ES2920140T3 - Anticuerpos neutralizantes del virus de la inmunodeficiencia humana (VIH) - Google Patents
Anticuerpos neutralizantes del virus de la inmunodeficiencia humana (VIH) Download PDFInfo
- Publication number
- ES2920140T3 ES2920140T3 ES19156884T ES19156884T ES2920140T3 ES 2920140 T3 ES2920140 T3 ES 2920140T3 ES 19156884 T ES19156884 T ES 19156884T ES 19156884 T ES19156884 T ES 19156884T ES 2920140 T3 ES2920140 T3 ES 2920140T3
- Authority
- ES
- Spain
- Prior art keywords
- seq
- pgt
- amino acid
- antibody
- acid sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/10—RNA viruses
- C07K16/112—Retroviridae (F), e.g. leukemia viruses
- C07K16/114—Lentivirus (G), e.g. human immunodeficiency virus [HIV], feline immunodeficiency virus [FIV] or simian immunodeficiency virus [SIV]
- C07K16/1145—Env proteins, e.g. gp41, gp110/120, gp160, V3, principal neutralising domain [PND] or CD4-binding site
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/12—Viral antigens
- A61K39/21—Retroviridae, e.g. equine infectious anemia virus
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/14—Antivirals for RNA viruses
- A61P31/18—Antivirals for RNA viruses for HIV
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/10—RNA viruses
- C07K16/112—Retroviridae (F), e.g. leukemia viruses
- C07K16/114—Lentivirus (G), e.g. human immunodeficiency virus [HIV], feline immunodeficiency virus [FIV] or simian immunodeficiency virus [SIV]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/51—Complete heavy chain or Fd fragment, i.e. VH + CH1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/515—Complete light chain, i.e. VL + CL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/16011—Human Immunodeficiency Virus, HIV
- C12N2740/16111—Human Immunodeficiency Virus, HIV concerning HIV env
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/16011—Human Immunodeficiency Virus, HIV
- C12N2740/16111—Human Immunodeficiency Virus, HIV concerning HIV env
- C12N2740/16122—New viral proteins or individual genes, new structural or functional aspects of known viral proteins or genes
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Virology (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Immunology (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biochemistry (AREA)
- Veterinary Medicine (AREA)
- Animal Behavior & Ethology (AREA)
- Communicable Diseases (AREA)
- Pharmacology & Pharmacy (AREA)
- Public Health (AREA)
- AIDS & HIV (AREA)
- Epidemiology (AREA)
- Hematology (AREA)
- Mycology (AREA)
- Microbiology (AREA)
- Tropical Medicine & Parasitology (AREA)
- Oncology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
La especificación muestra un método para obtener un anticuerpo ampliamente neutralizante (BNAB), que incluye la detección de cultivos de células B de memoria de una muestra de PBMC donante para la actividad de neutralización contra una pluralidad de las especies VIH-1, clonando una célula B de memoria que exhibe una actividad de neutralización amplia; y rescatar un anticuerpo monoclonal de ese cultivo de células B de memoria. Los anticuerpos monoclonales resultantes pueden caracterizarse por su capacidad de unir selectivamente epítopos de las proteínas Env en forma nativa o monomérica, así como para inhibir la infección de las especies VIH-1 de una pluralidad de clados. Se proporcionan composiciones que contienen anticuerpos anti-VIH monoclonales humanos utilizados para profilaxis, diagnóstico y tratamiento de la infección por VIH. Se proporcionan métodos para generar tales anticuerpos mediante inmunización utilizando epítopos de regiones conservadas dentro de los bucles variables de GP120. También se muestran inmunógenos para generar BNAB anti-VIH1. Además, se muestran métodos para la vacunación utilizando epítopos adecuados. (Traducción automática con Google Translate, sin valor legal)
Description
DESCRIPCIÓN
Anticuerpos neutralizantes del virus de la inmunodeficiencia humana (VIH)
CAMPO DE LA INVENCIÓN
La presente solicitud se refiere en general a la terapia, diagnóstico y seguimiento de la inmunodeficiencia humana infección por el virus (VIH). La aplicación está más específicamente relacionada con los anticuerpos monoclonales neutralizantes humanos específicos para el VIH-1, como los anticuerpos monoclonales neutralizantes amplios y potentes específicos para el VIH-1 y su fabricación y uso. La neutralización amplia sugiere que los anticuerpos pueden neutralizar los aislados de VIH-1 de diferentes individuos. Tales anticuerpos son útiles en composiciones farmacéuticas para la prevención y el tratamiento del VIH, y para el diagnóstico y control de la infección por VIH y para el diseño de inmunógenos de vacunas contra el VIH. Más específicamente, sin embargo, la invención proporciona el anticuerpo monoclonal humano anti-VIH 4869_K15 (PGT-133), es decir, un anticuerpo monoclonal anti-VIH que comprende una secuencia de cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 435 y una secuencia de cadena ligera que comprende el secuencia de aminoácidos de SEQ ID NO: 440.
ANTECEDENTES DE LA INVENCIÓN
El SIDA se notificó por primera vez en los Estados Unidos en 1981 y desde entonces se ha convertido en una importante epidemia mundial. El SIDA es causado por el virus de inmunodeficiencia humana o VIH. Al matar o dañar las células del sistema inmunitario del cuerpo, el VIH destruye progresivamente la capacidad del cuerpo para combatir infecciones y ciertos tipos de cáncer. Las personas diagnosticadas con SIDA pueden contraer enfermedades potencialmente mortales llamadas infecciones oportunistas. Estas infecciones son causadas por microbios como virus o bacterias que generalmente no enferman a las personas sanas. El VIH se transmite con mayor frecuencia a través de relaciones sexuales sin protección con una pareja infectada. El VIH también se transmite por contacto con sangre infectada.
El virus de la inmunodeficiencia humana (VIH) es la causa del síndrome de inmunodeficiencia adquirida (SIDA) (Barre-Sinoussi, F., et al, 1983, Science 220: 868-870; Gallo, R., et al, 1984, Science 224: 500-503). Actualmente hay 1,25 millones de personas en los EE.UU. Infectadas con el síndrome de inmunodeficiencia adquirida inducida por el VIH, según un informe del Centro para el Control de Enfermedades. La epidemia está creciendo más rápidamente entre las poblaciones minoritarias y es una de las principales causas de muerte de hombres afroamericanos de entre 25 y 44 años. Según el SIDA, afecta a casi siete veces más afroamericanos y tres veces más hispanos que blancos. En los últimos años, un número creciente de mujeres y niños afroamericanos están siendo afectados por el VIH/SIDA. Con más de 40 millones de personas infectadas en todo el mundo, la actual pandemia mundial del VIH se encuentra entre los mayores flagelos de enfermedades infecciosas en la historia humana. WALKER L.M. et al divulgan dos anticuerpos anti-VIH ampliamente neutralizantes, denominados PG9 y PG16. R. PEJCHAL et al divulgan las secuencias de CDR3 de la cadena pesada de los anticuerpos PG9 y PG16,
Por tanto, existe una necesidad para la identificación eficiente y producción de anticuerpos neutralizantes eficaz contra múltiples clados y cepas del VIH, así como la dilucidación del objetivo y los determinantes antigénicos a los que tales anticuerpos se unen.
SUMARIO DE LA INVENCIÓN
La presente solicitud proporciona un método para aislar anticuerpos monoclonales generalmente neutralizantes potentes contra el VIH. Las células mononucleares de sangre periférica (PBMC) se obtienen de un donante infectado con VIH seleccionado para la actividad neutralizante del VIH-1 en el plasma, y las células B de memoria se aíslan para cultivo in vitro. Los sobrenadantes de cultivo de células B pueden seleccionarse luego mediante un ensayo de neutralización primario en un formato de alto rendimiento, y los cultivos de células B que exhiben actividad neutralizante pueden seleccionarse para rescatar anticuerpos monoclonales. Se observa sorprendentemente que los anticuerpos neutralizantes obtenidos por este método no siempre exhiben la unión de gp120 o gp41 a niveles que se correlacionan con la actividad de neutralización. El método de la aplicación, por lo tanto, permite la identificación de nuevos anticuerpos con propiedades de neutralización de clado cruzado.
El anticuerpo monoclonal anti-VIH humano 4876_M06 (PGT-134) de la presente invención representa un miembro de una gran lista de anticuerpos monoclonales anti-VIH humanos estrechamente relacionados que incluyen 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489_I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134),
5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157) y 6881_N05 (PGT-158) y sus clones hermanos. Por ejemplo, un clon hermano ejemplar del anticuerpo 1443_Cl6 (PG16) (TCN-116) es el anticuerpo 1503 H05 (PG16) (TCN-119), el anticuerpo 1456 A12 (PG16) (TCN-117), el 1469 M23 (PG16) (TCN-118), el anticuerpo 1489_I13 (PG16) (TCN-120) o el anticuerpo 1480_I08 (PG16).. Sin embargo, estos anticuerpos monoclonales humanos anti-VIH y sus clones hermanos representan una materia que no está cubierta por la invención reivindicada. Por el contrario, la presente invención se dirige específicamente al anticuerpo monoclonal anti-VIH humano 4876_M06 (PGT-134) que tiene una cadena pesada variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 435 y una cadena ligera variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 440.
A continuación, la solicitud también proporciona las secuencias de aminoácidos de las CDR de las cadenas pesada y ligera de los anticuerpos monoclonales anti-VIH humanos de la gras lista anterior y del anticuerpo de la presente invención, que, sin embargo, no están cubiertos por la invención reivindicada:
Específicamente, la solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener cadena con tres CDR que pueden comprender una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de KYGMH (SEQ ID NO: 88), LISDDGMRKYHSDSMWG (SEQ ID NO: 89) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTSSDVGGFDSVS (SEQ ID NO: 97), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41)
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que pueden comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GFTFHK (SEQ ID NO: 266), LISDDGMRKY (SEQ ID NO: 267) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTSSDVGGFDSVS (SEQ ID NO: 97), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de KYGMH (SEQ ID NO: 88), LISDDGMRKYHSDSMWG (SEQ ID NO: 89) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTRSDVGGDSDS (SE). 92), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GFTFHK (SEQ ID NO: 266), LISDDGMRKY (SEQ ID NO: 267) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTRSDVGGFDSVS (SEQ ID NO: 92), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de KYGMH (SEQ ID NO: 88), LISDDGMRKYHSDSMWG (SEQ ID NO: 89) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTSRDVGGDSVS: 93), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GFTFHK (SEQ ID NO: 266), LISDDGMRKY (SEQ ID NO: 267) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTSRDVGGFDSVS (SEQ ID. 93), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR cwhich puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de KYGMH (SEQ ID NO: 88), LISDDGMRKYHSNSMWG (SEQ ID NO: 98) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTSSDVGGFDSVS (NGTSSDVGGFDSVS: 97), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena
pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de SYAFT (SEQ ID NO: 104), MVTPIFGEAKYSQRFEG (SEQ ID NO: 105) y DRRAVPIATDNWLDP (SEQ ID NO: 9), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de RASQTINNYLN (SEQ ID NO: 107), GASNLQN (SEQ ID NO: 108) y QQSFSTPRT (SEQ ID NO: 42).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste en Las secuencias de aminoácidos de GGTFSS (SEQ ID NO: 268), MVTPIFGEAK (SEQ ID NO: 269) y DRRAVPIATDNWLDP (SEQ ID NO: 9), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionado del grupo que consiste en las secuencias de aminoácidos de RASQTINNYLN (SEQ ID NO: 107), GASNLQN (SEQ ID NO: 108) y QQSFSTPRT (SEQ ID NO: 42).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de SYAFS (SEQ ID NO: 110), MITPVFGETKYAPRFQG (SEQ ID NO: 111) y DRRVVPMATDNWLDP (SEQ ID NO: 8), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de RASQTIHTYLN (SEQ ID NO: 113), GASTLQS (SEQ ID NO: 114) y QQSYSTPRT (SEQ ID NO: 43).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GGAFSS (SEQ ID NO: 270), MITPVFGETK (SEQ ID NO: 271), DRRVVPMATDNWLDP (SEQ ID NO: 8) y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de RASQTIHTYLN (SEQ ID NO: 113), GASTLQS (SEQ ID NO: 114) y QQSYSTPRT (SEQ ID NO: 43).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de DYYLH (SEQ ID NO: 116), LIDPENGEARYAEKFQG (SEQ ID NO: 117), GAVGADSGSWFDP (SEQ ID NO: 10) y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de SGSKLGDKYVS (SEQ ID NO: 120), ENDRRPS (SEQ ID NO: 121), QAWETTTTTFVF (SEQ ID NO: 44).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GYSFID (SEQ ID NO: 102), LIDPENGEAR (SEQ ID NO: 103), GAVGADSGSWFDP (SEQ ID NO: 10) y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de SGSKLGDKYVS (SEQ ID NO: 120), ENDRRPS (SEQ ID NO: 121), QAWETTTTTFVF (SEQ ID NO: 44).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de RQGMH (SEQ ID NO: 123), FIKYDGSEKYHADSVWG (SEQ ID NO: 124) y EAGGPDYRNGYNYYDFYDGYYNYHYMDV (SEQ ID NO: 7), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTSNDVGGYESV: 126), DVSKRPS (SEQ ID NO: 127) y KSLTSTRRRV (SEQ ID NO: 45).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GFDFSR (SEQ ID NO: 118), FIKYDGSEKY (SEQ ID NO: 272) y EAGGPDYRNGYNYYDFYDGYYNYHYMDV (SEQ ID NO: 7), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTSNDVGGYESVS: SEQ 126), DVSKRPS (SEQ ID NO: 127) y KSLTSTRRRV (SEQ ID NO: 45).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dichos anticuerpos pueden tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de DSYWS (SEQ ID NO: 90), YVHKSGDTNYSPSLKS (SEQ ID NO: 265), TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143) y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GEKSLGSRAVQ (SEQ ID NO: 150), NNQDRPS (SEQ ID NO: 151), HIWDSRVPTKWV (SEQ ID NO: 152).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GASISD (SEQ ID NO: 144), YVHKSGDTN (SEQ ID NO: 145),
TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143) y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GEKSLGSRAVQ (SEQ ID NO: 150), NNQDRPS (SEQ ID NO: 151), HIWDSRVPTKWV (SEQ ID NO: 152).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de DNYWS (SEQ ID NO: 261), YVHDSGDTNYNPSLKS (SEQ ID NO: 157), y TKHGRRIYGVVAFKEWFTYFYMDV (SEQ ID NO: 262), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GEESLGSRSVI (SEQ ID NO: 162), NNNDRPS (SEQ ID NO: 163) y HIWDSRRPTNWV (SEQ ID NO: 164).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GTLVRD (SEQ ID NO: 263), YVHDSGDTN (SEQ ID NO: 264) y TKHGRRIYGVVAFKEWFTYFYMDV (SEQ ID NO: 262), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en el secuencias de aminoácidos de GEESLGSRSVI (SEQ ID NO: 162), NNNDRPS (SEQ ID NO: 163) y HIWDSRRPTNWV (SEQ ID NO: 164).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de DAYWS (SEQ ID NO: 169), YVHHSGDTNYNPSLKR (SEQ ID NO: 170) y ALHGKRIYGIVALGELFTYFYMDV (SEQ ID NO: 171) y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GKESIGSRAVQ (SEQ ID NO: 178), NNQDRPA (SEQ ID NO: 179) y HIYDARGGTNWV (SEQ ID NO: 180).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GASIND (SEQ ID NO: 172), YVHHSGDTN (SEQ ID NO: 173) y ALHGKRIYGIVALGELFTYFYMDV (SEQ ID NO: 171), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GKESIGSRAVQ (SEQ ID NO: 178), NNQDRPA (SEQ ID NO: 179) y HIYDARGGTNWV (SEQ ID NO: 180).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de ACTYFWG (SEQ ID NO: 185), SLSHCQSFWGSGWTFHNPSLKS (SEQ ID NO: 186) y FDGEVLVYNHWPKPAWVDL (SEQ ID n O: 187) y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTATNFVS (SEQ ID NO: 194), GVDKRPP (SEQ ID NO: 195) y GSLVGNWDVI (SEQ ID NO: 196).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GESTGACT (SEQ ID NO: 188), SLSHCQSFWGSGWTF (SEQ ID NO: 189) y FDGEVLVYNHWPKPAWVDL (SEQ ID NO: 187) y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTATNFVS (SEQ ID NO: 194), GVDKRPP (SEQ ID NO: 195) y GSLVGNWDVI (SEQ ID NO: 196).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de ACDYFWG (SEQ ID NO: 201), GLSHCAGYYNTGWTYHNPSLKS (SEQ ID NO: 202) y FDGEVLVYHDWPKPAWVDL (SEQ ID NO: 203), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de TGTSNRFVS (SEQ ID NO: 210), GVNKRPS (SEQ ID NO: 211) y SSLVGNWDVI (SEQ ID NO: 212).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GDSTAACD (SEQ ID NO: 204), GLSHCAGYYNTGWTY (SEQ ID NO: 205) y FDGEVLVYHDWPKPAWVDL (SEQ ID NO: 203), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de TGTSNRFVS (SEQ ID NO: 210), GVNKRPS (SEQ ID NO: 211) y SSLVGNWDVI (SEQ ID NO: 212).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de TGHYYWG (SEQ ID NO: 217), HIHYTTAVLHNPSLKS (SEQ ID NO: 218) y SGGDILYYYEWQKPHWFSP (SEQ ID NO: 219) y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTSSDIGGWNFVS (SEQ
ID NO: 226), EVNKRPS (SEQ ID NO: 227) y SSLFGRWDVV (SEQ ID NO: 228).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GESINTGH (SEQ ID NO: 220), HIHYTTAVL (SEQ ID NO: 221) y SGGDILYYYEWQKPHWFSP (SEQ ID NO: 219) y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTSSDIGGWNFVS (SEQ ID NO: 226), EVNKRPS (SEQ ID NO: 227) y SSLFGRWDVV (SEQ ID NO: 228).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GGEWGDKDYHWG (SEQ ID NO: 233), SIHWRGTTHYKESLRR (SEQ ID NO: 234) y HRHHDVFMLVPIAGWFDV (SEQ ID NO: 235), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de RASQNINKNLA (SEQ ID NO: 243), ETYSKIA (SEQ ID NO: 244) y QQYEEWPRT (SEQ ID NO: 245).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluye una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GDSIRGGEWGDKD (SEQ ID NO: 236), SIHWRGTTH (SEQ ID NO: 237) y HRHHDVFMLVPIAGWFDV (SEQ ID NO: 235), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de RASQNINKNLA (SEQ ID NO: 243), ETYSKIA (SEQ ID NO: 244) y QQYEEWPRT (SEQ ID NO: 245).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GTDWGENDFHYG (SEQ ID NO: 250), SIHWRGRTTHYKTSFRS (SEQ ID NO: 251), HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252) y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de RASQNVKNNLA (SEQ ID NO: 259), DASSRAG (SEQ ID NO: 260), QQYEEWPRT (SEQ ID NO: 245).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GGSMRGTDWGEND (SEQ ID NO: 253), SIHWRGRTTH (SEQ ID NO: 254), HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252) y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de RASQNVKNNLA (SEQ ID NO: 259), DASSRAG (SEQ ID NO: 260), QQYEEWPRT (SEQ ID NO: 245).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de KYDVH (SEQ ID NO: 277), WMSHEGDKTESAQRFKG (SEQ ID NO: 278) y GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de SSTQSLRHSNGANYLA (SEQ ID NOQ: SEQ ID NO: 286), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GNTFSK (SEQ ID NO: 280), WMSHEGDKTE (SEQ ID NO: 281), GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de SSTQSLRHSNGANYLA (SEQ ID NO: 286), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de KYDVH (SEQ ID NO: 277), WISHERDKTESAQRFKG (SEQ ID NO: 293), GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de SSTQSLRHSNGANYLA:), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GNTFSK (SEQ ID NO: 280), WISHERDKTE (SEQ ID NO: 294), GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279) y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de SSTQSLRHSNGANYLA (SEQ ID NO: 286), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de KYDVH (SEQ ID NO: 277), WMSHEGDKTESAQRFKG (SEQ ID NO: 278) y GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de TSTQSLRHSNGANYLA (SEQ ID NOQ: SEQ ID NO: 303), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GNTFSK (SEQ ID NO: 280), WMSHEGDKTE (SEQ ID NO: 281), GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de TSTQSLRHSNGANYLA (SEQ ID NO: 303), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de KYDVH (SEQ ID NO: 277), WMSHEGDKTESAQRFKG (SEQ ID NO: 278), GSKHRLRDYVLYDDYGLINQQEWNDYLEFLDV (SEQ ID NO: 308), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de TSTQSLRHSNGANYLA: SEQ ID NO: 303, LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de GNTFRK (SEQ ID NO: 309), WMSHEGDKTE (SEQ ID NO: 281) y GSKHRLRDYVLYDDYGLINQQEWNDYLEFLDV (SEQ ID NO: 308), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionado del grupo que consiste en las secuencias de aminoácidos de TSTQSLRHSNGANYLA (SEQ ID NO: 303), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de RCNYFWG (SEQ ID NO: 320), SLSHCRSYYNTDWTYHNPSLKS (SEQ ID NO: 321) y FGGEVLVYRDWPKPAWVDL (SEQ ID NO: 322), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de TGTSNNFVS (SEQ ID NO: 325), EVNKRPS (SEQ ID NO: 227) y SSLVGNWDVI (SEQ ID NO: 212).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GDSTGRCN (SEQ ID NO: 323), SLSHCRSYYNTDWTY (SEQ ID NO: 324) y FGGEVLVYRDWPKPAWVDL (SEQ ID NO: 322), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de TGTSNNFVS (SEQ ID NO: 325), EVNKRPS (SEQ ID NO: 227) y SSLVGNWDVI (SEQ ID NO: 212).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de ACNSFWG (SEQ ID NO: 326), SLSHCASYWNRGWTYHNPSLKS (SEQ ID NO: 335) y FGGEVLRYTDWPKPAWVDL (SEQ ID NO: 336), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de TGTSNNFVS (SEQ ID NO: 325), (SEQ ID NO: 343) y (SEQ ID NO: 196).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GDSTAACN (SEQ ID NO: 337), SLSHCASYWNRGWTY (SEQ ID NO: 338) y FGGEVLRYTDWPKPAWVDL (SEQ ID NO: 336), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de TGTSNNFVS (SEQ ID NO: 325), DVNKRPS (SEQ ID NO: 343) y GSLVGNWDVI (SEQ ID NO: 196).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de TGHHYWG (SEQ ID NO: 348), HIHYNTAVLHNPALKS (SEQ ID NO: 349) y SGGDILYYIEWQKPHWFYP (SEQ ID NO: 350), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de SGTGSDIGSWNFVS (SEQ ID NO: 357), EVNRRRS (SEQ ID NO: 358) y SSLSGRWDIV (SEQ ID NO: 359).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GDSINTGH (SEQ ID NO: 351), HIHYNTAVL (SEQ ID NO: 352) y SGGDILYYIEWQKPHWFYP (SEQ ID NO: 350), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de SGTGSDIGSWNFVS (SEQ ID NO: 357), EVNRRRS (SEQ ID NO: 358) y SSLSGRWDIV (SEQ ID NO: 359).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GGEWGDSDYHWG (SEQ ID NO: 364), SIHWRGTTHYNAPFRG (SEQ ID NO: 365) y HKYHDIVMVVPIAGWFDP (SEQ ID NO: 366), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de RASQSVKNNLA (SEQ ID NO: 372), DTSSRAS (SEQ ID NO: 373) y QQYEEWPRT (SEQ ID NO: 245).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GGSIRGGEWGDSD (SEQ ID NO: 367), SIHWRGTTH (SEQ ID NO: 237) y HKYHDIVMVVPIAGWFDP (SEQ ID NO: 366), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de RASQSVKNNLA (SEQ ID NO: 372), DTSSRAS (SEQ ID NO: 373) y QQYEEWPRT (SEQ ID NO: 245).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que pueden comprender una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NHDVH (SEQ ID NO: 378), WMSHEGDKTGLAQKFQG (SEQ ID NO: 379), y GSKHRLRDYFLYNEYGPNYEEWGDYLATLDV (SEQ ID NO: 380), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de KCSHSLQHSTGANYLA (SEQ ID NO: 387), LATHRAS (SEQ ID NO: 388) y MQGLHSPWT (SEQ ID NO: 389).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede tener una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las Secuencias de aminoácidos de GNSFSN (SEQ ID NO: 381), WMSHEGDKTG (SEQ ID NO: 382) y GSKHRLRDYFLYNEYGPNYEEWGDYLATLDV (SEQ ID NO: 380), y una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de KCSHSLQHSTGANYLA (SEQ ID NO: 387), LATHRAS (SEQ ID NO: 388) y MQGLHSPWT (SEQ ID NO: 389).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de NYYWT (SEQ ID NO: 406); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de YISDRETTTYNPSLNS (SEQ ID NO: 407); una región CDR3 Vh que puede comprender la secuencia de aminoácidos de ARRGQRIYGVVSFGEFFYYYYMDV (SEQ ID NO: 408); una región CDR1 Vl que puede comprender la secuencia de aminoácidos de GRQALGSRAVQ (SEQ ID NO: 415); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de NNQDRPS (SEQ ID NO: 151); y una región CDR3 Vl que puede comprender la secuencia de aminoácidos de HMWDSRSGFSWS (SEQ ID NO: 416).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de GRFWS (SEQ ID NO: 421); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de YFSDTDRSEYNPSLRS (SEQ ID NO: 422); una región Cd R3 Vh que puede comprender la secuencia de aminoácidos de AQQGKRIYGIVSf Ge FFYYYYMDA (SEQ ID NO: 423); una región CDR1 Vl que puede comprender la secuencia de aminoácidos de GERSRGSRAVQ (SEQ ID NO: 430); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de NNQDRPA (SEQ ID NO: 179); y una región CDR3 Vl que puede comprender la secuencia de aminoácidos de HYWDSRSPISWI (SEQ ID NO: 431).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de GRFWS (SEQ ID NO: 421); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de YFSDTDRSEYNPSLRS (SEQ ID NO: 422); una región Cd R3 Vh que puede comprender la secuencia de aminoácidos de AQQGKRIYGIVSFGELFYYYYMDA (SEQ ID NO: 436); una región CDR1 Vl que puede comprender la secuencia de aminoácidos de GERSRGSRAVQ (SEQ ID NO: 430); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de NNQDRPA (SEQ ID NO: 179); y una región CDR3 Vl que puede comprender la secuencia de aminoácidos de HYWDSRSPISWI (SEQ ID NO: 431).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de TGHHYWG (SEQ ID NO: 348); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de HIHYNTAVLHNpA l KS (SEQ ID NO: 349); una región CDR3 Vh que puede comprender la secuencia de aminoácidos de SGGDILYYNEWq Kp HWFYP (SEQ iD NO: 445); una región CDR1 Vl que puede comprender la secuencia de aminoácidos de SGTASDIGSWNFVS (SEQ ID NO: 450); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de EVNRRRS (SEQ ID NO: 358); y
una región CDR3 Vl que puede comprender la secuencia de aminoácidos de SSLSGRWDIV (SEQ ID NO: 359).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de ACDYFWG (SEQ ID NO: 201); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de SLSHCAGYYNSGWTYHNPSLKS (SEQ ID NO: 455); una región CDR3 Vh que puede comprender la secuencia de aminoácidos de FGGDVLVYHDWPKPAWVDL (SEQ ID NO: 456); una región c DR1 Vl que puede comprender la secuencia de aminoácidos de TGNINNFVS (SEQ ID NO: 458); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de GVNKRPS (SEQ ID NO: 211); y una región CDR3 Vl que puede comprender la secuencia de aminoácidos de GSLAGNWDVV (SEQ ID NO: 459).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de GCDYFWG (SEQ ID NO: 464); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de GLSHCAGYYNTGWTYHNPSLKS (SEQ ID NO: 202); una región CDR3 Vh que puede comprender la secuencia de aminoácidos de FDGEVLVYNDWPKPAWVDL (SEQ ID NO: 465); una región c DR1 Vl que puede comprender la secuencia de aminoácidos de TGTSNNFVS (SEQ ID NO: 325); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de GVNKRPS (SEQ ID NO: 211); y una región CDR3 Vl que puede comprender la secuencia de aminoácidos de GSLVGNWDVI (SEQ ID NO: 196).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de KYPMY (SEQ ID NO: 475); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de AISGDAWHVVYSNSVQG (SEQ ID n O: 476); una región Cd R3 Vh que puede comprender la secuencia de aminoácidos de MFQESGPPRLDRWSGRNYYYYSGMDV (SEQ ID NO: 477); una región CDR1 VL que puede comprender la secuencia de aminoácidos de KSSESLRQSNGKTSLY (SEQ ID NO: 484); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de EVSNRFS (SEQ ID NO: 485); y una región CDR3 VL que puede comprender la secuencia de aminoácidos de MQSKDFPLT (SEQ ID NO: 486).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de KYPMY (SEQ ID NO: 475); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de AISADAWHVVYSGSVQG (SEQ ID n O: 491); una región Cd R3 Vh que puede comprender la secuencia de aminoácidos de MFQESGPPRFDSWSGRNYYYYSGMDV (SEQ ID NO: 492); una región Cd R1 Vl que puede comprender la secuencia de aminoácidos de KSSQSLRQSNGKTs Ly (SEQ ID NO: 498); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de EVSNRFS (SEQ ID NO: 485); y una región CDR3 Vl que puede comprender la secuencia de aminoácidos de (MQSKDFPLT (SEQ ID NO: 486).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de KRHMH (SEQ ID NO: 503); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de VISSDAIHVDYASSVRG (SEQ ID NO: 504); una región Cd R3 Vh que puede comprender la secuencia de aminoácidos de DRDGYGPPQIQTWSGRYLHLYSGIDA (SEQ ID NO: 505); una región CDR1 Vl que puede comprender la secuencia de aminoácidos de KSSQSLRQSNGKTy Ly (SEQ ID NO: 512); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de EVSIRFS (SEQ ID NO: 513); y una región CDR3 Vl que puede comprender el amino ácido de secuencia de MQSKDFPLT (SEQ ID NO: 486).
la solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de KYPMY (SEQ ID NO: 475); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de AISADAWHVDYAASVKD (SEQ ID n O: 518); una región Cd R3 Vh que puede comprender la secuencia de aminoácidos de NIEEFSVPQFDSWSGRSYYHYFGMDV (SEQ ID NO: 519); una región CDR1 Vl que puede comprender la secuencia de aminoácidos de SSSESLGRGDGRTYLH (SEQ ID NO: 526); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de EVSTRFS (SEQ ID NO: 527); y una región CDR3 VL que puede comprender la secuencia de aminoácidos de MQSRDFPIT (SEQ ID NO: 528).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de EYPMY (SEQ ID NO: 533); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de AISADAWHVDYAGSVRG (SEQ ID n O: 534); una región Cd R3 Vh que puede comprender la secuencia de aminoácidos de DGEEHKVPQLHSWSGRNLYHYTGFDV (SEQ ID NO: 535); una región CDR1 VL que puede comprender la secuencia de aminoácidos de KSSQSVRQSDGKTFLY (SEQ ID NO: 541); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de EGSSRFS (SEQ ID NO: 542); y una región CDR3 Vl que puede comprender la secuencia de aminoácidos de LQTKDFPLT (SEQ ID NO: 543).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de QYPMY (SEQ ID NO: 548); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de AISADAWHVDYPGSVRG (SEQ ID n O: 549); una región Cd R3 Vh que puede comprender la secuencia de aminoácidos de DGEEHKVPQLHSWSGRNLYHYTGFDV (SEQ ID NO: 535); una región CDR1 Vl que puede comprender la secuencia de aminoácidos de KSSQTVRQSDGKTFLY (SEQ
ID NO: 555); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de EGSNRFS (SEQ ID NO: 556); y una región CDR3 Vl que puede comprender la secuencia de aminoácidos de LQTKDFPLT (SEQ ID NO: 543).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de QYPMY (SEQ ID NO: 548); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de AISADAWHVDYAGSVRG (SEQ ID n O: 534); una región Cd R3 Vh que puede comprender la secuencia de aminoácidos de DGEEHEVPQLHsW s GRNLYHYTg Vd I (SEQ ID NO: 561); una región CDR1 Vl que puede comprender la secuencia de aminoácidos de KSSQSLRQSDGKTFLY (SEQ ID NO: 567); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de EASNRFS (SEQ ID NO: 568); y una región CDR3 Vl que puede comprender la secuencia de aminoácidos de MQTKDFPLT (SEQ ID NO: 569).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo puede comprender una región CDR1 Vh que puede comprender la secuencia de aminoácidos de KYPMY (SEQ ID NO: 475); una región CDR2 Vh que puede comprender la secuencia de aminoácidos de AISADAWHVDYPGSVRG (SEQ ID n O: 549); una región Cd R3 Vh que puede comprender la secuencia de aminoácidos de DGEEHEVPQLHSWSGRNLYHYTGVDV (SEQ ID NO: 574); una región CDR1 VL que puede comprender la secuencia de aminoácidos de KSSQSVRQSDGKTFLY (SEQ ID NO: 541); una región CDR2 Vl que puede comprender la secuencia de aminoácidos de EASKRFS (SEQ ID NO: 580); y una región CDR3 Vl que puede comprender la secuencia de aminoácidos de MQTKDFPLT (SEQ ID NO: 569).
La solicitud también proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo tiene una cadena pesada con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de KYGMH (SEQ ID NO: 88), LISDDGMRKYHSDSMWG (SEQ ID NO: 89), EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6), SYAFT (SEQ ID NO: 104), MVTPIFGEAKYSQRFEG (SEQ ID NO: 105), DRRAVPIATDNWLDP (SEQ ID NO: 9), SYAFS (SEQ: NO 110), MITPVFGETKYAPRFQG (SEQ ID NO: 111), DRRVVPMATDNWLDP (SEQ ID NO: 8), DYYLH (SEQ ID NO: 116), LIDPENGEARYAEKFQG (SEQ ID NO: 117), GAVGADSGSWFDP (SEQ ID NO: 10), RQGMH (SEQ ID NO: 123), FIKYDGSEKYHADSVWG (SEQ ID NO: 124), EAGGPDYRNGYNYYDFYDGYYNYHYMDV (SEQ ID NO: 7), LISDDGMRKYHSNSMWG (SEQ ID NO: 98), DSYWS (SEQ ID NO: 90), YVHKSGDTNYSPSLKS (SEQ ID NO: 265), TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143), DNYWS (SEQ ID NO: 261), YVHDSGDTNYNPSLKS (SEQ ID NO: 157), TKHGRRIYGVVAFKEWFTYFYMDV (SEQ ID NO: 262), DAYWS (SEQ ID NO: 169), YVHHSGDTNYNPSLKR (SEQ ID NO: 170), ALHGKRIYGIVALGELFTYFYMDV (SEQ ID NO: 171), ACTYFWG (SEQ ID NO: 185), SLSHCQSFWGSGWTFHNPSLKS (SEQ ID NO: 186), FDHWLV: 187), ACDYFWG (SEQ ID NO: 201), GLSHCAGYYNTGWTYHNPSLKS (SEQ ID NO: 202), FDGEVLVYHDWPKPAWVDL (SEQ ID NO: 203), TGHYYWG (SEQ ID NO: 217), HIHYTTAVLHNPSLK (SEQ ID NO: 219), GGEWGDKDYHWG (SEQ ID NO: 233), SIHWRGTTHYKESLRR (SEQ ID NO: 234), HRHHDVFMLVPIAGWFDV (SEQ ID NO: 235), GTDWGENDFHYG (SEQ ID NOT: 250), SIQ NOK: 251), HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252), KYDVH (SEQ ID NO: 277), WMSHEGDKTESAQRFKG (SEQ ID NO: 278), GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279), WISHERDKTESAQRFKG (SEQ ID NO: 293), y GSKHRLRDYVLYDDYGLINQQEWNDYLEFLDV (SEQ ID NO: 308), en donde dicho anticuerpo se une y neutraliza el VIH-1. Opcionalmente, este anticuerpo tiene una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTSSDVGGFDSVS (SEQ ID NO: 97), DVSHRPS (SEQ ID NO: 95), SSLTDRSHRI (SEQ ID NO: 41), RASQTINNYLN (SEQ ID NO: 107), GASNLQN (SEQ ID NO: 108), QQSFSTPRT (SEQ ID NO: 42), RASQTIHTYLN (SEQ ID NO: 113), GASTLQS (SEQ ID NO: 114), QQSYSTPRT (SEQ ID NO: 43), SGSKLGDKYVS (SEQ ID NO: 120), ENDRRPS (SEQ ID NO: 121), QAWETTTTTFVF (SEQ ID NO: 44), NGTSNDVGGYESVS (SEQ ID NO: 126), DVSKRPS (SEQ ID NO: 126), DVSKRPS: 127), KSLTSTRRRV (SEQ ID NO: 45), NGTRSDVGGFDSVS (SEQ ID NO: 92), NGTSRDVGGFDSVS (SEQ ID NO: 93), GEKSLGSRAVQ (SEQ ID NO: 150), NNQDRPS (SEQ ID NO: 151), HIWVV (SEQ ID NO: 152), GEESLGSRSVI (SEQ ID NO: 162), NNNDRPS (SEQ ID NO: 163), HIWDSRRPTNWV (SEQ ID NO: 164), GKESIGSRAVQ (SEQ ID NO: 178), NNQDRPA (SEQ ID NO: 179), HIYDARGGTNWV (SEQ ID NO: 180), NGTATNFVS (SEQ ID NO: 194), GVDKRPP (SEQ ID NO: 195), GSLVGNWDVI (SEQ ID NO: 196), TGTSNR FVS (SEQ ID NO: 210), GVNKRPS (SEQ ID NO: 211), SSLVGNWDVI (SEQ ID NO: 212), NGTSSDIGGWNFVS (SEQ ID NO: 226), EVNKRPS (SEQ ID NO: 227), SSLFGRWDVV (SEQ ID NO: 228), RASQNINKNLA (SEQ ID NO: 243), ETYSKIA (SEQ ID NO: 244), QQYEEWPRT (SEQ ID NO: 245), RASQNVKNNLA (SEQ ID NO: 259), DASSRAG (SEQ ID NO: 260), SSTQSLRHSNGANYLA (SEQ ID NO: 286), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288), y TSTQSLRHSNGANYLA (SEQ ID NO: 303).
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo tiene una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTSSDVGGFDSVS (SEQ ID NO: 97), DVSHRPS (SEQ ID NO: 95), SSLTDRSHRI (SEQ ID NO: 41), RASQTINNYLN (SEQ ID NO: 107), GASNLQN (SEQ ID NO: 108), QQSFSTPRT (SEQ ID NO: 42), RASQTIHTYLN (SEQ ID NO: 113), GASTLQS (SEQ ID NO: 114), QQSYSTPRT (SEQ ID NO: 43), SGSKLGDKYVS (SEQ ID NO: 120), ENDRRPS (SEQ ID NO: 121), QAWETTTTTFVF (SEQ ID NO: 44), NGTSNDVGGYESS SEQ ID NO: 126), DVSKRPS (SEQ ID NO: 127), KSLTSTRRRV (SEQ ID NO: 45), NGTRSDVGGFDSVS (SEQ ID NO: 92), NGTSRDVGGFDSVS (SEQ ID NO: 93), GEKSLGSRAVQ (SEQ ID NO: 150), NNQDRPS (SEQ ID NO: 151), HIWDSRVPTKWV (SEQ ID NO: 152), GEESLGSRSVI (SEQ ID NO: 162), NNNDRPS (SEQ ID NO: 163), HIWDSRRPTNWV (SEQ ID NO: 164), GKESIGSRAVQ (SEQ ID NO: 178), NNQDRPA (SEQ ID NO: 179),
HIYDARGGTNWV (SEQ ID NO: 180), NGTATNFVS (SEQ ID NO: 194), GV DKRPP (SEQ ID NO: 195), GSLVGNWDVI (SEQ ID NO: 196), TGTSNRFVS (SEQ ID NO: 210), GVNKRPS (SEQ ID NO: 211), SSLVGNWDVI (SEQ ID NO: 212), NGTSSDIGGWNFVS (SEQ ID NO: 226), EVNKRPS (SEQ ID NO: 227), SSLFGRWDVV (SEQ ID NO: 228), RASQNINKNLA (SEQ ID NO: 243), ETYSKIA (SEQ ID NO: 244), QQYEEWPRT (SEQ ID NO: 245), RASQNVKNNLA (SEQ ID NO: 259), DASSRAG (SEQ ID NO: 260), SSTQSLRHSNGANYLA (SEQ ID NO: 286), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288) y TSTQSLRHSNGANYLA (SEQ ID NO: 303), en donde dicho anticuerpo se une y neutraliza el VIH-1.
La solicitud proporciona un anticuerpo anti-VIH aislado, en donde dicho anticuerpo tiene una cadena pesada con tres CDR que puede comprender una secuencia de aminoácidos seleccionada del grupo que consiste de las secuencias de aminoácidos de GFTFHK (SEQ ID NO: 266), LISDDGMRKY (SEQ ID NO: 267), y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6), GGTFSS (SEQ ID NO: 268), MVTPIFGEAK (SEQ ID NO: 269), y DRRAVPIATDNWLDP (SEQ ID NOGA: (SEC. ID NO: 270), MITPVFGETK (SEQ ID NO: 271), DRRVVPMATDNWLDP (SEQ ID NO: 8), GYSFID (SEQ ID NO: 102), LIDPENGEAR (SEQ ID NO: 103), GAVGADSGSWFDP (SEQ ID NO: 10), GFDFSR (SEQ ID NO: 118), FIKYDGSEKY (SEQ ID NO: 272), y EAGGPDYRNGYNYYDFYDGYYNYHYMDV (SEQ ID NO: 7), GASISD (SEQ ID NO: 144), YVHKSGDTN (SEQ ID NO: 145), TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143), GTLVRD (SEQ ID NO: 263), YVHDSGDTN (SEQ ID NO: 264), TKHGRRIYGVVAFKEWFTYFYMDV (SEQ ID NO: 262), GASIND (SEQ ID NO: 172), YVHHSGDTN (SEQ ID NO: 173), ALHGKRIYGIVALGELFTYFYMDV (SEQ ID NO: 171), GESTGACT (SEQ ID NO: 188), SLSHCQSFWGSGWTF (SEQ ID NO: 189), FDGEVLVYNHWPKPAWVDL (SEQ ID NO: 187), GDSTAACD (SEQ ID NO: 204), GLSHCAGYYNTGWTY (SEQ ID NO: 205), FDGEVLVYHDWPKPAWVDL (SEQ ID NO: 203), GESINTGH (SEQ ID NO: 220), HIHYTTAVL (SEQ ID NO: 221), SGGDILYYYEWQKPHWFSP (SEQ ID NO: 219), GDSIRGGEWGDKD (SEQ ID NO: 236), SIHWRGTTH (SEQ ID NO: 237), HRHHDVVHHQVV: 235), GGSMRGTDWGEND (SEQ ID NO: 253), SIHWRGRTTH (SEQ ID NO: 254), HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252), GNTFSK (SEQ ID NO: 280), WMSHEGDKTE (SEQ ID NO: 281), GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279), WISHERDKTE (SEQ ID NO: 294), GNTFRK (SEQ ID NO: 309) y GSKHRLRDYVLYDDYGLINQQEWNDYLEFLDV (SEQ ID NO: 308), en donde dicho anticuerpo se une y neutraliza VIH-1. Opcionalmente, este anticuerpo tiene una cadena ligera con tres CDR que incluyen una secuencia de aminoácidos seleccionada del grupo que consiste en las secuencias de aminoácidos de NGTSSDVGGFDSVS (SEQ ID NO: 97), DVSHRPS (SEQ ID NO: 95), SSLTDRSHRI (SEQ ID NO: 41), RASQTINNYLN (SEQ ID NO: 107), GASNLQN (SEQ ID NO: 108), QQSFSTPRT (SEQ ID NO: 42), RASQTIHTYLN (SEQ ID NO: 113), GASTLQS (SEQ ID NO: 114), QQSYSTPRT (SEQ ID NO: 43), SGSKLGDKYVS (SEQ ID NO: 120), ENDRRPS (SEQ ID NO: 121), QAWETTTTTFVF (SEQ ID NO: 44), NGTSNDVGGYESVS (SEQ ID NO: 126), DVSKRPS (SEQ ID NO: 126), DVSKRPS(SEQ ID NO: 127), KSLTSTRRRV (SEQ ID NO: 45), NGTRSDVGGFDSVS (SEQ ID NO: 92), NGTSRDVGGFDSVS (SEQ ID NO: 93), GEKSLGSRAVQ (SEQ ID NO: 150), NNQDRPS (SEQ ID NO: 151), HIWVV (SEQ ID NO: 152), GEESLGSRSVI (SEQ ID NO: 162), NNNDRPS (SEQ ID NO: 163), HIWDSRRPTNWV (SEQ ID NO: 164), GKESIGSRAVQ (SEQ ID NO: 178), NNQDRPA (SEQ ID NO: 179), HIYDARGGTNWV (SEQ ID NO: 180), NGTATNFVS (SEQ ID NO: 194), GVDKRPP (SEQ ID NO: 195), GSLVGNWDVI (SEQ ID NO: 196), TGTSNRFVS (SEQ ID NO: 210), GVNKRPS (SEQ ID NO: 211), SSLVGNWDVI (SEQ ID NO: 212), NGTSSDIGGWNFVS (SEQ ID NO: 226), EVNKRPS (SEQ ID NO: 227), SSLFGRWDVV (SEQ ID NO: 228), RASQNINKNLA (SEQ ID NO: 243), ETYSKIA (SEQ ID NO: 244), QQYEEWPRT (SEQ ID NO: 245), RASQNVKNNLA (SEQ ID NO: 259), DASSRAG (SEQ ID NO: 260), SSTQSLRHSNGANYLA (SEQ ID NO: 286), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288), y TSTQSLRHSNGANYLA (SEQ ID NO: 303).
Además, la solicitud proporciona un anticuerpo anti-VIH aislado o fragmento del mismo, en donde dicho anticuerpo comprende: (a) una región CDR1 Vh incluyendo la secuencia de aminoácidos de SEQ ID NO: 88, 104, 110, 116, 123, 90, 261, 169, 185, 201, 217, 233, 250 o 277; (b) una región CDR2 Vh que incluye la secuencia de aminoácidos de SEQ ID NO: 98, 89, 105, 111, 117, 124, 265, 157, 170, 186, 202, 218, 234, 251, 278 o 293; y (c) una región CDR3 Vh que incluye la secuencia de aminoácidos de SEQ ID NO: 6, 9, 8, 10, 7, 143, 262, 171, 187, 203, 219, 235, 252, 279 o 308; en donde dicho anticuerpo se une y neutraliza el VIH-1. Este anticuerpo puede incluir además: (a) una región CDR1 Vl que incluye la secuencia de aminoácidos de SEQ ID NO: 93, 92, 97, 94, 107, 113, 120, 126, 150, 162, 178, 194, 210, 226, 243, 259, 286 o 303; (b) una región CDR2 Vl que incluye la secuencia de aminoácidos de SEQ ID NO: 95, 108, 114, 121, 127, 151, 163, 179, 195, 211, 227, 244, 260 o 287; y (c) una región CDR3 Vl incluyendo la secuencia de aminoácido de SEQ ID NO: 41, 42, 43, 44, 45, 152, 164, 180, 196, 212, 228, 245, o 288.
Alternativamente, la solicitud proporciona un anticuerpo anti-VIH aislado o un fragmento del mismo, en donde dicho anticuerpo incluye: (a) una región Vh CDR1 que incluye la secuencia de aminoácidos de SEQ ID NO: 266, 268, 270, 201, 118, 144, 263, 172, 188, 204, 220, 236, 253, 280 o 309; (b) una región CDR2 Vh que incluye la secuencia de aminoácidos de SEQ ID NO: 267, 269, 271, 103, 272, 145, 264, 173, 189, 205, 221,237, 254, 281 o 294; y (c) una región CDR3 Vh que incluye la secuencia de aminoácidos de SEQ ID NO: 6, 9, 8, 10, 7, 143, 262, 171, 187, 203, 219, 235, 252, 279 o 308; en donde dicho anticuerpo se une y neutraliza el VIH-1. Este anticuerpo puede incluir además: (a) una región CDR1 Vl que incluye la secuencia de aminoácidos de SEQ ID NO: 93, 92, 97, 94, 107, 113, 120, 126, 150, 162, 178, 194, 210, 226, 243, 259, 286 o 303; (b) una región CDR2 Vl que incluye la secuencia de aminoácidos de SEQ ID NO: 95, 108, 114, 121, 127, 151, 163, 179, 195, 211, 227, 244, 260 o 287; y (c) una región CDR3 Vl incluyendo la secuencia de aminoácidos de SEQ ID NO: 41, 42, 43, 44, 45, 152, 164, 180, 196, 212, 228, 245, o 288.
La solicitud proporciona además una gran lista de anticuerpos anti-VIH monoclonales completamente humanos aislados que incluyen las siguientes secuencias de aminoácidos seleccionados de (a)-(z), (aa)-(ab), and
(ad)-(am), que, sin embargo, representan solamente ejemplos y no están cubiertos por la invención reivindicada: a) una secuencia de cadena pesada que incluye la secuencia de aminoácidos de SEQ ID NO: 31 y una secuencia de cadena ligera que incluye la secuencia de aminoácidos de SEQ ID NO: 32, o b) una secuencia de cadena pesada que incluye la secuencia de aminoácidos de SEQ ID NO: 33 y una secuencia de cadena ligera que incluye la secuencia de aminoácidos de SEQ ID NO: 34, o c) una secuencia de cadena pesada que incluye la secuencia de aminoácidos de SEQ ID NO: 35 y una cadena ligera secuencia que puede comprender la secuencia de aminoácidos de SEQ ID NO: 36, o d) una secuencia de cadena pesada que incluye la secuencia de aminoácidos de SEQ ID NO: 37 y una secuencia de cadena ligera que incluye la secuencia de aminoácidos de SEQ ID NO: 38, o e) una secuencia de cadena pesada que incluye la secuencia de aminoácidos de SEQ ID NO: 39 y una secuencia de cadena ligera que incluye la secuencia de aminoácidos de SEQ ID NO: 40, o f) una secuencia de cadena pesada que incluye la secuencia de aminoácidos de SEQ ID NO: 140 y una secuencia de cadena ligera que incluye la secuencia de aminoácidos de SEQ
ID NO: 96, o g) una secuencia de cadena pesada que incluye la secuencia de aminoácidos de SEQ ID NO: 48 y una secuencia de cadena ligera que incluye la secuencia de aminoácidos de SEQ ID NO: 51, o h) una secuencia de cadena pesada que incluye la secuencia de aminoácidos de SEQ ID NO: 54 y una secuencia de cadena ligera que incluye la secuencia de aminoácidos de SEQ ID NO: 57, o i) una secuencia de cadena pesada que incluye la secuencia de aminoácidos de SEQ ID NO: 60 y una secuencia de cadena ligera que incluye la secuencia de aminoácidos de SEQ
ID NO: 32, o j) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO:
79 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 149, o k) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 156 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 161, o l) secuencia de cadena pesada que puede comprender una secuencia de aminoácidos de SEQ ID NO: 168 y secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 177, o m) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 184 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 193, o n) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 200 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 209, o o) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 216 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 225, o p) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 232 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 242 o q) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 249 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 258 o r) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 276 y secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 285 o s) secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 292 y secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 285 o t) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 298 y una secuencia de cadena ligera que puede comprender secuencia de aminoácidos de SEQ ID NO: 302 o u) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 307 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 313 o v) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 319 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 330 o w) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 334 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 393 o x) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 347 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 356 o y) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 363 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 397 o z) una secuencia de cadena pesada que puede comprender el la secuencia de aminoácidos de SEQ ID NO: 401 y una cadena ligera se secuencia que puede comprender la secuencia de aminoácidos de SEQ ID NO: 386, o aa) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 405 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 414, o ab) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 420 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 429, o ac) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 435 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 440, o ad) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 444 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 449, o ae) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 454 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 584, o af) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 463 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 470, o ag) una secuencia de cadena pesada que puede
comprender la secuencia de aminoácidos de SEQ ID NO: 474 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 483, o ah) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 490 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 497, o ai) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 502 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 511, o aj) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 517 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 525, o ak) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 532 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos SEQ ID NO: 540, o al) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 547 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 554, o am) una secuencia de cadena pesada que puede comprender la secuencia de aminoácidos de SEQ ID NO: 560 y una secuencia de cadena ligera que puede comprender la secuencia de aminoácidos de SEQ ID NO: 566. Por el contrario, la presente invención se dirige específicamente al anticuerpo monoclonal anti-VIH humano 4876_M06 (PGT-134) que tiene una cadena pesada variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 435 y una secuencia de cadena ligera variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 440.
La solicitud proporciona además una composición que incluye uno cualquiera de los anticuerpos anti-VIH aislados descritos en la presente memoria.
Opcionalmente, un anticuerpo monoclonal humano anti-VIH de la aplicación se aísla de una célula B de un donante humano infectado con VIH-1. En algunos aspectos, el anticuerpo es efectivo para neutralizar una pluralidad de diferentes clados de VIH. En algunos aspectos, el anticuerpo es eficaz para neutralizar una pluralidad de cepas diferentes dentro del mismo clado de VIH-1. En algunos aspectos, el anticuerpo neutralizante se une a las proteínas de envoltura de VIH gp120, o gp41 o proteína de envoltura en pseudoviriones de VIH-1 o expresadas en superficies celulares transfectadas o infectadas. En algunos aspectos, el anticuerpo neutralizante no se une a proteínas de envoltura recombinantes o monoméricas gp120, o gp41 o proteína de envoltura en pseudoviriones de VIH-1 o se expresa en superficies celulares transfectadas o infectadas, sino que se une a formas triméricas naturales de las proteínas Env de VIH-1.
La presente solicitud proporciona anticuerpos monoclonales humanos en donde los anticuerpos son potentes, ampliamente anticuerpo neutralizante (bNAb). En algunos aspectos, un anticuerpo ampliamente neutralizante se define como un bNAb que neutraliza las especies de VIH-1 que pertenecen a dos o más clados diferentes. En algunos aspectos, los diferentes clados se seleccionan del grupo que consiste en los clados A, B, C, D, E, AE, AG, G o F. En algunos aspectos, las cepas de VIH-1 de dos o más clados comprenden virus de clados no B.
En algunos aspectos, un anticuerpo ampliamente neutralizante se define como un bNAb que neutraliza al menos el 60% de los VIH-1 cepas enumeradas en las Tablas 18A-18F. En algunos aspectos, al menos el 70%, o al menos el 80%, o al menos el 90% de las cepas de VIH-1 enumeradas en las Tablas 18A-18F están neutralizadas.
En algunos aspectos, un anticuerpo ampliamente neutralizante potente se define como un bNAb que muestra una potencia de neutralización de al menos una pluralidad de especies de VIH-1 con un valor de CI50 de menos que 0,2 |jg/mL. En algunos aspectos, la potencia de neutralización de la especie VIH-1 tiene un valor de CI50 menor que 0,15 jg/mL, o menor que 0,10 jg/mL, o menos que 0,05 jg/mL. Un anticuerpo potente, ampliamente neutralizante, también se define como un bNAb que muestra una potencia de neutralización de al menos una pluralidad de especies de VIH-1 con un valor de CI90 de menos de 2,0 jg/mL. En algunos aspectos, la potencia de neutralización de las especies VIH-1 tiene un valor CI90 de menos de 1,0 jg/mL, o menos de 0,5 jg/mL.
Los ejemplos de anticuerpos monoclonales de la solicitudque neutralizan el VIH-1 incluyen 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN- 118), 1489_I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869 -K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157) y 6881_N05 (PGT-158) descritos en la presente. La presente invención, sin embargo, proporciona específicamente al anticuerpo monoclonal anti-VIH humano 4876_ m 06 (PGT-134) que tiene una cadena pesada variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 435 y una secuencia de cadena ligera variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 440.
Alternativamente, el anticuerpo monoclonal es un anticuerpo que se une al mismo epítopo que 1443_C16
(PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489 _I13 (PG16) (TCN- 120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT- 124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157), o 6881_N05 (PGT-158). Específicamente, los anticuerpos monoclonales PG9 y PG16 son anticuerpos neutralizantes amplios y potentes. Los anticuerpos se denominan en este documento respectivamente anticuerpos contra el VIH. La presente invención, sin embargo, se refiere específicamente a un anticuerpo que se une al mismo epítopo que 4876_M06 (PGT-134).
La solicitud proporciona un número de anticuerpos monoclonales humanos aislados, en donde cada uno de dichos monoclonal se une el anticuerpo a VIH-1 células infectadas o transfectadas; y se une al virus VIH-1. Se proporciona un anticuerpo neutralizante que tiene potencia para neutralizar el VIH-1, o un fragmento del mismo. En algunos aspectos, un anticuerpo neutralizante de la aplicación exhibe un índice de neutralización más alto y/o una mayor afinidad por unirse a las proteínas de envoltura gp120 o gp41 que los mAbs anti-VIH conocidos en la técnica, como el mAb b12. (Burton DR y col., Science Vol. 266. N° 5187, págs. 1024 - 1027). Los anticuerpos monoclonales ejemplares 1496_C09 (PG9), 1443_C16 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14) y 1495_C14 (PGC14) exhiben unión a la glicoproteína de la envoltura gp120, pero no gp41, en un ensayo ELISA, sin embargo, la unión a gp120 no siempre se correlacionan con la actividad de neutralización contra cepas específicas de VIH-1. En algunos aspectos, los anticuerpos monoclonales, por Ejemplo 1443_C16 (PG16) y 1496_C09 (PG9), muestran actividad de unión a gp120 nula o débil contra una cepa particular, pero se unen al trímero de VIH-1 en la superficie celular y/o virión transfectados o infectados y exhiben una amplia y potente actividad de neutralización contra esa cepa de VIH-1.
En un aspecto de la presente solicitud que, sin embargo, no representa una realización de la invención reivindicada, el anticuerpo es un anticuerpo monoclonal que puede comprender uno o más polipéptidos seleccionados del grupo que consiste de 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489_I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157) y 6881_N05 (PGT-158); que puede comprender una cadena pesada seleccionada del grupo que consiste en la cadena pesada de 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489_I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157) y 6881_N05 (PGT-158); que puede comprender una cadena pesada que puede comprender una CDR seleccionada del grupo que consiste en las CDR de la cadena pesada de 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489 _I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157) y 6881_N05 (PGT-158); que puede comprender una cadena ligera seleccionada del grupo que consiste en la cadena ligera de 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489_I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06
(PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157) y 6881_N05 (PGT-158); que puede comprender una cadena ligera que puede comprender una CDR seleccionada del grupo que consiste en las CDR de la cadena ligera de 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489 _I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT- 131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157) y 6881_N05 (PGT-158). Sin embargo, la presente invención se refiere específicamente al anticuerpo monoclonal anti-VIH humano 4876_M06 (PGT-134) que tiene una cadena pesada variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 435 y una cadena ligera variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 440. En otro aspecto de la presente solicitud, que, sin embargo, no representa una realización de la invención reivindicada, la solicitud se refiere a un anticuerpo o un fragmento del mismo, como fragmentos Fab, Fab', F(ab')2 y Fv que se unen a un epítopo o polipéptido inmunogénico capaz de unirse a un anticuerpo seleccionado de 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489 _I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145 _B14 (PGT-127), 5114_A19 (PGT-128), 5147 _N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157), y 6881_N05 (PGT-158). La presente invención, sin embargo, se refiere específicamente a un anticuerpo o un fragmento del mismo, como los fragmentos Fab, Fab', F(ab')2 y Fv que se une a un epítopo o polipéptido inmunogénico capaz de unirse al anticuerpo 4876_M06 (PGT-134).
La solicitud también se refiere a polipéptidos inmunogénicos que codifican dichos epítopos.
También se proporcionan moléculas de ácido nucleico que codifican tales anticuerpos, y vectores y células que llevan tales ácidos nucleicos. Más específicamente, la presente invención se refiere a una molécula de ácido nucleico que codifica el anticuerpo 4876_M06 (PG T-134), y a vectores y células que llevan dicha molécula de ácido nucleico. La aplicación se refiere a una composición farmacéutica que puede comprender al menos un anticuerpo o fragmento como se menciona en este documento, junto con un vehículo farmacéuticamente aceptable. Más específicamente, la presente invención se refiere a una composición farmacéutica que comprende el anticuerpo 4876_M06 (PGT-134) junto con un vehículo farmacéuticamente aceptable. Cualquier referencia a un método de tratamiento practicado en el cuerpo humano o animal debe interpretarse como los compuestos y composiciones de la invención para su uso en el tratamiento.
La solicitud se refiere a un método de inmunización, prevenir o inhibir la infección por VIH o una enfermedad relacionada con el VIH que puede comprender los pasos de identificar a un paciente en necesidad de tal tratamiento y administrar a dicho paciente una cantidad terapéuticamente eficaz de al menos una anticuerpo monoclonal como se menciona aquí.
En un aspecto adicional los anticuerpos del VIH de acuerdo con la aplicación están vinculados a un agente terapéutico o una etiqueta detectable.
Además, la solicitud proporciona métodos para estimular una respuesta inmune, tratar, prevenir o aliviar un síntoma de una infección viral del VIH mediante la administración de un anticuerpo del VIH a un sujeto
En otro aspecto, la solicitud proporciona métodos para administrar el anticuerpo de VIH de la aplicación a un sujeto antes de, y/o después de la exposición a un virus VIH. Por ejemplo, el anticuerpo del VIH de la aplicación se usa para tratar o prevenir la infección por el VIH. El anticuerpo del VIH se administra a una dosis suficiente para promover la eliminación viral o eliminar las células infectadas por el VIH.
También se incluye en la solicitud un método para determinar la presencia de una infección por el virus del VIH en un paciente, poniendo en contacto una muestra biológica obtenida del paciente con un anticuerpo VIH; detectar una cantidad del anticuerpo que se une a la muestra biológica; y comparar la cantidad de anticuerpo que se une a la
muestra biológica con un valor de control.
La solicitud proporciona además un kit de diagnóstico que puede comprender un anticuerpo monoclonal VIH.
La solicitud se refiere a un anticuerpo ampliamente neutralizante (bNAb) en donde los neutraliza al menos un anticuerpo miembro de cada clado con una mayor potencia que la de la b12 bNAbs, 2G12, 2F5 y 4E10, respectivamente.
La solicitud se refiere a un anticuerpo ampliamente neutralizante (bNAb) en donde se une el anticuerpo o no se unen proteínas monoméricas gp120 o gp41 del gen env de VIH-1. El anticuerpo se une con mayor afinidad a las formas triméricas del Env de VIH-1 expresadas en una superficie celular que a la gp120 monomérica o la gp140 trimerizada artificialmente. En algunos aspectos, el anticuerpo se une con alta afinidad a los trímeros gp160 de VIH-1 sin cortar en una superficie celular.
La solicitud se refiere a un anticuerpo ampliamente neutralizante (bNAb) en donde se une el anticuerpo a un epítopo dentro de la variable de bucle de gp120, en donde el epítopo puede comprender las regiones conservadas de V2 y V3 bucles de gp120, en donde el epítopo pueden comprender sitio de N-glicosilación en el residuo Asn-160 dentro del bucle V2 de gp120, en donde el anticuerpo se une a un epítopo presentado por un pico trimérico de gp120 en una superficie celular, en donde el epítopo no se presenta cuando gp120 se trimeriza artificialmente. En algunos aspectos, el anticuerpo no neutraliza el VIH-1 en ausencia del sitio de N-glicosilación en el residuo Asn-160 dentro del bucle V2 de gp120.
En otro aspecto la presente solicitud que, sin embargo, no representa una realización del invención reivindicada, la solicitud se refiere a un anticuerpo ampliamente neutralizante (bNAb) seleccionado del grupo que consiste en PG16 y PG9. Además, la solicitud se refiere a un anticuerpo ampliamente neutralizante (bNAb) seleccionado del grupo que consiste en 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489 _I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145 _B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_117 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157), y 6881_N05 (PGT-158). Por el contrario, la presente invención se refiere específicamente al anticuerpo 4876_M06 (PGT-134)
La solicitud se refiere a un antígeno o un polipéptido inmunogénico, o una vacuna que puede comprender tal antígeno o polipéptido inmunogénico, para producir un anticuerpo ampliamente neutralizante (bNAb) por una respuesta inmune, el antígeno que puede comprender un epítopo dentro de la variable bucle de gp120 según la aplicación.
La solicitud se refiere al método para la inmunización pasiva o activa de un individuo contra una pluralidad de especies de VIH-1 a través de uno o más clados, el método que puede comprender: proporcionar un anticuerpo ampliamente neutralizante (bNAb) en donde el bNAb neutraliza el VIH-1 especie que pertenece a dos o más clados, y además en donde la potencia de neutralización de al menos un miembro de cada clado está determinada por un valor de CI50 de menos de 0,005 pg/ml. En algunos aspectos de la presente solicitud, el anticuerpo se selecciona del grupo que consiste en PG9 y PG16. En otro aspecto de la presente solicitud que, sin embargo, no representa una realización de la invención reivindicada, el anticuerpo se selecciona del grupo que consiste en 1443_C16 (PG16) TCN-116 , 1503 H05 PG16 TCN-119 , 1456 A12 PG16 TCN-117 , 1469 M23 PG16 TCN-118 , 1489 I13

6881_N05 (PGT-158). Según la presente invención, el anticuerpo es 4876_M06 (PG T-134).
De acuerdo con la presente descripción, el anticuerpo es producido por la inmunización activa con un antígeno que puede comprender un epítope dentro de la variable de bucle de gp120, en donde el epítopo puede comprender las regiones conservadas de bucles V2 y V3 de gp120 o, en donde el epítopo puede comprender un sitio de N-glicosilación en el residuo Asn-160 dentro del bucle V2 de gp120. En algunos aspectos, el epítopo se presenta mediante una espiga trimérica de gp120 en una superficie celular, y el epítopo no se presenta cuando gp120 es
monomérico o trimerizado artificialmente.
La solicitud proporciona un método para obtener un anticuerpo monoclonal humano ampliamente neutralizante, el método incluye: (a) cribar cultivos de células B de memoria de una muestra de PBMC donante para una amplia actividad de neutralización contra una pluralidad de especies de VIH-1; (b) clonar una célula B de memoria que exhibe una amplia actividad de neutralización; y luego (c) rescatar el anticuerpo monoclonal del cultivo de células B de memoria clonal que exhibe una amplia actividad de neutralización. En un aspecto, la etapa de selección puede incluir la detección de transfectantes policlonales para la actividad de neutralización antes del paso de clonación de la transfección monoclonal. En este aspecto, la etapa de selección se repite opcionalmente después de la transfección monoclonal. Finalmente, en este aspecto, la secuencia de ADN del anticuerpo monoclonal se determina como parte del paso de rescate. Los ejemplos de anticuerpos que se generan pero que no forman parte de la invención incluyen, 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489_I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT- 128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137)), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT- 133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153)), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157) y 6881_N05 (PGT-158). Por el contrario, la presente invención se refiere al anticuerpo 4876_M06 (PGT-134).
Alternativamente, o además, el paso de selección incluye la determinación de secuencias de genes variables a partir de pocillos de células B seleccionados mediante secuenciación profunda, que opcionalmente es seguida por la alineación de secuencia para agrupar anticuerpos relacionados. En este aspecto alternativo, después del paso de selección, se realiza una transfección monoclonal como parte del paso de clonación. Posteriormente, en este aspecto alternativo, los transfectantes monoclonales se seleccionan para la actividad de neutralización contra un virus VIH de uno o más clados. Los anticuerpos ejemplares que se generan usando este aspecto, pero que no forman parte de la invención reivindicada, incluyen, 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN- 118), 1489 _I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN- 109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157) y 6881_ n 05 (PGT-158). Por el contrario, la presente invención se refiere al anticuerpo 4876_M06 (PGT-134).
BREVE DESCRIPCIÓN DE LOS DIBUJOS
La Figura 1A es un diagrama de árbol esquemático de secuencias de región variable alineadas con Clustal W de cadenas pesadas de los anticuerpos monoclonales.
La Figura 1B es un diagrama de árbol esquemático de secuencias de región variable alineadas con Clustal W de cadenas ligeras de los anticuerpos monoclonales.
La Figura 2 es un diagrama de flujo del proceso para el aislamiento de anticuerpos monoclonales según la invención.
La Figura 3A es un diagrama esquemático que resume los resultados de la detección para la neutralización y los ensayos de unión de la proteína VIH-env (gp120 y gp41) de los cuales se seleccionaron cultivos de células B para el rescate de anticuerpos y los anticuerpos monoclonales 1496_C09 (PG9), 1443_C16 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14) y 1495_C14 (PGC14) se derivaron. Se usó un valor de índice de neutralización 0f 1,5 como punto de corte.
La Figura 3B es un diagrama esquemático que resume la actividad neutralizante y las actividades de unión a la proteína VIH-env (gp120 y gp41) de los anticuerpos monoclonales 1496_C09 (PG9), 1443_C16 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14) y 1495_C14 (PGC14) según lo determinado por ensayos ELISA entre los sobrenadantes de células B usando un valor de corte del índice de neutralización de 2,0. El índice de neutralización se expresó como la proporción de unidades de luminiscencia relativa normalizadas (RLU) de SIVmac239 con respecto a la cepa viral de prueba derivada del mismo sobrenadante de cultivo de células B de prueba. Los valores de corte utilizados para distinguir los golpes neutralizantes se determinaron mediante el índice de neutralización de un gran número de pocillos de control negativo que contenían sobrenadantes de cultivo de células B derivados de donantes sanos.
La Figura 4 es una serie de gráficos que representan la actividad de neutralización de los anticuerpos monoclonales (PG16) y 1496_C09 (PG9) contra pseudovirus adicionales no incluidos en las Tablas 17A y 17B.
La Figura 5 es un gráfico que representa las curvas de respuesta a la dosis de 1456_P20 (PG20), 1495_C14 (PGC14) y 1460_G14 (PGG14) que se unen a gp120 recombinante en ELISA en comparación para controlar anti-gp120 (b12). Los datos se presentan como valores de DO promedio de pocillos ELISA triplicados obtenidos en la misma placa.
La Figura 6 es una serie de gráficos que representan los resultados de los ensayos de unión ELISA de anticuerpos monoclonales (PG16) y 1496_C09 (PG9) a VIH-1 YU2 gp140, JR-CSFgp120, péptido de regiones externas proximales a la membrana (MPER) de polipéptido gp41 y V3.
La Figura 7 es un gráfico que representa los resultados de un ensayo de unión que usa los anticuerpos monoclonales (PG16) y 1496_C09 (PG9) contra VIH-1 YU2 gp160 expresados en la superficie celular en presencia y ausencia de CD4 soluble (sCD4).
La Figura 8 es un gráfico que representa los resultados de un ensayo de unión que usa los anticuerpos monoclonales (PG16) y 1496_C09 (PG9) contra células transfectadas con gp160 V iH-1.
La Figura 9 es una serie de gráficos que representan los resultados de un ensayo de captura. Los datos describen la captura de pseudovirus JRCSF de entrada competente de anticuerpos monoclonales neutralizantes (PG16) y 1496_C09 (PG9) de una manera dependiente de la dosis.
La Figura 10A es un gráfico que representa los resultados de un ensayo de unión competitiva utilizando anticuerpos monoclonales sCD4, PG16 y PG9, en donde los anticuerpos reivindicados compiten por la unión del anticuerpo monoclonal (PG16) al pseudovirus pero controlan los anticuerpos b12, 2G12, 2F5 y 4E10 do no se une competitivamente al pseudovirus.
La Figura 10B es un gráfico que representa los resultados de un ensayo de unión competitiva utilizando anticuerpos monoclonales sCD4, PG16 y PG9, en donde los anticuerpos reivindicados compiten por la unión del anticuerpo monoclonal 1496_C09 (PG9) al pseudovirus pero controlan los anticuerpos b12, 2G12, 2F5 y 4E10 do no se une competitivamente al pseudovirus.
La Figura 11A es una serie de gráficos que representan los resultados de un ensayo de unión usando PG9 y PG16. Los datos muestran que PG9 y PG16 se unen a construcciones gp120 monoméricas y gp140 trimerizadas artificialmente según lo determinado por ELISA. Se usó IgG b12 como control para los ensayos ELISA.
La Figura 11B es una serie de gráficos que representan los resultados de un ensayo de unión usando PG9 y PG16. Los datos muestran que PG9 y PG16 se unen a Env expresados en la superficie de las células 293T según lo determinado por citometría de flujo. El bNAb b12 y el anticuerpo no neutralizante b6 se incluyen en los ensayos de unión a la superficie celular para mostrar los porcentajes esperados de Env escindido y no escindido expresados en la superficie celular.
La Figura 12 es una serie de gráficos que representan los resultados de un ensayo de unión que usa PG9 y PG16 y trímeros de VIH-1YU2 defectuosos en la escisión. PG9 y PG16 se unen con alta afinidad a los trímeros de VIH-1YU2 defectuosos de escisión según lo determinado por citometría de flujo. Las curvas de unión se generaron trazando el MFI de la unión al antígeno en función de la concentración de anticuerpos. La Figura 13A-E es una serie de gráficos que representan el mapeo de los epítopos PG9 y PG16. El anticuerpo de la competencia se indica en la parte superior de cada gráfico. Se incluye 2G12 para controlar la expresión de Env en la superficie celular. A: PG9 y PG16 compiten entre sí por la unión de Env a la superficie celular y ninguno de los anticuerpos compite con el anticuerpo b12 CD4bs por la unión a Env. B: la ligadura de Env de la superficie celular con sCD4 disminuye la unión de PG9 y PG16. Se incluye 2G12 para controlar el desprendimiento de gp120 inducido por CD4. C: sCD4 inhibe la unión de PG9 a gp140YU-2 trimerizada artificialmente según lo determinado por ELISA. D: PG9 compite con 10/76b (anti-V2), F425/b4e8 (anti-V3) y X5 (CD4i) por la unión de gp120 en ensayos ELISA de competición. E: PG9 y PG16 no se unen a variantes de VIH-1JR-CSF eliminadas en bucle variable expresadas en la superficie de las células 293T. La Figura 14 es una serie de gráficos que representan los resultados de los ensayos ELISA de competición utilizando el anticuerpo monoclonal PG9.
La Figura 15 es un gráfico que representa la unión de anticuerpos monoclonales, PG9 o PG16, a Env de VIH-1JR-FLACT E168K expresado en la superficie de las células 293T según lo determinado por citometría de flujo.
La Figura 16 es un gráfico que representa la unión del anticuerpo monoclonal PG9 a la gp120 desglicosilada. La Figura 17 es una serie de gráficos que representan la actividad de neutralización de PG9 y PG16 contra VIH-1SF162 y VIH-1SF162 K160N, que se determinó usando un ensayo de informe de replicación de luciferasa de una sola ronda del virus pseudotipado.
La Figura 18 es una serie de gráficos que representan la unión de PG9 y PG16 a trímeros mixtos. Las sustituciones de alanina en las posiciones 160 y 299 se introdujeron en Env VIH-1YU2 para abolir la unión de PG9 y PG16. También se introdujo una sustitución de alanina en la posición 295 en la misma construcción para anular la unión de 2G12. La cotransfección de células 293T con WT y plásmidos mutantes en una proporción 1:2 dio como resultado la expresión de 29% de homotrímeros mutantes, 44% de heterotrímeros con dos subunidades mutantes, 23% de heterotrímeros con una subunidad mutante y 4% de homotrímeros de tipo silvestre.
La Figura 19 es una serie de representaciones gráficas del número de diferencias de nucleótidos o aminoácidos en las secuencias de cadena pesada de 1443 clones hermanos C16 (PG16) entre sí. Tenga en cuenta que la diferencia de un solo nucleótido de 1408 108 se traduce en una secuencia de proteína idéntica de 1443 C16. La secuencia de nucleótidos de la cadena ligera 1408 108 es idéntica a la secuencia de
nucleótidos de la cadena ligera de 1443 C16.
La Figura 20A es un diagrama de árbol que ilustra la correlación de la cadena pesada de los clones hermanos 1443 C16 con la cadena pesada de 1496 C09 a nivel de nucleótidos.
La Figura 20B es un diagrama de árbol que ilustra la correlación de la cadena ligera de 1443 clones hermanos C16 con la cadena ligera de 1496 C09 a nivel de nucleótidos.
La Figura 21A es un diagrama de árbol que ilustra la correlación de la cadena pesada de 1443 clones hermanos C16 con la cadena pesada de 1496 C09 a nivel de proteína.
La Figura 21B es un diagrama de árbol que ilustra la correlación de la cadena ligera de 1443 clones hermanos C16 con la cadena ligera de 1496 C09 a nivel de proteína.
La Figura 22 es un diagrama de Venn que representa los virus utilizados en la detección primaria de neutralización del VIH (JR-CSF, MGRMC-26, 92BR020, 94UG103, 93IN905, 92TH021) y el número de anticuerpos neutralizantes identificados utilizando estos virus solos, o en las combinaciones demostradas. Se muestran los resultados de la detección de anticuerpos aislados de cultivos de células B establecidos a partir de cuatro donantes humanos (n° 517, 039, 196 y 584).
La Figura 23 es un diagrama de árbol que ilustra las relaciones entre las secuencias de genes variables de la cadena pesada de los anticuerpos PGT-121, PGT-122, PGT-123, PGT-125, PGT-126, PGT-130, PGT-135 y PGT-136. Barra de escala = 0,03. Un valor de cero demuestra que dos clones de células B separados produjeron un anticuerpo idéntico. Los anticuerpos están menos relacionados a medida que aumentan los valores proporcionados.
La Figura 24 es un diagrama de árbol que ilustra las relaciones entre las secuencias de genes variables de la cadena ligera de los anticuerpos PGT-121, PGT-122, PGT-123, PGT-125, PGT-126, PGT-130, PGT-135 y PGT-136. Barra de escala = 0,04. Un valor de cero demuestra que dos clones de células B separados produjeron un anticuerpo idéntico. Los anticuerpos están menos relacionados a medida que aumentan los valores proporcionados.
La Figura 25 es un diagrama de árbol que ilustra las relaciones entre las secuencias de genes variables de la cadena pesada de los anticuerpos PGT-141, PGT-142 y PGT-143. Barra de escala = 0,04. Un valor de cero demuestra que dos clones de células B separados produjeron un anticuerpo idéntico. Los anticuerpos están menos relacionados a medida que aumentan los valores proporcionados.
La Figura 26 es un diagrama de árbol que ilustra las relaciones entre las secuencias de genes variables de la cadena ligera de los anticuerpos Pg T-141, PGT-142 y PGT-143. Barra de escala = 0,04. Un valor de cero demuestra que dos clones de células B separados produjeron un anticuerpo idéntico. Los anticuerpos están menos relacionados a medida que aumentan los valores proporcionados.
La Figura 27 es un gráfico circular que muestra que un número limitado de especificidades de anticuerpos median una neutralización de suero amplia y potente en neutralizadores de élite (Walker LM, et al. PLOS Pathogen, 2010).
La Figura 28 es un diagrama esquemático que representa la plataforma de descubrimiento I-Star™ Human bNAb (anticuerpo ampliamente neutralizante) desarrollada por Theraclone Sciences.
La Figura 29 es un diagrama esquemático que representa el método de aislamiento de bNMab (anticuerpos monoclonales ampliamente neutralizantes) de las células B de memoria IgG-positivas (IgG+) desarrolladas por Theraclone Sciences.
La Figura 30 es una representación tridimensional generada por computadora de anticuerpos PG9 y PG16 específicos de trímero en las proximidades de regiones conservadas de V2 y V3, donde se unen.
La Figura 31 es una representación tridimensional generada por computadora de epítopos altamente conservados en el pico del VIH, incluidos los bucles V1/V2 y V3 a los que se unen PG9 y PG16 y los epítopos a los que PGT-121, PGT-122, PG T-123, PGT-125, PGT-126, PGT-130, PGT-135, PGT-136, PGT-141, PGT-142, PGT-143 y PGT-144.
La Figura 32 es un gráfico que representa la potencia de los anticuerpos monoclonales anti-VIH PGT-121, PGT-122, PGT-123, PGT-125, PGT-126, PGT-127, PGT-128, PGT-130, PGT-131, PGT-135, PGT-136, PGT-137, PGT-141, PGT-142, PGT-143, PGT-144, PGT-145 y PG9, expresados como la concentración inhibitoria semimáxima o CI50 (pg/ml). La barra para cada anticuerpo representa el valor medio de CI50.
La Figura 33A-D es una serie de gráficos que representan los anticuerpos PGT recientemente identificados que redefinen la neutralización amplia y potente del VIH. A, Key MAbs recapitulan completamente la neutralización del suero por el suero donante correspondiente. La amplitud del suero se coreló con la amplitud del MAb más amplio para cada donante (% de virus neutralizados a NT 50 >100 o CI50 < 50 pg/ml, respectivamente). Es de destacar que los MAb aislados del donante 39 no pudieron recapitular completamente la amplitud de neutralización del suero. B-D. Ciertos anticuerpos o combinaciones de anticuerpos pueden cubrir una amplia gama de aislados de VIH a bajas concentraciones de vacuna alcanzables. B, distribución de frecuencia acumulativa de valores CI50 de MAbs ampliamente neutralizantes probados contra un panel 162 de virus. El eje y muestra la frecuencia acumulada de los valores de CI50 hasta la concentración que se muestra en el eje x y, por lo tanto, también puede interpretarse como la amplitud en un límite de CI50 específico. C-D, porcentaje de virus cubiertos por MAbs individuales (líneas continuas) o por al menos uno de los MAbs en combinaciones duales (líneas negras discontinuas) que dependen de las concentraciones individuales. El área gris en ambos paneles es la cobertura de 26 MAbs probados en el panel de 162 virus (PGT121-123, PGT125-128, PGT130-131, PGT135-137, PGT141-145, PG9, PG16, PGC14, VRC01, PGV04, b12, 2G12, 4E10, 2F5) y representa la cobertura teórica máxima alcanzable
conocida hasta la fecha.
La Figura 34A es una tabla que representa la competencia de los MAb PGT con sCD4 (CD4 soluble), b12 (anti-CD4bs), 2G12 (anti-glicano), F425/b4e8 (anti-V3), X5 (CD4i), PG9 (anti-V1/V2 y V3, cuaternario) y entre sí. Los ensayos de competencia se realizaron por ELISA usando gp120 Bal o gp120 JR-FL, excepto el ensayo de competencia PG9, que se realizó en la superficie de células transfectadas JR-FL E168K o JR-CSF. Las cajas están codificadas por colores de la siguiente manera: rojo, 75-100% de competencia; naranja, 50-75% de competencia; amarillo, 25-50% de competencia; gris, <25% de competencia. Los experimentos se realizaron por duplicado, y los datos representan un promedio de al menos dos experimentos independientes. La Figura 34B-D es una serie de gráficos que representan el mapeo de epítopos de anticuerpos PGT. b, el análisis de microarrays Glycan (Consortium for Functional Glycomics, CFG, v 5,0) revela que los PGT MAbs 125, 126, 127, 128 y 130 contactan a Mana (313), Mana GlcNAc 2 (193), Mang (314) y Mang GlcNAcg (194) glicanos directamente. Solo se muestran las estructuras de glicanos con RFU (unidades fluorescentes relativas) > 3000. PGT-131 no mostró unión detectable a la matriz de glicanos CFG, pero se unió a Mangoligodendrons 30 (datos no mostrados). Las barras de error representan la desviación estándar. c, d, la unión de PGT MAbs 125, 126, 127, 128 y 130 a gp120 es competida por oligodendros Man 9 pero no por oligodendros Man4. La unión de 131 a la gp120 inmovilizada fue demasiado baja para medir cualquier competencia.
La Figura 35 es una serie de gráficos que representan la falta de polirreactividad de los anticuerpos monoclonales PGT (mAbs) en el ensayo ELISA. Los mAb PGT se probaron para determinar la reactividad de ELISA contra un panel de antígenos. Los bNAbs b12 y 4E10 también se incluyeron para comparación. d.s., bicatenario; s.s, monocatenario.
La Figura 36 es una serie de gráficos que representan los resultados de un análisis de la actividad de neutralización por clados de virus. La distribución de frecuencia acumulativa de valores CI50 de Mabs ampliamente neutralizantes probados contra un panel de virus 162 separado por los clados A, B, C, D, F, G, AE y AG. VRC01 se probó en un panel de virus diferente (n = 190, ref 6).
La Figura 37A-D es una serie de gráficos que muestran que la neutralización de MAb se correlaciona fuertemente con la neutralización del suero. Se muestra la correlación de CI50 s de los MAbs y NT 50 s de suero de los donantes correspondientes 17 (a), 36 (b), 39 (c) y 84 (d). Se utilizó la correlación de Spearman para los análisis estadísticos. Solo se incluyeron los virus neutralizados por el MAb (CI50 < 50 pg/ml) o el suero (NT 50 > 100).
La Figura 38A-B es una serie de gráficos que muestran que PGT 141-145 se une preferentemente a trímeros expresados en la superficie celular. A) Unión de PGT 141-145 a gp120 monomérico y construcciones de gp140 trimerizadas artificialmente según lo determinado por ELISA. Los bNAbs b12 y PG9 se incluyen para comparación. OD, densidad óptica (absorbancia a 450 nm). B) Unión de PGT 141-145 a Env expresada en la superficie de las células 293T según lo determinado por citometría de flujo. Los bNAbs 2G12 y PG9 se incluyen para comparación.
La Figura 39A-B es una serie de gráficos que muestran que los mAbs PGT 141-145 se unen a epítopos que se superponen a los de PG9 y PG16. A) Los PGT 141-145 son sensibles a la mutación N160K y los PGT 141-144 no logran neutralizar los pseudovirus producidos en presencia de kifunensina. El bNAb 2G12 también se incluyó para comparación. B) PG9 compite con los PGT 141-145 para unirse a los trímeros de la superficie celular. El bNAb 2G12 se incluyó como control negativo.
La Figura 40A-B es una serie de gráficos que muestran los PGT 121, 122 y 123 en competencia con los oligodendros. A diferencia de los PGT 125, 126, 127, 128 y 130, la unión de los PGT 121, 122 y 123 a gp120 no podría competir con los dendrones A) Man4 o B) Man9.
La Figura 41 es una serie de gráficos que muestran la actividad de neutralización de los fragmentos Fab. Los fragmentos Fab de PGTs-125, 126, 127, 128, 130 y 131 se generaron mediante digestión con Lys-C y la actividad neutralizante se probó contra el VIH-1jr-csf usando una sola ronda de ensayo de replicación de pseudovirus.
La Figura 42A-B es una serie de gráficos que muestran que la combinación de dos o tres especificidades de anticuerpos es suficiente para cubrir una amplia gama de aislados de VIH a la concentración alcanzable de la vacuna. Distribución de frecuencia acumulativa de los valores de CI50 de las combinaciones dobles (a) y triples (b) de actividades de neutralización (CI50 más baja en general contra cada aislamiento). El área gris representa la actividad teórica de neutralización máxima alcanzable conocida hasta la fecha.
La Figura 43A-C es una serie de gráficos que muestran que las combinaciones de dos o tres especificidades de anticuerpos son suficientes para cubrir una amplia gama de aislados de VIH a concentraciones alcanzables de vacuna. Distribución de frecuencia acumulativa de CA de los valores de CI50 de MAbs individuales (líneas continuas) y actividad de neutralización combinada (CI50 más baja general contra cada aislamiento) de dos o tres MAbs (líneas discontinuas). El área gris es la actividad de neutralización combinada de 25 MAbs probados en el panel de virus 162 (b12, 2G12, 4E10, 2F5, PG9, PG16, PGC14, PGV04, PGT 121-123, PGT 125-128, PGT 130-131, PGT 135-137, PGT 141-145) y representa la actividad teórica de neutralización máxima alcanzable conocida hasta la fecha. VRC01 y PGV04 en el panel c se miden en un panel de virus diferente (n = 97).
La Figura 44A-M es una serie de gráficos que representan el porcentaje de virus cubiertos por MAbs individuales (líneas continuas) o por al menos uno de los MAbs en combinaciones duales (líneas negras discontinuas) que dependen de las concentraciones individuales. El área gris en todos los paneles es la
cobertura de 26 MAbs probados en el panel de virus 162 (PGT121-123, PGT125-128, PGT130-131, PGT135-137, PGT141-145, PG9, PG16, PGC14, VRC01, PGV04, b12, 2G12, 4E10, 2F5) y representa la cobertura teórica máxima alcanzable conocida hasta la fecha.
Como la presente invención proporciona específicamente el anticuerpo monoclonal anti-VIH humano 4876_M06 (PGT-134) que tiene una región variable de cadena pesada o más bien una cadena pesada variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 435 y una región variable de cadena ligera o más bien una cadena ligera variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 440, solo las figuras que muestran PGT-134 o más bien sus secuencias de aminoácidos de región variable de cadena pesada y/o ligera son relevantes y se refieren a realizaciones de la presente invención.
DESCRIPCIÓN DETALLADA DE LA INVENCIÓN
En los sueros de pacientes infectados con el virus de inmunodeficiencia humana tipo 1 (VIH-1), los anticuerpos antivirus pueden detectarse durante un cierto período después de la infección sin ninguna manifestación clínica del síndrome de inmunodeficiencia adquirida (SIDA). En este estado de respuesta inmune activa, se espera un alto número de células B específicas de antígeno en la circulación. Estas células B se utilizan como socios de fusión para la generación de anticuerpos monoclonales humanos contra el VIH. Una desventaja importante para encontrar una composición de vacuna adecuada para la prevención más confiable de individuos humanos de la infección por VIH-1 y/o para un tratamiento terapéutico más exitoso de pacientes infectados es la capacidad del virus VIH-1 para escapar de la captura de anticuerpos por variación genética, que con mucha frecuencia, los esfuerzos notables de los investigadores son casi inútiles. Dichos mutantes de escape pueden caracterizarse por un cambio de solo uno o varios de los aminoácidos dentro de uno de los determinantes antigénicos dirigidos del y pueden ocurrir, por ejemplo, como resultado de una mutación espontánea o inducida. Además de la variación genética, ciertas otras propiedades de la glicoproteína de la envoltura del VIH-1 dificultan la obtención de anticuerpos neutralizantes, lo que hace que la generación de anticuerpos no neutralizantes indeseables sea una preocupación importante (ver, Phogat SK y Wyatt TA, Curr Pharm Design 2007; 13 (2): 213-227).
El VIH-1 se encuentra entre los patógenos virales genéticamente más diversos. De las tres ramas principales del árbol filogenético del VIH-1, los grupos M (principal), N (nuevo) y O (atípico), los virus del grupo M son los más extendidos y representan más del 99% de las infecciones globales. Este grupo se divide actualmente en nueve subtipos genéticos distintos, o clados (A a K), basados en secuencias de longitud completa. Env es el gen VIH-1 más variable, con hasta un 35% de diversidad de secuencias entre clados, un 20% de diversidad de secuencias dentro de los clados y hasta un 10% de diversidad de secuencias en una sola persona infectada (Shankarappa, R. et al. 1999. J Virol. 73: 10489-10502). El Clado B es dominante en Europa, América y Australia. El clado C es común en el sur de África, China e India y actualmente infecta a más personas en todo el mundo que cualquier otro clado (McCutchan, FE. 2000. Comprender la diversidad genética del VIH-1. SIDA 14 (Supl. 3): S31-S44). Los clados A y D son prominentes en África central y oriental.
Los anticuerpos neutralizantes (NAbs) contra las proteínas de la envoltura viral (Env) proporcionan una defensa inmune adaptativa contra la exposición al virus de inmunodeficiencia humana tipo 1 (VIH-1) al bloquear la infección de las células susceptibles (Kwong PD et al., 2002. Nature 420: 678-682). La eficacia de las vacunas contra varios virus se ha atribuido a su capacidad para provocar NAbs. Sin embargo, a pesar de los enormes esfuerzos, ha habido un progreso limitado hacia un inmunógeno eficaz para el VIH-1. (Burton, Dr 2002. Nat. Rev. Immunol. 2: 706 713).
El VIH-1 ha evolucionado con una amplia gama de estrategias para evadir la neutralización mediada por anticuerpos. (Barouch, DH Nature 455, 613-619 (2008); Kwong, PD & Wilson, IA Nat Immunol 10, 573-578 (2009); Karlsson Hedestam, GB, y col. Nat Rev Microbiol 6, 143-155 (2008)). Sin embargo, los anticuerpos ampliamente neutralizantes (bNAbs) se desarrollan con el tiempo en una proporción de individuos infectados con VIH-1. (Leonidas Stamatatos, l M, Dennis R Burton y John Mascola. Nature Medicine (E-Pub: 14 de junio de 2009); PMID: 19525964.) Se ha aislado un puñado de anticuerpos monoclonales ampliamente neutralizantes de donantes infectados con clado B. (Burton, DR, y col. Science 266, 1024-1027 (1994); Trkola, A., y col. J Virol 69, 6609-6617 (1995); Stiegler, G., y col. AIDS Res Hum Retroviruses 17, 1757-1765 (2001)). Estos anticuerpos tienden a mostrar menos amplitud y potencia contra los virus B no clado, y reconocen los epítopos del virus que hasta ahora no han logrado generar respuestas ampliamente neutralizantes cuando se incorporan a una amplia gama de inmunógenos. (Phogat, S. y Wyatt, R. Curr Pharm Design 13, 213-227 (2007); Montero, M., van Houten, NE, Wang, X. y Scott, JK Microbiol Mol Biol Rev 72, 54-84, tabla de contenido (2008); Scanlan, CN, Offer, J., Zitzmann, N. & Dwek, RA Nature 446, 1038-1045 (2007)). A pesar de la enorme diversidad del virus de inmunodeficiencia humana (VIH), todos los virus de VIH conocidos hasta la fecha interactúan con los mismos receptores celulares (CD4 y/o un correceptor, CCR5 o CXCR4). La mayoría de los anticuerpos neutralizantes se unen a las regiones funcionales involucradas en las interacciones del receptor y la fusión de la membrana celular. Sin embargo, la gran mayoría de los anticuerpos neutralizantes aislados hasta la fecha no reconocen más de un clado, por lo que exhiben una eficacia protectora limitada in vitro o in vivo. (Ver Binley JM et al., 2004. J. Virol. 78 (23): 13232-13252). Los raros anticuerpos monoclonales humanos (mAb) ampliamente neutralizantes que se han aislado de donantes humanos infectados con clado B VIH se unen a
productos del gen env de VIH-1, gp120 y la proteína transmembrana gp41. (Parren, PW et al. 1999. AIDS 13: S137-S162). Sin embargo, una característica bien conocida de la glicoproteína de la envoltura del VIH-1 es su extrema variabilidad. Se ha reconocido que incluso los epítopos relativamente conservados en el VIH-1, como el sitio de unión a CD4, muestran cierta variabilidad entre diferentes aislamientos (Poignard, P., et al., Ann. Rev. Immunol. (2001) 19: 253- 274). Incluso se puede esperar que un anticuerpo dirigido a uno de estos sitios conservados sufra una amplitud reducida de reactividad a través de múltiples aislados diferentes.
Los pocos anticuerpos monoclonales de reactivos de clado cruzado conocidos hasta la fecha se han aislado mediante procesos que implican la generación de paneles de anticuerpos virales específicos a partir de linfocitos de sangre periférica (PBL) de individuos infectados por VIH, ya sea mediante visualización de fagos o mediante técnicas de inmortalización convencionales, tales como hibridoma o transformación del virus Epstein Barr, electrofusión y similares. Estos se seleccionan en función de la reactividad in vitro a las proteínas del VIH-1, seguido de pruebas de actividad de neutralización del VIH.
Se usó un sistema de expresión de superficie de fago de anticuerpo para aislar el Fab neutralizador de clado cruzado (fragmento, unión a antígeno) b12 que se produce en una biblioteca combinatoria. El Fab b12 se cribó seleccionando la actividad de unión a la glicoproteína gp120 de la envoltura y se observó actividad neutralizante contra el aislado de VIH-1 (HXBc2). (Roben P et al., J. Virol. 68 (8): 4821-4828 (1994); Barbas CF et al., Proc. Natl. Acad. Sci. EE.UU. Vol. 89, pp. 9339-9343, (1992); Burton DP y col., Proc. Natl. Acad. Sci. EE.UU. Vol. 88, págs. 10134 10137 (1991)).
La inmortalización de células B humanas se utilizó para aislar los anticuerpos 2G12, 2F5, y 4E10 neutralizantes monoclonales de clado cruzado de individuos infectados por el VIH. El anticuerpo monoclonal 2G12 se une a un glucotope en la glicoproteína de la superficie gp120 del VIH-1 y se ha demostrado que muestra amplios patrones neutralizantes. (Trkola A., y col., J. Virol. 70 (2): 1100-1108 (1996), Buchacher, A., y col., 1994. AIDS Res. Hum. Retroviruses 10: 359-369). Se encontró que el anticuerpo monoclonal 2F5 que se había demostrado que se unía a una secuencia dentro del dominio externo de la glicoproteína de la envoltura gp41 del VIH-1 tenía amplias propiedades de neutralización. (Conley AJ Proc. Natl. Acad. Sci. EE.UU. Vol. 91, págs. 3348-3352 (1994); Muster T y col., J. Virol. 67 (11): 6642-6647 (1993); Buchacher A et al., 1992, Vaccines 92: 191-195). También se ha encontrado que el anticuerpo monoclonal 4E10, que se une a un nuevo epítopo C terminal de la secuencia ELDKWA en gp41 reconocido por 2F5, también tiene una actividad de neutralización potente de clado cruzado. (Buchacher, A., et al., 1994. AIDS Res. Hum. Retroviruses 10: 359-369; Stiegler, G., et al., 2001. AIDS Res. Hum. Retroviruses 17 (18): 1757-1765)).
Otros estudios sobre la neutralización de anticuerpos del VIH-1 (Nara, PL, et al. (1991) FASEB J. 5: 2437 2455.) se centraron en un único epítopo lineal en la tercera región hipervariable de la glicoproteína gp120 de la envoltura viral conocida como el bucle V3. Se sugiere neutralizar los anticuerpos contra este ciclo al inhibir la fusión de las membranas virales y celulares. Sin embargo, existe una variabilidad de secuencia dentro del bucle y los anticuerpos neutralizantes son sensibles a las variaciones de secuencia fuera del bucle (Albert J. et al., (1990) AIDS 4, 107-112). Por lo tanto, los anticuerpos de bucle anti-V3 a menudo son específicos de la cepa y las mutaciones en el bucle in vivo pueden proporcionar un mecanismo para el escape viral de la neutralización de anticuerpos. Hay alguna indicación de que no todos los anticuerpos neutralizantes actúan bloqueando la unión del virus, ya que varios anticuerpos monoclonales de ratón que inhiben la unión de CD4 a gp120 no son neutralizantes (Lasky LA, et al., (1987) Cell 50: 975- 985.) o solo débilmente neutralizantes (Sun N., et al., (1989) J. Virol. 63, 3579-3585).
Es ampliamente aceptado que dicha vacuna requerirá tanto la inmunidad mediada por células T como la provocación de una respuesta de anticuerpo ampliamente neutralizante (bNAb). (Barouch, d H Nature 455, 613-619 (2008); Walker, BD y Burton, DR Science 320, 760-764 (2008); Johnston, MI y Fauci, AS N Engl J Med 356, 2073 2081 (2007)) Todos los bNAbs conocidos brindan protección en los mejores modelos de primates disponibles (Veazey, RS, et al. Nat Med 9, 343-346 (2003); Hessell, AJ, et al. PLoS Pathog 5, e1000433 (2009); Parren, PW, et al. J Virol 75, 8340-8347 (2001); Mascola, JR Vaccine 20, 1922-1925 (2002); Mascola, JR, et al. Nat Med 6, 207-210 (2000); Mascola, JR y col., J. Virol 73, 4009-4018 (1999)). Por lo tanto, los anticuerpos ampliamente neutralizantes (bNAbs) se consideran los tipos de anticuerpos que una vacuna debería provocar. Desafortunadamente, los inmunógenos existentes, a menudo diseñados en base a estos bNAbs, no han logrado obtener respuestas NAb de la amplitud y potencia requeridas. Por lo tanto, es de alta prioridad identificar nuevos bNAbs que se unan a epítopos que puedan ser más susceptibles de incorporación en inmunógenos para obtener respuestas de NAb.
Walker, LM y col., Science Express, 3 de septiembre de 2009, describen anticuerpos ampliamente neutralizantes, que se desarrollan con el tiempo en algunos individuos infectados con VIH-1 y que se dirigen a los bucles V2 y V3 de gp120. Se les ha denominado PG9 y PG16. Pejchal, R. PNAS 107, 11483-11488 (2010) se refieren a la estructura y función del anticuerpo PG16 ampliamente reactivo, en donde la estructura cristalina revela que este anticuerpo específico del trímero Env VIH-1 posee una estructura de subdominio H3 de cabeza de martillo única que está compuesta de características inusuales en comparación con cualquier otro anticuerpo conocido: un tallo estable que media la extensa protuberancia de H3 desde el sitio de combinación y dos bucles interconectados, en donde uno de los cuales varía entre PG9 y PG16 y parece conferir especificidad fina. La presente solicitud, sin embargo,
proporciona un método novedoso para aislar nuevos anticuerpos monoclonales neutralizantes amplios y potentes contra el VIH. El método implica la selección de un donante de PBMC con un alto título de neutralización de anticuerpos en el plasma. Las células B se seleccionan para la actividad de neutralización antes del rescate de anticuerpos. Se obtienen nuevos anticuerpos ampliamente neutralizantes enfatizando la neutralización como el cribado inicial. Más específicamente, la presente invención se refiere al anticuerpo monoclonal humano anti-VIH 4876_M06 (PGT-134) que tiene una cadena pesada variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 435 y una cadena ligera variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 440..
La solicitud se refiere a un anticuerpo potente y ampliamente neutralizante (bNAb) en donde el anticuerpo neutraliza las especies de VIH-1 que pertenecen a dos o más clados, y además en donde la potencia de neutralización de al menos un miembro de cada clado está determinada por un valor CI50 de menos de 0,2 pg/mL. En algunos aspectos, los clados se seleccionan de Clado A, Clado B, Clado C, Clado D y Clado AE. En algunos aspectos, el VIH-1 que pertenece a dos o más clados no son virus Clado B. En algunos aspectos, el anticuerpo ampliamente neutralizante neutraliza al menos el 60% de las cepas de VIH-1 enumeradas en las Tablas 18A-18F. En algunas realizaciones, al menos el 70%, o al menos el 80%, o al menos el 90% de las cepas de VIH-1 enumeradas en las Tablas 18A-18F están neutralizadas.
La solicitud se refiere a anticuerpo potente ampliamente neutralizante (bNAb) en donde el anticuerpo neutraliza especie VIH-1 con una potencia de neutralización de al menos una pluralidad de especies VIH-1 con un valor de CI50 de menos de 0,2 pg/ml. En algunas realizaciones, la potencia de neutralización de las especies de VIH-1 tiene un valor de CI50 de menos de 0,15 pg/ml, o menos de 0,10 pg/ml, o menos de 0,05 pg/ml. En algunos aspectos, un anticuerpo potente y ampliamente neutralizante se define como un bNAb que muestra una potencia de neutralización de al menos una pluralidad de especies de VIH-1 con un valor de CI90 de menos de 2,0 pg/ml. En algunas realizaciones, la potencia de neutralización de las especies de VIH-1 tiene un valor CI90 de menos de 1,0 pg/ml, o menos de 0,5 pg/ml.
Se ilustra un método ejemplar en el esquema que se muestra en la Figura 4. Se obtuvieron células mononucleares de sangre periférica (PBMC) de un donante infectado con VIH seleccionado para la actividad neutralizante del VIH-1 en el plasma. Las células B de memoria se aislaron y los sobrenadantes de cultivo de células B se sometieron a una prueba primaria de ensayo de neutralización en un formato de alto rendimiento. Opcionalmente, los ensayos de unión al antígeno del VIH usando ELISA o métodos similares también se usaron como una pantalla. Los lisados de células B correspondientes a los sobrenadantes que exhiben actividad neutralizante se seleccionaron para el rescate de anticuerpos monoclonales por métodos recombinantes estándar.
En un aspecto, el rescate recombinante de los anticuerpos monoclonales implica el uso de un sistema de cultivo de células B como se describe en Weitcamp J-H y col., J. Immunol. 171: 4680-4688 (2003). También puede emplearse cualquier otro método para el rescate de clones de células B individuales conocido en la técnica, tal como la inmortalización de células B con EBV (Traggiai E., y col., Nat. Med. 10 (8): 871-875 (2004)), electrofusión (Buchacher, A., et al., 1994. AIDS Res. Hum. Retroviruses 10: 359-369), e hibridoma de células B (Karpas.. A. et al, Proc Natl Acad Sci EE.UU. 98: 1799-1804 (2001).
En algunos aspectos, los anticuerpos monoclonales fueron rescatados de los cultivos de células B utilizando RT-PCR específico a gen de cadena variable, y transfectante con combinaciones de clones de la cadena H y L se seleccionaron nuevamente para neutralizar y actividades de unión al antígeno del VIH. Se seleccionaron mAb con propiedades de neutralización para caracterización adicional.
Se usó una nueva estrategia de alto rendimiento para seleccionar sobrenadantes de selección de cultivo que contienen IgG de aproximadamente 30.000 células B de memoria activadas de un donante infectado con clado A para la unión recombinante, monomérica de gp120JR-CSF y gp41HxB2 (Env) así como la actividad de neutralización contra VIH-1JR-CSF y VIH-1SF162 (ver Tabla 1).
Tabla 1: Evaluación de la celda B de memoria.

Inesperadamente, una gran proporción de los sobrenadantes de células B que neutralizaron VIH-1JR-CSF no se unieron a gp120JR-CSF o gp41HxB2 monoméricos, y solo hubo un número limitado de cultivos que neutralizaron ambos virus (Fig. 3B). Los genes de anticuerpos se rescataron de cinco cultivos de células B seleccionados para diferentes perfiles funcionales; uno unido a gp120 y solo neutralizado VIH-1SF162, dos unidos a gp120 y débilmente
neutralizado a ambos virus, y dos VIH-1JR-CSF potentemente neutralizados, no pudieron neutralizar VIH-1SF162 y no se unieron a gp120 o gp41 monoméricos. Cinco anticuerpos identificados de acuerdo con estos métodos se describen en este documento. Los anticuerpos se aislaron de una muestra humana obtenida a través del Protocolo G de la Iniciativa Internacional de Vacuna contra el SIDA (IAVI), y son producidos por los cultivos de células B denominados 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489 _I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT- 131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157) y 6881_N05 (PGT-158). Anticuerpos denominados 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489_I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157) y 6881_N05 (PGT-158), se aislaron de los correspondientes cultivos de células B. Se ha demostrado que estos anticuerpos neutralizan el VIH in vitro. Más específicamente, la invención se refiere al anticuerpo ampliamente neutralizante (bNAb) 4869_K15 (PGT-133).
El análisis de los genes variables de anticuerpos reveló que dos pares de anticuerpos estaban relacionados por hipermutación somática y que dos de las variantes somáticas contenían bucles CDRH3 inusualmente largos (Tabla 2). Los bucles largos de CDRH3 se han asociado previamente con polirreactividad. (Ichiyoshi, Y. y Casali, P. J Exp Med 180, 885-895 (1994)). Los anticuerpos se probaron contra un panel de antígenos y se confirmó que los anticuerpos no eran polirreactivos.
Tabla 2: Análisis de secuencia de genes variables de mAb
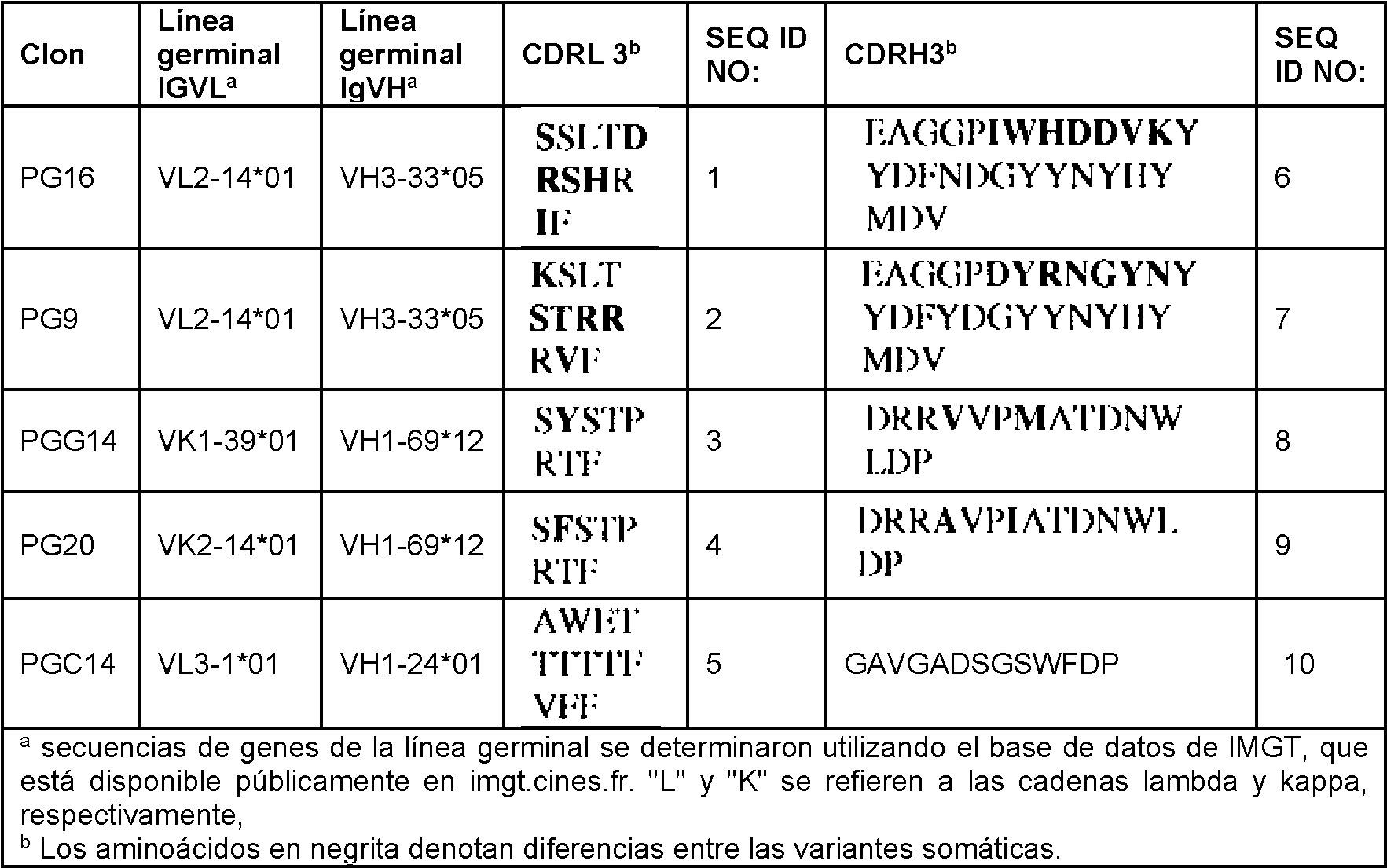

Tabla 3B. Resumen del uso del gen de la cadena ligera

Los anticuerpos ampliamente neutralizantes de los clones 1443_C16 (PG16) y 1496_C09 (PG9) obtenidos por este método no exhibieron unión gp120 o gp41 soluble a niveles que correlacionan con la actividad de neutralización. El método de la aplicación, por lo tanto, permite la identificación de nuevos anticuerpos con amplias propiedades de neutralización de clado cruzado independientemente de las actividades de unión en un cribado ELISA. En el presente documento se describe una caracterización adicional de PG16 y PG9.
Los cinco anticuerpos se probaron primero para determinar la actividad de neutralización frente a un panel de 16 pseudovirus de múltiples clados (Tabla 4). Dos de los anticuerpos que se unieron a gp120 monomérico en el cribado inicial (PGG14 y p G20) no mostraron amplitud o potencia de neutralización sustancial contra ninguno de los virus probados, y el tercer anticuerpo que se unió a gp120 (PGC14) neutralizó 4/16 virus con grados variables de potencia. Por el contrario, los dos anticuerpos que no lograron unirse a Env recombinante en el cribado inicial (PG9 y PG16) neutralizaron una gran proporción de los virus a concentraciones de sub microgramos por ml. PG9 y PG16 neutralizaron virus B no clado con mayor amplitud que tres de los cuatro bNAbs existentes. Esto es significativo teniendo en cuenta que la mayoría de las personas infectadas por VIH-1 en todo el mundo están infectadas con virus no clado B.
Tabla 4: Perfiles de neutralización de mAbs rescatados

a Nivel observado en curva
La Tabla 17A muestra los perfiles de neutralización (valores CI50) de anticuerpos monoclonales 1443_C16 (PG16) 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14) y 1496_C09 (PG9) y los conocidos anticuerpos neutralizantes de clado cruzado b12, 2G12, 2F5 y 4E10 en un panel diverso de 16 pseudovirus VIH de diferentes clados. 1443_C16 (PG16) y 1496_C09 (PG9) neutralizan las especies VIH-1 de los Clados A, B, C, D y CRF01_AE con mayor potencia para la mayoría de las cepas virales probadas que los anticuerpos neutralizantes amplios y potentes conocidos y generalmente aceptados. Sin embargo, los perfiles de neutralización de especies individuales de VIH-1 que pertenecen a estos clados varían entre 1443_C16 (PG16) y 1496_C09 (PG9) y los conocidos anticuerpos neutralizantes de clado cruzado b12, 2G12, 2F5 y 4E10. 1495_C14 (PGC14) neutraliza menos especies de VIH-1 de los Clados A, B y C comparables a otros anticuerpos neutralizantes. La Tabla 17B muestra los valores de CI90 de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) y los conocidos anticuerpos neutralizantes de clado cruzado b12, 2G12, 2F5 y 4E10 en el mismo panel de pseudovirus. La Figura 4 muestra las actividades de neutralización de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) contra otros seis pseudovirus del VIH (YU2, Bal, ADA, DU172, DU422 y ZM197) para los clados B y C no incluidos en las Tablas 17A y 17B.
PG9, PG16 y PGC14 se evaluaron a continuación en un panel grande de pseudovirus de múltiples clados que consta de 162 virus para evaluar adicionalmente la amplitud de neutralización y la potencia de estos tres anticuerpos (Tablas 5A-5B, Tablas 18A-18F y Tablas 19A-19B). Los bNAbs b12, 2G12, 2F5 y 4e 10, así como el suero del donante, también se incluyeron en el panel para comparación. En general, PG9 neutralizó 127 de 162 y PG16 neutralizó 119 de 162 virus con una potencia que frecuentemente excedía considerablemente la observada para los cuatro bNAbs de control.
Los valores medianos CI50 y el CI90 para los virus neutralizados a través de todos los clados eran un orden de magnitud inferior para PG9 y PG16 que cualquiera de los cuatro anticuerpos ampliamente neutralizantes existentes (Tabla 5A, las Tablas 18A-18F y en las Tablas 19A-19B). Ambos mAbs mostraron una amplitud de neutralización mayor en general que b12, 2G12 y 2F5 (Tabla 5B, Tablas 18A-18F y Tablas 19A-19B). A bajas concentraciones de anticuerpos, PG9 y PG16 también demostraron una mayor amplitud de neutralización que 4E10 (Tabla 5B). Además, ambos mAb neutralizaron potentemente un virus (IAVI-C18) que exhibe resistencia a los cuatro bNAbs existentes (Tablas 18A-18F). Las curvas de neutralización de mAb revelan que, mientras que las curvas de neutralización de PG9 generalmente exhiben pendientes pronunciadas, las curvas de neutralización para PG16 a veces exhiben pendientes graduales o mesetas con menos del 100% de neutralización. Aunque anteriormente se han informado curvas de neutralización con perfiles similares (WJ Honnen et al., J Virol 81, 1424 (febrero de 2007), A. Pinter et al., J Virol 79, 6909 (junio de 2005)), el mecanismo para esto no se entiende bien.
La comparación del perfil de neutralización del suero con el perfil de neutralización de PG9, PG16 y PGC14 reveló que estos tres anticuerpos podrían recapitular la amplitud de la neutralización del suero en la mayoría de los casos (Tablas 18A-18F). Por ejemplo, casi todos los virus que fueron neutralizados por el suero con un CI50 > 1: 500 fueron neutralizados por PG9 y/o PG16 a <0,05 pg/mL. El único caso en que esto no ocurrió fue contra el VIH-1SF162, pero este virus fue neutralizado por PGC14. A pesar de que PG9 y PG16 son variantes somáticas, exhibieron diferentes grados de potencia contra varios de los virus probados. Por ejemplo, PG9 neutralizó el VIH-16535,30 aproximadamente 185 veces más potente que PG16, y p G16 neutralizó el VIH-1MGRM-AG-001 aproximadamente 440 veces más potente que PG9. En algunos casos, los dos anticuerpos también diferían en la amplitud de neutralización; p G9 neutralizó nueve virus que no fueron afectados por PG16, y PG16 neutralizó dos virus que no fueron afectados por PG9. En base a estos resultados, se postula que la neutralización sérica amplia podría estar
mediada por variantes de anticuerpos somáticos que reconocen ligeramente diferentes epítopos y muestran diversos grados de amplitud y potencia de neutralización. contra cualquier virus dado. Ante una respuesta viral en evolución, parece razonable que el sistema inmunitario pueda seleccionar estos tipos de anticuerpos.
La comparación del perfil de neutralización del suero con el perfil de neutralización de PG9, PG16 y PGC14 reveló que estos tres anticuerpos podrían recapitular la amplitud de la neutralización del suero en la mayoría de los casos. Por ejemplo, casi todos los virus que fueron neutralizados por el suero con un CI50 > 1:1000 fueron neutralizados por PG9 y/o PG16 a <0,005 pg/mL. El único caso en que esto no ocurrió fue contra el VIH-1SF162, pero este virus fue neutralizado por PGC14. Las tablas 5 (a) y 5 (b) muestran las actividades de neutralización (amplitud y potencia, respectivamente) de PG9, PG16 y PGC14, así como cuatro bNAbs de control medidos por los valores de CI50. Las tablas 19A-19B muestran los resultados del mismo análisis utilizando valores CI90.
Tabla 5(A) Potencia de neutralización de mAbs

Las cajas se codifican por colores de la siguiente manera: blanco, potencia mediana >50 pg/mL; gris ligero, potencia mediana entre 2 y 20 pg/mL; gris mediano, potencia mediana entre 0,2 y 2 pg/mL; gris oscuro, potencia mediana <0,2 pg/mL.
Virus CRF_07BC y CRF_08BC no están incluidos en el análisis de clado porque solo se probó un virus de cada uno de los clados.
Tabla 5(B) Ancho de neutralización de mAbs

Las cajas se codifican por colores de la siguiente manera: blanco, ningún virus neutralizado; negro, 1 a 30% de virus neutralizado; gris ligero, 30 a 60% de virus neutralizado; gris medio, 60 a 90% de virus neutralizado; gris oscuro, 90 a 100% de virus neutralizado.
Virus CRF_07BC y CRF_08BC no están incluidos en el análisis de clado porque solo se probó un virus de cada uno de los clados.
A pesar del hecho de que PG9 y PG16 son variantes somáticas, exhibieron diferentes grados de potencia contra varios virus probados. Por ejemplo, PG9 neutralizó el virus 6535,30 aproximadamente 100 veces más potente que PG16, y PG16 neutralizó el virus MGRM-AG-001 aproximadamente 3000 veces más potente que PG9. En algunos casos, los dos anticuerpos también diferían en la amplitud de neutralización; PG9 neutralizó siete virus que no fueron neutralizados por PG16, y PG16 neutralizó tres virus que no fueron neutralizados por PG9. Sin estar limitado por la teoría, parece que la neutralización sérica amplia podría estar mediada por variantes somáticas que reconocen epítopos ligeramente diferentes y muestran grados variables de amplitud y potencia de neutralización contra cualquier virus dado. Ante una respuesta viral en evolución, es probable que el sistema inmunitario seleccione estos tipos de anticuerpos.
También se probó la capacidad de los anticuerpos para unirse a proteínas de envoltura de VIH recombinantes solubles. La Figura 5 muestra las curvas de respuesta a la dosis de 1456_P20 (PG20), 1495_C14 (PGC14) y 1460_G14 (PGG14) que se unen a gp120 recombinante en ELISA en comparación con el control anti-gp120 (b12). La Figura 6 muestra los ensayos de unión a ELISA de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) contra la cepa YU2 gp140 y JR-CSF gp120 del VIH-1, la región proximal de la membrana (MPER) de la glicoproteína gp41 de la envoltura del VIH-1 y el polipéptido V3. PG-9 se une a YU2 gp140 (CI50 ~ 20-40 nM), YU2 gp120 y se une débilmente a JR-CSF gp120. Sin embargo, PG16 se une débilmente a Yu2 gp120, pero no a la forma soluble de la glicoproteína de la envoltura del VIH-1, gp120 JR-CSF. Ninguno de los mAb se une a JR-FL gp120, JR-FL gp140, péptido MPER de gp41 o péptido V3.
La Figura 7 muestra la unión de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) al VIH-1 YU2 gp160 expresado en la superficie celular en presencia y ausencia de sCD4. La inhibición competitiva de la unión
por sCD4 indica que la unión del anticuerpo monoclonal 1496_C09 a la proteína de envoltura del VIH-1 gp160 expresada en la superficie celular se ve presumiblemente afectada debido a los cambios conformacionales inducidos por sCD4. Los datos sugieren además que 1443_C16 (PG16) y 1496_C09 (PG9) exhiben una unión relativamente más fuerte a las formas triméricas del Env de VIH-1 (gp160 y gp140) que a la gp120 monomérica.
La Figura 8 muestra la unión de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) a las células transfectadas por VIH-1. PG9 y PG16 no se unen a células no transfectadas. PG9 y PG16 se unen a células transfectadas con JR-CSF, ADA y YU2 gp160. PG9 y PG16 no se unen a células transfectadas con JR-FL gp160 (escindidas o sin escindir). PG9 y PG16 no se unen a las células transfectadas con ADA AV1/AV2. La unión de PG9 y PG16 a células transfectadas con gp160 de JR-CSF es inhibida por sCD4.
La Figura 9 muestra la captura del pseudovirus JR-CSF competente para la entrada neutralizando los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) de una manera dependiente de la dosis. La capacidad de ambos anticuerpos para capturar el pseudovirus JR-CSF es mayor que IgG b12 pero comparable a IgG 2G12. Se postula que la captura puede estar mediada por la unión de los mAbs al Env de VIH-1 en los viriones.
La Figura 10A muestra que sCD4, PG16 y PG9 compiten por la unión del anticuerpo monoclonal 1443_C16 (PG16) al pseudovirus JR-CSF, pero b12, 2G12, 2F5 y 4E10 no. La Figura 10B muestra que sCD4, PG16 y PG9 compiten por la unión del anticuerpo monoclonal 1496_C09 (PG9) al pseudovirus JR-CSF, pero b12, 2G12, 2F5 y 4E10 no. Esto sugiere que los mAbs PG16 y PG9 se unen a gp120 en un sitio diferente de los unidos por b12 y 2G12. La unión de PG9 y PG16 a la proteína de envoltura del VIH-1 se inhibe competitivamente por sCD4. Dado que los MAb no están inhibidos por el sitio de unión a CD4 MAb b12, esto sugiere que PG9 y PG16 se están uniendo a un epítopo que no está disponible para la unión de sCD4 a gp120 como resultado de cambios conformacionales. La incapacidad de PG9 y PG16 para unirse a gp120JRCSF o gp41HxB2 monoméricos en la pantalla inicial mientras se neutraliza el VIH-1JR-CSF sugiere que el epítopo dirigido por estos anticuerpos se expresa preferentemente en la proteína de envoltura de VIH trimérica. Se comparó la capacidad de PG9 y PG16 para unir gp120 monomérico de varias cepas diferentes, construcciones de gp140 trimerizadas artificialmente y Env trimérico expresado en la superficie de células transfectadas, respectivamente. Aunque ambos anticuerpos se unieron con alta afinidad al Env de la superficie celular, PG16 no se unió a ninguna de las construcciones solubles de gp120 o gp140 y PG9 se unió solo débilmente a gp120 monomérico y gp140 trimerizado de ciertas cepas (Fig. 11). Se ha demostrado previamente que una fracción sustancial de Env de la superficie celular está compuesta de moléculas de gp160 sin escindir. (Pancera, M. y Wyatt, R. Virology 332, 145-156 (2005)). El hecho de que ambos anticuerpos unidos con alta afinidad a los trímeros de VIH-1YU2 defectuosos de escisión se expresaron en la superficie de las células transfectadas (Figura 12) confirmó que PG9 y PG16 no exhiben una especificidad exclusiva para los trímeros de VIH-1 nativos.
Se investigaron los epítopos reconocidos por PG9 y PG16. Como los anticuerpos PG9 y PG16 son variantes somáticas, reconocen los mismos epítopos o superpuestos. Ambos anticuerpos compitieron de forma cruzada para unirse a las células transfectadas por VIH-1JR-CSF (Fig. 13A). La ligadura de gp120 monomérico o Env de superficie celular con CD4 soluble disminuyó la unión de PG9 y PG16, aunque ninguno de los anticuerpos compitió con los anticuerpos del sitio de unión de CD4 por la unión del trímero (Fig. 13a - 13C). Este resultado sugiere que los cambios conformacionales inducidos por CD4 causan una pérdida del epítopo dirigido por los anticuerpos.
Dado que PG9 se unió lo suficientemente bien a gp120 de ciertos aislamientos para generar curvas de unión a ELISA, los ELISA de competición se realizaron con PG9 usando un panel de anticuerpos neutralizantes y no neutralizantes. Estos datos revelaron que PG9 compitió en forma cruzada con anticuerpos anti-V2, anti-V3 y, en menor medida, CD4i para gp120. (Figuras 13D y 14).
Ni PG9 ni PG16 unidos a V1/V2 o V3 eliminaron las variantes de VIH-1JR-CSF expresadas en la superficie de las células transfectadas, sugiriendo además contribuciones de bucles variables en la formación de sus epítopos (Fig. 13E).
Para diseccionar la especificidad fina de PG9 y PG16, el escaneo de alanina se realizó usando un panel grande de mutantes de alanina Env de VIH -1JR-CSF que se han descrito previamente (Pantophlet, R., et al. J Virol 77, 642- 658 (2003); Pantophlet, R., et al. J Virol 83, 1649-1659 (2009); Darbha, R., et al. Biochemistry 43, 1410-1417 (2004); Scanlan, CN, et al. J Virol 76, 7306-7321 (2002)), así como varios mutantes nuevos de alanina. Se generaron pseudovirus que incorporan mutaciones de alanina Env únicas, y se analizó la actividad de neutralización de PG9 y PG16 contra cada pseudovirus mutante. Las mutaciones que dieron como resultado un escape viral de la neutralización de PG9 y PG16 se consideraron importantes para la formación de los epítopos PG9 y PG16 (tablas 12 y 13).
En base a estos criterios, y de acuerdo con los experimentos de competición, los residuos que forman los epítopos reconocidos por PG9 y p G16 parecen estar ubicados en regiones conservadas de los bucles V2 y V3 de gp120. Ciertas mutaciones del sitio de unión del coreceptor también tuvieron un efecto sobre la neutralización de PG9 y PG16, aunque en menor medida. En general, PG9 y PG16 dependían de los mismos residuos, aunque PG16 era más sensible a las mutaciones ubicadas en la punta del bucle V3 que PG9. Curiosamente, aunque ninguno de los
anticuerpos se unió a las células transfectadas de VIH-1JR-FL de tipo silvestre, una mutación D a K en la posición 168 en el bucle V2 del VIH-1JR-FL generó reconocimiento de PG9 y PG16 de alta afinidad (Tablas 18A-18F). N156 y N160, sitios de V2 N-glucosilación, también parecen ser críticos en la formación del epítopo ya que las sustituciones en estas posiciones dieron como resultado el escape de la neutralización de PG9 y p G16. La desglicosilación de gp120 abolió la unión de PG9 (Fig. 16), confirmando que ciertos glicanos pueden ser importantes en la formación del epítopo.
El VIH-1 SF162 contiene un raro polimorfismo N a K en la posición 160, y la mutación de este residuo a un Asn hace que este aislado sea sensible a PG9 y PG16 (Fig. 17).
La unión de PG9 y PG16 a trímeros nativos o bien podría ser una consecuencia de gp120 preferencial subunidad de reticulación o el reconocimiento de una conformación gp120 oligomérica preferido. Para abordar esta pregunta, se examinaron los perfiles de unión de PG9 y PG16 a trímeros de VIH-1YU2 mixtos, en los que dos subunidades gp120 que contenían mutaciones puntuales abolieron la unión de los dos anticuerpos. Una tercera sustitución que anula la unión de 2G12, que se une con alta afinidad tanto a la gp120 monomérica como a la env trimérica, también se introdujo en la misma construcción como control interno. El análisis de unión a la superficie celular reveló que los tres anticuerpos se unieron a los trímeros mixtos con una afinidad aparente similar a los trímeros de tipo silvestre y todos saturados a un nivel inferior similar (Fig. 18). Este resultado sugiere que la preferencia de PG9 y p G16 por Env trimérico se debe a la presentación de la subunidad gp120 en el contexto de la espiga trimérica en lugar de la reticulación gp120.
Se ha demostrado que los NAb que se unen a epítopos que abarcan partes del V2 o los dominios V2 y V3 pueden exhibir una potencia comparable a la de PG9 y PG16, aunque estos anticuerpos hasta ahora han mostrado una fuerte especificidad de cepa. (Honnen, WJ, y col. J Virol 81, 1424-1432 (2007); Gorny, MK, y col. J Virol 79, 5232 5237 (2005)). Es importante destacar que los epítopos reconocidos por estos anticuerpos han demostrado diferir de los de la secuencia consenso clado B solo por sustituciones de aminoácidos individuales, lo que sugiere la existencia de una estructura relativamente conservada dentro del dominio V2. (Honnen, WJ, et al. J Virol 81, 1424-1432 (2007)). Los resultados observados con PG9 y PG16 confirman que esta región sirve como un objetivo de neutralización potente y demuestra que los anticuerpos que reconocen partes conservadas de V2 y V3 pueden poseer una amplia reactividad.
La aplicación se basa en nuevos anticuerpos monoclonales y fragmentos de anticuerpos que neutralizan de forma amplia y potente la infección por VIH. En algunos aspectos, estos anticuerpos monoclonales y fragmentos de anticuerpos tienen una potencia particularmente alta para neutralizar la infección por VIH in vitro en múltiples clados o en un gran número de especies diferentes de VIH. Tales anticuerpos son deseables, ya que solo se requieren bajas concentraciones para neutralizar una cantidad dada de virus. Esto facilita mayores niveles de protección mientras se administran menores cantidades de anticuerpos. Los anticuerpos monoclonales humanos y los clones de células B inmortalizados que secretan tales anticuerpos se describen en el presente documento.
La solicitud proporciona métodos para usar el cribado funcional de alto rendimiento para seleccionar anticuerpos neutralizantes con una amplitud y potencia sin precedentes. La aplicación se refiere a otros anticuerpos potentes y ampliamente neutralizantes que pueden desarrollarse utilizando los mismos métodos. En particular, la solicitud se refiere a anticuerpos potentes y ampliamente neutralizantes contra diferentes cepas de VIH, en donde los bNAbs se unen pobremente a formas recombinantes de Env. La solicitud proporciona dos anticuerpos neutralizantes, PG9 y PG16, con amplias actividades neutralizantes, particularmente contra aislados B no clados. La solicitud proporciona anticuerpos inducidos por vacunas de alta especificidad que brindan protección contra una amplia gama de los aislados más prevalentes de VIH que circulan en todo el mundo. La solicitud proporciona anticuerpos con una potencia de neutralización muy alta y amplia, como la exhibida por PG9 y PG16 in vitro, que proporciona protección a concentraciones séricas relativamente modestas, y se generan por vacunación a diferencia de los NAb amplios conocidos en la técnica. La solicitud proporciona inmunógenos que pueden diseñarse para enfocar la respuesta inmune en regiones conservadas de bucles variables en el contexto del pico trimérico de la subunidad gp120 de la proteína Env.
La solicitud también se refiere a la caracterización del epítopo al que los anticuerpos se unen y el uso de ese epítopo en el aumento de una respuesta inmune.
La solicitud también se refiere a varios métodos y usos que implican los anticuerpos de la invención y los epítopos a los que se unen. Por ejemplo, los anticuerpos monoclonales de acuerdo con la aplicación pueden usarse como agentes terapéuticos. En algunos aspectos, los anticuerpos monoclonales se usan para la terapia adyuvante. La terapia adyuvante se refiere al tratamiento con los anticuerpos monoclonales terapéuticos, en donde la terapia adyuvante se administra después del tratamiento primario para aumentar las posibilidades de cura o reducir el riesgo estadístico de recaída.
La solicitud proporciona nuevos anticuerpos monoclonales o recombinantes que tienen una potencia particularmente alta para neutralizar el VIH. La aplicación también proporciona fragmentos de estos anticuerpos
recombinantes o monoclonales, particularmente fragmentos que retienen la actividad de unión a antígeno de los anticuerpos, por ejemplo, que retienen al menos una región determinante de complementariedad (CDR) específica para proteínas de VIH. En esta especificación, por "alta potencia en la neutralización del VIH" se entiende que una molécula de anticuerpo de la aplicación neutraliza el VIH en un ensayo estándar a una concentración inferior a los anticuerpos conocidos en la técnica.
Preferiblemente, la molécula de anticuerpo de la presente solicitud pueden neutralizar a una concentración de 0,16 pg/ml o inferior (es decir, 0,15, 0,125, 0,1, 0,075, 0,05, 0,025, 0,02, 0,016, 0,015, 0,0125, 0,01, 0,0075, 0,005, 0,004 o inferior), preferiblemente 0,016 pg/ml o inferior (una concentración de anticuerpo de 10-8 o inferior, preferiblemente 10-9 M o inferior, preferiblemente 10-10 M o inferior, es decir, 10-11 M, 10-12 M, 10-13 M o menos). Esto significa que solo se requieren concentraciones muy bajas de anticuerpos para la neutralización del 50% de un aislado clínico de VIH in vitro. La potencia se puede medir usando un ensayo de neutralización estándar como se describe en la técnica.
Los anticuerpos de la aplicación son capaces de neutralizar el VIH. Los anticuerpos monoclonales se pueden producir mediante procedimientos conocidos, por ejemplo, según lo descrito por R. Kennet et al. en "Monoclonal Antibodies and Functional Cell Lines; Progress and Applications". Plenum Press (Nueva York), 1984. Otros materiales y métodos aplicados se basan en procedimientos conocidos, por ejemplo, tal como se describe en J. Virol. 67: 6642 6647, 1993.
Estos anticuerpos pueden usarse como agentes profilácticos o terapéuticos con la formulación apropiada, o como una herramienta de diagnóstico.
Un "anticuerpo neutralizante" es aquel que puede neutralizar la capacidad de ese patógeno para iniciar y/o perpetuar una infección en un huésped y/o en células diana in vitro. La invención proporciona un anticuerpo humano monoclonal neutralizante, en donde el anticuerpo reconoce un antígeno del VIH.
A modo de ejemplo, un anticuerpo de acuerdo con la solicitud es un anticuerpo monoclonal de la siguiente lista de anticuerpos, en donde la presente invención, sin embargo, se refiere únicamente al anticuerpo 4876_M06 (PGT-134). A los anticuerpos de la presente solicitud se hace referencia en la presente como 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489_I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127)), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT- 156), 6892_C23 (PGT-157) y 6881_N05 (PGT-158). Estos anticuerpos se aislaron inicialmente de muestras humanas y son producidos por los cultivos de células B denominados 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489_I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN- 109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122) , 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127)), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157) y 6881_N05 (PGT-158). Se ha demostrado que estos anticuerpos neutralizan el VIH in vitro.
1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489_I13 (PG16) (TCN -120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123) , 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT- 141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT- 154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157) y 6881_N05 (PGT-158) han demostrado tener una amplia y potente actividad neutralizadora del VIH.
Las CDR de las cadenas pesadas de anticuerpos se denominan CDRH1, CDRH2 y CDRH3, respectivamente. De manera similar, las CDR de las cadenas ligeras de anticuerpos se denominan CDRL1, CDRL2 y CDRL3, respectivamente. La posición de los aminoácidos CDR se define según el sistema de numeración IMGT como: CDR1--IMGT posiciones 27 a 38, CDR2--IMGT posiciones 56 a 65 y CDR3 -- IMGT posiciones 105 a 117. (Lefranc, M P. et
al. 2003 IMGT unique numbering for immunoglobulin and T cell receptor variable regions and Ig superfamily V-like domains. Dev Comp Immunol. 27 (1): 55-77; Lefranc, M P. 1997. Unique database numbering system for immunogenetic analysis. Immunology Today, 18: 509; Lefranc, M P. 1999. The IMGT unique numbering for Immunoglobulins, T cell receptors and Ig-like domains. The Immunologist, 7: 132-136.)
Las secuencias de aminoácidos de Las regiones CDR3 de las cadenas ligera y pesada de los anticuerpos se muestran en las Tablas 3A y 3B.
Un filograma es un diagrama de ramificación (árbol) que se supone que es una estimación de la filogenia, las longitudes de las ramas son proporcionales a la cantidad de cambio evolutivo inferido. Se prepararon diagramas de árbol de las cinco cadenas pesadas y las cinco cadenas ligeras usando ClustalW (Larkin m A, Blackshields G., Brown NP, Chenna R., McGettigan PA, McWilliam H., Valentin F., Wallace IM, Wilm A., Lopez R., Thompson JD, Gibson TJ y Higgins DG Bioinformatics 23 (21): 2947-2948 (2007); Higgins DG et al. Nucleic Acids Research 22: 4673-4680. (1994)) y se muestran en las Figuras 1A y 1B respectivamente.
Se determinaron las secuencias de los anticuerpos, incluyendo las secuencias de las regiones variables de las cadenas pesadas gamma y ligeras kappa o lambda de los anticuerpos designados 1496_C09 (PG9), 1443_C16 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14) y 1495_C14 (PGC14). Además, se determinó la secuencia de cada uno de los polinucleótidos que codifican las secuencias de anticuerpos. A continuación se muestran las secuencias de polipéptidos y polinucleótidos de las cadenas pesadas gamma y cadenas ligeras kappa, con los péptidos señal en el extremo N (o extremo 5') y las regiones constantes en el extremo C (o el extremo 3') de las regiones variables, que se muestran en texto en negrita.
Secuencia de nucleótidos de cadena pesada gamma 1443_C16 (PG16) (TCN-116): secuencia de codificación 1443 C16 y3 (región variable en negrita)
ATGGAGTTTGGGCTGAGCTGGGTTTTCCTCGCAACTCTGTTAAGAGTTGTG AAGTGTCAGGAACAACTGGTGGAGTCTGGGGGAGGCGTGGTCCAGCC GGGGGGGTCCCTGAGACTCTCCTGTTTAGCGTCTGGATTCACGTTTC ACAAATATGGCATGCACTGGGTCCGCCAGGCTCCAGGCAAGGGCCTG GAGTGGGTGGCACTCATCTCAGATGACGGAATGAGGAAATATCATTC AGACTCCATGTGGGGCCGAGTCACCATCTCCAGAGACAATTCCAAGA
ACACTCTTTATCTGCAATTCAGCAGCCTGAAAGTCGAAGACACGGCT ATGTTCTTCTGTGCGAGAGAGGCTGGTGGGCCAATCTGGCATGACGA CGTC A AAT ATT ACG ATTTT AATG ACGGCT ACT AC AACT ACC ACT AC AT GGACGTCTGGGGCAAGGGGACCACGGTCACCGTCTCGAGCGCCTCCA CCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCT GGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACC GGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCT TCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGA CCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAAT CACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGG GGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGAT CTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAG ACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAAT GCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGG TCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTAC AAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCAT CTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCC CCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGT CAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGG CAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACG GCTCCTTCTTCCTCT AT AGC A AGCTC ACCGTGGAC A AGAGC AGGTGGC AG CAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCA CTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA (SEQ ID NO: 11)
1443_C16 (PG16) (TCN-116) secuencia de nucleótidos de región variable de cadena pesada gamma:
CAGGAACAACTGGTGGAGTCTGGGGGAGGCGTGGTCCAGCCGGGGGGGT
CCCTGAGACTCTCCTGTITAGCGTCTGGATTCACGTITCACAAATATGGCA
TGCACTGGGTCCGCCAGGCTCCAGGCAAGGGCCTGGAGTGGGTGGCACTC
ATCTCAGATGACGGAATGAGGAAATATCATTCAGACTCCATGTGGGGCCG
AGTCACCATCTCCAGAGACAATTCCAAGAACACTCTTTATCTGCAATTCA
GCAGCCTGAAAGTCGAAGACACGGCTATGTTCTTCTGTGCGAGAGAGGCT
GGTGGGCCA ATCTGGC ATGACGACGTC AA AT ATT ACGATTTTA ATG ACGG
CT ACT ACA ACT ACC ACT AC ATGGACGTCTGGGGCA AGGGG ACCACGGTCA
CCGTCTCGAGC (SEQ ID NO: 99)
Secuencia de aminoácidos de cadena pesada gamma 1443_C16 (PG16) (TCN-116): proteína expresada con región variable en negrita.
QEQLVESGGGVVQPGGSLRLSCLASGFTFHKYGMHWVRQAPGKGLEW VALISDDGMRKYHSDSMWGRVTISRDNSKNTLYLQFSSLKVEDTAMFFC AREAGGPIWHDDVKYYDFNDGYYNYHYMDVWGKGTTVTVSSASTKGPS VFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSS GLYSLSSWTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCP APELLGGPSVFLFPPKPKDTLM1SRTPEVTCWVDVSHEDPEVKFNWYVDGV
EVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIE KTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNG QPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHY TQKSLSLSPGK (SEQ ID NO: 12)
1443_C16 (PG16) (TCN-116) secuencia de aminoácidos de región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, Chothia CDR en negrita y cursiva)
QHQLVESGGGVVOPGGSLRLSCLASGFTT'WYGMHWVRQAPGKGLEWVAL
FS7W(;M/eAriISI)SMW(iRVTISRDNSKNTLYEOFSSLKVEDTAMM;( ’A R7^(;
(/' VI WHDI) VKY YDFNIX i Y YrN YH Y MI) VW G K( iT r V T V S S (SEQ ID NO: 31)
1443_C16 (PG16) (TCN-116) CDR de Kabat de la cadena pesada gamma:
CDR 1: KYGMH (SEQ ID NO: 88)
CDR 2: LISDDGMRKYHSDSMWG (SEQ ID NO: 89)
CDR 3: EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6)
1443_C16 (PG16) gamma:
CDR 1: GFTFHK (SEQ ID NO: 266)
CDR 2: LISDDGMRKY (SEQ ID NO: 267)
CDR 3: EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6)
1443_C16 (PG16) secuencia de nucleótido de cadena ligera lambda: secuencia de codificación 1443_C16 A2 (región variable en negrita)
ATGGCCTGGGCTCTGCTATTCCTCACCCTCTTCACTCAGGGCACAGGGTGC
T G G G G C C A G T C T G C C C T G A C T C A G C C T G C C T C C G T G T C T G G G T C T C C T
G G A C A G A C G A T C A C C A T C T C C T G C A A T G G A A C C A G C A G T G A C G T T G G
T G G A T T T G A C T C T G T C T C C T G G T A C C A A C A A T C C C C A G G G A A A G C C C
C C A A A G T C A T G G T T T T T G A T G T C A G T C A T C G G C C C T C A G G T A T C T C T A
A T C G C T T C T C T G G C T C C A A G T C C G G C A A C A C G G C C T C C C T G A C C A T C
T C T G G G C T C C A C A T T G A G G A C G A G G G C G A T T A T T T C T G C T C T T C A C T
G A C A G A C A G A A G C C A T C G C A T A T T C G G C G G C G G G A C C A A G G T G A C C
GTTCTAGGTCAGCCCAAGGCTGCCCCCTCGGTCACTCTGTTCCCGCCCTC
CTCTOAGGAGCTTCAAGCCAACAAGGCCACACTGCTGTGTCTGATAAGTG
ACTTCTACCCGGGAGCCGTGACAGTGGCCTGGAAGGCAGATAGCAGCCCC
GTCAAGGCGGGAGTGGAGACCACCACACCCTCCAAACAAAGCAACAACA
AGTACGCGGCC AGC AGCT ACCTG AGCCTGACGCG
TGAGCAGTGGAAGTCCCACAAAAGCTACAGCTGGGAGGTGACGCATGAA
GGG AGC ACCGTGGAG A AG AC AGTGGCCCCT ACAG A ATGTTC AT AG (SEQ
ID NO: 13)
1443_C16 (PG16) (TCN-116) secuencia de nucleótidos de región variable de cadena ligera lambda:
CAGTCTGCCCTGACTCAGCCTGCCTCCGTGTCTGGGTCTCCTGGACAGACG
ATCACCATCTCCTGCAATGGAACCAGCAGTGACGTTGGTGGATTTGACTC
TGTCTCCTGGTACCAACAATCCCCAGGGAAAGCCCCCAAAGTCATGGTTT
TTGATGTCAGTCATCGGGCCTCAGGTATGTCTAATCGCTTCTCTGGCTCCA
AGTCCGGCAACACGGCCTCCCTGACCATCTCTGGGCTCCAGATTGAGGAC
GAGGGCGATTATTTCTGCTCTTCACTGACAGACAGAAGCCATCGCATATT
CGGCGGCGGGACCAAGGTGAGCGTTCTA (SEQ ID NO: 100)
1443_C16 (PG16) (TCN-116) secuencia de aminoácidos de la cadena ligera lambda: proteína expresada con región variable en negrita.
Q S A L T Q P A S V S G S P G Q T I T I S C N G T S S D V G G F D S V S W Y Q Q S P G K A P K V M V
F D V S H R P S G I S N R F S G S K S G N T A S L T I S G L H I E D E G D Y F C S S L T D R S H R 1 F G
GGTKVTVLGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWK
ADSSPVKAGVETTTPSKQSNNKYAASSYESLTPEQWKSHKSYSCQVTHEGST
VEKTVAPTEGS (SEQ ID NO: 14)
1443_C16 (PG16) (TCN-116) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
OSALrOPASVSCiSPCiOririSCWG'/XS'Dl/G'GmS’KS'WYOOSPCiKAPKVMVl/j VS7//f/*S'GISNRESGSKSGNTASi:i'lSGEHIEDtiGDYEC&SA77Jlf,S7/J?/EGGGTK VTVL (SEQ ID NO: 32)
1443_C16 (PG16) (TCN-116) CDR de Kabat de la cadena ligera de lambda:
CDR 1: NGTSSDVGGFDSVS (SEQ ID NO: 97)
CDR 2: DVSHRPS (SEQ ID NO: 95)
CDR 3: SSLTDRSHRI (SEQ ID NO: 41)
1443_C16 (PG16) (TCN-116) CDR de Chothia de la cadena ligera lambda:
CDR 1: NGTSSDVGGFDSVS (SEQ ID NO: 97)
CDR 2: DVSHRPS (SEQ ID NO: 95)
CDR 3: SSLTDRSHRI (SEQ ID NO: 41)
1456_P20 (PG20) secuencia de nucleótidos de cadena pesada gamma: 1456_P20 y1 secuencia de codificación (región variable en negrita)
ATGGACTGGATTTGGAGGTTCCTCTTTGTGGTGGCAGCAGCTACAGGTGT CCAGTCCCAGGTCCGCCTGGTACAGTCTGGGCCTGAGGTGAAGAAGC CTGGGTCCTCGGTGACGGTCTCCTGCCAGGCTTCTGGAGGCACCTTC AGCAGTTATGCTTTCACCTGGGTGCGCCAGGCCCCCGGACAAGGTCT TGAGTGGTTGGGCATGGTCACCCCAATCTTTGGTGAGGCCAAGTACT CACAAAGATTCGAGGGCAGAGTCACCATCACCGCGGACGAATCCACG AGCACAACCTCCATAGAATTGAGAGGCCTGACATCCGAAGACACGGC CATTTATTACTGTGCGCGAGATCGGCGCGCGGTTCCAATTGCCACGG
ACAACTGGTTAGACCCCTGGGGCCAGGGGACCCTGGTCACCGTCTCG AGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAA GAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACT TCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGC GTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGC AGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTG C A ACGT G A ATC AC A AGCCC AGC A AC ACC A AGGT GG AC A AGAGAGTT G AG CCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGA ACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACA CCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTG AGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGG AGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCAC GTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATG GCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATC GAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGT ACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCT GACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGG AGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCT GGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCACCGTGGACAAGA GCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCT CTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATG
A (SEQ ID NO: 15)
1456_P20 (PG20) secuencia de nucleótidos de la región variable cadena pesada gamma:
C AGGTCCGCCTGGTAC AGTCTGGGCCTG AGGTG A AG A AGCCTGGGTCCTC GGTGACGGTCTCCTGCCAGGCTTCTGGAGGCACCTTCAGCAGTTATGCTTT CACCTGGGTGCGCCAGGCCCCCGGACAAGGTCrrGAGTGGrrGGGCA'rGG TCACCCCAATCTTTGGTGAGGCCAAGTACTCACAAAGATTCGAGGGCAGA GTCACCATCACCGCGGACGAATCCACGAGCACAACCTCCATAGAATTGAG AGGCCTGAC ATCCGA AG AC ACGGCC ATTT ATT ACTGTGCGCG AG ATCGGC GCGCGGTTCCAATTGCCACGGACAACTGGTTAGACCCCTGGGGCCAGGGG ACCCTGGTCACCGTCTCGAGC (SEQ ID N O : 101 )
1456_P20 (PG20) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
Q V R L V Q S G P E V K K P G S S V T V S C Q A S G G T F S S Y A F T W V R Q A P G Q G L E W L
G M V T P I F G E A K Y S Q R F E G R V T I T A D E S T S T T S I E L R G L T S E D T A I Y Y C A R D
RRAVPIATDNW LDPW GQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALG
Q.VKDYFPEPVTVSW NSGAITSGVIITFP A VI .QSSGI ,YSI .SSVVTVPSSSI jGTQ
TYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKD
TLMISRTPEVTCVVVDVSIIEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTY
RVVS VL TVLIIQDWFNGKEYKCKVSNKALPAPIEK l’ISKAKGQPRHPQVY I’LP
PSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSF
FLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK (SEQ ID
NO: 16)
1456_P20 (PG20) secuencia de aminoácidos de la región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
QVRI ,V Q S G P E V K K P G S S V T V S C Q A S G G 7 ’F S S Y A F T W V R Q A P G Q G I EW I JGMV 77 * /F G fi!A A Y S O R F E G R V T I T A D E S T S T T S I B L R G L T S E D T A I Y Y C A R D M ? A VPIA t d n w i . n n m í o g t i ,v t v s s (S E Q i d n o : 33 )
1456_P20 (PG20) CDR de Kabat de la cadena pesada gamma:
CDR 1: SYAFT (SEQ ID NO: 104)
CDR 2: MVTPIFGEAKYSQRFEG (SEQ ID NO: 105)
CDR 3: DRRAVPIATDNWLDP (SEQ ID NO: 9)
1456_P20 (PG20) CDR de Chothia de la cadena pesada gamma:
CDR 1: GGTFSS (SEQ ID NO: 268)
CDR 2: MVTPIFGEAK (SEQ ID NO: 269)
CDR 3: DRRAVPIATDNWLDP (SEQ ID NO: 9)
1456_P20 (PG20) secuencia de nucleótidos de la cadena ligera kappa: 1456_P20 ^1 secuencia de codificación (región variable en negrita)
ATGGACATGAGGGTCCCCGCTCAGCTCCTGGGGCTCCTGCTACTCTGGCT
C C G A G G T G C C A G A T G T G A C A T C C A G T T G A C C C A G T C T C C A T C C T C C C T
G T C T G C A T C T G T T G G C G A C A G A G T C T C C A T C A C T T G C C G G G C G A G T C
A G A C C A T T A A C A A C T A C T T A A A T T G G T A T C A A C A G A C A C C C G G G A A A
G C C C C T A A A C T C C T G A T C T A T G G T G C C T C C A A T T T G C A A A A T G G G G T
C C C A T C A A G G T T C A G C G G C A G T G G C T C T G G G A C A G A C T T C A C T C T C A
C C A T C A G C A G T C T G C A A C C T G A G G A T T T T G C A A C T T A C T A C T G T C A A C
A G A G T T T C A G T A C T C C G A G G A C C T T C G G C C A A G G G A C A C G A C T G G A T
ATTAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGAT
GAGCAGTTGAAATCTGGAACTGCCTCTG'ITGTGTGCCTGCTGAATAACTTC
T ATCCC AG AG AGGCC A AAGT ACAGTGG A AGGTGGAT A ACGCCCTCC A AT
CGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCAC
CTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAA
CACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGT
CACAAAGAGCTTCAACAGGGGAGAGTGTTAG (SEQ ID NO: 17)
1456_P20 (PG20) secuencia de nucleótidos de la región variable de la cadena ligera kappa:
GACATCCAGTTGACCCAGTCTCCATCCTCCCTGTCTGCATCTGTTGGCGAC
AG AGTCTCC ATCACTTGCCGGGCG AGTC AG ACC ATT A ACA ACT ACTT A A A
TTGGT ATCAAC AGACACCCGGGA A AGCCCCTA A ACTCCTGATCT ATGGTG
CCTCCAATTTGCAAAATGGGGTCCCATCAAGGTTCAGCGGCAGTGGCTCT
GGGACAGACTTCACTCTCACCATCAGCAGTCTGCAACCTGAGGATTrrGC AACITACTACTGTCAACAGAGrrrCAGTACTCCGAGGACCITC’GGCCAAG GG AC ACG ACTGG AT ATT A A A (SEQ ID NO: 106)
1456_P20 (PG20) secuencia de aminoácidos de la cadena ligera kappa: proteína expresada con la región variable en negrita.
DIQLTQSPSSLSASVGDRVSITCRASQTINNYLNWYQQTPGKAPKLLIYGA SNLQNGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSFSTPRTFGQGT RLDIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNfFYPREAKVQWKVDNA LQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPV TKSFNRGEC (SEQ ID NO: 18)
Secuencia de aminoácidos de la región variable de la cadena ligera kappa 1456_P20 (PG20): (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
DIQI /TQSPSSI AASVGDRVSITCRASQ77AW}7JVWYQQTPGKAPKI .1AVGASNL DACiVPSRFSGSGSGTDFTLTISSLOPEDFATYYCO O .S/vST /^rFGOGTRLDIK (SEQ ID NO: 34)
1456_P20 (PG20) CDR de Kabat de la cadena ligera kappa:
CDR 1: RASQTINNYLN (SEQ ID NO: 107)
CDR 2: GASNLQN (SEQ ID NO: 108)
CDR 3: QQSFSTPRT (SEQ ID NO: 42)
1456_P20 (PG20) CDR de Chothia de la cadena ligera Kappa:
CDR 1: RASQTINNYLN (SEQ ID NO: 107)
CDR 2: GASNLQN (SEQ ID NO: 108)
CDR 3: QQSFSTPRT (SEQ ID NO: 42)
1460_G14 (PGG14) secuencia de nucleótidos de cadena pesada gamma: 1460_G14 y1 secuencia de codificación (región variable en negrita)
ATGGACTGGATTTGGAGGTTCCTCTTGGTGGTGGCAGCAGCTACAGGTGT CCAGTCCCAGGTCCTGCTGGTGCAGTCTGGGACTGAGGTGAAGAAGC CTGGGTCCTCGGTGAAGGTCTCCTGTCAGGCTTCTGGAGGCGCCTTC AGTAGTTATGCTTTCAGCTGGGTGCGACAGGCCCCTGGACAGGGGCT TGAATGGATGGGCATGATCACCCCTGTCTTTGGTGAGACTAAATATG CACCGAGGTTCCAGGGCAGACTCACACTTACCGCGGAAGAATCCTTG AGCACCACCTACATGGAATTGAGAAGCCTGACATCTGATGACACGGC CTTTTATTATTGTACGAGAGATCGGCGCGTAGTTCCAATGGCCACAG ACAACTGGTTAGACCCCTGGGGCCAGGGGACGCTGGTCACCGTCTCG AGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAA GAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACT TCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGC GTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGC AGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTG CAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAG CCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGA
ACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACA CCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTG AGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGG AGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCAC GTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATG GCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATC GAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGT ACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCT GACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGG AGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCT GGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCACCGTGGACAAGA GCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCT CTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATG
A (SEQ ID NO: 19)
1460_G14 (PGG14) secuencia de nucleótidos de la región variable de la cadena pesada gamma:
CAGGTCCTGCTGGTGCAGTCTGGGACTGAGGTGAAGAAGCCTGGGTCCTC
GGTGAAGGTCTCCTGTCAGGCTTCTGGAGGCGCCTTCAGTAG1TATGCTTT
CAGCTGGGTGCGACAGGCCCCTGGACAGGGGCTTGAATGGATGGGCATG
ATC ACCCCTGTCHTTGGTG AG ACTA A AT ATGC ACCG AGGTTCC AGGGC AG
ACTCACACTTACCGCGGAAGAATCCTTGAGCACCACCTACATGGAATTGA
GAAGCCTGACATCTGATGACACGGCCTTTTATTATTGTACGAGAGATCGG
CGCGT AGTTCCAATGGCCACAG ACAACTGGTT AGACCCCTGGGGGCAGGG
GACGCTGGTCACCGTCTCGAGC (SEQ ID NO: 109)
1460_G14 secuencia de aminoácidos de la cadena pesada del gamma: proteína expresada con la región variable en negrita.
Q V L L V Q S G T E V K K P G S S V K V S C Q A S G G A F S S Y A F S W V R Q A P G Q G L E W M
G M I T P V F G E T K Y A P R F Q G R L T L T A E E S L S T T Y M E L R S L T S D D T A F Y Y C T R
D R R V V P M A T D N W L D P W G Q G T L V T V S S A S T K G P S V I P L A P S S K S T S G G T A A
IXiCI,VKDYIPHPVTVSWNSGAIXSGVIITFPAVIjQSSGI X SI^SV V TV PSSSIX ¡ TQTYICNVNIIKPSNTKVDKRVEPKSCDKTTITCPPCPAPE11 Xj GPSVFI J'PPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVIINAKTKPREEQYNS
TYRVVSVLTVLMQDWLNGKEYKCKVSNKALPAP1EKTISKAKGQPREPQVYT
LPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDG
SFFLYSKLTVDKSRWQQGNVFSCSVMHEALIINHYTQKSLSLSPG (SEQ ID
NO: 20)
1460_G14 secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en cursiva en negrita)
Q V LLVQSGTEV KKPGSS VKVSC QASGYM /vS’SYAFS W VRQAPC iQGLEW M( )M ITPVFGETKY APR1 OGRLTLTAEESLSTTYMELRSLTSDDT AFY YCTRD/?fl VV PMA TDWYI.DPWi iQGTLVTVSS (SEO ID NO: 35)
1460_G14 CDR de Kabat de cadena pesada gamma:
CDR 1: SYAFS (SEQ ID NO: 110)
CDR 2: MITPVFGETKYAPRFQG (SEQ ID NO: 111)
CDR 3: DRRVVPMATDNWLDP (SEQ ID NO: 8)
1460_G14 CDR de Chothia de la cadena pesada gamma:
CDR 1: GGAFSS (SEQ ID NO: 270)
CDR 2: MITPVFGETK (SEQ ID NO: 271)
CDR 3: DRRVVPMATDNWLDP (SEQ ID NO: 8)
1460_G14 (PGG14) secuencia de nucleótidos de la cadena ligera kappa: 1460_G14 O secuencia de codificación (región variable en negrita)
ATGGACATGAGGGTCCCCGCTCAGCTCCTGGGGCTCCTGCTCCTCTGGCTC
C G A G G T G C C A C A T G T G A C A T C C A G T T G A C C C A G T C T C C A T C C T C C C T G
T C T G C A T C T G T A G G A G A C A G G G T C A C C G T C A C T T G C C G G G C G A G T C A
G A C C A T A C A C A C C T A T T T A A A T T G G T A T C A G C A A A T T C C A G G A A A A G C
C C C T A A G C T C C T G A T C T A T G G T G C C T C C A C C T T G C A A A G T G G G G T C C
C G T C A A G G T T C A G T G G C A G T G G A T C T G G G A C A G A T T T C A C T C T C A C C
A T C A A C A G T C T C C A A C C T G A G G A C T T T G C A A C T T A C T A C T G T C A A C A G
A G T T A C A G T A C C C C A A G G A C C T T C G G C C A A G G G A C A C G A C T G G A T A T
TAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGA GCAGTTGA A ATCTGG A ACTGCCTCTGTTGTGTGCCTGCTGAAT A ACTTCT A
TCCC AG AG AGGCC A A AGT AC AGTGG A AGGTGG AT AACGCCCTCC A ATCG
GGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCT
ACAGCCTCAGCAGCACGCTGACGCTGAGCAAAGCAGACTACGAGAAACA
CAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCA
CAAAGAGCTTCAACAGGGGAGAGTGTTAG (SEQ ID NO: 21)
1460_G14 (PGG14) secuencia de nucleótidos de la región variable de la cadena ligera kappa:
GACATCCAGTTGACCCAGTCTCCATCCTCCCTGTCTGCATCTGTAGGAGAC
AGGGTCACCGTCACTTGCCGGGCGAGTCAGACCATACACACCTATTTAAA
TTGGT ATC AGC A A ATTCC AGG A A A AGCCCCT A AGCTCCTG ATCT ATGGTG
CCTCCACCITGCAAAGTGGGGTCCCGTCAAGGTTCAGTGGCAGTGGATCT
GGGACAGA1TTCACTCTCACCATCAACAGTCTCCAACCTGAGGACTTTGC
AACTTACTAGTGTCAACAGAGTTACAGTACCCCAAGGACCTTCGGGCAAG
GGACACGACTGGATATTAAA (SEQ ID N O : 112 )
1460_G14 secuencia de aminoácidos de cadena ligera kappa: proteína expresada con la región variable en negrita.
DIQLTQSPSSLSASVGDRVTVTCRASQTIHTYLNWYQQ1PGKAPKLLIYG ASTLQSGVPSRFSGSGSGTDFTLTINSLQPEDFATYYCQQSYSTPRTFGQG
TRLDIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNA LQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPV TKSFNRGEC (SEQ ID NO: 22)
1460_G14 secuencia de aminoácidos de la región variable de cadena ligera kappa: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
D I0i:r0SP SSI^A SV G D R V T V T C J M S 077 //m J V W Y00IPG K APK LLIYG A m OSGVPSRFSCiSGSGTDFTLTINSLQPEDFATYY(O a S m 7 >R7’FGOGTRLDIK (SEQ ID N O : 36 )
1460_G14 CDR de Kabat de la cadena ligera kappa:
CDR 1: RASQTIHTYLN (SEQ ID NO: 113)
CDR 2: GASTLQS (SEQ ID NO: 114)
CDR 3: QQSYSTPRT (SEQ ID NO: 43)
1460_G14 CDR de Chothia de la cadena ligera kappa:
CDR 1: RASQTIHTYLN (SEQ ID NO: 113)
CDR 2: GASTLQS (SEQ ID NO: 114)
CDR 3: QQSYSTPRT (SEQ ID NO: 43)
1495_C14 (PGC14) secuencia de nucleótidos de cadena pesada gamma: 1495_C14 y1 secuencia de codificación (región variable en negrita)
ATGGACTGGATTTGGAGGATCCTCCTCTTGGTGGCAGCAGCTACAGGCAC CCTCGCCGACGGCCACCTGGTTCAGTCTGGGGTTGAGGTGAAGAAGA CTGGGGCT AC AGT C A AA AT CTCCT GC AAGGTTT CTGG AT AC AGCTT C ATCGACTACTACCTTCATTGGGTGCAACGGGCCCCTGGAAAAGGCCT TG AGTGGGTGGGACTT ATTG ATCCTG AAA ATGGTG AGGCTCG AT ATG CAGAGAAGTTCCAGGGCAGAGTCACCATAATCGCGGACACGTCTATA GATACAGGCTACATGGAAATGAGGAGCCTGAAATCTGAGGACACGGC CGTGTATTTCTGTGCAGCAGGTGCCGTGGGGGCTGATTCCGGGAGCT GGTTCGACCCCTGGGGCCAGGGAACTCTGGTCACCGTCTCGAGCGCC TCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCAC CTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCG AACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCAC ACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTG GTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGT GAATCACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAA TCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCT GGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCA TGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCAC GAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGC ATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCG TGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGG
AGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAA ACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCC TGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGC CTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAA TGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCG ACGGCTCCTTCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGG CAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAA CCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA (SEQ ID NO: 23)
1495_C14 (PGC14) secuencia de región variable de nucleótidos de cadena pesada gamma:
GACGGCCACCTGGTTCAGTCTGGGGTTGAGGTGAAGAAGACTGGGGCTAC
AGTCAAAATCTCCTGCAAGGTTTCTGGATACAGCTTCATCGACTACTACCT
TCATTGGGTGCAACGGGCCCCTGGAAAAGGCCTTGAGTGGGTGGGACTTA
TTGATCCTGAAAATGGTGAGGCTCGATATGCAGAGAAGTTCCAGGGCAGA
GTC ACC AT AATCGCGGAC ACGTCT AT AG AT AC AGGCTAC ATGG A A ATG AG
GAGCCTGAAATCTGAGGACACGGCCGTGTATTTCTGTGCAGCAGGTGCCG
TGGGGGCTGA1TCCGGGAGCTGGTTCGACCCCTGGGGCCAGGGAACTCTG
GTCACGGTCTCGAGC (SEQ II) NO: 115)
1495_C14 (PGC14) secuencia de aminoácidos de la cadena pesada gamma: proteína expresada con región variable en negrita.
DG H LVQ SG VEVK K TG ATVK ISCK VSG YSFIDYYLH W VQ RAPG K G LEW V
G LIDPENG EARYAEK FQ G RVTIIADTSIDTG YM EM RSLK SEDTAVYFCAA
G A V G A D S G S W F D P W G Q G T L V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C
L V K D Y F P E P V T V S W N S G A L T S G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T
Y I C N V N H K P S N T K V D K R V E P K S C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T
L M 1 S R T P E V T C V V V D V S H E D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R
W S V L T V L H Q D W L N G K E Y K C K V S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T L P P
S R E E M T K N Q V S L T G L V K G F Y P S D I A V E W E S N G Q P E N N Y K I T P P V L D S D G S F F
L Y S K L T V D K S R W Q Q G N V F S C S V M H E A L H N H Y T Q K v S L S L S P G K ( S E Q I D N O :
24 )
1495_C14 (PGC14) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
D G H L V Q S G V E V K K T G A T V K I S C K V S G K S F /D Y Y L H W V O R A P G K G L E W V G /J
D P E N G E A R Y A E K F O G R V T I I A D T S I D T G Y M E M R S L K S E D T A V Y F C A A G A V GA
D S G S W F ¿ ) P W G O G T L V T V S S ( S E Q ID N O : 37 )
1495_C14 CDR de Kabat de cadena pesada gamma:
CDR 1: DYYLH (SEQ ID NO: 116)
CDR 2: LIDPENGEARYAEKFQG (SEQ ID NO: 117)
CDR 3: GAVGADSGSWFDP (SEQ ID NO: 10)
1495_C14 CDR de Chothia de la cadena pesada gamma:
CDR 1: GYSFID (SEQ ID NO: 102)
CDR 2: LIDPENGEAR (SEQ ID NO: 103)
CDR 3: GAVGADSGSWFDP (SEQ ID NO: 10)
1495_C14 (PGC14) secuencia de nucleótidos de la cadena ligera lambda: 1495_C14 ^3 secuencia de codificación (variable región en negrita)
A T G G C C T G G A T C C C T C T C T T C C T C G G C G T C C T T G C T T A C T G C A C A G A T T C C
G 1 A G I (TCC TA TG A A C TG A C TC A G C C A C C C TC A G TG TC C G TG TC C C C A
G GACAG ACAG CCAG CATCACCTG TTCTG G ATCTAAATTG G G G G ATAA
ATATGTTTCCTG G TATCAACTG AG G CCAG G CCAG TCCCCCATACTG G
TC ATG TATG AAAATG ACAG G CG G CCCTCCG G G ATCCCTG AG CG ATTC
TC CG G TTC CAATTCTG G CG ACACTG CCACTCTG ACCATCAG CG G G AC
CCAG GCTTTG G ATG AG G CTG ACTTCTACTG TCAG G CG TG G G AG ACCA
CC AC CACCACTTTTG TTTTCTTCG G CG G AG G G ACCCAG CTG ACCG TT
C T A G G T G A G C C C A A G G C T C C C C C G T C O G T C A C T C T G T T C C C G C C C T C C T C T
G A G G A G C T T C A A G C C A A C A A G G C C A C A C T G G T G T G T C T C A T A A G T G A C T T
C T A C C C G G G A G C C G T G A C A G T G G C C T O G A A O G C A G A T A G C A G C C C C G T C
A A G G C G G G A G T G G A G A C C A C C A C A C C C T C C A A A C A A A G C A A C A A C A A G T
A C G C G G C C A G C A G C T A C C T G A G C C T G A C G C C T G A G C A G T G G A A G T C C C A C
A A A A G C T A C A G C T G C C A G G T C A C G C A T G A A G G G A G C A C C G T G G A G A A G A
C A G T G G C C C C T A C A G A A T G T T C A T A G ( S E Q ID N O : 25 )
1495_C14 (PGC14) secuencia de nucleótidos de la región variable de la cadena ligera lambda:
TCCTATGAACTGACTCAGCCACCCTCAGTGTCCGTGTCCCCAGGACAGAC
AGCCAGCATCACCTGTTCTGGATCTAAATTGGGGGATAAATATGTTTCCTG
GTATCAACTGAGGCCAGGCCAGTCCCCCATACTGGTCATGTATGAAAATG
ACAGGCGGCCCTCCGGGATCCCTGAGCGATTCTCCGGTTCCAATTCTGGC
GACACTGCCACTCTGACCATCAGCGGGACCCAGGCTTTGGATGAGGCTGA
CTTCTACTGTCAGGCGTGGGAGACCACCACCACCACTTTTGTTTTCTTCGG
CGGAGGGACCCAGCTGACCGTTCTA (SEQ ID NO: 119)
1495_C14 (PGC14) secuencia de aminoácidos de la cadena ligera lambda: proteína expresada con región variable en negrita.
S Y E L T Q P P S V S V S P G Q T A S I T C S G S K L G D K Y V S W Y Q L R P G Q S P I L VIVI Y E N
D R R P S G I P E R F S G S N S G D T A T L T I S G T Q A L D E A D F Y C Q A W E T T T T T F V F F G
GGTQLTVLGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKA
DSSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHKSYSCQVTHEGSTV
EKTVAPTECS (SEQ ID NO: 26)
1495_C14 (PGC14) secuencia de aminoácidos de región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
SYELTOPPSVSVSPGOTASITGSGS’f t / ^ D A ' m WYOERPGOSPlEVMY/sVDKK PSGIPERFSGSNSGDTATI /USGTOAI ,DEADFY( OA WET'ITTTFVF 1 ( i( i( i l OI, TVE (SEQ ID NO: 38)
1495_C14 (PGC14) CDR de Kabat de la cadena ligera lambda:
CDR 1: SGSKLGDKYVS (SEQ ID NO: 120)
CDR 2: ENDRRPS (SEQ ID NO: 121)
CDR 3: QAWETTTTTFVF (SEQ ID NO: 44)
1495_C14 (PGC14) CDR de Chothia cadena ligera lambda:
CDR 1: SGSKLGDKYVS (SEQ ID NO: 120)
CDR 2: ENDRRPS (SEQ ID NO: 121)
CDR 3: QAWETTTTTFVF (SEQ ID NO: 44)
1496_C09 (PG9) (TCN-109) secuencia de nucleótidos de cadena pesada gamma: 1496_C09 secuencia de codificación y3 (región variable en negrita)
ATGG AGTTT GGGCT G AGCTGGGTTTTCCTCGTT GCTTT CTT A AG AGGT GTC CAGTGTCAGCGATTAGTGGAGTCTGGGGGAGGCGTGGTCCAGCCTGG GTCGTCCCTGAGACTCTCCTGTGCAGCGTCCGGATTCGACTTCAGTA GACAAGGCATGCACTGGGTCCGCCAGGCTCCAGGCCAGGGGCTGGA GTGGGTGGCATTTATTAAATATGATGGAAGTGAGAAATATCATGCTG ACTCCGTATGGGGCCGACTCAGCATCTCCAGAGACAATTCCAAGGAT ACGCTTT ATCTCCAAATGA AT AGCCTG AGAGTCG AGG ACACGGCT AC ATATTTTTGTGTGAGAGAGGCTGGTGGGCCCGACTACCGTAATGGGT ACAACTATTACGATTTCTATGATGGTTATTATAACTACCACTATATGG ACGTCTGGGGCAAAGGGACCACGGTCACCGTCTCGAGCGCCTCCACC AAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGG GGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGG TGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTC CCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGAC CGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATC ACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTG TGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGG GACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCT CCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGA CCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATG CCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGT CAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACA AGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATC TCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCC CATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTC AAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGC AGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGG CTCCTTCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGC
AGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCAC TACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA (SEQ ID NO: 27)
1496_C09 (PG9) (TCN-109) secuencia de nucleótidos de región variable de cadena pesada de cadena gamma:
CAGCGATTAGTGGAGTCTGGGGGAGGCGTGGTCCAGCCTGGGTCGTCCCT
GAGACTCTCCTGTGCAGCGTCCGGATTCGACTTCAGTAGACAAGGCATGC
ACTGGGTCCGCCAGGCTCCAGGCCAGGGGCTGGAGTGGGTGGCATTTATT
AAATATGATGGAAGTGAGAAATATCATGCTGACTCCGTATGGGGCCGAGT
C AGC ATCTCCAG AG AC AATTCC A AGG AT ACGCTTT ATCTCC A A ATG AAT A
GCCTGAGAGTCGAGGACACGGCTACATATTTTTGTGTGAGAGAGGCTGGT
GGGCCCG ACT ACCGT A ATGGGT ACA ACT ATT ACG ATTTCT ATG ATGGTT AT
T AT A ACT ACC ACT ATATGG ACCTCTGGGGC A A AGGG ACC ACGGTCACCGT
CTCGAGC (SEQ ID NO: 122)
1496_C09 (PG9) (TCN-109) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
Q R L V E S G G G V V Q P G S S L R L S C A A S G F D F S R Q G M H W V R Q A P G Q G L E W V A F I K
Y D G S E K Y I I A D S V W G R I J S I S R D N S K D T I ,Y I .Q M N S L R V E D T A T Y F C V R E A G G P
D Y R N G Y N Y Y D F Y D G Y Y N Y I I Y M D V W G K G T T V T V S S A S T K G P S V F P F A P S S K
S T S G G T A A L G C L V K D Y F P E P V T V S W N S G A L T S G V H T F P A V L Q S S G L Y S L S S V
V T W S S S L G T Q T Y I C N V N H K P S N T K V D K R V E P K S C D K T H T C P P C P A P E L L G G P
S V F L F P P K P K D T L M I S R T P E V T C V V V D V S H E D P E V K F N W Y V D G V E V H N A K T
K P R E E Q Y N S T Y R V V S V L T V L H Q D W L N G K E Y K C K V S N K A L P A P I E K T I S K A K G
Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K G F Y P S D I A V E W E S N G Q P E N N Y K T
T P P V I .D S D G S F F I ,Y S K I /T V D K S R W Q Q G N V F S C S V M H E A L I IN I I Y T Q K S I ,S I ,S P
G K ( S E Q ID N O : 28 )
1496_C09 (PG9) (TCN-109) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
Q R I , V H S G G G V V Q P G S S F R I ¿ C A A S G F f l F S f lO G M H W V R O A P G O G I .1 iW V A £ / A y / W A T f A n i A D X V W G R E S lS R D N S K D T L Y lj Q M N S E R V K D T A T Y F C V R / a i G G P D Y R N G Y N Y Y D F Y D G Y Y N Y H Y M I ) y W G K G T T V T V S S ( S E Q I D N O : 39 ) 1496_C09 (PG9) (TCN-109) CDR de Kabat de cadena pesada gamma:
CDR 1: RQGMH (SEQ ID NO: 123)
CDR 2: FIKYDGSEKYHADSVWG (SEQ ID NO: 124)
CDR 3: EAGGPDYRNGYNYYDFYDGYYNH (QYDGYYYHYQYYYYHYY)
1496_C09 (PG9) (TCN-109) CDR de Chothia de la cadena pesada gamma:
CDR 1: GFDFSR (SEQ ID NO: 118)
CDR 2: FIKYDGSEKY (SEQ ID NO: 272)
CDR 3: EAGGPDYRNGYNYYDFYDGYYNYHYMDV (SEQ ID NO: 7)
1496_C09 (PG9) (TCN-109) secuencia de nucleótidos de cadena ligera lambda: 1496_C09 secuencia de codificación A2 (región variable en negrita)

1496_C09 (PG9) (TCN-109) secuencia de nucleótidos de región variable de cadena ligera lambda:

1496_C09 (PG9) (TCN-109) secuencia de aminoácidos de cadena ligera lambda: proteína expresada con región variable en negrita.
Q SALTQ PASVSG SPG Q SITISCNG TSNDVG G YESVSW YQ Q H PG K APK VVI
YD VSK R PSG V SN RFSG SK SG NTA SLTISG LQ A ED EG DY YCK SLTSTRR RV
F G T G T K L T V L G Q P K A A P S V T L F P P S S E E L Q A N K A T L V C L I S D F Y P G A V T V A W
K A D S S P V K A G V E T T T P S K Q S N N K Y A A S S Y L S L T P E Q W K S H K S Y S C Q V T H E G S
T V E K T V A P T E C S ( S E Q ID N O : 30 )
1496_C09 (PG9) (TCN-109) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
O S A E r O P A S V S G S P G O S r n S C W G / W J E G Y / T E W S W Y O O H P G K A P K V V lY D Y S Á 7 ? P S G V S N R E S G S K S G N T A S L T lS G L O A E D E G D Y Y C ÁrA 7,71ST I?/?/fV T G T G T K L T V L (S E Q I D N O : 40 )
1496_C09 (PG9) (TCN-109) CDR de Kabat de la cadena ligera lambda:
CDR 1: NGTSNDVGGYESVS (SEQ ID NO: 126)
CDR 2: DVSKRPS (SEQ ID NO: 127)
CDR 3: KSLTSTRRRV (SEQ ID NO: 45)
1496_C09 (PG9) (TCN-109) CDR de Chothia de la cadena ligera lambda:
CDR 1: NGTSNDVGGYESVS (SEQ ID NO: 126)
CDR 2: DVSKRPS (SEQ ID NO: 127)
CDR 3: KSLTSTRRRV (SEQ ID NO: 45)
El anticuerpo 1443_C16 (PG16) incluye una región variable de la cadena pesada (SEQ ID NO: 31), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 99, y una región variable de la cadena ligera (SEQ ID NO: 32) codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 100.
Las CDR de cadena pesada del anticuerpo 1443_C16 (PG16) tienen las siguientes secuencias según la definición de Kabat: KYGMH (SEQ ID NO: 88), LISDDGMRKYHSDSMWG (SEQ ID NO: 89) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6). Las CDR de cadena ligera del anticuerpo 1443_C16 (PG16) tienen las siguientes secuencias según la definición de Kabat: NGTSSDVGGFDSVS (SEQ ID NO: 97), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41).
Las CDR de cadena pesada del anticuerpo 1443_C16 (PG16) tienen las siguientes secuencias según la definición de Chothia: GFTFHK (SEQ ID NO: 266), LISDDGMRKY (SEQ ID NO: 267) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID: 6). Las CDR de cadena ligera del anticuerpo 1443_C16 (PG16) tienen las siguientes secuencias según la definición de Chothia: NGTSSDVGGFDSVS (SEQ ID NO: 97), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41).
El anticuerpo 1456_ P20 (PG20) incluye una región variable de la cadena pesada (SEQ ID NO: 33), codificada por la secuencia de ácido nucleico que se muestra en la SEQ ID NO: 101, y una región variable de la cadena ligera (SEQ ID NO: 34) codificada por la secuencia de ácido nucleico mostrada en la SEQ ID NO: 106.
Las CDR de cadena pesada del anticuerpo 1456_ P20 (PG20) tienen las siguientes secuencias por definición Kabat: SYAFT (SEQ ID NO: 104), MVTPIFGEAKYSQRFEG (SEQ ID NO: 105) y DRRAVPIATDNWLDP (SEQ ID NO: 9). Las CDR de cadena ligera del anticuerpo 1456_P20 (PG20) tienen las siguientes secuencias según la definición de Kabat: RASQTINNYLN (SEQ ID NO: 107), GASNLQN (SEQ ID NO: 108) y QQSFSTPRT (SEQ ID NO: 42).
Las CDR de cadena pesada del anticuerpo 1456_P20 (PG20) tienen las siguientes secuencias según la definición de Chothia: GGTFSS (SEQ ID NO: 268), MVTPIFGEAK (SEQ ID NO: 269) y DRRAVPIATDNWLDP (SEQ ID NO: 9). Las CDR de cadena ligera del anticuerpo 1456_P20 (PG20) tienen las siguientes secuencias según la definición de Chothia: RASQTINNYLN (SEQ ID NO: 107), GASNLQN (SEQ ID NO: 108) y QQSFSTPRT (SEQ ID NO: 42).
El anticuerpo 1460_G14 (PGG14) incluye una región variable de cadena pesada (SEQ ID NO: 35), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 109, y una región variable de cadena ligera (SEQ ID NO: 36) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 112.
Las CDR de cadena pesada del anticuerpo 1460_G14 (PGG14) tienen las siguientes secuencias según la definición de Kabat: SYAFS (SEQ ID NO: 110), MITPVFGETKYAPRFQG (SEQ ID NO: 111) y DRRVVPMATDNWLDP (SEQ ID NO: 8). Las CDR de cadena ligera del anticuerpo 1460_G14 (PGG14) tienen las siguientes secuencias según la definición de Kabat: RASQTIHTYLN (SEQ ID NO: 113), GASTLQS (SEQ ID NO: 114), QQSYSTPRT (SEQ ID NO: 43).
Las CDR de cadena pesada del anticuerpo 1460_G14 (PGG14) tienen las siguientes secuencias según la definición de Chothia: GGAFSS (SEQ ID NO: 270), MITPVFGETK (SEQ ID NO: 271), DRRVVPMATDNWLDP (SEQ ID NO: 8). Las CDR de cadena ligera del anticuerpo 1460_G14 (PGG14) tienen las siguientes secuencias según la definición de Chothia: RASQTIHTYLN (SEQ ID NO: 113), GASTLQS (SEQ ID NO: 114), QQSYSTPRT (SEQ ID NO: 43).
El anticuerpo 1495_C14 (PGC14) incluye una región variable de cadena pesada (SEQ ID NO: 37), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 115, y una región variable de cadena ligera (SEQ ID NO: 38) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 119.
Las CDR de cadena pesada del anticuerpo 1495_C14 (PGC14) tienen las siguientes secuencias según la definición de Kabat: DYYLH (SEQ ID NO: 116), LIDPENGEARYAEKFQG (SEQ ID NO: 117), GAVGADSGSWFDP (SEQ ID NO: 10). Las CDR de cadena ligera del anticuerpo 1495_C14 (PGC14) tienen las siguientes secuencias según la definición de Kabat: SGSKLGDKYVS (SEQ ID NO: 120), ENDRRPS (SEQ ID NO: 121) y QAWETTTTTFVF (SEQ ID NO: 44).
Las CDR de cadena pesada del anticuerpo 1495_C14 (PGC14) tienen las siguientes secuencias según la definición de Chothia: GYSFID (SEQ ID NO: 102), LIDPENGEAR (SEQ ID NO: 103), GAVGADSGSWFDP (SEQ ID NO: 10). Las CDR de cadena ligera del anticuerpo 1495_C14 (PGC14) tienen las siguientes secuencias según la definición de Chothia: SGSKLGDKYVS (SEQ ID NO: 120), ENDRRPS (SEQ ID NO: 121) y QAWETTTTTFVF (SEQ ID NO: 44).
El anticuerpo 1496_C09 (PG9) incluye una región variable de la cadena pesada (SEQ ID NO: 39), codificada por la secuencia de ácido nucleico que se muestra en la SEQ ID NO: 122, y una región variable de la cadena ligera (SEQ ID NO: 40) codificado por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 125.
Las CDR de cadena pesada del anticuerpo 1496_C09 (PG9) tienen las siguientes secuencias según la definición de Kabat: RQGMH (SEQ ID NO: 123), FIKYDGSEKYHADSVWG (SEQ ID NO: 124), y EAGGPDYRNGYNYYDFYDGYYNYHYMDV (SEQ ID NO: 7). Las CDR de cadena ligera del anticuerpo 1496_C09 (PG9) tienen las siguientes secuencias según la definición de Kabat: NGTSNDVGGYESVS (SEQ ID NO: 126), DVSKRPS (SEQ ID NO: 127) y KSLTSTRRRV (SEQ ID NO: 45).
Las CDR de cadena pesada del anticuerpo 1496_C09 (PG9) tienen las siguientes secuencias según la definición de Chothia: GFDFSR (SEQ ID NO: 118), FIKYDGSEKY (SEQ ID NO: 272) y EAGGPDYRNGYNYYDFYDGYYNYHYMDV (SEQ ID NO: 7). Las CDR de cadena ligera del anticuerpo 1496_C09 (PG9) tienen las siguientes secuencias según la definición de Chothia: NGTSNDVGGYESVS (SEQ ID NO: 126), DVSKRPS (SEQ ID NO: 127) y KSLTSTRRRV (SEQ ID NO: 45).
Tabla 6A. Alineación de proteína de región variable de cadena pesada

Tabla 6B. Alineación de proteína de región variable de cadena ligera

Se determinaron las secuencias de clones hermanos para el anticuerpo monoclonal humano 1443_C16 (PG16), incluidas las secuencias de las regiones variables de las cadenas pesada Gamma y ligera Kappa o Lambda. Además, se determinó la secuencia de cada uno de los polinucleótidos que codifican las secuencias de anticuerpos. A continuación se muestran las secuencias de polipéptidos y polinucleótidos de las cadenas pesadas gamma y las cadenas ligeras kappa, con los péptidos señal en el extremo N (o extremo 5') y las regiones constantes en el extremo C (o extremo 3') de las regiones variables, que se muestran en texto en negrita.
1469_M23 (PG16) (TCN-118) secuencia de nucleótidos de cadena pesada gamma: 1469_M23 secuencia de codificación y3 (región variable en negrita)

1469_M23 (PG16) (TCN-118) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G G A A A A A C T G G T G G A G T C T G G G G G A G G C G T G G T C C A C C C G G G G G G G T
C C C T G A G A C T C T C C T G T T T A G C G T C T G G A T T C A C C T T T C A C A A A T A T G G C A
T G C A C T G G G T C C G C C A G G C T C C A G G C A A G G G C C T G G A G T G G G T G G C A C T C
A T C T C A G A T G A C G G A A T G A G G A A A T A T C A T T C A G A C T C C A T G T G G G G C C G
A G T C A C C A T C T C C A G A G A C A A T T C C A A G A A C A C T C T A T A T C T G C A A T T C a G
C A G C C T G A A A G T C G A A G A C A C G G C T A T G T T C T T C T G T G C G A G A G A G G C T G
G T G G G C C A A T C T G G C A T G A C G A C G T C A A A T A T T A C G A T T T T A A T G A C G G C
T A C T A C A A C T A C C A C T A C A T G G A C G T C T G G G G C A A G G G G A C C A C G G T C A C
C G tC T C C T C A ( S E Q II) N O : 128 )
1469_M23 (PG16) (TCN-118) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
Q E K L V E S G G G V V Q P G G S L R L S C L A S G F T F H K Y G M H W V R Q A P G K G L E W
V A L I S D D G M R K Y H S D S M W G R V T I S R D N S K N T L Y L Q F S S L K V E D T A M F F C
A R E A G G P I W H D D V K Y Y D F N D G Y Y N Y H Y M D V W G K G T T V T V S S A S T K G P S
V F P I .A P S S K S T S G G T A A I .G C I .V K D Y F P E P V T V S W N S G A I T S G 'V I I T I P A V I .Q S S
G E Y S D S S V V T W S S S E G T Q T Y I C N V N H K P S N T K V D K R V E P K S C D K T I I T C P P C P
A P E I A X I G P S V F I A ’P P K P K D T I .M I S R T P E V T C V V V D V S I I E D P E V K F N W Y V D G V
E V I 1 N A K T K P R E E Q Y N S T Y R V V S V E T V E I I Q D W E N G K E Y K C K .V S N K A L P A P I E
K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K G F Y P S D I A V E W E S N G
Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R W Q Q G N V F S C S V M I I E A L H N H Y
T Q K S L S L S P G K ( S E Q ID N O : 139 )
1469_M23 (PG16) (TCN-118) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en cursiva en negrita)
O I tK E V E S G G G V V O P G G S I RI S C I . A S G / 7 / ' 7 / Á Y ( Í M 11W V R O A P G K G I AA ¥ V A L ISDDGMRKYl 1 S D S M W G R V T I S R D N S K N T I Y l .O F S S L K V E D P A M F F C AR/sAG
07 7 W f W l ) VK Y Y D l - N I H i Y Y X YH Y M I ) F W G K X IT T V T V S S (S E Q II) N O : 140 )
CDR de Kabat de la cadena pesada gamma 1469_M23 (PG16) (TCN-118):
CDR 1: KYGMH (SEQ ID NO: 88)
CDR 2: LISDDGMRKYHSDSMWG (SEQ ID NO: 89)
CDR 3: EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6)
1469_M23 (PG16) (TCN-118) CDR de Chotia de cadena pesada gamma:
CDR 1: GFTFHK (SEQ ID NO: 266)
CDR 2: LISDDGMRKY (SEQ ID NO: 267)
CDR 3: EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6)
1469_M23 (PG16) (TCN-118) secuencia de nucleótidos de cadena ligera lambda): 1469_M23 A2 secuencia codificadora (región variable en negrita)
A T G G C C T G G G C T C T G C T A T T C C T C A C C C T C T T C A C T C A G G G C A C A G G C jT C C
T G G G G C C A G T C T G C C C T G A C T C A G C C T G C C T C C G T G T C T G G G T C T C C T
G G A C A G A C G A T C A C C A T C T C C T G C A A T G G A A C C A G A A G T G A C G T T G G
T G G A T T T G A C T C T G T C T C C T G G T A C C A A C A A T C C C C A G G G A G A G C C C
C C A A A G T C A T G G T T T T T G A T G T C A G T C A T C G G C C C T C A G G T A T C T C T A
A T C G C T T C T C T G G C T C C A A G T C C G G C A A C A C G G C C T C C C T G A C C A T C

C G G C G G C G G G A C C A A G C T G A C C G T T C T A (S E Q ID N O : 129 )
Secuencia de aminoácidos de cadena ligera lambda 1469_M23 (PG16) (TCN-118): proteína expresada con región variable en negrita.
Q S A L T Q P A S V S G S P G Q T I T I S C N G T R S D V G G F D S V S W Y Q Q S P G R A P K V M V
F D V S H R P S G I S N R F S G S K S G N T A S L T I S G L H I E D E G D Y F C S S L T D R S H R I F G
G G T K L T V L G Q P K A A P S V r L F P P S S E E L Q A N K A T L V C L I S D F Y P G A V I 'V A W K A
D S S P V K A G V E T T T P S K Q S N N K Y A A S S Y L S L T P E Q W K S H K S Y S C Q V T H E G S T V
E K T V A P T E C S ( S E Q ID N O : 142 )
1469_M23 (PG16) (TCN-118) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)

1469_M23 (PG16) (TCN-118) CDR de Kabat de la cadena ligera lambda:
CDR 1: NGTRSDVGGFDSVS (SEQ ID NO: 92)
CDR 2: DVSHRPS (SEQ ID NO: 95)
CDR 3: SSLTDRSHRI (SEQ ID NO: 41)
1469_M23 (PG16) (TCN-118) CDR de Chothia de la cadena ligera lambda:
CDR 1: NGTRSDVGGFDSVS (SEQ ID NO: 92)
CDR 2: DVSHRPS (SEQ ID NO: 95)
CDR 3: SSLTDRSHRI (SEQ ID NO: 41)
1456_A12 (PG16) (TCN-117) secuencia de nucleótidos de cadena pesada gamma: 1456_A12 secuencia de codificación y3 (región variable en negrita)
ATGG AGTTT GGGCT G AGCT GGGTTTTC CTC GC A ACTCTGTT A AG AGTT GT G AAGTGTCACGAACAACTGGTGGAGGCCGGGGGAGGCGTGGTCCAGC CGGGGGGGTCCCTGAGACTCTCCTGTTTAGCGTCTGGATTCACGTTT CACAAATATGGCATGCACTGGGTCCGCCAGGCTCCAGGCAAGGGCCT GGAGTGGGTGGCACTCATCTCAGATGACGGAATGAGGAAATATCATT CAGACTCCATGTGGGGCCGAGTCACCATCTCCAGAGACAATTCCAAG AACACTCTTTATCTGCAATTCAGCAGCCTGAGAGTCGAAGACACGGC TATGTTCTTCTGTGCGAGAGAGGCCGGTGGGCCAATCTGGCATGACG ACGTCAAATATTACGATTTTAATGACGGCTACTACAACTATCACTACA TGGACGTCTGGGGCAAGGGGACCAAGGTCACCGTCTCCTCAGCGTCG ACCAAGGGCCCATCGGTCTTCCCTCTGGCACCATCATCCAAGTCGACCTCT GGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACC GGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCT TCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGA CCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAAT CACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGG GGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGAT CTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAG ACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAAT GCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGG TCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTAC AAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCAT CTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCC CCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGT CAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGG CAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACG GCTCCTTCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAG CAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCA CTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA (SEQ ID NO: 46)
1456_A12 (PG16) (TCN-117) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A C G A A C A A C T G G T G G A G G C C G G G G G A G G C G T C iG T C C A G C C G G G G G G G T
C C C T G A G A C T C T C C T G T T T A G C G T C T G G A T T C A C G T T T C A C A A A T A T G G C A
T G C A C T G G G T C C G C C A G G C T C C A G G C A A G G G C C T G G A G T G G G T G G C A C T C
A T C T C A G A T G A C G G A A T G A G G A A A T A T C A T T C A G A C T C C A T G T G G G G C C G
A G T C A C C A T C T C C A G A G A C A A T T C C A A G A A C A C T C T T T A T C T G C A A T T C A
G C A G C C T G A G A G T C G A A G A C A C G G C T A T G T T C T T G T G T G C G A G A G A G G C C
G G T G G G C C A A T C T G G C A T G A C G A C G T C A A A T A T T A C G A T T T T A A T G A C G G
T G G A C G T C T G G G G C A A G G G G A C C A A G G T C A
1456_A12 (PG16) (TCN-117) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
H E Q L V E A G G G V V Q P G G S L R L S C L A S G F T F H K Y G M H W V R Q A P G K G L E W
V A L I S D D G M R K Y H S D S M W G R V T I S R D N S K N T L Y L Q F S S L R V E D T A M F F C
A R E A G G P I W H D D V K Y Y D F N D G Y Y N Y H Y M D V W G K G T K V T V S S A S 1 K G P S
V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S G A L T S G V H T F P A V L Q S S
G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T K V D K R V E P K S C D K T I I T C P P C P
A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S H E D P E V K F N W Y V D G V
E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D W L N G K E Y K C K V S N K A L P A P 1 E
K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K G F Y P S D I A V E W E S N G
Q P E N N Y K T T P P V L D S D G S F F L Y v S K L T V D K S R W Q Q G N V F S C S V M H E A L H N H Y T Q K S L S L S P G K ( S E Q ID N O : 47 )
Secuencia de aminoácidos de la región variable de la cadena pesada de la cadena pesada 1456_A12 (PG16) (TCN-117): (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
H E Q L V E A G G G V V Q P G C S L R E S C L A S G F T F //A Y G M H W V R Q A P G K C .L E W V A Z ,
/S D /X ¿ M /f Á T I I S D S M W G R V T I S R D N S K N T E Y E O F S S L R V E D T A M F E C A R E 7 iG ' ( ¡ r i W H D D V K Y Y D F N D C Y Y N Y H Y M I ) V W G K G T K V T V S S ( S E Q ID N O : 48 )
CDR de Kabat de la cadena pesada gamma 1456_A12 (PG16) (TCN-117):
CDR 1: KYGMH (SEQ ID NO: 88)
CDR 2: LISDDGMRKYHSDSMWG (SEQ ID NO: 89)
CDR 3: EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6)
1456_A12 (PG16) gamma:
CDR 1: GFTFHK (SEQ ID NO: 266)
CDR 2: LISDDGMRKY (SEQ ID NO: 267)
CDR 3: EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6)
1456_A12 (PG16) secuencia de nucleótido de cadena ligera lambda: secuencia de codificación 1456_A12 A2 (región variable en negrita)
ATGGCCTGGGCTTGCTATTCCTCACCCTCTTCACTCAGGGCACAGGGTCCT
G G G G C C A G T C T G C C C T G A C T C A G C C T G C C T C C G T G T C T G G G T C T C C T
G G A C A G A C G A T C A C C A T C T C C T G C A A T G G A A C C A G C C G T G A C G T T G G
T G G A T T T G A C T C T G T C T C C T G G T A T C A A C A A T C C C C A G G G A A A G C C C
C C A A A G T C A T G G T T T T T G A T G T C A G T C A T C G G C C C T C A G G T A T G T C T A
A T C G C T T C T C T G G C T C C A A G T C C G G C A A C A C G G C C T C C C T G A C C A T T
T C T G G G C T C C A C A T T G A G G A C G A G G G C G A T T A T T T C T G C T C T T C A T T
G A C A G A C A G A A G C C A T C G C A T A T T C G G C G G C G G G A C C A A G C T G A C C
GTTCTAGGTCAGCCCAAGGCTGCCCCCTCGGTCACTCTGTTCCCGCCCTC
CTCTGAGGAGCTTCAAGCCAACAAGGCGACACTGGTGTGTCTCATAAGTG
ACTTCT ACCCGGG AGCCGTGACAGTGGCCTGG A AGGCAG AT AGC AGCCCC
GTCAAGGCGGGAGTGGAGACCACCACACCCTCC-AAACAAAGCAACAACA
AGTACGCGGCCAGCAGCTACCTGAGCCTGACGCCTGAGCAGTGGAAGTCC
CACAAAAGCTACAGCTGCCAGGTCACGCATGAAGGGAGCACCGTGGAGA
AGACAGTGGCCCCTACAGAATGTTGATAG (SEQ ID NO: 49)
1456_A12 (PG16) (TCN-117) secuencia de nucleótidos de región variable de cadena ligera lambda:
CAGTCTGCCCTGACTCAGCCTGCCTCCGTGTCTGGGTCTCCTGGACAGACG
ATC ’ A( X A IX "IX X IX i( A A IX i ( A A( X ’ A( ¡( X X ¡T( i AC X '.TIC X í IX KIA1TIXI A( "IX "I GTCTCCTCiGTATCAACAATCCCCAGGGAAAGC1-CCCAAAGTCATGGTTTT
TG ATGTCAGTC ATCGGCCCTCAGGT ATGTCT A ATCGCTTCTCTGGCTCC A A
( IXXX¡(i(’AACAÍ X iC i( X "IX X X"IXIA(X’A IT IX IXX'.('.("IXCAC ATIX iA(id.ACX¡ AGGGCGAlTAITrCTGCTCITCAnGACAGACAGAAGCCAIX GCATAITCX¡ GCGGCGGGACCAAGCTGACCGITCTA (SEQ ID NO: 131)
1456_A12 (PG16) (TCN-117) secuencia de aminoácidos de cadena ligera lambda: proteína expresada con región variable en negrita.
Q S A L T Q P A S V S G S P G Q T I T I S C N G T S R D V G G F D S V S W Y Q Q S P G K A P K V M V
F D V S H R P S G M S N R F S G S K S G N T A S L T I S G L H I E D E G D Y F C S S L T D R S H R I F
GGGTKLTVLGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAW
KADSSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHKSYSCQVTHEGS
TVEKTVAPTECS (SEQ ID NO: 50)
1456_A12 (PG16) (TCN-117) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
o s a i : i o p a s vscísix i o r i n s c n g tsr d v g g id s ksw y o o s p g k a p k v m v i /) VSHRPSi iMSNRISGSKSGNTASI .TISGI a UEDEGDYFCSSLTDRSHRirGGGTK LTVL (SEQ ID NO: 51)
1456_A12 (PG16) (TCN-117) CDR de Kabat de la cadena ligera lambda:
CDR 1: NGTSRDVGGFDSVS (SEQ ID NO: 93)
CDR 2: DVSHRPS (SEQ ID NO: 95)
CDR 3: SSLTDRSHRI (SEQ ID NO: 41)
1456_A12 (PG16) (TCN-117) CDR de Chothia de la cadena ligera lambda:
CDR 1: NGTSRDVGGFDSVS (SEQ ID NO: 93)
CDR 2: DVSHRPS (SEQ ID NO: 95)
CDR 3: SSLTDRSHRI (SEQ ID NO: 41)
1503_H05 (PG16) (TCN-119) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación 1503_H05 y3 (región variable en negrita)
ATGGAGTTTGGCTGAGCTGGGTTTTCCTCGCAACTCTGTTAAGAGTTGTGA AGTGTCAGGAAAAACTGGTGGAGTCTGGGGGAGGCGTGGTCCAGCCG GGGGGGTCCCTGAGACTCTCCTGTTTAGCGTCTGGATTCACCTTTCA CAAATATGGCATGCACTGGGTCCGCCAGGCTCCAGGCAAGGGCCTGG AGTGGGTGGCACTCATCTCAGATGACGGAATGAGGAAATATCATTCA GACTCCATGTGGGGCCGAGTCACCATCTCCAGAGACAATTCCAAGAA CACTTTATATCTGCAATTCAGCAGCCTGAAAGTCGAAGACACGGCTA TGTTCTTCTGTGCGAGAGAGGCTGGTGGGCCAATCTGGCATGACGAC GTC A AAT ATT ACGATTTT AATG ACGGCT ACT ACAATT ACC ACTAC ATG GACGTCTGGGGCAAGGGGACCATTGTCACCGTCTCCTCAGCGTCGAC CAAGGGCCCATCGGTCTTCCCTCTGGCACCATCATCCAAGTCGACCTCTG GGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCG GTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTT CCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGA CCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAAT CACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGG GGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGAT CTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAG ACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAAT GCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGG TCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTAC AAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCAT CTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCC CCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGT CAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGG CAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACG GCTCCTTCTTCCTCT AT AGC A AGCTC ACCGTGGAC A AGAGC AGGTGGC AG CAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCA CTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA (SEQ ID NO: 52)
1503_H05 (PG16) (TCN-119) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G G A A A A A C T G G T G G A G T C T G G G G G A G G C G T G G T C C A G C C G G G G G G G T
C C C T G A G A C T C T C C T G T T T A G C G T C T G G A T T C A C C T T T C A C A A A T A T G G C A
T G C A G T G G G T C C G C C A G G C T C C A G G C A A G G G C C T G G A G T G G G T G G C A C T C
A T C T C A G A T G A C G G A A T G A G G A A A T A T C A T T C A G A C T C C A T G T G G G G C C G
A G T C A C C A T C T C C A G A G A C A A T T C C A A G A A C A C T T T A T A T C T G C A A T T C A
G C A G C C T G A A A G T C G A A G A C A C G G C T A T G T r C r r C T G T G C G A G A G A G G C T
G G T G G G C C A A T C T G G C A T G A C G A C G T C A A A T A T T A C G A T T T T A A T G A C G G
C T A C T A C A A T T A C C A C T A C A T G G A C G T C T G G G G C A A G G G G A C C A T T G T C A
C C G T C T C C T C A ( S E Q ID N O : 132 )
1503_H05 (PG16) (TCN-119) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
Q E K L V E S G G G V V Q P G G S L R L S C L A S G F T F H K Y G M H W V R Q A P G K G L E W
V A L I S D D G M R K Y H S D S M W G R V T 1 S R D N S K N T L Y L Q F S S L K V E D T A M F F C
A R E A G G P I W H D D V K Y Y D F N D G Y Y N Y H Y M D V W G K G T I V T V S S A S T K G P S
V F P I A P S S K S T S G G T A A IX j C I A K D Y F P E P V T V S W N S G A I X S G V I I T F P A V I JQ S S
G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T K V D K R V E P K S C D K T H T C P P C P
A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S H E D P E V K F N W Y V D G V
E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D W L N G K E Y K C K V S N K A L P A P I E
K T 1 S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K G F Y P S D I A V E W E S N G
Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R W Q Q G N V F S C S V M H E A L H N H Y
T Q K S L S L S P G K ( S E Q I D N O : 53 ) .
1503_H05 (PG16) (TCN-119) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
O E K L V E S G G G V V O P G G S L R L S C L A S G F T F T / f t Y G M H W V R O A P G K G L E W V A L /S D /X j M I f Á T H S D S M W G R V T I S R D N S K N T L Y L O F S S L K V E D T A M F F C A R / v t G a n W H l ) l ) V K Y Y D F N I X i Y Y N Y H Y M 1 ) VW G K G T I V T V S S ( S E Q ID N O : 54 )
1503_H05 (PG16) (TCN-119) CDR de Kabat de cadena pesada gamma:
CDR 1: KYGMH (SEQ ID NO: 88)
CDR 2: LISDDGMRKYHSDSMWG (SEQ ID NO: 89)
CDR 3: EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6)
1503_H05 (PG16) (TCN-119) CDR de Chothia de la cadena pesada gamma:
CDR 1: GFTFHK (SEQ ID NO: 266)
CDR 2: LISDDGMRKY (SEQ ID NO: 267)
CDR 3: EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6)
1503_H05 (PG16) (TCN-119) secuencia de nucleótidos de cadena ligera lambda: 1503_H05 Secuencia de codificación A2 (región variable en negrita)
ATGGCCTGGGCTTGCTATTCCTCACCCTCTTCACTCAGGGCACAGGGTCCT GGGGCCAGTCTGCCCTGACTCAGCCTGCCTCCGTGTCTGGGTCTCCT GGACAGACGATCACCATCTCCTGCAATGGAACCAGAAGTGACGTTGG TGGATTT GACTCTGTCTCCTGGTACC AACAATCCCC AGGGAAAGCCC CCAAAGTCATGGTTTTTGATGTCAGTCATCGGCCCTCAGGTATCTCTA ATCGCTTCTCTGGCTCCAAGTCCGGCAACACGGCCTCCCTGACCATC TCTGGGCTCCACATTGAGGACGAGGGCGATTATTTCTGCTCTTCACT GACAGACAGAAGCCATCGCATATTCGGCGGCGGGACCAAGGTGACC GTTCTAGGTCAGCCCAAGGCTGCCCCCTCGGTCACTCTGTTCCCGCCCTC CTCTGAGGAGCTTCAAGCCAACAAGGCCACACTGGTGTGTCTCATAAGTG ACTTCTACCCGGGAGCCGTGACAGTGGCCTGGAAGGCAGATAGCAGCCCC GTCAAGGCGGGAGTGGAGACCACCACACCCTCCAAACAAAGCAACAACA AGTACGCGGCCAGCAGCTACCTGAGCCTGACGCCTGAGCAGTGGAAGTCC
CACAAAAGCTACAGCTGCCAGGTCACGCATGAAGGGAGCACCGTGGAGA AGACAGTGGCCCCTACAGAATGTTCATAG (SEQ ID NO: 55)
1503_H05 (PG16) (TCN-119) secuencia de nucleótidos de región variable de cadena ligera lambda:
C A G T C T G C C C T G A C T C A G C C T G C C T C C G T G T C T G G G T C T C C T G G A C A G A C G
A T C A C C A T C T C C T G C A A T G G A A C C A G A A G T G A C G T T G G T G G A T T T G A C T C
T G T C T C C T G G T A C C A A C A A T C C C C A G G G A A A G C C C C C A A A G T C A T G G T T T
T T G A T G T C A G T C A T C G G C C C T C A G G T A T C T C T A A T C G C T T C T C T G G C T C C A
A G T C C G G C A A C A C G G C C T C C C T G A C C A T C T C T G G G C T C C A C A 1 T G A G G A C
G A G G G C G A T T A T T T C T G C T C T T C A C T G A C A G A C A G A A G C C A T C G C A T A T T
C G G C G G C G G G A C C A A G G T G A C C G T T C T A ( S E Q 11) N O : 133 )
1503_H05 (PG16) (TCN-119) secuencia de aminoácidos de cadena ligera lambda: proteína expresada con región variable en negrita.
Q SALTQ PASVSG SPG Q TITISCNG TRSDVG G FDSVSW YQ Q SPG K APK VM V
FDVSH RPSG1SNRFSGSKSG NTASLTISG LH IEDEGDYFCSSLTDRSH RIFG
G G T K V T V L G Q P K A A P S V T L F P P S S E E L Q A N K A T L V C L I S D F Y P G A V T V A W K
A D S S P V K A G V E T T T P S K Q S N N K Y A A S S Y L S L T P H Q W K S U K v S Y S C Q V r i l F G S 1’ V E K T V A P T E C S ( S E Q II ) N O : 56 )
1503_H05 (PG16) (TCN-119) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)

1503_H05 (PG16) (TCN-119) CDR de Kabat de la cadena ligera de lambda:
CDR 1: NGTRSDVGGFDSVS (SEQ ID NO: 92)
CDR 2: DVSHRPS (SEQ ID NO: 95)
CDR 3: SSLTDRSHRI (SEQ ID NO: 41)
1503_H05 (PG16) (TCN-119) CDR de Chothia de la cadena ligera lambda:
CDR 1: NGTRSDVGGFDSVS (SEQ ID NO: 92)
CDR 2: DVSHRPS (SEQ ID NO: 95)
CDR 3: SSLTDRSHRI (SEQ ID NO: 41)
1489_I13 (PG16) (TCN-120) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación 1489_I13 y3 (región variable en negrita)
ATGGAGTTTGGGCTGAGCTGGGTTTTCCTCGCAACTCTGTTAAGAGTTGTG AAGTGTCAGGAACAACTGTTGGAGTCTGGGGGAGGCGTGGTCCAGCC GGGGGGGTCCCTGAGACTCTCCTGTTTAGCGTCTGGATTCACGTTTC
ACAAATATGGCATGCACTGGGTCCGCCAGGCTCCAGGCAAGGGCCTG GAGTGGGTGGCACTCATCTCAGATGACGGAATGAGGAAATATCATTC AAACTCCATGTGGGGCCGAGTCACCATCTCCAGAGACAATTCCAAGA ACACTCTTTATCTGCAATTCAGCAGCCTGAAAGTCGAAGACACGGCT ATGTTCTTCTGTGCGAGAGAGGCTGGTGGGCCAATCTGGCATGACGA CGTCAAATATTACGATTTTAATGACGGCTACTACAACTACCACTACAT GGACGTCTGGGGCAAGGGGACCACGGTCACCGTCTCCTCAGCGTCGA CCAAGGGCCCATCGGTCTTCCCTCTGGCACCATCATCCAAGTCGACCTCTG GGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCG GTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTT CCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGA CCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAAT CACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGG GGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGAT CTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAG ACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAAT GCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGG TCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTAC AAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCAT CTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCC CCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGT CAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGG CAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACG GCTCCTTCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAG CAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCA CTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA (SEQ ID NO: 58)
1489_I13 (PG16) (TCN-120) secuencia de nucleótidos de región variable de cadena pesada gamma:

Secuencia de aminoácidos de cadena pesada gamma 1489_I13 (PG16) (TCN-120): proteína expresada con región variable en negrita.
Q E Q L L E S G G G V V Q P G G S L R L S C L A S G F T F H K Y G M H W V R Q A P G K G L E W
V A L I S D D G M R K Y H S N S M W G R V T I S R D N S K N T L Y L Q F S S L K V E D T A M F F C
A R E A G G P I W H D D V K Y Y D F N D G Y Y N Y H Y M D V W G K G T T V T V S S A S T K G P S
V F P 1.A P vS S K S T vS G G T A A I X3CI .V K D Y F P E P V T V S W N S G A I /T S G V Í I T F P A V I jQ S S
G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T K V D K R V E P K S C D K T H T C P P C P
A P E L L G G P S V F L F P P K P K D T L M 1 S R T P E V T C V V V D V S H E D P E V K F N W Y V D G V
E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D W L N G K E Y K C K V S N K A L P A P I E
K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K G F Y P S D I A V E W E S N G
Q P E N N Y K T T P P V I .D S D G S F F I ,Y S K I T V D K S R W Q Q G N V F S C S V M H E A I ,I I N I I Y
T Q K S L S L S P C iK (S E Q II) N O : 59 )
1489_I13 (PG16) (TCN-120) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
Q H Q IA ,E S G G G V V Q P G G S L R L S C I A S G F T F H K Y i ¡M I IW V R Q A P G K G I E W V A A I S D D G M R K Y l 1SN SM W C ¡R V T I S R D N S K N T I Y E O F S S I .K V E D T A M F F C A R A V H i ( ; r ¡ W H D I ) V K Y Y D 1 N I X , Y Y N Y H Y M I ) V WC i K ( ¡T T V T V S S (S E Q ID N O : 60 )
1489_I13 (PG16) (TCN-120) CDR de Kabat de la cadena pesada gamma:
CDR 1: KYGMH (SEQ ID NO: 88)
CDR 2: LISDDGMRKYHSNSMWG (SEQ ID NO: 98)
CDR 3: EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6)
1489_I13 (PG16) (TCN-120) CDR de Chothia de la cadena pesada gamma:
CDR 1: GFTFHK (SEQ ID NO: 266)
CDR 2: LISDDGMRKY (SEQ ID NO: 267)
CDR 3: EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6)
1489_I13 (PG16) (TCN-120) secuencia de nucleótidos de cadena ligera lambda: secuencia de codificación 1489_I13 A2 (región variable en negrita)
A T G G C C T G G G C T C T G C T A 1 T C C T C A C C C T C T T C A C T C A G G G C A C A G G G T C C
C G G G G G C A G T C T G C C C T G A C T C A G C C T G C C T C C G T G T C T G G G T C T C C T
G G A C A G A C G A T C A C C A T C T C C T G C A A T G G A A C C A G C A G T G A C G T T G G
T G G A T T T G A C T C T G T C T C C T G G T A T C A A C A A T C C C C A G G G A A A G C C C
C C A A A G T C A T G G T T T T T G A T G T C A G T C A T C G G C C C T C A G G T A T C T C T A
A T C G C T T C T C T G G C T C C A A G T C C G G C A A C A C G G C C T C C C T G A C C A T C
T C T G G G C T C C A C A T T G A G G A C G A G G G C G A T T A T T T C T G C T C T T C A C T
G A C A G A C A G A A G C C A T C G C A T A T T C G G C G G C G G G A C C A A G G T G A C C
G T T C T A G G T C A G C C C A A G G C T G C C C C C T C G G T C A C T C T G T T C C C G C C C T C
C T G T G A G G A G C T T C A A G C C A A C A A G G C C A C A C T G G T G T G T C T C A T A A G T G
A C T T C T A C C C G G C A G C C G T G A C A G T G O C C T G G A A G G C A G A T A G C A G G C C C
G T C A A G G C G G G A G T G G A G A C C A C C A C A C C C T C C A A A C A A A G C A A C A A C A
A G T A G G C G G C C A G C A G C T A C C T G A G C C T G A C G C C T G A G G A G T G G A A G T C C
C A C A A A A G C T A C A G C T G C C A G G T C A C G C A T G A A G G G A G C A C C G T G G A G A
A G A C A G T G G C C C C T A C A G A A T G T T C A T A G ( S E Q ID N O : 61 )
1489_I13 (PG16) (TCN-120) secuencia de nucleótidos de región variable de cadena ligera lambda:
C A G T C T G C C C T G A C T C A G C C T G C C T C C G T G T C T G G G T C T C C T G G A C A G A C G
A T C A C C A T C T C C T G C A A T G G A A C C A G C A G T G A C O T T G G T G G A T T T G A C T C
T G T C T C C T G G T A T C A A C A A T C C C C A G G G A A A G C C C C C A A A G T C A T G G T T T
T T G A T G T C A G T C A T C G G C C C T C A G G T A T C T C T A A T C G C T T C T C T G G C T C C A
A G T C G G G C A A C A C G G C C T C C C T G A C C A T C T C T G G G C T C C A C A T T G A G G A C
G A G G G C G A T T A T T T C T G C T C T T C A C T G A C A G A C A G A A G C C A T C G C A T A T T
C G G C G G C G G G A G C A A G G T G A C C G T T C T A (S E Q II) N O : 135 )
1489_I13 (PG16) (TCN-120) secuencia de aminoácidos de cadena ligera lambda: proteína expresada con región variable en negrita.
Q S A L T Q P A S V S G S P G Q T I T I S C N G T S S D V G G F D S V S W Y Q Q S P G K A P K V M V
F D V S H R P S G I S N R F S G S K S G N T A S L T I S G L H I E D E G D Y F C S S L T D R S H R I F G
G G T K V T V L G Q P K A A P S V T L F P P S S E E L Q A N K A T L V C L I S D F Y P G A V T V A W K
A D S S P V K A G V E T T T P S K Q S N N K Y A A S S Y L S L T P E Q W K S H K S Y S C Q V T H E G S T
V E K T V A P T E C S ( S E Q I D N O : 14 )
1489_I13 (PG16) (TCN-120) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva).
O S A i : r O P A S V S G S P G O i r n S C A (;7 :S \S 7 )E (; ( ; /7 X S K S ’W Y O O S P G K A P K V M V E /) K S 7 //e />S G lS N R l S G S K S G N r A S i: H S G L H lE D i: G D Y E C \S \S 72 /7 ) ^ S 7 / / f /P G G G I’K V T V L ( S E Q II) N O : 32 )
1489_I13 (PG16) (TCN-120) CDR de Kabat de cadena ligera lambda:
CDR 1: NGTSSDVGGFDSVS (SEQ ID NO: 97)
CDR 2: DVSHRPS (SEQ ID NO: 95)
CDR 3: SSLTDRSHRI (SEQ ID NO: 41)
1489_I13 (PG16) (TCN-120) CDR de Chothia de la cadena ligera lambda:
CDR 1: NGTSSDVGGFDSVS (SEQ ID NO: 97)
CDR 2: DVSHRPS (SEQ ID NO: 95)
CDR 3: SSLTDRSHRI (SEQ ID NO: 41)
1480_I08 secuencia de nucleótidos de cadena pesada gamma: 1480_I08 y3 secuencia de codificación (región variable en negrita)
ATGGAGTTTGGCTGAGCTGGGTTTTCCTCGCAACTCTGTTAAGAGTTGTGA AGTGTCAGGAACAACTGGTGGAGTCTGGGGGAGGCGTGGTCCAGCCG GGGGGGTCCCTGAGACTCTCCTGTTTAGCGTCTGGATTCACGTTTCA CAAATATGGCATGCACTGGGTCCGCCAGGCTCCAGGCAAGGGCCTGG AGTGGGTGGCACTCATCTCAGATGACGGAATGAGGAAATATCATTCA GACTCCATGTGGGGCCGAGTCACCATCTCCAGAGACAATTCCAAGAA CACTCTTTATCTGCAATTCAGCAGCCTGAAAGTCGAAGACACGGCTA TGTTCTTCTGTGCGAGAGAGGCTGGTGGGCCAATCTGGCATGACGAC
GTCAAAT ATT ACG ATTTTAATG ACGGCT ACT AC AACT ACCACT ACATG GACGTCTGGGGCAAGGGGACCACGGTCACCGTCTCCTCAGCGTCGAC CAAGGGCCCATCGGTCTTCCCTCTGGCACCATCATCCAAGTCGACCTCTG GGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCG GTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTT CCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGA CCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAAT CACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGG GGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGAT CTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAG ACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAAT GCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGG TCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTAC AAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCAT CTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCC CCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGT CAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGG CAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACG GCTCCTTCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAG CAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCA CTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA (SEQ ID NO: 64)
1480_I08 secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G G A A C A A C T G G T G G A G T C T G G G G G A G G C G T G G T C C A G C C G G G G G G G T
C C C T G A G A C T C T C C T G T T T A G C G T C T G G A T T C A C G T T T C A C A A A T A T G G C A
T G C A C T G G G T C C G C C A G G C T C C A G G C A A G G G C C T G G A G T G G G T G G C A C T C
A T C T C A G A T G A C G G A A T G A G G A A A T A T C A T T C A G A C T C C A T G T G G G G C C G
A G T C A C C A T C T C C A G A G A C A A T T C C A A G A A C A C T C T T T A T C T G C A A T T C A
G C A G C C T G A A A G T G G A A G A C A C G G C T A T G T T C T T C T G T G C G A G A G A G G C T
G G T G G G C C A A T C T G G C A T G A C G A C G T C -A A A T A T T A C G A T T T T A A T G A C G G
C T A C T A C A A C T A C C A C T A C A T G G A C G T C T G G G G C A A G G G G A C C A C G G T C A
C C G T C T C C T C A ( S E Q ID N O : 136 )
1480_I08 de secuencia de aminoácidos de la cadena pesada gamma: proteína expresada con región variable en negrita.
Q E Q L V E S G G G V V Q P G G S L R L S C L A S G F T F H K Y G M H W V R Q A P G K G L E W
V A L I S D D G M R K Y H S D S M W G R V T I S R D N S K N T L Y L Q F S S L K V E D T A M F F C
A R E A G G P I W H D D V K Y Y D F N D G Y Y N Y H Y M D V W G K G T T V T V S S A S T K G P S
V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S G A L T S G V H T F P A V L Q S S
G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T K V D K R V E P K S C D K T H T C P P C P
A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S H E D P E V K F N W Y V D G V
E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D W L N G K E Y K C K V S N K A L P A P I E
K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K G F Y P S D I A V E W E S N G
Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R W Q Q G N V F S C S V M H E A L H N H Y
T Q K S L S L S P G K (S E Q I D N O : 65 )
1480_I08 secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
O E Q L V E S G G G V V O P G G S L R L S C L A S G /'T f T / Á T G M I I W V R O A P G K G L E W V A L /S 7 X X > 'M /f Á T l lS D S M W G R V T I S R D N S K N T E Y E O F S S C K V E D T A M F F C A R / i / \ ( i ( ; n i \ Y I I I ) l ) V K Y Y I ) l X I H i Y Y N Y H Y M i n ' W G K G T T V T V S S ( S E Q I D N O : 31 )
1480_I08 CDR de Kabat de cadena pesada gamma:
CDR 1: KYGMH (SEQ ID NO: 88)
CDR 2: LISDDGMRKYHSDSMWG (SEQ ID NO: 89)
CDR 3: EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6)
1480_I08 CDR de Chothia de la cadena pesada gamma:
CDR 1: GFTFHK (SEQ ID NO: 266)
CDR 2: LISDDGMRKY (SEQ ID NO: 267)
CDR 3: EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6)
1480_I08 secuencia de nucleótidos de cadena ligera lambda: 1480_I08nn2 secuencia de codificación (la región variable en negrita)
ATGGCCTGGGCTCTGCTATTCGTCACCCTCCTCACTCAGGGCACAGGGTCC TGGGGCCAGTCTGCCCTGACTCAGCCTGCCTCCGTGTCTGGGTCTCCT GGACAGACGATCACCATCTCCTGCAATGGAACCAGCAGTGACGTTGG TGGATTTGACTCTGTCTCCTGGTATCAACAATCCCCAGGGAAAGCCC CCAAAGTCATGGTTTTTGATGTCAGTCATCGGCCCTCAGGTATCTCTA ATCGCTTCTCTGGCTCCAAGTCCGGCAACACGGCCTCCCTGACCATC TCTGGGCTCCACATTGAGGACGAGGGCGATTATTTCTGCTCTTCACT GACAGACAGAAGCCATCGCATATTCGGCGGCGGGACCAAGGTGACC GTTCTAGGTCAGCCCAAGGCTGCCCCCTCGGTCACTCTGTTCCCGCCCTC CTCTGAGGAGCTTCAAGCCAACAAGGCCACACTGGTGTGTCTCATAAGTG ACTTCTACCCGGGAGCCGTGACAGTGGCCTGGAAGGCAGATAGCAGCCCC GTCA AGGCGGGAGTGGAGACCACCACACCCTCCAA ACAA AGCAACA ACA AGTACGCGGCCAGCAGCTACCTGAGCCTGACGCCTGAGCAGTGGAAGTCC CACAAAAGCTACAGCTGCCAGGTCACGCATGAAGGGAGCACCGTGGAGA AGACAGTGGCCCCTACAGAATGTTCATAG (SEQ ID NO: 67)
1480_I08 secuencia de nucleótidos de región variable de cadena ligera lambda:
C A G T C T G C C C T G A C T C A G C C T G C C T C C G T G T C T G G G T C T C C T G G A C A G A C G
A T C A C C A T C T C C T G C A A T G G A A C C A G C A G T G A C G T T G G T G G A T T T G A C T C
T G T C T C C T G G T A T C A A C A A T C C C C A G G G A A A G C C C C C A A A G T C A T G G T T T
T T G A T G T C A G T C A T C G G C C C T C A G G T A T C T C T A A T C G C T T C T C T G G C T C C A
A G T C C G G C A A C A C G G C C T C C C T G A C C A T C T C T G G G C T C C A C A T T G A G G A C
G A G G G C G A T T A T T T C T G C T C T T C A C T G A C A G A C A G A A G C C A T C G C A T A T T
C G G C G G C G G G A C C A A G G T G A C C G T T C T A ( S E Q ID N O : 137 )
1480_I08 secuencia de aminoácidos de cadena ligera lambda: proteína expresada con región variable en negrita.
Q SALTQ PASVSG SPG Q TITISCNG TSSDVG G FDSVSW YQ Q SPG K APK VM V
FD VSH RPSG ISNRFSG SK SG NTASLTISG LH IEDEG DYFCSSLTDRSH RIFG
G G T K V T V L G Q P K A A P S V T L F P P S S E E L Q A N K A T L V C L I S D F Y P G A V T V A W K
A D S S P V K A G V E T T T P S K Q S N N K Y A A S S Y L S L T P E Q W K S H K S Y S C Q V T H E G S T
V E K T V A P T E C S ( S E Q I I ) N O : 14 )
1480_I08 secuencia de aminoácidos de región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)

1480_I08 CDR de Kabat de la cadena ligera lambda:
CDR 1: NGTSSDVGGFDSVS (SEQ ID NO: 97)
CDR 2: DVSHRPS (SEQ ID NO: 95)
CDR 3: SSLTDRSHRI (SEQ ID NO: 41)
1480_I08 CDR de Chothia de la cadena ligera lambda:
CDR 1: NGTSSDVGGFDSVS (SEQ ID NO: 97)
CDR 2: DVSHRPS (SEQ ID NO: 95)
CDR 3: SSLTDRSHRI (SEQ ID NO: 41)
El anticuerpo 1469_M23 (PG16) incluye una región variable de cadena pesada (SEQ ID NO: 139), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 128, y una luz región variable de cadena (SEQ ID NO: 142) codificada por la secuencia de ácido nucleico mostrada en la SEQ ID NO: 129.
Las CDR de cadena pesada del anticuerpo 1469_M23 (PG16) tienen las siguientes secuencias por definiciones Kabat y Chothia: KYGMH (SEQ ID NO: 88), LISDDGMRKYHSDSMWG (SEQ ID NO: 89) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6). Las CDR de cadena ligera del anticuerpo 1469_M23 (PG16) tienen las siguientes secuencias según las definiciones de Kabat y Chothia: NGTRSDVGGFDSVS (SEQ ID NO: 92), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41).
El anticuerpo 1456_A12 (PG16) incluye una región variable de cadena pesada (SEQ ID NO: 47), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 130, y una región variable de cadena ligera (SEQ ID NO: 50) codificada por el secuencia de ácido nucleico mostrada en la SEQ ID NO: 131.
Las CDR de cadena pesada del anticuerpo 1456_A12 (PG16) tienen las siguientes secuencias por definiciones de Kabat y Chothia: KYGMH (SEQ ID NO: 88), LISDDGMRKYHSDSMWG (SEQ ID NO: 89) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6). Las CDR de cadena ligera del anticuerpo 1456_A12 (PG16) tienen las siguientes secuencias según las definiciones de Kabat y Chothia: NGTSRDVGGFDSVS (SEQ ID NO: 93), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41).
El anticuerpo 1503_H05 (PG16) incluye una región de cadena pesada variable (SEQ ID NO: 53), codificada por la secuencia de ácido nucleico mostrada en la SEQ ID NO: 132, y una región variable de cadena ligera (SEQ ID NO: 56) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 133.
Las CDR de cadena pesada del anticuerpo 1503_H05 (PG16) tienen las siguientes secuencias por definiciones de Kabat y Chothia: KYGMH (SEQ ID NO: 88), LISDDGMRKYHSDSMWG (SEQ ID NO: 89) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6). Las CDR de cadena ligera del anticuerpo 1503_H05 (PG16) tienen las siguientes secuencias según las definiciones de Kabat y Chothia: NGTRSDVGGFDSVS (SEQ ID NO: 92), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41).
El anticuerpo 1489_I13 (PG16) incluye una región variable de cadena pesada (SEQ ID NO: 59), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 134, y una región variable de cadena ligera (SEQ ID NO: 14) codificada por el ácido nucleico de secuencia de ácido se muestra en la SEQ ID NO: 135.
Las CDR de cadena pesada del anticuerpo 1489_I13 (PG16) tienen las siguientes secuencias por definiciones Kabat y de Chothia: KYGMH (SEQ ID NO: 88), LISDDGMRKYHSNSMWG (SEQ ID NO: 98) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6). Las CDR de cadena ligera del anticuerpo 1489_I13 (PG16) tienen las siguientes secuencias según las definiciones de Kabat y Chothia: NGTSSDVGGFDSVS (SEQ ID NO: 97), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41).
El anticuerpo 1480_I08 (PG16) incluye una región variable de cadena pesada (SEQ ID NO: 65), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 136, y una región variable de cadena ligera (SEQ ID NO: 14) codificada por el ácido nucleico de secuencia de ácido se muestra en la SEQ ID NO: 137.
Las CDR de cadena pesada del anticuerpo 1480_I08 (PG16) tienen las siguientes secuencias por definiciones Kabat y de Chothia: KYGMH (SEQ ID NO: 88), LISDDGMRKYHSDSMWG (SEQ ID NO: 89) y EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6). Las CDR de cadena ligera del anticuerpo 1480_I08 (PG16) tienen las siguientes secuencias según las definiciones de Kabat y Chothia: NGTSSDVGGFDSVS (SEQ ID NO: 97), DVSHRPS (SEQ ID NO: 95) y SSLTDRSHRI (SEQ ID NO: 41).
Se determinaron las secuencias de anticuerpos monoclonales humanos adicionales, incluidas las secuencias de las regiones variables de las cadenas pesadas Gamma y Kappa o Lambda. Además, se determinó la secuencia de cada uno de los polinucleótidos que codifican las secuencias de anticuerpos. A continuación se muestran las secuencias de polipéptidos y polinucleótidos de las cadenas pesadas gamma y las cadenas ligeras kappa, con los péptidos señal en el extremo N (o extremo 5') y las regiones constantes en el extremo C (o extremo 3') de las regiones variables, que se muestran en texto en negrita.
4838_L06 (PGT-121) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
A T G A A A C A C C T G T G G T T C T T C C T T C T C C T G G T G G C A G C T C C C A G A T G G G T C
C T G T C A C A G A T G C A G T T A C A G G A G T C G G G C C C C G G A C T G G T G A A G C C
T T C G G A A A C C C T G T C C C T C A C G T G C A G T G T G T C T G G T G C C T C C A T A A
G T G A C A G T T A C T G G A G C T G G A T C C G G C G G T C C C C A G G G A A G G G A C T T
G A G T G G A T T G G G T A T G T C C A C A A A A G C G G C G A C A C A A A T T A C A G C C C
C T C C C T C A A G A G T C G A G T C A A C T T G T C G T T A G A C A C G T C C A A A A A T C
A G G T G T C C C T G A G C C T T G T G G C C G C G A C C G C T G C G G A C T C G G G C A A A
T A T T A T T G C G C G A G A A C A C T G C A C G G G A G G A G A A T T T A T G G A A T C G T
T G C C T T C A A T G A G T G G T T C A C C T A C T T C T A C A T G G A C G T C T G G G G C A
A T G G G A C T C A G G T C A C C G T C T C C T C A G C C T C C A C C A A G G G C C C A T C G G
T C 1 T C C C C C T G G C A C C C T C C T C C A A G A G C A C C T C T G G G G G C A C A G C G G C C
C T G G G C T G C C T G G T C A A G G A C T A C T T C C C C G A A C C G G T G A C G G T G T C G T G
G. A A C T C A G G C G C C C T G A C C A G C G G C G T G C A C A C C T T C C C G G C T G T C C T A C
A G T C C T C A G G A C T C T A C T C C C T C A G C A G C G T G G T G A C C G T G C C C T C C A G C
A G C T T G G G C A C C C A G A C C T A C A T C T G C A A C G T G A A T C A C A A G C C C A G C A A
C A C C A A G G T G G A C A A G A G A G T T G A G C C C A A A T C T T G T G A C A A A A C T C A C
A C A T G C C C A C C G T G C C C A G C A C C T G A A C T C C T G G G G G G A C C G T C A G T C T T
C C T C T T C C C C C C A A A A C C C A A G G A C A C C C T C A T G A T C T C C C G G A C C C C T G
A G G T C A C A T G C G T G G T G G T G G A C G T G A G C C A C G A A G A C C C T G A G G T C A A
G 1 T C A A C T G G T A C G T G G A C G G C G T G G A G G T G C A T A A T G C C A A G A C A A A G
C C G C G G G A G G A G C A G T A C A A C A G C A C G T A C C G T G T G G T C A G C G T C C T C A C
C G T C C T G C A C C A G G A C T G G C T G A A T G G C A A G G A G T A C A A G T G C A A G G T C T
C C A A C A A A G C C C T C C C A G C C C C C A T C G A G A A A A C C A T C T C C A A A G C C A A A
G G G C A G C C C C G A G A A C C A C A G G T G T A C A C C C T G C C C C C A T C C C G G G A G G
A G A T G A C C A A G A A C C A G G T C A G C C T G A C C T G C C T G G T C A A A G G C T T C T A T
C C C A G C G A C A T C C C C G T C G A G T C G G A G A G C A A T G G O C A G C C G O A G A A C A
A C T A C A A G A C C A C G C C T C C C G T G C T G G A C T C C G A C G G C T C C T T C T T C C T C T
A T A G C A A G C T C A C C G T G G A C A A G A G C A G G T G G C A G C A G G G G A A C G T C T T
C T C A T G C T C C G T O A T G C A T G A G G C T C T O C A C A A C C A C T A C A C G C A G A A G A
G C C T C T C C C T G T C T C C G G G T A A A T G A ( S E Q II) N O : 62 )
4838_L06 (PGT-121) secuencia de nucleótidos de la región variable de la cadena pesada gamma:
CAGATGCAGTrACAGGAGTCGGGCCCCGGACTGGTGAAGCCTTCGGAAA
CCCTGTCCCTCACGTGCAGTGTGTCTGGTGCCTCCATAAGTGACAGTTACT
GGAGCTGGATCCGGCGGTCCCCAGGGAAGGGACTTGAGTGGATTGGGTAT
GTCCACAAAAGCGGCGACACAAATTACAGCCCCTCCCTCAAGAGTCGAGT
CAACTTGTCGTTAGACACGTCCAAAAATCAGGTGTCCCTGAGCCTTGTGG
CCGCGACCGCTGCGGACTCGGGCAAATATTATTGCGCGAGAACACTGCAC
GGG AGGAG A ATTT ATGGA ATCGTTGCCTTC A ATG AGTGGTTCACCT ACTT
CTACATGGACGTCTGGGGCAATGGGACTCAGGTCACCGTCTCCTCA
ID NO: 63)
4838_L06 (PGT-121) de la cadena gamma pesada de secuencia de aminoácidos: proteína expresada con región variable en negrita.
Q M Q L Q E S G P G L V K P S E T L S L T C S V S G A S I S D S Y W S W I R R S P G K G L E W I G Y
V H K S G D T N Y S P S L K S R V N L S L D T S K N Q V S L S L V A A T A A D S G K Y Y C A R T L H
G R R 1 Y G I V A F N E W F T Y F Y M D V W G N G T Q V T V S S A S T K G P S V F P L A P S S K S T S
G G TA A LG C LV K D Y FPE PV T V SW N SG A L TSG V H TFPA V L Q SSG L Y SL SSV V T V
PSSSLGTQTYICNVNFTKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVF
LFPPK PK D TLM ISR TPEV TC V V V D V SH ED PEV K FN W Y V D G V EV H N A K TK PR
EEQ Y NSTYR VV SVLTVLH Q DW LNG K EYK CK VSN K A LPA PIEK TISK AK G Q PR
EPQ V YTLPPSR EEM TK N Q V SLTCLVK G FY PSD IA VEW ESN G Q PEN NY K TTPP
V L D SD G SFFLY SK LTV D K SR W Q Q G N V FSC SV M H EA LH N H Y TQ K SLSLSPG K
(SEQ ID NO: 66)
4838_L06 (PGT-121) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
QMOLOESGPGLVKPSETESLTCSVSGA.S/.SDSYW SWIRRSPGKGLEWIGFV //A
S'G/r/’AYSPSEKSRVNESEDTSKNOVSESEVAATAADSGKYYCARY’/J /O ’ftft/F (¡I VA I N i : \M TYl Y MI) FWGNGTOVTVSS (SEQ ID NO: 79)
4838_L06 (PGT-121) CDR de Kabat de cadena pesada gamma:
CDR 1: DSYWS (SEQ ID NO: 90)
CDR 2: YVHKSGDTNYSPSLKS (SEQ ID NO: 265)
CDR 3: TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143)
4838_L06 -121) CDR de Chothia de la cadena pesada gamma:
CDR 1: GASISD (SEQ ID NO: 144)
CDR 2: YVHKSGDTN (SEQ ID NO: 145)
CDR 3: TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143)
4838_L06 (PGT-121) secuencia de nucleótidos de cadena ligera lambda: secuencia de codificación (región variable en negrita)
ATGGCCrGGACCTTTCTCCTCCTCGGCCTCCTCTCTCACTGCACAGCCTCT
G TG ACCTCCG ATATATCTG TG GCCCCAG GAGAGACG GCCAGG ATTTC
CTG TG G G G AAAAG AG CCTTG G AAG TAG AG CTG TACAATG G TATCAAC
AC AG G G CCG G CCAG G CCCCCTCTTTAATCATATATAATAATCAG G AC
CG G CCCTCAG G G ATCCCTG AG CG ATTCTCTG G CTCCCCTG ACTCCCC
TTTTG G G ACCACG G CCACCCTG ACCATCACCAG TG TCG AAG CCG G G G
ATG A G G CC G A CTATTACTG TCATATATG G G ATAG TAG AG TTCCCACC
AAATGGGTCTTCGGCGGAGGGACCACGCTGACCGTGTTAGGTCAGCC
CAAGGCTGCCCCCTCGGTCACTCTGTTCCCGCCCTCCTCTGAGGAGCTTCA
AGCC A AC A AGGCC AC ACTGGTGTGTCTG ATA AGTG ACTTCT ACCCGGG AG
CCGTGACAGTGGCCTGGAAGGCAGATAGCAGCCCCGTCAAGGCGGGAGT
GG AG ACC ACC AC ACCCTCC A A AC A A AGC A AC A AC A AGT ACGCGGCC AGC
AGCT ACCTGAGCCTGACGCCTG AGCAGTGGA AGTCCCACA A AAGCT ACA
GCTGCCAGGTCACGCATGAAGGGAGCACCGTGGAGAAGACAGTGGCCCC
T AC AG A ATGTTC AT AG (SEQ ID NO: 146)
4838_L06 (PGT-121) secuencia de nucleótidos de región variable de cadena ligera lambda:
TCCGATATATCTGTGGCCCCAGGAGAGACGGCCAGGATTTCCTGTGGGGA
AAAGAGCCTTGGAAGTAGAGCTGTACAATGGTATCAACACAGGGCCGGC
CAGGCCCCCTCTTTAATCATATATAATA ATCAGGACCGGCCCTCAGGGAT
CCCTGAGCGATTCTCTGGCTCCCCTGACTCCCCTTTTGGGACCACGGCCAC
CCTGACC ATCACC AGTGTCGAAGCCGGGG ATG AGGCCG ACT ATT ACTGTC
ATATATGGGATAGTAGAGTTCCCACCAAATGGGTCTTCGGCGGAGGGACC
ACGCTGACCGTGTTA (SEQ ID NO: 147)
4838_L06 (PGT-121) secuencia de aminoácidos de cadena ligera lambda: proteína expresada con región variable en negrita.
SD ISVAPG ETARISCG EK SLG SRAVQ W YQ H RAG Q APSLIIYNNQ DRPSG IP
ER FSG SPDSPFG TTATLTITSVEAG DEADYYCH IW DSRVPTK W VFG G G TT
LTVLGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKADSSP
VKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHKSYSCQVTIIEGSTVEKTV
APTECS (SEQ ID NO: 148)
4838_L06 (PGT-121) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
SDISVAPGETAR1SCG7CÁ',S7>GS/?A YOW YOIIRAGOAPSLllYMVODAPSGIPHRF SGSPDSPrG'rrATLTITSVEAGDEADYYC7//U7ES7eV// >7’A,H T I:GGGrriE T V E
(SEQ ID NO: 149)
4838_L06 (PGT-121) CDR de Kabat de cadena ligera lambda:
CDR 1: GEKSLGSRAVQ (SEQ ID NO: 150)
CDR 2: NNQDRPS (SEQ ID NO: 151)
CDR 3: HIWDSRVPTKWV (SEQ ID NO: 152)
4838_L06 (PGT-121) CDR de Chothia de la cadena ligera lambda:
CDR 1: GEKSLGSRAVQ (SEQ ID NO: 150)
CDR 2: NNQDRPS (SEQ ID NO: 151)
CDR 3: HIWDSRVPTKWV (SEQ ID NO: 152)
4873_E03 (PGT-121) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
ATGAAACACCTGTGGTTCTTCCTTCTCCTGGTGGCAGCTCCCAGATGGGTC
CTGTCCAGATG CAGTTACAGG AG TCGG GCCCCG GACTG G TGAAG CCT
TCGG AAACCCTG TCCCTCACG TG CAG TG TG TCTG G TG CCTCCATAAG
TG ACAG TTACTG G AG CTG G ATCCG G CG G TCCCCAG G G AAG G G ACTTG
AG TG G ATTG G G TATG TCCACAAAAG CG G CG ACACAAATTACATCCCC
TCCCTCAAG AG TCG AG TCAACTTG TCG TTAG ACACG TCCAAAAATCA
G G TG TCCCTG AG CCTTG TG G CCG CG ACCG CTG CG G ACTCG G G CAAAT
ATTA TTG CG CG AG AACACTG CACG G G AG G AG AATTTATG G AATCG TT
G CCTTCAATG AG TG G TTCACCTACTTCTACATG G ACG TCTG G G G CAA
TGGGACTCAGGTCACCGTCTCCTCAGCCTCCACCAAGGGCCCATCGGTC
TTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCT
GGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGA
ACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAG
TCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAG
CTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACA
CCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAAAACTCACAC
ATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCC
TC1TCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAG
GTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTT
CAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCG
GGGG AGG AGC AGT AC A ACAGC ACGT ACCGTGTGGTCAGCGTCCTCACCGT
CCTGC ACC AGG ACTGGCTGA ATGGC A AGG AGT AC A AGTGC A AGGTCTCC
AACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAG
GGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGA
GATGACCAAGAACCAGGTCAGGCTGACCTGCCTGGTCAAAGGCTTCTATC
CCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAA
CTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTA
TAGCAAGCTCACCGTGGAC'AAGAGCAGGTGGCAGCAGGGGAACGTCTTC
TCATGCTCCGTGATGCATGAGGGTCTGCACAACCACTACACGCAGAAGAG
CCTCTCCCTGTCTCCGGGTAAATGA (SEQ I D N O : 62 )
4873_E03 (PGT-121) secuencia de nucleótidos de región variable de cadena pesada gamma:
CAGATGCAGTTACAGGAGTCGGGCCCCGGACTGGTGAAGCCTTCGGAAA
CCCTGTCCCTCACGTGCAGTGTGTCTGGTGGCTCCATAAGTGACAGTTACT
GGAGCTGGATCCGGCGGTCCCCAGGGAAGGGACTTGAGTGGATTGGGTAT
GTCCACAAAAGCGGCGACACAAATTACAGCCCCTCCCTCAAGAGTCGAGT
CAACTTGTCGTTAGACACGTCCAAAAATCAGGTGTCCCTGAGGCTTGTGG
CCGCGACCGCTGCGGACTCGGGCAAATATTATTGCGCGAGAACACTGCAC
GGGAGGAGAA1TTATGGAATCGTTGCCITCAATGAGTGGTTCACCTACTT
CTACATGGACGTCTGGGGCAATGGGACTCAGGTCACCGTCTCC1-CA
ID NO: 63)
4873_E03 (PGT-121) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
M K H L W F F L L L V A A P R W V L S Q M Q L Q E S G P G L V K P S E T L S L T C S V S G A S I S D S Y W S W I R R S P G K G L E W I G Y V H K S G D T N Y I P S L K S R V N L S L D T S K N Q V S L S L V A A T A A D S G K Y Y C A R T L H G R R I Y G I V A F N E W F T Y F Y M D V W G N G T Q V TVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSG VHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKS CDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPE VKFNW YVDGVEVIINAKTKPREEQYNSTYRVVSVITVI ,1IQDWI .NGKEYKC KVSNKALPAPIEKT1SKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYP SDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCS VMHEALHNHYTQKSLSLSPGK (SEQ ID NO: 66)
4873_E03 (PGT-121) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
OMOI -OESGPG.EVKPSETI .SLTCSVSGASISDS'YWS'WIRRSPGKGIEWIG YVHK
SGDTNYSPS] -KSRVNI .SLDTSKNQVSI .SI ,VAATAADSGKYYCAR77>//G7?ff/F (¡IVAFNEWFTYFYMD VWGNGTO VT VSS (SEQ ID NO: 79)
4873_E03 (PGT-121) CDR de Kabat de cadena pesada gamma:
CDR 1: DSYWS (SEQ ID NO: 90)
CDR 2: YVHKSGDTNYSPSLKS (SEQ ID NO: 265)
CDR 3: TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143)
4873_E03 -121) CDR de Chothia de la cadena pesada gamma:
CDR 1: GASISD (SEQ ID NO: 144)
CDR 2: YVHKSGDTN (SEQ ID NO: 145)
CDR 3: TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143)
4873_E03 (PGT-PG0 -73)) secuencia de nucleótidos de cadena ligera lambda: secuencia de codificación (región variable en negrita)
ATGGCCTGGACCTTTCTCCTCCTCGGCCTCCTCTCTCAGTGCACAGCCTCT
G T G A C C T C C G A T A T A T C T G T G G C C C C A G G A G A G A C G G C C A G G A T T T C
C T G T G G G G A A A A G A G C C T T G G A A G T A G A G C T G T A C A A T G G T A T C A A C
A C A G G G C C G G C C A G G C C C C C T C T T T A A T C A T A T A T A A T A A T C A G G A C
C G G C C C T C A G G G A T C C C T G A G C G A T T C T C T G G C T C C C C T G A C T C C C C
T T T T G G G A C C A C G G C C A C C C T G A C C A T C A C C A G T G T C G A A G C C G G G G
A T G A G G C C G A C T A T T A C T G T C A T A T A T G G G A T A G T A G A G T T C C C A C C
A A A T G G G T C T T C G G C G G A G G G A C C A C G C T G A C C G T G T T A G G T C A G C C
CAAGGCTGCCCCCTCGGTCACTCTGTTCCCGCCCTCCTCTGAGGAGCTTCA
AGCC A ACA AGGCC ACACTGGTGTGTCTC AT A AGTG ACTTCT ACCCGGG AG
CCGTGACAGTGGCCTGGAAGGCAGATAGCAGCCCCGTCAAGGCGGGAGT
GGAGACCACCACACCCTCCAAACAAAGCAACAACAAGTACGCGGCCAGC
AGCTACCTGAGCCTGACGCCTGAGCAGTGGAAGTCCCACAAAAGCTACA
GCTGCCAGGTCACGCATGAAGGGAGCACCGTGGAGAAGACAGTGGCCCC
TAC AGA ATGTTCATAG (SEQ ID NO: 146)
4873_E03 (PGT-121) secuencia de nucleótidos de región variable de cadena ligera lambda:
TCCGATATATCTGTGGCCCCAGGAGAGACGGCCAGGATTTCCTGTGGGGA
AAAGAGCCTTGGAAGTAGAGCTGTACAATGGTATCAACACAGGGCCGGC
CAGGCCCCCTCTTTAATCATATATAATAATCAGGACCGGCCCTCAGGGAT
CCCTGAGCGATTCTCTGGCTCCCCTGACTCCCCTTTTGGGACCACGGCCAC
CCTGACCATCACCAGTGTCGAAGCCGGGGATGAGGCCGACTATTACTGTC
ATATATGGGATAGTAGAGTTCCCACCAAATGGGTCTrCGGCGGAGGGACC ACGCTGACCGTGTTA (SEQ II) NO: 147)
4873_E03 (PGT-121) secuencia de aminoácidos de cadena ligera lambda: proteína expresada con región variable en negrita.
M A W T F L L L G L L S H C T A S V T S D I S V A P G E T A R I S C G E K S L G S R A V Q W Y Q H
R A G Q A P S L I I Y N N Q D R P S G I P E R F S G S P D S P F G T T A T L T I T S V E A G D E A D Y Y
CHIW DSRVPTKW VFGGGTTLTVLGQPKAAPSVTLFPPSSEELQANKATLVC
LISDFYPGAVTVAWKADSSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWK
SHKSYSCQVTHEGSTVEKTVAFrECS (SEQ ID NO: 148)
4873_E03 (PGT-121) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
SDISVAPGETARISCGflA'.S'AaS’/M W JWYOlIRAGOAPSEIIYMVO/JMS'GIPERF SGSPDSPFGTTATLTITS VE AGI )E AI) Y YCH/WDSR VPTKWVI ( i( X ilT L T V L (SEQ II) NO: 149)
4873_E03 (PGT-121) CDR de Kabat de cadena ligera lambda:
CDR 1: GEKSLGSRAVQ (SEQ ID NO: 150)
CDR 2: NNQDRPS (SEQ ID NO: 151)
CDR 3: HIWDSRVPTKWV (SEQ ID NO: 152)
4873_E03 (PGT-121) CDR de Chothia de la cadena ligera lambda:
CDR 1: GEKSLGSRAVQ (SEQ ID NO: 150)
CDR 2: NNQDRPS (SEQ ID NO: 151)
CDR 3: HIWDSRVPTKWV (SEQ ID NO: 152)
4877_D15 (PGT-122) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
ATGAAACACCTGTGGTTCTTCCTTCTCCTGGTGGCAGCTCCCAGATGGGTC
C T G T C C C A G G T T C A T C T G C A G G A G T C G G G C C C C G G A C T G G T G A A G C C
T T C G G A G A C C C T G T C C C T C A C G T G C A A T G T G T C T G G G A C C C T C G T G C
G T G A T A A C T A C T G G A G C T G G A T C A G A C A A C C C C T C G G G A A G C A A C C T
G A G T G G A T T G G C T A T G T C C A T G A C A G C G G G G A C A C G A A T T A C A A C C C
C T C C C T G A A G A G T C G A G T C C A C T T A T C G T T G G A C A A G T C C A A A A A C C
T G G T G T C C C T G A G G C T G A C C G G C G T G A C C G C C G C G G A C T C G G C C A T A
T A T T A T T G C G C G A C A A C A A A A C A C G G G A G G A G G A T T T A T G G C G T C G T
T G C C T T C A A A G A G T G G T T C A C C T A T T T C T A C A T G G A C G T C T G G G G C A
A A G G G A C T T C G G T C A C C G T C T C C T C A G C C T C C A C C A A G G G C C C A T C G G
TCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCC
CTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTG
GAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTAC
AGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGC
AGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAA
CACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAAAACTCAC
ACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTT
CCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTG
AGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAA
GTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAG
CCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCAC
CGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCT
CCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAA
GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGG
AGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTAT
CCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACA
ACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCT
ATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTT
CTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGA
GCCTCTCCCTGTCTCCGGGTAAATGA (SEQ ID NO: 153)
4877_D15 (PGT-122) secuencia de nucleótidos de región variable de cadena pesada gamma:
CAGGTTCATCTGCAGGAGTCGGGCCCCGGACTGGTGAAGCCTTCGGAGAC
CCTGTCCCTCACGTGCAATGTGTCTGGGACCCTCGTGCGTGATAACTACTG
GAGCTGGATCAGACAACCCCTCGGGAAGCAACCTGAGTGGATTGGCTATG
TCCATGACAGCGGGGACACGAATTACAACCCCTCCCTGAAGAGTCGAGTC
CACTTATCGTTGGACAAGTCCAAAAACCTGGTGTCCCTGAGGCTGACCGG
CGTGACCGCCGCGG ACTCGGCC AT AT ATT ATTGCGCGAC AAC AAAACACG
GGAGG AGG ATTT ATGGCGTCGTTGCCTTCA A AG AGTGGTTC ACCT ATTTCT
ACATGGACGTCTGGGGCAAAGGGACTTCGGTCACCGTCTCCTCA (SEQ ID
NO: 154)
4877_D15 (PGT-122) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
M KH LW FFLLLVAAPRW VLSQVHLQESG PGLVK PSETLSLTCNVSGTLVR
DNYW SW IRQPLGK Q PEW IG YVH DSGDTNYNPSLK SRVHLSLDKSKNLVS
LRLTGVTAADSAIYYCATTK HG RRIYG VVAFK EW FTYFYM DVW G K GTS
VTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTS
GVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPK
SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPE
VKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKC
KVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYP
SDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCS
VMHEALHNHYTQKSLSLSPGK (SEQ ID NO: 155)
4877_D15 (PGT-122) secuencia de aminoácidos de región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
OVHLOESGPGLVKPSETLSLTCN VSGTL FflflN YWS W1ROPLGKQPEWIG YVH /ASYjTX/TVYNPSI.KSRVIILSEDKSKNLVSTRETGVTAADSAIYYCAT /’ÁT/OTM/ YGVVA FKE WFTYF Y MI) VWCi KGTSVTVSS (SEQ II) NO: 156)
4877_D15 (-122 PGT) CDR de Kabat de cadena pesada gamma:
CDR 1: DNYWS (SEQ ID NO: 261)
CDR 2: YVHDSGDTNYNPSLKS (SEQ ID NO: 157)
CDR 3: TKHGRRIYGVVAFKEWFTYFYMDV (SEQ ID NO: 262)
4877_D15 (PGT-122) CDR de Chothia de la cadena pesada gamma:
CDR 1: GTLVRD (SEQ ID NO: 263)
CDR 2: YVHDSGDTN (SEQ ID NO: 264)
CDR 3: TKHGRRIYGVVAFKEWFTYFYMDV (SEQ ID NO: 262)
4877_D15 (PGT-122) secuencia de nucleótidos de la cadena ligera lambda: secuencia de codificación (región variable en negrita)
ATGGCCTGGACCGITCTCCTCCTCGGCCICX TCTCTCACTGCACAGGCGCG
G TG TCTACCTTTG TG TCAG TG GCCCCAG GACAGACG GCCAGG ATTACT
TG TG G G G AAG AG AG CCTTG G AAG TAG ATCTG TTATTTG G TATCAACA
G AG G C CAG G CCA G G CC CC TTCATTA ATC ATCTATA ATAA TAA TG AC C
G GCCCTCA G G G A TTCCTG A CC G A TTTTC TG G G TC CC CTG G CTC CA CT
TTTG G G AC CA CG G C CACCCTG ACCATCACCAG TG TCG AAG CCG G G G A
TG AG G CCG AC TATTATTG TCATATCTG G G ATAG TAG ACG ACCAACCA
ATTGGGTCTTCGGCGAAGGGACCACACTGATCGTGTTAGC.TCAGCCCA
AGGCTGCCCCCTCGGTC ACTCTGITCCCGCCCTCCTCTG AGG AGCTTC A AG
CCAACAAGGCCACACTGGTGTGTCTCATAAGTGACn CTACCCGGGAGCC
GTGACAGTGGCCTGGAAGGCAGATAGCAGCCCCGTCAAGGCGGGAGTGG
AGACCACCACACCCTCCAAACAAAGCAACAACAAGTACGCGGCCAGCAG
CTACCTGAGCCTGACGCCTGAGCAGTGGAAGTCCCACAAAAGCTACAGCT
GCCAGGTCACGCATGAAGGGAGCACCGTGGAGAAGACAGTGGCCCCTAC
AGAATGTTCATAG (SEQ ID NO: 158)
4877_D15 (PGT-122) secuencia de nucleótidos de la región variable de la cadena ligera lambda:
ACCTTTGTGTCAGTGGCCCCAGGACAGACGGCCAGGATTACTTGTGGGGA
AGAGAGCCTTGG AAGT ACí ATCTGTT ATTTGGTATCAACAGAGGCCAGGCC
AGGCCCCTTC ATT A ATC ATCT AT A AT A AT A ATG ACCGGCCCTC AGGG ATTC
CTGACCGATTTTCTGGGTCCCCTGGCTCCACTTTTGGGACCACGGGCACCC
TG ACCATC ACC AGTGTCG A AGCCGGGG ATG AGGCCG ACT ATT ATTGTC AT
ATCTGGG AT AGT AGACG ACC A ACC A ATTGGGTCTTCGGCGA AGGG ACCAC
ACTGATCGTGTTA (SEQ 11) NO: 159)
4877_D15 (PGT-122) secuencia de aminoácidos de la cadena ligera lambda: proteína expresada con región variable en negrita.
M A W T V L L L G L L S H C T G A V S T F V S V A P G Q T A R I T C G E E S L G S R S V I W Y Q Q
R P G Q A P S L I I Y N N N D R P S G I P D R F S G S P G S T F G T T A T L T I T S V E A G D E A D Y Y
C H I W D S R R P T N W V F G E G T T L I V L G Q P K A A I \S V T I T P P S S E E L Q A N K A T i: V C
LISDFYPGAVTVAWKADSSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWK
SHKSYSCQVTHEGSTVEKTVAPTECS (SEQ I!) NO: 160)
4877_D15 (PGT-122) secuencia de aminoácidos de región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
TlVSVAPGQTARITCGV îAVT/S'flSV'/WYOORPGOAPSLIIYAWATjflPSGIPDRF SGSPOSTPGrn w n :n T S V E A G D E A I)Y Y C ///W 7)S 'ffK /7W W m iEG,ITEIVT (SEQ ID NO: 161)
4877_D15 (PGT-122) CDR de Kabat de la cadena ligera lambda:
CDR 1: GEESLGSRSVI (SEQ ID NO: 162)
CDR 2: NNNDRPS (SEQ ID NO: 163)
CDR 3: HIWDSRRPTNWV (SEQ ID NO: 164)
4877_D15 (PGT-122) CDR de Chothia de la cadena ligera lambda:
CDR 1: GEESLGSRSVI (SEQ ID NO: 162)
CDR 2: NNNDRPS (SEQ ID NO: 163)
CDR 3: HIWDSRRPTNWV (SEQ ID NO: 164)
4858_P08 (PGT-123) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
ATGAAACACCTGTGGATCTTCCTTCTCCTGGTGGCAACTCCCAGATGGGTC
G A G T C C C A G C T G C A C C T G C A G G A G T C G G G C C C A G G G C T G G T G A A G C C
T C C G G A G A C C C T G T C C C T C A C G T G T A G T G T G T C T G G C G C C T C C A T C A
A T G A T G C C T A T T G G A G T T G G A T T C G G C A G T C C C C A G G G A A G C G G C C T
G A G T G G G T T G G A T A T G T C C A T C A C A G C G G T G A C A C A A A T T A T A A T C C
C T C A C T C A A G A G G C G C G T C A C G T T T T C A T T A G A C A C G G C C A A G A A T G
A A G T G T C C C T G A A A T T A G T A G A C C T G A C C G C T G C G G A C T C G G C C A C A
T A T T T T T G T G C G C G A G C A C T T C A C G G G A A G A G G A T T T A T G G G A T A G T
T G C C C T C G G A G A G T T G T T C A C C T A C T T C T A C A T G G A C G T C T G G G G C A
A G G G G A C T G C G G T C A C C G T C T C C T C A G C C T C C A C C A A G G G C C C A T C G G
TCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCC
CTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTG
GAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTAC
AGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGC
AGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAA
CACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAAAACTCAC
ACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTT
CCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTG
AGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAA
GTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAG
CCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCAC
CGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCT
CCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAA
GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGG
AGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTAT
CCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACA
ACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCT
ATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTT
CTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGA
GCCTCTCCCTGTCTCCGGGTAAATGA (SEQ I D NO: 165)
4858_P08 (PGT-123) secuencia de nucleótidos de región variable de cadena pesada gamma:
CAGCTGCACCTGCAGGAGTCGGGCCCAGGGCTGGTGAAGCCTCCGGAGA
(X X ’TGTCXXTCACGTGTAGTGTGTCTGGCGCCTCCATCAATGATGCCTATT
GGAGTTGGATTCGGCAGTCCCCAGGGAAGCGGCCTGAGTGGGTTGGATAT
GTCCATC ACAGCGGTGAC ACA A ATT AT AATCCCTCACTCA AG AGGCGCGT
CACGTTTTCATTAGACACGGCCAAGAATGAAGTGTCCCTGAAATTAGTAG
AC
( ’T( ;A( ( ’( i( 'IX¡C ■( i( iA (
rrc
'<¡( ¡( •( A( ATA I I I T I ( i I C ¡( ( ¡( ( iA( ¡(’A( T K ’A ( ’
GGGA AG AGGATTTATGGGAT AGTTGCCCTCGG AG AGTTGTTC ACCT ACTT
CTACATGGACGTCTGGGGCAAGGGGACTGCGGTCACCGTCTCCTCA (SEQ
ID NO: 166)
4858_P08 (PGT-123) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
M K H L W I F L L L V A T P R W V E S Q L H L Q E S G P G L V K P P E T L S L T C S V S G A S I N D
A Y W S W I R Q S P G K R P E W V G Y V H H S G D T N Y N P S L K R R V T F S L D T A K N E V S
L K L V D L T A A D S A T Y F C A R A L H G K R I Y G I V A L G E L F T Y F Y M D V W G K G T A
V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S G A L T S
G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T K V D K R V E P K
S C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S H E D P E
V K F N W Y V D G V E V I I N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D W L N G K E Y K C
K V S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K G F Y P
S D I A V E W E S N G Q P E N N Y K I T P P V L D S D G S F F L Y S K L T V D K S R W Q Q G N V F S C S
V M H E A L H N H Y T Q K S L S L S P G K ( S E Q I D N O : 167 )
4858_P08 (PGT-123) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
O L I I L O E S G P G L V K P P E T L S L T C S V S G A S /M P A Y W S W I R O S P G K R P E W V G Y V H
//■S’G /.)77 V Y N P S L K R R V T F S L D T A K N E V S L K L V D L T A A D S A T Y F ( 'A R A /- . / /G Á 7 f / Y G I V A lÁ .E I J T Y l Y M I )VAV C iK G T A V T V S S (S E Q I D N O : 168 )
4858_P08 CDR de Kabat de cadena pesada gamma (PGT-123):
CDR 1: DAYWS (SEQ ID NO: 169)
CDR 2: YVHHSGDTNYNPSLKR (SEQ ID NO: 170)
CDR 3: ALHGKRIYGIVALGELFTYFYMDV (SEQ ID NO: 171)
(] 4858_P08 -123) CDR de Chothia de la cadena pesada gamma:
CDR 1: GASIND (SEQ ID NO: 172)
CDR 2: YVHHSGDTN (SEQ ID NO: 173)
CDR 3: ALHGKRIYGIVALGELFTYFYMDV (SEQ ID NO: 171)
4858_P08 (PGT-123) secuencia de nucleótidos de cadena ligera lambda: secuencia de codificación (región variable en negrita)
A T G G C C T G G A C C G T T C T C C T C C T C G G C C T C C T C T C T C A C T G C A C A G G C T C T
C YG G C C T C C T C T A T G T C C G T G T C C C C G G G G G A G A C G G C C A A G A T C T C
C T G T G G A A A A G A G A G C A T T G G T A G C A G A G C T G T G C A A T G G T A T C A G C
A G A A G C C A G G C C A G C C C C C C T C A T T G A T T A T C T A T A A T A A T C A G G A C
C G C C C C G C A G G G G T C C C T G A G C G A T T C T C T G C C T C C C C T G A C T T C C G
T C C T G G G A C C A C G G C C A C C C T G A C C A T C A C C A A T G T C G A C G C C G A G G
A T G A G G C C G A C T A T T A C T G T C A T A T A T A T G A T G C T A G A G G T G G C A C C
A A T T G G G T C T T C G A C A G A G G G A C C A C A C T G A C C G T C T T A G G T C A G C C C
A A G G C T G C C C C C T C G G T C A C T C T G T T C C C G C C C T C C T C T G A G G A G C T T C A A
G C C A A C A A G G C C A C A C T G G T G T G T C T C A T A A G T G A C T T C T A C C C G G G A G C
C G T G A C A G T G G C C T G G A A G G C A G A T A G C A G C C C C G T C A A G G C G G G A G T G
G A G A C C A C C A C A C C C T C C A A A C A A A G C A A C A A C A A G T A C G C G G C C A G C A
G C T A C C T G A G C C T G A C G C C T G A G C A G T G G A A G T C C C A C A A A A G C T A C A G C
T G C C A G G T C A C G C A T G A A G G G A G C A C C G T G G A G A A G A C A G T G G C C C C T A
C A G A A T G T T C A T A G ( S E Q ID N O : 174 )
4858_P08 (PGT-123) secuencia de nucleótidos de región variable de cadena ligera lambda:

4858_P08 (PGT-123) secuencia de aminoácidos de cadena ligera lambda: proteína expresada con región variable en negrita.
M A W T V L L L G L L S H C T G S L A S S M S V S P G E T A K I S C G K E S I G S R A V Q W Y Q Q
K P G Q P P S L I I Y N N Q D R P A G V P E R F S A S P D F R P G T T A T L T I T N V D A E D E A D Y
Y C H I Y D A R G G T N W V F D R G T T L T V L G Q P K A A P S V T L I P P S S E E L Q A N K A I L V
C L I S D F Y P G A V T V A W K A D S S P V K A G V E T T T P S K Q S N N K Y A A S S Y L S L T P E Q W
K S H K S Y S C Q V T H E G S T V E K T V A P T E C S ( S E Q ID N O : 176 )
4858_P08 (PGT-123) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
S S M S V S P G E T A K I S C G K E S /G S T M F O W Y O O K P G O P P S L I I Y A V V O D K /M G V P E R
F S A S P D F R P G T T A T L T I T N V D A E D E A D Y Y C / / / m i f l G G 7 W y F D R G T T L T V L (S E Q ID N O : 177 )
4858_P08 (PGT-123) CDR de Kabat de la cadena ligera lambda:
CDR 1: GKESIGSRAVQ (SEQ ID NO: 178)
CDR 2: NNQDRPA (SEQ ID NO: 179)
CDR 3: HIYDARGGTNWV (SEQ ID NO: 180)
4858_P08 (PGT-123) CDR de Chothia de la cadena ligera lambda:
CDR 1: GKESIGSRAVQ (SEQ ID NO: 178)
CDR 2: NNQDRPA (SEQ ID NO: 179)
CDR 3: HIYDARGGTNWV (SEQ ID NO: 180)
5123_A06 (PGT-125) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
ATGAAACACCTGTGGTTCTTCTTCCTGCTGGTGGCGGCTCCCAGATGCGTC
CTGTCCCAGTCGCAGCTGCAGGAGTCGGGCCCACG ACTG GTGG AG GC
CTCG GAGACCCTG TCACTCACG TG CAATG TG TCCG G CG AG TCCACTG
G TG CCTGTACTTATTTCTG G G G CTG G G TCCG G CAG G CCCCAG G G AAG
G G G CTG G AG TG G ATCG G G AG TTTG TCCCATTG TCAG AG TTTCTG G G G
TTCC G G TTG G ACCTTCCACAACCCG TCTCTCAAG AG TCG ACTCACG A
TTTC ACTCG AC ACG CCCAAG AATCAG G TCTTCCTCAAG CTCACTTCTC
TG AC TG CC G C G G ACACG G CCACTTACTACTG TG CG CG ATTCG ACG G C
G AAG TC TTG G TCTATAATCATTG G CCAAAG CCG G CCTG G G TG G ACCT
CTGGGGCCGCGGAATACCGGTCACCGTCTCCTCAGCCTCCACCAAGGG
CCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCA
CAGCGGC(XTGGGCTG(XrrGCrrCAAGGACTACTTCCCCGAACCX3GTGACG
GTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGC
TGTCCT ACAGTCCTCAGG ACTCT ACTCCCTC AGC AGCGTGGTG ACCGTGCC
CTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGC
CCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAA
AACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGT
CAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGA
CCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAG
GTCA AGTTC A ACTGGT ACGTGGACGGCGTGG AGGTGC AT AATGCC A AG AC
AAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTC
CTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAA
GGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAG
CCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGG
GAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCT
TCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGA
GAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCT
TCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAA
CGTC1TCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGC
AGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA (SEQ ID NO: 181)
5123_A06 (PGT-125) secuencia de nucleótidos de región variable de cadena pesada gamma:
CAGTCGCAGCTGCAGGAGTCGGGCCCACGACTGGTGGAGGCCTCGGAGA
CCCTGTCACTCACGTGCAATGTGTCCGGCGAGTCCACTGGTGCCTGTACTT
ATTTCTGGGGCTGGGTCCGGCAGGCCCCAGGGAAGGGGCTGGAGTGGATC
GGGAGTTTGTCCCATTGTCAGAGTTTCTGGGGTTCXGGTTGGACCTTCCAC
AACCCGTCTCTCAAGAGTCGACTCACGATTTCACTCGACACGCCCAAGAA
TCAGGTCTTCCTCAAGCTCACTTCTCTGACTGCCGCGGACACGGCCACTTA
CT ACTGTGCGCG ATTCG ACGGCG A AGTCTTGGTCTAT AATC ATTGGCCA A
AGCCGGCCTGGGTGGACCTCTGGGGCCGCGGAATACCGGTCACCGTCTCC
TCA (SEQ ID NO: 182)
5123_A06 (PGT-125) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
M K H L W F F F L L V A A P R C V L S Q S Q L Q E S G P R L V E A S E T L S L T C N V S G E S T G
A C T Y F W G W V R Q A P G K G L E W I G S L S H C Q S F W G S G W T F H N P S L K S R L T I S
L D T P K N Q V F L K L T S L T A A D T A T Y Y C A R F D G E V L V Y N H W P K P A W V D L W
G R G I P V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S
G A L T v S G V H T F P A V L Q S S G L Y S L S S W T V P S S S L G T Q T Y I C N V N H K P S N T K V D K
R V E P K S C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S
H E D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D W L N G K
E Y K C K V S N K A L P A P 1 E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K
G F Y P S D I A V E W E S N G Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R W Q Q G N V
F S C S V M H E A L H N H Y T Q K S L S L S P C 5K (S E Q I D N O : 183 )
5123_A06 (PGT-125) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
O S Q L Q E S G P R L V E A S E T L S L T C N V S G & S T G A C r Y F W G W V R O A P G K G L E W I G S
L S H C O S F W G S G W I T 11 N P S I .K S RI .T IS I .D T P K N Q V F I ,K I T S L T A A D T A T Y Y C A *
R F D G E V L V Y N H W P K P A V V F D /.W G R G I P V T V S S (S E Q ID N O : 184 )
5123_A06 (PGT-125) CDR de Kabat de la cadena pesada gamma:
CDR 1: ACTYFWG (SEQ ID NO: 185)
CDR 2: SLSHCQSFWGSGWTFHNPSLKS (SEQ ID NO: 186)
CDR 3: FDGEVLVYNHWPKPAWVDL (SEQ ID NO: 187)
5123_A06 (PGT-125) CDR de Chothia de la cadena pesada gamma:
CDR 1: GESTGACT (SEQ ID NO: 188)
CDR 2: SLSHCQSFWGSGWTF (SEQ ID NO: 189)
CDR 3: FDGEVLVYNHWPKPAWVDL (SEQ ID NO: 187)
5123_A06 (1253_A06) secuencia de nucleótidos de cadena ligera lambda: secuencia de codificación (región variable en negrita)
A T G G C C T G G G C T C T G C T C C T C C T C A C C C T C C T C A C T C A G G G C A C A G G G G C
C T G G G C C C A G T C T G C C C T G A C T C A G C C T C C C T C C G C G T C C G G G T C T C C
T G G A C A G T C A A T C A C C A T C T C C T G C A A T G G A A C C G C C A C T A A C T T T G T
C T C C T G G T A C C A A C A A T T C C C A G A C A A G G C C C C C A A A C T C A T C A T T T T
T G G G G T C G A T A A G C G C C C C C C C G G T G T C C C C G A T C G T T T C T C T G G C T
C C C G G T C T G G C A C G A C G G C C T C C C T T A C C G T C T C C C G A C T C C A G A C T
G A C G A T G A G G C T G T C T A T T A T T G C G G T T C A C T T G T C G G C A A C T G G G A
T G T G A T T T T C G G C G G A G G G A C C A C C T T G A C C G T C C T A G G T C A G C C C A A
G G C T G C C C C C T C G G T C A C T C T G T T C C C G C C C T C C T C T G A G G A G C T T C A A G C
C A A C A A G G C C A C A C T G G T G T G T C T C A T A A G T G A C T T C T A C C C G G G A G C C G
T G A C A G T G G C C T G G A A G G C A G A T A G C A G C C C C G T C A A G G C G G G A G T G G A
G A C C A C C A C A C C C T C C A A A C A A A G C A A C A A C A A G T A C G C G G C C A G C A G C
T A C C T G A G C C T G A C G C C T G A G C A G T G G A A G T C C C A C A A A A G C T A C A G C T G
C C A G G T C A C G C A T G A A G G G A G C A C C G T G G A G A A G A C A G T G G C C C C T A C A
G A A T G T T C A T A G ( S E Q ID N O : 190 )
5123_A06 (PGT-125) secuencia de nucleótidos de región variable de cadena ligera lambda:
CAGTCTGCCCTGACTCAGCCTCCCTCCGCGTCCGGGTCTCCTGGACAGTCA
ATC ACCATCTCCTGC A ATGG A ACCGCCACT A ACITTGTCTCCTGGT ACCAA
CAATTCCCAGACAAGGCCCCCAAACTCATCATTTTTGGGGTCGATAAGCG
CCCCCCCGGTGTCCCCGATCGTTTCTCTGGCTCCCGGTCTGGCACGACGGC
CTCCCTT ACCGTCTCCCG ACTCC AG ACTG ACG ATGAGGCTGTCT ATT ATTG
CGGTTCACTTGTCGGCAACTGGGATGTGATTTTCGGCGGAGGGACCACCT
TGACGX3TCCTA (SEQ ID NO: 191)
5123_A06 (PGT-125) secuencia de aminoácidos de cadena ligera lambda: proteína expresada con región variable en negrita.
M A W A LLL LT LLT Q G TG A W A Q SA LT Q PPSA SG SPG Q Sm SC N G T A TN FV S
W YQ Q FPDK APKLIIFG VDKRPPG VPDRFSGSRSG TTASLTVSRLQ TDDEA
VYYCGSLVGNW DVIFGGGTTLTVLGQPKAAPSVTFFPPSSEEFQANKATFV
CLISDFYPGAVTVAWKADSSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQW
KSIIKSYSCQVTHEGSTVEKTVAPTECS (SEQ ID NO: 192)
5123_A06 (PGT-125) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
QSALTOPPSASGSPGOSITISCAG’/ ’ArAEKS’WYOOFPDKAPKLIIF G F D ^ P P G VPDRFSGSRSGrrASLTVSRLOrDDEAVYYCGSLVGAWDY/FGGGTTLTVL (SEQ ID NO: 193)
5123_A06 (PGT-125) CDR de Kabat de la cadena ligera lambda:
CDR 1: NGTATNFVS (SEQ ID NO: 194)
CDR 2: GVDKRPP (SEQ ID NO: 195)
CDR 3: GSLVGNWDVI (SEQ ID NO: 196)
5123_A06 (PGT-125) CDR de Chothia de la cadena ligera lambda:
CDR 1: NGTATNFVS (SEQ ID NO: 194)
CDR 2: GVDKRPP (SEQ ID NO: 195)
CDR 3: GSLVGNWDVI (SEQ ID NO: 196)
5141_B17 (PGT-126) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)

5141_B17 (PGT-126) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
M K H L W F F L L L V A A P R W V L S Q P Q L Q E S G P G L V E A S E T L S L T C T V S G D S T A
A C D Y F W G W V R Q P P G K G L E W I G G L S H C A G Y Y N T G W T Y H N P S L K S R L T I S
L D T P K N Q V F L K L N S V T A A D T A I Y Y C A R F D G E V L V Y H D W P K P A W V D L W G
RGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNS
GALTSGVIITFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNIIKPSNTKVDK
RVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTFMISRTPEVTCVVVDVS
HEDPEVKFNWYVDGVEVHNAKTKPREEQYNS'I’YRVVSVLTVLIIQDWLNGK
EYKCKVSNKALPAP1EKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVK
GFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNV
FSCSVMHEALHNHYTQKSLSLSPGK (SEQ II) NO: 199)
5141_B17 (PGT-126) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
QPQLQESGPGLVEASETLSLTCTVSGDS7V1ACDYFWGWVRQPPGKGLEW1GG
LSH CA (¡ YYNTG WTY\ 1NPSI-KSRI .TISLDTPKNQVF1,KI ,NS VT A ADTAI Y Y CAR
l lXii: VI. VYHDW PKPA V m U WGRGTLVTVSS (SEQ II) NO: 200)
5141_B17 CDR de Kabat de cadena pesada (PGT-126):
CDR 1: ACDYFWG (SEQ ID NO: 201)
CDR 2: GLSHCAGYYNTGWTYHNPSLKS (SEQ ID NO: 202)
CDR 3: FDGEVLVYHDWPKPAWVDL (SEQ ID NO: 203)
5141_B17 (PGT-126) CDR de Chothia de la cadena pesada gamma:
CDR 1: GDSTAACD (SEQ ID NO: 204)
CDR 2: GLSHCAGYYNTGWTY (SEQ ID NO: 205)
CDR 3: FDGEVLVYHDWPKPAWVDL (SEQ ID NO: 203)
5141_B17 (PGT) secuencia de nucleótidos de cadena ligera lambda: secuencia de codificación (región variable en negrita)
ATGGCCTGGGCTCTGCTCCTCCTCACCCTCCTCACTCAGGGCACAGGGGC
C T G G G C C C A G T C T G C C C T G A C T C A G C C T C C C T C C G C G T C C G G G T C T C C
T G G A C A G T C A A T C T C C A T C T C C T G C A C T G G A A C C A G C A A T A G G T T T G
T C T C C T G G T A C C A G C A A C A C C C A G G C A A G G C C C C C A A A C T C G T C A T T
T A T G G G G T C A A T A A G C G C C C C T C A G G T G T C C C T G A T C G T T T T T C T G G
C T C C A A G T C T G G C A A C A C G G C C T C C C T G A C C G T C T C T G G G C T C C A G A
C T G A C G A T G A G G C T G T C T A T T A C T G C A G C T C A C T T G T A G G C A A C T G G
G A T G T G A T T T T C G G C G G A G G G A C C A A G T T G A C C G T C C T G G G T C A G C C
CAAGGCTGCCCCCTCGGTCACTCTGTTCCCGCCCTCCTCTGAGGAGCTTCA
AGCC A AC A AGGCC AC ACTGGTGTGTCTCAT A AGTG ACTTCT ACCCGGG AG
CCGTGACAGTGGCCTGGAAGGCAGATAGCAGCCCCGTCAAGGCGGGAGT
GGAGACCACCACACCCTCCAAACAAAGCAACAACAAGTACGCGGCCAGC
AGCT ACCTGAGCCTGACGCCTG AGC AGTGG AAGTCCC AC AAAAGCT ACA
GCTGCCAGGTCACGCATGAAGGGAGCACCGTGGAGAAGACAGTGGCCCC
TACAGAATGTTCATAG (SEQ II) NO: 206)
5141_B17 (PGT-126) secuencia de nucleótidos de región variable de cadena ligera lambda:
C A G T C T G C C C T G A C T C A G C C T C C C T C C G C G T C C G G G T C T C C T G G A C A G T C A
A T C T C C A T C T C C T G C A C T G G A A C C A G C A A T A G G T T T G T C T C C T G G T A C C A G
C A A C A C C C A G G C A A G G C C C C C A A A C T C G T C A T T r A T G G G G T C A A T A A G C G
C C C C T C A G G T G T C C C T G A T C G T T T T T C T G G C T C C A A G T C T G G C A A C A C G G C
C T C C C T G A C C G T C T C T G G G C T C C A G A C T G A C G A T G A G G C T G T C T A T T A C T G
C A G C T C A C T T G T A G G C A A C T G G G A T G T G A T T T T C G G C G G A G G G A C C A A G T
T G A C C G T C C T G ( S E Q ID NO: 207 )
5141_B17 (PGT-126) secuencia de aminoácidos de cadena ligera lambda: proteína expresada con región variable en negrita.
M A W A L L L L T L L T Q G T G A W A Q S A L T Q P P S A S G S P G Q S I S I S C T G T S N R F V S
W Y Q Q H P G K A P K L V I Y G V N K R P S G V P D R F S G S K S G N T A S L T V S G L Q T D D E
A V Y Y C S S L V G N W D V I F G G G T K L T V L G Q P K A A P S V T E E P P S S H H L Q A N K A T L
V C L I S D F Y P G A V T V A W K A D S S P V K A G V E T T T P S K Q S N N K Y A A S S Y L S L T P E Q
W K S H K S Y S C Q V T H E G S T V E K T V A P T E C S ( S E Q ID N O : 208 )
5141_B17 (PGT-126) secuencia de aminoácidos de región variable de cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
O S A L T O P P S A S G S P G O S I S I S C y T G J S A /g F V S W Y O O H P C K A P K L V I Y G V A A /g P S G V P D R F S G S K S G N T A S L T V S G L Q T D D E A V Y Y C S S L V G A V Y D W F G G G T K L T V L
( S E Q ID N O : 209 )
5141_B17 (PGT-126) CDR de Kabat de la cadena ligera lambda:
CDR 1: TGTSNRFVS (SEQ ID NO: 210)
CDR 2: GVNKRPS (SEQ ID NO: 211)
CDR 3: SSLVGNWDVI (SEQ ID NO: 212)
5141_B17 (PGT-126) CDR de Chothia de la cadena ligera lambda:
CDR 1: TGTSNRFVS (SEQ ID NO: 210)
CDR 2: GVNKRPS (SEQ ID NO: 211)
CDR 3: SSLVGNWDVI (SEQ ID NO: 212)
5147_N06 (PGT-130) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
ATGAAACACCTGTGGTTCTTCCTCCTGCTGGTGGCGGCTCCCAGATGGGTC
CTGTCCCAGGTGCAGCTGCAGGAGTCGGGCCCAGGACTGGTGAAGCC
TG CG G AG ACCCTG TCCCTCACCTG CAG TG TCTCTG G AG AATCTATCA
ATACTG G TCATTACTACTG G G G CTG G G TCCG TCAG G TCCCAG G G AAG
G G A CTTG AG TG G ATAG G TCATATCCATTATACG ACG G CTG TCCTG CA
CA AC CC G TCCCTCAAG AG TCG ACTCACCATCAAAATTTACACG TTG A
G AAACCAG ATTACCCTG AG G CTCAG TAATG TG ACG G CCG CG G ACACG
G CCG TC TA TCACTG CG TACG ATCCG G CG G CG ACATCTTATATTATTAT
G AG TG GCAAAAG CCG CACTG G TTCTCTCCCTG G G G CCCG G G AATCCA
CGTCACCGTCTCGAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTG
GCAGCCTGGTCCAAGAGGACGTCTGGGGGCAGAGCGGCCCTGGGCTGCCT
GGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCG
CCCTGACCAGCGGCGTGCACACCTTCGCGGCTGTGCTACAGTGCTCAGGA
CTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCAC
CCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACAGCAAGGTG
GACAAGAGAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACC
GTGCCTAGCACCTGAACTCCTGGGGGGACCGTCAGTCITCCTCTTCCCCCC
AAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCG
TGGTGGTGGACGTGAGCCACGAAGAGCCTGAGGTCAAGTTCAACTGGTAC
GTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGC
AGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAG
GACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCC
TCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCG
AGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAG
AACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACAT
CGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACC
ACGCCTCCCGTGCTGG ACTCCG ACGGCTCCTTCTTCCTCT AT AGC A AGCTC
ACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGT
GATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGT
CTCCGGGTAAATGA (SEQ ID NO: 213)
5147_N06 (PGT-130) secuencia de nucleótidos de región variable de cadena pesada gamma:
CAGGTGCAGCTGGAGGAGTCGGGCCCAGGACTGGTGAAGCCTGCGGAGA
CCCTGTCCCTCACCTGCAGTGTCTCTGGAGAATCTATCAATACTGGTCAT1’
ACTACTGGGGCTGGGTCCGTCAGGTCCCAGGGAAGGGACTTGAGTGGATA
GGTCATATCGATTATACGACGGCTGTCCTGCACAACCCGTCCCTCAAGAG
TCG ACTC ACC ATC A A A ATTT AC ACGTTG AG A A ACC AG ATT ACCCTG AGGC
TCAGTAATGTGACGGCCGCGGACACGGCCGTCTATCACTGCGTACGATCC
GGCGGCGACATCTTATAITATTATGAGTGGCAAAAGCCGCACTGGTTCTC
TCCCTGGGGCCCGGGAATCCACGTCACCGTCTCGAGC (SEQ ID NO:214)
5147_N06 (PGT-130) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
M K H LW FFLLLVAAPRW VLSQ VQ LQ ESG PG LVK PAETLSLTCSVSG ESIN
TG H YYW G W VRQ VPG K G LEW IG H IH YTTAVLH NPSLK SRLTIK IYTLRN
Q ITLRLSNVTAADTAVYH CVRSG G DILYYYEW Q K PH W FSPW G PG IH VTV
S S A S I K G P S V I P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S G A L T S G V H
TFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCD
KTHTCPPCPAPELLGCiPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKF
NWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVS
NKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDI
AVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVM
H E A L H N H Y T Q K S L S L S P G K (S E Q I D N O : 215 )
5147_N06 (PGT-130) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
Q V Q L Q E S G P G L V K P A E T L S L T C S V S G £ S 7 A 7 G W Y Y W G W V R Q V P G K G L E W IG
/ / / / / > 77 > U / I1 N P S I K S R F T I K I Y T I .R N O I T L R L S N V T A A D T A V Y U C V R A G G D // ,
Y Y Y I iW O K P H VV7\S7JW G P ( i l l l V T V S S ( S E Q ID N O : 216 )
5147_N06 CDR de Kabat de cadena pesada gamma (PGT-130):
CDR 1: TGHYYWG (SEQ ID NO: 217)
CDR 2: HIHYTTAVLHNPSLKS (SEQ ID NO: 218)
CDR 3: SGGDILYYYEWQKPHWFSP (SEQ ID NO: 219)
5147_N0 -130) CDR de Chothia de la cadena pesada gamma:
CDR 1: GESINTGH (SEQ ID NO: 220)
CDR 2: HIHYTTAVL (SEQ ID NO: 221)
CDR 3: SGGDILYYYEWQKPHWFSP (SEQ ID NO: 219)
5147_N06 (PGT-130) secuencia de nucleótidos de cadena ligera lambda: secuencia de codificación (región variable en negrita)
A T G G C C T G G G C T C T G C T C C T C C T C A C C C T C C T C A C T C A G G G C A C A G G G T C C
T G G G C C C A G T C T G C C C T G A C T C A G C C T C C C T C C G C G T C C G G G T C T C T T
G G A C A G T C A G T C A C C A T C T C C T G C A A T G G A A C C A G C A G T G A C A T T G G
C G G T T G G A A T T T T G T C T C C T G G T A T C A A C A G T T C C C G G G C A G A G C C C
C C A G A C T C A T T A T T T T T G A G G T C A A T A A G C G G C C C T C A G G G G T C C C T
G G T C G C T T C T C T G G C T C C A A G T C G G G C A A T T C G G C C T C C C T G A C C G T
C T C T G G G C T C C A G T C T G A C G A T G A G G G T C A A T A T T T C T G C A G T T C A C
T T T T C G G C A G G T G G G A T G T T G T T T T T G G C G G G G G G A C C A A G C T G A C C
G T C C T A G G T C A G C C C A A G G C T G C C C C C T C G G T C A C T C T G T T C C C G C C C T C
C T C T G A G G A G C T T C A A G C C A A C A A G G C C A C A C T G G T G T G T C T C A T A A G T G
A C T T C T A C C C G G G A G C C G T G A C A G T G G C C T G G A A G G C A G A T A G C A G C C C C
G T C A A G G C G G G A G T G G A G A C C A C C A C A C C C T C C A A A C A A A G C A A C A A C A
A G T A C G C G G C C A G C A G C T A C C T G A G C C T G A C G C C T G A G C A G T G G A A G T C C
C A C A A A A G C T A C A G C T G C C A G G T C A C G C A T G A A G G G A G C A C C G T G G A G A
A G A C A G T G G C C C C T A C A G A A T G T T C A T A G ( S E Q I D N O : 222 )
5147_N06 (PGT-130) secuencia de nucleótidos de región variable de cadena ligera lambda:
CAGTCTGCCCTGACTCAGCCTCCCTCCGCGTCCGGGTCTCTTGGACAGTCA
GTCACCATCTCCTGCAATGGAACCAOCAGTGACATTGGCGGTTGOAATTT
TGTCTCCTGGT ATC A AC AGTTCCCGGGC AGAGCCCCCAGACTC ATT ATTTT
TGAGGTCAATAAGCGGCCCTCAGGGGTCCCTGGTCGCTTCTCTGGCTCCA
AGTCGGGCAATTCGGCCTCCCTGACCGTCTCTGGGCTCCAGTCTGACGAT
GAGGGTCAATATTTCTGCAGTTCACTTTTCGGCAGGTGGGATGTTGTTnT GGCGGGGGGACCAAGCTGACCGTCCTA (SEQ II) NO: 223)
5147_N06 (PGT-130) secuencia de aminoácidos de cadena ligera lambda: proteína expresada con región variable en negrita.
M AW ALLLLTLLTQ G TG SW AQ SALTQ PPSASG SLG Q SVTISCNG TSSDIG G
W NFVSW YQ Q FPG RAPRLIIFEVNK RPSG VPG RFSG SK SG NSASLTVSG LQ
SDDEGQYFCSSLFGRW DVVFGGGTKLTVLGQPKAAPSVTEIPPSSEELQAN
KATLVCLISDFYPGAVTVAWKADSSPVKAGVETTTPSKQSNNKYAASSYGSL
TPIiQWKSIIKS YSCQVTHEGST VEKT V APTECS (SEQ ID NO: 224)
5147_N06 (PGT-130) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
o s a i : r o p p s a s g s ix io s v t is c n g t s s d i g g w n i k s w y o o i -p g r APR1311 EVN
KKPSGVPGRFSGSKSGNSASLTVSGI.QSDDEGQYFC SS U (¡R\M)VV\ GGGTK
ETVL (SEQ ID NO: 225)
5147_N06 (PGT-130) CDR de Kabat de la cadena ligera lambda:
CDR 1: NGTSSDIGGWNFVS (SEQ ID NO: 226)
CDR 2: EVNKRPS (SEQ ID NO: 227)
CDR 3: SSLFGRWDVV (SEQ ID NO: 228)
5147_N06 (PGT-130) CDR de Chothia de la cadena ligera lambda:
CDR 1: NGTSSDIGGWNFVS (SEQ ID NO: 226)
CDR 2: EVNKRPS (SEQ ID NO: 227)
CDR 3: SSLFGRWDVV (SEQ ID NO: 228)
5343_B08 (PGT-135) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
ATGAAACACCTGTGGTTCTTCCTCTTGCTGGTGGCGGCTCCCAGATGGGTC
C'TGTCCCAGTTGCAGATGCAGGAGTCGGGCCCAGGACTGGTGAAGCC
TTCG G A G A CC CTG TCTCTG AG TTG CACTG TCTCTG G TG ACTCCATAA
G GG GTGG CG AG TG G G G CG ATAAAG ATTATCATTG G G G CTG G G TCCG
CCACTCAG CAG G AAAG G G CCTG G AG TG G ATTG G G AG TATCCATTG G A
G G G G G ACCACCCACTACAAAG AG TCCCTCAG G AG AAG AG TG AG TATG
TC G A TC G A CACG TCCAG G AATTG G TTCTCCCTG AG G CTG G CCTCTG T
G ACC G C CG CG G ACACG G CCG TCTACTTTTG TG CG AG ACACCG ACATC
ATG ATG TTTTCATG TTG G TCCCTATTG CG G G CTG G TTCG ACG TCTG G
GGCCCGGGAGTCCAGGTCACCGTCTCGAGCGCXTCCACCAAGGGCCCA
TCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGC
GGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGT
CGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTC
CT AC AGTCCTC AGG ACTCT ACTCCCTCAGC AGCGTGGTG ACCGTGCCCTCC
AGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAG
CAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAAAACT
CACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGT
CTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCC
TGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCA
AGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAA
GCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTC
ACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGG
TCTCC A AC A A AGCCCTCCC AGCCCCC ATCG AG A A A ACC ATCTCC A A AGCC
A A AGGGC AGCCCCG AG A ACC AC AGGTGT AC ACCCTGCCCCC ATCCCGGG
AGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTC
TATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGA
ACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTC
CTCT AT AGCA AGCTC ACCGTGGAC A AGAGC AGGTGGC AGCAGGGG A ACG
TCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAG
AAGAGCCTCTCCCTGTCTCCGGGTAAATGA (SEQ II) NO: 229)
5343_B08 (PGT-135) secuencia de nucleótidos de región variable de cadena pesada gamma:
CAGTTGCAGATGCAGGAGTCGGGCCCAGGACTGGTGAAGCCTTCGGAGA
CCCTGTCTCTGAGTTGCACTGTCTCTGGTGACTCCATAAGGGGTGGCGAGT
GGGGCG ATA A AG ATT ATC ATTGGGGCTGGGTCCGCC ACTC AGC AGG A A A
GGGCCTGGAGTGGATTGGGAGTATCCATTGGAGGGGGACCACCCACTACA
AAGAGTCCCTCAGGAGAAGAGTGAGTATGTCGATCGACACGTCCAGGAA
TTGGTTCTCCCTGAGGCTGGCCTCTGTGACCGCCGCGGACACGGCCGTCT
A C m T G T G C G A G A C A C C G A C A rc'A rcíATG r n rc 'A rcj r r íiG rcx ’( t a t t g
CGGGCTGGTTCGACGTCTGGGGCCCGGGAGTCCAGGTCACCGTCTCGAGC
(SEQ ID NO: 230)
5343_B08 (PGT-135) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
M K H LW FFLLLVAAPRW VLSQ LQ M Q ESG PG LVK PSETLSLSCTVSG DSIR
G G EW G DK DYH W G W VRH SAG K G LEW IG SIH W RG TTH YK ESLRRRVSM
SIDTSRNW FSLRLASVTAADTAVYFCARH RH H DVFM LVPIAG W FDVW G P
GVQVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSG
ALTSGVIITFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKR
VEPKSCDKTIITCPPCPAPEEEGGPSVEEFPPKPKDTEMISRTPEVTCVVVDVS
HEDPEVKFNWYVDGVHVIINAKTKPREEQYNSTYRVVSVLTVLHQDWLNGK
EYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVK
g f y p s d i a v e w e s n g q p e n n y k i t p p v l d s d g s f f l y s k l t v d k s r w q q g n v FSCSVMHEALHNIIYTQKSLSLSPGK (SEQ II) NO: 231)
5343_B08 (PGT-135) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
QI QMQESGPGI .VKPSETIM ,S ( TVS(¡I)SIR(¡(¡KWdDKDYl IWC.W VRIISAGK
GLEW1GS7//W KG777/YKES1.RRRVSMS1DTSRNWESLRLASVTAADTAVYFC
ARHRHHI)VIML VPÍAG WI I) VWGPG VOVTVSS (SEQ ID NO: 232)
5343_B08 (PGT-135) CDR de Kabat de la cadena pesada gamma:
CDR 1: GGEWGDKDYHWG (SEQ ID NO: 233)
CDR 2: SIHWRGTTHYKESLRR (SEQ ID NO: 234)
CDR 3: HRHHDVFMLVPIAGWFDV (SEQ ID NO: 235)
5343_B08 (PGT-135) CDR de Chothia de la cadena pesada gamma:
CDR 1: GDSIRGGEWGDKD (SEQ ID NO: 236)
CDR 2: SIHWRGTTH (SEQ ID NO: 237)
CDR 3: HRHHDVFMLVPIAGWFDV (SEQ ID NO: 235)
5343TB88) secuencia de nucleótidos de la cadena ligera de kappa: secuencia de codificación (región variable en negrita)
ATGGAAACCCCAGCTCAGCTTCTCTTCCTCCTGCTACTCTGGCTCCCAOAT
ACCACTGGAGAAATTGTGATGACGCAGTCTCCCGACACCCTGTCTGTC
TC TC CA G G G G AG AC AG TCACACTCTCCTG CAG G G CCAG TCAG AATAT
TA AC AA G A ATTTAG CCTG G TACCAATACAAACCTG G CCAG TCTCCCA
G G C TCG TAATTTTTG AAACATATAG CAAG ATCG CTG CTTTCCCTG CCA
G G TTCG TTG C CAG TG G TTCTG G G ACAG AG TTCACTCTCACCATCAAC
AA CA TG CA G TCTG AAG ATG TTG CAG TTTATTACTG TCAACAATATG AA
G AG TG GCCTCGG ACGTTCGG GCAAGG GACCAAG G TG GATATCAAACG
TACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTT
GAAATCTGG AACTCCCTCTOTTGTOTGCCTGCTG A ATA ACTTC ’T ATCCC AG
AGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAAC
TCCCAGGAGAGTGTCAGAGAGCAGGACAGCAAGGACAGCACCTACAGCC
TCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGT
CTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGA
GC ITCAACAGGGGAGAGTG ITAG(SEQ ID NO: 238)
5343_B08 (PGT-135) secuencia de nucleótidos de la región variable de la cadena ligera de kappa:
GAAATTGTGATGACGCAGTCTCCCGACACCGTGTCTGTCTCTCCAGGGGA
G AC AGTC AC ACTCTCCTGC AGGGCC AGTCAG A AT ATT A AC AAG A ATTT AG
CCTGGTACCAATACAAACCTGGCCAGTCTCCCAGGCTCGTAATTTTTGAA
ACAT AT AGC AAG ATCGCTGCTTTCCCTGCC AGGTTCOTTGCC AGTGGTTCT
GGGACAGAGTTCACTCTCACCATCAACAACATGCAGTCTGAAGATGTTGC
AGTTT ATT ACTGTC A ACAAT ATGA AGAGTGGCCTCGG ACGTTGGGGC AAG
GGACCAAGGTGGATATCAAA (SEQ ID NO: 239)
5343_B08 (PGT-135) secuencia de aminoácidos de la cadena ligera kappa: proteína expresada con región variable en negrita.
M ETPAQ LLFLLLLW LPDTTG EIVM TQ SPDTLSVSPG ETVTLSCRASQ NIN
K NLA W YQ YK PG Q SPRLVIFETYSK IAAFPARFVASG SG TEFTLTINNM Q S
EDVAVYYCQQYEEW PRTFGQGTKVDIKRTVAAPSVFIFPPSDEQLKSGTAS
V V C L L N N F Y P R E A K V Q W K V D N A L Q S G N S Q E S V T E Q D S K D S T Y S L S S T L T L S K
A D Y E K H K V Y A C E V T I I Q G L S S P V T K S F N R G E C ( S E Q I D N O : 240 )
5343_B08 (PGT-135) secuencia de aminoácidos de la región variable de la cadena ligera kappa: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
E l V M T Q S P D T L S V S P G E T V T L S C / M S O N I N K N I A 'W Y O Y K P G O S P R L V I F E 7Y .S m A F P A R F V A S G S G T E F T L T I N N M O S E D V A V Y Y C Q Q Y E T sW P /fY P G O G T K V D IK (S E Q I D N O : 242 )
5343_B08 (PGT-135) CDR de Kabat de cadena ligera kappa:
CDR 1: RASQNINKNLA (SEQ ID NO: 243)
CDR 2: ETYSKIA (SEQ ID NO: 244)
CDR 3: QQYEEWPRT (SEQ ID NO: 245)
5343_B08 (PGT-135) CDR de Chothia de la cadena ligera kappa:
CDR 1: RASQNINKNLA (SEQ ID NO: 243)
CDR 2: ETYSKIA (SEQ ID NO: 244)
CDR 3: QQYEEWPRT (SEQ ID NO: 245)
5344_E16 (PGT-135) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
A T G A A A C A C C T G T G G T T C T T C C T C T T G C T G G T G G C G G C T C C C A G A T G G G T C
CTGTCCCAGTTGCAG ATGCAG GAGTCG GG CCCAGG ACTG GTG AAGCC
TTCG G A G ACCCTG TCTCTG AG TTG CACTG TCTCTG G TG ACTCCATAA
G GG G TG G CG AG TG G G G CG ATAAAG ATTATCATTG G G G CTG G G TCCG
CC ACTCAG CAG G AAAG G G CCTG G AG TG G ATTG G G AG TATCCATTG G A
G G G G G AC CA CCCACTACAAAG AG TCCCTCAG G AG AAG AG TG AG TATG
TC G A TC G A CA CG TCCAG G AATTG G TTCTCCCTG AG G CTG G CCTCTG T
G ACC G C CG CG G A CA CG G C CG TC TAC TTTTG TG CG AG AC AC CG AC ATC
A T G A T G T T T T C A T G T T G G T C C C T A T T G C G G G C T G G T T C G A C G T C T G G
G G C C C G G G A G T C C A G G T C A C C G T C T C G A G C G C C T C C A C C A A G G G C C C A
TCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGC
GGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGT
CGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTC
CTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCC
AGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAG
CAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAAAACT
CACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGT
CTTCCTCTTCCCCCCAAAACCCAAGGACACGCTCATGATCTCCCGGACCCC
TGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCA
AGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAA
GCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTC
ACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGG
TCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCC
AAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGG
AGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTC
TATCCGAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGA
ACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTC
CTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACG
TCTTCTCATGCTCCGTGATGCATGAGGCTCTGGAGAACCACTACACGCAG
AAGAGCCTCTCCCTGTCTCCGGGTAAATGA (SEQ ID NO: 229)
5344_E16 (PGT-135) secuencia de nucleótidos de región variable de cadena pesada gamma:
CAGTTGCAGATGCAGGAGTCGGGCCCAGGACTGGTGAAGCCTTCGGAGA
CCCTGTCTCTGAGTTGCACTGTCTCTGGTGACTCCATAAGGGGTGGCGAGT
GGGGCGATAAAGATTATCATTGGGGCTGGGTCCGCCACTCAGCAGGAAA
GGGCCTGGAGTGGATTGGGAGTATCCATTGGAGGGGGACCACCCACTACA
AAGAGTCCCTCAGGAGAAGAGTGAGTATGTCGATCGACACGTCCAGGAA
TTGGTTCTCCCTGAGGCTGGCCTCTGTGACCGCCGCGGACACGGCCGTCT
ACTTTTGTGCGAGACACCGACATCATGATGTTTTCATGTTGGTCCCTATTG
CGGGCTGGTTCGACGTCTGGGGCCCGGGAGTCCAGGTCACCGTCTCGAGC
(SEQ ID NO: 230)
5344_E16 (PGT-135) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
M K H L W F F L L L V A A P R W V L S Q L Q M Q E S G P G L V K P S E T L S L S C T V S G D S I R
G G E W G D K D Y H W G W V R H S A G K G L E W I G S I H W R G T T H Y K E S L R R R V S M
S I D T S R N W F S L R L A S V T A A D T A V Y F C A R H R H H D V F M L V P 1 A G W F D V W G P
G VQ VTV SSASTK G PSVFPLAPSSK STSG G TAALG CLVK DYFPEPVTVSW NSG
ALTSG VH TFPAVLQ SSG LYSLSSVVTVPSSSLGTQ TYICNVNH K PSNTKVDK R
VEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLM ISRTPEVTCW VDVS
H EDPEVK FN W YVD G V EV H N AK TK PREEQ YNSTY RW SV LTV LH Q D W LN G K
EYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEM TKNQVSLTCLVK
GFYPSDIAVEW ESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRW QQGNV
FSCSVM HEALHNHYTQKSLSLSPGK (SEQ ID NO: 231)
5344_E16 (PGT-135) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
Q I v Q M Q E S G P G I V K P S E T L S L S C ' W S G D S I R G G E W d D K l ) Y 11W ( iW V R i iS A G K
C,iL P :W I(i. S 7 / / U 7 / ( ; 777 / Y K i : S I R R R V S M S I D T S R N W I S L R L A S V T A A I ) T A V Y I 'C A R H K H H 1 ) V l 'M L V l ’l A G W F I ) VW G P C iV O V T V S S (S E Q ID N O : 232 )
5344_E16 (PGT-135) CDR de Kabat de la cadena pesada gamma:
CDR 1: GGEWGDKDYHWG (SEQ ID NO: 233)
CDR 2: SIHWRGTTHYKESLRR (SEQ ID NO: 234)
CDR 3: HRHHDVFMLVPIAGWFDV (SEQ ID NO: 235)
5344_E16 (PGT-135) CDR de Chothia de la cadena pesada gamma:
CDR 1: GDSIRGGEWGDKD (SEQ ID NO: 236)
CDR 2: SIHWRGTTH (SEQ ID NO: 237)
CDR 3: HRHHDVFMLVPIAGWFDV (SEQ ID NO: 235)
5344_E16 (PGT-135) secuencia de nucleótidos de la cadena ligera de kappa: secuencia de codificación (región variable en negrita)
A T G G A A A C G G C A G C T C A G C T T C T C T T C C T C C T G C T A C T C T G G C T C C C A G A T
A C C A C T G G A G A A A T T G T G A T G A C G C A G T C T C C C G A C A C C C T G T C T G T C
T C T C C A G G G G A G A C A G T C A C A C T C T C C T G C A G G G C C A G T C A G A A T A T
T A A C A A G A A T T T A G C C T G G T A C C A A T A C A A A C C T G G C C A G T C T C C C A
G G C T C G T A A T T T T T G A A A C A T A T A G C A A G A T C G C T G C T T T C C C T G C C A
G G T T C G T T G C C A G T G G T T C T G G G A C A G A G T T C A C T C T C A C C A T C A A C
A A C A T G C A G T C T G A A G A T G T T G C A G T T T A T T A C T G T C A A C A A T A T G A A
G A G T G G C C T C G G A C G T T C G G G C A A G G G A C C A A G G T G G A T A T C A A A C G
T A C G G T G G C T G C A C C A T C T G T C T T C A T C T T C C C G C C A T C T G A T G A G C A G T T
G A A A T C T G G A A C T G C C T C T G T T G T G T G C C T G C T G A A T A A C T T C T A T C C C A G
A G A G G C C A A A G T A C A G T G G A A G G T G G A T A A C G C C C T C C A A T C G G G T A A C
T C C C A G G A G A G T G 7 C A C A G A G C A G G A C A G C A A G G A C A G C A C C T A C A G C C
T C A G C A G C A C C C T G A C G C T G A G C A A A G C A G A C T A C G A G A A A C A C A A A G T
C T A C G C C T G C G A A G T C A C C C A T C A G G G C C T G A G C T C G C C C G T C A C A A A G A
G C T T C A A C A G G G G A G A G T G T T A G ( S E Q ID N O : 238 )
5344_E16 (PGT-135) secuencia de nucleótidos de la región variable de la cadena ligera de kappa:
G A A A T T G T G A T G A C G C A G T C T C C C G A C A C C C T G T C T G T C T C T C C A G G G G A
G A C A G T C A C A C T C T C C T G C A G G G C C A G T C A G A A T A T T A A C A A G A A T T T A G
C C T G G T A C C A A T A C A A A C C T G G C C A G T C T C C C A G G C T C G T A A T T T T T G A A
A C A T A T A G C A A G A T C G C T G C T T T C C C T G C C A G G T T C G T T G C C A G T G G T T C T
G G G A C A G A G T T C A C T C T C A C C A T C A A C A A C A T G C A G T C T G A A G A T G T T G C
A G T T T A T T A C T G T C .A A C A A T A T G A A G A G T G G C C T C G G A C G T T C G G G C A A G
G G A C C A A G G T G G A T A T C A A A (S E Q ID N O : 239 )
5344_E16 (PGT-135) secuencia de aminoácidos de la cadena ligera kappa: proteína expresada con región variable en negrita.
M ETPAQ LLFLLLLW LPDTTG EIVM TQ SPDTLSVSPG ETVTLSCRASQ NIN
K NLA W YQ YK PG Q SPRLVIFETYSK IAAFPARFVASG SG TEFTLTINNM Q S
EDVAVYYCQQYEEW PRTFGQGTKVDIKRTVAAPSVFIFPPSDEQI.KSGTAS
V V C L L N N F Y P R E A K V Q W K V D N A L Q S G N v S Q E S V T E Q D S K D S T Y S L S S T L T L S K A D Y E K H K V Y A C E V T H Q G L S S P V T K S F N R G E C ( S E Q ID N O : 240 )
5344_E16 (PGT-135) secuencia de aminoácidos de la región variable de la cadena ligera kappa: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
E lV M T O S P iy r L S V S P G E T V T I J > C /M S O A / A A W E 4 W Y O Y K P G O S P R L V I I i r / Y S K I A A 1 P A R I V A S G S G T F 1 T I T I N N M O S F D V A V Y Y C O O Y l l E W P i m G Q G T K V D IK ( S E Q ID N O : 242 )
5344_E16 (PGT-135) CDR de Kabat de cadena ligera kappa:
CDR 1: RASQNINKNLA (SEQ ID NO: 243)
CDR 2: ETYSKIA (SEQ ID NO: 244)
CDR 3: QQYEEWPRT (SEQ ID NO: 245)
5344_E16 (PGT-135) CDR de Chothia de la cadena ligera kappa:
CDR 1: RASQNINKNLA (SEQ ID NO: 243)
CDR 2: ETYSKIA (SEQ ID NO: 244)
CDR 3: QQYEEWPRT (SEQ ID NO: 245)
5329_C19 (PGT-136) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
A T O A A A C A C C T O T G O T T C T T C C T C C T O C T A O T O G C G G C T C C C A O A T G G G T C
CTGTCG CAGCTG CAG TTGCAG GAATCG GG CCCAGG ACTG GTG AAGCC
TTCG G A G A CC CTG TCCCTG ACTTG CACAG TTTCTG G TG G CTCCATG A
G G G G C ACCG ACTG G G G CG AG AATG ACTTCCACTACG G CTG G ATCCG
CC AG TCCTCCG CAAAG G G G CTG G AG TG G ATTG G G AG CATCCATTG G A
G G G G G AG G A CCACCCACTACAAG ACG TCCTTCAG G AG TCG G G CCAC
CTTG TC G A TAG AC ACG TCCAATAATCG CTTCTCCCTG ACG TTTAG TTT
TG TG AC CG CC G C G G ACACG G CCG TCTACTATTG TG CG AG ACATAAAT
ATCA TG ATA TTTTCAG G G TG G TCC CTG TTG CG G G CTG G TTCG ACC CC
TGGGGCCAGGGATTACTGGTCACCGTCTCGAGCGCCTCCACCAAGGGC
C C A T C G G T C T T C C C C C T G G C A C C C T C C T C C A A G A G C A C C T C T G G G G G C A C
A G C G G C C C T G G G C T G C C T G G T C A A G O A C T A C T T C C C C G A A C C O C T O A C G O
T G T C G T G G A A C T C A G G C G C C C T G A C C A G C G G C G T G C A C A C C T T C C C G G C T
GTCCTACAGTCCTCAGGACTGTACTCCCTCAGCAGCGTGGTGACGGTGCC
C T C C A G C A G C T T G G G C A C C C A G A C C T A C A T C T G C A A C G T G A A T C A C A A G C
C C A G C A A C A C G A A G G T G G A C A A G A G A G T T G A G C G C A A A T C T T G T G A G A A
A A C T C A C A C A T G C C C A C C G T G C C C A G C A C C T G A A C T C C T G G G G G G A C C G T
C A G T C T T C C T C T T C C C C C C A A A A C C C A A G G A C A C C C T C A T G A T C T C C G G G A
C C C C T G A G G T C A C A T G C G T G G T G G T G G A C G T G A G C C A C G A A G A C C C T G A G
G T C A A G T T C A A C T G G T A C G T G G A C G G C G T G G A G G T G C A T A A T G C C A A G A C
A A A G C C G C G G G A G G A G C A G T A C A A C A G C A C G T A C C G T G T G G T C A G C G T C
C T C A C C G T C C T G C A G C A G G A C T G G C T G A A T G G C A A G G A G T A C A A G T G C A A
G G T C T C C A A C A A A G C C C T C C C A G C C C C C A T C G A G A A A A C C A T C T C C A A A G
C C A A A G G G C A G C C C C G A G A A C C A C A G G T G T A C A C C C T G C C C C C A T C C C G G
G A G G A G A T G A C C A A G A A C C A G G T C A G C C T G A C C T G C C T G G T C A A A G G C T
T C T A T G C C A G G G A C A T C G C C G T G G A G T G G G A G A G C A A T G G G C A G C C G G A
G A A C A A C T A C A A G A C C A C G C C T C C C G T G C T G G A C T C C G A C G G C T C C T T C T
T C C T C T A T A G C A A G C T C A C C G T G G A C A A G A G C A G G T G G C A G C A G G G G A A
C G T C T T C T G A T G C T C C G T G A T G C A T G A G G C T C T G C A C A A C C A C T A G A C G C
A G A A G A G G C T C T C C C T G T C T C C G G G T A A A T G A ( S E Q II) N O : 246 )
5329_C19 (PGT-136) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G G T G C A G T T G C A G G A A T C G G G C C C A G G A C T G G T G A A G G G T T C G G A G A
C C C T G T C C C T G A C T T G C A C A G T T T C T G G T G G C T C C A T G A G G G G C A C C G A C T
G G G G C G A G A A T G A C T T C C A C T A G G G C T G G A T C C G C C A G T C C T C G G C A A A G
G G G C T G G A G T G G A T T G G G A G C A T G C A T T G G A G G G G G A G G A G C A C C C A C T
A C A A G A C G T C C T T G A G G A G T G G G G C C A C C T T G T G G A T A G A C A C G T G C A A T
A A T C G C T r C T C C C T G A C G T T T A G T T T T G T G A C C G C C G C G G A C A C G G C C G T C T A C T A T T G T G C G A G A C A T A A A T A T C A T G A T A r n T C A G G G T G G T C C C T G T T
G C G G G C T G G T T C G A C C C C T G G G G C C A G G G A T T A C T G G T C A C C G T C T C G A G
C ( S E Q II) NO: 247 )
5329_C19 (PGT-136) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
M K H L W F F L L L V A A P R W V L S Q L Q L Q E S G P G L V K P S E T L S L T C T V S G G S M
R G T D W G E N D F H Y G W I R Q S S A K G L E W I G S I H W R G R T T H Y K T S F R S R A T L S I D T S N N R F S L T F S F V T A A D T A V Y Y C A R H K Y H D I F R V V P V A G W F D P W G Q G L L V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S G A L T S G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T K V D K R V E P K S C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S H E D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D W L N G K E Y K C K V S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K G F Y P S D I A V E W E S N G Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R W Q Q G N V F S C S V M H E A L H N H Y T Q K S L S L S P G K (S E Q II) N O : 248 )
5329_C19 (PGT-136) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
QiJOlJOVSGPGlXKmmJSl.TCrVSGGSMRG TD W aES D l IIYGWIROSSAKG UiW IG S7f/W W ;ir/77/Y K T SFR SRATLSIPTSNNRFSLTFSFVTAADTAVYYCA RHKYHÜIFRVVPVAC,H T D PWGOGLI V I VSS (SEQ ID NO: 249)
5329_C19 (PGT-136) CDR de Kabat de cadena pesada gamma:
CDR 1: GTDWGENDFHYG (SEQ ID NO: 250)
CDR 2: SIHWRGRTTHYKTSFRS (SEQ ID NO: 251)
CDR 3: HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252)
5329_C19 (PGT-136) CDR de Chothia de la cadena pesada gamma:
CDR 1: GGSMRGTDWGEND (SEQ ID NO: 253)
CDR 2: SIHWRGRTTH (SEQ ID NO: 254)
CDR 3: HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252)
5329_C19) secuencia de nucleótidos de la cadena ligera de kappa: secuencia de codificación (región variable en negrita)
ATGGAAACCCCAGCTCAGCTTCTCTTCCTCCTGCTACTCTGGCTCCCAGAT
A G C A C T G G A G A A A T A G T G A T G A C G C A G T C T C C A C C C A C C C T G T C T G T G
T C T C C A G G G G A A A C A G C C A C A C T C T C C T G T A G G G C C A G T C A G A A T G T
T A A G A A T A A T T T A G C C T G G T A C C A G C T G A A A C C T G G C C A G G C T C C C A
G G C T C C T C A T C T T T G A T G C G T C C A G C A G G G C C G G T G G T A T T C C T G A C
A G G T T C A G T G G C A G C G G T T A T G G G A C A G A C T T C A C T C T C A C C G T C A A
C A G T G T G C A G T C C G A A G A T T T T G G A G A T T A T T T T T G T C A G C A A T A T G A
A G A G T G G C C T C G G A C G T T C G G C C A A G G G A C C A A G G T G G A T A T C A A A C
GTACGGTGGCTGC ACC ATCTGTC1TCATCTTCCCGCCATCTG ATGAGC AGT
TGAAATCTGGAACTGCCTCTGITGTGTGCCTGCTGAATAACTTCTATCCCA
GAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAA
CTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGC
c t c a g c a g c a c c c t g a c g c t g a g c a a a g c a g a c t a c g a g a a a c a c a a a g
TCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAG
AGCTTCAACAGGGGAGAGTGTTAG (SEQ ID NO: 255)
5329_C19 (PGT-136) secuencia de nucleótidos de la región variable de la cadena ligera de kappa:
GAAATAOTOATGACGCAOTCTCCACCCACCCTOTCTGTGTCTCCAGGGGA
AACAOCCACACTCTCCTGTAGGGCCAOTCAGAATGTTAAGAATAATTTAG
CCTGGTACCAGCTGAAACCTGGCCAGGCTCCCAGGCTCCTCATCTTTGAT
GCGTCCAGCAGGGCCGGTGGTATTCCTGACAGGTTCAGTGGCAGCGGTTA
TGGGACAGACTTCACTCTCACCGTCAACAGTGTGCAGTCCGAAGA1TTTG
GAGATTATTTTTGTCAGCAATATGAAGAGTGGCCTCGGACGTTCGGCCAA
GGGACCAAGGTGGATATCAAA (SEQ ID NO: 256)
5329_C19 (PGT-136) secuencia de aminoácidos de la cadena ligera de kappa: proteína expresada con región variable en negrita.
M E T P A Q L L F L L L L W L P D S T G E I V M T Q S P P T L S V S P G E T A T L S C R A S Q N V K
N N L A W Y Q L K P G Q A P R L L I F D A S S R A G G I P D R F S G S G Y G T D F T L T V N S V Q S
E D F G D Y F C Q Q Y E E W P R T F G Q G T K V D I K R T V A A P S V F I I PPSDEQLKSGTAS
V VCI A .NNFYPREAKVQW KVDNAI .QSGNSQESVTEQDSKDSTYSI .SSTI TI ,SK
ADYEKHKVYACEVTHQGLSSPVTKSFNRGEC (SEQ ID NO: 257)
5329_C19 (PGT-136) secuencia de aminoácidos de la región variable de la cadena ligera kappa: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
FIVMTOSPPTI ,SVSPGETATI$C RASOS' V M M A W YOI KP( iQAPRI IW DA SS /L4GGIPDRFSGSGYGTDPTLTVNSVQSEDFCiDYFC GQG'rKVD IK (SEQ ID NO: 258)
5329_C19 (PGT-136) CDR de Kabat de cadena ligera kappa:
CDR 1: RASQNVKNNLA (SEQ ID NO: 259)
CDR 2: DASSRAG (SEQ ID NO: 260)
CDR 3: QQYEEWPRT (SEQ ID NO: 245)
5329_C19 (PGT-136) CDR de Chothia de la cadena ligera kappa:
CDR 1: RASQNVKNNLA (SEQ ID NO: 259)
CDR 2: DASSRAG (SEQ ID NO: 260)
CDR 3: QQYEEWPRT (SEQ ID NO: 245)
5366_P21 (PGT-136) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
ATGAAACACCTGTGGTTCTTCCTCCTGCTAGTGGCGGCTCCCAOATGGGTC
CTGTCG CAGCTG CAG TTGCAG GAATCG GG CCCAGG ACTG GTG AAGCC
TTCG G A G A CC CTG TCCCTG ACTTG CACAG TTTCTG G TG G CTCCATG A
G G G G C AC CG ACTG G G G CG AG AATG ACTTCCACTACG G CTG G ATCCG
CC AG TCCTCCG CAAAG G G G CTG G AG TG G ATTG G G AG CATCCATTG G A
G G G G G AG G A CCACCCACTACAAG ACG TCCTTCAG G AG TCG G G CCAC
CTTG TC G A TAG AC ACG TCCAATAATCG CTTCTCCCTG ACG TTTAG TTT
TG TG ACCG CCG CG G ACACG G CCG TCTACTATTG TG CG AG ACATA AAT
ATCA TG ATA TTTTCAG G G TG G TCCCTG TTG CG G G CTG G TTCG ACCCC
TGGGGCCAGGGATTACTGGTCACCGTCTCGAGCGCCTCCACCAAGGGC
CCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCAC
AGCGGCCCTGGGCTGCCTGGTCAAGGACTACrrCCCCGAACCGGTGACGG
TGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCITCCCGGCT
GTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCC
CTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGC
CCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAA
AACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGT
CAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGA
CCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAG
GTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGAC
AAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTC
CTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAA
GGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAG
CCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGG
GAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCT
TCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGA
GAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCT
TCCTCT AT AGC A AGCTC ACCGTGG AC A AG AGC AGGTGGC AGC AGGGG A A
CGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGC
AG A AG AGCCTCTCCCTGTCTCCGGGT A A ATGA (SEQ I D N O : 246 )
5366_P21 (PGT-136) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G C T G C A G T T G C A G G A A T C G G G C C C A G G A C T G G T G A A G C C T T C G G A G A
C C C T G T C C C T G A C T T G C A C A G T T T C T G G T G G C T C C A T G A G G G G C A C C G A C T
G G G G C G A G A A T G A C T T C C A C T A C G G C T G G A T C C G C C A G T C C T C C G C A A A G
G G G C T G G A G T G G A T T G G G A G C A T C C A T T G G A G G G G G A G G A C C A C C C A C T
A C A A G A C G T C C T T C A G G A G T C G G G C C A C C T T G T C G A T A G A C A C G T C C A A T
A A T C G C T T C T C C C T G A C G T T T A G T n T G T G A C C G C C G C G G A C A C G G C C G T C
T A C T A T T G T G C G A G A C A T A A A T A T C A T G A T A T T T T C A G G G T G G T C C C T G T T
G C G G G C T G G T T C G A C C C C T G G G G C C A G G G A T T A C T G G T C A C C G T C T C G A G
C (S E Q I D N O : 247 )
5366_P21 (PGT-136) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con región variable en negrita.
M K H L W F F L L L V A A P R W V L S Q L Q L Q E S G P G L V K P S E T L S L T C T V S G G S M
R G T D W G E N D F H Y G W I R Q S S A K G L E W I G S I H W R G R T T H Y K T S F R S R A T L S
I D T S N N R F S L T F S F V T A A D T A V Y Y C A R H K Y H D I F R V V P V A G W F D P W G Q G
L L V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S G A L
T S G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T K V D K R V E
P K vS C D K T I I T C P P C P A P E L I ,G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S I IE
D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R W S V L T V L H Q D W L N G K E Y
K C K V S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T E P P S R E E M T K N Q V S L T C L V K G F
Y P S D I A V E W E S N G Q P E N N Y K T T P P V F D S D G S F F E Y S K L T V D K S R W Q Q G N V F S
C S V M H E A L H N I I Y T Q K S L S L S P G K ( S E Q I D N O : 248 )
5366_P21 (PGT-136) secuencia de aminoácidos de región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
Q I ,Q I .Q E S G P G I .V K P S E T E S I T C W S G G S M R G TI) W G E N I ) F I IY G W I R O S S A K G
L E W lG M f / W 7 f ( ; i r / T / / Y K T S F R S R A T E S I D T S N N R F S L T F S F V T A A D T A V Y Y C A R H K Y H D I F R V V P V A G W F D F VK iO G L I V T V S S (S E Q ID N O : 249 )
5366_P21 (PGT-136) de la cadena gamma pesada CDR de Kabat:
CDR 1: GTDWGENDFHYG (SEQ ID NO: 250)
CDR 2: SIHWRGRTTHYKTSFRS (SEQ ID NO: 251)
CDR 3: HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252)
5366_P21 (PGT-136) CDR de Chothia de la cadena pesada gamma:
CDR 1: GGSMRGTDWG: 253)
CDR 2: SIHWRGRTTH (SEQ ID NO: 254)
CDR 3: HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252)
5366_P21 (PGT-136) secuencia de nucleótidos de la cadena ligera kappa: secuencia de codificación (región variable en negrita)
A T G G A A A C C C C A G C T C A G C T T C T C T T C C T C C T G C T A C T C T G G C T C C C A G A T
A G C A C T G G A G A A A T A G T G A T G A C G C A G T C T C C A C C C A C C C T G T C T G T G
T C T C C A G G G G A A A C A G C C A C A C T C T C C T G T A G G G C C A G T C A G A A T G T
T A A G A A T A A T T T A G C C T G G T A C C A G C T G A A A C C T G G C C A G G C T C C C A
G G C T C C T C A T C T T T G A T G C G T C C A G C A G G G C C G G T G G T A T T C C T G A C
A G G T T C A G T G G C A G C G G T T A T G G G A C A G A C T T C A C T C T C A C C G T C A A
C A G T G T G C A G T C C G A A G A T T T T G G A G A T T A T T T T T G T C A G C A A T A T G A
A G A G T G G C C T C G G A C G T T C G G C C A A G G G A C C A A G G T G G A T A T C A A A C
G T A C G G T G G C T G C A C C A T C T G T C T T C A T C T T C C C G C C A T C T G A T G A G C A G T
T G A A A T C T G G A A C T G C C T C T G T T G T G T G C C T G C T G A A T A A C T T C T A T C C C A
G A G A G G C C A A A G T A C A G T G G A A G G T G G A T A A C G C C C T C C A A T C G G G T A A
C T C C C A G G A G A G T G T C A C A G A G C A G G A C A G C A A G G A C A G C A C C T A C A G C
C T C A G C A G C A C C C T G A C G C T G A G C A A A G C A G A C T A C G A G A A A C A C A A A G
T C T A C G C C T G C G A A G T C A C C C A T C A G G G C C T G A G C T C G C C C G T C A C A A A G
A G C T T C A A C A G G G G A G A G T G T T A G ( S E Q ID N O : 255 )
5366_P21 (PGT-136) secuencia de nucleótidos de la región variable de la cadena ligera kappa:
G A A A T A G T G A T G A C G C A G T C T C C A C C C A C C C T G T C T G T G T C T C C A G G G O A
A A C A G C C A C A C T C T C C T G T A G G G C C A G T C A G A A T G T T A A G A A T A A T T T A G
C C T G G T A C C A G C T G A A A C C T G G C C A G G C T C C C A G G C T C C T C A T C T T T G A T
G C G T C C A G C A G G G C C G G T G G T A T T C C T G A C A G G T T C A G T G G C A G C G G T T A
T G G G A C A G A C T T C A C T G T C A C C G T C A A C A G T G T G C A G T C C G A A G A T T T T G
G A G A T T A T T T T T G T C A G C A A T A T G A A G A G T G G C C T C G G A C G T T C G G C C A A
G G G A C C A A G G T G G A T A T C A A A ( S E Q I D N O : 256 )
5366_P21 (PGT-136) secuencia de aminoácidos de la cadena ligera kappa: proteína expresada con región variable en negrita.
M E T P A Q L L F L L L L W L P D S T G E I V M T Q S P P T L S V S P G E T A T L S C R A S Q N V K
N N L A W Y Q L K P G Q A P R L L I F D A S S R A G G I P D R F S G S G Y G T D F T L T V N S V Q S
E D F G D Y F C Q Q Y E E W P R T F G Q G T K V D I K R T V A A P S V F I F P P S D E Q L K S G T A S
V V C L L N N F Y P R E A K V Q W K V D N A L Q S G N S Q E S V T E Q D S K D S T Y S L S S T L T L S K
A D Y E K I I K V Y A C E V T I I Q G L S S P V T K S F N R G E C (S E Q ID N O : 257 )
5366_P21 (PGT-136) secuencia de aminoácidos de la región variable de la cadena ligera kappa: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
E I V M T Q S P P T I .S V S P G E T A T I S C R A S O N V K N N 1 A W Y O I .K P G Q A P R I AAF D A S S
/ M G G lP D R F S G S G Y G T D F r L T V N S V O S E D F G D Y F C G C JY E E yV P /fT T G O G T K V D IK ( S E Q ID N O : 258 )
5366_P21 (PGT-136) CDR de Kabat de la cadena ligera kappa:
CDR 1: RASQNVKNNLA (SEQ ID NO: 259)
CDR 2: DASSRAG (SEQ ID NO: 260)
CDR 3: QQYEEWPRT (SEQ ID NO: 245)
5366_P21 (PGT-136) Kappa CDR de cadena ligera de Chothia:
CDR 1: RASQNVKNNLA (SEQ ID NO: 259)
CDR 2: DASSRAG (SEQ ID NO: 260)
CDR 3: QQYEEWPRT (SEQ ID NO: 245)
4964_G22 (PGT-141) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
A T G G A C T G G A T T T G G A G G A T C C T C T T C T T G G T G G C A G C A G T T G C A A G T G C
C C A C T C G C A G G T G C A G C T G G T G C A G T C T G G G C C G G A G G T G A A G A A G C
C T G G G T C C T C A G T G A A G G T C T C C T G C A A G G C C T C T G G A A A C A C C T T C
A G T A A A T A T G A T G T C C A C T G G G T A C G A C A G G C C A C T G G A C A G G G G C T
T G A A T G G G T G G G A T G G A T G A G T C A T G A G G G T G A T A A G A C A G A A T C T G
C A C A G A G A T T T A A G G G C C G A G T C A C C T T C A C G A G G G A C A C T T C C G C A
A G C A C A G C C T A C A T G G A A C T G C G C G G C C T G A C A T C T G A C G A C A C G G C
C A T C T A TT A T TG T ACG AG A G G C T C A A A A C A T C G T T T G C G AG A C T A C G T
T C T C T A C G A T G A C T A C G G C T T A A T T A A T T A T C A A G A G T G G A A T G A C T A
C C T T G A A T T T T T G G A C G T C T G G G G C C A T G G A A C C G C G G T C A C C G T C T
C C T C A G C C T C C A C C A A G G G C C C A T C G G T C T T C C C C C T G G C A C C C T C C T C C
A A G A G C A C C T C T G G G G G C A C A G C G G C C C T G G G C T G C C T G G T C A A G G A C T
A C T T C C C C G A A C C G G T G A C G G T G T C G T G G A A C T C A G G C G C C C T G A C C A G C
G G C G T G C A C A C C T T C C C G G C T G T C C T A C A G T C C T C A G G A C T C T A C T C C C T C
A G C A G C G T G G T G A C C G T G C C C T C C A G C A G C T T G G G C A C C C A G A C C T A C A T
C T G C A A C G T G A A T C A C A A G C C C A G C A A C A C C A A G G T G G A C A A G A G A G T T
G A G C C C A A A T C T T G T G A C A A A A C T C A C A C A T G C C C A C C G T G C C C A G C A C C
T G A A C T C C T G G G G G G A C C G T C A G T C T T C C T C T T C C C C C C A A A A C C C A A G G
A C A C C C T C A T G A T C T C C C G G A C C C C T G A G G T C A C A T G C G T G G T G G T G G A C
G T G A G C C A C G A A G A C C C T G A G G T C A A G T T C A A C T G G T A C G T G G A C G G C G T
G G A G G T G C A T A A T G C C A A G A C A A A G C C G C G G G A G G A G C A G T A C A A C A G C
A C G T A C C G T G T G G T C A G C G T C C T C A C C G T C C T G C A C C A G G A C T G G C T G A A
T G G C A A G G A G T A C A A G T G C A A G G T C T C C A A C A A A G C C C T C C C A G C C C C C A
T C G A G A A A A C C A T C T C C A A A G C C A A A G G G C A G C C C C G A G A A C C A C A G G T
G T A C A C C C T G C C C C C A T C C C G G G A G G A G A T G A C C A A G A A C C A G G T C A G C
C T G A C C T G C C T G G T C A A A G G C T T C T A T C C C A G C G A C A T C G C C G T G G A G T G
G G A G A G C A A T G G G C A G C C G G A G A A C A A C T A C A A G A C C A C G C C T C C C G T G
C T G G A C T C C G A C G G C T C C T T C T T C C T C T A T A G C A A G C T C A C C G T G G A C A A
4964_G22 (PGT-141) secuencia de nucleótidos de región variable de cadena pesada gamma:
CAGG TG CAG CTG G TG CAG TCTG G G CCG G AG G TG AAG AAG CCTG G G T
CCTCAG TG AAG G TCTCCTG CAAG G CCTCTG G AAACACCTTCAG TAAA
TATG ATG TCCACTG G G TACG ACAG G CCACTG G ACAG G G G CTTG AATG
G GTGG G ATG G ATG AG TCATG AG G G TG ATAAG ACAG AATCTG CACAG A
G ATTTAAG G G CCG AG TCACCTTCACG AG G G ACACTTCCG CAAG CACA
G CCTACATG G AACTG CG CG G CCTG ACATCTG ACG ACACG G CCATCTA
TTATTG TACG AG AG G CTCAAAACATCG TTTG CG AG ACTACG TTCTCTA
CG ATG ACTACG G CTTAATTAATTATCAAG AG TG G AATG ACTACCTTG A
A T T T T T G G A C G T C T G G G G C C A T G G A A C C G C G G T C A C C G T C T C C T C A
( S E Q I D N O : 274 )
4964_G22 (PGT-141) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MDWIWRILFLVAAVASAHSQ\QL\QSGPE\KKPGSS\K\SCK\SGNTFSK\
D V H W V R Q A T G Q G L E W V G W M S H E G D K T E S A Q R F K G R V T F T R D T S A S T A
Y M E L R G L T S D D T A I Y Y C T R G S K H R L R D Y V L Y D D Y G L I N Y Q E W N D Y L E F L
D V W G H G T A V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V
S W N S G A L T S G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T
K V D K R V E P K S C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V
W D V S H E D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L I I Q D
W L N G K E Y K C K V S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S
L T C L V K G F Y P S D I A V E W E S N G Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R
W Q Q G N V F S C S V M H E A L H N H Y T Q K S L S L S P G K ( S E Q II) N O : 275 )
4964_G22 (PGT-141) secuencia de aminoácidos de región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
O V Q L V O S G P E V K K P G S S V K V S C K A S G A T F S K Y D V H W V R O A T G Q G L E W V G
W M S H E G D K T E S h O R l ^^KGR V T I -T R D T S A S T A Y M E L R G E T S D D T A I Y Y C T R G .S K U R L R 1 ) Y V L Y D I ) Y G I J N Y O K W N D Y 1 J . I I J ) F W ( i l I G T A V T V S S ( S E Q II ) N O :
276 )
4964_G22 (-141 PGT) CDR de Kabat de cadena pesada gamma:
CDR 1: KYDVH (SEQ ID NO: 277)
CDR 2: WMSHEGDKTESAQRFKG (SEQ ID NO: 278)
CDR 3: GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279)
4964_G22 (PGT-141) CDR de Chothia de la cadena pesada gamma:
CDR 1: GNTFSK (SEQ ID NO: 280)
CDR 2: WMSHEGDKTE (SEQ ID NO: 281)
CDR 3: GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279)
4964_G22 (PGT-141) secuencia de nucleótidos de la cadena ligera kappa: secuencia de codificación (región variable en negrita)

282 )
4964_G22 (PGT-141) secuencia de nucleótidos de la región variable de la cadena ligera kappa:
G A T A C T G T C G T G A C T C A G T C T C C A C T C T C C C T G C C C G T C A C C C C T G G
A G A G G C G G C C T C C A T G T C C T G T T C G T C G A C T C A G A G C C T C C G G C A T A
G T A A T G G A G C C A A C T A T T T G G C T T G G T A T C A G C A C A A A C C G G G G C A G
T C T C C A C G A C T C C T A A T C C G T T T A G G T T C T C A A C G G G C C T C C G G G G T
C C C T G A C A G A T T C A G T G G C A G T G G A T C A G G C A C T C A T T T T A C A C T G A
A A A T C A G T A G A G T G G A G G C T G A A G A T G C T G C A A T T T A T T A T T G C A T G
C A A G G T C T G A A C C G T C C C T G G A C G T T C G G C A A G G G G A C C A A G T T G G A
A A T C A A A ( S E Q ID N O : 283 )
4964_G22 (PGT-141) secuencia de aminoácidos de la cadena ligera kappa: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MRLPAQLLGLLMLWVSGSSADTWTQSVLSLPXTPGEAASMSCSSTQSLRHS
N G A N Y L A W Y Q H K P G Q S P R L L I R L G S Q R A S G V P D R F S G S G S G T H F T L K I S R
V E A E D A A I Y Y C M Q G L N R P W T F G K G T K L E I K R T V A A P S V I II P P S D H Q L K S G
T A S V V C L L N N F Y P R E A K V Q W K V D N A L Q S G N S Q E S V T E Q D S K D S T Y S L S S T L T
L S K A D Y E K H K V Y A C E V T H Q G L S S P V T K S F N R G E C ( S E Q I D N O : 284 )
4964_G22 (PGT-141) secuencia de aminoácidos de la región variable de la cadena ligera kappa: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
D r V V T O S P L S I v P V r P G E A A S M S ( \S'S’7 ’O S 7 J/f / /S W G A A fK /v l W Y O I I K P G O S P R E E I R / Y ^ ' O / M S G V P D R lS G S G S G I 'H I T L K I S R V H A H D A A I Y Y C M O G M W / ^ r / T G K G T K L E I K (S E Q ID N O : 285 )
4964_G22 (PGT-141) CDR de Kabat de cadena ligera kappa:
CDR 1: SSTQSLRHSNGANYLA (SEQ ID NO: 286)
CDR 2: LGSQRAS (SEQ ID NO: 287)
CDR 3: MQGLNRPWT (SEQ ID NO: 288)
4964_G22 (PGT-141) CDR de Chothia de la cadena ligera kappa:
CDR 1: SSTQSLRHSNGANYLA (SEQ ID NO: 286)
CDR 2: LGSQRAS (SEQ ID NO: 287)
CDR 3: MQGLNRPWT (SEQ ID NO: 288)
4993_K13 (PGT-141) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
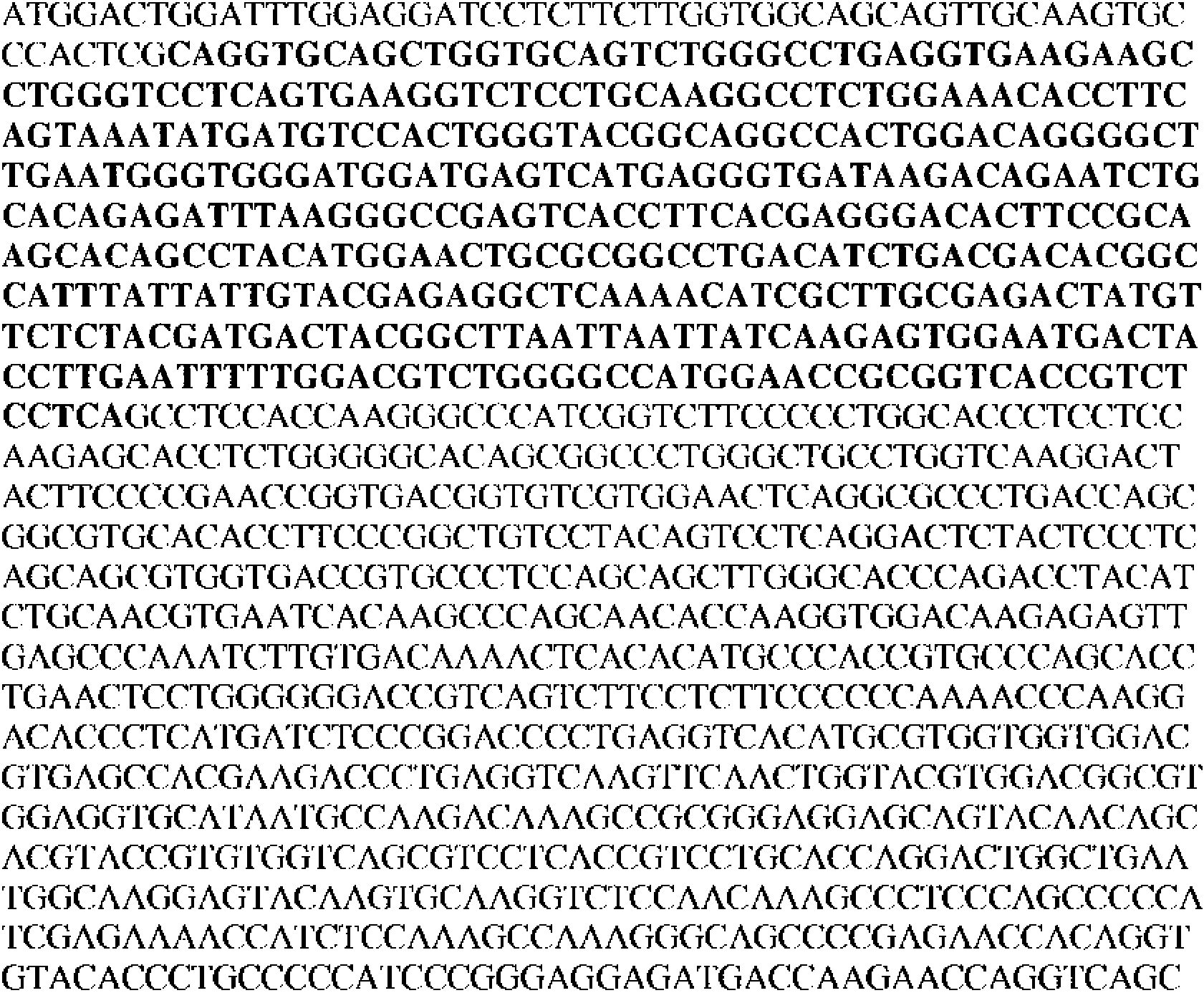
C T G A C C T G C C T G G T C A A A G G C T T C T A T G C C A G C G A C A T C G C C G T G G A G T G
G G A G A G C A A T G G G C A G C C G G A G A A C A A G T A C A A G A C C A C G C C T C C C G T G
C T G G A C T G C G A C G G C T C C T T C T T C C T C T A T A G G A A G C T C A C C G T G G A C A A
G A G C A G G T G G C A G C A G G G G A A C G T C T T C T C A T G G T C C G T G A T G C A T G A G G
C T C T G C A C A A C C A C T A C A C G C A G A A G A G C C T C T C C C T G T C T C C G G G T A A A
T G A ( S E Q I D N O : 289 )
4993_K13 (PGT-141) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G G T G C A G C T G G T G C A G T C T G G G C C T G A G G T G A A G A A G C C T G G G T
C C T C A G T G A A G G T C T C C T G C A A G G C C T C T G G A A A C A C C T T C A G T A A A
T A T G A T G T C C A C T G G G T A C G G C A G G C C A C T G G A C A G G G G C T T G A A T G
G G T G G G A T G G A T G A G T C A T G A G G G T G A T A A G A C A G A A T C T G C A C A G A
G A T T T A A G G G C C G A G T C A C C T T C A C G A G G G A C A C T T C C G C A A G C A C A
G C C T A C A T G G A A C T G C G C G G C C T G A C A T C T G A C G A C A C G G C C A T T T A
T T A T T G T A C G A G A G G C T C A A A A C A T C G C T T G C G A G A C T A T G T T C T C T A
A C G TT A T T T G T A G C G T A A C C G G T G C C T T G T G A G A G T T C A C A A T T T G A G T A C A A C A C G G A C G G T G G T G C A A A C T C G G A T C C T T A C C C C T T C T A G (S A
E Q I D N O : 290 )
4993_K13 (PGT-141) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
M D W Y V M //J / .F A A V A 5 A / / .S Q V Q L V Q S G P E V K K P G S S V K V S C K A S G N T F S K Y
D V H W V R Q A T G Q G L E W V G W M S H E G D K T E S A Q R F K G R V T F T R D T S A S T A
Y M E L R G L T S D D T A I Y Y C T R G S K H R L R D Y V L Y D D Y G L I N Y Q E W N D Y L E F L
D V W G H G T A V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V
S W N S G A L T S G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T
KVDKRVEPKSCDKTHTCPPCPAPEEEGGPSVFLFPPKPKDTEMISRTPEVTCV
V V D V S H E D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D
W L N G K E Y K C K V v S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S
L T G L V K G F Y P S D I A V E W E S N G Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R
W Q Q G N V F S C S V M H E A L I I N I I Y T Q K S L S L S P G K ( S E Q II) N O : 275 )
4993_K13 (PGT-141) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
O V O L V Q S G P E V K K P G S S V K V S C K A S G A O T F S K Y D V H W V R O A T G O G L E W V G
W M S H H G D K T H S A O R l ■KGR V T i n ’R D T S A S T A Y M E E R G L T S D D T A I Y Y C ’ r R G S K H R L R D Y V L Y D I ) Y U U N Y O l i W N l ) Y L E F L D F W G M G T A V T V S S (S E Q II ) N O :
2 76 )
4993_K13 (PGT-141) CDR de Kabat de la cadena pesada gamma:
CDR 1: KYDVH (SEQ ID NO: 277)
CDR 2: WMSHEGDKTESAQRFKG (SEQ ID NO: 278)
CDR 3: GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279)
4993_K13 (PGT-141) CDR de Chothia de la cadena pesada gamma:
CDR 1: GNTFSK (SEQ ID NO: 280)
CDR 2: WMSHEGDKTE (SEQ ID NO: 281)
CDR 3: GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279)
4993_K13 (PGT-141) secuencia de nucleótidos de cadena ligera kappa: secuencia de codificación (región variable en negrita)

282 )
4993_K13 (PGT-141) secuencia de nucleótidos de región variable de cadena ligera kappa:
G A T A C T G T C G T G A C T C A G T C T C C A C T C T C C C T G C C C G T C A C C C C T G G
A G A G G C G G C C T C C A T G T C C T G T T C G T C G A C T C A G A G C C T C C G G C A T A
G T A A T G G A G C C A A C T A T T T G G C T T G G T A T C A G C A C A A A C C G G G G C A G
T C T C C A C G A C T C C T A A T C C G T T T A G G T T C T C A A C G G G C C T C C G G G G T
C C C T G A C A G A T T C A G T G G C A G T G G A T C A G G C A C T C A T T T T A C A C T G A
A A A T C A G T A G A G T G G A G G C T G A A G A T G C T G C A A T T T A T T A T T G C A T G
C A A G G T C T G A A C C G T C C C T G G A C G T T C G G C A A G G G G A C C A A G T T G G A
A A T C A A A ( S K Q ID N O : 283 )
4993_K13 (PGT-141) secuencia de aminoácidos de la cadena ligera kappa: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MRLPAQLLGLLMIAWSGSSADT\\TQSPLSLP\TPGE\\SMSCSSTQSLRHS
N G A N Y L A W Y Q H K P G Q S P R L L I R L G S Q R A S G V P D R F S G S G S G T H F T L K I S R
V E A E D A A J Y Y C M Q G L N R P W T F G K G T K L E I K R T V A A P S V F I F P P S D E Q L K S G
TASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLT
LSKADYEKHKVYACEVTHQGLSSPVTKvSFNRGEC (SEQ ID NO: 284)
4993_K13 (PGT-141) secuencia de aminoácidos de la región variable de la cadena ligera kappa: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
DTVVTQSPI.SI .PVTPGEA ASMSÍ 'SSTOSLRHSNGA NYIA WYOI IKP( ¡QSPRIA A
RIXiSORA SGVPDR1 -SGSGSGTI IITI .KISR VEAEDA Al Y YC VT/’l (1K GTKLEIK (SEQ ID NO: 285)
4993_K13 (PGT-141) CDR de Kabat de cadena ligera kappa:
CDR 1: SSTQSLRHSNGANYLA (SEQ ID NO: 286)
CDR 2: LGSQRAS (SEQ ID NO: 287)
CDR 3: MQGLNRPWT (SEQ ID NO: 288)
4993_K13 (PGT-141) CDR de Chothia de la cadena ligera kappa:
CDR 1: SSTQSLRHSNGANYLA (SEQ ID NO: 286)
CDR 2: LGSQRAS (SEQ ID NO: 287)
CDR 3: MQGLNRPWT (SEQ ID NO: 288)
4995_E20 (PGT-142) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)

C T G A C C T G C C T G G T C A A A G G C T T C T A T C C C A G C G A C A T C G C C G T G G A G T G
G G A G A G C A A T G G G C A G C C G G A G A A C A A C T A C A A G A C C A C G C C T C C C G T G
C T G G A C T C C G A C G G C T C C T T C 1 T C C T C T A T A G C A A G C T C A C C G T G G A C A A
G A G C A G G T G G C A G C A G G G G A A C G T C T T C T C A T G C T C C G T G A T G C A T G A G G
C T C T G C A C A A C C A C T A C A C G C A G A A G A G C C T C T C C C T G T C T C C G G G T A A A
T G A ( S E Q ID N O : 314 )
4995_E20 (PGT-142) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G G T G C A G C T G G T G C A G T C T G G G C C T G A G G T G A A G A A G C C T G G G T
C C T C A G T G A A G G T C T C C T G C A A G G C C T C T G G A A A C A C C T T C A G T A A A
T A T G A T G T C C A C T G G G T A C G A C A G G C C A C T G G A C A G G G G C T T G A A T G
G G T G G G A T G G A T T A G T C A T G A G C G T G A T A A G A C A G A A T C T G C A C A G A
G A T T T A A G G G C C G A G T C A C C T T C A C G A G G G A C A C T T C C G C A A C C A C A
G C C T A C A T G G A A C T G C G C G G C C T G A C A T C T G A C G A C A C G G C C A T T T A
T T A T T G T A C G A G A G G C T C A A A A C A T C G C T T G C G A G A C T A C G T T C T C T A
C G A T G A C T A C G G C T T A A T T A A T T A T C A A G A G T G G A A T G A C T A C C T T G A
A T T T T T G G A C G T C T G G G G C C A T G G A A C C G C G G T C A C C G T C T C C T C A
(S E Q I D N O : 315 )
4995_E20 (PGT-142) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
A 7 D V V 7 V V m /7 ,V A A V A S 71 / / .S Q V Q L V Q S G P E V K K P G S S V K V S C K A S G N T F S K Y
D V H W V R Q A T G Q G L E W V G W I S H E R D K T E S A Q R F K G R V T F T R D T S A T T A Y
M E L R G L T S D D T A I Y Y C T R G S K H R L R D Y V L Y D D Y G L I N Y Q E W N D Y L E F L D
V W G H G T A V T V S S A S T K G P S V E P E A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S
W N S G A L T S G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T Y 1 C N V N H K P S N T K
V D K R V E P K S C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V
V D V S H E D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D W
L N G K E Y K C K V S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T
C L V K G F Y P S D I A V E W E S N G Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R W Q
Q G N V F S C S V M H E A L H N H Y T Q K S L S L S P G K ( S E Q ID N O : 291 )
4995_E20 (PGT-142) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
O V O L V O S G P E V K K P G S S V K V S C X A S G A T F S Á T D V I I W V R O A T G O G L E W V G
W I S H K R D K T K S A O R l K G R V T I T R D T S A I T A Y M E E R G I X S D D T A I Y Y C T R G S A ' H R L R D Y V L Y D I ) Y G U N Y O l í W N D Y L E F L D YW G H G T A V T V X S ( S E Q I D N O :
292 )
4995_E20 (PGT-142) CDR de Kabat de cadena pesada gamma:
CDR 1: KYDVH (SEQ ID NO: 277)
CDR 2: WISHERDKTESAQRFKG (SEQ ID NO: 293)
CDR 3: GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279)
4995_E20 (PGT-142) CDR de Chothia de la cadena pesada gamma:
CDR 1: GNTFSK (SEQ ID NO: 280)
CDR 2: WISHERDKTE (SEQ ID NO: 294)
CDR 3: GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279)
4995_E20 (PGT-142) secuencia de nucleótidos de cadena ligera kappa: secuencia de codificación (región variable en negrita)

2 82 )
4995_E20 (PGT-142) secuencia de nucleótidos de región variable de cadena ligera kappa:

4995_E20 (PGT-142) secuencia de aminoácidos de la cadena ligera kappa: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MRLPAQUX,LLMLWVSGSSADT\\TQSPLSLP\TPGE\\SMSCSSTQSLRHS
N G A N Y L A W Y Q H K P G Q S P R L L I R L G S Q R A S G V P D R F S G S G S G T H F T L K I S R
V E A E D A A I Y Y C M Q G L N R P W T F G K G T K L E I K R T V A A P S V I I 1 P P S D E Q L K S G
T A S W C L E N N F Y P R E A K V Q W K V D N A L Q S G N S Q E S V T E Q D S K D S T Y S L S S T L T
E S K A D Y E K I I K V Y A C E V T I I Q G L S S P V T K S F N R G E C ( S E Q ID N O : 284 )
4995_E20 (PGT-142) secuencia de aminoácidos de la región variable de la cadena ligera kappa: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
D r V V r O S P L S E P V r P G E A A S M S r S S y ’g V A m S W G A A Y / v i W Y O I lK P G O S P R E E I R //f>SC M A .S’G V P D R I rS G S G S G T I I lT E K I S R V E A E D A A I Y Y G M ( > 07 J V /f />W 7 ’E G K G T K L E I K ( S E Q ID N O : 285 )
4995_E20 (PGT-142) CDR de Kabat de la cadena ligera kappa:
CDR 1: SSTQSLRHSNGANYLA (SEQ ID NO: 286)
CDR 2: LGSQRAS (SEQ ID NO: 287)
CDR 3: MQGLNRPWT (SEQ ID NO: 288)
4995_E20 (PGT-142) CDR de Chothia de la cadena ligera kappa:
CDR 1: SSTQSLRHSNGANYLA (SEQ ID NO: 286)
CDR 2: LGSQRAS (SEQ ID NO: 287)
CDR 3: MQGLNRPWT (SEQ ID NO: 288)
4980_N08 (PGT-143) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
A T G G A C T G G A T T T G G A G G A T C C T C T T C T T G G T G G C A G C A G T T G C A A G T G C
C C A C G C G C A G G T G C A G C T G G A G C A G T C T G G G G C T G A G G T G A A G A A G C
C T G G G T C C T C A G T G A A G G T C T C C T G C A A G G C C T C T G G A A A C A C C T T C
A G T A A A T A T G A T G T C C A C T G G G T A C G A C A G G C C A C T G G A C A G G G G C T
T G A A T G G G T G G G A T G G A T G A G T C A T G A G G G T G A T A A G A C A G A A T C T G
C A C A G A G A T T T A A G G G G C G A G T C A C C T T C A C G A G G G A C A C T T C C G C A
A G C A C A G C C T A C A T G G A A C T G C G C G G C C T G A C A T C T G A C G A C A C G G C
C A T T T A T T A T T G T A C G A G A G G T T C A A A A C A T C G C T T G C G A G A C T A C G T
T C T C T A C G A T G A C T A C G G C T T A A T T A A T T A T C A A G A G T G G A A T G A C T A
C C T T G A A T T T T T G G A C G T C T G G G G C C A T G G A A C C G C G G T C A C C G T C T
C C T C A G C C T C C A C C A A G G G C C C A T C G G T C T T C C C C C T G G C A C C C T C C T C C
A A G A G C A C C T C T G G G G G C A C A G C G G C C C T G G G C T G C C T G G T C A A G G A C T
A C T T C C C C G A A C C G G T G A C G G T G T C G T G G A A C T C A G G C G C C C T G A C C A G C
G G C G T G C A C A C C T T C C C G G C T G T C C T A C A G T C C T C A G G A C T C T A C T C C C T C
A G C A G C G T G G T G A C C G T G C C C T C C A G C A G C T T G G G C A C C C A G A C C T A C A T
C T G C A A G G T G A A T C A C A A G C C C A G C A A C A C C A A G G T G G A C A A G A G A G T T
G A G C C C A A A T C T T G T G A C A A A A C T C A C A C A T G C C C A C C G T G C C C A G C A C C
T G A A C T C C T G G G G G G A C C G T C A G T C T T C C T C T T C C C C C C A A A A C C C A A G G
A C A C C C T C A T G A T C T C C C G G A C C C C T G A G G T C A C A T G C G T G G T G G T G G A C
G T G A G C C A C G A A G A C C C T G A G G T C A A G T T C A A C T G G T A C G T G G A C G G C G T
G G A G G T G C A T A A T G C C A A G A C A A A G C C G C G G G A G G A G C A G T A C A A C A G C
A C G T A C C G T G T G G T C A G C G T C C T C A C C G T C C T G C A C C A G G A C T G G C T G A A
T G G C A A G G A G T A C A A G T G C A A G G T C T C C A A C A A A G C C C T C C C A G C C C C C A
T C G A G A A A A C C A T C T C C A A A G C C A A A G G G C A G C C C C G A G A A C C A C A G G T
G T A C A C C C T G C C C C C A T C C C G G G A G G A G A T G A C C A A G A A C C A G G T C A G C
C T G A C C T G C C T G G T C A A A G G C T T C T A T C C C A G C G A C A T C G C C G T G G A G T G
G G A G A G C A A T G G G C A G C C G G A G A A C A A C T A C A A G A C C A C G C C T C C C G T G
C T G G A C T C C G A C G G C T C C T T C T T C C T C T A T A G C A A G C T C A C C G T G G A C A A
G A G C A G G T G G C A G C A G G G G A A C G T C T T C T C A T G C T C C G T G A T G C A T G A G G
C T C T G C A C A A C C A C T A C A C G C A G A A G A G C C T C T C C C T G T C T C C G G G T A A A
T G A ( S E Q II ) N O : 295 )
4980_N08 (PGT-143) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G G T G C A G C T G G A G C A G T C T G G G G C T G A G G T G A A G A A G C C T G G G T
C C T C A G T G A A G G T C T C C T G C A A G G C C T C T G G A A A C A C C T T C A G T A A A
T A T G A T G T C C A C T G G G T A C G A C A G G C C A C T G G A C A G G G G C T T G A A T G
G G T G G G A T G G A T G A G T C A T G A G G G T G A T A A G A C A G A A T C T G C A C A G A
G A T T T A A G G G G C G A G T C A C C T T C A C G A G G G A C A C T T C C G C A A G C A C A
G C C T A C A T G G A A C T G C G C G G C C T G A C A T C T G A C G A C A C G G C C A T T T A
T T A T T G T A C G A G A G G T T C A A A A C A T C G C T T G C G A G A C T A C G T T C T C T A
C G A T G A C T A C G G C T T A A T T A A T T A T C A A G A G T G G A A T G A C T A C C T T G A
A T T T T T G G A C G T C T G G G G C C A T G G A A C C G C G G T C A C C G T C T C C T C A
( S E Q II ) N O : 296 )
4980_N08 (PGT-143) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
A /D W 7 W /e / /J 7 ,V /M V A S 7 t /M Q V Q L E Q S G A E V K K P G S S V K V S C K A S G N T F S K Y
D V H W V R Q A T G Q G L E W V G W M S H E G D K T E S A Q R F K G R V T F T R D T S A S T A
Y M E L R G L T S D D T A I Y Y C T R G S K H R L R D Y V L Y D D Y G L I N Y Q E W N D Y L E F L
D V W G H G T A V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V
S W N S G A L T S G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T
K V D K R V E P K S C D K T H T C P P C P A P H L I X íG P S V F L F P P K P K D T L M I S R T P E V T C V
V V D V S H E D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D
W L N G K E Y K C K V S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S
L T C L V K G F Y P S D I A V E W E S N G Q P E N N Y K I T P P V L D S D G S F F L Y S K L T V D K S R
W Q Q G N V F S C S V M H E A L H N H Y T Q K S L S L S P G K ( S E Q I D N O : 297 )
4980_N08 (PGT-143) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
O V O L E O S G A E V K K P G S S V K V S C K A S G W 77 S K Y D V H W V R O A T G O G L E W V G
W M S H E G D K T E S A O R l K G R V T F r R D T S A S T A Y M E L R G E T S D D T A I Y Y C T R G ’S K H k L k D Y V L Y D D Y G I J N Y O E W N D Y L E F m V W G U G T A V I V S S ( S E Q ID N O :
298 )
4980_N08 (PGT-143) CDR de Kabat de la cadena pesada gamma:
CDR 1: KYDVH (SEQ ID NO: 277)
CDR 2: WMSHEGDKTESAQRFKG (SEQ ID NO: 278)
CDR 3: GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279)
4980_N08 (PGT-143) CDR de Chothia de la cadena pesada gamma:
CDR 1: GNTFSK (SEQ ID NO: 280)
CDR 2: WMSHEGDKTE (SEQ ID NO: 281)
CDR 3: GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279)
4980_N08 (PGT-143) secuencia de nucleótidos de la cadena ligera de kappa: secuencia codificante (región variable en negrita)
A T G A G G C T C C C T G C T C A G C T C C T G G G G C T G C T A A T G C T C T G G G T C T C T G G A
T C C A G T G C G G A T A C T G T C G T G A C T C A G T C T C C A C T C T C C C T G C C C G T C
A C C C C T G G A G A G G C G G C C T C C A T G T C C T G T A C G T C G A C T C A G A G C C T
C C G T C A T A G T A A T G G A G C C A A C T A T T T G G C T T G G T A C C A G C A C A A A C
C A G G G C A G T C T C C A C G A C T C C T A A T C C G T T T A G G T T C T C A A C G G G C C
T C C G G G G T C C C T G A C A G A T T C A G T G G C A G T G G A T C A G G C A C T C A T T T
T A C A C T G A A A A T C A G T C G A G T G G A G C C T G A A G A T G C T G C A A T T T A T T
A T T G C A T G C A A G G T C T G A A C C G T C C C T G G A C G T T C G G C A A G G G G A C C
A A G T T G G A A A T C A A A C G T A C G G T G G C T G C A C C A T C T G T C T r C A T C T T C C C
G C C A T C T G A T G A G C A G T T G A A A T C T G G A A C T G C C T C T G T T G T G T G C C T G C T
G A A T A A C T T C T A T C C C A G A G A G G C C A A A O T A C A G T G G A A G G T G G A T A A C
G C C C T C C A A T C G G G T A A C T C C C A G G A G A G T G T G A C A G A G C A G G A C A G C A
A G G A C A G C A C C T A C A G C C T C A G C A G C A C C C T G A C G C T G A G C A A A G C A G A
C T A C G A G A A A C A C A A A G T C T A C G C C T G C G A A G T C A C C C A T C A G G G C C T G A
G C T C G C C C G T C A C A A A G A G C T T C A A C A G G G G A G A G T G T T A G (SEQ ID NO:
299 )
4980_N08 (PGT-143) secuencia de nucleótidos de la región variable de la cadena ligera de kappa:
G A T A C T G T C G T G A C T C A G T C T C C A C T C T C C C T G C C C G T C A C C C C T G G
A G A G G C G G C C T C C A T G T C C T G T A C G T C G A C T C A G A G C C T C C G T C A T A
G T A A T G G A G C C A A C T A T T T G G C T T G G T A C C A G C A C A A A C C A G G G C A G
T C T C C A C G A C T C C T A A T C C G T T T A G G T T C T C A A C G G G C C T C C G G G G T
C C C T G A C A G A T T C A G T G G C A G T G G A T C A G G C A C T C A T T T T A C A C T G A
A A A T C A G T C G A G T G G A G C C T G A A G A T G C T G C A A T T T A T T A T T G C A T G
C A A G G T C T G A A C C G T C C C T G G A C G T T C G G C A A G G G G A C C A A G T T G G A
A A T C A A A (SEQ ID N O : 300)
4980_N08 (PGT-143) secuencia de aminoácidos de la cadena ligera kappa: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MRLPAQU.GUMLWVSGSSADT\XTQSPLSLP\TPGE\\SMSCTSTQSLRHS
N G A N Y L A W Y Q H K P G Q S P R L L I R L G S Q R A S G V P D R F S G S G S G T H F T L K I S R
V E P E D A A I Y Y C M Q G L N R P W T F G K G T K L E I K R T V A A P S V I I1PPSDEQEKSG
TASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLT
ESKADYEKIIKVYACHVTIIQGLSSPVTKSFNRGEC (SEQ ID NO: 301)
4980_N08 (PGT-143) secuencia de aminoácidos de la región variable de la cadena ligera kappa: (CDR de Kabat subrayadas, CDR Chothia en negrita y cursiva)
DrVVrOSPLSLPVrPGEAASMS('y:S,m S 7 J/e//SM ;A A >7vlWYOHKPGOSPRLLl R//jS ’0/M S’GVPDRFSGSGSGTIIITEKISRVEPEDAAIYYCA /()G /j\7f/, VV7Tl GK GTKLEIK (SEQ ID NO: 302)
4980_N08 (PGT-143) CDR de Kabat de la cadena ligera kappa:
CDR 1: TSTQSLRHSNGANYLA (SEQ ID NO: 303)
CDR 2: LGSQRAS (SEQ ID NO: 287)
CDR 3: MQGLNRPWT (SEQ ID NO: 288)
4980_N08 (PGT-143) CDR de Chothia de la cadena ligera kappa:
CDR 1: TSTQSLRHSNGANYLA (SEQ ID NO: 303)
CDR 2: LGSQRAS (SEQ ID NO: 287)
CDR 3: MQGLNRPWT (SEQ ID NO: 288)
4970_K22 (PGT-144) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
A T G G A C T G G A T T T G G A G G A T C C T C T T C T T G G T G G C A G C A G T T G C A A G T G C
C C A C T C G C A G G T G C A G C T G G T G C A G T C T G G G G C T G A G G T G A A G A A G C
C T G G G T C C T C A G T G A A G G T C T C C T G C A A G G C C T C T G G A A A C A C C T T C
A G G A A A T A T G A T G T C C A C T G G G T A C G A C A G G C C A C T G G A C A G G G G C T
T G A A T G G G T G G G A T G G A T G A G T C A T G A G G G T G A T A A G A C A G A A T C T G
C A C A G A G A T T T A A G G G C C G A G T C T C T T T C A C G A G G G A C A A T T C C G C A
A G C A C A G C C T A C A T T G A A C T G C G C G G C C T G A C A T C T G A C G A C A C G G C
C A T T T A T T A T T G T A C C G G A G G C T C A A A A C A T C G C T T G C G A G A C T A C G T
T C T C T A C G A T G A T T A C G G C C T A A T A A A T C A G C A A G A G T G G A A T G A C T
A C C T T G A A T T T T T G G A C G T C T G G G G C C A T G G A A C C G C G G T C A C C G T C
T C C T C A G C C T C C A C C A A G G G C C C A T C G G T C T T C C C C C T G G C A C C C T C C T C
C A A G A G C A C C T C T G G G G G C A C A G C G G C C C T G G G C T G C C T G G T C A A G G A C T
A C T T C C C C G A A C C G G T G A C G G T G T C G T G G A A C T C A G G C G C C C T G A C C A G C
G G C G T G C A C A C C T T C C C G G C T G T C C T A C A G T C C T C A G G A C T C T A C T C C C T C
A G C A G C G T G G T G A C C G T G C C C T C C A G C A G C T T G G G C A C C C A G A C C T A C A T
C T G C A A C G T G A A T C A C A A G C C C A G C A A C A C C A A G G T G G A C A A G A G A G T T
G A G C C C A A A T C T T G T G A C A A A A C T C A C A C A T G C C C A C C G T G C C C A G C A C C
T G A A C T C C T G G G G G G A C C G T C A G T C T T C C T C T T C C C C G C A A A A C C C A A G G
A C A C C G T C A T G A T C T C C C G G A C C C C T G A G G T C A C A T G C G T G G T G G T G G A C
G T G A G C C A C G A A G A C C C T G A G G T C A A G T T C A A C T G G T A C G T G G A C G G C G T
G G A G G T G C A T A A T G C C A A G A C A A A G C C G C G G G A G G A G C A G T A C A A C A G C
A C G T A C C G T G T G G T C A G C G T C C T C A C C G T C C T G C A C C A G G A C T G G C T G A A
T G G C A A G G A G T A C A A G T G C A A G G T C T C C A A C A A A G C C C T C C C A G C C C C C A
T C G A G A A A A C C A T C T C C A A A G C C A A A G G G C A G C C C C G A G A A C C A C A G G T
G T A C A C C C T G C C C C C A T C C C G G G A G G A G A T G A C C A A G A A C C A G G T C A G C
C T G A C C T G C C T G G T C A A A G G C T T C T A T C C C A G C G A C A T C G C C G T G G A G T G
G G A G A G C A A T G G G C A G C C G G A G A A C A A C T A C A A G A C C A C G C C T C C C G T G
C T G G A C T C C G A C G G C T C C T T C T T C C T C T A T A G C A A G C T C A C C G T G G A C A A
G A G C A G G T G G C A G C A G G G G A A C G T C T T C T C A T G C T C C G T G A T G C A T G A G G
C T C T G C A C A A C C A C T A C A C G C A G A A G A G C C T C T C C C T G T C T C C G G G T A A A
T O A ( S E Q ID N O : 304 )
4970_K22 (PGT-144) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G G T G C A G C T G G T G C A G T C T G G G G C T G A G G T G A A G A A G C C T G G G T
C C T C A G T G A A G G T C T C C T G C A A G G C C T C T G G A A A C A C C T T C A G G A A A
T A T G A T G T C C A C T G G G T A C G A C A G G C C A C T G G A C A G G G G C T T G A A T G
G G T G G G A T G G A T G A G T C A T G A G G G T G A T A A G A C A G A A T C T G C A C A G A
G A T T T A A G G G C C G A G T C T C T T T C A C G A G G G A C A A T T C C G C A A G C A C A
G C C T A C A T T G A A C T G C G C G G C C T G A C A T C T G A C G A C A C G G C C A T T T A
T T A T T G T A C C G G A G G C T C A A A A C A T C G C T T G C G A G A C T A C G T T C T C T A
C G A T G A T T A C G G C C T A A T A A A T C A G C A A G A G T G G A A T G A C T A C C T T G
A A T T T T T G G A C G T C T G G G G C C A T G G A A C C G C G G T C A C C G T C T C C T C A
( S E Q ID N O : 305 )
4970_K22 (PGT-144) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MDW¡WR/IH.VAAVASAHSQ\QL\QSGAE\KKPGSS\K\SCK\SGmFRK\
D V H W V R Q A T G Q G L E W V G W M S H E G D K T E S A Q R F K G R V S F T R D N S A S T A
Y I E L R G L T S D D T A I Y Y C T G G S K H R L R D Y V L Y D D Y G L I N Q Q E W N D Y L E F L
D V W G H G T A V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V
S W N S G A L T S G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T
K V D K R V E P K S C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T L M 1 S R T P E V T C V
V V D V S H E D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D
W L N G K E Y K C K V S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S
L T C L V K G F Y P S D I A V E W E S N G Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R
W Q Q G N V F S C S V M H E A L H N H Y T Q K S L S L S P G K ( S E Q ID N O : 306 )
4970_K22 (PGT-144) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
Q V Q L V Q S G A E V K K P G S S V K V S C K A S G A T F 7 ? A Q fD V H W V R Q A T G Q G L E W V G U ,M S 7 / / iQ 7 J Á 77 iS A O R F K G R V S F T R D N S A S T A Y I E I J * G E T S D D T A I Y Y C T G ( * S K
H R L R 1 ) Y VL Y 1)1) Y G I J N O O E W N I) Y L E F U ) VW G I I G T A V T V S S ( S E Q ID N O :
307 )
4970_K22 (PGT-144) CDR de Kabat de cadena pesada gamma:
CDR 1: KYDVH (SEQ ID NO: 277)
CDR 2: WMSHEGDKTESAQRFKG (SEQ ID NO: 278)
CDR 3: GSKHRLRDYVLYDDYGLINQQEWNDYLEFLDV (SEQ ID NO: 3090)
4970_K22 (PGT-144) CDR de Chothia de la cadena pesada gamma:
CDR 1: GNTFRK (SEQ ID NO: 309)
CDR 2: WMSHEGDKTE (SEQ ID NO: 281)
CDR 3: GSKHRLRDYVLYDDYGLINQQEWNDYLEFLDV (SEQ ID NO: 308)
4970_K22 (PGT-144) secuencia de nucleótidos de la cadena ligera de kappa: secuencia de codificación (región variable en negrita)
A T G A G G C T C C C T G C T C A G C T C C T G O G G C T O C T A A T G C T C T G G G T C T C T G G A
T C C A G T G C G G A T A C T G T C G T G A C T C A G T C T C C A C T C T C C C T G T C C G T C
A C C C C T G G A G A G G C G G C C T C C A T G T C C T G T A C G T C G A C T C A G A G C C T
C C G G C A T A G T A A T G G A G C C A A C T A T T T G G C T T G G T A C C A G C A C A A A C
C A G G G C A G T C T C C A C G A C T C C T A A T C C G T T T A G G T T C T C A A C G G G C C
T C C G G G G T C C C T G A C A G A T T C A G T G G C A G T G G A T C A G G C A C T C A T T T
T A C A C T G A A A A T C A G T A G A G T G G A G G C T G A C G A T G C T G C A A T T T A T T
A T T G C A T G C A A G G T C T G A A C C G T C C C T G G A C G T T C G G C A A G G G G A C C
A A G T T G G A G A T C A A A C G T A C G G T G G C T G C A C C A T C T G T C T T C A T C T T C C C
G C C A T C T G A T G A G C A G T T G A A A T C T G G A A C T G C C T C T G T T G T G T G C C T G C T
G A A T A A C T T C T A T C C C A G A G A G G C C A A A G T A C A G T G G A A G G T G G A T A A C
G C C C T C C A A T C G G G T A A C T C C C A G G A G A G T G T C A C A G A G C A G G A C A G C A
A G G A C A G C A C C T A C A G C C T C A G C A G C A C C C T G A C G C T G A G C A A A G C A G A
C T A C G A G A A A C A C A A A G T C T A C G C C T G C G A A G T G A C C C A T C A G G G C C T G A
G C T C G C C C G T C A C A A A G A G C T T C A A C A G G G G A G A G T G T T A G (S E Q ID N O :
310 )
4970_K22 (PGT-144) secuencia de nucleótidos de la región variable de la cadena ligera de kappa:
G A T A C T G T C G T G A C T C A G T C T C C A C T C T C C C T G T C C G T C A C C C C T G G A
G A G G C G G C C T C C A T G T C C T G T A C G T C G A C T C A G A G C C T C C G G C A T A G
T A A T G G A G C C A A C T A T T T G G C T T G G T A C C A G C A C A A A C C A G G G C A G T
C T C C A C G A C T C C T A A T C C G T T T A G G T T C T C A A C G G G C C T C C G G G G T C
C C T G A C A G A T T C A G T G G C A G T G G A T C A G G C A C T C A T T T T A C A C T G A A
A A T C A G T A G A G T G G A G G C T G A C G A T G C T G C A A T T T A T T A T T G C A T G C
A A G G T C T G A A C C G T C C C T G G A C G T T C G G C A A G G G G A C C A A G T T G G A G
A T C A A A (SEQ ID NO: 311)
4970_K22 (PGT-144) secuencia de aminoácidos de la cadena ligera kappa: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MRLPAQLLGUMI.WVSGSSADTX\TQSPLSLS\TPGE\\SMSCTSTQSLRHS
N G A N Y L A W Y Q H K P G Q S P R L L I R L G S Q R A S G V P D R F S G S G S G T H F T L K I S R
V E A D D A A I Y Y C M Q G L N R P W T F G K G T K L E I K R I VAAPSVFIFPPSDHQLKSG
TASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDvSTYSLSSTLT
LS K AD YEKH K V Y ACE VTHQGLSSPVT KSFNRGEC (SEQ ID NO: 312)
4970_K22 (PGT-144) secuencia de aminoácidos de la región variable de la cadena ligera kappa: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
DTVVTQSPI .SI ,S VTPC i FA ASMSC TS TOSLRHSNdA N V I A W YOIIKPGQSPRI .1A
R/.O'SG/MSGVPDRFSGSGSGTIIPTLKISR VEADDAAI Y Y( 'MOGLNRPWIVGK.
GTKLEIK (SEQ ID NO: 313)
4970_K22 (PGT-144) CDR de Kabat de cadena ligera kappa:
CDR 1: TSTQSLRHSNGANYLA (SEQ ID NO: 303)
CDR 2: LGSQRAS (SEQ ID NO: 287)
CDR 3: MQGLNRPWT (SEQ ID NO: 288)
4970_K22 (PGT-144) CDR de Chothia de la cadena ligera kappa:
CDR 1: TSTQSLRHSNGANYLA (SEQ ID NO: 303)
CDR 2: LGSQRAS (SEQ ID NO: 287)
CDR 3: MQGLNRPWT (SEQ ID NO: 288)
El anticuerpo 4838_L06 (PGT-121) incluye una región variable de la cadena pesada (SEQ ID NO: 79), codificada por la secuencia de ácido nucleico mostrada en la SEQ ID N°: 63, y una región variable de la cadena ligera (SEQ ID NO: 149) codificada por la secuencia de ácido nucleico mostrada en la SEQ ID NO: 147.
Las CDR de cadena pesada del anticuerpo 4838_L06 (PGT-121) tienen las siguientes secuencias según la definición de Kabat: DSYWS (SEQ ID NO: 90), YVHKSGDTNYSPSLKS (SEQ ID NO: 265) y TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143). Las CDR de cadena ligera del anticuerpo 4838_L06 (PGT-121) tienen las siguientes secuencias según la definición de Kabat: GEKSLGSRAVQ (SEQ ID NO: 150), NNq Dr PS (SEQ ID NO: 151) y HIWDSRVPTKWV (SEQ ID NO: 152).
Las CDR de cadena pesada del anticuerpo 4838_L06 (PGT-121) tienen las siguientes secuencias según la definición de Chothia: GASISD (SEQ ID NO: 144), YVHKSGDTN (SEQ ID NO: 145) y TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143) Las CDR de cadena ligera del anticuerpo 4838_L06 (PGT-121) tienen las siguientes secuencias según la definición de Chothia: GEKSLGSRAVQ (SEQ ID NO: 150), NNQDRPS (SEQ ID NO: 151) y HIWDSRVPTKWV (SEQ ID NO: 152).
El anticuerpo 4873_E03 (PGT-121) incluye una región variable de cadena pesada (SEQ ID NO: 79), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 63, y una región variable de cadena ligera (SEQ ID NO: 149) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 147.
Las CDR de cadena pesada del anticuerpo 4873_E03 (PGT-121) tienen las siguientes secuencias según la
definición de Kabat: DSYWS (SEQ ID NO: 90), YVHKSGDTNYSPSLKS (SEQ ID NO: 265) y TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143). Las CDR de cadena ligera del anticuerpo 4873_E03 (PGT-121) tienen las siguientes secuencias según definición de Kabat: GEKSLGSRAVQ (SEQ ID NO: 150), NNq Dr PS (SEQ ID NO: 151) y HIWDSRVPTKWV (SEQ ID NO: 152).
Las CDR de cadena pesada del anticuerpo 4873_E03 (PGT-121) tienen las siguientes secuencias según la definición de Chothia: GASISD (SEQ ID NO: 144), YVHKSGDTN (SEQ ID NO: 145) y TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143)) Las CDR de cadena ligera del anticuerpo 4873_E03 (PGT-121) tienen las siguientes secuencias según la definición de Chothia: GEKSLGSRAVQ (SEQ ID NO: 150), NNq Dr PS (SEQ ID NO: 151) y HIWDSRVPTKWV (SEQ ID NO: 152).
El anticuerpo (PGT-122) 4877_D15 incluye una región variable de cadena pesada (SEQ ID NO: 156), codificada por la secuencia de ácido nucleico mostrada en la SEQ ID NO: 154, y una región variable de cadena ligera (SEQ ID NO: 161) codificada por la secuencia de ácido nucleico mostrada en la SEQ ID NO: 159.
Las CDR de la cadena pesada del anticuerpo 4877_D15 (PGT-122) tienen las siguientes secuencias por Kabat definición: DNYWS (SEQ ID NO: 261), YVHDSGDTNYNPSLKS (SEQ ID NO: 157) y TKHGRRIYGVVAFKEWFTYFYMDV (SEQ ID NO: 262). Las CDR de cadena ligera del anticuerpo 4877_D15 (PGT-122) tienen las siguientes secuencias según la definición de Kabat: GEESLGSRSVI (SEQ ID NO: 162), NNn Dr PS (SEQ ID NO: 163) y HIWDSRRPTNWV (SEQ ID NO: 164).
Las CDR de cadena pesada del anticuerpo 4877_D15 (PGT-122) tienen las siguientes secuencias según la definición de Chothia: GTLVRD (SEQ ID NO: 263), YVHDSGDTN (SEQ ID NO: 264) y TKHGRRIYGVVAFKEWFTYFYMDV (SEQ ID NO: 262) Las CDR de cadena ligera del anticuerpo 4877_D15 (PGT-122) tienen las siguientes secuencias según la definición de Chothia: GEESLGSRSVI (SEQ ID NO: 162), NNn Dr PS (SEQ ID NO: 163) y HIWDSRRPTNWV (SEQ ID NO: 164).
El anticuerpo 4858_P08 (PGT-123) incluye una región variable de cadena pesada (SEQ ID NO: 168), codificada por la secuencia de ácido nucleico mostrada en la SEQ ID NO: 166, y una región variable de cadena ligera (SEQ ID NO: 177) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 175.
Las CDR de cadena pesada del anticuerpo 4858_P08 (PGT-123) tienen las siguientes secuencias según la definición de Kabat: DAYWS (SEQ ID NO: 169), YVHHSGDTNYNPSLKR (SEQ ID NO: 170), ALHGKRIYGIVALGELFTYFYMDV (SEQ ID NO: 171). Las CDR de cadena ligera del anticuerpo 4858_P08 (PGT-123) tienen las siguientes secuencias según la definición de Kabat: GKESIGSRAVQ (SEQ ID NO: 178), NNQd RpA (SEQ ID NO: 179) y HIYDARGGTNWV (SEQ ID NO: 180).
Las CDR de la cadena pesada del anticuerpo 4858_P08 (PGT-123) tienen las siguientes secuencias por definición de Chothia: GASIND (SEQ ID NO: 172), YVHHSGDTN (SEQ ID NO: 173), ALHGKRIYGIVALGELFTYFYMDV (SEQ ID NO: 171). Las CDR de cadena ligera del anticuerpo 4858_P08 (PGT-123) tienen las siguientes secuencias según la definición de Chothia: GKESIGSRAVQ (SEQ ID NO: 178), NNQd RpA (SEQ ID NO: 179), HIYDARGGTNWV (SEQ ID NO: 180).
El anticuerpo 5123_A06 (PGT-125) incluye una región variable de cadena pesada (SEQ ID NO: 164), codificada por la secuencia de ácido nucleico mostrada en la SEQ ID NO: 182, y una región variable de cadena ligera (SEQ ID NO: 193) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 191.
Las CDR de cadena pesada del anticuerpo 5123_A06 (PGT-125) tienen las siguientes secuencias según la definición de Kabat: ACTYFWG (SEQ ID NO: 185), SLSHCQSFWGSGWTFHNPSLKS (SEQ ID NO: 186) y FDGEVLVYNHWPKPAWVDL (SEQ ID NO: 187). Las CDR de cadena ligera del anticuerpo 5123_A06 (PGT-125) tienen las siguientes secuencias según la definición de Kabat: NGTATNFVS (SEQ ID NO: 194), GVDKRPP (SEQ ID NO: 195) y GSLVGNWDVI (SEQ ID NO: 196).
Las CDR de cadena pesada del anticuerpo 5123_A06 (PGT-125) tienen las siguientes secuencias según la definición de Chothia: GESTGACT (SEQ ID NO: 188), SLSHCQSFWGSGWTF (SEQ ID NO: 189) y FDGEVLVYNHWPKPAWVDL (SEQ ID NO: 187)) Las CDR de cadena ligera del anticuerpo 5123_A06 (PGT-125) tienen las siguientes secuencias según la definición de Chothia: NGTATNFVS (SEQ ID n O: 194), GVDk Rp P (SEQ ID NO: 195) y GSLVGNWDVI (SEQ ID NO: 196).
El anticuerpo 5141_B17 (PGT-126) incluye una región variable de cadena pesada (SEQ ID NO: 200), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 198, y una región variable de cadena ligera (SEQ ID NO: 209) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 207.
Las CDR de cadena pesada del anticuerpo 5141_B17 (PGT-126) tienen las siguientes secuencias según la definición de Kabat: ACDYFWG (SEQ ID NO: 201), GLSHCAGYYNTGWTYHNPSLKS (SEQ ID NO: 202) y
FDGEVLVYHDWPKPAWVDL (SEQ ID NO: 203). Las CDR de cadena ligera del anticuerpo 5141_B17 (PGT-126) tienen las siguientes secuencias según la definición de Kabat: TGTSNRFVS (SEQ ID NO: 210), GVNKRPS (SEQ ID NO: 211) y SSLVGNWDVI (SEQ ID NO: 212).
Las CDR de cadena pesada del anticuerpo 5141_B17 (PGT-126) tienen las siguientes secuencias según la definición de Chothia: GDSTAACD (SEQ ID NO: 204), GLSHCAGYYNTGWTY (SEQ ID NO: 205) y FDGEVLVYHDWPKPAWVDL (SEQ ID NO: 203)) Las CDR de cadena ligera del anticuerpo 5141_B17 (PGT-126) tienen las siguientes secuencias según la definición de Chothia: TGTSNRFVS (SEQ ID n O: 210), GVNk Rp S (SEQ ID NO: 211) y SSLVGNWDVI (SEQ ID NO: 212).
El anticuerpo 5147_N06 (PGT-130) incluye una región variable de cadena pesada (SEQ ID NO: 216), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 214, y una región variable de cadena ligera (SEQ ID NO: 225) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 223.
Las CDR de cadena pesada del anticuerpo 5147_N06 (PGT-130) tienen las siguientes secuencias según la definición de Kabat: TGHYYWG (SEQ ID NO: 217), HIHYTTAVLHNPSLKS (SEQ ID NO: 218) y SGGDILYYYEWQKPHWFSP (SEQ ID NO: 219). Las CDR de cadena ligera del anticuerpo 5147_N06 (PGT-130) tienen las siguientes secuencias según la definición de Kabat: NGTSSDIGGWNFVS (SEQ ID NO: 226), EVNKRPS (SEQ ID NO: 227) y SSLFGRWDVV (SEQ ID NO: 228).
Las CDR de cadena pesada del anticuerpo 5147_N06 (PGT-130) tienen las siguientes secuencias según la definición de Chothia: GESINTGH (SEQ ID NO: 220), HIHYTTAVL (SEQ ID NO: 221) y SGGDILYYYEWEWKKPHWFSP (SEQ ID NO: 219). Las CDR de cadena ligera del anticuerpo 5147_N06 (PGT-130) tienen las siguientes secuencias según la definición de Chothia: NGTSSDIGGWNFVS (SEQ ID NO: 226), Ev NKRPS (SEQ ID NO: 227) y SSLFGRWDVV (SEQ ID NO: 228).
El anticuerpo 5343_B08 (PGT-135) incluye una región variable de cadena pesada (SEQ ID NO: 232), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 230, y una región variable de cadena ligera (SEQ ID NO: 242) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 239.
Las CDR de cadena pesada del anticuerpo 5343_B08 (PGT-135) tienen las siguientes secuencias según la definición de Kabat: GGEWGDKDYHWG (SEQ ID NO: 233), SIHWRGTTHYKESLRR (SEQ ID NO: 234) y HRHHDVFMLVPIAGWFDV (SEQ ID NO: 235). Las CDR de cadena ligera del anticuerpo 5343_B08 (PGT-135) tienen las siguientes secuencias según la definición de Kabat: RASQNINKNLA (SEQ ID NO: 243), ETYs K iA (SEQ ID NO: 244) y QQYEEWPRT (SEQ ID NO: 245).
Las CDR de cadena pesada del anticuerpo 5343_B08 (PGT-135) tienen las siguientes secuencias según la definición de Chothia: GDSIRGGEWGDKD (SEQ ID NO: 236), SIHWRGTTH (SEQ ID NO: 237) y HRHHDVFMLVPIAGWFDV (SEQ ID NO: 235) Las CDR de cadena ligera del anticuerpo 5343_B08 (PGT-135) tienen las siguientes secuencias según la definición de Chothia: RASQNINKNLA (SEQ ID n O: 243), ETYSKIA (SEQ ID NO: 244) y QQYEEWPRT (SEQ ID NO: 245).
El anticuerpo 5344_E16 (PGT-135) incluye una región variable de la cadena pesada (SEQ ID NO: 232), codificada por la secuencia de ácido nucleico que se muestra en la SEQ ID NO: 230, y una región variable de la cadena ligera (SEQ ID NO: 242) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 239.
Las CDR de cadena pesada del anticuerpo 5344_E16 (PGT-135) tienen las siguientes secuencias según la definición de Kabat: GGEWGDKDYHWG (SEQ ID NO: 233), SIHWRGTTHYKESLRR (SEQ ID NO: 234) y HRHHDVFMLVPIAGWFDV (SEQ ID NO: 235). Las CDR de cadena ligera del anticuerpo 5344_E16 (PGT-135) tienen las siguientes secuencias según la definición de Kabat: RASQNINKNLA (SEQ ID NO: 243), ETYsKiA (SEQ ID NO: 244) y QQYEEWPRT (SEQ ID NO: 245).
Las CDR de cadena pesada del anticuerpo 5344_E16 (PGT-135) tienen las siguientes secuencias según la definición de Chothia: GDSIRGGEWGDKD (SEQ ID NO: 236), SIHWRGTTH (SEQ ID NO: 237) y HRHHDVFMLVPIAGWFDV (SEQ ID NO: 235). Las CDR de cadena ligera del anticuerpo 5344_E16 (PGT-135) tienen las siguientes secuencias según la definición de Chothia: RASQNINKNLA (SEQ ID n O: 243), ETYSKIA (SEQ ID NO: 244) y QQYEEWPRT (SEQ ID NO: 245).
El anticuerpo 5329_C19 (PGT-136) incluye una región variable de la cadena pesada (SEQ ID NO: 249), codificada por la secuencia de ácido nucleico que se muestra en la SEQ ID NO: 247, y una región variable de la cadena ligera (SEQ ID NO: 258) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 256.
Las CDR de cadena pesada del anticuerpo 5329_C19 (PGT-136) tienen las siguientes secuencias según la definición de Kabat: GTDWGENDFHYG (SEQ ID NO: 250), SIHWRGRTTHYKTSFRS (SEQ ID NO: 251) y HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252). Las CDR de cadena ligera del anticuerpo 5329_C19 (PGT-136) tienen
las siguientes secuencias según la definición de Kabat: RASQNVKNNLA (SEQ ID NO: 259), DASSRAG (SEQ ID NO: 260) y QQYEEWPRT (SEQ ID NO: 245).
Las CDR de cadena pesada del anticuerpo 5329_C19 (PGT-136) tienen las siguientes secuencias según la definición de Chothia: GGSMRGTDWGEND (SEQ ID NO: 253), SIHWRGRTTH (SEQ ID NO: 254) y HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252). Las CDR de cadena ligera del anticuerpo 5329_C19 (PGT-136) tienen las siguientes secuencias según la definición de Chothia: RASQNVKNNLA (SEQ ID NO: 259), DASSRAG (Se Q ID NO: 260) y QQYEEWPRT (SEQ ID NO: 245).
El anticuerpo 5366_P21 (PGT-136) incluye una región variable de cadena pesada (SEQ ID NO: 249), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 247, y una región variable de cadena ligera (SEQ ID NO: 258) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 256.
Las CDR de cadena pesada del anticuerpo 5366_P21 (PGT-136) tienen las siguientes secuencias según la definición de Kabat: GTDWGENDFHYG (SEQ ID NO: 250), SIHWRGRTTHYKTSFRS (SEQ ID NO: 251) y HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252). Las CDR de cadena ligera del anticuerpo 5366_P21 (PGT-136) tienen las siguientes secuencias según la definición de Kabat: RASQNVKNNLA (SEQ ID NO: 259), DASSRAG (SEQ ID NO: 260) y QQYEEWPRT (SEQ ID NO: 245).
Las CDR de cadena pesada del anticuerpo 5366_P21 (PGT-136) tienen las siguientes secuencias según la definición de Chothia: GGSMRGTDWGEND (SEQ ID NO: 253), SIHWRGRTTH (SEQ ID NO: 254) y HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252) Las CDR de cadena ligera del anticuerpo 5366_P21 (PGT-136) tienen las siguientes secuencias según la definición de Chothia: RASQNVKNNLA (SEQ ID NO: 259), DASSRAG (Se Q ID NO: 260) y QQYEEWPRT (SEQ ID NO: 245).
El anticuerpo 5964_G22 (PGT-141) incluye una región variable de cadena pesada (SEQ ID NO: 276), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 274, y una región variable de cadena ligera (SEQ ID NO: 285) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 283.
Las CDR de cadena pesada del anticuerpo 5964_G22 (PGT-141) tienen las siguientes secuencias según la definición de Kabat: KYDVH (SEQ ID NO: 277), WMSHEGDKTESAQRFKG (SEQ ID NO: 278) y GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279). Las CDR de cadena ligera del anticuerpo 5964_G22 (PGT-141) tienen las siguientes secuencias según la definición de Kabat: SSTQSLRHSNGANYLA (s Eq ID NO: 286), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
Las CDR de cadena pesada del anticuerpo 5964_G22 (PGT-141) tienen las siguientes secuencias según la definición de Chothia: GNTFSK (SEQ ID NO: 280), WMSHEGDKTE (SEQ ID NO: 281) y GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 27). Las CDR de cadena ligera del anticuerpo 5964_G22 (PGT-141) tienen las siguientes secuencias según la definición de Chothia: SSTQSLRHSNGANYLA (s Eq ID NO: 286), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
El anticuerpo 4993_K13 (PGT-141) incluye una región variable de cadena pesada (SEQ ID NO: 276), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 290, y una región variable de cadena ligera (SEQ ID NO: 285) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 283.
Las CDR de cadena pesada del anticuerpo 4993_K13 (PGT-141) tienen las siguientes secuencias según la definición de Kabat: KYDVH (SEQ ID NO: 277), WMSHEGDKTESAQRFKG (SEQ ID NO: 278) y GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279). Las CDR de cadena ligera del anticuerpo 4993_K13 (PGT-141) tienen las siguientes secuencias según la definición de Kabat: SSTQSLRHSNGANYLA (s Eq ID NO: 286), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
Las CDR de cadena pesada del anticuerpo 4993_K13 (PGT-141) tienen las siguientes secuencias según la definición de Chothia: GNTFSK (SEQ ID NO: 280), WMSHEGDKTE (SEQ ID NO: 281) y GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 27). Las CDR de cadena ligera del anticuerpo 4993_K13 (PGT-141) tienen las siguientes secuencias según la definición de Chothia: SSTQSLRHSNGANYLA (s Eq ID NO: 286), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
El anticuerpo 4995_E20 (PGT-142) incluye una región variable de cadena pesada (SEQ ID NO: 292), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 315, y una región variable de cadena ligera (SEQ ID NO: 285) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 283.
Las CDR de cadena pesada del anticuerpo 4995_E20 (PGT-142) tienen las siguientes secuencias según la definición de Kabat: KYDVH (SEQ ID NO: 277), WISHERDKTESAQRFKG (SEQ ID NO: 293) y GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279). Las CDR de cadena ligera del anticuerpo 4995_E20 (PGT-142) tienen las siguientes secuencias según la definición de Kabat: SSTQSLRHSNGANYLA (s Eq
ID NO: 286), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
Las CDR de cadena pesada del anticuerpo 4995_E20 (PGT-142) tienen las siguientes secuencias según la definición de Chothia: GNTFSK (SEQ ID NO: 280), WISHERDKTE (SEQ ID NO: 294) y GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279) Las CDR de cadena ligera del anticuerpo 4995_E20 (PGT-142) tienen las siguientes secuencias según la definición de Chothia: SSTQSLRHSNGANYLA (s Eq ID NO: 286), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
El anticuerpo 4980_N08 (PGT-143) incluye una región variable de cadena pesada (SEQ ID NO: 298), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 296, y una región variable de cadena ligera (SEQ ID NO: 302) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 300.
Las CDR de cadena pesada del anticuerpo 4980_N08 (PGT-143) tienen las siguientes secuencias según la definición de Kabat: KYDVH (SEQ ID NO: 277), WMSHEGDKTESAQRFKG (SEQ ID NO: 278) y GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279). Las CDR de cadena ligera del anticuerpo 4980_N08 (PGT-143) tienen las siguientes secuencias según la definición de Kabat: TSTQSLRHSNGANYLA (SEQ ID NO: 303), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
Las CDR de cadena pesada del anticuerpo 4980_N08 (PGT-143) tienen las siguientes secuencias según la definición de Chothia: GNTFSK (SEQ ID NO: 280), WMSHEGDKTE (SEQ ID NO: 281) y GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 27). Las CDR de cadena ligera del anticuerpo 4980_N08 (PGT-143) tienen las siguientes secuencias según la definición de Chothia: TSTQSLRHSNGANYLA (s Eq ID NO: 303), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
El anticuerpo 4970_K22 (PGT-144) incluye una región variable de cadena pesada (SEQ ID NO: 307), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 305, y una región variable de cadena ligera (SEQ ID NO: 313) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 311.
Las CDR de cadena pesada del anticuerpo 4970_K22 (PGT-144) tienen las siguientes secuencias según la definición de Kabat: KYDVH (SEQ ID NO: 277), WMSHEGDKTESAQRFKG (SEQ ID NO: 278) y GSKHRLRDYVLYDDYGLINQQEWNDYLEFLDV (SEQ ID NO: 308). Las CDR de cadena ligera del anticuerpo 4970_K22 (PGT-144) tienen las siguientes secuencias según la definición de Kabat: TSTQSLRHSNGANYLA (SEQ ID NO: 303), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
Las CDR de cadena pesada del anticuerpo 4970_K22 (PGT-144) tienen las siguientes secuencias según la definición de Chothia: GNTFRK (SEQ ID NO: 309), WMSHEGDKTE (SEQ ID NO: 281) y GSKHRLRDYVLYDDYGLINQQEWNDYLEFLDV (SEQ ID NO: 30) Las CDR de cadena ligera del anticuerpo 4970_K22 (PGT-144) tienen las siguientes secuencias según la definición de Chothia: TSTQSLRHSNGANYLA (SEQ ID NO: 303), LGSQRAS (SEQ ID NO: 287) y MQGLNRPWT (SEQ ID NO: 288).
Se determinaron las secuencias de anticuerpos monoclonales humanos adicionales, incluidas las secuencias de las regiones variables de las cadenas pesadas Gamma y Kappa o Lambda. Además, se determinó la secuencia de cada uno de los polinucleótidos que codifican las secuencias de anticuerpos. A continuación se muestran las secuencias de polipéptidos y polinucleótidos de las cadenas pesadas gamma y las cadenas ligeras kappa, con los péptidos señal en el extremo N (o extremo 5') y las regiones constantes en el extremo C (o extremo 3') de las regiones variables, que se muestran en texto en negrita.
5145_B14 (PGT-127) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)

C A C G C A G A A G A G C C T C T C G C T G T C T C C G G G T A A A T G A (S E Q ID N O : 316 )
5145_B14 (PGT-127) secuencia de nucleótidos de la región variable de la cadena pesada gamma:
C A G C C G C A G C T G C A G G A G T C G G G C C C A G G A C T G G T G G A G G C T T C G G A G A
C C C T G T C C C T C A C G T G C A C T G T G T C C G G C G A C T C C A C T G G T C G T T G T A A T T
A T T T C T G G G G C T G G G T C C G G C A G C G C C C A G G G A A G G G G C T G G A G T G G A T T
G G G A G T T T G T C C C A C T G T A G A A G T T A C T A C A A T A C T G A C T G G A C C T A C C A
C A A C G C G T C T C T C A A G A G T C G A G T G A C T A T T T C A C T C G A C A C G C C C A A G A
A T C A G G T C T T C C T G A G A T T G A C C T G T G T G A C C G C C G C G G A C A C G G C C A G T
T A T T A C T G T G C G C G A T T C G G C G G C G A A G T T C T A G T G T A C A G A G A T T G G C C
A A A G C C G G C C T G G G T C G A C C T C T G G G G C C G G G G A A C G C T G G T C G T C A C C G
T C T C G A G C (S E Q I D N O : 317 )
5145_B14 (PGT-127) secuencia de aminoácidos de la cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MKHLWFFLU.VAAPRWVLSQPQLQESGPGLXEASETLSLTCTXSGDSTGRC
N Y F W G W V R Q P P G K G L E W I G S L S H C R S Y Y N T D W T Y H N P S L K S R L T I S L D T
P K N Q V F L R L T S V T A A D T A T Y Y C A R F G G E V L V Y R D W P K P A W V D L W G R G
T L V V T V S S A S T K G P S V F P L A P S S K S T S G G T A A I X iC L V K D Y F P B P V T V S W N S C A I T S G V I T T F P A V I .Q S S G I ,Y S I .S S V V T V P S S S I X iT Q T Y I C N V N I I K P S N T K V D K R
V E P K S C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V W D V S
H E D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D W L N G K
E Y K C K V S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K
G F Y P S D I A V E W E S N G Q P E N N Y K T T P P V L D S D G S F F I ,Y S K L T V D K S R W Q Q G N V
F S C S V M I I E A L H N H Y T Q K S L S L S P G K (S E Q ID N O : 318 )
5145_B14 (PGT-127) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
Q P O L O E S G P G L V E A S E T L S L T C T V S G D S r G f lC A Í Y F W G W V R O P P G K G L E W I G S L S H C R S Y Y N T D W T Y U N V S l . K S R l A ' l S L D T P K N O V V L R l A ' S V l ' A A m A T Y Y C A R l ( , ( ¡ i : V L V Y R D W P K P A H V D / .W G R G I L V V I V S S ( S E Q ID N O : 319 )
5145_B14 (PGT-127) CDR de Kabat de la cadena pesada gamma:
CDR 1: RCNYFWG (SEQ ID NO: 320)
CDR 2: SLSHCRSYYNTDWTYHNPSLKS (SEQ ID NO: 321)
CDR 3: FGGEVLVYRDWPKPAWVDL (SEQ ID NO: 322)
5145_B14 (PGT-127) CDR de Chothia de la cadena pesada gamma:
CDR 1: GDSTGRCN (SEQ ID NO: 323)
CDR 2: SLSHCRSYYNTDWTY (SEQ ID NO: 324)
CDR 3: FGGEVLVYRDWPKPAWVDL (SEQ ID NO: 322)
5145_B14 (PGT-127) secuencia de nucleótidos de cadena ligera lambda: secuencia de codificación (región variable en negrita)
A T G G C C T G G G C T C T G C T C C T C C T C A C C C T C C T C A C T C A G G G C A C A G G G G C
C T G G G C C C A G T C T G C C C T G A C T C A G C C T C C C T C C G C G T C C G G G T C T C C
T G G A C A G T C A A T C A C C A T C T C C T G C A C T G G A A C C A G C A A T A A C T T T G T
C T C C T G G T A C C A A C A A T A C C C A G G C A A G G C C C C C A A A C T C G T C A T T T
A T G A G G T C A A T A A G C G C C C C T C A G G T G T C C C T G A T C G T T T C T C T G G C
T C C A A G T C T G G C A G C A C G G C C T C C C T G A C C G T C T C T G G A C T C C A G G C
T G A C G A T G A G G G T G T C T A T T A T T G T A G T T C A C T T G T A G G C A A C T G G G
A T G T G A T T T T C G G C G G A G G G A C C A A G T T G A C C G T C C T A G G T C A G C C C A
A G G C T G C C C C C T C G G T C A C T C T G T T C C C G C C C T C C T C T G A G G A G C T T C A A G
C C A A C A A G G C C A C A C T G G T G T G T C T C A T A A G T G A C T T C T A C C C G G G A G C C
G T G A C A G T G G C C T G G A A G G C A G A T A G C A G C C C C G T C A A G G C G G G A G T G G
A G A C C A C C A C A C C C T C C A A A C A A A G C A A C A A C A A G T A C G C G G C C A G C A G
C T A T C T G A G C C T G A C G C C T G A G C A G T G G A A G T C C C A C A G A A G C T A C A G C T
G C C A G G T C A C G C A T G A A G G G A G C A C C G T G G A G A A G A C A G T G G C C C C T A C
A G A A T G T T C A T A G ( S E Q ID N O : 327 )
5145_B14 (PGT-127) secuencia de nucleótidos de región variable de cadena ligera lambda:

5145_B14 (PGT-127) secuencia de aminoácidos de cadena ligera lambda: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MAWALLLLTLLTQGTGAWAQSALTQP?S\SGSPGQSlTlSCTGTSmFXSW\
Q Q Y P G K A P K L V I Y E V N K R P S G V P D R F S G S K S G S T A S L T V S G L Q A D D E G V Y
Y C S S L V G N W D V I F G G G T K L T V L G Q P K A A P S V T L F P P S S E E L Q A N K A T L V C L I
S D F Y P G A V T V A W K A D S S P V K A G V E T T T P S K Q S N N K Y A A S S Y L S L T P E Q W K S
H R S Y S C Q V T H E G S T V E K T V A P T E C S (S E Q II ) N O : 329 )
5145_B14 (PGT-127) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
O S A L T O P P S A S G S P C O S I T I S C T T G m W E y S W Y O O Y P G K A P K L V I Y E V A r flf fP S
G V P D R F S G S K S G S T A S L T V S G L O A D D E G V Y Y C S S L V G N W D V 7F G G G T K L T V L
(S E Q II) N O : 330 )
5145_B14 (PGT-127) CDR de Kabat de cadena ligera lambda:
CDR 1: TGTSNNFVS (SEQ ID NO: 325)
CDR 2: EVNKRPS (SEQ ID NO: 227)
CDR 3: SSLVGNWDVI (SEQ ID NO: 212)
5145_B14 (PGT-127) CDR de Chothia de la cadena ligera lambda:
CDR 1: TGTSNNFVS (SEQ ID NO: 325)
CDR 2: EVNKRPS (SEQ ID NO: 227)
CDR 3: SSLVGNWDVI (SEQ ID NO: 212)
5114_A19 (PGT-128) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)

G A G C ( S E Q ID N O : 332 )
5114_A19 (PGT-128) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
M K H L W F F L L L V A A P K W V L S Q P Q L Q E S G P T L \ E A S E T L S L T C A \ S G D S T \ A C
N S F W G W V R Q P P G K G L E W V G S L S H C A S Y W N R G W T Y H N P S L K S R L T L A L
D T P K N L V F L K L N S V T A A D T A T Y Y C A R F G G E V L R Y T D W P K P A W V D L W G
R G T L V T V S S A S T K G P S V F P L A P S v S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S
G A L T S G V U T F P A V L Q S S G L Y S I .S S V V T V P S S S I G T Q T Y I C N V N H K P S N T K V D K
R V F iP K S C D K T I I T C P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S
I I E D P E V K F N W 'Y V D G V E V I I N A K T K P R E E Q Y N S T Y R V V S V I T V I .1IQ D W I .N G K
e y k c k v s n k a l p a p i e k t i s k a k g q p r e p q v y t l p p s r e e m t k n q v s l t c l v k
G F Y P S D 1 A V E W E S N G Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R W Q Q G N V
F S C S V M H E A L H N H Y T Q K S L S L S P G K (S E Q I D N O : 333 )
5114_A19 (PGT-128) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
O P O L O E S G P T L V E A S E T L S L T C A V S G R S T A A C 7 V S F W G W V R Q P P G K G L E W V G
S L S H C A S Y W N R f í W T Y l IN P S I K S R I.T I .A I .D T P K N I .V F I .K I .N S V T A A D T A T Y Y C A K I C Í ¡ i : \ I .R Y T D W P K P A W’V D L W G R G T I .V I V S S ( S E Q ID N O : 334 )
5114_A19 (PGT-128) CDR de Kabat de cadena pesada gamma:
CDR 1: ACNSFWG (SEQ ID NO: 326)
CDR 2: SLSHCASYWNRGWTYHNPSLKS (SEQ ID NO: 335)
CDR 3: FGGEVLRYTDWPKPAWVDL (SEQ ID NO: 336)
5114_A19 (PGT-128) CDR de Chothia de la cadena pesada gamma:
CDR 1: GDSTAACN (SEQ ID NO: 337)
CDR 2: SLSHCASYWNRGWTY (SEQ ID NO: 338)
CDR 3: FGGEVLRYTDWPKPAWVDL (SEQ ID NO: 336)
5114_A19 (PGT-128) secuencia de nucleótidos de cadena ligera lambda: secuencia de codificación (región variable en negrita)
A T G G C C T G G G C T C T G C T C C T C C T C A C C C T C C T C A C T C A G G G C A C A G G G G C
C T G G G C C C A G T C T G C C C T G A C T C A G C C T C C C T C C G C G T C C G G G T C T C C
T G G A C A G T C A A T C A C C A T C T C C T G C A C T G G A A C C A G C A A T A A C T T T G T
C T C C T G G T A C C A G C A A C A C G C A G G C A A G G C C C C C A A G C T C G T C A T T T
A T G A C G T C A A T A A G C G C C C C T C A G G T G T C C C T G A T C G T T T C T C T G G C
T C C A A G T C T G G C A A C A C G G C C T C C C T G A C C G T C T C T G G A C T C C A G A C
T G A C G A T G A G G C T G T C T A T T A C T G C G G C T C A C T T G T A G G C A A C T G G G
A T G T G A T T T T C G G C G G A G G G A C C A A G T T G A C C G T C C T A G G T C A G C C C A
A G G C T G C C C C C T C G G T C A C T C T G T T C C C G C C C T C C T C T G A G G A G C T T C A A G
C C A A C A A G G C C A C A C T G G T G T G T C T C A T A A G T G A C T T C T A C C C G G G A G C C
G T G A C A G T G G C C T G G A A G G C A G A T A G C A G C C C C G T C A A G G C G G G A G T G G
A G A C C A C C A C A C C C T C C A A A C A A A G C A A C A A C A A G T A C G C G G C C A G C A G
C T A T C T G A G C C T G A C G C C T G A G C A G T G G A A G T C C C A C A G A A G C T A C A G C T
G C C A G G T C A C G C A T G A A G G G A G C A C C G T G G A G A A G A C A G T G G C C C C T A C
A G A A T G T T C A T A G ( S E Q ID N O : 390 )
5114_A19 (PGT-128) secuencia de nucleótidos de región variable de cadena ligera lambda:
C A G T C T G C C C T G A C T C A G C C T C C C T C C G C G T C C G G G T C T C C T G G A C A G T C A
A T C A C C A T C T G C T G C A C T G G A A C C A G C A A T A A C T T T G T C T C C T G G T A C C A G
C A A C A C G C A G G C A A G G C C C C C A A G C T C G T C A T T T A T G A C G T C A A T A A G C G
C C C C T C A G G T G T C C C T G A T C G n T C T C T G G C T C C A A G T C T G G C A A C A C G G C
C T C C C T G A C C G T C T C T G G A C T C C A G A C T G A C G A T G A G G C T G T C T A T T A C T G
C G G C T C A C T T G T A G G C A A C T G G G A T G T G A T T T T C G G C G G A G G G A C C A A G T
T G A C C G T C C T A (S E Q ID N O : 391 )
5114_A19 (PGT-128) secuencia de aminoácidos de cadena ligera lambda: proteína expresada con secuencia líder en cursiva y región variable en negrita.
A M V W \/7 J J T /X 7 ’( X /7 Y 7 /U y / lQ S A L T Q P P S A S G S P G Q S I T I S C T G T S N N F V S Y V Y
Q Q H A G K A P K L V I Y D V N K R P S G V P D R F S G S K S G N T A S L T V S G L Q T D D E A V
Y Y C G S L V G N W D V I F G G G T K L T V L G Q P K A A P S V T L F P P S S E E L Q A N K A T L V C
L I S D F Y P G A V T V A W K A D S S P V K A G V E T T T P S K Q S N N K Y A A S S Y L S L T P E Q W K
S H R S Y S C Q V T H E G S T V E K T V A P T E C S ( S E Q I D N O : 392 )
5114_A19 (PGT-128) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
OSALTOPPSASGSPGOSmSCTGTSNNFVSV/YOOHAGKAPKLVlYDVNKRPS
G V P D R F S G S K S G N T A S L T V S G L O T D D E A V Y Y C G S L V G A W D V 7 F G G G T K L T V L
(S E Q ID N O : 393 )
5114_A19 (PGT-128) CDR de Kabat de la cadena ligera lambda:
CDR 1: TGTSNNFVS (SEQ ID NO: 325)
CDR 2: DVNKRPS (SEQ ID NO: 343)
CDR 3: GSLVGNWDVI (SEQ ID NO: 196)
5114_A19 (PGT-128) CDR de Chothia de la cadena ligera lambda:
CDR 1: TGTSNNFVS (SEQ ID NO: 325)
CDR 2: DVNKRPS (SEQ ID NO: 343)
CDR 3: GSLVGNWDVI (SEQ ID NO: 196)
5136_H01 (PGT-131) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)

T C C G G G T A A A T G A ( S E Q ID N O : 344 )
5136_H01 (PGT-131) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G G T G C A A G T A C A G G A G T C G G G C C C A G G A C T G G T G A A G C C T T C G G A G A
C C C T T T G C C T C A C C T G C A C T G T C T C T G G T G A C T C C A T G A A C A C T G G T C A T C
A C T A C T G G G G C T G G G T C C G T C A G G T C C C A G G G A A G G G A C C G G A A T G G A T T
G C T C A C A T C C A C T A T A A T A C G G C T G T C T T A C A C A A T C C G G C C C T C A A G A G
T C G A G T C A C C A T T T C G A T T T T C A C C C T G A A G A A T C T G A T T A C G G T G A G C C T
C A G T A A T G T G A C C G C C G C G G A C A C G G C C G T C T A T T T C T G C G T T C G A T C C G
G C G G C G A C A T T T T A T A C T A T A T T G A G T G G G A A A A A C C C G A G T G G T T G T A T G
G G T G G G G C G G G G G A A T T T T G G T G A G G G T G T G G A G G (S E Q I D N O : 345 )
5136_H01 (PGT-131) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.

L S N V T A A D T A V Y F C V R S G G D I L Y Y I E W Q K P H W F Y P W G P G I L V T V S S A S T K
G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S G A L T S G V H T F P A V L
Q SvSG I ,Y S I . S S W T V P S S S I X iT Q T Y I C N V N I I K P S N T K V D K R V F P K S C D K T I ¡T C P
P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S H E D P E V K F N W Y V D
G V E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L F I Q D W L N G K E Y K C K V S N K A L P A
P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K G F Y P S D 1 A V E W E S
N G Q P E N N Y K I T P P V L D S D G S F F L Y S K L T V D K S R W Q Q G N V F S C S V M M E A L H N
H Y T Q K S L S L v S P G K (S E Q I D N O : 346 )
5136_H01 (PGT-131) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
O V O L O E S G P G L V K P S E T L S L T C T V S G D S /A T G / / I I Y W G W V R O V P G K G P E W I A
H 1 H Y N T A VIA IN P A I K S R V T I S I F T F K N I 4 T L S F S N V T A A D T A V Y F C V R S G G /J /X
Y F //:V V G A 7, //V V F ’>7, W C iF C U L V T V S S ( S E Q ID N O : 347 )
5136_H01 CDR de Kabat de cadena pesada gamma (PGT-131):
CDR 1: TGHHYWG (SEQ ID NO: 348)
CDR 2: HIHYNTAVLHNPALKS (SEQ ID NO: 349)
CDR 3: SGGDILYYIEWQKPHWFYP (SEQ ID NO: 350)
5136_H01 (PGT-131) CDR de Chothia de la cadena pesada gamma:
CDR 1: GDSINTGH (SEQ ID NO: 351)
CDR 2: HIHYNTAVL (SEQ ID NO: 352)
CDR 3: SGGDILYYIEWQKPHWFYP (SEQ ID NO: 350)
5136_H01 (PGT-131) secuencia de nucleótidos de cadena ligera lambda: secuencia de codificación (región variable en negrita)
A T G G C C T G G G C T C T G C T C C T C C T C A C C C T C C T C A C T C A G G G C A C A G G G T C C
T G G G C C C A G T C T G C C C T G A C T C A G C C T C C C T C C G C G T C C G G G T C T C T T
G G A C A G T C A C T C A C C A T C T C C T G C A G T G G A A C C G G C A G T G A C A T T G G
C A G T T G G A A T T T T G T C T C C T G G T A T C A A C A A T T C C C A G G C A G A G C C C
C C A A C C T C A T T A T T T T T G A G G T C A A T A G G C G G C G A T C A G G G G T C C C T
G A T C G C T T C T C T G G T T C C A A G T C G G G C A A T A C G G C C T C C C T G A C C G T
C T C T G G G C T C C G G T C T G A G G A T G A G G C T G A A T A T T T T T G C A G T T C C C
T T T C A G G C A G G T G G G A C A T T G T T T T T G G C G G A G G G A C C A A G G T G A C C
G T C C T A G G T C A G C C C A A G G C T G C C C C C T C G G T C A C T C T G T T C C C G C C C T C
C T C T G A G G A G C T T C A A G C C A A C A A G G C C A C A C T G G T G T G T C T C A T A A G T G
A C T T C T A G C C G G G A G C C G T G A C A G T G G C C T G G A A G G C A G A T A G C A G C C C C
G T C A A G G C G G G A G T G G A G A C C A C C A C A G C G T G C A A A C A A A G C A A C A A C A
A G T A C G C G G C C A G C A G C T A T C T G A G C C T G A C G C C T G A G C A G T G G A A G T C C
C A C A G A A G C T A C A G C T G C C A G G T C A C G C A T G A A G G G A G C A C C G T G G A G A
A G A C A G T G G C C G C T A C A G A A T G T T G A T A G (S E Q ID N O : 353 )
5136_H01 (PGT-131) secuencia de nucleótidos de región variable de cadena ligera lambda:
C A G T C T G C C C T G A C T C A G C C T C C C T C C G C G T C C G G G T C T C T T G G A C A G T C A
C T C A C C A T C T C C r G C A G T G G A A C C G G C A G T G A G A T r G G C A G T r G G A A T r T l( ¡T( l( ( T ( X JTA'IX\A( \ A I l( X X \( X X \( ¡AC X X X XX A \( X l( A II ATI I I
T G A G G T C A A T A G G C G G C G A T C A G G G G T C C C T G A T C G C T T C T C T G G T T C C A
A G T C G G G C A A T A C G G C C T C C C T G A C C G T C T C T G G G C T C C G G T C T G A G G A T
G A G G C T G A A T A T T T T T G C A G T T C C C T T T C A G G C A G G T G G G A C A T T G T T T T T
G G C G G A G G G A G C A A G G T G A C C G T C C T A ( S E Q ID N O : 354 )
5136_H01 (PGT-131) secuencia de aminoácidos de cadena ligera lambda: proteína expresada con secuencia líder en cursiva y región variable en negrita.
M A W A /J J X J L /J { 2 G 70 : S W /t Q S A L T Q P P S A S G S L G Q S L T I S C S G T G S D I G S W N F
V S W Y Q Q F P G R A P N L I I F E V N R R R S G V P D R F S G S K S G N T A S L T V S G L R S E D E
A E Y F C S S L S G R W D I V F G G G T K V T V L G Q P K A A P S V T L F P P S S H H E Q A N K A TI.
VCLISDFYPGAVTVAWKADSSPVKAGVEITTPSKQSNNKYAASSYLSLTPEQ
WKSHRSYSCQVTHEGSTVEKTVAPTECS (SEQ II) NO: 355)
5136_H01 (PGT-131) secuencia de aminoácidos de la región variable de la cadena ligera lambda: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
OSALIOPPSASGSEGOSI.TISC’STTmS’D/GSHWEKSWYOOrPGRAPNEIIl/iEA /M/TSGVPDRTSGSKSGNTASI/rVSGI.RSEDEAEYTCS'S’/AYf/OTD/VTGGGTKV TVE (SEQ ID NO: 356)
5136_H01 (PGT-131) CDR de Kabat de cadena ligera lambda:
CDR 1: SGTGSDIGSWNFVS (SEQ ID NO: 357)
CDR 2: EVNRRRS (SEQ ID NO: 358)
CDR 3: SSLSGRWDIV (SEQ ID NO: 359)
5136_H01 (PGT-131) CDR de Chothia de la cadena ligera lambda:
CDR 1: SGTGSDIGSWNFVS (SEQ ID NO: 357)
CDR 2: EVNRRRS (SEQ ID NO: 358)
CDR 3: SSLSGRWDIV (SEQ ID NO: 359)
5345_I01 (PGT-137) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
A T G A A A C A C C T G T G O T T C T T C C T C C T G C T G G T T G C G G C T C C C A G A T O T O T C
C T G T C T G A G G T G C A T C T G G A G G A G T C G G G C C C A G G A C T G G T G A G G C C
C T C G G A G A C C T T G T C C C T G A C T T G C A C G G C C T C T G G T G G C T C C A T A A
G G G G G G G C G A G T G G G G C G A T A G T G A C T A C C A C T G G G G C T G G G T C C G
C C A C T C T C C C G A A A A G G G A C T G G A A T G G A T T G G A A G T A T T C A T T G G C
G G G G G A C C A C C C A C T A C A A C G C G C C C T T C C G G G G G C G A G G C A G A T T
G T C G A T A G A C C T C T C C C G G A A T C A A T T C T C C C T G C G C C T G A C G T C T G
T G A C C G C C G A A G A C A C T G C C G T C T A T T A T T G T G T G A A G C A C A A A T A T
C A T G A C A T T G T C A T G G T G G T C C C C A T T G C G G G C T G G T T C G A C C C C T G
G G G C C A G G G A C T C C A G G T C A C C G T C T C G A G C G C C T C C A C C A A G G G C C C
A T C G G T C T T C C C C C T G G C A C C C T C C T C C A A G A G C A C C T C T G G G G G C A C A G
C G G C C C T G G G C T G C C T G G T C A A G G A C T A C T T C C C C G A A C C G G T G A C G G T G
T C G T G G A A C T C A G G C G C C C T G A C C A G C G G C G T G C A C A C C T T C C C G G C T G T
C C T A C A G T C C T C A G G A C T C T A C T C C C T C A G C A G C G T G G T G A C C G T G C C C T C
C A G C A G C T T G G G C A C C C A G A C C T A C A T C T G C A A C G T G A A T C A C A A G C C C A
G C A A C A C C A A G G T G G A C A A G A G A G T T G A G C C C A A A T C T T G T G A C A A A A C
T C A C A C A T G C C C A C C G T G C C C A G C A C C T G A A C T C C T G G G G G G A C C G T C A G
K T T ( ' (T ( r r c X X X X X AAAAC X X 7\A( ¡ ( íA(’ACX X T ( 'A IX ¡A IX T ( X X X i( ¡ACX X '
C T G A G G T C A C A T G C G T G G T G G T G G A C G T G A G C C A C G A A G A C C C T G A G G T C
A A G T T C A A C T G G T A C G T G G A C G G C G T G G A G G T G C A T A A T G C C A A G A C A A
A G C C G C G G G A G G A G C A G T A C A A C A G C A C G T A C C G T G T G G T C A G C G T C C T
C A C C G T C C T G C A C C A G G A C T G G C T G A A T G G C A A G G A G T A C A A G T G C A A G
G T C T C C A A C A A A G C C C T C C C A G C C C C C A T C G A G A A A A C C A T C T C C A A A G C
C A A A G G G C A G C C C C G A G A A C C A C A G G T G T A C A C C C T G C C C C C A T C C C G G
G A G G A G A T G A C C A A G A A C C A G G T C A G C C T G A C C T G C C T G G T C A A A G G C T
T C T A T C C C A G C G A C A T C G C C G T G G A G T G G G A G A G C A A T G G G C A G C C G G A
G A A C A A C T A C A A G A C C A C G C C T C C C G T G C T G G A C T C C G A C G G C T C C T T C T
T C C T C T A T A G C A A G C T C A C C G T G G A C A A G A G C A G G T G G C A G C A G G G G A A
C G T C T T C T C A T G C T C C G T G A T G C A T G A G G C T C T G C A C A A C C A C T A C A C G C
A G A A G A G C C T C T C C C T G T C T C C G G G T A A A T G A ( S E Q II) N O : 360 )
5345_I01 (PGT-137) secuencia de nucleótidos de región variable de la cadena pesada gamma:
G A G G T G C A T C T G G A G G A G T C G G G C C C A G G A C T G G T G A G G C C C T C G G A G A
C C T T G T C C C T G A C T T G C A C G G C C T C T G G T G G C T C C A T A A G G G G G G G C G A G
T G G G G C G A T A G T G A C T A C C A C T G G G G C T G G G T C C G C C A C T C T C C C G A A A A
G G G A C T G G A A T G G A T T G G A A G T A T T C A T T G G C G G G G G A C C A C C C A C T A C A
A G G C G C C C T T C C G G G G G C G A G G C A G A T T G T C G A T A G A C C T C T C C C G G A A T
C A A I T C T C C C T G C G C C T G A C G T C T G T G A C C G C C G A A G A C A C T G C C G T C T A T
T A T T G T G T G A A G C A C A A A T A T C A T G A C A T T G T C A T G G T G G T C C C C A T T G C G
G G C T G G T T C G A C C C C T G G G G C C A G G G A C T C C A G G T C A C C G T C T C G A G C (S E
Q I D N O : 361 )
5345_I01 (PGT-137) secuencia de aminoácidos de la cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MKHI.WFFU.FVAAPRCVISEXHLEESGPGLXRPSETLSLTCTASGGSIRGGE
W G D S D Y H W G W V R H S P E K G L E W I G S I H W R G T T H Y N A P F R G R G R L S I D L S
R N Q F S L R L T S V T A E D T A V Y Y C V K H K Y H D I V M V V P I A G W F D P W G Q G L Q V
t v s s a s t k g p s v f p l a p s s k s t s g g t a a l g c l v k d y f p e p v t v s w n s g a l t s g
V H T F P A V L Q S S G L Y S L S S W T V P S S S L G T Q T Y I C N V N H K P S N T K V D K R V E P K S
C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S H E D P E
V K I N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L I I Q D W F N G K E Y K C
K V S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K G F Y P
S D I A V E W E S N G Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R W Q Q G N V F S C S
V M I I E A I J IN I IY T Q K S I J S L S P G K ( S E Q ID N O : 362 )
5345_I01 (PGT-137) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
E V I I E E E S G P G L V R P S E T L S L T C T A S ( iG S 7 /f ( i( 'i7 i VV(i /J,S7.J Y IIW G W V R I1 S P E K G I E W IO S /y /W /f O Y V T /Y N A P l R G R G R L S I D E S R N O r S E R I .T S V T A E D T A V Y Y C V K H K Y H D l V M V V r i A ( ¡ W F D P m ,O G I O V T V S S (S E Q ID N O : 363 )
5345_I01 (PGT-137) CDR de Kabat de cadena pesada gamma:
CDR 1: GGEWGDSDYHWG (SEQ ID NO: 364)
CDR 2: SIHWRGTTHYNAPFRG (SEQ ID NO: 365)
CDR 3: HKYHDIVMVVPIAGWFDP (SEQ ID NO: 366)
PGT4545_ -137) CDR de Chothia de la cadena pesada gamma:
CDR 1: GGSIRGGEWGDSD (SEQ ID NO: 367)
CDR 2: SIHWRGTTH (SEQ ID NO: 237)
CDR 3: HKYHDIVMVVPIAGWFDP (SEQ ID NO: 366)
5345_I01 (PGT) secuencia de nucleótidos de cadena ligera kappa: secuencia de codificación (región variable en negrita)

A G C T T C A AC1 A G G G G A G A G T G T T A G (S E Q ID N O : 394 )
5345_I01 (PGT-137) secuencia de nucleótidos de región variable de cadena ligera kappa:
G A A A T A A T G A T G A C G C A G T C T C C A G C C A T C C T G T C T G T G T C T C C A G G A G A
C A G A G C C A C A C T C T C C T G C A G G G C G A G T C A G A G T G T G A A G A A T A A T T T A G
C C T G G T A C C A G A A G A G A C C T G G C C A G G C T C C C A G A C T C C T C A T C T T T G A T
A C A T C C A G C A G G G C C T C T G G T A T C C C T G C C A G G T T C A G T G G C G G T G G T T C
T G G G A C A G A G T T C A C T C T C A C C G T C A A C A G C A T G C A G T C T G A A G A C T T T G
C G A C T T A T T A C T G T C A G C A A T A T G A A G A G T G G C C T C G G A C G T T C G G C C A G
G G G A C C A A G G T G G A A A T C A A A ( S E Q ID N O : 395 )
5345_I01 (PGT-137) secuencia de aminoácidos de la cadena ligera kappa: proteína expresada con secuencia líder en cursiva y región variable en negrita.
M f T / M 0 / J J 7 i 4 J m / 7 ) 77 r ; E I M I V l T Q S P A I L S V S P G D R A T L S C R A S Q S V K N N
L A W Y Q K R P G Q A P R L L I F D T S S R A S G I P A R F S G G G S G T E F T L T V N S M Q S E D
F A T Y Y C Q Q Y E E Y V P R T F G Q G T K V E I K R T V A A P S V F I F P P S D E Q E K S G T A S V V
C E E N N E Y P R E A K V Q W K V D N A L Q S G N S Q E S V T E Q D S K D S T Y S L S S T E T L S K A D
Y E K H K V Y A C E V T H Q G L S S P V T K S F N R G E C ( S E Q II) N O : 396 )
5345_I01 (PGT-137) secuencia de aminoácidos de la región variable de la cadena ligera kappa: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
E I M M T O S P A I L S V S P G D R A T L S C / M S a S V K N N I A W Y O K R P G O A P R L L I F /97 S S R A S G I P A R F S G G G S G T E F T L T V N S M O S E D P A T Y Y C O O Y E E W P R jTF G O G T K V E I K ( S E Q II ) N O : 397 )
5345_I01 (PGT-137) CDR de Kabat de cadena ligera kappa:
CDR 1: RASQSVKNNLA (SEQ ID NO: 372)
CDR 2: DTSSRAS (SEQ ID NO: 373)
CDR 3: QQYEEWPRT (SEQ ID NO: 245)
5345_I01 (PGT-137) CDR de Chothia de la cadena ligera kappa:
CDR 1: RASQSVKNNLA (SEQ ID NO: 372)
CDR 2: DTSSRAS (SEQ ID NO: 373)
CDR 3: QQYEEWPRT (SEQ ID NO: 245)
4995_P16 (PGT-145) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
A T G G A C T G G A T T T G O A G G A T C C T C T T C T T G G T G G C A G C A G C T A C A A G T G C
C C A C T C C C A G G T G C A G T T G G T G C A G T C T G G G G C T G A A G T G A A G A A G C
C T G G G T C C T C A G T G A A G G T C T C C T G C A A G G C C T C T G G A A A C A G T T T C
A G T A A T C A T G A T G T C C A C T G G G T A C G A C A G G C C A C T G G A C A G G G G C T
T G A A T G G A T G G G A T G G A T G A G T C A T G A G G G T G A T A A G A C A G G C T T G G
C A C A A A A G T T T C A G G G C A G A G T C A C C A T C A C G A G G G A C A G T G G C G C A
A G T A C A G T C T A C A T G G A G T T G C G C G G C C T G A C A G C T G A C G A C A C G G C
C A T T T A T T A T T G T T T G A C C G G C T C A A A A C A T C G C C T G C G A G A T T A T T T
T C T G T A C A A T G A A T A T G G C C C C A A T T A T G A A G A G T G G G G T G A C T A C C
T T G C G A C T T T G G A C G T C T G G G G C C A T G G G A C C G C G G T C A C C G T C T C G
A G C G C C T C C A C C A A G G G C C C A T C G G T C T T C C C C C T G G C A C C C T C C T C C A A
G A G C A C C T C T G G G G G C A C A G C G G C C C T G G G C T G C C T G G T C A A G G A C T A C T
T C C C C G A A C C G G T G A C G G T G T C G T G G A A C T C A G G C G C C C T G A C C A G C G G C
G T G C A C A C C T T C C C G G C T G T C C T A C A G T C C T C A G G A C T C T A C T C C C T C A G C
A G C G T G G T G A C C G T G C C C T C C A G C A G C T T G G G C A C C C A G A C C T A C A T C T G
C A A C G T G A A T C A C A A G C C C A G C A A C A C C A A G G T G G A C A A G A G A G T T G A G
G C C A A A T C T T G T G A C A A A A C T C A C A C A T G C C C A C C G T G C C C A G C A C C T G A
A C T C C T G G G G G G A C C G T C A G T C T T C C T C T T C C C C C C A A A A C C C A A G G A C A
C C C T C A T G A T C T C C C G G A C C C C T G A G G T C A C A T G C G T G G T G G T G G A C G T G
A G C C A C G A A G A C C C T G A G G T C A A G T T C A A C T G G T A C G T G G A C G G C G T G G
A G G T G C A T A A T G C C A A G A C A A A G C C G C G G G A G G A G C A G T A C A A C A G C A C
G T A C C G T G T G G T C A G C G T C C T C A C C G T C C T G C A C C A G G A C T G G C T G A A T G
G C A A G G A G T A C A A G T G C A A G G T C T C C A A C A A A G C C C T C C C A G C C C C C A T C
G A G A A A A C C A T C T C C A A A G C C A A A G G G C A G C C C C G A G A A C C A C A G G T G T
A C A C C C T G C C C C C A T C C C G G G A G G A G A T G A C C A A G A A C C A G G T C A G C C T
G A C C T G C C T G G T C A A A G G C T T C T A T C C C A G C G A C A T C G C C G T G G A G T G G G
A G A G C A A T G G G C A G C C G G A G A A C A A C T A C A A G A C C A C G C C T C C C G T G C T
G G A C T C C G A C G G C T C C T T C T T C C T C T A T A G C A A G C T C A C C G T G G A C A A G A
G C A G G T G G C A G C A G G G G A A C G T C T T C T C A T G C T C C G T G A T G C A T G A G G C T
C T G C A C A A C C A C T A C A C G C A G A A G A G C C T C T C C C T G T C T C C G G G T A A A T G
A ( S E Q ID N O : 398 )
4995_P16 (PGT-145) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G G T G C A G T T G G T G C A G T C T G G G G C T G A A G T G A A G A A G C C T G G G T C C T C
A G T G A A G G T C T C C T G C A A G G C C T C T G G A A A C A G T T T C A G T A A T C A T G A T G
T C C A C I ’G G G T A C G A C A G G C C A C T G G A C A G G G G C I T G A A 'r G G A T G G G A T G
G A T G A G T C A T G A G G G T G A T A A G A C A G G C T T G G C A C A A A A G T T T C A G G G C
A G A G T C A C C A T C A C G A G G G A C A G T G G C G C A A G T A C A G T C T A C A T G G A G T T
G C G C G G C C T G A C A G C T G A C G A C A C G G C C A T T T A T T A T T G T T T G A C C G G C T
C A A A A C A T C G C C T G C G A G A T T A T T T T C T G T A C A A T G A A T A T G G C C C C A A T T
A T G A A G A G T G G G G T G A C T A C C T T G C G A C T T T G G A C G T C T G G G G C C A T G G G
A C C G C G G T C A C C G T C T C G A G C ( S E Q ID N O : 399 )
4995_P16 (PGT-145) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
Mn\VIWRILFLVAAATSAHSQ\QL\QSG\E\KKPGSS\KXSCKASGNSFSNH
D V H W V R Q A T G Q G L E W M G W M S H E G D K T G L A Q K F Q G R V T I T R D S G A S T
V Y M E L R G L T A D D T A I Y Y C L T G S K H R L R D Y F L Y N E Y G P N Y E E W G D Y L A T
L D V W G H G T A V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T
V S W N S G A L T S G V i n T ’P A V L Q S S G F Y S F S S W T V P S S S L G T Q T Y I C N V N lI K P S N
T K V D K R V E P K S C D K T H T C 'P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C
V V V D V S H E D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q
D W L N G K E Y K C K V S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V
S L T C L V K C iF Y P S D I A V E W E S N G Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R W Q Q G N V F S C S V M H E A F H N H Y T Q K S L S L S P G K (S E Q I D N O : 400 )
4995_P16 (PGT-145) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
O V O I ,V O S Ü A R V K K P C iS S ' VKVSCKASGNSFSNl ID V I 1W V K O A T G O G I J iW M G W M S H E G D K T G I A Q K I iR V H F R O S G A S r V Y M n i.R C il .T A D D T A I Y Y C I .T r A S ' KHRIADYFLYNEYGPNYEEMiDYIATWVWCillGTAVTVSS ( S E Q II) N O 401 )
4995_P16 (PGT-145) CDR de Kabat de la cadena pesada gamma:
CDR 1: NHDVH (SEQ ID NO: 378)
CDR 2: WMSHEGDKTGLAQKFQG (SEQ ID NO: 379)
CDR 3: GSKHRLRDYFLYNEYGPNYEEWGDYLATLDV (SEQ ID NO: 380)
4995_P16 (PGT-145) CDR de Chothia de la cadena pesada gamma:
CDR 1: GNSFSN (SEQ ID NO: 381)
CDR 2: WMSHEGDKTG (SEQ ID NO: 382)
CDR 3: GSKHRLRDYFLYNEYGPNYEEWGDYLATLDV (SEQ ID NO: 380)
[0600] 4995_P16 (PGT-145) secuencia de nucleótidos de la cadena ligera de kappa: secuencia de codificación (región variable en negrita)

N O : 383 )
4995_P16 (PGT-145) secuencia de nucleótidos de la región variable de la cadena ligera de kappa:
G A G G T T G T C A T A A C T C A G T C T C C A C T C T T C C T G C C C G T C A C C C C T G G A G A G
G C G G C C T C C T T G T C T T G C A A G T G C A G C C A C A G C C T C C A A C A T T C A A C T G G
A G C C A A C T A T T T G G C T T G G T A C C T G C A G A G A C C A G G G C A A A C T C C A C G C C
T G r r G A T C C A T T T G G C C A C T C A T C G G G C C T C C G G G G T C C C T G A C A G A T T C A
G T G G C A G T G G A T C A G G C A C A G A T T T T A C A C T T A A A A T C A G T C G A G T G G A G
T C T G A C G A T G T T G G A A C T T A T T A T T G C A T G C A G G G T C T G C A C A G T C C C T G G
A C G T T C G G C C A A G G G A C C A A G G T G G A G A T C A A A (S E Q II ) N O : 384 )
4995_P16 (PGT-145) secuencia de aminoácidos de la cadena ligera de kappa: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MRLPAQLLGLLMLWVSGSGAEX\\TQSPLFLP\TPGEAASLSCKCSHSLQHS
TGANYLAWYLQRPGQTPRLL1HLATHRASGVPDRFSGSGSGTDFTLKISR
VESDDVGTYYCMQGLHSPWTFGQGTKVEIKRTVAAPSVIIFPPSDEQEKS
GTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSST
LTLSKADYEKIIKVYACEVTHQGLSSPVTKSFNRGEC (SEQ ID NO: 385)
4995_P16 (PGT-145) secuencia de aminoácidos de la región variable de la cadena ligera kappa: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
EVVITQSPLFLPVTPGEAASLSC KCSHSLOHSTGANYIA WYI.QRPGQTPRLI.1
I \LATHRASQ 'VPDRI SGSGSGTDI TI.KISRVESDDVGTYYC MOGLHSPWTl GQ GTKVEIK (SEQ ID NO: 386)
4995_P16 (PGT-145) CDR de Kabat de cadena ligera kappa lambda:
CDR 1: KCSHSLQHSTGANYLA (SEQ ID NO: 387)
CDR 2: LATHRAS (SEQ ID NO: 388)
CDR 3: MQGLHSPWT (SEQ ID NO: 389)
4995_P16 (PGT-145) CDR de Chothia de la cadena ligera kappa:
CDR 1: KCSHSLQHSTGANYLA (SEQ ID NO: 387)
CDR 2: LATHRAS (SEQ ID NO: 388)
CDR 3: MQGLHSPWT (SEQ ID NO: 389)
El anticuerpo 5145_B14 (PGT-127) incluye una región variable de cadena pesada (SEQ ID NO: 319), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 317, y una región variable de cadena ligera (SEQ ID NO: 330) codificada por el ácido nucleico secuencia mostrada en SEQ ID NO: 328.
Las CDR de cadena pesada del anticuerpo 5145_B14 (PGT-127) tienen las siguientes secuencias según la definición de Kabat: RCNYFWG (SEQ ID NO: 320), SLSHCRSYYNTDWTYHNPSLKS (SEQ ID NO: 321) y FGGEVLVYRDWPKPAWVDL (SEQ ID NO: 322). Las CDR de cadena ligera del anticuerpo 5145_B14 (PGT-127) tienen las siguientes secuencias según la definición de Kabat: TGTSNNFVS (SEQ ID NO: 325), EVNKRPS (SEQ ID NO: 227) y SSLVGNWDVI (SEQ ID NO: 212).
Las CDR de cadena pesada del anticuerpo 5145_B14 (PGT-127) tienen las siguientes secuencias según la definición de Chothia: GDSTGRCN (SEQ ID NO: 323), SLSHCRSYYNTDWTY (SEQ ID NO: 324) y FGGEVLVYRDWPKPAWVDL (SEQ ID NO 322). Las CDR de cadena ligera del anticuerpo 5145_B14 (PGT-127) tienen las siguientes secuencias según la definición de Chothia: TGTSNNFVS (SEQ ID NO: 325), EVNKRPS (SEQ ID NO: 227) y SSLVGNWDVI (SEQ ID NO: 212).
El anticuerpo 5114_A19 (PGT-128) incluye una región variable de cadena pesada (SEQ ID NO: 334), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 332, y una región variable de cadena ligera (SEQ ID NO: 393) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 391.
Las CDR de cadena pesada del anticuerpo 5114_A19 (PGT-128) tienen las siguientes secuencias según la definición de Kabat: ACNSFWG (SEQ ID NO: 326), SLSHCASYWNRGWTYHNPSLKS (SEQ ID NO: 335) y FGGEVLRYTDWPKPAWVDL (SEQ ID NO: 336). Las CDR de cadena ligera del anticuerpo 5114_A19 (PGT-128) tienen las siguientes secuencias según la definición de Kabat: TGTSNNFVS (SEQ ID NO: 325), DVNKRPS (SEQ ID NO: 343), GSLVGNWDVI (SEQ ID NO: 196).
Las CDR de cadena pesada del anticuerpo 5114_A19 (PGT-128) tienen las siguientes secuencias según la definición de Chothia: GDSTAACN (SEQ ID NO: 337), SLSHCASYWNRGWTY (SEQ ID NO: 338), FGGEVLRYTDWPKPAWVDL (SEQ ID NO: 336).
Las CDR de cadena ligera del anticuerpo 5114_A19 (PGT-128) tienen las siguientes secuencias según la definición de Chothia: TGTSNNFVS (SEQ ID NO: 325), DVNKRPS (SEQ ID NO: 343), GSLVGNWDVI (SEQ ID NO: 196).
El anticuerpo 5136_H01 (PGT-131) incluye una región variable de cadena pesada (SEQ ID NO: 347), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 345, y una región variable de cadena ligera
(SEQ ID NO: 356) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 354.
Las CDR de cadena pesada del anticuerpo 5136_H01 (PGT-131) tienen las siguientes secuencias según la definición de Kabat: TGHHYWG (SEQ ID NO: 348), HIHYNTAVLHNPALKS (SEQ ID NO: 349) y SGGDILYYIEWQKPHWFYP (SEQ ID NO: 350). Las CDR de cadena ligera del anticuerpo 5136_H01 (PGT-131) tienen las siguientes secuencias según la definición de Kabat: SGTGSDIGSWNFVS (SEQ ID NO: 357), EVNRRRS (Se Q ID NO: 358) y SSLSGRWDIV (SEQ ID NO: 359).
Las CDR de cadena pesada del anticuerpo 5136_H01 (PGT-131) tienen las siguientes secuencias según la definición de Chothia: GDSINTGH (SEQ ID NO: 351), HIHYNTAVL (SEQ ID NO: 352) y SGGDILYYIEWQKPHWFYP (SEQ ID NO: 350). Las CDR de cadena ligera del anticuerpo 5136_H01 (PGT-131) tienen las siguientes secuencias según la definición de Chothia: SGTGSDIGSWNFVS (SEQ ID NO: 357), EVNRRRS (SEQ ID NO: 358) y SSLSGRWDIV (SEQ ID NO: 359).
El anticuerpo 5345_I01 (PGT-137) incluye una región variable de la cadena pesada (SEQ ID NO: 363), codificada por la secuencia de ácido nucleico que se muestra en la SEQ ID NO: 361, y una región variable de la cadena ligera (SEQ ID NO: 397) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 395.
Las CDR de cadena pesada del anticuerpo 5345_I01 (PGT-137) tienen las siguientes secuencias según la definición de Kabat: GGEWGDSDYHWG (SEQ ID NO: 364), SIHWRGTTHYNAPFRG (SEQ ID NO: 365) y HKYHDIVMVVPIAGWFDP (SEQ ID NO: 366). Las CDR de cadena ligera del anticuerpo 5345_I01 (PGT-137) tienen las siguientes secuencias según la definición de Kabat: RASQSVKNNLA (SEQ ID NO: 372), DTSSRAS (SEQ ID NO: 373) y QQYEEWPRT (SEQ ID NO: 245).
Las CDR de cadena pesada del anticuerpo 5345_I01 (PGT-137) tienen las siguientes secuencias según la definición de Chothia: GGSIRGGEWGDSD (SEQ ID NO: 367), SIHWRGTTH (SEQ ID NO: 237) y HKYHDIVMVVPIAGWFDP (SEQ ID NO: 366) Las CDR de cadena ligera del anticuerpo 5345_I01 (PGT-137) tienen las siguientes secuencias según la definición de Chothia: RASQSVKNNLA (SEQ ID NO: 372), DTSSRAS (SEQ ID NO: 373) y QQYEEWPRT (SEQ ID NO: 245).
El anticuerpo 4995_P16 (PGT-145) incluye una región variable de cadena pesada (SEQ ID NO: 401), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 399, y una región variable de cadena ligera (SEQ ID NO: 386) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 384.
Las CDR de cadena pesada del anticuerpo 4995_P16 (PGT-145) tienen las siguientes secuencias según la definición de Kabat: NHDVH (SEQ ID NO: 378), WMSHEGDKTGLAQKFQG (SEQ ID NO: 379) y GSKHRLRDYFLYNEYGPNYEEWGDYLATLDV (SEQ ID NO: 380). Las CDR de cadena ligera del anticuerpo 4995_P16 (PGT-145) tienen las siguientes secuencias según la definición de Kabat: KCSHSLQHSTGANYLA (s Eq ID NO: 387), LATHRAS (SEQ ID NO: 388) y MQGLHSPWT (SEQ ID NO: 389).
Las CDR de cadena pesada del anticuerpo 4995_P16 (PGT-145) tienen las siguientes secuencias según la definición de Chothia: GNSFSN (SEQ ID NO: 381), WMSHEGDKTG (SEQ ID NO: 382) y GSKHRLRDYFLYNEYGPNYEEWGDYLATLDV (SEQ ID NO: 380) Las CDR de cadena ligera del anticuerpo 4995_P16 (PGT-145) tienen lo siguiente secuencias por definición de Chothia: KCSHSLQHSTGANYLA (SEQ ID NO: 387), LATHRAS (SEQ ID NO: 388) y MQGLHSPWT (SEQ ID NO: 389).
Se determinaron las secuencias de anticuerpos monoclonales humanos adicionales, incluidas las secuencias de las regiones variables de las cadenas pesadas Gamma y Kappa o Lambda. Además, se determinó la secuencia de cada uno de los polinucleótidos que codifican las secuencias de anticuerpos. A continuación se muestran las secuencias de polipéptidos y polinucleótidos de las cadenas pesadas gamma y las cadenas ligeras kappa, con los péptidos señal en el extremo N (o extremo 5') y las regiones constantes en el extremo C (o extremo 3') de las regiones variables, que se muestran en texto en negrita.
4835_F12 (PGT-124) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (secuencia líder en cursiva, región variable en negrita)
/V TGAAA CA CCTGTGGTTCTTCCTCCTGCTGGTGGCAGCTCCCA GA TGGGTCCT
/irCCCAGGTGCAGCTGCAGGAGTCGGGCCCAGGACTGGTGAGACCTT
CGGAGACCCTGTCCGTCACCTGCATCGTCTCTGGGGGCTCCATCAGC
AATTACTACTGGACTTGGATCCGACAGTCCCCAGGAAAGGGACTGGA
GTGGATAGGCTATATTTCTGACAGAGAAACAACGACTTACAATCCCT
CCCTCAACAGTCGAGCCGTCATATCACGAGACACGTCGAAAAACCAA
TTGTCCCTACAATTACGTTCCGTCACCACTGCGGACACGGCCATCTAT
TTCTGTGCGACAGCGCGCCGAGGACAGAGGATTTATGGAGTGGTTTC
ATTTGGAGAGTTCTTCTACTACTACTACATGGACGTCTGGGGCAAAG
GGACTGCGGTCACCGTCTCCTCAGCGTCGACCAAGGGCCCATCGGTCTT
CCCTCTGGCACCATCATCCAAGTCGACCTCTGGGGGCACAGCGGCCCTGG
GCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAAC
TCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTC
CTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCT
TGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACC
AAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAAAACTCACACAT
GCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTC
TTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGT
CACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCA
ACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCG
GGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCC
TGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAA
CAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGG
CAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGAT
GACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCA
GCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTA
CAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAG
CAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCA
TGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCT
CTCCCTGTCTCCGGGTAAATGA(SEQ ID NO: 402)
4835_F12 (PGT-124) secuencia de nucleótidos de la región variable de la cadena pesada gamma:
CAGGTGCAGCTGCAGGAGTCGGGCCCAGGACTGGTGAGACCTTCGG
AGACCCTGTCCGTCACCTGCATCGTCTCTGGGGGCTCCATCAGCAAT
TACTACTGGACTTGGATCCGACAGTCCCCAGGAAAGGGACTGGAGTG
GATAGGCTATATTTCTGACAGAGAAACAACGACTTACAATCCCTCCCT
CAACAGTCGAGCCGTCATATCACGAGACACGTCGAAAAACCAATTGT
CCCTACAATTACGTTCCGTCACCACTGCGGACACGGCCATCTATTTCT
GTGCGACAGCGCGCCGAGGACAGAGGATTTATGGAGTGGTTTCATTT
GGAGAGTTCTTCTACTACTACTACATGGACGTCTGGGGCAAAGGGAC
TGCGGTCACCGTCTCCTCA(SRQ ID NO: 403)
4835_F12 (PGT-124) secuencia de aminoácidos de la cadena pesada del gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MKHLWFFLLLVAAPKWVLSQ\QLQESGPGL\RPSETLS\TC\\SGGSlSm\
W T W I R Q S P G K G L E W I G Y I S D R E T T T Y N P S L N S R A V I S R D T S K N Q L S L Q L R
S V T T A D T A I Y F C A T A R R G Q R I Y G V V S F G E F F Y Y Y Y M D V W G K G T A V T V S S
ASTKGPSVFPI .APSSKSTSGGTAAI ,GCI .VKDYFPEPVTVSWNSGAI/TSGVÍITF
PAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKT
HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRITEVTCVVVDVSHEDPEVKFN
WYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSN
KAEPAPIEKTISKAKGQPREPQVYTI PPSREEMTKNQVSLTCLVKGFYPSDIA
VEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNV1 SCSVMII
EALHNHYTQKSLSLSPGK (SEQ ID NO: 404)
4835_F12 (PGT-124) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
ff/r/77YNPSLNSRAVlSRDTSKNOI3>IX)I4<SVTTADTAIYFCATAftftO'Ofl/F(; VVSFGEFFYYYYMD FWGKGTA VTVSS (SEQ ID NO: 405)
CDR de Kabat de la cadena pesada gamma 4835_F12 (PGT-124):
CDR 1: NYYWT (SEQ ID NO: 406)
CDR 2: YISDRETTTYNPSLNS (SEQ ID NO: 407)
CDR 3: ARRGQRIYGVVSFGEFFYYYYMDV (SEQ ID NO: 408)
4835_F12 (PGT-124) CDR de Chothia de la cadena pesada gamma:
CDR 1: GGSISN (SEQ ID NO: 409)
CDR 2: YISDRETTT (SEQ ID NO: 410)
CDR 3: ARRGQRIYGVVSFGEFFYYYYMDV (SEQ ID NO: 408)
4835_F12) secuencia de nucleótidos de la cadena ligera: secuencia de codificación (región variable en negrita)
A TGGCCTGGA TCCCTCTCCTCCTCGGCCTCCTCTCTCA CTGCA CA GGGTCTGT
G A C G T C C T A T G T G A G C C C A C T G T C A G T G G C C C T G G G G G A G A C G G C C A
G G A T T T C C T G T G G A C G A C A G G C C C T T G G A A G T A G A G C T G T G C A G T G G
T A T C A A C A T A A G C C A G G C C A G G C C C C T A T T T T G C T C A T C T A T A A T A A T
C A A G A C C G G C C C T C A G G G A T C C C T G A G C G G T T C T C T G G C A C C C C T G A
T A T T A A T T T T G G G A C C A C G G C C A C C C T G A C T A T C A G C G G G G T C G A A G
T C G G G G A T G A A G C C G A C T A T T A C T G T C A C A T G T G G G A C T C T A G A A G T
G G T T T C A G T T G G T C T T T C G G C G G G G C G A C C A G G C T G A C C G T C C T A G G
TCAGCCCA AGGCTGCCCCCTCGGTCACTCTG’ITCCCGCCCTCCTCTGAGGA
GCTTCAAGCCAACAAGGCCACACTGGTGTGTCTCATAAGTGACTTCTACC
CGGCAGCCGTOACAOTGGCCTGOAAOGCAGATAOCAGCCCCGTCAAGGC
GGGAGTGGAGACCACCACACCCTCCAAACAAAGCAACAACAAGTACGCG
GCCAGCACCTATCTGAGCCTGACGCCTGAGCAGTGGAAGTCCCACAAAA
GCTACAGCTGCCAGGTCACGCATGAAOGOAOCACCGTGGAGAAGACAGT
GGCCCCTACAGAATGITCATAG (SEQ ID NO: 411)
4835_F12 (PGT-124) secuencia de nucleótidos de la región variable de la cadena ligera:
TCCTATGTGAGCCCACTGTCAGTGGCCCTGGGGGAGACGGCCAGGAT
TTCCTGTGGACGACAGGCCCTTGGAAGTAGAGCTGTGCAGTGGTATC
AACATAAGCCAGGCCAGGCCCCTATTTTGCTCATCTATAATAATCAAG
ACCGGCCCTCAGGGATCCCTGAGCGGTTCTCTGGCACCCCTGATATT
AATTTTGGGACCACGGCCACCCTGACTATCAGCGGGGTCGAAGTCGG
GGATGAAGCCGACTATTACTGTCACATGTGGGACTCTAGAAGTGGTT
TCAGTTGGTCTTTCGGCGGGGCGACCAGGCTGACCGTCCTA(SEQ ID
N O : 412 )
4835_F12 (PGT-124) secuencia de aminoácidos de la cadena ligera: proteína expresada con secuencia líder en cursiva y región variable en negrita.
A/AW/mXG7.LS7/C7GlSV7SYVSPLSVALGETARISCGRQALGSRAVQWYQ
HKPGQAPILLIYNNQDRPSGIPERFSGTPDINFGTTATLTISGVEVGDEAD
Y Y C H M W D S R S G F S W S F G G A T R L T V L G Q P K A A P S V T L I P P S S H H L Q A N K A T
L V C L I S D F Y P G A V T V A W K A D S S P V K A G V E T T T P S K Q S N N K Y A A S S Y L S L T P E
Q W K S H K S Y S C Q V T H E G S T V E K T V A P T E C S (S E Q I D N O : 413 )
4835_F12 (PGT-124) secuencia de aminoácidos de la región variable de la cadena ligera: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
SYVSPLSVAlXiETARlSC(¿/f(M//f,S7M V6AV YOHKPGOAPlLLlYMVCW/fP.S’Gl PERFSGTPDINKnTATITISGVEVGDEADYYCWMWYXSWjKS’lYS’FGüATRL TVL (SEQ ID NO: 414)
4835_F12 (PGT-124) CDR de Kabat de cadena ligera:
CDR 1: GRQALGSRAVQ (SEQ ID NO: 415)
CDR 2: NNQDRPS (SEQ ID NO: 151)
CDR 3: HMWDSRSGFSWS (SEQ ID NO: 416)
4835_F12 (PGT-124) CDR de Chothia de la cadena ligera:
CDR 1: GRQALGSRAVQ (SEQ ID NO: 415)
CDR 2: NNQDRPS (SEQ ID NO: 151)
CDR 3: HMWDSRSGFSWS (SEQ ID NO: 416)
4869_K15 (PGT-133) gamma pesado secuencia de nucleótidos de cadena: secuencia de codificación (región variable en negrita)
/ i TGAAA CA C C T G T G G T T C n C C n C T C C T G G T G G C A G C T C C C A GA T G G G T C G T
GTCCCAGGTGCATCTGCAAGAGTCGGGGCCAGGACTGGTGACGCCTT
CGGAAACCCTGTCCCTCACTTGCACTGTGTCGAATGGCTCCGTCAGT
GGTCGCTTCTGGAGCTGGATCCGGCAGTCCCCAGGGAGAGGACTGG
AATGGATCGGTTATTTTTCTGACACTGACAGGTCTGAATATAATCCTT
CTCTCAGGAGTCGACTCACCTTATCAGTAGATAGATCTAAGAACCAG
TTGTCCCTGAGATTGAAGTCCGTGACCGCTGCGGATTCGGCCACTTA
TTACTGTGCGAGAGCACAGCAGGGGAAGAGGATCTATGGAATAGTGT
CTTTCGGAGAGTTCTTCTATTATTATTACATGGACGCCTGGGGCAAAG
GG ACTCCGGTCACCGTCTCCTCAGCG TCG ACCA AGGGCCCATCGC.TCTT
CCCTCTGGCACCATCATCCAAGTCGACCTCTGGGGGCACAGCGGCCCTGG
GCTGCGT GGTC A AGG ACT ACTTCCCCG A ACCGGTG ACGGTGTCGTGG A AC
TCAGGCGCCCTGACCAGCGGCGTGCACACCTTCGCGGCTGTCCTACAGTC
CTCAGGACTCTACTGCCTCAGCAGCGTGGTGACCGTGCCGTCCAGCAGCT
TGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACC
AAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAAAACTCACACAT
GCCCACCGTGCGCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTG
TTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGT
CACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCA
ACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCG
GGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCC
TGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAA
CAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGG
CAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGAT
GACCAAGAACGAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATGCCA
GCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTA
CAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAG
CAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCA
TGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCT
CTCCCTGTCTCCGGGTAAATGA(SEQ ID NO: 417)
4869_K15 (PGT-133) secuencia de nucleótidos de región variable de cadena pesada gamma:
CAGGTGCATCTGCAAGAGTCGGGGCCAGGACTGGTGACGCCTTCGG
AAACCCTGTCCCTCACTTGCACTGTGTCGAATGGCTCCGTCAGTGGT
CGCTTCTGGAGCTGGATCCGGCAGTCCCCAGGGAGAGGACTGGAAT
GGATCGGTTATTTTTCTGACACTGACAGGTCTGAATATAATCCTTCTC
TCAGGAGTCGACTCACCTTATCAGTAGATAGATCTAAGAACCAGTTG
TCCCTGAGATTGAAGTCCGTGACCGCTGCGGATTCGGCCACTTATTA
CTGTGCGAGAGCACAGCAGGGGAAGAGGATCTATGGAATAGTGTCTT
TCGGAGAGTTCTTCTATTATTATTACATGGACGCCTGGGGCAAAGGG
ACTCCGGTCACCGTCTCCTCACSHQ ID NO: 418)
4869_K15 (PGT-133) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MK///VYF/7JXVA4P/ÍWVSQVHLQESGPGLVTPSETLSLTCTVSNGSVSGRF
WSWIRQSPGRGLEWIGYFSDTDRSEYNPSLRSRLTLSVDRSKNQLSLRLK
SVTAADSATYYCARAQQGKRIYGIVSFGEFFYYYYMDAWGKGTPVTVSS
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWN.SGALTSGVHTF
PAVLQSSGLYSLSSVV'l'VPSSSLGTQ'I’YIC'NVNIIKPSN'l’KVDKRVFPKSC'DKr
HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFN
WYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSN
KALPAPIEKT1SKAKGQPREPQVYTLPPSREEMTKNQVSLTGLVKGFYPSDIA
VEWESNGQPENNYKTTPPVI.DSrXiSITLYSKFrVDKSRWQQGNVFSCSVMII EALHNHYTQKSLSLSPGK (SEQ ID NO: 419)
4869_K15 (PGT-133) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
QVIII.QESGPG1.VTPSETI.SITCTVS NGS VSGRFWSWIRQSPC3RGLEWICi YFSl) 7’/j ^.S7:y n p s i r s ri ; n ,s v d r s k n q i .si .r i x s y t a a d s a t y y c a r a o o g k r iy GIVSFGEFFYYYYMDA WGKCiTPVTVSS (SEQ ID NO: 420)
CDR de Kabat de la cadena pesada gamma 4869_K15 (PGT-133):
CDR 1: GRFWS (SEQ ID NO: 421)
CDR 2: YFSDTDRSEYNPSLRS (SEQ ID NO: 422)
CDR 3: AQQGKRIYGIVSFGEFFYYYYMDA (SEQ ID NO: 423)
4869_K15 (PGT-133) CDR de Chothia de la cadena pesada gamma:
CDR 1: NGSVG NGS: IDR 1: NGS: 424)
CDR 2: YFSDTDRSE (SEQ ID NO: 425)
CDR 3: AQQGKRIYGIVSFGEFFYYYYMDA (SEQ ID NO: 423)
4869_K15 (PGT-133) secuencia de nucleótidos de la cadena ligera: secuencia de codificación (región variable en negrita)
A T G G C C T G G A T C C C T C T C C T C C T C G G C C T C C T C T C T C A C T G C A CA G G T T C T G A
CAC/TCGTTAAACCCACTGTCGCTGGCCCCAGGAGCGACGGCCAAAA
TTCCCTGCGGAGAAAGGAGCCGTGGAAGTAGGGCTGTCCAGTGGTAT
CAGCAGAAGCCAGGCCAGGCCCCCACATTGATCATTTATAATAATCA
AGACCGGCCCGCAGGGGTCTCTGAACGATTTTCTGGCAATCCTGACG
TCGCTATTGGGGTGACGGCCACCCTGACCATCAGTCGGGTCGAAGTC
GGGGATGAGGCCGACTATTATTGTCACTATTGGGACAGTAGAAGTCC
CATCAGCTGGATTTTCGGCGGAGGGACCCAGCTGACCGTCCTGGGTC
AGCCCAAGGCTGCCCCGTCGGTCACTCTGTTCCCGCCCTCCTCTGAGGAGC
TTC A AGCC A AC A ACGCC AC ACTGGTGTGTCTC AT A AGTGACTTCT ACCCG
GGAGCCGTGACAGTGGCCTOGAAGGCAGATAGCAGCCCCGTCAAGGCGG
GAGTGGAGACCACCACACCCTCCAAACAAAGCAACAACAAGTACGCGGC
CAGCAGCTATCTGAGCCTGACGCCTGAGCAGTGGAAGTCCCACAAAAGCT
ACAGCTGGCAGGTCACGCATGAAGGGAGCAGCGTGGAGAAGACAGTGGC
CCCTACAGAATGTTCATAG(SEQ ID NO: 426)
4869_K15 (PGT-133) secuencia de nucleótidos de la región variable de la cadena ligera:
TCGTTAAACCCACTGTCGCTGGCCCCAGGAGCGACGGCCAAAATTCC
CTGCGGAGAAAGGAGCCGTGGAAGTAGGGCTGTCCAGTGGTATCAG
CAGAAGCCAGGCCAGGCCCCCACATTGATCATTTATAATAATCAAGA
CCGGCCCGCAGGGGTCTCTGAACGATTTTCTGGCAATCCTGACGTCG
CTATTGGGGTGACGGCCACCCTGACCATCAGTCGGGTCGAAGTCGGG
GATGAGGCCGACTATTATTGTCACTATTGGGACAGTAGAAGTCCCAT
CAGCTGGATTTTCGGCGGAGGGACCCAGCTGACCGTCCTG(SEQ II)
N O : 427 )
4869_K15 (PGT-133) secuencia de aminoácidos de la cadena ligera: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MA W1PLLLGLLSHC1 GSD/SLNPLSLAPGATAKIPCGERSRGSRAVQWYQQ
KPGQAPTLIIYNNQDRPAGVSERFSGNPDVAIGVTATLTISRVEVGDEADY
YCHYWDSRSPISWIFGGGTQLTVLGQPKAAPSVTLFPPSSEELQANKATLV
C L I S D F Y P G A V r V A W K A D S S P V K A C iV H I T lP S K Q S N N K Y A A S S Y L S L T P E Q W K S H K S Y S C Q V T H E G S T V E K T V A P T E C S ( S E Q II ) N O : 428 )
4869_K15 (PGT-133) secuencia de aminoácidos de la región variable de la cadena ligera: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
S L N P L S L A P G A T A K 1P C G E R S R G S R A V O W Y O O K P G O A P T L I I Y N N O D R P A G V S E R F S G N P D V A I G V T A T L T I S R V E V G D E A D Y Y C / / Y W A ) S f f S P /S W /F G G G T O L T V L (S E Q II ) N O : 429 )
CDR de Kabat de la cadena ligera 4869_K15 (PGT-133):
CDR 1: GERSRGSRAVQ (SEQ ID NO: 430)
CDR 2: NNQDRPA (SEQ ID NO: 179)
CDR 3: HYWDSRSPISWI (SEQ ID NO: 431)
4869_K15 (PGT-133) CDR de Chothia de la cadena ligera:
CDR 1: GERSRGSRAVQ (SEQ ID NO: 430)
CDR 2: NNQDRPA (SEQ ID NO: 179)
CDR 3: HYWDSRSPISWI (SEQ ID NO: 431)
4876_M06 (PGT-134) gamma pesado secuencia de nucleótidos de cadena: secuencia de codificación (región variable en negrita)
A TGAAA CA C C T G T G G T T C T T C C T C C T G C T G G T G G C A G C T C C C A GA T G G G T C G T
G 7 C C C A G G T G C A T C T G C A A G A G T C G G G G C C A G G A C T G G T G A C G C C T T
C G G A A A C C C T G T C C C T C A C T T G C A C T G T G T C G A A T G G C T C C G T C A G T
G G T C G C T T C T G G A G C T G G A T C C G G C A G T C C C C A G G G A G A G G A C T G G
A A T G G A T C G G T T A T T T T T C T G A C A C T G A C A G G T C T G A A T A T A A T C C T T
C T C T C A G G A G T C G A C T C A C C T T A T C A G T C G A T A G A T C C A A G A A C C A G
T T G T C C C T A A A A T T G A A G T C C G T G A C C G C T G C G G A T T C G G C C A C T T A
T T A C T G T G C G A G A G C A C A A C A G G G G A A G A G G A T C T A T G G A A T A G T G T
C T T T C G G A G A G T T G T T C T A T T A T T A T T A C A T G G A C G C C T G G G G C A A A
G G G A C T C C G G T C A C C G T C T C C T C A G C G T C G A C C A A G G G C C C A T C G G T C
TTCCCTCTGGCACCATCATCCAAGTCGACCTCTGGGGGCACAGCGGCCCT
GGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGA
ACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAG
TCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAG
CTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACA
CCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAAAACTCACAC
ATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCC
TCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAG
GTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTT
C A ACTGGT ACGTGG ACGGCGTGG AGGTGC AT A ATGCCA AG AC A A AGCCG
CGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGT
CCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCC
AACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAG
GGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGA
GATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATC
CCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAA
CT AC A AG ACC ACGCCTCCCGTGCTGG ACTCCG ACGGCTCCTTCTTCCTCT A
TAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTC
TCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAG
CCTCTCCCTGTCTCCGGGTAAATGA(SEQ II) NO: 432)
4876_M06 (PGT-134) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G G T G C A T C T G C A A G A G T C G G G G C C A G G A C T G G T G A C G C C T T C G G
A A A C C C T G T C C C T C A C T T G C A C T G T G T C G A A T G G C T C C G T C A G T G G T
C G C T T C T G G A G C T G G A T C C G G C A G T C C C C A G G G A G A G G A C T G G A A T
G G A T C G G T T A T T T T T C T G A C A C T G A C A G G T C T G A A T A T A A T C C T T C T C
T C A G G A G T C G A C T C A C C T T A T C A G T C G A T A G A T C C A A G A A C C A G T T G
T C C C T A A A A T T G A A G T C C G T G A C C G C T G C G G A T T C G G C C A C T T A T T A
C T G T G C G A G A G C A C A A C A G G G G A A G A G G A T C T A T G G A A T A G T G T C T T
TCGGAGAGTTGTTCTATTATTATTACATGGACGCCTGGGGCAAAGGG ACTCCGGTCACCGTCTCCTCA(SEQ ID NO: 433)
4876_M06 (PGT-134) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
A /A // /A F /r/ 7 J X V A A P / ? V m ' S Q V H L Q E S G P G L V T P S E T L S L T C T V S N G S V S G R F
W S W I R Q S P G R G L E W I G Y F S D T D R S E Y N P S L R S R L T L S V D R S K N Q L S L K L K
S V T A A D S A T Y Y C A R A Q Q G K R I Y G I V S F G E L F Y Y Y Y M D A W G K G T P V T V S S
ASTKGPSVFPLAPSSKS'rSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTF
PAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKT
HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFN
WYVDGVHVIINAKTKPREEQYNSTYRVVSVLTVUIQDWLNGKHYKCKVSN
KALPAPIEKT1SKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIA
VEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMH
EALHNHYTQKSLSLSPGK (SEQ II) NO: 434)
4876_M06 (PGT-134) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
OVHLOESCPCLVTPSETLSLTCTVSiVGS KSGRFWS W1ROSPGRGLEWIG YFSD y y j f lS f l Y N P S F R S R i ; n . s v d r s k n q i .s f k l k s v i a a d s a t y y c a r a o o g a ^ / f g i v s i a i j j y y y ymda w g k c í t p v ~r v s s ( s e q i d n o : 435 )
4876_M06 (PGT-134) gamma de cadena pesada CDR de Kabat:
CDR 1: GRFWS (SEQ ID NO: 421)
CDR 2: YFSDTDRSEYNPSLRS (SEQ ID NO: 422)
CDR 3: AQQGKRIYGIVSFGELFYYYYMDA (SEQ ID NO: 436)
4876_M06 (PGT-134) CDR de Chothia de la cadena pesada gamma: NG IDS:
CDR 1: 424)
CDR 2: YFSDTDRSE (SEQ ID NO: 425)
CDR 3: AQQGKRIYGIVSFGELFYYYYDA (SEQ ID NO: 436)
4876_M06 (PGT-134) secuencia de nucleótidos de la cadena ligera: secuencia de codificación (región variable en negrita)
A T G G C C T G GA T C C C T C T C C T C C T C G G C C T C C T C T C T C A C T G C A CA G G T T C T G A
C 71 C 7 T C G T T A A A C C C A C T G T C G C T G G C C C C G G G A G C G A C G G C C A A A A
T T C C C T G C G G A G A A A G G A G C C G T G G A A G T A G G G C T G T C C A G T G G T A T
C A G C A G A A G C C A G G C C A G G C C C C C A C A T T G A T C A T T T A T A A T A A T C A
A G A C C G G C C C G C A G G G G T C T C T G A A C G A T T T T C T G G C A A T C C T G A C G
T C G C T A T T G G G G T G A C G G C C A C C C T G A C C A T C A G T C G G G T C G A A G T C
G G G G A T G A G G G C G A C T A T T A T T G T C A C T A T T G G G A C A G T A G A A G T C C
C A T C A G C T G G A T T T T C G C C G G A G G G A C C C A G T T G A C C G T C C T G G G T C
AGCCCAAOGCTGCCCCCTCGGTCACTCTGTTCCCGCCCTCCTCTGAGGAGC
TTCAAGCCAACAAGGCCACACTGGTGTGTCTCATAAGTGACTTCTACCCG
GGAGCCGTGACAGTGGCCTGGAAGGCAGATAGCAGCCCCGTCAAGGCGG
GAGTGGAGACCACCACACCCTCCAAACAAAGCAACAACAAGTACGCGGC
CAGCAGCTATCTGAGCCTGACGCCTGAGCAGTGGAAGTCCCACAAAAGCT
ACAGCTGCCAGGTCACGCATGAAGGGAGCACCGTGGAGAAGACAGTGGC
CCCTACAGAATGTTCATAG (SEQ ID NO: 437)
4876_M06 (PGT-134) secuencia de nucleótidos de la región variable de la cadena ligera:
TCGTTAAACCCACTGTCGCTGGCCCCGGGAGCGACGGCCAAAATTCC
CTGCGGAGAAAGGAGCCGTGGAAGTAGGGCTGTCCAGTGGTATCAG
CAGAAGCCAGGCCAGGCCCCCACATTGATCATTTATAATAATCAAGA
CCGGCCCGCAGGGGTCTCTGAACGATTTTCTGGCAATCCTGACGTCG
CTATTGGGGTGACGGCCACCCTGACCATCAGTCGGGTCGAAGTCGGG
GATGAGGGCGACTATTATTGTCACTATTGGGACAGTAGAAGTCCCAT
CAGCTGGATTTTCGCCGGAGGGACCCAGTTGACCGTCCTG ( S E Q ID
N O : 438 )
4876_M06 (PGT-134) secuencia de aminoácidos de la cadena ligera: proteína expresada con secuencia líder en cursiva y región variable en negrita.
A M W /W Z G / J A / / C T G S D 7 S L N P L S L A P G A T A K I P C G E R S R G S R A V Q Y V Y Q Q
K P G Q A P T L I I Y N N Q D R P A G V S E R F S G N P D V A I G V T A T L T I S R V E V G D E G D Y
Y C H Y W D S R S P I S W I F A G G T Q L T V L G Q P K A A P S V T E F P P S S E E E Q A N K A T E V
C L I S D F Y P G A V T V A W K A D S S P V K A G V E T T T P S K Q S N N K Y A A S S Y L S L T P E Q W
K S H K S Y S C Q V T H E G S T V E K T V A P T E C S ( S E Q ID N O : 439 )
4876_M06 (PGT-134) de la cadena ligera de la región variable de secuencia de aminoácidos: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
S L N P L S L A P G A T A K lP C fíE R S R fíS R A V O W Y O O K P G O A V T U lY N N O D R P A CiVS
E R F S G N P D V A I G V T A T L T I S R V E V G D E G D Y Y C H Y W D S R S P IS W IF A G G T O L T V
L ( S E Q ID N O : 440 )
4876_M06 (PGT-134) CDR de Kabat de la cadena ligera:
CDR 1: GERSRGSRAVQ (SEQ ID NO: 430)
CDR 2: NNQDRPA (SEQ ID NO: 179)
CDR 3: HYWDSRSPISWI (SEQ ID NO: 431)
4876_M06 (PGT-134) CDR de Chothia de la cadena ligera:
CDR 1: GERSRGSRAVQ (SEQ ID NO: 430)
CDR 2: NNQDRPA (SEQ ID NO: 179)
CDR 3: HYWDSRSPISWI (SEQ ID NO: 431)
Sin embargo, la presente invención está dirigida específicamente al anticuerpo monoclonal anti-VIH humano 4876_M06 (PGT-134) que tiene una cadena pesada variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 435 y una cadena ligera variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 440.
5131_A17 (PGT-132) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
A T G A A A C A C C T G T G G T T C T T C C T C C T G C T G G T G G C A G C T C C C A G A T G G G T C C T
77CCCAGGTGCAACTACAGGAGTCGGGCCCAGGACTGGTGAAGCCTT
CGGAGACCCTTTCCCTCACCTGCACTGTCTCTGGTGACTCCATCAACA
CTGGTCATCACTACTGGGGCTGGGTCCGTCAGGTCCCAGGGAAGGGA
CCGGAATGGATTGCTCACATCCACTATAATACGGCTGTCTTGCACAAT
CCGGCCCTCAAGAGTCGAGTCACCATTTCGATTTTCACCCTGAAGAA
TCTGATTACCCTGAGGCTCAGTAATATGACCGCCGCGGACACGGCCG
TCTATTTCTGCGTTCGATCCGGCGGCGACATTTTATACTATAATGAGT
GGCAAAAACCCCACTGGTTCTATCCCTGGGGCCCGGGAATTTTGGTC

ACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTA
CTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGA
CCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAA
GAGAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCX:
CAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAA
CCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGT
GGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGG
ACGGCGTGG AGGTGCAT A ATGCC A AG AC A A AGCCGCGGG AGG AGC AGT A
CAACAGCACGTACCGTGTGGTCAGCGTCCTCACGGTCCTGCACCAGGACT
G G C T G A A T G G C A A G G A G T A C A A G T G C A A G G T C T C C A A C A A A G C C C T C C C
AGCCCGGATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAA
C C A C A G G T G T A C A C C C T G C C C C C A T C C C G G G A G G A G A T G A C C A A G A A C C
A G G T C A G C C T G A C C T G C C T G G T C A A A G G C T T C T A T C C C A G C G A C A T C G C C
G T G G A G T G G G A G A G C A A T G G G C A G C C G G A G A A C A A C T A C A A G A C C A C G C
CTCCCGTGCTGG ACTCCG ACGGCTCCTTCTTCCTCT AT AGC A AGCTC ACCG
TGGACAAGAGCAGGTGGCAGCAGGGGAAGGTCTTCTCATGCTCCGTGATG
CATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCC
GGGTAAATGA(SEQ ID NO: 441)
5131_A17 (PGT-132) secuencia de nucleótidos de región variable de la cadena pesada gamma:
CAGGTGCAACTACAGGAGTCGGGCCCAGGACTGGTGAAGCCTTCGG
AGACCCTTTCCCTCACCTGCACTGTCTCTGGTGACTCCATCAACACTG
GTCATCACTACTGGGGCTGGGTCCGTCAGGTCCCAGGGAAGGGACC
GGAATGGATTGCTCACATCCACTATAATACGGCTGTCTTGCACAATCC
GGCCCTCAAGAGTCGAGTCACCATTTCGATTTTCACCCTGAAGAATCT
GATTACCCTGAGGCTCAGTAATATGACCGCCGCGGACACGGCCGTCT
ATTTCTGCGTTCGATCCGGCGGCGACATTTTATACTATAATGAGTGGC
AAAAACCCCACTGGTTCTATCCCTGGGGCCCGGGAATTTTGGTCACC
GTCTCGAGC(SHQ ID NO: 442)
5131_A17 (PGT-132) secuencia de aminoácidos de la cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
M K H L W F F L L L V A A P R WESQVQLQESGPGLVKPSETLSLTCTVSGDSINTGH
HYWGWVRQVPGKGPEWIAH1HYNTAVLHNPALKSRVTISIFTLKNLITL
RLSNMTAADTAVYFCVRSGGDILYYNEWQKPHWFYPWGPGILVTVSSAS
TKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPA
VLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHT
GPPCPAPEIJXiGPSVI LI PPKPKiyrLMISR ri’HV rC'VVVDVSHEDPEVKFNWY
VDG VEVHN A KTKPREEQYNSTYR V VS VLTVLHQDWLNGKEY KCK VSNKAL
PAPIEKTISKAKGQPRHPQVYTLPPSRI4ÍMTKNQVSLTCLVKGFYPSDIAVEW
ESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEAL
HNHYTQKSLSLSPGK (SEQ ID NO: 443)
5131_A17 (PGT-132) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
OVOLOESGPGLVKPSETLSLTCTVSGDS/ATG//IIYW GWVROVPGKGPEWIA
/////YA/AV/^IINPAI.KSRVriSIRLKNFirFRFSNM rAADTAVYFGVRAGGD/A F Y\FW ÜKPHWFY l>m iPGILVTVSS (SEQ II) NO: 444)
5131_A17 (PGT-132) CDR de Kabat de cadena pesada gamma:
CDR 1: TGHHYWG (SEQ ID NO: 348)
CDR 2: HIHYNTAVLHNPALKS (SEQ ID NO: 349)
CDR 3: SGGDILYYNEWQKPHWFYP (SEQ ID NO: 445)
5131_A17 (PGT-132) CDR de Chothia de la cadena pesada gamma:
CDR 1: GDSINTGH (SEQ ID NO: 351)
CDR 2: HIHYNTAVL (SEQ ID NO: 352)
CDR 3: SGGDILYYNEWQKPHWFYP (SEQ ID NO: 445)
5131_A17 (PGT-132) secuencia de nucleótidos de la cadena ligera: secuencia de codificación (región variable en negrita)
A T G G C C T G G G C T C T G C T C C T C C T C A C C C T C C T C A C T C A G G G C A CA G G G T C C T G
GGCCCAGTCTGCCCTGACTCAGCCTCCCTCCGCGTCCGGGTCTCTTG
GACAGTCACTCACCATCTCCTGCAGTGGAACCGCCAGTGACATTGGC
AGTTGGAATTTTGTCTCCTGGTATCAACAATTCCCAGGCAGAGCCCC
CAACCTCATTATTTTTGAGGTCAATAGGCGGCGATCAGGGGTCCCTG
ATCGCTTCTCTGGTTCCAAGTCGGGCAATACGGCCTCCCTGACCGTC
TCTGGGCTCCGG TCTGAGGATGAGGCTGAATATTTTTGCAGTTCCCT
TTCAGGCAGGTGGGACATTGTTTTTGGCGGAGGGACCAAGGTGACCG
TCCTAGGTCACCCCAAGGCTGCCCCCTCGGTCACTCTGTTCCCGCCCTCCT
CTGAGGAGCTTCAAGCCAACAAGGCCACACTGGTGTGTCTCATAAGTGAC
TTCT ACCCGGG AGCCGTG AC AGTGGCCTGG A AGGCAG AT AGC AGCCCCGT
CAAGOCGOGAGTGGAOACCACCACACCCTCCAAACAAAGCAACAACAAG
T ACGCGGCC AGC AGCT ACCTG AGCCTG ACGCCTG AGC AGTGG A AGTCCC A
CAAAAGCTACAGCTGCCAGGTCACGCATGAAGGGAGCACCGTGGAGAAG
ACAGTGGCCCCTACAGAATGTTCATAG(SEQ II) NO: 446)
5131_A17 (PGT-132) secuencia de nucleótidos de la región variable de la cadena ligera:
CAGTCTGCCCTGACTCAGCCTCCCTCCGCGTCCGGGTCTCTTGGACA
GTCACTCACCATCTCCTGCAGTGGAACCGCCAGTGACATTGGCAGTT
GGAATTTTGTCTCCTGGTATCAACAATTCCCAGGCAGAGCCCCCAAC
CTCATTATTTTTGAGGTCAATAGGCGGCGATCAGGGGTCCCTGATCG
CTTCTCTGGTTCCAAGTCGGGCAATACGGCCTCCCTGACCGTCTCTG
GGCTCCGGTCTGAGGATGAGGCTGAATATTTTTGCAGTTCCCTTTCA
GGCAGGTGGGACATTGTTTTTGGCGGAGGGACCAAGGTGACCGTCCT
A ( S E Q ID N O : 447 )
5131_A17 (PGT-132) secuencia de aminoácidos de cadena ligera: proteína expresada con secuencia líder en cursiva y región variable en negrita.
M A W A L L L L T L L T Q G T G S W A Q S A L T Q P P S A S G S L G Q S L T lS C S G T A S D lG S W m
VSWYQQFPGRAPNLIIFEVNRRRSGVPDRFSGSKSGNTASLTVSGLRSEDE
AEYFCSSLSGRWDIVFGGGTKVTVLGQPKAAPSVTEFPPSSEEEQANKATL
V C L I S D F Y P G A V T V A W K A D S S P V K A G V E T T T P S K Q S N N K Y A A S S Y L S L T P E Q
W K S H K S Y S C Q V T H E G S T V E K T V A P T E C S (S E Q I D N O : 448 )
5131_A17 (PGT-132) secuencia de aminoácidos de la región variable de la cadena ligera: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
O S A I T O P P S A S G S I G O S I [ I S ( \S (;7 A S 7 )/(; ,S 'V V W E K S W Y O Q I P C iR A P N I U W V N R R R S G W P D R IS C iS K S G N T A S F T V S G L R S E D E A E Y I C S S L S G R W I)IV \ ( i( i( iT K V T V L ( S E Q ID N O : 449 )
5131_A17 (PGT-132) cadena ligera CDR de Kabat:
CDR 1: SGTASDIGSWNFVS (SEQ ID NO: 450)
CDR 2: EVNRRRS (SEQ ID NO: 358)
CDR 3: SSLSGRWDIV (SEQ ID NO: 359)
5131_A17 (PGT-132) CDR de Chothia de la cadena ligera:
CDR 1: SGTASDIGSWNFVS (SEQ ID NO: 450)
CDR 2: EVNRRRS (SEQ ID NO: 358)
CDR 3: SSLSGRWDIV (SEQ ID NO: 359)
5138_G07 (PGT-138) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
A TG AAACA C C T G T G G T T C T T C C T C C T G C T G G T G G C A G C T C C C A GA T G G G T C C T
G7XCCAGCCGCAGCTGCAGGAGTCGGGGCCAGGACTGGTGGAGGCTT
CGGAGACCCTGTCCCTCACCTGCACTGTGTCCGGCGACTCCACTGCT
GCTTGTGACTATTTCTGGGGCTGGGTCCGGCAGCCCCCAGGGAAGGG
GCTGGAGTGGATTGGAAGTTTGTCACATTGTGCAGGTTACTACAATA
GTGGCTGGACCTACCACAACCCGTCTCTCAAGAGTCGACTCACGATT
TCACTCGACACGCCCAAGAATCAGGTCTTCCTGAAGTTAAATTCTGTG
ACCGCCGCGGACACGGCCATTTACTACTGTGCGCGATTCGGTGGCGA
CGTTTTGGTGTACCACGATTGGCCAAAGCCGGCCTGGGTCGACCTCT
GGGGCCGGGGAGTTTTGGTCACCGTCTCGAGCGCCTCCACCAAGGGC
CCATCGGTC1TCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCAC
AGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGG
TGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCT
GTCCT ACAGTCCTC AGG ACTCT ACTCCCTC AGC AGCGTGGTGACCGTGCC
CTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGC
CCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAA
AACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGT
CAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGA
CCCCTGAGGTCACAIXX GTGGIGGTGGACGTGAGCC ACGA AG ACCCTGAG
GTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGAC
AAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTC
CTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAA
GGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAG
CCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGG
GAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCT
TCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGA
GAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCT
TCCTCT AT AGC A AGCTC ACCGTGG AC A AG AGC AGGTGGC AGC AGGGG A A
CGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGC
AGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(SEQ ID NO: 451)
5138_G07 (PGT-138) secuencia de nucleótidos de región variable de la cadena pesada gamma:
CAGCCGCAGCTGCAGGAGTCGGGGCCAGGACTGGTGGAGGCTTCGG
AGACCCTGTCCCTCACCTGCACTGTGTCCGGCGACTCCACTGCTGCT
TGTGACTATTTCTGGGGCTGGGTCCGGCAGCCCCCAGGGAAGGGGCT
GGAGTGGATTGGAAGTTTGTCACATTGTGCAGGTTACTACAATAGTG
GCTGGACCTACCACAACCCGTCTCTCAAGAGTCGACTCACGATTTCA
CTCGACACGCCCAAGAATCAGGTCTTCCTGAAGTTAAATTCTGTGAC
CGCCGCGGACACGGCCATTTACTACTGTGCGCGATTCGGTGGCGACG
TTTTGGTGTACCACGATTGGCCAAAGCCGGCCTGGGTCGACCTCTGG
GGCCGGGGAGTTTTGGTCACCGTCTCGAGC (SEQ ID NO: 452)
5138_G07 (PGT-138) secuencia de aminoácidos de la cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MKHLWFFLLLVAArRWVLSQPQLQESGPGL\EASETLSLTCT\SGDSTAAC
D Y F W G W V R Q P P G K G L E W I G S L S H C A G Y Y N S G W T Y H N P S L K S R L T I S L D
T P K N Q V F L K L N S V T A A D T A I Y Y C A R F G G D V L V Y H D W P K P A W V D L W G R
GVLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSG
ALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKR
VEPKSCDKTIITCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVS
HEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGK
EYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVK
GFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQCiNV FSCSVMHEALHNHYTQKSLSLSPGK (SEQ II) NO: 453)
5138_G07 (PGT-138) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en cursiva en negrita)
QPQLQESGPGLVEASETLSLTCTVSGDS7V1ACDYFWGWVRQPPGKGLEWIGS
/A7/C’AG)TASGW7Y[ INPSI KSRI/TISIJ)TPKNQVFIXI.NSVTAADTAIYYCAR
FGGI)VLVYHDWPKPA WVDL WGRGVI .VTVSS (SEQ ID NO: 454)
5138_G07 (PGT-138) CDR de Kabat de la cadena pesada gamma:
CDR 1: ACDYFWG (SEQ ID NO: 201)
CDR 2: SLSHCAGYYNSGWTYHNPSLKS (SEQ ID NO: 455)
CDR 3: FGGDVLVYHDWPKPAWVDL (SEQ ID NO: 456)
5138_G07 (PGT-138) CDR de Chothia de la cadena pesada gamma:
CDR 1: GDSTAACD (SEQ ID NO: 204)
CDR 2: SLSHCAGYYNSGWTY (SEQ ID NO: 457)
CDR 3: FGGDVLVYHDWPKPAWVDL (SEQ ID NO: 456)
5138_G0) secuencia de nucleótidos de la cadena ligera: secuencia de codificación (región variable en negrita)
A T G G C C T G G G C T C T G C T C C T C C T C A C C C T C C T C A C T C A G G G C A C A G G G G C C T
G G G C C C A G T C T G C C C T G A C T C A G C C T C C C T C C G C G T C C G G G T C T C C T
G G A C A G T C A A T C A C C A T C T C C T G C A C T G G A A A T A T C A A T A A C T T T G T C
T C C T G G T A C C A A C A A C A C C C T G G C A A G G C C C C C A A A C T C G T C A T T T A
T G G G G T C A A T A A G C G C C C C T C A G G T G T C C C T G A T C G T T T T T C T G G C T
C C A A G T C T G G C A A C G C G G C C T C C C T G A C C G T C T C T G G A C T C C A G A C T
G A C G A T G A G G C T G T C T A T T A C T G C G G C T C A C T T G C A G G C A A C T G G G A
T G T G G T T T T C G G C G G A G G G A C C A A G T T G A C T G T C C T G G G K A G C C C A 1
GGCTGCCCCCTCGGTCACTCTGITCCCGCCCTCCTCTGAGG AGCITCAAGC
CAACAAGGCCACACTGGTGTOTCTCATAAOTOACTTCTACCCGGGAGCCG
TG AC AGTGGCCTGGA AGGCAGATAGCAGCCCCGTCA AGGCGGGAGTGGA
GACCACCACACCCTCCAAACAAAGCAACAACAAGTACGCGGCCAGCAGC
TACCTGAGCCTGACGCCTGAGCAGTGGAAGTCCCACAAAAGCTACAGCTG
CCAGGTCACGCATGAAGGGAGCACCGTGGAGAAGACAGTGGCCCCTACA
GAATGTTCATAG(SEQ ID NO: 581)
5138_G07 (PGT-138) secuencia de nucleótidos de la región variable de la cadena ligera:
CAGTCTGCCCTGACTCAGCCTCCCTCCGCGTCCGGGTCTCCTGGACA
GTCAATCACCATCTCCTGCACTGGAAATATCAATAACTTTGTCTCCTG
GTACCAACAACACCCTGGCAAGGCCCCCAAACTCGTCATTTATGGGG
TCAATAAGCGCCCCTCAGGTGTCCCTGATCGTTTTTCTGGCTCCAAGT
CTGGCAACGCGGCCTCCCTGACCGTCTCTGGACTCCAGACTGACGAT
GAGGCTGTCTATTACTGCGGCTCACTTGCAGGCAACTGGGATGTGGT
TTTCGGCGGAGGGACCAAGTTGACTGTCCTG(SKQ ID NO: 582)
5138_G07 (PGT-138) secuencia de aminoácidos de cadena ligera: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MAWAUn:r¡JJQGTGAWAQSALTQPPSASGSPGQSlTlSCTGNimF\SWY
QQHPGKAPKLVIYGVNKRPSGVPDRFSGSKSGNAASLTVSGLQTDDEAV
YYCGSLAGNWDVVFGGGTKLTVLGQPMAAPSVTLIPPSSEELQANKATEV
CIJSDFYPGA VTV AWK ADSSPVK AGVETTTPSKQSNNK Y A ASSYI .SI TPFQW
KSHKSYSCQVTHEGSTVEKTVAPTECS (SEQ ID NO: 583)
5138_G07 (PGT-138) secuencia de aminoácidos de la región variable de la cadena ligera: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
QSALTOPPSASGSPGOSITISCTGW/ANEES'WYOOHPGKAPKLVIYGVVVÁ'EPS’ G VPDRFSGS KSGN A ASLT VSGLOTDDEA V Y Y CGSLA GNWD W EGGGTKLT V
L (SEQ ID NO: 584)
5138_G07 (PGT-138) cadena ligera CDR de Kabat:
CDR 1: TGNINNFVS (SEQ ID NO: 458)
CDR 2: GVNKRPS (SEQ ID NO: 211)
CDR 3: GSLAGNWDVV (SEQ ID NO: 459)
5138_G07 (PGT-138) CDR de Chothia de la cadena ligera:
CDR 1: TGNINNFVS (SEQ ID NO: 458)
CDR 2: GVNKRPS (SEQ ID NO: 211)
CDR 3: GSLAGNWDVV (SEQ ID NO: 459)
5120_N10 (PGT-139) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
A T G A A A C A C C T G T G G T T C T T C C T C C T G C T G G T G G C A G C T C C C A G A T G G G T C C T
G 7 C C C A G C C G C A G C T G C A G G A G T C G G G G C C A G G A C T G G T G G A G G C T T
C G G A G A C C C T G T C C C T C A C C T G C A C T G T G T C C G G C G A C T C C A C T G C T
G G T T G T G A C T A T T T C T G G G G C T G G G T C C G G C A G C C C C C A G G G A A G G
G G C T G G A G T G G A T T G G G G G T T T G T C A C A T T G T G C A G G T T A C T A C A A T
A C T G G C T G G A C C T A C C A C A A C C C G T C T C T C A A G A G T C G A C T C A C G A T
T T C A C T C G A C A C G C C C A A G A A T C A G G T C T T C C T G A A G T T A A A T T C T G T
G A C C G C C G C G G A C A C G G C C A T T T A C T A C T G T G C G C G A T T C G A C G G C G
A A G T T T T G G T G T A C A A C G A T T G G C C A A A G C C G G C C T G G G T C G A C C T C
T G G G G C C G G G G A A C T T T G G T C A C C G T C T C G A G C C Í C C 1 CCACCAAGGG
CCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCA
C AGCGGCCCTGGGCT GCCTGGTC A AGG ACT ACTTCCCCG A ACCGGTG ACG
GTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGC
TGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCC
CTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGC
CCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAA
AACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGT
CAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGA
CCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAG
GTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGAC
A A AGCCGCGGGAGG AGC AGT AC A ACAGC ACGT ACCGTGTGGTCAGCGTC
CTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAA
GGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAG
CCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGG
GAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCT
TCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGA
GAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCT
TCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAA
CGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGC
AGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(SEQ I D NO: 460)
5120_N10 (PGT-139) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G C C G C A G C T G C A G G A G T C G G G G C C A G G A C T G G T G G A G G C T T C G G
A G A C C C T G T C C C T C A C C T G C A C T G T G T C C G G C G A C T C C A C T G C T G G T
T G T G A C T A T T T C T G G G G C T G G G T C C G G C A G C C C C C A G G G A A G G G G C T
G G A G T G G A T T G G G G G T T T G T C A C A T T G T G C A G G T T A C T A C A A T A C T G
G C T G G A C C T A C C A C A A C C C G T C T C T C A A G A G T C G A C T C A C G A T T T C A
C T C G A C A C G C C C A A G A A T C A G G T C T T C C T G A A G T T A A A T T C T G T G A C
C G C C G C G G A C A C G G C C A T T T A C T A C T G T G C G C G A T T C G A C G G C G A A G
T T T T G G T G T A C A A C G A T T G G C C A A A G C C G G C C T G G G T C G A C C T C T G G
G G C C G G G G A A C T T T G G T C A C C G T C T C G A G C (SEQ ID NO: 461)
5120_N10 (PGT-139) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MKHIAV¡TIJJ.VAAPRWVLSQPQLQESGPGL\EASETLSLTCT\SGDST\GC
DYFWGWVRQPPGKGLEWIGGLSHCAGYYNTGWTYHNPSLKSRLTISLD
TPKNQVFLKLNSVTAADTAIYYCARFDGEVLVYNDWPKPAWVDLWGRG
TLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGAL
TSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVE
PKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE
DPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEY
KCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGF
YPSD1AVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFS
CSVMHEALHNHYTQKSLSLSPGK (SEQ II) NO: 462)
5120_N10 (PGT-139) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
OPOLOESGPGLVEASETLSLTCTVSGflmGCPYFWGWVROPPGKGLEWIG (¡LSHCAGYYNTdWTYl INPS1 KSRI.TISLDTPKNQVFI K \ .NSVTAADTAIYYC AKFDGKVI. VYND WPKPA W VDLWC iR( .11, VTVSS (SEQ ID NO: 463)
5120_N10 (PGT-139) CDR de Kabat de la cadena pesada gamma:
CDR 1: GCDYFWG (SEQ ID NO: 464)
CDR 2: GLSHCAGYYNTGWTYHNPSLKS (SEQ ID NO: 202)
CDR 3: FDGEVLVYNDWPKPAWVDL (SEQ ID NO: 465)
5120_N10 (PGT-139) CDR de Chothia de la cadena pesada gamma:
CDR 1: GDSTAGCD (SEQ ID NO: 466)
CDR 2: GLSHCAGYYNTGWTY (SEQ ID NO: 205)
CDR 3: FDGEVLVYNDWPKPAWVDL (SEQ ID NO: 465)
51T_N10) secuencia de nucleótidos de la cadena ligera: secuencia de codificación (región variable en negrita)
A T G G C C T G G G C T C T G C T C C T C C T C A C C C T C C T C A C T C A G G G C A C A G G G G C C T
GGGCCCAGTCTGCCCTGACTCAGCCTCCCTCCGCGTCCGGGTCTCCT
GGACAGTCAATCACCATCTCCTGCACTGGAACCAGCAATAACTTTGT
CTCCTGGTACCAGCAACACCCAGCCAAGGCCCCCAAACTCGTCATTT
ATGGGGTCAATAAGCGCCCCTCAGGTGTCCCTGATCGTTTTTCTGGC
TCCAAGTCTGGCAACACGGCCTCCCTGACCGTCTCTGGACTCCAGAC
TGACGATGAGGCTGTCTATTACTGCGGCTCACTTGTAGGCAACTGGG
ATGTGATTTTCGGCGG AGGGACCAAGTTGACCGTCCTGGG1CAGCCC
ATGGCTGCCCCCTCGGTCACTCTGTTCCCGCCCTCCTCTGAGGAGCTTCAA
GCCAACAAGGCCACACTGGTGTGTCTCATAAGTGACTTCTACCCGGGAGC
CGTGACAGTGGCCTGGAAGGCAGATAGCAGCCCCGTCAAGGCGGGAGTG
GAGACCACCACACCCTCCAAACAAAGCAACAACAAGTACGCGGCCAGCA
GCT ACCTG AGCCTG ACGCCTG AGCAGTGG A AGTCCC AC A A A AGCT AC AGC
TGCCAGGTCACGCATGAAGGGAGCACCGTGGAGAAGACAGTGGCCCCTA
CAGAATGTTCATAG(SEQ ID NO: 467)
5120_N10 (PGT-139) secuencia de nucleótidos de la región variable de la cadena ligera:
CAGTCTGCCCTGACTCAGCCTCCCTCCGCGTCCGGGTCTCCTGGACA
GTCAATCACCATCTCCTGCACTGGAACCAGCAATAACTTTGTCTCCTG
GTACCAGCAACACCCAGCCAAGGCCCCCAAACTCGTCATTTATGGGG
TCAATAAGCGCCCCTCAGGTGTCCCTGATCGTTTTTCTGGCTCCAAGT
CTGGCAACACGGCCTCCCTGACCGTCTCTGGACTCCAGACTGACGAT
GAGGCTGTCTATTACTGCGGCTCACTTGTAGGCAACTGGGATGTGAT
TTTCGGCGGAGGGACCAAGTTGACCGTCCTG(SFQ ID NO: 468)
5120_N10 (PGT-139) secuencia de aminoácidos de cadena ligera: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MA WALLLLTLLTQGTGA WAQSALTQPPSASGSPGQSITISCTGTSNNFVSWY
QQHPAKAPKLVIYGVNKRPSGVPDRFSGSKSGNTASLTVSGLQTDDEAV
YYCGSLVGNWDVIFGGGTKLTVLGQPM A A P S V T L F P P S S H H L Q A N K A T I V
C L I S D F Y P G A V T V A W K A D S S P V K A G V E T T T P S K Q S N N K Y A A S S Y E S E T P E Q W
K S H K S Y S C Q V T H E G S T V E K T V A P T E C S ( S E Q I D N O : 469 )
5120_N10 (PGT-139) secuencia de aminoácidos de región variable de cadena ligera: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
O S A L T O P V S A S G S P G O S in S C T G T S N N F V S W Y O O H P A K A P K L V lY G V N K R P S G V P D R F S G S K S G N T A S L T V S G L Q T D D E A V Y Y C G S L I W W D V 7 P G G G T K L T V L ( S E Q ID N O : 470 )
5120_N10 cadena ligera (PGT-139) CDR de Kabat:
CDR 1: TGTSNNFVS (SEQ ID NO: 325)
CDR 2: GVNKRPS (SEQ ID NO: 211)
CDR 3: GSLVGNWDVI (SEQ ID NO: 196)
5120_N10 (PGT-139) CDR de Chothia de la cadena ligera:
CDR 1: TGTSNNFVS (SEQ ID NO: 325)
CDR 2: GVNKRPS (SEQ ID NO: 211)
CDR 3: GSLVGNWDVI (SEQ ID NO: 196)
El anticuerpo 4835_F12 (PGT-124) incluye una región variable de cadena pesada (SEQ ID NO: 405), codificada por el secuencia de ácido nucleico mostrada en SEQ ID NO: 403, y una región variable de cadena ligera (SEQ ID NO: 414) codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 412.
Las CDR de cadena pesada del 4835_F12 (PGT-124) los anticuerpos tienen las siguientes secuencias según la definición de Kabat: NYYWT (SEQ ID NO: 406), YISDRETTTYNPSLNS (SEQ ID NO: 407) y ARRGQRIYGVVSFGEFFYYYYMDV (SEQ ID NO: 408). Las CDR de cadena ligera del anticuerpo 4835_F12 (PGT-124) tienen las siguientes secuencias según la definición de Kabat: GRQALGSRAVQ (SEQ ID NO: 415), NNq Dr PS (SEQ ID NO: 151) y HMWDSRSGFSWS (SEQ ID NO: 416).
Las CDR de cadena pesada del anticuerpo 4835_F12 (PGT-124) tienen las siguientes secuencias según la definición de Chothia: GGSISN (SEQ ID NO: 409), YISDRETTT (SEQ ID NO: 410) y ARRGQRIYGVVSFGEFFYYYYMDV (SEQ ID NO: 408) Las CDR de cadena ligera del anticuerpo 4835_F12 (PGT-124) tienen las siguientes secuencias según la definición de Chothia: GRQALGSRAVQ (SEQ ID NO: 415), NNq Dr PS (SEQ ID NO: 151) y HMWDSRSGFSWS (SEQ ID NO: 416).
El anticuerpo 4869_K15 (PGT-133) incluye una región variable de cadena pesada (SEQ ID NO: 420), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 418, y una región variable de cadena ligera (SEQ ID NO: 429) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 427.
Las CDR de cadena pesada del anticuerpo 4869_K15 (PGT-133) tienen las siguientes secuencias según la definición de Kabat: GRFWS (SEQ ID NO: 421), YFSDTDRSEYNPSLRS (SEQ ID NO: 422) y
AQQGKRIYGIVSFGEFFYYYYMDA (SEQ ID NO: 423). Las CDR de cadena ligera del anticuerpo 4869_K15 (PGT-133) tienen las siguientes secuencias según Kabat definición: GERSRGSRAVQ (SEQ ID NO: 430), NNQDRPA (SEQ ID NO: 179), y HYWDSRSPISWI (SEQ ID NO: 431).
Las CDR de cadena pesada del anticuerpo 4869_K15 (PGT-133) tienen las siguientes secuencias según la definición de Chothia: NGSVSG (SEQ ID NO: 424), YFSDTDRSE (SEQ ID NO: 425) y AQQGKRIYGIVSFGEFFYYYYMDA (SEQ ID NO: 423) Las CDR de cadena ligera del anticuerpo 4869_K15 (PGT-133) tienen las siguientes secuencias según la definición de Chothia: GERSRGSRAVQ (SEQ iD NO: 430), Nn QDRPA (SEQ ID NO: 179) e HYWDSRSPISWI (SEQ ID NO: 431).
El anticuerpo 4876_M06 (PGT-134) incluye una región variable de cadena pesada (SEQ ID NO: 435), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 433, y una región variable de cadena ligera (SEQ ID NO: 440) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 438.
Las CDR de cadena pesada del anticuerpo 4876_M06 (PGT-134) tienen las siguientes secuencias según la definición de Kabat: GRFWS (SEQ ID NO: 421), YFSDTDRSEYNPSLRS (SEQ ID NO: 422) y AQQGKRIYGIVSFGELFYYYYMDA (SEQ ID NO: 436). Las CDR de cadena ligera del anticuerpo 4876_M06 (PGT-134) tienen las siguientes secuencias según la definición de Kabat: GERSRGSRAVQ (SEQ ID No : 430), NNQDRPA (SEQ ID NO: 179) e HYWDSRSPISWI (SEQ ID NO: 431).
Las CDR de cadena pesada del anticuerpo 4876_M06 (PGT-134) tienen las siguientes secuencias según la definición de Chothia: NGSVSG (SEQ ID NO: 424), YFSDTDRSE (SEQ ID NO: 425) y AQQGKRIYGIVSFGELFYYYYMDA (SEQ ID NO: 43) Las CDR de cadena ligera del anticuerpo 4876_M06 (PGT-134) tienen las siguientes secuencias según la definición de Chothia: GERSRGSRAVQ (SEQ ID NO: 430), Nn QDRPA (SEQ ID NO: 179) e HYWDSRSPISWI (SEQ ID NO: 431).
El anticuerpo 5131_A17 (PGT-132) incluye una región variable de la cadena pesada (SEQ ID NO: 444), codificada por la secuencia de ácido nucleico que se muestra en la SEQ ID NO: 442, y una región variable de la cadena ligera (SEQ ID NO: 449) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 447.
Las CDR de cadena pesada del anticuerpo 5131_A17 (PGT-132) tienen las siguientes secuencias según la definición de Kabat: TGHHYWG (SEQ ID NO: 348), HIHYNTAVLHNPALKS (SEQ ID NO: 349) y SGGDILYYNEWQKPHWFYP (SEQ ID NO: 445). Las CDR de cadena ligera del anticuerpo 5131_A17 (PGT-132) tienen las siguientes secuencias según la definición de Kabat: SGTASDIGSWNFVS (SEQ ID NO: 450), Ev NRRRS (SEQ ID NO: 358) y SSLSGRWDIV (SEQ ID NO: 359).
Las CDR de cadena pesada del anticuerpo 5131_A17 (PGT-132) tienen las siguientes secuencias según la definición de Chothia: GDSINTGH (SEQ ID NO: 351), HIHYNTAVL (SEQ ID NO: 352) y SGGDILYYNEWQKPHWFYP (SEQ ID NO: 445) Las CDR de cadena ligera del anticuerpo 5131_A17 (PGT-132) tienen las siguientes secuencias según la definición de Chothia: SGTASDIGSWNFVS (SEQ ID NO: 450), EVNRRRS (SEQ ID NO: 358) y SSLSGRWDIV (SEQ ID NO: 359).
El anticuerpo 5138_G07 (PGT-138) incluye una región variable de cadena pesada (SEQ ID NO: 454), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 452, y una región variable de cadena ligera (SEQ ID NO: 461) codificada por la secuencia de ácido nucleico mostrada en la SEQ ID NO: 459.
las CDR de cadena pesada de la (anticuerpo 5138_G07 PGT-138) tienen las siguientes secuencias por Kabat definición: ACDYFWG (SEQ ID NO: 201), SLSHCAGYYNSGWTYHNPSLKS (SEQ ID NO: 455) y FGGDVLVYHDWPKPAWVDL (SEQ ID NO: 456). Las CDR de cadena ligera del anticuerpo 5138_G07 (PGT-138) tienen las siguientes secuencias según la definición de Kabat: TGNINNFVS (SEQ ID NO: 458), GVNKRPS (SEQ ID NO: 211) y GSLAGNWDVV (SEQ ID NO: 459).
Las CDR de cadena pesada del anticuerpo 5138_G07 (PGT-138) tienen las siguientes secuencias según la definición de Chothia: GDSTAACD (SEQ ID NO: 204), SLSHCAGYYNSGWTY (SEQ ID NO: 457) y FGGDVLVYHDWPKPAWVDL (SEQ ID NO: 45) Las CDR de cadena ligera del anticuerpo 5138_G07 (PGT-138) tienen las siguientes secuencias según la definición de Chothia: TGNINNFVS (SEQ ID NO: 458), GVNKRPS (SEQ ID NO: 211) y GSLAGNWDVV (SEQ ID NO: 459).
El anticuerpo 5120_N10 (PGT-139) incluye una región variable de cadena pesada (SEQ ID NO: 463), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 461, y una región variable de cadena ligera (SEQ ID NO: 470) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 468.
Las CDR de cadena pesada del anticuerpo 5120_N10 (PGT-139) tienen las siguientes secuencias según la definición de Kabat: GCDYFWG (SEQ ID NO: 464), GLSHCAGYYNTGWTYHNPSLKS (SEQ ID NO: 202) y FDGEVLVYNDWPKPAWVDL (SEQ ID NO: 465). Las CDR de cadena ligera del anticuerpo 5120_N10 (PGT-139)
tienen las siguientes secuencias según la definición de Kabat: TGTSNNFVS (SEQ ID NO: 325), GVNKRPS (SEQ ID NO: 211) y GSLVGNWDVI (SEQ ID NO: 196).
Las CDR de cadena pesada del anticuerpo 5120_N10 (PGT-139) tienen las siguientes secuencias según la definición de Chothia: GDSTAGCD (SEQ ID NO: 466), GLSHCAGYYNTGWTY (SEQ ID NO: 205) y FDGEVLVYNDWPKPAWVDL (SEQ ID NO: 465) Las CDR de cadena ligera del anticuerpo 5120_N10 (PGT-139) tienen las siguientes secuencias según la definición de Chothia: TGTSNNFVS (SEQ ID n O: 325), GVNk Rp S (SEQ ID NO: 211) y GSLVGNWDVI (SEQ ID NO: 196).
Se determinaron las secuencias de anticuerpos monoclonales humanos adicionales, incluidas las secuencias de las regiones variables de las cadenas pesadas Gamma y Kappa o Lambda. Además, se determinó la secuencia de cada uno de los polinucleótidos que codifican las secuencias de anticuerpos. A continuación se muestran las secuencias de polipéptidos y polinucleótidos de las cadenas pesadas gamma y las cadenas ligeras kappa, con los péptidos señal en el extremo N (o extremo 5') y las regiones constantes en el extremo C (o extremo 3') de las regiones variables, que se muestran en texto en negrita.
6831_A21 (PGT-151) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (secuencia líder en cursiva, región variable en negrita)
A TG G A A T T G G G G C T G A G C T G G G T T T T C C T C G T T G G T C T C T T A A G A G G T G T C C A
C/TC/7CGGGTGCAGTTGGTGGAGTCGGGGGGAGGCGTGGTCCAGCCTG
GGAAGTCCGTGAGACTTTCCTGTGTAGTCTCCGATTTCCCCTTCAGCA
AGTATCCTATGTATTGGGTTCGCCAGGCTCCAGGCAAGGGGCTGGAG
TGGGTGGCAGCCATCTCCGGTGATGCCTGGCATGTGGTCTACTCAAA
TTCCGTGCAGGGCCGATTTCTCGTCTCCAGGGACAATGTCAAGAACA
CTCTATATTTAGAAATGAACAGCCTGAAAATTGAGGATACGGCCGTA
TATCGCTGCGCGAGAATGTTCCAGGAGTCTGGTCCACCACGTTTGGA
TCGTTGGAGCGGTCGAAATTATTACTATTATTCTGGTATGGACGTCTG
GGGCCAAGGGACCACGGTCACCGTCTCGAGCGCXTCCACCAAGC5C.CC
CATCGGTCTTCCCCCTOGCACCCTCCTCCAAGAGCACCTCTGGGGGCACA
GCGGCCCTGGGCTGCCTCGTCAAGGACTACTTCCCCGAACCGGTGACGGT
GTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTG
TCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCT
CCAGCAGCTTOGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCC
AGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAAAA
CTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCA
GTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACC
CCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGT
CAAOTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACA
AAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCC
TCACCGTCCTGCACCAOGACTGGCTGAATGOCAAGGAGTACAAGTGCAA
GGTCTCCAACAAAGCCCTCCCAGCCCCCATCOAGAAAACCATCTCCAAAG
CCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGG
GAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCT
TCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGA
GAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCrrCT
TCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAA
CGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGC
AGA AGAGCCTCTCCCTGTCTCCGGGT A A ATGA (SEQ ID NO:471)
6831_A21 (PGT-151) secuencia de nucleótidos de la región variable de la cadena pesada gamma:
CGGGTGCAGTTGGTGGAGTCGGGGGGAGGCGTGGTCCAGCCTGGGA
AGTCCGTGAGACTTTCCTGTGTAGTCTCCGATTTCCCCTTCAGCAAGT
ATCCTATGTATTGGGTTCGCCAGGCTCCAGGCAAGGGGCTGGAGTGG
GTGGCAGCCATCTCCGGTGATGCCTGGCATGTGGTCTACTCAAATTC
CGTGCAGGGCCGATTTCTCGTCTCCAGGGACAATGTCAAGAACACTC
TATATTTAGAAATGAACAGCCTGAAAATTGAGGATACGGCCGTATAT
CGCTGCGCGAGAATGTTCCAGGAGTCTGGTCCACCACGTTTGGATCG
TTGGAGCGGTCGAAATTATTACTATTATTCTGGTATGGACGTCTGGG
GCCAAGGGACCACGGTCACCGTCTCGAGC ( S E Q I D N O : 472 )
6831_A21 (PGT-151) secuencia de aminoácidos de la cadena pesada del gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MELGLSWVFL VGLLRG V(9C R VQL VESG GGVVQPG KS V RLSC V VSDFPFS K Y
PMYWVRQAPGKGLEWVAAISGDAWHVVYSNSVQGRFLVSRDNVKNTL
YLEMNSLKIEDTAVYRCARMFQESGPPRLDRWSGRNYYYYSGMDVWG
Q G T T V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S
G A L T S G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T Y 1 C N V N H K P S N T K V D K
R V E P K S C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S
H E D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R W S V L T V L H Q D W L N G K
E Y K C K V S N K A E P A P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K
G F Y P S D I A V E W E S N G Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R W Q Q G N V
F S C S V M H E A L H N H Y T Q K S L S L S P G K (S E Q ID N O : 473 )
6831_A21 (PGT-151) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en cursiva en negrita)
R V Q L V E S G G G V V O P G K S V R L S C V V S D F P F S K Y P M Y W V R O A P G K G L E W V A A
/S 'G /M U 7 /V V /Y S N S V O C .R I E V S R D N V K N T E Y E E M N S L K I E D T A V Y R C A R M F G
E S G l’P R L D R W S G R N Y Y Y Y S G M D V W CiOC.YYTVTVSS ( S E Q ID N O : 474 )
6831_A21 (PGT-151) CDR de Kabat de cadena pesada gamma:
CDR 1: KYPMY (SEQ ID NO: 475)
CDR 2: AISGDAWHVVYSNSVQG (SEQ ID NO: 476)
CDR 3: MFQESGPPRLDRWSGRNYYYYSYSMMDV (SEQ ID NO: 477)
6831_A21 (PGT-151) CDR de Chothia de la cadena pesada gamma:
CDR 1: DFPFSK (SEQ ID NO: 478)
CDR 2: AISGDAWHVV (SEQ ID NO: 479)
CDR 3: MFQESGPPRLDRWSGRNYYYYSGMDV (SEQ ID NO: 477)
6831_A21 (PG2031T-151)) secuencia de nucleótidos de la cadena ligera: secuencia de codificación (región variable en negrita)
A TGA GGCTCCCTGCTCA GCTCCTGGGGCTGCTAA TGCTCTGGA TA CCTGAA 77’
C4C7’GCAGACATTGTGATGACCCAGACTCCTCTCTCTTTGTCCGTCAC
CCCTGGACAGCCGGCCTCCATCTCCTGCAAGTCCAGTGAGAGCCTCC
GACAAAGTAATGGAAAGACCTCTTTGTATTGGTATCGGCAGAAGCCA
GGCCAGTCTCCACAACTCCTAGTGTTTGAAGTTTCTAATCGATTCTCT
GGCGTGTCGGATAGGTTTGTTGGCAGCGGGTCAGGGACAGACTTCAC
ACTGAGAATCAGCCGGG TAGAGGCTGAGGA TG T I GGATTTTATTACT
GCATGCAAAGTAAAGACTTCCCACTTACATTTGGCGGCGGGACCAAG
G T G G A T C T C A A A C G T A C G G T G G C T G C A C C A T C T G T C T T C A T C T T C C C G C C
A T C T G A T G A G C A G T T G A A A T C T G G A A C T G C C T C T G T T G T G T G C C T G C T G A A
T A A C T T C T A T C C C A G A G A G G C C A A A G T A C A G T G G A A G G T G G A T A A C G C C C
T C C A A T C G G G T A A C T C C C A G G A G A C iT G T C A C A G A G C A G G A C A G C A A G G A
C A G C A C C T A C A G C C T C A G C A G C A C C C T G A C G C T G A G C A A A G C A G A C T A C
G A G A A A C A C A A A G T C T A C G C C T G C G A A G T C A C C C A T C A G G G C C T G A G C T C
G C C C G T C A C A A A G A G C T T C A A C A G G G G A G A G T G T T A G ( S E Q ID N O : 480 )
6831_A21 (PGT-151) secuencia de nucleótidos de la región variable de la cadena ligera:
GACATTGTGATGACCCAGACTCCTCTCTCTTTGTCCGTCACCCCTGGA
CAGCCGGCCTCCATCTCCTGCAAGTCCAGTGAGAGCCTCCGACAAAG
TAATGGAAAGACCTCTTTGTATTGGTATCGGCAGAAGCCAGGCCAGT
CTCCACAACTCCTAGTGTTTGAAGTTTCTAATCGATTCTCTGGCGTGT
CGGATAGGTTTGTTGGCAGCGGGTCAGGGACAGACTTCACACTGAGA
ATCAGCCGGGTAGAGGCTGAGGATGTTGGATTTTATTACTGCATGCA
AAGTAAAGACTTCCCACTTACATTTGGCGGCGGGACCAAGGTGGATC
TCAAA ( S E Q ID NO:481)
Secuencia de aminoácidos de la cadena ligera 6831_A21 (PGT-151): proteína expresada con secuencia líder en cursiva y región variable en negrita.
MRLPAQLLGUMLWIPMTADWMTQTPLSLSVTPGQPASISCKSSESLRQSN GKTSLYWYRQKPGQSPQLLVFEVSNRFSGVSDRFVGSGSGTDFTLRISRV EAEDVGFYYCMQSKDFPLTFGGGTKVDLKRTVAAPSVFIFPPSDEQFKSGT A S V V C L L N N F Y P R E A K V Q W K V D N A L Q S G N S Q E S V T E Q D S K D S T Y S L S S T L T L
S K A D Y E K H K V Y A C E V T H Q G L S S P V T K S F N R G E C ( S E Q I D N O : 482 )
6831_A21 (PGT-151) secuencia de aminoácidos de la región variable de la cadena ligera: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
D lV M T O T P L S L S V m iO P A S lS C K S S E S L R O S N G K T S L r W Y R O K P G O S P O L L V F F V S N R F S Í iV S D R I • V G S G S G T D I T I .R I S R V E A E D V G F Y Y C M O S K D F P L T X G G G T K V D L K ( S E Q ID N O : 483 )
CDR de Kabat de la cadena ligera 6831_A21 (PGT-151):
CDR 1: KSSESLRQSNGKTSLY (SEQ ID NO: 484)
CDR 2: EVSNRFS (SEQ ID NO: 485)
CDR 3: MQSKDFPLT (SEQ ID NO: 486)
6831_A21 (PGT-151) CDR de Chothia de la cadena ligera:
CDR 1: KSSESLRQSNGKTSLY (SEQ ID NO: 484)
CDR 2: EVSNRFS (SEQ ID NO: 485)
CDR 3: MQSKDFPLT (SEQ ID NO: 486)
6889_I17 (PGT-152) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
ATGGAATTGGGGCTGAGCTGGGnnCCrCGTTGGTCTClTAAGAGGTGTCCA
C7GTCGGGTGCAGTTGGTGGAGTCGGGGGGAGGCGTGGTCCAGCCTG
GGAAGTCCGTGAGACTTTCCTGTGTAGTCTCTGATTTCCCCTTCAGCA
AGTATCCTATGTATTGGGTTCGCCAGGCTCCAGGCAAGGGGCTGGAG
TGGGTGGCAGCCATCTCCGCTGATGCCTGGCATGTGGTCTACTCAGG
CTCCGTGCAGGGCCGATTTCTCGTCTCCAGGGACAACTCCAAGAACA
TTCTGTATTTGGAAATGAACACCCTGAAAATTGAGGACACGGCCGTA
TATCGCTGCGCGAGAATGTTCCAGGAGTCTGGTCCACCACGTTTCGA
TTCTTGGAGCGGTCGAAATTACTACTATTACTCTGGTATGGACGTCTG
GGGCCAAGGGACCACGGTCACCGTCTCGAGCGCCTCCACCAAGC.GCC
CATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACA
GCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGT
GTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTG
TCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCT
CCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCC
A G C A A C A C C A A G G T G G A C A A G A G A G I T G A G C C C A A A T C T T G T G A C A A A A
CTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCA
GTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACC
('( I X5A( i( 5T(’AC’ATCKXi IX ¡( ITCi(i IXi(5A(Xi IX iA( K X A( XIAACiA(XX IX iAC i( i I
CAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACA
A AGCCGCGGG AGG AGC AGT AC AACAGC ACGT ACCGTGTGGTC AGCGTCC
TCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAA
GGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAG
CCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGG
GAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCT
TCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGA
GAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGC1-CCITCT
TCCTCT AT AGC AAGCTCACCGTGGACA AG AGC AGGTGGCAGC AGGGG A A
CGTCTTCTCATGCTGCGTGATGCATGAGGCTCTGCACAACCACTACACGC
AGAAGAGCCTCTCCCTGTGTCCGGGTAAATGA (SEQ II) NO:487)
6889_I17 (PGT-152) secuencia de nucleótidos de la región variable de la cadena pesada gamma:
CGGGTGCAGTTGGTGGAGTCGGGGGGAGGCGTGGTCCAGCCTGGGA
AGTCCGTGAGACTTTCCTGTGTAGTCTCTGATTTCCCCTTCAGCAAGT
ATCCTATGTATTGGGTTCGCCAGGCTCCAGGCAAGGGGCTGGAGTGG
GTGGCAGCCATCTCCGCTGATGCCTGGCATGTGGTCTACTCAGGCTC
CGTGCAGGGCCGATTTCTCGTCTCCAGGGACAACTCCAAGAACATTC
TGTATTTGGAAATGAACACCCTGAAAATTGAGGACACGGCCGTATAT
CGCTGCGCGAGAATGTTCCAGGAGTCTGGTCCACCACGTTTCGATTC
TTGGAGCGGTCGAAATTACTACTATTACTCTGGTATGGACGTCTGGG
GCCAAGGGACCACGGTCACCGTCTCGAGC (SEQ II) N 0 488)
6889_I17 (PGT-152) secuencia de aminoácidos de la cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
M E L G L S W V I L V G L L R G V H C R \ Q L \ E S G G G \ \ Q P G K S \R L S C \ \ S D F P F S K \
PMYWVRQAPGKGLEWVAAISADAYVHVVYSGSVQGRFLVSRDNSKNILY
LEMNTLKIEDTAVYRCARMFQESGPPRFDSWSGRNYYYYSGMDVWGQ
GTTVTVSSASTKGPSVFPI ,APSSKSTSGGTAALGCLVKDYFPEPVTVSWNSG
ALTSGVUTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKR
VEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVS
HEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGK
EYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVK
GFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNV
FSCSVMHEALHNHYTQKSLSLSPGK (SEQ II) NO: 489)
6889_I17 (PGT-152) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
RVQI .VESGGGVVQPGKSVRI ,SC V V S D E P F S K Y V M YWVROAK iK( II JAVVAA m /M H T/FFY SG SV O C iRl LVSRDNSKNILYLI^MNTI.KlHDrAVYRC ARM /'O E S G P P R F D S W S G R N Y Y Y Y S G M D V W G O C Y rY V V V S S (SEQ II) NO: 490)
6889_I17 (PGT-152) CDR de Kabat de la cadena pesada gamma:
CDR 1: KYPMY (SEQ ID NO: 475)
CDR 2: AISADAWHVVYSGSVQG (SEQ ID NO: 491)
CDR 3: MFQESGPPRFDSWSGRNYYYYSGMDV (SEQ ID NO: 492)
6889_I17 (PGT-152) CDR de Chothia de la cadena pesada gamma:
CDR 1: DFPFSK (SEQ ID NO: 478)
CDR 2: AISADAWHVV (SEQ ID NO: 493)
CDR 3: MFQESGPPRFDSWSGRNYYYYSGMDV (SEQ ID NO: 492)
6889_I17 () secuencia de nucleótidos de la cadena ligera: secuencia de codificación (región variable en negrita)
A TGA GGCTCCCTGCTCA GCTCCTGGGGCTGCTAA TGCTCTGGA TA CCTGAA 77’
7A7TGCCGACATTGTGATGACCCAGACTCCTCTCTCTTTGTCCGTCGAC
CCTGGACAGCCGGCCTCCATCTCCTGCAAGTCCAGTCAGAGCCTCCG
ACAAAGTAATGGAAAGACCTCTTTGTATTGGTATCAGCAGAAGCCAG
GCCAGTCTCCACAACTCCTAATATTTGAAGTTTCTAATCGATTCTCTG
GCGTGTCGGATAGGTTTGTTGGCAGCGGGTCAGGGACAGACTTCACA
CTGAGAATCAGCCGGGTAGAGGCTGAGGATGTTGGATTTTATTACTG
CATGCAAAGTAAAGACTTCCCACTCACCTTTGGCGGCGGGACCAAGG
TGGATCTCAA CCGTACGGTGGCTGC ACC ATCTGTCTTC ATCTTCCCGCC A
TCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAAT
A ACTTCT ATCCC AG AG AGGCCA A AGTACAGTGG A AGGTGGAT AACGCCCT
CCAATCGGGTAACTCCCAGGAGAGTGTCAGAGAGCAGGACAGCAAGGAC
AGC ACCT AC AGCCTC AGC AGC ACCCTG ACGCTG AGC A AAGC AG ACT ACG
AG AAACACA A AGTCT ACGCCTGCG A AGTC ACCC ATC AGGGCCTG AGCTCG
CCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG (SEQ ID NO:494)
6889_I17 (PGT-152) secuencia de nucleótidos de la región variable de la cadena ligera:
GACATTGTGATGACCCAGACTCCTCTCTCTTTGTCCGTCGACCCTGGA
CAGCCGGCCTCCATCTCCTGCAAGTCCAGTCAGAGCCTCCGACAAAG
TAATGGAAAGACCTCTTTGTATTGGTATCAGCAGAAGCCAGGCCAGT
CTCCACAACTCCTAATATTTGAAGTTTCTAATCGATTCTCTGGCGTGT
CGGATAGGTTTGTTGGCAGCGGGTCAGGGACAGACTTCACACTGAGA
ATCAGCCGGGTAGAGGCTGAGGATGTTGGATTTTATTACTGCATGCA
AAGTAAAGACTTCCCACTCACCTTTGGCGGCGGGACCAAGGTGGATC
TCAAC ( S E Q ID NO:495)
Secuencia de aminoácidos de la cadena ligera 6889_I17 (PGT-152): proteína expresada con secuencia líder en cursiva y región variable en negrita.
MRIPAQLLGl.LMLWIPEFIADl\MTQTPLSLS\DPGQPAS\SCKSSQSLRQSN
GKTSLYWYQQKPGQSPQLLIFEVSNRFSGVSDRFVGSGSGTDFTLRISRV
EAEDVGFYYCMQSKDFPLTFGGGTKVDLNR I V A A P S V r IF P P S D E Q E K S C . I
A S V V C L L N N F Y P R E A K V Q W K V D N A L Q S G N S Q E S V T E Q D S K D S T Y S L S S T L T L
S K A D Y E K H K V Y A C E V T H Q G L S S P V T K S F N R G E C (S E Q ID N O : 496 )
Secuencia de aminoácidos de la región variable de la cadena ligera de 6889_I17 (PGT-152): (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
D I V M T O T P I .SI S V D P G O P A S I S (
KSSOS/MOSNCKTSI.
F W Y O O K P G O S P O I J 41 ■
E K S W /? /<\SX iV S D R F V G S G S G T D I T L R I S R V E A E D V G P Y Y G A /(A S Á 7 )/,7 V / / T G G G T K V D L N ( S E Q ID N O : 497 )
CDR de Kabat de la cadena ligera de 6889_I17 (PGT-152):
CDR 1: KSSQSLRQSNGKTSLY (SEQ ID NO: 498)
CDR 2: EVSNRFS (SEQ ID NO: 485)
CDR 3: MQSKDFPLT (SEQ ID NO: 486)
6889_I17 (PGT-152) CDR de Chothia de la cadena ligera:
CDR 1: KSSQSLRQSNGKTSLY (SEQ ID NO: 498)
CDR 2: EVSNRFS (SEQ ID NO: 485)
CDR 3: MQSKDFPLT (SEQ ID NO: 486)
6891_F06 (PGT-153) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (secuencia líder en cursiva, región variable en negrita)
A T G G A A T T G G G G C T G A G C T G G G T T T T C C T C G T T G C T C I'C T T A A G A G G T G T C C A
G 7 G 7 C A G G T G C A G T T G G T G G A G T C G G G C G G A G G C G T G G T C C A G C C T G
G G A A G T C C C T G A G A C T C T C C T G T G T A G T C T C T A A T T T T C T C T T C A A T A
A A C G T C A C A T G C A C T G G G T C C G C C A G G C T C C A G G C A A G G G A C T A G A G
T G G A T A G C A G T C A T T T C C T C T G A T G C C A T T C A C G T A G A C T A C G C A A G T
T C C G T G C G G G G C C G A T C C C T C A T C T C C A G A G A C A A T T C C A A A A A T A G
T T T A T A T C T A G A C A T G A A T A A C C T G A A A A T T G A G G A C A C G G C C A C A T A
T T A T T G T G C A A G A G A T A G A G A C G G A T A T G G T C C A C C A C A G A T C C A G A
C T T G G A G C G G T C G A T A C C T C C A C C T T T A T T C T G G A A T A G A C G C C T G G
G G C C T A G G G A C C A C G G T C A C C G T C T C G A G C G C C T C C A C C A A G G G C C C A
TCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGC
GGCCCTGGGCTGCCTGGTCAAGGACTAOTCCCCGAACCGGTGACGGTGT
CGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTC
CTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCC
AGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAG
CAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAAAACT
CACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGT
C’TTCCTCTTCCGCCC A A A ACGC A AGG AC ACCCTC ATG ATCTCCCGG ACCCC
TGAGGTC' AC ATGCGTGGTGGTGG ACGTG AGCCACG A AG ACCCTGAGGTC A
AGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAA
GCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTC
ACCGTCCTGCAC CAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGG
TCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCC
AAAGGGCAGCCCCGAGAACXIACAGGTGTACACCCTGCCCCCATCCCGGG
AGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTC
TATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGA
ACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTC
CTCT.AT AGC A AGCTC ACCGTGG AC A AG AGC AGGTGGC AGC AGGGG A ACG
TCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTAGACGCAG
AAGAGCCTCTCCCTGTCTCCGGGTAAATGA (SEQ I D NO: 499)
6891_F06 (PGT-153) secuencia de nucleótidos de la región variable de la cadena pesada gamma:
C A G G T G C A G T T G G T G G A G T C G G G C G G A G G C G T G G T C C A G C C T G G G A
A G T C C C T G A G A C T C T C C T G T G T A G T C T C T A A T T T T C T C T T C A A T A A A C
G T C A C A T G C A C T G G G T C C G C C A G G C T C C A G G C A A G G G A C T A G A G T G
G A T A G C A G T C A T T T C C T C T G A T G C C A T T C A C G T A G A C T A C G C A A G T T C
C G T G C G G G G C C G A T C C C T C A T C T C C A G A G A C A A T T C C A A A A A T A G T T
T A T A T C T A G A C A T G A A T A A C C T G A A A A T T G A G G A C A C G G C C A C A T A T T
A T T G T G C A A G A G A T A G A G A C G G A T A T G G T C C A C C A C A G A T C C A G A C T
T G G A G C G G T C G A T A C C T C C A C C T T T A T T C T G G A A T A G A C G C C T G G G G
C C T A G G G A C C A C G G T C A C C G T C T C G A G C (SEQ ID Nü:500)
6891_F06 (PGT-153) secuencia de aminoácidos de la cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
A / / X G 7.S W / X V / U 77 ? G V ( ) C Q V Q L V E S G G G V V Q P G K S L R L S C V V S N F L F N K R
H M H W V R Q A P G K G L E W I A V I S S D A 1 H V D Y A S S V R G R S L I S R D N S K N S L Y L D
M N N L K I E D T A T Y Y C A R D R D G Y G P P Q I Q T W S G R Y L H L Y S G I D A W G L G T T
V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S G A L T S
GVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPK
SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCWVDVSHEDPE
VKFNWYVDGVEVIINAKTKPREEQYNSTYRVVSVI .TVLIIQDWLNGKEYKC
KVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYP
SDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCS
VMHEALHNHYTQKSLSLSPGK (SEQ II) NO: 501)
6891_F06 (PGT-153) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
OVOLVBSGCGVVOPGKSLRLSCVVSATXXTV/rRHMHWVROAPGKGLEWlAF /S'S7M///V/)YASSVR(.RSL]SRl)NSKNSLYU)MNNLKlEl)TATYYCAR/)ft/)GT GPPOIOTWSGRYLHLYSG/DAWCilJCíTWrVSS (SEQ II) NO: 502)
6891_F06 (PGT-153) CDR de Kabat de cadena pesada gamma:
CDR 1: KRHMH (SEQ ID NO: 503)
CDR 2: VISSDAIHVDYASSVRG (SEQ ID NO: 504)
CDR 3: DRDGYGPPQIQTWSGRYLHLYSGIDA (SEQ ID NO: 505)
6891_F06 (PGT-153) CDR de Chothia de la cadena pesada gamma:
CDR 1: NFLFNK (SEQ ID NO: 506)
CDR 2: VISSDAIHVD (SEQ ID NO: 507)
CDR 3: DRDGYGPPQIQTWSGRYLHLYSGIDA (SEQ ID NO: 505)
6891_F03) secuencia de nucleótidos de la cadena ligera: secuencia de codificación (región variable en negrita)
A T G A G G C T C C C T G C T C A G C T C C T G G G G C T G C T A A T G C T C T G G A T A C C T G A A T T
C A C 7 G C G G A C A T T G T G C T G A C C C A G A G C C C C C T C T T T C T G T C C G T C A G
T C C T G G A C A G C C G G C C T C C A T C T C C T G T A A G T C T A G T C A G A G C C T C C
G A C A A A G T A A T G G A A A G A C A T A T T T G T A T T G G T A C G T A C A A A A G T C C
G G C C A G T C T C C A C A A C C C C T G A T C C A G G A A G T T T C C A T T C G C T T C T C T
G G A G T G C C A G G T A G A T T C G C T G G C A G C G G A T C A G G G A C A G A C T T C A C
A C T G A A A A T C A G C C G G G T G G A G G C T G A A G A T G T T G G A G T T T A T T T C T
G C A T G C A A A G T A A A G A C T T T C C A C T C A C T T T T G G C G G A G G G A C C A A G
GTGGACCTCAATCGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCC
ATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAA
TAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCC
TCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGA
CAGCACCTACAGCCTCAGCAGCACCCTG ACGCTG AGC AAAGC AGACTAC
GAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTC
GCCCGTC AC A A AG AGCTTC A AC AGGGG AG AGTGTTAG (SEQ II) NO:508)
6891_F06 (PGT-153) secuencia de nucleótidos de la región variable de la cadena ligera:
GACATTGTGCTGACCCAGAGCCCCCTCTTTCTGTCCGTCAGTCCTGG
ACAGCCGGCCTCCATCTCCTGTAAGTCTAGTCAGAGCCTCCGACAAA
GTAATGGAAAGACATATTTGTATTGGTACGTACAAAAGTCCGGCCAG
TCTCCACAACCCCTGATCCAGGAAGTTTCCATTCGCTTCTCTGGAGTG
CCAGGTAGATTCGCTGGCAGCGGATCAGGGACAGACTTCACACTGAA
AATCAGCCGGGTGGAGGCTGAAGATGTTGGAGTTTATTTCTGCATGC
AAAGTAAAGACTTTCCACTCACTTTTGGCGGAGGGACCAAGGTGGAC
CTCAAT ( S E Q II) N O : 509 )
6891_F06 (PGT-153) secuencia de aminoácidos de cadena ligera: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MRLPAQUX}LLMLWIPHrTADl\LTQSPLFLS\SPGQPASlSCKSSQSLRQSN
GKTYLYWYVQKSGQSPQPLIQEVSIRFSGVPGRFAGSGSGTDFTLKISRV
EAEDVGVYFCMQSKDFPLTFGGGTKVDLNRTVAAPSVIII P P S D E Q E K S G T
A S V V C L L N N F Y P R E A K V Q W K V D N A L Q S G N S Q E S V T E Q D S K D S T Y S L S S T L T L
S K A D Y E K H K V Y A C E V T H Q G L S S P V T K S F N R G E C ( S E Q I D N O : 510 )
Secuencia de aminoácidos de la región variable de la cadena ligera de 6891_F06 (PGT-153): (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
D I V i : r O S P U ;E S V S P G O P A S I S C A \S m S 7 J/e a S ’A G ’A T > 7 ,y nW Y V O K S G O S P O P I .I O E K S /A K S ’G V P G R I A G S G S G r i ) F r E K l S R V E A E D V G V Y K M a S ’A 7 ) / 7 >/ / / ’K i G G ,l K V D L N ( S E Q I D N O : 511 )
CDR de Kabat de la cadena ligera 6891_F06 (PGT-153):
CDR 1: KSSQSLRQSNGKTYLY (SEQ ID NO: 512)
CDR 2: EVSIRFS (SEQ ID NO: 513)
CDR 3: MQSKDFPLT (SEQ ID NO: 486)
6891_F06 (PGT-153) CDR de Chothia de la cadena ligera:
CDR 1: KSSQSLRQSNGKTYLY (SEQ ID NO: 512)
CDR 2: EVSIRFS (SEQ ID NO: 513)
CDR 3: MQSKDFPLT (SEQ ID NO: 486)
6843_G20 (PGT-154) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
A TG G A A T T G G G G C T G A G C T G G G T T T T C C T C G T T G C T C T C n A A GA G G T G T C C A
G T G 7 C A G G T G C A G C T G G T G G A A T C G G G A G G A G G C G T G G T C C A G C C T G
G A A A G T C C C T C A G A C T C T C A T G T G T C G T C T C T A A T T T C A T C T T T A A T A
A A T A T C C T A T G T A T T G G G T C C G C C A G G C T C C A G G C A A G G G G C T G G A G
T G G G T G G C A G C C A T C T C C G C T G A T G C C T G G C A T G T A G A C T A C G C A G C
C T C C G T G A A G G A C C G A T T T C T C A T C T C C A G A G A C A A T T C C A A G A A T G
C T C T A T A T T T G G A A A T G A A C A C C C T G A G A G T T G A A G A C A C G G G T A T C
T A C T A C T G T G C G A G A A A T A T A G A G G A G T T T A G T G T T C C A C A G T T C G A
T T C T T G G A G C G G T C G A A G C T A C T A C C A C T A T T T T G G G A T G G A C G T C T
G G G G C C A A G G G A C C A C G G T C A C C G T C T C G A G C G C C T C C A C C A A G G G C
C C A T C G G T C T T C C C C C T G G C A C C C T C C T C C A A G A G C A C C T C T G G G G G C A C
A G C G G C C C T G G G C T G C C T G G T C A A G G A C T A C T T C C C C G A A C C G G T G A C G G
TGTCGTGGAACTCAGGCGCGCTGAGCAGCGGCGTGCACACCTTCGCGGCT
GTCCT AG AGTCGTC AGG ACTCT ACTCCCTCAGC AGCGTGGTG ACCGTGCC
CTCCAGCAGCTTGGGCACCCAGAGCTACATCTGCAACGTGAATCACAAGC
CCAGCAAGAGCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAA
AACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGT
CAGTCTTCCTCTTCGGGCCAAAACCCAAGGACAGGCTCATGATCTCCCGGA
CCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAG
GTCA AGTTC A ACTGGT ACGTGG ACGGCGTGG AGGTGC ATA ATGCC A AG AC
A A A G C C G C G G G A G G A G C A G T A C A A C A G C A C G T A C C G T G T G G T C A G C G T C
CTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAA
GGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAG
CCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGG
GAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCT
TCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGA
GAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCT
TCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAA
CGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGC
AGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA (SEQ ID NO: 514)
6843_G20 (PGT-154) secuencia de nucleótidos de región variable de la cadena pesada gamma:
C A G G T G C A G C T G G T G G A A T C G G G A G G A G G C G T G G T C C A G C C T G G A A
A G T C C C T C A G A C T C T C A T G T G T C G T C T C T A A T T T C A T C T T T A A T A A A T
A T C C T A T G T A T T G G G T C C G C C A G G C T C C A G G C A A G G G G C T G G A G T G G
G T G G C A G C C A T C T C C G C T G A T G C C T G G C A T G T A G A C T A C G C A G C C T C
C G T G A A G G A C C G A T T T C T C A T C T C C A G A G A C A A T T C C A A G A A T G C T C
T A T A T T T G G A A A T G A A C A C C C T G A G A G T T G A A G A C A C G G G T A T C T A C
T A C T G T G C G A G A A A T A T A G A G G A G T T T A G T G T T C C A C A G T T C G A T T C T
T G G A G C G G T C G A A G C T A C T A C C A C T A T T T T G G G A T G G A C G T C T G G G G
C C A A G G G A C C A C G G T C A C C G T C T C G A G C (SEQ I D N O : 515 )
6843_G20 (PGT-154) secuencia de aminoácidos de la cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MELGLSWVFLVAIJJ{GVQCQ\QLXESGGG\\QPGKSLRLSCVVSNFIFNKY
PMYWVRQAPGKGLEWVAAISADAWHVDYAASVKDRFLISRDNSKNALY
LEMNTLRVEDTGIYYCARNIEEFSVPQFDSWSGRSYYHYFGMDVWGQG
TTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGAL
TSGVHTFPAVLQSSGLYSLSSVVTVPSvSSLGTQTYICNVNHKPSNTKVDKRVE
PKSCDKTIITCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE
DPEVKFNWYVDGVEVIINAKTKPREEQYNSTYRVVSVITVI A IQDWI .NGKEY
KCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGF
YPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFvS CSVMHEALHNHYTQKSLSLSPGK (SEQ ID NO: 516)
6843_G20 (PGT-154) secuencia de aminoácidos de la región variable de la cadena pesada de rayos gamma: (CDR de Kabat subrayadass, CDR de Chothia en negrita cursiva)
Q VQL V ESGGG V VQPG K S LR ESC V V S AFVfW AYPMY W V RQ APG KG LE W V AA /S A /M W W flY A A S V K D RFLISRPN SK N A EY LEM N TERV ED 'm iY Y C 'ARNIEE fs vroins wsgrs yyh yfgmd ywgoc ; r rv iv ss (Seq id n ü : 5 i 7)
6843_G20 (PGT-154) CDR de Kabat de la cadena pesada gamma:
CDR 1: KYPMY (SEQ ID NO: 475)
CDR 2: AISADAWHVDYAASVKD (SEQ ID NO: 518)
CDR 3: NIEEFSVPQFDSWSGRSYYHYFGMDV (SEQ ID NO: 519)
6843_G20 (PGT-154) CDR de Chothia de la cadena pesada gamma:
CDR 1: NFIFNK (SEQ ID NO: 520)
CDR 2: AISADAWHVD (SEQ ID NO: 521)
CDR 3: NIEEFSVPQFDSWSGRSYYHYFGMDV (SEQ ID NO: 519)
6843_G20 (PGT-154) secuencia de nucleótidos de la cadena ligera: secuencia de codificación (región variable en negrita)
A T G A G G C T C C C T G C T C A G C T C C T G G G G C T G C T A A T G C T C T G G A T A C C T G A G T T
CGC7GCAGACATTGTGATGACTCAGACTCCTGTCTCTCTGTCCGTCAG
TCTTGGACAGGCGGCCTCCATCTCCTGCAGCTCCAGTGAGAGTCTCG
GACGTGGTGATGGAAGGACCTATTTGCATTGGTACCGACAGAAGCCA
GGCCAGACTCCACAATTACTCATGTATGAAGTTTCTACTCGATTCTCT
GGAGTGTCCGACAGGTTCGCTGGCAGCGGGTCACGTACACAATTCAC
ATTGAAAATTAGTCGGGTGGAGGCTGAAGATGTTGGCGTTTATTACT
GCATGCAAAGTAGAGACTTCCCAATCACTTTTGGCGGAGGGACCAGG
GTGGATCTCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCC
ATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAA
T A ACTTCT ATCCC AGAG AGGCC A A AGT AC AGTGGA AGGTGG AT A ACGCCC
TCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGA
CAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTAC
GAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTC
GCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG (SEQ ID NO:522)
6843_G20 (PGT-154) secuencia de nucleótidos de la región variable de la cadena ligera:
G A C A T T G T G A T G A C T C A G A C T C C T G T C T C T C T G T C C G T C A G T C T T G G A
C A G G C G G C C T C C A T C T C C T G C A G C T C C A G T G A G A G T C T C G G A C G T G G
T G A T G G A A G G A C C T A T T T G C A T T G G T A C C G A C A G A A G C C A G G C C A G A
C T C C A C A A T T A C T C A T G T A T G A A G T T T C T A C T C G A T T C T C T G G A G T G T
C C G A C A G G T T C G C T G G C A G C G G G T C A C G T A C A C A A T T C A C A T T G A A A
A T T A G T C G G G T G G A G G C T G A A G A T G T T G G C G T T T A T T A C T G C A T G C A
A A G T A G A G A C T T C C C A A T C A C T T T T G G C G G A G G G A C C A G G G T G G A T C
T C A A A ( S E Q ID N O : 523 )
Secuencia de aminoácidos de cadena ligera 6843_G20 (PGT-154): proteína expresada con secuencia líder en cursiva y región variable en negrita.
MRLPAQLLC,LLMLWIPKFAADI\MTQTP\SLS\SLGQ\\SISCSSSESLGRGD
G R T Y L H W Y R Q K P G Q T P Q L L M Y E V S T R F S G V S D R F A G S G S R T Q F T L K I S R
V E A E D V G V Y Y C M Q S R D F P I T F G G G T R V D L K R T V A A P S V F I F P P S D E Q L K S G
T A S V V C L L N N F Y P R E A K V Q W K V D N A L Q S G N S Q E S V T E Q D S K D S T Y S L S S T L T
L S K A D Y E K H K V Y A C E V T H Q G L S S P V T K S F N R G E C (S E Q ID N O : 524 )
Secuencia de aminoácidos de la región variable de la cadena ligera de 6843_G20 (PGT-154): (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
D I V M T a r P V S E S V S I X iO A A S lS C \S\S’A7iA’A G I fG 7 X ;R rm , / / W Y R O K P G O T P O E L M Y E K S ’YTfF.S'G V S D R F A G S G S R T O l'T E K lS R V E A E D V G V Y Y C /W AS’ffD /'V Y Y T G G G T R V D L K (S E Q ID NO: 525 )
CDR de Kabat de la cadena ligera 6843_G20 (PGT-154):
CDR 1: SSSESLGRGDGRTYLH (SEQ ID NO: 526)
CDR 2: EVSTRFS (SEQ ID NO: 527)
CDR 3: MQSRDFPIT (SEQ ID NO: 528)
6843_G20 (PGT-154) CDR de Chothia de la cadena ligera:
CDR 1: SSSESLGRGDGRTYLH (SEQ ID NO: 526)
CDR 2: EVSTRFS (SEQ ID NO: 527)
CDR 3: MQSRDFPIT (SEQ ID NO: 528)
6892_D19 (PGT-155) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (secuencia líder en cursiva, región variable en negrita)
A TG G A A T T G G G G C T G A G C T G G G T m C C T C G T C G T T C T C C T A A G A G G T G T C C A
C T G 7 C A G G T G C A T C T G G T G G A G T C G G G G G G A G G C G T G G T C C A A C C T G
G G A A G T C C C T A A G A C T C T C C T G T G A A A C C T C T G G C T T C A T C T T C A A C G
A A T A T C C C A T G T A T T G G A T C C G C C A G G C T C C A G G C A A G G G A C C G G A G
T G G G T G G C C G C C A T C T C C G C T G A C G C C T G G C A T G T G G A C T A C G C A G G
C T C C G T G C G G G G C C G A T T T A C C G T C T C C A G A G A C A A T T C T A A G A A T T
C T C T A T A T T T A G A C A T G A A G A G T C T G A A A G T T G A A G A C A C G G C T A T A T
A T T T C T G T G C G A A A G A T G G G G A G G A A C A C A A G G T A C C A C A A T T G C A T
T C C T G G A G C G G A C G A A A C T T A T A T C A C T A C A C T G G T T T T G A C G T C T G
G G G C C C A G G G A C C A C G G T C A C C G T C T C G A G C G C X T C C A C C A A G G G C C
C A T C G G T C I T C C C C C T G G C A C C C T C C T C C A A G A G C A C C T C T G G G G G C A C A
G C G G C C C T G G G C T G C C T G G T C A A G G A C T A C T T C G C C G A A C C G G T G A C G G T
G T C G T G G A A C T G A G G C G C C C T G A C C A G C G G C G T G C A C A C C T T C C C G G C T G
T C C T A C A G T C C T C A G G A C T C T A C T C C C T C A G C A G C G T G G T G A C C G T G C C C T
C C A G C A G C T T G G G C A C C C A G A C C T A C A T C T G C A A C G T G A A T C A C A A G C C C
A G C A A C A C C A A G G T G G A C A A G A G A G T T G A G C C C A A A T C T T G T G A C A A A A
C T G A C A C A T G C C C A C C G T G íX C A G C A C C T G A A C T C C T G G G G G G A C C G T G A
G T C T T C C T C T T C C C C C G A A A A C C C A A G G A C A C C C T C A T G A T C T C C C G G A C C
C C T G A G G T C A C A T G C G T G G T G G T G G A C G T G A G C C A C G A A G A C G C T G A G G T
C A A G T T C A A C T G G T A C G T G G A C G G C G T G G A G G T G C A T A A T G C C A A G A C A
A A G G C G C G G G A G G A G C A G T A C A A C A G C A C G T A C C G T G T G G T C A G C G T C C
T C A C C G T C C T G C A C C A G G A C T G G C T G A A T G G C A A G G A G T A C A A G T G C A A
GGTCTCCAACAAAGCCCrcCCAGCCCCCATCGAGAAAACCATCTGCAAAG
C C A A A G G G C A G C C C C G A G A A C C A C A G G T G T A C A C C C T G C C C C C A T C C C G G
G A G G A G A T G A C C A A G A A C C A G G T C A G C C T G A C C T G C C T G G T C A A A G G C T
T C T A T C C C A G C G A G A T C G C C G T G G A G T G G G A G A G C A A T G G G C A G C C G G A
G A A C A A C T A C A A G A C C A C G C C T C C C G T G C T G G A C T C C G A C G G C T C C T T C T
T C G T C T A T A G C A A G C T C A C C G T G G A C A A G A G C A G G T G G C A G C A G G G G A A
C G T C T T C T C A T G C T C C G T G A T G C A T G A G G C T C T G C A C A A C C A C T A C A C G C
A G A A G A G C C T C T C G G T G T C T C C G G G T A A A T G A (S E Q I D N O : 529 )
6892_D19 (PGT-155) secuencia de nucleótidos de región variable de cadena pesada gamma:
C A G G T G C A T C T G G T G G A G T C G G G G G G A G G C G T G G T C C A A C C T G G G A
A G T C C C T A A G A C T C T C C T G T G A A A C C T C T G G C T T C A T C T T C A A C G A A T
A T C C C A T G T A T T G G A T C C G C C A G G C T C C A G G C A A G G G A C C G G A G T G G
G T G G C C G C C A T C T C C G C T G A C G C C T G G C A T G T G G A C T A C G C A G G C T C
C G T G C G G G G C C G A T T T A C C G T C T C C A G A G A C A A T T C T A A G A A T T C T C
T A T A T T T A G A C A T G A A G A G T C T G A A A G T T G A A G A C A C G G C T A T A T A T T
T C T G T G C G A A A G A T G G G G A G G A A C A C A A G G T A C C A C A A T T G C A T T C C
T G G A G C G G A C G A A A C T T A T A T C A C T A C A C T G G T T T T G A C G T C T G G G G
C C C A G G G A C C A C G G T C A C C G T C T C G A G C ( S E Q II) N O : 530 )
6892_D19 (PGT-155) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
M E L G 1S W V F L W L L R G V H C Q V H L V E S G G G V V Q P G K S L R L S C E T S G F I F N E Y
P M Y W I R Q A P G K G P E W V A A I S A D A W H V D Y A G S V R G R F T V S R D N S K N S L Y
L D M K S L K V E D T A I Y F C A K D G E E H K V P Q L H S W S G R N L Y H Y T G F D V W G P G
T T V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S G A L
T S G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T K V D K R V E
P K S C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S H E
d p f a ^k f n w y v d g v e v i i n a k t k p r e e q y n s t y r v v s v e t v l i i q d w e n g k e y
K C K V S N K A E P A P I E K T I S K A K G Q P R E P Q V Y T I P P S R E E M T K N Q V S L T C L V K G F
Y P S D I A V E W E S N G Q P E N N Y K T T P P V E D S D G S 1 1 L Y S K E T V D K S R W Q Q G N V F S
C S V M H E A L H N H Y T Q K S L S L S P G K ( S E Q ID N O : 531 )
6892_D19 (PGT-155) secuencia de aminoácidos de la región variable de la cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
O V H L V E S G G G V V O P G K S L R L S C E T S G F 7 F A E Y P M Y W I R O A P G K G P E W V A A /S
A /M V V 7 /V D Y A C iS V R (;R lT V S R I ) N S K N S E Y E D M K S L K V E D T A I Y I C A K / X ; E E
H K V P Ü L H S W S G R N L Y H Y T G / l ) VW C iP G T T V T V S S (S E Q ID N O : 532 )
6892_D19 (PGT-155) CDR de Kabat de la cadena pesada gamma:
CDR 1: EYPMY (SEQ ID NO: 533)
CDR 2: AISADAWHVDYAGSVRG (SEQ ID NO: 534)
CDR 3: DGEEHKVPQLHSWSGRNLYHYTGFDV (SEQ ID NO: 535)
6892_D19 (PGT-155) CDR de Chothia de la cadena pesada gamma:
CDR 1: GFIFNE (SEQ ID NO: 536)
CDR 2: AISADAWHVD (SEQ ID NO: 521)
CDR 3: DGEEHKVPQLHSWSGRNLYHYTGFDV (SEQ ID NO: 535)
6892_D19 (PG6868T-155)) secuencia de nucleótidos de la cadena ligera: secuencia de codificación (región variable en negrita)
A T G A G G C T C C C T G C T C A G C T C C T G G G G C T G C T A A T G C T C T G G A T A C C T G A A C T
7 G C 1 G C A G A C A T T G T G A T G A C C C A G T C T C C T G T C T C T C T G T C C G T C A C
C C T C G G A C A G C C G G C C T C C A T G T C C T G C A A G T C C A G T C A G A G T G T C C
G A C A G A G T G A T G G C A A G A C T T T C T T A T A T T G G T A T C G A C A G A A G C C A
G G C C A G T C T C C A C A A C T G T T A A T A T A T G A G G G T T C G A G T C G A T T C T C T
G G A G T G T C A G A T A G G A T C T C T G G C A G C G G G T C A G G G A C A G A C T T C A C
A C T G A G G A T C A G T C G A G T G G A G G C T G A G G A T G C T G G C G T T T A C T T C T
G C T T G C A A A C T A A A G A C T T C C C C C T C A C T T T T G G C G G A G G G A C C A G G
G T G G A T C T C A A A G G T A C G G T G G C T G C A C C A T C T G T C T T C A T C T T C C C G C C
A T C T G A T G A G C A G T T G A A A T C T G G A A C T G C C T C T G T T G T G T G C C T G C T G A A
T A A C T T C T A T C C C A G A G A G G C C A A A G T A C A G T G G A A G G T G G A T A A C G C C C
T C C A A T C G G G T A A C T C C C A G G A G A G T G T C A C A G A G C A G G A C A G C A A G G A
C A G C A C C T A C A G C C T C A G C A G C A C C C T G A C G C T G A G C A A A G C A G A C T A C
G A G A A A C A C A A A G T C T A C G C C T G C G A A G T C A C C C A T C A G G G C C T G A G C T C
G C C C G T C A C A A A G A G C 1 T C A A C A G G G G A G A G T G T T A G ( S E Q ID N O : 537 )
6892_D19 (PGT-155) secuencia de nucleótidos de la región variable de la cadena ligera:
C C C A G T C T C C T G T C T C T C T G T C C G T C A C C C T C G G A
T G T C C T G C A A G T C C A G T C A G A G T G T C C G A C A G A G T T C T T A T A T T G G T A T C G A C A G A A G C C A G G C C A G T A A T A T A T G A G G G T T C G A G T C G A T T C T C T G G A G T G T T G G C A G C G G G T C A G G G A C A G A C T T C A C A C T G A G G A G G C T G A G G A T G C T G G C G T T T A C T T C T G C T T G C A C C C C T C A C T T T T G G C G G A G G G A C C A G G G T G G A T C

Secuencia de aminoácidos de la cadena ligera 6892_D19 (PGT-155): proteína expresada con secuencia líder en cursiva y región variable en negrita.
M R L P A Q L L G L L M L W IP E IA A D I V M T Q S P V S L S V T L G Q P A S M S C K S S Q S V R Q S
D G K T F L Y W Y R Q K P G Q S P Q L L I Y E G S S R F S G V S D R I S G S G S G T D F T L R I S R V
E A E D A G V Y F C L Q T K D F P L T F G G G T R V D L K R T V A A P S V F I I P P S D E Q L K S G T
A S V V C L L N N F Y P R E A K V Q W K V D N A L Q S G N S Q E S V T E Q D S K D S T Y S L S S T L T L
S K A D Y E K H K V Y A C E V T M Q G L S S P V T K S F N R G E C (S E Q II ) N O : 539 )
6892_D19 (PGT-155) Secuencia de aminoácidos de la región variable de la cadena ligera: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
DlVMTOSPVSESVTLCiOPASMSCXSSasyirasyJGATFV.yWYROKPGiOXPQLLl Y/sY>\X\S7f/\S'GVSI)RlSGSGSGTl)lTLRIXRVHAHl)AGVYF( L O T K D i P L ñ ( Xi( i TRVDLK (SEQ II) NO: 540)
6892_D19 (PGT-155) CDR de Kabat de la cadena ligera:
CDR 1: KSSQSVRQSDGKTFLY (SEQ ID NO: 541)
CDR 2: EGSSRFS (SEQ ID NO: 542)
CDR 3: LQTKDFPLT (SEQ ID NO: 543)
6892_D19 (PGT-155) CDR de Chothia de la cadena ligera:
CDR 1: KSSQSVRQSDGKTFLY (SEQ ID NO: 541)
CDR 2: EGSSRFS (SEQ ID NO: 542)
CDR 3: LQTKDFPLT (SEQ ID NO: 543)
6808_B09 (PGT-156) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)

A G A A G A G G C T G T G G G T G T G T C G G G G T A A A T G A ( S E Q ID N O : 544 )
6808_B09 (PGT-156) secuencia de nucleótidos de región variable de la cadena pesada gamma:
C A G G T G C A T C T G G T G G A G T C G G G G G G A G G C G T T G T C C A A C C T G G A A
A G T C C C T A A G A C T C T C C T G T G A A A C C T C T G G C T T C A T C T T C A A T C A A T
A T C C C A T G T A T T G G G T C C G C C A G G C T C C A G G C A A G G G A C C G G A G T G G
G T G G C C G C C A T C T C C G C T G A T G C C T G G C A T G T G G A C T A C C C A G G C T C
C G T G C G G G G C C G A T T T A C C G T C T C C A G A G A C A A T T C C A A G A G T T C T C
T A T A T T T A G A C A T G A A G A G T C T G A A A G T T G A A G A C A C G G C T A T A T A T T
T C T G T G C G A A A G A T G G G G A G G A A C A C A A G G T A C C A C A A T T G C A T T C C
T G G A G C G G A C G A A A C T T A T A T C A C T A C A C T G G T T T T G A C G T C T G G G G
C C C A G G G A C C A C G G T C A C C G T C T C G A G C ( S E Q ID N O : 545 )
6808_B09 (PGT-156) secuencia de aminoácidos de la cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
M £ / / ; L V W / 7 W / E / ? ( ; V / / C Q V H L V E S G G G V V Q P G K S L R L S C E T S G F I F N Q Y
P M Y W V R Q A P G K G P E W V A A I S A D A W H V D Y P G S V R G R F T V S R D N S K S S L Y
L D M K S L K V E D T A I Y F C A K D G E E H K V P Q L H S W S G R N L Y H Y T G F D V W G P G
T T V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S G A L
T S G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T K V D K R V E
P K S C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S H E
D P E V K F N W Y V D G V E V I I N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D W L N G K E Y
K C K V S N K A L P A P I E K T 1 S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K G F
Y P S D I A V E W E S N G Q P E N N Y K T T P P V L D S D G S F F L Y S K L T V D K S R W Q Q G N V F S
C S V M H E A L I I N I I Y T Q K S I ,S I J S P G K ( S E Q ID N O : 546 )
6808_B09 (PGT-156) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
Q V I I I , V E S G G G V V Q P G K S I ,R E S C E T S G F I F N Q Y P M Y W V R Q A P G K G P E W V A A ¿ M /M VV//V77Y1)GSVRGRITVSRDNSKSSLYLDMKSI.KVEDTAIYFCAK/X j’EE' HKVrOLHS WSGKNLYHYTGI l ) VW G P G I I V 1 V S S (S E Q ID N O : 547 )
6808_B09 (PGT-156) CDR de Kabat de la cadena pesada gamma:
CDR 1: QYPMY (SEQ ID NO: 548)
CDR 2: AISADAWHVDYPGSVRG (SEQ ID NO: 549)
CDR 3: DGEEHKVPQLHSWSGRNLYHYTGFDV (SEQ ID NO: 535)
6808_B09 (PGT-156) CDR de Chothia de la cadena pesada gamma:
CDR 1: GFIFNQ (SEQ ID NO: 550)
CDR 2: AISADAWHVD (SEQ ID NO: 521)
CDR 3: DGEEHKVPQLHSWSGRNLYHYTGFDV (SEQ ID NO: 535)
6808_B09) secuencia de nucleótidos de cadena ligera: secuencia de codificación (región variable en negrita)
A T O A G G C T C C C T G C T C A G C T C C T G G G G C T G C T A A T G C T C T G G A T A C C T G A A C T
7 G C 7 G C A G A C A T T G T G A T G A C C C A G T C T C C T G T C T C T C T G T C C G T C A C
C C T C G G A C A G C C G G C C T C C A T G T C C T G C A A G T C C A G T C A G A C T G T C C
G A C A G A G T G A T G G C A A G A C T T T C T T A T A T T G G T A T C G A C A G A A G G C A
G G C C A G T C T C C A C A A C T G T T A A T A T A T G A G G G T T C G A A T C G A T T C T C T
G G A G T G T C A G A T A G G A T C T C T G G C A G C G G G T C G G G G A C A G A T T T C A C
A C T G A G A A T C A G T C G A G T G G A G G C T G A G G A T G T T G G C G T T T A T T T C T
G C C T G C A A A C T A A A G A C T T C C C C C T C A C T T T T G G C G G A G G G A C C A G G
G T G G A T A T C A A A C G T A C G G T G G C T G C A C C A T C T G T C l T C A T C ' n C C C G C C
A T C T G A T G A G C A G T T G A A A T C T G G A A C T G C C T C T G T T G T G T G C C T G C T G A A
T A A C T T C T A T C C C A G A G A G G C C A A A G T A C A G T G G A A G G T G G A T A A C G C C C
T C C A A T C G G G T A A C T C C C A G G A G A G T G T C A C A G A G C A G G A C A G C A A G G A
CAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTAC
G A G A A A C A C A A A G T C T A C G C C T G C G A A G T C A C C C A T C A G G G C C T G A G C T C
G C C C G T C A C A A A G A G C T T C A A C A G G G G A G A G T G T T A G (S E Q ID N O : 551)
6808_B09 (PGT-156) secuencia de nucleótidos de región variable de cadena ligera:
G A C A T T G T G A T G A C C C A G T C T C C T G T C T C T C T G T C C G T C A C C C T C G G A
C A G C C G G C C T C C A T G T C C T G C A A G T C C A G T C A G A C T G T C C G A C A G A G
T G A T G G C A A G A C T T T C T T A T A T T G G T A T C G A C A G A A G G C A G G C C A G T
C T C C A C A A C T G T T A A T A T A T G A G G G T T C G A A T C G A T T C T C T G G A G T G T
C A G A T A G G A T C T C T G G C A G C G G G T C G G G G A C A G A T T T C A C A C T G A G A
A T C A G T C G A G T G G A G G C T G A G G A T G T T G G C G T T T A T T T C T G C C T G C A
A A C T A A A G A C T T C C C C C T C A C T T T T G G C G G A G G G A C C A G G G T G G A T A
T C A A A ( S E Q ID N O : 552 )
6808_B09 (PGT-156) secuencia de aminoácidos de cadena ligera: proteína expresada con secuencia líder en cursiva y región variable en negrita.
M / 7.P A ( ; / . / / ; / . / A / / .W / / / >/ - X 4 A D I V iV lT Q S P V S L S V T L G Q P A S M S C K S S Q T V R Q S
D G K T F L Y W Y R Q K A G Q S P Q L L I Y E G S N R F S G V S D R I S G S G S G T D F T L R I S R
V E A E D V G V Y F C L Q T K D F P L T F G G G T R V D I K R T V A A P S V 1 IF P P S D H Q L K S G
T A S V V C L L N N F Y P R E A K V Q W K V D N A L Q S G N S Q E S V T E Q D S K D S I Y S L S S T L T
L S K A D Y E K H K V Y A C E V T H Q G L S S P V T K S F N R G E C ( S E Q ID N O : 553 )
6808_B09 (PGT-156) luz región variable de la cadena de secuencia de aminoácidos: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
D I V M r O S P V S L S V r L G O P A S M S C A S S ^ y T / e a S ' / j G A T / X F W Y R O K A G O S P O I .F IY /Y A S 'A A /A O V S D R I S G S G S G T D I T I .R lS R V H A I U ) V G V Y I C 7 X / / A 7 J / 77 / / T G G G T R V D I K ( S E Q ID N O : 554 )
6808_B09 (PGT-156) CDR de Kabat de la cadena ligera:
CDR 1: KSSQTVRQSDGKTFLY (SEQ ID NO: 555)
CDR 2: EGSNRFS (SEQ ID NO: 556)
CDR 3: LQTKDFPLT (SEQ ID NO: 543)
6808_B09 (PGT-156) CDR de Chothia de la cadena ligera:
CDR 1: KSSQTVRQSDGKTFLY (SEQ ID NO: 555)
CDR 2: EGSNRFS (SEQ ID NO: 556)
CDR 3: LQTKDFPLT (SEQ ID NO: 543)
6892_C23 (PGT-157) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (secuencia líder en cursiva, región variable en negrita)


6892_C23 (PGT-157) secuencia de aminoácidos de cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
M E l.G íS W V l'L V A IJ .R C , W /C E V H L V E S G G G V V Q P G K S L R L S C V T S G F I F K Q Y
P M Y W I R Q A P G K G L E W V A A I S A D A W H V D Y A G S V R G R F T V S R D N S K N S L Y
L D M N S L T V E D T A I Y F C A K D G E E H E V P Q L H S W S G R N L Y H Y T G V D I W G P G
T T V T V S S A S T K G P S V F P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S G A L
T S G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T K V D K R V E
P K S C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S H E
D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D W L N G K E Y
K C K V S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K G F
Y P S D I A V E W E S N G Q P E N N Y K I T P P V L D S D G S F F L Y S K L T V D K S R W Q Q G N V F S
C S V M H E A L H N H Y T Q K S L S L S P G K ( S E Q II) N O : 559 )
6892_C23 (PGT-157) secuencia de aminoácidos de la región variable de la cadena pesada de rayos gamma: (CDR de Kabat subrayadas, CDR de Chothia en cursiva en negrita)
E V I I E V E S G G G V V O P G K S E R L S C V T S G f 7 e A Y ) Y P M Y W IR O A P G K G E I< W V A A 7 S A /M V V //V 7 ) Y A G S V R G R F T V S R D N S K N S E Y E I ) M N S E T V E D T A I Y F C A K / X ; £ / s H E v r o u / s W S G R M . Y H YTG W ) / W G P G T T V T V S S (S E Q ID N O : 560 )
6892_C23 (PGT-157) CDR de Kabat de la cadena pesada gamma:
CDR 1: QYPMY (SEQ ID NO: 548)
CDR 2: AISADAWHVDYAGSVRG (SEQ ID NO: 534)
CDR 3: DGEEHEVPQLHSWSGRNLYHYTGVDI (SEQ ID NO: 561)
6892_C23 (PGT-157) CDR de Chothia de la cadena pesada gamma:
CDR 1: GFIFKQ (SEQ ID NO: 562)
CDR 2: AISADAWHVD (SEQ ID NO: 521)
CDR 3: DGEEHEVPQLHSWSGRNLYHYTGVDI (SEQ ID NO: 561)
6892_C23 (PGT-157) secuencia de nucleótidos de la cadena ligera: secuencia de codificación (región variable en negrita)
A I V A G G C T C C C T G C T C A G C T C C T G G G G C T ’G C TA A T G C T C T G G A TA C C T G A A C T
7 A C T G C A G A C A T T G T G A T G A C C C A G A C T C C T G T C T C T C T G T C C G T C A C
C C T C G G A C A G C C G G C C T C C A T G T C C T G T A A G T C C A G T C A G A G C C T C C
G A C A A A G T G A T G G C A A G A C T T T C T T G T A T T G G T A T C G A C A G A A G G C A
G G C C A G T C T C C A C A A C T C C T A A T A T C T G A G G C T T C G A A T C G A T T C T C T
G G A G T G T C A G A T A G G T T C T C T G G C A G C G G T T C A G G G A C A G A C T T C A C
A C T G A A A A T C A G T C G G G T G G A G G C T G A G G A T G T T G G C A T T T A I T T C T
G C A T G C A A A C T A A A G A C T T C C C C C T C A C T T T T G G C G G A G G G A C C A A G
G T G G A T C T C A A A C G T A C G G T G G C T G C A C C A T C T G T C T T C A T C T T C C C G C C
A T C T G A T G A G C A G T T G A A A T C T G G A A C T G C C T C T G T T G T G T G C C T G C T G A A
T A A C T T C T A T C C C A G A G A G G C C A A A G T A C A G T G G A A G G T G G A T A A C G C C C
T C C A A T C G G G T A A C T C C C A G G A G A G T G T C A C A G A G C A G G A C A G C A A G G A
C A G C A C C T A C A G C C T C A G C A G C A C C C T G A C G C T G A G C A A A G C A G A C T A C
G A G A A A C A C A A A G T C T A C G C C T G C G A A G T C A C C C A T C A G G G C C T G A G C T C
G C C C G T C A C A A A G A G C T T C A A C A G G G G A G A G T G T T A G ( S E Q II ) N O : 563 )
6892_C23 (PGT-157) secuencia de nucleótidos de la región variable de la cadena ligera:
G A C A T T G T G A T G A C C C A G A C T C C T G T C T C T C T G T C C G T C A C C C T C G G
A C A G C C G G C C T C C A T G T C C T G T A A G T C C A G T C A G A G C C T C C G A C A A A
G T G A T G G C A A G A C T T T C T T G T A T T G G T A T C G A C A G A A G G C A G G C C A G
T C T C C A C A A C T C C T A A T A T C T G A G G C T T C G A A T C G A T T C T C T G G A G T G
T C A G A T A G G T T C T C T G G C A G C G G T T C A G G G A C A G A C T T C A C A C T G A A
A A T C A G T C G G G T G G A G G C T G A G G A T G T T G G C A T T T A T T T C T G C A T G C
A A A C T A A A G A C T T C C C C C T C A C T T T T G G C G G A G G G A C C A A G G T G G A T
C T C A A A (S E Q ID N O :564)
6892_C23 (PGT-157) Secuencia de aminoácidos de la cadena ligera: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MRLPAQLLGLLMI.WIPRIJ A D l \ M T Q T P \ S L S \ T L G Q P \ S M S C K S S Q S L R Q S
D G K T F L Y W Y R Q K A G Q S P Q L L I S E A S N R F S G V S D R F S G S G S G T D F T L K I S R
V E A E D V G I Y F C M Q T K D F P L T F G G G T K V D L K R I V A A P S V M I P P S D I iQ L K S C i
T A S V V C L L N N F Y P R E A K V Q W K V D N A L Q S G N S Q E S V T E Q D S K D S T Y S L S S T L T
L S K A D Y E K H K V Y A C E V T H Q G L S S P V T K S F N R G E C ( S E Q I D N O : 565 )
6892_C23 (PGT-157) Secuencia de aminoácidos de la región variable de la cadena ligera: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
D I V M T Q T P V S I ,S V T I jG Q P A S M S C K S S O S I .R O S I)G K T F P Y W Y R O K A G O S P O \A IS /sA 5 W A /\S 'G V S D R l;S C iS G S G T D F r L K lS R V E A E D V G I Y F C A /6 > y A 7 j /< 7 V / / l ( i ( i G T K V D L K ( S E Q ID N O : 566 )
6892_C23 (PGT-157) CDR de Kabat de la cadena ligera:
CDR 1: KSSQSLRQSDGKTFLY (SEQ ID NO: 567)
CDR 2: EASNRFS (SEQ ID NO: 568)
CDR 3: MQTKDFPLT (SEQ ID NO: 569)
6892_C23 (PGT-157) CDR de Chothia de la cadena ligera:
CDR 1: KSSQSLRQSDGKTFLY (SEQ ID NO: 567)
CDR 2: EASNRFS (SEQ ID NO: 568)
CDR 3: MQTKDFPLT (SEQ ID NO: 569)
6881_N05 (PGT-158) secuencia de nucleótidos de cadena pesada gamma: secuencia de codificación (región variable en negrita)
A TGGAATTGGGGCTGA GCTGGGmTCCTCGTCGCTCTCCTAA GA GGTGTCCA
C T G 7 G A G G T G C G T C T G A T G G A G T C G G G G G G A G G C G T G G T C C A G C C T G
G G A A G T C C C T C A G A C T C T C C T G T G T A A C C T C T G G C T T C A T C T T C A A A A
A A T A T C C T A T G T A C T G G A T C C G C C A G G C T C C A G G C A A G G G G C T G G A G
T G G G T G G C C G C C A T C T C C G C T G A T G C C T G G C A T G T G G A C T A C C C A G G
C T C C G T G C G G G G C C G A T T T A C C G T C T C A A G A G A C A A C T C C A A G A A T T
C T C T A T A T T T A G A C A T G A A T A G T C T G A C A G T A G A A G A C A C G G C T A T A T
ATTTTTGTGCGAAAGATGGGGAGGAACACGAAGTCCCACAACTGCAC

6881_N05 (PGT-158) secuencia de nucleótidos de la región variable de la cadena pesada de la cadena gamma:
G A G G T G C G T C T G A T G G A G T C G G G G G G A G G C G T G G T C C A G C C T G G G A
A G T C C C T C A G A C T C T C C T G T G T A A C C T C T G G C T T C A T C T T C A A A A A A T
A T C C T A T G T A C T G G A T C C G C C A G G C T C C A G G C A A G G G G C T G G A G T G G
G T G G C C G C C A T C T C C G C T G A T G C C T G G C A T G T G G A C T A C C C A G G C T C
C G T G C G G G G C C G A T T T A C C G T C T C A A G A G A C A A C T C C A A G A A T T C T C
T A T A T T T A G A C A T G A A T A G T C T G A C A G T A G A A G A C A C G G C T A T A T A T T
T T T G T G C G A A A G A T G G G G A G G A A C A C G A A G T C C C A C A A C T G C A C T C C
T G G A G C G G A C G A A A T T T A T A T C A C T A C A C T G G T G T A G A C G T C T G G G G
C C C A G G G A C C A C G G T C A C C G T C T C G A G C (S E Q ID N O : 571 )
6881_N05 (PGT-158) secuencia de aminoácidos de la cadena pesada gamma: proteína expresada con secuencia líder en cursiva y región variable en negrita.
MELGLSWVl LVALLRGVHCEXRLMESGGGWQPGKSLRLSCXTSGFIFKKY
P M Y W I R Q A P G K G L E W V A A I S A D A W H V D Y P G S V R G R F T V S R D N S K N S L Y
L D M N S L T V E D T A I Y F C A K D G E E H E V P Q L H S W S G R N L Y H Y T G V D V W G P G
T T V T V S S A S T K G P S V 1 P L A P S S K S T S G G T A A L G C L V K D Y F P E P V T V S W N S G A L
T S G V H T F P A V L Q S S G L Y S L S S V V T V P S S S L G T Q T Y I C N V N H K P S N T K V D K R V E
P K S C D K T H T C P P C P A P E L L G G P S V F L F P P K P K D T L M I S R T P E V T C V V V D V S H E
D P E V K F N W Y V D G V E V H N A K T K P R E E Q Y N S T Y R V V S V L T V L H Q D W L N G K E Y
K C K V S N K A L P A P I E K T I S K A K G Q P R E P Q V Y T L P P S R E E M T K N Q V S L T C L V K G F
y p s d i a v e w e s n g q p e n n y k t i p p v l d s d g s f f l y s k l t v d k s r w q q g n v f s C S V M I I E A L I IN I I Y T Q K S L S L S P G K ( S E Q I D N O : 572 )
6881_N05 (PGT-158) secuencia de aminoácidos de región variable de cadena pesada gamma: (CDR de Kabat subrayadas, CDR de Chothia en negrita cursiva)
E V R L M E S G G G V V Q P G K S L R L S C V T S G F /F A A Y P M Y W I R Q A P G K G L E W V A A / S A P A W //V 7.)Y P G S V R G R I T V S R D N S K N S I .Y L D M N S L T V I iD T A I Y F C A K D G E E / / / : v n o i I IS W S C R N L Y H Y T G V I ) F W G P G T T V T V S S ( S E Q ID N O : 573 )
6881_N05 (PGT-158) CDR de Kabat de cadena pesada gamma:
CDR 1: KYPMY (SEQ ID NO: 475)
CDR 2: AISADAWHVDYPGSVRG (SEQ ID NO: 549)
CDR 3: DGEEHEVPQLHSWSGRNLYHYTGVDV (SEQ ID NO: 574) PG
6881_N05 (PGT-158) CDR de Chothia de la cadena pesada gamma:
CDR 1: GFIFKK (SEQ ID NO: 575)
CDR 2: AISADAWHVD (SEQ ID NO: 521)
CDR 3: DGEEHEVPQLHSWSGRNLYHYTGVDV (SEQ ID NO: 574)
6881_N05 (PGT-158) secuencia de nucleótidos de cadena ligera: secuencia de codificación (región variable en negrita)

G C C C G T C A C A A A G A G C T T C A A C A G G G G A G A G T G T T A G ( S E Q ID N O : 576 )
6881_N05 (PGT-158) secuencia de nucleótidos de región variable de cadena ligera:
G A C A T T G T G A T G A C C C A G A C T C C T G T C T C T G T G T C C G T C A C C C T C G G
A C A G C C G G C C T C C A T G T C C T G C A A G T C C A G T C A G A G C G T C C G A C A A A
G T G A T G G C A A G A C T T T T T T A T A T T G G T A T C G A C A G A A G G C A G G C C A G
T C T C C A C A A C T C T T A A T A T A T G A G G C T T C G A A G C G A T T C T C T G G A G T G
T C A G A T A G G T T C T C T G G C A G C G G G T C A G G G A C A G A C T T C A C A C T G A A
A A T C A G T C G G G T G G G G G C T G A G G A T G T T G G C G T T T A T T T C T G C A T G C
A A A C T A A A G A C T T C C C C C T T A C T T T T G G C G G A G G G A C C A A G G T G G A T
C T C A A A ( S E Q ID N O : 577 )
6881_N05 (PGT-158) secuencia de aminoácidos de cadena ligera: proteína expresada con secuencia líder en cursiva y región variable en negrita.
M R I .r A Q U .G L L M I .W ¡ P M T A D lX M T Q T P \S X S \T L G Q P \S M S C K S S Q S \R Q S
D G K T F L Y W Y R Q K A G Q S P Q L L I Y E A S K R F S G V S D R F S G S G S G T D F T L K I S R
V G A E D V G V Y F C M Q T K D F P L T F G G G T K V D L K R T V A A P S V I I I P P S D E Q E K S
G T A S V V C L L N N F Y P R E A K V Q W K V D N A L Q S G N S Q E S V T E Q D S K D S T Y S L S S T
L T L S K A D Y I iK I I K V Y A C E V T H Q G L S S P V T K S F N R G B C ( S E Q I I ) N O : 578 )
6881_N05 (PGT-158) secuencia de aminoácidos de región variable de cadena ligera: (CDR de Kabat subrayadas, CDR de Chothia en negrita y cursiva)
1)1 V M T O T P V S V S V T I jG O P A S M S C X S'A 'aS ' V R O S D G K T F L YW Y R O K A C iO S P O I .1, IY AV15'Á7f/\S'( iV S I ) R F S G S G S G T I ) F T I X I S R V G A E I ) V G V Y F C /V/(9Y’Á 7 ) /<7 , / / / T G G G T K V D L K ( S E Q I D N O : 579 )
6881_N05 (PGT-158) CDR de Kabat de cadena ligera:
CDR 1: KSSQSVRQSDGKTFLY (SEQ ID NO: 541)
CDR 2: EASKRFS (SEQ ID NO: 580)
CDR 3: MQTKDFPLT (SEQ ID NO: 569)
6881_N05 (PGT-158) CDR de Chothia de la cadena ligera:
CDR 1: KSSQSVRQSDGKTFLY (SEQ ID NO: 541)
CDR 2: EASKRFS (SEQ ID NO: 580)
CDR 3: MQTKDFPLT (SEQ ID NO: 569)
El anticuerpo 6831_A21 (PGT-151) incluye una región variable de cadena pesada (SEQ ID NO: 474), codificada por el secuencia de ácido nucleico mostrada en SEQ ID NO: 472, y una región variable de cadena ligera (SEQ ID NO: 483) codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 481.
Las CDR de cadena pesada del anticuerpo 6831_A21 (PGT-151) tienen las siguientes secuencias según la definición de Kabat: KYPMY (SEQ ID NO: 475), AISGDAWHVVYSNSVQG (SEQ ID NO: 476) y MFQESGPPRLDRWSGRNYYYYSGMDV (SEQ ID NO: 477). Las CDR de cadena ligera del anticuerpo 6831_A21 (PGT-151) tienen las siguientes secuencias según la definición de Kabat: KSSESLRQSNGKTSLY (SEQ ID NO: 484), EVSNRFS (SEQ ID NO: 485) y MQSKDFPLT (SEQ ID NO: 486).
Las CDR de cadena pesada del anticuerpo 6831_A21 (PGT-151) tienen las siguientes secuencias según la definición de Chothia: DFPFSK (SEQ ID NO: 478), AISGDAWHVV (SEQ ID NO: 479) y MFQESGPPRLDRWSGRNYYYYSGMDV (SEQ ID NO: 477). Las CDR de cadena ligera del anticuerpo 6831_A21 (PGT-151) tienen las siguientes secuencias según la definición de Chothia: KSSESLRQSNGKTSLY (SEQ ID NO: 484), EVSNRFS (SEQ ID NO: 485) y MQSKDFPLT (SEQ ID NO: 486).
El anticuerpo 6889_I17 (PGT-152) incluye una región variable de cadena pesada (SEQ ID NO: 490), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 488, y una región variable de cadena ligera (SEQ ID NO: 497) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 495.
Las CDR de cadena pesada del anticuerpo 6889_I17 (PGT-152) tienen las siguientes secuencias según la definición de Kabat: KYPMY (SEQ ID NO: 475), AISADAWHVVYSGSVQG (SEQ ID NO: 491) y MFQESGPPRFDSWSGRNYYYYSGMDV (SEQ ID NO: 492). Las CDR de cadena ligera del anticuerpo 6889_I17 (PGT-152) tienen las siguientes secuencias según la definición de Kabat: KSSQSLRQSNGKTSLY (SEQ ID NO: 498), EVSNRFS (SEQ ID NO: 485) y MQSKDFPLT (SEQ ID NO: 486).
Las CDR de cadena pesada del anticuerpo 6889_I17 (PGT-152) tienen las siguientes secuencias según la definición de Chothia: DFPFSK (SEQ ID NO: 478), AISADAWHVV (SEQ ID NO: 493) y MFQESGPPRFDSWSGRNYYYYSGMDV (SEQ ID NO: 492) Las CDR de cadena ligera del anticuerpo 6889_I17 (PGT-152) tienen las siguientes secuencias según la definición de Chothia: KSSQSLRQSNGKTSLY (SEQ ID NO: 498), EVSNRFS (SEQ ID NO: 485) y MQSKDFPLT (SEQ ID NO: 486).
El anticuerpo 6891_F06 (PGT-153) incluye una región variable de cadena pesada (SEQ ID NO: 502),
codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 500, y una región variable de cadena ligera (SEQ ID NO: 511) codificada por el secuencia de ácido nucleico mostrada en la SEQ ID NO: 509.
Las CDR de la cadena pesada del anticuerpo 6891_F06 (PGT-153) tienen las siguientes secuencias según la definición de Kabat: KRHMH (SEQ ID NO: 503), VISSDAIHVDYASSVRG (SEQ ID NO: 504) y DRDGYGPPQIQTWSGRYLHLYSGIDA (SEQ ID NO: 505). Las CDR de cadena ligera del anticuerpo 6891_F06 (PGT-153) tienen las siguientes secuencias según la definición de Kabat: KSSQSLRQSNGKTYLY (SEQ ID NO: 512), EVSIRFS (SEQ ID NO: 513) y MQSKDFPLT (SEQ ID NO: 486).
Las CDR de cadena pesada del anticuerpo 6891_F06 (PGT-153) tienen las siguientes secuencias según la definición de Chothia: NFLFNK (SEQ ID NO: 506), VISSDAIHVD (SEQ ID NO: 507) y DRDGYGPPQIQTWSGRYLHLYSGIDA (SEQ ID NO: 50) Las CDR de cadena ligera del anticuerpo 6891_F06 (PGT-153) tienen las siguientes secuencias según la definición de Chothia: KSSQSLRQSNGKTYLY (SEQ ID NO: 512), EVSIRFS (SEQ ID NO: 513) y MQSKDFPLT (SEQ ID NO: 486).
El anticuerpo 6843_G20 (PGT-154) incluye una región variable de cadena pesada (SEQ ID NO: 517), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 515, y una región variable de cadena ligera (SEQ ID NO: 525) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 523.
Las CDR de cadena pesada del anticuerpo 6843_G20 (PGT-154) tienen las siguientes secuencias según la definición de Kabat: KYPMY (SEQ ID NO: 475), AISADAWHVDYAASVKD (SEQ ID NO: 518), y NIEEFSVPQFDSWSGRSYYHYFGMDV (SEQ ID NO: 519). Las CDR de cadena ligera del anticuerpo 6843_G20 (PGT-154) tienen las siguientes secuencias según la definición de Kabat: SSSESLGRGDGRTYLH (Se Q ID NO: 526), EVSTRFS (SEQ ID NO: 527) y MQSRDFPIT (SEQ ID NO: 528).
Las CDR de cadena pesada del anticuerpo 6843_G20 (PGT-154) tienen las siguientes secuencias según la definición de Chothia: NFIFNK (SEQ ID NO: 520), AISADAWHVD (SEQ ID NO: 521) y NIEEFSVPQFDSWSGRSYYHYFGMDV (SEQ ID NO: 519). Las CDR de cadena ligera del anticuerpo 6843_G20 (PGT-154) tienen las siguientes secuencias según la definición de Chothia: SSSESLGRGDGRTYLH (SEQ ID NO: 526), EVSTRFS (SEQ ID NO: 527) y MQSRDFPIT (SEQ ID NO: 528).
El anticuerpo 6892_D19 (PGT-155) incluye una región variable de cadena pesada (SEQ ID NO: 532), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 530, y una región variable de cadena ligera (SEQ ID NO: 540) codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 538.
Las CDR de cadena pesada del anticuerpo 6892_D19 (PGT-155) tienen las siguientes secuencias según la definición de Kabat: EYPMY (SEQ ID NO: 533), AISADAWHVDYAGSVRG (SEQ ID NO: 534) y DGEEHKVPQLHSWSGRNLYHYTGFDV (SEQ ID NO: 535). Las CDR de cadena ligera del anticuerpo 6892_D19 (PGT-155) tienen las siguientes secuencias según la definición de Kabat: KSSQSVRQSDGKTFLY (Se Q ID NO: 541), EGSSRFS (SEQ ID NO: 542) y LQTKDFPLT (SEQ ID NO: 543).
Las CDR de cadena pesada del anticuerpo 6892_D19 (PGT-155) tienen las siguientes secuencias según la definición de Chothia: GFIFNE (SEQ ID NO: 536), AISADAWHVD (SEQ ID NO: 521) y DGEEHKVPQLHSWSGRNLYHYTGFDV (SEQ ID NO: 535) Las CDR de cadena ligera del anticuerpo 6892_D19 (PGT-155) tienen las siguientes secuencias según la definición de Chothia: KSSQSVRQSDGKTFLY (SEQ ID NO: 541), EGSSRFS (SEQ ID NO: 542) y LQTKDFPLT (SEQ ID NO: 543).
El anticuerpo 6808_B09 (PGT-156) incluye una región variable de cadena pesada (SEQ ID NO: 547), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 545, y una región variable de cadena ligera (SEQ ID NO: 554) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 552.
Las CDR de cadena pesada del anticuerpo 6808_B09 (PGT-156) tienen las siguientes secuencias según la definición de Kabat: QYPMY (SEQ ID NO: 548), AISADAWHVDYPGSVRG (SEQ ID NO: 549) y DGEEHKVPQLHSWSGRNLYHYTGFDV (SEQ ID NO: 535). Las CDR de cadena ligera del anticuerpo 6808_B09 (PGT-156) tienen las siguientes secuencias según la definición de Kabat: KSSQTVRQSDGKTFLY (SEQ ID NO: 555), EGSNRFS (SEQ ID NO: 556) y LQTKDFPLT (SEQ ID NO: 543).
Las CDR de cadena pesada del anticuerpo 6808_B09 (PGT-156) tienen las siguientes secuencias según la definición de Chothia: GFIFNQ (SEQ ID NO: 550), AISADAWHVD (SEQ ID NO: 521) y DGEEHKVPQLHSWSGRNLYHYTGFDV (SEQ ID NO: 535). Las CDR de cadena ligera del anticuerpo 6808_B09 (PGT-156) tienen las siguientes secuencias según la definición de Chothia: KSSQTVRQSDGKTFLY (SEQ ID NO: 555), EGSNRFS (SEQ ID NO: 556) y LQTKDFPLT (SEQ ID NO: 543).
El anticuerpo 6892_C23 (PGT-157) incluye una región variable de cadena pesada (SEQ ID NO: 560), codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 558, y una región variable de cadena
ligera (SEQ ID NO: 566) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 564.
Las CDR de cadena pesada del anticuerpo 6892_C23 (PGT-157) tienen las siguientes secuencias según la definición de Kabat: QYPMY (SEQ ID NO: 548), AISADAWHVDYAGSVRG (SEQ ID NO: 534) y DGEEHEVPQLHSWSGRNLYHYTGVDI (SEQ ID NO: 561). Las CDR de cadena ligera del anticuerpo 6892_C23 (PGT-157) tienen las siguientes secuencias según la definición de Kabat: KSSQSLRQSDGKTFLY (SEQ ID NO: 567), EASNRFS (SEQ ID NO: 568) y MQTKDFPLT (SEQ ID NO: 569).
Las CDR de cadena pesada del anticuerpo 6892_C23 (PGT-157) tienen las siguientes secuencias según la definición de Chothia: GFIFKQ (SEQ ID NO: 562), AISADAWHVD (SEQ ID NO: 521) y DGEEHEVPQLHSWSGRNLYHYTGVDI (SEQ ID NO: 561). Las CDR de cadena ligera del anticuerpo 6892_C23 (PGT-157) tienen las siguientes secuencias según la definición de Chothia: KSSQSLRQSDGKTFLY (SEQ ID NO: 567), EASNRFS (SEQ ID NO: 568) y MQTKDFPLT (SEQ ID NO: 569).
El anticuerpo 6881_N05 (PGT-158) incluye una región variable de cadena pesada (SEQ ID NO: 573), codificada por la secuencia de ácido nucleico mostrada en SEQ ID NO: 571, y una región variable de cadena ligera (SEQ ID NO: 579) codificada por la secuencia de ácido nucleico que se muestra en SEQ ID NO: 577.
Las CDR de cadena pesada del anticuerpo 6881_N05 (PGT-158) tienen las siguientes secuencias según la definición de Kabat: KYPMY (SEQ ID NO: 475), AISADAWHVDYPGSVRG (SEQ ID NO: 549) y DGEEHEVPQLHSWSGRNLYHYTGVDV (SEQ ID NO: 574). Las CDR de cadena ligera del anticuerpo 6881_N05 (PGT-158) tienen las siguientes secuencias según la definición de Kabat: KSSQSVRQSDGKTFLY (Se Q ID NO: 541), EASKRFS (SEQ ID NO: 580) y MQTKDFPLT (SEQ ID NO: 569).
Las CDR de cadena pesada del anticuerpo 6881_N05 (PGT-158) tienen las siguientes secuencias según la definición de Chothia: GFIFKK (SEQ ID NO: 575), AISADAWHVD (SEQ ID NO: 521) y DGEEHEVPQLHSWSGRNLYHYTGVDV (SEQ ID NO: 57) Las CDR de cadena ligera del anticuerpo 6881_N05 (PGT-158) tienen las siguientes secuencias según la definición de Chothia: KSSQSVRQSDGKTFLY (SEQ ID NO: 541), EASKRFS (SEQ ID NO: 580) y MQTKDFPLT (SEQ ID NO: 569).
En un aspecto, un anticuerpo de acuerdo con la solicitud contiene una cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 12, 16, 20, 24, 28, 139, 47, 53, 59, 65, 62, 153 165, 181, 197, 213, 229, 246, 275, 291,297, 306, 318, 333, 346, 362, 400, 404, 419, 434, 443, 453, 462, 473, 489, 501, 516, 531, 546, 559 o 572, y una cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 14, 18, 22, 26, 30, 142, 50, 56, 148, 158, 174, 190, 206, 222, 238, 255, 284, 301, 312, 329, 392, 355, 396, 385, 413, 428, 439, 448, 583, 469, 482, 496, 510, 524, 539, 553, 565 o 578. Alternativamente, un anticuerpo de acuerdo con la solicitud contiene una región variable de cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 31, 33, 35, 37, 39, 140, 48, 54, 60, 79, 156, 168, 184200, 216, 232, 149, 276, 292, 298, 307, 319, 334, 347, 363, 401, 405, 420, 435, 444, 454, 463, 474, 490, 502, 517, 532, 547, 560 o 573, y una región variable de cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NOs: 32, 34, 36, 38, 40, 96, 51, 57, 149, 161, 177, 193, 209, 225, 242, 258, 285, 302, 313, 330, 393, 356, 397, 386, 414, 429, 440, 449, 584, 470, 483, 497, 511,525, 540, 554, 566 o 579. El anticuerpo de la invención, sin embargo, comprende específicamente una región variable de la cadena pesada que comprende la secuencia de aminoácidos de la SEQ ID NO: 435 y una región variable de la cadena ligera que comprende la secuencia de aminoácidos de la SEQ ID NO: 440.
En otro aspecto, un anticuerpo de acuerdo con la solicitud contiene una cadena pesada que tiene la secuencia de aminoácidos codificada por la secuencia de ácido nucleico de SEQ ID NO: 11, 15, 19, 23, 27, 138, 46, 52, 58, 64, 66, 166, 167, 183, 199, 215, 231,248, 273, 289, 295, 304, 314, 316, 331, 344, 360, 398, 402, 417, 432, 441, 451,460, 471,487, 499, 514, 529, 544, 557 o 570, y una cadena ligera que tiene la secuencia de aminoácidos codificada por la secuencia de ácido nucleico de la SEQ ID NO: 13, 17, 21, 25, 29, 141, 49, 55, 61, 67, 146, 160, 176, 192, 208, 224, 240, 257, 282, 299, 310, 327, 390, 353, 394, 383, 411, 426, 437, 446, 581, 467, 480, 494, 508, 522, 537, 551, 563 o 576. Alternativamente, un anticuerpo de acuerdo con la solicitud contiene una región variable de cadena pesada que tiene la secuencia de aminoácidos codificada por la secuencia de ácido nucleico de SEQ ID NO: 99, 101, 109, 115, 122, 128, 130, 132, 134, 136, 63, 154, 166, 182, 198, 214, 230, 247, 274, 290, 296, 305, 315, 317, 332, 345, 361, 399, 403, 418, 433, 442, 452, 461, 472, 488, 500, 515, 530, 545, 558 o 571, y una región variable de cadena ligera que tiene la secuencia de aminoácidos codificada por la secuencia de ácido nucleico de SEQ ID NO: 100, 106, 112, 119, 125, 129, 131, 133, 135, 137, 147, 159, 175, 191, 207, 223, 239, 256, 283, 300, 311, 328, 391, 354, 395, 384, 412, 427, 438, 447, 582, 468, 481,495, 509, 523, 538, 552, 564 o 577. Además, un anticuerpo de acuerdo con el la solicitud contiene una cadena pesada que tiene la secuencia de aminoácidos codificada por una secuencia de ácido nucleico de SEQ ID NO: 11, 15, 19, 23, 27, 138, 46, 52, 58, 64, 66, 166, 167, 183, 199215, 231, 248, 273, 289, 295, 304, 314, 316, 331, 344, 360, 398, 402, 417, 432, 441, 451, 460, 471, 487, 499, 514, 529, 544, 557, o 570, que contiene una mutación silenciosa o degenerada, y una cadena ligera que tiene la secuencia de aminoácidos codificada por la secuencia de ácido nucleico de SEQ ID NO: 13, 17, 21,25, 29, 141, 49, 55, 61, 67, 146, 160176, 192, 208, 224, 240, 257, 282, 299, 310, 327, 390, 353, 394, 383, 411, 426, 437, 446, 581, 467, 480, 494, 508, 522, 537, 551, 563 o 576, que contiene una mutación silenciosa o degenerada. Las mutaciones silenciosas y degeneradas alteran la secuencia
de ácido nucleico, pero no alteran la secuencia de aminoácidos resultante.
Por ejemplo, las tres CDR de cadena pesada incluyen una secuencia de aminoácidos de al menos 90%, 92%, 95%, 97%, 98%, 99% o más idénticas a la secuencia de aminoácidos de KYGMH (SEQ ID NO: 88), LISDDGMRKYHSDSMWG (SEQ ID NO: 89), EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6), SYAFT (SEQ ID NO: 104), MVTPIFGEAKYSQRFEG (SEQ ID NO: 105), DRRAVPIATDNWLDP (SEQ ID NO: 9), SYAFS (SEQ ID NO: 110), MITPVFGETKYAPRFQG (SEQ ID NO: 111), DRRVVPMATDNWLDP (SEQ ID NO: 8), DYYLH (SEQ ID NO: 116), LIDPENGEARYAEKFQG (SEQ ID NO: 117), GAVGADSGSWFDP (SEQ ID NO: 10), RQGMH (SEQ ID NO: 123), FIKYDGSEKYHADSVWG (SEQ ID NO: 124), EAGGPDYRNGYNYYDFYDGYYNYHYMDV (SEQ ID NO: 7), LISDDGMRKYHSNSMWG (SEQ ID NO: 98), DSYWS (SEQ ID NO: 90), YVHKSGDTNYSPSLKS (SEQ ID NO: 265), TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143), DNYWS (SEQ ID NO: 261), YVHDSGDTNYNPSLKS (SEQ ID NO: 157), TKHGRRIYGVVAFKEWFTYFYMDV (SEQ ID NO: 262), DAYWS (SEQ ID NO: 169), YVHHSGDTNYNPSLKR (SEQ ID NO: 170), ALHGKRIYGIVALGELFTYFYMDV (SEQ ID NO: 171), ACTYFWG (SEQ ID NO: 185), SLSHCQSFWGSGWTFHNPSLKS (SEQ ID NO: 186), FDGEVLVYNHWPKPAWVDL (SEQ ID NO: 187), ACDYFWG (SEQ ID NO: 201), GLSHCAGYYNTGWTYHNPSLKS (SEQ ID NO: 202), FDGEVLVYHDWPKPAWVDL (SEQ ID NO: 203), TGHYYWG (SEQ ID NO: 217), HIHYTTAVLHNPSLKS (SEQ ID NO: 218), SGGDILYYYEWQKPHWFSP (SEQ ID NO: 219), GGEWGDKDYHWG (SEQ ID NO: 233), SIHWRGTTHYKESLRR (SEQ ID NO: 234), HRHHDVFMLVPIAGWFDV (SEQ ID NO: 235), GTDWGENDFHYG (SEQ ID NO: 250), SIHWRGRTTHYKTSFRS (SEQ ID NO: 251), HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252), KYDVH (SEQ ID NO: 277), WMSHEGDKTESAQRFKG (SEQ ID NO: 278), GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279), WISHERDKTESAQRFKG (SEQ ID NO: 293), GSKHRLRDYVLYDDYGLINQQEWNDYLEFLDV (SEQ ID NO: 308), RCNYFWG (SEQ ID NO: 320), SLSHCRSYYNTDWTYHNPSLKS (SEQ ID NO: 321), FGGEVLVYRDWPKPAWVDL (SEQ ID NO: 322), ACNSFWG (SEQ ID NO: 326), SLSHCASYWNRGWTYHNPSLKS (SEQ ID NO: 335), FGGEVLRYTDWPKPAWVDL (SEQ ID NO: 336), TGHHYWG (SEQ ID NO: 348), HIHYNTAVLHNPALKS (SEQ ID NO: 349), SGGDILYYIEWQKPHWFYP (SEQ ID NO: 350), GGEWGDSDYHWG (SEQ ID NO: 364), SIHWRGTTHYNAPFRG (SEQ ID NO: 365), HKYHDIVMVVPIAGWFDP (SEQ ID NO: 366), NHDVH (SEQ ID NO: 378), WMSHEGDKTGLAQKFQG (SEQ ID NO: 379), GSKHRLRDYFLYNEYGPNYEEWGDYLATLDV (SEQ ID NO: 380), NYYWT (SEQ ID NO: 406), YISDRETTTYNPSLNS (SEQ ID NO: 407), ARRGQRIYGVVSFGEFFYYYYMDV (SEQ ID NO: 408), GRFWS (SEQ ID NO: 421), YFSDTDRSEYNPSLRS (SEQ ID NO: 422), AQQGKRIYGIVSFGEFFYYYYMDA (SEQ ID NO: 423), AQQGKRIYGIVSFGELFYYYYMDA (SEQ ID NO: 436), SGGDILYYNEWQKPHWFYP(SEQ ID NO: 445), SLSHCAGYYNSGWTYHNPSLKS (SEQ ID NO: 455), FGGDVLVYHDWPKPAWVDL (SEQ ID NO: 456), GCDYFWG (SEQ ID NO: 464), FDGEVLVYNDWPKPAWVDL (SEQ ID NO: 465), KYPMY (SEQ ID NO: 475), AISGDAWHVVYSNSVQG (SEQ ID NO: 476), MFQESGPPRLDRWSGRNYYYYSGMDV (SEQ ID NO: 477), AISADAWHVVYSGSVQG (SEQ ID NO: 491), MFQESGPPRFDSWSGRNYYYYSGMDV (SEQ ID NO: 492), KRHMH (SEQ ID NO: 503), VISSDAIHVDYASSVRG (SEQ ID NO: 504), DRDGYGPPQIQTWSGRYLHLYSGIDA (SEQ ID NO: 505), AISADAWHVDYAASVKD (SEQ ID NO: 518), NIEEFSVPQFDSWSGRSYYHYFGMDV (SEQ ID NO: 519), EYPMY (SEQ ID NO: 533), AISADAWHVDYAGSVRG (SEQ ID NO: 534), DGEEHKVPQLHSWSGRNLYHYTGFDV (SEQ ID NO: 535), QYPMY (SEQ ID NO: 548), AISADAWHVDYPGSVRG (SEQ ID NO: 549), DGEEHEVPQLHSWSGRNLYHYTGVDI (SEQ ID NO: 561), DGEEHEVPQLHSWSGRNLYHYTGVDV (SEQ ID NO: 574), (como se ha determinado por el método Kabat) o GFTFHK (SEQ ID NO: 266), LISDDGMRKY (SEQ ID NO: 267), EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6), GGTFSS (SEQ ID NO: 268), MVTPIFGEAK (SEQ ID NO: 269), DRRAVPIATDNWLDP (SEQ ID NO: 9), GGAFSS (SEQ ID NO: 270), MITPVFGETK (SEQ ID NO: 271), DRRVVPMATDNWLDP (SEQ ID NO: 8), GYSFID (SEQ ID NO: 102), LIDPENGEAR (SEQ ID NO: 103), GAVGADSGSWFDP (SEQ ID NO: 10), GFDFSR (SEQ ID NO: 118), FIKYDGSEKY (SEQ ID NO: 272), EAGGPDYRNGYNYYDFYDGYYNYHYMDV (SEQ ID NO: 7), GASISD (SEQ ID NO: 144), YVHKSGDTN (SEQ ID NO: 145), TLHGRRIYGIVAFNEWFTYFYMDV (SEQ ID NO: 143), GTLVRD (SEQ ID NO: 263), YVHDSGDTN (SEQ ID NO: 264), TKHGRRIYGVVAFKEWFTYFYMDV (SEQ ID NO: 262), GASIND (SEQ ID NO: 172), YVHHSGDTN (SEQ ID NO: 173), ALHGKRIYGIVALGELFTYFYMDV (SEQ ID NO: 171), GESTGACT (SEQ ID NO: 188), SLSHCQSFWGSGWTF (SEQ ID NO: 189), FDGEVLVYNHWPKPAWVDL (SEQ ID NO: 187), GDSTAACD (SEQ ID NO: 204), GLSHCAGYYNTGWTY (SEQ ID NO: 205), FDGEVLVYHDWPKPAWVDL (SEQ ID NO: 203), GESINTGH (SEQ ID NO: 220), HIHYTTAVL (SEQ ID NO: 221), SGGDILYYYEWQKPHWFSP (SEQ ID NO: 219), GDSIRGGEWGDKD (SEQ ID NO: 236), SIHWRGTTH (SEQ ID NO: 237), HRHHDVFMLVPIAGWFDV (SEQ ID NO: 235), GGSMRGTDWGEND (SEQ ID NO: 253), SIHWRGRTTH (SEQ ID NO: 254), HKYHDIFRVVPVAGWFDP (SEQ ID NO: 252), GNTFSK (SEQ ID NO: 280), WMSHEGDKTE (SEQ ID NO: 281), GSKHRLRDYVLYDDYGLINYQEWNDYLEFLDV (SEQ ID NO: 279), WISHERDKTE (SEQ ID NO: 294), GSKHRLRDYVLYDDYGLINQQEWNDYLEFLDV (SEQ ID NO: 308), o GNTFRK(SEQ ID NO: 309), GDSTGRCN (SEQ ID NO: 323), SLSHCRSYYNTDWTY (SEQ ID NO: 324), FGGEVLVYRDWPKPAWVDL (SEQ ID NO: 322), GDSTAACN (SEQ ID NO: 337), SLSHCASYWNRGWTY (SEQ ID NO: 338), FGGEVLRYTDWPKPAWVDL (SEQ ID NO: 336), GDSINTGH (SEQ ID NO: 351), HIHYNTAVL (SEQ ID NO: 352), SGGDILYYIEWQKPHWFYP (SEQ ID NO: 350), GGSIRGGEWGDSD (SEQ ID NO: 367), SIHWRGTTH (SEQ ID NO: 237), HKYHDIVMVVPIAGWFDP (SEQ ID NO: 366), GNSFSN (SEQ ID NO: 381), WMSHEGDKTG (SEQ ID NO: 382), GSKHRLRDYFLYNEYGPNYEEWGDYLATLDV (SEQ ID NO: 380), GGSISN (SEQ ID NO: 409), YISDRETTT (SEQ ID NO: 410), ARRGQRIYGVVSFGEFFYYYYMDV (SEQ ID NO: 408), NGSVSG (SEQ ID NO: 424), YFSDTDRSE (SEQ ID NO: 425), AQQGKRIYGIVSFGEFFYYYYMDA (SEQ ID NO: 423), AQQGKRIYGIVSFGELFYYYYMDA (SEQ
ID NO: 436), SGGDILYYNEWQKPHWFYP (SEQ ID NO: 445), SLSHCAGYYNSGWTY (SEQ ID NO: 457), FGGDVLVYHDWPKPAWVDL (SEQ ID NO: 456), GDSTAGCD (SEQ ID NO: 466), FDGEVLVYNDWPKPAWVDL (SEQ ID NO: 465), DFPFSK (SEQ ID NO: 478), AISGDAWHVV (SEQ ID NO: 479), MFQESGPPRLDRWSGRNYYYYSGMDV (SEQ ID NO: 477), AISADAWHVV (SEQ ID NO: 493), MFQESGPPRFDSWSGRNYYYYSGMDV (SEQ ID NO: 492), NFLFNK (SEQ ID NO: 506), VISSDAIHVD (SEQ ID NO: 507), DRDGYGPPQIQTWSGRYLHLYSGIDA (SEQ ID NO: 505), NFIFNK (SEQ ID NO: 520), AISADAWHVD (SEQ ID NO: 521), NIEEFSVPQFDSWSGRSYYHYFGMDV (SEQ ID NO: 519), GFIFNE (SEQ ID NO: 536), DGEEHKVPQLHSWSGRNLYHYTGFDV (SEQ ID NO: 535), GFIFNQ (SEQ ID NO: 550), GFIFKQ (SEQ ID NO: 562), DGEEHEVPQLHSWSGRNLYHYTGVDI (SEQ ID NO: 561), GFIFKK (SEQ ID NO: 575), DGEEHEVPQLHSWSGRNLYHYTGVDV (SEQ ID NO: 574), (como se ha determinado por el método Chothia), y una cadena ligera, con tres CDR que incluyen una secuencia de aminoácidos de al menos 90%, 92%, 95%, 97%, 98%, 99%, o más idéntico a la secuencia de aminoácidos de NGTSSDVGGFDSVS (SEQ ID NO: 97), DVSHRPS (SEQ ID NO: 95), SSLTDRSHRI (SEQ ID NO: 41), RASQTINNYLN (SEQ ID NO: 107), GASNLQN (SEQ ID NO: 108), QQSFSTPRT (SEQ ID NO: 42), RASQTIHTYLN (SEQ ID NO: 113), GASTLQS (SEQ ID NO: 114), QQSYSTPRT (SEQ ID NO: 43), SGSKLGDKYVS (SEQ ID NO: 120), ENDRRPS (SEQ ID NO: 121), QAWETTTTTFVF (SEQ ID NO: 44), NGTSNDVGGYESVS (SEQ ID NO: 126), DVSKRPS (SEQ ID NO: 127), KSLTSTRRRV (SEQ ID NO: 45), NGTRSDVGGFDSVS (SEQ ID NO: 92), NGTSRDVGGFDSVS (SEQ ID NO: 93), GEKSLGSRAVQ (SEQ ID NO: 150), NNQDRPS (SEQ ID NO: 151), HIWDSRVPTKWV (SEQ ID NO: 152), GEESLGSRSVI (SEQ ID NO: 162), NNNDRPS (SEQ ID NO: 163), HIWDSRRPTNWV (SEQ ID NO: 164), GKESIGSRAVQ (SEQ ID NO: 178), NNQDRPA (SEQ ID NO: 179), HIYDARGGTNWV (SEQ ID NO: 180), NGTATNFVS (SEQ ID NO: 194), GVDKRPP (SEQ ID NO: 195), GSLVGNWDVI (SEQ ID NO: 196), TGTSNRFVS (SEQ ID NO: 210), GVNKRPS (SEQ ID NO: 211), SSLVGNWDVI (SEQ ID NO: 212), NGTSSDIGGWNFVS (SEQ ID NO: 226), EVNKRPS (SEQ ID NO: 227), SSLFGRWDVV (SEQ ID NO: 228), RASQNINKNLA (SEQ ID NO: 243), ETYSKIA (SEQ ID NO: 244), QQYEEWPRT (SEQ ID NO: 245), RASQNVKNNLA (SEQ ID NO: 259), DASSRAG (SEQ ID NO: 260), SSTQSLRHSNGANYLA (SEQ ID NO: 286), LGSQRAS (SEQ ID NO: 287), MQGLNRPWT (SEQ ID NO: 288), o TSTQSLRHSNGANYLA (SEQ ID NO: 303), TGTSNNFVS (SEQ ID NO: 325), DVNKRPS (SEQ ID NO: 343), GSLVGNWDVI (SEQ ID NO: 196), SGTGSDIGSWNFVS (SEQ ID NO: 357), EVNRRRS (SEQ ID NO: 358), SSLSGRWDIV (SEQ ID NO: 359), RASQSVKNNLA (SEQ ID NO: 372), DTSSRAS (SEQ ID NO: 373), KCSHSLQHSTGANYLA (SEQ ID NO: 387), LATHRAS (SEQ ID NO: 388), MQGLHSPWT (SEQ ID NO: 389), GRQALGSRAVQ (SEQ ID NO: 415), HMWDSRSGFSWS (SEQ ID NO: 416), GERSRGSRAVQ (SEQ ID NO: 430), HYWDSRSPISWI (SEQ ID NO: 431), SGTASDIGSWNFVS (SEQ ID NO: 450), TGNINNFVS (SEQ ID NO: 458), GSLAGNWDVV (SEQ ID NO: 459), KSSESLRQSNGKTSLY (SEQ ID NO: 484), EVSNRFS (SEQ ID NO: 485), MQSKDFPLT (SEQ ID NO: 486), KSSQSLRQSNGKTSLY (SEQ ID NO: 498), KSSQSLRQSNGKTYLY (SEQ ID NO: 512), EVSIRFS (SEQ ID NO: 513), SSSESLGRGDGRTYLH (SEQ ID NO: 526), EVSTRFS (SEQ ID NO: 527), MQSRDFPIT (SEQ ID NO: 528), KSSQSVRQSDGKTFLY (SEQ ID NO: 541), EGSSRFS (SEQ ID NO: 542), LQTKDFPLT (SEQ ID NO: 543), KSSQTVRQSDGKTFLY (SEQ ID NO: 555), EGSNRFS (SEQ ID NO: 556), KSSQSLRQSDGKTFLY (SEQ ID NO: 567), EASNRFS (SEQ ID NO: 568), MQTKDFPLT (SEQ ID NO: 569), EASKRFS (SEQ ID NO: 580), (como se ha determinado por el método Kabat), o NGTSSDVGGFDSVS (SEQ ID NO: 97), DVSHRPS (SEQ ID NO: 95), SSLTDRSHRI (SEQ ID NO: 41), RASQTINNYLN (SEQ ID NO: 107), GASNLQN (SEQ ID NO: 108), QQSFSTPRT (SEQ ID NO: 42), RASQTIHTYLN (SEQ ID NO: 113), GASTLQS (SEQ ID NO: 114), QQSYSTPRT (SEQ ID NO: 43), SGSKLGDKYVS (SEQ ID NO: 120), ENDRRPS (SEQ ID NO: 121), QAWETTTTTFVF (SEQ ID NO: 44), NGTSNDVGGYESVS (SEQ ID NO: 126), DVSKRPS (SEQ ID NO: 127), KSLTSTRRRV (SEQ ID NO: 45), NGTRSDVGGFDSVS (SEQ ID NO: 92), NGTSRDVGGFDSVS (SEQ ID NO: 93) GEKSLGSRAVQ (SEQ ID NO: 150), NNQDRPS (SEQ ID NO: 151), HIWDSRVPTKWV (SEQ ID NO: 152), GEESLGSRSVI (SEQ ID NO: 162), NNNDRPS (SEQ ID NO: 163), HIWDSRRPTNWV (SEQ ID NO: 164), GKESIGSRAVQ (SEQ ID NO: 178), NNQDRPA (SEQ ID NO: 179), HIYDARGGTNWV (SEQ ID NO: 180), NGTATNFVS (SEQ ID NO: 194), GVDKRPP (SEQ ID NO: 195), GSLVGNWDVI (SEQ ID NO: 196), TGTSNRFVS (SEQ ID NO: 210), GVNKRPS (SEQ ID NO: 211), SSLVGNWDVI (SEQ ID NO: 212), NGTSSDIGGWNFVS (SEQ ID NO: 226), EVNKRPS (SEQ ID NO: 227), SSLFGRWDVV (SEQ ID NO: 228), RASQNINKNLA (SEQ ID NO: 243), ETYSKIA (SEQ ID NO: 244), QQYEEWPRT (SEQ ID NO: 245), RASQNVKNNLA (SEQ ID NO: 259), DASSRAG (SEQ ID NO: 260), SSTQSLRHSNGANYLA (SEQ ID NO: 286), LGSQRAS (SEQ ID NO: 287), MQGLNRPWT (SEQ ID NO: 288), TSTQSLRHSNGANYLA (SEQ ID NO: 303), TGTSNNFVS (SEQ ID NO: 325), DVNKRPS (SEQ ID NO: 343), GSLVGNWDVI (SEQ ID NO: 196), SGTGSDIGSWNFVS (SEQ ID NO: 357), EVNRRRS (SEQ ID NO: 358), SSLSGRWDIV (SEQ ID NO: 359), RASQSVKNNLA (SEQ ID NO: 372), DTSSRAS (SEQ ID NO: 373), KCSHSLQHSTGANYLA (SEQ ID NO: 387), LATHRAS (SEQ ID NO: 388), MQGLHSPWT (SEQ ID NO: 389), GRQALGSRAVQ (SEQ ID NO: 415), HMWDSRSGFSWS (SEQ ID NO: 416), GERSRGSRAVQ (SEQ ID NO: 430), HYWDSRSPISWI (SEQ ID NO: 431), SGTASDIGSWNFVS (SEQ ID NO: 450), TGNINNFVS (SEQ ID NO: 458), GSLAGNWDVV (SEQ ID NO: 459), KSSESLRQSNGKTSLY (SEQ ID NO: 484), EVSNRFS (SEQ ID NO: 485), MQSKDFPLT (SEQ ID NO: 486), KSSQSLRQSNGKTSLY (SEQ ID NO: 498), KSSQSLRQSNGKTYLY (SEQ ID NO: 512), EVSIRFS (SEQ ID NO: 513), SSSESLGRGDGRTYLH (SEQ ID NO: 526), EVSTRFS (SEQ ID NO: 527), MQSRDFPIT (SEQ ID NO: 528), KSSQSVRQSDGKTFLY (SEQ ID NO: 541), EGSSRFS (SEQ ID NO: 542), LQTKDFPLT (SEQ ID NO: 543), KSSQTVRQSDGKTFLY (SEQ ID NO: 555), EGSNRFS (SEQ ID NO: 556), KSSQSLRQSDGKTFLY (SEQ ID NO: 567), EASNRFS (SEQ ID NO: 568), MQTKDFPLT (SEQ ID NO: 569), EASKRFS (SEQ ID NO: 580), (como se ha determinado por el método Chothia)
La cadena pesada del anticuerpo monoclonal anti-VIH se deriva de un gen variable de línea germinal (V) tal como, por ejemplo, el gen de línea germinal IGHV1, IGHV3 o IGHV4 o un alelo del mismo.
Los anticuerpos anti-VIH de la aplicación incluyen una región de cadena pesada variable (Vh) codificada por una secuencia del gen de la línea germinal IGHV1, IGHV3 o IGHV4 humana o un alelo de la misma. Los anticuerpos de la invención se derivan de los genes IGHV1-2, IGHV1-8 o IGHV1-46, o un alelo de los mismos. Los alelos ejemplares del gen de la línea germinal IGHV1 incluyen, entre otros, IGHV1-2*02, IGHV1-2*04, IGHV1-8*01, IGHV1-46*01, IGHV1-46*02 o IGHV1-46*03. Las secuencias del gen de la línea germinal IGHV1 se muestran, por ejemplo, en los números de acceso L22582, X27506, X92340, M83132, X67905, L22583, Z29978, Z14309, Z14307, Z14300, Z14296 y Z14301. Las secuencias del gen de la línea germinal IGHV3 se muestran, por ejemplo, en los números de acceso AB019439, M99665, M77305, M77335 y M77334. Los anticuerpos de la aplicación se derivan de los genes IGHV4-59, IGHV4-64, IGHV4-b, IGHV4-39 o IGHV4-28, o un alelo de los mismos. Los alelos ejemplares del gen de la línea germinal IGHV4 incluyen, entre otros, IGHV4-59*01, IGHV4-59*07, IGHV4-59*02, IGHV4-59*03, IGHV4-59*04, IGHV4-61*08, IGHV4-b*02, IGHV4-b*01, IGHV4-39*07, IGHV4-39*03, IGHV4-39*06, IGHV4-39*01, IGHV4-39*02 o IGHV4-28*05. Se muestran las secuencias de genes de la línea germinal IGHV4, por ejemplo, en los números de acceso AB019439, L10094, X05715, X92259, X92297, M95116, Z14236, AM940222, X54447, X56362, Z14075, Z75352, AB019438, M29812, M95114, M95117, M95118, M95119, X56360, X87091, Z75359, Z14243, L10088, U03896, X56355, X56359, X92248, X92296, Z12371, M29811, L10097, X92230, X92250, X56356, Z75347, Z75348, AB019437, M95111, X92249, X92251, Z12366, Z75346, Z75361, Z12367, X56365 y X92289. Los anticuerpos anti-VIH de la aplicación incluyen una región Vh que está codificada por una secuencia de ácido nucleico que es al menos 80% homóloga a la secuencia del gen de la línea germinal IGHV1, IGHV3 o IGHV4 o un alelo de la misma. Preferiblemente, la secuencia de ácido nucleico es al menos 90%, 95%, 96%, 97% homóloga a la secuencia del gen de la línea germinal IGHV1, IGHV3 o IGHV4, y más preferiblemente, al menos 98%, 99% homóloga a IGHV1, IGHV3, o la secuencia del gen de la línea germinal IGHV4 o un alelo de la misma. La región Vh del anticuerpo anti-VIH es al menos un 80% homóloga a la secuencia de aminoácidos de la región Vh codificada por la secuencia del gen de la línea germinal IGHV1, IGHV3 o IGHV4 o un alelo de la misma. Preferiblemente, la secuencia de aminoácidos de la región Vh del anticuerpo anti-VIH es al menos 90%, 95%, 96%, 97% homóloga a la secuencia de aminoácidos codificada por la secuencia del gen de la línea germinal IGHV1, IGHV3 o IGHV4 o una alelo del mismo, y más preferiblemente, al menos 98%, 99% homólogo a la secuencia codificada por la secuencia del gen de la línea germinal IGHV1, IGHV3 o IGHV4 o un alelo de los mismos.
La cadena ligera del anticuerpo monoclonal anti-VIH de la aplicación se deriva de un gen de línea germinal variable (V) tal como, por ejemplo, el gen de línea germinal IGLV2, IGLV3, IGKV1, IGKV2, IGKV2D o IGKV3 o un gen alelo de los mismos.
Los anticuerpos anti-VIH de la aplicación también incluyen una región de cadena ligera variable (Vl) codificada por un gen de línea germinal humano IGLV2, IGLV3, IGKV1, IGKV2, IGKV2D, IGKV3 o IGKV3D o un alelo de los mismos. Se muestra una secuencia del gen de la línea germinal IGLV2 Vl humana, por ejemplo, números de acceso Z73664, L27822, Y12412 e Y12413. Se muestra una secuencia del gen de la línea germinal IGLV3 Vl humana, por ejemplo, número de acceso X57826. Los anticuerpos de la aplicación se derivan del gen de la línea germinal IGLV2-8, o un alelo del mismo.
Los alelos ejemplares del gen de la línea germinal IGLV2-8 incluyen, pero no se limitan a, IGLV2-8*01 e IGLV2-8*02. Los anticuerpos de la aplicación se derivan del gen de la línea germinal IGLV3-21, o un alelo del mismo. Los alelos ejemplares del gen de la línea germinal IGLV3-21 incluyen, entre otros, IGLV3-21*01, IGLV3-21*02 e IGLV3-21*03. Los anticuerpos de la aplicación se derivan de los genes de línea germinal IGKV2-28 e IGKV2D-28, o un alelo de los mismos. Los alelos ejemplares de los genes de línea germinal IGKV2-28 e IGKV2D-28 incluyen, entre otros, IGKV2-28*01 e IGKV2D-28*01. Los anticuerpos de la aplicación se derivan de los genes de línea germinal IGKV3-15 e IGKV3D-15, o un alelo de los mismos. Los alelos ejemplares de los genes de línea germinal IGKV3-15 e IGKV3D-15 incluyen, entre otros, IGKV3-15*01, IGKV3D-15*01 e IGKV3D-15*02 (P).
Se muestra una secuencia del gen de la línea germinal IGLV2 Vl humana, por ejemplo, números de acceso Z73657, Z73664, Z73642, X14616, X97466, Z73643, D87013, Z73641, X97462, D87021, Y12417, L27695 y Z22209. Se muestra una secuencia del gen de la línea germinal humana IGLV3 V L, por ejemplo, números de acceso X57826, X97464, Z73658, X97463, D87015, X97471, X97472, X56178, X97468, X71966, D87007, M94115, Z73666, X71968, X74474, Z73644, Z73646, X97469, Z73645, D87024, X97465, X97470 y X97473. Se muestra una secuencia del gen de la línea germinal IGKV1 VL humana, por ejemplo, números de acceso AF306358, AF490911, L12062, L12064, L12065, L12066, L12068, L12072, L12075, L12076, L12079, L12080, L12081, L12082, L120, L84 L12086: 12088, L12091, L12093, L12101, L12106, L12108, L12110, L12112, M95721, M95722, M95723, X73855, X73860, X98972, X98973, Z15073, Z15074, Z15075, Z150. Se muestra una secuencia del gen de la línea germinal IGKV3 VL humana, p. ej., Números de acceso X01668, M23090, X12686, X06583, X71883, X71891, X02725, L37728, L37727, L37730, L19271, L19272, X17264, X72815, X1868, X12687. X71895, X72820.
Alternativamente, los anticuerpos anti-VIH incluyen una región Vl que está codificada por una secuencia de ácido nucleico que es al menos 80% homóloga al gen de línea germinal IGLV2, IGLV3, IGKV1, IGKV2, IGKV2D,
IGKV3 o IGKV3D o un gen alelo de los mismos. Preferiblemente, la secuencia de ácido nucleico es al menos 90%, 95%, 96%, 97% homóloga al gen de línea germinal IGLV2, IGLV3, IGKV1, IGKV2, IGKV2D, IGKV3 o IGKV3D o un alelo de los mismos, y más preferiblemente, al menos 98%, 99% homólogo al gen germinal IGLV2, IGLV3, IGKV1, IGKV2, IGKV2D, IGKV3 o IGKV3D o un alelo de los mismos. La región Vl del anticuerpo anti-VIH es al menos un 80% homóloga a la secuencia de aminoácidos de la región Vl codificada en el gen de la línea germinal IGLV2, IGLV3, IGKV1, IGKV2, IGKV2D, IGKV3 o IGKV3D o un alelo de los mismos. Preferiblemente, la secuencia de aminoácidos de la región Vl del anticuerpo anti-VIH es al menos 90%, 95%, 96%, 97% homóloga a la secuencia de aminoácidos codificada por IGLV2, IGLV3, IGKV1, IGKV2, IGKV2D, IGKV3, o el gen de línea germinal IGKV3D o un alelo de los mismos, y más preferiblemente, al menos 98%, 99% homólogo a la secuencia codificada por el gen de línea germinal IGLV2, IGLV3, IGKV1, IGKV2, IGKV2D, IGKV3 o IGKV3D o un alelo de los mismos.


Tabla 10. Alineación de secuencias de proteina de cadena ligera de un dominio variable de clones hermanos 1443 C16 a 1443 C1B y 1496 C09.
Secuencias de Kabat CDR para los clones hermanos PG1G están destacadas en cajas.


Tabla 11. Secuencias de nucleótidos de consenso de CDR de Kabat de cadenas pesadas de clones hermanos 1443 PG16.

continuación

Tabla 12. Secuencias de nucleótidos de consenso de CDR de Kabat de cadenas ligeras de clones hermanos 1443 PG16.

continuación

Tabla 13. Secuencias de proteínas de consenso de CDR de Kabat CDRs de cadenas pesadas de clones hermanos 1443 PG16.

(continuación)
Consenso  EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6)
EAGGPIWHDDVKYYDFNDGYYNYHYMDV (SEQ ID NO: 6) 
Tabla 14. Secuencias de proteínas de consenso de CDR de Kabat CDRs de cadenas ligeras de clones hermanos de 1443 PG16.

Los anticuerpos monoclonales y recombinantes son particularmente útiles en la identificación y purificación de los polipéptidos individuales u otros antígenos contra los que se dirigen. Los anticuerpos de la aplicación tienen una utilidad adicional, ya que pueden emplearse como reactivos en inmunoensayos, radioinmunoensayos (RIA) o ensayos inmunosorbentes ligados a enzimas (ELISA). En estas aplicaciones, los anticuerpos pueden marcarse con un reactivo detectable analíticamente, como un radioisótopo, una molécula fluorescente o una enzima. Los anticuerpos también pueden usarse para la identificación y caracterización molecular (mapeo de epítopos) de antígenos.
Como se mencionó anteriormente, los anticuerpos de la aplicación pueden usarse para mapear los epítopos a los que se unen. Los solicitantes han descubierto que los anticuerpos 1443_C16 (PG16) (TCN-116), 1503 H05 PG16 TCN-119 , 1456 A12 PG16 TCN-117 , 1469 M23 PG16 TCN-118 , 1489 I13 PG16 TCN-120 ,

neutralizan el VIH. Aunque el solicitante no desea estar sujeto a esta teoría, se postula que los anticuerpos 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489_I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT
123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT-127), 5114_A19 (PGT-128), 5147_N06 (PGT-130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (PGT-157), y/o 6881_N05 (PGT-158) se unen a uno o más epítopos conformacionales formados por proteínas codificadas por VlH1. Sin embargo, la presente invención está dirigida específicamente al anticuerpo monoclonal anti-VIH humano 4876_M06 (PGT-134) que tiene una cadena pesada variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 435 y una cadena ligera variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 440.
La actividad de neutralización de los anticuerpos monoclonales humanos se probó frente a las cepas de VIH-1 SF162 y JR-CSF. Las cepas de VIH-1 SF162 y j R-CSF pertenecen ambas al clado B de VIH. Cada anticuerpo monoclonal clonal se cribó en cuanto a actividad de neutralización y anti-gp120, anti-gp41 e IgG total en ELISA cuantitativo. Para los anticuerpos monoclonales 1456_P20, 1495_C14 y 1460_G14 se detectó unión específica de antígeno anti-gp120. Se detectó actividad neutralizante contra SF162, pero no contra JR-CSF para 1456_P20 (PG20), 1495_C14 (PGC14) y 1460_G14 (PGG14). Para las dos preparaciones de anticuerpos monoclonales que no mostraron unión a gp120 en el ensayo ELISA, 1443_C16 (p G16) y 1496_C09 (PG9), se determinó la presencia de grandes cantidades de IgG humana en el ensayo. Sin embargo, 1443_C16 (PG16) y 1496_C09 (PG9) mostraron actividad neutralizante frente a la cepa JR-CSF del VIH-1, pero no frente a la cepa SF162. También se descubrió que 1443_C16 (PG16) y 1496_C09 (Pg 9) carecían de actividad de unión a gp41 en el ensayo ELISA.
Los epítopos reconocidos por estos anticuerpos pueden tener varios usos. Los epítopos y mimotopos en forma purificada o sintética se pueden usar para aumentar las respuestas inmunitarias (es decir, como una vacuna, o para la producción de anticuerpos para otros usos) o para examinar el suero del paciente en busca de anticuerpos que inmunorreaccionan con los epítopos o mimotopos. Preferiblemente, dicho epítopo o mimotopo, o antígeno que comprende dicho epítopo o mimotopo se usa como una vacuna para elevar una respuesta inmune. Los anticuerpos de la aplicación también pueden usarse en un método para controlar la calidad de las vacunas, en particular para verificar que el antígeno en una vacuna contenga el epítopo inmunogénico correcto en la conformación correcta.
Los epítopos también pueden ser útiles en la detección de ligandos que se unen a dichos epítopos. Tales ligandos bloquean preferiblemente los epítopos y por lo tanto previenen la infección. Se pueden usar técnicas estándar de biología molecular para preparar secuencias de ADN que codifican los anticuerpos o fragmentos de los anticuerpos de la presente solicitud. Las secuencias de ADN deseadas pueden sintetizarse completamente o en parte usando técnicas de síntesis de oligonucleótidos. Las técnicas de mutagénesis dirigida al sitio y reacción en cadena de la polimerasa (PCR) se pueden usar según corresponda.
Se puede usar cualquier sistema de célula huésped/vector adecuado para la expresión de las secuencias de ADN que codifican las moléculas de anticuerpo de la presente solicitud o fragmentos de las mismas. Las bacterias, por ejemplo, E. coli, y otros sistemas microbianos pueden usarse, en parte, para la expresión de fragmentos de anticuerpos tales como fragmentos Fab y F(ab')2 , y especialmente fragmentos Fv y fragmentos de anticuerpos de cadena sencilla, por ejemplo, cadena Fvs. Los sistemas de expresión de células huésped eucariotas, por ejemplo mamíferos, pueden usarse para la producción de moléculas de anticuerpos más grandes, incluidas moléculas de anticuerpos completas. Las células huésped de mamífero adecuadas incluyen células CHO, HEK293T, PER.C6, mieloma o hibridoma.
La presente solicitud también proporciona un proceso para la producción de una molécula de anticuerpo de acuerdo con la presente solicitud que comprende cultivar una célula huésped que comprende un vector de la presente aplicación en condiciones adecuadas para conducir a la expresión de proteína a partir de ADN que codifica la molécula de anticuerpo de la presente solicitud, y aislando la molécula de anticuerpo. La molécula de anticuerpo puede comprender solo un polipéptido de cadena pesada o ligera, en cuyo caso solo se necesita usar una secuencia codificante de polipéptido de cadena pesada o ligera para transfectar las células huésped. Para la producción de productos que comprenden cadenas pesadas y ligeras, la línea celular puede transfectarse con dos vectores, un primer vector que codifica un polipéptido de cadena ligera y un segundo vector que codifica un polipéptido de cadena pesada. Alternativamente, se puede usar un vector único, el vector incluye secuencias que codifican polipéptidos de cadena ligera y cadena pesada.
Alternativamente, los anticuerpos de acuerdo con la aplicación pueden producirse i) expresando una secuencia de ácido nucleico de acuerdo con la aplicación en una célula, y ii) aislando el producto de anticuerpo expresado. Además, el método puede incluir iii) purificar el anticuerpo. Las células B transformadas se seleccionan para aquellos que producen anticuerpos de la especificidad de antígeno deseada, y los clones de células B individuales se pueden producir a partir de las células positivas. La etapa de selección puede llevarse a cabo mediante ELISA, mediante tinción de tejidos o células (incluidas las células transfectadas), un ensayo de neutralización o uno de varios otros métodos conocidos en la técnica para identificar la especificidad de antígeno deseada. El ensayo puede seleccionar sobre la base del reconocimiento de antígeno simple, o puede seleccionar sobre la base de una función
deseada, por ejemplo, para seleccionar anticuerpos neutralizantes en lugar de solo anticuerpos de unión a antígeno, para seleccionar anticuerpos que pueden cambiar las características de las células diana, como sus cascadas de señalización, su forma, su tasa de crecimiento, su capacidad de influir en otras células, su respuesta a la influencia de otras células o de otros reactivos o por un cambio en las condiciones, su estado de diferenciación, etc.
El paso de clonación para separar los clones individuales de la mezcla de células positivas se pueden llevar a cabo utilizando dilución limitante, micromanipulación, deposición de células individuales por clasificación celular u otro método conocido en la técnica. Preferiblemente, la clonación se lleva a cabo usando dilución limitante.
Los clones de células B inmortalizados de la aplicación pueden usarse de diversas maneras, por ejemplo, como fuente de anticuerpos monoclonales, como fuente de ácido nucleico (ADN o ARNm) que codifica un anticuerpo monoclonal de interés, para investigación, etc.
A menos que se defina lo contrario, los términos científicos y técnicos utilizados en relación con la presente solicitud tendrán los significados que comúnmente entienden los expertos en la materia. Además, a menos que el contexto requiera lo contrario, los términos singulares incluirán pluralidades y los términos plurales incluirán el singular. En general, las nomenclaturas utilizadas en relación con el cultivo de células y tejidos, la biología molecular y la química e hibridación de proteínas y oligo- o polinucleótidos y técnicas de cultivo descritas en el presente documento son las bien conocidas y comúnmente utilizadas en la técnica. Se utilizan técnicas estándar para ADN recombinante, síntesis de oligonucleótidos y cultivo y transformación de tejidos (p. ej., electroporación, lipofección). Las reacciones enzimáticas y las técnicas de purificación se realizan de acuerdo con las especificaciones del fabricante o como se logra comúnmente en la técnica o como se describe en este documento. La práctica de la presente solicitud empleará, a menos que se indique específicamente lo contrario, métodos convencionales de virología, inmunología, microbiología, biología molecular y técnicas de ADN recombinante dentro de la habilidad de la técnica, muchos de los cuales se describen a continuación con fines ilustrativos. Dichas técnicas se explican completamente en la literatura. Ver, por ejemplo, Sambrook, et al. Molecular Cloning: A Laboratory Manual (2a Edición, 1989); Maniatis y col. Molecular Cloning: A Laboratory Manual (1982); DNA Cloning: A Practical Approach, vol. I y II (D. Glover, ed.); Oligonucleotide Synthesis (N. Gait, ed., 1984); Nucleic Acid Hybridization (B. Hames & S. Higgins, eds., 1985); Transcription and Translation (B. Hames & S. Higgins, eds., 1984); Animal Cell Culture (R. Freshney, ed., 1986); Perbal, A Practical Guide to Molecular Cloning (1984). Las nomenclaturas utilizadas en relación con, y los procedimientos y técnicas de laboratorio de química analítica, química orgánica sintética y química medicinal y farmacéutica descritas en el presente documento son las bien conocidas y comúnmente utilizadas en la técnica. Las técnicas estándar se utilizan para síntesis químicas, análisis químicos, preparación farmacéutica, formulación y administración, y tratamiento de pacientes.
Las siguientes definiciones son útiles para comprender la presente solicitud: el término "anticuerpo" (Ab) como se usa en el presente documento incluye anticuerpos monoclonales, anticuerpos policlonales, anticuerpos multiespecíficos (por ejemplo, anticuerpos biespecíficos) y fragmentos de anticuerpos, siempre que exhiben la actividad biológica deseada. El término "inmunoglobulina" (Ig) se usa indistintamente con "anticuerpo" en el presente documento.
Un "anticuerpo neutralizante" puede inhibir la entrada del virus VIH-1, por ejemplo SF162 y/o JR-CSF con un índice de neutralización> 1,5 o> 2,0. (Kostrikis LG et al. J Virol. 1996; 70 (1): 445-458.) Por "anticuerpos neutralizadores amplios y potentes" se entiende anticuerpos que neutralizan más de una especie de virus VIH-1 (de diversos clados y diferentes cepas dentro de un clado) en un ensayo de neutralización. Un anticuerpo neutralizante amplio puede neutralizar al menos 2,3,4, 5, 6, 7, 8, 9 o más cepas diferentes de VIH-1, las cepas que pertenecen al mismo o diferentes clados. Un anticuerpo neutralizante amplio puede neutralizar múltiples especies de VIH-1 que pertenecen a al menos 2,3,4, 5 o 6 clados diferentes. La concentración inhibitoria del anticuerpo monoclonal puede ser inferior a aproximadamente 25 mg/ml para neutralizar aproximadamente el 50% del virus de entrada en el ensayo de neutralización.
Un "anticuerpo aislado" es uno que se ha separado y/o recuperado de un componente de su entorno natural. Los componentes contaminantes de su entorno natural son materiales que interferirían con los usos diagnósticos o terapéuticos del anticuerpo, y pueden incluir enzimas, hormonas y otros solutos proteicos o no proteicos. En un aspecto, el anticuerpo se purifica: (1) a más del 95% en peso de anticuerpo según lo determinado por el método de Lowry, y lo más preferiblemente más del 99% en peso; (2) en un grado suficiente para obtener al menos 15 residuos de secuencia de aminoácidos N-terminales o interna mediante el uso de un secuenciador de copa giratoria; o (3) a la homogeneidad por SDS-PAGE en condiciones reductoras o no reductoras usando azul Coomassie o, preferiblemente, tinción de plata. El anticuerpo aislado incluye el anticuerpo in situ dentro de las células recombinantes ya que al menos un componente del entorno natural del anticuerpo no estará presente. Normalmente, sin embargo, el anticuerpo aislado se preparará por al menos una etapa de purificación.
La unidad básica de anticuerpos de cuatro cadenas es una glucoproteína heterotetramérica compuesta por dos cadenas ligeras (L) idénticas y dos cadenas pesadas (H) idénticas. Un anticuerpo IgM consta de 5 unidades heterotetraméricas básicas junto con un polipéptido adicional llamado cadena J, y por lo tanto contiene 10 sitios de
unión a antígeno, mientras que los anticuerpos IgA secretados pueden polimerizarse para forman conjuntos polivalentes que comprenden 2-5 de las unidades básicas de 4 cadenas junto con la cadena J. En el caso de las IgG, la unidad de 4 cadenas generalmente es de aproximadamente 150.000 daltons. Cada cadena L está unida a una cadena H por un enlace disulfuro covalente, mientras que las dos cadenas H están unidas entre sí por uno o más enlaces disulfuro dependiendo del isotipo de la cadena H. Cada cadena H y L también tiene puentes disulfuro intracadena regularmente espaciados. Cada cadena H tiene en el extremo N-terminal, una región variable (Vh) seguido de tres dominios constantes (Ch) para cada uno de las cadenas a y y y cuatro dominios Ch para isotipos p y g. Cada cadena L tiene en el extremo N, una región variable (Vl) seguida de un dominio constante (Cl) en su otro extremo. El Vl está alineado con el Vh y el Cl está alineado con el primer dominio constante de la cadena pesada (Ch1 ). Se cree que los residuos de aminoácidos particulares forman una interfaz entre las regiones variables de la cadena ligera y la cadena pesada. El emparejamiento de un Vh y Vl juntos forma un único sitio de unión a antígeno. Para la estructura y las propiedades de las diferentes clases de anticuerpos, véase, por ejemplo, Basic and Clinical Immunology, 8a edición, Daniel P. Stites, Abba I. Terr y Tristram G. Parslow (eds.), Appleton & Lange, Norwalk, Conn., 1994, página 71, y Capítulo 6.
La cadena L de cualquier especie de vertebrado puede asignarse a uno de dos tipos claramente distintos, llamados kappa (k ) y lambda (X), basados en las secuencias de aminoácidos de sus dominios constantes (Cl). Dependiendo de la secuencia de aminoácidos del dominio constante de sus cadenas pesadas (Ch), las inmunoglobulinas pueden asignarse a diferentes clases o isotipos. Hay cinco clases de inmunoglobulinas: IgA, IgD, IgE, IgG, e IgM, que tienen cadenas pesadas designadas alfa (a), delta (8, epsilon (g), gamma (y) y mu (p, respectivamente. Las clases y y a se dividen además en subclases sobre la base de diferencias relativamente menores en la secuencia y función de CH, por ejemplo, los humanos expresan las siguientes subclases: IgG1, IgG2, IgG3, IgG4, IgA1 e IgA2.
El término "variable" se refiere al hecho de que ciertos segmentos de los dominios V difieren ampliamente en la secuencia entre los anticuerpos. El dominio V media la unión del antígeno y define la especificidad de un anticuerpo particular para su antígeno particular. Sin embargo, la variabilidad no se distribuye uniformemente a través de la extensión de aminoácido 110 de las regiones variables. En cambio, las regiones V consisten en tramos relativamente invariables llamados regiones marco (FR) de 15-30 aminoácidos separados por regiones más cortas de extrema variabilidad llamadas "regiones hipervariables" que tienen cada una de 9-12 aminoácidos de longitud. Las regiones variables de las cadenas pesadas y ligeras nativas comprenden cada una cuatro FR, adoptando en gran medida una configuración de hoja p, conectada por tres regiones hipervariables, que forman bucles que se conectan y, en algunos casos, forman parte de la estructura de la hoja p. Las regiones hipervariables en cada cadena se mantienen juntas en estrecha proximidad por las FR y, con las regiones hipervariables de la otra cadena, contribuyen a la formación del sitio de unión a antígeno de los anticuerpos (ver Kabat et al., Sequences of Proteins of Immunological Interest, 5a Ed. Public Health Service, National Institutes of Health, Bethesda, Md (1991)). Los dominios constantes no están involucrados directamente en la unión de un anticuerpo a un antígeno, pero exhiben varias funciones efectoras, como la participación del anticuerpo en la citotoxicidad celular dependiente de anticuerpos (ADCC).
El término "región hipervariable" cuando se usa en el presente documento se refiere a los residuos de aminoácidos de un anticuerpo que son responsables de la unión al antígeno. La región hipervariable generalmente comprende residuos de aminoácidos de una "región determinante de complementariedad" o "CDR" (por ejemplo, alrededor de los residuos 24-34 (L1), 50-56 (L2) y 89-97 (L3) en la Vl, y alrededor de 31-35 (HI), 50-65 (H2) y 95-102 (H3) en el Vh cuando se numeran de acuerdo con el sistema de numeración de Kabat; Kabat et al., Sequences of Proteins of Immunological Interest, 5a Ed. Public Health Service, National Institutes of Health, Bethesda, Md (1991)); y/o aquellos residuos de un "bucle hipervariable" (p. ej., residuos 24-34 (L1), 50-56 (L2) y 89-97 (L3) en el Vl, y 26-32 (HI), 52 -56 (H2) y 95-101 (H3) en el Vh cuando se numeran de acuerdo con el sistema de numeración Chothia; Chothia y Lesk, J. Mol. Biol. 196: 901-917 (1987)); y/o aquellos residuos de un "bucle hipervariable"/CDR (p. ej., residuos 27 38 (L1), 56-65 (L2) y 105-120 (L3) en Vl y 27-38 (HI), 56-65 (H2) y 105-120 (H3) en el Vh cuando se numeran de acuerdo con el sistema de numeración Im Gt ; Lefranc, MP et al. Nucl. Acids Res. 27: 209-212 (1999), Ruiz, M. y col., Nucl. Acids Res. 28: 219-221 (2000)). Opcionalmente, el anticuerpo tiene inserciones simétricas en uno o más de los siguientes puntos 28, 36 (L1), 63, 74-75 (L2) y 123 (L3) en la Vl, y 28, 36 (HI), 63, 74 -75 (H2) y 123 (H3) en el Vh cuando se numera de acuerdo con AHo; Honneger, A. y Plunkthun, AJ Mol. Biol. 309: 657-670 (2001)).
Por "residuo de ácido nucleico de línea germinal" se entiende el residuo de ácido nucleico que se produce naturalmente en un gen de línea germinal que codifica una región constante o variable. El "gen de la línea germinal" es el ADN que se encuentra en una célula germinal (es decir, una célula destinada a convertirse en un óvulo o en el esperma). Una "mutación de la línea germinal" se refiere a un cambio heredable en un ADN particular que se ha producido en una célula germinal o en el cigoto en la etapa unicelular, y cuando se transmite a la descendencia, dicha mutación se incorpora en cada célula del cuerpo. Una mutación de la línea germinal contrasta con una mutación somática que se adquiere en una sola célula del cuerpo. En algunos casos, los nucleótidos en una secuencia de ADN de la línea germinal que codifica para una región variable están mutados (es decir, una mutación somática) y se sustituyen con un nucleótido diferente.
El término "anticuerpo monoclonal", como se usa en el presente documento, se refiere a un anticuerpo
obtenido de una población de anticuerpos sustancialmente homogéneos, es decir, los anticuerpos individuales que comprenden la población son idénticos excepto por posibles mutaciones naturales que pueden estar presentes en cantidades menores. Los anticuerpos monoclonales son altamente específicos y se dirigen contra un único sitio antigénico. Además, en contraste con las preparaciones de anticuerpos policlonales que incluyen diferentes anticuerpos dirigidos contra diferentes determinantes (epítopos), cada anticuerpo monoclonal se dirige contra un único determinante en el antígeno. Además de su especificidad, los anticuerpos monoclonales son ventajosos porque pueden sintetizarse sin contaminar por otros anticuerpos. El modificador "monoclonal" no debe interpretarse como que requiere la producción del anticuerpo por ningún método particular. Por ejemplo, los anticuerpos monoclonales útiles en la presente solicitud pueden prepararse mediante la metodología de hibridoma descrita por primera vez por Kohler et al., Nature, 256: 495 (1975), o pueden prepararse usando métodos de ADN recombinante en animales o plantas bacterianos, eucariotas células (véase, por ejemplo, la Patente de Estados Unidos Núm. 4,816,567). Los "anticuerpos monoclonales" también pueden aislarse de bibliotecas de anticuerpos de fago usando las técnicas descritas en Clackson et al., Nature, 352: 624-628 (1991) y Marks et al., J. Mol. Biol., 222: 581-597 (1991), por ejemplo.
En algunos aspectos, se usa el método alternativo de inmortalización de EBV descrito en WO2004/076677. Usando este método, las células B que producen el anticuerpo de la aplicación pueden transformarse con EBV en presencia de un activador policlonal de células B. La transformación con EBV es una técnica estándar y puede adaptarse fácilmente para incluir activadores policlonales de células B. Se pueden agregar estimulantes adicionales del crecimiento celular y la diferenciación durante la etapa de transformación para mejorar aún más la eficiencia. Estos estimulantes pueden ser citocinas como IL-2 e IL-15. En un aspecto particularmente preferido, se agrega IL-2 durante la etapa de inmortalización para mejorar aún más la eficacia de la inmortalización, pero su uso no es esencial.
Los anticuerpos monoclonales en el presente documento incluyen anticuerpos "quiméricos" en los que una porción de la cadena pesada y/o ligera es idéntica u homóloga a las secuencias correspondientes en anticuerpos derivados de una especie particular o que pertenecen a una clase o subclase de anticuerpo particular, mientras que el resto de la(s) cadena(s) es idéntico u homólogo a las secuencias correspondientes en anticuerpos derivados de otra especie o que pertenecen a otra clase o subclase de anticuerpos, así como a fragmentos de dichos anticuerpos, siempre que exhiban la actividad biológica deseada (ver Patente de Estados Unidos N° 4,816,567 y Morrison y col., Proc. Natl. Acad. Sci. EE.UU., 81: 6851-6855 (1984)). La presente solicitud proporciona secuencias de unión a antígeno de región variable derivadas de anticuerpos humanos. Por consiguiente, los anticuerpos quiméricos de interés principal en el presente documento incluyen anticuerpos que tienen una o más secuencias de unión a antígeno humano (por ejemplo, CDR) y que contienen una o más secuencias derivadas de un anticuerpo no humano, por ejemplo, una secuencia de región FR o C. Además, los anticuerpos quiméricos de interés principal en el presente documento incluyen aquellos que comprenden una secuencia de unión a antígeno de región variable humana de una clase o subclase de anticuerpo y otra secuencia, por ejemplo, secuencia de región FR o C, derivada de otra clase o subclase de anticuerpo. Los anticuerpos quiméricos de interés en el presente documento también incluyen aquellos que contienen secuencias de unión a antígeno de región variable relacionadas con los descritos en el presente documento o derivados de una especie diferente, tal como un primate no humano (por ejemplo, Old World Monkey, Ape, etc.). Los anticuerpos quiméricos también incluyen anticuerpos primatizados y humanizados.
Además, los anticuerpos quiméricos pueden comprender residuos que no se encuentran en el anticuerpo receptor o en el anticuerpo donador. Estas modificaciones se realizan para refinar aún más el rendimiento del anticuerpo. Para más detalles, ver Jones et al., Nature 321: 522-525 (1986); Riechmann y col., Nature 332: 323-329 (1988); y Presta, Curr. Op. Struct. Biol. 2: 593-596 (1992).
Un "anticuerpo humanizado" generalmente se considera un anticuerpo humano que tiene uno o más residuos de aminoácidos introducidos en él desde una fuente que no es humana. Estos residuos de aminoácidos no humanos a menudo se denominan residuos de "importación", que generalmente se toman de una región variable de "importación". La humanización se realiza tradicionalmente siguiendo el método de Winter y colaboradores (Jones et al., Nature, 321: 522-525 (1986); Reichmann et al., Nature, 332: 323-327 (1988); Verhoeyen et al., Science, 239: 1534 1536 (1988)), sustituyendo las secuencias de región hipervariable importadas por las secuencias correspondientes de un anticuerpo humano. Por consiguiente, tales anticuerpos "humanizados" son anticuerpos quiméricos (patente de Estados Unidos N° 4,816,567), en donde sustancialmente menos de una región variable humana intacta ha sido sustituida por la secuencia correspondiente de una especie no humana.
Un "anticuerpo humano" es un anticuerpo que contiene solo secuencias presentes en un anticuerpo producido naturalmente por un humano. Sin embargo, como se usa en el presente documento, los anticuerpos humanos pueden comprender residuos o modificaciones que no se encuentran en un anticuerpo humano natural, incluidas las modificaciones y secuencias variantes descritas en el presente documento. Estos se hacen típicamente para refinar o mejorar aún más el rendimiento del anticuerpo.
Un anticuerpo "intacto" es uno que comprende un sitio de unión a antígeno, así como un Cl y al menos dominios constantes de cadena pesada, Ch 1, Ch 2 y Ch 3. Los dominios constantes pueden ser dominios constantes de secuencia nativa (por ejemplo, dominios constantes de secuencia nativa humana) o una variante de secuencia de aminoácidos de los mismos. Preferiblemente, el anticuerpo intacto tiene una o más funciones efectoras.
Un "fragmento de anticuerpo" comprende una porción de un anticuerpo intacto, preferiblemente la región variable o de unión al antígeno del anticuerpo intacto. Los ejemplos de fragmentos de anticuerpos incluyen fragmentos Fab, Fab', F(ab' ) 2 y Fv; diacuerpos; anticuerpos lineales (véase la Patente de Estados Unidos N° 5,641,870; Zapata et al., Protein Eng. 8 (10): 1057-1062 [1995]); moléculas de anticuerpos de cadena sencilla; y anticuerpos multiespecíficos formados a partir de fragmentos de anticuerpos.
La frase "fragmento funcional o análogo" de un anticuerpo es un compuesto que tiene actividad biológica cualitativa en común con un anticuerpo de longitud completa. Por ejemplo, un fragmento funcional o análogo de un anticuerpo anti-IgE es uno que puede unirse a una inmunoglobulina IgE de tal manera que se evite o reduzca sustancialmente la capacidad de dicha molécula de tener la capacidad de unirse al receptor de alta afinidad, Fc^RI.
La digestión de anticuerpos con papaína produce dos fragmentos de unión a antígeno idénticos, llamados fragmentos "Fab", y un fragmento residual "Fc", una designación que refleja la capacidad de cristalizar fácilmente. El fragmento Fab consiste en una cadena L completa junto con el dominio de la región variable de la cadena H (Vh) y el primer dominio constante de una cadena pesada (Ch 1). Cada fragmento Fab es monovalente con respecto a la unión al antígeno, es decir, tiene un único sitio de unión al antígeno. El tratamiento con pepsina de un anticuerpo produce un solo fragmento F(ab' ) 2 grande que corresponde aproximadamente a dos fragmentos Fab unidos por disulfuro que tienen actividad de unión a antígeno divalente y todavía es capaz de reticular el antígeno. Los fragmentos Fab' difieren de los fragmentos Fab por tener pocos residuos adicionales en el extremo carboxi del dominio Ch1, incluyendo una o más cisteínas de la región de bisagra del anticuerpo. Fab'-SH es la designación en el presente documento para Fab' en donde los residuos de cisteína de los dominios constantes llevan un grupo tiol libre. Los fragmentos de anticuerpos F(ab' ) 2 originalmente se produjeron como pares de fragmentos Fab' que tienen cisteínas de bisagra entre ellos. También se conocen otros acoplamientos químicos de fragmentos de anticuerpos.
El fragmento "Fc" comprende las porciones carboxi-terminales de ambas cadenas H unidas por disulfuros. Las funciones efectoras de los anticuerpos están determinadas por secuencias en la región Fc, región que también es la parte reconocida por los receptores Fc (FcR) que se encuentran en ciertos tipos de células.
"Fv" es el fragmento de anticuerpo mínimo que contiene un sitio completo de reconocimiento y unión de antígeno. Este fragmento consiste en un dímero de un dominio de región variable de cadena pesada y ligera en asociación estrecha y no covalente. Del plegamiento de estos dos dominios emanan seis bucles hipervariables (tres bucles cada uno de la cadena H y L) que contribuyen los residuos de aminoácidos para la unión al antígeno y confieren especificidad de unión al antígeno al anticuerpo. Sin embargo, incluso una única región variable (o la mitad de un Fv que comprende solo tres CDR específicas para un antígeno) tiene la capacidad de reconocer y unirse al antígeno, aunque con una afinidad menor que el sitio de unión completo.
"Fv de cadena sencilla" también abreviado como "sFv" o "scFv" son fragmentos de anticuerpos que comprenden los dominios de anticuerpos Vh y Vl conectados en una cadena polipeptídica única. Preferiblemente, el polipéptido sFv comprende además un conector de polipéptido entre los dominios Vh y Vl que permite que sFv forme la estructura deseada para la unión al antígeno. Para una revisión de sFv, ver Pluckthun en The Pharmacology of Monoclonal Antibodies, vol. 113, Rosenburg y Moore, editores, Springer-Verlag, Nueva York, págs. 269-315 (1994); Borrebaeck 1995, infra.
El término "diacuerpos" se refiere a pequeños fragmentos de anticuerpos preparados mediante la construcción de fragmentos sFv (véase el párrafo anterior) con ligadores cortos (aproximadamente 5-10 residuos) entre los dominios Vh y Vl de manera que el emparejamiento entre cadenas pero no dentro de la cadena de los dominios V se logra, dando como resultado un fragmento bivalente, es decir, un fragmento que tiene dos sitios de unión a antígeno. Los diacuerpos biespecíficos son heterodímeros de dos fragmentos sFv "cruzados" en los que los dominios Vh y Vl de los dos anticuerpos están presentes en diferentes cadenas de polipéptidos. Los diacuerpos se describen más completamente en, por ejemplo, EP 404,097; WO 93/11161; y Hollinger y col., Proc. Natl. Acad. Sci. EE.UU., 90: 6444-6448 (1993).
Los anticuerpos de dominio (dAbs), que pueden producirse en forma completamente humana, son los fragmentos de anticuerpos de unión a antígeno más pequeños conocidos, que varían de 11 kDa a 15 kDa. Los dAbs son las regiones variables robustas de las cadenas pesadas y ligeras de las inmunoglobulinas (VH y VL respectivamente). Están altamente expresados en cultivo de células microbianas, muestran propiedades biofísicas favorables, incluida la solubilidad y la estabilidad de la temperatura, y son muy adecuados para la selección y la maduración por afinidad mediante sistemas de selección in vitro como la presentación en fagos. Los dAbs son bioactivos como monómeros y, debido a su pequeño tamaño y estabilidad inherente, pueden formatearse en moléculas más grandes para crear fármacos con semividas séricas prolongadas u otras actividades farmacológicas. Se han descrito ejemplos de esta tecnología en el documento WO9425591 para anticuerpos derivados de la Ig de la cadena pesada de Camelidae, así como en el documento US20030130496 que describe el aislamiento de anticuerpos completamente humanos de dominio único a partir de bibliotecas de fagos.
Como se usa en este documento, un anticuerpo que "internaliza" es uno que es tomado por (es decir, entra en) la célula tras la unión a un antígeno sobre una célula de mamífero (por ejemplo, un polipéptido de superficie celular o receptor). El anticuerpo internalizante incluirá, por supuesto, fragmentos de anticuerpos, anticuerpos humanos o quiméricos y conjugados de anticuerpos. Para ciertas aplicaciones terapéuticas, se contempla la internalización in vivo. El número de moléculas de anticuerpos internalizadas será suficiente o adecuado para matar una célula o inhibir su crecimiento, especialmente una célula infectada. Dependiendo de la potencia del anticuerpo o del conjugado de anticuerpos, en algunos casos, la absorción de una sola molécula de anticuerpo en la célula es suficiente para matar la célula diana a la que se une el anticuerpo. Por ejemplo, ciertas toxinas son altamente potentes para matar de modo que la internalización de una molécula de la toxina conjugada con el anticuerpo es suficiente para matar la célula infectada.
Como se usa en el presente documento, se dice que un anticuerpo es "inmunoespecífico", "específico para" o "se une específicamente" a un antígeno si reacciona a un nivel detectable con el antígeno, preferiblemente con una constante de afinidad, Ka, de mayor o igual a aproximadamente 104 M-1, o mayor o igual a aproximadamente 105 M-1, mayor o igual a aproximadamente 106 M-1, mayor o igual a aproximadamente 107 M-1, o mayor o igual que 108 M-1. La afinidad de un anticuerpo por su antígeno afín también se expresa comúnmente como una constante de disociación Kd, y en ciertos aspectos, el anticuerpo VIH1 se une específicamente a un polipéptido VIH1 si se une con una Kd menor o igual a 10-4 M, menor o igual a aproximadamente 10-5 M, menor o igual a aproximadamente 10-6 M, menor o igual a 10-7 M, o menor o igual a 10-8 M. Las afinidades de los anticuerpos se pueden determinar fácilmente utilizando técnicas convencionales, por ejemplo, las descritas por Scatchard et al. (Ann. NY Acad. Sci. EE.UU. 51: 660 (1949)).
Las propiedades de unión de un anticuerpo a antígenos, células o tejidos del mismo generalmente pueden determinarse y evaluarse usando métodos de inmunodetección que incluyen, por ejemplo, ensayos basados en inmunofluorescencia, tales como inmunohistoquímica (IHC) y/o clasificación de células activadas por fluorescencia (FACS).
Un anticuerpo que tiene una "característica biológica" de un anticuerpo designado es uno que posee una o más de las características biológicas de ese anticuerpo que lo distinguen de otros anticuerpos. Por ejemplo, en ciertos aspectos, un anticuerpo con una característica biológica de un anticuerpo designado se unirá al mismo epítopo que el unido por el anticuerpo designado y/o tiene una función efectora común como el anticuerpo designado.
El término anticuerpo "antagonista" se usa en el sentido más amplio e incluye un anticuerpo que bloquea, inhibe o neutraliza parcial o totalmente la actividad biológica de un epítopo, polipéptido o célula que se une específicamente. Los métodos para identificar anticuerpos antagonistas pueden comprender poner en contacto un polipéptido o célula específicamente unida por un anticuerpo antagonista candidato con el anticuerpo antagonista candidato y medir un cambio detectable en una o más actividades biológicas normalmente asociadas con el polipéptido o la célula.
Un "anticuerpo que inhibe el crecimiento de células infectadas" o un anticuerpo "inhibidor del crecimiento" es aquel que se une y da como resultado una inhibición medible del crecimiento de células infectadas que expresan o son capaces de expresar un epítopo de VIH1 unido por un anticuerpo. Los anticuerpos inhibidores del crecimiento preferidos inhiben el crecimiento de las células infectadas en más del 20%, preferiblemente de aproximadamente el 20% a aproximadamente el 50%, e incluso más preferiblemente, en más del 50% (por ejemplo, de aproximadamente el 50% a aproximadamente el 100%) en comparación con el control apropiado, el control típicamente es células infectadas no tratadas con el anticuerpo que se está probando. La inhibición del crecimiento se puede medir a una concentración de anticuerpo de aproximadamente 0,1 a 30 pg/ml o aproximadamente 0,5 nM a 200 nM en cultivo celular, donde la inhibición del crecimiento se determina 1-10 días después de la exposición de las células infectadas al anticuerpo. La inhibición del crecimiento de las células infectadas in vivo se puede determinar de varias maneras conocidas en la técnica.
El anticuerpo inhibe el crecimiento in vivo si la administración del anticuerpo a aproximadamente 1 pg/kg a aproximadamente 100 mg/kg de peso corporal reduce el porcentaje de células infectadas o el número total de células infectadas en aproximadamente 5 días a 3 meses desde la primera administración del anticuerpo, preferiblemente dentro de aproximadamente 5 a 30 días.
Un anticuerpo que "induce apoptosis" es uno que induce la muerte celular programada según se determina mediante la unión de anexina V, fragmentación de ADN, encogimiento celular, dilatación del retículo endoplásmico, fragmentación celular y/o formación de vesículas de membrana (llamadas apoptóticas cuerpos). Preferiblemente la célula es una célula infectada. Hay varios métodos disponibles para evaluar los eventos celulares asociados con la apoptosis. Por ejemplo, la translocación de fosfatidil serina (PS) se puede medir mediante la unión de anexina; la fragmentación del ADN se puede evaluar a través de la escala del ADN; y la condensación nuclear/cromatina junto con la fragmentación del ADN pueden evaluarse mediante cualquier aumento en las células hipodiploides. Preferiblemente, el anticuerpo que induce la apoptosis es uno que da como resultado aproximadamente 2 a 50 veces, preferiblemente aproximadamente 5 a 50 veces, y lo más preferiblemente aproximadamente 10 a 50 veces, la inducción de la unión de anexina con respecto a la célula no tratada en un ensayo de unión de anexina.
Las "funciones efectoras" del anticuerpo se refieren a aquellas actividades biológicas atribuibles a la región Fc (una región Fc de secuencia nativa o región Fc variante de secuencia de aminoácidos) de un anticuerpo, y varían con el isotipo del anticuerpo. Los ejemplos de funciones efectoras de anticuerpos incluyen: unión a C1q y citotoxicidad dependiente del complemento; unión al receptor de Fc; citotoxicidad celular dependiente de anticuerpos (ADCC); fagocitosis; regulación negativa de los receptores de la superficie celular (por ejemplo, receptor de células B); y activación de células B.
"Citotoxicidad mediada por células dependiente de anticuerpos" o "ADCC" se refiere a una forma de citotoxicidad en donde la Ig secretada se une a los receptores Fc (FcR) presentes en ciertas células citotóxicas (por ejemplo, células aniquilantes naturales (NK), neutrófilos, y macrófagos) permiten que estas células efectoras citotóxicas se unan específicamente a una célula diana portadora de antígeno y posteriormente maten a la célula diana con citotoxinas. Los anticuerpos "arman" las células citotóxicas y son necesarios para tal destrucción. Las células primarias para mediar las células ADCC, NK, expresan solo FcyRIII, mientras que los monocitos expresan FcyRI, FcyRII y FcyRIII. La expresión de FcR en células hematopoyéticas se resume en la Tabla 4 en la página 464 de Ravetch y Kinet, Annu. Rev. Immunol 9: 457-92 (1991). Para evaluar la actividad de ADCC de una molécula de interés, un ensayo de ADCC in vitrn, como el descrito en la patente de EE.UU. N° 5,500,362 o la patente de EE.UU. N° 5,821,337 se puede realizar. Las células efectoras útiles para tales ensayos incluyen células mononucleares de sangre periférica (PBMC) y células asesinas naturales (NK).
Alternativamente, o adicionalmente, la actividad ADCC de la molécula de interés puede evaluarse in vivo, por ejemplo, en un modelo animal como el descrito en Clynes et al., Proc. Natl. Acad. Sci. (Estados Unidos) 95: 652-656 (1998).
"Receptor Fc" o "FcR" describe un receptor que se une a la región Fc de un anticuerpo. En ciertos aspectos, el FcR es una secuencia nativa del FcR humano. Además, un FcR preferido es aquel que se une a un anticuerpo IgG (un receptor gamma) e incluye receptores de las subclases FcyRI, FcyRII y FcyRIII, incluidas variantes alélicas y formas empalmadas alternativamente de estos receptores. Los receptores FcyRII incluyen FcyRIIA (un "receptor activador") y FcyRIIB (un "receptor inhibidor"), que tienen secuencias de aminoácidos similares que difieren principalmente en sus dominios citoplasmáticos. El receptor activador FcyRIIA contiene un motivo de activación inmunoreceptor basado en tirosina (ITAM) en su dominio citoplasmático. El receptor inhibidor FcyRIIB contiene un motivo de inhibición inmunorreceptor basado en tirosina (ITIM) en su dominio citoplasmático. (ver revisión M. en Daeron, Annu. Rev. Immunol. 15: 203-234 (1997)). Los FcR se revisan en Ravetch y Kinet, Annu. Rev. Immunol 9: 457-92 (1991); Capel y col., Immunomethods 4: 25-34 (1994); y de Haas y col., J. Lab. Clin. Medicine. 126: 330-41 (1995). Otros términos FcR, incluidos los que se identificarán en el futuro, están incluidos en el término "FcR" en el presente documento. El término también incluye el receptor neonatal, FcRn, que es responsable de la transferencia de IgG maternas al feto (Guyer et al., J. Immunol. 117: 587 (1976) y Kim et al., J. Immunol. 24: 249 (1994)).
Las "células efectoras humanas" son leucocitos que expresan uno o más FcR y realizan funciones efectoras. Preferiblemente, las células expresan al menos FcyRIII y realizan la función efectora ADCC. Los ejemplos de leucocitos humanos que median en ADCC incluyen PBMC, células NK, monocitos, células T citotóxicas y neutrófilos; prefiriéndose las PBMC y las células NK. Las células efectoras pueden aislarse de una fuente nativa, por ejemplo, de sangre.
"Citotoxicidad dependiente del complemento" o "CDC" se refiere a la lisis de una célula diana en presencia de complemento. La activación de la vía del complemento clásico se inicia mediante la unión del primer componente del sistema del complemento (C1q) a los anticuerpos (de la subclase apropiada) que están unidos a su antígeno afín. Para evaluar la activación del complemento, un ensayo de CDC, por ejemplo, como se describe en Gazzano-Santoro et al., J. Immunol. Methods 202: 16 3 (1996), se pueden realizar.
Un "mamífero" para tratar una infección, se refiere a cualquier mamífero, incluidos humanos, animales domésticos y de granja, y animales de zoológico, deportivos o mascotas, como perros, gatos, vacas, caballos, ovejas, cerdos, cabras, conejos, etc. Preferiblemente, el mamífero es humano.
"Tratamiento" o "tratar" o "alivio" se refiere tanto a tratamiento terapéutico como a medidas profilácticas o preventivas; en donde el objetivo es prevenir o disminuir (reducir) la condición o trastorno patológico diana. Aquellos que necesitan tratamiento incluyen aquellos que ya tienen el trastorno, así como aquellos propensos a tener el trastorno o aquellos en quienes se debe prevenir el trastorno. Un sujeto o mamífero es "tratado" con éxito para una infección si, después de recibir una cantidad terapéutica de un anticuerpo de acuerdo con los métodos de la presente solicitud, el paciente muestra una reducción observable y/o medible en o la ausencia de uno o más de los siguientes: reducción en el número de células infectadas o ausencia de las células infectadas; reducción en el porcentaje de células totales que están infectadas; y/o alivio hasta cierto punto, uno o más de los síntomas asociados con la infección específica; reducción de la morbilidad y mortalidad, y mejora en los problemas de calidad de vida. Los parámetros anteriores para evaluar el tratamiento exitoso y la mejora de la enfermedad se pueden medir fácilmente mediante procedimientos de rutina familiares para un médico.
El término "cantidad terapéuticamente eficaz" se refiere a una cantidad de un anticuerpo o un fármaco eficaz para "tratar" una enfermedad o trastorno en un sujeto o mamífero. Ver la definición anterior de "tratar".
La administración "crónica" se refiere a la administración del (de los) agente(s) en un modo continuo en lugar de un modo agudo, para mantener el efecto terapéutico inicial (actividad) durante un período prolongado de tiempo. La administración "intermitente" es un tratamiento que no se realiza consecutivamente sin interrupción, sino que es de naturaleza cíclica.
La administración "en combinación con" uno o más agentes terapéuticos adicionales incluye la administración simultánea (concurrente) y consecutiva en cualquier orden.
Los "portadores" tal como se usan en el presente documento incluyen portadores, excipientes o estabilizadores farmacéuticamente aceptables que no son tóxicos para la célula o mamífero que está expuesto a los mismos a las dosis y concentraciones empleadas. A menudo, el vehículo fisiológicamente aceptable es una solución acuosa tamponada con pH. Los ejemplos de vehículos fisiológicamente aceptables incluyen tampones tales como fosfato, citrato y otros ácidos orgánicos; antioxidantes que incluyen ácido ascórbico; polipéptido de bajo peso molecular (menos de aproximadamente 10 residuos); proteínas, tales como albúmina sérica, gelatina o inmunoglobulinas; polímeros hidrófilos tales como polivinilpirrolidona; aminoácidos tales como glicina, glutamina, asparagina, arginina o lisina; monosacáridos, disacáridos y otros carbohidratos que incluyen glucosa, manosa o dextrinas; agentes quelantes como EDTA; alcoholes de azúcar tales como manitol o sorbitol; contraiones formadores de sal tales como sodio; y/o tensioactivos no iónicos como TWEEN™ polietilenglicol (PEG) y PLURONICS™.
El término "agente citotóxico" como se usa en el presente documento se refiere a una sustancia que inhibe o previene la función de las células y/o causa la destrucción de las células. El término pretende incluir isótopos radiactivos (p. ej., At211, I131, I125, Y90, Re186, Re188, Sm153, Bi212, P32 e isótopos radiactivos de Lu), agentes quimioterapéuticos, p. ej., metotrexato, adriamicina, alcaloides de la vinca (vincristina, vinblastina, etopósido), doxorrubicina, melfalán, mitomicina C, clorambucilo, daunorrubicina u otros agentes intercalantes, enzimas y fragmentos de los mismos, como enzimas nucleolíticas, antibióticos y toxinas, como toxinas de moléculas pequeñas. toxinas activas de origen bacteriano, fúngico, vegetal o animal, incluidos fragmentos y/o variantes de los mismos, y los diversos agentes antitumorales o anticancerígenos descritos a continuación. Otros agentes citotóxicos se describen a continuación.
Un "agente inhibidor del crecimiento" cuando se usa en el presente documento se refiere a un compuesto o composición que inhibe el crecimiento de una célula, ya sea in vitro o in vivo. Los ejemplos de agentes inhibidores del crecimiento incluyen agentes que bloquean la progresión del ciclo celular, tales como agentes que inducen la detención de G1 y la detención de la fase M. Los bloqueadores clásicos de la fase M incluyen los alcaloides de la vinca (vincristina, vinorelbina y vinblastina), taxanos e inhibidores de la topoisomerasa II como doxorrubicina, epirrubicina, daunorrubicina, etopósido y bleomicina. Los agentes que detienen a G1 también se extienden a la fase S de detención, por ejemplo, agentes alquilantes de ADN como tamoxifeno, prednisona, dacarbazina, mecloretamina, cisplatino, metotrexato, 5-fluorouracilo y araC. Se puede encontrar más información en The Molecular Basis of Cancer, Mendelsohn e Israel, eds., Capítulo 1, titulado "Cell cycle regulation, oncogenes, and antineoplastic drugs" por Murakami et al. (WB Saunders: Filadelfia, 1995), especialmente p. 13. Los taxanos (paclitaxel y docetaxel) son medicamentos contra el cáncer derivados del tejo. Docetaxel (TAXOTERE™, Rhone-Poulenc Rorer), derivado del tejo europeo, es un análogo semisintético del paclitaxel (TAXOL®, Bristol-Myers Squibb). El paclitaxel y el docetaxel promueven el ensamblaje de microtúbulos a partir de dímeros de tubulina y estabilizan los microtúbulos al prevenir la despolimerización, lo que resulta en la inhibición de la mitosis en las células.
"Etiqueta", como se usa en el presente documento, se refiere a un compuesto o composición detectable que se conjuga directa o indirectamente con el anticuerpo para generar un anticuerpo "marcado". El marcador puede ser detectable por sí mismo (por ejemplo, marcadores de radioisótopos o marcadores fluorescentes) o, en el caso de un marcador enzimático, puede catalizar la alteración química de un compuesto o composición de sustrato que es detectable.
El término "epítopo marcado" como se usa en el presente documento se refiere a un polipéptido quimérico que comprende un polipéptido fusionado con un "polipéptido etiqueta". El polipéptido etiqueta tiene suficientes residuos para proporcionar un epítopo contra el cual se puede formar un anticuerpo, pero es lo suficientemente corto como para que no interfiera con la actividad del polipéptido al que se fusiona. El polipéptido etiqueta también es preferiblemente bastante único, de modo que el anticuerpo no reacciona sustancialmente de forma cruzada con otros epítopos. Los polipéptidos etiqueta adecuados generalmente tienen al menos seis residuos de aminoácidos y habitualmente entre aproximadamente 8 y 50 residuos de aminoácidos (preferiblemente, entre aproximadamente 10 y 20 residuos de aminoácidos).
Una "molécula pequeña" se define aquí para tener un peso molecular inferior a aproximadamente 500 Daltons.
Los términos "ácido nucleico" y "polinudeótido" se usan indistintamente en el presente documento para referirse a ARN, ADN o polímeros mixtos de cadena simple o doble. Los polinucleótidos pueden incluir secuencias genómicas, secuencias extragenómicas y de plásmidos y segmentos genéticos más pequeños diseñados que expresan, o pueden adaptarse para expresar polipéptidos.
Un "ácido nucleico aislado" es un ácido nucleico que está sustancialmente separado de otras secuencias de ADN del genoma, así como de proteínas o complejos tales como ribosomas y polimerasas, que naturalmente acompañan a una secuencia nativa. El término abarca una secuencia de ácido nucleico que se ha eliminado de su entorno natural, e incluye aislados de ADN recombinantes o clonados y análogos sintetizados químicamente o análogos sintetizados biológicamente por sistemas heterólogos. Un ácido nucleico sustancialmente puro incluye formas aisladas del ácido nucleico. Por supuesto, esto se refiere al ácido nucleico como se aisló originalmente y no excluye genes o secuencias añadidas posteriormente al ácido nucleico aislado por la mano del hombre.
El término "polipéptido" se usa en su significado convencional, es decir, como una secuencia de aminoácidos. Los polipéptidos no están limitados a una longitud específica del producto. Los péptidos, oligopéptidos y proteínas se incluyen dentro de la definición de polipéptido, y dichos términos pueden usarse indistintamente en el presente documento a menos que se indique específicamente lo contrario. Este término tampoco se refiere o excluye modificaciones posteriores a la expresión del polipéptido, por ejemplo, glicosilaciones, acetilaciones, fosforilaciones y similares, así como otras modificaciones conocidas en la técnica, tanto de origen natural como de origen no natural. Un polipéptido puede ser una proteína completa, o una subsecuencia de la misma. Los polipéptidos particulares de interés en el contexto de esta aplicación son subsecuencias de aminoácidos que comprenden c Dr y que son capaces de unirse a un antígeno o célula infectada por VIH.
Un "polipéptido aislado" es uno que ha sido identificado y separado y/o recuperado de un componente de su entorno natural. En algunos aspectos, el polipéptido aislado se purificará (1) a más del 95% en peso de polipéptido según lo determinado por el método de Lowry, y lo más preferiblemente más del 99% en peso, (2) en un grado suficiente para obtener al menos 15 residuos de secuencia de aminoácidos N-terminal o interna mediante el uso de un secuenciador de copa giratoria, o (3) hasta homogeneidad mediante SDS-PAGE en condiciones reductoras o no reductoras usando azul Coomassie o, preferiblemente, tinción de plata. El polipéptido aislado incluye el polipéptido in situ dentro de las células recombinantes ya que al menos un componente del entorno natural del polipéptido no estará presente. Normalmente, sin embargo, el polipéptido aislado se preparará mediante al menos una etapa de purificación.
Un polinucleótido de "secuencia nativa" es uno que tiene la misma secuencia de nucleótidos que un polinucleótido derivado de la naturaleza. Un polipéptido de "secuencia nativa" es uno que tiene la misma secuencia de aminoácidos que un polipéptido (por ejemplo, anticuerpo) derivado de la naturaleza (por ejemplo, de cualquier especie). Tales polinucleótidos y polipéptidos de secuencia nativa pueden aislarse de la naturaleza o pueden producirse por medios recombinantes o sintéticos.
Una "variante" polinucleotídica, como se usa el término en el presente documento, es un polinucleótido que típicamente difiere de un polinucleótido específicamente descrito en el presente documento en una o más sustituciones, deleciones, adiciones y/o inserciones. Dichas variantes pueden ser de origen natural o pueden generarse sintéticamente, por ejemplo, modificando una o más de las secuencias de polinucleótidos de la aplicación y evaluando una o más actividades biológicas del polipéptido codificado como se describe en este documento y/o usando cualquiera de una serie de técnicas bien conocidas en la técnica.
Una "variante" de polipéptido, como se usa el término en el presente documento, es un polipéptido que típicamente difiere de un polipéptido específicamente descrito en el presente documento en una o más sustituciones, deleciones, adiciones y/o inserciones. Dichas variantes pueden ser de origen natural o pueden generarse sintéticamente, por ejemplo, modificando una o más de las secuencias de polipéptidos anteriores de la aplicación y evaluando una o más actividades biológicas del polipéptido como se describe en este documento y/o usando cualquiera de una serie de técnicas bien conocidas en la técnica.
Se pueden hacer modificaciones en la estructura de los polinucleótidos y polipéptidos de la presente solicitud y aún obtener una molécula funcional que codifica una variante o polipéptido derivado con características deseables. Cuando se desea alterar la secuencia de aminoácidos de un polipéptido para crear una variante o porción equivalente, o incluso mejorada, de un polipéptido de la aplicación, un experto en la materia típicamente cambiará uno o más de los codones de la codificación Secuencia de ADN
Por ejemplo, ciertos aminoácidos pueden ser sustituidos por otros aminoácidos en una estructura de proteína sin una pérdida apreciable de su capacidad para unirse a otros polipéptidos (por ejemplo, antígenos) o células. Dado que es la capacidad de unión y la naturaleza de una proteína que define la actividad funcional biológica de esa proteína, ciertas sustituciones de secuencia de aminoácidos se pueden hacer en una secuencia de proteína y, por supuesto, es la secuencia de codificación de ADN subyacente, y sin embargo obtener una proteína con similar propiedades. Por lo tanto, se contempla que se pueden realizar varios cambios en las secuencias peptídicas de las composiciones
descritas, o las secuencias de ADN correspondientes que codifican dichos péptidos sin pérdida apreciable de su utilidad o actividad biológica.
En muchos casos, una variante de polipéptido contendrá una o más sustituciones conservadoras. Una "sustitución conservadora" es aquella en donde un aminoácido se sustituye por otro aminoácido que tiene propiedades similares, de modo que un experto en la técnica de la química de péptidos esperaría que la estructura secundaria y la naturaleza hidropática del polipéptido no cambien sustancialmente.
Al realizar tales cambios, se puede considerar el índice hidropático de aminoácidos. La importancia del índice de aminoácidos hidropáticos para conferir una función biológica interactiva a una proteína se entiende generalmente en la técnica (Kyte y Doolittle, 1982). Se acepta que el carácter hidropático relativo del aminoácido contribuye a la estructura secundaria de la proteína resultante, que a su vez define la interacción de la proteína con otras moléculas, por ejemplo, enzimas, sustratos, receptores, ADN, anticuerpos, antígenos, y similares. A cada aminoácido se le ha asignado un índice hidropático en función de sus características de hidrofobicidad y carga (Kyte y Doolittle, 1982). Estos valores son: isoleucina (+4,5); valina (+4,2); leucina (+3,8); fenilalanina (+2,8); cisteína/cistina (+2,5); metionina (+1,9); alanina (+1,8); glicina (-0,4); treonina (-0,7); serina (-0,8); triptófano (-0,9); tirosina (-1,3); prolina (-1,6); histidina (-3,2); glutamato (-3,5); glutamina (-3,5); aspartato (-3,5); asparagina (-3,5); lisina (-3,9); y arginina (-4,5).
Se sabe en la técnica que ciertos aminoácidos pueden ser sustituidos por otros aminoácidos que tienen un índice o puntaje hidropático similar y todavía dan como resultado una proteína con actividad biológica similar, es decir, todavía obtienen una proteína biológica funcionalmente equivalente. Al realizar tales cambios, se prefiere la sustitución de aminoácidos cuyos índices hidropáticos están dentro de 2, los que están dentro de 1 son particularmente preferidos, y aquellos dentro de 0,5 son aún más particularmente preferidos. También se entiende en la técnica que la sustitución de aminoácidos similares puede realizarse eficazmente en base a la hidrofilia. La patente de Estados Unidos 4,554,101 establece que la mayor hidrofilia media local de una proteína, según se rige por la hidrofilia de sus aminoácidos adyacentes, se correlaciona con una propiedad biológica de la proteína.
Como se detalla en la Patente de Estados Unidos 4,554,101, los siguientes valores de hidrofilia se han asignado a residuos de aminoácidos: arginina (+3,0); lisina (+3,0); aspartato (+3,0 1); glutamato (+3,0 1); serina (+0,3); asparagina (+0,2); glutamina (+0,2); glicina (0); treonina (-0,4); prolina (-0,5 1); alanina (-0,5); histidina (-0,5); cisteína (-1,0); metionina (-1,3); valina (-1,5); leucina (-1,8); isoleucina (-1,8); tirosina (-2,3); fenilalanina (-2,5); triptófano (-3,4). Se entiende que un aminoácido puede ser sustituido por otro que tenga un valor de hidrofilia similar y aún así obtener una proteína biológicamente equivalente y, en particular, una proteína inmunológicamente equivalente. En tales cambios, se prefiere la sustitución de aminoácidos cuyos valores de hidrofilia están dentro de 2, los que están dentro de 1 son particularmente preferidos, y aquellos dentro de 0,5 son aún más particularmente preferidos.
Como se describió anteriormente, las sustituciones de aminoácidos se basan generalmente en la similitud relativa de los sustituyentes de la cadena lateral de aminoácidos, por ejemplo, su hidrofobicidad, hidrofilia, carga, tamaño y similares. Las sustituciones ejemplares que toman en consideración varias de las características anteriores son bien conocidas por los expertos en la técnica e incluyen: arginina y lisina; glutamato y aspartato; serina y treonina; glutamina y asparagina; y valina, leucina e isoleucina.
Las sustituciones de aminoácidos se pueden realizar adicionalmente sobre la base de similitud en polaridad, carga, solubilidad, hidrofobicidad, hidrofilia y/o la naturaleza anfipática de los residuos. Por ejemplo, los aminoácidos cargados negativamente incluyen ácido aspártico y ácido glutámico; los aminoácidos cargados positivamente incluyen lisina y arginina; y aminoácidos con grupos de cabeza polar sin carga que tienen valores de hidrofilia similares incluyen leucina, isoleucina y valina; glicina y alanina; asparagina y glutamina; y serina, treonina, fenilalanina y tirosina. Otros grupos de aminoácidos que pueden representar cambios conservadores incluyen: (1) ala, pro, gly, glu, asp, gln, asn, ser, thr; (2) cys, ser, tyr, thr; (3) val, ile, leu, met, ala, phe; (4) lys, arg, his; y (5) phe, tyr, trp, his. Una variante también puede, o alternativamente, contener cambios no conservativos. En un aspecto, los polipéptidos variantes difieren de una secuencia nativa por sustitución, deleción o adición de cinco aminoácidos o menos. Las variantes también pueden modificarse (o alternativamente) mediante, por ejemplo, la eliminación o adición de aminoácidos que tienen una influencia mínima sobre la inmunogenicidad, la estructura secundaria y la naturaleza hidropática del polipéptido.
Los polipéptidos pueden comprender una secuencia de señal (o líder) en el extremo N-terminal de la proteína, que dirige la transferencia de la proteína de forma cotranslacional o postraduccional. El polipéptido también puede conjugarse con un conector u otra secuencia para facilitar la síntesis, purificación o identificación del polipéptido (por ejemplo, poli-His), o para mejorar la unión del polipéptido a un soporte sólido. Por ejemplo, un polipéptido puede conjugarse con una región Fc de inmunoglobulina.
Cuando se comparan secuencias de polinucleótidos y polipéptidos, se dice que dos secuencias son "idénticas" si la secuencia de nucleótidos o aminoácidos en las dos secuencias es la misma cuando se alinea para una correspondencia máxima, como se describe a continuación. Las comparaciones entre dos secuencias se realizan típicamente comparando las secuencias en una ventana de comparación para identificar y comparar regiones locales
de similitud de secuencia. Una "ventana de comparación", como se usa en el presente documento, se refiere a un segmento de al menos aproximadamente 20 posiciones contiguas, generalmente de 30 a aproximadamente 75, de 40 a aproximadamente 50, en donde se puede comparar una secuencia con una secuencia de referencia del mismo número de posiciones contiguas después de que las dos secuencias estén alineadas de manera óptima.
La alineación óptima de secuencias para comparación se puede llevar a cabo usando el programa Megalign en el conjunto de software de bioinformática Lasergene (ADNSTAR, Inc., Madison, WI), usando parámetros predeterminados. Este programa incorpora varios esquemas de alineación descritos en las siguientes referencias: Dayhoff, MO (1978) A model of evolutionary change in proteins - Matrices for detecting distant relationships. En Dayhoff, M.O. (ed.) Atlas of Protein Sequence and Structure, National Biomedical Research Foundation, Washington DC Vol. 5, Suppl. 3, pp. 345-358; Hein J. (1990) Unified Approach to Alignment and Phylogenes pp. 626-645 Methods in Enzymology vol. 183, Academic Press, Inc., San Diego, Ca ; Higgins, D.G. y Sharp, P.M. (1989) CABIOS 5:151-153; Myers, E.W. and Muller W. (1988) CABIOS 4:11-17; Robinson, E.D. (1971) Comb. Theor 11:105; Santou, N. Nes, M. (1987) Mol. Biol. Evol. 4:406-425; Sneath, P.H.A. y Sokal, R.R. (1973) Numerical Taxonomy - the Principles and Practice of Numerical Taxonomy, Freeman Press, San Francisco, CA; Wilbur, W.J. y Lipman, D.J. (1983) Proc. Natl. Acad., Sci. EE.UU. 80:726-730.
Alternativamente, el alineamiento óptimo de secuencias para la comparación puede realizarse mediante el algoritmo de identidad local de Smith y Waterman (1981) Add. APL. Math 2: 4 8 2 , mediante el algoritmo de alineación de identidad de Needleman y Wunsch (1970) J. Mol. Biol. 48: 443, mediante la búsqueda de métodos de similitud de Pearson y Lipman (1988) Proc. Natl. Acad. Sci. EE.UU. 85: 2444, mediante implementaciones computarizadas de estos algoritmos (GAP, BESTFIT, BLAST, FASTA y TFASTA en el Wisconsin Genetics Software Package, Genetics Computer Group (GCG), 575 Science Dr., Madison, WI), o mediante inspección.
Un ejemplo preferido de algoritmos que son adecuados para determinar el porcentaje de identidad de secuencia y la similitud de secuencia son los algoritmos BLAST y BLAST 2,0, que se describen en Altschul et al. (1977) Nucl. Acids Res. 25: 3389-3402 y Altschul et al. (1990) J. Mol. Biol. 215: 403-410, respectivamente. BLAST y BLAST 2 , 0 pueden usarse, por ejemplo con los parámetros descritos en este documento, para determinar el porcentaje de identidad de secuencia para los polinucleótidos y polipéptidos de la aplicación. El software para realizar análisis BLAST está disponible públicamente a través del Centro Nacional de Información Biotecnológica.
En un ejemplo ilustrativo, los puntajes acumulativos se pueden calcular usando, para secuencias de nucleótidos, los parámetros M (puntaje de recompensa para un par de residuos coincidentes; siempre >0) y N (puntaje de penalización para residuos que no coinciden; siempre <0 ). La extensión de los aciertos de palabras en cada dirección se detiene cuando: la puntuación de alineación acumulativa cae en la cantidad X de su valor máximo alcanzado; el puntaje acumulativo va a cero o menos, debido a la acumulación de uno o más alineamientos de residuos de puntuación negativa; o se alcanza el final de cualquiera de las secuencias. Los parámetros del algoritmo BLAST W, T y X determinan la sensibilidad y la velocidad de la alineación. El programa BLASTN (para secuencias de nucleótidos) utiliza por defecto una longitud de palabra (W) de 11 y una expectativa (E) de 10, y la matriz de puntuación BLOSUM62 (ver Henikoff y Henikoff (1989) Proc. Natl. Acad. Sci. EE.UU. 89): 10915) alineaciones, (B) de 50, expectativa (E) de 10, M = 5, N = -4 y una comparación de ambas cadenas.
Para secuencias de aminoácidos, se puede usar una matriz de puntuación para calcular la puntuación acumulativa. La extensión de los aciertos de palabras en cada dirección se detiene cuando: la puntuación de alineación acumulativa cae en la cantidad X de su valor máximo alcanzado; el puntaje acumulativo va a cero o menos, debido a la acumulación de uno o más alineamientos de residuos de puntuación negativa; o se alcanza el final de cualquiera de las secuencias. Los parámetros del algoritmo BLAST W, T y X determinan la sensibilidad y la velocidad de la alineación.
En un enfoque, el "porcentaje de identidad de secuencia" se determina comparando dos secuencias óptimamente alineadas sobre una ventana de comparación de al menos 20 posiciones, en donde la porción de la secuencia de polinucleótidos o polipéptidos en la ventana de comparación puede comprender adiciones o deleciones (es decir, huecos) de 20 por ciento o menos, habitualmente de 5 a 15 por ciento, o de 10 a 12 por ciento, en comparación con las secuencias de referencia (que no comprende adiciones o deleciones) para la alineación óptima de las dos secuencias. El porcentaje se calcula determinando el número de posiciones en las que se producen bases de ácido nucleico o residuos de aminoácidos idénticos en ambas secuencias para producir el número de posiciones coincidentes, dividiendo el número de posiciones coincidentes por el número total de posiciones en la secuencia de referencia (es decir, el tamaño de la ventana) y multiplicando los resultados por 100 para producir el porcentaje de identidad de secuencia.
"Homología" se refiere al porcentaje de residuos en la variante de secuencia de polinucleótidos o polipéptidos que son idénticos a la secuencia no variante después de alinear las secuencias e introducir huecos, si es necesario, para lograr el porcentaje máximo de homología. En aspectos particulares, las variantes de polinucleótidos y polipéptidos tienen al menos 70%, al menos 75%, al menos 80%, al menos 90%, al menos 95%, al menos 98% o al menos 99% de homología de polinucleótidos u polipéptidos con un polinucleótido o polipéptido descrito aquí.
"Vector" incluye vectores lanzadera y de expresión. Típicamente, la construcción del plásmido también incluirá un origen de replicación (por ejemplo, el origen de replicación ColE1) y un marcador seleccionable (por ejemplo, resistencia a ampicilina o tetraciclina), para la replicación y selección, respectivamente, de los plásmidos en bacterias. Un "vector de expresión" se refiere a un vector que contiene las secuencias de control o elementos reguladores necesarios para la expresión de los anticuerpos, incluido el fragmento de anticuerpo de la aplicación, en células bacterianas o eucariotas. Los vectores adecuados se describen a continuación. Como se usa en esta especificación y en las reivindicaciones adjuntas, las formas singulares "un”, “una”, “el” y “ la" incluyen referencias en plural a menos que el contenido indique claramente lo contrario.
La aplicación también incluye secuencias de ácido nucleico que codifican parte o la totalidad de las cadenas ligeras y pesadas y CDR de la presente solicitud. Debido a la redundancia del código genético, existirán variantes de estas secuencias que codifican las mismas secuencias de aminoácidos.
Dichas secuencias de anticuerpos variantes compartirán el 70% o más (es decir, 80, 85, 90, 95, 97, 98, 99% o más) de identidad de secuencia con las secuencias mencionadas en la solicitud. Preferiblemente, dicha identidad de secuencia se calcula con respecto a la longitud completa de la secuencia de referencia (es decir, la secuencia mencionada en la solicitud). Preferiblemente, el porcentaje de identidad, como se menciona aquí, se determina usando BLAST versión 2,1,3 usando los parámetros predeterminados especificados por el NCBi (Centro Nacional de Información Biotecnológica; http://www.ncbi.nlm.nih.gov/) [Blosum 62 matriz; penalización por hueco abierto = 11 y penalización por extensión de hueco = 1].
Como entenderá el experto en la materia, la descripción general de los anticuerpos en el presente documento y los métodos de preparación y uso de los mismos también se aplican a constituyentes de polipéptidos de anticuerpos individuales y fragmentos de anticuerpos.
Los anticuerpos de la presente solicitud pueden ser anticuerpos policlonales o monoclonales. Sin embargo, según la invención, son monoclonales. En aspectos particulares, los anticuerpos de la presente solicitud son anticuerpos humanos. Los métodos para producir anticuerpos policlonales y monoclonales son conocidos en la técnica y se describen en general, por ejemplo, en la Patente de Estados Unidos Núm. 6,824,780.
Típicamente, los anticuerpos de la presente solicitud se producen de forma recombinante, usando vectores y métodos disponibles en la técnica, como se describe más adelante. Los anticuerpos humanos también pueden ser generados por células B activadas in vitro (véanse las patentes de Estados Unidos números 5,567,610 y 5,229,275).
Los anticuerpos humanos también pueden producirse en animales transgénicos (por ejemplo, ratones) que son capaces de producir un repertorio completo de anticuerpos humanos en ausencia de producción de inmunoglobulina endógena. Por ejemplo, se ha descrito que la eliminación homocigótica del gen de la región de unión de la cadena pesada (Jh) del anticuerpo en ratones mutantes quiméricos y de línea germinal da como resultado una inhibición completa de la producción de anticuerpos endógenos. La transferencia del conjunto de genes de inmunoglobulina de la línea germinal humana a dichos ratones mutantes de la línea germinal da como resultado la producción de anticuerpos humanos tras la exposición al antígeno. Ver, por ejemplo, Jakobovits et al., Proc. Natl. Acad. Sci. EE.UU., 90: 2551 (1993); Jakobovits et al., Nature, 362: 255-258 (1993); Bruggemann et al., Year in Immuno., 7:33 (1993); Pat. Nos. 5,545,806, 5,569,825, 5,591,669 (todos de GenPharm); Pat. N° 5,545,807; y WO 97/17852. Dichos animales pueden ser modificados genéticamente para producir anticuerpos humanos que comprenden un polipéptido de la presente solicitud.
En ciertos aspectos, los anticuerpos de la presente solicitud son anticuerpos quiméricos que comprenden secuencias derivadas de fuentes tanto humanas como no humanas. En aspectos particulares, estos anticuerpos quiméricos son humanizados o primatizados™. En la práctica, los anticuerpos humanizados son típicamente anticuerpos humanos en los que algunos residuos de la región hipervariable y posiblemente algunos residuos de FR están sustituidos por residuos de sitios análogos en anticuerpos de roedores.
En el contexto de la presente solicitud, los anticuerpos quiméricos también incluyen anticuerpos humanos en los que se retiene la región hipervariable humana o una o más CDR, pero una o más regiones de secuencia se han reemplazado por secuencias correspondientes de un animal no humano.
La elección de secuencias no humanas, tanto ligeras como pesadas, para usar en la fabricación de anticuerpos quiméricos es importante para reducir la antigenicidad y las respuestas de anticuerpos humanos no humanos cuando el anticuerpo está destinado para uso terapéutico humano. Es importante además que los anticuerpos quiméricos retengan una alta afinidad de unión por el antígeno y otras propiedades biológicas favorables. Para lograr este objetivo, de acuerdo con un método preferido, los anticuerpos quiméricos se preparan mediante un proceso de análisis de las secuencias parentales y diversos productos quiméricos conceptuales utilizando modelos tridimensionales de las secuencias parentales humanas y no humanas. Los modelos tridimensionales de inmunoglobulina están comúnmente disponibles y son familiares para los expertos en la materia. Se encuentran
disponibles programas informáticos que ilustran y muestran estructuras conformacionales tridimensionales probables de secuencias de inmunoglobulinas candidatas seleccionadas.
La inspección de estos cribados permite el análisis del papel probable de los residuos en el funcionamiento de la secuencia de inmunoglobulina candidata, es decir, el análisis de residuos que influyen en la capacidad de la inmunoglobulina candidata para unirse a su antígeno. De esta manera, los residuos de FR pueden seleccionarse y combinarse del receptor y de las secuencias de importación de modo que se logre la característica de anticuerpo deseada, tal como una mayor afinidad por el antígeno o los antígenos objetivo. En general, los residuos de la región hipervariable están directa y más sustancialmente implicados en la influencia de la unión al antígeno.
Como se indicó anteriormente, los anticuerpos (o inmunoglobulinas) se pueden dividir en cinco clases diferentes, en función de las diferencias en las secuencias de aminoácidos en la región constante de las cadenas pesadas. Todas las inmunoglobulinas dentro de una clase dada tienen regiones constantes de cadena pesada muy similares. Estas diferencias pueden detectarse mediante estudios de secuencia o más comúnmente por medios serológicos (es decir, mediante el uso de anticuerpos dirigidos a estas diferencias). Los anticuerpos, o fragmentos de los mismos, de la presente solicitud pueden ser de cualquier clase y, por lo tanto, pueden tener una cadena pesada gamma, mu, alfa, delta o épsilon. Una cadena gamma puede ser gamma 1, gamma 2, gamma 3 o gamma 4; y una cadena alfa puede ser alfa 1 o alfa 2.
En un aspecto, un anticuerpo de la presente solicitud, o fragmento del mismo, es una IgG. La IgG se considera la inmunoglobulina más versátil, porque es capaz de llevar a cabo todas las funciones de las moléculas de inmunoglobulina. La IgG es la principal Ig en el suero, y la única clase de Ig que cruza la placenta. IgG también corrige el complemento, aunque la subclase IgG4 no. Los macrófagos, monocitos, PMN y algunos linfocitos tienen receptores Fc para la región Fc de IgG. No todas las subclases se unen igualmente bien: IgG2 e IgG4 no se unen a los receptores Fc. Una consecuencia de la unión a los receptores Fc en PMN, monocitos y macrófagos es que la célula ahora puede internalizar mejor el antígeno. La IgG es una opsonina que mejora la fagocitosis. La unión de los receptores de IgG a Fc en otros tipos de células da como resultado la activación de otras funciones. Los anticuerpos de la presente solicitud pueden ser de cualquier subclase de IgG.
En otro aspecto, un anticuerpo, o fragmento del mismo, de la presente solicitud es una IgE. La IgE es la Ig sérica menos común, ya que se une muy fuertemente a los receptores Fc en los basófilos y los mastocitos incluso antes de interactuar con el antígeno. Como consecuencia de su unión a basófilos y mastocitos, la IgE está implicada en reacciones alérgicas. La unión del alergeno a la IgE en las células da como resultado la liberación de varios mediadores farmacológicos que provocan síntomas alérgicos. La IgE también juega un papel en las enfermedades parasitarias por helmintos. Los eosinófilos tienen receptores Fc para IgE y la unión de eosinófilos a helmintos recubiertos con IgE da como resultado la muerte del parásito. IgE no repara el complemento.
En diversos aspectos, los anticuerpos de la presente solicitud, y sus fragmentos, comprenden una cadena ligera variable que es kappa o lambda. La cadena de lamba puede ser cualquiera de los subtipos, incluidos, por ejemplo, lambda 1, lambda 2, lambda 3 y lambda 4.
Como se indicó anteriormente, la presente solicitud proporciona además fragmentos de anticuerpos que comprenden un polipéptido de la presente solicitud. En ciertas circunstancias, existen ventajas de usar fragmentos de anticuerpos, en lugar de anticuerpos completos. Por ejemplo, el tamaño más pequeño de los fragmentos permite un aclaramiento rápido y puede mejorar el acceso a ciertos tejidos, como los tumores sólidos. Los ejemplos de fragmentos de anticuerpos incluyen: fragmentos Fab, Fab', F(ab')2 y Fv; diacuerpos; anticuerpos lineales; anticuerpos de cadena sencilla; y anticuerpos multiespecíficos formados a partir de fragmentos de anticuerpos.
Se han desarrollado diversas técnicas para la producción de fragmentos de anticuerpos. Tradicionalmente, estos fragmentos se derivaron a través de la digestión proteolítica de anticuerpos intactos (véase, por ejemplo, Morimoto y col., Journal of Biochemical and Biofysical Methods 24: 107-117 (1992); y Brennan y col., Science, 229: 81 (1985)). Sin embargo, estos fragmentos ahora pueden ser producidos directamente por células huésped recombinantes. Los fragmentos de anticuerpos Fab, Fv y ScFv pueden expresarse y secretarse de E. coli, lo que permite la producción fácil de grandes cantidades de estos fragmentos. Los fragmentos Fab'-SH pueden recuperarse directamente de E. coli y acoplarse químicamente para formar fragmentos F(ab')2 (Carter et al., Bio/Technology 10:163-167 (1992)). Según otro enfoque, los fragmentos F(ab')2 pueden aislarse directamente del cultivo de células huésped recombinantes. Fragmento Fab y F(ab')2 con la vida media in vivo aumentada que comprende un epítopo de unión a receptor de rescate residuos se describen en la patente de Estados Unidos. N° 5,869,046. Otras técnicas para la producción de fragmentos de anticuerpos serán evidentes para el profesional experto.
En otros aspectos, el anticuerpo de elección es un fragmento Fv de cadena sencilla (scFv). Ver WO 93/16185; Pat. Nos 5,571,894; y 5,587,458. Fv y sFv son las únicas especies con sitios de combinación intactos que carecen de regiones constantes. Por lo tanto, son adecuados para reducir la unión inespecífica durante el uso in vivo. Las proteínas de fusión de sFv se pueden construir para producir la fusión de una proteína efectora en el extremo amino o carboxi de un sFv. Ver Antibody Engineering, ed. Borrebaeck, supra. El fragmento de anticuerpo también puede ser
un "anticuerpo lineal", por ejemplo, como se describe en la patente de EE.UU. 5,641,870 por ejemplo. Dichos fragmentos de anticuerpos lineales pueden ser monoespecíficos o biespecíficos.
En ciertos aspectos, los anticuerpos de la presente solicitud son biespecíficos o multiespecíficos. Los anticuerpos biespecíficos son anticuerpos que tienen especificidades de unión para al menos dos epítopos diferentes. Los anticuerpos biespecíficos ejemplares pueden unirse a dos epítopos diferentes de un solo antígeno. Otros de estos anticuerpos pueden combinar un primer sitio de unión a antígeno con un sitio de unión a un segundo antígeno. Alternativamente, un brazo anti-VIH1 se puede combinar con un brazo que se une a una molécula desencadenante en un leucocito, como una molécula de receptor de células T (por ejemplo, CD3), o receptores Fc para IgG (FcyR), como FcyRI (CD64), FcyRII (CD32) y FcyRIII (CD16), para enfocar y localizar mecanismos de defensa celular en la célula infectada. Los anticuerpos biespecíficos también se pueden usar para localizar agentes citotóxicos en células infectadas. Estos anticuerpos poseen un brazo de unión al VIH1 y un brazo que se une al agente citotóxico (p. ej., saporina, anti-interferón-a, alcaloide de la vinca, cadena de ricina A, metotrexato o hapteno isótopo radiactivo). Los anticuerpos biespecíficos pueden prepararse como anticuerpos de longitud completa o fragmentos de anticuerpos (por ejemplo, anticuerpos biespecíficos F(ab')2). El documento WO 96/16673 describe un anticuerpo biespecífico anti-ErbB2/anti-FcYRIII y la patente de EE.UU. N° 5,837,234 describe un anticuerpo anti-ErbB2/anti-FcYRI biespecífico. En el documento WO98/02463 se muestra un anticuerpo biespecífico anti-ErbB2/Fca. Pat. 5,821,337 enseña un anticuerpo biespecífico anti-ErbB2/anti-CD3.
Los métodos para fabricar anticuerpos biespecíficos son conocidos en la técnica. La producción tradicional de anticuerpos biespecíficos de longitud completa se basa en la coexpresión de dos pares de cadenas pesadas de cadena pesada de inmunoglobulina, donde las dos cadenas tienen especificidades diferentes (Millstein et al., Nature, 305: 537-539 (1983)). Debido a la variedad aleatoria de cadenas pesadas y ligeras de inmunoglobulina, estos hibridomas (quadromas) producen una mezcla potencial de diez moléculas de anticuerpos diferentes, de las cuales solo una tiene la estructura biespecífica correcta. La purificación de la molécula correcta, que generalmente se realiza mediante pasos de cromatografía de afinidad, es bastante engorrosa y los rendimientos del producto son bajos. Se describen procedimientos similares en el documento WO 93/08829 y en Traunecker et al., EMBO J., 10: 3655-3659 (1991).
De acuerdo con un enfoque diferente, las regiones variables de anticuerpos con las especificidades de unión deseadas (sitios de combinación de antibodiantígeno) se fusionan a secuencias de dominio constante de inmunoglobulina. Preferiblemente, la fusión es con un dominio constante de cadena pesada de Ig, que comprende al menos parte de las regiones de bisagra, Ch2 y Ch3. Se prefiere tener la primera región constante de cadena pesada (Ch1) que contiene el sitio necesario para la unión de la cadena ligera, presente en al menos una de las fusiones. Los ADN que codifican las fusiones de la cadena pesada de inmunoglobulina y, si se desea, la cadena ligera de inmunoglobulina, se insertan en vectores de expresión separados y se cotransfectan en una célula huésped adecuada. Esto proporciona una mayor flexibilidad para ajustar las proporciones mutuas de los tres fragmentos de polipéptidos en aspectos cuando las proporciones desiguales de las tres cadenas de polipéptidos utilizadas en la construcción proporcionan el rendimiento óptimo del anticuerpo biespecífico deseado. Sin embargo, es posible insertar las secuencias de codificación para dos o las tres cadenas de polipéptidos en un solo vector de expresión cuando la expresión de al menos dos cadenas de polipéptidos en proporciones iguales da como resultado altos rendimientos o cuando las proporciones no tienen un efecto significativo sobre el rendimiento de la combinación de cadena deseada.
En un aspecto de este enfoque, los anticuerpos biespecíficos están compuestos de una cadena pesada de inmunoglobulina híbrida con una primera especificidad de unión en un brazo, y un par híbrido de cadena pesadacadena ligera de inmunoglobulina (que proporciona una segunda especificidad de unión) en el otro brazo. Se descubrió que esta estructura asimétrica facilita la separación del compuesto biespecífico deseado de las combinaciones de cadena de inmunoglobulina no deseadas, ya que la presencia de una cadena ligera de inmunoglobulina en solo la mitad de la molécula biespecífica proporciona una forma fácil de separación. Este enfoque se describe en el documento WO 94/04690. Para más detalles sobre la generación de anticuerpos biespecíficos, véase, por ejemplo, Suresh et al., Methods in Enzymology, 121: 210 (1986).
Según otro enfoque descrito en la patente de EE.UU. N° 5,731,168, la interfaz entre un par de moléculas de anticuerpos se puede diseñar para maximizar el porcentaje de heterodímeros que se recuperan del cultivo celular recombinante. La interfaz preferida comprende al menos una parte del dominio Ch3. En este método, una o más cadenas laterales de aminoácidos pequeñas de la interfaz de la primera molécula de anticuerpo se reemplazan con cadenas laterales más grandes (por ejemplo, tirosina o triptófano). Las "cavidades" compensatorias de tamaño idéntico o similar a la(s) cadena(s) lateral(s) grande(s) se crean en la interfaz de la segunda molécula de anticuerpo reemplazando las cadenas laterales de aminoácidos grandes por otras más pequeñas (por ejemplo, alanina o treonina). Esto proporciona un mecanismo para aumentar el rendimiento del heterodímero sobre otros productos finales no deseados, como los homodímeros.
Los anticuerpos biespecíficos incluyen anticuerpos reticulados o "heteroconjugados". Por ejemplo, uno de los anticuerpos en el heteroconjugado se puede acoplar a la avidina, el otro a la biotina. Dichos anticuerpos, por ejemplo, se han propuesto para dirigir células del sistema inmunitario a células no deseadas (patente de Estados Unidos N°
4,676,980) y para el tratamiento de la infección por VIH (WO 91/00360, WO 92/200373 y EP 03089). Los anticuerpos heteroconjugados pueden prepararse usando cualquier método de reticulación conveniente. Los agentes de reticulación adecuados son bien conocidos en la técnica y se describen en las patentes de EE.UU. N° 4,676,980, junto con una serie de técnicas de reticulación.
Las técnicas para generar anticuerpos biespecíficos a partir de fragmentos de anticuerpos también se han descrito en la literatura. Por ejemplo, los anticuerpos biespecíficos pueden prepararse usando enlace químico. Brennan et al., Science, 229: 81 (1985) describen un procedimiento en donde los anticuerpos intactos se cortan proteolíticamente para generar fragmentos F(ab')2. Estos fragmentos se reducen en presencia del agente complejante de ditiol, arsenito de sodio, para estabilizar los ditioles vecinales y prevenir la formación de disulfuro intermolecular. Los fragmentos Fab' generados se convierten luego en derivados de tionitrobenzoato (TNB). Luego, uno de los derivados de Fab'-TNB se reconvierte en Fab'-tiol por reducción con mercaptoetilamina y se mezcla con una cantidad equimolar del otro derivado de Fab'-TNB para formar el anticuerpo biespecífico. Los anticuerpos biespecíficos producidos pueden usarse como agentes para la inmovilización selectiva de enzimas.
El reciente progreso ha facilitado la recuperación directa de fragmentos Fab'-SH a partir de E. coli, que puede acoplarse químicamente para formar anticuerpos biespecíficos. Shalaby y col., J. Exp. Med., 175: 217-225 (1992) describen la producción de una molécula de anticuerpo biespecífico humanizado F(ab')2. Cada fragmento Fab' se secretó por separado de E. coli y se sometió a acoplamiento químico dirigido in vitro para formar el anticuerpo biespecífico. El anticuerpo biespecífico así formado pudo unirse a las células que sobreexpresan el receptor ErbB2 y las células T humanas normales, así como desencadenar la actividad lítica de los linfocitos citotóxicos humanos contra objetivos de tumores de mama humanos.
También se han descrito diversas técnicas para elaborar y aislar fragmentos de anticuerpos biespecíficos directamente a partir de cultivos celulares recombinantes. Por ejemplo, se han producido anticuerpos biespecíficos usando cremalleras de leucina. Kostelny y col., J. Immunol., 148 (5): 1547-1553 (1992). Los péptidos con cremallera de leucina de las proteínas Fos y Jun se unieron a las porciones Fab' de dos anticuerpos diferentes mediante fusión génica. Los homodímeros de anticuerpos se redujeron en la región bisagra para formar monómeros y luego se reoxidaron para formar los heterodímeros de anticuerpos. Este método también se puede utilizar para la producción de homodímeros de anticuerpos. La tecnología de "diacuerpo" descrita por Hollinger et al., Proc. Natl. Acad. Sci. EE.UU., 90: 6444-6448 (1993) ha proporcionado un mecanismo alternativo para hacer fragmentos de anticuerpos biespecíficos. Los fragmentos comprenden un Vh conectado a un Vl por un enlazador que es demasiado corto para permitir el emparejamiento entre los dos dominios en la misma cadena. Por consiguiente, los dominios Vh y Vl de un fragmento se ven obligados a emparejarse con los dominios Vl y Vh complementarios de otro fragmento, formando así dos sitios de unión a antígeno. También se ha informado sobre otra estrategia para elaborar fragmentos de anticuerpos biespecíficos mediante el uso de dímeros de cadena sencilla Fv (sFv). Ver Gruber et al., J. Immunol., 152: 5368 (1994).
Se contemplan los anticuerpos con más de dos valencias. Por ejemplo, se pueden preparar anticuerpos triespecíficos. Tutt y col., J. Immunol. 147: 60 (1991). Un anticuerpo multivalente puede ser internalizado (y/o catabolizado) más rápido que un anticuerpo bivalente por una célula que expresa un antígeno al que se unen los anticuerpos. Los anticuerpos de la presente solicitud pueden ser anticuerpos multivalentes con tres o más sitios de unión a antígeno (por ejemplo, anticuerpos tetravalentes), que pueden producirse fácilmente mediante expresión recombinante de ácido nucleico que codifica las cadenas de polipéptidos del anticuerpo. El anticuerpo multivalente puede comprender un dominio de dimerización y tres o más sitios de unión a antígeno. El dominio de dimerización preferido comprende (o consiste en) una región Fc o una región bisagra. En este escenario, el anticuerpo comprenderá una región Fc y tres o más sitios de unión a antígeno amino terminal a la región Fc. El anticuerpo multivalente preferido en el presente documento comprende (o consiste en) tres a aproximadamente ocho, pero preferiblemente cuatro, sitios de unión a antígeno. El anticuerpo multivalente comprende al menos una cadena de polipéptidos (y preferiblemente dos cadenas de polipéptidos), en donde las cadenas de polipéptidos comprenden dos o más regiones variables. Por ejemplo, la cadena o cadenas polipeptídicas pueden comprender VD1-(X-i)n -VD2-(X2)n -Fc, en donde VD1 es una primera región variable, VD2 es una segunda región variable, Fc es una cadena polipeptídica de una región Fc, X1 y X2 representan un aminoácido o polipéptido, y n es 0 o 1. Por ejemplo, la cadena o cadenas de polipéptidos pueden comprender: enlazador flexible VH-CH1-cadena de región VH-CH1-Fc; o cadena de región VH-CH1-VH-CH1-Fc. El anticuerpo multivalente de la presente invención comprende además preferiblemente al menos dos (y preferiblemente cuatro) polipéptidos de región variable de cadena ligera. El anticuerpo multivalente en el presente documento puede, por ejemplo, comprender de aproximadamente dos a aproximadamente ocho polipéptidos de región variable de cadena ligera. Los polipéptidos de la región variable de la cadena ligera contemplados aquí comprenden una región variable de la cadena ligera y, opcionalmente, comprenden además un dominio Cl.
Los anticuerpos de la aplicación incluyen además anticuerpos de cadena sencilla. En aspectos particulares, los anticuerpos de la aplicación son anticuerpos internalizantes.
Se contemplan modificaciones en la secuencia de aminoácidos de los anticuerpos descritos en este documento. Por ejemplo, puede ser deseable mejorar la afinidad de unión y/u otras propiedades biológicas del
anticuerpo. Las variantes de secuencia de aminoácidos del anticuerpo pueden prepararse mediante la introducción de cambios de nucleótidos apropiados en un polinucleótido que codifica el anticuerpo, o una cadena del mismo, o mediante síntesis de péptidos. Dichas modificaciones incluyen, por ejemplo, deleciones y/o inserciones en y/o sustituciones de residuos dentro de las secuencias de aminoácidos del anticuerpo. Se puede hacer cualquier combinación de eliminación, inserción y sustitución para llegar al anticuerpo final, siempre que la construcción final posea las características deseadas. Los cambios de aminoácidos también pueden alterar los procesos postraduccionales del anticuerpo, como cambiar el número o la posición de los sitios de glucosilación. Cualquiera de las variaciones y modificaciones descritas anteriormente para los polipéptidos de la presente aplicación puede incluirse en los anticuerpos de la presente aplicación.
Un método útil para la identificación de ciertos residuos o regiones de un anticuerpo que son ubicaciones preferidas para la mutagénesis se denomina "mutagénesis de exploración de alanina" como se describe por Cunningham y Wells en Science, 244: 1081-1085 (1989). Aquí, se identifica un residuo o grupo de residuos diana (p. ej., residuos cargados como arg, asp, his, lys y glu) y se reemplazan por un aminoácido neutro o cargado negativamente (lo más preferiblemente alanina o polialanina) para afectar el interacción de los aminoácidos con el antígeno PSCA. Esas ubicaciones de aminoácidos que demuestran sensibilidad funcional a las sustituciones luego se refinan mediante la introducción de otras variantes u otras en, o para, los sitios de sustitución. Por lo tanto, aunque el sitio para introducir una variación de secuencia de aminoácidos está predeterminado, la naturaleza de la mutación per se no tiene que estar predeterminada. Por ejemplo, para analizar el rendimiento de una mutación en un sitio determinado, se realiza un escaneo de ala o mutagénesis aleatoria en el codón o región diana y las variantes de anticuerpos expresadas se seleccionan para la actividad deseada.
Las inserciones de secuencia de aminoácidos incluyen fusiones amino y/o carboxilo terminales que varían en longitud desde un residuo a polipéptidos que contienen cien o más residuos, así como inserciones dentro de residuos de aminoácidos individuales o múltiples. Los ejemplos de inserciones terminales incluyen un anticuerpo con un residuo de metionilo N-terminal o el anticuerpo fusionado a un polipéptido citotóxico. Otras variantes de inserción de un anticuerpo incluyen la fusión al término N o C del anticuerpo a una enzima (por ejemplo, para ADEPT) o un polipéptido que aumenta la vida media en suero del anticuerpo.
Otro tipo de variante es una variante de sustitución de aminoácidos. Estas variantes tienen al menos un residuo de aminoácido en la molécula de anticuerpo reemplazada por un residuo diferente. Los sitios de mayor interés para la mutagénesis por sustitución incluyen las regiones hipervariables, pero también se contemplan alteraciones de FR. Se contemplan sustituciones conservativas y no conservativas.
Las modificaciones sustanciales en las propiedades biológicas del anticuerpo se realizan mediante sustituciones de selección que difieren significativamente en su efecto de mantener (a) la estructura del esqueleto del polipéptido en el área de la sustitución, por ejemplo, como una conformación en lámina o helicoidal, (b) la carga o hidrofobicidad de la molécula en el sitio diana, o (c) la mayor parte de la cadena lateral.
Cualquier residuo de cisteína que no esté involucrado en el mantenimiento de la conformación adecuada del anticuerpo también puede sustituirse, generalmente con serina, para mejorar la estabilidad oxidativa de la molécula y evitar la reticulación aberrante. A la inversa, pueden agregarse enlaces de cisteína al anticuerpo para mejorar su estabilidad (particularmente cuando el anticuerpo es un fragmento de anticuerpo tal como un fragmento Fv).
Un tipo de variante de sustitución implica la sustitución de uno o más residuos de la región hipervariable de un anticuerpo original. Generalmente, la(s) variante(s) resultante(s) seleccionada(s) para un mayor desarrollo tendrá(n) propiedades biológicas mejoradas en relación con el anticuerpo original a partir del cual se generan. Una forma conveniente de generar tales variantes de sustitución implica la maduración de afinidad utilizando la presentación en fagos. Brevemente, varios sitios de regiones hipervariables (p. ej., 6-7 sitios) se mutan para generar todas las sustituciones de amino posibles en cada sitio. Las variantes de anticuerpos así generadas se muestran de forma monovalente a partir de partículas de fagos filamentosos como fusiones al producto del gen III de M13 empaquetado dentro de cada partícula. Las variantes mostradas en fagos se seleccionan luego por su actividad biológica (por ejemplo, afinidad de unión) como se describe aquí. Para identificar los sitios candidatos de la región hipervariable para la modificación, se puede realizar la mutagénesis de exploración de alanina para identificar los residuos de la región hipervariable que contribuyen significativamente a la unión al antígeno. Alternativamente, o adicionalmente, puede ser beneficioso analizar una estructura cristalina del complejo antígeno-anticuerpo para identificar puntos de contacto entre el anticuerpo y un antígeno o célula infectada. Tales residuos de contacto y residuos vecinos son candidatos para la sustitución de acuerdo con las técnicas elaboradas aquí. Una vez que se generan tales variantes, el panel de variantes se somete a selección como se describe en el presente documento y los anticuerpos con propiedades superiores en uno o más ensayos relevantes se pueden seleccionar para un mayor desarrollo.
Otro tipo de variante de aminoácidos del anticuerpo altera el patrón de glucosilación original del anticuerpo. Por alteración se entiende la eliminación de uno o más restos carbohidrato que se encuentran en el anticuerpo, y/o añadiendo uno o más sitios de glicosilación que no están presentes en el anticuerpo. La glucosilación de anticuerpos
está típicamente enlazada a N o enlazada a O. Enlazado a N se refiere a la unión del resto de carbohidrato a la cadena lateral de un residuo de asparagina. Las secuencias de tripéptidos asparagina-X-serina y asparagina-X-treonina, donde X es cualquier aminoácido excepto prolina, son las secuencias de reconocimiento para la unión enzimática del resto de carbohidrato a la cadena lateral de asparagina. Por lo tanto, la presencia de cualquiera de estas secuencias de tripéptidos en un polipéptido crea un sitio de glucosilación potencial. La glicosilación ligada a O se refiere a la unión de uno de los azúcares N-aceilgalactosamina, galactosa o xilosa a un ácido hidroxiamino, más comúnmente serina o treonina, aunque también se puede usar 5-hidroxiprolina o 5-hidroxilisina. La adición de sitios de glicosilación al anticuerpo se realiza convenientemente alterando la secuencia de aminoácidos de modo que contenga una o más de las secuencias de tripéptidos descritas anteriormente (para sitios de glicosilación unidos a N). La alteración también puede realizarse mediante la adición o sustitución por uno o más residuos de serina o treonina a la secuencia del anticuerpo original (para sitios de glicosilación enlazados a O).
El anticuerpo de la aplicación se modifica con respecto a la función efectora, por ejemplo, para mejorar la citotoxicidad mediada por células dependientes de antígeno (ADCC) y/o la citotoxicidad dependiente del complemento (CDC) del anticuerpo. Esto se puede lograr mediante la introducción de una o más sustituciones de aminoácidos en una región Fc del anticuerpo. Alternativa o adicionalmente, se pueden introducir residuos de cisteína en la región Fc, permitiendo así la formación de enlaces disulfuro entre cadenas en esta región. El anticuerpo homodimérico así generado puede tener una capacidad de internalización mejorada y/o una mayor destrucción celular mediada por el complemento y citotoxicidad celular dependiente de anticuerpos (ADCC). Ver Caron et al., J. Exp Med. 176: 1191 1195 (1992) y Shopes, BJ Immunol. 148: 2918-2922 (1992). Los anticuerpos homodiméricos con actividad antiinfecciosa mejorada también se pueden preparar usando reticuladores heterobifuncionales como se describe en Wolff et al., Cancer Research 53: 2560-2565 (1993). Alternativamente, se puede diseñar un anticuerpo que tiene regiones Fc duales y, por lo tanto, puede tener capacidades mejoradas de lisis del complemento y ADCC. Ver Stevenson et al., Anti-Cancer Drug Design 3: 219-230 (1989). Para aumentar la vida media en suero del anticuerpo, se puede incorporar un epítopo de unión al receptor de rescate en el anticuerpo (especialmente un fragmento de anticuerpo) como se describe en la patente de EE.UU. N° 5,739,277, por ejemplo. Como se usa en el presente documento, el término "epítopo de unión al receptor de rescate" se refiere a un epítopo de la región Fc de una molécula de IgG (por ejemplo, IgG 1, IgG 2, IgG 3 o IgG 4) que es responsable de aumentar el suero in vivo vida media de la molécula de IgG.
Los anticuerpos de la presente solicitud también pueden modificarse para incluir una etiqueta o etiqueta de epítopo, por ejemplo, para uso en aplicaciones de purificación o diagnóstico. La aplicación también se refiere a la terapia con inmunoconjugados que comprenden un anticuerpo conjugado con un agente anticancerígeno tal como un agente citotóxico o un agente inhibidor del crecimiento. Los agentes quimioterapéuticos útiles en la generación de tales inmunoconjugados se han descrito anteriormente.
Los conjugados de un anticuerpo y una o más toxinas de molécula pequeña, tales como una caliqueamicina, maytansinoides, un tricoteno y CC1065, y los derivados de estas toxinas que tienen actividad de toxina, también se contemplan en el presente documento.
En un aspecto, un anticuerpo (longitud completa o fragmentos) de la aplicación se conjuga con una o más moléculas maytansinoides. Los maytansinoides son inhibidores mitotóticos que actúan inhibiendo la polimerización de la tubulina. Maytansine se aisló por primera vez del arbusto de África oriental Maytenus serrata (patente de Estados Unidos N° 3,896,111). Posteriormente, se descubrió que ciertos microbios también producen maytansinoides, como el maytansinol y los ésteres de maytansinol C-3 (Patente de Estados Unidos Núm. 4,151,042). El maytansinol sintético y sus derivados y análogos se describen, por ejemplo, en la patente de EE.UU. Nos 4,137,230; 4,248,870; 4,256,746; 4,260,608; 4,265,814; 4,294,757; 4,307,016; 4,308,268; 4,308,269; 4,309,428; 4,313,946; 4,315,929; 4,317,821; 4,322,348; 4,331,598; 4,361,650; 4,364,866; 4,424,219; 4,450,254; 4,362,663; y 4,371,533.
En un intento por mejorar su índice terapéutico, maytansina y maytansinoides se han conjugado con anticuerpos que se unen específicamente a los antígenos de células tumorales. Los inmunoconjugados que contienen maytansinoides y su uso terapéutico se describen, por ejemplo, en la patente de EE.UU. Nos 5,208,020, 5,416,064 y la Patente Europea EP 0 425 235 B1. Liu y col., Proc. Natl. Acad. Sci. EE.UU. 93: 8618-8623 (1996) describe inmunoconjugados que comprenden un maytansinoide designado DM1 unido al anticuerpo monoclonal C242 dirigido contra el cáncer colorrectal humano. Se encontró que el conjugado era altamente citotóxico hacia las células cultivadas de cáncer de colon y mostró actividad antitumoral en un ensayo de crecimiento tumoral in vivo.
Los conjugados anticuerpo-maytansinoide se preparan uniendo químicamente un anticuerpo a una molécula maytansinoide sin disminuir significativamente la actividad biológica del anticuerpo o de la molécula maytansinoide. Un promedio de 3-4 moléculas maytansinoides conjugadas por molécula de anticuerpo ha demostrado eficacia para mejorar la citotoxicidad de las células diana sin afectar negativamente la función o la solubilidad del anticuerpo, aunque se esperaría que incluso una molécula de toxina/anticuerpo mejore la citotoxicidad por el uso de anticuerpo desnudo Los maytansinoides son bien conocidos en la técnica y pueden sintetizarse mediante técnicas conocidas o aislarse de fuentes naturales. Maytansinoides adecuados se describen, por ejemplo, en la patente de EE.UU. N° 5,208,020 y en las otras patentes y publicaciones no patentadas mencionadas anteriormente. Los maytansinoides preferidos son
maytansinol y análogos de maytansinol modificados en el anillo aromático o en otras posiciones de la molécula de maytansinol, tales como varios ésteres de maytansinol.
Hay muchos grupos de enlace conocidos en la técnica para preparar conjugados de anticuerpos, incluidos, por ejemplo, los descritos en la patente de EE.UU. N° 5,208,020 o Patente EP 0425235 B1, y Chari et al., Cancer Research 52: 127-131 (1992). Los grupos de enlace incluyen grupos disufida, grupos tioéter, grupos lábiles ácidos, grupos fotolabiles, grupos lábiles peptidasa, o grupos lábiles esterasa, como se describe en las patentes identificadas anteriormente, disulfuro y grupos tioéter preferidos.
Los inmunoconjugados pueden prepararse usando una variedad de agentes de acoplamiento de proteínas bifuncionales tales como N-succinimidilo-3-(2-piridilditio)propionato (SPDP), succinimidilo-4-(N-maleimidometilo)ciclohexano-1-carboxilato, iminotiolano (IT), derivados bifuncionales de imidoésteres (como dimetilo adipimidato HCL), ésteres activos (como disuccinimidilo suberato), aldehidos (como glutareldehído), compuestos de bis-azido (como bis (p-azidobenzoílo)hexanodiamina), bis-diazonio derivados (como bis-(p-diazoniumbenzoil)-etilenodiamina), diisocianatos (como tolueno 2,6-diisocianato) y compuestos de flúor bis-activos (como 1,5-difluoro-2,4-dinitrobenceno). Los agentes de acoplamiento particularmente preferidos incluyen N-succinimidilo-3-(2-piridilditio)propionato (SPDP) (Carlsson et al., Biochem. J. 173: 723-737 [1978]) y N-succinimidilo-4-(2-piridiltio)pentanoato (SPP) para proporcionar un enlace disulfuro. Por ejemplo, se puede preparar una inmunotoxina de ricina como se describe en Vitetta et al., Science 238: 1098 (1987). El ácido 1-isotiocianatobencil-3-metildietilentriaminopentaacético marcado con carbono 14 (MX-DTPA) es un agente quelante ejemplar para la conjugación de radionucleótido con el anticuerpo. Ver WO94/11026. El enlazador puede ser un "enlazador escindible" que facilita la liberación del fármaco citotóxico en la célula. Por ejemplo, un enlazador ácido-lábil, Cancer Research 52: 127-131 (1992); Pat. N° 5,208,020) se puede usar.
Otro inmunoconjugado de interés comprende un anticuerpo conjugado con una o más moléculas de caliqueamicina. La familia de antibióticos caliqueamicina es capaz de producir roturas de ADN bicatenario en concentraciones sub-picomolares. Para la preparación de conjugados de la familia de la caliqueamicina, véase la patente de EE.UU. Nos 5,712,374, 5,714,586, 5,739,116, 5,767,285, 5,770,701, 5,770,710, 5,773,001, 5,877,296 (todos a American Cyanamid Company). Otra droga que el anticuerpo puede conjugar es QFA, que es un antifolato. Tanto la caliqueamicina como el QFA tienen sitios de acción intracelulares y no cruzan fácilmente la membrana plasmática. Por lo tanto, la absorción celular de estos agentes a través de la internalización mediada por anticuerpos mejora en gran medida sus efectos citotóxicos.
Los ejemplos de otros agentes que pueden conjugarse con los anticuerpos de la aplicación incluyen BCNU, estreptozoicina, vincristina y 5-fluorouracilo, la familia de agentes conocidos colectivamente como complejo LL-E33288 descrito en la patente de EE.UU. Nos 5,053,394, 5,770,710, así como esperamicinas (Patente de Estados Unidos N° 5,877,296).
Las toxinas enzimáticamente activas y los fragmentos de las mismas que se pueden usar incluyen, por ejemplo, cadena A de difteria, fragmentos activos no ligantes de toxina de difteria, cadena de exotoxina A (de Pseudomonas aeruginosa), cadena de ricina A, cadena de abrina A, cadena de modeccina A, alfa-sarcina, proteínas Aleurites fordii, proteínas de diantina, proteínas de Phytolaca americana (PAPI, PAPII y PAP-S), inhibidor de momordica charantia, inhibidor de curcina, crotina, inhibidor de sapaonaria officinalis, gelonina, mitogelina, restrictocina, fenomicina, enomicina y tricotecenos. Véase, por ejemplo, el documento WO 93/21232.
La presente solicitud incluye además un inmunoconjugado formado entre un anticuerpo y un compuesto con actividad nucleolítica (por ejemplo, una ribonucleasa o una endonucleasa de ADN tal como una desoxirribonucleasa; ADNsa).
Para la destrucción selectiva de células infectadas, el anticuerpo incluye un átomo altamente radiactivo. Hay una variedad de isótopos radiactivos disponibles para la producción de anticuerpos anti-PSCA radioconjugados. Los ejemplos incluyen At211, I131, I125, Y90, Re186, Rc188, Sm153, Bi212, P32, Pb212 e isótopos radiactivos de Lu. Cuando el conjugado se usa para el diagnóstico, puede comprender un átomo radioactivo para estudios de centellografía, por ejemplo tc99m o I123, o una etiqueta de espín para magnetología nuclear resonancia magnética (RMN) (también conocida como resonancia magnética, resonancia magnética), como yodo-123, yodo-131, indio-111, flúor-19, carbono-13, nitrógeno-15, oxígeno-17, gadolinio, manganeso o hierro.
La etiqueta de radio u otra se incorpora en el conjugado de formas conocidas. Por ejemplo, el péptido puede ser biosintetizado o puede sintetizarse mediante síntesis química de aminoácidos usando precursores de aminoácidos adecuados que implican, por ejemplo, flúor-19 en lugar de hidrógeno. Las etiquetas como tc99m o I123, Re186, Re188 e In111 pueden unirse mediante un residuo de cisteína en el péptido. El itrio-90 puede unirse mediante un residuo de lisina. El método IODOGEN (Fraker et al. (1978) Biochem. Biophys. Res. Commun. 80: 49-57 se puede utilizar para incorporar yodo-123. "Monoclonal Antibodies in Immunoscintigraphy" (Chatal, CRC Press 1989) describe otros métodos en detalle.
Alternativamente, se forma una proteína de fusión que comprende el anticuerpo y el agente citotóxico, por ejemplo, mediante técnicas recombinantes o síntesis de péptidos. La longitud del ADN puede comprender regiones respectivas que codifican las dos porciones del conjugado, adyacentes entre sí o separadas por una región que codifica un péptido conector que no destruye las propiedades deseadas del conjugado. Los anticuerpos de la presente solicitud también se usan en la terapia de profármacos mediada por enzimas dependientes de anticuerpos (ADET) conjugando el anticuerpo con una enzima activadora de profármacos que convierte un profármaco (p. ej., un agente quimioterapéutico peptidílico, véase el documento WO81/01145) a un fármaco anticancerígeno activo (véase, p. ej., el documento WO 88/07378 y la patente de Estados Unidos N° 4,975,278).
El componente enzimático del inmunoconjugado útil para ADEPT incluye cualquier enzima capaz de actuar sobre un profármaco de tal manera que lo convierta en su forma citotóxica más activa. Las enzimas que son útiles en el método de esta aplicación incluyen, pero no se limitan a, fosfatasa alcalina útil para convertir profármacos que contienen fosfato en fármacos libres; arilsulfatasa útil para convertir profármacos que contienen sulfato en fármacos libres; citosina desaminasa útil para convertir la 5-fluorocitosina no tóxica en el medicamento contra el cáncer, 5-fluorouracilo; proteasas, como serratia proteasa, termolisina, subtilisina, carboxipeptidasas y catepsinas (como catepsinas B y L), que son útiles para convertir profármacos que contienen péptidos en fármacos libres; D-alanilcarboxipeptidasas, útiles para convertir profármacos que contienen sustituyentes de aminoácidos D; enzimas de corte de carbohidratos tales como p-galactosidasa y neuraminidasa útiles para convertir profármacos glicosilados en fármacos libres; p-lactamasa útil para convertir fármacos derivados con p-lactamas en fármacos libres; y penicilina amidasas, tales como penicilina V amidasa o penicilina G amidasa, útiles para convertir fármacos derivados en sus nitrógenos de amina con grupos fenoxiacetilo o fenilacetilo, respectivamente, en fármacos libres. Alternativamente, los anticuerpos con actividad enzimática, también conocidos en la técnica como "abzimas", pueden usarse para convertir los profármacos de la aplicación en fármacos activos libres (véase, por ejemplo, Massey, Nature 328: 457-458 (1987)). Los conjugados anticuerpo-abzima se pueden preparar como se describe en el presente documento para el suministro de la abzima a una población celular infectada.
Las enzimas de esta aplicación pueden unirse covalentemente a los anticuerpos mediante técnicas bien conocidas en la técnica, tales como el uso de los reactivos de reticulación heterobifuncionales discutidos anteriormente. Alternativamente, las proteínas de fusión que comprenden al menos la región de unión al antígeno de un anticuerpo de la aplicación unida a al menos una porción funcionalmente activa de una enzima de la aplicación pueden construirse usando técnicas de ADN recombinante bien conocidas en la técnica (véase, por ejemplo, Neuberger et al. al., Nature, 312: 604-608 (1984).
Se contemplan otras modificaciones del anticuerpo en el presente documento. Por ejemplo, el anticuerpo puede estar unido a uno de una variedad de polímeros no proteicos, por ejemplo, polietilenglicol, polipropilenglicol, polioxialquilenos o copolímeros de polietilenglicol y polipropilenglicol. El anticuerpo también puede quedar atrapado en microcápsulas preparadas, por ejemplo, por técnicas de coacervación o por polimerización interfacial (por ejemplo, hidroximetilcelulosa o microcápsulas de gelatina y microcápsulas de poli(metilmetacilato), respectivamente) en sistemas de administración de fármacos coloidales (por ejemplo, liposomas, microesferas de albúmina, microemulsiones, nanopartículas y nanocápsulas), o en macroemulsiones Dichas técnicas se describen en Remington's Pharmaceutical Sciences, 16a edición, Oslo, A., Ed., (1980).
Los anticuerpos descritos en este documento también se formulan como inmunoliposomas. Un "liposoma" es una vesícula pequeña compuesta de varios tipos de lípidos, fosfolípidos y/o surfactante que es útil para administrar un medicamento a un mamífero. Los componentes del liposoma se disponen comúnmente en una formación de bicapa, similar a la disposición de los lípidos de las membranas biológicas. Los liposomas que contienen el anticuerpo se preparan por métodos conocidos en la técnica, tal como se describe en Epstein et al., Proc. Natl. Acad. Sci. EE.UU., 82: 3688 (1985); Hwang y col., Proc. Natl Acad. Sci. EE.UU., 77: 4030 (1980); Pat. Nos 4,485,045 y 4,544,545; y WO97/38731 publicado el 23 de octubre de 1997. Los liposomas con tiempo de circulación mejorado se describen en la patente de EE.UU. N° 5,013,556.
Liposomas particularmente útiles se pueden generar mediante el método de evaporación de fase inversa con una composición lipídica que comprende fosfatidilcolina, colesterol y fosfatidiletanolamina derivatizada con PEG (PEG-PE). Los liposomas se extruyen a través de filtros de tamaño de poro definidos para producir liposomas con el diámetro deseado. Los fragmentos Fab' del anticuerpo de la presente solicitud pueden conjugarse con los liposomas como se describe en Martin et al., J. Biol. Chem 257: 286-288 (1982) mediante una reacción de intercambio de disulfuro. Un agente quimioterapéutico está opcionalmente contenido dentro del liposoma. Ver Gabizon et al., J. National Cancer Inst. 81 (19) 1484 (1989). Los anticuerpos de la presente solicitud, o sus fragmentos, pueden poseer cualquiera de una variedad de características biológicas o funcionales. En ciertos aspectos, estos anticuerpos son anticuerpos específicos de la proteína VIH1, lo que indica que se unen específicamente o se unen preferentemente al VIH1 en comparación con una célula de control normal.
En aspectos particulares, un anticuerpo de la presente solicitud es un anticuerpo antagonista, que bloquea o inhibe parcial o totalmente una actividad biológica de un polipéptido o célula a la que se une específica o preferentemente. En otros aspectos, un anticuerpo de la presente solicitud es un anticuerpo inhibidor del crecimiento,
que bloquea o inhibe parcial o totalmente el crecimiento de una célula infectada a la que se une. En otro aspecto, un anticuerpo de la presente solicitud induce apoptosis. En otro aspecto más, un anticuerpo de la presente solicitud induce o promueve la citotoxicidad mediada por células dependiente de anticuerpos o la citotoxicidad dependiente del complemento.
Las células o virus que expresan VIH1 descritos anteriormente se usan para seleccionar la muestra biológica obtenida de un paciente infectado con VIH1 en busca de anticuerpos que se unan preferentemente a los polipéptidos que expresan células VIH1 utilizando técnicas biológicas estándar. Por ejemplo, en ciertos aspectos, los anticuerpos pueden marcarse y detectarse la presencia de un marcador asociado con la célula, por ejemplo, usando análisis FMAT o FAC. En aspectos particulares, la muestra biológica es sangre, suero, plasma, lavado bronquial o saliva. Los métodos de la presente solicitud se pueden practicar usando técnicas de alto rendimiento.
Los anticuerpos humanos identificados pueden caracterizarse luego adicionalmente. Por ejemplo, los epítopos conformacionales particulares con los polipéptidos de VIH1 que son necesarios o suficientes para la unión del anticuerpo pueden determinarse, por ejemplo, usando mutagénesis dirigida al sitio de polipéptidos de VIH1 expresados. Estos métodos pueden adaptarse fácilmente para identificar anticuerpos humanos que se unen a cualquier proteína expresada en una superficie celular. Además, estos métodos pueden adaptarse para determinar la unión del anticuerpo al virus en sí mismo, en oposición a una célula que expresa VIH1 recombinante o infectada con el virus.
Las secuencias de polinucleótidos que codifican los anticuerpos, regiones variables de los mismos o fragmentos de unión a antígeno de los mismos pueden subclonarse en vectores de expresión para la producción recombinante de anticuerpos anti-VIH1 humanos. En un aspecto, esto se logra mediante la obtención de células mononucleares del paciente a partir del suero que contiene el anticuerpo VIH1 identificado; producir clones de células B a partir de las células mononucleares; inducir a las células B a convertirse en células plasmáticas productoras de anticuerpos; y el cribado de los sobrenadantes producidos por las células plasmáticas para determinar si contiene el anticuerpo VIH1. Una vez que se identifica un clon de células B que produce un anticuerpo contra el VIH1, se realiza una reacción en cadena de la polimerasa de transcripción inversa (RT-PCR) para clonar los ADN que codifican las regiones variables o porciones del anticuerpo contra el VIH1. Estas secuencias se subclonan luego en vectores de expresión adecuados para la producción recombinante de anticuerpos humanos contra el VIH1. La especificidad de unión puede confirmarse determinando la capacidad del anticuerpo recombinante para unirse a las células que expresan el polipéptido VIH1.
En aspectos particulares de los métodos descritos en este documento, las células B aisladas de sangre periférica o ganglios linfáticos se clasifican, por ejemplo, en base a que son positivas para CD19, y se colocan en placas, por ejemplo, tan bajas como una especificidad de célula única por pocillo, por ejemplo, en configuraciones de 96, 384 o 1536 pozos. Se induce que las células se diferencien en células productoras de anticuerpos, por ejemplo, células plasmáticas, y los sobrenadantes de cultivo se cosechan y se analizan para determinar su unión a las células que expresan el polipéptido del agente infeccioso en su superficie usando, por ejemplo, análisis FMAT o FACS. Luego, los pocillos positivos se someten a RT-PCR de pocillos completos para amplificar las regiones variables de la cadena pesada y ligera de la molécula de IgG expresada por las células plasmáticas hijas clonales. Los productos de PCR resultantes que codifican las regiones variables de la cadena pesada y ligera, o porciones de los mismos, se subclonan en vectores de expresión de anticuerpos humanos para expresión recombinante. Luego, los anticuerpos recombinantes resultantes se prueban para confirmar su especificidad de unión original y se pueden analizar adicionalmente para determinar la especificidad de pan a través de diversas cepas de aislados del agente infeccioso.
Por lo tanto, en un aspecto, un método de identificación de anticuerpos contra VIH1 se practica de la siguiente manera. Primero, los ADNc de VIH1 de longitud completa o aproximadamente de longitud completa se transfectan en una línea celular para la expresión de polipéptidos de VIH1. En segundo lugar, las muestras individuales de suero o plasma humano se analizan para detectar anticuerpos que se unen a los polipéptidos VIH1 expresados en células. Y, por último, los MAb derivados de individuos con plasma o suero positivo se caracterizan por unirse a los mismos polipéptidos de VIH1 expresados en células. Se puede realizar una definición más detallada de las especificidades finas de los MAb en este punto.
Los polinucleótidos que codifican los anticuerpos contra el VIH1 o partes de los mismos de la presente solicitud pueden aislarse de las células que expresan los anticuerpos contra el VIH1, de acuerdo con los métodos disponibles en la técnica y descritos aquí, incluida la amplificación por reacción en cadena de la polimerasa usando cebadores específicos para regiones conservadas de humanos polipéptidos de anticuerpos. Por ejemplo, las regiones variables de la cadena ligera y la cadena pesada pueden clonarse de la célula B de acuerdo con las técnicas de biología molecular descritas en el documento WO 92/02551; Patente de Estados Unidos N° 5,627,052; o Babcook y col., Proc. Natl. Acad. Sci. EE.UU. 93: 7843-48 (1996). En ciertos aspectos, los polinucleótidos que codifican todas o una región de las regiones variables de cadena pesada y ligera de la molécula de IgG expresada por las células plasmáticas hijas clonales que expresan el anticuerpo VIH1 se subclonan y secuencian. La secuencia del polipéptido codificado puede determinarse fácilmente a partir de la secuencia de polinucleótidos.
Los polinucleótidos aislados que codifican un polipéptido de la presente solicitud pueden subclonarse en un vector de expresión para producir de manera recombinante anticuerpos y polipéptidos de la presente aplicación, usando procedimientos conocidos en la técnica y descritos aquí.
Las propiedades de unión de un anticuerpo (o fragmento del mismo) a polipéptidos de VIH1 o células o tejidos infectados con HIv1 generalmente se pueden determinar y evaluar usando métodos de inmunodetección que incluyen, por ejemplo, ensayos basados en inmunofluorescencia, tales como inmunohistoquímica (IHC) y/o clasificación de células activadas por fluorescencia (FACS). Los métodos de inmunoensayo pueden incluir controles y procedimientos para determinar si los anticuerpos se unen específicamente a los polipéptidos VIH1 de uno o más clados o cepas específicas de VIH, y no reconocen o reaccionan de forma cruzada con las células de control normales.
Después de la selección previa de suero para identificar pacientes que producen anticuerpos contra un agente infeccioso o polipéptido del mismo, por ejemplo, VIH1, los métodos de la presente solicitud típicamente incluyen el aislamiento o purificación de células B de una muestra biológica obtenida previamente de un paciente o sujeto. El paciente o el sujeto pueden ser diagnosticados actualmente o previamente con o sospechar o tener una enfermedad o infección en particular, o el paciente o el sujeto puede considerarse libre o una enfermedad o infección en particular. Típicamente, el paciente o sujeto es un mamífero y, en aspectos particulares, un ser humano. La muestra biológica puede ser cualquier muestra que contenga células B, incluidos, entre otros, tejido ganglionar o ganglio linfático, derrames pleurales, sangre periférica, ascitis, tejido tumoral o líquido cefalorraquídeo (LCR). En varios aspectos, las células B se aíslan de diferentes tipos de muestras biológicas, como una muestra biológica afectada por una enfermedad o infección en particular. Sin embargo, se entiende que cualquier muestra biológica que comprenda células B puede usarse para cualquiera de los aspectos de la presente solicitud.
Una vez aisladas, las células B son inducidas a producir anticuerpos, por ejemplo, cultivando las células B en condiciones que soportan la proliferación o desarrollo de células B en un plasmacito, plasmablast o plasma. Luego, los anticuerpos se seleccionan, típicamente usando técnicas de alto rendimiento, para identificar un anticuerpo que se une específicamente a un antígeno diana, por ejemplo, un tejido, célula, agente infeccioso o polipéptido particular. En ciertos aspectos, se desconoce el antígeno específico, por ejemplo, el polipéptido de la superficie celular unido por el anticuerpo, mientras que en otros aspectos, se conoce el antígeno específicamente unido por el anticuerpo.
Según la presente solicitud, las células B pueden aislarse de una muestra biológica, por ejemplo, una muestra de tumor, tejido, sangre periférica o ganglio linfático, por cualquier medio conocido y disponible en la técnica. Las células B se clasifican típicamente por FACS en función de la presencia en su superficie de un marcador específico de células B, por ejemplo, CD19, CD138 y/o IgG de superficie. Sin embargo, se pueden emplear otros métodos conocidos en la técnica, tales como, p. ej., purificación de columna usando perlas magnéticas CD19 o perlas magnéticas específicas de IgG, seguido de elución de la columna. Sin embargo, el aislamiento magnético de las células B que utilizan cualquier marcador puede provocar la pérdida de ciertas células B. Por lo tanto, en ciertos aspectos, las células aisladas no se clasifican sino que, en cambio, las células mononucleares purificadas con phicol aisladas del tumor se colocan directamente en placas al número apropiado o deseado de especificidades por pozo.
Para identificar las células B que producen un anticuerpo infeccioso específico del agente, las células B se colocan típicamente en placas de baja densidad (por ejemplo, una especificidad de célula única por pocillo, 1-10 células por pocillo, 10-100 células por bien, 1-100 células por pozo, menos de 10 células por pozo o menos de 100 células por pozo) en placas de múltiples pocillos o microtitulación, por ejemplo, en configuraciones de 96, 384 o 1536 pozos. Cuando las células B se colocan inicialmente en una densidad superior a una célula por pocillo, los métodos de la presente solicitud pueden incluir el paso de diluir posteriormente las células en un pozo identificado como productor de un anticuerpo específico de antígeno, hasta una especificidad de célula única por se logra bien, facilitando así la identificación de la célula B que produce el anticuerpo antígeno específico. Los sobrenadantes celulares o una porción de los mismos y/o las células pueden congelarse y almacenarse para futuras pruebas y recuperación posterior de polinucleótidos de anticuerpos.
En ciertos aspectos, las células B se cultivan en condiciones que favorecen la producción de anticuerpos por las células B. Por ejemplo, las células B pueden cultivarse en condiciones favorables para la proliferación y diferenciación de células B para producir plasmablastos, plasmacitos o células plasmáticas productoras de anticuerpos. En aspectos particulares, las células B se cultivan en presencia de un mitógeno de células B, como lipopolisacárido (LPS) o ligando CD40. En un aspecto específico, las células B se diferencian de las células productoras de anticuerpos al cultivarlas con células de alimentación y/u otros activadores de células B, como el ligando CD40.
Los sobrenadantes de cultivo celular o los anticuerpos obtenidos a partir de los mismos pueden analizarse para determinar su capacidad de unirse a un antígeno diana, utilizando métodos de rutina disponibles en la técnica, incluidos los descritos en este documento. En aspectos particulares, los sobrenadantes de cultivo se analizan para detectar la presencia de anticuerpos que se unen a un antígeno diana utilizando métodos de alto rendimiento. Por ejemplo, las células B pueden cultivarse en placas de microtitulación de pocillos múltiples, de modo que los manipuladores de placas robóticas pueden usarse para muestrear simultáneamente sobrenadantes de células
múltiples y analizar la presencia de anticuerpos que se unen a un antígeno diana. En aspectos particulares, los antígenos se unen a perlas, por ejemplo, perlas paramagnéticas o de látex) para facilitar la captura de complejos de anticuerpo/antígeno. En otros aspectos, los antígenos y los anticuerpos están marcados con fluorescencia (con diferentes etiquetas) y el análisis FACS se realiza para identificar la presencia de anticuerpos que se unen al antígeno diana. En un aspecto, la unión de anticuerpos se determina usando análisis e instrumentación FMAT™ (Applied Biosystems, Foster City, CA). FMAT™ es una plataforma macroconfocal de fluorescencia para el cribado de alto rendimiento, que mezcla y lee ensayos no radiactivos utilizando células vivas o perlas.
En el contexto de comparar la unión de un anticuerpo a un antígeno diana particular (por ejemplo, una muestra biológica tal como tejido o células infectadas, o agentes infecciosos) en comparación con una muestra de control (por ejemplo, una muestra biológica tal como no infectada células, o un agente infeccioso diferente), en varios aspectos, se considera que el anticuerpo se une preferentemente a un antígeno diana particular si al menos dos veces, al menos tres veces, al menos cinco veces o al menos diez veces más el anticuerpo se une al antígeno diana particular en comparación con la cantidad que se une a una muestra de control.
Los polinucleótidos que codifican cadenas de anticuerpos, regiones variables de los mismos o fragmentos de los mismos, pueden aislarse de las células utilizando cualquier medio disponible en la técnica. En un aspecto, los polinucleótidos se aíslan usando la reacción en cadena de la polimerasa (PCR), por ejemplo, la transcripción inversa-PCR (RT-PCR) usando cebadores oligonucleotídicos que se unen específicamente a secuencias de polinucleótidos que codifican cadenas pesadas o ligeras o sus complementos usando procedimientos de rutina disponibles en la técnica. En un aspecto, los pocillos positivos se someten a RT-PCR de pocillos enteros para amplificar las regiones variables de la cadena pesada y ligera de la molécula de IgG expresada por las células plasmáticas hijas clonales. Estos productos de PCR pueden secuenciarse.
Los productos de PCR resultantes que codifican las regiones variables de la cadena pesada y ligera o porciones de las mismas se subclonan luego en vectores de expresión de anticuerpos humanos y se expresan de forma recombinante de acuerdo con procedimientos de rutina en la técnica (véase, por ejemplo, la Patente de Estados Unidos N° 7,112,439). Las moléculas de ácido nucleico que codifican un anticuerpo específico de tumor o fragmento del mismo, como se describe en el presente documento, pueden propagarse y expresarse de acuerdo con cualquiera de una variedad de procedimientos bien conocidos para la escisión, ligadura, transformación y transfección de ácido nucleico. Por lo tanto, en ciertos aspectos, se puede preferir la expresión de un fragmento de anticuerpo en una célula huésped procariota, como Escherichia coli (véase, por ejemplo, Pluckthun et al., Methods Enzymol. 178: 497-515 (1989)). En ciertos otros aspectos, la expresión del anticuerpo o un fragmento de unión a antígeno del mismo puede preferirse en una célula huésped eucariota, que incluye levadura (por ejemplo, Saccharomyces cerevisiae, Schizosaccharomyces pombe y Pichia pastoris); células animales (incluidas células de mamífero); o células vegetales. Los ejemplos de células animales adecuadas incluyen, pero no se limitan a, células de mieloma, COS, CHO o hibridoma. Los ejemplos de células vegetales incluyen células de tabaco, maíz, soja y arroz. Mediante métodos conocidos por los expertos en la técnica y basados en la presente descripción, se puede diseñar un vector de ácido nucleico para expresar secuencias extrañas en un sistema huésped particular, y luego secuencias de polinucleótidos que codifican el anticuerpo específico del tumor (o fragmento del mismo) puede ser insertado Los elementos reguladores variarán según el huesped particular.
Uno o más vectores de expresión replicables que contienen un polinucleótido que codifica una región variable y/o constante pueden prepararse y usarse para transformar una línea celular apropiada, por ejemplo, una línea celular de mieloma no productora, como una línea NSO de ratón o una bacteria, como E. coli, en donde se producirá el anticuerpo. Para obtener una transcripción y traducción eficientes, la secuencia de polinucleótidos en cada vector debe incluir secuencias reguladoras apropiadas, particularmente una secuencia promotora y líder unida operativamente a la secuencia de la región variable. Generalmente, los métodos particulares para producir anticuerpos de esta manera son bien conocidos y se usan habitualmente. Por ejemplo, procedimientos de biología molecular son descritos por Sambrook et al. (Molecular Cloning, A Laboratory Manual, 2a ed., Cold Spring Harbor Laboratory, Nueva York, 1989; véase también Sambrook et al., 3a ed., Cold Spring Harbor Laboratory, Nueva York, (2001)). Aunque no es necesario, en ciertos aspectos, las regiones de polinucleótidos que codifican los anticuerpos recombinantes pueden secuenciarse. La secuenciación de ADN se puede realizar como se describe en Sanger et al. (Proc. Natl. Acad. Sci. EE.UU. 74: 5463 (1977)) y el manual de secuenciación de plc de Amersham International e incluyendo mejoras al mismo.
En aspectos particulares, los anticuerpos recombinantes resultantes o los fragmentos de los mismos se prueban luego para confirmar su especificidad original y se pueden analizar adicionalmente para determinar la especificidad de pan, por ejemplo, con agentes infecciosos relacionados. En aspectos particulares, un anticuerpo identificado o producido de acuerdo con los métodos descritos en el presente documento se analiza para determinar la muerte celular mediante citotoxicidad celular dependiente de anticuerpos (ADCC) o apoptosis, y/o su capacidad para internalizarse.
La presente solicitud, en otros aspectos, proporciona composiciones de polinucleótidos. En algunos aspectos, estos polinucleótidos codifican un polipéptido de la aplicación, por ejemplo, una región de una cadena variable de un
anticuerpo que se une al VIH1. Los polinucleótidos de la aplicación son moléculas de ADN monocatenario (codificante o antisentido) o bicatenario (genómico, ADNc o sintético) o ARN. Las moléculas de ARN incluyen, pero no se limitan a, moléculas de ARNn, que contienen intrones y corresponden a una molécula de ADN de manera individual, y moléculas de ARNm, que no contienen intrones. Alternativamente, o además, las secuencias codificantes o no codificantes están presentes dentro de un polinucleótido de la presente solicitud. También alternativamente, o además, un polinucleótido está unido a otras moléculas y/o materiales de soporte de la aplicación. Los polinucleótidos de la aplicación se usan, por ejemplo, en ensayos de hibridación para detectar la presencia de un anticuerpo VIH1 en una muestra biológica, y en la producción recombinante de polipéptidos de la aplicación. Además, la aplicación incluye todos los polinucleótidos que codifican cualquier polipéptido de la presente solicitud.
En otros aspectos relacionados, la solicitud proporciona variantes de polinucleótidos que tienen identidad sustancial con las secuencias de 1443_C16 (PG16) (TCN-116), 1503 H05 (PG16) (TCN-119), 1456 A12 (PG16) (TCN-117), 1469 M23 (PG16) (TCN-118), 1489 _I13 (PG16) (TCN-120), 1480_I08 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14), 1495_C14 (PGC14), 1496_C09 (PG9) (TCN)-109), 4838_L06 (PGT-121), 4873_E03 (PGT-121), 4877_D15 (PGT-122), 4858_P08 (PGT-123), 6123_A06 (PGT-125), 5141_B17 (PGT-126), 5145_B14 (PGT- 127), 5114_A19 (PGT-128), 5147_N06 (PGT- 130), 5136_H01 (PGT-131), 5343_B08 (PGT-135), 5344_E16 (PGT-135), 5329_C19 (PGT-136), 5366_P21 (PGT-136)), 4964_G22 (PGT-141), 5345_I01 (PGT-137), 4993_K13 (PGT-141), 4995_E20 (PGT-142), 4980_N08 (PGT-143), 4970_K22 (PGT-144), 4995_P16 (PGT-145), 4835_F12 (PGT-124), 4869-K15 (PGT-133), 4876_M06 (PGT-134), 5131_A17 (PGT-132), 5138_G07 (PGT-138), 5120_N10 (PGT-139), 6831_A21 (PGT-151), 6889_I17 (PGT-152), 6891_F06 (PGT-153), 6843_G20 (PGT-154), 6892_D19 (PGT-155), 6808_B09 (PGT-156), 6892_C23 (p GT-157) y/o 6881_N05 (PGT-158), por ejemplo, aquellos que comprenden al menos 70% de identidad de secuencia, preferiblemente al menos 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% o 99% o más, identidad de secuencia en comparación con una secuencia de polinucleótidos de esta aplicación, según se determina usando los métodos descritos en el presente documento (por ejemplo, análisis BLAST usando parámetros estándar). Un experto en esta técnica reconocerá que estos valores pueden ajustarse apropiadamente para determinar la identidad correspondiente de proteínas codificadas por dos secuencias de nucleótidos teniendo en cuenta la degeneración de codones, la similitud de aminoácidos, el posicionamiento del marco de lectura y similares. Sin embargo, la presente invención está dirigida específicamente al anticuerpo monoclonal anti-VIH humano 4876_M06 (PGT-134) que tiene una cadena pesada variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 435 y una cadena ligera variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 440.
Típicamente, las variantes de polinucleótidos contienen una o más sustituciones, adiciones, deleciones y/o inserciones, preferiblemente de tal manera que las propiedades de unión inmunogénica del polipéptido codificado por el polinucleótido variante no disminuyan sustancialmente en relación con un polipéptido codificado por una secuencia de polinucleótidos específicamente establecido en este documento.
En aspectos adicionales, la presente solicitud proporciona fragmentos de polinucleótidos que comprenden varias longitudes de tramos contiguos de secuencia idénticos o complementarios a una o más de las secuencias descritas aquí. Por ejemplo, esta aplicación proporciona polinucleótidos que comprenden al menos aproximadamente 10, 15, 20, 30, 40, 50, 75, 100, 150, 200, 300, 400, 500 o 1000 o más nucleótidos contiguos de uno o más de las secuencias descritas aquí, así como todas las longitudes intermedias entre ellas. Como se usa aquí, el término "longitudes intermedias" se entiende para describir cualquier longitud entre los valores citados, tal como 16, 17, 18, 19, etc.; 21, 22, 23, etc.; 30, 31, 32, etc.; 50, 51, 52, 53, etc.; 100, 101, 102, 103, etc.; 150, 151, 152, 153, etc.; incluyendo todos los enteros hasta 200-500; 500-1,000, y similares.
En otro aspecto de la aplicación, se proporcionan composiciones de polinucleótidos que son capaces de hibridarse en condiciones de rigurosidad moderada a alta a una secuencia de polinucleótidos proporcionada en este documento, o un fragmento de la misma, o una secuencia complementaria de la misma. Las técnicas de hibridación son bien conocidas en la técnica de la biología molecular. Para fines de ilustración, las condiciones moderadamente estrictas adecuadas para probar la hibridación de un polinucleótido de esta aplicación con otros polinucleótidos incluyen prelavado en una solución de 5 X SSC, SDS al 0,5%, EDTA 1,0 mM (pH 8,0); hibridación a 50°C-60°C, 5 X SSC, durante la noche; seguido de lavar dos veces a 65°C durante 20 minutos con cada uno de SSC 2X, 0,5X y 0,2X que contenga SDS al 0,1%. Un experto en la materia comprenderá que la rigurosidad de la hibridación puede manipularse fácilmente, tal como alterando el contenido de sal de la solución de hibridación y/o la temperatura a la que se realiza la hibridación. Por ejemplo, en otro aspecto, las condiciones de hibridación altamente estrictas adecuadas incluyen las descritas anteriormente, con la excepción de que la temperatura de hibridación aumenta, por ejemplo, a 60-65°C o 65-70°C.
En algunos aspectos, el polipéptido codificado por la variante o fragmento de polinucleótido tiene la misma especificidad de unión (es decir, se une específica o preferentemente al mismo epítopo o cepa de VIH) que el polipéptido codificado por el polinucleótido nativo. En ciertos aspectos, los polinucleótidos descritos anteriormente, por ejemplo, variantes de polinucleótidos, fragmentos y secuencias de hibridación, codifican polipéptidos que tienen un nivel de actividad de unión de al menos aproximadamente 50%, preferiblemente al menos aproximadamente 70%, y más preferiblemente al menos aproximadamente 90% de eso para una secuencia de polipéptidos específicamente establecida aquí.
Los polinucleótidos de la presente solicitud, o fragmentos de los mismos, independientemente de la longitud de la secuencia codificante en sí, pueden combinarse con otras secuencias de ADN, tales como promotores, señales de poliadenilación, sitios de enzimas de restricción adicionales, sitios de clonación múltiple, otros códigos segmentos y similares, de modo que su longitud total puede variar considerablemente. Se emplea un fragmento de ácido nucleico de casi cualquier longitud, estando la longitud total preferiblemente limitada por la facilidad de preparación y uso en el protocolo de ADN recombinante pretendido. Por ejemplo, segmentos polinucleotídicos ilustrativos con longitudes totales de aproximadamente 10.000, aproximadamente 5000, aproximadamente 3000, aproximadamente 2.000, aproximadamente 1.000, aproximadamente 500, aproximadamente 200, aproximadamente 100, aproximadamente 50 pares de bases de longitud y similares, (incluidas todas las longitudes intermedias) se incluyen en muchas implementaciones de esta aplicación.
Los expertos en la técnica apreciarán que, como resultado de la degeneración del código genético, existen múltiples secuencias de nucleótidos que codifican un polipéptido como se describe en el presente documento. Algunos de estos polinucleótidos tienen una homología mínima con la secuencia de nucleótidos de cualquier gen nativo. No obstante, la aplicación contempla específicamente los polinucleótidos que codifican un polipéptido de la presente solicitud pero que varían debido a diferencias en el uso de codones. Además, los alelos de los genes que incluyen las secuencias de polinucleótidos se proporcionan aquí. Los alelos son genes endógenos que se alteran como resultado de una o más mutaciones, como deleciones, adiciones y/o sustituciones de nucleótidos. El ARNm y la proteína resultantes pueden, pero no necesariamente, tener una estructura o función alterada. Los alelos pueden identificarse utilizando técnicas estándar (como hibridación, amplificación y/o comparación de secuencias de bases de datos).
En ciertos aspectos de la presente solicitud, la mutagénesis de las secuencias polinucleotídicas descritas se realiza para alterar una o más propiedades del polipéptido codificado, como su especificidad de unión o fuerza de unión. Las técnicas para la mutagénesis son bien conocidas en la técnica y se usan ampliamente para crear variantes de polipéptidos y polinucleótidos. Se emplea un enfoque de mutagénesis, tal como mutagénesis específica de sitio, para la preparación de variantes y/o derivados de los polipéptidos descritos en este documento. Mediante este enfoque, se realizan modificaciones específicas en una secuencia de polipéptidos mediante mutagénesis de los polinucleótidos subyacentes que los codifican. Estas técnicas proporcionan un enfoque directo para preparar y probar variantes de secuencia, por ejemplo, incorporando una o más de las consideraciones anteriores, mediante la introducción de uno o más cambios de secuencia de nucleótidos en el polinucleótido.
La mutagénesis específica del sitio permite la producción de mutantes mediante el uso de secuencias de oligonucleótidos específicos que incluyen la secuencia de nucleótidos de la mutación deseada, así como un número suficiente de nucleótidos adyacentes, para proporcionar una secuencia cebadora de suficiente tamaño y complejidad de secuencia para formar un dúplex estable en ambos lados de la unión de eliminación que se atraviesa. Las mutaciones se emplean en una secuencia de polinucleótidos seleccionada para mejorar, alterar, disminuir, modificar o cambiar las propiedades del propio polinucleótido y/o alterar las propiedades, actividad, composición, estabilidad o secuencia primaria del polipéptido codificado.
En otros aspectos de la presente solicitud, las secuencias de polinucleótidos proporcionadas en el presente documento se usan como sondas o cebadores para la hibridación de ácido nucleico, por ejemplo, como cebadores de PCR. La capacidad de tales sondas de ácido nucleico para hibridarse específicamente con una secuencia de interés les permite detectar la presencia de secuencias complementarias en una muestra dada. Sin embargo, la aplicación abarca otros usos, como el uso de la información de secuencia para la preparación de cebadores de especies mutantes, o cebadores para usar en la preparación de otras construcciones genéticas. Como tal, los segmentos de ácido nucleico de la aplicación que incluyen una región de secuencia de al menos aproximadamente una secuencia contigua larga de 15 nucleótidos que tiene la misma secuencia que, o es complementaria a, una secuencia contigua larga de 15 nucleótidos descrita en el presente documento es particularmente útil. Secuencias contiguas idénticas o complementarias más largas, por ejemplo, las de aproximadamente 20, 30, 40, 50, 100, 200, 500, 1000 (incluidas todas las longitudes intermedias), incluidas las secuencias de longitud completa, y todas las longitudes intermedias, también se utilizan en ciertos aspectos.
Moléculas de polinucleótidos que tienen regiones de secuencia que consisten en tramos contiguos de nucleótidos de 10-14, 15-20, 30, 50, o incluso de 100-200 nucleótidos más o menos (incluyendo también longitudes intermedias), idénticos o complementarios a una secuencia de polinucleótidos descritos aquí, se contemplan particularmente como sondas de hibridación para uso en, por ejemplo, transferencia Southern y Northern, y/o cebadores para uso en, por ejemplo, reacción en cadena de la polimerasa (PCR). El tamaño total del fragmento, así como el tamaño del (de los) tramo(s) complementario(s), depende en última instancia del uso o aplicación prevista del segmento particular de ácido nucleico. Los fragmentos más pequeños se usan generalmente en aspectos de hibridación, en los que la longitud de la región complementaria contigua puede variar, como entre aproximadamente 15 y aproximadamente 100 nucleótidos, pero se pueden usar tramos de complementariedad contiguos más grandes, de acuerdo con la longitud de las secuencias complementarias que uno desea detectar.
El uso de una sonda de hibridación de aproximadamente 15-25 nucleótidos de longitud permite la formación
de una molécula dúplex que es estable y selectiva. Sin embargo, generalmente se prefieren las moléculas que tienen secuencias complementarias contiguas sobre tramos de más de 12 bases de longitud, para aumentar la estabilidad y la selectividad del híbrido, y así mejorar la calidad y el grado de moléculas híbridas específicas obtenidas. Generalmente se prefieren las moléculas de ácido nucleico que tienen tramos complementarios de genes de 15 a 25 nucleótidos contiguos, o incluso más largos donde se desee.
Las sondas de hibridación se seleccionan de cualquier parte de cualquiera de las secuencias descritas aquí. Todo lo que se requiere es revisar las secuencias establecidas en este documento, o en cualquier parte continua de las secuencias, desde aproximadamente 15-25 nucleótidos de longitud hasta y incluida la secuencia de longitud completa, que se desea utilizar como sonda o cebador. La elección de las secuencias de sonda y cebador se rige por varios factores. Por ejemplo, uno puede desear emplear cebadores desde el final de la secuencia total.
El polinucleótido de la presente solicitud, o fragmentos o variantes del mismo, se preparan fácilmente, por ejemplo, sintetizando directamente el fragmento por medios químicos, como se practica comúnmente usando un sintetizador de oligonucleótidos automatizado. Además, los fragmentos se obtienen mediante la aplicación de la tecnología de reproducción de ácido nucleico, como la tecnología PCR™ de la Patente de Estados Unidos 4,683,202, mediante la introducción de secuencias seleccionadas en vectores recombinantes para la producción recombinante, y mediante otras técnicas de ADN recombinante generalmente conocidas por los expertos en la técnica de biología molecular.
La solicitud proporciona vectores y células huésped que comprenden un ácido nucleico de la presente aplicación, así como técnicas recombinantes para la producción de un polipéptido de la presente aplicación. Los vectores de la aplicación incluyen aquellos capaces de replicarse en cualquier tipo de célula u organismo, incluidos, por ejemplo, plásmidos, fagos, cósmidos y mini cromosomas. En otros aspectos, los vectores que comprenden un polinucleótido de la presente solicitud son vectores adecuados para la propagación o replicación del polinucleótido, o vectores adecuados para expresar un polipéptido de la presente aplicación. Tales vectores son conocidos en la técnica y están disponibles comercialmente.
Los polinucleótidos de la presente solicitud se sintetizan, enteros o en partes, que luego se combinan, y se insertan en un vector usando técnicas rutinarias de biología molecular y celular, que incluyen, por ejemplo, subclonar el polinucleótido en un vector linealizado usando sitios de restricción y restricción apropiados. enzimas Los polinucleótidos de la presente solicitud se amplifican por reacción en cadena de la polimerasa usando cebadores oligonucleotídicos complementarios a cada cadena del polinucleótido. Estos cebadores también incluyen sitios de escisión de enzimas de restricción para facilitar la subclonación en un vector. Los componentes del vector replicable generalmente incluyen, pero no se limitan a, uno o más de los siguientes: una secuencia señal, un origen de replicación y uno o más marcadores o genes seleccionables.
Para expresar un polipéptido de la presente solicitud, las secuencias de nucleótidos que codifican el polipéptido, o equivalentes funcionales, se insertan en un vector de expresión apropiado, es decir, un vector que contiene los elementos necesarios para la transcripción y traducción de la secuencia de codificación insertada. Los métodos bien conocidos por los expertos en la técnica se usan para construir vectores de expresión que contienen secuencias que codifican un polipéptido de interés y elementos de control transcripcionales y traduccionales apropiados. Estos métodos incluyen técnicas de ADN recombinante in vitro, técnicas sintéticas y recombinación genética in vivo. Dichas técnicas se describen, por ejemplo, en Sambrook, J., et al. (1989) Molecular Cloning, A Laboratory Manual, Cold Spring Harbor Press, Plainview, NY, y Ausubel, FM et al. (1989) Current Protocols in Molecular Biology, John Wiley & Sons, Nueva York. NY
Se utiliza una variedad de sistemas de expresión vector/huésped para contener y expresar secuencias de polinucleótidos. Estos incluyen, pero no se limitan a, microorganismos tales como bacterias transformadas con vectores de expresión de ADN recombinante de bacteriófagos, plásmidos o cósmidos recombinantes; levadura transformada con vectores de expresión de levadura; sistemas de células de insectos infectados con vectores de expresión de virus (por ejemplo, baculovirus); sistemas de células vegetales transformados con vectores de expresión de virus (por ejemplo, virus de mosaico de coliflor, CaMV; virus de mosaico de tabaco, TMV) o con vectores de expresión bacterianos (por ejemplo, plásmidos Ti o pBR322); o sistemas de células animales.
En un aspecto, las regiones variables de un gen que expresa un anticuerpo monoclonal de interés se amplifican a partir de una célula de hibridoma usando cebadores de nucleótidos. Estos cebadores son sintetizados por un experto en la materia, o pueden adquirirse de fuentes disponibles comercialmente (véase, por ejemplo, Stratagene (La Jolla, California), que vende cebadores para amplificar regiones variables humanas y de ratón. Los cebadores se usan para amplificar regiones variables de cadena pesada o ligera, que luego se insertan en vectores como ImmunoZAP™ H o ImmunoZAP™ L (Stratagene), respectivamente. Estos vectores se introducen en E. coli, levaduras o sistemas de expresión basados en mamíferos. Se producen cantidades de una proteína de cadena sencilla que contiene una fusión de los dominios Vh y Vl utilizando estos métodos (véase Bird et al., Science 242: 423-426 (1988)).
Los "elementos de control" o "secuencias reguladoras" presentes en un vector de expresión son aquellas regiones no traducidas del vector, por ejemplo, potenciadores, promotores, regiones no traducidas 5' y 3', que interactúan con las proteínas celulares del huésped para llevar a cabo la transcripción y traducción. Tales elementos pueden variar en su fuerza y especificidad Dependiendo del sistema de vectores y del huésped utilizado, se usa cualquier número de elementos de transcripción y traducción adecuados, incluidos los promotores constitutivos e inducibles.
Los ejemplos de promotores adecuados para su uso con hospedadores procariotas incluyen el promotor phoa, los sistemas promotores de p-lactamasa y lactosa, el promotor de fosfatasa alcalina, un sistema promotor de triptófano (trp) y promotores híbridos como el promotor tac. Sin embargo, otros promotores bacterianos conocidos son adecuados. Los promotores para su uso en sistemas bacterianos también suelen contener una secuencia Shine-Dalgarno operativamente unida al ADN que codifica el polipéptido. Se usan promotores inducibles tales como el promotor híbrido lacZ del fagémido PBLu Es CRIPT (Stratagene, La Jolla, CA) o el plásmido PSPORT1 (Gibco BRL, Gaithersburg, MD) y similares.
Se conoce una variedad de secuencias promotoras para eucariotas y cualquiera se usa de acuerdo con la presente solicitud. Prácticamente todos los genes eucariotas tienen una región rica en AT ubicada aproximadamente de 25 a 30 bases aguas arriba del sitio donde se inicia la transcripción. Otra secuencia encontrada de 70 a 80 bases aguas arriba desde el inicio de la transcripción de muchos genes es una región CNCAAT donde N puede ser cualquier nucleótido. En el extremo 3' de la mayoría de los genes eucariotas hay una secuencia AATAAA que puede ser la señal para la adición de la cola poli A al extremo 3' de la codificación secuencia. Todas estas secuencias se insertan adecuadamente en vectores de expresión eucariotas.
En los sistemas celulares de mamíferos, generalmente se prefieren los promotores de genes de mamíferos o de virus de mamíferos. La expresión de polipéptidos de vectores en células huésped de mamíferos está controlada, por ejemplo, por promotores obtenidos de los genomas de virus tales como el virus del polioma, el virus de la viruela aviar, el adenovirus (p. ej., adenovirus 2), el virus del papiloma bovino, el virus del sarcoma aviar, el citomegalovirus (CMV), un retrovirus, el virus de la hepatitis B y, lo más preferiblemente, el Virus Simian 40 (SV40), de promotores de mamíferos heterólogos, por ejemplo, el promotor de actina o un promotor de inmunoglobulina, y de promotores de choque térmico, siempre que dichos promotores sean compatibles con sistemas de célula huésped. Si es necesario generar una línea celular que contenga múltiples copias de la secuencia que codifica un polipéptido, los vectores basados en SV40 o EBV pueden usarse ventajosamente con un marcador seleccionable apropiado. Un ejemplo de un vector de expresión adecuado es pcADN-3,1 (Invitrogen, Carlsbad, CA), que incluye un promotor de CMV.
Varios sistemas de expresión basados en virus están disponibles para la expresión de polipéptidos en mamíferos. Por ejemplo, en los casos en que se usa un adenovirus como vector de expresión, las secuencias que codifican un polipéptido de interés pueden ligarse en un complejo de transcripción/traducción de adenovirus que consiste en el promotor tardío y la secuencia líder tripartita. La inserción en una región E1 o E3 no esencial del genoma viral puede usarse para obtener un virus viable que sea capaz de expresar el polipéptido en células huésped infectadas (Logan, J. y Shenk, T. (1984) Proc. Natl. Acad. Sci. 81: 3655-3659). Además, los potenciadores de la transcripción, como el potenciador del virus del sarcoma de Rous (RSV), pueden usarse para aumentar la expresión en células huésped de mamíferos.
En sistemas bacterianos, cualquiera de varios vectores de expresión se selecciona dependiendo del uso previsto para el polipéptido expresado. Por ejemplo, cuando se desean grandes cantidades, se usan vectores que dirigen la expresión de alto nivel de proteínas de fusión que se purifican fácilmente. Dichos vectores incluyen, pero no se limitan a, los vectores de clonación y expresión de E. coli multifuncionales tales como BLUESCRIPT (Stratagene), en donde la secuencia que codifica el polipéptido de interés puede ligarse al vector en marco con secuencias para el terminal amino Met y los siguientes 7 residuos de p-galactosidasa, de modo que se produce una proteína híbrida; vectores pIN (Van Heeke, G. y SM Schuster (1989) J. Biol. Chem. 264: 5503-5509); y similares. Los vectores pGEX (Promega, Madison, WI) también se utilizan para expresar polipéptidos extraños como proteínas de fusión con glutatión S-transferasa (GST). En general, tales proteínas de fusión son solubles y pueden purificarse fácilmente de las células lisadas mediante adsorción a perlas de glutatión-agarosa seguidas de elución en presencia de glutatión libre. Las proteínas elaboradas en dichos sistemas están diseñadas para incluir sitios de escisión de proteasa de heparina, trombina o factor XA para que el polipéptido clonado de interés pueda liberarse del resto GST a voluntad.
En la levadura, Saccharomyces cerevisiae, se utilizan varios vectores que contienen promotores constitutivos o inducibles como el factor alfa, alcohol oxidasa y PGH. Los ejemplos de otras secuencias promotoras adecuadas para usar con huéspedes de levadura incluyen los promotores para la 3-fosfoglicerato quinasa u otras enzimas glicolíticas, tales como enolasa, gliceraldehído-3-fosfato deshidrognasa, hexoquinasa, piruvato descarboxilasa, fosfofructoquinasa, glucosa-6-fosfato isomerasa, 3-fosfoglicerato mutasa, piruvato quinasa, triosefosfato isomerasa, fosfoglucosa isomerasa y glucoquinasa. Para revisiones, ver Ausubel et al. (supra) y Grant et al. (1987) Methods Enzymol. 153: 516-544. Otros promotores de levadura que son promotores inducibles que tienen la ventaja adicional de la transcripción controlada por las condiciones de crecimiento incluyen las regiones promotoras del alcohol deshidrogenasa 2, isocitocromo C, fosfatasa ácida, enzimas degradativas asociadas con el metabolismo del nitrógeno,
metalotioneína, gliceraldehído-3-fosfato deshidrogenasa y enzimas responsables de la utilización de maltosa y galactosa. Los vectores y promotores adecuados para su uso en la expresión de levadura se describen adicionalmente en el documento EP 73.657. Los potenciadores de levadura también se usan ventajosamente con promotores de levadura.
En los casos en los que se usan vectores de expresión de plantas, la expresión de secuencias que codifican polipéptidos está dirigida por cualquiera de varios promotores. Por ejemplo, los promotores virales como los promotores 35S y 19S de CaMV se usan solos o en combinación con la secuencia líder omega de TMV (Takamatsu, N. (1987) EMBO J. 6: 307-311. Alternativamente, promotores de plantas como se utiliza la pequeña subunidad de RUBISc O o promotores de choque térmico (Coruzzi, G. et al. (1984) EMBO J. 3: 1671-1680; Broglie, R. et al. (1984) Science 224: 838-843; e Winter, J., et al. (1991) Results Probl. Cell Differ. 17: 85-105). Estas construcciones pueden introducirse en células vegetales mediante transformación directa de ADN o transfección mediada por patógenos. Dichas técnicas se describen en una serie de revisiones disponibles (ver, por ejemplo, Hobbs, S. o Murry, LE en McGraw Hill Yearbook of Science and Technology (1992) McGraw Hill, Nueva York, NY; pp. 191-196).
También se usa un sistema de insectos para expresar un polipéptido de interés. Por ejemplo, en uno de esos sistemas, el virus de la poliedrosis nuclear de Autographa californica (AcNPV) se usa como un vector para expresar genes extraños en células Spodoptera frugiperda o en larvas de Trichoplusia. Las secuencias que codifican el polipéptido se clonan en una región no esencial del virus, como el gen de la polihedrina, y se colocan bajo el control del promotor de la polihedrina. La inserción exitosa de la secuencia que codifica el polipéptido hace que el gen de la polihedrina esté inactivo y produce virus recombinantes que carecen de proteína de recubrimiento. Los virus recombinantes se usan luego para infectar, por ejemplo, células de S. frugiperda o larvas de Trichoplusia, en las que se expresa el polipéptido de interés (Engelhard, Ek et al. (1994) Proc. Natl. Acad. Sci. 91: 3224-3227).
Las señales de iniciación específicas también se usan para lograr una traducción más eficiente de secuencias que codifican un polipéptido de interés. Dichas señales incluyen el codón de iniciación ATG y secuencias adyacentes. En los casos en que las secuencias que codifican el polipéptido, su codón de iniciación y las secuencias aguas arriba se insertan en el vector de expresión apropiado, pueden no necesitarse señales de control transcripcionales o traduccionales adicionales. Sin embargo, en los casos en que solo se inserta la secuencia de codificación, o una porción de la misma, se proporcionan señales de control de traducción exógenas que incluyen el codón de iniciación ATG. Además, el codón de iniciación está en el marco de lectura correcto para garantizar la traducción correcta del polinucleótido insertado. Los elementos traduccionales exógenos y los codones de iniciación son de diversos orígenes, tanto naturales como sintéticos.
La transcripción de un ADN que codifica un polipéptido de la aplicación a menudo se incrementa insertando una secuencia potenciadora en el vector. Se conocen muchas secuencias potenciadoras, incluidas, por ejemplo, las identificadas en genes que codifican globina, elastasa, albúmina, □-fetoproteína e insulina. Típicamente, sin embargo, se usa un potenciador de un virus de células eucariotas. Los ejemplos incluyen el potenciador SV40 en el lado tardío del origen de replicación (pb 100-270), el potenciador del promotor temprano del citomegalovirus, el potenciador de polioma en el lado tardío del origen de replicación y los potenciadores de adenovirus. Véase también Yaniv, Nature 297: 17-18 (1982) sobre elementos potenciadores para la activación de promotores eucariotas. El potenciador se empalma en el vector en una posición 5' o 3' con respecto a la secuencia que codifica el polipéptido, pero preferiblemente se ubica en un sitio 5' del promotor.
Los vectores de expresión usados en células huésped eucariotas (levaduras, hongos, insectos, plantas, animales, humanos o células nucleadas de otros organismos multicelulares) también contienen secuencias necesarias para la terminación de la transcripción y para estabilizar el ARNm. Dichas secuencias están comúnmente disponibles en las regiones no traducidas 5' y, ocasionalmente 3', de ADN o ADNc eucariotas o virales. Estas regiones contienen segmentos de nucleótidos transcritos como fragmentos poliadenilados en la porción no traducida del ARNm que codifica el anticuerpo anti-PSCA. Un componente útil de terminación de la transcripción es la región de poliadenilación de la hormona de crecimiento bovina. Ver WO94/11026 y el vector de expresión divulgado en el mismo.
Las células huésped adecuadas para clonar o expresar el ADN en los vectores de la presente invención son las células procariotas, levaduras, plantas o eucariotas superiores descritas anteriormente. Los ejemplos de procariotas adecuados para este propósito incluyen eubacterias, como organismos Gram-negativos o Gram-positivos, por ejemplo, Enterobacteriaceae como Escherichia, por ejemplo, E. coli, Enterobacter, Erwinia, Klebsiella, Proteus, Salmonella, por ejemplo, Salmonella. typhimurium, Serratia, p. ej., Serratia marcescans y Shigella, así como Bacilli como B. subtilis y B. licheniformis (p. ej., B. licheniformis 41P divulgado en D-D 266,710 publicado el 12 de abril de 1989), Pseudomonas como P. aeruginosa, y Streptomyces. Un huésped de clonación de E. coli preferido es E. coli 294 (ATCC 31,446), aunque otras cepas tales como E. coli B, E. coli X1776 (ATCC 31,537) y E. coli W3110 (ATCC 27,325) son adecuadas. Estos ejemplos son ilustrativos más que limitativos.
Saccharomyces cerevisiae, o levadura de panadería común, es la más utilizada entre los microorganismos huéspedes eucariotas inferiores. Sin embargo, varios otros géneros, especies y cepas están comúnmente disponibles y utilizados en este documento, como Schizosaccharomyces pombe; huespedes de Kluyveromyces tales como, por
ejemplo, Klactis, K. fragilis (ATCC 12,424), K. bulgaricus (ATCC 16,045), K wickeramii (ATCC 24,178), K. waltii (ATCC 56,50o), K. drosophilarum (ATCC 36,906), K. thermotolerans, y K. marxianus; yarrowia (EP 402,226); Pichia pastoris.
(Documento EP 183,070); Candida Trichoderma reesia (EP 244,234); Neurospora crassa; Schwanniomyces como Schwanniomyces occidentalis; y hongos filamentosos tales como, por ejemplo, huéspedes Neurospora, Penicillium, Tolypocladium, y Aspergillus tales como A. nidulans y A. niger.
En ciertos aspectos, se elige una cepa de la célula huésped por su capacidad para modular la expresión de las secuencias insertadas o para procesar la proteína expresada de la manera deseada. Dichas modificaciones del polipéptido incluyen, pero no se limitan a, acetilación, carboxilación, glucosilación, fosforilación, lipidación y acilación. El procesamiento postraduccional que escinde una forma "prepro" de la proteína también se usa para facilitar la inserción, plegamiento y/o función correctos. Se eligen diferentes células huésped tales como CHO, COS, HeLa, MDCK, HEK293 y WI38, que tienen maquinaria celular específica y mecanismos característicos para tales actividades postraduccionales, para garantizar la correcta modificación y procesamiento de la proteína extraña.
Los métodos y reactivos específicamente adaptados para la expresión de anticuerpos o fragmentos de los mismos también son conocidos y están disponibles en la técnica, incluidos los descritos, por ejemplo, en las patentes de EE.UU. Nos 4816567 y 6331415. En diversos aspectos, las cadenas pesada y ligera de anticuerpos, o fragmentos de los mismos, se expresan a partir de los mismos o diferentes vectores de expresión. En un aspecto, ambas cadenas se expresan en la misma célula, lo que facilita la formación de un anticuerpo funcional o fragmento del mismo.
Los anticuerpos de longitud completa, los fragmentos de anticuerpos y las proteínas de fusión de anticuerpos se producen en bacterias, en particular cuando no se necesita la glicosilación y la función efectora de Fc, como cuando el anticuerpo terapéutico se conjuga con un agente citotóxico (por ejemplo, una toxina) y el inmunoconjugado por sí mismo muestra efectividad en la destrucción de células infectadas. Para la expresión de fragmentos de anticuerpos y polipéptidos en bacterias, véase, por ejemplo, la patente de EE.UU. Nos 5,648,237, 5,789,199 y 5,840,523, que describe la región de iniciación de la traducción (TIR) y las secuencias de señal para optimizar la expresión y la secreción. Después de la expresión, el anticuerpo se aísla de la pasta de células de E. coli en una fracción soluble y se puede purificar a través de, por ejemplo, una columna de proteína A o G dependiendo del isotipo. La purificación final se puede llevar a cabo utilizando un proceso similar al utilizado para purificar anticuerpos expresados, por ejemplo, en células CHO.
Las células huésped adecuadas para la expresión de polipéptidos y anticuerpos glicosilados se derivan de organismos multicelulares. Ejemplos de células de invertebrados incluyen células de plantas e insectos. Numerosas cepas y variantes baculovirales y las correspondientes células hospedadoras de insectos permisivas de hospedadores como Spodoptera frugiperda (oruga), Aedes aegypti (mosquito), Aedes albopicius (mosquito), Drosophila melanogaster (mosca de la fruta) y Bombyx mori han sido identificados. Una variedad de cepas virales para la transfección están disponibles públicamente, por ejemplo, la variante L-1 de Autographa californica NPV y la cepa Bm-5 de Bombyx mori NPV, y tales virus se usan como virus en el presente documento de acuerdo con la presente solicitud, particularmente para transfección de células de Spodoptera frugiperda. Los cultivos de células vegetales de algodón, maíz, papa, soja, petunia, tomate y tabaco también se utilizan como huéspedes.
La aplicación abarca los métodos de propagación de polipéptidos de anticuerpos y fragmentos de los mismos en células de vertebrados en cultivo (cultivo de tejidos). Ejemplos de líneas de células huésped de mamífero utilizadas en los métodos de la aplicación son la línea CV1 de riñón de mono transformada por SV40 (COS-7, ATCC CRL 1651); línea de riñón embrionario humano (células 293 o 293 subclonadas para crecimiento en cultivo en suspensión, Graham et al., J. Gen Virol. 36:59 (1977)); células de riñón de hámster bebé (BHK, ATCC CCL 10); Células de ovario de hámster chino/-DHFR (Ch O, Urlaub et al., Proc. Natl. Acad. Sci. EE.UU. 77: 4216 (1980)); células de sertoli de ratón (TM4, Mather, Biol. Reprod. 23: 243-251 (1980)); células de riñón de mono (CV1 ATCC Cc L 70); células de riñón de mono verde africano (VERO-76, ATCC CRL-1587); células de carcinoma cervical humano (He LA, ATCC CCL2); células de riñón canino (MDCK, ATCC CCL34); células de hígado de rata de búfalo (BRL 3A, At Cc CRL 1442); células de pulmón humano (W138, ATCC CCL 75); células hepáticas humanas (Hep G2, HB 8065); tumor mamario de ratón (MMT 060562, ATCC CCL51); Células TR1 (Mather y col., Annals NY Acad. Sci. 383: 44-68 (1982)); Células MRC 5; Células FS4; y una línea de hepatoma humano (Hep G2).
Las células huésped se transforman con los vectores de expresión o clonación descritos anteriormente para la producción de polipéptidos y se cultivan en medios nutrientes convencionales modificados según sea apropiado para inducir promotores, seleccionar transformantes o amplificar los genes que codifican las secuencias deseadas.
Para la producción a largo plazo de alto rendimiento de proteínas recombinantes, generalmente se prefiere la expresión estable. Por ejemplo, las líneas celulares que expresan establemente un polinucleótido de interés se transforman usando vectores de expresión que contienen orígenes virales de replicación y/o elementos de expresión endógenos y un gen marcador seleccionable en el mismo o en un vector separado. Después de la introducción del vector, se permite que las células crezcan durante 1-2 días en un medio enriquecido antes de cambiar a medio selectivo. El propósito del marcador seleccionable es conferir resistencia a la selección, y su presencia permite el crecimiento y la recuperación de células que expresan con éxito las secuencias introducidas. Los clones resistentes
de células transformadas de forma estable se proliferan usando técnicas de cultivo de tejidos apropiadas para el tipo de célula.
Se utilizan una pluralidad de sistemas de selección para recuperar líneas celulares transformadas. Estos incluyen, entre otros, la timidina quinasa del virus del herpes simple (Wigler, M. et al. (1977) Cell 11: 223-32) y la adenina fosforibosiltransferasa (Lowy, I. et al. (1990) Cell 22: 817-23) que se emplean en células tk- o aprt, respectivamente. Además, la resistencia a los antimetabolitos, antibióticos o herbicidas se utiliza como base para la selección; por ejemplo, dhfr, que confiere resistencia al metotrexato (Wigler, M. et al. (1980) Proc. Natl. Acad. Sci. 77: 3567-70); npt, que confiere resistencia a los aminoglucósidos, neomicina y G-418 (Colbere-Garapin, F. et al. (1981) J. Mol. Biol. 150: 1-14); y als o pat, que confieren resistencia al clorsulfuron y a la fosfinotricina acetiltransferasa, respectivamente (Murry, supra). Se han descrito genes seleccionables adicionales. Por ejemplo, trpB permite que las células utilicen indol en lugar de triptófano, y hisD permite que las células utilicen histinol en lugar de histidina (Hartman, SC y Rc Mulligan (1988) Proc. Natl. Acad. Sci. 85: 8047-51). El uso de marcadores visibles ha ganado popularidad con marcadores tales como antocianinas, beta-glucuronidasa y su sustrato GUS, y luciferasa y su sustrato luciferina, siendo ampliamente utilizado no solo para identificar transformantes, sino también para cuantificar la cantidad de expresión proteica transitoria o estable atribuible a un sistema de vector específico (Rhodes, C. A. et al. (1995) Methods Mol. Biol. 55: 121-131).
Aunque la presencia/ausencia de expresión del gen marcador sugiere que el gen de interés también está presente, se confirma su presencia y expresión. Por ejemplo, si la secuencia que codifica un polipéptido se inserta dentro de una secuencia del gen marcador, las células recombinantes que contienen secuencias se identifican por la ausencia de la función del gen marcador. Alternativamente, un gen marcador se coloca en tándem con una secuencia que codifica el polipéptido bajo el control de un único promotor. La expresión del gen marcador en respuesta a la inducción o selección generalmente indica también la expresión del gen en tándem.
Alternativamente, las células huésped que contienen y expresan una secuencia de polinucleótidos deseada se identifican mediante una variedad de procedimientos conocidos por los expertos en la materia. Estos procedimientos incluyen, entre otros, hibridaciones de ADN-ADN o ADN-RNA y técnicas de bioensayo o inmunoensayo de proteínas que incluyen, por ejemplo, tecnologías basadas en membrana, solución o chip para la detección y/o cuantificación de ácido nucleico o proteína.
En la técnica se conocen diversos protocolos para detectar y medir la expresión de productos codificados con polinucleótidos, utilizando anticuerpos policlonales o monoclonales específicos para el producto. Los ejemplos no limitantes incluyen el ensayo de inmunosorción ligada a enzimas (ELISA), el radioinmunoensayo (RIA) y la clasificación de células activadas por fluorescencia (FACS). Para algunas aplicaciones, se prefiere un inmunoensayo monoclonal basado en dos sitios que utiliza anticuerpos monoclonales reactivos a dos epítopos no interferentes en un polipéptido dado, pero también se puede emplear un ensayo de unión competitiva. Estos y otros ensayos se describen, entre otros lugares, en Hampton, R. et al. (1990; Serological Methods, a Laboratory Manual, APS Press, St Paul. Minn.) Y Maddox, DE et al. (1983; J. Exp. Med. 158: 1211-1216).
Los expertos en la técnica conocen diversos marcadores y técnicas de conjugación y se utilizan en diversos ensayos de ácidos nucleicos y aminoácidos. Los medios para producir hibridación marcada o sondas de PCR para detectar secuencias relacionadas con a polinucleótidos incluyen oligoetiquetado, traducción de nick, marcaje final o amplificación por PCR usando un nucleótido marcado. Alternativamente, las secuencias, o cualquier porción de las mismas, se clonan en un vector para la producción de una sonda de ARNm. Tales vectores son conocidos en la técnica, están disponibles comercialmente y se usan para sintetizar sondas de ARN in vitro mediante la adición de una ARN polimerasa apropiada tal como T7, T3 o SP6 y nucleótidos marcados. Estos procedimientos se llevan a cabo utilizando una variedad de kits disponibles comercialmente. Las moléculas o etiquetas indicadoras adecuadas, que se usan incluyen, pero no se limitan a, radionucleótidos, enzimas, agentes fluorescentes, quimioluminiscentes o cromogénicos, así como sustratos, cofactores, inhibidores, partículas magnéticas y similares.
El polipéptido producido por una célula recombinante es secretado o contenido intracelularmente dependiendo de la secuencia y/o el vector utilizado. Los vectores de expresión que contienen polinucleótidos de la aplicación están diseñados para contener secuencias de señal que dirigen la secreción del polipéptido codificado a través de una membrana celular procariota o eucariota.
En ciertos aspectos, un polipéptido de la aplicación se produce como un polipéptido de fusión que incluye además un dominio de polipéptido que facilita la purificación de proteínas solubles. Dichos dominios que facilitan la purificación incluyen, pero no se limitan a, péptidos quelantes de metales tales como módulos de histidina-triptófano que permiten la purificación en metales inmovilizados, dominios de proteína A que permiten la purificación en inmunoglobulina inmovilizada y el dominio utilizado en la extensión de FLAGS/purificación por afinidad. sistema (Amgen, Seattle, WA). La inclusión de secuencias enlazadoras escindibles tales como las específicas para Factor XA o enteroquinasa (Invitrogen. San Diego, CA) entre el dominio de purificación y el polipéptido codificado se utilizan para facilitar la purificación. Un vector de expresión ejemplar proporciona la expresión de una proteína de fusión que contiene un polipéptido de interés y un ácido nucleico que codifica 6 residuos de histidina que preceden a un sitio de
escisión de tiorredoxina o enteroquinasa. Los residuos de histidina facilitan la purificación en IMIAC (cromatografía de afinidad de iones metálicos inmovilizados) como se describe en Porath, J. et al. (1992, Prot. Exp. Purif. 3: 263-281) mientras que el sitio de escisión de enteroquinasa proporciona un medio para purificar el polipéptido deseado de la proteína de fusión. Una discusión de los vectores utilizados para producir proteínas de fusión se proporciona en Kroll, DJ et al. (1993; ADN Cell Biol. 12: 441-453).
En ciertos aspectos, un polipéptido de la presente solicitud se fusiona con un polipéptido heterólogo, que puede ser una secuencia señal u otro polipéptido que tiene un sitio de escisión específico en el extremo N-terminal de la proteína o polipéptido maduro. La secuencia señal heteróloga seleccionada preferiblemente es una que es reconocida y procesada (es decir, escindida por una peptidasa señal) por la célula huésped. Para las células huésped procariotas, la secuencia señal se selecciona, por ejemplo, del grupo de los líderes de fosfatasa alcalina, penicilinasa, 1pp o enterotoxina II termoestable. Para la secreción en levaduras, la secuencia señal se selecciona de entre, por ejemplo, el líder de invertasa de levadura, líder de factor □ (incluyendo líderes de factores □ Saccharomyces y Kluyveromyces), o líder de fosfatasa ácida, el C. albicans glucoamilasa líder, o la señal descrita en WO 90/13646. en la expresión de células de mamífero, están disponibles secuencias de señal de mamífero, así como líderes secretores virales, por ejemplo, la señal de herpes simplex gD.
Cuando se usan técnicas recombinantes, el polipéptido o anticuerpo se produce intracelularmente, en el espacio periplásmico, o se secreta directamente al medio. Si el polipéptido o anticuerpo se produce intracelularmente, como primer paso, los restos particulados, ya sea células huésped o fragmentos lisados, se eliminan, por ejemplo, por centrifugación o ultrafiltración. Carter et al., Bio/Technology 10:163-167 (1992) describen un procedimiento para aislar anticuerpos que se secretan al espacio periplásmico de E. coli. Brevemente, la pasta celular se descongela en presencia de acetato de sodio (pH 3,5), EDTA y fluoruro de fenilmetilsulfonilo (PMSF) durante aproximadamente 30 minutos. Los restos celulares se eliminan por centrifugación. Cuando el polipéptido o anticuerpo se secreta en el medio, los sobrenadantes de tales sistemas de expresión generalmente se concentran primero usando un filtro de concentración de proteínas disponible comercialmente, por ejemplo, una unidad de ultrafiltración Amicon o Millipore Pellicon. Opcionalmente, se incluye un inhibidor de proteasa tal como PMSF en cualquiera de los pasos anteriores para inhibir la proteólisis y se incluyen antibióticos para prevenir el crecimiento de contaminantes adventicios.
La composición de polipéptidos o anticuerpos preparada a partir de las células se purifica usando, por ejemplo, cromatografía de hidroxilapatita, electroforesis en gel, diálisis y cromatografía de afinidad, siendo la cromatografía de afinidad la técnica de purificación preferida. La idoneidad de la proteína A como ligando de afinidad depende de la especie y el isotipo de cualquier dominio Fc de inmunoglobulina que esté presente en el polipéptido o anticuerpo. La proteína A se utiliza para purificar anticuerpos o fragmentos de los mismos que se basan en humano y1, y2, o y4 cadenas pesadas (Lindmark et al, J. Immunol Meth 62:. 1-13 (1983)). La proteína G se recomienda para todos los isotipos de ratón y para los humanos y3 (Guss et al, EMBO J. 5:15671575 (1986)). La matriz a la que está unido el ligando de afinidad es con frecuencia agarosa, pero hay otras matrices disponibles. Las matrices mecánicamente estables, como el vidrio de poro controlado o el poli(estirenivinil)benceno permiten velocidades de flujo más rápidas y tiempos de procesamiento más cortos que los que se pueden lograr con agarosa. Cuando el polipéptido o anticuerpo comprende un dominio Ch3, la resina Bakerbond a Bx ™ (JT Baker, Phillipsburg, NJ) es útil para la purificación. Otras técnicas para la purificación de proteínas, como el fraccionamiento en una columna de intercambio iónico, precipitación de etanol, HPLC de fase inversa, cromatografía en sílice, cromatografía en heparina, cromatografía SEPHAROSE™ en una resina de intercambio aniónico o catiónico (como una columna de ácido poliaspártico), cromatofocusing, SDS-PAGE, y la precipitación de sulfato de amonio también están disponibles dependiendo del polipéptido o anticuerpo a recuperar.
Después de cualquier etapa de purificación preliminar, la mezcla que comprende el polipéptido o anticuerpo de interés y contaminantes se somete a cromatografía de interacción hidrófoba de pH bajo usando un tampón de elución a un pH entre aproximadamente 2,5-4,5, preferiblemente realizado a bajas concentraciones de sal (por ejemplo, de aproximadamente 0-0,25 M de sal).
La solicitud incluye además formulaciones farmacéuticas que incluyen un polipéptido, anticuerpo o modulador de la presente solicitud, con un grado deseado de pureza, y un vehículo, excipiente o estabilizador farmacéuticamente aceptable (Remingion's Pharmaceutical Sciences 16a edición, Osol, A. Ed. (1980)). En ciertos aspectos, las formulaciones farmacéuticas se preparan para mejorar la estabilidad del polipéptido o anticuerpo durante el almacenamiento, por ejemplo, en forma de formulaciones liofilizadas o soluciones acuosas.
Los vehículos, excipientes o estabilizadores aceptables no son tóxicos para los receptores a las dosis y concentraciones empleadas, e incluyen, por ejemplo, tampones tales como acetato, Tris, fosfato, citrato y otros ácidos orgánicos; antioxidantes que incluyen ácido ascórbico y metionina; conservantes (como cloruro de octadecildimetilbencilamonio; cloruro de hexametonio; cloruro de benzalconio, cloruro de bencetonio; fenol, alcohol butílico o bencílico; alquilo parabenos como metilo o propilo parabeno; catecol; resorcinol; ciclohexanol; 3-pentanol; y m-cresol); polipéptidos de bajo peso molecular (menos de aproximadamente 10 residuos); proteínas, tales como albúmina sérica, gelatina o inmunoglobulinas; polímeros hidrófilos tales como polivinilpirrolidona; aminoácidos tales como glicina, glutamina, asparagina, histidina, arginina o lisina; monosacáridos, disacáridos y otros carbohidratos que
incluyen glucosa, mañosa o dextrinas; agentes quelantes como EDTA; tonicificadores como trehalosa y cloruro de sodio; azúcares tales como sacarosa, manitol, trehalosa o sorbitol; tensioactivo tal como polisorbato; contraiones iónicos formadores de sal como el sodio; complejos metálicos (por ejemplo, complejos de proteína Zn); y/o tensioactivos no iónicos como TWEEN™, PLURONICS™ o polietilenglicol (PEG). En ciertas realizaciones, la formulación terapéutica comprende preferiblemente el polipéptido o anticuerpo a una concentración de entre 5 y 200 mg/ml, preferiblemente entre 10 y 100 mg/ml.
Las formulaciones en el presente documento también contienen uno o más agentes terapéuticos adicionales adecuados para el tratamiento de la indicación particular, por ejemplo, infección que se está tratando, o para prevenir efectos secundarios no deseados. Preferiblemente, el agente terapéutico adicional tiene una actividad complementaria al polipéptido o anticuerpo de la aplicación reenviada, y los dos no se afectan negativamente entre sí. Por ejemplo, además del polipéptido o anticuerpo de la aplicación, se agrega a la formulación un anticuerpo adicional o segundo, agente antivírico, agente antiinfeccioso y/o cardioprotector. Dichas moléculas están adecuadamente presentes en la formulación farmacéutica en cantidades que son efectivas para el propósito pretendido.
Los ingredientes activos, por ejemplo, polipéptidos y anticuerpos de la aplicación y otros agentes terapéuticos, también están atrapados en microcápsulas preparadas, por ejemplo, por técnicas de coacervación o por polimerización interfacial, por ejemplo, hidroximetilcelulosa o microcápsulas de gelatina-microcápsulas y polimetilmetacilato)., respectivamente, en sistemas de administración de fármacos coloidales (por ejemplo, liposomas, microesferas de albúmina, microemulsiones, nanopartículas y nanocápsulas) o en macroemulsiones. Dichas técnicas se describen en la 16a edición de Remingion's Pharmaceutical Sciences, Osol, A. Ed. (1980)
Se preparan preparaciones de liberación sostenida. Los ejemplos adecuados de preparaciones de liberación sostenida incluyen, pero no se limitan a, matrices semipermeables de polímeros hidrófobos sólidos que contienen el anticuerpo, cuyas matrices están en forma de artículos conformados, por ejemplo, películas o microcápsulas. Los ejemplos no limitantes de matrices de liberación sostenida incluyen poliésteres, hidrogeles (por ejemplo, poli(2-hidroxietilo-metacrilato) o alcohol (poli vinílico)), polilactidas (patente de Estados Unidos N° 3,773,919), copolímeros de ácido L-glutámico y y etilo-L-glutamato, etileno-acetato de vinilo no degradable, copolímeros degradables de ácido láctico-ácido glicólico como LUPRON DEPOT™ (microesferas inyectables compuestas de copolímero de ácido lácticoácido glicólico y acetato de leuprolida) y poli-D-(-)-3-ácido hidroxibirírico.
Las formulaciones a utilizar para la administración in vivo son preferiblemente estériles. Esto se logra fácilmente mediante filtración a través de membranas de filtración estériles.
Los anticuerpos de la aplicación se pueden acoplar a un fármaco para administrarlo a un sitio de tratamiento o se puede acoplar a una etiqueta detectable para facilitar la obtención de imágenes de un sitio que comprende células de interés, como las células infectadas con VIH. Los métodos para acoplar anticuerpos a fármacos y marcadores detectables son bien conocidos en la técnica, al igual que los métodos para formar imágenes usando marcadores detectables. Los anticuerpos marcados pueden emplearse en una amplia variedad de ensayos, empleando una amplia variedad de marcadores. La detección de la formación de un complejo anticuerpo-antígeno entre un anticuerpo de la aplicación y un epítopo de interés (un epítopo de VIH) se puede facilitar uniendo una sustancia detectable al anticuerpo. Los medios de detección adecuados incluyen el uso de marcadores tales como radionucleótidos, enzimas, coenzimas, fluorescentes, quimioluminiscentes, cromógenos, sustratos enzimáticos o cofactores, inhibidores enzimáticos, complejos de grupos protésicos, radicales libres, partículas, colorantes y similares. Los ejemplos de enzimas adecuadas incluyen peroxidasa de rábano picante, fosfatasa alcalina, p-galactosidasa o acetilcolinesterasa; ejemplos de complejos de grupos protésicos adecuados incluyen estreptavidina/biotina y avidina/biotina; ejemplos de materiales fluorescentes adecuados incluyen umbeliferona, fluoresceína, isotiocianato de fluoresceína, rodamina, diclorotriazinilamina, fluoresceína, cloruro de dansilo o ficoeritrina; un ejemplo de material luminiscente es el luminol; ejemplos de materiales bioluminiscentes incluyen luciferasa, luciferina y aequorina; y ejemplos de material radiactivo adecuado incluyen 125I, 131I,. 35S, o 3H. Tales reactivos marcados pueden usarse en una variedad de ensayos bien conocidos, tales como radioinmunoensayos, inmunoensayos enzimáticos, por ejemplo, ELISA, inmunoensayos fluorescentes y similares.
Los anticuerpos se etiquetan con tales etiquetas por métodos conocidos. Por ejemplo, los agentes de acoplamiento tales como aldehídos, carbodiimidas, dimaleimida, imidatos, succinimidas, benzadina bidiazotizada y similares se usan para marcar los anticuerpos con los marcadores fluorescentes, quimioluminiscentes y enzimáticos descritos anteriormente. Una enzima se combina típicamente con un anticuerpo usando moléculas puente tales como carbodiimidas, peryodato, diisocianatos, glutaraldehído y similares. Se describen diversas técnicas de marcado en Morrison, Methods in Enzymology 32b, 103 (1974), Syvanen y col., J. Biol. Chem 284, 3762 (1973) y Bolton y Hunter, Biochem J. 133, 529 (1973).
Un anticuerpo de acuerdo con la solicitud puede conjugarse con un resto terapéutico tal como una citotoxina, un agente terapéutico o un ion metálico radioactivo o radioisótopo. Los ejemplos de radioisótopos incluyen, entre otros, I-131, I-123, I-125, Y-90, Re-188, Re-186, At-211, Cu-67, Bi-212, Bi-213, Pd-109, Tc-99, In-111 y similares. Dichos conjugados de anticuerpos pueden usarse para modificar una respuesta biológica dada; el resto del fármaco no debe
interpretarse como limitado a los agentes terapéuticos químicos clásicos. Por ejemplo, el resto del fármaco puede ser una proteína o polipéptido que posee una actividad biológica deseada. Dichas proteínas pueden incluir, por ejemplo, una toxina tal como abrina, ricina A, exotoxina de pseudomonas o toxina de la difteria.
Las técnicas para conjugar tal resto terapéutico con anticuerpos son bien conocidas. Ver, por ejemplo, Arnon et al. (1985) "Monoclonal Antibodies for Immunotargeting of Drugs in Cancer Therapy", en Monoclonal Antibodies and Cancer Therapy, ed. Reisfeld y col. (Alan R. Liss, Inc.), págs. 243-256; ed. Hellstrom y col. (1987) "Antibodies for Drug Delivery", en Controlled Drug Delivery, ed. Robinson y col. (2a ed.; Marcel Dekker, Inc.), págs. 623-653; Thorpe (1985) "Antibody Carriers of Cytotoxic Agents in Cancer Therapy: A Review", en Monoclonal Antibodies '84: Biological and Clinical Applications, ed. Pinchera y col. pp. 475-506 (Editrice Kurtis, Milano, Italia, 1985); "Analysis, Results, and Future Prospective of the Therapeutic Use of Radiolabeled Antibody in Cancer Therapy", en Monoclonal Antibodies for Cancer Detection and Therapy, ed. Baldwin y col. (Academic Press, Nueva York, 1985), págs. 303-316; y Thorpe et al. (1982) Immunol. Rev. 62: 119-158.
Los métodos de diagnóstico generalmente implican poner en contacto una muestra biológica obtenida de un paciente, como, por ejemplo, sangre, suero, saliva, orina, esputo, una muestra de hisopo celular o una biopsia de tejido, con un anticuerpo VIH1 y determinar si el anticuerpo se une preferentemente a la muestra en comparación con una muestra de control o un valor de corte predeterminado, lo que indica la presencia de células infectadas. En aspectos particulares, al menos dos veces, tres veces o cinco veces más anticuerpos contra el VIH1 se unen a una célula infectada en comparación con una muestra de tejido o célula normal de control apropiada. Se determina un valor de corte predeterminado, por ejemplo, promediando la cantidad de anticuerpo VIH1 que se une a varias muestras de control apropiadas diferentes en las mismas condiciones utilizadas para realizar el ensayo de diagnóstico de la muestra biológica que se está analizando.
El anticuerpo unido se detecta usando los procedimientos descritos en este documento y conocidos en la técnica. En ciertos aspectos, los métodos de diagnóstico de la aplicación se practican utilizando anticuerpos contra el VIH1 que se conjugan con un marcador detectable, por ejemplo, un fluoróforo, para facilitar la detección del anticuerpo unido. Sin embargo, también se practican utilizando métodos de detección secundaria del anticuerpo VIH1. Estos incluyen, por ejemplo, RIA, ELISA, precipitación, aglutinación, fijación del complemento e inmunofluorescencia.
Los anticuerpos VIH1 de la presente solicitud son capaces de diferenciar entre pacientes con y sin una infección por VIH, y determinar si un paciente tiene una infección o no, utilizando los ensayos representativos proporcionados aquí. Según un método, se obtiene una muestra biológica de un paciente sospechoso de tener o se sabe que tiene infección por VIH1. En algunos aspectos, la muestra biológica incluye células del paciente. La muestra se pone en contacto con un anticuerpo VIH1, por ejemplo, durante un tiempo y bajo condiciones suficientes para permitir que el anticuerpo VIH1 se una a las células infectadas presentes en la muestra. Por ejemplo, la muestra se pone en contacto con un anticuerpo VIH1 durante 10 segundos, 30 segundos, 1 minuto, 5 minutos, 10 minutos, 30 minutos, 1 hora, 6 horas, 12 horas, 24 horas, 3 días o cualquier punto intermedio. La cantidad de anticuerpo unido al VIH1 se determina y compara con un valor de control, que puede ser, por ejemplo, un valor predeterminado o un valor determinado a partir de una muestra de tejido normal. Una mayor cantidad de anticuerpo unido a la muestra del paciente en comparación con la muestra de control es indicativa de la presencia de células infectadas en la muestra del paciente.
En un método relacionado, una muestra biológica obtenida de un paciente se pone en contacto con un anticuerpo VIH1 durante un tiempo y en condiciones suficientes para permitir que el anticuerpo se una a las células infectadas. Luego se detecta el anticuerpo unido, y la presencia de anticuerpo unido indica que la muestra contiene células infectadas. Este aspecto es particularmente útil cuando el anticuerpo VIH1 no se une a las células normales a un nivel detectable.
Los diferentes anticuerpos contra el VIH1 poseen diferentes características de unión y especificidad. Dependiendo de estas características, se utilizan anticuerpos específicos contra el VIH1 para detectar la presencia de una o más cepas de VIH1. Por ejemplo, ciertos anticuerpos se unen específicamente a solo una o varias cepas de VIH1, mientras que otros se unen a todas o la mayoría de las diferentes cepas de VIH1. Los anticuerpos específicos para una sola cepa de VIH1 se usan para identificar la cepa de una infección.
En ciertos aspectos, los anticuerpos que se unen a una célula infectada generan preferiblemente una señal que indica la presencia de una infección en al menos aproximadamente el 20% de los pacientes con la infección detectada, más preferiblemente al menos aproximadamente el 30% de los pacientes. Alternativamente, o además, el anticuerpo genera una señal negativa que indica la ausencia de la infección en al menos aproximadamente el 90% de los individuos sin que se detecte la infección. Cada anticuerpo satisface los criterios anteriores; sin embargo, los anticuerpos de la presente solicitud se usan en combinación para mejorar la sensibilidad.
La presente solicitud también incluye kits útiles para realizar ensayos de diagnóstico y pronóstico utilizando los anticuerpos de la presente aplicación. Los kits de la aplicación incluyen un recipiente adecuado que comprende un anticuerpo contra el VIH1 de la aplicación en forma marcada o no marcada. Además, cuando el anticuerpo se
suministra en una forma marcada adecuada para un ensayo de unión indirecta, el kit incluye además reactivos para realizar el ensayo indirecto apropiado. Por ejemplo, el kit incluye uno o más recipientes adecuados que incluyen sustratos enzimáticos o agentes derivatizantes, dependiendo de la naturaleza de la etiqueta. También se incluyen muestras de control y/o instrucciones.
La inmunización pasiva ha demostrado ser una estrategia efectiva y segura para la prevención y el tratamiento de enfermedades virales. (Ver Keller et al., Clin. Microbiol. Rev. 13: 602-14 (2000); Casadevall, Nat. Biotechnol. 20: 114 (2002); Shibata et al., Nat. Med. 5: 204-10 (1999); e Igarashi et al., Nat. Med. 5: 211-16 (1999)). La inmunización pasiva con anticuerpos monoclonales humanos proporciona una estrategia de tratamiento inmediato para la profilaxis de emergencia y el tratamiento del VIH1.
Los anticuerpos contra el VIH1 y sus fragmentos, y las composiciones terapéuticas, de la aplicación se unen específicamente o se unen preferentemente a las células infectadas, en comparación con las células y tejidos no infectados de control normal. Por lo tanto, estos anticuerpos contra el VIH1 se usan para atacar selectivamente células o tejidos infectados en un paciente, muestra biológica o población celular. A la luz de las propiedades de unión específicas de infección de estos anticuerpos, la presente solicitud proporciona métodos para regular (por ejemplo, inhibir) el crecimiento de células infectadas, métodos para matar células infectadas y métodos para inducir apoptosis de células infectadas. Estos métodos incluyen poner en contacto una célula infectada con un anticuerpo VIH1 de la aplicación. Estos métodos se practican in vitro, ex vivo e in vivo.
En varios aspectos, los anticuerpos de la aplicación son intrínsecamente terapéuticamente activos. Alternativamente, o además, los anticuerpos de la aplicación se conjugan con un agente citotóxico o agente inhibidor del crecimiento, por ejemplo, un radioisótopo o toxina que se usa en el tratamiento de células infectadas unidas o contactadas por el anticuerpo.
Los sujetos con riesgo de enfermedades o trastornos relacionados con el VIH1 incluyen pacientes que han entrado en contacto con una persona infectada o que han estado expuestos al VIH1 de alguna otra manera. La administración de un agente profiláctico puede ocurrir antes de la manifestación de los síntomas característicos de la enfermedad o trastorno relacionado con el VIH1, de tal manera que se previene o, como alternativa, se retrasa su progresión.
Se proporcionan además métodos para prevenir un aumento en el título del virus VIH1, replicación viral, proliferación viral o una cantidad de una proteína viral VIH1 en un sujeto. En un aspecto, un método incluye administrar al sujeto una cantidad de un anticuerpo VIH1 eficaz para prevenir un aumento en el título de VIH1, la replicación del virus o una cantidad de una proteína VIH1 de una o más cepas o aislados de VIH en el sujeto.
Para el tratamiento in vivo de pacientes humanos y no humanos, al paciente generalmente se le administra o se le proporciona una formulación farmacéutica que incluye un anticuerpo VIH1 de la aplicación. Cuando se utiliza para la terapia in vivo, los anticuerpos de la aplicación se administran al paciente en cantidades terapéuticamente eficaces (es decir, cantidades que eliminan o reducen la carga viral del paciente). Los anticuerpos se administran a un paciente humano, de acuerdo con métodos conocidos, como la administración intravenosa, por ejemplo, como un bolo o mediante infusión continua durante un período de tiempo, por vía intramuscular, intraperitoneal, intracerobrospinal, subcutánea, intraarticular, intrasinovial, vías intratecales, orales, tópicas o de inhalación. Los anticuerpos pueden administrarse por vía parenteral, cuando sea posible, en el sitio de la célula diana o por vía intravenosa. La administración intravenosa o subcutánea del anticuerpo se prefiere en ciertos aspectos. Las composiciones terapéuticas de la aplicación se administran a un paciente o sujeto de forma sistémica, parenteral o local.
Para la administración parenteral, los anticuerpos se formulan en una forma inyectable de dosificación unitaria (solución, suspensión, emulsión) en asociación con un vehículo parenteral farmacéuticamente aceptable. Ejemplos de tales vehículos son agua, solución salina, solución de Ringer, solución de dextrosa y albúmina de suero humano al 5%. También se utilizan vehículos no acuosos, como aceites fijos y oleato de etilo. Los liposomas se usan como portadores. El vehículo contiene pequeñas cantidades de aditivos, como sustancias que mejoran la isotonicidad y la estabilidad química, por ejemplo, tampones y conservantes. Los anticuerpos se formulan típicamente en tales vehículos a concentraciones de aproximadamente 1 mg/ml a 10 mg/ml.
La dosis y el régimen de dosificación dependen de una variedad de factores fácilmente determinados por un médico, como la naturaleza de la infección y las características del agente citotóxico particular o agente inhibidor del crecimiento conjugado con el anticuerpo (cuando se usa), por ejemplo, su índice terapéutico, el paciente y la historia del paciente. Generalmente, una cantidad terapéuticamente efectiva de un anticuerpo se administra a un paciente. En aspectos particulares, la cantidad de anticuerpo administrado está en el intervalo de aproximadamente 0,1 mg/kg a aproximadamente 50 mg/kg de peso corporal del paciente. Dependiendo del tipo y la gravedad de la infección, aproximadamente 0,1 mg/kg a aproximadamente 50 mg/kg de peso corporal (por ejemplo, aproximadamente 0,1-15 mg/kg/dosis) de anticuerpo es una dosis candidata inicial para la administración al paciente, ya sea, por ejemplo, por una o más administraciones separadas, o por infusión continua. El progreso de esta terapia se controla fácilmente mediante métodos y ensayos convencionales y se basa en criterios conocidos por el médico u otras personas expertas
en la técnica.
En un aspecto particular, se administra al paciente un inmunoconjugado que incluye el anticuerpo conjugado con un agente citotóxico. Preferiblemente, el inmunoconjugado es internalizado por la célula, dando como resultado una mayor eficacia terapéutica del inmunoconjugado para matar la célula a la que se une. En un aspecto, el agente citotóxico se dirige o interfiere con el ácido nucleico en la célula infectada. Los ejemplos de dichos agentes citotóxicos se describen anteriormente e incluyen, pero no se limitan a, maytansinoides, caliqueamicinas, ribonucleasas y endonucleasas de ADN.
Otros regímenes terapéuticos se combinan con la administración del anticuerpo VIH1 de la presente solicitud. La administración combinada incluye la coadministración, usando formulaciones separadas o una formulación farmacéutica única, y la administración consecutiva en cualquier orden, en donde preferiblemente hay un período de tiempo mientras que ambos (o todos) los agentes activos ejercen simultáneamente sus actividades biológicas. Preferiblemente, dicha terapia combinada da como resultado un efecto terapéutico sinérgico.
En ciertos aspectos, es deseable combinar la administración de un anticuerpo de la aplicación con otro anticuerpo dirigido contra otro antígeno asociado con el agente infeccioso.
Además de la administración de la proteína del anticuerpo al paciente, la solicitud proporciona métodos de administración del anticuerpo mediante terapia génica. Dicha administración de ácido nucleico que codifica el anticuerpo está comprendida por la expresión "administrar una cantidad terapéuticamente eficaz de un anticuerpo". Véase, por ejemplo, la publicación de solicitud de patente PCT WO96/07321 sobre el uso de terapia génica para generar anticuerpos intracelulares.
En otro aspecto, los anticuerpos anti-VIH1 de la aplicación se usan para determinar la estructura del antígeno unido, por ejemplo, epítopos conformacionales, cuya estructura se usa para desarrollar una vacuna que tiene o imita esta estructura, por ejemplo, a través de sustancias químicas modelado y métodos SAR. Dicha vacuna podría usarse para prevenir la infección por VIH1.
Los diferentes aspectos de la aplicación y las realizaciones de la presente invención se ilustrarán adicionalmente en los siguientes Ejemplos. EJEMPLOS
Como la presente invención proporciona específicamente el anticuerpo monoclonal humano anti-VIH 4876_M06 (PGT-134) que tiene una región variable de cadena pesada o más bien una cadena pesada variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 435 y una región variable de cadena ligera o más bien una cadena ligera variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 440, solo los ejemplos que incluyen PGT-134 o más bien sus secuencias de aminoácidos de la región variable de cadena pesada y/o ligera son relevantes y se refieren a realizaciones de la presente invención.
Ejemplo 1: Selección de la muestra de paciente
El suero de aproximadamente 1.800 donantes infectados con VIH-1 de Asia, Australia, Europa, América del Norte y los países de África subsahariana se seleccionaron para determinar la actividad de neutralización y se identificaron los donantes que exhiben la actividad de suero neutralizante más amplio y potente observada hasta la fecha. (Simek, MD, J Virol (2009)). Los anticuerpos monoclonales se generaron a partir de estos donantes utilizando diferentes enfoques.
Se seleccionó un paciente en función de la elegibilidad del paciente para la inscripción, que se definió como: hombre o mujer de al menos 18 años de edad con infección por VIH documentada durante al menos tres años, clínicamente asintomática en el momento de la inscripción y no actualmente recibiendo terapia antirretroviral. (Simek, MD, J Virol (julio de 2009) 83 (14): 7337-48). La selección de individuos para la generación de anticuerpos monoclonales se basó en un algoritmo de detección analítica de alto rendimiento de orden de rango. El voluntario fue identificado como un individuo con suero neutralizante amplio basado en una actividad neutralizante amplia y potente contra un panel de pseudovirus de clado cruzado.
Se usó una nueva estrategia de alto rendimiento para seleccionar sobrenadantes de cultivo que contienen IgG de aproximadamente 30.000 células B de memoria activadas de un donante infectado con clado A para la unión recombinante, monomérica de gp120 JR-CSF y gp41 HxB2 (Env), así como la neutralización actividad contra VIH-1 JR-CSF y VIH-1 SF162 como se muestra en la Tabla 1. Las células B de memoria se cultivaron a una densidad casi clonal de modo que el par de cadena pesada y ligera de anticuerpo auténtico se pudiera reconstituir de cada pocillo de cultivo.
Ejemplo 2: Generación de anticuerpos monoclonales
La plataforma de descubrimiento de anticuerpos monoclonales humanos utilizó un sistema de cultivo de
células B a corto plazo para interrogar al repertorio de células B de memoria. 30.300 CD19 se aislaron y de la superficie de IgG que expresan las células B de memoria de diez millones de células mononucleares de sangre periférica (PBMC) del donante infectado por VIH-1. Las células B CD19+/sIgG+ se sembraron en placas de microtitulación de 384 pocillos a un promedio de 1,3 células/pocillo en condiciones que promovieron la activación, proliferación, diferenciación terminal y secreción de anticuerpos de las células B. Los sobrenadantes de cultivo se seleccionaron en un formato de alto rendimiento para la reactividad de unión a gp120 y gp41 recombinantes inmovilizadas indirecta y directamente en placas ELISA, respectivamente. En paralelo, los sobrenadantes de cultivo también se seleccionaron para la actividad de neutralización en un ensayo de micro-neutralización de alto rendimiento.
Se aislaron regiones variables pesadas y ligeras a partir de lisados de hits neutralizantes seleccionados mediante amplificación por RT-PCR usando conjuntos de cebadores específicos de familia. A partir de reacciones positivas de PCR específicas de la familia, clones de los clones de la región VH o VL se clonaron en un vector de expresión corriente arriba a la secuencia del dominio constante de IgG1 humana. Los minipreps (QIAGEN, Valencia, c A) de estos grupos de ADN, derivados de cultivos bacterianos en suspensión, se combinaron en todos los posibles pares específicos de la familia de cadenas pesadas y ligeras y se usaron para transfectar transitoriamente células 293. Todos los sobrenadantes transfectantes que contenían anticuerpos recombinantes secretados se seleccionaron en ensayos ELISA y de neutralización. Para los pocillos de células B que contenían más de un clon de células B por pocillo de cultivo, se aislaron múltiples secuencias de dominio VH y VL. El ELISA (para pozos de células B positivas para ELISA) y los cribados de neutralización identificaron los grupos combinados de cadena pesada y ligera que reconstituyeron la actividad de unión y neutralización como se observó para el pozo de células B. Las secuencias de ADN de las regiones variables de la cadena pesada y ligera para todos los mAb neutralizantes se confirmaron mediante múltiples reacciones de secuenciación usando ADN purificado de maxipreps (QIAGEN).
Ejemplo 3: Cribado de anticuerpos monoclonales para la unión a gp120 y gp41 recombinantes mediante ensayo ELISA
Se obtuvo gp120 recombinante con secuencia derivada de gp120 del aislado primario de VIH-1 JR-CSF y expresado en células de insecto del depósito IAVI NAC. La gp41 recombinante generada con secuencias derivadas del clon HxB2 del VIH-1 y expresada en Pichia pastoris fue fabricada por Vybion, Inc., obtenida de los anticuerpos anti-gp120 de oveja del repositorio IAVI NAC utilizados como agente de captura para inmovilizar indirectamente gp120 en placas ELISA se compraron en Aalto Bio Reagents (Dublín, Irlanda). Todos los ensayos ELISA se realizaron a 25 pL/pocillo en placas MaxiSorp de Nunc.
En ELISA anti-gp120, se capturó gp120 recombinante (0,5 pg/ml) en placas ELISA de 384 pocillos prerecubiertas (a 4° C durante la noche) con anti-gp120 de cabra (5 pg/ml) en tampón de ensayo que contiene BSA (PBS con Tween-20 al 0,05%) durante 1 hora a temperatura ambiente. Después de que se eliminó el exceso de gp120 y las placas se lavaron tres veces con tampón de ensayo, se añadieron sobrenadantes de cultivo de células B diluidos 5 veces para incubar durante 1 hora a temperatura ambiente. Después de tres lavados en el tampón de ensayo, se añadió Ig Fc de cabra anti-humano conjugado con HRP secundario en tampón de ensayo que contenía BSA y se incubó durante aproximadamente 1 hora a temperatura ambiente. Se usó sustrato de 3,3',5,5'-tetrametilbencidina (TMB) para desarrollar las lecturas colorimétricas después de lavar las placas ELISA 3 veces.
Para ELISA anti-gp41, la gp41 recombinante se inmovilizó directamente en placas ELISA de 384 pocillos añadiendo 1 pg/ml e incubando a 4°C durante la noche, seguido de bloqueo con tampón de ensayo que contiene BSA. El resto del protocolo de ensayo fue similar al del ELISA anti-gp120.
Los resultados del ensayo ELISA se identificaron en un cribado de singlete basada en valores de densidad óptica (OD) por encima de 3 veces el fondo del ensayo. Se incluyó una curva estándar de titulación en serie del anticuerpo de control en cada placa.
Ejemplo 4: Ensayo de neutralización para el cribado de anticuerpos contra virus del VIH pseudotipados
El enfoque del ensayo de neutralización se ha descrito previamente (Binley JM, et al., (2004). Comprehensive Cross-Clado Neutralization Analysis of a Panel of Anti-Human Immunodeficiency Virus Type 1 Monoclonal Antibodies. J. Virol. 78: 13232-13252) y fue modificado y estandarizado para su implementación en formato de 384 pocillos.
La neutralización por anticuerpos monoclonales y sueros de pacientes se realizó usando una sola ronda de ensayo de replicación de pseudovirus. (Richman, DD, et al. Proc Natl Acad Sci EE.UU. 100, 4144-4149 (2003)). Los ensayos de neutralización de pseudovirus se realizaron utilizando mutantes de alanina JR-CSF de VIH-1 como se describe en Pantophlet, R., et al. J Virol 77, 642-658 (2003). La actividad de neutralización se midió como una reducción en la infectividad viral en comparación con un control libre de anticuerpos usando un ensayo TZM-BL. (Li, M., et al. J Virol 79, 10108-10125 (2005)). Los ensayos de neutralización de anticuerpos monoclonales utilizando células mononucleares de sangre periférica activadas por fitohemglutinina (PBMC) aisladas de tres donantes humanos sanos como células diana se realizaron como se describe en Scarlatti, G. et al, (1993) J. Infect. Dis. 168: 207-210; Polonis, V. et al, (2001) AIDS Res. Tararear. Retrovirus 17: 69-79. Los sobrenadantes de células B de memoria se seleccionaron en un ensayo de micro-neutralización contra VIH-1 SF162, VIH-1 JR-CSF y SIV mac239 (control
negativo). Este ensayo se basó en el ensayo de neutralización del VIH-1 pseudotipado de 96 pocilios (Monogram Biosciences) y se modificó para seleccionar sobrenadantes de cultivo de células B de 15 j l en un formato de 384 pocillos.
Se generaron virus seudotipados de aislados de SF162 y JR-CSF de VIH-1 y SIV mac239 (virus de control) co-transfectando células 293 de riñón embrionario humano (células 293) con 2 plásmidos que codifican la secuencia de ADNc de envoltorio y el resto del genoma del VIH por separado. En el vector de codificación del genoma del VIH, el gen Env fue reemplazado por el gen luciferasa de luciérnaga. Los sobrenadantes transfectantes que contenían virus pseudotipados se incubaron conjuntamente durante la noche (18 horas) con sobrenadantes de células B derivados de la activación de células mononucleares de sangre periférica (PBMC) de un donante infectado. Las células U87 transfectadas de manera estable con y que expresan CD4 más los coreceptores CCR5 y CXCR4 se añadieron a la mezcla y se incubaron durante 3 días a 37°C. Las células infectadas se cuantificaron por luminometría. SIVmac239 se usó como el virus de control negativo.
El índice de neutralización se expresó como la proporción de unidades de luminiscencia relativa normalizadas (RLU) de la cepa viral de prueba con respecto al virus de control SIVmac239 derivado del mismo sobrenadante de cultivo de células B de prueba. Los valores de corte utilizados para distinguir los golpes neutralizantes se determinaron por el índice de neutralización de un gran número de "pocillos de control negativo" que contenían sobrenadantes de cultivo de células B derivados de donantes sanos. La tasa de falsos positivos usando el valor de corte de 1,5 fue muy baja (1-3%; Figura 5A), y se redujo a cero si se usó el valor de corte de 2,0 (Figura 5B).
La Figura 5 resume los resultados del cribado de los que se seleccionaron cultivos de células B para el rescate de anticuerpos y se obtuvieron los anticuerpos monoclonales 1496_C09 (PG9), 1443_C16 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14) y 1495_C14 (PGC14). Los resultados revelan que la mayoría de los sobrenadantes de cultivo de células B neutralizantes no tenían reactividad de unión a proteínas gp120 o gp41 recombinantes solubles.
La Tabla 15 muestra los resultados de detección de los anticuerpos monoclonales 1496_C09 (PG9), 1443_C16 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14) y 1495_C14 (PGC14) durante el curso de su identificación en el método descrito en este solicitud. Se ilustra la actividad de neutralización de cada anticuerpo y su reactividad de unión correspondiente a gp120 o gp41 recombinante soluble, en el contexto del sobrenadante de cultivo de células B y los sobrenadantes de transfectante recombinante.
Tabla 15


Los anticuerpos monoclonales purificados 1496_C09 (PG9), 1443_C16 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14) y 1495_C14 (PGC14) se analizaron para neutralizar 6 cepas de VIH adicionales de los ciados A (94UG103), B (92BR020, JR-CSF), C (93IN905, IAVI_C22) y CRF01_AE (92TH021) (Tabla 16). Los anticuerpos 1496_C09 (PG9), 1443_C16 (PG16) y 1495_C14 (PGC14) mostraron un perfil de neutralización similar al obtenido con el perfil de neutralización de sueros donantes. Los pseudovirus se preincubaron con cada anticuerpo monoclonal
durante 1 hora o 18 horas antes de la infección de las células diana. valores CI50 derivados de 1 o 18 horas de preincubación fueron similares. Por lo tanto, en otros ensayos de neutralización que probaron anticuerpos monoclonales purificados, se usó 1 hora de preincubación.
La Tabla 17A muestra los perfiles de neutralización para los 5 anticuerpos monoclonales 1496_C09 (PG9), 1443_C16 (PG16), 1456_P20 (PG20), 1460_G14 (PGG14) y 1495_C14 (PGC14) en valores de CI 50 en un panel extendido de 16 pseudovirus, junto con los conocidos anticuerpos neutralizantes de clado cruzado b12, 2G12, 2F5 y 4E10.
La Tabla 17B muestra la CI90 de dos anticuerpos monoclonales, 1443_C16 (PG16) y 1496_C09 (PG9) en el mismo panel diverso expandido de 16 pseudovirus VIH de diferentes clados, junto con conocidos anticuerpos neutralizantes de clado cruzado b12, 2G12, 2F5 y 4E10. La Figura 4 muestra la actividad de neutralización de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) a otros 3 pseudovirus no incluidos en la Tabla 16.
Tabla 16. Ensayo de anticuerpo neutralizante: Sumario CI50

Tabla 17. Perfil de neutralización en un panel diverso de virus: Valores CI50

NA - No aplicable
CI50: Concentración inhibitoria para inhibir 50% del virus
Tabla 17B. Perfil de neutralización en un panel diverso de virus: Valores CI90 para mAbs PG9 y PG16.

NA - No aplicable
CI90: Concentración inhibitoria para inhibir 90% del virus
***Efecto de meseta
Ejemplo 5: Especificidad de unión de anticuerpos monoclonales para VIH gp120 por ensayo ELISA
Los anticuerpos monoclonales anti-gp120 purificados, 1456_P20 (PG20), 1460_G14 (PGG14) y 1495_C14 (PGC14), se confirmaron por reactividad de unión a gp120 en ensayos ELISA. Cuando se titulan en diluciones en serie, los tres anticuerpos exhibieron perfiles de unión similares que sugieren una avidez relativa significativamente mayor que el control anti-gp120 (b12). MAb b12 se dirige contra un epítopo que se superpone al sitio de unión a CD4. (Burton DR et al. 1994. Efficient neutralization of primary isolates of HIV-1 by a recombinant human monoclonal antibody. Science 266: 1024-1027).
La Figura 5 muestra curvas de respuesta a la dosis de 1456_P20 (PG20), 1460_G14 (PGG14) y 1495_C14 (PGC14) que se unen a gp120 recombinante en ELISA en comparación con el control anti-gp120 (b12). Los datos mostrados representaron valores promedio de OD de pocillos ELISA triplicados obtenidos en la misma placa.
Los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) se analizaron para determinar la unión a proteínas de envoltura recombinantes solubles derivadas de varias cepas de VIH en el ensayo ELISA. Los ensayos ELISA se realizaron como se describe en Pantophlet, R., et al. J Virol 77, 642-658 (2003). Para los ELISA de unión a antígeno, se agregaron diluciones en serie de PG9 a los pocillos recubiertos con antígeno y se sondeó la unión con inmunoglobulina de cabra anti-humana conjugada con fosfatasa alcalina G (IgG) F(ab')2 Ab (Pierce). Para los ELISA de competición, se añadieron mAb de la competencia a los pocillos de ELISA y se incubaron durante 15 minutos antes de añadir 15 pg/ml de PG9 biotinilado a cada pocillo. El p G9 biotinilado se detectó usando estreptavidina conjugada con fosfatasa alcalina (Pierce) y se visualizó usando sustrato de fosfato de p-nitrofenol (Sigma). Se usó VIH-HXB2 gp120 para ensayos ELISA de competición.
La Figura 6 muestra resultados de ensayos de unión a ELISA de anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) contra VIH-1 YU2 gp140, JR-CSFgp120, péptido de regiones externas proximales a la membrana (MPER) del polipéptido gp41 y V3. Luego se confirmó la especificidad de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) para gp120, pero se observó que la unión a la glicoproteína de la envoltura soluble era débil.
Ejemplo 6: Reactividad de unión de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) a proteínas de envoltura expresadas en la superficie celular transfectada y la competencia por CD4 soluble (sCD4).
Los ensayos de unión a células MAb se realizaron como se describe en Pancera, M. y Wyatt, R. Virology 332, 145-156 (2005). Se agregaron cantidades titulantes de PG9 y PG16 a células 293T transfectadas con Env VIH-1, se incubaron durante 1 hora a 4°C, se lavaron con tampón FACS y se tiñeron con IgG anti-humano de cabra
F(ab')2Conjugado con ficoeritina. Para los ensayos de competición, se añadieron a las células anticuerpos competidores 15 minutos antes de añadir 0,1 pg/ml de PG9 o PG16 biotinilado. Para los ensayos de inhibición de sCD4, se añadieron 40 pg/ml de sCD4 a las células y se incubaron durante 1 h a 4°C antes de agregar cantidades titulantes de anticuerpos. La unión se analizó usando citometría de flujo, y las curvas de unión se generaron trazando la intensidad de fluorescencia media de la unión al antígeno en función de la concentración de anticuerpos.
Se recubrieron placas ELISA de noventa y seis pocillos durante la noche a 4°C con 50 pL PBS que contiene 100 ng de gp120 o gp140 por pocillo. Los pocillos se lavaron cuatro veces con PBS que contenía Tween 20 al 0,025% y se bloquearon con BSA al 3% a temperatura ambiente durante 1 h. Se añadieron diluciones en serie de PG9 a los pocillos recubiertos con antígeno, se incubaron durante 1 hora a temperatura ambiente y se lavaron 4 veces con PBS suplementado con Tween 20. al 0,025%. La unión se sondeó con inmunoglobulina G humana de cabra conjugada con fosfatasa alcalina (IgG) F(ab')2 Ab (Pierce) diluido 1:1000 en PBS que contiene 1% de BSA y 0,025% de Tween 20. La placa se incubó a temperatura ambiente durante 1 h, se lavó cuatro veces y la placa se desarrolló agregando 50 ml de L sustrato de fosfatasa alcalina (Sigma) a 5 ml de tampón de tinción de fosfatasa alcalina (pH 9,8), de acuerdo con las instrucciones del fabricante. La densidad óptica a 405 nm se leyó en un lector de microplacas (Molecular Devices). Para los ELISA de competencia, se agregaron mAb de la competencia a los pozos de ELISA recubiertos con gp120 HxB2 o gp140 YU2 y se incubaron durante 15 minutos antes de agregar 15 pg/ml de PG9 biotinilado a cada pocillo. La PG9 biotinilada se detectó usando estreptavidina conjugada con fosfatasa alcalina (Pierce) y se visualizó usando sustrato de fosfato de p-nitrofenol (Sigma). Para los ELISA de inhibición de sCD4, se añadieron 5 pg/ml de sCD4 a los pocillos recubiertos con antígeno y se incubaron durante 15 minutos a temperatura ambiente antes de agregar cantidades titulantes de PG9. Se usó un lector de placas FACSArray™ (BD Biosciences, San José, CA) para el análisis de citometría de flujo y el software FlowJo™ para la interpretación de datos.
El VIH gp160 derivado de YU2 se transfectó en 293 células. La unión de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) se detectó en células transfectadas (Figura 7). La preincubación de las células transfectadas con CD4 soluble (sCD4) inhibió parcialmente la unión del anticuerpo monoclonal para 1496_C09 (PG9) y para 1443_C16 (PG16), lo que sugiere que la unión del anticuerpo se ve afectada por la presencia de sCD4. La unión se inhibe en al menos 15%, al menos 20%, al menos 25% o al menos 30%. También se detectó la unión de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) a las células 293 transfectadas con gp160 derivadas de las cepas JR-CSF y ADA (Figura 8). La sCD4 bloqueó la unión de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) a las células transfectadas con j R-CSF. Los resultados confirman además que las actividades de unión de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) se ven afectadas por la presencia de sCD4.
Ejemplo 7: Reactividad de unión de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) a pseudovirus.
El ensayo de captura de virus in vitro se usó para evaluar si los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) se unen a pseudovirus competentes de entrada intacta. Los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) se revistieron en el fondo de la placa de 96 pocillos mediante Fc antihumano. El pseudovirus Jr -CSF fue agregado y capturado por el anticuerpo monoclonal 1443_C16 (PG16) o 1496_C09 (PG9) de una manera dependiente de la dosis. Se agregaron células diana para iniciar la infección. La infección medida en RLU representaba la actividad de unión y captura de los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9). La Figura 9 muestra la unión y captura del pseudovirus JR-CSF por los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) de una manera dependiente de la dosis, que es similar o mejor que otro anticuerpo neutralizador amplio y potente conocido 2G12.
Ejemplo 8: Los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) compiten entre sí y con sCD4 en la unión al pseudovirus JR-CSF.
En una versión de competencia del ensayo de captura de virus donde el pseudovirus JR-CSF fue capturado por los anticuerpos monoclonales 1443_C16 (PG16), se midió la competencia de la captura por los anticuerpos monoclonales 1443_C16 (PG16), 1496_C09 (PG9) y sCD4. La Figura 10B muestra que la unión del anticuerpo monoclonal 1443_C16 (PG16) al pseudovirus JR-CSf estaba bloqueada por sí misma, el anticuerpo monoclonal 1496_C09 (PG9) y sCD4 de una manera dependiente de la dosis. De manera correspondiente, la Figura 10B muestra que la unión del anticuerpo monoclonal 1496_C09 (PG9) al pseudovirus JR-CSF estaba bloqueada por sí misma, el anticuerpo monoclonal 1443_C16 (PG16) y sCD4 de una manera dependiente de la dosis. Los resultados indicaron que los anticuerpos monoclonales 1443_C16 (PG16) y 1496_C09 (PG9) se unen a epítopos estrechamente relacionados en gp120 y su unión se ve afectada por la presencia de sCD4 presumiblemente debido a cambios conformacionales inducidos en la envoltura del VIH-1 por sCD4.
Ejemplo 9: Propiedades de unión a antígeno de PG9 y PG16.
Las propiedades de unión al antígeno de PG9 y PG16 se determinaron mediante ensayos ELISA como se muestra en la Figura 11A-B. Se determinó la unión de pG9 y PG16 a gp120 monomérico y construcciones de gp140 trimerizadas artificialmente (Fig. 11A). La unión de PG9 y pG16 a Env se expresa en la superficie de las células 293T
según lo determinado por citometría de flujo. (Fig. 11B). Se usó b12 como control para ensayos ELISA. El bNAb b12 y el anticuerpo no neutralizante b6 se incluyeron en los ensayos de unión a la superficie celular para mostrar los porcentajes esperados de Env escindido y no escindido expresado en la célula superficie.
Ejemplo 10: Unión de PG9 y PG16 a trímeros de VIH-1 YU2 defectuosos en la escisión.
La unión de PG9 y PG16 a trímeros de VIH-1 YU2 defectuosos en la escisión se determinó por citometría de flujo. PG9 y PG16 se unen con alta afinidad a los trímeros de VIH-1 YU2 defectuosos de escisión como se muestra en la Figura 12. Las curvas de unión se generaron trazando la intensidad de fluorescencia media (MFI) de la unión al antígeno en función de la concentración de anticuerpos.
Ejemplo 11: Mapeo de los epítopos PG9 y PG16.
El mapeo de los epítopos de los epítopos PG9 y PG16 se realizó mediante un ensayo de unión competitivo como se muestra en la Figura 13. PG9 y PG16 compitieron entre sí por la unión de Env a la superficie celular y ninguno de los anticuerpos compitió con el anticuerpo b12 CD4bs por la unión a Env. El anticuerpo de la competencia se indica en la parte superior de cada gráfico. (Fig. 13A). La ligadura de la superficie celular Env con sCD4 disminuyó la unión de p G9 y PG16. Se incluyó 2G12 para controlar la eliminación inducida por CD4 de gp120. (Fig. 13B). sCD4 inhibió la unión de PG9 a gp140 JR-CSF trimerizado artificialmente según lo determinado por ELISA. (Fig. 13C). PG9 compitió con 10/76b (anti-V2), F425/b4e8 (anti-V3) y X5 (CD4i) por la unión de gp120 en ensayos ELiSa de competición. (Fig. 13D). PG9 y PG16 no lograron unirse a las variantes de VIH-1 JR-CSF eliminadas en bucle variable expresadas en la superficie de las células 293T. Se incluyó 2G12 para controlar la expresión de Env en la superficie celular. (Fig. 13E).
Ejemplo 12: Ensayos ELISA de competición usando PG9.
Cuando se realizaron ensayos ELISA de competición usando PG9, PG9 compitió con c108g (anti-V2) y compitió parcialmente con 17b (CD4i). No se observó competencia con A32 (anti-C1/C2/C4/CD4i), C11 (C1), 2G12 (escudo de glucano), b6 (CD4bs), b3 (CD4bs) o 23b (C1/C5) para la unión de gp120 HxB2 como se muestra en la Figura 14.
Ejemplo 13: Unión de PG9 y PG16 a VIH-1 JR-FL E168K.
En la Figura 15 se muestra la unión del anticuerpo al VIH-1JR-FLACT E168K Env expresado en la superficie de las células 293T según lo determinado por citometría de flujo. Se usó un constructo citoplasmático con cola eliminada para aumentar la expresión de la superficie celular. El bNAb b12 y el anticuerpo no neutralizante b6 se incluyeron en los ensayos de unión a la superficie celular para mostrar los porcentajes esperados de Env escindido y no escindido expresados en la superficie celular. (Pancera M., et al. Virology 332: 145 (2005). El VIH-1JR-FL E168K se generó por mutagénesis dirigida al sitio. Las curvas de unión se generaron trazando el MFI de la unión al antígeno en función de la concentración de anticuerpos.
Ejemplo 14: Unión de PG9 a gp120 desglicosilada.
gp120DU422 se trató con 40 mU/pg de endoglicosidasa H (Endo H, New England Biolabs) en tampón de acetato de sodio durante 24 horas a 37°C. La gp120 tratada de forma simulada se trató en las mismas condiciones, pero la enzima se omitió de la reacción. La unión de PG9 y b6 a gp120 tratado con EndoH y simulado se determinó mediante ELISA como se muestra en la Figura 16.
Ejemplo 15: Actividad de neutralización contra VIH-1
sf162
K160N
Actividad de neutralización de PG9 y PG16 contra VIH-1 SF162 y VIH-1 SF162 K160N se determinó usando un ensayo indicador de replicación de luciferasa de una sola ronda del virus pseudotipado. El VIH-1 SF162 K160N se generó por mutagénesis dirigida al sitio como se muestra en la Figura 17.
Ejemplo 16: Unión de PG9 y PG16 a trituradores mixtos
Las sustituciones de alanina en las posiciones 160 y 299 se introdujeron en el VIH-1 YU2 Env para abolir la unión de PG9 y PG16. También se introdujo una sustitución de alanina en la posición 295 en la misma construcción para anular la unión de 2G12. La cotransfección de células 293T con WT y plásmidos mutantes en una proporción 1:2 dio como resultado la expresión de 29% de homotrímeros mutantes, 44% de heterotrímeros con dos subunidades mutantes, 23% de heterotrímeros con una subunidad mutante y 4% de homotrímeros de tipo silvestre. Estas proporciones se calcularon utilizando la fórmula descrita en Yang, X., Kurteva, S., Lee, S. y J. Sodroski, J Virol 79 (6): 3500-3508 (marzo de 2005), y se supone que es mutante y silvestre de tipo gp120 se mezclan aleatoriamente para formar recortadores. La unión de mAbs a los trímeros Env se determinó por citometría de flujo como se muestra en la Figura 18. Se incluyó b12 como control para la expresión de la superficie celular Env.
Ejemplo 17: Actividad de neutralización de PG9 o PG16 en VIH con mutaciones de alanina dentro de gp120.
Las mutaciones de alanina dentro de la gp120 del VIH disminuyen la actividad de neutralización de PG9 o PG16 como se muestra en la Tabla 21. En la tabla, la numeración de aminoácidos se basa en la secuencia de VIH-1 HxB2. Los cuadros están codificados por colores de la siguiente manera: blanco, el aminoácido es idéntico entre 0 y 49% de todos los aislados de VIH-1; gris claro, el aminoácido es idéntico entre el 50 y el 90% de los aislados; gris oscuro, el aminoácido es idéntico entre el 90 y el 100% de los aislamientos. La identidad de aminoácidos se determinó en base a una alineación de secuencia de los aislados de VIH-1 enumerados en la base de datos de secuencia de VIH en VIH-web.lanl.gov/content/VIH-db/mainpage.html. C se refiere a dominios constantes y V se refiere a bucles variables. La actividad de neutralización se informa como un aumento de veces en el valor de CI50 en relación con WT JR-CSF y se calculó usando la ecuación (CI50 mutante/CI50 WT). Las cajas están codificadas por colores de la siguiente manera: blanco, sustituciones que tuvieron un efecto negativo en la actividad de neutralización; gris claro, aumento de CI50 de 4-9 veces; gris medio, 10 - 100 veces aumento de CI50; gris oscuro, >100 veces aumento de CI50. Los experimentos se realizaron por triplicado y los valores representan un promedio de al menos tres experimentos independientes.
Tabla 18A

Tabla 18B

Tabla 18C

Tabla 18D

Tabla 18E

Tabla 18F

a Cuadros blancos indican un CI50 de >50 pg/mL, cuadros blancos indican 50 pg/mL > CI50 > 10 pg/mL, cuadros de color gris más ligero indican 10 pg/mL > CI50 > 1 pg/mL, cuandros grises medios indican 1 pg/mL > CI50 > 0,1 pg/mL, cuadros grises más oscuros indican CI50 < 0,01 pg/mL. N.D., no realizado.
b Cuandros blancos indican un CI50 de < 1:100 dilución, cuadros grises oscuros indican 1:50 > CI50 > 1:150, cuadros grises más ligeros indican 1:150 > CI50 > 1:500, cuadros grises medios indican 1:500 > CI50 > 1:1000, cuadros grises
más oscuros indican CI50 > 1:1000 dilución.
Tabla 19A. Potencia de neutralización.

Cuadros blancos indican una potencia media de >50 pg/mL, cuandros grises entre 20 y 50 pg/mL, gris más ligero entre 2 y 20 pg/mL, gris medio entre 0,2 y 2 pg/mL, y gris más oscuro < 0,2 pg/mL.
* Virus CRF_07BC y CRF_08BC no incluidos en el análisis de ciado porque solo existía un virus probado de cada uno de estos clados.
Tabla 19B. Anchura de neutralización.

Los cuadros blancos indican que ningún virus estaba neutralizado, gris más oscuro indica 1 a 30% de virus estaban neutralizados, gris más ligero indica 30 a 60% de virus estaban neutralizados, gris medio indica 60 a 90% de virus estaban neutralizado, y gris más oscuro indican 90 a 100% de virus estaban neutralizados.
* Virus CRF_07BC y CRF_08BC no incluidos en el análisis de clado porque solo existía un virus probado de cada uno de estos clados.
Tabla 20. La actividad de neutralización de PG9 y PG16 contra pseudovirus JR-CSF que contiene mutaciones de punto de alanina.

a Número de aminoácido se basa en la secuencia de VIH-1hxB2
b Cuadros blancos indican que el aminoácido es idéntico entre 0 a 49% de todos los aislados de VIH, cuadros de color gris ligero indican que el aminoácido es idéntico entre 50-90% de todos los aislados de VIH, y cuadros de color gris oscuro indican que el aminoácido es idéntico entre 90-100% de todos los aislados de VIH. La identidad de aminoácido fue determinada en base a la alineación de secuencia de aislados de VIH-1 enumerados en la base de datos de secuencia VIH en http://hiv-gov/content/hiv-db/mainpage.html.
c C se refiere a dominios constantes y V se refiere a bucles variables.
d La actividad de neutralización se informa como aumento de fold en valor CI50 relativo a WT JR-CSF y fue calculada utilizando la ecuación (mutante CI50 / CI50 WT). Blanco: Sustitutos que tuvieron un efecto depreciable en la actividad de neutralización, gris más ligero: aumento de 4-9 fold CI50, gris oscuro: aumento de 10-100 fold CI50, gris más oscuro: aumento >100 fold CI50. Los experimentos fueron realizados en triplicado y los valores representan un promedio de al menos tres experimentos independientes.
Tabla 21. Mutaciones de alanina que disminuyen la actividad de neutralización PG9 y PG16.
M utacióna,b Dominio g p l20 c Incremento fold CUo relativo al tipo silvestred
PG9 PG16

a La numeración de aminoácidos se basa en la secuencia de VIH-1hxB2.
b Las casillas están clasificadas por color de la siguiente manera: blanco, el aminoácido es idéntico entre 0 y 49% de todas las cepas de VIH-1; gris claro, el aminoácido es idéntico entre 50 y 90% de las cepas; gris oscuro, el aminoácido es idéntico entre 90 y 100% de las cepas. La identidad de aminoácidos se determinó en base a la alineación de secuencia de las cepas de VIH-1 enumeradas en la base de datos de la secuencia de VIH en http://hivweb.lanl.gov/content/hiv-db/mainpage.html.
c C se refiere a dominos constantes y V se refiere a bucles variables.
d La actividad de neutralización se informa como un incremento de fold en el valor CI50 relativo a WT JR-CSF y fue calculada utilizando la ecuación (CI50 mutante / CI50 WT). Las casillas están clasificadas por color de la siguiente manera: blanco, sustitutos que produjeron un efecto negativo en la actividad de neutralización; gris ligero, incremento en CI50 de 4 - 9 fold; gris medio, incremento en CI50 de 10 -100 fold, gris oscuro, incremnto de CI50 de >100 fold. Los experimentos fueron realizados en triplicado y los valores representan un promedio de al menos tres experimentos independientes.
Ejemplo 18: Identificación de 14443 clones hermanos C16 (PG16)
Se identificaron 1443 clones hermanos C16 mediante cribado de la transfección clonal de genes de la región variable rescatados para la neutralización de JR-CSR. Por lo tanto, los anticuerpos que se identificaron como 1443 clones hermanos C16 (PG16) tienen los mismos perfiles de neutralización del VIH que el 1443 C16 (PG16) monoclonal humano. Además, las secuencias de ácido nucleico o de aminoácidos de los anticuerpos de clones hermanos son al menos 50%, 55%, 60%, 70%, 75%, 80%, 85%, 90%, 95%, 99%, 100% o cualquier punto porcentual intermedio, idéntico a los de 1443 C16 (PG16).
Tabla 22

Nota que la región constante de los clones de cadena pesada 1456_A12 utilizados en transfección contiene un error generado durante el proceso de clonación que llevan a una falta de producción de IgG de longitud completa.
Ejemplo 19: 1443 C16 (PG16) Clones Hermanos de Anticuerpo y el Anticuerpo 1443 C16 (PG16) Muestran una Especificidad de Neutralización similar
Anticuerpos 1456 A12, 1503 H05, 1489 I13 y 1469 M23 se analizaron para determinar la actividad de neutralización contra varios pseudovirus que contienen mutaciones distintas que mapean el epítopo de reactividad de 1443 C16 (PG16) en gp120 en un ensayo estándar TZM-bl (Tabla 23). Al igual que 1443 C16 (p G16), que no se une o neutraliza JR-FL de tipo silvestre, sino que neutraliza JR-FL con la mutación E168K, todos los clones hermanos 1443 C16 (PG16) neutralizan JR-FL (E168K) con valores bajos de CI50. De manera similar, todos los clones hermanos 1443 C16 (PG16) no neutralizan los mutantes Y318A y los mutantes I309A de JR-CSF, donde la parte del epítopo de unión putativo se mapea en la punta V3.
Tabla 23. Especificidad de neutralización de 1443 clones hermanos C16 (PG16) como se muestra con mutaciones es ecíficas en 120.

Ejemplo 20: 1443 clones hermanos C16 (PG16) exhiben una amplitud y potencia de neutralización similares a 1443 C16 (PG16) para los virus Clado B y Clado C
Los anticuerpos 1456 A12, 1503 H05, 1489 I13 y 1469 M23 exhiben actividad de neutralización contra un panel de pseudovirus clado B y clado C con una amplitud similar a la de 1443 C16 (PG16) en un ensayo estándar TZM-bl (Tabla 24). La potencia de neutralización de cada clon hermano para cada pseudovirus es comparable a la de 1443 C16 (PG16). Cuando se determina el valor de CI50, el valor para el clon hermano está dentro de un rango de registro de 0,5 de 1443 C16 (PG16).
Tabla 24. Amplitud y potencia de neutralización de 1443 clones hermanos C16 (PG16).

Ejemplo 21: Resultados de detección primaria y confirmatoria para anticuerpos seleccionados aislados de cultivos de células B establecidos de donantes humanos.
La estrategia de detección utilizada en el aislamiento de los anticuerpos monoclonales PGT-121 (correspondiente a los clones 4838_L06 y 4873_E03), PGT-122 (correspondiente al clon 4877_D15), PGT-123 (correspondiente al clon 4858_P08), PGT-125 (correspondiente al clon 5123_A06), PGT-126 (correspondiente al clon 5141_B17), PGT-130 (correspondiente al clon 5147_N06), PGT-135 (correspondiente a los clones 5343_B08 y 5344_E16) y PGT-136 (correspondiente a los clones 5329_C19 y 5366_P21) es lo mismo que los mAbs PG9 y PG16, excepto que la neutralización funcional fue el único ensayo de detección primario utilizado (es decir, no se usó ELISA para detectar estos anticuerpos).
Además, la estrategia utilizada para identificar estos mAbs después del rescate de la reacción en cadena de la polimerasa de transcripción inversa (RT-PCR) difiere de los protocolos anteriores. Específicamente, además de realizar un paso de detección de neutralización primaria, se realizó un paso de detección confirmatoria para algunos de los resultados positivos identificados en el paso de detección primaria (Tablas 25-27). El paso de cribado confirmatorio se realizó utilizando el mismo ensayo que el paso de cribado primario. Después de la detección funcional, los lisados de cultivo de células B se sometieron a RT-PCR específica de la familia de genes variables, como se realizó previamente para identificar los mAb PG9 y PG16. Sin embargo, en lugar de clonar directamente en el vector de expresión de IgG1, los productos de PCR que representan las cadenas pesadas y ligeras rescatadas se sometieron a una secuenciación profunda, que también se conoce como "secuenciación de próxima generación", "secuenciación
454" o "secuenciación de pirosecuencia".
En el proceso de secuenciación profunda, se construyó una etiqueta de secuencia específica de la ubicación del pozo de células B en la segunda ronda de PCR para permitir la identificación del origen del pozo de células B de cada secuencia determinada en la posterior reacción de secuenciación agrupada. Se generó una o más secuencias de genes variables de consenso de cada pocillo de cultivo de células B mediante un algoritmo informático. Las secuencias consenso de un pozo de células B individuales se compararon luego entre todas las secuencias consenso generadas a partir de otros pozos de cultivo de células B. Se "agruparon" cadenas pesadas o secuencias de cadena ligera similares porque pueden derivarse mAb similares de la misma célula B precursora. Los genes variables seleccionados se clonaron luego en un vector de expresión de IgG1 para producir y purificar anticuerpos monoclonales. A diferencia de la estrategia de rescate anterior, la transfección policlonal no se realizó para detectar la actividad de neutralización para identificar genes variables potenciales del conjunto de productos de PCR antes de proceder a la transfección monoclonal.
La similitud entre los genes variables que estaban "agrupados" es evidente en la alineación de las alineaciones de secuencias de nucleótidos y aminoácidos (Tablas 28-31). Por ejemplo, los tres mAbs del donante 517, es decir, PGT-121, PGT-122 y PGT-123 están en el mismo grupo. El donante 196 proporcionó dos grupos de mAbs distantemente relacionados, con un grupo que incluye PGT-125 y PGT-126, y otro que incluye PGT-130. El donante 039 proporcionó dos grupos de mAbs distantemente relacionados, cada uno incluyendo PGT-135 o PGT-136.
Tabla 25.

Tabla 26.

Tabla 27.






Ejemplo 22: Los valores de neutralización (CI50, Cho, CI90, y CI95) contra 23 virus VIH para anticuerpos seleccionados aislados de cultivos de células B establecidos a partir de donantes humanos.
La Tabla 32 muestra los perfiles de neutralización (valores CI50) de los anticuerpos monoclonales PGT 121, PGT 122, PGT 123, PGT 125, PGT 126, PGT 130, PGT 135, PGT 136 y PG9 en un panel diverso de 23 virus VIH de diferentes clados (A, B, C, D, AE y AG). PGT 121, PGT 122, PGT 123, PGT 125, PGT 126, PGT 130, PGT 135 y PGT 136, todos neutralizan el virus en los clados A, B, C y D. Además, PGT 121, PGT 122 y PGT 123 también neutralizan virus en clado AG. PGT 125 neutraliza los clados A, B, C, D, AE, mientras que PGT 126 y PGT 130 neutralizan todos los clados, es decir, A, B, C, D, AE y AG.
La Tabla 33 muestra los valores CI50, CI80, CI90 e CI95 del anticuerpo monoclonal PGT 121 en el mismo panel de virus que se muestra en la Tabla 32. Los resultados que se muestran en esta tabla recapitulan los que se muestran en la Tabla 32 para el anticuerpo monoclonal PGT 121. Esta tabla demuestra además que el anticuerpo monoclonal PGT 121 neutraliza el virus VIH de los clados A, B, C y D fuertemente, como lo demuestran los bajos valores de CI95 mostrados para estos clados.
La Tabla 34 muestra los valores CI50, CI80, CI90 e CI95 del anticuerpo monoclonal PGT 122 en el mismo panel de virus que se muestra en la Tabla 32. Los resultados que se muestran en esta tabla recapitulan los que se muestran en la Tabla 32 para el PGT 122 anticuerpo monoclonal. Esta tabla demuestra además que el anticuerpo monoclonal PGT 122 neutraliza el virus del VIH de los clados A, B, C y D fuertemente, como lo demuestran los bajos valores de CI 95 mostrados para estos clados.
La Tabla 35 muestra los valores CI50, CI80, CI90 e CI95 del anticuerpo monoclonal PGT 123 en el mismo panel de virus que se muestra en la Tabla 32. Los resultados que se muestran en esta tabla recapitulan los que se muestran en la Tabla 32 para el PGT 123 anticuerpo monoclonal. Esta tabla demuestra además que el anticuerpo monoclonal PGT 123 neutraliza el virus del VIH de los clados A, B, C y D fuertemente, como lo demuestran los bajos valores de CI 95 mostrados para estos clados.
La Tabla 36 muestra los valores de CI50, CI80, CI90 e CI95 del anticuerpo monoclonal PGT 125 en el mismo panel de virus que se muestra en la Tabla 32. Los resultados que se muestran en esta tabla recapitulan los que se muestran en la Tabla 32 para el PGT 125 anticuerpo monoclonal. Esta tabla demuestra además que el anticuerpo monoclonal PGT 125 neutraliza el virus del VIH de los clados A, B, C, D y AE, como lo demuestran los bajos valores de CI 95 mostrados para estos clados.
La Tabla 37 muestra los valores CI50, CI80, CI90 e CI95 del anticuerpo monoclonal PGT 126 en el mismo panel de virus que se muestra en la Tabla 32. Los resultados que se muestran en esta tabla recapitulan los que se muestran en la Tabla 32 para el PGT 126 anticuerpo monoclonal. Esta tabla demuestra además que el anticuerpo monoclonal PGT 126 neutraliza el virus del VIH de los clados A, B, C y D fuertemente, como lo demuestran los bajos valores de CI 95 mostrados para estos clados.
La Tabla 38 muestra los valores CI50, CI80, CI90 e CI95 del anticuerpo monoclonal PGT 130 en el mismo panel de virus que se muestra en la Tabla 32. Los resultados que se muestran en esta tabla recapitulan los que se muestran en la Tabla 32 para el PGT 130 anticuerpo monoclonal. Esta tabla demuestra además que el anticuerpo monoclonal PGT 130 neutraliza el virus del VIH de los clados A, B, C y AE fuertemente, como lo demuestran los bajos valores de CI 95 mostrados para estos clados.
La Tabla 39 muestra los valores CI50, CI80, CI90 e CI95 del anticuerpo monoclonal PGT 135 en el mismo panel de virus que se muestra en la Tabla 32. Los resultados que se muestran en esta tabla recapitulan los que se muestran en la Tabla 32 para el PGT 135 anticuerpo monoclonal. Esta tabla demuestra además que el anticuerpo monoclonal PGT 135 neutraliza el virus del VIH de los clados B, C y D fuertemente, como lo demuestran los bajos valores de CI95 mostrados para estos clados.
La Tabla 40 muestra los valores CI50, CI80, CI90 e CI95 del anticuerpo monoclonal PGT 136 en el mismo panel de virus que se muestra en la Tabla 32. Los resultados que se muestran en esta tabla recapitulan los que se muestran en la Tabla 32 para el PGT 136 anticuerpo monoclonal. Esta tabla demuestra además que el anticuerpo monoclonal PGT 136 neutraliza el virus del VIH de los clados C y D fuertemente, como lo demuestran los bajos valores de CI95 mostrados para estos clados.
La Tabla 41 muestra los valores CI50, CI80, CI90 e CI95 del anticuerpo monoclonal PG9 en el mismo panel de virus que se muestra en la Tabla 32. Los resultados que se muestran en esta tabla recapitulan los que se muestran en la Tabla 32 para el PG9 anticuerpo monoclonal Esta tabla demuestra además que el anticuerpo monoclonal PG9 neutraliza el virus del VIH de los clados A, B, C, D y AE, como lo demuestran los bajos valores de CI95 mostrados para estos clados.
Para las Tablas 32-41, se aplica el siguiente esquema de codificación de color con respecto a la concentración
del anticuerpo apropiado:

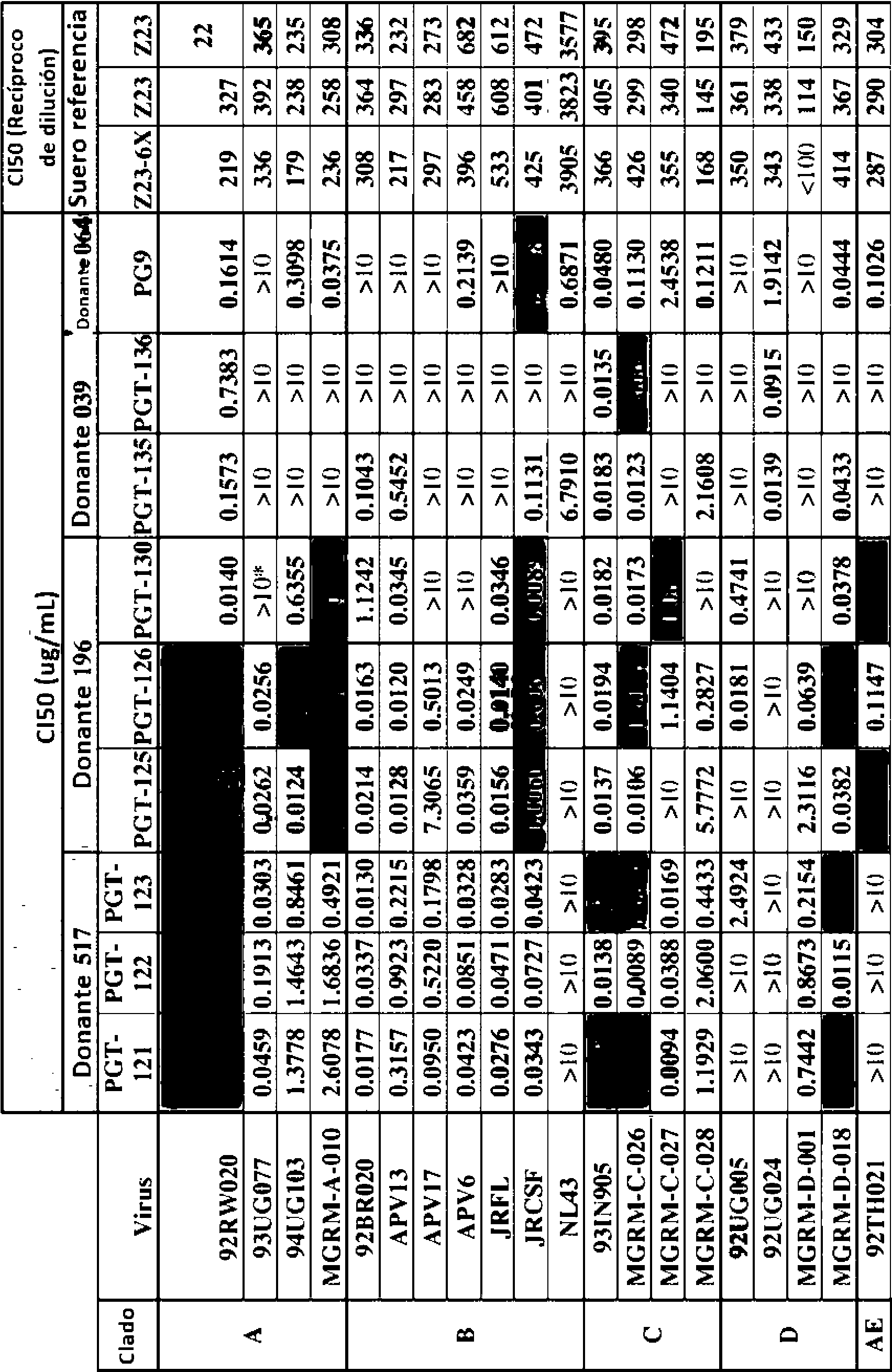

Tabla 33. Valores de neutralización para PGT-121 Neutralización or PGT-121 u /ml
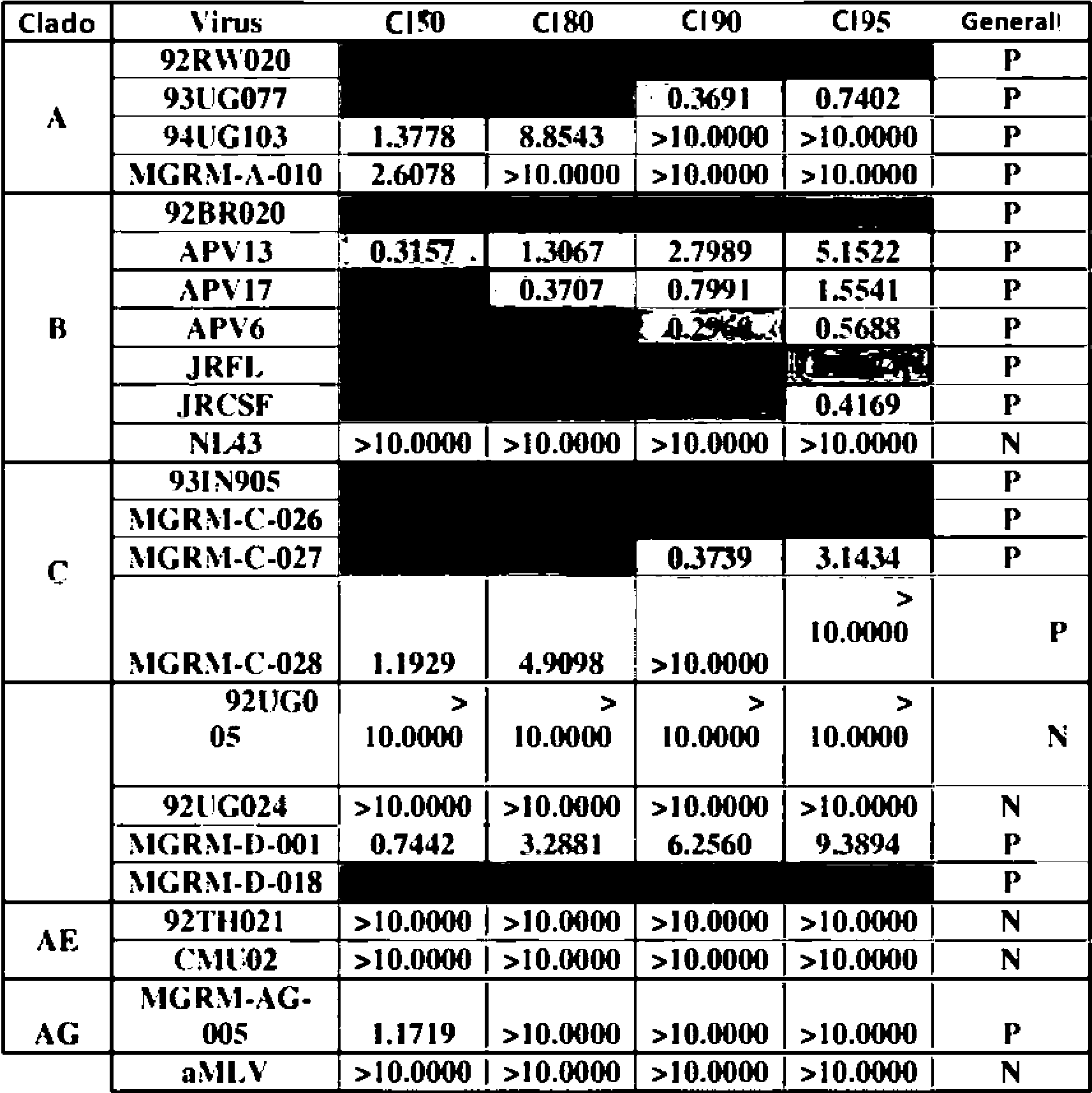
Tabla 34. Valores de neutralización para PGT-122
Neutralización por PGT-122 (ug/ml)


Tabla 35. Valores de neutralización para PGT-123
Neutralización por PGT-123 (ug/ml)

Tabla 36. Valores de neutralización para PGT-125.
Neutralización por PGT-125 (ug/m l)

Tabla 37. Valores de neutralización para PGT-126,
Neutralización or PGT-126 u /ml


Tabla 38. Valores de neutralización para PGT-130.
Neutralización or PGT-130 u /ml

Tabla 39. Valores de neutralización para PGT-135
Neutralización por PGT-135 (ug/ml)
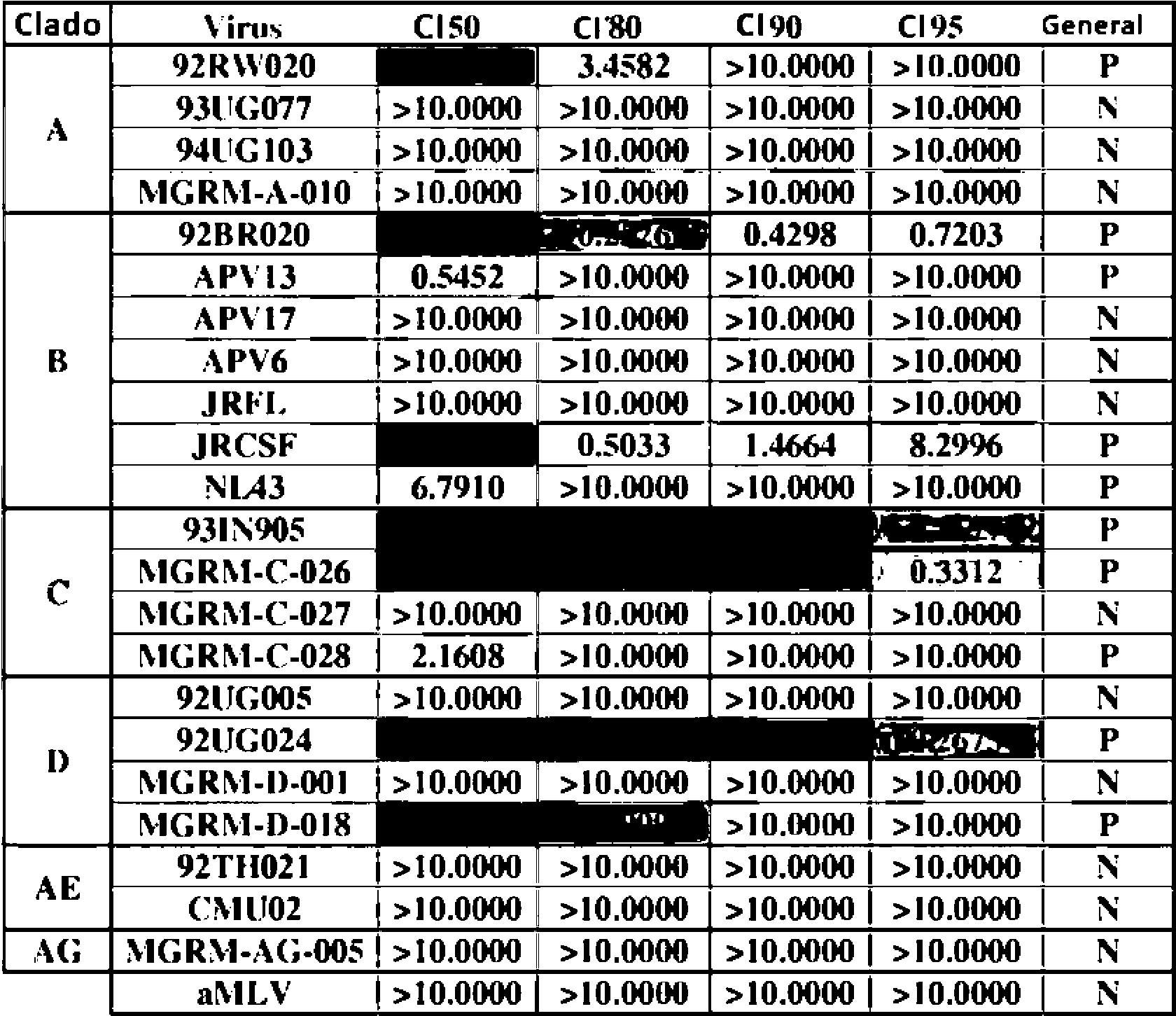
Tabla 40. Valores de neutralización para PGT-136
Neutralización por PGT-136 (ug/ml)


Tabla 41. Valores de neutralización para PG9
Neutralización or PG9 u /ml

Ejemplo 23: Uso de cadenas pesadas y ligeras para anticuerpos seleccionados aislados de cultivos de células B establecidos a partir de donantes humanos.
Anticuerpos monoclonales PGT-121 (correspondientes a los clones 4838_L06 y 4873_E03), PGT-122 (correspondientes al clon 4877_D15), PGT-123 (correspondientes al clon 4858_P08), PGT-125 (correspondientes al clon 5123_A06), PG T-126 (correspondientes al clon 5l4l_B17), PGT-130 (correspondientes al clon 5147_N06), PGT-135 (correspondientes a los clones 5343_B08 y 5344_E16) y PGT-136 (correspondientes a los clones 5329_C19 y 5366_P21) se derivan de genes de la línea germinal relacionados.
La similitud de los genes variables es evidente en función del uso de genes (tablas 42 y 43). Aunque los alelos exactos del gen utilizados pueden no ser definitivos, los alelos que probablemente se utilizan tienen el porcentaje de identidad con el gen de la línea germinal anotado.
Tabla 42. Uso de genes de cadena germinal de cadena pesada para PGT-121, PGT-122, PGT-123, PGT-125,
PGT-126, PGT-130, PGT-135 y PGT-136.

Tabla 43. Uso del gen de la línea germinal de la cadena ligera para PGT-121, PGT-122, PGT-123, PGT-125,
PGT-126, PGT-130, PGT-135 y PGT-136.

Ejemplo 24: Uso de cadenas pesadas y ligeras para anticuerpos seleccionados aislados de cultivos de células B establecidos a partir de donantes humanos.
Los anticuerpos monoclonales PGT-141 (correspondientes a los clones 4964_G22 y 4993_K13), PGT-142 (correspondientes al clon 4995_E20), PGT-143 (correspondientes al clon 4980_N08) y PGT-144 (correspondientes al clon 4970_K22) se derivan de genes de línea germinal relacionados.
La similitud de los genes variables es evidente en función del uso de genes (tablas 44 y 45). Aunque los alelos genéticos exactos utilizados pueden no ser definitivos, los alelos que probablemente se utilizan tienen el porcentaje de identidad con el gen de la línea germinal anotado.

Tabla 45. Uso del gen de la línea germinal de la cadena ligera para PGT-141, PGT-142, PGT-143 y PGT-144.

Ejemplo 25: Alineaciones de cadena pesada y ligera para anticuerpos seleccionados (PGT-141, PGT-142, PGT-143 y PGT-144).
Se proporcionan alineaciones de los genes (secuencias de ácido nucleico) y proteínas (secuencia de aminoácidos) para regiones variables de las cadenas pesadas y ligeras de los anticuerpos PGT-141, PGT-142, PGT-143 y PGT-144 en los cuadros 46-49.
Además, los árboles de relación de genes que representan la relación entre las cadenas pesadas o ligeras de estos anticuerpos entre sí se proporcionan en las Figuras 25 y 26, respectivamente.



Ejemplo 26: El cribado funcional de alto rendimiento de las células B activadas de 4 neutralizadores de élite africana produce un panel de nuevos anticuerpos ampliamente neutralizantes
Los anticuerpos PGT-121, PGT-122, PGT-123, PGT-125, PGT-126, PGT-130, PGT-135, PGT-136, PGT-141,
PG T-142, PGT-143 y PGT-144 se generaron según el I-STAR™ Human bNAb (Anticuerpo ampliamente neutralizante) Plataforma de descubrimiento representada en la Figura 28. El proceso de aislamiento implica la identificación de múltiples impactos neutralizantes de las células IgG+ Memoria B (como se muestra en la Figura 29). Una vez que se genera el anticuerpo monoclonal recombinante, se confirma la capacidad neutralizante del anticuerpo monoclonal. Como consecuencia de estos métodos, los anticuerpos recombinantes de la aplicación están altamente relacionados (como se muestra en los Ejemplos 21-24). Además, estos métodos identifican grupos de secuencias relacionadas con una mayor actividad de neutralización. Además, los anticuerpos de la aplicación se unen a regiones altamente conservadas del pico viral del VIH (Figuras 30 y 31).
Trece nuevos anticuerpos monoclonales se aislaron de 4 neutralizadores de élite del Protocolo G. La Tabla 50 proporciona información sobre las características de cada anticuerpo.
El mapeo preliminar indica que los anticuerpos de los donantes 17, 36 y 39 proporcionados en la Tabla 50 definen una colección de epítopos superpuestos y altamente conservados en la espiga viral. La evidencia de la naturaleza superpuesta de estos epítopos es proporcionada, por ejemplo, por los resultados de los estudios de competencia (Tabla 54). Como ejemplo, PGT-121 y P G T-125 demuestran una fuerte competencia para unirse a los epítopos que se superponen espacialmente.
Tabla 50
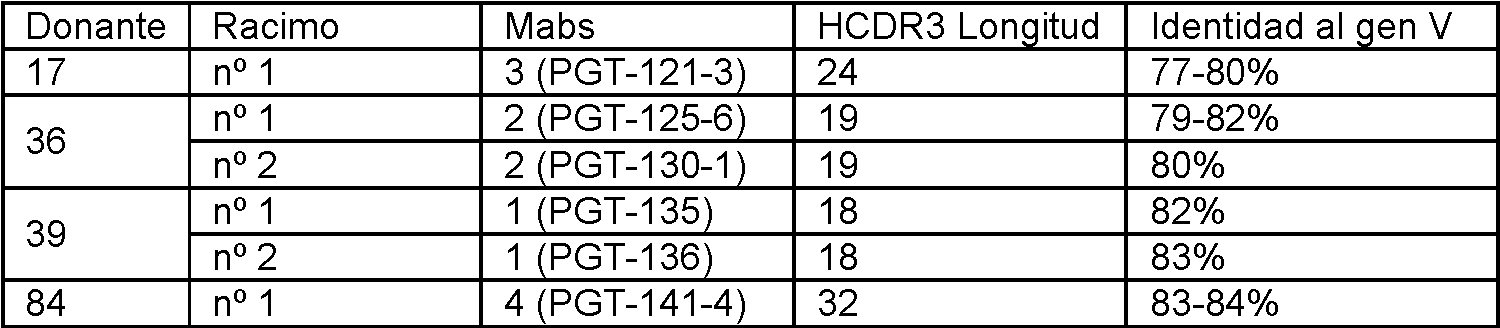
Tabla 51: Protocolo IAVI G: Puntuación de neutralizantes de élite >2,5

La Tabla 52 proporciona valores cuantitativos para la actividad neutralizante de cada anticuerpo monoclonal aislado de los 4 neutralizadores de élite de protocolo G.







IJ63
Tabla 53: Mapeo prelim inar de Mabs aislado de donantes 17, 36 y 39:
Competición cruzada (1)

+++ Competición fuerte; + Competición moderada, Competición débil; -ninguno
Tabla 54:

Ejemplo 26: Potencia de anticuerpo monoclonal anti-VIH de PGT
La potencia de anticuerpos monoclonales anti-VIH PGT-121, PGT-122, PGT-123, PGT-125, PGT-126, PGT-127, PGT-128, PGT-130, PGT-131, PGT-135, PGT-136, PGT -137, PGT-141, PGT-142, PGT-143, PGT-144, PGT-145 y PG9 se determinaron frente a un panel de virus 162. La Figura 32 muestra que la concentración mediana requerida para inhibir la actividad, o neutralizar, la mitad del virus en cada panel (p. ej, la mitad de la máxima concentración inhibitoria (CI50), expresada en |jg/ml, la media se representa por la barra negra en cada columna) para cada anticuerpo del grupo PGT es comparable o superior al control PG9.
Ejemplo 27: Aislamiento de anticuerpos anti-VIH PGT-127, PGT-128, PGT-131, PGT-137 y PGT-145
Los anticuerpos de la aplicación pueden aislarse de las células B de memoria en circulación como se describe en Walker LM et al, 2009, Science 326: 285-9. Específicamente, las células B IgG+ superficiales sembradas a una densidad casi clonal en microplacas de 384 pocillos se activaron en cultivo a corto plazo. Los sobrenadantes se seleccionaron para determinar la actividad de neutralización contra 2-4 virus seudotipados para los cuales se detectó actividad de neutralización a títulos más altos en el suero del donante. Las regiones variables de la cadena pesada y ligera se aislaron de los lisados de células B de éxitos neutralizantes seleccionados mediante transcripción inversa a partir de ARN seguido de amplificación por PCR multiplex usando conjuntos de cebadores de genes V específicos de familia. Los amplicones de cada lisado se marcaron de forma única con secuencias de identificador multiplex (MID) y 454 regiones de secuenciación (Roche). Se realizó una agrupación normalizada de gamma, cadenas kappa y lambda en base a la cuantificación de imágenes en gel de agarosa y la agrupación se analizó mediante secuenciación 454 Titanium®. Las secuencias de consenso de las cadenas Vh y Vl se generaron usando el Analizador de Variante Amplicon (Roche) y se asignaron a pozos de cultivo de células B específicas decodificando las etiquetas MID. Las
secuencias relacionadas clonalmente se identificaron mediante análisis clustal. Cadenas Vh y Vl seleccionadas se sintetizaron y se clonaron en vectores de expresión con el dominio constante apropiado IgG1, IgK o IgL. Los anticuerpos monoclonales se reconstituyeron mediante transfección transitoria en células HEK293 seguido de purificación a partir de sobrenadantes de cultivo sin suero.
La Tabla 55 proporciona los datos de uso de genes para las cadenas pesadas de anticuerpos monoclonales anti-VIH PGT-127, PGT-128, PGT-131, PGT-137 y PGT-145.
Tabla 55.

Ejemplo 28: Amplia cobertura de neutralización del VIH por múltiples anticuerpos de alta potencia Los anticuerpos neutralizantes ampliamente reactivos cruzados (bnMAbs) contra patógenos virales muy variables son muy buscados -después de tratar o proteger contra virus circulantes globales. Se probaron los repertorios de anticuerpos neutralizantes de cuatro donantes infectados por VIH con respuestas neutralizadoras notablemente amplias y potentes y se rescataron 17 nuevos anticuerpos monoclonales (mAb) que se neutralizaron ampliamente a través de clados. Muchos de estos nuevos anticuerpos monoclonales anti-VIH son casi 10 veces más potentes que los bnMAbs PG9, PG16 y VRC01 y 100 veces más potentes que los prototipos bnMAbs originales (Wu, X., et al. Science 329, 856- 861 (2010); Walker, LM, et al. Science 326, 285-289 (2009); Binley, JM, y otros J Virol 78, 13232 13252 (2004)). Los MAbs recapitulan en gran medida la amplitud y potencia de neutralización encontradas en el suero del donante correspondiente y muchos reconocen epítopos no descritos previamente en la glicoproteína gp120 de la envoltura (Env), iluminando nuevos objetivos para el diseño de la vacuna. El análisis de neutralización por el complemento completo de bnMAbs anti-VIH ahora disponibles revela que ciertas combinaciones de anticuerpos proporcionan una cobertura significativamente más favorable de la enorme diversidad de virus circulantes globales que otras y estas combinaciones podrían buscarse en regímenes de inmunización activa o pasiva. En general, el aislamiento de múltiples bnMAbs del VIH, de varios donantes, que, en conjunto, proporcionan una amplia cobertura a bajas concentraciones es un indicador muy positivo para el diseño eventual de una vacuna eficaz contra VIH basada en anticuerpos.
Las vacunas antivirales más exitosas provocan anticuerpos neutralizantes como un correlato de protección (Amanna, IJ, et al. Hum Vaccin 4, 316-319 (2008); Plotkin, SA Pediatr Infect Dis J 20, 63-75 (2001)). Para los virus altamente variables, como el VIH, el VHC y, en menor medida, la gripe, los esfuerzos de diseño de vacunas se han visto obstaculizados por las dificultades asociadas con la obtención de anticuerpos neutralizantes que son efectivos contra la enorme diversidad de aislados circulantes globales (es decir, anticuerpos ampliamente neutralizantes, también denominados bnAbs) (Barouch, DH Nature 455, 613-619 (2008); Karlsson Hedestam, GB, y col. Nat Rev Microbiol 6, 143-155 (2008)). Sin embargo, para el VIH, por ejemplo, el 10-30% de las personas infectadas, de hecho, desarrollan sueros ampliamente neutralizantes, y se han aislado bnMAbs protectores de donantes infectados (Wu, X., et al. Science 329, 856-861 (2010); Walker, LM, et al. Science 326, 285-289 (2009); Stamatatos, L., et al. Nat Med 15, 866-870 (2009); Trkola, A., y otros J Virol 69, 6609-6617 (1995); Stiegler, G., y col., AIDS Res Hum Retroviruses 17, 1757-1765 (2001); Burton, DR, y col. Science 266, 1024-1027 (1994); Kwong, PD y Wilson, IA Nat Immunol 10, 573 578 (2009)). Se ha sugerido que, dado el inmunógeno apropiado, debería ser posible obtener este tipo de respuestas mediante la vacunación (Schief, WR, et al. Curr Opin HIV AIDS 4, 431-440 (2009)) y comprender las propiedades de los bnMAbs se ha convertido en un gran impulso en la investigación de virus altamente variables.
Los sueros de aproximadamente 1.800 donantes infectados con VIH-1 se examinaron previamente para determinar la amplitud y potencia de neutralización, designando el 1% superior como "neutralizadores de élite", en base a una puntuación que incorpora tanto la amplitud como la potencia (Simek, MD, et al. J Virol 83, 7337-7348 (2009)). En este estudio, los bnMAbs se aislaron de los cuatro principales neutralizadores de élite (Tablas 56) seleccionando sobrenadantes de células B de memoria que contienen anticuerpos para una amplia actividad neutralizante usando un enfoque funcional de alto rendimiento recientemente descrito (Walker, LM, et al. Science 326, 285-289).
(2009)). Los genes variables de anticuerpos se rescataron de cultivos de células B que mostraban actividad neutralizante de clado cruzado y se expresaron como IgG de longitud completa. El análisis de las secuencias reveló que todos los mAbs aislados de cada donante individual pertenecen a un grupo de anticuerpos distante, pero relacionado clonalmente (Tabla 57). Dado que se ha propuesto que los anticuerpos de pacientes infectados con VIH-1 a menudo son polirreactivos (Haynes, BF, et al. Science 308, 1906-1908 (2005); Mouquet, H., y col. Nature 467, 591-595 (2010)), los nuevos mAbs se probaron para la unión a un panel de antígenos y mostraron que no eran polirreactivos (Fig. 36).
Tabla 56. Actividad neutralizantes de suero de donantes seleccionados

Tabla 61. Actividad de neutralización de los anticuerpos PGT nuevamente identificados
Clso mediano Porcentaje de virus neutralizado
(pg/ml) iCIso < 50 pg/ml Clso < 1 |igfml ICIso < 0.1 pg/ml

La potencia de neutralización media contra virus neutralizados con un CI50 <50 |jg/ml está codificada por colores de la siguiente manera: verde, 20-50 jg/ml; amarillo, 2-20 jg/ml; naranja, 0,2-2 jg/ml; rojo, <0,2 jg/ml. La amplitud de neutralización está codificada por colores de la siguiente manera: verde, 1% a 30%; amarillo, 30% a 60%; naranja, 60% a 90%; rojo, >90%.

PGT121 TLHGRRIYGIVAF- NEWFTYFYMDV 65 27 17% 21 %
TKHGRRIYGV-
PGT122 17 IGHV4-59*01 K>KJ6*03 24 VAFKEWFTYFYM- 66 31 18% 24 %
OV
PGT123 AL HGKRIYGIV AL
CE LFTYFY MOV 70 35 21 % 27%
FDGEVLVYNMWP-
PGT125 KPAWVOL 78 36 20% 27% ♦6eoCDR2
FDGEVLVYMOWP-
PGT126 67 30 17%
KPAWVDL 23% ♦6«*nCDR2 PGT127 FGGEVLVYRDWP- KPAWVDL 58 30 15% 23% ♦6*nC DR 2 PGT 128 36 lGHV4-30*07 IGKJ5*02 10 FGGEVLRYTDWP-KPAWVDL 75 36 10% 28% ♦6m C O R 2
SGGDI
PGT 130 L YYYE WQKPHWF • 83 42 22% 34%
SP
SGGOILYY1EWOK-
PGT131 PHWFYP 84 41
PGT 135 HRHHOVFMLVP1-
AGWFOV 67 37
PGT 136 HKYHOI-30 lGHV4-30*07 IGKJ5*02 18 FRW PVAGW FDP 60 33 PGT137 MKYHDIVMWPI- AGWFDP 77 38

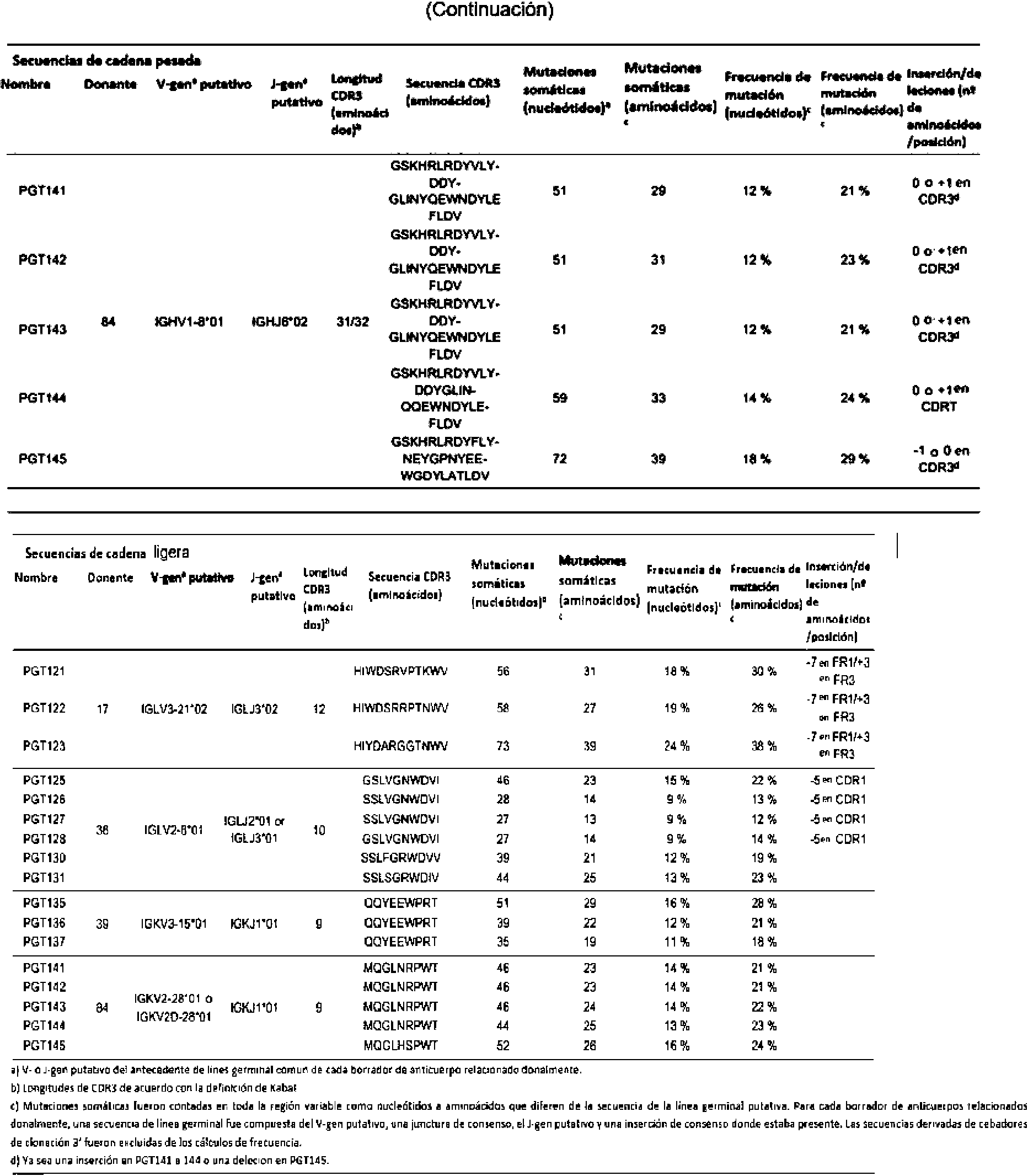
La potencia y la amplitud de los mAbs se evaluaron a continuación en un panel de 162 pseudovirus que representa todos los subtipos de VIH-1 circulantes principales (Tabla 58A-E y Tabla 61) (Walker, LM, et al. Science 326, 285-289 (2009)). Todos los mAb exhibieron actividad neutralizante de clado cruzado, pero más sorprendentemente, varios mostraron una potencia excepcional. La mediana de CI50s y CIg0s de los PGT 121-123 y 125-128 fueron casi 10 veces más bajos (es decir, más potentes) que los recientemente descritos PG9, PG16, VRC01 y PGV04 bnMAbs (Wu, X., et al. Science 329, 856-861 (2010); Walker, LM, et al. Science 326, 285-289 (2009)) y aproximadamente 100 veces más bajo que otros bnMAbs descritos anteriormente (Tabla 61). A concentraciones inferiores a 0,1 pg/ml, estos mAb todavía neutralizaron del 27% al 50% de los virus en el panel (Tabla 61 y Figura 33b). Aunque los PGT 135, 136 y 137 mostraron un grado menor de amplitud de neutralización general en relación con los otros mAb, todos neutralizaron más del 30% de los virus del clado C en el panel (Figura 36 y Tabla 58A). Estos resultados son significativos teniendo en cuenta que el clado C del VIH-1 predomina en África subsahariana y representa más del 50% de todas las infecciones por VIH-1 en todo el mundo.




IJ73

IJ74

IJ75

Muchos de los mAbs relacionados clonalmente mostraron diferentes grados de potencia de neutralización global. Por ejemplo, las Cl5os medias de los PGT 131, 136, 137 y 144 fueron aproximadamente de 10 a 50 veces más altas que las de sus clones hermanos relacionados somáticamente (Tabla 61). Además, en algunos casos, los mAb relacionados somáticamente exhibieron una neutralización similar potencia, pero diferentes grados de neutralización, contra el panel de virus probados (Tablas 58A- E y Tabla 61). Por ejemplo, p GT-128 neutralizó con una potencia global comparable pero una amplitud de neutralización significativamente mayor que los mAb PGT-125, -126 y -127
relacionados clonalmente (Tablas 58A-E y Tabla 61). En general, estas observaciones sugieren que la amplitud de neutralización del suero puede desarrollarse a partir de la selección sucesiva de mutantes somáticos que se unen a un epítopo modificado o una conformación de envoltura (Env) ligeramente diferente expresada en variantes de escape de virus. Además, estos resultados indican que la amplitud y potencia de neutralización sérica completa puede estar mediada por un pequeño número de mAbs seleccionados secuencialmente que se unen a epítopos distintos, pero superpuestos, expresados diferencialmente en varios aislamientos. A este respecto, las variantes somáticas de anticuerpos podrían "deslizarse" alrededor de la superficie de la espiga Env. La comparación de los perfiles de neutralización de los mAbs aislados de un donante dado con los perfiles de los sueros reveló que los mAbs aislados podrían recapitular en gran medida la amplitud y potencia de neutralización de suero correspondientes (Figs. 33a y 37).
Se determinaron los epítopos reconocidos por los bnMAbs recién aislados. Los ensayos de unión a ELISA indicaron que los PGT 121-123, 125-128, 130, 131 y 135-137 se unieron a gp120 monomérico (Tabla 59). En contraste, los PGT 141-145 bnMAbs exhibieron una fuerte preferencia por Env-VIH-1 trimérico unido a membrana (Figura 38). En base a este resultado, se postuló que estos bnMAbs se unieron a epítopos cuaternarios similares a los de los bnMAbs PG9 y PG16 recientemente descritos (Walker, LM, et al. Science 326, 285-289 (2009)). De hecho, esta hipótesis fue confirmada por estudios de competencia, sensibilidad N160K y, para PGT 141-144, una incapacidad para neutralizar los pseudovirus JR-CSF que expresan glicanos homogéneos Man 9 GlcNAc 2 (Walker, LM, et al. PLoS Pathog 6 (2010)) (Fig. 39).
Para definir los epítopos reconocidos por los anticuerpos PGT restantes, los ensayos ELISA de competición se llevaron a cabo con un panel de anticuerpos neutralizantes y no neutralizantes bien caracterizados (Fig. 34a). Inesperadamente, todos los anticuerpos restantes (PGT 121-123, 125-128, 130, 131, 135-137) compitieron con el bnMAb 2G12 específico de glucano. Este resultado fue sorprendente dado que 2G12 había formado previamente su propio grupo de competencia único. Todos los mAb, excepto los PGT 135, 136 y 137, también compitieron con un mAb específico del bucle V3 y no se unieron a gp120 ® V3, lo que sugiere que sus epítopos estaban cerca o contiguos al bucle V3 (Fig. 34a y Tabla 59) La desglicosilación de gp120 con Endo H abolió la unión de todos los mAbs, lo que indica que ciertos glucanos de oligomanosa fueron importantes para el reconocimiento del epítopo (Tabla 59). La competencia de estos mAbs con 2G12 y la falta de unión a la gp120 desglicosilada nos llevaron a investigar si estos anticuerpos contactaban a los glucanos directamente. El análisis de la matriz de Glycan reveló que los PGT 125-128 y 130 se unieron específicamente a Man 8 GlcNAc 2 y Man 9 GlcNAc 2, mientras que los anticuerpos restantes no mostraron unión detectable a glucanos con alto contenido de manosa (Fig. 34b). Curiosamente, la unión de PGT 125 128, 130 a gp120 fue competida por Man 9 pero, a diferencia de 2G12, no fue competida por manosa monomérica o Man 4 (brazo D1 de Man 9 GlcNAc 2) (Fig. 34c y 34d), lo que sugiere Un modo diferente de reconocimiento de glucano. Además, en contraste con 2G12, no se encontró evidencia de intercambio de dominio y los fragmentos Fab monoméricos exhibieron una potente actividad neutralizante (Fig. 41).
Para definir mejor los epítopos reconocidos por los mAbs, se evaluó la actividad neutralizante contra un panel grande de variantes de JR-CSF de VIH-1 que incorporan sustituciones de alanina individuales usando una única ronda de ensayo de replicación de pseudovirus (Tabla 60). En el panel de mutantes, los glicanos unidos a N en las posiciones 332 y/o 301 fueron importantes para la neutralización por los PGT 125-128, 130 y 131, lo que sugiere su participación directa en la formación del epítopo. La aparente dependencia de tan pocos glicanos sugiere que, aunque los PGT 125-128, 130 y 131 contactan a los glicanos Man 8-9 GlcNAc 2 directamente, su disposición en el contexto de gp120 es crítica para el reconocimiento de glicanos de alta afinidad y la potencia de neutralización. Esto se destaca aún más por la incapacidad de los PGT Mabs para neutralizar SIVmac239, VIH-2 o VHC, que muestran un alto nivel de glicosilación. Aunque los PGT 121-123 no lograron exhibir una unión detectable a los glucanos con alto contenido de manosa y competir con los azúcares de manosa (Fig. 40), las únicas sustituciones que abolieron completamente la neutralización por estos mAbs fueron aquellas que resultaron en la eliminación del glucano en la posición 332. Aunque se requerirán estudios estructurales para definir completamente los epítopos reconocidos por estos anticuerpos, el resultado anterior sugiere que los mabs PGT 121-123 se unen a un epítopo de proteína a lo largo del esqueleto del polipéptido gp120 que depende conformacionalmente del glucano N332 o que el glucano contribuye más fuertemente a la unión en el contexto de la proteína intacta.
Tabla 60A. Actividad neutralizante de PGT mAbs contra un panel de mutantes de alanina de JR-CSF.

Tabla 60B.

Tabla 60C.

J Numeración de aminoácidos se base en la secuencia de VIH-1hxS2
B C se refiere a dominios constantes y V se refiere a bucles variables
c Actividad de neutralización se informa como incremento en valor Clso relativo a WT JR-CSF y se calculó utilizando la ecuación (Clso mutante / Clso WT) Gris: sustituciones que tuvieron un efecto despreciable en la actividad de neutraliación, amarillo incremento de Clso de 10-40 fold, rojo incremento de Clso de >40 fold Expenmentos fueron realizados en duplicado y los valores representan un promedio de al menos dos experimentos independientes
Las vacunas contra agentes patógenos con baja diversidad antigénica, como el virus de la hepatitis B (VHB) o el sarampión, comúnmente alcanzan una eficacia del 90-95% (Plotkin. Vaccines (Elsevier Health Sciences, Filadelfia, 2008)). De manera similar, la vacuna contra la influenza logra una eficacia del 85-90% en años cuando la vacuna y la cepa circulante coinciden bien (Bridges, CB, et al. JAMA 284, 1655-1663 (2000); Herrera, GA, et al. Vaccine 25, 154 160 (2007)). Sin embargo, la eficacia cae severamente en años cuando hay un desajuste entre la vacuna y la cepa circulante. En el caso del VIH, la diversidad global de los virus circulantes es tal que la coincidencia entre los anticuerpos profilácticos y los virus circulantes, es decir, la cobertura viral de los anticuerpos, será crucial para el grado de eficacia de los enfoques de profilaxis activa o pasiva. Hasta la fecha, aunque el reciente rastro RV144 ha llevado a especular que se puede lograr cierto grado de protección contra el VIH a través de actividades extraneutralizantes de anticuerpos, como la citotoxicidad mediada por células dependiente de anticuerpos o la fagocitosis, la evidencia más fuerte para la protección es para neutralizar anticuerpos en modelos de primates no humanos que utilizan el desafío del virus de inmunodeficiencia humana simia (SHIV) (Parren, PW, et al. J Virol 75, 8340-8347 (2001); Nishimura, Y., y otros J Virol 76, 2123-2130 (2002); Hessell, AJ, y col. Nat Med 15, 951-954 (2009); Hessell, AJ, y col. PLoS Pathog 5, e1000433 (2009); Willey, R., y col. AIDS Res Hum Retroviruses 26, 89-98 (2010)).
La administración pasiva de anticuerpos neutralizantes en modelos animales sugiere que a menudo se requiere un título de suero de aproximadamente o más de 100 veces el CI50 para lograr un nivel significativo de protección (Parren, PW, et al. J Virol 75, 8340- 8347 (2001); Nishimura, Y., y otros J Virol 76, 2123-2130 (2002); Hessell, AJ, y otros Nat Nat 15, 951-954 (2009); Hessell, AJ, y otros PLoS Pathog 5, e1000433 (2009); Willey, R., y col., AIDS Res Hum Retroviruses 26, 89-98 (2010)). Por lo tanto, si una vacuna provoca una concentración de bNAb en suero del orden de 10 pg/ml, y si se supone una relación de CI50: suero protector de 1:100, entonces la protección se lograría con bNAb CI50 es menor que 0,1 pg/ml. Como segundo escenario conservador, para una relación CI50: suero protector de 1: 500, se lograría protección contra virus para los cuales la bNAb CI50 es inferior a 0,02 pg/ml. Como se muestra en la Figura 33b-d, aunque varios bnMAbs muestran amplitud a altas concentraciones, la cobertura viral a menudo cae bruscamente a concentraciones más bajas. Por lo tanto, si se obtienen o se administran por separado, solo los Abs más potentes, como 121 y 128, podrían lograr un nivel significativo de cobertura viral, en particular a las concentraciones correspondientes al escenario más conservador dado anteriormente. Como los bnMAbs muestran una amplitud diferente y, en algunos casos, complementaria, analizamos la cobertura lograda por las combinaciones de anticuerpos. Para las dos relaciones de concentración sérica CI50: protectora anteriores, una combinación de PGV04 y VRC01, los dos bnMAbs CD4bs más potentes, proporcionarían protección contra el 50% y el 3% de los virus, respectivamente (Fig. 33c). Por el contrario, para una vacuna que induce anticuerpos con alta potencia y amplitud favorable y no superpuesta, como 128 y 145, la cobertura se lograría contra 70% y 40% de virus para los dos escenarios (Fig. 33d). Varias combinaciones de dos bnMAbs, incluidas las dirigidas a epítopos
superpuestos, pueden proporcionar este grado de cobertura (Figura 44). En adición, una combinación de todas las bnMAbs cubriría 89% y 62% de los virus, de manera correspondiente. La cobertura contra una proporción tan grande de virus probablemente tendría un impacto importante en la pandemia.
En resumen, una vacuna eficaz contra el VIH-1 puede requerir la obtención de una combinación de potentes anticuerpos neutralizantes complementarios. La demostración de que se puede aislar un gran número de bNAbs potentes y diversos de varios individuos diferentes proporciona motivos para un renovado optimismo de que se pueda lograr una vacuna basada en anticuerpos. Críticamente, la aplicación instantánea proporciona la gran cantidad requerida de bNAbs potentes y diversos que comprenden una vacuna basada en anticuerpos.
Sumario de métodos
Los sobrenadantes de células B de memoria activada se seleccionaron en un formato de alto rendimiento para la actividad de neutralización usando un ensayo de micro-neutralización, como se describe (Walker, LM, et al. Science 326, 285-289 (2009)). Las regiones variables de la cadena pesada y ligera se aislaron de los lisados de células B de éxitos neutralizantes seleccionados por transcripción inversa a partir de ARN seguido de amplificación por PCR multiplex usando conjuntos de cebadores de genes V específicos de la familia. Para algunos anticuerpos, se usaron métodos de clonación tradicionales para el aislamiento de anticuerpos, como se describe (Walker, LM, et al. Science 326, 285-289 (2009)). Para otros anticuerpos, los amplicones de cada lisado se marcaron de forma única con secuencias de identificador multiplex (MID) y 454 regiones de secuenciación (Roche). Los ensayos de neutralización de pseudovirus de replicación única y los ensayos de unión a la superficie celular se realizaron como se describió anteriormente (Walker, LM, et al. Science 326, 285-289 (2009); Pantophlet, R., y otros J Virol 77, 642-658 (2003); Li, M., et al. J Virol 79, 10108-10125 (2005)). Las reactividades de glucano se perfilaron en un microarray de glucano impreso (versión 5,0 del Consortium for Functional Glycomics (CFG)) como se describió anteriormente (Blixt, O., et al. Proc Natl Acad Sci EE.UU. 101, 17033-17038 (2004)).
Anticuerpos y antígenos
El Consorcio de Anticuerpos Neutralizantes de IAVI adquirió los siguientes anticuerpos y reactivos: anticuerpo 2G12 (Polymun Scientific, Viena, Austria), anticuerpo F425/b4E8 (proporcionado por Lisa Cavacini, Centro Médico Beth Israel Deaconess, Boston, MA)), CD4 soluble (Progenics, Tarrytown, NY), HxB2 gp120, SF162 gp120, BaL gp120, JR-FL gp120, JR-CSF gp120 y YU2 gp120 (proporcionado por Guillaume Stewart-Jones, Oxford University). La ADA gp120 purificada se produjo en el laboratorio de Robert Doms, Universidad de Pennsylvania. Fab X5 se expresó en E. coli y purificado utilizando una columna de afinidad específica Fab antihumana. gp120 JRFL desglicosilado se expresó en células HEK 293S GnTI'/_ y se trató con Endo H (Roche).
Donantes
Los donantes identificados para este estudio fueron seleccionados del estudio patrocinado por IAVI, Protocolo G (Simek, MD, et al. J Virol 83, 7337-7348 (2009)). La elegibilidad para la inscripción en el Protocolo G se definió como: hombre o mujer de al menos 18 años de edad con infección por VIH documentada durante al menos tres años, clínicamente asintomática en el momento de la inscripción y que actualmente no reciben terapia antirretroviral. La selección de individuos para la generación de anticuerpos monoclonales se basó en un algoritmo analítico y de detección de alto rendimiento de orden de rango (Simek, MD, et al. J Virol 83, 7337-7348 (2009)). Los voluntarios fueron identificados como neutralizadores de élite basados en una actividad neutralizadora amplia y potente contra un panel de pseudovirus de clado cruzado (Simek, MD, et al. J Virol 83, 7337-7348 (2009)).
A islam iento de MAbs
El método para aislar MAbs humanos de las células B de memoria en circulación se ha descrito previamente (Walker, LM, et al. Science 326, 285-289 (2009)). Las células IgG+ B superficiales sembradas a una densidad casi clonal en microplacas de 384 pocillos se activaron en cultivo a corto plazo. Los sobrenadantes se seleccionaron para determinar la actividad de neutralización frente a 2-4 virus seudotipados para los cuales se detectó actividad de neutralización a títulos elevados en el suero del donante. Las regiones variables de la cadena pesada y ligera se aislaron de los lisados de células B de éxitos neutralizantes seleccionados por transcripción inversa a partir de ARN seguido de amplificación por PCR multiplex usando conjuntos de cebadores de genes V específicos de la familia. Los amplicones de cada lisado se marcaron de manera única con secuencias de identificador multiplex (MID) y 454 regiones de secuenciación (Roche, Indianápolis, IN). Se realizó una agrupación normalizada de cadenas gamma, kappa y lambda en base a la cuantificación de imágenes de gel de agarosa y la agrupación se analizó mediante secuenciación 454 Titanium®. Las secuencias de consenso de las cadenas VH y VL se generaron usando el Analizador de Variante Amplicon (Roche) y se asignaron a pozos de cultivo de células B específicas decodificando las etiquetas MID. Cadenas VH y VL seleccionadas se sintetizaron y se clonaron en vectores de expresión con el dominio constante apropiado de IgG1, IgG3 □o IgG4. Los anticuerpos monoclonales se reconstituyeron mediante transfección transitoria en células HEK293 seguido de purificación a partir de sobrenadantes de cultivo libres de suero.
Tabla 62

(Continuación)

Expresión y purificación de anticuerpos PGT
Los genes de anticuerpos se clonaron en un vector de expresión y se expresaron transitoriamente con el sistema de expresión FreeStyle 293 (Invitrogen, Carlsbad, CA). Los anticuerpos se purificaron usando cromatografía de afinidad (Protein A Sepharose Fast Flow, GE Healthcare, Reino Unido). La pureza y la integridad se verificaron con SDS-PAGE.
Ensayos de neutralización
La neutralización mediante anticuerpos monoclonales y sueros de donantes se realizó mediante Monogram Biosciences utilizando una única ronda de ensayo de replicación de pseudovirus como se describió previamente (Richman, DD, et al. Proc Natl Acad Sci EE.UU. 100, 4144-4149 (2003)). En resumen, los pseudovirus capaces de una única ronda de infección se produjeron mediante la co-transfección de células HEK293 con un plásmido subgenómico, pHIV-1lucu3, que incorpora un gen indicador de luciferasa de luciérnaga y un segundo plásmido, pCXAS que expresaba bibliotecas o clones Env de VIH-1. Después de la transfección, se recogieron pseudovirus y se usaron para infectar líneas celulares U87 que expresan co-receptores CCR5 o CXCR4. Los ensayos de neutralización de
pseudovirus que usan mutantes de alanina JR-CSF VIH-1 se describen completamente en otra parte (Walker, LM, et al. Science 326, 285-289 (2009)). La actividad de neutralización de MAb contra mutantes de alanina JR-CSF de VIH-1 se midió usando un ensayo Tz M-BL, como se describe (Walker, LM, et al. Science 326, 285-289 (2009)). Los pseudovirus tratados con kifunensina se produjeron tratando células 293T con kifunensina 25 pm el día de la transfección. Los sobrenadantes de células B de memoria se seleccionaron en un ensayo de microneutralización contra un panel cruzado de aislados de VIH-1 y SIVmac239 (control negativo). Este ensayo se basa en el ensayo de neutralización pseudotipado de VIH-1 de 96 pocillos (Monogram Biosciences) y se modificó para el cribado de 15 pL de sobrenadantes de cultivo de células B en un formato de 384 pocillos.
Ensayos de unión a la superficie celular
Se agregaron cantidades titulantes de anticuerpos a células 293T transfectadas con Env-VIH, se incubaron durante 1 hora a 37°C, se lavaron con tampón FACS y se tiñeron con IgG F(ab')2 antihumana de cabra conjugado con ficoeritina (Jackson ImmunoResearch, West Grove, PA). La unión se analizó usando citometría de flujo, y las curvas de unión se generaron trazando la intensidad de fluorescencia media de la unión al antígeno en función de la concentración de anticuerpos. Para ensayos competidores, se añadieron cantidades de titulación de anticuerpos competidores a las células 30 min antes de añadir MAbs PGT biotinilados a una concentración requerida para dar CE50.
Ensayos de ELISA
Para los ELISA de unión a antígeno, se añadieron diluciones en serie de MAb a los pocillos recubiertos con antígeno y se sondeó la unión con inmunoglobulina de cabra conjugada con fosfatasa alcalina G (IgG) F(ab')2 Ab (Pierce, Rockford, IL). Para los ELISA de competición, se añadieron cantidades de titulación de MAb de la competencia a los pocillos de ELISA recubiertos con gp120 y se incubaron durante 30 minutos antes de añadir MAb de PGT biotinilado a una concentración requerida para dar CI70. Los PGT biotinilados se detectaron usando estreptavidina conjugada con fosfatasa alcalina (Pierce) y se visualizaron usando sustrato de fosfato de p-nitrofenol (Sigma, St. Louis, MO).
Análisis de microarrays de glicanos
Los anticuerpos monoclonales se seleccionaron en una versión 5,0 de microarrays de glicanos impresos del Consortium for Functional Glycomics (CFG) como se describió anteriormente (Blixt, O., et al. Proc Natl Acad Sci EE.UU. 101, 17033-17038 (2004))). Los anticuerpos se usaron a una concentración de 30 pg/ml y se precomplejaron con un anticuerpo secundario de 15 pg/ml (Fc-rPE anti-humano de cabra, Jackson Immunoresearch) antes de la adición al portaobjetos. Los conjuntos completos de datos de la matriz de glucano para todos los anticuerpos se pueden encontrar en www.functionalglycomics.org en el archivo de datos de CFG en "cfg_rRequest_2250".
Síntesis del dendrón de oligomanosa
Los dendrones de oligomanosa (Man4D y MangD) se sintetizaron mediante cicloadición de alquino-azida catalizada por Cu(I) entre azido oligomanosa y la segunda generación de dendrón de alquinilo tipo AB3. Los procedimientos detallados y la caracterización se informaron previamente (Wang, SK, et al. Proc Natl Acad Sci EE.UU.
105, 3690-3695 (2008)).
Fabricación de m icroarrays gp120
Los portaobjetos de vidrio activados por NHS (portaobjetos Nexterion H, Schott North American) se imprimieron con un alfiler robótico (Arrayit 946) para depositar gp120 JRFL a concentraciones de 750 o 250 pg/ml en tampón de impresión (120 mM fosfato, pH 8,5; que contiene 5% de glicerol y 0,01% de Tween 20). Se utilizaron 12 réplicas para cada concentración. Los portaobjetos impresos se incubaron en una cámara de humedad relativa al 75% durante la noche y se trataron con solución de bloqueo (tampón de bloqueo superbloque en PBS, Thermo) a temperatura ambiente durante 1 h. Los portaobjetos se enjuagaron luego con PBS-T (Tween 20 al 0,05%) y tampón PBS, y se centrifugaron a 200 g para eliminar la solución residual de la superficie del portaobjetos.
Ensayo de competición de dendron-gp120 de oligomanosa con MAbs
Se mezclaron dendrones de oligomanosa diluidos en serie con MAb (40 pg/ml) en tampón PBS-BT (BSA al 1% y Tween 20 al 0,05% en PBS). Las mezclas se aplicaron directamente a cada subconjunto en portaobjetos. Después de la incubación en una cámara humidificada durante 1 hora a temperatura ambiente, los portaobjetos se enjuagaron secuencialmente con PBS-T y tampón PBS, y luego se centrifugaron a 200 g. Cada subconjunto se tiñó luego con IgG de cabra antihumano de cabra marcado con Cy3 (7,5 pg/ml en PBSBT) durante 1 hora en una cámara humidificada. Los portaobjetos se enjuagaron secuencialmente con PBS-T y agua demonizada y se centrifugaron a 200 g. La fluorescencia de las matrices finales se fotografió a una resolución de 10 pm (Ex: 540 nm; Em: 595 nm) con un lector de microarrays ArrayWorx (precisión aplicada).
Claims (13)
1. Un anticuerpo anti-VIH, en donde dicho anticuerpo es PGT-134 que tiene una cadena pesada variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 435 y una cadena ligera variable que comprende la secuencia de aminoácidos de la SEQ ID NO: 440.
2. El anticuerpo de la reivindicación 1, en donde el anticuerpo tiene una cadena pesada que comprende la secuencia de aminoácidos de la SEQ ID NO: 434 y una cadena ligera que comprende la secuencia de aminoácidos de la SEQ ID NO: 439.
3. Un fragmento de unión a antígeno del anticuerpo de acuerdo con la reivindicación 1 o 2.
4. El fragmento de unión a antígeno del anticuerpo de acuerdo con la reivindicación 3, que se selecciona del grupo que consiste de los fragmentos Fab, Fab', F(ab')2, Fv, Fv de cadena sencilla, diacuerpo y dominio de anticuerpo (dAb).
5. Una molécula de ácido nucleico que codifica el anticuerpo de acuerdo con la reivindicación 1o 2, o el fragmento de unión a antígeno del mismo de acuerdo con la reivindicación 3 o 4, en donde la molécula de ácido nucleico codifica preferiblemente una secuencia de cadena pesada variable que comprende la secuencia de ácidos nucleicos de la SEQ ID NO: 433 y una secuencia de cadena ligera variable que comprende la secuencia de ácidos nucleicos de la SEQ ID NO: 438 o una secuencia de cadena pesada que comprende la secuencia de ácidos nucleicos de la SEQ ID NO: 432 y una secuencia de cadena ligera que comprende la secuencia de ácidos nucleicos de la SEQ ID NO: 437.
6. La molécula de ácido nucleico de acuerdo con la reivindicación 5, que se selecciona del grupo que consiste de ADNc, ARNhn y ARNm.
7. Un vector que comprende la molécula de ácido nucleico de acuerdo con la reivindicación 5 o 6.
8. Una célula que comprende el vector de acuerdo con la reivindicación 7.
9. Un clon de células B inmortalizado que expresa el anticuerpo de acuerdo con la reivindicación 1 o 2.
10. Una composición farmacéutica que comprende por lo menos el anticuerpo o el fragmento de unión a antígeno como se enumera en cualquiera de las reivindicaciones 1 a 4 o la molécula de ácido nucleico como se enumera en la reivindicación 5 o 6, y un vehículo farmacéuticamente aceptable, respectivamente, en donde dicha composición farmacéutica comprende preferiblemente un segundo anticuerpo o un fragmento de unión a antígeno específico para un segundo epítopo.
11. El anticuerpo o fragmento de unión a antígeno como se enumera en cualquiera de las reivindicaciones 1 a 4 o la molécula de ácido nucleico como se enumera en la reivindicación 5 o 6 para su uso en el tratamiento o reducción del efecto de una infección por VIH o una enfermedad relacionada con el VIH o para la profilaxis posterior a la exposición o para su uso en el tratamiento de un individuo contra una pluralidad de especies de VIH-1.
12. El anticuerpo o fragmento de unión a antígeno para el uso de acuerdo con la reivindicación 11, caracterizado porque se administra un segundo agente terapéutico, en donde, preferiblemente, dicho segundo agente terapéutico es un agente antiviral.
13. Un método para producir el anticuerpo o fragmento de unión a antígeno de acuerdo con cualquiera de las reivindicaciones 1 a 4 que comprende (i) cultivar un clon de células B inmortalizado que expresa un anticuerpo como se enumera en la reivindicación 1 y (ii) aislar el anticuerpo.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US37860410P | 2010-08-31 | 2010-08-31 | |
| US38694010P | 2010-09-27 | 2010-09-27 | |
| US201161476978P | 2011-04-19 | 2011-04-19 | |
| US201161515548P | 2011-08-05 | 2011-08-05 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2920140T3 true ES2920140T3 (es) | 2022-08-01 |
Family
ID=45773488
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES16206293T Active ES2774369T3 (es) | 2010-08-31 | 2011-08-31 | Anticuerpo de neutralización del virus de la inmunodeficiencia humana |
| ES19156884T Active ES2920140T3 (es) | 2010-08-31 | 2011-08-31 | Anticuerpos neutralizantes del virus de la inmunodeficiencia humana (VIH) |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES16206293T Active ES2774369T3 (es) | 2010-08-31 | 2011-08-31 | Anticuerpo de neutralización del virus de la inmunodeficiencia humana |
Country Status (9)
| Country | Link |
|---|---|
| US (7) | US9464131B2 (es) |
| EP (7) | EP4226935A3 (es) |
| AU (6) | AU2011296065B2 (es) |
| CA (5) | CA2809837C (es) |
| ES (2) | ES2774369T3 (es) |
| PL (1) | PL3556396T3 (es) |
| PT (1) | PT3556396T (es) |
| SI (1) | SI3556396T1 (es) |
| WO (1) | WO2012030904A2 (es) |
Families Citing this family (104)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| SMT202000101T1 (it) | 2008-10-10 | 2020-03-13 | Childrens Medical Center | Vaccino con trimero di env di hiv-1 stabilizzato biochimicamente |
| RS53347B (sr) | 2008-12-09 | 2014-10-31 | Gilead Sciences, Inc. | Modulatori toll-sličnih receptora |
| SI3260136T1 (sl) | 2009-03-17 | 2021-05-31 | Theraclone Sciences, Inc. | Humani imunodeficientni virus (HIV)-nevtralizirajoča protitelesa |
| WO2012019168A2 (en) | 2010-08-06 | 2012-02-09 | Moderna Therapeutics, Inc. | Engineered nucleic acids and methods of use thereof |
| PT3556396T (pt) * | 2010-08-31 | 2022-07-04 | Scripps Research Inst | Anticorpos neutralizantes do vírus da imunodeficiência humana (vih) |
| EP2625189B1 (en) | 2010-10-01 | 2018-06-27 | ModernaTX, Inc. | Engineered nucleic acids and methods of use thereof |
| AU2012236099A1 (en) | 2011-03-31 | 2013-10-03 | Moderna Therapeutics, Inc. | Delivery and formulation of engineered nucleic acids |
| US9464124B2 (en) | 2011-09-12 | 2016-10-11 | Moderna Therapeutics, Inc. | Engineered nucleic acids and methods of use thereof |
| DE19216461T1 (de) | 2011-10-03 | 2021-10-07 | Modernatx, Inc. | Modifizierte nukleoside, nukleotide und nukleinsäuren und verwendungen davon |
| CA3018046A1 (en) | 2011-12-16 | 2013-06-20 | Moderna Therapeutics, Inc. | Modified nucleoside, nucleotide, and nucleic acid compositions |
| US9254311B2 (en) | 2012-04-02 | 2016-02-09 | Moderna Therapeutics, Inc. | Modified polynucleotides for the production of proteins |
| WO2013151665A2 (en) | 2012-04-02 | 2013-10-10 | modeRNA Therapeutics | Modified polynucleotides for the production of proteins associated with human disease |
| US9283287B2 (en) | 2012-04-02 | 2016-03-15 | Moderna Therapeutics, Inc. | Modified polynucleotides for the production of nuclear proteins |
| US9572897B2 (en) | 2012-04-02 | 2017-02-21 | Modernatx, Inc. | Modified polynucleotides for the production of cytoplasmic and cytoskeletal proteins |
| EP2900693A4 (en) * | 2012-09-26 | 2016-05-11 | Univ Duke | ADCC-mediating antibodies, combinations and uses thereof |
| CN118955699A (zh) * | 2012-10-18 | 2024-11-15 | 洛克菲勒大学 | 广泛中和性抗hiv抗体 |
| PL2922554T3 (pl) | 2012-11-26 | 2022-06-20 | Modernatx, Inc. | Na zmodyfikowany na końcach |
| SG10201705880QA (en) | 2013-01-07 | 2017-08-30 | Beth Israel Deaconess Medical Ct Inc | Stabilized human immunodeficiency virus (hiv) envelope (env) trimer vaccines and methods of using the same |
| SMT202100464T1 (it) | 2013-03-14 | 2021-11-12 | Macrogenics Inc | Molecole bispecifiche che sono immunoreattive con cellule effettrici immunitarie che esprimono un recettore di attivazione |
| US8980864B2 (en) | 2013-03-15 | 2015-03-17 | Moderna Therapeutics, Inc. | Compositions and methods of altering cholesterol levels |
| EP3027755B1 (en) * | 2013-08-02 | 2019-10-09 | The Regents of The University of California | Engineering antiviral t cell immunity through stem cells and chimeric antigen receptors |
| EP2848937A1 (en) | 2013-09-05 | 2015-03-18 | International Aids Vaccine Initiative | Methods of identifying novel HIV-1 immunogens |
| WO2015048770A2 (en) | 2013-09-30 | 2015-04-02 | Beth Israel Deaconess Medical Center, Inc. | Antibody therapies for human immunodeficiency virus (hiv) |
| WO2015048744A2 (en) | 2013-09-30 | 2015-04-02 | Moderna Therapeutics, Inc. | Polynucleotides encoding immune modulating polypeptides |
| EP3052521A1 (en) | 2013-10-03 | 2016-08-10 | Moderna Therapeutics, Inc. | Polynucleotides encoding low density lipoprotein receptor |
| DK3052518T3 (da) | 2013-10-04 | 2020-04-06 | Beth Israel Deaconess Medical Ct Inc | Stabiliserede humant immundefektvirus-(hiv)-klade c-kappe-(env)-trimer-vacciner og fremgangsmåder til anvendelse deraf |
| US10494422B2 (en) * | 2014-04-29 | 2019-12-03 | Seattle Children's Hospital | CCR5 disruption of cells expressing anti-HIV chimeric antigen receptor (CAR) derived from broadly neutralizing antibodies |
| US10093720B2 (en) * | 2014-06-11 | 2018-10-09 | International Aids Vaccine Initiative | Broadly neutralizing antibody and uses thereof |
| EP3160513B1 (en) | 2014-06-30 | 2020-02-12 | Glykos Finland Oy | Saccharide derivative of a toxic payload and antibody conjugates thereof |
| JP6522732B2 (ja) | 2014-07-11 | 2019-05-29 | ギリアード サイエンシーズ, インコーポレイテッド | Hivを治療するためのトール様受容体の調節因子 |
| WO2016037154A1 (en) | 2014-09-04 | 2016-03-10 | The United States Of America, As Represented By The Secretary, Department Of Health & Human Services | Recombinant hiv-1 envelope proteins and their use |
| SG11201701520TA (en) | 2014-09-16 | 2017-04-27 | Gilead Sciences Inc | Solid forms of a toll-like receptor modulator |
| CN106999571B (zh) | 2014-09-26 | 2020-10-02 | 贝斯以色列护理医疗中心有限公司 | 诱导针对人免疫缺陷病毒感染的保护性免疫性的方法和组合物 |
| WO2016054023A1 (en) * | 2014-09-29 | 2016-04-07 | Duke University | Hiv-1 antibodies and uses thereof (adcc and bispecific abs) |
| MX386297B (es) | 2014-09-29 | 2025-03-18 | Univ Duke | Moleculas biespecificas que comprenden un brazo orientado a la envoltura vih-1. |
| TW201713700A (zh) * | 2015-05-27 | 2017-04-16 | 台灣泰福生技股份有限公司 | 抗glypican-3抗體及其用於診斷及治療癌症之用途 |
| CA2997955A1 (en) | 2015-09-15 | 2017-03-23 | Gilead Sciences, Inc. | Modulators of toll-like receptors for the treatment of hiv |
| JP6955487B2 (ja) | 2015-09-24 | 2021-10-27 | アブビトロ, エルエルシー | Hiv抗体組成物および使用方法 |
| CA3045756A1 (en) | 2015-12-05 | 2017-06-08 | Centre Hospitalier Universitaire Vaudois | Hiv binding agents |
| DK3584252T3 (da) | 2015-12-15 | 2021-11-15 | Janssen Vaccines & Prevention Bv | Human immundefektvirus-antigener, -vektorer, -sammensætninger og fremgangsmåder til anvendelse deraf |
| JP6732915B2 (ja) | 2015-12-15 | 2020-07-29 | ギリアード サイエンシーズ, インコーポレイテッド | ヒト免疫不全ウイルス中和抗体 |
| CN107022027B (zh) * | 2016-02-02 | 2022-03-08 | 中国疾病预防控制中心性病艾滋病预防控制中心 | Hiv-1广谱中和抗体及其用途 |
| CN107033241B (zh) * | 2016-02-03 | 2022-03-08 | 中国疾病预防控制中心性病艾滋病预防控制中心 | Hiv-1广谱中和抗体及其用途 |
| US20190069528A1 (en) * | 2016-03-21 | 2019-03-07 | The George Washington University | Engineered human hookworms as a novel biodelivery system for vaccines and biologicals |
| US11299751B2 (en) | 2016-04-29 | 2022-04-12 | Voyager Therapeutics, Inc. | Compositions for the treatment of disease |
| EP3448874A4 (en) | 2016-04-29 | 2020-04-22 | Voyager Therapeutics, Inc. | COMPOSITIONS FOR TREATING A DISEASE |
| MA45381A (fr) | 2016-06-16 | 2021-04-21 | Janssen Vaccines & Prevention Bv | Formulation de vaccin contre le vih |
| US10961283B2 (en) | 2016-06-27 | 2021-03-30 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Self-assembling insect ferritin nanoparticles for display of co-assembled trimeric antigens |
| JP2019526580A (ja) | 2016-09-02 | 2019-09-19 | ヤンセン ファッシンズ アンド プリベンション ベーフェーJanssen Vaccines & Prevention B.V. | 抗レトロウイルス処置を受けている対象においてヒト免疫不全ウイルス感染に対する免疫応答を誘発するための方法 |
| PT3512543T (pt) | 2016-09-15 | 2020-10-13 | Janssen Vaccines & Prevention Bv | Trímero que estabiliza mutações das proteínas do envelope do hiv |
| WO2018075564A1 (en) | 2016-10-17 | 2018-04-26 | University Of Maryland, College Park | Multispecific antibodies targeting human immunodeficiency virus and methods of using the same |
| WO2018075559A1 (en) | 2016-10-17 | 2018-04-26 | Beth Israel Deaconess Medical Center, Inc. | Signature-based human immunodeficiency virus (hiv) envelope (env) trimer vaccines and methods of using the same |
| KR20200015759A (ko) | 2017-06-15 | 2020-02-12 | 얀센 백신스 앤드 프리벤션 비.브이. | Hiv 항원을 인코딩하는 폭스바이러스 벡터, 및 그 사용 방법 |
| AR112257A1 (es) | 2017-06-21 | 2019-10-09 | Gilead Sciences Inc | Anticuerpos multiespecíficos dirigidos al vih-1 gp120 y cd3 humana, composiciones que los comprende, ácido nucleico, vector y célula huésped relacionados, método para producirlos, método para detectar células que expresan gp120 y cd3, kit de anticuerpos, fragmentos de anticuerpo que se une a gp120 y método para producirlos |
| AU2018304502B2 (en) | 2017-07-19 | 2022-03-31 | Janssen Vaccines & Prevention B.V. | Trimer stabilizing HIV envelope protein mutations |
| US10510575B2 (en) | 2017-09-20 | 2019-12-17 | Applied Materials, Inc. | Substrate support with multiple embedded electrodes |
| WO2019079337A1 (en) | 2017-10-16 | 2019-04-25 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | RECOMBINANT HIV-1 ENVELOPE PROTEINS AND THEIR USE |
| KR20200098590A (ko) | 2017-12-12 | 2020-08-20 | 마크로제닉스, 인크. | 이중특이적 cd16-결합 분자 및 질환 치료에서의 그것의 용도 |
| US10555412B2 (en) | 2018-05-10 | 2020-02-04 | Applied Materials, Inc. | Method of controlling ion energy distribution using a pulse generator with a current-return output stage |
| EP3797118A4 (en) | 2018-05-22 | 2022-06-29 | Beth Israel Deaconess Medical Center, Inc. | Antibody therapies for human immunodeficiency virus (hiv) |
| DK4257600T3 (da) | 2018-07-03 | 2025-05-26 | Gilead Sciences Inc | Antistoffer rettet mod hiv gp120 og fremgangsmåder til at bruge dem |
| WO2020012435A1 (en) | 2018-07-13 | 2020-01-16 | Lausanne University Hospital | Hiv binding agents |
| AU2019338454A1 (en) | 2018-09-14 | 2021-04-08 | The Rockefeller University | Anti-HIV antibody 10-1074 variants |
| CN109251246B (zh) * | 2018-09-14 | 2022-01-28 | 南开大学 | Hiv-1广谱中和抗体及其用途 |
| WO2020086782A1 (en) * | 2018-10-24 | 2020-04-30 | The Wistar Institute Of Anatomy And Biology | Dna antibody constructs for use against hiv |
| JP7566257B2 (ja) * | 2018-10-29 | 2024-10-15 | 株式会社 免疫生物研究所 | 抗hiv抗体及びその製造方法 |
| US11476145B2 (en) | 2018-11-20 | 2022-10-18 | Applied Materials, Inc. | Automatic ESC bias compensation when using pulsed DC bias |
| US12459989B2 (en) | 2018-11-21 | 2025-11-04 | Beth Israel Deaconess Medical Center, Inc. | Antibody therapies for human immunodeficiency virus (HIV) |
| CN118315254A (zh) | 2019-01-22 | 2024-07-09 | 应用材料公司 | 用于控制脉冲电压波形的反馈回路 |
| US11508554B2 (en) | 2019-01-24 | 2022-11-22 | Applied Materials, Inc. | High voltage filter assembly |
| US12070495B2 (en) | 2019-03-15 | 2024-08-27 | Modernatx, Inc. | HIV RNA vaccines |
| TW202231277A (zh) * | 2019-05-21 | 2022-08-16 | 美商基利科學股份有限公司 | 鑑別對使用gp120 v3聚醣導向之抗體的治療敏感之hiv病患的方法 |
| TWI810456B (zh) | 2019-05-22 | 2023-08-01 | 美商基利科學股份有限公司 | Tlr7調節化合物及hiv疫苗之組合 |
| US20220267416A1 (en) | 2019-07-15 | 2022-08-25 | Lausanne University Hospital | Hiv binding agents |
| KR20240137107A (ko) | 2019-07-16 | 2024-09-19 | 길리애드 사이언시즈, 인코포레이티드 | Hiv 백신, 및 이의 제조 및 사용 방법 |
| WO2021086953A1 (en) * | 2019-10-28 | 2021-05-06 | Georgia Tech Research Corporation | Compositions and methods for prophylaxis of hiv |
| US11848176B2 (en) | 2020-07-31 | 2023-12-19 | Applied Materials, Inc. | Plasma processing using pulsed-voltage and radio-frequency power |
| JP7518286B2 (ja) | 2020-08-25 | 2024-07-17 | ギリアード サイエンシーズ, インコーポレイテッド | Hivを標的とする多重特異性抗原結合分子及び使用方法 |
| TW202406932A (zh) | 2020-10-22 | 2024-02-16 | 美商基利科學股份有限公司 | 介白素2-Fc融合蛋白及使用方法 |
| PL4244396T3 (pl) | 2020-11-11 | 2025-12-22 | Gilead Sciences, Inc. | Sposoby identyfikacji pacjentów z hiv wrażliwych na terapię przeciwciałami skierowanymi na miejsce wiązania cd4 gp120 |
| US11798790B2 (en) | 2020-11-16 | 2023-10-24 | Applied Materials, Inc. | Apparatus and methods for controlling ion energy distribution |
| US11901157B2 (en) | 2020-11-16 | 2024-02-13 | Applied Materials, Inc. | Apparatus and methods for controlling ion energy distribution |
| CN116973566A (zh) * | 2021-02-03 | 2023-10-31 | 广东菲鹏生物有限公司 | 一种鉴别结合突变型抗原的抗体的方法及试剂 |
| US11495470B1 (en) | 2021-04-16 | 2022-11-08 | Applied Materials, Inc. | Method of enhancing etching selectivity using a pulsed plasma |
| US11791138B2 (en) | 2021-05-12 | 2023-10-17 | Applied Materials, Inc. | Automatic electrostatic chuck bias compensation during plasma processing |
| US11948780B2 (en) | 2021-05-12 | 2024-04-02 | Applied Materials, Inc. | Automatic electrostatic chuck bias compensation during plasma processing |
| US11967483B2 (en) | 2021-06-02 | 2024-04-23 | Applied Materials, Inc. | Plasma excitation with ion energy control |
| US12148595B2 (en) | 2021-06-09 | 2024-11-19 | Applied Materials, Inc. | Plasma uniformity control in pulsed DC plasma chamber |
| US20220399186A1 (en) | 2021-06-09 | 2022-12-15 | Applied Materials, Inc. | Method and apparatus to reduce feature charging in plasma processing chamber |
| US12525441B2 (en) | 2021-06-09 | 2026-01-13 | Applied Materials, Inc. | Plasma chamber and chamber component cleaning methods |
| US11810760B2 (en) | 2021-06-16 | 2023-11-07 | Applied Materials, Inc. | Apparatus and method of ion current compensation |
| US11569066B2 (en) | 2021-06-23 | 2023-01-31 | Applied Materials, Inc. | Pulsed voltage source for plasma processing applications |
| US11776788B2 (en) | 2021-06-28 | 2023-10-03 | Applied Materials, Inc. | Pulsed voltage boost for substrate processing |
| US11476090B1 (en) | 2021-08-24 | 2022-10-18 | Applied Materials, Inc. | Voltage pulse time-domain multiplexing |
| US12106938B2 (en) | 2021-09-14 | 2024-10-01 | Applied Materials, Inc. | Distortion current mitigation in a radio frequency plasma processing chamber |
| US11694876B2 (en) | 2021-12-08 | 2023-07-04 | Applied Materials, Inc. | Apparatus and method for delivering a plurality of waveform signals during plasma processing |
| US11972924B2 (en) | 2022-06-08 | 2024-04-30 | Applied Materials, Inc. | Pulsed voltage source for plasma processing applications |
| US12315732B2 (en) | 2022-06-10 | 2025-05-27 | Applied Materials, Inc. | Method and apparatus for etching a semiconductor substrate in a plasma etch chamber |
| CA3259040A1 (en) | 2022-07-12 | 2024-01-18 | Gilead Sciences, Inc. | HIV Immunogenic Polypeptides and Vaccines and Their Uses |
| US12586768B2 (en) | 2022-08-10 | 2026-03-24 | Applied Materials, Inc. | Pulsed voltage compensation for plasma processing applications |
| AU2023330037A1 (en) | 2022-08-26 | 2025-03-06 | Gilead Sciences, Inc. | Dosing and scheduling regimen for broadly neutralizing antibodies |
| US12272524B2 (en) | 2022-09-19 | 2025-04-08 | Applied Materials, Inc. | Wideband variable impedance load for high volume manufacturing qualification and on-site diagnostics |
| US12111341B2 (en) | 2022-10-05 | 2024-10-08 | Applied Materials, Inc. | In-situ electric field detection method and apparatus |
| WO2026039311A1 (en) | 2024-08-10 | 2026-02-19 | Vectorgen | Lentiviral vector for treating human immunodeficiency virus infection |
Family Cites Families (92)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3773919A (en) | 1969-10-23 | 1973-11-20 | Du Pont | Polylactide-drug mixtures |
| US3896111A (en) | 1973-02-20 | 1975-07-22 | Research Corp | Ansa macrolides |
| US4151042A (en) | 1977-03-31 | 1979-04-24 | Takeda Chemical Industries, Ltd. | Method for producing maytansinol and its derivatives |
| US4137230A (en) | 1977-11-14 | 1979-01-30 | Takeda Chemical Industries, Ltd. | Method for the production of maytansinoids |
| FR2413974A1 (fr) | 1978-01-06 | 1979-08-03 | David Bernard | Sechoir pour feuilles imprimees par serigraphie |
| US4307016A (en) | 1978-03-24 | 1981-12-22 | Takeda Chemical Industries, Ltd. | Demethyl maytansinoids |
| US4265814A (en) | 1978-03-24 | 1981-05-05 | Takeda Chemical Industries | Matansinol 3-n-hexadecanoate |
| JPS5562090A (en) | 1978-10-27 | 1980-05-10 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| JPS55164687A (en) | 1979-06-11 | 1980-12-22 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| JPS5566585A (en) | 1978-11-14 | 1980-05-20 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| US4256746A (en) | 1978-11-14 | 1981-03-17 | Takeda Chemical Industries | Dechloromaytansinoids, their pharmaceutical compositions and method of use |
| JPS55102583A (en) | 1979-01-31 | 1980-08-05 | Takeda Chem Ind Ltd | 20-acyloxy-20-demethylmaytansinoid compound |
| JPS55162791A (en) | 1979-06-05 | 1980-12-18 | Takeda Chem Ind Ltd | Antibiotic c-15003pnd and its preparation |
| JPS55164685A (en) | 1979-06-08 | 1980-12-22 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| JPS55164686A (en) | 1979-06-11 | 1980-12-22 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| US4309428A (en) | 1979-07-30 | 1982-01-05 | Takeda Chemical Industries, Ltd. | Maytansinoids |
| JPS5645483A (en) | 1979-09-19 | 1981-04-25 | Takeda Chem Ind Ltd | C-15003phm and its preparation |
| JPS5645485A (en) | 1979-09-21 | 1981-04-25 | Takeda Chem Ind Ltd | Production of c-15003pnd |
| EP0028683A1 (en) | 1979-09-21 | 1981-05-20 | Takeda Chemical Industries, Ltd. | Antibiotic C-15003 PHO and production thereof |
| WO1981001145A1 (en) | 1979-10-18 | 1981-04-30 | Univ Illinois | Hydrolytic enzyme-activatible pro-drugs |
| WO1982001188A1 (en) | 1980-10-08 | 1982-04-15 | Takeda Chemical Industries Ltd | 4,5-deoxymaytansinoide compounds and process for preparing same |
| US4450254A (en) | 1980-11-03 | 1984-05-22 | Standard Oil Company | Impact improvement of high nitrile resins |
| US4554101A (en) | 1981-01-09 | 1985-11-19 | New York Blood Center, Inc. | Identification and preparation of epitopes on antigens and allergens on the basis of hydrophilicity |
| US4313946A (en) | 1981-01-27 | 1982-02-02 | The United States Of America As Represented By The Secretary Of Agriculture | Chemotherapeutically active maytansinoids from Trewia nudiflora |
| US4315929A (en) | 1981-01-27 | 1982-02-16 | The United States Of America As Represented By The Secretary Of Agriculture | Method of controlling the European corn borer with trewiasine |
| JPS57192389A (en) | 1981-05-20 | 1982-11-26 | Takeda Chem Ind Ltd | Novel maytansinoid |
| US4485045A (en) | 1981-07-06 | 1984-11-27 | Research Corporation | Synthetic phosphatidyl cholines useful in forming liposomes |
| NZ201705A (en) | 1981-08-31 | 1986-03-14 | Genentech Inc | Recombinant dna method for production of hepatitis b surface antigen in yeast |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| DD266710A3 (de) | 1983-06-06 | 1989-04-12 | Ve Forschungszentrum Biotechnologie | Verfahren zur biotechnischen Herstellung van alkalischer Phosphatase |
| US4544545A (en) | 1983-06-20 | 1985-10-01 | Trustees University Of Massachusetts | Liposomes containing modified cholesterol for organ targeting |
| US4879231A (en) | 1984-10-30 | 1989-11-07 | Phillips Petroleum Company | Transformation of yeasts of the genus pichia |
| US4683202A (en) | 1985-03-28 | 1987-07-28 | Cetus Corporation | Process for amplifying nucleic acid sequences |
| US4676980A (en) | 1985-09-23 | 1987-06-30 | The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Target specific cross-linked heteroantibodies |
| GB8610600D0 (en) | 1986-04-30 | 1986-06-04 | Novo Industri As | Transformation of trichoderma |
| US5567610A (en) | 1986-09-04 | 1996-10-22 | Bioinvent International Ab | Method of producing human monoclonal antibodies and kit therefor |
| IL85035A0 (en) | 1987-01-08 | 1988-06-30 | Int Genetic Eng | Polynucleotide molecule,a chimeric antibody with specificity for human b cell surface antigen,a process for the preparation and methods utilizing the same |
| GB8705477D0 (en) | 1987-03-09 | 1987-04-15 | Carlton Med Prod | Drug delivery systems |
| US4975278A (en) | 1988-02-26 | 1990-12-04 | Bristol-Myers Company | Antibody-enzyme conjugates in combination with prodrugs for the delivery of cytotoxic agents to tumor cells |
| US5053394A (en) | 1988-09-21 | 1991-10-01 | American Cyanamid Company | Targeted forms of methyltrithio antitumor agents |
| US5606040A (en) | 1987-10-30 | 1997-02-25 | American Cyanamid Company | Antitumor and antibacterial substituted disulfide derivatives prepared from compounds possessing a methyl-trithio group |
| US5770701A (en) | 1987-10-30 | 1998-06-23 | American Cyanamid Company | Process for preparing targeted forms of methyltrithio antitumor agents |
| GB8823869D0 (en) | 1988-10-12 | 1988-11-16 | Medical Res Council | Production of antibodies |
| EP0368684B2 (en) | 1988-11-11 | 2004-09-29 | Medical Research Council | Cloning immunoglobulin variable domain sequences. |
| US5175384A (en) | 1988-12-05 | 1992-12-29 | Genpharm International | Transgenic mice depleted in mature t-cells and methods for making transgenic mice |
| FR2646437B1 (fr) | 1989-04-28 | 1991-08-30 | Transgene Sa | Nouvelles sequences d'adn, leur application en tant que sequence codant pour un peptide signal pour la secretion de proteines matures par des levures recombinantes, cassettes d'expression, levures transformees et procede de preparation de proteines correspondant |
| EP0402226A1 (en) | 1989-06-06 | 1990-12-12 | Institut National De La Recherche Agronomique | Transformation vectors for yeast yarrowia |
| DE3920358A1 (de) | 1989-06-22 | 1991-01-17 | Behringwerke Ag | Bispezifische und oligospezifische, mono- und oligovalente antikoerperkonstrukte, ihre herstellung und verwendung |
| ES2096590T3 (es) | 1989-06-29 | 1997-03-16 | Medarex Inc | Reactivos biespecificos para la terapia del sida. |
| US5013556A (en) | 1989-10-20 | 1991-05-07 | Liposome Technology, Inc. | Liposomes with enhanced circulation time |
| US5208020A (en) | 1989-10-25 | 1993-05-04 | Immunogen Inc. | Cytotoxic agents comprising maytansinoids and their therapeutic use |
| CA2026147C (en) | 1989-10-25 | 2006-02-07 | Ravi J. Chari | Cytotoxic agents comprising maytansinoids and their therapeutic use |
| US7041293B1 (en) * | 1990-04-03 | 2006-05-09 | Genentech, Inc. | HIV env antibodies |
| US5229275A (en) | 1990-04-26 | 1993-07-20 | Akzo N.V. | In-vitro method for producing antigen-specific human monoclonal antibodies |
| WO1992000373A1 (en) | 1990-06-29 | 1992-01-09 | Biosource Genetics Corporation | Melanin production by transformed microorganisms |
| CA2090126C (en) | 1990-08-02 | 2002-10-22 | John W. Schrader | Methods for the production of proteins with a desired function |
| US5545806A (en) | 1990-08-29 | 1996-08-13 | Genpharm International, Inc. | Ransgenic non-human animals for producing heterologous antibodies |
| ATE158021T1 (de) | 1990-08-29 | 1997-09-15 | Genpharm Int | Produktion und nützung nicht-menschliche transgentiere zur produktion heterologe antikörper |
| US5571894A (en) | 1991-02-05 | 1996-11-05 | Ciba-Geigy Corporation | Recombinant antibodies specific for a growth factor receptor |
| WO1992020373A1 (en) | 1991-05-14 | 1992-11-26 | Repligen Corporation | Heteroconjugate antibodies for treatment of hiv infection |
| EP1400536A1 (en) | 1991-06-14 | 2004-03-24 | Genentech Inc. | Method for making humanized antibodies |
| US7018809B1 (en) | 1991-09-19 | 2006-03-28 | Genentech, Inc. | Expression of functional antibody fragments |
| FI941572A7 (fi) | 1991-10-07 | 1994-05-27 | Oncologix Inc | Anti-erbB-2-monoklonaalisten vasta-aineiden yhdistelmä ja käyttömenete lmä |
| WO1993008829A1 (en) | 1991-11-04 | 1993-05-13 | The Regents Of The University Of California | Compositions that mediate killing of hiv-infected cells |
| ATE207080T1 (de) | 1991-11-25 | 2001-11-15 | Enzon Inc | Multivalente antigen-bindende proteine |
| CA2372813A1 (en) | 1992-02-06 | 1993-08-19 | L.L. Houston | Biosynthetic binding protein for cancer marker |
| ZA932522B (en) | 1992-04-10 | 1993-12-20 | Res Dev Foundation | Immunotoxins directed against c-erbB-2(HER/neu) related surface antigens |
| CA2140280A1 (en) | 1992-08-17 | 1994-03-03 | Avi J. Ashkenazi | Bispecific immunoadhesins |
| DK0752248T3 (da) | 1992-11-13 | 2000-11-13 | Idec Pharma Corp | Terapeutisk anvendelse af kimæriske og radioaktivt mærkede antistoffer mod humant B-lymfocytbegrænset differentieringsantig |
| ES2162863T3 (es) | 1993-04-29 | 2002-01-16 | Unilever Nv | Produccion de anticuerpos o fragmentos (funcionalizados) de los mismos derivados de inmunoglobulinas de cadena pesada de camelidae. |
| US5773001A (en) | 1994-06-03 | 1998-06-30 | American Cyanamid Company | Conjugates of methyltrithio antitumor agents and intermediates for their synthesis |
| US5789199A (en) | 1994-11-03 | 1998-08-04 | Genentech, Inc. | Process for bacterial production of polypeptides |
| US6214388B1 (en) | 1994-11-09 | 2001-04-10 | The Regents Of The University Of California | Immunoliposomes that optimize internalization into target cells |
| AU4289496A (en) | 1994-12-02 | 1996-06-19 | Chiron Corporation | Method of promoting an immune response with a bispecific antibody |
| US5840523A (en) | 1995-03-01 | 1998-11-24 | Genetech, Inc. | Methods and compositions for secretion of heterologous polypeptides |
| US5731168A (en) | 1995-03-01 | 1998-03-24 | Genentech, Inc. | Method for making heteromultimeric polypeptides |
| US5641870A (en) | 1995-04-20 | 1997-06-24 | Genentech, Inc. | Low pH hydrophobic interaction chromatography for antibody purification |
| US5739277A (en) | 1995-04-14 | 1998-04-14 | Genentech Inc. | Altered polypeptides with increased half-life |
| US5869046A (en) | 1995-04-14 | 1999-02-09 | Genentech, Inc. | Altered polypeptides with increased half-life |
| US5712374A (en) | 1995-06-07 | 1998-01-27 | American Cyanamid Company | Method for the preparation of substantiallly monomeric calicheamicin derivative/carrier conjugates |
| US5714586A (en) | 1995-06-07 | 1998-02-03 | American Cyanamid Company | Methods for the preparation of monomeric calicheamicin derivative/carrier conjugates |
| US5837234A (en) | 1995-06-07 | 1998-11-17 | Cytotherapeutics, Inc. | Bioartificial organ containing cells encapsulated in a permselective polyether suflfone membrane |
| DE19544393A1 (de) | 1995-11-15 | 1997-05-22 | Hoechst Schering Agrevo Gmbh | Synergistische herbizide Mischungen |
| US5922845A (en) | 1996-07-11 | 1999-07-13 | Medarex, Inc. | Therapeutic multispecific compounds comprised of anti-Fcα receptor antibodies |
| US6824780B1 (en) | 1999-10-29 | 2004-11-30 | Genentech, Inc. | Anti-tumor antibody compositions and methods of use |
| EP1588166A4 (en) | 2003-01-09 | 2007-06-27 | Macrogenics Inc | VECTOR SYSTEM WITH DOUBLE EXPRESSION FOR EXPRESSING ANTIBODIES IN BACTERIAL AND MAMMAL CELLS |
| AU2004215125B2 (en) | 2003-02-26 | 2011-01-06 | Institute For Research In Biomedicine | Monoclonal antibody production by EBV transformation of B cells |
| US20080279879A1 (en) * | 2006-11-17 | 2008-11-13 | New York University | INDUCTION OF BROADLY REACTIVE NEUTRALIZING ANTIBODIES BY FOCUSING THE IMMUNE RESPONSE ON V3 EPITOPES OF THE HIV-1 gp120 ENVELOPE |
| CN102272158B (zh) | 2008-11-12 | 2014-05-07 | 乔治·K·刘易斯 | 源自记忆b细胞的人单克隆抗体的快速表达克隆 |
| US20100215691A1 (en) * | 2009-02-20 | 2010-08-26 | Parks Christopher L | Recombinant viral vectors |
| SI3260136T1 (sl) * | 2009-03-17 | 2021-05-31 | Theraclone Sciences, Inc. | Humani imunodeficientni virus (HIV)-nevtralizirajoča protitelesa |
| PT3556396T (pt) * | 2010-08-31 | 2022-07-04 | Scripps Research Inst | Anticorpos neutralizantes do vírus da imunodeficiência humana (vih) |
-
2011
- 2011-08-31 PT PT191568849T patent/PT3556396T/pt unknown
- 2011-08-31 EP EP23163985.7A patent/EP4226935A3/en active Pending
- 2011-08-31 EP EP14004015.5A patent/EP2926830B1/en active Active
- 2011-08-31 EP EP16206293.9A patent/EP3178489B1/en active Active
- 2011-08-31 ES ES16206293T patent/ES2774369T3/es active Active
- 2011-08-31 EP EP19156884.9A patent/EP3556396B1/en active Active
- 2011-08-31 ES ES19156884T patent/ES2920140T3/es active Active
- 2011-08-31 PL PL19156884.9T patent/PL3556396T3/pl unknown
- 2011-08-31 CA CA2809837A patent/CA2809837C/en active Active
- 2011-08-31 EP EP22168900.3A patent/EP4085924A1/en not_active Withdrawn
- 2011-08-31 CA CA3059961A patent/CA3059961C/en active Active
- 2011-08-31 CA CA3201524A patent/CA3201524C/en active Active
- 2011-08-31 SI SI201132061T patent/SI3556396T1/sl unknown
- 2011-08-31 EP EP24215148.8A patent/EP4549461A3/en active Pending
- 2011-08-31 EP EP11822530.9A patent/EP2611465A4/en not_active Withdrawn
- 2011-08-31 WO PCT/US2011/049880 patent/WO2012030904A2/en not_active Ceased
- 2011-08-31 AU AU2011296065A patent/AU2011296065B2/en active Active
- 2011-08-31 CA CA3109036A patent/CA3109036C/en active Active
- 2011-08-31 CA CA3249351A patent/CA3249351A1/en active Pending
-
2013
- 2013-02-28 US US13/780,776 patent/US9464131B2/en active Active
-
2016
- 2016-04-21 AU AU2016202543A patent/AU2016202543B2/en active Active
- 2016-05-12 US US15/152,630 patent/US10087239B2/en active Active
-
2017
- 2017-09-12 US US15/701,679 patent/US10836811B2/en active Active
-
2018
- 2018-01-04 AU AU2018200064A patent/AU2018200064B2/en active Active
-
2019
- 2019-10-02 US US16/591,175 patent/US11319362B2/en active Active
-
2020
- 2020-06-11 AU AU2020203853A patent/AU2020203853C1/en active Active
-
2021
- 2021-07-15 US US17/376,276 patent/US11845789B2/en active Active
-
2023
- 2023-08-18 US US18/452,002 patent/US12410243B2/en active Active
- 2023-09-26 AU AU2023237056A patent/AU2023237056B2/en active Active
-
2024
- 2024-05-30 AU AU2024203628A patent/AU2024203628A1/en active Pending
-
2025
- 2025-01-18 US US19/031,993 patent/US20250320281A1/en active Pending
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12312396B2 (en) | Monoclonal antibodies directed against trimeric forms of the HIV-1 envelope glycoprotein with broad and potent neutralizing activity | |
| US12410243B2 (en) | Methods of treating HIV-1 infection utilizing broadly neutralizing human immunodeficiency virus type 1 (HIV-1) GP120-specific monoclonal antibodies | |
| HK40123786A (en) | Human immunodeficiency virus (hiv)-neutralizing antibodies | |
| HK40101330A (en) | Human immunodeficiency virus (hiv)-neutralizing antibodies | |
| HK40076894A (en) | Human immunodeficiency virus (hiv)-neutralizing antibodies | |
| HK1240077A1 (en) | Human immunodeficiency virus (hiv)-neutralizing antibodies | |
| HK1240077B (en) | Human immunodeficiency virus (hiv)-neutralizing antibodies |