JP2014000086A - 真菌ペルオキシゲナーゼ及び適用方法 - Google Patents
真菌ペルオキシゲナーゼ及び適用方法 Download PDFInfo
- Publication number
- JP2014000086A JP2014000086A JP2013171739A JP2013171739A JP2014000086A JP 2014000086 A JP2014000086 A JP 2014000086A JP 2013171739 A JP2013171739 A JP 2013171739A JP 2013171739 A JP2013171739 A JP 2013171739A JP 2014000086 A JP2014000086 A JP 2014000086A
- Authority
- JP
- Japan
- Prior art keywords
- polypeptide
- seq
- sequence
- polynucleotide
- mature polypeptide
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 108010023506 peroxygenase Proteins 0.000 title claims abstract description 138
- 238000000034 method Methods 0.000 title claims description 121
- 230000002538 fungal effect Effects 0.000 title description 37
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 413
- 102000004196 processed proteins & peptides Human genes 0.000 claims abstract description 406
- 229920001184 polypeptide Polymers 0.000 claims abstract description 405
- 108091033319 polynucleotide Proteins 0.000 claims abstract description 111
- 239000002157 polynucleotide Substances 0.000 claims abstract description 111
- 102000040430 polynucleotide Human genes 0.000 claims abstract description 111
- 125000003729 nucleotide group Chemical group 0.000 claims abstract description 105
- 239000002773 nucleotide Substances 0.000 claims abstract description 103
- 230000000694 effects Effects 0.000 claims abstract description 81
- 239000000203 mixture Substances 0.000 claims abstract description 53
- 238000004519 manufacturing process Methods 0.000 claims abstract description 51
- 239000013604 expression vector Substances 0.000 claims abstract description 17
- 108090000623 proteins and genes Proteins 0.000 claims description 101
- 108091026890 Coding region Proteins 0.000 claims description 78
- JUJWROOIHBZHMG-UHFFFAOYSA-N Pyridine Chemical compound C1=CC=NC=C1 JUJWROOIHBZHMG-UHFFFAOYSA-N 0.000 claims description 57
- 230000014509 gene expression Effects 0.000 claims description 57
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 49
- 239000002299 complementary DNA Substances 0.000 claims description 49
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 47
- 102000004169 proteins and genes Human genes 0.000 claims description 45
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 44
- 108020004414 DNA Proteins 0.000 claims description 43
- 150000007523 nucleic acids Chemical class 0.000 claims description 43
- 150000001413 amino acids Chemical class 0.000 claims description 41
- 102000039446 nucleic acids Human genes 0.000 claims description 32
- 108020004707 nucleic acids Proteins 0.000 claims description 32
- 239000003599 detergent Substances 0.000 claims description 30
- 239000012634 fragment Substances 0.000 claims description 30
- 239000013612 plasmid Substances 0.000 claims description 29
- UMJSCPRVCHMLSP-UHFFFAOYSA-N pyridine Natural products COC1=CC=CN=C1 UMJSCPRVCHMLSP-UHFFFAOYSA-N 0.000 claims description 29
- 238000011282 treatment Methods 0.000 claims description 28
- 238000006243 chemical reaction Methods 0.000 claims description 26
- 238000006467 substitution reaction Methods 0.000 claims description 26
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 24
- 230000000295 complement effect Effects 0.000 claims description 20
- 238000012258 culturing Methods 0.000 claims description 20
- 238000007254 oxidation reaction Methods 0.000 claims description 20
- 241000588724 Escherichia coli Species 0.000 claims description 19
- 230000003647 oxidation Effects 0.000 claims description 17
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 claims description 17
- 150000001875 compounds Chemical class 0.000 claims description 16
- 230000008569 process Effects 0.000 claims description 15
- 238000012217 deletion Methods 0.000 claims description 14
- 230000037430 deletion Effects 0.000 claims description 14
- 239000007800 oxidant agent Substances 0.000 claims description 12
- 238000003780 insertion Methods 0.000 claims description 11
- 230000037431 insertion Effects 0.000 claims description 11
- 230000035772 mutation Effects 0.000 claims description 11
- 150000001204 N-oxides Chemical class 0.000 claims description 10
- 230000002255 enzymatic effect Effects 0.000 claims description 10
- 238000003259 recombinant expression Methods 0.000 claims description 10
- 230000009261 transgenic effect Effects 0.000 claims description 10
- MHAJPDPJQMAIIY-UHFFFAOYSA-N Hydrogen peroxide Chemical group OO MHAJPDPJQMAIIY-UHFFFAOYSA-N 0.000 claims description 9
- 239000000758 substrate Substances 0.000 claims description 9
- 230000001590 oxidative effect Effects 0.000 claims description 8
- 230000003197 catalytic effect Effects 0.000 claims description 7
- 230000014616 translation Effects 0.000 claims description 7
- 244000045069 Agrocybe aegerita Species 0.000 claims description 6
- 241001236774 Coprinellus radians Species 0.000 claims description 6
- 241000222511 Coprinus Species 0.000 claims description 6
- SMWDFEZZVXVKRB-UHFFFAOYSA-N Quinoline Chemical compound N1=CC=CC2=CC=CC=C21 SMWDFEZZVXVKRB-UHFFFAOYSA-N 0.000 claims description 6
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 claims description 6
- 239000000872 buffer Substances 0.000 claims description 6
- 230000001976 improved effect Effects 0.000 claims description 5
- 238000002955 isolation Methods 0.000 claims description 5
- 229910052760 oxygen Inorganic materials 0.000 claims description 5
- 239000001301 oxygen Substances 0.000 claims description 5
- 239000011541 reaction mixture Substances 0.000 claims description 5
- 238000005580 one pot reaction Methods 0.000 claims description 4
- 229910019142 PO4 Inorganic materials 0.000 claims description 3
- 125000000623 heterocyclic group Chemical group 0.000 claims description 3
- 239000003960 organic solvent Substances 0.000 claims description 3
- 241000222501 Agaricaceae Species 0.000 claims description 2
- 235000008121 Agrocybe aegerita Nutrition 0.000 claims description 2
- 150000007524 organic acids Chemical class 0.000 claims description 2
- 150000001451 organic peroxides Chemical class 0.000 claims description 2
- 239000010452 phosphate Substances 0.000 claims description 2
- 150000003222 pyridines Chemical class 0.000 claims description 2
- 241001660920 Agrocybe chaxingu Species 0.000 claims 1
- 241000222531 Bolbitiaceae Species 0.000 claims 1
- 241000222433 Tricholomataceae Species 0.000 claims 1
- 238000004090 dissolution Methods 0.000 claims 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 claims 1
- 125000004585 polycyclic heterocycle group Chemical group 0.000 claims 1
- 239000013598 vector Substances 0.000 abstract description 49
- 102000003992 Peroxidases Human genes 0.000 abstract description 16
- 241000682855 Aegerita Species 0.000 abstract description 13
- 108040007629 peroxidase activity proteins Proteins 0.000 abstract description 11
- 241000221198 Basidiomycota Species 0.000 abstract description 6
- 210000004027 cell Anatomy 0.000 description 180
- 102000004190 Enzymes Human genes 0.000 description 67
- 108090000790 Enzymes Proteins 0.000 description 67
- 229940088598 enzyme Drugs 0.000 description 64
- 241000196324 Embryophyta Species 0.000 description 60
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 44
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 44
- 235000001014 amino acid Nutrition 0.000 description 42
- 241000223218 Fusarium Species 0.000 description 40
- UHPMCKVQTMMPCG-UHFFFAOYSA-N 5,8-dihydroxy-2-methoxy-6-methyl-7-(2-oxopropyl)naphthalene-1,4-dione Chemical compound CC1=C(CC(C)=O)C(O)=C2C(=O)C(OC)=CC(=O)C2=C1O UHPMCKVQTMMPCG-UHFFFAOYSA-N 0.000 description 39
- 229940024606 amino acid Drugs 0.000 description 37
- 235000018102 proteins Nutrition 0.000 description 37
- 239000000047 product Substances 0.000 description 34
- 238000003752 polymerase chain reaction Methods 0.000 description 31
- 230000001580 bacterial effect Effects 0.000 description 27
- -1 aryl alcohols Chemical class 0.000 description 26
- 241000193830 Bacillus <bacterium> Species 0.000 description 21
- 238000010367 cloning Methods 0.000 description 21
- 230000004048 modification Effects 0.000 description 19
- 238000012986 modification Methods 0.000 description 19
- 239000000126 substance Substances 0.000 description 19
- 230000010076 replication Effects 0.000 description 17
- 240000006439 Aspergillus oryzae Species 0.000 description 16
- 235000002247 Aspergillus oryzae Nutrition 0.000 description 16
- 102000013142 Amylases Human genes 0.000 description 15
- 108010065511 Amylases Proteins 0.000 description 15
- 235000019418 amylase Nutrition 0.000 description 15
- 230000001105 regulatory effect Effects 0.000 description 15
- 230000009466 transformation Effects 0.000 description 15
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 14
- 101100161412 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) aap-2 gene Proteins 0.000 description 14
- 239000007788 liquid Substances 0.000 description 14
- 241000228212 Aspergillus Species 0.000 description 13
- 239000002609 medium Substances 0.000 description 13
- 235000014469 Bacillus subtilis Nutrition 0.000 description 12
- 102000035195 Peptidases Human genes 0.000 description 12
- 108091005804 Peptidases Proteins 0.000 description 12
- 239000000523 sample Substances 0.000 description 12
- 244000063299 Bacillus subtilis Species 0.000 description 11
- 108010084185 Cellulases Proteins 0.000 description 11
- 102000005575 Cellulases Human genes 0.000 description 11
- 241001494489 Thielavia Species 0.000 description 11
- 238000001802 infusion Methods 0.000 description 11
- 239000000463 material Substances 0.000 description 11
- 238000002703 mutagenesis Methods 0.000 description 11
- 231100000350 mutagenesis Toxicity 0.000 description 11
- 239000004382 Amylase Substances 0.000 description 10
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 10
- 241000194017 Streptococcus Species 0.000 description 10
- 241000223259 Trichoderma Species 0.000 description 10
- 229940072417 peroxidase Drugs 0.000 description 10
- 238000000746 purification Methods 0.000 description 10
- 241000894007 species Species 0.000 description 10
- 244000251987 Coprinus macrorhizus Species 0.000 description 9
- 235000001673 Coprinus macrorhizus Nutrition 0.000 description 9
- 108090001060 Lipase Proteins 0.000 description 9
- 102000004882 Lipase Human genes 0.000 description 9
- 240000007594 Oryza sativa Species 0.000 description 9
- 102000004316 Oxidoreductases Human genes 0.000 description 9
- 108090000854 Oxidoreductases Proteins 0.000 description 9
- 241000499912 Trichoderma reesei Species 0.000 description 9
- 230000015572 biosynthetic process Effects 0.000 description 9
- 108020004999 messenger RNA Proteins 0.000 description 9
- 238000002360 preparation method Methods 0.000 description 9
- 238000013518 transcription Methods 0.000 description 9
- 230000035897 transcription Effects 0.000 description 9
- 241000228245 Aspergillus niger Species 0.000 description 8
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 8
- 241000223198 Humicola Species 0.000 description 8
- 239000004367 Lipase Substances 0.000 description 8
- 235000007164 Oryza sativa Nutrition 0.000 description 8
- 239000004365 Protease Substances 0.000 description 8
- 239000000654 additive Substances 0.000 description 8
- 125000003118 aryl group Chemical group 0.000 description 8
- 238000004925 denaturation Methods 0.000 description 8
- 230000036425 denaturation Effects 0.000 description 8
- 230000010354 integration Effects 0.000 description 8
- 235000019421 lipase Nutrition 0.000 description 8
- 229910052757 nitrogen Inorganic materials 0.000 description 8
- 210000001938 protoplast Anatomy 0.000 description 8
- ILVXOBCQQYKLDS-UHFFFAOYSA-N pyridine N-oxide Chemical compound [O-][N+]1=CC=CC=C1 ILVXOBCQQYKLDS-UHFFFAOYSA-N 0.000 description 8
- 235000009566 rice Nutrition 0.000 description 8
- 238000003786 synthesis reaction Methods 0.000 description 8
- 210000001519 tissue Anatomy 0.000 description 8
- 108010035722 Chloride peroxidase Proteins 0.000 description 7
- 241000223221 Fusarium oxysporum Species 0.000 description 7
- 125000003412 L-alanyl group Chemical group [H]N([H])[C@@](C([H])([H])[H])(C(=O)[*])[H] 0.000 description 7
- 235000001006 Saccharomyces cerevisiae var diastaticus Nutrition 0.000 description 7
- 244000206963 Saccharomyces cerevisiae var. diastaticus Species 0.000 description 7
- 239000003054 catalyst Substances 0.000 description 7
- 229910001385 heavy metal Inorganic materials 0.000 description 7
- 238000009396 hybridization Methods 0.000 description 7
- 239000003921 oil Substances 0.000 description 7
- 235000019198 oils Nutrition 0.000 description 7
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 7
- 241000351920 Aspergillus nidulans Species 0.000 description 6
- 241000894006 Bacteria Species 0.000 description 6
- 108010059892 Cellulase Proteins 0.000 description 6
- 241000123346 Chrysosporium Species 0.000 description 6
- 241000233866 Fungi Species 0.000 description 6
- 108010029541 Laccase Proteins 0.000 description 6
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 6
- PXHVJJICTQNCMI-UHFFFAOYSA-N Nickel Chemical compound [Ni] PXHVJJICTQNCMI-UHFFFAOYSA-N 0.000 description 6
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 6
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 6
- 241000187432 Streptomyces coelicolor Species 0.000 description 6
- 239000002253 acid Substances 0.000 description 6
- 230000000996 additive effect Effects 0.000 description 6
- 108090000637 alpha-Amylases Proteins 0.000 description 6
- 125000000539 amino acid group Chemical group 0.000 description 6
- 238000004458 analytical method Methods 0.000 description 6
- 239000010426 asphalt Substances 0.000 description 6
- 238000004061 bleaching Methods 0.000 description 6
- 239000003795 chemical substances by application Substances 0.000 description 6
- 235000014113 dietary fatty acids Nutrition 0.000 description 6
- 238000004520 electroporation Methods 0.000 description 6
- 229930195729 fatty acid Natural products 0.000 description 6
- 239000000194 fatty acid Substances 0.000 description 6
- 238000000855 fermentation Methods 0.000 description 6
- 230000004151 fermentation Effects 0.000 description 6
- 230000006870 function Effects 0.000 description 6
- 239000008187 granular material Substances 0.000 description 6
- 238000005805 hydroxylation reaction Methods 0.000 description 6
- 239000003550 marker Substances 0.000 description 6
- VNWKTOKETHGBQD-UHFFFAOYSA-N methane Chemical compound C VNWKTOKETHGBQD-UHFFFAOYSA-N 0.000 description 6
- 244000005700 microbiome Species 0.000 description 6
- 239000002853 nucleic acid probe Substances 0.000 description 6
- 230000008488 polyadenylation Effects 0.000 description 6
- 230000002441 reversible effect Effects 0.000 description 6
- 238000012163 sequencing technique Methods 0.000 description 6
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 5
- 101000757144 Aspergillus niger Glucoamylase Proteins 0.000 description 5
- 241000193744 Bacillus amyloliquefaciens Species 0.000 description 5
- 241000194108 Bacillus licheniformis Species 0.000 description 5
- 241000146399 Ceriporiopsis Species 0.000 description 5
- 241000146406 Fusarium heterosporum Species 0.000 description 5
- 241000221779 Fusarium sambucinum Species 0.000 description 5
- 241000567178 Fusarium venenatum Species 0.000 description 5
- 241000193385 Geobacillus stearothermophilus Species 0.000 description 5
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 5
- 241001480714 Humicola insolens Species 0.000 description 5
- 102100027612 Kallikrein-11 Human genes 0.000 description 5
- 108700020962 Peroxidase Proteins 0.000 description 5
- 102000012288 Phosphopyruvate Hydratase Human genes 0.000 description 5
- 108010022181 Phosphopyruvate Hydratase Proteins 0.000 description 5
- 241000235070 Saccharomyces Species 0.000 description 5
- 241000194054 Streptococcus uberis Species 0.000 description 5
- 241000187747 Streptomyces Species 0.000 description 5
- 108010056079 Subtilisins Proteins 0.000 description 5
- 102000005158 Subtilisins Human genes 0.000 description 5
- YXFVVABEGXRONW-UHFFFAOYSA-N Toluene Chemical compound CC1=CC=CC=C1 YXFVVABEGXRONW-UHFFFAOYSA-N 0.000 description 5
- 101710152431 Trypsin-like protease Proteins 0.000 description 5
- 102000004139 alpha-Amylases Human genes 0.000 description 5
- 229940024171 alpha-amylase Drugs 0.000 description 5
- 229940025131 amylases Drugs 0.000 description 5
- 239000002585 base Substances 0.000 description 5
- 230000015556 catabolic process Effects 0.000 description 5
- 230000008859 change Effects 0.000 description 5
- 238000006731 degradation reaction Methods 0.000 description 5
- 150000004665 fatty acids Chemical class 0.000 description 5
- 230000012010 growth Effects 0.000 description 5
- 238000002744 homologous recombination Methods 0.000 description 5
- 230000006801 homologous recombination Effects 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 238000003199 nucleic acid amplification method Methods 0.000 description 5
- 235000015097 nutrients Nutrition 0.000 description 5
- 150000002978 peroxides Chemical class 0.000 description 5
- 230000037039 plant physiology Effects 0.000 description 5
- 239000010802 sludge Substances 0.000 description 5
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 5
- 229940115922 streptococcus uberis Drugs 0.000 description 5
- 238000013519 translation Methods 0.000 description 5
- 238000005406 washing Methods 0.000 description 5
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 4
- 241001674001 Chrysosporium tropicum Species 0.000 description 4
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 4
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 4
- 241000235395 Mucor Species 0.000 description 4
- 241000235403 Rhizomucor miehei Species 0.000 description 4
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 4
- 238000002105 Southern blotting Methods 0.000 description 4
- 108091081024 Start codon Proteins 0.000 description 4
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 4
- 108010048241 acetamidase Proteins 0.000 description 4
- 150000001299 aldehydes Chemical class 0.000 description 4
- 229960000723 ampicillin Drugs 0.000 description 4
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 4
- 230000003321 amplification Effects 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- 210000004899 c-terminal region Anatomy 0.000 description 4
- 239000012876 carrier material Substances 0.000 description 4
- 238000006555 catalytic reaction Methods 0.000 description 4
- 230000002759 chromosomal effect Effects 0.000 description 4
- 238000000605 extraction Methods 0.000 description 4
- 239000000499 gel Substances 0.000 description 4
- 230000002209 hydrophobic effect Effects 0.000 description 4
- 230000033444 hydroxylation Effects 0.000 description 4
- 230000002779 inactivation Effects 0.000 description 4
- 230000001965 increasing effect Effects 0.000 description 4
- 230000003834 intracellular effect Effects 0.000 description 4
- 239000011159 matrix material Substances 0.000 description 4
- 230000007935 neutral effect Effects 0.000 description 4
- 239000000123 paper Substances 0.000 description 4
- 238000012545 processing Methods 0.000 description 4
- 235000019419 proteases Nutrition 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 238000012216 screening Methods 0.000 description 4
- 239000002689 soil Substances 0.000 description 4
- 239000000243 solution Substances 0.000 description 4
- 239000007858 starting material Substances 0.000 description 4
- 239000004094 surface-active agent Substances 0.000 description 4
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 3
- CSCPPACGZOOCGX-UHFFFAOYSA-N Acetone Chemical compound CC(C)=O CSCPPACGZOOCGX-UHFFFAOYSA-N 0.000 description 3
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 3
- 241001019659 Acremonium <Plectosphaerellaceae> Species 0.000 description 3
- 102100034044 All-trans-retinol dehydrogenase [NAD(+)] ADH1B Human genes 0.000 description 3
- 101710193111 All-trans-retinol dehydrogenase [NAD(+)] ADH4 Proteins 0.000 description 3
- 108010037870 Anthranilate Synthase Proteins 0.000 description 3
- 241001513093 Aspergillus awamori Species 0.000 description 3
- 241000892910 Aspergillus foetidus Species 0.000 description 3
- 241000193422 Bacillus lentus Species 0.000 description 3
- WVDDGKGOMKODPV-UHFFFAOYSA-N Benzyl alcohol Chemical compound OCC1=CC=CC=C1 WVDDGKGOMKODPV-UHFFFAOYSA-N 0.000 description 3
- 101710121765 Endo-1,4-beta-xylanase Proteins 0.000 description 3
- 241000567163 Fusarium cerealis Species 0.000 description 3
- 241001112697 Fusarium reticulatum Species 0.000 description 3
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 3
- 108010073178 Glucan 1,4-alpha-Glucosidase Proteins 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- 125000000570 L-alpha-aspartyl group Chemical group [H]OC(=O)C([H])([H])[C@]([H])(N([H])[H])C(*)=O 0.000 description 3
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 3
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 3
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 3
- 241000186660 Lactobacillus Species 0.000 description 3
- 241000209510 Liliopsida Species 0.000 description 3
- 241000221960 Neurospora Species 0.000 description 3
- 108700026244 Open Reading Frames Proteins 0.000 description 3
- 241000228143 Penicillium Species 0.000 description 3
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 3
- 241000589516 Pseudomonas Species 0.000 description 3
- RWRDLPDLKQPQOW-UHFFFAOYSA-N Pyrrolidine Chemical compound C1CCNC1 RWRDLPDLKQPQOW-UHFFFAOYSA-N 0.000 description 3
- 108020004511 Recombinant DNA Proteins 0.000 description 3
- 244000061456 Solanum tuberosum Species 0.000 description 3
- 235000002595 Solanum tuberosum Nutrition 0.000 description 3
- 241000958303 Streptomyces achromogenes Species 0.000 description 3
- 241001468227 Streptomyces avermitilis Species 0.000 description 3
- 241000187392 Streptomyces griseus Species 0.000 description 3
- 241000187398 Streptomyces lividans Species 0.000 description 3
- 108090000787 Subtilisin Proteins 0.000 description 3
- 241000223258 Thermomyces lanuginosus Species 0.000 description 3
- 241000223260 Trichoderma harzianum Species 0.000 description 3
- 241000223261 Trichoderma viride Species 0.000 description 3
- 102000005924 Triose-Phosphate Isomerase Human genes 0.000 description 3
- 108700015934 Triose-phosphate isomerases Proteins 0.000 description 3
- 241000202898 Ureaplasma Species 0.000 description 3
- 240000006677 Vicia faba Species 0.000 description 3
- 235000010749 Vicia faba Nutrition 0.000 description 3
- 241000700605 Viruses Species 0.000 description 3
- IXKSXJFAGXLQOQ-XISFHERQSA-N WHWLQLKPGQPMY Chemical compound C([C@@H](C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CNC=N1 IXKSXJFAGXLQOQ-XISFHERQSA-N 0.000 description 3
- 240000008042 Zea mays Species 0.000 description 3
- 235000002017 Zea mays subsp mays Nutrition 0.000 description 3
- 108010051210 beta-Fructofuranosidase Proteins 0.000 description 3
- KGBXLFKZBHKPEV-UHFFFAOYSA-N boric acid Chemical compound OB(O)O KGBXLFKZBHKPEV-UHFFFAOYSA-N 0.000 description 3
- 238000010804 cDNA synthesis Methods 0.000 description 3
- 108010089934 carbohydrase Proteins 0.000 description 3
- 229940106157 cellulase Drugs 0.000 description 3
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 3
- 230000021615 conjugation Effects 0.000 description 3
- 108010005400 cutinase Proteins 0.000 description 3
- 230000000593 degrading effect Effects 0.000 description 3
- 238000011033 desalting Methods 0.000 description 3
- 239000003814 drug Substances 0.000 description 3
- 238000001914 filtration Methods 0.000 description 3
- 238000009472 formulation Methods 0.000 description 3
- 230000004927 fusion Effects 0.000 description 3
- 229930195733 hydrocarbon Natural products 0.000 description 3
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 3
- 239000003112 inhibitor Substances 0.000 description 3
- 239000000543 intermediate Substances 0.000 description 3
- 239000001573 invertase Substances 0.000 description 3
- 235000011073 invertase Nutrition 0.000 description 3
- 229940039696 lactobacillus Drugs 0.000 description 3
- 239000010410 layer Substances 0.000 description 3
- 229920005610 lignin Polymers 0.000 description 3
- 229910021645 metal ion Inorganic materials 0.000 description 3
- 108010009977 methane monooxygenase Proteins 0.000 description 3
- 230000000813 microbial effect Effects 0.000 description 3
- 238000007857 nested PCR Methods 0.000 description 3
- 229910052759 nickel Inorganic materials 0.000 description 3
- 229930027945 nicotinamide-adenine dinucleotide Natural products 0.000 description 3
- 239000002245 particle Substances 0.000 description 3
- 229920001223 polyethylene glycol Polymers 0.000 description 3
- 239000000376 reactant Substances 0.000 description 3
- 230000028327 secretion Effects 0.000 description 3
- 238000000926 separation method Methods 0.000 description 3
- 239000002904 solvent Substances 0.000 description 3
- 235000000346 sugar Nutrition 0.000 description 3
- 229910052717 sulfur Inorganic materials 0.000 description 3
- 239000011593 sulfur Substances 0.000 description 3
- 230000002103 transcriptional effect Effects 0.000 description 3
- 229910052720 vanadium Inorganic materials 0.000 description 3
- GPPXJZIENCGNKB-UHFFFAOYSA-N vanadium Chemical compound [V]#[V] GPPXJZIENCGNKB-UHFFFAOYSA-N 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- OEGPRYNGFWGMMV-UHFFFAOYSA-N (3,4-dimethoxyphenyl)methanol Chemical compound COC1=CC=C(CO)C=C1OC OEGPRYNGFWGMMV-UHFFFAOYSA-N 0.000 description 2
- SCYULBFZEHDVBN-UHFFFAOYSA-N 1,1-Dichloroethane Chemical compound CC(Cl)Cl SCYULBFZEHDVBN-UHFFFAOYSA-N 0.000 description 2
- LUBJCRLGQSPQNN-UHFFFAOYSA-N 1-Phenylurea Chemical compound NC(=O)NC1=CC=CC=C1 LUBJCRLGQSPQNN-UHFFFAOYSA-N 0.000 description 2
- JMTMSDXUXJISAY-UHFFFAOYSA-N 2H-benzotriazol-4-ol Chemical compound OC1=CC=CC2=C1N=NN2 JMTMSDXUXJISAY-UHFFFAOYSA-N 0.000 description 2
- 108020005345 3' Untranslated Regions Proteins 0.000 description 2
- OSJPPGNTCRNQQC-UWTATZPHSA-N 3-phospho-D-glyceric acid Chemical compound OC(=O)[C@H](O)COP(O)(O)=O OSJPPGNTCRNQQC-UWTATZPHSA-N 0.000 description 2
- 108010011619 6-Phytase Proteins 0.000 description 2
- RZVAJINKPMORJF-UHFFFAOYSA-N Acetaminophen Chemical compound CC(=O)NC1=CC=C(O)C=C1 RZVAJINKPMORJF-UHFFFAOYSA-N 0.000 description 2
- 229920002126 Acrylic acid copolymer Polymers 0.000 description 2
- 101710197633 Actin-1 Proteins 0.000 description 2
- 229920000936 Agarose Polymers 0.000 description 2
- 241000589158 Agrobacterium Species 0.000 description 2
- 102000007698 Alcohol dehydrogenase Human genes 0.000 description 2
- 108010021809 Alcohol dehydrogenase Proteins 0.000 description 2
- 108010025188 Alcohol oxidase Proteins 0.000 description 2
- 102000004400 Aminopeptidases Human genes 0.000 description 2
- 108090000915 Aminopeptidases Proteins 0.000 description 2
- 101100163849 Arabidopsis thaliana ARS1 gene Proteins 0.000 description 2
- 108010017640 Aspartic Acid Proteases Proteins 0.000 description 2
- 241000228215 Aspergillus aculeatus Species 0.000 description 2
- 241001225321 Aspergillus fumigatus Species 0.000 description 2
- 101000690713 Aspergillus niger Alpha-glucosidase Proteins 0.000 description 2
- 241000223651 Aureobasidium Species 0.000 description 2
- 108090000145 Bacillolysin Proteins 0.000 description 2
- 241000193752 Bacillus circulans Species 0.000 description 2
- 241000193749 Bacillus coagulans Species 0.000 description 2
- 108010029675 Bacillus licheniformis alpha-amylase Proteins 0.000 description 2
- 241000194103 Bacillus pumilus Species 0.000 description 2
- 241000193388 Bacillus thuringiensis Species 0.000 description 2
- 108091005658 Basic proteases Proteins 0.000 description 2
- 240000002791 Brassica napus Species 0.000 description 2
- 241000193764 Brevibacillus brevis Species 0.000 description 2
- 241000589876 Campylobacter Species 0.000 description 2
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 2
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 2
- 108010006303 Carboxypeptidases Proteins 0.000 description 2
- 102000005367 Carboxypeptidases Human genes 0.000 description 2
- 108010053835 Catalase Proteins 0.000 description 2
- 102100035882 Catalase Human genes 0.000 description 2
- 102000030523 Catechol oxidase Human genes 0.000 description 2
- 108010031396 Catechol oxidase Proteins 0.000 description 2
- 108010008885 Cellulose 1,4-beta-Cellobiosidase Proteins 0.000 description 2
- 108010022172 Chitinases Proteins 0.000 description 2
- 102000012286 Chitinases Human genes 0.000 description 2
- 241001674013 Chrysosporium lucknowense Species 0.000 description 2
- 241000080524 Chrysosporium queenslandicum Species 0.000 description 2
- 241000355696 Chrysosporium zonatum Species 0.000 description 2
- 241000193403 Clostridium Species 0.000 description 2
- 108020004705 Codon Proteins 0.000 description 2
- 241001337994 Cryptococcus <scale insect> Species 0.000 description 2
- 108010015742 Cytochrome P-450 Enzyme System Proteins 0.000 description 2
- 102000002004 Cytochrome P-450 Enzyme System Human genes 0.000 description 2
- 108010052832 Cytochromes Proteins 0.000 description 2
- 102000018832 Cytochromes Human genes 0.000 description 2
- 101710088194 Dehydrogenase Proteins 0.000 description 2
- 108010053770 Deoxyribonucleases Proteins 0.000 description 2
- 102000016911 Deoxyribonucleases Human genes 0.000 description 2
- MYMOFIZGZYHOMD-UHFFFAOYSA-N Dioxygen Chemical compound O=O MYMOFIZGZYHOMD-UHFFFAOYSA-N 0.000 description 2
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 2
- 241000194033 Enterococcus Species 0.000 description 2
- 108010062466 Enzyme Precursors Proteins 0.000 description 2
- 102000010911 Enzyme Precursors Human genes 0.000 description 2
- 108090000371 Esterases Proteins 0.000 description 2
- PLUBXMRUUVWRLT-UHFFFAOYSA-N Ethyl methanesulfonate Chemical compound CCOS(C)(=O)=O PLUBXMRUUVWRLT-UHFFFAOYSA-N 0.000 description 2
- IAYPIBMASNFSPL-UHFFFAOYSA-N Ethylene oxide Chemical group C1CO1 IAYPIBMASNFSPL-UHFFFAOYSA-N 0.000 description 2
- 241000206602 Eukaryota Species 0.000 description 2
- 101710157404 Flavin reductase Proteins 0.000 description 2
- 102100027944 Flavin reductase (NADPH) Human genes 0.000 description 2
- 241000589565 Flavobacterium Species 0.000 description 2
- 241000145614 Fusarium bactridioides Species 0.000 description 2
- 241000223194 Fusarium culmorum Species 0.000 description 2
- 241001014439 Fusarium sarcochroum Species 0.000 description 2
- 241000223192 Fusarium sporotrichioides Species 0.000 description 2
- 241000605909 Fusobacterium Species 0.000 description 2
- 102000048120 Galactokinases Human genes 0.000 description 2
- 108700023157 Galactokinases Proteins 0.000 description 2
- 241000146398 Gelatoporia subvermispora Species 0.000 description 2
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 2
- 241000626621 Geobacillus Species 0.000 description 2
- 101100369308 Geobacillus stearothermophilus nprS gene Proteins 0.000 description 2
- 101100080316 Geobacillus stearothermophilus nprT gene Proteins 0.000 description 2
- 108010015776 Glucose oxidase Proteins 0.000 description 2
- 239000004366 Glucose oxidase Substances 0.000 description 2
- 241000589989 Helicobacter Species 0.000 description 2
- SIKJAQJRHWYJAI-UHFFFAOYSA-N Indole Chemical compound C1=CC=C2NC=CC2=C1 SIKJAQJRHWYJAI-UHFFFAOYSA-N 0.000 description 2
- 241000235649 Kluyveromyces Species 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 2
- 125000003440 L-leucyl group Chemical group O=C([*])[C@](N([H])[H])([H])C([H])([H])C(C([H])([H])[H])([H])C([H])([H])[H] 0.000 description 2
- 125000002842 L-seryl group Chemical group O=C([*])[C@](N([H])[H])([H])C([H])([H])O[H] 0.000 description 2
- 241001149420 Laccaria bicolor Species 0.000 description 2
- 241000194036 Lactococcus Species 0.000 description 2
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- 108010054377 Mannosidases Proteins 0.000 description 2
- 102000001696 Mannosidases Human genes 0.000 description 2
- 241000589346 Methylococcus capsulatus Species 0.000 description 2
- YNAVUWVOSKDBBP-UHFFFAOYSA-N Morpholine Chemical compound C1COCCN1 YNAVUWVOSKDBBP-UHFFFAOYSA-N 0.000 description 2
- ZMXDDKWLCZADIW-UHFFFAOYSA-N N,N-Dimethylformamide Chemical compound CN(C)C=O ZMXDDKWLCZADIW-UHFFFAOYSA-N 0.000 description 2
- VZUNGTLZRAYYDE-UHFFFAOYSA-N N-methyl-N'-nitro-N-nitrosoguanidine Chemical compound O=NN(C)C(=N)N[N+]([O-])=O VZUNGTLZRAYYDE-UHFFFAOYSA-N 0.000 description 2
- 238000005481 NMR spectroscopy Methods 0.000 description 2
- UFWIBTONFRDIAS-UHFFFAOYSA-N Naphthalene Chemical compound C1=CC=CC2=CC=CC=C21 UFWIBTONFRDIAS-UHFFFAOYSA-N 0.000 description 2
- 241000588653 Neisseria Species 0.000 description 2
- 241000233892 Neocallimastix Species 0.000 description 2
- 241001072230 Oceanobacillus Species 0.000 description 2
- 241000233654 Oomycetes Species 0.000 description 2
- 241001236817 Paecilomyces <Clavicipitaceae> Species 0.000 description 2
- 102000007079 Peptide Fragments Human genes 0.000 description 2
- 108010033276 Peptide Fragments Proteins 0.000 description 2
- 241000222385 Phanerochaete Species 0.000 description 2
- 241000235648 Pichia Species 0.000 description 2
- NQRYJNQNLNOLGT-UHFFFAOYSA-N Piperidine Chemical compound C1CCNCC1 NQRYJNQNLNOLGT-UHFFFAOYSA-N 0.000 description 2
- 241000235379 Piromyces Species 0.000 description 2
- RJKFOVLPORLFTN-LEKSSAKUSA-N Progesterone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H](C(=O)C)[C@@]1(C)CC2 RJKFOVLPORLFTN-LEKSSAKUSA-N 0.000 description 2
- KAESVJOAVNADME-UHFFFAOYSA-N Pyrrole Chemical compound C=1C=CNC=1 KAESVJOAVNADME-UHFFFAOYSA-N 0.000 description 2
- 241000235402 Rhizomucor Species 0.000 description 2
- 241000316848 Rhodococcus <scale insect> Species 0.000 description 2
- 108010083644 Ribonucleases Proteins 0.000 description 2
- 102000006382 Ribonucleases Human genes 0.000 description 2
- 235000003534 Saccharomyces carlsbergensis Nutrition 0.000 description 2
- 241001123227 Saccharomyces pastorianus Species 0.000 description 2
- 241000607142 Salmonella Species 0.000 description 2
- 241000222480 Schizophyllum Species 0.000 description 2
- 241000235346 Schizosaccharomyces Species 0.000 description 2
- 101100097319 Schizosaccharomyces pombe (strain 972 / ATCC 24843) ala1 gene Proteins 0.000 description 2
- 238000012300 Sequence Analysis Methods 0.000 description 2
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 2
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 2
- 235000011684 Sorghum saccharatum Nutrition 0.000 description 2
- 241000191940 Staphylococcus Species 0.000 description 2
- 241000193996 Streptococcus pyogenes Species 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- 241001149964 Tolypocladium Species 0.000 description 2
- 108060008539 Transglutaminase Proteins 0.000 description 2
- 241000223262 Trichoderma longibrachiatum Species 0.000 description 2
- 235000021307 Triticum Nutrition 0.000 description 2
- 244000098338 Triticum aestivum Species 0.000 description 2
- 108060008724 Tyrosinase Proteins 0.000 description 2
- 102000003425 Tyrosinase Human genes 0.000 description 2
- 241000235013 Yarrowia Species 0.000 description 2
- 235000016383 Zea mays subsp huehuetenangensis Nutrition 0.000 description 2
- XJLXINKUBYWONI-DQQFMEOOSA-N [[(2r,3r,4r,5r)-5-(6-aminopurin-9-yl)-3-hydroxy-4-phosphonooxyoxolan-2-yl]methoxy-hydroxyphosphoryl] [(2s,3r,4s,5s)-5-(3-carbamoylpyridin-1-ium-1-yl)-3,4-dihydroxyoxolan-2-yl]methyl phosphate Chemical compound NC(=O)C1=CC=C[N+]([C@@H]2[C@H]([C@@H](O)[C@H](COP([O-])(=O)OP(O)(=O)OC[C@@H]3[C@H]([C@@H](OP(O)(O)=O)[C@@H](O3)N3C4=NC=NC(N)=C4N=C3)O)O2)O)=C1 XJLXINKUBYWONI-DQQFMEOOSA-N 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- 238000000246 agarose gel electrophoresis Methods 0.000 description 2
- 239000003570 air Substances 0.000 description 2
- 235000004279 alanine Nutrition 0.000 description 2
- 238000012867 alanine scanning Methods 0.000 description 2
- 101150078331 ama-1 gene Proteins 0.000 description 2
- 238000000137 annealing Methods 0.000 description 2
- 230000000692 anti-sense effect Effects 0.000 description 2
- 229940088710 antibiotic agent Drugs 0.000 description 2
- 239000012736 aqueous medium Substances 0.000 description 2
- 229940091771 aspergillus fumigatus Drugs 0.000 description 2
- 229940054340 bacillus coagulans Drugs 0.000 description 2
- 229940097012 bacillus thuringiensis Drugs 0.000 description 2
- 108010005774 beta-Galactosidase Proteins 0.000 description 2
- 102000005936 beta-Galactosidase Human genes 0.000 description 2
- 102000006995 beta-Glucosidase Human genes 0.000 description 2
- 108010047754 beta-Glucosidase Proteins 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- 239000012620 biological material Substances 0.000 description 2
- 230000033228 biological regulation Effects 0.000 description 2
- 239000004327 boric acid Substances 0.000 description 2
- 239000006227 byproduct Substances 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 2
- 230000006860 carbon metabolism Effects 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 238000004523 catalytic cracking Methods 0.000 description 2
- 230000036978 cell physiology Effects 0.000 description 2
- 210000002421 cell wall Anatomy 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 230000009920 chelation Effects 0.000 description 2
- 239000002962 chemical mutagen Substances 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 210000003763 chloroplast Anatomy 0.000 description 2
- 238000004587 chromatography analysis Methods 0.000 description 2
- 210000000349 chromosome Anatomy 0.000 description 2
- 238000003776 cleavage reaction Methods 0.000 description 2
- 239000011248 coating agent Substances 0.000 description 2
- 238000000576 coating method Methods 0.000 description 2
- 239000000571 coke Substances 0.000 description 2
- 239000000084 colloidal system Substances 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 239000010779 crude oil Substances 0.000 description 2
- 230000002950 deficient Effects 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 230000001627 detrimental effect Effects 0.000 description 2
- 238000002050 diffraction method Methods 0.000 description 2
- OSVXSBDYLRYLIG-UHFFFAOYSA-N dioxidochlorine(.) Chemical compound O=Cl=O OSVXSBDYLRYLIG-UHFFFAOYSA-N 0.000 description 2
- 229910001882 dioxygen Inorganic materials 0.000 description 2
- 238000004851 dishwashing Methods 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 238000010410 dusting Methods 0.000 description 2
- 235000013399 edible fruits Nutrition 0.000 description 2
- 238000001962 electrophoresis Methods 0.000 description 2
- 210000002257 embryonic structure Anatomy 0.000 description 2
- 239000003797 essential amino acid Substances 0.000 description 2
- 235000020776 essential amino acid Nutrition 0.000 description 2
- 230000007717 exclusion Effects 0.000 description 2
- 239000004744 fabric Substances 0.000 description 2
- 150000002191 fatty alcohols Chemical class 0.000 description 2
- 239000006260 foam Substances 0.000 description 2
- 239000000446 fuel Substances 0.000 description 2
- 239000000417 fungicide Substances 0.000 description 2
- 108020001507 fusion proteins Proteins 0.000 description 2
- 102000037865 fusion proteins Human genes 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 108010061330 glucan 1,4-alpha-maltohydrolase Proteins 0.000 description 2
- 229940116332 glucose oxidase Drugs 0.000 description 2
- 235000019420 glucose oxidase Nutrition 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 235000008216 herbs Nutrition 0.000 description 2
- 150000002391 heterocyclic compounds Chemical class 0.000 description 2
- 239000005556 hormone Substances 0.000 description 2
- 229940088597 hormone Drugs 0.000 description 2
- 150000002430 hydrocarbons Chemical class 0.000 description 2
- JYGXADMDTFJGBT-VWUMJDOOSA-N hydrocortisone Chemical compound O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 JYGXADMDTFJGBT-VWUMJDOOSA-N 0.000 description 2
- NPZTUJOABDZTLV-UHFFFAOYSA-N hydroxybenzotriazole Substances O=C1C=CC=C2NNN=C12 NPZTUJOABDZTLV-UHFFFAOYSA-N 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 238000011065 in-situ storage Methods 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 150000002500 ions Chemical class 0.000 description 2
- AWJUIBRHMBBTKR-UHFFFAOYSA-N isoquinoline Chemical compound C1=NC=CC2=CC=CC=C21 AWJUIBRHMBBTKR-UHFFFAOYSA-N 0.000 description 2
- 239000002655 kraft paper Substances 0.000 description 2
- JVTAAEKCZFNVCJ-UHFFFAOYSA-N lactic acid Chemical compound CC(O)C(O)=O JVTAAEKCZFNVCJ-UHFFFAOYSA-N 0.000 description 2
- 238000007834 ligase chain reaction Methods 0.000 description 2
- 235000009973 maize Nutrition 0.000 description 2
- 238000001819 mass spectrum Methods 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 2
- 108010020132 microbial serine proteinases Proteins 0.000 description 2
- 230000003505 mutagenic effect Effects 0.000 description 2
- 229920000847 nonoxynol Polymers 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- 239000001814 pectin Substances 0.000 description 2
- 229920001277 pectin Polymers 0.000 description 2
- 235000010987 pectin Nutrition 0.000 description 2
- NDTYTMIUWGWIMO-UHFFFAOYSA-N perillyl alcohol Chemical compound CC(=C)C1CCC(CO)=CC1 NDTYTMIUWGWIMO-UHFFFAOYSA-N 0.000 description 2
- 230000002085 persistent effect Effects 0.000 description 2
- 239000003208 petroleum Substances 0.000 description 2
- 238000005222 photoaffinity labeling Methods 0.000 description 2
- 229940085127 phytase Drugs 0.000 description 2
- 125000005575 polycyclic aromatic hydrocarbon group Chemical group 0.000 description 2
- 229920000642 polymer Polymers 0.000 description 2
- 229920005862 polyol Polymers 0.000 description 2
- 150000003077 polyols Chemical class 0.000 description 2
- 150000004032 porphyrins Chemical class 0.000 description 2
- 230000004481 post-translational protein modification Effects 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 235000013772 propylene glycol Nutrition 0.000 description 2
- 125000006239 protecting group Chemical group 0.000 description 2
- 101150054232 pyrG gene Proteins 0.000 description 2
- 230000035484 reaction time Effects 0.000 description 2
- 230000009257 reactivity Effects 0.000 description 2
- 230000006798 recombination Effects 0.000 description 2
- 238000005215 recombination Methods 0.000 description 2
- 238000007670 refining Methods 0.000 description 2
- 230000008929 regeneration Effects 0.000 description 2
- 238000011069 regeneration method Methods 0.000 description 2
- 239000011347 resin Substances 0.000 description 2
- 229920005989 resin Polymers 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 230000007017 scission Effects 0.000 description 2
- 230000003248 secreting effect Effects 0.000 description 2
- 238000010187 selection method Methods 0.000 description 2
- 150000004760 silicates Chemical class 0.000 description 2
- 238000002741 site-directed mutagenesis Methods 0.000 description 2
- 239000002002 slurry Substances 0.000 description 2
- 239000000344 soap Substances 0.000 description 2
- 150000005846 sugar alcohols Chemical class 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- CIHOLLKRGTVIJN-UHFFFAOYSA-N tert‐butyl hydroperoxide Chemical compound CC(C)(C)OO CIHOLLKRGTVIJN-UHFFFAOYSA-N 0.000 description 2
- 239000003440 toxic substance Substances 0.000 description 2
- 238000010361 transduction Methods 0.000 description 2
- 230000026683 transduction Effects 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 238000011426 transformation method Methods 0.000 description 2
- 230000001131 transforming effect Effects 0.000 description 2
- 102000003601 transglutaminase Human genes 0.000 description 2
- 238000005292 vacuum distillation Methods 0.000 description 2
- 229930007631 (-)-perillyl alcohol Natural products 0.000 description 1
- SXERGJJQSKIUIC-SSDOTTSWSA-N (2r)-2-phenoxypropanoic acid Chemical compound OC(=O)[C@@H](C)OC1=CC=CC=C1 SXERGJJQSKIUIC-SSDOTTSWSA-N 0.000 description 1
- OCUSNPIJIZCRSZ-ZTZWCFDHSA-N (2s)-2-amino-3-methylbutanoic acid;(2s)-2-amino-4-methylpentanoic acid;(2s,3s)-2-amino-3-methylpentanoic acid Chemical compound CC(C)[C@H](N)C(O)=O.CC[C@H](C)[C@H](N)C(O)=O.CC(C)C[C@H](N)C(O)=O OCUSNPIJIZCRSZ-ZTZWCFDHSA-N 0.000 description 1
- JQFLYFRHDIHZFZ-RXMQYKEDSA-N (2s)-3,3-dimethylpyrrolidine-2-carboxylic acid Chemical compound CC1(C)CCN[C@@H]1C(O)=O JQFLYFRHDIHZFZ-RXMQYKEDSA-N 0.000 description 1
- CNPSFBUUYIVHAP-AKGZTFGVSA-N (2s)-3-methylpyrrolidine-2-carboxylic acid Chemical compound CC1CCN[C@@H]1C(O)=O CNPSFBUUYIVHAP-AKGZTFGVSA-N 0.000 description 1
- FQVLRGLGWNWPSS-BXBUPLCLSA-N (4r,7s,10s,13s,16r)-16-acetamido-13-(1h-imidazol-5-ylmethyl)-10-methyl-6,9,12,15-tetraoxo-7-propan-2-yl-1,2-dithia-5,8,11,14-tetrazacycloheptadecane-4-carboxamide Chemical compound N1C(=O)[C@@H](NC(C)=O)CSSC[C@@H](C(N)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C)NC(=O)[C@@H]1CC1=CN=CN1 FQVLRGLGWNWPSS-BXBUPLCLSA-N 0.000 description 1
- PVPBBTJXIKFICP-UHFFFAOYSA-N (7-aminophenothiazin-3-ylidene)azanium;chloride Chemical compound [Cl-].C1=CC(=[NH2+])C=C2SC3=CC(N)=CC=C3N=C21 PVPBBTJXIKFICP-UHFFFAOYSA-N 0.000 description 1
- FUFLCEKSBBHCMO-UHFFFAOYSA-N 11-dehydrocorticosterone Natural products O=C1CCC2(C)C3C(=O)CC(C)(C(CC4)C(=O)CO)C4C3CCC2=C1 FUFLCEKSBBHCMO-UHFFFAOYSA-N 0.000 description 1
- OGBQILNBLMPPDP-UHFFFAOYSA-N 2,3,4,7,8-Pentachlorodibenzofuran Chemical compound O1C2=C(Cl)C(Cl)=C(Cl)C=C2C2=C1C=C(Cl)C(Cl)=C2 OGBQILNBLMPPDP-UHFFFAOYSA-N 0.000 description 1
- OMGHIGVFLOPEHJ-UHFFFAOYSA-N 2,5-dihydro-1h-pyrrol-1-ium-2-carboxylate Chemical compound OC(=O)C1NCC=C1 OMGHIGVFLOPEHJ-UHFFFAOYSA-N 0.000 description 1
- HIXDQWDOVZUNNA-UHFFFAOYSA-N 2-(3,4-dimethoxyphenyl)-5-hydroxy-7-methoxychromen-4-one Chemical compound C=1C(OC)=CC(O)=C(C(C=2)=O)C=1OC=2C1=CC=C(OC)C(OC)=C1 HIXDQWDOVZUNNA-UHFFFAOYSA-N 0.000 description 1
- FUOOLUPWFVMBKG-UHFFFAOYSA-N 2-Aminoisobutyric acid Chemical compound CC(C)(N)C(O)=O FUOOLUPWFVMBKG-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- CDUUKBXTEOFITR-BYPYZUCNSA-N 2-methyl-L-serine Chemical compound OC[C@@]([NH3+])(C)C([O-])=O CDUUKBXTEOFITR-BYPYZUCNSA-N 0.000 description 1
- ZTOJFFHGPLIVKC-UHFFFAOYSA-N 3-ethyl-2-[(3-ethyl-6-sulfo-1,3-benzothiazol-2-ylidene)hydrazinylidene]-1,3-benzothiazole-6-sulfonic acid Chemical compound S1C2=CC(S(O)(=O)=O)=CC=C2N(CC)C1=NN=C1SC2=CC(S(O)(=O)=O)=CC=C2N1CC ZTOJFFHGPLIVKC-UHFFFAOYSA-N 0.000 description 1
- GRFNBEZIAWKNCO-UHFFFAOYSA-N 3-pyridinol Chemical compound OC1=CC=CN=C1 GRFNBEZIAWKNCO-UHFFFAOYSA-N 0.000 description 1
- 108010091324 3C proteases Proteins 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- GCNTZFIIOFTKIY-UHFFFAOYSA-N 4-hydroxypyridine Chemical compound OC1=CC=NC=C1 GCNTZFIIOFTKIY-UHFFFAOYSA-N 0.000 description 1
- 101710163881 5,6-dihydroxyindole-2-carboxylic acid oxidase Proteins 0.000 description 1
- 101150104118 ANS1 gene Proteins 0.000 description 1
- 101100510736 Actinidia chinensis var. chinensis LDOX gene Proteins 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 241000222518 Agaricus Species 0.000 description 1
- 241000589155 Agrobacterium tumefaciens Species 0.000 description 1
- 102100027211 Albumin Human genes 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 102100034035 Alcohol dehydrogenase 1A Human genes 0.000 description 1
- 108700028369 Alleles Proteins 0.000 description 1
- 241000223600 Alternaria Species 0.000 description 1
- 241000534414 Anotopterus nikparini Species 0.000 description 1
- 241000219195 Arabidopsis thaliana Species 0.000 description 1
- 101710152845 Arabinogalactan endo-beta-1,4-galactanase Proteins 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 101710164651 Aromatic peroxygenase Proteins 0.000 description 1
- 108010046256 Aryl-alcohol oxidase Proteins 0.000 description 1
- 241000235349 Ascomycota Species 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 102000004580 Aspartic Acid Proteases Human genes 0.000 description 1
- 101000961203 Aspergillus awamori Glucoamylase Proteins 0.000 description 1
- 241001480052 Aspergillus japonicus Species 0.000 description 1
- 101900127796 Aspergillus oryzae Glucoamylase Proteins 0.000 description 1
- 101900318521 Aspergillus oryzae Triosephosphate isomerase Proteins 0.000 description 1
- 241000972773 Aulopiformes Species 0.000 description 1
- 244000075850 Avena orientalis Species 0.000 description 1
- 235000007319 Avena orientalis Nutrition 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 241001037822 Bacillus bacterium Species 0.000 description 1
- 241001328122 Bacillus clausii Species 0.000 description 1
- 241000193747 Bacillus firmus Species 0.000 description 1
- 101000695691 Bacillus licheniformis Beta-lactamase Proteins 0.000 description 1
- 241000194107 Bacillus megaterium Species 0.000 description 1
- 240000000511 Berberis pumila Species 0.000 description 1
- 102100030981 Beta-alanine-activating enzyme Human genes 0.000 description 1
- 102100032487 Beta-mannosidase Human genes 0.000 description 1
- 241000222490 Bjerkandera Species 0.000 description 1
- 241000222478 Bjerkandera adusta Species 0.000 description 1
- 241000222455 Boletus Species 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 235000011293 Brassica napus Nutrition 0.000 description 1
- 235000011299 Brassica oleracea var botrytis Nutrition 0.000 description 1
- 240000003259 Brassica oleracea var. botrytis Species 0.000 description 1
- 235000004977 Brassica sinapistrum Nutrition 0.000 description 1
- 241000219193 Brassicaceae Species 0.000 description 1
- CPELXLSAUQHCOX-UHFFFAOYSA-M Bromide Chemical class [Br-] CPELXLSAUQHCOX-UHFFFAOYSA-M 0.000 description 1
- 101100327917 Caenorhabditis elegans chup-1 gene Proteins 0.000 description 1
- 101100520142 Caenorhabditis elegans pin-2 gene Proteins 0.000 description 1
- 239000004215 Carbon black (E152) Substances 0.000 description 1
- UGFAIRIUMAVXCW-UHFFFAOYSA-N Carbon monoxide Chemical compound [O+]#[C-] UGFAIRIUMAVXCW-UHFFFAOYSA-N 0.000 description 1
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 1
- 229920003043 Cellulose fiber Polymers 0.000 description 1
- 102100037633 Centrin-3 Human genes 0.000 description 1
- 241001466517 Ceriporiopsis aneirina Species 0.000 description 1
- 241001646018 Ceriporiopsis gilvescens Species 0.000 description 1
- 241001277875 Ceriporiopsis rivulosa Species 0.000 description 1
- 241000524302 Ceriporiopsis subrufa Species 0.000 description 1
- 241000259840 Chaetomidium Species 0.000 description 1
- 241001057137 Chaetomium fimeti Species 0.000 description 1
- 229920002101 Chitin Polymers 0.000 description 1
- 229920001661 Chitosan Polymers 0.000 description 1
- 241000701248 Chlorella virus Species 0.000 description 1
- 239000004155 Chlorine dioxide Substances 0.000 description 1
- 241001556045 Chrysosporium merdarium Species 0.000 description 1
- 241000233652 Chytridiomycota Species 0.000 description 1
- 108020004638 Circular DNA Proteins 0.000 description 1
- 241000228437 Cochliobolus Species 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- VGMFHMLQOYWYHN-UHFFFAOYSA-N Compactin Natural products OCC1OC(OC2C(O)C(O)C(CO)OC2Oc3cc(O)c4C(=O)C(=COc4c3)c5ccc(O)c(O)c5)C(O)C(O)C1O VGMFHMLQOYWYHN-UHFFFAOYSA-N 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 241001085790 Coprinopsis Species 0.000 description 1
- 241001509964 Coptotermes Species 0.000 description 1
- 241000222356 Coriolus Species 0.000 description 1
- MFYSYFVPBJMHGN-ZPOLXVRWSA-N Cortisone Chemical compound O=C1CC[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 MFYSYFVPBJMHGN-ZPOLXVRWSA-N 0.000 description 1
- MFYSYFVPBJMHGN-UHFFFAOYSA-N Cortisone Natural products O=C1CCC2(C)C3C(=O)CC(C)(C(CC4)(O)C(=O)CO)C4C3CCC2=C1 MFYSYFVPBJMHGN-UHFFFAOYSA-N 0.000 description 1
- 241001252397 Corynascus Species 0.000 description 1
- 241000024311 Coryphantha cornifera Species 0.000 description 1
- 241000221755 Cryphonectria Species 0.000 description 1
- 229920000858 Cyclodextrin Polymers 0.000 description 1
- XDTMQSROBMDMFD-UHFFFAOYSA-N Cyclohexane Chemical compound C1CCCCC1 XDTMQSROBMDMFD-UHFFFAOYSA-N 0.000 description 1
- 108010025880 Cyclomaltodextrin glucanotransferase Proteins 0.000 description 1
- 102100030497 Cytochrome c Human genes 0.000 description 1
- 108010075031 Cytochromes c Proteins 0.000 description 1
- 102000016559 DNA Primase Human genes 0.000 description 1
- 108010092681 DNA Primase Proteins 0.000 description 1
- 230000004544 DNA amplification Effects 0.000 description 1
- 239000003298 DNA probe Substances 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 101100342470 Dictyostelium discoideum pkbA gene Proteins 0.000 description 1
- ZAFNJMIOTHYJRJ-UHFFFAOYSA-N Diisopropyl ether Chemical compound CC(C)OC(C)C ZAFNJMIOTHYJRJ-UHFFFAOYSA-N 0.000 description 1
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 1
- 108090000204 Dipeptidase 1 Proteins 0.000 description 1
- 108010016626 Dipeptides Proteins 0.000 description 1
- 241000935926 Diplodia Species 0.000 description 1
- 101710147028 Endo-beta-1,4-galactanase Proteins 0.000 description 1
- 108010013369 Enteropeptidase Proteins 0.000 description 1
- 102100029727 Enteropeptidase Human genes 0.000 description 1
- 101100385973 Escherichia coli (strain K12) cycA gene Proteins 0.000 description 1
- VGGSQFUCUMXWEO-UHFFFAOYSA-N Ethene Chemical compound C=C VGGSQFUCUMXWEO-UHFFFAOYSA-N 0.000 description 1
- 239000005977 Ethylene Substances 0.000 description 1
- 241000221433 Exidia Species 0.000 description 1
- 108010074860 Factor Xa Proteins 0.000 description 1
- 241000221207 Filobasidium Species 0.000 description 1
- 241000192125 Firmicutes Species 0.000 description 1
- 235000016623 Fragaria vesca Nutrition 0.000 description 1
- 240000009088 Fragaria x ananassa Species 0.000 description 1
- 235000011363 Fragaria x ananassa Nutrition 0.000 description 1
- 108010058643 Fungal Proteins Proteins 0.000 description 1
- 241000223195 Fusarium graminearum Species 0.000 description 1
- 241000427940 Fusarium solani Species 0.000 description 1
- 101150108358 GLAA gene Proteins 0.000 description 1
- 108010093031 Galactosidases Proteins 0.000 description 1
- 102000002464 Galactosidases Human genes 0.000 description 1
- 101100001650 Geobacillus stearothermophilus amyM gene Proteins 0.000 description 1
- 101000892220 Geobacillus thermodenitrificans (strain NG80-2) Long-chain-alcohol dehydrogenase 1 Proteins 0.000 description 1
- 239000005980 Gibberellic acid Substances 0.000 description 1
- 108010044091 Globulins Proteins 0.000 description 1
- 102000006395 Globulins Human genes 0.000 description 1
- 229920001503 Glucan Polymers 0.000 description 1
- 102100022624 Glucoamylase Human genes 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 102000004366 Glucosidases Human genes 0.000 description 1
- 108010056771 Glucosidases Proteins 0.000 description 1
- 108010055629 Glucosyltransferases Proteins 0.000 description 1
- 102000000340 Glucosyltransferases Human genes 0.000 description 1
- 108010073324 Glutaminase Proteins 0.000 description 1
- 102000009127 Glutaminase Human genes 0.000 description 1
- 108010068370 Glutens Proteins 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 244000068988 Glycine max Species 0.000 description 1
- 235000010469 Glycine max Nutrition 0.000 description 1
- 101150009006 HIS3 gene Proteins 0.000 description 1
- 108050006227 Haem peroxidases Proteins 0.000 description 1
- 101100295959 Halobacterium salinarum (strain ATCC 700922 / JCM 11081 / NRC-1) arcB gene Proteins 0.000 description 1
- 101100246753 Halobacterium salinarum (strain ATCC 700922 / JCM 11081 / NRC-1) pyrF gene Proteins 0.000 description 1
- 102000008015 Hemeproteins Human genes 0.000 description 1
- 108010089792 Hemeproteins Proteins 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- LPBWRHRHEIYAIP-KKUMJFAQSA-N His-Tyr-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O LPBWRHRHEIYAIP-KKUMJFAQSA-N 0.000 description 1
- ZHMZWSFQRUGLEC-JYJNAYRXSA-N His-Tyr-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZHMZWSFQRUGLEC-JYJNAYRXSA-N 0.000 description 1
- 101000780443 Homo sapiens Alcohol dehydrogenase 1A Proteins 0.000 description 1
- 101000773364 Homo sapiens Beta-alanine-activating enzyme Proteins 0.000 description 1
- 101000880522 Homo sapiens Centrin-3 Proteins 0.000 description 1
- 241000430519 Human rhinovirus sp. Species 0.000 description 1
- 241000223199 Humicola grisea Species 0.000 description 1
- AVXURJPOCDRRFD-UHFFFAOYSA-N Hydroxylamine Chemical compound ON AVXURJPOCDRRFD-UHFFFAOYSA-N 0.000 description 1
- PMMYEEVYMWASQN-DMTCNVIQSA-N Hydroxyproline Chemical compound O[C@H]1CN[C@H](C(O)=O)C1 PMMYEEVYMWASQN-DMTCNVIQSA-N 0.000 description 1
- 206010020649 Hyperkeratosis Diseases 0.000 description 1
- 241000411968 Ilyobacter Species 0.000 description 1
- 102100034343 Integrase Human genes 0.000 description 1
- 241000222342 Irpex Species 0.000 description 1
- 241000222344 Irpex lacteus Species 0.000 description 1
- 102000004195 Isomerases Human genes 0.000 description 1
- 108090000769 Isomerases Proteins 0.000 description 1
- 241001138401 Kluyveromyces lactis Species 0.000 description 1
- 241000235058 Komagataella pastoris Species 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- 125000001176 L-lysyl group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C([H])([H])C([H])([H])C([H])([H])C(N([H])[H])([H])[H] 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 1
- HXEACLLIILLPRG-YFKPBYRVSA-N L-pipecolic acid Chemical compound [O-]C(=O)[C@@H]1CCCC[NH2+]1 HXEACLLIILLPRG-YFKPBYRVSA-N 0.000 description 1
- DZLNHFMRPBPULJ-VKHMYHEASA-N L-thioproline Chemical compound OC(=O)[C@@H]1CSCN1 DZLNHFMRPBPULJ-VKHMYHEASA-N 0.000 description 1
- 125000000769 L-threonyl group Chemical group [H]N([H])[C@]([H])(C(=O)[*])[C@](O[H])(C([H])([H])[H])[H] 0.000 description 1
- KKJQZEWNZXRJFG-UHFFFAOYSA-N L-trans-4-Methyl-2-pyrrolidinecarboxylic acid Chemical compound CC1CNC(C(O)=O)C1 KKJQZEWNZXRJFG-UHFFFAOYSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- 125000003798 L-tyrosyl group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C([H])([H])C1=C([H])C([H])=C(O[H])C([H])=C1[H] 0.000 description 1
- 125000003580 L-valyl group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(C([H])([H])[H])(C([H])([H])[H])[H] 0.000 description 1
- 241001149568 Laccaria Species 0.000 description 1
- 241000235087 Lachancea kluyveri Species 0.000 description 1
- 108091026898 Leader sequence (mRNA) Proteins 0.000 description 1
- 241000222435 Lentinula Species 0.000 description 1
- 241000222118 Leptoxyphium fumago Species 0.000 description 1
- 240000000604 Lespedeza bicolor Species 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 241000219745 Lupinus Species 0.000 description 1
- 102000004317 Lyases Human genes 0.000 description 1
- 108090000856 Lyases Proteins 0.000 description 1
- 235000007688 Lycopersicon esculentum Nutrition 0.000 description 1
- NPBGTPKLVJEOBE-IUCAKERBSA-N Lys-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(O)=O)CCCNC(N)=N NPBGTPKLVJEOBE-IUCAKERBSA-N 0.000 description 1
- 101150068888 MET3 gene Proteins 0.000 description 1
- 241001344133 Magnaporthe Species 0.000 description 1
- 102100024295 Maltase-glucoamylase Human genes 0.000 description 1
- PWHULOQIROXLJO-UHFFFAOYSA-N Manganese Chemical compound [Mn] PWHULOQIROXLJO-UHFFFAOYSA-N 0.000 description 1
- 229920000057 Mannan Polymers 0.000 description 1
- 241000183011 Melanocarpus Species 0.000 description 1
- 241000123315 Meripilus Species 0.000 description 1
- 108010006035 Metalloproteases Proteins 0.000 description 1
- 102000005741 Metalloproteases Human genes 0.000 description 1
- 108090000157 Metallothionein Proteins 0.000 description 1
- 241001465754 Metazoa Species 0.000 description 1
- 108060004795 Methyltransferase Proteins 0.000 description 1
- 102000008109 Mixed Function Oxygenases Human genes 0.000 description 1
- 108010074633 Mixed Function Oxygenases Proteins 0.000 description 1
- 241000226677 Myceliophthora Species 0.000 description 1
- WHNWPMSKXPGLAX-UHFFFAOYSA-N N-Vinyl-2-pyrrolidone Chemical compound C=CN1CCCC1=O WHNWPMSKXPGLAX-UHFFFAOYSA-N 0.000 description 1
- 241000221961 Neurospora crassa Species 0.000 description 1
- 101100022915 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) cys-11 gene Proteins 0.000 description 1
- 108091005507 Neutral proteases Proteins 0.000 description 1
- 102000035092 Neutral proteases Human genes 0.000 description 1
- 244000061176 Nicotiana tabacum Species 0.000 description 1
- 235000002637 Nicotiana tabacum Nutrition 0.000 description 1
- 108090000913 Nitrate Reductases Proteins 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- IOVCWXUNBOPUCH-UHFFFAOYSA-N Nitrous acid Chemical compound ON=O IOVCWXUNBOPUCH-UHFFFAOYSA-N 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 102000007981 Ornithine carbamoyltransferase Human genes 0.000 description 1
- 101710113020 Ornithine transcarbamylase, mitochondrial Proteins 0.000 description 1
- 102100037214 Orotidine 5'-phosphate decarboxylase Human genes 0.000 description 1
- 108010055012 Orotidine-5'-phosphate decarboxylase Proteins 0.000 description 1
- 102000004020 Oxygenases Human genes 0.000 description 1
- 108090000417 Oxygenases Proteins 0.000 description 1
- CBENFWSGALASAD-UHFFFAOYSA-N Ozone Chemical compound [O-][O+]=O CBENFWSGALASAD-UHFFFAOYSA-N 0.000 description 1
- 241000194109 Paenibacillus lautus Species 0.000 description 1
- 101710083821 Peroxygenase 1 Proteins 0.000 description 1
- 101710083826 Peroxygenase 2 Proteins 0.000 description 1
- 241000222393 Phanerochaete chrysosporium Species 0.000 description 1
- 244000046052 Phaseolus vulgaris Species 0.000 description 1
- 241000286209 Phasianidae Species 0.000 description 1
- 241000222395 Phlebia Species 0.000 description 1
- 241000222397 Phlebia radiata Species 0.000 description 1
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical class OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 1
- 108091000080 Phosphotransferase Proteins 0.000 description 1
- 240000004713 Pisum sativum Species 0.000 description 1
- 235000010582 Pisum sativum Nutrition 0.000 description 1
- 241000222350 Pleurotus Species 0.000 description 1
- 244000252132 Pleurotus eryngii Species 0.000 description 1
- 235000001681 Pleurotus eryngii Nutrition 0.000 description 1
- 241000209504 Poaceae Species 0.000 description 1
- 241001451060 Poitrasia Species 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 1
- 229920002504 Poly(2-vinylpyridine-N-oxide) Polymers 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- 108010059820 Polygalacturonase Proteins 0.000 description 1
- 108010068086 Polyubiquitin Proteins 0.000 description 1
- TUZYXOIXSAXUGO-UHFFFAOYSA-N Pravastatin Natural products C1=CC(C)C(CCC(O)CC(O)CC(O)=O)C2C(OC(=O)C(C)CC)CC(O)C=C21 TUZYXOIXSAXUGO-UHFFFAOYSA-N 0.000 description 1
- 102000001253 Protein Kinase Human genes 0.000 description 1
- 241000589774 Pseudomonas sp. Species 0.000 description 1
- 241000589614 Pseudomonas stutzeri Species 0.000 description 1
- 241000577556 Pseudomonas wisconsinensis Species 0.000 description 1
- 241000383860 Pseudoplectania Species 0.000 description 1
- 241001497658 Pseudotrichonympha Species 0.000 description 1
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 1
- 244000184734 Pyrus japonica Species 0.000 description 1
- 108020004518 RNA Probes Proteins 0.000 description 1
- 239000003391 RNA probe Substances 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 108091030071 RNAI Proteins 0.000 description 1
- 244000088415 Raphanus sativus Species 0.000 description 1
- 235000006140 Raphanus sativus var sativus Nutrition 0.000 description 1
- 101000968489 Rhizomucor miehei Lipase Proteins 0.000 description 1
- 241000187561 Rhodococcus erythropolis Species 0.000 description 1
- 101100394989 Rhodopseudomonas palustris (strain ATCC BAA-98 / CGA009) hisI gene Proteins 0.000 description 1
- AJLFOPYRIVGYMJ-UHFFFAOYSA-N SJ000287055 Natural products C12C(OC(=O)C(C)CC)CCC=C2C=CC(C)C1CCC1CC(O)CC(=O)O1 AJLFOPYRIVGYMJ-UHFFFAOYSA-N 0.000 description 1
- 101900354623 Saccharomyces cerevisiae Galactokinase Proteins 0.000 description 1
- 101900084120 Saccharomyces cerevisiae Triosephosphate isomerase Proteins 0.000 description 1
- 241001407717 Saccharomyces norbensis Species 0.000 description 1
- 101100022918 Schizosaccharomyces pombe (strain 972 / ATCC 24843) sua1 gene Proteins 0.000 description 1
- 241000209056 Secale Species 0.000 description 1
- 235000007238 Secale cereale Nutrition 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 102000012479 Serine Proteases Human genes 0.000 description 1
- 108010022999 Serine Proteases Proteins 0.000 description 1
- DWAQJAXMDSEUJJ-UHFFFAOYSA-M Sodium bisulfite Chemical compound [Na+].OS([O-])=O DWAQJAXMDSEUJJ-UHFFFAOYSA-M 0.000 description 1
- 240000003768 Solanum lycopersicum Species 0.000 description 1
- 240000003829 Sorghum propinquum Species 0.000 description 1
- 244000062793 Sorghum vulgare Species 0.000 description 1
- 241000264435 Streptococcus dysgalactiae subsp. equisimilis Species 0.000 description 1
- 101100309436 Streptococcus mutans serotype c (strain ATCC 700610 / UA159) ftf gene Proteins 0.000 description 1
- 101100370749 Streptomyces coelicolor (strain ATCC BAA-471 / A3(2) / M145) trpC1 gene Proteins 0.000 description 1
- 241000187391 Streptomyces hygroscopicus Species 0.000 description 1
- 208000037065 Subacute sclerosing leukoencephalitis Diseases 0.000 description 1
- 206010042297 Subacute sclerosing panencephalitis Diseases 0.000 description 1
- KDYFGRWQOYBRFD-UHFFFAOYSA-N Succinic acid Natural products OC(=O)CCC(O)=O KDYFGRWQOYBRFD-UHFFFAOYSA-N 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-L Sulfate Chemical compound [O-]S([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 1
- 108010076818 TEV protease Proteins 0.000 description 1
- 241000228341 Talaromyces Species 0.000 description 1
- 241001215623 Talaromyces cellulolyticus Species 0.000 description 1
- 241001136494 Talaromyces funiculosus Species 0.000 description 1
- 241001540751 Talaromyces ruber Species 0.000 description 1
- 108020005038 Terminator Codon Proteins 0.000 description 1
- BGRWYDHXPHLNKA-UHFFFAOYSA-N Tetraacetylethylenediamine Chemical compound CC(=O)N(C(C)=O)CCN(C(C)=O)C(C)=O BGRWYDHXPHLNKA-UHFFFAOYSA-N 0.000 description 1
- PLGPSDNOLCVGSS-UHFFFAOYSA-N Tetraphenylcyclopentadienone Chemical compound O=C1C(C=2C=CC=CC=2)=C(C=2C=CC=CC=2)C(C=2C=CC=CC=2)=C1C1=CC=CC=C1 PLGPSDNOLCVGSS-UHFFFAOYSA-N 0.000 description 1
- 244000152045 Themeda triandra Species 0.000 description 1
- 241000228178 Thermoascus Species 0.000 description 1
- 241000223257 Thermomyces Species 0.000 description 1
- FZWLAAWBMGSTSO-UHFFFAOYSA-N Thiazole Chemical compound C1=CSC=N1 FZWLAAWBMGSTSO-UHFFFAOYSA-N 0.000 description 1
- 241000183057 Thielavia microspora Species 0.000 description 1
- 241000182980 Thielavia ovispora Species 0.000 description 1
- 241000183053 Thielavia subthermophila Species 0.000 description 1
- 241001495429 Thielavia terrestris Species 0.000 description 1
- 108091036066 Three prime untranslated region Proteins 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 108010022394 Threonine synthase Proteins 0.000 description 1
- 108090000190 Thrombin Proteins 0.000 description 1
- 241000222354 Trametes Species 0.000 description 1
- 241000222357 Trametes hirsuta Species 0.000 description 1
- 241000222355 Trametes versicolor Species 0.000 description 1
- 241000217816 Trametes villosa Species 0.000 description 1
- 102000004357 Transferases Human genes 0.000 description 1
- 108090000992 Transferases Proteins 0.000 description 1
- 241000378866 Trichoderma koningii Species 0.000 description 1
- 241000215642 Trichophaea Species 0.000 description 1
- 108090000631 Trypsin Proteins 0.000 description 1
- 102000004142 Trypsin Human genes 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 101150050575 URA3 gene Proteins 0.000 description 1
- 108090000848 Ubiquitin Proteins 0.000 description 1
- 102000044159 Ubiquitin Human genes 0.000 description 1
- 108091023045 Untranslated Region Proteins 0.000 description 1
- 241000082085 Verticillium <Phyllachorales> Species 0.000 description 1
- 241001507667 Volvariella Species 0.000 description 1
- 241000409279 Xerochrysium dermatitidis Species 0.000 description 1
- 241001523965 Xylaria Species 0.000 description 1
- 241000235015 Yarrowia lipolytica Species 0.000 description 1
- 235000005824 Zea mays ssp. parviglumis Nutrition 0.000 description 1
- 241000758405 Zoopagomycotina Species 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 239000008186 active pharmaceutical agent Substances 0.000 description 1
- 238000007792 addition Methods 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 108010045649 agarase Proteins 0.000 description 1
- 239000011543 agarose gel Substances 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- 108010050181 aleurone Proteins 0.000 description 1
- 239000003513 alkali Substances 0.000 description 1
- 150000001346 alkyl aryl ethers Chemical class 0.000 description 1
- 150000004996 alkyl benzenes Chemical class 0.000 description 1
- 125000000217 alkyl group Chemical group 0.000 description 1
- 150000008051 alkyl sulfates Chemical class 0.000 description 1
- 125000005466 alkylenyl group Chemical group 0.000 description 1
- 108010030291 alpha-Galactosidase Proteins 0.000 description 1
- 102000005840 alpha-Galactosidase Human genes 0.000 description 1
- 108010028144 alpha-Glucosidases Proteins 0.000 description 1
- CDUUKBXTEOFITR-UHFFFAOYSA-N alpha-methylserine Natural products OCC([NH3+])(C)C([O-])=O CDUUKBXTEOFITR-UHFFFAOYSA-N 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 238000012870 ammonium sulfate precipitation Methods 0.000 description 1
- 230000003625 amylolytic effect Effects 0.000 description 1
- 125000000129 anionic group Chemical group 0.000 description 1
- 239000003945 anionic surfactant Substances 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 230000003627 anti-cholesterol Effects 0.000 description 1
- 230000000433 anti-nutritional effect Effects 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 239000002246 antineoplastic agent Substances 0.000 description 1
- 229940041181 antineoplastic drug Drugs 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 101150009206 aprE gene Proteins 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 101150008194 argB gene Proteins 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 125000000637 arginyl group Chemical group N[C@@H](CCCNC(N)=N)C(=O)* 0.000 description 1
- 150000001491 aromatic compounds Chemical class 0.000 description 1
- 238000007262 aromatic hydroxylation reaction Methods 0.000 description 1
- 150000001495 arsenic compounds Chemical class 0.000 description 1
- 210000004507 artificial chromosome Anatomy 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- MXWJVTOOROXGIU-UHFFFAOYSA-N atrazine Chemical compound CCNC1=NC(Cl)=NC(NC(C)C)=N1 MXWJVTOOROXGIU-UHFFFAOYSA-N 0.000 description 1
- OHDRQQURAXLVGJ-HLVWOLMTSA-N azane;(2e)-3-ethyl-2-[(e)-(3-ethyl-6-sulfo-1,3-benzothiazol-2-ylidene)hydrazinylidene]-1,3-benzothiazole-6-sulfonic acid Chemical compound [NH4+].[NH4+].S/1C2=CC(S([O-])(=O)=O)=CC=C2N(CC)C\1=N/N=C1/SC2=CC(S([O-])(=O)=O)=CC=C2N1CC OHDRQQURAXLVGJ-HLVWOLMTSA-N 0.000 description 1
- 229940005348 bacillus firmus Drugs 0.000 description 1
- 230000008953 bacterial degradation Effects 0.000 description 1
- 101150103518 bar gene Proteins 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 229940077388 benzenesulfonate Drugs 0.000 description 1
- QRUDEWIWKLJBPS-UHFFFAOYSA-N benzotriazole Chemical compound C1=CC=C2N[N][N]C2=C1 QRUDEWIWKLJBPS-UHFFFAOYSA-N 0.000 description 1
- 239000012964 benzotriazole Substances 0.000 description 1
- 235000019445 benzyl alcohol Nutrition 0.000 description 1
- MSWZFWKMSRAUBD-UHFFFAOYSA-N beta-D-galactosamine Natural products NC1C(O)OC(CO)C(O)C1O MSWZFWKMSRAUBD-UHFFFAOYSA-N 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 108010055059 beta-Mannosidase Proteins 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 239000011942 biocatalyst Substances 0.000 description 1
- 230000002210 biocatalytic effect Effects 0.000 description 1
- 239000003139 biocide Substances 0.000 description 1
- 238000003766 bioinformatics method Methods 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000009141 biological interaction Effects 0.000 description 1
- 239000000090 biomarker Substances 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 230000036983 biotransformation Effects 0.000 description 1
- 239000007844 bleaching agent Substances 0.000 description 1
- 238000009835 boiling Methods 0.000 description 1
- 238000005282 brightening Methods 0.000 description 1
- 230000000711 cancerogenic effect Effects 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 125000004432 carbon atom Chemical group C* 0.000 description 1
- 229910002091 carbon monoxide Inorganic materials 0.000 description 1
- 150000004649 carbonic acid derivatives Chemical class 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 1
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 1
- 231100000315 carcinogenic Toxicity 0.000 description 1
- 238000004517 catalytic hydrocracking Methods 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 235000013339 cereals Nutrition 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 239000007795 chemical reaction product Substances 0.000 description 1
- 231100000481 chemical toxicant Toxicity 0.000 description 1
- 229960005091 chloramphenicol Drugs 0.000 description 1
- WIIZWVCIJKGZOK-RKDXNWHRSA-N chloramphenicol Chemical compound ClC(Cl)C(=O)N[C@H](CO)[C@H](O)C1=CC=C([N+]([O-])=O)C=C1 WIIZWVCIJKGZOK-RKDXNWHRSA-N 0.000 description 1
- 235000019398 chlorine dioxide Nutrition 0.000 description 1
- 238000011098 chromatofocusing Methods 0.000 description 1
- 238000013375 chromatographic separation Methods 0.000 description 1
- 150000001860 citric acid derivatives Chemical class 0.000 description 1
- 238000004140 cleaning Methods 0.000 description 1
- 238000002485 combustion reaction Methods 0.000 description 1
- 239000008139 complexing agent Substances 0.000 description 1
- 235000005822 corn Nutrition 0.000 description 1
- 229960004544 cortisone Drugs 0.000 description 1
- 238000005336 cracking Methods 0.000 description 1
- 150000001924 cycloalkanes Chemical class 0.000 description 1
- 230000001461 cytolytic effect Effects 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 101150005799 dagA gene Proteins 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 238000007872 degassing Methods 0.000 description 1
- 230000018044 dehydration Effects 0.000 description 1
- 238000006297 dehydration reaction Methods 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 238000001784 detoxification Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- GSPKZYJPUDYKPI-UHFFFAOYSA-N diethoxy sulfate Chemical compound CCOOS(=O)(=O)OOCC GSPKZYJPUDYKPI-UHFFFAOYSA-N 0.000 description 1
- 229940079919 digestives enzyme preparation Drugs 0.000 description 1
- 239000001177 diphosphate Substances 0.000 description 1
- XPPKVPWEQAFLFU-UHFFFAOYSA-J diphosphate(4-) Chemical class [O-]P([O-])(=O)OP([O-])([O-])=O XPPKVPWEQAFLFU-UHFFFAOYSA-J 0.000 description 1
- 235000011180 diphosphates Nutrition 0.000 description 1
- ZPWVASYFFYYZEW-UHFFFAOYSA-L dipotassium hydrogen phosphate Chemical compound [K+].[K+].OP([O-])([O-])=O ZPWVASYFFYYZEW-UHFFFAOYSA-L 0.000 description 1
- 235000019797 dipotassium phosphate Nutrition 0.000 description 1
- 229910000396 dipotassium phosphate Inorganic materials 0.000 description 1
- 238000004821 distillation Methods 0.000 description 1
- PMMYEEVYMWASQN-UHFFFAOYSA-N dl-hydroxyproline Natural products OC1C[NH2+]C(C([O-])=O)C1 PMMYEEVYMWASQN-UHFFFAOYSA-N 0.000 description 1
- GMSCBRSQMRDRCD-UHFFFAOYSA-N dodecyl 2-methylprop-2-enoate Chemical compound CCCCCCCCCCCCOC(=O)C(C)=C GMSCBRSQMRDRCD-UHFFFAOYSA-N 0.000 description 1
- 238000007876 drug discovery Methods 0.000 description 1
- 239000000975 dye Substances 0.000 description 1
- 238000002003 electron diffraction Methods 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 238000010828 elution Methods 0.000 description 1
- 210000002308 embryonic cell Anatomy 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 239000000598 endocrine disruptor Substances 0.000 description 1
- 231100000049 endocrine disruptor Toxicity 0.000 description 1
- 108010091371 endoglucanase 1 Proteins 0.000 description 1
- 108010091384 endoglucanase 2 Proteins 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 238000001952 enzyme assay Methods 0.000 description 1
- 210000002615 epidermis Anatomy 0.000 description 1
- 239000000262 estrogen Substances 0.000 description 1
- 229940011871 estrogen Drugs 0.000 description 1
- RTZKZFJDLAIYFH-UHFFFAOYSA-N ether Substances CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 1
- 241001233957 eudicotyledons Species 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 238000001704 evaporation Methods 0.000 description 1
- 230000008020 evaporation Effects 0.000 description 1
- 108010038658 exo-1,4-beta-D-xylosidase Proteins 0.000 description 1
- 108010093305 exopolygalacturonase Proteins 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 239000002979 fabric softener Substances 0.000 description 1
- 235000019387 fatty acid methyl ester Nutrition 0.000 description 1
- 238000004231 fluid catalytic cracking Methods 0.000 description 1
- 230000003325 follicular Effects 0.000 description 1
- 235000013305 food Nutrition 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- KFIFDKLIFPYSAZ-UHFFFAOYSA-N formyloxy(phenyl)borinic acid Chemical compound O=COB(O)C1=CC=CC=C1 KFIFDKLIFPYSAZ-UHFFFAOYSA-N 0.000 description 1
- 239000003205 fragrance Substances 0.000 description 1
- 238000004108 freeze drying Methods 0.000 description 1
- 238000012224 gene deletion Methods 0.000 description 1
- 230000009368 gene silencing by RNA Effects 0.000 description 1
- 102000034356 gene-regulatory proteins Human genes 0.000 description 1
- 108091006104 gene-regulatory proteins Proteins 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 230000035784 germination Effects 0.000 description 1
- IXORZMNAPKEEDV-UHFFFAOYSA-N gibberellic acid GA3 Natural products OC(=O)C1C2(C3)CC(=C)C3(O)CCC2C2(C=CC3O)C1C3(C)C(=O)O2 IXORZMNAPKEEDV-UHFFFAOYSA-N 0.000 description 1
- IXORZMNAPKEEDV-OBDJNFEBSA-N gibberellin A3 Chemical compound C([C@@]1(O)C(=C)C[C@@]2(C1)[C@H]1C(O)=O)C[C@H]2[C@]2(C=C[C@@H]3O)[C@H]1[C@]3(C)C(=O)O2 IXORZMNAPKEEDV-OBDJNFEBSA-N 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 229960002442 glucosamine Drugs 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 102000006602 glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 1
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 1
- 235000011187 glycerol Nutrition 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 1
- 229910052737 gold Inorganic materials 0.000 description 1
- 239000010931 gold Substances 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 229940093920 gynecological arsenic compound Drugs 0.000 description 1
- 150000003278 haem Chemical class 0.000 description 1
- 239000000383 hazardous chemical Substances 0.000 description 1
- 108010002430 hemicellulase Proteins 0.000 description 1
- 229940059442 hemicellulase Drugs 0.000 description 1
- 239000004009 herbicide Substances 0.000 description 1
- 125000005842 heteroatom Chemical group 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 230000003054 hormonal effect Effects 0.000 description 1
- 229960000890 hydrocortisone Drugs 0.000 description 1
- 150000002432 hydroperoxides Chemical class 0.000 description 1
- 239000003752 hydrotrope Substances 0.000 description 1
- 229960002591 hydroxyproline Drugs 0.000 description 1
- 108010002685 hygromycin-B kinase Proteins 0.000 description 1
- 150000003949 imides Chemical class 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- PZOUSPYUWWUPPK-UHFFFAOYSA-N indole Natural products CC1=CC=CC2=C1C=CN2 PZOUSPYUWWUPPK-UHFFFAOYSA-N 0.000 description 1
- RKJUIXBNRJVNHR-UHFFFAOYSA-N indolenine Natural products C1=CC=C2CC=NC2=C1 RKJUIXBNRJVNHR-UHFFFAOYSA-N 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 239000003295 industrial effluent Substances 0.000 description 1
- 230000004941 influx Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 229910001503 inorganic bromide Inorganic materials 0.000 description 1
- 239000002917 insecticide Substances 0.000 description 1
- 238000009434 installation Methods 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000009878 intermolecular interaction Effects 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- GCHPUFAZSONQIV-UHFFFAOYSA-N isovaline Chemical compound CCC(C)(N)C(O)=O GCHPUFAZSONQIV-UHFFFAOYSA-N 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 1
- 229960000318 kanamycin Drugs 0.000 description 1
- 229930027917 kanamycin Natural products 0.000 description 1
- 229930182823 kanamycin A Natural products 0.000 description 1
- 235000021332 kidney beans Nutrition 0.000 description 1
- HXEACLLIILLPRG-RXMQYKEDSA-N l-pipecolic acid Natural products OC(=O)[C@H]1CCCCN1 HXEACLLIILLPRG-RXMQYKEDSA-N 0.000 description 1
- 239000004310 lactic acid Substances 0.000 description 1
- 235000014655 lactic acid Nutrition 0.000 description 1
- 235000021374 legumes Nutrition 0.000 description 1
- 239000003446 ligand Substances 0.000 description 1
- 230000002366 lipolytic effect Effects 0.000 description 1
- 238000009630 liquid culture Methods 0.000 description 1
- 101150039489 lysZ gene Proteins 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 229910052748 manganese Inorganic materials 0.000 description 1
- 239000011572 manganese Substances 0.000 description 1
- 230000035800 maturation Effects 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 108010003855 mesentericopeptidase Proteins 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 229910044991 metal oxide Inorganic materials 0.000 description 1
- 150000004706 metal oxides Chemical class 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- AJLFOPYRIVGYMJ-INTXDZFKSA-N mevastatin Chemical compound C([C@H]1[C@@H](C)C=CC2=CCC[C@@H]([C@H]12)OC(=O)[C@@H](C)CC)C[C@@H]1C[C@@H](O)CC(=O)O1 AJLFOPYRIVGYMJ-INTXDZFKSA-N 0.000 description 1
- BOZILQFLQYBIIY-UHFFFAOYSA-N mevastatin hydroxy acid Natural products C1=CC(C)C(CCC(O)CC(O)CC(O)=O)C2C(OC(=O)C(C)CC)CCC=C21 BOZILQFLQYBIIY-UHFFFAOYSA-N 0.000 description 1
- 230000002906 microbiologic effect Effects 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 239000011859 microparticle Substances 0.000 description 1
- 230000000116 mitigating effect Effects 0.000 description 1
- 210000003470 mitochondria Anatomy 0.000 description 1
- 229940045641 monobasic sodium phosphate Drugs 0.000 description 1
- 229910000403 monosodium phosphate Inorganic materials 0.000 description 1
- 235000019799 monosodium phosphate Nutrition 0.000 description 1
- 231100000219 mutagenic Toxicity 0.000 description 1
- 239000003471 mutagenic agent Substances 0.000 description 1
- 231100000243 mutagenic effect Toxicity 0.000 description 1
- 239000006225 natural substrate Substances 0.000 description 1
- 101150095344 niaD gene Proteins 0.000 description 1
- BOPGDPNILDQYTO-NNYOXOHSSA-N nicotinamide-adenine dinucleotide Chemical compound C1=CCC(C(=O)N)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OC[C@@H]2[C@H]([C@@H](O)[C@@H](O2)N2C3=NC=NC(N)=C3N=C2)O)O1 BOPGDPNILDQYTO-NNYOXOHSSA-N 0.000 description 1
- MGFYIUFZLHCRTH-UHFFFAOYSA-N nitrilotriacetic acid Chemical compound OC(=O)CN(CC(O)=O)CC(O)=O MGFYIUFZLHCRTH-UHFFFAOYSA-N 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 239000002736 nonionic surfactant Substances 0.000 description 1
- SNQQPOLDUKLAAF-UHFFFAOYSA-N nonylphenol Chemical class CCCCCCCCCC1=CC=CC=C1O SNQQPOLDUKLAAF-UHFFFAOYSA-N 0.000 description 1
- 101150105920 npr gene Proteins 0.000 description 1
- 101150017837 nprM gene Proteins 0.000 description 1
- 230000031787 nutrient reservoir activity Effects 0.000 description 1
- 235000016709 nutrition Nutrition 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 239000012044 organic layer Substances 0.000 description 1
- 108090000021 oryzin Proteins 0.000 description 1
- 238000011909 oxidative ring-opening Methods 0.000 description 1
- 235000019629 palatability Nutrition 0.000 description 1
- NFHFRUOZVGFOOS-UHFFFAOYSA-N palladium;triphenylphosphane Chemical compound [Pd].C1=CC=CC=C1P(C=1C=CC=CC=1)C1=CC=CC=C1.C1=CC=CC=C1P(C=1C=CC=CC=1)C1=CC=CC=C1.C1=CC=CC=C1P(C=1C=CC=CC=1)C1=CC=CC=C1.C1=CC=CC=C1P(C=1C=CC=CC=1)C1=CC=CC=C1 NFHFRUOZVGFOOS-UHFFFAOYSA-N 0.000 description 1
- 239000013618 particulate matter Substances 0.000 description 1
- 239000006072 paste Substances 0.000 description 1
- 101150019841 penP gene Proteins 0.000 description 1
- 235000005693 perillyl alcohol Nutrition 0.000 description 1
- 238000005502 peroxidation Methods 0.000 description 1
- 210000002824 peroxisome Anatomy 0.000 description 1
- 150000004965 peroxy acids Chemical class 0.000 description 1
- 235000020030 perry Nutrition 0.000 description 1
- 239000003209 petroleum derivative Substances 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 239000012450 pharmaceutical intermediate Substances 0.000 description 1
- JTJMJGYZQZDUJJ-UHFFFAOYSA-N phencyclidine Chemical compound C1CCCCN1C1(C=2C=CC=CC=2)CCCCC1 JTJMJGYZQZDUJJ-UHFFFAOYSA-N 0.000 description 1
- 125000000951 phenoxy group Chemical group [H]C1=C([H])C([H])=C(O*)C([H])=C1[H] 0.000 description 1
- OSCBARYHPZZEIS-UHFFFAOYSA-N phenoxyboronic acid Chemical class OB(O)OC1=CC=CC=C1 OSCBARYHPZZEIS-UHFFFAOYSA-N 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 235000021317 phosphate Nutrition 0.000 description 1
- 108010082527 phosphinothricin N-acetyltransferase Proteins 0.000 description 1
- 150000003013 phosphoric acid derivatives Chemical class 0.000 description 1
- 229910052698 phosphorus Inorganic materials 0.000 description 1
- 239000011574 phosphorus Substances 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 102000020233 phosphotransferase Human genes 0.000 description 1
- 231100000614 poison Toxicity 0.000 description 1
- 239000002798 polar solvent Substances 0.000 description 1
- 229920002006 poly(N-vinylimidazole) polymer Polymers 0.000 description 1
- 229920000196 poly(lauryl methacrylate) Polymers 0.000 description 1
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 1
- 229920000058 polyacrylate Polymers 0.000 description 1
- 229920005646 polycarboxylate Polymers 0.000 description 1
- 125000003367 polycyclic group Chemical group 0.000 description 1
- 235000013824 polyphenols Nutrition 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 229920002451 polyvinyl alcohol Polymers 0.000 description 1
- 230000001124 posttranscriptional effect Effects 0.000 description 1
- 239000008057 potassium phosphate buffer Substances 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- TUZYXOIXSAXUGO-PZAWKZKUSA-N pravastatin Chemical compound C1=C[C@H](C)[C@H](CC[C@@H](O)C[C@@H](O)CC(O)=O)[C@H]2[C@@H](OC(=O)[C@@H](C)CC)C[C@H](O)C=C21 TUZYXOIXSAXUGO-PZAWKZKUSA-N 0.000 description 1
- 229960002965 pravastatin Drugs 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 239000000186 progesterone Substances 0.000 description 1
- 229960003387 progesterone Drugs 0.000 description 1
- 230000000750 progressive effect Effects 0.000 description 1
- 108060006613 prolamin Proteins 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 235000019833 protease Nutrition 0.000 description 1
- 230000004952 protein activity Effects 0.000 description 1
- 235000004252 protein component Nutrition 0.000 description 1
- 230000012846 protein folding Effects 0.000 description 1
- 108060006633 protein kinase Proteins 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- 229940024999 proteolytic enzymes for treatment of wounds and ulcers Drugs 0.000 description 1
- 239000003586 protic polar solvent Substances 0.000 description 1
- 101150108007 prs gene Proteins 0.000 description 1
- 101150086435 prs1 gene Proteins 0.000 description 1
- 101150070305 prsA gene Proteins 0.000 description 1
- 238000004537 pulping Methods 0.000 description 1
- UBQKCCHYAOITMY-UHFFFAOYSA-N pyridin-2-ol Chemical compound OC1=CC=CC=N1 UBQKCCHYAOITMY-UHFFFAOYSA-N 0.000 description 1
- 238000010791 quenching Methods 0.000 description 1
- 230000000171 quenching effect Effects 0.000 description 1
- 239000002994 raw material Substances 0.000 description 1
- 239000003642 reactive oxygen metabolite Substances 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000001172 regenerating effect Effects 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- 101150025220 sacB gene Proteins 0.000 description 1
- 235000019515 salmon Nutrition 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- HFHDHCJBZVLPGP-UHFFFAOYSA-N schardinger α-dextrin Chemical compound O1C(C(C2O)O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC(C(O)C2O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC2C(O)C(O)C1OC2CO HFHDHCJBZVLPGP-UHFFFAOYSA-N 0.000 description 1
- 239000013049 sediment Substances 0.000 description 1
- 238000007086 side reaction Methods 0.000 description 1
- 239000000377 silicon dioxide Substances 0.000 description 1
- 235000012239 silicon dioxide Nutrition 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- AJPJDKMHJJGVTQ-UHFFFAOYSA-M sodium dihydrogen phosphate Chemical compound [Na+].OP(O)([O-])=O AJPJDKMHJJGVTQ-UHFFFAOYSA-M 0.000 description 1
- FQENQNTWSFEDLI-UHFFFAOYSA-J sodium diphosphate Chemical compound [Na+].[Na+].[Na+].[Na+].[O-]P([O-])(=O)OP([O-])([O-])=O FQENQNTWSFEDLI-UHFFFAOYSA-J 0.000 description 1
- 235000010267 sodium hydrogen sulphite Nutrition 0.000 description 1
- 229940048086 sodium pyrophosphate Drugs 0.000 description 1
- MWNQXXOSWHCCOZ-UHFFFAOYSA-L sodium;oxido carbonate Chemical compound [Na+].[O-]OC([O-])=O MWNQXXOSWHCCOZ-UHFFFAOYSA-L 0.000 description 1
- 210000004872 soft tissue Anatomy 0.000 description 1
- 238000002798 spectrophotometry method Methods 0.000 description 1
- 238000001694 spray drying Methods 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 238000003756 stirring Methods 0.000 description 1
- 239000011550 stock solution Substances 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 235000011044 succinic acid Nutrition 0.000 description 1
- BDHFUVZGWQCTTF-UHFFFAOYSA-M sulfonate Chemical compound [O-]S(=O)=O BDHFUVZGWQCTTF-UHFFFAOYSA-M 0.000 description 1
- 150000003457 sulfones Chemical class 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 239000003826 tablet Substances 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 235000019818 tetrasodium diphosphate Nutrition 0.000 description 1
- 239000001577 tetrasodium phosphonato phosphate Substances 0.000 description 1
- 239000002562 thickening agent Substances 0.000 description 1
- 229960004072 thrombin Drugs 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 108091006106 transcriptional activators Proteins 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 150000003626 triacylglycerols Chemical class 0.000 description 1
- 239000001226 triphosphate Substances 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- 125000002264 triphosphate group Chemical class [H]OP(=O)(O[H])OP(=O)(O[H])OP(=O)(O[H])O* 0.000 description 1
- 101150016309 trpC gene Proteins 0.000 description 1
- 239000012588 trypsin Substances 0.000 description 1
- 108010060175 trypsinogen activation peptide Proteins 0.000 description 1
- WFKWXMTUELFFGS-UHFFFAOYSA-N tungsten Chemical compound [W] WFKWXMTUELFFGS-UHFFFAOYSA-N 0.000 description 1
- 229910052721 tungsten Inorganic materials 0.000 description 1
- 239000010937 tungsten Substances 0.000 description 1
- 238000000539 two dimensional gel electrophoresis Methods 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 238000002211 ultraviolet spectrum Methods 0.000 description 1
- 210000003934 vacuole Anatomy 0.000 description 1
- 230000002792 vascular Effects 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- WJUFSDZVCOTFON-UHFFFAOYSA-N veratraldehyde Chemical compound COC1=CC=C(C=O)C=C1OC WJUFSDZVCOTFON-UHFFFAOYSA-N 0.000 description 1
- 239000002699 waste material Substances 0.000 description 1
- 239000002023 wood Substances 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- 239000010457 zeolite Substances 0.000 description 1
- 239000004711 α-olefin Substances 0.000 description 1
Images
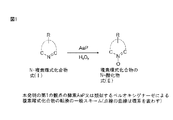






Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/0004—Oxidoreductases (1.)
- C12N9/0065—Oxidoreductases (1.) acting on hydrogen peroxide as acceptor (1.11)
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Organic Chemistry (AREA)
- Zoology (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- Microbiology (AREA)
- Biotechnology (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Enzymes And Modification Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Detergent Compositions (AREA)
- Pyridine Compounds (AREA)
Abstract
【課題】新規なペルオキシダーゼの提供。
【解決手段】ラクヨウショウジン担子菌株アグロシベ・アエゲリタ由来のペルオキシゲナーゼ活性を有するポリペプチド類及びそのようなポリペプチド類を含んで成る組成物類、それらのコードポリヌクレオチド、発現ベクター、及びそのようなポリヌクレオチド又はベクターを含んで成る組換え宿主細胞、前記ポリペプチドの生成方法、並びにその適用及び使用方法。
【選択図】なし
【解決手段】ラクヨウショウジン担子菌株アグロシベ・アエゲリタ由来のペルオキシゲナーゼ活性を有するポリペプチド類及びそのようなポリペプチド類を含んで成る組成物類、それらのコードポリヌクレオチド、発現ベクター、及びそのようなポリヌクレオチド又はベクターを含んで成る組換え宿主細胞、前記ポリペプチドの生成方法、並びにその適用及び使用方法。
【選択図】なし
Description
本発明は、ペルオキシゲナーゼ活性を有するポリペプチド類及びそのようなポリペプチド類を含んで成る組成物類、それらのコードポリヌクレオチド、発現ベクター、及びそのようなポリヌクレオチド又はベクターを含んで成る組換え宿主細胞、前記ポリペプチドの生成方法、並びにその適用及び使用方法、例えば式(I)のN−複素環を、1段階反応方法を用いて、少なくとも1つの酸化剤の存在下で、ペルオキシゲナーゼポリペプチドにより転換することによる、一般式(I)のN−複素環の式(II)のその対応するN−酸化物への酵素的位置選択性酸化方法に関する。
ラクヨウショウジン担子菌株アグロシベ・アエゲリタ(Agrocybe aegerita)(株TM-A1)からのハロペルオキシダーゼペルオキシゲナーゼ表示のAaPは、アリールアルコール及びアルデヒドを酸化することが見出された。AaPペルオキシゲナーゼは、イオンクロマトグラフィー及びSDS−PAGEのいくつかの段階により、A. アエゲリタTMA1から精製され、分子量が決定され、そしてN−末端の14個のアミノ酸配列が、2−D電気泳動の後、決定されたが、しかしそのコード遺伝子は単離されなかった(Ullrich et al., 2004, Appl. Env. Microbiol. 70(8): 4575-4581)。
WO2006/034702A1は、アグロシベ・アエゲリタTMA1のAaPペルオキシゲナーゼ酵素を用いて、活性化されていない炭化水素、例えばナフタレン、トルオール及びシクロヘキサンの酵素的ヒドロキシル化方法を開示する。これはまた、Ullrich and Hofrichter, 2005, FEBS Letters 579: 6247-6250にも記載されている。
DE10332065A1は、アグロシベ・アエゲリタTMA1のAaPペルオキシゲナーゼ酵素を用いることによる、アルデヒドの中間形成を通してのアルコールからの酸の酵素的調製方法を開示する。
AaPペルオキシゲナーゼによる芳香族ヒドロキシル化の急速且つ選択的な直接的分光光度検出方法が報告されている(Kluge et al., 2007, Appl Microbiol Biotechnol 75: 1473-1478)。
AaPペルオキシゲナーゼによる芳香族ヒドロキシル化の急速且つ選択的な直接的分光光度検出方法が報告されている(Kluge et al., 2007, Appl Microbiol Biotechnol 75: 1473-1478)。
芳香族過酸化処理にできる第2ペルオキシゲナーゼが、糞生菌類コプリナス・ラジアンスから単離され、そして特徴づけられ、N−末端の16個のアミノ酸が同定され、そして前に開示されたA. アエゲリタ株のAaP酵素のN−末端の14個のアミノ酸と共に一列整列されたが、しかしそのコード遺伝子は単離されなかった(Anh et al., 2007, Appl Env Microbiol 73(17): 5477-5485)。
有機分子中への酸素機能(酸化)の直接的位置選択性導入が化学合成において問題を構成することは良く知られている。ピリジン型の芳香族複素環の選択的N−酸化を触媒することは特に困難である。生成物、複素環式N−酸化物は、広範囲の種類の異なった合成において重要な中間体であり、そしてしばしば、生物学的に活性である。さらに、それらは、保護基、酸化剤、金属錯体におけるリガンド、及び特定の触媒として機能する。
ピリジン、その誘導体及び他のN−複素環の化学的酸化は、攻撃的/毒性化学物質/触媒を必要とし、そして一連の所望しない副産物(例えば、2−、3−及び/又は4−ヒドロキシピリジン誘導体)及び低い異性体収率を導く。文献によれば、ポリジンN−酸化物は、中でも次の出発化合物を用いて、ピリジンから化学的に合成され得る:
−過酸化水素(30%)、酢酸及びピリジン(ピリジン/水中、80℃)
−二酸化珪素及びピリジン上のリンタングステン酸(ピリジン中、80℃)
−タングステン酸塩、過酸化水素(30%)及びピリジン(ピリジン中、80℃)
−有機ヒドロトリオキシド及びピリジン(ピリジン中、-80〜-60℃)
−過酸化水素、マンガンテトラキス(2,6−クロロフェニル)ポルフィリン(ジクロロエタン中、25℃)
−ジメチルオキシラン及びピリジン(ジクロロエタン中、0℃)
−ペルフルオロ(シス−2,3−ジアルキルオキサジリジン)及びピリジン(ピリジン中、25℃)。
−二酸化珪素及びピリジン上のリンタングステン酸(ピリジン中、80℃)
−タングステン酸塩、過酸化水素(30%)及びピリジン(ピリジン中、80℃)
−有機ヒドロトリオキシド及びピリジン(ピリジン中、-80〜-60℃)
−過酸化水素、マンガンテトラキス(2,6−クロロフェニル)ポルフィリン(ジクロロエタン中、25℃)
−ジメチルオキシラン及びピリジン(ジクロロエタン中、0℃)
−ペルフルオロ(シス−2,3−ジアルキルオキサジリジン)及びピリジン(ピリジン中、25℃)。
複素環式窒素原子に対する酸化反応は通常、電子供与体及び分子酸素(O2)又はペルオキシド/トリオキシド(R−OOH, R-COOH)の存在下で、窒素を直接的に攻撃する反応性酸素種の発生に基づかれる。それらの高い反応性の酵素種は唯一の制限された位置選択性を有する。この理由のために、化学的N−酸化での収率は低く、そしてそれらは所望しない副産物を導き、そして複雑な操作を必要とする。
細胞内酵素、メタンモノオキシゲナーゼ(MMO, EC14. 13. 25)は、非特異的副反応下でピリジンをピリジンN−酸化物に転換することが知られている。MMO酵素は、いくつかのタンパク質成分から成り、そしてメチル栄養細菌(例えば、メチロコーカス・カプスラタス(Methylococcus capsulatus))により形成され;それは複雑な電子供与体、例えばNAOH又はNADPH、補助タンパク質(フラビンレダクターゼ、調節体タンパク質)及び分子酸素(O2)を必要とする。MMOの天然の基質は、メタノールに酸化されるメタンである。
特に非特異的生触媒として、MMOは、同様にメタン、一連の追加の基質、例えばn−アルカン類及びそれらの誘導体、シクロアルカン、芳香族化合物、一酸化炭素及び複素環式化合物を酸化し/ヒドロキシル化する。しかしながら、後者のもの及びピリジンは特に、非常に遅い速度でのみ転換され;ピリジンに関する比活性は0.029単位/mgのタンパク質である(Colby et al. 1977: The soluble methane monooxygenase of Methylococcus capsulatus. Biochem. J. 165: 395-402)。生理工学への酵素の利用は現在可能ではない。なぜならば、ほとんどの細胞内酵素のように、単離することが困難であり、低い安定性のものであり、そして必要とされる補助基質が比較的高価であるからである。
ピリジン分解細菌、例えばロドコッカスspp. (Rhodococcus spp.)又はアルスロバクターspp. (Arthrobactoer spp.)は、ピリジンN−酸化物を精製するいずれの酵素も有さないが、しかしむしろ、炭素でのピリジン環をヒドロキシル化するか(まれな)、又は環の特定結合を還元し(通常)、そして従って、分解を開始せしめる(Fetzner, S., 1998: Bacterial degradation of pyridine, indole, quinoline, and their derivatives under different redox conditions. Appl. Microbiol. Biotechnol. 49: 237-250)。
第1の観点においては、本発明は、
(a)配列番号2, 4, 6, 8, 10, 12, 14又は19のポリペプチドに対して少なくとも65%、 70%、75%、80%、85%、90%、95%、97%又は98%の同一性を有するアミノ酸配列を含んで成るポリペプチド;
(a)配列番号2, 4, 6, 8, 10, 12, 14又は19のポリペプチドに対して少なくとも65%、 70%、75%、80%、85%、90%、95%、97%又は98%の同一性を有するアミノ酸配列を含んで成るポリペプチド;
(b)(i)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17のポリペプチドコード配列;(ii)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るゲノムDNA配列に含まれるcDNA配列又はそのゲノムDNA配列;又は(iii)(i)又は(ii)の十分な長さの相補鎖と、少なくとも低い、中位の、中位に高い、又は高い緊縮条件下でハイブリダイズするポリヌクレオチドによりコードされるポリペプチド;
(c)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に対して少なくとも60%の同一性、好ましくは少なくとも65%、 70%、75%、80%、85%、90%、95%、97%又は98%の同一性を有するヌクレオチド配列を含んで成るポリヌクレオチドによりコードされるポリペプチド;
(d)次のモチーフ:
モチーフI: [FL]XX[YF]S[AN]X[FHY]G[GN]GX[YF]N (配列番号40)
モチーフII: G[GN]GX[YF]NXX[VA]AX[EH][LF]R (配列番号41 )
モチーフIII: RXXRI[QE][DEQ]S[IM]ATN (配列番号42)
モチーフIV: S[IM]ATN[PG][EQN][FM][SDN][FL] (配列番号43)
モチーフV: P[PDK][DG]F[HFW]R[AP] (配列番号44)
モチーフVl: [TI]XXXLYPNP[TK][GV] (配列番号45)の1又は複数のモチーフを含んで成るポリペプチド;及び
モチーフI: [FL]XX[YF]S[AN]X[FHY]G[GN]GX[YF]N (配列番号40)
モチーフII: G[GN]GX[YF]NXX[VA]AX[EH][LF]R (配列番号41 )
モチーフIII: RXXRI[QE][DEQ]S[IM]ATN (配列番号42)
モチーフIV: S[IM]ATN[PG][EQN][FM][SDN][FL] (配列番号43)
モチーフV: P[PDK][DG]F[HFW]R[AP] (配列番号44)
モチーフVl: [TI]XXXLYPNP[TK][GV] (配列番号45)の1又は複数のモチーフを含んで成るポリペプチド;及び
(e)配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドの1又は数個のアミノ酸の置換、欠失及び/又は挿入を含んで成る変異体から成る群から選択された、ペルオキシゲナーゼ活性を有する、好ましくは組換え的に生成される単離されたポリペプチドに関する。
第2の観点においては、本発明は、第1の観点のポリペプチドをコードするヌクレオチド配列を含んで成る単離されたポリヌクレオチドに関する。
本発明の第3の観点は、発現宿主においてポリペプチドの生成を指図する1又は数個の制御配列に対して操作可能的に結合される第2観点のポリヌクレオチドを含んで成る核酸構造体に関する。
本発明の第3の観点は、発現宿主においてポリペプチドの生成を指図する1又は数個の制御配列に対して操作可能的に結合される第2観点のポリヌクレオチドを含んで成る核酸構造体に関する。
第4の観点においては、本発明は、第3の観点の核酸構造体を含んで成る組換え発現ベクターに関する。
本発明の第5の観点は、第3の観点の核酸構造体又は第4の観点の発現ベクターを含んで成る組換えを宿主細胞に関する。
本発明の第5の観点は、第3の観点の核酸構造体又は第4の観点の発現ベクターを含んで成る組換えを宿主細胞に関する。
本発明の第6の観点は、(a)その野生形でポリペプチドを生成する細胞を、ポリペプチドの生成の助けになる条件下で培養し;そして(b)ポリペプチドを回収することを含んで成る、第1の観点のポリペプチドの生成方法に関する。
本発明の第7の観点は、(a)ポリペプチドをコードするヌクレオチド配列を含んで成る核酸構造体を含んで成る宿主細胞を、ポリペプチドの生成の助けになる条件下で培養し;そして(b)ポリペプチドを回収することを含んで成る、第1の観点のポリペプチドの生成方法に関する。
本発明の第8の観点は、親細胞よりも少なくポリペプチドを生成する変異体をもたらす、第1の観点のポリペプチドをコードするヌクレオチド配列を崩壊するか又は欠失することを含んで成る、親細胞の変異体の生成方法に関する。
本発明の第9の観点は、前記第8の観点の方法により生成される変異体細胞に関する。
第10の観点においては、本発明は、(a)の第9の観点変異体細胞を、タンパク質の生成の助けになる条件下で培養し;そして(b)タンパク質を回収することを含んで成る、タンパク質の生成方法に関する。
第10の観点においては、本発明は、(a)の第9の観点変異体細胞を、タンパク質の生成の助けになる条件下で培養し;そして(b)タンパク質を回収することを含んで成る、タンパク質の生成方法に関する。
本発明の第11の観点は、(a)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列中に少なくとも1つの突然変異を導入し、ここで前記変異体ヌクレオチド配列は配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドを含んで成るか又はそれから成るポリペプチドをコードし;そして(b)前記変異体ヌクレオチド配列を含んで成るポリヌクレオチドを回収することを含んで成る、ペルオキシゲナーゼ活性を有するポリペプチドをコードする変異体ヌクレオチド配列を含んで成るポリヌクレオチドの生成方法に関する。
本発明の観点は、前記第11の観点の方法により生成される変異体ポリヌクレオチドに関する。
第13の観点においては、本発明は、(a)ポリペプチドをコードする第12の観点の変異体ポリヌクレオチドを含んで成る細胞を、前記ポリペプチドの生成の助けに成る条件下で培養し;そして(b)前記ポリペプチドを回収することを含んで成る、ポリペプチドの生成方法に関する。
第13の観点においては、本発明は、(a)ポリペプチドをコードする第12の観点の変異体ポリヌクレオチドを含んで成る細胞を、前記ポリペプチドの生成の助けに成る条件下で培養し;そして(b)前記ポリペプチドを回収することを含んで成る、ポリペプチドの生成方法に関する。
本発明の第14の観点は、(a)ポリペプチドをコードするポリヌクレオチドを含んで成るトランスジェニック植物又は植物細胞を、前記ポリペプチドの生成の助けになる条件下で培養し;そして(b)前記ポリペプチドを回収することを含んで成る、第1の観点ポリペプチドの生成方法に関する。
本発明の第15の観点は、配列番号2のアミノ酸-43〜-1を含んで成るか又はそれらから成るシグナルペプチドをコードする第1ヌクレオチド配列及び配列番号2のアミノ酸1〜330を含んで成るか又はそれらから成るプロペプチドをコードする第2ヌクレオチド配列の1つ又は両者に対して操作可能的に結合されるタンパク質をコードする、前記第1及び第2ヌクレオチド配列に対して外来性の遺伝子を含んで成る核酸構造体に関する。
第16の観点においては、本発明は、前記観点の核酸構造体を含んで成る組換え発現ベクターに関する。
第17の観点は、前記観点の核酸構造体を含んで成る組換え宿主細胞に関する。
第17の観点は、前記観点の核酸構造体を含んで成る組換え宿主細胞に関する。
第18の観点は、(a)前記観点の組換え宿主細胞を、タンパク質の生成の助けになる条件下で培養し;そして(b)前記タンパク質を回収することを含んで成る、タンパク質の生成方法に関する。
ピリジンN−酸化物及び他のN−複素環式化合物を、その対応する前駆体から、非常に低いレベルの技法及び装置の複雑性及び同時に、安価な補助基質の使用を従って、調製するための方法を実施することが、本発明の目的である。出発化合物の転換は、無菌又は半無菌反応条件についての高められた要求を伴わないで、水性媒体において、非常に短いインキュベーション時間で、室温及び圧下でもたらされるであろう。反応生成物は、最小レベルの複雑性下で単離されるべきであり、そして異なった構造異性体の複雑化された分離は省略されるであろう。
本発明の第20の観点は、図1における式(I)のN−複素環を、1段階反応方法を用いて、少なくとも1つの酸化剤の存在下で、第1の観点下で定義されるようなペルオキシゲナーゼポリペプチドにより転換することによる、図1における式(I)のN−複素環の式(II)のその対応するN−酸化物への酵素的位置選択性酸化方法に関する。
もう1つの観点においては、本発明は、式(I)のN−複素環を、1段階反応方法を用いて、少なくとも1つの酸化剤の存在下で、真菌芳香族ハロペルオキシダーゼペルオキシゲナーゼポリペプチドにより転換することによる、式(I)の芳香族N−複素環の式(II)のその対応するN−酸化物への酵素的位置選択性酸化方法に関する。
本発明の最終観点は、前記第1の観点において定義されるようなポリペプチドを含んで成るいくつかのタイプの組成物、例えば洗剤組成物、皿洗い洗濯組成物、パルプ及び紙処理のための組成物、水処理のための組成物及び油処理のための組成物に関する。
定義:
ペルオキシゲナーゼ活性:用語“ペルオキシゲナーゼ活性”(AaP:E. C. 1. 11. 1.-)とは、広範囲の種類の化合物、例えばフェノール、ABTS[2, 2’−アジノビス(3−エチルベンズチアゾリン−6−スルホン酸)]、アリールアルコール、式IのN−複素環式化合物(図1を参照のこと)、及びアルデヒド及び無機臭化物を酸化する能力として本明細書において定義される。本発明のためには、ペルオキシゲナーゼ活性は、Kluge et al. (2007, Appl Microbiol Biotechnol 75: 1473-1478)により記載される分光光度方法に従って決定される。
ペルオキシゲナーゼ活性:用語“ペルオキシゲナーゼ活性”(AaP:E. C. 1. 11. 1.-)とは、広範囲の種類の化合物、例えばフェノール、ABTS[2, 2’−アジノビス(3−エチルベンズチアゾリン−6−スルホン酸)]、アリールアルコール、式IのN−複素環式化合物(図1を参照のこと)、及びアルデヒド及び無機臭化物を酸化する能力として本明細書において定義される。本発明のためには、ペルオキシゲナーゼ活性は、Kluge et al. (2007, Appl Microbiol Biotechnol 75: 1473-1478)により記載される分光光度方法に従って決定される。
本発明のポリペプチドは、配列番号2,4,6,8,10,12,14又は19の成熟ポリペプチドのペルオキシゲナーゼ活性の少なくとも20%、好ましくは少なくとも40%、より好ましくは少なくとも50%、より好ましくは少なくとも60%、より好ましくは少なくとも70%、より好ましくは少なくとも80%、さらにより好ましくは少なくとも90%、最も好ましくは少なくとも95%、及びさらに最も好ましくは少なくとも100%を有する。
単離されたポリペプチド:用語“単離されたポリペプチド”とは、本明細書において使用される場合、源から単離されるポリペプチドを言及する。好ましい観点いおいては、前記ポリペプチドは、SDS−PAGEにより決定される場合、少なくとも1%純粋、好ましくは少なくとも5%純粋、より好ましくは少なくとも10%純粋、より好ましくは少なくとも20%純粋、より好ましくは少なくとも40%純粋、より好ましくは少なくとも60%純粋、さらにより好ましくは少なくとも80%純粋、及び最も好ましくは少なくとも90%純粋である。
実質的に純粋なポリペプチド:用語“実質的に純粋なポリペプチド”とは、本明細書において、多くとも10%、好ましくは多くとも8%、より好ましくは多くとも6%、より好ましくは多くとも5%、より好ましくは多くとも4%、多くとも3%、さらにより好ましくは多くとも2%、最も好ましくは多くとも1%及びさらに最も好ましくは多くとも0.5%(重量による)の天然において又は組換え的に結合される他のポリペプチド材料を含むポリペプチド調製物を示す。従って、好ましくは、実質的に純粋なポリペプチドは、調製物の存在する合計ポリペプチド材料の少なくとも92%の純度、好ましくは少なくとも94%の純度、好ましくは少なくとも95%の純度、好ましくは少なくとも96%の純度、好ましくは少なくとも97%の純度、好ましくは少なくとも98%の純度、さらに好ましくは少なくとも99%の純度、最も好ましくは少なくとも99.5%の純度、及びさらに最も好ましくは少なくとも100%(重量による)の純度である。
本発明のポリペプチドは好ましくは、実質的に純粋な形で存在し、すなわちポリペプチド調製物は、天然において又は組換え的に結合される他のポリペプチド材料を実質的に有さない。これは、例えば、良く知られている組換え方法、又は従来の精製方法によりポリペプチドを調製することにより達成され得る。
成熟ポリペプチド:用語“成熟ポリペプチド”とは、翻訳及びいずれかの後−翻訳修飾、例えばN−末端プロセッシング、C−末端切断、グリコシル化、リン酸化、等に続いてその最終形で存在する、ペルオキゲナーゼ活性を有するポリペプチドとして本明細書において定義される。好ましい観点においては、成熟ポリペプチドは、N−末端ペプチド配列決定データに基づいて配列番号2の位置1〜330に示されるアミノ酸配列を有し(Ullrich et al., 2004, Appl. Env. Microbiol. 70(8): 4575-4581)、これはAaPペルオキシゲナーゼ酵素の成熟タンパク質の開始を解明する。
成熟ポリペプチドコード配列:用語“成熟ポリペプチドコード配列”とは、ペルオキゲナーゼ活性を有する成熟ポリペプチドをコードするヌクレオチド配列として本明細書において定義される。好ましい観点においては、成熟ポリペプチドコード配列は、配列番号1のヌクレオチド152〜1141である。
同一性:2種のアミノ酸配列間の又は2種のヌクレオチド配列間の関連性が、パラメーター“同一性”により記載される。
同一性:2種のアミノ酸配列間の又は2種のヌクレオチド配列間の関連性が、パラメーター“同一性”により記載される。
本発明のためには、2種のアミノ酸配列間の同一性の程度は、EMBOSSパッケージ(EMBOSS: The European Molecular Biology Open Software Suite, Rice et al., 2000, Trends in Genetics 16: 276-277)、好ましくはバージョン3.0.0又はその後のバージョンのNeedleプログラムにおいて実施されるようにして決定される。使用される任意のパラメーターは、10のギャップ開始ペナルティー、0.5のギャップ延長ペナルティー及びEBLOSUM62(BLOSUM62のEMBOSS バージョン)置換マトリックスである。Needle識別された“最長同一性”(-nobrief オプションを用いて得られた)の出力は、%同一性として使用され、そして次の通りにして計算される:
(同一の残基×100)/(一列整列の長さ−一列整列におけるギャップの数)。
(同一の残基×100)/(一列整列の長さ−一列整列におけるギャップの数)。
本発明のためには、2種のデオキシリボヌクレオチド配列間の同一性の程度は、EMBOSSパッケージ(EMBOSS: The European Molecular Biology Open Software Suite, Rice et al., 2000, Trends in Genetics 16: 276-277)、好ましくはバージョン3.0.0又はその後のバージョンのNeedleプログラムにおいて実施されるようにして決定される。使用される任意のパラメーターは、10のギャップ開始ペナルティー、0.5のギャップ延長ペナルティー及びEBLOSUM62(BLOSUM62のEMBOSS バージョン)置換マトリックスである。Needle識別された“最長同一性”(-nobrief オプションを用いて得られた)の出力は、%同一性として使用され、そして次の通りにして計算される:
(同一のデオキシリボヌクレオチ×100)/(一列整列の長さ−一列整列におけるギャップの合計数)。
(同一のデオキシリボヌクレオチ×100)/(一列整列の長さ−一列整列におけるギャップの合計数)。
相同配列:用語“相同配列”とは、配列番号2、4、6、8、10、12、14又は19で示されるポリペプチドを用いて、tfasty調査(Pearson, W.R., 1999, in Bioinformatics Methods and Protocols, S. Misener and S. A. Krawetz, ed., pp. 185-219)により0.001以下のE値(又は予測評点)を付与する予測されるタンパク質として本明細書において定義される。
ポリペプチドフラグメント:用語“ポリペプチドフラグメント”とは本明細書においては、配列番号2、4、6、8、10、12、14又は19、又はその相同配列の成熟ポリペプチドのアミノ及び/又はカルボキシル末端から欠失された1又は複数(数個)のアミノ酸を有するポリペプチドとして定義され、ここで前記フラグメントはペルオキシゲナーゼ活性を有する。
副配列:用語“副配列”とは本明細書においては、配列番号1、3、5、7、9、11 、13、15又は17、又はその相同配列の成熟ポリペプチドコード配列の5’及び/又は3’末端から欠失される1又は複数(数個)のヌクレオチドを有するヌクレオチド配列として定義され、ここで前記副配列はペルオキシゲナーゼ活性を有するポリペプチドフラグメントをコードする。
対立遺伝子変異体:本明細書においては、用語“対立遺伝子変異体”とは、同じ染色体遺伝子座を占める遺伝子の複数の他の形のいずれかを示す。対立遺伝子変動は、天然においては、突然変異を通して発生し、そして集団内の多形現象をもたらすことができる。遺伝子突然変異はサイレントであり得るか(コードされるポリペプチドの変化が存在しない)、又は変更されたアミノ酸配列を有するポリペプチドをコードすることができる。ポリペプチドの対立遺伝子変異体は、遺伝子の対立遺伝子によりコードされるポリペプチドである。
単離されたポリヌクレオチド:用語“単離されたポリヌクレオチド”とは、本明細書において使用される場合、源から単離されるポリヌクレオチドを言及する。好ましい観点いおいては、前記ポリヌクレオチドは、SDS−PAGEにより決定される場合、少なくとも1%純粋、好ましくは少なくとも5%純粋、より好ましくは少なくとも10%純粋、より好ましくは少なくとも20%純粋、より好ましくは少なくとも40%純粋、より好ましくは少なくとも60%純粋、さらにより好ましくは少なくとも80%純粋、及び最も好ましくは少なくとも90%純粋である。
実質的に純粋にポリヌクレオチド:用語“実質的に純粋なポリペプチド”とは、本明細書において使用される場合、他の外来性の又は所望しないヌクレオチドを有さず、そして遺伝子構築されたタンパク質生成システム内での使用のために適切な形で存在するポリヌクレオチド調製物を言及する。従って、実質的に純粋なポリヌクレオチドは、それが天然において又は組換え的に結合される他のポリヌクレオチド材料を、多くとも10重量%、好ましくは多くとも8重量%、より好ましくは多くとも6重量%、より好ましくは多くとも5重量%、より好ましくは多くとも4重量%、より好ましくは多くとも3重量%、さらにより好ましくは多くとも2重量%、最も好ましくは多くとも1重量%、及びさらに最も好ましくは多くとも0.5重量%含む。しかしながら、実質的に純粋なポリヌクレオチドは、天然に存在する5’及び3’未翻訳領域、例えばプロモーター及びターミネーターを含むことができる。
好ましくは、実質的に純粋なポリヌクレオチドは、少なくとも90%の純度、好ましくは少なくとも92%の純度、より好ましくは少なくとも94%の純度、より好ましくは少なくとも95%の純度、より好ましくは少なくとも96%の純度、より好ましくは少なくとも97%の純度、さらにより好ましくは少なくとも98%の純度、最も好ましくは少なくとも99%の純度、及びさらに最も好ましくは少なくとも99.5%(重量による)の純度が好ましい。本発明のポリヌクレオチドは好ましくは、実質的に純粋な形で存在し、すなわちポリヌクレオチド調製物は、それが天然において又は組換え的に結合される他のポリヌクレオチド材料を実質的に有さない。ポリヌクレオチドは、ゲノム、cDNA、RNA、半合成、合成起源、又はそれらのいずれかの組合せのものであり得る。
コード配列:本明細書において使用される場合、用語“コード配列”とは、そのタンパク質生成物のアミノ酸配列を直接的に特定するヌクレオチド配列を包含する。コード配列の境界は一般的に、ATG開始コドン又は他の開始コドン、例えばGTG及びTTGにより通常開始し、そして停止コドン、例えばTAA、TAG及びTGAで終結する読取枠により決定される。コード配列は、DNA、cDNA、又は組換えヌクレオチド配列であり得る。
cDNA:用語“cDNA”とは、本発明において使用される場合、真核細胞に由来する成熟のスプライスされたmRNA分子から逆転写により調製され得るDNA分子を包含する。cDNAは、その対応するゲノムDNAに通常存在するイントロン配列を欠いている。初期一次RNA転写体は、mRNAに対する前駆体であり、そしてそれは、成熟のスプライスされたmRNAとして出現する前、一連のプロセッシング現象を通して進行する。この現象は、スプライシングと呼ばれる工程によるイントロン配列の除去を包含する。従って、cDNAがmRNAに由来する場合、それはイントロン配列を欠いている。
核酸構造体:本明細粗において使用される場合、用語“核酸構造体”とは、天然に存在する遺伝子から単離され、又は他方では、天然に存在しないか、又は合成的である態様で核酸のセグメントを含むように修飾されている、一本鎖又は二本鎖核酸分子として定義される。用語“核酸構造体”とは、核酸構造体が本発明のコード配列の発現のために必要とされるすべての制御配列を含む場合、用語“発現カセット”と同じ意味である。
制御配列:用語“制御配列”とは、本発明のポリペプチドをコードするポリヌクレオチドの発現のために必要であるすべての成分を包含するよう定義される。個々の制御配列は、ポリペプチドをコードする核酸配列に対して生来であっても又は外来性であっても良く、又はお互いに対して生来であっても又は外来性であっても良い。そのような制御配列は、リーダー、ポリアデニル化配列、プロペプチド配列、プロモーター、シグナルペプチド配列、及び転写ターミネーターを包含するが、但しそれらだけには限定されない。最少で、制御配列は、プロモーター、及び転写及び翻訳停止シグナルを包含する。制御配列は、ポリペプチドをコードする核酸配列のコード領域と制御配列との連結を促進する特定の制限部位を導入するためにリンカーを提供され得る。
操作可能的に連結される:用語“操作可能的に連結される”とは、制御配列が、ポリペプチドのコード配列の発現を指図するようポリヌクレオチド配列のコード配列に対する位置で適切に配置されている配置として本明細書において定義される。
発現:用語“発現”とは、ポリペプチドの生成に包含されるいずれかの段階、例えば転写、後−転写修飾、翻訳、後−翻訳修飾及び分泌(但し、それらだけには制限されない)を包含する。
発現:用語“発現”とは、ポリペプチドの生成に包含されるいずれかの段階、例えば転写、後−転写修飾、翻訳、後−翻訳修飾及び分泌(但し、それらだけには制限されない)を包含する。
発現ベクター:本明細書においては、用語“発現ベクター”とは、本発明のポリペプチドとコードするポリヌクレオチドを含んで成り、そしてその発現を提供する追加のヌクレオチドに操作可能的に連結される線状又は環状DNA分子を包含する。
宿主細胞:用語“宿主細胞”とは、本明細書において使用される場合、本発明のポリヌクレオチドを含んで成る核酸構造体による形質転換、トランスフェクション、トランスダクション及び同様のものに対して感受性であるいずれかの細胞型を包含する。
宿主細胞:用語“宿主細胞”とは、本明細書において使用される場合、本発明のポリヌクレオチドを含んで成る核酸構造体による形質転換、トランスフェクション、トランスダクション及び同様のものに対して感受性であるいずれかの細胞型を包含する。
修飾:用語“修飾”とは本明細書において、配列番号2、4、6、8、10、12、14又は19、又はその相同配列の成熟ポリペプチドから成るポリペプチドのいずれかの化学的修飾、及びそのようなポリペプチドをコードするDNAの遺伝子操作を意味する。前記修飾は、1又は複数(数個)のアミノ酸の置換、欠失及び/又は挿入、及び1又は複数(数個)のアミノ酸側鎖の置換であり得る。
人工変異体:本明細書において使用される場合、用語“人工変異体”とは、1つの配列番号1、3、5、7、9、11 、13、15又は17、又はその相同配列の成熟ポリペプチドコード配列の修飾されたポリヌクレオチド配列を発現する生物により生成されるペルオキゲナーゼ活性を有するポリペプチドを意味する。修飾されたヌクレオチド配列は、配列番号1、3、5、7、9、11 、13、15又は17、又はその相同配列のポリヌクレオチド配列の修飾により、ヒト介在を通して得られる。
特定の記載:
多くの真菌ペルオキシゲナーゼゲノムDNA及びcDNAが、本出願の配列列挙においてコードされるアミノ酸配列と共に示される:
・配列番号1は、アグロシベ・アエゲリタ(Agrocybe aegerita)からのAaP1酵素をコードするcDNAポリヌクレオチド配列を示し、そのアミノ酸配列は配列番号2で示される。
・配列番号3は、アグロシベ・アエゲリタからのAaP2酵素をコードするcDNAポリヌクレオチド配列を示し、そのアミノ酸配列は配列番号4で示される。
多くの真菌ペルオキシゲナーゼゲノムDNA及びcDNAが、本出願の配列列挙においてコードされるアミノ酸配列と共に示される:
・配列番号1は、アグロシベ・アエゲリタ(Agrocybe aegerita)からのAaP1酵素をコードするcDNAポリヌクレオチド配列を示し、そのアミノ酸配列は配列番号2で示される。
・配列番号3は、アグロシベ・アエゲリタからのAaP2酵素をコードするcDNAポリヌクレオチド配列を示し、そのアミノ酸配列は配列番号4で示される。
・配列番号5は、ラカリア・ビコロル(Laccaria bicolor)からのペルオキシゲナーゼ酵素をコードするゲノムDNAポリヌクレオチド配列を示し、そのアミノ酸配列は配列番号6で示される。
・配列番号7は、コプリノプシス・シネレア・オカヤマ(Coprinopsis cinerea okayama)株7#130からのペルオキシゲナーゼ1酵素をコードするcDNAポリヌクレオチド配列(CC1G 08427)を示し、そのアミノ酸配列は配列番号8で示される(推定上のタンパク質UNIPROT:A8NAQ8)。
・配列番号7は、コプリノプシス・シネレア・オカヤマ(Coprinopsis cinerea okayama)株7#130からのペルオキシゲナーゼ1酵素をコードするcDNAポリヌクレオチド配列(CC1G 08427)を示し、そのアミノ酸配列は配列番号8で示される(推定上のタンパク質UNIPROT:A8NAQ8)。
・配列番号9は、コプリノプシス・シネレア・オカヤマ株7#130からのペルオキシゲナーゼ2酵素をコードするcDNAポリヌクレオチド配列(CC1 G 10475)を示し、そのアミノ酸配列は配列番号10で示される(推定上のタンパク質UNIPROT:A8NL34)。
・配列番号11は、コプリノプシス・シネレア・オカヤマ株7#130からのペルオキシゲナーゼ3酵素をコードするcDNAポリヌクレオチド配列(CC1 G 08981)を示し、そのアミノ酸配列は配列番号12で示される(推定上のタンパク質UNIPROT : A8P4U7)。
・配列番号11は、コプリノプシス・シネレア・オカヤマ株7#130からのペルオキシゲナーゼ3酵素をコードするcDNAポリヌクレオチド配列(CC1 G 08981)を示し、そのアミノ酸配列は配列番号12で示される(推定上のタンパク質UNIPROT : A8P4U7)。
・配列番号13は、コプリノプシス・シネレア・オカヤマ株7#130からのペルオキシゲナーゼ4酵素をコードするcDNAポリヌクレオチド配列(CC1 G 08975)を示し、そのアミノ酸配列は配列番号14で示される(推定上のタンパク質UNIPROT : A8P4T7)。
・配列番号15は、コプリナス・ラジアンス(Coprimus radians)DSM888 (DSMZ, Germanyから公的に入手できる)からのペルオキシゲナーゼ酵素の一部をコードする5’−末端部分cDNAポリヌクレオチド配列を示し、この部分アミノ酸配列は配列番号16で示される。
・配列番号15は、コプリナス・ラジアンス(Coprimus radians)DSM888 (DSMZ, Germanyから公的に入手できる)からのペルオキシゲナーゼ酵素の一部をコードする5’−末端部分cDNAポリヌクレオチド配列を示し、この部分アミノ酸配列は配列番号16で示される。
・配列番号17は、コプリナス・ラジアンスDSM888からのペルオキシゲナーゼ酵素の一部をコードする3’−末端部分cDNAポリヌクレオチド配列を示し、この部分アミノ酸配列は配列番号18で示される。
・配列番号19は、コプリナス・ラジアンスDSM888からのペルオキシゲナーゼ酵素の配列番号16及び18での部分配列の合併されたアミノ酸配列を示す。
・配列番号19は、コプリナス・ラジアンスDSM888からのペルオキシゲナーゼ酵素の配列番号16及び18での部分配列の合併されたアミノ酸配列を示す。
第1の観点においては、本発明は、
(a)配列番号2, 4, 6, 8, 10, 12, 14又は19のポリペプチドに対して少なくとも65%、 70%、75%、80%、85%、90%、95%、97%又は98%の同一性を有するアミノ酸配列を含んで成るポリペプチド;
(a)配列番号2, 4, 6, 8, 10, 12, 14又は19のポリペプチドに対して少なくとも65%、 70%、75%、80%、85%、90%、95%、97%又は98%の同一性を有するアミノ酸配列を含んで成るポリペプチド;
(b)(i)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17のポリペプチドコード配列;(ii)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るゲノムDNA配列に含まれるcDNA配列又はそのゲノムDNA配列;又は(iii)(i)又は(ii)の十分な長さの相補鎖と、少なくとも低い、中位の、中位に高い、又は高い緊縮条件下でハイブリダイズするポリヌクレオチドによりコードされるポリペプチド;
(c)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に対して少なくとも60%の同一性、好ましくは少なくとも65%、 70%、75%、80%、85%、90%、95%、97%又は98%の同一性を有するヌクレオチド配列を含んで成るポリヌクレオチドによりコードされるポリペプチド;
(d)次のモチーフ:
モチーフI: [FL]XX[YF]S[AN]X[FHY]G[GN]GX[YF]N (配列番号40)
モチーフII: G[GN]GX[YF]NXX[VA]AX[EH][LF]R (配列番号41 )
モチーフIII: RXXRI[QE][DEQ]S[IM]ATN (配列番号42)
モチーフIV: S[IM]ATN[PG][EQN][FM][SDN][FL] (配列番号43)
モチーフV: P[PDK][DG]F[HFW]R[AP] (配列番号44)
モチーフVl: [TI]XXXLYPNP[TK][GV] (配列番号45)の1又は複数のモチーフを含んで成るポリペプチド;及び
モチーフI: [FL]XX[YF]S[AN]X[FHY]G[GN]GX[YF]N (配列番号40)
モチーフII: G[GN]GX[YF]NXX[VA]AX[EH][LF]R (配列番号41 )
モチーフIII: RXXRI[QE][DEQ]S[IM]ATN (配列番号42)
モチーフIV: S[IM]ATN[PG][EQN][FM][SDN][FL] (配列番号43)
モチーフV: P[PDK][DG]F[HFW]R[AP] (配列番号44)
モチーフVl: [TI]XXXLYPNP[TK][GV] (配列番号45)の1又は複数のモチーフを含んで成るポリペプチド;及び
(e)配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドの1又は数個のアミノ酸の置換、欠失及び/又は挿入を含んで成る変異体から成る群から選択された、ペルオキシゲナーゼ活性を有する、好ましくは組換え的に生成される単離されたポリペプチドに関する。
好ましい態様においては、第1の観点のポリペプチドは、配列番号2, 4, 6, 8, 10, 12, 14又は19のアミノ酸配列;又はペルオキシゲナーゼ活性を有するそのフラグメントを含んで成るか又はそれらから成り;好ましくは前記ポリペプチドは、配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドを含んで成るか又はそれから成る。
好ましい態様は、(i)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列;(ii)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るゲノムDNA配列に含まれるcDNA配列又はそのゲノムDNA配列;又は(iii)(i)又は(ii)の十分な長さの相補鎖と、少なくとも中位の緊縮条件、好ましくは少なくとも中位の高いの緊縮条件、より好ましくは少なくとも高い緊縮条件下でハイブリダイズするポリヌクレオチドによりコードされる、第1の観点のポリペプチドに関する。
もう1つの好ましい態様は、配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に対して少なくとも60%の同一性、好ましくは少なくとも65%、 70%、75%、80%、85%、90%、95%、97%又は98%の同一性を有するヌクレオチド配列を含んで成るポリヌクレオチドによりコードされる、第1の観点のポリペプチドに関する。
また好ましくは、前記第1の観点のポリペプチドは、配列番号1, 3, 5, 7, 9, 11, 13, 15又は17のヌクレオチド配列;又はペルオキシゲナーゼ活性を有するフラグメントをコードするその副配列を含んで成るか又はそれから成るポリヌクレオチドによりコードされ;好ましくは、前記ポリヌクレオチドは、配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るか又はそれから成るポリヌクレオチドによりコードされる。
本発明のもう1つの好ましい態様においては、第1の観点のポリペプチドは、次のモチーフの1又は複数、好ましくは次のモチーフの2又はそれ以上、3又はそれ以上、4又はそれ以上、5又は6個を含んで成る:
モチーフI: [FL]XX[YF]S[AN]X[FHY]G[GN]GX[YF]N (配列番号40)
モチーフII: G[GN]GX[YF]NXX[VA]AX[EH][LF]R (配列番号41 )
モチーフIII: RXXRI[QE][DEQ]S[IM]ATN (配列番号42)
モチーフIV: S[IM]ATN[PG][EQN][FM][SDN][FL] (配列番号43)
モチーフV: P[PDK][DG]F[HFW]R[AP] (配列番号44)
モチーフVl: [TI]XXXLYPNP[TK][GV] (配列番号45)。
モチーフI: [FL]XX[YF]S[AN]X[FHY]G[GN]GX[YF]N (配列番号40)
モチーフII: G[GN]GX[YF]NXX[VA]AX[EH][LF]R (配列番号41 )
モチーフIII: RXXRI[QE][DEQ]S[IM]ATN (配列番号42)
モチーフIV: S[IM]ATN[PG][EQN][FM][SDN][FL] (配列番号43)
モチーフV: P[PDK][DG]F[HFW]R[AP] (配列番号44)
モチーフVl: [TI]XXXLYPNP[TK][GV] (配列番号45)。
好ましくは、前記第1の観点のポリペプチドは、配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドの1又は数個のアミノ酸の置換、欠失及び/又は挿入を含んで成る変異体である。
好ましくは、アミノ酸変化は、マイナーな性質のもの、すなわち保存性アミノ酸置換又は置換;1〜約30個のアミノ酸の小さな欠失;小さなアミノ−又はカルボキシル−末端、例えばアミノ末端メチオニン残基の延長;約20〜25個までの残基の小さなリンカーペプチド;又は実行電荷又は他の機能、例えばポリ−ヒスチジン路、抗原性エピトープ又は結合ドメインを変えることにより精製を促進する小さな延長のものであり;換言すれば、タンパク質の折りたたみ及び/又は活性に有意に影響を及ぼさない変化である。
保存性置換の例は、塩基性アミノ酸(アルギニン、リシン及びヒスチジン)、酸性アミノ酸(グルタミン酸及びアスパラギン酸)、極性アミノ酸(グルタミン及びアスパラギン)、疎水性アミノ酸(ロイシン、イソロイシン及びバリン)、芳香族アミノ酸(フェニルアラニン、トリプトファン及びチロシン)、及び小さなアミノ酸(グリシン、アラニン、セリン、トレオニン及びメチオニン)のグループ内である。一般的に、比活性を変更しないアミノ酸置換は当業界において知られており、そしてたとえば、H. Neurath and R.L. Hill, 1979, The Proteins, Academic Press, New York により記載されている。最も通常生じる交換は次のものである: Ala/Ser, Val/Ile, Asp/Glu, Thr/Ser, Ala/Gly, Ala/Thr, Ser/Asn, Ala/Val, Ser/Gly, Tyr/Phe, Ala/ Pro, Lys/Arg, Asp/Asn, Leu/Ile, Leu/Val, Ala/Glu及びAsp/Gly。
20の標準アミノ酸の他に、非標準のアミノ酸(例えば、4−ヒドロキシプロリン、6−N−メチルリシン、2−アミノイソ酪酸、イソバリン及びα−メチルセリン)は、野生型ポリペプチドのアミノ酸残基により置換され得る。限定された数の非保存性アミノ酸、すなわち遺伝子コードによりコードされないアミノ酸、及び不自然なアミノ酸は、アミノ酸残基により置換され得る。不自然なアミノ酸は、化学的に合成され得、そして好ましくは、市販されており、そしてピペコリン酸、チアゾリジンカルボン酸、デヒドロプロリン、3−及び4−メチルプロリン及び3,3−ジメチルプロリンを包含する。
他方では、アミノ酸変化は、ポリペプチドの生理化学的性質が変更されるような性質のものである。例えば、アミノ酸変化は、ポリペプチドの熱安定性を改良し、基質変異性を変更し、pH最適性を変え、そして同様のことをする。
親ポリペプチドにおける必須アミノ酸は、当業界において知られている方法、例えば特定部位の突然変異誘発、又はアラニン−走査突然変異誘発に従って同定され得る(Cunningham and Wells, Science 244: 1081-1085, 1989)。後者の技法においては、単一のアラニンの突然変異が分子におけるあらゆる残基に導入され、そして得られる変異体分子は、分子の活性に対して決定的であるアミノ酸残基を同定するために、生物学的活性(すなわち、ペルオキシゲナーゼ活性)について試験される。また、Hilton など., J. Biol. Chem. 271: 4699-4708, 1996を参照のこと。
酵素又は他の生物学的相互作用の活性部位はまた、推定上の接触部位アミノ酸の突然変異に関して、核磁気共鳴、結晶学、電子回折、又は光親和性ラベリングのような技法により決定されるように、構造の物理的分析によっても決定され得る。例えば、de Vos など., Science 255: 306-312, 1992; Smith など., J. Mol. Biol. 224: 899-904, 1992; Wlodaver など., FEBS Lett. 309: 59-64, 1992を参照のこと。必須アミノ酸の本体はまた、本発明のポリペプチドに関連するポリペプチドとの同一性の分析からも推定され得る。
単一又は複数のアミノ酸置換、欠失及び/又は挿入は、突然変異誘発、組換え及び/又はシャフリング、続く適切なスクリーニング方法、例えばReidhaar-Olson and Sauer (Science 241: 53-57, 1988), Bowie and Sauer (Proc. Natl. Acad. Sci. USA 86: 2152-2156, 1989), WO95/17413号又はWO95/22625号により開示される既知の方法を用いて、生成され、そして試験され得る。使用され得る他の方法は、エラープロンPCR、ファージ表示(例えば、Lowman など., Biochem. 30: 10832-10837, 1991; Ladner など., アメリカ特許第5,223,409号;Huse, WIPO Publication WO92/06204号)及び特定領域の突然変異誘発(Derbyshire など., Gene 46: 145, 1986; Ner など., DNA 7: 127, 1988)を包含する。
突然変異誘発/シャフリング方法は、宿主細胞においてクローン化され、突然変異誘発されたポリペプチドの活性を検出するために、高い処理量の自動化されたスクリーニング方法と組み合わされ得る(Ness など., 1999, Nature Biotechnology 17: 893-896)。活性ポリペプチドをコードする突然変異誘発されたDNA分子は、宿主細胞から回収され、そして近代装置を用いて急速に配列決定され得る。それらの方法は、興味あるポリペプチドにおける重要な個々のアミノ酸残基の急速な決定を可能にし、そして未知の構造体のポリペプチドに適用され得る。
配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドのアミノ酸置換、欠失及び/又は挿入の合計数は、10、好ましくは9、より好ましくは8、より好ましくは7、より好ましくは多くとも6、より好ましくは5、より好ましくは4、さらにより好ましくは3、最も好ましくは2、及びさらに最も好ましくは1である。
好ましくは、前記第1の観点のポリペプチドは、受託番号DSM21289としてDSMZによりブダベスト条約下で2008年3月14日に寄託されたE. コリNN049991に含まれるか;又は受託番号DSM21290としてDSMZによりブダベスト条約下で2008年3月14日に寄託されたE. コリNN049992に含まれるプラスミドに含まれるプラスミドに含まれるポリヌクレオチドによりコードされる。
もう1つの好ましい態様は、成熟ポリペプチドが配列番号2のアミノ酸1〜330である、本発明の第1の観点のポリペプチドに関する。
成熟ポリペプチドコード配列が配列番号1のヌクレオチド152〜1141であることは、本発明の第1の観点においても好ましい。
成熟ポリペプチドコード配列が配列番号1のヌクレオチド152〜1141であることは、本発明の第1の観点においても好ましい。
ハイブリダイゼーション:
配列番号1, 3, 5, 7, 9, 11, 13, 15又は17のヌクレオチド配列又はその副配列、及び配列番号2, 4, 6, 8, 10, 12, 14又は19のアミノ酸配列又はそのフラグメントは、当業界において良く知られている方法に従って、異なった属又は種の株からのペルオキシゲナーゼ活性を有するポリペプチドをコードするDNAを同定し、そしてクローン化するための核酸プローブを企画するために使用され得る。特に、そのようなプローブは、そこにおける対応する遺伝子を同定し、そして単離するために、標準のサザンブロット方法に従って、興味ある属又は種のゲノム又はcDNAとのハイブリダイゼーションのために使用され得る。そのようなプローブは、完全な配列よりも相当に短いが、しかし少なくとも14個、好ましくは少なくとも25個、より好ましくは少なくとも35個、及び最も好ましくは少なくとも70個の長さのヌクレオチドであるべきである。しかしながら、好ましくは、核酸プローブは少なくとも100個の長さのヌクレオチドである。
配列番号1, 3, 5, 7, 9, 11, 13, 15又は17のヌクレオチド配列又はその副配列、及び配列番号2, 4, 6, 8, 10, 12, 14又は19のアミノ酸配列又はそのフラグメントは、当業界において良く知られている方法に従って、異なった属又は種の株からのペルオキシゲナーゼ活性を有するポリペプチドをコードするDNAを同定し、そしてクローン化するための核酸プローブを企画するために使用され得る。特に、そのようなプローブは、そこにおける対応する遺伝子を同定し、そして単離するために、標準のサザンブロット方法に従って、興味ある属又は種のゲノム又はcDNAとのハイブリダイゼーションのために使用され得る。そのようなプローブは、完全な配列よりも相当に短いが、しかし少なくとも14個、好ましくは少なくとも25個、より好ましくは少なくとも35個、及び最も好ましくは少なくとも70個の長さのヌクレオチドであるべきである。しかしながら、好ましくは、核酸プローブは少なくとも100個の長さのヌクレオチドである。
例えば、核酸プローブは、少なくとも200個、好ましくは少なくとも300個、より好ましくは少なくとも400個、又は最も好ましくは少なくとも500個の長さのヌクレオチドであり得る。さらに長いプローブ、例えば少なくとも600個、好ましくは少なくとも700個、より好ましくは少なくとも800個、又は最も好ましくは少なくとも900個の長さのヌクレオチドである核酸プローブが使用され得る。DNA及びRNAの両プローブが使用され得る。プローブは典型的には、対応する遺伝子を検出するためにラベルされる(例えば、32P, 3H, 35S, ビオチン、又はアビジンにより)。そのようなプローブは、本発明により包含される。
従って、そのような他の生物から調製されたゲノムDNAライブラリーは、上記に記載されるプローブとハイブリダイズし、そしてペルオキシゲナーゼ活性を有するポリペプチドをコードするDNAについてスクリーンされ得る。そのような生物からのゲノム又は他のDNAは、アガロース又はポリアクリルアミドゲル電気泳動、又は他の分離技法により分離され得る。ライブラリーからのDNA又は分離されたDNAが、ニトロセルロース又は他の適切なキャリヤー材料に移行され、そしてその上に固定され得る。配列番号1と相同であるクローン又はDNA、又はその副配列を同定するためには、キャリヤー材料がサザンブロットに使用される。
本発明のためには、ハイブリダイゼーションは、ヌクレオチド配列が、非常に低い〜非常に高い緊縮条件下で、配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列、配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るゲノムDNA配列に含まれるcDNA配列又はそのゲノムDNA配列;その十分な長さの相補的鎖、又はその副配列に対応するラベルにされた核酸プローブにハイブリダイズすることを示す。核酸プローブがそれらの条件下でハイブリダイズする分子は、X−線フィルムを用いて検出される。
少なくとも100個の長さのヌクレオチドの長さの長いプローブに関して、非常に低い〜非常に高い緊縮条件は、最適には12〜24時間の標準のサザンブロット方法に従っての、5×SSPE、 0.3%SDS、 200μg/ml の剪断され、そして変性されたサケ精子DNA、及び25%ホルムアミド(非常に低い及び低い緊縮に関して)、35%ホルムアミド(中位及び中−高緊縮に関して)、又は50%ホルムアミド(高い及び非常に高い緊縮に関して)における42℃でのプレハイブリダイゼーション及びハイブリダイゼーションとして定義される。
少なくとも100個の長さのヌクレオチドの長いプローブに関しては、キャリヤー材料は最終的に、2×SSC、 0.2%SDS溶液を用いて、好ましくは少なくとも45℃(非常に低い緊縮)、より好ましくは少なくとも50℃(低いの緊縮)、より好ましくは少なくとも55℃(中位の高い緊縮)、より好ましくは少なくとも60℃(中くらいに高い緊縮)、さらにより好ましくは少なくとも65℃(高い緊縮)及び最も好ましくは少なくとも70℃(非常に高い緊縮)で、それぞれ15分間、3度洗浄される。
約15個〜約70個の長さのヌクレオチドである短いプローブに関しては、緊縮条件は、0.9MのNaCl、0.09Mのトリス−HCl, pH7.6、 6mM のEDTA、 0.5のNP-40, 1×Denhardt’s溶液、1mMのピロリン酸ナトリウム、1mMの一塩基性リン酸ナトリウム、0.1mMのATP及び0.2mgの酵母RNA(ml当たり)における、Bolton and McCarthy(1962、Proceedings of the National Academy of Sciences USA 48: 1390)に従って計算されたTmよりも約5℃〜約10℃低い温度での、最適には12〜24時間の標準のサザンブロット方法に従ってのプレハイブリダイゼーション、ハイブリダイゼーション、及び後−ハイブリダイゼーション洗浄として定義される。
約15個〜約70個の長さのヌクレオチドである短いプローブに関しては、キャリヤー材料は、6×SSC及び0.1%SDSにより15分間、1度、及び6×SSCを用いて、計算されたTmよりも約5℃〜約10℃低い温度でそれぞれ15分間、2度、洗浄される。
ポリペプチド源:
本発明のポリペプチドは、いずれかの属の微生物から得られる。本発明のためには、用語“〜から得られる”とは、所定の源に関して本明細書において使用される場合、ヌクレオチド配列によりコードされるポリペプチドが前記源により、又はその源からのヌクレオチド配列が挿入されている細胞により生成されることを意味する。好ましい態様においては、ポリペプチドは細胞外に分泌される。
本発明のポリペプチドは、いずれかの属の微生物から得られる。本発明のためには、用語“〜から得られる”とは、所定の源に関して本明細書において使用される場合、ヌクレオチド配列によりコードされるポリペプチドが前記源により、又はその源からのヌクレオチド配列が挿入されている細胞により生成されることを意味する。好ましい態様においては、ポリペプチドは細胞外に分泌される。
本発明のペルオキシゲナーゼ活性を有するポリペプチドは、細菌ポリペプチドであり得る。例えば、前記ポリペプチドは、ペルオキシゲナーゼ活性を有するグラム陽性細菌ポリペプチド、例えばバチルス(Bacillus)、ストレプトコーカス(Streptococcus)、ストレプトミセス(Streptomyces)、スタフィロコーカス(Staphylococcus)、エンテロコーカス(Enterococcus)、ラクトバチルス(Lactobacillus)、ラクトコーカス(Lactococcus)、クロストリジウム(Clostridium)、ゲオバシラス(Geobacillus)又はオセアノバチルス(Oceanobacillus)ポリペプチド、又はペルオキシゲナーゼ活性を有するグラム陰性細菌ポリペプチド、例えばE. コリ(E. coli)、シュードモナス(Pseudomonas)、サルモネラ(Salmonella)、カムフィロバクター(Campylobacter)、ヘリコバクター(Helicobacter)、フラボバクテリウム(Flavobacterium)、フソバクテリウム(Fusobacterium)、イリオバクター(llyobacter)、ネイセリア(Neisseria)又はウレアプラズマ(Ureaplasma)ポリペプチドであり得る。
好ましい観点においては、前記ポリペプチドは、ペルオキシゲナーゼ活性を有する、バチルス・アルカロフィラス(Bacillus alkalophilus)、バチルス・アミロリケファシエンス(Bacillus amyloliquefaciens)、バチルス・ブレビス(Bacillus brevis)、バチルス・サーキュランス(Bacillus circulans)、バチルス・クラウジ(Bacillus clausii)、バチルス・コアギュランス(Bacillus coagulans)、バチルス・ファーマス(Bacillus firmus)、バチルス・ラウタス(Bacillus lautus)、バチルス・レンタス(Bacillus lentus)、バチルス・リケニホルミス(Bacillus licheniformis)、バチルス・メガテリウス(Bacillus megaterium)、バチルス・プミラス(Bacillus pumilus)、バチルス・ステアロサーモフィラス(Bacillus stearothermophilus)、バチルス・サブチリス(Bacillus subtilis)又はバチルス・スリンジエンシス(Bacillus thuringiensis)ポリペプチドであり得るである。
もう1つの好ましい観点においては、前記ポリペプチドは、ペルオキシゲナーゼ活性を有する、ストレプトコーカス・エクイシミリス(Streptococcus equisimilis)、ストレプトコーカス・ピオゲネス(Streptococcus pyogenes)、ストレプトコーカス・ウベリス(Streptococcus uberis)、又はストレプトコーカス・エクイsubsp. ズーエピデミカス(Streptococcus egui subsp. Zooepidemicus)ポリペプチドである。
もう1つの好ましい観点においては、前記ポリペプチドは、ペルオキシゲナーゼ活性を有する、ストレプトミセス・アクロモゲネス(Streptomyces achromogenes)、ストレプトミセス・アベルミチリス(Streptomyces avermitilis)、ストレプトミセス・コエリカラー(Streptomyces coelicolor)、ストレプトミセス・グリセウス(Streptomyces griseus)又はストレプトミセス・リビダンズ(Streptomyces lividans)ポリペプチドである。
本発明のペルオキシゲナーゼ活性を有するポリペプチドは、ペルオキシゲナーゼ活性を有する、菌類ポリペプチド、及びより好ましくは、酵母ポリペプチド、例えばカンジダ(Candida)、クルイベロミセス(Kluyveromyces)、ピチア(Pichia)、サッカロミセス(Saccharomyces)、シゾサッカロミセス(Schizos accharomyces)、又はヤロウイア(Yarrowia)ポリペプチド;又はより好ましくは、ペルオキシゲナーゼ活性を有する、糸状菌ポリペプチド、例えばアクレモニウム(Acremonium)、アガリカス(Agaricus)、アルテマリア(Alternaria)、アスペルギラス(Aspergillus)、アウレオバシジウム(Aureobasidium)、ボトリオスパエリア(Botryospaeria)、セリポリオプシス(Ceriporiopsis)、カエトミヂウム(Chaetomidium)、クリソスポリウム(Chrysosporium)、クラビセプス(Claviceps)、コクリオボラス(Cochliobolus)、コプリノプシス(Coprinopsis)、コプトテルメス(Coptotermes)、
コリナスカス(Corynascus)、クリホネクトリア(Cryphonectria)、クリプトコーカス(Cryptococcus)、ジプロヂア(Diplodia)、エキシヂア(Exidia)、フィリバシジウム(Filibasidium)、フサリウム(Fusarium)、ギベレラ(Gibberella)、ホロマスチゴトルデス(Holomastigotoides)、ヒューミコラ(Humicola)、イルペックス(Irpex)、レンチヌラ(Lentinula)、レプトスパエリア(Leptospaeria)、マグナポリス(Magnaporthe)、メラノカルパス(Melanocarpus)、メリピラス(Meripilus)、ムコル(Mucor)、ミセリオプソラ(Myceliophthora)、ネオカノマスチックス(Neocallimastix)、ネウロスポラ(Neurospora)、パエシロミセス(Paecilomyces)、ペニシリウム(Penicillium)、
ファネロカエテ(Phanerochaete)、ピロミセス(Piromyces)、ポイトラシア(Poitrasia)、シュードプレクタニア(Pseudoplectania)、シュードトリコニンファ(Pseudotrichonympha)、リゾムコル(Rhizomucor)、シゾフィラム(Schizophyllum)、シタリジウム(Scytalidium)、タラロミセス(Talaromyces)、サーモアスカス(Thermoascus)、チエラビア(Thielavia)、トリポクラジウム(Tolypocladium)、トリコダーマ(Trichoderma)、トリコファエア(Trichophaea)、ベルチシリウム(Verticillium)、ボルバリエラ(Volvariella)、又はキシラリア(Xylaria)ポリペプチドであり得る。
好ましい観点においては、ポリペプチドは、ペルオキシゲナーゼ活性を有する、サッカロミセス・カルスベルゲンシス(Saccharomyces carlsbergensis)、サッカロミセス・セレビシアエ(Saccharomyces cerevisiae)、サッカロミセス・ジアスタチカス(Saccharomyces diastaticus)、サッカロミセス・ドウグラシ(Saccharomyces douglasii)、サッカロミセス・クルイベリ(Saccharomyces kluyveri)、サッカロミセス・ノルベンシス(Saccharomyces norbensis)又はサッカロミセス・オビホルミス(Saccharomyces oviformis)ポリペプチドである。
もう1つの好ましい観点においては、ポリペプチドは、ペルオキシゲナーゼ活性を有する、アクレモニウム・セルロリチカス(Acremonium cellulolyticus)、アスペルギラス・アキュレアタス(Aspergillus aculeatus)、アスペルギラス・アワモリ(Aspergillus awamori)、アスペルギラス・フミガタス(Aspergillus fumigatus)、アスペルギラス・ホエチダス(Aspergillus foetidus)、アスペルギラス・ジャポニカス(Aspergillus japonicus)、アスペルギラス・ニジュランス(Aspergillus nidulans)、アスペルギラス・ニガー(Aspergillus niger)、アスペルギラス・オリザエ(Aspergillus oryzae)、クロソスポリウム・ケラチノフィラム(Chrysosporium keratinophilum)、クロソスポリウム・ルクノウェンス(Chrysosporium lucknowense)、クロソスポリウム・トロピカム(Chrysosporium tropicum)、クロソスポリウム・メルダリウム(Chrysosporium merdarium)、クロソスポリウム・イノプス(Chrysosporium inops)、クロソスポリウム・パニコラ(Chrysosporium pannicola)、クロソスポリウム・クイーンズランジカム(Chrysosporium queenslandicum)、クロソスポリウム・ゾナタム(Chrysosporium zonatum)、
フサリウム・バクトリジオイデス(Fusarium bactridioides)、フサリウム・セレアリス(Fusarium cerealis)、フサリウム・クロックウェレンズ(Fusarium crookwellense)、フサリウム・クルモラム(Fusarium culmorum)、フサリウム・グラミネアラム(Fusarium graminearium)、フサリウム・グラミナム(Fusarium graminum)、フサリウム・ヘテロスポラム(Fusarium heterosporum)、フサリウム・ネグンジ(Fusarium negundi)、フサリウム・オキシスポラム(Fusarium oxysporum)、フサリウム・レチキュラタム(Fusarium reticulatum)、フサリウム・ロゼウム(Fusariumu roseum)、フサリウム・サムブシウム(Fusarium sambucinum)、フサリウム・サルコクロウム(Fusarium sarcochroum)、フサリウム・スポロトリキオイデス(Fusarium sporotrichioides)、フサリウム・スルフレウム(Fusarium sulphureum)、フサリウム・トルロサム(Fusarium torulosaum)、フサリウム・トリコセシオイデス(Fusarium trichothecioides)、フサリウム・ベネナタム(Fusarium venenatum)、
ヒュミコラ・グリセア(Humicola grisea)、ヒュミコラ・インソレンス(Humicola insolens)、ヒュミコラ・ラヌギノサ(Humicola lanuginosa)、イルペックス・ラクテウス(Irpex lacteus)、ムコル・ミエヘイ(Mucor miehei)、ミセリオプラソ・サーモフィラ(Myceliophthora thermophila)、ネウロスポラ・クラサ(Neurospora crassa)、ペニシリウム・フニクロサム(Penicillium funiculosum)、ペニシリウム・プルプロゲナム(Penicillium purpurogenum)、ファネロカエテ・キソスポリウム(Phanerochaete chrysosporium)、チエラビア・アクロマチカ(Thielavia achromatica)、チエラビア・アルボミセス(Thielavia albomyces)、チエラビア・アルボピロサ(Thielavia albopilosa)、チエラビア・アウストラレインシス(Thielavia australeinsis)、チエラビア・フィメチ(Thielavia fimeti)、チエラビア・ミクロスポラ(Thielavia microspora)、
チエラビア・オビスポラ(Thielavia ovispora)、チエラビア・ペルバナ(Thielavia peruviana)、チエラビア・スペデドニウム(Thielavia spededonium)、チエラビア・セトサ(Thielavia setosa)、チエラビア・サブサーモフィラ(Thielavia subthermophila)、チエラビア・テレストリス(Thielavia terrestris)、トリコダーマ・ハルジアナル(Trichoderma harzianum)、トリコダーマ・コニンギ(Trichoderma koningii)、トリコダーマ・ロンジブラキアタム(Trichoderma longibrachiatum)、トリコダーマ・レセイ(Trichoderma reesei)、又はトリコダーマ・ビリデ(Trichoderma viride)ポリペプチドである。
もう1つの好ましい観点においては、前記ポリペプチドは、ボルビチアセアエ(Bolbitiaceae)(例えば、アグロシベ spp.)又はコプリナセアエ(Coprinaceae)(例えば、コプリナス spp.)科の担子菌からである。
前述の種に関しては、本発明は完全及び不完全状態の両者、及び他の分類学的同等物、例えばアナモルフを、それらが知られている種の名称にかかわらず、包含することが理解されるであろう。当業者は適切な同等物の正体を容易に理解するであろう。
前述の種に関しては、本発明は完全及び不完全状態の両者、及び他の分類学的同等物、例えばアナモルフを、それらが知られている種の名称にかかわらず、包含することが理解されるであろう。当業者は適切な同等物の正体を容易に理解するであろう。
それらの種の株は、次の多くの培養物寄託所から容易に入手できる:American Type Culture Collection (ATCC), Deutsche Sammlung von Mikroorganismen und Zellkulturen GmbH (DSM), Centraalbureau Voor Schimmelcaltures (CBS), 及びAgricultural Research Service Patent Culture Collection, Northern Regional Research Center (NRRL)。
さらに、そのようなポリペプチドは、他の源、例えば天然源(例えば、土壌、培養土、水、等)から単離された微生物から、上記プローブを用いて同定され、そして得られる。天然の生息地から微生物を単離する技法は当業界において良く知られている。次に、ポリヌクレオチド配列は、もう1つの微生物のゲノム又はcDNAライブラリーを同様にスクリーニングすることによって誘導され得る。ポリペプチドをコードするポリヌクレオチド配列がプローブにより検出されると、配列は当業者に知られている技法を用いることによって同定され、又はクローン化され得る(例えば、Sambrook など.,1989年、前記を参照のこと)。
本発明のポリペプチドはまた、もう1つのポリペプチドが前記ポリペプチドのそのフラグメントのN−末端又はC−末端で融合されている、融合された又は切断可能な融合ポリペプチドも包含することができる。融合されたポリペプチドは、もう1つのポリペプチドをコードするヌクレオチド配列(又はその一部)を、本発明のヌクレオチド配列(又はその一部)に融合することによって生成される。融合ポリペプチドを生成するための技法は、当業界において知られており、そしてポリペプチドをコードするコード配列を、それらが整合して存在し、そして融合されたポリペプチドの発現が同じプロモーター及びターミネーターの制御下にあるよう、連結することを包含する。
融合ポリペプチドはさらに、切断部位を含んで成ることができる。融合タンパク質の分泌に基づいて、前記部位が切断され、融合タンパク質からペルオキシゲナーゼ活性を有するポリペプチドが開放される。切断部位の例は、次のものを包含するが、但しそれらだけには限定されない:ジペプチドLys−ArgをコードするKex2部位(Martin et al., 2003, J. Ind. Microbiol. Biotechnol. 3: 568-76; Svetina et al., 2000, J. Biotechnol. 76: 245-251 ; Rasmussen-Wilson et al., 1997, Appl. Environ. Microbiol. 63: 3488-3493; Ward et al., 1995, Biotechnology 13: 498-503; and Contreras et al., 1991 , Biotechnology 9: 378-381)、アルギニン残基の後、第Xa因子プロテアーゼにより切断されるIle−(Glu又はAsp)−Gly−Arg部位(Eaton et al., 1986, Biochem. 25: 505-512)、
リシンの後、エンテロキナーゼにより切断されるAsp−Asp−Asp−Asp−Lys部位(Collins-Racie et al., 1995, Biotechnology 13: 982-987)、Genenase Iにより切断されるHis−Tyr−Glu部位又はHis−Tyr−Asp部位(Carter et al., 1989, Proteins: Structure, Function, and Genetics 6: 240-248)、Argの後、トロンビンにより切断されるLeu−Val−Pro−Arg−Gly−Ser部位(Stevens, 2003, Drug Discovery World 4: 35-48)、Glnの後、TEVプロテアーゼにより切断されるGlu−Asn−Leu−Tyr−Phe−Gln−Gly部位(Stevens, 2003, 前記)、及びGlnの後、遺伝子的に構築された形のヒトライノウィルス3Cプロテアーゼにより切断されるLeu−Glu−Val−Leu−Phe−Gln−Gly−Pro部位(Stevens, 2003, 前記)。
ポリヌクレオチド:
本発明はまた、ペルオキシゲナーゼ活性を有する本発明のポリペプチドをコードするヌクレオチド配列を含んで成るか又はそれらから成る単離されたポリヌクレオチドにも関する。
本発明はまた、ペルオキシゲナーゼ活性を有する本発明のポリペプチドをコードするヌクレオチド配列を含んで成るか又はそれらから成る単離されたポリヌクレオチドにも関する。
好ましい観点においては、ヌクレオチド配列は、配列番号1, 3, 5, 7, 9, 11, 13, 15又は17を含んで成るか又はそれから成る。もう1つのさらに好ましい観点においては、ヌクレオチド配列は、受託番号DSM21289としてDSMZによりブダベスト条約下で2008年3月14日に寄託されたE. コリNN049991に含まれるか;又は受託番号DSM21290としてDSMZによりブダベスト条約下で2008年3月14日に寄託されたE. コリNN049992に含まれるプラスミドに含まれるポリヌクレオチドによりコードされる、プラスミドに含まれる配列を含んで成るか又はそれから成る。
もう1つの好ましい観点においては、ヌクレオチド配列は、配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るか又はそれから成る。もう1つの好ましい観点においては、ヌクレオチド配列は、配列番号1のヌクレオチド152〜1141を含んで成るか又はそれらから成る。もう1つのより好ましい観点においては、ヌクレオチド配列は、受託番号DSM21289としてDSMZによりブダベスト条約下で2008年3月14日に寄託されたE. コリNN049991に含まれるか;又は受託番号DSM21290としてDSMZによりブダベスト条約下で2008年3月14日に寄託されたE. コリNN049992に含まれるプラスミドに含まれるポリヌクレオチドによりコードされる、プラスミドに含まれる成熟ポリペプチドコード配列を含んで成るか又はそれから成る。
本発明はまた、遺伝子コードの縮重により配列番号1, 3, 5, 7, 9, 11, 13, 15又は17又はその成熟ポリペプチドコード配列とは異なる、配列番号2, 4, 6, 8, 10, 12, 14又は19又はその成熟ポリペプチドのアミノ酸配列を含んで成るか、又はそれから成るポリペプチドをコードするヌクレオチド配列を包含する。本発明はまた、ペルオキシゲナーゼ活性を有する配列番号2, 4, 6, 8, 10, 12, 14又は19のフラグメントをコードする、配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の副配列にも関する。
本発明はまた、変異体ヌクレオチド配列が配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドをコードする、配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に少なくとも1つの突然変異を含んで成るか、又はそれから成る変異体ポリヌクレオチドにも関する。
ポリペプチドをコードするポリヌクレオチドを単離し、又はクローン化するために使用される技法は、当業界において知られており、そしてゲノムDNAからの単離、cDNAからの調製、又はそれらの組み合わせを包含する。そのようなゲノムDNAからの本発明のポリヌクレオチドのクローニングは、例えば良く知られているポリメラーゼ鎖反応(PCR)、又は共有する構造特徴を有するクローン化されたDNAフラグメントを検出するために発現ライブラリーの抗体スクリーニングを用いることによってもたらされ得る。例えば、Innisなど., 1990, PCR: A Guide to Methods and Application; Academic Press, New York を参照のこと。他の核酸増幅方法、例えばリガーゼ鎖反応(LCR)、連結された活性化転写(LAT)及び核酸配列に基づく増幅(NASBA)が使用され得る。ポリヌクレオチドは、担子菌(Basidiomycete)、又は他の又は関連する生物からクローン化され得、そして従って、ヌクレオチド配列のポリペプチドコード領域の対立遺伝子又は種変異体であり得る。
本発明はまた、配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に対して、好ましくは少なくとも60%、より好ましくは少なくとも65%、より好ましくは少なくとも70%、より好ましくは少なくとも75%、より好ましくは少なくも80%、より好ましくは少なくとも85%、さらにより好ましくは少なくとも90%、最も好ましくは95%、及びさらに最も好ましくは少なくとも96%、少なくとも97%、少なくとも98%又は少なくとも99%の程度の同一性を有する、活性ポリペプチドをコードするヌクレオチド配列を含んで成るか、又はそれから成るポリヌクレオチドにも関する。
本発明のポリペプチドをコードするヌクレオチド配列の修飾は、そのポリペプチドに実質的に類似するポリペプチドの合成のために必要である。用語、ポリペプチドに“実質的に類似する”とは、ポリペプチドの天然に存在しない形を言及する。それらのポリペプチドは、その天然源から単離されたポリペプチドとは、いくつかの構築された態様で異なり、例えば非活性、熱安定性、pH最適性又は同様のものにおいて異なる変異体であり得る。
変異体配列は、配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列として提供されるヌクレオチド配列、例えばその副配列に基づいて、及び/又はヌクレオチド配列によりコードされるポリペプチドのもう1つのアミノ酸配列を生ぜしめないが、しかし酵素の生成のために意図された宿主生物のコドン使用法に対応するヌクレオチド置換の導入により、又は異なったアミノ酸配列を生ぜしめることができるヌクレオチド置換の導入により構成され得る。ヌクレオチド置換の一般的記載のためには、Fordなど., 1991, Protein Expression and Purification 2:95-107を参照のこと。
そのような置換は、分子の機能に対して決定的である領域外で行われ、そしてさらに活性ポリペプチドをもたらすことは、当業者に明らかであろう。本発明の単離されたポリヌクレオチドによりコードされるポリペプチドの活性に必須であり、そして従って、好ましくは置換を受けやすくないアミノ酸残基は、当業界において知られている方法、例えば特定部位の突然変異誘発又はアラニン−走査突然変異誘発に従って同定され得る(例えば、Cunningham and Wells, 1989, Science 244: 1081-1085を参照のこと)。後者の技法においては、突然変異は分子における正に荷電された残基ごとに導入され、そしてその得られる変異体分子は、分子の活性に対して決定的であるアミノ酸残基を同定するためにペルオキシゲナーゼ活性について試験される。基質−酵素相互作用の部位はまた、核磁気共鳴分析、クリスタログラフィー又は光親和性ラベリングのような技法により決定されるように、立体構造体の分析により決定され得る(例えば、de Vos など., 1992, 前記; Smith など., 1992,前記; Wlodaver など., 1992, 前記を参照のこと)。
本発明はまた、(i)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列;(ii)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るゲノムDNA配列に含まれるcDNA配列又はそのゲノムDNA配列;又は(iii)(i)又は(ii)の十分な長さの相補鎖;又はその対立遺伝子変異体及び副配列に対しいて、非常に低い緊縮条件、好ましくは低い緊縮条件、より好ましくは中位の緊縮条件、より好ましくは中くらいの高い緊縮条件、さらにより好ましくは高い緊縮条件、及び最も好ましくは非常に高い緊縮条件下でハイブリダイズする(Sambrookなど., 1989、前記)、本発明のポリペプチドをコードする単離されたポリヌクレオチドにも関する。好ましくは観点においては、前記相補鎖は、配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチド配列の十分な長さの相補鎖である。
本発明はまた、(a)(i)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列;(ii)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るゲノムDNA配列に含まれるcDNA配列又はそのゲノムDNA配列;又は(iii)(i)又は(ii)の十分な長さの相補鎖と、非常に低い、低い、中位、中くらいの高い、高い、又は非常に高い緊縮条件条件下でDNA集団とをハイブリダイズし;そして(b)ペルオキシゲナーゼ活性を有するポリペプチドをコードする前記ハイブリダイズするポリヌクレオチドを単離することにより得られる、単離されたポリヌクレオチドにも関する。好ましくは観点においては、前記相補鎖は、配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチド配列の十分な長さの相補鎖である。
核酸構造体:
本発明はまた、制御配列と適合できる条件下で、適切な宿主細胞におけるコード配列の発現を指図する1又は複数(数個)の制御配列に操作可能的に連結される本発明の単離されたポリヌクレオチドを含んで成る核酸構造体にも関する。
本発明はまた、制御配列と適合できる条件下で、適切な宿主細胞におけるコード配列の発現を指図する1又は複数(数個)の制御配列に操作可能的に連結される本発明の単離されたポリヌクレオチドを含んで成る核酸構造体にも関する。
本発明のポリペプチドをコードする単離されたポリヌクレオチドは、ポリペプチドの発現を提供するために種々の手段で操作され得る。ベクター中へのその挿入の前、ポリヌクレオチド配列の操作は、発現ベクターに依存して、所望されるか又は必要とされる。組換えDNA方法を用いてポリヌクレオチド配列を修飾するための技法は、当業界において良く知られている。
制御配列は、適切なプロモーター配列、すなわち本発明のポリペプチドをコードするポリヌクレオチドの発現のために宿主細胞により認識されるヌクレオチド配列であり得る。プロモーター配列は、ポリペプチドの発現を仲介する転写制御配列を含む。プロモーターは、宿主細胞において転写活性を示すいずれかのヌクレオチド配列、例えば変異体の、切断された、及びハイブリッドのプロモーターであり得、そして宿主細胞に対して相同であるか又は異種である細胞外又は細胞内ポリペプチドをコードする遺伝子から得られる。
特に細胞宿主細胞において本発明の核酸構造体の転写を方向づけるための適切なプロモーターの例は、E.コリlacオペロン、ストレプトミセス・コエリカラー(Streptomyces coelicolor)アガラーゼ遺伝子(dagA)、バチルス・サブチリス(Bacillus subtilis)Lバンスクラーゼ遺伝子(sacB)、バチルス・リケニホルミス(Bacillus licheniformis)α−アミラーゼ遺伝子(amyL)、Bチルス・ステアロサーモフィラス(Bacillus stearothermophilus)マルトゲン性アミラーゼ遺伝子(amyM)、バチルス・アミロリケファシエンス(Bacillus amyloliguefaciens) α−アミラーゼ遺伝子(amyQ)、バチルス・リケニホルミスペニシリナーゼ遺伝子(penP)、バチルス・サブチリスxylA及びzylB遺伝子及び原生動物のβ−ラクタマーゼ遺伝子から得られるプロモーター(Villa−Kamaroffなど., 1978, Proceedings of the National Academy of Sciences USA 75: 3727-3731)、及びtac プロモーター(De Boer など., 1983, Proceedings of the National Academy of Science USA 80: 21-25)である。さらなるプロモーターは、“Useful proteins from recombinant bacteria” in Scientific American, 1980, 242: 74-94; 及びSambrookなど., 1989, 前記に記載される。
糸状菌宿主細胞における本発明の核酸構造体の転写を方向づけるための適切なプロモーターの例は、アスペルギラス・オリザエTAKAアミラーゼ、リゾムコル・ミエヘイ アスパラギン酸プロテイナーゼ、アスペルギラス・ニガー中性α−アミラーゼ、アスペルギラス・ニガー酸安定性α−アミラーゼ、アスペルギラス・ニガー又はアスペルギラス・アワモリグルコアミラーゼ(glaA)、リゾムコル・ミエヘイリパーゼ、アスペルギラス・オリザエ アルカリプロテアーゼ、アスペルギラス・オリザエトリオースリン酸イソメラーゼ、アスペルギラス・ニジュランスアセトアミダーゼ、フサリウム・ベネナタムアミログルコシダーゼ(WO00/56900号)、フサリウム・ベネナタムDaria(WO00/56900号)、フサリウム・ベネナタムQuinm(WO00/56900号)、フサリウム・オキシスポラムトリプシン様プロテアーゼ(WO96/00787号)、
トリコダーマ・レセイβ−グルコシダーゼ、トリコダーマ・レセイセロビオヒドロラーゼI、トリコダーマ・レセイエンドグルカナーゼI、トリコダーマ・レセイエンドグルカナーゼII、トリコダーマ・レセイエンドグルカナーゼIII 、トリコダーマ・レセイエンドグルカナーゼIV、トリコダーマ・レセイエンドグルカナーゼV、トリコダーマ・レセイキシラナーゼI、トリコダーマ・レセイキシラナーゼII、トリコダーマ・レセイβ−キシロシダーゼ、並びにNA2-tpiプロモーター(アスペルギラス・ニガー中性α−アミラーゼ及びアスペルギラス・オリザエトリオースリン酸イソメラーゼをコードする遺伝子からのプロモーターのハイブリッ)ド、及びそれらの変異体の切断され、及びハイブリッドのプロモーターである。
酵母宿主においては、有用なプロモーターは、サッカロミセス・セレビシアエ(Saccharomyces cerevisiae)エノラーゼ(ENO−1)、サッカロミセス・セレビシアエガラクトキナーゼ(GAL1)、サッカロミセス・セレビシアエアルコールデヒドロゲナーゼ/グリセルアルデヒド−3−リン酸デヒドロゲナーゼ(ADH1、ADH2/GAP)、サッカロミセス・セレビシアエトリオースホスフェートイソメラーゼ(TPI)、サッカロミセス・セレビシアエ金属チオニン(CUP1)、サッカロミセス・セレビシアエ3−ホスホグリセレートキナーゼ及びピチア・パストリスアルコールオキシダーゼ(AOX1)から得られる。酵母宿主細胞のための他の有用なプロモーターは、Romunosなど., 1992, Yeast8:423−488により記載される。
制御配列はまた、適切な転写ターミネーター配列、すなわち転写を終結するために宿主細胞により認識される配列でもあり得る。ターミネーター配列は、ポリペプチドをコードするヌクレオチド配列の3’側末端に操作可能的に連結される。選択の宿主細胞において機能的であるいずれかのターミネーターが本発明において使用され得る。
糸状菌宿主細胞のための好ましいターミネーターは、アスペルギラス・オリザエTAKAアミラーゼ、アスペルギラス・ニガーグルコアミラーゼ、アスペルギラス・ニジュランスアントラニル酸シンターゼ、アスペルギラス・ニガーα−グルコシダーゼ及びフサリウム・オキシスポラムトリプシン−様プロテアーゼについての遺伝子から得られる。
糸状菌宿主細胞のための好ましいターミネーターは、アスペルギラス・オリザエTAKAアミラーゼ、アスペルギラス・ニガーグルコアミラーゼ、アスペルギラス・ニジュランスアントラニル酸シンターゼ、アスペルギラス・ニガーα−グルコシダーゼ及びフサリウム・オキシスポラムトリプシン−様プロテアーゼについての遺伝子から得られる。
酵母宿主細胞のための好ましいターミネーターは、サッカロミセス・セレビシアエエノラーゼ、サッカロミセス・セレビシアエチトクロムC(CYC1)、及びサッカロミセス・セレビシアエグリセルアルデヒド−3−リン酸デヒドロゲナーゼについての遺伝子から得られる。酵母宿主細胞のための他の有用なターミネーターは、Romanosなど., 1992, 前記により記載される。
制御配列はまた、適切なリーダー配列、すなわち宿主細胞による翻訳のために重要であるmRNAの非翻訳領域でもあり得る。リーダー配列は、ポリペプチドをコードするヌクレオチド配列の5’末端に操作可能的に連結される。選択の宿主細胞において機能的であるいずれかのリーダー配列が、本発明において使用され得る。
糸状菌宿主細胞のための好ましいリーダーは、アスペルギラス・オリザエTAKAアミラーゼ、アスペルギラス・ニジュランストリオースリン酸イソメラーゼについての遺伝子から得られる。
酵母宿主細胞のための適切なリーダーは、サッカロミセス・セレビシアエエノラーゼ(ENO−1)、サッカロミセル・セレビシアエ3−ホスホグリセレートキナーゼ、サッカロミセス・セレビシアエα−因子及びサッカロミセス・セレビシアエアルコールデヒドロゲナーゼ/グリセルアルデヒド−3−リン酸デヒドロゲナーゼ(ADH2/GAP)についての遺伝子から得られる。
制御配列はまた、ポリアデニル化配列、すなわちヌクレオチド配列の3’末端に操作可能に連結され、そして転写される場合、転写されたmRNAにポリアデノシン残基を付加するためにシグナルとして宿主細胞により認識される配列でもあり得る。選択の宿主細胞において機能的であるいずれかのポリアデニル化配列が,本発明において使用される。
糸状菌宿主細胞のための好ましいポリアデニル化配列は、アスペルギラス・オリザエTAKAアミラーゼ、アスペルギラス・ニガーグルコアミラーゼ、アスペルギキラス・ニジュランスアントラニル酸シンターゼ、フサリウム・オキシスポラムトリプシン−様プロテアーゼ及びアスペルギラス・ニガーα−グルコシダーゼについての遺伝子から得られる。
酵母宿主細胞のための有用なポリアデニル化配列は、Guo and Sherman, 1995, Molecular Cellular Biology 15: 5983-5990により記載されている。
酵母宿主細胞のための有用なポリアデニル化配列は、Guo and Sherman, 1995, Molecular Cellular Biology 15: 5983-5990により記載されている。
制御配列はまた、ポリペプチドのアミノ末端に連結されるアミノ酸配列をコードし、そしてそのコードされたポリペプチドを細胞の分泌路中に方向づけるシグナルペプチドコード配列でもあり得る。核酸配列のコード配列の5’側末端は、本来、分泌されたポロペプチドをコードするコード領域のセグメントと翻訳読み取り枠を整合して、天然において連結されるシグナルペプチドコード配列を含むことができる。他方では、コード配列の5’側末端は、そのコード配列に対して外来性であるシグナルペプチドコード配列を含むことができる。そのコード配列が天然において、シグナルペプチドコード配列を含まない外来性シグナルペプチドコード配列が必要とされる。他方では、外来性シグナルペプチドコード配列は、ポリペプチドの増強された分泌を得るために、天然のシグナルペプチドコード配列を単純に置換することができる。しかしながら、分泌路中に発現されたポリペプチドを方向づけるいずれかのシグナルペプチドコード配列が、本発明に使用され得る。
細菌宿主細胞のための効果的なシグナルペプチドコード配列は、バチルスNCIB11837マルトゲン性アミラーゼ、バチルス・ステアロサーモフィラスα−アミラーゼ、バチルス・リケニホルミススブチリシン、バチルス・リケニホルミスβ−ラクタマーゼ、バチルス・アステロサーモフィラス中性プロテアーゼ(nprT, nprS, nprM)、バチルス・クラウジアルカリンプロテアーゼ(aprH)及びバチルス・スブチリスprsAについての遺伝子から得られるシグナルペプチド領域である。追加のシグナルペプチドは、Sinomen and Palva, 1993, Microbiological Reviews 57: 109-137 により記載される。
糸状菌宿主細胞のための効果的なシグナルペプチドコード配列は、アスペルギラス・オリザエTAKAアミラーゼ、アスペルギラス・ニガー中性アミラーゼ、アスペルギラス・ニガーグルコアミラーゼ、リゾムコル・ミエヘイアスペラギン酸プロテイナーゼ、ヒューミコラ・インソレンスセルラーゼ、ヒューミコラ・インソレンスエンドグカナーゼV及びヒューミコラ・ラヌギノサリパーゼについての遺伝子から得られたシグナルペプチドコート領域である。
酵母宿主細胞のための有用なシグナルペプチドは、サッカロミセス・セレビシアエα−因子及びサッカロミセル・セレビシアエインバーターゼについての遺伝子から得られる。他の有用なシグナルペプチドコード配列は、Romanos など., 1992, 前記により記載される。
好ましい観点においては、シグナルペプチドは、配列番号2のアミノ酸-43〜-1を含んで成るか又はそれらから成る。もう1つの好ましい観点においては、シグナルペプチドコード配列は、配列番号1のヌクレオチド23〜151を含んで成るか又はそれらから成る。
好ましい観点においては、シグナルペプチドは、配列番号2のアミノ酸-43〜-1を含んで成るか又はそれらから成る。もう1つの好ましい観点においては、シグナルペプチドコード配列は、配列番号1のヌクレオチド23〜151を含んで成るか又はそれらから成る。
制御配列はまた、ポリペプチドのアミノ末端で位置するアミノ酸配列をコードするプロペプチドコード配列であり得る。得られるポリペプチドは、プロ酵素又はプロポリペプチド(又は多くの場合、チモーゲン)として知られている。プロポリペプチドは一般的に不活性であり、そしてプロポリペプチドからプロペプチドの触媒又は自己触媒分解により成熟した活性ポリペプチドに転換され得る。プロペプチドコード配列は、バチルス・サブチリスアルカリプロテアーゼ(aprE)、バチルス・サブチリス中性プロテアーゼ(nprT)、サッカロミセス・セレビシアエα−因子、リゾムコル・ミエヘイ アスパラギン酸プロテイナーゼ遺伝子、及びミセリオプソラ・サーモフィリア ラッカーゼについての遺伝子から得られる(WO95/33836号)。
シグナルペプチド及びプロペプチド配列の両者がポリペプチドのアミノ末端に存在する場合、そのプロペプチド配列は、ポリペプチドのアミノ末端の次に位置し、そしてシグナルペプチド領域は、プロペプチド配列のアミノ末端の次に位置する。
宿主細胞の増殖に関して、ポリペプチドの発現の調節を可能にする調節配列を付加することがまた所望される。調節システムの例は、調節化合物の存在を包含する、化学的又は物理的刺激に応答して、遺伝子の発現の開始又は停止を引き起こすそれらのシステムである。原核生物系における調節システムは、lac, tac及びxylオペレーターシステムお包含する。酵母においては、ADH2システム又はGAL1システムが使用され得る。
糸状菌においては、TAKAα−アミラーゼプロモーター、アスペルギラス・ニガーグルコアミラーゼプロモーター及びアスペルギラス・オリザエグルコアミラーゼプロモーターが、調節配列として使用さえ得る。調節配列の他の列は、遺伝子増幅を可能にするそれらの配列である。真核システムにおいては、それらはメトトレキセートの存在下で増幅されるジヒドロ葉酸レダクターゼ遺伝子、及び重金属と共に増幅されるメタロチオネイン遺伝子を包含する。それらの場合、ポリペプチドをコードする核酸配列が、調節配列により操作可能的に連結される。
発現ベクター:
本発明はまた、本発明のポリヌクレオチド、プロモーター、及び転写及び翻訳停止シグナルを含んで成る組換え発現ベクターにも関する。上記の種々の核酸及び制御配列は、1又は複数(数個)の便利な制限部位でポリペプチドをコードするヌクレオチド配列の挿入又は置換を可能にするためにそれらの部位を含むことができる組換え発現ベクターを生成するために一緒に連結され得る。他方では、本発明のポリヌクレオチド配列は、前記ヌクレオチド配列又は前記配列を含んで成る核酸構造体を、発現のための適切なベクター中に挿入することによって発現され得る。発現ベクターを創造する場合、そのコード配列はベクターに位置し、その結果、コード配列は発現のための適切な制御配列により操作可能的に連結される。
本発明はまた、本発明のポリヌクレオチド、プロモーター、及び転写及び翻訳停止シグナルを含んで成る組換え発現ベクターにも関する。上記の種々の核酸及び制御配列は、1又は複数(数個)の便利な制限部位でポリペプチドをコードするヌクレオチド配列の挿入又は置換を可能にするためにそれらの部位を含むことができる組換え発現ベクターを生成するために一緒に連結され得る。他方では、本発明のポリヌクレオチド配列は、前記ヌクレオチド配列又は前記配列を含んで成る核酸構造体を、発現のための適切なベクター中に挿入することによって発現され得る。発現ベクターを創造する場合、そのコード配列はベクターに位置し、その結果、コード配列は発現のための適切な制御配列により操作可能的に連結される。
組換え発現ベクターは、組換えDNA方法に便利にゆだねられ得、そしてヌクレオチド配列の発現をもたらすことができるいずれかのベクター(例えば、プラスミド又はウィルス)であり得る。ベクターの選択は典型的には、ベクターが導入される予定である宿主細胞とベクターとの適合性に依存するであろう。ベクターは、線状又は閉環された環状プラスミドであり得る。
ベクターは自律的に複製するベクター、すなわち染色体存在物として存在するベクター(その複製は染色体複製には無関係である)、例えばプラスミド、染色体外要素、ミニクロモソーム又は人工染色体であり得る。ベクターは自己複製を確かめるためのいずれかの手段を含むことができる。他方では、ベクターは、糸状菌細胞中に導入される場合、ゲノム中に組み込まれ、そしてそれが組み込まれている染色体と一緒に複製されるベクターであり得る。さらに、宿主細胞のゲノム中に導入される全DNA又はトランスポゾンを一緒に含む、単一のベクター又はプラスミド、又は複数のベクター又はプラスミドが使用され得る。
本発明のベクターは好ましくは、形質転換された、トランスフェクトされた、形質導入された、又は同様の細胞の容易な選択を可能にする1又は複数(数個)の選択マーカーを含む。選択マーカーは、1つの遺伝子であり、その生成物は、殺生物剤又はウィルス耐性、重金属に対する耐性、栄養要求性に対する原栄養要求性、及び同様のものを提供する。
細菌選択マーカーの例は、バチルス・サブチリス又はバチルス・リケニホルミスからのdal遺伝子、又は抗生物質耐性、例えばアンピシリン、カナマイシン、クロラムフェニコール又はテトラサイクロン耐性を付与するマーカーである。酵母宿主細胞のための適切なマーカーは、ADE2、HIS3、LEU2、LYS2、MET3、TRP1及びURA3である。
細菌選択マーカーの例は、バチルス・サブチリス又はバチルス・リケニホルミスからのdal遺伝子、又は抗生物質耐性、例えばアンピシリン、カナマイシン、クロラムフェニコール又はテトラサイクロン耐性を付与するマーカーである。酵母宿主細胞のための適切なマーカーは、ADE2、HIS3、LEU2、LYS2、MET3、TRP1及びURA3である。
糸状菌宿主細胞に使用するための選択マーカーは、次の群から選択されるが、但しそれらだけには限定されない;amdS (アセトアミダーゼ)、argB (オルニチンカルバモイルトランスフェラーゼ)、bar (ホスフィノトリシンアセチルトランスフェラーゼ)、hph (ヒグロマイシンホスホトランスフェラーゼ)、niaD (硝酸レダクターゼ)、pyrG (オロチジン−5’−リン酸デカルボキシラーゼ)、sC (硫酸アデニルトランスフェラーゼ) 及びtrpC (アントラニル酸シンターゼ)、並びにそれらの同等物。アスペルギラス・ニジュランス又はアスペルギラス・オリザエのamdS及びpyrG遺伝子及びストレプトミセス・ヒグロスコピカスのbar遺伝子が、アスペルギラス細胞への使用のために好ましい。
本発明のベクターは好ましくは、宿主細胞ゲノム中へのベクターの安定した組み込み、又は細胞のゲノムに無関係に細胞におけるベクターの自律的複製を可能にする要素を含む。
宿主細胞のゲノム中への組み込みのためには、ベクターは、相同又は非相同組換えによるゲノム中へのベクターの安定した組み込みのためのベクター中のポリペプチド、又はいずれか他の要素をコードするポリヌクレオチド配列に依存する。他方では、ベクターは、染色体における正確な位置で、宿主細胞のゲノム中への相同組換えによる組み込みを方向づけるための追加のヌクレオチド配列を含むことができる。正確な位置での組み込みの可能性を高めるために、組み込み要素は好ましくは、相同組換えの可能性を高めるためにその対応する標的配列と高い程度の同一性を示す十分な数の核酸、例えば100〜10,000個の塩基対、好ましくは400〜10,000個の塩基対、及び最も好ましくは800〜10,000個の塩基対を含むべきである。組み込み要素は、宿主細胞のゲノムにおける標的配合と相同であるいずれかの配列であり得る。さらに、組み込み要素は、非コード又はコードヌクレオチド配列であり得る。他方では、ベクターは非相同組換えにより宿主細胞のゲノム中に組み込まれ得る。
自律複製のためには、ベクターはさらに、問題の宿主細胞においてのベクターの自律的な複製を可能にする複製の起点を含んで成る。複製の起点は、細胞において機能する自律複製を仲介するいずれかのプラスミド複製体であり得る。用語“複製の起点”又は“プラスミド複製体”とは、本明細書においては、プラスミド又はベクターのインビボでの複製を可能にするヌクレオチド配列として定義される。
複製の細菌起点の例は、E.コリにおける複製を可能にするプラスミドpBR322, pUC19, pACYC177及びpACYC184, 及びバチルスにおける複製を可能にするpUB110, pE194, pTA1060及びpAMβ1の複製の起点である。
酵母宿主細胞への使用のための複製の起点の例は、複製の2ミクロン起点、すなわちARS1, ARS4, ARS1及びCEN3の組み合わせ、及びARS4及びCEN6の組み合わせである。
酵母宿主細胞への使用のための複製の起点の例は、複製の2ミクロン起点、すなわちARS1, ARS4, ARS1及びCEN3の組み合わせ、及びARS4及びCEN6の組み合わせである。
糸状菌細胞において有用な複製の起点の例は、AMA1及びANS1である(Gems など., 1991 , Gene 98:61-67; Cullen et al., 1987, Nucleic Acids Research 15: 9163-9175; WO 00/24883号)。AMA1遺伝子の単離及び前記遺伝子を含んで成るプラスミド又はベクターの構成は、WO00/24883号に開示される方法に従って達成され得る。
本発明のポリヌクレオチドの1以上のコピーが、遺伝子生成物の生成を高めるために宿主細胞中に挿入され得る。ポリヌクレオチドのコピー数の上昇は、宿主細胞ゲノム中に配列の少なくとも1つの追加のコピーを組み込むことによって、又はポリヌクレオチドと共に増幅可能な選択マーカー遺伝子を含むことによって得られ、ここで細胞は選択マーカー遺伝子の増幅されたコピーを含み、そしてそれにより、ポリヌクレオチドの追加のコピーが、適切な選択剤の存在下で前記細胞を培養することによって選択され得る。
本発明の組換え発現ベクターを構成するために上記要素を連結するために使用される方法は、当業者に良く知られている(例えば、Sambrookなど., 1989, 前記を参照のこと)。
宿主細胞:
本発明はまた、ポリペプチドの組換え生成において都合良く使用される、本発明のポリヌクレオチドを含んで成る組換え宿主にも関する。本発明のポリヌクレオチドを含んで成るベクターは、そのベクターが染色体組み込み体として、又は前記のような自己複製染色体外ベクターとして維持されるように、宿主細胞中に導入される。用語“宿主細胞”とは、複製の間に生じる突然変異のために、親細胞と同一ではない親細胞のいずれかの子孫を包含する。宿主細胞の選択は、ポリペプチドをコードする遺伝子及びその源に、かなりの程度依存するであろう。
本発明はまた、ポリペプチドの組換え生成において都合良く使用される、本発明のポリヌクレオチドを含んで成る組換え宿主にも関する。本発明のポリヌクレオチドを含んで成るベクターは、そのベクターが染色体組み込み体として、又は前記のような自己複製染色体外ベクターとして維持されるように、宿主細胞中に導入される。用語“宿主細胞”とは、複製の間に生じる突然変異のために、親細胞と同一ではない親細胞のいずれかの子孫を包含する。宿主細胞の選択は、ポリペプチドをコードする遺伝子及びその源に、かなりの程度依存するであろう。
宿主細胞は、本発明のポリペプチドの組換え生成において有用ないずれかの細胞、例えば原核生物、又は真核生物であり得る。
原核宿主細胞は、いずれかのグラム陽性細菌又はグラム陰性細菌であり得る。グラム陽性細菌は、バチルス(Bacillus)、ストレプトコーカス(Streptococcus)、ストレプトミセス(Streptomyces)、スタフィロコーカス(Staphylococcus)、エンテロコーカス(Enterococcus)、ラクトバチルス(Lactobacillus)、ラクトコーカス(Lactococcus)、クロストリジウム(Clostridium)、ゲオバシラス(Geobacillus)又はオセアノバチルス(Oceanobacillus)を包含するが、但しそれらだけには限定されない。グラム陰性細菌は、E. コリ(E. coli)、シュードモナス(Pseudomonas)、サルモネラ(Salmonella)、カムフィロバクター(Campylobacter)、ヘリコバクター(Helicobacter)、フラボバクテリウム(Flavobacterium)、フソバクテリウム(Fusobacterium)、イリオバクター(llyobacter)、ネイセリア(Neisseria)又はウレアプラズマ(Ureaplasma)を包含するが、但しそれらだけには限定されない。
細菌宿主細胞は、いずれかのバチルス細菌であり得る。本発明の実質において有用なバチルス細胞は、バチルス・アルカロフィラス、バチルス・アミロリケファシエンス、バチルス・ブレビス、バチルス・サーキュランス、バチルス・クラウジ、バチルス・コアギュランス、バチルス・ファーマス、バチルス・ラウタス、バチルス・レンタス、バチルス・リケニホルミス、バチルス・メガテリウス、バチルス・プミラス)、バチルス・ステアロサーモフィラス、バチルス・サブチリス又はバチルス・スリンジエンシス細胞を包含するが、但しそれらだけには限定されない。
好ましい観点においては、細菌宿主細胞は、バチルス・アミロリケファシエンス、バチルス・レンタス、バチルス・リケニホルミス、バチルス・ステアロサーモフィラス又はバチルス・サブチリス細胞である。より好ましい観点においては、細菌宿主は、バチルス・アミロリケファシエンス細胞である。もう1つのより好ましい観点においては、細菌宿主細胞はバチルス・クラウジ細胞である。もう1つのより好ましい観点においては、細菌宿主は、バチルス・リケニホルミス細胞である。もう1つのより好ましい観点においては、細菌宿主細胞は、バチルス・サブチリス細胞である。
細菌宿主細胞はまた、いずれかのストレプトコーカス細胞であり得る。本発明の実施において有用なストレプトコーカス細胞は、ストレプトコーカス・エクシミリス、ストレプトコーカス・ピロゲネス、ストレプトコーカス・ウベリス及びストレプトコーカス・エクsubs. ズーエピデミカスを包含するが、但しそれらだけには限定されない。
好ましい観点においては、細菌宿主細胞は、ストレプトコーカス・エクシミリス細胞である。もう1つの好ましい観点においては、細菌宿主細胞は、ストレプトコーカス・ウベリス細胞である。もう1つの好ましい観点においては、細菌宿主細胞はストレプトコーカス・エクsubs. ズーエピデミカス細胞である。
細菌宿主細胞はまた、いずれかのストレプトミセス細胞であり得る。本発明の実施において有用なストレプトミセス細胞は、ストレプトミセス・アクロモゲネス、ストレプトミセス・アベルミチリス、ストレプトミセス・コエリカラー、ストレプトミセス・グリセウス及びストレプトミセス・リビダンスを包含するが、但しそれらだけには限定されない。
好ましい観点においては、細菌宿主細胞は、ストレプトミセス・アクロモゲネス細胞である。もう1つの好ましい観点においては、細菌宿主は、ストレプトミセス・アベルミチリス細胞である。もう1つの好ましい観点においては、細菌宿主は、ストレプトミセス・コエリカラー細胞である。もう1つの好ましい観点においては、細菌宿主は、ストレプトミセス・グリセウス細胞である。もう1つの好ましい観点においては、細菌宿主は、ストレプトミセス・リビダンス細胞である。
バチルス細胞中へのDNA導入は例えば、コンピテント細胞(例えば、Young and Spizizin, 1961, Journal of Bacteriology 81: 823-829, 又はDubnau and Davidoff-Abelson, 1971, Journal of Molecular Biology 56: 209-221 を参照のこと)を用いてプロトプラスト形質転換(例えば、Changand Cohen, 1979, Molecular General Genetics 168: 111-115)、エレクトロポレーション(例えば、Shigekawa and Dower, 1988, Biotechniques 6: 742-751を参照のこと)又は接合(例えば、Koehler and Thorne, 1987, Journal of Bacteriology 169: 5771-5278を参照のこと)によりもたらされ得る。E. コリ細胞中へのDNAの導入は、例えばプロトプラスト形質転換(例えば、Hanahan, 1983, J. MoI. Biol. 166: 557-580を参照のこと)又はエレクトロポレーション(例えば、Dower et al., 1988, Nucleic Acids Res. 16: 6127-6145を参照のこと)によりもたらされ得る。
ストレプトミセス細胞へのDNAの導入は例えば、プロトプラスト形質転換(例えば、Gong et al., 2004, Folia Microbiol. (Praha) 49: 399-405を参照のこと)、接合(例えば、Mazodier et al., 1989, J. Bacteriol. 171 : 3583-3585を参照のこと)、又は形質導入(例えば、Burke et al., 2001 , Proc. Natl. Acad. Sci. USA 98:6289-6294を参照のこと)によりもたらされ得る。シュードモナス細胞中へのDNAの導入は例えば、エレクトロポレートン(例えば、Choi et al., 2006, J. Microbiol. Methods 64: 391-397を参照のこと)、又は接合(例えば、Pinedo and Smets, 2005, Appl. Environ. Microbiol. 71 : 51-57を参照のこと)によりもたらされ得る。
ストレプトコーカス細胞へのDNAの導入は例えば、天然のコンピテンス(例えば、Perry and Kuramitsu, 1981 , Infect. Immun. 32: 1295-1297を参照のこと)、プロトプラスト形質転換(例えば、Catt and Jollick, 1991 , Microbios. 68: 189-2070を参照のこと)、エレクトロポレーション(例えば、Buckley et al., 1999, Appl. Environ. Microbiol. 65: 3800-3804を参照のこと)、又は接合(例えば、Clewell, 1981 , Microbiol. Rev. 45: 409-436を参照のこと)によりもたらされ得る。しかしながら、宿主細胞中へのDNAの導入について知られているいずれの方法でも使用され得る。
宿主細胞は、真核生物、例えば哺乳類、昆虫、植物、又は菌類細胞であり得る。
好ましい態様においては、宿主細胞は菌類細胞である“菌類”とは、本明細書において使用される場合、門アスコミコタ(Ascomycota)、バシジオミコタ(Basidiomycota)、キトリジオミコタ(Chytridiomycota)及びヅイゴミコタ(Zygomycota)(Hawksworth など., Ainsworth and Bisby’s Dictionary of the Fungi, 8th edition, 1995, CAB International, University Press, Cambridge, UKにより定義される)、及びオーミコタ(Oomycota)(Hawksworth など., 1995, 前記、171ページに引用される)、並びに栄養胞子菌(Hawksworh など., 1995, 前記)を包含する。
好ましい態様においては、宿主細胞は菌類細胞である“菌類”とは、本明細書において使用される場合、門アスコミコタ(Ascomycota)、バシジオミコタ(Basidiomycota)、キトリジオミコタ(Chytridiomycota)及びヅイゴミコタ(Zygomycota)(Hawksworth など., Ainsworth and Bisby’s Dictionary of the Fungi, 8th edition, 1995, CAB International, University Press, Cambridge, UKにより定義される)、及びオーミコタ(Oomycota)(Hawksworth など., 1995, 前記、171ページに引用される)、並びに栄養胞子菌(Hawksworh など., 1995, 前記)を包含する。
より好ましい態様においては、菌類宿主細胞は酵母細胞である“酵母”とは、本明細書において使用される場合、子嚢胞子酵母(Endomycetals)、担子胞子酵母、及び不完全菌類(Blastomycetes)に属する酵母を包含する。酵母の分類は未来において変化し得るので、本発明のためには、酵母は、Biology and Activities of Yeast (Skinner, F.A., Passmore, S.M., and Davenport, R.R., eds. Soc. App. Bacteriol. Symposium Series No. 9, 1980) に記載のようにして定義されるであろう。
さらにより好ましい態様においては、酵母宿主細胞は、カンジダ(Candida)、ハンセヌラ(Hunsenula)、クレベロミセス(Kluyveromyces)、ピチア(Pichia)、サッカロミセス(Saccharomyces)、シゾサッカロミセス(Schizosaccharomyces)又はヤロウィア(Yarrowia)である。
最も好ましい態様においては、酵母宿主細胞は、サッカロミセス・カルスベルゲンシス(Saccharomyces carlsbergensis)、サッカロミセス・セレビシアエ(Saccharomyses cerevisiae)、サッカロミセス・ジアスタチカス(Saccharomyces diastaticus)、サッカロミセス・ドウグラシ(Saccharomyces douglasii)、サッカロミセス・クルイビリ(Saccharomyces kluyveri)、サッカロミセス・ノルベンシス(Saccharomyces norbensisi)、又はサッカロミセス・オビホルミス(Saccharomyces oviformis)細胞である。もう1つの最も好ましい態様においては、酵母宿主細胞は、クルベロミセス・ラクチス(Kluyveromyces lactis)である。もう1つの最も好ましい態様においては、酵母宿主細胞は、ヤロウィア・リポリチカ(Yarrowia lipolytica)細胞である。
もう1つのより好ましい態様においては、菌類宿主細胞は糸状菌細胞である。“糸状菌”とは、ユーミコタ(Eumycota)及びオーミコタ(Oomycota)のすべての糸状形を包含する(Hawksworthなど., 1995, 前記により定義されるような)。糸状菌は一般的に、キチン、セルロース、グルカン、キトサン、マンナン及び他の複合多糖類から構成される菌子体壁により特徴づけられる。成長増殖は、菌子拡張によってであり、そして炭素代謝は絶対好気性である。対照的に、酵母、例えばサッカロミセス・セレビシアエによる成長増殖は、単細胞葉状体の発芽によってであり、そして炭素代謝は発酵性である。
さらにより好ましい態様においては、糸状菌宿主細胞は、アクレモニウム(Acremonium)、アスペルギラス(Aspergillus)、アウレオバシジュウム(Aureobasidium)、ベルカンデラ(Bjerkandera)、セリポリオプシス(Ceriporiopsis)、クロソスポリウム(Chrysosporium)、コプリナス(Coprinus)、コリオラス(Coriolus)、クリプトコーカス(Cryptococcus)、フィロバシジウム(Filobasidium)、フサリウム(Fusarium)、ヒューミコラ(Humicola)、マグナポルセ(Magnaporthe)、ムコル(Mucor)、ミセリオプソラ(Myceliophthora)、ネオカリマスチックス(Neocallimastix)、ネウロスポラ(Neurospora)、、パエシロミセス(Paecilomyces)、ペニシリウム(Penicilium)、ファネロカエト(Phanerochaete)、フェビア(Phlebia)、ピロミセス(Piromyces)、プレウロタス(Pleurotus)、シゾフィラム(Schizophyllum)、タラロミセス(Talaromyces)、サーモアスカス(Thermoascus)、チエラビア(Thielavia)、トリポクラジウム(Tolypocladium)、トラメテス(Trametes)又はトリコダーマ(Trichoderma)の種の細胞であるが、但しそれらだけには限定されない。
最も好ましい態様においては、糸状菌宿主細胞は、アスペルギラス・アワモリ、アスペルギラス・フミガタス、アスペルギラス・ホエチダス、アスペルギラス・ジャポニカ、アスペルギラス・ニジュランス、アスペルギラス・ニガー又はアスペルギラス・オリザエ細胞である。もう1つの最も好ましい態様においては、糸状菌宿主細胞は、フサリウム・バクトリジオイデス、フサリウム・クロックウェレンズ 、フサリウム・セレアリス、フサリウム・クルモラム、フサリウム・グラミネアラム、フサリウム・グラミナム、フサリウム・ヘテロスポラム、フサリウム・ネグンジ、フサリウム・オキシスポラム、フサリウム・レチキュラタム、フサリウム・ロゼウム、フサリウム・サムブシウム、フサリウム・サルコクロウム、フサリウム・ソラニ、フサリウム・スポロトリキオイデス、フサリウム・スルフレウム、フサリウム・トルロサム、フサリウム・トリコセシオイデス又はフサリウム・ベネナタム細胞である。
さらに最も好ましい観点においては、糸状菌親宿主細胞は、ベルカンデラ・アダスタ(Bjerkandera adusta)、セリポリオプシス・アネイリナ(Ceriporiopsis aneirina)、セリポリオプシス・カレギエア(Ceriporiopsis caregiea)、セリポリオプシス・ギルベセンス(Ceriporiopsis gilvescens)、セリポリオプシス・パノシンタ(Ceriporiopsis pannocinta)、セリポリオプシス・リブロサ(Ceriporiopsis rivulosa)、セリポリオプシス・スブルファ(Ceriporiopsis subrufa)又はセリポリオプシス・スベルミスポラ(Ceriporiopsis subvermispora)、
クロソスポリウム・ケラチノフィラム(Chrysosporium keratinophilum)、クロソスポリウム・ルクノウェンス(Chrysosporium lucknowense)、クロソスポリウム・トロピカム(Chrysosporium tropicum)、クロソスポリウム・メルダリウム(Chrysosporium merdarium)、クロソスポリウム・イノプス(Chrysosporium inops)、クロソスポリウム・パニコラ(Chrysosporium pannicola)、クロソスポリウム・クイーンズランジカム(Chrysosporium queenslandicum)、クロソスポリウム・ゾナタム(Chrysosporium zonatum)、
コプリナス・シネレス(Coprinus cinereus)、コリオラス・ヒルスタス(Coriolus hirsutus)、ヒューミコラ・インソレンス、ヒューミコラ・ラヌギノサ、ムコル・ミエヘイ、ミセリオプソラ・サーモフィリア、ネウロスポラ・クラサ、ペニシリウム・プルプロゲナム、ファネロカエト・キソスポリウム(Phanerochaete chrysosporium)、フェビア・ラジアタ(Phlebia radiata)、プレウロタス・エリンギ(Pleurotus eryngii)、チエラビア・テレストリス、トラメテス・ビロサ(Trametes villosa)、トラメテス・ベルシコロル(Trametes versicolor)、トリコダーマ・ハルジアナム、トリコダーマ・コニンギ、トリコダーマ・ロンジブラキアタム、トリコダーマ・レセイ又はトリコダーマ・ビリデ細胞である。
菌類細胞は、プロトプラスト形質転換、プロトプラストの形質転換、及びそれ自体知られている態様での細胞壁の再生を包含する工程により形質転換され得る。アスペルギラス及びトリコダーマ宿主細胞の形質転換のための適切な方法は、ヨーロッパ特許第238023号及びYeltonなど., 1984, Proceedings of the National Academy of Sciences USA 81; 1474-1874に記載される。
フラリウム種を形質転換するための適切な方法は、Malardierなど., 1989, Gene78: 147-156, 及びWO96/00787号により記載される。酵母は、Becker and Guarente. In Abelson, J.N. and Simon, M.I., editors, Guide to Yeast Genetics and Molecular Biology, Methods in Enzymology, Volume 194, pp 182-187, Academic Press, Inc., New York; Ito など, 1983, Journal of Bacteriology 153: 163; 及びHinnen など, 1978, Proceedings of the National Academy of Sciences USA 75; 1920により記載される方法を用いて形質転換され得る。
生成方法:
本発明はまた、(a)その野生型において、前記ポリペプチドの生成の助けと成る条件下でポリペプチドを生成することができる細胞を培養し;そして(b)前記ポリペプチドを回収することを含んで成る、本発明のポリペプチドの生成方法にも関する。
本発明はまた、(a)本明細書に記載されるように、ポリペプチドの生成を助ける条件下で宿主細胞を培養し;そして(b)ポリペプチドを回収することを含んで成る、本発明のポリペプチドを生成するための方法にも関する。
本発明はまた、(a)その野生型において、前記ポリペプチドの生成の助けと成る条件下でポリペプチドを生成することができる細胞を培養し;そして(b)前記ポリペプチドを回収することを含んで成る、本発明のポリペプチドの生成方法にも関する。
本発明はまた、(a)本明細書に記載されるように、ポリペプチドの生成を助ける条件下で宿主細胞を培養し;そして(b)ポリペプチドを回収することを含んで成る、本発明のポリペプチドを生成するための方法にも関する。
本発明はまた、(a)ポリペプチドの生成を助ける条件下で宿主細胞を培養し、ここで前記宿主細胞は配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に少なくとも1つの突然変異を有する変異体ヌクレオチド配列を含んで成り、ここで前記変異体ヌクレオチド配列は配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドを含んで成るか、又はそれれから成るポリペプチドをコードし;そして(b)ポリペプチドを回収することを含んで成る、本発明のポリペプチドを生成するための方法にも関する。
本発明の生成方法においては、細胞は、当業界において知られている方法を用いて、ポリペプチドの生成のために適切な栄養培地において培養される。例えば、細胞は、ポリペプチドの発現及び/又は単離を可能にする、適切な培地において、及び条件下で行われる実験室用又は産業用発酵器において、振盪フラスコ培養、小規模又は大規模発酵(連続、バッチ、供給バッチ、又は団体状態発酵を包含する)により培養され得る。培養は、炭素及び窒素源及び無機塩を含んで成る適切な栄養培地において、当業界において知られている方法を用いて行われる。適切な培地は、市販されているか、又は公開されている組成(例えば、American Type Culture Collection のカタログにおける)に従って調製され得る。ポリペプチドが栄養培地に分泌される場合、ポリペプチドは培地から直接的に回収され得る。ポリペプチドが分泌されない場合、それは細胞溶解物から回収され得る。
ポリペプチドは、そのポリペプチドに対して特異的である、当業界において知られている方法を用いて検出され得る。それらの検出方法は、特定の抗体、ポリペプチド生成物の形成、又は酵素基質の消出の使用を包含する。例えば、酵素アッセイは、本明細書に記載されるようなポリペプチドの活性を決定するために使用され得る。
得られるポリペプチドは、当業界において知られている方法により回収され得る。例えば、ポリペプチドは、従来の方法、例えば遠心分離、濾過、抽出、噴霧−乾燥、蒸発又は沈殿(但し、それらだけには限定されない)により、栄養培地から回収され得る。
本発明のポリペプチドは、当業界において知られている種々の方法、例えばクロマトグラフィー(例えば、イオン交換、親和性、疎水性、クロマトフォーカシング及びサイズ排除)、電気泳動方法(例えば、分離用等電点電気泳動)、示差溶解性(例えば、硫酸アンモニウム沈殿)、SDS−PAGE又は抽出(但し、それらだけには限定されない)により精製され得る(例えば、Protein Purification, J.C. Janson and Lars Ryden, editors, VCH Publlishers, New York, 1989を参照のこと)。
トタンスジェニック植物:
本発明はまた、ポリペプチドを、回収できる量で発現し、そして生成するために、本発明のペルオキシゲナーゼ活性を有するポリペプチドをコードする単離されたポリヌクレオチドを含んで成る植物、例えばトランスジェニック植物、その植物部分又は植物細胞にも関する。ポリペプチドは、植物又は植物部分から回収され得る。他方では、組換えポリペプチドを含む植物又は植物部分は、食物又は飼料の品質を改良し、例えば栄養価値、嗜好性及び流動性質を改良するために、又は抗栄養因子を破壊するために使用され得る。
本発明はまた、ポリペプチドを、回収できる量で発現し、そして生成するために、本発明のペルオキシゲナーゼ活性を有するポリペプチドをコードする単離されたポリヌクレオチドを含んで成る植物、例えばトランスジェニック植物、その植物部分又は植物細胞にも関する。ポリペプチドは、植物又は植物部分から回収され得る。他方では、組換えポリペプチドを含む植物又は植物部分は、食物又は飼料の品質を改良し、例えば栄養価値、嗜好性及び流動性質を改良するために、又は抗栄養因子を破壊するために使用され得る。
トランスジェニック植物は、双子葉植物又は単子葉植物であり得る。単子葉植物の例は、草、例えば湿潤地の草本(ブルーグラス、イチゴツナギ属)、飼草、例えばウシノケグサ、ドクムギ、温帯性草本、例えばヌカボ、及び穀類、例えば小麦、オート麦、ライ麦、イネ、モロコシ、及びトウモロコシ(サトウモロコシ)である。
双子葉植物の例は、タバコ、マメ科植物、例えばルピナス、ジャガイモ、砂糖大根、エンドウ、インゲン豆及び大豆、及びアブラナ科植物(ブラシカセアエ科(Brassicaceae))、例えばカリフラワー、ナタネ種子及び密接に関連するモデル生物アラビドプシス・タリアナ(Arabidopsis thaliana)である。
植物部分の例は、茎、カルス、葉、根、果物、種子及び塊茎、並びにそれらの部分を含んで成る個々の組織、例えば表皮、葉肉、柔組織、維管束組織、分裂組織である。また特定の植物細胞区画、例えばクロロプラスト、アポプラスト、ミトコンドリア、液胞、ペルオキシゾーム及び細胞質が、植物部分であると思われる。さらに、組織起源が何であろうと、いずれの植物細胞でも、植物部分であると思われる。同様に、植物部分、例えば本発明の利用を促進するために単離された特定の組織及び細胞はまた、植物部分、例えば胚、内生精子、アリューロン及び被膜であると思われる。
そのような植物、植物部分及び植物細胞の子孫はまた、本発明の範囲内に包含される。
本発明のポリペプチドを発現するトランスジェニック植物又は植物細胞は、当業界において知られている方法に従って構成され得る。手短には、植物又は植物細胞は、本発明のポリペプチドをコードする、1又は複数(数個)の発現構造体を、植物宿主ゲノム又はクロロプラストゲノム中に導入し、そして得られる修飾された植物又は植物細胞をトランスジェニック植物又は植物細胞中に成長せしめることによって構成される。
本発明のポリペプチドを発現するトランスジェニック植物又は植物細胞は、当業界において知られている方法に従って構成され得る。手短には、植物又は植物細胞は、本発明のポリペプチドをコードする、1又は複数(数個)の発現構造体を、植物宿主ゲノム又はクロロプラストゲノム中に導入し、そして得られる修飾された植物又は植物細胞をトランスジェニック植物又は植物細胞中に成長せしめることによって構成される。
便利には、発現構造体は、選択の植物又は植物におけるヌクレオチド配列の発現のために必要とされる適切な調節配列により操作可能的に連結される本発明のポリペプチドをコードするポリヌクレオチドを含んで成る核酸構造体である。さらに、発現構造体は、発現構造体が組み込まれている宿主細胞を同定するために有用な選択マーカー、及び問題の植物中への構造体の導入のために必要なDNA配列を含んで成る(後者は、使用されるDBA導入方法に依存する)。
調節配列、例えばプロモーター及びターミネーター配列、及び任意には、シグナル又はトランスジット配列の選択は、例えばポリペプチドがいつ、どこで及びいかにして発現されることを所望するかに基づかれる。例えば、本発明のポリペプチドをコードする遺伝子の発現は、構成的又は誘発的であり、又は進行的、段階又は組織特異的であり、そして遺伝子生成物は、特定組織又は植物部分、例えば種子又は葉に標的化され得る。調節配列は、Taqueなど., 1988, Plant Physiology 86: 506により記載される。
構成的発現のために、次のプロモーターが使用され得る:35S−CaMVプロモーター(Franck など., 1980, Cell 21: 285-294)、トウモロコシユビキチン1(Christensen AH, Sharrock RA and Quail 1992. Maize polyubiquitin genes: structure, thermal perturbation of expression and transcript splicing, and promoter activity following transfer to protoplasts by electroporation)、又はイネアクチン1プロモーター(Plant Mo. Biol. 18,675-689. ; Zhang W, McElroy D. and Wu R 1991, Analysis of rice Act1 5'region activity in transgenic rice plants. Plant Cell 3,1155-1165)。
器官特異的プロモーターは例えば、貯蔵吸込み組織、例えば種子、ジャガイモ塊茎及び果物(Edwards & Coruzzi, 1990, Ann. Rev. Genet. 24: 275-303)、又は代謝吸込み組織、例えば分裂組織(Ito など., 1994, Plant Mol. Biol. 24: 863-878)からのプロモーター、種子特異的プロモーター、例えばイネからのグルテリン、プロラミン、グロブリン又はアルブミンプロモーター(Wu など., 1998, Plant and Cell Physiology 39: 885- 889)、Vicia fabaからのレグニンB4及び未知の種子タンパク質遺伝子からのVicia fabaプロモーター(Conrad など., 1998, Journal of Plant Physiology 152: 708-711)、種子油タンパク質からのプロモーター(Chen など., 1998, Plant and Cell Physiology 39: 935-941)、ブラシカ・ナパス(Brassica napus)からの貯蔵タンパク質napAプロモーター又は当業界において知られている、例えばWO91/14772号に記載されるようないずれか他の種子特異的プロモーターであり得る。
さらに、プロモーターは、葉特異的プロモーター、例えばイネ又はトマトからのrbcsプロモーター(Kyozuka など., 1993, Plant Physiology 102: 991-1000)、クロレラウィルスアデニンメチルトランスフェラーゼ遺伝子プロモーター(Mitra and Higgins, 1994, Plant Molecular Biology 26: 85-93)、又はイネからのaldP遺伝子プロモーター(Kagaya など., 1995, Molecular and General Genetics 248: 668-674)、又は創傷誘発性プロモーター、例えばジャガイモpin2プロモーター(Xu など., 1993, Plant Molecular Biology 22 : 573-588)であり得る。同様に、プロモーターは、非生物学的処理、例えば温度、渇水又は塩分の変更により誘発できるか、又はプロモータを活性化する外部的に適用される物質、例えばエタノール、エストロゲン、植物ホルモン様エチレン、アブシジン酸、ジベレリン酸及び/又は重金属により誘発できる。
プロモーターエンハンサー要素がまた、植物におけるポリペプチドのより高い発現を達成するために使用され得る。例えば、プロモーターエンハンサー要素は、プロモーターと、本発明のポリペプチドをコードするヌクレオチド配列との間に位置するイントロンであり得る。例えば、Xuなど., 1993(前記)は、発現を増強するためへのイネアクチン1遺伝子の最初のイントロンの使用を開示する。
発現構造体の選択マーカー遺伝子及びいずれか他の部分は、当業界において入手できるそれらから選択され得る。
発現構造体の選択マーカー遺伝子及びいずれか他の部分は、当業界において入手できるそれらから選択され得る。
核酸構造体は、当業界において知られている従来の技法、例えばアグロバクテリウム介在性形質転換、ウィルス介在性形質転換、マイクロインジェクション、粒子衝撃、バイオリステック形質転換及びエレクトロポレーションに従って、植物ゲノム中に組込まれる(Gasserなど., 1990, Science 244: 1293; Potrykus, 1990, BiolTechnology 8 : 535; Shimamoto など., 1989, Nature 338: 274)。
現在、アグロバクテリウム・ツメファシエンス介在性遺伝子トランスファーは、トランスジェニック双子葉類を生成するための選択方法であり(再考のためには、Hooykas and Schilperoort, 1992, Plant Molecular Biology 19: 15-38を参照のこと)、そして、それはまた、単子葉類を形質転換するためにも使用され得るが、しかし他の形質転換方法が一般的にそれらの植物のために好ましい。
現在、アグロバクテリウムアプローチを補足する、トランスジェニック単子葉類を生成するための選択方法は、胚細胞又は成長胚の粒子衝撃である(形質転換DNAにより被覆された微小金又はタングステン粒子)(Christou, 1992, Plant Journal 2 : 275-281; Shimamoto, 1994, Current Opinion Biotechnology 5: 158-162; Vasil など., 1992, BiolTechnology 10: 667-674)。単子葉類の形質転換のための他の方法は、Omirullehなど., 1993, Plant Molecular Biology21: 415-428により記載されるようにプロトプラスト形質転換に基づかれる。
形質転換に続いて、そこに組込まれた発現構造体を有する形質転換体が選択され、そして当業界において良く知られていた方法に従って、完全な植物に再生される。しばすば、形質転換方法は、2種の別々のT-DNA構造体による同時形質転換を用いることによる、再生の間又は次の生成において、選択遺伝子の選択的排除、又は特異的組換え酵素による選択遺伝子の部位特異的排除のために企画される。
本発明はまた、(a)本発明のペルオキシゲナーゼ活性有するポリペプチドをコードする核酸配列を含んで成るトランスジェニック植物又は植物細胞を、前記ポリペプチドの生成の助けとなる条件下で栽培し、そして(b)前記ポリペプチドを回収することを含んで成る、本発明のポリペプチドを生成するための方法にも関する。
ペルオキシゲナーゼ活性の除去又は低減:
本発明はまた、同じ条件下で培養される場合、親細胞よりもポリペプチドを低く生成する変異体細胞をもたらす、本発明のポリペプチドをコードするポリヌクレオチド配列又はその一部を破壊するか又は削除することを含んで成る、親細胞の変異体の生成方法にも関する。
本発明はまた、同じ条件下で培養される場合、親細胞よりもポリペプチドを低く生成する変異体細胞をもたらす、本発明のポリペプチドをコードするポリヌクレオチド配列又はその一部を破壊するか又は削除することを含んで成る、親細胞の変異体の生成方法にも関する。
変異体細胞は、当業界において良く知られている方法、例えば挿入、破壊、置換又は欠失を用いて、本発明のポリペプチドをコードするヌクレオチド配列の発現を低めるか又は排除することにより構成され得る。好ましい観点においては、ヌクレオチド配列は不活性化される。修飾されるか又は不活性化されるヌクレオチド配列は、例えば活性のために必須であるコード領域又はその一部、又はコード領域の発現のために必要とされる調節要素であり得る。そのような調節又は制御配列の例は、プロモーター配列又はその機能的部分、すなわちヌクレオチド配列の発現に影響を及ぼすのに十分である部分であり得る。可能な修飾のための他の制御配列は、リーダー、ポリアデニル化配列、プロペプチド配列、シグナルペプチド配列、転写ターミネーター、及び転写活性化因子を包含するが、但しそれらだけには限定されない。
ヌクレオチド配列の修飾又は不活性化は、親細胞を突然変異誘発にゆだね、そしてヌクレオチド配列の発現が低められているか又は排除されている変異体細胞を選択することにより行われ得る。特異的又はランダムであり得る突然変異誘発は、例えば適切な物理的又は化学的突然変異誘発剤の使用により、適切なオリゴヌクレオチドの使用により、又はDNA配列をPCR生成された突然変異誘発にゆだねることにより行われ得る。さらに、突然変異誘発は、それらの突然変異誘発剤のいずれかの組み合わせの使用により行われ得る。
本発明のために適切な物理的又は化学的突然変異誘発剤の例は、紫外線(UV)照射、ヒドロキシルアミン、N−メチル−N’−ニトロ−N−ニトロソグアニジン(MNNG)、O−メチルヒドロキシルアミン、亜硝酸、エチルメタンスルホネート(EMS)、亜硫酸水素ナトリウム、蟻酸及びヌクレオチド類似体を包含する。
そのような剤が使用される場合、突然変異誘発は典型的には、選択の突然変異誘発の存在下で突然変異誘発されるベき親細胞をインキュベートし、そして低められた遺伝子の発現を示すか又は発現を示さない変異体細胞をスクリーニングし、そして/又は選択することによって行われる。
ヌクレオチド配列の修飾又は不活性化は、その転写又は翻訳のために必要とされる遺伝子又は調節要素における1又は複数のヌクレオチドの導入、置換又は除去により達成され得る。例えば、ヌクレオチドは、停止コドン導入、開始コドンの除去又は読み取り枠の変更をもたらすために、挿入され又は除去され得る。そのような修飾又は不活性化は、当業者において知られている方法に従って、特定部位の突然変異誘発又はPCR生成された突然変異誘発により達成され得る。主に、修飾はインビボで、すなわち修飾されるべきヌクレオチド配列を発現する細胞に対して直接的に行われ得るが、修飾は下記に例示されるようにインビトロで行われ得ることが好ましい。
細胞によるヌクレオチド配列の発現を排除するか又は低めるための便利な手段の例は、遺伝子置換、遺伝子削除又は遺伝子破壊の技法に基づかれる。例えば、遺伝子破壊方法においては、内因性ヌクレオチドに対応する核酸配列が、欠失遺伝子を生成するために、親細胞を形質転換する欠失性核酸配列を生成するようインビトロで突然変異誘発される。相同組換えにより、その欠失性核酸配列は、その内因性遺伝子又は遺伝子フラグメントを置換する。その欠失性ヌクレオチド配列はまた、ヌクレオチド配列が修飾されているか又は破壊されている形質転換体の選択のために使用され得るマーカーをコードする。特に好ましい観点においては、ヌクレオチド配列は、選択マーカー、例えば本明細書に記載されるようなそれらにより破壊される。
他方では、ヌクレオチド配列の修飾又は不活性化は、ヌクレオチド配列に対して相補的な配列を用いて、確立されたアンチセンス又はRNAi技法により行われ得る。より特定には、細胞によるヌクレオチド配列の発現は、細胞において転写され得、そして細胞において生成されるポリペプチドmRNAに対してハイブリダイズすることができる遺伝子のヌクレオチド配列に相補的な配列を導入することによって低められるか又は排除され得る。相補的アンチセンスヌクレオチド配列のポリペプチドmRNAへのハイブリダイズを可能にする条件下で、翻訳されるタンパク質の量が低められ又は排除される。
本発明はさらに、親細胞に比較して、ポリペプチドを少なく生成するか又はポリペプチドを生成しない変異体細胞をもたらす、ポリペプチドをコードするヌクレオチド配列又はその制御配列の破壊又は欠失を含んで成る親細胞の変異体細胞に関する。
そのようにして創造されたポリペプチド欠失変異体細胞は、生来及び/又は異種ポリペプチドの発現のための宿主として特に有用である。従って、本発明はさらに、(a)ポリペプチドの生成のために適切な条件下で変異体細胞を培養し;そして(b)ポリペプチドを回収することを含んで成る、相同体又は異種ポリペプチドの生成方法に関する。用語“異種ポリペプチド”とは、宿主細胞に対して生来ではないポリペプチド、生来の配列を変更するために修飾が行われている生来のタンパク質、又はその発現が組換えDNA技法による宿主細胞の操作の結果として定量的に変更されている生来のタンパク質として本明細書において定義される。
さらなる観点においては、本発明は、本発明のポリペプチド及び興味あるタンパク質生成物の両者を生成する細胞の発酵によりペルオキシゲナーゼ活性を実質的に有さないタンパク質生成物の生成方法に関し、ここで前記方法は、発酵が完結される前、その間、又は完結された後、ペルオキシゲナーゼ活性を阻害することができる、有効量の剤を、発酵ブイヨンに添加し、その発酵ブイヨンから興味ある生成物を回収し、そして任意には、回収された生成物を、さらなる精製にゆだねることを含んで成る。
さらなる観点においては、本発明はペルオキシゲナーゼ活性を実質的に有さないタンパク質生成物の生成方法に関し、ここで前記方法は、細胞を、生成物の発現を可能にする条件下で培養し、ペルオキシゲナーゼ活性を実質的に低めるために、前記得られる培養物ブイヨンを、組み合わされたpH及び温度処理にゆだね、そして培養物ブイヨンから生成物を回収することを含んで成る。他方では、前記組み合わされたpH及び温度処理は、培養物ブイヨンから回収された酵素調製物に対して行なわれ得る。前記組み合わされたpH及び温度処理は任意には、ペルオキシゲナーゼンヒビターによる処理と組合して使用され得る。
本発明のこの観点によれば、ペルオキシゲナーゼ活性の少なくとも60%、好ましくは少なくとも75%、より好ましくは少なくとも85%、さらにより好ましくは少なくとも95%、及び最も好ましくは少なくとも99%を除去することが可能である。ペルオキシゲナーゼ活性の完全な除去は、この方法の使用により得られる。
前記組み合わされたpH及び温度処理は好ましくは、所望する効果を達成するための十分な時間、典型的には30〜60分間、2〜4又は9〜11の範囲のpH及び少なくとも60〜70℃の範囲の温度で行われる。
興味ある生成物の培養及び精製のために使用される方法は、当業界において知られている方法により行われ得る。
興味ある生成物の培養及び精製のために使用される方法は、当業界において知られている方法により行われ得る。
ペルオキシゲナーゼを実質的に有さない生成物を生成するための本発明の方法は、真核生物ポリペプチド、特に菌類タンパク質、例えば酵素の生成において特に興味あるものである。前記酵素は、例えば澱粉分解酵素、脂肪分解酵素、タンパク質分解酵素、細胞分解酵素、オキシドレダクターゼ又は植物細胞壁分解酵素から選択され得る。
そのような酵素の例は、アミノペプチダーゼ、アミラーゼ、アミログルコシダーゼ、カルボヒドラーゼ、カルボキシペプチダーゼ、カタラーゼ、セロビオヒドロラーゼ、セルラーゼ、キチナーゼ、クチナーゼ、シクロデキストリン、グルコシルトランスフェラーゼ、デオキシリボヌクレアーゼ、エンドグルカナーゼ、エステラーゼ、ガラクトシダーゼ、β−ガラクトシダーゼ、グルコアミラーゼ、グルコースオキシダーゼ、グルコシダーゼ、ハロペルオキシダーゼ、ヘミセルラーゼ、インバーターゼ、イソメラーゼ、ラッカーゼ、リガーゼ、リパーゼ、リアーゼ、マンノシダーゼ、オキシダーゼ、ペクチン分解酵素、ペルオキシダーゼ、フィターゼ、フェノールオキシダーゼ、ポリフェノールオキシダーゼ、タンパク質分解酵素、リボヌクレアーゼ、トランスフェラーゼ、トランスグルタミナーゼ又はキシラナーゼを包含する。ペルオキシゲナーゼ欠失細胞はまた、医薬的に興味あるもの、例えばホルモン、成長因子、受容体及び同様のものの異種タンパク質を発現するために使用され得る。
用語“真核生物ポリペプチド”とは、生来のポリペプチドのみだけではなく、またアミノ酸置換、欠失又は付加、又は活性、熱安定性、pH耐性及び同様のものを増強するための他のそのような修飾により修飾されているそれらのポリペプチド、例えば酵素を包含する。
もう1つの観点においては、本発明は、本発明の方法により生成される、ペルオキシゲナーゼ活性を実質的に有さないタンパク質生成物に関する。
もう1つの観点においては、本発明は、本発明の方法により生成される、ペルオキシゲナーゼ活性を実質的に有さないタンパク質生成物に関する。
組成物:
本発明はまた、本発明のポリペプチドを含んで成る組成物にも関する。好ましくは、組成物はそのようなポリペプチドにおいて富化される。用語“富化される”とは、組成物中のペルオキシゲナーゼ活性が、少なくとも1.1の富化因子、高められていることを示す。
本発明はまた、本発明のポリペプチドを含んで成る組成物にも関する。好ましくは、組成物はそのようなポリペプチドにおいて富化される。用語“富化される”とは、組成物中のペルオキシゲナーゼ活性が、少なくとも1.1の富化因子、高められていることを示す。
組成物は、主要酵素成分、例えば単一成分組成として本発明のポリペプチドを含んで成る。他方では、組成物は、複数の酵素活性、例えばアミノペプチダーゼ、アミラーゼ、カルボヒドラーゼ、カルボキシペプチダーゼ、カタラーゼ、セルラーゼ、キチナーゼ、クチナーゼ、シクロデキストリングリコシルトランスフェラーゼ、デオキシリボヌクレアーゼ、エステラーゼ、α−ガラクトシダーゼ、β−ガラクトシダーゼ、グルコアミラーゼ、α−グルコシダーゼ、β−グルコシダーゼ、ハロペルオキシダーゼ、インバーターゼ、ラッカーゼ、リパーゼ、マンノシダーゼ、オキシダーゼ、ペクチン分解酵素、ペプチドグルタミナーゼ、ペルオキシダーゼ、フィターゼ、ポリフェノールオキシダーゼ、タンパク質分解酵素、リボヌクレアーゼ、トランスグルタミナーゼ又はキシラナーゼを含んで成る。
追加の酵素は、例えばアスペルギラス属、好ましくはアスペルギラス・アキュレアタス(Aspergillus aculeatus)、アスペルギラス・アワモリ(Aspergillus awamori)、アスペルギラス・ホエチダス(Aspergillus foetidus)、アスペルギラス・ジャポニカス(Aspergillus japonicus)、アスペルギラス・ニジュランス(Aspergillus nidulans)、アスペルギラス・ニガー(Aspergillus niger)、又はアスペルギラス・オリザエ(Aspergillus oryzae)、フサリウム属、例えばフサリウム・バクトリジオイデス(Fusarium bactridioides)、フサリウム・セレアリス(Fusarium cerealis)、フサリウム・クロックウェレンズ(Fusarium crookwellense)、フサリウム・クルモラム(Fusarium culmorum)、フサリウム・グラミネアラム(Fusarium graminearium)、フサリウム・グラミナム(Fusarium graminum)、フサリウム・ヘテロスポラム(Fusarium heterosporum)、フサリウム・ネグンジ(Fusarium negundi)、フサリウム・オキシスポラム(Fusarium oxysporum)、フサリウム・レチキュラタム(Fusarium reticulatum)、フサリウム・ロゼウム(Fusariumu roseum)、フサリウム・サムブシウム(Fusarium sambucinum)、
フサリウム・サルコクロウム(Fusarium sarcochroum)、フサリウム・スポロトリキオイデス(Fusarium sporotrichioides)、フサリウム・スルフレウム(Fusarium sulphureum)、フサリウム・トルロサム(Fusarium torulosaum)、フサリウム・トリコセシオイデス(Fusarium trichothecioides)、又はフサリウム・ベネナタム(Fusarium venenatum)、ヒュミコラ属、好ましくはヒュミコラ・インソレンス(Humicola insolens)、又はヒュミコラ・ラヌギノサ(Humicola lanuginosa)、トリコダーマ属、好ましくはトリコダーマ・ハルジアナル(Trichoderma harzianum)、トリコダーマ・コニンギ(Trichoderma koningii)、トリコダーマ・ロンジブラキアタム(Trichoderma longibrachiatum)、トリコダーマ・レセイ(Trichoderma reesei)又はトリコダーマ・ビリデ(Trichoderma viride)に属する微生物により生成され得る。
ポリペプチド組成物は、当業界において知られている方法に従って調製され得、そして液体又は乾燥組成物の形で存在することができる。例えば、ポリペプチド組成物は、顆粒又は微粒子の形で存在することができる。組成物に包含されるべきポリペプチドは、当業界において知られている方法に従って安定化され得る。
本発明のポリペプチド組成物の好ましい使用の例は下記に与えられる。本発明のポリペプチド組成物の用量、及び組成物が使用される他の条件は、当業界において知られている方法に基づいて決定され得る。本発明はまた、ペルオキシゲナーゼ活性を有するポリペプチド、又はその組成物の使用方法にも向けられる。
芳香族N−複素環式化合物のその対応するN−酸化物への酵素的酸化:
式(I)の出発化合物が好ましくは、特に高いペルオキシゲナーゼ活性を有する、真菌アグロシベ・アエゲリタの芳香族ハロペルオキシダーゼペルオキシゲナーゼ(アグロシベ・アエゲリタペルオキシゲナーゼ−アグロシベ・アエゲリタペルオキシダーゼ=AaP1)、及び少なくとも1つの酸化剤と反応せしめられ、ここで複素環式窒素の位置選択的酸化が生じる。
式(I)の出発化合物が好ましくは、特に高いペルオキシゲナーゼ活性を有する、真菌アグロシベ・アエゲリタの芳香族ハロペルオキシダーゼペルオキシゲナーゼ(アグロシベ・アエゲリタペルオキシゲナーゼ−アグロシベ・アエゲリタペルオキシダーゼ=AaP1)、及び少なくとも1つの酸化剤と反応せしめられ、ここで複素環式窒素の位置選択的酸化が生じる。
本発明の使用される酸化剤は好ましくは、H2O2、有機過酸化物又はヒドロ過酸化物、例えばtert−ブチルヒドロ過酸化物、空気又は酸素(O2)である。高価な電子供与体、例えばNADH又はNADPH(酸化剤の濃度:0.01〜10mモル/l、好ましくは0.1〜2mモル/lのH2O2)を排除することが本発明の方法において可能である。
酵素AaP1により式(I)の化合物の転換をさらに促進するために、H2O2−生成酵素、特にオキシダーゼ、例えばグルコースオキシダーゼ又はアリールアルコールオキシダーゼ及びそれらの基質(グルコース又はベンジルアルコール)を、反応混合物にさらに添加することが可能である。
本発明に従っての酵素的細胞フリー方法の基本は、P450−様触媒性質を有する新規の細胞外ハロペルオキシダーゼペルオキシゲナーゼ(=芳香族ペルオキシゲナーゼ)であり、そして特に緩衝水溶液中、適切な酸化剤(例えば、過酸化物)の存在下で、芳香族N−複素環式化合物(例えば、ピリジン)を、その対応するN−酸化物に酸化し、そしてそのようにすることにより、高い選択性(95%以上のN−酸化物)を達成する。
使用される酵素は、ペルオキシダーゼ及びペルオキシゲナーゼ機能を有する特定の細胞外ヘム−チオレートタンパク質である。それは、ボルビチアセアエ(例えば、アグロシベspp.)及びコプリナセアエ(例えば、コプリナスssp.)科の担子菌により形成され、そしてこれまで記載されているペルオキシダーゼ及びシトクロムP450とは明らかに異なる特定の触媒性質により特徴づけられる。酵素生成は好ましくは、液体培養、生成物反応体及び窒素富化培地において実施される(Ullrich, R., 2005, Thesis, IHI Zittau; Kluge, M. 2006, Diploma thesis, IHI Zittau)。
化学合成に比較して、AaP1として知られる酵素により触媒される反応は、高く濃縮された、攻撃的及び環境的に有害な試薬を必要とせず、そして生成物を回収する場合、異性体混合物を分離するために化学的に徹底した及び手間がかかる精製段階を排除することが可能である。典型的には、前記酵素は、0.02U/ml〜10U/mlのAaP1、特に0.09〜8U/mlのAaP1の濃度で使用される。これは、記載される反応工程を、特に環境的に好意的にする。
純粋な化学合成に対する追加の利点は、室温及び標準の空気圧下での本発明のペルオキシゲナーゼ−触媒された反応による操作から成る。好ましい態様においては、前記方法は、緩衝水溶液において実施される。水性媒体において反応を安定化するためには、有機酸、好ましくはクエン酸及びリン酸塩、好ましくはリン酸水素カリウムに基づく緩衝液を、反応混合物に添加することが可能である(緩衝液濃度:5mモル/l〜500mモル/l、好ましくは20〜100mモル/l)。
溶解性を改良するためには、有機溶媒が反応混合物に添加され、そして2相システムで作業することが可能である。本発明に従って有用な溶媒は、プロトン性溶媒、例えばメタノール又はエタノール、又は非プロトン性極性溶媒、例えばエーテル(例えば、ジイソプロピルエーテル)、アセトン、アセトニトリル、DMSO(ジメチルスルホキシド)及びDMF(N, N−ジメチルホルムアミド)である。
使用される式(I)の出発化合物は特に、次のグループからの化合物である:ピリジン、置換されたピリジン(R=-X, -NO2, −アルキル、−フェニル、-NH2, -OH)、キノリン、イソキノリン及びそれらの誘導体、数個のヘテロ原子を有する芳香族化合物、及び多環式N−複素環式化合物。反応は、5℃〜40℃の範囲内で、好ましくは20〜30℃で実施される。反応時間は典型的には、0.5〜120分、特に5〜50分である。達成されるN−酸化物の収率は、10〜99%、好ましくは20〜90%の範囲内である。ピリジンをピリジンN−酸化物に酸化できる唯一の他の酵素(メタンモノオキシゲナーゼ、MMO)による触媒に対する、N−複素環式化合物のペルオキシゲナーゼ触媒された反応の利点は、次のものから成る:
・ i) より高い比活性、
・ ii) 高価な電子供与体[NAD(P)H]の代わりに安価な過酸化物の使用、
・ iii)フラビンレダクターゼ及び調節タンパク質からのヒドロキシル化酵素の独立性、
・iv) 細胞破壊を伴わないでの単純な酵素回収、及び
・ v) 不安定な細胞内及び部分的膜結合されたMMOに比較して、細胞外AaP1及び類似するペルオキシゲナーゼの高い安定性。
・ ii) 高価な電子供与体[NAD(P)H]の代わりに安価な過酸化物の使用、
・ iii)フラビンレダクターゼ及び調節タンパク質からのヒドロキシル化酵素の独立性、
・iv) 細胞破壊を伴わないでの単純な酵素回収、及び
・ v) 不安定な細胞内及び部分的膜結合されたMMOに比較して、細胞外AaP1及び類似するペルオキシゲナーゼの高い安定性。
AaP1−触媒された反応に関しては、1段階工程において補助基質として過酸化物のみを必要とする単一の細胞外生触媒の助けにより、活性化されてないN−複素環式化合物、例えばピリジンを、位置選択的にその対応するN−酸化物(例えば、ピリジンN−酸化物)に転換することが初めて可能である。この方法は、広範囲の異なった全化学の分野において、中でも、活性成分、医薬中間体、特定の触媒及び酸化剤の調製、及び不安定な分子への保護基の導入のために使用され得る。本発明は、図面に示される例に関して、下記により詳細に例示されるが、本発明はそれらの例に制限されるものではない。
パルプ及び製紙産業へのペルオキシゲナーゼの適用:
ペルオキシゲナーゼは、好ましい態様においては、パルプ及び製紙産業内で異なった適用のために使用され得る。この酵素は、クラフトパルプ、砕木パルプ及び化学−砕木パルプの漂白工程において脱リグニン化を高めるために使用され得る。漂白工程の目的は、セルロース繊維から褐色のリグニン分子を除去することであり;これは従来、典型的には、酸化化学物質、例えば二酸化塩素、酸素、オゾン又は過酸化水素を用いての漂白連鎖、及び酸化段階間でのアルカリ抽出において行われる。
ペルオキシゲナーゼは、好ましい態様においては、パルプ及び製紙産業内で異なった適用のために使用され得る。この酵素は、クラフトパルプ、砕木パルプ及び化学−砕木パルプの漂白工程において脱リグニン化を高めるために使用され得る。漂白工程の目的は、セルロース繊維から褐色のリグニン分子を除去することであり;これは従来、典型的には、酸化化学物質、例えば二酸化塩素、酸素、オゾン又は過酸化水素を用いての漂白連鎖、及び酸化段階間でのアルカリ抽出において行われる。
リグニン分子における芳香族構造体の酸化により、リグリンはより親水性になり、そして従来の酸化化学物質により、さらに分解される場合、パルプからの抽出を容易にし、従って、パルプの同じ輝度レベルを得るためには、より少ない量の従来の漂白化学物質が必要とされる。芳香族構造体の潜在的側鎖ヒドロキシル化、アルキル−アリールエーテルの分解、及び複雑なリグニン構造体に存在するアルコール及びアルデヒド構造体の酸化が、漂白工程を改良し、そして従来の化学物質を倹約する。
例えば、クラフトパルプの脱リグニンに関するもう1つの態様においては、ペルオキシゲナーゼは、ラッカーゼ/メディエーター又はペルオキシダーゼ/メディエーター脱リグニン化に使用されるメディエーターの現場生成のために使用され得、この工程は例えば、Call et al, Journal of Biotechnology 53 (1997) p. 163-202により記載されている。そのように呼ばれるN−OH型、例えばヒドロキシベンゾトリアゾールのメディエーターは、この工程において高い脱リグニン化効果を示す化合物である。ヒドロキシベンゾトリアゾールは、ペルオキシゲナーゼの使用により、より安価な化合物ベンゾトリアゾールのヒドロキシル化による工程において現場生成され得る。N−OH型の他の複素環式化合物は、同じ手段で生成される。
もう1つの態様においては、ペルオキシゲナーゼ酵素は、化学、砕木及び化学−砕木パルプのピッチ除去/脱樹脂化を改良するために使用され得る。ピッチ及び樹脂は天然において木材に見出される疎水性化合物について通常使用される用語である。樹脂は、従来の化学パルプ処理工程において一定の程度まで除去され/分解されるが、しかし化合物のいくらかは、それらの化合物の疎水性のために所望する程度まで除去することが困難であり、芳香族構造体のヒドロキシル化又はアリールアルコール又はフェノール構造体の酸化が脱樹脂化を改良し、そしてその手段で、パルプ/製紙の性質を改良し、洗浄のための停止時間を倹約し、そしパルプに均等に懸濁される疎水性化合物を維持するために添加される化学物質を実質的に倹約する。
水処理産業内でのペルオキシゲナーゼ:
ペルオキシゲナーゼは、水処理産業内で種々の目的のために適用され得る。構想される適用の実際すべては、扱いにくく、毒性で、分解されにくく且つ/又は生活性物質のペルオキシゲナーゼ触媒された変性に対応する。それらの物質、例えば活性化されたスラッジ、物質反応体(例えば、移動層、逆流スラッジブランケット、膜、等)、好気性及び嫌気性ダイジェスター、透明剤及びラグーン(但し、それらだけには限定されない)の変性(すなわち、酸化)は、従来の水処理操作によりそれらの緩和策を促進するであおる。
ペルオキシゲナーゼは、水処理産業内で種々の目的のために適用され得る。構想される適用の実際すべては、扱いにくく、毒性で、分解されにくく且つ/又は生活性物質のペルオキシゲナーゼ触媒された変性に対応する。それらの物質、例えば活性化されたスラッジ、物質反応体(例えば、移動層、逆流スラッジブランケット、膜、等)、好気性及び嫌気性ダイジェスター、透明剤及びラグーン(但し、それらだけには限定されない)の変性(すなわち、酸化)は、従来の水処理操作によりそれらの緩和策を促進するであおる。
水処理操作内のペルオキシゲナーゼの比活性及び触媒活性の主張される有益性は、変性の主要供給物に従って分類され得る。
第1のシナリオにおいては、前記物質のペルオキシゲナーゼ−介在性変性は、従来の水処理操作による続く除去のために、直接的に及び/又は危険な物質の生物利用能を高めることにより、その物質の危険な性質を低める。例としては、次のものを列挙することができる:持続性物質、例えば除草剤/殺真菌剤(例えば、フェニルウレア、フェノキシ)、アトラジン、フェニル炭化水素&PAH、殺虫剤、DDT、PCB、PCDD, PCDF及び界面活性剤及び出現する微量汚染物質(EMP)、例えば内分泌崩壊物質、医薬(例えば、抗生物質/抗菌剤、卵胞ホルモン)、パーソナルケア製品及び同様のもの。大部分、前記物質は、非選択性で、非触媒性で且つ非再生性の傾向がある、より高価な処理よりも、ペルオキシゲナーゼは選択性及び特異性を好ましくする低濃度レベルで存在する傾向がある。
第2シナリオにおいては、物質のペルオキシゲナーゼ変性は、水処理操作の効率/性能を改良する。ペルオキシゲナーゼによる難分解性有機物質(すなわち、“処理されていない”、及び“処理できない/不活性/硬質COD”)の酸化は、主要な設備投資を伴わないで、従来の水処理操作の全体の除去速度を速めることができるCOD:BOD比を低める。類似する態様で、潜在的に毒性の物質のペルオキシゲナーゼ−介在性酸化は、健康、及び生物学的栄養物除去(BNR)システム(例えば、反応体、消化物、ラグーン、スラッジ、層、フィルター及び清浄物)の効率を改良することができる。改良された有機除去速度の他に、ペルオキシゲナーゼは流入物の解毒によりメタン形成を増強し、そしてCOD:BOD比を低めることができる。
第3シナリオにおいては、ペルオキシゲナーゼ活性が、局部物質の同時酸化を伴って、産業流出物に存在する残留過酸化物を低めるために使用され得る。
第4シナリオにおいては、ペルオキシゲナーゼ活性は、一次及び二次/生物学的スラッジの凝集挙動性を改良するために使用され得る。コロイド間、及びコロイドと大きな凝集体との間の共有架橋の生成を触媒することにより、従来の脱水(例えば、増粘機、形成機、層、遠心分離機、プレート及びフレーム、等)の前、スラッジを調節するために使用される化学物質の量が低められ得、そして/又はスラッジの脱水挙動性が活性化される化学物質を伴って又はそれを伴わないで、改良され得る。
第4シナリオにおいては、ペルオキシゲナーゼ活性は、一次及び二次/生物学的スラッジの凝集挙動性を改良するために使用され得る。コロイド間、及びコロイドと大きな凝集体との間の共有架橋の生成を触媒することにより、従来の脱水(例えば、増粘機、形成機、層、遠心分離機、プレート及びフレーム、等)の前、スラッジを調節するために使用される化学物質の量が低められ得、そして/又はスラッジの脱水挙動性が活性化される化学物質を伴って又はそれを伴わないで、改良され得る。
酵素的油処理内へのペルオキシゲナーゼ適用:
石油製品は、エネルギー及び原料の最も重要な源であるが、しかしながら、世界の石油埋蔵量は減少しているので、重質原油及びビチューメン沈殿物は、再生できるエネルギー源の種々の開発に使用されるべきであろう。重質原油は高い粘度であり、そして抽出するには困難であり;さらに、重質原油は、高い量の硫黄、窒素、芳香族化合物及び重金属を含み;それらの化合物は、使用の前、減じるべきである。原油の精製において、生物工学、特にオキシドレダクターゼに基づく技法を使用するためへの種々の可能性ある適用がAyala, M. et al. (Biocatalysis and Biotransformation, 2007, 25:2, 1 14-129により言及されている。種々の態様がさらに下記に記載される。
石油製品は、エネルギー及び原料の最も重要な源であるが、しかしながら、世界の石油埋蔵量は減少しているので、重質原油及びビチューメン沈殿物は、再生できるエネルギー源の種々の開発に使用されるべきであろう。重質原油は高い粘度であり、そして抽出するには困難であり;さらに、重質原油は、高い量の硫黄、窒素、芳香族化合物及び重金属を含み;それらの化合物は、使用の前、減じるべきである。原油の精製において、生物工学、特にオキシドレダクターゼに基づく技法を使用するためへの種々の可能性ある適用がAyala, M. et al. (Biocatalysis and Biotransformation, 2007, 25:2, 1 14-129により言及されている。種々の態様がさらに下記に記載される。
アスファルテンは、N−アルカンに不溶性であるが、しかしトルエンに溶解性である石油の一部として定義される。アスファルテン画分は、高粘度、及びエマルジョン、ポリマー及びコークスを形成する傾向のような所望しない油性質を大部分、担当すると思われる。窒素、酸素及び硫黄へテロ原子が、非−及び複素環式基として存在する。さらに、有意な量のポルフィリン(ペトロポルフィリン)は、ニッケル及びバナジウムを含むことが見出され得る。ペルオキシゲナーゼを用いてのアスファルテンの変性は、広範囲の次の有益な効果を有するであろう:高められた水溶解性、高められた沸点、低い分子間相互作用、低粘度及び改良された生物学的反応性。
従って、ペルオキシゲナーゼは、低い粘度をもたらし、そして溶媒の必要性及びコークスの形成を低める品質向上の前、適用され得る。オキシドレダクターゼ、特にラッカーゼ、フェノールオキシダーゼ、ハロペルオキシダーゼ及びペルオキシダーゼ、又は微生物、特にロードコーカス・エリトロポリス(Rhodococcus erythropolis)又は類似する細菌細胞との組合された又は続く反応がさらに、変性又は分解を増強するであろう。処理は、脱塩の前、脱塩と組合して、又は続く加工、例えば真空蒸留、水処理装置、ハイドロクラッカー、又は流動触媒分解装置による加工の間又はそれに続いて、実施され得る。水又は水相溶性溶媒におけるニ相システムが任意には、適用され得る。
精製された燃料における芳香族化合物の存在は、不完全燃焼及び粒状物質の同時形成を導く。多環式芳香族炭化水素は、それらの発癌性及び突然変異誘発活性のために、実質的な健康危険性であると思われる。ペルオキシゲナーゼによる多環式芳香族炭化水素の処理は、親化合物によりも、より溶解性で且つ有意に低い突然変異誘発性である生成物をもたらす。
バナジウム及びニッケルのような重金属イオンは天然において、300ppm又はそれ以上の程度、Canadian Oil Sandsビチューメンに存在する。それらのイオンは、ビチューメン内のペトロポルフィンと呼ばれる生物マーカーとのキレート化を通して強く維持されることが知られている。金属イオンは、分解及び水処理の間、使用される下流の触媒を害するよう作用することにおいて、ビチューメンの品質向上に対して有害である。石油中の重金属は、2種の他の主要石油を導く。1つは、廃棄物処理問題をもたらす、高濃度の金属酸化物と共に灰の形成である。第2は、選択性及び活性を低める触媒分解の間、触媒の有害化である。現在、これらの問題を軽減するための方法はなく;現在の実施は、多量の触媒を使用することである。
商業的適用はまだ知られていないが、精製産業内である生物工学を用いることが研究されて来た。C. フマゴからのクロロペルオキシダーゼ(CPO)と呼ばれるヘム−ペルオキシダーゼ酵素がペトロポリフィンの酸化開環による金属イオンのキレート化を分解できたことが、Fedorakなどにより、1990年代初期に示されている。続いて、開放される金属イオンが、有機層から水層中に抽出され、ビチューメンから遠のく。1990年代後期において、Torres及びVazquez-Duhaltは、シトクロムc(ペルオキシダーゼ様活性を有する小さなヘムタンパク質)を用いての類似する反応性を示している。
それらの酵素はペトロポリフィリンに対して興味ある活性示したが、それらは大規模な産業適用のための使用を不可能にするいくつかの欠点を有する。最初に、それらの基質(例えば、過酸化水素)の存在下で、酵素自体が酸化され、そして活性を失う。ヘム活性部位は、H2O2により酸化されることが知られており;それらの酵素の半減期は1nMのH2O2において数分の程度である。第2に、酵素発現レベルは非常に低い。
ペルオキシゲナーゼによる油、ビチューメン、アスファルテン又はペトロプロフィリンの処理は、重金属の含有率、特にニッケル及びバナジウムの含有率を有意に減じる。その処理は好ましくは、触媒分解装置への前、いずれかの段階で行われる。
液体炭化水素燃料に関する規制は、連続的に必要とするより低い硫黄含有率である。従来の脱流は、水素化処理の間、実施され、ここでさらに、窒素、酸素及び砒素化合物が減じられるか又は除去される。ペルオキシゲナーゼ処理は、特に続いて蒸留段階が存在する場合、硫黄含有率を有意に低めることができる。その処理は、脱塩の前、脱塩と組合して、又は真空蒸留、水素処理、水素分解又は液体触媒分解のような続く処理の間又はそれに続いて行われ得る。
薬物/化学合成への真菌ペルオキシゲナーゼの適用:
シトクロムP450酵素に類似して、ペルオキシゲナーゼは、種々の化学物質、例えば活性医薬成分及び中間体の化学合成に使用され得、そして特に、ペルオキシゲナーゼは好都合には、光学的に純粋なキラル化合物の合成のために使用され得る。そのような可能なペルオキシゲナーゼ触媒された反応の例は、次のものである:
シトクロムP450酵素に類似して、ペルオキシゲナーゼは、種々の化学物質、例えば活性医薬成分及び中間体の化学合成に使用され得、そして特に、ペルオキシゲナーゼは好都合には、光学的に純粋なキラル化合物の合成のために使用され得る。そのような可能なペルオキシゲナーゼ触媒された反応の例は、次のものである:
・ヒドロコルチゾンへのライヒシュタインSの11β−ヒドロキシル化(アメリカ特許第4353985号)。
・コルチゾンへのプロゲステロンの転換(ステロイド修飾/生成)。
・コンパクチンからのPravastin、すなわち抗−コレステロール薬物の生成(Biotechnol. Lett. 2003, 25, 1827)。
・4−位置でのR−2−フェノキシプロピオン酸のヒドロキシル化。
・コルチゾンへのプロゲステロンの転換(ステロイド修飾/生成)。
・コンパクチンからのPravastin、すなわち抗−コレステロール薬物の生成(Biotechnol. Lett. 2003, 25, 1827)。
・4−位置でのR−2−フェノキシプロピオン酸のヒドロキシル化。
・P450酵素を用いてのリモンからの抗癌薬物ペリリル(perillyl)アルコールの生触媒性生成(Appl. Environ. Microbiol. 2005, 71 , 1737)。
ピリジン、ピロール、ピロリジン、ピペリジン、イミダゾール、チアゾール、モルホリン又はピリミジンのN−酸化された形を含む化合物が特に適切である(Source Refs: J. B. van Beilen, et al., Trends Biotechnol., 2003, 21 , 170. and V.B. Urlacher and S. Eiben, Trends Biotechnol., 2006, 24, 324)。
ピリジン、ピロール、ピロリジン、ピペリジン、イミダゾール、チアゾール、モルホリン又はピリミジンのN−酸化された形を含む化合物が特に適切である(Source Refs: J. B. van Beilen, et al., Trends Biotechnol., 2003, 21 , 170. and V.B. Urlacher and S. Eiben, Trends Biotechnol., 2006, 24, 324)。
洗剤組成物へのペルオキシゲナーゼの適用:
本発明のペルオキシゲナーゼ酵素は、洗剤組成物に添加され得、そして従って、洗剤組成物の成分に成ることができる。
本発明のペルオキシゲナーゼ酵素は、洗剤組成物に添加され得、そして従って、洗剤組成物の成分に成ることができる。
本発明の洗剤組成物は、手動又は機械洗濯用洗剤組成物、例えば染色された布の前処理のために適切な洗濯用添加剤組成物及びすすぎ用布ソフトナー組成物として配合され得、又は一般的な家庭用硬質表面洗浄操作における使用のための洗剤組成物として配合され得、又は手動又は機械皿洗い操作のために配合され得る。
特定の観点においては、本発明は、本発明の酵素を含んで成る洗剤添加剤を提供する。前記洗剤添加剤及び洗剤組成物は、1又は複数の他の酵素、例えばプロテアーゼ、リパーゼ、クチナーゼ、アミラーゼ、カーボヒドラーゼ、セルラーゼ、ペクチナーゼ、マンナナーゼ、アラビナーゼ、ガラクタナーゼ、キシラナーゼ、オキシダーゼ、例えばラッカーゼ及び/又はポロキシダーゼを含んで成ることができる。
一般的に、選択された酵素の性質は、選択された洗剤と適合できるべきであり(すなわち、他の酵素及び非酵素の成分、等とのpH−最適適合性)、そして酵素は効果的な量で存在すべきである。
プロテアーゼ:適切なプロテアーゼは、動物、植物又は微生物起源のものを包含する。微生物起源が好ましい。化学的に修飾された、又はタンパク質構築された変異体が含まれる。プロテアーゼは、セリンプロテアーゼ又は金属プロテアーゼ、好ましくはアルカリ微生物プロテアーゼ又はトリプシン−様プロテアーゼであり得る。アルカリプロテアーゼの例は、スブチリシン、特にバチルスに由来するそれらのもの、例えばスブチリシンNovo、スブチリシンCarlsberg、スブチリシン309、スブチリシン147及びスブチリシン168(WO89/06279号に記載される)である。トリプシン−様プロテアーゼの例は、トリプシン(例えば、ブタ又はウシ起源のもの)、及びWO89/06270号及びWO94/25583号に記載されるフサリウムプロテアーゼである。
有用なプロテアーゼの例は、WO92/19729号、WO98/20115号、WO98/20116号及びWO98/34946号に記載される変異体、特に1又は複数の次の位置での置換を有する変異体である:27, 35, 57, 76, 87, 97, 101, 104, 120, 123, 167, 170, 194, 206, 218, 222, 224, 235及び274−特定の配列及び位置を言及する。
好ましい市販のプロテアーゼ酵素は、AlcalaseTM, SavinaseTM, PrimaseTM, DuralaseTM, EsperaseTM及びKannaseTM (Novo Nordisk A/S), MaxataseTM, MaxacalTM, MaxapemTM, ProperaseTM, PurafectTM, Purafect OxPTM, FN2TM及びFN3TM (Genencor International Inc.) を包含する。
リパーゼ:適切なリパーゼは、細菌又は菌類起源のそれらのものを包含する。化学的に修飾された又はタンパク質構築された変異体が包含される。有用なリパーゼの例は、ヒューミコラ(別名、サーモミセス)、例えばヨーロッパ特許第258068号及び第305216号に記載のようなヒューミコラ・ラウギノサ(T.ラウギノサ)、又はWO96/13580号に記載のようなヒューミコラ・インソレンス、P.アルカリゲネス又はP.プソイドアルカリゲネス(ヨーロッパ特許第218272号)、P.セパシア(ヨーロッパ特許第331376号)、P.スツゼリ(P.stutzeri)(イギリス特許第1,372,034号)、P.フルオレセンス、プソイドモナスsp. SD705株(WO75/06720号及びWO96/27002号)、P.ウイスコンシネンシス(WO96/12012号)からのリパーゼ、バチルスリーパーゼ、例えばB.スブチリス(Dartoisなど. (1993), Biochemica et Biophysica Acta, 1131, 253-360)、B. ステアロサーモフィラス(日本特許64/744992)又はB.プミラス(WO91/16422号)からのリーパーゼを包含する。
他の例は、リパーゼ変異体、例えばWO92/05249号、WO94/01541号、ヨーロッパ特許第407225号、ヨーロッパ特許第206105号、WO95/35381号、WO96/00292号、WO95/30744号、WO94/25576号、WO95/14783号、WO95/22615号、WO97/04079号及びWO97/0720号に記載されるものを包含する。
好ましい市販のリパーゼ酵素は、LipolaseTM 及びLipolase UltraTM (Novo Nordisk A/S) を包含する。
好ましい市販のリパーゼ酵素は、LipolaseTM 及びLipolase UltraTM (Novo Nordisk A/S) を包含する。
アミラーゼ:適切なアミラーゼ(α−及び/又はβ)は、細菌又は菌類起源のそれらのものを包含する。化学的に修飾された又はタンパク質構築された変異体が包含される。アミラーゼは、バチルス、例えばイギリス特許第1,296,839号により詳細に記載される、B.リケニルホルミスの特許株から得られるα−アミラーゼを包含する。
有用なアミラーゼの例は、WO94/02597号、WO94/18314号、WO96/23873号及びWO/43424号に記載される変異体、特に1又は複数の次の位置での置換を有する変異体である:15, 23, 105, 106, 124, 128, 133, 154, 156, 181, 188, 190, 197, 202, 208, 209, 243, 264, 304, 305, 391, 408及び444−特定の配列及び位置を言及する。
市販のアミラーゼは、DuramylTM, TermamaylTM, FungamylTM 及びBAMTM (Novo Nordisk A/S), RapidaseTM 及びPurastarTM (Genencor International Inc.)である。
市販のアミラーゼは、DuramylTM, TermamaylTM, FungamylTM 及びBAMTM (Novo Nordisk A/S), RapidaseTM 及びPurastarTM (Genencor International Inc.)である。
セルラーゼ:適切なセルラーゼは、細菌又は菌類起源のそれらのものを包含する。化学的に修飾された又はタンパク質構築された変異体が包含される。適切なセルラーゼは、バチルス、ヒューミコラ、フサリウム、チエラビア、アクレモニウム属からのセルラーゼ、例えばアメリカ特許第4,435,307号、アメリカ特許第5,648,263号、アメリカ特許第5,691,178号、アメリカ特許第5,776,757号及びWO89/09259号に開示されるヒューミコラ・インソレンス、マイセリオプソラ・サーモフィラ/オキシスポラムから生成される菌類セルラーゼを包含する。
特に適切なセルラーゼは、色彩保護有益性を有するアルカリ又は中性セルラーゼである。そのようなセルラーゼの例は、ヨーロッパ特許第0495257号、ヨーロッパ特許第0531372号、WO96/11262号、WO96/29397号、WO98/08940号に記載されるセルラーゼである。例の例は、WO94/07998号、ヨーロッパ特許第0531315号、アメリカ特許第5,457,046号、アメリカ特許第5,685,593号、アメリカ特許第5,763,254号、WO95/24471号、WO98/12307号及びWO1999/001544号に記載されるそれらのものである。
市販のセルラーゼは、CelluzymeTM 及びCarezymeTM (Novo Nordisk A/S), ClazinaseTM 及びPuradex HATM (Genencor International Inc.) 及びKAC−500 (B)TM (Kao Corporation) を包含する。
ペルオキシダーゼ/オキシダーゼ:適切なペルオキシダーゼ/オキシダーゼは、植物、細菌又は菌類起源のそれらのものを包含する。化学的に修飾された又はタンパク質構築された変異体が包含される。有用なペルオキシダーゼの例は、コプリナス、例えばコプリナス・シネレウス、及びWO93/24618 号、WO95/10602号及びWO98/15257号に記載されるそれらのようなそれらの変異体からのペルオキシダーゼを包含する。
市販のペルオキシダーゼは、GuardzymeTM (Novo Nordisk A/S) を包含する。
市販のペルオキシダーゼは、GuardzymeTM (Novo Nordisk A/S) を包含する。
洗剤酵素は、1又は複数の酵素を含む別々の添加剤を添加することにより、又はそれらの酵素のすべてを含んで成る組合された添加剤を添加することにより洗剤組成物に包含され得る。本発明の洗剤添加剤、すなわち別々の添加剤又は組合された添加剤が、例えば粒質物、液体、スラリー、等として配合され得る。好ましくは洗剤添加剤配合物は、粒質物、特に非−ダスチング粒質物、液体、特に安定された液体又はスラリーである。
非−ダスチング粒質物は、アメリカ特許第4,106,991号及び第4,661,452号に開示のようにして生成され得、そして任意には、当業界において知られている方法により被覆され得る。蝋被覆材料の例は、1000〜20,000の平均モル重量を有するポリ(酸化エチレン)生成物(ポリエチレングリコール、PEG);16〜50の酸化エチレン単位を有する、エトキシル化されたノニルフェノール;12〜20個の炭素原子を有するアルコールを有し、そして15〜80の酸化エチレン単位を有する、エトキシ化された脂肪アルコール;脂肪アルコール、脂肪酸;及び脂肪酸のモノ−、ジ−及びトリグリセリドである。流動層技法による適用のために適切なフィルム形成被覆材料の例は、イギリス特許第1483591号に与えられている。例えば、液体酵素調製物は、確立された方法に従って、ポリオール、例えばプロピレングリコール、糖又は糖アルコール、硫酸又は硼酸を添加することによって、安定化される。保護された酵素は、ヨーロッパ特許第238,216号に開示される方法に従って調製され得る。
本発明の洗剤組成物は、いずれかの便利な形、例えば棒状、錠剤、粉末、顆粒、ペースト又は液体の形で存在することができる。液体洗剤は、水性であり、典型的には、70%までの水及び0〜30%の有機溶媒を含み、又は非水性であり得る。
洗剤組成物は、非イオン性、例えば半−極性及び/又はアニオン性及び/又はカチオン性及び/又は両性イオンであり得る1又は複数の界面活性剤を含んで成る。界面活性剤は典型的には、0.1〜60重量%のレベルで存在する。
洗剤組成物は、非イオン性、例えば半−極性及び/又はアニオン性及び/又はカチオン性及び/又は両性イオンであり得る1又は複数の界面活性剤を含んで成る。界面活性剤は典型的には、0.1〜60重量%のレベルで存在する。
そこに含まれる場合、洗剤は通常、約1%〜約40%のアニオン性界面活性剤、例えば線状アルキルベンゼンスルホネート、α−オレフィンスルホネート、アルキルスルフェート(脂肪酸スルフェート)、アルコールエトキシスルフェート、第二アルカンスルホネート、α−スルホ脂肪酸メチルエステル、アルキル−又はアルケニル琥珀酸又は石鹸を含むであろう。
そこに含まれる場合、界面活性剤は通常、約0.2%〜約40%の非イオン性界面活性剤、例えばアルコールエトキシレート、ノニルフェノールエトキシレート、アルキルポリグリコシド、アルキルジメチルアミンオキシド、エトキシル化された脂肪酸モノエタノールアミド、脂肪酸モノエタノールアミド、ポリヒドロキシアルキル脂肪酸アミド、又はグルコサミンのN−アシルN−アルキル誘導体(“グルコサミド”)を含むであろう。
洗剤は、0〜65%の洗剤ビルダー又は錯生成剤、例えばゼオライト、ジホスフェート、三リン酸、ホスホネート、カーボネート、シトレート、ニトリロ三酢酸、エチレンジアミン四酢酸、ジエチレントリアミン六酢酸、アルキル−又はアルキニル琥珀酸、可溶性シリケート又は層化されたシリケート(例えばHoechstからのSKS−6)を含むことができる。
洗剤は、1又は複数のポリマーを含んで成る。例としては、カルボキシメチルセルロース、ポリ(ビニルピロリドン)、ポリ(エチレングリコール)、ポリ(ビニルアルコール)、ポリ(ビニルピリジン−N−オキシド)、ポリ(ビニルイミダゾール)、ポリカルボキシレート(例えばポリアクリレート、マレイン酸/アクリル酸コポリマー及びラウリルメタクリレート/アクリル酸コポリマーを含んで成る。
洗剤は、H2O2源を含んで成る漂白システム、例えば過酸形成漂白活性化剤、例えばテトラアセチルエチレンジアミン又はノナノイルオキシベンゼンスルホネートと共に組合され得る過硼酸塩又は過炭酸塩を含むことができる。他方では、漂白システムは、例えばアミド、イミド又はスルホン型のペルオキシ酸を含むことができる。
本発明の洗剤組成物の酵素は、従来の安定剤、例えばポリオール、例えばプロピレングリコール又はグリセロール、糖又は糖アルコール、乳酸、硼酸又は硼酸誘導体、例えば芳香族硼酸エステル又はフェニル硼素酸誘導体、例えば4−ホルミルフェニル硼素酸を用いて安定化され得、そして前記組成物は、例えばWO92/19709号及びWO92/19708号に記載のようにして配合され得る。
洗剤はまた、他の従来の洗剤組成物、例えば布コンディショナー、例えばクレー、泡増強剤、石鹸泡抑制剤、抗腐蝕剤、土壌懸濁剤、抗−土壌再沈着剤、染料、殺菌剤、蛍光増白剤、ヒドロトロープ、曇りインヒビター、又は香料を含むことができる。
洗剤組成物においては、いずれかの酵素、特に本発明の酵素は、洗浄液体1L当たり0.01−100mgの酵素タンパク質、好ましくは洗浄液体1L当たり0.05−5mgの酵素タンパク質、特に洗浄液体1L当たり0.1−1mgの酵素タンパク質に対応する量で添加され得ることが、現在企画される。
洗剤組成物においては、いずれかの酵素、特に本発明の酵素は、洗浄液体1L当たり0.01−100mgの酵素タンパク質、好ましくは洗浄液体1L当たり0.05−5mgの酵素タンパク質、特に洗浄液体1L当たり0.1−1mgの酵素タンパク質に対応する量で添加され得ることが、現在企画される。
本発明の酵素はさらに、WO97/07202号(引例として本明細書組み込まれる)に開示される洗剤配合物に導入され得る。
本明細書に記載される発明は、本明細書に開示される特許の態様により範囲を限定されるものではない。何故ならば、それらの態様は本発明のいくつかの観点を例示するものである。いずれかの同等の態様が本発明の範囲内で意図される。実際、本明細書に示され、そして記載されるそれらの修飾の他に、本発明の種々の修飾は、前述の記載から当業者に明らかになるであろう。そのような修飾はまた本発明の範囲内にある。抵触の場合、定義を包含する本発明の開示は調整するであろう。
本明細書に記載される発明は、本明細書に開示される特許の態様により範囲を限定されるものではない。何故ならば、それらの態様は本発明のいくつかの観点を例示するものである。いずれかの同等の態様が本発明の範囲内で意図される。実際、本明細書に示され、そして記載されるそれらの修飾の他に、本発明の種々の修飾は、前述の記載から当業者に明らかになるであろう。そのような修飾はまた本発明の範囲内にある。抵触の場合、定義を包含する本発明の開示は調整するであろう。
例1:A. アエゲリタ及びC. ラジアンスからのペルオキシゲナーゼ遺伝子のクローニング:
酵素の培養条件、活性測定及び精製は、アグロシベ・アエゲリタペルオキシダーゼ(Ullrich et al., 2004, Appl. Env. Microbiol. 70(8): 4575-4581)及びコプリナス・ラジアンスペルオキシダーゼ(Anh et al., 2007, Appl Env Microbiol 73(17): 5477-5485)について、前に記載されている。
酵素の培養条件、活性測定及び精製は、アグロシベ・アエゲリタペルオキシダーゼ(Ullrich et al., 2004, Appl. Env. Microbiol. 70(8): 4575-4581)及びコプリナス・ラジアンスペルオキシダーゼ(Anh et al., 2007, Appl Env Microbiol 73(17): 5477-5485)について、前に記載されている。
核酸の単離及びcDNA合成:
コプリナス・ラジアンス(菌株DSMZ888, 培養日12)及びアグロシベ・アエゲリタ(菌株TM-A1-K, 培養日16)の菌糸を、振盪培養物(上記の特定の増殖条件)からの濾過により得た。続く凍結乾燥(Alpha 2-4凍結乾燥機、Christ, Osterode, Germany)の後、ゲノムDNAを、前に記載されるプロトコール(Nikolcheva and Baerlocher, 2002)を用いて、単離した。Trizol試薬(Invitrogen, Karlsruhe, Germany)を用いて、全RNAを単離し、これを-80℃で貯蔵した。
コプリナス・ラジアンス(菌株DSMZ888, 培養日12)及びアグロシベ・アエゲリタ(菌株TM-A1-K, 培養日16)の菌糸を、振盪培養物(上記の特定の増殖条件)からの濾過により得た。続く凍結乾燥(Alpha 2-4凍結乾燥機、Christ, Osterode, Germany)の後、ゲノムDNAを、前に記載されるプロトコール(Nikolcheva and Baerlocher, 2002)を用いて、単離した。Trizol試薬(Invitrogen, Karlsruhe, Germany)を用いて、全RNAを単離し、これを-80℃で貯蔵した。
cDNA合成のために、全RNA(1.0μg)を、ポリT−アンカープライマー(コプリナス・アジアンスの場合、ポリT−アンカー2−プライマー)を用いることにより感作した。その後、全mRNAを、"RevertAidTM H Minus M-MuLV"逆転写酵素(Fermentas, St. Leon-Rot, Germany)を用いることにより、3’末端に付加されるアンカー配列によりcDNAに逆転写し;さらに、反応混合物に1μlのTS−Short−プライマー(10μM)を添加するこにより、アンカー配列を、Matzなど. (1999)のプロトコールを用いて、前記cDNAの5’末端に付加した。
PCR条件:
PCR(ポリメラーゼ鎖反応)増幅のために、"MasterCycler EP Gradient S"グラジエントサイクラー(Eppendorf, Hamburg, Germany)を適用した。すべてのプライマーは、MWG Biotech (Ebersberg, Germany)から得られた。cDNA合成、すなわち3’RACE(cDNA末端の急速増幅)及び5’RACE実験のために使用されるプライマーが、表1に列挙される。変性プライマーは表2に列挙される。AaP遺伝子のための特異的プライマーが表3に列挙される。ネステットPCR法を、1:100に希釈されたPCR生成物により実施した。
PCR(ポリメラーゼ鎖反応)増幅のために、"MasterCycler EP Gradient S"グラジエントサイクラー(Eppendorf, Hamburg, Germany)を適用した。すべてのプライマーは、MWG Biotech (Ebersberg, Germany)から得られた。cDNA合成、すなわち3’RACE(cDNA末端の急速増幅)及び5’RACE実験のために使用されるプライマーが、表1に列挙される。変性プライマーは表2に列挙される。AaP遺伝子のための特異的プライマーが表3に列挙される。ネステットPCR法を、1:100に希釈されたPCR生成物により実施した。

PCR反応(25μl)は、10μlのPCR Master Mix (HotMaster MixTM, 2.5-倍に 濃縮された; 5Prime, Hamburg, Germany)、特異的プライマーの場合、10μMの源液からの、及び変性プライマーに関しては、100μMの原液からの1μlの個々のプライマー、1μlのcDNA及びPCRグレードの水を含んだ。PCRを次のようにして開始した:95℃で3分間の初期変性、95℃で45秒間の続く変性(35サイクル)、52.7℃(変性されたプライマーの場合)又は“4+2規則”に従っての温度(Rychlik and Rhoads (1989)、特異的プライマーの場合)での45秒間のアニーリング、及び72℃で1.5分間の延長、最終延長は、72℃で10分間を要した。
得られるPCR生成物を、精製し(SureCleanTM, Bioline, Luckenwalde, Germany)、そしてクローン化した。
クローニング、配列決定及び配列分析:
pSTBlue-1 AccepTorTM Vector Kit (Merck (Novagen), Darmstadt, Germany)によるPCRフラグメントのdU/A−クローニングに由来するプラスミドを、コロニーPCR(Sambrook and Maniatis, 1989)により検証し、そしていくつかの独立したクローンを、配列決定のために使用した。
pSTBlue-1 AccepTorTM Vector Kit (Merck (Novagen), Darmstadt, Germany)によるPCRフラグメントのdU/A−クローニングに由来するプラスミドを、コロニーPCR(Sambrook and Maniatis, 1989)により検証し、そしていくつかの独立したクローンを、配列決定のために使用した。
配列決定を、AutoRead SequencingTM Kit (both GE Healthcare, Munich, Germany)と組合して、ALFexpressll装置上で実施した。ソフトウェアBioEdit7.0を、配列分析及び複数の一列整列のために使用した(Hall, 1999, Nucleic Acids Symp Ser 41 , 95-98)。
コプリナス・ラジアンス:N−末端及び1つの内部ペプチドフラグメントのペプチド配列の知識に基づいて、変性されたプライマーを、コプリナス・ラジアンス(菌株DMSZ888)におけるハロペルオキシダーゼ遺伝子のフラグメントを部分的に増幅するためにcDNAに対して使用した。変性されたプライマーCop1-For and Cop6-Rev (約700 bpのサイズ)の適用に由来する初期PCR生成物を精製し、クローン化し、1つのクローンを配列決定し(配列番号15)、そして基本的な局部一列整列調査用具(BLAST)研究により、CPO配列に対する相同性として同定した。cDNAの3’末端を得るために、cDNA末端の急速増幅(3’RACE)を実施した。AP2−プライマーを、変性されたプライマーCop5-Forと組合して使用し、cDNAからフラグメント(約500bp)を増幅し、これをクローン化し、そしてその後、完全に配列決定した(配列番号17)(3種の独立したクローン)。
アグロシベ・アエゲリタ:N−末端及び5つの内部ペプチドフラグメントのペプチド配列の知識に基づいて、変性されたプライマーを、アグロシベ・アエゲリタ(菌株TM-A1-K)におけるハロペルオキシダーゼ遺伝子のフラグメントを増幅するためにcDNAに対して使用した。変性プライマーAap1-For及びAap6-Rev(約880bpのサイズ)の適用に由来する1つの初期PCR生成物を得た。2種の3’RACE-PCR生成物を、それぞれ、AaP1-For及び APプライマー(約1200bp)によるPCRを用いることにより、及びAaP4-For及びAPプライマー(ネステッドPCR、約650bp)によるPCRを用いることにより生成した。すべての3種のフラグメントを、アガロースゲル上で精製し、そしてクローン化した。いくつかの独立したクローンを十分に配列決定し;すべての配列を合成配列に対してアセンブリーした。
合成配列を、基本的局部一列整列調査用具(BLAST)研究により、CPO配列に対する相同性として同定した。5’RACEを、特異的プライマー混合物SO-Mix(90%のヒール−特異的プライマー及び10%のヒール−キャリヤープライマーを含む、10μM)及び変性プライマーAaP4−Revにより実施した。次に、希釈されたPCR生成物を、SO−混合物及び変性プライマーAaP2−Revと共にネステッドPCRに使用した。約350bpの得られるバンドをゲルから切除し、精製し、そしてクローン化した。いくつかの独立したクローンを十分に配列決定した。
2種の異なっているが、しかし相同の配列を発見した。1つの配列は、すでに知られている合成配列とオーバーラップし、そしてAaP1遺伝子のcDNA配列を完結した。このデータに基づいて、特異的プライマーを、AaP1遺伝子及びAaP2遺伝子の両者のために企画した。
プライマー組合せ1AaP-For1 及び 1AaP-Rev4によるcDNAレベルでのPCRの実施は、AaP1遺伝子の完全に十分な長さのcDNA配列フラグメントをもたらした。このフラグメントをクローン化し、そして1つのクローンを完全に配列決定した(配列番号1)。このクローンを、受託番号DSM21289を有するEscherichia coli NNO49991として、2008年3月14日、DSMZに寄託した。
cDNAレベルでのAaP2遺伝子の完結のために、3’RACEを実施した:プライマー組合せ2AaP-For1 及びAPプライマーによるPCRは、約1300bpの長さのフラグメントをもたらした。このフラグメントをまたクローン化し、2種のクローンを十分に配列決定し、そしてAaP2遺伝子の完全なcDNA配列(配列番号2)を示した。このクローンを、受託番号DSM21290を有するEscherichia coli NN049992として、2008年3月14日、DSMZに寄託した。
cDNA配列の完結の後、特異的プライマーを、AaP遺伝子のゲノムフラグメントを増幅するためにPCRに使用した。プライマー組合せ1AaP-For2 及び 1AaP-Rev4を用いて、ゲノムDNA(約1400bp)からのAaP1の遺伝子領域を増幅し、前記領域はシグナルペプチドを有さない成熟タンパク質をコードし、そして完全な3’UTRもまた含んで成る。プライマー組合せ2AaP-For1及び2AaP-Rev2を用いて、ゲノムDNA(約1500bp)からのAaP2遺伝子の完全なCDS及び3’UTRを増幅した。両PCR生成物を精製し、クローン化し、そして少なくとも2種の独立したクローンを十分に配列決定した。
例2:真菌ペルオキシゲナーゼに特有なアミノ酸モチーフ:
本発明者は、AaP1及びAaP2の十分な長さのペルオキシゲナーゼアミノ酸配列を分析し、そしてそれらが、成熟ペプチド配列が2つのドメインを含んで成るものとして見られ得ることにおいて、ユニークであることを見出した。
本発明者は、AaP1及びAaP2の十分な長さのペルオキシゲナーゼアミノ酸配列を分析し、そしてそれらが、成熟ペプチド配列が2つのドメインを含んで成るものとして見られ得ることにおいて、ユニークであることを見出した。
AaP1アミノ酸配列(配列番号2)の最初の半分は、クロロペルオキシダーゼCPOと十分に最もらしく一列整列する。第2に、AaP1ペプチドのC末端半分は、ゲノム配列決定を通して同定されるラカリア(Laccaria)及びコプリナス・シネレウスの推定上の読み取り枠配列を除いて、データベースにおけるいずれのアミノ酸配列とも相同性を共有しない。
N末端の半分が既知クロロペルオキシダーゼに対する類似性を共有するが、ところがC末端部分は共有しない2種のドメイン構造体がこの種類のペルオキシゲナーゼの明白な特徴を有することが非常に有望であろう。
本発明者は、多くの類似する配列と、本明細書において推定されるアミノ酸配列とを図4A−Dにおいて一列整列し、そしていくつかの同一の保存されたモチーフを同定した。モチーフ調査のためのパターンは、特徴間の終止符“.”及びハイフォン“−”は任意である差異を伴って、PROSITEデータベースに使用されるパターン型に基づかれる。PROSITE資料からのPROSITEパターンの定義は次の通りである:
本発明者は、多くの類似する配列と、本明細書において推定されるアミノ酸配列とを図4A−Dにおいて一列整列し、そしていくつかの同一の保存されたモチーフを同定した。モチーフ調査のためのパターンは、特徴間の終止符“.”及びハイフォン“−”は任意である差異を伴って、PROSITEデータベースに使用されるパターン型に基づかれる。PROSITE資料からのPROSITEパターンの定義は次の通りである:
・アミノ酸についての標準IUPAC1文字コードが使用される。
・記号“x”は、いずれのアミノ酸でも許容できる位置に関して使用される。
・不明瞭性は、四角括弧“[ ]”内に、与えられる位置での許容できるアミノ酸を列挙することにより示される。例えば、[ALT]はAla又はLeu又はThrを表す。
・不明瞭性はまた、1対の大括弧“{ }”内に列挙することにより示され、与えられる位置での許容できないアミノ酸を示す。例えば、{AM}は、Ala及びMetを除くいずれかのアミノ酸を示す。
・記号“x”は、いずれのアミノ酸でも許容できる位置に関して使用される。
・不明瞭性は、四角括弧“[ ]”内に、与えられる位置での許容できるアミノ酸を列挙することにより示される。例えば、[ALT]はAla又はLeu又はThrを表す。
・不明瞭性はまた、1対の大括弧“{ }”内に列挙することにより示され、与えられる位置での許容できないアミノ酸を示す。例えば、{AM}は、Ala及びMetを除くいずれかのアミノ酸を示す。
・パターンにおける個々の要素は、“−”により、その隣接体から分離される。(patmatdb 及び fuzzproにおいては任意である)。
・パターン中の要素の反復は、括弧内の数値又は数範囲を有するその要素に続くことにより示され得る。例:x(3)はx−x−xに対応し、x(2,4)はx−x又はx−x−x又はx−x−x−xに対応する。
・パターン中の要素の反復は、括弧内の数値又は数範囲を有するその要素に続くことにより示され得る。例:x(3)はx−x−xに対応し、x(2,4)はx−x又はx−x−x又はx−x−x−xに対応する。
・パターンが配列のN−又はC−末端のいずれかに制限される場合、そのパターンは“<”の記号で出発するか、又はそれぞれ、“>”の記号で終結する。
・終止符はパターンの最後である。(patmatdb 及び fuzzproにおいては任意である)。
・終止符はパターンの最後である。(patmatdb 及び fuzzproにおいては任意である)。
従来のクロロペルオキシダーゼを排除するために、本発明者は、一列整列されたペルオキシゲナーゼタンパク質のC末端半分側への保存されたモチーフについての調査を限定した。本発明者は、ペルオキシゲナーゼを見出すために非常に有用なものとして次の保存されたモチーフを同定した:
モチーフI: [FL]XX[YF]S[AN]X[FHY]G[GN]GX[YF]N (配列番号40)
モチーフII: G[GN]GX[YF]NXX[VA]AX[EH][LF]R (配列番号41 )
モチーフIII: RXXRI[QE][DEQ]S[IM]ATN (配列番号42)
モチーフIV: S[IM]ATN[PG][EQN][FM][SDN][FL] (配列番号43)
モチーフV: P[PDK][DG]F[HFW]R[AP] (配列番号44)
モチーフVl: [TI]XXXLYPNP[TK][GV] (配列番号45)。
モチーフI: [FL]XX[YF]S[AN]X[FHY]G[GN]GX[YF]N (配列番号40)
モチーフII: G[GN]GX[YF]NXX[VA]AX[EH][LF]R (配列番号41 )
モチーフIII: RXXRI[QE][DEQ]S[IM]ATN (配列番号42)
モチーフIV: S[IM]ATN[PG][EQN][FM][SDN][FL] (配列番号43)
モチーフV: P[PDK][DG]F[HFW]R[AP] (配列番号44)
モチーフVl: [TI]XXXLYPNP[TK][GV] (配列番号45)。
そのようなモチーフ又はプロフィールが、新規真菌ペルオキシゲナーゼの同定のために、調査プログラム、例えばFuzzproに入力され得る(Fuzzproは、Alan Bleasby, European Bioinformatics Institute, Wellcome Trust Genome Campus, Hinxton, Cambridge CB10 1 SD, UKにより書かれた)。Fuzzproは、EMBOSSパッケージ(EMBOSS: The European Molecular Biology Open Software Suite (2000), Rice, P. Longden, I. and Bleasby, A. Trends in Genetics 16, (6) pp276-277)の一部である。
表4に示される%同一性は、配列列挙に列挙されるペルオキシゲナーゼアミノ酸配列の“すべてに対するすべて(all against all)”の一列整列に基づいて計算された。マトリックスにおける横列i及び縦列jへの入力は、(一列整列における合計長さog−一列整列におけるギャップの合計長さ)により割算された、配列iと配列jとの間の一列整列における正確な適合数として計算される。個々の一列整列は、EMBOSSパッケージ (http://www.emboss.org) バージョン2.8.0からのNeedleプログラムを用いて行われる。
プログラムNeedleは、Needleman, S. B. and Wunsch, C. D. (J. Mol. Biol., 1970, 48: 443-453); and Kruskal, J. B. (1983) An overview of sequence comparison In D.Sankoff and J. B. Kruskal, (ed.), Time warps, string edits and macromolecules: the theory and practice of sequence comparison, pp. 1-44 Addison Wesleyに記載される全体的一列整列アルゴリズムを実施する。一列整列は、次のパラメーターを使用した:
ギャップ開始ペナルティー:10.00
ギャップ延長ペナルティー:0.50
置換マトリックス:BLOSUM62
ギャップ延長ペナルティー:0.50
置換マトリックス:BLOSUM62
例3:アスペルギラス組換え発現宿主の構成:
AaP1及びAaP2の全読取り枠をコードするcDNA配列を、それぞれ配列番号1及び3として列挙する。PCRプライマーを、終結コドンまで、ATG開始コドンから全読取り枠を増幅するよう企画した。HindIII −BamHI切断されたpDau109アスペルギラス発現ベクターのためのクローニング部位の境界に対して相同の15個の塩基対の5’側配列を有するプライマーを合成した。pDau109は、引用により本明細書に組み込まれる、WO2005/042735号に開示される。従って、プライマーは2つの領域から成り、1つの領域はペルオキシゲナーゼに対して特異的であり、そして50℃又はそれ以上のおおよそのアニーリング温度及び制限酵素境界で発現プラスミドに対して相同の15個の塩基対を有する。
AaP1及びAaP2の全読取り枠をコードするcDNA配列を、それぞれ配列番号1及び3として列挙する。PCRプライマーを、終結コドンまで、ATG開始コドンから全読取り枠を増幅するよう企画した。HindIII −BamHI切断されたpDau109アスペルギラス発現ベクターのためのクローニング部位の境界に対して相同の15個の塩基対の5’側配列を有するプライマーを合成した。pDau109は、引用により本明細書に組み込まれる、WO2005/042735号に開示される。従って、プライマーは2つの領域から成り、1つの領域はペルオキシゲナーゼに対して特異的であり、そして50℃又はそれ以上のおおよそのアニーリング温度及び制限酵素境界で発現プラスミドに対して相同の15個の塩基対を有する。
プラスミドpDau109をBamHI及びHindIII により二重消化し、そしてベクターを、アガロースゲル電気泳動により、及びIllustraTM DNA及びゲルバンド精製キット(GE Healthcare)の使用により、スタッファーフラグメントから精製した。プライマーは下記に示される:
プライマーAaP1F: 5' acacaactggggatccaccatgaaatacttcagcctgttc (配列番号46)
プライマーAaP1R: 5' agatctcgagaagcttaatctcgcccgtacgggaat (配列番号47)
プライマーAaP2F: 5' acacaactggggatccaccatgaaatattttcccctgttcc (配列番号48)
プライマーAaP2R: 5' agatctcgagaagcttaatctcgcccgtatgggaag (配列番号49)。
プライマーAaP1F: 5' acacaactggggatccaccatgaaatacttcagcctgttc (配列番号46)
プライマーAaP1R: 5' agatctcgagaagcttaatctcgcccgtacgggaat (配列番号47)
プライマーAaP2F: 5' acacaactggggatccaccatgaaatattttcccctgttcc (配列番号48)
プライマーAaP2R: 5' agatctcgagaagcttaatctcgcccgtatgggaag (配列番号49)。
プライマーの下線部分は、ベクターにおけるクローニング部位をオーバーラップするよう企画され、そしてInFusionTMクローニングのために、後で必要とされる。
発現力セットを生成するために使用されるPCR反応を、次の通りにして実施した:
Phusion Hot StartTM 高適合性DNAポリメラーゼ(F-540, New England Biolabs)システムを用いて、cDNAプラスミドから発現カセットを増幅した。GCに富んでいる鋳型のための緩衝液を、標準の緩衝液の代わり使用した。MJ Research PTC-200 DNAエンジンを用いて、PCR反応も実施した。
次の条件を用いた:
発現力セットを生成するために使用されるPCR反応を、次の通りにして実施した:
Phusion Hot StartTM 高適合性DNAポリメラーゼ(F-540, New England Biolabs)システムを用いて、cDNAプラスミドから発現カセットを増幅した。GCに富んでいる鋳型のための緩衝液を、標準の緩衝液の代わり使用した。MJ Research PTC-200 DNAエンジンを用いて、PCR反応も実施した。
次の条件を用いた:
GC5×緩衝液 10μl
20mMのdNTP 1μl
プライマーF 1μl
プライマーR 1μl
DNA鋳型10ng 1μl
dH2O 35.5μl
Phusion Hot (2μ/μl) 0.5μl
20mMのdNTP 1μl
プライマーF 1μl
プライマーR 1μl
DNA鋳型10ng 1μl
dH2O 35.5μl
Phusion Hot (2μ/μl) 0.5μl
PCRプログラム:
95℃、30秒
次での25サイクル:
98℃ 10秒
50℃ 20秒
72℃ 30秒
72℃で10分間の最終延長。
95℃、30秒
次での25サイクル:
98℃ 10秒
50℃ 20秒
72℃ 30秒
72℃で10分間の最終延長。
PCRプログラムが終結した後、反応を10℃に冷却した。25μlの個々のPCR生成物を、1%アガロースTBEゲル上で実施し、そして単一PCRバンドを、Illustra DNA及びゲルバンド精製キット(GE Healthcare)を用いて精製した。精製されたPCR生成物はクローニングのために準備ができた。クローニングのためのInFusionTMシステムを、調製されたベクター(BD Biosciences)中へのフラグメントのクローニングのために使用した。クローニング方法は、InFusionTM 取り扱い説明書に記載のようにして正確に従った。処理されたプラスミド及び挿入体を用いて、前記方法に従って、InFusionTM Blue E. コリ細胞を形質転換し、そして50mg/lのアンピシリンを有するLB上にプレートした。
37℃で一晩のインキュベーションの後、コロニーは、LBアンピシリンプレート上での選択下で増殖することが見られた。AaP1構造体の10のコロニー及びAaP2構造体の10のコロニーを、50mg/mlのアンピシリンを有するLB液体において培養し、そしてプラスミドをJETQUICKTM Plasmid Purification Spin Kit 方法 (Genomed)に従って単離した。
単離されたプラスミドを、PCR誤差を有さなかった代表的プラスミド発現クローンを決定するために、ベクタープライマーにより配列決定した。1つの誤差を有さないAaP1クローン及び1つの誤差を有さないAaP2のクローンを、さらに研究するために選択した:
NP003506: Aap1ペルオキシゲナーゼ
NP003507: Aap2ペルオキシゲナーゼ。
NP003506: Aap1ペルオキシゲナーゼ
NP003507: Aap2ペルオキシゲナーゼ。
次に、プラスミドDNAを、JETSTAR 2.0 Plasmid Mini/Midi/Maxi- プロトコール (Genomed)を用いて単離する。このようにして精製されたプラスミドDNAを用いて、引用により本明細書に組み込まれるWO2005/042735号(P.34-35)の方法に従って、標準の菌類発現宿主、例えばアスペルギラス・オリザエを形質転換した。次に、SDS PAGE分析により判断される場合、組換えAaPタンパク質を生成できるアスペルギラス形質転換体を、小さな(200ml)又は非常に大きな(15m3以上)タンクにおいて発酵し、組換え生成された酵素の続く濾過、濃縮及び/又は精製のために、十分な培養物液体を生成した。
例4:ラッカリア・ビカラー(Laccaria bicolor)ペルオキシゲナーゼのクローニング:
適切な発現カセットを、例えば前のセクションに記載されるようにして、InFusionTMクローニングのために企画されたプライマーを用いて、ゲノムL. ビカラーDNA(配列番号5)又はそれからのcDNAのいずれかから得た。完全な読取り枠を増幅するよう設定され、そしてpDau109における発現のために適切なプライマーは次の通りである:
前方向プライマー: 5' acacaactggggatccaccatggctcgccttactttcct (配列番号50)
逆方向プライマー: 5' agatctcgagaagcttactttccataagggaagatctg (配列番号51)。
適切な発現カセットを、例えば前のセクションに記載されるようにして、InFusionTMクローニングのために企画されたプライマーを用いて、ゲノムL. ビカラーDNA(配列番号5)又はそれからのcDNAのいずれかから得た。完全な読取り枠を増幅するよう設定され、そしてpDau109における発現のために適切なプライマーは次の通りである:
前方向プライマー: 5' acacaactggggatccaccatggctcgccttactttcct (配列番号50)
逆方向プライマー: 5' agatctcgagaagcttactttccataagggaagatctg (配列番号51)。
下線の配列は、上記に詳細に説明されたInFusionTMクローニング方法のために必要とされるベクター配列を表す。得られる1167bpのフラグメントは、BamHI-HindIII により切断されたpDau109ベクターとの15bpのオーバーラップを有するであろう。
例えばアスペルギラス・オリザエにおける組換え発現を、AaP1及びAaP2酵素について上記に記載されるようにして実施する。
例えばアスペルギラス・オリザエにおける組換え発現を、AaP1及びAaP2酵素について上記に記載されるようにして実施する。
例5:コプリナス・シネレウスペルオキシゲナーゼのクローニング:
適切な発現カセットを、例えば前のセクションに記載されるようにして、InFusionTMクローニングのために企画されたプライマーを用いて、ゲノムコプリナス・シネレウスDNA又はそれからのcDNA(配列番号7,9、11、13又は15)のいずれかから得た。1つのペルオキシゲナーゼ(配列番号8)の完全な読取り枠を増幅するよう設定され、そしてpDau109における発現のために適切なプライマーは次の通りである:
前方向プライマー: 5' acacaactggggatccaccatgatctcgacctcgaagca (配列番号52)
逆方向プライマー: 5' agatctcgagaagcttaatcactcttgccccaggg (配列番号53)。
適切な発現カセットを、例えば前のセクションに記載されるようにして、InFusionTMクローニングのために企画されたプライマーを用いて、ゲノムコプリナス・シネレウスDNA又はそれからのcDNA(配列番号7,9、11、13又は15)のいずれかから得た。1つのペルオキシゲナーゼ(配列番号8)の完全な読取り枠を増幅するよう設定され、そしてpDau109における発現のために適切なプライマーは次の通りである:
前方向プライマー: 5' acacaactggggatccaccatgatctcgacctcgaagca (配列番号52)
逆方向プライマー: 5' agatctcgagaagcttaatcactcttgccccaggg (配列番号53)。
下線の配列は、上記に詳細に説明されたInFusionTMクローニング方法のために必要とされるベクター配列を表す。得られるフラグメントは、BamHI-HindIII により切断されたpDau109ベクターとの15bpのオーバーラップを有するであろう。
1つのペルオキシゲナーゼ(配列番号10)の完全な読取り枠を増幅するよう設定され、そしてpDau109における発現のために適切なプライマーは次の通りである:
前方向プライマー: 5' acacaactggggatccaccatggtttcgtgcaagctcc (配列番号54)
逆方向プライマー: 5' agatctcgagaagcttacagtgtaccatacggtttca (配列番号55)。
1つのペルオキシゲナーゼ(配列番号10)の完全な読取り枠を増幅するよう設定され、そしてpDau109における発現のために適切なプライマーは次の通りである:
前方向プライマー: 5' acacaactggggatccaccatggtttcgtgcaagctcc (配列番号54)
逆方向プライマー: 5' agatctcgagaagcttacagtgtaccatacggtttca (配列番号55)。
下線の配列は、上記に詳細に説明されたInFusionTMクローニング方法のために必要とされるベクター配列を表す。得られるフラグメントは、BamHI-HindIII により切断されたpDau109ベクターとの15bpのオーバーラップを有するであろう。
1つのペルオキシゲナーゼ(配列番号12)の完全な読取り枠を増幅するよう設定され、そしてpDau109における発現のために適切なプライマーは次の通りである:
前方向プライマー: 5' acacaactggggatccaccatgaacggtctgttcgcca (配列番号56)
逆方向プライマー: 5' agatctcgagaagcttagttacgtccgtaggggaac (配列番号57)。
1つのペルオキシゲナーゼ(配列番号12)の完全な読取り枠を増幅するよう設定され、そしてpDau109における発現のために適切なプライマーは次の通りである:
前方向プライマー: 5' acacaactggggatccaccatgaacggtctgttcgcca (配列番号56)
逆方向プライマー: 5' agatctcgagaagcttagttacgtccgtaggggaac (配列番号57)。
下線の配列は、上記に詳細に説明されたInFusionTMクローニング方法のために必要とされるベクター配列を表す。得られるフラグメントは、BamHI-HindIII により切断されたpDau109ベクターとの15bpのオーバーラップを有するであろう。
1つのペルオキシゲナーゼ(配列番号14)の完全な読取り枠を増幅するよう設定され、そしてpDau109における発現のために適切なプライマーは次の通りである:
前方向プライマー: 5' acacaactggggatccaccatgctcaaaccgcgtgttc (配列番号58)
逆方向プライマー: 5' agatctcgagaagcttaatcgtgtccgtaagggaaaa (配列番号59)。
1つのペルオキシゲナーゼ(配列番号14)の完全な読取り枠を増幅するよう設定され、そしてpDau109における発現のために適切なプライマーは次の通りである:
前方向プライマー: 5' acacaactggggatccaccatgctcaaaccgcgtgttc (配列番号58)
逆方向プライマー: 5' agatctcgagaagcttaatcgtgtccgtaagggaaaa (配列番号59)。
下線の配列は、上記に詳細に説明されたInFusionTMクローニング方法のために必要とされるベクター配列を表す。得られるフラグメントは、BamHI-HindIII により切断されたpDau109ベクターとの15bpのオーバーラップを有するであろう。
例えば、上記列挙されるコプリナス ペルオキシゲナーゼの個々のアスペルギラス・オリザエにおける組換え発現を、AaP1及びAaP2酵素についての前のセクションに記載されるようにして、実施する。
例えば、上記列挙されるコプリナス ペルオキシゲナーゼの個々のアスペルギラス・オリザエにおける組換え発現を、AaP1及びAaP2酵素についての前のセクションに記載されるようにして、実施する。
例6:AaP1酵素によるピリジンのピリジンN−酸化物への転換:
2mMのピリジンを、リン酸カリウム緩衝水溶液(20mM、pH=7.0)に溶解し、そして密閉されたガラス容器において24℃で、2mMのH2O2(20×100μM)及び2単位のアグロシベ・アエゲリタAaP1ペルオキシダーゼ(ベラトリルアルコールのベラトリルアルデヒドへの酸化に基づく単位:Ullrich et al., 2004, Appl. Environ. Microbiol: 70, 4575-81)と共に、1mlの合計体積で撹拌する。反応時間は、合計120分であった(25mMのNaOHとの反応による急冷)。
2mMのピリジンを、リン酸カリウム緩衝水溶液(20mM、pH=7.0)に溶解し、そして密閉されたガラス容器において24℃で、2mMのH2O2(20×100μM)及び2単位のアグロシベ・アエゲリタAaP1ペルオキシダーゼ(ベラトリルアルコールのベラトリルアルデヒドへの酸化に基づく単位:Ullrich et al., 2004, Appl. Environ. Microbiol: 70, 4575-81)と共に、1mlの合計体積で撹拌する。反応時間は、合計120分であった(25mMのNaOHとの反応による急冷)。
この反応から検出される生成物(収率25%)は、保持時間、及びUV及び質量スペクトルを通して、純正標準(Fluka)に対して、独占的にピリジンN−酸化物であった。クロマトグラフィー分離及び生成物同定を、特定のカラム(Phenomex synergi 4 microns Fusion-RP 8OA, 150 x 2 mm)及びAgilent LC-MS-DADシステムを用いてもたらした。
生物学的材料の寄託:
次の生物学的材料を、ブダペスト条約下で、DSMZ(Deutsche Sammlung von Mikroorganismen und Zellkulturen GmbH)に寄託し、そして次の受託番号を得た。2種のE. コリ クローンは、それぞれ、配列番号1/2及び3/4で示されるアグロシベ・アエゲリタTM-A1-KのAaP1及びAaP2ペルオキシゲナーゼ酵素をコードするcDNA遺伝子を含んで成る標準プラスミドをそれぞれ含む。
次の生物学的材料を、ブダペスト条約下で、DSMZ(Deutsche Sammlung von Mikroorganismen und Zellkulturen GmbH)に寄託し、そして次の受託番号を得た。2種のE. コリ クローンは、それぞれ、配列番号1/2及び3/4で示されるアグロシベ・アエゲリタTM-A1-KのAaP1及びAaP2ペルオキシゲナーゼ酵素をコードするcDNA遺伝子を含んで成る標準プラスミドをそれぞれ含む。
寄託物 受託番号 寄託の日
E. coli NN049991 (AaP1 ) DSM 21289 2008年3月14日
E. coli NN049992 (AaP2) DSM 21290 2008年3月14日
前記株は、培養物への接近が、それらに権利を与えらる外国特許法により決定される本特許出願の係属の間、入手できることを保証する条件下で寄託された。寄託物は、寄託された株の実質的に純粋な培養物を示す。寄託物は、本出願の対応物又はその子孫が出願される国々における外国特許法により要求される場合、入手できる。しかしながら、寄託物の入手可能性は、政府の指令により許される特許権の失効において本発明を実施する許可を構成しないことが理解されるべきである。
E. coli NN049991 (AaP1 ) DSM 21289 2008年3月14日
E. coli NN049992 (AaP2) DSM 21290 2008年3月14日
前記株は、培養物への接近が、それらに権利を与えらる外国特許法により決定される本特許出願の係属の間、入手できることを保証する条件下で寄託された。寄託物は、寄託された株の実質的に純粋な培養物を示す。寄託物は、本出願の対応物又はその子孫が出願される国々における外国特許法により要求される場合、入手できる。しかしながら、寄託物の入手可能性は、政府の指令により許される特許権の失効において本発明を実施する許可を構成しないことが理解されるべきである。
Claims (70)
- (a)配列番号2, 4, 6, 8, 10, 12, 14又は19のポリペプチドに対して少なくとも60%の同一性を有するアミノ酸配列を含んで成るポリペプチド;
(b)(i)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17のポリペプチドコード配列;(ii)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るゲノムDNA配列に含まれるcDNA配列又はそのゲノムDNA配列;又は(iii)前記(i)もしくは(ii)の十分な長さの相補鎖と、少なくとも低い、中位の、中位に高い、又は高い緊縮条件下でハイブリダイズするポリヌクレオチドによりコードされるポリペプチド;
(c)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に対して少なくとも60%の同一性を有するヌクレオチド配列を含んで成るポリヌクレオチドによりコードされるポリペプチド;
(d)次のモチーフ:
モチーフI: [FL]XX[YF]S[AN]X[FHY]G[GN]GX[YF]N (配列番号40)
モチーフII: G[GN]GX[YF]NXX[VA]AX[EH][LF]R (配列番号41 )
モチーフIII: RXXRI[QE][DEQ]S[IM]ATN (配列番号42)
モチーフIV: S[IM]ATN[PG][EQN][FM][SDN][FL] (配列番号43)
モチーフV: P[PDK][DG]F[HFW]R[AP] (配列番号44)
モチーフVl: [TI]XXXLYPNP[TK][GV] (配列番号45)の1又は複数のモチーフを含んで成るポリペプチド;及び
(e)配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドの1又は数個のアミノ酸の置換、欠失及び/又は挿入を含んで成る変異体から成る群から選択された、ペルオキシゲナーゼ活性を有する単離されたポリペプチド。 - 配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドに対して少なくとも60%の同一性を有するアミノ酸配列を含んで成る、請求項1記載のポリペプチド。
- 配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドに対して少なくとも65%の同一性を有するアミノ酸配列を含んで成る、請求項2記載のポリペプチド。
- 配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドに対して少なくとも70%の同一性を有するアミノ酸配列を含んで成る、請求項3記載のポリペプチド。
- 配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドに対して少なくとも75%の同一性を有するアミノ酸配列を含んで成る、請求項4記載のポリペプチド。
- 配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドに対して少なくとも80%の同一性を有するアミノ酸配列を含んで成る、請求項5記載のポリペプチド。
- 配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドに対して少なくとも85%の同一性を有するアミノ酸配列を含んで成る、請求項6記載のポリペプチド。
- 配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドに対して少なくとも90%の同一性を有するアミノ酸配列を含んで成る、請求項7記載のポリペプチド。
- 配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドに対して少なくとも95%の同一性を有するアミノ酸配列を含んで成る、請求項8記載のポリペプチド。
- 配列番号2, 4, 6, 8, 10, 12, 14又は19のアミノ酸配列;又はペルオキシゲナーゼ活性を有するそのフラグメントを含んで成るか又はそれから成る、請求項1記載のポリペプチド。
- 配列番号2, 4, 6, 8, 10, 12, 14又は19のアミノ酸配列を含んで成るか又はそれから成る、請求項10記載のポリペプチド。
- 配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドを含んで成るか又はそれから成る、請求項10記載のポリペプチド。
- (i)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列;(ii)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るゲノムDNA配列に含まれるcDNA配列又はそのゲノムDNA配列;又は(iii)(i)又は(ii)の十分な長さの相補鎖と、少なくとも中位の緊縮条件下でハイブリダイズするポリヌクレオチドによりコードされる、請求項1記載のポリペプチド。
- (i)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列;(ii)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るゲノムDNA配列に含まれるcDNA配列又はそのゲノムDNA配列;又は(iii)(i)又は(ii)の十分な長さの相補鎖と、少なくとも中位に高い緊縮条件下でハイブリダイズするポリヌクレオチドによりコードされる、請求項13記載のポリペプチド。
- (i)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列;(ii)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るゲノムDNA配列に含まれるcDNA配列又はそのゲノムDNA配列;又は(iii)(i)又は(ii)の十分な長さの相補鎖と、少なくとも高い緊縮条件下でハイブリダイズするポリヌクレオチドによりコードされる、請求項14記載のポリペプチド。
- 配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に対して少なくとも60%の同一性を有するヌクレオチド配列を含んで成るポリヌクレオチドによりコードされる、請求項1記載のポリペプチド。
- 配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に対して少なくとも65%の同一性を有するヌクレオチド配列を含んで成るポリヌクレオチドによりコードされる、請求項16記載のポリペプチド。
- 配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に対して少なくとも70%の同一性を有するヌクレオチド配列を含んで成るポリヌクレオチドによりコードされる、請求項17記載のポリペプチド。
- 配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に対して少なくとも75%の同一性を有するヌクレオチド配列を含んで成るポリヌクレオチドによりコードされる、請求項18記載のポリペプチド。
- 配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に対して少なくとも80%の同一性を有するヌクレオチド配列を含んで成るポリヌクレオチドによりコードされる、請求項19記載のポリペプチド。
- 配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に対して少なくとも85%の同一性を有するヌクレオチド配列を含んで成るポリヌクレオチドによりコードされる、請求項20記載のポリペプチド。
- 配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に対して少なくとも90%の同一性を有するヌクレオチド配列を含んで成るポリヌクレオチドによりコードされる、請求項21記載のポリペプチド。
- 配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に対して少なくとも95%の同一性を有するヌクレオチド配列を含んで成るポリヌクレオチドによりコードされる、請求項22記載のポリペプチド。
- 配列番号1, 3, 5, 7, 9, 11, 13, 15又は17のヌクレオチド配列;又はペルオキシゲナーゼ活性を有するフラグメントをコードするその副配列を含んで成るか又はそれから成るポリヌクレオチドによりコードされる、請求項1記載のポリペプチド。
- 配列番号1, 3, 5, 7, 9, 11, 13, 15又は17のヌクレオチド配列を含んで成るか又はそれから成るポリヌクレオチドによりコードされる、請求項24記載のポリペプチド。
- 配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るか又はそれからなるポリヌクレオチドによりコードされる、請求項24記載のポリペプチド。
- 次のモチーフ:
モチーフI: [FL]XX[YF]S[AN]X[FHY]G[GN]GX[YF]N (配列番号40)
モチーフII: G[GN]GX[YF]NXX[VA]AX[EH][LF]R (配列番号41 )
モチーフIII: RXXRI[QE][DEQ]S[IM]ATN (配列番号42)
モチーフIV: S[IM]ATN[PG][EQN][FM][SDN][FL] (配列番号43)
モチーフV: P[PDK][DG]F[HFW]R[AP] (配列番号44)
モチーフVl: [TI]XXXLYPNP[TK][GV] (配列番号45)の1又は複数のモチーフを含んで成る、請求項1記載のポリペプチド。 - 前記ポリペプチドが、配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドの1又は数個のアミノ酸の置換、欠失及び/又は挿入を含んで成る変異体である、請求項1記載のポリペプチド。
- 受託番号DSM21289としてDSMZによりブダベスト条約下で2008年3月14日に寄託されたE. コリNN049991に含まれるか;又は受託番号DSM21290としてDSMZによりブダベスト条約下で2008年3月14日に寄託されたE. コリNN049992に含まれるプラスミドに含まれるポリヌクレオチドによりコードされる、請求項1記載のポリペプチド。
- 前記成熟ポリペプチドが、配列番号2のアミノ酸1〜330である、請求項1〜29のいずれか1項記載のポリペプチド。
- 前記成熟ポリペプチドコード配列が、配列番号1のヌクレオチド152〜1141である、請求項1〜30のいずれか1項記載のポリペプチド。
- 請求項1〜31のいずれか1項記載のポリペプチドをコードするヌクレオチド配列を含んで成る単離されたポリヌクレオチド。
- 配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列に少なくとも1つの突然変異を含んで成り、ここで前記変異体ヌクレオチド配列が、配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドをコードする、請求項32記載の単離されたポリヌクレオチド。
- 発現宿主におけるポリペプチドの生成を指図する1又は数個の制御配列に操作可能的に結合される請求項32又は33記載のポリヌクレオチドを含んで成る核酸構造体。
- 請求項34記載の核酸構造体を含んで成る組換え発現ベクター。
- 請求項34記載の核酸構造体を含んで成る組換え宿主細胞。
- (a)その野生形でポリペプチドを生成する細胞を、ポリペプチドの生成の助けになる条件下で培養し;そして(b)ポリペプチドを回収することを含んで成る、請求項1〜31のいずれか1項記載のポリペプチドの生成方法。
- (a)ポリペプチドをコードするヌクレオチド配列を含んで成る核酸構造体を含んで成る宿主細胞を、ポリペプチドの生成の助けになる条件下で培養し;そして(b)ポリペプチドを回収することを含んで成る、請求項1〜31のいずれか1項記載のポリペプチドの生成方法。
- 親細胞よりも少なくポリペプチドを生成する変異体をもたらす、請求項1〜31のいずれか1項記載のポリペプチドをコードするヌクレオチド配列を崩壊するか又は欠失することを含んで成る、親細胞の変異体の生成方法。
- 請求項39記載の方法により生成される変異体細胞。
- 生来の又は異種タンパク質をコードする遺伝子をさらに含んで成る、請求項40記載の変異体細胞。
- (a)請求項41記載の変異体細胞を、タンパク質の生成の助けになる条件下で培養し;そして(b)タンパク質を回収することを含んで成る、タンパク質の生成方法。
- (a)(i)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列;(ii)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るゲノムDNA配列に含まれるcDNA配列又はそのゲノムDNA配列;又は(iii)(i)又は(ii)の十分な長さの相補鎖と、少なくとも中位の緊縮条件下で、DNA集団とをハイブリダイズし;そして(b)ペルオキシゲナーゼ活性を有するポリペプチドをコードする、ハイブリダイズするポリヌクレオチドを単離することにより得られる、請求項32又は33記載の単離されたポリヌクレオチド。
- (a)(i)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列;(ii)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るゲノムDNA配列に含まれるcDNA配列又はそのゲノムDNA配列;又は(iii)(i)又は(ii)の十分な長さの相補鎖と、少なくとも中位に高い緊縮条件下で、DNA集団とをハイブリダイズし;そして(b)ペルオキシゲナーゼ活性を有するポリペプチドをコードする、ハイブリダイズするポリヌクレオチドを単離することにより得られる、請求項43記載の単離されたポリヌクレオチド。
- (a)(i)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列;(ii)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列を含んで成るゲノムDNA配列に含まれるcDNA配列又はそのゲノムDNA配列;又は(iii)(i)又は(ii)の十分な長さの相補鎖と、少なくとも高い緊縮条件下で、DNA集団とをハイブリダイズし;そして(b)ペルオキシゲナーゼ活性を有するポリペプチドをコードする、ハイブリダイズするポリヌクレオチドを単離することにより得られる、請求項44記載の単離されたポリヌクレオチド。
- 前記成熟ポリペプチドコード配列が、配列番号1のヌクレオチド152〜1141である、請求項43〜45のいずれか1項記載の単離されたポリヌクレオチド。
- (a)配列番号1, 3, 5, 7, 9, 11, 13, 15又は17の成熟ポリペプチドコード配列中に少なくとも1つの突然変異を導入し、ここで前記変異体ヌクレオチド配列は配列番号2, 4, 6, 8, 10, 12, 14又は19の成熟ポリペプチドを含んで成るか又はそれから成るポリペプチドをコードし;そして(b)前記変異体ヌクレオチド配列を含んで成るポリヌクレオチドを回収することを含んで成る、ペルオキシゲナーゼ活性を有するポリペプチドをコードする変異体ヌクレオチド配列を含んで成るポリヌクレオチドの生成方法。
- 請求項47記載の方法により生成される変異体ポリヌクレオチド。
- (a)ポリペプチドをコードする請求項48記載の変異体ポリヌクレオチドを含んで成る細胞を、前記ポリペプチドの生成の助けに成る条件下で培養し;そして(b)前記ポリペプチドを回収することを含んで成る、ポリペプチドの生成方法。
- (a)ポリペプチドをコードするポリヌクレオチドを含んで成るトランスジェニック植物又は植物細胞を、前記ポリペプチドの生成の助けになる条件下で培養し;そして(b)前記ポリペプチドを回収することを含んで成る、請求項1〜31のいずれか1項記載のポリペプチドの生成方法。
- 配列番号2のアミノ酸-43〜-1を含んで成るか又はそれらから成るシグナルペプチドをコードする第1ヌクレオチド配列及び配列番号2のアミノ酸1〜330を含んで成るか又はそれらから成るプロペプチドをコードする第2ヌクレオチド配列の1つ又は両者に対して操作可能的に結合されるタンパク質をコードする、前記第1及び第2ヌクレオチド配列に対して外来性の遺伝子を含んで成る核酸構造体。
- 請求項51記載の核酸構造体を含んで成る組換え発現ベクター。
- 請求項51記載の核酸構造体を含んで成る組換え宿主細胞。
- (a)請求項53記載の組換え宿主細胞を、タンパク質の生成の助けになる条件下で培養し;そして(b)前記タンパク質を回収することを含んで成る、タンパク質の生成方法。
- 図1における式(I)のN−複素環を、1段階反応方法を用いて、少なくとも1つの酸化剤の存在下で、請求項1〜31のいずれか1項記載のペルオキシゲナーゼポリペプチドにより転換することによる、図1における式(I)のN−複素環の式(II)のその対応するN−酸化物への酵素的位置選択性酸化方法。
- 前記使用されるN−複素環が、ピリジンであることを特徴とする、請求項55記載の方法。
- 前記使用される複素環が、置換されたピリジン又は多環式複素環(例えば、キノリン)であることを特徴とする、請求項55記載の方法。
- 前記ペルオキシゲナーゼが、ボルビチアセアエ(Bolbitiaceae)、コプリナセアエ(Coprinaceae)又はトリコロマタセアエ(Tricholomataceae)科の代表物から誘導される、請求項55〜57のいずれか1項記載の方法。
- 前記ペルオキシゲナーゼが、アグロシベ・アエゲリタ(Agrocybe aegerita)、アグロシベ・カキシング(Agrocybe chaxingu)、コプリナス・ラジアンス(Coprinus radians)又はコプリナス・ベルチキュラタス(Coprinus verticulatus)から誘導される、請求項58記載の方法。
- 前記酸化剤が、過酸化水素、有機過酸化物、空気又は酸素である、請求項55〜59のいずれか1項記載の方法。
- 前記酸化剤が、図1における式(I)の化合物の濃度に基づいて、触媒量で、好ましくは0.01%以下の量で使用されることを特徴とする、請求項55〜60のいずれか1項記載の方法。
- 追加のH2O2−生成酵素が、ペルオキシゲナーゼポリペプチドと式(I)の化合物との反応をさらに促進するために、反応混合物に添加される、請求項55〜61のいずれか1項記載の方法。
- 有機酸及び/又はホスフェートに基づく緩衝液が、反応を安定化するために、反応に添加される、請求項55〜62のいずれか1項記載の方法。
- 前記反応が、10℃〜40℃の温度範囲内で実施される、請求項55〜63のいずれか1項記載の方法。
- 前記基質溶解が、有機溶媒の添加により、改良される、請求項55〜64のいずれか1項記載の方法。
- 請求項1〜31のいずれか1項記載のポリペプチドを含んで成る洗剤組成物。
- 請求項1〜31のいずれか1項記載のポリペプチドを含んで成る皿洗い機用洗剤組成物。
- 請求項1〜31のいずれか1項記載のポリペプチドを含んで成るパルプ及び紙処理のための組成物。
- 請求項1〜31のいずれか1項記載のポリペプチドを含んで成る水処理のための組成物。
- 請求項1〜31のいずれか1項記載のポリペプチドを含んで成る油処理のための組成物。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DE102007016139.7 | 2007-03-30 | ||
| DE102007016139A DE102007016139A1 (de) | 2007-03-30 | 2007-03-30 | Verfahren zur regioselektiven Oxygenierung von N-Heterozyklen |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2010500298A Division JP5411121B2 (ja) | 2007-03-30 | 2008-03-31 | 真菌ペルオキシゲナーゼ及び適用方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2014000086A true JP2014000086A (ja) | 2014-01-09 |
Family
ID=39591196
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2010500298A Expired - Fee Related JP5411121B2 (ja) | 2007-03-30 | 2008-03-31 | 真菌ペルオキシゲナーゼ及び適用方法 |
| JP2013171739A Pending JP2014000086A (ja) | 2007-03-30 | 2013-08-21 | 真菌ペルオキシゲナーゼ及び適用方法 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2010500298A Expired - Fee Related JP5411121B2 (ja) | 2007-03-30 | 2008-03-31 | 真菌ペルオキシゲナーゼ及び適用方法 |
Country Status (9)
| Country | Link |
|---|---|
| US (2) | US8367387B2 (ja) |
| EP (3) | EP2158313B1 (ja) |
| JP (2) | JP5411121B2 (ja) |
| CN (1) | CN101802180B (ja) |
| AT (1) | ATE548449T1 (ja) |
| CA (1) | CA2682451C (ja) |
| DE (1) | DE102007016139A1 (ja) |
| DK (1) | DK2158313T3 (ja) |
| WO (1) | WO2008119780A2 (ja) |
Families Citing this family (40)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2553109B1 (en) * | 2010-03-28 | 2018-10-24 | Novozymes A/S | Regioselective hydroxylation of aliphatic hydrocarbons employing a fungal peroxygenase |
| WO2013004639A2 (en) | 2011-07-07 | 2013-01-10 | Novozymes A/S | Enzymatic preparation of diols |
| WO2013021059A1 (en) | 2011-08-10 | 2013-02-14 | Novozymes A/S | Polypeptides having peroxygenase activity and polynucleotides encoding same |
| US9382559B2 (en) * | 2011-08-10 | 2016-07-05 | Novozymes A/S | Polypeptides having peroxygenase activity and polynucleotides encoding same |
| EP2742060B1 (en) | 2011-08-10 | 2017-03-01 | Novozymes A/S | Polypeptides having peroxygenase activity and polynucleotides encoding same |
| WO2013021064A1 (en) | 2011-08-10 | 2013-02-14 | Novozymes A/S | Polypeptides having peroxygenase activity and polynucleotides encoding same |
| WO2013021062A1 (en) | 2011-08-10 | 2013-02-14 | Novozymes A/S | Polypeptides having peroxygenase activity and polynucleotides encoding same |
| WO2013021060A1 (en) | 2011-08-10 | 2013-02-14 | Novozymes A/S | Polypeptides having peroxygenase activity and polynucleotides encoding same |
| WO2013021065A1 (en) | 2011-08-10 | 2013-02-14 | Novozymes A/S | Polypeptides having peroxygenase activity and polynucleotides encoding same |
| WO2013079531A2 (en) | 2011-12-02 | 2013-06-06 | Novozymes A/S | Polypeptides having peroxygenase activity and polynucleotides encoding same |
| US9404093B2 (en) | 2011-12-02 | 2016-08-02 | Novozymes A/S | Polypeptides having peroxygenase activity and polynucleotides encoding same |
| WO2013144105A1 (en) | 2012-03-31 | 2013-10-03 | Novozymes A/S | Epoxidation using peroxygenase |
| BR112014032865A2 (pt) | 2012-07-18 | 2017-08-01 | Novozymes As | método para tratamento de têxtil de poliéster, e, composição |
| WO2014015256A2 (en) | 2012-07-20 | 2014-01-23 | Novozymes A/S | Enzymatic oxidation of 5-hydroxymethylfurfural and derivatives thereof |
| WO2014056920A2 (en) | 2012-10-12 | 2014-04-17 | Novozymes A/S | Polypeptides having peroxygenase activity |
| CN104704114A (zh) * | 2012-10-12 | 2015-06-10 | 诺维信公司 | 具有过氧合酶活性的多肽 |
| CN104718287B (zh) | 2012-10-12 | 2018-02-06 | 诺维信公司 | 具有过氧合酶活性的多肽 |
| CN104704116B (zh) * | 2012-10-12 | 2018-09-28 | 诺维信公司 | 具有过氧合酶活性的多肽 |
| US9499801B2 (en) | 2012-10-12 | 2016-11-22 | Novozymes A/S | Polypeptides having peroxygenase activity |
| WO2014056916A2 (en) | 2012-10-12 | 2014-04-17 | Novozymes A/S | Polypeptides having peroxygenase activity |
| CN104704115B (zh) * | 2012-10-12 | 2018-11-02 | 诺维信公司 | 具有过氧合酶活性的多肽 |
| EP2906689B1 (en) | 2012-10-12 | 2018-12-12 | Novozymes A/S | Polypeptides having peroxygenase activity |
| WO2014090940A1 (en) * | 2012-12-14 | 2014-06-19 | Novozymes A/S | Removal of skin-derived body soils |
| EP2871233A1 (de) | 2013-11-12 | 2015-05-13 | Brandenburgische Technische Universität Cottbus-Senftenberg | Verfahren zur Herstellung von biogenen Stoffen |
| MX2016006238A (es) * | 2013-11-18 | 2016-10-05 | Enzymatic Deinking Tech Llc | Tratamiento enzimatico de fibra virgen y papel reciclado para reducir los niveles de aceite mineral residual para la produccion de papel. |
| CN105793418A (zh) * | 2013-11-29 | 2016-07-20 | 诺维信公司 | 过氧合酶变体 |
| WO2016207373A1 (en) | 2015-06-26 | 2016-12-29 | Novozymes A/S | Polypeptides having peroxygenase activity |
| DK3392341T3 (da) | 2017-04-20 | 2021-04-06 | Consejo Superior Investigacion | Fremgangsmåde til afkortning af carbonhydridkæden i en carboxylsyre ved hjælp af en peroxygenase |
| NL2021113B1 (en) | 2018-06-13 | 2019-12-19 | Univ Delft Tech | Synthesis of aromatic epoxide derived compounds |
| EP3818164B1 (en) * | 2018-07-03 | 2023-08-02 | Ruhr-Universität Bochum | Plasma-driven biocatalysis |
| EP3594332A1 (en) * | 2018-07-10 | 2020-01-15 | Consejo Superior de Investigaciones Cientificas | Method of heterologous expression of active fungal unspecific peroxygenase in bacterial host cells for fatty-acid epoxidation and other oxygenation reactions |
| EP3660147A1 (en) | 2018-11-30 | 2020-06-03 | Consejo Superior de Investigaciones Cientificas (CSIC) | Process for selective synthesis of 4-hydroxyisophorone and 4-ketoisophorone by fungal peroxygenases |
| US20220064516A1 (en) * | 2019-01-03 | 2022-03-03 | Locus Oil Ip Company, Llc | Materials and Methods for Extended Reduction of Heavy Crude Oil Viscosity |
| WO2021005013A1 (en) | 2019-07-05 | 2021-01-14 | Bisy Gmbh | Recombinant heme thiolate oxygenases |
| CN116568818A (zh) | 2020-09-23 | 2023-08-08 | 吉柯生物科技有限公司 | 细菌非特异性过加氧酶(bupo)及其方法和用途 |
| DE102021204094A1 (de) | 2021-04-25 | 2022-10-27 | Brandenburgische Technische Universität Cottbus-Senftenberg | In-vitro Arzneimittel aus Prodrugs und deren Verwendung |
| WO2023031462A1 (de) | 2021-09-03 | 2023-03-09 | Brandenburgische Technische Universitaet Cottbus-Senftenberg | Verfahren zur zellfreien herstellung von unspezifischen peroxygenasen |
| DE102021209758A1 (de) | 2021-09-03 | 2023-03-09 | Brandenburgische Technische Universität Cottbus-Senftenberg | Verfahren zur zellfreien Herstellung von unspezifischen Peroxygenasen und deren Verwendung |
| DE102021214582A1 (de) | 2021-12-17 | 2023-06-22 | Brandenburgische Technische Universität Cottbus-Senftenberg | Verfahren zur zellfreien Herstellung von unspezifischen Peroxygenasen und deren Verwendung |
| CN116240246B (zh) * | 2021-12-20 | 2025-01-21 | 浙江金朗博药业有限公司 | 利用过氧化物酶合成骨化二醇的方法 |
Family Cites Families (73)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB1296839A (ja) | 1969-05-29 | 1972-11-22 | ||
| GB1372034A (en) | 1970-12-31 | 1974-10-30 | Unilever Ltd | Detergent compositions |
| US3826746A (en) | 1972-07-18 | 1974-07-30 | Mobil Oil Corp | Lubricant compositions |
| GB1483591A (en) | 1973-07-23 | 1977-08-24 | Novo Industri As | Process for coating water soluble or water dispersible particles by means of the fluid bed technique |
| GB1590432A (en) | 1976-07-07 | 1981-06-03 | Novo Industri As | Process for the production of an enzyme granulate and the enzyme granuate thus produced |
| DK187280A (da) | 1980-04-30 | 1981-10-31 | Novo Industri As | Ruhedsreducerende middel til et fuldvaskemiddel fuldvaskemiddel og fuldvaskemetode |
| US4353985A (en) | 1980-07-14 | 1982-10-12 | Schering Aktiengesellschaft | Process for the preparation of 11 β-hydroxy steroids |
| DK263584D0 (da) | 1984-05-29 | 1984-05-29 | Novo Industri As | Enzymholdige granulater anvendt som detergentadditiver |
| JPH0697997B2 (ja) | 1985-08-09 | 1994-12-07 | ギスト ブロカデス ナ−ムロ−ゼ フエンノ−トチヤツプ | 新規の酵素的洗浄剤添加物 |
| EG18543A (en) | 1986-02-20 | 1993-07-30 | Albright & Wilson | Protected enzyme systems |
| DK122686D0 (da) | 1986-03-17 | 1986-03-17 | Novo Industri As | Fremstilling af proteiner |
| ATE110768T1 (de) | 1986-08-29 | 1994-09-15 | Novo Nordisk As | Enzymhaltiger reinigungsmittelzusatz. |
| NZ221627A (en) | 1986-09-09 | 1993-04-28 | Genencor Inc | Preparation of enzymes, modifications, catalytic triads to alter ratios or transesterification/hydrolysis ratios |
| DE3854249T2 (de) | 1987-08-28 | 1996-02-29 | Novonordisk As | Rekombinante Humicola-Lipase und Verfahren zur Herstellung von rekombinanten Humicola-Lipasen. |
| JPS6474992A (en) | 1987-09-16 | 1989-03-20 | Fuji Oil Co Ltd | Dna sequence, plasmid and production of lipase |
| EP0471265B1 (en) | 1988-01-07 | 1995-10-25 | Novo Nordisk A/S | Specific protease |
| DK6488D0 (da) | 1988-01-07 | 1988-01-07 | Novo Industri As | Enzymer |
| JP3079276B2 (ja) | 1988-02-28 | 2000-08-21 | 天野製薬株式会社 | 組換え体dna、それを含むシュードモナス属菌及びそれを用いたリパーゼの製造法 |
| WO1989009259A1 (en) | 1988-03-24 | 1989-10-05 | Novo-Nordisk A/S | A cellulase preparation |
| US5776757A (en) | 1988-03-24 | 1998-07-07 | Novo Nordisk A/S | Fungal cellulase composition containing alkaline CMC-endoglucanase and essentially no cellobiohydrolase and method of making thereof |
| US5223409A (en) | 1988-09-02 | 1993-06-29 | Protein Engineering Corp. | Directed evolution of novel binding proteins |
| GB8915658D0 (en) | 1989-07-07 | 1989-08-23 | Unilever Plc | Enzymes,their production and use |
| IL97645A (en) | 1990-03-23 | 1997-03-18 | Gist Brocades Nv | Production of enzymes in seeds and their use |
| EP0528828B2 (de) | 1990-04-14 | 1997-12-03 | Genencor International GmbH | Alkalische bacillus-lipasen, hierfür codierende dna-sequenzen sowie bacilli, die diese lipasen produzieren |
| CA2082279C (en) | 1990-05-09 | 2007-09-04 | Grethe Rasmussen | Cellulase preparation comprising an endoglucanase enzyme |
| DK115890D0 (da) | 1990-05-09 | 1990-05-09 | Novo Nordisk As | Enzym |
| DE69129988T2 (de) | 1990-09-13 | 1999-03-18 | Novo Nordisk A/S, Bagsvaerd | Lipase-varianten |
| IL99552A0 (en) | 1990-09-28 | 1992-08-18 | Ixsys Inc | Compositions containing procaryotic cells,a kit for the preparation of vectors useful for the coexpression of two or more dna sequences and methods for the use thereof |
| DE69133035T2 (de) | 1991-01-16 | 2003-02-13 | The Procter & Gamble Company, Cincinnati | Kompakte Waschmittelzusammensetzungen mit hochaktiven Cellulasen |
| EP0511456A1 (en) | 1991-04-30 | 1992-11-04 | The Procter & Gamble Company | Liquid detergents with aromatic borate ester to inhibit proteolytic enzyme |
| DK0583420T3 (da) | 1991-04-30 | 1996-07-29 | Procter & Gamble | Builderholdige flydende detergenter med borsyre-polyol-kompleks til inhibering af proteolytisk enzym |
| KR100258460B1 (ko) | 1991-05-01 | 2000-06-01 | 한센 핀 베네드 | 안정화 효소 및 세제 조성물 |
| DK72992D0 (da) | 1992-06-01 | 1992-06-01 | Novo Nordisk As | Enzym |
| DK88892D0 (da) | 1992-07-06 | 1992-07-06 | Novo Nordisk As | Forbindelse |
| EP0651794B1 (en) | 1992-07-23 | 2009-09-30 | Novozymes A/S | MUTANT $g(a)-AMYLASE, DETERGENT AND DISH WASHING AGENT |
| EP1431389A3 (en) | 1992-10-06 | 2004-06-30 | Novozymes A/S | Cellulase variants |
| CZ293163B6 (cs) | 1993-02-11 | 2004-02-18 | Genencor International, Inc. | Mutanta alfa-amylázy, její použití, kódová DNA pro tuto mutantu, vektor pro expresi, hostitelské buňky, čisticí prostředek a prostředek pro zkapalnění škrobu |
| ATE287946T1 (de) | 1993-04-27 | 2005-02-15 | Genencor Int | Neuartige lipasevarianten zur verwendung in reinigungsmitteln |
| DK52393D0 (ja) | 1993-05-05 | 1993-05-05 | Novo Nordisk As | |
| JP2859520B2 (ja) | 1993-08-30 | 1999-02-17 | ノボ ノルディスク アクティーゼルスカブ | リパーゼ及びそれを生産する微生物及びリパーゼ製造方法及びリパーゼ含有洗剤組成物 |
| EP0724631A1 (en) | 1993-10-13 | 1996-08-07 | Novo Nordisk A/S | H 2?o 2?-stable peroxidase variants |
| JPH07143883A (ja) | 1993-11-24 | 1995-06-06 | Showa Denko Kk | リパーゼ遺伝子及び変異体リパーゼ |
| DE4343591A1 (de) | 1993-12-21 | 1995-06-22 | Evotec Biosystems Gmbh | Verfahren zum evolutiven Design und Synthese funktionaler Polymere auf der Basis von Formenelementen und Formencodes |
| US5605793A (en) | 1994-02-17 | 1997-02-25 | Affymax Technologies N.V. | Methods for in vitro recombination |
| EP0746618B1 (en) | 1994-02-22 | 2002-08-21 | Novozymes A/S | A method of preparing a variant of a lipolytic enzyme |
| WO1995024471A1 (en) | 1994-03-08 | 1995-09-14 | Novo Nordisk A/S | Novel alkaline cellulases |
| JP3851656B2 (ja) | 1994-05-04 | 2006-11-29 | ジェネンコア インターナショナル インコーポレーテッド | 改善された界面活性剤耐性を有するリパーゼ |
| WO1995033836A1 (en) | 1994-06-03 | 1995-12-14 | Novo Nordisk Biotech, Inc. | Phosphonyldipeptides useful in the treatment of cardiovascular diseases |
| WO1995035381A1 (en) | 1994-06-20 | 1995-12-28 | Unilever N.V. | Modified pseudomonas lipases and their use |
| WO1996000292A1 (en) | 1994-06-23 | 1996-01-04 | Unilever N.V. | Modified pseudomonas lipases and their use |
| ATE294871T1 (de) | 1994-06-30 | 2005-05-15 | Novozymes Biotech Inc | Nicht-toxisches, nicht-toxigenes, nicht- pathogenes fusarium expressionssystem und darin zu verwendende promotoren und terminatoren |
| DE69535733T2 (de) | 1994-10-06 | 2009-04-23 | Novozymes A/S | Ein enzympräparat mit endoglucanase aktivität |
| BE1008998A3 (fr) | 1994-10-14 | 1996-10-01 | Solvay | Lipase, microorganisme la produisant, procede de preparation de cette lipase et utilisations de celle-ci. |
| BR9509525A (pt) | 1994-10-26 | 1995-10-26 | Novo Nordisk As | Construção de dna vetor de expressão recombinante célula processo para produzir a enzima que exibe atividade lipolítica enzima que exibe atividade lipolítica preparação de enzima aditivo de detergente e composição de detergente |
| AR000862A1 (es) | 1995-02-03 | 1997-08-06 | Novozymes As | Variantes de una ó-amilasa madre, un metodo para producir la misma, una estructura de adn y un vector de expresion, una celula transformada por dichaestructura de adn y vector, un aditivo para detergente, composicion detergente, una composicion para lavado de ropa y una composicion para la eliminacion del |
| JPH08228778A (ja) | 1995-02-27 | 1996-09-10 | Showa Denko Kk | 新規なリパーゼ遺伝子及びそれを用いたリパーゼの製造方法 |
| EP0815209B2 (en) | 1995-03-17 | 2015-02-25 | Novozymes A/S | Novel endoglucanases |
| WO1997007202A1 (en) | 1995-08-11 | 1997-02-27 | Novo Nordisk A/S | Novel lipolytic enzymes |
| AU6414196A (en) | 1995-07-14 | 1997-02-18 | Novo Nordisk A/S | A modified enzyme with lipolytic activity |
| US5763385A (en) | 1996-05-14 | 1998-06-09 | Genencor International, Inc. | Modified α-amylases having altered calcium binding properties |
| AU3938997A (en) | 1996-08-26 | 1998-03-19 | Novo Nordisk A/S | A novel endoglucanase |
| BR9711479B1 (pt) | 1996-09-17 | 2009-08-11 | variante de celulase tendo uma resistência aumentada a tensìdeo de ánion. | |
| CA2265734A1 (en) | 1996-10-08 | 1998-04-16 | Novo Nordisk A/S | Diaminobenzoic acid derivatives as dye precursors |
| US6300116B1 (en) | 1996-11-04 | 2001-10-09 | Novozymes A/S | Modified protease having improved autoproteolytic stability |
| BR9712473B1 (pt) | 1996-11-04 | 2009-08-11 | variantes de subtilase e composições. | |
| WO1998034946A1 (en) | 1997-02-12 | 1998-08-13 | Massachusetts Institute Of Technology | Daxx, a novel fas-binding protein that activates jnk and apoptosis |
| AU7908898A (en) | 1997-07-04 | 1999-01-25 | Novo Nordisk A/S | Family 6 endo-1,4-beta-glucanase variants and cleaning composit ions containing them |
| DK1124949T3 (da) | 1998-10-26 | 2006-11-06 | Novozymes As | Konstruktion og screening af et DNA-bibliotek af interesse i trådformede svampeceller |
| CN100482801C (zh) | 1999-03-22 | 2009-04-29 | 诺沃奇梅兹有限公司 | 用于在真菌细胞中表达基因的启动子 |
| DE10332065A1 (de) | 2003-07-11 | 2005-01-27 | Friedrich-Schiller-Universität Jena | Verfahren zur enzymatischen Darstellung von Säuren aus Alkoholen über die intermediäre Bildung von Aldehyden |
| DE602004022967D1 (de) | 2003-10-30 | 2009-10-15 | Novozymes As | Kohlenhydratbindende module |
| DE102004047774A1 (de) | 2004-09-28 | 2006-03-30 | Jenabios Gmbh | Verfahren zur enzymatischen Hydroxylierung nicht-aktivierter Kohlenwasserstoffe |
| EP2069513A4 (en) * | 2006-08-04 | 2012-03-21 | California Inst Of Techn | METHOD AND SYSTEMS FOR THE SELECTIVE FLUORINATION OF ORGANIC MOLECULES |
-
2007
- 2007-03-30 DE DE102007016139A patent/DE102007016139A1/de not_active Withdrawn
-
2008
- 2008-03-31 CN CN200880017970.5A patent/CN101802180B/zh not_active Expired - Fee Related
- 2008-03-31 AT AT08718350T patent/ATE548449T1/de active
- 2008-03-31 DK DK08718350.5T patent/DK2158313T3/da active
- 2008-03-31 US US12/532,870 patent/US8367387B2/en not_active Expired - Fee Related
- 2008-03-31 EP EP08718350A patent/EP2158313B1/en not_active Not-in-force
- 2008-03-31 EP EP12161074A patent/EP2471911A3/en not_active Withdrawn
- 2008-03-31 JP JP2010500298A patent/JP5411121B2/ja not_active Expired - Fee Related
- 2008-03-31 EP EP12158017.9A patent/EP2468852B1/en not_active Not-in-force
- 2008-03-31 CA CA2682451A patent/CA2682451C/en not_active Expired - Fee Related
- 2008-03-31 WO PCT/EP2008/053798 patent/WO2008119780A2/en not_active Ceased
-
2012
- 2012-12-20 US US13/722,019 patent/US20130115662A1/en not_active Abandoned
-
2013
- 2013-08-21 JP JP2013171739A patent/JP2014000086A/ja active Pending
Non-Patent Citations (4)
| Title |
|---|
| JPN6013020666; Appl. Environ. Microbiol. Vol.70, No.8, 2004, p.4575-4581 * |
| JPN6013020667; Appl. Microbiol. Biotechnol. Vol.84, 2009, p.885-897 * |
| JPN6013020668; FEBS Letters Vol.579, 2005, p.6247-6250 * |
| JPN6013020669; Appl. Microbiol. Biotechnol. Vol.71, 2006, p.276-288 * |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2158313B1 (en) | 2012-03-07 |
| WO2008119780A3 (en) | 2009-03-12 |
| JP2010523079A (ja) | 2010-07-15 |
| CN101802180B (zh) | 2017-04-05 |
| EP2471911A2 (en) | 2012-07-04 |
| DK2158313T3 (da) | 2012-05-14 |
| WO2008119780A2 (en) | 2008-10-09 |
| US20130115662A1 (en) | 2013-05-09 |
| US8367387B2 (en) | 2013-02-05 |
| CN101802180A (zh) | 2010-08-11 |
| EP2158313A2 (en) | 2010-03-03 |
| EP2468852A1 (en) | 2012-06-27 |
| EP2468852B1 (en) | 2014-07-16 |
| CA2682451A1 (en) | 2008-10-09 |
| US20100279366A1 (en) | 2010-11-04 |
| JP5411121B2 (ja) | 2014-02-12 |
| ATE548449T1 (de) | 2012-03-15 |
| DE102007016139A1 (de) | 2008-10-02 |
| CA2682451C (en) | 2015-11-24 |
| EP2471911A3 (en) | 2012-12-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5411121B2 (ja) | 真菌ペルオキシゲナーゼ及び適用方法 | |
| US8377693B2 (en) | Polypeptides having cellobiohydrolase activity and polynucleotides encoding same | |
| US9057040B2 (en) | Laccase variants | |
| EP2906685B1 (en) | Polypeptides having peroxygenase activity | |
| CN103827297B (zh) | 具有过氧化酶活性的多肽及编码该多肽的多核苷酸 | |
| US9404093B2 (en) | Polypeptides having peroxygenase activity and polynucleotides encoding same | |
| CN103732740B (zh) | 具有过氧化酶活性的多肽及编码该多肽的多核苷酸 | |
| EP2906687B1 (en) | Polypeptides having peroxygenase activity | |
| EP2906686B1 (en) | Polypeptides having peroxygenase activity | |
| EP2906688B1 (en) | Polypeptides having peroxygenase activity | |
| EP2906689B1 (en) | Polypeptides having peroxygenase activity | |
| EP2906690B1 (en) | Polypeptides having peroxygenase activity | |
| CN103748217B (zh) | 具有过氧化酶活性的多肽及编码该多肽的多核苷酸 | |
| US9453207B2 (en) | Polypeptides having peroxygenase activity | |
| CN103748217A (zh) | 具有过氧化酶活性的多肽及编码该多肽的多核苷酸 | |
| WO2014056916A2 (en) | Polypeptides having peroxygenase activity |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20141125 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20150421 |