KR20120007002A - 압스크립션 기반 분자 검출 - Google Patents
압스크립션 기반 분자 검출 Download PDFInfo
- Publication number
- KR20120007002A KR20120007002A KR1020117024467A KR20117024467A KR20120007002A KR 20120007002 A KR20120007002 A KR 20120007002A KR 1020117024467 A KR1020117024467 A KR 1020117024467A KR 20117024467 A KR20117024467 A KR 20117024467A KR 20120007002 A KR20120007002 A KR 20120007002A
- Authority
- KR
- South Korea
- Prior art keywords
- dna
- sequence
- target
- primer
- tap
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 238000001514 detection method Methods 0.000 title description 68
- 238000010521 absorption reaction Methods 0.000 title description 10
- 108020004414 DNA Proteins 0.000 claims abstract description 248
- 238000000034 method Methods 0.000 claims abstract description 130
- 108091029523 CpG island Proteins 0.000 claims abstract description 55
- 239000013615 primer Substances 0.000 claims description 165
- 239000002987 primer (paints) Substances 0.000 claims description 165
- 102000040430 polynucleotide Human genes 0.000 claims description 70
- 239000002157 polynucleotide Substances 0.000 claims description 70
- 238000003752 polymerase chain reaction Methods 0.000 claims description 69
- 108091033319 polynucleotide Proteins 0.000 claims description 69
- 238000003199 nucleic acid amplification method Methods 0.000 claims description 63
- 125000003729 nucleotide group Chemical group 0.000 claims description 63
- 230000003321 amplification Effects 0.000 claims description 62
- 239000002773 nucleotide Substances 0.000 claims description 61
- 239000000523 sample Substances 0.000 claims description 54
- 239000011324 bead Substances 0.000 claims description 47
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 claims description 40
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 claims description 40
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 claims description 38
- 239000012634 fragment Substances 0.000 claims description 30
- 230000000295 complement effect Effects 0.000 claims description 29
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 claims description 24
- 239000007787 solid Substances 0.000 claims description 20
- 229960002685 biotin Drugs 0.000 claims description 19
- 235000020958 biotin Nutrition 0.000 claims description 19
- 239000011616 biotin Substances 0.000 claims description 19
- 238000004809 thin layer chromatography Methods 0.000 claims description 17
- 108091008146 restriction endonucleases Proteins 0.000 claims description 16
- 230000005291 magnetic effect Effects 0.000 claims description 14
- 108010024636 Glutathione Proteins 0.000 claims description 12
- 239000003153 chemical reaction reagent Substances 0.000 claims description 12
- 229960003180 glutathione Drugs 0.000 claims description 12
- 108010090804 Streptavidin Proteins 0.000 claims description 11
- 108020001507 fusion proteins Proteins 0.000 claims description 10
- 102000037865 fusion proteins Human genes 0.000 claims description 10
- 238000004949 mass spectrometry Methods 0.000 claims description 7
- 230000010076 replication Effects 0.000 claims description 7
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 claims description 5
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 claims description 5
- 238000005251 capillar electrophoresis Methods 0.000 claims description 3
- 230000003100 immobilizing effect Effects 0.000 claims description 3
- 238000000638 solvent extraction Methods 0.000 claims 1
- 230000011987 methylation Effects 0.000 abstract description 51
- 238000007069 methylation reaction Methods 0.000 abstract description 51
- 238000012546 transfer Methods 0.000 abstract description 8
- 239000000090 biomarker Substances 0.000 abstract 1
- 108091034117 Oligonucleotide Proteins 0.000 description 65
- 238000006243 chemical reaction Methods 0.000 description 41
- 108090000623 proteins and genes Proteins 0.000 description 40
- 206010028980 Neoplasm Diseases 0.000 description 33
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 31
- 238000009739 binding Methods 0.000 description 28
- 230000008569 process Effects 0.000 description 28
- 102000039446 nucleic acids Human genes 0.000 description 26
- 108020004707 nucleic acids Proteins 0.000 description 26
- 150000007523 nucleic acids Chemical class 0.000 description 26
- 230000027455 binding Effects 0.000 description 25
- 102000004169 proteins and genes Human genes 0.000 description 23
- 238000003556 assay Methods 0.000 description 22
- 235000018102 proteins Nutrition 0.000 description 22
- 238000013518 transcription Methods 0.000 description 22
- 230000035897 transcription Effects 0.000 description 22
- 201000011510 cancer Diseases 0.000 description 20
- LSNNMFCWUKXFEE-UHFFFAOYSA-M Bisulfite Chemical compound OS([O-])=O LSNNMFCWUKXFEE-UHFFFAOYSA-M 0.000 description 19
- 230000015572 biosynthetic process Effects 0.000 description 18
- 238000007906 compression Methods 0.000 description 17
- 230000006835 compression Effects 0.000 description 17
- 230000003993 interaction Effects 0.000 description 17
- 239000000047 product Substances 0.000 description 16
- 238000003786 synthesis reaction Methods 0.000 description 16
- 238000009396 hybridization Methods 0.000 description 14
- 238000000137 annealing Methods 0.000 description 13
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 13
- 239000003999 initiator Substances 0.000 description 13
- 102000005720 Glutathione transferase Human genes 0.000 description 12
- 108010070675 Glutathione transferase Proteins 0.000 description 12
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 12
- 238000003776 cleavage reaction Methods 0.000 description 11
- 238000005259 measurement Methods 0.000 description 11
- 230000035945 sensitivity Effects 0.000 description 11
- 241000282414 Homo sapiens Species 0.000 description 10
- 239000000872 buffer Substances 0.000 description 10
- 238000007855 methylation-specific PCR Methods 0.000 description 10
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 9
- 230000007017 scission Effects 0.000 description 9
- 210000004027 cell Anatomy 0.000 description 8
- 238000010828 elution Methods 0.000 description 8
- 230000002441 reversible effect Effects 0.000 description 8
- 239000006228 supernatant Substances 0.000 description 8
- 238000012360 testing method Methods 0.000 description 8
- 108091093088 Amplicon Proteins 0.000 description 7
- 108010037462 Cyclooxygenase 2 Proteins 0.000 description 7
- XQQIMTUYVDUWKJ-DJLDLDEBSA-N Ethenodeoxyadenosine Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CN2C3=NC=C2)=C3N=C1 XQQIMTUYVDUWKJ-DJLDLDEBSA-N 0.000 description 7
- 102100038280 Prostaglandin G/H synthase 2 Human genes 0.000 description 7
- 102100034803 Small nuclear ribonucleoprotein-associated protein N Human genes 0.000 description 7
- 230000029087 digestion Effects 0.000 description 7
- 108010039827 snRNP Core Proteins Proteins 0.000 description 7
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 6
- 230000006819 RNA synthesis Effects 0.000 description 6
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 6
- 239000002253 acid Substances 0.000 description 6
- 150000007513 acids Chemical class 0.000 description 6
- 230000008901 benefit Effects 0.000 description 6
- 239000012148 binding buffer Substances 0.000 description 6
- 229940104302 cytosine Drugs 0.000 description 6
- 238000013461 design Methods 0.000 description 6
- 230000000977 initiatory effect Effects 0.000 description 6
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 6
- 238000002493 microarray Methods 0.000 description 6
- 238000002156 mixing Methods 0.000 description 6
- 229920000642 polymer Polymers 0.000 description 6
- 239000013641 positive control Substances 0.000 description 6
- 238000002360 preparation method Methods 0.000 description 6
- 241000894007 species Species 0.000 description 6
- 210000001519 tissue Anatomy 0.000 description 6
- 210000004881 tumor cell Anatomy 0.000 description 6
- 108091029430 CpG site Proteins 0.000 description 5
- 108091028043 Nucleic acid sequence Proteins 0.000 description 5
- 238000012408 PCR amplification Methods 0.000 description 5
- 108700025716 Tumor Suppressor Genes Proteins 0.000 description 5
- 102000044209 Tumor Suppressor Genes Human genes 0.000 description 5
- 210000004369 blood Anatomy 0.000 description 5
- 239000008280 blood Substances 0.000 description 5
- 239000000539 dimer Substances 0.000 description 5
- 150000002500 ions Chemical class 0.000 description 5
- 238000004519 manufacturing process Methods 0.000 description 5
- 230000037452 priming Effects 0.000 description 5
- 239000000758 substrate Substances 0.000 description 5
- 230000002103 transcriptional effect Effects 0.000 description 5
- 230000004568 DNA-binding Effects 0.000 description 4
- 102000004190 Enzymes Human genes 0.000 description 4
- 108090000790 Enzymes Proteins 0.000 description 4
- 101000615488 Homo sapiens Methyl-CpG-binding domain protein 2 Proteins 0.000 description 4
- 102000006890 Methyl-CpG-Binding Protein 2 Human genes 0.000 description 4
- 108010072388 Methyl-CpG-Binding Protein 2 Proteins 0.000 description 4
- 102100021299 Methyl-CpG-binding domain protein 2 Human genes 0.000 description 4
- 238000011529 RT qPCR Methods 0.000 description 4
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 4
- 238000002487 chromatin immunoprecipitation Methods 0.000 description 4
- 230000000694 effects Effects 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 4
- 229940088598 enzyme Drugs 0.000 description 4
- 238000007667 floating Methods 0.000 description 4
- 238000010348 incorporation Methods 0.000 description 4
- 230000014759 maintenance of location Effects 0.000 description 4
- 238000012216 screening Methods 0.000 description 4
- 239000007790 solid phase Substances 0.000 description 4
- 239000000126 substance Substances 0.000 description 4
- 238000005406 washing Methods 0.000 description 4
- 102100024458 Cyclin-dependent kinase inhibitor 2A Human genes 0.000 description 3
- 102000053602 DNA Human genes 0.000 description 3
- 239000003155 DNA primer Substances 0.000 description 3
- 238000002965 ELISA Methods 0.000 description 3
- 241000588724 Escherichia coli Species 0.000 description 3
- 102100031181 Glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 3
- 108700043128 MBD2 Proteins 0.000 description 3
- MLZQJGWTFNIFJR-UFLZEWODSA-N N1C(N)=NC=2N=CNC2C1=O.OC(=O)CCCC[C@@H]1SC[C@@H]2NC(=O)N[C@H]12 Chemical compound N1C(N)=NC=2N=CNC2C1=O.OC(=O)CCCC[C@@H]1SC[C@@H]2NC(=O)N[C@H]12 MLZQJGWTFNIFJR-UFLZEWODSA-N 0.000 description 3
- 239000004677 Nylon Substances 0.000 description 3
- 238000002679 ablation Methods 0.000 description 3
- 238000000246 agarose gel electrophoresis Methods 0.000 description 3
- 150000001413 amino acids Chemical group 0.000 description 3
- 239000000427 antigen Substances 0.000 description 3
- 238000013459 approach Methods 0.000 description 3
- 239000003795 chemical substances by application Substances 0.000 description 3
- 230000001419 dependent effect Effects 0.000 description 3
- 239000012149 elution buffer Substances 0.000 description 3
- 238000002474 experimental method Methods 0.000 description 3
- 239000007850 fluorescent dye Substances 0.000 description 3
- 238000005194 fractionation Methods 0.000 description 3
- 239000011521 glass Substances 0.000 description 3
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 3
- 238000004128 high performance liquid chromatography Methods 0.000 description 3
- 230000006607 hypermethylation Effects 0.000 description 3
- 238000011534 incubation Methods 0.000 description 3
- 238000011835 investigation Methods 0.000 description 3
- 239000000463 material Substances 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 239000012528 membrane Substances 0.000 description 3
- 229920001778 nylon Polymers 0.000 description 3
- 210000000056 organ Anatomy 0.000 description 3
- 108090000765 processed proteins & peptides Proteins 0.000 description 3
- 238000011002 quantification Methods 0.000 description 3
- 238000011084 recovery Methods 0.000 description 3
- 238000005070 sampling Methods 0.000 description 3
- 239000011734 sodium Substances 0.000 description 3
- 239000011780 sodium chloride Substances 0.000 description 3
- 238000010186 staining Methods 0.000 description 3
- 239000011534 wash buffer Substances 0.000 description 3
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 2
- 101100294756 Caenorhabditis elegans ntp-1 gene Proteins 0.000 description 2
- 102000014914 Carrier Proteins Human genes 0.000 description 2
- 108010009392 Cyclin-Dependent Kinase Inhibitor p16 Proteins 0.000 description 2
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 2
- YCKRFDGAMUMZLT-UHFFFAOYSA-N Fluorine atom Chemical compound [F] YCKRFDGAMUMZLT-UHFFFAOYSA-N 0.000 description 2
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 2
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 2
- 108010058683 Immobilized Proteins Proteins 0.000 description 2
- KFZMGEQAYNKOFK-UHFFFAOYSA-N Isopropanol Chemical compound CC(C)O KFZMGEQAYNKOFK-UHFFFAOYSA-N 0.000 description 2
- 102100025825 Methylated-DNA-protein-cysteine methyltransferase Human genes 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- 239000000020 Nitrocellulose Substances 0.000 description 2
- 239000004793 Polystyrene Substances 0.000 description 2
- 206010036790 Productive cough Diseases 0.000 description 2
- 108090000190 Thrombin Proteins 0.000 description 2
- 108091023040 Transcription factor Proteins 0.000 description 2
- 102000040945 Transcription factor Human genes 0.000 description 2
- 239000007984 Tris EDTA buffer Substances 0.000 description 2
- 239000007983 Tris buffer Substances 0.000 description 2
- 230000001594 aberrant effect Effects 0.000 description 2
- 230000002159 abnormal effect Effects 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 230000006978 adaptation Effects 0.000 description 2
- 229960005305 adenosine Drugs 0.000 description 2
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine group Chemical group [C@@H]1([C@H](O)[C@H](O)[C@@H](CO)O1)N1C=NC=2C(N)=NC=NC12 OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 2
- 108091007433 antigens Proteins 0.000 description 2
- 102000036639 antigens Human genes 0.000 description 2
- 238000003491 array Methods 0.000 description 2
- 108091008324 binding proteins Proteins 0.000 description 2
- 210000001124 body fluid Anatomy 0.000 description 2
- 239000010839 body fluid Substances 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 238000004587 chromatography analysis Methods 0.000 description 2
- 238000012937 correction Methods 0.000 description 2
- 230000001351 cycling effect Effects 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 238000003745 diagnosis Methods 0.000 description 2
- 238000002405 diagnostic procedure Methods 0.000 description 2
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 2
- 229910052731 fluorine Inorganic materials 0.000 description 2
- 239000011737 fluorine Substances 0.000 description 2
- 230000007274 generation of a signal involved in cell-cell signaling Effects 0.000 description 2
- 238000010438 heat treatment Methods 0.000 description 2
- 238000000126 in silico method Methods 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 239000004816 latex Substances 0.000 description 2
- 229920000126 latex Polymers 0.000 description 2
- 239000003446 ligand Substances 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 108040008770 methylated-DNA-[protein]-cysteine S-methyltransferase activity proteins Proteins 0.000 description 2
- 239000000203 mixture Substances 0.000 description 2
- 230000035772 mutation Effects 0.000 description 2
- 239000013642 negative control Substances 0.000 description 2
- 229920001220 nitrocellulos Polymers 0.000 description 2
- 239000012071 phase Substances 0.000 description 2
- 229920001184 polypeptide Polymers 0.000 description 2
- 229920002223 polystyrene Polymers 0.000 description 2
- 102000004196 processed proteins & peptides Human genes 0.000 description 2
- 238000000159 protein binding assay Methods 0.000 description 2
- 238000002331 protein detection Methods 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- -1 rRNA Proteins 0.000 description 2
- 239000011541 reaction mixture Substances 0.000 description 2
- 230000002829 reductive effect Effects 0.000 description 2
- 239000011347 resin Substances 0.000 description 2
- 229920005989 resin Polymers 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 238000012163 sequencing technique Methods 0.000 description 2
- 229910052708 sodium Inorganic materials 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 238000001228 spectrum Methods 0.000 description 2
- 210000003802 sputum Anatomy 0.000 description 2
- 208000024794 sputum Diseases 0.000 description 2
- 230000002194 synthesizing effect Effects 0.000 description 2
- 229960004072 thrombin Drugs 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 2
- 231100000588 tumorigenic Toxicity 0.000 description 2
- 230000000381 tumorigenic effect Effects 0.000 description 2
- 230000007306 turnover Effects 0.000 description 2
- 229940035893 uracil Drugs 0.000 description 2
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- PBQSVGKAWZFQPO-UFLZEWODSA-N 5-[(3aS,4S,6aR)-2-oxo-1,3,3a,4,6,6a-hexahydrothieno[3,4-d]imidazol-4-yl]pentanoic acid 7H-purin-6-amine Chemical compound N1=CN=C2N=CNC2=C1N.OC(=O)CCCC[C@@H]1SC[C@@H]2NC(=O)N[C@H]12 PBQSVGKAWZFQPO-UFLZEWODSA-N 0.000 description 1
- LRSASMSXMSNRBT-UHFFFAOYSA-N 5-methylcytosine Chemical compound CC1=CNC(=O)N=C1N LRSASMSXMSNRBT-UHFFFAOYSA-N 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- OYJCVIGKMXUVKB-GARJFASQSA-N Ala-Leu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N OYJCVIGKMXUVKB-GARJFASQSA-N 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- VHUUQVKOLVNVRT-UHFFFAOYSA-N Ammonium hydroxide Chemical compound [NH4+].[OH-] VHUUQVKOLVNVRT-UHFFFAOYSA-N 0.000 description 1
- WVNFNPGXYADPPO-BQBZGAKWSA-N Arg-Gly-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O WVNFNPGXYADPPO-BQBZGAKWSA-N 0.000 description 1
- UZSQXCMNUPKLCC-FJXKBIBVSA-N Arg-Thr-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UZSQXCMNUPKLCC-FJXKBIBVSA-N 0.000 description 1
- QEYJFBMTSMLPKZ-ZKWXMUAHSA-N Asn-Ala-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O QEYJFBMTSMLPKZ-ZKWXMUAHSA-N 0.000 description 1
- KVPHTGVUMJGMCX-BIIVOSGPSA-N Asp-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N)C(=O)O KVPHTGVUMJGMCX-BIIVOSGPSA-N 0.000 description 1
- UMHUHHJMEXNSIV-CIUDSAMLSA-N Asp-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UMHUHHJMEXNSIV-CIUDSAMLSA-N 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- 101100512078 Caenorhabditis elegans lys-1 gene Proteins 0.000 description 1
- 208000005623 Carcinogenesis Diseases 0.000 description 1
- 102000053642 Catalytic RNA Human genes 0.000 description 1
- 108090000994 Catalytic RNA Proteins 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- 230000026641 DNA hypermethylation Effects 0.000 description 1
- 238000007399 DNA isolation Methods 0.000 description 1
- 230000007067 DNA methylation Effects 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 108010031042 Death-Associated Protein Kinases Proteins 0.000 description 1
- 102000005721 Death-Associated Protein Kinases Human genes 0.000 description 1
- 102100038587 Death-associated protein kinase 1 Human genes 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 241000709738 Enterobacteria phage fr Species 0.000 description 1
- 241000709744 Enterobacterio phage MS2 Species 0.000 description 1
- RFTVTKBHDXCEEX-WDSKDSINSA-N Glu-Ser-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RFTVTKBHDXCEEX-WDSKDSINSA-N 0.000 description 1
- 102100030943 Glutathione S-transferase P Human genes 0.000 description 1
- XMPXVJIDADUOQB-RCOVLWMOSA-N Gly-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C([O-])=O)NC(=O)CNC(=O)C[NH3+] XMPXVJIDADUOQB-RCOVLWMOSA-N 0.000 description 1
- NTBOEZICHOSJEE-YUMQZZPRSA-N Gly-Lys-Ser Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O NTBOEZICHOSJEE-YUMQZZPRSA-N 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 101000956145 Homo sapiens Death-associated protein kinase 1 Proteins 0.000 description 1
- 101001010139 Homo sapiens Glutathione S-transferase P Proteins 0.000 description 1
- 206010062717 Increased upper airway secretion Diseases 0.000 description 1
- LJHGALIOHLRRQN-DCAQKATOSA-N Leu-Ala-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LJHGALIOHLRRQN-DCAQKATOSA-N 0.000 description 1
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 1
- FDBTVENULFNTAL-XQQFMLRXSA-N Leu-Val-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N FDBTVENULFNTAL-XQQFMLRXSA-N 0.000 description 1
- CKSXSQUVEYCDIW-AVGNSLFASA-N Lys-Arg-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N CKSXSQUVEYCDIW-AVGNSLFASA-N 0.000 description 1
- PBIPLDMFHAICIP-DCAQKATOSA-N Lys-Glu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PBIPLDMFHAICIP-DCAQKATOSA-N 0.000 description 1
- INMBONMDMGPADT-AVGNSLFASA-N Lys-Met-Met Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CCCCN)N INMBONMDMGPADT-AVGNSLFASA-N 0.000 description 1
- XFOAWKDQMRMCDN-ULQDDVLXSA-N Lys-Phe-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CCCCN)CC1=CC=CC=C1 XFOAWKDQMRMCDN-ULQDDVLXSA-N 0.000 description 1
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 1
- 206010027146 Melanoderma Diseases 0.000 description 1
- 241000699666 Mus <mouse, genus> Species 0.000 description 1
- 241000699660 Mus musculus Species 0.000 description 1
- JBGUABYKJUDGTK-UFLZEWODSA-N N1C(=O)N=C(N)C=C1.OC(=O)CCCC[C@@H]1SC[C@@H]2NC(=O)N[C@H]12 Chemical compound N1C(=O)N=C(N)C=C1.OC(=O)CCCC[C@@H]1SC[C@@H]2NC(=O)N[C@H]12 JBGUABYKJUDGTK-UFLZEWODSA-N 0.000 description 1
- SXDXWIKQDGPTEE-UFLZEWODSA-N N1C(=O)NC(=O)C(C)=C1.OC(=O)CCCC[C@@H]1SC[C@@H]2NC(=O)N[C@H]12 Chemical compound N1C(=O)NC(=O)C(C)=C1.OC(=O)CCCC[C@@H]1SC[C@@H]2NC(=O)N[C@H]12 SXDXWIKQDGPTEE-UFLZEWODSA-N 0.000 description 1
- 206010061309 Neoplasm progression Diseases 0.000 description 1
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 1
- 108020005187 Oligonucleotide Probes Proteins 0.000 description 1
- 101150000187 PTGS2 gene Proteins 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- QSWKNJAPHQDAAS-MELADBBJSA-N Phe-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O QSWKNJAPHQDAAS-MELADBBJSA-N 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- FEPSEIDIPBMIOS-QXEWZRGKSA-N Pro-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 FEPSEIDIPBMIOS-QXEWZRGKSA-N 0.000 description 1
- FFSLAIOXRMOFIZ-GJZGRUSLSA-N Pro-Gly-Trp Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)O)C(=O)CNC(=O)[C@@H]1CCCN1 FFSLAIOXRMOFIZ-GJZGRUSLSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 102000055027 Protein Methyltransferases Human genes 0.000 description 1
- 108700040121 Protein Methyltransferases Proteins 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- 241000607142 Salmonella Species 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 1
- WSTIOCFMWXNOCX-YUMQZZPRSA-N Ser-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N WSTIOCFMWXNOCX-YUMQZZPRSA-N 0.000 description 1
- PTWIYDNFWPXQSD-GARJFASQSA-N Ser-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N)C(=O)O PTWIYDNFWPXQSD-GARJFASQSA-N 0.000 description 1
- UGTZYIPOBYXWRW-SRVKXCTJSA-N Ser-Phe-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O UGTZYIPOBYXWRW-SRVKXCTJSA-N 0.000 description 1
- 241000270295 Serpentes Species 0.000 description 1
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- 101710136739 Teichoic acid poly(glycerol phosphate) polymerase Proteins 0.000 description 1
- 108700009124 Transcription Initiation Site Proteins 0.000 description 1
- DWAMXBFJNZIHMC-KBPBESRZSA-N Tyr-Leu-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O DWAMXBFJNZIHMC-KBPBESRZSA-N 0.000 description 1
- KDKLLPMFFGYQJD-CYDGBPFRSA-N Val-Ile-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N KDKLLPMFFGYQJD-CYDGBPFRSA-N 0.000 description 1
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 1
- 230000005856 abnormality Effects 0.000 description 1
- 206010000210 abortion Diseases 0.000 description 1
- 231100000176 abortion Toxicity 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 239000007801 affinity label Substances 0.000 description 1
- 108010047495 alanylglycine Proteins 0.000 description 1
- 235000001014 amino acid Nutrition 0.000 description 1
- 239000000908 ammonium hydroxide Substances 0.000 description 1
- 108010062796 arginyllysine Proteins 0.000 description 1
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 1
- 239000012620 biological material Substances 0.000 description 1
- 238000001369 bisulfite sequencing Methods 0.000 description 1
- 238000009534 blood test Methods 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- 230000036952 cancer formation Effects 0.000 description 1
- 230000005907 cancer growth Effects 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- 231100000504 carcinogenesis Toxicity 0.000 description 1
- 230000022131 cell cycle Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 238000003759 clinical diagnosis Methods 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 239000013068 control sample Substances 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 230000009260 cross reactivity Effects 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 230000009615 deamination Effects 0.000 description 1
- 238000006481 deamination reaction Methods 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 238000004925 denaturation Methods 0.000 description 1
- 230000036425 denaturation Effects 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000010454 developmental mechanism Effects 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 238000009509 drug development Methods 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 239000000975 dye Substances 0.000 description 1
- 238000013399 early diagnosis Methods 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- 238000001976 enzyme digestion Methods 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- 238000001215 fluorescent labelling Methods 0.000 description 1
- 235000013305 food Nutrition 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 238000005227 gel permeation chromatography Methods 0.000 description 1
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 1
- 108010050848 glycylleucine Proteins 0.000 description 1
- 108010015792 glycyllysine Proteins 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 238000010501 iterative synthesis reaction Methods 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 1
- 201000005243 lung squamous cell carcinoma Diseases 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 238000001465 metallisation Methods 0.000 description 1
- 230000001394 metastastic effect Effects 0.000 description 1
- 206010061289 metastatic neoplasm Diseases 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- 102000031635 methyl-CpG binding proteins Human genes 0.000 description 1
- 108091009877 methyl-CpG binding proteins Proteins 0.000 description 1
- 239000011859 microparticle Substances 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 230000004660 morphological change Effects 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- 239000002853 nucleic acid probe Substances 0.000 description 1
- 238000001668 nucleic acid synthesis Methods 0.000 description 1
- 239000002777 nucleoside Substances 0.000 description 1
- 239000002751 oligonucleotide probe Substances 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 238000012803 optimization experiment Methods 0.000 description 1
- 230000005298 paramagnetic effect Effects 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 238000005192 partition Methods 0.000 description 1
- 102000013415 peroxidase activity proteins Human genes 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 208000026435 phlegm Diseases 0.000 description 1
- 239000013612 plasmid Substances 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 239000004800 polyvinyl chloride Substances 0.000 description 1
- 238000007781 pre-processing Methods 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000000750 progressive effect Effects 0.000 description 1
- 108010031719 prolyl-serine Proteins 0.000 description 1
- 108010004914 prolylarginine Proteins 0.000 description 1
- WQGWDDDVZFFDIG-UHFFFAOYSA-N pyrogallol Chemical compound OC1=CC=CC(O)=C1O WQGWDDDVZFFDIG-UHFFFAOYSA-N 0.000 description 1
- 238000012175 pyrosequencing Methods 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 229910052761 rare earth metal Inorganic materials 0.000 description 1
- 150000002910 rare earth metals Chemical class 0.000 description 1
- 238000003753 real-time PCR Methods 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 230000003252 repetitive effect Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 108091092562 ribozyme Proteins 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 238000012772 sequence design Methods 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 108010026333 seryl-proline Proteins 0.000 description 1
- 238000010008 shearing Methods 0.000 description 1
- 239000000741 silica gel Substances 0.000 description 1
- 229910002027 silica gel Inorganic materials 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 238000000527 sonication Methods 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 238000004448 titration Methods 0.000 description 1
- 239000001226 triphosphate Substances 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- 230000005751 tumor progression Effects 0.000 description 1
- 238000002562 urinalysis Methods 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 239000013598 vector Substances 0.000 description 1
- 238000012800 visualization Methods 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
Images







Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6844—Nucleic acid amplification reactions
- C12Q1/686—Polymerase chain reaction [PCR]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/117—Nucleic acids having immunomodulatory properties, e.g. containing CpG-motifs
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/154—Methylation markers
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Genetics & Genomics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Molecular Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Immunology (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- Analytical Chemistry (AREA)
- Biomedical Technology (AREA)
- Plant Pathology (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
본 발명은 압스크립션® 및 불완전 전사 기술에 기초하여 바이오마커를 검출하는 방법을 제공한다. 특히, 본 발명은 조그만 DNA 샘플로부터 CpG 섬의 메틸화를 검출하기 위한 중아황산염 프리 방법을 제공한다. 본 방법은 멀티플렉싱, 즉 복합법에 적합하고, 단 시간에 단일 샘플로부터 다수의 CpG 섬을 분석하기 위해 사용될 수 있다.
Description
본 발명은 2009년 3월 15일자로 제출된 미국 가출원 번호 61/160,335을 기초로 하여 우선권주장하고, 그 출원의 전체 내용은 여기에 참조로 통합되어 있다.
암은 세포 사이의 상호 작용을 중재하고 세포 분할 사이클을 조절하는 다수의 종양-억제 유전자의 표출을 통하여 적극적으로 회피된다. 양성 및 악성 종양에 대한 연구에 의하면, 암은 무작위로 원(原) 종양 형성 유전자의 표출을 촉진시키거나 또는 종양-억제자 유전자 및 DNA 교정 유전자의 표출 또는 작용을 감소시키도록 변화하는, 무작위로 축적된 다수 단계의 프로세스를 통하여 생기게 된다. 신체의 돌연변이가 종양-억제 유전자 및 DNA 교정 유전자에서의 이러한 변화 중 일부를 설명한다. 그러나, DNA 과다메틸화 및 과소메틸화와 같은 유전 외적 변화 또한 종양 억제 유전자 또는 원 종양 형성 유전자의 불활성화 또는 촉진을 통하여 암을 유발시킴에 있어서 큰 역할을 함이 최근에 명백해졌다. CpG 프로모터 섬(island)의 과다메틸화는 암 발생 초기 단계에 일어나서 모든 종양에서 발견되므로, 이는 진단 표시자로서 매우 유용하고, 나아가 암의 치료가 효과적인 초기 단계에서 비외과적으로 검출될 수 있게 한다. 예컨대, 전하는 바에 따르면, DAP 키나아제, p16과 MGMT와 같은 유전자의 프로모터 부위의 과다메틸화는 편평세포폐암종(Belinsky et al .(2006). Cancer Res. 66:3338-44, Palmisano et al . 2000.Cancer Res. 60:5954-8)의 진단 이전 3년까지 흡연자의 가래에서 검출된다. 유전자의 소규모 패널의 과다메틸화는 유방 암의 초기 단계에 검출되었지만, 정상 또는 양성 유방 조직(Krassenstein et al . (2004). Clin Cancer Res. 10:28-32)에서는 검출되지 않았다.
CpG 섬에서 시토신의 메틸화는 종양 억제 유전자를 포함하여 많은 유전자의 감소된 발현을 야기하는 대부분의 암에서 초기 나타나는 일이다. 종양 세포 DNA에서 CpG 섬 메탈화의 조사는 이와 같은 유전 외적 변화가 종양 진행에서 돌연변이의 영향과 충분히 필적할만큼 일반적이라는 것을 암시한다. 비정상적인 메틸화의 초기 검출은 치료가 매우 효과적일 때 규칙적 선별검사 및 초기 진단을 가능하게 할 수 있다. 초기의 유전 외적 변화는 단지 종양 조직 그 자체에서가 아닌, 혈청 또는 다른 체액(오줌, 가래, 침)에서 종종 검출되고, 이는 유전 외적 진단 테스트가 이러한 체액 등을 사용하여 비외과적으로 수행될 수 있다. CpG 섬 메틸화에 기초한 진단 테스트는 또한 약물 개발, 그러한 약물에 반응하는 환자 집단의 식별 및 치료 후 모니터링을 위해서도 이용될 수 있다. 특이 암에 대한 메틸화 특징의 설명 및 메틸화 검출의 민감도에서의 최근 개선됨에 따라 체액으로부터 DNA를 샘플링함으로써 종양을 시험하는 것을 가능하게 해 왔다. 종양 세포는 질병의 비교적 초기 단계로부터 DNA를 혈액으로 방출한다. 암 환자의 혈액내 DNA 중 3% 내지 90% 이상이 종양 기원(origin)(Kim et al .(2004) J. Clin. Oncol. 22:2363-70)인 것으로 알려져 있다. PCR-기반 메틸화 분석법의 발전은 혈액, 가래 및 오줌으로부터 종양의 존재를 비외과적으로 검출할 수 있도록 하였다. 한 연구에서 메틸화 검출은 이상(aberrant) 암전이 세포를 검출함에 있어서 요세포진(尿細胞診) 보다 더 민감하였다. 임상적 민감도는 단일 메틸화 표시자를 사용하는 혈액 샘플의 조사에서 전형적으로 낮다. 그러나, 혈액 샘플로부터의 임상적 특이성은 100%에 근접한다. 임상적 민감도는 단일 CpG 섬 그 이상을 평가하는 메틸화 테스트와 함께 증가되어야 한다.
체액 그 자체에서의 비정상적 메틸화 DNA의 출현은 어떠한 기관이 종양에 의해 영향을 받는지를 정확히 보여주는데 도움이 되지 않는다. 놀랍게도 종양의 조직 기원을 규명하는데는 적은 정보가 필요하다. 다수의 메틸화 선별검사 연구는 메틸화 특징; 메틸화된 CpG 섬의 집합체가 특이 기관으로부터의 암과 강하게 연관된다는 것을 규명하였다. 어느 한 조사에서, 3 내지 4 후보 CpG 섬의 이상 메틸화는 15가지 암 타입의 70-90%를 식별하기에 충분하였다(Esteller et al . (2001) Cancer Res. 61:3225-9). 일반적인 종양에 대하여 개발된 메틸화 프로필은 모 종양의 조직 기원을 정확히 식별하기 위하여 종양 세포 라인에 적용될 수 있다(Graziano et al. (2004) Clin. Cancer Res. 10:2784).
이러한 결과는 다른 종양 타입의 메틸화 특징이 배양 조직의 성장과 연관된 선택압에 의해 크게 영향받지 않는다는 것을 암시한다. 메틸화 프로필의 유용성은 단순한 혈액 테스트를 통하여 접근할 수 있는 기관내의 암을 검출할 수 있는 능력을 크게 향상시킨다.
임상 샘플에서 메틸화의 검출은 암의 초기 검출을 가능하게 할 것이다. 간단하고 민감한 다중 검출 분석법의 발전은 작은 임상 샘플이 다양한 CpG 섬의 상태에 대하여 프로필화되는 것을 가능하게 할 것이다. 이런 종류의 정보는 진단 및 치료에서 매우 중요해질 것이다.
DNA
메틸화를 검출하는 방법
다수의 방법이 표적 DNA내의 메틸화-CpG(mCpG)를 검출하기 위하여 사용되어져 왔다. 현재 사용되는 주된 세가지의 방법이 아래에 기술되어 진다.
중아황산염법 ( Bisulfite Method ) . 가장 일반적으로 사용되는 메틸화 검출 방법은 DNA의 중아황산염 변이에 기초한다. 이는 메틸화된 시토신을 바뀌지 않는 상태로 남겨두는 동안 시토신 잔기를 우라실로 탈아미노화시키는 결과를 초래한다. PCR 증폭되자 마자, 메틸화된 시토신은 시토신으로 복제되고, 우라실은 티민으로 복제된다. 결과적으로, 특정 위치에서 시토신의 정체 내지 잔류는 메틸화를 의미한다. 그 다음, 변이된 DNA가 예컨대 서열 분석, 메틸화-특이 PCR (MSP)(Herman et al . (1996) Proc. Natl. Acad. Sci. USA 93:9821-26), 또는 하이브리드화(hybridize)(예컨대, 마이크로어레이 또는 블롯(blot)으로)에 의해 분석된다. MSP에서, 한 쌍의 메틸화-특이 올리고뉴클레오티드 프라이머가 중아황산염-처리 DNA에 부가되고, PCR이 표적 DNA를 증폭시키기 위하여 수행된다. 형광-기반 정량 실시간 PCR 또한 중아황산염-변이 DNA에 수행될 수 있다(Eads et al . (2000) Nucl. Acids Res. 28:E32; Zeschnigk et al . (2004) Nucl. Acids Res. 32:e125).
보정된, MSP의 형광-기반 변형체는 샘플에서 메틸화된 DNA 양의 정량화를 제공하기 위하여 실시간 PCR을 이용한다. 이러한 PCR 기반 방법의 중요하고 근본적인 가정은 프라이머/프로브에 의해 알아차려지는 몇몇 CpG 부위들이 표적 CpG 섬의 전체 상태를 반영한다 라는 것이다. 통상적으로 이는 심하게 메틸화되거나 또는 완전히 비메틸화된 섬에 대하여는 사실인 반면, 부분적으로 메틸화된 표적은 아마 메틸화- 또는 비메틸화-특이 반응으로 기록되지 않는다.
중아황산염 변이의 이점은 비메틸화된 부위와 대조적으로 메틸화된 부위를 다르게 표지함으로써 메틸화 패턴을 검출하는 서열 방법을 제공한다는 점이다. 복제된 중아황산염-처리 DNA를 서열화하는 것은 메틸화 검출을 위해 가장 일반적으로 사용되는 방법이다. 그것은 MSP 기반 방법 보다 훨씬 더 많은 수의 CpG 부위를 샘플링하는 것에 더하여, 중아황산염 처치의 성공에 대한 정보를 제공한다. 그러나, 그것의 복잡성 및 비용 때문에, 중아황산염 서열화는 임상적 진단 보다는 표시자 발견에 더 적합하다. 중아황산염 처치는 입력 DNA의 상당비율을 파괴하고, 이는 제한된 민감도 및 상당량의 DNA를 필요로 하게 된다. 중아황산염 처리된 DNA의 품질관리 평가가 잘못된 결과를 회피하기 위하여 검출 시험을 수행하기 이전에 행하여질 필요가 있다. 중아황산염 처치 동안의 불완전한 시토신 탈아미노화 때문에, MSP-기반 측정법에 비하여 잠재적인 거짓양성 결과가 있을 수 있다. 중아황산염 처리 DNA의 증폭은 비메탈화된 DNA를 돕는 PCR 바이어스에 의해 영향받는다. 이러한 문제점은 통상 프라이머 어닐링 조건을 최적화시킴으로써 교정될 수 있지만, 이는 프라이머 디자인 및 테스팅을 복잡하게 한다. 디지털 중아황산염-PCR을 사용함으로써 템플릿 바이어스는 제거될 수 있다. 반응 당 평균 한 복사체 이하로의 DNA 희석은 템플릿 사이의 경쟁을 제거한다. 개개의 분자는 클로닝에 의해 도입된 바이어스 없이 서열화될 수 있다.
mCpG를 분석하기 위하여 중아황산염 처치를 채택한 상업적인 키트, 시약 및 시스템이 이용가능하다. 발생기구학(Berlin)은 두가지 다른 변형체의 메티라이트 분석법(MethyLight assay), 정량 메티라이트(Quantitative MethyLight (QM))라 불려지는 정량 실시간 PCR의 적응 및 헤비 메틸(xHeavy Methyl(HM))을 제공한다. QM은 형광성 신호를 발생시키기 위하여 타크만(Taqman®) 프로브를 이용한다. 증폭 과정 동안에, 불소가 타크만 프로브로부터 분할되고, 이는 결과적으로 형광성이 실시간으로 검출될 수 있게 한다(Wojdacz & Dobrovic (2007) Nucl. Acids Res. 35:e41). HM은 차단제 올리고뉴클레오티드가 반응에 첨가되는 QM의 적응이다. 이러한 차단제 뉴클레오티드는 비메틸화된 DNA의 증폭을 방지하고, 이는 결과적으로 증대된 측정 민감도를 가져온다 (Cottrell et al . (2004) Nucl. Acids Res. 32:e10). 파이로시퀀싱(Pyrosequencing®)은 또한 바이오타제(Biotage)로부터의 파이로 Q-CpGTM 시스템에 의해 예시된 바와 같이, 중아황산염-변이 DNA로부터의 메틸화 정량화에 이용될 수 있다(Uppsala, Sweden; Tost et al. (2003) Biotechniques 35:152-56).
비록 중아황산염 변이가 널리 사용될지라도, 그것이 야기하는 광범위한 DNA 분해 또는 붕괴는 소수의 분자가 증폭되기에 충분히 길 때 샘플링 에러를 가져올 수 있다(Ehrich et al . (2007) Nucl. Acids Res. 35:e29). 게다가, 그 측정법은 시간 소모적이며, 가혹한 기질 변성 단계를 요하고, 중아황산염 처치 동안의 불안정한 시토신 탈아미노화 때문에 높은 확율의 거짓양성 결과를 초래한다.
메틸화-민감성 제한 효소 소화법 . DNA에서 mCpG를 검출하는 두가지 타입의 방법은 제한 엔도뉴클레아제에 의한 차별적 절단에 의존한다. DNA는 MSRE(메틸화-민감성 제한 엔도뉴클레아제) 또는 MDRE(메틸화 의존 제한 엔도뉴클레아제)에 의해 처리되고, 증폭되고, 그 다음에 마이크로어레이 또는 겔전기영동에 의해 분석된다. HpaII 및 AciI와 같은 MSRE는 그것이 만약 비메틸화된 경우 DNA 서열을 절단한다. MDRE는 절단을 위해 DNA 서열의 메틸화를 필요로 하는 제한 엔도뉴클레아제이다. DNA 샘플을 이러한 효소 중 어느 하나로 처리하고 이어서 대조 샘플과 대조함으로써, DNA 샘플의 메틸화 상태가 결정될 수 있다. MDRE로 처리된 후, 특이 DNA 샘플의 소화가 일어나면, 그 DNA는 메틸화된 것으로 간주될 수 있다. 역으로, 그 DNA가 MSRE로 처리되었을 때 절단되지 않으면, 그 샘플은 메틸화된 것으로 간주될 수 있다. 절단된 양과 절단되지 않은 DNA의 양을 비교함으로써, 메틸화 정도가 예측될 수 있다. 이러한 타입의 메틸화 분석을 위한 일반적 판독법은 이어지는 증폭단계 및 소화된 DNA의 형광 레이벌링 단계를 거치는 것이다. 그 다음, 단편은 라이브러리 마이크로어레이로 하이브리드화되고, 전기 이동에 의해 분석 또는 간단히 해결될 수 있다.
상업적으로 이용가능한 제한 엔도뉴클레아제-기반 시스템은 마이크로어레이 판독법(Lippman et al . (2004) Nature 430:471-76)을 이용하는 오리온스 메틸스코프(Orion's MethylScope) 및 정량적 실시간 PCR(Ordway et al . (2006) Carcinogenesis 27:2409-23)을 채택한 메티스크린(MethyScreen)을 포함한다.
비록 DNA의 중아황산염 처리와 관련하여 코브라(COBRA (Xiong & Laird (1997) Nucl. Acids Res. 25:2532-34))라 불려지는 과정에서 종종 수행되지만, MSRE/MDRE 소화법의 이점은 DNA의 사전-처리가 필요하지 않다는 점이다. 이러한 과정에서 일부 단점은 너무 시간이 걸리고 표적 DNA내의 MSRE/MDRE 인식 서열의 존재에 의존적이라는 것이다. 게다가, 이러한 접근법은 비교적 비효율적이고, 이는 그 결과치의 신뢰도를 감소시킬 수 있다. 평가되는 CpG 부위는 소수의 제한 효소 인식 부위내에 있는 것뿐이며, 그러한 부위의 상태는 그 부위가 속하는 전체 CpG 섬의 상태를 반영하지 않을 수 있다. 불완전한 소화는 특히 절단 반응이 이어지는 증폭 단계에 종속될 때 종종 거짓 양성을 야기한다. 제한 엔도뉴클레아제 절단 측정법은 MSP와 같은 중아황산염 방법과 비교해 볼 때 민감도가 매우 떨어지며, 이는 샘플에서 적어도 10% 메틸화된 DNA의 검출을 가능하게 한다 (Singer-Sam et al . Nucleic Acids Res, 1990. 18:687; Yegnasubramanian et al . Nucleic Acids Res. (2006) 34:e19).
염색질 면역침강법. mCpG를 검출하기 위해 일반적으로 채택되는 세번째 방법은 염색질 면역침강법(ChIP)이다. 전형적으로, 세포들은 고정되고, 그 다음 메틸화된 DNA는 메틸 결합 단백질을 위해 특정된 항체를 사용하여 면역침강된다. 결과적인 DNA는 증폭되고, 라벨링되고, 마이크로어레이 분석법에서의 하이브리드화로 분석된다. 이러한 방법의 이점은 상기 측정법이 적은 량의 살아있는 세포로부터 수행될 수 있고 또는 DNA 정제가 요구되지 않는다는 점이다. 이러한 측정법은 또한 불필요하고 오염된 DNA가 분석 이전에 제거되기 때문에, 민감도를 증대시킨다. 그러나, ChIP 방법은 매우 시간 소모적이고, 여러 단계와 관련되고, 값비싼 시약을 필요로 한다. 어떤 측정법은 완료하는데 5일만큼의 시간이 걸린다.
메틸 결합 단백질을 사용하는 방법 . 비메틸화된 DNA들로부터 메틸화된 DNA를 분리하에 있어서 대안적이고 보다 민감도가 높은 접근접은 메틸-CpG 결합 영역(MBD) 단백질 또는 5-메틸-C에 대항하는 항체를 사용하는 것과 관련된다. MBD 단백질은 메틸화 CpG 부위에 대하여 높은 친화력을 가지고, 비메틸화된 DNA에 대하여는 매우 낮은 친화력을 가진다 (Fraga et al . Nucleic Acids Res. (2003) 31:1765-74). 샘플은 다양한 포맷 (자성 비드, 기둥, PCR 튜브 벽)으로 고정화된 MBD 단백질과 함께 배양된다. 메틸화 DNA 포획은 통상 포획된 DNA의 증폭 이전에 선행된다. MBD-기반 DNA 검출은 메틸화된 부위 모두가 결합에 기여할 수 있어, 전체 섬이 메틸-CpGs에 대하여 샘플링되는 것을 허용한다는 주된 이점을 가진다. 이러한 특징은 부분적으로 메틸화된 섬에서 비메틸화된 부위가 프라이머/프로브 부위에 대응될 때, 그 결합 측정법이 MSP 및 제한 엔도뉴클레아제-기반 측정법에 영향을 줄 수 있는 거짓 음성에 덜 취약하도록 한다(Yegnasubramanian et al.Nucleic Acids Res. (2006) 34:e19). 이러한 상황은 부분적으로 메틸화된 CpG 섬을 함유하는 초기 단계 종양 세포를 포함하는 임상 샘플에서 일반적이다. MBD 기반 결합 측정법은 매우 민감도가 높아, 메틸화된 DNA의 160pg (~25 세포와 동등함) 또는 500 비메틸화 분자내에서의 1 메틸화 분자까지 검출할 수 있게 한다(Gebhard et al . Nucleic Acids Res. (2006) 34:e8256). 이는 MSP (1 메틸화 분자/1,000 비메틸화 분자)의 민감도에 근접한다. 컴페어 MBD(COMPARE MBD) 측정법은 결합 단계 이전에 HpaII ( MSRE)로 소화시키는 단계를 포함시킴으로써 실시간 MSP (1 메틸화 분자/10,000 비메틸화 분자) 만큼 민감할 수 있다. PCR 프라이밍 부위들 사이의 위치에서 비메틸화 DNA의 절단은 완전히 메틸화된 인공 메틸화 DNA를 함유하는 DNA와 함께 높은 민감도를 제공한다(Yegnasubramanian et al . Nucleic Acids Res. (2006) 34:e19). 그러나, 이러한 전략은 일부 부분적으로 메틸화된 섬이 임상 샘플에서 비메틸화된 것으로 기록될 수 있다는 점에서 제한 엔도뉴클레아제의 사용과 관련된 불이익을 줄 수 있다(Yegnasubramanian, et al.supra).
암 성장 및 진화에서 CpG 메틸화가 중요하기 때문에, 메틸화 CpG DNA을 위한 빠르고 신뢰성 있고 민감한 테스트는 암 선별검사를 위하여 중요하고 유용한 도구를 제공하게 될 것이다.
발명의 개요
본 발명은 샘플에서 적어도 하나의 표적 폴리뉴클레오티드를 검출하기 위한 방법을 제공한다. 이 방법은 개괄적으로 표적 폴리뉴클레오티드를 함유하는 샘플을, 폴리뉴클레오티드의 표적 서열에 특이적으로 하이브리드화하고 폴리뉴클레오티드의 표적 서열을 증폭시키는 프라이머 쌍과 접촉시키는 단계를 수반한다. 이 단계에 있어서, 프라이머 쌍은 표적 폴리뉴클레오티드 서열에 인접하는 제 1 서열에 상보적인 3' 서열과, 5' 포획 태그를 갖는 제 1 프라이머를 포함한다. 이 쌍의 제 2 프라이머는 반대쪽 가닥 위의 폴리뉴클레오티드 표적 서열에 인접하는 제 2 서열에 상보적인 3' 서열과, 압스크립션을 다이렉팅하기 위한 수단을 제공하는 5' 서열을 갖는다. 이 프라이머 쌍을 사용하여 증폭시킨 후에 (예를 들어, PCR), 증폭된 표적 서열을 5' 포획 태그를 결속시키는 고정화 분자와 접촉시킴으로써, 상기 증폭된 표적 서열을 포획한다. 적어도 하나의 압스크립트는 그후 압스크립션을 다이렉팅하기 위한 수단으로부터 전사되고 압스크립트가 표적 폴리뉴클레오티드의 존재의 표시로서 검출된다.
포획은 전형적으로 고체 지지체에 결합되거나 결합될 수 있는 친화력 시약 또는 결합 쌍을 통해 될 것이다. 예를 들어, 5' 포획 태그는 비오틴이 될 수 있으며, 이것은 올리고뉴클레오티드 프라이머 안에 쉽게 혼입될 수 있고, 5' 포획 태그에 결합되는 분자는 고체 지지체 위에 스트렙타아비딘 고정화될 수 있다. 예컨대 비즈, 튜브, 및 마이크로타이터 플레이트와 같은 여러가지 고체 지지체가 본 발명의 방법에 사용하기에 적합하다. 편리하게도, 스텝타비딘 및 다른 결합 쌍 분자는 용액중에 비결합 시약으로부터 고체 상의 신속한 분리를 허용하는 자성 비드에 결합될 수 있다. 본 발명의 특정 실시예에서, 비결합 시약, 프라이머, 및 폴리뉴클레오티드는 과정에 있어서 다음 단계에 앞서, 고정화 및 포획된 폴리뉴클레오티드로부터 세척될 수 있고, 이것은 방법의 효율성을 증가시킬 수 있다. 그러나, 이것은 전체 방법이 분리 단계 없이 단일 포트나 튜브에서 수행될 수 있을 때는 필요하지 않다.
PCR는 일반적으로 예를 들어, 내열성 DNA 폴리머라제 또는 내열성 RNA 폴리머라제를 사용하는 증폭 단계에 사용된다. 하지만, 당업계에 공지된 다양한 표적 증폭 방법은 본 발명의 방법에 사용하기에 적합할 수 있다.
본원에 기술된 바와 같이 압스크립트를 검출하기 위해서는 이것들로 제한되지는 않지만, 질량 분석법, 모세관 전기이동 또는 박층 크로마토그래피를 포함하여, 다양한 방법이 이용가능하다. 특정 양태에서는, 검출가능하게 표지된 뉴클레오티드 또는 다른 표지를 본 발명의 방법에 의해 발생된 압스크립트 신호 안에 혼입시킴으로써, 사용될 수 있는 검출 기술의 민감도를 증가시키거나 확장할 수 있다. 예를 들어, 검출가능하게 표지된 뉴클레오티드는 형광성 뉴클레오티드일 수 있다.
본 발명에 의해 발생된 압스크립트는 일반적으로 길이가 짧을 것이다 (예를 들어 3-20 뉴클레오티드). 길이가 3 뉴클레오티드만큼 짧은 압스크립트가 본원에 기재된 방법에 일반적으로 사용된다.
증폭 중에 사용된 쌍의 제 2 프라이머는 반대쪽 가닥위에 폴리뉴클레오티드의 표적 서열에 인접하는 제 2 서열에 상보적인 3' 서열과, 압스크립션을 다이렉팅하기 위한 수단을 제공하는 5' 서열을 갖는다.
특정 실시예에서, 상기 수단은 표적을 태그화하거나 확인하는데 사용되는 α-TAP (표적 부착 프로브) 서열에 의해 제공된다. α-TAP는 TAP 서열에 상보적으로 설계되며 APC(Abortive Promoter Cassette: 불완전 프로모터 카세트)의 부착을 허용한다. α-TAP을 단일 가닥으로서 유지하고 그로써 TAP 서열에 하이브리드화를 이용가능하게 하기 위해서, 비-천연 뉴클레오티드가 5' α-TAP 서열과, 프라이머에서 표적에 인접하는 서열에 상보적인 3' 서열 사이에 포함될 수 있다. 비-천연 뉴클레오티드, 예컨대 에테노-디옥시아데노신은 증폭 중에 폴리머라제에 의해 인식되지 않는다. 따라서, 프라이머에서 비-천연 뉴클레오티드로부터의 하류의 서열은 복제되지 않고 그 서열들은 외가닥으로 남아있다.
일단 APC가, 형성되는 TAP-α-TAP 하이브리드를 통해 증폭된 표적에 결합되면, 압스크립트는 표적의 존재를 검출하기 위한 표시 또는 신호로서 APC 로부터 전사된다. 결합되는 APC는 이중 가닥 부분이거나 또는 프로브의 하이브리드화에 의해 이중 가닥으로 만들어진다.
본 발명의 특정 실시예에서, 완전한 중복 APC가 증폭 반응 동안에 APC의 하나의 가닥을 포함하는 프라이머 서열로부터 발생될 수 있다. 편리하게도, 압스크립션는 내열성 RNA 폴리머라제와 뉴클레오티드를 반응에 포함함으로써 증폭 중에 수행될 수 있다. 이와 같이, 이 실시예에서는, 증폭 반응을 위한 제 2 프라이머가 APC 서열을 포함한다. 중복 APC가 발생될 때 (예를 들어 PCR에 의해), 압스크립트는 APC로부터 전사되고 그들이 생산될 때 검출되거나 (예를 들어, 실시간으로), 또는 본원에 기재된 압스크립트 검출 방법에 의해 나중에 분석될 수 있다.
본 발명은 PCR과 비교할 때 검출 기술의 확대된 레퍼토리를 가지고, DNA 및 RNA 표적을 포함하는, 관심의 대상인 다양한 표적 폴리뉴클레오티드를 검출하기 위해 신속하고, 민감하고, 특이적인 방법을 제공한다. PCR과는 달리, 본 방법은 또한 예컨대 메틸화 DNA 표적과 같이 변형된 폴리뉴클레오티드 표적를 검출하는데 적합하다. 이러한 방법에 따르면, 메틸화 게놈 DNA 단편을 먼저 표적 폴리뉴클레오티드는 분할하지 않는 제한 효소를 써서, 메틸화 표적 폴리뉴클레오티드 (예컨대 CpG 섬)을 함유하는 게놈 DNA 샘플을 분할함으로써 고립시키고, 또는 분할하는 동안에 표적의 대표 단편을 적합하게 생성한다. 분할된 게놈 DNA은 그후 고정화 메틸 결합 영역, 예컨대 본원에 기재된 GST-MBD2 융합 단백질과 접촉된다. 이렇게 하여, 메틸화 게놈 DNA 단편들이 고정화되고 따라서 샘플에서 비-메틸화 DNA 단편들로부터 고립된다. 선택적으로는, 메틸화 게놈 DNA 단편을 고정화 MBD로부터 용출시키고 분석하기 전에 회수(회복)될 수 있다. 예를 들어, GST-MBD2 융합 단백질이 메틸화 CpG 섬 표적을 고정화하는데 사용되는 경우, 융합 단백질의 GST 부분이 글루타티온 수지 (DNA과 상호작용하기 전 또는 후에)에 결합될 수 있고, 결합된 메틸화 DNA 단편은 글루타티온으로 용출될 수 있다.
본 발명의 방법은 또한 다중화에 적합하다. 본 발명의 특정 실시예에 따르면, 복수의 다른 표적 폴리뉴클레오티드는 반응에서 복수의 제 1 및 제 2 프라이머 쌍을 포함함으로서 동시에 프로세싱되고, 각각의 프라이머 쌍은 다른 표적 폴리뉴클레오티드에 특이적으로 하이브리드화되도록 설계된다. 프라임화 증폭을 통해 표적이 부착되는 각각의 표적에 대해 다른, 유일한(독특한) APCs을 설계함으로써 (본원에 기재된 바와 같이, APC-함유 프라이머의 일부로서 또는 TAP-α-TAP 하이브리드를 통해), 복수의 표적의 각각의 존재는 발생되는 APC 신호를 통해 확인될 수 있다. 예를 들어, 각각의 APC는 분자량 또는 뉴클레오티드 서열을 기반으로 구별가능하도록 설계될 수 있다. 본 발명의 이들 실시예에 따르면, 적어도 5, 10, 20, 50, 100 또는 그 이상의 표적들이 단일 검사법으로 검출될 수 있다.
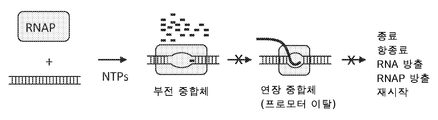
도 1은 본 발명의 압스크립션®방법에 의해 이용되는 불완전 전사(abortive transcription)의 프로세스를 도해한다. 불완전 전사는 RNA 폴리머라제 (RNAP)가 반복적으로 짧은 불완전 전사(abortive transcripts) (일반적으로 2 내지 12 nt 길이)를 만드는 프로머터에서 트랩(trap)될 때, 대부분의 프로모터에서 일어난다. 불완전 전사 중에, RNAP 는 프로모터를 이동시키거나 떠나지 않는다. 정상 전사 동안에는, RNAP는 결국은 안정적이고 진보적인 신장 복합체로의 형태구조적인 변화인, 프로모터 이탈이라 부르는 프로세스를 겪어, 그후 종료 신호에 도달할 때까지 전사를 계속한다. 불완전 복합체에서 트랩 RNAP가 반복적으로 1분 당 수천개의 동일한 짧은 올리고뉴클레오티드를 합성하는, 인공 프로모터 또는 불완전 프로모터 카세트 (APCs: Abortive Promoter Cassettes)가 개발되었다. 각각의 APC 는 분리될 수 있고 정량화될 수 있는 특이적인 길이와 서열의 다른 압스크립트를 만들도록 설계된다.
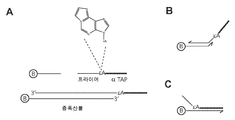
도 2는 압스크립션®을 사용한, 단백질, RNA 및 DNA 표적의 검출을 도해한다. APCs는 표적 부착 프로브 (TAP)에 부착되고, 이것은 분자 표적에 특이적으로 결합한다. (도 2A). DNA 와 RNA의 검출을 위해서, TAPs 은 특이적으로 하이브리드화하는 올리고뉴클레오티드 또는 특이적으로 핵산 표적에 결합하는 단백질을 포함한다(도 2B). 단백질 검출을 위해서, APCs 는 단백질 표적 예컨대 항체 또는 리간드에 결합하는 어떠한 분자에 부착될 수 있다. 도 2C는 APC 가 항체에 부착되는 본 발명의 실시예를 도해한다. 표적 단백질은 효소결합 면역흡착 분석법 (ELISA)에 사용되는 전략과 유사한 단백질 표적의 포획과 검출을 위해, APC-항체 복합체와 고체 지지체 위에 고정화된 제 2 항체 사이에 "샌드위치"될 수 있다.
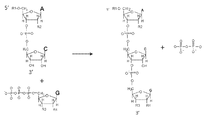
도 3은 압스크립션 ®의 디뉴클레오티드 개시와 하나의 NTP를 첨가한 후에 종료를 도해한다. 압스크립트 길이는 묘사된 바와 같이, NTPs (R3에서 3'-O-Me-NTPs)를 종결하는 사슬의 포함에 의해 또는 하나 이상의 NTPs 을 반응으로부터 제외시킴으로써 제한될 수 있다. R1 = 친화력 태그, 형광성 태그; R2 = OH, OMe, H; R3 = OH, OMe, H; R4 = OH, OMe, H.
도 4A 와 4B 는 질량 분석법에 의한 압스크립트의 검출을 도해한다. 개시자 GpA 및 GTP 를 포함한 압스크립션® 반응은 역-상 HPLC.에 의해 분별되었다. 칼럼의 산출이 질량 분석계 안으로 도입되었다. 도 4A 는 체류 시간의 함수로서 전체 이온 수에 관하여 칼럼 프로파일을 보여준다. 도 4B 는 트리뉴클레오티드 압스크립트 GAG 피크 (체류 시간 5.4 분)에 대한 이온 스펙트럼을 보여준다. 단일- 및 2배-하전된(charged) GAG 종들은 각각 956.1 and 477.6의 m/z 값을 가진다. 2배 하전된 종들의 나트륨 부가물은 978.2의a m/z 를 갖는다.
도 5 는 본 발명의 메틸화 검출 방법에 사용된 GST-MBD 단백질의 구조를 보여준다. 도 5 A 은 MBD 영역이 GST 영역의 카복실 말단에의 연결을 보여준다. 영역 (SEQ ID NO:1)을 연결하는 아미노산 서열은 화살표로 표시된 트롬빈 분할 부위를 함유한다. 도 5B 은 마우스 MBD2b 의 DNA 결합 영역(SEQ ID NO:2)에 대한 아미노산 서열을 보여준다. 밑줄친 아미노산은 MBD 단백질의 DNA 결합 영역들 사이에서 보존 잔기와 상응한다 (Ohki 외. (1999) EMBO J. 18:6653-61). 도 5 C 는 고정화 GST-MBD를 사용한 메틸화 DNA 분획법의 결과를 보여준다. S (상청액) 부분은 증폭된 비메틸화 SNRPN CpG 섬 DNA를 함유한다. E1 는 고정화 단백질로부터 용출된, 증폭된 메틸화 SNRPN CpG 섬 DNA을 함유한다. 분획 E2 와 E3 는 동일한 고정화 단백질로부터의 2개의 추가적 연속적 용리이다. 도 5 D 는 HeLa 세포에서 메틸화되지 않은, PTGS2 DNA의 분획법을 보여준다. PTGS2 DNA 의 모두는 비결합 상청액 부분 S에서 회수된다.
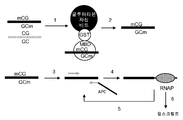
도 6 은 TAP-APC 의 표적 CpG 섬의 증폭화 단편에 대한 결합을 포함하는, α-TAP 압스크립션® 기반 CpG 메틸화 검출에 대한 계획을 도해하는 흐름도이다. 프로세스에서의 단계들은 숫자로 표시된다. 도 6A은 메틸화 CpG 를 함유하는 DNA의 초기 포획을 도해한다. 단계 1: 메틸화 DNA 단편은 고정화 GST-MBD 단백질을 써서 메틸화되지않은 DNA 단편으로부터 분리된다. 단계 2: 메틸화 DNA 단편은 열처리 또는 단백질분해효소 또는 글루타티온에 노출시킴으로써 방출된다. 도 6B 는 태그화된 DNA 단편의 증폭 태그화 및 포획을 보여준다. 단계 3: 표적 CpG 섬은 친화력 표지 (보여준 바와 같이 비오틴 (B)과 같은)로 태그화되고 비오티닐화 프라이머와 비-코딩 뉴클레오티드를 함유하는 프라이머를, 프라이머 서열과 항-TAP 서열 (α-TAP) 사이에 혼입시킴으로써 PCR 동안에, 단일 가닥 연장된다. 단계 4: 비오티닐화 엠플리콘이 스트렙타아비딘-자성 비드에 결합된다. 단계 5: APC 은 TAP 서열과 α-TAP 서열 사이에 하이브리드화에 의해 엠플리콘에 결합된다. 압스크립션®은 RNA 폴리머라제 (RNAP)를 APCs를 함유하는 비드-고정화 복합체와 접촉시킴으로써 수행된다.
도 7A-7C 는 본보기 표적- 특이적인 증폭 프라이머와 항-TAP (α-TAP) 프라이머/프로브들 사이의 상호작용을 도해한다. 도7A 는 CpG 섬 증폭에 사용된 PCR 프라이머와 엠플리콘에서의 그들의 상대적인 위치를 도해한다. 도 7B 과 7C는 잘못 설계된 α-TAP 프라이머/프로브에 의한 적합하지 않은 검사법 결과를 도해한다.
도 8은 TaqMan® PCR 대(對) 도 6에 묘사된 압스크립션® PCR 방법에 의한 DNA 검출의 상대적인 민감도를 보여준다. 분획되지 않은 메틸화 HeLa DNA로부터의 GSTP1 CpG 섬의 단편은 9000 내지 30의 출발 복제 개수/PCR로부터 증폭되었다. 도 8A 는 TaqMan®PCR 결과를 보여준다. TaqMan®PCR 프라이머는 SEQ ID NO: 3 및 SEQ ID NO: 4였다. 9000 복제의 검출은 28 PCR 싸이클을 필요로하였다. 도 8 B 은 29 PCR 싸이클 후에 압스크립션® PCR 검출의 결과를 보여준다. 압스크립션/PCR 프라이머는 SEQ ID NO:12 과 SEQ ID NO:13였다. TAP-APC 는 SEQ ID NO:28 과 SEQ ID NO:32을 어닐링함으로서 만들어졌다. APC는 압스크립트 GAG를 인코딩하였다. 압스크립트 은 박층 크로마토그래피 (TLC)과 UV 셰도잉을 사용하여 검출되었다. 면적은 압스크립트를 함유하는 크로마토그래피 피크의 면적을 말한다.
도 9는 지시된 양의 투입 DNA의 PCR 증폭과 이어서 압스크립션®의 2시간과 8시간 후에 TLC 를 사용한 CY5TM 표지된 압스크립트 의 검출을 보여준다.
도10 는 APC-프라이머의 사용과 함께, APC을 엠플리콘 안에 직접적인 혼입을 사용하여, 메틸화 DNA 검출을 위한 계획을 보여주는 흐름도이다. 숫자들은 계획에서의 단계들을 나타낸다. 단계 1 과 2 는 도 6A에서 도해한 바와 같이, 고정화 GST-MBD 단백질을 사용하는, 메틸화 DNA의 분획을 묘사한다. 단계 3 은 표적화된 서열과, 엠플리콘에 APC를 부착하기 위해 사용되는 프라이머 사이의 관계를 보여준다. 왼쪽방향의 프라이머는 종래의 PCR 프라이머이다. 오른쪽방향 프라이머는 3' 프라이밍 서열과 5' 말단에서 외가닥 APC를 갖는다. 단계 4 와 5 는 표적의 PCR 증폭을 나타낸다. 단계 6 은 PCR 후에 압스크립션® 단계를 나타낸다. PCR 반응은 RNA 폴리머라제, 개시자 및 하나 이상의 NTP로 보충된다.
도 11 은 GAPDH CpG 섬에 대한 APC 프로모터 쌍의 확인을 도해한다. 도 11 A 는 APC 프라이머 C443에 의한 자가-프라이밍으로 인한 배경 신호와, C443 (SEQ ID NO:33)과 역 프라이머 C446(SEQ ID NO:34) 사이에 프라이머-다이머의 형성으로 인한 배경의 평가를 보여준다. C443 단독 또는 C443와 C446의 조합을 함유하는 DNA이 빠져있는 PCR 반응을 56.4℃ 내지 68.5℃ 의 어닐링 온도의 범위에서 수행하고 이어서 1시간의 압스크립션®을 수행하였다. 압스크립트의 제조는 TLC-UV 셰도잉에 의해 분석되었다. 단지 HeLa DNA를 함유하는 양성 대조군 만이 압스크립트 GAG를 생산하였다. 도 11 B 는 동일한 샘플 세트로부터 압스크립트의 LC-MS 검출의 결과를 보여준다.
도 2는 압스크립션®을 사용한, 단백질, RNA 및 DNA 표적의 검출을 도해한다. APCs는 표적 부착 프로브 (TAP)에 부착되고, 이것은 분자 표적에 특이적으로 결합한다. (도 2A). DNA 와 RNA의 검출을 위해서, TAPs 은 특이적으로 하이브리드화하는 올리고뉴클레오티드 또는 특이적으로 핵산 표적에 결합하는 단백질을 포함한다(도 2B). 단백질 검출을 위해서, APCs 는 단백질 표적 예컨대 항체 또는 리간드에 결합하는 어떠한 분자에 부착될 수 있다. 도 2C는 APC 가 항체에 부착되는 본 발명의 실시예를 도해한다. 표적 단백질은 효소결합 면역흡착 분석법 (ELISA)에 사용되는 전략과 유사한 단백질 표적의 포획과 검출을 위해, APC-항체 복합체와 고체 지지체 위에 고정화된 제 2 항체 사이에 "샌드위치"될 수 있다.
도 3은 압스크립션 ®의 디뉴클레오티드 개시와 하나의 NTP를 첨가한 후에 종료를 도해한다. 압스크립트 길이는 묘사된 바와 같이, NTPs (R3에서 3'-O-Me-NTPs)를 종결하는 사슬의 포함에 의해 또는 하나 이상의 NTPs 을 반응으로부터 제외시킴으로써 제한될 수 있다. R1 = 친화력 태그, 형광성 태그; R2 = OH, OMe, H; R3 = OH, OMe, H; R4 = OH, OMe, H.
도 4A 와 4B 는 질량 분석법에 의한 압스크립트의 검출을 도해한다. 개시자 GpA 및 GTP 를 포함한 압스크립션® 반응은 역-상 HPLC.에 의해 분별되었다. 칼럼의 산출이 질량 분석계 안으로 도입되었다. 도 4A 는 체류 시간의 함수로서 전체 이온 수에 관하여 칼럼 프로파일을 보여준다. 도 4B 는 트리뉴클레오티드 압스크립트 GAG 피크 (체류 시간 5.4 분)에 대한 이온 스펙트럼을 보여준다. 단일- 및 2배-하전된(charged) GAG 종들은 각각 956.1 and 477.6의 m/z 값을 가진다. 2배 하전된 종들의 나트륨 부가물은 978.2의a m/z 를 갖는다.
도 5 는 본 발명의 메틸화 검출 방법에 사용된 GST-MBD 단백질의 구조를 보여준다. 도 5 A 은 MBD 영역이 GST 영역의 카복실 말단에의 연결을 보여준다. 영역 (SEQ ID NO:1)을 연결하는 아미노산 서열은 화살표로 표시된 트롬빈 분할 부위를 함유한다. 도 5B 은 마우스 MBD2b 의 DNA 결합 영역(SEQ ID NO:2)에 대한 아미노산 서열을 보여준다. 밑줄친 아미노산은 MBD 단백질의 DNA 결합 영역들 사이에서 보존 잔기와 상응한다 (Ohki 외. (1999) EMBO J. 18:6653-61). 도 5 C 는 고정화 GST-MBD를 사용한 메틸화 DNA 분획법의 결과를 보여준다. S (상청액) 부분은 증폭된 비메틸화 SNRPN CpG 섬 DNA를 함유한다. E1 는 고정화 단백질로부터 용출된, 증폭된 메틸화 SNRPN CpG 섬 DNA을 함유한다. 분획 E2 와 E3 는 동일한 고정화 단백질로부터의 2개의 추가적 연속적 용리이다. 도 5 D 는 HeLa 세포에서 메틸화되지 않은, PTGS2 DNA의 분획법을 보여준다. PTGS2 DNA 의 모두는 비결합 상청액 부분 S에서 회수된다.
도 6 은 TAP-APC 의 표적 CpG 섬의 증폭화 단편에 대한 결합을 포함하는, α-TAP 압스크립션® 기반 CpG 메틸화 검출에 대한 계획을 도해하는 흐름도이다. 프로세스에서의 단계들은 숫자로 표시된다. 도 6A은 메틸화 CpG 를 함유하는 DNA의 초기 포획을 도해한다. 단계 1: 메틸화 DNA 단편은 고정화 GST-MBD 단백질을 써서 메틸화되지않은 DNA 단편으로부터 분리된다. 단계 2: 메틸화 DNA 단편은 열처리 또는 단백질분해효소 또는 글루타티온에 노출시킴으로써 방출된다. 도 6B 는 태그화된 DNA 단편의 증폭 태그화 및 포획을 보여준다. 단계 3: 표적 CpG 섬은 친화력 표지 (보여준 바와 같이 비오틴 (B)과 같은)로 태그화되고 비오티닐화 프라이머와 비-코딩 뉴클레오티드를 함유하는 프라이머를, 프라이머 서열과 항-TAP 서열 (α-TAP) 사이에 혼입시킴으로써 PCR 동안에, 단일 가닥 연장된다. 단계 4: 비오티닐화 엠플리콘이 스트렙타아비딘-자성 비드에 결합된다. 단계 5: APC 은 TAP 서열과 α-TAP 서열 사이에 하이브리드화에 의해 엠플리콘에 결합된다. 압스크립션®은 RNA 폴리머라제 (RNAP)를 APCs를 함유하는 비드-고정화 복합체와 접촉시킴으로써 수행된다.
도 7A-7C 는 본보기 표적- 특이적인 증폭 프라이머와 항-TAP (α-TAP) 프라이머/프로브들 사이의 상호작용을 도해한다. 도7A 는 CpG 섬 증폭에 사용된 PCR 프라이머와 엠플리콘에서의 그들의 상대적인 위치를 도해한다. 도 7B 과 7C는 잘못 설계된 α-TAP 프라이머/프로브에 의한 적합하지 않은 검사법 결과를 도해한다.
도 8은 TaqMan® PCR 대(對) 도 6에 묘사된 압스크립션® PCR 방법에 의한 DNA 검출의 상대적인 민감도를 보여준다. 분획되지 않은 메틸화 HeLa DNA로부터의 GSTP1 CpG 섬의 단편은 9000 내지 30의 출발 복제 개수/PCR로부터 증폭되었다. 도 8A 는 TaqMan®PCR 결과를 보여준다. TaqMan®PCR 프라이머는 SEQ ID NO: 3 및 SEQ ID NO: 4였다. 9000 복제의 검출은 28 PCR 싸이클을 필요로하였다. 도 8 B 은 29 PCR 싸이클 후에 압스크립션® PCR 검출의 결과를 보여준다. 압스크립션/PCR 프라이머는 SEQ ID NO:12 과 SEQ ID NO:13였다. TAP-APC 는 SEQ ID NO:28 과 SEQ ID NO:32을 어닐링함으로서 만들어졌다. APC는 압스크립트 GAG를 인코딩하였다. 압스크립트 은 박층 크로마토그래피 (TLC)과 UV 셰도잉을 사용하여 검출되었다. 면적은 압스크립트를 함유하는 크로마토그래피 피크의 면적을 말한다.
도 9는 지시된 양의 투입 DNA의 PCR 증폭과 이어서 압스크립션®의 2시간과 8시간 후에 TLC 를 사용한 CY5TM 표지된 압스크립트 의 검출을 보여준다.
도10 는 APC-프라이머의 사용과 함께, APC을 엠플리콘 안에 직접적인 혼입을 사용하여, 메틸화 DNA 검출을 위한 계획을 보여주는 흐름도이다. 숫자들은 계획에서의 단계들을 나타낸다. 단계 1 과 2 는 도 6A에서 도해한 바와 같이, 고정화 GST-MBD 단백질을 사용하는, 메틸화 DNA의 분획을 묘사한다. 단계 3 은 표적화된 서열과, 엠플리콘에 APC를 부착하기 위해 사용되는 프라이머 사이의 관계를 보여준다. 왼쪽방향의 프라이머는 종래의 PCR 프라이머이다. 오른쪽방향 프라이머는 3' 프라이밍 서열과 5' 말단에서 외가닥 APC를 갖는다. 단계 4 와 5 는 표적의 PCR 증폭을 나타낸다. 단계 6 은 PCR 후에 압스크립션® 단계를 나타낸다. PCR 반응은 RNA 폴리머라제, 개시자 및 하나 이상의 NTP로 보충된다.
도 11 은 GAPDH CpG 섬에 대한 APC 프로모터 쌍의 확인을 도해한다. 도 11 A 는 APC 프라이머 C443에 의한 자가-프라이밍으로 인한 배경 신호와, C443 (SEQ ID NO:33)과 역 프라이머 C446(SEQ ID NO:34) 사이에 프라이머-다이머의 형성으로 인한 배경의 평가를 보여준다. C443 단독 또는 C443와 C446의 조합을 함유하는 DNA이 빠져있는 PCR 반응을 56.4℃ 내지 68.5℃ 의 어닐링 온도의 범위에서 수행하고 이어서 1시간의 압스크립션®을 수행하였다. 압스크립트의 제조는 TLC-UV 셰도잉에 의해 분석되었다. 단지 HeLa DNA를 함유하는 양성 대조군 만이 압스크립트 GAG를 생산하였다. 도 11 B 는 동일한 샘플 세트로부터 압스크립트의 LC-MS 검출의 결과를 보여준다.
용어 정의
전술한 일반적 설명 및 상세한 설명은 단지 예시적이고 설명적일 뿐이므로, 본 발명의 청구범위를 제한하지 않음은 자명하다. 여기서 사용된 바와 같이, 특별히 다르게 기술되지 않았다면, 단수의 사용은 복수를 포함하는 개념으로 해석된다. 또한, "또는"은 특별히 다르게 기술되지 않았다면, "및/또는"을 의미한다. 또한, 용어 "포함한다", "포함하는", "포함한다" 및 "포함하는" 또는 그 다른 변형은 비-배타적인 포함을 전부 커버하는 것으로 해석되어야 한다. 따라서, 프로세스, 방법, 조성, 반응 혼합물, 키트 또는 일련의 구성요소를 포함하는 장치는 그러한 구성을 포하는 것 뿐만 아니라, 그러한 프로세스, 방법, 조성, 반영 혼합물, 키트 또는 장치에 명백히 나열되지 않은 다른 성분까지 포함하는 것으로 해석되어야 할 것이다.
여기서 사용된 머리글은 단지 구조적 목적을 위한 것일 뿐, 설명되는 발명을 제한하는 것으로 해석되지 않아야 한다.
특별한 정의가 제공되지 않으면, 여기서 사용된 명명법, 실험 절차 및 분자 생물학 기술, 생화학 및 유기 화학은 종래 기술로서 널리 알려진 것이다. 표준 화학 및 생물학 부호 및 약어가 그러한 부호 및 약어에 의해 표시되는 풀 네임과 교차적으로 사용된다. 따라서, 예컨대 용어 "디옥시리보핵산" 및 "DNA"는 동일한 의미를 가지는 것으로 이해된다. 화학 합성, 화학 분석, 재조합 DNA 방법론 및 올리고뉴클레오티드 합성에 대한 표준 기술이 사용될 수 있다. 반응 및 정제 기술은 예컨대 제조사의 사양에 따른 키트를 사용하여 수행될 수 있다. 전술한 기술 및 과정은 일반적으로 종래 널리 알려진 방법에 의해 수행될 수 있다. 본 사양은 다양한 일반 또는 보다 구체적인 참조자료에 인용 및 논의되고 있다. 참조. Sambrook et al. Molecular Cloning: A Laboratory Manual (2d ed., Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y. (1989)); Ausubel et al . Current Protocols in Molecular Biology (John Wiley & Sons Inc., N.Y. (2003)). 이러한 참조자료의 내용이 전체적으로 참조되었다.
본원에 사용된 "약"은, "약"으로 칭해진 숫자가 언급된 수 ± 언급된 수의 1-10%를 포함하는 것을 의미한다. 예를 들어, "약" 50 뉴클레오티드는 45-55 뉴클레오티드, 또는 상황에 따라, 49-51 뉴클레오티드를 의미할 수 있다. 여기에 그것이 나타날 때마다, "45-55"와 같은 숫자 범위는 주어진 범위에서의 각 정수를 의미하고, 예컨대 "45-55 뉴클레오티드"는 핵산이 45 뉴클레오티드, 46 뉴클레오티드, 등을 포함하여 55 뉴클레오티드까지 포함하는 것을 의미한다.
본원에 사용된 "전사"는 DNA(즉, 템플릿)의 하나의 가닥으로부터 RNA 복사체를 만드는 효소적 합성 과정을 의미하는 것으로서, 이 과정에서 상기 DNA 한 가닥은 RNA 폴리머라제(예컨대, DNA-의존성 RNA 폴리머라제)에 의해 촉진된다.
본원에 사용된 "불완전(abortive) 전사"는 상보적 핵산 템플릿 서열의 적어도 일 부분에 대응하는 올리고뉴클레오티드를 반복적으로 합성 및 그 합성을 종결시키는 RNA 폴리머라제-매개 과정이다. 체내에서 합성된 불완전 올리고뉴클레오티드는 뉴클레오티드의 길이와 상이하고, 전사 개시 부위 또는 그 근처의 서열에 상보적이다.
"압스크립션®"은 체외에서 분석적 용도로 최적화된 불완전 전사의 한 형태이며, 이는 체외에서 합성적 또는 자연적으로 발생하는 프로모터 서열로부터 짧고 균일한 RNA 전사체 또는 "압스크립트"를 반복적으로 생산하기 위한 것이다. 용어 "압스크립트(압스크립트, 대문자)"는 압스크립션® 반응 또는 측정에서 생산된 최적화된, 합성 전사체를 일반적인 용어 "압스크립트(압스크립트)"[이는 또한 본래 일어나는 바와 같이 정상적인 전사 과정 동안에 생산되는 단기 불완전 전사체를 포함하는 개념이다]와 구별하기 위하여 사용된다.
"반복적"은 관심 서열의 동일하거나 매우 유사한 복제를 하는 반복적 합성을 의미한다.
"종료자" 또는 "전사 종료자"는 RNA 사슬 종결 화합물, 중합체 또는 프로세스를 의미한다. 본 발명의 종료자는 예컨대 뉴클레오티드 유사체일 수 있고, 이는 RNA 합성 동안에 추가적인 뉴클레오티드가 RNA 사슬에 부가되는 것을 방지하기 위하여 RNA 사슬에 혼입될 수 있다.
"증폭"은 DNA 단편 또는 영역과 같은 폴리뉴클레오티드의 동일한 복사체를 만드는 과정을 의미한다. 증폭은 일반적으로 폴리머라제 연쇄 반응(PCR)에 의해 달성되지만, 종래에 알려진 다른 방법이 본 발명의 DNA 단면을 증폭시키는데 사용될 수 있다.
"표적 DNA 서열" 또는 "표적 DNA"는 검출, 특징화 또는 정량화가 요구되어지는 DNA관심 서열이다. 표적 DNA의 실제 뉴클레오티드 서열은 공지된 것일 수도 있고, 아닐 수도 있다. 표적 DNA는 전형적으로 CpG 메틸화 상태가 의심되는 DNA이다. "표적 DNA 단편"은 표적 DNA 서열을 함유하는 DNA 세그먼트이다. 표적 DNA 단편은 예컨대 전단 처리(shearing) 또는 음파 처리를 포함하는 다른 방법에 의해 생산될 수 있지만, 대부분은 하나 이상의 제한 엔도뉴클레아제으로 소화시켜 만들어 낸다.
"템플릿"은 이로부터 상보적 올리고- 또는 폴리뉴클레오티드 복사체가 합성되는 폴리뉴클레오티드이다.
"합성"은 일반적으로 화학적 또는 효소적 방법에 의해 핵산을 생산하는 과정을 의미한다. 화학 합성은 전형적으로 사용될 수 있는 외가닥 핵산, 프라이머 및 프로브를 생산하기 위해 사용된다. 효소 매개 "합성"은 전사와 템플릿으로부터의 복제를 포함한다. 합성은 표적의 단일 복사체 또는 다중 복사체를 만드는 것을 포함한다. "다중 복사체"는 적어도 2개의 복사체를 의미한다. "복사체"는 반드시 템플릿 서열과 상보적이거나 동일한 완벽한 서열을 의미할 필요가 없다. 예컨대, 복사체는 뉴클레오티드 유사체, (상보적이지는 않지만 템플릿에 하이브리드화될 수 있는 서열을 포함하여 프라이머에 의해 도입되는 서열 변형체와 같은) 고의적 서열 변형체, 및/또는 합성 동안 발생할 수 있는 서열 이상을 포함할 수 있다.
"폴리뉴클레오티드" 및 "핵산(분자)"는 어떠한 길이의 뉴클레오티드 중합 형태를 교차적으로 의미하는데 사용된다. 폴리뉴큭ㄹ레오티드는 디옥시리보뉴클레오티드, 리보튜클레오티드 및/또는 그들의 유사체를 포함할 수 있다. 뉴클레오티드는 변이 또는 비-변이될 수 있고, 어떠한 3차원 구조를 가질 수 있고, 공지 또는 비공지된 어떠한 기능을 수행할 수 있다. 용어 "폴리뉴클레오티드"는 외가닥, 이중가닥 및 삼중 나선형 분자를 포함한다. 폴리뉴클레오티드의 비-제한적인 예로는 다음:유전자 또는 유전자 단편, 엑손, 인트론, mRNA, tRNA, rRNA, 리보자임, cDNA, 재조합 폴리뉴클레오티드, 분지 폴리뉴클레오티드, 플라스미드, 벡터, 어떤 서열의 고립된 DNA, 어떤 서열의 고립된 RNA, 핵산 프로브 및 프라이머과 같다.
"올리고뉴클레오티드"는 2 내지 약 100 뉴클레오티드 사이의 단일- 또는 이중-가닥 핵산, 전형적으로는 DNA를 가지는 폴리뉴클레오티드를 의미한다. 올리고뉴클레오티드는 또는 올리고머 또는 올리고스로 알려져 있고, 유전자 및 다른 생물학적 재료로부터 고립화될 수 있거나 또는 종래의 방법에 의해 화학적으로 합성될 수 있다. "프라이머"는 적어도 6개의 뉴클레오티드를 함유하는 올리고뉴클레오티드를 의미하고, 통상 외가닥이며, 이는 효소-매개 핵산 합성의 개시를 위한 3'-히드록실 말단을 제공한다. "폴리뉴클레오티드 프로브" 또는 "프로브"는 상보적인 폴리뉴클레오티드 서열에 특이적으로 하이브리드화되는 폴리뉴클레오티드이다. "특이적 결합" 또는 "특이적 하이브리드화"는 주어진 조건에서 다른 분자에 하나의 분자를 결합, 이중화(duplexing), 또는 하이브리드화하는 것을 의미한다. 따라서, 프로브 또는 프라이머는 주어진 결합 조건하에서 단지 그 의도된 표적 폴리뉴클레오티드에만 "특이적으로 하이브리드화"하고, 항체는 주어진 결합 조건하에서 단지 그 의도된 표적 항원에만 "특이적으로 결합"한다. 주어진 조건은 결합 또는 하이브리드화를 위해 표시된 것이며, 이는 버퍼, 이온강도, 온도 및 당업자에게 알려진 다른 인자를 포함한다. 당업자는 또한 특이 결합이 붕괴 또는 해리될 수 있고, 그 결과 예컨대 항체-항원, 수용체-리간드 및 프라이머-표적 폴리뉴클레오티드 결합을 용출 또는 융해시킬 수 있는 조건을 알 수 있을 것이다.
"핵산 서열"은 DNA 또는 RNA와 같은 올리고뉴클레오티드 또는 폴리뉴클레오티드내의 뉴클레오티드 염기 서열을 의미한다. 이중-가닥 분자에 비하여, 외-가닥 분자가 양쪽 가닥, 왓슨-크릭 염기쌍으로 추론되는 상보적 가닥을 나타내는 것으로 사용된다.
"상보적" 또는 "상보성"은 (올리고뉴클레오티드일 수 있는) 제1 폴리뉴클레오티드가 제2 뉴클레오티드(이 또한 올리고뉴클레오티드일 수 있다)와 "역평행 연합" 상태에 있는 것을 의미한다. "역평행 연합"은 두개의 뉴클레오티드의 정렬을 의미하는데, 이는 개별 뉴클레오티드 또는 두개의 연합된 폴리뉴클레오티드의 염기가 왓슷-크릭 염기-쌍 법칙에 따라 실질적으로 쌍을 이룬 것을 의미한다. 상보성은 "부분적"일 수 있고, 이는 폴리뉴클레오티드 염기의 단지 일부가 상기 염기 쌍 법칙에 따라 매칭된 것을 의미한다. 또는, "폴리뉴클레오티드 사이에 "완벽" 또는 "전체" 상보성이 있을 수 있다. 핵산 기술 분야의 당업자는 예컨대 제1 뉴클레오티드의 길이, 그것이 올리고뉴클레오티드인지, 제1 뉴클레오티드의 염기 조합 및 서열, 이온 강도 및 부조화 염기 쌍의 발생을 포함하여 다수의 변수들을 고려함으로써, 경험적으로 이중 안정성을 판단할 수 있다.
"하이브리드화"는 6개 이상의 뉴클레오티드를 함유하는 올리고뉴클레오티드 및 폴리뉴클레오티드를 포함하여 상보적인 핵산의 염기-쌍을 의미한다. 하이브리드화 및 하이브리드화 강도(즉, 핵산 사이의 연합 강도)는 핵산 사이의 상보성 정도, 관련된 반응 조건의 엄격성, 형성된 혼성체의 녹는점(Tm) 및 이중 핵산내의 G:C 비율과 같은 인자에 의해 영향받는다. 일반적으로 "하이브리드화" 방법은 상보적인 폴리뉴클레오티드를 표적 핵산(즉, 직접 또는 간접 수단에 의해 검출되는 서열)에 어닐링하는 것과 관련된다. 상보적 서열을 함유하는 2개의 폴리뉴클레오티드 및/또는 올리고뉴클레오티드를 서로 배치시키고 염기 쌍 상호작용을 통해 서로 어닐링하는 것은 널리 인식되는 현상이다.
"중합체"는 성분의 조립체이다. 중합체는 안정적 또는 불안정할 수 있고, 직접적 또는 간접적으로 검출될 수 있다. 예컨대, 반응의 주어진 어떤 성분 및 반응의 산출물 타입, 중합체의 존재가 고려될 수 있다. 예컨대, 불완전 전사 방법에서 중합체는 최종적 불완전 전사 또는 복제 산물과 같이 최종적 반복적 합성 산물에 대하여 일반적으로 중간에 일어난다.
"메틸화"는 메틸 기 (-CH3)를 분자, 전형적으로는 DNA 또는 RNA내에 있는 뉴클레오티드 염기에 부가하는 것을 의미한다. "mCpG"는 위치 5(5-메틸시토신 또는 5-Me C)에서 C가 메틸화되는 5'-CG-3' 디뉴클레오티드를 의미한다. "CpG 섬"은 높은 빈도의 CpG 디뉴클레오티드를 함유하는 게놈 부위이다. CpG 섬은 포유동물 유전자 프로모터의 대략 40%이며, 인간 프로모터의 70%가 높은 CpG를 가진다. 참조 e.g. Fatemi et al . (2005) Nucleic Acids Res. 33:e176. doi:10.1093/nar/gni180. PMID 16314307.
"프로모터"는 인접 유전자의 전사를 가능하게 하는 DNA 부위를 의미한다. 프로모터는 전형적으로 5'이고, 유전자의 전사 착수의 개시 부위에 근접해 있고, 유전자의 전사 위치를 정확히 하기 위하여 RNA 폴리머라제 및 연합된 전사 인자를 다이렉팅한다.
"마이크로어레이" 및 "어레이"는 올리고- 또는 폴리뉴클레오티드와 같은 복합체, 샘플 또는 분자의 집합체 배열을 교차적으로 의미한다. 어레이는 전형적으로 "자체 위치를 가지는데", 개개의 집합체 성분은 배열내에서 유일한, 인식 가능한 위치를 가진다. 어레이는 글래스 슬라이드와 같은 고체 기질, 나이트로셀룰로스 멤브레인과 같은 반-고체 기질, 튜브 또는 마이크로타이터 플레이트 웰과 같은 관(vessel)에 형성될 수 있다. 어레이의 전형적 배열은 마이크로타이터 플레이트와 같이 8 행 12 열 배치이지만, 본 발명의 방법에 사용되기에 적합한 다른 배열이 당업자에게 알려진 바와 같이 사용될 수 있다.
"고체 지지체"는 예컨대 포획 프로브 또는 다른 올리고- 또는 폴리뉴클레오티드, 폴리펩티드, 항체 또는 다른 요구되는 분자 또는 중합체를 고정화하기 위하여 사용될 수 있는 모든 고체상을 의미한다. 적합한 고체 지지체는 종래기술로 널리 알려져 있고, 마이크로타이터 플레이트, 테스트 튜브 벽체, 폴리스티렌 비드, 상자성 또는 비-자성 비드, 글래스 슬라이드, 나이트로셀룰로스 멤브레인, 나일론 멤브레인 및 라텍스 입자와 같은 마이크로입자를 포함하지만, 이에 제한되는 것은 아니다.
고체 지지체의 전형적 재료는 폴리비닐 클로라이드(PVC), 폴리스티렌, 셀룰로스, 아가로스, 덱스트란, 글래스, 나일론, 라텍스 및 그 유도체를 포함하지만, 이에 제한되지 않는다. 게다가, 고체 지지체는 코팅 및 유도체화될 수 있고, 또는 그렇지 않으면 요구되는 분자의 부착을 촉진시키거나 또는 비-특히 결합 또는 다른 요구되지 않는 상호작용을 지체시키기 위하여 변경될 수 있다. 특이 "고체상"을 선택하는 것은 통상 중요하지 않고, 방법 및 채택된 측정법에 따라 당업자에 의해 선택될 수 있다. 편리하게는, 고체 지지체는 다양한 검출 방법을 수용할 수있도록 선택된다. 예컨대 96 또는 384 웰 플레이트는 자동화되는 측정법, 예컨대 로보틱 워크스테이션용으로 사용될 수 있고, 이 경우 예컨대 플레이트 리더를 사용하여 검출될 것이다. 본 발명의 방법은 예컨대, 필름-기반 가시화를 이용하여 방사선 사진 촬영 검출과 관련될 수 있다. 고체 지지체는 얇은 니토로셀룰로스 또는 나이론 멤버레인과 같은 얇은 멤버레인, 겔 또는 박층 크로마토그래피 플레이트일 수 있다. 분자를 고체상에서 고정화시키는 적합한 방법은 이온 상호작용, 소수 상호작용, 공유 상호작용 및 그 조합을 포함한다. 그러나, 고정화 방법은 일반적으로 중요하지 않으며, 비특징화된 애드숍션(adsorbtion) 메커니슴과 관련된다. "고체 지지체"는 불용성이거나 또는 이어지는 작용에 의해 불용성을 가질 수 있는 모든 재료를 의미한다. 고체 지지체는 포획 시약을 끌어 당기고 고정화시킬 수 있는 고유 특성을 가진 것으로 선택될 수 있다. 대안적으로, 고체 지지체는 예컨대 "포획" 시약을 끌어 당기고 고정화시킬 수 있는 추가적 분자를 함유할 수 있다.
"항체" 또는 "항체들"은 예컨대 항체의 Fab, Fab', and F(ab)2 단편과 같은 자연적으로 발생하는 분자의 모든 항원-결합 부분, 단편 또는 소단위 뿐만 아니라 다클론성 및 단클론성 항체와 같은 자연 발생적인 종까지 포함한다. 또한 본 발명의 방법에 사용하기 위하여 재조합 항체, 자른 항체, 단일 사슬 항체, 키메라 항체 및 잡종 항체를 고려해 볼 수 있고, 나아가 인간에 맞게 제조된 항체 및 다른 비-자연발생적인 항체 형태를 포함하고, 이에 제한되는 것은 아니다.
본 발명은 압스크립션®이라 불려지는 분자 검출 기술에 기초하는데, 이 기술은 불완전 전사(도 1)로 알려진 자연 현상에 기초하고 있다. 압스크립션®은 단백질, 핵산, SNP 및 CpG 메틸화를 포함하여 광범위한 표적을 검출 및 정량화하는 강력한 방법이다(미국 특허 출원 제10/602,045, 10/790,766, 및 10/488,971호; 미국 특허 제 7,045,319, 및 7,226,738호). 압스크립션®은 RNA 폴리머라제(RNAP)가 프로모터의 견고하게 결합된 상태로 머무르면서, 짧은 RNA 또는 불완전 전사체(앱스크립트, 압스크립트)를 반복적으로 생산하는 것으로서, 전사의 개시 상태 동안에 일어난다(Hsu, Biochim. Biophys. Acta (2002) 1577:191-207; Hsu et al . Biochemistry (2003) 42:3777-86; Vo et al . Biochemistry (2003) 42:3798-811; Vo et al . Biochemistry (2003) 42:3787-97; Hsu et al . Biochemistry (2006) 45:8841-54). 프로모터 및 초기 전사 세그먼트의 서열은 그 합성 속도 뿐만 아니라 지배적 앱스크립트의 길이에 상당한 효과를 준다(Hsu et al . Biochemistry (2006) 45:8841-54.28). 불완전 프로모터 카세트(APC)라 불려지는, 매우 최적화된 다수의 불완전 프로모터가 상당히 높은 속도로 상이한 서열 및 길이(3 내지 12 nt 사이)의 압스크립트를 만들도록 개발 및 최적화되어 왔다.
RNAP는 잘려진 RNA 합성 라운드 사이에 프로모터로부터 해리되지 않기 때문에, 짧은 압스크립트의 발생은 매우 효과적이다. 이는 각각의 충분히 긴 전사체를 생산한 후에 이루어지고, 이는 기질이 소모될 때까지 높은 생산 속도로 압스크립트를 계속 생산할 것이다. 이는 분당 APC당 수천개의 압스크립트를 급속히 생산하게 된다. 압스크립트는 표적 증폭 과정이라기 보다는 신호 증폭이다.
본 발명은 최적화된 메틸 결합 영역(MBD) 폴리펩티드를 포함하는 mCpG 표적 부위 프로브를 통하여 DNA내의 CpG 메틸화를 검출하는 간단하고 민감한 방법을 제공한다. mCpG 표적 부위 프로브는 신호 발생기에 직접 또는 간접적으로 결합될 수 있고, 상기 신호 발생기는 CpG 메틸화의 표지자로 측정될 수 있는 검출 가능 신호를 생성한다.
본 발명의 어떤 실시예에서, 신호 발생은 불완전 프로모터 카세트(APC) 신호 발생기가 mCpG 표적 특이 프로브를 통하여 표적 mCpG 부위에 결합되는 압스크립션 과정에 기초한다. RNA 폴리머라제는 APC내에서 합성 또는 자연 발생하는 불완전 프로모터로부터 균일하고 짧은 RNA 분자를 메틸화 CpGs의 존재 신호(표지자)로서 생산한다. 본 발명의 다른 실시예에서, 신호-발생 카세트는 PCR 또는 다른 복제 및/또는 증폭 방법에 의해 검출 가능한 RNA 또는 DNA 신호를 생성할 수 있다.
본 발명에 따른 방법은 중아황산염 처지가 필요하지 않기 때문에, 현재의 CpG 메틸화 검출 방법에 비하여 상당한 이점을 가진다. 따라서, 광범위한 DNA 분해 및 표적 DNA의 화학적 처리와 관련된 서열 복합도 감소가 본 발명의 실시예에서 전체적으로 회피될 수 있다. 본 발명에 따른 방법은 빠른 속도이고, 일반적으로 하루만에 수행될 수 있다. 게다가, 본 발명은 멀티플렉스 및 자동화 응용 장치에 적합화될 수 있다.
본 발명의 압스크립션-기반 메틸화 검출 측정법은 선형의 강력한 신호 증폭 과정(압스크립션)을 표적 증폭 과정(즉, 폴리머라제 연쇄 반응 또는 PCR)과 결합할 수 있는 독특한 가능성을 제공할 수 있다. 이는 매우 높은 민감도를 제공하고, 테스트 시에 단지 조그만 양의 초기 물질을 사용하게 한다. 게다가, 샘플에서 각각의 표적으로부터 동일한 신호 분자를 만들어 내는 홍당무과산화효소 또는 알칼리성 포스파타제와 같은 다른 신호 증폭 방법과 달리, 압스크립션 기반 증폭은 각각의 표적으로부터 상이한 신호를 만들어 내도록 구성될 수 있다. 그 다음, 짧은 올리고뉴클레오티드 형태인 이러한 신호는 다양한 방법에 의해 검출될 수 있다. 압스크립션-기반 측정법은 다른 DNA 메틸화 검출 측정법 보다 훨씬 더 적은 인간의 노동 시간을 요하고, 시약 비용은 매우 경제적이고, 장비 가격 또한 저가이다. 또한, 이러한 측정법은 양성 및 음성 대조군 템플릿을 포함함으로써, 매우 높은 특히 검출을 가능하게 하고, 나아가 다른 표적 검출 방법 보다 보다 적은 거짓 양성을 가져 온다.
압스크립션
®
기술
압스크립션® 기술은 전장(full-length) RNA 전사체가 만들어지기 전에, 상당히 다수의 짧은 불완전 전사체가 RNA 폴리머라제에 의해 전장 RNA 전사 개시 이전에 합성된다는 관찰에 기초한다. 이하 설명되는 바와 같이, 불완전 전사체는 전사 과정의 정상적인 부산물이지만, 전장 RNA 전사체(이는 전사 과정의 기능적으로 정보화된 생성물이다)와 사이즈 및 제조 방식에 있어서 구별될 수 있다.
전사 과정. 전사는 DNA 템플릿(즉, 유전자)으로부터 RNA 전사체를 선택적으로 합성하기 위하여 진행생물 및 원핵생물서 활용된 복합적이고 매우 조절된 과정이다 (참조. Record et al . (1996) Escherichia coli and Salmonella , (Neidhart, ed.; ASM Press, Washington, DC); deHaseth et al . (1998) J. Bact. 180:3019-25; Hsu (2002) Biochim. Biophys. Acta. 1577:191-207; Murakami & Darst (2003) Curr. Opin. Struct. Biol. 13:31-39; Young et al . (2002). Cell. 109:417-420). 세포 환경에서 전사는 5 단계를 포함한다. 1. 사전 개시, 이 동안에도 전사 기구(예컨대, RNA 폴리머라제(RNAP) 및 전사 인자)는 프로모터에 도입된다; 2. 개시, 이 동안에 RNA 합성이 시작된다; 3. 프로모터 이탈, 이 동안에 RNA 폴리머라제가 프로모터를 이탈시키고, (통상 대략 12-mer RNA의 합성 후에) 불완전 개시가 중단된다; 4. 연장, 이 동안에 RNAP는 템플릿 DNA 가닥을 따라 점진적으로 이동하고, 그 결과 전장 RNA 전사체를 합성한다; 종료, 이 동안에 RNA 합성은 종료되고 RNAP는 템플릿 DNA로부터 분리된다.
전장 RNA 전사 이전에 불완전 전사체 생산. 전형적으로, RNAP는 첫번째 시도에서 프로모터로부터 이탈되지 않고, 그 대신 불완전 전사체라 불려지는 짧은 RNA 산출물을 합성 및 방출하는 다중 불완전 사이클을 이룬다. RNAP는 RNAP가 한계 길이의 RNA 산출물을 합성하는데 성공할 때에만 프로모터 DNA와의 그 상호작용을 취소할 수 없게 끝내게 하고, DNA 템플릿을 따라 점진적으로 위치 이동하면서 전장 RNA 전사체를 합성하기 시작한다 (참조 Hsu (2002) Biochim. Biophys. Acta. 1577:191-207; Hsu et al . (2003) Biochemistry 42: 3777-86; Vo et al . (2003) Biochemistry 42:3787-97; Vo et al . (2003) Biochemistry: 42:3798-11). 프로모터 이탈 (상기 단계 3) 이전에, RNAP는 프로모터 영역 및 그 근처에 결합된 상태로 머무르고, 그에 의해 단 시간에 다수 차례의 불완전 합성을 가능하게 한다.
압스크립션 ® 기술. 압스크립션® 기술은 상당히 많은 수의 검출 가능 불완전 전사체(압스크립트)를 생산하기 위하여 불완전 RNA 합성의 자연적 현상을 활용한다. 압스크립션® 불완전 전사에 기초한 등온, 강력한, 선형 신호 발생 시스템이다. 압스크립션® 방법에서, 불완전 프로모터 카세트(APC)는 표적 부위 프로브(TSP)를 통하여 표적 분자에 결합된다. 그 다음, E. coli RNA 폴리머라제와 같은 RNA 폴리머라제가 APC를 템플릿으로 사용하는데, 이는 짧고 균일한 RNA 분자 또는 압스크립트(불완전 전사체) 형태인 표적에 대하여 상당히 많은 수의 신호를 발생시키기 위함이다.
압스크립션 검출 방법은 광범위한 관심 분자(즉, 표적)를 검출하도록 적응될 수 있는 3개의 기본 단계를 가진다. 첫째, APC는 표적 부위 프로브(TSP)를 통하여 관심 표적 분자에 국한된다(localized). 둘째, 압스크립트가 상기 국한된 APC로부터 합성된다. 최종적으로, 압스크립트는 표적 검출 수단으로 검출되고, 현존 표적 분자의 양에 대한 표지자로서 정량화될 수 있다. 상기 과정은 RNAP가 여러 차례의 불완전 RNA 합성 사이에, 각각의 전장 전사체를 생산한 후에 이루어지는 것과 같이 프로모터로부터 이탈하거나 분리되지 않기 때문에, 매우 효과적이다. 게다가, 단지 균일하고 짧은 RNA 신호가 합성되고, 이는 보다 긴 올리고- 및 폴리뉴클레오티드와 비교해 볼 때, 보다 적은 노력으로 보다 빨리 생산될 수 있다.
프로모터 이탈(및 그 이후 불완전 합성의 종료)에 요구되는 인자 및 조건이 불완전하게 이해된다 할지라도, 충분한 지식에 의하면 불완전 전사체 합성을 유리하게 하는 합성 환경을 만들 수 있고, 나아가 전장 RNA 생산을 불가능하게 할 수 있다. 일 실시예에서, 압스크립션은 정의된 디뉴클레오티드 개시자로 개시되는 압스크립트를 생산하는 합성 단계에서 제어되고, 그 다음 도 3에 도시된 비제한적 예에 도시된 바와 같이 하나 이상의 NTP의 부가후에 종료된다. 압스크립트 길이는 사슬 종료 NTP(예컨대, 3'-O-Me-NTP)를 사용하거나 또는 반응으로부터 하나 이상의 NTP를 제외시킴으로써 3 뉴클레오티드 (nt) 만큼 짧게 제한될 수 있다.
다른 실시예에서, 압스크립트 길이는 중단 신호가 도달되기 이전에 전사를 위해 이용할 수 있는 별개, 제한적 수의 뉴클레오티드를 가지는 합성 템플릿을 제공함으로써 프로모터/템플릿 단계에서 제어된다. 단일 압스크립션 반응에서 단일 APC로부터 생산되는 압스크립트의 균일성 덕분에, 존재하는 표적의 양에 직접 비례하는 압스크립트 신호를 얻을 수 있다. 따라서, 압스크립션은 mCpG와 같은 표적을 측정하기 위한 정성 및 정량 시스템이다.
불완전 프로모터는 표적 증폭 고정을 통하여 DNA에 혼입될 수 있고, 또한 제2 가닥의 하이브리드화에 의해 단일-가닥 DNA 표적에 형성될 수 있다. 그러나, 보다 일반적으로는, 압스크립션은 APC를 그 표적에 결합함으로써 광범위한 표적 분자를 검출하는데 사용될 수 있다(도 2). 단백질, RNA 또는 DNA의 검출을 위하여, APC는 표적 부착 프로브(TAP)에 연결되고, 이러한 TAP는 분자 표적에 결합하게 될 것이다(도 2A). DNA 및 RNA의 검출을 위하여, TAP는 핵산 표적에 특이적으로 결합하는 올리고뉴클레오티드 또는 단백질을 포함한다(도 2B). 단백질 검출을 위하여, APC는 단백질 표적에 결합하는 모든 것에 부가될 수 있다. 여러 측정법이 개발되고 있는데, 이런 측정법은 ELISA와 유사하고 동일한 표적에 다이렉팅되는 두개의 항체, 즉 표적 포획을 위한 하나와 APC 부가를 위한 하나를 이용하고 있다(도 2C).
트리뉴클레오티드
합성.
트리뉴클레오티드 압스크립트는 사슬 종결자 NTP의 개입으로 배타적으로 만들어질 수 있거나 또는 하나 이상의 NTP를 제외시킴으로써 만들어질 수 있다. 압스크립트는 압스크립션 동안에, 변이된 디뉴클레오티드(Dissinger & Hanna, J. Biol. Chem (1990) 265:7662-8: Dissinger & Hanna, J. Mol. Biol. (1991) 219:11-25; Hanna, Meth. Enzymol., (1989) 180:383-409; Hanna et al . Biochemistry (1989) 28:5814-20; Hanna & Meares, Proc. Natl. Acad. Sci. U S A, (1983) 80:4238-42; Hanna & Meares, Biochemistry (1983) 22:3546-51.29-34), or NTPs (Hanna, et al . Nucleic Acids Res. (1999) 27:1369-76; He et al, Nucleic Acids Res (1995) 23:1231-8)를 혼입함으로써 검출 또는 포획을 위해 라벨링될 수 있다. 여기서, "라벨(즉, 표지)"은 분자위에 일부분의 존재가 직접 또는 간적적으로 검출 및 구별될 수 있도록 하는 것을 의미한다. 일반적으로, 라벨은 본래의 비-표지 종 보다 보다 효과적 및/또는 특이적으로 쉽게 검출된다. 본 발명의 방법의 사용에 적합한 라벨은 형광 기, (비오틴과 같은) 친화력 태그 및 전하 또는 질량 변이 뉴클레오티드를 포함한다.
일 실시예에서, 여기에 설명된 측정법은 분자 중량 또는 이동도에서 달라지는 상이한 트리뉴클레오티드 압스크립트의 생산과 관련된다. 트리뉴클레오티드는 디뉴클레오티드 개시자와 뉴클레오시드 트리포스페이트를 결합함으로써 APC에 분당 1000 내지 2000의 속도로 RNAP에 의해 만들어진다. 트리뉴클레오티드 압스크립트는 급속 TLC 및 UV 쉐도우잉 또는 질량 분석법에 의해 라벨링 없이 검출될 수 있다. 대안적으로, 압스크립트는 디뉴클레오티드 개시자에 혼입된 라벨(예컨대, 형광 부분)을 통해 검출될 수 있다.
본 발명은 폴리뉴클레오티드를 함유하는 샘플을, 폴리뉴클레오티드의 표적 서열을 특이적으로 하이브리드화하고 증폭시키는, 프라이머 쌍과 접촉시킴으로써 샘플내 폴리뉴클레오티드를 검출할 수 있는 방법을 제공한다. 프라이머 쌍은 폴리뉴클레오티드와 상보적이고, 표적 서열 측면에 있고, 5' 포획 태그를 함유하는 제1 프라이머를 포함한다.
제2 프라이머는 3개의 영역: 제1 프라이머의 표적 서열의 반대측에 있는 표적 서열 측면에 있는 폴리뉴클레오티드에 상보적인 3' 서열; APC를 부가하기 위해 사용되는 5' α-TAP 서열; 3' 및 5' 서열 사이의 비-천연 뉴클레오티드를 가진다.
폴리뉴클레오티드의 표적 서열은 상기 제1 및 제2 프라이머를 사용하여 증폭되고(예컨대, 폴리머라제 연쇄 반응), 상기 증폭된 표적 서열은 5' 포획 태그를 결합하는 분자를 함유하는 고체 지지체상에서 포획된다. 이용가능한 PCR 기술 또는 적합한 핵산 증폭 방법은 내열성 DNA 폴리머라제 및/또는 RNA 폴리머라제 효소를 사용하는 PCR 방법과 같이 이러한 단계에 채택될 수 있다. 예컨대, 포획 태그는 비오틴일 수 있고, 고체 지지체는 자성 비드와 같은 스트렙타아비딘 비드일 수 있다. 그 다음, 포획된 증폭산물(amplicon)은 비결합 프라이머를 제거하기 위하여 세정될 수 있고, 바람직하게는 고체 지지체로부터 용출될 수 있다.
표적 폴리뉴클레오티드 서열의 검출을 위하여, 프로브는 상기 증폭산물에 하이브리드화된다. 이러한 프로브는 α-TAP 서열에 상보적인 5' TAP 서열을 포함한다. 제2 PCR 프라이머내에 비-천연 뉴클레오티드를 개재하고 있기 때문에, α-TAP 서열은 PCR 동안에 복사되지 않으며, 증폭 동안에 외가닥으로 머무르고, 그 결과 프로브의 TAP 서열이 상기 증폭된 표적을 변성시키지 않으면서 하이브리드화될 수 있도록 한다. 에테노-디옥시아데노신은 비-천연 뉴클레오티드로 사용될 수 있지만, 당업자는 복제를 종료시킬 수 있는 추가적으로 적합한 비-천연 뉴클레오티드(예컨대, 뉴클레오티드 유사체)를 인지할 수 있고, 따라서 이러한 것이 에테노-디옥시아데노신과 대체될 수 있다. 프로브는 APC를 또한 포함하고, 이러한 APC는 상술한 바와 같이 압스크립션 방법을 사용하여 압스크립트를 합성할 수 있는 템플릿을 제공한다. 최종적으로, 압스크립트는 모든 적합한 방법에 의해 검출되고, 특히 여기서 압스크립트 검출을 위해 설명된 방법, 즉 질량 분석법, 모세관 전기이동 또는 박층 크로마토그래피에 의해 검출된다. 전형적으로, 압스크립트는 3 내지 20 뉴클레오티드의 길이를 가지며, 압스크립션 동안에 검출가능하게 표지된(예컨대, 형광질) 뉴클레오티드를 혼입함으로써 표지될 수 있다.
본 발명의 다른 실시예에서, TAP/α-TAP 단계는 제2 증폭 프라이머의 5' 말단에 APC 서열을 포함시고, 비-천연적으로 발생하는 뉴클레오티드를 제외시킴으로써 제거될 수 있다. 그런 실시예에서, 이중-가닥 APC는 증폭 동안에 상기 증폭된 표적 서열에 인접하여 발생되고, 이는 RNAP 및 뉴클레오티드를 부가하자 마자 압스크립션을 다이렉팅시킬 것이다. 만약 이러한 압스크립션 시약이 증폭 동안에 존재한다면, 압스크립션 및 증폭은 동일한 튜브내에서 동시에 수행될 수 있다.
본 발명의 이러한 방법은 각각의 폴리뉴클레오티드에 특이한 프라이머 쌍을 반응에 포함시킴으로써, 멀티플렉싱(즉, 동시에 다수의 폴리뉴클레오티드 검출)에 적합하도록 적응될 수 있다. 본 발명의 실시예에 의하면, 각각의 프라이머 쌍은 폴리뉴클레오티드의 유일한 표적 서열을 특이적으로 하이브리드화하고 증폭하도록 설계된다. 각각의 프라이머 쌍에 대한 α-TAP 서열은 또한 유일하고, 그 결과 표적 서열에 대한 식별자로서 기능하게 된다. PCR 증폭 이후, 유일한 식별 APC를 포함하는 상보적 TAP 서열을 하이브리드화함으로써, 각각의 폴리뉴클레오티드의 존재가 다발성 반응에서 생산된 압스크립트에 근거하여 추궁될 수 있다. 따라서, 유일 APC는 각각의 증폭된 표적 폴리뉴클레오티드에 부가되고, APC로부터 생산된 구별가능한 압스크립트 신호가 표적 폴리뉴클레오티드의 존재에 대한 지시자로서 검출 및 측정될 수 있다. 예컨대, 각각의 APC는 분자 중량 또는 뉴클레오티드 서열에 기초하여 구별가능한 압스크립트를 발생시키도록 설계될 수 있다. 단일 반응에서, 5, 10, 20 또는 그 이상의 유일 표적 서열이 검출될 수 있다.
본 발명은 또한 중아황산염에 의한 탈아미노화의 사용 없이도 CpG 섬의 메틸화 상태를 결정할 수 있는 방법을 제공한다. 그런 방법은 표적 증폭을 선형 신호 증폭 과정, 즉 압스크립션과 결합시키고, 그것을 매우 민감하게 만든다.
본 발명의 어떤 실시예에서, 표적 폴리뉴클레오티드는 메틸화된 CpG 섬 또는 복수의 CpG 섬(즉, 멀티플렉싱)이다. 이러한 실시예에서, 메틸화된 CpG 섬을 함유하는 게놈 DNA는 미리 정해진 제한 효소에 의해 먼저 절단되는데, 여기서 상기 제한 효소는 다발성 측정에서 섬 또는 그 섬의 어떠한 것을 절단하지 않는다. 그 다음, 메틸화 DNA 단편은 고정화 MBD 시약 및 특이한 CpG 관심 서열을 위한 정보를 가진 포획 단편을 사용하여, 게놈 DNA로부터 포획된다. 본 발명에 따른 방법에 의하면, 상기 프로세스는 메틸화 DNA 보강 과정을 사용하여 단편화된 게놈 DNA로부터 메틸화 DNA의 고립화를 개시한다. 본 발명의 일 태양에 있어서, 상기 보강 방법은 글루타티온-S-트렌스퍼라제 융합 단백질을 사용하는데, 이는 메틸화 DNA에 대해 매우 특이한 쥐 MBD2로부터 메틸 결합 영역을 함유한다. MBD2-융합 단백질에 결합된 메틸화 DNA는 글루타티온 자성 비드에 의해 급속하게 포획되고, 폴리머라제 연쇄 반응에 의해 증폭용 버퍼내로 직접 용출된다. 관심 CpG 섬은 한 쌍의 변이된 PCR 프라이머를 사용하여 증폭된다. 첫 번째 프라이머는 스트렙타아비딘 자성 비드로의 표적 CpG 섬의 이어지는 포획이 가능하도록 하는 비오틴 기를 함유한다. 두 번째 프라이머는 특이 APC의 부착을 위하여 증폭산물을 "마크"하는 섬-특이 서열을 함유한다. 일단 증폭되면, 섬은 스트렙타아비딘 비드에 포획되고; 유일 APC는 하이브리드화에 의해 부가되고; 압스크립션이 개시된다. 그에 의해, 각각의 CpG 섬은 상이한 압스크립트를 발생시키고; 따라서 다수의 CpG 섬이 각각의 반응에서 심문받게 된다.
대안적으로, APC 서열은 제2 증폭 프라이머내 및 증폭 동안 발생된 APC 중복체(duplex)로 혼입될 수 있다. 이러한 접근접은 증폭 반응에 RNAP 및 뉴클레오티디를 포함시킴으로써, 증폭 및 압스크립션이 동시에 수행될 수 있게 한다. 본 방법은 표적 증폭을 신호 증폭과 결합시키기 때문에, 대부분의 메틸화 DNA 검출 방법과 비교하여 보다 적은 스타팅 DNA가 필요하고, 메틸화 DNA를 고립화시키는 초기 단계를 위해 2 ng 이하의 게놈 DNA도 충분하다. 전체 측정법은 매우 급속이고, 대부분의 경쟁적 측정법과 대비하여 보다 적은 작동 시간을 필요로 한다. 상기 측정법은 자성 비드를 가지고 기술된 대로 사용될 수 있고, 또한 마이크로타이터 플레이트 형태로 높은 산출량 선별검사용으로도 구성될 수 있다.
실시예
실시예
1.
압스크립션
®
방법
압스크립션®은 이전에 기술되어 졌다. 예컨대, 미국 특허 출원 제09/984,664호(2001년 10월 30일 출원)로 출원되어 현재 미국 특허 제7,045,319호로 등록된 건; 미국 특허 출원 제10/425,037호(2003년 4월 29일 출원)로 출원된 건; 미국 특허 출원 제10/600,581호(2003년 6월 23일 출원)로 출원된 건; 미국 특허 출원 제10/602,045호(2003년 6월 24일 출원)로 출원된 건; 미국 특허 출원 제10/607,136 호(2003년 6월 27일 출원)로 출원되어 현재 미국 특허 제7,226,738호로 등록된 건; 미국 특허 출원 제10/686,713호(2003년 10월 17일 출원)로 출원된 건; 미국 특허 출원 제10/976,240호(2004년 10월 29일 출원)로 출원된 건; 미국 특허 출원 제10/790,766 호(2004년 3월 3일 출원)로 출원된 건; 미국 특허 출원 제10/488,971호(2004년 10월 18일 출원)로 출원된 건; 및 미국 특허 출원 제10/551,775호(2006년 9월 14일 출원)로 출원된 건을 참조하라. 그리고, 상기 출원의 내용은 전체적으로 여기에 구체화되어 있다.
실시예
2.
압스크립트의
질량 분석 검출법
트리뉴클레오티드 압스크립트는 HPLC에 의한 디뉴클레오티드 개시자(initiator)부터의 분할을 따르는 질량 분석법에 의해 검출된다. 분할의 출력은 도4A에 도시된 바와 같이 크로마토그래피 보존 시간에 대한 전체 이온 총수로 그래프 그려진다. 어떠한 이온에 대한 크로마토그래피 프로파일이 유사하게 그래프 그려질 수 있다. 특정 보존 시간에서의 특정 m/z 종(species)의 기여는 압스크립트의 양을 크로마토그래피 피크 아래의 영역으로 주는 것으로 계산될 수 있다. 도 4B는 압스크립트 GAG(5.4분의 보존 시간)와 관련된 이온 스펙트럼을 도시한다. GAG 산출량은 477.6, 956.1 및 978.2 m/z의 값을 가진 종의 합이 된다. 이러한 종들은 각각 더블 차지, 단일 차지 및 나트륨 부가체(sodium adduct)로 설명된다.
실시예
3.
GST
-
MBD
단백질 준비
쥐 MBD2로부터의 메틸 결합 영역(MBD)를 함유하는 GST 융합 단백질은 도 5에 도시된 바와 같이 구성된다. MDB 영역에 대한 코돈은 대장균(E. coli)에서의 표출로 최적화되었다. 그러한 구성은 GST 및 MBD 영역 사이에 트롬빈 절단 부위를 포함한다. GST 단백질은 또한 APC 또는 비오틴의 부착에 사용되는 4개의 표면 시스테인 잔기를 함유한다. GST-MBD 단백질의 상세내용은 2008년 5월 15일에 출원된 미국 특허 출원 제61/053,648호에서 제공되며, 그 구체 내용은 여기서 참조되며, 특히 실시예 2-11은 MBD 융합 단백질의 준비 및 사용을 기술하고 있다.
GST 영역은 메틸화 DNA를 가진 융합 단백질 또는 그 복합체가 글루타티온 레진 또는 비드에서 고립화되고 글루타티온과 용출되는 것을 허용하거나 또는 GST를 인식하는 항체로 포획되거나 검출되는 것을 허용한다.
MBD2b 단백질로부터의 MBD가 최종적인 구성체로 선택되어지는데, 이는 MBD2b가 알려진 메틸 CpG 결합 단백질 중에서 Me-CpG 부위에 대한 가장 높은 친화력을 가지며, 비메틸화된 CpG와 가장 낮은 교차반응성을 가지기 때문이다. 그것은 Me-CpG 부위에 대한 친화력이 MeCP2 보다 25 내지 100 배 높으며, 메틸화 DNA에 대한 선호도가 MeCP2 보다 9.7 내지 43 배 높다(Fraga et al. (2003) Nucleic Acids Res., 31:1765-74). 부가적으로, MBD2 CpG 인식에서 서열 맥락 효과(context effect)가 없으며, 이에 반해 CpG 부위 근처에 A-T의 런(run)을 요하는 MeCP2에 대하여는 존재한다. 따라서, 보다 많은 수의 mCpG 부위가 MeCP2 보다는 MDB2에 의해 인식된다.
실시예
4. 고정화
GST
-
MBD2
는 심지어 입력
DNA
의 2
ng
이하와도 메틸화
DNA
에 대한 높은 특이성을 가진다
GST-MBD 단백질은 글루타티온 자성 비드에 부착되고, 높은 특이성으로 회복될 수 있는 최소 스타팅 DNA 샘플 사이즈를 결정하기 위하여, 변하는 메틸화 DNA의 양을 고립화하는데 사용되었다. SssI 메틸라제로 인공적으로 메틸화된 HeLa 게놈 DNA 또는 HeLa DNA가 1000 rpm으로 믹싱하는 횡형 회전체로, 22℃에서 1시간 동안 GST-MBD 자성 비드와 함께 배양되었다. 비결합 DNA를 함유하는 상청액(supernatant)을 제거한 후에, 결합 DNA는 1000 rpm으로 믹싱하는 횡형 회전체로, 80℃에서 10분 동안 배양함으로써 비드로부터 용출되었다. 용출된 DNA 샘플은 검출을 위한 SYBR®그린 염색제와 함께 프라이머 쌍 5'-ggtacgaaaaggcggaaaga-3' (SEQ ID NO:6) 및 5'-tgtgggaaagctggaatatc-3' (SEQ ID NO:7)를 사용하여, pPCR에 의한 PTGS2 (GenBank GI:34576917)의 존재에 대하여 테스트되었다. PTGS2는 HeLa에서 비메틸화되고, 결합 반응의 상청액에 남아있을 것으로 기대된다. 인공적으로 메틸화된 DNA의 2 ng 게놈 DNA 입력의 94% 회수(recovery)가 용출된 부분에서 관찰된 반면, HeLa로부터 비메틸화된 PTGS2 DNA의 100%가 예상된 바와 같이 상청액 부분에서 회수되었다. 메틸화된 HeLa DNA 1 ng의 입력 시, PTGS2 DNA 73%가 결합되어 열 용출(elution)로 회수되었다. 변이되지 않은 HeLa로부터 비메틸화된 형태의 어떠한 결합도 검출되지 않았다. 아가로스 겔 전기이동 염색법에 의해 시각화될 수 있는 최저 DNA 양(2 ng)은 대략 300 세포에 해당한다. 심지어 보다 적은 DNA가 증폭산물(amplicon) 검출을 위해 압스크립션을 사용하여 고립화 및 검출될 수 있다.
실시예
5.
압스크립션
®
기반
CpG
메틸화 측정
도 6은 다수의 CpG 섬의 메틸화 상태를 결정하기 위한 전체 프로토콜을 도시한다. 간단하게, 게놈 DNA 샘플로부터의 단편화된 메틸화 DNA는 고립되고, 그에 이어 메틸화 상태가 조사 중인 특이 CpG 섬의 증폭이 뒤따르게 된다. 증폭을 위하여, 하나의 프라이머는 비오틴과 같은 친화력 태그를 함유하는데, 이는 섬의 회복 및 고정화를 가능하게 한다. 두번째 프라이머는 불완전 프로모터 카세트(Abortive Promoter Cassette)의 부착을 위한 서열을 함유한다.
이러한 방법은 호환 PCR 프라이머가 설계될 수 있는 만큼, 샘플내에 많은 CpG 섬의 증폭 및 고립화를 가능하게 한다. DNA는 "C"의 "dU"로의 전환을 야기하는 중아황산염 처치로 탈아미노화되지 않기 때문에, 탈아미노화에 의해 야기되는 서열 이질성의 상실(loss)과 관련하여 문제가 되는 조직이 회피된다. 프라이머 부위는 표적에서 특이 서열에 엄격하게 제한되지 않기 때문에, 다수의 호환 프라이머 세트의 설계를 허용할 정도로 프라이머 배치에서 충분한 융통성이 있다(Henegariu et al . Biotechniques (1997) 23:504-11; Onishi et al . J. Agric. Food Chem. (2005) 53:9713). 다른 APC가 각각의 표적 CpG 섬에 부착됨으로써, 각각에 대하여 다른 압스크립트 신호를 발생시킨다. 따라서, 단일 샘플로부터 다수의 CpG 섬의 동시 검출이 달성될 수 있다.
간단하게, 고유 게놈 DNA는 단편화된 다음, 실시예 3에서 상술된 글루타티온-S-트랜스퍼라제 (GST)-메틸 결합 영역(MBD) 융합 단백질을 함유하는 글루타티온 비드에 결합된다. 단지 메틸화된 DNA만이 결합한다 (도 6A, 단계 1). 세정 후, 메틸화된 DNA가 비드로부터 용출되고(도 6A, 단계 2) 정보를 얻은 섬은 PCR에 의해 증폭된다(도 6B, 단계 3). 프라이머 중 하나는 5' 말단에 포획 태그 (예컨대, 비오틴)을 함유한다(도 7A). 두번째 프라이머는 2개의 영역을 함유한다. 제1 영역은 표적 DNA에 상보적인 폴리뉴클레오티드 서열이다. 제 2 영역은 표적 DNA 또는 다른 섬과 유사하지 않은 임의 서열이다(도 7A). 이러한 제 2 서열은 불완전 프로모터 카세트(APC)와 결합되는 표적 부착 프로브(TAP) 서열에 상보적이다. TAP 서열에 상보적인 것을 안티-TAP 서열(α-TAP)이라 불려진다. α-TAP 서열은 표적 DNA의 PCR 증폭 동안, 표적에 하이브리드화되는 프라이머 서열과 α-TAP 서열(도 7A에서의 εA 뉴클레오티드) 사이의 연결부에서 비-천연 뉴클레오티드의 포함에 기인하여 외가닥으로 머무른다. 증폭 후, 섬음 예컨대 스트렙타아비딘 비드상에서 고정화되고(도 6B, 단계 4), 잔여 게놈 DNA 및 프라이머는 세정된다. 그 다음, TAP-APC 폴리뉴클레오티드는 증폭된 표적 DNA와 접촉되고 외가닥 안티-TAP 서열에 하이브리드화된다(도 6C, 단계 5). 유리(free) TAP-APC는 세정되고, 압스크립션® 시약이 압스크립트 신호를 발생시키기 위해 부가된다(도 6C, 단계 5). 게다가, 상기 방법의 상세 내용은 아래에 기술된다.
단계 1: 게놈
DNA
의 절단
초기의 소화 단계는 CpG 섬 또는 그것의 상당 부분을 함유하는 단편을 발생시키기 위해 설계되었다. 제한 부위는 분석될 영역 바깥에 속하도록 선택되었고, 그러한 제한 부위는 메틸화 의존적이지도 메틸화 민감적이지도 않다. 4 기제 인식 서열을 가지는 제한 효소가 사용되었다. 표 1은 다르게 메틸화된 것으로 보고된 6개의 CpG 샘플에 대하여 MseI 또는 DdeI에 의해 발생시킨 단편 사이즈 리스트를 나타낸다. 벤더의 제한 버퍼(NEB 버퍼 4)내에서 MseI (NEB, Beverly, MA)의 20 유닛과 함께 게놈 DNA의 3㎍까지 기계적으로 소화되었다. 절단 반응이 37℃에서 적어도 8시간 동안 배양되었다. 절단의 정도는 MseI 서열을 함유하는 프라이머를 사용하여 소화 샘플상에 PCR를 수행하여 측정되었다. 양성 대조군(positive control)은 MseI로 처리되지 않은 게놈 DNA 및 MseI 소화에 의해 영향받지 않는 프라이머를 사용하여 MseI 처리된 DNA의 증폭 반응이다.
소화의 목적은 정상적으로 메틸화된 인접 CpG 서열로부터 표적 섬을 풀어서, 비메틸화된 섬을 메틸화된 DNA 부분으로 전달하기 위함이다. 대부분의 경우에, MseI 또는 Dde I는 단일 단편을 생성하고, 이는 많은 인접 서열을 포함하지 않으면서 섬 서열의 양을 설명해 준다. 예외는 DdeI와 MGMT의 과잉 절단이었다. 이 경우에, 대안적인 효소가 만족스러운 결과를 가져다 주었다. CpG 섬이 여러 단편으로 단편화되는 경우, 각각의 세그먼트는 그 자신의 프라이머 세트로 분석될 수 있다.
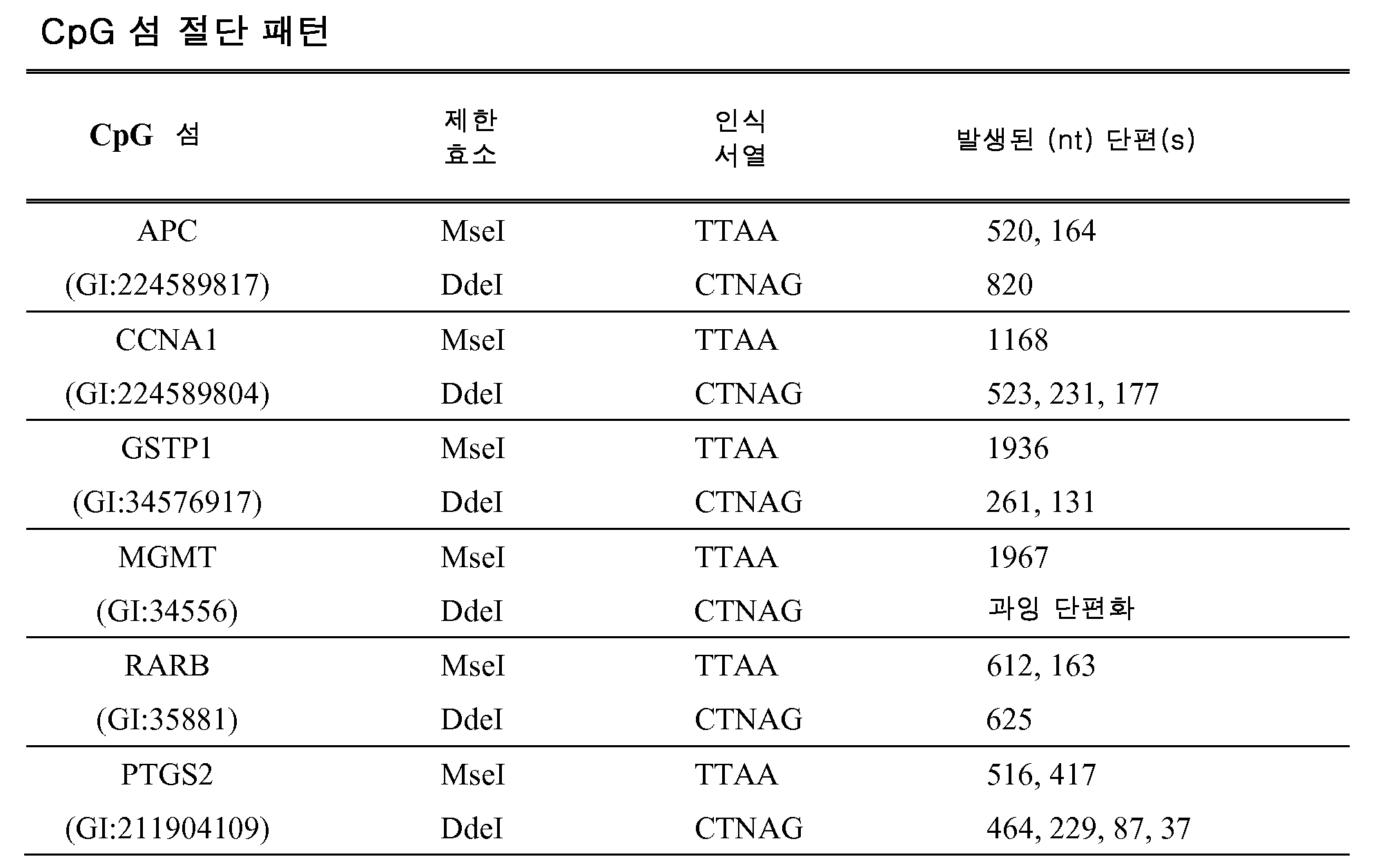
단계 2: 메틸화
DNA
의 고립화 및 회복
메틸화 DNA 포획 단계는 클루타티온 지지 자성 비드를 위해 포맷되어졌다. GST-MBD 단백질은 과잉 GST-MBD 단백질을 제거한 후, DNA 샘플내에 떠 있는 비드위에 사전 구비되었다. 비드를 떠 있는 상태로 유지하기 위하여 믹싱과 함께 상온(22~24℃)에서 1 시간 동안 DNA 결합이 수행되었다 (Eppendorf Thermomixer, 1000 rpm). DNA 샘플은 전형적으로 결합 버퍼의 50㎕ 부피에서 게놈 DNA의 1 ng 내지 50 ng를 함유하였다. 결합 단계의 완료 시, 비드는 희토류 자석을 가진 튜브의 측면에 펠릿화(pelleted)되었고, 비메틸화 DNA를 함유하는 상청액은 제거되었다. 비드는 결합 버퍼(160 mM)와 동일한 NaCl 농도를 함유하는 세정 버퍼의 400㎕로 2번 세정되었다. 각각의 세정은 믹싱(1000 rpm)으로 상온에서 5분 동안 시행되었다. 최종적인 세정은 TE 버퍼(10 mM Tris pH 8, 1 mM EDTA)로 수행되었다. 비드는 400㎕ TE에 떠 있었고, 즉시 자석으로 펠릿화되었다. TE 세정 버퍼는 폐기되었고, 비드는 용출 버퍼의 50㎕에 떠 있었다(10 mM Tris pH 8, 1 mM EDTA).
메틸화 DNA는 여러 대안적인 방법으로 비드로부터 용출될 수 있다. TE 버퍼내의 비드는 믹싱(1000 rpm)으로 80℃에서 10분 동안 배양될 수 있다. 비드는 자석으로 펠릿화되고, 용출된 DNA는 회복된다. 대안적 방법으로, 비드는 0.1% SDS를 함유하는 용출 버퍼내에 떠 있다. 결합 메틸화 DNA의 완전한 용출은 50℃에서 한번의 20분 배양으로 달성될 수 있다. 용출된 DNA는 만약 Tween-20과 같은 비이온 세제가 PCR 버퍼에 포함되어 있다면, 추가적 프로세싱 없이 PCR 준비상태에 있게 된다(Goldenberger et al 참조. PCR Methods Appl. (1995) 4:368-70). 용출은 또한 pH 8의 최소 20 mM 글루타티온을 함유하는 용출 버퍼에 10분 동안 비드를 노출시켜 수행될 수 있다. 도 5C는 HeLa DNA의 SNRPN CpG 섬 분별(fractionation) 결과를 도시한다. 메틸화 DNA는 열 처치와 함께 릴리스된다. SNRPN은 날인된(imprinted) 유전자이다. 하나의 복사체는 완전히 메틸화되고, 다른 복사체는 정상적으로 비메틸화된다. 예상대로, SNRPN 복사체의 반이 상청액에서 발견되었고(도 5C 부분 S, 비메틸화 부분), 복사체의 반은 첫 번째 용출 (도 5C, 부분 E1, 메틸화 부분)에서 비드로부터 용출되었다. 메틸화 DNA 모두는 첫번째 용출에서 추출되었다. 첫 번째 용출 후 두번의 순차적 용출(E2 및 E3)은 SNRPN DNA를 함유하지 않는다. (HeLa에서 비메틸화된) PTGS2 유전자의 CpG 섬이 음성 대조군으로 사용되었다(도 5D). PTGS2 DNA 모두는 상청액 부분에 나타났다.
단계 3:
태그된
프라이머를
가지는
PCR
증폭
CpG 섬 세그먼트는 증폭되었고, 불완전 프로모터 카세트(APC)의 부착에 사용되는 외가닥 올리고뉴클레오티드 서열 및 비오틴 친화력 태그로 라벨링된다. PCR 반응은 1x 핫 스타트 태그 버퍼 (Fermentas) 0.8 mM dNTPs (0.2 mM each), 2 mM MgCl2, and 5 % (v/v) DMSO를 함유한다. 비오틴 태그 처리된 프라이머 및 α-TAP 프라이머가 각각 1  로 존재하였다. 증폭이 트루스타트(TrueStartTM) 핫 스타트 태그 DNA 폴리머라제 (Fermentas)의 2 유닛/20㎕ 반응으로 수행되었다. 하나의 유닛은 74℃에서 30분간 dNTP 10nmol의 편입과 동등하다. 사이클링 조건은 1분 동안 95℃였고, 이어서 30초 동안 95℃의, 30초 동안 62℃의 그리고 30초 동안 72℃의 32 사이클까지 이루어졌다. 최종적인 신장(elongation) 단계는 72℃에서 5분 동안이었다. 완료된 반응은 4℃에서 유지되었다. 도 5C 및 5D는 아가로스 겔 전기이동에 의해 분별 및 증폭된 DNA의 검출을 도시한다.
로 존재하였다. 증폭이 트루스타트(TrueStartTM) 핫 스타트 태그 DNA 폴리머라제 (Fermentas)의 2 유닛/20㎕ 반응으로 수행되었다. 하나의 유닛은 74℃에서 30분간 dNTP 10nmol의 편입과 동등하다. 사이클링 조건은 1분 동안 95℃였고, 이어서 30초 동안 95℃의, 30초 동안 62℃의 그리고 30초 동안 72℃의 32 사이클까지 이루어졌다. 최종적인 신장(elongation) 단계는 72℃에서 5분 동안이었다. 완료된 반응은 4℃에서 유지되었다. 도 5C 및 5D는 아가로스 겔 전기이동에 의해 분별 및 증폭된 DNA의 검출을 도시한다.
α-
TAP
프라이머
서열 디자인
프라이머는 PCR 반응에서 존재하는 3개의 올리고뉴클레오티드 프라이머/α-TAP 서열 중에서 상호작용을 최소화함으로써 높은 신호 강도로 최적화되었다. 비오틴 태그 처리된 PCR 프라이머 및 α-TAP의 3' 말단이 증폭 동안에 DNA 합성을 준비시키기 위해 사용되었고, 프라이머:프라이머 상호 작용 및 프라이머 헤어핀 루프의 ㅎ혀형ra성을 최소화하기 위하여 프라이머 소프트웨어(Oligo Explorer 1.2)를 사용하여 설계되었다. 제2 프라이머의 5' 말단에 있는 α-TAP는 증폭산물내로 편입되도록 설계되었고, 비-코딩 뉴클레오티드이며, α-TAP으로부터 프라이머 서열을 분리시키는 에테노A(εA)의 존재 때문에 외가닥으로 머무른다. 태그 폴리머라제를 포함하는 대부분의 DNA 폴리머라제는 dNTP 반대 εA를 편입할 수 없고, 합성을 종료할 수도 없다(도 7) (Patel et al . 참조 J. Biol. Chem. (2001) 276:5044-51). 유사 뉴클레오티드는 α-TAP 서열이 PCR 동안 복제되는 것을 방지한다. α-TAP 서열과 어느 프라이머 서열 사이의 잠재적 상호작용은 전체 외가닥인 α-TAP의 비특정 고정화로부터의 거짓 양성 및 PCR의 억제를 회피하기 위하여 최소화된다.
프라이머 디자인은 3 단계를 거쳤다. 첫째, 프라이머 서열은 다음의 기준: 즉내에서 최적화되었다. 상기 기준들은 1) 16 내지 20 nt 사이의 프라이머 길이; 2) 60℃에 근접한 Tm; 3) 기재 쌍 3' 말단을 가지는 프라이머-프라이머 상호작용이 제거되어야 하는 것; 4) 다른 프라이머-프라이머 상호작용은 Tm<16℃일 것; 및 5) Tm>8℃인 헤어핀 구조는 거부되리 것이다. 6개의 CpG 섬에 대한 프라이머 쌍은 이러한 기준을 사용하여 성공적으로 발달하였다.
프라이머 최적화에서의 제2 단계는 TAP-APC의 부착 또는 PCR과 간섭할 수 있는 α-TAP-프라이머 올리고뉴클레오티드내의 헤어핀 구조체를 제거하는 것이었다. 6개의 α-TAP 후보 서열 집합은 RNA 파지 MS2, Fr 및 Qβ 서열에 기초하여 설계되었다. 각각의 후보 α-TAP는 인실리코로 테스트되었고, TAP-어닐링 조건하에서 Tm>26℃를 가지는 헤어핀을 형성했던 것은 헤어핀을 제거하도록 변경되었고 다시 테스트되었다(Zuker, Nucleic Acids Res. (2003) 31:3406-15). α-TAP 서열을 변경시킴에 있어서 유일한 제한은 프라이밍 서열과 상당한 상보성을 획득하지 않도록 하는 것이었다. α-TAP와 결합된 프라이머 서열 사이의 잠재적 헤어핀 상호 작용은 인실리코로 테스트되었고, 필요하다면 α-TAP 서열은 헤어핀 안정성을 최소화하거나 또는 헤어핀으로부터의 프라이머 신장을 방지하도록 변경되었다. 예시적인 프라이머-α-TAP 올리고뉴클레오티드(SEQ ID NO:42)는 사용되는 PCR 조건하에서 41℃의 Tm 을 가지는 헤어핀 구조를 가지지만, 증폭된 CDKN2A DNA는 역 프라이머 SEQ ID NO:43와 결합하여 α-TAP 연장부를 결여하는 프라이머 만큼 효과적이다. 최종적으로, α-TAP와 비오틴 태그 처리된 프라이머 사이의 상호작용은 파이머 말단에 첨부된 α-TAP를 가진 CpG 섬 서열을 사용하여 그것을 비오틴 태그 처리된 프라이머 서열과 함께 프라이머로 선택하고, 프라이머 설계 소프트웨어에서 테스트되었다. α-TAP 및 역 프라이머 쌍은 파일의 말단에 첨부된 α-TAP과 관련된 CpG 섬을 위해 개발되었고, 그것을 비오틴 태그 처리된 프라이머 서열과 함께 프라이머로 선택하였다. α-TAP 및 역 프라이머 쌍은 아래의 표 2에 도시된 바와 같이 CpG 섬에 대하여 발전되었다.

TAP
-
APC
설계
TAP-APC는 TAP-APC 비-템플릿 가닥을 상보적인 APC 템플릿 가닥에 하이브리드화시킴으로써 만들어졌다. APC 부분은 이중-가닥이며 TAP 세그먼트는 비-템플릿 가닥으로부터 연장되는 외가닥이다. TAP-APC는 APC의 집합이 단일 반응으로 사용하기 위한 동일 압스크립트를 인코딩하거나 또는 TAP-APC 각각의 집합이 다중 검출을 가능하도록 다른 압스크립트로 인코딩하도록 설계되었다. 외가닥 단일 TAP-APC는 아래의 표 3에 도시된 바와 같이 α-TAP를 위해 설계되었다.

외가닥 단일 TAP-APC는 통상의 템플릿 가닥에 어닐링되어 동일한 압스크립트(SEQ ID NO:32)를 인코딩하였따.
다중-호환 TAP-APC는 그 자신의 템플릿과 각각 페어되어 유일한 압스크립트를 인코딩하였다. 다중 TAP-APC(표 4)의 집합은 아래의 표 4에 도시된 CpG 섬을 검출하기 위하여 함께 사용될 수 있다.

단계 4 및 5.
스트렙타아비딘
비드에의
증폭산물의
부착 및
TAP
-
APC
의 결합
비오틴 태그 처리된 증폭산물은 이어지는 측정 단계에서 유리(free) 프로브 및 비결합 APC를 제거하기 위하여 스트렙타아비딘 비드에 결합되었다.
최적화 실험에서, 비오틴 태그 처리된 프라이머의 10 pmol 존재하에서, 스트렙타아비딘 자성 비드로의 증폭산물의 완벽한 결합이 비오틴 태그 처리된 올리고뉴클레오티드의 40 pmol의 전체 결합 용량과 함께 관찰되었다. 결합 시간은 결합 반응의 버퍼 상으로부터의 증폭산물의 제거를 측정하기 위하여 아가로스 겔 전기이동을 사용하여 상기 측정 시간 경과를 최소화하기 위하여 최적화되었다. 비오틴 태그 처리된 증폭산물의 정량 결합이 비드와 DNA 샘플을 혼합시키는 5분 내에 관찰되었다.
TAP-APC의 증폭산물에의 부착은 스트렙타아비딘 비드의 첨가 이전 또는 증폭산물을 비드에 결합시킨 후(이어서, 유리 프리머-αTAP 올리고뉴클레오티드를 제거하기 위한 세정 단계가 뒤따른다)에 성공적으로 수행되었다. TAP에 대한 Tm 은 사용된 어닐링 조건(150 mM Na+)하에서 55.8-64℃ 사이의 범위이다. TAP-APC는 0.5  첨가되었고, 최소 15 분 동안 51℃에서 배양되었다. 효과적인 결합을 달성하기 위하여 아주 높은 엄격함이 요구되지 않는다. TAP 및 α-TAP의 분석은 이러한 어닐링 조건하에서 헤어핀 형성은 중요하지 않다는 것을 나타내었다. 반응의 서열 복잡성은 다중 PCR을 받게되는 준비물에서 심지어 낮았다. 기껏, α-TAP 및 TAP의 3 쌍이 3중 반응에 존재하고, 이러한 서열은 교차-하이브리드화를 방지하기 위하여 임의적으로 변경될 수 있다. 이런 어닐링 단계는 구배 써모사이클러(thermocycler)의 온도에 대하여 최적화되었고, 가장 짧은 어닐링 시간은 증폭산물의 전기이동도 변화를 종점(endpoint)으로 사용하여 결정되어졌다.
첨가되었고, 최소 15 분 동안 51℃에서 배양되었다. 효과적인 결합을 달성하기 위하여 아주 높은 엄격함이 요구되지 않는다. TAP 및 α-TAP의 분석은 이러한 어닐링 조건하에서 헤어핀 형성은 중요하지 않다는 것을 나타내었다. 반응의 서열 복잡성은 다중 PCR을 받게되는 준비물에서 심지어 낮았다. 기껏, α-TAP 및 TAP의 3 쌍이 3중 반응에 존재하고, 이러한 서열은 교차-하이브리드화를 방지하기 위하여 임의적으로 변경될 수 있다. 이런 어닐링 단계는 구배 써모사이클러(thermocycler)의 온도에 대하여 최적화되었고, 가장 짧은 어닐링 시간은 증폭산물의 전기이동도 변화를 종점(endpoint)으로 사용하여 결정되어졌다.
PCR 반응은 150 mM의 최종 NaCl 농도를 제공하기 위하여 DNA 결합 버퍼내에서 1:1로 희석화되었다. 적절한 TAP-APC가 최종 0.5  의 농도에 이르기까지 각각의 DNA 샘플에 첨가되었고, 이어서 최소 15분 동안 51℃에서의 배양이 뒤따랐다.
의 농도에 이르기까지 각각의 DNA 샘플에 첨가되었고, 이어서 최소 15분 동안 51℃에서의 배양이 뒤따랐다.
스트렙타아비딘 자성 비드는 PCR 튜브에 부분 표본화되었다. 비드는 50% (v/v) 결합 버퍼의 100㎕로 세정되었따. 세정된 비드는 DNA 샘플내에 떠 있게 유지되었고, 이어서 최소 5분 동안 51℃에서 배양되었다.
결합 반응은 비드를 자석으로 펠릿시키고 결합 버퍼를 제거함으로써 종료되었다. 비드는 50% (v/v) 결합 버퍼(150 mM)와 동일한 NaCl 농도를 함유하는 세정 버퍼의 180㎕내에서 2번 세정되었다. 각각의 세정 단계는 51℃에서 5분 동안의 배양을 포함하였고, 상기 비드는 급속히 자석으로 펠릿되었다. 세번째 세정은 40 mM HEPES pH 7.5, 40 mM KCl에서 수행되었다. 비드는 냉장 보관될 수 있거나 또는 즉시 압스크립션시킬 수 있다.
단계 6:
압스크립션
증폭산물:TAP-APC를 함유하는 비드는 저장 버퍼를 제거하기 위하여 자석으로 펠릿되었고, 1mM 디뉴클레오티드 개시자(GpA), 1 mM NTP (GTP) 및 RNA 폴리머라제의 0.4 유닛을 함유하는 압스크립션 버퍼의 10 ㎕에 떠 있게 유지되었다. 하나의 유닛은 65℃에서 60분간 NTP 1 nmol의 편입을 촉진시킨다. 압스크립션 반응은 77℃에서 1시간 동안 배양되었다.
압스크립트는 불소를 함유하는 실리카 겔 TLC상에 1.5㎕ 샘플을 스포팅(spotting)함으로써 UV-쉐도우잉에 의해 검출되었다. TLC는 용제(이소프로판올:암모늄 하이드록사이드:활성제 용액, 6:3:1) 100 ml를 함유하는 밀폐 쳄버에서 성장되었다. 압스크립트는 도 8B(UV-쉐도우잉)에 도시된 바와 같이 단파 UV 광하에서 검은 스폿으로 검출되었다.
LC-MS 검출에 대하여 압스크립션 반응의 10㎕는 384 웰 플레이트내의 HPLC 그레이드 워터의 20㎕내로 희석화되었다. 10 마이크로리터가 처리되었고, 도 8C에 도시된 바와 같이 LC-MS로 정량화되었다.

도 8은 두가지 방법에 대하여 동일한 프라이밍 부위를 사용하여 타크맨(TaqMan®)과 비교하여, 적정(滴定)된 HeLa의 α-TAP 압스크립션®-기반 검출 결과치를 나타낸다. 5'-gcgggaccctccagaa-3' (SEQ ID NO:3) 및 5'-actcactggtggcgaagact-3' (SEQ ID NO:4)가 qPCR 증폭을 위하여 사용되었다. 5'-FAM-accacccttataaggctcggaggcc-Iowa BlackTM FQ quencher-3' (SEQ ID NO:5)은 형광성 프로브이다. 5'-actcactggt ggcgaagact-3' (SEQ ID NO: 13) 및 5'-cctccatcccaaagta[εA]gcgggaccctccagaa-3' (SEQ ID NO: 12)는 α-TAP 프라이머 쌍이다. 도 8B는 TLC 검출 결과치를 나타낸다. 압스크립션/PCR 프라이머는 SEQ ID NO:12 및 SEQ ID NO:13이다. TAP-APC는 SEQ ID NO:28 및 SEQ ID NO:32를 어닐링하여 만들어진다. APC는 압스크립트 GAG로 부호화하였다. 압스크립트는 박층 크로마토그래피 (TLC) 및 UV 쉐도우잉을 이용하여 검출되었다. UV-쉐도우잉을 사용하여 29 사이클에서의 검출 한계치(LOD)는 100복사체였다. 도 8C는 도 8B에서 분석된 동일한 샘플에 대한 LC-MS 검출 결과치를 나타낸다. PCR 반응에 대한 DNA 입력은 30 내지 9000 게놈 복사체로 달리하였다. 29 사이클에서 LC-MS에 대한 LOD는 30복사체이다. 면적은 압스크립트 (GAG)를 함유하는 크로마토그래피 피크의 면적을 나타낸다.
타크맨(TaqMan®) PCR은 100 복사체의 검출을 위하여 35 사이클을 필요로 하고, 30 복사체의 검출을 위하여 37 사이클을 필요로 하였다(도 8A 및 표 5). 압스크립션 기반 검출은 타크맨, 심지어 TLC 및 UV-쉐도우잉을 하는 타크맨 보다 보다 ㄷ더 민감하였다.
만약 UV-쉐도우잉이 형광성 압스크립트의 검출로 대체된다면, TLC 기반 검출은 보다 민감하다. CDKN2A CpG 섬에서 메틸된 게놈 DNA는 비오틴 group (SEQ ID NO:43) 및 안티-TAP 서열 (SEQ ID NO:42)을 함유하는 프라이머로 증폭되었다. 스타팅 게놈 DNA의 양은 10 ng, 2.5 ng, 640 pg 및 160 pg였다. 이는 게놈 DNA의3000, 750, 188 또는 47 복사체에 대응한다. AUC를 인코딩하는 TAP-APC를 첨가한 다음, 압스크립션은 45℃에서 디뉴클레오티드 ApU 및 CTP로 라벨링된 Cy5TM의 존재하에서 수행되었다. 샘플은 꺼내졌고(1 ㎕) 급속 TLC에 분석되어졌다. 스타팅 DNA의 2.5 ng로부터의 압스크립트는 2시간의 압스크립션 후에 비쥬얼화될 수 있고, 47 복사체가 도 9에 도시된 바와 같이 8시간의 압스크립션 후에 용이하게 검출될 수 ㅇ있다.
이 실험에서, 압스크립션 산물은 Cy5TM-라벨 트리뉴클레오티드 AUC이다. Cy5TM는 실질적으로 다른 여러 형광 염색제와 비교하여 다소 좋지 못한 개시자이고, 따라서 트리뉴클레오티드 합성에 대한 턴오버를 비-라벨(unlabeled) 디뉴클레오티드의 대략 8%까지 감소시킨다. 이러한 이유 때문에, Cy5TM은 이러한 측정법에서 선택할 수 있는 바람직한 염색제가 될 수 없을지도 모르지만, 비-라벨 개시자로 얻는 것의 35%까지 근접하는 턴오버를 제공하는, 플루오레세인 또는 DyLight(Pierce)와 같은 다른 염색제로 대체될 수 있다. 대략 4 배 높은 효율을 가진 염색제를 사용함으로써, 대응되게 시간은 줄여질 수 있고, 이는 2 시간내에 스타팅 DNA의 적어도 50 복사체의 검출을 가능하게 한다. 플루오레세인은 저가인 장파 UV 라잇으로 검출될 수 있는 추가적 이점도 가진다.
실시예
6.
APC
-
프라이머에
의한 2-단계
CpG
섬 메틸화 검출
2 단계 검출 방법을 사용하여, 메틸화 DNA는 3-단계 α-TAP 방법과 같이 단편화된 게놈 DNA로부터 고립되었다(실시예 5). 메틸화된 DNA 단편은 상술한 바와 같이 고정화 GST-MBD 단백질 (도 10; 단계 1)과 결합되었다. 메틸화 단편은 비메틸화 DNA를 제거하기 위해 세정한 후, 열 또는 글루타티온에 노출시켜 릴리스되었다(도 10; 단계 2)
표적 CpG 섬은 증폭되었고 5' 말단에 APC 서열을 함유하는 프라이머를 사용하여 태그된다(도 10; 단계 3). APC의 외가닥 형태는 비활성이지만, 그것이 표적의 증폭 동안 이중-가닥 형태로 전환될 때 활성화된다(도 10;단계 4). 따라서, 압스크립션은 개시자 NTP 및 RNAP가 포함되면, PCR 반응 동안에 수행될 수 있다.
실시예
7.
APC
-
프라이머의
설계 및 유효성 검증
APC-프라이머는 자가 프라이밍(self priming)과 역 프라이머와의 프라이머 이량체 형성을 회피하도록 설계되었다. 적어도, 이러한 이유에 의해 높은 레벨의 백그라운드 압스크립션을 생성할 수 있는 활성 듀플렉스 프로모터를 생성할 수 있다. 잠재적 프라이머 서열은 프라이머 이량체 및 자가 프라임을 형성할 수 있는 잠재력에 대하여 실시예 5에서 설명된 바와 같이 스크리닝되었다. APC 프라이머의 APC 부분은 44 nt이고, 여기서 33 nt는 압스크립션에 많은 영향 주지 않으면서 변화될 수 있다. 대부분의 경우에, 잠재적 자가 프라이밍 또는 프라이머 이량체 상호 작용은 APC-프라이머의 APC 세그먼트의 서열을 변화시켜 제거될 수 있다.
잠재적 상호작용이 없는 것으로 예상되는 프라이머 쌍은 그 프라이머 단독으로 백그라운드 신호를 생성하는지 여부를 판단하기 위하여 어닐링 온도 범위에 걸쳐 DNA의 부재하에서 PCR 반을 수행함으로써 테스트되었다. 먼저, APC-프라이머는 자가 프라이멍 레벨을 결정하기 위해 테스트되었다. 그 다음, DNA 없이 PCR 반응이 APC 프라이머 및 역 프라이머와 함께 수행되었는데, 이는 프라이머 이량체 효과를 테스트하기 위함이다. 완료된 PCR 반응물에는 1 mM 디뉴클레오티드 개시자, 1 mM NTP, RNA 폴리머라제 0.4 유닛이 보충되었고, 압스크립션에 의해 분석되었다. 도 11은 GAPDH CpG 섬을 표적 설정한 프라이머 쌍(SEQ ID NO:33 및 SEQ ID NO:34)에 대한 압스크립션 결과치를 나타낸다. 도 11A는 APC 프라이머 단독(SEQ ID NO:34) 및 HeLa 게놈 DNA에 포함된 양성 대조군과 함께 있는 프라이머 쌍에 대한 TLC 데이터를 도시한다. 인코딩된 압스크립트 GAG는 단지 양성 대조군에서 검출될 수 있다. 도 11B는 동일한 샘플에 대한 LC-MS 데이터를 도시한다. 유일한 양성 대조군이 압스크립트를 생성했고, 이에 반하여 DNA 결여 반응은 넓은 범위의 어닐링 온도에 걸쳐 중요한 신호를 생성하지 않았다. CpG 섬을 위해 개발된 APC-프라이머/역 프라이머 쌍은 아래 표 6에서 제공된다.
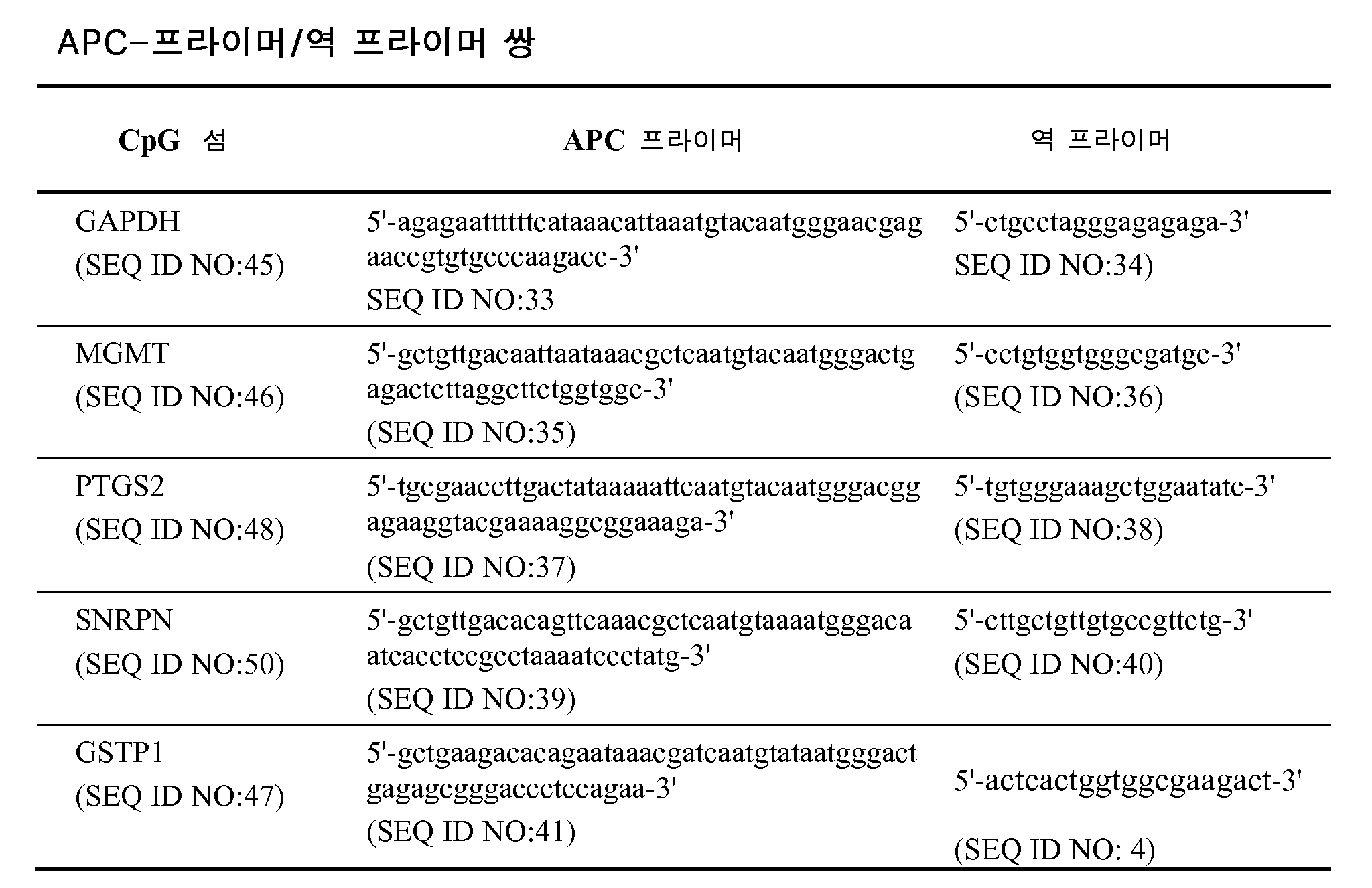
실시예
8. α-
TAP
및
APC
-
프라이머
방법에 의해 종양 세포 라인으로부터 메틸화 DNA 검출 비교
PCR 반응은 2 mM MgCl2, 0.8 mM dNTPs (0.2 mM each), and 5% (v/v) DMSO를 함유하는 벤더의 1X 버퍼내에서 핫 스타트 타크(Hot Start Taq) (Fermentas) 0.4 유닛으로 수행되었다. 핫 스타트 타크의 한 유닛이 74℃에서 30분간 dNTP 10nmol에 편입된다. APC-프라이머 및 역 프라이머는 각 1  이었다. 사이클링 조건은 1분 동안 95℃였고, 이어서 30초 동안 95℃의, 30초 동안 62℃의 그리고 30초 동안 72℃의 32 사이클까지 이루어졌다. 최종적인 신장 단계는 72℃에서 5분 동안이었다. 완료된 반응은 4℃에서 유지되었다. 완료된 PCR 반응물(10㎕)에는 1 mM 디뉴클레오티드 개시자, 1 mM NTP, RNA 폴리머라제 0.4 유닛이 보충되었다. 그 다음, 압스크립션이 77℃에서 1시간까지 동안 수행되었다.
이었다. 사이클링 조건은 1분 동안 95℃였고, 이어서 30초 동안 95℃의, 30초 동안 62℃의 그리고 30초 동안 72℃의 32 사이클까지 이루어졌다. 최종적인 신장 단계는 72℃에서 5분 동안이었다. 완료된 반응은 4℃에서 유지되었다. 완료된 PCR 반응물(10㎕)에는 1 mM 디뉴클레오티드 개시자, 1 mM NTP, RNA 폴리머라제 0.4 유닛이 보충되었다. 그 다음, 압스크립션이 77℃에서 1시간까지 동안 수행되었다.
만약 디뉴클레오티드 개시자 및 NTP가 각각 1mM로 PCR 반응에 포함되면, 압스크립션은 PCR 동안 수행될 수 있다. 내열성 RNA 폴리머라제가 20㎕ 반응에 대하여 0.4 유닛 첨가되었다. 하나의 유닛은 65℃에서 60분간 NTP 1nmol의 편입을 촉진시킨다. 압스크립션 반응물은 77℃에서 1시간 동안 배양되었다. 압스크립트는 실시예 2 및 5에서 상술된 바와 같이 검출될 수 있다.

표 7은 종양 세포 라인으로부터 메틸화 DNA의 압스크립션-기반 검출 결과치를 나타낸다. 다수의 분별 실험을 통해 한번 측정된 샘플을 가지고 자기 복제 측정이 수행되었다. GAPDH CpG 섬은 비메틸화되었는데, 이는 만약 종양이 이 섬에서 정상 메틸화 상태를 유지한다면 예상된 것이었다. SNRPN CpG 섬은 날인된 유전자에 대한 예측과 맞아 떨어졌다. 다른 섬은 LNCaP내의 DAPK1을 제외(이는 메틸화 상태에 대하여 다른 결과이다)하고는 공개된 결과와 일관되었다. (Yegnasubramanian et al . (2004) Cancer Res. 64:1975-86; Lin et al . (2001) Am J. Pathol. 159:1815-26; Paz et al . (2003) Cancer Res. 63:1114-21; Toyota et al . (2000) Cancer Res. 60-4044-48; Lodygin et al . (2005) Cancer Res. 65:4218-27).
SEQUENCE LISTING
<110> RIBOMED BIOTECHNOLOGIES, INC
HANNA, Michelle M
MCCARTHY, David
<120> ABSCRIPTION BASED MOLECULAR DETECTION
<130> 115-00301.US
<150> 61/160,335
<151> 2009-03-15
<160> 50
<170> PatentIn version 3.5
<210> 1
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 1
Leu Val Pro Arg Gly Ser Pro Gly Ile Ser Gly Gly Gly Gly Gly Ile
1 5 10 15
Arg
<210> 2
<211> 70
<212> PRT
<213> Mus musculus
<400> 2
Glu Ser Gly Lys Arg Met Asp Cys Pro Ala Leu Pro Pro Gly Trp Lys
1 5 10 15
Lys Glu Glu Val Ile Arg Lys Ser Gly Leu Ser Ala Gly Lys Ser Asp
20 25 30
Val Tyr Tyr Phe Ser Pro Ser Gly Lys Lys Phe Arg Ser Lys Pro Gln
35 40 45
Leu Ala Arg Tyr Leu Gly Asn Ala Val Asp Leu Ser Ser Phe Asp Phe
50 55 60
Arg Thr Gly Lys Met Met
65 70
<210> 3
<211> 16
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 3
gcgggaccct ccagaa 16
<210> 4
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucletide primer
<400> 4
actcactggt ggcgaagact 20
<210> 5
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide probe
<220>
<221> misc_feature
<222> (1)..(1)
<223> fluroscein - adenosine
<220>
<221> misc_feature
<222> (25)..(25)
<223> Iowa Black FQ quencher - cytosine
<400> 5
accaccctta taaggctcgg aggcc 25
<210> 6
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 6
ggtacgaaaa ggcggaaaga 20
<210> 7
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 7
tgtgggaaag ctggaatatc 20
<210> 8
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<220>
<221> misc_feature
<222> (25)..(25)
<223> etheno-deoxyadenosine
<400> 8
cacaggtcaa aggtcataaa aatgatttcc cataccaagc accgt 45
<210> 9
<211> 17
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<220>
<221> misc_feature
<222> (1)..(1)
<223> biotin-guanine
<400> 9
gtcctcctca cactccg 17
<210> 10
<211> 34
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<220>
<221> misc_feature
<222> (18)..(18)
<223> etheno-deoxyadenosine
<400> 10
caccgtcgaa tctctccacc gtgtgcccaa gacc 34
<210> 11
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> thetic oligonucleotide primer
<220>
<221> misc_feature
<222> (1)..(1)
<223> biotin-guanine
<400> 11
gtgcctttca ttccatccag cc 22
<210> 12
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<220>
<221> misc_feature
<222> (19)..(19)
<223> etheno-deoxyadenosine
<400> 12
ccaagaagcc acacgacaag cgggaccctc cagaa 35
<210> 13
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<220>
<221> misc_feature
<222> (1)..(1)
<223> biotin-adenine
<400> 13
actcactggt ggcgaagact 20
<210> 14
<211> 34
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<220>
<221> misc_feature
<222> (17)..(17)
<223> etheno-deoxyadenosine
<400> 14
cctccatccc aaagtaacct ctgctccctc cgaa 34
<210> 15
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<220>
<221> misc_feature
<222> (1)..(1)
<223> biotin-cytosine
<400> 15
ccgatggcct agacactg 18
<210> 16
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<220>
<221> misc_feature
<222> (22)..(22)
<223> etheno-deoxyadenosine
<400> 16
gaaaggacta caaaggacag aaggtacgaa aaggcggaaa ga 42
<210> 17
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<220>
<221> misc_feature
<222> (1)..(1)
<223> biotin-thymine
<400> 17
tgtgggaaag ctggaatatc 20
<210> 18
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<220>
<221> misc_feature
<223> etheno-deoxyadenosine
<220>
<221> misc_feature
<222> (21)..(21)
<223> etheno-deoxyadenosine
<400> 18
cgaaaatgca tctgagtagc aacctccgcc taaaatccct atg 43
<210> 19
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<220>
<221> misc_feature
<223> biotin-guanine
<400> 19
ggtatcctgt ccgctcgca 19
<210> 20
<211> 89
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 20
catttttatg acctttgacc tgtgaaattt atgtttgaca gatcttacaa tgcatgctat 60
aataccacta acggtgcttt aaaattccg 89
<210> 21
<211> 65
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 21
cggaatttta aagcaccgtt agtggtatta tagcatgcat tgtaagatct gtcaaacata 60
aattt 65
<210> 22
<211> 82
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 22
gtcgtgtggc ttcttggaaa tttatgtttg acagatctta caatgcatgc tataatacca 60
ctgaaggtga tataaaattc cg 82
<210> 23
<211> 65
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 23
cggaatttta tatcaccttc agtggtatta tagcatgcat tgtaagatct gtcaaacata 60
aattt 65
<210> 24
<211> 64
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 24
tactttggga tggagggctg ctggaggcgg gtataattta gccagcaccg aatagttacg 60
gtcg 64
<210> 25
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 25
cgaccgtaac tattcggtgc ttagggcagc gcccccgcct ccacgagc 48
<210> 26
<211> 85
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 26
catttttatg acctttgacc tgtggctgtt gacacagaat aaacgctcaa tgtacaatgg 60
gatggagagg tgctttagta gtgtt 85
<210> 27
<211> 77
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 27
ggagagattc gacggtgctg ttgacacaga ataaacgctc aatgtacaat gggatggaga 60
ggtgctttag tagtgtt 77
<210> 28
<211> 78
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 28
gtcgtgtggc ttcttgggct gttgacacag aataaacgct caatgtacaa tgggatggag 60
aggtgcttta gtagtgtt 78
<210> 29
<211> 77
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 29
tactttggga tggagggctg ttgacacaga ataaacgctc aatgtacaat gggatggaga 60
ggtgctttag tagtgtt 77
<210> 30
<211> 83
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 30
tctgtccttt gtagtccttt cggctgttga cacagaataa acgctcaatg tacaatggga 60
tggagaggtg ctttagtagt gtt 83
<210> 31
<211> 81
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 31
gctactcaga tgcattttcg gctgttgaca cagaataaac gctcaatgta caatgggatg 60
gagaggtgct ttagtagtgt t 81
<210> 32
<211> 61
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 32
aacactacta aagcacctct ccatcccatt gtacattgag cgtttattct gtgtcaacag 60
c 61
<210> 33
<211> 60
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 33
agagaatttt ttcataaaca ttaaatgtac aatgggaacg agaaccgtgt gcccaagacc 60
<210> 34
<211> 17
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 34
ctgcctaggg agagaga 17
<210> 35
<211> 63
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 35
gctgttgaca attaataaac gctcaatgta caatgggact gagactctta ggcttctggt 60
ggc 63
<210> 36
<211> 17
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 36
cctgtggtgg gcgatgc 17
<210> 37
<211> 65
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 37
tgcgaacctt gactataaaa attcaatgta caatgggacg gagaaggtac gaaaaggcgg 60
aaaga 65
<210> 38
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 38
tgtgggaaag ctggaatatc 20
<210> 39
<211> 65
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 39
gctgttgaca cagttcaaac gctcaatgta aaatgggaca atcacctccg cctaaaatcc 60
ctatg 65
<210> 40
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 40
cttgctgttg tgccgttctg 20
<210> 41
<211> 60
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 41
gctgaagaca cagaataaac gatcaatgta taatgggact gagagcggga ccctccagaa 60
<210> 42
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 42
caggtaaaga tccagaaccc aacatgctcg gagttaatag cacc 44
<210> 43
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide primer
<400> 43
gcgctacctg attcaattc 19
<210> 44
<211> 1101
<212> DNA
<213> Homo sapiens
<400> 44
ttaaaaaaat ctgttttgtt ctatgtgatt ttcccatacc aagcaccgtg cccggcacaa 60
gctgggatcc cagtacacat ctcgggacgg aagaaccgtg tttccctaga acccagtcag 120
agggcagctt agcaatgtgt cacaggtggg gcgcccgcgt tccgggcgga cgcactggct 180
ccccggccgg cgtgggtgtg gggcgagtgg gtgtgtgcgg ggtgtgcgcg gtagagcgcg 240
ccagcgagcc cggagcgcgg agctgggagg agcagcgagc gccgcgcaga acccgcagcg 300
ccggcctggc agggcagctc ggaggtgggt gggccgcgcc gccagcccgc ttgcagggtc 360
cccattggcc gcctgccggc cgccctccgc ccaaaaggcg gcaaggagcc gagaggctgc 420
ttcggagtgt gaggaggaca gccggaccga gccaacgccg gggactttgt tccctccgcg 480
gaggggactc ggcaactcgc agcggcaggg tctggggccg gcgcctggga gggatctgcg 540
ccccccactc actccctagc tgtgttcccg ccgccgcccc ggctagtctc cggcgctggc 600
gcctatggtc ggcctccgac agcgctccgg agggaccggg ggagctccca ggcgcccggg 660
actggagact gatgcatgag ggggctacgg aggcgcagga gcggtggtga tggtctggga 720
agcggagctg aagtgccctg ggctttggtg aggcgtgaca gtttatcatg accgtgttca 780
ggcaggaaaa cgtggatgat tactacgaca ccggcgagga acttggcagt ggacagtttg 840
cggttgtgaa gaaatgccgt gagaaaagca ccggcctcca gtatgccgcc aaattcatca 900
agaaaaggag gactaagtcc agccggcggg gtgtgagccg cgaggacatc gagcgggagg 960
tcagcatcct gaaggagatc cagcacccca atgtcatcac cctgcacgag gtctatgaga 1020
acaagacgga cgtcatcctg atcttggaac tcgttgcagg tggcgagctg tttgacttct 1080
tagctgaaaa ggaatcttta a 1101
<210> 45
<211> 2666
<212> DNA
<213> Homo sapiens
<400> 45
ttaagcaaag attatcacca ggcaggctaa acttagcaac cggcttttag ctagaagggc 60
agggggctgg tgtcaggtta tgctgggcca gcaaagaggc ccgggatccc cctcccatgc 120
acctgctgat gggccaaggc caccccaccc cacccccttc cttacaagtg ttcagcaccc 180
tcccatccca cactcacaaa cctggccctc tgccctccta ccagaagaat ggatcccctg 240
tgggaggggg caggggacct gttcccaccg tgtgcccaag acctcttttc ccactttttc 300
cctcttcttg actcaccctg ccctcaatat cccccggcgc agccagtgaa agggagtccc 360
tggctcctgg ctcgcctgca cgtcccaggg cggggaggga cttccgccct cacgtcccgc 420
tcttcgcccc aggctggatg gaatgaaagg cacactgtct ctctccctag gcagcacagc 480
ccacaggttt ccaggagtgc ctttgtggga ggcctctggg cccccaccag ccatcctgtc 540
ctccgcctgg ggccccagcc cggagagagc cgctggtgca cacagggccg ggattgtctg 600
ccctaattat caggtccagg ctacagggct gcaggacatc gtgaccttcc gtgcagaaac 660
ctccccctcc ccctcaagcc gcctcccgag cctccttcct ctccaggccc ccagtgccca 720
gtgcccagtg cccagcccag gcctcggtcc cagagatgcc aggagccagg agatggggag 780
ggggaagtgg gggctgggaa ggaaccacgg gcccccgccc gaggcccatg ggcccctcct 840
aggcctttgc ctgagcagtc cggtgtcact accgcagagc ctcgaggaga agttccccaa 900
ctttcccgcc tctcagcctt tgaaagaaag aaaggggagg gggcaggccg cgtgcagccg 960
cgagcggtgc tgggctccgg ctccaattcc ccatctcagt cgttcccaaa gtcctcctgt 1020
ttcatccaag cgtgtaaggg tccccgtcct tgactcccta gtgtcctgct gcccacagtc 1080
cagtcctggg aaccagcacc gatcacctcc catcgggcca atctcagtcc cttcccccct 1140
acgtcggggc ccacacgctc ggtgcgtgcc cagttgaacc aggcggctgc ggaaaaaaaa 1200
aagcggggag aaagtagggc ccggctacta gcggttttac gggcgcacgt agctcaggcc 1260
tcaagacctt gggctgggac tggctgagcc tggcgggagg cggggtccga gtcaccgcct 1320
gccgccgcgc ccccggtttc tataaattga gcccgcagcc tcccgcttcg ctctctgctc 1380
ctcctgttcg acagtcagcc gcatcttctt ttgcgtcgcc aggtgaagac gggcggagag 1440
aaacccggga ggctagggac ggcctgaagg cggcaggggc gggcgcaggc cggatgtgtt 1500
cgcgccgctg cggggtgggc ccgggcggcc tccgcattgc aggggcgggc ggaggacgtg 1560
atgcggcgcg ggctgggcat ggaggcctgg tgggggaggg gaggggaggc gtgtgtgtcg 1620
gccggggcca ctaggcgctc actgttctct ccctccgcgc agccgagcca catcgctcag 1680
acaccatggg gaaggtgaag gtcggagtca acgggtgagt tcgcgggtgg ctggggggcc 1740
ctgggctgcg accgcccccg aaccgcgtct acgagccttg cgggctccgg gtctttgcag 1800
tcgtatgggg gcagggtagc tgttccccgc aaggagagct caaggtcagc gctcggacct 1860
ggcggagccc cgcacccagg ctgtggcgcc ctgtgcagct ccgcccttgc ggcgccatct 1920
gcccggagcc tccttcccct agtccccaga aacaggaggt ccctactccc gcccgagatc 1980
ccgacccgga cccctaggtg ggggacgctt tctttccttt cgcgctctgc ggggtcacgt 2040
gtcgcagagg agcccctccc ccacggcctc cggcaccgca ggccccggga tgctagtgcg 2100
cagcgggtgc atccctgtcc ggatgctgcg cctgcggtag agcggccgcc atgttgcaac 2160
cgggaaggaa atgaatgggc agccgttagg aaagcctgcc ggtgactaac cctgcgctcc 2220
tgcctcgatg ggtggagtcg cgtgtggcgg ggaagtcagg tggagcgagg ctagctggcc 2280
cgatttctcc tccgggtgat gcttttccta gattattctc tggtaaatca aagaagtggg 2340
tttatggagg tcctcttgtg tcccctcccc gcagaggtgt ggtggctgtg gcatggtgcc 2400
aagccgggag aagctgagtc atgggtagtt ggaaaaggac atttccaccg caaaatggcc 2460
cctctggtgg tggccccttc ctgcagcgcc ggctcacctc acggccccgc ccttcccctg 2520
ccagcctagc gttgacccga ccccaaaggc caggctgtaa atgtcaccgg gaggattggg 2580
tgtctgggcg cctcggggaa cctgcccttc tccccattcc gtcttccgga aaccagatct 2640
cccaccgcac cctggtctga ggttaa 2666
<210> 46
<211> 1975
<212> DNA
<213> Homo sapiens
<400> 46
ttaaaacaac agaaacctat tgtctcacac ttccgggggc cagaagtttg aaacccaggt 60
gtgttaggat cctgctccct ctgaaggctc cagggaagag tgtcctctgc tccctccgaa 120
ggctccaggg aagggtctgt cctcttaggc ttctggtggc ttgcaggtgc agccctccaa 180
tcctcctccc caagcggcct tctgcctata aggacacgag tcatactgga tgaggggccc 240
actaattgat ggcttctgta aagtccccat ctccaaataa ggtcacattg tgaggtactg 300
ggagttagga ctccaacata gcttctctgg tggacacaat tcaactccta ataacgtcca 360
cacaacccca agcagggcct ggcaccctgt gtgctctctg gagagcggct gagtcaggct 420
ctggcagtgt ctaggccatc ggtgactgca gcccctggac ggcatcgccc accacaggcc 480
ctggaggctg cccccacggc cccctgacag ggtctctgct ggtctggggg tccctgacta 540
ggggagcggc accaggaggg gagagactcg cgctccgggc tcagcgtagc cgccccgagc 600
aggaccggga ttctcactaa gcgggcgccg tcctacgacc cccgcgcgct ttcaggacca 660
ctcgggcacg tggcaggtcg cttgcacgcc cgcggactat ccctgtgaca ggaaaaggta 720
cgggccattt ggcaaactaa ggcacagagc ctcaggcgga agctgggaag gcgccgcccg 780
gcttgtaccg gccgaagggc catccgggtc aggcgcacag ggcagcggcg ctgccggagg 840
accagggccg gcgtgccggc gtccagcgag gatgcgcaga ctgcctcagg cccggcgccg 900
ccgcacaggg catgcgccga cccggtcggg cgggaacacc ccgcccctcc cgggctccgc 960
cccagctccg cccccgcgcg ccccggcccc gcccccgcgc gctctcttgc ttttctcagg 1020
tcctcggctc cgccccgctc tagaccccgc cccacgccgc catccccgtg cccctcggcc 1080
ccgcccccgc gccccggata tgctgggaca gcccgcgccc ctagaacgct ttgcgtcccg 1140
acgcccgcag gtcctcgcgg tgcgcaccgt ttgcgacttg gtgagtgtct gggtcgcctc 1200
gctcccggaa gagtgcggag ctctccctcg ggacggtggc agcctcgagt ggtcctgcag 1260
gcgccctcac ttcgccgtcg ggtgtggggc cgccctgacc cccacccatc ccgggcgagc 1320
tccaggtgcg ccccaagtgc ctcccaggtg ttgcccagcc tttccccggg cctggggttc 1380
ctggactagg ctgcgctgca gtgactgtgg actggcgtgt ggcgggggtc gtggcagccc 1440
ctgccttacc tctaggtgcc agccccaggc ccgggccccg ggttcttcct acccttccat 1500
gctgccagct ttccctccgc cagctgctcc aggaagcttc cagaagcccc tgcgcgggcc 1560
ttggcttgca gcaacccttt agcatactta ggcagagtcc catatttcct tcctgctgga 1620
ggccaagttc taggggcctt ctggttacta tggctggtgt ttgtgtacat cataccctaa 1680
ctgtattcat caacacttag agtaagcaag gctcgctgga gagccacaca cactgggcac 1740
cgtaatgtcg gttataacac cgcagaggag ttctgaacta tgtatttcgc actcctgggt 1800
tcatcatctc ctgaaatctc agggtggtgt ttgctctcag ttgcttcagc tgagtagctg 1860
gctttctgtc ctggaaagca gactttgtac atgtgtgtgc aacctatgcc tgctgagatc 1920
atcatcagac agggaagcgg cttggtccag agagctgttc tcagtagaat gttaa 1975
<210> 47
<211> 1935
<212> DNA
<213> Homo sapiens
<400> 47
ttaatacctg ggtgatggga tgatctgtac agcaaaccat catggcgcac acacctatgt 60
aacaaacctg cacatcctct acatgtaccc cagaacttca aataaaagtt ggacggccag 120
gcgtggtggc tcacgcctgt aatcccagca ctttgggaag ccgaggcgtg cagatcacct 180
aaggtcagga gttcgagacc agcccggcca acatggtgaa accccgtctc tactaaaaat 240
acaaaaatca gccagatgtg gcacgcacct ataattccac ctactcggga ggctgaagca 300
gaattgcttg aacccgagag gcggaggttg cagtgagccg ccgagatcgc gccactgcac 360
tccagcctgg gccacagcgt gagactacgt cataaaataa aataaaataa cacaaaataa 420
aataaaataa aataaaataa aataaaataa aataaaataa aataaaataa aaaaataaaa 480
taaaataaaa taaaataaag caatttcctt tcctctaagc ggcctccacc cctctcccct 540
gccctgtgaa gcgggtgtgc aagctccggg atcgcagcgg tcttagggaa tttccccccg 600
cgatgtcccg gcgcgccagt tcgctgcgca cacttcgctg cggtcctctt cctgctgtct 660
gtttactccc taggccccgc tggggacctg ggaaagaggg aaaggcttcc ccggccagct 720
gcgcggcgac tccggggact ccagggcgcc cctctgcggc cgacgcccgg ggtgcagcgg 780
ccgccggggc tggggccggc gggagtccgc gggaccctcc agaagagcgg ccggcgccgt 840
gactcagcac tggggcggag cggggcggga ccacccttat aaggctcgga ggccgcgagg 900
ccttcgctgg agtttcgccg ccgcagtctt cgccaccagt gagtacgcgc ggcccgcgtc 960
cccggggatg gggctcagag ctcccagcat ggggccaacc cgcagcatca ggcccgggct 1020
cccggcaggg ctcctcgccc acctcgagac ccgggacggg ggcctagggg acccaggacg 1080
tccccagtgc cgttagcggc tttcaggggg cccggagcgc ctcggggagg gatgggaccc 1140
cgggggcggg gagggggggc agactgcgct caccgcgcct tggcatcctc ccccgggctc 1200
cagcaaactt ttctttgttc gctgcagtgc cgccctacac cgtggtctat ttcccagttc 1260
gaggtaggag catgtgtctg gcagggaagg gaggcagggg ctggggctgc agcccacagc 1320
ccctcgccca cccggagaga tccgaacccc cttatccctc cgtcgtgtgg cttttacccc 1380
gggcctcctt cctgttcccc gcctctcccg ccatgcctgc tccccgcccc agtgttgtgt 1440
gaaatcttcg gaggaacctg tttccctgtt ccctccctgc actcctgacc cctccccggg 1500
ttgctgcgag gcggagtcgg cccggtcccc acatctcgta cttctccctc cccgcaggcc 1560
gctgcgcggc cctgcgcatg ctgctggcag atcagggcca gagctggaag gaggaggtgg 1620
tgaccgtgga gacgtggcag gagggctcac tcaaagcctc ctgcgtaagt gaccatgccc 1680
gggcaagggg agggggtgct gggccttagg gggctgtgac taggatcggg ggacgcccaa 1740
gctcagtgcc cctccctgag ccatgcctcc cccaacagct atacgggcag ctccccaagt 1800
tccaggacgg agacctcacc ctgtaccagt ccaataccat cctgcgtcac ctgggccgca 1860
cccttggtga gtcttgaacc tccaagtcca gggcaggcat gggcaagcct ctgcccccgg 1920
agcccttttg tttaa 1935
<210> 48
<211> 937
<212> DNA
<213> Homo sapiens
<400> 48
ttaaccttac tcgccccagt ctgtcccgac gtgacttcct cgaccctcta aagacgtaca 60
gaccagacac ggcggcggcg gcgggagagg ggattccctg cgcccccgga cctcagggcc 120
gctcagattc ctggagagga agccaagtgt ccttctgccc tcccccggta tcccatccaa 180
ggcgatcagt ccagaactgg ctctcggaag cgctcgggca aagactgcga agaagaaaag 240
acatctggcg gaaacctgtg cgcctggggc ggtggaactc ggggaggaga gggagggatc 300
agacaggaga gtggggacta ccccctctgc tcccaaattg gggcagcttc ctgggtttcc 360
gattttctca tttccgtggg taaaaaaccc tgcccccacc gggcttacgc aattttttta 420
aggggagagg agggaaaaat ttgtgggggg tacgaaaagg cggaaagaaa cagtcatttc 480
gtcacatggg cttggttttc agtcttataa aaaggaaggt tctctcggtt agcgaccaat 540
tgtcatacga cttgcagtga gcgtcaggag cacgtccagg aactcctcag cagcgcctcc 600
ttcagctcca cagccagacg ccctcagaca gcaaagccta cccccgcgcc gcgccctgcc 660
cgccgctgcg atgctcgccc gcgccctgct gctgtgcgcg gtcctggcgc tcagccatac 720
aggtgagtac ctggcgccgc gcaccgggga ctccggttcc acgcacccgg gcagagtttc 780
cgctctgacc tcctgggtct atcccagtac tccgacttct ctccgaatag agaagctacg 840
tgacttggga aagagcttgg accgctagag ttcgaaagaa ctccgtggat attccagctt 900
tcccacaagc actgatcatt atgagccagt tacttaa 937
<210> 49
<211> 704
<212> DNA
<213> Homo sapiens
<400> 49
ttaatagcac ctcctccgag cactcgctca cggcgtcccc ttgcctggaa agataccgcg 60
gtccctccag aggatttgag ggacagggtc ggagggggct cttccgccag caccggagga 120
agaaagagga ggggctggct ggtcaccaga gggtggggcg gaccgcgtgc gctcggcggc 180
tgcggagagg gggagagcag gcagcgggcg gcggggagca gcatggagcc ggcggcgggg 240
agcagcatgg agccttcggc tgactggctg gccacggccg cggcccgggg tcgggtagag 300
gaggtgcggg cgctgctgga ggcgggggcg ctgcccaacg caccgaatag ttacggtcgg 360
aggccgatcc aggtgggtag agggtctgca gcgggagcag gggatggcgg gcgactctgg 420
aggacgaagt ttgcagggga attggaatca ggtagcgctt cgattctccg gaaaaagggg 480
aggcttcctg gggagttttc agaaggggtt tgtaatcaca gacctcctcc tggcgacgcc 540
ctgggggctt gggaagccaa ggaagaggaa tgaggagcca cgcgcgtaca gatctctcga 600
atgctgagaa gatctgaagg ggggaacata tttgtattag atggaagtat gctctttatc 660
agatacaaaa tttacgaacg tttgggataa aaagggagtc ttaa 704
<210> 50
<211> 1238
<212> DNA
<213> Homo sapiens
<400> 50
ttaaaggctg cggactgtgc tactgcccct tctgatgccc cctcctctac acagcaatca 60
ttcagcgtcc cttagtcact ccggacagcg acaggccccg cggccgccat gcccaccgcc 120
tccatgccat gcccaccgcc gccatgccta ccgccgccaa agtccaccac cgccatgcct 180
acccgctgcc aatgcccacc gccgccaata cccactgtcg ccgccttccc cctacctccc 240
agccacttcc tacggactct ccccgcgccg cgaccaccaa cacaaccccc accactgtca 300
caccgactca tccccctggt ccactgccat agcctcctcg cctcggtcac tgcgacgaat 360
tcccccccca gtcgccccac gtaccctgct ccaccacgca gtggtcacta ttatacacct 420
acctgcgctc aacaccccct aaataccgat cacttcacgt accttcgccc cgccacaatc 480
actccaatat acctacctcc gcctaaaatc cctatgcact ggtcccccca cgtaccctcg 540
ccacacggaa ctgcaatcac cctgatgtac ccacctccac ccatgtccct tgcccactgc 600
ggttaccccg catgctccca gtcaccaccg cccttcccac cgcagacacc cgcaatagga 660
cctgtcgcga caccacagtt gggggcggat gggggacgcg ccccaatgcg agcggacagg 720
ataccatcgg ggcagaacgg cacaacagca agcctctgaa cattccggat ctggttctcc 780
agaacaaagg actttagggc ccaaattccg tttattcagt actccaagtc ctaaaaactt 840
ggaatatctg atgaataaaa gtggccgctc cccaggctgt ctcttgagag aagccaccgg 900
cacagctgac cttgcccgct ccatcgcgtc actgaccgct cctcagacag atgcgtcagg 960
catctccggc ggccgctcca ctctgcgcca gactcgctgc agcagcggca ggcttcgcac 1020
acatccccgc ctgagcatgc gcgccagcct gcctctgcgg ccgcgcaggc gtgcttgttt 1080
gccgcagtgc aggggtccca gctccctccc tcaccggaat gacctggggg gagggggcta 1140
ctggacccct agggccccac agcactgttg caatgagagg gggcctctag aaaccataag 1200
caacctggga tcaatggaca tgtctacctg ttttttaa 1238
Claims (23)
- 샘플에서 적어도 하나의 표적 폴리뉴클레오티드를 검출하기 위한 방법으로서,
a)적어도 하나의 폴리뉴클레오티드를 함유하는 샘플을, 적어도 하나의 폴리뉴클레오티드의 표적 서열을 특이적으로 하이브리드화하고 그것을 증폭시키는, 프라이머 쌍과 접촉시키는 단계, 이때 프라이머 쌍은
i) (1) 폴리뉴클레오티드의 표적 서열에 인접하는 제 1 서열에 상보적인 3' 서열과,
(2) 5' 포획 태그;
를 포함하는 제 1 프라이머와,
ii) (1)폴리뉴클레오티드의 표적 서열에 인접하는 제 2 서열에 상보적인 3' 서열과,
(2) 압스크립션을 다이렉팅(directing)하기 위한 수단을 제공하는 5' 서열;
을 포함하는 제 2 프라이머로 이루어지고,
b)상기 제 1 및 제 2 프라이머로부터 상기 표적 서열을 증폭시키는 단계;
c)상기 증폭된 표적 서열을, 상기 5' 포획 태그를 결속시키는 고정화 분자와 접촉시킴으로써, 상기 폴리뉴클레오티드의 증폭된 표적 서열을 포획하는 단계 ;
d)압스크립션을 다이렉팅하기 위한 수단으로부터 적어도 하나의 압스크립트를 전사하는 단계; 및
e)단계 d)에서 전사된 적어도 하나의 압스크립트를 검출하는 단계
를 포함하는 것을 특징으로 하는 방법. - 제 1항에 있어서, 다음의 단계 전에, 비결합 시약, 프라이머 및 폴리뉴클레오티드가 고정화 및 포획된 폴리뉴클레오티드로부터 세척되는 것을 특징으로 하는 방법.
- 제 1항에 있어서, 상기 증폭은 폴리머라제 연쇄 반응을 수행하는 것으로 이루어지는 것을 특징으로 하는 방법.
- 제 3항에 있어서, 상기 폴리머라제 연쇄 반응은 내열성 DNA 폴리머라제와 내열성 RNA 폴리머라제 중 적어도 하나로 수행되는 것을 특징으로 하는 방법.
- 제 1항에 있어서, 상기 5' 포획 태그는 비오틴이고, 5' 포획 태그에 결합하는 분자는 스트렙타아비딘인 것을 특징으로 하는 방법.
- 제 1항에 있어서, 5' 포획 태그에 결합하는 분자는 자성 비드 및 마이크로타이터 플레이트 중에서 선택된 고체 지지체 위에 고정화되는 것을 특징으로 하는 방법.
- 제 1항에 있어서, 단계 d) 동안에 검출가능하게 표지된 뉴클레오티드가 적어도 하나의 압스크립트 내로 혼입되는 것을 특징으로 하는 방법 .
- 제 7항에 있어서, 검출가능하게 표지된 뉴클레오티드는 형광성 뉴클레오티드인 것을 특징으로 하는 방법.
- 제 1항에 있어서, 적어도 하나의 압스크립트를 검출하는 단계는 질량 분석법, 모세관 전기이동 또는 박층 크로마토그래피를 포함하는 것을 특징으로 하는 방법.
- 제 1항에 있어서, 적어도 하나의 압스크립트는 길이가 3-20 뉴클레오티드인 것을 특징으로 하는 방법.
- 제 10항에 있어서, 적어도 하나의 압스크립트는 길이가 3 뉴클레오티드인 것을 특징으로 하는 방법.
- 제 1항에 있어서, 압스크립션를 다이렉팅하기 위한 수단은 APC를 포함하는 것을 특징으로 하는 방법.
- 제 1항에 있어서, 압스크립션를 다이렉팅하기 위한 수단은:
i) 유일한 CpG 섬을 식별하는 5' α-TAP 서열; 및
ii) 5' α-TAP 서열과 표적 서열에 인접하는 제 2 서열에 상보적인 3' 서열 사이에 비-천연 뉴클레오티드;를 포함하고
상기 단계 d)는:
i) 프로브를 증폭된 표적 서열에 하이브리드화하는 단계, 이때 프로브는 α-TAP 서열에 상보적인 5' TAP 서열과 3' APC를 포함하며;
그리고
ii) APC로부터 적어도 하나의 압스크립트를 전사하는 단계를 포함하는 것을 특징으로 하는 방법. - 제 13항에 있어서, 비-천연 뉴클레오티드는 증폭하는 동안 α-TAP 의 복제를 방지하고, 그로인해 α-TAP 서열은 단계 a)로부터 c)까지 동안에 외가닥으로 남아있는 것을 특징으로 하는 방법.
- 제 14항에 있어서, 비-천연 뉴클레오티드는 에테노-디옥시아데노신인 것을 특징으로 하는 방법.
- 제 1항에 있어서, 적어도 하나의 표적 폴리뉴클레오티드가 복수의 다른 표적 폴리뉴클레오티드를 포함하고, 단계 a) 부터 e)까지가 복수의 제 1 및 제 2 프라이머 쌍들과 함께 동시에 수행되며, 각각의 프라이머 쌍은 다른 표적에 특이적으로 혼성화되는 것을 특징으로 하는 방법.
- 제 16항에 있어서, 압스크립션를 다이렉팅하기 위한 수단은 복수의 표적들의 각각에 대해 유일한 압스크립트를 생산하는 것을 특징으로 하는 방법.
- 제 17항에 있어서, 유일한 APC는 분자 중량 또는 뉴클레오티드 서열을 기반으로 서로 구별가능한 것을 특징으로 하는 방법.
- 제 16항에 있어서, 복수의 다른 표적은 적어도 10개의 다른 표적을 포함하는 것을 특징으로 하는 방법.
- 제 1항에 있어서, 적어도 하나의 표적 폴리뉴클레오티드는 메틸화 CpG 섬이고 샘플은 고립된 메틸화 게놈 DNA 단편을 포함하는 것을 특징으로 하는 방법.
- 제 20항에 있어서, 메틸화 게놈 DNA 단편은
a)적어도 하나의 메틸화 표적 폴리뉴클레오티드를 함유하는 게놈 DNA 샘플을, 표적 폴리뉴클레오티드 CpG 섬은 분할하지 않는 제한 효소로 분할하는 단계;
b)분할된 게놈 DNA을 고정화 MBD와 접촉시킴으로써, 샘플로부터 메틸화 게놈 DNA를 고정화하는 단계; 및
c)선택적으로, 메틸화 게놈 DNA을 고정화 MBD으로부터 회복시키고, 그로인해 메틸화 게놈 DNA 단편들을 고립시키는 단계
에 의해 고립되는 것을 특징으로 하는 방법 - 제 21항에 있어서, MBD는 GST-MBD2 융합 단백질인 것을 특징으로 하는 방법.
- 제 22항에 있어서, GST-MBD2 융합 단백질은 글루타티온-함유 고체 지지체 위에 고정화되는 것을 특징으로 하는 방법.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US16033509P | 2009-03-15 | 2009-03-15 | |
| US61/160,335 | 2009-03-15 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20120007002A true KR20120007002A (ko) | 2012-01-19 |
Family
ID=42731027
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020117024467A Withdrawn KR20120007002A (ko) | 2009-03-15 | 2010-03-15 | 압스크립션 기반 분자 검출 |
Country Status (12)
| Country | Link |
|---|---|
| US (1) | US8263339B2 (ko) |
| EP (1) | EP2408935A4 (ko) |
| JP (1) | JP2012520086A (ko) |
| KR (1) | KR20120007002A (ko) |
| CN (1) | CN102421914A (ko) |
| AU (1) | AU2010225937B2 (ko) |
| CA (1) | CA2755668A1 (ko) |
| IL (1) | IL215164A0 (ko) |
| MX (1) | MX2011009736A (ko) |
| RU (1) | RU2011141720A (ko) |
| WO (1) | WO2010107716A2 (ko) |
| ZA (1) | ZA201107560B (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021075764A1 (ko) * | 2019-10-15 | 2021-04-22 | 프로지니어 주식회사 | 다중 바이오마커 검출 방법 |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5211790B2 (ja) * | 2007-03-26 | 2013-06-12 | 住友化学株式会社 | Dnaメチル化測定方法 |
| EP2297346B1 (en) | 2008-05-15 | 2015-04-15 | Ribomed Biotechnologies, Inc. | METHODS AND REAGENTS FOR DETECTING CpG METHYLATION WITH A METHYL CpG BINDING PROTEIN (MBP) |
| US8211644B2 (en) | 2008-07-13 | 2012-07-03 | Ribomed Biotechnologies, Inc. | Molecular beacon-based methods for detection of targets using abscription |
| AU2010225937B2 (en) | 2009-03-15 | 2014-09-18 | Ribomed Biotechnologies, Inc. | Abscription based molecular detection |
| US20130157266A1 (en) * | 2009-03-15 | 2013-06-20 | Ribomed Biotechnologies, Inc. | Abscription based molecular detection of dna methylation |
| CN103926369B (zh) * | 2014-05-06 | 2015-06-17 | 山东师范大学 | 糖蜜中生物素的提取方法及其薄层层析扫描检测方法 |
| CN105112508A (zh) * | 2015-07-31 | 2015-12-02 | 上海捷瑞生物工程有限公司 | 一种基于连接的dna甲基化快速荧光法高通量检测方法 |
| GB201810571D0 (en) * | 2018-06-27 | 2018-08-15 | Cs Genetics Ltd | Reagents and methods for the analysis of circulating microparticles |
| CN117003850B (zh) * | 2023-09-19 | 2024-04-12 | 汲迈生命科技(苏州)有限公司 | 一种甲基化富集蛋白及其编码基因、制备方法和应用 |
Family Cites Families (59)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3996345A (en) | 1974-08-12 | 1976-12-07 | Syva Company | Fluorescence quenching with immunological pairs in immunoassays |
| US4351760A (en) | 1979-09-07 | 1982-09-28 | Syva Company | Novel alkyl substituted fluorescent compounds and polyamino acid conjugates |
| US4582788A (en) | 1982-01-22 | 1986-04-15 | Cetus Corporation | HLA typing method and cDNA probes used therein |
| US4786600A (en) | 1984-05-25 | 1988-11-22 | The Trustees Of Columbia University In The City Of New York | Autocatalytic replication of recombinant RNA |
| US5503979A (en) | 1984-05-25 | 1996-04-02 | The Trustees Of Columbia University In The City Of New York | Method of using replicatable hybridzable recombinant RNA probes |
| US4683194A (en) | 1984-05-29 | 1987-07-28 | Cetus Corporation | Method for detection of polymorphic restriction sites and nucleic acid sequences |
| US4739044A (en) | 1985-06-13 | 1988-04-19 | Amgen | Method for derivitization of polynucleotides |
| US4757141A (en) | 1985-08-26 | 1988-07-12 | Applied Biosystems, Incorporated | Amino-derivatized phosphite and phosphate linking agents, phosphoramidite precursors, and useful conjugates thereof |
| US5654176A (en) | 1987-05-28 | 1997-08-05 | Amrad Corporation Limited | Fusion proteins containing glutathione-s-transferase |
| WO1989001050A1 (en) | 1987-07-31 | 1989-02-09 | The Board Of Trustees Of The Leland Stanford Junior University | Selective amplification of target polynucleotide sequences |
| US5246866A (en) | 1987-12-23 | 1993-09-21 | Hitachi Software Engineering Co., Ltd. | Method for transcription of a DNA sequence |
| US5130238A (en) | 1988-06-24 | 1992-07-14 | Cangene Corporation | Enhanced nucleic acid amplification process |
| CA2001110A1 (en) | 1988-11-18 | 1990-05-18 | Zvi G. Loewy | Compositions and process for amplifying and detecting nucleic acid sequences |
| US5508178A (en) | 1989-01-19 | 1996-04-16 | Rose; Samuel | Nucleic acid amplification using single primer |
| CA2020958C (en) | 1989-07-11 | 2005-01-11 | Daniel L. Kacian | Nucleic acid sequence amplification methods |
| US5766849A (en) | 1989-07-11 | 1998-06-16 | Gen-Probe Incorporated | Methods of amplifying nucleic acids using promoter-containing primer sequence |
| US5215899A (en) | 1989-11-09 | 1993-06-01 | Miles Inc. | Nucleic acid amplification employing ligatable hairpin probe and transcription |
| US5194370A (en) | 1990-05-16 | 1993-03-16 | Life Technologies, Inc. | Promoter ligation activated transcription amplification of nucleic acid sequences |
| US5503978A (en) * | 1990-06-11 | 1996-04-02 | University Research Corporation | Method for identification of high affinity DNA ligands of HIV-1 reverse transcriptase |
| US5595891A (en) | 1990-07-19 | 1997-01-21 | Behringwerke Ag | Method for producing a polynucleotide for use in single primer amplification |
| US5888819A (en) | 1991-03-05 | 1999-03-30 | Molecular Tool, Inc. | Method for determining nucleotide identity through primer extension |
| US5169766A (en) | 1991-06-14 | 1992-12-08 | Life Technologies, Inc. | Amplification of nucleic acid molecules |
| PL170837B1 (pl) | 1991-10-18 | 1997-01-31 | Monsanto Co | S rod ek g r zybobó j c zy PL PL PL PL PL PL |
| KR100249110B1 (ko) | 1992-05-06 | 2000-04-01 | 다니엘 엘. 캐시앙 | 핵산 서열 증폭 방법, 이에 이용되는 조성물 및 키트 |
| ES2104160T3 (es) | 1992-07-31 | 1997-10-01 | Behringwerke Ag | Metodo para introducir secuencias definidas en el extremo 3' de polinucleotidos. |
| ZA936016B (en) | 1992-08-24 | 1994-03-10 | Akzo Nv | Method for nucleic acid amplification |
| US5571669A (en) | 1993-01-14 | 1996-11-05 | The University Of Pennsylvania | Transcription and nucleic acid sequence determination with short primer DNA/RNA molecules and RNA polymerase |
| US5597694A (en) | 1993-10-07 | 1997-01-28 | Massachusetts Institute Of Technology | Interspersed repetitive element-bubble amplification of nucleic acids |
| GB2284209A (en) | 1993-11-25 | 1995-05-31 | Ole Buchardt | Nucleic acid analogue-induced transcription of RNA from a double-stranded DNA template |
| US5648211A (en) | 1994-04-18 | 1997-07-15 | Becton, Dickinson And Company | Strand displacement amplification using thermophilic enzymes |
| FR2724934B1 (fr) | 1994-09-26 | 1997-01-24 | Bio Merieux | Oligonucleotide chimere et son utilisation dans l'obtention de transcrits d'un acide nucleique |
| US5684142A (en) | 1995-06-07 | 1997-11-04 | Oncor, Inc. | Modified nucleotides for nucleic acid labeling |
| FR2737223B1 (fr) | 1995-07-24 | 1997-09-12 | Bio Merieux | Procede d'amplification de sequences d'acide nucleique par deplacement, a l'aide d'amorces chimeres |
| US5912340A (en) | 1995-10-04 | 1999-06-15 | Epoch Pharmaceuticals, Inc. | Selective binding complementary oligonucleotides |
| AU3891097A (en) | 1996-07-24 | 1998-02-10 | Michelle M. Hanna | Base-protected nucleotide analogs with protected thiol groups |
| US5849546A (en) | 1996-09-13 | 1998-12-15 | Epicentre Technologies Corporation | Methods for using mutant RNA polymerases with reduced discrimination between non-canonical and canonical nucleoside triphosphates |
| US5846723A (en) | 1996-12-20 | 1998-12-08 | Geron Corporation | Methods for detecting the RNA component of telomerase |
| US5858801A (en) | 1997-03-13 | 1999-01-12 | The United States Of America As Represented By The Secretary Of The Navy | Patterning antibodies on a surface |
| US6251594B1 (en) | 1997-06-09 | 2001-06-26 | Usc/Norris Comprehensive Cancer Ctr. | Cancer diagnostic method based upon DNA methylation differences |
| US6114519A (en) | 1997-10-15 | 2000-09-05 | Isis Pharmaceuticals, Inc. | Synthesis of sulfurized oligonucleotides |
| US6268131B1 (en) | 1997-12-15 | 2001-07-31 | Sequenom, Inc. | Mass spectrometric methods for sequencing nucleic acids |
| AUPP312998A0 (en) | 1998-04-23 | 1998-05-14 | Commonwealth Scientific And Industrial Research Organisation | Diagnostic assay |
| EP1257662A2 (en) | 1999-10-06 | 2002-11-20 | Amersham Biosciences Corp. | Method for detecting mutations using arrayed primer extension |
| DE10019058A1 (de) | 2000-04-06 | 2001-12-20 | Epigenomics Ag | Detektion von Variationen des DNA-Methylierungsprofils |
| US6756200B2 (en) | 2001-01-26 | 2004-06-29 | The Johns Hopkins University School Of Medicine | Aberrantly methylated genes as markers of breast malignancy |
| ATE429511T1 (de) | 2001-03-01 | 2009-05-15 | Epigenomics Ag | Verfahren zur entwicklung von gensätzen zu diagnostischen und therapeutischen zwecken auf grundlage des expressions- und methylierungsstatus der gene |
| US20020168641A1 (en) | 2001-03-09 | 2002-11-14 | Bruce Mortensen | Fluorescein-cyanine 5 as a fluorescence resonance energy transfer pair |
| US20030104432A1 (en) * | 2001-07-27 | 2003-06-05 | The Regents Of The University Of California | Methods of amplifying sense strand RNA |
| DE10139283A1 (de) | 2001-08-09 | 2003-03-13 | Epigenomics Ag | Verfahren und Nukleinsäuren zur Analyse von Colon-Krebs |
| US7045319B2 (en) | 2001-10-30 | 2006-05-16 | Ribomed Biotechnologies, Inc. | Molecular detection systems utilizing reiterative oligonucleotide synthesis |
| US20040054162A1 (en) | 2001-10-30 | 2004-03-18 | Hanna Michelle M. | Molecular detection systems utilizing reiterative oligonucleotide synthesis |
| AU2002352143A1 (en) | 2001-11-23 | 2003-06-10 | Epigenomics Ag | Method and nucleic acids for the analysis of a lymphoid cell proliferative disorder |
| KR20070012779A (ko) * | 2003-10-29 | 2007-01-29 | 리보메드 바이오테그놀로지스 인코포레이티드 | 반복적 올리고뉴클레오티드 합성을 위한 조성물, 방법 및검출 기법 |
| US7425415B2 (en) | 2005-04-06 | 2008-09-16 | City Of Hope | Method for detecting methylated CpG islands |
| US20080124716A1 (en) | 2006-11-29 | 2008-05-29 | Northrop Grumman Systems Corporation | Method and device for time-effective biomolecule detection |
| EP2297346B1 (en) * | 2008-05-15 | 2015-04-15 | Ribomed Biotechnologies, Inc. | METHODS AND REAGENTS FOR DETECTING CpG METHYLATION WITH A METHYL CpG BINDING PROTEIN (MBP) |
| US8211644B2 (en) | 2008-07-13 | 2012-07-03 | Ribomed Biotechnologies, Inc. | Molecular beacon-based methods for detection of targets using abscription |
| CN101381779B (zh) * | 2008-10-21 | 2011-06-08 | 广州益善生物技术有限公司 | kRas基因突变的检测探针、液相芯片及其检测方法 |
| AU2010225937B2 (en) | 2009-03-15 | 2014-09-18 | Ribomed Biotechnologies, Inc. | Abscription based molecular detection |
-
2010
- 2010-03-15 AU AU2010225937A patent/AU2010225937B2/en not_active Ceased
- 2010-03-15 WO PCT/US2010/027367 patent/WO2010107716A2/en not_active Ceased
- 2010-03-15 US US12/724,416 patent/US8263339B2/en not_active Expired - Fee Related
- 2010-03-15 CA CA2755668A patent/CA2755668A1/en not_active Abandoned
- 2010-03-15 RU RU2011141720/10A patent/RU2011141720A/ru unknown
- 2010-03-15 CN CN2010800176206A patent/CN102421914A/zh active Pending
- 2010-03-15 KR KR1020117024467A patent/KR20120007002A/ko not_active Withdrawn
- 2010-03-15 JP JP2012500861A patent/JP2012520086A/ja active Pending
- 2010-03-15 MX MX2011009736A patent/MX2011009736A/es active IP Right Grant
- 2010-03-15 EP EP20100753943 patent/EP2408935A4/en not_active Withdrawn
-
2011
- 2011-09-15 IL IL215164A patent/IL215164A0/en unknown
- 2011-10-14 ZA ZA2011/07560A patent/ZA201107560B/en unknown
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021075764A1 (ko) * | 2019-10-15 | 2021-04-22 | 프로지니어 주식회사 | 다중 바이오마커 검출 방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20100233709A1 (en) | 2010-09-16 |
| AU2010225937A1 (en) | 2011-11-10 |
| AU2010225937B2 (en) | 2014-09-18 |
| WO2010107716A3 (en) | 2011-03-03 |
| MX2011009736A (es) | 2012-06-01 |
| RU2011141720A (ru) | 2013-04-27 |
| CN102421914A (zh) | 2012-04-18 |
| US8263339B2 (en) | 2012-09-11 |
| JP2012520086A (ja) | 2012-09-06 |
| EP2408935A4 (en) | 2012-10-03 |
| CA2755668A1 (en) | 2010-09-23 |
| EP2408935A2 (en) | 2012-01-25 |
| ZA201107560B (en) | 2012-12-27 |
| WO2010107716A2 (en) | 2010-09-23 |
| IL215164A0 (en) | 2011-12-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102945867B1 (ko) | 폐 신생물 검출에서 메틸화된 dna, rna, 및 단백질의 특성화 | |
| KR20120007002A (ko) | 압스크립션 기반 분자 검출 | |
| AU2017260630B2 (en) | Detection of lung neoplasia by analysis of methylated DNA | |
| US6960436B2 (en) | Quantitative methylation detection in DNA samples | |
| KR20220092856A (ko) | 폐 신생물을 갖는 것으로 의심되는 대상체에서의 메틸화 dna, rna 및 단백질의 특징규명 | |
| KR102223014B1 (ko) | 전암병변의 검출방법 | |
| EP2297346B1 (en) | METHODS AND REAGENTS FOR DETECTING CpG METHYLATION WITH A METHYL CpG BINDING PROTEIN (MBP) | |
| US20150240310A1 (en) | Detection and Quantification of Hydroxymethylated Nucleotides in a Polynucleotide Preparation | |
| CN109952381B (zh) | 用于多重检测甲基化dna的方法 | |
| KR20070011354A (ko) | 취약 x염색체 증후군과 같은 strp의 검출 방법 | |
| US7906288B2 (en) | Compare-MS: method rapid, sensitive and accurate detection of DNA methylation | |
| WO2014020124A1 (en) | Means and methods for the detection of dna methylation | |
| WO2021072435A2 (en) | Methods and systems for detection of nucleic acid modifications | |
| JP7712208B2 (ja) | 標的核酸の検出方法 | |
| US20130157266A1 (en) | Abscription based molecular detection of dna methylation | |
| CA2561991A1 (en) | Detecting gene methylation | |
| EP3625370A1 (en) | Composite epigenetic biomarkers for accurate screening, diagnosis and prognosis of colorectal cancer | |
| US20170191069A1 (en) | ABORTIVE PROMOTER CASSETTES AND METHODS FOR FUSION TO TARGETS AND QUANTITATIVE CpG ISLAND METHYLATION DETECTION USING THE SAME | |
| Feng et al. | Breast Cancer Patients: Diagnostic Epigenetic Markers in Blood | |
| HK40004890A (en) | Multiple detection method of methylated dna | |
| HK40004890B (en) | Multiple detection method of methylated dna | |
| JP2007295855A (ja) | 核酸修飾解析のためのサンプル核酸の製造方法と、当該サンプル核酸を用いた核酸修飾を検出する方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20111017 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| PC1203 | Withdrawal of no request for examination | ||
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |