JP3556966B2 - コプロセッサ - Google Patents
コプロセッサ Download PDFInfo
- Publication number
- JP3556966B2 JP3556966B2 JP31385093A JP31385093A JP3556966B2 JP 3556966 B2 JP3556966 B2 JP 3556966B2 JP 31385093 A JP31385093 A JP 31385093A JP 31385093 A JP31385093 A JP 31385093A JP 3556966 B2 JP3556966 B2 JP 3556966B2
- Authority
- JP
- Japan
- Prior art keywords
- circuit
- signal
- bus
- control
- slave
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images
























Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/16—Combinations of two or more digital computers each having at least an arithmetic unit, a program unit and a register, e.g. for a simultaneous processing of several programs
- G06F15/163—Interprocessor communication
- G06F15/17—Interprocessor communication using an input/output type connection, e.g. channel, I/O port
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3877—Concurrent instruction execution, e.g. pipeline or look ahead using a secondary processor, e.g. coprocessor
- G06F9/3879—Concurrent instruction execution, e.g. pipeline or look ahead using a secondary processor, e.g. coprocessor for non-native instruction execution, e.g. executing a command; for Java instruction set
- G06F9/3881—Arrangements for communication of instructions and data
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units
- G06F9/3887—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units controlled by a single instruction for multiple data lanes [SIMD]
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computer Hardware Design (AREA)
- Mathematical Physics (AREA)
- Advance Control (AREA)
- Information Transfer Systems (AREA)
Description
【0001】
本発明は並列処理装置に関する。
【0002】
ウィルソン(Wilson)の米国特許第5,129,092号では、画像および空間的に関連のあるデータなどのデータ行列を処理するための単一命令多重データ(SIMD)並列処理装置を開示している。図1および図2に関連して図示しまた解説しているように、この処理装置は隣接する処理ユニット間に直接データ通信リンクを有する隣り合わせ処理ユニットの線型連鎖を含む。
【0003】
ウィルソン092号で図1、図2、図5との関連で図示しまた説明しているように、処理ユニットは8個のグループを構成し、ホストコンピュータと制御装置はどちらもデータバイト線と称する8ビット線経由でこのグループからのデータを送受信可能である。
【0004】
ウィルソン092号では図6Aおよび図6Bとの関連でメモリと加算器(アキュムレータ)間のデータ置換のための置換演算も説明している。
【0005】
ヒリス(Hillis)の米国特許第5,113,510号ではシンキングマシンズ社(Thinking Machines Corporation )製のSIMD並列処理装置であるコネクションマシン(Connection Machine)において使用するために明らかに開発された多処理装置内のキャッシュメモリを操作するための技術を開示している。図3との関連で図示しまた解説しているように、多処理装置システムのそれぞれの処理装置は対応するキャッシュへ接続している。キャッシュメモリがミス信号を出力すると、バス調停ユニットはそれぞれの連続したキャッシュで現在の更新が実行されている間は更新を実行し得ないことを示す信号を供給して、優先連鎖の中の更新を要求している第1のキャッシュが一時的に他の全ての更新要求を無効にする。更新要求を受信すると、共有メモリは指定されたアドレスのデータを取得してデータレディ信号と、アドレスと、データを出力する。アドレスがキャッシュの問題となるアドレス指定範囲内に有る場合またはキャッシュが更新要求の供給源の場合、キャッシュメモリはアドレスおよびデータ信号を受信し保存する。その結果、全てのキャッシュは任意の範囲検出装置によってのみ制限される主メモリからの更新データを受信する。
【0006】
本発明では並列処理装置における基本的な問題を取り扱う。
【0007】
SIMD並列処理装置は、それぞれがメモリ中の自分のデータをアクセス可能な処理ユニットを含む。それぞれの処理装置が独立した命令のシーケンスを実行可能な多重命令多重データ(MIMD)並列処理装置とは異なり、SIMD並列処理装置内の全ての処理ユニットはおなじ命令のストリームを受信する。
【0008】
SIMD並列処理装置は画像処理などのデータアレイに対する演算に特に有用である。しかし従来のSIMD並列処理装置はホスト処理装置のバスへ接続された補助演算装置として効率的な演算を行なうようには設計されていない。幾つかの在来のSIMD並列処理装置はデータ入出力について主としてシフトレジスタに頼っており、ホスト処理装置のバスからのデータ受信において互換性がない。その他のSIMD並列処理装置は隅角を折り返す回路に水平方向の様式でデータを供給して、ここからそれぞれの処理ユニットへ垂直方向の様式でデータを供給している。別のSIMD並列処理装置では、それぞれの処理ユニットのキャッシュメモリはバスを介して共有メモリをアクセス可能だが、多数の処理ユニットのそれぞれをホスト装置のメモリへホスト装置のバスを経由して接続するには実際的とは言えない。
【0009】
本発明はSIMD並列処理装置などの並列処理装置がホスト処理装置のバスのスレーブおよびマスタとなり得るような回路を提供することによってこれとこれに関連した問題を軽減するアーキテクチャの発見に基づくものである。その結果、並列処理装置はホスト処理装置のバスのスレーブとして命令を受信できるがその他の目的たとえばデータを処理ユニットへ入出力するなどではホスト処理装置のバスのマスタとなることが出来る。
【0010】
本アーキテクチャはホスト処理装置の中央演算処理装置(CPU)およびメモリなどのその他の部材も接続されているホストバスへ接続することが出来る補助演算装置として実施可能である。補助演算装置は複数の処理ユニットを含む。補助演算装置はまた補助演算装置を制御しまた処理ユニットを制御するための信号を供給するように接続してある制御回路も含む。最後に、補助演算装置はホスト装置へ接続するためのホストバス接続回路も含む。
【0011】
ホストバス接続回路はスレーブ回路とマスタ回路を含んでいる。スレーブ回路は補助演算装置の演算を要求するホストバスからの信号を受信し、これに応じて補助演算装置の制御回路へ信号を供給して補助演算装置に要求された演算を実行させる。マスタ回路は補助演算装置の制御回路からデータ転送操作を要求する信号を受信し、これに応じてホストバスへホストバスの操作を要求する信号を供給し、補助演算装置からホストバスへまたはホストバスから補助演算装置へのいずれかにデータを転送し要求されたデータ転送操作を実行する。
【0012】
上述したような補助演算装置のアーキテクチャは多くの方法で有利である。
【0013】
処理ユニットへのデータ入出力操作は補助演算装置の通常操作に統合することが可能であり、これによって大きな柔軟性が得られる。たとえば、巨大なアレイの小から大まで異なる大きさの部分を定義するデータが特定の補助演算装置の操作で必要に応じて容易に取り扱うことが出来るように、いろいろな大きさのいずれかのデータブロックを要求に応じて転送することが出来る。さらに、転送はデータブロックからのデータ項目が処理ユニット間で等しく分配されるように実施することが可能である。
【0014】
柔軟なブロックの大きさとデータ項目を等しく分配する能力は画像処理の用途で特に重要である。これらの特徴のため、画像または異なる大きさの画像の別の部分を定義するデータを処理ユニットへ供給することが出来る。たとえば、それぞれの処理ユニットはメモリ回路を含むように実施可能であり、それぞれのデータの画素または一群の画素を定義しているワードをそれぞれの処理ユニットのメモリ回路内にロードすることが出来る。さらに、それぞれの処理ユニットのメモリ回路は処理ユニットの処理回路の内部レジスタより多くのデータ項目を保存し得るような充分な大きさをとることが出来るので、メモリ回路が処理回路のためのキャッシュ機能を実行できる。処理ユニットは1次元アレイを構成できまた全ての処理ユニットのメモリ回路全部で一枚以上の画像を保存するのに充分な大きさに出来、それぞれの処理ユニットのメモリ回路がそれぞれの画像内のそれぞれの水平方向の画像ブロックからのそれぞれのワードを保存する。それぞれの水平方向の画像ブロックは水平方向の様式で処理ユニットのアレイに充分に適合するだけの小さい単一行または行の一部である。
【0015】
コプロセッサのアーキテクチャは多数のバス手順およびブロック寸法のいずれにも適合することが出来る。特定のバス手順用のスレーブ回路およびマスタ回路は従来の部材を用いて容易にまた安価に製作可能である。コプロセッサ制御回路は複雑さのあらゆる適切なレベルを提供可能で、たとえばコプロセッサの演算を実行させるために実行されるマイクロ命令を保存する制御保存回路を用いて実施可能である。マイクロ命令はホストバスからスレーブ回路によってロードすることが出来、ホスト処理装置のブロックの大きさに適合するように出来る。
【0016】
上述のコプロセッサのアーキテクチャによればホストバスの他のマスタからの入力または出力操作の要求に応答するために別個の制御回路を有する必要がなくなる。別のマスタはマスタ回路に入力または出力操作を実行させるようにコプロセッサ制御回路が要求するように制御保存回路内へマイクロ命令をロードすることが出来る。
【0017】
上述のコプロセッサのアーキテクチャによれば、それぞれの処理ユニットは水平方向のフォーマットでのデータを取り扱うように構成することが出来る。データ項目は水平方向のフォーマットで受信されまた操作が水平方向のフォーマットで実行されることから、隅角で折り返す回路は必要とされない。
【0018】
図1はホスト処理装置のバスへコプロセッサとして接続することのできる並列処理装置の一般的部材を示す略ブロック図である。
【0019】
図2Aは図1のスレーブ回路がコプロセッサの処理要求に応答する一般的動作を示す流れ図である。
【0020】
図2Bは図1のコプロセッサ内の処理ユニットからホストバス上のスレーブ回路へデータを転送するマスタの処理における一般的動作を示す流れ図である。
【0021】
図2Cは図1のコプロセッサ内の一組の処理ユニットへホストバス上のスレーブ回路からデータを転送するマスタの処理における一般的動作を示す流れ図である。
【0022】
図3はSparc−Station のSバスに接続したSIMD並列処理装置の実施における部材を示す略ブロック図である。
【0023】
図4は図3の制御回路の部材を示す略ブロック図である。
【0024】
図5は図3の処理ユニットの部材を示す略ブロック図である。
【0025】
図6は図4の制御保存回路にマイクロ命令をロードすることにおける一般的動作を示す流れ図である。
【0026】
図7は図3のボックスへのクロック信号を制御する部材を示す略ブロック図である。
【0027】
図8は図7のDVMAシーケンサをSバスにまたマスタ回路のその他の回路に接続する線を表わす略ブロック図である。
【0028】
図9は図7のスレーブシーケンサをSバスへまたスレーブ回路のその他の部材へ接続する線を示す略ブロック図である。
【0029】
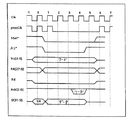
図10は図9のスレーブシーケンサがエラーを含む信号にどのように応答するかを示すタイミング図である。
【0030】
図11は制御/状態レジスタからデータを読み出す操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【0031】
図12は制御/状態レジスタ内にRUNビットを書き込む操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【0032】
図13は起動用PROMからデータを読み出す操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【0033】
図14は制御保存回路からデータを読み出す操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【0034】
図15は制御保存回路へデータを書き込む操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【0035】
図16はホスト装置のメモリからデータを読み出すDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答するかを示すタイミング図である。
【0036】
図17は図16の操作の間にパイプライン・レジスタ回路を通るデータの動きを示す略流れ図である。
【0037】
図18はホスト装置のメモリからのデータを書き込むDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答するかを示すタイミング図である。
【0038】
図19は図18の操作の間にパイプライン・レジスタ回路を通るデータの動きを示す略流れ図である。
【0039】
図20は複数ワードを読み込むDMA操作を要求する信号に図8のDVMAシーケンサがどのように応答を開始するかを示すタイミング図である。
【0040】
図21は複数ワードを読み込むDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答を完了するかを示すタイミング図である。
【0041】
図22は図20および図21の操作の間にパイプライン・レジスタ回路を通過するデータの動きを示す略流れ図である。
【0042】
図23は複数ワードを書き込むDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答を開始するかを示すタイミング図である。
【0043】
図24は複数ワードを書き込むDMA操作を要求する信号に対して図8のDMVAシーケンサがどのように応答を完了するかを示すタイミング図である。
【0044】
図25は図23および図24の操作の間にパイプライン・レジスタ回路を通過するデータの動きを示す略流れ図である。
【0045】
図1から図2Cでは本発明の一般的特徴を図示している。図1では、ホスト処理装置のバスへコプロセッサとして接続可能な並列処理装置の部材を示す。図2Aではコプロセッサ内の制御回路へデータを供給するスレーブ操作における動作を示す。図2Bではホストバス上のスレーブへ処理ユニットからのデータを転送するマスタの操作における動作を示す。図2Cでは一組の処理ユニットへホストバス上のスレーブからのデータを転送するマスタの操作における動作を示す。
【0046】
図1のホスト処理装置は、その他の部材たとえばホスト装置の中央演算処理装置(CPU)14やメモリ16などを接続可能なホストバス12を含む。ホストバス12はホストバス制御回路18で制御可能である。その他の各種部材たとえば入出力装置や別のコプロセッサなどをホストバス12に接続することが可能である。
【0047】
図1のコプロセッサ20は、処理ユニット22、コプロセッサ20を制御するためのコプロセッサ制御回路24、コプロセッサ20をホスト装置10に接続するためのホストバス接続回路30を含む並列処理装置である。コプロセッサ制御回路24は処理ユニット22へ制御信号を供給する。
【0048】
ホストバス接続回路30はスレーブ回路32とマスタ回路34を含む。
【0049】
スレーブ回路32はコプロセッサの操作を要求する信号を受信するようにホストバス12へ接続されており、この信号はたとえばホスト装置のCPU14が供給し得るものである。スレーブ回路32も要求されたコプロセッサの操作が実行されるようにコプロセッサ制御回路24へ信号を供給することにより応答するために接続されている。
【0050】
マスタ回路34はデータ転送操作を要求する信号を受信するように制御回路24へ接続されている。これに呼応して、マスタ回路34はホストバス操作を要求する信号をホストバス12へ供給する。これらの信号は、たとえばホストバス12の制御要求を含み、ホストバス制御回路18はバス制御を許可することによりこれに応答することが出来る。マスタ回路34はまた1つの処理ユニット22からホストバス12へ、またはホストバス12から少なくとも1つの処理ユニット22の組へ、要求されたデータ転送が実行されるようにデータを転送する。
【0051】
図2Aにおいて、囲み50の動作では、スレーブ回路32はホストバス12からコプロセッサの操作要求を表わす信号を受信している。信号は適用可能なバス手順にしたがってホストバス12に接続されたマスタが供給できる。囲み52の動作では、スレーブ回路32がコプロセッサ制御回路24へ信号を供給して要求に応答している。この信号は、たとえば制御信号であったり、またはホストバス12から要求の一部として受信したアドレスまたはその他のデータ項目を含むことが出来る。
【0052】
図2Bにおいて、囲み60の動作では、コプロセッサ制御回路24は処理ユニット22へまたマスタ回路34へ信号を供給し、マスタ回路34が処理ユニットの1つからのデータ項目を取得するようにしている。囲み62の動作では、コプロセッサ制御回路24はデータ転送操作を要求する信号をマスタ回路34へ供給している。要求された操作には処理ユニットからのデータ項目をホストバス12に接続したスレーブへ転送する出力操作が含まれる。囲み64の動作では、マスタ回路34はホストバス12の制御を要求する信号を供給して要求に応答している。ホストバス制御回路18がマスタ回路34にホストバスの制御を許可すると、囲み66の動作で、マスタ回路34はホストバス12を経由してスレーブへデータ項目を供給する。
【0053】
図2Cにおいて、囲み70の動作では、コプロセッサ制御回路24はデータ転送操作を要求する信号をマスタ回路34へ供給している。要求された操作にはデータ項目をホストバス12に接続したスレーブから受信する入力操作が含まれる。囲み72の動作では、マスタ回路34はホストバス12の制御を要求する信号を供給することで要求に応答している。ホストバス制御回路18がマスタ回路34にホストバスの制御を許可すると、囲み74の動作で、マスタ回路34はホストバス12を経由してスレーブからデータ項目を受信する。囲み76の動作では、コプロセッサ制御回路24はマスタ回路34および処理ユニット22へ信号を供給して、マスタ回路34が少なくとも1つの処理ユニット22の組へデータ項目を供給するようにしている。
【0054】
図8から図25では本発明を実施するために上述の一般的実施の特徴をどのように使用できるかを示している。図8および図9では、DVMAシーケンサ282およびスレーブシーケンサ284がその他の部材にどのように接続されるかを図示している。図10から図15では、スレーブシーケンサ284が操作要求にどのように応答するかを示している。図16から図19ではマスタシーケンサ282が単一ワード読み込みと書き出し操作の要求に対してどのように応答するかを示している。図20から図25では複数ワード読み込みまたは書き出しが行なわれるようなバースト転送操作の要求に対してどのように応答するかを示している。
【0055】
上述のように、DVMAインタフェース112およびスレーブインタフェース114はそれぞれに各々のシーケンサつまりDVMAシーケンサ282およびスレーブシーケンサ284を用いて実施することが出来る。図8ではDVMAシーケンサ282がSバス102およびその他の部材へどのように接続されるかを示す。図9ではスレーブシーケンサ284がSバス102およびその他の部材へどのように接続されるかを示す。
【0056】
DVMAシーケンサ282およびスレーブシーケンサ284は、サン・マイクロシステムズ社部品番号800−5922−10、Sバス仕様書B.0版、1990年に記載されている要件にしたがってそれぞれ実施し、仕様書からSバス102に供給すべき信号、Sバス102からの信号に応答するために利用可能な周期、Sバス102における信号のタイミング、Sバス102上の信号の手順、および起動用PROM116に必要な内容を決定することが出来る。図8および図9でClk 、D[31:0] 、BReq* 、BGnt* 、Rd、Siz[2:0]、Ack[2:0]、As* 、PA[27:0]、SSel* と印を付けてある線はSバス仕様書B.0版から理解できよう。DVMAシーケンサ282およびスレーブシーケンサ284はたとえば、トランジスタを用いてまたは図10から図25に関連して詳細を説明したような信号を提供する1つまたはそれ以上のプログラマブルロジックアレイ(PLA)を用いてそれぞれ実施することが出来る。説明した実施において、信号は一般にprocClk の昇端でコプロセッサ内部へ進むが、データはレジスタ付トランシーバ188を経由してまたいくつかの信号はClk の昇端でDVMAシーケンサ282およびスレーブシーケンサ284内部へ進行する。
【0057】
図8において、DVMAシーケンサ282はSバス102およびSバスバッファ198を含むその他の部材へ信号を供給する方法を制御するレジスタ兼復号回路154からの信号を受信する。図示したように、Sバスバッファ198はSバス102のD[31:0] 線へ接続されており、Sバスバッファ198はSバス102のタイミング制約を満足させるようにDVMAシーケンサ282の制御下で動作する。レジスタ付トランシーバ194およびSバスレジスタ196は一方でパイプライン段階を提供する。レジスタ付トランシーバ194はレジスタ付トランシーバ122と協働してケーブル118の両端での信号の刻時の信頼性を確保する。
【0058】
上述のフィールドに加えて、それぞれのマイクロ命令はDVMAシーケンサ282の動作に関連するフィールドを含むことが出来る。単一のビットで現在の周期がSバスDMA読取かどうかを示すことが出来る。3ビットのフィールドで大きさを示すために標準Sバス符号化を用いるバースト転送の大きさを示すことが出来る。2ビットのフィールドで待機しない状態、バス許可を待機する状態、SバススレーブからのAck[2:0]線上のワード信号を待機する状態を含めSバスDMAマスタの周期の状態を示すことが出来る。別の2ビットフィールドで分岐に関する情報を提供でき、これには直前の動作がキャリーまたはボロー信号を提供したこと、直前の動作の結果が0だったこと、直前の動作の結果が否定またはReturnAck だったこと、Sバス制御回路がバス許可を下げることによって全てのドライバを停止させ、シーケンサが転送を実行するためにDVMAシーケンサ282を再起動しなければならないような条件を示すための値を有する。
【0059】
DVMAシーケンサ282により制御されるそれぞれのデータ転送動作は、Sバス102の制御要求を出さなければならないことを示すレジスタ兼復号回路154からのバス要求信号に応答して開始することが出来る。バス要求信号はDVMAシーケンサ282がSバス102上のBReq* 線を引き下げるため提供する単一ビットとすることが出来る。同時に、DVMAシーケンサ282はクロック制御論理回路280に信号を供給してレジスタ兼復号回路154へのクロック信号の供給を停止させることが出来る。
【0060】
バス要求信号を供給する前に、レジスタ兼復号回路154は要求されたデータ転送動作を準備するために必要とされる全ての他の動作を実行することが出来る。たとえば、アドレスを表わすデータ項目をレジスタ付トランシーバ194内に保存し、また書き込み動作のためには書き込むべきデータ項目をレジスタ付トランシーバ122内に保存することが出来る。いずれの場合にも、データ項目は処理ユニット130から取得することが出来、ユニットの1つが適切なマイクロプロセッサ220および222の動作を通じてまたはSRAM240からのデータ項目を取り込むことによってデータ項目を取得でき、またはデータ項目を定数バッファ192から取得することが出来る。
【0061】
バス要求信号を供給する際に、レジスタ兼復号回路154は読み取り/書き込み信号およびブロックサイズ信号を供給することも出来る。読み取り/書き込み信号は要求された動作が読み込み動作であるかまたは書き込み動作であるかを表わし、ブロックサイズ信号は転送すべきデータブロックの大きさを表わす。BReq* 線を引き下げてBGnt* 線上にSバス102の制御を取得していることを表わす信号を受信したあと、DVMAシーケンサ282はSバス102のRd線に読み取り/書き込み信号を供給しまたSバス102のSiz[2:0]線にブロックサイズ信号を供給することも可能である。
【0062】
BReq* 線に応答して、Sparc−Station 100内のSバス制御回路はDVMAシーケンサ282のBGnt* 線を引き下げ、Sバス102の制御を渡す。BGnt* に応答して、DVMAシーケンサ282は以下に詳細を説明するような信号を供給して要求されたデータ転送動作を実行し、Sバス102に接続されたスレーブの読み取りまたは書き込みを行なう。読み込み動作中、スレーブがAck[2:0]線上に信号を供給し続けて線D[31:0] にデータを供給する場合はいつでもDVMAシーケンサ282がSバスバッファ198へ制御信号を供給してデータを受信する準備が出来ていなければならない。DVMAシーケンサ282はまたクロック制御論理回路280へも信号を送りレジスタ兼復号回路154がクロックパルスを受信して受信データを保存するようにSバスレジスタ196を制御することが出来るように準備する必要がある。書き込み動作中、DVMAシーケンサ282は同様に信号を供給してSバスレジスタ196からのデータがSバスバッファ198を介してSバスの線D[31:0] へ供給されるようにする。
【0063】
図8に図示した回路に加えて、図1のマスタ回路34の機能を実行するために各種の付加回路を用意することが出来る。たとえば、マスタ回路34は処理ユニット全てに接続した共通データバス156を含むことが出来る。図5との関連ですでに説明したように、マスタ回路34はそれぞれの処理ユニットについて、処理ユニットをデータ供給源であると示すためまたはデータの宛先である一組の処理ユニット内に処理ユニットが存在することを示すために制御回路126が信号を供給するレジスタ付トランシーバ212を含むことも出来る。
【0064】
共通データバス156とレジスタ付トランシーバ212はSバス102との間でのデータ転送経路を提供しており、これはそれぞれの処理ユニットへの独立した線など他の構造より一層効率的であり得る。この経路を通って、データを処理ユニットからレジスタ付トランシーバ122へ、またレジスタ付トランシーバ194、Sバスレジスタ196、Sバスバッファ198を経由してSバス102へ直接転送できる。同様に、Sバス102からのデータをSバスバッファ198、Sバスレジスタ196、およびレジスタ付トランシーバ194を介してレジスタ付トランシーバ122へさらに一組の処理ユニットへ直接転送することが出来る。つまりレジスタ付トランシーバ122、レジスタ付トランシーバ194、およびSバスレジスタ196は共通データバス156とSバス102の間で転送されるデータ項目を保存するためのパイプラインとして機能することになる。図5との関連で前述したように、レジスタ兼復号回路154は書き込み可能信号を供給して処理ユニット内のSRAM240にその組のそれぞれの処理ユニットのレジスタ付トランシーバ212からのデータを保存することが出来る。
【0065】
上述の回路により提供される経路は隅角折り返し回路を含んでいない。これはそれぞれの処理ユニットが水平方向のフォーマットにあるデータを取り扱うように構成されている場合に好適である。
【0066】
図8の回路はホスト装置CPU14の介在なしに図1のメモリ16などのメモリに対するダイレクトメモリアクセス(DMA)方式読み取りおよび書き込みを実行できる。たとえば、画像処理を実行する上では、マスタ回路14はホスト装置のCPUとは独立に、マイクロプロセッサ220および222の要求およびSRAM240の容量に従い画像の部分を定義するデータの読み取りまたは書き込みが出来る。この能力は連続した画像内の多数のタイルのそれぞれを取り扱うために使用可能である。SRAM240はマイクロプロセッサ220および222の内部レジスタより多くのデータ項目を保存できるため、SRAM240を用いてマイクロプロセッサ220および222のためのデータの取込みが可能である。
【0067】
図9では、スレーブシーケンサ284はSバス102上の線SSel* 、AS* 、Rd、Siz[2:0]、PA[27:0]で要求された動作を表わす信号を受信する。
【0068】
Sバス102はこれに接続しているそれぞれのスレーブに対してSSel* 線を含む。バス制御回路がスレーブのアドレス空間内の位置を表わす仮想アドレスをD[31:0] 線上で受信すると、バス制御回路はスレーブのSSel* 線を低値に引き下げることでスレーブによる操作要求を表わす。バス制御回路は仮想アドレスを適切な物理アドレスへ変換しまたPA[27:0]線上の物理アドレスを供給し、その時点でバス制御回路はAS* 線を用いて、SSel* 、Rd、およびSiz[2:0]線が有効でありアドレスがPA[27:0]上にありまたマスタがD[31:0] 線上の仮想アドレスを供給停止可能であることを示すことが出来る。
【0069】
SSel* 、Rd、およびSiz[2:0]線上の信号はスレーブシーケンサ284がSバス102、Sバスレジスタ188、Sバスバッファ190を含むほかの部材へ信号を供給する方法を制御する。たとえばSSel* 線とAS* 線の降端に応答して、スレーブシーケンサ284はSバス102のAck[2:0]線上に信号を供給し、Rd、Siz[2:0]、PA[27:0]線上の要求がエラーかを示す、または要求された動作を実行する上でD[31:0] 線上で読み込むまたは書き込むことの出来るデータユニットの大きさを示す。Sバススレーブは一般に16ワードブロックまでのバイトサイズとは異なるいくつかの大きさの転送を取り扱う許可を有しているものの、スレーブシーケンサ284は限られた能力でのみ実施する必要がある。たとえば、スレーブシーケンサ284はワードおよびバイト単位の転送だけを取り扱うことが出来、また線Ack[2:0]上にワードまたはバイトを示すことが出来る。
【0070】
図示したように、Sバスバッファ190はSバス102のD[31:0] 線に接続されており、Sバスバッファ190はスレーブシーケンサ284の制御下でSバス102のタイミングの制約を満足させるように動作する。Sバスレジスタ188はSバス102からクロックを供給されているが、スレーブシーケンサ284により制御されることでトランシーバ124および制御保存回路150との間のケーブル118両端での信号の刻時の信頼性を確保するようにパイプライン段階を提供する。スレーブシーケンサ284はたとえば、Sバスレジスタ188がデータを受信する方向を決定して、所定の周期の間にこれを有効または無効にすることが出来る。
【0071】
同様に、アドレスバッファ182はSバス102のPA[27:0]線に接続されており、スレーブシーケンサ284の制御下でケーブル118経由でCSアドレスバッファ180へと起動用PROM116へのアドレスを供給する。起動用PROM116はスレーブシーケンサ284の制御下にあるバッファ184を介してSバス102のD[31:0] 線へ出力を供給する。スレーブシーケンサ284はまたバッファ184の1ビットを直接駆動して制御/状態レジスタ168内のRUNビットの値を示すことの出来る接続も有している。
【0072】
スレーブシーケンサ284はまたクロック制御論理回路280とケーブル118経由で制御保存回路150の書き込み可能線とケーブル118経由でMAR152およびCSアドレスバッファ180の出力イネーブル線へも信号を供給する。出力イネーブル信号はMAR152およびCSアドレスバッファ180からの出力をゲートする従来回路へ供給して制御保存回路150をアクセスするためのアドレスを選択することが出来る。図示した線に加えて、スレーブシーケンサ284はトランシーバ124へ制御信号を供給するようにも接続してある。
【0073】
スレーブシーケンサ280により制御される動作には、制御保存回路150からデータを読み込むまたはデータを書き出す操作、出力/状態レジスタ168からデータを読み込むまたはデータを書き出す操作、およびSバス102へ起動用PROM116からデータを読み出す操作が含まれる。必要であればスレーブシーケンサ284はアドレスバッファ182が線PA[27:0]から起動用PROM116へまたCSアドレスバッファ180へのアドレスを示すデータを提供することが出来るように制御信号を供給することが出来る。アドレスの高次ビットから、スレーブシーケンサ284はアドレスが起動用PROM116用か、制御保存回路150用か、または制御/状態レジスタ168用かを決定できる。たとえば、0から(256K−1)のアドレスは起動用PROM116用、アドレス256Kから(512K−1)は制御保存回路150用、またアドレス512Kから(768K−1)は制御/状態レジスタ168用とすることが出来る。
【0074】
スレーブシーケンサ284は起動用PROM116へ出力イネーブル信号を供給してアドレスバッファ182内のデータで示されるアドレスからデータを読み出すことが出来る。次に、スレーブシーケンサ284はバッファ184に制御信号を供給してSバス102の線D[31:0] 上に起動用PROM116からのデータを供給できるようにすることが出来る。起動用PROM116は一度に1バイトを供給するので、スレーブシーケンサ284は起動用PROM116用アドレスとSiz[2:0]線上のワード信号を受信した場合Ack[2:0]線上に1バイト信号を供給する。
【0075】
スレーブシーケンサ284はMAR152およびCSアドレスバッファ180の出力イネーブルへ信号を供給してCSアドレスバッファ180からのアドレスが制御保存回路150へ供給されるようにする。Rd線に従ってスレーブシーケンサ284は制御保存回路150の出力イネーブル端子へ動作が読み込みまたは書き込み操作どちらであるかを表わす信号を供給する。スレーブシーケンサ284はさらに制御保存回路150へまたはここからワードを転送する信号を供給することが出来る。
【0076】
操作が制御保存回路150からの1ワード読み出しの場合スレーブシーケンサ284は選択信号をトランシーバ124へまた制御信号をSバスレジスタ188とSバスバッファ190へ供給してワードをSバス102の線D[31:0] へ転送することが出来る。スレーブシーケンサ284は制御保存回路150がコプロセッサとホスト装置のCPUの間のメールボックスとして使用されている場合また診断動作中にも制御保存回路150からSバス102へデータを転送することが出来る。
【0077】
操作が制御保存回路150への書き込みの場合、スレーブシーケンサ284は制御信号をSバスバッファ190およびSバスレジスタ188へまた選択信号をトランシーバ124へ供給することにより、書き込むワードを線D[31:0] から適切なトランシーバ124の1つへ転送できる。スレーブシーケンサ284の主な機能の1つはSバス102から制御保存回路へこの方法でマイクロ命令を転送することである。スレーブシーケンサ284はまた制御保存回路150がコプロセッサとホスト装置のCPUの間のメールボックスとして使用中の場合制御保存回路150へSバス102からのデータを転送することも出来る。
【0078】
現行の実施において操作が制御/保存レジスタ168の読み取りまたは書き込みの場合、RUNビットだけが読み出しまたは書き込みされる。スレーブシーケンサ284は書き込むべきデータを直接制御/状態レジスタ168へ供給するように接続してあり、また制御/状態レジスタ168から直接読み込まれるデータを受信するように接続してある。読み込み操作の場合、スレーブシーケンサ284はRUNビットの値をバッファ184を介して1つまたはそれ以上の線D[31:0] へ供給することが出来る。書き込み操作の場合、PA[27:0]線上のアドレスはRUNビットをセットするかまたはクリアするかを表わし、スレーブシーケンサ284はセットまたはクリア信号を制御/状態レジスタ168へ直接供給することが出来る。
【0079】
図10から図15はスレーブシーケンサ284により制御される操作の間にどのように信号が供給されるかを詳細に図示している。図16から図25ではDVMAシーケンサ282により制御される操作の間にどのように信号が供給されるかを詳細に図示している。いずれの場合にも、操作を制御するシーケンサ内の論理は受信する信号に基づいて別の部材への信号を供給する。論理は従来のデジタル論理設計の原則にしたがって設計することが出来る。
【0080】
図10から図25に図示した信号の大半は図8および図9を参照して上述したものである。さらに、それぞれのタイミング図はClk 信号およびprocClk 信号を含んでいる。Sバス102は図7を参照して上述したようにクロック制御論理回路280で受信するClk 線を有している。クロック制御論理回路280はその結果レジスタ兼復号回路154へprocClk 信号を供給する。
【0081】
クロック制御論理回路280は3入力の単一ANDゲートのように動作することが出来る。1つの入力はSバス102からのClk である。もう1つの入力はスレーブシーケンサ284が低値にすることでprocClk 信号を停止させる線であり、第3の入力はDVMAシーケンサ282が低値にすることでprocClk 信号を停止させる線である。従って、procClk はスレーブシーケンサ284またはDVMAシーケンサ282いずれかにより停止できるが、両方のシーケンサが再開を許可した場合に限って再開することが出来る。prokClk 信号上の不用意なスパイクを防止するため、スレーブシーケンサ284およびDVMAシーケンサ282はSバスのClk 信号が低値の間だけクロック制御信号の状態を変更できるようになっている。
【0082】
図10は動作中にprocClk 信号を停止させることなくスレーブシーケンサにより実行される動作を示している。言い換えれば、動作中のClk 線上のそれぞれのパルスがprocClk パルスを発生させるので、コプロセッサがマイクロ命令を実行することになる。
【0083】
Clk 周期−1の間に、現在のバスマスタはSiz[2:0]およびRd線上に信号を供給開始し、仮想アドレスVAをD[31:0] 線上に供給し続ける。Clk 周期0の間に、ホストバス制御回路はスレーブシーケンサ284のAS* 線とSSel* 線を低値にする。ホストバス制御回路はまたPA[27:0]上にVAから得られた物理アドレスも供給し現在のバスマスタはVAの供給を停止する。
【0084】
これに応答して、スレーブシーケンサ284はSiz[2:0]上の信号で示されたブロックサイズがスレーブシーケンサ284で支持されていない大きさであると決定する。つまりClk 周期1の間に、スレーブシーケンサ284はエラーを表わす信号をAck[2:0]に供給開始する。この信号を検出するとホストバス制御回路はAS* 線をClk 周期2の間に低値にする。Clk 周期2の間にエラー信号の終端を検出すると、ホストバス制御回路はClk 周期3の間にSSel* を低値にしてPA[27:0]への物理アドレスの供給を停止する。同様にエラー信号の終端を検出すると、現在のバスマスタはClk 周期3の間にSiz[2:0]およびRdへの信号供給を停止する。
【0085】
図11から図15はClk 周期0の間に供給される信号がエラーではないとスレーブシーケンサ284が決定しそれによって要求された動作を実行し、マイクロ命令の実行を阻止するためにクロック制御論理回路280へprocClk 信号を停止させる信号を送出する動作を図示している。それぞれの動作が完了すると、スレーブシーケンサ284はクロック制御論理回路280を開放しprocClk パルスがまた供給されるようにする。
【0086】
図11は制御/状態レジスタ168のRUNビットを読み取る動作を図示している。Clk 周期1の間にスレーブシーケンサ284はクロック制御論理回路280へ信号を送出してprocClk を停止させ、アドレスバッファ182を経由してCSアドレスバッファ180へPA[27:0]上の物理アドレスを供給するのに必要な全ての信号を供給する。Clk 周期2および3の間に次のようなことが起こる。物理アドレスは制御/状態レジスタ168をアドレスするように接続してあるCSアドレスバッファ180へ伝えられる。スレーブシーケンサ284はRUNビットの値Reg を制御/状態レジスタ168から読み出す。スレーブシーケンサ284はまたReg をRUN線上のバッファ184へ供給する。Clk 周期3の間にスレーブシーケンサ284はワードが供給されることを表わす信号をAck[2:0]に供給する。Clk 周期4の間にスレーブシーケンサ284は制御信号をバッファ184へ供給することでReg をD[31:0] 線上に供給する。おなじ周期中にスレーブシーケンサ284はクロック制御論理回路280へ信号を送ってマイクロ命令の実行を再開できるようにprocClk を再開させる。
【0087】
Clk 周期4の開始時にAck[2:0]でワード信号を受信すると、ホストバス制御回路はClk 周期4の間にAS* を低値にする。同様に、現在のバスマスタはD[31:0] 線上に供給された場合にReg を取り扱うように準備することでワード信号に応答する。
【0088】
図12は制御/状態レジスタ168に書き込む動作、特定すれば制御保存回路150のアドレスnに保存されたマイクロ命令ルーチンの実行を開始するためにRUNビットを設定する動作を示している。上述のように、アドレス0はRUNビットがセットされていない間にMAR152へ読み込まれており、制御保存回路150へ繰り返して供給され、制御保存回路は次に実行するno op 命令を供給する。図12に図示したのと同様の動作を用いてRUNビットをクリアすることが出来る。
【0089】
Clk 周期1の間に、スレーブシーケンサ284はクロック制御論理回路280へ信号を送出してprocClk を停止させ、アドレスバッファ182を経由してCSアドレスバッファ180へPA[27:0]の物理アドレスを供給するのに必要な全ての信号を供給する。おなじ周期中に、現在のバスマスタは制御/状態レジスタ168に書き込むデータをD[31:0] 上に供給開始することが出来る。スレーブシーケンサ284はD[31:0] の最上位ビットからまたはこれ以外ではPA[27:0]のアドレスの高次ビットからRUNビットをセットするかまたはクリアするかを決定することが出来る。
【0090】
Clk 周期2および3では、スレーブシーケンサ284がD[31:0] の最上位ビットまたはPA[27:0]のアドレスの高次ビットに従って制御/状態レジスタ168のRUNビットをセットするかまたはクリアする信号を供給する。Clk 周期3ではスレーブシーケンサ284はAck[2:0]上にワード信号を供給する。
【0091】
Ack[2:0]上のワード信号をClk 周期4の開始時に受信すると、ホストバス制御回路はClk 周期4の間にAS* を低値にする。同様に、現在のバスマスタはD[31:0] 上へのデータ供給を停止する。
【0092】
Clk 周期5の間に、スレーブシーケンサ284はクロック制御論理回路280へ信号を送ってマイクロ命令の実行をClk 周期6の間に再開できるようにprocClk を再開させる。ここでアドレス0のマイクロ命令の実行によりアドレスnをMAR152に読み込ませ、nのマイクロ命令がClk 周期7の間に取り込まれClk 周期8で復号される。つまり、Clk 周期8では、新しいアドレスがマイクロ命令の制御下にMAR152へ読み込まれマイクロ命令の実行を開始したことになる。
【0093】
図13は起動用PROM116からのバイトを読み込む動作を示し図11に図示した動作と非常に良く似ている。主な相違はClk 周期2、3、4にみられる。Clk 周期2および3では、スレーブシーケンサ284が起動用PROM116へ出力イネーブル信号を供給してアドレスバッファ182からのアドレスが起動用PROM116を経由して伝達されまた1バイトを読み出すようにする。Clk 周期3で、スレーブシーケンサ284は1バイトを供給することを示す信号をAck[2:0]に供給する。Clk 周期4では、スレーブシーケンサ284はクロック信号をバッファ184へ供給することでそのバイトをD[31:0] へ供給する。おなじ周期中に、スレーブシーケンサ284はクロック制御論理回路280へ信号を送りマイクロ命令の実行を再開し得るようにprocClk を再開させる。
【0094】
Clk 周期4の初めにAck[2:0]上にバイト信号を受信すると、ホストバス制御回路はClk 周期4の間AS* を低値にする。同様に、起動時には通常ホスト装置のCPUである現在のバスマスタが、D[31:0] に供給される場合にそのバイトを取り扱うように準備することでバイト信号に応答する。
【0095】
図14はClk 周期0の初めにSiz[2:0]へ現在のバスマスタにより供給される信号で表わされる制御保存回路150からのワードを読み取る動作を示す。Clk 周期1の間に、スレーブシーケンサ284はクロック制御回路280へ信号を送ってprocClk を停止させ、またアドレスバッファ182を介してCSアドレスバッファ180へPA[27:0]の物理アドレスを供給するのに必要な全ての信号を供給する。Clk 周期2では、スレーブシーケンサ284は出力イネーブル信号をCSアドレスバッファ180へ送出して物理アドレスがClk 周期3の間に制御保存回路150へ供給されるようにする。
【0096】
Clk 周期2から4までのそれぞれで、スレーブシーケンサ284はSバスレジスタ188およびSバスバッファ190へ制御信号を送出してパイプライン中のどのようなデータでもD[31:0] へ転送させる。Clk 周期2および3の間また他の図面においても同様な周期の間に供給されたデータは有用なデータであるとは限らないのでジャンク(屑)と称される。Clk 周期3および4の間に、CSアドレスバッファ180内の物理アドレスに応答して制御保存回路150から読み出されたワードが適切なトランシーバ124のひとつを介してSバスレジスタ188へ転送され、さらにSバスバッファ190を通してClk 周期4の終までにD[31:0] へ確実に達するようにする。
【0097】
Clk 周期3の間に、スレーブシーケンサ284はワードをSバスレジスタ188へ保存するための制御信号を供給し、Ack[2:0]にワードが供給されることを表わす信号も供給する。Clk 周期4の間に、スレーブシーケンサ284はクロック制御論理回路280へprocClk を再開させる信号を送出してマイクロ命令の実行を再開させることが出来る。
【0098】
Clk 周期4の初めにAck[2:0]上でワード信号を受信すると、ホストバス制御回路はClk 周期4の間AS* を低値にする。同様に、現在のバスマスタはワードがD[31:0] に供給されるときに取り扱えるように準備することでワード信号に応答する。
【0099】
図15は制御保存回路150にワードを書き込む動作を示している。Clk 周期1の間に、スレーブシーケンサ284はクロック制御論理回路280へ信号を送出してprocClk を停止させ、またアドレスバッファ182を介してCSアドレスバッファ180へPA[27:0]上に物理アドレスを供給するために必要な全ての信号を供給する。同一周期中に、現在のバスマスタは制御保存回路150へ書き込むワードをD[31:0] に供給開始する。
【0100】
Clk 周期2では、スレーブシーケンサ284が出力イネーブル信号をCSアドレスバッファ180に供給して制御保存回路150へ物理アドレスが供給されるようにする。おなじ周期中に、スレーブシーケンサ284はSバスレジスタ188のD[31:0] にワードを保存するための制御信号も供給する。
【0101】
Clk 周期3の間に、スレーブシーケンサ284はAck[2:0]にワードが書き込まれつつあることを示す信号を供給する。Clk 周期4では、スレーブシーケンサ284は制御保存回路150を書き込み可能とするための信号を供給しまた書き込むワードを適切なトランシーバ124の1つを経由して制御保存回路150へ転送するための信号を供給し、信号が書き込まれる。
【0102】
Ack[2:0]上にClk 周期4の初めにワード信号を受信すると、ホストバス制御回路はClk 周期4の間AS* を高値にする。同様に、現在のバスマスタはD[31:0] 上へのワード供給を停止する。
【0103】
Clk 周期5の間に、スレーブシーケンサ284は出力イネーブル信号を供給して、次のマイクロ命令を取り出すための準備としてMAR152からのアドレスが制御保存回路150へ供給されるようにする。おなじ周期中に、スレーブシーケンサ284はクロック制御論理回路280へ信号を送出しClk 周期6の間にマイクロ命令の実行が再開できるようにprocClk を再開させる。
【0104】
図16はスレーブからのワードをレジスタ兼復号回路154からの信号に応答して読み出すDMA動作を図示している。Clk 周期−2(図示していない)では、レジスタ兼復号回路154が読み込むべきワードについての仮想アドレスVAをレジスタ付トランシーバ194を経由してSバスレジスタ196へ転送する動作を完了できる。おなじ周期中に、レジスタ兼復号回路154はDVMAシーケンサ282に動作を要求する信号を供給できる。これに応じて、DVMAシーケンサ282はクロック制御論理回路280にすぐに信号を送ってprocClk を停止させ、DVMAシーケンサ282が要求された動作を実行し続けるために別のprocClk パルスが必要となるまでマイクロ命令の実行が中断される。つまりprocClk はClk 周期−1の間パルス出力されないことになる。
【0105】
Clk 周期−1の間、DVMAシーケンサ282はBReq* 線を低値にしてSバス102の制御を要求する。これに応じて、Sバス制御回路はDVMAシーケンサ282のBGnt* 線をClk 周期0の間低値にして、バス制御を許可する。場合によっては、BGnt* 信号までにさらなる周期が挟まることもあり得る。
【0106】
BGnt* 信号を受信すると、DVMAシーケンサ282はレジスタ兼復号回路154の要求した動作の実行を開始する。Clk 周期1では、DVMAシーケンサ282はSiz[2:0]線上にワード信号またRd線上に読み込み信号を供給する。また、DVMAシーケンサ282はSバスバッファ198に制御信号を供給してSバスレジスタ196からのVAがD[31:0] 線上に供給されるようにする。次に、DVMAシーケンサ282はクロック制御論理回路280に信号を送出してprocClk を再開させ、Clk 周期2の間に1つのprocClk パルスが発生するようにして次のマイクロ命令を実行させる。このマイクロ命令の実行では、レジスタ兼復号回路154がSバスレジスタ196とレジスタ付トランシーバ194を経由してデータを転送する方向を変化させる信号を供給し、データはSバス102からSバスバッファ198を通って受信できるようになる。
【0107】
図16において、Sバス制御回路はVAをすぐに物理アドレスへ変換し、またClk 周期2の間にPA[27:0]線上に物理アドレスを供給する。場合によっては、物理アドレスの供給までにさらなる周期が挟まることもあり得る。物理アドレスがすでに利用可能であることを示すために、Sバス制御回路はClk 周期2の間にAS* 線も低値にする。
【0108】
AS* に応答して、DVMAシーケンサ282はClk 周期3と4と5の間にSバスバッファ198へ制御信号を供給し、VAがもはやD[31:0] に供給されていないことを示す。その結果、スレーブがClk 周期4の間にAck[2:0]にワード信号を供給すると、D[31:0] 上のワードをClk 周期5の間にSバスレジスタ196へ転送できる。Sバス制御回路はBGnt* およびAS* を高値にすることでワード信号に応答するが、DVMAシーケンサ282がすでにSバス102を必要としないためこれは許容し得ることである。
【0109】
DVMAシーケンサ282はクロック制御論理回路280に信号を送出してprocClk を再開させることでワード信号に応答し、マイクロ命令のシーケンスが実行されワードの受信と宛先への転送が実行される。レジスタ兼復号回路154はClk 周期6の間にマイクロ命令を実行し、ワードがD[31:0] から消去されるまでにSバスレジスタ196内に保存されるように信号を供給する。次のマイクロ命令でレジスタ付トランシーバ194ならびに122を介して一組の処理ユニットへワードを転送することが出来る。
【0110】
図17は図16におけるいくつかのClk 周期のそれぞれの終端でのパイプライン・レジスタの略図を示している。それぞれの略図では、パイプラインは下端のSバス102へと上端の1つまたはそれ以上の処理ユニットから延出している。最上部のパイプラインの段階は処理ユニットのレジスタ付トランシーバ212を表わす。第2の段階はレジスタ付トランシーバ122を示す。第3の段階はレジスタ付トランシーバ194を示す。第4の段階はSバスレジスタ196を表わす。図16の動作に関係しないデータは破線で示してある。
【0111】
略図310は、Clk 周期−4などのClk 周期−2より幾らか先に始まり、仮想アドレスVAは処理ユニットの1つのレジスタ付トランシーバ212に存在する。略図312および314では、VAはレジスタ付トランシーバ122へさらにレジスタ付トランシーバ194へ転送されており、パイプラインは図16のClk 周期−2の終端での状態になっている。
【0112】
略図316では、Clk 周期−1のあとのパイプラインを示し、Sバスレジスタ196内にVAがある。次に、Clk 周期2の終端までに、VAは保存されなくなり、パイプラインは略図318に図示したように図16の動作に関連するデータをまったく含まなくなる。
【0113】
略図320ではClk 周期6以降のパイプラインを示し、Sバス102からのデータワードはSバスレジスタ196に保存されている。略図322、324、326はClk 周期7、8、9でワードがどのように転送されて全処理ユニットのレジスタ付トランシーバ212に到達するかを示している。Clk 周期10では、ワードは一組の処理ユニットのそれぞれのSRAM240内に書き込まれ、動作を完了できる。
【0114】
図17に図示したいくつかの段階はそれぞれのマイクロ命令を実行した結果として発生することが出来る。たとえば、略図310、312、314、316は図16のClk 周期−1より先行する周期において実行したマイクロ命令の結果として発生し、また略図320、322、324、326はそれぞれClk 周期6、7、8、9で実行したマイクロ命令の結果として発生するものである。略図318はマイクロ命令の実行の全ての作用を明示的に図示してはいないが、Clk 周期2で実行したマイクロ命令は前述のように後続のデータ転送方向に影響を有している。
【0115】
図18はレジスタ兼復号回路154からの信号に応答してワードを書き込むDMA動作を図示している。Clk 周期−2(図示していない)において、レジスタ兼復号回路154はレジスタ付トランシーバ194を経由してSバスレジスタ196に書き込むワードについての仮想アドレスVAを転送しまたレジスタ付トランシーバ122を経由してレジスタ付トランシーバ194に書き込むワードを転送する動作を完了することが出来る。おなじ周期中に、レジスタ兼復号回路154はDVMAシーケンサ282に動作を要求する信号を供給できる。これに応じて、DVMAシーケンサ282はすぐにクロック制御論理回路280へ信号を供給してprocClk を停止させ、DVMAシーケンサ282が要求された動作を実行し続けるために別のprocClk パルスが必要となるまでマイクロ命令の実行が中断される。つまりprocClk はClk 周期−1の間はパルス出力されないことになる。
【0116】
Clk 周期−1の間、DVMAシーケンサ282はBReq* 線を低値にしてSバス102の制御を要求する。これに応じてSバス制御回路はDVMAシーケンサ282のBGnt* 線をClk 周期0の間低値にして、バス制御を許可する。場合によってはBGnt* 信号以前にさらなる周期が挟まることも有り得る。
【0117】
BGnt* 信号を受信すると、DVMAシーケンサ282はレジスタ兼復号回路154の要求した動作を実行開始する。Clk 周期1では、DVMAシーケンサ282はSiz[2:0]にワード信号またRdに読み取り信号を供給する。また、DVMAシーケンサ282はSバスバッファ198に制御信号を供給してSバスレジスタ196からのVAがD[31:0] 線上に供給されるようにする。次に、DVMAシーケンサ282はクロック制御論理回路280に信号を送出してClk 周期2の間にprocClk パルスを1つ供給させ、次のマイクロ命令が実行されるようにする。このマイクロ命令の実行において、レジスタ兼復号回路154はレジスタ付トランシーバ194からSバスレジスタ196へ書き込むワードを送出する信号を供給して書き込むワードがSバスバッファ198を経由してSバス102へ供給できるようにする。
【0118】
図18では、Sバス制御回路はVAをすぐに物理アドレスへ変換して、Clk 周期2の間に物理アドレスをPA[27:0]へ供給する。場合によっては物理アドレスが供給されるまでにさらなる周期が挟まることもあり得る。物理アドレスが利用可能になったことを示すため、Sバス制御回路はClk 周期2の間にAS* も低値にする。
【0119】
スレーブがClk 周期4の間にAck[2:0]にワードを受信したことを表わすワード信号を供給すると、DVMAシーケンサ282はClk 周期5でデータワードの供給を停止する。Sバス制御回路はBGnt* 線およびAS* 線を低値にすることでワード信号にも応答するが、DVMAシーケンサ282がもはやSバス102を必要としないためこれは許容し得ることである。
【0120】
DVMAシーケンサ282はクロック制御論理回路280へ信号を送出してprocClk を再開させてワード信号にも応答し、マイクロ命令の通常の実行が再びClk 周期5で開始できるようにする。スレーブはすでにSiz[2:0]とPA[2:0] を必要としないので、これらの線上の信号は周期6で消去される。
【0121】
図19は図18のいくつかのClk 周期のそれぞれの終端でのレジスタのパイプラインの略図である。
【0122】
略図350は、Clk 周期−4などClk 周期−2より幾らか先に始まり、仮想アドレスVAが処理ユニットの1つのレジスタ付トランシーバ212に存在している。略図352はClk 周期−3のことがあり、VAはレジスタ付トランシーバ122へ転送されており、書き込むデータワードは処理ユニットの1つのレジスタ付トランシーバ212に存在している。略図354では、VAはレジスタ付トランシーバ194へさらに転送されており、データワードがレジスタ付トランシーバ122へ転送されているので、パイプラインは図18のClk 周期−2の終端での状態になっている。
【0123】
略図356はClk 周期−1のあとでのパイプラインを示し、VAはSバスレジスタ196にまたデータワードはレジスタ付トランシーバ194にある。次に、Clk 周期2の終端までに、データワードはSバスレジスタ196に到達し略図358に図示したようにSバス102へ供給できるようになる。
【0124】
図16から図19の単一ワードDMA読み出しおよび書き込み動作は、たとえばカーネルまたはその他の特定のデータを1つまたはそれ以上の処理ユニットとホスト装置のメモリまたは別のメモリ装置の間での転送を行なうためにデバッグしている間に使用することが出来る。
【0125】
また図16および図19に図示したように単一ワードのDMA読み出しおよび書き込み動作は図14および図15のスレーブ動作と組み合わせることによって処理ユニットとホスト装置のCPUの間または制御保存回路150を介して別のバスマスタの間でデータ転送するために使用できる。言い換えれば、スレーブシーケンサ284はここへまたはここからDMA読み出しまたは書き込み動作が実行されるスレーブとなることが出来る。一般に、スレーブシーケンサ284が制御保存回路150から読み出しまたはここへ書き込んでいるどのClk 周期でも、スレーブシーケンサ284がクロック制御論理回路280へ信号を送出してprocClk を停止させることが出来る。その他のClk 周期の間、マスタシーケンサ282はマスタ動作を実行するための必要に応じてクロック制御論理回路へ信号を送ってprocClk を再開させることが出来る。
【0126】
同様に、図18および図19に図示したような単一ワードのDMA書き込み動作は図12の場合と類似のスレーブ動作と組み合わせることによってRUNビットをクリアし、コプロセッサが実際にそれ自身を停止させることが出来るようになっている。言い換えれば、レジスタ兼復号回路154はRUNビットのクリアを検出してno op 命令を実行することによりこれに応答することが出来る。
【0127】
しかし単一ワードのDMA読み出しおよび書き込み動作は画像の転送のためには効率的ではない。このような転送は通常大量のワードが関係してくるためである。
【0128】
図20から図25は複数ワードのDMA読み出しおよび書き込みを図示している。これらの動作はブロック転送またはバースト転送とも称し、画像の一部または全部を定義するデータの転送において非常に有用であり得る。
【0129】
図20および図21では、レジスタ兼復号回路154からの信号に応答してスレーブから複数ワードを読み出すDMA動作の開始と終了をそれぞれ示している。図20においてClk 周期4を通る第1の数周期では、図16のそれと同一であるが、仮想アドレスVAがワードブロック内のどのワードを第1に転送するかを示している点で異なっている。
【0130】
ブロック転送はSiz[2:0]で示されるため、スレーブは一連のデータワードを供給することで応答する。スレーブはたとえば、図20のClk 周期5の初めで示したように、各周期に1つのワードを供給できる。スレーブはこれ以外に図21に図示したように1つおきの周期ごとに1ワードを供給することも出来る。いずれの場合にも、スレーブは図21のClk 周期6に図示したように複数ワードの転送が完了するまで継続することになる。より一般的には、データワード間のほとんどすべての他のクロック周期番号でスレーブにデータの供給または併合を許容することが出来るが、トランザクションが長すぎればバス制御回路がこれを終了させてもよい。マスタはスレーブがAck[2:0]上に信号を供給する場合いつでも別のワードを供給できなければならない。
【0131】
図20のClk 周期6から10のそれぞれと図21のClk 周期2、4、6の間、クロック制御論理回路280はprocClk パルスを供給してDVMAシーケンサ282からの信号に応答し、レジスタ兼復号回路154がマイクロ命令を実行する。これらのマイクロ命令の実行において、レジスタ兼復号回路154はD[31:0] からSバスレジスタ196にデータワードそれぞれを保存するためとパイプラインに沿って処理ユニットへデータワードを進めるために信号を供給する。一方、図21のClk 周期1、3、5の間、DVMAシーケンサ282はクロック制御論理回路280へ信号を供給してprocClk を停止させる。
【0132】
その結果、図21のClk 周期4の間にAck[2:0]に最後のワード信号を供給すると、Sバス制御回路はBGnt* とAS* 線を高値にしてワード信号に応答する。これはDVMAシーケンサ282がもはやSバス102を必要としないため許容し得ることである。DVMAシーケンサ282はクロック制御論理回路280へ信号を送ってprocClk を再開させ、処理ユニットへのデータワード転送を完了するためのマイクロ命令がClk 周期6から10の間に実行されるようにする。
【0133】
図22は図20および図21のいくつかのClk 周期のそれぞれの終端におけるレジスタのパイプラインの略図である。略図370および372はそれぞれ図17の略図310および324と同一である。略図374では、図20のClk 周期7のあとのパイプラインを示し、第1のデータワードはレジスタ付トランシーバ194に保存されており、第2のデータワードはSバスレジスタ196に保存されている。同様に、略図376および378はそれぞれ図20のClk 周期8と9のあとのパイプラインを示し、この時点でパイプラインはデータワードで埋められている。Clk 周期9のあとで開始して、それぞれの処理ユニットのレジスタ付トランシーバ212に保存されているデータワードは一組の処理ユニットのそれぞれのSRAM240に保存することが出来る。たとえば、レジスタ兼復号回路154はそれぞれのClk 周期にマイクロ命令を実行して書き込みイネーブル信号をそれぞれの周期にただ1つの処理ユニットのSRAM240へ供給し、データワードが均等に分配され1つのデータワードがそれぞれの処理ユニットに格納されるようにすることが出来る。
【0134】
スレーブが全てのClk 周期でワードを供給する場合、DVMAシーケンサ282はクロック制御論理回路280に信号を供給して、全てのClk 周期でprocClk パルスを供給させ、図20に図示したようにパイプラインを満たしておくことが出来る。スレーブが1つおきのClk 周期でデータワードを供給する場合、DVMAシーケンサ282はクロック制御論理回路280に信号を供給して1つおきのClk 周期にprocClk パルスを供給させて、D[31:0] からのデータワードが交互のClk 周期でSバスレジスタ196に保存されるようにして、図21に図示したようにパイプラインを満たしておくことが出来る。一般に、DVMAシーケンサ282はクロック制御論理回路280に信号を送出することによってD[31:0] にワードが存在することを示すスレーブからのAck[2:0]上の信号に応答し、procClk パルスを供給することでスレーブがワードを供給するどのような周期にもDVMAシーケンサ282がデータを取り扱えるようにしている。
【0135】
略図380は図21のClk 周期6のあとのパイプラインを示しており、スレーブからの最後のデータワードNがSバスレジスタ196に保存されている。略図382、384、386はそれぞれ図21のClk 周期7、8、9のあとのパイプラインを示しており、ワードNがどのようにレジスタ付トランシーバ212に到達し、ここからSRAM240へ保存されて複数ワードの読み込み動作を完了するかを示している。前述のように、データワードは均等に分配でき、1つのワードがそれぞれの処理ユニットのSRAM240に保存される。
【0136】
スレーブからの複数ワードを保存するために利用できる時間が限られているので、転送が完了するまで複数ワード転送でのワードについての操作を実行するのは通常不可能である。しかしこれが可能だとすると、画像を読み込むとおりに画像を縮小するまたはその他の処理を施すことまたは直前に保存した画像と読み出した画像を比較することが可能となり有利であろう。
【0137】
図23および図24ではそれぞれレジスタ兼復号回路154からの信号に応答してスレーブへ複数ワードを書き込むDMA動作の開始と終了を図示している。Clk 周期4を通る図23の第1の数周期は図18と同一であるが、仮想アドレスVAがワードブロック内のどのワードを第1に転送するかを示している点で異なっている。
【0138】
ブロック転送はSiz[2:0]で示されるので、スレーブは図23のClk 周期5で始まるAck[2:0]上の一連のワード信号で応答し、それぞれのワード信号でデータワードがスレーブに受信されたことを示す。それぞれのワード信号に応答して、DVMAシーケンサ282は次のデータワードをD[31:0] へ供給する。スレーブは図23に図示したように全周期でAck[2:0]にワード信号を供給しまたは図24に図示したように1つおきにまたは上述のようにワード間の何らかのほかのクロック周期数を有する別の間隔で、図24のClk 周期5で図示したように複数ワードの転送が完了するまで供給することが出来る。
【0139】
図23のClk 周期5から10のそれぞれと図24の周期0、2、4を除く図24のClk 周期−1、1、3の間、、DVMAシーケンサ282はクロック制御回路280へ信号を送出してそれぞれの周期でprocClk パルスを供給させ、これに応じてレジスタ兼復号回路154はマイクロ命令を実行する。これらのマイクロ命令の実行において、レジスタ兼復号回路154はSバスレジスタ196とレジスタ付トランシーバ194とレジスタ付トランシーバ122とそれぞれの処理ユニットのレジスタ付トランシーバ212へ信号を供給し、データワードがSバス102に向かい処理ユニットからパイプラインに沿って進むようにする。一方、図24の周期0、2、4の間、DVMAシーケンサ282はクロック制御回路280に信号を送出してprocClk 信号を停止させる。たとえば、レジスタ兼復号回路154はそれぞれのClk 周期でマイクロ命令を実行して、それぞれのClk 周期で別の処理ユニットのレジスタ付トランシーバ212へ供給源選択信号を供給し、1つのデータワードがそれぞれの処理ユニットから受信されるようにすることが出来る。
【0140】
その結果、スレーブが図24のClk 周期4の間にAck[2:0]に最後のワード信号を供給すると、Sバス制御回路はBGnt* とAs* 線を高値にすることでワード信号に応答するが、これはDVMAシーケンサ282がもはやSバス102を必要としていないため許容し得ることである。DVMAシーケンサ282はクロック制御論理回路280に信号を送出してprocClk を再開させ、通常のマイクロ命令の実行がClk 周期5で再開されるようにする。
【0141】
図25は図23および図24のいくつかのClk 周期のそれぞれの終端でのレジスタのパイプラインの略図を示している。略図410および412はそれぞれ図19の略図350および352と同一である。略図414は図23のClk 周期−2のあとのパイプラインを示し、仮想アドレスVAがレジスタ付トランシーバ194に存在しまたこの後ろのパイプラインがワード1とワード2で埋められている。略図416および418は図23のClk 周期−1および2のあとのパイプラインをそれぞれ示しており、このあとパイプラインはAck[2:0]上のスレーブからのワード信号の準備としてデータワードで埋められている。
【0142】
スレーブが図23のように全てのClk 周期でまたは図24のように1つおきのClk 周期でAck[2:0]にワード信号を供給すると、DVMAシーケンサ282は同様に全てのClk 周期でまたは1つおきのClk 周期でそれぞれSバス102にデータワードを供給することができる。略図420、422、424、426ではそれぞれ図24のClk 周期−3、−1、1、3のあとのパイプラインを示しており、ワードNがどのようにSバスレジスタ196へ到達し、ここからSバス102へ供給されて複数ワードの書き込み動作を完了できるかを示している。
【0143】
図15から図25の動作を行なうために実行するマイクロ命令は、図6について前述したように、ホスト装置のメモリから制御保存回路150へロードすることが出来る。ホスト装置は開始点と長さによるなどで制御保存回路150の内容の記録を保存するようにプログラムしておくことが出来る。
【0144】
上述の実施はマイクロ命令に条件の検査を行なうことを許可していない。DVMAシーケンサ282がホストバスを待機している場合はいつでもマイクロ命令の実行を阻止するので、マイクロ命令はホストバス上で遅延が存在しないかのように実行される。
【0145】
上述の実施例で示唆されるように、典型的なマイクロ命令のシーケンスはパイプライン中に仮想アドレスを供給することから開始することが出来る。書き込み動作を実行中の場合には、シーケンスはパイプライン中に書き込むべきデータも供給可能である。そのあとでバス制御を要求する。バス制御が受け入れられると、アドレスが供給され、書き込み動作の場合にはデータがパイプラインに送出される。スレーブが書き込み動作に応答すると、データはパイプラインへ供給される。読み込み動作の場合、データはスレーブが供給したかのようにパイプラインから保存される。
【0146】
本発明は米国特許第5,065,437号、米国特許第5,048,109号、米国特許第5,129,014号、米国特許第5,131,049号に記載されている形式の画像処理を含む多くの方法に応用することが出来る。これらの画像処理技術では第1の画像を定義するデータを使用して、浸蝕や拡大といった上述のセラの書籍に記載されている演算などの操作を通じて第2の画像を取得している。このような演算は、たとえばそれぞれが原本画像をシフトしてシフトした画像を取得し次に原本画像からの値とシフトした画像からの値をそれぞれの位置で用いてブール代数演算を実行するような一連の下位演算により実行できる。コプロセッサはこのような演算を上述のようにホストメモリからDMA操作を通して取得した画像データについて実行することが出来る。
【0147】
本発明はその他の各種の演算たとえば画素の計数、グレースケール形態化、歪曲検出、および画像に対するブール演算などを実行するために応用することも可能である。
【0148】
本発明は多数の画像を取り扱うようなまたは非常に大きな画像を取り扱うような状況に特に関連する。画像をホストバス経由で転送する能力はこのような状況で非常に重要である。
【0149】
本発明はコプロセッサがホストバスのほかのマスタとコプロセッサの制御保存回路を通じて通信するような実施に関連して説明した。本発明はまたその他の通信技術たとえばホストメモリの一領域を介してまたはホスト処理装置への割り込み線を介して実施してもよい。
【0150】
本発明は並列処理装置内の処理装置がホストバス上に供給されるアドレスを取得できるような実施に関連して説明した。本発明はまたホストバスへのアドレスを取得するためのその他の技術たとえば特化したアドレス計算回路などを用いて実施してもよい。
【図面の簡単な説明】
【図1】ホスト処理装置のバスへコプロセッサとして接続することのできる並列処理装置の一般的部材を示す略ブロック図である。
【図2】Aは図1のスレーブ回路がコプロセッサの処理要求に応答する一般的動作を示す流れ図、Bは図1のコプロセッサ内の処理ユニットからホストバス上のスレーブ回路へデータを転送するマスタの処理における一般的動作を示す流れ図、Cは図1のコプロセッサ内の一組の処理ユニットへホストバス上のスレーブ回路からデータを転送するマスタの処理における一般的動作を示す流れ図である。
【図3】Sparc−Station のSバスに接続したSIMD並列処理装置の実施における部材を示す略ブロック図である。
【図4】図3の制御回路の部材を示す略ブロック図である。
【図5】図3の処理ユニットの部材を示す略ブロック図である。
【図6】図4の制御保存回路にマイクロ命令をロードすることにおける一般的動作を示す流れ図である。
【図7】図3のボックスへのクロック信号を制御する部材を示す略ブロック図である。
【図8】図7のDVMAシーケンサをSバスにまたマスタ回路のその他の回路に接続する線を表わす略ブロック図である。
【図9】図7のスレーブシーケンサをSバスへまたスレーブ回路のその他の部材へ接続する線を示す略ブロック図である。
【図10】図9のスレーブシーケンサがエラーを含む信号にどのように応答するかを示すタイミング図である。
【図11】制御/状態レジスタからデータを読み出す操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【図12】制御/状態レジスタ内にRUNビットを書き込む操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【図13】起動用PROMからデータを読み出す操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【図14】制御保存回路からデータを読み出す操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【図15】制御保存回路へデータを書き込む操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【図16】ホスト装置のメモリからデータを読み出すDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答するかを示すタイミング図である。
【図17】図16の操作の間にパイプライン・レジスタ回路を通るデータの動きを示す略流れ図である。
【図18】ホスト装置のメモリからのデータを書き込むDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答するかを示すタイミング図である。
【図19】図18の操作の間にパイプライン・レジスタ回路を通るデータの動きを示す略流れ図である。
【図20】複数ワードを読み込むDMA操作を要求する信号に図8のDVMAシーケンサがどのように応答を開始するかを示すタイミング図である。
【図21】複数ワードを読み込むDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答を完了するかを示すタイミング図である。
【図22】図20および図21の操作の間にパイプライン・レジスタ回路を通過するデータの動きを示す略流れ図である。
【図23】複数ワードを書き込むDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答を開始するかを示すタイミング図である。
【図24】複数ワードを書き込むDMA操作を要求する信号に対して図8のDMVAシーケンサがどのように応答を完了するかを示すタイミング図である。
【図25】図23および図24の操作の間にパイプライン・レジスタ回路を通過するデータの動きを示す略流れ図である。
【符号の説明】
10 ホスト処理装置、12 ホストバス、14 CPU、16 メモリ、18ホストバス制御回路、20 コプロセッサ、22 処理ユニット、24 コプロセッサ制御回路、30 ホストバス接続回路、32 スレーブ回路、34 マスタ回路、100 Sparc−Station ワークステーション、102 Sバス、112 DVMAインタフェース、114 スレーブインタフェース、116 起動用PROM、118 ケーブル、122 レジスタ付トランシーバ、124 トランシーバ124、126 制御回路、130 処理ユニット、150 制御保存回路、152 MAR、154 レジスタ兼復号回路、156 共通データバス、180 CSアドレスバッファ、188 Sバスレジスタ、190 Sバスバッファ、192 定数バッファ、194 レジスタ付トランシーバ、196Sバスレジスタ、198 Sバスバッファ、212 レジスタ付トランシーバ、220 マイクロプロセッサ、240 SRAM、280 クロック制御論理回路、282 DVMAシーケンサ、284 スレーブシーケンサ
本発明は並列処理装置に関する。
【0002】
ウィルソン(Wilson)の米国特許第5,129,092号では、画像および空間的に関連のあるデータなどのデータ行列を処理するための単一命令多重データ(SIMD)並列処理装置を開示している。図1および図2に関連して図示しまた解説しているように、この処理装置は隣接する処理ユニット間に直接データ通信リンクを有する隣り合わせ処理ユニットの線型連鎖を含む。
【0003】
ウィルソン092号で図1、図2、図5との関連で図示しまた説明しているように、処理ユニットは8個のグループを構成し、ホストコンピュータと制御装置はどちらもデータバイト線と称する8ビット線経由でこのグループからのデータを送受信可能である。
【0004】
ウィルソン092号では図6Aおよび図6Bとの関連でメモリと加算器(アキュムレータ)間のデータ置換のための置換演算も説明している。
【0005】
ヒリス(Hillis)の米国特許第5,113,510号ではシンキングマシンズ社(Thinking Machines Corporation )製のSIMD並列処理装置であるコネクションマシン(Connection Machine)において使用するために明らかに開発された多処理装置内のキャッシュメモリを操作するための技術を開示している。図3との関連で図示しまた解説しているように、多処理装置システムのそれぞれの処理装置は対応するキャッシュへ接続している。キャッシュメモリがミス信号を出力すると、バス調停ユニットはそれぞれの連続したキャッシュで現在の更新が実行されている間は更新を実行し得ないことを示す信号を供給して、優先連鎖の中の更新を要求している第1のキャッシュが一時的に他の全ての更新要求を無効にする。更新要求を受信すると、共有メモリは指定されたアドレスのデータを取得してデータレディ信号と、アドレスと、データを出力する。アドレスがキャッシュの問題となるアドレス指定範囲内に有る場合またはキャッシュが更新要求の供給源の場合、キャッシュメモリはアドレスおよびデータ信号を受信し保存する。その結果、全てのキャッシュは任意の範囲検出装置によってのみ制限される主メモリからの更新データを受信する。
【0006】
本発明では並列処理装置における基本的な問題を取り扱う。
【0007】
SIMD並列処理装置は、それぞれがメモリ中の自分のデータをアクセス可能な処理ユニットを含む。それぞれの処理装置が独立した命令のシーケンスを実行可能な多重命令多重データ(MIMD)並列処理装置とは異なり、SIMD並列処理装置内の全ての処理ユニットはおなじ命令のストリームを受信する。
【0008】
SIMD並列処理装置は画像処理などのデータアレイに対する演算に特に有用である。しかし従来のSIMD並列処理装置はホスト処理装置のバスへ接続された補助演算装置として効率的な演算を行なうようには設計されていない。幾つかの在来のSIMD並列処理装置はデータ入出力について主としてシフトレジスタに頼っており、ホスト処理装置のバスからのデータ受信において互換性がない。その他のSIMD並列処理装置は隅角を折り返す回路に水平方向の様式でデータを供給して、ここからそれぞれの処理ユニットへ垂直方向の様式でデータを供給している。別のSIMD並列処理装置では、それぞれの処理ユニットのキャッシュメモリはバスを介して共有メモリをアクセス可能だが、多数の処理ユニットのそれぞれをホスト装置のメモリへホスト装置のバスを経由して接続するには実際的とは言えない。
【0009】
本発明はSIMD並列処理装置などの並列処理装置がホスト処理装置のバスのスレーブおよびマスタとなり得るような回路を提供することによってこれとこれに関連した問題を軽減するアーキテクチャの発見に基づくものである。その結果、並列処理装置はホスト処理装置のバスのスレーブとして命令を受信できるがその他の目的たとえばデータを処理ユニットへ入出力するなどではホスト処理装置のバスのマスタとなることが出来る。
【0010】
本アーキテクチャはホスト処理装置の中央演算処理装置(CPU)およびメモリなどのその他の部材も接続されているホストバスへ接続することが出来る補助演算装置として実施可能である。補助演算装置は複数の処理ユニットを含む。補助演算装置はまた補助演算装置を制御しまた処理ユニットを制御するための信号を供給するように接続してある制御回路も含む。最後に、補助演算装置はホスト装置へ接続するためのホストバス接続回路も含む。
【0011】
ホストバス接続回路はスレーブ回路とマスタ回路を含んでいる。スレーブ回路は補助演算装置の演算を要求するホストバスからの信号を受信し、これに応じて補助演算装置の制御回路へ信号を供給して補助演算装置に要求された演算を実行させる。マスタ回路は補助演算装置の制御回路からデータ転送操作を要求する信号を受信し、これに応じてホストバスへホストバスの操作を要求する信号を供給し、補助演算装置からホストバスへまたはホストバスから補助演算装置へのいずれかにデータを転送し要求されたデータ転送操作を実行する。
【0012】
上述したような補助演算装置のアーキテクチャは多くの方法で有利である。
【0013】
処理ユニットへのデータ入出力操作は補助演算装置の通常操作に統合することが可能であり、これによって大きな柔軟性が得られる。たとえば、巨大なアレイの小から大まで異なる大きさの部分を定義するデータが特定の補助演算装置の操作で必要に応じて容易に取り扱うことが出来るように、いろいろな大きさのいずれかのデータブロックを要求に応じて転送することが出来る。さらに、転送はデータブロックからのデータ項目が処理ユニット間で等しく分配されるように実施することが可能である。
【0014】
柔軟なブロックの大きさとデータ項目を等しく分配する能力は画像処理の用途で特に重要である。これらの特徴のため、画像または異なる大きさの画像の別の部分を定義するデータを処理ユニットへ供給することが出来る。たとえば、それぞれの処理ユニットはメモリ回路を含むように実施可能であり、それぞれのデータの画素または一群の画素を定義しているワードをそれぞれの処理ユニットのメモリ回路内にロードすることが出来る。さらに、それぞれの処理ユニットのメモリ回路は処理ユニットの処理回路の内部レジスタより多くのデータ項目を保存し得るような充分な大きさをとることが出来るので、メモリ回路が処理回路のためのキャッシュ機能を実行できる。処理ユニットは1次元アレイを構成できまた全ての処理ユニットのメモリ回路全部で一枚以上の画像を保存するのに充分な大きさに出来、それぞれの処理ユニットのメモリ回路がそれぞれの画像内のそれぞれの水平方向の画像ブロックからのそれぞれのワードを保存する。それぞれの水平方向の画像ブロックは水平方向の様式で処理ユニットのアレイに充分に適合するだけの小さい単一行または行の一部である。
【0015】
コプロセッサのアーキテクチャは多数のバス手順およびブロック寸法のいずれにも適合することが出来る。特定のバス手順用のスレーブ回路およびマスタ回路は従来の部材を用いて容易にまた安価に製作可能である。コプロセッサ制御回路は複雑さのあらゆる適切なレベルを提供可能で、たとえばコプロセッサの演算を実行させるために実行されるマイクロ命令を保存する制御保存回路を用いて実施可能である。マイクロ命令はホストバスからスレーブ回路によってロードすることが出来、ホスト処理装置のブロックの大きさに適合するように出来る。
【0016】
上述のコプロセッサのアーキテクチャによればホストバスの他のマスタからの入力または出力操作の要求に応答するために別個の制御回路を有する必要がなくなる。別のマスタはマスタ回路に入力または出力操作を実行させるようにコプロセッサ制御回路が要求するように制御保存回路内へマイクロ命令をロードすることが出来る。
【0017】
上述のコプロセッサのアーキテクチャによれば、それぞれの処理ユニットは水平方向のフォーマットでのデータを取り扱うように構成することが出来る。データ項目は水平方向のフォーマットで受信されまた操作が水平方向のフォーマットで実行されることから、隅角で折り返す回路は必要とされない。
【0018】
図1はホスト処理装置のバスへコプロセッサとして接続することのできる並列処理装置の一般的部材を示す略ブロック図である。
【0019】
図2Aは図1のスレーブ回路がコプロセッサの処理要求に応答する一般的動作を示す流れ図である。
【0020】
図2Bは図1のコプロセッサ内の処理ユニットからホストバス上のスレーブ回路へデータを転送するマスタの処理における一般的動作を示す流れ図である。
【0021】
図2Cは図1のコプロセッサ内の一組の処理ユニットへホストバス上のスレーブ回路からデータを転送するマスタの処理における一般的動作を示す流れ図である。
【0022】
図3はSparc−Station のSバスに接続したSIMD並列処理装置の実施における部材を示す略ブロック図である。
【0023】
図4は図3の制御回路の部材を示す略ブロック図である。
【0024】
図5は図3の処理ユニットの部材を示す略ブロック図である。
【0025】
図6は図4の制御保存回路にマイクロ命令をロードすることにおける一般的動作を示す流れ図である。
【0026】
図7は図3のボックスへのクロック信号を制御する部材を示す略ブロック図である。
【0027】
図8は図7のDVMAシーケンサをSバスにまたマスタ回路のその他の回路に接続する線を表わす略ブロック図である。
【0028】
図9は図7のスレーブシーケンサをSバスへまたスレーブ回路のその他の部材へ接続する線を示す略ブロック図である。
【0029】
図10は図9のスレーブシーケンサがエラーを含む信号にどのように応答するかを示すタイミング図である。
【0030】
図11は制御/状態レジスタからデータを読み出す操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【0031】
図12は制御/状態レジスタ内にRUNビットを書き込む操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【0032】
図13は起動用PROMからデータを読み出す操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【0033】
図14は制御保存回路からデータを読み出す操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【0034】
図15は制御保存回路へデータを書き込む操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【0035】
図16はホスト装置のメモリからデータを読み出すDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答するかを示すタイミング図である。
【0036】
図17は図16の操作の間にパイプライン・レジスタ回路を通るデータの動きを示す略流れ図である。
【0037】
図18はホスト装置のメモリからのデータを書き込むDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答するかを示すタイミング図である。
【0038】
図19は図18の操作の間にパイプライン・レジスタ回路を通るデータの動きを示す略流れ図である。
【0039】
図20は複数ワードを読み込むDMA操作を要求する信号に図8のDVMAシーケンサがどのように応答を開始するかを示すタイミング図である。
【0040】
図21は複数ワードを読み込むDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答を完了するかを示すタイミング図である。
【0041】
図22は図20および図21の操作の間にパイプライン・レジスタ回路を通過するデータの動きを示す略流れ図である。
【0042】
図23は複数ワードを書き込むDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答を開始するかを示すタイミング図である。
【0043】
図24は複数ワードを書き込むDMA操作を要求する信号に対して図8のDMVAシーケンサがどのように応答を完了するかを示すタイミング図である。
【0044】
図25は図23および図24の操作の間にパイプライン・レジスタ回路を通過するデータの動きを示す略流れ図である。
【0045】
図1から図2Cでは本発明の一般的特徴を図示している。図1では、ホスト処理装置のバスへコプロセッサとして接続可能な並列処理装置の部材を示す。図2Aではコプロセッサ内の制御回路へデータを供給するスレーブ操作における動作を示す。図2Bではホストバス上のスレーブへ処理ユニットからのデータを転送するマスタの操作における動作を示す。図2Cでは一組の処理ユニットへホストバス上のスレーブからのデータを転送するマスタの操作における動作を示す。
【0046】
図1のホスト処理装置は、その他の部材たとえばホスト装置の中央演算処理装置(CPU)14やメモリ16などを接続可能なホストバス12を含む。ホストバス12はホストバス制御回路18で制御可能である。その他の各種部材たとえば入出力装置や別のコプロセッサなどをホストバス12に接続することが可能である。
【0047】
図1のコプロセッサ20は、処理ユニット22、コプロセッサ20を制御するためのコプロセッサ制御回路24、コプロセッサ20をホスト装置10に接続するためのホストバス接続回路30を含む並列処理装置である。コプロセッサ制御回路24は処理ユニット22へ制御信号を供給する。
【0048】
ホストバス接続回路30はスレーブ回路32とマスタ回路34を含む。
【0049】
スレーブ回路32はコプロセッサの操作を要求する信号を受信するようにホストバス12へ接続されており、この信号はたとえばホスト装置のCPU14が供給し得るものである。スレーブ回路32も要求されたコプロセッサの操作が実行されるようにコプロセッサ制御回路24へ信号を供給することにより応答するために接続されている。
【0050】
マスタ回路34はデータ転送操作を要求する信号を受信するように制御回路24へ接続されている。これに呼応して、マスタ回路34はホストバス操作を要求する信号をホストバス12へ供給する。これらの信号は、たとえばホストバス12の制御要求を含み、ホストバス制御回路18はバス制御を許可することによりこれに応答することが出来る。マスタ回路34はまた1つの処理ユニット22からホストバス12へ、またはホストバス12から少なくとも1つの処理ユニット22の組へ、要求されたデータ転送が実行されるようにデータを転送する。
【0051】
図2Aにおいて、囲み50の動作では、スレーブ回路32はホストバス12からコプロセッサの操作要求を表わす信号を受信している。信号は適用可能なバス手順にしたがってホストバス12に接続されたマスタが供給できる。囲み52の動作では、スレーブ回路32がコプロセッサ制御回路24へ信号を供給して要求に応答している。この信号は、たとえば制御信号であったり、またはホストバス12から要求の一部として受信したアドレスまたはその他のデータ項目を含むことが出来る。
【0052】
図2Bにおいて、囲み60の動作では、コプロセッサ制御回路24は処理ユニット22へまたマスタ回路34へ信号を供給し、マスタ回路34が処理ユニットの1つからのデータ項目を取得するようにしている。囲み62の動作では、コプロセッサ制御回路24はデータ転送操作を要求する信号をマスタ回路34へ供給している。要求された操作には処理ユニットからのデータ項目をホストバス12に接続したスレーブへ転送する出力操作が含まれる。囲み64の動作では、マスタ回路34はホストバス12の制御を要求する信号を供給して要求に応答している。ホストバス制御回路18がマスタ回路34にホストバスの制御を許可すると、囲み66の動作で、マスタ回路34はホストバス12を経由してスレーブへデータ項目を供給する。
【0053】
図2Cにおいて、囲み70の動作では、コプロセッサ制御回路24はデータ転送操作を要求する信号をマスタ回路34へ供給している。要求された操作にはデータ項目をホストバス12に接続したスレーブから受信する入力操作が含まれる。囲み72の動作では、マスタ回路34はホストバス12の制御を要求する信号を供給することで要求に応答している。ホストバス制御回路18がマスタ回路34にホストバスの制御を許可すると、囲み74の動作で、マスタ回路34はホストバス12を経由してスレーブからデータ項目を受信する。囲み76の動作では、コプロセッサ制御回路24はマスタ回路34および処理ユニット22へ信号を供給して、マスタ回路34が少なくとも1つの処理ユニット22の組へデータ項目を供給するようにしている。
【0054】
図8から図25では本発明を実施するために上述の一般的実施の特徴をどのように使用できるかを示している。図8および図9では、DVMAシーケンサ282およびスレーブシーケンサ284がその他の部材にどのように接続されるかを図示している。図10から図15では、スレーブシーケンサ284が操作要求にどのように応答するかを示している。図16から図19ではマスタシーケンサ282が単一ワード読み込みと書き出し操作の要求に対してどのように応答するかを示している。図20から図25では複数ワード読み込みまたは書き出しが行なわれるようなバースト転送操作の要求に対してどのように応答するかを示している。
【0055】
上述のように、DVMAインタフェース112およびスレーブインタフェース114はそれぞれに各々のシーケンサつまりDVMAシーケンサ282およびスレーブシーケンサ284を用いて実施することが出来る。図8ではDVMAシーケンサ282がSバス102およびその他の部材へどのように接続されるかを示す。図9ではスレーブシーケンサ284がSバス102およびその他の部材へどのように接続されるかを示す。
【0056】
DVMAシーケンサ282およびスレーブシーケンサ284は、サン・マイクロシステムズ社部品番号800−5922−10、Sバス仕様書B.0版、1990年に記載されている要件にしたがってそれぞれ実施し、仕様書からSバス102に供給すべき信号、Sバス102からの信号に応答するために利用可能な周期、Sバス102における信号のタイミング、Sバス102上の信号の手順、および起動用PROM116に必要な内容を決定することが出来る。図8および図9でClk 、D[31:0] 、BReq* 、BGnt* 、Rd、Siz[2:0]、Ack[2:0]、As* 、PA[27:0]、SSel* と印を付けてある線はSバス仕様書B.0版から理解できよう。DVMAシーケンサ282およびスレーブシーケンサ284はたとえば、トランジスタを用いてまたは図10から図25に関連して詳細を説明したような信号を提供する1つまたはそれ以上のプログラマブルロジックアレイ(PLA)を用いてそれぞれ実施することが出来る。説明した実施において、信号は一般にprocClk の昇端でコプロセッサ内部へ進むが、データはレジスタ付トランシーバ188を経由してまたいくつかの信号はClk の昇端でDVMAシーケンサ282およびスレーブシーケンサ284内部へ進行する。
【0057】
図8において、DVMAシーケンサ282はSバス102およびSバスバッファ198を含むその他の部材へ信号を供給する方法を制御するレジスタ兼復号回路154からの信号を受信する。図示したように、Sバスバッファ198はSバス102のD[31:0] 線へ接続されており、Sバスバッファ198はSバス102のタイミング制約を満足させるようにDVMAシーケンサ282の制御下で動作する。レジスタ付トランシーバ194およびSバスレジスタ196は一方でパイプライン段階を提供する。レジスタ付トランシーバ194はレジスタ付トランシーバ122と協働してケーブル118の両端での信号の刻時の信頼性を確保する。
【0058】
上述のフィールドに加えて、それぞれのマイクロ命令はDVMAシーケンサ282の動作に関連するフィールドを含むことが出来る。単一のビットで現在の周期がSバスDMA読取かどうかを示すことが出来る。3ビットのフィールドで大きさを示すために標準Sバス符号化を用いるバースト転送の大きさを示すことが出来る。2ビットのフィールドで待機しない状態、バス許可を待機する状態、SバススレーブからのAck[2:0]線上のワード信号を待機する状態を含めSバスDMAマスタの周期の状態を示すことが出来る。別の2ビットフィールドで分岐に関する情報を提供でき、これには直前の動作がキャリーまたはボロー信号を提供したこと、直前の動作の結果が0だったこと、直前の動作の結果が否定またはReturnAck だったこと、Sバス制御回路がバス許可を下げることによって全てのドライバを停止させ、シーケンサが転送を実行するためにDVMAシーケンサ282を再起動しなければならないような条件を示すための値を有する。
【0059】
DVMAシーケンサ282により制御されるそれぞれのデータ転送動作は、Sバス102の制御要求を出さなければならないことを示すレジスタ兼復号回路154からのバス要求信号に応答して開始することが出来る。バス要求信号はDVMAシーケンサ282がSバス102上のBReq* 線を引き下げるため提供する単一ビットとすることが出来る。同時に、DVMAシーケンサ282はクロック制御論理回路280に信号を供給してレジスタ兼復号回路154へのクロック信号の供給を停止させることが出来る。
【0060】
バス要求信号を供給する前に、レジスタ兼復号回路154は要求されたデータ転送動作を準備するために必要とされる全ての他の動作を実行することが出来る。たとえば、アドレスを表わすデータ項目をレジスタ付トランシーバ194内に保存し、また書き込み動作のためには書き込むべきデータ項目をレジスタ付トランシーバ122内に保存することが出来る。いずれの場合にも、データ項目は処理ユニット130から取得することが出来、ユニットの1つが適切なマイクロプロセッサ220および222の動作を通じてまたはSRAM240からのデータ項目を取り込むことによってデータ項目を取得でき、またはデータ項目を定数バッファ192から取得することが出来る。
【0061】
バス要求信号を供給する際に、レジスタ兼復号回路154は読み取り/書き込み信号およびブロックサイズ信号を供給することも出来る。読み取り/書き込み信号は要求された動作が読み込み動作であるかまたは書き込み動作であるかを表わし、ブロックサイズ信号は転送すべきデータブロックの大きさを表わす。BReq* 線を引き下げてBGnt* 線上にSバス102の制御を取得していることを表わす信号を受信したあと、DVMAシーケンサ282はSバス102のRd線に読み取り/書き込み信号を供給しまたSバス102のSiz[2:0]線にブロックサイズ信号を供給することも可能である。
【0062】
BReq* 線に応答して、Sparc−Station 100内のSバス制御回路はDVMAシーケンサ282のBGnt* 線を引き下げ、Sバス102の制御を渡す。BGnt* に応答して、DVMAシーケンサ282は以下に詳細を説明するような信号を供給して要求されたデータ転送動作を実行し、Sバス102に接続されたスレーブの読み取りまたは書き込みを行なう。読み込み動作中、スレーブがAck[2:0]線上に信号を供給し続けて線D[31:0] にデータを供給する場合はいつでもDVMAシーケンサ282がSバスバッファ198へ制御信号を供給してデータを受信する準備が出来ていなければならない。DVMAシーケンサ282はまたクロック制御論理回路280へも信号を送りレジスタ兼復号回路154がクロックパルスを受信して受信データを保存するようにSバスレジスタ196を制御することが出来るように準備する必要がある。書き込み動作中、DVMAシーケンサ282は同様に信号を供給してSバスレジスタ196からのデータがSバスバッファ198を介してSバスの線D[31:0] へ供給されるようにする。
【0063】
図8に図示した回路に加えて、図1のマスタ回路34の機能を実行するために各種の付加回路を用意することが出来る。たとえば、マスタ回路34は処理ユニット全てに接続した共通データバス156を含むことが出来る。図5との関連ですでに説明したように、マスタ回路34はそれぞれの処理ユニットについて、処理ユニットをデータ供給源であると示すためまたはデータの宛先である一組の処理ユニット内に処理ユニットが存在することを示すために制御回路126が信号を供給するレジスタ付トランシーバ212を含むことも出来る。
【0064】
共通データバス156とレジスタ付トランシーバ212はSバス102との間でのデータ転送経路を提供しており、これはそれぞれの処理ユニットへの独立した線など他の構造より一層効率的であり得る。この経路を通って、データを処理ユニットからレジスタ付トランシーバ122へ、またレジスタ付トランシーバ194、Sバスレジスタ196、Sバスバッファ198を経由してSバス102へ直接転送できる。同様に、Sバス102からのデータをSバスバッファ198、Sバスレジスタ196、およびレジスタ付トランシーバ194を介してレジスタ付トランシーバ122へさらに一組の処理ユニットへ直接転送することが出来る。つまりレジスタ付トランシーバ122、レジスタ付トランシーバ194、およびSバスレジスタ196は共通データバス156とSバス102の間で転送されるデータ項目を保存するためのパイプラインとして機能することになる。図5との関連で前述したように、レジスタ兼復号回路154は書き込み可能信号を供給して処理ユニット内のSRAM240にその組のそれぞれの処理ユニットのレジスタ付トランシーバ212からのデータを保存することが出来る。
【0065】
上述の回路により提供される経路は隅角折り返し回路を含んでいない。これはそれぞれの処理ユニットが水平方向のフォーマットにあるデータを取り扱うように構成されている場合に好適である。
【0066】
図8の回路はホスト装置CPU14の介在なしに図1のメモリ16などのメモリに対するダイレクトメモリアクセス(DMA)方式読み取りおよび書き込みを実行できる。たとえば、画像処理を実行する上では、マスタ回路14はホスト装置のCPUとは独立に、マイクロプロセッサ220および222の要求およびSRAM240の容量に従い画像の部分を定義するデータの読み取りまたは書き込みが出来る。この能力は連続した画像内の多数のタイルのそれぞれを取り扱うために使用可能である。SRAM240はマイクロプロセッサ220および222の内部レジスタより多くのデータ項目を保存できるため、SRAM240を用いてマイクロプロセッサ220および222のためのデータの取込みが可能である。
【0067】
図9では、スレーブシーケンサ284はSバス102上の線SSel* 、AS* 、Rd、Siz[2:0]、PA[27:0]で要求された動作を表わす信号を受信する。
【0068】
Sバス102はこれに接続しているそれぞれのスレーブに対してSSel* 線を含む。バス制御回路がスレーブのアドレス空間内の位置を表わす仮想アドレスをD[31:0] 線上で受信すると、バス制御回路はスレーブのSSel* 線を低値に引き下げることでスレーブによる操作要求を表わす。バス制御回路は仮想アドレスを適切な物理アドレスへ変換しまたPA[27:0]線上の物理アドレスを供給し、その時点でバス制御回路はAS* 線を用いて、SSel* 、Rd、およびSiz[2:0]線が有効でありアドレスがPA[27:0]上にありまたマスタがD[31:0] 線上の仮想アドレスを供給停止可能であることを示すことが出来る。
【0069】
SSel* 、Rd、およびSiz[2:0]線上の信号はスレーブシーケンサ284がSバス102、Sバスレジスタ188、Sバスバッファ190を含むほかの部材へ信号を供給する方法を制御する。たとえばSSel* 線とAS* 線の降端に応答して、スレーブシーケンサ284はSバス102のAck[2:0]線上に信号を供給し、Rd、Siz[2:0]、PA[27:0]線上の要求がエラーかを示す、または要求された動作を実行する上でD[31:0] 線上で読み込むまたは書き込むことの出来るデータユニットの大きさを示す。Sバススレーブは一般に16ワードブロックまでのバイトサイズとは異なるいくつかの大きさの転送を取り扱う許可を有しているものの、スレーブシーケンサ284は限られた能力でのみ実施する必要がある。たとえば、スレーブシーケンサ284はワードおよびバイト単位の転送だけを取り扱うことが出来、また線Ack[2:0]上にワードまたはバイトを示すことが出来る。
【0070】
図示したように、Sバスバッファ190はSバス102のD[31:0] 線に接続されており、Sバスバッファ190はスレーブシーケンサ284の制御下でSバス102のタイミングの制約を満足させるように動作する。Sバスレジスタ188はSバス102からクロックを供給されているが、スレーブシーケンサ284により制御されることでトランシーバ124および制御保存回路150との間のケーブル118両端での信号の刻時の信頼性を確保するようにパイプライン段階を提供する。スレーブシーケンサ284はたとえば、Sバスレジスタ188がデータを受信する方向を決定して、所定の周期の間にこれを有効または無効にすることが出来る。
【0071】
同様に、アドレスバッファ182はSバス102のPA[27:0]線に接続されており、スレーブシーケンサ284の制御下でケーブル118経由でCSアドレスバッファ180へと起動用PROM116へのアドレスを供給する。起動用PROM116はスレーブシーケンサ284の制御下にあるバッファ184を介してSバス102のD[31:0] 線へ出力を供給する。スレーブシーケンサ284はまたバッファ184の1ビットを直接駆動して制御/状態レジスタ168内のRUNビットの値を示すことの出来る接続も有している。
【0072】
スレーブシーケンサ284はまたクロック制御論理回路280とケーブル118経由で制御保存回路150の書き込み可能線とケーブル118経由でMAR152およびCSアドレスバッファ180の出力イネーブル線へも信号を供給する。出力イネーブル信号はMAR152およびCSアドレスバッファ180からの出力をゲートする従来回路へ供給して制御保存回路150をアクセスするためのアドレスを選択することが出来る。図示した線に加えて、スレーブシーケンサ284はトランシーバ124へ制御信号を供給するようにも接続してある。
【0073】
スレーブシーケンサ280により制御される動作には、制御保存回路150からデータを読み込むまたはデータを書き出す操作、出力/状態レジスタ168からデータを読み込むまたはデータを書き出す操作、およびSバス102へ起動用PROM116からデータを読み出す操作が含まれる。必要であればスレーブシーケンサ284はアドレスバッファ182が線PA[27:0]から起動用PROM116へまたCSアドレスバッファ180へのアドレスを示すデータを提供することが出来るように制御信号を供給することが出来る。アドレスの高次ビットから、スレーブシーケンサ284はアドレスが起動用PROM116用か、制御保存回路150用か、または制御/状態レジスタ168用かを決定できる。たとえば、0から(256K−1)のアドレスは起動用PROM116用、アドレス256Kから(512K−1)は制御保存回路150用、またアドレス512Kから(768K−1)は制御/状態レジスタ168用とすることが出来る。
【0074】
スレーブシーケンサ284は起動用PROM116へ出力イネーブル信号を供給してアドレスバッファ182内のデータで示されるアドレスからデータを読み出すことが出来る。次に、スレーブシーケンサ284はバッファ184に制御信号を供給してSバス102の線D[31:0] 上に起動用PROM116からのデータを供給できるようにすることが出来る。起動用PROM116は一度に1バイトを供給するので、スレーブシーケンサ284は起動用PROM116用アドレスとSiz[2:0]線上のワード信号を受信した場合Ack[2:0]線上に1バイト信号を供給する。
【0075】
スレーブシーケンサ284はMAR152およびCSアドレスバッファ180の出力イネーブルへ信号を供給してCSアドレスバッファ180からのアドレスが制御保存回路150へ供給されるようにする。Rd線に従ってスレーブシーケンサ284は制御保存回路150の出力イネーブル端子へ動作が読み込みまたは書き込み操作どちらであるかを表わす信号を供給する。スレーブシーケンサ284はさらに制御保存回路150へまたはここからワードを転送する信号を供給することが出来る。
【0076】
操作が制御保存回路150からの1ワード読み出しの場合スレーブシーケンサ284は選択信号をトランシーバ124へまた制御信号をSバスレジスタ188とSバスバッファ190へ供給してワードをSバス102の線D[31:0] へ転送することが出来る。スレーブシーケンサ284は制御保存回路150がコプロセッサとホスト装置のCPUの間のメールボックスとして使用されている場合また診断動作中にも制御保存回路150からSバス102へデータを転送することが出来る。
【0077】
操作が制御保存回路150への書き込みの場合、スレーブシーケンサ284は制御信号をSバスバッファ190およびSバスレジスタ188へまた選択信号をトランシーバ124へ供給することにより、書き込むワードを線D[31:0] から適切なトランシーバ124の1つへ転送できる。スレーブシーケンサ284の主な機能の1つはSバス102から制御保存回路へこの方法でマイクロ命令を転送することである。スレーブシーケンサ284はまた制御保存回路150がコプロセッサとホスト装置のCPUの間のメールボックスとして使用中の場合制御保存回路150へSバス102からのデータを転送することも出来る。
【0078】
現行の実施において操作が制御/保存レジスタ168の読み取りまたは書き込みの場合、RUNビットだけが読み出しまたは書き込みされる。スレーブシーケンサ284は書き込むべきデータを直接制御/状態レジスタ168へ供給するように接続してあり、また制御/状態レジスタ168から直接読み込まれるデータを受信するように接続してある。読み込み操作の場合、スレーブシーケンサ284はRUNビットの値をバッファ184を介して1つまたはそれ以上の線D[31:0] へ供給することが出来る。書き込み操作の場合、PA[27:0]線上のアドレスはRUNビットをセットするかまたはクリアするかを表わし、スレーブシーケンサ284はセットまたはクリア信号を制御/状態レジスタ168へ直接供給することが出来る。
【0079】
図10から図15はスレーブシーケンサ284により制御される操作の間にどのように信号が供給されるかを詳細に図示している。図16から図25ではDVMAシーケンサ282により制御される操作の間にどのように信号が供給されるかを詳細に図示している。いずれの場合にも、操作を制御するシーケンサ内の論理は受信する信号に基づいて別の部材への信号を供給する。論理は従来のデジタル論理設計の原則にしたがって設計することが出来る。
【0080】
図10から図25に図示した信号の大半は図8および図9を参照して上述したものである。さらに、それぞれのタイミング図はClk 信号およびprocClk 信号を含んでいる。Sバス102は図7を参照して上述したようにクロック制御論理回路280で受信するClk 線を有している。クロック制御論理回路280はその結果レジスタ兼復号回路154へprocClk 信号を供給する。
【0081】
クロック制御論理回路280は3入力の単一ANDゲートのように動作することが出来る。1つの入力はSバス102からのClk である。もう1つの入力はスレーブシーケンサ284が低値にすることでprocClk 信号を停止させる線であり、第3の入力はDVMAシーケンサ282が低値にすることでprocClk 信号を停止させる線である。従って、procClk はスレーブシーケンサ284またはDVMAシーケンサ282いずれかにより停止できるが、両方のシーケンサが再開を許可した場合に限って再開することが出来る。prokClk 信号上の不用意なスパイクを防止するため、スレーブシーケンサ284およびDVMAシーケンサ282はSバスのClk 信号が低値の間だけクロック制御信号の状態を変更できるようになっている。
【0082】
図10は動作中にprocClk 信号を停止させることなくスレーブシーケンサにより実行される動作を示している。言い換えれば、動作中のClk 線上のそれぞれのパルスがprocClk パルスを発生させるので、コプロセッサがマイクロ命令を実行することになる。
【0083】
Clk 周期−1の間に、現在のバスマスタはSiz[2:0]およびRd線上に信号を供給開始し、仮想アドレスVAをD[31:0] 線上に供給し続ける。Clk 周期0の間に、ホストバス制御回路はスレーブシーケンサ284のAS* 線とSSel* 線を低値にする。ホストバス制御回路はまたPA[27:0]上にVAから得られた物理アドレスも供給し現在のバスマスタはVAの供給を停止する。
【0084】
これに応答して、スレーブシーケンサ284はSiz[2:0]上の信号で示されたブロックサイズがスレーブシーケンサ284で支持されていない大きさであると決定する。つまりClk 周期1の間に、スレーブシーケンサ284はエラーを表わす信号をAck[2:0]に供給開始する。この信号を検出するとホストバス制御回路はAS* 線をClk 周期2の間に低値にする。Clk 周期2の間にエラー信号の終端を検出すると、ホストバス制御回路はClk 周期3の間にSSel* を低値にしてPA[27:0]への物理アドレスの供給を停止する。同様にエラー信号の終端を検出すると、現在のバスマスタはClk 周期3の間にSiz[2:0]およびRdへの信号供給を停止する。
【0085】
図11から図15はClk 周期0の間に供給される信号がエラーではないとスレーブシーケンサ284が決定しそれによって要求された動作を実行し、マイクロ命令の実行を阻止するためにクロック制御論理回路280へprocClk 信号を停止させる信号を送出する動作を図示している。それぞれの動作が完了すると、スレーブシーケンサ284はクロック制御論理回路280を開放しprocClk パルスがまた供給されるようにする。
【0086】
図11は制御/状態レジスタ168のRUNビットを読み取る動作を図示している。Clk 周期1の間にスレーブシーケンサ284はクロック制御論理回路280へ信号を送出してprocClk を停止させ、アドレスバッファ182を経由してCSアドレスバッファ180へPA[27:0]上の物理アドレスを供給するのに必要な全ての信号を供給する。Clk 周期2および3の間に次のようなことが起こる。物理アドレスは制御/状態レジスタ168をアドレスするように接続してあるCSアドレスバッファ180へ伝えられる。スレーブシーケンサ284はRUNビットの値Reg を制御/状態レジスタ168から読み出す。スレーブシーケンサ284はまたReg をRUN線上のバッファ184へ供給する。Clk 周期3の間にスレーブシーケンサ284はワードが供給されることを表わす信号をAck[2:0]に供給する。Clk 周期4の間にスレーブシーケンサ284は制御信号をバッファ184へ供給することでReg をD[31:0] 線上に供給する。おなじ周期中にスレーブシーケンサ284はクロック制御論理回路280へ信号を送ってマイクロ命令の実行を再開できるようにprocClk を再開させる。
【0087】
Clk 周期4の開始時にAck[2:0]でワード信号を受信すると、ホストバス制御回路はClk 周期4の間にAS* を低値にする。同様に、現在のバスマスタはD[31:0] 線上に供給された場合にReg を取り扱うように準備することでワード信号に応答する。
【0088】
図12は制御/状態レジスタ168に書き込む動作、特定すれば制御保存回路150のアドレスnに保存されたマイクロ命令ルーチンの実行を開始するためにRUNビットを設定する動作を示している。上述のように、アドレス0はRUNビットがセットされていない間にMAR152へ読み込まれており、制御保存回路150へ繰り返して供給され、制御保存回路は次に実行するno op 命令を供給する。図12に図示したのと同様の動作を用いてRUNビットをクリアすることが出来る。
【0089】
Clk 周期1の間に、スレーブシーケンサ284はクロック制御論理回路280へ信号を送出してprocClk を停止させ、アドレスバッファ182を経由してCSアドレスバッファ180へPA[27:0]の物理アドレスを供給するのに必要な全ての信号を供給する。おなじ周期中に、現在のバスマスタは制御/状態レジスタ168に書き込むデータをD[31:0] 上に供給開始することが出来る。スレーブシーケンサ284はD[31:0] の最上位ビットからまたはこれ以外ではPA[27:0]のアドレスの高次ビットからRUNビットをセットするかまたはクリアするかを決定することが出来る。
【0090】
Clk 周期2および3では、スレーブシーケンサ284がD[31:0] の最上位ビットまたはPA[27:0]のアドレスの高次ビットに従って制御/状態レジスタ168のRUNビットをセットするかまたはクリアする信号を供給する。Clk 周期3ではスレーブシーケンサ284はAck[2:0]上にワード信号を供給する。
【0091】
Ack[2:0]上のワード信号をClk 周期4の開始時に受信すると、ホストバス制御回路はClk 周期4の間にAS* を低値にする。同様に、現在のバスマスタはD[31:0] 上へのデータ供給を停止する。
【0092】
Clk 周期5の間に、スレーブシーケンサ284はクロック制御論理回路280へ信号を送ってマイクロ命令の実行をClk 周期6の間に再開できるようにprocClk を再開させる。ここでアドレス0のマイクロ命令の実行によりアドレスnをMAR152に読み込ませ、nのマイクロ命令がClk 周期7の間に取り込まれClk 周期8で復号される。つまり、Clk 周期8では、新しいアドレスがマイクロ命令の制御下にMAR152へ読み込まれマイクロ命令の実行を開始したことになる。
【0093】
図13は起動用PROM116からのバイトを読み込む動作を示し図11に図示した動作と非常に良く似ている。主な相違はClk 周期2、3、4にみられる。Clk 周期2および3では、スレーブシーケンサ284が起動用PROM116へ出力イネーブル信号を供給してアドレスバッファ182からのアドレスが起動用PROM116を経由して伝達されまた1バイトを読み出すようにする。Clk 周期3で、スレーブシーケンサ284は1バイトを供給することを示す信号をAck[2:0]に供給する。Clk 周期4では、スレーブシーケンサ284はクロック信号をバッファ184へ供給することでそのバイトをD[31:0] へ供給する。おなじ周期中に、スレーブシーケンサ284はクロック制御論理回路280へ信号を送りマイクロ命令の実行を再開し得るようにprocClk を再開させる。
【0094】
Clk 周期4の初めにAck[2:0]上にバイト信号を受信すると、ホストバス制御回路はClk 周期4の間AS* を低値にする。同様に、起動時には通常ホスト装置のCPUである現在のバスマスタが、D[31:0] に供給される場合にそのバイトを取り扱うように準備することでバイト信号に応答する。
【0095】
図14はClk 周期0の初めにSiz[2:0]へ現在のバスマスタにより供給される信号で表わされる制御保存回路150からのワードを読み取る動作を示す。Clk 周期1の間に、スレーブシーケンサ284はクロック制御回路280へ信号を送ってprocClk を停止させ、またアドレスバッファ182を介してCSアドレスバッファ180へPA[27:0]の物理アドレスを供給するのに必要な全ての信号を供給する。Clk 周期2では、スレーブシーケンサ284は出力イネーブル信号をCSアドレスバッファ180へ送出して物理アドレスがClk 周期3の間に制御保存回路150へ供給されるようにする。
【0096】
Clk 周期2から4までのそれぞれで、スレーブシーケンサ284はSバスレジスタ188およびSバスバッファ190へ制御信号を送出してパイプライン中のどのようなデータでもD[31:0] へ転送させる。Clk 周期2および3の間また他の図面においても同様な周期の間に供給されたデータは有用なデータであるとは限らないのでジャンク(屑)と称される。Clk 周期3および4の間に、CSアドレスバッファ180内の物理アドレスに応答して制御保存回路150から読み出されたワードが適切なトランシーバ124のひとつを介してSバスレジスタ188へ転送され、さらにSバスバッファ190を通してClk 周期4の終までにD[31:0] へ確実に達するようにする。
【0097】
Clk 周期3の間に、スレーブシーケンサ284はワードをSバスレジスタ188へ保存するための制御信号を供給し、Ack[2:0]にワードが供給されることを表わす信号も供給する。Clk 周期4の間に、スレーブシーケンサ284はクロック制御論理回路280へprocClk を再開させる信号を送出してマイクロ命令の実行を再開させることが出来る。
【0098】
Clk 周期4の初めにAck[2:0]上でワード信号を受信すると、ホストバス制御回路はClk 周期4の間AS* を低値にする。同様に、現在のバスマスタはワードがD[31:0] に供給されるときに取り扱えるように準備することでワード信号に応答する。
【0099】
図15は制御保存回路150にワードを書き込む動作を示している。Clk 周期1の間に、スレーブシーケンサ284はクロック制御論理回路280へ信号を送出してprocClk を停止させ、またアドレスバッファ182を介してCSアドレスバッファ180へPA[27:0]上に物理アドレスを供給するために必要な全ての信号を供給する。同一周期中に、現在のバスマスタは制御保存回路150へ書き込むワードをD[31:0] に供給開始する。
【0100】
Clk 周期2では、スレーブシーケンサ284が出力イネーブル信号をCSアドレスバッファ180に供給して制御保存回路150へ物理アドレスが供給されるようにする。おなじ周期中に、スレーブシーケンサ284はSバスレジスタ188のD[31:0] にワードを保存するための制御信号も供給する。
【0101】
Clk 周期3の間に、スレーブシーケンサ284はAck[2:0]にワードが書き込まれつつあることを示す信号を供給する。Clk 周期4では、スレーブシーケンサ284は制御保存回路150を書き込み可能とするための信号を供給しまた書き込むワードを適切なトランシーバ124の1つを経由して制御保存回路150へ転送するための信号を供給し、信号が書き込まれる。
【0102】
Ack[2:0]上にClk 周期4の初めにワード信号を受信すると、ホストバス制御回路はClk 周期4の間AS* を高値にする。同様に、現在のバスマスタはD[31:0] 上へのワード供給を停止する。
【0103】
Clk 周期5の間に、スレーブシーケンサ284は出力イネーブル信号を供給して、次のマイクロ命令を取り出すための準備としてMAR152からのアドレスが制御保存回路150へ供給されるようにする。おなじ周期中に、スレーブシーケンサ284はクロック制御論理回路280へ信号を送出しClk 周期6の間にマイクロ命令の実行が再開できるようにprocClk を再開させる。
【0104】
図16はスレーブからのワードをレジスタ兼復号回路154からの信号に応答して読み出すDMA動作を図示している。Clk 周期−2(図示していない)では、レジスタ兼復号回路154が読み込むべきワードについての仮想アドレスVAをレジスタ付トランシーバ194を経由してSバスレジスタ196へ転送する動作を完了できる。おなじ周期中に、レジスタ兼復号回路154はDVMAシーケンサ282に動作を要求する信号を供給できる。これに応じて、DVMAシーケンサ282はクロック制御論理回路280にすぐに信号を送ってprocClk を停止させ、DVMAシーケンサ282が要求された動作を実行し続けるために別のprocClk パルスが必要となるまでマイクロ命令の実行が中断される。つまりprocClk はClk 周期−1の間パルス出力されないことになる。
【0105】
Clk 周期−1の間、DVMAシーケンサ282はBReq* 線を低値にしてSバス102の制御を要求する。これに応じて、Sバス制御回路はDVMAシーケンサ282のBGnt* 線をClk 周期0の間低値にして、バス制御を許可する。場合によっては、BGnt* 信号までにさらなる周期が挟まることもあり得る。
【0106】
BGnt* 信号を受信すると、DVMAシーケンサ282はレジスタ兼復号回路154の要求した動作の実行を開始する。Clk 周期1では、DVMAシーケンサ282はSiz[2:0]線上にワード信号またRd線上に読み込み信号を供給する。また、DVMAシーケンサ282はSバスバッファ198に制御信号を供給してSバスレジスタ196からのVAがD[31:0] 線上に供給されるようにする。次に、DVMAシーケンサ282はクロック制御論理回路280に信号を送出してprocClk を再開させ、Clk 周期2の間に1つのprocClk パルスが発生するようにして次のマイクロ命令を実行させる。このマイクロ命令の実行では、レジスタ兼復号回路154がSバスレジスタ196とレジスタ付トランシーバ194を経由してデータを転送する方向を変化させる信号を供給し、データはSバス102からSバスバッファ198を通って受信できるようになる。
【0107】
図16において、Sバス制御回路はVAをすぐに物理アドレスへ変換し、またClk 周期2の間にPA[27:0]線上に物理アドレスを供給する。場合によっては、物理アドレスの供給までにさらなる周期が挟まることもあり得る。物理アドレスがすでに利用可能であることを示すために、Sバス制御回路はClk 周期2の間にAS* 線も低値にする。
【0108】
AS* に応答して、DVMAシーケンサ282はClk 周期3と4と5の間にSバスバッファ198へ制御信号を供給し、VAがもはやD[31:0] に供給されていないことを示す。その結果、スレーブがClk 周期4の間にAck[2:0]にワード信号を供給すると、D[31:0] 上のワードをClk 周期5の間にSバスレジスタ196へ転送できる。Sバス制御回路はBGnt* およびAS* を高値にすることでワード信号に応答するが、DVMAシーケンサ282がすでにSバス102を必要としないためこれは許容し得ることである。
【0109】
DVMAシーケンサ282はクロック制御論理回路280に信号を送出してprocClk を再開させることでワード信号に応答し、マイクロ命令のシーケンスが実行されワードの受信と宛先への転送が実行される。レジスタ兼復号回路154はClk 周期6の間にマイクロ命令を実行し、ワードがD[31:0] から消去されるまでにSバスレジスタ196内に保存されるように信号を供給する。次のマイクロ命令でレジスタ付トランシーバ194ならびに122を介して一組の処理ユニットへワードを転送することが出来る。
【0110】
図17は図16におけるいくつかのClk 周期のそれぞれの終端でのパイプライン・レジスタの略図を示している。それぞれの略図では、パイプラインは下端のSバス102へと上端の1つまたはそれ以上の処理ユニットから延出している。最上部のパイプラインの段階は処理ユニットのレジスタ付トランシーバ212を表わす。第2の段階はレジスタ付トランシーバ122を示す。第3の段階はレジスタ付トランシーバ194を示す。第4の段階はSバスレジスタ196を表わす。図16の動作に関係しないデータは破線で示してある。
【0111】
略図310は、Clk 周期−4などのClk 周期−2より幾らか先に始まり、仮想アドレスVAは処理ユニットの1つのレジスタ付トランシーバ212に存在する。略図312および314では、VAはレジスタ付トランシーバ122へさらにレジスタ付トランシーバ194へ転送されており、パイプラインは図16のClk 周期−2の終端での状態になっている。
【0112】
略図316では、Clk 周期−1のあとのパイプラインを示し、Sバスレジスタ196内にVAがある。次に、Clk 周期2の終端までに、VAは保存されなくなり、パイプラインは略図318に図示したように図16の動作に関連するデータをまったく含まなくなる。
【0113】
略図320ではClk 周期6以降のパイプラインを示し、Sバス102からのデータワードはSバスレジスタ196に保存されている。略図322、324、326はClk 周期7、8、9でワードがどのように転送されて全処理ユニットのレジスタ付トランシーバ212に到達するかを示している。Clk 周期10では、ワードは一組の処理ユニットのそれぞれのSRAM240内に書き込まれ、動作を完了できる。
【0114】
図17に図示したいくつかの段階はそれぞれのマイクロ命令を実行した結果として発生することが出来る。たとえば、略図310、312、314、316は図16のClk 周期−1より先行する周期において実行したマイクロ命令の結果として発生し、また略図320、322、324、326はそれぞれClk 周期6、7、8、9で実行したマイクロ命令の結果として発生するものである。略図318はマイクロ命令の実行の全ての作用を明示的に図示してはいないが、Clk 周期2で実行したマイクロ命令は前述のように後続のデータ転送方向に影響を有している。
【0115】
図18はレジスタ兼復号回路154からの信号に応答してワードを書き込むDMA動作を図示している。Clk 周期−2(図示していない)において、レジスタ兼復号回路154はレジスタ付トランシーバ194を経由してSバスレジスタ196に書き込むワードについての仮想アドレスVAを転送しまたレジスタ付トランシーバ122を経由してレジスタ付トランシーバ194に書き込むワードを転送する動作を完了することが出来る。おなじ周期中に、レジスタ兼復号回路154はDVMAシーケンサ282に動作を要求する信号を供給できる。これに応じて、DVMAシーケンサ282はすぐにクロック制御論理回路280へ信号を供給してprocClk を停止させ、DVMAシーケンサ282が要求された動作を実行し続けるために別のprocClk パルスが必要となるまでマイクロ命令の実行が中断される。つまりprocClk はClk 周期−1の間はパルス出力されないことになる。
【0116】
Clk 周期−1の間、DVMAシーケンサ282はBReq* 線を低値にしてSバス102の制御を要求する。これに応じてSバス制御回路はDVMAシーケンサ282のBGnt* 線をClk 周期0の間低値にして、バス制御を許可する。場合によってはBGnt* 信号以前にさらなる周期が挟まることも有り得る。
【0117】
BGnt* 信号を受信すると、DVMAシーケンサ282はレジスタ兼復号回路154の要求した動作を実行開始する。Clk 周期1では、DVMAシーケンサ282はSiz[2:0]にワード信号またRdに読み取り信号を供給する。また、DVMAシーケンサ282はSバスバッファ198に制御信号を供給してSバスレジスタ196からのVAがD[31:0] 線上に供給されるようにする。次に、DVMAシーケンサ282はクロック制御論理回路280に信号を送出してClk 周期2の間にprocClk パルスを1つ供給させ、次のマイクロ命令が実行されるようにする。このマイクロ命令の実行において、レジスタ兼復号回路154はレジスタ付トランシーバ194からSバスレジスタ196へ書き込むワードを送出する信号を供給して書き込むワードがSバスバッファ198を経由してSバス102へ供給できるようにする。
【0118】
図18では、Sバス制御回路はVAをすぐに物理アドレスへ変換して、Clk 周期2の間に物理アドレスをPA[27:0]へ供給する。場合によっては物理アドレスが供給されるまでにさらなる周期が挟まることもあり得る。物理アドレスが利用可能になったことを示すため、Sバス制御回路はClk 周期2の間にAS* も低値にする。
【0119】
スレーブがClk 周期4の間にAck[2:0]にワードを受信したことを表わすワード信号を供給すると、DVMAシーケンサ282はClk 周期5でデータワードの供給を停止する。Sバス制御回路はBGnt* 線およびAS* 線を低値にすることでワード信号にも応答するが、DVMAシーケンサ282がもはやSバス102を必要としないためこれは許容し得ることである。
【0120】
DVMAシーケンサ282はクロック制御論理回路280へ信号を送出してprocClk を再開させてワード信号にも応答し、マイクロ命令の通常の実行が再びClk 周期5で開始できるようにする。スレーブはすでにSiz[2:0]とPA[2:0] を必要としないので、これらの線上の信号は周期6で消去される。
【0121】
図19は図18のいくつかのClk 周期のそれぞれの終端でのレジスタのパイプラインの略図である。
【0122】
略図350は、Clk 周期−4などClk 周期−2より幾らか先に始まり、仮想アドレスVAが処理ユニットの1つのレジスタ付トランシーバ212に存在している。略図352はClk 周期−3のことがあり、VAはレジスタ付トランシーバ122へ転送されており、書き込むデータワードは処理ユニットの1つのレジスタ付トランシーバ212に存在している。略図354では、VAはレジスタ付トランシーバ194へさらに転送されており、データワードがレジスタ付トランシーバ122へ転送されているので、パイプラインは図18のClk 周期−2の終端での状態になっている。
【0123】
略図356はClk 周期−1のあとでのパイプラインを示し、VAはSバスレジスタ196にまたデータワードはレジスタ付トランシーバ194にある。次に、Clk 周期2の終端までに、データワードはSバスレジスタ196に到達し略図358に図示したようにSバス102へ供給できるようになる。
【0124】
図16から図19の単一ワードDMA読み出しおよび書き込み動作は、たとえばカーネルまたはその他の特定のデータを1つまたはそれ以上の処理ユニットとホスト装置のメモリまたは別のメモリ装置の間での転送を行なうためにデバッグしている間に使用することが出来る。
【0125】
また図16および図19に図示したように単一ワードのDMA読み出しおよび書き込み動作は図14および図15のスレーブ動作と組み合わせることによって処理ユニットとホスト装置のCPUの間または制御保存回路150を介して別のバスマスタの間でデータ転送するために使用できる。言い換えれば、スレーブシーケンサ284はここへまたはここからDMA読み出しまたは書き込み動作が実行されるスレーブとなることが出来る。一般に、スレーブシーケンサ284が制御保存回路150から読み出しまたはここへ書き込んでいるどのClk 周期でも、スレーブシーケンサ284がクロック制御論理回路280へ信号を送出してprocClk を停止させることが出来る。その他のClk 周期の間、マスタシーケンサ282はマスタ動作を実行するための必要に応じてクロック制御論理回路へ信号を送ってprocClk を再開させることが出来る。
【0126】
同様に、図18および図19に図示したような単一ワードのDMA書き込み動作は図12の場合と類似のスレーブ動作と組み合わせることによってRUNビットをクリアし、コプロセッサが実際にそれ自身を停止させることが出来るようになっている。言い換えれば、レジスタ兼復号回路154はRUNビットのクリアを検出してno op 命令を実行することによりこれに応答することが出来る。
【0127】
しかし単一ワードのDMA読み出しおよび書き込み動作は画像の転送のためには効率的ではない。このような転送は通常大量のワードが関係してくるためである。
【0128】
図20から図25は複数ワードのDMA読み出しおよび書き込みを図示している。これらの動作はブロック転送またはバースト転送とも称し、画像の一部または全部を定義するデータの転送において非常に有用であり得る。
【0129】
図20および図21では、レジスタ兼復号回路154からの信号に応答してスレーブから複数ワードを読み出すDMA動作の開始と終了をそれぞれ示している。図20においてClk 周期4を通る第1の数周期では、図16のそれと同一であるが、仮想アドレスVAがワードブロック内のどのワードを第1に転送するかを示している点で異なっている。
【0130】
ブロック転送はSiz[2:0]で示されるため、スレーブは一連のデータワードを供給することで応答する。スレーブはたとえば、図20のClk 周期5の初めで示したように、各周期に1つのワードを供給できる。スレーブはこれ以外に図21に図示したように1つおきの周期ごとに1ワードを供給することも出来る。いずれの場合にも、スレーブは図21のClk 周期6に図示したように複数ワードの転送が完了するまで継続することになる。より一般的には、データワード間のほとんどすべての他のクロック周期番号でスレーブにデータの供給または併合を許容することが出来るが、トランザクションが長すぎればバス制御回路がこれを終了させてもよい。マスタはスレーブがAck[2:0]上に信号を供給する場合いつでも別のワードを供給できなければならない。
【0131】
図20のClk 周期6から10のそれぞれと図21のClk 周期2、4、6の間、クロック制御論理回路280はprocClk パルスを供給してDVMAシーケンサ282からの信号に応答し、レジスタ兼復号回路154がマイクロ命令を実行する。これらのマイクロ命令の実行において、レジスタ兼復号回路154はD[31:0] からSバスレジスタ196にデータワードそれぞれを保存するためとパイプラインに沿って処理ユニットへデータワードを進めるために信号を供給する。一方、図21のClk 周期1、3、5の間、DVMAシーケンサ282はクロック制御論理回路280へ信号を供給してprocClk を停止させる。
【0132】
その結果、図21のClk 周期4の間にAck[2:0]に最後のワード信号を供給すると、Sバス制御回路はBGnt* とAS* 線を高値にしてワード信号に応答する。これはDVMAシーケンサ282がもはやSバス102を必要としないため許容し得ることである。DVMAシーケンサ282はクロック制御論理回路280へ信号を送ってprocClk を再開させ、処理ユニットへのデータワード転送を完了するためのマイクロ命令がClk 周期6から10の間に実行されるようにする。
【0133】
図22は図20および図21のいくつかのClk 周期のそれぞれの終端におけるレジスタのパイプラインの略図である。略図370および372はそれぞれ図17の略図310および324と同一である。略図374では、図20のClk 周期7のあとのパイプラインを示し、第1のデータワードはレジスタ付トランシーバ194に保存されており、第2のデータワードはSバスレジスタ196に保存されている。同様に、略図376および378はそれぞれ図20のClk 周期8と9のあとのパイプラインを示し、この時点でパイプラインはデータワードで埋められている。Clk 周期9のあとで開始して、それぞれの処理ユニットのレジスタ付トランシーバ212に保存されているデータワードは一組の処理ユニットのそれぞれのSRAM240に保存することが出来る。たとえば、レジスタ兼復号回路154はそれぞれのClk 周期にマイクロ命令を実行して書き込みイネーブル信号をそれぞれの周期にただ1つの処理ユニットのSRAM240へ供給し、データワードが均等に分配され1つのデータワードがそれぞれの処理ユニットに格納されるようにすることが出来る。
【0134】
スレーブが全てのClk 周期でワードを供給する場合、DVMAシーケンサ282はクロック制御論理回路280に信号を供給して、全てのClk 周期でprocClk パルスを供給させ、図20に図示したようにパイプラインを満たしておくことが出来る。スレーブが1つおきのClk 周期でデータワードを供給する場合、DVMAシーケンサ282はクロック制御論理回路280に信号を供給して1つおきのClk 周期にprocClk パルスを供給させて、D[31:0] からのデータワードが交互のClk 周期でSバスレジスタ196に保存されるようにして、図21に図示したようにパイプラインを満たしておくことが出来る。一般に、DVMAシーケンサ282はクロック制御論理回路280に信号を送出することによってD[31:0] にワードが存在することを示すスレーブからのAck[2:0]上の信号に応答し、procClk パルスを供給することでスレーブがワードを供給するどのような周期にもDVMAシーケンサ282がデータを取り扱えるようにしている。
【0135】
略図380は図21のClk 周期6のあとのパイプラインを示しており、スレーブからの最後のデータワードNがSバスレジスタ196に保存されている。略図382、384、386はそれぞれ図21のClk 周期7、8、9のあとのパイプラインを示しており、ワードNがどのようにレジスタ付トランシーバ212に到達し、ここからSRAM240へ保存されて複数ワードの読み込み動作を完了するかを示している。前述のように、データワードは均等に分配でき、1つのワードがそれぞれの処理ユニットのSRAM240に保存される。
【0136】
スレーブからの複数ワードを保存するために利用できる時間が限られているので、転送が完了するまで複数ワード転送でのワードについての操作を実行するのは通常不可能である。しかしこれが可能だとすると、画像を読み込むとおりに画像を縮小するまたはその他の処理を施すことまたは直前に保存した画像と読み出した画像を比較することが可能となり有利であろう。
【0137】
図23および図24ではそれぞれレジスタ兼復号回路154からの信号に応答してスレーブへ複数ワードを書き込むDMA動作の開始と終了を図示している。Clk 周期4を通る図23の第1の数周期は図18と同一であるが、仮想アドレスVAがワードブロック内のどのワードを第1に転送するかを示している点で異なっている。
【0138】
ブロック転送はSiz[2:0]で示されるので、スレーブは図23のClk 周期5で始まるAck[2:0]上の一連のワード信号で応答し、それぞれのワード信号でデータワードがスレーブに受信されたことを示す。それぞれのワード信号に応答して、DVMAシーケンサ282は次のデータワードをD[31:0] へ供給する。スレーブは図23に図示したように全周期でAck[2:0]にワード信号を供給しまたは図24に図示したように1つおきにまたは上述のようにワード間の何らかのほかのクロック周期数を有する別の間隔で、図24のClk 周期5で図示したように複数ワードの転送が完了するまで供給することが出来る。
【0139】
図23のClk 周期5から10のそれぞれと図24の周期0、2、4を除く図24のClk 周期−1、1、3の間、、DVMAシーケンサ282はクロック制御回路280へ信号を送出してそれぞれの周期でprocClk パルスを供給させ、これに応じてレジスタ兼復号回路154はマイクロ命令を実行する。これらのマイクロ命令の実行において、レジスタ兼復号回路154はSバスレジスタ196とレジスタ付トランシーバ194とレジスタ付トランシーバ122とそれぞれの処理ユニットのレジスタ付トランシーバ212へ信号を供給し、データワードがSバス102に向かい処理ユニットからパイプラインに沿って進むようにする。一方、図24の周期0、2、4の間、DVMAシーケンサ282はクロック制御回路280に信号を送出してprocClk 信号を停止させる。たとえば、レジスタ兼復号回路154はそれぞれのClk 周期でマイクロ命令を実行して、それぞれのClk 周期で別の処理ユニットのレジスタ付トランシーバ212へ供給源選択信号を供給し、1つのデータワードがそれぞれの処理ユニットから受信されるようにすることが出来る。
【0140】
その結果、スレーブが図24のClk 周期4の間にAck[2:0]に最後のワード信号を供給すると、Sバス制御回路はBGnt* とAs* 線を高値にすることでワード信号に応答するが、これはDVMAシーケンサ282がもはやSバス102を必要としていないため許容し得ることである。DVMAシーケンサ282はクロック制御論理回路280に信号を送出してprocClk を再開させ、通常のマイクロ命令の実行がClk 周期5で再開されるようにする。
【0141】
図25は図23および図24のいくつかのClk 周期のそれぞれの終端でのレジスタのパイプラインの略図を示している。略図410および412はそれぞれ図19の略図350および352と同一である。略図414は図23のClk 周期−2のあとのパイプラインを示し、仮想アドレスVAがレジスタ付トランシーバ194に存在しまたこの後ろのパイプラインがワード1とワード2で埋められている。略図416および418は図23のClk 周期−1および2のあとのパイプラインをそれぞれ示しており、このあとパイプラインはAck[2:0]上のスレーブからのワード信号の準備としてデータワードで埋められている。
【0142】
スレーブが図23のように全てのClk 周期でまたは図24のように1つおきのClk 周期でAck[2:0]にワード信号を供給すると、DVMAシーケンサ282は同様に全てのClk 周期でまたは1つおきのClk 周期でそれぞれSバス102にデータワードを供給することができる。略図420、422、424、426ではそれぞれ図24のClk 周期−3、−1、1、3のあとのパイプラインを示しており、ワードNがどのようにSバスレジスタ196へ到達し、ここからSバス102へ供給されて複数ワードの書き込み動作を完了できるかを示している。
【0143】
図15から図25の動作を行なうために実行するマイクロ命令は、図6について前述したように、ホスト装置のメモリから制御保存回路150へロードすることが出来る。ホスト装置は開始点と長さによるなどで制御保存回路150の内容の記録を保存するようにプログラムしておくことが出来る。
【0144】
上述の実施はマイクロ命令に条件の検査を行なうことを許可していない。DVMAシーケンサ282がホストバスを待機している場合はいつでもマイクロ命令の実行を阻止するので、マイクロ命令はホストバス上で遅延が存在しないかのように実行される。
【0145】
上述の実施例で示唆されるように、典型的なマイクロ命令のシーケンスはパイプライン中に仮想アドレスを供給することから開始することが出来る。書き込み動作を実行中の場合には、シーケンスはパイプライン中に書き込むべきデータも供給可能である。そのあとでバス制御を要求する。バス制御が受け入れられると、アドレスが供給され、書き込み動作の場合にはデータがパイプラインに送出される。スレーブが書き込み動作に応答すると、データはパイプラインへ供給される。読み込み動作の場合、データはスレーブが供給したかのようにパイプラインから保存される。
【0146】
本発明は米国特許第5,065,437号、米国特許第5,048,109号、米国特許第5,129,014号、米国特許第5,131,049号に記載されている形式の画像処理を含む多くの方法に応用することが出来る。これらの画像処理技術では第1の画像を定義するデータを使用して、浸蝕や拡大といった上述のセラの書籍に記載されている演算などの操作を通じて第2の画像を取得している。このような演算は、たとえばそれぞれが原本画像をシフトしてシフトした画像を取得し次に原本画像からの値とシフトした画像からの値をそれぞれの位置で用いてブール代数演算を実行するような一連の下位演算により実行できる。コプロセッサはこのような演算を上述のようにホストメモリからDMA操作を通して取得した画像データについて実行することが出来る。
【0147】
本発明はその他の各種の演算たとえば画素の計数、グレースケール形態化、歪曲検出、および画像に対するブール演算などを実行するために応用することも可能である。
【0148】
本発明は多数の画像を取り扱うようなまたは非常に大きな画像を取り扱うような状況に特に関連する。画像をホストバス経由で転送する能力はこのような状況で非常に重要である。
【0149】
本発明はコプロセッサがホストバスのほかのマスタとコプロセッサの制御保存回路を通じて通信するような実施に関連して説明した。本発明はまたその他の通信技術たとえばホストメモリの一領域を介してまたはホスト処理装置への割り込み線を介して実施してもよい。
【0150】
本発明は並列処理装置内の処理装置がホストバス上に供給されるアドレスを取得できるような実施に関連して説明した。本発明はまたホストバスへのアドレスを取得するためのその他の技術たとえば特化したアドレス計算回路などを用いて実施してもよい。
【図面の簡単な説明】
【図1】ホスト処理装置のバスへコプロセッサとして接続することのできる並列処理装置の一般的部材を示す略ブロック図である。
【図2】Aは図1のスレーブ回路がコプロセッサの処理要求に応答する一般的動作を示す流れ図、Bは図1のコプロセッサ内の処理ユニットからホストバス上のスレーブ回路へデータを転送するマスタの処理における一般的動作を示す流れ図、Cは図1のコプロセッサ内の一組の処理ユニットへホストバス上のスレーブ回路からデータを転送するマスタの処理における一般的動作を示す流れ図である。
【図3】Sparc−Station のSバスに接続したSIMD並列処理装置の実施における部材を示す略ブロック図である。
【図4】図3の制御回路の部材を示す略ブロック図である。
【図5】図3の処理ユニットの部材を示す略ブロック図である。
【図6】図4の制御保存回路にマイクロ命令をロードすることにおける一般的動作を示す流れ図である。
【図7】図3のボックスへのクロック信号を制御する部材を示す略ブロック図である。
【図8】図7のDVMAシーケンサをSバスにまたマスタ回路のその他の回路に接続する線を表わす略ブロック図である。
【図9】図7のスレーブシーケンサをSバスへまたスレーブ回路のその他の部材へ接続する線を示す略ブロック図である。
【図10】図9のスレーブシーケンサがエラーを含む信号にどのように応答するかを示すタイミング図である。
【図11】制御/状態レジスタからデータを読み出す操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【図12】制御/状態レジスタ内にRUNビットを書き込む操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【図13】起動用PROMからデータを読み出す操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【図14】制御保存回路からデータを読み出す操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【図15】制御保存回路へデータを書き込む操作を要求する信号に対して図9のスレーブシーケンサがどのように応答するかを示すタイミング図である。
【図16】ホスト装置のメモリからデータを読み出すDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答するかを示すタイミング図である。
【図17】図16の操作の間にパイプライン・レジスタ回路を通るデータの動きを示す略流れ図である。
【図18】ホスト装置のメモリからのデータを書き込むDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答するかを示すタイミング図である。
【図19】図18の操作の間にパイプライン・レジスタ回路を通るデータの動きを示す略流れ図である。
【図20】複数ワードを読み込むDMA操作を要求する信号に図8のDVMAシーケンサがどのように応答を開始するかを示すタイミング図である。
【図21】複数ワードを読み込むDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答を完了するかを示すタイミング図である。
【図22】図20および図21の操作の間にパイプライン・レジスタ回路を通過するデータの動きを示す略流れ図である。
【図23】複数ワードを書き込むDMA操作を要求する信号に対して図8のDVMAシーケンサがどのように応答を開始するかを示すタイミング図である。
【図24】複数ワードを書き込むDMA操作を要求する信号に対して図8のDMVAシーケンサがどのように応答を完了するかを示すタイミング図である。
【図25】図23および図24の操作の間にパイプライン・レジスタ回路を通過するデータの動きを示す略流れ図である。
【符号の説明】
10 ホスト処理装置、12 ホストバス、14 CPU、16 メモリ、18ホストバス制御回路、20 コプロセッサ、22 処理ユニット、24 コプロセッサ制御回路、30 ホストバス接続回路、32 スレーブ回路、34 マスタ回路、100 Sparc−Station ワークステーション、102 Sバス、112 DVMAインタフェース、114 スレーブインタフェース、116 起動用PROM、118 ケーブル、122 レジスタ付トランシーバ、124 トランシーバ124、126 制御回路、130 処理ユニット、150 制御保存回路、152 MAR、154 レジスタ兼復号回路、156 共通データバス、180 CSアドレスバッファ、188 Sバスレジスタ、190 Sバスバッファ、192 定数バッファ、194 レジスタ付トランシーバ、196Sバスレジスタ、198 Sバスバッファ、212 レジスタ付トランシーバ、220 マイクロプロセッサ、240 SRAM、280 クロック制御論理回路、282 DVMAシーケンサ、284 スレーブシーケンサ
Claims (1)
- ホスト処理装置のホストバスに接続可能なコプロセッサであって、
前記ホストバスからスレーブ要求信号を受信するため前記ホストバスに接続されたスレーブ回路と、ホストバスの操作を要求する信号を前記ホストバスに供給するため前記ホストバスに接続され、かつ、前記コプロセッサから前記ホストバスに又は前記ホストバスから前記コプロセッサにデータを転送するため前記ホストバスに接続されたマスタ回路とを含む、前記コプロセッサを前記ホストバスに電気的に接続するホストバス接続回路と、
操作を実行することにより各々が制御信号に応答する2つ又はそれ以上の処理ユニットと、処理ユニット命令を含む制御信号を供給することにより前記処理ユニットを制御し、転送信号を供給することにより前記マスタ回路を制御するコプロセッサ制御回路とを含む処理回路と、
を備え、
前記コプロセッサ制御回路は、
制御保存命令を含むデータを保存するための制御保存回路と、
前記制御保存回路に保存された前記制御保存命令にアクセスする制御保存シーケンサと、
前記制御保存命令が前記制御保存シーケンサによってアクセスされた時に、前記アクセスされた制御保存命令を用いて、前記制御信号及び前記転送信号を含む信号を供給する信号供給回路とを含み、
前記処理回路は更に、
前記コプロセッサ制御回路から前記制御信号を受信するため前記コプロセッサ制御回路に接続され、かつ、該制御信号を前記処理ユニットに供給するため前記処理ユニットに接続され、処理ユニット命令を前記処理ユニットの全ての処理回路に並列に供給する制御信号回路と、
前記コプロセッサ制御回路からの転送信号を受信するため前記コプロセッサ回路に接続され、かつ、該転送信号を前記マスタ回路に供給するため前記マスタ回路に接続された転送信号回路と、
マスタ要求信号を前記マスタ回路から受信するため前記マスタ回路に接続され、該マスタ要求信号に応答して前記処理ユニットによる処理ユニット命令の実行を制御するための同期回路と、
を含み、
前記スレーブ回路は更に、前記制御保存回路のデータを保存するため前記制御保存回路に接続されており、該スレーブ回路は、前記制御保存回路の制御保存命令のシーケンスを保存することにより、及び前記コプロセッサ制御回路に信号を供給することにより、前記スレーブ要求信号のシーケンスに応答して、前記制御保存シーケンサを前記制御保存回路内に保存された制御保存命令のシーケンスにアクセスさせ、前記信号供給回路が処理ユニット命令のシーケンスを含む前記制御信号の組及び転送信号のシーケンスを供給することによって、前記アクセスされた制御保存命令のシーケンスに応答し、
前記マスタ回路が前記転送信号回路からの前記転送信号のシーケンスを受信し、これに応答してホストバスの操作を要求する信号を前記ホストバスに供給し、かつ、前記コプロセッサから前記ホストバスへ、又は前記ホストバスから前記コプロセッサへデータを転送し、
前記処理ユニットの全てが前記処理ユニット命令のシーケンスに応答して操作を並行して実行すると共に、前記マスタ回路が処理ユニットから前記ホストバスに、又は前記ホストバスから1つ又はそれ以上の処理ユニットの組にデータを転送し、これにより前記コプロセッサが前記スレーブ要求信号により要求された前記コプロセッサの操作を実行し、
前記マスタ回路が更に、マスタ要求信号のシーケンスを前記同期回路に供給することにより前記転送信号のシーケンスに応答し、前記同期回路が、前記処理ユニットによる処理ユニット命令の実行を制御することによって前記マスタ要求信号のシーケンスに応答し、これにより処理ユニットから前記ホストバスへ、又は前記ホストバスから1つ又はそれ以 上の処理ユニットの組へのデータの転送が、前記処理ユニット及びマスタ回路の同期操作により実行される、
ように構成されたコプロセッサ。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US07/993,256 US5655131A (en) | 1992-12-18 | 1992-12-18 | SIMD architecture for connection to host processor's bus |
| US993256 | 1992-12-18 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPH0773155A JPH0773155A (ja) | 1995-03-17 |
| JP3556966B2 true JP3556966B2 (ja) | 2004-08-25 |
Family
ID=25539306
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP31385093A Expired - Fee Related JP3556966B2 (ja) | 1992-12-18 | 1993-12-14 | コプロセッサ |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US5655131A (ja) |
| EP (1) | EP0602915B1 (ja) |
| JP (1) | JP3556966B2 (ja) |
| DE (1) | DE69327150T2 (ja) |
Families Citing this family (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2987308B2 (ja) * | 1995-04-28 | 1999-12-06 | 松下電器産業株式会社 | 情報処理装置 |
| US6321323B1 (en) * | 1997-06-27 | 2001-11-20 | Sun Microsystems, Inc. | System and method for executing platform-independent code on a co-processor |
| US6560674B1 (en) | 1998-10-14 | 2003-05-06 | Hitachi, Ltd. | Data cache system |
| US6608625B1 (en) | 1998-10-14 | 2003-08-19 | Hitachi, Ltd. | Three dimensional graphic processor |
| US6434649B1 (en) * | 1998-10-14 | 2002-08-13 | Hitachi, Ltd. | Data streamer |
| US6347344B1 (en) * | 1998-10-14 | 2002-02-12 | Hitachi, Ltd. | Integrated multimedia system with local processor, data transfer switch, processing modules, fixed functional unit, data streamer, interface unit and multiplexer, all integrated on multimedia processor |
| KR100385233B1 (ko) * | 2000-03-14 | 2003-05-23 | 삼성전자주식회사 | 데이터 프로세싱 시스템의 익스포넌트 유닛 |
| TW514791B (en) * | 2001-05-28 | 2002-12-21 | Via Tech Inc | Structure, method and related control chip for accessing device of computer system with system management bus |
| US6901421B2 (en) | 2002-03-25 | 2005-05-31 | The Boeing Company | System, method and computer program product for signal processing of array data |
| US7500083B2 (en) * | 2005-08-15 | 2009-03-03 | Silicon Informatics | Accelerated processing with scheduling to configured coprocessor for molecular data type by service and control coprocessor upon analysis of software code |
| US7490223B2 (en) * | 2005-10-31 | 2009-02-10 | Sun Microsystems, Inc. | Dynamic resource allocation among master processors that require service from a coprocessor |
| JP4931912B2 (ja) * | 2006-04-26 | 2012-05-16 | パナソニック株式会社 | 信号伝送方法、送受信装置及び通信システム |
| JP2010003151A (ja) * | 2008-06-20 | 2010-01-07 | Renesas Technology Corp | データ処理装置 |
| KR20110013868A (ko) * | 2009-08-04 | 2011-02-10 | 삼성전자주식회사 | 멀티 코멘드 셋 동작 및 우선처리 동작 기능을 갖는 멀티 프로세서 시스템 |
| US8732437B2 (en) * | 2010-01-26 | 2014-05-20 | Oracle America, Inc. | Low-overhead misalignment and reformatting support for SIMD |
| US9262704B1 (en) * | 2015-03-04 | 2016-02-16 | Xerox Corporation | Rendering images to lower bits per pixel formats using reduced numbers of registers |
| US9665415B2 (en) * | 2015-09-26 | 2017-05-30 | Intel Corporation | Low-latency internode communication |
| CN108268281B (zh) * | 2017-01-04 | 2021-12-07 | 中科创达软件股份有限公司 | 处理器协同方法及电路 |
Family Cites Families (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3537074A (en) * | 1967-12-20 | 1970-10-27 | Burroughs Corp | Parallel operating array computer |
| JPS56164464A (en) * | 1980-05-21 | 1981-12-17 | Tatsuo Nogi | Parallel processing computer |
| US4745546A (en) * | 1982-06-25 | 1988-05-17 | Hughes Aircraft Company | Column shorted and full array shorted functional plane for use in a modular array processor and method for using same |
| US4814973A (en) * | 1983-05-31 | 1989-03-21 | Hillis W Daniel | Parallel processor |
| US4850027A (en) * | 1985-07-26 | 1989-07-18 | International Business Machines Corporation | Configurable parallel pipeline image processing system |
| US4907148A (en) * | 1985-11-13 | 1990-03-06 | Alcatel U.S.A. Corp. | Cellular array processor with individual cell-level data-dependent cell control and multiport input memory |
| US4873626A (en) * | 1986-12-17 | 1989-10-10 | Massachusetts Institute Of Technology | Parallel processing system with processor array having memory system included in system memory |
| US5129092A (en) * | 1987-06-01 | 1992-07-07 | Applied Intelligent Systems,Inc. | Linear chain of parallel processors and method of using same |
| DE3851005T2 (de) * | 1987-06-01 | 1995-04-20 | Applied Intelligent Syst Inc | Paralleles Nachbarverarbeitungssystem und -Verfahren. |
| US5230042A (en) * | 1987-09-25 | 1993-07-20 | Minolta Camera Kabushiki Kaisha | Digital image processing apparatus |
| JPH01147656A (ja) * | 1987-12-03 | 1989-06-09 | Nec Corp | マイクロプロセッサ |
| US5113510A (en) * | 1987-12-22 | 1992-05-12 | Thinking Machines Corporation | Method and apparatus for operating a cache memory in a multi-processor |
| US5148547A (en) * | 1988-04-08 | 1992-09-15 | Thinking Machines Corporation | Method and apparatus for interfacing bit-serial parallel processors to a coprocessor |
| JPH0786870B2 (ja) * | 1988-04-15 | 1995-09-20 | 株式会社日立製作所 | コプロセツサのデータ転送制御方法およびその回路 |
| US5038282A (en) * | 1988-05-11 | 1991-08-06 | Massachusetts Institute Of Technology | Synchronous processor with simultaneous instruction processing and data transfer |
| US5268856A (en) * | 1988-06-06 | 1993-12-07 | Applied Intelligent Systems, Inc. | Bit serial floating point parallel processing system and method |
| US5251295A (en) * | 1988-07-11 | 1993-10-05 | Minolta Camera Kabushiki Kaisha | Image processing system having slave processors for controlling standard and optional modules |
| GB2225882A (en) * | 1988-12-06 | 1990-06-13 | Flare Technology Limited | Computer bus structure for multiple processors |
| JPH02230383A (ja) * | 1989-03-03 | 1990-09-12 | Hitachi Ltd | 画像処理装置 |
| JP3066908B2 (ja) * | 1990-08-27 | 2000-07-17 | キヤノン株式会社 | 符号,復号装置 |
| US5379438A (en) * | 1990-12-14 | 1995-01-03 | Xerox Corporation | Transferring a processing unit's data between substrates in a parallel processor |
| US5325500A (en) * | 1990-12-14 | 1994-06-28 | Xerox Corporation | Parallel processing units on a substrate, each including a column of memory |
| US5375080A (en) * | 1992-12-18 | 1994-12-20 | Xerox Corporation | Performing arithmetic on composite operands to obtain a binary outcome for each multi-bit component |
| US5450603A (en) * | 1992-12-18 | 1995-09-12 | Xerox Corporation | SIMD architecture with transfer register or value source circuitry connected to bus |
| US5437045A (en) * | 1992-12-18 | 1995-07-25 | Xerox Corporation | Parallel processing with subsampling/spreading circuitry and data transfer circuitry to and from any processing unit |
| US5428804A (en) * | 1992-12-18 | 1995-06-27 | Xerox Corporation | Edge crossing circuitry for SIMD architecture |
| US5450604A (en) * | 1992-12-18 | 1995-09-12 | Xerox Corporation | Data rotation using parallel to serial units that receive data from memory units and rotation buffer that provides rotated data to memory units |
| US5408670A (en) * | 1992-12-18 | 1995-04-18 | Xerox Corporation | Performing arithmetic in parallel on composite operands with packed multi-bit components |
-
1992
- 1992-12-18 US US07/993,256 patent/US5655131A/en not_active Expired - Lifetime
-
1993
- 1993-12-10 DE DE69327150T patent/DE69327150T2/de not_active Expired - Fee Related
- 1993-12-10 EP EP93309997A patent/EP0602915B1/en not_active Expired - Lifetime
- 1993-12-14 JP JP31385093A patent/JP3556966B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| EP0602915A3 (en) | 1996-01-24 |
| DE69327150D1 (de) | 2000-01-05 |
| EP0602915A2 (en) | 1994-06-22 |
| DE69327150T2 (de) | 2000-04-13 |
| JPH0773155A (ja) | 1995-03-17 |
| EP0602915B1 (en) | 1999-12-01 |
| US5655131A (en) | 1997-08-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3556966B2 (ja) | コプロセッサ | |
| US5133062A (en) | RAM buffer controller for providing simulated first-in-first-out (FIFO) buffers in a random access memory | |
| US4949301A (en) | Improved pointer FIFO controller for converting a standard RAM into a simulated dual FIFO by controlling the RAM's address inputs | |
| US5696989A (en) | Microcomputer equipped with DMA controller allowed to continue to perform data transfer operations even after completion of a current data transfer operation | |
| US6636927B1 (en) | Bridge device for transferring data using master-specific prefetch sizes | |
| US4835684A (en) | Microcomputer capable of transferring data from one location to another within a memory without an intermediary data bus | |
| US5307471A (en) | Memory controller for sub-memory unit such as disk drives | |
| US5341495A (en) | Bus controller having state machine for translating commands and controlling accesses from system bus to synchronous bus having different bus protocols | |
| US4580213A (en) | Microprocessor capable of automatically performing multiple bus cycles | |
| JP2001084229A (ja) | Simd型プロセッサ | |
| JPS6339072A (ja) | デ−タ処理システム | |
| JPH06214945A (ja) | コンピュータシステム及び情報の高速転送方法 | |
| US5430853A (en) | Update of control parameters of a direct memory access system without use of associated processor | |
| CN100481044C (zh) | 数据处理装置 | |
| US5414866A (en) | One-chip microcomputer with parallel operating load and unload data buses | |
| US5341508A (en) | Processing unit having multiple synchronous bus for sharing access and regulating system bus access to synchronous bus | |
| US5243702A (en) | Minimum contention processor and system bus system | |
| EP0073081B1 (en) | Data processing system having a control device for controlling an intermediate memory during a bulk data transport between a source device and a destination device | |
| JP2533886B2 (ja) | デ―タ転送方式 | |
| JP2687716B2 (ja) | 情報処理装置 | |
| JP2594611B2 (ja) | Dma転送制御装置 | |
| JPH03132857A (ja) | 複数cpu間データ転送回路 | |
| JP2531209B2 (ja) | チャネル装置 | |
| JPH04109351A (ja) | Dmaコントローラ | |
| JPH0736806A (ja) | Dma方式 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20031219 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20040317 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20040416 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20040514 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |