ES2871384T3 - Predicción de inmunogenicidad de los epítopos de células T - Google Patents
Predicción de inmunogenicidad de los epítopos de células T Download PDFInfo
- Publication number
- ES2871384T3 ES2871384T3 ES14722117T ES14722117T ES2871384T3 ES 2871384 T3 ES2871384 T3 ES 2871384T3 ES 14722117 T ES14722117 T ES 14722117T ES 14722117 T ES14722117 T ES 14722117T ES 2871384 T3 ES2871384 T3 ES 2871384T3
- Authority
- ES
- Spain
- Prior art keywords
- peptide
- cells
- binding
- mhc
- modified
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/20—Allele or variant detection, e.g. single nucleotide polymorphism [SNP] detection
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
- C12Q1/6886—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material for cancer
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/80—Vaccine for a specifically defined cancer
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/156—Polymorphic or mutational markers
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Immunology (AREA)
- Genetics & Genomics (AREA)
- Analytical Chemistry (AREA)
- Biophysics (AREA)
- Molecular Biology (AREA)
- Microbiology (AREA)
- Medicinal Chemistry (AREA)
- Biotechnology (AREA)
- Organic Chemistry (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Epidemiology (AREA)
- Mycology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Medical Informatics (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Theoretical Computer Science (AREA)
- Evolutionary Biology (AREA)
- Oncology (AREA)
- Pathology (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Biochemistry (AREA)
- General Engineering & Computer Science (AREA)
- Hospice & Palliative Care (AREA)
- General Chemical & Material Sciences (AREA)
- Gastroenterology & Hepatology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Peptides Or Proteins (AREA)
Abstract
Un método implementado por ordenador para predecir péptidos modificados inmunogénicos que comprenden modificaciones de aminoácidos, siendo dichas modificaciones sustituciones, comprendiendo el método las etapas: a) determinar una puntuación para la unión de un péptido modificado a una o más moléculas del MHC, b) determinar una puntuación para la unión del péptido no modificado a la una o más moléculas del MHC, y c) determinar una puntuación para la unión del péptido modificado cuando está presente en un complejo MHC-péptido a uno o más receptores de células T, que comprende determinar una puntuación para las similitudes químicas y físicas entre los aminoácidos no modificados y modificados, en la que la puntuación de las similitudes químicas y físicas se determina sobre la base de la probabilidad de que los aminoácidos se intercambien en la naturaleza, en la que cuanto más frecuentemente se intercambian los aminoácidos en la naturaleza, más similares se consideran los aminoácidos, en la que se determinan las similitudes químicas y físicas utilizando matrices de sustitución, en el que el péptido no modificado y el péptido modificado son idénticos pero para la modificación o modificaciones, en el que el péptido no modificado y el péptido modificado tienen una longitud de 8 a 15 aminoácidos, y en el que se predice que el péptido modificado es inmunogénico si (i) el péptido no modificado tiene una puntuación para unirse a una o más moléculas del MHC que satisfacen un umbral que indica la unión a una o más moléculas del MHC y (ii) el péptido modificado tiene una puntuación para unirse a una o más moléculas del MHC que satisfacen un umbral que indica la unión a una o más moléculas del MHC y (iii) los aminoácidos no modificados y modificados tienen una puntuación para las similitudes químicas y físicas que satisfacen un umbral que indica la diferencia química y física.
Description
DESCRIPCIÓN
Predicción de inmunogenicidad de los epítopos de células T
Campo técnico
La presente enseñanza se refiere a métodos para predecir epítopos de células T. En particular, la presente enseñanza se refiere a métodos para predecir si las modificaciones en péptidos o polipéptidos tales como neoantígenos asociados a tumores son inmunogénicas o no. Los métodos de la enseñanza son útiles, en particular, para la provisión de vacunas que son específicas para el tumor de un paciente y, por lo tanto, en el contexto de vacunas personalizadas contra el cáncer.
Antecedentes
Las vacunas personalizadas contra el cáncer son vacunas terapéuticas diseñadas a medida para dirigirse a mutaciones específicas de tumores que son exclusivas de un paciente determinado. Este tratamiento ofrece una gran esperanza para los pacientes con cáncer, ya que no daña las células sanas y tiene el potencial de proporcionar una remisión de por vida. Sin embargo, no todas las mutaciones expresadas por el tumor pueden usarse como diana para una vacuna. De hecho, la mayoría de las mutaciones somáticas del cáncer no conducirán a una respuesta inmune cuando se vacunen (J. C. Castle et al., Exploiting the mutanome for tumor vaccination. Cancer Research 72, 1081 (2012)). Dado que los tumores pueden codificar hasta 100.000 mutaciones somáticas (MR Stratton, Science Signaling 331, 1553 (2011)) mientras que las vacunas se dirigen solo a un puñado de epítopos, es evidente que un objetivo fundamental de la inmunoterapia del cáncer es identificar qué mutaciones es probable que sean inmunogénicas.
Desde una perspectiva biológica, para que una mutación somática genere una respuesta inmune, se deben cumplir varios criterios: el alelo que contiene la mutación debe ser expresado por la célula, la mutación debe estar en una región codificadora de proteínas y no sinónima, la proteína traducida debe ser escindida por el proteasoma y un epítopo que contiene la mutación debe ser presentado por el complejo MHC, el epítopo presentado debe ser reconocido por un receptor de células T (TCR) y, finalmente, el complejo TCR-pMHC debe lanzar una señalización en cascada que active las células T (S. Whelan, N. Goldman, Molecular biology and evolution 18, 691 (2001)). Hasta ahora no se ha presentado ningún algoritmo que sea capaz de predecir con un alto grado de certeza qué mutaciones es probable que cumplan con todos estos criterios. En el presente informe se consideran varios factores que pueden contribuir a la inmunogenicidad, comparando estos factores con datos experimentales y proponiendo un modelo simple para identificar mutaciones inmunogénicas.
Predicción de la unión del MHC: Estado de la técnica
Hace más de 20 años, se estableció que hay posiciones en un péptido de unión al MHC que contribuyen más a la capacidad de unión que otras (por ejemplo, (A. Sette et al., Proceedings of the National Academy of Sciences 86, 3296 (1989))). La identificación y descripción de esas posiciones de anclaje permitió encontrar patrones de péptidos de unión a MHC y, por lo tanto, fueron la base para desarrollar métodos de predicción. En los últimos años se han logrado avances significativos en el campo de los modelos in silico de la maquinaria de procesamiento de antígenos. Los dos enfoques pioneros, que se desarrollaron a fines de la década de 1990, BIMAS (KC Parker, MA Bednarek, JE Coligan, The Journal of Immunology 152, 163 (1994)) y SYFPEITHI (H.-G. Rammensee, J. Bachmann, NPN Emmerich, OA Bachor, S. Stevanovic, Immunogenetics 50, 213 (1999)), se basaron en el conocimiento de las posiciones de anclaje y en los motivos específicos de alelos derivados. A medida que se dispuso de más y más datos experimentales de unión de péptidos al MHC, se han desarrollado más herramientas utilizando una amplia variedad de técnicas estadísticas e informáticas (vease la Fig. 1 para una descripción general). Los denominados métodos basados en matrices utilizan matrices de puntuación específicas de la posición para determinar si una secuencia de péptidos coincide con el motivo de unión de un alelo del MHC particular. Otra clase de métodos de predicción de unión al MHC utilizan técnicas de aprendizaje automático, tal como las redes neuronales artificiales o las máquinas de vectores de soporte (véase la Figura 1). El rendimiento de estos algoritmos depende en gran medida de la cantidad y la calidad del conjunto de datos de entrenamiento disponible para cada modelo de alelo (por ejemplo, "HLA-A*02:01", "H2-Db", etc.) para "aprender" patrones/características subyacentes, que tienen capacidad de predicción de la unión. Recientemente, están surgiendo métodos basados en estructuras, que evitan el cuello de botella de tener un gran conjunto de entrenamiento, ya que se basan únicamente en estructuras cristalinas péptido-MHC y funciones de puntuación (por ejemplo, diferentes funciones de energía) para predecir interacciones péptido-MHC, por ejemplo mediante minimización de energía (véase la Fig. 1). Sin embargo, la precisión de esos enfoques todavía está muy por detrás de los métodos basados en secuencias. Los estudios de evaluación comparativa muestran que la herramienta basada en redes neuronales artificiales NetMHC (C. Lundegaard et al., Nucleic Acids Research 36, W509 (2008)) y el algoritmo basado en matrices SMM (B. Peters, A. Sette, BMC bioinformatics 6, 132 (2005)) obtienen mejores resultados en los datos de evaluación probados (B. Peters, A. Sette, BMC bioinformatics 6, 132 (2005); H.H. Lin, S. Ray, S. Tongchusak, EL Reinherz, V. Brusic, BMC Immunology 9, 8 (2008)). Ambos enfoques están integrados en los llamados métodos de consenso IEDB, disponibles en la base de datos de epítopos inmunes (Y. Kim et al., Nucleic Acids Research 40, W525 (2012)). El modelado de interacciones de unión péptido-MHC II es mucho más complejo que para MHC I, ya que las moléculas del MHC II poseen un surco de unión con extremos abiertos en cada lado,
permitiendo la unión de péptidos de diferentes longitudes. Mientras que los péptidos que se unen al MHC I están restringidos principalmente a 8-12 aminoácidos, esta longitud puede diferir dramáticamente para los péptidos del MHC II (9-30 aminoácidos). Un estudio de evaluación comparativa reciente muestra que los métodos de predicción del MHC II disponibles ofrecen una precisión limitada en comparación con la predicción del MHC I (H.H. Lin, S. Ray, S. Tongchusak, EL Reinherz, V. Brusic, BMC Immunology 9, 8 (2008)).
El primer uso sistemático y a gran escala de esos algoritmos para encontrar epítopos de células T fue realizado por Moutaftsi et al., (M. Moutaftsi et al., Nature Biotechnology 24, 817 (2006)), en el que se combinaron diferentes herramientas para predecir posibles candidatos a vacuna de ratones C57BL76 infectados con el virus vaccinia, se extrajeron esplenocitos y se midieron las respuestas de las células T CD8+ contra el 1% superior de los péptidos predichos. Identificaron 49 (de 2256) péptidos que indujeron una respuesta de células T. Desde entonces se han publicado muchos estudios utilizando diversas herramientas de predicción de la unión del MHC para buscar epítopos de células T como candidatos para una vacuna, principalmente para patógenos, por ejemplo, Leishmania major (C. Herrera-Najera, R. Piña-Aguilar, F. Xacur-García, M.J. Ramírez-Sierra, E. Dumonteil, Proteomics 9, 1293 (2009)). Sin embargo, utilizar únicamente herramientas de predicción de la unión del MHC I para la predicción de la inmunogenicidad es engañoso, ya que esas herramientas están entrenadas para predecir si un péptido dado tiene el potencial de unirse a un alelo del MHC dado. El fundamento de usar predicciones de unión del MHC para predecir la inmunogenicidad es la suposición de que los péptidos que se unen con alta afinidad a un alelo del MHC respectivo tienen más probabilidades de ser inmunogénicos (A. Sette et al., The Journal of Immunology 153, 5586 (1994)). Sin embargo, hay numerosos estudios que indican que también una baja afinidad de unión al MHC puede resultar en una alta inmunogenicidad (M.C. Feltkamp, M.P. Vierboom, W.M. Kast, C.J. Melief, Molecular Immunology 31, 1391 (1994)) y que la estabilidad del péptido-MHC puede ser un mejor predictor de inmunogenicidad que la afinidad por el péptido (M. Harndahl et al., European Journal of Immunology 42, 1405 (2012)). Por esa razón, la predicción de la inmunogenicidad no fue muy precisa hasta ahora, lo que se refleja en las bajas tasas de éxito para predecir la inmunogenicidad. No obstante, la unión de péptidos es una condición necesaria pero no suficiente para el reconocimiento de epítopos de células T, y una predicción eficaz puede reducir drásticamente el número de péptidos que se van a probar experimentalmente. Está claro que el desarrollo de un modelo que predice la inmunogenicidad también debe tener en cuenta el reconocimiento del receptor de células T (TCR) así como la tolerancia central, es decir, la selección negativa y positiva de células T durante el desarrollo en el timo.
El documento de la técnica anterior Castle et al., 2012 (Cancer Res; 72: 1081-1091) describe un proceso de selección de mutaciones para pruebas de validación e inmunogenicidad. El documento de la técnica anterior Nielsen et al., 2007 describe un método bioinformático que tiene en cuenta tanto la información de la secuencia de péptidos como de HLA, y genera predicciones cuantitativas de la afinidad de cualquier interacción péptido-HLA-I (PLoS ONE 2: e796). Sin embargo, ninguno de los documentos de la técnica anterior citados anteriormente en este documento enseña un método como se define en las reivindicaciones de la presente solicitud.
Existe la necesidad de un modelo predictivo, que sea capaz de modelar todos los aspectos mencionados anteriormente para predecir con precisión la inmunogenicidad de un epítopo, en lugar de solo la unión.
Descripción
Resumen
La presente invención está definida por las reivindicaciones adjuntas.
En un aspecto, la presente enseñanza se refiere a un método para predecir modificaciones de aminoácidos inmunogénicos, comprendiendo el método las etapas de:
a) determinar una puntuación para la unión de un péptido modificado a una o más moléculas del MHC, y
b) determinar una puntuación para la unión del péptido no modificado a una o más moléculas del MHC, y/o
c) determinar una puntuación para la unión del péptido modificado cuando está presente en un complejo MHC-péptido a uno o más receptores de células T.
En una realización, el péptido modificado comprende un fragmento de una proteína modificada, comprendiendo dicho fragmento la modificación o modificaciones presentes en la proteína. En una realización, el péptido o proteína no modificada tiene el aminoácido de la línea germinal en la posición o posiciones correspondientes a la posición o posiciones de la modificación o modificaciones en el péptido o proteína modificada.
En una realización, el péptido o proteína no modificada y el péptido o proteína modificada son idénticos excepto por la modificación o modificaciones. Preferiblemente, el péptido o proteína no modificada y el péptido o proteína modificada tienen la misma longitud y/o secuencia (excepto por la modificación o modificaciones).
En una realización, el péptido no modificado y el péptido modificado tienen de 8 a 15, preferiblemente de 8 a 12 aminoácidos de longitud.
En una realización, la una o más moléculas del MHC comprenden diferentes tipos de moléculas del MHC, en particular diferentes alelos del MHC. En una realización, la una o más moléculas del MHC son moléculas del MHC de clase I y/o moléculas del MHC de clase II. En una realización, la una o más moléculas del MHC comprenden un conjunto de alelos del MHC tal como un conjunto de alelos del MHC de un individuo o un subconjunto del mismo.
En una realización, la puntuación para la unión a una o más moléculas del MHC se determina mediante un proceso que comprende una comparación de secuencias con una base de datos de motivos de unión al MHC.
En una realización, la etapa a) comprende determinar si dicho puntaje satisface un umbral predeterminado para la unión a una o más moléculas del MHC y/o la etapa b) comprende determinar si dicho puntaje satisface un umbral predeterminado para unirse a una o más moléculas del MHC. En una realización, el umbral aplicado en la etapa a) es diferente al umbral aplicado en la etapa b). En una realización, el umbral predeterminado de unión a una o más moléculas del MHC refleja una probabilidad de unión a una o más moléculas del MHC.
En una realización, el uno o más receptores de células T comprenden un conjunto de receptores de células T, tal como un conjunto de receptores de células T de un individuo o un subconjunto del mismo. En una realización, la etapa c) comprende asumir que dicho conjunto de receptores de células T no incluye receptores de células T que se unen al péptido no modificado cuando están presentes en un complejo MHC-péptido y/o no incluye receptores de células T que se unen al péptido no modificado cuando está presente en un complejo MHC-péptido con alta afinidad.
En una realización, la etapa c) comprende determinar una puntuación para las similitudes químicas y físicas entre los aminoácidos modificados y no modificados. En una realización, la etapa c) comprende determinar si dicha puntuación satisface un umbral predeterminado para las similitudes químicas y físicas entre aminoácidos. En una realización, dicho umbral predeterminado para las similitudes químicas y físicas entre aminoácidos refleja una probabilidad de que los aminoácidos sean química y físicamente similares. En una realización, la puntuación de las similitudes químicas y físicas se determina sobre la base de la probabilidad de que los aminoácidos se intercambien en la naturaleza. En una realización, cuanto más frecuentemente se intercambian los aminoácidos en la naturaleza, más similares se consideran los aminoácidos y viceversa. En una realización, las similitudes químicas y físicas se determinan utilizando matrices logarítmicas de probabilidades basadas en la evolución.
En una realización, si el péptido no modificado tiene una puntuación para unirse a una o más moléculas del MHC que satisfacen un umbral que indica la unión a una o más moléculas del MHC y el péptido modificado tiene una puntuación para unirse a una o más moléculas del MHC que satisface un umbral que indica unión a una o más moléculas del MHC, la modificación o péptido modificado se predice como inmunogénico si los aminoácidos no modificados y modificados tienen una puntuación para las similitudes químicas y físicas que satisfacen un umbral que indica disimilitud química y física.
En una realización, si el péptido no modificado se une a una o más moléculas del MHC o tiene una probabilidad de unirse a una o más moléculas del MHC y el péptido modificado se une a una o más moléculas del MHC o tiene una probabilidad de unirse a una o más moléculas del MHC, la modificación o el péptido modificado se predice como inmunogénico si los aminoácidos no modificados y modificados son química y físicamente diferentes o tienen una probabilidad de ser química y físicamente diferentes.
En una realización, la modificación no está en una posición de anclaje para unirse a una o más moléculas del MHC.
En una realización, si el péptido no modificado tiene una puntuación para unirse a una o más moléculas del MHC que satisfacen un umbral que indica que no se une a una o más moléculas del MHC y el péptido modificado tiene una puntuación para unirse a uno o más moléculas del MHC que satisfacen un umbral que indica la unión a una o más moléculas del MHC, se predice que la modificación o el péptido modificado es inmunogénico.
En una realización, si el péptido no modificado no se une a una o más moléculas del MHC o tiene una probabilidad de no unirse a una o más moléculas del MHC y el péptido modificado se une a una o más moléculas del MHC o tiene una probabilidad para unirse a una o más moléculas del MHC, se predice que la modificación o el péptido modificado es inmunogénico.
En una realización, la modificación está en una posición de anclaje para unirse a una o más moléculas del MHC.
En una realización, el método de la enseñanza comprende realizar la etapa a) en dos o más péptidos modificados diferentes, comprendiendo dichos dos o más péptidos modificados diferentes la misma modificación o modificaciones. En una realización, los dos o más péptidos modificados diferentes que comprenden la misma modificación o modificaciones comprenden fragmentos diferentes de una proteína modificada, comprendiendo dichos fragmentos diferentes la misma modificación o modificaciones presentes en la proteína. En una realización, los dos o más péptidos modificados diferentes que comprenden la misma modificación o modificaciones comprenden todos los fragmentos de
unión al MHC potenciales de una proteína modificada, comprendiendo dichos fragmentos la misma modificación o modificaciones presentes en la proteína. En una realización, el método de la enseñanza comprende además seleccionar (el, los) péptido o péptidos modificado de los dos o más péptidos modificados diferentes que comprenden la misma modificación o modificaciones que tienen una probabilidad o tienen la probabilidad más alta de unirse a una o más moléculas del MHC. En una realización, los dos o más péptidos modificados diferentes que comprenden la misma modificación o modificaciones difieren en la longitud y/o la posición de la modificación o modificaciones.
En una realización, el método de la enseñanza comprende realizar la etapa a) y opcionalmente una o ambas etapas b) y c) en dos o más péptidos modificados diferentes. En una realización, dichos dos o más péptidos modificados diferentes comprenden la misma modificación o modificaciones y/o comprenden modificaciones diferentes. En una realización, las diferentes modificaciones están presentes en la misma y/o en diferentes proteínas. El conjunto de dos o más péptidos modificados diferentes usados en la etapa a) y opcionalmente una o ambas etapas b) y c) pueden ser iguales o diferentes. En una realización, el conjunto de dos o más péptidos modificados diferentes usados en la etapa b) y/o la etapa c) es un subconjunto del conjunto de dos o más péptidos modificados diferentes usados en la etapa a). Preferiblemente, dicho subconjunto incluye el péptido o péptidos que puntúan mejor en la etapa a).
En una realización, el método de la enseñanza comprende comparar las puntuaciones de dos o más de dichos péptidos modificados diferentes. En una realización, el método de la enseñanza comprende clasificar dos o más de dichos péptidos modificados diferentes. En una realización, una puntuación para la unión del péptido modificado a una o más moléculas del MHC se pondera más alta que una puntuación para la unión del péptido modificado cuando está presente en un complejo MHC-péptido a uno o más receptores de células T, preferiblemente una puntuación para las similitudes químicas y físicas entre los aminoácidos no modificados y modificados y una puntuación para la unión del péptido modificado cuando está presente en un complejo MHC-péptido a uno o más receptores de células T, preferiblemente una puntuación para las similitudes químicas y físicas entre los aminoácidos no modificados y modificados se ponderan más alto que una puntuación para la unión del péptido no modificado a una o más moléculas del MHC.
En una realización, el método de la enseñanza comprende además identificar mutaciones no sinónimas en una o más regiones codificantes de proteínas.
En una realización, las modificaciones se identifican de acuerdo con la enseñanza secuenciando parcial o completamente el genoma o transcriptoma de una o más células tales como una o más células cancerosas y opcionalmente una o más células no cancerosas e identificando mutaciones en una o más regiones codificadoras de proteínas.
En una realización, dichas mutaciones son mutaciones somáticas. En una realización, dichas mutaciones son mutaciones cancerosas.
En una realización, el método de la enseñanza se usa en la fabricación de una vacuna. En una realización, la vacuna se deriva de (a) modificación o modificaciones o (a) péptido o péptidos modificados predichos como inmunogénicos por los métodos de la enseñanza.
En un aspecto adicional, la presente enseñanza proporciona un método para proporcionar una vacuna que comprende la etapa:
identificar (a) modificación (es) o (a) péptido o péptidos modificados predichos como inmunogénicos por los métodos de la enseñanza.
En una realización, el método comprende además la etapa:
proporcionar una vacuna que comprende un péptido o polipéptido que comprende la modificación o las modificaciones o los péptidos modificados predichos como inmunogénicos, o un ácido nucleico que codifica el péptido o polipéptido.
En un aspecto adicional, la presente enseñanza proporciona una vacuna que se puede obtener usando los métodos de acuerdo con la enseñanza. En este documento se describen realizaciones preferidas de tales vacunas.
Una vacuna proporcionada de acuerdo con la enseñanza puede comprender un vehículo farmacéuticamente aceptable y opcionalmente puede comprender uno o más adyuvantes, estabilizadores, etc. La vacuna puede estar en forma de vacuna terapéutica o profiláctica.
Otro aspecto se refiere a un método para inducir una respuesta inmune en un paciente, que comprende administrar al paciente una vacuna proporcionada de acuerdo con la enseñanza.
Otro aspecto se refiere a un método de tratamiento de un paciente con cáncer que comprende las etapas:
(a) proporcionar una vacuna por los métodos de acuerdo con la enseñanza; y
(b) administrar dicha vacuna al paciente.
Otro aspecto se refiere a un método de tratamiento de un paciente con cáncer que comprende administrar la vacuna de acuerdo con la enseñanza al paciente.
En aspectos adicionales, la enseñanza proporciona las vacunas descritas en el presente documento para su uso en los métodos de tratamiento descritos en el presente documento, en particular para su uso en el tratamiento o la prevención del cáncer.
Los tratamientos del cáncer descritos en este documento se pueden combinar con resección quirúrgica y/o radiación y/o quimioterapia tradicional.
Otras características y ventajas de las presentes enseñanzas serán evidentes a partir de la siguiente descripción detallada y reivindicaciones.
Descripción detallada
Aunque la presente enseñanza se describe en detalle a continuación, debe entenderse que esta enseñanza no se limita a las metodologías, protocolos y reactivos particulares descritos en este documento, ya que estos pueden variar. También debe entenderse que la terminología utilizada en este documento tiene el propósito de describir únicamente realizaciones particulares, y no pretende limitar el alcance de la presente enseñanza, que estará limitada únicamente por las reivindicaciones adjuntas. A menos que se defina de otro modo, todos los términos técnicos y científicos usados en este documento tienen los mismos significados que los entendidos comúnmente por un experto en la técnica.
A continuación, se describirán los elementos de la presente enseñanza. Estos elementos se enumeran con realizaciones específicas, sin embargo, debe entenderse que pueden combinarse de cualquier manera y en cualquier número para crear realizaciones adicionales. Los ejemplos descritos de forma diversa y las realizaciones preferidas no deben interpretarse como que limitan la presente enseñanza a solo las realizaciones descritas explícitamente. Debe entenderse que esta descripción apoya y engloba realizaciones que combinan las realizaciones descritas explícitamente con cualquier número de los elementos descritos y/o preferidos. Además, cualquier permutación y combinación de todos los elementos descritos en esta solicitud deben considerarse divulgadas por la descripción de la presente solicitud a menos que el contexto indique lo contrario.
Preferiblemente, los términos usados en este documento se definen como se describe en A multilingual glossary of biotechnological terms: (IUPAC Recommendations)", H.G.W. Leuenberger, B. Nagel y H. Kolbl, Eds., (1995) Helvetica Chimica Acta, CH-4010 Basilea, Suiza.
La práctica de la presente enseñanza empleará, a menos que se indique lo contrario, métodos convencionales de bioquímica, biología celular, inmunología y técnicas de ADN recombinante que se explican en la literatura en el campo (véase, por ejemplo, Molecular Cloning: A laboratory Manual, 2a edición, J. Sambrook y et al., Cold Spring Harbor Laboratory Press, Cold Spring Harbor 1989).
A lo largo de esta memoria descriptiva y las reivindicaciones que siguen, a menos que el contexto requiera lo contrario, la palabra "comprende", y variaciones tales como "que comprende", se entenderá que implica la inclusión de un miembro, número entero o etapa o grupo de miembros, números enteros o etapas pero no la exclusión de cualquier otro miembro, número entero o etapa o grupo de miembros, números enteros o etapas aunque en algunas realizaciones dicho otro miembro, número entero o etapa o grupo de miembros, números enteros o etapas establecidos pueden ser excluidos, es decir, el objeto consiste en la inclusión de un miembro, número entero o etapa o grupo de miembros, números enteros o etapas establecidos. Los términos "un" y "uno, una" y "el, la" y referencias similares utilizadas en el contexto de la descripción de la enseñanza (especialmente en el contexto de las reivindicaciones) deben interpretarse para cubrir tanto el singular como el plural, a menos que se indique lo contrario en este documento o sea claramente contradicho por el contexto. La mención de intervalos de valores en el presente documento está destinada simplemente a servir como un método abreviado para hacer referencia individualmente a cada valor separado que se encuentre dentro del intervalo. A menos que se indique lo contrario en el presente documento, cada valor individual se incorpora en la memoria descriptiva como si se mencionara individualmente en el presente documento.
Todos los métodos descritos en el presente documento se pueden realizar en cualquier orden adecuado a menos que se indique lo contrario en el presente documento o que el contexto lo contradiga claramente de otro modo. El uso de todos y cada uno de los ejemplos, o ejemplo de expresión (por ejemplo, "tal como"), proporcionado en el presente documento está destinado simplemente a ilustrar mejor la enseñanza y no supone una limitación en el alcance de la enseñanza reivindicada. Ninguna expresión en la memoria descriptiva debe interpretarse como que indica algún elemento no reivindicado esencial para la práctica de la enseñanza.
De acuerdo con la presente enseñanza, el término "péptido" se refiere a sustancias que comprenden dos o más, preferiblemente 3 o más, preferiblemente 4 o más, preferiblemente 6 o más, preferiblemente 8 o más, preferiblemente 10 o más, preferiblemente 13 o más, preferiblemente 16 más, preferiblemente 21 o más y hasta preferiblemente 8, 10, 20, 30, 40 o 50, en particular 100 aminoácidos unidos covalentemente por enlaces peptídicos. El término "polipéptido"
o "proteína" se refiere a péptidos grandes, preferiblemente a péptidos con más de 100 residuos de aminoácidos, pero en general los términos "péptido", "polipéptido" y "proteína" son sinónimos y se usan indistintamente en este documento.
De acuerdo con la enseñanza, el término "modificación" con respecto a péptidos, polipéptidos o proteínas se refiere a un cambio de secuencia en un péptido, polipéptido o proteína en comparación con una secuencia parental tal como la secuencia de un péptido, polipéptido o proteína de tipo silvestre. El término incluye variantes de inserción de aminoácidos, variantes de adición de aminoácidos, variantes de eliminación de aminoácidos y variantes de sustitución de aminoácidos, preferiblemente variantes de sustitución de aminoácidos. Todos estos cambios de secuencia de acuerdo con la enseñanza pueden potencialmente crear nuevos epítopos.
Las variantes de inserción de aminoácidos comprenden inserciones de uno o dos o más aminoácidos en una secuencia de aminoácidos particular.
Las variantes de adición de aminoácidos comprenden fusiones del terminal amino y/o carboxilo de uno o más aminoácidos, tales como 1, 2, 3, 4 o 5, o más aminoácidos.
Las variantes de eliminación de aminoácidos se caracterizan por la eliminación de uno o más aminoácidos de la secuencia, tal como por la eliminación de 1, 2, 3, 4 o 5, o más aminoácidos.
Las variantes de sustitución de aminoácidos se caracterizan porque se elimina al menos un residuo en la secuencia y se inserta otro residuo en su lugar.
De acuerdo con la enseñanza, una modificación o un péptido modificado usado para ensayar en los métodos de la enseñanza puede derivarse de una proteína que comprende una modificación.
El término "derivado" significa de acuerdo con la enseñanza que una entidad particular, en particular una secuencia peptídica particular, está presente en el objeto del que se deriva. En el caso de secuencias de aminoácidos, especialmente regiones de secuencia particulares, "derivadas" significa en particular que la secuencia de aminoácidos relevante se deriva de una secuencia de aminoácidos en la que está presente.
Una proteína que comprende una modificación a partir de la cual se puede derivar una modificación o un péptido modificado usado para probar en los métodos de la enseñanza puede ser un neoantígeno.
De acuerdo con la enseñanza, el término "neoantígeno" se refiere a un péptido o proteína que incluye una o más modificaciones de aminoácidos en comparación con el péptido o proteína parental. Por ejemplo, el neoantígeno puede ser un neoantígeno asociado a tumor, en el que el término "neoantígeno asociado a tumor" incluye un péptido o proteína que incluye modificaciones de aminoácidos debido a mutaciones específicas del tumor.
De acuerdo con la enseñanza, el término "mutación específica del tumor" o "mutación específica de cáncer" se refiere a una mutación somática que está presente en el ácido nucleico de un tumor o célula cancerosa pero ausente en el ácido nucleico de una célula correspondiente normal, es decir, no tumoral o no cancerosa. Los términos "mutación específica del tumor" y "mutación del tumor" y los términos "mutación específica del cáncer" y "mutación del cáncer" se usan indistintamente en el presente documento.
El término "respuesta inmune" se refiere a una respuesta corporal integrada a una diana tal como un antígeno y preferiblemente se refiere a una respuesta inmune celular o una respuesta inmune celular así como también humoral. La respuesta inmune puede ser protectora/preventiva/profiláctica y/o terapéutica.
"Inducir una respuesta inmune" puede significar que no hubo respuesta inmune antes de la inducción, pero también puede significar que hubo un cierto nivel de respuesta inmune antes de la inducción y después de la inducción se potencia dicha respuesta inmune. Por lo tanto, "inducir una respuesta inmunitaria" también incluye "potenciar una respuesta inmunitaria". Preferiblemente, después de inducir una respuesta inmune en un sujeto, dicho sujeto está protegido de desarrollar una enfermedad tal como una enfermedad cancerosa o la condición de la enfermedad mejora induciendo una respuesta inmune. Por ejemplo, se puede inducir una respuesta inmune contra un antígeno expresado en un tumor en un paciente que padece una enfermedad cancerosa o en un sujeto que tiene riesgo de desarrollar una enfermedad cancerosa. Inducir una respuesta inmune en este caso puede significar que el estado de enfermedad del sujeto mejora, que el sujeto no desarrolla metástasis o que el sujeto que está en riesgo de desarrollar una enfermedad cancerosa no desarrolla una enfermedad cancerosa.
Los términos "respuesta inmune celular" y "respuesta celular" o términos similares se refieren a una respuesta inmune dirigida a células caracterizada por la presentación de un antígeno con MHC clase I o clase II que involucra células T o linfocitos T que actúan como "colaboradoras" o "asesinos". Las células T colaboradoras (también denominadas células T CD4+) desempeñan un papel central al regular la respuesta inmune y las células asesinas (también denominadas células T citotóxicas, células T citolíticas, células T CD8+ o CTL) matan las células enfermas tal como las células cancerosas, evitando la producción de más células enfermas. En realizaciones preferidas, la presente
enseñanza implica la estimulación de una respuesta CTL antitumoral contra células tumorales que expresan uno o más antígenos expresados en tumores y que presentan preferiblemente tales antígenos expresados en tumores con MHC clase I.
Un "antígeno" de acuerdo con la enseñanza cubre cualquier sustancia, preferiblemente un péptido o proteína, que es un objetivo de y/o induce una respuesta inmune tal como una reacción específica con anticuerpos o linfocitos T (células T). Preferiblemente, un antígeno comprende al menos un epítopo tal como un epítopo de células T. Preferiblemente, un antígeno en el contexto de la presente enseñanza es una molécula que, opcionalmente después del procesamiento, induce una reacción inmune, que preferiblemente es específica para el antígeno (incluidas las células que expresan el antígeno). El antígeno o un epítopo de células T del mismo se presenta preferiblemente por una célula, preferiblemente por una célula presentadora de antígeno que incluye una célula enferma, en particular una célula cancerosa, en el contexto de moléculas del MHC, lo que da como resultado una respuesta inmune contra el antígeno (incluidas las células que expresan el antígeno).
En una realización, un antígeno es un antígeno tumoral (también denominado antígeno expresado por tumor en este documento), es decir, una parte de una célula tumoral tal como una proteína o péptido expresado en una célula tumoral que puede derivarse del citoplasma, la superficie celular o el núcleo celular, en particular aquellos que se encuentran principalmente intracelularmente o como antígenos de superficie de células tumorales. Por ejemplo, los antígenos tumorales incluyen el antígeno carcinoembrionario, a1-fetoproteína, isoferritina y sulfoglicoproteína fetal, a2-H-ferroproteína y Y-fetoproteína. De acuerdo con la presente enseñanza, un antígeno tumoral comprende preferiblemente cualquier antígeno que se exprese y, opcionalmente, sea característico con respecto al tipo y/o nivel de expresión para tumores o cánceres así como para células tumorales o cancerosas, es decir, un antígeno asociado a tumores. En una realización, el término "antígeno asociado a tumores" se refiere a proteínas que están en condiciones normales expresadas específicamente en un número limitado de tejidos y/u órganos o en etapas específicas de desarrollo, por ejemplo, los antígenos asociados a tumores pueden estar por debajo de las condiciones normales expresadas específicamente en el tejido del estómago, preferiblemente en la mucosa gástrica, en los órganos reproductores, por ejemplo, en los testículos, en el tejido trofoblástico, por ejemplo, en la placenta, o en las células de la línea germinal, y se expresan o expresan de manera aberrante en uno o más tumores o tejidos cancerosos. En este contexto, "un número limitado" significa preferiblemente no más de 3, más preferiblemente no más de 2. Los antígenos tumorales en el contexto de la presente enseñanza incluyen, por ejemplo, antígenos de diferenciación, preferiblemente antígenos de diferenciación específicos del tipo celular, es decir, proteínas que están en condiciones normales expresadas específicamente en un cierto tipo de células en una determinada etapa de diferenciación, antígenos de cáncer/testículo, es decir, proteínas que están en condiciones normales expresadas específicamente en testículos y, a veces, en placenta, y antígenos específicos de la línea germinal. Preferiblemente, el antígeno tumoral o la expresión aberrante del antígeno tumoral identifica células cancerosas. En el contexto de la presente enseñanza, el antígeno tumoral que expresa una célula cancerosa en un sujeto, por ejemplo, un paciente que padece una enfermedad cancerosa, es preferiblemente una autoproteína en dicho sujeto. En realizaciones preferidas, el antígeno tumoral en el contexto de la presente enseñanza se expresa en condiciones normales específicamente en un tejido u órgano que no es esencial, es decir, tejidos u órganos que cuando son dañados por el sistema inmunológico no conducen a la muerte del sujeto, o en órganos o estructuras del cuerpo que no son o sólo difícilmente accesibles por el sistema inmunológico.
De acuerdo con la enseñanza, los términos "antígeno tumoral", "antígeno expresado por el tumor", "antígeno canceroso" y "antígeno expresado por cáncer" son equivalentes y se usan indistintamente en el presente documento.
El término "inmunogenicidad" se refiere a la efectividad relativa para inducir una respuesta inmune que se asocia preferiblemente con tratamientos terapéuticos, tales como tratamientos contra cánceres. Como se usa en este documento, el término "inmunogénico" se refiere a la propiedad de tener inmunogenicidad. Por ejemplo, el término "modificación inmunogénica" cuando se usa en el contexto de un péptido, polipéptido o proteína se refiere a la efectividad de dicho péptido, polipéptido o proteína para inducir una respuesta inmune causada por y/o dirigida contra dicha modificación. Preferiblemente, el péptido, polipéptido o proteína no modificados no induce una respuesta inmune, induce una respuesta inmune diferente o induce un nivel diferente, preferiblemente un nivel más bajo, de respuesta inmune.
Los términos "complejo mayor de histocompatibilidad" y la abreviatura "MHC" incluyen moléculas del MHC de clase I y MHC de clase II y se refieren a un complejo de genes que se encuentra en todos los vertebrados. Las proteínas o moléculas del MHC son importantes para la señalización entre linfocitos y células presentadoras de antígeno o células enfermas en reacciones inmunes, en las que las proteínas o moléculas del MHC se unen a péptidos y los presentan para su reconocimiento por receptores de células T. Las proteínas codificadas por el MHC se expresan en la superficie de las células y presentan tanto antígenos propios (fragmentos de péptidos de la propia célula) como antígenos no propios (por ejemplo, fragmentos de microorganismos invasores) a una célula T.
La región del MHC se divide en tres subgrupos, clase I, clase II y clase III. Las proteínas del MHC de clase I contienen una cadena a y una microglobulina p2 (que no forma parte del MHC codificado por el cromosoma 15). Presentan fragmentos de antígeno a las células T citotóxicas. En la mayoría de las células del sistema inmunológico, específicamente en las células presentadoras de antígenos, las proteínas del MHC de clase II contienen cadenas a y
p y presentan fragmentos de antígeno a las células T colaboradoras. La región del MHC de clase III codifica otros componentes inmunitarios, tales como los componentes del complemento y algunos que codifican citocinas.
El MHC es poligénico (hay varios genes del MHC de clase I y MHC de clase II) y polimórfico (hay múltiples alelos de cada gen).
Como se usa en el presente documento, el término "haplotipo" se refiere a los alelos de HLA que se encuentran en un cromosoma y las proteínas codificadas por ellos. El haplotipo también puede referirse al alelo presente en cualquier locus dentro del MHC. Cada clase del MHC está representada por varios loci: por ejemplo, HLA-A (antígeno leucocitario humano A), HLA-B, HLA-C, HLA-E, HLA-F, HLA-G, HLA-H, HLA-J , HLA-K, HLA-L, HLA-P y HLA-V para clase I y HLA-DRA, HLA-DRB 1-9, HLA, HLA-DQA1, HLA-DQB 1, HLA-DPA1, HLA-DPB1 , HLA-DMA, HLA-DMB, HLA-DOa y HLA-DOB para la clase II. Los términos "alelo del HLA" y "alelo del MHC" se usan indistintamente en el presente documento.
Los MHC exhiben un polimorfismo extremo: dentro de la población humana hay, en cada locus genético, un gran número de haplotipos que comprenden alelos distintos. Diferentes alelos polimórficos del MHC, tanto de clase I como de clase II, tienen diferentes especificidades de péptidos: cada alelo codifica proteínas que se unen a péptidos que exhiben patrones de secuencia particulares.
En una realización preferida de todos los aspectos de la enseñanza, una molécula del MHC es una molécula de HLA.
En el contexto de la presente enseñanza, el término "péptido de unión a MHC" incluye péptidos de unión a MHC de clase I y/o clase II o péptidos que pueden procesarse para producir péptidos de unión a MHC de clase I y/o clase II. En el caso de complejos del m Hc de clase I/péptido, los péptidos de unión son típicamente de 8 a 12, preferiblemente de 8 a 10 aminoácidos de longitud, aunque los péptidos más largos o más cortos pueden ser eficaces. En el caso de complejos del MHC de clase II/péptido, los péptidos de unión tienen típicamente de 9 a 30, preferiblemente de 10 a 25 aminoácidos de longitud y en particular de 13 a 18 aminoácidos de longitud, mientras que los péptidos más largos y más cortos pueden ser eficaces.
Si un péptido se va a presentar directamente, es decir, sin procesamiento, en particular sin escisión, tiene una longitud que es adecuada para unirse a una molécula del MHC, en particular a una molécula del MHC de clase I, y preferiblemente es de 7-30 aminoácidos de longitud tal como 7-20 aminoácidos de longitud, más preferiblemente 7 12 aminoácidos de longitud, más preferiblemente 8-11 aminoácidos de longitud, en particular 9 o 10 aminoácidos de longitud.
Si un péptido es parte de una entidad más grande que comprende secuencias adicionales, por ejemplo de una secuencia de vacuna o polipéptido, y se presentará después del procesamiento, en particular después de la escisión, el péptido producido por procesamiento tiene una longitud que es adecuada para unirse a una molécula del MHC, en particular una molécula del MHC de clase I, y preferiblemente es de 7-30 aminoácidos de longitud tal como de 7-20 aminoácidos de longitud, más preferiblemente de 7-12 aminoácidos de longitud, más preferiblemente de 8-11 aminoácidos de longitud, en particular de 9 o 10 aminoácidos de longitud. Preferiblemente, la secuencia del péptido que se presentará después del procesamiento se deriva de la secuencia de aminoácidos de un antígeno o polipéptido usado para la vacunación, es decir, su secuencia corresponde sustancialmente y es preferiblemente completamente idéntica a un fragmento del antígeno o polipéptido.
Por lo tanto, un péptido de unión al MHC en una realización comprende una secuencia que corresponde sustancialmente y es preferiblemente completamente idéntica a un fragmento de un antígeno.
El término "epítopo" se refiere a un determinante antigénico en una molécula tal como un antígeno, es decir, a una parte o fragmento de la molécula que es reconocida por el sistema inmunológico, por ejemplo, que es reconocida por una célula T, en particular cuando se presenta en el contexto de moléculas del MHC. Un epítopo de una proteína tal como un antígeno tumoral comprende preferiblemente una porción continua o discontinua de dicha proteína y está preferiblemente entre 5 y 100, preferiblemente entre 5 y 50, más preferiblemente entre 8 y 30, lo más preferiblemente entre 10 y 25 aminoácidos de longitud, por ejemplo, el epítopo puede tener preferiblemente 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24 o 25 aminoácidos de longitud. Se prefiere particularmente que el epítopo en el contexto de la presente enseñanza sea un epítopo de células T.
De acuerdo con la enseñanza, un epítopo puede unirse a moléculas del MHC tales como moléculas del MHC en la superficie de una célula y, por lo tanto, puede ser un "péptido de unión al MHC".
Como se usa en el presente documento, el término "neoepítopo" se refiere a un epítopo que no está presente en una referencia tal como una célula normal no cancerosa o de línea germinal pero que se encuentra en células cancerosas. Esto incluye, en particular, situaciones en las que en una célula normal no cancerosa o de la línea germinal se encuentra un epítopo correspondiente; sin embargo, debido a una o más mutaciones en una célula cancerosa, la secuencia del epítopo se cambia para dar como resultado el neoepítopo.
Como se usa en este documento, el término "epítopo de células T" se refiere a un péptido que se une a una molécula del MHC en una configuración reconocida por un receptor de células T. Normalmente, los epítopos de células T se presentan en la superficie de una célula presentadora de antígeno.
Como se usa en este documento, el término "predecir epítopos de células T" se refiere a una predicción de si un péptido se unirá a una molécula del MHC y será reconocido por un receptor de células T. El término "predecir epítopos de células T" es esencialmente sinónimo de la frase "predecir si un péptido es inmunogénico".
De acuerdo con la enseñanza, un epítopo de células T puede estar presente en una vacuna como parte de una entidad mayor, tal como una secuencia de vacuna y/o un polipéptido que comprende más de un epítopo de células T. El péptido o epítopo de células T presentado se produce siguiendo un procesamiento adecuado.
Los epítopos de células T pueden modificarse en uno o más residuos que no son esenciales para el reconocimiento de TCR o para la unión al MHC. Dichos epítopos de células T modificados pueden considerarse inmunológicamente equivalentes.
Preferiblemente, un epítopo de células T cuando se presenta por el MHC y es reconocido por un receptor de células T es capaz de inducir en presencia de señales coestimuladoras apropiadas, expansión clonal de la célula T que transporta al receptor de células T reconociendo específicamente el complejo péptido/MHC.
Preferiblemente, un epítopo de células T comprende una secuencia de aminoácidos que corresponde sustancialmente con la secuencia de aminoácidos de un fragmento de un antígeno. Preferiblemente, dicho fragmento de un antígeno es un péptido presentado por el MHC de clase I y/o clase II.
Un epítopo de células T de acuerdo con la enseñanza se refiere preferiblemente a una porción o fragmento de un antígeno que es capaz de estimular una respuesta inmune, preferiblemente una respuesta celular contra el antígeno o células caracterizadas por la expresión del antígeno y preferiblemente por la presentación del antígeno tal como células enfermas, en particular células cancerosas. Preferiblemente, un epítopo de células T es capaz de estimular una respuesta celular contra una célula caracterizada por la presentación de un antígeno con MHC de clase I y preferiblemente es capaz de estimular un linfocito T citotóxico sensible al antígeno (CTL).
"Procesamiento de antígenos" o "procesamiento" se refiere a la degradación de un péptido, polipéptido o proteína en productos de procesión, que son fragmentos de dicho péptido, polipéptido o proteína (por ejemplo, la degradación de un polipéptido en péptidos) y la asociación de uno o más de estos fragmentos (por ejemplo, mediante unión) con moléculas del MHC para su presentación por células, preferiblemente células presentadoras de antígenos, a células T específicas.
Las "células presentadoras de antígeno" (APC) son células que presentan fragmentos peptídicos de antígenos proteicos en asociación con moléculas del MHC en su superficie celular. Algunas APC pueden activar células T específicas de antígeno.
Las células presentadoras de antígeno profesionales son muy eficaces para internalizar el antígeno, ya sea por fagocitosis o por endocitosis mediada por receptor, y luego exhiben un fragmento del antígeno, unido a una molécula del MHC de clase II, en su membrana. La célula T reconoce e interactúa con el complejo antígeno-molécula del MHC de clase II en la membrana de la célula presentadora de antígeno. Luego, la célula presentadora de antígeno produce una señal coestimuladora adicional, que conduce a la activación de la célula T. La expresión de moléculas coestimuladoras es una característica definitoria de las células presentadoras de antígenos profesionales.
Los principales tipos de células presentadoras de antígeno profesionales son las células dendríticas, que tienen la gama más amplia de presentación de antígenos, y son probablemente las células presentadoras de antígenos, macrófagos, células B y ciertas células epiteliales activadas más importantes. Las células dendríticas (DC) son poblaciones de leucocitos que presentan antígenos capturados en tejidos periféricos a las células T a través de las vías de presentación de antígenos del MHC de clase II y I. Es bien sabido que las células dendríticas son potentes inductores de respuestas inmunes y la activación de estas células es una etapa crítica para la inducción de inmunidad antitumoral. Las células dendríticas se clasifican convenientemente como células "inmaduras" y "maduras", que pueden usarse como una forma sencilla de discriminar entre dos fenotipos bien caracterizados. Sin embargo, no debe interpretarse que esta nomenclatura excluye todas las posibles etapas intermedias de diferenciación. Las células dendríticas inmaduras se caracterizan por ser células presentadoras de antígenos con una alta capacidad de captación y procesamiento de antígenos, lo que se correlaciona con la alta expresión del receptor de Fcy y del receptor de manosa. El fenotipo maduro se caracteriza típicamente por una menor expresión de estos marcadores, pero una alta expresión de las moléculas de la superficie celular responsables de la activación de las células T, tal como MHC de clase I y II, moléculas de adhesión (por ejemplo, CD54 y CD11) y moléculas coestimuladoras (por ejemplo, CD40, CD80, CD86 y 4-1 BB). La maduración de las células dendríticas se conoce como el estado de activación de las células dendríticas en el que dichas células dendríticas presentadoras de antígenos conducen al cebado de las células T, mientras que la presentación por las células dendríticas inmaduras produce tolerancia. La maduración de las células dendríticas es causada principalmente por biomoléculas con características microbianas detectadas por receptores
innatos (ADN bacteriano, ARN viral, endotoxina, etc.), citocinas proinflamatorias (TNF, IL-1, IFN), ligadura de CD40 en la superficie de las células dendríticas por CD40L, y sustancias liberadas por las células que sufren una muerte celular estresante. Las células dendríticas pueden obtenerse cultivando células de médula ósea in vitro con citocinas, tales como el factor estimulante de colonias de granulocitos y macrófagos (GM-CSF) y el factor de necrosis tumoral alfa.
Las células presentadoras de antígenos no profesionales no expresan constitutivamente las proteínas del MHC de clase II necesarias para la interacción con células T no alteradas; estos se expresan solo tras la estimulación de las células presentadoras de antígenos no profesionales por ciertas citocinas tales como IFNy.
Las células presentadoras de antígenos se pueden cargar con péptidos presentados por el MHC de clase I transduciendo las células con ácido nucleico, preferiblemente ARN, que codifica un péptido o polipéptido que comprende el péptido que se va a presentar, por ejemplo, un ácido nucleico que codifica un antígeno o polipéptido utilizado para la vacunación.
En algunas realizaciones, se puede administrar a un paciente una composición farmacéutica o vacuna que comprende un vehículo de suministro de ácido nucleico que se dirige a una célula dendrítica u otra célula presentadora de antígeno, lo que da como resultado una transfección que se produce in vivo. La transfección in vivo de células dendríticas, por ejemplo, se puede realizar generalmente usando cualquier método conocido en la técnica, tal como los descritos en el documento WO 97/24447, o el enfoque de pistola de genes descrito por Mahvi et al., Immunology and Cell Biology 75: 456-460, 1997.
De acuerdo con la enseñanza, el término "célula presentadora de antígeno" también incluye células diana.
"Célula diana" significará una célula que es diana para una respuesta inmune tal como una respuesta inmune celular. Las células diana incluyen células que presentan un antígeno, es decir, un fragmento de péptido derivado de un antígeno, e incluyen cualquier célula indeseable, tal como una célula cancerosa. En realizaciones preferidas, la célula diana es una célula que expresa un antígeno como se describe en el presente documento y que presenta preferiblemente dicho antígeno con el MHC de clase I.
El término "porción" se refiere a una fracción. Con respecto a una estructura particular tal como una secuencia de aminoácidos o proteína, el término "porción" de la misma puede designar una fracción continua o discontinua de dicha estructura. Preferiblemente, una porción de una secuencia de aminoácidos comprende al menos 1%, al menos 5%, al menos 10%, al menos 20%, al menos 30%, preferiblemente al menos 40%, preferiblemente al menos 50%, más preferiblemente al menos al menos el 60%, más preferiblemente al menos el 70%, incluso más preferiblemente al menos el 80% y lo más preferiblemente al menos el 90% de los aminoácidos de dicha secuencia de aminoácidos. Preferiblemente, si la porción es una fracción discontinua, dicha fracción discontinua está compuesta por 2, 3, 4, 5, 6, 7, 8 o más partes de una estructura, siendo cada parte un elemento continuo de la estructura. Por ejemplo, una fracción discontinua de una secuencia de aminoácidos puede estar compuesta por 2, 3, 4, 5, 6, 7, 8 o más, preferiblemente no más de 4 partes de dicha secuencia de aminoácidos, en la que cada parte preferiblemente comprende en al menos 5 aminoácidos continuos, al menos 10 aminoácidos continuos, preferiblemente al menos 20 aminoácidos continuos, preferiblemente al menos 30 aminoácidos continuos de la secuencia de aminoácidos.
Los términos "parte" y "fragmento" se usan indistintamente en este documento y se refieren a un elemento continuo. Por ejemplo, una parte de una estructura tal como una secuencia de aminoácidos o una proteína se refiere a un elemento continuo de dicha estructura. Una porción, una parte o un fragmento de una estructura preferiblemente comprende una o más propiedades funcionales de dicha estructura. Por ejemplo, una porción, una parte o un fragmento de un epítopo, péptido o proteína es preferiblemente inmunológicamente equivalente al epítopo, péptido o proteína del que deriva. En el contexto de la presente enseñanza, una "parte" de una estructura tal como una secuencia de aminoácidos preferiblemente comprende, preferiblemente consta de al menos 10%, al menos 20%, al menos 30%, al menos 40%, al menos 50 %, al menos 60%, al menos 70%, al menos 80%, al menos 85%, al menos 90%, al menos 92%, al menos 94%, al menos 96%, al menos 98%, al menos 99% de la estructura completa o secuencia de aminoácidos.
El término "célula inmunorreactiva" en el contexto de la presente enseñanza se refiere a una célula que ejerce funciones efectoras durante una reacción inmunitaria. Una "célula inmunorreactiva" preferiblemente es capaz de unirse a un antígeno o una célula caracterizada por la presentación de un antígeno o un fragmento de péptido del mismo (por ejemplo, un epítopo de células T) y mediar una respuesta inmune. Por ejemplo, tales células secretan citocinas y/o quimiocinas, secretan anticuerpos, reconocen células cancerosas y, opcionalmente, eliminan tales células. Por ejemplo, las células inmunorreactivas comprenden células T (células T citotóxicas, células T colaboradoras, células T que infiltran tumores), células B, células asesinas naturales, neutrófilos, macrófagos y células dendríticas. Preferiblemente, en el contexto de la presente enseñanza, "células inmunorreactivas" son células T, preferiblemente células T CD4+ y/o CD8+.
Preferiblemente, una "célula inmunorreactiva" reconoce un antígeno o un fragmento de péptido del mismo con cierto grado de especificidad, en particular si se presenta en el contexto de moléculas del MHC tales como en la superficie
de células presentadoras de antígenos o células enfermas tales como células cancerosas. Preferiblemente, dicho reconocimiento permite que la célula que reconoce un antígeno o un fragmento de péptido del mismo sea sensible o reactiva. Si la célula es una célula T colaboradora (célula T CD4+) que porta receptores que reconocen un antígeno o un fragmento peptídico del mismo en el contexto de moléculas del MHC de clase II, dicha capacidad de respuesta o reactividad puede implicar la liberación de citocinas y/o la activación de linfocitos CD8+ (CTL) y/o células B. Si la célula es un CTL, dicha capacidad de respuesta o reactividad puede implicar la eliminación de células presentadas en el contexto de moléculas del MHC de clase I, es decir, células caracterizadas por la presentación de un antígeno con MHC de clase I, por ejemplo, mediante apoptosis o lisis de células mediadas por perforina. De acuerdo con la enseñanza, la capacidad de respuesta de los CTL puede incluir flujo de calcio sostenido, división celular, producción de citocinas tales como IFN-y y TNF-a, sobrerregulación de marcadores de activación tales como CD44 y CD69, y destrucción citolítica específica de células diana que expresan antígenos. La capacidad de respuesta de CTL también se puede determinar usando un informador artificial que indique con precisión la capacidad de respuesta de CTL. Dichos CTL que reconocen un antígeno o un fragmento de antígeno y son sensibles o reactivos también se denominan en este documento "CTL sensibles a antígenos". Si la célula es una célula B, dicha capacidad de respuesta puede implicar la liberación de inmunoglobulinas.
Los términos "célula T" y "linfocito T" se utilizan indistintamente en este documento e incluyen células T colaboradoras (células T CD4+) y células T citotóxicas (CTL, células T CD8+) que comprenden células T citolíticas.
Las células T pertenecen a un grupo de glóbulos blancos conocidos como linfocitos y desempeñan un papel central en la inmunidad mediada por células. Se pueden distinguir de otros tipos de linfocitos, tales como las células B y las células asesinas naturales por la presencia de un receptor especial en su superficie celular llamado receptor de células T (TCR). El timo es el principal órgano responsable de la maduración de las células T. Se han descubierto varios subconjuntos diferentes de células T, cada uno con una función distinta.
Las células T colaboradoras ayudan a otros glóbulos blancos en los procesos inmunológicos, incluida la maduración de las células B en células plasmáticas y la activación de células T citotóxicas y macrófagos, entre otras funciones. Estas células también se conocen como células T CD4+ porque expresan la proteína CD4 en su superficie. Las células T colaboradoras se activan cuando se les presentan antígenos peptídicos mediante moléculas del MHC de clase II que se expresan en la superficie de las células presentadoras de antígenos (APC). Una vez activadas, se dividen rápidamente y secretan pequeñas proteínas llamadas citocinas que regulan o ayudan en la respuesta inmune activa.
Las células T citotóxicas destruyen las células infectadas por virus y las células tumorales, y también están implicadas en el rechazo de trasplantes. Estas células también se conocen como células T CD8+, ya que expresan la glicoproteína CD8 en su superficie. Estas células reconocen sus dianas al unirse al antígeno asociado con el MHC de clase I, que está presente en la superficie de casi todas las células del cuerpo.
La mayoría de las células T tienen un receptor de células T (TCR) que existe como un complejo de varias proteínas. El receptor de células T real está compuesto por dos cadenas de péptidos separadas, que se producen a partir de los genes alfa y beta del receptor de células T independientes (TCRa y TCRp) y se denominan cadenas a y p del TCR. Las células T y8 (células T gamma delta) representan un pequeño subconjunto de células T que poseen un receptor de células T (TCR) distinto en su superficie. Sin embargo, en las células T y§, el TCR está formado por una cadena y y una cadena 8. Este grupo de células T es mucho menos común (2% del total de células T) que las células T ap.
La primera señal en la activación de las células T se proporciona mediante la unión del receptor de las células T a un péptido corto presentado por el MHC en otra célula. Esto asegura que solo se active una célula T con un TCR específico para ese péptido. La célula asociada suele ser una célula presentadora de antígeno, tal como una célula presentadora de antígeno profesional, generalmente una célula dendrítica en el caso de respuestas no alteradas, aunque las células B y los macrófagos pueden ser APC importantes.
De acuerdo con la presente enseñanza, una molécula es capaz de unirse a una diana si tiene una afinidad significativa por dicha diana predeterminada y se une a dicha diana predeterminada en ensayos estándar. La "afinidad" o "afinidad de unión" se mide a menudo mediante la constante de disociación de equilibrio (Kd). Una molécula no es (sustancialmente) capaz de unirse a una diana si no tiene una afinidad significativa por dicha diana y no se une significativamente a dicha diana en ensayos estándar.
Los linfocitos T citotóxicos se pueden generar in vivo mediante la incorporación de un antígeno o un fragmento de péptido del mismo en células presentadoras de antígeno in vivo. El antígeno o un fragmento de péptido del mismo puede representarse como proteína, como ADN (por ejemplo, dentro de un vector) o como ARN. El antígeno puede procesarse para producir un péptido asociado para la molécula del MHC, mientras que puede presentarse un fragmento del mismo sin necesidad de procesamiento adicional. Este último es el caso en particular, si estos pueden unirse a moléculas del MHC. En general, es posible la administración a un paciente mediante inyección intradérmica. Sin embargo, la inyección también puede realizarse intranodalmente en un ganglio linfático (Maloy et al. (2001), Proc Natl Acad Sci USA 98: 3299-303). Las células resultantes presentan el complejo de interés y son reconocidas por linfocitos T citotóxicos autólogos que luego se propagan.
La activación específica de células T CD4+ o CD8+ puede detectarse de diversas formas. Los métodos para detectar la activación de células T específicas incluyen detectar la proliferación de células T, la producción de citocinas (por ejemplo, linfocinas) o la generación de actividad citolítica. Para las células T CD4+, un método preferido para detectar la activación de células T específicas es la detección de la proliferación de células T. Para las células T CD8+, un método preferido para detectar la activación específica de las células T es la detección de la generación de actividad citolítica.
Por "célula caracterizada por la presentación de un antígeno" o "célula que presenta un antígeno" o expresiones similares se entiende una célula tal como una célula enferma, por ejemplo, una célula cancerosa, o una célula presentadora de antígeno que presenta el antígeno que expresa o un fragmento derivado de dicho antígeno, por ejemplo, por procesamiento del antígeno, en el contexto de moléculas del MHC, en particular moléculas del MHC clase I. De manera similar, los términos "enfermedad caracterizada por la presentación de un antígeno" denotan una enfermedad que involucra células caracterizadas por la presentación de un antígeno, en particular con MHC de clase I. La presentación de un antígeno por una célula puede efectuarse transfectando la célula con un ácido nucleico como el ARN que codifica el antígeno.
Por "fragmento de un antígeno que se presenta" o expresiones similares se entiende que el fragmento puede ser presentado por el MHC de clase I o clase II, preferiblemente MHC de clase I, por ejemplo, cuando se agrega directamente a las células presentadoras de antígeno. En una realización, el fragmento es un fragmento que es presentado naturalmente por células que expresan un antígeno.
El término "inmunológicamente equivalente" significa que la molécula inmunológicamente equivalente tal como la secuencia de aminoácidos inmunológicamente equivalente exhibe las mismas o esencialmente las mismas propiedades inmunológicas y/o ejerce los mismos o esencialmente los mismos efectos inmunológicos, por ejemplo, con respecto a el tipo de efecto inmunológico, tal como la inducción de una respuesta inmune humoral y/o celular, la fuerza y/o duración de la reacción inmune inducida, o la especificidad de la reacción inmune inducida. En el contexto de la presente enseñanza, el término "inmunológicamente equivalente" se usa preferiblemente con respecto a los efectos o propiedades inmunológicos de un péptido usado para inmunización. Por ejemplo, una secuencia de aminoácidos es inmunológicamente equivalente a una secuencia de aminoácidos de referencia si dicha secuencia de aminoácidos cuando se expone al sistema inmunológico de un sujeto induce una reacción inmunitaria que tiene la especificidad de reaccionar con la secuencia de aminoácidos de referencia.
El término "funciones efectoras inmunes" en el contexto de la presente enseñanza incluye cualquier función mediada por componentes del sistema inmunológico que dan como resultado, por ejemplo, la destrucción de células tumorales o la inhibición del crecimiento tumoral y/o inhibición del desarrollo de tumores, incluida la inhibición de la diseminación y metástasis tumorales. Preferiblemente, las funciones efectoras inmunes en el contexto de la presente enseñanza son funciones efectoras mediadas por células T. Tales funciones comprenden, en el caso de una célula T colaboradora (célula T CD4+), el reconocimiento de un antígeno o un fragmento de antígeno en el contexto de moléculas del MHC de clase II por receptores de células T, la liberación de citocinas y/o la activación de linfocitos CD8+ (CTL) y/o células B, y en el caso de CTL, el reconocimiento de un antígeno o un fragmento de antígeno en el contexto de moléculas del MHC de clase I por receptores de células T, la eliminación de células presentadas en el contexto de moléculas del MHC de clase I, es decir, células caracterizadas por la presentación de un antígeno con MHC de clase I, por ejemplo, mediante apoptosis o lisis celular mediada por perforina, producción de citocinas yal como IFN-y y TNF-a, y citolíticos específicos que destruyen las células diana que expresan antígenos.
De acuerdo con la enseñanza, el término "puntuación" se refiere a un resultado, normalmente expresado numéricamente, de una prueba o examen. Términos como "mejor puntuación" o "la mejor puntuación" se relacionan con un mejor resultado o el mejor resultado de una prueba o examen.
Términos tales como "predecir", "que predice" o "predicción" se refieren a la determinación de una probabilidad.
De acuerdo con la enseñanza, determinar una puntuación para la unión de un péptido a una o más moléculas del MHC incluye determinar la probabilidad de unión de un péptido a una o más moléculas del MHC.
Puede determinarse una puntuación para la unión de un péptido a una o más moléculas del MHC usando cualquier péptido: herramientas de predicción de la unión del MHC. Por ejemplo, se puede utilizar el recurso de análisis de la base de datos de epítopos inmunes (IEDB-AR: http://tools.iedb.org).
Las predicciones se hacen generalmente contra un conjunto de moléculas del MHC tal como un conjunto de diferentes alelos del MHC tal como todos los alelos posibles del MHC o un conjunto o subconjunto de alelos del MHC encontrados en un paciente que preferiblemente tiene la modificación o modificaciones) cuya inmunogenicidad se determinará de acuerdo con la enseñanza.
De acuerdo con la enseñanza, determinar una puntuación para la unión de un péptido modificado cuando está presente en un complejo MHC-péptido a uno o más receptores de células T incluye determinar la probabilidad de unión de un péptido cuando está presente en un complejo con una molécula del MHC a los receptores de células T.
Se pueden hacer predicciones contra un receptor de células T tal como un receptor de células T que se encuentra en un paciente o preferiblemente contra un conjunto de receptores de células T tal como un conjunto desconocido de diferentes receptores de células T o un conjunto o subconjunto de receptores de células T encontrado en un paciente que tiene preferiblemente la modificación o modificaciones cuya inmunogenicidad se determinará de acuerdo con la enseñanza.
Además, las predicciones se hacen generalmente contra un conjunto de moléculas del MHC, tal como un conjunto de diferentes alelos del MHC, como todos los alelos del MHC posibles o un conjunto o subconjunto de alelos del MHC que se encuentran en un paciente que preferiblemente tiene la modificación o modificaciones cuya inmunogenicidad se determinará de acuerdo con la enseñanza.
Se puede determinar una puntuación para la unión de un péptido modificado cuando está presente en un complejo MHC-péptido a uno o más receptores de células T estimando el efecto de la modificación sobre la unión de un complejo péptido-MHC del receptor de células T, dado un repertorio de receptores de células T (desconocido). La puntuación para la unión de un péptido modificado cuando está presente en un complejo MHC-péptido a uno o más receptores de células T puede definirse generalmente como una especie de proxy para el reconocimiento de una molécula de péptido-MHC dada a un receptor de células T coincidente.
La puntuación para la unión de un péptido modificado cuando está presente en un complejo MHC-péptido a uno o más receptores de células T puede determinarse determinando las diferencias fisicoquímicas entre el aminoácido modificado y el no modificado. Por ejemplo, pueden usarse matrices de sustitución. Estas matrices describen la velocidad a la que un aminoácido de una secuencia cambia a otros estados de aminoácidos a lo largo del tiempo.
Por ejemplo, se pueden usar matrices logarítmicas de probabilidades tales como matrices logarítmicas de probabilidades basadas en la evolución: una sustitución con una puntuación baja del logaritmo de probabilidades tiene una mayor probabilidad de encontrar un receptor de células T coincidente del grupo de receptores de células T (desconocidas) que una sustitución con una alta puntuación logarítmica de probabilidad (debido a la selección negativa de péptidos no modificados que coinciden con el receptor de células T). Sin embargo, existen otras formas de determinar esta puntuación. Por ejemplo, considerando la posición de la mutación en el péptido (algunas posiciones pueden tener un menor impacto en la unión que otras), teniendo en cuenta los vecinos más cercanos del aminoácido sustituido (lo que podría afectar la estructura secundaria del aminoácido sustituido), teniendo en cuenta la secuencia completa del péptido, teniendo en cuenta la información estructural completa del péptido en la molécula del MHC, etc. La determinación de la puntuación también podría implicar la determinación de un repertorio de receptores de células T (tal como el repertorio de receptores de células T de un paciente o un subconjunto del mismo), por ejemplo, mediante NGS y realizando simulaciones de acoplamiento de complejos de péptido-MHC del receptor de células T.
La presente enseñanza también puede comprender realizar el método de la enseñanza en diferentes péptidos que comprenden la misma modificación o modificaciones y/o diferentes modificaciones.
El término "péptidos diferentes que comprenden la misma modificación o modificaciones" en una realización se refiere a péptidos que comprenden o consisten en diferentes fragmentos de una proteína modificada, comprendiendo dichos diferentes fragmentos las mismas modificaciones presentes en la proteína pero que difieren en longitud y/o posición de la modificación o modificaciones. Si una proteína tiene una modificación en la posición x, dos o más fragmentos de dicha proteína que comprenden cada uno una ventana de secuencia diferente de dicha proteína que cubre dicha posición x se consideran péptidos diferentes que comprenden las misma modificaciones.
El término "péptidos diferentes que comprenden modificaciones diferentes" en una realización se refiere a péptidos de la misma y/o diferentes longitudes que comprenden diferentes modificaciones de la misma y/o proteínas diferentes. Si una proteína tiene modificaciones en las posiciones x e y, dos fragmentos de dicha proteína que comprenden cada uno una ventana de secuencia de dicha proteína que cubre la posición x o la posición y se consideran péptidos diferentes que comprenden modificaciones diferentes.
La presente enseñanza también puede comprender la ruptura de secuencias de proteínas que tienen modificaciones cuya inmunogenicidad se determinará de acuerdo con la enseñanza en longitudes de péptido apropiadas para la unión del MHC y determinar las puntuaciones para la unión a una o más moléculas del MHC de diferentes péptidos modificados que comprenden las mismas y/o diferentes modificaciones de las mismas y/o diferentes proteínas. Las salidas pueden clasificarse y pueden consistir en una lista de péptidos y sus puntuaciones previstas, lo que indica su probabilidad de unión.
La etapa de determinar una puntuación para la unión del péptido no modificado a una o más moléculas del MHC y/o la etapa de determinar una puntuación para la unión del péptido modificado cuando está presente en un complejo MHC-péptido a uno o más receptores de células T pueden realizarse posteriormente con todos los péptidos modificados diferentes que comprenden las mismas y/o diferentes modificaciones, un subconjunto de las mismas, por ejemplo, aquellos péptidos modificados que comprenden las mismas y/o diferentes modificaciones que puntúan mejor para unirse a una o más moléculas del MHC, o solo con el péptido modificado que puntúa mejor para unirse a una o más moléculas del MHC.
Después de dichas etapas adicionales, los resultados pueden clasificarse y pueden consistir en una lista de péptidos y sus puntuaciones previstas, lo que indica su probabilidad de ser inmunogénicos.
Preferiblemente, en tal clasificación, una puntuación para la unión del péptido modificado a una o más moléculas del MHC se pondera más alta que una puntuación para la unión del péptido modificado cuando está presente en un complejo MHC-péptido a uno o más receptores de células T, preferiblemente una puntuación para las similitudes químicas y físicas entre los aminoácidos no modificados y modificados y una puntuación para la unión del péptido modificado cuando está presente en un complejo MHC-péptido a uno o más receptores de células T, preferiblemente una puntuación para las similitudes químicas y físicas entre los aminoácidos no modificados y modificados se ponderan más que una puntuación para la unión del péptido no modificado a una o más moléculas del MHC.
Las modificaciones de aminoácidos cuya inmunogenicidad se va a determinar de acuerdo con la presente enseñanza pueden resultar de mutaciones en el ácido nucleico de una célula. Tales mutaciones pueden identificarse mediante técnicas de secuenciación conocidas.
En una realización, las mutaciones son mutaciones somáticas específicas de cáncer en una muestra de tumor de un paciente con cáncer que pueden determinarse identificando diferencias de secuencia entre el genoma, exoma y/o transcriptoma de una muestra de tumor y el genoma, exoma y/o o transcriptoma de una muestra no tumorígena.
De acuerdo con la enseñanza, una muestra de tumor se refiere a cualquier muestra tal como una muestra corporal derivada de un paciente que contiene o se espera que contenga células tumorales o cancerosas. La muestra corporal puede ser cualquier muestra de tejido tal como sangre, una muestra de tejido obtenida del tumor primario o de metástasis tumorales o cualquier otra muestra que contenga células tumorales o cancerosas. Preferiblemente, una muestra corporal es sangre y se determinan mutaciones somáticas o diferencias de secuencia específicas del cáncer en una o más células tumorales circulantes (CTC) contenidas en la sangre. En otra realización, una muestra de tumor se refiere a una o más células tumorales o cancerosas aisladas tales como células tumorales circulantes (CTC) o una muestra que contiene una o más células tumorales o cancerosas aisladas tales como células tumorales circulantes (CTC).
Una muestra no tumoral se refiere a cualquier muestra tal como una muestra corporal derivada de un paciente u otro individuo que preferiblemente es de la misma especie que el paciente, preferiblemente un individuo sano que no contiene o no se espera que contenga células tumorales o cancerosas. La muestra corporal puede ser cualquier muestra de tejido tal como sangre o una muestra de un tejido no tumorígena.
La enseñanza puede implicar la determinación de la firma de mutación del cáncer de un paciente. El término "firma de mutación cancerosa" puede referirse a todas las mutaciones cancerosas presentes en una o más células cancerosas de un paciente o puede referirse solo a una parte de las mutaciones cancerosas presentes en una o más células cancerosas de un paciente. Por consiguiente, la presente enseñanza puede implicar la identificación de todas las mutaciones específicas de cáncer presentes en una o más células cancerosas de un paciente o puede implicar la identificación de solo una parte de las mutaciones específicas de cáncer presentes en una o más células cancerosas de un paciente. Generalmente, los métodos de la enseñanza proporcionan la identificación de una serie de mutaciones que proporcionan un número suficiente de modificaciones o péptidos modificados para ser incluidos en los métodos de la enseñanza.
Preferiblemente, las mutaciones identificadas de acuerdo con la presente enseñanza son mutaciones no sinónimas, preferiblemente mutaciones no sinónimas de proteínas expresadas en una célula tumoral o cancerosa.
En una realización, las mutaciones somáticas específicas de cáncer o las diferencias de secuencia se determinan en el genoma, preferiblemente el genoma completo, de una muestra de tumor. Por la tanto, la enseñanza puede comprender identificar la firma de la mutación del cáncer del genoma, preferiblemente el genoma completo de una o más células cancerosas. En una realización, la etapa de identificar mutaciones somáticas específicas de cáncer en una muestra de tumor de un paciente con cáncer comprende identificar el perfil de mutación de cáncer de todo el genoma.
En una realización, las mutaciones somáticas específicas de cáncer o las diferencias de secuencia se determinan en el exoma, preferiblemente en todo el exoma, de una muestra de tumor. Por lo tanto, la enseñanza puede comprender identificar la firma de mutación del cáncer del exoma, preferiblemente el exoma completo de una o más células cancerosas. En una realización, la etapa de identificar mutaciones somáticas específicas de cáncer en una muestra de tumor de un paciente con cáncer comprende identificar el perfil de mutación de cáncer en todo el exoma.
En una realización, las mutaciones somáticas específicas de cáncer o las diferencias de secuencia se determinan en el transcriptoma, preferiblemente el transcriptoma completo, de una muestra de tumor. Por lo tanto, la enseñanza puede comprender identificar la firma de mutación del cáncer del transcriptoma, preferiblemente el transcriptoma completo de una o más células cancerosas. En una realización, la etapa de identificar mutaciones somáticas específicas de cáncer en una muestra de tumor de un paciente con cáncer comprende identificar el perfil de mutación de cáncer en todo el transcriptoma.
En una realización, la etapa de identificar mutaciones somáticas específicas del cáncer o identificar diferencias de secuencia comprende la secuenciación de una sola célula de una o más, preferiblemente 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 o incluso más células cancerosas. Por lo tanto, la enseñanza puede comprender identificar una firma de mutación cancerosa de dichas una o más células cancerosas. En una realización, las células cancerosas son células tumorales circulantes. Las células cancerosas, tal como las células tumorales circulantes, pueden aislarse antes de la secuenciación de células individuales.
En una realización, la etapa de identificar mutaciones somáticas específicas de cáncer o identificar diferencias de secuencia implica el uso de secuenciación de próxima generación (NGS).
En una realización, la etapa de identificar mutaciones somáticas específicas de cáncer o identificar diferencias de secuencia comprende secuenciar el ADN y/o el ARN genómico de la muestra de tumor.
Para revelar mutaciones somáticas específicas de cáncer o diferencias de secuencia, la información de secuencia obtenida de la muestra de tumor se compara preferiblemente con una referencia, tal como la información de secuencia obtenida de la secuenciación de ácidos nucleicos, tal como ADN o ARN de células normales no cancerosas, tales como células de línea germinal que pueden obtenerse del paciente o de un individuo diferente. En una realización, el ADN de la línea germinal genómica normal se obtiene a partir de células mononucleares de sangre periférica (PBMC)
El término "genoma" se refiere a la cantidad total de información genética en los cromosomas de un organismo o una célula.
El término "exoma" se refiere a parte del genoma de un organismo formado por exones, que codifican porciones de genes expresados. El exoma proporciona el modelo genético utilizado en la síntesis de proteínas y otros productos génicos funcionales. Es la parte más funcionalmente relevante del genoma y, por lo tanto, es más probable que contribuya al fenotipo de un organismo. Se estima que el exoma del genoma humano comprende el 1,5% del genoma total (Ng, PC et al., PLoS Gen., 4 (8): 1-15, 2008).
El término "transcriptoma" se refiere al conjunto de todas las moléculas de ARN, incluyendo ARNm, ARNr, ARNt y otro ARN no codificante producido en una célula o una población de células. En el contexto de la presente enseñanza, el transcriptoma significa el conjunto de todas las moléculas de ARN producidas en una célula, una población de células, preferiblemente una población de células cancerosas, o todas las células de un individuo dado en un momento determinado.
Un "ácido nucleico" es según la enseñanza preferiblemente ácido desoxirribonucleico (ADN) o ácido ribonucleico (ARN), más preferiblemente ARN, lo más preferiblemente ARN transcrito in vitro (ARN IVT) o ARN sintético. Los ácidos nucleicos incluyen, según la enseñanza, ADN genómico, ADNc, ARNm, moléculas producidas de forma recombinante y sintetizadas químicamente. De acuerdo con la enseñanza, un ácido nucleico puede estar presente como una molécula monocatenaria o bicatenaria y lineal o covalentemente cerrada circularmente. Un ácido nucleico puede, según la enseñanza, aislarse. El término "ácido nucleico aislado" significa, de acuerdo con la enseñanza, que el ácido nucleico (i) se amplificó in vitro, por ejemplo mediante la reacción en cadena de la polimerasa (PCR), (ii) se produjo de forma recombinante mediante clonación, (iii) se purificó, por ejemplo, mediante escisión y separación mediante electroforesis en gel, o (iv) se sintetizó, por ejemplo, mediante síntesis química. Puede emplearse un ácido nucleico para la introducción, es decir, transfección de células, en particular, en forma de ARN que puede prepararse mediante transcripción in vitro a partir de una plantilla de ADN. Además, el ARN se puede modificar antes de la aplicación mediante la estabilización de las secuencias, la protección y la poliadenilación.
El término "material genético" se refiere a un ácido nucleico aislado, ya sea ADN o ARN, una sección de una doble hélice, una sección de un cromosoma o el genoma completo de un organismo o célula, en particular su exoma o transcriptoma.
El término "mutación" se refiere a un cambio o diferencia en la secuencia de ácido nucleico (sustitución, adición o eliminación de nucleótidos) en comparación con una referencia. Una "mutación somática" puede ocurrir en cualquiera de las células del cuerpo, excepto en las células germinales (espermatozoides y óvulos) y, por lo tanto, no se transmiten a los niños. Estas alteraciones pueden (pero no siempre) causar cáncer u otras enfermedades. Preferiblemente, una mutación es una mutación no sinónima. El término "mutación no sinónima" se refiere a una mutación, preferiblemente una sustitución de nucleótidos, que da como resultado un cambio de aminoácido tal como una sustitución de aminoácido en el producto de traducción.
De acuerdo con la enseñanza, el término "mutación" incluye mutaciones puntuales, Indels, fusiones, cromotripsis y ediciones de ARN.
De acuerdo con la enseñanza, el término "Indel" describe una clase de mutación especial, definida como una mutación que da como resultado una inserción y eliminación colocalizada y una ganancia o pérdida neta de nucleótidos. En las regiones codificantes del genoma, a menos que la longitud de un indel sea un múltiplo de 3, producen una mutación por desplazamiento del marco de lectura. Los indeles se pueden contrastar con una mutación puntual; en la que un
Indel inserta y elimina nucleótidos de una secuencia, una mutación puntual es una forma de sustitución que reemplaza uno de los nucleótidos.
Las fusiones pueden generar genes híbridos formados a partir de dos genes previamente separados. Puede ocurrir como resultado de una translocación, eliminación intersticial o inversión cromosómica. A menudo, los genes de fusión son oncogenes. Los genes de fusión oncogénicos pueden conducir a un producto génico con una función nueva o diferente a la de los dos compañeros de fusión. Alternativamente, un protooncogén se fusiona con un promotor fuerte y, por lo tanto, la función oncogénica se establece para que funcione mediante una sobrerregulación causada por el promotor fuerte del compañero de fusión secuencia arriba. Los transcriptos de fusión oncogénica también pueden ser causadas por eventos de empalme trans o de lectura.
De acuerdo con la enseñanza, el término "cromotripsis" se refiere a un fenómeno genético por el cual regiones específicas del genoma se rompen y luego se unen mediante un solo evento devastador.
De acuerdo con la enseñanza, el término "edición de ARN" o "editar ARN" se refiere a procesos moleculares en los que el contenido de información en una molécula de ARN se altera mediante un cambio químico en la composición de la base. La edición de ARN incluye modificaciones de nucleósidos tales como desaminaciones de citidina (C) a uridina (U) y adenosina (A) a inosina (I), así como adiciones e inserciones de nucleótidos sin plantilla. La edición de ARN en ARNm altera eficazmente la secuencia de aminoácidos de la proteína codificada para que difiera de la predicha por la secuencia de ADN genómico.
El término "firma de mutación del cáncer" se refiere a un conjunto de mutaciones que están presentes en las células cancerosas en comparación con las células de referencia no cancerosas.
De acuerdo con la enseñanza, se puede usar una "referencia" para correlacionar y comparar los resultados obtenidos en los métodos de enseñanza a partir de una muestra de tumor. Normalmente, la "referencia" puede obtenerse sobre la base de una o más muestras normales, en particular muestras que no se ven afectadas por una enfermedad cancerosa, obtenidas de un paciente o de uno o más individuos diferentes, preferiblemente individuos sanos, en particular individuos de la misma especie. Una "referencia" puede determinarse empíricamente analizando un número suficientemente grande de muestras normales.
Se puede usar cualquier método de secuenciación adecuado de acuerdo con la enseñanza para determinar mutaciones, prefiriéndose las tecnologías de secuenciación de próxima generación (NGS). Los métodos de secuenciación de tercera generación podrían sustituir a la tecnología NGS en el futuro para acelerar la etapa de secuenciación del método. Para fines de aclaración: los términos "Secuenciación de próxima generación" o "NGS" en el contexto de la presente enseñanza se refieren a todas las nuevas tecnologías de secuenciación de alto rendimiento que, en contraste con la metodología de secuenciación "convencional" conocida como química de Sanger, leen plantillas de ácido nucleico al azar en paralelo a lo largo de todo el genoma rompiendo todo el genoma en pequeños trozos. Dichas tecnologías NGS (también conocidas como tecnologías de secuenciación masivamente paralela) son capaces de entregar información de secuencia de ácido nucleico de un genoma completo, exoma, transcriptoma (todas las secuencias transcritas de un genoma) o metiloma (todas las secuencias metiladas de un genoma) en períodos de muy poco tiempo, por ejemplo dentro de 1-2 semanas, preferiblemente dentro de 1-7 días o más preferiblemente dentro de menos de 24 horas y permitir, en principio, enfoques de secuenciación de células individuales. Se pueden usar múltiples plataformas n Gs que están disponibles comercialmente o que se mencionan en la literatura en el contexto de la presente enseñanza, por ejemplo, las descritas en detalle en Zhang et al., 2011: The impact of nextgeneration sequencing on genomics. J. Genet Genomics 38 (3), 95-109; o en Voelkerding et al., 2009: Next generation sequencing: From basic research to diagnostics. Clinical chemistry 55, 641-658. Ejemplos no limitantes de tales tecnologías/plataformas NGS son
1) La tecnología de secuenciación por síntesis conocida como pirosecuenciación implementada, por ejemplo en el GS-FLX 454 Genome SequencerMR de la empresa asociada a Roche 454 Life Sciences (Branford, Connecticut), descrito por primera vez en Ronaghi et al., 1998: A sequencing method based on real-time pyrophosphate". Science 281. (5375), 363-365. Esta tecnología utiliza una PCR en emulsión en la que las perlas de unión a ADN monocatenarias se encapsulan mediante agitación vigorosa en micelas acuosas que contienen reactivos de PCR rodeados de aceite para amplificación por PCR en emulsión. Durante el proceso de pirosecuenciación, la luz emitida por las moléculas de fosfato durante la incorporación de nucleótidos se registra a medida que la polimerasa sintetiza la cadena de ADN.
2) Los enfoques de secuenciación por síntesis desarrollados por Solexa (ahora parte de Illumina Inc., San Diego, California) que se basan en terminadores de colorantes reversibles e implementados por ejemplo en Illumina/Solexa Genome AnalyzerMR y en Illumina HiSeq 2000 Genome AnalyzerMR. En esta tecnología, los cuatro nucleótidos se agregan simultáneamente en fragmentos de racimo cebados con oligo en canales de celdas de flujo junto con la ADN polimerasa. La amplificación de puente extiende las cadenas de grupos con los cuatro nucleótidos marcados con fluorescencia para la secuenciación.
3) Enfoques de secuenciación por ligadura, por ejemplo implementados en la plataforma SOLidMR de Applied Biosystems (ahora Life Technologies Corporation, Carlsbad, California). En esta tecnología, se marca un conjunto de todos los posibles oligonucleótidos de una longitud fija de acuerdo con la posición secuenciada. Los oligonucleótidos
se hibridan y se ligan; la ligadura preferencial por ADN ligasa para emparejar secuencias da como resultado una señal informativa del nucleótido en esa posición. Antes de la secuenciación, el ADN se amplifica mediante PCR en emulsión. La perla resultante, cada una de las cuales contiene solo copias de la misma molécula de ADN, se deposita en un portaobjetos de vidrio. Como segundo ejemplo, la plataforma PolonatorMR G.007 de Dover Systems (Salem, New Hampshire) también emplea un enfoque de secuenciación por ligación mediante el uso de una PCR de emulsión basada en perlas y ordenada al azar para amplificar fragmentos de ADN para la secuenciación paralela.
4) Tecnologías de secuenciación de una sola molécula, tales como por ejemplo las implementadas en el sistema PacBio RS de Pacific Biosciences (Menlo Park, California) o en la plataforma HeliScopeMR de Helicos Biosciences (Cambridge, Massachusetts). La característica distintiva de esta tecnología es su capacidad para secuenciar moléculas simples de ADN o ARN sin amplificación, definida como secuenciación de ADN de una sola molécula en tiempo real (SMRT). Por ejemplo, HeliScope utiliza un sistema de detección de fluorescencia de alta sensibilidad para detectar directamente cada nucleótido a medida que se sintetiza. Un enfoque similar basado en la transferencia de energía por resonancia de fluorescencia (FRET) se ha desarrollado en Visigen Biotechnology (Houston, Texas). Otras técnicas de molécula única basadas en fluorescencia son de U.S. Genomics (GeneEngineMR) y Genovoxx (AnyGeneMR).
5) Nanotecnologías para la secuenciación de una sola molécula en las que se utilizan varias nanoestructuras que se disponen, por ejemplo en un chip para monitorear el movimiento de una molécula de polimerasa en una sola cadena durante la replicación. Ejemplos no limitativos de enfoques basados en nanotecnologías son la plataforma GridONMR de Oxford Nanopore Technologies (Oxford, Reino Unido), las plataformas de secuenciación de nanoporos asistida por hibridación (HANSMR) desarrolladas por Nabsys (Providence, Rhode Island), y la plataforma patentada de secuenciación de ADN basada en ligasa con tecnología de nanoesferas de ADN (DNB) denominada ligadura combinatoria de sonda-anclaje (cPALMR).
6) Tecnologías basadas en microscopía electrónica para secuenciación de una sola molécula, por ejemplo las desarrolladas por LightSpeed Genomics (Sunnyvale, California) y Halcyon Molecular (Redwood City, California). 7) Secuenciación de semiconductores de iones que se basa en la detección de iones de hidrógeno que se liberan durante la polimerización del ADN. Por ejemplo, Ion Torrent Systems (San Francisco, California) utiliza una matriz de pozos micromecanizados de alta densidad para realizar este proceso bioquímico de forma masivamente paralela. Cada pocillo contiene una plantilla de ADN diferente. Debajo de los pozos hay una capa sensible a los iones y debajo de ella un sensor de iones patentado.
Preferiblemente, las preparaciones de ADN y ARN sirven como material de partida para NGS. Dichos ácidos nucleicos se pueden obtener fácilmente a partir de muestras tales como material biológico, por ejemplo, de tejidos tumorales incrustados en parafina (FFPE) recién congelados o fijados en formalina o de células recién aisladas o de CTC que están presentes en la sangre periférica de los pacientes. El ADN o ARN genómico normal no mutado se puede extraer de tejido somático normal, sin embargo, se prefieren las células de la línea germinal en el contexto de la presente enseñanza. El ADN o ARN de la línea germinal se puede extraer de las células mononucleares de sangre periférica (PBMC) en pacientes con neoplasias malignas no hematológicas. Aunque los ácidos nucleicos extraídos de tejidos FFPE o células individuales recién aisladas están muy fragmentados, son adecuados para aplicaciones de NGS.
En la bibliografía se describen varios métodos de NGS dirigidos para la secuenciación del exoma (para una revisión, véase, por ejemplo, Teer y Mullikin 2010: Human Mol Genet 19 (2), R145-51), todos los cuales pueden usarse junto con la presente enseñanza. Muchos de estos métodos (descritos, por ejemplo, como captura del genoma, partición del genoma, enriquecimiento del genoma, etc.) utilizan técnicas de hibridación e incluyen enfoques de hibridación basados en matrices (por ejemplo, Hodges et al. 2007: Nat. Genet. 39, 1522-1527) y basados en líquidos (por ejemplo, Choi et al., 2009: Proc. Natl. Acad. Sci USA 106, 19096-19101). También se encuentran disponibles kits comerciales para la preparación de muestras de ADN y la posterior captura del exoma: por ejemplo, Illumina Inc. (San Diego, California) ofrece el kit de preparación de muestras de ADN TruSeqMR y el kit de enriquecimiento del exoma TruSeqMR.
Con el fin de reducir el número de hallazgos falsos positivos en la detección de mutaciones somáticas específicas de cáncer o diferencias de secuencia cuando se comparan, por ejemplo, la secuencia de una muestra de tumor con la secuencia de una muestra de referencia, tal como la secuencia de una muestra de línea germinal, se prefiere determinar la secuencia en réplicas de uno o ambos tipos de muestras. Por lo tanto, se prefiere que la secuencia de una muestra de referencia, tal como la secuencia de una muestra de la línea germinal, se determine dos veces, tres veces o más. Alternativa o adicionalmente, la secuencia de una muestra de tumor se determina dos veces, tres veces o más. También puede ser posible determinar la secuencia de una muestra de referencia, tal como la secuencia de una muestra de línea germinal y/o la secuencia de una muestra de tumor más de una vez, determinando al menos una vez la secuencia en el ADN genómico y determinando al menos una vez la secuencia en ARN de dicha muestra de referencia y/o de dicha muestra tumoral. Por ejemplo, al determinar las variaciones entre réplicas de una muestra de referencia, tal como una muestra de línea germinal, se puede estimar la tasa esperada de mutaciones somáticas de falso positivo (FDR) como una cantidad estadística. Las repeticiones técnicas de una muestra deben generar resultados idénticos y cualquier mutación detectada en esta "comparación igual frente a la misma" es un falso positivo. En particular, para determinar la tasa de descubrimiento falso para la detección de mutaciones somáticas en una muestra de tumor en relación con una muestra de referencia, se puede usar una repetición técnica de la muestra de referencia como referencia para estimar el número de falsos positivos. Además, varias métricas relacionadas con la calidad (por ejemplo, cobertura o calidad de SNP) se pueden combinar en una sola puntuación de calidad utilizando un enfoque de aprendizaje automático. Para una variación somática dada, se pueden contar todas las demás
variaciones con un puntaje de calidad superior, lo que permite una clasificación de todas las variaciones en un conjunto de datos.
En el contexto de la presente enseñanza, el término "ARN" se refiere a una molécula que comprende al menos un residuo de ribonucleótido y que preferiblemente está compuesta total o sustancialmente por residuos de ribonucleótido. "Ribonucleótido" se refiere a un nucleótido con un grupo hidroxilo en la posición 2' de un grupo p-D-ribofuranosilo. El término "ARN" comprende ARN bicatenario, ARN monocatenario, ARN aislado, tal como ARN parcial o completamente purificado, ARN esencialmente puro, ARN sintético y ARN generado de forma recombinante, tal como ARN modificado que se diferencia del ARN natural por adición, eliminación, sustitución y/o alteración de uno o más nucleótidos. Tales alteraciones pueden incluir la adición de material no nucleotídico, tal como en el extremo o extremos de un ARN o internamente, por ejemplo en uno o más nucleótidos del ARN. Los nucleótidos en las moléculas de ARN también pueden comprender nucleótidos no estándar, tales como nucleótidos de origen no natural o nucleótidos o desoxinucleótidos sintetizados químicamente. Estos ARN alterados pueden denominarse análogos o análogos de ARN de origen natural.
De acuerdo con la presente enseñanza, el término "ARN" incluye y preferiblemente se refiere a "ARNm". El término "ARNm" significa "ARN mensajero" y se refiere a un "transcripto" que se genera usando una plantilla de ADN y codifica un péptido o polipéptido. Normalmente, un ARNm comprende una 5'-UTR, una región codificante de proteína y una 3'-Ut R. El ARNm solo posee una vida media limitada en las células e in vitro. En el contexto de la presente enseñanza, el ARNm puede generarse mediante transcripción in vitro a partir de una plantilla de ADN. El experto en la materia conoce la metodología de transcripción in vitro. Por ejemplo, existe una variedad de kits de transcripción in vitro disponibles comercialmente.
De acuerdo con la enseñanza, la estabilidad y la eficacia de traducción del ARN pueden modificarse según se requiera. Por ejemplo, el ARN puede estabilizarse y su traducción aumentada mediante una o más modificaciones que tienen efectos estabilizadores y/o un aumento de la eficiencia de traducción del ARN. Tales modificaciones se describen, por ejemplo, en el documento PCT/EP2006/009448. Para aumentar la expresión del ARN utilizado de acuerdo con la presente enseñanza, se puede modificar dentro de la región codificante, es decir, la secuencia que codifica el péptido o proteína expresados, preferiblemente sin alterar la secuencia del péptido o proteína expresados, para aumentar el contenido de GC para aumentar la estabilidad del ARNm y realizar una optimización de codones y, por lo tanto, mejorar la traducción en las células.
El término "modificación" en el contexto del ARN usado en la presente enseñanza incluye cualquier modificación de un ARN que no está presente de forma natural en dicho ARN.
En una realización de la enseñanza, el ARN utilizado de acuerdo con la enseñanza no tiene 5'-trifosfatos desprotegidos. La eliminación de dichos 5'-trifosfatos desprotegidos se puede lograr tratando el ARN con una fosfatasa.
El ARN de acuerdo con la enseñanza puede tener ribonucleótidos modificados para aumentar su estabilidad y/o disminuir la citotoxicidad. Por ejemplo, en una realización, en el ARN usado de acuerdo con la enseñanza, la 5-metilcitidina se sustituye parcial o completamente, preferiblemente completamente, por citidina. Alternativa o adicionalmente, en una realización, en el ARN usado de acuerdo con la enseñanza, la pseudouridina se sustituye parcial o completamente, preferiblemente completamente, por uridina.
En una realización, el término "modificación" se refiere a proporcionar un ARN con una protección de 5' o análogo de protección de 5'. El término "protección de 5'" se refiere a una estructura de protección que se encuentra en el extremo 5' de una molécula de ARNm y generalmente consiste en un nucleótido de guanosina conectado al ARNm a través de un enlace inusual de 5' a 5' trifosfato. En una realización, esta guanosina está metilada en la posición 7. El término "protección convencional de 5'" se refiere a una protección 5' de ARN natural, preferiblemente a la protección de 7-metilguanosina (m7G). En el contexto de la presente enseñanza, el término "protección de 5'" incluye un análogo de protección de 5' que se asemeja a la estructura de protección del ARN y se modifica para poseer la capacidad de estabilizar el ARN y/o mejorar la traducción del ARN si está unido al mismo, preferiblemente in vivo y/o en una célula.
Proporcionar un ARN con una protección de 5' o un análogo de protección de 5' se puede lograr mediante la transcripción in vitro de una plantilla de ADN en presencia de dicha protección de 5 'o análogo de protección de 5', en la que dicha protección de 5' se incorpora co-transcripcionalmente en la cadena de ARN generada, o el ARN puede generarse, por ejemplo, mediante transcripción in vitro, y la protección de 5' puede unirse al ARN posttranscripcionalmente usando enzimas de protección, por ejemplo, enzimas de protección del virus vaccinia.
El ARN puede comprender modificaciones adicionales. Por ejemplo, una modificación adicional del ARN usado en la presente enseñanza puede ser una extensión o truncamiento de la cola poli(A) de origen natural o una alteración de las regiones 5' o 3' no traducidas (UTR) como la introducción de una UTR que no está relacionada con la región codificante de dicho ARN, por ejemplo, el intercambio de la 3'-UTR existente con o la inserción de una o más, preferiblemente dos copias de una 3'-UTR derivada de un gen de globina, tales como alfa2-globina, alfal-globina, beta-globina, preferiblemente beta-globina, más preferiblemente beta-globina humana.
El ARN que tiene una secuencia poli-A sin enmascarar se traduce de manera más eficaz que el ARN que tiene una secuencia poli-A enmascarada. El término "cola de poli(A)" o "secuencia poli(A)" se refiere a una secuencia de residuos de adenilo (A) que normalmente se encuentra en el extremo 3' de una molécula de ARN y "secuencia de poli-A desenmascarada" significa que la secuencia de poli-A en el extremo 3' de una molécula de ARN termina con una A de la secuencia poli-A y no es seguida por nucleótidos distintos de A ubicado en el extremo 3', es decir, secuencia abajo, de la secuencia poli-A. Además, una secuencia poli-A larga de aproximadamente 120 pares de bases da como resultado una estabilidad de transcripción y una eficiencia de traducción óptimas del ARN.
Por lo tanto, para aumentar la estabilidad y/o la expresión del ARN usado de acuerdo con la presente enseñanza, se puede modificar para que esté presente junto con una secuencia de poli-A, preferiblemente con una longitud de 10 a 500, más preferiblemente de 30 a 300, incluso más preferiblemente de 65 a 200 y especialmente de 100 a 150 residuos de adenosina. En una realización especialmente preferida, la secuencia de poli-A tiene una longitud de aproximadamente 120 residuos de adenosina. Para aumentar aún más la estabilidad y/o la expresión del ARN usado de acuerdo con la enseñanza, se puede desenmascarar la secuencia de poli-A.
Además, la incorporación de una región no traducida 3' (UTR) en la región no traducida 3' de una molécula de ARN puede dar como resultado una mejora en la eficacia de la traducción. Puede conseguirse un efecto sinérgico incorporando dos o más de dichas regiones 3' no traducidas. Las regiones 3' no traducidas pueden ser autólogas o heterólogas al ARN en el que se introducen. En una realización particular, la región 3' no traducida se deriva del gen de la p-globina humana.
Una combinación de las modificaciones descritas anteriormente, es decir, la incorporación de una secuencia de poli-A, el desenmascaramiento de una secuencia de poli-A y la incorporación de una o más regiones 3' no traducidas, tiene una influencia sinérgica sobre la estabilidad del ARN y aumento de la eficiencia de la traducción.
El término "estabilidad" del ARN se refiere a la "vida media" del ARN. La "vida media" se refiere al período de tiempo que se necesita para eliminar la mitad de la actividad, cantidad o número de moléculas. En el contexto de la presente enseñanza, la vida media de un ARN es indicativa de la estabilidad de dicho ARN. La vida media del ARN puede influir en la "duración de la expresión" del ARN. Se puede esperar que el ARN que tiene una vida media larga se exprese durante un período de tiempo prolongado.
Por supuesto, si de acuerdo con la presente enseñanza se desea disminuir la estabilidad y/o la eficiencia de traducción del a Rn , es posible modificar el ARN para interferir con la función de los elementos descritos anteriormente aumentando la estabilidad y/o eficiencia de traducción del ARN.
El término "expresión" se usa de acuerdo con la enseñanza en su significado más general y comprende la producción de ARN y/o péptidos, polipéptidos o proteínas, por ejemplo, por transcripción y/o traducción. Con respecto al ARN, el término "expresión" o "traducción" se refiere en particular a la producción de péptidos, polipéptidos o proteínas. También comprende la expresión parcial de ácidos nucleicos. Además, la expresión puede ser transitoria o estable.
De acuerdo con la enseñanza, el término expresión también incluye una "expresión aberrante" o "expresión anormal". "Expresión aberrante" o "expresión anormal" significa de acuerdo con la enseñanza que la expresión se altera, preferiblemente aumenta, en comparación con una referencia, por ejemplo, un estado en un sujeto que no tiene una enfermedad asociada con la expresión aberrante o anormal de una determinada proteína, por ejemplo, un antígeno tumoral. Un aumento de expresión se refiere a un aumento de al menos un 10%, en particular al menos un 20%, al menos un 50% o al menos un 100% o más. En una realización, la expresión solo se encuentra en un tejido enfermo, mientras que la expresión en un tejido sano está reprimida.
El término "expresado específicamente" significa que una proteína se expresa esencialmente solo en un tejido u órgano específico. Por ejemplo, un antígeno tumoral expresado específicamente en la mucosa gástrica significa que dicha proteína se expresa principalmente en la mucosa gástrica y no se expresa en otros tejidos o no se expresa en un grado significativo en otros tipos de tejidos u órganos. Así, una proteína que se expresa exclusivamente en células de la mucosa gástrica y en un grado significativamente menor en cualquier otro tejido, tal como los testículos, se expresa específicamente en células de la mucosa gástrica. En algunas realizaciones, un antígeno tumoral también puede expresarse específicamente en condiciones normales en más de un tipo de tejido u órgano, tal como en 2 o 3 tipos de tejidos u órganos, pero preferiblemente en no más de 3 tipos de tejidos u órganos diferentes. En este caso, el antígeno tumoral se expresa específicamente en estos órganos. Por ejemplo, si un antígeno tumoral se expresa en condiciones normales preferiblemente en una extensión aproximadamente igual en pulmón y estómago, dicho antígeno tumoral se expresa específicamente en pulmón y estómago.
En el contexto de la presente enseñanza, el término "transcripción" se refiere a un proceso, en el que el código genético en una secuencia de ADN se transcribe en ARN. Posteriormente, el ARN puede traducirse en proteína. De acuerdo con la presente enseñanza, el término "transcripción" comprende "transcripción in vitro", en el que el término "transcripción in vitro" se refiere a un proceso en el que el ARN, en particular el ARNm, se sintetiza in vitro en un sistema libre de células, preferiblemente usando extractos celulares apropiados. Preferiblemente, los vectores de clonación se aplican para la generación de transcripciones. Estos vectores de clonación se designan generalmente
como vectores de transcripción y, de acuerdo con la presente enseñanza, están abarcados por el término "vector". De acuerdo con la presente enseñanza, el ARN usado en la presente enseñanza es preferiblemente ARN transcrito in vitro (ARN-IVT) y puede obtenerse mediante transcripción in vitro de una plantilla de ADN apropiada. El promotor para controlar la transcripción puede ser cualquier promotor de cualquier ARN polimerasa. Ejemplos particulares de ARN polimerasas son las ARN polimerasas T7, T3 y SP6. Preferiblemente, la transcripción in vitro de acuerdo con la enseñanza está controlada por un promotor T7 o SP6. Puede obtenerse una plantilla de ADN para la transcripción in vitro clonando un ácido nucleico, en particular ADNc, e introduciéndolo en un vector apropiado para la transcripción in vitro. El ADNc puede obtenerse mediante transcripción inversa de ARN.
El término "traducción" de acuerdo con la enseñanza se refiere al proceso en los ribosomas de una célula mediante el cual una cadena de ARN mensajero dirige el ensamblaje de una secuencia de aminoácidos para producir un péptido, polipéptido o proteína.
Las secuencias de control de la expresión o secuencias reguladoras, que de acuerdo con la enseñanza pueden estar unidas funcionalmente con un ácido nucleico, pueden ser homólogas o heterólogas con respecto al ácido nucleico. Una secuencia codificante y una secuencia reguladora están unidas "funcionalmente" si están unidas covalentemente, de modo que la transcripción o traducción de la secuencia codificante está bajo el control o bajo la influencia de la secuencia reguladora. Si la secuencia codificante se va a traducir en una proteína funcional, con un enlace funcional de una secuencia reguladora con la secuencia codificante, la inducción de la secuencia reguladora conduce a una transcripción de la secuencia codificante, sin provocar un cambio del marco de lectura en la secuencia codificante o incapacidad de la secuencia codificante para traducirse en la proteína o péptido deseado.
El término "secuencia de control de la expresión" o "secuencia reguladora" comprende, de acuerdo con la enseñanza, promotores, secuencias de unión a ribosomas y otros elementos de control, que controlan la transcripción de un ácido nucleico o la traducción del ARN derivado. En determinadas formas de realización de la enseñanza, se pueden controlar las secuencias reguladoras. La estructura precisa de las secuencias reguladoras puede variar dependiendo de la especie o dependiendo del tipo de célula, pero generalmente comprende secuencias 5' no transcritas y 5' y 3' no traducidas, que están involucradas en el inicio de la transcripción o traducción, tales como la Caja TATA, la secuencia de protección, secuencia CAAT y similares. En particular, las secuencias reguladoras no transcritas 5' comprenden una región promotora que incluye una secuencia promotora para el control transcripcional del gen unido funcionalmente. Las secuencias reguladoras también pueden comprender secuencias potenciadoras o secuencias activadoras cadena arriba.
Preferiblemente, de acuerdo con la enseñanza, el ARN que se va a expresar en una célula se introduce en dicha célula. En una realización de los métodos de acuerdo con la enseñanza, el ARN que se va a introducir en una célula se obtiene mediante la transcripción in vitro de una plantilla de ADN apropiada.
De acuerdo con la enseñanza, términos tales como "ARN capaz de expresarse" y "ARN que codifica" se usan indistintamente en este documento y con respecto a un péptido o polipéptido particular significa que el ARN, si está presente en el entorno apropiado, preferiblemente dentro de una célula, puede expresarse para producir dicho péptido o polipéptido. Preferiblemente, el ARN de acuerdo con la enseñanza puede interactuar con la maquinaria de traducción celular para proporcionar el péptido o polipéptido que es capaz de expresar.
Los términos tales como "transferir", "introducir" o "transfectar" se usan indistintamente en el presente documento y se refieren a la introducción de ácidos nucleicos, en particular ácidos nucleicos exógenos o heterólogos, en particular ARN en una célula. De acuerdo con la presente enseñanza, la célula puede formar parte de un órgano, un tejido y/o un organismo. De acuerdo con la presente enseñanza, la administración de un ácido nucleico se logra como ácido nucleico desnudo o en combinación con un reactivo de administración. Preferiblemente, la administración de ácidos nucleicos se realiza en forma de ácidos nucleicos desnudos. Preferiblemente, el ARN se administra en combinación con sustancias estabilizantes tales como inhibidores de RNasa. La presente enseñanza también prevé la introducción repetida de ácidos nucleicos en las células para permitir una expresión sostenida durante períodos de tiempo prolongados.
Las células se pueden transfectar con cualquier portador con el que se pueda asociar ARN, por ejemplo, formando complejos con el ARN o formando vesículas en las que el ARN está encerrado o encapsulado, lo que da como resultado una mayor estabilidad del ARN en comparación con el ARN desnudo. Los vehículos útiles de acuerdo con la enseñanza incluyen, por ejemplo, vehículos que contienen lípidos tales como lípidos catiónicos, liposomas, en particular liposomas catiónicos y micelas y nanopartículas. Los lípidos catiónicos pueden formar complejos con ácidos nucleicos cargados negativamente. Se puede usar cualquier lípido catiónico de acuerdo con la enseñanza.
Preferiblemente, la introducción de ARN que codifica un péptido o polipéptido en una célula, en particular en una célula presente in vivo, da como resultado la expresión de dicho péptido o polipéptido en la célula. En realizaciones particulares, se prefiere el direccionamiento de los ácidos nucleicos a células particulares. En tales realizaciones, un portador que se aplica para la administración del ácido nucleico a una célula (por ejemplo, un retrovirus o un liposoma) exhibe una molécula de direccionamiento. Por ejemplo, una molécula tal como un anticuerpo que es específico para una proteína de membrana de superficie en la célula diana o un ligando para un receptor en la célula diana puede
incorporarse al portador de ácido nucleico o puede unirse al mismo. En caso de que el ácido nucleico se administre mediante liposomas, las proteínas que se unen a una proteína de la membrana de la superficie que está asociada con la endocitosis pueden incorporarse en la formulación de liposomas para permitir el direccionamiento y/o la absorción. Dichas proteínas abarcan proteínas de la cápside de fragmentos de las mismas que son específicas para un tipo celular particular, anticuerpos contra proteínas que están internalizadas, proteínas que se dirigen a una ubicación intracelular, etc.
El término "célula" o "célula huésped" es preferiblemente una célula intacta, es decir, una célula con una membrana intacta que no ha liberado sus componentes intracelulares normales tales como enzimas, orgánulos o material genético. Una célula intacta es preferiblemente una célula viable, es decir, una célula viva capaz de llevar a cabo sus funciones metabólicas normales. Preferiblemente, dicho término se refiere de acuerdo con la enseñanza a cualquier célula que pueda transformarse o transfectarse con un ácido nucleico exógeno. El término "célula" incluye, de acuerdo con la enseñanza, células procariotas (por ejemplo, E. coli) o células eucariotas (por ejemplo, células dendríticas, células B, células CHO, células COS, células K562, células HEK293, células HELA, células de levadura y células de insectos). El ácido nucleico exógeno se puede encontrar dentro de la célula (i) libremente disperso como tal, (ii) incorporado en un vector recombinante, o (iii) integrado en el genoma de la célula huésped o a Dn mitocondrial. Se prefieren particularmente las células de mamíferos, tales como células de humanos, ratones, hámsteres, cerdos, cabras y primates. Las células pueden derivar de un gran número de tipos de tejidos e incluyen células primarias y líneas celulares. Los ejemplos específicos incluyen queratinocitos, leucocitos de sangre periférica, células madre de la médula ósea y células madre embrionarias. En realizaciones adicionales, la célula es una célula presentadora de antígeno, en particular una célula dendrítica, un monocito o macrófago.
Una célula que comprende una molécula de ácido nucleico expresa preferiblemente el péptido o polipéptido codificado por el ácido nucleico.
El término "expansión clonal" se refiere a un proceso en el que se multiplica una entidad específica. En el contexto de la presente enseñanza, el término se usa preferiblemente en el contexto de una respuesta inmunológica en la que los linfocitos son estimulados por un antígeno, proliferan y se amplifica el linfocito específico que reconoce dicho antígeno. Preferiblemente, la expansión clonal conduce a la diferenciación de los linfocitos.
Los términos tales como "reducir" o "inhibir" se refieren a la capacidad de causar una disminución general, preferiblemente del 5% o más, del 10% o más, del 20% o más, más preferiblemente del 50% o más, y más preferiblemente del 75% o más, en el nivel. El término "inhibir" o frases similares incluye una inhibición completa o esencialmente completa, es decir, una reducción hasta cero o esencialmente hasta cero.
Los términos tales como "aumentar", "mejorar", "promover" o "prolongar" se refieren preferiblemente a un aumento, mejora, promoción o prolongación en aproximadamente al menos un 10%, preferiblemente al menos un 20%, preferiblemente al menos un 30%, preferiblemente al menos 40%, preferiblemente al menos 50%, preferiblemente al menos 80%, preferiblemente al menos 100%, preferiblemente al menos 200% y en particular al menos 300%. Estos términos también pueden referirse a un aumento, mejora, promoción o prolongación desde cero o un nivel no medible o no detectable hasta un nivel de más de cero o un nivel que es medible o detectable.
La presente enseñanza proporciona vacunas tales como vacunas contra el cáncer diseñadas sobre la base de modificaciones de aminoácidos o péptidos modificados que se predice que son inmunogénicos por los métodos de la presente enseñanza.
De acuerdo con la enseñanza, el término "vacuna" se refiere a una preparación farmacéutica (composición farmacéutica) o producto que tras la administración induce una respuesta inmune, en particular una respuesta inmune celular, que reconoce y ataca a un patógeno o una célula enferma tal como una célula cancerosa. Se puede usar una vacuna para la prevención o el tratamiento de una enfermedad. El término "vacuna contra el cáncer personalizada" o "vacuna contra el cáncer individualizada" se refiere a un paciente de cáncer en particular y significa que una vacuna contra el cáncer se adapta a las necesidades o circunstancias especiales de un paciente de cáncer individual.
En una realización, una vacuna proporcionada de acuerdo con la enseñanza puede comprender un péptido o polipéptido que comprende una o más modificaciones de aminoácidos o uno o más péptidos modificados que se predice que son inmunogénicos por los métodos de la enseñanza o un ácido nucleico, preferiblemente ARN, que codifica dicho péptido o polipéptido.
Las vacunas contra el cáncer proporcionadas de acuerdo con la enseñanza cuando se administran a un paciente proporcionan uno o más epítopos de células T adecuados para estimular, cebar y/o expandir células T específicas para el tumor del paciente. Las células T se dirigen preferiblemente contra las células que expresan antígenos de los que se derivan los epítopos de las células T. Por lo tanto, las vacunas descritas en el presente documento son preferiblemente capaces de inducir o promover una respuesta celular, preferiblemente actividad de células T citotóxicas, contra una enfermedad cancerosa caracterizada por la presentación de uno o más neoantígenos asociados a tumores con MHC de clase I. Dado que una vacuna proporcionada de acuerdo con la presente enseñanza se dirigirá a mutaciones específicas del cáncer, será específica para el tumor del paciente.
Una vacuna proporcionada de acuerdo con la enseñanza se refiere a una vacuna que cuando se administra a un paciente proporciona preferiblemente uno o más epítopos de células T, tales como 2 o más, 5 o más, 10 o más, 15 o más, 20 o más, 25 o más, 30 o más y preferiblemente hasta 60, hasta 55, hasta 50, hasta 45, hasta 40, hasta 35 o hasta 30 epítopos de células T, incorporando modificaciones de aminoácidos o péptidos modificados predichos como inmunogénicos por los métodos de la enseñanza. Dichos epítopos de células T también se denominan "neoepítopos" en el presente documento. La presentación de estos epítopos por las células de un paciente, en particular las células presentadoras de antígenos, preferiblemente da como resultado células T dirigidas a los epítopos cuando se unen al MHC y, por lo tanto, al tumor del paciente, preferiblemente al tumor primario, así como a las metástasis tumorales, que expresan antígenos a partir de los cuales los epítopos de células T se derivan y presentan los mismos epítopos en la superficie de las células tumorales.
Los métodos de la enseñanza pueden comprender la etapa adicional de determinar la utilidad de las modificaciones de aminoácidos identificadas o péptidos modificados para la vacunación contra el cáncer. Por lo tanto, las etapas adicionales pueden involucrar uno o más de las siguientes: (i) evaluar si las modificaciones están ubicadas en epítopos presentados por MHC conocidos o predichos, (ii) pruebas in vitro y/o in silico si las modificaciones están ubicadas en epítopos presentados por MHC, por ejemplo, probar si las modificaciones son parte de secuencias de péptidos que se procesan y/o presentan como epítopos presentados por MHC, y (iii) probar in vitro si los epítopos modificados previstos, en particular cuando están presentes en su contexto de secuencia natural, por ejemplo, cuando están flanqueadas por secuencias de aminoácidos que también flanquean dichos epítopos en la proteína de origen natural, y cuando se expresan en células presentadoras de antígenos son capaces de estimular células T tales como células T del paciente que tienen la especificidad deseada. Cada una de estas secuencias flanqueantes puede comprender 3 o más, 5 o más, 10 o más, 15 o más, 20 o más y preferiblemente hasta 50, hasta 45, hasta 40, hasta 35 o hasta 30 aminoácidos y pueden flanquear la secuencia del epítopo de terminal N y/o el terminal C.
Los péptidos modificados determinados de acuerdo con la enseñanza pueden clasificarse por su utilidad como epítopos para la vacunación contra el cáncer. Por lo tanto, en un aspecto, el método de la enseñanza comprende un proceso analítico manual o informático en el que los péptidos modificados identificados se analizan y seleccionan por su utilidad en la vacuna respectiva que se va a proporcionar. En una realización preferida, dicho proceso analítico es un proceso basado en algoritmos computacionales. Preferiblemente, dicho proceso analítico comprende determinar y/o clasificar epítopos de acuerdo con una predicción de su capacidad de ser inmunogénicos.
Los neoepítopos identificados de acuerdo con la enseñanza y proporcionados por una vacuna de la enseñanza están presentes preferiblemente en forma de un polipéptido que comprende dichos neoepítopos tales como un polipéptido poliepitópico o un ácido nucleico, en particular ARN, que codifica dicho polipéptido. Además, los neoepítopos pueden estar presentes en el polipéptido en forma de una secuencia de vacuna, es decir, presentes en su contexto de secuencia natural por ejemplo, flanqueados por secuencias de aminoácidos que también flanquean dichos epítopos en la proteína de origen natural. Cada una de estas secuencias flanqueantes puede comprender 5 o más, 10 o más, 15 o más, 20 o más y preferiblemente hasta 50, hasta 45, hasta 40, hasta 35 o hasta 30 aminoácidos y pueden flanquear la secuencia del epítopo del terminal N y/o terminal C. Por lo tanto, una secuencia de vacuna puede comprender 20 o más, 25 o más, 30 o más, 35 o más, 40 o más y preferiblemente hasta 50, hasta 45, hasta 40, hasta 35 o hasta 30 aminoácidos. En una realización, los neoepítopos y/o las secuencias de la vacuna se alinean en el polipéptido de cabeza a cola.
En una realización, los neoepítopos y/o secuencias de vacuna están espaciados por enlazadores, en particular enlazadores neutros. El término "enlazador" de acuerdo con la enseñanza se refiere a un péptido añadido entre dos dominios peptídicos, tales como epítopos o secuencias de vacunas, para conectar dichos dominios peptídicos. No existe una limitación particular con respecto a la secuencia del enlazador. Sin embargo, se prefiere que la secuencia enlazadora reduzca el impedimento estérico entre los dos dominios peptídicos, esté bien traducida y soporte o permita el procesamiento de los epítopos. Además, el enlazador debe tener pocos elementos de secuencia inmunogénica o ninguno. Los enlazadores preferiblemente no deberían crear neoepítopos no endógenos como los generados a partir de la sutura de unión entre neoepítopos adyacentes, que podrían generar reacciones inmunes no deseadas. Por lo tanto, la vacuna poliepitópica debería contener preferiblemente secuencias enlazadoras que sean capaces de reducir el número de epítopos de unión al MHC no deseados. Hoyt et al., (EMBO J. 25 (8), 1720-9, 2006) y Zhang et al. (J. Biol. Chem., 279 (10), 8635-41, 2004) han demostrado que las secuencias ricas en glicina perjudican el procesamiento proteasómico y, por lo tanto, el uso de secuencias enlazadoras ricas en glicina actúa para minimizar el número de péptidos que contienen enlazador que pueden ser procesados por el proteasoma. Además, se observó que la glicina inhibía una fuerte unión en las posiciones de los surcos de unión del MHC (Abastado et al., J. Immunol. 151 (7), 3569 75, 1993). Schlessinger et al., (Proteins, 61 (1), 115-26, 2005) habían descubierto que los aminoácidos glicina y serina incluidos en una secuencia de aminoácidos dan como resultado una proteína más flexible que es más eficientemente traducida y procesada por el proteasoma, lo que permite un mejor acceso a la neoepítopos codificados. Cada enlazador puede comprender 3 o más, 6 o más, 9 o más, 10 o más, 15 o más, 20 o más y preferiblemente hasta 50, hasta 45, hasta 40, hasta 35 o hasta 30 amino ácidos. Preferiblemente, el enlazador está enriquecido en aminoácidos glicina y/o serina. Preferiblemente, al menos el 50%, al menos el 60%, al menos el 70%, al menos el 80%, al menos el 90% o al menos el 95% de los aminoácidos del enlazador son glicina y/o serina. En una realización preferida, un enlazador está compuesto sustancialmente por los aminoácidos glicina y serina. En una realización, el enlazador comprende la secuencia de aminoácidos (GGS)a(GSS)b(GGG)c(SSG)d(GSG)e en la que a, b, c, d y e es
independientemente un número seleccionado entre 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 o 20 y en la que a b c d e son diferentes de 0 y preferiblemente son 2 o más, 3 o más, 4 o más o 5 o más. En una realización, el enlazador comprende una secuencia como se describe en el presente documento que incluye las secuencias del enlazador descritas en los ejemplos tales como la secuencia GGSGGGGSG.
En una realización particularmente preferida, un polipéptido que incorpora uno o más neoepítopos tales como un polipéptido poliepitópico de acuerdo con la presente enseñanza se administra a un paciente en forma de ácido nucleico, preferiblemente ARN tal como ARN in vitro transcrito o sintético, que puede expresarse en células de un paciente, tal como células presentadoras de antígenos, para producir el polipéptido. La presente enseñanza también prevé la administración de uno o más polipéptidos multiepitópicos que para el propósito de la presente enseñanza están comprendidos por el término "polipéptido poliepitópico", preferiblemente en forma de un ácido nucleico, preferiblemente ARN tal como ARN in vitro transcrito o sintético, que puede expresarse en células de un paciente, tales como células presentadoras de antígenos, para producir uno o más polipéptidos. En el caso de una administración de más de un polipéptido multiepitópico, los neoepítopos proporcionados por los diferentes polipéptidos multiepitópicos pueden ser diferentes o superponerse parcialmente. Una vez presente en las células de un paciente, tal como las células presentadoras de antígenos, el polipéptido de acuerdo con la enseñanza se procesa para producir los neoepítopos identificados de acuerdo con la enseñanza. La administración de una vacuna proporcionada de acuerdo con la enseñanza puede proporcionar epítopos presentados por el MHC de clase II que son capaces de provocar una respuesta de células T colaboradoras CD4+ contra células que expresan antígenos de los que se derivan los epítopos presentados por el MHC. Alternativa o adicionalmente, la administración de una vacuna proporcionada de acuerdo con la enseñanza puede proporcionar epítopos presentados por MHC de clase I que son capaces de provocar una respuesta de células T CD8+ contra células que expresan antígenos de los que se derivan los epítopos presentados por el MHC. Además, la administración de una vacuna proporcionada de acuerdo con la enseñanza puede proporcionar uno o más neoepítopos (incluidos neoepítopos y neoepítopos conocidos identificados de acuerdo con la enseñanza) así como uno o más epítopos que no contienen mutaciones somáticas específicas del cáncer pero que son expresados por células cancerosas y preferiblemente induciendo una respuesta inmune contra las células cancerosas, preferiblemente una respuesta inmune específica del cáncer. En una realización, la administración de una vacuna proporcionada de acuerdo con la enseñanza proporciona neoepítopos que son epítopos presentados por el MHC de clase II y/o son capaces de provocar una respuesta de células T colaboradoras c D4+ contra células que expresan antígenos de los que se derivan los epítopos presentados por el MHC así como epítopos que no contienen mutaciones somáticas específicas de cáncer que son epítopos presentados por el MHC de clase I y/o son capaces de provocar una respuesta de células T CD8+ contra células que expresan antígenos de los que se derivan los epítopos presentados por el MHC. En una realización, los epítopos que no contienen mutaciones somáticas específicas de cáncer se derivan de un antígeno tumoral. En una realización, los neoepítopos y epítopos que no contienen mutaciones somáticas específicas del cáncer tienen un efecto sinérgico en el tratamiento del cáncer. Preferiblemente, una vacuna proporcionada de acuerdo con la enseñanza es útil para la estimulación poliepitópica de respuestas de células T citotóxicas y/o colaboradoras.
La vacuna proporcionada de acuerdo con la enseñanza puede ser una vacuna recombinante.
El término "recombinante" en el contexto de la presente enseñanza significa "fabricado mediante ingeniería genética". Preferiblemente, una "entidad recombinante" tal como un polipéptido recombinante en el contexto de la presente enseñanza no se produce de forma natural, y preferiblemente es el resultado de una combinación de entidades tales como secuencias de aminoácidos o ácidos nucleicos que no se combinan en la naturaleza. Por ejemplo, un polipéptido recombinante en el contexto de la presente enseñanza puede contener varias secuencias de aminoácidos tales como neoepítopos o secuencias de vacuna derivadas de diferentes proteínas o diferentes porciones de la misma proteína fusionadas juntas, por ejemplo, mediante enlaces peptídicos o enlazadores apropiados.
El término "de origen natural", como se usa en este documento, se refiere al hecho de que un objeto se puede encontrar en la naturaleza. Por ejemplo, un péptido o ácido nucleico que está presente en un organismo (incluidos los virus) y que puede aislarse de una fuente en la naturaleza y que no ha sido modificado intencionalmente por el hombre en el laboratorio es de origen natural.
Los agentes, composiciones y métodos descritos en el presente documento se pueden usar para tratar a un sujeto con una enfermedad, por ejemplo, una enfermedad caracterizada por la presencia de células enfermas que expresan un antígeno y presentan un fragmento del mismo. Las enfermedades particularmente preferidas son las enfermedades cancerosas. Los agentes, composiciones y métodos descritos en este documento también pueden usarse para inmunización o vacunación para prevenir una enfermedad descrita en este documento.
De acuerdo con la enseñanza, el término "enfermedad" se refiere a cualquier estado patológico, incluidas las enfermedades cancerosas, en particular las formas de enfermedades cancerosas descritas en el presente documento.
El término "normal" se refiere al estado sano o las condiciones en un sujeto o tejido sano, es decir, condiciones no patológicas, en las que "saludable" significa preferiblemente no canceroso.
"Enfermedad que implica células que expresan un antígeno" significa de acuerdo con la enseñanza que se detecta la expresión del antígeno en células de un tejido u órgano enfermo. La expresión en las células de un tejido u órgano enfermo puede aumentar en comparación con el estado en un tejido u órgano sano. Un aumento se refiere a un aumento de al menos un 10%, en particular al menos un 20%, al menos un 50%, al menos un 100%, al menos un 200%, al menos un 500%, al menos un 1.000%, al menos un 10.000% o incluso más. En una realización, la expresión solo se encuentra en un tejido enfermo, mientras que la expresión en un tejido sano está reprimida. De acuerdo con la enseñanza, las enfermedades que involucran o están asociadas con células que expresan un antígeno incluyen enfermedades cancerosas.
De acuerdo con la enseñanza, el término "tumor" o "enfermedad tumoral" se refiere a un crecimiento anormal de células (llamadas células neoplásicas, células tumorigénicas o células tumorales) que preferiblemente forman una hinchazón o una lesión. Por "célula tumoral" se entiende una célula anormal que crece mediante una proliferación celular rápida y descontrolada y continúa creciendo después de que cesan los estímulos que iniciaron el nuevo crecimiento. Los tumores muestran una falta parcial o total de organización estructural y coordinación funcional con el tejido normal y, por lo general, forman una masa distinta de tejido, que puede ser benigno, premaligno o maligno.
El cáncer (término médico: neoplasia maligna) es una clase de enfermedades en las que un grupo de células muestra un crecimiento descontrolado (división más allá de los límites normales), invasión (intrusión y destrucción de tejidos adyacentes) y, a veces, metástasis (diseminación a otras ubicaciones del cuerpo a través de la linfa o la sangre). Estas tres propiedades malignas de los cánceres los diferencian de los tumores benignos, que son autolimitados y no invaden ni hacen metástasis. La mayoría de los cánceres forman un tumor, pero algunos, como la leucemia, no lo hacen. Malignidad, neoplasia maligna y tumor maligno son esencialmente sinónimos de cáncer.
La neoplasia es una masa anormal de tejido como resultado de una neoplasia. La neoplasia (nuevo crecimiento en griego) es la proliferación anormal de células. El crecimiento de las células excede y no está coordinado con el de los tejidos normales que lo rodean. El crecimiento persiste de la misma manera excesiva incluso después de la cesación de los estímulos. Por lo general, causa un bulto o un tumor. Las neoplasias pueden ser benignas, premalignas o malignas.
El "crecimiento de un tumor" o " crecimiento tumoral" de acuerdo con la enseñanza se refiere a la tendencia de un tumor a aumentar su tamaño y/o a la tendencia de las células tumorales a proliferar.
Para los propósitos de la presente enseñanza, los términos "cáncer" y "enfermedad cancerosa" se usan de manera intercambiable con los términos "tumor" y "enfermedad tumoral".
Los cánceres se clasifican por el tipo de célula que se asemeja al tumor y, por lo tanto, el tejido que se presume es el origen del tumor. Estos son la histología y la ubicación, respectivamente.
El término "cáncer" de acuerdo con la enseñanza comprende carcinomas, adenocarcinomas, blastomas, leucemias, seminomas, melanomas, teratomas, linfomas, neuroblastomas, gliomas, cáncer de recto, cáncer de endometrio, cáncer de riñón, cáncer suprarrenal, cáncer de tiroides, cáncer de sangre, cáncer de piel, cáncer de cerebro, cáncer de cuello uterino, cáncer intestinal, cáncer de hígado, cáncer de colon, cáncer de estómago, cáncer de intestino, cáncer de cabeza y cuello, cáncer gastrointestinal, cáncer de ganglio linfático, cáncer de esófago, cáncer colorrectal, cáncer de páncreas, cáncer de oído, nariz y garganta (ENT), cáncer de mama, cáncer de próstata, cáncer de útero, cáncer de ovario y cáncer de pulmón y sus metástasis. Ejemplos de los mismos son carcinomas de pulmón, carcinomas de mama, carcinomas de próstata, carcinomas de colon, carcinomas de células renales, carcinomas de cuello uterino o metástasis de los tipos de cáncer o tumores descritos anteriormente. El término cáncer de acuerdo con la enseñanza también comprende metástasis de cáncer y recidiva de cáncer.
Por "metástasis" se entiende la diseminación de células cancerosas desde su sitio original a otra parte del cuerpo. La formación de metástasis es un proceso muy complejo y depende del desprendimiento de células malignas del tumor primario, la invasión de la matriz extracelular, la penetración de las membranas basales endoteliales para ingresar a la cavidad y vasos corporales, y luego, después de ser transportadas por la sangre, infiltración de órganos diana. Finalmente, el crecimiento de un nuevo tumor, es decir, un tumor secundario o un tumor metastásico, en el sitio diana depende de la angiogénesis. La metástasis tumoral a menudo ocurre incluso después de la extirpación del tumor primario porque las células o componentes tumorales pueden permanecer y desarrollar potencial metastásico. En una realización, el término "metástasis" de acuerdo con la enseñanza se refiere a "metástasis distante" que se refiere a una metástasis que está alejada del tumor primario y del sistema de ganglios linfáticos regionales.
Las células de un tumor secundario o metastásico son como las del tumor original. Esto significa, por ejemplo, que, si el cáncer de ovario hace metástasis en el hígado, el tumor secundario está formado por células ováricas anormales, no por células hepáticas anormales. El tumor en el hígado se denomina cáncer de ovario metastásico, no cáncer de hígado.
El término "células tumorales circulantes" o "CTC" se refiere a células que se han desprendido de un tumor primario o metástasis tumorales y circulan en el torrente sanguíneo. Las CTC pueden constituir semillas para el crecimiento
posterior de tumores adicionales (metástasis) en diferentes tejidos. Las células tumorales circulantes se encuentran en frecuencias del orden de 1-10 CTC por ml de sangre total en pacientes con enfermedad metastásica. Se han desarrollado métodos de investigación para aislar las CTC. Se han descrito varios métodos de investigación en la técnica para aislar las CTC, por ejemplo, técnicas que utilizan el hecho de que las células epiteliales expresan comúnmente la proteína de adhesión celular EpCAM, que está ausente en las células sanguíneas normales. La captura basada en perlas inmunomagnéticas implica el tratamiento de muestras de sangre con anticuerpos contra EpCAM que se han conjugado con partículas magnéticas, seguido de la separación de las células marcadas en un campo magnético. A continuación, las células aisladas se tiñen con anticuerpo contra otro marcador epitelial, citoqueratina, así como un marcador de leucocitos común CD45, para distinguir las CTC raras de los glóbulos blancos contaminantes. Este enfoque robusto y semiautomático identifica las CTC con un rendimiento promedio de aproximadamente 1 CTC/ml y una pureza del 0,1% (Allard et al., 2004: Clin Cancer Res 10, 6897-6904). Un segundo método para aislar las CTC utiliza un dispositivo de captura de CTC basado en microfluidos que implica hacer fluir sangre completa a través de una cámara incrustada con 80.000 micropostes que se han vuelto funcionales al recubrir con anticuerpos contra EpCAM. Luego, las CTC se tiñen con anticuerpos secundarios contra citoqueratina o marcadores específicos de tejido, tales como PSA en el cáncer de próstata o HER2 en el cáncer de mama, y se visualizan mediante escaneo automático de micropostes en múltiples planos a lo largo de coordenadas tridimensionales. Los chips de CTC son capaces de identificar células tumorales circulantes positivas para citoqueratina en pacientes con un rendimiento medio de 50 células/ml y una pureza que oscila entre el 1 y el 80% (Nagrath et al., 2007: Nature 450, 1235-1239). Otra posibilidad para aislar las CTC es utilizar la prueba de células tumorales circulantes (CTC) CellSearchMR de Veridex, LLC (Raritan, NJ) que captura, identifica y cuenta las CTC en un tubo de sangre. El sistema CellSearchMR es una metodología aprobada por la Administración de Alimentos y Fármacos de los Estados Unidos (FDA) para el recuento de CTC en sangre completa que se basa en una combinación de etiquetado inmunomagnético y microscopía digital automatizada. Hay otros métodos para aislar CTC descritos en la literatura, todos los cuales pueden usarse junto con la presente enseñanza.
Una recaída o recurrencia ocurre cuando una persona se ve afectada nuevamente por una condición que la afectó en el pasado. Por ejemplo, si un paciente ha sufrido una enfermedad tumoral, ha recibido un tratamiento satisfactorio de dicha enfermedad y vuelve a desarrollar dicha enfermedad, dicha enfermedad recién desarrollada puede considerarse como recaída o recurrencia. Sin embargo, de acuerdo con la enseñanza, una recaída o recurrencia de una enfermedad tumoral puede ocurrir, pero no necesariamente, en el sitio de la enfermedad tumoral original. Así, por ejemplo, si una paciente ha sufrido un tumor de ovario y ha recibido un tratamiento exitoso, una recaída o recurrencia puede ser la aparición de un tumor de ovario o la aparición de un tumor en un sitio diferente al ovario. Una recaída o recurrencia de un tumor también incluye situaciones en las que un tumor ocurre en un sitio diferente al sitio del tumor original así como en el sitio del tumor original. Preferiblemente, el tumor original para el que el paciente ha recibido un tratamiento es un tumor primario y el tumor en un sitio diferente al sitio del tumor original es un tumor secundario o metastásico.
Por "tratar" se entiende administrar un compuesto o composición como se describe en el presente documento a un sujeto para prevenir o eliminar una enfermedad, incluida la reducción del tamaño de un tumor o el número de tumores en un sujeto; detener o retrasar una enfermedad en un sujeto; inhibir o retrasar el desarrollo de una nueva enfermedad en un sujeto; disminuir la frecuencia o gravedad de los síntomas y/o las recurrencias en un sujeto que actualmente tiene o que ha tenido una enfermedad anteriormente; y/o prolongar, es decir, aumentar la vida útil del sujeto. En particular, el término "tratamiento de una enfermedad" incluye curar, acortar la duración, mejorar, prevenir, ralentizar o inhibir la progresión o empeorar, o prevenir o retrasar la aparición de una enfermedad o los síntomas de la misma.
Por "estar en riesgo" se entiende un sujeto, es decir, un paciente, que se identifica con una probabilidad mayor de lo normal de desarrollar una enfermedad, en particular cáncer, en comparación con la población general. Además, un sujeto que ha tenido, o que tiene actualmente, una enfermedad, en particular cáncer, es un sujeto que tiene un mayor riesgo de desarrollar una enfermedad, ya que dicho sujeto puede continuar desarrollando una enfermedad. Los sujetos que actualmente tienen, o que han tenido, un cáncer también tienen un mayor riesgo de metástasis del cáncer.
El término "inmunoterapia" se refiere a un tratamiento que implica la activación de una reacción inmunitaria específica. En el contexto de la presente enseñanza, términos como "proteger", "prevenir", "profiláctico", "preventivo" o "protector" se relacionan con la prevención o el tratamiento, o ambos, de la aparición y/o propagación de una enfermedad en un sujeto y, en particular, para minimizar la posibilidad de que un sujeto desarrolle una enfermedad o para retrasar el desarrollo de una enfermedad. Por ejemplo, una persona en riesgo de tener un tumor, como se describió anteriormente, sería un candidato para la terapia para prevenir un tumor.
Una administración profiláctica de una inmunoterapia, por ejemplo, una administración profiláctica de una vacuna de la enseñanza, protege preferiblemente al receptor del desarrollo de una enfermedad. Una administración terapéutica de una inmunoterapia, por ejemplo, una administración terapéutica de una vacuna de la enseñanza, puede conducir a la inhibición del progreso/crecimiento de la enfermedad. Esto comprende la desaceleración del progreso/crecimiento de la enfermedad, en particular una interrupción del progreso de la enfermedad, que preferiblemente conduce a la eliminación de la enfermedad.
La inmunoterapia se puede realizar usando cualquiera de una variedad de técnicas, en las que los agentes proporcionados en el presente documento funcionan para eliminar las células enfermas de un paciente. Tal eliminación
puede tener lugar como resultado de potenciar o inducir una respuesta inmune en un paciente específico para un antígeno o una célula que expresa un antígeno.
En determinadas realizaciones, la inmunoterapia puede ser inmunoterapia activa, en la que el tratamiento se basa en la estimulación in vivo del sistema inmunitario endógeno del huésped para reaccionar contra las células enfermas con la administración de agentes modificadores de la respuesta inmunitaria (tales como polipéptidos y ácidos nucleicos como los proporcionados en este documento).
Los agentes y composiciones proporcionados en este documento pueden usarse solos o en combinación con regímenes terapéuticos convencionales tales como cirugía, irradiación, quimioterapia y/o trasplante de médula ósea (autólogo, singénico, alogénico o no relacionado).
El término "inmunización" o "vacunación" describe el proceso de tratar a un sujeto con el propósito de inducir una respuesta inmune por razones terapéuticas o profilácticas.
El término "in vivo" se refiere a la situación en un sujeto.
Los términos "sujeto", "individuo", "organismo" o "paciente" se usan indistintamente y se refieren a vertebrados, preferiblemente mamíferos. Por ejemplo, los mamíferos en el contexto de la presente enseñanza son humanos, primates no humanos, animales domesticados tales como perros, gatos, ovejas, vacas, cabras, cerdos, caballos, etc., animales de laboratorio tales como ratones, ratas, conejos, conejillos de Indias, etc., así como animales en cautiverio tales como animales de zoológicos. El término "animal" como se usa en este documento también incluye humanos. El término "sujeto" también puede incluir un paciente, es decir, un animal, preferiblemente un ser humano que tiene una enfermedad, preferiblemente una enfermedad como se describe en el presente documento.
El término "autólogo" se usa para describir cualquier cosa que se derive del mismo sujeto. Por ejemplo, "trasplante autólogo" se refiere a un trasplante de tejido u órganos derivados del mismo sujeto. Tales procedimientos son ventajosos porque superan la barrera inmunológica que de otro modo da como resultado el rechazo.
El término "heterólogo" se usa para describir algo que consta de múltiples elementos diferentes. Por ejemplo, la transferencia de la médula ósea de un individuo a otro individuo constituye un trasplante heterólogo. Un gen heterólogo es un gen derivado de una fuente distinta al sujeto.
Como parte de la composición para una inmunización o una vacunación, preferiblemente uno o más agentes como se describen en este documento se administran junto con uno o más adyuvantes para inducir una respuesta inmune o para aumentar una respuesta inmune. El término "adyuvante" se refiere a compuestos que prolongan o potencian o aceleran una respuesta inmunitaria. La composición de la presente enseñanza ejerce preferiblemente su efecto sin adición de adyuvantes. Además, la composición de la presente solicitud puede contener cualquier adyuvante conocido. Los adyuvantes comprenden un grupo heterogéneo de compuestos tales como emulsiones oleosas (por ejemplo, adyuvantes de Freund), compuestos minerales (tales como alumbre), productos bacterianos (tales como la toxina de Bordetella pertussis), liposomas y complejos inmunoestimulantes. Ejemplos de adyuvantes son monofosforil-lípido-A (MPL SmithKline Beecham). Saponinas tales como QS21 (SmithKline Beecham), DQS21 (SmithKline Beecham; documento WO 96/33739), Qs 7, Qs 17, QS18 y QS-L1 (So et al., 1997, Mol. Cells 7: 178-186), adyuvantes incompletos de Freund, adyuvantes completos de Freund, vitamina E, montánido, alumbre, oligonucleótidos CpG (Krieg et al., 1995, Nature 374: 546-549), y diversas emulsiones de agua en aceite que se preparan a partir de aceites biológicamente degradables tales como escualeno y/o tocoferol.
También se pueden administrar otras sustancias que estimulan una respuesta inmune del paciente. Es posible, por ejemplo, usar citocinas en una vacunación, debido a sus propiedades reguladoras sobre los linfocitos. Dichas citocinas comprenden, por ejemplo, interleucina-12 (IL-12) que se demostró que aumenta las acciones protectoras de las vacunas (véase Science 268: 1432-1434, 1995), GM-CSF e IL-18.
Hay una serie de compuestos que potencian una respuesta inmune y que, por lo tanto, pueden usarse en una vacunación. Dichos compuestos comprenden moléculas coestimulantes proporcionadas en forma de proteínas o ácidos nucleicos tales como B7-1 y B7-2 (CD80 y CD86, respectivamente).
De acuerdo con la enseñanza, una muestra corporal puede ser una muestra de tejido, que incluye fluidos corporales y/o una muestra celular. Tales muestras corporales pueden obtenerse de manera convencional, tal como mediante biopsia de tejido, incluida la biopsia por punción, y extrayendo sangre, aspirado bronquial, esputo, orina, heces u otros fluidos corporales. De acuerdo con la enseñanza, el término "muestra" también incluye muestras procesadas tales como fracciones o aislados de muestras biológicas, por ejemplo, ácidos nucleicos o aislados de células.
Los agentes tales como vacunas y composiciones descritas en el presente documento pueden administrarse mediante cualquier ruta convencional, incluso mediante inyección o infusión. La administración puede realizarse, por ejemplo, por vía oral, intravenosa, intraperitoneal, intramuscular, subcutánea o transdérmica. En una realización, la administración se lleva a cabo por vía intranodal, por ejemplo mediante inyección en un ganglio linfático. Otras formas
de administración prevén la transfección in vitro de células presentadoras de antígeno tales como células dendríticas con los ácidos nucleicos descritos en el presente documento, seguida de la administración de las células presentadoras de antígeno.
Los agentes descritos en este documento se administran en cantidades eficaces. Una "cantidad eficaz" se refiere a la cantidad que logra una reacción deseada o un efecto deseado solo o junto con dosis adicionales. En el caso del tratamiento de una enfermedad particular o de una afección particular, la reacción deseada se refiere preferiblemente a la inhibición del curso de la enfermedad. Esto comprende ralentizar el progreso de la enfermedad y, en particular, interrumpir o revertir el progreso de la enfermedad. La reacción deseada en un tratamiento de una enfermedad o de una afección también puede ser un retraso del inicio o una prevención del inicio de dicha enfermedad o dicha condición.
Una cantidad eficaz de un agente descrito en el presente documento dependerá de la afección a tratar, la gravedad de la enfermedad, los parámetros individuales del paciente, incluida la edad, la afección fisiológica, el tamaño y el peso, la duración del tratamiento, el tipo de una terapia acompañante (si está presente), la vía de administración específica y factores similares. Por consiguiente, las dosis administradas de los agentes descritos en este documento pueden depender de varios de dichos parámetros. En el caso de que una reacción en un paciente sea insuficiente con una dosis inicial, se pueden usar dosis más altas (o dosis efectivamente más altas logradas por una vía de administración diferente, más localizada).
Las composiciones farmacéuticas descritas en el presente documento son preferiblemente estériles y contienen una cantidad eficaz de la sustancia terapéuticamente activa para generar la reacción deseada o el efecto deseado.
Las composiciones farmacéuticas descritas en el presente documento se administran generalmente en cantidades farmacéuticamente compatibles y en una preparación farmacéuticamente compatible. El término "farmacéuticamente compatible" se refiere a un material no tóxico que no interactúa con la acción del componente activo de la composición farmacéutica. Las preparaciones de este tipo pueden contener habitualmente sales, sustancias tampón, conservantes, vehículos, sustancias complementarias que mejoran la inmunidad tales como adyuvantes, por ejemplo, oligonucleótidos CpG, citocinas, quimiocinas, saponina, GM-CSF y/o ARN y, en su caso, otros compuestos terapéuticamente activos. Cuando se usan en medicina, las sales deben ser farmacéuticamente compatibles. Sin embargo, las sales que no son farmacéuticamente compatibles pueden usarse para preparar sales farmacéuticamente compatibles y están incluidas en la enseñanza. Las sales farmacológica y farmacéuticamente compatibles de este tipo comprenden de forma no limitativa las preparadas a partir de los siguientes ácidos: ácido clorhídrico, bromhídrico, sulfúrico, nítrico, fosfórico, maleico, acético, salicílico, cítrico, fórmico, malónico, succínico y similares. También se pueden preparar sales farmacéuticamente compatibles como sales de metales alcalinos o sales de metales alcalinotérreos, tales como sales de sodio, sales de potasio o sales de calcio.
Una composición farmacéutica descrita en el presente documento puede comprender un vehículo farmacéuticamente compatible. El término "vehículo" se refiere a un componente orgánico o inorgánico, de naturaleza natural o sintética, en el que el componente activo se combina para facilitar la aplicación. De acuerdo con la enseñanza, el término "vehículo farmacéuticamente compatible" incluye uno o más rellenos sólidos o líquidos compatibles, diluyentes o sustancias encapsulantes que son adecuados para la administración a un paciente. Los componentes de la composición farmacéutica de la enseñanza son normalmente tales que no se produce interacción que perjudique sustancialmente la eficacia farmacéutica deseada.
Las composiciones farmacéuticas descritas en este documento pueden contener sustancias tampón adecuadas tales como ácido acético en una sal, ácido cítrico en una sal, ácido bórico en una sal y ácido fosfórico en una sal.
Las composiciones farmacéuticas pueden contener, cuando sea apropiado, también conservantes adecuados tales como cloruro de benzalconio, clorobutanol, parabeno y timerosal.
Las composiciones farmacéuticas se proporcionan normalmente en una forma de dosificación uniforme y se pueden preparar de una manera ya conocida. Las composiciones farmacéuticas de la enseñanza pueden estar en forma de cápsulas, comprimidos, grageas, soluciones, suspensiones, jarabes, elixires o en forma de emulsión, por ejemplo.
Las composiciones adecuadas para la administración parenteral normalmente comprenden una preparación acuosa o no acuosa estéril del compuesto activo, que preferiblemente es isotónica a la sangre del receptor. Ejemplos de vehículos compatibles y disolventes son la solución de Ringer y la solución isotónica de cloruro de sodio. Además, se utilizan aceites fijos normalmente estériles como medio de solución o suspensión.
La presente enseñanza se describe en detalle mediante las figuras y ejemplos siguientes, que se utilizan sólo con fines ilustrativos y no pretenden ser limitantes. Debido a la descripción y los ejemplos, el experto en la materia puede acceder a otras formas de realización que también se incluyen en la enseñanza.
Figuras
Figura 1. Descripción general de la predicción de unión al MHC
Figura 2. Análisis de inmunogenicidad en función de la puntuación de Mmut para 50 mutaciones B16F10 priorizadas y 82 mutaciones CT26.WT priorizadas (132 mutaciones en total), de las cuales 30 eran inmunogénicas. Todas las vacunaciones se realizaron con ARN. Para B 16F10, se ensayó la inmunogenicidad desafiando las BMDC con ARN y midiendo la respuesta inmune de los esplenocitos con ELISPOT y FACS. Para CT26.WT se ensayó la inmunogenicidad desafiando las BMDC con ARN y péptidos por separado y midiendo la respuesta inmune de los esplenocitos con ELISPOT; una mutación se consideraba inmunogénica si el péptido o el ARN registraban una respuesta inmune. A. Una distribución acumulativa de mutaciones inmunogénicas en función de la puntuación de Mmut. El gráfico muestra el número total de mutaciones por debajo de una puntuación determinada de Mmut (rojo), de éstos, el número de mutaciones que fueron inmunogénicas (azul) y el porcentaje de mutaciones inmunogénicas del total (negro). B. Histograma del porcentaje de mutaciones inmunogénicas por compartimiento de Mmut para los siguientes intervalos: < 0,3, (0,3; 1), > 1. Los errores que se muestran son errores estándar.
Figura 3. Análisis de la inmunogenicidad de B16F10 y CT26.WT en función de Mmut. Distribución acumulativa de mutaciones inmunogénicas en función de la puntuación de Mmut para B16 (A) y CT26 (C). Histograma del porcentaje de mutaciones inmunogénicas por compartimiento de Mmut para los siguientes intervalos: (0,1; 0,3), (0,3; 1), (1, ~) para B16 (B) y CT26 (D). Las Figuras A y B se basan en los análisis de 50 mutaciones priorizadas de B16F10, de las cuales 12 eran inmunogénicas. Las Figuras C y D se basan en el análisis de 82 mutaciones priorizadas de B16F10, de las cuales 30 eran inmunogénicas. Para más detalles, véase la leyenda de la Figura 2. Los errores son errores estándar.
Figura 4. Modelos de inmunogenicidad e hipótesis de control. La inmunogenicidad de clase I, denotada por Ha, asume que tanto los epítopos WT como MUT son presentados por células, y que la suficiencia de mutación alteró las propiedades fisicoquímicas del aminoácido para que el sistema inmunológico registre este cambio y genere una respuesta inmune (denotada por el rayo). La hipótesis de Hn, que sirve como control para Ha, es simplemente la hipótesis de Ha invertida, es decir, que la mutación no alteró significativamente las propiedades fisicoquímicas del aminoácido y, por lo tanto, tiene una menor probabilidad de ser "detectada" por el sistema inmunológico y generar una respuesta inmune. En la inmunogenicidad de clase II (Hb U Hc) no se presenta el epítopo WT pero sí el epítopo MUT. Hb y Hc se distinguen por puntuaciones T altas (T > t) frente a bajas (T < t), respectivamente. Nótese que para a* = a, el modelo Hbc1 de inmunogenicidad (Mmut <p) es una combinación de los cuatro grupos: Hbc1 = U[Ha,Hb,Hc,H^.
Figura 5. Relación hipotética del puntaje T con la inmunogenicidad. De acuerdo con el modelo de inmunogenicidad de clase I, durante el desarrollo de las células T, se eliminaron los TCR que se unían fuertemente al epítopo de tipo silvestre. Los TCR existentes deberían exhibir solo una afinidad de unión débil o nula al epítopo de tipo silvestre (A). Los epítopos que contienen una sustitución de aminoácidos que tiene una puntuación T alta tienen propiedades fisicoquímicas similares a las del aminoácido de tipo silvestre y, por lo tanto, probablemente tendrán poco impacto en la afinidad de unión a los TCR existentes (B). Los epítopos que contienen una sustitución de aminoácidos con una puntuación T tienen una mayor probabilidad de aumentar la afinidad de unión que los TCR exactos y, por lo tanto, una mayor probabilidad de ser inmunogénicos (C). En esta ilustración esquemática, la codificación de colores se usa para emparejar células T con un péptido coincidente. Las mutaciones naranja/amarillo representan mutaciones con puntuaciones T altas (similares a las WT), mientras que las mutaciones azul/púrpura representan mutaciones con puntuaciones T bajas (diferencia fisicoquímica significativa en comparación con la WT).
Figura 6. Distribución acumulativa de mutaciones inmunogénicas en función de Mmut. A. Comparación del porcentaje de mutaciones inmunogénicas que satisfacen la hipótesis de control inicia1Hbc1 {Mmut < p}, con el porcentaje de mutaciones inmunogénicas que satisfacen la hipótesis parcial Ha': Hbc1 n {T < t}, la hipótesis parcia1Hbc2: Hbc1 n {Mmut < a} y la hipótesis completa Ha: Hbc1 n {Mmut < a} n {T < t}, para a = 1, t = 1. B. Comparación del porcentaje de mutaciones inmunogénicas que satisfacen las hipótesis de control iniciales Hbc1 {Mmut < p} con el porcentaje de mutaciones inmunogénicas que satisfacen las hipótesis parciales inversas: Hbc1 n {T > t} y Hbc1 n {Mmut > a}. El análisis en A y B se basa en los conjuntos de datos agrupados de B16F10 y c T26.Wt , que comprenden 132 mutaciones, de las cuales 30 eran inmunogénicas. Cada punto de datos en los gráficos se basa en >4 mutaciones.
Figura 7. Distribución acumulativa de mutaciones inmunogénicas en función de la puntuación de Mmut. Comparación del porcentaje de mutaciones inmunogénicas que satisfacen la hipótesis de control inicia1Hbc1 {Mmut < p}, con el porcentaje de mutaciones inmunogénicas que satisfacen la hipótesis parcia1Ha : Hbc1 n {T < t}, la hipótesis parcial Hbc2: Hbc1 n {Mmut < a} y la hipótesis completa Ha: Hbc1 n {Mmut < a} n {T < t}, dado a = 1, t = 1 para B16 (A) y CT26 (C). Comparación del porcentaje de mutaciones inmunogénicas que satisfacen las hipótesis de control inicia1Hbc1 {Mmut < p} con el porcentaje de mutaciones inmunogénicas que satisfacen las hipótesis parciales inversas: Hbc1 n {T> t} y Hbc1 n {Mmut > a} para B16 (B) y CT26 (D).
Las Figuras A y B se basan en el análisis de las 50 mutaciones priorizadas de B16F10, de las cuales 12 eran inmunogénicas. Las Figuras C y D se basan en las 82 mutaciones priorizadas de B16F10, de las cuales 30 eran inmunogénicas. Cada punto de datos en los gráficos se basa en >4 mutaciones.
Figura 8. Control de la inmunogenicidad de WT. Para comprobar si la omisión de las soluciones MUT+/WT+ tuvo un impacto en estos hallazgos, se excluyó del conjunto de datos 9 mutaciones MUT+/WT+ y 2 mutaciones para las que no se ha medido el WT, dejando un total de 121 mutaciones (43 B16 y 78 CT26) de las cuales 19 fueron MUT+/WT-(5 para B16 y 14 para c T26). Nuevamente se encontraron las mismas tendencias que en el conjunto de datos
completo, es decir, respuesta altamente no lineal en función de la puntuación de Mmut, superioridad de la hipótesis de HA sobre la hipótesis parcial e inferioridad de las hipótesis invertidas en comparación con el control de referencia Hbci. A. Distribución acumulada de la inmunogenicidad en función de la puntuación de Mmut. B. Histograma del porcentaje de mutaciones inmunogénicas por compartimiento de Mmut. C. Comparación del porcentaje de mutaciones inmunogénicas que satisfacen las hipótesis de control iniciales Hbc1 con Ha , Hbc2 Y Ha. D. Comparación del porcentaje de mutaciones inmunogénicas que satisfacen la hipótesis de control inicia1Hbc1 con la hipótesis inversa. Véase la leyenda de la Figura 5 para obtener detalles adicionales.
Figura 9. Fracción de mutaciones inmunogénicas en función de RPKM. Rojo: todas las 50 mutaciones B16 y las 82 mutaciones CT26 sin filtro (132 mutaciones en total). Azul: mutaciones que superan la hipótesis de Ha con a = 1, p = 0,5, t= 1. B. Porcentaje de mutaciones inmunogénicas para diferentes intervalos de RPKM sin filtro. Los contenedores de RPKM son: 1 = (0, 1), 2 = (1,5), 3 = (5, 50), 4 = (50, ~). C. Porcentaje de mutaciones inmunogénicas para diferentes intervalos de RPKM bajo la hipótesis de Ha con a = 1, p = 0,5, t = 1. Los contenedores de RPKM son: 1 = (0, 1), 2 = (1, ~). Los errores son SE.
Figura 10. Epítopos inmunogénicos de clase II mutados en posición de anclaje y no anclaje. Los motivos de la posición de anclaje se analizaron usando SYFPEITHI.
Figura 11. Modelos propuestos para epítopos inmunogénicos asociados a tumores.
Figura 12. Ejemplo de un método para ponderar la posición del rango de mutaciones. Para cada mutación, la posición del rango en la lista de mutaciones clasificadas se puede ponderar aún más por el número de soluciones para las cuales la combinación de tipos de HLA para el paciente, las posibles longitudes de ventana para el tipo de HLA y la posición de la mutación dentro del epítopo dieron como resultado una solución con Mmut bajo o resultó en una clasificación Ha y/o Hb U Hc. Dado que todas las soluciones por mutación pueden presentarse potencialmente en paralelo, este factor de ponderación puede ser un contribuyente importante a la posición de rango de la mutación.
Figura 13. Ejemplo de gráfico de dispersión de todas las soluciones de epítopos para la mutación chr14_52837882 de CT26 contra Mmut y AM = Mmut - Mwt.
Ejemplos
Las técnicas y métodos usados en este documento se describen en este documento o se llevan a cabo de una manera ya conocida y como se describe, por ejemplo, en Sambrook et al., Molecular Cloning: A Laboratory Manual, 2a edición (1989) Cold Spring Harbor Laboratory. Press, Cold Spring Harbor, Nueva York. Todos los métodos, incluido el uso de kits y reactivos, se llevan a cabo de acuerdo con la información del fabricante, a menos que se indique específicamente lo contrario.
Ejemplo 1: Establecimiento de un modelo para predecir la inmunogenicidad de los epítopos de células T
Previamente se exploró la inmunogenicidad de 50 mutaciones somáticas identificadas en la línea celular de melanoma murino B16F10 (J. C. Castle et al., Exploiting the mutanome for tumor vaccination. Cancer Research 72, 1081 (2012)). Estas 50 mutaciones se seleccionaron de un conjunto de 563 mutaciones somáticas no sinónimas expresadas principalmente para maximizar la expresión del MHC de clase I (J.C. Castle et al., Exploiting the mutanome for tumor vaccination. Cancer Research 72, 1081 (2012)) (véase también el Ejemplo 2). Para cada mutación, se predijo el epítopo mínimo, es decir, el epítopo con la puntuación de consenso del MHC de clase I más baja (Y. Kim et al., Nucleic Acids Research 40, W525 (2012)) (definido aquí como Mmut) al buscar en el espacio de todos los posibles alelos del MHC de clase I, posibles longitudes de epítopo y ventanas de secuencia (en la que colocar la mutación) (J.C. Castle et al., Exploiting the mutanome for tumor vaccination. Cancer Research 72, 1081 (2012)). La medición de la inmunogenicidad de estas mutaciones usando vacunación de ARN seguida de lectura de péptidos (véase el Ejemplo 2) confirmó los hallazgos anteriores usando vacunación de péptidos (J.C. Castle et al., Exploiting the mutanome for tumor vaccination. Cancer Research 72, 1081 (2012)), y mostró que solo 12 de 50 mutaciones (24%) eran inmunogénicas (Tabla 1), con secuencias MUT+/WT- que comprenden solo el 10% de todas las mutaciones probadas.
Tabla 1. Número de mutaciones inmunogénicas después de la vacunación con ARN de las cepas murinas B19F10 y
CT26.WT

*Se excluyeron de esta tabla dos mutaciones CT26 MUT+ porque aún no se ha medido su reactividad de WT. En total, hubo 18 mutaciones MUT+ de las 82 mutaciones CT26 medidas hasta el momento, lo que resultó en una tasa de éxito del 22%.
Los resultados del caso de prueba murino B16F10 demuestran que la selección sin alteración de mutaciones no sinónimas expresadas con puntuaciones de Mmut bajas (< 3,9) produce tasas de éxito bastante bajas para predecir la inmunogenicidad. Por lo tanto, se requiere una mejor comprensión de los mecanismos que impulsan la inmunogenicidad para que las vacunas personalizadas dirigidas a neoantígenos específicos de tumores se conviertan en terapias efectivas. En un esfuerzo por descubrir variables adicionales que contribuyan a la inmunogenicidad, se exploró la inmunogenicidad de mutaciones somáticas no sinónimas expresadas identificadas en una línea celular colorrectal murina CT26.WT. En total, se seleccionaron 96 mutaciones en función de sus puntuaciones de Mmut (baja frente a alta), RPKM media (baja frente a alta) y localización celular (intracelular frente a extracelular), y se evaluó la inmunogenicidad mediante vacunación con a Rn con ambos lectura de péptidos y ARN (véase el Ejemplo 2 para obtener más detalles). Junto con la línea celular B16F10, este conjunto de datos consta de 132 epítopos, cuya inmunogenicidad se midió ex vivo en esplenocitos murinos.
La puntuación de consenso del MHC. Para investigar la dependencia de la inmunogenicidad en Mmut, se graficó el porcentaje acumulado de mutaciones inmunogénicas en función de Mmut, es decir, el porcentaje de mutaciones con una puntuación de Mmut menor que un umbral dado (denotado por p) que eran inmunogénicas. Un análisis de los conjuntos de datos combinados de B16 y CT26 que abarcan un total de 132 mutaciones revela una dependencia altamente no lineal de la tasa de éxito de la inmunogenicidad en Mmut(Fig. 2A). La Fig. 2A muestra que las mutaciones inmunogénicas se enriquecen con puntuaciones de Mmut extremadamente bajas (< ~0,2). Para Mmut < 0,1, el porcentaje de mutaciones inmunogénicas alcanza un máximo de ~ 60% y decae rápidamente a medida que aumenta Mmut, cayendo por debajo de ~ 25% para Mmut ^ 2. El porcentaje de mutaciones inmunogénicas con Mmut < 0,3 frente a > 0,3 fue del 44,4% en comparación con el 17,1%, una diferencia estadísticamente significativa (valor p = 0,004, prueba exacta de Fisher, de una cola). Un histograma del porcentaje de mutaciones inmunogénicas para tres contenedores de Mmut: < 0,3, (0,3; 1) y > 1 muestra que el porcentaje de mutaciones inmunogénicas disminuye a medida que aumenta Mmut (Fig. 2B). Las diferencias entre la tasa de éxito de los compartimientos más bajos (Mmut < 0,3), 44,4%, y tanto el compartimiento central, 20,7%, como el compartimiento más alto (Mmut> 1), 15,8%, en la Fig.2B fueron estadísticamente significativos (valores P = 0,05 y 0,004, respectivamente, prueba exacta de Fisher, una cola), lo que indica que para Mmut > ~0,3 la tasa de éxito desciende de manera estadísticamente significativa. También se observa una tendencia similar en la tasa de éxito al analizar los mutanomas B16 y CT26 por separado (Fig. 3).
Hasta ahora, los criterios para seleccionar mutaciones se centraron en la presentación, y se ha observado que restringir la puntuación de unión a MHC del epítopo mutado permite la predicción de epítopos inmunogénicos con hasta un 60% de precisión. La presentación, sin embargo, es una condición necesaria pero no suficiente para inducir inmunogenicidad. Al identificar criterios adicionales para el reconocimiento de TCR, se puede mejorar aún más la precisión de esta predicción. Se plantea la hipótesis de dos mecanismos mutuamente excluyentes para impulsar la inmunogenicidad, a los que se hace referencia como modelos de inmunogenicidad de clase I y clase II.
Inmunogenicidad de clase I. Para que el repertorio de TCR reconozca un epítopo mutado y genere una respuesta inmune, se plantea la hipótesis de que deben cumplirse tres condiciones (HA Fig.4): (i) el epítopo de tipo silvestre, en algún momento durante el desarrollo del organismo, fue presentado al sistema inmunológico que conduce a la eliminación de los TCR coincidentes a través de una fuerte unión de TCR/pMHC, (ii) se presenta el epítopo mutado, y (iii) las propiedades fisicoquímicas del aminoácido mutado son suficientemente "diferentes" de las del aminoácido de tipo silvestre (por alguna métrica que se define a continuación) para que el repertorio de TCR sea capaz de "detectar" o "registrar" esta sustitución. Las condiciones (i) y (ii) aseguran que el sistema inmunológico esté realmente expuesto al cambio, es decir, la mutación. La condición (iii) requiere que la mutación cambie significativamente el carácter fisicoquímico del aminoácido de tipo silvestre de modo que la afinidad de unión del epítopo mutado al TCR existente (no eliminado) aumente potencialmente, activando de esta manera la cascada de señalización que conduce a una respuesta inmune (Fig. 5).
La puntuación de reconocimiento de TCR. Los modelos de inmunogenicidad de clase I requieren una métrica para estimar la diferencia fisicoquímica entre dos aminoácidos. Es bien sabido en la evolución molecular que es probable que los aminoácidos que se intercambian con frecuencia tengan similitudes químicas y físicas, mientras que los aminoácidos que se intercambian rara vez tienen diferentes propiedades fisicoquímicas. La probabilidad de que ocurra una sustitución dada en la naturaleza en comparación con la probabilidad de que esta sustitución ocurra por casualidad se mide mediante matrices logarítmicas de probabilidades. Los patrones observados en matrices logarítmicas de probabilidades impuestas por la selección natural "reflejan la similitud de las funciones de los residuos de aminoácidos en sus interacciones débiles entre sí en la conformación tridimensional de las proteínas" (M.O. Dayhoff, RM Schwartz, B.C. Orcutt, A model for evolutionary change. M.O. Dayhoff, ed. Atlas of protein sequence and structure Vol.5, 345 (1978)). Por lo tanto, se utilizaron matrices logarítmicas de probabilidades basadas en la evolución, a las que se hace referencia en el presente documento como "puntuaciones T" para reflejar el reconocimiento de TCR, como matrices de puntuación eficaces para sustituciones de aminoácidos asociados al cáncer. Es probable que se produzcan sustituciones con puntuaciones T positivas (es decir, logarítmicas de probabilidades) en la naturaleza y, por lo tanto, correspondan a dos aminoácidos que tienen propiedades fisicoquímicas similares. El modelo de clase I predice que las sustituciones con puntuaciones T positivas tendrían una menor probabilidad de ser inmunogénicas. Por el contrario, las sustituciones con puntuaciones T negativas reflejan sustituciones que es poco probable que ocurran en la naturaleza y, por lo tanto, corresponden a dos aminoácidos que tienen propiedades fisicoquímicas significativamente diferentes. De acuerdo con este modelo, tales sustituciones tendrían una mayor probabilidad de ser inmunogénicas.
Se compararon diferentes métodos de estimación de matrices logarítmicas de probabilidades y se encontró que los resultados son en gran medida robustos para el método exacto elegido. El enfoque de estimación basado en la máxima probabilidad (ML) conocido como WAG (S. Whelan, N. Goldman, Molecular Biology and Evolution 18, 691 (2001)), utilizando una distancia PAM (mutación puntual aceptada) de 250, pareció separar mejor las mutaciones inmunogénicas predichas de las no inmunogénicas y, por lo tanto, se presentan los resultados con esta matriz (véase el Ejemplo 2 para obtener más detalles).
Inmunogenicidad de clase II. En el modelo de inmunogenicidad de clase II, se plantea la hipótesis de que es probable que una mutación sea inmunogénica si el sistema inmunológico nunca antes ha visto el epítopo de tipo silvestre y, por lo tanto, es desafiado por el epítopo mutado. Por lo tanto, para que una mutación sea inmunogénica en este modelo, se plantea la hipótesis de que deben cumplirse dos condiciones: (i) el epítopo de tipo silvestre nunca se presentó al sistema inmunológico, (ii) se presenta el péptido mutado. Estas condiciones pueden satisfacerse conjuntamente si, por ejemplo, la mutación golpea una posición de anclaje, cambiando así un epítopo "no ligante" en un "ligante". Formalmente, la inmunogenicidad de clase II se puede separar en dos subhipótesis: puntuaciones T altas (Hb en la Figura 4) y puntuaciones T bajas (Hc en la Figura 4). Sin embargo, dado que se supone que no se presenta el epítopo de tipo silvestre, no se espera que la naturaleza de la sustitución de aminoácidos tenga un impacto en el reconocimiento de TCR y, por lo tanto, se equiparará la inmunogenicidad de clase II con la hipótesis unificada: Hb U HC.
Ensayo de inmunogenicidad de clase I. Los supuestos de inmunogenicidad de clase I (Ha en la Fig.4) se pueden reformular matemáticamente de la siguiente manera: se requiere que se presente el epítopo de tipo silvestre (Mwt < a), se presente el epítopo mutado (Mmut < p) y la sustitución del aminoácido no sea trivial (T < t ), en el que Mwt se define como la puntuación de consenso del MHC del epítopo mutado (mismo alelo de HLA y longitud de ventana) reemplazando el aminoácido mutado con el aminoácido de tipo silvestre, y T denota la puntuación de T. Dado que las tres condiciones son necesarias, se espera que la precisión del clasificador de Ha sea mayor en comparación con un clasificador basado solo en Mmut (Hbci en la Figura 4) o en comparación con las hipótesis parciales: Hbci n {Mwt < a} y HBC1 n {T < t}. Por lo tanto, se calcula el porcentaje de mutaciones inmunogénicas (número de verdaderos positivos dividido por la suma de verdaderos positivos y falsos positivos) en función de p para Hbci, para la hipótesis parcia1Ha : Hbci n {T < t} y para la hipótesis parcial Hbc2: Hbci n {Mwt < a}. Se encontró que un umbral conservador para t en el intervalo de “ 0,5 a 1 se desempeñó mejor (el intervalo de la matriz WAG250 es de -5,1 (sustitución de F ^ G) a 5,4 (sustitución F ^ Y). También se encontró que a se puede restringir de forma conservadora en comparación con p, estableciendo a = 1. La Figura 6A muestra de hecho que, al considerar el mutanoma agrupado de B16 y CT26, los clasificadores basados en Hbc2 y Ha' alcanzaron una mayor precisión que la hipótesis de control inicia1Hbc-i . Además un clasificador con base en la hipótesis completa Ha alcanzó mayor precisión que las hipótesis parciales Hbct y Hbc2’, demostrando así un efecto aditivo. Las mismas conclusiones se mantienen al analizar los conjuntos de datos B16 y CT26 por separado (Fig. 7).
Dado que se postula que las condiciones Mwt < a y T < t son condiciones necesarias para la inmunogenicidad, se esperaría que un clasificador con base en la condición Hbci n {T > t} o la condición Hbci n {Mwt > a} (es decir, negando la condición secundaria) funcionaría peor que Hbc-i . De hecho, se encontró que este es el caso de B16 y CT26 cuando se analizan juntos (Fig. 6B) o por separado (Fig. 7). Por lo tanto, se llegó a la conclusión de que los conjuntos de datos de B16 y CT26 apoyan tanto juntos como por separado la hipótesis de Ha. La omisión de mutaciones en las que el ARN WT también mostró reactividad no afectó estas conclusiones (Fig. 8).
Control de la hipótesis de Ha. Aunque las mutaciones con puntuaciones T altas pueden seguir siendo inmunogénicas, una hipótesis que enriquece tales mutaciones debería enriquecer estadísticamente mutaciones no inmunogénicas. Por lo tanto, si se compara la hipótesis de Ha (Hbc2 n {T < t}) con su inversa, (Hbc2 n {T > t}) (Hn en la Fig. 4), se debería observar un agotamiento estadísticamente significativo de mutaciones inmunogénicas. De hecho, la Tabla 2 muestra que para Mmut < P = 0,5, Mwt < a = 1 y T < t = 1, Ha supera a Hn, con una tasa de éxito del 52,5% (n = 21) en comparación con 21,4% (n = 14; P = 0,068, prueba exacta de Fisher de una cola).
Tabla 2. Porcentaje de mutaciones inmunogénicas bajo diversas hipótesis con base en los conjuntos de datos r B1 T2 m r n n 1 m i n

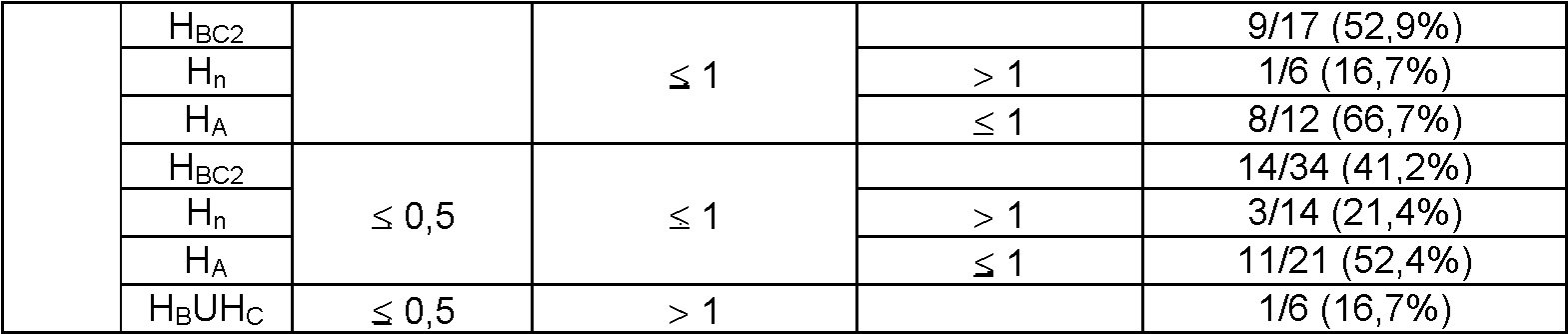
Ha ta m b ié n se co m p o rta m e jo r que Hbc2 de con tro l in ic ia l, que a lca n za el 41 ,2 % (n = 35). A m ed id a que d ism in u ye p, la d ife re n c ia en tre las ta sa s de éx ito de Ha y H n aum en ta , ya que cuan to m ás es tric ta es la co nd ic ión en p, m ás fa lsos p o s itivo s se e lim in a n de l g ru p o Ha. P o r e jem p lo , pa ra p = 0 ,25, la ta sa de éx ito de l g rupo Ha fu e de l 67 % (n = 14) en co m p a ra c ió n con una ta sa de éx ito del 17% (n = 6 ) para el g rupo H n (P = 0 ,066 , p rueba exac ta de F ishe r de una cola), vé a se la T ab la 3.
T ab la 3. L is ta c la s ifica d a de 133 m u ta c io n e s B 16 F 10 /C T 26.W T m ed id a s que sa tis fa cen la h ipó tes is de con tro l bás ica Hbci (M mut < 0 ,25) d e sg lo sad a en las tres c lases de h ipó tes is desa rticu la d a s : h ipó tes is de Ha para m u ta c io n e s in m un o g é n ica s , (M wt < 0,8, T < 0,5), h ipó tes is de H n/H A in ve rsa e n riq u e ce d o ra para m u ta c io n e s no in m un o g é n ica s (M wt < 0,8, T > 0 ,5 ) e h ipó tes is HbUHc para m u ta c io n e s in m u n o g é n ica s (M wt > 0,8). S e p ro p o n e que los ca n d id a to s de Ha Y HbUHc se c la s ifiq u e n en fu n c ió n de la im p o rta n c ia re la tiva de va ria b le s d is tin tivas . P a ra Ha, el o rden p ro p u e s to es: M mut (d e sce n d e n te ) ^ P un tuac ión T (de sce n d e n te ) ^ Mwt d e sce nd e n te . P ara HbUHc, el o rden p ropues to es M mut n n ^ w n n . L rr r n rr r n r

En el E jem p lo 3 se da un e je m p lo de fac to re s de ponde rac ión a d ic iona les que pueden m e jo ra r aún m ás la c las ificac ión de inm un o g e n ic id a d .
De m an e ra m ás genera l, la lista de m utac iones que sa tis facen Hbc1 (M mut^ P) se puede c la s ifica r en las tres ca tegorías : Ha, H n y HbUHc (T ab la 3), en las que Ha e n riq u e ce las m u ta c io n e s in m unogén icas , H n e n riq u e ce las m uta c io n e s no in m un o g é n ica s . En el caso de B16 y C T26, los tre s ca n d id a to s en el g rupo HbUHc no e ran in m unogén icos , co n tra r ia m e n te a n u e s tra s e xp e c ta tiva s . S in e m b a rg o , si se e lige un um bra l a * m ás rea lis ta pa ra Mwt ta l que a * >> a, e n to n ce s no habría p re d icc io n e s que pud ie ran p ro ba rse pa ra HbUHc.
P rec is ión m áx im a de c la s ifica d o re s de inm un o g e n ic id a d . De acue rd o con la T ab la 1, la ta sa de éx ito p rom ed io para la in m un o g e n ic id a d de p red icc ión en los con ju n to s de da tos co m b in a d o s de B16 y C T 26 fue de l 22 ,7% (= 30 /132). A l
aplicar el umbral más estricto en la puntuación de Mmut (p = 0,1), la precisión de un clasificador de inmunogenicidad aumenta al 60% (= 6/10; Hbc1 en la Tabla 2). Combinando Hbc1 ya sea con la condición Mwt < a o la condición T < t (a = 1, t = 1), la precisión aumenta al 66,7% (= 6/9). El clasificador basado en Ha, que combina ambos criterios, da como resultado una respuesta aditiva, que aumenta la precisión al 75% (= 6/8) (Tabla 2).
Epítopo B16 MUT33. El epítopo de clase Ha que fue clasificado como el más alto por todos los modelos evolutivos (excepto la matriz PAM) en el conjunto de datos B16/CT26 agrupado fue MUT33 de B16 (véase Tabla 3). Un análisis adicional reveló que MUT33 de hecho invocaba una respuesta CD8+ restringida al MHC de clase I y exhibía inmunogenicidad ex vivo contra el epítopo mínimo predicho (datos no mostrados).
Papel de la expresión génica. El gráfico de la fracción de mutaciones inmunogénicas (número de mutaciones inmunogénicas con valores de RPKM por debajo de un umbral determinado sobre el número total de mutaciones inmunogénicas) en función de los valores de RPKM para B16 y CT26 indica que esta relación se estanca algo en valores de RPKM muy bajos ( Figura 9A). Este efecto se observa tanto si se aplica el criterio de Ha como si no. Graficar el porcentaje de mutaciones inmunogénicas para diferentes contenedores de RPKM (Fig. 9B y C) sugiere que los valores de RPKM < ~1 tienen una tasa de éxito algo menor (con o sin la aplicación de la hipótesis de filtrado de Ha), aunque sugestivo, debe tenerse en cuenta que estos resultados están dentro del intervalo de error.
Estudio de epítopos CD8+ publicados. A continuación, nos interesó observar si los antígenos tumorales definidos por células T publicados con sustituciones de un solo aminoácido que provocan una respuesta restringida de c D8+ cumplían con los modelos de inmunogenicidad. De los 17 epítopos que se publicaron (P. Van der Bruggen, V. Stroobant, N. Vigneron, B. Van den Eynde. (Cancer Immun, http://www.cancerimmunity.org/peptide/, 2013)) (Tabla 4), cinco cumplieron los criterios de a (a = 0,7, p = 0,2, t = 0,5), cuatro cumplieron los criterios para HcUHb (a = 2,2, p = 0,4) y dos cumplieron el criterio de Hn (a = 0,6, p = 0,3, t = 1,7).
Tabla 4. Epítopos publicados con sustitución de un solo aminoácido generando respuestas CD8+. Véase el Ejemplo 2 para el listado de referencias. Las mutaciones de la posición de anclaje en el grupo de HbUHc están resaltadas en roo

con ase ena arx eogarmo e proa aes e ,eyena en coor: <,; , < <; > Por lo tanto, las hipótesis de Ha y HcUHb juntas representaron aproximadamente el 50% de los epítopos publicados. Curiosamente, 3 de los 4 epítopos publicados que cumplían la condición de HcUHb (recuadros rojos en la Tabla 4) tenían una puntuación de Mwt mayor que 10 debido a mutaciones en la posición de anclaje (Fig. 10). Dado que el requisito para la hipótesis de HcUHb es que la probabilidad de que cualquier célula presente el epítopo de tipo silvestre durante el desarrollo del organismo se mantenga insignificantemente pequeña, se espera que el umbral de Mwt se mantenga alto, es decir, a * >> a. De hecho, al aumentar a de 0,8 a > 3, los falsos positivos para B16/CT26 en la Tabla 3 desaparecen. Por lo tanto, un umbral más realista para Mwt bajo la hipótesis de HcUHb puede estar entre 3 y 10.
La línea celular MZ7-MEL. Para probar la capacidad estos modelos de inmunogenicidad para predecir epítopos inmunogénicos en un modelo de tumor humano, se exploró la línea celular MZ7-MEL, establecida en 1988 a partir de una metástasis esplénica de un paciente con melanoma maligno (V. Lennerz et al., Proceedings of the National Academy of Sciences of the United States of America 102, 16013 (2005)). El cribado de una biblioteca de ADNc de células MZ7-MEL con células T autólogas reactivas a tumores reveló al menos cinco neoantígenos capaces de generar respuestas CD8+ (V. Lennerz et al., Proceedings of the National Academy of Sciences of the United States of America 102, 16013 (2005)). Este constituye el mayor conjunto de neoantígenos CD8+ derivados de un paciente hasta la fecha. Aplicando estos modelos de inmunogenicidad a estos epítopos, se encontró que tres neoantígenos se clasificaron como epítopos Ha, y un neoantígeno, una mutación de posición de anclaje, se clasificó como un epítopo HbUHc (flechas en la Tabla 4 y Fig. 10). Por lo tanto, cuatro de los cinco epítopos podrían explicarse por nuestros modelos de inmunogenicidad.
Para probar nuestra capacidad para predecir estos epítopos de novo en la línea celular MZ7-MEL, se secuenció el exoma de la línea celular MZ7-MEL (véase los Métodos). En total, se identificaron 743 mutaciones no sinónimas expresadas. Las cinco mutaciones identificadas previamente por Lennerz et al., (V. Lennerz et al., Proceedings of the
National Academy of Sciences of the United States of America 102, 16013 (2005)). Luego se calculó para cada mutación la puntuación T, Mmut y Mwt, informando también el alelo HLA y el epítopo que resultó en la puntuación de consenso mínima del MHC para la mutación dada. Las mutaciones se clasificaron en uno de tres grupos: Ha, HbUHc y Hn usando los umbrales a = 0,8, p = 0,2, t = 0,5 (más la condición RPKM > 0,2), y luego se clasificaron con base en su potencial para ser inmunogénicos, como se explica en la Tabla 3. Se encontró que de 743 mutaciones, 32 mutaciones cumplieron los criterios de Ha (Tabla 5), 12 cumplieron el criterio HbUHc (Tabla 6) y 15 cumplieron el criterio de Hn.
Tabla 5. Mutaciones de células MZ-MEL clasificadas por Ha.32 de las 743 mutaciones no sinónimas expresadas en MZ7-MEL se clasificaron como inmunogénicas para Ha usando los umbrales: a = 0,8; p = 0,2; t = 0,5. La clasificación se basa en un esquema de clasificación de Mmut (descendente) ^ puntuación T (descendente). Los neoantígenos inmunogénicos identificados por Lennerz et al.., están resaltados en amarillo. Además se requería que RPKM excediera 0,2
^MZ7-M EL
^MZ7-M EL
^MZ7-M EL

*La clasificación se basa en Mmut y la puntuación T
** La puntuación T se basa en la Matrix logarítmica de probabilidades WAG250
Tabla 6. Mutaciones de células MZ7-MEL clasificadas como HbUHc. 12 de las 743 mutaciones no sinónimas expresadas en MZ7-MEL se clasificaron como inmunogénicas para HbUHc usando los umbrales: a* = 0,8; p = 0,2; RPKM > 2. La clasificación se basa en un esquema de clasificación de Mmut (descendente) ^ Mwt (ascendente). Los neoantígenos inmunogénicos identificados por Lennerz et al., están resaltados en amarillo.
MZ7-MEL


* La clasificación se basa en Mmut y Mwt
De las 32 mutaciones clasificadas como HA, las tres mutaciones de clase Ha identificadas por Lennerz et al. (SIRT2, SNRPD1 y RBAF600) se clasificaron en las posiciones 2a, 4a y 13ava de 18 clases de clasificación, utilizando un esquema de clasificación de puntuación de Mmut ^ T (véase la Tabla 3). De las 12 mutaciones clasificadas como HbUHc, la cuarta mutación de Lennerz et al. (SNRP116) se clasifica en la 3era posición. Además, si se empleó un umbral más alto (más realista) para Mwt (por ejemplo, a* ~5), entonces la cuarta mutación de Lennerz et al., se clasifica en la 1a posición (junto con una única mutación de posición de anclaje adicional - Tabla 7). Finalmente, se predijo que las cuatro mutaciones de Lennerz et al. tienen el alelo correcto de HLA, la longitud del epítopo y la posición de la mutación de acuerdo con lo informado por los autores.
Tabla 7. Mutaciones de células MZ7-MEL clasificadas como HbUHc. Dos de las 743 expresaron mutaciones no sinónimas expresadas en MZ7-MEL se clasificaron como inmunogénicas para HbUHc utilizando los umbrales: a* = 5, p = 0,2 y RPKM > 2. La clasificación se basa en un esquema de clasificación de Mmut (descendente) ^ Mwt (ascendente). Los neoantígenos inmunogénicos identificados por Lennerz et al. están resaltados en amarillo.

Conclusiones
El análisis de los conjuntos de datos de B16 y CT26 respalda un modelo en el que se confiere inmunogenicidad si se cumplen tres condiciones: se presenta el péptido de tipo silvestre, se presenta el péptido mutado y la sustitución de aminoácidos tiene una puntuación logarítmica de probabilidades suficientemente baja. (Figura 11A). Este modelo de inmunogenicidad, al que se hace referencia como inmunogenicidad de clase I, está respaldado además en el modelo de línea celular de melanoma humano, MZ7-MEL. El modelo MZ7-MEL y los neoantígenos restringidos CD8+ publicados respaldan un segundo modelo, al que se hace referencia como inmunogenicidad de clase II, en el que no se presenta el epítopo de tipo silvestre, pero una sustitución (por ejemplo, en una posición de anclaje) conduce a un aumento significativo en la puntuación de consenso del MHC (> 5 a 10), lo que da como resultado un epítopo nuevo, nunca antes visto (Fig. 11B). Este marco para definir la inmunogenicidad se captura con un esquema de clasificación de tres variables (Mmut, Mwt, puntuación T). Usando este esquema de clasificación se pudieron reducir 743 mutaciones de MZ7-MEL a una listado de 34 mutaciones, con 3 de los 5 epítopos de Lennerz et al., que se clasifican en las 5 clases principales.
La Tabla 7 demuestra que las mutaciones inmunogénicas de clase II son raras. De 743 mutaciones, solo 2 se clasificaron como inmunogénicas de clase II (utilizando un umbral realista para Mwt) en comparación con aproximadamente 30 mutaciones inmunogénicas de clase I. También se observó una escasez de mutaciones de la clase HbUHc en los modelos de melanoma de ratón (Tabla 8). Esta observación subraya la importancia de las mutaciones inmunogénicas de clase I para personalizar las vacunas, que se espera sean las mutaciones de tipo dominante que se encuentran en las muestras de pacientes que pueden utilizarse para la vacunación. Al mismo tiempo, el hecho de que uno de los cinco epítopos encontrados por Lennerz et al., era inmunogénico de clase II puede indicar que las mutaciones inmunogénicas de clase II son más potentes o de alguna manera las selecciona el sistema inmunológico.
Tabla 8. Número de mutaciones candidatas de Ha y HbUHc en diferentes modelos de tumores (a = 0,8, a * = 5, p = 0,2, x = 0,5).
Hi ótesis
roo .
0
O

Ejemplo 2: Materiales y métodos
Los materiales y métodos usados en el Ejemplo 1 se describen a continuación:
A n im a le s
Los ra tones C 57 B L /6 J y B a lb /cJ (C R L ) se m an tu v ie ro n de acue rdo con las p o líticas fe d e ra le s y es ta ta le s sobre in ve s tig a c ió n con a n im a le s en la U n ive rs id ad de M ainz.
C é lu la s pa ra m e lan o m a y m ode lo de tu m o r m urino co lo rrec ta l
La línea ce lu la r de m e lan o m a B 16 F 10 (P rod u c to : A T C C C R L-6475 , N ú m ero de lote: 58078645 ) y la línea ce lu la r de ca rc ino m a de co lon C T 26.W T (P roduc to : A T C C C R L-2638 , N úm ero de lote: 58494154 ) se adq u irie ro n en 2010 a tra v é s de la A m e rica n T ype C u ltu re C o llec tion . S e usaron pases te m p ra n o s (te rce ro , cu a rto ) de cé lu la s para e x p e rim e n to s de se cu e nc iac ión . Las cé lu las se an a liza ro n de fo rm a ru tin a ria para d e te c ta r M ycop la sm a . No se han a u ten tica d o n u e vam e n te las cé lu la s d e sd e su recepc ión . La línea ce lu la r M Z 7 -M E L (e s ta b le c id a en e n e ro de 1988) y una línea ce lu la r B au tó log a tra n s fo rm a d a po r el v iru s de E p s te in -B a rr se o b tuv ie ron del Dr. T ho m a s W o lfe l (D e p a rta m e n to de M ed ic ina , O n co lo g ía H em ato ló g ica , U n ive rs id ad J o h a n n e s G u tenbe rg ).
P é p tid o s s in té tico s
Los pép tido s se a d q u irie ro n a tra v é s de Je rin i P e p tid e T e c h n o lo g ie s (B erlín , A le m a n ia ) o se s in te tiza ro n en la in s ta la c ió n de p é p tid o s T R O N . Los p é p tid o s s in té tico s te n ía n 27 a m in o á c id o s de long itu d con el a m in o á c id o m u tado (M U T ) o de tip o s ilve s tre (W T ) en la pos ic ión 14.
In m u n iza c ió n de ra tones
Se in yec ta ron po r v ía in tra ve n o sa ra tones he m b ra C 57 B L /6 o B a lb /c de la m ism a edad con 20 |jg de A R N m tran sc rito in v itro fo rm u la d o con 20 j l de L ip o fe c ta m in e MR R N A iM A X (In v itro g e n ) en P B S en un vo lu m e n de inyecc ió n to ta l de 200 j l (3 ra tones po r g rupo). Los ra tones se inm un iza ron los d ías 0, 3, 7, 14 y 18. V e in titré s d ías desp ué s de la inyecc ió n in ic ia l, se sa c rifica ro n los ra to n e s y se a is la ron los e sp le n o c ito s pa ra p ru e b a s in m un o ló g ica s (véa se el ensayo E L IS P O T). Las secu e nc ias de A D N que rep resen tan una (m o n o e p íto p o ) o dos m u tac iones (b ie p íto p o ) se cons truye ron u tilizando la se cu e nc ia de 27 a m ino á c id o s (aa ) con la m u tac ión en la pos ic ión 14 y se c lona ron en la cadena de pS T 1-2 B g U T R -A 120 (S. H o ltka m p e t al., B lood 108, 4009 (2006)). La tra n s c r ip c ió n in v itro de esta p lan tilla y la pu rifica c ió n se d e sc rib ie ro n p re v ia m e n te (S. K re ite r e t al., C a n c e r Im m uno logy , Im m u n o th e ra p y 56, 1577 (2007)).
E nsayo Im m u n o S p o t ligado a en z im a s
Se d e sc rib ie ro n p re v ia m e n te el e n sa yo Im m u n o S p o t ligado a enz im a (E L IS P O T ) (S. K re ite r e t al., C a n ce r R esearch 70, 9031 (2010 )) y la gen e ra c ió n de cé lu la s d e n d rítica s d e riva d a s de m édu la ósea s in g é n ica (B M D C ) com o e s tim u la d o re s (L. M B et al., J. Im m uno l. M e th o d s 223, 77 (1999)). P ara el m ode lo B 16F10 , las B M D C se pu lsa ron con pép tido s (6 jg /m l) , con la m uta c ió n ind icada , el p ép tido de tip o s ilve s tre o de co n tro l co rre sp o n d ie n te (V S V -N P ). Para el m ode lo C T26, ad e m á s de la rees tim u lac ión con pép tidos, las B M D C se tran s fe c ta ro n con el A R N m tran sc rito in v itro co rre sp o n d ie n te y ta m b ié n se u tiliza ron para la rees tim u lac ión . P ara el ensayo , se in cu b a ro n 5 x 104 B M D C con 5 x 105 e sp le n oc ito s rec ién a is la d o s en una p laca de m ic ro titu la c ió n recu b ie rta con a n ticu e rp o an ti-IF N y (10 g/m l, c lon A N 18 ; M ab tech ). D e spués de 18 horas a 37 °C, se de tec tó la secrec ión de c itoc inas con un a n ticue rpo an ti-IF N -y (c lon R 4-6A 2 ; M ab tech ). Los núm e ro s de pun tos se con ta ro n y a n a liza ron con el a n a liz a d o r E L IS P O T Im m u n o S p o t® S5 V e rsa , el so ftw a re de a d q u is ic ió n de im á ge n e s Im m u n o C a p tu re MR y el so ftw a re de an á lis is Im m u n o S p o t® V e rs ió n 5. El aná lis is es ta d ís tico se rea lizó m ed ia n te la p rueba t de S tu d e n t y la p rueba de M a n n -W h itn e y (p ru e b a no pa ram é trica ). Las re sp u e s ta s se co n s id e ra ro n s ig n ifica tiva s con un v a lo r p <0,05.
E n sa yo de c ito c in a s in tra ce lu la re s
Se so m e tie ro n a lícu o ta s de los e sp le n oc ito s p re p a ra do s para el ensayo E L IS P O T a aná lis is de p ro d u cc ió n de c itoc inas m ed ia n te c ito m e tría de flu jo in trace lu la r. C on este fin, se se m b ra ro n 2 x 106 e sp le n oc ito s p o r m ue s tra en m ed io de cu ltivo (R P M I FC S al 10% ) sup lem e n ta d o con el inh ib id o r de G o lg i B re fe ld in A (10 jg /m l) en una p laca de 96 pocillos. Las cé lu las de cada an im a l se rees tim u la ro n du ra n te 5 h a 37 °C con 2 x 105 B M D C pu lsa d as con pép tidos o tra n s fe c ta d a s con A R N . D espués de la incubac ión , las cé lu la s se lava ron con PBS, se resu sp e n d ie ro n en 50 j l de P B S y se tiñ e ro n e x tra ce lu la rm e n te con los s ig u ie n te s a n ticu e rp o s a n ti-ra tón du ran te 20 m in a 4 °C: F ITC an ti-C D 4, A P C -C y7 a n ti-C D 8 (B D P h a rm ingen ). D e sp u é s de la in cubac ión , las cé lu la s se lava ron con P B S y p o s te r io rm e n te se resu sp e n d ie ro n en 100 j l de so luc ión de C y to fix /C y to p e rm (B D B io sc ie n ce ) du ran te 20 m in a 4 °C para la p e rm e a b iliza c ió n de la m em b ran a exte rna . D e sp u é s de la p e rm e a b iliza c ió n , las cé lu la s se lava ron con P e rm /T a m p ó n de L avado (B D B iosc ience ), se resu sp e n d ie ro n en 50 j l/m u e s tra en P e rm /T a m p ó n de L avado y se tiñ e ro n in tra ce lu la rm e n te con los s ig u ie n te s a n tic u e rp o s a n ti-ra tó n d u ra n te 30 m in a 4 °C: PE anti-IFN Y, P E -C y7 an ti-T N F -a , A P C a n ti-IL 2 (B D P h a rm ingen ). D e spués de la va r con P e rm /T a m p ó n de Lavado, las cé lu las se resu sp e n d ie ro n en P B S que co n te n ía p a ra fo rm a ld e h íd o al 1% para a n á lis is de c ito m e tría de flu jo . Las m ue s tra s se a n a liza ro n u tiliza n d o un c itó m e tro BD F A C S C a n to MR II y F low Jo (V e rs ión 7.6.3).
S e cu e n c ia c ió n de p ró x im a gen e ra c ió n
E xtracc ión de ác ido nuc le ico : se e x tra je ron A D N y A R N de cé lu la s a g rane l y A D N de te jid o s de ra tón usando el k it de sa n g re y te jid o Q iagen D N e a sy (pa ra A D N ) y el k it Q iagen R N e a sy M ic ro (pa ra A R N ).
Secuenciación del exorna de ADN: la captura del exorna para B16F10, C57BL/6J y CT26.WT y la nueva secuenciación del ADN para Balb/cJ se realizaron por triplicado como se describió anteriormente (JC Castle et al., Exploiting the mutanome for tumor vaccination. Cáncer Research 72, 1081 (2012)). La captura del exorna para la nueva secuenciación del ADN de MZ7-MEL/EBV-B se realizó por duplicado utilizando el ensayo de captura basado en una solución Agilent XT Human all Exon 50 Mb, diseñado para capturar todas las regiones codificantes de proteínas. Se fragmentaron 3 |jg de ADN genómico purificado (ADNg) a 150-200 pb utilizando un dispositivo de ultrasonido Covaris S2. Los fragmentos se repararon en los extremos, se fosforilaron en 5' y se adenilaron en 3' de acuerdo con las instrucciones del fabricante. Se ligaron adaptadores de extremos emparejados específicos de indexación Agilent a los fragmentos de ADNg usando una relación molar de adaptador a ADNg de 10:1. La amplificación previa a la captura de 4 ciclos se realizó utilizando los cebadores de PCR de precaptura de indexación InPE 1.0 y SureSelect de Agilent y la polimerasa Herculasa II. Se hibridaron 500 ng de fragmentos de ADNg enriquecidos con PCR, ligados con adaptador, con cebos de captura del exoma de Agilent durante 24 horas a 65 °C. Los complejos de cebo de ADNg/ARN hibridados se eliminaron utilizando perlas magnéticas recubiertas de estreptavidina, se lavaron y los cebos de ARN se escindieron durante la elución en tampón de elución SureSelect. Los fragmentos de ADNg eluidos se amplificaron por PCR después de la captura durante 10 ciclos usando PCR post-captura de indexación SureSelect y cebadores de PCR de índice y polimerasa Herculasa II. Todas las limpiezas se realizaron con 1,8 veces el volumen de perlas magnéticas Agencourt AMPure XP. Todos los controles de calidad se realizaron con el ensayo Qubit HS de Invitrogen y el tamaño del fragmento se determinó mediante el ensayo de ADN 2100 Bioanalyzer HS de Agilent. Las bibliotecas de ADNg enriquecidas del exoma se agruparon en el cBot usando el kit de agrupación Truseq SR v2.5 usando una biblioteca de 7 pM y se secuenciaron 1x100 pb en HiSeq2000 Illumina usando los kits Truseq SBS.
Perfiles de expresión génica de ARN (ARN-Seq): Se prepararon por duplicado bibliotecas de ADNc de ARNm-seq con código de barras, a partir de 5 jg de ARN total (protocolo de ARNm-seq de Illumina modificado utilizando reactivos NEB). Se aisló ARNm utilizando perlas magnéticas de Oligo (dT) Seramag (Thermo Scientific) y se fragmentaron utilizando cationes divalentes y calor. Los fragmentos resultantes (160-220 pb) se convirtieron en ADNc usando cebadores aleatorios y SuperScriptII (Invitrogen) seguido de síntesis de la segunda cadena usando ADN polimerasa I y RNasaH. El ADNc se reparó en los extremos, se fosforiló en 5' y se adeniló en 3' de acuerdo con las instrucciones del kit de la biblioteca de ARN NEB. Se ligaron adaptadores específicos multiplex de Illumina con una sola proyección en T 3' con ADN ligasa T4 usando una relación molar de 10:1 de adaptador con respecto al inserto de ADNc. Las bibliotecas de ADNc se purificaron y se seleccionaron por tamaño a 300 pb (gel SizeSelect, al 2% E-Gel, Invitrogen). El enriquecimiento, la adición del índice de seis bases de Illumina y las secuencias específicas de la celda de flujo se realizó mediante PCR utilizando la ADN polimerasa Phusion y los cebadores de PCR específicos de Illumina. Todas las limpiezas hasta esta etapa se realizaron con 1,8 veces el volumen de perlas magnéticas Agencourt AMPure XP. Todos los controles de calidad se realizaron con el ensayo Qubit HS de Invitrogen y el tamaño del fragmento se determinó mediante el ensayo de ADN 2100 Bioanalyzer Hs de Agilent. Las bibliotecas de ARN-Seq con código de barras se agruparon y se secuenciaron 50 pb como se describió anteriormente.
Análisis de datos de NGS, expresión génica: las lecturas de la secuencia de salida de las muestras de ARN se procesaron previamente de acuerdo con el protocolo estándar de Illumina, incluido el filtrado para lecturas de baja calidad. Las lecturas de secuencia se alinearon con la secuencia genómica de referencia mm9 (A.T. Chinwalla et al., Nature 420, 520 (2002)) o hg18 (F. Collins, E. Lander, J. Rogers, R. Waterston, I. Conso, Nature 431, 931 (2004)) con Bowite (versión 0.12.5) (B. Langmead, C. Trapnell, M. Pop, S.L. Salzberg, Genome Biol 10, R25 (2009)). Para las alineaciones del genoma se permitieron dos desajustes y solo se informó la mejor alineación ("-v2-mejor"), para las alineaciones de transcripción se usaron los parámetros predeterminados. Las lecturas no alineables con la secuencia genómica se alinearon con una base de datos de todas las posibles secuencias de unión exón-exón de los genes conocidos de UCSC (F. Hsu et al., Bioinformatics 22, 1036 (2006)). Los valores de expresión se determinaron mediante la intersección de las coordenadas de lectura con las de los transcriptos de RefSeq, contando las lecturas de exón y unión superpuestas y normalizando a las unidades de expresión de RPKM (Lecturas que mapean por Kilobase del modelo de exón por millón de lecturas mapeadas) (A. Mortazavi, B.A. Williams, K McCue, L. Schaeffer, B. Wold, Nature methods 5, 621 (2008)).
Análisis de datos de NGS, descubrimiento de mutaciones somáticas: Se identificaron mutaciones somáticas como se describió previamente (J. C. Castle et al., Exploiting the mutanome for tumor vaccination. Cancer Research 72, 1081 (2012)). La secuencia se lee alineada con el genoma de referencia mm9 o hg 18 usando bwa (opciones predeterminadas, versión 0.5.8c) (H. Li, R. Durbin, Bioinformatics 25, 1754 (2009)). Se eliminaron las lecturas ambiguas que mapean en múltiples ubicaciones del genoma. Las mutaciones se identificaron mediante un consenso de dos programas de software: samtools (versión 0.1.8) (H. Li, Bioinformatics 27, 1157 (2011)) y SomaticSniper (A. McKenna et al., Genome Research 20, 1297 (2010)). Para B16F10 y C57BL/6J, también se incluyó GATK (A. McKenna et al., Genome Research 20, 1297 (2010)). A las posibles variaciones somáticas identificadas en todas las réplicas respectivas se les asignó un valor de confianza de "tasa de descubrimiento falso" (FDR) (M. Lower et al., PLoS computational biology 8, e1002714 (2012)) (solo CT26 y MZ7-MEL).
Selección y validación de mutaciones
Los criterios para seleccionar las 50 mutaciones de B16F10 para las pruebas de inmunogenicidad se describieron previamente (J. C. Castle et al., Exploiting the mutanome for tumor vaccination. Cancer Research 72, 1081 (2012)). Estos criterios para las mutaciones incluyeron: (i) presencia en las tres réplicas de B16F10 y ausencia de todos los triplicados de C57BL/6, (ii) ocurrencia en una transcripto de RefSeq, (iii) causar un cambio no sinónimo, (iv) ocurrencia en genes expresados en B16F10 (RPKM mediana en las réplicas > 10, expresión del exón > 0) y (v) para cada mutación, la puntuación de Mmut (véase más abajo) debía ser < 5. De las 59 mutaciones restantes, el producto de los intervalos de cuantiles de la puntuación de MHC de clase I, la puntuación del MHC de clase II y se formó la expresión del transcripto, y se seleccionaron las primeras 50 mutaciones (0,1<Mmut<3,9) para su confirmación mediante PCR (véase (J. C. Castle et al., Exploiting the mutanome for tumor vaccination. Cancer Research 72, 1081 (2012)) para más detalles). Los criterios para las 96 mutaciones CT26.WT seleccionadas para las pruebas de inmunogenicidad se refinaron aún más e incluyeron lo siguiente: (i) presencia en todas las tres réplicas CT26.WT y ausencia de todas las tres réplicas de Balb/cJ, (ii) FDR < 0,05, (iii) ocurrencia en un transcripto génico conocido de UCSC, (iv) causan cambios no sinónimos, (v) no están presentes en la base de datos dbSNP (vi) no están en una región de repetición genómica. De las 493 mutaciones restantes, se definieron ocho grupos de 12 miembros de acuerdo con tres características: puntuación de Mmut (la más baja -[0,1; 1,9] frente a la más alta - [3,9 - 20,3]), compartimiento de la proteína (extracelular, intracelular) y expresión génica (por debajo frente a por encima de la media de 7,1 RPKM), seleccionando mutaciones de acuerdo con un algoritmo codicioso y ajustando los umbrales en consecuencia. 94 de las 96 mutaciones resultantes se confirmaron mediante PCR seguida de secuenciación de Sanger.
Los criterios para seleccionar mutaciones de MZ7-ML para el análisis incluyeron: (i) presencia en dos réplicas de MZ7-MEL y ausencia de dos réplicas de EBV-B autólogas, seguidas de las etapas (ii) a (vi) descritas anteriormente para CT26.WT. La aplicación de las etapas (i) -(vi) redujo la lista inicial de -8000 mutaciones a 743.
Predicción de la unión al MHC y cálculo de la puntuación de Mmut
Las predicciones de unión al MHC se realizan utilizando la herramienta de consenso de recursos de análisis de IEDB (http)://tools.immuneepitope.org/analyze/html/mhc binding.html) (Y. Kim et al., Nucleic Acids Research 40, W525 (2012)), que combina los mejores métodos de predicción de desempeño basados en estudios de evaluación comparativa (HH Lin, S. Ray, S. Tongchusak, EL Reinherz, V. Brusic, BMC Immunology 9, 8 (2008); B. Peters et al. , PLoS computational biology 2, e65 (2006)) de ANN (C. Lundegaard et al., Nucleic Acids Research 36, W509 (2008); M. Nielsen et al., Protein Science 12, 1007 (2009)), SMM (B. Peters, A. Sette, BMC bioinformatics 6, 132 (2005)) y para algunos modelos de alelos también comblib (J. Sidney et al., Immunome Research 4, 2 (2008)). El enfoque de consenso combina las puntuaciones de predicción de todas las herramientas generando un intervalo percentil, que refleja las puntuaciones de predicción de unión del péptido dado contra las puntuaciones de péptidos de cinco millones de péptidos aleatorios del Sw ISSPROT.
Para cada mutación se calcularon las puntuaciones de consenso predichas del MHC para todas las posibles (i) ventanas de secuencia (en las que colocar la mutación), (ii) longitudes de epítopo y (iii) posibles alelos del MHC clase I murino. El mínimo de todas las puntuaciones de consenso del MHC se definió como la puntuación de Mmut.
Cálculo de matrices logarítmicas de probabilidades y puntuación T
Las matrices logarítmicas de probabilidades se pueden estimar a partir de comparaciones de alineación de secuencias de grandes bases de datos de proteínas. Las primeras matrices logarítmicas de probabilidades se basaron en la comparación por pares de secuencias (BLOSUM62 (S. Kreiter et al., Cancer Immunology, Immunotherapy 56, 1577 (2007))) y el método de estimación de máxima parsimonia (MP) (por ejemplo, PAM250 (Mo Dayhoff, R.M. Schwartz, BC Orcutt, A model for evolutionary change. Mo Dayhoff, ed. Atlas of protein sequence and structure Vol.5, 345 (1978)), JTT250 (S.Q. Le, O. Gascuel, Molecular biology and evolution 25, 1307 (2008)) y la matriz de Gonnet (C.C .Dang, V. Lefort, V.S. Le, Q.S. Le, O. Gascuel, Bioinformatics 27, 2758 (2011))). Más recientemente, se desarrollaron métodos basados en la máxima probabilidad (ML) (por ejemplo, VT160 (P.G. Higgs, TK Attwood, Bioinformatics and molecular evolution. (Wiley-Blackwell, 2009)), WAG (S. Whelan, N. Goldman, Molecular biology and evolution 18, 691 (2001)) y LG (V. Lennerz et al., Proceedings of the National Academy of Sciences of the United States of America 102, 16013 (2005))). Dado que ML no se limita a la comparación de secuencias estrechamente relacionadas, como es el caso de los enfoques basados en MP, se espera que este enfoque de estimación sea el más preciso.
El cálculo de la matriz logarítmica de probabilidad se ha descrito en detalle en otra parte (C. C. Dang, V. Lefort, V. S. Le, Q. S. Le, O. Gascuel, Bioinformatics 27, 2758 (2011)). Brevemente, el modelo estándar para la sustitución de aminoácidos asume un modelo Markoviano, continuo en el tiempo y reversible en el tiempo, representado por una matriz de tasa de 20 * 20 Qy, en la que q¡j (i £ j) es el número de sustituciones del aminoácido i por j por unidad de a - 1 ( 4 ■
tiempo, y en la que los elementos diagonales se eligen para satisfacer i* ‘ Q se puede descomponer de manera que Qy = Sy ■ m para i t j, en la que Si,j es una matriz de intercambiabilidad simétrica, m es la probabilidad de observar el aminoácido i (C.C. Dang, V. Leifort, V.S. Le, Q.S. Le, O. Gascuel, Bioinformatics 27, 2758 (2011)).
i = - Y , 7Tí Q í ’
Finalmente, Q se normaliza de manera que ¿ una unidad de tiempo t = 1,0 corresponde a la sustitución
esperada 1,0 por sitio, o una "mutación puntual aceptada" por sitio, denotado por una distancia PAM de 100 (MO Dayhoff, R.M. Schwartz, B.C. Orcutt, A model for evolutionary change. M.O. Dayhoff, ed. Atlas of protein sequence and structure Vol.5, 345 (1978); S.Q. Le, O. Gascuel, Molecular biology and evolution 25, 1307 (2008); C.C. Dang, V. Lefort, V.S. Le, Q.S. Le, O. Gascuel, Bioinformatics 27, 2758 (2011)). La probabilidad de que el aminoácido i sea reemplazado por el aminoácido j después del tiempo t, Pr (i ^ j | t) = Py(t), está dada por la matriz de probabilidad de 20 x 20 P(t) = etQ (con notación que denota exponenciación matricial). La matriz logarítmica de probabilidades niPM) T „ = 101og10 calculada para el tiempo t viene dada por la matriz logarítmica de probabilidades 20 x 20 v J (M. O. Dayhoff, R. M. Schwartz, B. C. Orcutt, A model for evolutionary change. M.O. Dayhoff, ed. Atlas of protein sequence and structure Vol.5, 345 (1978, 1978)). Una media reversible en el tiempo que îPy(t) = ^jPji(t), y por lo tanto Ti,j es simétrica (P. G. Higgs, T. K. Attwood, Bioinformatics and molecular evolution. (Wiley-Blackwell, 2009)).
La puntuación T para la sustitución i ^ j se define en este documento como Tij, y depende del modelo evolutivo y del tiempo t. Se exploraron varios modelos y distancias PAM para la puntuación T, incluidos PAM, BLOSUM62, JTT, VT160, Gonnet, WAG, WAG* y LG (véanse las referencias anteriores). Las cifras de este informe se generaron utilizando una puntuación T basada en el modelo WAG y una distancia PAM de 250. Una distancia PAM tan grande significa que existe una posibilidad sustancial de que el aminoácido cambie (P.G. Higgs, TK Attwood, Bioinformatics and molecular evolution (Wiley-Blackwell, 2009)), y es útil para detectar relaciones distantes entre secuencias en las que los residuos pueden no ser idénticos pero las propiedades fisicoquímicas de los aminoácidos se conservan (M.O. Dayhoff, RM Schwartz, B.C. Orcutt, A model for evolutionary change M.O. Dayhoff, ed. Atlas of protein sequence and structure Vol.5, 345 (1978); P.G. Higgs, T.K. Attwood, Bioinformatics and molecular evolution (Wiley-Blackwell, 2009)).
Usando una estadística de prueba de distribución t, se compararon las puntuaciones T medias de epítopos inmunogénicos frente a no inmunogénicos de la Tabla 3 para la matriz WAG utilizando varias puntuaciones PAM (1, 10, 25, 50, 100, 150, 200 y 250). El análisis de la estadística de prueba mostró que el valor P disminuyó en forma monótona con la distancia PAM, lo que implica que una distancia PAM de 250 era la solución óptima, como era de esperar (datos no mostrados). La clasificación en HA y Hn fue la misma para todas las matrices excepto para la matriz PAM, que es la menos precisa de todos los modelos evolutivos. De todos los modelos evolutivos, el modelo WAG250 resultó en la máxima separación entre los epítopos HA y Hn en la Tabla 3, midiendo la separación con la estadística de prueba: [puntuación T máxima (Ha) - puntuación T mínima (Hn)] /o (puntuación T (Ha), puntuación T (Hn)) (datos no mostrados). La misma estadística de prueba también fue máxima para una distancia PAM 250 en comparación con una distancia más pequeña.
Epítopos CD8+ publicados
Se recogieron epítopos CD8+ con aminoácidos mutados simples de la lista de antígenos tumorales resultantes de mutaciones publicadas por el Cancer Immunity Journal (P. Van der Bruggen, V. Stroobant, N. Vigneron, B. Van den Eynde. (Cancer Immun, http://www.cancerimmunity.org/peptide/, 2013) (http://cancerimmunity.org/peptide/mutations/) (http://cancerimmunity.org/peptide/mutations/). Los alelos de HLA se tomaron de la tabla publicada o del artículo original si este último era más preciso. Las referencias enumeradas en la Tabla 4 son las siguientes: (1) Lennerz et al., PNAS 102 (44), págs. 16013-16018 (2005); (2) Karanikas et al., Cancer Res 61 (9), págs. 3718-3724 (2001); (3) Sensi et al., Cancer Res 65 (2), págs. 632-640 (2005); (4) Linard et al., J. Immunol 168 (9), págs. 4802-4808 (2002); (5) Zorn et al., Eur. J. Immunol 29 (2), págs. 592-601 (1999); (6) Graf et al., Blood 109 (7), págs. 2985-2988 (2007) ); (7 ) Robbins et al., J. Exp. Med 183 (3), págs. 1185-1192 (1996); (8) Vigneron et al., Cancer Immun 2, pág. 9 (2002); (9 ) Echchakir et al., Cancer Res 61 (10), págs 4078-4083 (2001); (10) Hogan et al., Cancer Res 58 (22), págs. 5144 5150 (1998); (11) Ito et al., En t. J. Cancer 120 (12), págs. 2618-2624 (2007); (12) Wolfel et al., Science 269 (5228), págs. 1281-1284 (1995); (13) Gjertsen et al., En t. J. Cancer 72 (5), págs. 784-790 (1997).
Ejemplo 3: Ejemplo de un esquema para ponderar las puntuaciones de mutación para mejorar la priorización de mutaciones inmunogénicas
El ARN que se inyecta en la célula, una vez traducido y escindido en péptidos cortos, puede presentarse en diferentes tipos de HLA dentro de la célula. Por lo tanto, es lógico pensar que cuantos más tipos de HLA se predice que tengan una puntuación de consenso del MHC baja (o similar), es más probable que una mutación determinada sea inmunogénica, ya que potencialmente puede mostrarse en más de un tipo de HLA en paralelo. Por lo tanto, sopesar las mutaciones por el número de tipos de HLA para los que la mutación se clasifica como HA y/o HBUHC o incluso sopesar cada mutación simplemente por el número de tipos de HLA que tienen una puntuación de Mmut baja puede mejorar la clasificación de inmunogenicidad. En la solución más general, cuando se inyecta un ARN de 27 mer o péptido en la célula, no solo existe la libertad de seleccionar el tipo de HLA, sino también la longitud del péptido y la posición de la mutación dentro de este péptido. Por lo tanto, se pueden escanear todos los tipos de HLA posibles, todas las longitudes de ventana posibles y todas las posiciones posibles para la mutación dentro de la ventana y calcular el número de soluciones (por mutación dada) que se clasifican como Ha y/o HbUHc (Fig.12). Este puede ser un factor de ponderación importante para la priorización de mutaciones para seleccionar los epítopos más eficaces para la vacunación. En la Figura 13 se muestra un ejemplo de un diagrama de dispersión de todas estas soluciones en función de Mmut y AM = Mmut -Mwt.
Claims (26)
1. Un método implementado por ordenador para predecir péptidos modificados inmunogénicos que comprenden modificaciones de aminoácidos, siendo dichas modificaciones sustituciones, comprendiendo el método las etapas: a) determinar una puntuación para la unión de un péptido modificado a una o más moléculas del MHC,
b) determinar una puntuación para la unión del péptido no modificado a la una o más moléculas del MHC, y c) determinar una puntuación para la unión del péptido modificado cuando está presente en un complejo MHC-péptido a uno o más receptores de células T, que comprende determinar una puntuación para las similitudes químicas y físicas entre los aminoácidos no modificados y modificados, en la que la puntuación de las similitudes químicas y físicas se determina sobre la base de la probabilidad de que los aminoácidos se intercambien en la naturaleza, en la que cuanto más frecuentemente se intercambian los aminoácidos en la naturaleza, más similares se consideran los aminoácidos, en la que se determinan las similitudes químicas y físicas utilizando matrices de sustitución,
en el que el péptido no modificado y el péptido modificado son idénticos pero para la modificación o modificaciones, en el que el péptido no modificado y el péptido modificado tienen una longitud de 8 a 15 aminoácidos, y en el que se predice que el péptido modificado es inmunogénico si (i) el péptido no modificado tiene una puntuación para unirse a una o más moléculas del MHC que satisfacen un umbral que indica la unión a una o más moléculas del MHC y (ii) el péptido modificado tiene una puntuación para unirse a una o más moléculas del MHC que satisfacen un umbral que indica la unión a una o más moléculas del MHC y (iii) los aminoácidos no modificados y modificados tienen una puntuación para las similitudes químicas y físicas que satisfacen un umbral que indica la diferencia química y física.
2. El método de la reivindicación 1, en el que el péptido modificado comprende un fragmento de una proteína modificada, comprendiendo dicho fragmento la modificación o modificaciones presentes en la proteína.
3. El método de la reivindicación 1 o 2, en el que el péptido no modificado tiene el aminoácido de línea germinal en la posición o posiciones correspondientes a la posición o posiciones de la modificación o modificaciones en el péptido modificado.
4. El método de una cualquiera de las reivindicaciones 1 a 3, en el que el péptido no modificado y el péptido modificado tienen una longitud de 8 a 12 aminoácidos.
5. El método de una cualquiera de las reivindicaciones 1 a 4, en el que una o más moléculas del MHC comprenden diferentes tipos de moléculas del MHC, en particular diferentes alelos del MHC.
6. El método de una cualquiera de las reivindicaciones 1 a 5, en el que una o más moléculas del MHC son moléculas del MHC de clase I y/o moléculas del MHC de clase II.
7. El método de una cualquiera de las reivindicaciones 1 a 6, en el que la puntuación para la unión a una o más moléculas del MHC se determina mediante un proceso que comprende una comparación de secuencia con una base de datos de motivos de unión al MHC.
8. El método de una cualquiera de las reivindicaciones 1 a 7, en el que tanto la etapa a) como la etapa b) comprenden determinar si dicha puntuación satisface un umbral predeterminado para unirse a una o más moléculas del m Hc , y en el que el umbral aplicado en la etapa a) es diferente al umbral aplicado en la etapa b).
9. El método de la reivindicación 8, en el que el umbral predeterminado de unión a una o más moléculas del MHC refleja una probabilidad de unión a una o más moléculas del MHC.
10. El método de una cualquiera de las reivindicaciones 1 a 9, en el que las similitudes químicas y físicas se determinan usando matrices logarítmicas de probabilidades con base en la evolución.
11. El método de una cualquiera de las reivindicaciones 1 a 10, en el que la modificación no está en una posición de anclaje para unirse a una o más moléculas del MHC.
12. El método de una cualquiera de las reivindicaciones 1 a 11, que comprende realizar la etapa a) en dos o más péptidos modificados diferentes, comprendiendo dichos dos o más péptidos modificados diferentes la misma modificación o modificaciones.
13. El método de la reivindicación 12, en el que los dos o más péptidos modificados diferentes que comprenden la misma modificación o modificaciones comprenden fragmentos diferentes de una proteína modificada, comprendiendo dichos fragmentos diferentes la misma modificación o modificaciones presentes en la proteína.
14. El método de la reivindicación 12 o 13, en el que los dos o más péptidos modificados diferentes que comprenden la misma modificación o modificaciones comprende todos los fragmentos de unión al MHC potenciales de una proteína modificada, comprendiendo dichos fragmentos la misma modificación o modificaciones presentes en la proteína.
15. El método de cualquiera de las reivindicaciones 12 a 14, que comprende además seleccionar (el, los) péptido o péptidos de los dos o más péptidos modificados diferentes que comprenden la misma modificación o modificaciones que tienen una probabilidad o tienen la probabilidad más alta de unirse a una o más moléculas del MHC.
16. El método de una cualquiera de las reivindicaciones 12 a 15, en el que los dos o más péptidos modificados diferentes que comprenden la misma modificación o modificaciones difieren en la longitud y/o posición de la modificación o modificaciones.
17. El método de una cualquiera de las reivindicaciones 1 a 16, que comprende realizar la etapa a) y opcionalmente uno o ambas etapas b) y c) en dos o más péptidos modificados diferentes.
18. El método de la reivindicación 17, en el que dichos dos o más péptidos modificados diferentes comprenden la misma modificación o modificaciones y/o comprenden modificaciones diferentes.
19. El método de la reivindicación 18, en el que las diferentes modificaciones están presentes en la misma y/o en diferentes proteínas.
20. El método de una cualquiera de las reivindicaciones 12 a 19, que comprende comparar las puntuaciones de dos o más de dichos péptidos modificados diferentes.
21. El método de la reivindicación 20, en el que una puntuación para la unión del péptido modificado a una o más moléculas del MHC se pondera más alta que una puntuación para las similitudes químicas y físicas entre los aminoácidos no modificados y modificados, y una puntuación para las similitudes químicas y físicas entre los aminoácidos no modificados y modificados se ponderan más alto que una puntuación para la unión del péptido no modificado a una o más moléculas del MHC.
22. El método de una cualquiera de las reivindicaciones 1 a 21, que comprende además identificar mutaciones no sinónimas en una o más regiones codificantes de proteínas.
23. El método de una cualquiera de las reivindicaciones 1 a 22, en el que las modificaciones se identifican secuenciando parcial o completamente el genoma o transcriptoma de una o más células tales como una o más células cancerosas y opcionalmente una o más células no cancerosas e identificando mutaciones en una o más regiones codificantes de proteínas.
24. El método de la reivindicación 22 o 23, en el que dichas mutaciones son mutaciones somáticas.
25. El método de una cualquiera de las reivindicaciones 22 a 24, en el que dichas mutaciones son mutaciones cancerosas.
26. Un método para proporcionar una vacuna que comprende las etapas:
a) identificar (a) modificación o modificaciones o (a) péptido o péptidos modificados que se predice que son inmunogénicos mediante el método de una cualquiera de las reivindicaciones 1 a 25, y
b) proporcionar una vacuna que comprende un péptido o polipéptido que comprende la modificación o modificaciones o un péptido o péptidos modificados que se predice que son inmunogénicos, o un ácido nucleico que codifica el péptido o polipéptido.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/EP2013/001400 WO2014180490A1 (en) | 2013-05-10 | 2013-05-10 | Predicting immunogenicity of t cell epitopes |
| PCT/EP2014/001232 WO2014180569A1 (en) | 2013-05-10 | 2014-05-07 | Predicting immunogenicity of t cell epitopes |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2871384T3 true ES2871384T3 (es) | 2021-10-28 |
Family
ID=48539078
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES14722117T Active ES2871384T3 (es) | 2013-05-10 | 2014-05-07 | Predicción de inmunogenicidad de los epítopos de células T |
Country Status (24)
| Country | Link |
|---|---|
| US (2) | US11222711B2 (es) |
| EP (2) | EP3895727A1 (es) |
| JP (4) | JP6710634B2 (es) |
| KR (1) | KR102399419B1 (es) |
| CN (3) | CN113219179B (es) |
| AU (4) | AU2014264943B2 (es) |
| CA (1) | CA2911945C (es) |
| CY (1) | CY1124176T1 (es) |
| DK (1) | DK2994159T3 (es) |
| ES (1) | ES2871384T3 (es) |
| HR (1) | HRP20210773T1 (es) |
| HU (1) | HUE055146T2 (es) |
| IL (2) | IL242281B (es) |
| LT (1) | LT2994159T (es) |
| MX (1) | MX382293B (es) |
| PL (1) | PL2994159T3 (es) |
| PT (1) | PT2994159T (es) |
| RS (1) | RS61868B1 (es) |
| RU (2) | RU2724370C2 (es) |
| SG (1) | SG11201508816RA (es) |
| SI (1) | SI2994159T1 (es) |
| SM (1) | SMT202100300T1 (es) |
| WO (2) | WO2014180490A1 (es) |
| ZA (1) | ZA201508048B (es) |
Families Citing this family (70)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014180490A1 (en) * | 2013-05-10 | 2014-11-13 | Biontech Ag | Predicting immunogenicity of t cell epitopes |
| CN113791220A (zh) | 2014-09-10 | 2021-12-14 | 豪夫迈·罗氏有限公司 | 免疫原性突变体肽筛选平台 |
| WO2016128060A1 (en) * | 2015-02-12 | 2016-08-18 | Biontech Ag | Predicting t cell epitopes useful for vaccination |
| EA201792501A1 (ru) | 2015-05-13 | 2018-10-31 | Эйдженус Инк. | Вакцины для лечения и профилактики рака |
| AU2016341309A1 (en) | 2015-10-22 | 2018-06-07 | Modernatx, Inc. | Cancer vaccines |
| ES2970865T3 (es) | 2015-12-16 | 2024-05-31 | Gritstone Bio Inc | Identificación, fabricación y uso de neoantígenos |
| IL260030B2 (en) | 2016-01-08 | 2025-12-01 | Nykode Therapeutics ASA | Therapeutic anticancer neoepitope vaccine |
| US20170224796A1 (en) | 2016-02-05 | 2017-08-10 | Xeme Biopharma Inc. | Therapeutic Cancer Vaccine Containing Tumor-Associated Neoantigens and Immunostimulants in a Delivery System |
| JP6710004B2 (ja) * | 2016-03-15 | 2020-06-17 | Repertoire Genesis株式会社 | 免疫療法のためのモニタリングまたは診断ならびに治療剤の設計 |
| JP2019513373A (ja) * | 2016-03-31 | 2019-05-30 | ネオン セラピューティクス, インコーポレイテッド | ネオ抗原およびその使用方法 |
| GB201607521D0 (en) * | 2016-04-29 | 2016-06-15 | Oncolmmunity As | Method |
| US20190237158A1 (en) * | 2016-08-31 | 2019-08-01 | Medgenome, Inc. | Methods to analyze genetic alterations in cancer to identify therapeutic peptide vaccines and kits therefore |
| US10350280B2 (en) * | 2016-08-31 | 2019-07-16 | Medgenome Inc. | Methods to analyze genetic alterations in cancer to identify therapeutic peptide vaccines and kits therefore |
| KR101925040B1 (ko) * | 2016-11-11 | 2018-12-04 | 한국과학기술정보연구원 | Mhc와 펩타이드 사이의 결합 친화성 예측 방법 및 장치 |
| CN110651189B (zh) | 2017-03-03 | 2024-10-25 | 特雷斯生物有限公司 | 肽疫苗 |
| EA201992416A1 (ru) | 2017-04-10 | 2020-02-25 | Имматикс Байотекнолоджиз Гмбх | Пептиды и комбинации пептидов для применения в иммунотерапии лейкозов и других видов рака |
| SG11201909058WA (en) | 2017-04-10 | 2019-10-30 | Immatics Biotechnologies Gmbh | Peptides and combination of peptides for use in immunotherapy against leukemias and other cancers |
| CA3060569A1 (en) * | 2017-04-19 | 2018-10-25 | Gritstone Oncology, Inc. | Neoantigen identification, manufacture, and use |
| EP3933408A1 (en) | 2017-05-30 | 2022-01-05 | Nant Holdings IP LLC | Circulating tumor cell enrichment using neoepitopes |
| WO2018224166A1 (en) | 2017-06-09 | 2018-12-13 | Biontech Rna Pharmaceuticals Gmbh | Methods for predicting the usefulness of disease specific amino acid modifications for immunotherapy |
| CN109081867B (zh) * | 2017-06-13 | 2021-05-28 | 北京大学 | 癌症特异性tcr及其分析技术和应用 |
| WO2019036043A2 (en) * | 2017-08-16 | 2019-02-21 | Medgenome Inc. | METHOD FOR GENERATING A COCKTAIL OF PERSONALIZED ANTICANCER VACCINES FROM TUMOR DERIVED GENETIC MODIFICATIONS FOR THE TREATMENT OF CANCER |
| US20200363414A1 (en) * | 2017-09-05 | 2020-11-19 | Gritstone Oncology, Inc. | Neoantigen Identification for T-Cell Therapy |
| EP3688165A4 (en) * | 2017-09-25 | 2021-09-29 | Nant Holdings IP, LLC | VALIDATION OF THE PRESENTATION OF NEOEPITOPES |
| EP4576103A3 (en) * | 2017-10-10 | 2025-08-27 | Gritstone bio, Inc. | Neoantigen identification using hotspots |
| CN111630602A (zh) * | 2017-11-22 | 2020-09-04 | 磨石肿瘤生物技术公司 | 减少新抗原的接合表位呈递 |
| EP3743102A1 (en) | 2018-01-26 | 2020-12-02 | Nantcell, Inc. | Compositions and methods for combination cancer vaccine and immunologic adjuvant therapy |
| WO2019147921A1 (en) | 2018-01-26 | 2019-08-01 | Nantcell, Inc. | Rapid verification of virus particle production for a personalized vaccine |
| CN108491689B (zh) * | 2018-02-01 | 2019-07-09 | 杭州纽安津生物科技有限公司 | 基于转录组的肿瘤新抗原鉴定方法 |
| EP3759131A4 (en) * | 2018-02-27 | 2021-12-01 | Gritstone bio, Inc. | NEOANTIGEN IDENTIFICATION WITH PAN ALLELE MODELS |
| MA52363A (fr) | 2018-04-26 | 2021-03-03 | Agenus Inc | Compositions peptidiques de liaison à une protéine de choc thermique (hsp) et leurs méthodes d'utilisation |
| JP7642530B2 (ja) | 2018-09-04 | 2025-03-10 | トレオス バイオ リミテッド | ペプチドワクチン |
| MX2021003654A (es) | 2018-09-27 | 2021-05-28 | Nykode Therapeutics AS | Metodo para seleccionar neoepitopes. |
| CN109295097B (zh) * | 2018-09-30 | 2020-09-25 | 北京鼎成肽源生物技术有限公司 | 一种mrfft2细胞 |
| CN109294997B (zh) * | 2018-09-30 | 2020-09-25 | 北京鼎成肽源生物技术有限公司 | 一种lrfft1细胞 |
| WO2020101037A1 (ja) * | 2018-11-16 | 2020-05-22 | 株式会社Tnpパートナーズ | オーダーメイド医療基幹システム |
| BR112021005353A2 (pt) * | 2018-11-21 | 2021-06-15 | Nec Corporation | método e sistema de direcionamento de epitopos para imunoterapia baseada em neoantígeno |
| CN111621564B (zh) * | 2019-02-28 | 2022-03-25 | 武汉大学 | 一种鉴定有效肿瘤新抗原的方法 |
| TWI894138B (zh) * | 2019-03-06 | 2025-08-21 | 美商西雅圖項目公司 | 利用ii 類mhc 模型鑑別新抗原 |
| WO2020208555A1 (en) * | 2019-04-09 | 2020-10-15 | Eth Zurich | Systems and methods to classify antibodies |
| WO2020223361A1 (en) * | 2019-04-30 | 2020-11-05 | Memorial Sloan Kettering Cancer Center | System and methods for identification of non-immunogenic epitopes and determining efficacy of epitopes in therapeutic regimens |
| CN110322925B (zh) * | 2019-07-18 | 2021-09-03 | 杭州纽安津生物科技有限公司 | 一种预测融合基因产生新生抗原的方法 |
| KR102184720B1 (ko) * | 2019-10-11 | 2020-11-30 | 한국과학기술원 | 암 세포 표면의 mhc-펩타이드 결합도 예측 방법 및 분석 장치 |
| CN111429965B (zh) * | 2020-03-19 | 2023-04-07 | 西安交通大学 | 一种基于多连体特征的t细胞受体对应表位预测方法 |
| KR102425492B1 (ko) * | 2020-04-27 | 2022-07-26 | 한림대학교 산학협력단 | Sars-cov-2 바이러스에 대한 에피토프 기반 펩타이드 백신의 개발 방법 |
| CN116710115A (zh) | 2020-11-20 | 2023-09-05 | 思维疗法股份有限公司 | 用于优化的肽疫苗的组合物和方法 |
| US11161892B1 (en) | 2020-12-07 | 2021-11-02 | Think Therapeutics, Inc. | Method of compact peptide vaccines using residue optimization |
| US11058751B1 (en) | 2020-11-20 | 2021-07-13 | Think Therapeutics, Inc. | Compositions for optimized RAS peptide vaccines |
| US11421015B2 (en) | 2020-12-07 | 2022-08-23 | Think Therapeutics, Inc. | Method of compact peptide vaccines using residue optimization |
| AU2022233019A1 (en) * | 2021-03-11 | 2023-09-28 | INSERM (Institut National de la Santé et de la Recherche Médicale) | Tumor neoantigenic peptides |
| US20250352577A1 (en) * | 2021-03-11 | 2025-11-20 | Mnemo Therapeutics | Tumor neoantigenic peptides and uses thereof |
| KR20240006721A (ko) * | 2021-03-11 | 2024-01-15 | 엥스띠뛰 퀴리 | 막 형질 전환 네오 안티젠 펩타이드 |
| KR102769935B1 (ko) * | 2021-03-30 | 2025-02-19 | 한국과학기술원 | 펩타이드-mhc에 대한 t 세포 활성의 예측 방법 및 분석장치 |
| US11464842B1 (en) | 2021-04-28 | 2022-10-11 | Think Therapeutics, Inc. | Compositions and method for optimized peptide vaccines using residue optimization |
| US20240366754A1 (en) | 2021-10-15 | 2024-11-07 | BioNTech SE | Pharmaceutical compositions for delivery of viral antigens and related methods |
| WO2023089203A1 (en) * | 2021-11-22 | 2023-05-25 | Centre Hospitalier Universitaire Vaudois | Methods for predicting immunogenicity of mutations or neoantigenic peptides in tumors |
| US20250345416A1 (en) | 2022-01-27 | 2025-11-13 | BioNTech SE | Pharmaceutical compositions for delivery of herpes simplex virus antigens and related methods |
| EP4519675A4 (en) * | 2022-05-03 | 2026-04-08 | 3T Biosciences Inc | T-LYMPHOCYTE TARGET DISCOVERY |
| CN115171787A (zh) * | 2022-07-08 | 2022-10-11 | 腾讯科技(深圳)有限公司 | 抗原预测方法、装置、设备以及存储介质 |
| WO2024013330A1 (en) * | 2022-07-14 | 2024-01-18 | Universität Zürich | Immunogenic personalised cancer vaccines |
| EP4306125A1 (en) * | 2022-07-14 | 2024-01-17 | Universität Zürich | Immunogenic personalised cancer vaccines |
| KR102611717B1 (ko) * | 2022-11-08 | 2023-12-08 | 주식회사 제로믹스 | 면역원성 에피토프를 예측하는 방법 및 이를 이용한 장치 |
| KR102936738B1 (ko) * | 2022-11-08 | 2026-03-10 | 인바이츠지노믹스 주식회사 | 신생항원 에피토프의 면역원성을 예측하는 방법 및 이를 이용한 장치 |
| WO2025030097A2 (en) | 2023-08-03 | 2025-02-06 | BioNTech SE | Pharmaceutical compositions for delivery of herpes simplex virus antigens and related methods |
| WO2025030165A1 (en) | 2023-08-03 | 2025-02-06 | BioNTech SE | Pharmaceutical compositions for delivery of herpes simplex virus antigens and related methods |
| WO2025128926A1 (en) | 2023-12-13 | 2025-06-19 | Amazon Technologies, Inc. | Methods of identifying and treating individuals with elevated cancer risk |
| US20250197924A1 (en) | 2023-12-15 | 2025-06-19 | Amazon Technologies, Inc. | Methods for selection and combination of sequencing results from biological samples for neoantigen scoring |
| WO2025202937A1 (en) | 2024-03-26 | 2025-10-02 | BioNTech SE | Cancer vaccines |
| WO2026072916A1 (en) | 2024-09-30 | 2026-04-02 | Amazon Technologies, Inc. | Structural variant detection in circulating tumor dna |
| WO2026073127A1 (en) | 2024-09-30 | 2026-04-02 | Amazon Technologies, Inc. | Dual assay to boost accuracy of detected actionable variants in liquid biopsy |
Family Cites Families (108)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4897355A (en) | 1985-01-07 | 1990-01-30 | Syntex (U.S.A.) Inc. | N[ω,(ω-1)-dialkyloxy]- and N-[ω,(ω-1)-dialkenyloxy]-alk-1-yl-N,N,N-tetrasubstituted ammonium lipids and uses therefor |
| US5804381A (en) | 1996-10-03 | 1998-09-08 | Cornell Research Foundation | Isolated nucleic acid molecule encoding an esophageal cancer associated antigen, the antigen itself, and uses thereof |
| US5703055A (en) | 1989-03-21 | 1997-12-30 | Wisconsin Alumni Research Foundation | Generation of antibodies through lipid mediated DNA delivery |
| US5264618A (en) | 1990-04-19 | 1993-11-23 | Vical, Inc. | Cationic lipids for intracellular delivery of biologically active molecules |
| US6235525B1 (en) | 1991-05-23 | 2001-05-22 | Ludwig Institute For Cancer Research | Isolated nucleic acid molecules coding for tumor rejection antigen precursor MAGE-3 and uses thereof |
| US5824315A (en) | 1993-10-25 | 1998-10-20 | Anergen, Inc. | Binding affinity of antigenic peptides for MHC molecules |
| UA56132C2 (uk) | 1995-04-25 | 2003-05-15 | Смітклайн Бічем Байолоджікалс С.А. | Композиція вакцини (варіанти), спосіб стабілізації qs21 відносно гідролізу (варіанти), спосіб приготування композиції вакцини |
| US7422902B1 (en) | 1995-06-07 | 2008-09-09 | The University Of British Columbia | Lipid-nucleic acid particles prepared via a hydrophobic lipid-nucleic acid complex intermediate and use for gene transfer |
| EP0871747A1 (en) | 1996-01-02 | 1998-10-21 | Chiron Viagene, Inc. | Immunostimulation mediated by gene-modified dendritic cells |
| JP4108126B2 (ja) | 1996-04-26 | 2008-06-25 | リュクスウニヴェルシテート テ レイデン | T細胞ペプチド・エピトープの選択と産生方法および選択したエピトープを組込むワクチン |
| CN1138533C (zh) | 1996-09-13 | 2004-02-18 | 利普森有限公司 | 脂质体 |
| EP0839912A1 (en) | 1996-10-30 | 1998-05-06 | Instituut Voor Dierhouderij En Diergezondheid (Id-Dlo) | Infectious clones of RNA viruses and vaccines and diagnostic assays derived thereof |
| US6074645A (en) | 1996-11-12 | 2000-06-13 | City Of Hope | Immuno-reactive peptide CTL epitopes of human cytomegalovirus |
| TR200001253T2 (tr) | 1997-11-06 | 2000-11-21 | Roche Diagnostics Gmbh | Tümöre özel antijenler |
| US6432925B1 (en) | 1998-04-16 | 2002-08-13 | John Wayne Cancer Institute | RNA cancer vaccine and methods for its use |
| EP1117430A1 (en) | 1998-10-05 | 2001-07-25 | Genzyme Corporation | Genes differentially expressed in cancer cells to design cancer vaccines |
| CN100352921C (zh) | 1999-05-06 | 2007-12-05 | 威克福雷大学 | 用于鉴定引起免疫反应的抗原的组合物和方法 |
| EP1261704B1 (en) | 1999-11-30 | 2009-07-01 | Ludwig Institute For Cancer Research | Isolated nucleic acid molecules encoding cancer associated antigens, the antigens per se, and uses thereof |
| US7462354B2 (en) | 1999-12-28 | 2008-12-09 | Pharmexa Inc. | Method and system for optimizing minigenes and peptides encoded thereby |
| EP1242108B1 (en) | 1999-12-28 | 2007-07-11 | Pharmexa Inc. | Optimized minigenes and peptides encoded thereby |
| WO2001093902A2 (en) | 2000-06-07 | 2001-12-13 | Biosynexus Incorporated | Immunostimulatory rna/dna hybrid molecules |
| US6472176B2 (en) | 2000-12-14 | 2002-10-29 | Genvec, Inc. | Polynucleotide encoding chimeric protein and related vector, cell, and method of expression thereof |
| WO2002069232A2 (en) * | 2001-02-19 | 2002-09-06 | Merck Patent Gmbh | Method for identification of t-cell epitopes and use for preparing molecules with reeduced immunogenicity |
| ES2340499T3 (es) | 2001-06-05 | 2010-06-04 | Curevac Gmbh | Arnm de antigeno tumoral estabilizado con un contenido de g/c aumentado. |
| DE10162480A1 (de) | 2001-12-19 | 2003-08-07 | Ingmar Hoerr | Die Applikation von mRNA für den Einsatz als Therapeutikum gegen Tumorerkrankungen |
| AUPS054702A0 (en) | 2002-02-14 | 2002-03-07 | Immunaid Pty Ltd | Cancer therapy |
| WO2003106692A2 (en) | 2002-06-13 | 2003-12-24 | Merck Patent Gmbh | Methods for the identification of all-antigens and their use for cancer therapy and transplantation |
| DE10229872A1 (de) | 2002-07-03 | 2004-01-29 | Curevac Gmbh | Immunstimulation durch chemisch modifizierte RNA |
| WO2005023295A2 (en) * | 2003-09-10 | 2005-03-17 | De Staat Der Nederlanden, Vert. Door De Minister Van Vws | Naturally processed immunodominant peptides derived from neisseria meningitidis porin a protein and their use |
| DE10344799A1 (de) | 2003-09-26 | 2005-04-14 | Ganymed Pharmaceuticals Ag | Identifizierung von Oberflächen-assoziierten Antigenen für die Tumordiagnose und -therapie |
| WO2005039533A1 (en) | 2003-10-15 | 2005-05-06 | Medigene Ag | Method of administering cationic liposomes comprising an active drug |
| PL1692516T3 (pl) | 2003-10-24 | 2011-05-31 | Immunaid Pty Ltd | Sposób terapii |
| US7303881B2 (en) | 2004-04-30 | 2007-12-04 | Pds Biotechnology Corporation | Antigen delivery compositions and methods of use |
| DE102004023187A1 (de) | 2004-05-11 | 2005-12-01 | Ganymed Pharmaceuticals Ag | Identifizierung von Oberflächen-assoziierten Antigenen für die Tumordiagnose und -therapie |
| DE102004057303A1 (de) | 2004-11-26 | 2006-06-01 | Merck Patent Gmbh | Stabile Kristallmodifikationen von DOTAP Chlorid |
| CA2592972A1 (en) | 2004-12-29 | 2006-07-06 | Mannkind Corporation | Methods to bypass cd+4 cells in the induction of an immune response |
| DK2439273T3 (da) | 2005-05-09 | 2019-06-03 | Ono Pharmaceutical Co | Humane monoklonale antistoffer til programmeret død-1(pd-1) og fremgangsmåder til behandling af cancer ved anvendelse af anti-pd-1- antistoffer alene eller i kombination med andre immunterapeutika |
| PT1907424E (pt) | 2005-07-01 | 2015-10-09 | Squibb & Sons Llc | Anticorpos monoclonais humanos para o ligando 1 de morte programada (pd-l1) |
| PL2578685T3 (pl) | 2005-08-23 | 2020-01-31 | The Trustees Of The University Of Pennsylvania | Rna zawierający zmodyfikowane nukleozydy i sposoby jego zastosowania |
| DE102005041616B4 (de) | 2005-09-01 | 2011-03-17 | Johannes-Gutenberg-Universität Mainz | Melanom-assoziierte MHC Klasse I assoziierte Oligopeptide und für diese kodierende Polynukleotide und deren Verwendungen |
| EP1762575A1 (en) | 2005-09-12 | 2007-03-14 | Ganymed Pharmaceuticals AG | Identification of tumor-associated antigens for diagnosis and therapy |
| JP2009532664A (ja) | 2006-02-27 | 2009-09-10 | アリゾナ・ボード・オブ・リージェンツ・フォー・アンド・オン・ビハーフ・オブ・アリゾナ・ステイト・ユニバーシティ | 癌の治療のためのノボペプチドの同定および使用 |
| PL1989544T3 (pl) * | 2006-03-02 | 2012-01-31 | Antitope Ltd | Testy na komórkach T |
| US20090304711A1 (en) | 2006-09-20 | 2009-12-10 | Drew Pardoll | Combinatorial Therapy of Cancer and Infectious Diseases with Anti-B7-H1 Antibodies |
| DE102006060824B4 (de) | 2006-12-21 | 2011-06-01 | Johannes-Gutenberg-Universität Mainz | Nachweis von individuellen T-Zell-Reaktionsmustern gegen Tumor-assoziierte Antigene (TAA) in Tumorpatienten als Basis für die individuelle therapeutische Vakzinierung von Patienten |
| KR101523391B1 (ko) | 2006-12-27 | 2015-05-27 | 에모리 유니버시티 | 감염 및 종양 치료를 위한 조성물 및 방법 |
| US8877206B2 (en) | 2007-03-22 | 2014-11-04 | Pds Biotechnology Corporation | Stimulation of an immune response by cationic lipids |
| US8140270B2 (en) | 2007-03-22 | 2012-03-20 | National Center For Genome Resources | Methods and systems for medical sequencing analysis |
| BR122017025062B8 (pt) | 2007-06-18 | 2021-07-27 | Merck Sharp & Dohme | anticorpo monoclonal ou fragmento de anticorpo para o receptor de morte programada humano pd-1, polinucleotídeo e composição compreendendo o referido anticorpo ou fragmento |
| EP2060583A1 (en) | 2007-10-23 | 2009-05-20 | Ganymed Pharmaceuticals AG | Identification of tumor-associated markers for diagnosis and therapy |
| DK2276486T3 (da) | 2008-03-24 | 2013-11-25 | 4Sc Discovery Gmbh | Nye substituerede imidazo-quinoliner |
| EP2276495B1 (en) | 2008-04-17 | 2018-11-21 | PDS Biotechnology Corporation | Stimulation of an immune response by enantiomers of cationic lipids |
| CN101289496B (zh) * | 2008-05-30 | 2011-06-29 | 中国医学科学院医学生物学研究所 | 能激发机体抗结核杆菌的保护性免疫反应的抗原表位筛选方法及用途 |
| DE102008061522A1 (de) | 2008-12-10 | 2010-06-17 | Biontech Ag | Verwendung von Flt3-Ligand zur Verstärkung von Immunreaktionen bei RNA-Immunisierung |
| CA2769670C (en) | 2009-07-31 | 2018-10-02 | Ethris Gmbh | Rna with a combination of unmodified and modified nucleotides for protein expression |
| WO2013040142A2 (en) | 2011-09-16 | 2013-03-21 | Iogenetics, Llc | Bioinformatic processes for determination of peptide binding |
| EP2569633B1 (en) | 2010-05-14 | 2016-02-10 | The General Hospital Corporation | Compositions and methods of identifying tumor specific neoantigens |
| EP2625189B1 (en) | 2010-10-01 | 2018-06-27 | ModernaTX, Inc. | Engineered nucleic acids and methods of use thereof |
| AU2012236099A1 (en) | 2011-03-31 | 2013-10-03 | Moderna Therapeutics, Inc. | Delivery and formulation of engineered nucleic acids |
| DE102011102734A1 (de) | 2011-05-20 | 2012-11-22 | WMF Württembergische Metallwarenfabrik Aktiengesellschaft | Vorrichtung zum Aufschäumen von Milch, Getränkebereiter mit dieser Vorrichtung und Verfahren zum Aufschäumen von Milch |
| PL3892295T3 (pl) | 2011-05-24 | 2023-07-24 | BioNTech SE | Zindywidualizowane szczepionki przeciwnowotworowe |
| WO2012159643A1 (en) | 2011-05-24 | 2012-11-29 | Biontech Ag | Individualized vaccines for cancer |
| DE19216461T1 (de) | 2011-10-03 | 2021-10-07 | Modernatx, Inc. | Modifizierte nukleoside, nukleotide und nukleinsäuren und verwendungen davon |
| CA3018046A1 (en) | 2011-12-16 | 2013-06-20 | Moderna Therapeutics, Inc. | Modified nucleoside, nucleotide, and nucleic acid compositions |
| US20150030576A1 (en) | 2012-01-10 | 2015-01-29 | Moderna Therapeutics, Inc. | Methods and compositions for targeting agents into and across the blood-brain barrier |
| EP3072898A1 (en) | 2012-02-20 | 2016-09-28 | Universita' degli Studi di Milano | Homo- and heterodimeric smac mimetic compounds as apoptosis inducers |
| US20130255281A1 (en) | 2012-03-29 | 2013-10-03 | General Electric Company | System and method for cooling electrical components |
| WO2013151665A2 (en) | 2012-04-02 | 2013-10-10 | modeRNA Therapeutics | Modified polynucleotides for the production of proteins associated with human disease |
| WO2014012051A1 (en) | 2012-07-12 | 2014-01-16 | Persimmune, Inc. | Personalized cancer vaccines and adoptive immune cell therapies |
| WO2014093924A1 (en) | 2012-12-13 | 2014-06-19 | Moderna Therapeutics, Inc. | Modified nucleic acid molecules and uses thereof |
| KR102121086B1 (ko) | 2012-11-01 | 2020-06-09 | 팩터 바이오사이언스 인크. | 세포에서 단백질을 발현시키는 방법들과 생성물들 |
| PL2922554T3 (pl) | 2012-11-26 | 2022-06-20 | Modernatx, Inc. | Na zmodyfikowany na końcach |
| US20160022840A1 (en) | 2013-03-09 | 2016-01-28 | Moderna Therapeutics, Inc. | Heterologous untranslated regions for mrna |
| EP2968391A1 (en) | 2013-03-13 | 2016-01-20 | Moderna Therapeutics, Inc. | Long-lived polynucleotide molecules |
| WO2014152211A1 (en) | 2013-03-14 | 2014-09-25 | Moderna Therapeutics, Inc. | Formulation and delivery of modified nucleoside, nucleotide, and nucleic acid compositions |
| US20160032316A1 (en) | 2013-03-14 | 2016-02-04 | The Trustees Of The University Of Pennsylvania | Purification and Purity Assessment of RNA Molecules Synthesized with Modified Nucleosides |
| WO2014152027A1 (en) | 2013-03-15 | 2014-09-25 | Moderna Therapeutics, Inc. | Manufacturing methods for production of rna transcripts |
| US10590161B2 (en) | 2013-03-15 | 2020-03-17 | Modernatx, Inc. | Ion exchange purification of mRNA |
| WO2014144039A1 (en) | 2013-03-15 | 2014-09-18 | Moderna Therapeutics, Inc. | Characterization of mrna molecules |
| WO2014152031A1 (en) | 2013-03-15 | 2014-09-25 | Moderna Therapeutics, Inc. | Ribonucleic acid purification |
| US20160017313A1 (en) | 2013-03-15 | 2016-01-21 | Moderna Therapeutics, Inc. | Analysis of mrna heterogeneity and stability |
| EP2971165A4 (en) | 2013-03-15 | 2016-11-23 | Moderna Therapeutics Inc | DISSOLUTION OF DNA FRAGMENTS IN MRNA MANUFACTURING METHODS |
| EP2983702A2 (en) | 2013-04-07 | 2016-02-17 | The Broad Institute, Inc. | Compositions and methods for personalized neoplasia vaccines |
| WO2014180490A1 (en) * | 2013-05-10 | 2014-11-13 | Biontech Ag | Predicting immunogenicity of t cell epitopes |
| WO2015014375A1 (en) | 2013-07-30 | 2015-02-05 | Biontech Ag | Tumor antigens for determining cancer therapy |
| EP3041934A1 (en) | 2013-09-03 | 2016-07-13 | Moderna Therapeutics, Inc. | Chimeric polynucleotides |
| WO2015034925A1 (en) | 2013-09-03 | 2015-03-12 | Moderna Therapeutics, Inc. | Circular polynucleotides |
| WO2015038892A1 (en) | 2013-09-13 | 2015-03-19 | Moderna Therapeutics, Inc. | Polynucleotide compositions containing amino acids |
| US9950065B2 (en) | 2013-09-26 | 2018-04-24 | Biontech Rna Pharmaceuticals Gmbh | Particles comprising a shell with RNA |
| EP3052479A4 (en) | 2013-10-02 | 2017-10-25 | Moderna Therapeutics, Inc. | Polynucleotide molecules and uses thereof |
| EP3052511A4 (en) | 2013-10-02 | 2017-05-31 | Moderna Therapeutics, Inc. | Polynucleotide molecules and uses thereof |
| WO2015058780A1 (en) | 2013-10-25 | 2015-04-30 | Biontech Ag | Method and kit for determining whether a subject shows an immune response |
| EP3076994A4 (en) | 2013-12-06 | 2017-06-07 | Modernatx, Inc. | Targeted adaptive vaccines |
| EP3053585A1 (en) | 2013-12-13 | 2016-08-10 | Moderna Therapeutics, Inc. | Alternative nucleic acid molecules and uses thereof |
| JP2017507703A (ja) | 2014-02-05 | 2017-03-23 | バイオエヌテック アーゲーBioNTech AG | カニューレ、注射または注入装置、およびカニューレまたは注射もしくは注入装置を使用する方法 |
| PL4023249T3 (pl) | 2014-04-23 | 2025-03-10 | Modernatx, Inc. | Szczepionki z kwasem nukleinowym |
| WO2015172843A1 (en) | 2014-05-16 | 2015-11-19 | Biontech Diagnostics Gmbh | Methods and kits for the diagnosis of cancer |
| WO2016062323A1 (en) | 2014-10-20 | 2016-04-28 | Biontech Ag | Methods and compositions for diagnosis and treatment of cancer |
| PT4023755T (pt) | 2014-12-12 | 2023-07-05 | CureVac SE | Moléculas de ácido nucleico artificiais para uma expressão melhorada de proteína |
| EP3240558A1 (en) | 2014-12-30 | 2017-11-08 | CureVac AG | Artificial nucleic acid molecules |
| WO2016155809A1 (en) | 2015-03-31 | 2016-10-06 | Biontech Rna Pharmaceuticals Gmbh | Lipid particle formulations for delivery of rna and water-soluble therapeutically effective compounds to a target cell |
| ES2970865T3 (es) | 2015-12-16 | 2024-05-31 | Gritstone Bio Inc | Identificación, fabricación y uso de neoantígenos |
| CA3060569A1 (en) | 2017-04-19 | 2018-10-25 | Gritstone Oncology, Inc. | Neoantigen identification, manufacture, and use |
| AU2018279627B2 (en) | 2017-06-09 | 2023-08-10 | Seattle Project Corp. | Neoantigen identification, manufacture, and use |
| US20200363414A1 (en) | 2017-09-05 | 2020-11-19 | Gritstone Oncology, Inc. | Neoantigen Identification for T-Cell Therapy |
| EP4576103A3 (en) | 2017-10-10 | 2025-08-27 | Gritstone bio, Inc. | Neoantigen identification using hotspots |
| CN111630602A (zh) | 2017-11-22 | 2020-09-04 | 磨石肿瘤生物技术公司 | 减少新抗原的接合表位呈递 |
| EP3759131A4 (en) | 2018-02-27 | 2021-12-01 | Gritstone bio, Inc. | NEOANTIGEN IDENTIFICATION WITH PAN ALLELE MODELS |
-
2013
- 2013-05-10 WO PCT/EP2013/001400 patent/WO2014180490A1/en not_active Ceased
-
2014
- 2014-05-07 US US14/787,110 patent/US11222711B2/en active Active
- 2014-05-07 EP EP21159558.2A patent/EP3895727A1/en active Pending
- 2014-05-07 CN CN202110057195.3A patent/CN113219179B/zh active Active
- 2014-05-07 RS RS20210634A patent/RS61868B1/sr unknown
- 2014-05-07 PL PL14722117T patent/PL2994159T3/pl unknown
- 2014-05-07 CN CN201480026604.1A patent/CN105451759B/zh active Active
- 2014-05-07 EP EP14722117.0A patent/EP2994159B1/en active Active
- 2014-05-07 CN CN202511277379.5A patent/CN121130065A/zh active Pending
- 2014-05-07 ES ES14722117T patent/ES2871384T3/es active Active
- 2014-05-07 RU RU2015153007A patent/RU2724370C2/ru not_active Application Discontinuation
- 2014-05-07 DK DK14722117.0T patent/DK2994159T3/da active
- 2014-05-07 HU HUE14722117A patent/HUE055146T2/hu unknown
- 2014-05-07 PT PT147221170T patent/PT2994159T/pt unknown
- 2014-05-07 SG SG11201508816RA patent/SG11201508816RA/en unknown
- 2014-05-07 WO PCT/EP2014/001232 patent/WO2014180569A1/en not_active Ceased
- 2014-05-07 CA CA2911945A patent/CA2911945C/en active Active
- 2014-05-07 RU RU2020110192A patent/RU2020110192A/ru unknown
- 2014-05-07 AU AU2014264943A patent/AU2014264943B2/en active Active
- 2014-05-07 KR KR1020157035178A patent/KR102399419B1/ko active Active
- 2014-05-07 SI SI201431821T patent/SI2994159T1/sl unknown
- 2014-05-07 SM SM20210300T patent/SMT202100300T1/it unknown
- 2014-05-07 LT LTEP14722117.0T patent/LT2994159T/lt unknown
- 2014-05-07 HR HRP20210773TT patent/HRP20210773T1/hr unknown
- 2014-05-07 MX MX2015015511A patent/MX382293B/es unknown
- 2014-05-07 JP JP2016512248A patent/JP6710634B2/ja active Active
-
2015
- 2015-10-26 IL IL242281A patent/IL242281B/en active IP Right Grant
- 2015-10-29 ZA ZA2015/08048A patent/ZA201508048B/en unknown
-
2019
- 2019-12-06 AU AU2019275637A patent/AU2019275637A1/en not_active Abandoned
-
2020
- 2020-02-14 JP JP2020023610A patent/JP6882550B2/ja active Active
- 2020-04-02 IL IL273785A patent/IL273785A/en unknown
-
2021
- 2021-05-06 JP JP2021078360A patent/JP7405792B2/ja active Active
- 2021-05-19 CY CY20211100436T patent/CY1124176T1/el unknown
- 2021-11-30 US US17/539,157 patent/US20220093209A1/en active Pending
-
2022
- 2022-02-10 AU AU2022200863A patent/AU2022200863B2/en active Active
-
2023
- 2023-12-14 JP JP2023210801A patent/JP2024037890A/ja active Pending
-
2025
- 2025-08-27 AU AU2025223777A patent/AU2025223777A1/en active Pending
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2871384T3 (es) | Predicción de inmunogenicidad de los epítopos de células T | |
| US20230190898A1 (en) | Individualized vaccines for cancer | |
| US20210164034A1 (en) | Individualized vaccines for cancer | |
| HK40061930A (en) | Predicting immunogenicity of t cell epitopes | |
| HK40057481A (en) | Predicting immunogenicity of t cell epitopes | |
| BR112017017293B1 (pt) | Método para predizer uma ou mais modificações de aminoácidos imunogênicos, método para selecionar e/ou classificar modificações de aminoácidos imunogênicos, método para fornecer uma vacina e vacina | |
| HK1215169B (en) | Predicting immunogenicity of t cell epitopes | |
| BR112015028126B1 (pt) | Previsão de imunogenicidade de epítopos de células t | |
| CA2982971A1 (en) | Predicting t cell epitopes useful for vaccination |