KR20200038533A - 결합제 - Google Patents
결합제 Download PDFInfo
- Publication number
- KR20200038533A KR20200038533A KR1020207007972A KR20207007972A KR20200038533A KR 20200038533 A KR20200038533 A KR 20200038533A KR 1020207007972 A KR1020207007972 A KR 1020207007972A KR 20207007972 A KR20207007972 A KR 20207007972A KR 20200038533 A KR20200038533 A KR 20200038533A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- amino acid
- antigen
- acid sequence
- clone
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images


















Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
- A61K39/001102—Receptors, cell surface antigens or cell surface determinants
- A61K39/001129—Molecules with a "CD" designation not provided for elsewhere
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/39558—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against tumor tissues, cells, antigens
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Immunology (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Veterinary Medicine (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Epidemiology (AREA)
- Oncology (AREA)
- Mycology (AREA)
- Microbiology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Cell Biology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicinal Preparation (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Epoxy Compounds (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Steroid Compounds (AREA)
- Saccharide Compounds (AREA)
- Plural Heterocyclic Compounds (AREA)
- Nitrogen And Oxygen Or Sulfur-Condensed Heterocyclic Ring Systems (AREA)
Abstract
Description
도 2. 생식계 돌연변이에 대한 CDR 잔기 내성 분석. 854 개의 고유한 scFv 클론의 ELISA-양성 집단의 CDR에서 뮤린 아미노산 보유 빈도의 플롯이 각각 VH (A) 및 VL (B) 도메인에 대해 도시되어 있다. HCDR3 이외의 인간/뮤린 잔기 돌연변이 유발을 표적으로 하는 잔기만이 플롯팅되었다. 각각의 플롯에서, CDR 잔기는 X-축에 나타내고 Y-축은 각 뮤린 잔기의 보유율을 나타낸다. X-축에서 괄호 안에 표시된 CDR 잔기는 이식에 사용된 인간 생식계에서 발견된 것과 동일하다 (IGKV2-28 및 IGHV5-51). 괄호 안에 없지만 값이 0으로 설정된 HCDR2의 잔기는 이식 과정 동안 인간 생식계로 돌연변이되었다. 두 플롯 모두에서 75 %의 회색 점선은 인간 생식계에 의한 뮤린 잔기 대체의 내성에 대한 컷오프를 나타낸다.
도 3. 인간, 마우스 및 시노 (cyno) CD47-Fc 단백질에 대한 IgG 결합에 대한 직접 적정 ELISA. 키메라 항-CD47 (mVH/mVL), 인간 IgG1 널(null) 형태의 라이브러리-유래 클론을 인간, 마우스 및 시노 CD47-Fc 단백질 (A-H)에 대한 직접 결합 ELISA에서 적정하였다 (μg/ml). mVH/mVL, 라이브러리-유래 클론 및 디자이너 클론 MH는 CD47의 3 개의 오솔로그 (ortholog) 모두에 대한 결합 활성을 입증하였다. 클론 VH-A1/VL-B1은 인간 및 시노 CD47에 결합하지만 마우스에는 결합하지 않는다. 클론 TTP는 거의 모든 결합 기능을 잃었다. 각 그래프에서, X-축은 μg/ml의 IgG 농도를 나타내고 Y-축은 결합 신호 (OD 450 nm)를 나타낸다.
도 4. ELISA-기반 CD47-Fc-SIRPα 경쟁 분석. 플레이트-결합된 인간 SIRPα에 대한 인간 (A), 시노 (B) 및 마우스 (C) CD47-Fc 단백질에 대한 ELISA 결합 신호를 적정 경쟁자 라이브러리-유래 리드의 존재하에 시험하였다: IgG1 널 형태의 A-D5, G-B6, D-H3 및 VH-A1/VL-B1, 음성 대조군으로서 이소타입 IgG1 및 양성 대조군으로서 IgG1 널 형태의 mVH/mVL. 모든 라이브러리-유래 IgG 및 mVH/mVL은 인간, 뮤린 및 시노 CD47-Fc 단백질의 결합에서 농도-의존적 감소를 나타내어 공유 에피토프의 유지를 시사한다. 특히, 클론 A-D5는 mVH/mVL과 비교하여 마우스 CD47의 중화에서 현저하게 증가된 효능을 나타내었고, VH-A1/VL-B1은 뮤린 CD47의 활성을 중화시키는 능력을 나타내지 않았다. 디자이너 클론 MH 및 TTP는 둘다 어떠한 중화 신호도 나타내지 않았으며 명확성을 위해 여기에 플롯팅되지 않았다. 각 그래프에서, X-축은 nM의 항체 농도를 나타내고 Y-축은 결합 신호 (OD 450 nm)를 나타낸다. 도면 범례에서 "IC"는 이소타입 대조군을 지칭한다.
도 5. 우선 순위가 지정된 리드 클론에 대한 결합 특이성 분석. IgG1 (A) 및 IgG1 널 (B) 형태에서의 mVH/mVL에 대한 오프-타겟 동족체 결합 위험 및 IgG1 널 형태에서의 라이브러리-유래 리드 A-D5 (C), VH-A1/VL-B1 (D), F-E7 (E), D-H3 (F) 및 G-B6 (G)는 CD47-Fc 오솔로그상의 직접 ELISA 및 각각의 X-축 상에 표지된 14 개의 인간 면역 글로불린 수퍼패밀리 단백질의 패널에 의해 시험되었다 ("B"는 빈칸을 지칭함). 인간, 시노 및 뮤린 CD47-Fcs (h/c/mCD47-Fc)에 대한 결합은 1 μg/ml의 IgG 농도에서 수행되었다. 다른 모든 단백질에 대한 결합은 10 μg/ml의 IgG 농도에서 수행되었다. 각 플롯에서 Y-축은 결합 신호 (OD 450nm)를 나타낸다. 거의 모든 IgG에 대해, hCD47-Fc, mCD37-Fc 및 cCD47-Fc 단독에 대한 결합이 관찰되었다. 다른 인간 단백질에 대해서는 백그라운드 이상의 결합이 관찰되지 않았다. 특히, 클론 VH-A1/VL-B1은 뮤린 CD47에 대한 반응성을 다시 나타내지 않았다.
도 6. 인간 및 시노 CD47+ CHO-K1 세포에 대한 유세포 분석 결합. 상업용 항-CD47 항체 MS1991, 인간 IgG1 ("I IgG1") 및 IgG4 ("I IgG4") 이소타입 대조군, IgG1 널 ("IgG1N") 및 IgG4 (S228P) 형태의 리드 라이브러리-유래 IgG는 시노-형질 감염된 CHO-K1 세포 (A), 인간-형질 감염된 CHO-K1 세포 (B) 및 야생형 (wt, 즉 형질 감염되지 않은) CHO-K1 세포 (C)에 대한 특이적 결합에 대해 시험되었다. IgG는 24-100,000 ng/ml 범위의 농도에서 시험되었다. 농도-의존적 결합은 모든 CD47-특이적 항체에 대한 인간 및 시노 세포주 모두에 대해 관찰되었지만 이소타입 대조군은 아니었다. 백그라운드 이상의 낮은-수준 결합 신호는 대부분의 항체에 대한 야생형 CHO-K1 세포에 대해 관찰되었으며, mVH/mVL-유래 IgG에 대한 신호는 더욱 강력했고 VH-A1/VL-B1 IgG에 대한 신호는 특히 낮았다. 각 그래프에서, X-축은 시험된 각각의 IgG 및 그 농도를 ng/ml로 나타내고, Y-축은 평균 형광 강도 (MFI)를 나타낸다.
도 7. 인간 HL60 세포에 대한 결합의 유세포 분석 테스트. 상업용 항-CD47 항체 MS1991, 인간 IgG1 및 IgG4 이소타입 대조군 (각각 "I IgG1"및 "I IgG4"), IgG1 널 ("IgG1N) 및 IgG4 (S228P) 형태의 리드 라이브러리-유래 IgG는 HL60 세포상에서 특이적 결합에 대해 시험되었다. IgG는 24-100000 ng/ml 범위의 농도에서 시험되었다. 이소타입 대조군 이외의 모든 클론에 대해 농도-의존적 결합이 관찰되었다. 각 그래프에서, X-축은 시험된 각각의 IgG 및 그 농도를 ng/ml로 나타내고, Y-축은 평균 형광 강도 (MFI)를 나타낸다.
도 8. 성장 위험 ELISA. 이 분석은 IgG1 널 형태의 A-D5, G-B6, D-H3, VH-A1/VL-B1 및 mVH/mVL 항체가 음으로 하전된 생체 분자 인슐린 (A), 이중-가닥 DNA (dsDNA) (B) 및 단일-가닥 DNA (ssDNA) (C)에 거의 또는 전혀 결합하지 않음을 보여주었다. 각 그래프에서, X-축은 μg/ml의 IgG 농도를 나타내고 Y-축은 결합 신호 (OD 450 nm)를 나타낸다. 보코시주맙 (Bococizumab) 및 브리아키누맙 (Briakinumab) 유사체에 대해 관찰된 바와 같이, 이들 분자에 대한 강한 오프-타겟 결합은 치료용 항체의 임상 성능이 부실하다는 고위험 지표인 것으로 나타났다.
도 9. 인간, 마우스 및 시노 CD47-Fc 단백질에 결합하는 디자이너 IgG에 대한 직접 적정 ELISA. 키메라 항-CD47 (mVH/mVL), 인간 IgG1 널 형태의 디자이너 A-D5-유래 클론을 인간 (A), 시노 (B) 및 마우스 (C) CD47-Fc 단백질에 대한 직접 결합 ELISA에서 적정하였다 (μg/ml으로). 각 그래프에서, X-축은 μg/ml의 IgG 농도를 나타내고 Y-축은 결합 신호 (OD 450 nm)를 나타낸다. 클론 A-D5.7은 단지 시노 CD47에 대한 약한 결합을 나타냈고 클론 A-D5.10은 마우스 CD47에 대한 거의 모든 결합 기능을 상실했지만, 대부분의 클론은 CD47의 모든 3 개 오솔로그에 대한 결합 활성을 입증하였다. 도면 범례에서, "IgG1NI"는 IgG1 널 이소타입을 지칭한다.
도 10. 디자이너 IgG에 대한 ELISA-기반 CD47-Fc-SIRPα 경쟁 분석. 플레이트-결합된 인간 SIRPα에 대한 인간 (A), 시노 (B) 및 마우스 (C) CD47-Fc 단백질에 대한 ELISA 결합 신호를 IgG1 널 형태의 적정된 경쟁자 디자이너 IgG의 존재하에, 음성 대조군으로서 이소타입 IgG1 ("IgG1NI"로 표시됨) 및 IgG1 널 형태의 mVH/mVL을 양성 대조군으로 하여 시험하였다. 각 그래프에서, X-축은 nM의 IgG 농도를 나타내고 Y-축은 결합 신호 (OD 450 nm)를 나타낸다. 특히, 몇몇 A-D5-유래 클론은 mVH/mVL과 비교하여 마우스 CD47의 중화에서 현저하게 증가된 효능을 나타냈다. 디자이너 클론 A-D5.7 및 A-D5.10는 약한 ELISA 결합 신호를 보이는 오솔로그에서 둘다 어떠한 중화 신호도 나타내지 않았으며 명확성을 위해 여기에 플롯팅되지 않았다.
도 11. 인간, 마우스 및 시노 CD47-Fc 단백질에 결합하는 A-D5.4-유래 디자이너 IgG에 대한 직접 적정 ELISA. 인간 IgG1 널 형태의 키메라 항-CD47 (mVH/mVL), 디자이너 A-D5.4-유래 클론을 인간 (A), 시노 (B) 및 마우스 (C) CD47-Fc 단백질에 대한 직접 결합 ELISA에서 적정하였다 (μg/ml으로). 각 그래프에서, X-축은 μg/ml의 IgG 농도를 나타내고 Y-축은 결합 신호 (OD 450 nm)를 나타낸다. 모든 클론은 CD47의 모든 3 개 오솔로그에 대한 결합 활성을 나타냈다. 도면 범례에서, "IgG1NI"는 IgG1 널 이소타입을 지칭한다.
도 12. 디자이너 IgG에 대한 ELISA-기반 CD47-Fc-SIRPα 경쟁 분석. 플레이트-결합된 인간 SIRPα에 대한 인간 (A), 시노 (B) 및 마우스 (C) CD47-Fc 단백질에 대한 ELISA 결합 신호를 IgG1 널 형태의 적정된 경쟁자 디자이너 IgG의 존재하에, 음성 대조군으로서 이소타입 IgG1 ("IgG1NI"로 표시됨) 및 IgG1 널 형태의 mVH/mVL을 양성 대조군으로 하여 시험하였다. 각 그래프에서, X-축은 nM의 IgG 농도를 나타내고 Y-축은 결합 신호 (OD 450 nm)를 나타낸다. 특히, 몇몇 A-D5.4-유래 클론은 mVH/mVL과 비교하여 마우스 CD47의 중화에서 현저하게 증가된 효능을 나타냈다.
도 13. 디자이너 클론 A-D5.4 및 A-D5.16에 대한 결합 특이성 분석. IgG1 널 형태의 A-D5.4 (A) 및 A-D5.16 (B)에 대한 오프-타겟 동족체 결합 위험은 CD47-Fc 오솔로그상의 직접 ELISA 및 14 개의 인간 면역 글로불린 수퍼패밀리 단백질의 패널에 의해 시험되었다 (각 X-축에 표지되어 있는 "B"는 빈칸을 지칭함). 모든 단백질에 대한 결합은 10 μg/ml의 IgG 농도에서 수행되었다. 각 플롯에서 Y-축은 결합 신호 (OD 450nm)를 나타낸다. 두 IgG 모두에 대해, hCD47-Fc, mCD37-Fc 및 cCD47-Fc 단독에 대한 결합이 관찰되었다. 다른 인간 단백질에 대해서는 백그라운드 이상의 결합이 관찰되지 않았다.
도 14. 디자이너 클론 A-D5.4 및 A-D5.16에 대한 성장 위험 ELISA. 이 분석은 IgG1 널 형태의 A-D5.4 및 A-D5.16 항체가 음으로 하전된 생체 분자 인슐린 (A), 이중-가닥 DNA (dsDNA) (B) 및 단일-가닥 DNA (ssDNA) (C)에 낮은 (음성 대조군인 우스테키누맙 (Ustekinumab) 이하) 결합을 나타냄을 보여주었다. 각 그래프에서, X-축은 μg/ml의 IgG 농도를 나타내고 Y-축은 결합 신호 (OD 450 nm)를 나타낸다. 보코시주맙 및 브리아키누맙 유사체에 대해 관찰된 바와 같이, 이들 분자에 대한 강한 오프-타겟 결합은 치료용 항체의 임상 성능이 부실하다는 고위험 지표인 것으로 나타났다.
