KR20170036643A - 인슐린의 제조 방법 - Google Patents
인슐린의 제조 방법 Download PDFInfo
- Publication number
- KR20170036643A KR20170036643A KR1020160122485A KR20160122485A KR20170036643A KR 20170036643 A KR20170036643 A KR 20170036643A KR 1020160122485 A KR1020160122485 A KR 1020160122485A KR 20160122485 A KR20160122485 A KR 20160122485A KR 20170036643 A KR20170036643 A KR 20170036643A
- Authority
- KR
- South Korea
- Prior art keywords
- leu
- insulin
- gly
- proinsulin
- cys
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images






Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/575—Hormones
- C07K14/62—Insulins
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B01—PHYSICAL OR CHEMICAL PROCESSES OR APPARATUS IN GENERAL
- B01D—SEPARATION
- B01D15/00—Separating processes involving the treatment of liquids with solid sorbents; Apparatus therefor
- B01D15/08—Selective adsorption, e.g. chromatography
- B01D15/26—Selective adsorption, e.g. chromatography characterised by the separation mechanism
- B01D15/32—Bonded phase chromatography
- B01D15/325—Reversed phase
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B01—PHYSICAL OR CHEMICAL PROCESSES OR APPARATUS IN GENERAL
- B01D—SEPARATION
- B01D15/00—Separating processes involving the treatment of liquids with solid sorbents; Apparatus therefor
- B01D15/08—Selective adsorption, e.g. chromatography
- B01D15/26—Selective adsorption, e.g. chromatography characterised by the separation mechanism
- B01D15/36—Selective adsorption, e.g. chromatography characterised by the separation mechanism involving ionic interaction, e.g. ion-exchange, ion-pair, ion-suppression or ion-exclusion
- B01D15/361—Ion-exchange
- B01D15/362—Cation-exchange
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B01—PHYSICAL OR CHEMICAL PROCESSES OR APPARATUS IN GENERAL
- B01D—SEPARATION
- B01D15/00—Separating processes involving the treatment of liquids with solid sorbents; Apparatus therefor
- B01D15/08—Selective adsorption, e.g. chromatography
- B01D15/26—Selective adsorption, e.g. chromatography characterised by the separation mechanism
- B01D15/36—Selective adsorption, e.g. chromatography characterised by the separation mechanism involving ionic interaction, e.g. ion-exchange, ion-pair, ion-suppression or ion-exclusion
- B01D15/361—Ion-exchange
- B01D15/363—Anion-exchange
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K1/00—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length
- C07K1/14—Extraction; Separation; Purification
- C07K1/16—Extraction; Separation; Purification by chromatography
- C07K1/18—Ion-exchange chromatography
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K1/00—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length
- C07K1/14—Extraction; Separation; Purification
- C07K1/16—Extraction; Separation; Purification by chromatography
- C07K1/20—Partition-, reverse-phase or hydrophobic interaction chromatography
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y304/00—Hydrolases acting on peptide bonds, i.e. peptidases (3.4)
- C12Y304/17—Metallocarboxypeptidases (3.4.17)
- C12Y304/17002—Carboxypeptidase B (3.4.17.2)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y304/00—Hydrolases acting on peptide bonds, i.e. peptidases (3.4)
- C12Y304/21—Serine endopeptidases (3.4.21)
- C12Y304/21001—Chymotrypsin (3.4.21.1)
Landscapes
- Chemical & Material Sciences (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Analytical Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Genetics & Genomics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Medicinal Chemistry (AREA)
- Molecular Biology (AREA)
- Zoology (AREA)
- Gastroenterology & Hepatology (AREA)
- Diabetes (AREA)
- Endocrinology (AREA)
- Toxicology (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Wood Science & Technology (AREA)
- Peptides Or Proteins (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Enzymes And Modification Thereof (AREA)
Abstract
본 발명은 고농도의 프로인슐린을 효소 분해하여 인슐린으로 전환시키는 단계를 포함하는, 프로인슐린으로부터 인슐린을 제조하는 방법, 인슐린을 정제하는 방법 및 이로부터 제조된 인슐린에 관한 것이다.
Description
본 발명은 고농도의 프로인슐린을 효소 분해하여 인슐린으로 전환시키는 단계를 포함하는, 프로인슐린으로부터 인슐린을 제조하는 방법, 인슐린을 정제하는 방법 및 이로부터 제조된 인슐린에 관한 것이다.
재조합 인슐린의 제조 방법은 반 합성 인슐린 (semi-synthetic insulin)의 제조 방법부터, 두 쇄 방법 (two chain method)을 거쳐 프로인슐린으로부터 인슐린을 제조하는 방법까지 지속적으로 개발되어 왔다.
두 쇄 방법과 반 합성 방법을 제외한 프로인슐린으로부터 인슐린을 제조하는 방법 중 트립신 (Trypsin) 및 카복시펩티다제 B (Carboxypeptidase B)를 사용하여 프로인슐린을 인슐린으로 전환시키는 공정은 수년 동안 사용되어 왔었다 [참조: Krmmler, W., Clark, j., Steiner, D.F., Fed. Proc. 30 (1971) 1210; Kemmler, W., Peterson, J.D., Steiner, D.F.,J. Biol.Chem., 246 (1971) 6788-6791]. 그러나, 이 방법을 사용하여 인슐린을 생산하는 경우에는 일반적인 컬럼 등의 정제 방법으로는 제거가 어려운 불순물, 특히 B 쇄의 마지막 아미노산 트레오닌이 소실된 사람 인슐린[Des-Thr(B30)-인슐린] 형태가 조건에 따라 그 함량은 다르나 대부분의 조건에서 인슐린 제조 시 생성되는 타 불순물에 비하여 다량 (4 ~ 10 %)으로 형성된다고 알려져 있다.
반 합성 방법의 경우는 C-펩타이드를 천연형과 다르게 변형하여 트립신 처리 만으로 프로인슐린 유사체에서 C-펩타이드를 제거 할 수 있게 하였고, B 쇄의 마지막 아미노산인 트레오닌이 제거된 형태가 생성되게 한다. 그 다음, 생성된 인슐린의 B쇄의 마지막 아미노산에 트레오닌 이스터 (L-Threonine t-butyl ester)를 합성으로 붙인 후 생성된 인슐린-이스터와 B 쇄의 마지막 아미노산 트레오닌이 소실된 사람 인슐린[Des-Thr(B30)-인슐린] 형태를 분리해 내는 방법을 사용한다. 반면, 사람 프로인슐린을 중간체로서 사용하는 방법의 경우에는 Des-Thr(B30)-인슐린이 효소 전환 (Enzymatic conversion) 공정 중에 다량 생성됨으로 인하여 이의 억제를 위한 시도가 존재하였다.
예를 들어, 미국등록특허 US5457066 에서는 효소 전환 공정에서 2가 금속 이온을 도입함으로써 Des-Thr-B30-인슐린의 생성량을 감소시켰다고 보고한 바 있다.
또한, Son YJ et al (Biotechnol Prog. 2009 Jul-Aug;25(4):1064-70) 및 미국공개특허 2012-0214964 에 따르면, 'cytraconylation' 이란 방법을 사용하여 B30 트레오닌 근처의 B29 리신 사이트를 블로킹 (blocking) 하는 반응을 시킨 후 효소 전환 공정을 수행하여 Des-Thr(B30)-인슐린의 생성량을 감소시켰다고 보고한 바 있다.
그러나, 이러한 방법들은 효소 전환 공정 이후 수행되는 정제 공정에서, 첨가제들에 의한 잠재적인 문제를 야기할 수 있다. 또한, 공정에 상기 Des-Thr(B30)-인슐린의 생성을 막기 위한 첨가제의 추가 및/또는 첨가제의 제거 (unblock) 공정이 포함되어야 한다는 점에서, 공정의 복잡성을 증가 시켜 나중에는 비용의 증가로 이어질 수 있는 문제점이 있다.
이러한 배경 하에 본 발명자들은 프로인슐린을 중간체로 사용하는 인슐린 제조 방법에 있어서, 불순물의 생성을 최소화할 수 있는 방법을 개발하고자 예의 노력한 결과, 고농도의 프로인슐린 시료에 효소 전환 공정을 수행하는 방법을 개발하였다. 본 발명에서 개발된 상기 방법을 통하여 Des-Thr(B30)-인슐린의 생성을 효과적으로 감소시킬 수 있다.
본 발명의 하나의 목적은 고농도의 프로인슐린을 효소 분해하여 인슐린으로 전환시키는 단계를 포함하는, 프로인슐린으로부터 인슐린을 제조하는 방법을 제공하는 것이다.
본 발명의 다른 목적은 고농도의 프로인슐린을 효소 분해하여 인슐린으로 전환시켜, 인슐린을 포함하는 시료를 제조하는 단계; 및 상기 제조된 시료를 정제 공정에 적용하는 단계를 포함하는, 인슐린의 정제 방법을 제공하는 것이다.
본 발명의 다른 목적은 상기 방법으로 제조된 인슐린을 제공하는 것이다.
본 발명을 구현하기 위한 하나의 양태는 50mg/ml 이상 농도의 프로인슐린을 효소 분해하여 인슐린으로 전환시키는 단계를 포함하는, 프로인슐린으로부터 인슐린을 제조하는 방법이다.
하나의 구체예로서, 상기 효소는 트립신, 카르복시펩티데이즈 B, 또는 이들의 조합인 것을 특징으로 한다.
다른 구체예로서, 상기 프로인슐린의 농도는 50mg/ml 내지 300 mg/ml 인 것을 특징으로 한다.
다른 구체예로서, 상기 프로인슐린의 농도는 100mg/ml 내지 300mg/ml 인 것을 특징으로 한다.
다른 구체예로서, 상기 프로인슐린의 농도는 200mg/ml 내지 300mg/ml 인 것을 특징으로 한다.
다른 구체예로서, 상기 트립신의 비율은 프로인슐린 대비 1/7,500 내지 1/40,000 (weight/weight) 인 것을 특징으로 한다.
다른 구체예로서, 상기 트립신의 비율은 프로인슐린 대비 1/15,000 에서 1/40,000 (weight/weight) 인 것을 특징으로 한다.
다른 구체예로서, 상기 트립신의 비율은 프로인슐린 대비 1/20,000 에서 1/40,000 (weight/weight) 인 것을 특징으로 한다.
다른 구체예로서, 상기 트립신의 비율은 프로인슐린 대비 1/30,000 에서 1/40,000 (weight/weight) 인 것을 특징으로 한다.
다른 구체예로서, 상기 카르복시펩티데이즈 B 의 비율은 프로인슐린 대비 1/600 에서 1/20,000 인 (weight/weight) 인 것을 특징으로 한다.
다른 구체예로서, 상기 카르복시펩티데이즈 B 의 비율은 프로인슐린 대비 1/600 에서 1/15,000 인 (weight/weight) 인 것을 특징으로 한다.
다른 구체예로서, 효소 반응에서의 pH 는 6.5 에서 9.0 인 것을 특징으로 한다.
다른 구체예로서, 효소 반응에서의 pH 는 7.0 에서 8.5 인 것을 특징으로 한다.
다른 구체예로서, 효소 반응에서의 온도는 4.0 에서 25.0 ℃ 인 것을 특징으로 한다.
다른 구체예로서, 효소 반응 시간은 4.0 시간에서 55 시간 인 것을 특징으로 한다.
다른 구체예로서, 효소 반응의 완충액은 1mM 내지 100 mM의 Tris-HCl 인 것을 특징으로 한다.
다른 구체예로서, 효소 반응의 완충액은 금속 이온을 포함하지 않는 것을 특징으로 한다.
다른 구체예로서, 상기 프로인슐린 또는 인슐린은 아날로그 형태 인 것을 특징으로 한다.
다른 구체예로서, 추가로 프로인슐린으로부터 전환된 인슐린을 포함하는 시료를 크로마토그래피에 적용하여 인슐린을 정제하는 단계를 포함하는 것을 특징으로 한다.
다른 구체예로서, 크로마토그래피는 양이온 교환 크로마토그래피 또는 역상 크로마토그래피인 것을 특징으로 한다.
다른 구체예로서, 양이온 교환 크로마토그래피에 프로인슐린으로부터 전환된 인슐린을 포함하는 시료를 적용하여 인슐린을 정제한 다음, 역상 크로마토그래피를 수행하는 것을 특징으로 한다.
다른 구체예로서, 역상 크로마토그래피 또는 음이온 교환 크로마토그래피를 수행하는 것을 추가로 포함하는 것을 특징으로 한다.
다른 구체예로서, 상기 프로인슐린은 양이온 교환 컬럼 또는 역상 칼럼으로 부분 정제된 것을 특징으로 한다.
다른 구체예로서, 상기 프로인슐린은 양이온 교환 칼럼 또는 역상 칼럼으로 부분 정제된 것일 수 있으나, 이에 제한되지 않는다.
다른 구체예로서, 상기 방법으로 제조된 인슐린을 포함하는 시료는 Des-Thr(B30)-인슐린 불순물의 함량이 5% 미만인 것을 특징으로 한다.
본 발명을 구현하기 위한 다른 양태는 고농도의 프로인슐린을 효소 분해하여 인슐린으로 전환시켜, 인슐린을 포함하는 시료를 제조하는 단계; 및 상기 제조된 시료를 정제 공정에 적용하는 단계를 포함하는, 인슐린의 정제 방법이다.
하나의 구체예로서, 상기 크로마토그래피는 양이온 교환 크로마토그래피 또는 역상 크로마토그래피인 것을 특징으로 한다.
다른 구체예로서, 양이온 교환 크로마토그래피에 프로인슐린으로부터 전환된 인슐린을 포함하는 시료를 적용하여 인슐린을 정제한 다음, 역상 크로마토그래피를 수행하는 것을 특징으로 한다.
본 발명을 구현하기 위한 다른 양태는 상기 방법으로 제조된 인슐린이다.
본 발명의 방법을 통하여, 불순물이 효과적으로 제어된 인슐린 시료를 제조할 수 있으며, 인슐린 정제 효율을 현저하게 증가시킬 수 있다. 따라서, 이를 대량 인슐린 제조에 적용하여 불순물 제거를 위한 비용 감소를 기대할 수 있다.
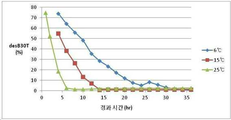
도 1은 효소처리 시 프로인슐린 농도 조건에 따른 불순물 감소 효과를 분석한 그래프 이다.
도 2는 효소처리 시 반응 온도 조건에 따른 불순물 감소 효과를 분석한 그래프 이다.
도 3은 효소처리 시 반응 pH 조건에 따른 불순물 감소 효과를 분석한 그래프 이다.
도 4는 Des-Thr(B30)-인슐린 아날로그를 과량으로 포함한 인슐린 아날로그 시료의 역상 크로마토그래피 분석 결과를 나타낸 것이다.
도 5a 내지 도 5c는 순수하게 정제된 인슐린 아날로그의 순도를 고압 크로마토그래피로 분석한 결과이다. (도 5a) C18 RP-HPLC, (도 5b) C4 RP-HPLC, (도 5c) SEC-HPLC.
도 2는 효소처리 시 반응 온도 조건에 따른 불순물 감소 효과를 분석한 그래프 이다.
도 3은 효소처리 시 반응 pH 조건에 따른 불순물 감소 효과를 분석한 그래프 이다.
도 4는 Des-Thr(B30)-인슐린 아날로그를 과량으로 포함한 인슐린 아날로그 시료의 역상 크로마토그래피 분석 결과를 나타낸 것이다.
도 5a 내지 도 5c는 순수하게 정제된 인슐린 아날로그의 순도를 고압 크로마토그래피로 분석한 결과이다. (도 5a) C18 RP-HPLC, (도 5b) C4 RP-HPLC, (도 5c) SEC-HPLC.
본 발명을 구현하기 위한 하나의 양태는 고농도의 프로인슐린을 효소 분해하여 인슐린으로 전환시키는 단계를 포함하는, 프로인슐린으로부터 인슐린을 제조하는 방법을 제공한다.
본 발명의 방법에서 상기 프로인슐린은 고농도로 사용될 수 있다.
구체적으로, 50mg/ml 이상의 프로인슐린을 효소 전환에 사용할 수 있다. 보다 더 구체적으로, 상기 방법에서 프로인슐린의 농도는 50mg/ml 내지 300 mg/ml, 구체적으로 100mg/ml 내지 300mg/ml, 보다 더 구체적으로 200mg/ml 내지 300mg/ml 일 수 있으나, 이에 제한되지 않는다.
상기 프로인슐린을 효소분해하여 인슐린으로 전환시키는 것은, 본 발명에서 효소 전환 (enzymatic conversion)으로도 명명된다.
상기 "효소 전환"이란 A 쇄와 B 쇄 사이에 C-펩타이드를 포함하는 프로인슐린 (Proinsulin)을 인슐린 (Insulin)으로 효소를 이용하여 전환시키는 것을 말한다.
본 발명에서 상기 효소 전환은 트립신, 카르복시펩티데이즈 B, 또는 이들의 조합에서 선택된 것을 이용하여 효소 전환할 수 있다.
본 발명에서 상기 트립신은, 프로인슐린 대비 1/7,500 내지 1/40,000 의 비율 (weight/weight), 구체적으로 1/15,000 에서 1/40,000 (weight/weight), 보다 구체적으로 1/20,000 에서 1/40,000 (weight/weight), 보다 더 구체적으로 1/30,000 에서 1/40,000 (weight/weight) 의 비율로 사용될 수 있으나, 이에 제한되지 않는다.
본 발명에서 상기 카르복시펩티데이즈 B는 프로인슐린 대비 1/600 에서 1/20,000 (weight/weight), 구체적으로 1/600 에서 1/15,000 (weight/weight) 의 비율로 사용될 수 있으나, 이에 제한되지 않는다.
한편, 트립신 및 카르복시펩티데이즈 B를 모두 사용하는 경우에, 앞서 기술한 트립신 및 카르복시펩티데이즈 B의 비율들을 서로 조합하여 사용할 수 있다.
본 발명의 효소 전환 반응에서의 pH 는 프로인슐린으로부터 인슐린의 효과적인 전환이 가능하다면 특별히 이에 제한되지 않으나, pH 6.5 내지 9.0, 구체적으로 7.0 에서 8.5 일 수 있으나, 이에 제한되지 않는다.
본 발명의 효소 전환 반응에서의 온도는 4.0 에서 25.0℃ 일 수 있으나, 이에 제한되지 않는다.
본 발명의 효소 반응 시간은 4.0 시간에서 55 시간 일 수 있으나, 이에 제한되지 않는다.
본 발명의 효소 반응의 완충액은 1mM 내지 100 mM의 Tris-HCl일 수 있으나, 이에 제한되지 않는다.
본 발명의 효소 반응의 완충액은 금속 이온을 포함하지 않지 않을 수 있으나, 이에 제한되지 않는다.
하기에서는 프로인슐린 및 인슐린에 대하여 보다 상세히 설명한다.
본 발명에서 용어, "프로인슐린 (proinsulin)"은 인슐린의 전구체 분자를 말한다. 상기 프로인슐린은 인슐린 A 쇄 및 B 쇄, 그리고 그 사이에 C-펩타이드를 포함할 수 있다. 상기 프로인슐린은 사람 프로인슐린일 수 있다.
본 발명에서 용어, "인슐린 (insulin)"은 체내의 혈당을 조절하는 역할을 수행하는 단백질을 말한다.
천연형 인슐린은 췌장에서 분비되는 호르몬으로서 일반적으로 세포 내 글루코스 흡수를 촉진하고 지방의 분해를 억제하여 체내의 혈당을 조절하는 역할을 한다.
인슐린은 혈당조절 기능이 없는 프로인슐린 (proinsulin) 형태에서 프로세싱을 거쳐 혈당 조절 기능을 가지는 인슐린이 된다. 인슐린은 2개의 폴리펩티드 사슬, 즉 각각 21개 및 30개 아미노산 잔기를 포함하는 A-쇄 및 B-쇄로 구성되어 있고, 이들은 2개의 이황화 다리로 상호 연결되어 있다. 천연형 인슐린의 A-쇄 및 B-쇄는 각각 하기 서열번호: 1 및 2 로 표시되는 아미노산 서열을 포함할 수 있다.
A-쇄:
Gly-Ile-Val-Glu-Gln-Cys-Cys-Thr-Ser-Ile-Cys-Ser-Leu-Tyr-Gln-Leu-Glu-Asn-Tyr-Cys-Asn (서열번호: 1)
B-쇄:
Phe-Val-Asn-Gln-His-Leu-Cys-Gly-Ser-His-Leu-Val-Glu-Ala-Leu-Tyr-Leu-Val-Cys-Gly-Glu-Arg-Gly-Phe-Phe-Tyr-Thr-Pro-Lys-Thr (서열번호: 2)
본 발명에서 상기 프로인슐린 및 인슐린은 천연형 인슐린 및 인슐린 아날로그의 형태를 모두 포함하는 개념이다.
본 발명에서 프로인슐린 아날로그 또는 인슐린 아날로그 (analog)는 천연형과 비교하였을 때, B 쇄 또는 A 쇄의 아미노산이 변이된 것을 포함한다. 상기 인슐린 아날로그는 천연형 인슐린과 동일 또는 상응하는 생체 내의 혈당 조절기능을 보유할 수 있다.
구체적으로, 상기 프로인슐린 아날로그 또는 인슐린 아날로그는 천연형에서 적어도 하나 이상의 아미노산이 치환 (substitution), 추가 (addition), 결실 (deletion), 수식 (modification) 및 이들의 조합으로 이루어지는 군에서 선택되는 변형이 일어난 것일 수 있으나, 이에 제한되지 않는다.
본 발명의 실시예에서 사용된 인슐린 아날로그는 유전자 재조합 기술로 만든 인슐린 아날로그이며, 상기 인슐린 아날로그는 역방향 인슐린 (inverted insulin), 인슐린 변이체 (variants), 인슐린 단편 (fragments) 등의 개념을 포함한다.
인슐린 아날로그는 천연형 인슐린과 동일 또는 상응하는 생체 내의 혈당 조절기능을 보유하는 펩타이드로서, 이러한 펩타이드는 인슐린 아고니스트 (agonist), 유도체 (derivatives), 단편 (fragments), 변이체 (variants) 등의 개념을 모두 포함한다.
상기 인슐린 유도체는 체내에서 혈당을 조절하는 기능을 보유하면서, 천연형 인슐린의 A-쇄 및 B-쇄의 아미노산 서열 각각에 대해 상동성을 보이며, 아미노산 한 잔기의 일부 그룹이 화학적으로 치환 (예: alpha-methylation, alpha-hydroxylation), 제거 (예: deamination) 또는 수식 (예: N-methylation) 된 형태의 펩타이드 형태를 포함한다. 상기 인슐린 단편은 인슐린에 하나 이상의 아미노산이 추가 또는 삭제된 형태를 의미하며 추가된 아미노산은 천연에 존재하지 않는 아미노산 (예: D형 아미노산)일 수 있고, 이러한 인슐린 단편은 체내에서 혈당을 조절하는 기능을 보유한다.
상기 인슐린 변이체는 인슐린과 아미노산 서열이 하나 이상 다른 펩타이드로서 체내에서 혈당을 조절하는 기능을 보유한다.
본 발명의 인슐린 아고니스트, 유도체, 단편 및 변이체에서 각각 사용된 제조방법은 독립적으로 사용될 수 있고 조합도 가능하다. 예를 들어 아미노산 서열이 하나 이상 다르고 아미노 말단 아미노산 잔기에 탈아미노화 (deamination)가 도입된 것으로 체내에서 혈당을 조절하는 기능을 보유한 펩타이드 역시 본 발명의 범주에 포함된다.
구체적으로, 상기 프로인슐린 또는 인슐린 아날로그는 인슐린 B쇄의 1번 아미노산, 2번 아미노산, 3번 아미노산, 5번 아미노산, 8번 아미노산, 10번 아미노산, 12번 아미노산, 16번 아미노산, 23번 아미노산, 24번 아미노산, 25번 아미노산, 26번 아미노산, 27번 아미노산, 28번 아미노산, 29번 아미노산, 30번 아미노산, A쇄의 1번 아미노산, 2번 아미노산, 5번 아미노산, 8번 아미노산, 10번 아미노산, 12번 아미노산, 14번 아미노산, 16번 아미노산, 17번 아미노산, 18번 아미노산, 19번 아미노산 및 21번 아미노산으로 이루어진 군에서 선택된 하나 또는 그 이상의 아미노산이 다른 아미노산으로 치환 된 것일 수 있으며, 보다 구체적으로는 B쇄의 8번 아미노산, 16번 아미노산, 23번 아미노산, 24번 아미노산, 25번 아미노산, A쇄의 1번 아미노산, 2번 아미노산, 14번 아미노산 및 19번 아미노산으로 이루어진 군에서 선택된 하나 또는 그 이상의 아미노산이 다른 아미노산으로 치환된 것일 수 있다. 구체적으로, 상기 기술한 아미노산에서 1 이상, 2 이상, 3 이상, 4 이상, 5 이상, 6 이상, 7 이상, 8 이상, 9 이상, 10 이상, 11 이상, 12 이상, 13 이상, 14 이상, 15 이상, 16 이상, 17 이상, 18 이상, 19 이상, 20 이상, 21 이상, 22 이상, 23 이상, 24 이상, 25 이상, 26 이상, 또는 27 이상의 아미노산이 다른 아미노산으로 치환된 것일 수 있으나, 이에 제한되지 않는다.
상기 기술한 위치의 아미노산 잔기들은 또한 알라닌, 글루탐산, 아스파라긴, 이소루신, 발린, 글루타민, 글리신, 라이신, 히스티딘, 시스테인, 페닐알라닌, 트립토판, 프로린, 세린, 트레오닌 또는/및 아스파르트산으로 치환될 수 있다.
그 예로 천연형 인슐린 A쇄의 14번 아미노산인 티로신이 글루탐산으로 치환된 것일 수 있다.
상기 아미노산의 치환 또는 부가 시에는 인간 단백질에서 통상적으로 관찰되는 20개의 아미노산뿐만 아니라 비정형 또는 비-자연적 발생 아미노산을 사용할 수 있다. 비정형 아미노산의 상업적 출처에는 Sigma-Aldrich, ChemPep 및 Genzymepharmaceuticals가 포함될 수 있다. 이러한 아미노산이 포함된 펩티드와 전형적인 펩티드 서열은 상업화된 펩티드 합성 회사, 예를 들어 미국의 American peptide company, Bachem이나 한국의 Anygen을 통해 합성 및 구매가능하다.
보다 구체적으로, 상기 인슐린 아날로그는 하기 일반식 1으로 표시되는 서열번호 3의 A쇄, 또는/및 하기 일반식 2로 표시되는 서열번호 4의 B쇄를 포함하는 것일 수 있다. 또한, 상기 A-쇄 및 B-쇄 서열이 이황화 결합으로 상호 연결된 형태일 수 있다. 다만, 이에 제한되는 것은 아니다.
[일반식 1]
Xaa1-Xaa2-Val-Glu-Gln-Cys-Cys-Thr-Ser-Ile-Cys-Ser-Leu-Xaa3-Gln-Leu-Glu-Asn-Xaa4-Cys-Asn (서열번호: 3)
상기 일반식 1에서,
Xaa1은 글리신 또는 알라닌이고,
Xaa2는 이소류신 또는 알라닌이며,
Xaa3는 타이로신, 글루탐산, 아스파라긴, 히스티딘, 라이신, 알라닌, 또는 아스파르트 산이며,
Xaa4는 타이로신, 글루탐산, 세린, 트레오닌, 또는알라닌임.
[일반식 2]
Phe-Val-Asn-Gln-His-Leu-Cys-Xaa5-Ser-His-Leu-Val-Glu-Ala-Leu-Xaa6-Leu-Val-Cys-Gly-Glu-Arg-Xaa7-Xaa8-Xaa9-Tyr-Thr-Pro-Lys-Thr (서열번호: 4)
상기 일반식 2에서,
Xaa5는 글리신 또는 알라닌이며,
Xaa6은 타이로신, 글루탐산, 세린, 트레오닌 또는 아스파르트 산이며,
Xaa7은 글리신 또는 알라닌이며,
Xaa8은 페닐알라닌 또는 알라닌이며,
Xaa9는 페닐알리닌, 아스파르트 산, 글루탐산, 알라닌, 또는 결실임.
보다 더 구체적으로, 상기 인슐린 아날로그는
(i) 상기 일반식 1에서 Xaa1은 알라닌이고, Xaa2는 이소류신이며, Xaa3는 타이로신이며, Xaa4는 타이로신인 A쇄 및 상기 일반식 2에서 Xaa5는 글리신이고, Xaa6은 타이로신이며, Xaa7은 글리신이며, Xaa8은 페닐알라닌이며, Xaa9은 페닐알라닌인 B쇄를 포함하거나;
(ii) 상기 일반식 1에서 Xaa1은 글리신이고, Xaa2는 알라닌이며, Xaa3는 타이로신이며, Xaa4는 타이로신인 A쇄 및 상기 일반식 2에서 Xaa5는 글리신이고, Xaa6은 타이로신이며, Xaa7은 글리신이며, Xaa8은 페닐알라닌이며, Xaa9은 페닐알라닌인 B쇄를 포함하거나;
(iii) 상기 일반식 1에서 Xaa1은 글리신이고, Xaa2는 이소류신이며, Xaa3는 글루탐산, 아스파라긴, 히스티딘, 라이신, 알라닌 또는 아스파르트 산이며, Xaa4는 타이로신인 A쇄 및 상기 일반식 2에서 Xaa5는 글리신이고, Xaa6은 타이로신, Xaa7은 글리신이며, Xaa8은 페닐알라닌이며, Xaa9은 페닐알라닌인 B쇄를 포함하거나;
(iv) 상기 일반식 1에서 Xaa1은 글리신이고, Xaa2는 이소류신이며, Xaa3는 타이로신이며, Xaa4는 알라닌, 글루탐산, 세린, 또는 트레오닌인 A쇄 및 상기 일반식 2에서 Xaa5는 글리신이고, Xaa6은 타이로신이며, Xaa7은 글리신이며, Xaa8은 페닐알라닌이며, Xaa9은 페닐알라닌인 B쇄를 포함하거나;
(v) 상기 일반식 1에서 Xaa1은 글리신이고, Xaa2는 이소류신이며, Xaa3는 타이로신이며, Xaa4는 타이로신인 A쇄 및 상기 일반식 2에서 Xaa5는 알라닌이고, Xaa6은 타이로신, Xaa7은 글리신이며, Xaa8은 페닐알라닌이며, Xaa9은 페닐알라닌인 B쇄를 포함하거나;
(vi) 상기 일반식 1에서 Xaa1은 글리신이고, Xaa2는 이소류신이며, Xaa3는 타이로신이며, Xaa4는 타이로신인 A쇄 및 상기 일반식 2에서 Xaa5는 글리신이고, Xaa6은 글루탐산, 세린, 트레오닌, 또는 아스파르트 산이며, Xaa7은 글리신, Xaa8은 페닐알라닌이며, Xaa9은 페닐알라닌인 B쇄를 포함하거나;
(vii) 상기 일반식 1에서 Xaa1은 글리신이고, Xaa2는 이소류신이며, Xaa3는 타이로신이며, Xaa4는 타이로신인 A쇄 및 상기 일반식 2에서 Xaa5는 글리신이고, Xaa6는 타이로신이며, Xaa7은 알라닌이며, Xaa8은 페닐알라닌이고, Xaa9는 페닐알라닌인 B쇄를 포함하거나;
(viii) 상기 일반식 1에서 Xaa1은 글리신이고, Xaa2는 이소류신이며, Xaa3는 타이로신이며, Xaa4는 타이로신인 A쇄 및 상기 일반식 2에서 Xaa5는 글리신이고, Xaa6은 타이로신이며, Xaa7은 글리신이며, Xaa8은 알라닌이며, Xaa9는 페닐알라닌인 B쇄를 포함하는 것일 수 있다.
(ix) 상기 일반식 1에서 Xaa1은 글리신이고, Xaa2는 이소류신이며, Xaa3는 타이로신이며, Xaa4는 타이로신인 A쇄 및 상기 일반식 2에서 Xaa5는 글리신이고, Xaa6은 타이로신이며, Xaa7은 글리신이며, Xaa8은 페닐알라닌이며, Xaa9는 알라닌, 아스파르트 산, 또는 글루탐산인 B쇄를 포함하는 것일 수 있다.
(x) 상기 일반식 1에서 Xaa1은 글리신이고, Xaa2는 이소류신이며, Xaa3는 글루탐산이며, Xaa4는 타이로신인 A쇄 및 상기 일반식 2에서 Xaa5는 글리신이고, Xaa6은 타이로신이며, Xaa7은 글리신이며, Xaa8은 페닐알라닌이며, Xaa9는 결실된 것인 B쇄를 포함하는 것일 수 있다.
(xi) 상기 일반식 1에서 Xaa1은 글리신이고, Xaa2는 이소류신이며, Xaa3는 알라닌이며, Xaa4는 타이로신인 A쇄 및 상기 일반식 2에서 Xaa5는 글리신이고, Xaa6은 글루탐산이며, Xaa7은 글리신이며, Xaa8은 페닐알라닌이며, Xaa9는 결실된 것인 B쇄를 포함하는 것일 수 있다.
그러나, 상기 예에 제한되는 것은 아니다. 그 예로, 상기 기술한 특징적인 아미노산 서열을 포함하면서, 해당 인슐린 아날로그와 70% 이상, 구체적으로는 80% 이상, 보다 구체적으로는 90% 이상, 보다 더 구체적으로는 95% 이상의 상동성을 가지며, 혈당 조절 기능을 보유한 펩타이드 역시 본 발명의 범주에 포함된다.
본 발명에서 용어, "상동성 (homology)"은 천연형 (wild type) 단백질의 아미노산 서열 또는 이를 코딩하는 폴리뉴클레오티드 서열과의 유사한 정도를 나타내기 위한 것으로서, 본 발명의 아미노산 서열 또는 폴리뉴클레오티드 서열과 상기와 같은 퍼센트 이상의 동일한 서열을 가지는 서열을 포함한다. 이러한 상동성은 두 서열을 육안으로 비교하여 결정할 수도 있으나, 비교대상이 되는 서열을 나란히 배열하여 상동성 정도를 분석해 주는 생물정보 알고리즘 (bioinformatic algorithm)을 사용하여 결정할 수 있다. 상기 두 개의 아미노산 서열 사이의 상동성은 백분율로 표시할 수 있다. 유용한 자동화된 알고리즘은 Wisconsin Genetics Software Package (Genetics Computer Group, Madison, W, USA)의 GAP, BESTFIT, FASTA와 TFASTA 컴퓨터 소프트웨어 모듈에서 이용가능하다. 상기 모듈에서 자동화된 배열 알고리즘은 Needleman & Wunsch와 Pearson & Lipman과 Smith & Waterman 서열 배열 알고리즘을 포함한다. 다른 유용한 배열에 대한 알고리즘과 상동성 결정은 FASTP, BLAST, BLAST2, PSIBLAST와 CLUSTAL W를 포함하는 소프트웨어에서 자동화되어 있다.
상기 인슐린 아날로그는 A1G → A, A2I → A, A19Y → A, B8G → A, B23G → A, B24F → A, B25F → A, A14Y → E, A14Y → N, A14Y → H, A14Y → K, A19Y → E, A19Y → S, A19Y → T, B16Y → E, B16Y → S, B16Y → T, A14Y → A, A14Y → D, B16Y → D, B25F → D, B25F → E, A14Y → D /B25F → 결실, 및/또는 A14Y → D/ B16Y → E/ B25F → 결실와 같은 변이를 가질 수 있으나, 이에 제한되지 않는다 (여기서, 가장 전단에 기재된 A 혹은 B는 인슐린 A쇄 또는 B쇄를 말하며, 기재된 숫자는 해당 쇄에서 아미노산 번호를 말한다. 뒤에 기재된 알파벳은 IUPAC 에 따라 명명되는 아미노산의 약어를 칭한다. 예컨대, G->A 인 경우, 글리신이 알라닌으로 치환된 것을 말한다.).
본 발명에 적용될 수 있는 인슐린 아날로그의 예는 앞서 기술한 바에 제한되는 것이 아니며, 당업계에 공지된 다양한 인슐린 아날로그를 본 발명의 방법에 적용할 수 있다.
또한, 이러한 인슐린 아날로그를 프로인슐린 아날로그로 설계하여 적용하는 것은 당업자에게 용이한 범주이다.
본 발명의 방법에 사용되는 상기 프로인슐린은 미생물에서 발현한 후, 이를 부분 정제하여 수득한 것일 수 있으나, 이에 제한되지 않는다. 특히, 상기 프로인슐린은 양이온 교환 컬럼으로 부분 정제된 것일 수 있다.
구체적으로, 상기 프로인슐린은 (a) 봉입체 (inclusion body) 형태로 미생물 내에서 발현한 후, 이로부터 봉입체를 분리하는 단계; (b) 분리된 프로인슐린을 포함하는 봉입체로부터 프로인슐린을 재접힘 (refolding) 하는 단계; 및 (c) 상기 (b) 단계에서 수득한 프로인슐린을 정제하는 단계를 포함할 수 있다.
그 예로, 하기와 같은 과정을 통하여 수행될 수 있다.
구체적으로, 봉입체 형태로 미생물 내에서 발효를 통하여 프로인슐린을 발현 및 형성 시킨다. 미생물 내부에 형성된 봉입체를 분리해내기 위해 고압 세포 파쇄장치 (microfluidizer)를 사용하여 미생물의 세포막을 파쇄한다. 세포막이 파쇄된 미생물을 원심분리와 세척 과정을 수행하여 인슐린 전구체 (proinsulin)를 포함하는 봉입체 만을 분리, 획득한다.
획득한 봉입체 펠렛 (pellet)에 포함되어있는 인슐린 전구체 단백질의 이황화 결합을 환원시키기 위해서 글라이신 (Glycine) 용액 버퍼에서 환원제와 반응시켜 준 후, 카오트로픽 보조제를 첨가하여 단백질 구조를 선형화할 수 있다. 그 다음, 원심분리를 통해 잔존물을 제거하고 저온에서 증류수 (DW)로 희석하여 카오트로픽 보조제와 환원제 농도를 낮춰 줌으로서 정확한 인슐린 전구체 구조를 갖는 단백질을 형성할 수 있다.
그 다음, 정확하게 형성된 프로인슐린을 분리하기 위하여 양이온 혹은 음이온 교환 컬럼을 적용할 수 있다.
본 발명의 방법은 추가로 프로인슐린으로부터 효소 전환된 인슐린을 포함하는 시료를 정제하는 단계를 포함할 수 있다.
구체적으로, 프로인슐린으로부터 전환된 인슐린을 포함하는 시료를 크로마토그래피에 적용하여 인슐린에 적용할 수 있다.
상기 크로마토그래피는 인슐린의 효과적인 정제를 가지고 올 수 있다면 특별히 그 종류에 제한되지 않으나, 양이온 교환 크로마토그래피 또는 역상 크로마토그래피일 수 있다.
본 발명에서 용어, "양이온 교환 크로마토그래피"는 양이온 교환 수지를 충진한 컬럼을 이용한 크로마토그래피를 말한다. 상기 양이온 교환 수지는 다른 수용액에 첨가되어 수용액 속의 양이온과 자신의 양이온을 교환하는 역할을 하는 합성수지이다. 상기 양이온 교환 수지는 당업계에서 통상적으로 사용되는 것을 다양하게 사용할 수 있으며, 이에 제한되지는 않으나, 구체적으로 COO- 또는 SO3 2-의 작용기를 가지고 있는 컬럼을 사용할 수 있으며, 그 예로 메틸설포네이트 (S), 설포프로필 (SP), 카르복시메틸 (CM), 폴리아스파르트산(Poly aspartic acid), 설포에틸(SE), 설포프로필(SP), 포스페이트(P) 또는 설포네이트(S) 등을 가지는 컬럼을 사용할 수 있다.
상기 양이온 교환 크로마토그래피는 평형화된 양이온 교환 컬럼에 상기 시료를 적용하여 인슐린을 컬럼에 결합시킨 후, 용출 완충액을 이용하여 용출시킴으로써 수행될 수 있다.
상기 양이온 교환 컬럼의 평형은 다양한 완충용액을 이용하여 수행할 수 있으며, 그 예로 사이트레이트, 아세테이트, 포스페이트, MOPS 혹은 MES 완충액 등을 사용할 수 있다.
상기 용출 완충액은 다양한 염 용액을 이용하여 수행할 수 있으며, 그 예로 NaCl 혹은 KCl 염 완충액을 사용할 수 있다. 상기 용출은 선형 농도 구배, 혹은 단계식 (stepwise) 농도 구배 등의 방법을 이용할 수 있으나, 상기 기술한 바에 제한되는 것은 아니다.
또한, 인슐린의 정제는 양이온 교환 크로마토그래피를 수행한 후에 역상 크로마토그래피를 수행하는 것을 포함할 수 있다.
상기 "역상 크로마토그래피"는 극성이 작은 고정상과 극성이 큰 이동상의 조합을 사용하여 혼합물을 분리하는 크로마토그래피를 말한다.
상기 역상 크로마토그래피 수지는 당업계에서 통상적으로 사용되는 것을 다양하게 사용할 수 있으며, 이에 제한되지는 않으나, 구체적으로 실리카 나 폴리머 메트릭스에 탄소체인 형태의 작용기 혹은 폴리머 메트릭스 자체가 작용기로 작용 할 수 있는 컬럼을 사용할 수 있으며, 그 예로 C2, C4, C8, C18 또는 폴리스티렌/다이비닐 벤젠 (polystyrene/divinyl benzene) 등을 가지는 컬럼을 사용할 수 있다.
상기 역상 크로마토그래피는 평형화된 컬럼에 상기 시료를 적용하여 인슐린을 컬럼에 결합시킨 후, 용출 완충액을 이용하여 용출시킴으로써 수행될 수 있다.
상기 역상 크로마토그래피의 평형은 다양한 용액을 이용하여 수행할 수 있으며, 그 예로 포스페이트 완충액 혹은 TFA/TAE 등이 포함된 물 등을 사용할 수 있다.
상기 용출 완충액은 다양한 유기용매 용액을 이용하여 수행할 수 있으며, 그 예로 에탄올, 아이소프로판올 혹은 아세토나이트릴 등을 사용할 수 있다. 상기 용출은 선형 농도 구배, 혹은 단계식 (stepwise) 농도 구배 등의 방법을 이용할 수 있으나, 상기 기술한 바에 제한되는 것은 아니다.
또한, 프로인슐린 및 인슐린의 정제는 양이온 교환 크로마토그래피를 수행한 후에 음이온 교환 크로마토그래피를 수행하는 것을 포함할 수 있다.
본 발명에서 용어, "음이온 교환 크로마토그래피"는 음이온 교환 수지를 충진한 컬럼을 이용한 크로마토그래피를 말한다. 상기 음이온 교환 수지는 다른 수용액에 첨가되어 수용액 속의 음이온과 자신의 음이온을 교환하는 역할을 하는 합성수지이다. 상기 음이온 교환 수지는 당업계에서 통상적으로 사용되는 것을 다양하게 사용할 수 있으며, 이에 제한되지는 않으나, 구체적으로 N+ 작용기를 가지고 있는 컬럼을 사용할 수 있으며, 그 예로 쿼터너리암모늄(Q), 쿼터너리아미노에틸 (QAE), 디에틸아미노에틸 (DEAE), 폴리에틸렌이민 (PEI), 디메틸아미노메틸(DMAE), 또는 트리메틸아미노에틸 (TMAE) 등을 가지는 컬럼을 사용할 수 있다.
음이온 교환 크로마토그래피는 평형화된 음이온 교환 컬럼에 상기 시료를 적용하여 프로인슐린 및 인슐린을 컬럼에 결합시킨 후, 용출 완충액을 이용하여 용출시킴으로써 수행될 수 있다.
상기 음이온 교환 컬럼의 평형은 다양한 완충용액을 이용하여 수행할 수 있으며, 그 예로 트리스, 비스트리스, 히스티딘 혹은 HEPES 완충액 등을 사용할 수 있다.
상기 용출 완충액은 다양한 염 용액을 이용하여 수행할 수 있으며, 그 예로 NaCl 혹은 KCl 염 완충액을 사용할 수 있다. 상기 용출은 선형 농도 구배, 혹은 단계식 (stepwise) 농도 구배 등의 방법을 이용할 수 있으나, 상기 기술한 바에 제한되는 것은 아니다.
또한, 본 발명의 효소 반응을 이용한, 인슐린 제조를 위해 사용되는 프로인슐린은 양이온 교환 칼럼 또는 역상 칼럼으로 부분 정제된 것일 수 있으나, 이에 제한되지 않는다.
한편, 특별히 이에 제한되지 않으나, 본 발명의 방법에 따르면 Des-Thr(B30)-인슐린 불순물의 함량이 5% 미만, 구체적으로 3% 미만, 보다 더 구체적으로 2% 미만, 더욱 더 구체적으로 1% 미만으로 인슐린을 제조할 수 있다.
본 발명을 구현하기 위한 다른 양태는 고농도의 프로인슐린을 효소 분해하여 인슐린으로 전환시켜, 인슐린을 포함하는 시료를 제조하는 단계; 및 상기 제조된 시료를 정제 공정에 적용하는 단계를 포함하는, 인슐린의 정제 방법을 제공한다.
상기 정제 방법은 크로마토그래피 공정에 의해 수행될 수 있다.
앞서 설명한 인슐린을 포함하는 시료의 제조 단계, 정제 단계, 크로마토그래피 공정에 대해서는 앞서 설명한 바와 같다.
본 발명을 구현하는 다른 양태는 상기 방법으로 제조된 인슐린을 제공한다.
상기 방법 및 인슐린에 대해서는 앞서 설명한 바와 같다.
이하, 하기 실시예에 의하여 본 발명을 보다 상세하게 설명한다. 단, 하기 실시예는 본 발명을 예시하기 위한 것일 뿐 본 발명의 범위가 이들로 한정되는 것은 아니다.
실시예 1: 프로인슐린 아날로그의 발현
T7 프로모터 조절하의 재조합 프로인슐린 아날로그들의 발현을 수행하였다. 각 아날로그의 인슐린에 해당되는 부분의 서열을 표 1에 나타내었다.






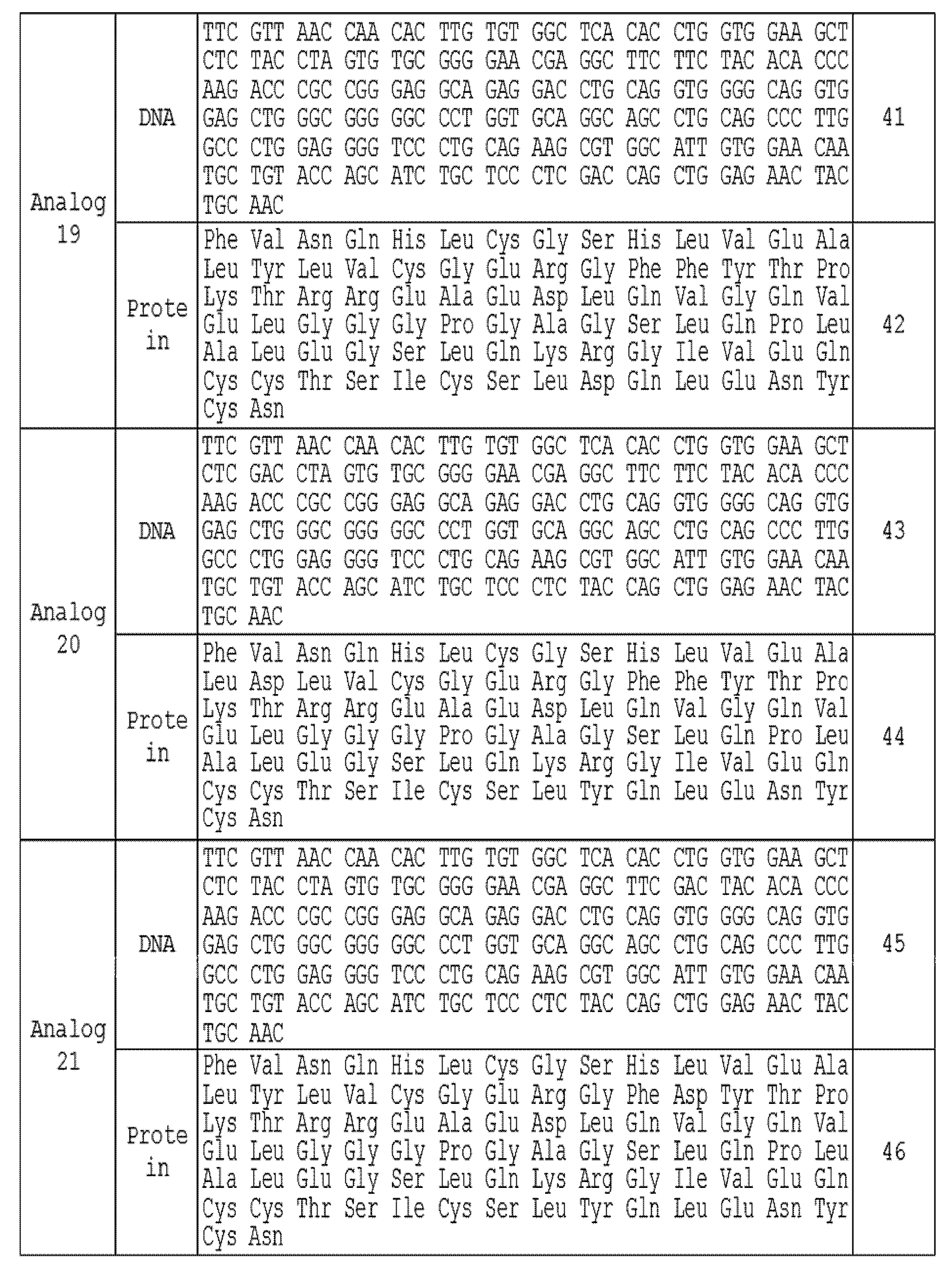

각각의 재조합 인슐린 아날로그 발현 벡터로 E.coli BL21-DE3 (E. coli B F-dcm ompT hsdS(rB-mB-) gal λDE3); 노바젠)을 형질전환하였다. 형질전환 방법은 노바젠사에서 추천하는 방법을 따랐다. 각 재조합 발현 벡터가 형질 전환된 각각의 단일 콜로니를 취하여 암피실린 (50 ㎍/ml)이 포함된 2X 루리아 브로스 (Luria Broth, LB) 배지에 접종하고, 37℃에서 15시간 배양하였다. 재조합 균주 배양액과 30% 글리세롤이 포함된 2X LB 배지를 1:1 (v/v)의 비율로 혼합하여 각 1 ml씩 크라이오-튜브에 분주하고, -140℃에 보관하였다. 이를 재조합 프로인슐린단백질의 생산을 위한 세포 스톡(cell stock)으로 사용하였다.
재조합 프로인슐린 아날로그들의 발현을 위하여, 각 세포 스톡 1 바이알을 녹여 500 ml의 2X 루리아 브로스에 접종하고 37℃에서 10~18시간 동안 진탕 배양한 배양액 중 200 ml을 취해 신선한 500 ml의 2X 루리아 브로스가 담긴 플라스크 2개에 각각 100 ml씩 접종하고 37℃에서 1~5시간 동안 진탕 배양하였으며 이를 종 배양액으로 사용하였다. 50 L 발효기 (MSJ-U2, B.E.MARUBISHI, 일본)를 이용하여 종 배양액을 17 L의 발효 배지에 접종하고 초기 회분식 (batch) 발효를 시작하였다. 배양조건은 온도 37℃, 공기량 20 L/분 (1 vvm), 교반 속도 500 rpm 그리고 30% 암모니아수를 사용하여 pH 6.70으로 유지시켰다. 발효 진행은 배양액 내의 영양소가 제한되었을 때, 추가배지 (feeding solution)를 첨가하여 유가배양 (fed-batch) 을 진행하였다. 균주의 성장은 OD 값에 의해 모니터링하며, OD 값이 100이상에서 최종 농도 500 μM의 IPTG를 도입하였다. 배양은 도입 후 약 20~25시간까지 더 진행하며, 배양 종료 후, SDS PAGE를 이용하여 과발현 된 프로인슐린 아날로그를 확인하였다. 프로인슐린 아날로그가 과발현 된 재조합 균주는 원심 분리기를 사용하여 수확하여 사용 시까지 -80℃에 보관하였다.
실시예 2: 재조합 프로인슐린 아날로그의 회수 및 재접힘 (refolding)
상기 실시예 1에서 발현시킨 재조합 프로인슐린 아날로그들을 가용성 형태로 바꾸기 위해 세포를 파쇄하고 리폴딩하였다. 세포 펠렛 170 g (wet weight)을 1 L 용해 완충액 (50 mM Tris-HCl (pH 9.0), 1 mM EDTA (pH 8.0), 0.2 M NaCl 및 0.5% 트리톤 X-100)에 재부유하였다. 미세용액화 (microfluidizer) 프로세서 M-110EH (AC Technology Corp. Model M1475C)를 이용하여 15,000 psi 압력으로 수행하여 세포를 파쇄하였다. 파쇄된 세포 용해물을 12,000 g로 4℃에서 30분 원심분리하여 상층액을 버리고, 1 L 세척완충액 (0.5% 트리톤 X-100 및 50 mM Tris-HCl(pH 8.0), 0.2 M NaCl, 1 mM EDTA)에 재부유하였다. 12,000 g로 4℃에서 30분 동안 원심분리하여 펠렛을 증류수에 재부유한 후, 동일한 방법으로 원심분리하였다. 펠렛을 취하여 600 ml의 완충액(1 M Glycine, 3.78 g Cysteine-HCl, pH 10.6)에 재부유하여 상온에서 1.5시간 동안 교반하였다. 재부유된 재조합 프로인슐린 아날로그 회수를 위하여 우레아를 추가한 후 상온에서 교반하였다. 가용화된 재조합 프로인슐린 아날로그의 재접힘 (refolding)을 위하여 4℃에서 40분간 원심분리한 후 상층액을 취한 후 3 ~ 12 L의 증류수에 연동펌프 (peristaltic pump)를 이용하여 넣어주면서 4~8℃에서 17시간이상 교반하였다.
실시예 3: 양이온 교환 크로마토그래피 정제
에탄올이 포함된 20 mM 소디움 사이트레이트 (pH 3.0) 완충액으로 평형화된 SP-FF (GE healthcare, 미국) 컬럼에 재접합이 끝난 시료를 pH 조정 후 결합시킨 다음 염화칼륨 0.5 M과 에탄올이 포함된 20 mM 소디움 사이트레이트 (pH 3.0) 완충액을 사용하여 농도가 0% 에서 100% 가 되도록 선형 농도 구배로 프로인슐린 아날로그 단백질을 용출하였다.
실시예 4: 효소처리에 의한 프로인슐린의 인슐린으로의 전환 (conversion)
실시예 1에서 나열 된 아날로그 중 8번 아날로그를 대표로 사용하여 효소처리에 의한 프로인슐린의 인슐린으로의 전환 시험을 실시하였다. SP-FF 컬럼으로 용출된 프로인슐린 아날로그 시료를 최종 pH 7.0 ~ 8.5 로 조절한 후 농축 하여 단백질의 농도가 5 ~ 300 mg/ml이 되도록 한다. 본 효소 반응은 제작자의 프로토콜에 따라 수행되었다. 50 mM Tris-HCL에 첨가된 단백질 시료에 단백량의 약 1/3,900 ~ 1/62,400 중량비 (weight/weight ratio)에 해당하는 트립신(Trypsin, Roche, 독일)과 1/644 ~ 1/19,300 중량비에 해당하는 카복시펩티데이즈 B (Carboxypeptidase B, Roche, 독일)를 첨가한 후, 약 4~25℃에서 0~55시간 교반하였다. 효소반응을 종료하기 위하여 pH를 3.5 이하로 낮추었다.
실시예 5: 효소전환 방법에서의 불순물 감소 효과 확인
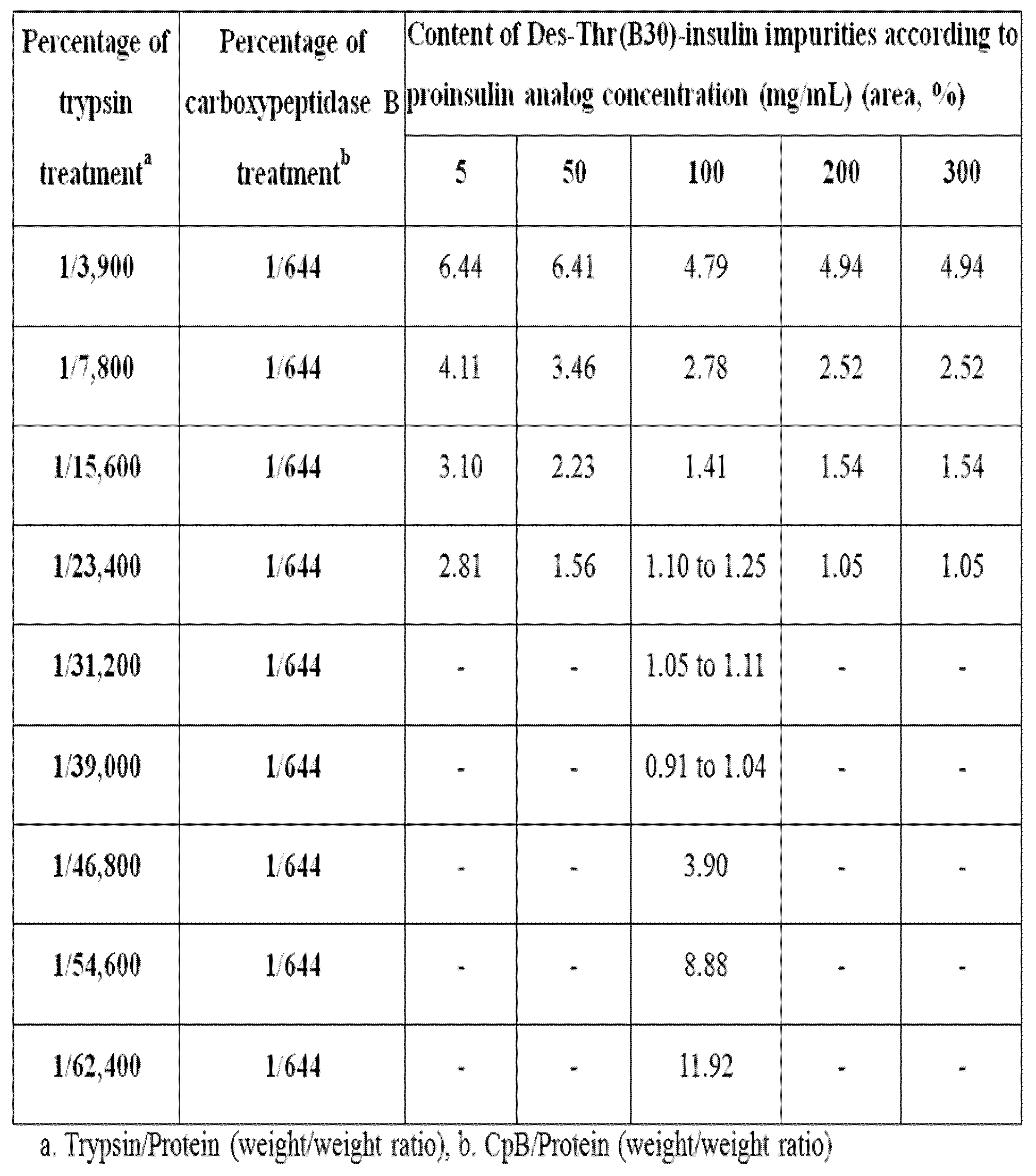
상기 실시예 4 에서는 Des-Thr(B30)-인슐린 아날로그 불순물을 최소화 하기 위한 최적화된 고농도 조건을 확립하였다. 프로인슐린을 5mg/ml, 50mg/ml, 100mg/ml, 200mg/ml, 300mg/ml 농도 조건 하에, 단백량의 1/3,900 ~ 1/62,400 중량비에 해당하는 트립신과 1/644 ~ 1/19,300 중량비에 해당하는 카복시펩티데이즈 B 를 첨가한 후, 실시예 4 에서 언급한 교반 및 반응종료 방법 따라 실시하고, RP-HPLC (C4)분석법을 이용하여, 각 농도조건 하에서의 Des-Thr(B30)-인슐린 불순물 함량을 확인하였다.
그 결과, Des-Thr(B30)-인슐린 아날로그 불순물은 단백량의 1/3,900 ~ 1/62,400 중량비에 해당하는 트립신과 1/644 중량비의 카복시펩티다제 B를 처리 했을 때의 조건하에서 프로인슐린 5 ~ 50 mg/ml 농도조건에서 약 1.6 ~ 6.4 % 발생 하였으나, 100 mg/ml ~ 300 mg/ml 의 고농도 조건에서는 발생 정도를 획기적으로 낮추어 약 1 % 내외로 발생을 억제 할 수 있었다 (표 2, 및 도 1).
반응 온도에 따른 최적화 시간도 0 시간부터 36 시간 이상 (최대 55시간)까지 테스트 하였으며 각 온도에 따른 온도 조건을 도 2에 나타내었다. 저온에서 실온까지 온도에 따라 반응 속도는 달라 지지만 감소 효과는 동일 함을 확인 하였다. pH 조건에 따른 트립신의 최적조건도 확인 하였으며 도 3에 나타내었다.
또한, 카복시펩티다제 B의 중량비에 의해서도 Des-Thr(B30)-인슐린 아날로그 불순물의 생성이 조절됨을 확인하였다.
단백량의 1/31,200 중량비에 해당하는 트립신과 1/644 ~ 1/19,300 중량비에 해당하는 카복시펩티다제 B를 처리 했을 때 100 mg/ml 고 농도 조건에서 1 % 내외로 Des-Thr(B30)-인슐린 아날로그 불순물의 발생을 억제 할 수 있음을 확인 하였다 (표 3).

실시예 6: 양이온 교환 크로마토 그래피 정제
반응이 끝난 시료를 20 mM 소디움 사이트레이트 (pH 3.0) 완충액으로 평형화된 SP-HP (GE healthcare, 미국) 컬럼에 다시 결합시킨 후, 염화칼륨 0.5 M과 에탄올이 포함된 20 mM 소디움 사이트레이트 (pH 3.0) 완충액을 사용한 선형 농도 구배를 이용하여 인슐린 아날로그 단백질을 용출하였다.
실시예 7: 역상 크로마토 그래피 정제
상기 실시예 6에서 얻어진 시료에서 인슐린 아날로그를 순수 분리하기 위해 소디움포스페이트와 아이소프로판올을 포함한 버퍼로 평형화된 역상 크로마토 그래피 Source30RPC (GE healthcare, 미국)에 결합시킨 후, 소디움포스페이트와 이소프로판올을 포함한 완충액을 사용하여 선형 농도 구배로 인슐린 아날로그 단백질을 용출하였다.
Des-Thr(B30)-인슐린 아날로그를 과량 (약 10%) 포함한 인슐린 아날로그의 분석은 고압 크로마토그래피 (HPLC) (도 4)로 확인하였으며, Des-Thr(B30)-인슐린 불순물을 최소화 하기 위한 효소 전환 공정이 적용되어 정제된 최종 인슐린 아날로그의 순도와 불순물의 확인은 고압 크로마토그래피 (HPLC) (도 5) 분석을 통하여 확인하였다. 그 결과 주요 불순물인 Des-Thr(B30)-인슐린 아날로그와 디아미데이션 형태의 인슐린 아날로그는 각각 1 % 미만이었으며, 전체 순도는 98.5 % 이상 이었다.
이상의 설명으로부터, 본 발명이 속하는 기술분야의 당업자는 본 발명이 그 기술적 사상이나 필수적 특징을 변경하지 않고서 다른 구체적인 형태로 실시될 수 있다는 것을 이해할 수 있을 것이다. 이와 관련하여, 이상에서 기술한 실시 예들은 모든 면에서 예시적인 것이며 한정적인 것이 아닌 것으로서 이해해야만 한다. 본 발명의 범위는 상기 상세한 설명보다는 후술하는 특허 청구범위의 의미 및 범위 그리고 그 등가 개념으로부터 도출되는 모든 변경 또는 변형된 형태가 본 발명의 범위에 포함되는 것으로 해석되어야 한다.
<110> HANMI PHARM. CO., LTD.
<120> METHOD OF INSULIN PRODUCTION
<130> KPA151030-KR-P1
<150> KR 10-2015-0135872
<151> 2015-09-24
<160> 52
<170> KopatentIn 2.0
<210> 1
<211> 21
<212> PRT
<213> Homo sapiens
<400> 1
Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln Leu
1 5 10 15
Glu Asn Tyr Cys Asn
20
<210> 2
<211> 30
<212> PRT
<213> Homo sapiens
<400> 2
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr
20 25 30
<210> 3
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> Insulin analog, formula 1
<220>
<221> MISC_FEATURE
<222> (1)
<223> Xaa is glycine or alanine
<220>
<221> MISC_FEATURE
<222> (2)
<223> Xaa is isoleucine or alanine
<220>
<221> MISC_FEATURE
<222> (14)
<223> Xaa is tyrosine, glutamic acid, asparagine, histidine, lysine,
alanine, or aspartic acid
<220>
<221> MISC_FEATURE
<222> (19)
<223> Xaa is tyrosine, glutamic acid, serine, threonine or alanine
<400> 3
Xaa Xaa Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Xaa Gln Leu
1 5 10 15
Glu Asn Xaa Cys Asn
20
<210> 4
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> Insulin analog, formula 2
<220>
<221> MISC_FEATURE
<222> (8)
<223> Xaa is glycine or alanine
<220>
<221> MISC_FEATURE
<222> (16)
<223> Xaa is Tyrosine, glutamic acid, serine, threonine or aspartic
acid
<220>
<221> MISC_FEATURE
<222> (23)
<223> Xaa is glycine or alanine
<220>
<221> MISC_FEATURE
<222> (24)
<223> Xaa is phenylalanine or alanine
<220>
<221> MISC_FEATURE
<222> (25)
<223> Xaa is phenylalanine, aspartic acid, glutamic acid alanine or
deletion
<400> 4
Phe Val Asn Gln His Leu Cys Xaa Ser His Leu Val Glu Ala Leu Xaa
1 5 10 15
Leu Val Cys Gly Glu Arg Xaa Xaa Xaa Tyr Thr Pro Lys Thr
20 25 30
<210> 5
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 1
<400> 5
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtgcgat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaact actgcaac 258
<210> 6
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 1
<400> 6
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Ala Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 7
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 2
<400> 7
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcgc ggtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaact actgcaac 258
<210> 8
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 2
<400> 8
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ala Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 9
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 3
<400> 9
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaacg cgtgcaac 258
<210> 10
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 3
<400> 10
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Ala Cys Asn
85
<210> 11
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 4
<400> 11
ttcgttaacc aacacttgtg tgcgtcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaact actgcaac 258
<210> 12
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 4
<400> 12
Phe Val Asn Gln His Leu Cys Ala Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 13
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 5
<400> 13
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgagcgt tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaact actgcaac 258
<210> 14
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 5
<400> 14
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Ala Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 15
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 6
<400> 15
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggcg cgttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaact actgcaac 258
<210> 16
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 6
<400> 16
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Ala Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 17
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 7
<400> 17
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcgcgtacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaact actgcaac 258
<210> 18
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 7
<400> 18
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Ala Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 19
<211> 261
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 8
<400> 19
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctcgaacag 240
ctggagaact actgcaactg a 261
<210> 20
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 8
<400> 20
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Glu Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 21
<211> 261
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 9
<400> 21
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctcaaccag 240
ctggagaact actgcaactg a 261
<210> 22
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 9
<400> 22
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Asn Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 23
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 10
<400> 23
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctccatcag 240
ctggagaact actgcaac 258
<210> 24
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 10
<400> 24
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu His Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 25
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 11
<400> 25
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctcaagcag 240
ctggagaact actgcaac 258
<210> 26
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 11
<400> 26
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Lys Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 27
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 12
<400> 27
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaacg agtgcaac 258
<210> 28
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 12
<400> 28
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Glu Cys Asn
85
<210> 29
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 13
<400> 29
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaact cctgcaac 258
<210> 30
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 13
<400> 30
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Ser Cys Asn
85
<210> 31
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 14
<400> 31
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaaca cctgcaac 258
<210> 32
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 14
<400> 32
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Thr Cys Asn
85
<210> 33
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 15
<400> 33
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctcgagct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaact actgcaac 258
<210> 34
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 15
<400> 34
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Glu
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 35
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 16
<400> 35
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctccct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaact actgcaac 258
<210> 36
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 16
<400> 36
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Ser
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 37
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 17
<400> 37
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctcaccct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaact actgcaac 258
<210> 38
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 17
<400> 38
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Thr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 39
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 18
<400> 39
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctcgcccag 240
ctggagaact actgcaac 258
<210> 40
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 18
<400> 40
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Ala Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 41
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 19
<400> 41
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctcgaccag 240
ctggagaact actgcaac 258
<210> 42
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 19
<400> 42
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Asp Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 43
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 20
<400> 43
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctcgacct agtgtgcggg 60
gaacgaggct tcttctacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaact actgcaac 258
<210> 44
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 20
<400> 44
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Asp
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Phe Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 45
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 21
<400> 45
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcgactacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaact actgcaac 258
<210> 46
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 21
<400> 46
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Asp Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 47
<211> 258
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 22
<400> 47
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tcgagtacac acccaagacc cgccgggagg cagaggacct gcaggtgggg 120
caggtggagc tgggcggggg ccctggtgca ggcagcctgc agcccttggc cctggagggg 180
tccctgcaga agcgtggcat tgtggaacaa tgctgtacca gcatctgctc cctctaccag 240
ctggagaact actgcaac 258
<210> 48
<211> 86
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 22
<400> 48
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Glu Tyr Thr Pro Lys Thr Arg Arg
20 25 30
Glu Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro
35 40 45
Gly Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys
50 55 60
Arg Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Tyr Gln
65 70 75 80
Leu Glu Asn Tyr Cys Asn
85
<210> 49
<211> 255
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 23
<400> 49
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctctacct agtgtgcggg 60
gaacgaggct tctacacacc caagacccgc cgggaggcag aggacctgca ggtggggcag 120
gtggagctgg gcgggggccc tggtgcaggc agcctgcagc ccttggccct ggaggggtcc 180
ctgcagaagc gtggcattgt ggaacaatgc tgtaccagca tctgctccct cgaacagctg 240
gagaactact gcaac 255
<210> 50
<211> 85
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 23
<400> 50
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Tyr
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Tyr Thr Pro Lys Thr Arg Arg Glu
20 25 30
Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro Gly
35 40 45
Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys Arg
50 55 60
Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Glu Gln Leu
65 70 75 80
Glu Asn Tyr Cys Asn
85
<210> 51
<211> 255
<212> DNA
<213> Artificial Sequence
<220>
<223> Analog 24
<400> 51
ttcgttaacc aacacttgtg tggctcacac ctggtggaag ctctcgagct agtgtgcggg 60
gaacgaggct tctacacacc caagacccgc cgggaggcag aggacctgca ggtggggcag 120
gtggagctgg gcgggggccc tggtgcaggc agcctgcagc ccttggccct ggaggggtcc 180
ctgcagaagc gtggcattgt ggaacaatgc tgtaccagca tctgctccct cgcccagctg 240
gagaactact gcaac 255
<210> 52
<211> 85
<212> PRT
<213> Artificial Sequence
<220>
<223> Analog 24
<400> 52
Phe Val Asn Gln His Leu Cys Gly Ser His Leu Val Glu Ala Leu Glu
1 5 10 15
Leu Val Cys Gly Glu Arg Gly Phe Tyr Thr Pro Lys Thr Arg Arg Glu
20 25 30
Ala Glu Asp Leu Gln Val Gly Gln Val Glu Leu Gly Gly Gly Pro Gly
35 40 45
Ala Gly Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln Lys Arg
50 55 60
Gly Ile Val Glu Gln Cys Cys Thr Ser Ile Cys Ser Leu Ala Gln Leu
65 70 75 80
Glu Asn Tyr Cys Asn
85
Claims (26)
- 50mg/ml 이상 농도의 프로인슐린을 효소 분해하여 인슐린으로 전환시키는 단계를 포함하는, 프로인슐린으로부터 인슐린을 제조하는 방법.
- 제1항에 있어서, 상기 효소는 트립신, 카르복시펩티데이즈 B, 또는 이들의 조합인, 방법.
- 제1항 또는 제2항에 있어서, 상기 프로인슐린의 농도는 50mg/ml 내지 300 mg/ml인, 방법.
- 제3항에 있어서, 상기 프로인슐린의 농도는 100mg/ml 내지 300mg/ml인, 방법.
- 제3항에 있어서, 상기 프로인슐린의 농도는 200mg/ml 내지 300mg/ml인, 방법.
- 제2항에 있어서, 상기 트립신의 비율은 프로인슐린 대비 1/7,500 내지 1/40,000 (weight/weight)인 방법.
- 제2항에 있어서, 상기 트립신의 비율은 프로인슐린 대비 1/15,000 에서 1/40,000 (weight/weight)인 방법.
- 제2항에 있어서, 상기 트립신의 비율은 프로인슐린 대비 1/20,000 에서 1/40,000 (weight/weight)인 방법.
- 제2항에 있어서, 상기 트립신의 비율은 프로인슐린 대비 1/30,000 에서 1/40,000 (weight/weight)인 방법.
- 제2항 및 제6항 내지 제9항 중 어느 한 항에 있어서, 상기 카르복시펩티데이즈 B 의 비율은 프로인슐린 대비 1/600 에서 1/20,000 인 (weight/weight)인 방법.
- 제2항 및 제6항 내지 제9항 중 어느 한 항에 있어서, 상기 카르복시펩티데이즈 B 의 비율은 프로인슐린 대비 1/600 에서 1/15,000 인 (weight/weight)인 방법.
- 제1항 또는 제2항에 있어서, 효소 반응에서의 pH 는 6.5 에서 9.0 인, 방법.
- 제1항 또는 제2항에 있어서, 효소 반응에서의 pH 는 7.0 에서 8.5 인, 방법.
- 제1항 또는 제2항에 있어서, 효소 반응에서의 온도는 4.0 에서 25.0 ℃ 인, 방법.
- 제1항 또는 제2항에 있어서, 효소 반응 시간은 4.0 시간에서 55 시간인, 방법.
- 제1항에 있어서, 상기 프로인슐린 또는 인슐린은 아날로그 형태인, 방법.
- 제1항에 있어서, 상기 방법은 추가로 프로인슐린으로부터 전환된 인슐린을 포함하는 시료를 크로마토그래피에 적용하여 인슐린을 정제하는 단계를 포함하는, 방법.
- 제17항에 있어서, 상기 크로마토그래피는 양이온 교환 크로마토그래피 또는 역상 크로마토그래피인, 방법.
- 제18항에 있어서, 역상 크로마토그래피 또는 음이온 교환 크로마토그래피를 수행하는 단계를 추가로 포함하는, 방법.
- 제1항에 있어서, 상기 프로인슐린은 양이온 교환 컬럼 또는 역상 컬럼으로 부분 정제된 것인, 방법.
- 제1항에 있어서, 상기 방법으로 제조된 인슐린을 포함하는 시료는 Des-Thr(B30)-인슐린 불순물의 함량이 5% 미만인, 방법.
- 제1항에 있어서, 효소 반응의 완충액은 1mM 내지 100 mM의 Tris-HCL인, 방법.
- 제1항에 있어서, 효소 반응의 완충액은 금속 이온을 포함하지 않는 것인, 방법.
- (a) 제1항의 방법으로 인슐린을 포함하는 시료를 제조하는 단계; 및
(b) 상기 시료를 크로마토그래피 공정에 적용하는 단계를 포함하는,
인슐린의 정제 방법.
- 제24항에 있어서, 상기 크로마토그래피는 양이온 교환 크로마토그래피 또는 역상 크로마토그래피인, 방법.
- 제25항에 있어서, 역상 크로마토그래피 또는 음이온 교환 크로마토그래피에 적용하는 단계를 추가로 포함하는, 방법.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020150135872 | 2015-09-24 | ||
| KR20150135872 | 2015-09-24 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20170036643A true KR20170036643A (ko) | 2017-04-03 |
Family
ID=58386604
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020160122485A Withdrawn KR20170036643A (ko) | 2015-09-24 | 2016-09-23 | 인슐린의 제조 방법 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US20180291077A1 (ko) |
| EP (1) | EP3341405A4 (ko) |
| JP (1) | JP2018531007A (ko) |
| KR (1) | KR20170036643A (ko) |
| CN (1) | CN108473548A (ko) |
| TW (1) | TW201726702A (ko) |
| WO (1) | WO2017052305A1 (ko) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019066570A1 (ko) * | 2017-09-28 | 2019-04-04 | 한미약품 주식회사 | 지속형 단쇄 인슐린 아날로그 및 이의 결합체 |
| WO2020138952A1 (ko) * | 2018-12-27 | 2020-07-02 | 주식회사 폴루스 | 인슐린 전구체의 인슐린 효소 전환용 조성물 및 이를 이용하여 인슐린 전구체를 인슐린으로 전환하는 방법 |
| KR20230032321A (ko) | 2021-08-30 | 2023-03-07 | 순천대학교 산학협력단 | 아미노산 특이적 차단제 및 이의 용도 |
| KR20230032320A (ko) | 2021-08-30 | 2023-03-07 | 순천대학교 산학협력단 | 트립신 특이적 형광 프로브 및 이의 용도 |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2764197C1 (ru) * | 2016-09-23 | 2022-01-14 | Ханми Фарм. Ко., Лтд. | Аналоги инсулина с пониженной аффинностью к рецептору инсулина и их применение |
| AR111341A1 (es) * | 2017-03-23 | 2019-07-03 | Hanmi Pharm Ind Co Ltd | Un conjugado del análogo de insulina con afinidad reducida para el receptor de insulina y uso del mismo |
| WO2020130749A1 (ko) * | 2018-12-21 | 2020-06-25 | 한미약품 주식회사 | 글루카곤, glp-1 및 gip 수용체 모두에 활성을 갖는 삼중 활성체 및 인슐린을 포함하는 약학 조성물 |
| US10799564B1 (en) | 2019-05-06 | 2020-10-13 | Baxter International Inc. | Insulin premix formulation and product, methods of preparing same, and methods of using same |
| TWI844709B (zh) | 2019-07-31 | 2024-06-11 | 美商美國禮來大藥廠 | 鬆弛素(relaxin)類似物及其使用方法 |
| CN116425884B (zh) * | 2023-03-09 | 2024-04-26 | 北京惠之衡生物科技有限公司 | 一种德谷胰岛素的纯化及制备方法 |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE3501641A1 (de) * | 1985-01-19 | 1986-07-24 | Hoechst Ag, 6230 Frankfurt | Verfahren zur gewinnung von insulin-vorlaeufern aus reaktionsgemischen, die bei der faltung von insulin-vorlaeufern aus den entsprechenden s-sulfonaten anfallen |
| IL84110A (en) * | 1986-10-14 | 1992-11-15 | Lilly Co Eli | Process for transforming a human insulin precursor to a human insulin |
| TW224471B (ko) * | 1991-11-26 | 1994-06-01 | Lilly Co Eli | |
| NZ279002A (en) * | 1994-12-29 | 1999-02-25 | Bio Technology General Corp | Production of recombinant human insulin by folding a proinsulin hybrid polypeptide obtained from a bacterial cell |
| KR0150565B1 (ko) * | 1995-02-15 | 1998-08-17 | 김정재 | 유전자 조환에 의한 사람 인슐린 전구체의 제조 및 이를 이용한 인슐린의 제조방법 |
| DE60236014D1 (de) * | 2001-11-19 | 2010-05-27 | Novo Nordisk As | Verfahren zur herstellung von insulinverbindungen |
| US7790677B2 (en) * | 2006-12-13 | 2010-09-07 | Elona Biotechnologies | Insulin production methods and pro-insulin constructs |
| RU2458989C1 (ru) * | 2008-08-07 | 2012-08-20 | Байокон Лимитид | Способ получения аналогов инсулина из их соответствующих предшественников (варианты) |
| UA91281C2 (ru) * | 2008-11-26 | 2010-07-12 | Общество С Ограниченной Ответственностью «Мако» | Способ получения рекомбинантного инсулина человека |
| RU2014126244A (ru) * | 2011-11-28 | 2016-01-27 | Фэйзбио Фармасьютикалз, Инк. | Лекарственные средства, содержащие аминокислотные последовательности инсулина |
| WO2013149729A2 (en) * | 2012-04-04 | 2013-10-10 | Glucometrix Ag | Proinsulin with enhanced helper sequence |
| TWI708782B (zh) * | 2013-02-26 | 2020-11-01 | 南韓商韓美藥品股份有限公司 | 新穎胰島素類似物及其用途 |
| EP3098235A4 (en) * | 2014-01-20 | 2017-10-18 | Hanmi Pharm. Co., Ltd. | Long-acting insulin and use thereof |
-
2016
- 2016-09-23 WO PCT/KR2016/010713 patent/WO2017052305A1/en not_active Ceased
- 2016-09-23 US US15/762,613 patent/US20180291077A1/en not_active Abandoned
- 2016-09-23 TW TW105131169A patent/TW201726702A/zh unknown
- 2016-09-23 CN CN201680055642.9A patent/CN108473548A/zh active Pending
- 2016-09-23 EP EP16849030.8A patent/EP3341405A4/en not_active Withdrawn
- 2016-09-23 KR KR1020160122485A patent/KR20170036643A/ko not_active Withdrawn
- 2016-09-23 JP JP2018515617A patent/JP2018531007A/ja active Pending
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019066570A1 (ko) * | 2017-09-28 | 2019-04-04 | 한미약품 주식회사 | 지속형 단쇄 인슐린 아날로그 및 이의 결합체 |
| WO2020138952A1 (ko) * | 2018-12-27 | 2020-07-02 | 주식회사 폴루스 | 인슐린 전구체의 인슐린 효소 전환용 조성물 및 이를 이용하여 인슐린 전구체를 인슐린으로 전환하는 방법 |
| KR20230032321A (ko) | 2021-08-30 | 2023-03-07 | 순천대학교 산학협력단 | 아미노산 특이적 차단제 및 이의 용도 |
| KR20230032320A (ko) | 2021-08-30 | 2023-03-07 | 순천대학교 산학협력단 | 트립신 특이적 형광 프로브 및 이의 용도 |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2017052305A1 (en) | 2017-03-30 |
| JP2018531007A (ja) | 2018-10-25 |
| US20180291077A1 (en) | 2018-10-11 |
| EP3341405A1 (en) | 2018-07-04 |
| CN108473548A (zh) | 2018-08-31 |
| EP3341405A4 (en) | 2019-05-01 |
| TW201726702A (zh) | 2017-08-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20170036643A (ko) | 인슐린의 제조 방법 | |
| US20230167421A1 (en) | Variants of a DNA Polymerase of the Polx Family | |
| JP2018531007A6 (ja) | インスリンの製造方法 | |
| CN113767168B (zh) | 高效引入赖氨酸衍生物的氨酰基—tRNA合成酶 | |
| CN108239633B (zh) | 一种催化活性得到提高的d-阿洛酮糖-3-差向异构酶的突变体及其应用 | |
| AU2020242724B2 (en) | Aminoacyl-tRNA synthetase for efficiently introducing lysine derivative in protein | |
| CN113631712B (zh) | 利用双质粒系统在蛋白中引入非天然氨基酸 | |
| US12454556B2 (en) | Fusion polypeptides for target peptide production | |
| KR20230144058A (ko) | 서브틸리신 변이체 및 그의 용도 | |
| CA2613471A1 (en) | Cell lines for expressing enzyme useful in the preparation of amidated products | |
| CN117088946A (zh) | 一种环状细菌素as-48的全生物合成方法 | |
| US20220411764A1 (en) | Thioredoxin mutant, preparation method thereof, and application thereof in production of recombinant fusion protein | |
| CN109136209B (zh) | 肠激酶轻链突变体及其应用 | |
| CN109852601B (zh) | 一种可高效应用的n-糖基化褐藻胶裂解酶突变体及基因工程菌构建方法 | |
| CN113652409B (zh) | 一种新的甘草次酸葡糖醛酸基转移酶突变体及其应用 | |
| CN112824527A (zh) | 人工设计的赖氨酰内切酶及编码序列和发酵方法 | |
| CN113201074B (zh) | 一种pkek融合蛋白及制备方法与应用 | |
| WO2020026045A2 (en) | Leader sequence for higher expression of recombinant proteins | |
| US20060024796A1 (en) | Transcriptional activator gene for genes involved in cobalamin biosynthesis | |
| CA3243916A1 (en) | METHODS FOR PRODUCING HUMAN ANALOGUE INSULINS AND THEIR DERIVATIVES IN A MAMMALIAN CELL | |
| US20190048326A1 (en) | Variant polypeptides capable of aminating aliphatic alpha keto acids | |
| JP7333913B2 (ja) | アンブレインの効率的製造方法 | |
| CN114380903A (zh) | 一种胰岛素或其类似物前体 | |
| Na et al. | Expression and purification of ubiquitin-specific protease (UBP1) of Saccharomyces cerevisiae in recombinant Escherichia coli | |
| KR101814048B1 (ko) | 대량 생산이 가능하도록 개선된 경구투여용 트롬보포이에틴 및 이의 대량 생산공정 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application |
Patent event code: PA01091R01D Comment text: Patent Application Patent event date: 20160923 |
|
| PG1501 | Laying open of application | ||
| PC1203 | Withdrawal of no request for examination | ||
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |