ES2702053T3 - Composiciones terapéuticas de nucleasas y métodos - Google Patents
Composiciones terapéuticas de nucleasas y métodos Download PDFInfo
- Publication number
- ES2702053T3 ES2702053T3 ES16198956T ES16198956T ES2702053T3 ES 2702053 T3 ES2702053 T3 ES 2702053T3 ES 16198956 T ES16198956 T ES 16198956T ES 16198956 T ES16198956 T ES 16198956T ES 2702053 T3 ES2702053 T3 ES 2702053T3
- Authority
- ES
- Spain
- Prior art keywords
- domain
- polypeptide
- linker
- hybrid nuclease
- rnase
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases [RNase]; Deoxyribonucleases [DNase]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
- A61K31/713—Double-stranded nucleic acids or oligonucleotides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/43—Enzymes; Proenzymes; Derivatives thereof
- A61K38/46—Hydrolases (3)
- A61K38/465—Hydrolases (3) acting on ester bonds (3.1), e.g. lipases, ribonucleases
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/04—Drugs for disorders of the alimentary tract or the digestive system for ulcers, gastritis or reflux esophagitis, e.g. antacids, inhibitors of acid secretion, mucosal protectants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/16—Drugs for disorders of the alimentary tract or the digestive system for liver or gallbladder disorders, e.g. hepatoprotective agents, cholagogues, litholytics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/12—Drugs for disorders of the urinary system of the kidneys
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P15/00—Drugs for genital or sexual disorders; Contraceptives
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P15/00—Drugs for genital or sexual disorders; Contraceptives
- A61P15/08—Drugs for genital or sexual disorders; Contraceptives for gonadal disorders or for enhancing fertility, e.g. inducers of ovulation or of spermatogenesis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P15/00—Drugs for genital or sexual disorders; Contraceptives
- A61P15/10—Drugs for genital or sexual disorders; Contraceptives for impotence
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P15/00—Drugs for genital or sexual disorders; Contraceptives
- A61P15/12—Drugs for genital or sexual disorders; Contraceptives for climacteric disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/02—Drugs for skeletal disorders for joint disorders, e.g. arthritis, arthrosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/08—Drugs for skeletal disorders for bone diseases, e.g. rachitism, Paget's disease
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P21/00—Drugs for disorders of the muscular or neuromuscular system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P21/00—Drugs for disorders of the muscular or neuromuscular system
- A61P21/04—Drugs for disorders of the muscular or neuromuscular system for myasthenia gravis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P27/00—Drugs for disorders of the senses
- A61P27/02—Ophthalmic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
- A61P3/10—Drugs for disorders of the metabolism for glucose homeostasis for hyperglycaemia, e.g. antidiabetics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/06—Immunosuppressants, e.g. drugs for graft rejection
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P5/00—Drugs for disorders of the endocrine system
- A61P5/14—Drugs for disorders of the endocrine system of the thyroid hormones, e.g. T3, T4
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P7/00—Drugs for disorders of the blood or the extracellular fluid
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P7/00—Drugs for disorders of the blood or the extracellular fluid
- A61P7/06—Antianaemics
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N11/00—Carrier-bound or immobilised enzymes; Carrier-bound or immobilised microbial cells; Preparation thereof
- C12N11/02—Enzymes or microbial cells immobilised on or in an organic carrier
- C12N11/06—Enzymes or microbial cells immobilised on or in an organic carrier attached to the carrier via a bridging agent
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/96—Stabilising an enzyme by forming an adduct or a composition; Forming enzyme conjugates
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y301/00—Hydrolases acting on ester bonds (3.1)
- C12Y301/27—Endoribonucleases producing 3'-phosphomonoesters (3.1.27)
- C12Y301/27005—Pancreatic ribonuclease (3.1.27.5)
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02P—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN THE PRODUCTION OR PROCESSING OF GOODS
- Y02P20/00—Technologies relating to chemical industry
- Y02P20/50—Improvements relating to the production of bulk chemicals
- Y02P20/582—Recycling of unreacted starting or intermediate materials
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Pharmacology & Pharmacy (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Genetics & Genomics (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Immunology (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Microbiology (AREA)
- Endocrinology (AREA)
- Diabetes (AREA)
- Reproductive Health (AREA)
- Physical Education & Sports Medicine (AREA)
- Orthopedic Medicine & Surgery (AREA)
- Neurology (AREA)
- Rheumatology (AREA)
- Hematology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Gynecology & Obstetrics (AREA)
- Biophysics (AREA)
- Epidemiology (AREA)
- Gastroenterology & Hepatology (AREA)
- Obesity (AREA)
- Emergency Medicine (AREA)
Abstract
Un polipéptido que comprende una RNasa, una DNasa y un dominio Fc variante, en el que la RNasa se acopla operativamente, opcionalmente con un enlazador, al dominio Fc variante, y en el que la DNasa se acopla operativamente, opcionalmente con un enlazador, al dominio Fc variante, en el que el dominio Fc variante es un dominio Fc de IgG1 humana variante que comprende una sustitución de aminoácidos que disminuye la unión, en comparación con el tipo natural, a un receptor Fcγ o a una proteína complemento o los dos, en el que el polipéptido tiene una función efectora reducida opcionalmente seleccionada del grupo que consiste en opsonización, fagocitosis, citotoxicidad dependiente del complemento y citotoxicidad celular dependiente de un anticuerpo.
Description
DESCRIPCIÓN
Composiciones terapéuticas de nucleasas y métodos
Referencia cruzada a solicitudes relacionadas
Esta solicitud reclama el beneficio de la Solicitud Provisional de EE. UU. N.° 61/257.458, presentada el 2 de noviembre de 2009 y la Solicitud Provisional de EE. UU. N.° 61/370.752, presentada el 4 de agosto de 2010.
Declaración respecto a la investigación o desarrollo con fondos federales
La presente invención se realizó con el apoyo de los Institutos Nacionales de Salud (subvenciones AI44257, NS065933 y AR048796), la Alianza para la Investigación del Lupus y el Fondo para el Descubrimiento de Ciencias Biológicas del Estado de Washington (2087750). El gobierno tiene ciertos derechos en la invención.
Referencia a una lista de secuencias
Esta solicitud incluye una Lista de secuencias enviada por vía electrónica como un archivo de texto de nombre XXXXXPCT_sequencelisting.txt, creado el mes XX de 20XX, con un tamaño de X bytes. La lista de secuencias se incorpora a modo de referencia.
Antecedentes
La liberación excesiva de partículas de (ribo)nucleoproteínas procedentes de células muertas y agonizantes puede causar la patología del lupus mediante dos mecanismos: (i) deposición o formación in situ de complejos de cromatina/anti-cromatina que causan nefritis y conducen a la pérdida de la función renal; y (ii) las nucleoproteínas activan la inmunidad innata a través del receptor de tipo toll (TLR) 7, 8 y 9, así como la vía o vías independientes de TLR. La liberación de nucleoproteínas puede servir como un antígeno potente para autoanticuerpos en el LES, proporcionando la amplificación de células B y la activación de DC a través del co-compromiso de receptores de antígeno y TLRs. De este modo, existe una necesidad de un medio para eliminar los antígenos que incitan y/o atenúan la estimulación inmunitaria, la amplificación inmunitaria, y la enfermedad mediada por complejos inmunitarios en sujetos en necesidad del mismo.
Resumen
La invención se expone en las reivindicaciones. En un aspecto, la invención proporciona un polipéptido que comprende una RNasa, una DNasa y un dominio Fc variante, en el que la RNasa se acopla operativamente, opcionalmente con un enlazador, al dominio Fc variante, y en el que la DNasa se acopla operativamente, opcionalmente con un enlazador, al dominio Fc variante, en el que el dominio Fc variante es un dominio Fc de IgG1 humana variante que comprende una sustitución de aminoácidos que disminuye la unión, en comparación con el tipo natural, a un receptor Fcy o a una proteína del complemento o los dos, en el que el polipéptido tiene una función efectora reducida seleccionada opcionalmente del grupo que consiste en opsonización, fagocitosis, citotoxicidad dependiente del complemento y citotoxicidad celular dependiente de un anticuerpo.
En otro aspecto, la invención proporciona una composición que comprende el polipéptido del primer aspecto y un portador farmacéuticamente aceptable.
Aspectos adicionales de la invención proporcionan un ácido nucleico que codifica el polipéptido del primer aspecto, un vector de expresión recombinante que codifica ese ácido nucleico y una célula huésped transformada con ese vector de expresión recombinante.
Otro aspecto de la invención proporciona un método de fabricación del polipéptido del primer aspecto, que comprende: proporcionar una célula huésped que comprende una secuencia de ácido nucleico que codifica el polipéptido; y mantener la célula huésped bajo condiciones en las que se expresa el polipéptido.
Un aspecto adicional de la invención proporciona el polipéptido del primer aspecto, para su uso en un método para tratar o prevenir una afección asociada con una respuesta inmunitaria anormal.
En la presente memoria se desvela una molécula de nucleasa híbrida que comprende un primer dominio nucleasa y un dominio Fc, en el que el primer dominio nucleasa se acopla operativamente al dominio Fc. En algunas realizaciones, la molécula de nucleasa híbrida incluye además un primer dominio enlazador, y el primer dominio nucleasa se acopla operativamente al dominio Fc por medio del primer dominio enlazador.
En algunas realizaciones, una molécula de nucleasa híbrida es un polipéptido, en el que la secuencia de aminoácidos del primer dominio nucleasa comprende una secuencia de aminoácidos de la RNasa de tipo natural humana, en el que el primer dominio enlazador es (Gly4Ser)n, en el que n es 0, 1, 2, 3, 4 o 5, en el que la secuencia
de aminoácidos del dominio Fc comprende una secuencia de aminoácidos del dominio Fc de IgG1 de tipo natural
humana, y en el que el primer dominio enlazador se acopla al extremo C-terminal del primer dominio nucleasa y al
extremo N-terminal del dominio Fc. En algunas realizaciones, una molécula de nucleasa híbrida es un polipéptido
que comprende o que consiste en una secuencia mostrada en la Tabla 2. En algunas realizaciones, una molécula de
nucleasa híbrida es un polipéptido que comprende la SEQ ID NO: 149. En algunas realizaciones, una molécula nucleasa híbrida es un polipéptido que comprende la SEQ ID NO: 145. En algunas realizaciones, una molécula nucleasa híbrida es un polipéptido que comprende la SEQ ID NO: 161. En algunas realizaciones, una molécula nucleasa híbrida es un polipéptido que comprende la SEQ ID NO: 162. En algunas realizaciones, una molécula nucleasa híbrida es un polipéptido que comprende la SEQ ID NO: 163.
En algunas realizaciones, una molécula de nucleasa híbrida comprende DNasa1 humana de tipo natural ligada con
IgG1 humana de tipo natural. En algunas realizaciones, una molécula de nucleasa híbrida comprende DNasa1
G105R A114F humana ligada a un dominio Fc de IgG1 humana de tipo natural por medio de un dominio enlazador
(gly4ser)n, en el que n = 0, 1, 2, 3, 4, o 5. En algunas realizaciones, una molécula de nucleasa híbrida comprende
RNasa1 humana de tipo natural ligada a IgG1 humana de tipo natural ligada a DNasa1 humana de tipo natural. En
algunas realizaciones, una molécula de nucleasa híbrida comprende RNasa1 humana de tipo natural ligada a IgG1
humana de tipo natural ligada a DNasa1 G105R A114F humana. En algunas realizaciones, una molécula de
nucleasa híbrida es un polipéptido, en el que la secuencia de aminoácidos del primer dominio nucleasa comprende
una secuencia de aminoácidos de RNasa, en el que el primer dominio enlazador comprende entre 5 y 32
aminoácidos de longitud, en el que la secuencia de aminoácidos del dominio Fc comprende una secuencia de
aminoácidos del dominio Fc humano, y en el que el primer dominio enlazador se acopla al extremo C-terminal del
primer dominio nucleasa y al extremo N-terminal del dominio Fc. En algunas realizaciones, el dominio enlazador
incluye (gly4ser)5 y sitios de restricción BglII, Agel, y XhoI. En algunas realizaciones, una molécula de nucleasa
híbrida es un polipéptido, en el que la secuencia de aminoácidos del primer dominio nucleasa comprende una
secuencia de aminoácidos de RNasa humana, en el que el primer dominio enlazador es un péptido NLG
comprendido entre 5 y 32 aminoácidos de longitud, en el que la secuencia de aminoácidos del dominio Fc
comprende una secuencia de aminoácidos del dominio Fc de tipo natural humana, y en el que el primer dominio
enlazador se acopla al extremo C-terminal del primer dominio nucleasa y al extremo N-terminal del dominio Fc.
En algunas realizaciones, el dominio Fc se une a un receptor de Fc en una célula humana. En algunas realizaciones,
la semivida en suero de la molécula es significativamente más larga que la semivida en suero de solo el primer
dominio nucleasa. En algunas realizaciones, la actividad de la nucleasa del primer dominio nucleasa de la molécula
es la misma o mayor que solo el dominio nucleasa. En algunas realizaciones, la administración de la molécula a un
ratón aumenta la tasa de supervivencia del ratón como se mide mediante un ensayo de modelo de ratón de lupus.
En algunas realizaciones, una molécula de nucleasa híbrida incluye una secuencia líder. En algunas realizaciones,
la secuencia líder es el péptido VK3LP humano procedente de la familia de la cadena ligera kappa humana, y la
secuencia líder se acopla al extremo N-terminal del primer dominio nucleasa.
En algunas realizaciones, la molécula es un polipéptido. En algunas realizaciones, la molécula es un polinucleótido.
En algunas realizaciones, el primer dominio nucleasa comprende una RNasa. En algunas realizaciones, la RNasa es
una RNasa humana. En algunas realizaciones, la RNasa es un polipéptido que comprende una secuencia de
aminoácidos al menos 90 % similar a una secuencia de aminoácidos de RNasa expuesta en la Tabla 2. En algunas
realizaciones, la RNasa es un miembro de la familia de la RNasa A humana. En algunas realizaciones, la RNasa es
una RNasa1 pancreática humana.
En algunas realizaciones, el primer dominio nucleasa comprende una DNasa. En algunas realizaciones, la DNasa es
una DNasa humana. En algunas realizaciones, la DNasa es un polipéptido que comprende una secuencia de
aminoácidos al menos 90 % similar a una secuencia de aminoácidos de DNasa expuesta en la Tabla 2. En algunas
realizaciones, la DNasa se selecciona del grupo que consiste en DNasa I humana, TREX1, y DNasa 1L3 humana.
En algunas realizaciones, el dominio Fc es un dominio Fc humano. En algunas realizaciones, el dominio Fc es un
dominio Fc de tipo natural. En algunas realizaciones, el dominio Fc es un dominio Fc mutante. En algunas
realizaciones, el dominio Fc es un dominio Fc de IgG1 humana. En algunas realizaciones, el dominio Fc es un
polipéptido que comprende una secuencia de aminoácidos al menos 90 % similar a una secuencia de aminoácidos
del dominio Fc expuesta en la Tabla 2.
En algunas realizaciones, el primer dominio enlazador tiene una longitud de aproximadamente 1 a aproximadamente
50 aminoácidos. En algunas realizaciones, el primer dominio enlazador tiene una longitud de aproximadamente 5 a
aproximadamente 31 aminoácidos. En algunas realizaciones, el primer dominio enlazador tiene una longitud de
aproximadamente 15 a aproximadamente 25 aminoácidos. En algunas realizaciones, el primer dominio enlazador
tiene una longitud de aproximadamente 20 a aproximadamente 32 aminoácidos. En algunas realizaciones, el primer
dominio enlazador tiene una longitud de aproximadamente 20 aminoácidos. En algunas realizaciones, el primer
dominio enlazador tiene una longitud de aproximadamente 25 aminoácidos. En algunas realizaciones, el primer
dominio enlazador tiene una longitud de aproximadamente 18 aminoácidos. En algunas realizaciones, el primer
dominio enlazador comprende un péptido gly/ser. En algunas realizaciones, el péptido gly/ser es de fórmula (Gly4Ser)n, en el que n es un número entero positivo seleccionado del grupo que consiste en 1, 2, 3, 4, 5, 6, 7, 8, 9, y 10. En algunas realizaciones, el péptido gly/ser incluye (Gly4Ser)3. En algunas realizaciones, el péptido gly/ser incluye (Gly4Ser)4. En algunas realizaciones, el péptido gly/ser incluye (Gly4Ser)5. En algunas realizaciones, el primer dominio enlazador incluye al menos un sitio de restricción. En algunas realizaciones, el primer dominio enlazador incluye aproximadamente 12 o más nucleótidos, incluyendo al menos un sitio de restricción. En algunas realizaciones, el primer dominio enlazador incluye dos o más sitios de restricción. En algunas realizaciones, el primer dominio enlazador incluye una pluralidad de sitios de restricción. En algunas realizaciones, el primer dominio enlazador comprende un péptido NLG. En algunas realizaciones, el primer dominio enlazador comprende un sitio de glicosilación ligado a N.
En algunas realizaciones, el primer dominio nucleasa se ligado al extremo N-terminal del dominio Fc. En algunas realizaciones, el primer dominio nucleasa se liga al extremo C-terminal del dominio Fc.
En algunas realizaciones, la molécula de nucleasa híbrida incluye además un segundo dominio nucleasa. En algunas realizaciones, el primer dominio nucleasa y el segundo dominio nucleasa son dominios nucleasa distintos. En algunas realizaciones, el primer dominio nucleasa y el segundo dominio nucleasa son los mismos dominios nucleasa. En algunas realizaciones, el segundo dominio nucleasa se liga al extremo C-terminal del dominio Fc. En algunas realizaciones, el segundo dominio nucleasa se liga al extremo N-terminal del dominio Fc. En algunas realizaciones, el segundo dominio nucleasa se liga al extremo C-terminal del primer dominio nucleasa. En algunas realizaciones, el segundo dominio nucleasa se liga al extremo N-terminal del primer dominio nucleasa.
Asimismo, se desvela en la presente memoria un polipéptido dimérico que comprende un primer polipéptido y un segundo polipéptido, en el que el primer polipéptido comprende un primer dominio nucleasa, y un dominio Fc, en el que el primer dominio nucleasa se acopla operativamente al dominio Fc. En algunas realizaciones, el segundo polipéptido es una segunda molécula de nucleasa híbrida que comprende un segundo dominio nucleasa, y un segundo dominio Fc, en el que el segundo dominio nucleasa se acopla operativamente al segundo dominio Fc. Asimismo, se desvela en la presente memoria una composición farmacéutica que comprende al menos una molécula de nucleasa híbrida y/o al menos un polipéptido dimérico como se describe en la presente memoria, y un excipiente farmacéuticamente aceptable.
Asimismo, se desvela en la presente memoria una molécula de ácido nucleico que codifica una molécula de nucleasa híbrida desvelada en la presente memoria. Asimismo, se desvela en la presente memoria un vector de expresión recombinante que comprende una molécula de ácido nucleico desvelada en la presente memoria. Asimismo, se describe en la presente memoria una célula huésped transformada con un vector de expresión recombinante desvelado en la presente memoria.
Asimismo, se desvela en la presente memoria un método de fabricación de una nucleasa híbrida desvelada en la presente memoria, que comprende: proporcionar una célula huésped que comprende una secuencia de ácido nucleico que codifica la molécula de nucleasa híbrida; y mantener la célula huésped bajo condiciones en las que se expresa la molécula de nucleasa híbrida.
Asimismo, se desvela en la presente memoria un método para tratar o prevenir una afección asociada con una respuesta inmunitaria anormal, que comprende administrar a un paciente en necesidad del mismo una cantidad eficaz de una molécula de nucleasa híbrida aislada desvelada en la presente memoria. En algunas realizaciones, la afección es una enfermedad autoinmunitaria. En algunas realizaciones, la enfermedad autoinmunitaria se selecciona del grupo que consiste en diabetes mellitus dependiente de insulina, esclerosis múltiple, encefalomielitis autoinmune experimental, artritis reumatoide, artritis autoinmune experimental, miastenia gravis, tiroiditis, una forma experimental de uveorretinitis, tiroiditis de Hashimoto, mixedema primario, tirotoxicosis, anemia perniciosa, gastritis atrófica autoinmune, enfermedad de Addison, menopausia prematura, infertilidad masculina, diabetes juvenil, síndrome de Goodpasture, pénfigo vulgar, penfigoide, oftalmía simpática, uveítis facogénica, anemia hemolítica autoinmune, leucopenia idiopática, cirrosis biliar primaria, hepatitis Hbs-ve crónica activa, cirrosis criptogénica, colitis ulcerosa, síndrome de Sjogren, esclerodermia, granulomatosis de Wegener, polimiositis, dermatomiositis, LE discoide, lupus eritematoso sistémico (LES), y enfermedad del tejido conectivo. En algunas realizaciones, la enfermedad autoinmunitaria es lupus eritematoso sistémico.
Breve descripción de las diversas vistas de los dibujos
Estas y otras características, aspectos y ventajas de la presente invención se entenderán mejor con respecto a la siguiente descripción y dibujos adjuntos, en los que:
La Figura (FIG.) 1 muestra la secuencia de nucleótidos y de aminoácidos de la mRNasa-mIgG2a con mutaciones en P238S, K322S, y P331S. Esta secuencia se enumera en el listado de secuencias como huVK3LP+mrib1+mIgG2A-C-2S (SEQ ID NO: 114).
La FIG. 2 muestra un diagrama esquemático de algunas realizaciones de moléculas de nucleasa híbridas descritas en la presente memoria.
La FIG. 3 muestra el análisis en gel de SDS-PAGE de mRNasa-mIgG2a-c en condiciones tanto reductoras como no reductoras.
La FIG. 4 muestra el análisis de inmunoprecipitación en gel de mRNasa-mIg2a-c.
La FIG. 5 muestra un título de ELISA para un anticuerpo anti-ARN antes y después de la inyección intravenosa de la molécula nucleasa híbrida RNasa-Ig procedente del ratón 410. Los datos muestran que la inyección de RNasa-Ig causó una reducción en el título del anticuerpo anti-ARN que persistió durante más de 3 semanas. La FIG. 6 muestra que la adición de RNasa-Ig abolió la inducción del interferón-a a partir de células mononucleares de sangre periférica humanas estimuladas utilizando complejos inmunitarios formados con suero de un paciente con SLE (J11) más extracto nuclear (EN). El título del anticuerpo anti-ARN se redujo después de la inyección de RNasa-Ig.
La FIG. 7 muestra que la adición de RNasa-Ig abolió la inducción del interferón-a a partir de células mononucleares de sangre periférica humanas estimuladas utilizando complejos inmunitarios formados con suero de un paciente con SLE (J11) más extracto nuclear.
La FIG. 8 muestra el análisis de difusión enzimática radial simple (DERS) de suero a partir de dos RNasas de ratones transgénicos (Tg) en comparación con un ratón B6 normal.
La FIG. 9 muestra la concentración de RNasaA en ratones Tg y ratones dobles Tg (DTg) medida por ELISA. Cada punto representa la concentración medida en un ratón individual.
La FIG. 10 muestra la supervivencia de ratones TLR7.1 Tg frente a ratones TLR7.1xRNasaA DTg.
La FIG.11 muestra la PCR cuantitativa de GRIs en bazos de ratones Tg frente a ratones DTg.
La FIG. 12 muestra una estructura de prototipo para la creación de diferentes realizaciones de moléculas de nucleasa híbridas.
La FIG. 13 muestra la cinética enzimática para las moléculas de nucleasa híbrida hRNasa1-G88D-hIgG1 SCCH-P238S-K322S-P331S como se mide utilizando el sustrato RNase Alert™.
La FIG. 14 muestra la unión de hRNasa1-TN-hlgG1-TN a las estirpes celulares monocíticas humanas U937 y THP1. El pico de la izquierda en ambos gráficos es el control y el pico de la derecha en ambos gráficos es hRNasa1-TN-hlgG1-TN.
La FIG. 15 muestra la actividad de bloqueo de la IgIV humana para la unión a células U937 y THP-1 por hRNasa1-TN-hlgG1-TN.
La FIG. 16 muestra los resultados de un ensayo de digestión de ADN por formas alternativas de Trex1-(g4s)nmIgG.
La FIG. 17 muestra los resultados de una membrana Western para los sobrenadantes del cultivo de trex1-(Gly4S)4-Ig y trex1-(Gly4S)5-Ig a partir de transfecciones transitorias de COS-7.
La FIG. 18 muestra patrones de digestión de ADN por diferentes clones CHO-DG44 transfectados de forma estable designados como 2A3, 3A5, y 8H8, que expresan moléculas de nucleasa híbridas ADNasa1L3-mIgG2ac.
La FIG. 19 muestra patrones de digestión de ADN de cantidades decrecientes de moléculas de nucleasa híbridas DNasa1L3-Ig después de varios tiempos de incubación con y sin heparina como inhibidor enzimático.
La FIG. 20 muestra una membrana de Western de proteínas de fusión immuneprecipitadas a partir de células COS transfectadas de forma transitoria que expresan diferentes realizaciones de moléculas de nucleasa híbridas hRNasa1-Ig-hDNasa1 o hDNasa1-Ig.
La FIG. 21 muestra el análisis DERS para evaluar la presencia de actividad de la RNasa en los sobrenadantes COS que expresan diferentes realizaciones de moléculas de nucleasa híbridas hRNasa1-Ig-hDNasa1 o hDNasa1-lg.
La FIG. 22 muestra una figura mixta que demuestra los resultados de los ensayos de actividad de la nucleasa DNasa realizados en sobrenadantes de COS de células transfectadas. La descripción de la numeración (p. ej., 090210-8 y 091210-8) de la FIG. 21 se aplica a esta figura también.
La FIG. 23 muestra la cinética enzimática ensayada utilizando el sustrato Rnase Alert (Ambion/IDT) y la fluorescencia se cuantificó con un lector de microplacas Spectramax M2. Los datos se analizaron utilizando el software Softmax Pro (Molecular Devices). Las velocidades de reacción en las diferentes concentraciones de sustrato se midieron y los datos se muestran como un gráfico de Lineweaver-Burk. El valor de Km aparente, corregido para el volumen es de 280 nM.
La FIG. 24 muestra los niveles de anticuerpos anti-ARN en sueros de ratón de ratones dobles transgénicos H564 y H564-RNasaA en intervalos sucesivos como el ratón transgénico de la misma edad.
Descripción detallada
Los términos utilizados en las reivindicaciones y en la memoria descriptiva se definen como se expone a continuación a menos que se especifique lo contrario. En caso de conflicto directo con un término utilizado en una solicitud de patente provisional principal, el término utilizado en la presente memoria descriptiva prevalecerá.
"Aminoácido" se refiere a aminoácidos de origen natural y sintéticos, así como análogos de aminoácidos y miméticos de aminoácidos que funcionan de una manera similar a los aminoácidos de origen natural. Los aminoácidos de origen natural son aquellos codificados por el código genético, así como aquellos aminoácidos que se modifican posteriormente, p. ej., hidroxiprolina, Y-carboxiglutamato, y O-fosfoserina. Los análogos de aminoácidos se refieren a
compuestos que tienen la misma estructura química básica que un aminoácido de origen natural, es decir, un carbono a que se une a un hidrógeno, un grupo carboxilo, un grupo amino, y un grupo R, p. ej., homoserina, norleucina, sulfóxido de metionina, metionina metil sulfonio. Dichos análogos tienen grupos R modificados (p. ej., norleucina) o esqueletos peptídicos modificados, pero retienen la misma estructura química básica que un aminoácido de origen natural. Miméticos de aminoácidos se refiere a compuestos químicos que tienen una estructura que es diferente de la estructura química general de un aminoácido, pero que funciona de una manera similar a un aminoácido de origen natural.
Los aminoácidos pueden ser referidos en la presente memoria por cualquiera de sus símbolos comúnmente conocidos de tres letras o por los símbolos de una letra recomendados por la Comisión de Nomenclatura Bioquímica IUPAC-IUB. Igualmente, los nucleótidos pueden referirse por sus códigos de una sola letra comúnmente aceptados.
Una "sustitución de aminoácidos" se refiere al reemplazo de al menos un residuo de aminoácidos existente en una secuencia de aminoácidos predeterminada (una secuencia de aminoácidos de un polipéptido de partida) con un segundo residuo de aminoácidos de "reemplazo" diferente. Una "inserción de aminoácidos" se refiere a la incorporación de al menos un aminoácido adicional en una secuencia de aminoácidos predeterminada. Si bien la inserción consistirá habitualmente en la inserción de uno o dos residuos de aminoácidos, pueden hacerse las presentes "inserciones peptídicas" más extensas, p. ej., por inserción de aproximadamente tres a aproximadamente cinco o incluso hasta aproximadamente diez, quince o veinte residuos de aminoácidos. El residuo o residuos insertados pueden ser de origen natural o de origen no natural, como se ha desvelado anteriormente. Una "deleción de aminoácidos" se refiere a la eliminación de al menos un residuo de aminoácidos de una secuencia de aminoácidos predeterminada.
"Polipéptido", "péptido" y "proteína" se utilizan indistintamente en la presente memoria para referirse a un polímero de residuos de aminoácidos. Los términos se aplican a polímeros de aminoácidos en los que uno o más residuos de aminoácidos es un mimético químico artificial de un correspondiente aminoácido de origen natural, así como a polímeros de aminoácidos de origen natural y a polímeros de aminoácidos de origen no natural.
"Ácido nucleico" se refiere a desoxirribonucleótidos o ribonucleótidos y polímeros de los mismos en forma monocatenaria o bicatenaria. A menos que se limite específicamente, el término abarca ácidos nucleicos que contienen análogos conocidos de nucleótidos naturales que tienen propiedades de unión similares al ácido nucleico de referencia y se metabolizan de una manera similar en los nucleótidos de origen natural. A menos que se indique lo contrario, una secuencia de ácidos nucleicos particular también abarca implícitamente variantes modificadas de manera conservadora de las mismas (p. ej., sustituciones de codones degenerados) y secuencias complementarias, así como la secuencia indicada explícitamente. Específicamente, puede conseguirse sustituciones de codones degenerados mediante la generación de secuencias en las que la tercera posición de uno o más codones seleccionados (o todos) se sustituye con residuos de base mixta y/o residuos de desoxiinosina (Batzer et al., Nucleic Acid Res. 19:5081, 1991; Ohtsuka et al., J. Biol. Chem. 260:2605-2608, 1985); y Cassol et al., 1992; Rossolini et al., Mol. Cell. Probes. 8:91-98, 1994). Para arginina y leucina, las modificaciones en la segunda base pueden también ser conservadoras. El término ácido nucleico se utiliza indistintamente con gen, ADNc y ARNm codificado por un gen.
Los polinucleótidos de la presente invención pueden estar compuestos de cualquier polirribonucleótido o polidesoxirribonucleótido, que puede ser ARN o ADN no modificado o ARN o ADN modificado. Por ejemplo, los polinucleótidos pueden estar compuestos de ADN monocatenario y bicatenario, el ADN es una mezcla de regiones monocatenarias y bicatenarias, ARN monocatenario y bicatenario, y el ARN es una mezcla de regiones monocatenarias y bicatenarias, moléculas híbridas que comprenden ADN y ARN que puede ser monocatenarias o, más normalmente, bicatenarias o una mezcla de regiones monocatenarias y bicatenarias. Además, el polinucleótido puede estar compuesto de regiones tricatenarias que comprenden ARN o ADN o ambos ARN y ADN. Un polinucleótido también puede contener una o más bases modificadas o esqueletos de ADN o ARN modificados para su estabilidad o por otros motivos. Las bases "modificadas" incluyen, por ejemplo, bases tritiladas y bases inusuales, tales como inosina. Una variedad de modificaciones puede realizarse en el ADN y ARN; de este modo, "polinucleótido" abarca formas modificadas química, enzimática o metabólicamente.
Como se utiliza en la presente memoria, la expresión "molécula de nucleasa híbrida" se refiere a polinucleótidos o polipéptidos que comprenden al menos un dominio nucleasa y al menos un dominio Fc. Las moléculas de nucleasa híbridas también se refieren como proteína o proteínas de fusión y gen o genes de fusión. Por ejemplo, en una realización, una molécula de nucleasa híbrida puede ser un polipéptido que comprende al menos un dominio Fc ligado a un dominio nucleasa, tal como DNasa y/o RNasa. Como otro ejemplo, una molécula de nucleasa híbrida puede incluir un dominio nucleasa de RNasa, un dominio enlazador y un dominio Fc. La SEQ ID NO: 161 es un ejemplo de una molécula de nucleasa híbrida. Otros ejemplos se describen con más detalle a continuación. En una realización, una molécula de nucleasa híbrida de la invención puede incluir modificaciones adicionales. En otra realización, una molécula de nucleasa híbrida puede modificarse para añadir un resto funcional (p. ej., PEG, un fármaco, o una etiqueta).
En ciertos aspectos, las moléculas de nucleasa híbridas de la invención pueden emplear uno o más "dominios enlazadores", tales como enlazadores polipeptídicos. Como se utiliza en la presente memoria, la expresión "dominio enlazador" se refiere a una secuencia que conecta dos o más dominios en una secuencia lineal. Como se utiliza en la presente memoria, el término "enlazador polipeptídico" se refiere a una secuencia peptídica o polipeptídica (p. ej., una secuencia peptídica o polipeptídica sintética) que conecta dos o más dominios en una secuencia lineal de aminoácidos de una cadena polipeptídica. Por ejemplo, enlazadores polipeptídicos pueden utilizarse para conectar un dominio nucleasa a un dominio Fc. Preferentemente, dichos enlazadores polipeptídicos pueden aportar flexibilidad a la molécula polipeptídica. En ciertas realizaciones, el enlazador polipeptídico se utiliza para conectar (p. ej., fundir genéticamente) uno o más dominios Fc y/o uno o más dominios nucleasa. Una molécula de nucleasa híbrida de la invención puede comprender más de un dominio enlazador o enlazador peptídico.
Como se utiliza en la presente memoria, la expresión "enlazador polipeptídico gly-ser" se refiere a un péptido que consiste en los residuos de glicina y serina. Un enlazador polipéptido gly/ser a modo de ejemplo comprende la secuencia de aminoácidos Ser(Gly4Ser)n. En una realización, n = 1. En una realización, n = 2. En otra realización, n = 3, es decir, Ser(Gly4Ser)3. En otra realización, n = 4, es decir, Ser(Gly4Ser)4. En otra realización, n = 5. En otra realización, n = 6. En otra realización, n = 7. En otra realización, n = 8. En otra realización, n = 9. En otra realización, n = 10. Otro enlazador polipéptido gly/ser a modo de ejemplo comprende la secuencia de aminoácidos Ser(Gly4Ser)n. En una realización, n = 1. En una realización, n = 2. En una realización preferente, n = 3. En otra realización, n = 4. En otra realización, n = 5. En otra realización, n = 6.
Como se utiliza en la presente memoria, los términos "ligado", "fusionado", o "fusión", se utilizan indistintamente. Estos términos se refieren a la combinación de dos o más elementos o componentes o dominios, por cualquier medio, incluyendo conjugación química o medios recombinantes. Los métodos de conjugación química (p. ej., utilizando agentes de reticulación heterobifuncionales) se conocen en la materia.
Como se utiliza en la presente memoria, la expresión "región Fc" se definirá como la porción de una inmunoglobulina nativa formada por los respectivos dominios Fc (o restos Fc) de sus dos cadenas pesadas.
Como se utiliza en la presente memoria, la expresión "dominio Fc" se refiere a una porción de una cadena pesada sencilla de inmunoglobulina (Ig). Como tal, el dominio Fc también puede referirse como "Ig" o "IgG." En algunas realizaciones, un dominio Fc comienza en la región bisagra justo aguas arriba del sitio de escisión de papaína y finaliza en el extremo C-terminal del anticuerpo. Por consiguiente, un dominio Fc completo comprende al menos un dominio bisagra, un dominio CH2 y un dominio CH3. En ciertas realizaciones, un dominio Fc comprende al menos uno de: un dominio bisagra (p. ej., región bisagra superior, intermedia, y/o inferior), un dominio CH2, un dominio CH3, un dominio CH4, o una variante, porción, o fragmento del mismo. En otras realizaciones, un dominio Fc comprende un dominio Fc completo (es decir, un dominio bisagra, un dominio CH2 y un dominio CH3). En una realización, un dominio Fc comprende un dominio bisagra (o porción del mismo) fusionado a un dominio CH3 (o porción del mismo). En otra realización, un dominio Fc comprende un dominio CH2 (o porción del mismo) fusionado a un dominio CH3 (o porción del mismo). En otra realización, un dominio Fc consiste en un dominio CH3 o porción del mismo. En otra realización, un dominio Fc consiste en un dominio bisagra (o porción del mismo) y un dominio CH3 (o porción del mismo). En otra realización, un dominio Fc consiste en un dominio CH2 (o porción del mismo) y un dominio CH3. En otra realización, un dominio Fc consiste en un dominio bisagra (o porción del mismo) y un dominio CH2 (o porción del mismo). En una realización, un dominio Fc carece de al menos una porción de un dominio CH2 (p. ej., la totalidad o parte de un dominio CH2). En una realización, un dominio Fc de la invención comprende al menos la porción de una molécula de Fc conocida en la materia que se requiere para la unión a FcRn. En otra realización, un dominio Fc de la invención comprende al menos la porción de una molécula de Fc conocida en la materia que se requiere para la unión a FcyR. En una realización, un dominio Fc de la invención comprende al menos la porción de una molécula de Fc conocida en la materia que se requiere para la unión a la proteína A. En una realización, un dominio Fc de la invención comprende al menos la porción de una molécula de Fc conocida en la materia que se requiere para la unión a la proteína G. Un dominio Fc se refiere en la presente memoria en general a un polipéptido que comprende la totalidad o parte del dominio Fc de una cadena pesada de inmunoglobulina. Esto incluye, entre otros, polipéptidos que comprenden todos los dominios completos CH1, bisagra, CH2, y/o CH3, así como fragmentos de dichos péptidos que comprenden solamente, p. ej., el dominio bisagra, CH2 y CH3. El dominio Fc puede derivarse a partir de una inmunoglobulina de cualquier especie y/o cualquier subtipo, incluyendo, entre otros, un anticuerpo IgGl, IgG2, IgG3, IgG4, IgD, IgA, IgE, o IgM humana. El dominio Fc abarca moléculas variantes de Fc y Fc nativas. Al igual que con las variantes de Fc y Fc nativos, la expresión dominio Fc incluye moléculas en forma monomérica o multimérica, si se digieren del anticuerpo completo o se producen por otros medios.
Como se expone en la presente memoria, un experto en la materia entenderá que cualquier dominio Fc puede ser modificado de forma tal que varía la secuencia de aminoácidos del dominio Fc nativo de una molécula de inmunoglobulina de origen natural. En ciertas realizaciones a modo de ejemplo, el dominio Fc retiene una función efectora (p. ej., unión a FcyR).
Los dominios Fc de un polipéptido de la invención pueden derivarse de diferentes moléculas de inmunoglobulina. Por ejemplo, un dominio Fc de un polipéptido puede comprender un dominio CH2 y/o CH3 derivado de una molécula de IgG1 y una región bisagra derivada de una molécula de IgG3. En otro ejemplo, un dominio Fc puede comprender
una región bisagra quimérica derivada, en parte, de una molécula de IgG1 y, en parte, de una molécula de IgG3. En otro ejemplo, un dominio Fc puede comprender una bisagra quimérica derivada, en parte, de una molécula de IgG1 y, en parte, de una molécula de IgG4.
Una secuencia de polipéptidos o aminoácidos "derivada de" un polipéptido o proteína designado se refiere al origen del polipéptido. Preferentemente, la secuencia de polipéptidos o aminoácidos que se deriva de una secuencia particular tiene una secuencia de aminoácidos que es esencialmente idéntica a la secuencia o una porción de la misma, en la que la porción consiste en al menos 10-20 aminoácidos, preferentemente al menos 20-30 aminoácidos, más preferentemente al menos 30-50 aminoácidos, o que es de otra manera identificable para un experto en la materia por tener su origen en la secuencia.
Los polipéptidos derivados de otro péptido pueden tener una o más mutaciones en relación con el polipéptido de partida, p. ej., uno o más residuos de aminoácidos que han sido sustituidos con otro residuo de aminoácidos o que tiene una o más inserciones o deleciones de residuos de aminoácidos.
Un polipéptido puede comprender una secuencia de aminoácidos que es de origen no natural. Dichas variantes tienen necesariamente menos del 100 % de identidad de secuencia o similitud con las moléculas de nucleasa híbridas de partida. En una realización preferente, la variante tendrá una secuencia de aminoácidos de aproximadamente 75 % a menos del 100 % de identidad de secuencia de aminoácidos o similitud con la secuencia de aminoácidos del polipéptido de partida, más preferentemente de aproximadamente 80 % a menos del 100 %, más preferentemente de aproximadamente 85 % a menos del 100 %, más preferentemente de aproximadamente 90 % a menos del 100 % (p. ej., 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 % o, 99 %) y más preferentemente de aproximadamente 95 % a menos del 100 %, p. ej., sobre la longitud de la molécula variante.
En una realización, existe una diferencia de aminoácidos entre una secuencia polipeptídica de partida y la secuencia derivada de la misma. La identidad o similitud con respecto a esta secuencia se define en la presente memoria como el porcentaje de residuos de aminoácidos en la secuencia candidata que es idéntico (es decir, mismo residuo) con los residuos de aminoácidos de partida, después de alinear las secuencias e introducir huecos, si es necesario, para conseguir el porcentaje máximo de identidad de secuencias.
En una realización, un polipéptido de la invención consiste en, consiste esencialmente en, o comprende una secuencia de aminoácidos seleccionada entre la Tabla 2 y variantes funcionalmente activas de la misma. En una realización, un polipéptido incluye una secuencia de aminoácidos al menos 80 %, 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, o 99 % idéntica a una secuencia de aminoácidos expuesta en la Tabla 2. En una realización, un polipéptido incluye una secuencia de aminoácidos contiguos al menos 80 %, 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, o 99 % idéntica a una secuencia de aminoácidos contiguos expuesta en la Tabla 2. En una realización, un polipéptido incluye una secuencia de aminoácidos que tiene al menos 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 200, 300, 400, o 500 (o cualquier número entero en estos números) aminoácidos contiguos de una secuencia de aminoácidos expuesta en la Tabla 2.
En una realización, los péptidos de la invención se codifican por una secuencia nucleotídica. Las secuencias nucleotídicas de la invención pueden ser útiles para una serie de aplicaciones, incluyendo: clonación, terapia génica, expresión y purificación de proteínas, introducción de mutaciones, vacunación con ADN de un huésped en necesidad del mismo, generación de anticuerpos para, p. ej., inmunización pasiva, PCR, generación de cebadores y sondas, diseño y generación de ARNip (véase, p. ej., la web de Dharmacon siDesign), y similares. En una realización, la secuencia nucleotídica de la invención comprende, consiste en, o consiste esencialmente en, una secuencia nucleotídica seleccionada entre la Tabla 2. En una realización, una secuencia nucleotídica incluye una secuencia nucleotídica al menos 80 %, 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, o 99 % idéntica a una secuencia nucleotídica expuesta en la Tabla 2. En una realización, una secuencia nucleotídica incluye una secuencia nucleotídica contigua al menos 80 %, 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, o 99 % idéntica a una secuencia nucleotídica contigua expuesta en Tabla 2. En una realización, una secuencia nucleotídica incluye una secuencia nucleotídica que tiene al menos 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 200, 300, 400, o 500 (o cualquier número entero en estos números) nucleótidos contiguos de una secuencia nucleotídica expuesta en la Tabla 2.
Las moléculas de nucleasa híbridas preferentes de la invención comprenden una secuencia (p. ej., al menos un dominio Fc) derivada de una secuencia de inmunoglobulina humana. No obstante, las secuencias pueden comprender una o más secuencias de otra especie de mamífero. Por ejemplo, un dominio Fc o dominio nucleasa de primate puede incluirse en la secuencia del sujeto. Alternativamente, uno o más aminoácidos murinos pueden estar presentes en un polipéptido. En algunas realizaciones, las secuencias polipeptídicas de la invención no son inmunogénicas y/o han reducido su inmunogenicidad.
Un experto en la materia también entenderá que las moléculas de nucleasa híbridas de la invención pueden alterarse de manera tal que varían la secuencia de las secuencias de origen natural o nativas de las que se
derivaron, al tiempo que retienen la actividad deseable de las secuencias nativas. Por ejemplo, pueden efectuarse sustituciones de nucleótidos o de aminoácidos que conducen a sustituciones conservadoras o cambios en residuos de aminoácidos "no esenciales". Una molécula de ácido nucleico aislada que codifica una variante no natural de una molécula de nucleasa híbrida derivada de una inmunoglobulina (p. ej., un dominio Fc) puede crearse introduciendo una o más sustituciones, adiciones o deleciones de nucleótidos en la secuencia nucleotídica de la inmunoglobulina de manera tal que una o más sustituciones, adiciones o deleciones de aminoácidos se introducen en la proteína codificada. Las mutaciones pueden introducirse por técnicas convencionales, tales como mutagénesis dirigida al sitio y mutagénesis mediada por PCR.
Las moléculas de nucleasa híbridas peptídicas de la invención pueden comprender sustituciones de aminoácidos conservadores en uno o más residuos de aminoácidos, p. ej., en residuos de aminoácidos esenciales o no esenciales. Una "sustitución de aminoácidos conservadores" es aquella en la que el residuo de aminoácidos se reemplaza con un residuo de aminoácidos que tiene una cadena lateral similar. Las familias de residuos de aminoácidos que tienen cadenas laterales similares se han definido en la materia, incluyendo cadenas laterales básicas (p. ej., lisina, arginina, histidina), cadenas laterales ácidas (p. ej., ácido aspártico, ácido glutámico), cadenas laterales polares no cargadas (p. ej., glicina, asparagina, glutamina, serina, treonina, tirosina, cisteína), cadenas laterales no polares (p. ej., alanina, valina, leucina, isoleucina, prolina, fenilalanina, metionina, triptófano), cadenas laterales ramificadas en beta (por ejemplo, treonina, valina, isoleucina) y cadenas laterales aromáticas (p. ej., tirosina, fenilalanina, triptófano, histidina). De este modo, un residuo de aminoácidos no esenciales en un polipéptido de unión se reemplaza preferentemente con otro residuo de aminoácidos de la misma familia de cadena lateral. En otra realización, una variable de cadena de aminoácidos puede reemplazarse con una variable de cadena estructuralmente similar que difiere en el orden y/o composición de los miembros de la familia de cadena lateral. Alternativamente, en otra realización, pueden introducirse mutaciones aleatoriamente a lo largo de la totalidad o parte de una secuencia codificante, tal como mediante mutagénesis de saturación, y los mutantes resultantes pueden incorporarse en los polipéptidos de unión de la invención e identificarse sistemáticamente por su capacidad para unirse a la diana deseada.
El término "mejorar" se refiere a cualquier resultado terapéuticamente beneficioso en el tratamiento de un estado de enfermedad, p. ej., un estado de enfermedad autoinmunitaria (por ejemplo, LES), incluyendo profilaxis, disminución en la gravedad o progresión, remisión, o cura del mismo.
La expresión "in situ se refiere a procesos que ocurren en una célula viva que crece separada de un organismo vivo, p. ej., que crece en un cultivo tisular.
La expresión "in vivo" se refiere a procesos que ocurren en un organismo vivo.
El término "mamífero" o "sujeto" o "paciente", como se utiliza en la presente invención, incluye tanto seres humanos como no humanos e incluye, entre otros, seres humanos, primates no humanos, caninos, felinos, murinos, bovinos, equinos, y porcinos.
El término porcentaje de "identidad", en el contexto de dos o más secuencias de ácidos nucleicos o de polipéptidos, se refiere a dos o más secuencias o subsecuencias que tienen un porcentaje especificado de nucleótidos o residuos de aminoácidos que son los mismos, cuando se comparan y alinean para la máxima correspondencia, como se mide utilizando uno de los algoritmos de comparación de secuencias descritos a continuación (p. ej., BLASTP y BLASTN u otros algoritmos disponibles para los expertos) o mediante inspección visual. Dependiendo de la aplicación, el porcentaje de "identidad" puede existir sobre una región de la secuencia que compara, p. ej., más de un dominio funcional, o, alternativamente, existe sobre la longitud completa de las dos secuencias a comparar.
Para la comparación de secuencias, normalmente una secuencia actúa como secuencia de referencia con la que se comparan las secuencias de ensayo. Cuando se utiliza un algoritmo de comparación de secuencias, las secuencias de ensayo y de referencia se introducen en un ordenador, las coordenadas posteriores se designan, si es necesario, y se designan los parámetros del programa de algoritmo de secuencias. El algoritmo de comparación de secuencias calcula entonces el porcentaje de identidad de secuencias para la secuencia o secuencias de ensayo con respecto a la secuencia de referencia, en función de los parámetros del programa designados.
El alineamiento óptimo de secuencias para su comparación puede llevarse a cabo, p. ej., mediante el algoritmo de homología local de Smith y Waterman, Adv. Appl. Math. 2:482 (1981), mediante el algoritmo de alineamiento de homología de Needleman y Wunsch, J. Mol. Biol. 48:443 (1970), mediante la búsqueda del método de similitud de Pearson y Lipman, Proc. Natl. Acad. Sci. EE. UU. 85:2444 (1988), mediante implementaciones computarizadas de estos algoritmos (GAP, BESTFIT, FASTA y TFASTA en el paquete de programas de Wisconsin Genetics, Genetics Computer Group, 575 Science Dr., Madison, Wis.), o mediante inspección visual (véase en general Ausubel et al., infra).
Un ejemplo de un algoritmo que es adecuado para determinar el porcentaje de identidad de secuencia y la similitud de secuencias es el algoritmo BLAST, que se describe en Altschul et al., J. Mol. Biol. 215:403-410 (1990). El
software para realizar análisis BLAST está disponible públicamente a través de la web del Centro Nacional para la Información Biotecnológica.
La expresión "cantidad suficiente" significa una cantidad suficiente para producir un efecto deseado, p. ej., una cantidad suficiente para modular la agregación de proteínas en una célula.
La expresión "cantidad terapéuticamente eficaz" es una cantidad que es eficaz para mejorar un síntoma de una enfermedad. Una cantidad terapéuticamente eficaz puede ser una "cantidad profilácticamente eficaz" cuando la profilaxis puede considerarse terapia.
Cabe señalar que, al igual que se utiliza en la memoria descriptiva y en las reivindicaciones adjuntas, las formas en singular de "un", "una" y "el", "la" incluyen referentes en plural a menos que el contexto dicte claramente lo contrario. Composiciones
Moléculas de nucleasa híbridas
En algunas realizaciones, una composición de la divulgación incluye una molécula de nucleasa híbrida. En algunas realizaciones, una molécula de nucleasa híbrida incluye un dominio nucleasa ligado operativamente a un dominio Fc. En algunas realizaciones, una molécula de nucleasa híbrida incluye un dominio nucleasa ligado a un dominio Fc. En algunas realizaciones, la molécula de nucleasa híbrida es una proteína nucleasa. En algunas realizaciones, la molécula de nucleasa híbrida es un polinucleótido de nucleasa.
En algunas realizaciones, el dominio nucleasa se liga al dominio Fc por un dominio enlazador. En algunas realizaciones, el dominio enlazador es un péptido enlazador. En algunas realizaciones, el dominio enlazador es un nucleótido enlazador. En algunas realizaciones, la molécula de nucleasa híbrida incluye una molécula líder, p. ej., un péptido líder. En algunas realizaciones, la molécula líder es un péptido líder situado en el extremo N-terminal del dominio nucleasa. En algunas realizaciones, la molécula de nucleasa híbrida incluirá un codón de terminación. En algunas realizaciones, el codón de terminación se encontrará en el extremo C-terminal del dominio Fc.
En algunas realizaciones, la molécula de nucleasa híbrida incluye además un segundo dominio nucleasa. En algunas realizaciones, el segundo dominio nucleasa se liga al dominio Fc por un segundo dominio enlazador. En algunas realizaciones, el segundo dominio enlazador se encontrará en el extremo C-terminal del dominio Fc. La Figura 12 muestra al menos una realización de una molécula de nucleasa híbrida. En algunas realizaciones, una molécula de nucleasa híbrida incluye una secuencia mostrada en la Tabla 2.
En algunas realizaciones, una molécula de nucleasa híbrida es una molécula de RNasa o molécula de DNasa o una molécula multienzimática (p. ej., RNasa y DNasa o dos nucleasas de ARN o ADN con diferente especificidad para un sustrato) unida a un dominio Fc que se une específicamente a complejos inmunitarios extracelulares. En algunas realizaciones, el dominio Fc no se une eficazmente a receptores Fcy. En un aspecto, la molécula de nucleasa híbrida no se une eficazmente a C1q. En otros aspectos, la molécula de nucleasa híbrida comprende un dominio Fc en la región marco de IgG1. En otros aspectos, la molécula de nucleasa híbrida comprende además mutaciones en los dominios bisagra, CH2 y/o CH3. En otros aspectos, las mutaciones son P238S, P331S o N297S, y pueden incluir mutaciones en una o más de tres cisteínas bisagra. En algunos de estos aspectos, las mutaciones en una o más de tres cisteínas bisagra pueden ser SCC o SSS. En otros aspectos, las moléculas contienen la bisagra SCC, pero por lo demás son de tipo natural para los dominios CH2 y CH3 de Fc de IgG1 humana, y se unen eficazmente a receptores Fc, lo que facilita la captación de la molécula de nucleasa híbrida en el compartimento endocítico de las células a las que se unen. En otros aspectos, la molécula tiene una actividad contra los sustratos de ARN monocatenario y/o bicatenario.
En algunos aspectos, la actividad de la molécula de nucleasa híbrida es detectable in vitro y/o in vivo. En algunos aspectos, la molécula de nucleasa híbrida se une a una célula, a una célula maligna, o a una célula cancerosa e interfiere con su actividad biológica.
En otro aspecto, se proporciona una molécula de RNasa multifuncional que se une a otra enzima o anticuerpo con especificidad de unión, tal como scFv orientado selectivamente a ARN o a un segundo dominio nucleasa con las mismas o diferentes especificidades que el primer dominio.
En otro aspecto, se proporciona una molécula de DNasa multifuncional que se une a otra enzima o anticuerpo con especificidad de unión, tal como scFv orientado selectivamente a ADN o a un segundo dominio nucleasa con las mismas o diferentes especificidades que el primer dominio.
En otro aspecto, una molécula de nucleasa híbrida se adapta para prevenir o tratar una enfermedad o trastorno en un mamífero mediante la administración de una molécula de nucleasa híbrida unida a una región Fc, en una cantidad terapéuticamente eficaz al mamífero en necesidad del mismo, en el que la enfermedad se previene o se trata. En otros aspectos, la enfermedad o trastorno es una enfermedad autoinmunitaria o cáncer. En algunos de
estos aspectos, la enfermedad autoinmunitaria es diabetes mellitus dependiente de insulina, esclerosis múltiple, encefalomielitis autoinmune experimental, artritis reumatoide, artritis autoinmune experimental, miastenia gravis, tiroiditis, una forma experimental de uveorretinitis, tiroiditis de Hashimoto, mixedema primario, tirotoxicosis, anemia perniciosa, gastritis atrófica autoinmune, enfermedad de Addison, menopausia prematura, infertilidad masculina, diabetes juvenil, síndrome de Goodpasture, pénfigo vulgar, penfigoide, oftalmía simpática, uveítis facogénica, anemia hemolítica autoinmune, leucopenia idiopática, cirrosis biliar primaria, hepatitis Hbs-ve crónica activa, cirrosis criptogénica, colitis ulcerosa, síndrome de Sjogren, esclerodermia, granulomatosis de Wegener, polimiositis, dermatomiositis, LE discoide, lupus eritematoso sistémico, y enfermedad del tejido conectivo.
En algunas realizaciones, las dianas de la actividad enzimática de RNasa de las moléculas de nucleasa híbridas de RNasa son principalmente extracelulares, que consisten en, p. ej., ARN contenido en complejos inmunitarios con autoanticuerpo anti-RNP y el ARN se expresa en la superficie de las células sometidas a apoptosis. En algunas realizaciones, la molécula de nucleasa híbrida de RNasa está activa en el entorno ácido de las vesículas endocíticas. En algunas realizaciones, una molécula de nucleasa híbrida de RNasa incluye un dominio Fc de tipo natural (tn) con el fin de permitir, p. ej., que la molécula se una a FcR y entre en el compartimento endocítico a través de la vía de entrada utilizada por complejos inmunitarios. En algunas realizaciones, una molécula de nucleasa híbrida de RNasa que incluye un dominio Fc tn se adapta para que sea activa tanto extracelularmente como en el entorno endocítico (en el que puede expresarse TLR7). En algunos aspectos, esto permite que una molécula de nucleasa híbrida de RNasa que incluye un dominio Fc tn detenga la señalización de TLR7 a través de complejos inmunitarios previamente envueltos o por ARNs que activan TLR7 después de la infección viral. En algunas realizaciones, la RNasa tn de una molécula de nucleasa híbrida de RNasa no es resistente a la inhibición por un inhibidor citoplásmico de RNasa. En algunas realizaciones, la RNasa tn de una molécula de nucleasa híbrida de RNasa no está activa en el citoplasma de una célula.
En algunas realizaciones, una molécula de nucleasa híbrida que incluye un dominio Fc tn se utiliza para la terapia de una enfermedad autoinmunitaria, por ejemplo, LES.
En algunas realizaciones, se aumenta la unión del Fc dominio a un receptor de Fc (FcR), p. ej., por alteraciones de glicosilación y/o cambios en la secuencia de aminoácidos. En algunas realizaciones, una molécula de nucleasa híbrida tiene una o más alteraciones de Fc que aumentan la unión FcR.
Se prevén formas alternativas para la construcción de una molécula de nucleasa híbrida unida a un dominio Fc. En algunas realizaciones, la orientación de dominio puede alterarse para construir una molécula de Ig-RNasa o una molécula de Ig-DNasa o una molécula de RNasa-Ig o una molécula de RNasa-Ig que retiene la unión de FcR y tiene dominios nucleasa activos.
En algunas realizaciones, las moléculas de nucleasa híbridas de DNasa incluyen un dominio Fc tn que puede permitir, p. ej., que las moléculas se sometan a endocitosis después de la unión de FcR. En algunas realizaciones, las moléculas de nucleasa híbridas de DNasa pueden ser activas hacia los complejos inmunitarios extracelulares que contienen ADN, p. ej., ya sea en forma soluble o depositado como complejos insolubles.
En algunas realizaciones, las moléculas de nucleasa híbridas incluyen tanto DNasa como RNasa. En algunas realizaciones, estas moléculas de nucleasa híbridas pueden mejorar la terapia de LES puesto que pueden, p. ej., digerir los complejos inmunitarios que contienen ARN, ADN, o una combinación de ARN y ADN; y cuando incluyen además un dominio Fc tn, son activas tanto extracelularmente como en el compartimento endocítico en el que pueden localizarse TLR7 y TLR9.
En algunas realizaciones, los dominios enlazadores incluyen 3, 4 o 5 variantes (gly4ser) que alteran la longitud del enlazador por progresiones de 5 aminoácidos. En otra realización, un dominio enlazador es de aproximadamente 18 aminoácidos de longitud e incluye un sitio de glicosilación ligado a N, que puede ser sensible a la escisión por proteasas in vivo. En algunas realizaciones, un sitio de glicosilación ligado a N puede proteger las moléculas de nucleasa híbridas de la escisión en el dominio enlazador. En algunas realizaciones, un sitio de glicosilación ligado a N puede ayudar en la separación del plegado de dominios funcionales independientes separados por el dominio enlazador.
En algunas realizaciones, las moléculas de nucleasa híbridas pueden incluir dominios Fc de IgG1 humana mutantes y/o de tipo natural. En algunas realizaciones, las moléculas de nucleasa híbridas pueden expresarse a partir de transfecciones transitorias de COS y CHO estables. En algunas realizaciones, la unión CD80/86 y la actividad de RNasa se conservan en una molécula de nucleasa híbrida. En algunas realizaciones, las moléculas de nucleasa híbridas incluyen construcciones DNasa1L3-Ig-enlazador-RNasa. En algunas realizaciones, una molécula de nucleasa híbrida incluye una construcción DNasa1-Ig-enlazador-RNasa o una construcción RNasa-Ig-enlazador-DNasa. En algunas realizaciones, las uniones de fusión entre dominios enzimáticos y los otros dominios de la molécula de nucleasa híbrida se optimizan.
En algunas realizaciones, las moléculas de nucleasa híbridas incluyen moléculas de nucleasa híbridas DNasa-Ig y/o moléculas de nucleasa híbridas DNasa-RNasa híbrida.
En algunas realizaciones, una molécula de nucleasa híbrida incluye TREX1. En algunas realizaciones, una molécula de nucleasa híbrida TREX1 puede digerir cromatina. En algunas realizaciones, una molécula de nucleasa híbrida TREX1 se expresa por una célula. En algunas realizaciones, la molécula de nucleasa híbrida expresada incluye TREX-1 murino y un dominio Fc (tn o mutante) murino. En algunas realizaciones, un dominio enlazador de 20-25 aminoácidos (aa) entre TREX1 y la bisagra de IgG puede ser necesario para permitir la actividad de DNasa. En algunas realizaciones, una molécula de nucleasa híbrida con un dominio enlazador de 15 aa no está activa. En algunas realizaciones, el uso de los dominios enlazadores de 20 y 25 aminoácidos (además de 2 o más aminoácidos para incorporar sitios de restricción) da lugar a la actividad funcional medida por la digestión de la cromatina. En algunas realizaciones, una región hidrófoba de aproximadamente 72 aa puede ser eliminada desde el extremo COOH de TREX-1 antes de la fusión con el dominio Fc por el dominio enlazador. En algunas realizaciones, una versión de dominio enlazador de 20 aminoácidos de la molécula de nucleasa híbrida exhibe altos niveles de expresión en comparación con los controles y/u otras moléculas de nucleasa híbridas. En algunas realizaciones, los ensayos enzimáticos cinéticos se utilizan para comparar la actividad enzimática de las moléculas de nucleasa híbridas y controles de una manera cuantitativa.
En algunas realizaciones, una optimización adicional de la unión de fusión elegida para el truncamiento de una enzima TREX1 puede utilizarse para mejorar la expresión de las moléculas de nucleasa híbridas.
En algunas realizaciones, la molécula de nucleasa híbrida incluye una molécula de nucleasa híbrida de dominio Fc que incluye TREX1-enlazador-Ig humana con dominios enlazadores de 20 y/o 25 aa. En algunas realizaciones, el dominio o los dominios enlazadores son variantes de un casete (gly4ser)4 o (gly4ser)5 con uno o más sitios de restricción unidos para su incorporación en la construcción de moléculas de nucleasa híbridas. En algunas realizaciones, debido a la dimerización cabeza-cola útil para la actividad enzimática TREX1; puede utilizarse un dominio enlazador flexible mayor para facilitar el plegado apropiado.
En algunas realizaciones, la molécula de nucleasa híbrida es una molécula de nucleasa híbrida que incluye TREX1 en tándem. En algunas realizaciones, un método alternativo para facilitar el plegado cabeza-cola de TREX1 es generar una molécula de nucleasa híbrida de TREX1-TREX1-Ig híbrido que incorpora dos dominios TREX1 en tándem, seguido por un dominio enlazador y un dominio Fc de Ig. En algunas realizaciones, el posicionamiento de casetes de TREX1 de una manera cabeza-cola puede corregirse para el plegado cabeza-cola en cualquiera de los brazos de la inmunoenzima e introducir un único dominio funcional que incluye TREX1 en cada brazo de la molécula. En algunas realizaciones, cada inmunoenzima de una molécula de nucleasa híbrida tiene dos enzimas TREX1 funcionales unidas a un único dominio Fc de IgG.
En algunas realizaciones, la molécula de nucleasa híbrida incluye TREX1-enlazador1-Ig-enlazador2-RNasa.
En algunas realizaciones, la molécula de nucleasa híbrida incluye RNasa-Ig-enlazador-TREX1. En algunas realizaciones, los casetes se derivan de la fusión de amino y carboxilo de cada enzima para su incorporación en las moléculas de nucleasa híbridas en las que se invierte la configuración enzimática. En algunas realizaciones, la enzima RNasa exhibe actividad funcional comparable independientemente de su posición en las moléculas de nucleasa híbridas. En algunas realizaciones, las moléculas de nucleasa híbridas alternativas pueden diseñarse para ensayar si una configuración particular demuestra la mejora de la expresión y/o función de los componentes de molécula de nucleasa híbrida.
En algunas realizaciones, la molécula de nucleasa híbrida incluye 1L3-Ig. En algunas realizaciones, la 1L3 DNasa se construye a partir de una secuencia murina y se expresa. En algunas realizaciones, la enzima está activa. En algunas realizaciones, una nucleasa híbrida que incluye 1L3 DNasa-Ig-RNasa murina se construye y se expresa. En algunas realizaciones, la molécula incluye 1L3-Ig humana, 1L3-Ig-RNasa humana, y/o RNasa-Ig-1L3 humana.
En algunas realizaciones, las moléculas de nucleasa híbridas incluyen DNasa1-Ig. En algunas realizaciones, un alelo variante de origen natural, A114F, que muestra la sensibilidad reducida a actina se incluye en una molécula de nucleasa híbrida incluye DNasa1-Ig. En algunas realizaciones, esta mutación se introduce en una molécula de nucleasa híbrida para generar un derivado más estable de la DNasa1 humana. En algunas realizaciones, se fabrica un DNasa1-enlazador-Ig que contiene un dominio enlazador de 20 o 25 aa. En algunas realizaciones, las moléculas de nucleasa híbridas incluyen RNasa-Ig-enlazador-DNasa1 en las que se encuentra el dominio DNasa1 en el lado COOH del dominio Fc de Ig. En algunas realizaciones, se fabrican moléculas de nucleasa híbridas que incorporan DNasa1 e incluyen: DNasa1-enlazador-Ig-enlazador2-RNasa, y/o RNasa-Ig-enlazador-DNasa1.
Otro aspecto de la presente divulgación es el uso de métodos de terapia génica para tratar o prevenir trastornos, enfermedades y afecciones con una o más moléculas de nucleasa híbridas. Los métodos de terapia génica se refieren a la introducción de secuencias de ácido nucleico de la molécula de nucleasa híbrida (ADN, ARN y ADN o ARN antisentido) en un animal para conseguir la expresión del polipéptido o polipéptidos de la presente invención. Este método puede incluir la introducción de uno o más polinucleótidos que codifican un polipéptido de la molécula de nucleasa híbrida de la presente invención ligada operativamente a un promotor y otros elementos genéticos necesarios para la expresión del polipéptido por el tejido diana.
En aplicaciones de terapia génica, los genes de moléculas de nucleasa híbridas se introducen en células con el fin de conseguir la síntesis in vivo de un producto genético terapéuticamente eficaz. La "terapia génica" incluye las terapias génicas convencionales en las que se consigue un efecto duradero mediante un único tratamiento, y la administración de agentes terapéuticos génicos, que implica la administración única o administración repetida de un ADN o ARNm terapéuticamente eficaz. Los oligonucleótidos pueden modificarse para potenciar su captación, p. ej., mediante la sustitución de sus grupos fosfodiéster cargados negativamente con grupos no cargados.
Dominios Fc
En algunas realizaciones, una molécula de nucleasa híbrida incluye un dominio Fc. Los dominios Fc útiles para producir las moléculas de nucleasa híbridas de la presente invención pueden obtenerse a partir de una serie de fuentes diferentes. En realizaciones preferentes, un dominio Fc de la molécula de nucleasa híbrida se deriva de una inmunoglobulina humana. Se entiende, sin embargo, que el dominio Fc puede derivarse de una inmunoglobulina de otra especie de mamífero, incluyendo, por ejemplo, especies roedoras (p. ej. un ratón, rata, conejo, conejillo de indias) o primates no humanos (p. ej., chimpancé, macaco). Además, el dominio Fc de la molécula de nucleasa híbrida o porción del mismo puede derivarse de cualquier clase de inmunoglobulina, incluyendo IgM, IgG, IgD, IgA e IgE, y cualquier isotipo de inmunoglobulina, incluyendo IgG1, IgG2, IgG3 e IgG4. En una realización preferente, se utiliza el isotipo humano IgG1.
Una variedad de secuencias génicas del dominio Fc (p. ej., secuencias génicas de la región constante humana) se disponen en forma de depósitos accesibles al público. Los dominios de la región constante que comprenden una secuencia del dominio Fc pueden seleccionarse por tener una función efectora particular (o carecer de una función efectora particular) o con una modificación particular para reducir la inmunogenicidad. Muchas secuencias de anticuerpos y genes que codifican al anticuerpo se han publicado y las secuencias del dominio Fc adecuadas (p. ej., secuencias de bisagra, CH2 y/o CH3, o porciones de las mismas) pueden derivarse de estas secuencias utilizando técnicas reconocidas en la materia. El material genético obtenido utilizando cualquiera de los métodos anteriores puede entonces alterarse o sintetizarse para obtener polipéptidos de la presente invención. Se apreciará además que el alcance de esta invención abarque alelos, variantes y mutaciones de las secuencias de ADN de la región constante.
Las secuencias del dominio Fc pueden clonarse, p. ej., utilizando la reacción en cadena de la polimerasa y los cebadores que se seleccionan para amplificar el dominio de interés. Para clonar una secuencia del dominio Fc a partir de un anticuerpo, el ARNm puede aislarse del hibridoma, bazo o células linfáticas, transcribirse de forma inversa en el ADN, y los genes de anticuerpos se amplifican por PCR. Los métodos de amplificación por PCR se describen con detalle en las patentes de Estados Unidos n.° 4.683.195; 4.683.202; 4.800.159; 4.965.188; y en, p. ej., "PCR Protocols: A Guide to Methods and Applications" Innis et al. eds., Academic Press, San Diego, Calif. (1990); Ho et al. 1989. Gene 77:51; Horton et al. 1993. Methods Enzymol. 217:270). La PCR puede ser iniciada por cebadores de la región constante consenso o mediante cebadores más específicos basados en las secuencias de ADN de cadena pesada y ligera y de aminoácidos publicadas. Como se ha discutido anteriormente, la PCR también se puede utilizar para aislar clones de ADN que codifican las cadenas pesadas y ligeras del anticuerpo. En este caso, las bibliotecas pueden identificarse sistemáticamente por cebadores consenso o sondas homólogas mayores, tales como sondas de región constante de ratón. Numerosos conjuntos de cebadores adecuados para la amplificación de genes de anticuerpos se conocen en la materia (p. ej., cebadores en 5' basados en la secuencia del extremo N-terminal de los anticuerpos purificados (Benhar y Pastan. 1994. Protein Engineering 7:1509); amplificación rápida de los extremos de ADNc (Ruberti, F. et al. 1994. J. Immunol. Methods 173:33); secuencias líder del anticuerpo (Larrick et al. 1989 Biochem. Biophys. Res. Commun. 160:1250). La clonación de secuencias de anticuerpos se describe adicionalmente en Newman et al., patente de Estados Unidos n.° 5.658.570, presentada el 25 de enero de 1995.
Las moléculas de nucleasa híbridas de la invención pueden comprender uno o más dominios Fc (p. ej., 2, 3, 4, 5, 6, 7, 8, 9, 10, o más dominios Fc). En una realización, los dominios Fc pueden ser de diferentes tipos. En una realización, al menos un dominio Fc presente en la molécula de nucleasa híbrida comprende un dominio bisagra o porción del mismo. En otra realización, la molécula de nucleasa híbrida de la invención comprende al menos un dominio Fc que comprende al menos un dominio CH2 o porción del mismo. En otra realización, la molécula de nucleasa híbrida de la invención comprende al menos un dominio Fc que comprende al menos un dominio CH3 o porción del mismo. En otra realización, la molécula de nucleasa híbrida de la invención comprende al menos un dominio Fc que comprende al menos un dominio CH4 o porción del mismo. En otra realización, la molécula de nucleasa híbrida de la invención comprende al menos un dominio Fc que comprende al menos un dominio bisagra o porción del mismo y al menos un dominio CH2 o porción del mismo (p. ej., en la orientación bisagra-CH2). En otra realización, la molécula de nucleasa híbrida de la invención comprende al menos un dominio Fc que comprende al menos un dominio CH2 o porción del mismo y al menos un dominio CH3 o porción del mismo (p. ej., en la orientación CH2-CH3). En otra realización, la molécula de nucleasa híbrida de la invención comprende al menos un dominio Fc que comprende al menos un dominio bisagra o porción del mismo, al menos un dominio CH2 o porción del mismo, y al menos un dominio CH3 o porción del mismo, por ejemplo en la orientación bisagra-CH2-CH3, bisagra-CH3-CH2, o CH2-CH3-bisagra.
En ciertas realizaciones, la molécula de nucleasa híbrida comprende al menos una región Fc completa derivada de una o más cadenas pesada de inmunoglobulinas (p. ej., un dominio Fc que incluye los dominios bisagra, CH2 y CH3 aunque estos no tienen que derivarse del mismo anticuerpo). En otras realizaciones, la molécula de nucleasa híbrida comprende al menos dos dominios Fc completos derivados de una o más cadenas pesadas de inmunoglobulina. En realizaciones preferentes, el dominio Fc completo se deriva de una cadena pesada de inmunoglobulina IgG humana (p. ej., IgG1 humana).
En otra realización, una molécula de nucleasa híbrida de la invención comprende al menos un dominio Fc que comprende un dominio CH3 completo. En otra realización, una molécula de nucleasa híbrida de la invención comprende al menos un dominio Fc que comprende un dominio CH2 completo. En otra realización, una molécula de nucleasa híbrida de la invención comprende al menos un dominio Fc que comprende al menos un dominio CH3, y al menos uno de una región bisagra, y un dominio CH2. En una realización, una molécula de nucleasa híbrida de la invención comprende al menos un dominio Fc que comprende un dominio bisagra y CH3. En otra realización, una molécula de nucleasa híbrida de la invención comprende al menos un dominio Fc que comprende un dominio bisagra, CH2 y CH3. En realizaciones preferentes, el dominio Fc se deriva de una cadena pesada de inmunoglobulina IgG humana (p. ej., IgG1 humana).
Los dominios de región constante o porciones de los mismos que componen un dominio Fc de una molécula de nucleasa híbrida de la invención pueden derivarse de diferentes moléculas de inmunoglobulina. Por ejemplo, un polipéptido de la invención puede comprender un dominio CH2 o porción del mismo derivado de una molécula de IgG1 y una región CH3 o porción de la misma derivada de una molécula de IgG3. En otro ejemplo, una molécula de nucleasa híbrida puede comprender un dominio Fc que comprende un dominio bisagra derivado, en parte, de una molécula de IgG1 y, en parte, de una molécula de IgG3. Como se expone en la presente invención, un experto en la materia entenderá que un dominio Fc puede ser alterado de tal forma que varíe la secuencia de aminoácidos de una molécula de anticuerpo de origen natural.
En otra realización, una molécula de nucleasa híbrida de la invención comprende uno o más dominios Fc truncados que son, no obstante, suficientes para conferir propiedades de unión del receptor de Fc (FcR) a la región Fc. De este modo, un dominio Fc de una molécula de nucleasa híbrida de la invención puede comprender o consistir en una porción de unión a FcRn. Las porciones de unión a FcRn pueden derivarse de las cadenas pesadas de cualquier isotipo, incluyendo IgG1, IgG2, IgG3 e IgG4. En una realización, se utiliza una porción de unión a FcRn de un anticuerpo del isotipo humano IgG1. En otra realización, se utiliza una porción de unión a FcRn de un anticuerpo de isotipo humano IgG4.
En una realización, una molécula de nucleasa híbrida de la invención carece de uno o más dominios de región constante de una región Fc completa, es decir, se delecionan parcial o totalmente. En ciertas realizaciones, las moléculas de nucleasa híbridas de la invención carecerán de un dominio CH2 completo (construcciones ACH2). Los expertos en la materia apreciarán que tales construcciones pueden resultar preferentes debido a las propiedades reguladoras del dominio CH2 de la tasa catabólica del anticuerpo. En ciertas realizaciones, las moléculas de nucleasa híbridas de la invención comprenden regiones Fc delecionadas en el dominio CH2 derivadas de un vector (p. e., de IDEC Pharmaceuticals, San Diego) que codifican un dominio de región constante de IgG1 humana (véase, p. ej., el documento WO 02/060955A2 y el documento WO02/096948A2). Este vector a modo de ejemplo se modifica por ingeniería genética para delecionar el dominio CH2 y proporcionar un vector sintético que expresa una región constante de IgG1 delecionada en el dominio. Se observará que estas construcciones a modo de ejemplo están modificadas por ingeniería genética preferentemente para fusionar el dominio CH3 de unión directamente a una región bisagra del respectivo dominio Fc.
En otras construcciones, puede ser deseable proporcionar un espaciador peptídico entre uno o más dominios Fc constituyentes. Por ejemplo, un espaciador peptídico puede colocarse entre una región bisagra y un dominio CH2 y/o entre un dominio CH2 y CH3. Por ejemplo, las construcciones compatibles podrían expresarse cuando se haya delecionado el dominio CH2 y el dominio CH3 restante (sintético o no sintético) se una a la región bisagra con un espaciador peptídico de 1-20, 1-10, o 1-5 aminoácidos. Tal espaciador peptídico puede añadirse, por ejemplo, para asegurar que los elementos reguladores del dominio de la región constante permanezcan libres y accesibles o que la región bisagra siga siendo flexible. Preferentemente, cualquier péptido enlazador compatible con la presente invención será relativamente no inmunogénico y no impedirá el plegado apropiado de Fc.
Cambios en los aminoácidos de Fc
En ciertas realizaciones, un dominio Fc empleado en una molécula de nucleasa híbrida de la invención se altera, p. ej., mediante la mutación de aminoácidos (p. ej., adición, deleción o sustitución). Como se utiliza en la presente memoria, la expresión "variante del dominio Fc" se refiere a un dominio Fc que tiene al menos una sustitución de aminoácidos en comparación con Fc de tipo natural del que se deriva el dominio Fc. Por ejemplo, cuando el dominio Fc se deriva de un anticuerpo de IgG1 humana, una variante comprende al menos una mutación de aminoácidos (p. ej., sustitución) en comparación con un aminoácido de tipo natural en la posición correspondiente de la región Fc de IgG1 humana.
La sustitución o sustituciones de aminoácidos de una variante Fc pueden situarse en una posición en el dominio Fc referida según corresponda al número de porción que ese residuo daría en una región Fc en un anticuerpo.
En una realización, la variante Fc comprende una sustitución en una posición de aminoácidos situada en un dominio bisagra o porción del mismo. En otra realización, la variante Fc comprende una sustitución en una posición de aminoácidos situada en un dominio CH2 o porción del mismo. En otra realización, la variante Fc comprende una sustitución en una posición de aminoácidos situada en un dominio CH3 o porción del mismo. En otra realización, la variante Fc comprende una sustitución en una posición de aminoácidos situada en un dominio CH4 o porción del mismo.
En ciertas realizaciones, las moléculas de nucleasa híbridas de la invención comprenden una variante Fc que comprende más de una sustitución de aminoácidos. Las moléculas de nucleasa híbridas de la invención pueden comprender, por ejemplo, 2, 3, 4, 5, 6, 7, 8, 9, 10 o más sustituciones de aminoácidos. Preferentemente, las sustituciones de aminoácidos están situadas espacialmente separadas unas de otras por un intervalo de al menos 1 posición de aminoácidos o más, por ejemplo, al menos 2, 3, 4, 5, 6, 7, 8, 9, o 10 o más posiciones de aminoácidos. Más preferentemente, los aminoácidos modificados por ingeniería genética están situados espacialmente separados unos de otros por un intervalo de al menos 5, 10, 15, 20, o 25 o más posiciones de aminoácidos.
En ciertas realizaciones, la variante Fc confiere una mejora en al menos una función efectora conferida por un dominio Fc que comprende dicho dominio Fc de tipo natural (p. ej., una mejora en la capacidad del dominio Fc para unirse a receptores Fc (p. ej., FcyRI, FcyRII, o FcyRIII) o proteínas del complemento (por ejemplo, C1q), o para activar la citotoxicidad dependiente de un anticuerpo (CCDA), fagocitosis, o citotoxicidad dependiente del complemento (CDC)). En otras realizaciones, la variante Fc proporciona un residuo de cisteína modificado por ingeniería genética.
Las moléculas de nucleasa híbridas de la invención pueden emplear variantes Fc reconocidas en la materia que se conocen por conferir una mejora en la función efectora y/o unión a FcR. Específicamente, una molécula de nucleasa híbrida de la invención puede incluir, por ejemplo, un cambio (p. ej., una sustitución) en una o más de las posiciones de los aminoácidos descritos en las publicaciones PCT internacionales WO88/07089A1, W096/14339A1, WO98/05787A1, W098/23289A1, WO99/51642A1, WO099/58572A1, WO00/09560A2, WO00/32767A1, WO00/42072A2, WO02/44215A2, WO02/060919A2, WO03/074569A2, WO04/016750A2, WO04/029207A2, WO04/035752A2, WO04/063351 A2, WO04/074455A2, WO04/099249A2, WO05/040217A2, WO04/044859, WO05/070963A1, WO05/077981A2, WO05/092925A2, WO05/123780A2, WO06/019447A1, WO06/047350A2, y WO06/085967A2; las publicaciones de patentes de Estados Unidos n.° US2007/0231329, US2007/0231329, US2007/0237765, US2007/0237766, US2007/0237767, US2007/0243188, US20070248603, US20070286859, US20080057056.; o las patentes de Estados Unidos n.° 5.648.260; 5.739.277; 5.834.250; 5.869.046; 6.096.871; 6.121.022; 6.194.551; 6.242.195; 6.277.375; 6.528.624; 6.538.124; 6.737.056; 6.821.505; 6.998.253; 7.083.784; y 7.317.091. En una realización, el cambio específico (p. ej., la sustitución específica de uno o más aminoácidos desvelados en la materia) puede efectuarse en una o más de las posiciones de aminoácidos desveladas. En otra realización, puede realizarse un cambio diferente en una o más de las posiciones de aminoácidos desveladas (p. ej., la sustitución diferente de una o más posiciones de aminoácidos desveladas en la materia).
En ciertas realizaciones, una molécula de nucleasa híbrida de la invención comprende una sustitución de aminoácidos en un dominio Fc que altera las funciones efectoras independientes del antígeno del anticuerpo, en particular la semivida en circulación del anticuerpo. Tales moléculas de nucleasa híbridas exhiben un aumento o disminución de la unión a FcRn en comparación con las moléculas de nucleasa híbridas que carecen de estas sustituciones y, por lo tanto, tienen un aumento o disminución de la semivida en el suero, respectivamente. Se prevé que las variantes Fc con afinidad mejorada para FcRn tienen semividas en suero más largas, y tales moléculas tienen aplicaciones útiles en métodos para tratar mamíferos en los que se desea un semivida larga del polipéptido administrado, p. ej., para tratar una enfermedad o trastorno crónico. Por el contrario, se espera que las variantes Fc con disminución de la afinidad de unión a FcRn tengan semividas más cortas, y tales moléculas también son útiles, por ejemplo, para la administración a un mamífero en el que un tiempo de circulación acortado puede ser ventajoso, p. ej., en el diagnóstico por imágenes in vivo o en situaciones en las que el polipéptido de partida tiene efectos secundarios tóxicos cuando está presente en la circulación durante periodos prolongados. Asimismo, es menos probable que las variantes Fc con disminución de la afinidad de unión a FcRn atraviesen la placenta y, en consecuencia, resultan también útiles en el tratamiento de enfermedades o trastornos en mujeres embarazadas. Además, otras aplicaciones en las que puede ser deseable una afinidad de unión a FcRn reducida incluyen aquellas aplicaciones en las que se desea la localización del cerebro, riñón, y/o hígado. En una realización a modo de ejemplo, las moléculas de nucleasa híbridas de la invención exhiben una reducción del transporte a través del epitelio de los glomérulos del riñón de la vasculatura. En otra realización, las moléculas de nucleasa híbridas de la invención exhiben un transporte reducido a través de la barrera hematoencefálica (BHE) del cerebro en el espacio vascular. En una realización, una molécula de nucleasa híbrida con unión a FcRn alterada comprende al menos un dominio Fc (p. ej., uno o dos dominios Fc) que tienen una o más sustituciones de aminoácidos en el "bucle de unión a FcRn" de un dominio Fc. Las sustituciones de aminoácidos a modo de ejemplo que alteraron la actividad de unión a FcRn se desvelan en la publicación PCT internacional n.° WO05/047327.
En otras realizaciones, una molécula de nucleasa híbrida de la invención comprende una variante Fc que comprende una sustitución de aminoácidos que altera las funciones efectoras dependientes del antígeno del polipéptido, en particular, CDD o la activación del complemento, p. ej., en comparación con una región Fc de tipo natural. En una realización a modo de ejemplo, dichas moléculas de nucleasa híbridas exhiben unión alterada a un receptor gamma Fc (p. ej., CD16). Tales moléculas de nucleasa híbridas exhiben ya sea un aumento o disminución de la unión a gamma FcR en comparación con los polipéptidos de tipo natural y, por lo tanto, median en la función efectora mejorada o reducida, respectivamente. Se prevé que las variantes Fc con afinidad mejorada para FcyRs potencien la función efectora, y tales moléculas tienen aplicaciones útiles en métodos de tratamiento de mamíferos en los que se desea la destrucción de la molécula diana. Por el contrario, se espera que las variantes Fc con una disminución de la afinidad de unión a FcyR reduzcan la función efectora, y tales moléculas también son útiles, por ejemplo, para el tratamiento de condiciones en las que la destrucción de células diana no es deseable, p. ej., cuando las células normales pueden expresar moléculas diana, o cuando la administración crónica del polipéptido podría dar lugar a la activación del sistema inmunitario no deseada. En una realización, el polipéptido que comprende Fc exhibe al menos una función efectora dependiente del antígeno alterada seleccionada del grupo que consiste en opsonización, fagocitosis, citotoxicidad dependiente del complemento, citotoxicidad celular dependiente de un antígeno (CCDA), o modulación de células efectoras en comparación con un polipéptido que comprende una región Fc de tipo natural.
En una realización, las moléculas de nucleasa híbridas exhiben una unión alterada a un FcyR activador (p. ej., FcyI, FcYlla, o FcYRIIIa). En otra realización, las moléculas de nucleasa híbridas exhiben una afinidad de unión alterada a un FcyR inhibidor (p. ej. FcYRIIb). Las sustituciones de aminoácidos a modo de ejemplo que alteraron FcR o la actividad de unión al complemento se desvelan en la publicación PCT internacional n.° WO05/063815.
Una molécula de nucleasa híbrida de la invención también puede comprender una sustitución de aminoácidos que altera la glicosilación de la molécula de nucleasa híbrida. Por ejemplo, el dominio Fc de la molécula de nucleasa híbrida puede comprender un dominio Fc que tiene una mutación que conduce a la reducción de la glicosilación (p. ej., glicosilación ligada a N u O) o puede comprender una glicoforma alterada del dominio Fc de tipo natural (p. ej., un glicano con un contenido bajo en fucosa o exento de fucosa). En otra realización, la molécula de nucleasa híbrida tiene una sustitución de aminoácidos próxima o dentro de un motivo de glicosilación, por ejemplo, un motivo de glicosilación ligada a N que contiene la secuencia de aminoácidos NXT o NXS. Las sustituciones de aminoácidos a modo de ejemplo que reducen o alteran la glicosilación se desvelan en la publicación PCT internacional n.° WO05/018572 y en la publicación de patente de Estados Unidos n.° 2007/0111281.
En otras realizaciones, una molécula de nucleasa híbrida de la invención comprende al menos un dominio Fc que tiene un residuo de cisteína modificado por ingeniería genética o análogo del mismo que se encuentra en la superficie expuesta al disolvente. Preferentemente, el residuo de cisteína modificado por ingeniería genética o análogo del mismo no interfiere con una función efectora conferida por Fc. Más preferentemente, la alteración no interfiere con la capacidad de Fc para unirse a receptores Fc (p. ej., FcyRI, FcyRII, o FcyRIII) o proteínas del complemento (p. ej., C1q), o para activar la función efectora inmunitaria (p. ej., citotoxicidad dependiente de un anticuerpo (CCDA), fagocitosis o citotoxicidad dependiente del complemento (CDC)). En realizaciones preferentes, las moléculas de nucleasa híbridas de la invención comprenden un dominio Fc que comprende al menos un residuo de cisteína libre modificado por ingeniería genética o análogo del mismo que está esencialmente libre de enlaces disulfuro con un segundo residuo de cisteína. Cualquiera de los residuos de cisteína modificados por ingeniería genética anteriores o análogos de los mismos pueden conjugarse posteriormente con un dominio funcional utilizando técnicas reconocidas en la materia (p. ej., conjugados con un enlazador heterobifuncional reactivo con tiol).
En una realización, la molécula de nucleasa híbrida de la invención puede comprender un dominio Fc fusionado genéticamente que tiene dos o más de sus dominios Fc constituyentes seleccionados independientemente entre los dominios Fc descritos en la presente memoria. En una realización, los dominios Fc son los mismos. En otra realización, al menos dos de los dominios Fc son diferentes. Por ejemplo, los dominios Fc de las moléculas de nucleasa híbridas de la invención comprenden el mismo número de residuos de aminoácidos o pueden diferir en su longitud en uno o más residuos de aminoácidos (p. ej., aproximadamente 5 residuos de aminoácidos (p. ej., 1, 2, 3, 4, o 5 residuos de aminoácidos), aproximadamente 10 residuos, aproximadamente 15 residuos, aproximadamente 20 residuos, aproximadamente 30 residuos, aproximadamente 40 residuos, o aproximadamente 50 residuos). En otras realizaciones, los dominios Fc de las moléculas de nucleasa híbridas de la invención pueden diferir en la secuencia en una o más posiciones de aminoácidos. Por ejemplo, al menos dos de los dominios Fc pueden diferir en aproximadamente 5 posiciones de aminoácidos (por ejemplo, 1, 2, 3, 4, o 5 posiciones de aminoácidos), aproximadamente 10 posiciones, aproximadamente 15 posiciones, aproximadamente 20 posiciones, aproximadamente 30 posiciones, aproximadamente 40 posiciones, o aproximadamente 50 posiciones).
Dominios enlazadores
En algunas realizaciones, una molécula de nucleasa híbrida incluye un dominio enlazador. En algunas realizaciones, una molécula de nucleasa híbrida incluye una pluralidad de dominios enlazadores. En algunas realizaciones, el dominio enlazador es un enlazador polipeptídico. En ciertos aspectos, es deseable emplear un enlazador
polipeptídico para fusionar uno o más dominios Fc a uno o más dominios de nucleasa para formar una molécula nucleasa híbrida.
En una realización, el enlazador polipeptídico es sintético. Como se utiliza en la presente memoria, el término "sintético" con respecto a un enlazador polipeptídico incluye péptidos (o polipéptidos) que comprenden una secuencia de aminoácidos (que puede o no puede ser de origen natural) que se liga en una secuencia lineal de aminoácidos a una secuencia (que puede o no puede ser de origen natural) (p. ej., una secuencia de dominio Fc) a la que no se liga naturalmente en la naturaleza. Por ejemplo, el enlazador polipeptídico puede comprender polipéptidos de origen no natural que son formas modificadas de polipéptidos de origen natural (p. ej., que comprenden una mutación, tal como una adición, sustitución o deleción) o que comprenden una primera secuencia de aminoácidos (que puede o no puede ser de origen natural). Los enlazadores polipeptídicos de la invención se pueden emplear, por ejemplo, para asegurar que los dominios Fc se yuxtaponen para asegurar el plegado y formación propios de un dominio Fc funcional. Preferentemente, un enlazador polipeptídico compatible con la presente invención será relativamente no inmunogénico y no inhibe cualquier asociación no covalente entre subunidades monoméricas de una proteína de unión.
En ciertas realizaciones, las moléculas de nucleasa híbridas de la invención emplean un enlazador polipeptídico para unirse a cualquiera de dos o más dominios del marco en una única cadena polipeptídica. En una realización, los dos o más dominios pueden seleccionarse independientemente de cualquiera de los dominios Fc o dominios nucleasa discutidos en la presente memoria. Por ejemplo, en ciertas realizaciones, un enlazador polipeptídico puede utilizarse para fusionar dominios Fc idénticos, formando con ello una región Fc homomérica. En otras realizaciones, un enlazador polipeptídico puede utilizarse para fusionar diferentes dominios Fc (p. ej., un dominio Fc de tipo natural y una variante de dominio Fc), formando de este modo una región Fc heteromérica. En otras realizaciones, un enlazador polipeptídico de la invención puede utilizarse para fusionar genéticamente el extremo C-terminal de un primer dominio Fc (p. ej., un dominio bisagra o porción del mismo, un dominio CH2 o porción del mismo, un dominio CH3 completo o porción del mismo, una porción de unión a FcRn, una porción de unión a FcyR, una porción de unión al complemento, o porción del mismo) al extremo N-terminal de un segundo dominio Fc (p. ej., un dominio Fc completo).
En una realización, un polipéptido enlazador comprende una parte de un dominio Fc. Por ejemplo, en una realización, un enlazador polipeptídico puede comprender un dominio bisagra de inmunoglobulina de un anticuerpo de IgG1, IgG2, IgG3, y/o IgG4. En otra realización, un enlazador polipeptídico puede comprender un dominio CH2 de anticuerpo de IgG3, IgG1, IgG2, y/o IgG4. En otras realizaciones, un enlazador polipeptídico puede comprender un dominio CH3 de un anticuerpo de IgG3, IgG1, IgG2, y/o IgG4. Otras porciones de una inmunoglobulina (p. ej., una inmunoglobulina humana) pueden utilizarse también. Por ejemplo, un enlazador polipeptídico puede comprender un dominio CH1 o porción del mismo, un dominio CL o porción del mismo, un dominio VH o porción del mismo, o un dominio VL o porción del mismo. Dichas porciones pueden derivarse de cualquier inmunoglobulina, incluyendo, por ejemplo, un anticuerpo de IgG3, IgG1, IgG2, y/o IgG4.
En realizaciones a modo de ejemplo, un enlazador polipeptídico puede comprender al menos una porción de una región bisagra de inmunoglobulina. En una realización, un enlazador polipeptídico comprende un dominio bisagra superior (p. ej., un dominio bisagra superior de IgG1, IgG2, IgG3, o IgG4). En otra realización, un enlazador polipeptídico comprende un dominio bisagra intermedio (p. ej., un dominio bisagra intermedio de IgG1, IgG2, IgG3, o un IgG4). En otra realización, un enlazador polipeptídico comprende un dominio bisagra inferior (p. ej., un dominio bisagra inferior de IgG1, IgG2, IgG3 o IgG4).
En otras realizaciones, los enlazadores polipeptídicos pueden construirse combinando elementos de bisagra derivados de los mismos o diferentes isotipos de anticuerpos. En una realización, el enlazador polipeptídico comprende una bisagra quimérica que comprende al menos una porción de una región bisagra de IgG1 y al menos una porción de una región bisagra de IgG2. En una realización, el enlazador polipeptídico comprende una bisagra quimérica que comprende al menos una porción de una región bisagra de IgG1 y al menos una porción de una región bisagra de IgG3. En otra realización, un enlazador polipeptídico comprende una bisagra quimérica que comprende al menos una porción de una región bisagra de IgGl y al menos una porción de una región bisagra IgG4. En una realización, el enlazador polipeptídico comprende una bisagra quimérica que comprende al menos una porción de una región bisagra de IgG2 y al menos una porción de una región bisagra de IgG3. En una realización, el enlazador polipeptídico comprende una bisagra quimérica que comprende al menos una porción de una región bisagra de IgG2 y al menos una porción de una región bisagra de IgG4. En una realización, el enlazador polipeptídico comprende una bisagra quimérica que comprende al menos una porción de una región bisagra de IgG1, al menos una porción de una región bisagra de IgG2, y al menos una porción de una región bisagra de IgG4. En otra realización, un enlazador polipeptídico puede comprender una bisagra superior e intermedia de IgG1 y un único motivo de repetición de bisagra intermedia de IgG3. En otra realización, un enlazador polipeptídico puede comprender una bisagra superior de IgG4, una bisagra intermedia de IgG1 y una bisagra inferior de IgG2.
En otra realización, un enlazador polipeptídico comprende o consiste en un enlazador gly-ser. Como se utiliza en la presente memoria, la expresión "enlazador gly-ser" se refiere a un péptido que consiste en los residuos de glicina y serina. Un enlazador gly/ser a modo de ejemplo comprende una secuencia de aminoácidos de la fórmula (Gly4Ser)n,
en la que n es un número entero positivo (p. ej., 1, 2, 3, 4, o 5). Un enlazador gly/ser preferente es (Gly4Ser)4. Otro enlazador gly/ser preferente es (Gly4Ser)3. Otro enlazador gly/ser preferente es (Gly4Ser)5. En ciertas realizaciones, el enlazador gly-ser puede insertarse entre otras dos secuencias del enlazador polipeptídico (p. ej., cualquiera de las secuencias enlazadoras polipeptídicas descritas en la presente memoria). En otras realizaciones, un enlazador glyser está unido en uno o ambos extremos de otra secuencia del enlazador polipeptídico (p. ej., cualquiera de las secuencias enlazadoras polipeptídicas descritas en la presente memoria). En otras realizaciones, dos o más enlazadores gly-ser se incorporan en serie en un enlazador polipeptídico. En una realización, un enlazador polipeptídico de la invención comprende al menos una porción de una región bisagra superior (p. ej., derivada de una molécula de IgG1, IgG2, IgG3, o IgG4), al menos una porción de una región bisagra intermedia (p. ej., derivada de una molécula de IgG1, IgG2, IgG3, o IgG4) y una serie de residuos de aminoácidos gly/ser (p. ej., un enlazador gly/ser, tal como (Gly4Ser)n).
En una realización, un enlazador polipeptídico de la invención comprende un dominio de región bisagra de inmunoglobulina de origen no natural, p. ej., un dominio de región bisagra que no se encuentra de forma natural en el polipéptido que comprende el dominio de región bisagra y/o un dominio de región bisagra que ha sido alterado de manera que difiere en la secuencia de aminoácidos de un dominio de región bisagra de inmunoglobulina de origen natural. En una realización, las mutaciones pueden efectuarse en los dominios de la región bisagra para fabricar un enlazador polipeptídico de la invención. En una realización, un enlazador polipeptídico de la invención comprende un dominio bisagra que no comprende un número de cisteínas de origen natural, es decir, el enlazador polipeptídico comprende o bien un menor número de cisteínas o bien un mayor número de cisteínas que una bisagra de molécula de origen natural.
En otras realizaciones, un enlazador polipeptídico de la invención comprende una secuencia peptídica biológicamente relevante o una porción de la secuencia de la misma. Por ejemplo, una secuencia peptídica biológicamente relevante puede incluir, entre otros, secuencias derivadas de un péptido anti-rechazo o anti inflamatorio. Dichos péptidos anti-rechazo o anti-inflamatorios pueden seleccionarse del grupo que consiste en un péptido inhibidor de citoquina, un péptido inhibidor de la adhesión celular, un péptido inhibidor de la trombina, y un péptido inhibidor de plaquetas. En una realización preferente, un enlazador polipeptídico comprende una secuencia peptídica seleccionada del grupo que consiste en una secuencia peptídica inhibidora de IL-1 o antagonista, una secuencia peptídica mimética de eritropoyetina (EPO), una secuencia peptídica mimética de trombopoyetina (TPO), una secuencia peptídica mimética de FGCE, una secuencia peptídica antagonista del FNT, una secuencia peptídica de unión a integrina, una secuencia peptídica antagonista de selectina, una secuencia peptídica anti-patógenos, una secuencia peptídica mimética del péptido intestinal vasoactivo (PIV), una secuencia peptídica antagonista de la calmodulina, un antagonista de mastocitos, una secuencia peptídica antagonista de SH3, una secuencia peptídica antagonista del receptor de uroquinasa (UK), una secuencia peptídica mimética de somatostatina o cortistatina, y una secuencia peptídica que inhibe macrófagos y/o células T. Las secuencias peptídicas a modo de ejemplo, cualquiera de las cuales se pueden emplear como un enlazador polipeptídico, se desvelan en la patente de Estados Unidos n.° 6.660.843.
Se entenderá que las formas variantes de estos enlazadores polipeptídicos a modo de ejemplo pueden crearse introduciendo una o más sustituciones, adiciones o deleciones de nucleótidos en la secuencia de nucleótidos que codifica un enlazador polipeptídico de manera tal que una o más sustituciones, adiciones o deleciones de aminoácidos se introducen en el enlazador polipeptídico. Por ejemplo, las mutaciones pueden introducirse por técnicas convencionales, tales como mutagénesis dirigida al sitio y mutagénesis mediada por PCR.
Los enlazadores polipeptídicos de la invención son al menos un aminoácido en longitud y pueden comprender diferentes longitudes. En una realización, un enlazador polipeptídico de la invención es de aproximadamente 1 a aproximadamente 50 aminoácidos de longitud. Como se utiliza en este contexto, el término "aproximadamente" indica /- dos residuos de aminoácidos. Ya que la longitud del enlazador debe ser un número entero positivo, la longitud de aproximadamente 1 a aproximadamente 50 aminoácidos de longitud, significa una longitud de 1 a 48-52 aminoácidos de longitud. En otra realización, un enlazador polipeptídico de la invención es de aproximadamente 10 20 aminoácidos de longitud. En otra realización, un enlazador polipeptídico de la invención es de aproximadamente 15 a aproximadamente 50 aminoácidos de longitud.
En otra realización, un enlazador polipeptídico de la invención es de aproximadamente 20 a aproximadamente 45 aminoácidos de longitud. En otra realización, un enlazador polipeptídico de la invención es de aproximadamente 15 a aproximadamente 25 aminoácidos de longitud. En otra realización, un enlazador polipeptídico de la invención es de aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44,45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, o más aminoácidos de longitud.
Los enlazadores polipeptídicos pueden introducirse en las secuencias polipeptídicas utilizando técnicas conocidas en la materia. Las modificaciones pueden ser confirmadas por el análisis de secuencia de ADN. El ADN plasmídico puede utilizarse para transformar células huésped para la producción estable de los polipéptidos producidos.
Dominios nucleasa
En ciertos aspectos, una molécula de nucleasa híbrida incluye un dominio nucleasa. Por consiguiente, las moléculas de nucleasa híbridas de la invención comprenden normalmente al menos un dominio nucleasa y al menos un dominio Fc ligado. En ciertos aspectos, una molécula de nucleasa híbrida incluye una pluralidad de dominios nucleasa.
En algunas realizaciones, un dominio de nucleasa es DNasa. En algunas realizaciones, la DNasa es una DNasa secretada tipo I. En algunas realizaciones, la DNasa es DNasa 1 y/o una enzima similar a DNasa 1 (DNasaL), 1-3. En algunas realizaciones, la DNasa es TREX1.
En algunas realizaciones, un dominio nucleasa es una RNasa. En algunas realizaciones, la RNasa es una RNasa extracelular o secretora de la superfamilia de la RNasa A, p. ej., RNasa A.
En una realización, el dominio nucleasa se liga operativamente (p. ej., conjuga químicamente o fusiona genéticamente (p. ej., ya sea directamente o por un enlazador polipeptídico)) al extremo N-terminal de un dominio Fc. En otra realización, el dominio nucleasa se liga operativamente (p. ej., conjuga químicamente o fusiona genéticamente (p. ej., ya sea directamente o por un enlazador polipeptídico)) al extremo C-terminal de un dominio Fc. En otras realizaciones, un dominio nucleasa se liga operativamente (p. ej., conjuga químicamente o fusiona genéticamente (p. ej., ya sea directamente o por un enlazador polipeptídico)) por una cadena lateral de aminoácidos de un dominio Fc. En ciertas realizaciones a modo de ejemplo, el dominio nucleasa se fusiona a un dominio Fc por un dominio bisagra de inmunoglobulina humana o porción del mismo.
En ciertas realizaciones, las moléculas de nucleasa híbridas de la invención comprenden dos o más dominios nucleasa y al menos un dominio Fc. Por ejemplo, los dominios nucleasa pueden ligarse operativamente tanto a los extremos N-terminal y C-terminal de un dominio Fc. En otras realizaciones a modo de ejemplo, los dominios nucleasa pueden ligarse operativamente a los extremos N- y C-terminales de múltiples dominios Fc (p. ej., dos, tres, cuatro, cinco, o más dominios Fc) que se ligan entre sí en serie para formar una matriz en tándem de dominios Fc. En otras realizaciones, dos o más dominios nucleasa se ligan entre sí (p. ej., por un enlazador polipeptídico) en serie, y la matriz en tándem de dominios nucleasa se liga operativamente (p. ej., conjuga químicamente o fusiona genéticamente (p. ej., ya sea directamente o por un enlazador polipeptídico)) ya sea en el extremo C-terminal o N-terminal de un dominio Fc o una matriz en tándem de dominios Fc. En otras realizaciones, la matriz en tándem de dominios nucleasa se liga operativamente tanto al extremo C-terminal como al extremo N-terminal de un dominio Fc o una matriz en tándem de dominios Fc.
En otras realizaciones, uno o más dominios nucleasa pueden insertarse entre dos dominios Fc. Por ejemplo, uno o más dominios nucleasa pueden formar la totalidad o parte de un enlazador polipeptídico de una molécula de nucleasa híbrida de la invención.
Las moléculas de nucleasa híbridas preferentes de la invención comprenden al menos un dominio nucleasa (p. ej., RNasa o DNasa), al menos un dominio enlazador, y al menos un dominio Fc.
En ciertas realizaciones, las moléculas de nucleasa híbridas de la invención tienen al menos un dominio nucleasa específico para una molécula diana que media un efecto biológico. En otra realización, la unión de las moléculas de nucleasa híbridas de la invención a una molécula diana (p. ej., ADN o ARN) da lugar a la reducción o eliminación de la molécula diana, p. ej., de una célula, un tejido, o de la circulación.
En ciertas realizaciones, las moléculas de nucleasa híbridas de la invención pueden comprender dos o más dominios nucleasa. En una realización, los dominios nucleasa son idénticos, p. ej., RNasa y RNasa, o TREX1 y TREX1. En otra realización, los dominios nucleasa son diferentes, p. ej., DNasa y RNasa.
En otras realizaciones, las moléculas de nucleasa híbridas de la invención pueden ensamblarse entre sí o con otros polipéptidos para formar proteínas de unión que tienen dos o más polipéptidos ("multímeros"), en los que al menos un polipéptido del multímero es una molécula de nucleasa híbrida de la invención. Las formas multiméricas a modo de ejemplo incluyen proteínas de unión alteradas diméricas, triméricas, tetraméricas, hexaméricas y similares. En una realización, los polipéptidos del multímero son los mismos (es decir, proteínas de unión alteradas homoméricas, p. ej., homodímeros, homotetrámeros). En otra realización, los polipéptidos del multímero son diferentes (p. ej. heteroméricos).
Métodos de fabricación de moléculas de nucleasa híbridas
Las moléculas de nucleasa híbridas de la presente invención pueden fabricarse en gran medida en células huésped transformadas utilizando técnicas de ADN recombinante. Para ello, se prepara una molécula de ADN recombinante que codifica el péptido. Los métodos de preparación de tales moléculas de ADN son bien conocidos en la materia. Por ejemplo, las secuencias que codifican los péptidos podrían extirparse del ADN utilizando enzimas de restricción
adecuadas. Alternativamente, la molécula de ADN podría sintetizarse utilizando técnicas de síntesis química, tales como el método con fosforamidato. Asimismo, podría utilizarse una combinación de estas técnicas.
La invención también incluye un vector capaz de expresar los péptidos en un huésped apropiado. El vector comprende la molécula de ADN que codifica los péptidos ligados operativamente a secuencias de control de expresión apropiadas. Los métodos que afectan a este enlace operativo, antes o después de que se inserte la molécula de ADN en el vector, son bien conocidos. Las secuencias de control de la expresión incluyen promotores, activadores, potenciadores, operadores, dominios nucleasa ribosomales, señales de inicio, señales de terminación, señales de capuchón, señales de poliadenilación y otras señales implicadas en el control de la transcripción o la traducción.
El vector resultante que tiene la molécula de ADN en el mismo se utiliza para transformar un huésped apropiado. Esta transformación puede realizarse utilizando métodos bien conocidos en la materia.
Cualquiera de un gran número de células huésped disponible y bien conocida puede utilizarse en la práctica de la presente invención. La selección de un huésped particular depende de una serie de factores reconocidos por la materia. Estos incluyen, por ejemplo, compatibilidad con el vector de expresión elegido, toxicidad de los péptidos codificados por la molécula de ADN, tasa de transformación, facilidad de recuperación de los péptidos, características de expresión, bioseguridad y costes. Hay que alcanzar un equilibrio de estos factores para el entendimiento de que no todos los huéspedes pueden ser igualmente eficaces para la expresión de una secuencia de ADN particular. Dentro de estas directrices generales, los huéspedes microbianos útiles incluyen bacterias (tales como E. coli sp.), levaduras (tales como Saccharomyces sp.) y otros hongos, insectos, plantas, células de mamíferos (incluyendo humanos) en cultivo, u otros huéspedes conocidos en la materia.
A continuación, el huésped transformado se cultiva y se purifica. Las células huésped pueden cultivarse bajo condiciones de fermentación convencionales de forma que se expresan los compuestos deseados. Tales condiciones de fermentación son bien conocidas en la materia. Finalmente, los péptidos se purifican a partir del cultivo por métodos bien conocidos en la materia.
Los compuestos también pueden prepararse por métodos sintéticos. Por ejemplo, pueden utilizarse técnicas de síntesis en fase sólida. Las técnicas adecuadas son bien conocidas en la materia, e incluyen las descritas en Merrifield (1973), Chem. Polypeptides, págs. 335-61 (Katsoyannis y Panayotis eds.); Merrifield (1963), J. Am. Chem. Soc. 85:2149; Davis et al. (1985), Biochem. Intl. 10:394-414; Stewart y Young (1969), Solid Phase Peptide Synthesis; patente de Estados Unidos. n.° 3.941.763; Finn et al. (1976), The Proteins (3a ed.) 2: 105-253; y Erickson et al. (1976), The Proteins (3a ed.) 2: 257-527. La síntesis en fase sólida es la técnica preferente para fabricar péptidos individuales ya que es el método más rentable para fabricar pequeños péptidos. Los compuestos que contienen péptidos derivatizados o que contienen grupos no peptídicos pueden sintetizarse por técnicas de química orgánica bien conocidas.
Otros métodos de expresión/síntesis de moléculas se conocen en general en la materia por un experto.
Composiciones farmacéuticas y métodos de uso terapéuticos
En ciertas realizaciones, solamente se administra una molécula de nucleasa híbrida. En ciertas realizaciones, una molécula de nucleasa híbrida se administra antes de la administración de al menos otro agente terapéutico. En ciertas realizaciones, una molécula de nucleasa híbrida se administra simultáneamente con la administración de al menos otro agente terapéutico. En ciertas realizaciones, una molécula de nucleasa híbrida se administra después de la administración de al menos otro agente terapéutico. En otras realizaciones, una molécula de nucleasa híbrida se administra antes de la administración de al menos otro agente terapéutico. Como un experto en la materia apreciará, en algunas realizaciones, la molécula de nucleasa híbrida se combina con el otro agente/compuesto. En algunas realizaciones, la molécula de nucleasa híbrida y otro agente se administran simultáneamente. En algunas realizaciones, la molécula de nucleasa híbrida y otro agente no se administran simultáneamente, la molécula de nucleasa híbrida se administra antes o después de que se administre el agente. En algunas realizaciones, el sujeto recibe tanto la molécula de nucleasa híbrida como el otro agente durante un mismo periodo de prevención, aparición de un trastorno, y/o periodo de tratamiento.
Las composiciones farmacéuticas de la invención pueden administrarse en terapia de combinación, es decir, combinadas con otros agentes. En ciertas realizaciones, la terapia de combinación comprende molécula de nucleasa, en combinación con al menos otro agente. Los agentes incluyen, entre otros, composiciones químicas preparadas sintéticamente in vitro, anticuerpos, regiones de unión a antígenos, y combinaciones y conjugados de los mismos. En ciertas realizaciones, un agente puede actuar como un agonista, antagonista, modulador alostérico, o toxina.
En ciertas realizaciones, la invención proporciona composiciones farmacéuticas que comprenden una molécula de nucleasa híbrida junto con un diluyente, portador, solubilizante, emulsionante, conservante y/o adyuvante farmacéuticamente aceptable.
En ciertas realizaciones, la invención proporciona composiciones farmacéuticas que comprenden una molécula de nucleasa híbrida y una cantidad terapéuticamente eficaz de al menos un agente terapéutico adicional, junto con un diluyente, portador, solubilizante, emulsionante, conservante y/o adyuvante farmacéuticamente aceptable.
En ciertas realizaciones, los materiales de formulación aceptables son preferentemente no tóxicos para los receptores en las dosificaciones y concentraciones empleadas. En algunas realizaciones, el material o materiales de formulación son para administración SC y/o IV. En ciertas realizaciones, la composición farmacéutica puede contener materiales de formulación para modificar, mantener o conservar, por ejemplo, el pH, la osmolalidad, la viscosidad, la claridad, el color, la isotonicidad, el olor, la esterilidad, la estabilidad, la velocidad de disolución o liberación, la adsorción o la penetración de la composición. En ciertas realizaciones, los materiales de formulación adecuados incluyen, entre otros, aminoácidos (tales como glicina, glutamina, asparagina, arginina o lisina); antimicrobianos; antioxidantes (tales como ácido ascórbico, sulfito de sodio o hidrogenosulfito de sodio); tampones (tales como borato, bicarbonato, Tris-HCl, citratos, fosfatos u otros ácidos orgánicos); agentes de carga (tales como manitol o glicina); agentes quelantes (tales como ácido etilendiaminotetraacético (EDTA)); agentes complejantes (tales como cafeína, polivinilpirrolidona, beta-ciclodextrina o hidroxipropil-beta-ciclodextrina); materiales de carga; monosacáridos; disacáridos; y otros carbohidratos (tales como glucosa, manosa o dextrinas); proteínas (tales como seroalbúmina, gelatina o inmunoglobulinas); colorantes, aromatizantes y agentes de dilución; agentes emulsionantes; polímeros hidrófilos (tales como polivinilpirrolidona); polipéptidos de bajo peso molecular; contraiones formadores de sal (tales como sodio); conservantes (tales como cloruro de benzalconio, ácido benzoico, ácido salicílico, timerosal, alcohol fenetílico, metilparabeno, propilparabeno, clorhexidina, ácido sórbico o peróxido de hidrógeno); disolventes (tales como glicerina, propilenglicol o polietilenglicol); alcoholes de azúcar (tales como manitol o sorbitol); agentes de suspensión; tensioactivos o agentes humectantes (tales como plurónicos, PEG, ésteres de sorbitán, polisorbatos, tales como polisorbato 20, polisorbato 80, tritón, trometamina, lecitina, colesterol, tiloxapal); agentes potenciadores de la estabilidad (tales como sacarosa o sorbitol); agentes potenciadores de la tonicidad (tales como haluros de metal alcalino, preferentemente cloruro de sodio o potasio, manitol sorbitol); vehículos de administración; diluyentes; excipientes y/o adyuvantes farmacéuticos. (Remington's Pharmaceutical Sciences, 18a edición, A. R. Gennaro, ed., Mack Publishing Company (1995). En algunas realizaciones, la formulación comprende TFS; 20 mM de NaOAc, pH 5,2, 50 mM de NaCl, y/o 10 mM de NaOAc, pH 5,2, sacarosa al 9 %.
En ciertas realizaciones, una molécula de nucleasa híbrida y/o una molécula terapéutica se liga a un vehículo que extiende la semivida conocida en la materia. Tales vehículos incluyen, entre otros, polietilenglicol, glicógeno (p. ej., glicosilación de la molécula de nucleasa híbrida), y dextrano. Tales vehículos se describen, p. ej., en la solicitud de patente de Estados Unidos número de serie 09/428.082, en la actualidad la patente de Estados Unidos n.° 6.660.843 y la solicitud PCT publicada n.° WO 99/25044.
En ciertas realizaciones, la composición farmacéutica óptima será determinada por un experto en la materia dependiendo de, por ejemplo, la vía de administración pretendida, el formato de administración y la dosificación deseada. Véase, por ejemplo, Remington's Pharmaceutical Sciences, supra. En ciertas realizaciones, tales composiciones pueden influir en el estado físico, estabilidad, velocidad de liberación in vivo y velocidad de depuración in vivo de los anticuerpos de la invención.
En ciertas realizaciones, el vehículo o portador primario en una composición farmacéutica puede ser acuoso o no acuoso en la naturaleza. Por ejemplo, en ciertas realizaciones, un vehículo o portador adecuado puede ser agua para inyección, solución salina fisiológica o líquido cefalorraquídeo artificial, posiblemente suplementado con otros materiales comunes en composiciones para administración parenteral. En algunas realizaciones, la solución salina comprende solución salina tamponada con fosfato isotónica. En ciertas realizaciones, la solución salina tamponada neutra o solución salina mezclada con seroalbúmina son vehículos a modo de ejemplo adicionales. En ciertas realizaciones, las composiciones farmacéuticas comprenden por lo tanto tampón Tris de aproximadamente pH 7,0 8,5, o tampón acetato de aproximadamente pH 4,0-5,5 que puede incluir además sorbitol o un sustituto adecuado. En ciertas realizaciones, una composición que comprende una molécula de nucleasa híbrida, con o sin al menos un agente terapéutico adicional, puede prepararse para el almacenamiento mezclando la composición seleccionada que tiene el grado deseado de pureza con agentes de formulación opcionales (Remington's Pharmaceutical Sciences, supra) en forma de una torta liofilizada o una solución acuosa. Además, en ciertas realizaciones, una composición que comprende una molécula de nucleasa híbrida, con o sin al menos un agente terapéutico adicional, puede formularse como un liofilizado utilizando excipientes apropiados, tales como sacarosa.
En ciertas realizaciones, la composición farmacéutica puede seleccionarse para la administración parenteral. En ciertas realizaciones, las composiciones pueden seleccionarse para inhalación o para administración a través del tracto digestivo, tal como por vía oral. La preparación de tales composiciones farmacéuticamente aceptables está dentro de la capacidad de un experto en la materia.
En ciertas realizaciones, los componentes de la formulación están presentes en concentraciones que son aceptables en el sitio de administración. En ciertas realizaciones, se utilizan tampones para mantener la composición en un pH fisiológico o un pH ligeramente inferior, normalmente dentro de un intervalo de pH de aproximadamente 5 a aproximadamente 8.
En ciertas realizaciones, cuando se contempla la administración parenteral, una composición terapéutica puede estar en forma de una solución acuosa parenteralmente aceptable libre de pirógenos que comprende una molécula de nucleasa híbrida deseada, con o sin agentes terapéuticos adicionales, en un vehículo farmacéuticamente aceptable. En ciertas realizaciones, un vehículo para la inyección parenteral es agua destilada estéril en la que una molécula de nucleasa híbrida, con o sin al menos un agente terapéutico adicional, se formula como una solución isotónica estéril, apropiadamente preservada. En ciertas realizaciones, la preparación puede implicar la formulación de la molécula deseada con un agente, tal como microesferas inyectables, partículas bioerosionables, compuestos poliméricos (tales como ácido poliláctico o ácido poliglicólico), perlas o liposomas, que puede proporcionar la liberación controlada o sostenida del producto que puede ser administrado por una inyección de depósito. En ciertas realizaciones, el ácido hialurónico también puede ser utilizado, y puede tener el efecto de favorecer la duración sostenida en la circulación. En ciertas realizaciones, los dispositivos de administración de fármacos implantables pueden utilizarse para introducir la molécula deseada.
En ciertas realizaciones, una composición farmacéutica puede formularse para inhalación. En ciertas realizaciones, una molécula de nucleasa híbrida, con o sin al menos un agente terapéutico adicional, se puede formular como un polvo seco para inhalación. En ciertas realizaciones, una solución de inhalación que comprende una molécula de nucleasa híbrida, con o sin al menos un agente terapéutico adicional, puede formularse con un propulsor para la administración en aerosol. En ciertas realizaciones, las soluciones se pueden nebulizar. La administración pulmonar se describe adicionalmente en la solicitud PCT n.° PCT/US94/001875, que describe la administración pulmonar de proteínas modificadas químicamente.
En ciertas realizaciones, se contempla que las formulaciones pueden administrarse por vía oral. En ciertas realizaciones, una molécula de nucleasa híbrida, con o sin al menos un agente terapéutico adicional, que se administra de esta manera puede formularse con o sin los portadores habitualmente utilizados en la composición de formas de dosificación sólidas, tales como comprimidos y cápsulas. En ciertas realizaciones, una cápsula puede diseñarse para liberar la porción activa de la formulación en el punto del aparato digestivo cuando se maximiza la biodisponibilidad y se minimiza la degradación presistémica. En ciertas realizaciones, al menos un agente adicional puede incluirse para facilitar la absorción de una molécula de nucleasa híbrida y/o cualquiera de los agentes terapéuticos adicionales. En ciertas realizaciones, diluyentes, aromatizantes, ceras de bajo punto de fusión, aceites vegetales, lubricantes, agentes de suspensión, agentes disgregantes de comprimidos, y aglutinantes también pueden emplearse.
En ciertas realizaciones, una composición farmacéutica puede implicar una cantidad eficaz de una molécula nucleasa híbrida, con o sin al menos un agente terapéutico adicional, en una mezcla con excipientes no tóxicos que son adecuados para la fabricación de comprimidos. En ciertas realizaciones, mediante la disolución de los comprimidos en agua estéril, u otro vehículo apropiado, las soluciones pueden prepararse en forma de dosis unitaria. En ciertas realizaciones, los excipientes adecuados incluyen, entre otros, diluyentes inertes, tales como carbonato de calcio, carbonato de sodio o bicarbonato, lactosa o fosfato de calcio; o agentes de unión, tales como almidón, gelatina o acacia; o agentes lubricantes, tales como estearato de magnesio, ácido esteárico, o talco.
Las composiciones farmacéuticas adicionales resultarán evidentes para los expertos en la materia, incluyendo formulaciones que implican una molécula de nucleasa híbrida, con o sin al menos un agente o agentes terapéuticos adicionales, en formulaciones de administración sostenida o controlada. En ciertas realizaciones, las técnicas para formular una variedad de otros medios de administración sostenida o controlada, tales como vehículos liposomales, micropartículas bioerosionables o perlas porosas e inyecciones de depósito, también son conocidas por los expertos en la materia. Véase, por ejemplo, la solicitud PCT n.° PCT/US93/00829 que describe la liberación controlada de micropartículas poliméricas porosas para la administración de composiciones farmacéuticas. En ciertas realizaciones, las preparaciones de liberación sostenida pueden incluir matrices de polímeros semipermeables en forma de artículos conformados, p. ej., películas o microcápsulas. Las matrices de liberación sostenida pueden incluir poliésteres, hidrogeles, polilactidas (patente de Estados Unidos n.° 3.773.919 y el documento EP 058.481), copolímeros de ácido L-glutámico y gamma etil-L-glutamato (Sidman et al., Biopolymers, 22:547-556 (1983)), poli (2-hidroxietil-metacrilato) (Langer et al., J. Biomed. Mater. Res., 15:167-277 (198l) y Langer, Chem Tech., 12:98-105 (1982)), etilvinilacetato (Langer et al., supra) o ácido poli-D(-)-3-hidroxibutírico (documento EP 133.988). En ciertas realizaciones, las composiciones de liberación sostenida también pueden incluir liposomas, que pueden prepararse por cualquiera de varios métodos conocidos en la materia. Véase, p. ej., Eppstein et al., Proc. Natl. Acad. Sci. EE. UU., 82:3688-3692 (1985); documento EP 036.676; documento EP 088.046 y documento EP 143.949.
La composición farmacéutica que se utilizará normalmente para la administración in vivo es estéril. En ciertas realizaciones, esto se puede lograr por filtración a través de membranas estériles de filtración. En ciertas realizaciones, cuando la composición se liofiliza, la esterilización que utiliza este método puede llevarse a cabo ya sea antes o después de la liofilización y reconstitución. En ciertas realizaciones, la composición para administración parenteral puede almacenarse en forma liofilizada o en una solución. En ciertas realizaciones, las composiciones parenterales se disponen en general en un recipiente que tiene un puerto de acceso estéril, por ejemplo, una bolsa o vial para soluciones intravenosas que tiene un tapón perforable por una aguja de inyección hipodérmica.
En ciertas realizaciones, una vez que se ha formulado la composición farmacéutica, esta puede ser almacenada en viales estériles como solución, suspensión, gel, emulsión, un sólido o como un polvo deshidratado o liofilizado. En ciertas realizaciones, dichas formulaciones se pueden almacenar ya sea en una forma lista para su utilización o en una forma (p. ej., liofilizada) que requiere una reconstitución antes de la administración.
En ciertas realizaciones, se proporcionan kits para producir una unidad de administración de una dosis única. En ciertas realizaciones, el kit puede contener tanto un primer recipiente que tiene una proteína seca como un segundo recipiente que tiene una formulación acuosa. En ciertas realizaciones, se incluyen los kits que contienen jeringas precargadas de una sola cámara y de múltiples cámaras (p. ej., jeringas de líquido y liojeringas).
En ciertas realizaciones, la cantidad eficaz de una composición farmacéutica que comprende una molécula de nucleasa híbrida, con o sin al menos un agente terapéutico adicional, que va a emplearse terapéuticamente dependerá, por ejemplo, del contexto y de los objetivos terapéuticos. Un experto en la materia apreciará que los niveles de dosificación apropiados para el tratamiento, de acuerdo con ciertas realizaciones, variarán de este modo dependiendo, en parte, de la molécula administrada, de la indicación para la cual se está utilizando la molécula de nucleasa híbrida, con o sin al menos un agente terapéutico adicional, la vía de administración, y el tamaño (peso corporal, superficie corporal o tamaño de órganos) y/o condición (edad y salud general) del paciente. En ciertas realizaciones, el médico clínico puede valorar la dosificación y modificar la vía de administración para obtener el efecto terapéutico óptimo. En ciertas realizaciones, una dosificación típica puede oscilar entre aproximadamente 0,1 g/kg y aproximadamente 100 o más mg/kg, dependiendo de los factores mencionados anteriormente. En ciertas realizaciones, la dosificación puede oscilar entre 0,1 mg/kg y aproximadamente 100 mg/kg; o de 1 g/kg a aproximadamente 100 mg/kg; o de 5 g/kg a aproximadamente 100 mg/kg.
En ciertas realizaciones, la frecuencia de dosificación tendrá en cuenta los parámetros farmacocinéticos de una molécula de nucleasa híbrida y/o cualquiera de los agentes terapéuticos adicionales en la formulación utilizada. En ciertas realizaciones, un médico clínico administrará la composición hasta que se alcance una dosificación que consiga el efecto deseado. En ciertas realizaciones, por lo tanto, la composición se puede administrar como una dosis única, o como dos o más dosis (que pueden contener o no la misma cantidad de la molécula deseada) con el tiempo, o como una infusión continua por un dispositivo de implantación o catéter. El refinamiento adicional de la dosificación apropiada se realiza rutinariamente por los expertos en la materia y está dentro del ámbito de las tareas realizadas rutinariamente por ellos. En ciertas realizaciones, las dosificaciones apropiadas pueden determinarse mediante el uso de datos de dosis-respuesta apropiados.
En ciertas realizaciones, la vía de administración de la composición farmacéutica está de acuerdo con métodos conocidos, p. ej., por vía oral, a través de una inyección por vías intravenosa, intraperitoneal, intracerebral (intraparenquimal), intracerebroventricular, intramuscular, subcutánea, intraocular, intraarterial, intraportal, o intralesional; mediante sistemas de liberación sostenida o mediante dispositivos de implantación. En ciertas realizaciones, las composiciones pueden administrarse por inyección de bolos o de manera continua mediante infusión, o mediante un dispositivo de implantación.
En ciertas realizaciones, la composición puede administrarse localmente por la implantación de una membrana, esponja u otro material apropiado sobre el que se haya absorbido o encapsulado la molécula deseada. En ciertas realizaciones, cuando se utiliza un dispositivo de implantación, el dispositivo puede implantarse en cualquier tejido u órgano adecuado, y la administración de la molécula deseada puede realizarse por difusión, un bolo de liberación retardada, o una administración continua.
En ciertas realizaciones, puede ser deseable utilizar una composición farmacéutica que comprende una molécula de nucleasa híbrida, con o sin al menos un agente terapéutico adicional, de una manera ex vivo. En tales casos, células, tejidos y/u órganos que han sido extraídos del paciente se exponen a una composición farmacéutica que comprende una molécula de nucleasa híbrida, con o sin al menos un agente terapéutico adicional, después de lo cual las células, los tejidos y/u los órganos se implantan posteriormente de nuevo en el paciente.
En ciertas realizaciones, una molécula de nucleasa híbrida y/o cualquiera de los agentes terapéuticos adicionales pueden administrarse por implantación de ciertas células que han sido modificadas por ingeniería genética, utilizando métodos, tales como los descritos en la presente memoria, para expresar y secretar los polipéptidos. En ciertas realizaciones, tales células pueden ser células de animales o humanas, y pueden ser autólogas, heterólogas, o xenogénicas. En ciertas realizaciones, las células pueden ser inmortalizadas. En ciertas realizaciones, con el fin de disminuir la posibilidad de una respuesta inmunológica, las células pueden ser encapsuladas para evitar la infiltración de tejidos circundantes. En ciertas realizaciones, los materiales para encapsulación son normalmente cuerpos o membranas poliméricos semipermeables biocompatibles que permiten la liberación del producto proteico o productos proteicos pero impiden la destrucción de las células por el sistema inmunitario del paciente o por otros factores perjudiciales de los tejidos circundantes.
Las moléculas de nucleasa híbridas de la presente invención son particularmente eficaces en el tratamiento de trastornos autoinmunitarios o respuestas inmunitarias anormales. A este respecto, se apreciará que las moléculas de nucleasa híbridas de la presente invención se puedan utilizar para controlar, suprimir, modular, tratar o eliminar las
respuestas inmunitarias no deseadas tanto externas como autoantígenas. En otras realizaciones, los polipéptidos de la presente invención pueden utilizarse para tratar trastornos inmunitarios que incluyen, entre otros, diabetes mellitus dependiente de insulina, esclerosis múltiple, encefalomielitis autoinmune experimental, artritis reumatoide, artritis autoinmune experimental, miastenia gravis, tiroiditis, una forma experimental de uveorretinitis, tiroiditis de Hashimoto, mixedema primario, tirotoxicosis, anemia perniciosa, gastritis atrófica autoinmune, enfermedad de Addison, menopausia prematura, infertilidad masculina, diabetes juvenil, síndrome de Goodpasture, pénfigo vulgar, penfigoide, oftalmía simpática, uveítis facogénica, anemia hemolítica autoinmune, leucopenia idiopática, cirrosis biliar primaria, hepatitis Hbs-ve crónica activa, cirrosis criptogénica, colitis ulcerosa, síndrome de Sjogren, esclerodermia, granulomatosis de Wegener, polimiositis, dermatomiositis, LE discoide, lupus eritematoso sistémico, y enfermedad del tejido conectivo.
Ejemplos
A continuación, se presentan ejemplos de realizaciones específicas para llevar a cabo la presente invención. Los ejemplos se ofrecen solo a efectos ilustrativos, y no tienen por objeto limitar el alcance de la presente invención en modo alguno. Se han hecho esfuerzos para asegurar la exactitud con respecto a los números utilizados (p. ej., cantidades, temperaturas, etc.), pero algunos errores y desviaciones experimentales deberían, por supuesto, permitirse.
La práctica de la presente invención empleará, a menos que se indique lo contrario, métodos convencionales de química, bioquímica de proteínas, técnicas de ADN recombinante y farmacología, dentro de la capacidad de la materia. Tales técnicas se explican completamente en la literatura. Véase, p. ej., T.E. Creighton, Structures and Molecular Properties (W.H. Freeman and Company, 1993); A.L. Lehninger, Biochemistry (Worth Publishers, Inc., adición actual); Sambrook, et al., Molecular Cloning: A Laboratory Manual (2a edición, 1989); Methods in Enzymology (S. Colowick y N. Kaplan eds., Academic Press, Inc..); Remington's Pharmaceutical Sciences, 18a Edición (Easton, Pensilvania: Mack Publishing Company, 1990); Carey y Sundberg Advanced Organic Chemistry 3a Ed. (Plenum Press) vols. A y B (1992).
Ejemplo 1: Construcción de genes de fusión que expresa RNasa-Ig.
La RNasa 1 murina se amplificó como un ADNc de longitud completa de una biblioteca EST (del Dr. C. Raine, Albert Einstein School of Medicine, Bronx, NY) que envió el clon a nuestro laboratorio sin MTA. La secuencia de cebadores específicos 5' y 3' utilizados provino a partir de las secuencias publicadas. La secuencia del clon se verificó mediante análisis de secuenciación. El número de acceso a Genebank es el número de ID de CNIB 19752. La RNasa 1 humana de longitud completa se aisló a partir de un ADNc cebado de oligo dT y cebado al azar derivado de un ARN total de páncreas humano (Ambion/Applied Biosystems, Austin, TX).
Una vez aislado un clon de longitud completa, los cebadores se diseñaron para crear un gen de fusión con los dominios Fc de IgG2a de ratón (SEQ ID NO: 114) o IgG1 humana (SEQ ID NO: 110). Dos cebadores diferentes se diseñaron para la secuencia en 5' fusionada en el extremo amino terminal de la cola Fc; el primero incorpora el péptido líder nativo de RNasa de ratón (o de ser humano), mientras que el segundo se une a un sitio Agel al extremo amino terminal de RNasa en el sitio de escisión por el péptido señal predicho con el fin de fundir la RNasa a un péptido líder VKIII humano que ya se había clonado y utilizado para otros estudios de expresión. Para la RNasa murina, la secuencia del primer cebador es:
mribNL5'
30 meros (RNasa 5' con líder nativo y HindIII+Kozak)
gTT AAg CTT gCC ACC ATg ggT CTg gAg AAg TCC CTC ATT CTg-3' (SEQ ID NO:1)
El segundo cebador crea una unión de fusión génica entre una secuencia líder existente y la secuencia madura en el extremo 5' de la RNasa, en el sitio de escisión del péptido líder predicho o cerca del sitio de escisión del péptido líder predicho.
27 meros (secuencia madura 5' de RNasa (sin líder, con sitio Agel)
5'-gAT ACC ACC ggT Agg gAA TCT gCA gCA CAg AAg TTT CAg-3' (SEQ ID NO: 2)
La secuencia del cebador 3' para la fusión a IgG2a murina en el extremo carboxi de la RNasa y en el extremo amino terminal de la cola Fc es la siguiente:
mrib3NH2
28 meros (extremo 3' de RNasa con sitio XhoI para la fusión a mIgG2a).
5'-ggC TCg AgC ACA gTA gCA TCA AAg tGG ACT ggT ACg TAg g-3' (SEQ ID NO: 3).
Dos más oligos se diseñaron para crear un gen de fusión que expresa Ig-RNasa, en el que la cola de Ig es un extremo amino terminal en el dominio enzimático de la RNasa.
mrib5X
Extremo 5' de RNasa de 36 meros con enlazador de aa y sitio Xbal para la fusión a un extremo carboxi del dominio Fc.
5’-AAA TCT AgA CCT CAA CCA ggT Agg gAA TCT gCA gCA CAg AAg TTT CAg-3’ (SEQ ID NO:4)
mrib3X
Extremo 3' de RNasa de 31 meros con dos codones de terminación y sitio XbaI para la fusión a un extremo carboxi del dominio Fc.
5'-TCT AgA CTA TCA CAC AgT AgC ATC AAA gTg gAC Tgg TAC gTA g-3' (SEQ ID NO: 5).
Ejemplo 2: Aislamiento de scFvs anti-ARN o anti-ADN a partir de hibridomas que expresan anticuerpos monoclonales.
Un hibridoma anti-ARN designado H564 se utilizó para aislar regiones V específicas para ARN. Antes de la recolección, las células de hibridoma anti-ARN H564 se mantuvieron en crecimiento en fase logarítmica durante varios días en medio RPMI 1640 (Invitrogen/Life Technologies, Gaithersburg, Md.) suplementado con glutamina, piruvato, aminoácidos no esenciales en DMEM y penicilina-estreptomicina. Las células se aglomeraron por centrifugación del medio de cultivo, y 2x107 células se utilizaron para preparar ARN. Se aisló ARN de las células de hibridoma utilizando el kit QIAGEN RNAeasy (Valencia, Calif.), el kit de aislamiento de ARN total y QIAGEN QIAshredder de acuerdo con las instrucciones del fabricante anexas al kit. Cuatro microgramos (4 |jg) de ARN total se utilizaron como molde para preparar ADNc mediante transcripción inversa. El ARN, 300 ng de cebadores aleatorios, 500 ng de Oligo dT (12-18), y 1 j l de 25 mM de dNTPs se combinaron y desnaturalizaron a 80 °C durante 5 minutos antes de la adición de enzimas. Se añadió transcriptasa inversa Superscript III (Invitrogen, Life Technologies) al ARN además de una mezcla de cebador en un volumen total de 25 pl en presencia de un tampón de segunda cadena 5 veces y DTT 0,1 M proporcionado con la enzima. La reacción de transcripción inversa se dejó proceder a 50 °C durante una hora.
El ADNc generado en la reacción de la transcriptasa inversa se purificó por kits de purificación por PCR QIAquick (Qiagen, Valencia CA) y se ajustaron con una secuencia poli-G utilizando transferasa terminal (Invitrogen, Carlsbad, CA) de acuerdo con las instrucciones del fabricante. El ADNc ajustado se purificó de nuevo por purificación por PCR QIAquick y se eluyó en 30 ul de tampón de elución (tampón TE) provisto de los kits. Dos microlitros de ADNc ajustado se utilizaron como molde junto con un cebador 5' ancla-cola que contiene un dominio poli-C, y una región constante específica, cebadores 3' degenerado para amplificar por PCR las regiones variables de la cadena ligera y pesada del anticuerpo H564. Las dos cadenas variables se diseñaron con sitios de enzimas de restricción de modo que un scFv podría ensamblarse por tres formas de ligamiento de las dos regiones V a una secuencia enlazadora después de la digestión de enzimas de amplificación y restricción.
Un péptido enlazador (gly4ser)4 que se inserta entre las dos regiones V se incorporó por amplificación de esta secuencia enlazadora por PCR de extensión solapada utilizando los cebadores solapados que codifican las dos mitades de la molécula. Los fragmentos de PCR se aislaron por electroforesis en gel de agarosa, los fragmentos se aislaron mediante el corte de las bandas apropiadas del gel y la purificación del DNA amplificado utilizando kits de extracción de gel QIAquick (QIAGEN, Valencia, CA). Los derivados de scFv del hibridoma H564 se ensamblaron como genes de fusión VP-enlazador-VL que podrían unirse a cualquiera de los extremos de un gen de fusión que expresa Ig más grande. El dominio V.sub.P se amplificó sin un péptido líder, pero incluía un sitio de restricción Agel en 5' para la fusión al sitio de restricción V.sub.L y BglII en el extremo 3' para la fusión al dominio enlazador.
El scFv-Ig se ensambló mediante la inserción del fragmento scFv HindIII-XhoI en pDG que contenía la bisagra de IgG1 humana, regiones CH2 y CH3, que se digirió con enzimas de restricción, HindIII y XhoI. Después del ligamento, los productos de ligamento se transformaron en bacterias DH5-alfa. El ADNc de scFv-Ig se sometió a una secuenciación de ciclos en un termociclador PE 9700 con un programa de 25 ciclos por desnaturalización a 96 °C durante 10 segundos, hibridación a 50 °C durante 30 segundos, y extensión a 72 °C durante 4 minutos. Los cebadores de secuenciación eran cebadores directos e inversos pDG que se hibridan con el dominio CH2 humano en la porción de la región constante de IgG. Las reacciones de secuenciación se realizaron utilizando Big Dye Terminator Ready Sequencing Mix v3.1 (PE-Applied Biosystems, Foster City, Calif.) de acuerdo con las instrucciones del fabricante. Las muestras se purificaron posteriormente utilizando columnas Autoseq G25 (GE Healthcare) y los eluatos se secaron en un secador de vacío Savant, se desnaturalizaron en el reactivo de supresión para moldes (PE-ABI), y se analizaron en un analizador genético ABI 310 (PE-Applied Biosystems). La secuencia se editó, se tradujo, y se analizó utilizando un Vector Nti versión 10.0 (Informax/Invitrogen, North Bethesda, Md.).
Construcción de un gen de fusión que expresa RNasal-hlgGl humana (SEQ ID NO: 125-127).
La RNasal humana (SEQ ID NO: 113) se aisló mediante amplificación por PCR a partir de ARN total de páncreas humano obtenido de Ambion/Applied Biosystems (Austin, TX). Cuatro microgramos (4 |jg) de ARN total se utilizaron como molde para preparar ADNc mediante transcripción inversa. El ARN, 300 ng de cebadores aleatorios, 500 ng de Oligo dT (12-18), y 1 ul de 25 mM de dNTPs se combinaron y desnaturalizaron a 80 °C durante 5 minutos antes de la adición de enzima. La transcriptasa inversa Superscrit III (Invitrogen, Life Technologies) se añadió al ARN además de la mezcla de cebador en un volumen total de 25 pl en presencia de un tampón de segunda cadena y DTT 0,1 M proporcionado con la enzima. La reacción de transcripción inversa se dejó proceder a 50 °C durante una hora. Las reacciones se purificaron adicionalmente mediante columnas de purificación de PCR QIAquick, y el ADNc se eluyó en 40 microlitros de tampón TE antes de su uso en reacciones de PCR. Dos microlitros de ADNc eluido se añadieron a reacciones de PCR que contenían 50 pmol de cebadores 5' y 3' específicos para RNasa1 humana, y 45 microlitros de supermezcla de alta fidelidad de PCR (Invitrogen, Carlsbad, CA) se añadieron a tubos de 0,2 ml de reacción de PCR. Las reacciones de PCR se realizaron utilizando un termociclador C1000 (BioRad, Hercules CA). Las reacciones incluyeron una etapa de desnaturalización inicial a 95 °C durante 2 minutos, seguido por 34 ciclos con desnaturalización a 94 °C durante 30 s, hibridación a 50 °C durante 30 s, y una etapa de extensión a 68 °C durante 1 minuto, seguido de una extensión final de 4 minutos a 72 °C. Una vez que se aislaron las colas de tipo natural, los fragmentos se clonaron con TOPO en vectores pCR2.1; el ADN se preparó mediante los kits spin plasmid miniprep de QIAGEN de acuerdo con las instrucciones del fabricante. El ADN plasmídico se secuenció utilizando una mezcla de reacción preparada ABI Dye Terminator v3.1 de acuerdo con las instrucciones del fabricante.
Ejemplo 3: Aislamiento de dominios Fc de ratón y humanos e introducción de mutaciones en la secuencia codificante.
Para el aislamiento de dominios Fc de ratón (SEQ ID NO: 114) y humanos (SEQ ID NO: 110), el RNA se deriva de tejidos de ratón o humanos según se indica. Una suspensión de células individuales se generó a partir del bazo de ratón en un medio de cultivo RPMI. Alternativamente, las CMSP humanas se aislaron a partir de sangre fresca, entera utilizando medios de separación de linfocitos (MSL) de Organon Teknika (Durham, NC), capas leucoplaquetarias recolectadas de acuerdo con las instrucciones del fabricante, y las células se lavaron tres veces en TFS antes de su uso. Las células se aglomeraron por centrifugación del medio de cultivo, y 2x107 células se utilizaron para preparar ARN. Se aisló el ARN de las células utilizando el kit RNAeasy de QIAGEN (Valencia, Calif.), el kit de aislamiento de ARN total y las columnas QIAshredder de QIAGEN de acuerdo con las instrucciones del fabricante anexas a los kits. Un microgramo (4 jg ) de ARN total se utilizó como molde para preparar ADNc mediante transcripción inversa. El ARN, 300 ng de cebadores aleatorios, 500 ng de Oligo dT (12-18), y 1 pl de 25 mM de dNTPs se combinaron y desnaturalizaron a 80 °C durante 5 minutos antes de la adición de enzima. La transcriptasa inversa Superscript III (Invitrogen, Life Technologies) se añadió al ARN además de una mezcla de cebador en un volumen total de 25 pl en presencia de un tampón segunda cadena y DTT 0,1 M proporcionado con la enzima. La reacción de transcripción inversa se dejó proceder a 50 °C durante una hora. El ADNc se purificó utilizando columnas de purificación PCR QIAquick (QIAGEN) de acuerdo con las instrucciones del fabricante, y se eluyó en 40 microlitros de tampón TE antes de su uso en reacciones de PCR.
Los dominios Fc de ratón y humanos de tipo natural se aislaron mediante amplificación por PCR utilizando el ADNc descrito anteriormente como molde. Los siguientes cebadores se utilizaron para la amplificación inicial de secuencias de tipo natural, pero se incorporaron los cambios mutacionales deseados en el dominio bisagra:
mahIgG1CH2M: 47 meros
5'-tgtccaccgtgtccagcacctgaactcctgggtggatcgtcagtcttcc-3' (SEQ ID NO: 6)
hlgG1-5scc: 49 meros
5'-agatctcgagcccaaatcttctgacaaaactcacacatgtccaccgtgt-3' (SEQ ID NO: 7)
mahIgG1S: 51 meros
5'-tctagattatcatttacccggagacagagagaggctcttctgcgtgtagtg-3' (SEQ ID NO: 8)
muIgG2aCH2: 58meros
5'-cctccatgcaaatgcccagcacctaacctcttgggtggatcatccgtcttcatcttcc-3' (SEQ ID NO: 9)
mIgG2a-5scc: 47meros
5'-gaagatctcgagcccagaggtcccacaatcaagccctctcctcca-3' (SEQ ID NO: 10)
mIgG2a3S: 48meros
5'-gtttctagattatcatttacccggagtccgagagaagctcttagtcgt-3' (SEQ ID NO: 11)
Las reacciones de PCR se realizaron utilizando un termociclador C1000 (BioRad, Hercules CA) o un termociclador Eppendorf (ThermoFisher Scientific, Houston TX). Las reacciones incluyeron una etapa inicial de desnaturalización a 95 °C durante 2 minutos, seguido por 34 ciclos con una desnaturalización a 94 °C durante 30 s, hibridación a 50 °C, durante 30 s, y una etapa de extensión a 72 °C durante 1 minuto, seguido de una extensión final de 4 minutos a 72 °C. Una vez que se aislaron las colas de tipo natural, los fragmentos se clonaron con TOPO en vectores pCR2.1, el ADN se preparó utilizando los kits spin plasmid miniprep de QIAGEN de acuerdo con las instrucciones del fabricante y los clones se secuenciaron utilizando reacciones de secuenciación ABI Dye Terminator v3.1 de acuerdo con las instrucciones del fabricante.
El ADN de los clones correctos se utilizó como moldes en PCRs de extensión solapada para introducir mutaciones en las posiciones deseadas en la secuencia de codificación para IgG2a de ratón o IgG1 humana. Las reacciones de PCR se establecieron utilizando clones de tipo natural de longitud completa como molde (1 microlitro), 50 pmol de cebadores 5' y 3' hasta que se incrementó cada porción de PCR del dominio Fc e incluyendo el sitio de la mutación deseada a partir de cada dirección, y supermezcla de alta fidelidad PCR (Invitrogen, Carlsbad CA) en volúmenes de reacción de 50 microlitros utilizando un ciclo de amplificación corto. Como ejemplo de mutagénesis con PCR solapada, la combinación de cebadores utilizada para introducir la mutación P331S en IgG1 humana, fue según se indica:
Un subfragmento 5' se amplificó utilizando el clon de tipo natural de longitud completa como molde, y el cebador 5' fue hIgG1-5scc: 5'-agatctcgagcccaaatcttctgacaaaactcacacatgtccaccgtgt-3' (SEQ ID NO: 12), mientras que el cebador 3' era P331AS: 5'-gttttctcgatggaggctgggagggctttgttggagacc-3' (SEQ ID NO: 13). Un subfragmento 3' se amplificó utilizando el clon de tipo natural de longitud completa como molde y el cebador 5' fue P331S: 5'aaggtctccaacaaagccctcccagcctccatcgagaaaacaatctcc-3' (SEQ ID NO: 14), mientras que el cebador 3' era mahIgGIS: 5'-tctagattatcatttacccggagacagagagaggctcttctgcgtgtagtg- 3' (SEQ ID NO: 15).
Una vez que los subfragmentos se amplificaron y aislaron por electroforesis en gel de agarosa, estos se purificaron por columnas de purificación en gel QIAquick y se eluyeron en 30 microlitros de tampón TE de acuerdo con las instrucciones del fabricante. Dos rondas de PCR se realizaron con los dos subfragmentos como moldes solapados en nuevas reacciones. El ciclador se pausó y los cebadores de flanqueo 5' (hIgG1-5scc, véase anteriormente) y 3' (mahlgG1S, véase anteriormente) se añadieron a las reacciones (50 pmol cada uno). Las amplificaciones por PCR se llevaron a cabo entonces durante 34 ciclos en las condiciones descritas para las moléculas de tipo natural anteriores. Los fragmentos de longitud completa se aislaron por electroforesis en gel, y se clonaron con TOPO en vectores pCR2.1 para el análisis secuencial. Los fragmentos de los clones con la secuencia correcta se subclonaron después en vectores de expresión para la creación de las diferentes moléculas de nucleasa híbridas descritas en la presente memoria.
Ejemplo 4: Expresión de la RNasa-Ig (SEQ ID NO 124, 125, 126,127, 174 (nucleótido) o 160, 161, 162 163, 175 (aminoácido)), DNasa-Ig (SEQ ID NO: 118, 119, 120, 121, 122, 123, 186 (nucleótido) o SEQ ID NO 154, 155, 156, 157, 158, 159, 187 (aminoácido)), construcciones de fusión de múltiples subunidades de Ig (SEQ ID NO: 115, 116, 117, 172, 176, 178, 180 (nucleótido) o SEQ ID NO 151 152, 153, 173, 177, 179, 181 (aminoácido)), y proteínas de fusión que expresa scFv-Ig H564 en estirpes celulares CHO estables.
Este ejemplo ilustra la expresión de los diferentes genes de fusión que expresa Ig descritos en la presente memoria en estirpes celulares eucariotas y la caracterización de las proteínas de fusión expresadas por SDS-PAGE y por ELISA de tipo sándwich de IgG.
Los fragmentos génicos de fusión que expresan Ig con la secuencia correcta se insertaron en el vector de expresión pDG de mamífero, y el ADN de los clones positivos se amplificó utilizando kits de preparación plasmídica de QIAGEN (Qiagen, Valencia, CA). El ADN plasmídico recombinante (100 |jg) se linealizó en una región no esencial por digestión con AscI, se purificó mediante extracción con fenol, y se volvió a suspender en un medio de cultivo tisular, Excell 302 (catálogo n.° 14312-79P, JRH Biosciences, Lenexa, Kans./SAFC). Las células para la transfección, las células CHO-DG44, se mantuvieron en crecimiento logarítmico, y 107 células se recolectaron para cada reacción de transfección. El ADN linealizado se añadió a las células CHO en un volumen total de 0,8 ml para la electroporación.
La producción estable de la proteína de fusión que expresa Ig se consiguió mediante la electroporación de un plásmido amplificable seleccionable pDG que contiene el ADNc de RNasa-Ig bajo el control del promotor de CMV, en células de ovario de hámster chino (CHO). El vector pDG es una versión modificada de pcDNA3 que codifica el marcador seleccionable DHFR con un promotor atenuado para aumentar la presión de selección del plásmido. El ADN plasmídico se preparó utilizando kits maxiprep de Qiagen, y el plásmido purificado se linealizó en un sitio AscI único antes de la extracción con fenol y precipitación con etanol. Se añadió ADN de esperma de salmón (Sigma-Aldrich, St. Louis, Mo.) como ADN portador, y 100 jg de cada ADN plasmídico y portador se utilizaron para transfectar 107 células CHO-DG44 por electroporación. Las células se cultivaron hasta la fase logarítmica en un medio Excell 302 (JRH Biosciences) que contenía glutamina (4 mM), piruvato, insulina recombinante, penicilinaestreptomicina y aminoácidos no esenciales 2x DMEM (procedentes de Life Technologies, Gaithersburg, Md.), en lo sucesivo referido como medio "Excell 302 completo". Los medios para las células no transfectadas también contenían HT (diluida a partir de una solución 100x de hipoxantina y timidina) (Invitrogen/Life Technologies). Los medios para las transfecciones bajo selección contenían diferentes niveles de metotrexato (Sigma-Aldrich) como agente selectivo, que oscilan desde 50 nM a 1 pM. Las electroporaciones se realizaron a 280 voltios, 950 microfaradios. Se dejó que las células transfectadas se recuperaran durante la noche en medios no selectivos antes de la siembra selectiva en placas en placas de fondo plano de 96 pocillos (Costar) en diferentes diluciones en serie que oscilan de 125 células/pocillo a 2.000 células/pocillo. Los medios de cultivo para la clonación de células eran Excell 302 completo, que contenía 50 nM de metotrexato. Una vez que la excrecencia clonal era suficiente, las diluciones en serie de los sobrenadantes del cultivo de los pocillos maestros se identificaron sistemáticamente para la expresión de la proteína de fusión que expresa Ig mediante el uso de un ELISA tipo sándwich de IgG.
Brevemente, las placas NUNC Immulon II se revistieron durante la noche a 4 °C con 7,5 microgramos/ml de F(ab'2) de cabra anti-IgG de ratón (KPL Labs, Gaithersburg, MD) en TFS. Las placas se bloquearon en TFS/ASB al 3 %, y diluciones en serie de sobrenadantes de cultivo se incubaron a temperatura ambiente durante 2-3 horas. Las placas se lavaron tres veces en TFS/Tween 20 al 0,05 % y se incubaron con F(ab'2) de cabra anti-IgG2a de ratón conjugada con peroxidasa de rábano picante (Southern Biotecnologías) e IgG de cabra anti-ratón (KPL) mezclados entre sí, cada uno a 1:3500 en TFS/a Sb al 1,0 %, durante 1-2 horas a temperatura ambiente. Las placas se lavaron cuatro veces en TFS/Tween 20 al 0,05%, y la unión se detectó con SureBlue Reserve, sustrato TMB (laboratorios KPL, Gaithersburg, MD). Las reacciones se detuvieron mediante la adición de un volumen equitativo de HCl IN, y las placas se leyeron a 450 nM en un lector de placas Spectramax Pro (Microdevices, Sunnyvale CA). Los clones con la mayor producción de la proteína de fusión se ampliaron en T25 y luego en matraces T75 para proporcionar un número adecuado de células para la congelación y para incrementar la producción de la proteína de fusión. Los niveles de producción se aumentaron aún más en cultivos a partir de los cuatro mejores clones mediante amplificación progresiva en medios de cultivo que contenían metotrexato. En cada pase sucesivo de células, el medio Excell 302 completo contenían una mayor concentración de metotrexato, de manera tal que solo las células que amplificaron el plásmido DHFR podrían sobrevivir. El nivel de producción de los cuatro mejores pocillos maestros no amplificados de los transfectantes CHO que expresan RNasalg osciló entre 30-50 microgramos/ml de cultivo. Los cultivos amplificados se ensayaron actualmente para determinar los niveles de producción.
Los sobrenadantes se recogieron de las células CHO que expresan RNasa-Ig, se filtraron a través de filtros que expresan PES de 0,2 pm (Nalgene, Rochester, N.Y.) y se pasaron sobre una columna de proteína A-agarosa (agarosa reticulada IPA 300) (Repligen, Needham, Masa.). La columna se lavó con tampón de lavado de columna (90 mM de Tris-Base, 150 mM de NaCl, azida de sodio al 0,05 %, pH 8,7), y la proteína unida se eluyó utilizando tampón citrato 0,1 M, pH 3,0. Las fracciones se recogieron y se determinó la concentración proteínica a 280 nm utilizando un espectrofotómetro de micromuestras Nanodrop (Wilmington DE), y una determinación en blanco utilizando tampón citrato 0,1 M, pH 3,0. Las fracciones que contenían una proteína de fusión se agruparon, y el intercambio de tampón se realizó por espines en serie en TFS utilizando concentradores Centricon seguido de filtración a través de dispositivos con un filtro de 0,2 pm para reducir la posibilidad de contaminación por endotoxinas. Un coeficiente de extinción de 1,05 se determinó utilizando las herramientas de análisis de proteínas en el paquete de programas Vector NTI versión 10.0 (Informax, North Bethesda, Md.) y el sitio de escisión predicho a partir de las herramientas en línea de análisis de proteínas ExPasy.
Ejemplo 5: análisis por SDS-PAGE de la proteína de fusión que expresa RNasalg.
La RNasa-Ig purificada (SEQ ID NO: 115) se analizó por electroforesis en geles de poliacrilamida con SDS. Las muestras de proteína de fusión se hirvieron en un tampón de muestra SDS con y sin reducción de los enlaces disulfuro y se aplicaron en geles de Tris-BIS al 10 % SDS (catálogo n.° NP0301, Novex, Carlsbad, CA). Cinco microgramos de cada proteína purificada se cargaron en los geles. Las proteínas se visualizaron después de la electroforesis mediante tinción con azul de Coomassie (reactivo de tinción gel code blue Pierce, catálogo n.° 24590, Pierce, Rockford, III.), y decoloración en agua destilada. Los marcadores de peso molecular se incluyeron en el mismo gel (patrones pretintados de Kaleidoscope, catálogo n.° 161-0324, Bio-Rad, Hercules, Calif.). Otras muestras se analizaron según se indica: proteína de fusión que expresan RNasa-Ig en el tampón de muestreo (62,5 mM de Tris-HCl, pH 6,8, SDS al 2 %, glicerol al 10 %, azul de bromofenol al 0,01 %) con y sin 2-mercaptoetanol al 5 %) se cargó en el gel premoldeado al 4-12 % (Bio-RAD). El gel se analizó a 100 voltios hasta que el colorante salga del gel. El gel se tiñó en Gel Code Blue (Thermo Scientific) a temperatura ambiente durante la noche y luego se lavó con agua.
La FIG. 3 muestra la proteína de fusión que expresa RNasa-Ig en comparación con IgG de ratón. Rnasa-Ig se purificó a partir del sobrenadante de células CHO transfectadas mediante la unión y elución de proteína A-sefarosa. El gel SDS-PAGE muestra que Rnasa-Ig es de aproximadamente 50 kDa cuando se reduce y aproximadamente 110 kDa cuando no se reduce.
Ejemplo 6: Detección de RNasa-Ig en sueros de ratón.
Ensayo por DERS
El gel de agarosa al 2 % se preparó con agua destilada. Poli-IC (Sigma) se disolvió en agua destilada en 3 mg/ml y la placa de gel se preparó según se indica: 1,5 ml de tampón de reacción (0,2 M de Tris-HCl, pH 7,0, 40 mM de EDTA y 0,1 mg/ml de bromuro de etidio), 1 ml de poli-IC y 0,5 ml de agua se colocaron en el tubo y se mantuvieron a 50 °C durante 5 min. Se añadieron 3 ml de agarosa (mantenida a 50 °C) al tubo. La mezcla se vertió inmediatamente sobre una placa de vidrio. Los pocillos de muestreo se perforaron en el gel. 2 pl de cada muestra de suero se cargaron en pocillos y el gel se incubó a 37 °C durante 4 horas en la cámara húmeda. A continuación, el gel se incubó en un tampón (20 mM de acetato de sodio, pH 5,2, 20 mg/ml de bromuro de etidio) en hielo durante 30 min y se leyó bajo UV.
La FIG. 4 muestra la actividad de RNasa de tres ratones (410, 413, y 418) después de una inyección intravenosa de proteína de fusión que expresa RNasa-Ig (SEQ ID NO: 150) (purificada en este experimento a partir del
sobrenadante de células COS transfectadas mediante la unión y elución de la proteína A sefarosa). Un patrón se utilizó en la fila superior. Observe una segunda inyección para el ratón 410 (véase la flecha) después de 2 semanas.
2 |jl de suero de cada uno de los tres ratones se cargaron en gel de agarosa al 1 % que contenía 0,5 mg/ml de poli-C. El gel se incubó durante 4 horas en una cámara húmeda a 37 °C, y luego se sumergió en un tampón que contenía 20 mM de acetato de sodio y 20 ug/ml de bromuro de etidio durante 30 min. La actividad de la RNasa se refleja en el tamaño y la intensidad en torno al pocillo central. Estos datos muestran que la proteína de fusión que expresa RNasa-Ig tiene una semivida prolongada en suero de ratón.
Ejemplo 7: Uso de ELISA anti-ARN para medir los anticuerpos específicos de ARN en sueros de ratón.
Una placa de 96 pocillos (Nunc, Thermal Fisher Scientific) se revistió con 50 pg/ml de poli-L-lisina (Sigma) durante la noche. Después de lavarse cinco veces con TFS que contenía Tween al 0,05 %, la placa se revistió con 10 pg/ml de ARN de levadura en TFS a 4 °C durante la noche. Después de lavarse cinco veces, la placa se bloqueó con TFS que contenía ASB al 1 % a temperatura ambiente durante 2 horas. Las muestras de suero en 1:50 de dilución se añadieron a la placa y se incubaron a 4 °C durante la noche. El medio de cultivo de hibridoma H564 (anti-RNA) se utilizó como patrón, utilizando diluciones en serie dobles a partir de 1:300. El anticuerpo de detección fue IgG anti ratón conjugada con fosfatasa alcalina (Jackson Lab), y se añadió a la placa a 1:5.000 durante 1 hora a temperatura ambiente. El sustrato de fosfatasa (Sigma) se disolvió en tampón de desarrollo (ThermoFisher Scientific) y se añadió a la placa en 50 jl/pocillo. Las muestras se leyeron a 405 nm utilizando un lector de placas Spectramax Plus (Microdevices, Sunnyvale, CA).
La FIG. 5 muestra los resultados del título ELISA del anticuerpo anti-ARN antes y después de la inyección intravenosa de la proteína de fusión que expresa RNasa-Ig (SEQ ID NO: 150) del ratón 410. La placa con poli-L-lisina pre-revestida (50 pg/ml) se revistió con 10 ug/ml de ARN de levadura. El suero (1:50) se cargó en la placa y se incubó durante la noche a 4 °C. El anticuerpo de detección fue IgG anti-ratón con fosfatasa alcalina (Jackson Labs) a 1:5.000 durante 1 hora a temperatura ambiente, y después se añadió sustrato de fosfatasa y se leyó a 405 nm. Los datos muestran que la inyección de la RNasa-Ig causó una reducción en el título de anticuerpo anti-ARN que persistió durante más de 3 semanas.
La FIG. 6 muestra los resultados del título ELISA de anticuerpo anti-ARN antes y después de la inyección de proteína de fusión que expresa RNasa-Ig (SEQ ID NO: 150) a partir de tres semanas del ratón 413. El experimento se efectuó como se describe para el ratón 410. El título del anticuerpo anti-ARN se redujo después de la inyección de la RNasa-Ig.
Ejemplo 8: La producción de IFN-alfa por CMSPs humanas se inhibe por la adición de RNasalg a cultivos in vitro. La adición de RNasa-Ig (SEQ ID NO: 150) abolió la inducción de interferón-a a partir de células mononucleares de sangre periférica humanas estimuladas utilizando complejos inmunitarios formados con suero de un paciente con LES (J11) más extracto nuclear (EN). Brevemente, las placas ELISA se revistieron con 50 microlitros 1:2.500 de anticuerpo de captura (anti-IFN alfa, PBL 21112-1, Piscataway, NJ), y se incubaron durante la noche a 4 °C. Las placas se lavaron con TFS/Tween 20 al 0,05 %, se bloquearon en TFS/ASB al 1 % durante 2 horas a temperatura ambiente, se lavaron con TFS/Tween-20 al 0,05 %, y se incubaron con diluciones estándar de IFN-alfa, o con diluciones en serie de muestras de suero, y se incubaron 2 horas a temperatura ambiente. Las placas se lavaron y se incubaron con 1:2.000 de anticuerpo de detección (PBL 31101-2, Piscataway, NJ) en TFS/ASB al 1 %. Las placas se lavaron en TFS/Tween-20 al 0,05 %, y se incubaron con 50 microlitros de burro anti-conejo-PRP (Jackson Immunoresearch, Westgrove, PA) a 1:12.000 en TFS/ASB al 1 %. Las placas se lavaron cinco veces antes de la adición de sustrato TMB. Las reacciones se detuvieron mediante la adición de A volumen H2S042N, y las muestras se leyeron a 450 nm en un lector de placas Spectramax Pro (Microdevices, Sunnyvale, CA). Los resultados se muestran en la Fig. 7, que muestra que la adición de RNasa-Ig abolió la inducción de interferón-a partir de células mononucleares de sangre periférica humanas estimuladas utilizando complejos inmunitarios formados con suero de un paciente con LES (J11) más extracto nuclear.
Ejemplo 9: Fenotipo de ratones dobles transgénicos que expresan TLR7.1xRNasaA.
Se crearon ratones que sobreexpresan RNasa A (Tg RNasa). Esta nucleasa se expresa a niveles elevados en ratones Tg que expresan RNasa (véase la Fig. 8). Se desarrolló un método único de difusión radial (DERS) (panel izquierdo) y una ELISA mucho más cuantitativa para cuantificar la RNasa en el suero (véase la Fig. 9). Se cruzó los ratones Tg que expresan RNasa con Tg que expresan TLR7.1 para crear ratones dobles Tg (DTg). Los ratones que expresan TLR7.1 tienen 8-16 copias de TLR7 y desarrollan una enfermedad similar al lupus muy agresiva, rápidamente progresiva y comienzan a morir a los 3 meses de edad con una supervivencia media de 6 meses. En un análisis preliminar, se hizo sangrar a los DTg y a los controles de los miembros de camadas a los 3 meses de edad para ver si los ratones DTg exhibían signos de mejora. Como se muestra en la Fig. 8, los ratones DTg tenían niveles muy altos de RNasa en su suero (equivalente a> 13 U/ml de RNasa basándose en nuestro patrón con actividad específica de 993 U/mg). La concentración de RNasaA en los ratones Tg y DTg también se midió mediante el ensayo de ELISA como se muestra en la Fig. 9. Los ratones Tg que expresan RNasa A y Dtg que expresan TLT7.1XRNasaA tenían concentraciones séricas de RNasa A entre 1-2 ng/ml.
Método detallado para ELISA que expresa RNasa A (Ejemplo 9, Figura 9)
1. Revestir la placa con An anti-RNasaA de Abcam (ab6610): 2,5-10 ug/ml O/N en 4C.
2. Lavar la placa 3 veces con Tween al 0,05 %/1XTFS.
3. Bloquear con ASB al 1 % en TFS durante al menos 1 hora.
4. Lavar la placa 3 veces con Tween al 0,05 %/1XTFS.
5. Cargar las muestras. Diluciones de muestra a 1:50.
6. Incubar a temperatura ambiente durante 2 horas.
7. Lavar la placa 3 veces con Tween al 0,05 %/1XTFS.
8. Preparar la dilución de An anti-RNasa marcado con biotina a una dilución de 1:4.500 (2,2 ug/ml). Dejar a TA durante 1 hora (Rockland 200-4688: 10 mg/ml).
9. Lavar la placa 3 veces.
10. Diluir StrepAV con PRP (Biolegend 405210) 1:2.500. Cubrir con papel de aluminio y dejar a TA durante 25-30 min.
11. Lavar 6 veces, dejar que el líquido se asiente en los pocillos durante al menos 30 segundos entre lavados. 12. Agregar sustrato BD OptEIA A+B 1:1. Esperar hasta que el color cambie 5-10 minutos máx. No permita que el nivel del pocillo superior exceda 1,0. Agregar 80 ul. (cat n.°: 51-2606KC; reactivo A, 51-2607KC; reactivo B).
13. Agregar 40 ul de ácido sulfúrico 1 M para detener la reacción.
Información del producto/reactivo:
An de RNasaA: ab6610 (90 mg/ml).
Tampón de ELISA: ASB al 1 % en TFS.
Tampón de lavado de ELISA: Tween al 0,05 %/1XTFS.
An Anti-RNasaA conjugado con biotina: Rockland: 200-4688 (10 mg/ml).
StrepAV con PRP: Biolegend 405210.
Reactivo A y B de BD OptEIA: 51-2606KC y 51-2607KC.
Ejemplo 10. Curvas de supervivencia para cepas de ratón transgénico que expresa TLR7.1.
Se observó una diferencia altamente significativa entre DTg y los controles de miembros de camadas que expresan TLR7.1 en la supervivencia. Como se muestra en la Figura 10, a los 10 meses, el 61 % de los ratones que expresan TLR7.1 habían muerto, mientras que el 31 % de ratones DTg habían muerto. Estos datos muestran que la sobreexpresión de RNasaA ejerció un fuerte efecto terapéutico. Las razones por las que los ratones que expresan TLR7.1 mueren prematuramente no son del todo claras, aunque la anemia grave, trombocitopenia, y glomerulonefritis podrían desempeñar un papel. Para determinar si el recuento de glóbulos rojos y plaquetas se vio afectado positivamente por la expresión de RNasaA en los ratones DTg, se realizaron los recuentos sanguíneos, pero no se encontraron diferencias entre los ratones que expresan TLR7.1 y DTg. En cambio, no hubo una mejora significativa en la histopatología del riñón en los ratones DTg. Se observó una disminución de la deposición de IgG y C3 en ratones DTg. La tinción PAS, que refleja la inflamación en el mesangio también se redujo en ratones DTg en comparación con los controles de miembros de camada que expresan TLR7.1. Cuando ahora se ha comparado la infiltración de macrófagos de los riñones utilizando anticuerpo anti-MAC-2 (galectina 3) (Lyoda et al. Nephrol Dial Transplat 22: 3451, 2007), había muchas menos células positivas mac-2 en los glomérulos de los ratones DTg. Los resultados de recuento de 20 glomérulos por ratón en 5 ratones en cada grupo revelaron una media /- EE de 3,8 /-1,1 y 1,4 /- 0,2 para los ratones simples frente a DTg respectivamente, p = 0,05. Además, se cuantificó el tamaño del ovillo glomerular y se observó una reducción significativa en el tamaño del ovillo glomerular en los ratones DTg (179 /- 41 frente a 128 /- 16,8 um2 en ratones simples frente a DTg respectivamente, p = 0,037). En resumen, los ratones DTg que expresan TLR7.1XRNAsa sobrevivieron durante más tiempo que sus miembros de camada simples Tg que expresan TLR7.1 y tienen menos inflamación y daños en los riñones.
Ejemplo 11. Análisis de GRIs en bazos de ratones Tg que expresan TLR.
El análisis de los genes de respuesta de interferón (GRIs) en los bazos de ratones Tg que expresan TLR7.1 y ratones DTg que expresan TLR7.1X RNasaA mostró que la expresión del gen IRF7 era significativamente menor en los ratones DTg (p = 0,03). Algunos GRIs incluyendo MX1 y VIG1 fueron más bajos en los ratones DTg en comparación con los ratones Tg, pero las diferencias no fueron significativas. Véase la Figura 11. La PCR cuantitativa se realizó según se indica: el ARN total se aisló de bazos de ratón utilizando el mini kit RNeasy (Qiagen, Valencia, CA, EE. UU.), la DNasa se trató utilizando Turbo DNA-free (Applied Biosystems, Foster City, CA, EE. UU) y ADNc de primera cadena se produjo con el kit de ARN-a-ADNc (Applied Biosystems) utilizando cebadores aleatorios. El 260/280 se comprendió entre 1,7 y 2,0 para el ARN aislado medido con un NanoDrop (Thermo Scientific, Waltham, MA, EE. uU.). El ADNc se diluyó hasta un equivalente de 1ng/ul de ARN total y 8 ul se utilizaron por reacción. Los cebadores para el gen de referencia (18s) y los genes de interés (GOI) se sintetizaron (IDT, Coralville, Iowa, EE. UU.) y se diluyeron en las concentraciones apropiadas para PCRc utilizando agua de grado molecular. Los resultados de BLAST de los cebadores muestran homología de secuencia específica solo para el gen de referencia o GOI. Las reacciones por duplicado (20 ul) se analizaron en un sistema ABI Fast 7500 utilizando una mezcla 1:1 de molde y el cebador en mezcla maestra SensiMix SYBR bajo en contenido de ROX (Bioline, Londres,
RU). La cuantificación relativa se calculó utilizando el método 2-ddCT con ratones B6 de tipo natural de la misma edad que el valor basal para determinar los cambios múltiplos para cada GOI. Las curvas de disociación para las reacciones muestran un único pico de fusión para cada gen. La curva del patrón mostró eficiencias de amplificación similares para cada gen y que las concentraciones del molde estaban dentro del intervalo dinámico lineal para cada uno de los conjuntos de cebadores.
Ejemplo 12. Estructuras para generar moléculas de nucleasa híbridas.
Las moléculas de nucleasa híbridas se diseñaron para incorporar estructuras deseadas y actividad funcional de las estructuras de enzima individuales o de múltiples enzimas como casetes modulares con sitios de enzimas de restricción compatibles para la ida y la vuelta y el intercambio del dominio. La estructura esquemática de diferentes realizaciones de moléculas de nucleasa híbridas se ilustra en la Figura 12. Los cebadores se muestran en la Tabla 1. Las secuencias de nucleótidos y de aminoácidos de las moléculas de nucleasa híbridas representativas se muestran en la Tabla 2.
Enfoque general para la generación de moléculas de nucleasa híbridas
Los ADNc humanos se aislaron a partir de ARN de páncreas humano (Ambion) o ARN de CMSPs humanas a partir de linfocitos normales de sangre periférica humanos (aproximadamente 5x10e6) utilizando kits RNAeasy QIAgen (Valencia, CA) y kits QIAshredder para homogeneizar los lisados celulares (Qiagen, Valencia, CA). Las CMSP humanas se aislaron a partir de sangre humana heparinizada diluida 1:1 en D-TFS y se estratificaron en gradientes de Ficoll por medio de separación de linfocitos MSL (MP Biomedicals, Irvine, CA),.
El ARN de bazo de ratón se aisló utilizando kits RNAeasy QIAgen (Valencia, CA) a partir de aproximadamente 5x10e6 esplenocitos. Las células se aglomeraron por centrifugación del medio de cultivo, y se utilizaron 5x10e6 células para preparar ARN. Se aisló el ARN de las células utilizando el kit RNAeasy QIAGEN (Valencia, Calif ), el kit de aislamiento de ARN total y QIAshredder QIAGEN de acuerdo con las instrucciones del fabricante anexas al kit. Uno a dos microgramos (1-2 |jg) de ARN total se utilizaron como molde para preparar ADNc mediante transcripción inversa. El ARN, 300 ng de cebadores aleatorios, 500 ng de Oligo dT (12-18), y 1 pl de 25 mM de dNTps se combinaron y desnaturalizaron a 80 °C durante 5 minutos antes de la adición de la enzima. La transcriptasa inversa Superscript III (Invitrogen, Life Technologies) se añadió al ARN además de una mezcla de cebador en un volumen total de 25 pl en presencia de tampón de segunda cadena 5 veces y 0,1 M DTT proporcionado con la enzima. La reacción de transcripción inversa se dejó proceder a 50 °C durante una hora.
Entre 10-100 ng de ADNc se utilizaron en reacciones de amplificación por PCR utilizando cebadores específicos para el gen de la nucleasa de interés (RNasaA, RNasa1, DNasa1, Trex1, DNasa1L3, etc.). Para las reacciones de clonación iniciales, los cebadores se diseñaron para aislar ADNc de longitud completa o productos de truncamiento que codifican el gen de interés. Los fragmentos de PCR de longitud completa o más cortos se aislaron por electroforesis en gel de agarosa, y se purificaron utilizando columnas QIAquick Qiagen para eliminar nucleótidos, cebadores, y productos amplificados no deseados. Los fragmentos purificados se clonaron con TOPO en vectores de clonación pCR2.1 (Invitrogen, Carlsbad, CA) y se transformaron en bacterias competentes TOP10. Las colonias aisladas se recogieron en medios de caldo Luria que contenía 50 ug/ml de carbenicilina, y se cultivaron durante la noche para aislar plásmidos. Los clones con TOPO se identificaron sistemáticamente para insertos del tamaño correcto por digestión con enzimas de restricción EcoRI (NEB, Ipswich, MA) y electroforesis en gel de agarosa de los fragmentos digeridos. El análisis de la secuencia de ADN de clones positivos se realizó con ABI Ready Reaction Mix v 3.1 y se analizó utilizando un secuenciador de ADN ABI 3730 XL. Una vez que se obtuvieron los clones correctos, otras modificaciones de secuencia se diseñaron y se realizaron reacciones de PCR para generar los alelos deseados o casetes de expresión. Los productos de truncamiento y alelos se generaron mediante mutagénesis por PCR utilizando cebadores solapados para la introducción de mutaciones en posiciones específicas en los genes. Los enlazadores se sintetizaron mediante PCR solapada utilizando los cebadores solapados internos y rondas sucesivas de PCR para unir una secuencia adicional a cada extremo terminal. Las moléculas de nucleasa híbridas se ensamblaron como una variable de cadena de varios casetes intercambiables. Las moléculas de la realización preferente contienen un péptido líder fijo, un casete de nucleasa, un casete opcional que codifica una opción de diferentes enlazadores polipeptídicos, un casete de dominio Fc de Ig, ya sea con un codón de terminación o un enlazador en el extremo carboxilo del dominio CH3, y para moléculas de tipo resolvICase, un segundo casete enlazador, seguido de un segundo casete de nucleasa. La Figura 12 ilustra la estructura de tipo casete de estas moléculas de nucleasa híbridas y ejemplos de secuencias potenciales insertadas en cada posición. Una vez que las moléculas de nucleasa híbridas se ensamblaron, se transfirieron a un plásmido de expresión pDG de mamífero apropiado para la expresión transitoria en células COS7 u otras células y la expresión estable en células CHO-DG44 utilizando la selección para DHFR con metotrexato.
Expresión transitoria de moléculas de nucleasa híbridas
Las células COS-7 se transfectaron transitoriamente con el vector de expresión pDG que contenía insertos de genes de la molécula nucleasa híbrida. El día antes de la transfección, las células se sembraron en 4x10e5 células por placa de Petri de 60 mm en 4 ml de DMEM (crecimiento celular ThermoFisher/Mediatech) medio de cultivo tisular
de SFB al 10 %. El medio basal DMEM se suplemento con 4,5 g/l de glucosa, piruvato de sodio, 4 mM de L-glutamina, y aminoácidos no esenciales. El suero fetal bovino (Hyclone, Logan, UT ThermoFisher Scientific) se añadió al medio en un volumen final del 10 %. Las células se incubaron a 37 °C, CO2 al 5 % durante la noche y tenían una confluencia de aproximadamente 40-80 % en el día de la transfección. El ADN plasmídico se preparó utilizando kits miniprep QIAprep de Qiagen (Valencia, CA) de acuerdo con las instrucciones del fabricante, y se eluyó en 50 ul de tampón Te. Las concentraciones de ADN se midieron utilizando un espectrofotómetro Nanodrop 1000 (Thermo Fisher Scientific, Wilmington DE). El ADN plasmídico se transfectó utilizando el reactivo de transfección Polyfect (Qiagen, Valencia, CA) de acuerdo con las instrucciones del fabricante, utilizando 2,5 ug de ADN plasmídico por placa de Petri de 60 mm y 15 ul de reactivo Polyfect en 150 ul de cócteles de transfección DMEM libres de suero. Después de la formación del complejo, las reacciones se diluyeron en 1 ml de medio de crecimiento celular que contenía suero y todos los suplementos, y se añadieron gota a gota a las placas que contenían 3 ml de medio de cultivo completo DMEM fresco. Las transfecciones transitorias se incubaron durante 48-72 horas antes de recolectar los sobrenadantes del cultivo para su posterior análisis.
Generación de transfectantes CHO-DG44 estables que expresan las moléculas de nucleasa híbridas de interés
La producción estable de las moléculas de nucleasa híbridas se logró mediante la electroporación de un plásmido seleccionable amplificable, pDG, que contiene el ADNc que incluye nucleasa-Ig bajo el control del promotor de CMV en células de ovario de hámster chino (CHO). El vector pDG es una versión modificada de pcDNA3 que codifica el marcador seleccionable DHFR con un promotor atenuado para aumentar la presión de selección para el plásmido. El ADN plasmídico se preparó utilizando kits maxiprep Qiagen, y el plásmido purificado se linealizó en un sitio AscI único antes de la extracción con fenol y precipitación con etanol. El ADN de esperma de salmón (Sigma-Aldrich, St. Louis, MO) se añadió como ADN portador, y 100 |jg de cada uno de los ADN plasmídicos y portadores se utilizó para transfectar 107 células CHO-DG44 por electroporación. Las células se cultivaron hasta la fase logarítmica en medio Excell 302 (JRH Biosciences) que contenía glutamina (4 mM), piruvato, insulina recombinante, penicilinaestreptomicina y aminoácidos no esenciales 2x DMEM (procedentes de Life Technologies, Gaithersburg, Md.), en lo sucesivo referido como medio "Excell 302 completo". Los medios para las células no transfectadas también contenían HT (diluido a partir de una solución 100x de hipoxantina y timidina) (Invitrogen/Life Technologies). Los medios para las transfecciones bajo la selección contenían diferentes niveles de metotrexato (Sigma-Aldrich) como agente selectivo, que oscilan desde 50 nM a 1 pM. Las electroporaciones se realizaron a 280 voltios, 950 microfaradios. Se dejó que las células transfectadas se recuperaran durante la noche en medios no selectivos antes de la siembra en placas selectiva en placas de 96 pocillos de fondo plano (Costar) en diferentes diluciones en serie que oscilan de 125 células/pocillo a 2.000 células/pocillo. Los medios de cultivo para la clonación celular era Excell 302 completo, que contenía 50 nM de metotrexato. Una vez que la excrecencia clonal era suficiente, las diluciones en serie de los sobrenadantes del cultivo de los pocillos maestros se identificaron sistemáticamente para la expresión de moléculas de nucleasa híbridas mediante el uso de un ELISA de tipo sándwich de IgG. Brevemente, las placas NUNC Immulon II se revistieron durante la noche a 4 °C con 7,5 microgramos/ml de F(ab'2) de cabra anti-IgG de ratón (KPL Labs, Gaithersburg, MD) o 2 ug/ml de IgG de cabra anti-humano o anti-ratón (Jackson ImmunoResearch, West Grove PA) en TFS. Las placas se bloquearon en TFS/ASB al 2,3 %, y las diluciones en serie de sobrenadantes de cultivo se incubaron a temperatura ambiente durante 2-3 horas. Las placas se lavaron tres veces en TFS/Tween 20 al 0,05 % y se incubaron con F(ab'2) de cabra anti-IgG2a de ratón conjugado con peroxidasa de rábano picante (Southern Biotecnologías) e IgG de cabra anti-ratón (KPL) mezclados entre sí, cada uno a 1:3.500 en TFS/ASB al 1,0 %, o F(ab'2) de cabra anti-IgG1 de humano conjugado con peroxidasa de rábano picante (Jackson Immunoresearch, West Grove, PA) a 1:2.500 durante 1-2 horas a temperatura ambiente. Las placas se lavaron cuatro veces en TFS/Tween 20 al 0,05 %, y la unión se detectó con SureBlue Reserve, sustrato TMB (KPL Labs, Gaithersburg, MD). Las reacciones se detuvieron mediante la adición de un volumen equitativo de HCl IN, y las placas se leyeron a 450 nm en un lector de placas Spectramax Pro (Microdevices, Sunnyvale CA). Los clones con la mayor producción de la molécula de nucleasa híbrida se ampliaron en matraces T25 y T75 para proporcionar un número adecuado de células para la congelación y para el incremento de la producción de la proteína de fusión. Los niveles de producción se aumentaron aún más en cultivos a partir de los cuatro mejores clones mediante amplificación progresiva de medios de cultivo que contenían metotrexato. En cada pase sucesivo de células, el medio Excell 302 completo contenía una mayor concentración de metotrexato, de manera tal que solo las células que amplificaron el plásmido DHFR podrían sobrevivir.
Los sobrenadantes se recogieron de las células CHO que expresan la molécula de nucleasa híbrida, se filtraron a través de filtros que expresan PES de 0,2 jm (Nalgene, Rochester, N.Y.) y se pasaron sobre una columna de proteína A-agarosa (agarosa reticulada IPA 300) (Repligen, Needham, Mass.). La columna se lavó con tampón de lavado de columna (90 mM de Tris-Base, 150 mM de NaCl, azida de sodio al 0,05 %, pH 8,7), y la proteína unida se eluyó utilizando tampón citrato 0,1 M, pH 3,0. Las fracciones se recogieron y se determinó la concentración de proteínas a 280 nm utilizando un espectrofotómetro de micromuestras Nanodrop (Wilmington DE), y la determinación en blanco utilizando tampón citrato 0,1 M, pH 3,0. Las fracciones que contenían moléculas de nucleasa híbridas se agruparon, y el intercambio de tampón se realizó en espines en serie en TFS utilizando concentradores Centricon seguido de filtración a través de dispositivos de filtro de 0,2 pm para reducir la posibilidad de contaminación por endotoxinas.
Ejemplo 13. Análisis de cinética enzimática para hRNasa1-G88D-hIgG1 [SCCH-P238S-K322S-P331S1.
La secuencia que expresa RNasa1 humana se aisló a partir de ARN de páncreas humano por transcripción inversa y amplificación por PCR de ADNc cebado al azar como se describe en el Ejemplo 12 para las moléculas de nucleasa. Los siguientes cebadores a 50 pmoles por reacción se utilizaron a partir del conjunto de cebadores enumerados en la tabla de cebadores de PCR.
hRNasa5'edad: accggtaaggaatcccgggccaagaaattcc (SEQ ID NO: 16)
hRNasa3'bx: ctcgagatctgtagagtcctccacagaagcatcaaagtgg (SEQ ID NO: 17)
La forma mutante de RNasa G88D humana se creó utilizando los dos cebadores siguientes en PCR y las reacciones de PCR solapada para introducir una mutación en la posición 88 que altera la resistencia de la enzima al inhibidor citoplásmico.
hRNasaG88D-S: agactgccgcctgacaaacgactccaggtaccc (SEQ ID NO: 18)
hRNAsaG88D-AS: gggtacctggagtcgtttgtcaggcggcagtct (SEQ ID NO: 19)
Las versiones tanto de tipo natural como mutantes de RNasa1 humana se aislaron y se clonaron como se ha descrito anteriormente para las moléculas de nucleasa híbridas. La secuencia de tipo natural se clonó utilizando los dos primeros cebadores enumerados anteriormente. Una vez que los fragmentos de RNasa se clonaron con TOPO y se secuenciaron, los casetes de Agel-XhoI se transfirieron al vector de expresión pDG ya que contiene el inserto VK3LP humano y el casete de IgG1-TN humano. Las construcciones se verificaron mediante digestión, y el ADN plasmídico se preparó para transfecciones transitorias. Una vez que la función se confirmó a partir de las transfecciones transitorias a pequeña escala, las moléculas se transfectaron de forma estable en CHO-DG44 con el fin de expresar cantidades suficientes para su posterior análisis in vitro. La proteína de fusión RNasa1 humana de tipo natural se muestra en la Tabla 2, hVK3LP-hRNasa1-TN-hIgGl-TN (sEq ID NO: 163). Del mismo modo, la RNasa1 humana de tipo natural también se expresó como un gen de fusión con un dominio enlazador (gly4ser)4 (SEQ ID NO: 125 o SEQ ID NO: 161) o (gly4ser)5 (SEQ ID NO: 126 o SEQ ID NO: 162) insertado entre el casete de hRNasa y el dominio Fc de hlgG1. El mutante G88D de RNasa1 humana también se expresó como un gen de fusión designado hVK3LP-hRNasa-G88D-hIgG1-TN (SEQ ID NO: 124 o 160) o hIgG1-SCCH-P238S-K322S-P331S (SEQ ID NO: 174 o 175), enumerado en la Tabla 2.
El gráfico de Lineweaver Burk de la cinética enzimática para la hRNasa1-G88D-hIgG1 mutante [SCCH-P238S-K322S-P331S] (SEQ ID NO: 175) se muestra en la Figura 13. Para definir adicionalmente las características funcionales de la proteína de fusión que expresa RNasa-Ig bivalente, se realizaron determinaciones preliminares de la constante de Michaelis, Km. La cinética enzimática de la proteína de fusión que expresa RNasa1-Ig humana purificada se ensayó utilizando el sustrato RNase Alert (Ambion/IDT, San Diego, Ca .) de acuerdo con las instrucciones del fabricante y la fluorescencia ensayó utilizando un lector de microplacas Spectramax M2 (Molecular Devices, Sunnyvale, CA). Los datos de fluorescencia se recogieron en intervalos de 30 segundos en el transcurso de una incubación de 30 minutos, y se analizaron utilizando software SoftmaxPro (Molecular Devices). Las velocidades de reacción en las diferentes concentraciones de sustrato se midieron y los datos se muestran en la forma de un gráfico de Lineweaver Burke.
Ejemplo 14. Análisis de la unión de hRNasa1-hlgG a líneas monocíticas humanas.
Las moléculas de nucleasa híbridas purificadas con proteína A que expresan hRNasa1-hlgG1-TN se incubaron con las estirpes celulares monocíticas humanas THP-1 o U937 para evaluar la unión mediada por FcR de moléculas que contienen Fc de tipo natural o mutante. La Figura 14 muestra el patrón de unión de hRNasa1-TN-hlgG1-TN (SEQ ID NO: 161) a estas dos estirpes celulares. Las células se incubaron con 5 ug/ml de proteína de fusión purificada en TFS/SFB al 2 % durante 45 minutos en hielo, se lavaron tres veces en TFS/SFB al 2 %, y se incubaron con IgG de cabra anti-humano con FITC (Fc específico) (Jackson Immunoresearch, West Grove, PA) a 1:200 durante 45 minutos en hielo. Las células se lavaron dos veces en TFS/SFB al 2 % y se analizaron por citometría de flujo utilizando un citómetro de flujo por CCAF Canto (BD, Franklin Lakes, NJ), y el software FlowJo (TreeStar, Ashland, OR).
Ejemplo 15. Bloqueo de IgIV de la unión de hRNasa1-hlgG1 a líneas monocíticas humanas.
Las células THP-1 o U937 se preincubaron con IgIV a partir de 10 mg/ml y se realizaron diluciones en serie 10 veces a través de los pocillos de una placa de 96 pocillos. Las células (aproximadamente 1x10e6 por pocillo) se incubaron en hielo durante 45 minutos. Las células preunidas se lavaron dos veces y la hRNasa1-TN-hlgG1-TN conjugada con AF750 (SEQ ID NO: 161) en aproximadamente 5 ug/ml se añadió a cada pocillo. Las reacciones de unión se incubaron 45 minutos en hielo, se lavaron dos veces en TFS/SFB al 2 %, y se analizaron por citometría de flujo como se ha descrito anteriormente. IgIV fue capaz de bloquear parcialmente la unión de la proteína de fusión de nucleasa marcada, pero incluso a 10 mg/ml, aún existe una unión residual detectable por encima del fondo. La FIG.
15 muestra la actividad de bloqueo de IgIV humana para la unión a células U937 y t HP-1 por hRNasa1-TN-hlgG1-TN (SEQ ID NO: 161).
Ejemplo 16. Ensayo de actividad de Trex1-Ig.
T rex1 murino se clonó a partir de ADNc de ratón utilizando los cebadores listados a continuación:
mTrex1-5'edad: accggtatgggctcacagaccctgccccatggtcaca (SEQ ID NO: 20)
mTrex1-3'bx: ctcgagatctgttgttccagtggtagccggagtgccgtacatg (SEQ ID NO: 21)
Las reacciones de PCR se realizaron utilizando 50 pmol de cada cebador en un volumen total de 50 ul, en virtud de un perfil de amplificación de 94 °C durante 30 s; 50 °C durante 60 s; 68 °C durante 90 s para 35 ciclos de amplificación. Los productos de PCR se clonaron en el vector pCR2.1 y los clones se identificaron sistemáticamente con TOPO como se ha descrito previamente para la clonación de genes de fusión de nucleasa prototipo. Una vez que se verificó la secuencia, los casetes se subclonaron en el vector de expresión pDG fusionado a la cola mlgG o se co-clonaron con uno de los enlazadores (g4s)n para construir moléculas Trex1-Ink con diferentes enlazadores de longitud. Los aislados plasmídicos se transfectaron transitoriamente en células COS como se ha descrito y los transfectantes estables CHO se generaron como se describe para los genes de fusión de nucleasa prototipo.
Los genes de fusión se construyeron codificando Trex1Ig según se indica: los genes incorporan el péptido líder VK3 humano fusionado a Trex1 murino truncado en el extremo terminal COOH por 72 aminoácidos (para eliminar las secuencias orientadas selectivamente nucleares intracelulares) fusionados a un enlazador (gly4ser)4 (SEQ ID NO: 130) o (gly4ser)5 (SEQ ID NO: 131), fusionado al alelo IgG2a/c murino que incorpora algunos cambios de la secuencia de IgGc del alelo de IgG2a Balb/c.
Las actividades exonucleasa de Trex1-Ig se midieron en reacciones de 30 ul que contenían 20 mM de Tris (pH 7,5), 5 mM de MgCh, 2 mM de DTT, utilizando un oligonucleótido de 36 meros como sustrato. Las reacciones de incubación se dejaron proceder durante 20-30 min a 37 °C. Las muestras se sometieron a electroforesis de ADN en geles de poliacrilamida al 23 % durante la noche. Los geles se incubaron en tampón TBE que contenía 0,5 ug/ml de bromuro de etidio. El ADN se visualizó mediante transiluminador UV y se fotografió utilizando una cámara digital Kodak EDAS 290 equipada con filtros de bromuro de etidio y se analizó utilizando software Kodak Molecular Imaging. Los resultados del ensayo de actividad trex1 para COS produjeron mTrex1-(g4s)4-mIgG2a-c (SEQ ID NO: 166) y mTrex1-(g4s)5-mIgG2a-c (SEQ ID NO: 167) se muestran en la Figura 16.
Ejemplo 17. Membrana Western de moléculas de nucleasa híbridas individuales que expresan mTrex1-Ig producidas por transfección transitoria COS-7.
Las células COS-7 se transfectaron transitoriamente con plásmidos que contenían moléculas de nucleasa híbridas que codifican Trex1-Ig según se indica: los genes incorporan el péptido líder VK3 humano fusionado a Trex1 murino truncado en el extremo terminal COOH por 72 aminoácidos (para eliminar las secuencias de orientación selectiva de envoltura nuclear) fusionados a un enlazador (gly4ser)4 o (gly4ser)5, fusionados al alelo IgG2a/c murino que incorpora algunos cambios de la secuencia de IgGc del alelo de IgG2a Balb/c. Los sobrenadantes de COS se recolectaron después de 72 horas y las muestras de ,5-1,0 ml (dependiendo del experimento) se inmunoprecipitaron durante la noche a 4 °C con 100 ul de perlas de proteína A-agarosa. Las perlas de proteína A se centrifugaron y lavaron dos veces en TFS antes de la resuspensión en la reducción del tampón de carga de SDS-PAGE. Las muestras se trataron con calor a 100 °C durante 5 minutos, las perlas de proteína A se centrifugaron para aglomerarse, y el tampón de muestra se cargó en geles de SDS-PAGE al 10 %. Las muestras se sometieron a electroforesis a 150 voltios durante 1,5-2 horas, y los geles se transfirieron a membranas de nitrocelulosa a 30 mAmp durante 1 hora. Las membranas Western se bloquearon en TBS/leche descremada al 5 % durante la noche. Las membranas se incubaron con 1:2.500 cabra anti-IgG2a/c de ratón conjugado con PRP (peroxidasa de rábano picante) (específico de Fc, KPL) durante 1,5 horas a temperatura ambiente, se lavaron en TFS/Tween20 al 0,5 % cinco o más veces, y las membranas se desarrollaron utilizando reactivo ECL. La FIG. 17 muestra una membrana Western de inmunoprecipitados a partir de sobrenadantes de cultivo de COS7 que expresan proteínas de fusión mTrex1-(g4s)4 (SEQ ID NO: 166) o (g4s)5-mIgG2a-c: (SEQ ID NO 167).
Ejemplo 18. Actividad de exonucleasa de proteínas de fusión derivadas de CHO que expresan DNasa1L3Ig.
DNasa1L3 se clonó a partir de ADNc de bazo de ratón utilizando el siguiente par de cebadores para clonar la mDNasa1L3 incluyendo su secuencia peptídica líder nativa.
mdnasa1L3-NL: GTT AAG CTT GCC ACC ATG TCC CTG CAC CCA GCT TCC CCA CGC CTG (SEQ ID NO: 22)
Mdnasa1L3-3bx: CTC GAG ATC TGA GGA GCG ATT GCC TTT TTT TCT CTT TTT GAG AG (SEQ ID NO: 23) Alternativamente, las reacciones de PCR se establecieron utilizando el siguiente par de cebadores para unirse al péptido líder VK3 humano en lugar del líder nativo.
mdnasa1L3-edad: ACC GGT CTA AGG CTC TGC TCC TTC AAT GTG AGG TCC TTT GGA (SEQ ID NO: 24) Mdnasa1L3-3bx: CTC GAG ATC TGA GGA GCG ATT GCC TTT TTT TCT CTT TTT GAG AG (SEQ ID NO: 25)
Las reacciones de PCR se realizaron utilizando 50 pmol de cada cebador en un volumen total de 50 ul, en virtud de un perfil de amplificación de 94 °C durante 30 s; 50 °C durante 60 s; 68 °C durante 90 s para 35 ciclos de amplificación. Los productos de PCR se clonaron en el vector pCR2.1 y los clones se identificaron sistemáticamente con TOPO como se ha descrito previamente para la clonación de genes de fusión de nucleasa prototipo. Una vez que se verificó la secuencia, los casetes se subclonaron en el vector de expresión pDG fusionado a la cola mlgG. Los aislados plasmídicos se transfectaron transitoriamente en células COS como se ha descrito y los transfectantes CHO estables se generaron como se describe para los genes de fusión de nucleasa prototipo.
La actividad de exonucleasa en extractos proteínicos de clones de CHO que expresan DNasa1L3Ig (SEQ ID NO: 185) se midió en reacciones de 30 ul que contenían 20 mM de Tris (pH 7,5), 5 mM de MgCh, 2 mM de DTT, y un sustrato. La incubación duró 20-30 min a 37 °C. Las muestras se analizaron luego en ADN en gel de agarosa durante la noche. El gel se incubó en tampón TBE que contenía bromuro de etidio. El ADN se visualizó bajo UV. Los resultados del análisis de digestión de cromatina se muestran en la Figura 18.
Ejemplo 19. Ajuste de la dosis de volúmenes crecientes de sobrenadante de CHO para la actividad exonucleasa. La Figura 19 muestra el análisis del ajuste de los patrones de digestión de exonucleasa obtenidos a partir de sobrenadantes de COS que expresan proteínas de fusión DNasa1L3Ig (SEQ ID NO: 183 o 185). Los ensayos de degradación del ADN nuclear se realizaron según se indica: las células HeLa se cultivaron en medio DMEM y se aislaron los núcleos a partir de 10e5 células utilizando lisis NP-40. Los núcleos se diluyeron en 200 ul de tampón de reacción que contenía 10mM de Hepes (pH 7,0), 50 mM de NaCl, 2 mM de MgCb, 2 mM de CaCb, y 40 mM de bglicerofosfato. Los núcleos se incubaron durante 3 horas a 37 °C en los volúmenes de sobrenadante de cultivo indicados en la figura a partir de células COS transfectadas con DNasa1 L3. El ADN nuclear se aisló utilizando minikit blood DNA de QIAmp. El ADN se analizó por electroforesis en gel de agarosa al 1,5 %. Para las reacciones de control, se utilizó heparina a 250 u.i/ml para inhibir la actividad nucleasa.
Ejemplo 20: Construcción y expresión de moléculas de nucleasa híbridas de enzimas simple y dobles que expresan DNasa1-Ig.
Se han notificado alelos de origen natural de moléculas que expresan DNasa1 humana o similares a DNasa1. La mutación A114F ha sido notificada previamente para producirse en las variantes naturales de enzimas similares a DNasa1 humana, y para dar como resultado la resistencia de la actina de las enzimas que contienen este cambio de secuencia. Véase Pan, CQ, Dodge TH, Baker DL, Prince WE, Sinicropi DV, y Lazarus RA. J Biol Chem 273: 18374 18381, (1998); Zhen A, Parmelee D, Hyaw H, Coleman TA, Su K, Zhang J, Gentz R, Ruben S, Rosen C, y Li Y. Biochem y Biophys Res Comm 231: 499-504 (1997); y Rodríguez AM, Rodin D, H Nomura, Morton CC, Weremowicz S, y Schneider MC. Genomics 42: 507-513 (1997), todos los cuales se incorporan a la presente a modo de referencia.
De manera similar, la mutación G105R se ha notificado recientemente como un polimorfismo de un solo nucleótido en el gen que codifica la DNasa 1 humana que es polimórfica en algunas o todas las poblaciones, y que es relevante para la autoinmunidad. (Véase Yasuda T, Ueki M, Takeshita H, Fujihara J, Kimura-Kataoka K, Lida R, Tsubota E, Soejima M, Koda Y, Dato H, Panduro A. Int J Biochem Cell Biol 42(7): 1216-25 (2010), incorporado a la presente a modo de referencia). Las variantes alélicas en esta posición dieron como resultado isoformas de DNasa 1 que albergan una alta actividad relativa al tipo natural. Otra mutación polimórfica (R21S) de origen natural también se notificó para conferir una actividad superior. (Véase Yasuda, supra).
A pacientes con LES se les notificó que tenían niveles significativamente disminuidos de actividad de DNasa 1 (Véase Martinez-Valle F, Balada E, Ordi-Ros J, Bujan-Rivas S, Sellas-Fernandez A, Vilardell-Tarres M. Lupus 18(5): 418-423 (2009), incorporado a la presente a modo de referencia).
Las variantes enzimáticas de origen natural pueden de este modo ser menos inmunogénicas cuando se administran a pacientes, ya que estas isoformas se producen en la población humana. Se razonó que la combinación de propiedades de resistencia a actina de alelos similares a A114F con el aumento de la actividad enzimática de los alelos similares a G105R generaría nuevas variantes alélicas de DNasa1 humana que podrían mostrar una mejor actividad clínica in vitro e in vivo. Según nuestro conocimiento, el nuestro es la primera notificación de esta nueva forma mutante de DNasa1 generada a partir de una combinación de dos variantes de origen natural G105R y A114F.
La DNasa 1 humana se aisló como se ha descrito previamente a partir de ARN de páncreas humano (Ambion), por ADNc cebado al azar y PCR utilizando los siguientes conjuntos de cebadores:
5'hDNasa1-edad: GTT ACC GGT CTG AAG ATC GCA GCC TTC AAC ATC CAG (SEQ ID NO: 26) 5'hDNasa1-bx: GTT CTC GAG ATC TTT CAG CAT CAC CTC CAC TGG ATA GTG (SEQ ID NO: 27) Alternativamente, los casetes de DNasa 3' se amplificaron por PCR utilizando el siguiente par de cebadores. 3'hDNasa1-RV: GTT GAT ATC CTG AAG ATC GCA GCC TTC AAC ATC CAG (SEQ ID NO: 28)
3'hDNasa1-terminación: GTT TCT AGA TTA TCA CTT CAG CAT CAC CTC CAC TGG ATA GTG (SEQ ID NO: 29)
Las reacciones de PCR se realizaron utilizando 50 pmol de cada cebador, 2 ul de ADNc, en un volumen total de 50 ul utilizando Platinum PCR Supermix como se ha descrito previamente. El perfil de amplificación era de 94 °C durante 30 s; 55 °C durante 30 s; 68 °C durante 90 s para 35 ciclos.
Una vez que el gen de tipo natural se amplificó por PCR, los fragmentos se sometieron a electroforesis en gel y 850 pb de fragmentos se purificaron mediante purificación en columna de QIAquick. Los fragmentos se clonaron en pCR2.1, se transformaron por clonación con TOPO de acuerdo con las instrucciones del fabricante como se describe para las otras construcciones. Una vez que se verificó la secuencia, los cebadores de PCR se utilizaron para generar subfragmentos que contienen alelos de origen natural para DNasa1 que han sido notificados para mejorar la actividad específica y mejorar la resistencia en la actividad inhibidora de la actina. Estos subfragmentos contenían una secuencia de solapamiento, lo que permite la amplificación de subclones de Dnasa1 completos que contienen las variaciones alélicas deseadas. Las células COS 7 se transfectaron transitoriamente en placas de Petri de 60 mm utilizando el reactivo de transfección Polyfect (Qiagen, Valencia, CA). El ADN plasmídico se preparó utilizando kits miniprep QlAprep de Qiagen de acuerdo con las instrucciones del fabricante. Los plásmidos se eluyeron en 50 ul de tampón TE. La concentración de ADN se midió utilizando el Nanodrop y una alícuota equivalente a 2,5 ug de ADN plasmídico utilizado para cada reacción de transfección. Cada casete de expresión DNasalg (SEQ ID NOS: 118, 119, 120, 121, 122 o 123) o RNasa-Ig-DNasa (SEQ ID NOS: 115, 116, 117) se insertó en el vector de expresión de mamífero pDG, una derivado de pcDNA3.1. Se incubaron las células transfectadas durante 72 horas a 37 °C, CO2 al 5 % antes de la recolección de los sobrenadantes del cultivo para su posterior análisis. Los sobrenadantes de cultivo se recolectaron, las células residuales se centrifugaron a partir de la solución, y el líquido se transfirió a tubos nuevos.
Las células COS-7 se transfectaron transitoriamente con plásmidos que contenían alelos mutantes de DNasa1 humana (SEQ ID NO: 118) o DNasa1 de origen natural o tipo salvaje (G105R y/o A114F) (SEQ ID NO: 115, 116, o 117) fusionados al dominio Fc de IgG1 humana de tipo natural. Este casete bisagra-CH2-CH3 contiene una sola mutación C^-S en la región bisagra para eliminar la primera cisteína en este dominio, ya que no está apareado debido a la ausencia de su socio de apareamiento presente en la cadena ligera del anticuerpo. Además, las proteínas de fusión de múltiples nucleasas más complejas también se expresaron a partir de transfecciones transitorias de células COS. El análisis por membrana Western se realizó en los sobrenadantes de los transfectantes transitorios. Las moléculas mostradas en la Figura 20 contienen DNasa1 humana fusionada con el dominio Fc de tipo natural de IgG1 humana (SEQ ID NO: 154, 155, 156, o 159) o incluyen RNasa1 humana (tipo natural) fusionada al dominio Fc de bisagra SCC-CH2-CH3 de IgG1 humana, seguido de un nuevo enlazador que contiene un sitio de glicosilación ligado a N para proteger el dominio enlazador de la escisión por proteasa, y las formas de alelo de tipo natural (SEQ ID NO: 153) o mutante (SEQ ID NO: 151 o 152) de DNasa1 humana en el extremo carboxi de la molécula. Los sobrenadantes de COS se recolectaron después de 72 horas y ,5-1,0 ml de muestras (dependiendo del experimento) se inmunoprecipitaron durante la noche a 4 °C con perlas de 100 ul de proteína A-agarosa. Las perlas de proteína A se centrifugaron y lavaron dos veces en TFS antes de la resuspensión en tampón de carga de SDS-PAGE, para la reducción o no reducción de geles NuPAGE del tampón de muestra LDS. Las muestras se calentaron de acuerdo con las instrucciones del fabricante, las perlas de proteína A se centrifugaron para aglomerarse, y el tampón de muestra se cargó en geles de gradiente NuPAGE al 5-12 %. Las muestras se sometieron a electroforesis a 150 voltios durante 1,5-2 horas, y los geles se transfirieron a membranas de nitrocelulosa a 30 mAmp durante 1 hora. Las membranas Western se bloquearon en TBS/leche descremada al 5 % durante la noche. Las membranas se incubaron con 1:2500 IgG de cabra anti-humano conjugada con PRP (peroxidasa de rábano picante) (específico de Fc, Jackson Immunoresearch) o IgG de cabra anti-ratón durante 1,5 horas a temperatura ambiente, se lavaron en TFS/Tween20 al 0,5 % cinco o más veces, y las membranas se desarrollaron utilizando reactivo ECL.
Ejemplo 22. Identificación sistemática de los sobrenadantes de COS para la actividad de la enzima nucleasa.
La Figura 21 muestra los resultados de ensayos del análisis de la actividad de RNasa (DERS) en sobrenadantes de COS recolectados que expresan proteínas de fusión hDNAsa1lg y hRNasa1-Ig-hDNasa1 por DERS.
Los sobrenadantes de COS de transfecciones transitorias de las nucleasas individuales o multiespecíficas de hDNasalg se ensayaron para la actividad de la nucleasa como se indica. Un gel de agarosa al 2 % se preparó con agua destilada. Poli-C (Sigma) se disolvió en agua destilada a 3 mg/ml. La placa de gel se preparó según se indica: 1,5 ml de tampón de reacción (Tris-HCl 0,2 M, pH 7,0, 40 mM de EDTA y 0,1 mg/ml de bromuro de etidio), 1 ml de poli-C y 0,5 ml de agua se colocaron en el tubo y se mantuvieron a 50 °C durante 5 min. Se añadieron 3 ml de agarosa (mantenida a 50 °C) en el tubo. La mezcla se vertió inmediatamente sobre la placa de vidrio. Los pocillos de muestreo se perforaron en el gel. Aproximadamente 2 ul de cada muestra se cargaron y el gel se incubó a 37 °C durante 4 horas en la cámara húmeda. A continuación, el gel se incubó en un tampón (20 mM de acetato de sodio, pH 5,2, 20 mg/ml de bromuro de etidio) en hielo durante 30 min. Los geles se fotografiaron en un transiluminador UV utilizando un sistema DC290 de cámara digital Kodak equipado con filtros de bromuro de etidio y se analizaron utilizando el software Kodak Molecular Imaging.
La Figura 22 muestra una figura mixta que presenta los resultados de los ensayos de la actividad de la nucleasa DNasa realizados en sobrenadantes de COS de células transfectadas. Los sobrenadantes de cultivo se recolectaron 72 horas después de la transfección de los siguientes clones de proteínas de fusión que expresan Ig de tipo natural y mutante de DNasa1: (1) 090210-8 = hDNAsa1-TN-hIgG1 TN (SEQ ID NO: 154); (2) 090210- 9 = hDNasa1-G105R; A114F-hIgG1 TN (SEQ ID NO: 159); (3) 091210-8 = hRNasa1-TN-hIgG1-TN-DNasa1-G105R; A114F (SEQ ID NO: 151), y (4) 091210-14 = hRNasa-TN-hIgG1-TN-DNasa1-A114F (SEQ ID NO: 152).
El pH de los sobrenadantes se ajustó a ,0 con tampón de bicarbonato para facilitar la unión de las proteínas de fusión Ig expresada a perlas de proteína A-agarosa. El panel A de la Figura 23 muestra el análisis de electroforesis en gel de la digestión de ADN plasmídico: la suspensión de proteína A-agarosa (50 ul por muestra) se lavó en TFS, y se incubó durante la noche a 4 °C con 100 ul del sobrenadante del cultivo para inmunoprecipitar proteínas de fusión Ig. Los inmunoprecipitados se lavaron 4-5 veces en 750 ul de TFS, se centrifugaron a aproximadamente 3.500 rpm, seguido por la aspiración de TFS. Los precipitados de una proteína A final se resuspendieron en 50 ul de tampón de reacción que contenía 20 mM de Tris pH 7,5, 2 mM de CaCI2 y 2 mM de MgCI2 que contiene 1,5 ug de ADN plasmídico (vector de expresión pDG). Las reacciones se incubaron durante 30 minutos a 37 °C, se calentaron a 65 °C durante 5 min, y el a Dn presente en las reacciones se analizó por electroforesis en gel de agarosa en TBE-geles de agarosa al 1,5 %.
El panel B muestra los resultados de un ensayo de actividad de la nucleasa realizado en los mismos sobrenadantes de cultivo utilizando el kit DNase Alert (IDT/Ambion). Los tubos de reacción que contienen el sustrato liofilizado DNase Alert (50 pmoles) se resuspendieron con 5 ul de ddH2O libre de nucleasa suministrado con el kit, 5 ul 10X de tampón DNase alert, y 40 ul de suspensión de proteína A inmunoprecipitada según se indica: para estas inmunoprecipitaciones, 50 ul de perlas de proteína A-agarosa se incubaron durante la noche con 50 ul del sobrenadante del cultivo. Las muestras se lavaron a continuación 5 veces con 0,75 ml de TFS. Los precipitados de proteína A final se resuspendieron en 80 ul de ddH2O libre de nucleasa, y 40 ul de la suspensión (la mitad del precipitado) se transfirió a los tubos de reacción. Los controles negativos con IP transfectada de manera simulada y ddH2O también se establecieron. Un control positivo también se estableció conteniendo DNasa1 proporcionada con el kit (2 unidades). Las reacciones se incubaron 1 hora a 37 °C y se expusieron a una longitud de onda corta de transiluminación UV para visualizar la fluorescencia. Las cantidades relativas de la digestión del ADN se indican mediante el grado de fluorescencia.
Ejemplo 22: Examen de células positivas mac-2 en ratones DTg.
La mortalidad temprana del lupus se debe en general a nefritis o infección resultante de la inmunosupresión por tratar la nefritis. Por lo tanto, un resultado extremadamente importante para cualquier nueva terapia es la mejora en la nefritis. Mientras que los estudios en seres humanos se limitan a la cuantificación de la proteinuria y creatinina, en ratones se puede obtener una evaluación precisa de la inflamación y el daño a los riñones por histología e inmunocitoquímica. Se notifica que los ratones dobles transgénicos (DTg) que expresan TLR7.1 x RNasa mostraron anticuerpos anti-ARN más bajos, menos activación de células B, menos depósitos inmunitarios y menos glomérulos de tinción de PAS positiva. Se comparó aún más la infiltración de macrófagos de los riñones utilizando el anticuerpo anti-Mac-2 (galectina3) (Iyoda et al. Nephrol Dial Transplant 22: 3451, 2007). Las secciones congeladas de los riñones obtenidos de ratones simples o dobles Tg se examinaron para las cantidades de macrófagos Mac-2+, así como el tamaño glomerular como se describe (Iyoda et al.). Veinte glomérulos seleccionados al azar (del lado exterior al lado interior del riñón) se contaron para células positivas. Hay muchas menos células de tinción positiva mac-2 en los glomérulos de DTgs en comparación con ratones simples Tg (datos no mostrados). Los resultados del recuento de 20 glomérulos por ratón en un estudio piloto de n = 4-5 en cada grupo revelaron una media /- EE de 3,8 /- 1,1 y 1,4 /- 0,2 para ratones simples frente a DTg respectivamente, p = 0,05. Además, se cuantificó el tamaño del ovillo glomerular y se observó una reducción significativa en el tamaño del ovillo glomerular en los ratones DTg (179,4 /- 41 frente a 128 /- 16,8 um2 en un ratón simple frente a DTg respectivamente, p = 0,037). Ejemplo 23: Valor de Km de la proteína de fusión que expresa RNasaA-Ig murina purificada
Para definir aún más las características funcionales de la proteína de fusión que expresa RNasa-Ig bivalente (SEQ ID NO: 150), se realizaron determinaciones de la constante de Michaelis, Km. Como se muestra en la Fig. 23, la enzima tiene una alta afinidad con un valor Km provisional de 280 nM (como comparación, la RNasa A tiene un valor Km de 34 nM utilizando poliC como sustrato (delCardayre et al, Prot Eng 8:261, 1995)). La Fig. 23 muestra la cinética enzimática que se analizó utilizando el sustrato Rnase Alert (Ambion/IDT) y la fluorescencia se cuantificó con un lector de microplacas Spectramax M2. Los datos se analizaron utilizando el software Softmax Pro (Molecular Devices). Las velocidades de reacción en las diferentes concentraciones de sustrato se midieron y los datos se muestran como un gráfico de Lineweaver- Burk. El valor Km aparente corregido para el volumen es de 280 nM. Ejemplo 24. Análisis de ratones Tg 564Igi para anticuerpos anti-ARN.
Ratones Tg 564Igi: el Dr. Imanishi-Kara insertó los genes VDJ reordenados a partir del hibridoma H564 en el loci Igh e Igk endógeno para crear el ratón 564Igi en un antecedente B6. Los sueros de estos ratones tiñeron el citoplasma y los nucleolos de las células fijadas indican una especificidad anti-ARN predominante. Consistente con este hallazgo
y de especial relevancia para esta solicitud de patente, la producción de anticuerpos se inhibió cuando estos ratones se hicieron deficientes de TRL7 lo que indica que el estímulo para la producción de anticuerpos es de hecho ARN. Esta cepa de ratón desarrolla glomerulonefritis de aparición tardía. Se analizó la expresión de anticuerpos anti-ARN en ratones transgénicos para H564 y también los ratones dobles transgénicos coexpresan transgenes 564Ig y RNasa. La Figura 24 compara los niveles de anticuerpos anti-ARN en suero de ratón en intervalos sucesivos al igual que estos ratones transgénicos de la misma edad.
Véase Gavalchin, J., R.A. Seder, y S.K. Datta. 1987. The NZB X SWR model of lupus nephritis. I. Crossreactive idiotypes of monoclonal anti-DNA antibodies in relation to antigenic specificity, charge, and allotype. Identification of interconnected idiotype families inherited from the normal SWR and the autoimmune NZB parents. J. Immunol. 138:128-137; y Berland, R., L. Fernandez, E. Kari, J.H. Han, I. Lomakin, S. Akira, H.H. Wortis, J.F. Kearney, A.A. Ucci, y T. Imanishi-Kari. 2006. Toll-like receptor 7-dependent loss of B cell tolerance in pathogenic autoantibody knockin mice. Immunity 25:429-440.
Ejemplo 25: Evaluación in vitro de la actividad biológica de la molécula de nucleasa híbrida.
Una o más moléculas de nucleasa híbridas se purifican, p. ej., por cromatografía de afinidad o intercambio iónico como se ha descrito previamente en los ejemplos anteriores. En algunos ejemplos, la molécula de nucleasa híbrida es un polipéptido. En algunos ejemplos, la molécula de nucleasa híbrida incluye una o más secuencias de la Tabla 2. En algunos ejemplos, la molécula es SEQ ID NO: 161, 162, o 163. En algunos ejemplos, la molécula incluye SEQ ID NO: 145 y SEQ ID NO: 149. En algunos ejemplos, la molécula es SEQ ID NO: 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 166, 167, 169, 170, 171, 173, 175, 177, 179, 181, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, o 207. La molécula de nucleasa híbrida puede ser cualquiera de las desveladas en la presente memoria y cualquiera que pueda ser construida a partir de las secuencias desveladas en la presente memoria (véase la Tabla 2), p. ej., tomando un dominio nucleasa y ligándolo a un dominio Fc; o, p. ej., tomando un dominio nucleasa y ligándolo a un dominio Fc con un dominio enlazador. Varios dominios enlazadores (p. ej., los descritos en la presente memoria) pueden utilizarse para ligar los dominios Fc y/o dominios nucleasa. Por ejemplo, pueden utilizarse los dominios enlazadores de 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 o más aminoácidos de longitud. Las moléculas se ensayan para determinar la actividad de nucleasa específica in vitro utilizando ensayos cualitativos para verificar que poseen la función de nucleasa deseada. Las actividades específicas se determinan en general por ensayos cinéticos basados en fluorescencia que utilizan sustratos, tales como reactivos del kit RNase o DNase Alert, y un lector de placas de fluorescencia configurado para tomar lecturas como una función del tiempo. Además, las soluciones de proteínas se comprueban en general para la contaminación por endotoxinas utilizando kits disponibles comercialmente, tales como el kit de lisado de amebocitos de Limulus (LAL) de Pyrotell, 0,06 UE/ml de límite de detección de Cape Cod, Inc. (E. Palmouth, MA). Las moléculas se ensayan después utilizando una variedad de ensayos in vitro para la actividad biológica.
Una serie de ensayos in vitro medirán el efecto de las moléculas en la producción de citoquinas por CMSP humanas en respuesta a diversos estímulos en presencia o ausencia de las moléculas en los cultivos. Las CMSP normales o de un paciente humano (aproximadamente 1x10e6 células) se cultivan durante 24, 48, o 96 horas dependiendo del ensayo. Las CMSP se cultivan en presencia de estímulos, tales como ligandos TLR, anticuerpos coestimuladores, complejos inmunitarios, y sueros normales o autoinmunitarios. Los efectos de las moléculas en la producción de citoquinas se miden utilizando reactivos disponibles comercialmente, tales como los kits de par de anticuerpos de Biolegend (San Diego, CA) para IL-6, IL-8, IL-10, IL-4, IFN-gamma, FNT-alfa. Los sobrenadantes de cultivo a partir de cultivos in vitro se recolectan a las 24, 48 horas o en puntos temporales posteriores para determinar los efectos de las moléculas en la producción de citoquinas. La producción de IFN-alfa se mide utilizando, p. ej., anticuerpos IFN-alfa anti-humanos y reactivos de curva convencionales disponibles a partir de una fuente de interferón PBL (Piscataway, NJ). Un conjunto similar de ensayos se realiza utilizando subpoblaciones de linfocitos humanos (monocitos aislados, células B, pDCs, células T, etc.); purificadas utilizando, p. ej., kits comercialmente disponibles de aislamiento a base de perlas magnéticas disponibles de Miltenyi Biotech (Auburn, CA).
Además, el efecto de las moléculas en la expresión de los receptores de activación de linfocitos, tales como CD5, CD23, CD69, CD80, CD86, y CD25 se evalúa en diversos puntos temporales después de la estimulación. Las CMSP o subpoblaciones celulares aisladas se someten a citometría de flujo de múltiples colores para determinar cómo estas moléculas afectan a la expresión de diferentes receptores asociados con la activación celular inmunitaria.
Otro conjunto de ensayos medirá los efectos de estas moléculas en la proliferación de diferentes subpoblaciones de linfocitos in vitro. Estos ensayos utilizarán, p. ej., tinción CFDA-SE (Invitrogen, Carlsbad, CA) de CMSPs humanas antes de la estimulación. c Fs E en 5 mM se diluye a 1:3000 en TFS/ASB al 0,5 % con 10e7-10e8 CMSPs o subconjuntos de células purificadas y reacciones de marcado se incubaron durante 3-4 minutos a 37 °C antes de lavarse varias veces en RPMI/SFB al 10 % para eliminar CFSE restante. Las células marcadas con CFSE se incuban a continuación en reacciones de co-cultivo con diversos estímulos (ligandos TLR, anticuerpos coestimuladores, etc.) y las moléculas durante 4 días antes del análisis de proliferación celular por citometría de flujo utilizando anticuerpos específicos de la subpoblación celular conjugada con colorante.
El efecto de estas moléculas en la maduración in vitro de monocitos en DCs y macrófagos también se evaluó utilizando ambas muestras de CMSP normales y de pacientes.
La eficacia de una molécula de nucleasa híbrida se demuestra comparando los resultados de un ensayo de células tratadas con una molécula de nucleasa híbrida desvelado en la presente memoria con los resultados del ensayo de las células tratadas con formulaciones de control. Después del tratamiento, los niveles de los diversos marcadores (p. ej., citoquinas, receptores de superficie celular, proliferación) descritos anteriormente se mejoran generalmente en un grupo tratado con una molécula efectiva con respecto a los niveles de los marcadores existentes antes del tratamiento, o con relación a los niveles medidos en un grupo de control.
Ejemplo 26: Administración de una molécula de nucleasa híbrida a un mamífero que la necesita.
En el estudio se utilizan mamíferos (p. ej., ratones, ratas, roedores, seres humanos, conejillos de indias). A los mamíferos se les administra (p. ej., por vía intravenosa) una o más moléculas de nucleasa híbridas que comprenden una o más secuencias de la Tabla 2 o un control. En algunos ejemplos, la molécula es SEQ ID NO: 161, 162, o 163. En algunos ejemplos, la molécula incluye SEQ ID NO: 145 y SEQ ID NO: 149. En algunos ejemplos, la molécula es SEQ ID NO: 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 166, 167, 169, 170, 171, 173, 175, 177, 179, 181, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, o 207. La molécula de nucleasa híbrida puede ser cualquiera de las desveladas en la presente memoria y cualquiera que pueda ser construida a partir de las secuencias desveladas en la presente memoria (véase la Tabla 2), p. ej., tomando un dominio nucleasa y ligándolo a un dominio Fc; o, p. ej., tomando un dominio nucleasa y ligándolo a un dominio Fc con un dominio enlazador. Varios dominios enlazadores (p. ej., los descritos en la presente memoria) pueden utilizarse para ligar los dominios Fc y/o dominios nucleasa. Por ejemplo, pueden utilizarse los dominios enlazadores de 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 o más aminoácidos de longitud. En algunos ejemplos, la molécula de nucleasa híbrida se formula de un portador farmacéuticamente aceptable. En algunos ejemplos, la molécula se formula como se describe en la sección de composiciones farmacéuticas anterior. La molécula de nucleasa híbrida se orienta selectivamente a RNasa y/o DNasa.
Se utilizan múltiples rondas de dosis cuando se considere útil. Se controlan los efectos en los niveles de IFN-alfa, los niveles de genes de respuesta a IFN-alfa, los títulos de autoanticuerpos, la función y la patología renal, y/o los niveles de complejos inmunitarios circulantes en los mamíferos. Estudios similares se realizan con diferentes protocolos de tratamiento y vías de administración (p. ej., administración intramuscular, etc.). La eficacia de una molécula de nucleasa híbrida se demuestra mediante la comparación de los niveles de IFN-alfa, los niveles de genes de respuesta a IFN-alfa, los títulos de autoanticuerpos, la función y la patología renal, y/o los niveles de complejos inmunitarios circulantes en los mamíferos tratados con una molécula de nucleasa híbrida desvelados en la presente memoria para mamíferos tratados con formulaciones de control.
En un ejemplo, un sujeto humano en necesidad del tratamiento se selecciona o identifica. El sujeto puede estar en necesidad de, p. ej., reducir una causa o síntoma de LES. La identificación del sujeto se puede producir en un entorno clínico, o en otro lugar, p. ej., en el domicilio del sujeto a través de uso propio por parte del sujeto de un kit de autodiagnóstico.
En el tiempo cero, una primera dosis adecuada de una molécula de nucleasa híbrida se administra al sujeto. La molécula de nucleasa híbrida se formula como se describe en la presente memoria. Después de un periodo de tiempo después de la primera dosis, p. ej., 7 días, 14 días, y 21 días, se evalúa la condición del sujeto, por ejemplo, midiendo los niveles de IFN-alfa, los niveles de genes de respuesta a IFN-alfa, los títulos de autoanticuerpos, la función y la patología renal, y/o los niveles de complejos inmunitarios circulantes. Otros criterios pertinentes también se pueden medir. El número y la potencia de las dosis se ajustan de acuerdo a las necesidades del sujeto.
Después del tratamiento, los niveles de IFN-alfa del sujeto, los niveles de genes de respuesta a IFN-alfa, los títulos de autoanticuerpos, la función y la patología renal, y/o los niveles de complejos inmunitarios circulantes se reducen y/o mejoran con respecto a los niveles existentes antes del tratamiento, o con relación a los niveles medidos en un sujeto aquejado de manera similar pero no tratado/de control.
En otro ejemplo, un sujeto roedor en necesidad del tratamiento se selecciona o identifica. La identificación del sujeto puede producirse en un entorno de laboratorio o en otra parte.
En el tiempo cero, una primera dosis adecuada de una molécula de nucleasa híbrida se administra al sujeto. La molécula de nucleasa híbrida se formula como se describe en la presente memoria. Después de un periodo de tiempo después de la primera dosis, p. ej., 7 días, 14 días, y 21 días, se evalúa la condición del sujeto, p. ej., midiendo los niveles de IFN-alfa, los niveles de genes de respuesta a IFN-alfa, los títulos de autoanticuerpos, la función y la patología renal, y/o los niveles de complejos inmunitarios circulantes. Otros criterios pertinentes también se pueden medir. El número y la potencia de las dosis se ajustan de acuerdo a las necesidades del sujeto.
Después del tratamiento, los niveles de IFN-alfa del sujeto, los niveles de genes de respuesta a IFN-alfa, los títulos de autoanticuerpos, la función y la patología renal, y/o los niveles de complejos inmunitarios circulantes se reducen y/o mejoran con respecto a los niveles existentes antes del tratamiento, o con relación a los niveles medidos en un sujeto aquejado de manera similar pero no tratado/de control.
Aunque la invención se ha mostrado y descrito particularmente haciendo referencia a una realización preferida y varias realizaciones alternativas, los expertos en la técnica relevante entenderán que se pueden realizar varios cambios en la forma y detalles de estas sin alejarse del alcance de la invención.
Todas las referencias, patentes emitidas y solicitudes de patente citadas en el cuerpo de la presente memoria descriptiva se incorporan por la presente a modo de referencia en su totalidad, a todos los efectos.
TABLAS



TABLA 2
SEQ ID DESCRIP SECUENCIA (LAS SECUENCIAS NUCLEOTÍDICAS SON 3’-5') NO: CIÓN
I CC 1 nk agatctctccgqaqgaggtggctcaggtggtggaggatctggaggaggtgggag tgg tg ga gg tg g ttc taccg g tc tcg ag
1C1 G 4 S r: - 1 agatctctccggagqaggtggctcaggtggtggaggatctggaggaggtggctc aggtggtggaggatctggaggaggtgggagtaccggrcrcgag
1 C¿ G 4 S 5 3 agatctctccggaggaggtggctcaggtggtggaggazctggaggaggtggctc aggtggtggaggatctggaggaggtgggagtctcgag 1C3 3 ' hSNasa gtcgacggagctagcagccccgtqaacgtgagcagccccagcgtgcaggatatc p o o r i ccttccctgggcaaggaatcccgggccaagaaattccagcggcagcatatggac tcagacagttcccccagcagcagctccacctactgtaaccaaatgatgaggcgc cggaatatgacacaggggcggtgcaaaccagtgaacacctttgtgcacgagccc ctggtagatgtccagaatg tctg tttccaggaaaaggtcacctgcaagaacggg cagggcaactgctacaagagcaactccagcatgcacatcacagactgccgcctg acaaacgactccaggtaccccaactgtgcataccggaccagcccqaaggagaga ca ca tca ttg tg g cc tg tg a a g g g a g ccca ta tg tg cca g tcca c tttg a tg c t tc tg tg g a g g a c tc ta cc ta a ta a tc ta g a
I C 4 hDKaaa1- gatatcctgaagatcgcagccttcaacatccagacatttggggagaccaagatg ~ i ' - tccaa tg ccaccc tcg tca gc ta ca ttg tg ca ga tcc tga gccgc ta tga ca tc n i I I h A; A l gccctggtccaggaggtcagagacagccacctgaccgccgrggggaagctgctg 14F gacaacctcaatcaggatgcaccagacacctatcactacgtggtcagtgagcca ctgggacggaacagctataaggagcgctacctgttcgtgtacaggcctgaccag g tg tc tgcggtqqacagctactactacgatgatggctgcgagccctgcaggaac ga ca cc ttcaaccg ag ag cca ttca ttg tca gg ttc ttc rcccg g ttca cag ag g tcagggagtttgccattg ttcccctgcatgcggccccgggggacgcagtagcc gaga tcgacgctctc ta tgacgtctacctggatg tccaagagaaat.ggggcttg gaggacgtca tg ttgatgggcgact tcaatgcgggctgcagcta tg tgagaccc tcccag tgg tca tcca tccgcctg tggacaagccccaccttccag tggc tga tc cccgacagcgctqacaccacagctacacccacgcactgtgcctatgacaggatc g tg g ttgca g g g a tq c tg c tccg a g g cg ccg ttg ttcccg a c rcg g c tc ttccc tttaac ttccaggctgcc ta tggcctgag tgaccaactggcccaagcca tcag t gaccactatccagtggaggtgatgctgaagtgataazcraga
1C5 hDKasal- gatatcctgaagatcgcagccttcaacatccagacatttggggagaccaagatg r - TN tccaa tg ccaccc tcg tca gc ta ca ttg tg ca ga tcc tga gccgc ta tga ca tc gccctgg tccagg agg tcag agac:agcc:ac:ctgac:tgccgt.ggggaagcLgctg gacaacctcaatcaggatgcaccagacacctatcactacg~gg~cagtgagcca ctgggacggaacagctataaggagcgctacctgttcgtgtacaggcctgaccag g tg tc tgcggtggacagctactactacgatgatggctgcgagccctgcgggaac gacacc ttcaaccgagagccagcca ttg tcagg ttc ttc tcccgg ttcacagag g tcagggagtttgccattg ttcccctgcatgcggccccgggggacgcagtagcc


TABLA 2
SEQ ID DESCRIP SECUENCIA (LAS SECUENCIAS NUCLEOTÍDICAS SON 3'-5') NO: CIÓN
humana acctttgtgcacgagcccctggtagatgtccagaatgtctgtttccaggaaaag gtcacctgcaagaacgggcagggcaactgctacaagagcaactccagcatgcac atcacagactgccgcctgacaaacggctccaggtaccccaactgtgcataccgg accagcccgaaggagagacacatcattgtggcctgtgaagggagcccatatgtg ccag tcca c tttg a tg c tac tg tg tag____________________________ 11-3 hi:VK3LF i gttaagcttgccaccatggaaaccccagcgcagcttc tc ttcctcctgctactc T.r ih l Ini tggctcccagataccaccggtagggaarctgcagcacagaagtttcagcggcag gG2A C- cacatggatccagatggttcctccatcaacagccccacctactgcaaccaaatg 20 atgaaacgccgggatatgacaaatgggtcatgcaagcccgtgaacaccttcgtg catgagcccttggcagatgtccaggccgtctgctcccaggaaaatgtcacctgc aagaacaggaagagcaactgctacaagagcagctctgccctgcacatcactgac tgccacctgaagggcaactccaagtatcccaactgtgactacaagaccactcaa taccagaagcacatcattgtggcctgtgaagggaacccctacgtaccagtccac t t tgatgctactgtgctcgagcccagaggtctcacaatcaagccctctccteca tgcaaatgcccagcacctaacctcttgggtggatca tccgtc t tc a tc t tc c c t ccaaagatcaaggatgtactcatgatctccctgagccccatggtcacatgtgtg gtggtggatgtgagcgaggatgacccagacgtccagatcagctggtttgtgaac aacgtggaagtacacacagctcagacacaaacccatagagaggattacaacagt actctccgggtggtcagtgccctccccatccagcaccaggactggatgagtggc aaggagttcaaatgctcggrcaacaacaaagacctcccagcgtccaccgagaga accatctcaaaacccagagggccagtaagagctccacaggtatatgtcttgcct ccaccagcagaagagatgactaagaaagagt tcagtctgacctgcatgatcaca ggcttcttacctgccgaaattgctgtggactggaccagcaatgggcgtacagag caaaactacaagaacaccgcaacagtcctggactctgatggttcttacttcatg tacagcaagctcagagtacaaaagagcacttgggaaagaggaagtcttttcgcc tgctcagtggtccacgagggtctgcacaatcaccttacgactaagagcttctct cggactccgggtaaatgataatctagaa___________________________ 11 D huVK3LF- aaqctcgccgccatggaaaccccaqcgcagcttctcttcctcctgctactctgg hRKasaTN ctcccagataccaccggtaaggaatcccgggccaagaaattccagcggcagcat -hlgGTN- atggactcagacagttcccccagcagcagctccacctactgtaaccaaatgatg NLG- aggcgccggaatatgacacaggggcggtgcaaaccagtgaacacctttgtgcac hDKAsa1- gagcccctggtagatgtccagaatgtctgtttccaggaaaaggtcacctgcaag 105-1I A aacgggcagggcaactgctacaagagcaactccagcatgcacatcacagactgc cgcctgacaaacggctccaggtaccccaactgtgcataccggaccagcccgaag gagagacacatcattgtggcctgtgaagggagcccatatgtgccagtccacttt ga tgc ttc tg tggaggactc tacagatctcgagcccaaatcttctgacaaaact cacacatgtccaccgtgcccagcacctgaactcctggggggaccgtcagtcttc ctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtc acatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactgg tacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcag tacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactgg ctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagccccc atcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtac accctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgc ctggtcaaaggcttcLaLcccagcgacaLcgccgtggagtgggagagcaatggg cagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctcc ttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaac gtcttctcatgctccgtgatgcatgagggtctgcacaaccactacacgcagaag agcctctctctgtctccgggtaaagtcgacggtgctagcagccatgtgaatgtg agcagccctagcgtgcaggatatcctgaagatcgcagccttcaacacccagaca tttggggagaccaagatgtccaatgccaccctcgtcagctacattgtgcagatc ctgagccgctatgacatcgccctggtccaggaggtcagagacagccacctgact gccgtggggaagctgctggacaacctcaatcaggatgcaccagacacctatcac tacgtggtcagtgagccactgggacggaacagctacaaggagcgctacctgttc gtgtacaggcctgaccaggtgtctgcggtggacagctactactacgatgatggc tgcgagccctgcgggaacgacaccttcaaccgagagccagccattgtcagg t t c ttc tcccggttcacagaggtcagggagtttgccattg ttcccctgcatgcggcc ccgggggacgcagtagccgagatcgacgctctctatgacgtctacctggatgtc caagagaaatggggctcggaggacgtcatgTtgatgggcgacttcaatgcgggc




TABLA 2
SEQ ID DESCRIP SECUENCIA (LAS SECUENCIAS NUCLEOTÍDICAS SON 3'-5')
NO: 
C-105R; A'l ggggagaccaagatgtccaatgccaccctcgtcagctacattgtgcagatcctg liF- agccgctatgacatcgccctggtccaggaggtcagagacagccacctgactgcc gtggggaagctgctggacaacctcaatcaggatgcaccagacacctatcactac hlgGlTN gtggtcagtgagccactgggacggaacagctataaggagcgctacctgttcgtg tacaggcctgaccaggtgtctgcggtggacagctactactacgatgatggctgc gagccctgcaggaacgacaccttcaaccgagagccattcattgtcaggttcttc tcccggttcacagaggtcagggagtttgccattgttcccctgcatgcggccccg ggggacgcagtagccgagatcgacgctctctatgacgtctacctggatgtccaa gagaaarggggcttggaggacgtcatgttgatgggcgacttcaatgcgggctgc agctatgtgagaccctcccagtggtcatccatccgcctgtggacaagccccacc ttccagtggctgatccccgacagcgccgacaccacagctacacccacgcaccgt gcctatgacaggatcgtggttgcagggatgctgctccgaggcgccgttgttccc gactcggctcttccctttaacttccaggctgcctatggcctgagtgaccaactg gcccaagccatcagtgaccactatccagtggaggtgatgctgaaagatctcgag cccaaatcttctgacaaaactcacacatgtccaccgtgcccagcacctgaactc ctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatg atctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagac cctgaggtcaagt tcaactggtacgtggacggcgtggaggtgcataatgccaag acaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctc accgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctcc aacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcag ccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaag aaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgcc gtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctccc gtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaag agcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctg cacaaccactacacgcagaagagcctctctctgtctccgggtaaatgataatct aqa
124 hVKJLP- gttaagcttgccaccatggaaaccccagcgcagcttctcttcctcctgctactc
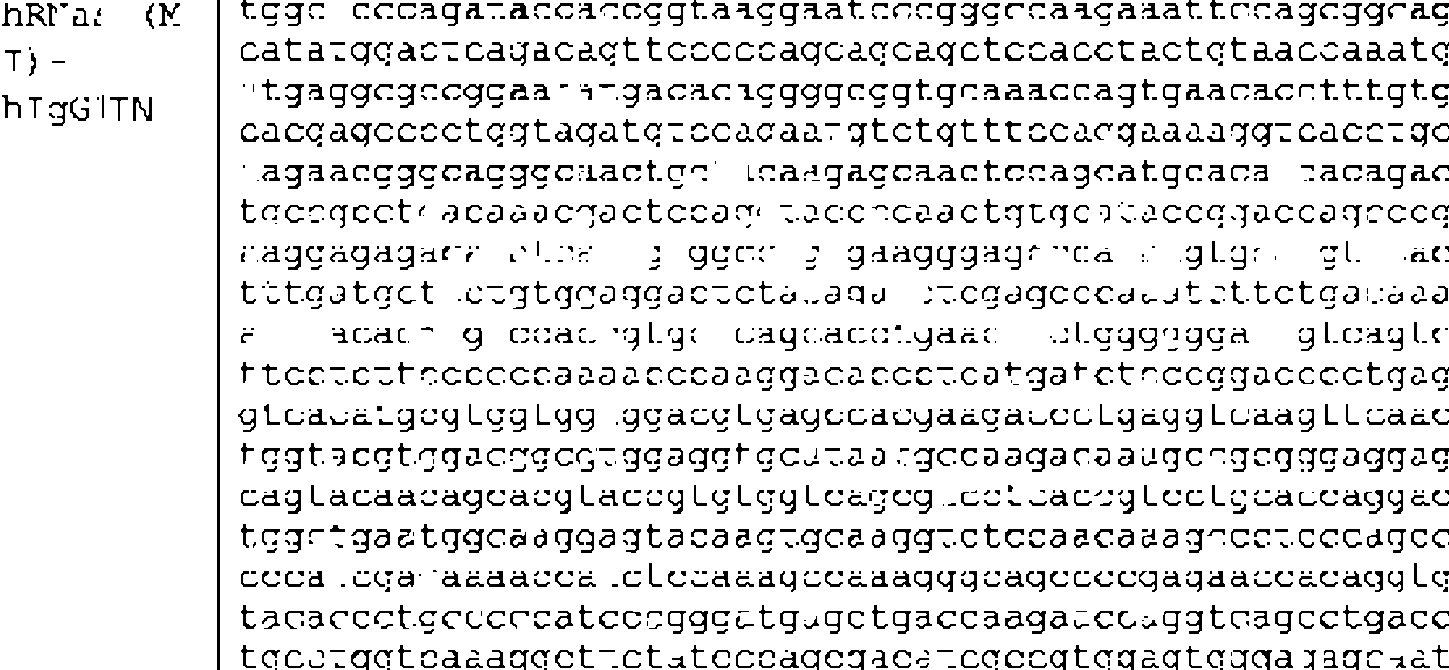
gggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggc tccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcagggg aacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcag aagagcctctcrctgtctccgggtaaatgataatctaga
_2d hVKJLP- gttaagcttgccaccatggaaaccccagcgcagcttctcttcctcctgctactc


TABLA 2
SEQ ID DESCRIP SECUENCIA (LAS SECUENCIAS NUCLEOTÍDICAS SON 3-5') NO: CIÓN
tcc ttcttcctctacag caagctcaccgtgga caagagcaggtgg cagcagggg aac gtcttctcatgctcc gtgatgcatgaggc tctgcacaaccac tacacgcag
de la
ctg gctgtccacagacgt gctctggagaacac ttccatttctcag ggacatcca transcripción cctccagtgcccagaccgccccgtgtggtggacaagctccctictgtgcattgci: (FL) de cc agggaaagcctg tagccctggggcca gtgagatcacaggtc tgagcaaagct Trexl murino gagctggaagtacaggggcgtcaacgcttcga tgacaacctggcc atcctgctc cga gccttcctgcagcgc cagccacagccttg ctgccttgtggca cacaacggt gacc gctatgactttcct ctgctccagacaga gcttgctaggctg agcactccc agt cccctagatggtacc ttctgtgtggacag catcgctgcccta aaggccttg gaac aagctagcagcccc tcagggaatggttc gaggaaaagctac agcctgggc agc atctacacccgcctg tactggcaagcacc gacagactcacat actgctgaa ggtg atgttctaaccctg ctcagcatctgtca gtggaagccacag gccctactg cag tgggtggacgaacat gcccggccctttag caccgtcaagccc atgtacggc act ccggctaccactgga acaaccaacctaag gccacatgctgcc acagctact aca cccctggccacagcc aatggaagtcccag caatggcaggagc aggcgacct aag agtcctcctccagag aaggLcccagaagc cccatcacaggag gggctgctg gccc cactgagcctgctga ccctcctgaccttg gcaatagccactc tgtatgga ct cctcctgqcctcac ccgggcaqtaa
125 nTREXlmi atg ggctcacagaccctg ccccatggtcacat gcagaccctcatc ttcttagac nec ctg gaagccactggcctg ccttcgtctcggcc cgaagtcacagag ctgtgcctg ctg gctgtccacagacgc gctctggagaacac ttccatttcccag ggacatcca cct ccagtgcccagaccg ccccgtgtggtgga caagctctctctg tgcattgct cca gggaaagcctgtagc cctggggccagtga gatcacaggtctg agcaaagct gagc tggaagtacagggg cgtcaacgcttcga tgacaacctggcc atcctgctc cga gccttcctgcagcgc cagccacagccttg ctgccttgtggca cacaacggt gacc gctatgactttcct ctgcLccagacaga gcttgctaggctg agcactccc agt cccctagatggtacc ttctgtgtggacag catcgctgcccta aaggccttg gaac aagctagcagcccc tcagggaatggttc gaggaaaagctac agcctgggc ag catctacacccgc ctgtactggcaagc accgacagactcaca tactgctgaa ggtg atgttcraaccctg ctcagcatctgtca gtggaagccacag gccctactg cag tgggtggacgaacat gcccggccctttag caccgtcaagccc atgtacggc ac tccqgccaccactg qaacaacaqatctcg ag
130 Tre:>íl aag cttgccaccatggaa accccagcgcagct tctcttcctcctg ccactctgg murino- ctcc cagat.accaccggtatgggc tcacagaccctgcccca tggtcacatgcag (G4S) 4- acc ctcatcttcttagac ctggaagccaccgg cctgccttcgtct cggcccgaa nlgti2a gtca cagagctgtgcctg ctggctgtccacag acgtgctctggag aacacttcc r.
att tctcagggacatcca cctccagtgcccag accgccccgtgtg gtggacaag ctc tctctgtgcattgct ccagggaaagcctg tagccctggggcc agtgagatc aca ggtctgagcaaagct gagctggaagtaca ggggcgtcaacgc ttcgatgac aac ctggccatcctgctc cgagccttcctgca gcgccagccacag ccttgctgc ctt gtggcacacaacggt gaccgctatgactt tcctctgctccag acagagctt gcta ggctgagcactccc agtcccctagacgg taccttctgtgtg gacagcatc gctg ccctaaaggccttgg aacaagctagcag cccctcagggaat ggttcgagg aaa agctacagcctgg gcagcatctacac ccgcctgtactggcaa gcaccgaca gact cacatactgctgaag gtgatgttctaac cctgctcagcatc tgtcagtgg aag ccacaggccctactg cagtgggtggacga acatgcccggccc tttagcacc gtca agcccatgtacggc actccggctaccac tggaacaacagat ctctccgga ggag gtggctcaggtggtg gaggatctggagg aggtggctcaggg agtggtgga ggtg gttctaccggtctcg agcccagaggtcc cacaatcaagccc tctcctcca tgc aaatgcccagcacctaa cctcttgggtggatcatcc gtcttcat.cttccct cca aagatcaaggatgta ctcacgatccccct gagccccatggtc acatgtgtg gtg gtggatgtgag cgaggatgacccag acgtccagatca gctggtttgtgaac aac gtggaagtacacaca gctcagacacaaac ccatagagaggat tacaacagt act ctccgggtggtcagt gccctccccatcca gcaccaggactgg atgagtggc aag gagttcaaatgct cggtcaacaacaa agacctcccagcgtcc atcgagaga acc atctcaaaacccaga gggccagtaagagc tccacaggtatat gLcttgcct
TABLA 2
SEQ ID DESCRIP SECUENCIA (LAS SECUENCIAS NUCLEOTÍDICAS SON 3'-5')
ccaccagcacaagagatgactaa gaaagagttcagtctgacctgc atgatcaca ggcttcttacctgccgaaartgc tgtggactggaccagcaatggg cgtacagag caaaactacaagaacacc gcaacagtcctggactctgatggttct tacttcatg tacagcaagctcagagtacaaaa gagcacttgggaaagaggaagt cttttcgcc t gctcagtggtccacgagggtctgcacaatcaccttacgactaagagcttctct  cggactccgggtaaatgataatctaga
cggactccgggtaaatgataatctaga
i r. Trexl aagcttgccaccat ggaaaccccagcgcagcrtctcttcctc ctgctactctgg 1 ctcc cagataccaccggtatgggctcacagaccctgccccatggtcacatgcag muriño-(<34$)5” accc tcatcttcttagacctggaagccactggcctgccttcgtctcggcccgaa gtca cagagctgtgcctgctggctgtccacagacg tgctctggagaacacttcc mIgG2a-c
atttctcagggacatccacctcc agtgcccagaccgccccgtgtg gtggacaag ctctctctgtgcattgctccagg gaaagcctgtagccctggggcc agtgagatc acaggtctgagcaaagctgagct ggaagtacaggggcgtcaacgc ttcgatgac aacctggccatcctgctcc gagccttcctgcagcgccagccac agccttgctgc ct tgtggcacacaacggtgaccgctatgactttcctctgctccagacagagc tt gctaggctgagcactcccagtcc cctagatggtaccttctgtgtg gacagcatc gctg ccctaaaggccttggaacaagctagcagcccctcagggaaLggttcgagg aaaa gctacagcctgggcagcatctacacccgcctgtactggcaagcaccgaca gact cacatactgctgaaggtgatgttetaaccct gctcagcatctgtcagtgg aagccacaggccctactgcagtg ggtggacgaacatgcccggccc tttagcacc gtcaagcccatgtacggcactcc ggctaccactggaacaacagat ctctccgga ggaggtggctcaggtggtggagg atctggaggaggtggctcaggt ggtggagga tctg gaggaggtgggagtctcgagcccagaggtcccacaatcaagccctctcct ccatgcaaatgcccagcacctaa cctcttgggtggatcatccgtc ttcatcttc cctccaaagatcaaggatgtact catgatctccctgagccccatgg tcacatgt gtgg tggtggatgtgagcgaggatgacccagacgtccagatcagctggtttgtg aacaacgtggaagtacacacagc tcagacacaaacccatagagag gattacaac agta ctctccgggtggtcagtgccctccccatccagcaccaggactggatgagt ggcaaggagttcaaatgctcggt caacaacaaagacctcccagcg tccatcgag agaaccatctcaaaacccagagg gccagtaagagctccacaggta tatgtcttg cctccaccagcagaagagatgac taagaaagagttcagtctgacc tgcatgatc acag gcttcttacctgccgaaattgctgtggactggaccagcaatgggcgtaca gagcaaaactacaagaaca ccgcaacagtcctggactctgatg gttcttacttc atgtacagcaagctcagagtaca aaagagcacttgggaaagagga agtcttttc gcct gctcagtggtccacgagggtctgcacaatcaccttacgactaagagcttc tctc ggactccgggtaaatgataatctaga
132 enlazador gtcga cggcgcggccgccagccccgtgaacgtgagcagccccagcgtgcaggat

133 T raxl aa gettgccaccatggaaaccccagcgcagcttet ettcctcctgctactctgg murino- ctcccagataccaccggt atgggctcacagaccctgccccatggt cacatgcag Tiaxl- accctcatcttcttagacctgga agccactggcctgccttcgtct cggcccgaa gtcacagagctgtgcctgctggc tgtccacagacgtgctctggag aacacttcc (G4S) L>-atttctcagggacatccacctcc agtgcccagaccgccccgtgtg gtggacaag nTgG?a-c ctctctctgtgcattgct ccagggaaagcctgtagccctggggcc agtgagatc acaggtctgagcaaagctgagct ggaagtacaggggcgtcaacgc ttcgargac aacctggccatcctgctccgagc cttcctgcagcgccagccacag ccttgctgc cttgtggcacacaacggtgaccg ctatgactttcctctgctccaga cagagctt gctaggctgagcactcccagtcc cctagatggtaccttctgtgtg gacagcatc gctgccctaaaggccttggaaca agctagcagcccctcagggaat ggttcgagg aaaagctacagcctgggcagcat ctacacccgcctgtactggcaa gcaccgaca gactcacatactgctgaaggtga tgttctaaccctgctcagcatc tgtcagtgg aagccacaggccctactgcagtg ggtggacgaacatgcccggccc tttagcacc gtcaagcccatgtacggcactcc ggctaccactggaacaacagat ctcatgggc tcacagaccctgccccacggtca catgcagaccctcatcttctta gacctggaa gcca ctggcctgccttcgtctcggcccgaagtca cagagctgtgcctgctggct gtcc acagacgtgctctggagaacacttccatttctcagggacatccacctcca gtgc ccagaccgccccgtgtggtggacaagctctctctgtgcattgctccaggg



TABLA 2
S

1VK3LP- metpaql lfllllwlpdttglkiaafniq tfgetkmsnatlvsyivqilsrydi jOKasal ( alvqevrdshltavgklldnlnqdap dtyhyvvseplgrnsykeryl fvyrpdq TNí - vsavdsyyyddg cepcgndtfnrepaivrffsr ftevrefaivplhaapgdava

1





TABLA 2
SEQ ID DESCRIP SECUENCIA (LAS SECUENCIAS NUCLEOTÍDICAS SON 3'-5') NO: CIÓN
gagaaatggggcttggaggacgtcatgttgatgggcgacttcaatgcgggctgc agctatgtgagaccctcccagtggtcatccatccgcctgtggacaagccccacc ttccagtggctgatccccgacagcgctgacaccacagctacacccacgcactgt gcctatgacaggatcgtggttgcagggatgctgctccgaggcgccgttgttccc gactcggctcttccctttaacttccaggctgccta tggcctgagtgaccaactg gcccaagccatcagtgaccactatccagtggaggtgatgctgaaagatctctcc ggaggaggtggctcaggtggtggaggatctggaggaggtggctcaggtggtgga ggatctggaggaggtgggagtctcgagcccaaatcttctgacaaaactcacaca tgtccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctctte cccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgc gtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggracgtg gacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaac agcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaat ggcaaggagtaeaagtgcaaggtctccaacaaagccctcccagcccccatcgag aaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctg cccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctgg te aaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccg gagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttc ctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttc tcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctc tc tc tg tc tc c g g g taaagtcgacggagctagcagccccgtgaacgtgagcagc cccagcgtgcaggatatcccttccctgggcaaggaatcccgggccaagaaatte cagcggcagcatatggactcagacagttcccccagcagcagctccacctactgt aaccaaatgatgaggcgccggaatatgacacaggggcggtgcaaaccagtgaac acctttgtgcacgagcccctggtagatgtccagaatgtctgtttccaggaaaag gtcacctgcaagaacgggcagggcaactgctacaagagcaactccagcatgcac atcacagactgccgcctgacaaacggctccaggtaccccaactgtgcataccgg accagcccgaaggagagacacatcattgtggcctgtgaagggagcccatatgtg ccag tccactttga tgcttc tg tggaggactc tacctaa taa tc taga IV 3 ív jV K J I P - m e tp a q ll f l l l lw lp d t tg lk ia a fn iq t f ge tkm sn a tlvsy ivq ils ryd i h C H a a a ' l - a lvqevrdsh ltavgklld r.lr.qdapdtyhyw sop lgrnsykery lfvyrpdq G'l 05 A; M vsavdsyyyddgcepcrndtfnrep fivrffsrftevre fa ivp lhaapgdava 14 F - eidalydvyldvqekwgledvralmgdfnagcsyvrpsqwssirlwtsptfqwli CLIÍ.) 5 pdsadttatpthcaydrivvagm llrgavvpdsalpfnfqaayglsdqlaqa is pvevmlkdlsggggsggggsggggsggggsggggslepkssdkthtcppcp 2 — t: 1 y G1 — dhy
ape1lggpsv f 1f ppkp kdtlm i s r tpevtcw vdvs hedpev k f nwyvdgvev TN-XLG- hnaktkpreeqynstyrvvsvltvlhqdw lngkeykckvsnkalpapiektisk k Sí-Jasa 1 - akgqprepqvytlp p s rd e ltk n q v s ltc lv k g fypsdiavewesngqpennyk TN ttp p v ld sd g s ff lyskltvdksrwqqgnvfscsvmhealhnhytqkslslspg kvdgasspvnvsspsvqdipslgkesrakkfqrqhmdsdsspsssstycnqmmr r rnmtqgrckpvntfvheplvdvqnvcfqekvtckngqgncyksnssmhitdcr ltngsrypncayrtspkerhiivacegspyvpvhfdasvedat
130 gttaagcttgccaccatggaaaccccagcgcagcttctcttcctcctgctactc tggctcccagataccaccggtctgaagatcgcagccttcaacatccagacattt ggggagaccaagatgtccaatgccaccctcgtcagctacattgtgcagatcctg agccgctatgacatcgccctggtccaggaggtcagagacagccacctgactgcc gtggggaagctgctggacaacctcaatcaggatgcaccagacacctatcactac  gtggtcagtgagccactgggacggaacagctataaggagcgctacctgttcgtg tacaggcctgaccaggtgtctgcggtggacagctactactacgatgatggctgc h Si-Jas a l gagccctgcaggaacgacaccttcaaccgagagccattcattgtcaggttcttc - TN tcccggttcacagaggtcagggagtttgccattgttcccctgcatgcggccccg ggggacgcagtagccgagatcgacgctctctatgacgtctacctggatgtccaa gagaaatggggcttggaggacgtcatgttgatgggcgacttcaatgcgggctgc agctatgtgagaccctcccagtggtcatccatccgcctgtggacaagccccacc ttccagtggctgatccccgacagcgctgacaccacagctacacccacgcactgt gcctatgacaggatcgtggttgcagggatgctgctccgaggcgccgttgttccc gactcggctcttccctttaacttccaggctgccta tggcctgagtgaccaactg gcccaagccatcagtgaccactatccagtggaggtgatgctgaaagatctcgag cccaaatcttctgacaaaactcacacatgtccaccgtgcccagcacctgaactc
gtggtcagtgagccactgggacggaacagctataaggagcgctacctgttcgtg tacaggcctgaccaggtgtctgcggtggacagctactactacgatgatggctgc h Si-Jas a l gagccctgcaggaacgacaccttcaaccgagagccattcattgtcaggttcttc - TN tcccggttcacagaggtcagggagtttgccattgttcccctgcatgcggccccg ggggacgcagtagccgagatcgacgctctctatgacgtctacctggatgtccaa gagaaatggggcttggaggacgtcatgttgatgggcgacttcaatgcgggctgc agctatgtgagaccctcccagtggtcatccatccgcctgtggacaagccccacc ttccagtggctgatccccgacagcgctgacaccacagctacacccacgcactgt gcctatgacaggatcgtggttgcagggatgctgctccgaggcgccgttgttccc gactcggctcttccctttaacttccaggctgccta tggcctgagtgaccaactg gcccaagccatcagtgaccactatccagtggaggtgatgctgaaagatctcgag cccaaatcttctgacaaaactcacacatgtccaccgtgcccagcacctgaactc



TABLA 2
SEQ ID DESCRIP SECUENCIA (LAS SECUENCIAS NUCLEOTÍDICAS SON 3'-5 ') NO: CIÓN

1
1 
1
1


TABLA 2
SEQ ID DESCRIP SECUENCIA (LAS SECUENCIAS NUCLEOTÍDICAS SON 3'-5')



1

TABLA 2
S  SECUENCIA (LAS SECUENCIAS NUCLEOTÍDICAS SON 3'-5 ')
SECUENCIA (LAS SECUENCIAS NUCLEOTÍDICAS SON 3'-5 ')


La invención comprende al menos las siguientes realizaciones:
Lista de realizaciones:
1. Una molécula de nucleasa híbrida que comprende un primer dominio nucleasa y un dominio Fc, en la que el primer dominio nucleasa se acopla operativamente al dominio Fc.
2. La molécula de nucleasa híbrida de la realización 1, en la que la molécula de nucleasa híbrida es un polipéptido, en la que la secuencia de aminoácidos del primer dominio nucleasa comprende una secuencia de aminoácidos de RNasa humana de tipo natural tal como se expone en la SEQ ID NO: 149, en la que la secuencia de aminoácidos del dominio Fc comprende una secuencia de aminoácidos del dominio Fc de IgG1 humana de tipo natural tal como se expone en la SeQ ID NO: 145.
3. La molécula de nucleasa híbrida de la realización 1, en la que la molécula de nucleasa híbrida es un polipéptido que consiste en la SEQ ID NO: 163.
4. La molécula de nucleasa híbrida de la realización 1, en la que la molécula de nucleasa híbrida comprende DNasa1 humana de tipo natural ligada a una IgG1 humana de tipo natural.
5. La molécula de nucleasa híbrida de la realización 1, en la que la molécula de nucleasa híbrida comprende DNasa1 G105R A114F humana ligada a IgG1 humana de tipo natural.
6. La molécula de nucleasa híbrida de la realización 1, en la que la molécula de nucleasa híbrida comprende RNasa1 humana de tipo natural ligada a IgG1 humana de tipo natural ligada a DNasa1 humana de tipo natural. 7. La molécula de nucleasa híbrida de la realización 1, en la que la molécula de nucleasa híbrida comprende RNasa1 humana de tipo natural ligada a IgG1 humana de tipo natural ligada a DNasa1 G105R A114F humana. 8. La molécula de nucleasa híbrida de la realización 1, en la que el dominio Fc se une a un receptor de Fc en una célula humana.
9. La molécula de nucleasa híbrida de la realización 1, en la que la semivida en suero de la molécula es significativamente mayor que la semivida en suero del primer dominio nucleasa solo.
10. La molécula de nucleasa híbrida de la realización 1, en la que la actividad nucleasa del primer dominio nucleasa de la molécula es igual o mayor al del dominio nucleasa solo.
11. La molécula de nucleasa híbrida de la realización 1, en la que la administración de la molécula a un ratón incrementa las tasas de supervivencia del ratón según se mide en un ensayo en un modelo del lupus en ratones. 12. La molécula de nucleasa híbrida de la realización 1, en la que la molécula comprende además un primer dominio enlazador, y en la que el primer dominio nucleasa se acopla operativamente al dominio Fc mediante el primer dominio enlazado.
13. La molécula de nucleasa híbrida de la realización 12, en la que la molécula de nucleasa híbrida es un polipéptido, en el que la secuencia de aminoácidos del primer dominio nucleasa comprende una secuencia de aminoácidos de RNasa, en el que el primer dominio enlazador comprende entre 5 y 32 aminoácidos de longitud, en el que la secuencia de aminoácidos del dominio Fc comprende una secuencia de aminoácidos del dominio Fc humano y en el que el primer dominio enlazador se acopla al extremo C-terminal del primer dominio nucleasa y al extremo N-terminal del dominio Fc.
14. La molécula de nucleasa híbrida de la realización 12, en la que la molécula de nucleasa híbrida es un polipéptido, en el que la secuencia de aminoácidos del primer dominio nucleasa comprende una secuencia de aminoácidos de RNasa humana, en el que el primer dominio enlazador es un péptido NLG entre 5 y 32 aminoácidos de longitud, en el que la secuencia de aminoácidos del dominio Fc comprende una secuencia de aminoácidos del dominio Fc humano de tipo natural, y en el que el primer dominio enlazador se acopla al extremo C-terminal del primer dominio nucleasa y el extremo N-terminal del dominio Fc.
15. La molécula de nucleasa híbrida de la realización 1, que además comprende una secuencia líder.
16. La molécula de nucleasa híbrida de la realización 15, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que la secuencia líder es un péptido VK3LP humano, y en la que la secuencia líder se acopla al extremo N-terminal del primer dominio nucleasa.
17. La molécula de nucleasa híbrida de la realización 1, en la que la molécula es un polipéptido.
18. La molécula de nucleasa híbrida de la realización 1, en la que la molécula es un polinucleótido.
19. La molécula de nucleasa híbrida de la realización 1, en la que el primer dominio nucleasa comprende una RNasa.
20. La molécula de nucleasa híbrida de la realización 19, en la que la RNasa es una RNasa humana.
21. La molécula de nucleasa híbrida de la realización 19, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que la RNasa es un polipéptido que comprende una secuencia de aminoácidos al menos 90% similar a una secuencia de aminoácidos de RNasa expuesta en la Tabla 2.
22. La molécula de nucleasa híbrida de la realización 19, en la que la RNasa es RNasa1 pancreática humana.
23. La molécula de nucleasa híbrida de la realización 1, en la que el primer dominio nucleasa comprende una DNasa.
24. La molécula de nucleasa híbrida de la realización 23, en la que la DNasa es una DNasa humana.
25. La molécula de nucleasa híbrida de la realización 23, en la que la molécula de nucleasa híbrida es un polipéptido y en la que la DNasa es un polipéptido que comprende una secuencia de aminoácidos al menos 90% similar a una secuencia de aminoácidos de DNasa expuesta en la Tabla 2.
26. La molécula de nucleasa híbrida de la realización 23, en la que la DNasa se selecciona del grupo que consiste en DNasa I humana, TREX1 y DNasa 1L3.
27. La molécula de nucleasa híbrida de la realización 1, en la que el dominio Fc es un dominio Fc humano.
28. La molécula de nucleasa híbrida de la realización 1, en la que el dominio Fc es un dominio Fc de tipo natural. 29. La molécula de nucleasa híbrida de la realización 1, en la que el dominio Fc es un dominio Fc mutante.
30. La molécula de nucleasa híbrida de la realización 1, en la que el dominio Fc es un dominio Fc de IgG1 humana.
31. La molécula de nucleasa híbrida de la realización 1, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el dominio Fc es un polipéptido que comprende una secuencia de aminoácidos al menos 90% similar a una secuencia de aminoácidos de un dominio Fc expuesta en la Tabla 2.
32. La molécula de nucleasa híbrida de la realización 12, en la que la molécula de nucleasa híbrida es un polipéptido y en la que el primer dominio enlazador tiene una longitud de aproximadamente 1 a aproximadamente 50 aminoácidos.
33. La molécula de nucleasa híbrida de la realización 12, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el primer dominio enlazador tiene una longitud de aproximadamente 5 a aproximadamente 32 aminoácidos.
34. La molécula de nucleasa híbrida de la realización 12, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el primer dominio enlazador tiene una longitud de aproximadamente 15 a aproximadamente 25 aminoácidos.
35. La molécula de nucleasa híbrida de la realización 12, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el primer dominio enlazador tiene una longitud de aproximadamente 20 a aproximadamente 32 aminoácidos.
36. La molécula de nucleasa híbrida de la realización 12, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el primer dominio enlazador tiene una longitud de aproximadamente 20 aminoácidos.
37. La molécula de nucleasa híbrida de la realización 12, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el primer dominio enlazador tiene una longitud de aproximadamente 25 aminoácidos.
38. La molécula de nucleasa híbrida de la realización 12, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el primer dominio enlazador tiene una longitud de aproximadamente 18 aminoácidos.
39. La molécula de nucleasa híbrida de la realización 12, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el primer dominio enlazador comprende un péptido de gly/ser.
40. La molécula de nucleasa híbrida de la realización 39, en la que el péptido de gly/ser es de la fórmula (Gly4Ser)n, en la que n es un número entero positivo seleccionado del grupo que consiste en 1, 2, 3, 4, 5, 6, 7, 8, 9 y 10.
41. La molécula de nucleasa híbrida de la realización 39, en la que el péptido de gly/ser comprende (Gly4Ser)3, (Gly4Ser)4 o (Gly4Ser)5.
42. La molécula de nucleasa híbrida de la realización 12, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el primer dominio enlanzador comprende un péptido NLG.
43. La molécula de nucleasa híbrida de la realización 12, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el primer dominio enlazador comprende un sitio de glicosilación ligado a N.
44. La molécula de nucleasa híbrida de la realización 1, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el primer dominio nucleasa está ligado al extremo N-terminal del dominio Fc.
45. La molécula de nucleasa híbrida de la realización 1, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el primer dominio nucleasa está ligado al extremo C-terminal del dominio Fc.
46. La molécula de nucleasa híbrida de la realización 1, que comprende además un segundo dominio nucleasa. 47. La molécula de nucleasa híbrida de la realización 46, en la que el primer y el segundo dominios nucleasa son dominios nucleasa distintos.
48. La molécula de nucleasa híbrida de la realización 46, en la que el primer y el segundo dominios nucleasa son los mismos dominios nucleasa.
49. La molécula de nucleasa híbrida de la realización 46, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el segundo dominio nucleasa está ligado al extremo C-terminal del dominio Fc.
50. La molécula de nucleasa híbrida de la realización 46, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el segundo dominio nucleasa está ligado al extremo N-terminal del dominio Fc.
51. La molécula de nucleasa híbrida de la realización 46, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el segundo dominio nucleasa está ligado al extremo C-terminal del primer dominio nucleasa.
52. La molécula de nucleasa híbrida de la realización 46, en la que la molécula de nucleasa híbrida es un polipéptido, y en la que el segundo dominio nucleasa está ligado al extremo N-terminal del primer dominio nucleasa.
53. Un polipéptido dimérico que comprende un primer polipéptido y un segundo polipéptido, en el que el primer polipéptido comprende un primer dominio nucleasa y un dominio Fc, en el que el primer dominio nucleasa se acopla operativamente al dominio Fc.
54. El polipéptido dimérico de la realización 53, en el que el segundo polipéptido es una segunda molécula nucleasa híbrida que comprende un segundo dominio nucleasa y un segundo dominio Fc, en el que el segundo dominio nucleasa se acopla operativamente al segundo dominio Fc.
55. Una composición farmacéutica que comprende al menos una molécula de nucleasa híbrida y/o al menos un polipéptido dimérico de acuerdo con cualquiera de las realizaciones 1-54, y un excipiente farmacéuticamente aceptable.
56. Una molécula de ácido nucleico que codifica la molécula de nucleasa híbrida de acuerdo con la realización 17.
57. Un vector de expresión recombinante que comprende una molécula de ácido nucleico de acuerdo con la realización 56.
58. Una célula huésped transformada con el vector de expresión recombinante de acuerdo con la realización 57. 59. Un método para obtener la molécula de nucleasa híbrida de la realización 1, que comprende: proporcionar una célula huésped que comprende una secuencia de ácido nucleico que codifica la molécula de nucleasa híbrida; y mantener la célula huésped bajo condiciones en las que se expresa la molécula de nucleasa híbrida.
60. Un método para tratar o prevenir una afección asociada con una respuesta inmunitaria anormal, que comprende administrar a un paciente en necesidad del mismo una cantidad eficaz de una molécula de nucleasa híbrida aislada de la realización 1.
61. El método de la realización 60, en el que la afección es una enfermedad autoinmunitaria.
62. El método de la realización 61, en el que la enfermedad autoinmunitaria se selecciona del grupo que consiste en diabetes mellitus dependiente de insulina, esclerosis múltiple encefalomielitis autoinmune experimental, artritis reumatoide, artritis autoinmune experimental, miastenia gravis, tiroiditis, una forma experimental de uveorretinitis, tiroiditis de Hashimoto, mixedema primario, tirotoxicosis, anemia perniciosa, gastritis atrófica autoinmune, enfermedad de Addison, menopausia prematura, infertilidad masculina, diabetes juvenil, síndrome de Goodpasture, pénfigo vulgar, penfigoide, oftalmía simpática, uveítis facogénica, anemia hemolítica autoinmune, leucopenia idiopática, cirrosis biliar primaria, hepatitis Hbs-ve crónica activa, cirrosis criptogénica, colitis ulcerosa, síndrome de Sjogren, esclerodermia, granulomatosis de Wegener, polimiositis, dermatomiositis, LE discoide, lupus eritematoso sistémico (LES) y enfermedad del tejido conectivo.
63. El método de la realización 61, en el que la enfermedad autoinmune es LES.
Claims (15)
1. Un polipéptido que comprende una RNasa, una DNasa y un dominio Fc variante, en el que la RNasa se acopla operativamente, opcionalmente con un enlazador, al dominio Fc variante, y en el que la DNasa se acopla operativamente, opcionalmente con un enlazador, al dominio Fc variante, en el que el dominio Fc variante es un dominio Fc de IgG1 humana variante que comprende una sustitución de aminoácidos que disminuye la unión, en comparación con el tipo natural, a un receptor Fcy o a una proteína complemento o los dos, en el que el polipéptido tiene una función efectora reducida opcionalmente seleccionada del grupo que consiste en opsonización, fagocitosis, citotoxicidad dependiente del complemento y citotoxicidad celular dependiente de un anticuerpo.
2. El polipéptido de la reivindicación 1, en el que:
(a) la RNasa es una RNasa humana, tal como una RNasa 1 pancreática humana; y/o
(b) la DNasa se selecciona del grupo que consiste en una DNasa humana de Tipo 1, una DNasa 1L3 humana o TREX1 humana; y/o
(c) el dominio Fc comprende un dominio bisagra, un dominio CH2 y un dominio CH3; y/o
(d) una secuencia líder, tal como el péptido VK3LP humano, se acopla al extremo N-terminal de la RNasa o al extremo N-terminal de la DNasa.
3. El polipéptido de la reivindicación 1 o la reivindicación 2, en el que:
(a) el dominio Fc comprende un dominio bisagra modificado que comprende al menos una sustitución, opcionalmente en el que el dominio bisagra modificado comprende una mutación en una o más de tres cisteínas bisagra, tales como SCC o SSS; y/o
(b) en el que el dominio Fc comprende un dominio CH2 modificado que comprende al menos una sustitución, opcionalmente en el que la sustitución se selecciona del grupo que consiste en P238S, P331S, N297S o una combinación de los mismos.
4. El polipéptido de la reivindicación 1 o la reivindicación 2, en el que
(a) la RNasa comprende una secuencia de aminoácidos al menos 90 % idéntica a la secuencia de aminoácidos expuesta en SEQ ID NO: 149 opcionalmente sin su secuencia líder, o comprende 100 o más aminoácidos contiguos de la SEQ ID NO: 149; y/o
(b) en el que la DNasa comprende una DNasa humana, opcionalmente DNasa 1, opcionalmente que comprende una secuencia de aminoácidos expuesta en SEQ ID No :139, SEQ ID NO:143 o SEQ ID No :142 o que comprende una secuencia de aminoácidos al menos 90 % idéntica a la secuencia de aminoácidos expuesta en SEQ ID NO:139, SEQ ID NO:143 o SEQ ID NO:142; y/o
(c) el dominio Fc comprende una secuencia de aminoácidos al menos 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 % o 98 % idéntica a la secuencia de aminoácidos expuesta en SEQ ID NO: 145, que comprende opcionalmente un dominio bisagra modificado que comprende al menos una sustitución, opcionalmente en el que el dominio bisagra modificado comprende una mutación en una o más de tres cisteínas, tales como SCC o SSS; y/o comprende opcionalmente una o más mutaciones de Fc seleccionadas entre P238S, P331S, K322S y N279S.
5. El polipéptido de la reivindicación 1, en el que:
el polipéptido comprende una secuencia de aminoácidos al menos 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 % o 98 % idéntica a la secuencia de aminoácidos expuesta en SEQ ID NO: 153, opcionalmente sin su secuencia líder;
opcionalmente en el que el dominio Fc comprende un dominio bisagra modificado que comprende al menos una sustitución, opcionalmente en el que el dominio bisagra modificado comprende una mutación en una o más de tres cisteínas de bisagra, tales como SCC o SSS; y/o un dominio CH2 modificado que comprende al menos una sustitución seleccionada del grupo que consiste en P238S, P331S, N297S o una combinación de los mismos.
6. El polipéptido de cualquier reivindicación precedente, en el que:
la RNasa se acopla operativamente al dominio Fc por un dominio enlazador, opcionalmente en el que el dominio enlazador es un enlazador polipeptídico, tal como un enlazador gly-ser; y/o
en el que la RNasa se acopla operativamente al extremo N-terminal del dominio Fc, opcionalmente con un enlazador; y/o en el que la RNasa se acopla operativamente al extremo C-terminal del dominio Fc, opcionalmente con un enlazador; y/o en el que el polipéptido comprende una secuencia líder peptídica VK3LP humana acoplada al extremo N-terminal de la RNasa.
7. El polipéptido de cualquier reivindicación precedente, en el que:
la DNasa se acopla operativamente al dominio Fc por un segundo dominio enlazador, opcionalmente en el que el segundo dominio enlazador es un enlazador polipeptídico, tal como un péptido NLG; y/o
en el que la DNasa se acopla operativamente al extremo N-terminal del dominio Fc, opcionalmente con un enlazador; y/o
en el que la DNasa se acopla operativamente al extremo C-terminal del dominio Fc, opcionalmente con un enlazador; y/o
en el que el polipéptido comprende una secuencia líder peptídica VK3LP humana acoplada al extremo N-terminal de la DNasa.
8. Una composición que comprende el polipéptido de cualquiera de las reivindicaciones precedentes y un portador farmacéuticamente aceptable.
9. Una molécula de ácido nucleico que codifica el polipéptido según cualquiera de las reivindicaciones 1 a 7.
10. Un vector de expresión recombinante que comprende una molécula de ácido nucleico según la reivindicación 9.
11. Una célula huésped transformada con el vector de expresión recombinante según la reivindicación 10.
12. Un método de fabricación del polipéptido de cualquiera de las reivindicaciones 1 a 7, que comprende: proporcionar una célula huésped que comprende una secuencia de ácido nucleico que codifica el polipéptido; y mantener la célula huésped bajo condiciones en las que se expresa el polipéptido.
13. Un polipéptido de cualquiera de las reivindicaciones 1 a 7 para su uso en un método para tratar o prevenir una afección asociada con una respuesta inmunitaria anormal;
opcionalmente en el que la afección es una enfermedad autoinmunitaria, opcionalmente lupus eritematoso sistémico (LES), u opcionalmente seleccionada del grupo que consiste en diabetes mellitus dependiente de insulina, esclerosis múltiple, encefalomielitis autoinmune experimental, artritis reumatoide, artritis autoinmune experimental, miastenia gravis, tiroiditis, una forma experimental de uveorretinitis, tiroiditis de Hashimoto, mixedema primario, tirotoxicosis, anemia perniciosa, gastritis atrófica autoinmune, enfermedad de Addison, menopausia prematura, infertilidad masculina, diabetes juvenil, síndrome de Goodpasture, pénfigo vulgar, penfigoide, oftalmía simpática, uveítis facogénica, anemia hemolítica autoinmune, leucopenia idiopática, cirrosis biliar primaria, hepatitis Hbs-ve crónica activa, cirrosis criptogénica, colitis ulcerosa, síndrome de Sjogren, esclerodermia, granulomatosis de Wegener, polimiositis, dermatomiositis, LE discoide, lupus eritematoso sistémico (LES), y enfermedad del tejido conectivo.
14. Un polipéptido dimérico que comprende un polipéptido de una cualquiera de las reivindicaciones 1-7, opcionalmente un homodímero.
15. Una composición que comprende el polipéptido dimérico de la reivindicación 14 y un excipiente farmacéuticamente aceptable.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US25745809P | 2009-11-02 | 2009-11-02 | |
| US37075210P | 2010-08-04 | 2010-08-04 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2702053T3 true ES2702053T3 (es) | 2019-02-27 |
Family
ID=43923071
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES10827655.1T Active ES2626000T3 (es) | 2009-11-02 | 2010-11-02 | Composiciones terapéuticas de nucleasas y métodos |
| ES16198956T Active ES2702053T3 (es) | 2009-11-02 | 2010-11-02 | Composiciones terapéuticas de nucleasas y métodos |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES10827655.1T Active ES2626000T3 (es) | 2009-11-02 | 2010-11-02 | Composiciones terapéuticas de nucleasas y métodos |
Country Status (25)
| Country | Link |
|---|---|
| US (10) | US20130089546A1 (es) |
| EP (3) | EP2496691B1 (es) |
| JP (7) | JP6199033B2 (es) |
| KR (5) | KR101934923B1 (es) |
| CN (3) | CN102770533B (es) |
| AU (4) | AU2010313103B2 (es) |
| BR (1) | BR112012010202A2 (es) |
| CA (2) | CA3091939A1 (es) |
| CY (3) | CY1119166T1 (es) |
| DK (3) | DK3202898T3 (es) |
| ES (2) | ES2626000T3 (es) |
| HR (2) | HRP20170757T1 (es) |
| HU (2) | HUE041426T2 (es) |
| IL (4) | IL297588A (es) |
| LT (3) | LT3460056T (es) |
| MX (3) | MX341084B (es) |
| NZ (1) | NZ813794A (es) |
| PL (2) | PL3202898T3 (es) |
| PT (2) | PT2496691T (es) |
| RS (1) | RS55989B1 (es) |
| SG (3) | SG10201406801XA (es) |
| SI (3) | SI3202898T1 (es) |
| SM (1) | SMT201700248T1 (es) |
| WO (1) | WO2011053982A2 (es) |
| ZA (3) | ZA201705246B (es) |
Families Citing this family (75)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101934923B1 (ko) | 2009-11-02 | 2019-04-10 | 유니버시티 오브 워싱톤 스루 이츠 센터 포 커머셜리제이션 | 치료학적 뉴클레아제 조성물 및 방법 |
| PH12013502441B1 (en) * | 2011-04-29 | 2019-02-08 | Univ Washington | Therapeutic nuclease compositions and methods |
| JP6261500B2 (ja) | 2011-07-22 | 2018-01-17 | プレジデント アンド フェローズ オブ ハーバード カレッジ | ヌクレアーゼ切断特異性の評価および改善 |
| FR2983212A1 (fr) | 2011-11-28 | 2013-05-31 | Lfb Biotechnologies | Aptameres anti-fh, procede pour leur obtention et utilisations |
| US9603907B2 (en) | 2012-02-01 | 2017-03-28 | Protalix Ltd. | Dry powder formulations of dNase I |
| WO2014152955A1 (en) | 2013-03-14 | 2014-09-25 | Regeneron Pharmaceuticals, Inc. | Apelin fusion proteins and uses thereof |
| US20150044192A1 (en) | 2013-08-09 | 2015-02-12 | President And Fellows Of Harvard College | Methods for identifying a target site of a cas9 nuclease |
| US9359599B2 (en) | 2013-08-22 | 2016-06-07 | President And Fellows Of Harvard College | Engineered transcription activator-like effector (TALE) domains and uses thereof |
| US9340799B2 (en) | 2013-09-06 | 2016-05-17 | President And Fellows Of Harvard College | MRNA-sensing switchable gRNAs |
| US9526784B2 (en) | 2013-09-06 | 2016-12-27 | President And Fellows Of Harvard College | Delivery system for functional nucleases |
| US9388430B2 (en) | 2013-09-06 | 2016-07-12 | President And Fellows Of Harvard College | Cas9-recombinase fusion proteins and uses thereof |
| PL3063275T3 (pl) | 2013-10-31 | 2020-03-31 | Resolve Therapeutics, Llc | Terapeutyczne fuzje nukleaza-albumina i sposoby |
| AU2014346559B2 (en) | 2013-11-07 | 2020-07-09 | Editas Medicine,Inc. | CRISPR-related methods and compositions with governing gRNAs |
| CN105916881A (zh) | 2013-11-20 | 2016-08-31 | 瑞泽恩制药公司 | Aplnr调节剂及其用途 |
| US20150165054A1 (en) | 2013-12-12 | 2015-06-18 | President And Fellows Of Harvard College | Methods for correcting caspase-9 point mutations |
| WO2016022363A2 (en) | 2014-07-30 | 2016-02-11 | President And Fellows Of Harvard College | Cas9 proteins including ligand-dependent inteins |
| WO2016069889A1 (en) * | 2014-10-31 | 2016-05-06 | Resolve Therapeutics, Llc | Therapeutic nuclease-transferrin fusions and methods |
| JP7109784B2 (ja) | 2015-10-23 | 2022-08-01 | プレジデント アンド フェローズ オブ ハーバード カレッジ | 遺伝子編集のための進化したCas9蛋白質 |
| JP7308034B2 (ja) | 2016-07-01 | 2023-07-13 | リゾルブ セラピューティクス, エルエルシー | 最適化二重ヌクレアーゼ融合物および方法 |
| KR102547316B1 (ko) | 2016-08-03 | 2023-06-23 | 프레지던트 앤드 펠로우즈 오브 하바드 칼리지 | 아데노신 핵염기 편집제 및 그의 용도 |
| US11661590B2 (en) | 2016-08-09 | 2023-05-30 | President And Fellows Of Harvard College | Programmable CAS9-recombinase fusion proteins and uses thereof |
| US11542509B2 (en) | 2016-08-24 | 2023-01-03 | President And Fellows Of Harvard College | Incorporation of unnatural amino acids into proteins using base editing |
| EP3526320A1 (en) | 2016-10-14 | 2019-08-21 | President and Fellows of Harvard College | Aav delivery of nucleobase editors |
| WO2018119359A1 (en) | 2016-12-23 | 2018-06-28 | President And Fellows Of Harvard College | Editing of ccr5 receptor gene to protect against hiv infection |
| EP3351263A1 (en) | 2017-01-20 | 2018-07-25 | Universitätsklinikum Hamburg-Eppendorf | Pharmaceutical preparation for treating or preventing tissue adhesion |
| JP2020510038A (ja) | 2017-03-09 | 2020-04-02 | プレジデント アンド フェローズ オブ ハーバード カレッジ | がんワクチン |
| EP3592853A1 (en) | 2017-03-09 | 2020-01-15 | President and Fellows of Harvard College | Suppression of pain by gene editing |
| JP2020510439A (ja) | 2017-03-10 | 2020-04-09 | プレジデント アンド フェローズ オブ ハーバード カレッジ | シトシンからグアニンへの塩基編集因子 |
| CA3057192A1 (en) | 2017-03-23 | 2018-09-27 | President And Fellows Of Harvard College | Nucleobase editors comprising nucleic acid programmable dna binding proteins |
| JP6263298B1 (ja) * | 2017-05-09 | 2018-01-17 | 東京瓦斯株式会社 | 検針データの処理システム、その処理プログラム、その処理装置、その処理方法、およびガスメータ |
| WO2018209320A1 (en) | 2017-05-12 | 2018-11-15 | President And Fellows Of Harvard College | Aptazyme-embedded guide rnas for use with crispr-cas9 in genome editing and transcriptional activation |
| WO2019023680A1 (en) | 2017-07-28 | 2019-01-31 | President And Fellows Of Harvard College | METHODS AND COMPOSITIONS FOR EVOLUTION OF BASIC EDITORS USING PHAGE-ASSISTED CONTINUOUS EVOLUTION (PACE) |
| EP3668972B8 (en) * | 2017-08-18 | 2024-11-13 | Neutrolis, Inc. | Engineered dnase enzymes and use in therapy |
| BR112020003670A2 (pt) | 2017-08-22 | 2020-09-01 | Sanabio, Llc | receptores de interferon solúveis e usos dos mesmos |
| EP3676376B1 (en) | 2017-08-30 | 2025-01-15 | President and Fellows of Harvard College | High efficiency base editors comprising gam |
| KR20250107288A (ko) | 2017-10-16 | 2025-07-11 | 더 브로드 인스티튜트, 인코퍼레이티드 | 아데노신 염기 편집제의 용도 |
| WO2019118949A1 (en) | 2017-12-15 | 2019-06-20 | The Broad Institute, Inc. | Systems and methods for predicting repair outcomes in genetic engineering |
| AU2019266327B2 (en) | 2018-05-11 | 2025-11-06 | Beam Therapeutics Inc. | Methods of editing single nucleotide polymorphism using programmable base editor systems |
| EP3797160A1 (en) | 2018-05-23 | 2021-03-31 | The Broad Institute Inc. | Base editors and uses thereof |
| US12522807B2 (en) | 2018-07-09 | 2026-01-13 | The Broad Institute, Inc. | RNA programmable epigenetic RNA modifiers and uses thereof |
| AU2019316094B2 (en) | 2018-08-03 | 2026-02-19 | Beam Therapeutics Inc. | Multi-effector nucleobase editors and methods of using same to modify a nucleic acid target sequence |
| AU2019358915B2 (en) * | 2018-10-08 | 2025-09-18 | Neutrolis, Inc. | Engineering of DNASE enzymes for manufacturing and therapy |
| US11058724B2 (en) | 2018-10-08 | 2021-07-13 | Neutrolis, Inc. | Methods of using DNASE1-like 3 in therapy |
| US10988746B2 (en) | 2018-10-08 | 2021-04-27 | Neutrolis, Inc. | Manufacturing and engineering of DNASE enzymes for therapy |
| WO2020092453A1 (en) | 2018-10-29 | 2020-05-07 | The Broad Institute, Inc. | Nucleobase editors comprising geocas9 and uses thereof |
| US20220282275A1 (en) | 2018-11-15 | 2022-09-08 | The Broad Institute, Inc. | G-to-t base editors and uses thereof |
| US20220089786A1 (en) * | 2019-01-04 | 2022-03-24 | Resolve Therapeutics, Llc | Treatment of sjogren's disease with nuclease fusion proteins |
| US12351837B2 (en) | 2019-01-23 | 2025-07-08 | The Broad Institute, Inc. | Supernegatively charged proteins and uses thereof |
| US11352613B2 (en) | 2019-02-04 | 2022-06-07 | Neutrolis, Inc. | Engineered human extracellular DNASE enzymes |
| WO2020181193A1 (en) | 2019-03-06 | 2020-09-10 | The Broad Institute, Inc. | T:a to a:t base editing through adenosine methylation |
| WO2020181178A1 (en) | 2019-03-06 | 2020-09-10 | The Broad Institute, Inc. | T:a to a:t base editing through thymine alkylation |
| WO2020181195A1 (en) | 2019-03-06 | 2020-09-10 | The Broad Institute, Inc. | T:a to a:t base editing through adenine excision |
| WO2020181180A1 (en) | 2019-03-06 | 2020-09-10 | The Broad Institute, Inc. | A:t to c:g base editors and uses thereof |
| WO2020181202A1 (en) | 2019-03-06 | 2020-09-10 | The Broad Institute, Inc. | A:t to t:a base editing through adenine deamination and oxidation |
| JP7657726B2 (ja) | 2019-03-19 | 2025-04-07 | ザ ブロード インスティテュート,インコーポレーテッド | 編集ヌクレオチド配列を編集するための方法および組成物 |
| US12473543B2 (en) | 2019-04-17 | 2025-11-18 | The Broad Institute, Inc. | Adenine base editors with reduced off-target effects |
| WO2021030666A1 (en) | 2019-08-15 | 2021-02-18 | The Broad Institute, Inc. | Base editing by transglycosylation |
| US12435330B2 (en) | 2019-10-10 | 2025-10-07 | The Broad Institute, Inc. | Methods and compositions for prime editing RNA |
| US20230086199A1 (en) | 2019-11-26 | 2023-03-23 | The Broad Institute, Inc. | Systems and methods for evaluating cas9-independent off-target editing of nucleic acids |
| US20230062096A1 (en) * | 2020-01-11 | 2023-03-02 | Yale University | Compositions and methods for treating, ameliorating, and/or preventing diseases or disorders caused by or associated with dnase1 and/or dnase1l3 deficiency |
| WO2021158921A2 (en) | 2020-02-05 | 2021-08-12 | The Broad Institute, Inc. | Adenine base editors and uses thereof |
| EP3881862A1 (de) * | 2020-03-18 | 2021-09-22 | Pharis Biotec GmbH | Polypeptid zur therapie von glomerulären nierenerkrankungen und analyse des verlaufes und prognose der abhängigen syndrome |
| WO2021222318A1 (en) | 2020-04-28 | 2021-11-04 | The Broad Institute, Inc. | Targeted base editing of the ush2a gene |
| DE112021002672T5 (de) | 2020-05-08 | 2023-04-13 | President And Fellows Of Harvard College | Vefahren und zusammensetzungen zum gleichzeitigen editieren beider stränge einer doppelsträngigen nukleotid-zielsequenz |
| CA3181572A1 (en) * | 2020-06-08 | 2021-12-16 | Paul STABACH | Compositions and methods for treating and/or preventing coagulopathy and/or sepsis in patients suffering from bacterial and/or viral infections |
| EP4171614A1 (en) | 2020-06-29 | 2023-05-03 | Resolve Therapeutics, LLC | Treatment of sjogren's syndrome with nuclease fusion proteins |
| US12336973B2 (en) | 2020-09-25 | 2025-06-24 | Providence Health & Services—Oregon | Cancer therapeutic compositions and methods targeting DNAse1L3 |
| US12180521B2 (en) | 2021-02-19 | 2024-12-31 | Theripion, Inc. | Paraoxonase fusion polypeptides and related compositions and methods |
| WO2022178307A1 (en) | 2021-02-19 | 2022-08-25 | Beam Therapeutics Inc. | Recombinant rabies viruses for gene therapy |
| EP4399303A1 (en) | 2021-09-08 | 2024-07-17 | Beam Therapeutics, Inc. | Viral guide rna delivery |
| CA3263821A1 (en) | 2022-08-16 | 2024-02-22 | The Broad Institute, Inc. | ADVANCED CYTOSIN DESAMINASE AND DNA EDITING METHODS USING IT |
| WO2024155745A1 (en) | 2023-01-18 | 2024-07-25 | The Broad Institute, Inc. | Base editing-mediated readthrough of premature termination codons (bert) |
| WO2025147696A1 (en) | 2024-01-05 | 2025-07-10 | Resolve Therapeutics, Llc | Treatment of symptoms associated with sars-cov viral infection or a prior sars-cov viral infection with nuclease agents |
| US12416020B2 (en) | 2024-02-20 | 2025-09-16 | Wyvern Pharmaceuticals Inc. | Plasmid encoding a TLR3 and Fc fusion protein |
| WO2026072421A2 (en) | 2024-09-27 | 2026-04-02 | The Broad Institute, Inc. | Base editing methods and compositions for editing prnp in the treatment of prion disease |
Family Cites Families (137)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3773919A (en) | 1969-10-23 | 1973-11-20 | Du Pont | Polylactide-drug mixtures |
| US3941763A (en) | 1975-03-28 | 1976-03-02 | American Home Products Corporation | PGlu-D-Met-Trp-Ser-Tyr-D-Ala-Leu-Arg-Pro-Gly-NH2 and intermediates |
| US4263428A (en) | 1978-03-24 | 1981-04-21 | The Regents Of The University Of California | Bis-anthracycline nucleic acid function inhibitors and improved method for administering the same |
| IE52535B1 (en) | 1981-02-16 | 1987-12-09 | Ici Plc | Continuous release pharmaceutical compositions |
| DE3374837D1 (en) | 1982-02-17 | 1988-01-21 | Ciba Geigy Ag | Lipids in the aqueous phase |
| HUT35524A (en) | 1983-08-02 | 1985-07-29 | Hoechst Ag | Process for preparing pharmaceutical compositions containing regulatory /regulative/ peptides providing for the retarded release of the active substance |
| EP0143949B1 (en) | 1983-11-01 | 1988-10-12 | TERUMO KABUSHIKI KAISHA trading as TERUMO CORPORATION | Pharmaceutical composition containing urokinase |
| US4965188A (en) | 1986-08-22 | 1990-10-23 | Cetus Corporation | Process for amplifying, detecting, and/or cloning nucleic acid sequences using a thermostable enzyme |
| US4683202A (en) | 1985-03-28 | 1987-07-28 | Cetus Corporation | Process for amplifying nucleic acid sequences |
| US4683195A (en) | 1986-01-30 | 1987-07-28 | Cetus Corporation | Process for amplifying, detecting, and/or-cloning nucleic acid sequences |
| US4800159A (en) | 1986-02-07 | 1989-01-24 | Cetus Corporation | Process for amplifying, detecting, and/or cloning nucleic acid sequences |
| US5453269A (en) * | 1986-04-14 | 1995-09-26 | The General Hospital Corporation | Heterobifunctional antibodies having dual specificity for fibrin and thrombolylic agents and methods of use |
| WO1988007089A1 (en) | 1987-03-18 | 1988-09-22 | Medical Research Council | Altered antibodies |
| US5559212A (en) | 1988-04-06 | 1996-09-24 | Alfacell Corporation | Frog embryo and egg-derived tumor cell anti-proliferation protein |
| US6780613B1 (en) | 1988-10-28 | 2004-08-24 | Genentech, Inc. | Growth hormone variants |
| US5225538A (en) | 1989-02-23 | 1993-07-06 | Genentech, Inc. | Lymphocyte homing receptor/immunoglobulin fusion proteins |
| US5840840A (en) | 1990-04-17 | 1998-11-24 | The United States Of America As Represented By The Department Of Health And Human Services | Selective RNase cytotoxic reagents |
| AU653937B2 (en) | 1991-04-17 | 1994-10-20 | Medisup International N.V. | Water-soluble polypeptides having high affinity for interferons alpha and beta |
| US5637481A (en) | 1993-02-01 | 1997-06-10 | Bristol-Myers Squibb Company | Expression vectors encoding bispecific fusion proteins and methods of producing biologically active bispecific fusion proteins in a mammalian cell |
| IE922437A1 (en) | 1991-07-25 | 1993-01-27 | Idec Pharma Corp | Recombinant antibodies for human therapy |
| WO1993015722A1 (en) | 1992-02-07 | 1993-08-19 | Syntex (Usa) Inc. | Controlled delivery of pharmaceuticals from preformed porous microparticles |
| GB9300686D0 (en) | 1993-01-15 | 1993-03-03 | Imp Cancer Res Tech | Compounds for targeting |
| US20030108548A1 (en) | 1993-06-01 | 2003-06-12 | Bluestone Jeffrey A. | Methods and materials for modulation of the immunosuppressive activity and toxicity of monoclonal antibodies |
| GB9422383D0 (en) | 1994-11-05 | 1995-01-04 | Wellcome Found | Antibodies |
| US6348343B2 (en) | 1995-02-24 | 2002-02-19 | Genentech, Inc. | Human DNase I variants |
| US6096871A (en) | 1995-04-14 | 2000-08-01 | Genentech, Inc. | Polypeptides altered to contain an epitope from the Fc region of an IgG molecule for increased half-life |
| US5739277A (en) | 1995-04-14 | 1998-04-14 | Genentech Inc. | Altered polypeptides with increased half-life |
| US5869046A (en) | 1995-04-14 | 1999-02-09 | Genentech, Inc. | Altered polypeptides with increased half-life |
| US6121022A (en) | 1995-04-14 | 2000-09-19 | Genentech, Inc. | Altered polypeptides with increased half-life |
| US6127977A (en) | 1996-11-08 | 2000-10-03 | Cohen; Nathan | Microstrip patch antenna with fractal structure |
| US5989830A (en) * | 1995-10-16 | 1999-11-23 | Unilever Patent Holdings Bv | Bifunctional or bivalent antibody fragment analogue |
| US6482626B2 (en) | 1996-02-05 | 2002-11-19 | Genentech, Inc. | Human DNase |
| US6716974B1 (en) * | 1996-05-31 | 2004-04-06 | Maine Medical Center Research Institute | Therapeutic and diagnostic methods and compositions based on jagged/notch proteins and nucleic acids |
| US6391607B1 (en) | 1996-06-14 | 2002-05-21 | Genentech, Inc. | Human DNase I hyperactive variants |
| ATE386809T1 (de) | 1996-08-02 | 2008-03-15 | Bristol Myers Squibb Co | Ein verfahren zur inhibierung immunglobulininduzierter toxizität aufgrund von der verwendung von immunoglobinen in therapie und in vivo diagnostik |
| US7247302B1 (en) | 1996-08-02 | 2007-07-24 | Bristol-Myers Squibb Company | Method for inhibiting immunoglobulin-induced toxicity resulting from the use of immunoglobulins in therapy and in vivo diagnosis |
| WO1998016254A1 (en) | 1996-10-17 | 1998-04-23 | Immunomedics, Inc. | Non-antigenic toxin-conjugate and fusion protein of internalizing receptor system |
| US6653104B2 (en) | 1996-10-17 | 2003-11-25 | Immunomedics, Inc. | Immunotoxins, comprising an internalizing antibody, directed against malignant and normal cells |
| WO1998023289A1 (en) | 1996-11-27 | 1998-06-04 | The General Hospital Corporation | MODULATION OF IgG BINDING TO FcRn |
| US6277375B1 (en) | 1997-03-03 | 2001-08-21 | Board Of Regents, The University Of Texas System | Immunoglobulin-like domains with increased half-lives |
| US7074897B2 (en) | 1997-06-16 | 2006-07-11 | Genentech, Inc. | Pro943 polypeptides |
| US20020192659A1 (en) | 1997-09-17 | 2002-12-19 | Genentech, Inc. | Secreted and transmembrane polypeptides and nucleic acids encoding the same |
| US5840296A (en) | 1997-10-15 | 1998-11-24 | Raines; Ronald T. | Engineered cytotoxic ribonuclease A |
| US6280991B1 (en) | 1997-10-15 | 2001-08-28 | Wisconsin Alumni Research Foundation | Engineered cytotoxic ribonclease |
| ES2292236T3 (es) | 1998-04-02 | 2008-03-01 | Genentech, Inc. | Variantes de anticuerpos y sus fragmentos. |
| US6194551B1 (en) | 1998-04-02 | 2001-02-27 | Genentech, Inc. | Polypeptide variants |
| US6528624B1 (en) | 1998-04-02 | 2003-03-04 | Genentech, Inc. | Polypeptide variants |
| US6242195B1 (en) | 1998-04-02 | 2001-06-05 | Genentech, Inc. | Methods for determining binding of an analyte to a receptor |
| GB9809951D0 (en) | 1998-05-08 | 1998-07-08 | Univ Cambridge Tech | Binding molecules |
| EP1105427A2 (en) | 1998-08-17 | 2001-06-13 | Abgenix, Inc. | Generation of modified molecules with increased serum half-lives |
| US6660843B1 (en) | 1998-10-23 | 2003-12-09 | Amgen Inc. | Modified peptides as therapeutic agents |
| EP1006183A1 (en) | 1998-12-03 | 2000-06-07 | Max-Planck-Gesellschaft zur Förderung der Wissenschaften e.V. | Recombinant soluble Fc receptors |
| US6239257B1 (en) | 1998-12-30 | 2001-05-29 | Alfacell Corporation | Family of proteins belonging to the pancreatic ribonuclease a superfamily |
| HU230769B1 (hu) | 1999-01-15 | 2018-03-28 | Genentech Inc. | Módosított effektor-funkciójú polipeptid-változatok |
| US6737056B1 (en) | 1999-01-15 | 2004-05-18 | Genentech, Inc. | Polypeptide variants with altered effector function |
| IL147270A0 (en) | 1999-07-02 | 2002-08-14 | Genentech Inc | Fusion peptides comprising a peptide ligand domain and a multimerization domain |
| US6175003B1 (en) | 1999-09-10 | 2001-01-16 | Alfacell Corporation | Nucleic acids encoding ribonucleases and methods of making them |
| EP1246643A4 (en) | 1999-10-14 | 2005-05-11 | Jeffery A Ledbetter | DNA VACCINES ENCODING ANTIGEN ASSOCIATED WITH CD40-BINDING DOMAIN |
| GB0029407D0 (en) | 2000-12-01 | 2001-01-17 | Affitech As | Product |
| PT1355919E (pt) | 2000-12-12 | 2011-03-02 | Medimmune Llc | Moléculas com semivida longa, composições que as contêm e suas utilizações |
| US7829084B2 (en) | 2001-01-17 | 2010-11-09 | Trubion Pharmaceuticals, Inc. | Binding constructs and methods for use thereof |
| US20030133939A1 (en) | 2001-01-17 | 2003-07-17 | Genecraft, Inc. | Binding domain-immunoglobulin fusion proteins |
| US7754208B2 (en) | 2001-01-17 | 2010-07-13 | Trubion Pharmaceuticals, Inc. | Binding domain-immunoglobulin fusion proteins |
| AU2002327164A1 (en) | 2001-01-29 | 2002-12-09 | Idec Pharmaceuticals Corporation | Engineered tetravalent antibodies and methods of use |
| BR0206985A (pt) | 2001-01-29 | 2005-04-19 | Idec Pharma Corp | Anticorpos modificados e métodos de uso |
| AU2002248571B2 (en) * | 2001-03-07 | 2007-01-18 | Merck Patent Gmbh | Expression technology for proteins containing a hybrid isotype antibody moiety |
| JP4586310B2 (ja) | 2001-07-04 | 2010-11-24 | 株式会社Ihi | セラミックス複合部材の製造方法 |
| US20060040262A1 (en) * | 2002-12-27 | 2006-02-23 | Morris David W | Novel compositions and methods in cancer |
| US20040002587A1 (en) | 2002-02-20 | 2004-01-01 | Watkins Jeffry D. | Fc region variants |
| US7317091B2 (en) | 2002-03-01 | 2008-01-08 | Xencor, Inc. | Optimized Fc variants |
| CA2478011C (en) | 2002-03-01 | 2013-05-21 | Immunomedics, Inc. | Bispecific antibody point mutations for enhancing rate of clearance |
| US20040132101A1 (en) * | 2002-09-27 | 2004-07-08 | Xencor | Optimized Fc variants and methods for their generation |
| US7662925B2 (en) | 2002-03-01 | 2010-02-16 | Xencor, Inc. | Optimized Fc variants and methods for their generation |
| CA2489446A1 (en) | 2002-06-14 | 2003-12-24 | Wisconsin Alumni Research Foundation | Ribonuclease zymogen design |
| EP1534335B9 (en) | 2002-08-14 | 2016-01-13 | Macrogenics, Inc. | Fcgammariib-specific antibodies and methods of use thereof |
| WO2004029207A2 (en) | 2002-09-27 | 2004-04-08 | Xencor Inc. | Optimized fc variants and methods for their generation |
| US20060235208A1 (en) | 2002-09-27 | 2006-10-19 | Xencor, Inc. | Fc variants with optimized properties |
| DE60334141D1 (de) | 2002-10-15 | 2010-10-21 | Facet Biotech Corp | VERÄNDERUNG VON FcRn-BINDUNGSAFFINITÄTEN ODER VON SERUMHALBWERTSZEITEN VON ANTIKÖRPERN MITTELS MUTAGENESE |
| CA2503390A1 (en) | 2002-11-01 | 2004-05-21 | Genentech, Inc. | Compositions and methods for the treatment of immune related diseases |
| GB2395337B (en) | 2002-11-14 | 2005-12-28 | Gary Michael Wilson | Warning Unit |
| JP2006524039A (ja) | 2003-01-09 | 2006-10-26 | マクロジェニクス,インコーポレーテッド | 変異型Fc領域を含む抗体の同定および作製ならびにその利用法 |
| US20090010920A1 (en) | 2003-03-03 | 2009-01-08 | Xencor, Inc. | Fc Variants Having Decreased Affinity for FcyRIIb |
| US8388955B2 (en) | 2003-03-03 | 2013-03-05 | Xencor, Inc. | Fc variants |
| US7067298B2 (en) | 2003-03-31 | 2006-06-27 | Ambion, Inc. | Compositions and methods of using a synthetic Dnase I |
| US7666417B2 (en) * | 2003-04-22 | 2010-02-23 | Fred Hutchinson Cancer Research Center | Methods and compositions for treating autoimmune diseases or conditions |
| US7754209B2 (en) * | 2003-07-26 | 2010-07-13 | Trubion Pharmaceuticals | Binding constructs and methods for use thereof |
| CN1871259A (zh) | 2003-08-22 | 2006-11-29 | 比奥根艾迪克Ma公司 | 具有改变的效应物功能的经改进的抗体和制备它的方法 |
| GB0324368D0 (en) | 2003-10-17 | 2003-11-19 | Univ Cambridge Tech | Polypeptides including modified constant regions |
| ES2672640T3 (es) | 2003-11-05 | 2018-06-15 | Roche Glycart Ag | Moléculas de unión a antígeno con afinidad de unión a receptores Fc y función efectora incrementadas |
| WO2005063815A2 (en) * | 2003-11-12 | 2005-07-14 | Biogen Idec Ma Inc. | Fcϝ receptor-binding polypeptide variants and methods related thereto |
| WO2005047327A2 (en) | 2003-11-12 | 2005-05-26 | Biogen Idec Ma Inc. | NEONATAL Fc RECEPTOR (FcRn)-BINDING POLYPEPTIDE VARIANTS, DIMERIC Fc BINDING PROTEINS AND METHODS RELATED THERETO |
| US20050249723A1 (en) | 2003-12-22 | 2005-11-10 | Xencor, Inc. | Fc polypeptides with novel Fc ligand binding sites |
| JP2008504008A (ja) | 2003-12-31 | 2008-02-14 | メルク パテント ゲゼルシャフト ミット ベシュレンクテル ハフトング | 改良された薬物動態を有するFc−エリスロポエチン融合タンパク質 |
| CA2552788C (en) | 2004-01-12 | 2013-09-24 | Applied Molecular Evolution, Inc. | Fc region variants |
| WO2005080586A1 (en) * | 2004-02-13 | 2005-09-01 | Immunomedics, Inc. | Fusion proteins containing recombinant cytotoxic rnases |
| EP1737890A2 (en) | 2004-03-24 | 2007-01-03 | Xencor, Inc. | Immunoglobulin variants outside the fc region |
| WO2005123780A2 (en) | 2004-04-09 | 2005-12-29 | Protein Design Labs, Inc. | Alteration of fcrn binding affinities or serum half-lives of antibodies by mutagenesis |
| WO2005115477A2 (en) | 2004-04-13 | 2005-12-08 | Quintessence Biosciences, Inc. | Non-natural ribonuclease conjugates as cytotoxic agents |
| WO2006085967A2 (en) | 2004-07-09 | 2006-08-17 | Xencor, Inc. | OPTIMIZED ANTI-CD20 MONOCONAL ANTIBODIES HAVING Fc VARIANTS |
| CN103172731A (zh) | 2004-07-15 | 2013-06-26 | 赞科股份有限公司 | 优化的Fc变体 |
| BRPI0514259A (pt) | 2004-08-11 | 2008-06-03 | Trubion Pharmaceuticals Inc | proteìna de fusão de domìnio de ligação |
| WO2006047350A2 (en) | 2004-10-21 | 2006-05-04 | Xencor, Inc. | IgG IMMUNOGLOBULIN VARIANTS WITH OPTIMIZED EFFECTOR FUNCTION |
| DE102005009219A1 (de) | 2005-02-25 | 2006-08-31 | Martin-Luther-Universität Halle-Wittenberg | Ribonuclease-Tandemenzyme und Verfahren zu ihrer Herstellung |
| WO2006105062A2 (en) | 2005-03-29 | 2006-10-05 | Verenium Corporation | Altered antibody fc regions and uses thereof |
| JP2008539753A (ja) | 2005-05-09 | 2008-11-20 | グリクアート バイオテクノロジー アクチェンゲゼルシャフト | 修飾fc領域およびfc受容体との結合変更を有する抗原結合分子 |
| WO2006138458A1 (en) | 2005-06-16 | 2006-12-28 | Wisconsin Alumni Research Foundation | Cytotoxic ribonuclease variants |
| US7655757B2 (en) | 2005-06-16 | 2010-02-02 | Wisconsin Alumni Research Foundation | Cytotoxic ribonuclease variants |
| US20080279850A1 (en) | 2005-07-25 | 2008-11-13 | Trubion Pharmaceuticals, Inc. | B-Cell Reduction Using CD37-Specific and CD20-Specific Binding Molecules |
| HRP20140338T1 (hr) | 2005-07-25 | 2014-06-20 | Emergent Product Development Seattle, Llc | Smanjenje broja b-stanica upotrebom molekula koje se specifiäśno vežu na cd37 i cd20 |
| BRPI0617688A2 (pt) | 2005-10-21 | 2011-06-07 | Hoffmann La Roche | método para expressão recombinante de um polipeptìdeo |
| BRPI0710011A2 (pt) | 2006-04-14 | 2011-08-02 | Trubion Pharmaceuticals Inc | proteìnas de ligação compreendendo articulação de imunoglobulina e regiões fc dotadas de funções efetoras fc alteradas |
| ATE547123T1 (de) * | 2006-04-21 | 2012-03-15 | Mab Factory Gmbh | Antikörper-rnase-konjugat |
| GB0611444D0 (en) * | 2006-06-09 | 2006-07-19 | Medical Res Council Technology | Rnase H2 complex and genes therefor |
| WO2007146968A2 (en) | 2006-06-12 | 2007-12-21 | Trubion Pharmaceuticals, Inc. | Single-chain multivalent binding proteins with effector function |
| EP1905841A1 (en) * | 2006-09-25 | 2008-04-02 | Max Delbrück Centrum für Molekulare Medizin (MDC) Berlin-Buch; | Trex1 as a marker for lupus erythematosus |
| EP2144930A1 (en) | 2007-04-18 | 2010-01-20 | ZymoGenetics, Inc. | Single chain fc, methods of making and methods of treatment |
| US20090258005A1 (en) * | 2007-05-29 | 2009-10-15 | Trubion Pharmaceuticals Inc. | Therapeutic compositions and methods |
| WO2008156713A2 (en) | 2007-06-12 | 2008-12-24 | Wyeth | Anti-cd20 therapeutic compositions and methods |
| JP2010532764A (ja) * | 2007-07-06 | 2010-10-14 | トゥルビオン・ファーマシューティカルズ・インコーポレーテッド | C末端に配置された特異的結合性ドメインを有する結合性ペプチド |
| WO2009015345A1 (en) | 2007-07-25 | 2009-01-29 | Amgen Inc. | Pharmaceutical compositions comprising fc fusion proteins |
| WO2009012600A1 (en) | 2007-07-26 | 2009-01-29 | Novagen Holding Corporation | Fusion proteins |
| EP2220125A4 (en) | 2007-11-13 | 2010-12-29 | Sapphire Energy Inc | PRODUCTION OF FC HYBRID POLYPEPTIDES IN EUKARYOTIC ALGAE |
| EP2365003A1 (en) | 2008-04-11 | 2011-09-14 | Emergent Product Development Seattle, LLC | CD37 immunotherapeutic and combination with bifunctional chemotherapeutic thereof |
| BRPI0913778A2 (pt) | 2008-09-26 | 2015-10-20 | Genentech Inc | "métodos de identificação de lúpus, para prever a responsividade, de diagnóstico, para auxiliar o diagnóstico, usos de um agente terapêutico, métodos de identificação, métodos, métodos para selecionar um paciente, para avaliar se um sujeito nestá em risco de desenvolver lúpus, de diagnóstico de lúpus, para prognóstico de lúpus e para auxiliar o prognóstico" |
| US8029782B2 (en) | 2008-10-01 | 2011-10-04 | Quintessence Biosciences, Inc. | Therapeutic ribonucleases |
| KR101934923B1 (ko) * | 2009-11-02 | 2019-04-10 | 유니버시티 오브 워싱톤 스루 이츠 센터 포 커머셜리제이션 | 치료학적 뉴클레아제 조성물 및 방법 |
| TWI529163B (zh) | 2011-01-25 | 2016-04-11 | 陶氏農業科學公司 | 用於製備4-胺基-5-氟-3-鹵素-6-(經取代之)吡啶甲酸酯的方法 |
| KR20130129438A (ko) | 2011-02-23 | 2013-11-28 | 암젠 인크 | Uvc 노출을 위한 세포 배양 배지 및 이와 관련된 방법 |
| BR112013021785A8 (pt) | 2011-02-25 | 2018-07-03 | Recombinetics Inc | animais geneticamente modificados e métodos para fazer os mesmos |
| PH12019502377A1 (en) | 2011-04-21 | 2022-11-14 | Isis Pharmaceuticals Inc | Modulation of hepatitis b virus (hbv) expression |
| PH12013502441B1 (en) | 2011-04-29 | 2019-02-08 | Univ Washington | Therapeutic nuclease compositions and methods |
| US20140178479A1 (en) | 2011-08-12 | 2014-06-26 | Perosphere, Inc. | Concentrated Felbamate Formulations for Parenteral Administration |
| WO2013180295A1 (ja) | 2012-06-01 | 2013-12-05 | 日本電信電話株式会社 | パケット転送処理方法およびパケット転送処理装置 |
| PL3063275T3 (pl) | 2013-10-31 | 2020-03-31 | Resolve Therapeutics, Llc | Terapeutyczne fuzje nukleaza-albumina i sposoby |
| US9300829B2 (en) | 2014-04-04 | 2016-03-29 | Canon Kabushiki Kaisha | Image reading apparatus and correction method thereof |
| JP7308034B2 (ja) | 2016-07-01 | 2023-07-13 | リゾルブ セラピューティクス, エルエルシー | 最適化二重ヌクレアーゼ融合物および方法 |
| JP6349003B1 (ja) | 2017-03-17 | 2018-06-27 | 東洋ビーネット株式会社 | 耐熱性ルシフェラーゼ |
-
2010
- 2010-11-02 KR KR1020127014363A patent/KR101934923B1/ko active Active
- 2010-11-02 PL PL16198956T patent/PL3202898T3/pl unknown
- 2010-11-02 ES ES10827655.1T patent/ES2626000T3/es active Active
- 2010-11-02 KR KR1020227009207A patent/KR102624939B1/ko active Active
- 2010-11-02 IL IL297588A patent/IL297588A/en unknown
- 2010-11-02 SM SM20170248T patent/SMT201700248T1/it unknown
- 2010-11-02 LT LTEP18190143.0T patent/LT3460056T/lt unknown
- 2010-11-02 PT PT108276551T patent/PT2496691T/pt unknown
- 2010-11-02 ES ES16198956T patent/ES2702053T3/es active Active
- 2010-11-02 HU HUE16198956A patent/HUE041426T2/hu unknown
- 2010-11-02 SG SG10201406801XA patent/SG10201406801XA/en unknown
- 2010-11-02 JP JP2012537194A patent/JP6199033B2/ja active Active
- 2010-11-02 SG SG10201912571XA patent/SG10201912571XA/en unknown
- 2010-11-02 EP EP10827655.1A patent/EP2496691B1/en active Active
- 2010-11-02 BR BR112012010202A patent/BR112012010202A2/pt not_active Application Discontinuation
- 2010-11-02 PL PL10827655T patent/PL2496691T3/pl unknown
- 2010-11-02 LT LTEP16198956.1T patent/LT3202898T/lt unknown
- 2010-11-02 EP EP16198956.1A patent/EP3202898B1/en active Active
- 2010-11-02 HU HUE10827655A patent/HUE032166T2/en unknown
- 2010-11-02 SI SI201031820T patent/SI3202898T1/sl unknown
- 2010-11-02 DK DK16198956.1T patent/DK3202898T3/en active
- 2010-11-02 LT LTEP10827655.1T patent/LT2496691T/lt unknown
- 2010-11-02 CN CN201080060471.1A patent/CN102770533B/zh active Active
- 2010-11-02 DK DK10827655.1T patent/DK2496691T3/en active
- 2010-11-02 SI SI201032038T patent/SI3460056T1/sl unknown
- 2010-11-02 CA CA3091939A patent/CA3091939A1/en active Pending
- 2010-11-02 KR KR1020187037619A patent/KR102118584B1/ko active Active
- 2010-11-02 US US13/505,421 patent/US20130089546A1/en not_active Abandoned
- 2010-11-02 HR HRP20170757TT patent/HRP20170757T1/hr unknown
- 2010-11-02 PT PT16198956T patent/PT3202898T/pt unknown
- 2010-11-02 NZ NZ813794A patent/NZ813794A/en unknown
- 2010-11-02 AU AU2010313103A patent/AU2010313103B2/en active Active
- 2010-11-02 CN CN202110852975.7A patent/CN113528485B/zh active Active
- 2010-11-02 SG SG10201912573YA patent/SG10201912573YA/en unknown
- 2010-11-02 DK DK18190143.0T patent/DK3460056T3/da active
- 2010-11-02 EP EP18190143.0A patent/EP3460056B1/en active Active
- 2010-11-02 CN CN201610979041.9A patent/CN106399276B/zh active Active
- 2010-11-02 CA CA2779615A patent/CA2779615C/en active Active
- 2010-11-02 WO PCT/US2010/055131 patent/WO2011053982A2/en not_active Ceased
- 2010-11-02 KR KR1020247000800A patent/KR20240007725A/ko not_active Ceased
- 2010-11-02 SI SI201031462A patent/SI2496691T1/sl unknown
- 2010-11-02 RS RS20170510A patent/RS55989B1/sr unknown
- 2010-11-02 KR KR1020207015149A patent/KR102378465B1/ko active Active
- 2010-11-02 MX MX2012005062A patent/MX341084B/es active IP Right Grant
- 2010-11-02 MX MX2014013439A patent/MX360465B/es unknown
-
2011
- 2011-08-03 US US13/197,731 patent/US8841416B2/en active Active
-
2012
- 2012-04-29 IL IL219475A patent/IL219475A0/en active IP Right Grant
- 2012-04-30 MX MX2018013333A patent/MX2018013333A/es unknown
-
2013
- 2013-03-12 US US13/796,730 patent/US20130177561A1/en not_active Abandoned
- 2013-03-13 US US13/799,843 patent/US20130184334A1/en not_active Abandoned
- 2013-03-13 US US13/799,854 patent/US20130183308A1/en not_active Abandoned
-
2014
- 2014-04-22 US US14/258,319 patent/US20140227269A1/en not_active Abandoned
- 2014-10-16 US US14/516,161 patent/US9790479B2/en active Active
-
2016
- 2016-03-09 JP JP2016045546A patent/JP2016174604A/ja active Pending
- 2016-04-06 AU AU2016202135A patent/AU2016202135B2/en active Active
-
2017
- 2017-05-22 CY CY20171100532T patent/CY1119166T1/el unknown
- 2017-08-03 ZA ZA2017/05246A patent/ZA201705246B/en unknown
- 2017-08-17 US US15/679,746 patent/US11306297B2/en active Active
-
2018
- 2018-02-14 AU AU2018201071A patent/AU2018201071B2/en active Active
- 2018-02-15 JP JP2018024633A patent/JP7081935B2/ja active Active
- 2018-09-05 ZA ZA201805962A patent/ZA201805962B/en unknown
- 2018-11-21 IL IL263180A patent/IL263180B/en active IP Right Grant
- 2018-12-12 HR HRP20182102TT patent/HRP20182102T1/hr unknown
- 2018-12-21 CY CY20181101388T patent/CY1121220T1/el unknown
-
2020
- 2020-04-22 AU AU2020202688A patent/AU2020202688B2/en active Active
- 2020-04-28 IL IL274309A patent/IL274309B2/en unknown
- 2020-07-28 JP JP2020127299A patent/JP2021006026A/ja active Pending
- 2020-07-30 JP JP2020128888A patent/JP7237045B2/ja active Active
- 2020-08-21 ZA ZA2020/05216A patent/ZA202005216B/en unknown
- 2020-11-03 CY CY20201101036T patent/CY1123684T1/el unknown
-
2022
- 2022-03-16 US US17/696,364 patent/US12435322B2/en active Active
-
2023
- 2023-02-28 JP JP2023029040A patent/JP7657249B2/ja active Active
-
2024
- 2024-12-25 JP JP2024228230A patent/JP2025041849A/ja active Pending
-
2025
- 2025-08-08 US US19/294,688 patent/US20260035680A1/en active Pending
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2702053T3 (es) | Composiciones terapéuticas de nucleasas y métodos | |
| MX2013012612A (es) | Composiciones de nucleasa terapeuticas y metodos. | |
| AU2013203097B2 (en) | Therapeutic nuclease compositions and methods | |
| AU2023201735A1 (en) | Therapeutic Nuclease Compositions and Methods | |
| HK1242370A1 (en) | Therapeutic nuclease compositions and methods | |
| HK1242370B (en) | Therapeutic nuclease compositions and methods | |
| HK1173660B (en) | Therapeutic nuclease compositions and methods | |
| HK1173660A (en) | Therapeutic nuclease compositions and methods | |
| HK40006279B (en) | Therapeutic nuclease compositions and methods | |
| HK40006279A (en) | Therapeutic nuclease compositions and methods |