도 15. CHO-K1 세포에 대한 라이브러리-유래 및 디자이너 IgG의 유세포 분석 결합. 상업용 항-CD47 항체 MS1991, 인간 IgG1 및 IgG4 이소타입 대조군 (각각 "I IgG1"및 "I IgG4"로 표시됨) 및 IgG1 널 및 IgG 형태 둘다의 리드 IgG A-D5, A-D5.4 및 A-D5.16는 야생형 (즉, 형질 감염되지 않은) CHO-K1 세포에 대한 특이적 결합에 대해 시험되었다. IgG는 24-25,000 ng/ml 범위의 농도에서 시험되었다. 농도-의존적 결합은 IgG1 널 및 IgG4 형태 둘다에서 모 mVH/mVL 항체에 대해 관찰되었지만, 이소타입 대조군, MS1991 및 IgG A-D5, 두개의 IgG 형태에서의 A-D5.4 및 A-D5에 대해서는 결합이 약하거나 또는 전혀 관찰되지 않았다. 각 그래프에서, X-축은 ng/ml의 IgG 농도를 나타내고, Y-축은 MFI를 나타낸다.
도 16. 인간 HL60 세포에 대한 결합의 유세포 분석 시험. 상업용 항-CD47 항체 MS1991, 인간 IgG1 및 IgG4 이소타입 대조군 (각각 "I IgG1"및 "I IgG4"로 표시됨), IgG1 널 및 IgG4 (S228P) 형태의 리드 IgG가 HL60 세포에 대한 특이적 결합에 대해 시험되었다. IgG는 24-100000 ng/ml 범위의 농도에서 시험되었다. 이소타입 대조군 이외의 모든 클론에 대해 농도-의존적 결합이 관찰되었다. 각 그래프에서, X-축은 ng/ml의 IgG 농도를 나타내고, Y-축은 MFI를 나타낸다.
도 17. 리드 항체 v-도메인에서의 T 세포 에피토프 펩티드 함량. mVH/mVL, A-D5, A-D5.4 A-D5.16 및 A-D5.16-DI 항체의 v-도메인은 생식계 (GE), 고 친화성 외래 (HAF), 저 친화성 외래 (LAF) 및 TCED+ T 세포 수용체 에피토프의 존재하에 시험되었다. mVH/mVL의 VH 및 VL 도메인은 다수의 고위험 인간 T 세포 에피토프 및 적은 생식계 에피토프를 포함하는 것으로 밝혀졌다. 모든 리드 클론에서, 고위험 에피토프 함량은 현저히 감소되었고 생식계 에피토프 함량은 상당히 개선되었다.
도 18. 인간, 마우스 및 시노 CD47-Fc 단백질에 결합하는 A-D5.16 및 A-D5.16-DI 디자이너 IgG에 대한 직접 적정 ELISA. 인간 IgG1 널 형식의 키메라 항-CD47 (mVH/mVL), 디자이너 A-D5.16 및 A-D5.16-DI 클론은 인간 (A), 시노 (B) 및 마우스 (C) CD47-Fc 단백질에 대한 직접 결합 ELISA에서 적정되었다 (μg/ml으로). 모든 클론은 CD47의 모든 3 개 오솔로그에 대한 결합 활성을 나타냈다. 각 그래프에서, X-축은 ng/ml의 IgG의 농도를 나타내고, Y-축은 결합 신호 (OD 450 nm)를 나타낸다.
도 19. 디자이너 IgG에 대한 ELISA-기반 CD47-Fc-SIRPα 경쟁 분석. 플레이트-결합된 인간 SIRPα에 대한 인간 (A), 시노 (B) 및 마우스 (C) CD47-Fc 단백질에 대한 ELISA 결합 신호를 IgG1 널 형태의 적정된 경쟁자 디자이너 IgG의 존재하에, 음성 대조군으로서 이소타입 IgG1 및 IgG1 널 형태의 mVH/mVL을 양성 대조군으로 하여 시험하였다. 각 그래프에서, X-축은 nM의 항체 농도를 나타내고, Y-축은 결합 신호 (OD 450 nm)를 나타낸다.
도 20. 유세포 분석 식세포 작용 분석. (A) 인간 CD14+ 대식세포에 의한 CSFE-표지된 HL60 세포의 식세포 작용의 유세포 분석을 IgG4 (S228P) 형태의 클론 A-D5, A-D5.4, A-D5.16 및 mVH/mVL 및 추가적으로 IgG1 널 형식의 A-D5 ("IgG1 A-D5N"으로 표시됨)에 대해 다중 농도로 수행하였다 (X-축에 나타낸 바와 같이). X-축은 항체 농도 (μg/ml)를 나타내고, Y-축은 CFSE+ 및 CD14+인 세포%를 나타낸다. (B) 이어서 분석을 표준 농도 10 μg/ml에서 IgG4 형태의 A-D5 및 mVH/mVL에 대한 다수의 인간 대식세포 공여자에 걸쳐 반복하였다. X-축은 공여자 번호를 나타내고, Y-축은 CFSE+ 및 CD14+인 세포%를 나타낸다. "V"는 비히클을 나타낸다.








Claims (34)
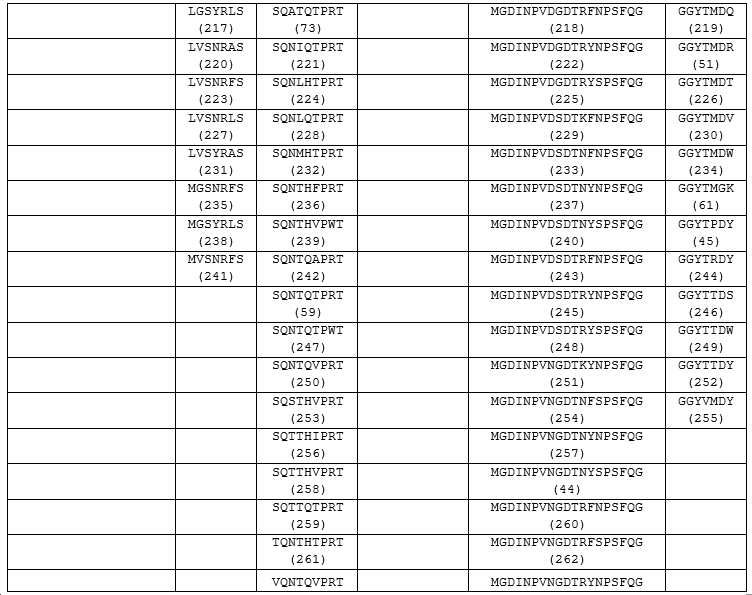
- 인간 CD47 및 시노몰구스 원숭이 CD47에 특이적으로 결합하고, 선택적으로 마우스 CD47 또는 이의 항원-결합 부분에 결합하는 항체 분자로서, 상기 항체 분자 또는 항원-결합 부분은 하기를 갖는 중쇄 가변 영역을 포함하는 것인, 항체 분자:
하기 순서로 아미노산 서열을 갖는 HCDR1 : G-S-G-Y-T/S-F-T-N-Y-Y (서열번호 30);
하기 순서로 아미노산 서열을 갖는 HCDR2: I-N-P-V-N/D-G-D-T-N/R-F/Y-N/S-P-S-F-Q-G (서열번호 31); 및
하기 순서로 아미노산 서열을 갖는 HCDR3: G-G-F/Y-T-M/P-D (서열번호 32). - 청구항 1에 있어서, 하기를 갖는 경쇄 가변 영역을 포함하는 것인, 항체 분자 또는 항원-결합 부분:
하기 순서로 아미노산 서열을 갖는 LCDR1: S-S-Q-S-L-L/V-H-S-N/Q/A-G-Y/N-N/T-Y (서열번호 41);
하기 순서로 아미노산 서열을 갖는 LCDR2: L/K-V/G-S-N/Y-R-A/F/L-S (서열번호 39); 및
하기 순서로 아미노산 서열을 갖는 LCDR3: Q/N/A-T/L-Q/H-T/V-P-R (서열번호 42). - 청구항 2에 있어서, 하기를 포함하는 것인, 항체 분자 또는 항원-결합 부분:
(a) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVNGDTNYSPSFQG (서열번호 87) (HCDR2), GGYTPD (서열번호 88) (HCDR3), SSQSLLHSNGYNY (서열번호 89) (LCDR1), KGSNRFS (서열번호 47) (LCDR2) 및 NLHVPR (서열번호 90) (LCDR3) [클론 D-H3]; 또는
(b) 아미노산 서열 GSGYTFTNYY (서열번호 15) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYTY (서열번호 92) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5]; 또는
(c) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVNGDTNFSPSFQG (서열번호 94) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLVHSNGYTY (서열번호 95) (LCDR1), KGSYRAS (서열번호 58) (LCDR2) 및 NTQTPR (서열번호 96) (LCDR3) [클론 G-B6]; 또는
(d) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVNGDTNYNPSFQG (서열번호 97) (HCDR2), GGYTMG (서열번호 98) (HCDR3), SSQSLVHSNGNTY (서열번호 19) (LCDR1), KGSYRFS (서열번호 63) (LCDR2) 및 ATHTPR (서열번호 99) (LCDR3) [클론 F-E7]; 또는
(e) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYSPSFQG (서열번호 100) (HCDR2), GGFTMD (서열번호 101) (HCDR3), SSQSLLHSNGYNY (서열번호 89) (LCDR1), KGSNRAS (서열번호 67) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 VH-A1/VL-B1]; 또는
(f) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYSPSFQG (서열번호 100) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYNY (서열번호 89) (LCDR1), LGSNRFS (서열번호 71) (LCDR2) 및 NTQTPR (서열번호 96) (LCDR3) [클론 MH]; 또는
(g) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYSPSFQG (서열번호 100) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYNY (서열번호 89) (LCDR1), LGSNRAS (서열번호 72) (LCDR2) 및 ATQTPR (서열번호 102) (LCDR3) [클론 TTP]; 또는
(h) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYTY (서열번호 92) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.1]; 또는
(i) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYNPSFQG (서열번호 103) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYTY (서열번호 92) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.2]; 또는
(j) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYSPSFQG (서열번호 100) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYTY (서열번호 92) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.3]; 또는
(k) 아미노산 서열 GSGYTFTNYY (서열번호 15) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYNY (서열번호 89) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.4]; 또는
(l) 아미노산 서열 GSGYTFTNYY (서열번호 15) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYNY (서열번호 89) (LCDR1), KGSNRLS (서열번호 75) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.5]; 또는
(m) 아미노산 서열 GSGYTFTNYY (서열번호 15) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYNY (서열번호 89) (LCDR1), KGSNRLS (서열번호 75) (LCDR2) 및 NTQTPR (서열번호 96) (LCDR3) [클론 A-D5.6]; 또는
(n) 아미노산 서열 GSGYTFTNYY (서열번호 15) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYNY (서열번호 89) (LCDR1), LGSNRLS (서열번호 77) (LCDR2) 및 NTQTPR (서열번호 96) (LCDR3) [클론 A-D5.7]; 또는
(o) 아미노산 서열 GSGYTFTNYY (서열번호 15) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSQGYTY (서열번호 104) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.8]; 또는
(p) 아미노산 서열 GSGYTFTNYY (서열번호 15) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYTY (서열번호 92) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 QTHTPR (서열번호 105) (LCDR3) [클론 A-D5.9]; 또는
(q) 아미노산 서열 GSGYTFTNYY (서열번호 15) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSQGYTY (서열번호 104) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 QTHTPR (서열번호 105) (LCDR3) [클론 A-D5.10]; 또는
(r) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYNY (서열번호 89) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.11]; 또는
(s) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYNPSFQG (서열번호 103) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYNY (서열번호 89) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.12]; 또는
(t) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYSPSFQG (서열번호 100) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYNY (서열번호 89) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.13]; 또는
(u) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYSPSFQG (서열번호 100) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSSGYNY (서열번호 106) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.14]; 또는
(v) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYSPSFQG (서열번호 100) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSGGYNY (서열번호 107) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.15]; 또는
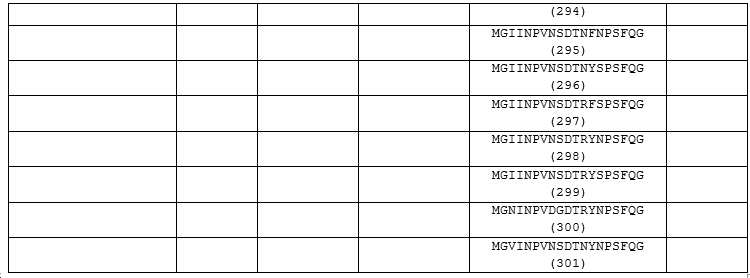
(w) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYSPSFQG (서열번호 100) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSAGYNY (서열번호 108) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.16]; 또는
(x) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYSPSFQG (서열번호 100) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSTGYNY (서열번호 109) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.17]; 또는
(y) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYSPSFQG (서열번호 100) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNAYNY (서열번호 110) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.18]; 또는
(z) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYSPSFQG (서열번호 100) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSAGYNY (서열번호 108) (LCDR1), KVSNRFS (서열번호 85) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.16-DI]; 또는
(z.1) 아미노산 서열 GSGYTFTNYY (서열번호 15) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYTY (서열번호 92) (LCDR1), KVSNRFS (서열번호 85) (LCDR2) 및 NTHTPR (서열번호 93) LCDR3) [클론 A-D5-DI]. - 청구항 1에 있어서,
아미노산 서열 GSGYTFTNYY (서열번호 15) 또는 GSGYSFTNYY (서열번호 86)를 갖는 HCDR1;
아미노산 서열 INPVDGDTNYNPSFQG (서열번호 91) 또는 INPVDGDTRYSPSFQG (서열번호 100)를 갖는 HCDR2; 및
아미노산 서열 GGYTMD (서열번호 16)를 갖는 HCDR3을 포함하고, 선택적으로 하기를 추가로 포함하는 것인 항체 분자 또는 항원-결합 부분:
아미노산 서열 SSQSLLHSNGYNY (서열번호 89) 또는 SSQSLLHSNGYTY (서열번호 92) 또는 SSQSLLHSAGYNY (서열번호 108)를 갖는 LCDR1;
아미노산 서열 KVSNRLS (서열번호 53) 또는 KVSNRFS (서열번호 85)를 갖는 LCDR2; 및
아미노산 서열 NTHTPR (서열번호 93)를 갖는 LCDR3. - 청구항 3 또는 4에 있어서, 하기를 포함하는 항체 분자 또는 항원-결합 부분:
(a) 아미노산 서열 GSGYTFTNYY (서열번호 15) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYTY (서열번호 92) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5]; 또는
(b) 아미노산 서열 GSGYTFTNYY (서열번호 15) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYNY (서열번호 89) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.4]; 또는
(c) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYSPSFQG (서열번호 100) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSAGYNY (서열번호 108) (LCDR1), KVSNRLS (서열번호 53) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.16]; 또는
(d) 아미노산 서열 GSGYSFTNYY (서열번호 86) (HCDR1), INPVDGDTRYSPSFQG (서열번호 100) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSAGYNY (서열번호 108) (LCDR1), KVSNRFS (서열번호 85) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5.16-DI]; 또는
(e) 아미노산 서열 GSGYTFTNYY (서열번호 15) (HCDR1), INPVDGDTNYNPSFQG (서열번호 91) (HCDR2), GGYTMD (서열번호 16) (HCDR3), SSQSLLHSNGYTY (서열번호 92) (LCDR1), KVSNRFS (서열번호 85) (LCDR2) 및 NTHTPR (서열번호 93) (LCDR3) [클론 A-D5-DI]. - 청구항 1 내지 5 중 어느 한 항에 있어서, 번역 후 변형 부위, 예를 들어 글리코실화 부위, 탈아미노화 부위, 인산화 부위 또는 이성질화/단편화 부위를 제거하는 하나 이상의 치환, 결실 또는 삽입을 포함하는 것인, 항체 분자 또는 항원-결합 부분.
- 청구항 1 내지 6 중 어느 한 항에 있어서, 인간, 인간화 또는 키메라인 것인, 항체 분자 또는 항원-결합 부분.
- 청구항 1 내지 7 중 어느 한 항에 있어서, 상기 CDRs이 삽입된 하나 이상의 인간 가변 도메인 프레임워크 스캐폴드를 포함하는 것인, 항체 분자 또는 항원-결합 부분.
- 청구항 1 내지 8 중 어느 한 항에 있어서, 상기 해당 HCDR 서열이 삽입된 IGHV5-51 인간 생식계 스캐폴드를 포함하는 것인, 항체 분자 또는 항원-결합 부분.
- 청구항 2 내지 9 중 어느 한 항에 있어서, 상기 해당 LCDR 서열이 삽입된 IGKV2-28 인간 생식계 스캐폴드를 포함하는 것인, 항체 분자 또는 항원-결합 부분.
- 청구항 1 내지 10 중 어느 한 항에 있어서, 면역학적으로 불활성인 불변 영역을 포함하는 것인, 항체 분자 또는 항원-결합 부분.
- 청구항 1 내지 11 중 어느 한 항에 있어서, Fab 단편, F(ab)2 단편, Fv 단편, 4량체 항체, 4가 항체, 다중 특이적 항체 (예를 들어, 2가 항체), 단일 도메인 항체 (예를 들어, VHH 또는 VNAR 또는 이의 단편), 단일 클론 항체 또는 융합 단백질인 것인, 항체 분자 또는 항원-결합 부분.
- 치료제에 연결된 청구항 1 내지 12 중 어느 한 항에 정의된 항체 분자 또는 이의 항원-결합 부분을 포함하는 것인, 면역 접합체.
- 청구항 1 내지 12 중 어느 한 항에 정의된 항체 분자 또는 이의 항원-결합 부분을 암호화하는, 핵산 분자.
- 청구항 14의 핵산 분자를 포함하는 벡터.
- 청구항 14에 정의된 핵산 분자 또는 청구항 15에 정의된 벡터를 포함하는 것인, 숙주 세포.
- 하기를 포함하는 항-CD47 항체 및/또는 이의 항원-결합 부분의 제조 방법:
항체 및/또는 이의 항원-결합 부분의 발현 및/또는 생성을 유발하는 조건 하에서 청구항 16에 정의된 바와 같은 숙주 세포를 배양하는 단계,및
숙주 세포 또는 배양물로부터 항체 및/또는 이의 항원-결합 부분을 분리하는 단계. - 청구항 1 내지 12 중 어느 한 항에 정의된 항체 분자 또는 이의 항원-결합 부분 또는 청구항 13에 정의된 면역 접합체 또는 청구항 14에 정의된 핵산 분자 또는 청구항 15에 정의된 벡터를 포함하는, 약학적 조성물.
- 유효량의 청구항 1 내지 12 중 어느 한 항에 정의된 항체 분자 또는 이의 항원-결합 부분, 또는 청구항 13에 정의된 면역 접합체 또는 청구항 14에 정의된 핵산 분자, 또는 청구항 15에 정의된 벡터, 또는 청구항 18에 정의된 약학적 조성물을 투여하는 단계를 포함하는, 개체에서의 면역 반응을 증진시키는 방법.
- 유효량의 청구항 1 내지 12 중 어느 한 항에 정의된 항체 분자 또는 이의 항원-결합 부분, 또는 청구항 13에 정의된 면역 접합체, 또는 청구항 14에 정의된 핵산 분자, 또는 청구항 15에 정의된 벡터, 또는 청구항 18에 정의된 약학적 조성물을 투여하는 단계를 포함하는 것인, 개체에서 암을 치료 또는 예방하는 방법.
- 청구항 20에 있어서, 상기 암은 췌장암, 흑색종, 유방암, 폐암, 기관지암, 결장 직장암, 전립선암, 위암, 난소암, 방광암, 뇌 또는 중추 신경계암, 말초 신경계암, 식도암, 자궁 경부암, 자궁암 또는 자궁 내막암, 구강암 또는 인두암, 간암, 신장암, 고환암, 담관암, 소장 또는 맹장암, 침샘암, 갑상선암, 부신암, 골육종, 연골육종 및 혈액학적 조직의 암으로 이루어진 군으로부터 선택된 것인, 방법.
- 암 치료에 사용하기 위한, 청구항 1 내지 12 중 어느 한 항에 정의된 항체 분자 또는 이의 항원-결합 부분, 또는 청구항 13에 정의된 면역 접합체, 또는 청구항 14에 정의된 핵산 분자, 또는 청구항 15에 정의된 벡터 또는 청구항 18에 정의된 약학적 조성물.
- 청구항 22, 또는 청구항 20 또는 21에 있어서, 상기 항체, 이의 항원-결합 부분, 면역 접합체, 핵산, 벡터 또는 약학적 조성물은 제 2 치료제, 예를 들어 항암제와 개별적으로, 순차적으로, 또는 동시에 조합하여 병용 사용을 위한 것인, 청구항 22에 따라 사용하기 위한 항체 분자 또는 이의 항원-결합 부분, 또는 면역 접합체, 또는 핵산 분자, 또는 벡터, 또는 청구항 20 또는 21에 따른 치료 방법.
- 암 치료용 의약의 제조에 있어서, 청구항 1 내지 12 중 어느 한 항에 정의된 항체 분자 또는 이의 항원-결합 부분, 또는 청구항 13에 정의된 면역 접합체, 또는 청구항 14에 정의된 핵산 분자, 또는 청구항 15에 정의된 벡터, 또는 청구항 18에 정의된 약학적 조성물의 용도.
- 유효량의 청구항 1 내지 12 중 어느 한 항에 정의된 항체 분자 또는 이의 항원-결합 부분, 또는 청구항 13에 정의된 면역 접합체, 또는 청구항 14에 정의된 핵산 분자, 또는 청구항 15에 정의된 벡터, 또는 청구항 18에 정의된 약학적 조성물을 투여하는 단계를 포함하는 것인, 객체에서 허혈-재관류 손상, 자가 면역 질환 또는 염증성 질환을 치료 또는 예방하는 방법.
- 청구항 25에 있어서, 상기 자가면역 질환 또는 염증성 질환은 관절염, 다발성 경화증, 건선, 크론병, 염증성 장 질환, 루푸스, 그레이브스병 (Grave's disease) 및 하시모토 갑상선염 (Hashimoto's thyroiditis) 및 강직성 척추염으로 이루어진 군으로부터 선택된 것인, 방법.
- 허혈-재관류 손상, 자가 면역 질환 또는 염증성 질환의 치료에 사용하기 위한 것인, 청구항 1 내지 12 중 어느 한 항에 정의된 항체 분자 또는 이의 항원-결합 부분, 또는 청구항 13에 정의된 면역 접합체, 또는 청구항 14에 정의된 핵산 분자, 또는 청구항 15에 정의된 벡터, 또는 청구항 18에 정의된 약학적 조성물.
- 허혈-재관류 손상, 자가 면역 질환 또는 염증성 질환의 치료를 위한 의약의 제조에 있어서, 청구항 1 내지 12 중 어느 한 항에 정의된 항체 분자 또는 이의 항원-결합 부분, 또는 청구항 13에 정의된 면역 접합체, 또는 청구항 14에 정의된 핵산 분자, 또는 청구항 15에 정의된 벡터, 또는 청구항 18에 정의된 약학적 조성물의 용도.
- 유효량의 청구항 1 내지 12 중 어느 한 항에 정의된 항체 분자 또는 이의 항원-결합 부분, 또는 청구항 13에 정의된 면역 접합체, 또는 청구항 14에 정의된 핵산 분자, 또는 청구항 15에 정의된 벡터, 또는 청구항 18에 정의된 약학적 조성물을 투여하는 단계를 포함하는 것인, 객체에서 심혈관 질환 (예를 들어, 관상 동맥 심장 질환 또는 죽상 동맥 경화증) 또는 섬유화 질환을 치료 또는 예방하는 방법.
- 청구항 29에 있어서, 상기 섬유화 질환은 심근 경색, 협심증, 골관절염, 폐 섬유증, 낭포성 섬유증, 기관지염 및 천식으로 이루어진 군으로부터 선택된 것인, 방법.
- 심혈관 질환 (예를 들어, 관상 동맥 심장 질환 또는 죽상 동맥 경화증) 또는 섬유화 질환의 치료에 사용하기 위한 것인, 청구항 1 내지 12 중 어느 한 항에 정의된 항체 분자 또는 이의 항원-결합 부분, 또는 청구항 13에 정의된 면역 접합체, 또는 청구항 14에 정의된 핵산 분자, 또는 청구항 15에 정의된 벡터, 또는 청구항 18에 정의된 약학적 조성물.
- 심혈관 질환 (예를 들어, 관상 동맥 심장 질환 또는 죽상 동맥 경화증) 또는 섬유화 질환의 치료를 위한 의약의 제조에서의, 청구항 1 내지 12 중 어느 한 항에 정의된 항체 분자 또는 이의 항원-결합 부분, 또는 청구항 13에 정의된 면역 접합체, 또는 청구항 14에 정의된 핵산 분자, 또는 청구항 15에 정의된 벡터, 또는 청구항 18에 정의된 약학적 조성물의 용도.
- 하기 단계를 포함하는 인간 CD47 및 시노몰구스 원숭이 CD47 및 선택적으로 마우스 CD47, 또는 이들의 항원-결합 부분에 특이적으로 결합하는 항체 분자를 제조하는 방법:
(1) 비-인간 공급원으로부터의 항-CD47 CDR을 인간 v-도메인 프레임워크에 이식하여 인간화된 항-CD47 항체 분자 또는 이의 항원-결합 부분을 생성하는 단계;
(2) CDR에서 하나 이상의 돌연변이를 포함하는 인간화된 항-CD47 항체 분자 또는 이의 항원-결합 부분의 클론의 파지 라이브러리를 생성하는 단계;
(3) 상기 파지 라이브러리를, 인간 CD47 및 시노몰구스 원숭이 CD47 및 선택적으로 마우스 CD47에 결합에 대해 스크리닝하는 단계;
(4) 스크리닝 단계 (3)으로부터, 인간 CD47 및 시노몰구스 원숭이 CD47 및 선택적으로 마우스 CD47에 대한 결합 특이성을 갖는 클론을 선별하는 단계; 및
(5) 단계 (4)에서 선별된 클론으로부터 인간 CD47 및 시노몰구스 원숭이 CD47 및 선택적으로 마우스 CD47 또는 이의 항원-결합 부분에 특이적으로 결합하는 항체 분자를 생성하는 단계. - 청구항 33에 있어서, 단계 (5)에서 생성된 항체 분자 또는 이의 항원-결합 부분에서 인간화를 향상시키고 및/또는 인간 T 세포 에피토프 함량을 최소화하고 및/또는 제조 특성을 향상시키기 위해, 단계 (4)에서 선별된 클론을 기초로, 예를 들어 단계 (4)에서 선택된 클론의 CDR의 특정 위치에서 추가 탐색 돌연변이 유발을 기초로 하여 추가적인 클론을 생성하는 추가적인 단계를 포함하는 것인, 방법.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GB1713298.6 | 2017-08-18 | ||
| GBGB1713298.6A GB201713298D0 (en) | 2017-08-18 | 2017-08-18 | Binding agents |
| GB1802595.7 | 2018-02-16 | ||
| GBGB1802595.7A GB201802595D0 (en) | 2018-02-16 | 2018-02-16 | Binding agents |
| GBGB1808570.4A GB201808570D0 (en) | 2018-05-24 | 2018-05-24 | Binding agents |
| GB1808570.4 | 2018-05-24 | ||
| PCT/GB2018/052347 WO2019034895A1 (en) | 2017-08-18 | 2018-08-17 | LIAISON AGENTS |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20200038533A true KR20200038533A (ko) | 2020-04-13 |
| KR102781208B1 KR102781208B1 (ko) | 2025-03-17 |
Family
ID=63371721
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020207007972A Active KR102781208B1 (ko) | 2017-08-18 | 2018-08-17 | 결합제 |
Country Status (14)
| Country | Link |
|---|---|
| US (4) | US10683350B2 (ko) |
| EP (2) | EP3668897B1 (ko) |
| JP (3) | JP7256580B2 (ko) |
| KR (1) | KR102781208B1 (ko) |
| CN (1) | CN111212852A (ko) |
| AU (2) | AU2018316742B2 (ko) |
| BR (1) | BR112020003306A2 (ko) |
| CA (1) | CA3072998A1 (ko) |
| ES (1) | ES2983651T3 (ko) |
| IL (1) | IL272643A (ko) |
| MX (1) | MX2020001873A (ko) |
| RU (1) | RU2020109544A (ko) |
| SG (1) | SG11202001425TA (ko) |
| WO (1) | WO2019034895A1 (ko) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022124764A1 (ko) * | 2020-12-07 | 2022-06-16 | (주)이노베이션바이오 | Cd47에 특이적인 항체 및 이의 용도 |
| WO2023277281A1 (ko) * | 2021-06-30 | 2023-01-05 | (주)이노베이션바이오 | Cd47에 특이적인 인간화 항체 및 이를 포함하는 cd47 관련 질환의 예방 또는 치료용 약학적 조성물 |
| WO2023191117A1 (ko) * | 2022-03-28 | 2023-10-05 | (주)이노베이션바이오 | 친화도가 성숙된 cd47에 특이적인 인간화 항체 |
Families Citing this family (50)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111212852A (zh) | 2017-08-18 | 2020-05-29 | 超人肆有限公司 | 结合剂 |
| GB201804860D0 (en) | 2018-03-27 | 2018-05-09 | Ultrahuman Two Ltd | CD47 Binding agents |
| GB201906685D0 (en) | 2019-05-13 | 2019-06-26 | Ultrahuman Six Ltd | Activatable protein constructs and uses thereof |
| PH12021553197A1 (en) | 2019-06-19 | 2022-11-07 | Lepu Biopharma Co Ltd | Anti-cd47 antibodies and uses thereof |
| KR20240137107A (ko) | 2019-07-16 | 2024-09-19 | 길리애드 사이언시즈, 인코포레이티드 | Hiv 백신, 및 이의 제조 및 사용 방법 |
| JP2022548310A (ja) * | 2019-09-23 | 2022-11-17 | シートムエックス セラピューティクス,インコーポレイテッド | 抗cd47抗体、活性化可能抗cd47抗体、およびその使用方法 |
| ES2973832T3 (es) | 2019-10-18 | 2024-06-24 | Forty Seven Inc | Terapias combinadas para el tratamiento de síndromes mielodisplásicos y leucemia mieloide aguda |
| JP2022552748A (ja) | 2019-10-31 | 2022-12-19 | フォーティ セブン, インコーポレイテッド | 抗cd47及び抗cd20による血液癌の治療 |
| IL294032A (en) | 2019-12-24 | 2022-08-01 | Carna Biosciences Inc | Compounds that regulate diacylglycerol kinase |
| WO2021142331A1 (en) * | 2020-01-10 | 2021-07-15 | Dyne Therapeutics, Inc. | Muscle targeting complexes and uses thereof for modulation of genes associated with cardiac muscle disease |
| WO2021142269A1 (en) * | 2020-01-10 | 2021-07-15 | Dyne Therapeutics, Inc. | Muscle targeting complexes and uses thereof for modulation of genes associated with muscle atrophy |
| TWI890283B (zh) | 2020-02-14 | 2025-07-11 | 美商基利科學股份有限公司 | 結合ccr8之抗體及融合蛋白及其用途 |
| CN115916963A (zh) | 2020-03-27 | 2023-04-04 | 门德斯有限公司 | 白血病来源的经修饰细胞用于增强过继性细胞治疗的效力的离体用途 |
| EP4171617A1 (en) | 2020-06-30 | 2023-05-03 | Mendus B.V. | Use of leukemia-derived cells in ovarian cancer vaccines |
| CN111733162A (zh) * | 2020-07-01 | 2020-10-02 | 江苏莱森生物科技研究院有限公司 | 一种经基因修饰的cd47蛋白及其单克隆抗体和应用 |
| WO2022007947A1 (zh) * | 2020-07-10 | 2022-01-13 | 信达生物制药(苏州)有限公司 | 抗cd47抗体或其抗原结合片段和dna甲基化转移酶抑制剂的组合及其用途 |
| US12071481B2 (en) | 2020-12-23 | 2024-08-27 | D-10 Therapeutics, Inc. | Anti-CD47 antibodies and uses thereof |
| CA3212351A1 (en) | 2021-03-12 | 2022-09-15 | Mendus B.V. | Methods of vaccination and use of cd47 blockade |
| CN112794903B (zh) * | 2021-04-14 | 2021-06-25 | 广州市雷德生物科技有限公司 | 一种特异性结合IFN-γ的抗体及其应用 |
| TW202302145A (zh) | 2021-04-14 | 2023-01-16 | 美商基利科學股份有限公司 | CD47/SIRPα結合及NEDD8活化酶E1調節次單元之共抑制以用於治療癌症 |
| AU2022299051B2 (en) | 2021-06-23 | 2025-03-13 | Gilead Sciences, Inc. | Diacylglyercol kinase modulating compounds |
| JP7686091B2 (ja) | 2021-06-23 | 2025-05-30 | ギリアード サイエンシーズ, インコーポレイテッド | ジアシルグリセロールキナーゼ調節化合物 |
| JP7651018B2 (ja) | 2021-06-23 | 2025-03-25 | ギリアード サイエンシーズ, インコーポレイテッド | ジアシルグリセロールキナーゼ調節化合物 |
| MX2023014762A (es) | 2021-06-23 | 2024-01-15 | Gilead Sciences Inc | Compuestos moduladores de diacilglicerol quinasa. |
| WO2023070353A1 (en) * | 2021-10-27 | 2023-05-04 | Adagene Pte. Ltd. | Anti-cd47 antibodies and methods of use thereof |
| AU2022375782B2 (en) | 2021-10-28 | 2026-02-26 | Gilead Sciences, Inc. | Pyridizin-3(2h)-one derivatives |
| JP7787991B2 (ja) | 2021-10-29 | 2025-12-17 | ギリアード サイエンシーズ, インコーポレイテッド | Cd73化合物 |
| US12122764B2 (en) | 2021-12-22 | 2024-10-22 | Gilead Sciences, Inc. | IKAROS zinc finger family degraders and uses thereof |
| KR20240123836A (ko) | 2021-12-22 | 2024-08-14 | 길리애드 사이언시즈, 인코포레이티드 | 이카로스 아연 핑거 패밀리 분해제 및 이의 용도 |
| TW202340168A (zh) | 2022-01-28 | 2023-10-16 | 美商基利科學股份有限公司 | Parp7抑制劑 |
| CA3251615A1 (en) | 2022-01-31 | 2023-08-03 | Centessa Pharmaceuticals (Uk) Limited | Activable Bispecific Anti-CD47 and Anti-PD-L1 Proteins and Their Uses |
| WO2023178181A1 (en) | 2022-03-17 | 2023-09-21 | Gilead Sciences, Inc. | Ikaros zinc finger family degraders and uses thereof |
| KR20240165995A (ko) | 2022-03-24 | 2024-11-25 | 길리애드 사이언시즈, 인코포레이티드 | Trop-2 발현 암의 치료를 위한 병용요법 |
| TWI876305B (zh) | 2022-04-05 | 2025-03-11 | 美商基利科學股份有限公司 | 用於治療結腸直腸癌之組合療法 |
| CR20240451A (es) | 2022-04-21 | 2024-12-04 | Gilead Sciences Inc | Compuestos de modulación de kras g12d |
| KR20250028371A (ko) | 2022-07-01 | 2025-02-28 | 길리애드 사이언시즈, 인코포레이티드 | Cd73 화합물 |
| CA3259040A1 (en) | 2022-07-12 | 2024-01-18 | Gilead Sciences, Inc. | HIV Immunogenic Polypeptides and Vaccines and Their Uses |
| WO2024064668A1 (en) | 2022-09-21 | 2024-03-28 | Gilead Sciences, Inc. | FOCAL IONIZING RADIATION AND CD47/SIRPα DISRUPTION ANTICANCER COMBINATION THERAPY |
| AU2023409398A1 (en) | 2022-12-22 | 2025-06-05 | Gilead Sciences, Inc. | Prmt5 inhibitors and uses thereof |
| AU2024252725A1 (en) | 2023-04-11 | 2025-11-06 | Gilead Sciences, Inc. | Kras modulating compounds |
| CR20250446A (es) | 2023-04-21 | 2025-12-02 | Gilead Sciences Inc | Inhibidores de prmt5 y usos de los mismos |
| AU2024306338A1 (en) | 2023-06-30 | 2026-01-08 | Gilead Sciences, Inc. | Kras modulating compounds |
| CN121620513A (zh) | 2023-07-26 | 2026-03-06 | 吉利德科学公司 | Parp7抑制剂 |
| KR20260046403A (ko) | 2023-07-26 | 2026-04-07 | 길리애드 사이언시즈, 인코포레이티드 | Parp7 저해제 |
| US20250109147A1 (en) | 2023-09-08 | 2025-04-03 | Gilead Sciences, Inc. | Kras g12d modulating compounds |
| US20250101042A1 (en) | 2023-09-08 | 2025-03-27 | Gilead Sciences, Inc. | Kras g12d modulating compounds |
| US20250154172A1 (en) | 2023-11-03 | 2025-05-15 | Gilead Sciences, Inc. | Prmt5 inhibitors and uses thereof |
| WO2025137640A1 (en) | 2023-12-22 | 2025-06-26 | Gilead Sciences, Inc. | Azaspiro wrn inhibitors |
| WO2025245003A1 (en) | 2024-05-21 | 2025-11-27 | Gilead Sciences, Inc. | Prmt5 inhibitors and uses thereof |
| US20260098049A1 (en) | 2024-08-12 | 2026-04-09 | Gilead Sciences, Inc. | Kras modulating compounds |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20060121150A (ko) * | 2003-11-11 | 2006-11-28 | 추가이 세이야쿠 가부시키가이샤 | 인간화 항-cd47 항체 |
| WO2014093678A2 (en) * | 2012-12-12 | 2014-06-19 | Frazier William A | Therapeutic cd47 antibodies |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE102007001370A1 (de) * | 2007-01-09 | 2008-07-10 | Curevac Gmbh | RNA-kodierte Antikörper |
| CN101231382B (zh) | 2008-02-26 | 2010-09-01 | 上海激光等离子体研究所 | 用于啁啾脉冲放大的光谱调制整形装置 |
| PT2569013T (pt) | 2010-05-14 | 2017-02-08 | Univ Leland Stanford Junior | Anticorpos monoclonais humanizados e quiméricos para cd47 |
| KR102100388B1 (ko) * | 2012-02-06 | 2020-04-13 | 인히브릭스, 인크. | Cd47 항체 및 그 사용 방법 |
| US20140140989A1 (en) | 2012-02-06 | 2014-05-22 | Inhibrx Llc | Non-Platelet Depleting and Non-Red Blood Cell Depleting CD47 Antibodies and Methods of Use Thereof |
| US9221908B2 (en) * | 2012-12-12 | 2015-12-29 | Vasculox, Inc. | Therapeutic CD47 antibodies |
| EP3221358B1 (en) * | 2014-11-18 | 2021-07-21 | Janssen Pharmaceutica, N.V. | Cd47 antibodies, methods, and uses |
| MX391051B (es) * | 2014-12-30 | 2025-03-21 | Celgene Corp | Anticuerpos anti-cd47 y usos de los mismos. |
| US10647756B2 (en) * | 2015-05-18 | 2020-05-12 | Pfizer Inc. | Humanized antibodies |
| RU2748401C2 (ru) * | 2015-09-18 | 2021-05-25 | Арч Онколоджи, Инк. | Терапевтические антитела к CD47 |
| PT3402820T (pt) * | 2016-01-11 | 2020-08-20 | Forty Seven Inc | Anticorpos monoclonais anti-cd47 quiméricos, de ratinho ou humanizados |
| CN111212852A (zh) | 2017-08-18 | 2020-05-29 | 超人肆有限公司 | 结合剂 |
| GB201804860D0 (en) | 2018-03-27 | 2018-05-09 | Ultrahuman Two Ltd | CD47 Binding agents |
-
2018
- 2018-08-17 CN CN201880066662.5A patent/CN111212852A/zh active Pending
- 2018-08-17 CA CA3072998A patent/CA3072998A1/en active Pending
- 2018-08-17 WO PCT/GB2018/052347 patent/WO2019034895A1/en not_active Ceased
- 2018-08-17 BR BR112020003306-5A patent/BR112020003306A2/pt unknown
- 2018-08-17 SG SG11202001425TA patent/SG11202001425TA/en unknown
- 2018-08-17 ES ES18759711T patent/ES2983651T3/es active Active
- 2018-08-17 RU RU2020109544A patent/RU2020109544A/ru unknown
- 2018-08-17 MX MX2020001873A patent/MX2020001873A/es unknown
- 2018-08-17 AU AU2018316742A patent/AU2018316742B2/en active Active
- 2018-08-17 JP JP2020530735A patent/JP7256580B2/ja active Active
- 2018-08-17 KR KR1020207007972A patent/KR102781208B1/ko active Active
- 2018-08-17 EP EP18759711.7A patent/EP3668897B1/en active Active
- 2018-08-17 EP EP24179206.8A patent/EP4435008A2/en not_active Withdrawn
-
2019
- 2019-08-19 US US16/543,884 patent/US10683350B2/en active Active
-
2020
- 2020-02-12 IL IL272643A patent/IL272643A/en unknown
- 2020-05-19 US US16/877,938 patent/US11370840B2/en active Active
-
2022
- 2022-06-24 US US17/849,101 patent/US20220332819A1/en not_active Abandoned
-
2023
- 2023-03-27 JP JP2023049983A patent/JP7564274B2/ja active Active
-
2024
- 2024-09-23 US US18/893,023 patent/US20250109202A1/en active Pending
- 2024-09-26 JP JP2024167571A patent/JP7825015B2/ja active Active
-
2025
- 2025-06-26 AU AU2025204808A patent/AU2025204808A1/en active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20060121150A (ko) * | 2003-11-11 | 2006-11-28 | 추가이 세이야쿠 가부시키가이샤 | 인간화 항-cd47 항체 |
| WO2014093678A2 (en) * | 2012-12-12 | 2014-06-19 | Frazier William A | Therapeutic cd47 antibodies |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022124764A1 (ko) * | 2020-12-07 | 2022-06-16 | (주)이노베이션바이오 | Cd47에 특이적인 항체 및 이의 용도 |
| WO2023277281A1 (ko) * | 2021-06-30 | 2023-01-05 | (주)이노베이션바이오 | Cd47에 특이적인 인간화 항체 및 이를 포함하는 cd47 관련 질환의 예방 또는 치료용 약학적 조성물 |
| WO2023191117A1 (ko) * | 2022-03-28 | 2023-10-05 | (주)이노베이션바이오 | 친화도가 성숙된 cd47에 특이적인 인간화 항체 |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2018316742B2 (en) | 2025-04-10 |
| MX2020001873A (es) | 2020-10-22 |
| US20200277375A1 (en) | 2020-09-03 |
| JP7825015B2 (ja) | 2026-03-05 |
| EP3668897B1 (en) | 2024-06-05 |
| AU2025204808A1 (en) | 2025-07-17 |
| BR112020003306A2 (pt) | 2020-08-25 |
| CA3072998A1 (en) | 2019-02-21 |
| JP7256580B2 (ja) | 2023-04-12 |
| JP2023073339A (ja) | 2023-05-25 |
| JP2025000787A (ja) | 2025-01-07 |
| ES2983651T3 (es) | 2024-10-24 |
| SG11202001425TA (en) | 2020-03-30 |
| AU2018316742A1 (en) | 2020-03-19 |
| JP7564274B2 (ja) | 2024-10-08 |
| US10683350B2 (en) | 2020-06-16 |
| IL272643A (en) | 2020-03-31 |
| EP4435008A2 (en) | 2024-09-25 |
| EP3668897A1 (en) | 2020-06-24 |
| KR102781208B1 (ko) | 2025-03-17 |
| US11370840B2 (en) | 2022-06-28 |
| RU2020109544A (ru) | 2021-09-20 |
| US20190375840A1 (en) | 2019-12-12 |
| WO2019034895A1 (en) | 2019-02-21 |
| US20220332819A1 (en) | 2022-10-20 |
| JP2020531048A (ja) | 2020-11-05 |
| US20250109202A1 (en) | 2025-04-03 |
| CN111212852A (zh) | 2020-05-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7564274B2 (ja) | 結合剤 | |
| KR102929571B1 (ko) | Cd47 결합제 | |
| US11851460B2 (en) | PD1 binding agents | |
| JP7169296B2 (ja) | 結合剤 | |
| US12415861B2 (en) | Anti C-MET antibodies | |
| CN114981301B (zh) | Pd1和vegfr2双结合剂 | |
| HK40116834A (en) | Binding agents | |
| AU2026202717A1 (en) | Anti c-met antibodies | |
| HK40028664A (en) | Binding agents | |
| HK40028664B (en) | Binding agents |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20200318 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| A201 | Request for examination | ||
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20210813 Comment text: Request for Examination of Application |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20240329 Patent event code: PE09021S01D |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
Patent event code: PE07011S01D Comment text: Decision to Grant Registration Patent event date: 20241209 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
Comment text: Registration of Establishment Patent event date: 20250310 Patent event code: PR07011E01D |
|
| PR1002 | Payment of registration fee |
Payment date: 20250311 End annual number: 3 Start annual number: 1 |
|
| PG1601 | Publication of registration |