KR20170036016A - 항-pd-1 항체 - Google Patents
항-pd-1 항체 Download PDFInfo
- Publication number
- KR20170036016A KR20170036016A KR1020177005011A KR20177005011A KR20170036016A KR 20170036016 A KR20170036016 A KR 20170036016A KR 1020177005011 A KR1020177005011 A KR 1020177005011A KR 20177005011 A KR20177005011 A KR 20177005011A KR 20170036016 A KR20170036016 A KR 20170036016A
- Authority
- KR
- South Korea
- Prior art keywords
- ser
- thr
- val
- leu
- antibody
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images

















Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P11/00—Drugs for disorders of the respiratory system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P11/00—Drugs for disorders of the respiratory system
- A61P11/04—Drugs for disorders of the respiratory system for throat disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/04—Antibacterial agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/04—Antibacterial agents
- A61P31/06—Antibacterial agents for tuberculosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/10—Antimycotics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/14—Antivirals for RNA viruses
- A61P31/16—Antivirals for RNA viruses for influenza or rhinoviruses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P33/00—Antiparasitic agents
- A61P33/02—Antiprotozoals, e.g. for leishmaniasis, trichomoniasis, toxoplasmosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P33/00—Antiparasitic agents
- A61P33/02—Antiprotozoals, e.g. for leishmaniasis, trichomoniasis, toxoplasmosis
- A61P33/06—Antimalarials
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P33/00—Antiparasitic agents
- A61P33/10—Anthelmintics
- A61P33/12—Schistosomicides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/02—Antineoplastic agents specific for leukemia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2818—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against CD28 or CD152
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/64—General methods for preparing the vector, for introducing it into the cell or for selecting the vector-containing host
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/74—Inducing cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/32—Fusion polypeptide fusions with soluble part of a cell surface receptor, "decoy receptors"
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/50—Cell markers; Cell surface determinants
- C12N2501/599—Cell markers; Cell surface determinants with CD designations not provided for elsewhere
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A50/00—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE in human health protection, e.g. against extreme weather
- Y02A50/30—Against vector-borne diseases, e.g. mosquito-borne, fly-borne, tick-borne or waterborne diseases whose impact is exacerbated by climate change
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Veterinary Medicine (AREA)
- Engineering & Computer Science (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Immunology (AREA)
- Genetics & Genomics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Oncology (AREA)
- Biochemistry (AREA)
- Communicable Diseases (AREA)
- Molecular Biology (AREA)
- Pulmonology (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Biophysics (AREA)
- Virology (AREA)
- Tropical Medicine & Parasitology (AREA)
- Cell Biology (AREA)
- Hematology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Mycology (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Otolaryngology (AREA)
- Epidemiology (AREA)
- Dermatology (AREA)
Abstract
Description














Claims (46)
- PD-1에 결합하는 단리된 항체 또는 이의 단편으로서, 상기 항체 또는 이의 단편이 서열번호: 24, 34, 45, 55, 65, 75, 85, 95, 105, 및 115로 이루어진 그룹으로부터 선택되는 아미노산 서열과 적어도 80% 상동성을 갖는 경쇄 CDR1 서열; 서열번호: 25, 35, 46, 56, 66, 76, 86, 96, 106, 및 116으로 이루어진 그룹으로부터 선택되는 아미노산 서열과 적어도 80% 상동성을 갖는 경쇄 CDR2 서열; 서열번호: 26, 36, 47, 57, 67, 77, 87, 97, 107, 및 117로 이루어진 그룹으로부터 선택되는 아미노산 서열과 적어도 80% 동일성을 갖는 경쇄 CDR3 서열; 서열번호: 19, 29, 40, 50, 60, 70, 80, 90, 100, 및 110으로 이루어진 그룹으로부터 선택되는 아미노산 서열과 적어도 80% 상동성을 갖는 중쇄 CDR1 서열; 서열번호: 20, 30, 41, 51, 61, 71, 81, 91, 101, 및 111로 이루어진 그룹으로부터 선택되는 아미노산 서열과 적어도 80% 상동성을 갖는 중쇄 CDR2 서열; 및 서열번호: 21, 31, 42, 52, 62, 72, 82, 92, 102, 및 112로 이루어진 그룹으로부터 선택되는 아미노산 서열과 적어도 80% 상동성을 갖는 중쇄 CDR3 서열을 포함하는, 단리된 항체 또는 이의 단편.
- 청구항 1에 있어서,
상기 항체 또는 이의 단편이 서열번호: 24, 34, 45, 55, 65, 75, 85, 95, 105, 및 115로 이루어진 그룹으로부터 선택되는 아미노산 서열로 이루어진 경쇄 CDR1; 서열번호: 25, 35, 46, 66, 76, 86, 96, 106, 및 116으로 이루어진 그룹으로부터 선택되는 아미노산 서열로 이루어진 경쇄 CDR2; 서열번호: 26, 36, 47, 57, 67, 77, 87, 97, 107, 및 117로 이루어진 그룹으로부터 선택되는 아미노산 서열로 이루어진 경쇄 CDR3; 서열번호: 19, 29, 40, 50, 60, 70, 80, 90, 100, 및 110으로 이루어진 그룹으로부터 선택되는 아미노산 서열로 이루어진 중쇄 CDR1; 서열번호: 20, 30, 41, 51, 61, 71, 81, 91, 101, 및 111로 이루어진 그룹으로부터 선택되는 아미노산 서열로 이루어진 중쇄 CDR2; 및 서열번호: 21, 31, 42, 52, 62, 72, 82, 92, 102, 및 112로 이루어진 그룹으로부터 선택되는 아미노산서열로 이루어진 중쇄 CDR3을 포함하는, 단리된 항체 또는 이의 단편. - 청구항 1에 있어서,
상기 항체 또는 이의 단편이 서열번호: 24, 25, 및 26 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 경쇄 CDR1, CDR2, 및 CDR3; 및 서열번호: 19, 20 및 21 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 중쇄 CDR1, CDR2, 및 CDR3을 포함하는, 단리된 항체 또는 이의 단편. - 청구항 1에 있어서,
상기 항체 또는 이의 단편이 서열번호: 34, 35, 및 36 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 경쇄 CDR1, CDR2, 및 CDR3; 및 서열번호: 29, 30 및 31 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 중쇄 CDR1, CDR2, 및 CDR3를 포함하는, 단리된 항체 또는 이의 단편. - 청구항 1에 있어서,
상기 항체 또는 이의 단편이 서열번호: 45, 46, 및 47 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 경쇄 CDR1, CDR2, 및 CDR3; 및 서열번호: 40, 41 및 42 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 중쇄 CDR1, CDR2, 및 CDR3을 포함하는, 단리된 항체 또는 이의 단편. - 청구항 1에 있어서,
상기 항체 또는 이의 단편이 서열번호: 55, 56, 및 57 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 경쇄 CDR1, CDR2, 및 CDR3; 및 서열번호: 50, 51 및 52 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 중쇄 CDR1, CDR2, 및 CDR3을 포함하는, 단리된 항체 또는 이의 단편. - 청구항 1에 있어서,
상기 항체 또는 이의 단편이 서열번호: 65, 66, 및 67 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 경쇄 CDR1, CDR2, 및 CDR3; 및 서열번호: 60, 61 및 62 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 중쇄 CDR1, CDR2, 및 CDR3을 포함하는, 단리된 항체 또는 이의 단편. - 청구항 1에 있어서,
상기 항체 또는 이의 단편이 서열번호: 75, 76, 및 77 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 경쇄 CDR1, CDR2, 및 CDR3; 및 서열번호: 70, 71 및 72 각각에 따른 아미노산 서열과 적어도 80% 동일성을 갖는 아미노산 서열을 포함하는 중쇄 CDR1, CDR2, 및 CDR3을 포함하는, 단리된 항체 또는 이의 단편. - 청구항 1에 있어서,
상기 항체 또는 이의 단편이 서열번호: 85, 86, 및 87 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 경쇄 CDR1, CDR2, 및 CDR3; 및 서열번호: 80, 81 및 82 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 중쇄 CDR1, CDR2, 및 CDR3을 포함하는, 단리된 항체 또는 이의 단편. - 청구항 1에 있어서,
상기 항체 또는 이의 단편이 서열번호: 95, 96, 및 97 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 경쇄 CDR1, CDR2, 및 CDR3; 및 서열번호: 90, 91 및 92 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 중쇄 CDR1, CDR2, 및 CDR3을 포함하는, 단리된 항체 또는 이의 단편. - 청구항 1에 있어서,
상기 항체 또는 이의 단편이 서열번호: 105, 106, 및 107 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 경쇄 CDR1, CDR2, 및 CDR3; 및 서열번호: 100, 101 및 102 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 중쇄 CDR1, CDR2, 및 CDR3을 포함하는, 단리된 항체 또는 이의 단편. - 청구항 1에 있어서,
상기 항체 또는 이의 단편이 서열번호: 115, 116, 및 117 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 경쇄 CDR1, CDR2, 및 CDR3; 및 서열번호: 110, 111 및 112 각각에 따른 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 중쇄 CDR1, CDR2, 및 CDR3을 포함하는, 단리된 항체 또는 이의 단편. - 청구항 1 내지 청구항 12 중 어느 한 청구항에 있어서,
상기 항체 또는 이의 단편이 키메라 또는 인간화된, 단리된 항체 또는 이의 단편. - PD-1에 결합하는 단리된 항체 또는 이의 단편으로서, 상기 항체 또는 이의 단편이 서열번호: 23, 33, 44, 54, 64, 74, 84, 94, 104, 114, 133, 및 143으로 이루어진 그룹으로부터 선택되는 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 경쇄 가변 영역; 및 서열번호: 18, 28, 39, 49, 59, 69, 79, 89, 99, 109, 131, 및 141로 이루어진 그룹으로부터 선택되는 아미노산 서열과 적어도 80% 상동성을 갖는 아미노산 서열을 포함하는 중쇄 가변 영역을 포함하는, 단리된 항체 또는 이의 단편.
- 청구항 14에 있어서,
상기 항체 또는 이의 단편이 서열번호: 23, 33, 44, 54, 64, 74, 84, 94, 104, 114, 133, 및 143으로 이루어진 그룹으로부터 선택되는 아미노산 서열을 포함하는 경쇄 가변 영역; 및 서열번호: 18, 28, 39, 49, 59, 69, 79, 89, 99, 109, 131, 및 141로 이루어진 그룹으로부터 선택되는 아미노산 서열을 포함하는 중쇄 가변 영역을 포함하는, 단리된 항체 또는 이의 단편. - PD-1과 결합하는 단리된 항체 또는 이의 단편으로서, 상기 항체 또는 이의 단편이 서열번호: 131에 따른 경쇄 가변 영역 및 서열번호: 131에 따른 중쇄 가변 영역을 포함하는, 단리된 항체 또는 이의 단편.
- PD-1과 결합하는 단리된 항체 또는 이의 단편으로서, 상기 항체 또는 이의 단편이 서열번호: 143에 따른 경쇄 가변 영역 및 서열번호: 141에 따른 중쇄 가변 영역을 포함하는, 단리된 항체 또는 이의 단편.
- PD-1에 결합하는 단리된 항체 또는 이의 단편으로서, 상기 항체 또는 이의 단편이 서열번호: 139 또는 153에 따른 경쇄 및 서열번호: 135에 따른 중쇄를 포함하는, 단리된 항체 또는 이의 단편.
- PD-1에 결합하는 단리된 항체 또는 이의 단편으로서, 상기 항체 또는 이의 단편이 서열번호: 139 또는 153에 따른 경쇄 및 서열번호: 137에 따른 중쇄를 포함하는, 단리된 항체 또는 이의 단편.
- PD-1에 결합하는 단리된 항체 또는 이의 단편으로서, 상기 항체 또는 이의 단편이 서열번호: 149에 따른 경쇄 및 서열번호: 145에 따른 중쇄를 포함하는, 단리된 항체 또는 이의 단편.
- PD-1에 결합하는 단리된 항체 또는 이의 단편으로서, 상기 항체 또는 이의 단편이 서열번호: 149에 따른 경쇄 및 서열번호: 147에 따른 중쇄를 포함하는, 단리된 항체 또는 이의 단편.
- 청구항 1 내지 청구항 21 중 어느 한 항에 따른 항체 또는 이의 단편과 동일한 에피토프에 결합하는 단리된 항체 또는 이의 단편.
- 단리된 항체 또는 이의 단편으로서, 상기 항체 또는 이의 단편이 PD-1에 결합하는 것에 대해 청구항 1 내지 청구항 21 중 어느 한 청구항에 따른 항체 또는 이의 단편과 경쟁하고, 상기 경쟁이 ELISA, 유동 세포측정 또는 표면 플라스몬 공명 (SPR) 검정에 의해 측정되는, 단리된 항체 또는 이의 단편.
- 청구항 1 내지 청구항 21 중 어느 한 항에 있어서,
상기 항체 또는 이의 단편이 모노클로날 항체, scFv, Fab 단편, Fab' 단편 및 F(ab)' 단편으로 이루어진 그룹으로부터 선택되는, 단리된 항체 또는 이의 단편. - 청구항 1 내지 청구항 21 중 어느 한 항에 있어서,
상기 항체 또는 이의 단편이 치료학적 제제에 연결되거나 접합된, 항체 또는 이의 단편. - 청구항 25에 있어서,
상기 치료학적 제제가 세포독성 약물, 방사능활성 동위원소, 면역조절제 또는 항체인, 항체 또는 이의 단편. - PD-1에 결합하는 단리된 항체 또는 이의 단편으로서, 상기 항체 또는 이의 단편이 PD-1에 대해 약 1nM 내지 약 0.01nM의 친화성을 갖는, 단리된 항체 또는 이의 단편.
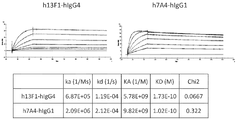
- 청구항 27에 있어서,
상기 항체 또는 이의 단편이 PD-1에 대해 약 1nM 이하의 친화성을 갖는, 단리된 항체 또는 이의 단편. - 청구항 27에 있어서,
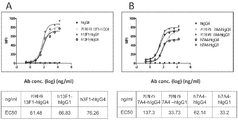
상기 항체 또는 이의 단편이 PD-1에 대해 약 0.1nM 이하의 친화성을 갖는, 단리된 항체 또는 이의 단편. - PD-1에 결합하는 단리된 항체 또는 이의 단편으로서, 상기 항체가 5 ng/mL 내지 약 1000 ng/mL의 결합 EC50을 갖는, 단리된 항체 또는 이의 단편.
- PD-1에 결합하는 단리된 항체 또는 이의 단편으로서, 상기 항체가 PD-1의 PD-L1으로의 결합을 차단하는, 단리된 항체 또는 이의 단편.
- 청구항 31에 있어서,
상기 항체 또는 이의 단편이 약 5 ng/mL 내지 약 1000 ng/mL의 IC50으로 PD-1의 PD-L1 또는 PD-L2로의 결합을 차단하는, 단리된 항체 또는 이의 단편. - PD-1에 결합하는 단리된 항체 또는 이의 단편으로서, 상기 항체 또는 단편이 염증 사이토킨 생산에 의해 측정된 바와 같이 T 세포 활성화를 증가시키는, 단리된 항체 또는 단편.
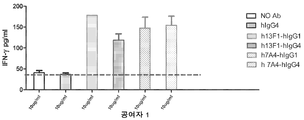
- 청구항 28에 있어서,
상기 항체 또는 이의 단편이 IL-2 및 IFNγ의 T 세포 생산을 증가시키는, 단리된 항체 또는 이의 단편. - PD-1에 결합하는 단리된 항체 또는 이의 단편으로서, 상기 항체 또는 이의 단편이 10D1, 4C10, 7D3, 13F1, 15H5, 14A6, 22A5, 6E1, 5A8, 7A4, 및/또는 7A4D로 이루어진 그룹으로부터 선택되는 하이브리도마에 의해 생산되는, 단리된 항체 또는 이의 단편.
- 청구항 1 내지 청구항 35 중 어느 한 항에 따른 항체 또는 단편 및 약제학적으로 허용되는 담체를 포함하는 조성물.
- 청구항 1 내지 청구항 35 중 어느 한 항에 따른 항체 또는 이의 단편을 암호화하는 단리된 폴리뉴클레오타이드.
- 청구항 37에 따른 단리된 폴리뉴클레오타이드를 포함하는 발현 벡터.
- 청구항 38에 따른 발현 벡터를 포함하는 숙주 세포.
- 10D1, 4C10, 7D3, 13F1, 15H5, 14A6, 22A5, 6E1, 5A8, 7A4 및 7A4D로 이루어진 그룹으로부터 선택되는 단리된 하이브리도마 세포주.
- T 세포와 청구항 1 내지 청구항 35 중 어느 한 항에 따른 항체 또는 이의 단편을 접촉시킴을 포함하는, T 세포 활성화를 증가시키기 위한 방법.
- 청구항 1 내지 청구항 35 중 어느 한 청구항에 따른 치료학적 유효량의 단리된 항체 또는 이의 단편을 대상체에게 투여함을 포함하는, 대상체에서 종양을 감소시키거나 종양 세포 성장을 억제하기 위한 방법.
- 청구항 1 내지 청구항 35 중 어느 한 청구항에 따른 치료학적 유효량의 단리된 항체 또는 이의 단편을 대상체에게 투여함을 포함하는, 이를 필요로 하는 대상체에서 암을 치료하기 위한 방법.
- 청구항 43에 있어서,
상기 암이 림프종, 백혈병, 흑색종, 신경교종, 유방암, 폐암, 결장암, 골암, 난소암, 방광암, 신장암, 간암, 위암, 직장암, 고환암, 침샘암, 갑상선암, 흉선암, 상피암, 두경부암, 위함, 췌장암 또는 이의 조합으로 이루어진 그룹으로부터 선택되는, 방법. - 청구항 1 내지 청구항 35 중 어느 한 청구항에 따른 치료학적 유효량의 단리된 항체 또는 이의 단편을 대상체에게 투여함을 포함하는, 치료를 필요로 하는 대상체에서 감염성 질환을 치료하기 위한 방법.
- 청구항 45에 있어서,
상기 감염성 질환이 칸디다증, 칸디다혈증, 아스페르길루스증, 스트렙토코커스 폐렴, 스트렙토코커스 피부 및 구강인두 병태, 그람 음성 패혈증, 결핵, 단핵증, 인플루엔자, 호흡 신시티알 바이러스에 의해 유발되는 호흡 병, 말라리아, 주혈흡충증 및 트리파노소마증으로 이루어진 그룹으로부터 선택되는, 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2014082721 | 2014-07-22 | ||
| CNPCT/CN2014/082721 | 2014-07-22 | ||
| PCT/US2015/041575 WO2016014688A2 (en) | 2014-07-22 | 2015-07-22 | Anti-pd-1 antibodies |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20170036016A true KR20170036016A (ko) | 2017-03-31 |
| KR102524920B1 KR102524920B1 (ko) | 2023-04-25 |
Family
ID=55163959
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020177005011A Active KR102524920B1 (ko) | 2014-07-22 | 2015-07-22 | 항-pd-1 항체 |
Country Status (16)
| Country | Link |
|---|---|
| US (3) | US10428146B2 (ko) |
| EP (1) | EP3171892B1 (ko) |
| JP (2) | JP6986965B2 (ko) |
| KR (1) | KR102524920B1 (ko) |
| CN (1) | CN106573052B (ko) |
| AU (2) | AU2015292678B2 (ko) |
| BR (2) | BR112017001385B1 (ko) |
| CA (1) | CA2955788C (ko) |
| ES (1) | ES2905301T3 (ko) |
| IL (2) | IL250222B (ko) |
| MX (1) | MX388181B (ko) |
| NZ (1) | NZ728688A (ko) |
| RU (1) | RU2711141C2 (ko) |
| SG (2) | SG11201700496WA (ko) |
| WO (1) | WO2016014688A2 (ko) |
| ZA (1) | ZA201700551B (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20200252917A1 (en) * | 2017-04-03 | 2020-08-06 | Huawei Technologies Co., Ltd. | Methods and Systems for Resource Configuration of Wireless Communication Systems |
Families Citing this family (65)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| MY184154A (en) | 2013-12-12 | 2021-03-23 | Shanghai hengrui pharmaceutical co ltd | Pd-1 antibody, antigen-binding fragment thereof, and medical application thereof |
| TWI693232B (zh) | 2014-06-26 | 2020-05-11 | 美商宏觀基因股份有限公司 | 與pd-1和lag-3具有免疫反應性的共價結合的雙抗體和其使用方法 |
| KR102524920B1 (ko) | 2014-07-22 | 2023-04-25 | 아폴로믹스 인코포레이티드 | 항-pd-1 항체 |
| US10435470B2 (en) | 2014-08-05 | 2019-10-08 | Cb Therapeutics, Inc. | Anti-PD-L1 antibodies |
| TWI773646B (zh) | 2015-06-08 | 2022-08-11 | 美商宏觀基因股份有限公司 | 結合lag-3的分子和其使用方法 |
| CN114591433A (zh) | 2015-07-13 | 2022-06-07 | 西托姆克斯治疗公司 | 抗pd-1抗体、可活化抗pd-1抗体及其使用方法 |
| WO2017019846A1 (en) | 2015-07-30 | 2017-02-02 | Macrogenics, Inc. | Pd-1-binding molecules and methods use thereof |
| CN114605548A (zh) | 2015-09-01 | 2022-06-10 | 艾吉纳斯公司 | 抗-pd-1抗体及其使用方法 |
| EA201890790A1 (ru) | 2015-09-29 | 2018-10-31 | Селджин Корпорейшн | Связывающие pd-1 белки и способы их применения |
| US12030942B2 (en) | 2015-10-02 | 2024-07-09 | Les Laboratoires Servier | Anti-PD-1 antibodies and compositions |
| EP3370768B9 (en) | 2015-11-03 | 2022-03-16 | Janssen Biotech, Inc. | Antibodies specifically binding pd-1 and their uses |
| US10954301B2 (en) | 2015-12-14 | 2021-03-23 | Macrogenics, Inc. | Bispecific molecules having immunoreactivity with PD-1 and CTLA-4, and methods of use thereof |
| CN107286242B (zh) * | 2016-04-01 | 2019-03-22 | 中山康方生物医药有限公司 | 抗pd-1的单克隆抗体 |
| EP3448987A4 (en) | 2016-04-29 | 2020-05-27 | Voyager Therapeutics, Inc. | COMPOSITIONS FOR TREATING A DISEASE |
| EP3448875A4 (en) * | 2016-04-29 | 2020-04-08 | Voyager Therapeutics, Inc. | COMPOSITIONS FOR TREATING A DISEASE |
| KR102379464B1 (ko) | 2016-06-20 | 2022-03-29 | 키맵 리미티드 | 항-pd-l1 항체 |
| AU2017328309B2 (en) * | 2016-09-14 | 2020-10-15 | Beijing Hanmi Pharm. Co., Ltd. | Antibody specifically binding to PD-1 and functional fragment thereof |
| BR112019004733A2 (pt) | 2016-09-19 | 2019-05-28 | Celgene Corp | métodos de tratamento de distúrbios imunes usando proteínas de ligação a pd-1 |
| EP3515943A4 (en) | 2016-09-19 | 2020-05-06 | Celgene Corporation | METHODS OF TREATING VITILIGO WITH PD-1 BINDING PROTEINS |
| BR112018013653B1 (pt) * | 2016-10-15 | 2020-12-15 | Innovent Biologics (Suzhou) Co., Ltd | Anticorpos anti-pd-1, processo para produção do mesmo e uso dos anticorpos |
| TWI780083B (zh) * | 2016-11-18 | 2022-10-11 | 丹麥商賽門弗鎮公司 | 抗pd-1抗體及組成物 |
| JP7106538B2 (ja) | 2016-12-07 | 2022-07-26 | アジェナス インコーポレイテッド | 抗体およびその使用方法 |
| CN106519034B (zh) * | 2016-12-22 | 2020-09-18 | 鲁南制药集团股份有限公司 | 抗pd-1抗体及其用途 |
| RU2768404C2 (ru) * | 2016-12-23 | 2022-03-24 | Ремд Биотерапьютикс, Инк. | Иммунотерапия с применением антител, связывающих белок 1 программируемой смерти клеток (pd-1) |
| CN117586401A (zh) | 2017-01-20 | 2024-02-23 | 大有华夏生物医药集团有限公司 | 抗pd-1抗体及其用途 |
| CN108341871A (zh) | 2017-01-24 | 2018-07-31 | 三生国健药业(上海)股份有限公司 | 抗pd-1单克隆抗体及其制备方法和应用 |
| IL268836B2 (en) | 2017-02-24 | 2024-04-01 | Macrogenics Inc | Bispecific binding molecules that are capable of binding cd137 and tumor antigens, and uses thereof |
| EA201992350A1 (ru) | 2017-04-05 | 2020-03-23 | Симфоген А/С | Комбинированные лекарственные средства, нацеленные на pd-1, tim-3 и lag-3 |
| MX2019012295A (es) | 2017-04-14 | 2020-02-07 | Tollnine Inc | Polinucleotidos inmunomoduladores, conjugados de anticuerpos de los mismos y metodos para su uso. |
| US11492403B2 (en) | 2017-04-20 | 2022-11-08 | Dana-Farber Cancer Institute, Inc. | Anti-phosphotyrosinylated programmed death 1 (PD-1) monoclonal antibodies, methods of making and methods of using thereof |
| WO2019005635A2 (en) * | 2017-06-25 | 2019-01-03 | Systimmune, Inc. | ANTI-PD-1 ANTIBODIES AND METHODS OF PREPARATION AND USE |
| CN118909118A (zh) * | 2017-09-07 | 2024-11-08 | 奥古斯塔大学研究所公司 | 程序性细胞死亡蛋白1抗体 |
| KR20190065234A (ko) * | 2017-11-30 | 2019-06-11 | 그리폴스 다이어그노스틱 솔루션즈 인크. | 면역 관문 억제제인 pd-1 및 pd-l1에 대한 항체 치료를 모니터링하기 위한 면역분석 및 조작된 단백질 |
| CN111356702B (zh) * | 2017-12-06 | 2022-07-26 | 正大天晴药业集团南京顺欣制药有限公司 | 抗pd-l1抗体及其抗原结合片段 |
| CN108059678B (zh) * | 2017-12-08 | 2020-05-22 | 浙江大学 | 全人源抗pdl-1单链抗体b30及其应用 |
| CN108059677B (zh) * | 2017-12-08 | 2020-05-22 | 浙江大学 | 全人源抗pdl-1单链抗体b36及其应用 |
| CN107880127B (zh) * | 2017-12-08 | 2020-05-22 | 浙江大学 | 全人源抗pdl-1单链抗体b129及其应用 |
| US12398209B2 (en) | 2018-01-22 | 2025-08-26 | Janssen Biotech, Inc. | Methods of treating cancers with antagonistic anti-PD-1 antibodies |
| CA3091373A1 (en) * | 2018-02-17 | 2019-08-22 | Apollomics Inc. | Cancer treatment using combination of neutrophil modulator with modulator of immune checkpoint |
| KR102909650B1 (ko) * | 2018-03-13 | 2026-01-08 | 터스크 테라퓨틱스 리미티드 | 종양 특이적 세포 고갈에 대한 항-cd25 |
| CN117568287A (zh) * | 2018-04-15 | 2024-02-20 | 深圳市亦诺微医药科技有限公司 | 结合pd-1的抗体及其用途 |
| CN112236455B (zh) * | 2018-05-17 | 2023-05-16 | 南京维立志博生物科技有限公司 | 结合pd-1的抗体及其用途 |
| TWI806870B (zh) * | 2018-05-23 | 2023-07-01 | 中國大陸商大有華夏生物醫藥集團有限公司 | 抗pd-1抗體及其用途 |
| CN120714024A (zh) | 2018-06-20 | 2025-09-30 | 因赛特公司 | 抗pd-1抗体及其用途 |
| CN110624106A (zh) * | 2018-06-22 | 2019-12-31 | 嘉和生物药业有限公司 | Pd-1信号通路拮抗剂与艾滋病疫苗的联合应用 |
| CN112424231B (zh) | 2018-07-19 | 2022-09-13 | 大有华夏生物医药集团有限公司 | 抗pd-1抗体及其剂量和用途 |
| CN111423510B (zh) * | 2019-01-10 | 2024-02-06 | 迈威(上海)生物科技股份有限公司 | 重组抗人pd-1抗体及其应用 |
| JP7604379B2 (ja) * | 2019-02-03 | 2024-12-23 | ジエンス ヘンルイ メデイシンカンパニー リミテッド | 抗pd-1抗体、その抗原結合フラグメントおよびそれらの医薬用途 |
| WO2020249003A1 (en) * | 2019-06-10 | 2020-12-17 | Apollomics Inc. (Hangzhou) | Antibody-interleukin fusion protein and methods of use |
| WO2021006199A1 (ja) | 2019-07-05 | 2021-01-14 | 小野薬品工業株式会社 | Pd-1/cd3二重特異性タンパク質による血液がん治療 |
| EP4011918A4 (en) | 2019-08-08 | 2023-08-23 | ONO Pharmaceutical Co., Ltd. | DUAL SPECIFIC PROTEIN |
| WO2021063201A1 (zh) * | 2019-09-30 | 2021-04-08 | 四川科伦博泰生物医药股份有限公司 | 抗pd-1抗体及其用途 |
| CN114728068A (zh) * | 2019-11-13 | 2022-07-08 | 国立大学法人京都大学 | Pd-1信号抑制剂的联合疗法 |
| CN113134080A (zh) * | 2020-01-17 | 2021-07-20 | 嘉和生物药业有限公司 | 抗pd-1抗体和呋喹替尼联合在制备治疗癌症的药物中的用途 |
| BR112022017136A2 (pt) | 2020-02-28 | 2022-10-11 | Tallac Therapeutics Inc | Conjugação mediada por transglutaminase |
| WO2022068891A1 (zh) * | 2020-09-30 | 2022-04-07 | 苏州沙砾生物科技有限公司 | Pd-1抗体及其制备方法与应用 |
| GB202107994D0 (en) | 2021-06-04 | 2021-07-21 | Kymab Ltd | Treatment of cancer |
| CN115611981A (zh) * | 2021-07-12 | 2023-01-17 | 嘉和生物药业有限公司 | 抗pd-1抗体在治疗外周t细胞淋巴瘤中的应用 |
| CN115607664A (zh) * | 2021-07-15 | 2023-01-17 | 嘉和生物药业有限公司 | 抗pd-1抗体在治疗宫颈癌中的应用 |
| CN115607663A (zh) * | 2021-07-15 | 2023-01-17 | 嘉和生物药业有限公司 | 抗pd-1抗体在治疗原发纵隔大b细胞淋巴瘤中的应用 |
| JP2025504020A (ja) | 2022-01-28 | 2025-02-06 | ジョージアミューン・インコーポレイテッド | Pd-1アゴニストであるプログラム細胞死タンパク質1に対する抗体 |
| WO2024119068A2 (en) * | 2022-12-02 | 2024-06-06 | Ohio State Innovation Foundation | S100a7 as a diagnostic marker and therapeutic target for disorders |
| WO2024160721A1 (en) | 2023-01-30 | 2024-08-08 | Kymab Limited | Antibodies |
| WO2024228167A1 (en) | 2023-05-03 | 2024-11-07 | Iox Therapeutics Inc. | Inkt cell modulator liposomal compositions and methods of use |
| WO2025128263A1 (en) * | 2023-12-15 | 2025-06-19 | Pharmaessentia Corporation | Anti-pd-1 monoclonal antibody and methods of preparation thereof |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8735553B1 (en) * | 2013-09-13 | 2014-05-27 | Beigene, Ltd. | Anti-PD1 antibodies and their use as therapeutics and diagnostics |
Family Cites Families (102)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5225539A (en) | 1986-03-27 | 1993-07-06 | Medical Research Council | Recombinant altered antibodies and methods of making altered antibodies |
| WO1988007089A1 (en) | 1987-03-18 | 1988-09-22 | Medical Research Council | Altered antibodies |
| US5859205A (en) | 1989-12-21 | 1999-01-12 | Celltech Limited | Humanised antibodies |
| US5994514A (en) | 1991-08-14 | 1999-11-30 | Genentech, Inc. | Immunoglobulin variants |
| WO1993022332A2 (en) | 1992-04-24 | 1993-11-11 | Board Of Regents, The University Of Texas System | Recombinant production of immunoglobulin-like domains in prokaryotic cells |
| AU691811B2 (en) | 1993-06-16 | 1998-05-28 | Celltech Therapeutics Limited | Antibodies |
| US5595756A (en) * | 1993-12-22 | 1997-01-21 | Inex Pharmaceuticals Corporation | Liposomal compositions for enhanced retention of bioactive agents |
| CA2143491C (en) | 1994-03-01 | 2011-02-22 | Yasumasa Ishida | A novel peptide related to human programmed cell death and dna encoding it |
| US6194551B1 (en) | 1998-04-02 | 2001-02-27 | Genentech, Inc. | Polypeptide variants |
| US6528624B1 (en) | 1998-04-02 | 2003-03-04 | Genentech, Inc. | Polypeptide variants |
| GB9809951D0 (en) | 1998-05-08 | 1998-07-08 | Univ Cambridge Tech | Binding molecules |
| HU230769B1 (hu) | 1999-01-15 | 2018-03-28 | Genentech Inc. | Módosított effektor-funkciójú polipeptid-változatok |
| US6737056B1 (en) | 1999-01-15 | 2004-05-18 | Genentech, Inc. | Polypeptide variants with altered effector function |
| EP1210428B1 (en) | 1999-08-23 | 2015-03-18 | Dana-Farber Cancer Institute, Inc. | Pd-1, a receptor for b7-4, and uses therefor |
| EP1210424B1 (en) | 1999-08-23 | 2007-02-07 | Dana-Farber Cancer Institute, Inc. | Novel b7-4 molecules and uses therefor |
| CN1423700A (zh) | 2000-03-24 | 2003-06-11 | 麦克美特股份公司 | 含有针对nkg2d受体复合物的表位的结合位点的多功能多肽 |
| CA2399940A1 (en) | 2000-04-13 | 2001-10-25 | The Rockefeller University | Enhancement of antibody-mediated immune responses |
| ATE540579T1 (de) | 2000-11-15 | 2012-01-15 | Ono Pharmaceutical Co | Pd-1-defiziente maus und ihre verwendung |
| PT1355919E (pt) | 2000-12-12 | 2011-03-02 | Medimmune Llc | Moléculas com semivida longa, composições que as contêm e suas utilizações |
| US20030133939A1 (en) | 2001-01-17 | 2003-07-17 | Genecraft, Inc. | Binding domain-immunoglobulin fusion proteins |
| AU2002306596B2 (en) | 2001-02-27 | 2008-01-17 | The Government Of The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Analogs of thalidomide as potential angiogenesis inhibitors |
| AU2002248571B2 (en) | 2001-03-07 | 2007-01-18 | Merck Patent Gmbh | Expression technology for proteins containing a hybrid isotype antibody moiety |
| AR036993A1 (es) | 2001-04-02 | 2004-10-20 | Wyeth Corp | Uso de agentes que modulan la interaccion entre pd-1 y sus ligandos en la submodulacion de respuestas inmunologicas |
| US7662925B2 (en) | 2002-03-01 | 2010-02-16 | Xencor, Inc. | Optimized Fc variants and methods for their generation |
| US7317091B2 (en) | 2002-03-01 | 2008-01-08 | Xencor, Inc. | Optimized Fc variants |
| ES2350687T3 (es) | 2002-07-03 | 2011-01-26 | Ono Pharmaceutical Co., Ltd. | Composiciones de inmunopotenciación. |
| WO2004042017A2 (en) | 2002-10-31 | 2004-05-21 | Genentech, Inc. | Methods and compositions for increasing antibody production |
| CN1753912B (zh) | 2002-12-23 | 2011-11-02 | 惠氏公司 | 抗pd-1抗体及其用途 |
| US7960512B2 (en) | 2003-01-09 | 2011-06-14 | Macrogenics, Inc. | Identification and engineering of antibodies with variant Fc regions and methods of using same |
| JP2006524039A (ja) | 2003-01-09 | 2006-10-26 | マクロジェニクス,インコーポレーテッド | 変異型Fc領域を含む抗体の同定および作製ならびにその利用法 |
| US7563869B2 (en) | 2003-01-23 | 2009-07-21 | Ono Pharmaceutical Co., Ltd. | Substance specific to human PD-1 |
| US8084582B2 (en) | 2003-03-03 | 2011-12-27 | Xencor, Inc. | Optimized anti-CD20 monoclonal antibodies having Fc variants |
| CN1871259A (zh) | 2003-08-22 | 2006-11-29 | 比奥根艾迪克Ma公司 | 具有改变的效应物功能的经改进的抗体和制备它的方法 |
| US20060134105A1 (en) | 2004-10-21 | 2006-06-22 | Xencor, Inc. | IgG immunoglobulin variants with optimized effector function |
| US20050249723A1 (en) | 2003-12-22 | 2005-11-10 | Xencor, Inc. | Fc polypeptides with novel Fc ligand binding sites |
| GB0400440D0 (en) | 2004-01-09 | 2004-02-11 | Isis Innovation | Receptor modulators |
| US8911726B2 (en) | 2004-09-22 | 2014-12-16 | Kyowa Hakko Kirin Co., Ltd | Stabilized human Igg4 antibodies |
| TW200639163A (en) | 2005-02-04 | 2006-11-16 | Genentech Inc | RAF inhibitor compounds and methods |
| CN1296385C (zh) * | 2005-03-30 | 2007-01-24 | 王哲 | 抗猪生长激素单克隆抗体及制备方法及应用 |
| RU2494107C2 (ru) | 2005-05-09 | 2013-09-27 | Оно Фармасьютикал Ко., Лтд. | Моноклональные антитела человека к белку программируемой смерти 1 (pd-1) и способы лечения рака с использованием анти-pd-1-антител самостоятельно или в комбинации с другими иммунотерапевтическими средствами |
| CN104356236B (zh) | 2005-07-01 | 2020-07-03 | E.R.施贵宝&圣斯有限责任公司 | 抗程序性死亡配体1(pd-l1)的人单克隆抗体 |
| RU2432362C2 (ru) | 2005-11-30 | 2011-10-27 | Эбботт Лэборетриз | Моноклональные антитела и их применения |
| CN101365682A (zh) | 2005-12-08 | 2009-02-11 | 千禧药品公司 | 具有激酶抑制活性的双环化合物 |
| RU2429244C2 (ru) | 2006-03-23 | 2011-09-20 | Байоарктик Ньюросайенс Аб | Улучшенные селективные в отношении протофибрилл антитела и их применение |
| ATE552245T1 (de) | 2006-05-15 | 2012-04-15 | Merck Sharp & Dohme | Antidiabetische bicyclische verbindungen |
| CN101104640A (zh) | 2006-07-10 | 2008-01-16 | 苏州大学 | 抗人pd-l1单克隆抗体制备及应用 |
| CN101563105B (zh) | 2006-07-10 | 2013-01-23 | 拜奥根Idec马萨诸塞公司 | 用于抑制smad4-缺陷癌症的组合物和方法 |
| US20080227704A1 (en) * | 2006-12-21 | 2008-09-18 | Kamens Joanne S | CXCL13 binding proteins |
| CN103536915A (zh) * | 2006-12-27 | 2014-01-29 | 埃默里大学 | 用于治疗传染病和肿瘤的组合物和方法 |
| AU2008255352B2 (en) | 2007-05-31 | 2014-05-22 | Genmab A/S | Stable IgG4 antibodies |
| US7615883B2 (en) | 2007-06-06 | 2009-11-10 | Meheen H Joe | Wind driven venturi turbine |
| HRP20131167T1 (hr) | 2007-06-18 | 2014-01-03 | Merck Sharp & Dohme B.V. | Antitijela za humani receptor programirane smrti pd-1 |
| AU2014201367B2 (en) | 2007-06-18 | 2016-01-28 | Merck Sharp & Dohme B.V. | Antibodies to human programmed death receptor pd-1 |
| US9243052B2 (en) | 2007-08-17 | 2016-01-26 | Daniel Olive | Method for treating and diagnosing hematologic malignancies |
| BRPI0817427A8 (pt) | 2007-10-16 | 2019-01-29 | Chugai Pharmaceutical Co Ltd | anticorpo anti-bst2 |
| JO3076B1 (ar) | 2007-10-17 | 2017-03-15 | Janssen Alzheimer Immunotherap | نظم العلاج المناعي المعتمد على حالة apoe |
| WO2009114335A2 (en) | 2008-03-12 | 2009-09-17 | Merck & Co., Inc. | Pd-1 binding proteins |
| WO2010098788A2 (en) | 2008-08-25 | 2010-09-02 | Amplimmune, Inc. | Pd-i antagonists and methods for treating infectious disease |
| JP5794917B2 (ja) | 2008-09-12 | 2015-10-14 | アイシス・イノベーション・リミテッドIsis Innovationlimited | Pd−1特異抗体およびその使用 |
| US8927697B2 (en) | 2008-09-12 | 2015-01-06 | Isis Innovation Limited | PD-1 specific antibodies and uses thereof |
| KR101814408B1 (ko) | 2008-09-26 | 2018-01-04 | 다나-파버 캔서 인스티튜트 인크. | 인간 항-pd-1, pd-l1, 및 pd-l2 항체 및 그의 용도 |
| KR101050829B1 (ko) | 2008-10-02 | 2011-07-20 | 서울대학교산학협력단 | 항 pd-1 항체 또는 항 pd-l1 항체를 포함하는 항암제 |
| CA2744449C (en) | 2008-11-28 | 2019-01-29 | Emory University | Methods for the treatment of infections and tumors |
| AU2009333580B2 (en) | 2008-12-09 | 2016-07-07 | Genentech, Inc. | Anti-PD-L1 antibodies and their use to enhance T-cell function |
| US20100197924A1 (en) | 2008-12-22 | 2010-08-05 | Millennium Pharmaceuticals, Inc. | Preparation of aminotetralin compounds |
| WO2010089411A2 (en) | 2009-02-09 | 2010-08-12 | Universite De La Mediterranee | Pd-1 antibodies and pd-l1 antibodies and uses thereof |
| EP2406284B9 (en) | 2009-03-10 | 2017-03-01 | Biogen MA Inc. | Anti-bcma antibodies |
| US9493578B2 (en) | 2009-09-02 | 2016-11-15 | Xencor, Inc. | Compositions and methods for simultaneous bivalent and monovalent co-engagement of antigens |
| US8389689B2 (en) | 2009-10-28 | 2013-03-05 | Janssen Biotech, Inc. | Anti-GLP-1R antibodies and their uses |
| US10053513B2 (en) | 2009-11-30 | 2018-08-21 | Janssen Biotech, Inc. | Antibody Fc mutants with ablated effector functions |
| PL3053932T3 (pl) | 2010-02-19 | 2021-03-08 | Xencor, Inc. | Nowe immunoadhezyny CTLA4-IG |
| CN102892786B (zh) | 2010-03-11 | 2016-03-16 | Ucb医药有限公司 | Pd-1抗体 |
| BR112012024489A2 (pt) | 2010-03-29 | 2016-05-31 | Zymeworks Inc | anticorpos com função efetora suprimida ou aumentada |
| US20120100166A1 (en) | 2010-07-15 | 2012-04-26 | Zyngenia, Inc. | Ang-2 Binding Complexes and Uses Thereof |
| SG10201602394QA (en) | 2011-03-29 | 2016-05-30 | Roche Glycart Ag | Antibody FC Variants |
| ES2676205T3 (es) | 2011-03-31 | 2018-07-17 | Merck Sharp & Dohme Corp. | Formulaciones estables de anticuerpos para el receptor PD-1 humano de muerte programada y tratamientos relacionados |
| KR101970025B1 (ko) | 2011-04-20 | 2019-04-17 | 메디뮨 엘엘씨 | B7-h1 및 pd-1과 결합하는 항체 및 다른 분자들 |
| MD20130089A2 (ro) | 2011-05-02 | 2014-05-31 | Ym Biosciences Australia Pty Ltd | Metodă de tratament al mielomului multiplu |
| PL2718322T3 (pl) | 2011-06-06 | 2019-07-31 | Novo Nordisk A/S | Lecznicze przeciwciała |
| JP6238459B2 (ja) | 2011-08-01 | 2017-11-29 | ジェネンテック, インコーポレイテッド | Pd−1軸結合アンタゴニストとmek阻害剤を使用する癌の治療方法 |
| HRP20201595T1 (hr) | 2011-11-28 | 2020-12-11 | Merck Patent Gmbh | Anti-pd-l1 protutijela i njihova uporaba |
| JP6226752B2 (ja) | 2012-02-09 | 2017-11-08 | 中外製薬株式会社 | 抗体のFc領域改変体 |
| WO2013165690A1 (en) | 2012-04-30 | 2013-11-07 | Medimmune, Llc | Molecules with reduced effector function and extended half-lives, compositions, and uses thereof |
| CN113967253A (zh) | 2012-05-15 | 2022-01-25 | 百时美施贵宝公司 | 通过破坏pd-1/pd-l1信号传输的免疫治疗 |
| WO2013181452A1 (en) | 2012-05-31 | 2013-12-05 | Genentech, Inc. | Methods of treating cancer using pd-l1 axis binding antagonists and vegf antagonists |
| HK1204557A1 (en) | 2012-05-31 | 2015-11-27 | Sorrento Therapeutics, Inc. | Antigen binding proteins that bind pd-l1 |
| RU2014153675A (ru) | 2012-07-03 | 2016-08-27 | Янссен Альцгеймер Иммунотерапи | Антитела к с-концевым и центральным эпитопам а-бета |
| JP6403166B2 (ja) | 2012-08-03 | 2018-10-10 | ダナ−ファーバー キャンサー インスティテュート, インコーポレイテッド | 単一抗原抗pd−l1およびpd−l2二重結合抗体およびその使用方法 |
| CA2886433C (en) | 2012-10-04 | 2022-01-04 | Dana-Farber Cancer Institute, Inc. | Human monoclonal anti-pd-l1 antibodies and methods of use |
| CA2889182A1 (en) | 2012-10-26 | 2014-05-01 | The University Of Chicago | Synergistic combination of immunologic inhibitors for the treatment of cancer |
| WO2014100490A1 (en) | 2012-12-19 | 2014-06-26 | Adimab, Llc | Multivalent antibody analogs, and methods of their preparation and use |
| AR093984A1 (es) | 2012-12-21 | 2015-07-01 | Merck Sharp & Dohme | Anticuerpos que se unen a ligando 1 de muerte programada (pd-l1) humano |
| TWI682941B (zh) | 2013-02-01 | 2020-01-21 | 美商再生元醫藥公司 | 含嵌合恆定區之抗體 |
| EP2840892B1 (en) | 2013-02-20 | 2018-04-18 | Regeneron Pharmaceuticals, Inc. | Non-human animals with modified immunoglobulin heavy chain sequences |
| WO2014152195A1 (en) | 2013-03-15 | 2014-09-25 | Regeneron Pharmaceuticals, Inc. | Il-33 antagonists and uses thereof |
| US9676853B2 (en) | 2013-05-31 | 2017-06-13 | Sorrento Therapeutics, Inc. | Antigen binding proteins that bind PD-1 |
| TWI726608B (zh) | 2014-07-03 | 2021-05-01 | 英屬開曼群島商百濟神州有限公司 | 抗pd-l1抗體及其作為治療及診斷之用途 |
| KR102524920B1 (ko) | 2014-07-22 | 2023-04-25 | 아폴로믹스 인코포레이티드 | 항-pd-1 항체 |
| US10435470B2 (en) | 2014-08-05 | 2019-10-08 | Cb Therapeutics, Inc. | Anti-PD-L1 antibodies |
| US9139653B1 (en) | 2015-04-30 | 2015-09-22 | Kymab Limited | Anti-human OX40L antibodies and methods of treatment |
| CN114591433A (zh) * | 2015-07-13 | 2022-06-07 | 西托姆克斯治疗公司 | 抗pd-1抗体、可活化抗pd-1抗体及其使用方法 |
| WO2017024465A1 (en) | 2015-08-10 | 2017-02-16 | Innovent Biologics (Suzhou) Co., Ltd. | Pd-1 antibodies |
-
2015
- 2015-07-22 KR KR1020177005011A patent/KR102524920B1/ko active Active
- 2015-07-22 MX MX2017000985A patent/MX388181B/es unknown
- 2015-07-22 WO PCT/US2015/041575 patent/WO2016014688A2/en not_active Ceased
- 2015-07-22 ES ES15824277T patent/ES2905301T3/es active Active
- 2015-07-22 SG SG11201700496WA patent/SG11201700496WA/en unknown
- 2015-07-22 RU RU2017105915A patent/RU2711141C2/ru active
- 2015-07-22 US US15/328,225 patent/US10428146B2/en active Active
- 2015-07-22 JP JP2017525309A patent/JP6986965B2/ja active Active
- 2015-07-22 AU AU2015292678A patent/AU2015292678B2/en active Active
- 2015-07-22 CA CA2955788A patent/CA2955788C/en active Active
- 2015-07-22 EP EP15824277.6A patent/EP3171892B1/en active Active
- 2015-07-22 BR BR112017001385-1A patent/BR112017001385B1/pt active IP Right Grant
- 2015-07-22 SG SG10201900571YA patent/SG10201900571YA/en unknown
- 2015-07-22 NZ NZ728688A patent/NZ728688A/en unknown
- 2015-07-22 BR BR122020025583-8A patent/BR122020025583B1/pt active IP Right Grant
- 2015-07-22 CN CN201580040301.XA patent/CN106573052B/zh active Active
-
2017
- 2017-01-22 IL IL250222A patent/IL250222B/en active IP Right Grant
- 2017-01-24 ZA ZA2017/00551A patent/ZA201700551B/en unknown
-
2019
- 2019-08-12 US US16/538,448 patent/US10981994B2/en active Active
-
2020
- 2020-05-14 JP JP2020085029A patent/JP2020188760A/ja active Pending
-
2021
- 2021-01-18 AU AU2021200264A patent/AU2021200264B2/en active Active
- 2021-03-08 US US17/195,226 patent/US11560429B2/en active Active
- 2021-04-18 IL IL282403A patent/IL282403B2/en unknown
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8735553B1 (en) * | 2013-09-13 | 2014-05-27 | Beigene, Ltd. | Anti-PD1 antibodies and their use as therapeutics and diagnostics |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20200252917A1 (en) * | 2017-04-03 | 2020-08-06 | Huawei Technologies Co., Ltd. | Methods and Systems for Resource Configuration of Wireless Communication Systems |
| US12114316B2 (en) * | 2017-04-03 | 2024-10-08 | Huawei Technologies Co., Ltd. | Methods and systems for resource configuration of wireless communication systems |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU2021200264B2 (en) | Anti-pd-1 antibodies | |
| AU2021203593B2 (en) | Anti-pd-l1 antibodies | |
| CN108779175B (zh) | NKp46结合蛋白的可变区 | |
| JP2020508079A (ja) | 抗pd−l1抗体及びその使用 | |
| KR102920224B1 (ko) | 인간화 항-VEGF Fab 항체 단편 및 이의 용도 | |
| JP2024081718A (ja) | Fcバリアント組成物およびその使用方法 | |
| JP2024528682A (ja) | 薬物組成物及び用途 | |
| JP2019534292A (ja) | 組み合わせた抗cd40抗体および使用方法 | |
| KR102920217B1 (ko) | 인간화 항-vegf 단클론 항체 | |
| KR20220131279A (ko) | 항lag3단일 클론 항체 및 그 제조 방법과 응용 | |
| TW202241509A (zh) | Anti-pd-1抗體及其用途 | |
| CN112079924B (zh) | Pd-l1靶向结合剂及其用途 | |
| HK40025947A (en) | Anti-pd-l1 antibodies | |
| HK40025946A (en) | Anti-pd-l1 antibodies | |
| HK40025947B (zh) | 抗pd-l1抗体 | |
| RU2834713C1 (ru) | Антитела, связывающие il4r, и их применение | |
| HK40112828A (zh) | 抗pd-l1抗体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20170222 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| A201 | Request for examination | ||
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20200624 Comment text: Request for Examination of Application |
|
| PN2301 | Change of applicant |
Patent event date: 20200826 Comment text: Notification of Change of Applicant Patent event code: PN23011R01D |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20220627 Patent event code: PE09021S01D |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
Patent event code: PE07011S01D Comment text: Decision to Grant Registration Patent event date: 20230214 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
Comment text: Registration of Establishment Patent event date: 20230419 Patent event code: PR07011E01D |
|
| PR1002 | Payment of registration fee |
Payment date: 20230420 End annual number: 3 Start annual number: 1 |
|
| PG1601 | Publication of registration |