WO2016143449A1 - 含意ペア拡張装置、そのためのコンピュータプログラム、及び質問応答システム - Google Patents
含意ペア拡張装置、そのためのコンピュータプログラム、及び質問応答システム Download PDFInfo
- Publication number
- WO2016143449A1 WO2016143449A1 PCT/JP2016/053750 JP2016053750W WO2016143449A1 WO 2016143449 A1 WO2016143449 A1 WO 2016143449A1 JP 2016053750 W JP2016053750 W JP 2016053750W WO 2016143449 A1 WO2016143449 A1 WO 2016143449A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- pair
- implication
- unary
- pattern
- repair
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/332—Query formulation
- G06F16/3329—Natural language query formulation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/247—Thesauruses; Synonyms
Definitions
- the present invention relates to natural language processing, and more particularly, to a technique for efficiently generating a pair of two language patterns in which a certain pattern implies another pattern.
- a sentence “pollution causes lung cancer” is typically obtained as an answer. This is because these two sentences have the common expression “cause (lung cancer)”.
- the appropriate answers are not limited to those that have a common expression with the question.
- the phrase “smoking causes lung cancer” is considered a good answer.
- the knowledge that “A causes B” can be rephrased as “A brings B” is necessary.
- a and B are variables and can be replaced with arbitrary words.
- n-term language pattern an expression composed of a combination of a predicate and n (n is an integer of 0 or more) terms is called an n-term language pattern.
- a causes B is a binary language pattern composed of a combination of a predicate “cause” and two terms consisting of variable terms A and B.
- Non-Patent Document 1 There is Non-Patent Document 1 described later as a conventional technique for acquiring an implication pair.
- the technique described in Non-Patent Document 1 collects pattern pairs having an implication relationship as follows. Learning data is constructed by manually collecting pattern pairs having an implication relationship in advance. Machine learning of a determinator that determines whether one of the learning patterns is implied when one of the two language patterns is given using a score such as N-gram and distribution similarity as a feature amount. . When the learning of the discriminator is completed, a large number of implication pair candidates are randomly generated from a corpus including a large number of sentences. Each of these candidates is determined by a determiner. As a result, by collecting pattern pairs determined to have an implication relationship, new implication pairs that are not included in the learning data can be collected.
- an object of the present invention is to provide an implication relationship pair expansion device that can predict what kind of implication pair can be obtained by extending an existing implication pair and can guarantee its accuracy to some extent.
- the implication pair expansion device expands an implication pair by generating an implication pair of n terms from an implication pair of m terms.
- m and n are integers satisfying m ⁇ n at 0 or more.
- Each implication pair includes a pair of a first language pattern and a second language pattern implied by the first language pattern.
- the implication pair expansion device includes a generation rule storage means for storing a generation rule for generating an n-ary implication pair from an m-ary implication pair.
- the generation rule includes mn items for each of the conditions that the m-ary implication pair should satisfy in order to apply the generation rule and each of the language patterns that constitute the m-ary implication pair when the condition is satisfied.
- the implication pair expansion device further receives an implication pair of m terms, and for each of the generation rules stored in the generation rule storage means for the implication pair of m terms, the condition of the generation rule is an implication pair of m terms.
- m is 0, and the implication pair of the m term is an implication pair of predicates each consisting of a predicate.
- n is 1.
- the implication pair expansion device may further include a transition rule applying means for expanding the implication pair of m terms by applying the transition rule to the implication pairs of m terms.
- the implication pair expanding device further includes a transition rule applying means for expanding the n-term implication pair by applying the transition rule to the n-term implication pair generated by the rule applying means.
- the computer program according to the second aspect of the present invention causes a computer to function as all means of any implication pair expansion device.
- a question answering system includes an implication pair storage unit for storing an implication pair expanded by any of the above-described implication pair expansion devices, and a document storage unit that stores a plurality of documents.
- a pattern expansion means for expanding using an implication pair stored in the table, and an expression matching the language pattern expanded by the pattern expansion means is retrieved from a document stored in the document storage means and is suitable as an answer to a question.
- search means for calculating the score indicating the correctness and the language that matches the search candidate among the answer candidates searched by the search means Those with priority number of variables included in the turn is large, and a selection means for selecting an answer using the score.
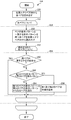
- FIG. 2 is a block diagram of an unary repair extension unit shown in FIG. 1.
- FIG. 1 is a flowchart which shows the control structure of the program which implement
- FIG. 6 is a flowchart showing details of a binary pair generation process shown in FIG. 5. It is a graph which shows the evaluation of the whole una repair obtained by experiment.
- unary pattern refers to a pattern consisting of one variable, a predicate, and a particle that connects them in Japanese. Examples include “cause A” and “provide A”.
- Unary implication pattern pair refers to two unary patterns that have a semantic relationship in which one implies the other. Pairs such as “cause A” and “provide A” are examples. It is also simply called “Una Repair”.
- Binary pattern means a pattern consisting of two variables, a predicate, and, in Japanese, a particle that connects them. Examples are “A causes B”, “A brings B”, and the like.
- a binary entailment pattern pair refers to two binary patterns that have a semantic relationship in which one implies the other.
- a pair consisting of “A brings B” and “A causes B” is an example. Also simply called “binary pair”.
- N-ant pattern generally refers to a pattern in which a variable is composed of an N term, a predicate, and a particle that connects them.
- An N-ant implication pattern pair (referred to as "" N-aripair ”) refers to an N-ant pattern pair in which one implies the other.
- Predicate is transformed into passive
- Predicate is transformed into possible form
- the unary repair is extended using transitive temperament. That is, when there are two pairs of unpairs P ⁇ Q and Q ⁇ R, P ⁇ R is generated from these.
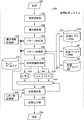
- FIG. 1 shows a block diagram of an implication pattern pair expansion apparatus 50 according to an embodiment of the present invention.
- an implication pattern pair expansion device 50 uses an extended unary pair DB 60 and an extended binary pair DB 62 using a first unary DB 52, a second unary DB 54, a verb implication DB 56, and a context similarity storage unit 58. Is output.
- the first unary DB 52 and the second unary DB 54 are both databases that store existing unary repairs. These may be obtained in any way. It may be created manually or may be generated mechanically by some processing. In this embodiment, the first unary DB 52 and the second unary DB 54 are used as the unary DB, but the number of these is not limited. One may be sufficient and three or more may be sufficient. If the unary repair is generated using the verb implication DB 56, the unary DB may not be used at all.
- the verb implication DB 56 records a plurality of verb pairs that are prepared in advance and have an implication relationship.
- An example of a verb implication pair is the verb implication pair “Bring ⁇ Cause”.
- verb implication data https://alaginrc.nict.go.jp/ constructed manually by the applicant is used as this data.
- This verb implication DB 56 contains 52,689 pairs of verb implication pairs.
- the data recorded in the context similarity storage unit 58 is for calculating the context similarity of two words.
- the context similarity is simply a measure indicating how similar the positions on the sentence where two words appear are.
- the context similarity is calculated using two word co-occurrence degrees, and is obtained by the following procedure.
- the co-occurrence degree f ij between the word v i and each context word v j is obtained.
- the context word of the word v i say that of all the words that appear in the context of the occurrences of the word v i.
- the range of the context may be arbitrarily determined. For example, a sentence in which the word appears, a predetermined number of sentences around the sentence, sentences in the same paragraph, and the like are conceivable.
- a vector is obtained by arranging the co-occurrence degrees f ij obtained by this processing in the order of the context words v j . This vector can be thought of as a context vector for the word v i. This, the context vector of the word v i written as a vector f i *.
- the vector f i * is a vector composed of all the values corresponding to the word v i and the context word in the co-occurrence degree f ij .
- the cosine similarity of the vectors f i * and f j * is calculated for all combinations of the word v i and the word v j in the set V of all words, and the value is set as the context similarity ⁇ ij .
- the context similarity storage unit 58 stores the context similarity between any two words calculated in advance by the above procedure.
- the implication pattern pair expansion device 50 transforms the unary pairs stored in the first unary DB 52 and the second unary DB 54 into a format handled by the implication pattern pair expansion device 50, and represents a value representing the data source of each unary pair.
- the unary repair adding unit 100 that adds and outputs the identifier of each unary DB, the unary repair DB 102 that stores the unary pair output by the unary repair adding unit 100, and the context implication storage unit from each of the verb implication pairs stored in the verb implication DB 56
- a unary repair generation unit 104 that generates unary repairs using the context similarity stored in 58 and additionally outputs them to the unrepair DB 102.
- the implication pattern pair expansion device 50 further performs an expansion process with reference to the kanji dictionary 106 for each of the kanji dictionary 106 that stores the kanji of the word and its reading in a machine-readable format, and the unary repair stored in the unary repair DB 102.
- the binary pair generation rule storage unit 110 Stored in the unary pair extension unit 108 for outputting a plurality of unpairs, the binary pair generation rule storage unit 110 storing the generation rules for generating binary pairs from the unary pairs, and the binary pair generation rule storage unit 110
- a binary pair adding unit 112 for generating a binary pair by applying the generation rule to each unary pair recorded in the extended unary pair DB 60 and outputting the binary pair to the extended binary pair DB 62 is included.
- unary repair generation unit 104 shown in FIG. 1 can be realized by a computer program.
- the program includes a step 140 for securing and initializing a storage area at the start of the program, a step 142 for reading all verb implication pairs from the verb implication DB 56, and a step 144 for executing the processing 146 for each verb implication pair. including.
- the process 146 assigns “A”, “A”, “A”, and “A” to each of the verbs constituting the verb implication pair to be processed.
- Step 166 for selecting a higher pair and step 168 for adding the selected pair as a new unpair to the unary pair DB 102 are included.
- Step 166 for selecting a higher pair and step 168 for adding the selected pair as a new unpair to the unary pair DB 102 are included.
- the pattern pair obtained in this way it is desirable to manually check the validity as an implication pair and delete inappropriate ones.
- when registering a new unary pair or binary pair it is compared with a negative example that has been stored in advance or prepared in advance. Examples are excluded from registration.
- unary repair extension unit 108 shown in FIG. 1 can be realized by a computer program.
- This program converts the computer to a record reading unit 180 that reads a record of unary repairs from the unary repair DB 102, and to each passive pattern read by the record reading unit 180 into a passive state for each of the patterns constituting the pair.
- a passive / possible type adding unit 182 that adds a new unar repair obtained by the combination to the extended unary repair DB 60 together with the original unar repair and an extended unrepair DB 60 by the passive / possible type adding unit 182
- the unary repair stored in the extended unrepair DB 60 in which the first half of the first unary repair matches the first half of the second unar repair, is searched for each of these combinations
- the first half of the first unar repair and the second In combination with a second half portion of the repair to generate a new Yunaripea to function as transitivity pair adding unit 184 for adding the expanded Yunaripea DB 60.
- the unary repair is further expanded by applying the predicate sway and the ending modification to each unary before the processing of the passive / possible shape adding unit 182.
- a pattern obtained by converting a predicate written in Kanji into kana is created with reference to the Kanji dictionary 106, and unary repairs having a new pattern are added.
- unary repairs such as “kanji ⁇ kana” and “kana ⁇ kanji” such as “A happens ⁇ A happens” and “A happens ⁇ A happens” are also generated at the same time, and are stored in the extended unrepair DB 60. to add. Strictly speaking, such a pair is not in an “entailment” relationship. However, in the context of “paraphrasing” in question answering, it is considered beneficial to have such a pair.
- the transitive tempo pair adding unit 184 is realized by a computer program.
- FIG. 4 shows the control structure of such a computer program in the form of a flowchart. This program includes a step 220 of reading all unrepairs from the extended unrepair DB 60 and a step 222 of executing the process 224 for each read unrepair.
- the process 224 includes a step 250 for reading from the extended unrepair DB 60 all unary repairs having the first half that matches the latter half of the unar repair to be processed, and a step 252 for executing the process 254 for each of the unrepairs read in the step 250. Including.
- the pair selected as the processing target in step 222 is referred to as a first unary pair
- the pair selected as the processing target in step 252 is referred to as a second unary repair.
- the process 254 determines whether or not the predicate of the first unary repair is a combination of “kanji ⁇ kana” and the predicate of the second unary repair is a combination of “kana ⁇ kana”. If the result is affirmative, the process ends and the process proceeds to the next second unrepair. When the determination result in step 280 is negative, the first half of the first unar repair matches the second half of the second unar repair.
- a pair P ⁇ R is generated from a pair P ⁇ Q and a pair Q ⁇ R by a so-called transition rule, and added to the extended unary pair DB 60.
- step 286 is not based on transition rules.
- the process of step 286 is performed when the second half of the first unar repair is equal to the first half of the second unar repair, and the first half of the first unar repair is equal to the second half of the second unar repair. . That is, it is a case where the first unar repair and the second unar repair are opposite to each other. That is, both P ⁇ Q and Q ⁇ P exist. The fact that both these two unary repairs are present is considered to have the same relationship as the so-called “equivalent” between these two unpairs.
- unary repairs corresponding to “kinematic pair” referred to in logic are generated for both of these two unary repairs and added to the extended unrepair DB 60. That is, the unary repair of ⁇ Q ⁇ ⁇ P is added for P ⁇ Q (“ ⁇ ” represents negative), and the unary repair of ⁇ P ⁇ ⁇ Q is added for the unary repair of Q ⁇ P.
- the kinematic pair is also true, so if there is a P ⁇ Q unary, the kinematic pair ⁇ Q ⁇ ⁇ P may be unconditionally added. Seem.
- the kinematic pair is not always correct. Therefore, here, only when two unary repairs are equivalent to each other, their pair is added.
- binary pair adding unit 112 shown in FIG. 1 is also realized by a computer program.
- This program includes a step 320 for reading all unrepairs from the extended unrepair DB 60, and a step 322 for executing a process 324 for generating a binary pair from the unrepairs for each read unrepair.
- each binary generation rule generates a binary pair by modifying the condition that the unary repair must satisfy in order to apply the binary rule to the unary repair, and how the pattern pair that constitutes the unary repair is satisfied when the condition is satisfied. It consists of an instruction part that describes. The instruction part actually describes a sentence transformation rule.
- the process 354 determines whether or not the condition for applying the binary pair generation rule to be processed is satisfied by the unary repair being processed, and if not satisfied, the application of the rule ends step 380 and step 380.
- the binary pair generation rule selected in step 352 in FIG. 6 is applied to the unary pair selected in step 322 in FIG. 5 to generate a binary pair in steps 382 and 382. Adding the generated binary pair to the extended binary pair DB 62 and terminating the application of this binary pair generation rule.
- binary pair generation rules stored in the binary pair generation rule storage unit 110 are described in the If-then format in the present embodiment.
- One binary pair generation rule is described to generate one binary pair by applying to one unary pair.
- the main binary pair generation rules are as follows.
- a new binary pair is generated by applying the same conversion rule to the first half, second half of the unary repair, or both.
- a binary pair can be generated using the same generation rule even when “de” is used as a condition instead of “ga”.
- a unitary pair that combines the same unitary pattern is created, and a binary pair is created by performing the same operation as above. For example, a binary pair such as “A uses B ⁇ A that uses B” is generated from the pattern “use A” and stored in the extended binary pair DB 62.
- the binary pair generation rule is stored as data outside the program, but the present invention is not limited to such an embodiment.
- the generation rule may be described in the form of a program and dynamically loaded when the program is executed.
- the generation rules may be sequentially described in the instruction format in the main body of the program.
- the individual rules may be prepared in advance as separate files, or the entire rules may be combined into one file.
- each rule is prepared in advance as a set of a condition part and a deformation rule to be applied to each pattern when the condition part is satisfied by unpair, and may be prepared in some form.
- the rule format may be a data format or a program format.
- the rules may be incorporated into the program main body in an algorithm format, or may be stored as an external file in the program format so that the rules can be read from the outside during execution.
- the above-described implication pattern pair expansion device 50 operates as follows. Before the implication pattern pair expansion device 50 executes the following processing, the first unary DB 52, the second unary DB 54, the verb implication DB 56, the context similarity storage unit 58, the kanji dictionary 106, and the binary pair generation rule The contents of the storage unit 110 need to be prepared in advance.
- the unary repair adding unit 100 sequentially reads unary pairs from the first unary DB 52 and the second unary DB 54, transforms each into a format handled by the implication pattern pair expansion device 50, and represents a value representing the data source of each unpair.
- the identifier of each unary DB is added and output to the unary repair DB 102.
- the unary repair generation unit 104 generates unar repairs as follows using the context similarity stored in the context similarity storage unit 58, and additionally outputs the unar repair to the unar repair DB 102. Referring to FIG. 2, unary repair generation unit 104 secures and initializes a storage area at the start of processing (step 140).
- the unary pair generation unit 104 reads all verb implication pairs from the verb implication DB 56 (step 142).
- the unary pair generation unit 104 executes the process 146 for each of the read verb implication pairs (step 144).
- the unary pair generation unit 104 assigns “A”, “A”, “A”, and “A” to each of the verbs constituting the verb implication pair to be processed.
- a plurality of candidate pairs of unary implication patterns are generated (step 160).
- the unary repair generation unit 104 performs a context similarity calculation process 164 between each of the candidate pairs obtained in this way (step 162).
- the unary repair generation unit 104 selects the unar repair having the highest context similarity between patterns constituting the unar repair based on the calculated context similarity (step 166) and adds the unar repair to the unar repair DB 102 as a new unar repair (step 168). ).
- the identifier of the verb implication DB 56 is given to the new unary repair as a data source of the new unary repair, and the identifier of the original verb implication pair is also given.
- the unary pair generation unit 104 performs such processing for all verb implication pairs read from the verb implication DB 56.
- the unary repair expansion unit 108 When the unary repair adding unit 100 and the unary repair generating unit 104 complete the addition of the unary repair to the unary repair DB 102, the unary repair expansion unit 108 generates a plurality of unrepairs from each of the unary repairs stored in the unary repair DB 102, and outputs them to the extended unrepair DB 60. That is, with reference to FIG. 3, the record reading unit 180 of the unary repair extension unit 108 reads unary repair records from the unary repair DB 102. The passive / possible shape adding unit 182 transforms each of the unary repairs read by the record reading unit 180 into passive states and transforms into possible forms for each of the unary patterns constituting the unar repair.
- a plurality of new unrepairs obtained in combination are added to the extended unrepair DB 60 together with the original unrepairs.
- the identifier of the unary repair that is the basis of the new unpair and the flag that identifies the applied deformation are given to the new unrepair.
- the transitive tempo pair adding unit 184 further extends the unary repair by applying the predicate expression fluctuation and the ending modification to each unary repair. .
- the transitive tempo pair adding unit 184 creates a unary pattern obtained by converting the kana dictionary 106 by referring to the kanji dictionary 106 for the predicate written in kanji, and adds a unary pair having a new pattern.
- the transitive tempo pair adding unit 184 also generates unary repairs of “kanji ⁇ kana” and “kana ⁇ kanji” at the same time and adds them to the extended unary repair DB 60. Thereafter, the transitive tempo pair adding unit 184 searches for a combination of unary repairs stored in the extended unary repair DB 60, in which the second half of the first unary repair matches the first half of the second unary repair.
- the transitive tempo pair adding unit 184 For each of the retrieved unary repair combinations, the transitive tempo pair adding unit 184 generates a new unar repair by combining the first half of the first unar repair and the second half of the second unar repair, and adds the new unar repair to the extended unrepair DB 60. .
- transitive tempo pair adding unit 184 reads all unary repairs from extended unary repair DB 60 (step 220), and executes processing 224 for each read unearly pair (step 222). ). That is, in step 222, the transitive tempo pair adding unit 184 selects the read unary repairs as processing targets in a predetermined order in order, and processes 224 as follows for the selected unary repair (first unary repair). Execute.
- the transitive tempo pair adding unit 184 reads all unary repairs having the first half that matches the latter half of the unary repair to be processed from the extended unrepair DB 60 (step 250).
- the transitive tempo pair adding unit 184 executes the following processing 254 for each unary repair (second unary repair) read in step 250 (step 252).
- the transition tempo pair adding unit 184 performs processing if the predicate of the first unary repair is a combination of “kanji ⁇ kana” and the predicate of the second unary repair is a combination of “kana ⁇ kanji”.
- the process proceeds to the next second unrepair (Yes at step 280).
- the transitional tempo pair adding unit 184 determines whether or not the first half pattern of the first unary repair matches the second half pattern of the second unary repair (step 282). When the determination is NO, the transitive tempo pair adding unit 184 adds the unary consisting of the first half pattern of the first unary repair and the second half pattern of the second unary repair to the extended unrepair DB 60 as a new unrepair (step 284). When the determination in step 282 is affirmative, the transitive tempo pair adding unit 184 adds a unary corresponding to the kinematic pair to the extended unrepair DB 60 for each of the first and second unary repairs (step 286).
- a pair P ⁇ R is generated from a pair P ⁇ Q and a pair Q ⁇ R by a so-called transition rule, and added to the extended unary pair DB 60.
- a pair ⁇ Q ⁇ ⁇ P is added for P ⁇ Q
- a pair ⁇ P ⁇ ⁇ Q is added for the pair Q ⁇ P.
- the extended unary pair DB 60 is expanded from the unary pairs and verb implication pairs stored in the first unary DB52, the second unary DB54, and the verb implication DB56. Unar repairs are accumulated and can be used.
- the unary repair generated by the transition rule is given a flag indicating that it was added by the transition rule with the identifiers of the two pairs of the original unary repair, and the unary repair added by the same value is the original Two sets of unpaired identifiers and a flag indicating that they are added by the same value are given.
- the binary pair adding unit 112 when the accumulation of unary pairs in the extended unary pair DB 60 is completed, the binary pair adding unit 112 generates a plurality of binary pairs for each unary pair stored in the extended unary pair DB 60 as follows. Store in DB62. Specifically, with reference to FIG. 5, the binary pair adding unit 112 reads all unary repairs from the extended unrepair DB 60 (step 320). The binary pair adding unit 112 selects the read unary pairs in order (step 322), and executes a process 324 for generating a binary pair from the unary pair for each of them.
- the binary pair adding unit 112 reads all binary pair generation rules from the binary pair generation rule storage unit 110 shown in FIG. 1 in the process 324 of FIG. 5 (step 350). Further, the binary pair adding unit 112 sequentially selects each of the generation rules read in step 350 for the selected unary pair to be processed (step 352), and executes the process 354. In process 354, the binary pair adding unit 112 determines whether or not the unary pair being processed satisfies a condition for applying the binary pair generation rule to be processed (step 380). If the condition is not satisfied, the application of this rule is terminated, and the process proceeds to the application of the next generation rule (NO in step 380).
- step 380 When the determination in step 380 is affirmative, the binary pair adding unit 112 generates a binary pair by applying the binary pair generation rule being processed to the unary pair to be processed (step 382). The binary pair adding unit 112 adds the binary pair generated in this way to the extended binary pair DB 62 and ends the application of the binary pair generation rule (step 384).
- the following binary pair is generated from the unary pair “use A ⁇ use A”.
- the binary pair adding unit 112 applies the generation rule stored in the binary pair generation rule storage unit 110 to all the unary pairs stored in the extended unary pair DB 60, and generates all the generated binary pairs (excluding negative examples). Is added to the extended binary pair DB 62, and the binary pair obtained by extending from the first unary DB 52, the second unary DB 54, and the verb implication DB 56 is accumulated in the extended binary pair DB 62 and can be used. . At this time, the identifier of the unary pair that is the source of the binary pair and the identifier of the applied generation rule are added to each binary pair as information.
- the unary repair generated by the above method can also be used in the question answering system by the following method.
- verb implication DB 56 verb implication data (https://alaginrc.nict.go.jp/) constructed manually by the applicant as described above was used. This verb implication DB 56 contains 52,689 pairs of verb implication pairs. On the other hand, the process of the unpair repair generation part 104 was performed, and the obtained unar repair was checked manually and the positive example was accumulate
- the following number of pairs were obtained.
- the number of unpairs before applying the transition rule was 901,232. This is more than eight times the original number of unpairs.
- the extension by the transitive temperament yielded 2,864,415 new repairs.
- the number of pairs is about three times that before applying the transition rule.
- 42,096,327 binary pairs were finally generated. It is about 280 times the number of original unar repairs.
- the pair generated by the above process was scored as follows by heuristics.
- f represents the total frequency of the occurrence of two unary patterns that have generated a certain pair in the Web 600 million document.
- ⁇ and ⁇ are given as follows according to the original unary pattern.
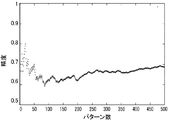
- FIG. 7 is a graph showing the overall evaluation of unary repairs. This graph is an evaluation of all unar repairs (3,765,647) obtained in the expanded unar repair DB 60 as follows.
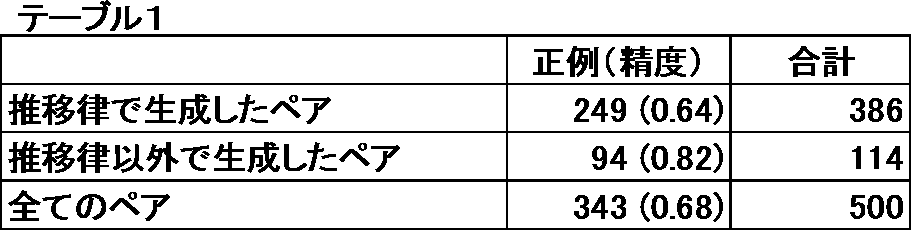
- FIG. 8 is a diagram in which 500 pairs of unary pairs are randomly sampled and evaluated, sorted in descending order of priority (score), and the accuracy of the top n is plotted. Overall, the accuracy was about 0.68. However, as shown in Table 1, an accuracy exceeding 0.8 was obtained for unary repairs other than transition rules.
- ⁇ Modification> application of the transition rule is limited to two stages. This is because the process takes time when there are three or more stages. In principle, this transition rule can be applied to any number of steps.
- the processing 224 shown in FIG. 4 may be applied in a nested format. However, a decrease in accuracy is expected as the number of application steps of the transition rule increases. Practically, it is considered that the limit is about three or four stages. However, depending on the method of processing, it may be possible to prevent a decrease in accuracy even if a transition rule is applied between a larger number of implication pairs. These need further verification in the future.
- the transition rule is applied after the unary repair is extended.
- the transitional temperament may be applied not after the extension of the unary repair but before the verb implication pair stage or before the extension of the unary repair.
- a new verb implication pair obtained by applying the transitive temperament may be inappropriate due to the ambiguity of the verb itself. Therefore, it is necessary to remove inappropriate pairs by checking after applying the transition rule.
- Such a risk is low at the time of applying the transition rule to the unary repair before expansion, but the number of new unar repairs obtained by applying the transition rule is considered to be smaller than when applying the transition rule after expansion.
- the unary pair is expanded to the binary pair.
- the present invention is not limited to such an embodiment.
- the term can be expanded to a three-term pair (referred to as “ternary repair”).
- An example of a ternary repair is “A sends C to B”.
- a method based on a generation rule similar to that at the time of extension from unary pair to binary pair can be used as it is.
- specifying the conditions under which the rule can be applied is more complicated than in the case of binary pairs, and the resulting variety of ternary pairs is larger than in the case of binary pairs. Can be longer.
- an implication pair between complex language patterns having one or more terms can be generated from a simple verb implication pair by applying a simple rule.
- this method if an implied pair of a necessary verb is prepared, an implication pair composed of various patterns related thereto is automatically generated.
- a large number of implication pairs that cannot be covered only by pairs acquired by machine learning as in the past can be acquired.
- the implication pairs obtained by this extension can be predicted from the underlying verbal implication pairs.
- it can be ensured that the accuracy of the finally adopted data becomes a certain value. Therefore, it is possible to efficiently collect a set of implication pairs with high accuracy that can be used in a system using a natural language such as a question answering system as compared with the conventional technique.
- the implication pattern pair expansion device 50 can obtain a plurality of DBs such as the extended unary pair DB 60 and the extended binary pair DB 62.
- the second embodiment relates to a question answering system that retrieves an answer to a question from a web archive using such a plurality of DBs.
- the question answering system according to the second embodiment handles a DB storing an implication pair in which variables are expanded to a pattern including up to n terms, that is, an extended N-ant DB. To do.
- extended unary pair, extended binary pair, and general extended N-aripair are collectively referred to as an extended pair in the following, and the DBs (extended unary pair DB 60, extended binary pair DB 62, etc.) storing these respectively are collectively referred to as an extended pair DB. Call it.
- the question answering system 500 receives a question 502 by voice and outputs a reply 504 to the question by voice.
- the question 502 may be received by a microphone and a voice processing unit provided in the question answering system 500, or may be received from another terminal through a network.
- the voice recognition unit 520 performs voice recognition on the question 502, and outputs a question sentence composed of text with grammatical information.
- the syntax analysis unit 522 obtains a positive sentence by applying a syntax conversion rule prepared in advance to the question sentence, further performs dependency analysis and syntax analysis, and shows a semantic dependency relationship between words. Output dependency information in graph format.
- the pattern extraction unit 526 scans this dependency information and extracts a pattern from a path connecting words existing on the graph. At this time, the upper limit of the number of terms of the variables included in the pattern is N.
- the maximum value of the number of terms is stored in the maximum term number storage unit 524, and the pattern extraction unit 526 reads this value and extracts a pattern including a maximum of N terms from the dependency information.
- a pattern with N variables is called an N-ant pattern. Therefore, patterns extracted by the pattern extraction unit 526 are unary patterns, binary patterns,..., N-ant patterns.
- the pattern extraction unit 526 extracts unary patterns by replacing nouns with variables in a path connecting nouns and predicates on a graph. Similarly, the pattern extraction unit 526 extracts a binary pattern by replacing two nouns with variables in a path connecting two nouns and a predicate on the graph. The same applies hereinafter.
- the pattern extraction unit 526 attaches a constraint corresponding to the semantic class of the noun to the variable. For example, if the noun is a place name, a restriction such as “place name” is given to the variable. This way, when searching for answers, you can exclude candidates that are similar in syntax but are not semantically irrelevant.
- the question answering system 500 includes an extended pair DB up to an extended N-ant DB 530 storing an N-ari pair in addition to the extended unary pair DB 60 and the extended binary pair DB 62 described above.
- N 2 may be used.
- the question answering system 500 includes only the extended unary pair DB 60 and the extended binary pair DB 62 as implication pairs.
- the pattern extracted by the pattern extraction unit 526 is extended by the pattern extension unit 528 using the extended unary repair DB 60, the extended binary pair DB 62,..., And the extended N-aripair DB 530.
- the pattern extension unit 528 extends the pattern using the extended unrepair DB 60.
- the pattern extension unit 528 extends the pattern using the extended binary pair DB 62.
- the pattern expansion unit 528 expands an implication pair using the extended unary pair DB 60, the extended binary pair DB 62,..., And the extended N-aripair DB 530 in order.
- the question answering system 500 is controlled by the pattern extension unit 528, and selectively selects the extended pair DB specified by the pattern extension unit 528 among the extended unpair DB 60, the extended binary pair DB 62,..., The extended N-aripair DB 530. Includes a selector 532 connected to the pattern expansion unit 528.
- unary pairs, binary pairs,..., N-aripairs obtained by extraction by the pattern extraction unit 526 are implication pairs stored in the extended unary pair DB 60, extended binary pair DB 62,..., And extended N-aripair DB 530, respectively. Both are greatly extended using.
- the pattern expansion unit 528 outputs a large number of patterns in which variables are restricted.
- the question answering system 500 includes a web archive 534 that stores a large amount of data on the web.
- the answer candidate search unit 536 searches the web archive 534 for a sentence having an expression that matches a large number of patterns output from the pattern expansion unit 528, and whether or not each expansion pair DB matches each pair. Sort and output according to The answer candidates output by the answer candidate search unit 536 are classified and stored in the unary answer candidate storage unit 538, the binary answer candidate storage unit 540,..., The N-ant answer candidate storage unit 542, respectively.
- the answer candidate search unit 536 includes a discriminator that has been subjected to machine learning using learning data in advance.
- This discriminator extracts the semantic class of words included in the pattern, the pattern used when searching for the answer candidate, the semantic similarity with the original question sentence, the answer candidate and it An answer candidate is searched for including various factors such as the degree of relevance to the pattern used at the time, and a score indicating the appropriateness as an answer to the question 502 is assigned to each answer candidate.
- the question answering system 500 is further prepared in advance for selecting an answer from among answer candidates stored in the unary answer candidate storage unit 538, binary answer candidate storage unit 540,..., N-ant answer candidate storage unit 542.
- a threshold value storage unit 546 that stores a threshold value
- a single answer candidate storage unit 538 that has a score equal to or higher than the threshold value stored in the threshold value storage unit 546
- a binary answer candidate storage unit 540 ,...
- An answer selection unit 548 for selecting from among answer candidates stored in the N-ant answer candidate storage unit 542.
- the answer selection unit 548 first has an answer candidate searched using a pattern with the most variables among answer candidates, and among them, the score is the highest and the score is a threshold value. The above is selected as an answer. If there is no such answer candidate, the answer selection unit 548 attempts to select an answer from the answer candidates searched using a pattern having a smaller number of variables. Thereafter, the same processing is performed until the value of the variable becomes 1.
- the answer selection unit 548 selects answers by giving priority to answer candidates searched using patterns with many variables. Therefore, the question answering system 500 selects any one of the N-ant answer candidate storage unit 542,..., The binary answer candidate storage unit 540, and the unary answer candidate storage unit 538 according to control by the answer selection unit 548. Further included is a selector 544 that couples to the input of 548.
- the answer candidate selected according to a predetermined criterion is selected.
- the threshold for selecting an answer candidate may be constant regardless of the number of variables included in the pattern used to search for the answer candidate, or as the number of variables increases. May be made smaller.
- the answer candidate having the highest score among the found answer candidates may be used as an answer, or the number of variables in the pattern used in the search may be You may make it select the thing with the highest score among the most answer candidates.
- the answer selected by the answer selection unit 548 is passed to the answer output unit 550.
- the answer output unit 550 outputs the answer to the path corresponding to the input path of the question 502 as the answer 504 in a format corresponding to the input format. For example, when the question 502 is input via a microphone or the like provided in the question answering system 500, the answer output unit 550 converts the answer 504 into a voice and outputs the voice through a speaker. When the question 502 is sent as voice via the network, the answer output unit 550 sends data processed to be outputted as voice to the address from which the question 502 has been sent.
- the question answering system 500 includes the extended unary pair DB 60, extended binary pair DB 62,..., Extended N-aripair expanded by the implication pattern pair expanding device 50 according to the first embodiment.
- the pattern obtained from the question 502 is expanded using the DB 530.
- the number of these extended pairs is very large, and the number of patterns obtained from the question 502 is also very large.
- the answer candidates are searched from the web archive 534 using such a large number of patterns. Therefore, even if the syntax format is significantly different from that of the question 502, there is a high possibility of searching for an appropriate answer.
- the pattern pair is expanded using the transition rule, there is a high possibility that an unexpected pattern answer different from the pattern obtained from the question 502 is obtained.
- answer candidates having a large number of variables included in the pattern used when searching for answers are preferentially selected. As a result, there is an effect that there is a high possibility that a more specific and appropriate answer can be obtained for the question 502.
- the implication pattern pair expansion device 50 according to the first embodiment, the question answering system 500 according to the second embodiment, and the other modified examples include computer hardware and a computer executed on the computer hardware. It can be realized by a program.
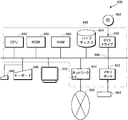
- FIG. 11 shows the external appearance of the computer system 930
- FIG. 12 shows the internal configuration of the computer system 930.
- the computer system 930 includes a computer 940 having a memory port 952 and a DVD (Digital Versatile Disc) drive 950, a keyboard 946, a mouse 948, and a monitor 942.
- a computer 940 having a memory port 952 and a DVD (Digital Versatile Disc) drive 950, a keyboard 946, a mouse 948, and a monitor 942.
- DVD Digital Versatile Disc
- the computer 940 in addition to the memory port 952 and the DVD drive 950, the computer 940 includes a CPU (Central Processing Unit) 956, a bus 966 connected to the CPU 956, the memory port 952, and the DVD drive 950, and a boot program. And the like, a random access memory (RAM) 960 connected to the bus 966 for storing program instructions, system programs, work data, and the like, and a hard disk 954.
- the computer system 930 further includes a network interface (I / F) 944 that provides a connection to a network 968 that allows communication with other terminals.
- I / F network interface
- the removable memory 964 that can be attached to the RAM 960, the hard disk 954, and the memory port 952 includes the first unary DB 52, the second unary DB 54, the verb implication DB 56, the context similarity storage unit 58, and the extended unrepair shown in FIG. DB 60, extended binary pair DB 62, kanji dictionary 106, binary pair generation rule storage unit 110, extended N-ant DB 530, web archive 534, answer candidate storage units 538, 540 and 542, maximum term number storage unit 524 and threshold value It functions as a storage device such as the storage unit 546. Data that does not require rewriting of information, such as the Chinese character dictionary 106, may be stored in a CD-ROM or DVD 962 and loaded into the DVD drive 950 for reading.
- a computer program for causing the computer system 930 to function as each functional unit of the implication pattern pair expansion device 50 or the question answering system 500 according to the above-described embodiment is a DVD 962 or a removable memory mounted on the DVD drive 950 or the memory port 952. 964 and further transferred to the hard disk 954.
- the program may be transmitted to the computer 940 through the network 968 and stored in the hard disk 954.
- the program is loaded into the RAM 960 when executed.
- the program may be loaded directly from the DVD 962 into the RAM 960 from the removable memory 964 or via the network 968.
- This program includes an instruction sequence including a plurality of instructions for causing the computer 940 to function as each functional unit of the implication pattern pair expansion device 50 or the question answering system 500 according to the above embodiment.
- Some of the basic functions required to cause computer 940 to perform this operation are an operating system or third party program that runs on computer 940 or various dynamically linkable programming toolkits or programs installed on computer 940. Provided by the library and dynamically linked and executed when the program is executed. Therefore, this program itself does not necessarily include all of the object code or script for realizing the functions necessary for realizing the system and method of this embodiment.
- This program can be used as a system as described above by dynamically calling the appropriate program in the appropriate function or programming toolkit or program library at run time in a controlled manner to achieve the desired result. It is only necessary to include an instruction for realizing the function. Of course, all necessary functions may be provided only by the program.
- each functional unit of the implication pattern pair expansion device 50 or the question answering system 500 is processed by being distributed to different computers, or is distributed and processed by different computers existing in different regions via a network. You may do it.
- the present invention can be used for a system that needs to perform natural language processing in a unified and efficient manner using various language expressions using a natural language, such as a question answering system, a guidance system, and a robot dialogue system.
- a natural language such as a question answering system, a guidance system, and a robot dialogue system.
- Implication pattern pair expansion device First unary DB 54 Second Unari DB 56 Verb Implication DB 58 Context Similarity Storage Unit 60 Extended Unary Repair DB 62 Extended Binary Pair DB 100 Una Repair Addition Unit 102 Una Repair DB 104 Unary Repair Generation Unit 106 Kanji Dictionary 108 Unar Repair Extension Unit 110 Binary Pair Generation Rule Storage Unit 112 Binary Pair Addition Unit 164 Context Similarity Calculation Processing 180 Record Reading Unit 182 Passive / Possible Form Addition Unit 184 Transition Rule Pair Addition Unit 500 Question Answering System 522 Syntax analysis unit 526 Pattern extraction unit 528 Pattern expansion unit 534 Web archive 536 Answer candidate search unit 548 Answer selection unit
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
本明細書では、「ユナリパターン」とは、変数が1つと述語、及び日本語ではそれらを結ぶ助詞からなるパターンのことをいう。上に挙げた「Aを引き起こす」、「Aをもたらす」などがその例である。
<基本的考え方>
第1の実施の形態は、動詞の間の含意関係を記述した既存の動詞含意データベース(DB)からユナリペアを生成する。こうして得たユナリペアに、さらに既存のユナリパターンDBから生成したユナリペアを加える。得られた複数のユナリペアを概略以下の手法でさらに拡張する。詳細については後述する。
(2)述部を可能形に変形
これらの変形を、各ペアのうち一方のみ、他方のみ、及び双方に施すことができる。
図1に、本発明の一実施の形態に係る含意パターンペア拡張装置50のブロック図を示す。図1を参照して、含意パターンペア拡張装置50は、第1のユナリDB52、第2のユナリDB54、動詞含意DB56、及び文脈類似度記憶部58を用いて、拡張ユナリペアDB60及び拡張バイナリペアDB62を出力するためのものである。
図1を参照して、上記した含意パターンペア拡張装置50は以下のように動作する。なお、含意パターンペア拡張装置50が以下の処理を実行するに先立って、第1のユナリDB52、第2のユナリDB54、動詞含意DB56、文脈類似度記憶部58、漢字辞書106及びバイナリペア生成規則記憶部110については予めその内容を準備しておく必要がある。

(2)読み又は形態(可能形・受動態)が異なる同じ述語
(3)上記以外で第1のユナリDB52及び第2のユナリDB54から拡張されたユナリペア
そして、データの由来にかかわらず、上記ウェブから収集した文書中の頻度がある定数未満のパターンの優先順位は最も低くなるように設定した。後述の評価実験では、ウェブ上から収集した文書の数は6億であり、最も優先順位を低く設定するためのしきい値は10とした。
以上に構成を説明した第1の実施の形態による含意ペア(ユナリペア及びバイナリペア)の評価実験について述べる。この実験では、第1のユナリDB52及び第2のユナリDB54の代わりに、3つのユナリペアの集合を用いた。これらのうち第1のものは、既存のユナリペアから、ペアを構成するパターン間の文脈類似度が上位であるものを人手でチェックして構築したもので、83,706例のユナリペアからなる。第2のものは、既存の述語対から助詞が「を」「に」「で」である述語を選択してユナリペアとしたものである。この際、意味があいまいなものは人手でチェックし、さらに正例と判断されたもののみを選択することにより構築したもので、7,334例のユナリペアからなる。第3のものは、出願人がこれまでに構築してきたいくつかのデータを基に得た27,369例の正例からなるものである。
・推移律で拡張したパターン:α=-0.2、β=-0.8
・上記以外のパターン:α=0.1、β=-0.3
図7はユナリペアの全体の評価を示すグラフである。このグラフは以下の様にして拡張ユナリペアDB60に得られたユナリペア全体(3,765,647個)を評価したものである。
本実施の形態では、推移律の適用を2段階にとどめている。これは、3段階以上になると、処理に時間を要するためである。原理的には、この推移律は何段階にでも適用できる。図4に示す処理224を入れ子形式で適用すればよい。もっとも、推移律の適用段階の数が多くなると精度の低下が予測される。実用的には3段階又は4段階程度が限度であると考えられる。しかし、処理の仕方によってはそれ以上の数の含意ペアの間で推移律を適用しても精度の低下を防止できるかも知れない。それらについては今後の検証が必要である。
上記第1の実施の形態に係る含意パターンペア拡張装置50により、拡張ユナリペアDB60及び拡張バイナリペアDB62のように、複数のDBを得ることができる。第2の実施の形態は、そのような複数のDBを用いて質問に対する回答をウェブアーカイブから検索する質問応答システムに関する。なお、この第2の実施の形態に係る質問応答システムは、一般的な例として、変数をn項まで含むパターンにまで拡張した含意ペアを記憶したDB、すなわち拡張N-アリDBまで扱うものとする。拡張ユナリペア、拡張バイナリペア、及び一般的な拡張N-アリペアをまとめて、以下では拡張ペアと呼び、これらをそれぞれ記憶したDB(拡張ユナリペアDB60、拡張バイナリペアDB62等)を総称して拡張ペアDBと呼ぶ。
上記第1の実施の形態に係る含意パターンペア拡張装置50、第2の実施の形態に係る質問応答システム500及びその他の変形例は、コンピュータハードウェアと、そのコンピュータハードウェア上で実行されるコンピュータプログラムとにより実現できる。図11はこのコンピュータシステム930の外観を示し、図12はコンピュータシステム930の内部構成を示す。
52 第1のユナリDB
54 第2のユナリDB
56 動詞含意DB
58 文脈類似度記憶部
60 拡張ユナリペアDB
62 拡張バイナリペアDB
100 ユナリペア追加部
102 ユナリペアDB
104 ユナリペア生成部
106 漢字辞書
108 ユナリペア拡張部
110 バイナリペア生成規則記憶部
112 バイナリペア追加部
164 文脈類似度計算処理
180 レコード読出部
182 受動態・可能形追加部
184 推移律ペア追加部
500 質問応答システム
522 構文解析部
526 パターン抽出部
528 パターン拡張部
534 ウェブアーカイブ
536 回答候補検索部
548 回答選択部
Claims (6)
- m項の含意ペアからn項の含意ペアを生成することで含意ペアを拡張するための含意ペア拡張装置であって、ただしm及びnは0以上でm<nを満たす整数であり、前記含意ペアの各々は、第1の言語パターンと、前記第1の言語パターンが含意する第2の言語パターンとのペアを含み、
前記含意ペア拡張装置は、前記m項の含意ペアから前記n項の含意ペアを生成するための生成規則を記憶するための生成規則記憶手段を含み、当該生成規則は、当該生成規則を適用するために前記m項の含意ペアが充足すべき条件と、当該条件が充足されたときに前記m項の含意ペアを構成する言語パターンの各々に対するn-m個の変数の追加を含む言語パターンの変形規則を規定し、
前記m項の含意ペアを受け、当該m項の含意ペアに対して、前記生成規則記憶手段に記憶された生成規則の各々について、当該生成規則の条件が前記m項の含意ペアにより充足されるか否か判定するための判定手段と、
前記判定手段により前記条件が充足されると判定された生成規則の前記変形規則を前記m項の含意ペアを構成する各言語パターンに適用することにより、前記n項の含意ペアを生成するための規則適用手段とを含む、含意ペア拡張装置。 - 前記mは0であり、
前記m項の含意ペアは、各々が述語からなる述語の含意ペアである、請求項1に記載の含意ペア拡張装置。 - 前記nは1である、請求項2に記載の含意ペア拡張装置。
- さらに、前記m項の含意ペアについて推移律を適用することにより、前記m項の含意ペアを拡張するための推移律適用手段を含む、請求項1~請求項3のいずれかに記載の含意ペア拡張装置。
- コンピュータを、請求項1~請求項4のいずれかに記載の全ての手段として機能させる、コンピュータプログラム。
- 請求項1~請求項4のいずれかに記載の含意ペア拡張装置により拡張された含意ペアを記憶するための含意ペア記憶手段と、
複数の文書を記憶した文書記憶手段と、
質問を受け、当該質問を構文解析することにより、当該質問に対する回答が持つべき言語パターンを抽出するためのパターン抽出手段と、
前記パターン抽出手段により抽出された言語パターンの各々を、前記含意ペア記憶手段に記憶された含意ペアを用いて拡張するためのパターン拡張手段と、
前記パターン拡張手段により拡張された言語パターンに合致する表現を前記文書記憶手段に記憶された文書から検索し、前記質問に対する回答としてのふさわしさを示すスコアを算出するための検索手段と、
前記検索手段により検索された回答候補のうち、検索時に合致した言語パターンに含まれる変数の数が多いものを優先して、前記スコアを用いて回答を選択するための選択手段とを含む、質問応答システム。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP16761421.3A EP3267327A4 (en) | 2015-03-06 | 2016-02-09 | Entailment pair expansion device, computer program therefor, and question-answering system |
| US15/553,998 US10380250B2 (en) | 2015-03-06 | 2016-02-09 | Entailment pair extension apparatus, computer program therefor and question-answering system |
| CN201680013131.0A CN107408110B (zh) | 2015-03-06 | 2016-02-09 | 含意配对扩展装置、记录介质以及提问应答系统 |
| KR1020177023997A KR102468481B1 (ko) | 2015-03-06 | 2016-02-09 | 함의 페어 확장 장치, 그것을 위한 컴퓨터 프로그램, 및 질문 응답 시스템 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015-044419 | 2015-03-06 | ||
| JP2015044419A JP6551968B2 (ja) | 2015-03-06 | 2015-03-06 | 含意ペア拡張装置、そのためのコンピュータプログラム、及び質問応答システム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2016143449A1 true WO2016143449A1 (ja) | 2016-09-15 |
Family
ID=56876607
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2016/053750 Ceased WO2016143449A1 (ja) | 2015-03-06 | 2016-02-09 | 含意ペア拡張装置、そのためのコンピュータプログラム、及び質問応答システム |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US10380250B2 (ja) |
| EP (1) | EP3267327A4 (ja) |
| JP (1) | JP6551968B2 (ja) |
| KR (1) | KR102468481B1 (ja) |
| CN (1) | CN107408110B (ja) |
| WO (1) | WO2016143449A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019125145A (ja) * | 2018-01-16 | 2019-07-25 | ヤフー株式会社 | 情報処理装置、情報処理方法、及び情報処理プログラム |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11140115B1 (en) | 2014-12-09 | 2021-10-05 | Google Llc | Systems and methods of applying semantic features for machine learning of message categories |
| US11042579B2 (en) * | 2016-08-25 | 2021-06-22 | Lakeside Software, Llc | Method and apparatus for natural language query in a workspace analytics system |
| JP6726638B2 (ja) * | 2017-05-11 | 2020-07-22 | 日本電信電話株式会社 | 含意認識装置、方法、及びプログラム |
| JP7614738B2 (ja) * | 2020-05-14 | 2025-01-16 | エヌ・ティ・ティ・コムウェア株式会社 | 検索装置および検索方法、学習装置および学習方法、質問回答予測システムおよび質問回答予測方法、並びにプログラム |
| CN111931018B (zh) * | 2020-10-14 | 2021-02-02 | 北京世纪好未来教育科技有限公司 | 试题匹配及试题拆分方法、装置和计算机存储介质 |
| CN112434517B (zh) * | 2020-11-09 | 2023-08-04 | 西安交通大学 | 一种结合主动学习的社区问答网站答案排序方法及系统 |
| JP7851275B2 (ja) * | 2023-08-18 | 2026-04-24 | Lineヤフー株式会社 | 情報処理装置、情報処理方法及び情報処理プログラム |
Family Cites Families (34)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6735622B1 (en) * | 1997-04-23 | 2004-05-11 | Xerox Corporation | Transferring constraint descriptors between light-weight devices for document access |
| CN101377777A (zh) * | 2007-09-03 | 2009-03-04 | 北京百问百答网络技术有限公司 | 一种自动问答方法和系统 |
| US8275803B2 (en) * | 2008-05-14 | 2012-09-25 | International Business Machines Corporation | System and method for providing answers to questions |
| US8332394B2 (en) * | 2008-05-23 | 2012-12-11 | International Business Machines Corporation | System and method for providing question and answers with deferred type evaluation |
| JP5398007B2 (ja) * | 2010-02-26 | 2014-01-29 | 独立行政法人情報通信研究機構 | 関係情報拡張装置、関係情報拡張方法、及びプログラム |
| US8554542B2 (en) * | 2010-05-05 | 2013-10-08 | Xerox Corporation | Textual entailment method for linking text of an abstract to text in the main body of a document |
| US11068657B2 (en) * | 2010-06-28 | 2021-07-20 | Skyscanner Limited | Natural language question answering system and method based on deep semantics |
| US8595213B2 (en) * | 2010-07-15 | 2013-11-26 | Semmle Limited | Type inference for datalog with complex type hierarchies |
| US9020872B2 (en) * | 2010-12-21 | 2015-04-28 | International Business Machines Corporation | Detecting missing rules with most general conditions |
| CN103221947B (zh) * | 2011-10-20 | 2016-05-25 | 日本电气株式会社 | 文本含意辨认装置、文本含意辨认方法和计算机可读记录介质 |
| CA2793268A1 (en) * | 2011-10-21 | 2013-04-21 | National Research Council Of Canada | Method and apparatus for paraphrase acquisition |
| JP5825676B2 (ja) * | 2012-02-23 | 2015-12-02 | 国立研究開発法人情報通信研究機構 | ノン・ファクトイド型質問応答システム及びコンピュータプログラム |
| JP5924666B2 (ja) * | 2012-02-27 | 2016-05-25 | 国立研究開発法人情報通信研究機構 | 述語テンプレート収集装置、特定フレーズペア収集装置、及びそれらのためのコンピュータプログラム |
| WO2013136532A1 (en) * | 2012-03-14 | 2013-09-19 | Nec Corporation | Term synonym acquisition method and term synonym acquisition apparatus |
| WO2014132402A1 (ja) * | 2013-02-28 | 2014-09-04 | 株式会社東芝 | データ処理装置および物語モデル構築方法 |
| WO2014182820A2 (en) * | 2013-05-07 | 2014-11-13 | Haley Paul V | System for knowledge acquisition |
| US20140372102A1 (en) * | 2013-06-18 | 2014-12-18 | Xerox Corporation | Combining temporal processing and textual entailment to detect temporally anchored events |
| JP6131765B2 (ja) * | 2013-08-06 | 2017-05-24 | 富士ゼロックス株式会社 | 情報処理装置及び情報処理プログラム |
| JP6150291B2 (ja) * | 2013-10-08 | 2017-06-21 | 国立研究開発法人情報通信研究機構 | 矛盾表現収集装置及びそのためのコンピュータプログラム |
| JP5904559B2 (ja) * | 2013-12-20 | 2016-04-13 | 国立研究開発法人情報通信研究機構 | シナリオ生成装置、及びそのためのコンピュータプログラム |
| JP6403382B2 (ja) * | 2013-12-20 | 2018-10-10 | 国立研究開発法人情報通信研究機構 | フレーズペア収集装置、及びそのためのコンピュータプログラム |
| JP5907393B2 (ja) * | 2013-12-20 | 2016-04-26 | 国立研究開発法人情報通信研究機構 | 複雑述語テンプレート収集装置、及びそのためのコンピュータプログラム |
| US20150199339A1 (en) * | 2014-01-14 | 2015-07-16 | Xerox Corporation | Semantic refining of cross-lingual information retrieval results |
| CN103902652A (zh) * | 2014-02-27 | 2014-07-02 | 深圳市智搜信息技术有限公司 | 自动问答系统 |
| US10055402B2 (en) * | 2014-03-17 | 2018-08-21 | Accenture Global Services Limited | Generating a semantic network based on semantic connections between subject-verb-object units |
| CN103902733B (zh) * | 2014-04-18 | 2017-02-01 | 北京大学 | 基于疑问词扩展的信息检索方法 |
| KR20150129134A (ko) * | 2014-05-08 | 2015-11-19 | 한국전자통신연구원 | 질의 응답 시스템 및 그 방법 |
| JP6008067B2 (ja) * | 2014-07-22 | 2016-10-19 | 日本電気株式会社 | テキスト処理システム、テキスト処理方法およびテキスト処理プログラム |
| US9946763B2 (en) * | 2014-11-05 | 2018-04-17 | International Business Machines Corporation | Evaluating passages in a question answering computer system |
| US10783159B2 (en) * | 2014-12-18 | 2020-09-22 | Nuance Communications, Inc. | Question answering with entailment analysis |
| US20160299881A1 (en) * | 2015-04-07 | 2016-10-13 | Xerox Corporation | Method and system for summarizing a document |
| US20170046139A1 (en) * | 2015-08-14 | 2017-02-16 | Xiaohua Yi | Parsing and Interpretation of Logical Statements |
| US11520813B2 (en) * | 2016-01-04 | 2022-12-06 | International Business Machines Corporation | Entailment knowledge base in natural language processing systems |
| US10628738B2 (en) * | 2017-01-31 | 2020-04-21 | Conduent Business Services, Llc | Stance classification of multi-perspective consumer health information |
-
2015
- 2015-03-06 JP JP2015044419A patent/JP6551968B2/ja active Active
-
2016
- 2016-02-09 EP EP16761421.3A patent/EP3267327A4/en not_active Withdrawn
- 2016-02-09 US US15/553,998 patent/US10380250B2/en active Active
- 2016-02-09 KR KR1020177023997A patent/KR102468481B1/ko active Active
- 2016-02-09 WO PCT/JP2016/053750 patent/WO2016143449A1/ja not_active Ceased
- 2016-02-09 CN CN201680013131.0A patent/CN107408110B/zh active Active
Non-Patent Citations (4)
| Title |
|---|
| CHIKARA HASHIMOTO ET AL.: "Doshi Gan'i Kankei Database no Jido Kakucho", THE ASSOCIATION FOR NATURAL LANGUAGE PROCESSING DAI 16 KAI NENJI TAIKAI HAPPYO RONBUNSHU, 8 March 2010 (2010-03-08), pages 940 - 943, XP009505707 * |
| JUN GOTO ET AL.: "A Disaster Information Analysis System Based on Question Answering", JOURNAL OF NATURAL LANGUAGE PROCESSING, vol. 20, no. 3, 14 June 2013 (2013-06-14), pages 367 - 404, XP055299433 * |
| See also references of EP3267327A4 * |
| TAKUYA KAWADA ET AL.: "Jisei-Modality o Koryo shita Gan'i Pattern Pair no Seisei", THE ASSOCIATION FOR NATURAL LANGUAGE PROCESSING DAI 20 KAI NENJI TAIKAI HAPPYO RONBUNSHU, 18 March 2014 (2014-03-18), pages 562 - 265, XP009505705 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019125145A (ja) * | 2018-01-16 | 2019-07-25 | ヤフー株式会社 | 情報処理装置、情報処理方法、及び情報処理プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JP6551968B2 (ja) | 2019-07-31 |
| KR20170122755A (ko) | 2017-11-06 |
| JP2016164708A (ja) | 2016-09-08 |
| US20180067922A1 (en) | 2018-03-08 |
| KR102468481B1 (ko) | 2022-11-18 |
| EP3267327A1 (en) | 2018-01-10 |
| EP3267327A4 (en) | 2018-12-05 |
| CN107408110B (zh) | 2020-12-15 |
| CN107408110A (zh) | 2017-11-28 |
| US10380250B2 (en) | 2019-08-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6551968B2 (ja) | 含意ペア拡張装置、そのためのコンピュータプログラム、及び質問応答システム | |
| KR102256240B1 (ko) | 논팩토이드형 질의 응답 시스템 및 방법 | |
| KR102292040B1 (ko) | 기계 독해 기반 지식 추출을 위한 시스템 및 방법 | |
| JP7842236B2 (ja) | 言語モデルニューラルネットワークを使用したインライン証拠付き出力シーケンスの生成 | |
| JP2019082931A (ja) | 検索装置、類似度算出方法、およびプログラム | |
| CN117575026A (zh) | 基于外部知识增强的大模型推理分析方法、系统及产品 | |
| WO2025205335A1 (ja) | 情報処理装置、情報処理方法、プログラム及び記録媒体 | |
| JP4361299B2 (ja) | 評価表現抽出装置、プログラム、及び記憶媒体 | |
| Uy et al. | A study on the use of genetic programming for automatic text summarization | |
| JPWO2009113289A1 (ja) | 新規事例生成装置、新規事例生成方法及び新規事例生成用プログラム | |
| Kardava | Automated root identification and pattern detection for agglutinative language processing: Enhancing machine learning models for complex morphological structures | |
| JP4940251B2 (ja) | 文書処理プログラム及び文書処理装置 | |
| CN116991969B (zh) | 可配置语法关系的检索方法、系统、电子设备及存储介质 | |
| JP7762249B2 (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| JP6476638B2 (ja) | 固有用語候補抽出装置、固有用語候補抽出方法、及び固有用語候補抽出プログラム | |
| CN111159366A (zh) | 一种基于正交主题表示的问答优化方法 | |
| JP5416021B2 (ja) | 機械翻訳装置、機械翻訳方法、およびそのプログラム | |
| Testas | Natural Language Processing with Pandas, Scikit-Learn, and PySpark | |
| Bruttan et al. | Research of approaches to the recognition of semantic images of scientific publications based on neural networks | |
| JP2008217529A (ja) | テキスト分析装置およびテキスト分析プログラム | |
| CN118780287A (zh) | 一种文本的语义匹配方法和系统 | |
| JP2024108058A (ja) | 検索サーバ、検索システム、検索方法、及び、検索プログラム | |
| CN121562635A (zh) | 一种基于机器学习的英语翻译系统 | |
| JP2025153639A (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| JP2025153636A (ja) | 情報処理装置、情報処理方法、及びプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 16761421 Country of ref document: EP Kind code of ref document: A1 |
|
| REEP | Request for entry into the european phase |
Ref document number: 2016761421 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 15553998 Country of ref document: US |
|
| ENP | Entry into the national phase |
Ref document number: 20177023997 Country of ref document: KR Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |