조한다) 또는 100ul의 용적에서 H1H20295P2로 지정된 대조군 II 항체 100ug, 또는 100ul의 용적에서 PBS를 복막내 투여하였다. 본원에서 이전에 주지된 바와 같이, 대조군 II는 실시예 2, 표 3에 기재된 바와 같이 제조된 IsdB에 특이적인 2가 항체이고 서열번호 138/146의 HCVR/LCVR 아미노산 서열을 포함한다. 마우스는 감염 후 4일때까지 매일 무게를 측정하고 체중에서의 변화를 기록하였다. 마우스는 4일째에 안락사키고 신장을 수거하여 세균 기관 부하를 결정하였다. 간략하게, 신장은 프로그램-E를 사용한 gentleMACS Octo 분해자 (Miltenyi Biotec)를 사용하여 5mL PBS 중에서 파쇄시키고 파쇄물을 이어서 PBS 중에 희석시키고 다중의 10-배 연속 희석물은 LB 한천 플레이트 상에 분주하고 37℃에서 밤새 항온처리하였다. 다음 날, 개별 콜로니를 계수하여 세균 부하를 결정하였고 결과는 CFU/그램 조직으로서 보고하였다.
결과 개요 및 결론:
[00269] H1H20631D로 지정된 이특이적 항-IsdB x 항-C1q 항체는 사람화된 C1q 마우스 균주에서 신장 부하를 개선시키는데 있어서의 효능에 대해 대조군 항체와 함께 시험하였다(n=5). 이소형 대조군 항체 (상기된 대조군 II)로 처리된 마우스와 비교하여, 7로그의 에스, 아우레우스 MRSA (MW2 및 CA127) CFU가 4일째 신장으로부터 회수된 경우, 2-4 로그 감소는 IsdB X C1q 이특이적 항체, H1H20631D를 사용한 처리 후 전체 CFU에서 관찰되었다.
[00270] 이를 종합해 보면, 항-IsdB x 항-C1q 이특이적 항체는 에스. 아우레우스 MSSA 및 MRSA 균혈증과 함께 사람화된 C1q 마우스 균주에서 신장 세균 부하를 감소시키는데 효과적이다.
표로 만든 데이터 요약:
[00271] 하기 표 21은 5mg/kg의 항-IsdB x 항-C1q 이특이적 및 대조군 항체를 사용한 처리 3일 후 신장에서 에스. 아우레우스 부하를 보여준다.
[표 21]

실시예 13. 에스. 아우레우스 MRSA 균혈증의 마우스 모델에서 표준 치료 항생제와 조합된 항-IsdB x 항-C1q 항체의 생물학적 활성 결정
[00272] 실시예 12에서 상기된 균혈증 모델을 사용하여 표준 치료 항생제와 조합하여 사용되는 경우 세균 부하를 감소시키는데 있어서 에스. 아우레우스 MRSA 균주에 대한 항-IsdB x 항-C1q 이특이적 항체의 활성을 평가하였다.
실험 과정:
[00273] 사람화된 C1q (C1qHu/Hu) 마우스는 200ul의 용적에서 에스. 아우레우스 MW2의 마우스 당 1.3 x 108 콜로니 형성 유닛 (CFU)으로 복막내 감염시켰다. 에스. 아우레우스 MW2는 37℃에서 TSB 중에서 로그 단계 OD600 ≤ 1로 성장시키고 PBS 중에서 3회 세척하고 감염을 위해 목적하는 밀도로 조정하였다. 감염 후 18시간에 개시하여, 마우스 2개 그룹(n=5)을 1일, 2일 및 3일째에 하루 2회 경구 위관영양법 (200ul 용적)에 의해 80mg/kg의 라인졸리드로 처리하였다. 감염 24시간 후, 마우스에 복막으로 H1H2063ID로 지정된, 단일 100ug 용량의 항-IsdB x 항-C1q 이특이적 항체(표 6 참조) 또는 100ul의 용적에서 PBS를 투여하였다. 마우스는 감염 4일 후때까지 매일 무게를 측정하고 체중에서의 변화를 기록하였다. 마우스는 4일째에 안락사키고 신장, 폐 및 심장을 수거하여 기관 부하를 결정하였다. 간략하게, 기관은 프로그램-E를 사용한 gentleMACS Octo 분해자 (Miltenyi Biotec)를 사용하여 5mL PBS 중에서 파쇄시켰다. 조직 파쇄물을 이어서 PBS 중에 희석시키고 다중의 10-배 연속 희석물을 LB 한천 플레이트 상에 분주하고 37℃에서 밤새 항온처리하였다. 다음 날, 개별 콜로니를 계수하여 세균 부하를 결정하였고 결과는 CFU/그램 조직으로서 보고하였다.
결과 개요 및 결론:
[00274] 이특이적 항-IsdB x 항-C1q 항체, H1H20631D는 사람화된 C1q 마우스의 신장, 폐 및 심장에서 세균 부하를 감소시키는데 있어서 효능을 위해 표준 치료 항생제인 라인졸리드와 함께 시험하였다. 감염 대조군 마우스 (어떠한 항생제 또는 항체도 투여되지 않은 마우스)와 비교하여, 에스. 아우레우스 CFU의 8.5 로그가 4일째 신장으로부터 회수되는 경우, H1H20631D를 사용한 처리 후 전체 CFU에서의 2.5 로그 감소가 관찰되었고 반면 라인졸리드 처리를 사용한 CFU에서 약하게 2 로그 감소 미만인 것으로 관찰되었다. H1H20631D 및 라인졸리드의 조합으로 처리된 마우스에서, 에스. 아우레우스 CFU의 3.5 로그 감소가 관찰되었다. 폐에서, 단일 제제, H1H20631D 또는 라인졸리드를 사용한 처리는 전체 CFU에서 2로그 감소를 유도하였다. H1H20631D 및 라인졸리드의 조합으로 처리된 마우스에서, 에스. 아우레우스 CFU의 4 로그 감소가 관찰되었다. 유사하게, 심장에서, H1H20631D를 사용한 처리는 4로그 CFU 감소를 유도하였고 라인졸리드는 3로그 CFU 감소를 유도하였다. H1H20631D 및 라인졸리드와 조합하여 처리된 마우스에서, 본원 발명자는 심장으로부터 임의의 세균을 배양할 수 없었다(표에서의 데이터는 103 CFU의 검정에서 검출 한계이다).
[00275] 이를 종합해 보면, 항-IsdB x 항-C1q 이특이적 항체는 에스. 아우레우스 MRSA 균혈증과 함께 사람화된 C1q 마우스 균주에서 기관 세균 부하를 감소시키는데 라인졸리드와 부가적 효능을 가질 수 있다.
표로 만들어진 데이터 요약:
[00276] 하기 표 22는 라인졸리드 및 이특이적 5mg/kg의 항-IsdB x 항-C1q를 사용한 처리 3일 후 신장에서 에스. 아우레우스 부하를 보여준다.
[표 22]

[00277] 하기 표 23은 라인졸리드 및 이특이적 5mg/kg의 항-IsdB x 항-C1q를 사용한 처리 3일 후 폐에서 에스, 아우레우스 부하를 보여준다.
[표 23]
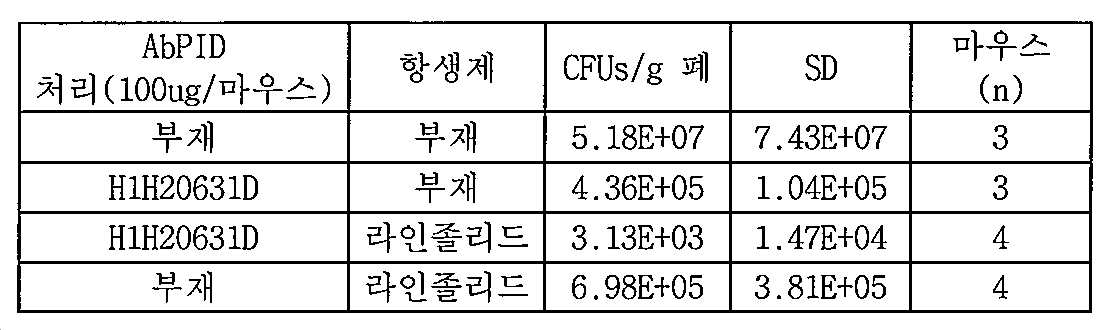
[00278] 하기 표 24는 라인졸리드 및 이특이적 5mg/kg의 항-IsdB x 항-C1q를 사용한 처리 3일 후 심장에서 에스. 아우레우스 부하를 보여준다.
[표 24]

[00279] 본원의 개시내용은 본원에 기재된 특정 구현예에 의해 범위로 제한되지 말아야 한다. 실제로, 본원에 기재된 것들에 추가로 본원 개시내용의 다양한 변형은 이전의 기재사항을부터 당업자에게 자명해질 것이다. 상기 변형은 첨부된 청구항의 범위내에 있는 것으로 의도된다.
<110> Regeneron Pharmaceuticals, Inc.
<120> Bispecific Antigen-Binding Molecules
That Bind a Staphylococcus Target Antigen and a Complement
Component and Uses Thereof
<130> 10342WO01
<150> 62/565,569
<151> 2017-09-29
<150> 62/654,576
<151> 2018-04-09
<160> 172
<170> FastSEQ for Windows Version 4.0
<210> 1
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 1
gaagtgcagc tggtggagtc tgggggaggc gtggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cagccttgat gattatgcca tgcactgggt ccgtcaaact 120
ccagggaagg gtctggagtg ggtctctctt attagtgggg atggtagtcg cacatcctat 180
gcagactctg tgaagggccg attcaccatc tccagagaca acagcaaaaa ctccctgtat 240
ctgaaaatga acagtctgag aactgaggac accgccttgt attactgtac aaaagatccc 300
cataactcca actggttcga cccctggggc cagggaaccc tggtcaccgt ctcctca 357
<210> 2
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 2
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Thr Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Leu Ile Ser Gly Asp Gly Ser Arg Thr Ser Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Ser Leu Tyr
65 70 75 80
Leu Lys Met Asn Ser Leu Arg Thr Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Lys Asp Pro His Asn Ser Asn Trp Phe Asp Pro Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 3
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 3
ggattcagcc ttgatgatta tgcc 24
<210> 4
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 4
Gly Phe Ser Leu Asp Asp Tyr Ala
1 5
<210> 5
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 5
attagtgggg atggtagtcg caca 24
<210> 6
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 6
Ile Ser Gly Asp Gly Ser Arg Thr
1 5
<210> 7
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 7
acaaaagatc cccataactc caactggttc gacccc 36
<210> 8
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 8
Thr Lys Asp Pro His Asn Ser Asn Trp Phe Asp Pro
1 5 10
<210> 9
<211> 363
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 9
caggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cgtctggatt caccttcagt agctatggca tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtggcagtt atatggtatg atggaagtaa taaaaactat 180
gcagactccg tgaagggccg attcaccatc tccagagaca gttccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggctgtgt attactgtgc gagagagaat 300
agcgagggct attattacgg tatggacgtc tggggccaag ggaccacggt caccgtctcc 360
tca 363
<210> 10
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 10
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Tyr Asp Gly Ser Asn Lys Asn Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Ser Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Asn Ser Glu Gly Tyr Tyr Tyr Gly Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 11
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 11
ggattcacct tcagtagcta tggc 24
<210> 12
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 12
Gly Phe Thr Phe Ser Ser Tyr Gly
1 5
<210> 13
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 13
atatggtatg atggaagtaa taaa 24
<210> 14
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 14
Ile Trp Tyr Asp Gly Ser Asn Lys
1 5
<210> 15
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 15
gcgagagaga atagcgaggg ctattattac ggtatggacg tc 42
<210> 16
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 16
Ala Arg Glu Asn Ser Glu Gly Tyr Tyr Tyr Gly Met Asp Val
1 5 10
<210> 17
<211> 354
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 17
caggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cgtctggatt caccttcagt agctacggca tgcactgggt ccgccaggct 120
ccaggcaagg gactggaatg ggtgacgaat atatggtatg atggaaataa taaatactat 180
acagactccg tgaagggccg attcaccatc tccagagaca attccaagaa tacactgtat 240
ttgcaaatga acagcctgac agccgaagac acggctgtgt attactgtgc gagagatgga 300
gactattacg ttatggacgt ctggggccaa gggaccacgg tcaccgtctc ctca 354
<210> 18
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 18
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Thr Asn Ile Trp Tyr Asp Gly Asn Asn Lys Tyr Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Thr Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Asp Tyr Tyr Val Met Asp Val Trp Gly Gln Gly Thr
100 105 110
Thr Val Thr Val Ser Ser
115
<210> 19
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 19
ggattcacct tcagtagcta cggc 24
<210> 20
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 20
Gly Phe Thr Phe Ser Ser Tyr Gly
1 5
<210> 21
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 21
atatggtatg atggaaataa taaa 24
<210> 22
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 22
Ile Trp Tyr Asp Gly Asn Asn Lys
1 5
<210> 23
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 23
gcgagagatg gagactatta cgttatggac gtc 33
<210> 24
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 24
Ala Arg Asp Gly Asp Tyr Tyr Val Met Asp Val
1 5 10
<210> 25
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 25
gaggtgcagc tggtgcagtc tggaccagag gtgaaaaagc ccggggagtc tctgaagatc 60
tcctgtaagg gttctggata caactttctc ggttactgga tcggctgggt gcgccagatg 120
cccgagaaag gcctggaatg gatggcgttc atctatcccg gtgactctga tttcagatac 180
agtccgtcct tccaaggcca ggtcaccatc tcagtcgaca ggtccgtcac cactgcctac 240
ctccattgga gcagcctgaa ggcctcggac accggcatat atttttgtgt gagacagact 300
ggcaacggta tggacgtctg gggccaaggg accacggtca ccgtctcctc a 351
<210> 26
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 26
Glu Val Gln Leu Val Gln Ser Gly Pro Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Lys Ile Ser Cys Lys Gly Ser Gly Tyr Asn Phe Leu Gly Tyr
20 25 30
Trp Ile Gly Trp Val Arg Gln Met Pro Glu Lys Gly Leu Glu Trp Met
35 40 45
Ala Phe Ile Tyr Pro Gly Asp Ser Asp Phe Arg Tyr Ser Pro Ser Phe
50 55 60
Gln Gly Gln Val Thr Ile Ser Val Asp Arg Ser Val Thr Thr Ala Tyr
65 70 75 80
Leu His Trp Ser Ser Leu Lys Ala Ser Asp Thr Gly Ile Tyr Phe Cys
85 90 95
Val Arg Gln Thr Gly Asn Gly Met Asp Val Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 27
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 27
ggatacaact ttctcggtta ctgg 24
<210> 28
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 28
Gly Tyr Asn Phe Leu Gly Tyr Trp
1 5
<210> 29
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 29
atctatcccg gtgactctga tttc 24
<210> 30
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 30
Ile Tyr Pro Gly Asp Ser Asp Phe
1 5
<210> 31
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 31
gtgagacaga ctggcaacgg tatggacgtc 30
<210> 32
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 32
Val Arg Gln Thr Gly Asn Gly Met Asp Val
1 5 10
<210> 33
<211> 375
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 33
caggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cgtctggatt caccttcagt aactatggca tgcattgggt ccgccaggct 120
ccaggcaagg ggctggagtg gttggcagtt atatactatg atggaattaa gagatactat 180
ggggactccg tgcagggccg attcattatc tccagagaca attccaagaa cacgctttat 240
ctgcaaatga acagccttag agacgaagac acggctgtgt attactgtgc gcgggcattt 300
tcagcggctg gcccgtacaa ctactactac gctatggacg tctggggcca agggaccacg 360
gtcaccgtct cctca 375
<210> 34
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 34
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Ala Val Ile Tyr Tyr Asp Gly Ile Lys Arg Tyr Tyr Gly Asp Ser Val
50 55 60
Gln Gly Arg Phe Ile Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Asp Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Phe Ser Ala Ala Gly Pro Tyr Asn Tyr Tyr Tyr Ala Met
100 105 110
Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120 125
<210> 35
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 35
ggattcacct tcagtaacta tggc 24
<210> 36
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 36
Gly Phe Thr Phe Ser Asn Tyr Gly
1 5
<210> 37
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 37
atatactatg atggaattaa gaga 24
<210> 38
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 38
Ile Tyr Tyr Asp Gly Ile Lys Arg
1 5
<210> 39
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 39
gcgcgggcat tttcagcggc tggcccgtac aactactact acgctatgga cgtc 54
<210> 40
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 40
Ala Arg Ala Phe Ser Ala Ala Gly Pro Tyr Asn Tyr Tyr Tyr Ala Met
1 5 10 15
Asp Val
<210> 41
<211> 375
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 41
gaggtgcagc tggtggagtc tgggggaggc ttggtacagc ctggagggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt aattatgaga tgaactgggt ccgccaggct 120
ccagggaagg ggctggattg ggtttcatac attagtacta gtggtagtgt catatactac 180
gcagactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctcactgtat 240
ctggaaatga acagcctgag agccgaggac acggctgttt attactgtgc gaggggttac 300
gatttttgga gtggttccga ctactactac ggtatggacg tctggggcca agggaccacg 360
gtcaccgtct cctca 375
<210> 42
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 42
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Glu Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Asp Trp Val
35 40 45
Ser Tyr Ile Ser Thr Ser Gly Ser Val Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Glu Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Tyr Asp Phe Trp Ser Gly Ser Asp Tyr Tyr Tyr Gly Met
100 105 110
Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120 125
<210> 43
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 43
ggattcacct tcagtaatta tgag 24
<210> 44
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 44
Gly Phe Thr Phe Ser Asn Tyr Glu
1 5
<210> 45
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 45
attagtacta gtggtagtgt cata 24
<210> 46
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 46
Ile Ser Thr Ser Gly Ser Val Ile
1 5
<210> 47
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 47
gcgaggggtt acgatttttg gagtggttcc gactactact acggtatgga cgtc 54
<210> 48
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 48
Ala Arg Gly Tyr Asp Phe Trp Ser Gly Ser Asp Tyr Tyr Tyr Gly Met
1 5 10 15
Asp Val
<210> 49
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 49
gaggtgcagc tggtgcagtc tggagcagag gtgaaaaagc ccggggactc tctgaagatc 60
tcctgtaagg gttctggata cagctttacc acctactgga tcggctgggt gcgccagatg 120
cccgggaaag gcctggagtg gatggggatc atctttcctg gtgactctga taccagatac 180
agcccgtcct tccaaggcca ggtcaccatc tcagccgaca agtccatcaa caccgcctac 240
ctacagtgga gcagcctgaa ggcctcggac accgccatat attactgtgc gagacataac 300
cgatgggtgg ccgactactg gggccaggga accctggtca ccgtctcctc a 351
<210> 50
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 50
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Asp
1 5 10 15
Ser Leu Lys Ile Ser Cys Lys Gly Ser Gly Tyr Ser Phe Thr Thr Tyr
20 25 30
Trp Ile Gly Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Phe Pro Gly Asp Ser Asp Thr Arg Tyr Ser Pro Ser Phe
50 55 60
Gln Gly Gln Val Thr Ile Ser Ala Asp Lys Ser Ile Asn Thr Ala Tyr
65 70 75 80
Leu Gln Trp Ser Ser Leu Lys Ala Ser Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Arg His Asn Arg Trp Val Ala Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 51
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 51
ggatacagct ttaccaccta ctgg 24
<210> 52
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 52
Gly Tyr Ser Phe Thr Thr Tyr Trp
1 5
<210> 53
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 53
atctttcctg gtgactctga tacc 24
<210> 54
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 54
Ile Phe Pro Gly Asp Ser Asp Thr
1 5
<210> 55
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 55
gcgagacata accgatgggt ggccgactac 30
<210> 56
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 56
Ala Arg His Asn Arg Trp Val Ala Asp Tyr
1 5 10
<210> 57
<211> 348
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 57
caggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcaa cgtctggatt caccttcagt agctatggca tgcactgggt ccgccaggct 120
ccaggcaagg gactggagtg ggtggcactg atatggtatg atagaaataa tgaatattat 180
gcagactccg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggctgtgt attactgtgc gagaggggag 300
tgggagatgg actactgggg ccagggaacc ctggtcaccg tctcctca 348
<210> 58
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 58
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Thr Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Leu Ile Trp Tyr Asp Arg Asn Asn Glu Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Glu Trp Glu Met Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 59
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 59
ggattcacct tcagtagcta tggc 24
<210> 60
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 60
Gly Phe Thr Phe Ser Ser Tyr Gly
1 5
<210> 61
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 61
atatggtatg atagaaataa tgaa 24
<210> 62
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 62
Ile Trp Tyr Asp Arg Asn Asn Glu
1 5
<210> 63
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 63
gcgagagggg agtgggagat ggactac 27
<210> 64
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 64
Ala Arg Gly Glu Trp Glu Met Asp Tyr
1 5
<210> 65
<211> 327
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 65
gaaattgtgt tgacacagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gaatgttcgc agcggctatt tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggtacatcca ccagggtcac tggcatccca 180
gacaggttca gtggctttgg gtctgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagtatggta attcacctct tttcactttc 300
ggcggaggga ccaaggtgga gatcaaa 327
<210> 66
<211> 109
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 66
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Asn Val Arg Ser Gly
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Thr Ser Thr Arg Val Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Phe Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Gly Asn Ser Pro
85 90 95
Leu Phe Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 67
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 67
cagaatgttc gcagcggcta t 21
<210> 68
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 68
Gln Asn Val Arg Ser Gly Tyr
1 5
<210> 69
<211> 9
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 69
ggtacatcc 9
<210> 70
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 70
Gly Thr Ser
1
<210> 71
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 71
cagcagtatg gtaattcacc tcttttcact 30
<210> 72
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 72
Gln Gln Tyr Gly Asn Ser Pro Leu Phe Thr
1 5 10
<210> 73
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 73
gaaatagtga tgacacagtc tccagccacc ctgtctgtgt ctccagggga aagagccacc 60
ctctcctgca cggccagtca gactattaac agcaatttag cctggtacca acagagacct 120
ggccaggctc ccaggctcct catctatggt gcatccacca gggccactgg taccccagcc 180
aggttcagag gcagtgggtc tgggaccgaa ttcactctca ccatcagcag cctgctgtct 240
gaagattttg cagtttatta ctgtcagaat tataataact ggccgccggg gggcccccgc 300
actttcggcc ctgggaccaa agtggatatc aaa 333
<210> 74
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 74
Glu Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Thr Ala Ser Gln Thr Ile Asn Ser Asn
20 25 30
Leu Ala Trp Tyr Gln Gln Arg Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Thr Arg Ala Thr Gly Thr Pro Ala Arg Phe Arg Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Leu Ser
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Asn Tyr Asn Asn Trp Pro Pro
85 90 95
Gly Gly Pro Arg Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys
100 105 110
<210> 75
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 75
cagactatta acagcaat 18
<210> 76
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 76
Gln Thr Ile Asn Ser Asn
1 5
<210> 77
<211> 9
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 77
ggtgcatcc 9
<210> 78
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 78
Gly Ala Ser
1
<210> 79
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 79
cagaattata ataactggcc gccggggggc ccccgcact 39
<210> 80
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 80
Gln Asn Tyr Asn Asn Trp Pro Pro Gly Gly Pro Arg Thr
1 5 10
<210> 81
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 81
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctataggaga cagagtcacc 60
atcacttgcc ggacgagtca ggacattaac aattatttag cctggtatca gcagaaacca 120
gggaaagttc ctaaactcct gatcttttct gcatccactt tgcaatcagg ggtcccatct 180
cggttcagcg gcagtggatt tgggacagat ttcactttca taatcagcag cctgcagcct 240
gaggatgttg caacttattt ctgtcaaaag tatgacagtg gccgcggcct cagtttcggc 300
ggagggacca aggtggagat caaa 324
<210> 82
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 82
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Ile Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Thr Ser Gln Asp Ile Asn Asn Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Val Pro Lys Leu Leu Ile
35 40 45
Phe Ser Ala Ser Thr Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Phe Gly Thr Asp Phe Thr Phe Ile Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Val Ala Thr Tyr Phe Cys Gln Lys Tyr Asp Ser Gly Arg Gly
85 90 95
Leu Ser Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 83
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 83
caggacatta acaattat 18
<210> 84
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 84
Gln Asp Ile Asn Asn Tyr
1 5
<210> 85
<211> 9
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 85
tctgcatcc 9
<210> 86
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 86
Ser Ala Ser
1
<210> 87
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 87
caaaagtatg acagtggccg cggcctcagt 30
<210> 88
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 88
Gln Lys Tyr Asp Ser Gly Arg Gly Leu Ser
1 5 10
<210> 89
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 89
gaggtgcagc tggtgcagtc tggagcagag gtgaaaaagc ccggggagtc tctgaagatc 60
tcctgtaagg cttctggata caattttaat agctattgga tcggctgggt gcgccagatg 120
cccgggaagg gcctggagtg gatgggaatc gtctttcctg gtgactctga taccagatac 180
agtccgtcct tccaaggcca ggtcaccatc tcagccgacg agtccatcaa caccgcctac 240
ctgcagtgga gcagcctgaa ggcctcggac accgccgtgt attactgtgc gaggcacaca 300
aggtggtacc ttgactactg gggccaggga accctggtca ccgtctcctc a 351
<210> 90
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 90
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Lys Ile Ser Cys Lys Ala Ser Gly Tyr Asn Phe Asn Ser Tyr
20 25 30
Trp Ile Gly Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Ile Val Phe Pro Gly Asp Ser Asp Thr Arg Tyr Ser Pro Ser Phe
50 55 60
Gln Gly Gln Val Thr Ile Ser Ala Asp Glu Ser Ile Asn Thr Ala Tyr
65 70 75 80
Leu Gln Trp Ser Ser Leu Lys Ala Ser Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Thr Arg Trp Tyr Leu Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 91
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 91
ggatacaatt ttaatagcta ttgg 24
<210> 92
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 92
Gly Tyr Asn Phe Asn Ser Tyr Trp
1 5
<210> 93
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 93
gtctttcctg gtgactctga tacc 24
<210> 94
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 94
Val Phe Pro Gly Asp Ser Asp Thr
1 5
<210> 95
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 95
gcgaggcaca caaggtggta ccttgactac 30
<210> 96
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 96
Ala Arg His Thr Arg Trp Tyr Leu Asp Tyr
1 5 10
<210> 97
<211> 354
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 97
caggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgtag cgtctggatt caccttcagt agttatggct ttcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtggcagtt atttggtatg atggaagtaa tgaaggctat 180
gtagactccg tgaggggccg attcaccatc tccagagact tttccaagaa cacgttgtat 240
ctgcaaatga acagcctgag aatcgaggac acggctgtgt attactgtgc gagacggggg 300
gactattaca ttatggacgt ctggggccaa gggaccacgg tcaccgtctc ctca 354
<210> 98
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 98
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Phe His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Tyr Asp Gly Ser Asn Glu Gly Tyr Val Asp Ser Val
50 55 60
Arg Gly Arg Phe Thr Ile Ser Arg Asp Phe Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ile Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Gly Asp Tyr Tyr Ile Met Asp Val Trp Gly Gln Gly Thr
100 105 110
Thr Val Thr Val Ser Ser
115
<210> 99
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 99
ggattcacct tcagtagtta tggc 24
<210> 100
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 100
Gly Phe Thr Phe Ser Ser Tyr Gly
1 5
<210> 101
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 101
atttggtatg atggaagtaa tgaa 24
<210> 102
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 102
Ile Trp Tyr Asp Gly Ser Asn Glu
1 5
<210> 103
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 103
gcgagacggg gggactatta cattatggac gtc 33
<210> 104
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 104
Ala Arg Arg Gly Asp Tyr Tyr Ile Met Asp Val
1 5 10
<210> 105
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 105
gaggtgcagc tggtgcagtc tggagcagag gtgaaaaagc ccggggagtc tctgaagatc 60
ttctgtaagg gttctggata cagctttatc aacgactgga tcggctgggt gcgccagatg 120
cccgggaaag gcctggaatg gatgggtctg atctttcctg gtgactctga taccagatat 180
agtccggttt tccaaggcca cgtcaccatc tcagccgacc agtccatcga caccgcctat 240
ctgcagtgga acagcctgaa ggcctcggac accgccatat attactgtgc ggtgttacga 300
tactggcact tcgctatctg gggccgtggc accctggtca ccgtctcctc a 351
<210> 106
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 106
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Lys Ile Phe Cys Lys Gly Ser Gly Tyr Ser Phe Ile Asn Asp
20 25 30
Trp Ile Gly Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Leu Ile Phe Pro Gly Asp Ser Asp Thr Arg Tyr Ser Pro Val Phe
50 55 60
Gln Gly His Val Thr Ile Ser Ala Asp Gln Ser Ile Asp Thr Ala Tyr
65 70 75 80
Leu Gln Trp Asn Ser Leu Lys Ala Ser Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Val Leu Arg Tyr Trp His Phe Ala Ile Trp Gly Arg Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 107
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 107
ggatacagct ttatcaacga ctgg 24
<210> 108
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 108
Gly Tyr Ser Phe Ile Asn Asp Trp
1 5
<210> 109
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 109
atctttcctg gtgactctga tacc 24
<210> 110
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 110
Ile Phe Pro Gly Asp Ser Asp Thr
1 5
<210> 111
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 111
gcggtgttac gatactggca cttcgctatc 30
<210> 112
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 112
Ala Val Leu Arg Tyr Trp His Phe Ala Ile
1 5 10
<210> 113
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 113
gaggtgcagc tggtgcagtc tggaccagag gtgaaaaagc ccggggagtc tttgaagatc 60
gcctgtaagg cttctggata cagttttacc agctactgga tcggttgggt gcgccagatg 120
cccgggaaag gcctggagtg gatggggatc atctttcctg ctgactctga taccagatac 180
agcccgtcct tccaaggcca ggtcaccatc tcagccgaca agtccatcac caccgcctac 240
ctgcagtgga ggagtctgca ggcctcggac accgccaaat attactgtgt gcgacatgta 300
cgatggtccg gggagaactg gggccaggga accctggtca ccgtctcctc a 351
<210> 114
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 114
Glu Val Gln Leu Val Gln Ser Gly Pro Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Lys Ile Ala Cys Lys Ala Ser Gly Tyr Ser Phe Thr Ser Tyr
20 25 30
Trp Ile Gly Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Phe Pro Ala Asp Ser Asp Thr Arg Tyr Ser Pro Ser Phe
50 55 60
Gln Gly Gln Val Thr Ile Ser Ala Asp Lys Ser Ile Thr Thr Ala Tyr
65 70 75 80
Leu Gln Trp Arg Ser Leu Gln Ala Ser Asp Thr Ala Lys Tyr Tyr Cys
85 90 95
Val Arg His Val Arg Trp Ser Gly Glu Asn Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 115
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 115
ggatacagtt ttaccagcta ctgg 24
<210> 116
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 116
Gly Tyr Ser Phe Thr Ser Tyr Trp
1 5
<210> 117
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 117
atctttcctg ctgactctga tacc 24
<210> 118
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 118
Ile Phe Pro Ala Asp Ser Asp Thr
1 5
<210> 119
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 119
gtgcgacatg tacgatggtc cggggagaac 30
<210> 120
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 120
Val Arg His Val Arg Trp Ser Gly Glu Asn
1 5 10
<210> 121
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 121
gaggtgcagc tggtgcagtc tggagcagaa gtaagaaagc ccggggagtc tctgaagatc 60
tcctgtaagg gttctggatt cagttttacc agctactgga tcggctgggt gcgccagatg 120
cccgggaaag gcctggagtg gatggggatc atctttcctg ctgactctga taccagatac 180
agcccgtcct tccaaggcca agtcaccatc tcggccgaca agtccatcaa caccgcctac 240
ctgcagtgga gaagcctgaa ggtctcggac accgccatgt attactgtac gaaactacag 300
tactggtact tcgatctctg gggccgtggc accctggtca ccgtctcctc a 351
<210> 122
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 122
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Arg Lys Pro Gly Glu
1 5 10 15
Ser Leu Lys Ile Ser Cys Lys Gly Ser Gly Phe Ser Phe Thr Ser Tyr
20 25 30
Trp Ile Gly Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Phe Pro Ala Asp Ser Asp Thr Arg Tyr Ser Pro Ser Phe
50 55 60
Gln Gly Gln Val Thr Ile Ser Ala Asp Lys Ser Ile Asn Thr Ala Tyr
65 70 75 80
Leu Gln Trp Arg Ser Leu Lys Val Ser Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Thr Lys Leu Gln Tyr Trp Tyr Phe Asp Leu Trp Gly Arg Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 123
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 123
ggattcagtt ttaccagcta ctgg 24
<210> 124
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 124
Gly Phe Ser Phe Thr Ser Tyr Trp
1 5
<210> 125
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 125
atctttcctg ctgactctga tacc 24
<210> 126
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 126
Ile Phe Pro Ala Asp Ser Asp Thr
1 5
<210> 127
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 127
acgaaactac agtactggta cttcgatctc 30
<210> 128
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 128
Thr Lys Leu Gln Tyr Trp Tyr Phe Asp Leu
1 5 10
<210> 129
<211> 354
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 129
caggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cgtctggatt caccttcagt agctatggca tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtggcactt atatggtatg atggaagtaa taaatacttt 180
gcagactccg tgaagggccg attcaccatc tccagagaca tttccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggctgtgt attactgtgc gagagatggg 300
gactactacg gtatggacgt ctggggccag gggaccacgg tcaccgtctc ctca 354
<210> 130
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 130
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Leu Ile Trp Tyr Asp Gly Ser Asn Lys Tyr Phe Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Ile Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Asp Tyr Tyr Gly Met Asp Val Trp Gly Gln Gly Thr
100 105 110
Thr Val Thr Val Ser Ser
115
<210> 131
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 131
ggattcacct tcagtagcta tggc 24
<210> 132
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 132
Gly Phe Thr Phe Ser Ser Tyr Gly
1 5
<210> 133
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 133
atatggtatg atggaagtaa taaa 24
<210> 134
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 134
Ile Trp Tyr Asp Gly Ser Asn Lys
1 5
<210> 135
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 135
gcgagagatg gggactacta cggtatggac gtc 33
<210> 136
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 136
Ala Arg Asp Gly Asp Tyr Tyr Gly Met Asp Val
1 5 10
<210> 137
<211> 375
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 137
gaagtgcagc tggtggagtc tgggggaggt ctggtacagc ctggcaggtc cctgagactc 60
tcctgtacaa cctctggatt cacctttgat gattatgcca tgcactgggt ccggcaagtt 120
ccagggcagg gcctggagtg ggtcgcaggt cttagctgga acagtgatac cataggctat 180
gcggactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ttccctgtat 240
ctgcaaatga aaagtctgaa agctgaggac acggccttat attactgtac aaaagatttc 300
taccatagtt tgaataattg gaactactac tactttgact actggggcca gggaaccctg 360
gtcaccgtct cctca 375
<210> 138
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 138
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Thr Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Val Pro Gly Gln Gly Leu Glu Trp Val
35 40 45
Ala Gly Leu Ser Trp Asn Ser Asp Thr Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Lys Ser Leu Lys Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Lys Asp Phe Tyr His Ser Leu Asn Asn Trp Asn Tyr Tyr Tyr Phe
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 139
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 139
ggattcacct ttgatgatta tgcc 24
<210> 140
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 140
Gly Phe Thr Phe Asp Asp Tyr Ala
1 5
<210> 141
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 141
cttagctgga acagtgatac cata 24
<210> 142
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 142
Leu Ser Trp Asn Ser Asp Thr Ile
1 5
<210> 143
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 143
acaaaagatt tctaccatag tttgaataat tggaactact actactttga ctac 54
<210> 144
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 144
Thr Lys Asp Phe Tyr His Ser Leu Asn Asn Trp Asn Tyr Tyr Tyr Phe
1 5 10 15
Asp Tyr
<210> 145
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 145
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gagcattagc agctatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccagtt tgcaaagtgg ggtcccgtca 180
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttacta ctgtcaacag agttacagta cccctccgat caccttcggc 300
caagggacac gactggagat taaa 324
<210> 146
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 146
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Pro
85 90 95
Ile Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys
100 105
<210> 147
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 147
cagagcatta gcagctat 18
<210> 148
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 148
Gln Ser Ile Ser Ser Tyr
1 5
<210> 149
<211> 9
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 149
gctgcatcc 9
<210> 150
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 150
Ala Ala Ser
1
<210> 151
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 151
caacagagtt acagtacccc tccgatcacc 30
<210> 152
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 152
Gln Gln Ser Tyr Ser Thr Pro Pro Ile Thr
1 5 10
<210> 153
<211> 375
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 153
cagctgcagc tgcaggagtc gggcccagga ctggtgaagc cttcggagac cctgtccctc 60
acctgcactg tctctggtgg ctccatcagc agcagtagtt actactgggt ctggatccgc 120
cagcccccag ggaaggggct ggaatggatt ggtaatatct attttagtgg gagcacatac 180
tacaacccgt ccctcaagag tcgagtcacc ataaccgttg acacgtccaa gaaccagttc 240
tccctgaaaa tgacctctgt gaccgccgca gacacggctg tatattactg tgcgagaccc 300
ttctatggtt cgagggggga ctactactac ggtatggacg tctggggcca agggaccacg 360
gtcaccgtct cctca 375
<210> 154
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 154
Gln Leu Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Gly Ser Ile Ser Ser Ser
20 25 30
Ser Tyr Tyr Trp Val Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
35 40 45
Trp Ile Gly Asn Ile Tyr Phe Ser Gly Ser Thr Tyr Tyr Asn Pro Ser
50 55 60
Leu Lys Ser Arg Val Thr Ile Thr Val Asp Thr Ser Lys Asn Gln Phe
65 70 75 80
Ser Leu Lys Met Thr Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Arg Pro Phe Tyr Gly Ser Arg Gly Asp Tyr Tyr Tyr Gly Met
100 105 110
Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120 125
<210> 155
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 155
ggtggctcca tcagcagcag tagttactac 30
<210> 156
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 156
Gly Gly Ser Ile Ser Ser Ser Ser Tyr Tyr
1 5 10
<210> 157
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 157
atctatttta gtgggagcac a 21
<210> 158
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 158
Ile Tyr Phe Ser Gly Ser Thr
1 5
<210> 159
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 159
gcgagaccct tctatggttc gaggggggac tactactacg gtatggacgt c 51
<210> 160
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 160
Ala Arg Pro Phe Tyr Gly Ser Arg Gly Asp Tyr Tyr Tyr Gly Met Asp
1 5 10 15
Val
<210> 161
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 161
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggtgcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagtatggta gctcaccttg gacgttcggc 300
caagggacca aggtggaaat caaa 324
<210> 162
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 162
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Gly Ser Ser Pro
85 90 95
Trp Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 163
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 163
cagagtgtta gcagcagcta c 21
<210> 164
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 164
Gln Ser Val Ser Ser Ser Tyr
1 5
<210> 165
<211> 9
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 165
ggtgcatcc 9
<210> 166
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 166
Gly Ala Ser
1
<210> 167
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 167
cagcagtatg gtagctcacc ttggacg 27
<210> 168
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 168
Gln Gln Tyr Gly Ser Ser Pro Trp Thr
1 5
<210> 169
<211> 582
<212> PRT
<213> Artificial Sequence
<220>
<223> IsdB-6xHis
aa 1-2 and 575-576: linker
aa 3-574: aa 41-613 of WP_063557416.1
<400> 169
Ala Ser Ala Glu Glu Thr Gly Gly Thr Asn Thr Glu Ala Gln Pro Lys
1 5 10 15
Thr Glu Ala Val Ala Ser Pro Thr Thr Thr Ser Glu Lys Ala Pro Glu
20 25 30
Thr Lys Pro Val Ala Asn Ala Val Ser Val Ser Asn Lys Glu Val Glu
35 40 45
Ala Pro Thr Ser Glu Thr Lys Glu Ala Lys Glu Val Lys Glu Val Lys
50 55 60
Ala Pro Lys Glu Thr Lys Glu Val Lys Pro Ala Ala Lys Ala Thr Asn
65 70 75 80
Asn Thr Tyr Pro Ile Leu Asn Gln Glu Leu Arg Glu Ala Ile Lys Asn
85 90 95
Pro Ala Ile Lys Asp Lys Asp His Ser Ala Pro Asn Ser Arg Pro Ile
100 105 110
Asp Phe Glu Met Lys Lys Lys Asp Gly Thr Gln Gln Phe Tyr His Tyr
115 120 125
Ala Ser Ser Val Lys Pro Ala Arg Val Ile Phe Thr Asp Ser Lys Pro
130 135 140
Glu Ile Glu Leu Gly Leu Gln Ser Gly Gln Phe Trp Arg Lys Phe Glu
145 150 155 160
Val Tyr Glu Gly Asp Lys Lys Leu Pro Ile Lys Leu Val Ser Tyr Asp
165 170 175
Thr Val Lys Asp Tyr Ala Tyr Ile Arg Phe Ser Val Ser Asn Gly Thr
180 185 190
Lys Ala Val Lys Ile Val Ser Ser Thr His Phe Asn Asn Lys Glu Glu
195 200 205
Lys Tyr Asp Tyr Thr Leu Met Glu Phe Ala Gln Pro Ile Tyr Asn Ser
210 215 220
Ala Asp Lys Phe Lys Thr Glu Glu Asp Tyr Lys Ala Glu Lys Leu Leu
225 230 235 240
Ala Pro Tyr Lys Lys Ala Lys Thr Leu Glu Arg Gln Val Tyr Glu Leu
245 250 255
Asn Lys Ile Gln Asp Lys Leu Pro Glu Lys Leu Lys Ala Glu Tyr Lys
260 265 270
Lys Lys Leu Glu Asp Thr Lys Lys Ala Leu Asp Glu Gln Val Lys Ser
275 280 285
Ala Ile Thr Glu Phe Gln Asn Val Gln Pro Thr Asn Glu Lys Met Thr
290 295 300
Asp Leu Gln Asp Thr Lys Tyr Val Val Tyr Glu Ser Val Glu Asn Asn
305 310 315 320
Glu Ser Met Met Asp Thr Phe Val Lys His Pro Ile Lys Thr Gly Met
325 330 335
Leu Asn Gly Lys Lys Tyr Met Val Met Glu Thr Thr Asn Asp Asp Tyr
340 345 350
Trp Lys Asp Phe Met Val Glu Gly Gln Arg Val Arg Thr Ile Ser Lys
355 360 365
Asp Ala Lys Asn Asn Thr Arg Thr Ile Ile Phe Pro Tyr Val Glu Gly
370 375 380
Lys Thr Leu Tyr Asp Ala Ile Val Lys Val His Val Lys Thr Ile Asp
385 390 395 400
Tyr Asp Gly Gln Tyr His Val Arg Ile Val Asp Lys Glu Ala Phe Thr
405 410 415
Lys Ala Asn Thr Asp Lys Ser Asn Lys Lys Glu Gln Gln Asp Asn Ser
420 425 430
Ala Lys Lys Glu Ala Thr Pro Ala Thr Pro Ser Lys Pro Thr Pro Ser
435 440 445
Pro Val Glu Lys Glu Ser Gln Lys Gln Asp Ser Gln Lys Asp Asp Asn
450 455 460
Lys Gln Leu Pro Ser Val Glu Lys Glu Asn Asp Ala Ser Ser Glu Ser
465 470 475 480
Gly Lys Asp Lys Thr Pro Ala Thr Lys Pro Thr Lys Gly Glu Val Glu
485 490 495
Ser Ser Ser Thr Thr Pro Thr Lys Val Val Ser Thr Thr Gln Asn Val
500 505 510
Ala Lys Pro Thr Thr Ala Ser Ser Lys Thr Thr Lys Asp Val Val Gln
515 520 525
Thr Ser Ala Gly Ser Ser Glu Ala Lys Asp Ser Ala Pro Leu Gln Lys
530 535 540
Ala Asn Ile Lys Asn Thr Asn Asp Gly His Thr Gln Ser Gln Asn Asn
545 550 555 560
Lys Asn Thr Gln Glu Asn Lys Ala Lys Ser Leu Pro Gln Thr Leu Glu
565 570 575
His His His His His His
580
<210> 170
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> C1q subcomponent a chain
amino acids 1-245 of accession number NP_057075.1
<400> 170
Met Glu Gly Pro Arg Gly Trp Leu Val Leu Cys Val Leu Ala Ile Ser
1 5 10 15
Leu Ala Ser Met Val Thr Glu Asp Leu Cys Arg Ala Pro Asp Gly Lys
20 25 30
Lys Gly Glu Ala Gly Arg Pro Gly Arg Arg Gly Arg Pro Gly Leu Lys
35 40 45
Gly Glu Gln Gly Glu Pro Gly Ala Pro Gly Ile Arg Thr Gly Ile Gln
50 55 60
Gly Leu Lys Gly Asp Gln Gly Glu Pro Gly Pro Ser Gly Asn Pro Gly
65 70 75 80
Lys Val Gly Tyr Pro Gly Pro Ser Gly Pro Leu Gly Ala Arg Gly Ile
85 90 95
Pro Gly Ile Lys Gly Thr Lys Gly Ser Pro Gly Asn Ile Lys Asp Gln
100 105 110
Pro Arg Pro Ala Phe Ser Ala Ile Arg Arg Asn Pro Pro Met Gly Gly
115 120 125
Asn Val Val Ile Phe Asp Thr Val Ile Thr Asn Gln Glu Glu Pro Tyr
130 135 140
Gln Asn His Ser Gly Arg Phe Val Cys Thr Val Pro Gly Tyr Tyr Tyr
145 150 155 160
Phe Thr Phe Gln Val Leu Ser Gln Trp Glu Ile Cys Leu Ser Ile Val
165 170 175
Ser Ser Ser Arg Gly Gln Val Arg Arg Ser Leu Gly Phe Cys Asp Thr
180 185 190
Thr Asn Lys Gly Leu Phe Gln Val Val Ser Gly Gly Met Val Leu Gln
195 200 205
Leu Gln Gln Gly Asp Gln Val Trp Val Glu Lys Asp Pro Lys Lys Gly
210 215 220
His Ile Tyr Gln Gly Ser Glu Ala Asp Ser Val Phe Ser Gly Phe Leu
225 230 235 240
Ile Phe Pro Ser Ala
245
<210> 171
<211> 253
<212> PRT
<213> Artificial Sequence
<220>
<223> C1q subcomponent b chain
amino acids 1-253 of accession number NP_000482.3
<400> 171
Met Met Met Lys Ile Pro Trp Gly Ser Ile Pro Val Leu Met Leu Leu
1 5 10 15
Leu Leu Leu Gly Leu Ile Asp Ile Ser Gln Ala Gln Leu Ser Cys Thr
20 25 30
Gly Pro Pro Ala Ile Pro Gly Ile Pro Gly Ile Pro Gly Thr Pro Gly
35 40 45
Pro Asp Gly Gln Pro Gly Thr Pro Gly Ile Lys Gly Glu Lys Gly Leu
50 55 60
Pro Gly Leu Ala Gly Asp His Gly Glu Phe Gly Glu Lys Gly Asp Pro
65 70 75 80
Gly Ile Pro Gly Asn Pro Gly Lys Val Gly Pro Lys Gly Pro Met Gly
85 90 95
Pro Lys Gly Gly Pro Gly Ala Pro Gly Ala Pro Gly Pro Lys Gly Glu
100 105 110
Ser Gly Asp Tyr Lys Ala Thr Gln Lys Ile Ala Phe Ser Ala Thr Arg
115 120 125
Thr Ile Asn Val Pro Leu Arg Arg Asp Gln Thr Ile Arg Phe Asp His
130 135 140
Val Ile Thr Asn Met Asn Asn Asn Tyr Glu Pro Arg Ser Gly Lys Phe
145 150 155 160
Thr Cys Lys Val Pro Gly Leu Tyr Tyr Phe Thr Tyr His Ala Ser Ser
165 170 175
Arg Gly Asn Leu Cys Val Asn Leu Met Arg Gly Arg Glu Arg Ala Gln
180 185 190
Lys Val Val Thr Phe Cys Asp Tyr Ala Tyr Asn Thr Phe Gln Val Thr
195 200 205
Thr Gly Gly Met Val Leu Lys Leu Glu Gln Gly Glu Asn Val Phe Leu
210 215 220
Gln Ala Thr Asp Lys Asn Ser Leu Leu Gly Met Glu Gly Ala Asn Ser
225 230 235 240
Ile Phe Ser Gly Phe Leu Leu Phe Pro Asp Met Glu Ala
245 250
<210> 172
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> C1q subcomponent c chain
amino acids 1-245 of accession number NP_758957.2
<400> 172
Met Asp Val Gly Pro Ser Ser Leu Pro His Leu Gly Leu Lys Leu Leu
1 5 10 15
Leu Leu Leu Leu Leu Leu Pro Leu Arg Gly Gln Ala Asn Thr Gly Cys
20 25 30
Tyr Gly Ile Pro Gly Met Pro Gly Leu Pro Gly Ala Pro Gly Lys Asp
35 40 45
Gly Tyr Asp Gly Leu Pro Gly Pro Lys Gly Glu Pro Gly Ile Pro Ala
50 55 60
Ile Pro Gly Ile Arg Gly Pro Lys Gly Gln Lys Gly Glu Pro Gly Leu
65 70 75 80
Pro Gly His Pro Gly Lys Asn Gly Pro Met Gly Pro Pro Gly Met Pro
85 90 95
Gly Val Pro Gly Pro Met Gly Ile Pro Gly Glu Pro Gly Glu Glu Gly
100 105 110
Arg Tyr Lys Gln Lys Phe Gln Ser Val Phe Thr Val Thr Arg Gln Thr
115 120 125
His Gln Pro Pro Ala Pro Asn Ser Leu Ile Arg Phe Asn Ala Val Leu
130 135 140
Thr Asn Pro Gln Gly Asp Tyr Asp Thr Ser Thr Gly Lys Phe Thr Cys
145 150 155 160
Lys Val Pro Gly Leu Tyr Tyr Phe Val Tyr His Ala Ser His Thr Ala
165 170 175
Asn Leu Cys Val Leu Leu Tyr Arg Ser Gly Val Lys Val Val Thr Phe
180 185 190
Cys Gly His Thr Ser Lys Thr Asn Gln Val Asn Ser Gly Gly Val Leu
195 200 205
Leu Arg Leu Gln Val Gly Glu Glu Val Trp Leu Ala Val Asn Asp Tyr
210 215 220
Tyr Asp Met Val Gly Ile Gln Gly Ser Asp Ser Val Phe Ser Gly Phe
225 230 235 240
Leu Leu Phe Pro Asp
245
Claims (48)
- 하기를 포함하는 단리된 이특이적 항원 결합 분자:
a) 스타필로코커스 (Staphylococcus) 종 표적 항원에 결합하는 제1 항원-결합 도메인; 및
b) 보체 성분에 결합하는 제2 항원-결합 도메인. - 제1항에 있어서, 상기 이특이적 항원-결합 분자가 약 10nM 이하의 EC50으로 스타필로코커스 종 표적 항원에 결합하는, 단리된 이특이적 항원 결합 분자.
- 제1항 또는 제2항에 있어서, 상기 이특이적 항원 결합 분자가 약 10nM 이하의 EC50으로 스타필로코커스 종상에서 사람 C1q 침적을 촉진시키는, 단리된 이특이적 항원 결합 분자.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 상기 제1 항원 결합 도메인이 스타필로코커스 아우레우스(Staphylococcus aureus) 표적 항원에 결합하는, 단리된 이특이적 항원 결합 분자.
- 제4항에 있어서, 상기 제1 항원 결합 도메인이 스타필로코커스 아우레우스 IsdB 항원에 결합하는, 단리된 이특이적 항원 결합 분자.
- 제5항에 있어서, 상기 스타필로코커스 아우레우스 IsdB 단백질이 서열번호 169의 아미노산 3 내지 574의 아미노산 서열을 포함하는, 단리된 이특이적 항원 결합 분자.
- 제1항 내지 제6항 중 어느 한 항에 있어서, 상기 제2 항원 결합 도메인이 보체 성분 C1q에 결합하는, 단리된 이특이적 항원 결합 분자.
- 제7항에 있어서, 상기 보체 성분 C1q가 사람 C1q인, 단리된 이특이적 항원 결합 분자.
- 제5항 내지 제8항 중 어느 한 항에 있어서, 상기 제1 항원 결합 도메인이 표면 플라스몬 공명 검정에서 측정시, 약 25nM 미만, 약 20nM 미만, 약 15nM 미만, 약 10nM 미만, 약 5nM 미만, 약 1nM 미만, 약 500 pM 미만, 약 400 pM 미만, 약 300 pM 미만, 약 200 pM 미만, 약 100 pM 미만, 약 90 pM 미만, 약 80 pM 미만, 약 70 pM 미만, 약 60 pM 미만, 약 50 pM 미만, 약 40 pM 미만, 약 30 pM 미만, 약 20 pM 미만, 약 10 pM 미만, 약 5 pM 미만, 약 4 pM 미만, 약 2 pM 미만, 약 1 pM 미만, 약 0.5 pM 미만, 약 0.2 pM 미만, 약 0.1 pM 미만, 또는 약 0.05 pM 미만의 KD로 스타필로코커스 아우레우스 IsdB에 결합하는, 단리된 이특이적 항원 결합 분자.
- 제7항 내지 제9항 중 어느 한 항에 있어서, 상기 제2 항원 결합 도메인이 표면 플라스몬 공명 검정에서 측정시, 약 25nM 미만, 약 20nM 미만, 약 15nM 미만, 약 10nM 미만, 약 5nM 미만, 약 1nM 미만, 약 500 pM 미만, 약 400 pM 미만, 약 300 pM 미만, 약 200 pM 미만, 약 100 pM 미만, 약 90 pM 미만, 약 80 pM 미만, 약 70 pM 미만, 약 60 pM 미만, 약 50 pM 미만, 약 40 pM 미만, 약 30 pM 미만, 약 20 pM 미만, 약 10 pM 미만, 약 5 pM 미만, 약 4 pM 미만, 약 2 pM 미만, 약 1 pM 미만, 약 0.5 pM 미만, 약 0.2 pM 미만, 약 0.1 pM 미만, 또는 약 0.05 pM 미만의 KD로 보체 성분 C1q에 결합하는, 단리된 이특이적 항원 결합 분자.
- 제1항 내지 제10항 중 어느 한 항에 있어서, 상기 제1 항원-결합 도메인이 하기를 포함하는, 단리된 이특이적 항원 결합 분자:
a) 서열번호 138의 아미노산 서열 또는 서열번호 154의 아미노산 서열을 포함하는 중쇄 가변 영역 (HCVR) 내에 함유된 3개의 중쇄 상보성 결정 영역 (HCDR); 및
b) 서열번호 146의 아미노산 서열 또는 서열번호 162의 아미노산 서열을 포함하는 경쇄 가변 영역 (LCVR) 내에 함유된 3개의 경쇄 상보성 결정 영역 (LCDR), - 제11항에 있어서, 상기 HCDR이 하기를 포함하는, 단리된 이특이적 항원 결합 분자:
a) 서열번호 140의 아미노산 서열을 포함하는 중쇄 CDR1 (HCDR1), 서열번호 142의 아미노산 서열을 포함하는 중쇄 CDR2 (HCDR2), 및 서열번호 144의 아미노산 서열을 포함하는 중쇄 CDR3 (HCDR3); 또는
b) 서열번호 156의 아미노산 서열을 포함하는 HCDR1; 서열번호 158의 아미노산 서열을 포함하는 HCDR2; 및 서열번호 160의 아미노산 서열을 포함하는 HCDR3. - 제12항에 있어서, 상기 LCDR이 하기를 포함하는, 단리된 이특이적 항원 결합 분자:
a) 서열번호 148의 아미노산 서열을 포함하는 경쇄 CDR1 (LCDR1), 서열번호 150의 아미노산 서열을 포함하는 경쇄 CDR2 (LCDR2), 및 서열번호 152의 아미노산 서열을 포함하는 경쇄 CDR3 (LCDR3); 또는
b) 서열번호 164의 아미노산 서열을 포함하는 LCDR1; 서열번호 166의 아미노산 서열을 포함하는 LCDR2; 및 서열번호 168의 아미노산 서열을 포함하는 LCDR3. - 제13항에 있어서, 상기 제1 항원 결합 도메인이 하기를 포함하는, 단리된 이특이적 항원 결합 분자:
a) 서열번호 140, 142, 144의 아미노산 서열을 포함하는 HCDR (HCDR1, HCDR2, HCDR3) 세트, 및 서열번호 148, 150, 152의 아미노산 서열을 포함하는 LCDR (LCDR1, LCDR2, LCDR3) 세트; 또는
b) 서열번호 156,158, 160의 아미노산 서열을 포함하는 HCDR (HCDR1, HCDR2, HCDR3) 세트, 및 서열번호 164, 166, 168의 아미노산 서열을 포함하는 LCDR (LCDR1, LCDR2, LCDR3) 세트. - 제1항 내지 제14항 중 어느 한 항에 있어서, 상기 제1 항원 결합 도메인이 서열번호 138/146 또는 서열번호 154/162의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하는, 단리된 이특이적 항원 결합 분자.
- 제1항 내지 제15항 중 어느 한 항에 있어서, 상기 제2 항원 결합 도메인이 C1q에 결합하고, C1q가 서열번호 170, 171 및 172의 아미노산 서열을 포함하는, 단리된 이특이적 항원 결합 분자.
- 제16항에 있어서, 상기 이특이적 항원 결합 분자가 약 10nM 이하의 IC50으로 사람 C1q의 사람 IgG1-k로의 결합을 차단하는, 단리된 이특이적 항원 결합 분자.
- 제17항에 있어서, 상기 이특이적 항원 결합 분자가 약 50nM 이하의 IC50으로 사람 C1q의 사람 IgM으로의 결합을 차단하는, 단리된 이특이적 항원 결합 분자.
- 제1항 내지 제18항 중 어느 한 항에 있어서, 상기 제2 항원-결합 도메인이 하기를 포함하는, 단리된 이특이적 항원 결합 분자:
a) 서열번호 2, 10, 18, 26, 34, 42, 50, 58, 66, 74, 82, 90, 98, 106, 114, 122, 또는 130의 아미노산 서열을 포함하는 HCVR 내 함유된 3개의 HCDR; 및
b) 서열번호 146의 아미노산 서열 또는 서열번호 162의 아미노산 서열을 포함하는 LCVR 내에 함유된 3개의 LCDR. - 제19항에 있어서, 상기 제2 항원 결합 도메인이 하기를 포함하는, 단리된 이특이적 항원 결합 분자:
a) 서열번호 4, 12, 20, 28, 36, 44, 52, 60, 68, 76, 84, 92, 100, 108, 116, 124, 또는 132의 아미노산 서열을 포함하는 HCDR1;
b) 서열번호 6, 14, 22, 30, 38, 46, 54, 62, 70, 78, 86, 94, 102, 110, 118, 126, 또는 134의 아미노산 서열을 포함하는 HCDR2; 및
c) 서열번호 8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, 104, 112, 120, 128, 또는 136의 아미노산 서열을 포함하는 HCDR3. - 제20항에 있어서, 상기 제2 항원-결합 도메인이 하기를 포함하는, 단리된 이특이적 항원 결합 분자:
a) 서열번호 148의 아미노산 서열을 포함하는 LCDR1; 서열번호 150의 아미노산 서열을 포함하는 LCDR2; 및 서열번호 152의 아미노산 서열을 포함하는 LCDR3; 또는
b) 서열번호 164의 아미노산 서열을 포함하는 LCDR1, 서열번호 166의 아미노산 서열을 포함하는 LCDR2, 및 서열번호 168의 아미노산 서열을 포함하는 경쇄 CDR3. - 제20항에 있어서, 상기 제2 항원 결합 도메인이 하기를 포함하는, 단리된 이특이적 항원 결합 분자:
a) 서열번호 4, 6, 8; 서열번호 12, 14, 16; 서열번호 92, 94, 96; 서열번호 100, 102, 104; 또는 서열번호 108, 110, 112의 아미노산 서열을 포함하는 HCDR (HCDR1, HCDR2, HCDR3) 세트, 및 서열번호 148, 150, 152의 아미노산 서열을 포함하는 LCDR (LCDR1, LCDR2, LCDR3) 세트; 또는
b) 서열번호 20, 22, 24; 서열번호 28, 30, 32; 서열번호 36, 38, 40; 서열번호 44, 46, 48; 서열번호 52, 54, 56; 서열번호 60, 62, 64; 서열번호 68, 70, 72; 서열번호 76, 78, 80; 서열번호 84, 86, 88; 서열번호 116, 118, 120; 서열번호 124, 126, 128; 또는 서열번호 132, 134, 136의 아미노산 서열을 포함하는 HCDR (HCDR1, HCDR2, HCDR3) 세트, 및 서열번호 164, 166, 168의 아미노산 서열을 포함하는 LCDR (LCDR1, LCDR2, LCDR3) 세트. - 제1항 내지 제22항 중 어느 한 항에 있어서, 하기를 포함하는, 단리된 이특이적 항원 결합 분자:
a) 서열번호 140, 142, 144의 아미노산 서열을 포함하는 3개의 HCDR, 및 서열번호 148, 150, 152의 아미노산 서열을 포함하는 3개의 LCDR을 포함하는 제1 항원 결합 도메인; 및
b) 서열번호 4, 6, 8의 아미노산 서열을 포함하는 3개의 HCDR, 및 서열번호 148, 150, 152의 아미노산 서열을 포함하는 3개의 LCDR을 포함하는 제2 항원 결합 도메인. - 제1항 내지 제23항 중 어느 한 항에 있어서, 하기를 포함하는, 단리된 이특이적 항원 결합 분자:
a) 서열번호 140, 142, 144의 아미노산 서열을 포함하는 3개의 HCDR, 및 서열번호 148, 150, 152의 아미노산 서열을 포함하는 3개의 LCDR을 포함하는 제1 항원-결합 도메인; 및
b) 서열번호 108, 110, 112의 아미노산 서열을 포함하는 3개의 HCDR, 및 서열번호 148, 150, 152의 아미노산 서열을 포함하는 3개의 LCDR을 포함하는 제2 항원 결합 도메인. - 제1항 내지 제24항 중 어느 한 항에 있어서, 하기를 포함하는, 단리된 이특이적 항원 결합 분자:
a) 서열번호 138/146 또는 서열번호 154/162의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하는 제1 항원 결합 도메인; 및
b) 서열번호 2/146, 10/146, 90/146, 98/146, 106/146, 66/162, 74/162, 82/162, 18/162, 26/162, 34/162, 42/162, 50/162, 58/162, 114/162, 122/162 또는 130/162의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하는 제2 항원 결합 도메인. - 제25항에 있어서,
a) 상기 제1 항원 결합 도메인이 서열번호 138/146의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하고;
b) 상기 제2 항원 결합 도메인이 서열번호 2/146의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하는, 단리된 이특이적 항원 결합 분자. - 제25항에 있어서,
a) 상기 제1 항원 결합 도메인이 서열번호 138/146의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하고;
b) 상기 제2 항원 결합 도메인이 서열번호 106/146의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하는, 단리된 이특이적 항원 결합 분자. - 서열번호 138/146의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하는 참조 항체와 IsdB상의 동일한 에피토프에 결합하는, 단리된 이특이적 항원 결합 분자.
- 서열번호 2/146 또는 서열번호 106/146의 아미노산 서열을 포함하는 HCVR/LCVR 쌍을 포함하는 참조 항체와 사람 C1q 상의 동일한 에피토프에 결합하는 단리된 이특이적 항원 결합 분자.
- 제1항 내지 제29항 중 어느 한 항의 이특이적 항원-결합 분자 및 약제학적으로 허용되는 담체 또는 희석제를 포함하는 약제학적 조성물.
- 제1항 내지 제29항 중 어느 한 항의 이특이적 항체를 암호화하는 뉴클레오타이드 서열을 포함하는 핵산.
- 제31항의 핵산을 포함하는 발현 벡터.
- 제32항의 발현 벡터를 포함하는 숙주 세포.
- 제1항 내지 제29항 중 어느 한 항의 단리된 이특이적 항체 또는 제30항의 약제학적 조성물을 대상체에게 투여함을 포함하는, 대상체에서 스타필로코커스 종의 성장을 억제하는 방법.
- 제34항에 있어서, 상기 스타필로코커스 종이 스타필로코커스 아우레우스인, 방법.
- 제35항에 있어서, 상기 스타필로코커스 종이 메티실린 내성 스타필로코커스 아우레우스인, 방법.
- 제1항 내지 제29항 중 어느 한 항의 단리된 이특이적 항체 또는 제30항의 약제학적 조성물을 대상체에게 투여함을 포함하는, 대상체에서 스타필로코커스 종으로의 감염을 치료하거나 예방하는 방법.
- 제37항에 있어서, 상기 스타필로코커스 종이 스타필로코커스 아우레우스인, 방법.
- 제38항에 있어서, 상기 스타필로코커스 종이 메티실린 내성 스타필로코커스 아우레우스인, 방법.
- 제34항 내지 제39항 중 어느 한 항에 있어서, 제2 치료학적 제제를 투여하는 것을 추가로 포함하는, 방법.
- 제40항에 있어서, 상기 제2 치료학적 제제가 항생제, 스타필로코커스 항원에 결합하는 항체, 스타필로코커스 독소에 결합하는 항체, 사람 또는 시노몰구스 C1q에 결합하는 항체, 스타필로코커스 종에 특이적인 백신, 항체 약물 접합체, 항생제와 접합된 이특이적 항체 또는 이의 조합을 포함하는, 방법.
- 제34항 내지 제41항 중 어느 한 항에 있어서, 상기 대상체가 피부 감염, 봉와직염, 폐렴, 뇌수막염, 요로 감염, 독성 쇼크 증후군, 심내막염, 심낭염, 골수염, 균혈증, 또는 패혈증을 포함하는 질환 또는 장애를 갖는, 방법.
- 제34항 내지 제41항 중 어느 한 항에 있어서, 상기 대상체가 수술 과정을 진행하였거나 진행할, 방법.
- 제43항에 있어서, 상기 수술 과정이 보철을 이식함을 포함하는, 방법.
- 제44항에 있어서, 상기 보철이 의지 (prosthetic limb) 또는 관절인, 방법.
- 제44항에 있어서, 상기 보철이 보철 팔 또는 다리인, 방법.
- 제44항에 있어서, 상기 보철이 성형용 보철인, 방법.
- 제47항에 있어서, 상기 성형용 보철이 안구 보철, 또는 실리콘 손, 손가락, 유방, 발, 발가락 또는 안면 이식인, 방법.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762565569P | 2017-09-29 | 2017-09-29 | |
| US62/565,569 | 2017-09-29 | ||
| US201862654576P | 2018-04-09 | 2018-04-09 | |
| US62/654,576 | 2018-04-09 | ||
| PCT/US2018/053064 WO2019067682A1 (en) | 2017-09-29 | 2018-09-27 | BISPECIFIC ANTIGEN-BINDING MOLECULES BINDING TO TARGET STAPHYLOCOCCUS ANTIGEN AND COMPONENT COMPONENT, AND USES THEREOF |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200058525A true KR20200058525A (ko) | 2020-05-27 |
Family
ID=63858177
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020207012271A Withdrawn KR20200058525A (ko) | 2017-09-29 | 2018-09-27 | 스타필로코커스 표적 항원 및 보체 성분에 결합하는 이특이적 항원-결합 분자 및 이의 용도 |
Country Status (17)
| Country | Link |
|---|---|
| US (2) | US10865236B2 (ko) |
| EP (1) | EP3688029A1 (ko) |
| JP (1) | JP2021500865A (ko) |
| KR (1) | KR20200058525A (ko) |
| CN (1) | CN111148758B (ko) |
| AU (1) | AU2018341587A1 (ko) |
| BR (1) | BR112020004977A2 (ko) |
| CA (1) | CA3076632A1 (ko) |
| CL (1) | CL2020000755A1 (ko) |
| CO (1) | CO2020003948A2 (ko) |
| IL (1) | IL273227A (ko) |
| MA (1) | MA50659A (ko) |
| MX (1) | MX2020002976A (ko) |
| MY (1) | MY199789A (ko) |
| PH (1) | PH12020500375A1 (ko) |
| SG (1) | SG11202001160XA (ko) |
| WO (1) | WO2019067682A1 (ko) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA3110377A1 (en) | 2018-11-21 | 2020-05-28 | Regeneron Pharmaceuticals, Inc. | Anti-staphylococcus antibodies and uses thereof |
| KR20210126641A (ko) | 2019-02-12 | 2021-10-20 | 리제너론 파아마슈티컬스, 인크. | 보체 및 표적 항원에 결합하기 위해 이중 특이적 항체를 사용하는 조성물 및 방법 |
| EP3983015A1 (en) | 2019-06-11 | 2022-04-20 | Regeneron Pharmaceuticals, Inc. | Anti-pcrv antibodies that bind pcrv, compositions comprising anti-pcrv antibodies, and methods of use thereof |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IL85035A0 (en) | 1987-01-08 | 1988-06-30 | Int Genetic Eng | Polynucleotide molecule,a chimeric antibody with specificity for human b cell surface antigen,a process for the preparation and methods utilizing the same |
| EP1400536A1 (en) | 1991-06-14 | 2004-03-24 | Genentech Inc. | Method for making humanized antibodies |
| US6596541B2 (en) | 2000-10-31 | 2003-07-22 | Regeneron Pharmaceuticals, Inc. | Methods of modifying eukaryotic cells |
| US7850962B2 (en) | 2004-04-20 | 2010-12-14 | Genmab A/S | Human monoclonal antibodies against CD20 |
| JP5307708B2 (ja) | 2006-06-02 | 2013-10-02 | リジェネロン・ファーマシューティカルズ・インコーポレイテッド | ヒトil−6受容体に対する高親和性抗体 |
| WO2009029132A2 (en) * | 2007-05-31 | 2009-03-05 | Merck & Co., Inc. | Antigen-binding proteins targeting s. aureus orf0657n |
| ES3000111T3 (en) * | 2009-02-13 | 2025-02-27 | Immunomedics Inc | Intermediates for preparing conjugates with an intracellularly-cleavable linkage |
| MY192182A (en) | 2009-06-26 | 2022-08-04 | Regeneron Pharma | Readily isolated bispecific antibodies with native immunoglobulin format |
| SMT202600080T1 (it) | 2010-02-08 | 2026-03-09 | Regeneron Pharma | Topo con catena leggera comune |
| US9988439B2 (en) | 2011-12-23 | 2018-06-05 | Nicholas B. Lydon | Immunoglobulins and variants directed against pathogenic microbes |
| US20140212409A1 (en) * | 2012-08-13 | 2014-07-31 | Kyowa Hakko Kirin Co., Ltd. | METHOD FOR INCREASING DEPOSITION OF COMPLEMENT C3b ON BACTERIAL SURFACE AND PHAGOCYTOSIS BY PHAGOCYTE AND A THERAPEUTIC METHOD AND A THERAPEUTIC AGENT FOR BACTERIAL INFECTIONS |
| JOP20200236A1 (ar) * | 2012-09-21 | 2017-06-16 | Regeneron Pharma | الأجسام المضادة لمضاد cd3 وجزيئات ربط الأنتيجين ثنائية التحديد التي تربط cd3 وcd20 واستخداماتها |
| BR112015010125A2 (pt) * | 2012-11-06 | 2017-08-22 | Medimmune Llc | Anticorpo isolado ou seu fragmento de ligação, composição, ácido nucleico isolado, métodos de determinação da presença de s. aureus em uma amostra de teste, de tratamento de uma infecção por s. aureus em um paciente, de prevenção ou redução da gravidade de sepsia associada a s. aureus em um paciente, de atraso do início de sepsia associada a infecção por s. aureus em um paciente, de prevenção do início de sepsia associada a infecção por s. aureus em um paciente, de redução de carga bacteriana de s. aureus na corrente sanguínea ou coração em um paciente, e de redução da aglutinação bacteriana de s. aureus e/ou formação de lesões tromboembólicas em um paciente |
| TWI635098B (zh) | 2013-02-01 | 2018-09-11 | 再生元醫藥公司 | 含嵌合恆定區之抗體 |
| EP4545567A3 (en) * | 2013-03-13 | 2025-08-13 | Regeneron Pharmaceuticals, Inc. | Mice expressing a limited immunoglobulin light chain repertoire |
| JOP20160154B1 (ar) * | 2015-07-31 | 2021-08-17 | Regeneron Pharma | أجسام ضادة مضاد لل psma، وجزيئات رابطة لمستضد ثنائي النوعية الذي يربط psma و cd3، واستخداماتها |
| AU2016325630B2 (en) * | 2015-09-23 | 2022-11-17 | Regeneron Pharmaceuticals, Inc. | Optimized anti-CD3 bispecific antibodies and uses thereof |
-
2018
- 2018-09-27 CA CA3076632A patent/CA3076632A1/en active Pending
- 2018-09-27 KR KR1020207012271A patent/KR20200058525A/ko not_active Withdrawn
- 2018-09-27 CN CN201880062741.9A patent/CN111148758B/zh not_active Expired - Fee Related
- 2018-09-27 US US16/143,901 patent/US10865236B2/en active Active
- 2018-09-27 AU AU2018341587A patent/AU2018341587A1/en not_active Abandoned
- 2018-09-27 SG SG11202001160XA patent/SG11202001160XA/en unknown
- 2018-09-27 MX MX2020002976A patent/MX2020002976A/es unknown
- 2018-09-27 WO PCT/US2018/053064 patent/WO2019067682A1/en not_active Ceased
- 2018-09-27 JP JP2020517784A patent/JP2021500865A/ja active Pending
- 2018-09-27 MA MA050659A patent/MA50659A/fr unknown
- 2018-09-27 EP EP18786601.7A patent/EP3688029A1/en not_active Withdrawn
- 2018-09-27 BR BR112020004977-8A patent/BR112020004977A2/pt not_active IP Right Cessation
- 2018-09-27 MY MYPI2020001618A patent/MY199789A/en unknown
-
2020
- 2020-02-24 PH PH12020500375A patent/PH12020500375A1/en unknown
- 2020-03-11 IL IL273227A patent/IL273227A/en unknown
- 2020-03-24 CL CL2020000755A patent/CL2020000755A1/es unknown
- 2020-03-31 CO CONC2020/0003948A patent/CO2020003948A2/es unknown
- 2020-11-13 US US17/097,371 patent/US20210147519A1/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| CL2020000755A1 (es) | 2020-08-14 |
| CA3076632A1 (en) | 2019-04-04 |
| EP3688029A1 (en) | 2020-08-05 |
| US20190100575A1 (en) | 2019-04-04 |
| SG11202001160XA (en) | 2020-03-30 |
| BR112020004977A2 (pt) | 2020-10-06 |
| IL273227A (en) | 2020-04-30 |
| US10865236B2 (en) | 2020-12-15 |
| CN111148758A (zh) | 2020-05-12 |
| CN111148758B (zh) | 2022-12-09 |
| WO2019067682A1 (en) | 2019-04-04 |
| JP2021500865A (ja) | 2021-01-14 |
| MY199789A (en) | 2023-11-23 |
| MX2020002976A (es) | 2020-07-24 |
| AU2018341587A1 (en) | 2020-04-23 |
| PH12020500375A1 (en) | 2020-12-07 |
| CO2020003948A2 (es) | 2020-04-24 |
| US20210147519A1 (en) | 2021-05-20 |
| MA50659A (fr) | 2020-08-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11571482B2 (en) | Human antibodies to S. aureus Hemolysin A toxin | |
| KR102534895B1 (ko) | 항-c5 항체 및 이의 용도 | |
| AU2013302925B2 (en) | Anti-PCSK9 antibodies with pH-dependent binding characteristics | |
| KR102185516B1 (ko) | Fel d1에 대한 사람 항체 및 그것의 사용방법 | |
| CN113354732B (zh) | 针对埃博拉病毒糖蛋白的人抗体 | |
| KR102146692B1 (ko) | 항-pdgfr-베타 항체 및 이의 용도 | |
| JP2024147596A (ja) | レプチン受容体および/またはgp130に結合する二重特異性抗原結合分子、ならびにその使用方法 | |
| US12552856B2 (en) | Anti-PCRV antibodies that bind PCRV, compositions comprising anti-PCRV antibodies, and methods of use thereof | |
| KR20170098888A (ko) | 인플루엔자 헤마글루티닌에 대한 인간 항체 | |
| HUE031725T2 (en) | High Human Human Protease Activated Receptor-2 Affinity | |
| KR20140069331A (ko) | 항-ErbB3 항체 및 이의 용도 | |
| KR20140130709A (ko) | 클로스트리듐 디피실리 독소에 대한 사람 항체 | |
| JP2022512904A (ja) | 抗Staphylococcus抗体およびその使用 | |
| US20210147519A1 (en) | Bispecific antigen-binding molecules that bind a staphylococcus target antigen and a complement component and uses thereof | |
| EA047177B1 (ru) | АНТИТЕЛА К PcrV, КОТОРЫЕ СВЯЗЫВАЮТ PcrV, КОМПОЗИЦИИ, СОДЕРЖАЩИЕ АНТИТЕЛА К PcrV, И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | |
| EA041355B1 (ru) | ЧЕЛОВЕЧЕСКИЕ АНТИТЕЛА К ТОКСИНУ ГЕМОЛИЗИНУ А S.aureus |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20200427 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| A201 | Request for examination | ||
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20210927 Comment text: Request for Examination of Application |
|
| PC1202 | Submission of document of withdrawal before decision of registration |
Comment text: [Withdrawal of Procedure relating to Patent, etc.] Withdrawal (Abandonment) Patent event code: PC12021R01D Patent event date: 20230306 |
|
| WITB | Written withdrawal of application |