RU2180974C2 - Process of compression of insulated layers - Google Patents
Process of compression of insulated layers Download PDFInfo
- Publication number
- RU2180974C2 RU2180974C2 RU2000107717A RU2000107717A RU2180974C2 RU 2180974 C2 RU2180974 C2 RU 2180974C2 RU 2000107717 A RU2000107717 A RU 2000107717A RU 2000107717 A RU2000107717 A RU 2000107717A RU 2180974 C2 RU2180974 C2 RU 2180974C2
- Authority
- RU
- Russia
- Prior art keywords
- signal
- speech
- word
- sections
- section
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 7
- 238000007906 compression Methods 0.000 title description 15
- 230000006835 compression Effects 0.000 title description 15
- 230000003044 adaptive effect Effects 0.000 claims abstract description 10
- 238000013139 quantization Methods 0.000 claims abstract description 9
- 230000000694 effects Effects 0.000 abstract description 2
- 230000003247 decreasing effect Effects 0.000 abstract 2
- 238000002955 isolation Methods 0.000 abstract 1
- 239000000126 substance Substances 0.000 abstract 1
- 230000005236 sound signal Effects 0.000 description 6
- 230000007704 transition Effects 0.000 description 6
- 238000001228 spectrum Methods 0.000 description 4
- 230000000873 masking effect Effects 0.000 description 3
- 238000005070 sampling Methods 0.000 description 3
- 230000005540 biological transmission Effects 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 230000000737 periodic effect Effects 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 206010011878 Deafness Diseases 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000013144 data compression Methods 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 230000010355 oscillation Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000013707 sensory perception of sound Effects 0.000 description 1
- 238000004088 simulation Methods 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 210000001260 vocal cord Anatomy 0.000 description 1
Images

Landscapes
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
Description
Изобретение относится к технике цифровой обработки речи и может быть использовано в различных приложениях, например в системах речевого ответа абонентам телефонной сети (автоответчики), в справочных службах, для озвучивания объявлений на транспорте, в общественных местах и т.д. The invention relates to techniques for digital speech processing and can be used in various applications, for example, in voice response systems for telephone network subscribers (answering machines), in help services, for voicing announcements in vehicles, in public places, etc.
Известен алгоритм сжатия данных звука ISO/MPEG (MUSICAM), использующий информационное сжатие для передачи с высоким качеством сигналов звукового сопровождения телевизионных программ, а также программ цифрового спутникового радиовещания [1] . Этот алгоритм основан на особенностях восприятия звуков ухом человека - так называемом психоакустическом эффекте. Доказано, что человек воспринимает примерно 10% информации, содержащейся в звуковом сигнале, остальные 90% являются избыточными и их можно не передавать по каналу связи. Сигнал определенной частоты (тон), воздействуя на ухо человека, не позволяет различать (маскирует) другие тоны, близкие к данному по частоте и меньшие по уровню. В реальном звуковом сигнале одновременно присутствуют несколько маскирующих тонов на различных частотах. Компоненты сигнала, уровни которых ниже порога маскирования, ухом не воспринимаются и являются избыточными. The well-known audio data compression algorithm ISO / MPEG (MUSICAM), using information compression to transmit high-quality sound signals of television programs, as well as digital satellite broadcasting programs [1]. This algorithm is based on the perception of sounds by the human ear, the so-called psychoacoustic effect. It is proved that a person perceives about 10% of the information contained in an audio signal, the remaining 90% are redundant and can not be transmitted over the communication channel. A signal of a certain frequency (tone), acting on a person’s ear, does not allow one to distinguish (mask) other tones that are close to a given frequency and lower in level. In a real sound signal, several masking tones at different frequencies are present simultaneously. Signal components whose levels are below the masking threshold are not perceived by the ear and are redundant.
Недостатком описанного алгоритма сжатия звукового сигнала является сложность в его реализации. Как и в частотных вокодерах, для сжатия осуществляется анализ мгновенного энергетического спектра сигнала, в данном случае с помощью гребенки фильтров, разделяющих спектр на 32 частотных полосы. В каждой из них по отдельности выполняется аналого-цифровое преобразование, обработке подвергаются поочередно "кадры" сигнала длительностью 24 мсек, с частотой выборки отсчетов, равной 48 кГц. Устранение из передаваемого "кадра" частотных полос с уровнем сигнала ниже порога маскирования, в сочетании с динамическим распределением битов информации между оставшимися полосами, позволяет достичь почти 6-кратного сжатия спектра стереофонического сигнала, с сохранением практически неизменного, очень высокого качества звучания. The disadvantage of the described audio signal compression algorithm is the difficulty in its implementation. As in frequency vocoders, the compression analyzes the instantaneous energy spectrum of the signal, in this case, using a comb of filters dividing the spectrum into 32 frequency bands. In each of them, an analog-to-digital conversion is performed separately, processing is carried out in succession "frames" of the signal with a duration of 24 ms, with a sampling frequency of samples equal to 48 kHz. Elimination of frequency bands with a signal level below the masking threshold from the transmitted “frame”, in combination with the dynamic distribution of information bits between the remaining bands, allows achieving almost 6-fold compression of the stereo signal spectrum, while maintaining an almost unchanged, very high sound quality.
Сложность в реализации алгоритма [1] оправдана необходимостью получения высокого качества звучания радиовещательного стереофонического сигнала, которое вовсе не требуется в устройствах типа автоответчиков, для справочных служб и т.д., где достаточно только обеспечить высокую разборчивость и натуральность речи. The complexity in the implementation of the algorithm [1] is justified by the need to obtain high quality sound of a broadcasting stereo signal, which is not required at all in devices such as answering machines, for help services, etc., where it is enough to ensure high intelligibility and naturalness of speech.
Наиболее близким техническим решением (прототипом) является алгоритм цифрового преобразования звукового сигнала на примере изолированных слов, произносимых произвольным диктором, описанный в [2]. Этот адаптивный алгоритм, использующий избыточность речевого сигнала во временной области, позволяет обеспечить распознавание произвольного голоса, независимо от его громкости, темпа речи и частоты основного тона. В отличие от [1], где так же, как и во всех известных вокодерных системах передачи речи, сжатие сигнала достигается путем устранения его частотной избыточности, в [2] показана возможность использования временной избыточности речевого сигнала. Эта избыточность проявляется в сильных корреляционных связях, охватывающих до (10-12) соседних отсчетов речевого сигнала, взятых с частотой дискретизации, равной 8 кГц. В свою очередь, связи между соседними отсчетами вызваны резкой неравномерностью спектра мощности речевого сигнала, имеющего максимум в области (400-500) Гц и быстро спадающего на высоких частотах со скоростью от 6 до 12 дБ на октаву. The closest technical solution (prototype) is the digital signal conversion algorithm for an audio signal using isolated words spoken by an arbitrary speaker as described in [2]. This adaptive algorithm, using the redundancy of the speech signal in the time domain, allows for the recognition of arbitrary voice, regardless of its volume, speech rate and pitch frequency. In contrast to [1], where, as in all known vocoder speech transmission systems, signal compression is achieved by eliminating its frequency redundancy, [2] shows the possibility of using temporal redundancy of a speech signal. This redundancy is manifested in strong correlation relationships, covering up to (10-12) neighboring samples of the speech signal, taken with a sampling frequency of 8 kHz. In turn, the connections between neighboring samples are caused by a sharp unevenness of the power spectrum of the speech signal, which has a maximum in the region of (400-500) Hz and quickly decreases at high frequencies with a speed of 6 to 12 dB per octave.
Особенно заметно проявляется избыточность речи при произнесении так называемых вокализованных (гласных) звуков, которым соответствуют участки локальной стационарности протяженностью до (150-200) мсек. На каждом таком участке размещаются десятки почти однотипных отрезков сигнала с периодом основного тона речи, индивидуального для каждого голоса. Для мужских голосов этот период колебания голосовых связок составляет (5-20) мсек, а для высоких женских и детских голосов он изменяется в диапазоне (2-5) мсек. Speech redundancy is especially noticeable when pronouncing the so-called voiced (vowels) sounds, which correspond to sections of local stationarity with a length of up to (150-200) ms. Each such section contains dozens of almost the same type of signal segments with a period of the main tone of speech, individual for each voice. For male voices, this period of oscillation of the vocal cords is (5-20) ms, and for high female and children's voices it varies in the range (2-5) ms.
Произнесение звонких согласных (типа "б", "в", "г", "д" и т.д.), а также "м", "н" тоже сопровождается периодическим повторением отрезков основного тона речи, изменяется только их форма, амплитуда и количество на протяжении звучания данной согласной. И только глухие согласные (например, "п", "ф", "к", т" и другие) не содержат в своем составе периодических отрезков, звуковой сигнал напоминает шум и отличается низким уровнем звучания, малой протяженностью во времени и высокой частотой смены знака сигнала (переходов через ноль). Pronouncing voiced consonants (such as "b", "c", "g", "d", etc.), as well as "m", "n", is also accompanied by a periodic repetition of segments of the main tone of speech, only their shape changes, amplitude and quantity throughout the sound of the given consonant. And only deaf consonants (for example, "n", "f", "k", t "and others) do not contain periodic segments, the sound signal resembles noise and is characterized by a low sound level, small length in time and high frequency of change Sign of the signal (zero crossing).
Недостатком прототипа [2] является то, что алгоритм его функционирования направлен, главным образом, на распознавание изолированных (разделенных паузами) слов, произносимых любым голосом, а задача сжатия речи путем устранения избыточности рассматривается как вспомогательная и решается лишь частично. При этом устраняется та небольшая часть избыточности, которая связана с индивидуальными особенностями голоса диктора. Основная же часть избыточности, вызванная многократной повторяемостью отрезков сигнала на периодах основного тона речи, сохраняется неизменной. The disadvantage of the prototype [2] is that the algorithm of its operation is mainly aimed at recognizing isolated (paused) words spoken by any voice, and the task of compressing speech by eliminating redundancy is considered as auxiliary and is only partially solved. This eliminates that small part of the redundancy that is associated with the individual characteristics of the voice of the speaker. The main part of the redundancy caused by the multiple repeatability of signal segments at periods of the main tone of speech remains unchanged.
Техническим результатом предлагаемого изобретения является сокращение объема памяти, удешевление и уменьшение габаритов постоянных запоминающих устройств, необходимых для хранения и воспроизведения требуемой речевой информации, содержащей изолированные (разделенные паузами) слова. The technical result of the invention is to reduce the amount of memory, cheaper and smaller dimensions of permanent storage devices needed to store and play the required speech information containing isolated (separated by pauses) words.
Предлагаемый способ сжатия изолированных слов, заключающийся в том, что по превышению заданного порогового уровня определяются начало и конец очередного слова, оно предварительно записывается в оперативное запоминающее устройство (О3У) и подразделяется на отрезки равной длины, в каждом из которых вычисляется средний модуль сигнала и число смен знака, по этим данным определяются два "образа" слова, описывающие характер изменения сигнала во времени по уровню и мгновенной частоте, отличается тем, что определяются участки локальной стационарности внутри слова, на которых одновременно уровень сигнала и его мгновенная частота почти не изменяются, внутри каждого такого участка выделяется отрезок сигнала, служащий эталонным периодом основного тона речи, данные отрезки сигнала один за другим переписываются в постоянное запоминающее устройство (ПЗУ), при этом каждый из них снабжается "паролем", содержащим информацию о продолжительности данного отрезка сигнала, числе его повторений при воспроизведении слова и величине адаптивного шага квантования, пропорционального среднему модулю сигнала на данном участке локальной стационарности. The proposed method for compressing isolated words, which consists in the fact that when the specified threshold level is exceeded, the beginning and end of the next word are determined, it is previously written into the random access memory (O3U) and is divided into segments of equal length, in each of which the average signal modulus and number are calculated sign changes, according to these data two “images” of the word are determined that describe the nature of the signal change in time in terms of level and instantaneous frequency, it differs in that sections of the local station are determined differences within the word, at which the signal level and its instantaneous frequency almost do not change at the same time, within each such section a signal segment is selected that serves as a reference period of the main tone of speech, these signal segments are written one by one to a permanent storage device (ROM), each of these, it is supplied with a “password” containing information about the duration of a given segment of the signal, the number of its repetitions during the reproduction of a word and the value of the adaptive quantization step proportional to the average I will add a signal on this site of local stationarity.
В соответствии с предлагаемым способом опишем подход к сжатию речевых сигналов, основанный на упрощенном описании одного эталонного, из числа периодически повторяющихся на каждом из участков локальной стационарности, отрезка с периодом основного тона речи, и дальнейшем синтезе речи по этим отрезкам. In accordance with the proposed method, we describe an approach to the compression of speech signals based on a simplified description of one reference, from the number of periodically repeating at each of the sections of local stationarity, a segment with a period of the main tone of speech, and further speech synthesis along these segments.
Сжатие происходит на временной основе, при этом используется избыточность квазистационарных участков вокализованной речи и устраняются малые уровни, т.е. сигнал в паузах приравнивается к нулю. Речь разбивается на отрезки, равные 16 мсек, не превышающие половины интервала локальной стационарности (порядка 40 мсек). На каждом отрезке определяется средний модуль, число переходов через ноль и устанавливается адаптивный шаг квантования по уровню, равный половине среднего модуля. Использование адаптивного шага квантования позволяет снизить разрядность кода отсчета речевого сигнала без заметных потерь почти в 3 раза. Compression occurs on a temporary basis, using redundancy of quasi-stationary sections of voiced speech and eliminating small levels, i.e. the signal in pauses is equal to zero. The speech is divided into segments equal to 16 ms, not exceeding half the interval of local stationarity (about 40 ms). On each segment, the average module is determined, the number of transitions through zero, and an adaptive quantization step is set at a level equal to half the average module. The use of an adaptive quantization step allows one to reduce the bit depth of the reference code of the speech signal without noticeable losses by almost 3 times.
На вокализованном участке в процессе синтеза слова воспроизводится один период основного тона речи столько раз, сколько звучит этот участок слова. On a voiced section during the synthesis of a word, one period of the fundamental tone of speech is played as many times as this section of the word sounds.
Невокализованные участки речи сжимаются в меньшей степени, но они короче гласных звуков, поэтому, взяв за основу средний период основного тона речи и его повторяемость, можно сжать сигнал приблизительно в 10 раз, что в сочетании с использованием адаптивного шага квантования и снижением разрядности кода отсчета дает выигрыш порядка 30 раз. Unvoiced sections of speech are compressed to a lesser degree, but they are shorter than vowels, therefore, taking the average period of the main tone of speech and its repeatability as a basis, you can compress the signal by about 10 times, which, combined with the use of an adaptive quantization step and a decrease in the digit code win about 30 times.
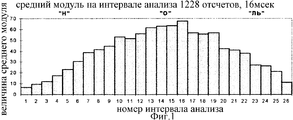
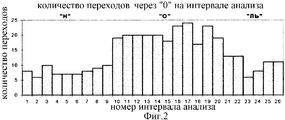
На фиг. 1 и 2 изображены гистограммы распределения во времени среднего модуля сигнала и количества переходов через ноль на интервалах анализа длиной 16 мсек, при произнесении женским голосом слова "НОЛЬ". Эти гистограммы представляют собой два "образа" слова, описывающие характер изменения сигнала во времени по уровню и мгновенной частоте. На фиг. 2 отчетливо заметны участки локальной стационарности, соответствующие звукам "Н" (с 1 по 9), "О" (с 10 по 20) и "ЛЬ" (с 21 по 26). Этим участкам на фиг. 1 соответствуют разные средние модули сигнала. In FIG. Figures 1 and 2 show histograms of the time distribution of the average signal modulus and the number of transitions through zero at
На фиг. 3 представлены временные диаграммы реального речевого сигнала при произнесении слова "НОЛЬ". Разделение всего слова на интервалы локальной стационарности, соответствующие звукам "Н" длиной 144 мсек, "О" длиной 176 мсек, "ЛЬ" длиной 96 мсек основано на данных гистограммы на фиг. 2. In FIG. 3 shows time diagrams of a real speech signal when pronouncing the word “ZERO”. The division of the whole word into local stationarity intervals corresponding to sounds “H” with a length of 144 ms, “O” with a length of 176 ms, and “L” with a length of 96 ms is based on the histogram data in FIG. 2.
Общая протяженность слова составляет 416 мсек или 3328 отсчетов частоты дискретизации 8 кГц. На фиг. 3 явно прослеживаются периоды основного тона речи, для данного голоса порядка 3 мсек, или 24 отсчета. The total word length is 416 ms or 3328 samples of a sampling frequency of 8 kHz. In FIG. 3 periods of the main tone of speech are clearly traced, for a given voice of the order of 3 ms, or 24 counts.
На периодах основного тона речи имеется два перехода через ноль для невокализованных звуков "Н" и "ЛЬ". Для вокализованного звука "О" частота переходов через ноль вдвое выше. Средние уровни сигнала на невокализованных участках в 1,5-2 раза ниже, чем на вокализованном. Каждый из участков локальной стационарности характеризуется своей формой сигнала, многократно повторяющейся с периодом основного тона речи. On periods of the main tone of speech, there are two transitions through zero for unvoiced sounds "H" and "L". For voiced sound "O", the frequency of transitions through zero is twice as high. The average signal levels in unvoiced areas are 1.5-2 times lower than in voiced areas. Each of the sections of local stationarity is characterized by its own waveform, which is repeated many times with the period of the main tone of speech.
Используя гистограмму на фиг. 1, можно подразделить каждый звук на несколько участков, близких по уровню. Внутри каждого из них можно выделить один период основного тона и повторить его в соответствии с длиной данного участка. Using the histogram in FIG. 1, you can subdivide each sound into several sections, similar in level. Inside each of them, one period of the fundamental tone can be distinguished and repeated in accordance with the length of the given section.
Дополнительное сжатие достигается путем снижения разрядности кода отсчета сигнала. Для этого шаг квантования по уровню устанавливается адаптивным, пропорционально среднему модулю сигнала на интервале анализа. Моделирование на ПК алгоритма сжатия показало, что удовлетворительное качество звучания достигается при использовании трехразрядного кода. Это соответствует передаче знакового разряда отсчета и двух разрядов модуля, то есть чисел ±3, поэтому выбран адаптивный шаг квантования, равный половине среднего модуля сигнала. Additional compression is achieved by reducing the bit depth of the signal reference code. For this, the quantization step by level is set adaptive in proportion to the average signal modulus in the analysis interval. The PC simulation of the compression algorithm showed that a satisfactory sound quality is achieved using a three-bit code. This corresponds to the transmission of the sign digit of the reference and two bits of the module, that is, numbers ± 3; therefore, an adaptive quantization step equal to half the average signal module is selected.
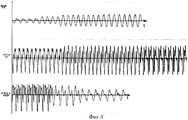
На фиг. 4 приведены временные диаграммы синтезированного по описанному алгоритму слова. В соответствии с гистограммой на фиг. 1, для описания звука "Н" выбраны четыре эталонных периода основного тона речи с разной величиной адаптивного шага квантования. Для вокализованного звука "О" выбрано всего три эталонных периода основного тона, один на границе звуков "Н-О", второй в середине звука "О" и третий на переходе звука "О" в "ЛЬ". Поскольку звук "О" наиболее протяженный и составляет почти половину слова, на нем достигается наиболее эффективное сжатие. Звук "ЛЬ" наименее протяженный и для его описания достаточно трех эталонных периодов основного тона речи, а именно на переходе "О" в "ЛЬ", в середине звука и в конце, на участке затухания сигнала. In FIG. Figure 4 shows the time diagrams of a word synthesized by the described algorithm. According to the histogram of FIG. 1, four reference periods of the fundamental tone of speech with different sizes of the adaptive quantization step were selected to describe the sound “H”. For the voiced sound “O”, only three reference periods of the fundamental tone were selected, one at the boundary of the sounds “Н-О”, the second in the middle of the sound “О” and the third at the transition of the sound “О” to “Л”. Since the sound "O" is the longest and makes up almost half the word, the most effective compression is achieved on it. The “L” sound is the least extended and three reference periods of the main tone of speech are enough to describe it, namely, at the transition “O” to “L”, in the middle of the sound and at the end, in the signal attenuation section.
Всего на протяжении слова были выбраны и запомнены десять эталонных периодов основного тона речи общей протяженностью 240 трехразрядных отсчетов, то есть 90 байт. С учетом необходимых описаний ("пароля") каждого эталонного периода, по два байта на период, на все синтезированное слово потребуется 110 байт. In total, ten reference periods of the main tone of speech with a total length of 240 three-digit samples, that is, 90 bytes, were selected and remembered throughout the word. Given the necessary descriptions (“password”) of each reference period, two bytes per period, 110 bytes will be required for the entire synthesized word.
До сжатия слово содержало 3328 восьмиразрядных отсчетов, то есть для его описания требовалось 3328 байт. Таким образом, предложенный алгоритм обеспечил 30-кратное сжатие необходимого объема памяти. При этом сохранилась узнаваемость по голосу, качество звучания соответствовало экспертной оценке в 3 балла по 5-балльной шкале. Before compression, the word contained 3328 eight-bit samples, that is, 3328 bytes were required to describe it. Thus, the proposed algorithm provided 30-fold compression of the required amount of memory. At the same time, voice recognition was preserved, the sound quality corresponded to an expert rating of 3 points on a 5-point scale.
Отметим также, что предложенный алгоритм сжатия позволяет с легкостью осуществлять обмен степени сжатия на качество звучания путем изменения разрядности кода отсчетов сигнала и количества эталонных периодов основного тона речи, входящих в состав синтезированного слова. We also note that the proposed compression algorithm makes it easy to exchange the degree of compression for sound quality by changing the bit depth of the code of the signal samples and the number of reference periods of the main tone of speech included in the synthesized word.
Литература
1. Алгоритм сжатия данных звука ISO/MPEG (MUSICAM). Глеб Высоцкий, [Image] GS Урал, июль 1998 г., статья в сети Интернет.Literature
1. The algorithm for compressing audio data ISO / MPEG (MUSICAM). Gleb Vysotsky, [Image] GS Ural, July 1998, an article on the Internet.
2. Брайнина И. С., Кузнецов М.В. Устройство для распознавания изолированных слов. Патент 2136659, 6 G 10 L 7/04, БИ 24, 1999. 2. Brainina I.S., Kuznetsov M.V. Device for recognition of isolated words. Patent 2136659, 6 G 10
Claims (1)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| RU2000107717A RU2180974C2 (en) | 2000-03-29 | 2000-03-29 | Process of compression of insulated layers |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| RU2000107717A RU2180974C2 (en) | 2000-03-29 | 2000-03-29 | Process of compression of insulated layers |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| RU2180974C2 true RU2180974C2 (en) | 2002-03-27 |
| RU2000107717A RU2000107717A (en) | 2002-04-10 |
Family
ID=20232545
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| RU2000107717A RU2180974C2 (en) | 2000-03-29 | 2000-03-29 | Process of compression of insulated layers |
Country Status (1)
| Country | Link |
|---|---|
| RU (1) | RU2180974C2 (en) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE3808038A1 (en) * | 1988-03-10 | 1989-09-28 | Siemens Ag | Method for the automatic matching of a speech recognition system |
| US5268991A (en) * | 1990-03-07 | 1993-12-07 | Mitsubishi Denki Kabushiki Kaisha | Apparatus for encoding voice spectrum parameters using restricted time-direction deformation |
| US5933803A (en) * | 1996-12-12 | 1999-08-03 | Nokia Mobile Phones Limited | Speech encoding at variable bit rate |
| RU2136059C1 (en) * | 1998-01-05 | 1999-08-27 | Поволжский институт информатики, радиотехники и связи | Device for identifying isolated words |
-
2000
- 2000-03-29 RU RU2000107717A patent/RU2180974C2/en active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE3808038A1 (en) * | 1988-03-10 | 1989-09-28 | Siemens Ag | Method for the automatic matching of a speech recognition system |
| US5268991A (en) * | 1990-03-07 | 1993-12-07 | Mitsubishi Denki Kabushiki Kaisha | Apparatus for encoding voice spectrum parameters using restricted time-direction deformation |
| US5933803A (en) * | 1996-12-12 | 1999-08-03 | Nokia Mobile Phones Limited | Speech encoding at variable bit rate |
| RU2136059C1 (en) * | 1998-01-05 | 1999-08-27 | Поволжский институт информатики, радиотехники и связи | Device for identifying isolated words |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Ainsworth | Mechanisms of Speech Recognition: International Series in Natural Philosophy | |
| KR100361236B1 (en) | Transmission System Implementing Differential Coding Principle | |
| US8229738B2 (en) | Method for differentiated digital voice and music processing, noise filtering, creation of special effects and device for carrying out said method | |
| FI20011508A7 (en) | Variable-rate vocoder | |
| US20190378532A1 (en) | Method and apparatus for dynamic modifying of the timbre of the voice by frequency shift of the formants of a spectral envelope | |
| JP2903533B2 (en) | Audio coding method | |
| US7583804B2 (en) | Music information encoding/decoding device and method | |
| DE69905152T2 (en) | DEVICE AND METHOD FOR IMPROVING THE QUALITY OF ENCODED LANGUAGE BY MEANS OF BACKGROUND | |
| EP1426926A2 (en) | Apparatus and method for changing the playback rate of recorded speech | |
| KR100750115B1 (en) | Audio signal encoding and decoding method and apparatus therefor | |
| JP2000152394A (en) | Hearing device for mild hearing loss, transmission system for mild hearing loss, recording / reproducing device for mild hearing loss, and reproducing device for mild hearing loss | |
| JP2586043B2 (en) | Multi-pulse encoder | |
| RU2180974C2 (en) | Process of compression of insulated layers | |
| JP2776300B2 (en) | Audio signal processing circuit | |
| JP4322390B2 (en) | Auditory training method | |
| WO1991006945A1 (en) | Speech compression system | |
| Thibolet et al. | A comparison of the performance of four low-bit-rate speech waveform coders | |
| Holmes | A survey of methods for digitally encoding speech signals | |
| JPH058839B2 (en) | ||
| JPH0376480B2 (en) | ||
| JP2847730B2 (en) | Audio coding method | |
| JPH0414813B2 (en) | ||
| KR0144841B1 (en) | Apparatus for adaptive encoding and decoding of sound signals | |
| DISSERTA et al. | Spectral Coding and Post-Processing of High Quality Audio | |
| JPH03132800A (en) | Multi-pulse type voice encoding and decoding device |