FR2769921A1 - Moyens de documentation de repertoires en immunorecepteurs nkr et/ou en immunorecepteurs contreparties activatrices ou non inhibitrices d'immunorecepteurs nkr - Google Patents
Moyens de documentation de repertoires en immunorecepteurs nkr et/ou en immunorecepteurs contreparties activatrices ou non inhibitrices d'immunorecepteurs nkr Download PDFInfo
- Publication number
- FR2769921A1 FR2769921A1 FR9713115A FR9713115A FR2769921A1 FR 2769921 A1 FR2769921 A1 FR 2769921A1 FR 9713115 A FR9713115 A FR 9713115A FR 9713115 A FR9713115 A FR 9713115A FR 2769921 A1 FR2769921 A1 FR 2769921A1
- Authority
- FR
- France
- Prior art keywords
- sep
- oligonucleotide
- sequence
- nkr
- seq
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 208000015181 infectious disease Diseases 0.000 title claims description 3
- 238000012544 monitoring process Methods 0.000 title claims 5
- 108091034117 Oligonucleotide Proteins 0.000 claims abstract description 179
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 claims abstract description 78
- 238000000034 method Methods 0.000 claims abstract description 42
- 241000282414 Homo sapiens Species 0.000 claims abstract description 27
- 102100022682 NKG2-A/NKG2-B type II integral membrane protein Human genes 0.000 claims abstract description 15
- 101150069255 KLRC1 gene Proteins 0.000 claims abstract description 9
- 101100404845 Macaca mulatta NKG2A gene Proteins 0.000 claims abstract description 9
- 239000000872 buffer Substances 0.000 claims abstract description 9
- TWRXJAOTZQYOKJ-UHFFFAOYSA-L Magnesium chloride Chemical compound [Mg+2].[Cl-].[Cl-] TWRXJAOTZQYOKJ-UHFFFAOYSA-L 0.000 claims abstract description 8
- 101001109503 Homo sapiens NKG2-C type II integral membrane protein Proteins 0.000 claims abstract description 7
- 102100022683 NKG2-C type II integral membrane protein Human genes 0.000 claims abstract description 7
- 238000011534 incubation Methods 0.000 claims abstract description 6
- 229910001629 magnesium chloride Inorganic materials 0.000 claims abstract description 4
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 claims abstract description 3
- 239000003153 chemical reaction reagent Substances 0.000 claims abstract description 3
- 238000000338 in vitro Methods 0.000 claims abstract description 3
- -1 p58.2 Proteins 0.000 claims abstract 3
- 108020004414 DNA Proteins 0.000 claims description 47
- 239000002299 complementary DNA Substances 0.000 claims description 40
- 210000004027 cell Anatomy 0.000 claims description 31
- 239000002773 nucleotide Substances 0.000 claims description 30
- 125000003729 nucleotide group Chemical group 0.000 claims description 30
- 238000009396 hybridization Methods 0.000 claims description 26
- 102100023678 Killer cell lectin-like receptor subfamily B member 1 Human genes 0.000 claims description 18
- 210000000822 natural killer cell Anatomy 0.000 claims description 17
- 241001465754 Metazoa Species 0.000 claims description 14
- 108010001880 NK Cell Lectin-Like Receptor Subfamily C Proteins 0.000 claims description 12
- 102000000834 NK Cell Lectin-Like Receptor Subfamily C Human genes 0.000 claims description 12
- 239000012472 biological sample Substances 0.000 claims description 12
- 210000001519 tissue Anatomy 0.000 claims description 12
- 101710175177 Very-long-chain 3-oxoacyl-CoA reductase Proteins 0.000 claims description 11
- 101710187138 Very-long-chain 3-oxoacyl-CoA reductase-A Proteins 0.000 claims description 11
- 101710187143 Very-long-chain 3-oxoacyl-CoA reductase-B Proteins 0.000 claims description 11
- 210000000056 organ Anatomy 0.000 claims description 11
- 101001109501 Homo sapiens NKG2-D type II integral membrane protein Proteins 0.000 claims description 10
- 102100022680 NKG2-D type II integral membrane protein Human genes 0.000 claims description 10
- 230000000694 effects Effects 0.000 claims description 10
- 238000002054 transplantation Methods 0.000 claims description 9
- 108010043610 KIR Receptors Proteins 0.000 claims description 7
- 102000002698 KIR Receptors Human genes 0.000 claims description 7
- 101001109508 Homo sapiens NKG2-A/NKG2-B type II integral membrane protein Proteins 0.000 claims description 6
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 6
- 150000001413 amino acids Chemical class 0.000 claims description 6
- 238000001514 detection method Methods 0.000 claims description 6
- 239000003550 marker Substances 0.000 claims description 6
- 208000023275 Autoimmune disease Diseases 0.000 claims description 5
- 102100037363 Killer cell immunoglobulin-like receptor 2DL1 Human genes 0.000 claims description 5
- 230000002349 favourable effect Effects 0.000 claims description 5
- 230000003211 malignant effect Effects 0.000 claims description 5
- 230000004913 activation Effects 0.000 claims description 4
- 210000001185 bone marrow Anatomy 0.000 claims description 4
- 230000002068 genetic effect Effects 0.000 claims description 4
- 238000007857 nested PCR Methods 0.000 claims description 4
- 238000012216 screening Methods 0.000 claims description 4
- 108020004635 Complementary DNA Proteins 0.000 claims description 3
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 claims description 3
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 claims description 3
- 241000234435 Lilium Species 0.000 claims description 3
- YPLVCBKEPJPBDQ-MELADBBJSA-N Lys-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N YPLVCBKEPJPBDQ-MELADBBJSA-N 0.000 claims description 3
- 208000030852 Parasitic disease Diseases 0.000 claims description 3
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 claims description 3
- 238000011161 development Methods 0.000 claims description 3
- 229940079593 drug Drugs 0.000 claims description 3
- 239000003814 drug Substances 0.000 claims description 3
- 208000035143 Bacterial infection Diseases 0.000 claims description 2
- 208000035473 Communicable disease Diseases 0.000 claims description 2
- 101150074862 KLRC3 gene Proteins 0.000 claims description 2
- 102100022701 NKG2-E type II integral membrane protein Human genes 0.000 claims description 2
- 208000036142 Viral infection Diseases 0.000 claims description 2
- 208000022362 bacterial infectious disease Diseases 0.000 claims description 2
- 210000004698 lymphocyte Anatomy 0.000 claims description 2
- 201000004792 malaria Diseases 0.000 claims description 2
- 230000007918 pathogenicity Effects 0.000 claims description 2
- 210000005259 peripheral blood Anatomy 0.000 claims description 2
- 239000011886 peripheral blood Substances 0.000 claims description 2
- 229920002401 polyacrylamide Polymers 0.000 claims description 2
- 230000002285 radioactive effect Effects 0.000 claims description 2
- 239000011541 reaction mixture Substances 0.000 claims description 2
- 239000000523 sample Substances 0.000 claims description 2
- 230000009261 transgenic effect Effects 0.000 claims description 2
- 230000009385 viral infection Effects 0.000 claims description 2
- 208000031886 HIV Infections Diseases 0.000 claims 1
- 208000037357 HIV infectious disease Diseases 0.000 claims 1
- VEPIBPGLTLPBDW-URLPEUOOSA-N Ile-Phe-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N VEPIBPGLTLPBDW-URLPEUOOSA-N 0.000 claims 1
- 201000010099 disease Diseases 0.000 claims 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims 1
- 208000033519 human immunodeficiency virus infectious disease Diseases 0.000 claims 1
- 230000001173 tumoral effect Effects 0.000 claims 1
- 239000001103 potassium chloride Substances 0.000 abstract description 3
- WCUXLLCKKVVCTQ-UHFFFAOYSA-M Potassium chloride Chemical compound [Cl-].[K+] WCUXLLCKKVVCTQ-UHFFFAOYSA-M 0.000 abstract 2
- 239000012805 animal sample Substances 0.000 abstract 1
- 235000011164 potassium chloride Nutrition 0.000 abstract 1
- 108020003175 receptors Proteins 0.000 description 98
- 102000005962 receptors Human genes 0.000 description 98
- 150000007523 nucleic acids Chemical class 0.000 description 52
- 108020004707 nucleic acids Proteins 0.000 description 26
- 102000039446 nucleic acids Human genes 0.000 description 26
- 102100033634 Killer cell immunoglobulin-like receptor 2DL3 Human genes 0.000 description 15
- 239000012190 activator Substances 0.000 description 12
- 239000003112 inhibitor Substances 0.000 description 12
- 230000002401 inhibitory effect Effects 0.000 description 12
- 238000003752 polymerase chain reaction Methods 0.000 description 12
- 238000000137 annealing Methods 0.000 description 11
- 239000013615 primer Substances 0.000 description 10
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 9
- 239000000047 product Substances 0.000 description 9
- 101000804877 Schizosaccharomyces pombe (strain 972 / ATCC 24843) 5'-3' exoribonuclease 1 Proteins 0.000 description 8
- 238000006243 chemical reaction Methods 0.000 description 8
- 238000002360 preparation method Methods 0.000 description 8
- 210000004988 splenocyte Anatomy 0.000 description 8
- 238000012408 PCR amplification Methods 0.000 description 7
- 230000003213 activating effect Effects 0.000 description 7
- 238000011830 transgenic mouse model Methods 0.000 description 7
- 230000003321 amplification Effects 0.000 description 5
- 239000008346 aqueous phase Substances 0.000 description 5
- 239000012634 fragment Substances 0.000 description 5
- 239000003446 ligand Substances 0.000 description 5
- 238000003199 nucleic acid amplification method Methods 0.000 description 5
- 239000008188 pellet Substances 0.000 description 5
- 101000945333 Homo sapiens Killer cell immunoglobulin-like receptor 2DL3 Proteins 0.000 description 4
- 241000699660 Mus musculus Species 0.000 description 4
- 239000000427 antigen Substances 0.000 description 4
- 108091007433 antigens Proteins 0.000 description 4
- 102000036639 antigens Human genes 0.000 description 4
- 208000032839 leukemia Diseases 0.000 description 4
- 239000000203 mixture Substances 0.000 description 4
- 238000003757 reverse transcription PCR Methods 0.000 description 4
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 3
- 102000007469 Actins Human genes 0.000 description 3
- 108010085238 Actins Proteins 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- 101000945490 Homo sapiens Killer cell immunoglobulin-like receptor 3DL2 Proteins 0.000 description 3
- 108060003951 Immunoglobulin Proteins 0.000 description 3
- 102100034840 Killer cell immunoglobulin-like receptor 3DL2 Human genes 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- 238000007792 addition Methods 0.000 description 3
- 230000000735 allogeneic effect Effects 0.000 description 3
- 238000005119 centrifugation Methods 0.000 description 3
- 230000009089 cytolysis Effects 0.000 description 3
- 102000018358 immunoglobulin Human genes 0.000 description 3
- 239000012074 organic phase Substances 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 230000001225 therapeutic effect Effects 0.000 description 3
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 2
- HEDRZPFGACZZDS-UHFFFAOYSA-N Chloroform Chemical compound ClC(Cl)Cl HEDRZPFGACZZDS-UHFFFAOYSA-N 0.000 description 2
- 108091026890 Coding region Proteins 0.000 description 2
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 2
- 101000945339 Homo sapiens Killer cell immunoglobulin-like receptor 2DS2 Proteins 0.000 description 2
- 101000945342 Homo sapiens Killer cell immunoglobulin-like receptor 2DS4 Proteins 0.000 description 2
- 101000581981 Homo sapiens Neural cell adhesion molecule 1 Proteins 0.000 description 2
- KFZMGEQAYNKOFK-UHFFFAOYSA-N Isopropanol Chemical compound CC(C)O KFZMGEQAYNKOFK-UHFFFAOYSA-N 0.000 description 2
- 101150018199 KLRC4 gene Proteins 0.000 description 2
- 102100033630 Killer cell immunoglobulin-like receptor 2DS2 Human genes 0.000 description 2
- 102100033624 Killer cell immunoglobulin-like receptor 2DS4 Human genes 0.000 description 2
- 108090001090 Lectins Proteins 0.000 description 2
- 102000004856 Lectins Human genes 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- 102100022700 NKG2-F type II integral membrane protein Human genes 0.000 description 2
- 206010028980 Neoplasm Diseases 0.000 description 2
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 description 2
- SPLBRAKYXGOFSO-UNQGMJICSA-N Pro-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@@H]2CCCN2)O SPLBRAKYXGOFSO-UNQGMJICSA-N 0.000 description 2
- 108010006785 Taq Polymerase Proteins 0.000 description 2
- 239000011543 agarose gel Substances 0.000 description 2
- 238000004925 denaturation Methods 0.000 description 2
- 230000036425 denaturation Effects 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 230000001900 immune effect Effects 0.000 description 2
- 210000000987 immune system Anatomy 0.000 description 2
- 108091008042 inhibitory receptors Proteins 0.000 description 2
- PHTQWCKDNZKARW-UHFFFAOYSA-N isoamylol Chemical compound CC(C)CCO PHTQWCKDNZKARW-UHFFFAOYSA-N 0.000 description 2
- 239000002523 lectin Substances 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- 239000013642 negative control Substances 0.000 description 2
- 238000001556 precipitation Methods 0.000 description 2
- 108090000765 processed proteins & peptides Proteins 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- 238000012163 sequencing technique Methods 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 238000011282 treatment Methods 0.000 description 2
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- 206010057248 Cell death Diseases 0.000 description 1
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 description 1
- 108010036949 Cyclosporine Proteins 0.000 description 1
- 108090000695 Cytokines Proteins 0.000 description 1
- 102000004127 Cytokines Human genes 0.000 description 1
- 239000003155 DNA primer Substances 0.000 description 1
- 102100028972 HLA class I histocompatibility antigen, A alpha chain Human genes 0.000 description 1
- 102100028976 HLA class I histocompatibility antigen, B alpha chain Human genes 0.000 description 1
- 108010075704 HLA-A Antigens Proteins 0.000 description 1
- 108010058607 HLA-B Antigens Proteins 0.000 description 1
- 102000006354 HLA-DR Antigens Human genes 0.000 description 1
- 108010058597 HLA-DR Antigens Proteins 0.000 description 1
- 206010066476 Haematological malignancy Diseases 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000945331 Homo sapiens Killer cell immunoglobulin-like receptor 2DL4 Proteins 0.000 description 1
- 101000945351 Homo sapiens Killer cell immunoglobulin-like receptor 3DL1 Proteins 0.000 description 1
- 101000945492 Homo sapiens Killer cell immunoglobulin-like receptor 3DS1 Proteins 0.000 description 1
- 102100034343 Integrase Human genes 0.000 description 1
- 102100033633 Killer cell immunoglobulin-like receptor 2DL4 Human genes 0.000 description 1
- 102100033627 Killer cell immunoglobulin-like receptor 3DL1 Human genes 0.000 description 1
- 102100034833 Killer cell immunoglobulin-like receptor 3DS1 Human genes 0.000 description 1
- 102000043129 MHC class I family Human genes 0.000 description 1
- 108091054437 MHC class I family Proteins 0.000 description 1
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 1
- 241001101720 Murgantia histrionica Species 0.000 description 1
- 208000001388 Opportunistic Infections Diseases 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 206010052779 Transplant rejections Diseases 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- 238000000246 agarose gel electrophoresis Methods 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 238000011319 anticancer therapy Methods 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 238000010322 bone marrow transplantation Methods 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 229960001265 ciclosporin Drugs 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 229930182912 cyclosporin Natural products 0.000 description 1
- WRTKMPONLHLBBL-KVQBGUIXSA-N dXTP Chemical compound O1[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)C[C@@H]1N1C(NC(=O)NC2=O)=C2N=C1 WRTKMPONLHLBBL-KVQBGUIXSA-N 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000002939 deleterious effect Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 239000005549 deoxyribonucleoside Substances 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 230000003394 haemopoietic effect Effects 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- 230000036737 immune function Effects 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 238000002650 immunosuppressive therapy Methods 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 239000002198 insoluble material Substances 0.000 description 1
- 230000003902 lesion Effects 0.000 description 1
- 210000000265 leukocyte Anatomy 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 230000002934 lysing effect Effects 0.000 description 1
- 230000000813 microbial effect Effects 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- 206010039073 rheumatoid arthritis Diseases 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 230000020382 suppression by virus of host antigen processing and presentation of peptide antigen via MHC class I Effects 0.000 description 1
- 238000002560 therapeutic procedure Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 239000001226 triphosphate Substances 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- UNXRWKVEANCORM-UHFFFAOYSA-N triphosphoric acid Chemical compound OP(O)(=O)OP(O)(=O)OP(O)(O)=O UNXRWKVEANCORM-UHFFFAOYSA-N 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- 238000001291 vacuum drying Methods 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6881—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for tissue or cell typing, e.g. human leukocyte antigen [HLA] probes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Immunology (AREA)
- General Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Wood Science & Technology (AREA)
- Analytical Chemistry (AREA)
- Zoology (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Medicinal Chemistry (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Biotechnology (AREA)
- Microbiology (AREA)
- Physics & Mathematics (AREA)
- Biochemistry (AREA)
- Cell Biology (AREA)
- General Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Communicable Diseases (AREA)
- Oncology (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
L'invention concerne une méthode in vitro de documentation d'un répertoire en immunorécepteur (s) NKR et/ou contreparties de NKR, comprenant i. l'utilisation d'au moins une paire d'oligonucléotides 3' et 5' capable de s'hybrider à un récepteur cible NKR, ou contrepartie de NKR, et de ne pas s'hybrider à un récepteur contrepartie fonctionnelle de ce récepteur cible, ii. la mise en contact de cette paire d'oligonucléotides 3' et 5' avec l'ADN ou ADNc d'un échantillon à étudier, et iii. la détection des hybrides éventuellement formés. L'invention vise également les applications biologiques de cette méthode, notamment criblage de banques d'organes, tissus, cellules en vue de greffes, et à des kits pour sa mise en oeuvre.
Description
Moyens de documentation de répertoires
en immunorécepteurs NKR et/ou en irtirnunorécepteurs
contreparties activatrices ou non inhibitrices
d'immunorécepteurs NKR
La présente invention concerne des moyens permettant de documenter les répertoires d'un individu humain ou animal en immunorécepteurs NKR (Natural Killer Receptor) du type des immunoglobulines ou du type des lectines, et en immunorécepteurs contreparties activatrices, ou à tout le moins non inhibitrices, d'immunorécepteurs NKR Elle vise également leurs applications biologiques.
en immunorécepteurs NKR et/ou en irtirnunorécepteurs
contreparties activatrices ou non inhibitrices
d'immunorécepteurs NKR
La présente invention concerne des moyens permettant de documenter les répertoires d'un individu humain ou animal en immunorécepteurs NKR (Natural Killer Receptor) du type des immunoglobulines ou du type des lectines, et en immunorécepteurs contreparties activatrices, ou à tout le moins non inhibitrices, d'immunorécepteurs NKR Elle vise également leurs applications biologiques.
Les fonctions immunitaires d'un homme ou d'un animal sont définies par plusieurs catégories de molécules hautement diversifiées, telles que notamment le système des groupes sanguins AD, la famille des molécules du CMH
(Complexe Majeur d'Histocompatibilité, appelé chez l'homme, système HLA -Human Leukocyte Antigen-), la famille des récepteurs pour l'antigène des lymphocytes T (TCR) et des lymphocytes B ( BCR) . L'ensemble des molécules qu'un individu adulte exprime, ou est capable d' exprimer, pour chacune de ces différentes familles constitue, exception faite des vrais jumeaux, un répertoire évolutif qui lui est propre et qui intervient dans la reconnaissance du soi ou du non-soi.
(Complexe Majeur d'Histocompatibilité, appelé chez l'homme, système HLA -Human Leukocyte Antigen-), la famille des récepteurs pour l'antigène des lymphocytes T (TCR) et des lymphocytes B ( BCR) . L'ensemble des molécules qu'un individu adulte exprime, ou est capable d' exprimer, pour chacune de ces différentes familles constitue, exception faite des vrais jumeaux, un répertoire évolutif qui lui est propre et qui intervient dans la reconnaissance du soi ou du non-soi.
D' autres grands répertoires ont été plus récemment identifiés. I1 s'agit du répertoire en récepteurs NKR de type immunoglobuline et du répertoire en récepteurs NKR de type lectine. Les recepteurs NKR de type immunoglobuline comprennent les récepteurs KIR (Killer cell Inhibitory
Receptor) tels que notamment les récepteurs p58.l, p58.2, p70. INH, pl40. INH. Les récepteurs NKR de type lectine comprennent les récepteurs inhibiteurs NKG2 tels que notamment les récepteurs NKG2A et NKG2B L'ensemble de ces récepteurs NKR sont à fonction inhibitrice. Des récepteurs qui leur sont hautement homologues, en particulier au niveau extracytoplasmique, assurent toutefois des fonctions activatrices, ou à tout le moins non inhibitrices : il s'agit des récepteurs KAR (Killer cell Activatory Receptor) homologues aux récepteurs KIR, et des récepteurs NKG2C,
NKG2D, NKG2E et NKG2F homologues aux récepteurs NKG2A et
NKG2 B Les récepteurs contreparties activatrices, ou à tout le moins non inhibitrices, de récepteurs inhibiteurs NKR sont ci-après désignés, par souci de fluidité, contreparties de NKR
Les récepteurs NKR et les récepteurs contreparties de
NKR sont naturellement exprimés par les cellules NK et par des sous-populations de cellules T. Plusieurs de ces récepteurs peuvent être exprimés par une même cellule. Tous ces récepteurs, qu'ils soient inhibiteurs (i.e. NKR) ou qu ils soient activateurs ou non inhibiteurs (î.e. contreparties de NKR), ont en commun d'avoir pour ligand des molécules qui ne sont pas dérivées d'antigène : les ligands des récepteurs NKR et des récepteurs contreparties de NKR sont des molécules du CMH de classe I.
Receptor) tels que notamment les récepteurs p58.l, p58.2, p70. INH, pl40. INH. Les récepteurs NKR de type lectine comprennent les récepteurs inhibiteurs NKG2 tels que notamment les récepteurs NKG2A et NKG2B L'ensemble de ces récepteurs NKR sont à fonction inhibitrice. Des récepteurs qui leur sont hautement homologues, en particulier au niveau extracytoplasmique, assurent toutefois des fonctions activatrices, ou à tout le moins non inhibitrices : il s'agit des récepteurs KAR (Killer cell Activatory Receptor) homologues aux récepteurs KIR, et des récepteurs NKG2C,
NKG2D, NKG2E et NKG2F homologues aux récepteurs NKG2A et
NKG2 B Les récepteurs contreparties activatrices, ou à tout le moins non inhibitrices, de récepteurs inhibiteurs NKR sont ci-après désignés, par souci de fluidité, contreparties de NKR
Les récepteurs NKR et les récepteurs contreparties de
NKR sont naturellement exprimés par les cellules NK et par des sous-populations de cellules T. Plusieurs de ces récepteurs peuvent être exprimés par une même cellule. Tous ces récepteurs, qu'ils soient inhibiteurs (i.e. NKR) ou qu ils soient activateurs ou non inhibiteurs (î.e. contreparties de NKR), ont en commun d'avoir pour ligand des molécules qui ne sont pas dérivées d'antigène : les ligands des récepteurs NKR et des récepteurs contreparties de NKR sont des molécules du CMH de classe I.
La reconnaissance de son ligand par un récepteur NKR déclenche la transduction à la cellule d'un message visant à inhiber son activité, e.g. diminution ou arrêt de la cytolyse, de la sécrétion de cytokines, alors que la
reconnaissance de son ligand par un récepteur contrepartie de NKR y induit un message activateur, ou à tout le moins non inhibiteur. A la résultante entre récepteurs NKR et
récepteurs contreparties de NKR ainsi activés par leurs
ligands, correspond un signal, globalement négatif ou positif, d'activation des cellules NK et/ou T qui les exp riment.
reconnaissance de son ligand par un récepteur contrepartie de NKR y induit un message activateur, ou à tout le moins non inhibiteur. A la résultante entre récepteurs NKR et
récepteurs contreparties de NKR ainsi activés par leurs
ligands, correspond un signal, globalement négatif ou positif, d'activation des cellules NK et/ou T qui les exp riment.
Les récepteurs NKR et leurs contreparties participent
ainsi au contrôle, positif ou négatif, des réactions
allogéniques d'un système immunitaire donné vis-à-vis de ce qu'il considère alors comme non-soi par exemple, des cellules cancéreuses ou infectées, ou bien encore des cellules de greffe ou transplantation allo- ou xéno génétique.
ainsi au contrôle, positif ou négatif, des réactions
allogéniques d'un système immunitaire donné vis-à-vis de ce qu'il considère alors comme non-soi par exemple, des cellules cancéreuses ou infectées, ou bien encore des cellules de greffe ou transplantation allo- ou xéno génétique.
Les récepteurs NKR et leurs contreparties participent en effet aux réactions entre hôte et greffon lors d'une greffe (ou transplantation) de cellules, tissu ou organe qui présente < nt) un certain degré d'incompatibilité antigénique avec l'hôte. L'implication de récepteurs NKR et de leurs contreparties dans la tolérance envers des greffes incompatibles, et dans l'effet sélectif de lyse de cellules malignes parfois observé après greffe de moelle osseuse, ou effet GVL (Graft Versus Leukemia), a en effet été démontrée in vivo (cf. Cambiaggi et al. 1997, Proc. Natl. Acad. Sci.
USA, vol. 94, p. 8088-8092 ; Albi et al. 1996, Sood, vol.
87, n09, p. 3993-4000).
Or, les moyens pouvant actuellement être mis en oeuvre dans un contexte médical ne permettent pas de documenter l'ensemble des répertoires d'un patient, d'un organe, d'un tissu ou de cellules.
C'est ainsi qu'actuellement, seule la compatibilité des molécules HLA-A, HLA-B et HLA-DR du donneur et du receveur est vérifiée préalablement à une greffe ou transplantation allo- ou xéno-génique. Ces critères de compatibilité n' apparaissent toutefois pas comme suffisants. Des traitements immunosuppresseurs (par exemple, à base de cyclosporine) doivent compléter ces procédures de greffe ou transplantation de manière à inhiber le système immunitaire du patient. De tels traitements sont à hauts risques pour le patient qui est alors susceptible de développer des infections opportunistes. Ces traitements immunosuppresseurs doivent de plus être maintenus à un certain niveau pendant plusieurs années, et le patient doit alors résister aux effets délétères des médicaments. Finalement, la réussite de telles procédures de greffe ou transplantation reste incertaine. En effet, des rejets de greffe de la part du receveur, ou bien encore, dans le cas de greffes comprenant des cellules immuno-compétentes, des réactions du greffon contre l'hôte (effet GVH, Graft Versus Host) sont malgré tout observés. De telles réactions de rejet ou de GVH conduisent généralement à de très sévères lésions; actuellement, elles ne peuvent toutefois être totalement écartées, et donc prévenues.
Des effets bénéfiques inattendus de greffes allogéniques ont par ailleurs parfois été observés : des greffes allogéniques de moelle osseuse sur des patients leucémiques aplasiques ont parfois conduit à un effet thérapeutique anti-tumoral par lyse des cellules malignes du receveur et préservation de ses cellules saines. Cet effet thérapeutique sélectif, dans lequel sont impliquées les cellules NK et T, est désigné par GVL (Graft Versus
Leukemia). Potentiellement, une greffe (ou une transplantation) de tissu hématopoïétique en général, et de moelle osseuse en particulier, peut conduire à un effet thérapeutique dans le cadre de malignités hématologiques telles qu'une leucémie, par lyse sélective de celles des cellules du receveur qui ne présentent plus les antigènes d'histocompatibilité présentés par les cellules saines. Les moyens actuellement disponibles pour le milieu médical ne permettent toutefois pas de prédire si l'organe ou le tissu considéré exercera un effet sélectif GVL pour le receveur considéré. en que connu, l'effet sélectif GVL ne peut donc actuellement être mis à profit dans le cadre d'une thérapie anti-cancéreuse.
Leukemia). Potentiellement, une greffe (ou une transplantation) de tissu hématopoïétique en général, et de moelle osseuse en particulier, peut conduire à un effet thérapeutique dans le cadre de malignités hématologiques telles qu'une leucémie, par lyse sélective de celles des cellules du receveur qui ne présentent plus les antigènes d'histocompatibilité présentés par les cellules saines. Les moyens actuellement disponibles pour le milieu médical ne permettent toutefois pas de prédire si l'organe ou le tissu considéré exercera un effet sélectif GVL pour le receveur considéré. en que connu, l'effet sélectif GVL ne peut donc actuellement être mis à profit dans le cadre d'une thérapie anti-cancéreuse.
Les moyens actuellement développés dans le cadre de
recherches expérimentales afin de documenter les différents
répertoires de cellules humaines ou animales ne permettent par ailleurs pas de documenter précisément le répertoire en
récepteurs NKR et en récepteurs contreparties de NKR l'identité précise de chaque récepteur NKR ou contrepartie de NKR ne peut être déterminée. Du fait de la forte homologie, en particulier au niveau extracytoplasmique, entre un récepteur NKR et un récepteur contrepartie de ce
NKR (e.g. jusqu'à 96% d'homologie entre KIR et KAR), l'utilisation d'anticorps ne permet en effet souvent pas de discriminer entre des NKR qui sont inhibiteurs et leurs contreparties à fonctions activatrices, ou à tout le moins non inhibitrices. Les amorces oligonucléotidiques actuellement disponibles ne permettent quant à elles pas la mise en oeuvre d'une amplification en chaîne par polymérase capable de discriminer entre par exemple un NKR p58. 1 et un
NKR p58. 2, ou entre un NKR p70. INH et un NKR p140. INM.
recherches expérimentales afin de documenter les différents
répertoires de cellules humaines ou animales ne permettent par ailleurs pas de documenter précisément le répertoire en
récepteurs NKR et en récepteurs contreparties de NKR l'identité précise de chaque récepteur NKR ou contrepartie de NKR ne peut être déterminée. Du fait de la forte homologie, en particulier au niveau extracytoplasmique, entre un récepteur NKR et un récepteur contrepartie de ce
NKR (e.g. jusqu'à 96% d'homologie entre KIR et KAR), l'utilisation d'anticorps ne permet en effet souvent pas de discriminer entre des NKR qui sont inhibiteurs et leurs contreparties à fonctions activatrices, ou à tout le moins non inhibitrices. Les amorces oligonucléotidiques actuellement disponibles ne permettent quant à elles pas la mise en oeuvre d'une amplification en chaîne par polymérase capable de discriminer entre par exemple un NKR p58. 1 et un
NKR p58. 2, ou entre un NKR p70. INH et un NKR p140. INM.
Finalement, pour documenter précisément le répertoire en immunorécepteurs NKR et en leurs contreparties, il faut actuellement avoir recours après une étape de purification des récepteurs visés (e.g. par FACScan), à une étape de séquençage nucléotidique. La documentation du répertoire
NKR /contreparties de NKR n'est donc actuellement pas réalisable en routine dans un contexte de type médical. Le niveau de stimulation et d'inhibition des programmes d'activation des cellules NK et T, et donc le potentiel de résistance d'un individu vis-à-vis du développement d'infections microbiennes ou parasitaires, de maladies auto-immunes, ou bien encore de cellules malignes, ne peut donc être mesuré. Il résulte également de cette absence de moyens adaptés pour la documentation des répertoi res NKR/contreparties de NKR que les effets sélectifs de type
GVL ne peuvent être utilisés en thérapie, et que les réactions GVH ou de rejets lors de greffes ou de transplantations allo- ou xéno-géniques ne peuvent être complètement écartées.
NKR /contreparties de NKR n'est donc actuellement pas réalisable en routine dans un contexte de type médical. Le niveau de stimulation et d'inhibition des programmes d'activation des cellules NK et T, et donc le potentiel de résistance d'un individu vis-à-vis du développement d'infections microbiennes ou parasitaires, de maladies auto-immunes, ou bien encore de cellules malignes, ne peut donc être mesuré. Il résulte également de cette absence de moyens adaptés pour la documentation des répertoi res NKR/contreparties de NKR que les effets sélectifs de type
GVL ne peuvent être utilisés en thérapie, et que les réactions GVH ou de rejets lors de greffes ou de transplantations allo- ou xéno-géniques ne peuvent être complètement écartées.
La présente invention propose donc des moyens permettant de documenter, pour un échantillon biologique donné, les répertoires en immunorécepteurs NKR et en immunorécepteurs contreparties activatrices ou à tout le moins non inhibitrices de récepteurs NKR Ces moyens permettent notamment de distinguer aisément entre un récepteur NKR et sa contrepartie activatrice ou non inhibitrice, ainsi que de distinguer entre différents récepteurs NKR, ou entre différentes contreparties de NKR
Elle vise également les applications biologiques, et en particulier médicales et vétérinaires, de ces moyens.
Elle vise également les applications biologiques, et en particulier médicales et vétérinaires, de ces moyens.
Les moyens selon l'invention présentent notamment 1' avantage d'être aisément utilisables dans un contexte médical ou vétérinaire, par exemple en hôpital ou clinique.
La présente invention a pour objet une méthode in vitro de documentation d'un répertoire en immunorécepteur(s) NKR comprenant notamment les récepteurs KIR p58.l, p58.2, p70.INH, pl40.INH, et les récepteurs NKG2A et NKG2B et/ou d'un répertoire en immunorécepteur(s) contrepartie(s) de
NKR, comprenant notamment les récepteurs KAR p50.l, p50.2, p70.ACT, pl40.ACT, et les récepteurs NKG2C, NKG2D, NKG2E,
NKG2F, ces immunorécepteurs étant ci-après désigné(s) récepteur(s) cible(s), caractérisée en ce qu'elle comprend
i. l'utilisation d'au moins une paire
d'oligonucléotides, l'un étant désigné
oligonucléotide 3' et l'autre oligonucléotide 5',
les oligonucléotides 3' et 5' d'une même dite
paire étant tous deux capables, dans des
conditions d'hybridation correspondant à une
incubation pendant 1 min dans un tampon [T ris -HCl
20mM pH8,4; KCl 50mM; MgCl2 2,5mM] à une
température comprise entre 50"C et 650C environ,
de s'hybrider à l'ADN ou à l'ADNc d'un récepteur
cible NKR, ou contrepartie de NKR, mais ne
s'hybridant pas, dans les mêmes conditions
d'hybridation, avec l'ADN ou l'ADNc d'un récepteur
contrepartie de NKR, ou respectivement d' un
récepteur NKR, contrepartie fonctionnelle dudit
récepteur cible,
ii. la mise en contact de populations ADN ou ADNc
d'un échantillon biologique d'origine humaine ou
animale pour lequel on souhaite documenter le
répertoire en immunorécepteur(s) cible(s), avec un
excès d'au moins une paire d'oligonucléotides 3'
et 5' selon i. dans des conditions favorables à
l'hybridation de cette paire oligonucléotides 3'
et 5' sur les ADN ou sur les ADNc de l'échantillon
biologique, et
iii. la détection des hybrides éventuellement formés
entre ces ADN ou ADNc et la ou les paire(s)
d'oligonucléotides 3' et 5'.
NKR, comprenant notamment les récepteurs KAR p50.l, p50.2, p70.ACT, pl40.ACT, et les récepteurs NKG2C, NKG2D, NKG2E,
NKG2F, ces immunorécepteurs étant ci-après désigné(s) récepteur(s) cible(s), caractérisée en ce qu'elle comprend
i. l'utilisation d'au moins une paire
d'oligonucléotides, l'un étant désigné
oligonucléotide 3' et l'autre oligonucléotide 5',
les oligonucléotides 3' et 5' d'une même dite
paire étant tous deux capables, dans des
conditions d'hybridation correspondant à une
incubation pendant 1 min dans un tampon [T ris -HCl
20mM pH8,4; KCl 50mM; MgCl2 2,5mM] à une
température comprise entre 50"C et 650C environ,
de s'hybrider à l'ADN ou à l'ADNc d'un récepteur
cible NKR, ou contrepartie de NKR, mais ne
s'hybridant pas, dans les mêmes conditions
d'hybridation, avec l'ADN ou l'ADNc d'un récepteur
contrepartie de NKR, ou respectivement d' un
récepteur NKR, contrepartie fonctionnelle dudit
récepteur cible,
ii. la mise en contact de populations ADN ou ADNc
d'un échantillon biologique d'origine humaine ou
animale pour lequel on souhaite documenter le
répertoire en immunorécepteur(s) cible(s), avec un
excès d'au moins une paire d'oligonucléotides 3'
et 5' selon i. dans des conditions favorables à
l'hybridation de cette paire oligonucléotides 3'
et 5' sur les ADN ou sur les ADNc de l'échantillon
biologique, et
iii. la détection des hybrides éventuellement formés
entre ces ADN ou ADNc et la ou les paire(s)
d'oligonucléotides 3' et 5'.
Par contrepartie fonctionnelle d'un récepteur, nous entendons dans la présente demande un récepteur à structure homologue, en particulier au niveau extracytoplasmique, mais à fonction différente : par exemple, une contrepartie fonctionnelle du récepteur NKR p58.l est le récepteur contrepartie de NKR p50.l, et réciproquement; de même le récepteur NKR p58.2 et le récepteur contrepartie de NKR p50.2 sont l'un pour l'autre des contreparties fonctionnelles.
La présente méthode permet donc notamment de distinguer un récepteur NKR (ou contrepartie de NKR) d'un récepteur contrepartie fonctionnelle de ce récepteur.
La (ou les) paire(s) d'oligonucléotides 3' et 5' est (sont) en particulier capables de borner, sur l'ADN ou 1'ADNc d'un récepteur cible qui leur correspond, une séquence d'oligonucléotides (bornes incluses) qui est absente de la séquence ADN ou ADNc d'un récepteur avec lequel elle(s) est (sont) capable(s) de ne pas s'hybrider dans les conditions d'hybridation données sous i) cidessus.
De manière avantageuse, ladite ou au moins une desdites paire(s) d'oligonucléotides 3' et 5' utilisée(s) est en outre capable, dans les mêmes conditions d'hybridation que celles définies sous i. , de ne pas s'hybrider à l'ADN ou ADNc d'un récepteur, indifféremment
NKR ou contrepartie de NKR, autre que ledit récepteur cible.
NKR ou contrepartie de NKR, autre que ledit récepteur cible.
Selon une disposition particulière de cette manière avantageuse, ladite (ou au moins une desdites) paire(s) d'oligonucléotides 3' et 5' capable, dans les conditions d'hybridation définies sous i. ci-dessus, de s'hybrider à l'ADN ou l'ADNc d'un récepteur p58.l (ou p50.1), et de ne pas s'hybrider à l'ADN ou l'ADNc d'un récepteur p50. 1 (ou respectivement p58. 1) est en outre capable de ne pas s'hybrider dans les mêmes conditions d'hybridation à l'ADN ou l'ADNc d'un récepteur p58.2 ou p50. 2.
Selon une deuxième disposition particulière de cette manière avantageuse, ladite, ou au moins une desdites, paire(s) d'oligonucléotides 3' et 5' capable, dans les conditions d'hybridation définies sous i. cidessus, de s'hybrider à l'ADN ou l'ADNc d'un récepteur p58.2 (ou p50.2), et de ne pas s'hybrider à l'ADN ou l'ADNc d'un récepteur p50.2 (ou respectivement p58.2) est en outre capable de ne pas s'hybrider dans les mêmes conditions d'hybridation à l'ADN ou l'ADNc d'un récepteur p58.l ou p50. 1.
Selon une troisième disposition particulière de cette manière avantageuse, ladite (ou au moins une desdites) paire(s) d'oligonucléotides 3' et 5' capable, dans les conditions d'hybridation définies sous i. cidessus, de s'hybrider à l'ADN ou l'ADNc d'un récepteur p70.INH (ou p70.ACT), et de ne pas s'hybrider à l'ADN ou 1' ADNc d'un récepteur p70.ACT (ou respectivement p70. INH) est en outre capable de ne pas s'hybrider dans les mêmes conditions d'hybridation à l'ADN ou 1'ADNc d'un récepteur pl40. INH ou pl40.ACT.
Selon une quatrième disposition particulière de cette manière avantageuse, ladite, ou au moins une desdites, paire(s) d'oligonucléotides 3' et 5' capable, dans les conditions d'hybridation définies sous i. cidessus, de s'hybrider à l'ADN ou 1' ADNc d'un récepteur pl40. INH (ou pl40.ACT), et de ne pas s'hybrider à l'ADN ou 1'ADNc d'un récepteur pl40.ACT (ou respectivement pl40.INH) est en outre capable de ne pas s'hybrider dans les mêmes conditions d'hybridation à l'ADN ou 1' ADNc d'un récepteur p70. INH ou p70.ACT.
Selon un mode de réalisation avantageux de l'invention, l'oligonucléotide 5' d'une dite paire d'oligonucléotides 3' et 5' utilisée pour un récepteur cible NKR (ou contrepartie de NKR) est capable, dans les conditions d'hybridation définies sous i. ci-dessus, de s'hybrider à l'ADN ou à l'ADNc d'un récepteur contrepartie de NKR (ou respectivement NKR), contrepartie fonctionnelle dudit récepteur cible NKR (ou respectivement contrepartie de NKR). Selon une disposition avantageuse de ce mode de réalisation, la séquence de l'oligonucléotide 5' d'une dite paire d'oligonucléotides 3' et 5' utilisée pour un récepteur cible NKR (ou contrepartie de NKR) comprend la séquence de l'oligonucléotide 5' d'une autre dite paire d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur contrepartie de NKR (ou respectivement NKR), contrepartie fonctionnelle dudit récepteur cible NKR (ou respectivement contrepartie de NKR).
Selon un autre mode de réalisation avantageux de l'invention, l'oligonucléotide 3' d'une dite paire d'oligonucléotides 3' et 5' , utilisée pour un récepteur cible KAR, est capable, dans les mêmes dites conditions d'hybridation, de s'hybrider à l'ADN ou ADNc dudit récepteur cible KAR au niveau d'un enchaînement nucléotidique qui comprend une séquence correspondant, selon le code génétique universel, et en tenant compte de la dégénérescence dudit code, à la séquence d'acides aminés
Lys Ile Pro Phe Thr Ile (K I P F T I) ou Lys Leu Pro Phe
Thr Ile (K L P F T I) (SEQ ID n026 ou 27).
Lys Ile Pro Phe Thr Ile (K I P F T I) ou Lys Leu Pro Phe
Thr Ile (K L P F T I) (SEQ ID n026 ou 27).
Selon un mode de réalisation particulièrement avantageux de l'invention, ladite (ou au moins une desdites) paire(s) d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur KIR est choisie parmi le groupe de paires d'oligonucléotides 3' et 5' constitué par
- un oligonucléotide 5' comprenant la séquence
SEQ ID n01, ou une séquence en dérivant, et au moins
un oligonucléotide 3' comprenant la séquence SEQ ID
n05, n02, n06 ou n07, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence
SEQ ID n04, ou une séquence en dérivant, et au moins
un oligonucléotide 3' comprenant la séquence SEQ ID
n05, n02, n06 ou n07, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence
SEQ ID n09, ou une séquence en dérivant, et au moins
un oligonucléotide 3' comprenant la séquence SEQ ID
n05, n02, n06 ou n07, ou une séquence en dérivant,
- au moins un oligonucléotide 5' comprenant la
séquence SEQ ID ne10, ne11, ne12, ou ne13, ou une
séquence en dérivant, et un oligonucléotide 3'
comprenant la séquence SEQ ID n014, ou une séquence
en dérivant.
- un oligonucléotide 5' comprenant la séquence
SEQ ID n01, ou une séquence en dérivant, et au moins
un oligonucléotide 3' comprenant la séquence SEQ ID
n05, n02, n06 ou n07, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence
SEQ ID n04, ou une séquence en dérivant, et au moins
un oligonucléotide 3' comprenant la séquence SEQ ID
n05, n02, n06 ou n07, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence
SEQ ID n09, ou une séquence en dérivant, et au moins
un oligonucléotide 3' comprenant la séquence SEQ ID
n05, n02, n06 ou n07, ou une séquence en dérivant,
- au moins un oligonucléotide 5' comprenant la
séquence SEQ ID ne10, ne11, ne12, ou ne13, ou une
séquence en dérivant, et un oligonucléotide 3'
comprenant la séquence SEQ ID n014, ou une séquence
en dérivant.
Par séquence dérivant d'une première séquence, nous entendons dans la présente demande une séquence dérivée de la première notamment par inversion, délétion, addition, ou substitution de nucléotide(s), et présentant les propriétés d'hybridation que l'acide nucléique correspondant à la première séquence présente dans les conditions i. ci-avant définies.
Selon une disposition de ce mode de réalisation particulièrement avantageux, ladite paire d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur p58.l correspond à un oligonucléotide 5' comprenant la SEQ ID n01, ou une séquence en dérivant, et un équimélange de quatre oligonucléotides 3', chacun d'eux comprenant la SEQ ID n05, n02, n06 ou n07, ou une séquence en dérivant.
Selon une autre disposition de ce mode de réalisation particulièrement avantageux, ladite paire d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur p58.2 correspond à un oligonucléotide 5' comprenant la SEQ ID n04, ou une séquence en dérivant, et un équimélange de quatre oligonucléotides 3', chacun d'eux comprenant la SEQ ID n05, n02, n 6 ou nQ7, ou une séquence en dérivant.
Selon encore une autre disposition de ce mode de réalisation particulièrement avantageux, ladite paire d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur p70.INH correspond à un oligonucléotide 5' comprenant la SEQ ID n"9, ou une séquence en dérivant, et un équimélange de quatre oligonucléotides 3', chacun d'eux comprenant la SEQ ID n05, n"2, n06 ou n"7, ou une séquence en dérivant.
Selon encore une autre disposition de ce mode de réalisation particulièrement avantageux, ladite paire d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur pl40.INH correspond à un équimélange de quatre oligonucléotides 5' , chacun d' eux comprenant la SEQ ID ne10, ne11, n"12 ou ne13, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la SEQ ID ne14, ou une séquence en dérivant.
Selon un autre mode de réalisation particulièrement avantageux de l'invention, ladite (ou au moins une desdites) paire(s) d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur KAR est choisie parmi le groupe de paires d'oligonucléotides 3' et 5' constitué par
- un oligonucléotide 5' comprenant la séquence SEQ ID n01, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n"3, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence SEQ ID n"8, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n03, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence SEQ ID n"9, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n03, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence SEQ ID ne15, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n03, ou une séquence en dérivant.
- un oligonucléotide 5' comprenant la séquence SEQ ID n01, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n"3, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence SEQ ID n"8, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n03, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence SEQ ID n"9, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n03, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence SEQ ID ne15, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n03, ou une séquence en dérivant.
Selon une disposition de cet autre mode de réalisation particulièrement avantageux, ladite paire d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur p50. 1 correspond à un oligonucléotide 5' comprenant la SEQ ID n01, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la SEQ ID n"3, ou une séquence en dérivant.
Selon une autre disposition de cet autre mode de réalisation particulièrement avantageux, ladite paire d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur p50.2 correspond à un oligonucléotide 5' comprenant la SEQ ID n08, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la SEQ ID n03, ou une séquence en dérivant.
Selon encore une autre disposition de cet autre mode de réalisation particulièrement avantageux, ladite paire d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur p70.ACT correspond à un oligonucléotide 5' comprenant la SEQ ID n09, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la SEQ ID n03, ou une séquence en dérivant.
Selon encore une autre disposition de cet autre mode de réalisation particulièrement avantageux, ladite paire d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur p140.ACT correspond à un oligonucléotide 5' comprenant la SEQ ID ne15, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la SEQ ID n03, ou une séquence en dérivant.
Selon encore un autre mode de réalisation particulièrement avantageux de l'invention, ladite (ou au moins une desdites) paire(s) d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur NKG2 est choisie parmi le groupe de paires d'oligonucléotides 3' et 5' constitué par
- un oligonucléotide 5' comprenant la séquence
SEQ ID n016, ou une séquence en dérivant, et un
oligonucléotide 3' comprenant la séquence SEQ ID
ne17, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence
SEQ ID ne18, ou une séquence en dérivant, et un
oligonucléotide 3' comprenant la séquence SEQ ID
ne17, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence
SEQ ID ne19, ou une séquence en dérivant, et un
oligonucléotide 3' comprenant la séquence SEQ ID
ne17, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence SEQ ID ne20, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n021, ou une séquence en dérivant.
- un oligonucléotide 5' comprenant la séquence
SEQ ID n016, ou une séquence en dérivant, et un
oligonucléotide 3' comprenant la séquence SEQ ID
ne17, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence
SEQ ID ne18, ou une séquence en dérivant, et un
oligonucléotide 3' comprenant la séquence SEQ ID
ne17, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence
SEQ ID ne19, ou une séquence en dérivant, et un
oligonucléotide 3' comprenant la séquence SEQ ID
ne17, ou une séquence en dérivant,
- un oligonucléotide 5' comprenant la séquence SEQ ID ne20, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n021, ou une séquence en dérivant.
Selon une première disposition de cet encore autre mode de réalisation particulièrement avantageux, ladite paire d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur NKG2A (inhibiteur) correspond à un oligonucléotide 5' comprenant la SEQ ID ne16, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la SEQ ID ne17, ou une séquence en dérivant.
Selon une deuxième disposition de cet encore autre mode de réalisation particulièrement avantageux, ladite paire d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur NKG2B (inhibiteur) correspond à un oligonucléotide 5' comprenant la SEQ ID ne18, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la SEQ ID ne17, ou une séquence en dérivant.
Selon une troisième disposition de cet encore autre mode de réalisation particulièrement avantageux, ladite paire d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur NKG2C (activateur) correspond à un oligonucléotide 5' comprenant la SEQ ID ne19, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la SEQ ID ne17, ou une séquence en dérivant.
Selon une quatrième disposition de cet encore autre mode de réalisation particulièrement avantageux, ladite paire d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur NKG2D (activateur) correspond à un oligonucléotide 5' comprenant la SEQ ID n020, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la SEQ ID n021, ou une séquence en dérivant.
Lesdites conditions favorables à l'hybridation de la ou des paires d'oligonucléotides 3' et 5' mises en contact avec 1'ADN ou l'ADNc de l'échantillon biologique correspondent avantageusement à une incubation pendant 1 min dans un tampon [Tris-HC1 20mM pH8,4; KCl 50mM; MgCl2 2,5mM] à une température comprise entre 50 C et 650C environ. De telles conditions sont en particulier prés entées dans les exemples.
De manière avantageuse, les deux oligonucléotides 3' ou 5' d'une même dite paire sont chacun couplés à un marqueur, notamment couplée à un marqueur fluorescent ou radioactif, tel que du 32p, permettant la révélation des hybrides qu'ils forment éventuellement avec lesdites populations ADN ou ADNc dudit échantillon biologique.
De manière également avantageuse, ladite (ou lesdites) paire(s) d'oligonucléotide(s) 3' et 5' sert (servent) d'amorces respectivement 3' et 5' pour une extension par
ADN polymérase, telle qu'une Taq polymérase. Des conditions favorables à une telle extension comprennent, outre l'ajout d'ADN polymérase, l'ajout des 4 dNTP (désoxyribonucléosidetriphosphate) en présence d'un tampon de type Tris-HCl.
ADN polymérase, telle qu'une Taq polymérase. Des conditions favorables à une telle extension comprennent, outre l'ajout d'ADN polymérase, l'ajout des 4 dNTP (désoxyribonucléosidetriphosphate) en présence d'un tampon de type Tris-HCl.
Lesdits hybrides éventuellement formés sont alors, préalablement à leur détection, amplifiés par au moins une
PCR (amplification en chaîne par polymérase; cf. les brevets EP 201 184 et EP 200 362) ou RT-PCR dans le cas d'ADNc rétrotranscrit à partir d'ARNm. Le cas échéant, lesdits hybrides éventuellement formés sont amplifiés par "Nested PCR" (double PCR emboîtée). Des exemples de conditions favorables à 1' amplification par PCR sont donnés dans les exemples.
PCR (amplification en chaîne par polymérase; cf. les brevets EP 201 184 et EP 200 362) ou RT-PCR dans le cas d'ADNc rétrotranscrit à partir d'ARNm. Le cas échéant, lesdits hybrides éventuellement formés sont amplifiés par "Nested PCR" (double PCR emboîtée). Des exemples de conditions favorables à 1' amplification par PCR sont donnés dans les exemples.
Selon un autre mode de réalisation avantageux de l'invention, ladite détection des hybrides éventuellement formés comprend en outre la résolution sur gel de polyacrylamide du mélange réactionnel issu de la mise en contact, ainsi que la révélation de la présence ou de l'absence de bandes électrophorétiques contenant lesdits hybrides éventuellement formés.
Selon un autre mode de réalisation de l'invention, le répertoire en immunorécepteurs documenté est quantifié par référence aux quantités de ss-actine mesurées sur le même échantillon biologique, ou par référence aux quantités d'une molécule spécifique d'un type cellulaire présentes dans ledit échantillon biologique, tel que notamment les molécules CD56 pour les cellules NK.
La méthode selon l'invention peut être appliquée à la documentation d'un répertoire génotypique en immunorécepteurs NKR et/ou en immunorécepteurs contreparties de NKR : l'étape ii. de mise en contact définie ci-dessus est alors réalisée avec les populations
ADN génomique de l'échantillon biologique.
ADN génomique de l'échantillon biologique.
La méthode selon l'invention peut également être appliquée à la documentation d'un répertoire d'expression en immunorécepteurs NKR et/ou en immunorécepteurs contreparties de NKR : l'étape ii. de mise en contact définie ci-dessus est alors réalisée avec les populations
ADNc, rétro-transcrites des populations ARNm de 1' échantillon biologique.
ADNc, rétro-transcrites des populations ARNm de 1' échantillon biologique.
Des échantillons biologiques d'origine humaine ou animale particulièrement appropriés à la mise en oeuvre de la méthode selon l'invention comprennent du sang périphérique, de la moelle osseuse, des lymphocytes, des cellules NK et/ou T, des cellules transgéniques exprimant des immunorécepteurs, une fraction isolée à partir de ces échantillons.
La méthode selon l'invention peut être notamment appliquée au criblage d'une banque d'organes, de tissus ou de cellules.
Elle permet ainsi une meilleure prévision
- de l'acceptation ou de rejet, par un homme ou un animal, de cellules, d'un tissu ou d'un organe génétiquement différent(es),
- de l'inocuité ou de la pathogénicité (effet GVH), pour un homme ou un animal, d'une greffe ou transplantation, en particulier de cellules, tissu, ou organe génétiquement différent(es),
- d'un effet potentiel de type GVL que des cellules, un tissu ou un organe génétiquement différent(es) pourraient exercer sur un homme ou animal.
- de l'acceptation ou de rejet, par un homme ou un animal, de cellules, d'un tissu ou d'un organe génétiquement différent(es),
- de l'inocuité ou de la pathogénicité (effet GVH), pour un homme ou un animal, d'une greffe ou transplantation, en particulier de cellules, tissu, ou organe génétiquement différent(es),
- d'un effet potentiel de type GVL que des cellules, un tissu ou un organe génétiquement différent(es) pourraient exercer sur un homme ou animal.
La méthode selon l'invention permet également le suivi de l'éventuelle apparition de telles réactions après greffe ou transplantation allo- ou xénogénique.
La méthode selon l'invention peut également être appliquée à la détermination de l'état d'activation de cellules NK et/ou T à un instant donné chez un animal ou un homme. Elle permet alors la prévision ou le suivi de l'état de résistance d'un animal ou d'un homme vis-à-vis d'une infection virale, telle qu'une infection par un VIH, d'une infection parasitaire, telle que la malaria, d'une infection bactérienne, vis-à-vis d'une maladie auto-immune, telle que la polyarthrite rhumatoïde, ou bien encore vis-à vis du développement de cellules malignes telles que des cellules leucémiques. L'utilisation prévisionnelle de la méthode selon l'invention est d'un intérêt particulier dans le cadre d'épidémies.
La méthode selon l'invention peut également être avantageusement appliquée au criblage de médicaments actifs vis-à-vis de maladies infectieuses, de maladies autoimmunes, ou de maladies tumorales.
La présente invention a également pour objet un kit pour la mise en oeuvre de ladite méthode comprenant dans un récipient, au moins une dite paire d'oligonucléotides, les réactifs pour la réalisation de ladite ou lesdites méthode(s) tels que tampon, marqueur (éventuellement couplé aux oligonucléotides de la dite paire), ainsi qu'un mode d'emploi.
D'autres caractéristiques et avantages de la présente invention apparaîtront encore à travers les exemples de réalisation suivants, donnés à titre indicatif et non limitatifs.
Lesdits exemples font référence aux Figures 1 et 2
La Figure 1 représente les produits issus d'une amplification par PCR (amplification en chaîne par polymérase après PT transcription enzymatique inverse à l'aide de paires d'oligonucléotides selon l'invention servant d'amorces), des séquences codantes pour p50.2 (Fig.
La Figure 1 représente les produits issus d'une amplification par PCR (amplification en chaîne par polymérase après PT transcription enzymatique inverse à l'aide de paires d'oligonucléotides selon l'invention servant d'amorces), des séquences codantes pour p50.2 (Fig.
1A) et p58.2 (Fig.lB) dans des cellules NK humaines;
La Figure 2 représente les produits issus d'une amplification par PCR de la séquence codante pour p50.2 à partir du DNA génomique de souris transgéniques p50.2t.
La Figure 2 représente les produits issus d'une amplification par PCR de la séquence codante pour p50.2 à partir du DNA génomique de souris transgéniques p50.2t.
Exemple 1 : Documentation du répertoire NKF/contreparties de NKR exprimé par une population de cellules NK humaines (PT-PCR).
1. Préparation des AW
Des préparations ARN ont été réalisées à partir de cellules NK humaines clonées et phénotypées p50.2+ et/ou p58.2+. La technique immunologique ne permet pas de documenter précisément un tel répertoire : l'anticorps
GL183 (Immunotech) reconnaît à la fois le récepteur NKR inhibiteur p58.2 et sa contrepartie activatrice p50.2. Des cellules NK humaines clonées et phénotypées p50.2- et p58.2à l'aide de l'anticorps GL183 servent de témoins négatifs.
Des préparations ARN ont été réalisées à partir de cellules NK humaines clonées et phénotypées p50.2+ et/ou p58.2+. La technique immunologique ne permet pas de documenter précisément un tel répertoire : l'anticorps
GL183 (Immunotech) reconnaît à la fois le récepteur NKR inhibiteur p58.2 et sa contrepartie activatrice p50.2. Des cellules NK humaines clonées et phénotypées p50.2- et p58.2à l'aide de l'anticorps GL183 servent de témoins négatifs.
Les préparations AEN sont réalisées comme suit.
Extraction
100 ul de Trizol (Gibco BRL catégorie n015596-026) ont été ajoutés à 106 cellules. On mélange en pipetant plusieurs fois, sans utiliser de mélangeur à vortex. On laisse la solution 5 minutes à température ambiante puis on ajoute 20 ul de chloroforme sans alcool isoamylique. On mélange à nouveau sans utiliser de mélangeur à vortex et on laisse la solution se reposer 5 minutes à température ambiante. On centrifuge alors à 4 C pendant 15 minutes de manière à bien séparer la phase organique inférieure, qui contient 1'ADN, de la phase aqueuse supérieure qui contient l'ARN. On récupère la phase aqueuse sans perturber l'interface entre phase aqueuse et phase organique.
100 ul de Trizol (Gibco BRL catégorie n015596-026) ont été ajoutés à 106 cellules. On mélange en pipetant plusieurs fois, sans utiliser de mélangeur à vortex. On laisse la solution 5 minutes à température ambiante puis on ajoute 20 ul de chloroforme sans alcool isoamylique. On mélange à nouveau sans utiliser de mélangeur à vortex et on laisse la solution se reposer 5 minutes à température ambiante. On centrifuge alors à 4 C pendant 15 minutes de manière à bien séparer la phase organique inférieure, qui contient 1'ADN, de la phase aqueuse supérieure qui contient l'ARN. On récupère la phase aqueuse sans perturber l'interface entre phase aqueuse et phase organique.
Précipitation
50 ul d'isopropanol sont ajoutés à la phase aqueuse et on laisse L'AFIN précipiter pendant 15 minutes à température ambiante. On centrifuge alors pendant 10 minutes à 4"C. Le surnageant est éliminé, et le culot est lavé avec 100 ul d'éthanol à 70%. Après centrifugation pendant 5 minutes à 4 C (7500 g), on laisse sécher à l'air libre (sans sécher sous vide). Le culot D'ART est remis en suspension dans 20 Al d'H20.
50 ul d'isopropanol sont ajoutés à la phase aqueuse et on laisse L'AFIN précipiter pendant 15 minutes à température ambiante. On centrifuge alors pendant 10 minutes à 4"C. Le surnageant est éliminé, et le culot est lavé avec 100 ul d'éthanol à 70%. Après centrifugation pendant 5 minutes à 4 C (7500 g), on laisse sécher à l'air libre (sans sécher sous vide). Le culot D'ART est remis en suspension dans 20 Al d'H20.
2. Préparation des paires d'oligonucléotides
Le tableau 1 ci-dessous présente les paires d'oligonucléotides utilisées. Sont ici rapportés les résultats relatifs à l'utilisation des paires d'oligonucléotides C (SEQ ID n04 en tant qu'oligonucléotide 5' et un équimélange de SEQ ID n05, n"2, n"6 et n"7 en tant qu'oligonucléotide 3') et D (SEQ ID n 8 en tant qu' oligonucléotide 5' et SEQ ID n03 en tant qu'oligonucléotide 3' ) présentées dans le tableau 1. Les séquences ADNc, sur la base desquelles ces paires d'oligonucléotides ont été mises au point, sont présentées dans le tableau 2 ci-dessous (nom des clones ADNc et numéro d'accès sur Genbank). Pour chaque paire d'oligonucléotides, ont ainsi été pris en compte les variants alléliques et les variants d'excision-épissage (épissage alternatif) connus d' un même récepteur.
Le tableau 1 ci-dessous présente les paires d'oligonucléotides utilisées. Sont ici rapportés les résultats relatifs à l'utilisation des paires d'oligonucléotides C (SEQ ID n04 en tant qu'oligonucléotide 5' et un équimélange de SEQ ID n05, n"2, n"6 et n"7 en tant qu'oligonucléotide 3') et D (SEQ ID n 8 en tant qu' oligonucléotide 5' et SEQ ID n03 en tant qu'oligonucléotide 3' ) présentées dans le tableau 1. Les séquences ADNc, sur la base desquelles ces paires d'oligonucléotides ont été mises au point, sont présentées dans le tableau 2 ci-dessous (nom des clones ADNc et numéro d'accès sur Genbank). Pour chaque paire d'oligonucléotides, ont ainsi été pris en compte les variants alléliques et les variants d'excision-épissage (épissage alternatif) connus d' un même récepteur.
Chaque paire d'oligonucléotides est construite, après alignement des séquences ADNc connues des différents variants d'un même récepteur cible (e. g. le KIR p58.2), de manière à ce que cette paire puisse déterminer, sur l'ensemble de ces variants, les bornes d'un fragment consensus, sans pour autant pouvoir faire de même sur un quelconque variant du récepteur contrepartie du récepteur cible (e.g. le KAR p50.2). La séquence de chaque oligonucléotide d'une même paire est ensuite optimisée de manière à ce que la température d' annelage (annealing en anglais) de chacune d'elles soit proche (e.g. AT < 50C).
Chaque oligonucléotide présente en effet une température d'annelage (ou d'hybridation) qui lui est propre. Cette température d' annelage est fonction du rapport R - -- + O x100 et de la longueur de
nombre total de bases
(A T+G +C) l'oligonucléotide considéré selon la formule : Température d'annelage (ou d'hybridation) d'un oligonucléotide =
650
Tm = 69,3 + 0,41 (R) - (en C)
longueur en pb
Or, dans une réaction de type amplification en chaîne par polymérase les oligonucléotides d'une même paire doivent pouvoir tous deux s' anneler au récepteur cible dans des conditions de réaction communes, ceci afin de servir d'amorces à l'amplification du fragment consensus. Si les oligonucléotides d'une même paire présentent des températures propres d'annelage proches (e.g. 54 C et 56 C), ils pourront s'hybrider au récepteur cible, sans pour autant s'hybrider au récepteur contrepartie correspondant, à une température de 540C ou 550C.
nombre total de bases
(A T+G +C) l'oligonucléotide considéré selon la formule : Température d'annelage (ou d'hybridation) d'un oligonucléotide =
650
Tm = 69,3 + 0,41 (R) - (en C)
longueur en pb
Or, dans une réaction de type amplification en chaîne par polymérase les oligonucléotides d'une même paire doivent pouvoir tous deux s' anneler au récepteur cible dans des conditions de réaction communes, ceci afin de servir d'amorces à l'amplification du fragment consensus. Si les oligonucléotides d'une même paire présentent des températures propres d'annelage proches (e.g. 54 C et 56 C), ils pourront s'hybrider au récepteur cible, sans pour autant s'hybrider au récepteur contrepartie correspondant, à une température de 540C ou 550C.
Si les oligonucléotides d'une même paire présentent par contre des températures propres d' annelage très distantes (e.g. 490C et 560C), la réaction d'hybridation au récepteur cible est préférentiellement conduite à la plus basse des deux températures (e. g. 490C ou 500C), ce qui permet de maintenir la reconnaissance de sa cible nucléotidique par l'oligonucléotide dont la température propre d'annelage est la plus basse. Dans cette situation, une diminution de spécificité peut toutefois intervenir il peut être observé que certaines paires d'oligonucléotides parviennent, dans de telles conditions de température, à s'hybrider au récepteur-contrepartie du récepteur cible. Une manière de remédier à cette perte de spécificité consiste à augmenter la longueur de l'oligonucléotide dont la température propre d'annelage est la plus basse, sans faire perdre à la paire d'oligonucléotides considérée sa spécificité.
3. Amplification en chaîne par polymérase après transcription enzymatique inverse (PT-PCR).
5 ug d'ARN totaux sont transcrits en ADNc par incubation avec une transcriptase inverse (PT) à l'aide du kit First Strand DNA-Ready to go (Pharmacia). 10 ul d'ADNc sur les 33 ul obtenus sont mis en contact avec les paires d'oligonucléotides C et D qui servent alors d'amorces (cf. tableau 1): 10 ul de produit issu de RT; Tampon PCR 10X 10 l; MgCl2 50mM; dXTP 10 mM; Oligonucléotides 3' à 10 uM: 5 l; Oligonucléotide 5' 10 M : 5 l; Taq polymérase 0,5 ul; H2O : qsp 100 ul. L'amplification par PCR (DNA engine PTC 200, MJ Research, Massachussets) est réalisée en suivant les étapes suivantes
- étape n 1 (dénaturation initiale) : 5 min à 94 C,
- étape n02 : 35 cycles comprenant
a) dénaturation 1 min à 940C
b) annelage 1 min à 550C pour
la paire C et 50 0C pour la
paire D d'oligonucléotides,
c) extension 1 min à 72"C,
- étape n 3: (extension finale)
1 min à 720 C.
- étape n 1 (dénaturation initiale) : 5 min à 94 C,
- étape n02 : 35 cycles comprenant
a) dénaturation 1 min à 940C
b) annelage 1 min à 550C pour
la paire C et 50 0C pour la
paire D d'oligonucléotides,
c) extension 1 min à 72"C,
- étape n 3: (extension finale)
1 min à 720 C.
La durée de l'extension 2c peut être augmentée si le fragment à amplifier a une grande taille (e.g. supérieure à 1000-1400pb environ).
La température de l'étape d'annelage 2b dépend de la paire d'oligonucléotides utilisés comme amorces (cf. point 2. ciavant). Elle correspond à une température consensus entre les températures propres d' annelage de chacun des deux oligonucléotides faisant paire (température moyenne ou température la plus basse des deux). Cette température est généralement comprise entre 450C et 700 C, préférentiellement entre 500C et 650C.
10 ul des produits issus de l'amplification par RT-PCR sont résolus par electrophorèse sur gel d'agarose à 2 a en parallèle avec des marqueurs de poids moléculaires (M).
Les résultats sont illustrés sur les figures 1A et 1 1B
La figure 1 illustre l'amplification par PCR après PT
(transcription enzymatique inverse) des séquences codantes pour p58.2 et p50.2 de cellules NK humaines.
La figure 1 illustre l'amplification par PCR après PT
(transcription enzymatique inverse) des séquences codantes pour p58.2 et p50.2 de cellules NK humaines.
En figure 1A est illustrée le résultat de la résolution électrophorétique des produits issus de l'amplification par RT-PCR après mise en contact de la paire d'amorces D selon l'invention (cf. tableau 1) avec les populations ADNc de cellules NK humaines phénotypées p50.2+ et p58.2+ (piste +) à l' aide de l' anticorps GL183, ou avec les populations ADNc de cellules NK humaines phénotypées p50.2- et p58.2-
(piste -) à l' aide de ce même anticorps GL183. En piste M, sont résolus des marqueurs de poids moléculaire.
(piste -) à l' aide de ce même anticorps GL183. En piste M, sont résolus des marqueurs de poids moléculaire.
En figure 1 B, est illustrée le résultat de la résolution électrophorétique des produits issus de l'amplification par RT-PCR après mise en contact de la paire d' amorces C selon l'invention (cf. tableau 1) avec les populations ADNc de cellules NK humaines phénotypées p50.2+ et p58.2+ (piste +) à l' aide de l' anticorps GL183, ou avec les populations ADNc de cellules NK humaines phénotypées p50.2- et p58.2-
(piste -) à l'aide de ce même anticorps GL183. En piste M, sont résolus des marqueurs de poids moléculaire.
(piste -) à l'aide de ce même anticorps GL183. En piste M, sont résolus des marqueurs de poids moléculaire.
Il peut observé que les paires d'oligonucléotides C et D selon l'invention permettent de reconnaître respectivement un phénotype, respectivement, p58.2+ et p50.2+, en reconnaissant un fragment de, respectivement, 653 pb et 533pb. La méthode selon l'invention permet donc de discriminer entre un phénotype p58.2+ (récepteur KIR, à fonction inhibitrice) et un phénotype p50.2+ (récepteur KAR contrepartie de 58.2, à fonction activatrice), ce qui n' était jusqu' à présent pas réalisable sous séquençage.
Exemple 2 : Documentation du répertoire génétique
(potentiel) NKR/contreparties de NKR d'une population de splénocytes de souris transgéniques p50.2+ (PCR).
(potentiel) NKR/contreparties de NKR d'une population de splénocytes de souris transgéniques p50.2+ (PCR).
1 - Préparation des ADN
Des préparations ADN ont été réalisées à partir de splénocytes de souris transgéniques p50.2+. La technique immunologique ne permet pas de déterminer si de tels splénocytes sont p50.2+ (récepteur KAR, activateur) ou p58.2+ (récepteur KIR, inhibiteur, ou bien encore p50.2+ et p58.2+). Des splénocytes de souris non transgéniques
(p50.2-) servent de témoins négatifs.
Des préparations ADN ont été réalisées à partir de splénocytes de souris transgéniques p50.2+. La technique immunologique ne permet pas de déterminer si de tels splénocytes sont p50.2+ (récepteur KAR, activateur) ou p58.2+ (récepteur KIR, inhibiteur, ou bien encore p50.2+ et p58.2+). Des splénocytes de souris non transgéniques
(p50.2-) servent de témoins négatifs.
Extraction
Cette étape est réalisée comme décrit en exemple 1. Les ADN étant contenus dans la phase organique inférieure, c' est ici cette phase qui est récupérée après avoir éliminé la phase aqueuse et un peu d'interface.
Cette étape est réalisée comme décrit en exemple 1. Les ADN étant contenus dans la phase organique inférieure, c' est ici cette phase qui est récupérée après avoir éliminé la phase aqueuse et un peu d'interface.
Précipitation
On ajoute 30 ul ul méthanol à 100% et on laisse reposer 5 minutes à température ambiante. Après centrifugation pendant 5 minutes à 40C (2 000g), on jette le surnageant et on lave le culot avec 100 ul de citrate de sodium 0,1M dans de l'méthanol à 10%. On laisse 30 minutes à température ambiante en mélangeant de temps en temps. On centrifuge pendant 5 minutes à 40C (2 000g). On répète ce lavage une seconde fois.
On ajoute 30 ul ul méthanol à 100% et on laisse reposer 5 minutes à température ambiante. Après centrifugation pendant 5 minutes à 40C (2 000g), on jette le surnageant et on lave le culot avec 100 ul de citrate de sodium 0,1M dans de l'méthanol à 10%. On laisse 30 minutes à température ambiante en mélangeant de temps en temps. On centrifuge pendant 5 minutes à 40C (2 000g). On répète ce lavage une seconde fois.
Le culot d'ADN obtenu est remis en suspension dans 200 ul d'méthanol à 70%. On laisse 15 minutes à température ambiante en mélangeant de temps en temps et on centrifuge pendant 5 minutes à 40C (2 000g).
Le culot est mis à sécher brièvement sous vide (1 à 2 ug d'ADN environ sont obtenus) et est remis en suspension dans 10 pl de NaOH 8mM. En cas de présence de matériel insoluble, on microcentrifuge 10 minutes à température ambiante. On transfère le surnageant dans un nouveau tube.
Le pH est neutralisé en ajoutant 1,25 ul d'Hepes 0,1 M pour 10 ul.
2 - Préparation des paires d'oligonucléotides
Les paires d'oligonucléotides sont préparées comme décrit en exemple 1. Sont ici rapportés les résultats relatifs à la paire D d' oligonucléotides (SEQ ID n"8 en tant qu' oligonucléotide 5' et SEQ ID n"3 en tant qu' oligonucléotide 3') selon l'invention (cf. tableau 1 ci dessous).
Les paires d'oligonucléotides sont préparées comme décrit en exemple 1. Sont ici rapportés les résultats relatifs à la paire D d' oligonucléotides (SEQ ID n"8 en tant qu' oligonucléotide 5' et SEQ ID n"3 en tant qu' oligonucléotide 3') selon l'invention (cf. tableau 1 ci dessous).
3 - Amplification en chaîne par polymérase (PCR)
L'amplification en chaîne par polymérase est réalisée comme décrit en exemple 1 en mettant en contact les préparations d' ADN génomiques obtenues avec des paires d'oligonucléotides D servant alors d'amorces.
L'amplification en chaîne par polymérase est réalisée comme décrit en exemple 1 en mettant en contact les préparations d' ADN génomiques obtenues avec des paires d'oligonucléotides D servant alors d'amorces.
Les produits issus de l'amplification sont résolus sur gel d'agarose à 2% en parallèle avec des marqueurs de poids moléculaires (M).
Les résultats de résolution électrophorétique sur gel d'agarose à 2% des produits issus de la PCR sont illustrés par la figure 2.
La figure 2 illustre 1' amplification par PCR de la séquence codante pour p50.2 à partir du DNA génomique de splénocytes de souris transgéniques p50.2+ : y est illustrée le résultat de la résolution électrophorétique des produits issus de l'amplification par PCR après mise en contact de la paire d'amorces D selon l'invention (cf. tableau 1) avec les populations ADN de splénocytes de souris transgéniques p50.2+ (pistes +) ou de souris non transgéniques p50.2
(pistes -). En piste M, sont résolus des marqueurs de poids moléculaires.
(pistes -). En piste M, sont résolus des marqueurs de poids moléculaires.
Les amorces D selon l'invention permettent de reconnaitre un fragment de 533 pb présent sur l'ADN de splénocytes murins p50.2+ et absent sur l'ADN de splénocytes murins p50.2-.
Des résultats comparables ont été obtenus avec les paires d' oligonucléotides A, B et E à L présentées dans le tableau 1 ci-après et ont également permis de documenter les récepteurs visés (cf. colonne "molécule" du tableau 1).
Tableau 1
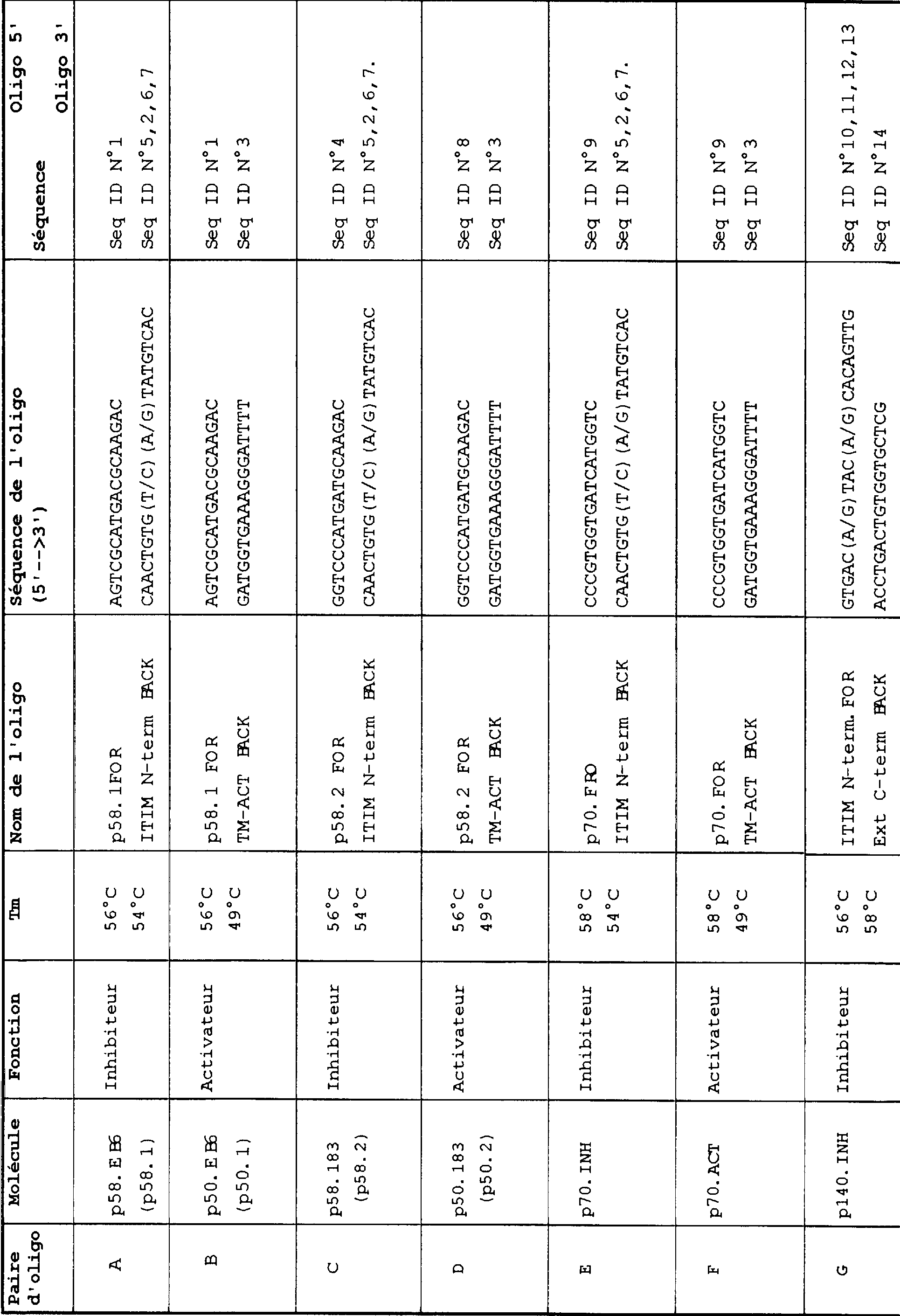
<SEP> Paire <SEP> Molécule <SEP> Fonction <SEP> Tm <SEP> Nom <SEP> de <SEP> l'oligo <SEP> Séquence <SEP> de <SEP> l'oligo <SEP> Oligo <SEP> 5'
<tb> d'oligo <SEP> (5'-- > 3') <SEP> Séquence
<tb> Oligo <SEP> 3'
<tb> Inhibiteur <SEP> 56 C
<tb> A <SEP> p58.E <SEP> B6 <SEP> p58. <SEP> 1FOR <SEP> AGTCGCATGACGCAAGAC <SEP> Seq <SEP> ID <SEP> N 1
<tb> 54 C
<tb> (p58.1) <SEP> ITIM <SEP> N-term <SEP> BACK <SEP> CAACTGTG <SEP> (T/C) <SEP> (A/G)TATGTCAC <SEP> Seq <SEP> ID <SEP> N 5,2,6,7
<tb> Activateur <SEP> 56 C
<tb> <SEP> B <SEP> p50.E <SEP> B6 <SEP> p58.1 <SEP> FOR <SEP> AGTCGCATGACGCAAGAC <SEP> Seq <SEP> ID <SEP> N 1
<tb> 49 C
<tb> (p50.1) <SEP> TM-ACT <SEP> BACK <SEP> GATGGTGAAAGGGATTTT <SEP> Seq <SEP> ID <SEP> N 3
<tb> C <SEP> p58.183 <SEP> Inhibiteur <SEP> 56 C <SEP> p58.2 <SEP> FOR <SEP> GGTCCCATGATGCAAGAC <SEP> Seq <SEP> ID <SEP> N 4
<tb> (p58.2) <SEP> 54 C
<tb> ITIM <SEP> N-term <SEP> BACK <SEP> CAACTGTG <SEP> (T/C) <SEP> (A/G) <SEP> TATGTCAC <SEP> Seq <SEP> ID <SEP> N <SEP> 5,2,6,7.
<tb>
<tb> d'oligo <SEP> (5'-- > 3') <SEP> Séquence
<tb> Oligo <SEP> 3'
<tb> Inhibiteur <SEP> 56 C
<tb> A <SEP> p58.E <SEP> B6 <SEP> p58. <SEP> 1FOR <SEP> AGTCGCATGACGCAAGAC <SEP> Seq <SEP> ID <SEP> N 1
<tb> 54 C
<tb> (p58.1) <SEP> ITIM <SEP> N-term <SEP> BACK <SEP> CAACTGTG <SEP> (T/C) <SEP> (A/G)TATGTCAC <SEP> Seq <SEP> ID <SEP> N 5,2,6,7
<tb> Activateur <SEP> 56 C
<tb> <SEP> B <SEP> p50.E <SEP> B6 <SEP> p58.1 <SEP> FOR <SEP> AGTCGCATGACGCAAGAC <SEP> Seq <SEP> ID <SEP> N 1
<tb> 49 C
<tb> (p50.1) <SEP> TM-ACT <SEP> BACK <SEP> GATGGTGAAAGGGATTTT <SEP> Seq <SEP> ID <SEP> N 3
<tb> C <SEP> p58.183 <SEP> Inhibiteur <SEP> 56 C <SEP> p58.2 <SEP> FOR <SEP> GGTCCCATGATGCAAGAC <SEP> Seq <SEP> ID <SEP> N 4
<tb> (p58.2) <SEP> 54 C
<tb> ITIM <SEP> N-term <SEP> BACK <SEP> CAACTGTG <SEP> (T/C) <SEP> (A/G) <SEP> TATGTCAC <SEP> Seq <SEP> ID <SEP> N <SEP> 5,2,6,7.
<tb>
D <SEP> p50.183 <SEP> Activateur <SEP> 56 C <SEP> p58.2 <SEP> FOR <SEP> GGTCCCATGATGCAAGAC <SEP> Seq <SEP> ID <SEP> N 8
<tb> (p50.2) <SEP> 49 C
<tb> TM-ACT <SEP> BACK <SEP> GATGGTGAAAGGGATTTT <SEP> Seq <SEP> ID <SEP> N 3
<tb> E <SEP> p70.INH <SEP> Inhibiteur <SEP> 58 C
<tb> p70.FRO <SEP> CCCGTGGTGATCATGGTC <SEP> Seq <SEP> ID <SEP> N 9
<tb> 54 C
<tb> ITIM <SEP> N-term <SEP> BACK <SEP> CAACTGTG <SEP> (T/C) <SEP> (A/G)TATGTCAC <SEP> Seq <SEP> ID <SEP> N <SEP> 5,2,6,7.
<tb>
<tb> (p50.2) <SEP> 49 C
<tb> TM-ACT <SEP> BACK <SEP> GATGGTGAAAGGGATTTT <SEP> Seq <SEP> ID <SEP> N 3
<tb> E <SEP> p70.INH <SEP> Inhibiteur <SEP> 58 C
<tb> p70.FRO <SEP> CCCGTGGTGATCATGGTC <SEP> Seq <SEP> ID <SEP> N 9
<tb> 54 C
<tb> ITIM <SEP> N-term <SEP> BACK <SEP> CAACTGTG <SEP> (T/C) <SEP> (A/G)TATGTCAC <SEP> Seq <SEP> ID <SEP> N <SEP> 5,2,6,7.
<tb>
F <SEP> p70.ACT <SEP> Activateur <SEP> 58 C
<tb> p70.FOR <SEP> CCCGTGGTGATCATGGTC <SEP> Seq <SEP> ID <SEP> N 9
<tb> 49 C
<tb> TM-ACT <SEP> BACK <SEP> GATGGTGAAAGGGATTTT <SEP> Seq <SEP> ID <SEP> N 3
<tb> G <SEP> p140.INH <SEP> Inhibiteur <SEP> 56 C
<tb> ITIM <SEP> N-term.FOR <SEP> GTGAG <SEP> (A/G) <SEP> TAG <SEP> (A/G) <SEP> CACAGTTG <SEP> Seq <SEP> ID <SEP> N 10,11,12,13
<tb> 58 C
<tb> Ext <SEP> C-term <SEP> BACK <SEP> ACCTGACTGTGGTGCTCG <SEP> Seq <SEP> ID <SEP> N 14
<tb> Tableau 1 (suite)

<tb> p70.FOR <SEP> CCCGTGGTGATCATGGTC <SEP> Seq <SEP> ID <SEP> N 9
<tb> 49 C
<tb> TM-ACT <SEP> BACK <SEP> GATGGTGAAAGGGATTTT <SEP> Seq <SEP> ID <SEP> N 3
<tb> G <SEP> p140.INH <SEP> Inhibiteur <SEP> 56 C
<tb> ITIM <SEP> N-term.FOR <SEP> GTGAG <SEP> (A/G) <SEP> TAG <SEP> (A/G) <SEP> CACAGTTG <SEP> Seq <SEP> ID <SEP> N 10,11,12,13
<tb> 58 C
<tb> Ext <SEP> C-term <SEP> BACK <SEP> ACCTGACTGTGGTGCTCG <SEP> Seq <SEP> ID <SEP> N 14
<tb> Tableau 1 (suite)
H <SEP> p140.ACT <SEP> Activateur <SEP> 58 C
<tb> p140.FOR <SEP> ACCTACAGATGTTATGGTTCTGTT <SEP> Seq <SEP> ID <SEP> N 15
<tb> 49 C
<tb> TM-ACT <SEP> BACK <SEP> GATGGTGAAAGGATTTT <SEP> Seq <SEP> ID <SEP> N 13
<tb> Inhibiteur <SEP> 54 C
<tb> I <SEP> NKG2A <SEP> NKG2A <SEP> FOR <SEP> TCTACATTAATACAGAGGCAC <SEP> Seq <SEP> ID <SEP> N 16
<tb> 54 C
<tb> NKG2A/ <SEP> B/C. <SEP> BACK <SEP> ATCTATAGAAAGCAGACT <SEP> Seq <SEP> ID <SEP> N 17
<tb> Inhibiteur <SEP> 52 C
<tb> J <SEP> NKG2 <SEP> B <SEP> NKG2 <SEP> B <SEP> FOR <SEP> ATTCCCTCACGTCATTGT <SEP> Seq <SEP> ID <SEP> N 18
<tb> 54 C
<tb> NKG2a/ <SEP> B/C. <SEP> BACK <SEP> ATCTATAGAAAGCAGACT <SEP> Seq <SEP> ID <SEP> N 17
<tb> K <SEP> NKG2C <SEP> Activateur <SEP> 54 C
<tb> NKG2C. <SEP> FOR <SEP> AGTAAACAAAGAGGAACCTTC <SEP> Seq <SEP> ID <SEP> N 19
<tb> 54 C
<tb> NKG2A/ <SEP> B/C. <SEP> BACK <SEP> ATCTATAGAAAGCAGACT <SEP> Seq <SEP> ID <SEP> N 17
<tb> L <SEP> NKG2D <SEP> Activateur <SEP> 56 C
<tb> NKG2D. <SEP> FOR <SEP> AGCAAAGAGGACCAGGATTTA <SEP> Seq <SEP> ID <SEP> N 20
<tb> 58 C
<tb> NKG2D. <SEP> BACK <SEP> CACAGTCCTTTGCATGCAGAT <SEP> Seq <SEP> ID <SEP> N 21
<tb> M <SEP> CD56 <SEP> 51 C
<tb> 5' <SEP> hCD56 <SEP> ATCCAGTACACTGATGAC <SEP> Seq <SEP> ID <SEP> N 22
<tb> 54 C
<tb> 3' <SEP> hCD56 <SEP> GTCGATGGATGGTGAAGA <SEP> Seq <SEP> ID <SEP> N 23
<tb> N <SEP> Actine <SEP> 62 C
<tb> 5' <SEP> Actine <SEP> TACCACTGGCATCGTGATGGACT <SEP> Seq <SEP> ID <SEP> N 24
<tb> 64 C
<tb> 3' <SEP> Actine <SEP> TCCTTCTGCATCCTGTCGGCAAT <SEP> Seq <SEP> ID <SEP> N 25
<tb>
TABLEAU 2

<tb> p140.FOR <SEP> ACCTACAGATGTTATGGTTCTGTT <SEP> Seq <SEP> ID <SEP> N 15
<tb> 49 C
<tb> TM-ACT <SEP> BACK <SEP> GATGGTGAAAGGATTTT <SEP> Seq <SEP> ID <SEP> N 13
<tb> Inhibiteur <SEP> 54 C
<tb> I <SEP> NKG2A <SEP> NKG2A <SEP> FOR <SEP> TCTACATTAATACAGAGGCAC <SEP> Seq <SEP> ID <SEP> N 16
<tb> 54 C
<tb> NKG2A/ <SEP> B/C. <SEP> BACK <SEP> ATCTATAGAAAGCAGACT <SEP> Seq <SEP> ID <SEP> N 17
<tb> Inhibiteur <SEP> 52 C
<tb> J <SEP> NKG2 <SEP> B <SEP> NKG2 <SEP> B <SEP> FOR <SEP> ATTCCCTCACGTCATTGT <SEP> Seq <SEP> ID <SEP> N 18
<tb> 54 C
<tb> NKG2a/ <SEP> B/C. <SEP> BACK <SEP> ATCTATAGAAAGCAGACT <SEP> Seq <SEP> ID <SEP> N 17
<tb> K <SEP> NKG2C <SEP> Activateur <SEP> 54 C
<tb> NKG2C. <SEP> FOR <SEP> AGTAAACAAAGAGGAACCTTC <SEP> Seq <SEP> ID <SEP> N 19
<tb> 54 C
<tb> NKG2A/ <SEP> B/C. <SEP> BACK <SEP> ATCTATAGAAAGCAGACT <SEP> Seq <SEP> ID <SEP> N 17
<tb> L <SEP> NKG2D <SEP> Activateur <SEP> 56 C
<tb> NKG2D. <SEP> FOR <SEP> AGCAAAGAGGACCAGGATTTA <SEP> Seq <SEP> ID <SEP> N 20
<tb> 58 C
<tb> NKG2D. <SEP> BACK <SEP> CACAGTCCTTTGCATGCAGAT <SEP> Seq <SEP> ID <SEP> N 21
<tb> M <SEP> CD56 <SEP> 51 C
<tb> 5' <SEP> hCD56 <SEP> ATCCAGTACACTGATGAC <SEP> Seq <SEP> ID <SEP> N 22
<tb> 54 C
<tb> 3' <SEP> hCD56 <SEP> GTCGATGGATGGTGAAGA <SEP> Seq <SEP> ID <SEP> N 23
<tb> N <SEP> Actine <SEP> 62 C
<tb> 5' <SEP> Actine <SEP> TACCACTGGCATCGTGATGGACT <SEP> Seq <SEP> ID <SEP> N 24
<tb> 64 C
<tb> 3' <SEP> Actine <SEP> TCCTTCTGCATCCTGTCGGCAAT <SEP> Seq <SEP> ID <SEP> N 25
<tb>
TABLEAU 2
<tb> <SEP> Paire <SEP> Numéro <SEP>
<tb> d'oligonucléotides <SEP> | <SEP> nom <SEP> du <SEP> CDNA <SEP> | <SEP> d'accès
<tb> <SEP> sur
<tb> <SEP> Genbank
<tb> <SEP> A <SEP> cl-42 <SEP> U24076
<tb> <SEP> NKAT-I <SEP> L41267
<tb> <SEP> cl-47. <SEP> 11 <SEP> U24078
<tb> <SEP> B <SEP> X98858 <SEP> X98585
<tb> <SEP> X98892 <SEP> X98892 <SEP>
<tb> <SEP> NKAT-7AA <SEP> L76670
<tb> <SEP> NKAT-9AA <SEP> L76672
<tb> <SEP> C <SEP> cl-43 <SEP> U24075
<tb> <SEP> NKAT-6AA <SEP> L76669
<tb> <SEP> NKAT-2 <SEP> BA <SEP> L76663
<tb> <SEP> cl-6 <SEP> U24074
<tb> <SEP> NKAT-2 <SEP> L41268
<tb> <SEP> KIR-023GB <SEP> U73395
<tb> <SEP> NKAT-2AB <SEP> L76662
<tb> <SEP> NKAT-3DA <SEP> L76664
<tb> <SEP> D <SEP> |cl-49 <SEP> |U24079
<tb> <SEP> NKAT-5 <SEP> L41347
<tb> <SEP> X89893 <SEP> X89893 <SEP>
<tb> <SEP> cl-39 <SEP> U24077
<tb> <SEP> NKAT-8 <SEP> L76671
<tb> <SEP> NKAT-5DA <SEP> L76667
<tb> <SEP> E <SEP> X94262 <SEP> X94262
<tb> <SEP> NKAT-3 <SEP> L41269
<tb> <SEP> NK <SEP> BI-1 <SEP> U31416
<tb> <SEP> NK <SEP> BI-2 <SEP> U33328
<tb> <SEP> KIR-103AS <SEP> U71199
<tb> <SEP> KIR-103AST <SEP> U73394
<tb> <SEP> cl-1.1 <SEP> X94373
<tb> <SEP> cl-ll <SEP> U30274
<tb> <SEP> cl-2 <SEP> |U30273
<tb>
Tableau 2 (suite)

<tb> d'oligonucléotides <SEP> | <SEP> nom <SEP> du <SEP> CDNA <SEP> | <SEP> d'accès
<tb> <SEP> sur
<tb> <SEP> Genbank
<tb> <SEP> A <SEP> cl-42 <SEP> U24076
<tb> <SEP> NKAT-I <SEP> L41267
<tb> <SEP> cl-47. <SEP> 11 <SEP> U24078
<tb> <SEP> B <SEP> X98858 <SEP> X98585
<tb> <SEP> X98892 <SEP> X98892 <SEP>
<tb> <SEP> NKAT-7AA <SEP> L76670
<tb> <SEP> NKAT-9AA <SEP> L76672
<tb> <SEP> C <SEP> cl-43 <SEP> U24075
<tb> <SEP> NKAT-6AA <SEP> L76669
<tb> <SEP> NKAT-2 <SEP> BA <SEP> L76663
<tb> <SEP> cl-6 <SEP> U24074
<tb> <SEP> NKAT-2 <SEP> L41268
<tb> <SEP> KIR-023GB <SEP> U73395
<tb> <SEP> NKAT-2AB <SEP> L76662
<tb> <SEP> NKAT-3DA <SEP> L76664
<tb> <SEP> D <SEP> |cl-49 <SEP> |U24079
<tb> <SEP> NKAT-5 <SEP> L41347
<tb> <SEP> X89893 <SEP> X89893 <SEP>
<tb> <SEP> cl-39 <SEP> U24077
<tb> <SEP> NKAT-8 <SEP> L76671
<tb> <SEP> NKAT-5DA <SEP> L76667
<tb> <SEP> E <SEP> X94262 <SEP> X94262
<tb> <SEP> NKAT-3 <SEP> L41269
<tb> <SEP> NK <SEP> BI-1 <SEP> U31416
<tb> <SEP> NK <SEP> BI-2 <SEP> U33328
<tb> <SEP> KIR-103AS <SEP> U71199
<tb> <SEP> KIR-103AST <SEP> U73394
<tb> <SEP> cl-1.1 <SEP> X94373
<tb> <SEP> cl-ll <SEP> U30274
<tb> <SEP> cl-2 <SEP> |U30273
<tb>
Tableau 2 (suite)
<tb> F <SEP> NKAT-10 <SEP> L76661
<tb> <SEP> KIR-123FM <SEP> U73396
<tb> G <SEP> NKAT-4 <SEP> L41270
<tb> <SEP> X94374 <SEP> X94374
<tb> <SEP> X93595 <SEP> X93595
<tb> <SEP> X93596 <SEP> X93596
<tb> <SEP> NKAT-4 <SEP> BA <SEP> L76666
<tb> <SEP> NKAT-4AA <SEP> L76665
<tb> <SEP> cl-5 <SEP> U30272
<tb> I <SEP> NKG2A <SEP> X54867
<tb> J <SEP> NKG2B <SEP> X54868
<tb> K <SEP> NKG2C <SEP> X54869
<tb> L <SEP> NKG2D <SEP> X54870
<tb>
LISTE DE SEQUENCES (1) INFORMATIONS GENERALES
(i) DEPOSANT:
(A) NOM: IN. SE. RM.
<tb> <SEP> KIR-123FM <SEP> U73396
<tb> G <SEP> NKAT-4 <SEP> L41270
<tb> <SEP> X94374 <SEP> X94374
<tb> <SEP> X93595 <SEP> X93595
<tb> <SEP> X93596 <SEP> X93596
<tb> <SEP> NKAT-4 <SEP> BA <SEP> L76666
<tb> <SEP> NKAT-4AA <SEP> L76665
<tb> <SEP> cl-5 <SEP> U30272
<tb> I <SEP> NKG2A <SEP> X54867
<tb> J <SEP> NKG2B <SEP> X54868
<tb> K <SEP> NKG2C <SEP> X54869
<tb> L <SEP> NKG2D <SEP> X54870
<tb>
LISTE DE SEQUENCES (1) INFORMATIONS GENERALES
(i) DEPOSANT:
(A) NOM: IN. SE. RM.
(B) RUE 101 rue de Tolbiac
(C) VILLE: PARIS
(E) PAYS: FIANCE
(F) CODE POSTAL: 75654
(ii) TITRE DE L'INVENTION Méthode de documentation en immunorécepteurs
NKR et en immunorécepteurs contreparties de NKR
(iii) NOMBRE DE SEQUENCES: 27
(iv) FORME DECHIFFRABLE PAR ORDINATEUR
(A) TYPE DE SUPPORT: Floppy disk
(B) ORDINATEUR: IBM PC compatible
(C) SYSTEME D' EXPLOITATION: PC-DOS/MS-DOS
(D) LOGICIEL: PatentIn Release #1.0, Version #1.30 (OEB) (2) INFORMATIONS POUR LA SEQ ID NO: 1:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: p58.i FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 1:
AGTCGCATGA CGCAAGAC 18 (3) INFORMATIONS POUR LA SEQ ID NO: 2:
(i) CAPACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term BACK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 2:
CAACTGTGTG TATGTCAC 18 (4) INFORMATIONS POUR LA SEQ ID NO: 3:
(i) CARACTERSTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: TM-ACT WCK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 3:
GATGGTGAAA GGGATTTT 18 (5) INFORMATIONS POUR LA SEQ ID NO: 4:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: P58.2.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 4:
GGTCCCATGA TGCAAGAC 18 (6) INFORMATIONS POUR LA SEQ ID NO: 5:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS simple
(D) CONFIGUPATION linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term BACK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 5:
CAACTGTGTA TATGTCAC 18 (7) INFOPMATIONS POUR LA SEQ ID NO: 6:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS simple
(D) CONFIGUPATION linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term 3XCK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 6:
CAACTGTGCA TATGTCAC 18 (8) INFOPMATIONS POUR LA SEQ ID NO: 7:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term BACK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 7:
CAACTGTGCG TATGTCAC 18 (9) INFOPMATIONS POUR LA SEQ ID NO: 8:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: p58.2 FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 8:
GGTCCCATGA TGCAAGAC 18 (
(i) CAPACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: p70.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 9:
CCCGTGGTGA TCATGGTC 18 (11) INFORMATIONS POUR LA SEQ ID NO: 10:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 10:
GTGACATACA CACAGTTG 18 (12) INFORMATIONS POUR LA SEQ ID NO: 11:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 11:
GTGACATACG CACAGTTG 18 (13) INFORMATIONS POUR LA SEQ ID NO: 12:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
< B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique (vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 12:
GTGACGTACA CACAGTTG 18 (14) INFOPMATIONS POUR LA SEQ ID NO: 13:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
< B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
< ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 13:
GTGACGTACG CACAGTTG 18 (15) INFORD4ATIONS POUR LA SEQ ID NO: 14:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: Ext C-term BACK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 14:
ACCTGACTGT GGTGCTCG 18 (16) INFOPMATIONS POUR LA SEQ ID NO: 15:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 24 paires de bases
( S TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: pl40.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 15:
ACCTACAGAT GTTATGGTTC TGTT 24 (17) INFORMATIONS POUR LA SEQ ID NO: 16:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 21 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: NKG2A.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 16:
TCTACATTAA TACAGAGGCA C 21 (18) INFORMATIONS POUR LA SEQ ID NO: 17:
(i) CAPACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
( S TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: NKG2A/B/C. BACK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 17:
ATCTATAGAA AGCAGACT 18 (19) INFOPMATIONS POUR LA SEQ ID NO: 18:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: NKG2B FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 18:
ATTCCCTCAC GTCATTGT 18 (20) INFOPMATIONS POUR LA SEQ ID NO: 19:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 21 paires de bases
( S TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: NKG2C.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 19:
AGTAAACAAA GAGGAACCTT C 21 (21) INFORMATIONS POUR LA SEQ ID NO: 20:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 21 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: NKG2D.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 20:
AGCAAAGAGG ACCAGGATTT A 21 (22) INFORMATIONS POUR LA SEQ ID NO: 21:
(i) CAPACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 21 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: NKG2D. BkCK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 21:
CACAGTCCTT TGCATGCAGA T 21 (23) INFOSMATIONS POUR LA SEQ ID NO: 22:
(i) CARXCTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURkTION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: 5' hCD56
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 22:
ATCCAGTACA CTGATGAC 18 (24) INFORMATIONS POUR LA SEQ ID NO: 23:
(i) CARXCTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: 3'hCD56
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 23:
GTCGATGGAT GGTGAAGA 18 (25) INFORMATIONS POUR LA SEQ ID NO: 24:
(i) CARRCTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 23 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: 5' Actine
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 24:
TACCACTGGC ATCGTGATGG ACT 23 (26) INFORATIONS POUR LA SEQ ID NO: 25:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 23 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: 3' Actine
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 25:
TCCTTCTGCA TCCTGTCGGC AAT 23 (27) INFORMATIONS POUR LA SEQ ID NO: 26:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 6 acides aminés
(B) TYPE: acide aminé
(C) NOMBRE DE BRINS:
(D) CONFIGURRTION: linéaire
(ii) TYPE DE MOLECULE: peptide
(iii) HYPOTHETIQUE: NON
(iv) ANTI-SENS: NON
(vi) ORIGINE:
(C) INDIVIDU/ISOLE:
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 26
Lys Ile Pro Phe Thr Ile
1 5 (28) INFORMATIONS POUR LA SEQ ID NO: 27
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 6 acides aminés
(B) TYPE: acide aminé
(C) NOMBRE DE BRINS
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: peptide
(iii) HYPOTHETIQUE: NON
(iv) ANTI-SENS NON
(vi) ORIGINE:
(C) INDIVIDU/ISOLE:
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 27
Lys Leu Pro Phe Thr Ile
1 5
(C) VILLE: PARIS
(E) PAYS: FIANCE
(F) CODE POSTAL: 75654
(ii) TITRE DE L'INVENTION Méthode de documentation en immunorécepteurs
NKR et en immunorécepteurs contreparties de NKR
(iii) NOMBRE DE SEQUENCES: 27
(iv) FORME DECHIFFRABLE PAR ORDINATEUR
(A) TYPE DE SUPPORT: Floppy disk
(B) ORDINATEUR: IBM PC compatible
(C) SYSTEME D' EXPLOITATION: PC-DOS/MS-DOS
(D) LOGICIEL: PatentIn Release #1.0, Version #1.30 (OEB) (2) INFORMATIONS POUR LA SEQ ID NO: 1:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: p58.i FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 1:
AGTCGCATGA CGCAAGAC 18 (3) INFORMATIONS POUR LA SEQ ID NO: 2:
(i) CAPACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term BACK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 2:
CAACTGTGTG TATGTCAC 18 (4) INFORMATIONS POUR LA SEQ ID NO: 3:
(i) CARACTERSTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: TM-ACT WCK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 3:
GATGGTGAAA GGGATTTT 18 (5) INFORMATIONS POUR LA SEQ ID NO: 4:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: P58.2.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 4:
GGTCCCATGA TGCAAGAC 18 (6) INFORMATIONS POUR LA SEQ ID NO: 5:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS simple
(D) CONFIGUPATION linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term BACK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 5:
CAACTGTGTA TATGTCAC 18 (7) INFOPMATIONS POUR LA SEQ ID NO: 6:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS simple
(D) CONFIGUPATION linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term 3XCK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 6:
CAACTGTGCA TATGTCAC 18 (8) INFOPMATIONS POUR LA SEQ ID NO: 7:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term BACK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 7:
CAACTGTGCG TATGTCAC 18 (9) INFOPMATIONS POUR LA SEQ ID NO: 8:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: p58.2 FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 8:
GGTCCCATGA TGCAAGAC 18 (
(i) CAPACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: p70.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 9:
CCCGTGGTGA TCATGGTC 18 (11) INFORMATIONS POUR LA SEQ ID NO: 10:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 10:
GTGACATACA CACAGTTG 18 (12) INFORMATIONS POUR LA SEQ ID NO: 11:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 11:
GTGACATACG CACAGTTG 18 (13) INFORMATIONS POUR LA SEQ ID NO: 12:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
< B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique (vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 12:
GTGACGTACA CACAGTTG 18 (14) INFOPMATIONS POUR LA SEQ ID NO: 13:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
< B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
< ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: ITIM N-term.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 13:
GTGACGTACG CACAGTTG 18 (15) INFORD4ATIONS POUR LA SEQ ID NO: 14:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: Ext C-term BACK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 14:
ACCTGACTGT GGTGCTCG 18 (16) INFOPMATIONS POUR LA SEQ ID NO: 15:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 24 paires de bases
( S TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: pl40.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 15:
ACCTACAGAT GTTATGGTTC TGTT 24 (17) INFORMATIONS POUR LA SEQ ID NO: 16:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 21 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: NKG2A.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 16:
TCTACATTAA TACAGAGGCA C 21 (18) INFORMATIONS POUR LA SEQ ID NO: 17:
(i) CAPACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
( S TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: NKG2A/B/C. BACK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 17:
ATCTATAGAA AGCAGACT 18 (19) INFOPMATIONS POUR LA SEQ ID NO: 18:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGUPATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: NKG2B FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 18:
ATTCCCTCAC GTCATTGT 18 (20) INFOPMATIONS POUR LA SEQ ID NO: 19:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 21 paires de bases
( S TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: NKG2C.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 19:
AGTAAACAAA GAGGAACCTT C 21 (21) INFORMATIONS POUR LA SEQ ID NO: 20:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 21 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: NKG2D.FOR
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 20:
AGCAAAGAGG ACCAGGATTT A 21 (22) INFORMATIONS POUR LA SEQ ID NO: 21:
(i) CAPACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 21 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: NKG2D. BkCK
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 21:
CACAGTCCTT TGCATGCAGA T 21 (23) INFOSMATIONS POUR LA SEQ ID NO: 22:
(i) CARXCTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURkTION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: 5' hCD56
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 22:
ATCCAGTACA CTGATGAC 18 (24) INFORMATIONS POUR LA SEQ ID NO: 23:
(i) CARXCTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 18 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: 3'hCD56
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 23:
GTCGATGGAT GGTGAAGA 18 (25) INFORMATIONS POUR LA SEQ ID NO: 24:
(i) CARRCTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 23 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS: simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: 5' Actine
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 24:
TACCACTGGC ATCGTGATGG ACT 23 (26) INFORATIONS POUR LA SEQ ID NO: 25:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 23 paires de bases
(B) TYPE: nucléotide
(C) NOMBRE DE BRINS simple
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: Autre acide nucléique
(vi) ORIGINE:
(C) INDIVIDU/ISOLE: 3' Actine
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 25:
TCCTTCTGCA TCCTGTCGGC AAT 23 (27) INFORMATIONS POUR LA SEQ ID NO: 26:
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 6 acides aminés
(B) TYPE: acide aminé
(C) NOMBRE DE BRINS:
(D) CONFIGURRTION: linéaire
(ii) TYPE DE MOLECULE: peptide
(iii) HYPOTHETIQUE: NON
(iv) ANTI-SENS: NON
(vi) ORIGINE:
(C) INDIVIDU/ISOLE:
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 26
Lys Ile Pro Phe Thr Ile
1 5 (28) INFORMATIONS POUR LA SEQ ID NO: 27
(i) CARACTERISTIQUES DE LA SEQUENCE:
(A) LONGUEUR 6 acides aminés
(B) TYPE: acide aminé
(C) NOMBRE DE BRINS
(D) CONFIGURATION: linéaire
(ii) TYPE DE MOLECULE: peptide
(iii) HYPOTHETIQUE: NON
(iv) ANTI-SENS NON
(vi) ORIGINE:
(C) INDIVIDU/ISOLE:
(xi) DESCRIPTION DE LA SEQUENCE: SEQ ID NO: 27
Lys Leu Pro Phe Thr Ile
1 5
Claims (23)
- d'oligonucléotides 3' et 5'.entre ces ADN ou ADNc et la ou les paire(s)iii. la détection des hybrides éventuellement formésbiologique, etet 5' sur les ADN ou sur les ADNc de 1' échantillonl'hybridation de cette paire oligonucléotides 3'et 5' selon i. dans des conditions favorables àexcès d'au moins une paire d'oligonucléotides 3'répertoire en immunorécepteur(s) cible(s), avec unanimale pour lequel on souhaite documenter led'un échantillon biologique d'origine humaine ouii. la mise en contact de populations ADN ou ADNcrécepteur cible,récepteur NKR, contrepartie fonctionnelle duditcontrepartie de NKR, ou respectivement d'und'hybridation, avec l'ADN ou l'ADNc d'un récepteurs'hybridant pas, dans les mêmes conditionscible NKR, ou contrepartie de NKR, mais nede s'hybrider à l'ADN ou à l'ADNc d'un récepteurtempérature comprise entre 500C et 650C environ,20mM pH8,4; KCl 50mM; MgCl2 2,5mM] à uneincubation pendant 1 min dans un tampon [Tris-HClconditions d'hybridation correspondant à unepaire étant tous deux capables, dans desles oligonucléotides 3' et 5' d'une même diteoligonucléotide 3' et l'autre oligonucléotide 5',d'oligonucléotides, l'un étant désignéi. l'utilisation d'au moins une pairecomprendrécepteur(s) cible(s), caractérisée en ce qu'elleces immunorécepteurs étant ci-après désigné(s)pl40.ACT, et les récepteurs NKG2C, NKG2D, NKG2E, NKG2F,notamment les récepteurs KAR p50.1, p50.2, p70.ACT,immunorécepteur (s) contrepartie(s) de NKR, comprenantrécepteurs NKG2A et NKG2 B, et/ou d'un répertoire enrécepteurs KIR p58.1, p58.2, p70.INH, p140.INH, et lesimmunorécepteur(s) NKR comprenant notamment lesREVENDICATIONS 1. Méthode in vitro de documentation d'un répertoire en
- 2. Méthode selon la revendication 1, caractérisée en ce que ladite ou au moins une desdites paire(s) d'oligonucléotides 3' et 5' utilisée(s) est en outre capable, dans les mêmes conditions d'hybridation que celles définies sous i., de ne pas s'hybrider à l'ADN ou ADNc d'un récepteur, indifféremment NKR ou contrepartie de NKR, autre que ledit récepteur cible.
- 3. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce que l' oligonucléotide 5' d'une dite paire d'oligonucléotides 3' et 5' utilisée pour un récepteur cible NKR (ou contrepartie de NKR) est capable dans les mêmes dites conditions d' hybridation de s'hybrider à l'ADN ou à l'ADNc d'un récepteur contrepartie de NKR (ou respectivement NKR), contrepartie fonctionnelle dudit récepteur cible NKR (ou respectivement contrepartie de NKR).
- 4. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce que l'oligonucléotide 3' d'une dite paire d'oligonucléotides 3' et 5', utilisée pour un récepteur cible KAR, est capable, dans les mêmes dites conditions d'hybridation, de s'hybrider à l'ADN ou ADNc dudit récepteur cible KAR au niveau d'un enchaînement nucléotidique qui comprend une séquence correspondant, selon le code génétique universel, et en tenant compte de la dégénérescence dudit code, à la séquence d'acides aminésLys Ile Pro Phe Thr Ile (K I P F T I) ou Lys Leu Pro PheThr Ile (K L P F T I) (SEQ ID n026 ou 27).
- 5. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce que ladite (ou au moins une desdites) paire(s) d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur KIR est choisie parmi le groupe de paires d' oligonucléotides 3' et 5' constitué par- un oligonucléotide 5' comprenant la séquenceSEQ ID n01, ou une séquence en dérivant, et au moinsun oligonucléotide 3' comprenant la séquence SEQ IDn05, n02, n06 ou n07, ou une séquence en dérivant,- un oligonucléotide 5' comprenant la séquenceSEQ ID n04, ou une séquence en dérivant, et au moinsun oligonucléotide 3' comprenant la séquence SEQ IDn05, n02, n06 ou n07, ou une séquence en dérivant,- un oligonucléotide 5' comprenant la séquenceSEQ ID n09, ou une séquence en dérivant, et au moinsun oligonucléotide 3' comprenant la séquence SEQ IDn05, n02, n06 ou n07, ou une séquence en dérivant,- au moins un oligonucléotide 5' comprenant laséquence SEQ ID ne10, ne11, ne12, ou n 13, ou uneséquence en dérivant, et un oligonucléotide 3'comprenant la séquence SEQ ID n 14, ou une séquenceen dérivant.
- 6. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce que ladite (ou au moins une desdites) paire(s) d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur KAR est choisie parmi le groupe de paires d'oligonucléotides 3' et 5' constitué par- un oligonucléotide 5' comprenant la séquence SEQ ID n"l, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n03, ou une séquence en dérivant,- un oligonucléotide 5' comprenant la séquence SEQ ID n"8, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n03, ou une séquence en dérivant,- un oligonucléotide 5' comprenant la séquence SEQ ID n"9, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n03, ou une séquence en dérivant,- un oligonucléotide 5' comprenant la séquence SEQID ne15, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n03, ou une séquence en dérivant.
- 7. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce que ladite (ou au moins une desdites) paire(s) d'oligonucléotides 3' et 5' ayant pour récepteur cible un récepteur NKG2 est choisie parmi le groupe de paires d'oligonucléotides 3' et 5' constitué par- un oligonucléotide 5' comprenant la séquenceSEQ ID n016, ou une séquence en dérivant, et unoligonucléotide 3' comprenant la séquence SEQ IDne17, ou une séquence en dérivant,- un oligonucléotide 5' comprenant la séquenceSEQ ID ne18, ou une séquence en dérivant, et unoligonucléotide 3' comprenant la séquence SEQ IDne17, ou une séquence en dérivant,- un oligonucléotide 5' comprenant la séquenceSEQ ID ne19, ou une séquence en dérivant, et unoligonucléotide 3' comprenant la séquence SEQ IDne17, ou une séquence en dérivant,- un oligonucléotide 5' comprenant la séquence SEQ ID ne20, ou une séquence en dérivant, et un oligonucléotide 3' comprenant la séquence SEQ ID n021, ou une séquence en dé rivant.
- 8. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce que les deux oligonucléotides 3' ou 5' d'une même dite paire sont chacun couplés à un marqueur, notamment couplée à un marqueur fluorescent ou radioactif, tel que du 32p, permettant la révélation des hybrides qu'ils forment éventuellement avec lesdites populations ADN ou ADNc dudit échantillon biologique.
- 9. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce que ladite (ou lesdites) paire(s) d'oligonucléotide(s) 3' et 5' sert (servent) d' amorces respectivement 3' et 5' pour une extension parADN polymérase.
- 10. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce que lesdits hybrides éventuellement formés sont amplifiés par au moins une PCR préalablement à leur détection.
- 11. Méthode selon 1' une quelconque des revendications précédentes, caractérisée en ce que lesdits hybrides éventuellement formés sont amplifiés par "Nested PCR"(double PCR emboîtée).
- 12. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce que ladite détection des hybrides éventuellement formés comprend en outre la résolution sur gel de polyacrylamide du mélange réactionnel issu de la mise en contact, ainsi que la révélation de la présence ou de l'absence de bandes électrophorétiques contenant lesdits hybrides éventuellement formés.
- 13. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce qu'elle est appliquée à la documentation d'un répertoire génotypique en immunorécepteurs NKR et/ou en immunorécepteurs contreparties de NKR
- 14. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce qu'elle est appliquée à la documentation d'un répertoire d'expression en immunorécepteurs WR R et/ou en immunorécepteurs contreparties de NKR
- 15. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce que ledit échantillon biologique d'origine humaine ou animale est du sang périphérique, de la moelle osseuse, des lymphocytes, des cellules NK et/ou T, des cellules transgéniques exprimant des immunorécepteurs, une fraction isolée à partir de ces échantillons.
- 16. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce qu'elle est appliquée au criblage d'une banque d'organes, de tissus ou de cellules.
- 17. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce qu'elle est appliquée à la prévision ou au suivi de l'acceptation ou du rejet, par un homme ou un animal, de cellules, tissu ou organe génétiquement différent (es).
- 18. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce qu'elle est appliquée à la prévision ou au suivi de l'inocuité ou de la pathogénicité (GVH) d'une greffe ou transplantation, par un homme ou un animal, de cellules, tissu ou organe génétiquement différent (es ) .
- 19. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce qu'elle est appliquée à la prévision ou au suivi, pour un homme ou un animal, d'un effet de type GVL de la part de cellules, tissu ou organe génétiquement différent (es ) .
- 20. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce qu'elle est appliquée à la détermination de l'état d'activation de cellules W et/ou T à un instant donné chez un animal ou un homme.
- 21. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce qu'elle est appliquée à la prévision ou au suivi de l'état de résistance d'un animal ou d'un homme vis-à-vis d'une infection virale, telle qu'une infection par un VIH, d'une infection parasitaire, telle que la malaria, d'une infection bactérienne, vis-àvis d'une maladie auto-immune, telle que la polyarthrite rhumatoïde, ou bien encore vis-à-vis du développement de cellules malignes telles que des cellules leucémiques.
- 22. Méthode selon l'une quelconque des revendications précédentes, caractérisée en ce qu' elle est appliquée au criblage de médicaments actifs vis-à-vis de maladies infectieuses, de maladies auto-immunes, ou de maladies tumo rales.
- 23. Kit pour la mise en oeuvre de la méthode selon l'une quelconque des revendications 1 à 22, caractérisé en ce qu'il comprend, dans un récipient, au moins une dite paire d'oligonucléotides 3' et 5' , les réactifs pour la réalisation de ladite ou lesdites méthode (s ) tels que tampon, marqueur (éventuellement couplé aux oligonucléotides de la dite paire), ainsi qu'un mode d'emploi.
Priority Applications (8)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR9713115A FR2769921B1 (fr) | 1997-10-20 | 1997-10-20 | Moyens de documentation de repertoires en immunorecepteurs nkr et/ou en immunorecepteurs contreparties activatrices ou non inhibitrices d'immunorecepteurs nkr |
| PCT/FR1998/002244 WO1999020794A1 (fr) | 1997-10-20 | 1998-10-20 | Moyens de documentation de repertoires en immunorecepteurs nkr et/ou en immunorecepteurs contreparties activatrices ou non inhibitrices d'immunorecepteurs nkr |
| JP2000517112A JP2002510461A (ja) | 1997-10-20 | 1998-10-20 | Nkr免疫レセプタ及び/又はnkr免疫レセプタを活性化するか又は阻害しない相対物目録の文書化手段 |
| CA002306445A CA2306445A1 (fr) | 1997-10-20 | 1998-10-20 | Moyens de documentation de repertoires en immunorecepteurs nkr et/ou en immunorecepteurs contreparties activatrices ou non inhibitrices d'immunorecepteurs nkr |
| US09/529,759 US20020192644A1 (en) | 1997-10-20 | 1998-10-20 | Documentation means for repertoires of nkr immunoreceptors and/or activatory or non-inhibitory immunoreceptor counterparts of nkr immnunoreceptors |
| EP98950162A EP1017854A1 (fr) | 1997-10-20 | 1998-10-20 | Moyens de documentation de repertoires en immunorecepteurs nkr et/ou en immunorecepteurs contreparties activatrices ou non inhibitrices d'immunorecepteurs nkr |
| US10/633,771 US20040259103A1 (en) | 1997-10-20 | 2003-08-04 | Means of documenting repertoires of NKR immunoreceptors and/or of activatory or non-inhibitory immunoreceptor counterparts of NKR immunoreceptors |
| US11/104,353 US20050191695A1 (en) | 1997-10-20 | 2005-04-12 | Documentation means for repertoires of NKR immunoreceptors and/or activatory or non-inhibitory immunoreceptor counterparts of NKR immunoreceptors |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR9713115A FR2769921B1 (fr) | 1997-10-20 | 1997-10-20 | Moyens de documentation de repertoires en immunorecepteurs nkr et/ou en immunorecepteurs contreparties activatrices ou non inhibitrices d'immunorecepteurs nkr |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| FR2769921A1 true FR2769921A1 (fr) | 1999-04-23 |
| FR2769921B1 FR2769921B1 (fr) | 2000-08-18 |
Family
ID=9512426
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| FR9713115A Expired - Fee Related FR2769921B1 (fr) | 1997-10-20 | 1997-10-20 | Moyens de documentation de repertoires en immunorecepteurs nkr et/ou en immunorecepteurs contreparties activatrices ou non inhibitrices d'immunorecepteurs nkr |
Country Status (6)
| Country | Link |
|---|---|
| US (3) | US20020192644A1 (fr) |
| EP (1) | EP1017854A1 (fr) |
| JP (1) | JP2002510461A (fr) |
| CA (1) | CA2306445A1 (fr) |
| FR (1) | FR2769921B1 (fr) |
| WO (1) | WO1999020794A1 (fr) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112553317A (zh) * | 2019-09-25 | 2021-03-26 | 北京大学人民医院(北京大学第二临床医学院) | 一种检测nkg2c基因型的试剂盒与应用 |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR2769921B1 (fr) * | 1997-10-20 | 2000-08-18 | Inst Nat Sante Rech Med | Moyens de documentation de repertoires en immunorecepteurs nkr et/ou en immunorecepteurs contreparties activatrices ou non inhibitrices d'immunorecepteurs nkr |
| FR2858631A1 (fr) * | 2004-09-24 | 2005-02-11 | Centre Nat Rech Scient | Procede de detection et d'identification de la presence de matieres biologiques provenant de poissons, et oligonucleotides pour sa mise en oeuvre |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5976819A (en) * | 1995-11-21 | 1999-11-02 | National Jewish Medical And Research Center | Product and process to regulate actin polymerization in T lymphocytes |
| US5847093A (en) * | 1996-12-27 | 1998-12-08 | Incyte Pharmaceuticals, Inc. | Human apoptosis regulator |
| FR2769921B1 (fr) * | 1997-10-20 | 2000-08-18 | Inst Nat Sante Rech Med | Moyens de documentation de repertoires en immunorecepteurs nkr et/ou en immunorecepteurs contreparties activatrices ou non inhibitrices d'immunorecepteurs nkr |
-
1997
- 1997-10-20 FR FR9713115A patent/FR2769921B1/fr not_active Expired - Fee Related
-
1998
- 1998-10-20 WO PCT/FR1998/002244 patent/WO1999020794A1/fr not_active Ceased
- 1998-10-20 CA CA002306445A patent/CA2306445A1/fr not_active Abandoned
- 1998-10-20 US US09/529,759 patent/US20020192644A1/en not_active Abandoned
- 1998-10-20 JP JP2000517112A patent/JP2002510461A/ja active Pending
- 1998-10-20 EP EP98950162A patent/EP1017854A1/fr not_active Withdrawn
-
2003
- 2003-08-04 US US10/633,771 patent/US20040259103A1/en not_active Abandoned
-
2005
- 2005-04-12 US US11/104,353 patent/US20050191695A1/en not_active Abandoned
Non-Patent Citations (5)
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112553317A (zh) * | 2019-09-25 | 2021-03-26 | 北京大学人民医院(北京大学第二临床医学院) | 一种检测nkg2c基因型的试剂盒与应用 |
| CN112553317B (zh) * | 2019-09-25 | 2022-05-17 | 北京大学人民医院(北京大学第二临床医学院) | 一种检测nkg2c基因型的试剂盒与应用 |
Also Published As
| Publication number | Publication date |
|---|---|
| WO1999020794A1 (fr) | 1999-04-29 |
| US20050191695A1 (en) | 2005-09-01 |
| EP1017854A1 (fr) | 2000-07-12 |
| CA2306445A1 (fr) | 1999-04-29 |
| US20020192644A1 (en) | 2002-12-19 |
| US20040259103A1 (en) | 2004-12-23 |
| FR2769921B1 (fr) | 2000-08-18 |
| JP2002510461A (ja) | 2002-04-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101900639B1 (ko) | 암 항원 특이적 t 세포의 수용체 유전자 및 그것에 따라 코드되는 펩티드 및 이들의 사용 | |
| Yamada et al. | A rat genetic linkage map and comparative maps for mouse or human homologous rat genes | |
| Yang et al. | Combining SSH and cDNA microarrays for rapid identification of differentially expressed genes | |
| US10648036B2 (en) | Receptor gene for peptide cancer antigen-specific T cell | |
| Cabrera et al. | Analysis of HLA expression in human tumor tissues | |
| CA2452099C (fr) | Methode de diagnostic prenatal sur cellule foetale isolee du sang maternel | |
| JP2000500339A (ja) | T細胞レセプターαおよびβ鎖CDR3部のファミリー内フラグメント分析方法 | |
| JPWO2001092572A1 (ja) | Hlaタイプを決定するためのキット及び方法 | |
| EP0677582B1 (fr) | Transcrits du gène de CMH de classe I HLA-G et leurs applications | |
| CN103251952B (zh) | 在肿瘤中差异表达的基因产物及其用途 | |
| EP0566685B1 (fr) | PROCEDE DE DESCRIPTION DES REPERTOIRES D'ANTICORPS (Ab) ET DES RECEPTEURS DES CELLULES T (TcR) DU SYSTEME IMMUNITAIRE D'UN INDIVIDU | |
| EP0772694A1 (fr) | Systeme de sondes permettant d'effectuer le typage hla dr, et procede de typage utilisant lesdites sondes | |
| EP0549776B1 (fr) | Systeme de sondes permettant d'effectuer le typage hla dr, et procede de typage utilisant lesdites sondes | |
| EP0654094A1 (fr) | Sequences d'oligonucleotides pour la detection specifique de mollicutes par amplification de genes conserves | |
| FR2769921A1 (fr) | Moyens de documentation de repertoires en immunorecepteurs nkr et/ou en immunorecepteurs contreparties activatrices ou non inhibitrices d'immunorecepteurs nkr | |
| JP2002503096A (ja) | 腫瘍拒絶抗原前駆体mage−c1およびmage−c2をコードする単離核酸分子とその利用方法 | |
| JPH05276954A (ja) | 新規なdna塩基配列およびその用途 | |
| US5512437A (en) | Method for determining head and neck squamous cell carcinomas, prostate carcinomas, and bladder tumors by assaying for mage-3 | |
| FR2749308A1 (fr) | Sondes nucleotidiques et procede pour determiner le typage hla dqb1 | |
| Ragupathi et al. | The relative distribution of B35 alleles and their IEF isotypes in a HLA‐B35‐positive population | |
| WO1989001978A1 (fr) | Sondes moleculaires d'adn specifique du genome male du genre bos | |
| FR2690460A1 (fr) | Préparation et utilisation de sondes d'acide nucléique spécifiques du chromosome 21. | |
| WO1991013171A1 (fr) | Procede d'estimation d'un type d'antigene de leucocytes humains | |
| CA2308019A1 (fr) | Methode de diagnostic in vitro de pathologies associees a des remaniements geniques et trousses de diagnostic | |
| FR2854903A1 (fr) | Utilisation des loci bage (b melanoma antigens) comme marqueurs tumoraux |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| ST | Notification of lapse | ||
| RN | Application for restoration | ||
| FC | Decision of inpi director general to approve request for restoration | ||
| ST | Notification of lapse |
Effective date: 20070629 |