WO2024252750A1 - ノイズキャンセル装置、ノイズキャンセル方法及びプログラム - Google Patents
ノイズキャンセル装置、ノイズキャンセル方法及びプログラム Download PDFInfo
- Publication number
- WO2024252750A1 WO2024252750A1 PCT/JP2024/009443 JP2024009443W WO2024252750A1 WO 2024252750 A1 WO2024252750 A1 WO 2024252750A1 JP 2024009443 W JP2024009443 W JP 2024009443W WO 2024252750 A1 WO2024252750 A1 WO 2024252750A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- noise
- noise cancellation
- sound
- event
- model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images











Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/20—Speech recognition techniques specially adapted for robustness in adverse environments, e.g. in noise, of stress induced speech
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
Definitions
- This disclosure relates to a noise cancellation device, a noise cancellation method, and a program.
- Patent Document 1 discloses a voice input/output method that improves the difficulty of a user speaking when there is a lot of surrounding noise, etc. Specifically, when audio sound, surrounding noise, and the user's voice are simultaneously present in an acoustic space, this voice input/output method extracts only the user's voice by erasing the echo component of the user's voice, the component corresponding to the audio signal, and the surrounding noise from the microphone output signal. In particular, the voice input/output method calculates a gain that takes into account the sound pressure level of surrounding noise, etc., and corrects the signal level of each frequency band of the voice using a voice correction filter before outputting it from the speaker. This allows the user to clearly hear the content of the voice they themselves have spoken.
- the difference signal between the microphone output signal and the user's voice signal is eliminated as ambient noise. Therefore, when eliminating ambient noise, sound signals other than the user's voice are suppressed. Therefore, sound signals other than the user's voice, such as sound signals that suggest a sense of realism in the acoustic space (for example, the clapping sound of a toast at an online social gathering, or ambient noise at an online exhibition), are also suppressed. In other words, the sense of realism in the acoustic space could be lost.
- a sense of realism in the acoustic space for example, the clapping sound of a toast at an online social gathering, or ambient noise at an online exhibition
- the present disclosure has been devised in consideration of the above-mentioned conventional circumstances, and aims to provide a noise cancellation device, a noise cancellation method, and a program that efficiently eliminate surrounding noise without compromising the sense of realism in the acoustic space around the user.
- the present disclosure provides a noise cancellation device including an acquisition unit that acquires data on the situation in an acoustic space in which a sound collection device is placed, a determination unit that determines the content or type of the data, a selection unit that selects a noise cancellation model for canceling noise sounds other than a desired noise sound that constitutes part of the noise sounds contained in a sound signal in the acoustic space collected by the sound collection device based on the content or type, and an output control unit that uses the selected noise cancellation model to output an output audio signal that has been subjected to noise cancellation processing that cancels noise sounds other than the desired noise sound contained in the sound signal.
- the present disclosure also provides a noise cancellation method executed by a noise cancellation device, the noise cancellation method including the steps of acquiring data on the situation in an acoustic space in which a sound collection device is placed, determining the content or type of the data, selecting a noise cancellation model for canceling noise sounds other than a desired noise sound that constitutes part of the noise sounds contained in a sound signal in the acoustic space collected by the sound collection device based on the content or type, and outputting an output audio signal that has been subjected to noise cancellation processing to cancel noise sounds other than the desired noise sound contained in the sound signal using the selected noise cancellation model.
- the present disclosure also provides a program for causing a noise cancellation device, which is a computer, to perform the following steps: acquiring data on the situation within an acoustic space in which a sound collection device is placed; determining the content or type of the data; selecting, based on the content or type, a noise cancellation model for canceling noise sounds other than a desired noise sound that constitutes part of the noise sounds contained in a sound signal in the acoustic space collected by the sound collection device; and outputting, using the selected noise cancellation model, an output audio signal that has been subjected to noise cancellation processing that cancels noise sounds other than the desired noise sound contained in the sound signal.
- ambient noise can be efficiently eliminated without compromising the sense of realism in the acoustic space around the user.
- FIG. 1 is a diagram showing an example of a system configuration of an online processing system according to a first embodiment
- FIG. 2 is a block diagram showing an example of the hardware configuration of the PC shown in FIG.
- FIG. 1 is a diagram showing an example of the contents of a model selection table according to the first embodiment
- FIG. 1 is a diagram showing an example of a time chart for model selection according to the first embodiment
- 1 is a flowchart showing an example of an operation procedure of a PC according to a first embodiment in a chronological order
- FIG. 11 is a block diagram showing an example of a hardware configuration of a PC according to a second embodiment.
- FIG. 13 is a diagram showing an example of the contents of a model selection table according to the second embodiment.
- FIG. 1 is a diagram showing an example of a system configuration of an online processing system according to a first embodiment
- FIG. 2 is a block diagram showing an example of the hardware configuration of the PC shown in FIG.
- FIG. 1 is a diagram showing an example of the
- FIG. 13 is a time chart showing an example of model selection according to the second embodiment; 11 is a flowchart showing an example of an operation procedure of a PC according to a second embodiment in a chronological order. A flowchart showing a detailed example of the operation procedure of step St13 in FIG. A flowchart showing a detailed example of the operation procedure of step St17 in FIG.
- FIG. 13 is a block diagram showing an example of a hardware configuration of a PC according to a third embodiment.
- FIG. 13 is a diagram showing an example of the contents of a model selection table according to the third embodiment.
- 11 is a flowchart showing an example of an operation procedure of a PC according to a third embodiment in a chronological order.
- an online processing system is exemplified in which an event such as an online meeting is held by a plurality of people using personal computers (PCs) connected to each other via a network so as to be able to communicate data with each other, and microphones connected to the PCs (see FIG. 1 ).
- PCs personal computers
- FIG. 1 is a diagram showing an example of the system configuration of the online processing system 100 according to the first embodiment.
- the online processing system 100 includes at least an event schedule database DB1 and n (n: an integer of 2 or more) PCs 10, 20, ..., N0 connected to each other so as to be able to perform data communication via a network NW1.
- Microphones MC1, MC2, ..., MCn are connected to each of the PCs 10, 20, ..., N0, respectively, for picking up sounds such as the speech of users SP1, SP2, ..., SPn who are the users of the respective PCs.
- the network NW1 may be a wired network, a wireless network, or a combination of a wired network and a wireless network.
- the wired network may be, for example, a wired Local Area Network (LAN) or a wired Wide Area Network (WAN).
- the wireless network may be, for example, a wireless LAN, a wireless WAN, or a cellular wireless communication.
- the explanation will be centered on user SP1, who is the organizer of the event, and will mainly explain the configuration and operation of PC 10, which cancels (eliminates) noise sounds around user SP1 contained in the sound signal picked up by microphone MC1 used by user SP1.
- user SP1 is the organizer of the event
- the other users SP2, ..., SPn are each participants of the event.
- the roles of users SP1, SP, ..., SPn may be appropriately determined depending on the content of the event executed using online processing system 100, and are not limited to user SP1 being the organizer, and another user may be the organizer.
- the event schedule database DB1 stores and manages data (event schedule data IVL1) indicating the contents of each event executed using the online processing system 100.
- the event schedule data IVL1 is composed of records that each have actual data consisting of the following items for each event: an event ID, which is identification information for the event, the event contents or event type, the start time of the event, and the end time of the event.
- an event with an event ID of "0001” has an event content of "online meeting” (not shown in FIG. 1), a start time of "10:00", and an end time of "11:00”.
- an event with an event ID of "0002” has an event content of "online drinking party” (not shown in FIG. 1), a start time of "19:00", and an end time of "21:00”.
- PC10 is an example of a noise cancellation device according to the present disclosure, and selects a noise cancellation model (see below) for canceling noise around user SP1 contained in a sound signal picked up by microphone MC1 based on event schedule data IVL1 in event schedule database DB1.
- PC10 uses the selected noise cancellation model to perform noise cancellation processing for canceling noise contained in the sound signal picked up by microphone MC1, and outputs a sound signal after noise cancellation processing (output audio signal).
- the output audio signal may be output from speaker SPK1 (see FIG. 2), or may be transmitted to other PCs 20, ..., N0, or a combination of these.
- the description of the configuration and operation of PC10 may be similarly applied to some or all of the other PCs 20, ..., N0.
- the microphone MC1 may have the same configuration as a known microphone, and picks up sounds in the acoustic space where the user SP1 is (e.g., the speech of the user SP1, noise around the user SP1), and sends the picked-up sound as an electrical signal (sound signal) to the PC 10.
- the sound signal picked up by the microphone MC1 is input to the PC 10 (see Figure 2).
- the microphone MC1 also picks up the sound signals sent from each of the other PCs 20, ..., N0 during the event, which are output from the speaker SPK1 of the PC 10 (see Figure 2).
- This picked-up sound signal may include not only the speech of each of the other users SP2, ..., SPn, but also sounds that suggest a sense of realism in the acoustic space where each user is (e.g., applause, surrounding noise).
- Speaker SPK1 may have the same configuration as a well-known speaker, and outputs an output audio signal that has been subjected to noise cancellation processing by PC10. Speaker SPK1 also outputs audio signals sent from each of the other PCs 20, ..., N0 and received by PC10.
- FIG. 2 is a block diagram showing an example of the hardware configuration of the PC 10 in FIG. 1.
- the PC 10 is connected to allow input of data signals from a microphone MC1 and an event schedule database DB1, and is further connected to allow output of data signals to a speaker SPK1.
- the PC 10 is a general-purpose computer device, and may be configured as a smartphone or tablet terminal other than a personal computer as one aspect of the noise cancellation device according to the present disclosure.
- the PC 10 includes at least a processor PRC1 and a memory 11 as hardware components.
- the PC 10 may further include an input device such as a mouse that accepts operations from the user SP1.
- the processor PRC1 functions as a controller that manages the overall operation of the PC 10, and performs control processing for managing the operation of each part of the PC 10, input/output processing of data signals/control signals between each part of the PC 10, calculation processing of data signals/control signals, and storage processing of data signals/control signals.
- the processor PRC1 may be configured, for example, as a Central Processing Unit (CPU), a Digital Signal Processor (DSP), a Field Programmable Gate Array (FPGA), or a Graphical Processing Unit (GPU).
- CPU Central Processing Unit
- DSP Digital Signal Processor
- FPGA Field Programmable Gate Array
- GPU Graphical Processing Unit
- the processor PRC1 inputs a sound signal (hereinafter, for convenience, may be referred to as an "input sound signal") picked up by the microphone MC1 in cooperation with the memory 11, and performs various signal processing (for example, noise cancellation processing) on the input sound signal.
- a sound signal hereinafter, for convenience, may be referred to as an "input sound signal” picked up by the microphone MC1 in cooperation with the memory 11, and performs various signal processing (for example, noise cancellation processing) on the input sound signal.
- the memory 11 includes at least a Read Only Memory (ROM) and a Random Access Memory (RAM).
- the ROM stores programs that define various processes executed by the processor PRC1 and data required for the execution of the programs in association with each other.
- the RAM temporarily stores data or information acquired or generated by the processor PRC1.
- the memory 11 is referred to as appropriate during the execution of processes by the processor PRC1.
- the memory 11 also stores multiple noise cancellation models. In the illustrated example of FIG. 2, each of the three noise cancellation models M1, M2, and M3 is read from the memory 11 and loaded into the processor PRC1, but the number is not limited to three.
- Each of the noise cancellation models M1 to M3 is equipped with AI (artificial intelligence) and is data or a parameter set of a model that has been previously learned by machine learning or the like.
- Each of the noise cancellation models M1 to M3 cancels (eliminates) noise contained in the input sound signal other than the "noise sound not to be eliminated" (an example of a desired noise sound) corresponding to each model.
- the memory 11 also stores the model selection table TBL1 shown in FIG. 3. The noise cancellation models and the model selection table TBL1 will be described later with reference to FIG. 3.
- the processor PRC1 functionally comprises an event content determination unit 12, a usage model selection unit 13, a noise cancellation processing unit 14, a selector 15, an audio output unit 16, and a transmission unit 17. Note that all or at least one of the event content determination unit 12, the usage model selection unit 13, the noise cancellation processing unit 14, and the selector 15 may be incorporated and operated as a function that can be realized by applications that communicate data with each other via the network NW1.
- the event content determination unit 12 is an example of an acquisition unit and a determination unit, and has a function as an interface with the event schedule database DB1.
- the event content determination unit 12 determines the content of the event schedule data IVL1 read from the event schedule database DB1, and sends the determination result to the usage model selection unit 13. For example, when the event content determination unit 12 reads the event schedule data IVL1 of event ID "0001", it determines that the event content is "online meeting” (not shown), the start time is "10:00", and the end time is "11:00”. When the event content determination unit 12 reads the event schedule data IVL1 of event ID "0002”, it determines that the event content is "online drinking party” (not shown), the start time is "19:00", and the end time is "21:00".
- the event schedule data IVL1 may be event schedule data that the user SP1, who is the event organizer, inputs directly without going through the event schedule database DB1, instead of the event schedule data read out from the event schedule database DB1.
- a screen for inputting the event content (type) is displayed via a display device connected to the PC 10 used by the user SP1, and the user SP1 inputs the event content (type) into the PC 10 via the input device.
- the usage model selection unit 13 is an example of a selection unit, and inputs the judgment result from the event content judgment unit 12, and further reads out a model selection table (see FIG. 3) from the memory 11. Based on the input judgment result and the model selection table (see FIG. 3), the usage model selection unit 13 selects a noise cancellation model for canceling noise sounds other than the desired noise sound that constitutes part of the noise sound contained in the input sound signal from the microphone MC1 (i.e., the data signal of the sound picked up by the microphone MC1 in the acoustic space where the user SP is located). The usage model selection unit 13 sends result data indicating the selected noise cancellation model to the noise cancellation processing unit 14.
- event schedule data directly input by the user SP1 who is the event organizer
- the noise cancellation model selected based on the input judgment result can be switched to a new noise cancellation model during the event period.
- FIG. 3 is a diagram showing an example of the contents of the model selection table TBL1 according to the first embodiment.
- Figure 4 is a diagram showing an example of a time chart for model selection according to the first embodiment.
- the model selection table TBL1 is composed of a multi-line record that associates, for each scheduled event name, a "scheduled event name", an "event type”, a "noise sound that is not to be cancelled", and a "noise cancellation model”.
- Event Plan Name is the name of an event to be executed using the online processing system 100 in FIG. 1.
- “Online Drinking Party”, “Online Preview”, “Online Lecture”, and “Online Meeting” are shown, but the name is not limited to these.
- Event type is the type of event indicated by “Event plan name.”
- the type of “online drinking party” is “drinking party”
- the type of “online preview” is “preview”
- the type of “online lecture” is “lecture”
- the type of “online meeting” is “regular meeting.”
- Noise cancellation model 2 is an example of a desired noise sound, and indicates a type of noise sound that is not eliminated by the “noise cancellation model” so as not to spoil the atmosphere (sense of realism) during the event.
- the "noise cancellation model” is a model formed in advance by machine learning or the like so as not to eliminate the "noise sound not to be eliminated” and to eliminate noise sounds other than the "noise sound not to be eliminated”.
- the "noise cancellation model 2" does not eliminate the noise sound of "applause", and eliminates noise sounds other than "applause”.
- the noise cancellation model 2 may be any one of the noise cancellation models M1 to M3 in FIG. 1.
- Noise cancellation model 3 does not eliminate the noise sound of "ambient environment noise", and eliminates noise sounds other than “ambient environment noise”.
- the noise cancellation model 3 may be any one of the noise cancellation models M1 to M3 in FIG. 1.
- the “noise cancellation model 4" does not eliminate the noise sound of "laughter, applause", and eliminates noise sounds other than "laughter, applause”.
- Noise cancellation model 4 may be any one of noise cancellation models M1 to M3 in FIG. 1. In the case of a "normal meeting" type, all noise sounds are eliminated by "noise cancellation model 1.”
- Noise cancellation model 1 may be any one of noise cancellation models M1 to M3 in FIG. 1.
- the horizontal axis in Figure 4 indicates time.
- the usage model selection unit 13 selects "noise cancellation model 2" corresponding to the record of "online drinking party” or “drinking party” in the model selection table TBL1 as the noise cancellation model to be used by the noise cancellation processing unit 14 during the period of the event IV1 (for example, the period from time t1 to time t2).
- the usage model selection unit 13 selects "noise cancellation model 1" corresponding to the record of "online meeting” or "regular meeting” in the model selection table TBL1 as the noise cancellation model to be used by the noise cancellation processing unit 14 during the period of the event IV2 (for example, the period from time t1 to time t2).
- the noise cancellation processing unit 14 is an example of an output control unit, and in accordance with the result data from the usage model selection unit 13, the noise cancellation processing unit 14 has the selector 15 select and acquire data or a parameter set of a noise cancellation model corresponding to the result data. Using the noise cancellation model acquired via the selector 15, the noise cancellation processing unit 14 performs noise cancellation processing to cancel noise sounds contained in the input sound signal from the microphone MC1 other than noise sounds that are not eliminated by the noise cancellation model. The noise cancellation processing unit 14 sends an output audio signal, which is the sound signal after the noise cancellation processing, to each of the audio output unit 16 and the transmission unit 17.
- the audio output unit 16 outputs the output audio signal from the noise cancellation processing unit 14 from the speaker SPK1.
- the transmitting unit 17 transmits the output audio signal from the noise cancellation processing unit 14 to each of the other PCs 20, ..., N0 via the network NW1. Note that although the transmitting unit 17 is illustrated as constituting part of the processor PRC1, it may be provided separately from the processor PRC1.
- FIG. 5 is a flowchart showing an example of the operation procedure of the PC 10 according to the first embodiment in chronological order.
- Each process shown in FIG. 5 is mainly executed by the processor PRC1 (see FIG. 2).
- the process shown in FIG. 5 is executed, for example, for each event, and is executed when the event starts or immediately before the start of the event.
- the processor PRC1 acquires and reads out at least one event schedule data IVL1 from the event schedule database DB1 connected to the PC10 (step St1). Based on the event schedule data IVL1 read out in step St1, the processor PRC1 determines the event type (content) of the event identified by the event schedule data IVL1 (step St2). For example, when the processor PRC1 reads out the event schedule data IVL1 for event ID "0001", it determines that the event type (content) is "online meeting". At this time, the event schedule data IVL1 may be event schedule data that the user SP1, who is the event organizer, inputs directly without going through the event schedule database DB1, instead of the event schedule data read out from the event schedule database DB1.
- the processor PRC1 selects a noise cancellation model corresponding to the event type based on the event type (contents) determined in step St2 and the model selection table TBL1 read from the memory 11 (step St3). In other words, the processor PRC1 selects a noise cancellation model for canceling only noise sounds other than "noise sounds not to be cancelled" corresponding to the event type (contents) determined in step St2 so as not to impair the sense of realism of the event during the event period.
- the processor PRC1 reads and acquires the noise cancellation model selected in step St3 from the memory 11 (step St4).
- the processor PRC1 uses the noise cancellation model acquired in step St4 to perform noise cancellation processing to eliminate noise sounds included in the input sound signal from the microphone MC1 other than the "noise sounds not to be eliminated” corresponding to the noise cancellation model (step St5).
- the processor PRC1 outputs the output sound signal after the noise cancellation processing performed in step St5 (step St6).
- the output form of this output sound signal may be output from the speaker SPK1 (see FIG. 2), or may be transmitted to other PCs 20, ..., N0, or a combination of these. If the processor PRC1 detects an input indicating the end of the event (step St7, YES), the processing of the processor PRC1 shown in FIG. 5 ends.
- step St7 if no input has been made to end the event (step St7, NO), the process of the processor PRC1 returns to step St1.
- the processor PRC1 repeatedly executes the series of processes from step St1 to step St7 during the period from when the event starts to when it ends.
- the PC 10 as an example of a noise cancellation device acquires data (for example, event schedule data IVL1) related to the situation in the acoustic space in which the sound collection device (microphone MC1) is placed, and determines the content or type of the data. Based on the determined content or type, the PC 10 selects a noise cancellation model for canceling noise sounds other than "noise sounds not to be eliminated" corresponding to the noise cancellation model, which are included in the sound signal (input sound signal) in the acoustic space collected by the sound collection device.
- data for example, event schedule data IVL1
- the PC 10 selects a noise cancellation model for canceling noise sounds other than "noise sounds not to be eliminated" corresponding to the noise cancellation model, which are included in the sound signal (input sound signal) in the acoustic space collected by the sound collection device.
- the PC 10 uses the selected noise cancellation model to output an output audio signal that has been subjected to noise cancellation processing for canceling noise sounds other than "noise sounds not to be eliminated” corresponding to the noise cancellation model included in the input sound signal.
- This allows the PC 10 to efficiently cancel (erase) unnecessary surrounding noise sounds that are unrelated to the realism of the event, without impairing the realism of the event taking place in the acoustic space around the user SP1. Therefore, the user can comfortably participate in the event without impairing the realism of the event and without worrying about the surrounding noise sounds.
- the configuration example of the online processing system according to the second embodiment may be the same as the configuration example of the online processing system 100 according to the first embodiment, or may be different. To simplify the following explanation, the configuration example of the online processing system according to the second embodiment will be explained as being the same as the configuration example of the online processing system 100 according to the first embodiment. However, in the second embodiment, the PC 10 does not necessarily need to read and acquire the event schedule data IVL1 from the event schedule database DB1.
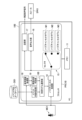
- FIG. 6 is a block diagram showing an example of the hardware configuration of a PC 10A according to the second embodiment.
- the PC 10A is connected to allow input of a data signal from a microphone MC1, and is further connected to allow output of a data signal to a speaker SPK1.
- the PC 10A is a general-purpose computer device, and may be configured as a smartphone or tablet terminal other than a personal computer as one aspect of the noise cancellation device according to the present disclosure.
- the PC 10A includes at least a processor PRC1A and a memory 11 as hardware components.
- the PC 10A may further include an input device such as a mouse that accepts operations from a user SP1.
- PC 10A components that have the same configuration and operation as PC 10 in FIG. 2 are given the same reference numerals, and explanations are simplified or omitted, and differences are explained.
- the memory 11 stores the model selection table TBL1A shown in FIG. 7.
- the model selection table TBL1A will be described later with reference to FIG. 7.
- the processor PRC1A functionally comprises a voice recognition processing unit 18, an utterance content determination unit 19, a usage model selection unit 13A, a noise cancellation processing unit 14, a selector 15, an audio output unit 16, a transmission unit 17, and a receiving unit RC1.
- the receiving unit RC1 receives a received voice signal transmitted via the network NW1.
- This received voice signal may be, for example, a sound signal of a person, machine, etc. picked up by the microphone MC2 on the PC20 side, or a sound signal of a person, machine, etc. picked up by the microphone MCn on the PCN0 side, or a combination of these.
- the received voice signal received by the receiving unit RC1 is input to the voice recognition processing unit 18 in the same way as the sound signal picked up by the microphone MC1.
- the voice recognition processing unit 18 is an example of an acquisition unit, and receives as input sound signals the sound signal of the sound picked up by the microphone MC1 and the received voice signal from the receiving unit RC1, and executes voice recognition processing using the input sound signal as input.
- the voice recognition processing unit 18 sends the result data of the voice recognition processing to the speech content determination unit 19.
- the method of the voice recognition processing performed by the voice recognition processing unit 18 here may be a publicly known technology, and the method is not particularly important in embodiment 2.
- the speech content determination unit 19 is an example of a determination unit, and determines the speech content indicated by the result data based on the result data of the voice recognition processing from the voice recognition processing unit 18.
- the speech content determination unit 19 sends the determination result data of the speech content to the usage model selection unit 13A.
- the method by which the speech content determination unit 19 determines the speech content may be a publicly known technology, and the method is not particularly important in embodiment 2. Note that although the voice recognition processing unit 18 and the speech content determination unit 19 are provided as separate components in FIG. 6, they may also be configured as a single unit functionally.
- the usage model selection unit 13A is an example of a selection unit, and inputs the judgment result from the speech content judgment unit 19, and further reads out a model selection table (see FIG. 7) from the memory 11. Based on the input judgment result and the model selection table (see FIG. 7), the usage model selection unit 13A selects a noise cancellation model for canceling noise sounds other than the desired noise sound that constitutes part of the noise sound contained in the input sound signal from the microphone MC1 (i.e., the data signal of the sound picked up by the microphone MC1 in the acoustic space where the user SP is located). The usage model selection unit 13A sends result data indicating the selected noise cancellation model to the noise cancellation processing unit 14.
- Fig. 7 is a diagram showing an example of the contents of the model selection table TBL1A according to the second embodiment.
- Fig. 8 is a diagram showing an example of a time chart of model selection according to the second embodiment.
- the model selection table TBL1A is composed of a multi-row record that associates "utterance content", "noise sound not to be cancelled", and "noise cancellation model" for each utterance content.
- the "speech content” is the speech content obtained based on a voice recognition process and a speech content determination process that use as input the sound picked up by the microphone MC1 (e.g., the voice spoken by the user SP1, or sounds coming from surrounding objects other than the user SP).
- the sound picked up by the microphone MC1 e.g., the voice spoken by the user SP1, or sounds coming from surrounding objects other than the user SP.
- “Cheers,” “How's the machine working,” and “Thank you for listening” are shown, but the content need not be limited to these.
- Noise sound not to be eliminated is an example of a desired noise sound, and indicates a type of noise sound that is not eliminated by the “noise cancellation model” so as not to impair the atmosphere (sense of realism) in the acoustic space where the user SP1 is located.
- the "noise cancellation model” is a model formed in advance by machine learning or the like so as not to eliminate “noise sound not to be eliminated” and to eliminate noise sounds other than "noise sound not to be eliminated”. In the case of the speech content "Cheers”, the "noise cancellation model 2" does not eliminate the noise sound of "applause", and eliminates noise sounds other than "applause”.
- the noise cancellation model 2 may be any one of the noise cancellation models M1 to M3 in FIG. 1.
- the “noise cancellation model 3” does not eliminate the noise sound of "factory noise”, and eliminates noise sounds other than "factory noise”.
- the noise cancellation model 3 may be any one of the noise cancellation models M1 to M3 in FIG. 1.
- "Noise Cancellation Model 2” does not eliminate the "applause” noise, but eliminates all other noise sounds besides "applause.”
- PC 10A uses the sound signals picked up by microphones MC1, MC2, and MC3 as input sound signals, and is able to select noise cancellation model 3 for not canceling factory noise contained in the speech content (e.g., "machine condition") corresponding to the input sound signal.
- This allows PC 10A to cancel other unnecessary noise sounds without canceling mechanical sounds generated in the factory to an extent that does not impair the sense of realism during a remote call or online meeting held in the factory where microphones MC1, MC2, and MC3 are located.
- the horizontal axis in Figure 8 indicates time.
- scenario SCN1 in Figure 8 when the judgment result from the utterance content judgment unit 19 is "Cheers", the usage model selection unit 13A selects "Noise cancellation model 2" corresponding to the record for "Cheers” in the model selection table TBL1A as the noise cancellation model to be used by the noise cancellation processing unit 14 for a certain period of time (the period from time t3 to time t4) after the utterance of "Cheers" starts at time t1 and ends at time t3.
- the usage model selection unit 13A selects "Noise cancellation model 2" corresponding to the record of "Cheers” in the model selection table TBL1A as the noise cancellation model to be used by the noise cancellation processing unit 14 during the period from when the utterance of "Cheers” is started at time t1 to when the judgment result from the utterance content judgment unit 19 becomes "Machine condition" at time t5 (the period from time t3 to time t5).
- the usage model selection unit 13A selects "noise cancellation model 3" corresponding to the record for "machine condition” in the model selection table TBL1A as the noise cancellation model to be used by the noise cancellation processing unit 14 for a certain period of time (the period from time t6 to time t2) after the recording of the sound of "machine condition” starts at time t5 and ends at time t6.
- the usage model selection unit 13A selects "noise cancellation model 1" for canceling all noise sounds as the noise cancellation model to be used by the noise cancellation processing unit 14 during the period from time t1 to time t2 during which no speech content is input from the speech content judgment unit 19, regardless of the model selection table TBL1A.
- Fig. 9 is a flowchart showing an example of the operation procedure of the PC 10A according to the second embodiment in chronological order.
- Fig. 10 is a flowchart showing a detailed example of the operation procedure of step St13 in Fig. 9.
- Fig. 11 is a flowchart showing a detailed example of the operation procedure of step St17 in Fig. 9.
- Each process shown in Figs. 9 to 11 is mainly executed by the processor PRC1A (see Fig. 6).
- the process shown in Fig. 9 is executed, for example, every time sound is picked up by the microphone MC1.
- the processor PRC1A executes a voice recognition process on an input sound signal picked up by a microphone MC1 placed in the acoustic space where the user SP1 is located (step St11). Based on the result data of the voice recognition process in step St11, the processor PRC1A determines the spoken content indicated by the voice recognition process (step St12). For example, when the result data of the voice recognition process of the input sound signal is "So, let's have a toast to celebrate Mr. AA's new beginning!, the processor PRC1 determines that the spoken content is "Cheers.”
- the processor PRC1A selects a noise cancellation model corresponding to the speech content based on the speech content determined in step St12 and the model selection table TBL1A read from the memory 11 (step St13). In other words, the processor PRC1A selects a noise cancellation model for canceling only noise sounds other than the "noise sounds not to be cancelled" corresponding to the speech content determined in step St12 so as not to impair the sense of realism of the atmosphere during the period in which the speech content determined in step St12 is picked up. Details of the processing of this step St13 will be described later with reference to FIG. 10. The processor PRC1A reads and acquires the noise cancellation model selected in step St13 from the memory 11 (step St14).
- the processor PRC1A uses the noise cancellation model acquired in step St14 to perform noise cancellation processing to eliminate noise sounds other than the "noise sounds not to be eliminated” corresponding to the noise cancellation model, which are included in the input sound signal from the microphone MC1 (step St15).
- the processor PRC1A outputs the output sound signal after the noise cancellation processing performed in step St15 (step St16).
- the output form of this output sound signal may be output from the speaker SPK1 (see FIG. 2), may be transmitted to other PCs 20, ..., N0, or may be a combination of these.
- the processor PRC1A determines whether or not it is necessary to return the noise cancellation model (step St17). Details of the processing of step St17 will be described later with reference to FIG. 11.
- step St18 If the processor PRC1A detects an input to end the operation of the PC10A (step St18, YES), the processing of the processor PRC1A shown in FIG. 9 ends.
- processor PRC1A determines whether input has been made to end the operation of PC10A (step St18, NO). If no input has been made to end the operation of PC10A (step St18, NO), the process of processor PRC1A returns to step St11. In other words, processor PRC1A repeatedly executes the series of processes from step St11 to step St18 until the operation ends.
- step St13 in FIG. 9 will be described.
- the processor PRC1A determines whether or not an utterance for switching the currently used noise cancellation model to a new one has been detected based on the utterance content determined in step St12 (step St13-1). If it is determined that an utterance for switching the noise cancellation model to a new one has not been detected (step St13-1, NO), the processing of the processor PRC1A ends.
- the processor PRC1A determines whether or not an utterance for switching the currently used noise cancellation model has been detected (step St13-2, YES), it selects a noise cancellation model corresponding to the utterance content based on the utterance content determined in step St12 and the model selection table TBL1A read from the memory 11 (step St13-2). After step St13-2, the processing of the processor PRC1A ends.
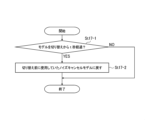
- step St17 in FIG. 9 the detailed operation procedure of step St17 in FIG. 9 will be described.
- the processor PRC1A determines whether a certain time (t: default value) has elapsed since the noise cancellation model was switched to be used in step St14 (step St17-1). If it is determined that the certain time (t: default value) has not elapsed since the noise cancellation model was switched (step St17-1, NO), the processing of the processor PRC1A ends. In this case, the processor PRC1A continues to use the noise cancellation model currently in use.
- step St17-2 YES
- step St17-2 YES
- the PC 10A as an example of a noise cancellation device acquires data on the situation in the acoustic space in which the sound collection device (microphone MC1) is placed (for example, data indicating the contents of the speech indicated by the voice recognition result of the input sound signal collected by the microphone MC1) and determines the contents or type of the data. Based on the determined contents or type, the PC 10A selects a noise cancellation model for canceling noise sounds other than the "noise sounds not to be eliminated" corresponding to the noise cancellation model, which are included in the sound signal (input sound signal) in the acoustic space collected by the sound collection device.
- the PC 10A uses the selected noise cancellation model to output an output audio signal that has been subjected to noise cancellation processing for canceling noise sounds other than the "noise sounds not to be eliminated” corresponding to the noise cancellation model included in the input sound signal.
- This allows the PC 10A to efficiently cancel (erase) unnecessary surrounding noise sounds that are unrelated to the realism of the atmosphere, without impairing the atmosphere (realism) of the speech taking place in the acoustic space around the user SP1. Therefore, user SP1 can perform the process comfortably without losing the sense of realism of the surrounding atmosphere and without being bothered by surrounding noise.
- ⁇ Third embodiment> In the third embodiment, which is a combination of the first and second embodiments, an example is described in which a noise cancellation model is selected according to the event schedule data (see the first embodiment) during an event, and a noise cancellation model is selected in an interrupt manner according to the content spoken during the event.
- the configuration example of the online processing system according to the third embodiment may be the same as the configuration example of the online processing system 100 according to the first and second embodiments, or may be different. To simplify the following explanation, the configuration example of the online processing system according to the third embodiment will be explained as being the same as the configuration example of the online processing system 100 according to the first embodiment.
- FIG. 12 is a block diagram showing an example of the hardware configuration of the PC 10B according to the third embodiment.
- the PC 10B is connected to the microphone MC1 and the event schedule database DB1 so that data signals can be input, and is further connected to the speaker SPK1 so that data signals can be output.
- the PC 10B is a general-purpose computer device, and may be configured as a smartphone or a tablet terminal other than a personal computer as one aspect of the noise cancellation device according to the present disclosure.
- the PC 10B includes at least a processor PRC1B and a memory 11 as hardware components.
- the PC 10B may further include an input device such as a mouse that accepts operations by the user SP1.
- the PC 10A may further include a receiving unit RC1 that receives a received voice signal sent from an external PC and sends it to the voice recognition processing unit 18 as shown in FIG. 6.
- PC 10B components that have the same configuration and operation as PC 10 in FIG. 2 or PC 10A in FIG. 6 are given the same reference numerals, and explanations are simplified or omitted, and differences are explained.
- the memory 11 stores the model selection table TBL1B shown in FIG. 13.
- the model selection table TBL1B will be described later with reference to FIG. 13.
- the processor PRC1B functionally comprises an event content determination unit 12, a voice recognition processing unit 18, an utterance content determination unit 19, a usage model selection unit 13B, a noise cancellation processing unit 14, a selector 15, an audio output unit 16, and a transmission unit 17.
- the usage model selection unit 13B is an example of a selection unit, and inputs the determination result from the event content determination unit 12, and further reads out a model selection table (see FIG. 13) from the memory 11. Based on the input determination result and the model selection table (see FIG. 13), the usage model selection unit 13B selects a noise cancellation model for canceling noise sounds other than the desired noise sound that constitutes part of the noise sound contained in the input sound signal from the microphone MC1 (i.e., the data signal of the sound picked up by the microphone MC1 in the acoustic space where the user SP is located). The usage model selection unit 13B sends result data indicating the selected noise cancellation model to the noise cancellation processing unit 14.
- the usage model selection unit 13B may also input the judgment result from the speech content judgment unit 19 during the event period. In this case, the usage model selection unit 13B reads out a model selection table (see FIG. 13) from the memory 11. Based on the judgment result from the speech content judgment unit 19 and the model selection table (see FIG. 13), the usage model selection unit 13B interruptively selects a noise cancellation model for canceling noise sounds other than the desired noise sounds that constitute part of the noise sounds contained in the input sound signal from the microphone MC1 (i.e., the data signal of the sound picked up by the microphone MC1 in the acoustic space where the user SP is).
- a noise cancellation model for canceling noise sounds other than the desired noise sounds that constitute part of the noise sounds contained in the input sound signal from the microphone MC1 (i.e., the data signal of the sound picked up by the microphone MC1 in the acoustic space where the user SP is).
- a noise cancellation model different from the noise cancellation model to be used during the event period (in other words, the noise cancellation model selected according to the event schedule data) may be selected.
- the usage model selection unit 13B sends result data indicating the selected noise cancellation model to the noise cancellation processing unit 14.
- model selection table TBL1B will be described with reference to FIG. 13.
- FIG. 13 is a diagram showing an example of the contents of model selection table TBL1B according to embodiment 3.
- Model selection table TBL1B is a table that combines model selection table TBL1 in FIG. 3 and model selection table TBL1A in FIG. 7.
- model selection table TBL1B gives priority to selecting the contents of model selection table TBL1A over the contents of model selection table TBL1.
- noise cancellation model 1 is selected when an online meeting event starts and the utterance "cheers" is detected and determined during the event
- the usage model selection unit 13B will interrupt the use of noise cancellation model 1 and select and switch to noise cancellation model 2, which corresponds to the utterance of "cheers,” during the use of noise cancellation model 1.
- noise cancellation model 3 is selected at the start of an online lecture event and the utterance "cheers" is detected and determined during the event, the usage model selection unit 13B will interrupt the use of noise cancellation model 3 and select and switch to noise cancellation model 2, which corresponds to the utterance of "cheers.”
- FIG. 14 is a flowchart showing an example of the operation procedure of the PC 10B according to the third embodiment in chronological order.
- Each process shown in FIG. 14 is mainly executed by the processor PRC1B (see FIG. 12).
- the process shown in FIG. 14 is executed, for example, for each event, when the event starts or immediately before the start of the event.
- the same process as that in FIG. 5 or FIG. 9 will be assigned the same step number, and the description will be simplified or omitted, and differences will be described.
- step St2 the result of the determination in step St2 is input to the processor PRC1B.
- the speech content shown in FIG. 13 is not detected and determined in the input sound signal picked up by the microphone MC1 in steps St11 and St12, the processing result of step St12 is not input to the processor PRC1B.
- step St2 If only the determination result in step St2 is input, the processor PRC1B selects a noise cancellation model corresponding to the event type based on the event type (contents) determined in step St2 and the model selection table TBL1 read from the memory 11 (step St31).
- step St31 when the processor PRC1B receives both the judgment results from steps St2 and St12, it selects a noise cancellation model corresponding to the speech content judged in step St12 in an interrupt manner based on the model selection table TBL1B in FIG. 13 (step St31).
- the process from step St31 onwards is similar to the process from step St14 onwards shown in FIG. 9, so a detailed description will be omitted.
- PC 10B as an example of a noise cancellation device acquires data relating to the situation in the acoustic space in which the sound collection device (microphone MC1) is placed (for example, event schedule data IVL1, or data indicating the speech content indicated by the event schedule data IVL1 and the voice recognition result of the input sound signal collected by the microphone MC1), and determines the content or type of the data. Based on the determined content or type, PC 10B selects a noise cancellation model for canceling noise sounds other than "noise sounds that are not to be cancelled" according to the noise cancellation model, which are included in the sound signal (input sound signal) in the acoustic space collected by the sound collection device.
- data relating to the situation in the acoustic space in which the sound collection device (microphone MC1) is placed for example, event schedule data IVL1, or data indicating the speech content indicated by the event schedule data IVL1 and the voice recognition result of the input sound signal collected by the microphone MC1
- PC 10B selects a noise cancellation model for
- PC 10B uses the selected noise cancellation model to output an output audio signal that has been subjected to noise cancellation processing that cancels noise sounds other than "noise sounds that are not to be cancelled” according to the noise cancellation model, which are included in the input sound signal. This allows PC 10B to efficiently cancel (erase) unnecessary surrounding noise that is unrelated to the realism of the atmosphere during an event taking place in the acoustic space around user SP1, or the atmosphere (realism) of speech that occurs during the event. Therefore, user SP1 can comfortably carry out processing without compromising the realism of the surrounding atmosphere and without being concerned about surrounding noise.
- An acquisition unit an event content determination unit 12 and a voice recognition processing unit 18 that acquires data related to the situation in an acoustic space in which a sound collection device (a microphone MC1) is placed;
- a determination unit an event content determination unit 12, an utterance content determination unit 19) for determining the content or type of the data;
- a selection unit utilization model selection unit 13 that selects a noise cancellation model for canceling noise sounds other than a desired noise sound that constitutes a part of the noise sound included in the sound signal in the acoustic space collected by the sound collection device based on the content or type;
- an output control unit a noise cancellation processing unit 14, an audio output unit 16 that outputs an output audio signal that has been subjected to a noise cancellation process that cancels noise sounds other than the desired noise sound included in the sound signal using the selected noise cancellation model;
- Noise cancellation device This allows the noise cancellation device to efficiently cancel (erase) unnecessary surrounding noise sounds that are unrelated to the realism of the event, without impairing the noise cancellation model
- the data is schedule data including a type of event to be held in the acoustic space;
- the selection unit selects the noise cancellation model based on a type of the event.
- the noise cancellation device according to technology 1. This allows the noise cancellation device to appropriately select a noise cancellation model depending on the type of event taking place in the acoustic space.
- the schedule data includes information on start and end times of the event
- the selection unit selects the noise cancellation model to be continuously used during the event.
- the noise cancellation device according to the first or second aspect of the present invention. This allows the noise cancellation device to continue using the same noise cancellation model throughout the duration of the event, taking into account the start and end times of the event.
- the acquisition unit acquires, as the data, data resulting from speech recognition of the sound signal collected by the sound collection device;
- the determination unit determines the content of the user's utterance indicated by the result data of the voice recognition,
- the selection unit selects the noise cancellation model based on a result of the determination of the speech content.
- the noise cancellation device according to any one of the first to third aspects. As a result, when the voice recognition result of the voice, etc., contained in the input sound signal picked up by the microphone MC1 indicates the content of the user's speech, the noise cancellation device can select and use an appropriate noise cancellation model so as not to impair the realism of the atmosphere at the time of the speech.
- the selection unit switches to another noise cancellation model that was used before the selection.
- the noise cancellation device according to any one of the first to fourth aspects. This allows the noise cancellation device to assume that usage of the selected noise cancellation model will settle down over a certain period of time, and appropriate noise cancellation processing can be performed by returning to the original noise cancellation model before selection.
- the selection unit selects the selected noise cancellation model so as to continue to use the selected noise cancellation model until a certain time has elapsed since the selection of the noise cancellation model.
- the noise cancellation device according to any one of claims 4 to 5. This allows the noise cancellation device to assume that the period suitable for using the switched noise cancellation model is a certain period of time, and until the certain period of time has elapsed, the noise cancellation process can be appropriately performed so as not to impair the realism of the atmosphere that triggered the switch.
- the data includes schedule data including a type of an event to be held in the acoustic space, and voice recognition result data of the sound signal collected by the sound collection device,
- the selection unit selects to use a first noise cancellation model (e.g., noise cancellation model 1) based on a type of the event during the period of the event, and selects to interrupt and use a second noise cancellation model (e.g., noise cancellation model 2) based on the speech content when the speech content indicated by the voice recognition result data is detected during the period of the event.
- a first noise cancellation model e.g., noise cancellation model 1
- a second noise cancellation model e.g., noise cancellation model 2
- the noise cancellation device can select a noise cancellation model according to the speech and perform appropriate noise cancellation processing according to the atmosphere so that the sense of realism at the time of speech is not lost due to the noise cancellation model selected in response to the event due to the speech.
- a noise cancellation method performed by a noise cancellation device comprising: Obtaining data about a situation in an acoustic space in which a sound pickup device is located; determining the content or type of the data; A step of selecting a noise cancellation model for canceling noise sounds other than a desired noise sound that constitutes a part of the noise sounds included in the sound signal in the acoustic space collected by the sound collection device based on the content or type; and outputting an output audio signal that has been subjected to a noise cancellation process using the selected noise cancellation model to cancel noise sounds other than the desired noise sound that are included in the sound signal.
- Noise cancellation method can efficiently cancel (erase) unnecessary surrounding noise sounds that are unrelated to the realism of the event, without impairing the realism of the event taking place in the acoustic space around the user SP1.
- the noise cancellation device is a computer. Obtaining data about a situation in an acoustic space in which a sound pickup device is located; determining the content or type of the data; A step of selecting a noise cancellation model for canceling noise sounds other than a desired noise sound that constitutes a part of the noise sounds included in the sound signal in the acoustic space collected by the sound collection device based on the content or type; outputting an output audio signal subjected to noise cancellation processing for canceling noise sounds other than the desired noise sound contained in the sound signal using the selected noise cancellation model; program.
- the noise canceling device in which the program is installed can efficiently cancel (erase) unnecessary surrounding noise sounds that are unrelated to the realism of the event, without impairing the realism of the event taking place in the acoustic space around the user SP1.
- the present disclosure is useful as a noise cancellation device, a noise cancellation method, and a program that efficiently eliminates ambient noise without compromising the sense of realism in the acoustic space around the user.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Quality & Reliability (AREA)
- Signal Processing (AREA)
- Soundproofing, Sound Blocking, And Sound Damping (AREA)
Abstract
ノイズキャンセル装置は、収音デバイスが配置されている音響空間内の状況に関するデータを取得する取得部と、データの内容或いは種別を判定する判定部と、内容或いは種別に基づいて、収音デバイスにより収音された音響空間内の音信号に含まれるノイズ音をキャンセルするためのノイズキャンセルモデルを選択する選択部と、選択されたノイズキャンセルモデルを用いて、音信号に含まれるノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力する出力制御部と、を備える。
Description
本開示は、ノイズキャンセル装置、ノイズキャンセル方法及びプログラムに関する。
特許文献1には、周囲のノイズ等が大きい場合の利用者による発声のしにくさを改善する音声入出力方式が開示されている。具体的には、この音声入出力方式は、オーディオ音と周辺ノイズと利用者の発声音声とが同時に音響空間内に存在する場合に、マイクロホンの出力信号から、利用者の発声のエコー成分、オーディオ信号に対応する成分、周辺ノイズをそれぞれ消去することにより、利用者の発声音声のみを抽出する。特に、音声入出力方式は、周辺ノイズ等の音圧レベルを考慮したゲインを算出し、発声音声の各周波数帯域の信号レベルを音声補正用フィルタで補正した後にスピーカから出力する。これにより、利用者は自分が発声した音声の内容を明瞭に聴くことができる。
特許文献1の構成では、マイクロホンの出力信号と利用者の発声音声の信号との差分信号を周辺ノイズとして消去する。このため、周辺ノイズを消去する際に、利用者の発声音声以外の音信号を抑圧してしまう。したがって、利用者の発声音声以外の音信号として、例えば音響空間内での臨場感を示唆する音信号(例えばオンライン懇親会での乾杯の拍手音、オンライン展示会での周囲の騒音)も抑圧されてしまう。つまり、音響空間内での臨場感が損なわれる可能性があった。特に、近年流行している人工知能(Artificial Intelligence)を用いた学習済みモデルによってノイズ消去を行う場合、利用者の発声音声以外の音信号を抑圧するため、同様にその音響空間内の臨場感が損なわれる可能性が高く、改善の余地があった。
本開示は、上述した従来の事情に鑑みて案出され、ユーザの周囲の音響空間内の臨場感を損なことなく、周囲のノイズ音を効率的に消去するノイズキャンセル装置、ノイズキャンセル方法及びプログラムを提供することを目的とする。
本開示は、収音デバイスが配置されている音響空間内の状況に関するデータを取得する取得部と、前記データの内容或いは種別を判定する判定部と、前記内容或いは種別に基づいて、前記収音デバイスにより収音された前記音響空間内の音信号に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択する選択部と、選択された前記ノイズキャンセルモデルを用いて、前記音信号に含まれる前記所望ノイズ音以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力する出力制御部と、を備える、ノイズキャンセル装置を提供する。
また、本開示は、ノイズキャンセル装置により実行されるノイズキャンセル方法であって、収音デバイスが配置されている音響空間内の状況に関するデータを取得するステップと、前記データの内容或いは種別を判定するステップと、前記内容或いは種別に基づいて、前記収音デバイスにより収音された前記音響空間内の音信号に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択するステップと、選択された前記ノイズキャンセルモデルを用いて、前記音信号に含まれる前記所望ノイズ音以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力するステップと、を有する、ノイズキャンセル方法を提供する。
また、本開示は、コンピュータであるノイズキャンセル装置に、収音デバイスが配置されている音響空間内の状況に関するデータを取得するステップと、前記データの内容或いは種別を判定するステップと、前記内容或いは種別に基づいて、前記収音デバイスにより収音された前記音響空間内の音信号に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択するステップと、選択された前記ノイズキャンセルモデルを用いて、前記音信号に含まれる前記所望ノイズ音以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力するステップと、を実現させるための、プログラムを提供する。
本開示によれば、ユーザの周囲の音響空間内の臨場感を損なことなく、周囲のノイズ音を効率的に消去できる。
以下、適宜図面を参照しながら、本開示に係るノイズキャンセル装置、ノイズキャンセル方法及びプログラムを具体的に開示した実施の形態を詳細に説明する。但し、必要以上に詳細な説明は省略する場合がある。例えば、既によく知られた事項の詳細説明や実質的に同一の構成に対する重複説明を省略する場合がある。これは、以下の説明が不必要に冗長になることを避け、当業者の理解を容易にするためである。なお、添付図面及び以下の説明は、当業者が本開示を十分に理解するために提供されるものであり、これらにより特許請求の範囲に記載の主題を限定することは意図されていない。
<実施の形態1>
実施の形態1では、本開示に係るノイズキャンセル装置の一実施態様として、複数人がネットワークを介してデータ通信可能に接続されたPersonal Computer(PC)とそのPCに接続されたマイクとをそれぞれ用いて行うオンラインミーティング等のイベントを実行するオンライン処理システムを例示する(図1参照)。
実施の形態1では、本開示に係るノイズキャンセル装置の一実施態様として、複数人がネットワークを介してデータ通信可能に接続されたPersonal Computer(PC)とそのPCに接続されたマイクとをそれぞれ用いて行うオンラインミーティング等のイベントを実行するオンライン処理システムを例示する(図1参照)。
まず、図1を参照して、実施の形態1に係るオンライン処理システム100のシステム構成例について説明する。図1は、実施の形態1に係るオンライン処理システム100のシステム構成例を示す図である。オンライン処理システム100は、イベント予定データベースDB1と、ネットワークNW1を介して相互にデータ通信可能に接続されたn(n:2以上の整数)台のPC10、20、…、N0と、を少なくとも含む。PC10、20、…、N0のそれぞれに対応するように、それぞれのPCの使用者であるユーザSP1、SP2、…、SPnの発話音声等の音を収音するためのマイクMC1、MC2、…、MCnが接続されている。
ネットワークNW1は、有線ネットワーク、無線ネットワーク、或いは有線ネットワーク及び無線ネットワークの組み合わせ、のいずれでもよい。有線ネットワークは、例えば有線Local Area Network(LAN)、或いは、有線Wide Area Network(WAN)等でよい。無線ネットワークは、例えば無線LAN、無線WAN、或いは、セルラー無線通信等でよい。
以下、説明を分かり易くするために、イベントの開催者であるユーザSP1を中心として、ユーザSP1が使用するマイクMC1により収音された音信号に含まれるユーザSP1の周囲のノイズ音をキャンセル(消去)するPC10の構成及び動作を主に説明する。ユーザSP1がイベントの開催者である場合、他のユーザSP2、…、SPnはそれぞれイベントの参加者となる。なお、ユーザSP1、SP、…、SPnの役割はオンライン処理システム100を用いて実行されるイベントの内容に応じて適宜決められれば良く、ユーザSP1が開催者であることに限定されず、他のユーザが開催者であっても構わない。
イベント予定データベースDB1は、オンライン処理システム100を用いて実行される各種のイベントごとに、そのイベントの内容を示すデータ(イベント予定データIVL1)を保持管理している。イベント予定データIVL1は、例えばイベントの識別情報であるイベントID、イベント内容或いはイベント種別、イベントの開始時刻、及び、イベントの終了時刻の各項目からなる実データをイベントごとに有するレコード単位で構成されている。例えば、イベントID「0001」のイベントは、イベント内容が「オンラインミーティング」(図1では図示略)であり、開始時刻が「10:00」で終了時刻が「11:00」である。同様に、イベントID「0002」のイベントは、イベント内容が「オンライン飲み会」(図1では図示略)であり、開始時刻が「19:00」で終了時刻が「21:00」である。
PC10は、本開示に係るノイズキャンセル装置の一例であり、マイクMC1により収音された音信号に含まれるユーザSP1の周囲のノイズ音をキャンセルするためのノイズキャンセルモデル(後述参照)をイベント予定データベースDB1のイベント予定データIVL1に基づいて選択する。PC10は、選択したノイズキャンセルモデルを用いて、マイクMC1により収音された音信号に含まれるノイズ音をキャンセルするノイズキャンセル処理を施し、ノイズキャンセル処理後の音信号(出力音声信号)を出力する。出力音声信号の出力形態は、スピーカSPK1(図2参照)から出力してもよいし、他のPC20、…、N0に送信してもよいし、それらの組み合わせであってもよい。なお、PC10の構成及び動作の説明は、他のPC20、…、N0の一部或いは全部に同様に適用しても構わない。
マイクMC1は、周知のマイクロホンの構成と同一でよく、ユーザSP1がいる音響空間内の音(例えばユーザSP1の発話音声、ユーザSP1の周囲のノイズ音)を収音し、その収音された音の電気信号(音信号)をPC10に送る。PC10には、マイクMC1により収音された音信号が入力される(図2参照)。また、マイクMC1は、イベント中に他のPC20、…、N0のそれぞれから送られてくる音声信号がPC10のスピーカSPK1(図2参照)から出力された音を収音する。この収音した音声信号には、他のユーザSP2、…、SPnのそれぞれの発話音声だけでなく、それぞれのユーザがいる音響空間内の臨場感を示唆する音(例えば拍手音、周囲の騒音)が含まれることがある。
スピーカSPK1は、周知のスピーカの構成と同一でよく、PC10によってノイズキャンセル処理された後の出力音声信号を出力する。また、スピーカSPK1は、他のPC20、…、N0のそれぞれから送られてPC10が受信した音声信号を出力する。
次に、図2を参照して、図1のPC10のハードウェア構成例について説明する。図2は、図1のPC10のハードウェア構成例を示すブロック図である。PC10は、マイクMC1及びイベント予定データベースDB1のそれぞれからデータ信号の入力が可能に接続され、更に、スピーカSPK1にデータ信号の出力が可能に接続されている。PC10は、汎用的なコンピュータ装置であり、本開示に係るノイズキャンセル装置の一態様として、パーソナルコンピュータ以外にスマートフォン或いはタブレット端末で構成されても構わない。PC10は、プロセッサPRC1と、メモリ11と、をハードウェア構成として少なくとも含む。なお、PC10は、ユーザSP1の操作を受け付けるマウス等の入力デバイスも更に含む構成としてよい。
プロセッサPRC1は、PC10の全体的な動作を司るコントローラとして機能し、PC10の各部の動作を統括するための制御処理、PC10の各部との間のデータ信号/制御信号の入出力処理、データ信号/制御信号の演算処理及びデータ信号/制御信号の記憶処理を行う。プロセッサPRC1は、例えばCentral Processing Unit(CPU)、Digital Signal Processor(DSP)、Field Programmable Gate Array(FPGA)、或いは、Graphical Processing Unit(GPU)により構成されてよい。プロセッサPRC1は、メモリ11と協働しながら、マイクMC1により収音された音信号(以下、「入力音信号」と便宜的に称する場合がある)を入力し、この入力音信号に対して各種の信号処理(例えばノイズキャンセル処理)を施す。
メモリ11は、少なくともRead Only Memory(ROM)及びRandom Access Memory(RAM)を備える。ROMは、プロセッサPRC1が実行する各種の処理を規定するプログラムとそのプログラムの実行に必要となるデータとを関連付けて保存している。RAMは、プロセッサPRC1が取得或いは生成したデータ若しくは情報を一時的に保存する。メモリ11は、プロセッサPRC1による処理の実行中に適宜参照される。また、メモリ11は、複数個のノイズキャンセルモデルを保存している。図2の図示例では、3つのノイズキャンセルモデルM1、M2、M3のそれぞれがメモリ11から読み出されてプロセッサPRC1にロードされているが、3つに限定されない。ノイズキャンセルモデルM1~M3のそれぞれは、AI(人工知能)を搭載し、予め機械学習等によって学習されて形成されたモデルのデータ或いはパラメータセットである。ノイズキャンセルモデルM1~M3のそれぞれは、入力となる入力音信号に含まれる、各モデルに応じた「消去しないノイズ音」(所望ノイズ音の一例)以外のノイズをキャンセル(消去)する。また、メモリ11は、図3に示すモデル選択テーブルTBL1を保存している。ノイズキャンセルモデル及びモデル選択テーブルTBL1については図3を参照して後述する。
ここで、プロセッサPRC1が機能的に実行する処理の実行主体の構成例を詳述する。プロセッサPRC1は、イベント内容判定部12と、利用モデル選択部13と、ノイズキャンセル処理部14と、セレクタ15と、音声出力部16と、送信部17と、を機能的に備える。なお、イベント内容判定部12、利用モデル選択部13、ノイズキャンセル処理部14、およびセレクタ15のうちのすべて、あるいは少なくとも1つが、ネットワークNW1を介して互いにデータ通信を行うアプリケーションにより実現可能な機能として組み込まれて動作してもよい。
イベント内容判定部12は、取得部及び判定部の一例であり、イベント予定データベースDB1との間のインターフェースとしての機能を備える。イベント内容判定部12は、イベント予定データベースDB1から読み出したイベント予定データIVL1の内容を判定し、その判定結果を利用モデル選択部13に送る。例えば、イベント内容判定部12は、イベントID「0001」のイベント予定データIVL1を読み出した場合、そのイベント内容が「オンラインミーティング」(図示略)であり、開始時刻が「10:00」で終了時刻が「11:00」であると判定する。また、イベント内容判定部12は、イベントID「0002」のイベント予定データIVL1を読み出した場合、そのイベント内容が「オンライン飲み会」(図示略)であり、開始時刻が「19:00」で終了時刻が「21:00」であると判定する。このとき、イベント予定データIVL1は、イベント予定データベースDB1からの読み出されたイベント予定データに代えて、イベント開催者であるユーザSP1がイベント予定データベースDB1を介さずに直接入力したイベント予定データであってもよい。この場合、ユーザSP1が使用するPC10に接続された表示デバイスを介してイベント内容(種別)を入力する画面が表示され、ユーザSP1は、入力デバイスを介してイベント内容(種別)をPC10に入力する。
利用モデル選択部13は、選択部の一例であり、イベント内容判定部12からの判定結果を入力し、更に、メモリ11からモデル選択テーブル(図3参照)を読み出す。利用モデル選択部13は、入力した判定結果とモデル選択テーブル(図3参照)とに基づいて、マイクMC1からの入力音信号(つまり、ユーザSPがいる音響空間内でマイクMC1により収音された音のデータ信号)に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択する。利用モデル選択部13は、選択したノイズキャンセルモデルを示す結果データをノイズキャンセル処理部14に送る。また、入力した判定結果の代わりに、イベント開催者であるユーザSP1が直接入力したイベント予定データが使用される場合、ノイズキャンセルモデルが選択されるだけでなく、入力した判定結果に基づき選択されたノイズキャンセルモデルをイベント期間中に新たなノイズキャンセルモデルとして切り替えることができる。
ここで、図3及び図4を参照して、モデル選択テーブルTBL1及びノイズキャンセルモデルの選択例について説明する。図3は、実施の形態1に係るモデル選択テーブルTBL1の内容例を示す図である。図4は、実施の形態1に係るモデル選択のタイムチャート例を示す図である。モデル選択テーブルTBL1は、イベント予定名ごとに、「イベント予定名」と「イベント種別」と「消去しないノイズ音」と「ノイズキャンセルモデル」とを対応付けた複数行レコードにより構成される。
図3に示すように、「イベント予定名」は、図1のオンライン処理システム100を用いて実行されるイベントの名称である。図3の例では「オンライン飲み会」、「オンライン内見」、「オンライン講演会」、「オンラインミーティング」が示されているがこれらに限定されなくてよい。
「イベント種別」は、「イベント予定名」が示すイベントの種別である。「オンライン飲み会」の種別は「飲み会」、「オンライン内見」の種別は「内見」、「オンライン講演会」の種別は「講演」、「オンラインミーティング」の種別は「通常会議」である。
「消去しないノイズ音」は、所望ノイズ音の一例であり、「ノイズキャンセルモデル」によってイベント期間中の雰囲気(臨場感)が損なわれないように消去されないノイズ音の種別を示す。「ノイズキャンセルモデル」は、「消去しないノイズ音」を消去せずかつ「消去しないノイズ音」以外のノイズ音を消去するように予め機械学習等によって形成されたモデルである。種別「飲み会」の場合には「ノイズキャンセルモデル2」によって「拍手」のノイズ音が消去されず、「拍手」以外のノイズ音が消去される。ノイズキャンセルモデル2は、図1のノイズキャンセルモデルM1~M3のうちいずれか1つであってよい。種別「内見」の場合には「ノイズキャンセルモデル3」によって「周囲環境騒音」のノイズ音が消去されず、「周囲環境騒音」以外のノイズ音が消去される。ノイズキャンセルモデル3は、図1のノイズキャンセルモデルM1~M3のうちいずれか1つであってよい。種別「講演」の場合には「ノイズキャンセルモデル4」によって「笑い声、拍手」のノイズ音が消去されず、「笑い声、拍手」以外のノイズ音が消去される。ノイズキャンセルモデル4は、図1のノイズキャンセルモデルM1~M3のうちいずれか1つであってよい。種別「通常会議」の場合には「ノイズキャンセルモデル1」によって全てのノイズ音が消去される。ノイズキャンセルモデル1は、図1のノイズキャンセルモデルM1~M3のうちいずれか1つであってよい。
図4の横軸は時間を示す。図4に示すように、利用モデル選択部13は、イベント内容判定部12からの判定結果が「オンライン飲み会」或いは「飲み会」である場合、そのイベントIV1の期間中(例えば時刻t1~時刻t2の期間中)、モデル選択テーブルTBL1の「オンライン飲み会」或いは「飲み会」のレコードに対応する「ノイズキャンセルモデル2」を、ノイズキャンセル処理部14が使用するべきノイズキャンセルモデルとして選択する。
また、利用モデル選択部13は、イベント内容判定部12からの判定結果が「オンラインミーティング」或いは「通常会議」である場合、そのイベントIV2の期間中(例えば時刻t1~時刻t2の期間中)、モデル選択テーブルTBL1の「オンラインミーティング」或いは「通常会議」のレコードに対応する「ノイズキャンセルモデル1」を、ノイズキャンセル処理部14が使用するべきノイズキャンセルモデルとして選択する。
ノイズキャンセル処理部14は、出力制御部の一例であり、利用モデル選択部13からの結果データにしたがって、その結果データに相当するノイズキャンセルモデルのデータ或いはパラメータセットをセレクタ15に選択させて取得する。ノイズキャンセル処理部14は、セレクタ15を介して取得したノイズキャンセルモデルを用いて、マイクMC1からの入力音信号に含まれるノイズ音のうち、ノイズキャンセルモデルで消去されないノイズ音以外のノイズ音をキャンセルするためのノイズキャンセル処理を施す。ノイズキャンセル処理部14は、ノイズキャンセル処理後の音信号である出力音声信号を音声出力部16及び送信部17のそれぞれに送る。
音声出力部16は、ノイズキャンセル処理部14からの出力音声信号をスピーカSPK1から出力する。
送信部17は、ノイズキャンセル処理部14からの出力音声信号を、ネットワークNW1を介して他のPC20、…、N0のそれぞれに送信する。なお、送信部17は、プロセッサPRC1の一部を構成するものとして図示しているが、プロセッサPRC1とは別体で設けられてもよい。
次に、図5を参照して、実施の形態1に係るPC10の動作手順例について説明する。図5は、実施の形態1に係るPC10の動作手順例を時系列に示すフローチャートである。図5に示す各処理は、主にプロセッサPRC1(図2参照)によって実行される。図5に示す処理は、例えば1つのイベントごとに実行され、そのイベントが開始された時或いはその開始直前のタイミングに実行される。
図5において、プロセッサPRC1は、PC10と接続されているイベント予定データベースDB1から少なくとも1つのイベント予定データIVL1を取得して読み出す(ステップSt1)。プロセッサPRC1は、ステップSt1で読み出したイベント予定データIVL1に基づいて、そのイベント予定データIVL1で特定されるイベントのイベント種別(内容)を判定する(ステップSt2)。例えば、プロセッサPRC1は、イベントID「0001」のイベント予定データIVL1を読み出した場合、そのイベント種別(内容)が「オンラインミーティング」であると判定する。このとき、イベント予定データIVL1は、イベント予定データベースDB1からの読み出されたイベント予定データに代えて、イベント開催者であるユーザSP1がイベント予定データベースDB1を介さずに直接入力したイベント予定データであってもよい。
プロセッサPRC1は、ステップSt2で判定したイベント種別(内容)とメモリ11から読み出したモデル選択テーブルTBL1とに基づいて、イベント種別に対応するノイズキャンセルモデルを選択する(ステップSt3)。つまり、プロセッサPRC1は、ステップSt2で判定したイベント種別のイベント期間中にそのイベントの臨場感を損ねないために、そのイベント種別(内容)に対応する「消去しないノイズ音」以外のノイズ音のみキャンセルするためのノイズキャンセルモデルを選択する。プロセッサPRC1は、ステップSt3で選択したノイズキャンセルモデルをメモリ11から読み出して取得する(ステップSt4)。
プロセッサPRC1は、ステップSt4で取得したノイズキャンセルモデルを用いて、マイクMC1からの入力音信号に含まれる、ノイズキャンセルモデルに対応する「消去しないノイズ音」以外のノイズ音を消去するためのノイズキャンセル処理を施す(ステップSt5)。プロセッサPRC1は、ステップSt5で行ったノイズキャンセル処理後の出力音声信号を出力する(ステップSt6)。この出力音声信号の出力形態は、スピーカSPK1(図2参照)から出力してもよいし、他のPC20、…、N0に送信してもよいし、それらの組み合わせであってもよい。プロセッサPRC1がイベント終了の旨の入力を検知した場合(ステップSt7、YES)、図5に示すプロセッサPRC1の処理は終了する。
一方、イベント終了の旨の入力がされていない場合(ステップSt7、NO)、プロセッサPRC1の処理はステップSt1に戻る。つまり、プロセッサPRC1は、イベント開始されてからイベント終了するまでの期間中、ステップSt1~ステップSt7の一連処理を繰り返し実行する。
以上により、実施の形態1に係るオンライン処理システム100では、ノイズキャンセル装置の一例としてのPC10は、収音デバイス(マイクMC1)が配置されている音響空間内の状況に関するデータ(例えばイベント予定データIVL1)を取得し、そのデータの内容或いは種別を判定する。PC10は、その判定した内容或いは種別に基づいて、収音デバイスにより収音された音響空間内の音信号(入力音信号)に含まれる、ノイズキャンセルモデルに応じた「消去しないノイズ音」以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択する。PC10は、選択されたノイズキャンセルモデルを用いて、入力音信号に含まれるノイズキャンセルモデルに応じた「消去しないノイズ音」以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力する。これにより、PC10は、ユーザSP1の周囲の音響空間内で行われているイベントの臨場感を損なうことなく、イベントの臨場感とは関係の無い余計な周囲のノイズ音を効率的にキャンセル(消去)することができる。したがって、ユーザは、イベントの臨場感が損なわれずにかつ周囲のノイズ音を気にすることなく快適にイベントを行うことができる。
<実施の形態2>
実施の形態2では、実施の形態1のイベント期間中に同一のノイズキャンセルモデルを継続使用する形態とは異なり、イベント期間中とは直接関係なく、何かしらの発話が音声認識されたことを契機として一定期間中においてその音声認識結果に対応する「消去しないノイズ音」以外のノイズ音を消去するためのノイズキャンセルモデルを選択する例を説明する。
実施の形態2では、実施の形態1のイベント期間中に同一のノイズキャンセルモデルを継続使用する形態とは異なり、イベント期間中とは直接関係なく、何かしらの発話が音声認識されたことを契機として一定期間中においてその音声認識結果に対応する「消去しないノイズ音」以外のノイズ音を消去するためのノイズキャンセルモデルを選択する例を説明する。
実施の形態2に係るオンライン処理システムの構成例は実施の形態1に係るオンライン処理システム100の構成例と同一であってもよいし、異なってもよい。以下の説明を簡単にするために、実施の形態2に係るオンライン処理システムの構成例は実施の形態1に係るオンライン処理システム100の構成例と同一であると例示して説明する。但し、実施の形態2では、PC10は、イベント予定データベースDB1からイベント予定データIVL1を読み出して取得する必要は必ずしも無い。
まず、図6を参照して、実施の形態2に係るノイズキャンセル装置の一例としてのPC10Aのハードウェア構成例について説明する。図6は、実施の形態2に係るPC10Aのハードウェア構成例を示すブロック図である。PC10Aは、マイクMC1からデータ信号の入力が可能に接続され、更に、スピーカSPK1にデータ信号の出力が可能に接続されている。PC10Aは、汎用的なコンピュータ装置であり、本開示に係るノイズキャンセル装置の一態様として、パーソナルコンピュータ以外にスマートフォン或いはタブレット端末で構成されても構わない。PC10Aは、プロセッサPRC1Aと、メモリ11と、をハードウェア構成として少なくとも含む。なお、PC10Aは、ユーザSP1の操作を受け付けるマウス等の入力デバイスも更に含む構成としてよい。
PC10Aの説明において、図2のPC10の構成及び動作と同一の構成及び動作を行うものには同一の符号を付与して説明を簡略化或いは省略し、異なる内容について説明する。
メモリ11は、図7に示すモデル選択テーブルTBL1Aを保存している。モデル選択テーブルTBL1Aについては図7を参照して後述する。
ここで、プロセッサPRC1Aが機能的に実行する処理の実行主体の構成例を詳述する。プロセッサPRC1Aは、音声認識処理部18と、発話内容判定部19と、利用モデル選択部13Aと、ノイズキャンセル処理部14と、セレクタ15と、音声出力部16と、送信部17と、受信部RC1と、を機能的に備える。
受信部RC1は、ネットワークNW1を介して送信された受話音声信号を受信する。この受話音声信号は、例えばPC20側のマイクMC2により収音された人、機械等が発する音の音信号でもよいし、PCN0側のマイクMCnにより収音された人、機械等が発する音の音信号でもよいし、それらの組み合わせであってもよい。受信部RC1が受信した受話音声信号は、マイクMC1により収音された音の音信号と同様に音声認識処理部18に入力される。
音声認識処理部18は、取得部の一例であり、マイクMC1により収音された音の音信号と受信部RC1からの受話音声信号とを入力音信号として入力し、その入力音信号を入力とした音声認識処理を実行する。音声認識処理部18は、音声認識処理の結果データを発話内容判定部19に送る。ここで音声認識処理部18が行う音声認識処理の方式は公知技術であってよく、実施の形態2においてその方式は特に問わない。
発話内容判定部19は、判定部の一例であり、音声認識処理部18からの音声認識処理の結果データに基づいて、その結果データが示す発話内容を判定する。発話内容判定部19は、発話内容の判定結果データを利用モデル選択部13Aに送る。ここで発話内容判定部19が発話内容を判定する方式は公知技術であってよく、実施の形態2においてその方式は特に問わない。なお、図6では音声認識処理部18と発話内容判定部19とを別構成として設けてあるが、機能的に両者が一体的に構成されても構わない。
利用モデル選択部13Aは、選択部の一例であり、発話内容判定部19からの判定結果を入力し、更に、メモリ11からモデル選択テーブル(図7参照)を読み出す。利用モデル選択部13Aは、入力した判定結果とモデル選択テーブル(図7参照)とに基づいて、マイクMC1からの入力音信号(つまり、ユーザSPがいる音響空間内でマイクMC1により収音された音のデータ信号)に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択する。利用モデル選択部13Aは、選択したノイズキャンセルモデルを示す結果データをノイズキャンセル処理部14に送る。
ここで、図7及び図8を参照して、モデル選択テーブルTBL1A及びノイズキャンセルモデルの選択例について説明する。図7は、実施の形態2に係るモデル選択テーブルTBL1Aの内容例を示す図である。図8は、実施の形態2に係るモデル選択のタイムチャート例を示す図である。モデル選択テーブルTBL1Aは、発話内容ごとに、「発話内容」と「消去しないノイズ音」と「ノイズキャンセルモデル」とを対応付けた複数行レコードにより構成される。
図7に示すように、「発話内容」は、マイクMC1により収音された音(例えばユーザSP1が発話した音声、ユーザSP以外の周囲の物体から生じている音)を入力とした音声認識処理及び発話内容判定処理に基づいて得られた発話内容である。図7の例では「乾杯」、「機械の調子」、「ご清聴ありがとうございました」が示されているがこれらに限定されなくてよい。
「消去しないノイズ音」は、所望ノイズ音の一例であり、「ノイズキャンセルモデル」によってユーザSP1がいる音響空間内の雰囲気(臨場感)が損なわれないように消去されないノイズ音の種別を示す。「ノイズキャンセルモデル」は、「消去しないノイズ音」を消去せずかつ「消去しないノイズ音」以外のノイズ音を消去するように予め機械学習等によって形成されたモデルである。発話内容「乾杯」の場合には「ノイズキャンセルモデル2」によって「拍手」のノイズ音が消去されず、「拍手」以外のノイズ音が消去される。ノイズキャンセルモデル2は、図1のノイズキャンセルモデルM1~M3のうちいずれか1つであってよい。発話内容「機械の調子」の場合には「ノイズキャンセルモデル3」によって「工場騒音」のノイズ音が消去されず、「工場騒音」以外のノイズ音が消去される。ノイズキャンセルモデル3は、図1のノイズキャンセルモデルM1~M3のうちいずれか1つであってよい。発話内容「ご清聴ありがとうございました」の場合には「ノイズキャンセルモデル2」によって「拍手」のノイズ音が消去されず、「拍手」以外のノイズ音が消去される。
例えばマイクMC1が工場部門内に配置されたマイクであり、マイクMC2、MC3のそれぞれが工場管理部門内に配置されたマイクである場合を想定する。この場合、本実施の形態では、PC10Aは、マイクMC1、MC2、MC3のそれぞれにより収音された音の音信号を入力音信号とし、その入力音信号に対応する発話内容(例えば「機械の調子」)に含まれる工場騒音をキャンセルしないためのノイズキャンセルモデル3を選択することが可能となる。これにより、PC10Aは、マイクMC1、MC2、MC3のそれぞれが配置されている工場内で行っているリモート通話或いはオンラインミーティングの際に、その臨場感を損ねない程度に工場内で発生している機械音をキャンセルしないで他の余計なノイズ音をキャンセルすることができる。
図8の横軸は時間を示す。図8のシナリオSCN1に示すように、利用モデル選択部13Aは、発話内容判定部19からの判定結果が「乾杯」である場合、時刻t1で「乾杯」の発話が開始されて時刻t3で「乾杯」の発話が終了された後の一定期間(時刻t3から時刻t4までの期間)、モデル選択テーブルTBL1Aの「乾杯」のレコードに対応する「ノイズキャンセルモデル2」を、ノイズキャンセル処理部14が使用するべきノイズキャンセルモデルとして選択する。
また、図8のシナリオSNC2に示すように、利用モデル選択部13Aは、発話内容判定部19からの判定結果が「乾杯」である場合、時刻t1で「乾杯」の発話が開始されて時刻t5で発話内容判定部19からの判定結果が「機械の調子」となるまでの期間(時刻t3から時刻t5までの期間)、モデル選択テーブルTBL1Aの「乾杯」のレコードに対応する「ノイズキャンセルモデル2」を、ノイズキャンセル処理部14が使用するべきノイズキャンセルモデルとして選択する。更に、利用モデル選択部13Aは、時刻t5で割り込んできた発話内容判定部19からの判定結果「機械の調子」に基づいて、時刻t5で「機械の調子」の音が収音開始されて時刻t6で「機械の調子」の音が収音終了された後の一定期間(時刻t6から時刻t2までの期間)、モデル選択テーブルTBL1Aの「機械の調子」のレコードに対応する「ノイズキャンセルモデル3」を、ノイズキャンセル処理部14が使用するべきノイズキャンセルモデルとして選択する。
図8のシナリオSCN3に示すように、利用モデル選択部13Aは、発話内容判定部19からの判定結果が何も無い場合、発話内容判定部19からの発話内容が入力されていない間の時刻t1から時刻t2までの期間、モデル選択テーブルTBL1Aに拘わらず、全てのノイズ音をキャンセルするための「ノイズキャンセルモデル1」を、ノイズキャンセル処理部14が使用するべきノイズキャンセルモデルとして選択する。
次に、図9~図11を参照して、実施の形態2に係るPC10Aの動作手順例について説明する。図9は、実施の形態2に係るPC10Aの動作手順例を時系列に示すフローチャートである。図10は、図9のステップSt13の詳細な動作手順例を示すフローチャートである。図11は、図9のステップSt17の詳細な動作手順例を示すフローチャートである。図9~図11に示す各処理は、主にプロセッサPRC1A(図6参照)によって実行される。図9に示す処理は、例えばマイクMC1により音が収音される度に実行される。
図9において、プロセッサPRC1Aは、ユーザSP1がいる音響空間内に配置されているマイクMC1により収音された入力音信号の音声認識処理を実行する(ステップSt11)。プロセッサPRC1Aは、ステップSt11での音声認識処理の結果データに基づいて、その音声認識処理が示す発話内容を判定する(ステップSt12)。例えば、プロセッサPRC1は、入力音信号の音声認識処理の結果データが「それでは、AAさんの門出を祝って、乾杯!」である場合、発話内容が「乾杯」であると判定する。
プロセッサPRC1Aは、ステップSt12で判定した発話内容とメモリ11から読み出したモデル選択テーブルTBL1Aとに基づいて、発話内容に対応するノイズキャンセルモデルを選択する(ステップSt13)。つまり、プロセッサPRC1Aは、ステップSt12で判定した発話内容が収音された期間中にその雰囲気の臨場感を損ねないために、その発話内容に対応する「消去しないノイズ音」以外のノイズ音のみキャンセルするためのノイズキャンセルモデルを選択する。このステップSt13の処理の詳細については、図10を参照して後述する。プロセッサPRC1Aは、ステップSt13で選択したノイズキャンセルモデルをメモリ11から読み出して取得する(ステップSt14)。
プロセッサPRC1Aは、ステップSt14で取得したノイズキャンセルモデルを用いて、マイクMC1からの入力音信号に含まれる、ノイズキャンセルモデルに対応する「消去しないノイズ音」以外のノイズ音を消去するためのノイズキャンセル処理を施す(ステップSt15)。プロセッサPRC1Aは、ステップSt15で行ったノイズキャンセル処理後の出力音声信号を出力する(ステップSt16)。この出力音声信号の出力形態は、スピーカSPK1(図2参照)から出力してもよいし、他のPC20、…、N0に送信してもよいし、それらの組み合わせであってもよい。プロセッサPRC1Aは、ノイズキャンセルモデルの戻し要否を判定する(ステップSt17)。このステップSt17の処理の詳細については、図11を参照して後述する。
プロセッサPRC1AがPC10Aの動作終了の入力を検知した場合(ステップSt18、YES)、図9に示すプロセッサPRC1Aの処理は終了する。
一方、PC10Aの動作終了の旨の入力がされていない場合(ステップSt18、NO)、プロセッサPRC1Aの処理はステップSt11に戻る。つまり、プロセッサPRC1Aは、動作終了するまでの期間中、ステップSt11~ステップSt18の一連処理を繰り返し実行する。
ここで、図10を参照して、図9のステップSt13の詳細な動作手順について説明する。
図10において、プロセッサPRC1Aは、ステップSt12で判定した発話内容に基づいて、現在使用中のノイズキャンセルモデルを新たに切り替えるための発話を検知したか否かを判定する(ステップSt13-1)。ノイズキャンセルモデルを新たに切り替えるための発話が検知されていないと判定された場合には(ステップSt13-1、NO)、プロセッサPRC1Aの処理は終了する。
一方、プロセッサPRC1Aは、現在使用中のノイズキャンセルモデルを新たに切り替えるための発話を検知したか否かを判定した場合には(ステップSt13-2、YES)、ステップSt12で判定した発話内容とメモリ11から読み出したモデル選択テーブルTBL1Aとに基づいて、発話内容に対応するノイズキャンセルモデルを選択する(ステップSt13-2)。ステップSt13-2の後、プロセッサPRC1Aの処理は終了する。
ここで、図11を参照して、図9のステップSt17の詳細な動作手順について説明する。
図11において、プロセッサPRC1Aは、ステップSt14で使用するためにノイズキャンセルモデルを切り替えた時点から一定時間(t:既定値)が経過したか否かを判定する(ステップSt17-1)。ノイズキャンセルモデルを切り替えた時点から一定時間(t:既定値)が経過していないと判定された場合には(ステップSt17-1、NO)、プロセッサPRC1Aの処理は終了する。この場合、プロセッサPRC1Aは、現在使用中のノイズキャンセルモデルの使用を継続する。
一方、プロセッサPRC1Aは、ノイズキャンセルモデルを切り替えた時点から一定時間(t:既定値)が経過したと判定した場合(ステップSt17-2、YES)、ステップSt14でノイズキャンセルモデルを切り替える前に使用していた元のノイズキャンセルモデルの使用に切り替える(ステップSt17-2)。ステップSt17-2の後、プロセッサPRC1Aの処理は終了する。
以上により、実施の形態2に係るオンライン処理システム100では、ノイズキャンセル装置の一例としてのPC10Aは、収音デバイス(マイクMC1)が配置されている音響空間内の状況に関するデータ(例えばマイクMC1により収音された入力音信号の音声認識結果が示す発話内容を示すデータ)を取得し、そのデータの内容或いは種別を判定する。PC10Aは、その判定した内容或いは種別に基づいて、収音デバイスにより収音された音響空間内の音信号(入力音信号)に含まれる、ノイズキャンセルモデルに応じた「消去しないノイズ音」以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択する。PC10Aは、選択されたノイズキャンセルモデルを用いて、入力音信号に含まれるノイズキャンセルモデルに応じた「消去しないノイズ音」以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力する。これにより、PC10Aは、ユーザSP1の周囲の音響空間内で行われている発話時の雰囲気(臨場感)を損なうことなく、その雰囲気の臨場感とは関係の無い余計な周囲のノイズ音を効率的にキャンセル(消去)することができる。したがって、ユーザSP1は、周囲の雰囲気の臨場感が損なわれずにかつ周囲のノイズ音を気にすることなく快適に処理を行うことができる。
<実施の形態3>
実施の形態3では、実施の形態1及び実施の形態2を組み合わせた形態であり、イベント期間中はそのイベント予定データ(実施の形態1参照)に応じたノイズキャンセルモデルを選択し、そのイベント期間中に発話された内容に応じてノイズキャンセルモデルを割込み的に選択する例を説明する。
実施の形態3では、実施の形態1及び実施の形態2を組み合わせた形態であり、イベント期間中はそのイベント予定データ(実施の形態1参照)に応じたノイズキャンセルモデルを選択し、そのイベント期間中に発話された内容に応じてノイズキャンセルモデルを割込み的に選択する例を説明する。
実施の形態3に係るオンライン処理システムの構成例は実施の形態1、2に係るオンライン処理システム100の構成例と同一であってもよいし、異なってもよい。以下の説明を簡単にするために、実施の形態3に係るオンライン処理システムの構成例は実施の形態1に係るオンライン処理システム100の構成例と同一であると例示して説明する。
まず、図12を参照して、実施の形態3に係るノイズキャンセル装置の一例としてのPC10Bのハードウェア構成例について説明する。図12は、実施の形態3に係るPC10Bのハードウェア構成例を示すブロック図である。PC10Bは、マイクMC1及びイベント予定データベースDB1のそれぞれからデータ信号の入力が可能に接続され、更に、スピーカSPK1にデータ信号の出力が可能に接続されている。PC10Bは、汎用的なコンピュータ装置であり、本開示に係るノイズキャンセル装置の一態様として、パーソナルコンピュータ以外にスマートフォン或いはタブレット端末で構成されても構わない。PC10Bは、プロセッサPRC1Bと、メモリ11と、をハードウェア構成として少なくとも含む。なお、PC10Bは、ユーザSP1の操作を受け付けるマウス等の入力デバイスも更に含む構成としてよい。なお、図12では図示を省略しているが、図6のように、PC10Aは、外部のPCから送られてくる受話音声信号を受信して音声認識処理部18に送る受信部RC1の構成を、更に備えてもよい。
PC10Bの説明において、図2のPC10或いは図6のPC10Aの構成及び動作と同一の構成及び動作を行うものには同一の符号を付与して説明を簡略化或いは省略し、異なる内容について説明する。
メモリ11は、図13に示すモデル選択テーブルTBL1Bを保存している。モデル選択テーブルTBL1Bについては図13を参照して後述する。
ここで、プロセッサPRC1Bが機能的に実行する処理の実行主体の構成例を詳述する。プロセッサPRC1Bは、イベント内容判定部12と、音声認識処理部18と、発話内容判定部19と、利用モデル選択部13Bと、ノイズキャンセル処理部14と、セレクタ15と、音声出力部16と、送信部17と、を機能的に備える。
利用モデル選択部13Bは、選択部の一例であり、イベント内容判定部12からの判定結果を入力し、更に、メモリ11からモデル選択テーブル(図13参照)を読み出す。利用モデル選択部13Bは、入力した判定結果とモデル選択テーブル(図13参照)とに基づいて、マイクMC1からの入力音信号(つまり、ユーザSPがいる音響空間内でマイクMC1により収音された音のデータ信号)に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択する。利用モデル選択部13Bは、選択したノイズキャンセルモデルを示す結果データをノイズキャンセル処理部14に送る。
また、利用モデル選択部13Bは、イベント期間中に発話内容判定部19からの判定結果を入力する場合がある。この場合、利用モデル選択部13Bは、メモリ11からモデル選択テーブル(図13参照)を読み出す。利用モデル選択部13Bは、発話内容判定部19からの判定結果とモデル選択テーブル(図13参照)とに基づいて、マイクMC1からの入力音信号(つまり、ユーザSPがいる音響空間内でマイクMC1により収音された音のデータ信号)に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを割込み的に選択する。この場合に、イベント期間中に使用するためのノイズキャンセルモデル(言い換えると、イベント予定データに応じて選択されたノイズキャンセルモデル)とは異なるノイズキャンセルモデルが選択されることもある。利用モデル選択部13Bは、選択したノイズキャンセルモデルを示す結果データをノイズキャンセル処理部14に送る。
ここで、図13を参照して、モデル選択テーブルTBL1Bについて説明する。図13は、実施の形態3に係るモデル選択テーブルTBL1Bの内容例を示す図である。モデル選択テーブルTBL1Bは、図3のモデル選択テーブルTBL1と図7のモデル選択テーブルTBL1Aとが組み合わされたテーブルである。モデル選択テーブルTBL1Bは、ノイズキャンセルモデルを選択する際、モデル選択テーブルTBL1の内容よりも、モデル選択テーブルTBL1Aの内容を優先的に選択する。
例えば、オンラインミーティングのイベントが開始されるにあたってノイズキャンセルモデル1が選択されてそのイベント期間中に、「乾杯」という発話が検知かつ判定された場合、利用モデル選択部13Bは、ノイズキャンセルモデル1の使用中に、「乾杯」という発話内容に対応するノイズキャンセルモデル2を割込み的に選択して切り替える。
他には例えば、オンライン講演会のイベントが開始されるにあたってノイズキャンセルモデル3が選択されてそのイベント期間中に、「乾杯」という発話が検知かつ判定された場合、利用モデル選択部13Bは、ノイズキャンセルモデル3の使用中に、「乾杯」という発話内容に対応するノイズキャンセルモデル2を割込み的に選択して切り替える。
次に、図14を参照して、実施の形態3に係るPC10Bの動作手順例について説明する。図14は、実施の形態3に係るPC10Bの動作手順例を時系列に示すフローチャートである。図14に示す各処理は、主にプロセッサPRC1B(図12参照)によって実行される。図14に示す処理は、例えば1つのイベントごとに実行され、そのイベントが開始された時或いはその開始直前のタイミングに実行される。また、図14の説明において、図5或いは図9の処理と同一の処理については同一のステップ番号を付与して説明を簡略化或いは省略し、異なる内容について説明する。
図14において、ステップSt2での判定結果はプロセッサPRC1Bに入力される。しかし、ステップSt11及びステップSt12において、マイクMC1により収音された入力音信号に図13に示す発話内容が検知かつ判定されなければ、ステップSt12の処理結果はプロセッサPRC1Bには入力されない。
プロセッサPRC1Bは、ステップSt2での判定結果だけを入力した場合には、ステップSt2で判定したイベント種別(内容)とメモリ11から読み出したモデル選択テーブルTBL1とに基づいて、イベント種別に対応するノイズキャンセルモデルを選択する(ステップSt31)。
一方、プロセッサPRC1Bは、ステップSt2での判定結果及びステップSt12での判定結果の両方を入力した場合には、図13のモデル選択テーブルTBL1Bに基づいて、ステップSt12で判定された発話内容に対応するノイズキャンセルモデルを割込み的に切り替えるように選択する(ステップSt31)。ステップSt31以降の処理については、図9に示すステップSt14以降の処理と同様であるため、詳細な説明は省略する。
以上により、実施の形態3に係るオンライン処理システム100では、ノイズキャンセル装置の一例としてのPC10Bは、収音デバイス(マイクMC1)が配置されている音響空間内の状況に関するデータ(例えばイベント予定データIVL1、或いは、イベント予定データIVL1及びマイクMC1により収音された入力音信号の音声認識結果が示す発話内容を示すデータ)を取得し、そのデータの内容或いは種別を判定する。PC10Bは、その判定した内容或いは種別に基づいて、収音デバイスにより収音された音響空間内の音信号(入力音信号)に含まれる、ノイズキャンセルモデルに応じた「消去しないノイズ音」以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択する。PC10Bは、選択されたノイズキャンセルモデルを用いて、入力音信号に含まれるノイズキャンセルモデルに応じた「消去しないノイズ音」以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力する。これにより、PC10Bは、ユーザSP1の周囲の音響空間内で行われているイベント期間中の雰囲気或いはそのイベント期間中に起きた発話時の雰囲気(臨場感)を損なうことなく、その雰囲気の臨場感とは関係の無い余計な周囲のノイズ音を効率的にキャンセル(消去)することができる。したがって、ユーザSP1は、周囲の雰囲気の臨場感が損なわれずにかつ周囲のノイズ音を気にすることなく快適に処理を行うことができる。
<本開示の技術について>
以上説明したように、本開示には以下に示す技術思想が開示されている。
以上説明したように、本開示には以下に示す技術思想が開示されている。
<技術1>
収音デバイス(マイクMC1)が配置されている音響空間内の状況に関するデータを取得する取得部(イベント内容判定部12、音声認識処理部18と、
前記データの内容或いは種別を判定する判定部(イベント内容判定部12、発話内容判定部19)と、
前記内容或いは種別に基づいて、前記収音デバイスにより収音された前記音響空間内の音信号に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択する選択部(利用モデル選択部13)と、
選択された前記ノイズキャンセルモデルを用いて、前記音信号に含まれる前記所望ノイズ音以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力する出力制御部(ノイズキャンセル処理部14、音声出力部16)と、を備える、
ノイズキャンセル装置。
これにより、ノイズキャンセル装置は、ユーザSP1の周囲の音響空間内で行われているイベントの臨場感を損なうことなく、イベントの臨場感とは関係の無い余計な周囲のノイズ音を効率的にキャンセル(消去)することができる。
収音デバイス(マイクMC1)が配置されている音響空間内の状況に関するデータを取得する取得部(イベント内容判定部12、音声認識処理部18と、
前記データの内容或いは種別を判定する判定部(イベント内容判定部12、発話内容判定部19)と、
前記内容或いは種別に基づいて、前記収音デバイスにより収音された前記音響空間内の音信号に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択する選択部(利用モデル選択部13)と、
選択された前記ノイズキャンセルモデルを用いて、前記音信号に含まれる前記所望ノイズ音以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力する出力制御部(ノイズキャンセル処理部14、音声出力部16)と、を備える、
ノイズキャンセル装置。
これにより、ノイズキャンセル装置は、ユーザSP1の周囲の音響空間内で行われているイベントの臨場感を損なうことなく、イベントの臨場感とは関係の無い余計な周囲のノイズ音を効率的にキャンセル(消去)することができる。
<技術2>
前記データは、前記音響空間内で行われるイベントの種別を含むスケジュールデータであり、
前記選択部は、前記イベントの種別に基づいて、前記ノイズキャンセルモデルを選択する、
技術1に記載のノイズキャンセル装置。
これにより、ノイズキャンセル装置は、音響空間内で行われるイベントの種別に応じて適切にノイズキャンセルモデルを選択できる。
前記データは、前記音響空間内で行われるイベントの種別を含むスケジュールデータであり、
前記選択部は、前記イベントの種別に基づいて、前記ノイズキャンセルモデルを選択する、
技術1に記載のノイズキャンセル装置。
これにより、ノイズキャンセル装置は、音響空間内で行われるイベントの種別に応じて適切にノイズキャンセルモデルを選択できる。
<技術3>
前記スケジュールデータは、前記イベントの開始時刻及び終了時刻の情報を含み、
前記選択部は、前記イベントの期間中に前記ノイズキャンセルモデルを継続使用するように選択する、
技術1又は技術2に記載のノイズキャンセル装置。
これにより、ノイズキャンセル装置は、イベントの開始時刻及び終了時刻を考慮した開催期間中において同一のノイズキャンセルモデルを継続使用できる。
前記スケジュールデータは、前記イベントの開始時刻及び終了時刻の情報を含み、
前記選択部は、前記イベントの期間中に前記ノイズキャンセルモデルを継続使用するように選択する、
技術1又は技術2に記載のノイズキャンセル装置。
これにより、ノイズキャンセル装置は、イベントの開始時刻及び終了時刻を考慮した開催期間中において同一のノイズキャンセルモデルを継続使用できる。
<技術4>
前記取得部は、前記データとして、前記収音デバイスにより収音された前記音信号を音声認識した結果データを取得し、
前記判定部は、前記音声認識の前記結果データが示すユーザの発話内容を判定し、
前記選択部は、前記発話内容の判定結果に基づいて、前記ノイズキャンセルモデルを選択する、
技術1~3のうちいずれか一項に記載のノイズキャンセル装置。
これにより、ノイズキャンセル装置は、マイクMC1により収音された入力音信号に含まれる音声等の音声認識結果がユーザの発話内容を示す場合に、その発話時の雰囲気の臨場感を損ねないように適切なノイズキャンセルモデルを選択かつ使用できる。
前記取得部は、前記データとして、前記収音デバイスにより収音された前記音信号を音声認識した結果データを取得し、
前記判定部は、前記音声認識の前記結果データが示すユーザの発話内容を判定し、
前記選択部は、前記発話内容の判定結果に基づいて、前記ノイズキャンセルモデルを選択する、
技術1~3のうちいずれか一項に記載のノイズキャンセル装置。
これにより、ノイズキャンセル装置は、マイクMC1により収音された入力音信号に含まれる音声等の音声認識結果がユーザの発話内容を示す場合に、その発話時の雰囲気の臨場感を損ねないように適切なノイズキャンセルモデルを選択かつ使用できる。
<技術5>
前記選択部は、前記ノイズキャンセルモデルを選択してから一定時間が経過した場合に、前記選択の前に使用していた他のノイズキャンセルモデルに切り替える、
技術1~4のうちいずれか一項に記載のノイズキャンセル装置。
これにより、ノイズキャンセル装置は、一定時間の経過によって選択したノイズキャンセルモデルの使用状況が落ち着くと想定可能であり、選択前の元のノイズキャンセルモデルに戻すことで適切なノイズキャンセル処理を実行できる。
前記選択部は、前記ノイズキャンセルモデルを選択してから一定時間が経過した場合に、前記選択の前に使用していた他のノイズキャンセルモデルに切り替える、
技術1~4のうちいずれか一項に記載のノイズキャンセル装置。
これにより、ノイズキャンセル装置は、一定時間の経過によって選択したノイズキャンセルモデルの使用状況が落ち着くと想定可能であり、選択前の元のノイズキャンセルモデルに戻すことで適切なノイズキャンセル処理を実行できる。
<技術6>
前記選択部は、前記ノイズキャンセルモデルを選択してから一定時間が経過するまで、選択した前記ノイズキャンセルモデルを継続使用するように選択する、
技術4又は技術5に記載のノイズキャンセル装置。
これにより、ノイズキャンセル装置は、切り替えたノイズキャンセルモデルの使用に適する期間が一定時間であると想定可能であり、その一定時間が経過するまでは切り替えの契機となった雰囲気の臨場感を損ねないように適切にノイズキャンセル処理を実行できる。
前記選択部は、前記ノイズキャンセルモデルを選択してから一定時間が経過するまで、選択した前記ノイズキャンセルモデルを継続使用するように選択する、
技術4又は技術5に記載のノイズキャンセル装置。
これにより、ノイズキャンセル装置は、切り替えたノイズキャンセルモデルの使用に適する期間が一定時間であると想定可能であり、その一定時間が経過するまでは切り替えの契機となった雰囲気の臨場感を損ねないように適切にノイズキャンセル処理を実行できる。
<技術7>
前記データは、前記音響空間内で行われるイベントの種別を含むスケジュールデータと、前記収音デバイスにより収音された前記音信号の音声認識結果データと、を有し、
前記選択部は、前記イベントの期間中に前記イベントの種別に基づく第1ノイズキャンセルモデル(例えばノイズキャンセルモデル1)を使用するよう選択し、かつ、前記イベントの期間中に前記音声認識結果データが示す発話内容が検知された場合に前記発話内容に基づく第2ノイズキャンセル(例えばノイズキャンセルモデル2)を割り込んで使用するよう選択する、
技術1~6のうちいずれか一項に記載のノイズキャンセル装置。
これにより、ノイズキャンセル装置は、イベント期間中に突発的にユーザ等の発話があった場合にその発話によってイベントに対応して選択したノイズキャンセルモデルによって発話時の臨場感を損ねることが無いように、その発話に応じたノイズキャンセルモデルを選択することによってその雰囲気に応じた適切なノイズキャンセル処理を実行できる。
前記データは、前記音響空間内で行われるイベントの種別を含むスケジュールデータと、前記収音デバイスにより収音された前記音信号の音声認識結果データと、を有し、
前記選択部は、前記イベントの期間中に前記イベントの種別に基づく第1ノイズキャンセルモデル(例えばノイズキャンセルモデル1)を使用するよう選択し、かつ、前記イベントの期間中に前記音声認識結果データが示す発話内容が検知された場合に前記発話内容に基づく第2ノイズキャンセル(例えばノイズキャンセルモデル2)を割り込んで使用するよう選択する、
技術1~6のうちいずれか一項に記載のノイズキャンセル装置。
これにより、ノイズキャンセル装置は、イベント期間中に突発的にユーザ等の発話があった場合にその発話によってイベントに対応して選択したノイズキャンセルモデルによって発話時の臨場感を損ねることが無いように、その発話に応じたノイズキャンセルモデルを選択することによってその雰囲気に応じた適切なノイズキャンセル処理を実行できる。
<技術8>
ノイズキャンセル装置により実行されるノイズキャンセル方法であって、
収音デバイスが配置されている音響空間内の状況に関するデータを取得するステップと、
前記データの内容或いは種別を判定するステップと、
前記内容或いは種別に基づいて、前記収音デバイスにより収音された前記音響空間内の音信号に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択するステップと、
選択された前記ノイズキャンセルモデルを用いて、前記音信号に含まれる前記所望ノイズ音以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力するステップと、を有する、
ノイズキャンセル方法。
これにより、ノイズキャンセル方法によれば、ユーザSP1の周囲の音響空間内で行われているイベントの臨場感を損なうことなく、イベントの臨場感とは関係の無い余計な周囲のノイズ音を効率的にキャンセル(消去)することができる。
ノイズキャンセル装置により実行されるノイズキャンセル方法であって、
収音デバイスが配置されている音響空間内の状況に関するデータを取得するステップと、
前記データの内容或いは種別を判定するステップと、
前記内容或いは種別に基づいて、前記収音デバイスにより収音された前記音響空間内の音信号に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択するステップと、
選択された前記ノイズキャンセルモデルを用いて、前記音信号に含まれる前記所望ノイズ音以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力するステップと、を有する、
ノイズキャンセル方法。
これにより、ノイズキャンセル方法によれば、ユーザSP1の周囲の音響空間内で行われているイベントの臨場感を損なうことなく、イベントの臨場感とは関係の無い余計な周囲のノイズ音を効率的にキャンセル(消去)することができる。
<技術9>
コンピュータであるノイズキャンセル装置に、
収音デバイスが配置されている音響空間内の状況に関するデータを取得するステップと、
前記データの内容或いは種別を判定するステップと、
前記内容或いは種別に基づいて、前記収音デバイスにより収音された前記音響空間内の音信号に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択するステップと、
選択された前記ノイズキャンセルモデルを用いて、前記音信号に含まれる前記所望ノイズ音以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力するステップと、を実現させるための、
プログラム。
これにより、プログラムがインストールされたノイズキャンセル装置は、ユーザSP1の周囲の音響空間内で行われているイベントの臨場感を損なうことなく、イベントの臨場感とは関係の無い余計な周囲のノイズ音を効率的にキャンセル(消去)することができる。
コンピュータであるノイズキャンセル装置に、
収音デバイスが配置されている音響空間内の状況に関するデータを取得するステップと、
前記データの内容或いは種別を判定するステップと、
前記内容或いは種別に基づいて、前記収音デバイスにより収音された前記音響空間内の音信号に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択するステップと、
選択された前記ノイズキャンセルモデルを用いて、前記音信号に含まれる前記所望ノイズ音以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力するステップと、を実現させるための、
プログラム。
これにより、プログラムがインストールされたノイズキャンセル装置は、ユーザSP1の周囲の音響空間内で行われているイベントの臨場感を損なうことなく、イベントの臨場感とは関係の無い余計な周囲のノイズ音を効率的にキャンセル(消去)することができる。
以上、添付図面を参照しながら各種の実施の形態について説明したが、本開示はかかる例に限定されない。当業者であれば、特許請求の範囲に記載された範疇内において、各種の変更例、修正例、置換例、付加例、削除例、均等例に想到し得ることは明らかであり、それらについても本開示の技術的範囲に属すると了解される。また、発明の趣旨を逸脱しない範囲において、上述した各種の実施の形態における各構成要素を任意に組み合わせてもよい。
なお、本出願は、2023年6月5日出願の日本特許出願(特願2023-092729)に基づくものであり、その内容は本出願の中に参照として援用される。
本開示は、ユーザの周囲の音響空間内の臨場感を損なことなく、周囲のノイズ音を効率的に消去するノイズキャンセル装置、ノイズキャンセル方法及びプログラムとして有用である。
10、20、N0 PC
11 メモリ
12 イベント内容判定部
13、13A 利用モデル選択部
14 ノイズキャンセル処理部
15 セレクタ
16 音声出力部
17 送信部
18 音声認識処理部
19 発話内容判定部
100 オンライン処理システム
DB1 イベント予定データベース
M1、M2、M3 ノイズキャンセルモデル
MC1、MC2、MCn マイク
PRC1、PRC1A プロセッサ
11 メモリ
12 イベント内容判定部
13、13A 利用モデル選択部
14 ノイズキャンセル処理部
15 セレクタ
16 音声出力部
17 送信部
18 音声認識処理部
19 発話内容判定部
100 オンライン処理システム
DB1 イベント予定データベース
M1、M2、M3 ノイズキャンセルモデル
MC1、MC2、MCn マイク
PRC1、PRC1A プロセッサ
Claims (9)
- 収音デバイスが配置されている音響空間内の状況に関するデータを取得する取得部と、
前記データの内容或いは種別を判定する判定部と、
前記内容或いは種別に基づいて、前記収音デバイスにより収音された前記音響空間内の音信号に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択する選択部と、
選択された前記ノイズキャンセルモデルを用いて、前記音信号に含まれる前記所望ノイズ音以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力する出力制御部と、を備える、
ノイズキャンセル装置。 - 前記データは、前記音響空間内で行われるイベントの種別を含むスケジュールデータであり、
前記選択部は、前記イベントの種別に基づいて、前記ノイズキャンセルモデルを選択する、
請求項1に記載のノイズキャンセル装置。 - 前記スケジュールデータは、前記イベントの開始時刻及び終了時刻の情報を含み、
前記選択部は、前記イベントの期間中に前記ノイズキャンセルモデルを継続使用するように選択する、
請求項2に記載のノイズキャンセル装置。 - 前記取得部は、前記データとして、前記収音デバイスにより収音された前記音信号を音声認識した結果データを取得し、
前記判定部は、前記音声認識の前記結果データが示すユーザの発話内容を判定し、
前記選択部は、前記発話内容の判定結果に基づいて、前記ノイズキャンセルモデルを選択する、
請求項1に記載のノイズキャンセル装置。 - 前記選択部は、前記ノイズキャンセルモデルを選択してから一定時間が経過した場合に、前記選択の前に使用していた他のノイズキャンセルモデルに切り替える、
請求項4に記載のノイズキャンセル装置。 - 前記選択部は、前記ノイズキャンセルモデルを選択してから一定時間が経過するまで、選択した前記ノイズキャンセルモデルを継続使用するように選択する、
請求項4又は5に記載のノイズキャンセル装置。 - 前記データは、前記音響空間内で行われるイベントの種別を含むスケジュールデータと、前記収音デバイスにより収音された前記音信号の音声認識結果データと、を有し、
前記選択部は、前記イベントの期間中に前記イベントの種別に基づく第1ノイズキャンセルモデルを使用するよう選択し、かつ、前記イベントの期間中に前記音声認識結果データが示す発話内容が検知された場合に前記発話内容に基づく第2ノイズキャンセルを割り込んで使用するよう選択する、
請求項1に記載のノイズキャンセル装置。 - ノイズキャンセル装置により実行されるノイズキャンセル方法であって、
収音デバイスが配置されている音響空間内の状況に関するデータを取得するステップと、
前記データの内容或いは種別を判定するステップと、
前記内容或いは種別に基づいて、前記収音デバイスにより収音された前記音響空間内の音信号に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択するステップと、
選択された前記ノイズキャンセルモデルを用いて、前記音信号に含まれる前記所望ノイズ音以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力するステップと、を有する、
ノイズキャンセル方法。 - コンピュータであるノイズキャンセル装置に、
収音デバイスが配置されている音響空間内の状況に関するデータを取得するステップと、
前記データの内容或いは種別を判定するステップと、
前記内容或いは種別に基づいて、前記収音デバイスにより収音された前記音響空間内の音信号に含まれるノイズ音の一部を構成する所望ノイズ音以外のノイズ音をキャンセルするためのノイズキャンセルモデルを選択するステップと、
選択された前記ノイズキャンセルモデルを用いて、前記音信号に含まれる前記所望ノイズ音以外のノイズ音をキャンセルするノイズキャンセル処理を施した出力音声信号を出力するステップと、を実現させるための、
プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2025525953A JPWO2024252750A1 (ja) | 2023-06-05 | 2024-03-11 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023-092729 | 2023-06-05 | ||
| JP2023092729 | 2023-06-05 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024252750A1 true WO2024252750A1 (ja) | 2024-12-12 |
Family
ID=93795831
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2024/009443 Ceased WO2024252750A1 (ja) | 2023-06-05 | 2024-03-11 | ノイズキャンセル装置、ノイズキャンセル方法及びプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2024252750A1 (ja) |
| WO (1) | WO2024252750A1 (ja) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1185185A (ja) * | 1997-09-05 | 1999-03-30 | Oki Electric Ind Co Ltd | 音声認識システムおよび音声認識制御プログラムを記録した記録媒体 |
| JP2003241788A (ja) * | 2002-02-20 | 2003-08-29 | Ntt Docomo Inc | 音声認識装置及び音声認識システム |
| JP2005122042A (ja) * | 2003-10-20 | 2005-05-12 | Toyota Motor Corp | 音声認識装置、音声認識方法、音声合成装置、音声合成方法、音声認識システム、音声合成システム、音声認識合成装置、およびナビゲーションシステム、ならびに移動体 |
| JP2015069063A (ja) * | 2013-09-30 | 2015-04-13 | 日本電気通信システム株式会社 | 音声認識システム、音声認識方法、及び音声認識プログラム |
| US20200013395A1 (en) * | 2019-08-20 | 2020-01-09 | Lg Electronics Inc. | Intelligent voice recognizing method, apparatus, and intelligent computing device |
| US20220238091A1 (en) * | 2021-01-27 | 2022-07-28 | Dell Products L.P. | Selective noise cancellation |
-
2024
- 2024-03-11 WO PCT/JP2024/009443 patent/WO2024252750A1/ja not_active Ceased
- 2024-03-11 JP JP2025525953A patent/JPWO2024252750A1/ja active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1185185A (ja) * | 1997-09-05 | 1999-03-30 | Oki Electric Ind Co Ltd | 音声認識システムおよび音声認識制御プログラムを記録した記録媒体 |
| JP2003241788A (ja) * | 2002-02-20 | 2003-08-29 | Ntt Docomo Inc | 音声認識装置及び音声認識システム |
| JP2005122042A (ja) * | 2003-10-20 | 2005-05-12 | Toyota Motor Corp | 音声認識装置、音声認識方法、音声合成装置、音声合成方法、音声認識システム、音声合成システム、音声認識合成装置、およびナビゲーションシステム、ならびに移動体 |
| JP2015069063A (ja) * | 2013-09-30 | 2015-04-13 | 日本電気通信システム株式会社 | 音声認識システム、音声認識方法、及び音声認識プログラム |
| US20200013395A1 (en) * | 2019-08-20 | 2020-01-09 | Lg Electronics Inc. | Intelligent voice recognizing method, apparatus, and intelligent computing device |
| US20220238091A1 (en) * | 2021-01-27 | 2022-07-28 | Dell Products L.P. | Selective noise cancellation |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2024252750A1 (ja) | 2024-12-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9344815B2 (en) | Method for augmenting hearing | |
| CN112735462B (zh) | 分布式麦克风阵列的降噪方法和语音交互方法 | |
| US9613028B2 (en) | Remotely updating a hearing and profile | |
| CN114255776B (zh) | 使用互连电子设备进行音频修改 | |
| CN110677717B (zh) | 一种音频补偿方法、智能电视及存储介质 | |
| AU2016201028A1 (en) | Signal enhancement using wireless streaming | |
| CN104036771A (zh) | 信号处理装置、信号处理方法和存储介质 | |
| CN115250397A (zh) | Tws耳机和tws耳机的播放方法及装置 | |
| US20190221226A1 (en) | Electronic apparatus and echo cancellation method applied to electronic apparatus | |
| JP2007096389A (ja) | 回帰音除去装置 | |
| CN115209302A (zh) | 音频降噪处理方法、装置、设备、介质及程序产品 | |
| CN116112839B (zh) | 无线耳机的切换控制方法、系统及无线耳机 | |
| US12499901B2 (en) | Noise reduction using synthetic audio | |
| JP2026026128A (ja) | 音声送受信システム | |
| CN114141261B (zh) | 回声消除方法、装置、计算机设备和存储介质 | |
| WO2024252750A1 (ja) | ノイズキャンセル装置、ノイズキャンセル方法及びプログラム | |
| WO2021144964A1 (ja) | ヒアリングデバイス、ヒアリングデバイスの調整方法 | |
| US20210183363A1 (en) | Method for operating a hearing system and hearing system | |
| US12413928B2 (en) | Voice processing system, voice processing method, and recording medium having voice processing program recorded thereon | |
| JP2019537071A (ja) | 分散したマイクロホンからの音声の処理 | |
| US10979803B2 (en) | Communication apparatus, communication method, program, and telepresence system | |
| JP7375817B2 (ja) | 音声処理装置、通話デバイス、音声処理方法、およびプログラム | |
| CN114550744A (zh) | 一种多设备交互音频降噪方法、系统、设备、存储介质 | |
| CN115767358A (zh) | 听力保护方法、系统、tws耳机和智能终端设备 | |
| JP2020127071A (ja) | 電子機器及びその制御方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 24818989 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2025525953 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2025525953 Country of ref document: JP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |