JP2004234582A - 辞書構築方法,システム及び画面 - Google Patents
辞書構築方法,システム及び画面 Download PDFInfo
- Publication number
- JP2004234582A JP2004234582A JP2003025359A JP2003025359A JP2004234582A JP 2004234582 A JP2004234582 A JP 2004234582A JP 2003025359 A JP2003025359 A JP 2003025359A JP 2003025359 A JP2003025359 A JP 2003025359A JP 2004234582 A JP2004234582 A JP 2004234582A
- Authority
- JP
- Japan
- Prior art keywords
- term
- search
- data
- dictionary
- terms
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images




Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Machine Translation (AREA)
Abstract
【課題】作業工数が膨大にかかっていた分野用語辞書の構築を、検索機能の履歴データから抽出された用語と元の辞書用語との比較により容易に構築することである。また、検索履歴データを利用することにより、実際に現在使われている用語を辞書の登録候補とすることが可能となり、より利用価値の高い辞書が構築する。
【解決手段】検索機能の利用履歴データから検索キーワードやその他の検索属性情報を抽出し、保存する手段と、すでに存在する辞書、あるいは辞書の用語分類データと、抽出された検索キーワードを比較し、重複しない用語のみを抽出,保存する手段と、すでに存在する辞書、あるいは用語分類データを表示する手段と、重複を除去した用語データから辞書登録候補を絞り込み、表示する手段と、絞り込まれた登録候補用語をすでに存在する辞書、あるいは用語分類データの中の用語と対応付ける編集手段と、編集結果を保存する手段とを有することである。
【選択図】 図1
【解決手段】検索機能の利用履歴データから検索キーワードやその他の検索属性情報を抽出し、保存する手段と、すでに存在する辞書、あるいは辞書の用語分類データと、抽出された検索キーワードを比較し、重複しない用語のみを抽出,保存する手段と、すでに存在する辞書、あるいは用語分類データを表示する手段と、重複を除去した用語データから辞書登録候補を絞り込み、表示する手段と、絞り込まれた登録候補用語をすでに存在する辞書、あるいは用語分類データの中の用語と対応付ける編集手段と、編集結果を保存する手段とを有することである。
【選択図】 図1
Description
【0001】
【発明の属する技術分野】
本発明は辞書を構築する辞書構築方法,辞書構築システム,画面装置に関する。
【0002】
【従来の技術】
インターネットやドキュメント管理システムにおいて、情報ソースとなるドキュメントやデータファイル等のコンテンツの量が膨大になってくると、ユーザが必要とする情報を入手するための手間も一般に多くなる。そこで、少ない手間で必要な情報を入手するために、ユーザが利用したい情報の分野毎の専門用語、および、その上位概念や下位概念,別名,類義語等の用語間の関係をあらかじめコンピュータが理解可能なように辞書データベース化しておき、この辞書データベースを情報の検索や抽出,分類に利用している。
【0003】
しかしながら、上記のような専門用語の辞書データベースを構築する作業は、従来、その分野の有識者により人手で行われ、その作業工数も語数に応じてかなり多いという課題があった。具体的には、一般的な辞書構築方法としては、専門分野のドキュメントを入力として、これを自動的に用語に切り出す処理(形態素解析処理)を行って得られた用語集合に対して、人手で不要用語除去や分類作業を行っていた。
【0004】
これらの人手作業を低減するために、特開平11−296549号公報では概念情報の辞書編集のためのユーザインタフェースについて記載されており、特に関連度を用いて関連する概念情報の候補を一覧する方法が記載されている。
【0005】
【特許文献1】
特開平11−296549号公報
【0006】
【発明が解決しようとする課題】
従来技術では、特定分野のドキュメント、あるいはドキュメント群を入力として形態素解析を行い、得られた用語集合を用語間の関連度合い等を利用して分類、あるいは分類候補を提示している。
【0007】
しかしながら、入力を特定分野のドキュメントとすることにより、以下の課題がある。
【0008】
まず、ドキュメントは用語の集合体であることから、専門用語を抽出する処理として形態素解析処理を用いる必要があるが、これにより一般にノイズ(不要用語)除去の手間が発生し、ドキュメントの規模に応じて増大する傾向にある。このノイズ除去にドキュメント中の用語出現頻度等のパラメータが使われる場合があるが、出現頻度が極端に多い、あるいは少ないことと、専門用語である可能性との関連性は一概に言えない。
【0009】
また、用語の出現頻度等で一律に傾向を把握することはできても、古い用語と最新の用語を区別することはできず、用語の鮮度維持という観点では従来技術は利用できない。
【0010】
そこで、本発明の目的は、辞書構築工数を低減する辞書構築方法,システム及び画面を提供することである。
【0011】
【課題を解決するための手段】
本発明の一つの特徴は、辞書を構築する方法において、検索履歴情報から抽出された検索キーワード又は検索属性情報から、辞書を構築することである。
【0012】
なお、本発明のその他の特徴は本願特許請求の範囲に記載のとおりである。
【0013】
【発明の実施の形態】
以下、図面を用いて本発明の実施の形態を説明する。
【0014】
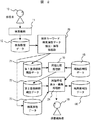
第1の実施例は、検索者10(ユーザ)が検索機能を利用した際の検索履歴データを利用して、用語辞書の構築支援を行う例であり、図1はその一例である。
【0015】
本実施例における検索機能とは、ファイルシステム,ドキュメント管理システム,メールシステム,インターネット等の検索エンジン等において、ユーザが必要とするファイル内の情報をキーワードを入力することで検索する機能を意味する。
【0016】
ここで「ファイル」とは、ワードプロセッサやエディタ等で作成されたドキュメントデータやHTML(Hyper Text Markup Language),XML(eXtensibleMarkup Language )等のインターネットにおける標準的なドキュメントデータ,ソフトウェアを記述するプログラムデータ,形状データ,解析データ,画像データ,動画データ等、データの1単位を意味する。
【0017】
また、検索キーワードはキーボード入力,音声入力等、最終的に単語として電子化できるものを意味する。
【0018】
まず、ユーザ検索者10が検索機能11を用いて自由に検索を行う。具体的には、ユーザがインターネットの検索エンジンを使用することである。これにより、検索履歴データ12が得られる。なお、検索者10が検索機能11を用いて検索する回数が多いほど、検索履歴データ12の量が多く、より充実した辞書を構築することが可能である。
【0019】
そこで、この検索履歴データ12から、検索キーワード抽出・保存処理部13は、検索キーワードを抽出し、その結果を第1登録候補用語データ14としてデータベースに格納する。次に、用語比較処理部16は、すでに専門用語辞書が存在する場合は、これを編集前用語データ15として、第1登録候補用語データ14と用語の文字列パタンマッチングを行い、編集前用語データ15に存在しない登録候補用語を抽出し、その結果を第2登録候補用語データ17としてデータベースに格納する。
【0020】
また、初回利用で編集前用語データ15が存在しない場合は、基本となる用語分類データを作成して、編集前用語データ15としてもよい。
【0021】
これにより、古い用語と最新の用語を区別することが可能となり、用語の鮮度維持をすることができる。
【0022】
次に、用語構成表示・編集処理部18では、最初に編集前用語データ15を読み込み、次に、辞書編集者19の指定する絞り込み条件に従って、第2登録候補用語データ17を読み込む。
【0023】
ここで登録候補用語の絞り込み方法の例としては、
[表記] [意味]
X* :先頭にXがつく用語すべて
X??? :Xの後に任意の3文字が続く
等の正規表現を利用して文字列マッチングを行う方法がある。
【0024】
また、用語構成表示とは、文字列の用語データは一般に上位語,下位語等の分類階層を持つことから、ツリー形式で画面上に表示することを意味する。
【0025】
以降、辞書編集者の操作により、画面上で、第2登録候補用語データから選択された用語を、ツリー形式で表示された編集前用語データ15の中の最適なノード(用語)の下に追加することで、用語編集を実行する。
【0026】
最後に、編集終了後は、編集結果を編集後用語データ100としてデータベースに保存する。
【0027】
なお、上記の説明では編集前用語データ15と編集後用語データ100は区別したが、一つのデータとして、編集後に上書きしてもよい。
【0028】
以上の実施の形態より、検索履歴情報から作業工数を少なくて、用語鮮度の高い辞書を構築することが可能となる。
【0029】
第2の実施例は、第1の実施例に、さらに検索属性データを利用して、辞書編集効率の向上をねらった例であり、図2はその一例である。
【0030】
検索機能11によって出力された検索履歴データ12から、検索キーワード,検索属性データ抽出・保存処理部20は、検索キーワード、および検索属性データを抽出し、その結果を、検索キーワードは第1登録候補用語データ21として、検索属性データは23としてデータベースに格納する。この際、21と23のデータ間は用語ID等で関連付けておく。
【0031】
ここで検索属性データとは、検索者が検索機能を利用して検索した際の日時,ヒット数等、1回の検索操作に関する情報である。また、検索者を特定できるデータ、たとえば、使用マシンのID(IPアドレス等)や、システムへのログイン情報から得られるユーザ情報も検索属性データに含まれる。
【0032】
用語構成表示・編集処理部24では、最初に編集前用語データ15を読み込み、次に、辞書編集者19の指定する絞り込み条件に従って、第2登録候補用語データ22を読み込む。
【0033】
ここで登録候補用語の絞り込みとしては、第一の実施例の正規表現を絞り込み条件とする方法の他に、検索日時,検索者,検索ヒット率等の検索属性データ
23を用いて絞り込み条件とする。検索条件の例としては以下の通り。
検索日時:2000年1月1日〜2001年12月31日
検索者:山田太郎
検索ヒット数:10件未満(または以上)
また、システムのユーザ管理情報からユーザの組織情報が得られる場合は、上記の検索者の部分に会社・部・課等の組織情報を指定してもよい。これにより、たとえば「A会社」向け,「B設計部」向けといった専門辞書の構築が容易になる。また、検索ヒット数を絞り込み条件として用いることにより、まだ、あまり一般的に使われない用語、あるいは逆に、すでに一般的に使われている用語をある程度絞り込める。また、検索ヒット数0件の場合は、検索キーワードが正しくない可能性が高いと判断してもよい。
【0034】
第3の実施例は、第2の実施例における第1登録候補用語データ21,第2登録候補用語データ22,検索属性データ23のデータ構造の一例であり、図3はその一例である。
【0035】
テーブル30は第2の実施例における第1登録候補用語データ21,第2登録候補用語データ22のデータ構造で、登録候補用語ID31と登録候補用語32を一つの行として対応付ける。
【0036】
さらにテーブル33は第2の実施例における検索属性データ23のデータ構造で、登録候補用語ID34と検索日時35,検索者36、等の検索属性データを一つの行として対応付ける。ここでは検索者36を識別するために、マシンの
IPアドレスを利用している。
【0037】
このようなデータ構造にすることによって、新たな検索属性項目の追加が容易になる。
【0038】
第4の実施例は、第2の実施例における検索機能利用時、および辞書構築時の処理の流れを示し、図4はその一例である。
【0039】
検索機能利用時は、処理40のように、検索者10が検索機能を利用して情報を検索した履歴を検索履歴データ12として保存する。
【0040】
一方、辞書構築時には、最初に、処理41のように、検索履歴データ12から検索キーワード,検索属性データを抽出し、検索キーワードを第1登録候補用語データ21,検索属性データ23として保存する。
【0041】
次に、処理42のように、編集前用語データ15と第1登録候補用語データ
21を比較して、編集前用語データ15に存在しない登録候補用語を抽出し、第2登録候補用語データ22として保存する。
【0042】
さらに、辞書編集時には、処理43のように、第2登録候補用語データ22と編集前用語データ15を読み込んで表示し、辞書編集者19がその表示を受け付けて、指示を行うことにより用語の編集が行われる。編集後、処理44のように、編集結果を編集後用語データ100として保存する。
【0043】
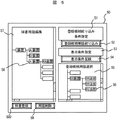
第5の実施例は、第1,第2の実施例における辞書編集画面の例を示し、図5はその一例である。
【0044】
画面50は、編集前用語データ15をツリー表示・編集するエリア57(画面左側)と、登録候補用語を選択するエリア(画面右側)に分かれる。
【0045】
登録候補用語絞り込み条件指定エリア51では、第1の実施例で示した用語の正規表現による絞り込み条件や、第2の実施例で示した検索属性データによる絞り込み条件を入力する。絞り込み条件入力後、登録候補用語絞り込みボタン52をマウス等のポインティングデバイスでクリックすることにより、登録候補絞り込み処理が実行される。
【0046】
次に、表示条件指定エリア53では、上記で絞り込まれた用語の表示順序等、表示条件を指定する。表示条件としては、単純な用語一覧表示で降順,昇順の他、文字列パタンマッチングにより階層化して表示する方法等がある。表示条件入力後、表示条件反映ボタン54をマウス等のポインティングデバイスでクリックすることにより、表示反映処理が実行され、登録候補用語選択エリア55に結果が表示される。
【0047】
登録候補用語選択エリア55で、辞書編集者が辞書に登録したい用語56をマウス等のポインティングデバイスで選択し、これを辞書用語編集エリア57の該当すると思われる用語58のところにドラッグ&ドロップする。その結果、辞書用語編集エリア57のドロップ先の用語58の下位階層に、用語56が追加される。
【0048】
なお、辞書用語編集エリア57内でも用語の移動がドラッグ&ドロップで任意に行え、不要な用語があれば、用語選択後、用語削除ボタン59をマウス等のポインティングデバイスでクリックすることにより、削除可能である。
【0049】
最終的に辞書編集作業が終了した時点で、辞書登録ボタン500をマウス等のポインティングデバイスでクリックすることにより、編集後用語データとして保存される。
【0050】
これにより、辞書登録用語を登録する際に、編集前用語データ15(既存の辞書)の用語と関連付けて辞書登録用語を登録することが可能となる。
【0051】
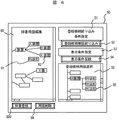
第6の実施例は、第5の実施例における辞書用語編集エリアの別の画面例を示し、図6はその一例である。
【0052】
登録候補用語選択エリア55で、辞書編集者が辞書に登録したい用語56をマウス等のポインティングデバイスで選択すると、その用語56が辞書用語編集エリア60の中央部に表示される。
【0053】
同時に、用語56と編集前用語データの各用語との文字列パタンマッチングにより、文字列一致度を算出する。たとえば、登録候補用語が「XXZ装置」の場合、「X装置」との文字列一致度の例としては、
一致文字検出方向:後方
位置が一致した文字数:a=2文字
それ以外に一致した文字:b=1文字
(文字列一致度)=w1×a+w2×b
ここで、w1,w2は重み(0以上の数値)で、一般に、w1>w2とする。辞書用語編集エリア60の中央部からの距離は、例として、
(距離)=1/(文字列一致度)
のように、文字列一致度の逆数を用いる方法がある。
【0054】
以上の方法により辞書用語編集エリア60で各用語の配置位置を決定すると、用語61に類似する用語が中央部近くに、類似しない用語が遠くに表示される。
【0055】
辞書編集者は用語61の近くに表示されている用語の中から該当すると思われる用語62のところにドラッグ&ドロップする。その結果、辞書用語編集エリアのドロップ先の用語62の下位階層に、用語61が追加される。
【0056】
これにより、辞書登録用語を登録する際に、編集前用語データ15(既存の辞書)に含まれる一致度の高い用語と関連付けて辞書登録用語を登録することが可能となる。
【0057】
第7の実施例は、本発明を辞書構築サービスに適用した場合のシステム構成例であり、図7はその一例である。
【0058】
検索サービスを行うための検索エンジン用サーバ72は、インターネット等のネットワーク74を介して、情報ソース73から検索用のインデックスを生成しておく。また、情報検索者76は検索用クライアント75を通じて、ネットワーク74を介して検索エンジン用サーバ72にアクセスする。ここで、システム管理者70は管理用クライアント71を通じて検索エンジン用サーバ72を管理している。
【0059】
辞書構築サービスを受ける者は、同じ組織に属する情報検索者76の検索履歴データ78を、辞書構築サービス提供者79に提供することを許可する。
【0060】
辞書構築サービス提供者79は検索履歴データ78、および利用者データ77を、本発明ですでに述べた辞書構築支援システム700に取り込み、専門用語辞書を構築する。
【0061】
サービス料金は、最終成果物である辞書の語数や情報検索者76の人数等でランク分けして設定してもよい。
【0062】
これにより、顧客に対して、円滑な辞書構築サービスを行うことが可能となる。
【0063】
以上により、様々な実施の形態について説明したが、これを実現する装置は、専用の装置として構成することも可能であるが、図8に例示するように、キーボード81と、前述したようなデータや処理プログラムを入力する入力手段,入力されたデータやプログラムをデータベースとして蓄積する記憶部,演算部などを備えたコンピュータ本体82と、ディスプレイ83で構成される汎用のコンピュータシステムとその上で稼働する処理プログラムによって実現することが可能である。
【0064】
このような汎用のコンピュータシステムに処理プログラムを付加して実現するときには、処理プログラムは図9に例示するような磁気ディスク91や図10に例示するようなCD−ROM101などのメディアに記録して配送,保管,実装され、コンピュータ本体82に設けた磁気ディスク読み取り装置やCD−ROM読み取り装置によって読み取って該コンピュータ本体82内に取り込まれる。通信ネットワークを通じて配送される処理プログラムを入力手段によって取り込んで実現する場合には、取り込んだ処理プログラムを磁気ディスク等のメディアに記憶させて保存することにより、繰り返し使用できるようにする。
【0065】
【発明の効果】
本発明によれば、辞書構築工数を低減する辞書構築方法,システム及び画面を提供できる。
【図面の簡単な説明】
【図1】本発明の実施例において、ユーザが検索機能を利用した際の検索履歴データを利用して、用語辞書の構築支援を実現するための機能ブロック図の一例である。
【図2】図1において、検索属性データを利用して、辞書編集効率の向上を実現する機能ブロック図の一例である。
【図3】図1,図2におけるデータベースのデータ構造図の一例である。
【図4】図2における検索機能利用時、および辞書構築時の処理の流れを表すフロー図の一例である。
【図5】第1,第2の実施例における辞書編集画面の一例である。
【図6】図5における辞書用語編集エリアの別画面の一例である。
【図7】本発明を辞書構築サービスに適用した場合のシステム構成例である。
【図8】コンピュータシステムの一例。
【図9】磁気ディスクの一例。
【図10】CD−ROMの一例。
【符号の説明】
10,36…検索者、11…検索機能、12,78…検索履歴データ、13…検索キーワード抽出・保存処理部、14,21…第1登録候補用語データ、15…編集前用語データ、16…用語比較処理部、17,22…第2登録候補用語データ、18,24…用語構成表示・編集処理部、19…辞書編集者、20…検索キーワード,検索属性データ抽出・保存処理部、23…検索属性データ、30,33…テーブル、31,34…登録候補用語ID、32,56,61…登録候補用語、35…検索日時、40…図1,図2の検索時の処理ステップ、41,42,43,44…辞書構築時の処理ステップ、50…画面、51…登録候補用語絞り込み条件指定エリア、52…登録候補用語絞り込みボタン、53…表示条件指定エリア、54…表示条件反映ボタン、55…登録候補用語選択エリア、57,60…辞書用語編集エリア、58,62…登録先用語(親)、59…用語削除ボタン、70…システム管理者、71…管理用クライアント、72…検索エンジン用サーバ、73…情報ソース、74…ネットワーク、75…検索用クライアント、76…情報検索者、77…利用者データ、79…辞書構築サービス提供者、81…キーボード、82…コンピュータ本体、83…ディスプレイ、91…磁気ディスク、100…編集後用語データ、101…CD−ROM、500…辞書登録ボタン、700…辞書構築支援システム。
【発明の属する技術分野】
本発明は辞書を構築する辞書構築方法,辞書構築システム,画面装置に関する。
【0002】
【従来の技術】
インターネットやドキュメント管理システムにおいて、情報ソースとなるドキュメントやデータファイル等のコンテンツの量が膨大になってくると、ユーザが必要とする情報を入手するための手間も一般に多くなる。そこで、少ない手間で必要な情報を入手するために、ユーザが利用したい情報の分野毎の専門用語、および、その上位概念や下位概念,別名,類義語等の用語間の関係をあらかじめコンピュータが理解可能なように辞書データベース化しておき、この辞書データベースを情報の検索や抽出,分類に利用している。
【0003】
しかしながら、上記のような専門用語の辞書データベースを構築する作業は、従来、その分野の有識者により人手で行われ、その作業工数も語数に応じてかなり多いという課題があった。具体的には、一般的な辞書構築方法としては、専門分野のドキュメントを入力として、これを自動的に用語に切り出す処理(形態素解析処理)を行って得られた用語集合に対して、人手で不要用語除去や分類作業を行っていた。
【0004】
これらの人手作業を低減するために、特開平11−296549号公報では概念情報の辞書編集のためのユーザインタフェースについて記載されており、特に関連度を用いて関連する概念情報の候補を一覧する方法が記載されている。
【0005】
【特許文献1】
特開平11−296549号公報
【0006】
【発明が解決しようとする課題】
従来技術では、特定分野のドキュメント、あるいはドキュメント群を入力として形態素解析を行い、得られた用語集合を用語間の関連度合い等を利用して分類、あるいは分類候補を提示している。
【0007】
しかしながら、入力を特定分野のドキュメントとすることにより、以下の課題がある。
【0008】
まず、ドキュメントは用語の集合体であることから、専門用語を抽出する処理として形態素解析処理を用いる必要があるが、これにより一般にノイズ(不要用語)除去の手間が発生し、ドキュメントの規模に応じて増大する傾向にある。このノイズ除去にドキュメント中の用語出現頻度等のパラメータが使われる場合があるが、出現頻度が極端に多い、あるいは少ないことと、専門用語である可能性との関連性は一概に言えない。
【0009】
また、用語の出現頻度等で一律に傾向を把握することはできても、古い用語と最新の用語を区別することはできず、用語の鮮度維持という観点では従来技術は利用できない。
【0010】
そこで、本発明の目的は、辞書構築工数を低減する辞書構築方法,システム及び画面を提供することである。
【0011】
【課題を解決するための手段】
本発明の一つの特徴は、辞書を構築する方法において、検索履歴情報から抽出された検索キーワード又は検索属性情報から、辞書を構築することである。
【0012】
なお、本発明のその他の特徴は本願特許請求の範囲に記載のとおりである。
【0013】
【発明の実施の形態】
以下、図面を用いて本発明の実施の形態を説明する。
【0014】
第1の実施例は、検索者10(ユーザ)が検索機能を利用した際の検索履歴データを利用して、用語辞書の構築支援を行う例であり、図1はその一例である。
【0015】
本実施例における検索機能とは、ファイルシステム,ドキュメント管理システム,メールシステム,インターネット等の検索エンジン等において、ユーザが必要とするファイル内の情報をキーワードを入力することで検索する機能を意味する。
【0016】
ここで「ファイル」とは、ワードプロセッサやエディタ等で作成されたドキュメントデータやHTML(Hyper Text Markup Language),XML(eXtensibleMarkup Language )等のインターネットにおける標準的なドキュメントデータ,ソフトウェアを記述するプログラムデータ,形状データ,解析データ,画像データ,動画データ等、データの1単位を意味する。
【0017】
また、検索キーワードはキーボード入力,音声入力等、最終的に単語として電子化できるものを意味する。
【0018】
まず、ユーザ検索者10が検索機能11を用いて自由に検索を行う。具体的には、ユーザがインターネットの検索エンジンを使用することである。これにより、検索履歴データ12が得られる。なお、検索者10が検索機能11を用いて検索する回数が多いほど、検索履歴データ12の量が多く、より充実した辞書を構築することが可能である。
【0019】
そこで、この検索履歴データ12から、検索キーワード抽出・保存処理部13は、検索キーワードを抽出し、その結果を第1登録候補用語データ14としてデータベースに格納する。次に、用語比較処理部16は、すでに専門用語辞書が存在する場合は、これを編集前用語データ15として、第1登録候補用語データ14と用語の文字列パタンマッチングを行い、編集前用語データ15に存在しない登録候補用語を抽出し、その結果を第2登録候補用語データ17としてデータベースに格納する。
【0020】
また、初回利用で編集前用語データ15が存在しない場合は、基本となる用語分類データを作成して、編集前用語データ15としてもよい。
【0021】
これにより、古い用語と最新の用語を区別することが可能となり、用語の鮮度維持をすることができる。
【0022】
次に、用語構成表示・編集処理部18では、最初に編集前用語データ15を読み込み、次に、辞書編集者19の指定する絞り込み条件に従って、第2登録候補用語データ17を読み込む。
【0023】
ここで登録候補用語の絞り込み方法の例としては、
[表記] [意味]
X* :先頭にXがつく用語すべて
X??? :Xの後に任意の3文字が続く
等の正規表現を利用して文字列マッチングを行う方法がある。
【0024】
また、用語構成表示とは、文字列の用語データは一般に上位語,下位語等の分類階層を持つことから、ツリー形式で画面上に表示することを意味する。
【0025】
以降、辞書編集者の操作により、画面上で、第2登録候補用語データから選択された用語を、ツリー形式で表示された編集前用語データ15の中の最適なノード(用語)の下に追加することで、用語編集を実行する。
【0026】
最後に、編集終了後は、編集結果を編集後用語データ100としてデータベースに保存する。
【0027】
なお、上記の説明では編集前用語データ15と編集後用語データ100は区別したが、一つのデータとして、編集後に上書きしてもよい。
【0028】
以上の実施の形態より、検索履歴情報から作業工数を少なくて、用語鮮度の高い辞書を構築することが可能となる。
【0029】
第2の実施例は、第1の実施例に、さらに検索属性データを利用して、辞書編集効率の向上をねらった例であり、図2はその一例である。
【0030】
検索機能11によって出力された検索履歴データ12から、検索キーワード,検索属性データ抽出・保存処理部20は、検索キーワード、および検索属性データを抽出し、その結果を、検索キーワードは第1登録候補用語データ21として、検索属性データは23としてデータベースに格納する。この際、21と23のデータ間は用語ID等で関連付けておく。
【0031】
ここで検索属性データとは、検索者が検索機能を利用して検索した際の日時,ヒット数等、1回の検索操作に関する情報である。また、検索者を特定できるデータ、たとえば、使用マシンのID(IPアドレス等)や、システムへのログイン情報から得られるユーザ情報も検索属性データに含まれる。
【0032】
用語構成表示・編集処理部24では、最初に編集前用語データ15を読み込み、次に、辞書編集者19の指定する絞り込み条件に従って、第2登録候補用語データ22を読み込む。
【0033】
ここで登録候補用語の絞り込みとしては、第一の実施例の正規表現を絞り込み条件とする方法の他に、検索日時,検索者,検索ヒット率等の検索属性データ
23を用いて絞り込み条件とする。検索条件の例としては以下の通り。
検索日時:2000年1月1日〜2001年12月31日
検索者:山田太郎
検索ヒット数:10件未満(または以上)
また、システムのユーザ管理情報からユーザの組織情報が得られる場合は、上記の検索者の部分に会社・部・課等の組織情報を指定してもよい。これにより、たとえば「A会社」向け,「B設計部」向けといった専門辞書の構築が容易になる。また、検索ヒット数を絞り込み条件として用いることにより、まだ、あまり一般的に使われない用語、あるいは逆に、すでに一般的に使われている用語をある程度絞り込める。また、検索ヒット数0件の場合は、検索キーワードが正しくない可能性が高いと判断してもよい。
【0034】
第3の実施例は、第2の実施例における第1登録候補用語データ21,第2登録候補用語データ22,検索属性データ23のデータ構造の一例であり、図3はその一例である。
【0035】
テーブル30は第2の実施例における第1登録候補用語データ21,第2登録候補用語データ22のデータ構造で、登録候補用語ID31と登録候補用語32を一つの行として対応付ける。
【0036】
さらにテーブル33は第2の実施例における検索属性データ23のデータ構造で、登録候補用語ID34と検索日時35,検索者36、等の検索属性データを一つの行として対応付ける。ここでは検索者36を識別するために、マシンの
IPアドレスを利用している。
【0037】
このようなデータ構造にすることによって、新たな検索属性項目の追加が容易になる。
【0038】
第4の実施例は、第2の実施例における検索機能利用時、および辞書構築時の処理の流れを示し、図4はその一例である。
【0039】
検索機能利用時は、処理40のように、検索者10が検索機能を利用して情報を検索した履歴を検索履歴データ12として保存する。
【0040】
一方、辞書構築時には、最初に、処理41のように、検索履歴データ12から検索キーワード,検索属性データを抽出し、検索キーワードを第1登録候補用語データ21,検索属性データ23として保存する。
【0041】
次に、処理42のように、編集前用語データ15と第1登録候補用語データ
21を比較して、編集前用語データ15に存在しない登録候補用語を抽出し、第2登録候補用語データ22として保存する。
【0042】
さらに、辞書編集時には、処理43のように、第2登録候補用語データ22と編集前用語データ15を読み込んで表示し、辞書編集者19がその表示を受け付けて、指示を行うことにより用語の編集が行われる。編集後、処理44のように、編集結果を編集後用語データ100として保存する。
【0043】
第5の実施例は、第1,第2の実施例における辞書編集画面の例を示し、図5はその一例である。
【0044】
画面50は、編集前用語データ15をツリー表示・編集するエリア57(画面左側)と、登録候補用語を選択するエリア(画面右側)に分かれる。
【0045】
登録候補用語絞り込み条件指定エリア51では、第1の実施例で示した用語の正規表現による絞り込み条件や、第2の実施例で示した検索属性データによる絞り込み条件を入力する。絞り込み条件入力後、登録候補用語絞り込みボタン52をマウス等のポインティングデバイスでクリックすることにより、登録候補絞り込み処理が実行される。
【0046】
次に、表示条件指定エリア53では、上記で絞り込まれた用語の表示順序等、表示条件を指定する。表示条件としては、単純な用語一覧表示で降順,昇順の他、文字列パタンマッチングにより階層化して表示する方法等がある。表示条件入力後、表示条件反映ボタン54をマウス等のポインティングデバイスでクリックすることにより、表示反映処理が実行され、登録候補用語選択エリア55に結果が表示される。
【0047】
登録候補用語選択エリア55で、辞書編集者が辞書に登録したい用語56をマウス等のポインティングデバイスで選択し、これを辞書用語編集エリア57の該当すると思われる用語58のところにドラッグ&ドロップする。その結果、辞書用語編集エリア57のドロップ先の用語58の下位階層に、用語56が追加される。
【0048】
なお、辞書用語編集エリア57内でも用語の移動がドラッグ&ドロップで任意に行え、不要な用語があれば、用語選択後、用語削除ボタン59をマウス等のポインティングデバイスでクリックすることにより、削除可能である。
【0049】
最終的に辞書編集作業が終了した時点で、辞書登録ボタン500をマウス等のポインティングデバイスでクリックすることにより、編集後用語データとして保存される。
【0050】
これにより、辞書登録用語を登録する際に、編集前用語データ15(既存の辞書)の用語と関連付けて辞書登録用語を登録することが可能となる。
【0051】
第6の実施例は、第5の実施例における辞書用語編集エリアの別の画面例を示し、図6はその一例である。
【0052】
登録候補用語選択エリア55で、辞書編集者が辞書に登録したい用語56をマウス等のポインティングデバイスで選択すると、その用語56が辞書用語編集エリア60の中央部に表示される。
【0053】
同時に、用語56と編集前用語データの各用語との文字列パタンマッチングにより、文字列一致度を算出する。たとえば、登録候補用語が「XXZ装置」の場合、「X装置」との文字列一致度の例としては、
一致文字検出方向:後方
位置が一致した文字数:a=2文字
それ以外に一致した文字:b=1文字
(文字列一致度)=w1×a+w2×b
ここで、w1,w2は重み(0以上の数値)で、一般に、w1>w2とする。辞書用語編集エリア60の中央部からの距離は、例として、
(距離)=1/(文字列一致度)
のように、文字列一致度の逆数を用いる方法がある。
【0054】
以上の方法により辞書用語編集エリア60で各用語の配置位置を決定すると、用語61に類似する用語が中央部近くに、類似しない用語が遠くに表示される。
【0055】
辞書編集者は用語61の近くに表示されている用語の中から該当すると思われる用語62のところにドラッグ&ドロップする。その結果、辞書用語編集エリアのドロップ先の用語62の下位階層に、用語61が追加される。
【0056】
これにより、辞書登録用語を登録する際に、編集前用語データ15(既存の辞書)に含まれる一致度の高い用語と関連付けて辞書登録用語を登録することが可能となる。
【0057】
第7の実施例は、本発明を辞書構築サービスに適用した場合のシステム構成例であり、図7はその一例である。
【0058】
検索サービスを行うための検索エンジン用サーバ72は、インターネット等のネットワーク74を介して、情報ソース73から検索用のインデックスを生成しておく。また、情報検索者76は検索用クライアント75を通じて、ネットワーク74を介して検索エンジン用サーバ72にアクセスする。ここで、システム管理者70は管理用クライアント71を通じて検索エンジン用サーバ72を管理している。
【0059】
辞書構築サービスを受ける者は、同じ組織に属する情報検索者76の検索履歴データ78を、辞書構築サービス提供者79に提供することを許可する。
【0060】
辞書構築サービス提供者79は検索履歴データ78、および利用者データ77を、本発明ですでに述べた辞書構築支援システム700に取り込み、専門用語辞書を構築する。
【0061】
サービス料金は、最終成果物である辞書の語数や情報検索者76の人数等でランク分けして設定してもよい。
【0062】
これにより、顧客に対して、円滑な辞書構築サービスを行うことが可能となる。
【0063】
以上により、様々な実施の形態について説明したが、これを実現する装置は、専用の装置として構成することも可能であるが、図8に例示するように、キーボード81と、前述したようなデータや処理プログラムを入力する入力手段,入力されたデータやプログラムをデータベースとして蓄積する記憶部,演算部などを備えたコンピュータ本体82と、ディスプレイ83で構成される汎用のコンピュータシステムとその上で稼働する処理プログラムによって実現することが可能である。
【0064】
このような汎用のコンピュータシステムに処理プログラムを付加して実現するときには、処理プログラムは図9に例示するような磁気ディスク91や図10に例示するようなCD−ROM101などのメディアに記録して配送,保管,実装され、コンピュータ本体82に設けた磁気ディスク読み取り装置やCD−ROM読み取り装置によって読み取って該コンピュータ本体82内に取り込まれる。通信ネットワークを通じて配送される処理プログラムを入力手段によって取り込んで実現する場合には、取り込んだ処理プログラムを磁気ディスク等のメディアに記憶させて保存することにより、繰り返し使用できるようにする。
【0065】
【発明の効果】
本発明によれば、辞書構築工数を低減する辞書構築方法,システム及び画面を提供できる。
【図面の簡単な説明】
【図1】本発明の実施例において、ユーザが検索機能を利用した際の検索履歴データを利用して、用語辞書の構築支援を実現するための機能ブロック図の一例である。
【図2】図1において、検索属性データを利用して、辞書編集効率の向上を実現する機能ブロック図の一例である。
【図3】図1,図2におけるデータベースのデータ構造図の一例である。
【図4】図2における検索機能利用時、および辞書構築時の処理の流れを表すフロー図の一例である。
【図5】第1,第2の実施例における辞書編集画面の一例である。
【図6】図5における辞書用語編集エリアの別画面の一例である。
【図7】本発明を辞書構築サービスに適用した場合のシステム構成例である。
【図8】コンピュータシステムの一例。
【図9】磁気ディスクの一例。
【図10】CD−ROMの一例。
【符号の説明】
10,36…検索者、11…検索機能、12,78…検索履歴データ、13…検索キーワード抽出・保存処理部、14,21…第1登録候補用語データ、15…編集前用語データ、16…用語比較処理部、17,22…第2登録候補用語データ、18,24…用語構成表示・編集処理部、19…辞書編集者、20…検索キーワード,検索属性データ抽出・保存処理部、23…検索属性データ、30,33…テーブル、31,34…登録候補用語ID、32,56,61…登録候補用語、35…検索日時、40…図1,図2の検索時の処理ステップ、41,42,43,44…辞書構築時の処理ステップ、50…画面、51…登録候補用語絞り込み条件指定エリア、52…登録候補用語絞り込みボタン、53…表示条件指定エリア、54…表示条件反映ボタン、55…登録候補用語選択エリア、57,60…辞書用語編集エリア、58,62…登録先用語(親)、59…用語削除ボタン、70…システム管理者、71…管理用クライアント、72…検索エンジン用サーバ、73…情報ソース、74…ネットワーク、75…検索用クライアント、76…情報検索者、77…利用者データ、79…辞書構築サービス提供者、81…キーボード、82…コンピュータ本体、83…ディスプレイ、91…磁気ディスク、100…編集後用語データ、101…CD−ROM、500…辞書登録ボタン、700…辞書構築支援システム。
Claims (14)
- 辞書を構築する方法において、
検索履歴情報から抽出された検索キーワード又は検索属性情報から、辞書を構築する辞書構築方法。 - 請求項1において、
前記検索履歴情報を入力とし、第1の検索用語を抽出し、第1登録候補用語データに保存する処理と、
編集前用語データと前記第1登録候補用語データとを比較し、前記編集前用語データに含まれていない第2の検索用語を前記第1登録候補用語データから抽出し、第2登録候補用語データとして保存する処理と、
前記編集前用語データに含まれる用語に前記第2の検索用語を関連づける処理と、
関連づけられた前記第2の検索用語を前記編集後用語データとして追加する処理とを有することを特徴とする辞書構築方法。 - 請求項2において、
前記編集前用語データを階層的に表示する処理を有することを特徴とする辞書構築方法。 - 請求項2において、
前記編集前用語データと前記編集後用語データは、同一のデータであることを特徴とする辞書構築方法。 - 請求項2記載の前記編集前用語データに含まれる用語に前記第2の検索用語を関連づける処理は、
前記第2の検索用語の中から登録候補の登録候補用語を選択する処理と、
前記登録候補用語を前記編集前用語データから検索し、類似度の高い用語順に提示する処理とを有することを特徴とする辞書構築方法。 - 請求項5記載の前記登録候補用語を前記編集前用語データから検索することは、正規表現又は検索属性データにより検索することを特徴とする辞書構築方法。
- 請求項2記載の前記編集前用語データに含まれる用語に前記第2の検索用語を関連づける処理は、
前記第2の検索用語の中から選択された登録候補用語を表示領域の中心部に配置して表示し、前記選択された登録候補用語と、前記編集前用語データに含まれる各用語との一致度を算出し、一致度の大きいものほど前記中心部に近く、一致度の小さいものほど前記中心部から遠い位置に、前記編集前用語データに含まれる各用語を表示する処理を有することを特徴とする辞書構築方法。 - 請求項2記載の前記編集前用語データに含まれる用語に前記第2の検索用語を関連づける処理は、
前記第2の検索用語の絞り込みを行うために、絞り込み条件を入力する処理と、
前記絞り込み条件を満足する第3の検索用語を検索し、提示する処理と、
前記第3の検索用語から登録候補用語を選択する処理とを有することを特徴とする辞書構築方法。 - 請求項8記載の前記第2の検索用語の絞り込みを行う処理は、
検索属性データ又は正規表現を利用して登録候補用語の絞り込み条件を入力する処理と、
前記絞り込み条件を満足する第3の検索用語を検索し、提示する処理と、
前記第3の検索用語から登録候補用語を選択する処理とを有することを特徴とする辞書構築処理。 - コンピュータに請求項2記載の辞書構築処理を実行させるためのプログラム。
- コンピュータに請求項2記載の辞書構築処理を実行させるためのプログラムを記録したコンピュータ読み取り可能な記憶媒体。
- 検索履歴データから登録候補用語の絞り込みを行うために、登録候補用語の絞り込み条件を入力する部分と、
絞り込まれた前記登録候補用語を表示する部分とを有する画面装置。 - 請求項12において、
前記登録候補用語を表示する表示条件を入力する部分とを有する画面装置。 - 検索履歴情報を入力とし、第1の検索用語を抽出し、第1登録候補用語データに保存する装置と、
編集前用語データと前記第1登録候補用語データとを比較し、前記編集前用語データに含まれていない第2の検索用語を前記第1登録候補用語データから抽出し、第2登録候補用語データに保存する装置と、
前記編集前用語データに含まれる用語に前記第2の検索用語を関連づける装置と、
関連づけられた前記第2の用語を前記編集後用語データに追加する装置とを有することを特徴とする辞書構築システム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003025359A JP2004234582A (ja) | 2003-02-03 | 2003-02-03 | 辞書構築方法,システム及び画面 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003025359A JP2004234582A (ja) | 2003-02-03 | 2003-02-03 | 辞書構築方法,システム及び画面 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2004234582A true JP2004234582A (ja) | 2004-08-19 |
Family
ID=32953661
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003025359A Withdrawn JP2004234582A (ja) | 2003-02-03 | 2003-02-03 | 辞書構築方法,システム及び画面 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2004234582A (ja) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008090802A (ja) * | 2006-10-05 | 2008-04-17 | Pioneer Electronic Corp | 情報処理装置、情報処理方法、およびプログラム |
| JP2010009262A (ja) * | 2008-06-26 | 2010-01-14 | Yahoo Japan Corp | ユーザに固有のイベントを判定する情報管理装置、情報管理方法及びプログラム |
| JP2010277415A (ja) * | 2009-05-29 | 2010-12-09 | Nippon Telegr & Teleph Corp <Ntt> | キーワード抽出方法、キーワード抽出装置およびキーワード抽出プログラム |
| JP2012190254A (ja) * | 2011-03-10 | 2012-10-04 | Fujitsu Ltd | 商品情報登録プログラム、商品情報登録方法および商品情報登録装置 |
| KR20210120584A (ko) * | 2020-03-27 | 2021-10-07 | 구주원 | 용어사전을 이용한 작업내역 기록 방법 및 시스템 |
| CN114077665A (zh) * | 2020-08-20 | 2022-02-22 | 中国电信股份有限公司 | 文本的分类的方法、存储介质及计算装置 |
-
2003
- 2003-02-03 JP JP2003025359A patent/JP2004234582A/ja not_active Withdrawn
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008090802A (ja) * | 2006-10-05 | 2008-04-17 | Pioneer Electronic Corp | 情報処理装置、情報処理方法、およびプログラム |
| JP2010009262A (ja) * | 2008-06-26 | 2010-01-14 | Yahoo Japan Corp | ユーザに固有のイベントを判定する情報管理装置、情報管理方法及びプログラム |
| JP2010277415A (ja) * | 2009-05-29 | 2010-12-09 | Nippon Telegr & Teleph Corp <Ntt> | キーワード抽出方法、キーワード抽出装置およびキーワード抽出プログラム |
| JP2012190254A (ja) * | 2011-03-10 | 2012-10-04 | Fujitsu Ltd | 商品情報登録プログラム、商品情報登録方法および商品情報登録装置 |
| KR20210120584A (ko) * | 2020-03-27 | 2021-10-07 | 구주원 | 용어사전을 이용한 작업내역 기록 방법 및 시스템 |
| KR102576985B1 (ko) * | 2020-03-27 | 2023-09-11 | 구주원 | 용어사전을 이용한 작업내역 기록 방법 및 시스템 |
| CN114077665A (zh) * | 2020-08-20 | 2022-02-22 | 中国电信股份有限公司 | 文本的分类的方法、存储介质及计算装置 |
| CN114077665B (zh) * | 2020-08-20 | 2025-02-07 | 中国电信股份有限公司 | 文本的分类的方法、存储介质及计算装置 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3870666B2 (ja) | 文書検索方法および装置並びにその処理プログラムを記録した記録媒体 | |
| US6915308B1 (en) | Method and apparatus for information mining and filtering | |
| KR100544514B1 (ko) | 검색 쿼리 연관성 판단 방법 및 시스템 | |
| CN103430172B (zh) | 检索装置、检索方法及程序 | |
| JP2001134575A (ja) | 頻出パターン検出方法およびシステム | |
| CN113190687A (zh) | 知识图谱的确定方法、装置、计算机设备及存储介质 | |
| CN112269816B (zh) | 一种政务预约事项相关性检索方法 | |
| JPH08153121A (ja) | 文書情報分類方法および文書情報分類装置 | |
| WO2009154153A1 (ja) | 文書検索システム | |
| US20040015485A1 (en) | Method and apparatus for improved internet searching | |
| JP2004220215A (ja) | 計算機を利用した業務誘導支援システムおよび業務誘導支援方法 | |
| JP2000285134A (ja) | 文書管理方法および文書管理装置および記憶媒体 | |
| CN103294845B (zh) | 业务分析设计辅助装置以及业务分析设计辅助方法 | |
| JP2011501849A (ja) | 情報マップ管理システムおよび情報マップ管理方法 | |
| CN102890690A (zh) | 目标信息搜索方法和装置 | |
| JP2000231570A (ja) | インターネット情報処理装置、インターネット情報処理方法およびその方法をコンピュータに実行させるプログラムを記録したコンピュータ読み取り可能な記録媒体 | |
| JP2004234582A (ja) | 辞書構築方法,システム及び画面 | |
| JP3429225B2 (ja) | データ検索プログラムを記憶した記憶媒体 | |
| CN107291951A (zh) | 数据处理方法、装置、存储介质和处理器 | |
| JPH1145252A (ja) | 情報検索装置およびその装置としてコンピュータを機能させるためのプログラムを記録したコンピュータ読み取り可能な記録媒体 | |
| JP2000231569A (ja) | インターネット情報検索装置、インターネット情報検索方法およびその方法をコンピュータに実行させるプログラムを記録したコンピュータ読み取り可能な記録媒体 | |
| JP4426893B2 (ja) | 文書検索方法、文書検索プログラムおよびこれを実行する文書検索装置 | |
| JPH117452A (ja) | ネットワークを介した情報収集方法および装置と該方法を実施するプログラムを記録した記録媒体 | |
| CN114528290A (zh) | 一种基于Solr的知识管理和检索方法及系统 | |
| JPH10228488A (ja) | 情報検索収集方法およびそのシステム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD01 | Notification of change of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7421 Effective date: 20060420 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20060822 |
|
| A761 | Written withdrawal of application |
Free format text: JAPANESE INTERMEDIATE CODE: A761 Effective date: 20060927 |